ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности, к системе распознавания рукописных и печатных документов и изображений низкого качества.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известно решение, выбранное в качестве наиболее близкого аналога, US 8908969 B2, 09.12.2014. В данном решении раскрыт способ распознавания изображений. Способ содержит этапы: получение изображения документа; обнаружение объектов изображения на изображении; сопоставление процессором объектов изображения с заранее определенным типом документа, при этом объекты изображения отличают тип документа от других типов документов, и при этом объекты изображения включают в себя элементы привязки; создание процессором описания гибкой структуры, соответствующего заданному типу документа, на основе обнаруженных объектов изображения, при этом описание гибкой структуры включает в себя набор элементов поиска для каждого поля данных в изображении документа, причем каждый элемент поиска имеет связанный поиск критерий; поиск с помощью алгоритма поиска дополнительных изображений документа для определения соответствующего типа документа из дополнительных изображений документа, при этом каждое из дополнительных изображений документа относится к типу документа, соответствующему заранее определенному типу документа; изменение описания гибкой структуры на основе упомянутого поиска дополнительных изображений документов, при этом алгоритм поиска сконфигурирован для обнаружения полей данных на основе описания гибкой структуры, причем упомянутые поля данных соответствуют заданному типу документа; и повторение упомянутого поиска и изменения описания гибкой структуры до тех пор, пока не будет достигнут или превышен определенный уровень точности.
Приведенное выше известное из уровня техники решение направлено на решение проблемы распознавания изображений. Однако стоит отметить, что в известном уровне техники не раскрыты технологии, позволяющие добиться максимально высокой скорости распознавания, при этом сохраняя точность уверенного распознавания. Предложенное решение распознает текст в печатных и рукописных изображениях плохого качества с артефактами и нарушенной геометрией, сделанных в том числе с мобильных телефонов, автоматическое распознавание которых в настоящее время практически невозможно.
Предлагаемое решение направлено на устранение недостатков современного уровня техники и отличается от известных ранее тем, что предложенная система: содержит нестандартные ансамбли специализированных нейросетей; использует non-local block слой, который изначально предназначался для анализа видео, в нейронной сети для решения задач OCR; использует технику multi-head attention для детализации "маски внимания" на каждом шаге декодирования нейронной сети на задаче OCR. Также, предлагаемое изобретение использует особый способ выпрямления трехмерного тензора, суть которого заключается в том, что в первую очередь осуществляется конкатенация one-hot закодированных пространственных координат каждого супер-пикселя с самой картой признаков по глубине и только затем, осуществляется выпрямление. Благодаря этому, не вводя никаких дополнительных параметров/весов в нейронную сеть, как это практикуется в других архитектурах, мы достигаем эффекта "location awareness" для декодера и увеличиваем качество предсказаний, и способность сети улавливать пространственные корреляции между супер-пикселями на карте признаков.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное решение, является создание системы распознавания структурированных изображений c использованием нейронных сетей, которая охарактеризована в независимом пункте формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в повышении качества распознавания рукописных и печатных документов и изображений с низким качеством.
