ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к области компьютерной техники, в частности к обработке цифровых данных для поиска графической информации.
УРОВЕНЬ ТЕХНИКИ
[0002] На сегодняшний день поиск графической информации применяется в различных областях техники. Существует множество поисковых механизмов, позволяющих осуществлять подбор требуемой информации на основе задаваемого поискового запроса или эталонного образца, на основании которого будет выполняться поиск схожих данных. Таким системами являются, например, Яндекс.Картинки, Google Pictures и т.п.
[0003] Одним из приоритетных направлений применения таких поисковых систем является работа с информацией, относящейся к результатам интеллектуальной деятельности (РИД), таким как товарные знаки и промышленные образцы, где тождество сравниваемых обозначений играет ключевую роль для выполнения качественной процедуры поиска схожих изображений.
[0004] В качестве одного из аналогов можно рассматривать сервис поиска графических изображений РИД eSearch plus Европейского патентного ведомства (https://euipo.europa.eu/eSearch/), которая позволяет осуществлять поиск схожей графической информации на основании формируемого поискового запроса с помощью загрузки примера изображения в поисковый индекс системы. Недостатками данной системы является отсутствие возможности уточнения поискового запроса с помощью фильтрации нерелевантных РИД, а также недостаточная точность поиска, что приводит к зашумлению итоговой поисковой выдачи и снижению общего качества работы системы.
[0005] Из уровня техники также известны подходы в применения алгоритмов машинного обучения для поиска схожей графической информации, например, такие решения раскрываются в следующих патентных документах: US 20190102601 A1 (LexsetAi LLC, 04.04.2019), JP 2018160256 A (Hamada et al., 11.10.2018), US 9740963 B2 (SRI International, 22.08.2017). Данные подходы опираются на тренировку алгоритма на базе искусственной нейронной сети (ИНС) для классификации изображений и определении схожих графических образов.
[0006] По своей технической сути наиболее близкое решение раскрывается в патентной заявке KR 20190098801 A (TUAT СО LTD, 23.08.2019), которая описывает систему поиска информации о РИД, в частности, товарных знаках на основании применения алгоритма машинного обучения на базе сверточной нейронной сети (англ. Convolutional Neural Network - CNN), который тренируется на массиве данных, формируемом их опубликованных графических изображений.
[0007] Недостатками известных решений является недостаточная точность поискового алгоритма, которая ограничивается набором обучаемых материалов, которые как правило не проходят достаточной степеней предобработки и их аугментации для формирования обучающей выборки для алгоритмов машинного обучения, которая позволит сформировать более универсальный поисковый индекс, который позволит искать с повышенной точностью совпадающие графические образы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0008] Настоящее изобретение направлено на решение технической проблемы, заключающейся в создании поискового механизма, обеспечивающего быстрый и качественный поиск графической информации, связанной с РИД.
[0009] Техническим результатом является повышение точности и скорости поиска графической информации.
[0010] Дополнительным техническим результатом является отсутствие необходимости разметки данных для формирования обучающей выборки модели машинного обучения.
[0011] Заявленное изобретение осуществляется за счет выполнения компьютерно-реализуемого способа поиска графических изображений, выполняемого с помощью процессора и содержащего этапы, на которых:
- получают входное изображение или текст, на основании которых формируют поисковый запрос;
- выполняют обработку входного изображения с помощью алгоритмов библиотек OpenCV и Pillow;
- с помощью модели машинного обучения на базе искусственной нейронной сети (ИНС), обученной на графических изображениях и содержащей базу данных их векторных представлений, выполняют обработку входного изображения, в ходе которого переводят изображение в пиксельную матрицу, по которой определяются ключевые параметры изображения и их расположение во входном изображении, и формируют векторное представление изображения с помощью алгоритма максимизации;
- формируют поисковый индекс для входного изображения с помощью сравнения близости векторного представления входного изображения с векторными представлениями в базе данных ИНС, причем сравнение выполняется с помощью алгоритма приближенного поиска ближайших соседей, основанного на иерархических графах;
- определяют и предоставляют по меньшей мере одно изображение из базы данных на основании сравнения векторных представлений по упомянутому поисковому индексу.
[0012] В одном из частных вариантов реализации способа изображения выбираются из группы: товарные знаки и/или промышленные образцы.
[0013] В другом частном варианте реализации способа на этапе формирования поискового запроса выполняется аннотация входного изображения на предмет выявления и распознавания текстовой информации.
[0014] В другом частном варианте реализации способа выявленная текстовая информация на входном изображении добавляется в поисковый запрос.
[0015] В другом частном варианте реализации способа дополнительно уточняют поисковый индекс с помощью по меньшей мере одного дополнительного параметра входного изображения, выбираемого из группы: принадлежность к классам МКТУ или МКПО, данным правообладателя, данным автора, дату или диапазон дат подачи или публикации документа.
[0016] В другом частном варианте реализации способа ИНС представляет собой глубокую сверточную нейронную сеть (ГСНС).
