Нижеследующее относится к области генетических анализов, медицинской области и к их применению, например, в медицинской области, в том числе, в области онкологии, области ветеринарии и так далее.
Геномный анализ различных тканей человека привел к более глубокому пониманию клеточных путей и различных патологических состояний на биомолекулярном уровне. Анализ различных злокачественных тканей по отношению к образцам нормальной ткани делает возможным более глубокое понимание опухолеродных процессов и способствует усовершенствованному определению стадии и подклассификации различных злокачественных новообразований. Многие исследования также показали, что сигнатуры экспрессии генов, которые могут содержать один, несколько, дюжины или сотни генов, могут значительно улучшать диагностическую классификацию, прогнозирование и предсказание терапевтического ответа при злокачественной опухоли.
В клинической обстановке геномный анализ можно использовать для того, чтобы определять характеристики повреждения. Однако такая практика влечет за собой получение ткани из повреждения через инвазивную биопсию. Процедура не подходит для некоторых пациентов со злокачественными опухолями, которые часто находятся в ослабленном физическом состоянии, поскольку это вызывает физических и психологический стресс и создает возможность для инфицирования места биопсии.
В отличие от геномных исследований, визуализирующие исследования представляют собой часть обычного клинического ухода. Медицинская визуализация с использованием таких способов, как магнитный резонанс (MR), компьютерная томография (CT) и так далее, в целом является неинвазивной (несмотря на то, что можно вводить внутривенное контрастное средство), и она получила широкое одобрение как среди практикующих медиков, так и среди пациентов. Визуализация может предоставлять важную анатомическую и морфологическую информацию. В таких модальностях, как позитронно-эмиссионная томография (PET), также можно получать функциональную информацию.
Интегрированное фенотипирование относится к способам, в которых устанавливают корреляцию между радиологическими данными (т.е. медицинскими изображениями) и геномными данными (например, данные генетического секвенирования, данные микрочипов и так далее). См., например, Gevaert et al, «Non-small cell lung cancer: identifying prognostic imaging bio маркер by leveraging public gene expression microarray data-methods and preliminary results», Radiology, том 264(2), страницы 387-96 (август 2012 года); Rutman et al, «Radiogenomics: creating a link between molecular diagnostics and diagnostic imaging», Eur J Radiol., том 70(2), страницы 232-41 (2009 год); Segal et al, «Decoding global gene expression programs in liver cancer by noninvasive imaging», Nat Biotechnol., том 25(6), страницы 675-80 (2007 год). В способах интегрированного фенотипирования конкретные опухолевые визуализационные фенотипы служат в качестве посредника для сигнатур экспрессии генов, сообщающего неинвазивный, но точный диагноз в отношении подтипа опухоли и молекулярной биологии.
В WO 2009/105530 A2 описаны способ и устройство для классификации возможно злокачественных повреждений по наборам DCE-MRI изображений, которые включают получение набора MRI изображений срезов, получаемых в соответствующие различные моменты времени, где каждое изображение среза содержит воксели, характеризующие по меньшей мере одну область, представляющую интерес (ROI). Изображения обрабатывают для того, чтобы определять границы ROI, и обрабатывают воксели внутри идентифицированных границ в соответствующих областях изображения из каждого периода времени для того, чтобы извлекать кинетические признаки текстуры. Кинетические признаки текстуры затем используют в процессе классификации, который классифицирует ROI как злокачественную или доброкачественную. Злокачественные повреждения дополнительно классифицирует для того, чтобы отделять TN-повреждения от не TN-повреждений.
Далее рассмотрены усовершенствованные устройства и способы, в которых преодолены указанные выше и другие ограничения.
По одному из аспектов предложен постоянный запоминающий носитель, который хранит инструкции, исполняемые с помощью устройства обработки электронных данных для того, чтобы осуществлять способ, как определено в пункте 1 формулы изобретения. Вычисление значений признаков текстуры изображения может включать вычисление одой или нескольких матриц совместной встречаемости уровней яркости (GLCM) для изображения анатомического признака, представляющего интерес, у субъекта, и вычисление значений признаков текстуры изображения на основе одной или нескольких GLCM. Набор признаков текстуры изображения может включать признаки текстуры изображения Haralick и/или Tamura или признаки Gabor или признаки участка полосы частот вейвлета. Способ дополнительно может включать: вычисление эталонных значений признаков текстуры изображения для по меньшей мере набора признаков текстуры изображения из изображений анатомического признака, представляющего интерес, у эталонных субъектов эталонной популяции; деление эталонных значений признаков текстуры изображения на различные популяционные группы, представляющие различные значения молекулярного признака, представляющего интерес, на основе известных значений молекулярного признака, представляющего интерес, для эталонных субъектов; и обучение классификатора, используемого при классификации, для того, чтобы различать различные популяционные группы на основе эталонных значений признаков текстуры изображения.
По другому аспекту устройство содержит постоянный запоминающий носитель, как изложено непосредственно в предшествующем абзаце, и устройство обработки электронных данных, выполненное с возможностью исполнять инструкции, хранимые в постоянном запоминающем носителе.
По другому аспекту способ (соответственно выполняемый посредством устройства обработки электронных данных) включает признаки, как определено в пункте 14 формулы изобретения. Вычисление эталонных значений признаков текстуры изображения может включать вычисление одной или нескольких матриц совместной встречаемости уровней яркости (GLCM) для каждого изображения, и вычисление эталонных значений признаков текстуры изображения на основе одной или нескольких GLCM. Множество признаков текстуры изображения может включать по меньшей мере одно из признаков текстуры изображения Haralick и признаков текстуры изображения Tamura. Обучение может включать: осуществление одномерного анализа для каждого признака текстуры изображения из множества признаков текстуры изображения для того, чтобы количественно определять статистическую значимость каждого признака текстуры изображения для того, чтобы различать различные популяционные группы; выбор значимого поднабора признаков текстуры изображения из множества признаков текстуры изображения, имеющего наивысшую статистическую значимость; и обучение классификатора с использованием только значимого поднабора признаков текстуры изображения. Способ дополнительно может включать: вычисление значений признаков текстуры изображения по меньшей мере для некоторых из множества признаков текстуры изображения по изображению анатомического признака, представляющего интерес, у тестируемого субъекта, и классификацию тестируемого субъекта, соответствующего молекулярному признаку, представляющему интерес, с использованием обученного классификатора.
В приведенных выше аспектах, анатомический признак, представляющий интерес, может представлять собой повреждение, например, повреждение молочной железы, и молекулярный признак, представляющий интерес, может представлять собой маркер гормонального рецептора, например, маркер эстрогенового рецептора (ER) или маркер прогестеронового рецептора (PR). В приведенных выше аспектах изображения могут представлять собой магнитно-резонансные (MR) изображения. В приведенных выше аспектах, субъекты могут представлять собой субъектов-людей, например, пациентов, или ветеринарных субъектов (например, собак или кошек).
