ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области техники хранения данных, в частности к устройству хранения данных, например к компьютерному устройству для хранения, в частности, больших объемов данных и управления ими и для обеспечения этих данных для клиента для операций считывания и записи.
УРОВЕНЬ ТЕХНИКИ
Большие базы данных в памяти используются в настоящее время на производственных базах и служат в качестве запоминающих устройств типа «ключ-значение», баз данных для оперативной (онлайн) обработки транзакций (online transaction processing - OLTP), крупномасштабных веб-приложений, онлайновых игр большой емкости с несколькими участниками, представлений контроллерных сетей программно-заданных сетей (software defined network - SDN), средств научного моделирования, и т.д. Эти приложения создаются для сохранения скоростей транзакций с использованием множественных вариантов контекста исполнения, например, потоков в архитектурах, где все находится в совместном использовании, с неоднородным доступом к памяти (non-uniform memory access - NUMA), в результате чего набор данных логически разделяется, и каждый раздел связывается с контекстом исполнения, который является ответственным за обработку транзакций в его разделе.
Установка контрольных точек и логический журнал отката могут быть использованы в наборах данных в памяти для обеспечения возможности восстановления набора данных в случае системного сбоя. Надежность транзакций обновления обеспечивается посредством периодического процесса установки контрольных точек, который сбрасывает согласованное мгновенное состояние в устройство постоянного хранения, и посредством логического журнала отката, который записывает все запросы на модификацию между последовательными контрольными точками. После системного сбоя, процесс восстановления использует последнюю постоянную контрольную точку для инициализации состояния памяти и процедуру воспроизведения, для воспроизведения журнала отката для восстановления состояния приложений в момент времени перед моментом времени сбоя.
Проектирование ведения журнала отката, перед лицом высоких скоростей обновления наборов данных, остается постоянной задачей для проектировщиков баз данных. Ведение журнала отката тесно связано с установкой контрольных точек. Процесс установки контрольных точек должен иметь низкие непроизводительные затраты и должен быть очень эффективным для поддержки высоких скоростей обновления и частой установки контрольных точек для уменьшения размера журнала отката и связанной с ним длительности воспроизведения журнала в момент восстановления. Поскольку контрольные точки запускаются повторно, обычно может быть использована пошаговая установка контрольных точек, при которой детектируются и сохраняются только объекты, измененные с момента времени предшествующей контрольной точки.
При ведении логического журнала отката обычно сохраняются запросы на модификацию для набора данных, в то время как эти модификации вступают в действие в наборе данных в памяти. Поскольку скорость обновления устройства постоянного хранения является, обычно, значительно меньшей, чем скорость обновления памяти, может возникнуть напряженность, вследствие замедления обработки транзакций для сохранения более полного журнала этих транзакций.
Tuan Cao и другие, в работе: ʺFast Checkpoint Recovery Algorithms for Frequently Consistent Applicationsʺ, SIGMOD´11, июнь 2011, Афины, Греция, описывают методику, использующую запоминающие устройства специального назначения для обеспечения возможности ведения журнала транзакций при максимальном быстродействии памяти.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задачей настоящего изобретения является обеспечение устройства хранения данных, которое уменьшает воздействие, оказываемое на обработку транзакций, во время ведения журнала отката, связанного с набором данных.
Эта задача решена посредством объекта изобретения, указанного в независимых пунктах формулы изобретения. Дополнительные варианты осуществления заявлены в зависимых пунктах формулы изобретения и в нижеследующем описании.
Согласно одному аспекту настоящего изобретения, обеспечено устройство хранения данных, содержащее модуль управления, первый модуль хранения, второй модуль хранения, третий модуль хранения и буфер. Первый модуль хранения выполнен с возможностью хранения множества наборов данных, а модуль управления выполнен с возможностью приема запросов на операции, подлежащие выполнению на множестве наборов данных в первом модуле хранения, исполнения принятых запросов и копирования множества наборов данных, хранящихся или содержащихся в первом модуле хранения, во второй модуль хранения в заданный момент времени. Модуль управления дополнительно выполнен с возможностью добавления принятых запросов на операции в буфер и сохранения буфера в третьем модуле хранения посредством средства синхронизации. Устройство хранения данных выполнено с возможностью инициализации множества наборов данных в первом модуле хранения из второго модуля хранения и выполнения операций, соответствующих запросам из третьего модуля хранения, в сценарии восстановления.
Модуль управления, упомянутый здесь, может быть процессором или центральным обрабатывающим блоком устройства хранения данных, например, любым видом компьютера, выполненного с возможностью обеспечения услуги наборов данных для множества запрашивающих устройств или клиентов. Первый модуль хранения может быть непостоянной памятью, а второй модуль хранения может быть постоянной памятью, например, жестким диском или любым другим видом блока постоянной памяти. Буфер содержит все списки, используемые для записей запросов и журнала отката. Набор данных может называться полосой, содержащей по меньшей мере одну запись типа «ключ-значение».
Блок управления может быть выполнен с возможностью назначения прямой корреляции между буфером и третьим модулем хранения. Например, буфер может быть отображен в третьем модуле хранения, например, посредством назначения прямой побайтовой корреляции буфера с третьим модулем хранения. Для отображения буфера в третьем модуле хранения, может быть использована соответствующая функция операционной системы устройства хранения данных, например, функция mmap() системы Unix. Отображаемая или отображаемая в памяти секция может быть, в частности, секцией памяти модуля хранения, к которой можно прямо обратиться через указатель или дескриптор файла. Такая побайтовая корреляция может быть, затем, использована другим функциональным блоком, например, любым из модулей устройства хранения данных, как если бы это была секция памяти соответствующего модуля. Сохранение буфера в третьем модуле хранения может быть выполнено посредством системного вызова, например.