[0017] В другом частном варианте реализации способа на этапе обработки входного изображения выполняется ряд преобразований изображения, которые включают в себя: приведение изображения к размеру 224x224 пикселя без искажений, перевод изображения в градации серого, удаление шума, формирование фиктивного режима RGB из одного канала градации серого, нормализация каналов RGB.
[0018] В другом частном варианте реализации способа при удалении шума удаляются высококонтрастные пиксели входного изображения на фоне одного цвета.
[0019] В другом частном варианте реализации способа при формировании фиктивного режима RGB формируется три одинаковых цветовых канала.
[0020] В другом частном варианте реализации способа выявление текстовых данных на входном изображении осуществляется с помощью сверточной рекуррентной нейронной сети (СРНС), обученной на предмет классификации текстовой информации и обеспечивающей определение координат найденной информации на изображении.
[0021] В другом частном варианте реализации способа выявленная текстовая информация обрабатывается рекуррентной нейронной сетью (РНС), выполняющей преобразование фрагмента изображения в текстовую форму.
[0022] Заявленное изобретение также осуществляется с помощью системы поиска графических изображений, которая содержит по меньшей мере один процессор и средство памяти, хранящее машиночитаемые инструкции, которые при их исполнении процессором выполняют вышеуказанный способ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
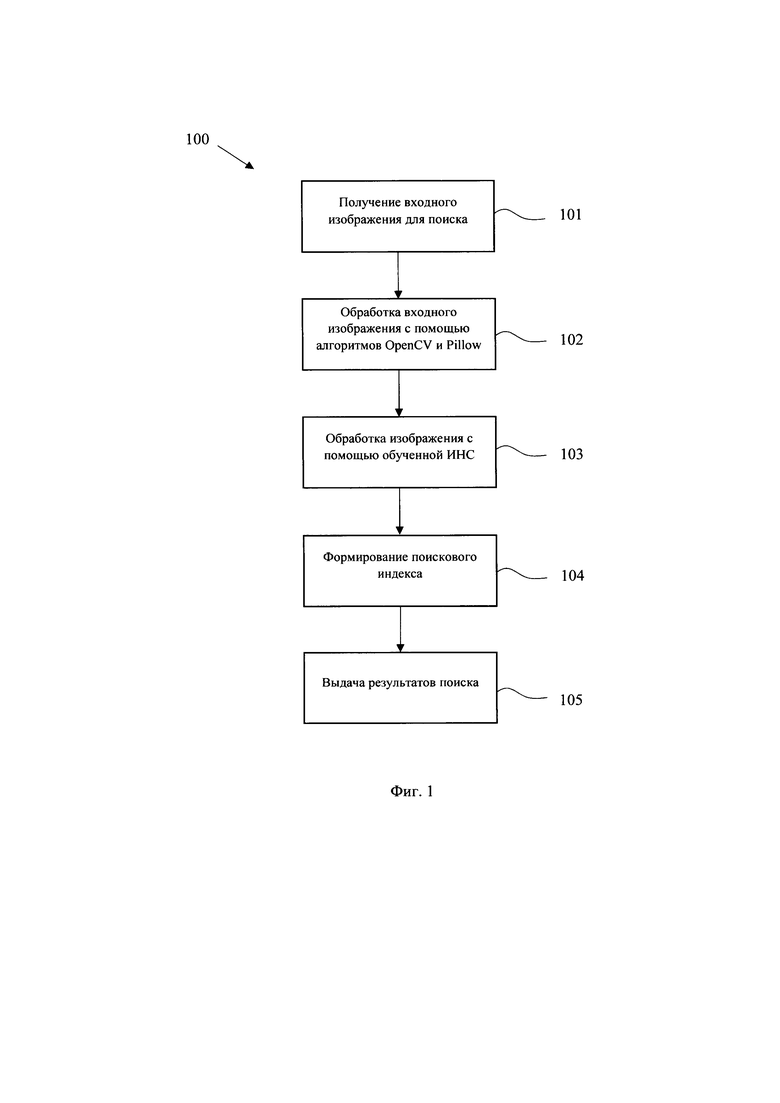
[0023] Фиг. 1 иллюстрирует блок-схему общего выполнения этапов заявленного способа.
[0024] Фиг. 2 иллюстрирует блок-схему процесса подготовки обучающей выборки для тренировки ИНС.