Одно преимущество основано на неинвазивной идентификации молекулярного признака в ткани на основе комбинации признаков текстуры.
Другое преимущество основано на предоставлении общего подходя для разработки классификатора для того, чтобы классифицировать ткань, соответствующую молекулярному признаку на основе данных визуализации.
Многие дополнительные преимущества и эффекты будут видны специалистам в данной области при прочтении следующего подробного описания.
Изобретение может принимать форму различных компонентов и компоновок компонентов, а также различных операций процесса и последовательностей операций процесса. Чертежи приведены только с целью иллюстрировать предпочтительные варианты осуществления, и их не следует толковать в качестве ограничения изобретения.
На фиг. 1 схематически представлена система для разработки классификатора для того, чтобы классифицировать ткань в соответствии и с молекулярным признаком на основе данных визуализации.
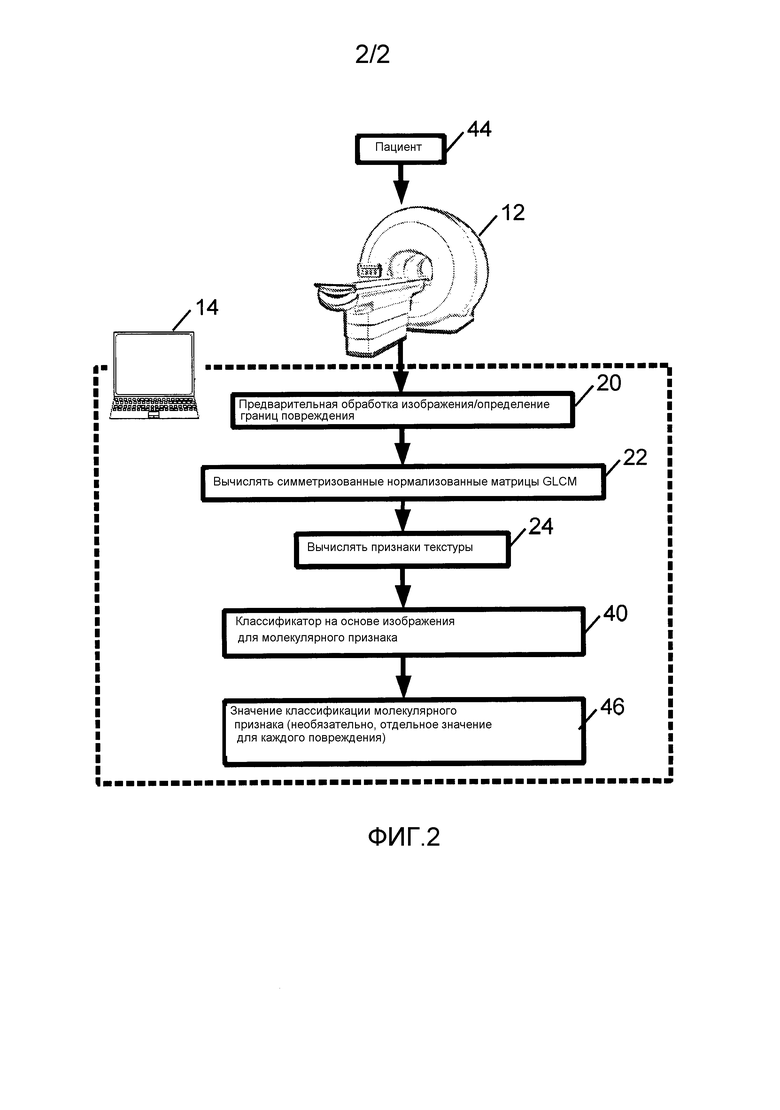
На фиг. 2 схематически представлена система для идентификации молекулярного признака в ткани на основе комбинации признаков текстуры.
В настоящем документе описаны способы интегрированного фенотипирования, в которых используют признаки текстуры, например, вычисленные по матрице совместной встречаемости уровней яркости (GLCM), генерируемой по изображению повреждения или части изображения повреждения. Признак текстуры представляет собой свойство интенсивности (обычно усредняемое по площади или объему) и, соответственно, не зависит (за исключением статистических вариаций) от размера или геометрической формы повреждения на изображении. Можно быстро вычислять большое число различных признаков текстуры. Текстура медицинского изображения представляет пространственную вариацию в масштабе размеров, которые больше, чем разрешение изображения (размер пикселя или вокселя), которое типично порядка миллиметров на медицинских изображениях, получаемых посредством магнитно-резонансных (MR), компьютерно-томографических (CT) или других стандартных способов медицинской визуализации. Таким образом, пространственный масштаб текстуры изображения имеет порядок величины, большей, чем размер гена, белка или другого молекулярного признака, представляющего интерес.
Однако, к удивлению, авторы изобретения обнаружили, что некоторые признаки текстуры изображения проявляют статистически значимую корреляцию с молекулярными признаками. Кроме того, авторы изобретения обнаружили, что выраженность статистической корреляции между признаком текстуры изображения и данным молекулярным признаком широко варьирует среди различных признаков текстуры изображения. В экспериментах, проведенных авторами изобретения, корреляция между молекулярным признаком и признаком текстуры изображения, как измеряют посредством статистической значимости (p-значение, вычисленное с использованием критерия суммы рангов Вилкоксона), варьирует больше чем на порядок величины среди различных признаков из набора признаков текстуры Haralick. Без ограничения какой-либо конкретной методикой работы, полагают, что эта корреляция между текстурой и молекулярным признаком является последствием влияния молекулярного признака пространственную структуру малого масштаба (локальное окружение) ткани повреждения. Поскольку эта пространственная структура малого масштаба может иметь различные характеристики (например, симметрию, анизотропию, периодичность, паттерны, масштабы размеров и так далее) в зависимости от конкретного молекулярного признака, варьирует выраженность корреляции между молекулярным признаком и различными признаками текстуры изображения.
Ввиду приведенного выше, в настоящем документе описана разработка и использование медицинского диагностического классификатора для классификации повреждения с учетом молекулярного признака на основе значений набора отличительных признаков текстуры изображения.