В сценарии восстановления, сохраненные запросы, которые не были обработаны или исполнены, воспроизводятся. Например, в случае сбоя последовательного восстановления первого модуля хранения из второго модуля хранения, запросы, хранящиеся в третьем модуле хранения, выполняются (=воспроизводятся) на первом модуле хранения для инициализации данных в момент времени сбоя или отказа системы.
Второй модуль хранения содержит контрольную точку, которая была описана выше, а третий модуль хранения содержит файл журнала отката. Буфер содержит буфер журнала отката, отображенный в файле. Модули хранения и буфер могут быть секциями одного и того же физического запоминающего устройства.
Второй модуль хранения может быть выполнен с возможностью содержания постоянной копии согласованного состояния множества наборов данных в заданный момент времени из первого модуля хранения. Модуль управления может быть выполнен с возможностью назначения буферу прямой корреляции с третьим модулем хранения.
Такое устройство хранения данных обеспечивает возможность того, что буфер запросов используется для обновления контента третьего модуля хранения. В частности, одни и те же ячейки памяти используются для записей журнала и запросов таким образом, чтобы журнал отката не был записан в отдельных ячейках памяти. Таким образом, запись операций отдельного журнала отката больше не требуется.
Согласно одному варианту осуществления настоящего изобретения, второй модуль хранения выполнен с возможностью содержания постоянной копии согласованного состояния множества наборов данных во время множества заданных моментов времени из первого модуля хранения.
Постоянная копия может быть создана в периодически повторяющиеся моменты времени с постоянным или изменяющимся временным интервалом между ними. Второй модуль хранения может содержать только одну копию, которая заменяется новой копией при каждом процессе обновления, или он может содержать более одной копии из последних N процессов обновления, где N может быть постоянной, и самая старая копия перезаписывается.
Согласно дополнительному варианту осуществления настоящего изобретения, модуль управления выполнен с возможностью приема запросов на операции, подлежащие выполнению на множестве наборов данных в первом модуле хранения, исполнения принятых запросов и копирования множества наборов данных в первом модуле хранения во второй модуль хранения во время множества последовательных заданных моментов времени.
Множество наборов данных в первом модуле хранения может копироваться во второй модуль хранения периодически и повторно с постоянными или изменяющимися временными интервалами между последовательными процессами копирования.
Согласно дополнительному варианту осуществления настоящего изобретения, буфер является круговым буфером.
Таким образом, записи запросов записываются в буфер, начиная с произвольного смещения, и осуществляется циклический переход в начало буфера. Размер буфера может быть ограничен заданным значением.
Согласно дополнительному варианту осуществления настоящего изобретения, буфер выполнен с возможностью использования одних и тех же ячеек буфера для добавления принятых запросов на операции, подлежащие выполнению на первом модуле хранения, и для обновления третьего модуля хранения.
Таким образом, никакая копия в буфере не требуется для хранения файла журнала, поскольку одни и те же ячейки в буфере используются для записей запросов и записей журнала.
Согласно дополнительному варианту осуществления настоящего изобретения, модуль управления выполнен с возможностью маркировки запросов на операции, выполняемые на наборах данных в первом модуле хранения, которые использовались для обновления третьего модуля хранения.
Маркировка запроса может произойти с использованием указателя на ячейку памяти или логическое место в памяти, которое содержит запрос, или с использованием флага, идентифицирующего один запрос, который был выполнен на диске.
Таким образом, записи запросов, которые были записаны на третий модуль хранения, или которые были использованы для обновления третьего модуля хранения, могут быть перезаписаны в кольцевом буфере. Записи запросов, которые не промаркированы, не могут быть перезаписаны, поскольку эти записи необходимы для обновления второго модуля хранения.
Согласно дополнительному варианту осуществления настоящего изобретения, модуль управления выполнен с возможностью повторного обновления наборов данных во втором модуле хранения.
Таким образом, период между последовательными процессами обновления может быть адаптирован таким образом, чтобы размер буфера и время, необходимое для обновления второго модуля хранения, могли быть оптимизированы, в частности, уменьшены. Дополнительно, скорость обновления второго модуля хранения может быть учтена, в частности, когда запись операций на второй модуль хранения является продолжительной вследствие физической записи операций в постоянную память, такую как диск.
Согласно дополнительному варианту осуществления настоящего изобретения, модуль управления выполнен с возможностью верификации того, является ли обновление наборов данных во втором модуле хранения успешным, и немаркировки соответствующих запросов как обновленных, во втором модуле хранения, в случае, когда обновление не является успешным.
Другими словами, только те записи запросов, которые были обновлены во втором модуле хранения, маркируются как обновленные, иначе, эти запросы обновляются на последующем этапе обновления.
Согласно дополнительному варианту осуществления настоящего изобретения, устройство хранения данных выполнено с возможностью обновления только тех наборов данных во втором модуле хранения, на которых была выполнена операция в первом модуле хранения. А именно, обновляются только те наборы данных во втором модуле хранения, которые были объектом для операции в первом модуле хранения.