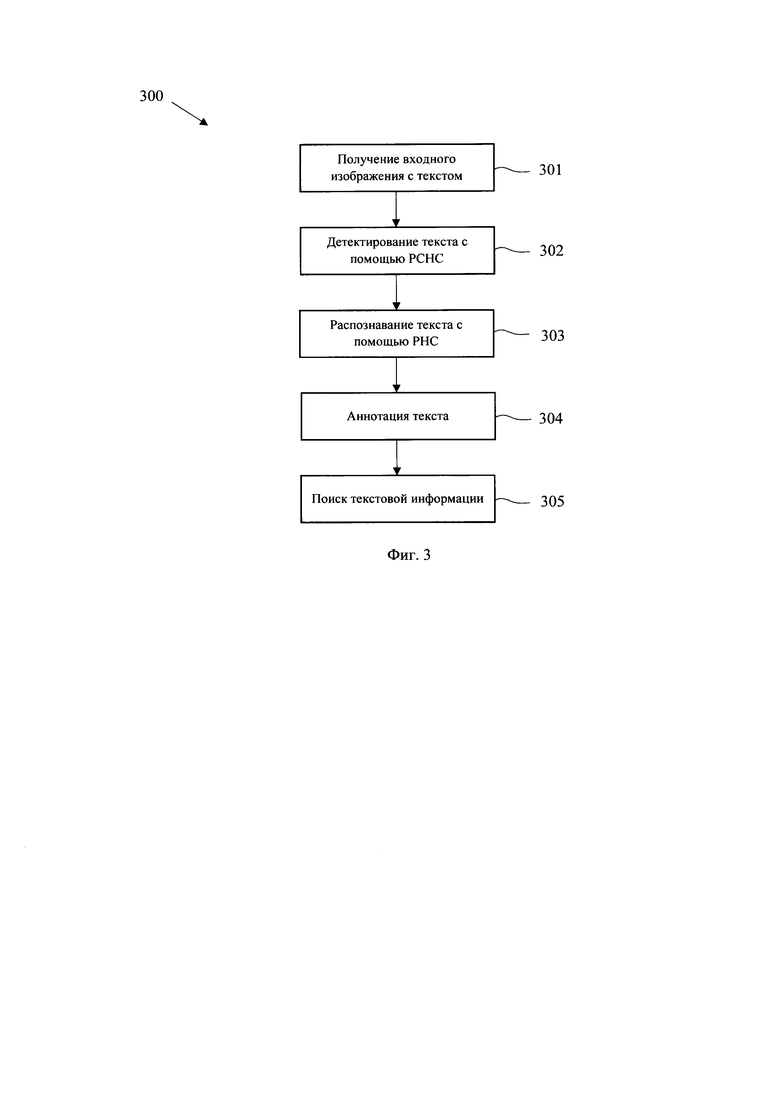
[0025] Фиг. 3 иллюстрирует блок-схему процесса обработки текстовой информации, присутствующей на изображениях.
[0026] Фиг. 4 иллюстрирует пример архитектуры взаимодействия элементов поисковой системы.
[0027] Фиг. 5 иллюстрирует пример захвата входного изображения непосредственно с помощью пользовательского устройства.
[0028] Фиг. 6 иллюстрирует пример формирования поискового индекса с выделением текстовой информации из входного изображения.
[0029] Фиг. 7 иллюстрирует пример вычислительного устройства для реализации заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0030] На Фиг. 1 представлен общий процесс выполнения заявленного способа (100) поиска изображений. На этапе (101) выполняется формирование поискового запроса, который может содержать входное изображение для последующего поиска схожей графической информации. Изображение может подаваться на вход системы в одном из применимых графических форматов, например, JPEG, PNG, TIFF, PNG и т.п.
[0031] Входное изображение обрабатывается с помощью алгоритмов библиотеки OpenCV и Pillow (102) для его приведения в требуемый вид и качество для целей последующей работы поискового механизма. Данный этап более детально будет рассмотрен с отсылкой к Фиг. 2.
[0032] Начальным шагом для формирования модели анализа изображений является получение первичного («сырого») набора данных, на которых будет строиться обучающая выборка для ИНС. Набор первичных данных может представлять собой массив пар неразмеченных изображений различного разрешения в черно-белом и цветном представлении и файлов XML, содержащих набор атрибутов для изображения согласно требованиям патентного законодательства (к таким атрибутам относятся данные о правообладателе, дате и месте регистрации, перечень классов МКТУ/МКПО, в которых зарегистрирован объект, срок действия правовой охраны, текстовое описание объекта, текстовая расшифровка объекта, если он содержит текстовую информацию и др.).
[0033] Способ (200) формирования обучающей выборки для ИНС заключается в процессе предобработки (201) каждого входного изображения с помощью набора алгоритмов открытых библиотек OpenCV и Pillow. Данные алгоритмы включают в себя: изменение масштаба изображения (2011), перевод изображения в бинарный черно-белый вид (2012), выделение контуров изображения (2013), размытие изображения (2014), удаление шумов (2015), генерирование дополнительных изображений с искажениями (2016), которые могут имитировать различное аугментированные изображения, в частности, другого качества, перспективы, формировать повороты изображения и т.п.. Для вышеупомянутых алгоритмов осуществляется подбор гиперпараметров, обеспечивающих должное качество обработки изображения с получением требуемого результата. Применение библиотек OpenCV и Pillow позволяет на основании преобразований каждого входного изображения подготовить обучающую выборку для ИНС, которая впоследствии будет применяться для поиска схожих изображений.