Со ссылкой на фиг. 1, описана иллюстративная система для разработки такого классификатора. Эталонных субъектов популяции 10 эталонных субъектов визуализируют с использованием магнитно-резонансного (MR) сканера 12 (проиллюстрирован MR сканер Philips Achieva 1,5T, доступный в Koninklijke Philips Electronics NV, Eindhoven, Netherlands, но подходят и другие MR сканеры). Эталонные субъекты популяции 10 подвергаются подходящим диагностическим исследованиям для того, чтобы определять, имеет ли каждый эталонный субъект молекулярный признак или он молекулярного признака не имеет. (В более общем смысле, значение молекулярного признака, представляющего интерес, известно для каждого эталонного субъекта популяции 10). В качестве иллюстративного примера, эталонными субъектами могут быть женщины с повреждениями молочной железы, которые прошли биопсию, а молекулярным признаком, представляющим интерес, может быть маркер злокачественной опухоли молочной железы, такой как маркер эстрогенового рецептора (ER), непосредственно оцениваемый с помощью анализа на микрочипе, тестов на основе полимеразной цепной реакции (ПЦР), генетического (ДНК или РНК) секвенирования, гистопатологического анализа или так далее, осуществляемого на образцах, полученных посредством биопсии (или хирургического вмешательства). В целом, молекулярный признак, представляющий интерес, может представлять собой отдельный ген, группу генов, путь активации гена, некодирующую РНК, множественные РНК или однонуклеотидный полиморфизм или полиморфизм числа копий или эпигенетический полиморфизм или тому подобное. В медицинских применениях, эталонными субъектами популяции 10 являются эталонные субъекты-люди; однако, раскрытые способы альтернативно можно применять в ветеринарной практике, и в этом случае эталонными субъектами, соответственно, являются эталонные собаки, эталонные кошки или тому подобное.
Для каждого эталонного субъекта популяции 10 выходные данные MR сканера 12 представляют собой медицинское изображение (или набор медицинских изображений) повреждения (или, в более общем смысле, анатомического признака, представляющего интерес, у эталонного субъекта). Следует понимать, что иллюстративный MR сканер 12 содержит электронику для реконструирования «необработанных» полученных данных визуализации (например, выборки данных о k-пространстве в случае типичной MR визуализации или проекционные данные в случае компьютерной томографии и так далее) для того, чтобы генерировать медицинское изображение, и что эта электроника также может осуществлять обработку изображения после реконструкции. Хотя в иллюстративных примерах, приведенных в настоящем документе, используют MR визуализацию или MRI с динамически усиленным контрастом, предусмотрено использование другой модальности визуализации, такой как компьютерно-томографическая (CT) визуализация. Необязательно, визуализацию можно осуществлять в сочетании с введенным экзогенным контрастным средством. Также следует принимать во внимание, что в некоторых вариантах осуществления медицинские изображения различных эталонных субъектов популяции 10 можно получать посредством двух или более различных MR сканеров.
Все также со ссылкой на фиг. 1, получаемые изображения вводят в компьютер или другое устройство 14 обработки электронных данных, которое осуществляет обработку, как схематически показано на фиг. 1 и как описано в настоящем документе. Компьютер или другое устройство 14 обработки электронных данных может представлять собой встроенный компонент MR сканера 12, например, то же самое аппаратное обеспечение, которое выполняет реконструкцию изображений; альтернативно, компьютер или другое устройство 14 обработки электронных данных может быть отделено от MR сканера 12. Осуществляемая обработка необязательно начинается с различных операций 20 предварительной обработки и/или сегментации изображения. Типично, область изображения, соответствующую повреждению, идентифицируют или очерчивают с использованием автоматизированного алгоритма сегментации и/или посредством ручного определения контуров повреждения. Последующую обработку, соответственно, осуществляют только на идентифицированной/очерченной части изображения, соответствующей повреждению. Дополнительная обработка необязательно включает квантование уровней яркости для того, чтобы снижать общее число уровней яркости (например, изображение, которое имеет 16-битные уровни яркости со значениями в диапазоне от 0 до 65535, можно квантовать до 8-битных уровней яркости со значениями в диапазоне от 0 до 255). Эту обработку 20 осуществляют для каждого изображения популяции 10. каждое изображение также помечают или иным образом связывают с значением молекулярного признака для визуализируемого человека.
В иллюстративном варианте осуществления признаки текстуры для каждой части изображения, соответствующей повреждению, вычисляют на основе матрицы совместной встречаемости уровней яркости (GLCM), которую вычисляют в операции 22. GLCM представляет собой матрицу, элементы которой хранят счеты для числа возникновения соответствующих пространственных комбинаций значений пикселей (или вокселей). Например, подходящая GLCM для двухмерного изображения с 8-битными значениями пикселей (в диапазоне от 0 до 255), соответственно, представляет собой матрицу 256×256, где элемент (i,j) хранит счет возникновений пространственной комбинации пикселя со значением i «рядом с» пикселем со значением j. (Ценность выполнения квантования становится очевидной, поскольку исходное изображение с 16-битными уровнями яркости будет использовать GLCM 65536×65536, которая имеет 4 миллиарда элементов, по сравнению с 65536 элементами для GLCM 256×256 квантованного изображения или подизображения). Различные GLCM можно определять в зависимости от выбора пространственной зависимости для «рядом с» (например, непосредственно справа, непосредственно сверху, по диагонали) и в зависимости от выбора расстояния между пикселями с значениями i и j (непосредственно смежно или разделены одним, двумя, тремя или большим числом промежуточных пикселей). В некоторых номенклатурах пиксель i обозначают как опорный пиксель, пиксель j обозначают как соседний пиксель, расстояние между пикселями i и j обозначают как смещение (например, смещение на один пиксель в случае для непосредственно смежных, смещение на два пикселя, если имеет место один промежуточный пикселе, и так далее). Также предусмотрено использовать GLCM, в которой элементы матрицы хранят счеты для более сложных пространственных расположений.
Для вычисления текстур GLCM типично симметризуют, например, посредством хранения в элементе матрицы (i, j) счета всех элементов со значениями (i, j) и со значениями (j, i), и также посредством хранения одного и того же счета в элементе матрицы (j, i). Предусмотрены другие подходы к симметризации - результат симметризации состоит в том, что значение элемента матрицы (i, j) равно значению элемента матрицы (j, i). Для вычисления текстур GLCM также типично нормализуют с тем, чтобы значение каждого элемента матрицы (i, j) представляло вероятность того, что соответствующая комбинация (i, j) (или ее симметризованная версия (i, j) или (j, i)) встречается на изображении, для которого вычисляют GLCM.