Этот вариант осуществления относится к пошаговому обновлению и может уменьшить непроизводительные затраты, поскольку только измененные наборы данных в памяти обновляются на диске.
Согласно дополнительному варианту осуществления настоящего изобретения, первый модуль хранения является непостоянным модулем хранения.
Первый модуль хранения может быть, например, памятью с произвольным доступом (random access memory - RAM), выполненной с возможностью хранения баз данных в памяти и обеспечения доступа к базе данных для запрашивающих устройств.
В этом варианте осуществления, первый модуль хранения, который является непостоянным модулем хранения, обеспечивает возможность эффективных операций считывания/записи и, таким образом, может увеличить эффективность системы.
Согласно дополнительному варианту осуществления настоящего изобретения, третий модуль хранения является постоянным модулем хранения, например, жестким диском или твердотельным диском, или любым другим видом постоянного устройства хранения данных.
В этом варианте осуществления, третий модуль хранения обновляется изменениями для наборов данных в первом модуле хранения. Поскольку длительность операций на дисковом накопителе является большей, чем на RAM, такая система оптимизируется как для безопасности данных, так и для высокой эффективности.
Согласно дополнительному варианту осуществления настоящего изобретения, первый модуль хранения выполнен с возможностью назначения множества наборов данных для множества групп наборов данных, причем устройство хранения данных содержит множество буферов и, причем, каждый из множества буферов назначается для одной группы наборов данных, соответственно.
Другими словами, первый модуль хранения содержит базу данных в памяти. В этом варианте осуществления, каждой группе наборов данных или разделу назначается один буфер, таким образом, чтобы запрашивание, регистрация запросов и обновление могли быть выполнены отдельно для каждой группы из множества групп наборов данных.
Согласно дополнительному варианту осуществления настоящего изобретения, устройство хранения данных выполнено с возможностью восстановления множества наборов данных в первом модуле хранения на основе наборов данных второго модуля хранения и запросов, содержащихся в третьем модуле хранения.
Таким образом, обеспечена возможность восстановления после системного сбоя.
Согласно дополнительному варианту осуществления настоящего изобретения, к наборам данных в первом модуле хранения применяются только те из запросов, содержащихся в третьем модуле хранения, которые не были обновлены во втором модуле хранения.
Другими словами, устройство хранения данных, описанное здесь, предлагает технологию проектирования журнала отката, посредством которой меньшее воздействие оказывается на обработку транзакций, меньшая поддержка необходима от файловой системы, и, таким образом, больше записей журнала отката записывается на диск. Может быть использована специальная модель потоков, которая применяет разделение принципа участия между исполнением транзакций и обработкой журнала отката. Посредством выполнения этого, может быть достигнута значительная эффективность обработки журнала отката.
Один аспект устройства хранения данных может быть описан как использование разъединения рабочих потоков, которые исполняют запросы в запоминающем устройстве типа «ключ-значение», и коммуникационных потоков, которые пересылают буферы запросов к рабочим потокам. Когда буфер запроса содержит спецификацию запроса, и именно эту спецификацию необходимо сохранить в журнале отката, описываемая методика считывает спецификацию запроса прямо в запись журнала отката, и, затем, пересылает ссылку на эту запись для исполнения. Кроме того, посредством использования отображенного в памяти файла для размещения записей журнала отката, обеспечивается проектирование с истинным нулевым копированием в ходе всей обработки.
Таким образом, эта методика устраняет потребность в копировании спецификации запроса для исполнения, журнала отката и файловых выходных данных. Таким образом, используется проектирование спецификаций запросов с истинным нулевым копированием. Дополнительно, воздействие, оказываемое на рабочие потоки обработкой журнала отката, может быть минимизировано, и приватизируется страница журнала отката для множественных записей журнала отката, посредством чего минимизируется синхронизация с так называемым Свободным-Списком (FreeList). Свободный-Список является списком, имеющим размер, конфигурируемый следующим образом: он определяет максимальное количество записей отката, которые могут быть потеряны в результате системного сбоя, и он определяет частоту системных вызовов синхронизации.
Методика, описанная выше, может использовать API отображаемых в памяти файлов для сбрасывания файлов, и, таким образом, она нуждается только в минимальных непроизводительных затратах на файловую систему и может выгодно использовать непрерываемую сбоями поддержку msync() для обеспечения гарантий согласованности, не замечающей сбои.