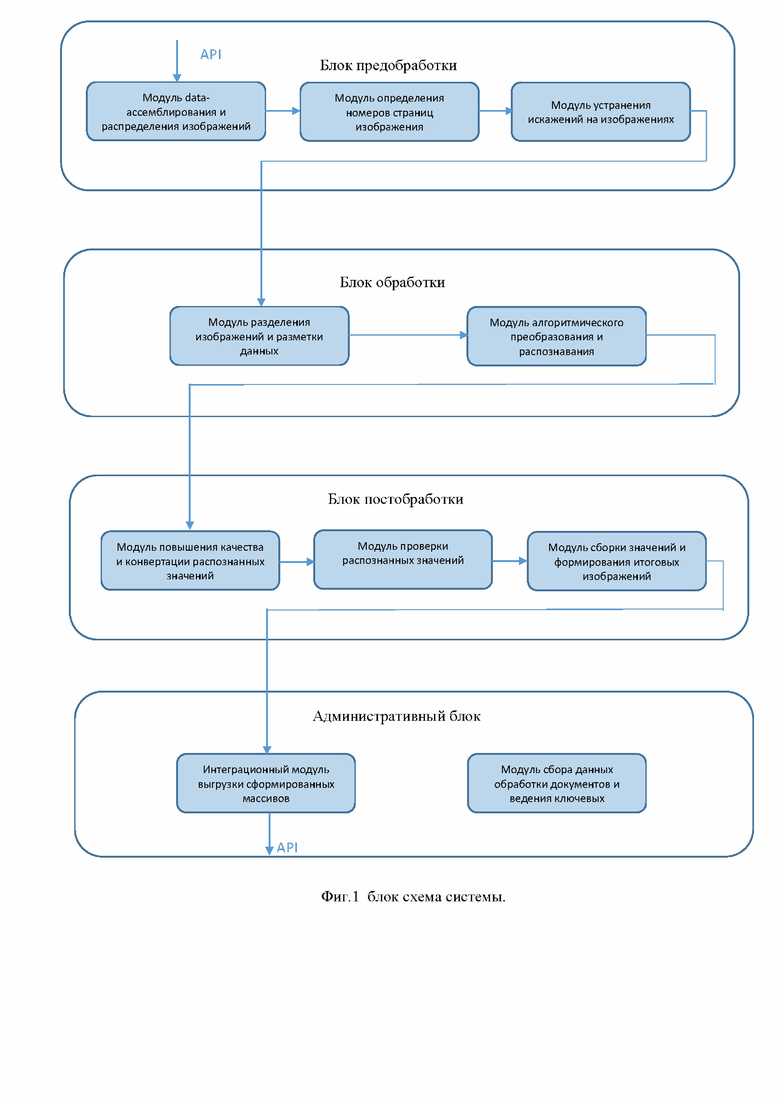
Заявленный результат достигается за счет осуществления системы распознавания структурированных изображений c использованием нейронных сетей, где система содержит:
модуль data-ассемблирования и распределения полученных изображений, выполненный с возможностью получения исходных изображений, хранения изображений и отправки изображений в очередь для дальнейшей обработки;
модуль определения номеров страниц изображений, выполненный с возможностью распознавания номера страницы структурированного изображения;
модуль устранения искажений на изображениях, реализованный в качестве сверточной нейронной сети с несколькими взаимодействующими ветвями, выполненный с возможностью определения ключевых точек изображения;
модуль разделения изображений и разметки данных для обучения нейронной сети, с визуальным контролем изображений;
модуль алгоритмического преобразования и распознавания композицией нейронных сетей, выполненный с возможностью оценки степени достоверности распознавания;
модуль повышения качества и конвертации распознанных значений, выполненный с возможностью, конвертации распознанных изображений и контроля качества распознавания изображений;
модуль проверки распознанных значений;
модуль сборки значений и формирования итоговых изображений;
интеграционный модуль выгрузки сформированных массивов данных из баз данных;
модуль сбора данных обработки документов и ведения ключевых показателей, выполненный с возможностью осуществления контроля за эффективностью распознавания документов.
В другом частном варианте реализации описываемой системы, структурированные изображения — это любые виды документов.
В другом частном варианте реализации описываемой системы, структурированные изображения это:
анкеты, кадровая, бухгалтерская, рукописная документации, в том числе документация с геометрическими искажениями.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг.1 иллюстрирует блок схему предлагаемой системы.