[0034] Преобразования изображения выполняются с помощью библиотек OpenCV и Pillow и применяются последовательно к каждому изображению из обучающей выборки. С помощью алгоритма (2011) изображение приводится к размеру 224x224 пикселя без искажений (недостающая часть заполняется черным цветом). С помощью алгоритма (2012) независимо от исходного цветового режима изображение переводится в градации серого. На данном шаге формируется фиктивный режим RGB из одного канала градации серого (цвет изображения не меняется, но теперь оно содержит три одинаковых цветовых канала, что является необходимым для работы модели представления данных).
[0035] С помощью алгоритма выделения контуров (2013) на изображении выделяются контуры (увеличивается их толщина) для более четкого определения границ объектов. Экспериментальным путем было установлено, что для лучшего качества обучения модели распознавания изображения, контуром стоит считать любую линию, в том числе и перепад между цветами (за исключением градиентных областей). С помощью алгоритма размытия (2014) изначально высококонтрастные изображения (с большим перепадом значений смежных пикселей) сглаживаются на границах цветовых элементов. В результате получается изображение, которое имеет четкие, но однородные контуры. С помощью алгоритма (2015) удаляются шумы (отдельные высококонтрастные пиксели на фоне одного цвета). С помощью алгоритма аугментации (2016) к исходному изображению применяются несколько фильтров, которые наносят искажения (шум, поворот по осям координат, сдвиг изображения относительно начала координат). При этом сохраняется исходное изображение, что позволяет сформировать минивыборку исходного изображения и набора аугментированных изображений к нему. Это позволяет сделать модель более устойчивой к различного рода искажениям на изображении из запроса.
[0036] Каждое обработанное на этапе (201) изображение на этапе (202) кодируется в векторное представление для формирования обучающей выборки ИНС (203). Эта процедура включает в себя алгоритм аннотации данных, алгоритм базовой обработки изображений, использование модели для представления изображений в виде вектора и модели формирования пространства для хранения и доступа к созданным векторам.
[0037] Модель представления данных в векторном виде основана на технологии конволюционных (сверточных) нейронных сетей (CNN). Используется глубокая CNN на основе архитектуры CLIP. На входе изображение переводится в матричное представление, где каждый элемент отражает значение конкретного пикселя картинки. Далее эта матрица проходит ряд линейных и нелинейных преобразований, в результате которых получается новая матрица значений, содержащая в себе информацию о ключевых элементах изображения и их положения в композиции. Далее через алгоритм максимизации значений ключевых точек получается плоский вектор высокой размерности (512 элементов). Все вектора сохраняются в базе данных.
[0038] Для модели использована реализация CLIP ViT-B/32, которая была предварительно обучена на наборе данных ImageNet (около 10 млн. изображений, разбитых на 1000 классов). Из модели был исключен ряд последних слоев, которые слишком сильно усредняют информацию об изображении для его последующей классификации. Некоторые существующие решения пытаются классифицировать изображение по классам МКТУ/МКПО, но на практике, в отсутствие сильной связи между изображением и классом, это дает нерелевантные результаты поиска.
[0039] В ходе экспертиментов был выбран один из активационных слоев сети, который возвращает вектор размерностью 512x3x1 и содержит абстрактное представление изображения. Далее, к полученному вектору применяется векторное преобразование, основанное на методе RMAC. Данный метод позволяет максимизировать значения тех элементов вектора, которые соответствуют позициям максимального перепада цвета в исходном изображении. Это позволяет выделить информацию о наборе контуров в изображении. Результатом работы метода является одномерный вектор размерностью 512. Все полученные вектора сохраняются в формат HDF5 - основной формат для хранения векторных данных большой размерности. Такой подход позволяет учитывать особенности поиска сходных изображений для поставленной задачи, а именно - приоритет контуров и композиции над цветовой палитрой.
[0040] На основе векторов из базы данных с использованием open-source решений архитектуры ANN (приближенный поиск ближайших соседей с помощью иерархических графов) создается поисковый индекс для всех векторов в базе данных (фактически происходит расчет системы координат и размещение векторов в этой системе). Модель формирования пространства векторов основана на алгоритмах поиска ближайших соседей HNSW (https://arxiv.org/ftp/arxiv/papers/1603/1603.09320.pdf) и FAISS (https://nlpub.mipt.ru/Faiss), которые позволяют кластеризовать полученные вектора таким образом, что в пределах одного кластера располагаются вектора, минимально отличающиеся друг от друга максимальным количеством элементов. Благодаря этому появляется возможность, взяв любой вектор, выделить группу векторов, которые входят в его кластер. Такие вектора соответствуют изображениям из первичных данных, которые максимально похожи на исходный вектор.