При объединении этих признаков, описанная методика журнала отката может, в частности, иметь низкие непроизводительные затраты и может быть очень эффективной, посредством чего обеспечивается возможность обработки большего количества запросов и запоминания более полных журналов за более короткие интервалы времени.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления настоящего изобретения будут описаны в отношении следующих фигур, в которых:
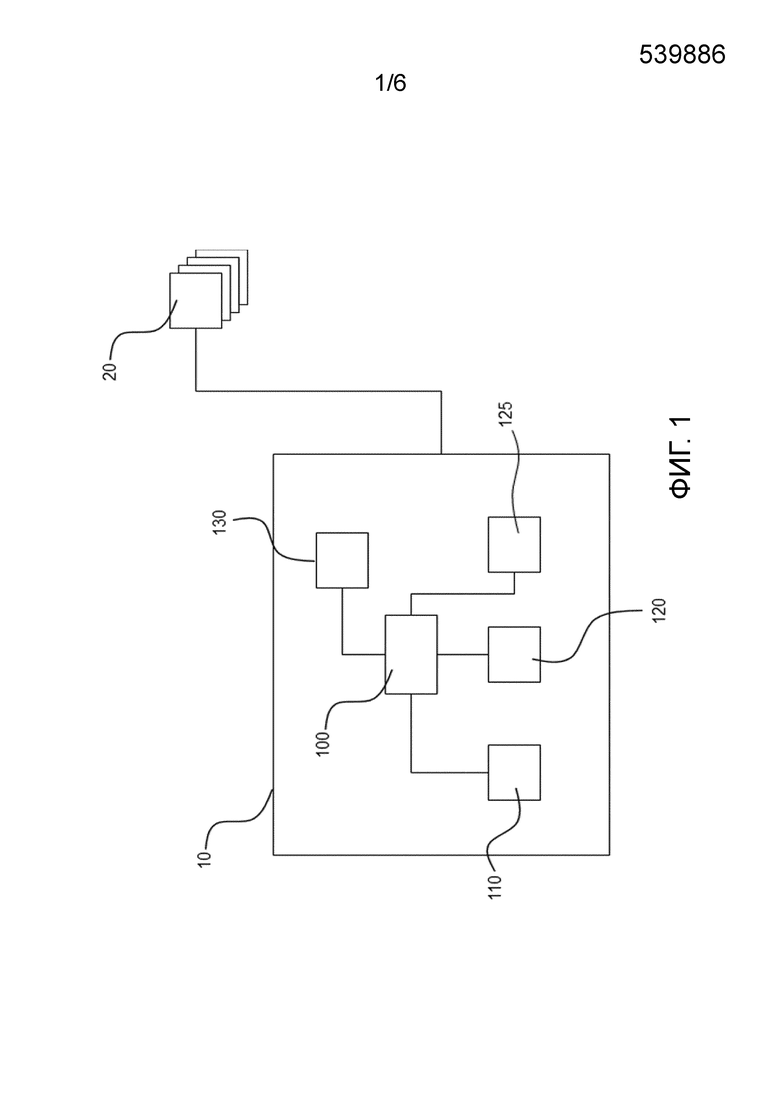
Фиг. 1 схематично показывает устройство хранения данных, согласно иллюстративному варианту осуществления настоящего изобретения, соединенное с множеством запрашивающих устройств;
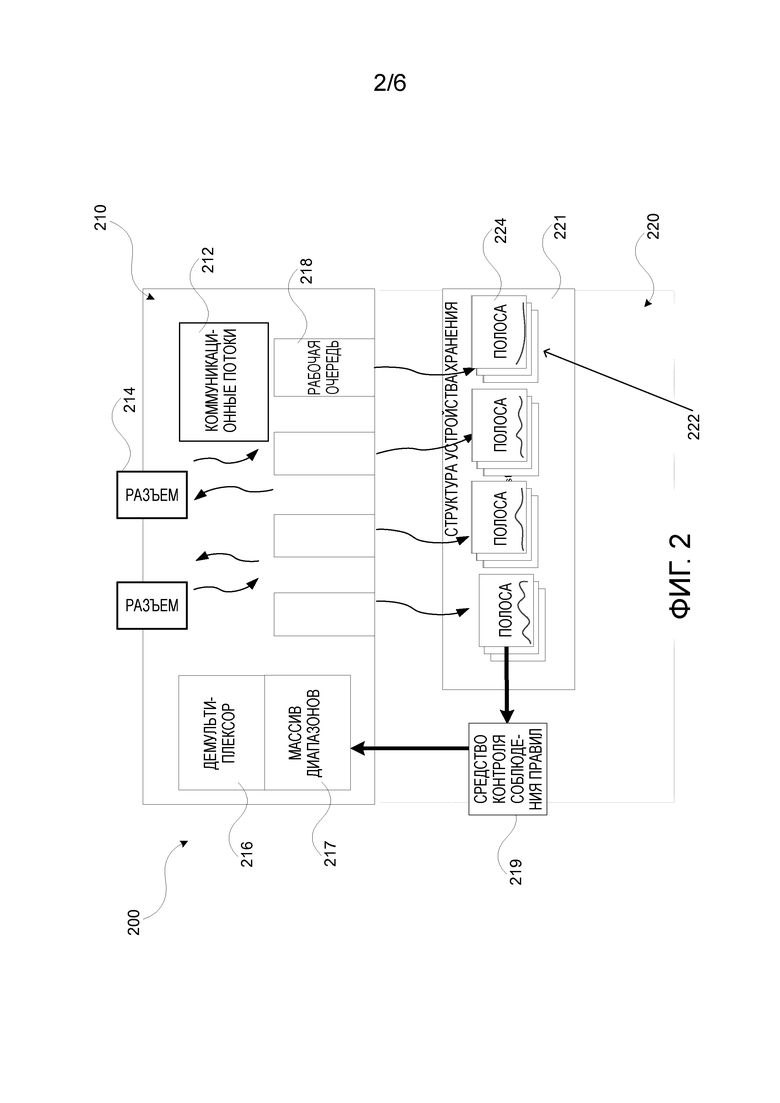
Фиг. 2 схематично показывает модель потоков запоминающего устройства типа «ключ-значение» устройства хранения данных, согласно иллюстративному варианту осуществления настоящего изобретения;
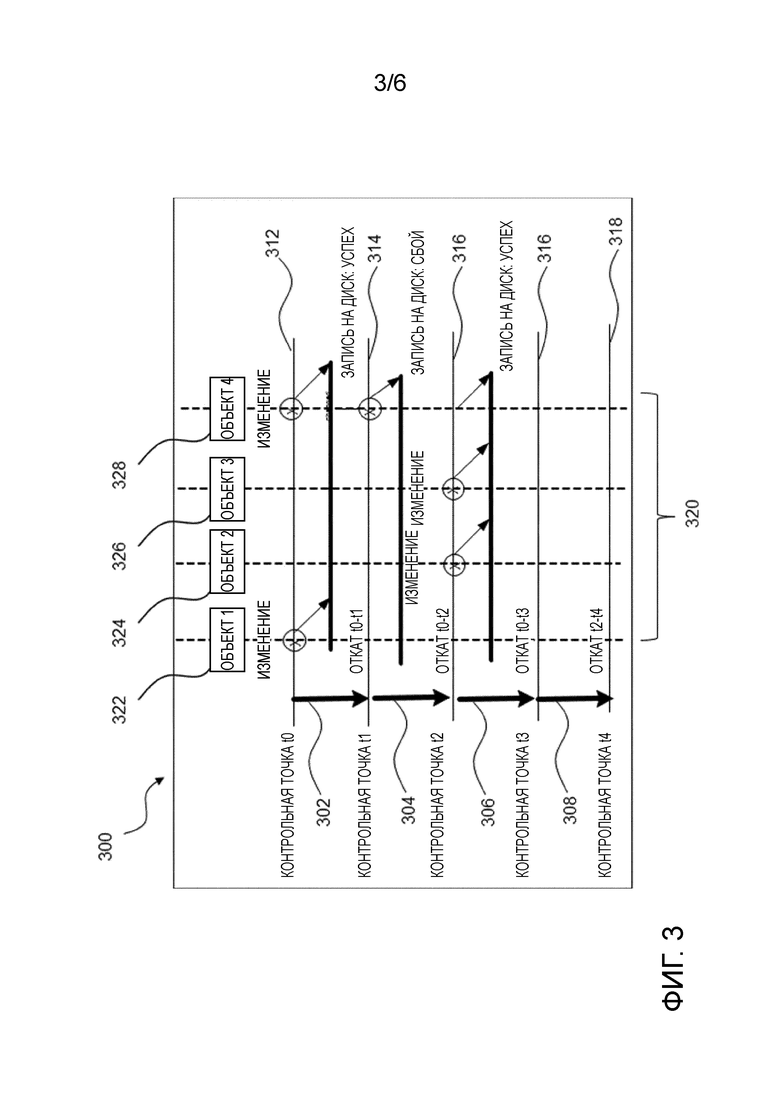
Фиг. 3 схематично показывает файл журнала отката устройства хранения данных, согласно иллюстративному варианту осуществления настоящего изобретения;