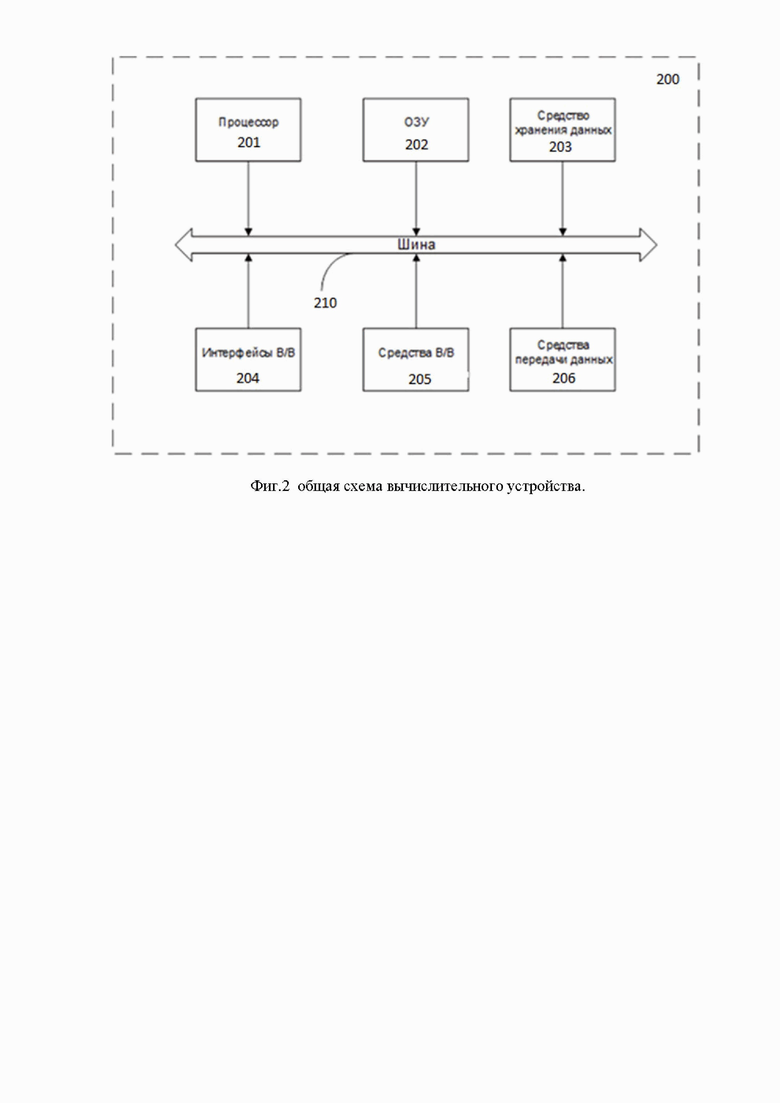
Фиг.2 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
На текущий момент высока потребность в распознавания с высокой скоростью и точностью различных видов изображений, содержащих рукописный или печатный текст. Для решения подобных задач обычно применяют различные примитивные методы распознавания, которые не обеспечивают быстрое и качественное распознавание текста с изображений, в том числе изображений с геометрическими искажениями.
Настоящее изобретение представляет собой сложно уровневую систему распознавания структурированных изображений при помощи нейронных сетей.
В рамках единой системы объединены следующие технологии:
автоматизированное получение информации из скан-образов, фотоматериалов, и видеоматериалов;
повышенное качество распознавания на 30-50% больше, чем у известных аналогов, достигается за счет использования нестандартной композиции нейросетей, работающих по определённым собственному эвристическому алгоритму.
Natural language processing для обработки ошибок и автоматизированной классификации сущностей в базе знаний проекта.
Предлагаемое решение представляет из себя композицию нейросетей и эвристических алгоритмов. Основу составляют четыре обученных модели нейросетей: (определения изображении углов и линий, определение на изображении слов и объектов, двух различных моделей нейросетей распознающих на изображении слова и символы). Набор данных (датасет) используемый для обучения нейронных сетей суммарно состоял более, чем из миллиона изображений.
Композиция представляет из себя собранный в определенной последовательности набор основных нейронных моделей и других модулей обработки, каждый из которых последовательно по определённому алгоритму выполняет свою задачу по обработке изображений, начиная от выделения месторасположения интересующего объекта, с его дальнейшей предобработкой и заканчивая распознаванием информации в конкретных найденных зонах интереса.
Принцип работы системы.