В операции 22 можно вычислять одну GLCM или можно вычислять две или более GLCM. Например, в одном из вариантов осуществления четыре симметризованных и нормализованных GLCM вычисляют - одну для горизонтального расположения со смещением =1, одну для вертикального расположения со смещением =1, одну для диагонального расположения «/» со смещением =1 и одну для диагонального расположения «\» со смещением =1. Дополнительные или альтернативые GLCM можно вычислять для различных смещений (например смещение =2) и/или для дополнительных пространственных расположений. В целом, существует по меньшей мере три различных категории признаков текстуры: модели на основе функции плотности вероятности, модели на основе общей геометрической формы и частичные модели («Texture Features for Content-based Retrieval» - Nicu Sebe and Michael S. Lew, глава в: Principles of Visual Information Retrieval, Springer, ISBN 1-852333-381-2, стр. 51-86, январь 2001 года, http://staff.science.uva.nl/~nicu/publications/texture_chapter.pdf). Модели на основе функции плотности вероятности включают 1) параметрические способы, такие как гауссово-марковское случайное поле, марковское случайное поле с кликами, признаки Вольда и 2) непараметрические способы, такие как способы совместной встречаемости уровней яркости, которые измеряют локальное взаимодействие значений интенсивности пар пикселей. Способы на основе общей геометрической формы включают, например, гармонические (автокорреляция и спектр мощности Фурье, которые измеряют периодически) или примитивные (раньше, Габор и математическая морфология) способы. Частичные способы используют фракталы и линии для того, чтобы оценивать текстуру, тогда как примитивные способы обнаруживают набор пространственно компактных перцептуальных признаков, таких как линии, ребра и экстремумы интенсивности. Иллюстративные примеры используют определенные иллюстративные признаки текстуры; однако те же способы применимы ко всем категориям моделей текстур, обозначенным выше. В операции 24 значения признаков текстуры изображения для набора признаков текстуры изображения вычисляют на основе одной или нескольких GLCM. Можно вычислять различные признаки текстуры. В некоторых вариантах осуществления набор признаков текстуры включает один или несколько признаков текстуры набора признаков текстуры Haralick (см., например, Haralick et al, «Textural Features for Image Classification», IEEE Transactions on Systems, Man and Cybernetics том SMC-3 №6, стр. 610-621 (1973)), которые вычисляют в операции 24. В качестве другого примера можно вычислять один или несколько признаков текстуры из набора признаков текстуры Tamura. См., например, Howarth et al, «Evaluation of Texture Features for Content-Based Image Retrieval», P. Enser et al. (Eds.): CIVR 2004, LNCS 3115, стр. 326-334 (2004). Также предусмотрены другие признаки текстуры, вычисляемые по GLCM. Также следует принимать во внимание, что в вариантах осуществления, в которых две или более GLCM вычисляют в операции 22, один и тот же признак текстуры можно вычислять для каждой GLCM, таким образом, генерируя эффективно различающиеся признаки текстуры одного и того же типа, но для различных GLCM. (В качестве иллюстративного примера, если двенадцать признаков Haralick вычисляют для каждой из четырех различных GLCM (например горизонтальной, вертикальной и двух противоположных диагональных расположений), то это в целом предусматривает 48 признаков текстуры.
Эти признаки текстуры представляют собой свойства интенсивности изображения повреждения и не зависят от размера или геометрической формы повреждения на медицинском изображении. GLCM вычисляют посредством подсчета встречаемости пространственных расположений на изображении, таким образом, эффективно выполняя усреднение по изображению. Признаки текстуры, вычисляемые с использованием GLCM различных пространственных расположений, предоставляют возможность захвата пространственной структуры малого масштаба, которая имеет различающиеся направления анизотропии или симметрии. Признаки текстуры, вычисляемые с использованием GLCM с различными значениями смещения, обеспечивают возможность захвата пространственной структуры малого масштаба, имеющей различающиеся пространственные масштабы. Кроме того, различные типы признаков текстуры, например, различные признаки текстуры из набора Haralick, захватывают различные визуальные, статистические, информационные и/или корреляционные аспекты текстуры. Таким образом, набор признаков текстуры, выводимых посредством операций 22, 24, содержит обилие информации о пространственной структуре повреждения малого масштаба.
С другой стороны, нет очевидной причинный ожидать, что данный молекулярный признак привнесет конкретную пространственную структуру малого масштаба, захватываемую на изображении, и поэтому нет априорной причины ожидать, что какой-либо конкретный признак текстуры будет коррелировать с каким-либо конкретным молекулярным признаком. В действительности, неочевидно, что данный молекулярный признак, представляющий интерес, такой как молекулярный признак, связанный со злокачественной опухолью молочной железы, вовсе должен иметь какое-либо влияние на пространственную структуру малого масштаба. Как описано в настоящем документе, экспериментально установлено, что имеет место определенная корреляция между молекулярным признаком и признаком текстуры изображения в случае некоторых молекулярных признаков и для некоторых признаков текстуры изображения.
Все также со ссылкой на фиг. 1, значения признаков текстуры изображения, генерируемые с помощью операций 22, 24 для набора признаков текстуры изображения, следовательно, используют для тог, чтобы эмпирически обнаруживать отличительные признаки текстуры, а также для того, чтобы генерировать классификатор, использующий комбинацию отличительных признаков текстуры для того, чтобы классифицировать ткань, соответствующую молекулярному признаку, представляющему интерес. С этой целью помеченные или иным образом известные значения молекулярных признаков для эталонных субъектов популяции 10 используют для того, чтобы делить значения признаков текстуры изображения, генерируемые с помощью операций 22, 24, на две популяционные группы: (1) популяционная группа 30, которая содержит значения признаков текстуры изображения для эталонных субъектов с молекулярным признаком, представляющим интерес, (например ER+ в одном иллюстративном примере пациентов со злокачественной опухолью молочной железы); и (2) популяционная группа 32, которая содержит значения признаков текстуры изображения для эталонных субъектов без молекулярного признака, представляющего интерес (например, ER-).
Одномерный анализ 34 используют для того, чтобы идентифицировать отличительные признаки текстуры, которые можно использовать для того, чтобы различать две популяционные группы 30, 32. В подходящем подходе для каждого признака текстуры изображения осуществляют тест на статистическую значимость. Принимают нуль-гипотезу о том, что анализируемый признак текстуры не является отличительным, и критерий проверки статистической гипотезы, такой как критерий суммы рангов Вилкоксона или критерий Стьюдента применяют для того, чтобы генерировать p-значение, отражающее вероятность того, что значения анализируемых признаков текстуры изображения будут иметь распределение, наблюдаемое в популяционных группах 30, 32, если эта нуль-гипотеза верна. Более низкое значение для p-значения указывает на более низкую вероятность наблюдения распределения значений в популяционных группах 30, 32, если признак текстуры не коррелирует с молекулярным признаком (ER+ в сравнении с ER- в приведенном выше примере), или, наоборот, низкое значение p-значения указывает на то, что анализируемый признак текстуры изображения является отличительным для молекулярного признака, представляющего интерес.
Многомерный анализ 36 используют для того, чтобы для молекулярного признака генерировать классификатор 40 на основе изображения. В многомерном анализе 36, соответственно, используют набор статистически значимых признаков текстуры изображения, идентифицируемых посредством одномерного анализа 34. Можно использовать различные подходы для обучения классификатора, например, способ опорных векторов (SVM), нейронную сеть, генетические алгоритмы или тому подобное. Выходные данные многомерного анализа 36 представляют собой классификатор, работающий на наборе статистически значимых признаков текстуры изображения. Многомерный анализ 36 генерирует классификатор 40, который различает популяционные группы 30, 32, эталонные субъекты которой имеют различные соответствующие значения для молекулярного признака, представляющего интерес. Молекулярный признак, т.е. Фенотип, можно охарактеризовать с помощью состояния экспрессии одного гена (например ESR1 для определения положительности ER) или с помощью состояния активации определенного пути (например, все гены-мишени гена ESR1 в качестве считываемых данных об активации пути эстрогенового рецептора (ER)). Биологический путь может быть представлен в виде набора узлов (например, генов) и взаимодействий, которые описывают функциональные взаимосвязи между этим узлами. Молекулярный признак также можно охарактеризовать посредством состояния активации некодирующей РНК или целой сети РНК или тому подобное.