[0041] Валидация модели формирования пространства реализуется с помощью тестовой выборки изображений, которая содержит массивы данных следующей структуры: целевое изображение из запроса + противопоставленные изображения, которые сигнализируют о том, что сходство настолько велико, что изображение из запроса несет риск отказа в регистрации в качестве товарного знака или промышленного образца. Точность работы оценивалась по количеству противпоставленных изображений, которые модель возвращала в ответ на изображение из запроса в пределах первых 20 результатов. В случае если в ответе содержатся все противпоставленные изображения, модель получает оценку 1, если ни одного - 0, если часть изображений присутствует - 0,5 независимо от количества. Тестовая выборка была составлена с привлечением специалистов в области интеллектуальной собственности. В выборку были включены только практические примеры, с которыми сталкивались специалисты. Массив тестовых данных составил 50 примеров. По метрике точности AUC (Accuracy) были достигнуты следующие результаты: 91% при учете только полных противопоставлений (1 и 0); 95% при равном учете оценок 1 и 0,5.
[0042] При получении нового изображения в запросе на этап (101), оно проходит алгоритм аннотации, алгоритм базовой обработки, алгоритм извлечения текста (опционально) и с помощью модели представлений на этапе (103) кодируется в вектор фиксированной величины. Далее на этапе (104) полученный вектор временно помещается в ранее созданное векторное пространство с помощью модели представления данных на базе ИНС. Алгоритм базовой обработки на этапе (102) включает в себя преобразования входного изображения с помощью применения алгоритмов, указанных в способе (200)
[0043] Алгоритм аннотации на основе ElasticSearch (в данном случае под алгоритмом аннотации понимается создание аналога обратного поискового индекса ElasticSearch -Inverted Index (https://ru.wikipedia.org/wiki/Инвертированный_индекс), который помимо текста также может хранить в себе векторное представление изображений, формирует матрицу размерностью «Кол-во изображений» X «кол-во классов МКТУ/МКПО + кол-во атрибутов изображения из файла XML» и размещает ее в базе данных PostgreeSQL. Все текстовые значения из матрицы проходят индексацию на основе поискового алгоритма ElasticSearch для возможности проведения текстового поиска в первичных данных. Состав выборки может быть расширен за счет алгоритма извлечения текста из изображения и поиска среди первичных данных на основании текстовой аннотации, который будет раскрыт далее в настоящем описании.
[0044] Модель формирования пространства векторов, полученных на наборе первичных данных, возвращает индексы векторов, соответствующих максимально похожим изображениям в первичных данных по отношению к вектору изображения из поискового запроса. На основании индексов формируется выборка изображений из первичного набора данных и их выдача по итогам обработки поискового запроса (105).
[0045] Каждое входное изображение также может анализироваться с помощью способа выявления и обработки текстовой информации (300) на предмет выявления такой информации. Классификация текстуальности (для изображений, которые содержат только нестилизованный текст, и по факту являются текстовыми/словесными товарными знаками) может выполняться с помощью модели Mask-CNN, которая классифицирует изображение в один из двух классов - только текст/все другие изображения.
[0046] При работе с РИД, такими как товарные знаки и промышленные образцы, зачастую текстовая информация может иметь доминирующий характер и должна также анализироваться на предмет возможного пересечения, например, при анализе наличия схожих обозначений, либо возможного смешения со словесными (текстовыми) товарными знаками.
[0047] Если входное изображение содержит текстовую информацию (301), то выполняется его обработка с помощью вышеуказанных алгоритмов OpenCV и Pillow, а также последующее применение двух моделей машинного обучения для детектирования и распознавания текста. На этапе (302) осуществляется выявления местоположения на изображении текстовой информации с помощью модели машинного обучения на базе рекуррентной сверточной нейронной сети (РСНС), например, MaskRCNN. Данная РСНС проверяет наличие текста на изображении и формирует координаты его местоположения. Если текст не найден, алгоритм прекращает работу. Если текст найден, его координаты передаются второй ИНС на основе алгоритма СНС (303), которая переводит фрагмент изображения по указанным координатам в текст.
[0048] Далее полученный текст передается в виде запроса в поисковый алгоритм ElasticSearch (304), который на основе ранее построенного обратного поискового индекса проводит поиск в базе данных по атрибуту текстуального описания изображений (305). Найденные изображения включаются в общий результирующий ответ на поступивший запрос на этапе (101). В этом случае приоритет в ответе имеют изображения, которые были получены в результате работы моделей представления и формирования векторного пространства данных.
[0049] Дополнительно входящий запрос на поиск изображений может содержать уточняющие параметры, например, принадлежность к классам МКТУ или МКПО, данным правообладателя, данным автора, дату или диапазон дат подачи или публикации документа и т.п.Фильтр полей для поиска может быть расширен и сформирован исходя из возможности аннотирования таких поисковых критериев, относительно который возможна группировка РИД.