На обработку поступает изображение содержащее печатный или рукописный текст. Изображением может являться отсканированный или сфотографированный документ, в том числе низкого качества с геометрическими искажениями. Поступившее изображение проходит этап предобработки - устранение геометрических и цветовых и иных искажений объекта, усиление контраста. Следующим этапом изображения поступают в очередь сервиса резки, где из них выделяется структурная информация, блоки текста, и происходит локализация слов (печатных и рукописных). Деткеция слов происходит с помощью архитектуры Faster-RCNN. В качестве feature extractor“а используется архитектура Residual Network без финального пуллинга и полносвязных слоев. Пространственные размерности входного изображения – 1000х1000 пикселей. Слова, найденные на изображении, отправляются в сервисы распознавания печатного и рукописного текста. Модель распознавания текста состоит из конволюционного кодировщкиа, извлекающего из изображения высокоуровневые признаки, и рекуррентного декодировщика с механизмом внимания (attention meachanism). Последний элемент позволяет декодировщику во время декодирования уделять внимание релевантным частям изображения. Модель для распознавания выдает последовательность символов, где каждый символ является индексом класса из словаря, и матрицу с вероятностным распределением размером (m, t), где m — количество классов в словаре, а t — количество шагов декодирования.
В случае классификации результата распознавания, как содержащего ошибку данные могут отправляться на ввод и разметку оператору. После распознавания всех слов на документе, происходит извлечение пар «ключ»: «значение» из документа с помощью информации о структуре документа и содержании текстовых полей, где «ключом» является поле, необходимое заказчику, а «значением» – текст, заполненный клиентом заказчика. Для этих целей применяются эвристики, позволяющие найти наиболее вероятный блок текста, содержащий «значение», а для блока текста, содержащего «ключ». Описание «ключей» происходит в мета-шаблоне, в котором находится информация о полях, их типы, варианты написания наименований. Успешно распознанные параметры из цифровых данных сохраняются в системе. Вся информация доступна пользователю через графический интерфейс, где он имеет возможность отслеживать необходимые отчеты.
Подробное описание модулей системы.
Модуль data-ассемблирования и распределения информации состоит из набора интерфейсов, используемых для получения данных поступающих в систему (таких как: массивы изображений, другие данные, получаемые через API и т.д.), а также базы данных используемой для хранения полученных данных, объектного хранилища изображений. Кроме того, модуль включает специализированную подсистему отправки данных в очереди для их дальнейшей обработки. Высокоскоростная загрузка данных происходит по протоколу https. Поддерживается скорость загрузки не менее 10 активных соединений со скорость загрузки до 25 000 изображений в час.
Модуль устранения искажений на изображениях проводит определение ключевых точек изображения с помощью архитектуры HRNetV1 (High Resolution Network), которая состоит из нескольких параллельных сверточных ветвей разного разрешения. В сети так же есть exchange block“и, которые позволяют разным независимым ветвям обмениваться информацией, суть признаками, извлеченными на разных разрешениях. В конце сети стоит 1х1 свертка, сжимающая пространство признаков до k каналов, где k — количество ключевых точек. После этого происходит поканальное применение двумерного softmax слоя для получения двумерного вероятностного распределения. Выбрав на каждом канале наиболее вероятный пиксель на выходе получается k ключевых точек. Далее по ключевым точкам строится матрица гомографии и проводится перспективная трансформация изображения.
Модуль разделения изображений и разметки данных с визуальным контролем, включает в себя набор шаблонов с качеством обработки 60-80% от общего количества обрабатываемых документов, в зависимости от качества изображения или фотографии. Данный в модуль загружаются с помощью интерфейса чтения из очередей, далее используется конфигурационный блок для выбора соответствующего функционала нахождения зон интереса. С помощью набор специализированных подпрограмм и нейронных сетей модуль определяет области со значимой информацией. Модуль из изображений осуществляет выделение структурной информации, такой как: ячейки таблиц, блоки текста, и осуществляет локализацию слов (печатных и рукописных). Модуль обладает подсистемой записи в объектное хранилище вырезанных областей и подсистему отправки сообщений в очередь распознавания. Служит для первого этапа обработки исходной информации – нахождения регионов интереса (зон изображения, содержащих значимую информацию), выделения их и записи в соответствующую базу данных, а также для отправки на дальнейшее распознавание.
Модуль алгоритмического преобразования и распознавания композицией нейронных сетей документов содержит набор архитектур нейронных сетей для различных видов входящей информации с соответствующими блоками алгоритмической пред- и постобработки.
Модуль служит для распознавания информации в поступивших к нему регионах интереса. В модуле заложены обученные модели нейронных сетей следующих типов.
Модель распознавание рукописного текста.