Некоторые иллюстративные реализации многомерного анализа 36 представляют собой следующее.
В одном подходе многомерный анализ 36 основан на комбинации главных значимых признаков из одномерного анализа 34. Иерархическую или неиерархическую (т.е. «плоскую») кластеризацию можно осуществлять с использованием всех вычисленных признаков текстуры или с использованием одного значимого признака с наилучшим p-значением или с использованием набора значимых признаков с «главными N» p-значениями, например, из главных 3-4 значимых признаков. Для того чтобы минимизировать дисперсию внутри кластера, можно использовать гэп-статистику. В некоторых вариантах осуществления кластеризация определяет оптимальное число кластеров для данных. Альтернативно, можно использовать подход кластеризации, который имеет априори фиксированное число кластеров. Для того чтобы определять обогащение конкретного класса внутри кластера пациентов, можно использовать гипергеометрический тест.
В другом подходе многомерный анализ 36 использует способ обучения с учителем, с ранжированием и выбором признаков с использованием классификатора (например, SVM, нейронная сеть или тому подобное). Классы определяют посредством экспрессии гена, например, ER+ и ER- или CDKN2A+ и CDKNA2- или тому подобное. На основе этих меток образцов в пределах этой классификации, ранжируют признаки визуализации, необязательно, с использованием перекрестной валидации (например, с использованием тройной перекрестной валидации). Используя признаки с наивысшим рангом, классификатор 40 обучают для того, чтобы классифицировать данные визуализации по классам ER+ и ER- (или по классам CDKNA+ и CDKNA- и так далее). Перекрестная валидация, если ее используют, снижает вариабельность эффективности классификатора. Результаты валидации усредняют по раундам перекрестной валидации. Один раунд перекрестной валидации включает деление массива данных на комплементарные поднаборы, затем выполнение классификации на одном из поднаборов (обучающий набор) и валидацию классификации на другом поднаборе (тестовый набор). Для каждого такого разделения данных модель аппроксимируют к обучающим данным и затем точность предсказания оценивают с использованием тестовых данных. Также предусмотрено использование внешнего цикла, который стоит в стороне от поднабора данных для валидации.
В другом подходе в многомерном анализе 36 используют выбор признаков с помощью генетического алгоритма или подхода SVM. Инструмент на основе генетического алгоритма (GA) автоматически выделят поднабор признаков, который лучше всего предсказывает контрольные метки образцов. (Следует отметить, что в этом случае одномерный анализ 34 можно опустить).
В еще одном другом подходе в многомерном анализе 36 используют корреляцию между молекулярными признаками и признаками визуализации. Определяют корреляцию каждого признака текстуры изображения с каждым из молекулярных признаков для того, чтобы выбирать пару или пары с наивысшей корреляцией для признаков визуализации и геномных признаков для применения в качестве классификатор 40.
Это является лишь иллюстративными примерами, и другие подходы многомерного анализа можно использовать в зависимости от типа классификатора, подлежащего обучению (например, бинарный классификатор или многоклассовый классификатор; плоский классификатор или иерархический классификатор; и так далее) и другие факторы проектирования, такие как (максимальное) число признаков текстуры изображения, желаемых для использования в операции классификации (см. фиг. 2). Также предусмотрено смещение выбора признаков в операциях 34, 36 в направлении минимизации общего числа GLCM, вычисляемых во время фазы классификации. Например, один подход предназначен для того, чтобы вычислять главные N статистически наиболее значимых признаков текстуры изображения, независимо от того, какая GLCM служит источником главных N признаков текстуры, и затем выбирать поднабор главных K из главных N признаков (где K<N, например, K=0,5N или K=0,25N), что минимизирует число GLCM, необходимых для того, чтобы генерировать главные K признаков.
Со ссылкой на фиг. 2, бинарный классификатор 40 можно использовать для того, чтобы классифицировать пациента 44, соответствующего молекулярному признаку (ER+ или ER- в иллюстративном примере). MR сканер 12 (или другой MR сканер) визуализирует пациента 44 для того, чтобы генерировать медицинские изображения, которые подвергают предварительной обработке и выделяют повреждение, представляющее интерес, с использованием той же операции(й) 20, как использовали для медицинских изображений обучающей популяции 10 (см. фиг. 1). Признаки текстуры вычисляют с использованием операций 22, 24 параллельно с обработкой обучающей популяции 10. Необязательно операцию 24 ограничивают вычислением только статистически значимых признаков текстуры, которые служат в качестве входных данных бинарного классификатора 40. Аналогичным образом, операцию 22 можно ограничивать вычислением только тех GLCM, по которым вычисляют статистически значимые признаки текстуры, которые служат в качестве входных данных бинарного классификатора 40. Это может снижать вычислительную сложность фазы классификации.
Статистически значимые признаки, вычисляемые по изображениям субъекта 44, вводят в классификатор 40, который выводит значение 46 классификации молекулярного признака для субъекта 44. Типично, это значение 46 не является конечным медицинским результатом, например, пациенту 44 не ставят диагноз только на основе значения 46 классификации молекулярного признака. Скорее, значение 46 используют в сочетании с другой информацией (включая молекулярные данные, непосредственно определяемые по биоптату пациента 44, если такие данные доступны), которую просматривает врач или другой медицинский персонал для того, чтобы генерировать диагноз для пациента 44.
В иллюстративном примере на фиг. 1 и 2 молекулярный признак представляет собой бинарный признак, например, ER+ или ER-. Также предусмотрено использование такой же обработки для того, чтобы генерировать классификатор для того, чтобы классифицировать пациента, соответствующего молекулярному признаку, который имеет три или больше возможных значениях. В качестве другого варианта, молекулярный признак может иметь иерархические свойства, например, злокачественная опухоль молочной железы с различными подтипами. В этом случае многомерный анализ 36, соответственно, обучает иерархический классификатор. В качестве еще одного другого варианта, предусмотрен пропуск одномерного анализа 34 и осуществление многомерного анализа 36, соответствующего всем признакам текстуры изображения, генерируемым с помощью операций 22, 24.
Задание классификации на фиг. 2 необязательно можно выполнять для различных повреждений одного и того же пациента. Это может позволить врачу различать, например, злокачественные и доброкачественные повреждения у одного и того же пациента, эта задача, как правило, влечет за собой получение множества биоптатов для того, чтобы получать образец ткани из каждого повреждения.