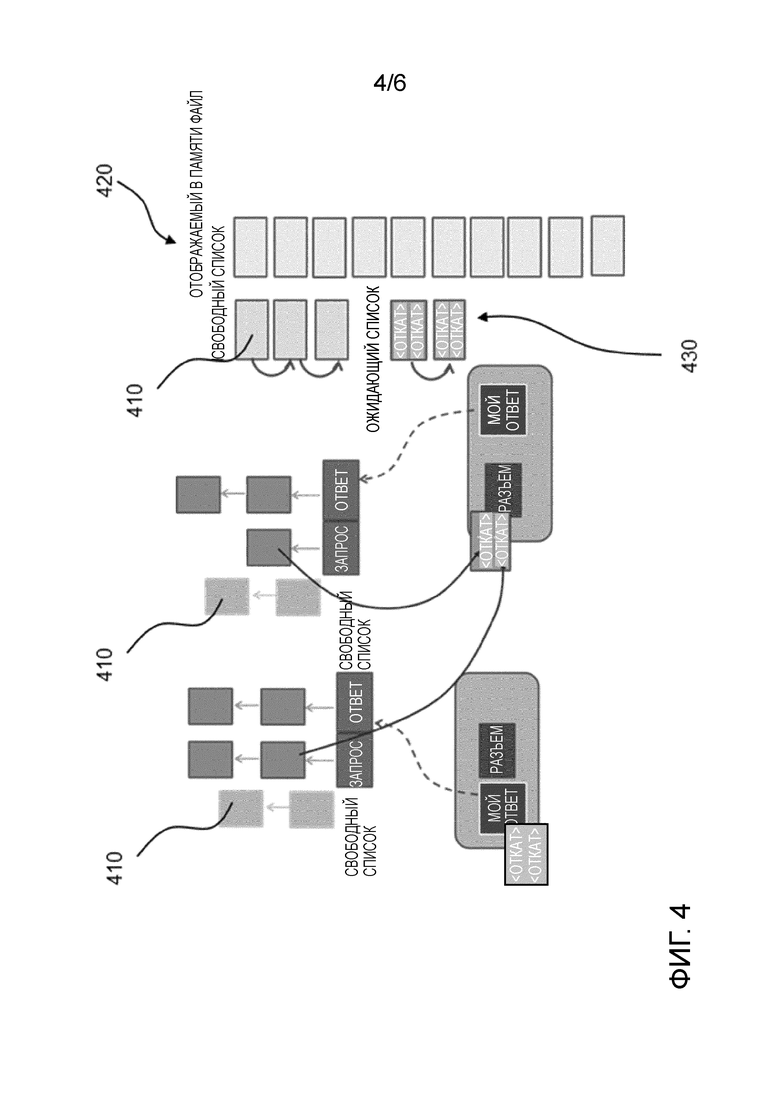
Фиг. 4 схематично показывает коммуникационные потоки, каждый из которых имеет свой приватный журнал отката, согласно иллюстративному варианту осуществления настоящего изобретения;
Фиг. 5 схематично показывает обработку блока-регистратора в устройстве хранения данных, согласно иллюстративному варианту осуществления настоящего изобретения;
Фиг. 6 схематично показывает обработку коммуникационного блока в устройстве хранения данных, согласно иллюстративному варианту осуществления настоящего изобретения;
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Фиг. 1 показывает устройство 10 хранения данных с модулем 100 управления, первым модулем 110 хранения, вторым модулем 120 хранения, третьим модулем 125 хранения и буфером 130, причем устройство 10 хранения данных соединено с возможностью связи с одним или несколькими запрашивающими устройствами 20, которые могут называться клиентами. Устройство хранения данных может также называться сервером.