Модель распознавания рукописного текста представляет из себя комбинацию кодировщика, конволюционной нейронной сети архитектуры Inception-ResNetV2, извлекающего из изображения необходимые для распознавания признаки, и декодировщика, рекуррентной нейронной сети с GRU-ячейками, использующими механизм внимания типа Luong Attention, осуществляющего непосредственное распознавание изображения основываясь на последовательности признаков, извлеченных кодировщиком. Attention mechanism позволяет декодировщику «смотреть» на релевантные части изображения во время предсказания каждого символа, что значительно увеличивает точность модели. На выходе этой сети мы имеем строку, где каждый символ – цифра, символизирующая букву; расшифровка производится благодаря сопоставлению предсказанной моделью строки и словаря.
Классификация полей, фрагментов изображений и целых изображений.
Классификация разного рода элементов происохдит за счет использования архитектуры Residual Network. Архитектура сосотит из несколько stage“ий, каждый из которых, в свою очередь, включает в себя несколько Bottleneck/Basic блоков. Каждый блок представляет из себя несколько последовательно расположенных сверточных слоев с обходящей связью между началом и концом блока. После всех stage“ий получившиеся карты признаков проходят через average pooling размером 1 и получившийся вектор проходит через один полносвязный слой, сжимающий пространство признаков до количества классов, и через softmax-активацию, выдающую вероятностное распределение на входном пространстве.
Модель распознавания печатного текста.
Модель распознавания печатного текста также представляет из себя классическую seq2seq архитектуру. Отличительной особенностью этой модели является CTC-функция ошибок(Connectionist Temopral Classification Loss), которая, с помощью рекуррентного алгоритма backward-forward и методов динамического программирования, осуществляет измерение ошибки сети и позволяет осуществлять распознавание текста на неотсегментированных изображениях.
Распознавание (классификация) объектов.
Эта задача решается с помощью архитектуры Faster R-CNN. Она состоит из: feature extractor“а, который извлекает высокоуровневые признаки из изображения, суть четырехмерный тензор, region proposal элемента, производящего регионы интереса, ROI Pooling слоя, необходимого для получения признакового вектора фиксированного размера для каждого региона инетереса, и непосредственного детектора, который представляет из себя несколько последовательно расположенных полносвязных слоев и две «головы», каждая из которых, основываясь на признаках, которыми обладает регион интереса, предсказывает координаты bounding box“а вокруг объекта и класс этого объекта соответственно.
Модуль алгоритмического преобразования и распознавания выполнен с возможностью оценки степени достоверности распознавания. В случае классифицирования результата распознавания поля как содержащего ошибку такое поле отправляется в сервис разметки данных. При этом порог уверенности может формироваться динамически, что позволяет задавать различные требования к уверенности распознавания в зависимости от требований пользователя и типов обрабатываемых документов. Модуль обеспечивает порог уверенности на уровне не менее 98-99%: после контроля в правильно распознанных полях будет не более 2 ошибок на 100 полей.
Модуль повышения качества и конвертации распознанных значений позволяет улучшить качество распознавания с помощью словарей и алгоритмов, а также конвертирует эти данные в вид, соответствующий требованиям пользователя. В результате работы модуля более 99% полей передаются на контроль качества в нормализованном виде.
Модуль необходим для конвертации распознанных данных в вид, требуемый пользователю, а также для дополнительного улучшения качества распознавания за счет использования словарей и алгоритмов. Для проверки и нормализации данных имеется возможность настроить постобработку в зависимости от сложности поля.