На иллюстративной фиг. 2 задание классификации выполняют посредством того же компьютера 14, который использовали в фазе обучения (фиг. 1). Альтернативно, задание классификации можно выполнять с помощью другого компьютера. Например, в одной предполагаемой реализации задание обучения (фиг. 1) выполняют в коммерческой исследовательской лаборатории, и результирующее задание классификации реализуют в виде постоянного запоминающего носителя, хранящего инструкции, исполняемые посредством компьютера для того, чтобы осуществлять операции 20, 22, 24 обработки и классификатор 40. Обучающую систему (фиг. 1) можно аналогичным образом реализовать в виде постоянного запоминающего носителя. Постоянный запоминающий носитель может включать в себя, например: привод жесткого диска или другой магнитный запоминающий носитель; оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), флэш-память или другой электронный запоминающий носитель; оптический диск или другой оптический запоминающий носитель; различные их сочетания; или тому подобное. Также следует принимать во внимание, что компьютер 14 можно реализовать в виде «облачного» компьютера, содержащего сеть компьютеров.
Раскрытая обработка интегрированного фенотипирования извлекает и ранжирует признаки визуализации (например, на основе текстуры) и связывает эти признаки с молекулярным признаком с тем, чтобы: 1) в отсутствии молекулярных признаков, можно было делать заключение о вероятности определенного молекулярного признака и 2) если доступна информация о молекулярных признаках из данных биопсии, то визуализация и биопсия вместе могут давать более полную картину о подтипе опухоли и прогнозировать ответ на терапию. В раскрытой обработке интегрированного фенотипирования используют неинвазивные признаки визуализации текстуры, получаемые из обычного потока операций клинической визуализации, чтобы охарактеризовать молекулярные свойства биологии опухоли и заболевания и направлять клиническую тактику. Это предоставляет способ анализа как клинического фенотипа in vivo, так и молекулярных основ заболевания на уровне всего генома.
Далее описан фактически выполненный пример раскрытой обработки интегрированного фенотипирования.
В фазе обучения (соответствующей фиг. 1), данные визуализации субъектов обучающей популяции 10 предварительно обрабатывали (операция 20), включая квантование интенсивностей изображений на уменьшенное число дискретных уровней яркости. Вычисление 22 GLCM осуществляли следующим образом. Для двухмерного (2D) анализа каждого из подизображений повреждения вычисляли GLCM для четырех различных направлений. Для трехмерного (3D) анализа каждого из подобъемов повреждения, вычисляют GLCM для тринадцати различных направлений.
Вычисление 24 признаков текстуры осуществляли следующим образом. Для 2D анализа вычисляли и набор признаков текстуры Haralick и набор признаков текстуры Tamura. Для 3D анализа вычисляли только набор признаков текстуры Haralick. Признаки Haralick и Tamura, использованные в этом примере, перечислены в таблицах 1 и 2. См. Haralick et al., «Textural Features for Image Classification», IEEE Transactions on Systems, Man and Cybernetics, том SMC-3 № 6, стр. 610-621 (1973); Howarth et al, «Evaluation of Texture Features for Content-Based Image Retrieval», P. Enser et al. (Eds.): CIVR 2004, LNCS 3115, стр. 326-334 (2004).
На основе аннотаций пациентов (например, гистопатологические данные, метки подтипов с использованием данных секвенирования РНК и ответа на терапию) создавали две подгруппы пациентов: ER+ (соответствующая группе 30 с молекулярным признаком), и ER-(соответствующая группе 32 без молекулярного признака).
Одномерный анализ 34 осуществляли следующим образом. Критерий суммы рангов Вилкоксона использовали в качестве теста на статистическую значимость для того, чтобы обнаруживать MR признаки текстуры изображения, которыми отличаются два класса 30, 32 изображений со статистической значимостью. В таблицах 3-6 представлены p-значения для идентифицированных значимых признаков, позволяющих различать гормональные рецепторы, подтип и состояние ответа. В этих таблицах p-значение можно грубо рассматривать как вероятность того, что группы ER+ и ER- будут проявлять наблюдаемое (статистическое) различие в признаке текстуры изображения, анализируемом при нуль-гипотезе о том, что анализируемый признак текстуры изображения не имеет корреляции с состоянием ER. Таким образом, более низкое p-значение указывает на то, что нуль-гипотеза менее вероятна, и, наоборот, что более вероятно, что наблюдаемое (статистическое) различие в анализируемом признаке текстуры изображения на самом деле является статистически значимым. Вкратце, признаки текстуры изображения с меньшими p-значениями считают более статистически значимыми, чем признаки текстуры изображения с более высокими p-значениями.
В таблице 4 перечислены значимые признаки текстуры изображения, генерируемые по изображениям повреждений молочной железы для определения значение эстрогенового рецептора (ER+ или ER-). В таблице 4 диапазон p-значений от наименьшего значения p=0,001614 (для диапазона суммарной дисперсии признака текстуры изображения) до высокого значения p=0,04720 (для средней суммарной дисперсии признака текстуры изображения). Это различие в p-значении составляет больше порядка величины, что указывает на сильное различие в корреляции различных признаков текстуры изображения. Кроме того, p-значения для всех наиболее статистически значимых признаков текстуры малы. p-значения всех значимых признаков текстуры изображения, перечисленных в таблице 3, отвечают порогу уровня значимости α=0,05 (where p<α определяют как статистически значимое), и 11 признаков отвечают более строгому порогу α=0,01.
В таблице 5 перечислены значимые признаки текстуры изображения, генерируемые по изображениям повреждений молочной железы для определения значения прогестеронового рецептора (PR+ или PR-). В таблице 5 диапазон p-значений от наименьшего значения p=0,0003730 (для диапазона суммарной дисперсии признака текстуры изображения) до высокого значения p=0,04362 (для признака регулярности текстуры изображения). Эта разность p-значений составляет больше двух порядков величины, и снова все p-значения для большинства статистически значимых признаков текстуры отвечают порогу уровня значимости α=0,05, а 20 признаков отвечают более строгому порогу α=0,01.
В таблице 6 продемонстрировано, что значимые признаки текстуры изображения могут коррелировать с молекулярными признаками, связанными с ответом на терапию.
Кроме того, признаки изображения могут быть связаны с нарушением регуляции биомолекулярного пути, определяемым мутациями, полиморфизмом числа копий, эпигенетической маркировкой, транскриптами генов и некодирующими транскриптами. В одном из примеров молекулярный анализ идентифицировал генную сигнатуру для активности пути TGF-β. Одномерный анализ осуществляли для признаков текстуры той же группы пациентов, которую использовали при генерировании этой сигнатуры, и идентифицированный признак текстуры «диапазон углового второго момента» различает пациентов с повышающей или понижающей активностью пути TGF-β (p=0,0002). Это представляет собой вариант осуществления того, как признаки текстуры могут служить в качестве заменителей молекулярных признаков, основанных на пути, и влиять на принятие клинического решения. Можно принимать во внимание другие пути, например, путь фосфатидилинозитол-3-киназы (PI-3K)/Akt, путь Jak-STAT и другие.