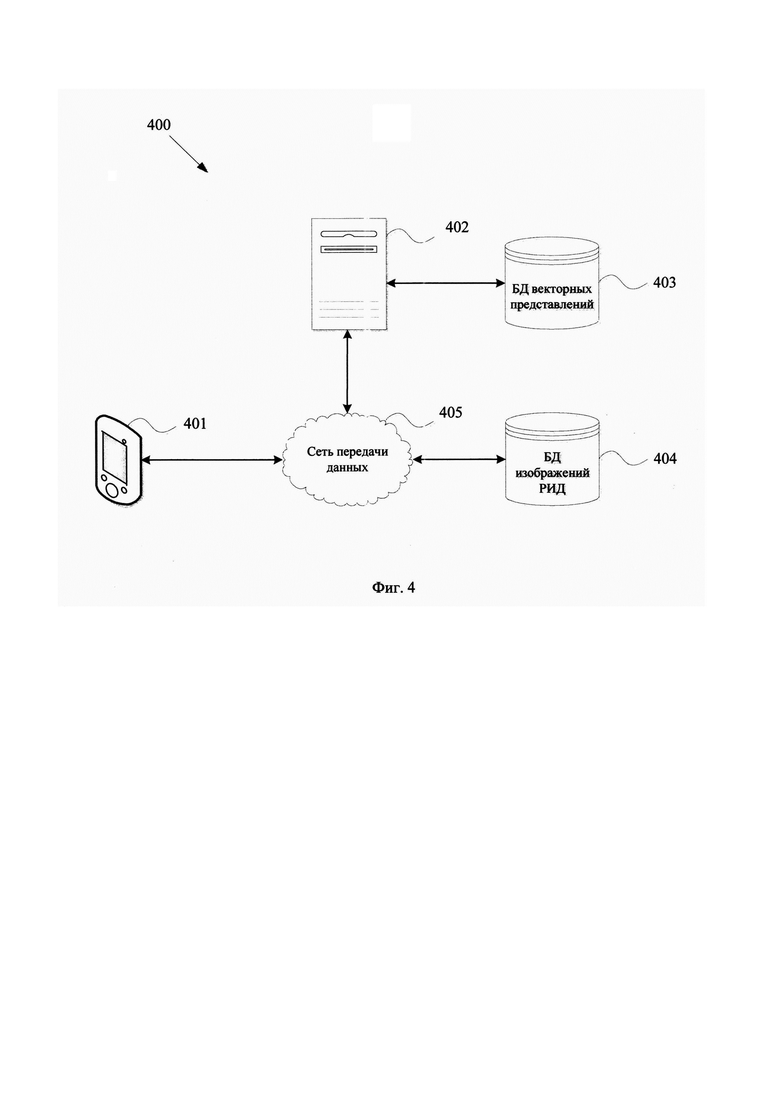
[0050] На Фиг. 4 представлен пример архитектуры системы взаимодействия (400) для доступа к заявленному поисковому сервису. Доступ может осуществляться с помощью клиент-серверной платформы, при которой основные вычислительные мощности располагаются на серверной части (402), выполняющий вышеописанные способы поиска изображений, к которой через сеть передачи данных (405) осуществляется доступ через клиентское устройство (401). В качестве сети передачи данных (405) используется сеть Интернет, организованная с помощью известных подходов для формирования канала передачи данных, например, с помощью сотовой связи, Wi-Fi, LAN и т.п.
[0051] Поисковый запрос формируется с помощью компьютерного пользовательского устройства (401). Такое устройство может представлять собой, например, смартфон, персональный компьютер, ноутбук, игровая приставка, умное носимое устройство, планшет и т.п. Запрос на выполнение поиска может осуществляться с помощью загрузки в поисковую платформу, размещенную на сервере (402) входного изображения, либо с помощью программных средств дополненной реальности, которые могут осуществлять захват изображения с помощью камеры устройства (401) и использования его в качестве входного изображения.
[0052] База данных векторных представлений (403) может храниться непосредственно на сервере (402) или располагаться на внешнем ресурсе, например, облачное хранилище данных. Такая база данных (403) хранит сформированные моделью машинного обучения вектора изображений для осуществления поискового процесса. База данных изображений РИД (404) представляет собой одно или несколько хранилищ информации, содержащее графические представления РИД, например, база данных товарных знаков или промышленных образцов. База данных изображений (404) используется для получения новых изображений для формирования поискового индекса для ИНС на сервере (402), выполняющий процесс кодирования новых изображений и обработки поступающих поисковых запросов от устройства (401).