В модуле проверки распознанных значений, значения проходят несколько этапов проверки. Первоначально осуществляется проверка значений на требования по размеру и символам. Выборочно с определенной вероятностью проверяются значения из массива данных. В заключении делаются проверки по словарям, связям с другими полями на документе. Дополнительно, для обеспечения качества ввода более 99,5%, для полей повышенного качества может осуществляться контроль методом двойной обработки: например, поле обрабатывается нейросетью и параллельно может осуществляться ввод оператором. Далее осуществляется сверка значений. По результатам работы данного сервиса общее качество обработки и проверки данных будет не ниже 98% (не более 2 ошибок на 100 полей) в общем случае и не ниже 99,5% (не более 1 ошибки на 200 полей) для полей с требованиями повышенного качества обработки. Причем, под значениями понимаются значения, которые сохраняются после распознавания и выборочно с определенной вероятностью проверяются на требования по размеру и символам. В заключении делаются проверки по словарям, связям с другими полями (значениями) в документе
После получения всех возможных значений документа будет осуществляется объединение данных посредством модуля сборки значений и формирования итоговых данных. В данном модуле осуществляется проверка того, что по всем полям получено значение. Если заполненные данные соответствуют требованиям по обработке, документ считается собранным, значения полей сохраняются в электронном хранилище готовых документов, в удобном виде для поиска и просмотра информации. Если условия сборки не выполняются, документ (изображение) бракуется с указанием причины. Скорость сборки данных соответствует общей производительности системы и составляет более 3 млн документов в мес, включающих более 30 млн полей.
На основании собранных данных в зависимости от требований заказчика будет осуществляться формирование итоговой базы данных и выгрузка данных посредством интеграционного модуля выгрузки сформированных БД. Модуль поддерживает как стандартный формат выгрузки CSV, так и возможность подключать программируемые библиотеки для выгрузки по API, включая передачу изображений, в т.ч. через ftp. Выгрузка может осуществляться разово, по требования, или периодически, по расписанию. Все собранные поля должны передаваться на выгрузку и выгружаться, что в дальнейшем подтверждается соответствующими логами.
Модуль сбора данных обработки документов и ведения ключевых показателей платформы осуществляет контроль за эффективностью распознавания документов, ведет логирование и отображает такие ключевые показатели как: общее количество обработанных документов и полей, скорость распознавания, процент ошибок, процент недостоверно распознанных документов и полей, себестоимость обработки документов и полей. Показатели рассчитываются для каждого типа обрабатываемых документов отдельно.
Инновационность применяемого подхода заключается в широком использовании новейших моделей искусственных нейронных сетей, таких как конволюционно-рекуррентные нейронные сети (CNN + RNN [LSTM]), на базе архитектуры Faster-RCNN глубокого обучения на всех этапах обработки входной информации. Это даёт возможность автоматически выстроить сложнейшие модели, которые могут учитывать самые тонкие нюансы входящей информации, а также способствует высокой степени автоматизации всех этапов обработки изображения, благодаря чему система превосходит существующие известные аналоги по параметрам точности и скорости (показатель скорости до 5 сек. за изображение в одном потоке) обработки цифровых материалов. Используемый подход обеспечивает высокую точность распознавания информации (98-99%), а также даёт возможность для высокой степени автоматизации всех этапов обработки изображения.
Основой платформы является использование на всех этапах обработки входной информации четырех основных современных моделей нейронных сетей глубокого обучения.
Обучение нейронных сетей.
Сервис сбора дата-сетов осуществляет автоматическое формирование необходимых значений из баз. Данные - .csv файл, в котором содержится название изображения и аннотация к нему (2 столбца). Изображения хранятся в папке «images». Сеть принимает мини-пакет из 10 изображений-аннотаций и осуществляет прямой проход этого мини-пакета, суть изображений. На выход получаем трехмерный тензор с условными вероятностями размера B x M x N, где B - размер мини-пакета, M - количество шагов декодирования, N - размер вокабуляра. Декодер является авто-регрессионным с последовательной природой декодирования: делает все за несколько таймстепов. На каждом тайм-степе выдается матрица размера B x N, после чего измеряется кросс-энтропия с выданной матрицей и тагретом на текущий таймстеп, веткор размером B, в котором указан индекс текущей буквы для каждой последовательности в мини-пакете. После лосс суммируется со всех шагов декодирования и умножается на определенный взвешивающий коэффициент. Далее вычисляются частные производные дифференцируемой функции ошибок по весам сети и формируется градиент для обновления веса сети с помощью алгоритма обратного распространения ошибки. Для получения результата, самих предсказанных последовательностей, необходимо взять argmax(dim=2).