В фактически выполненном примере для того, чтобы определять подходящее число уровней квантования яркости и расстояние GLCM (т. е. смещение) для генерации GLCM (операции 20, 22 на фиг. 1), массив различных значений использовали для того, чтобы генерировать различные матрицы GLCM, и оценивали непротиворечивость числа значимых признаков. В качестве другого пути, в некоторых вариантах осуществления выполняют итерации операций 20, 22, 24, 34 обработки для того, чтобы оптимизировать квантование уровней яркости и смещение GLCM (и, необязательно, пространственное расположение GLCM) для того, чтобы генерировать признаки текстуры изображения с достаточной статистической значимостью.
Несмотря на то, что одномерный анализ 34 идентифицирует статистически значимые корреляции между молекулярными признаками и признаками текстуры изображения, он не предоставляет первооснов для понимания, почему такие корреляции существуют для определенных пар молекулярных признаков и признаков текстуры изображения. Исследование первооснов этих корреляций может иметь существенное значение; однако раскрытые способы интегрированного фенотипирования, соответственно, работают на эмпирической основе и не полагаются на понимание первооснов, лежащих в источнике таких корреляций. Достаточно понимать (как описано в настоящем документе), что такие корреляции существуют, и использовать подходящий анализ статистической значимости (или другой инструмент, такой как генетический алгоритм) для того, чтобы идентифицировать такие корреляции, а также для того, чтобы генерировать классификатор 40 молекулярных признаков на основе идентифицированных корреляций.
Также можно осуществлять коррекцию тестирования со множеством гипотез. Дополнительно, чтобы устанавливать точность и надежность значимых признаков, признаки текстуры изображения можно вычислять для областей изображения без повреждения, чтобы верифицировать, что статистически значимые признаки не наблюдаются в этих областях без повреждений. В качестве другой квалификационной операции, значимые признаки текстуры изображения можно вычислять для изображений различных срезов через повреждение для того, чтобы определять, зависит ли наблюдение значимых признаков текстуры изображения от ориентации среза и/или местоположения в повреждении. Статистически значимые признаки, которые не наблюдают на всем протяжении повреждения, в целом не являются предпочтительными для использования в классификаторе 40; однако значимые признаки, которые постоянно наблюдают на всем протяжении повреждения, но только для определенной ориентации среза (например, только для осевых срезов, а не для коронарных или сагиттальных срезов), можно использовать с тем ограничением, что признак представляет собой входные данные для классификатора 40 только для наблюдаемой ориентации среза (например, только, осевые срезы).
Раскрытые способы интегрированного фенотипирования могут генерировать связи между признаками текстуры изображения и различными молекулярными признаками, таким как: связь с геномными подтипами; связь с отдельными генами (ген с экспрессией, значительно отличающееся для каждого индивидуума); связь с целым путем активации гена (для каждого пути, который демонстрирует статистически значимое обогащение генов с различной экспрессией, например, с использованием гипергеометрического теста); связь с некодирующей РНК (микроРНК и длинная некодирующая РНК); и так далее. Связь можно выполнять, например, с путем TGFβ, путем PI3K/AKT/mTOR.
Далее описан дополнительный пример фазы классификации (фиг. 2). Получали магнитно-резонансные (MR) изображения пациента 44 после контрастирования с жироподавлением и коррекцией перемещения. (Снова следует понимать, что в более общем смысле раскрытые способы интегрированного фенотипирования можно использовать в ветеринарном контексте, и в этом случае пациента 44 заменяет собака, кошка или другой ветеринарный субъект). В операции 22 одну или несколько GLCM вычисляют на основе изображения пациента, и значения признаков текстуры изображения вычисляют в соответствии с операцией 24. В одном подходящем процессе классификации (т. е., классификаторе 40), кратные log2 изменения значений определяют для признаков текстуры изображения между подгруппами категории (например ER+ или ER-). Центроид для двух подгрупп вычисляют на основе скорректированных по значимости кратных log2 изменений значений, и пациента 44 приписывают к группе, связанной с ближайшим центроидом.
Иллюстративные варианты осуществления относятся к неинвазивному определению ER-состояния пациента. В более общем смысле, раскрытые способы интегрированного фенотипирования позволяют проводить тесты на присутствие/характеристики какого-либо гормонального рецептора или сигнатуры генома (например, для того, чтобы определять молекулярный подтип, ответ на терапию и так далее).
Кроме того, хотя в иллюстративных вариантах осуществления используют магнитно-резонансную (MR) визуализацию, ожидают, что раскрытые способы интегрированного фенотипирования можно применять для того, чтобы устанавливать связь молекулярных признаков с признаками текстуры изображения изображений, полученных с помощью других модальностей, таких как компьютерная томография (CT). Это является обоснованным ожиданием, поскольку наблюдаемые корреляции молекулярных признаков и признаков текстуры MR изображения указывают на то, что злокачественные повреждения имеют пространственную структуру малого масштаба в масштабе, который можно захватывать посредством MR визуализации, и другие модальности визуализации, такие как CT, имеют схожее пространственное разрешение. Различия в механизмах контрастирования между различными модальностями визуализации (например, MR или CT) могут вести к различиям (например, к усилению или частичному или полному подавлению) в определенных признаках текстуры на изображениях в определенных модальностях визуализации и, кроме того, также ожидается, что параметры визуализации и/или использование экзогенного контрастного средства влияют на то, какие признаки текстуры изображения проявляются на данном медицинском изображении повреждения, полученном с помощью данной модальности визуализации. Тем не менее эмпирический и независящий от модальности характер раскрытых подходов интегрированного фенотипирования облегчают идентификацию и использование корреляций между молекулярными признаками, представляющими интерес, и любыми признаками текстуры изображения, проявленными в данной модальность визуализации при данных условиях визуализации.
Изобретение описано со ссылкой на предпочтительные варианты осуществления. Очевидно, модификации и изменения придут на ум при прочтении и осмыслении предшествующего подробного описания. Подразумевают, что изобретение следует толковать как включающее все такие модификации и изменения до тех пор, пока они входят в объем приложенной формулы изобретения или ее эквивалентов.