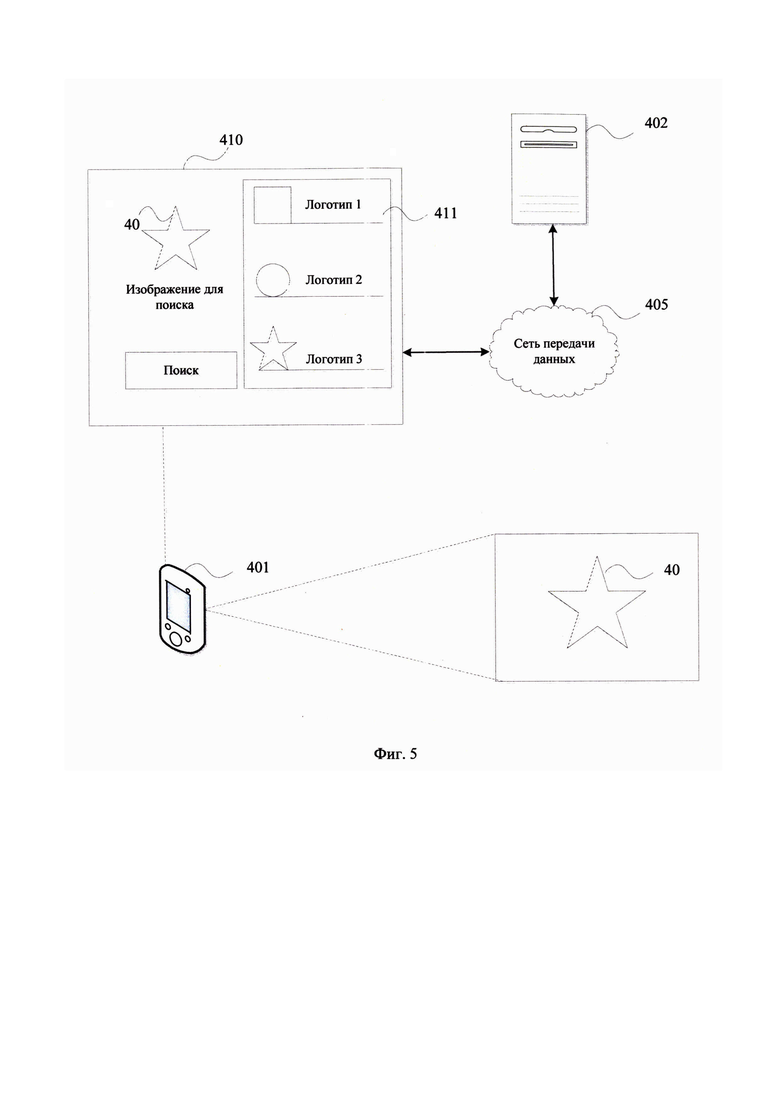
[0053] На Фиг. 5 представлен пример формирования поискового запроса с помощью захвата изображения с помощью камеры устройства (401). На полученном изображении определяется объект поиска (40), которое будет выступать в качестве входного изображения для поиска. Поиск изображений может выполняться с помощью специализированного приложения, содержащего графический интерфейс пользователя (410), обеспечиваемый требуемый функционал. По факту анализа полученного объекта поиска (40) выполняется отображение выявленных схожих изображений (411).
[0054] На Фиг. 6 представлен пример обработки входного изображения (40) с помощью вышеуказанной модели распознавания текстовой информации. Изображение (40) разделяется на графическую (41) и текстовую информацию (42). Текстовая информация с помощью способа (300) обрабатывается для формирования поискового индекса. При обработке входных изображений может применяться также технология, описанная в статье Character Region Awareness for Text Detection (Youngmin Baek et al. arXiv:1904.01941v1 [cs.CV] 3 Apr 2019). При использовании данного подхода используются алгоритмы машинного обучения, которые выделяют каждый символ (421) - (428) из захваченного изображения и передаваться в обученную ИНС, обученную на двумерных Гауссовских преобразованиях для каждого буквенного символа, что позволяет более точно распознать каждый текстовый символ.
[0055] На Фиг. 7 представлен пример общего вида вычислительного устройства (500), на базе которого может быть реализована одна или несколько автоматизированных систем, обеспечивающих реализацию заявленного способа выполнения поискового процесса, обработки данных и сопутствующих этапов обработки данных. Упомянутые в настоящих материалах заявки такие устройства, как сервер, устройство пользователя и т.д. могут выполняться полностью или частично на базе устройства (500).
[0056] В общем случае, устройство (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (502) и ПЗУ (503), интерфейсы ввода/вывода (504), устройства ввода/вывода (505), и устройство для сетевого взаимодействия (506).
[0057] Процессор (501) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в устройстве (500) также необходимо учитывать графический процессор, например, GPU NVIDIA или Graphcore, тип которых также является пригодным для полного или частичного выполнения вышеописанных одного или нескольких способов обработки данных, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[0058] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (502) может выступать доступный объем памяти графической карты или графического процессора.