Предложенная система использует non-local block слой, который изначально предназначался для анализа видео, в нейронной сети для решения задач OCR, а также использует технику multi-head attention для генерации масок внимания, каждая из которых уделяет внимание разным частям изображения, на каждом шаге декодирования нейронной сети на задаче OCR. Предлагаемое изобретение также использует специфический способ выпрямления четырехмерного тензора. Суть способа заключается в том, чтобы для каждой позиции в карте признаков сформировать вектор, состоящий из one-hot закодированных пространственных координат позиции, и сконкатенировать его с самой картой признаков по глубине и уже после этого осуществить выпрямление карты признаков в последовательность признаков. Благодаря этому, не вводя никаких дополнительных параметров/весов в нейронную сеть, как это практикуется в других архитектурах, мы достигаем эффекта "location awareness" для декодера и увеличиваем качество предсказаний, и способность сети улавливать пространственные корреляции между супер-пикселями на карте признаков. Еще одним уникальным параметром предлагаемой системы является специфические пространственные размерности входного изображения - 1420х142. Экспериментальным путем был установлен прирост качества распознавания от такого необычно большого размера. В других же подходах/архитектурах для распознавания такие специфические размеры и ориентированности входного изображения не встречаются.
Данное техническое решение предназначено для распознавания текстовых данных с различных изображений: фотографий и скан-образов, при помощи системы, в основе которой используются технологии нейронных сетей и машинного обучения с заданным и гарантированным качеством и скоростью. К основным обрабатываемым документам относятся любые структурированные документы: анкеты, архивные документы, бухгалтерские документы, ценники, комплекты документов и другие, включая рукописные документы, фотографии низкого качества и другие сложные изображение с нарушенной геометрией, распознавание которых автоматически в настоящее время практически невозможно.
На Фиг. 2 далее будет представлена общая схема вычислительного устройства (200), которое имеет возможность обеспечивать необходимую обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (200) содержит такие компоненты, как: один или более процессоров (201), по меньшей мере одну память (202), средство хранения данных (203), интерфейсы ввода/вывода (204), средство В/В (205), средства сетевого взаимодействия (206).
Процессор (201) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (200) или функциональности одного или более его компонентов. Процессор (201) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (202).
Память (202), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (203) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (203) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (204) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (204) зависит от конкретного исполнения устройства (200), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (205) в любом воплощении системы, реализующей описываемый способ, должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (206) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (205) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (200) сопряжены посредством общей шины передачи данных (210).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ нейросетевого распознавания рукописных текстовых данных на изображениях | 2024 |
|
RU2837308C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ХИМИЧЕСКОЙ ИНФОРМАЦИИ ИЗ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2021 |
|