Изобретение относится к области генетических анализов и может быть использовано, в частности, в медицинской области. Значения признаков текстуры изображения вычисляют для набора признаков текстуры изображения по изображению анатомического признака, представляющего интерес, у субъекта, и субъекта классифицируют в соответствии с молекулярным признаком, представляющим интерес, на основе вычисленных значений признаков текстуры изображения. Значения признаков текстуры изображения можно вычислять по одной или более матрицам совместной встречаемости уровней яркости (GLCM), и признаки текстуры изображения могут содержать признаки текстуры изображения Haralick и/или Tamura. Для обучения классификатора эталонные значения признаков текстуры изображения вычисляют по меньшей мере для набора признаков текстуры изображения по изображениям анатомического признака, представляющего интерес, у эталонных субъектов. Эталонные значения признаков текстуры изображения делят на различные популяционные группы, представляющие различные значения молекулярного признака, представляющего интерес, и классификатор обучают различать различные популяционные группы на основе эталонных значений признаков текстуры изображения. Изобретение позволяет обеспечить неинвазивную идентификацию на основе комбинации признаков текстуры. 3 н. и 11 з.п. ф-лы, 6 табл., 2 ил.
1. Постоянный запоминающий носитель, который хранит инструкции, исполняемые с помощью устройства обработки электронных данных для того, чтобы осуществлять способ, который включает в себя:
вычисление значений признаков текстуры изображения для набора признаков текстуры изображения по изображению анатомического признака, представляющего интерес, у субъекта; при этом вычисление содержит:
вычисление одной или более матриц совместной встречаемости уровней яркости (GLCM) для изображения анатомического признака, представляющего интерес, у субъекта; и
вычисление значений признаков текстуры изображения на основе одной или более GLCM; и
классификацию субъекта, соответствующего молекулярному признаку, представляющему интерес, на основе значений признаков текстуры изображения, вычисляемых для набора признаков текстуры изображения, и пространственной структуры набора признаков текстуры изображения.
2. Постоянный запоминающий носитель по п. 1, в котором вычисление одной или более GLCM включает в себя вычисление одной или более симметризованных и нормализованных GLCM для изображения анатомического признака, представляющего интерес, у субъекта.
3. Постоянный запоминающий носитель по п. 1, в котором вычисление значений признаков текстуры изображения дополнительно включает в себя квантование уровней яркости изображения анатомического признака, представляющего интерес, у субъекта перед вычислением одной или более GLCM.
4. Постоянный запоминающий носитель по п. 1, в котором вычисление одной или более GLCM включает в себя вычисление двух или более GLCM, которые имеют по меньшей мере одно из (1) отличающихся смещений и (2) отличающихся пространственных расположений.
5. Постоянный запоминающий носитель по п. 1, в котором набор признаков текстуры изображения включает в себя признаки текстуры изображения Haralick и/или включает в себя признаки текстуры изображения Tamura.
6. Постоянный запоминающий носитель по п. 1, в котором способ дополнительно содержит:
вычисление эталонных значений признаков текстуры изображения по меньшей мере для набора признаков текстуры изображения по изображениям анатомического признака, представляющего интерес, у эталонных субъектов эталонной популяции;
деление эталонных значений признаков текстуры изображения на различные популяционные группы, представляющие различные значения молекулярного признака, представляющего интерес, на основе известных значений молекулярного признака, представляющего интерес, для эталонных субъектов; и
обучение классификатора, используемого при классификации, чтобы различать различные популяционные группы на основе эталонных значений признаков текстуры изображения.
7. Постоянный запоминающий носитель по п. 6, в котором эталонные значения признаков текстуры изображения вычисляют для расширенного набора признаков текстуры изображения, содержащего набор признаков текстуры изображения, и обучение содержит:
осуществление одномерного анализа для того, чтобы количественно определять статистическую значимость каждого признака текстуры изображения из расширенного набора признаков текстуры изображения, чтобы различать различные популяционные группы; и
выбор набора признаков текстуры изображения в качестве поднабора из расширенного набора признаков текстуры изображения, которые имеют наивысшую статистическую значимость.
8. Постоянный запоминающий носитель по п. 7, в котором одномерный анализ содержит использование критерия суммы рангов Вилкоксона или t-критерия Стьюдента для того, чтобы количественно определять статистическую значимость.
9. Постоянный запоминающий носитель по п. 1, в котором изображение анатомического признака, представляющего интерес, у субъекта представляет собой магнитно-резонансное (MR) изображение.
10. Постоянный запоминающий носитель по п. 9, в котором молекулярный признак, представляющий интерес, представляет собой ген, группу генов, путь активации гена, некодирующую РНК или множество некодирующих РНК.
11. Постоянный запоминающий носитель по п. 10, в котором анатомический признак, представляющий интерес, представляет собой повреждение молочной железы, а молекулярный признак, представляющий интерес, представляет собой маркер эстрогенового рецептора (ER), маркер прогестеронового рецептора (PR), маркер рецептора эпидермального фактора роста человека 2-го типа (Her2) или нарушение регулярности пути TGFβ.
12. Устройство классификации субъекта с использованием признаков текстуры изображения, содержащее:
постоянный запоминающий носитель по п. 1; и
устройство обработки электронных данных, выполненное с возможностью исполнять инструкции, сохраненные в постоянном запоминающем носителе.
13. Способ классификации субъекта с использованием признаков текстуры изображения, содержащий:
вычисление эталонных значений признаков текстуры изображения для множества признаков текстуры изображения по изображениям анатомического признака, представляющего интерес, у эталонных субъектов эталонной популяции;
деление эталонных значений признаков текстуры изображения на различные популяционные группы, представляющие различные значения молекулярного признака, представляющего интерес, на основе известных значений молекулярного признака, представляющего интерес, для эталонных субъектов; и
обучение классификатора различать различные популяционные группы на основе эталонных значений признаков текстуры изображения и пространственных структур набора эталонных признаков текстуры изображения;
получение медицинского изображения анатомического признака, представляющего интерес, у пациента с использованием медицинской визуализации пациента;
вычисление значений признаков текстуры пациента для множества признаков текстуры изображения по медицинскому изображению анатомического признака, представляющего интерес, у пациента; и
применение обученного классификатора к значениям признаков текстуры пациента для вывода значения классификации молекулярного признака для молекулярного признака, представляющего интерес, для пациента, причем этапы вычисления эталонных значений признаков текстуры изображения, деления, обучения, вычисления значений признаков текстуры пациента, и применения осуществляют с помощью устройства обработки электронных данных.
14. Способ по п. 13, дополнительно содержащий:
(i) вычисление значений признаков текстуры изображения по меньшей мере для некоторых из множества признаков текстуры изображения по изображению анатомического признака, представляющего интерес, у тестируемого субъекта; и
(ii) классификацию тестируемого субъекта, соответствующего молекулярному признаку, представляющему интерес, с использованием обученного классификатора;
причем операции (i) и (ii) осуществляют посредством устройства обработки электронных данных.
| US 2008195322 A1, 14.08.2008 | |||
| US 2011026798 A1, 02.03.2011 | |||
| US 2002046198 A1, 18.04.2002. |