[0059] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0060] Для организации работы компонентов устройства (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0061] Для обеспечения взаимодействия пользователя с устройством (500) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор, мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0062] Средство сетевого взаимодействия (506) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (506) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0063] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| Устройство для семантической классификации и поиска в архивах оцифрованных киноматериалов | 2016 |
|
RU2628192C2 |
| СИСТЕМА И СПОСОБ АУГМЕНТАЦИИ ОБУЧАЮЩЕЙ ВЫБОРКИ ДЛЯ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2758683C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| Способ и система для хранения множества документов | 2018 |
|
RU2744028C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| Способ и сервер для определения обучающего набора для обучения алгоритма машинного обучения (MLA) | 2020 |
|
RU2817726C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |


Настоящее изобретение относится к области компьютерной техники, в частности к обработке цифровых данных для поиска графической информации. Заявленное изобретение осуществляется за счет выполнения компьютерно-реализуемого способа поиска графических изображений, выполняемого с помощью процессора и содержащего этапы, на которых: выполняют обработку входного изображения с помощью алгоритмов библиотек OpenCV и Pillow, с помощью которых выполняется перевод изображения в градации серого и удаление шума, причем при удалении шума удаляются высококонтрастные пиксели входного изображения на фоне одного цвета; с помощью модели машинного обучения на базе искусственной нейронной сети (ИНС), обученной на графических изображениях и содержащей базу данных их векторных представлений, выполняют обработку входного изображения, в ходе которого переводят изображение в пиксельную матрицу, по которой определяются ключевые параметры изображения и их расположение во входном изображении, и формируют векторное представление изображения с помощью алгоритма максимизации; формируют поисковый индекс для входного изображения с помощью сравнения близости векторного представления входного изображения с векторными представлениями в базе данных ИНС, причем сравнение выполняется с помощью алгоритма приближенного поиска ближайших соседей, основанного на иерархических графах, которые позволяют кластеризовать полученные векторы таким образом, что в пределах одного кластера располагаются векторы, минимально отличающиеся друг от друга максимальным количеством элементов; определяют и предоставляют по меньшей мере одно изображение из базы данных на основании сравнения векторных представлений по упомянутому поисковому индексу. Технический результат - повышение точности и скорости поиска графической информации. 2 н. и 9 з.п. ф-лы, 7 ил.
1. Компьютерно-реализуемый способ поиска графических изображений, выполняемый с помощью процессора и содержащий этапы, на которых:
- получают входное изображение, на основании которого формируют поисковый запрос;
- выполняют обработку входного изображения с помощью алгоритмов библиотек OpenCV и Pillow, с помощью которых выполняется перевод изображения в градации серого и удаление шума, причем при удалении шума удаляются высококонтрастные пиксели входного изображения на фоне одного цвета;
- с помощью модели машинного обучения на базе искусственной нейронной сети (ИНС), обученной на графических изображениях и содержащей базу данных их векторных представлений, выполняют обработку входного изображения, в ходе которого переводят изображение в пиксельную матрицу, по которой определяются ключевые параметры изображения и их расположение во входном изображении, и формируют векторное представление изображения с помощью алгоритма максимизации;
- формируют поисковый индекс для входного изображения с помощью сравнения близости векторного представления входного изображения с векторными представлениями в базе данных ИНС, причем сравнение выполняется с помощью алгоритма приближенного поиска ближайших соседей, основанного на иерархических графах, которые позволяют кластеризовать полученные векторы таким образом, что в пределах одного кластера располагаются векторы, минимально отличающиеся друг от друга максимальным количеством элементов;
- определяют и предоставляют по меньшей мере одно изображение из базы данных на основании сравнения векторных представлений по упомянутому поисковому индексу.
2. Способ по п. 1, характеризующийся тем, что изображения выбираются из группы: товарные знаки и/или промышленные образцы.
3. Способ по п. 2, характеризующийся тем, что на этапе формирования поискового запроса выполняется аннотация входного изображения на предмет выявления и распознавания текстовой информации.
4. Способ по п. 3, характеризующийся тем, что выявленная текстовая информация на входном изображении добавляется в поисковый запрос.
5. Способ по п. 2, характеризующийся тем, что дополнительно уточняют поисковый индекс с помощью по меньшей мере одного дополнительного параметра входного изображения, выбираемого из группы: принадлежность к классам МКТУ или МКПО, данным правообладателя, данным автора, дату или диапазон дат подачи или публикации документа.
6. Способ по п. 1, характеризующийся тем, что ИНС представляет собой глубокую сверточную нейронную сеть (ГСНС).
7. Способ по п. 1, характеризующийся тем, что на этапе обработки входного изображения выполняется ряд преобразований изображения, которые включают в себя: приведение изображения к размеру 224×224 пикселя без искажений, формирование фиктивного режима RGB из одного канала градации серого.
8. Способ по п. 7, характеризующийся тем, что при формировании фиктивного режима RGB формируется три одинаковых цветовых канала.
9. Способ по п. 3, характеризующийся тем, что выявление текстовых данных на входном изображении осуществляется с помощью сверточной рекуррентной нейронной сети (СРНС), обученной на предмет классификации текстовой информации и обеспечивающей определение координат найденной информации на изображении.
10. Способ по п. 9, характеризующийся тем, что выявленная текстовая информация обрабатывается рекуррентной нейронной сетью (РНС), выполняющей преобразование фрагмента изображения в текстовую форму.
11. Система поиска графических изображений, содержащая по меньшей мере один процессор и средство памяти, хранящее машиночитаемые инструкции, которые при их исполнении процессором выполняют способ по любому из пп. 1-10.
| CN 112884005 A, 01.06.2021 | |||
| CN 112580574 A, 30.03.2021 | |||
| US 2021303903 A1, 30.09.2021 | |||
| WO 2017134519 A1, 10.08.2017 | |||
| CN 102622420 B, 30.10.2013 | |||
| WO 2019237646 A1, 19.12.2019 | |||
| CN 107122375 A, 01.09.2017. |