Модуль 100 управления, модули 110, 120, 125 хранения и буфер выполнены с возможностью выполнения функций, описанных выше и ниже.
Фиг. 2 показывает общую модель 200 потоков запоминающего устройства типа «ключ-значение», которая может быть использована устройством 10 хранения данных для обработки запросов данных от запрашивающих устройств 20 и для управления данными, хранящимися в модулях хранения. Абстракция 221 Структуры Памяти назначает наборы полос 224, причем каждая полоса представляет совокупность строк некоторой таблицы, определенной в запоминающем устройстве типа «ключ-значение», для множества разделов 222 данных. Обработка операций запоминающего устройства типа «ключ-значение» разделена между Внешней Частью 210 (Front End - FE) и Внутренней Частью 220 (Back End - BE). Набор рабочих очередей 218, каждая из которых содержит пару из операционной очереди запросов и ее очереди ответов, является основным интерфейсом между FE 210 и BE 220. Каждая очередь связана с рабочим потоком BE.
FE 210 содержит набор коммуникационных потоков 212, и демультиплексор 216. Демультиплексор 216 используется для синтаксического анализа запроса и для определения конкретной очереди для постановки в нее запроса. Предпочтительно, FE 210 содержит, дополнительно, массив 217 диапазонов, который выполнен с возможностью установления связи несвязного (под-)набора полос каждой рабочей очереди 218 и используется для демультиплексирования. Коммуникационные потоки 212 считывают данные с коммуникационных разъемов, принимающих запросы, определяют целевые очереди с использованием демультиплексора 216, и отправляют запрос в очереди запросов. В обратном направлении, коммуникационные потоки считывают очереди ответов и доставляют ответы к соответствующим разъемам 214.
BE 220 содержит набор рабочих потоков, и, для каждого потока, соответствующий набор полос 224, который может поступить из разных таблиц, называемый разделом 222. Распределение всех полос для разделов и назначение потоков для разделов определяют разделение.
Предпочтительно, BE 220 содержит средство 219 контроля соблюдения правил, которое выполнено с возможностью обновления Массива Диапазонов для перераспределения запроса среди очередей, для лучшей адаптации к воспринимаемой нагрузке.
Рабочий поток выводит запрос из его очереди запросов, исполняет его на одной из полос в его разделе и пересылает ответ в его очередь ответов.
Коммуникационный поток 212 считывает данные из набора сетевых разъемов 214, принимает запросы на транзакции, определяет целевые очереди с использованием демультиплексора 216 и пересылает запросы в очереди запросов. В обратном направлении, коммуникационный поток 212 считывает данные из очередей ответов, доставляет ответы к соответствующим разъемам 214, и возвращает освобожденный буфер запросов/ответов в свободный-список.
Коммуникационный поток 212 использует свободный список предварительно распределенных буферов запросов/ответов, связанных с рабочей очередью, для предотвращения копирования данных запросов и ответов. Эта идея дополнительно использована для ведения журнала отката. А именно, когда буфер запросов содержит спецификацию запроса, и именно эта спецификация сохраняется в журнале отката, изобретенный способ повторно использует спецификацию для двух целей, и посредством использования отображаемого в памяти файла обеспечивает проектирование с истинным нулевым копированием.
Фиг. 3 показывает контент файла 300 журнала отката во времени. Вертикальные стрелки 302, 304, 306 представляют запись всех запросов на модификацию, которые появляются между моментами времени, указанными на обозначении стрелки, а именно, между двумя последовательными моментами t0, t1, t2, t3 времени, соответственно.
В момент времени t0, захватывается мгновенный снимок t0-состояния, и начинается журнал отката. В момент времени t1, являются доступными успешная контрольная точка t0, и откат t0-t1. В момент времени t2 контрольная точка t1 претерпевает сбой, так что журнал отката должен включать в себя все записи t0-t2.
В момент времени t3 контрольная точка t2 является успешной, так что в момент времени t3 журнал отката очищается и включает в себя только записи из t2-t3.
Фиг. 3 показывает пример установки контрольных точек и обработки журнала отката по множественным последовательным интервалам 312, 314, 316, 318 контрольных точек для описания логических взаимоотношений между ведением журнала отката и установкой контрольных точек.