RU2774665C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| Способ и система поддержки принятия врачебных решений с использованием математических моделей представления пациентов | 2017 |
|
RU2703679C2 |
| Способ оптического распознавания текстовых строк, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании | 2024 |
|
RU2837307C1 |
| Способ формирования математических моделей пациента с использованием технологий искусственного интеллекта | 2017 |
|
RU2720363C2 |
Изобретение относится к области вычислительной техники. Техническим результатом является повышение качества распознавания структурированных изображений. Система распознавания структурированных изображений c использованием нейронных сетей содержит: модуль data-ассемблирования и распределения полученных изображений; модуль определения номеров страниц изображений; модуль устранения искажений на изображениях; модуль разделения изображений и разметки данных для обучения нейронной сети; модуль алгоритмического преобразования и распознавания композицией нейронных сетей; модуль повышения качества и конвертации распознанных значений; модуль проверки распознанных значений; модуль сборки значений и формирования итоговых изображений; интеграционный модуль выгрузки сформированных массивов данных из баз данных; модуль сбора данных обработки документов и ведения ключевых показателей. 2 з.п. ф-лы, 2 ил.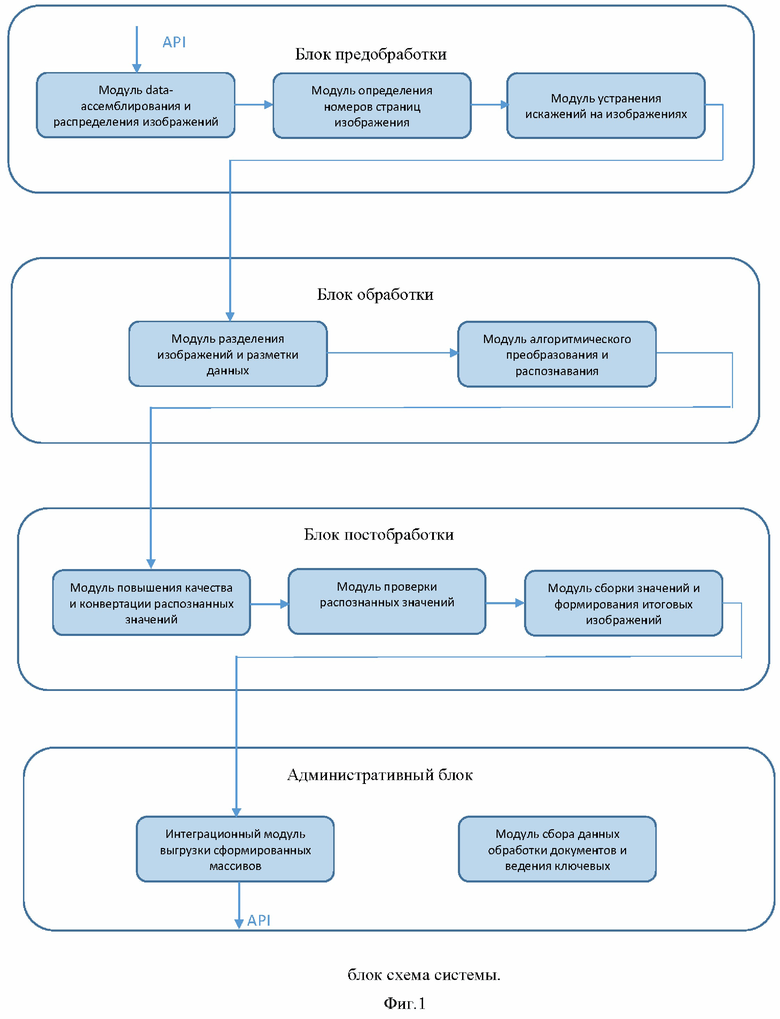
1. Система распознавания структурированных изображений c использованием нейронных сетей, содержащая:
модуль data-ассемблирования и распределения полученных изображений, выполненный с возможностью получения исходных изображений, хранения изображений и отправки изображений в очередь для дальнейшей обработки;
модуль определения номеров страниц изображений, выполненный с возможностью распознавания номера страницы структурированного изображения;
модуль устранения искажений на изображениях, реализованный в качестве сверточной нейронной сети с несколькими взаимодействующими ветвями, выполненный с возможностью определения ключевых точек изображения и устранения искажений на изображениях по ключевым точкам;
модуль разделения изображений и разметки данных для обучения нейронной сети, с визуальным контролем изображений, выполненный с возможностью нахождения регионов интереса на изображениях и отправки их на дальнейшее распознавание;
модуль распознавания текстовой информации на изображениях композицией нейронных сетей и оценки степени достоверности полученных результатов распознавания, выполненный с возможностью распознавания текстовой информации в поступивших регионах интереса на изображениях и выполнения оценки степени достоверности полученных результатов распознавания;
модуль повышения качества и конвертации распознанных значений, выполненный с возможностью конвертации распознанных изображений и контроля качества распознавания изображений;
модуль проверки распознанных значений;
модуль сборки значений и формирования итоговых изображений;
интеграционный модуль выгрузки сформированных массивов данных из баз данных;
модуль сбора данных обработки документов и ведения ключевых показателей, выполненный с возможностью осуществления контроля за эффективностью распознавания документов.
2. Система по п.1, в которой структурированные изображения - это печатные и рукописные текстовые документы.
3. Система по п.1, в которой структурированные изображения это:
анкеты, кадровая, бухгалтерская, рукописная документации, в том числе документация с геометрическими искажениями.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 8908969 B2, 09.12.2014 | |||
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| ГЕНЕРАЦИЯ РАЗМЕТКИ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ ДЛЯ ОБУЧАЮЩЕЙ ВЫБОРКИ | 2017 |
|
RU2668717C1 |