Показан набор потоков (выровненных рядом друг с другом слева направо и указанных вертикальными пунктирными линиями), которые непрерывно модифицируют набор резидентных в памяти объектов. В момент времени контрольной точки, обеспечивается согласованный мгновенный снимок контента 320 памяти, и объекты 322, 324, 326, 328 в мгновенном снимке, которые модифицированы относительно последней успешной контрольной точки, называемые набором изменений, сбрасываются на диск, т.е. во второй модуль 120 хранения. Контент 320 памяти хранится в первом модуле 110 хранения.
Если последняя контрольная точка (t[n-1]) не была успешной, то наборы изменений для текущей (tn) и последней контрольной точки (t[n-1]) являются унифицированными (объединенными). Могут быть использованы разные способы для детектирования наборов изменений и управления ими.
Логический журнал отката обеспечивает согласованную запись запросов на операции модификации на наборах данных, которые, позже, захватываются в наборах изменений при установке контрольных точек. Таким образом, файлы журнала отката начинаются и очищаются относительно временного интервала последней успешной контрольной точки.
Методика ведения журнала отката с нулевым копированием устройства 10 хранения данных обеспечивает минимальные непроизводительные затраты файловой системы. Эта методика определяет блок-регистратор, который управляет потоком регистратора и коммуникационным потоком, которые выполнены с возможностью выполнения функций блока 110 управления устройства 10 хранения данных, и которые будут объяснены со ссылкой на следующие фигуры.
Фиг. 4 показывает взаимодействие и/или связь между обоими потоками. Связь осуществляется через Свободный-Список 410, упомянутый выше. Поток регистратора помещает страницы в Свободный-Список, коммуникационный поток считывает страницы из Свободного-Списка.
Отображаемый в памяти файл 420 используется для хранения журнала отката максимального необходимого размера, с некоторым количеством записей, достаточным для поддержки конфигурируемого количества сбоев контрольных точек. Журнал в файле является «круговым», что означает, что журнал начинается при произвольном смещении и осуществляет циклический переход к началу файла. Размер буфера может быть ограничен заданным значением. Смещение первой логической записи сохраняется в соответствующем файле контрольных точек. Разные файлы журналов отката могут быть размещены на разных дисках.
Адресное пространство файла разделяется на страницы отката (страница отката может быть кратным числом страниц операционной системы (operating system - OS)), и это пространство разделяется на диапазоны адресов Сохраненных-Страниц (SavedPages) и Доступных-Страниц (AvailablePages). Сохраненные-Страницы представляют собой диапазон, где хранятся активные записи журнала отката. Доступные-Страницы являются страницами, которые являются доступными для хранения следующих записей отката. Свободный-Список страниц отката, отображаемый в Доступных-Страницах, содержит страницы, которые коммуникационный поток может распределить и приватизировать. Размер Свободного-Списка определяет количество данных, готовых к утрате в случае отказа системы. Когда Свободный-Список исчерпывается, коммуникационный поток зацикливается в ожидании его пополнения.
Ожидающий-Список (PendingList) 430 страниц отката содержит список страниц, которые ожидают обработки потоком регистратора. Если страницы в Ожидающем-Списке являются только частично заполненными, то поток регистратора может объединить все записи журнала отката в меньшее количество страниц, которые он будет фактически сохранять. Поток регистратора сохраняет страницы в Ожидающем-Списке посредством синхронного системного вызова msync(). В то время как msync() выполняется на странице, ее адрес добавляется к Сохраненным-Страницам; регистратор извлекает новую страницу из Доступных-Страниц и помещает эту страницу в Свободный-Список.
После приема транзакции обновления, коммуникационный поток использует свою приватную страницу отката (распределенную из Свободного-Списка блока-регистратора), форматирует запись отката при текущем смещении на странице и считывает параметры транзакции из сетевого разъема в запись отката. Затем, он сохраняет указатель на запись отката в буфере запросов/ответов, и пересылает буфер запросов в очередь запросов.
Когда запрос поступает в рабочий поток, поток считывает запись отката, исполняет ее и сохраняет состояние ответа в записи отката. Поскольку коммуникационный поток обслуживает все возможные рабочие потоки, могут существовать сценарии, где разные потоки обновляют одну и ту же строку, например, после повторного вычисления связи рабочих потоков с разделами. Таким образом, обновление на одной и той же строке может появиться в разных файлах журнала отката. Рабочий поток, поэтому, вставляет упорядочивающий счетчик количества транзакций строки в запись журнала отката.
Когда страница является полной, или после истечения конфигурируемого интервала Tr сброса журнала отката, коммуникационный поток проверяет достоверность того, что релевантные рабочие потоки обработали свои записи журнала отката на странице. Поток может считать последнюю запись релевантного рабочего потока на странице для определения ее состояния завершения. Затем, коммуникационный поток ставит страницу в очередь в Ожидающий-Список 430 и распределяет новую страницу из Свободного-Списка 410. Интервал Tr конфигурируется таким образом, что в сценарии с низкой скоростью обновления рабочей нагрузки, поток регистратора сохраняет Ожидающий-Список своевременно, без необходимости ожидания коммуникационным потоком пополнения Свободного-Списка.
Коммуникационный поток и поток регистратора могут запрашивать начало и конец процесса установки контрольных точек. В начале контрольной точки, коммуникационный поток добавляет специальный маркер на странице перед записью журнала отката для новой контрольной точки. Смещение этого маркера сохраняется в соответствующем файле контрольных точек. Поток регистратора, детектирующий успешное завершение последней контрольной точки, перемещает страницы в Сохраненных-Страницах, соответствующие записям журнала отката, которые охватывает последняя контрольная точка, в Доступные-Страницы.
После системного сбоя, процесс восстановления использует последнюю постоянную контрольную точку для инициализации состояния памяти, и процедуру Воспроизведения, для воспроизведения журнала отката для воссоздания состояния приложений в некоторый момент времени перед моментом времени сбоя. Процедура Воспроизведения просматривает параллельно файлы журнала отката на основании смещений, сохраненных в файле контрольных точек, и применяет транзакции, заданные в записях отката, к состоянию наборов данных в памяти.
Поскольку записи отката строк могут быть рассеяны по множеству файлов, процедура Воспроизведения может поддерживать связное двоичное дерево для строки для поглощения встречающихся вне очереди записей. Когда встречается следующая по порядку запись отката, она обрабатывается немедленно, и, после нее, все следующие записи в дереве.
Свободный-Список 410 и отображаемый в памяти файл 420, в частности, указывают на один и тот же адрес физической памяти, так что дополнительная копия журнала отката не требуется.
Фиг. 5 и 6 показывают реализацию проектирования журнала отката в оперативном запоминающем устройстве типа «ключ-значение». На этих фигурах, Ожидающий-Список является списком страниц журнала отката, а Доступные-Страницы и Сохраненные-Страницы являются пространствами адресов отображаемых в памяти файлов, описанных со ссылкой на фиг. 4.
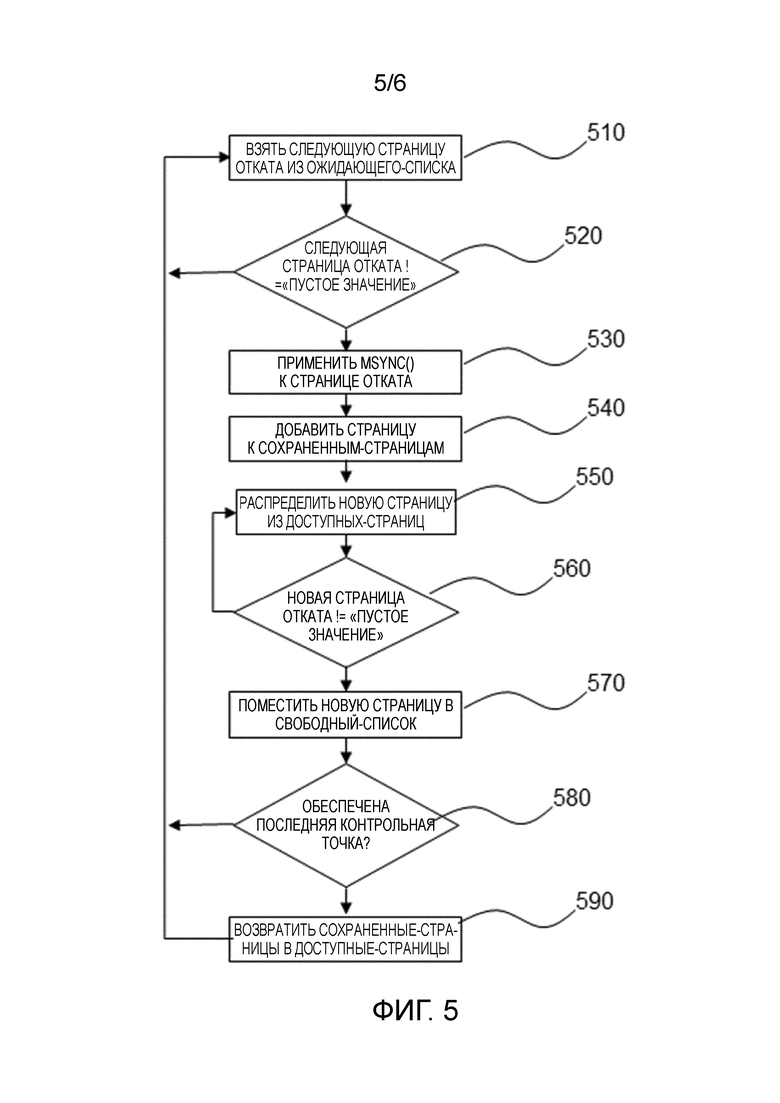
Фиг. 5 показывает блок-схему последовательности операций потока регистратора. Поток обслуживает Ожидающий-Список, и, когда он не пустой, удаляет страницу из списка и сохраняет ее посредством системного вызова синхронизации, например, msync().
На этапе 510, следующая страница отката берется из Ожидающего-Списка до тех пор, пока имеются страницы отката, указанные ветвлением 520. Затем, на этапе 530, страницы отката синхронизируются, и добавляются к Сохраненным-Страницам, на этапе 540. На этапе 550, новая страница распределяется из доступных страниц до тех пор, пока не останется доступных дополнительных страниц, на этапе 560. На этапе 570, новая страница вставляется в Свободный-Список и, в зависимости от того, обеспечена ли 580 или нет последняя контрольная точка, либо Сохраненные-Страницы возвращаются в Доступные-Страницы 590, либо следующая страница отката берется из Ожидающего-Списка 510.
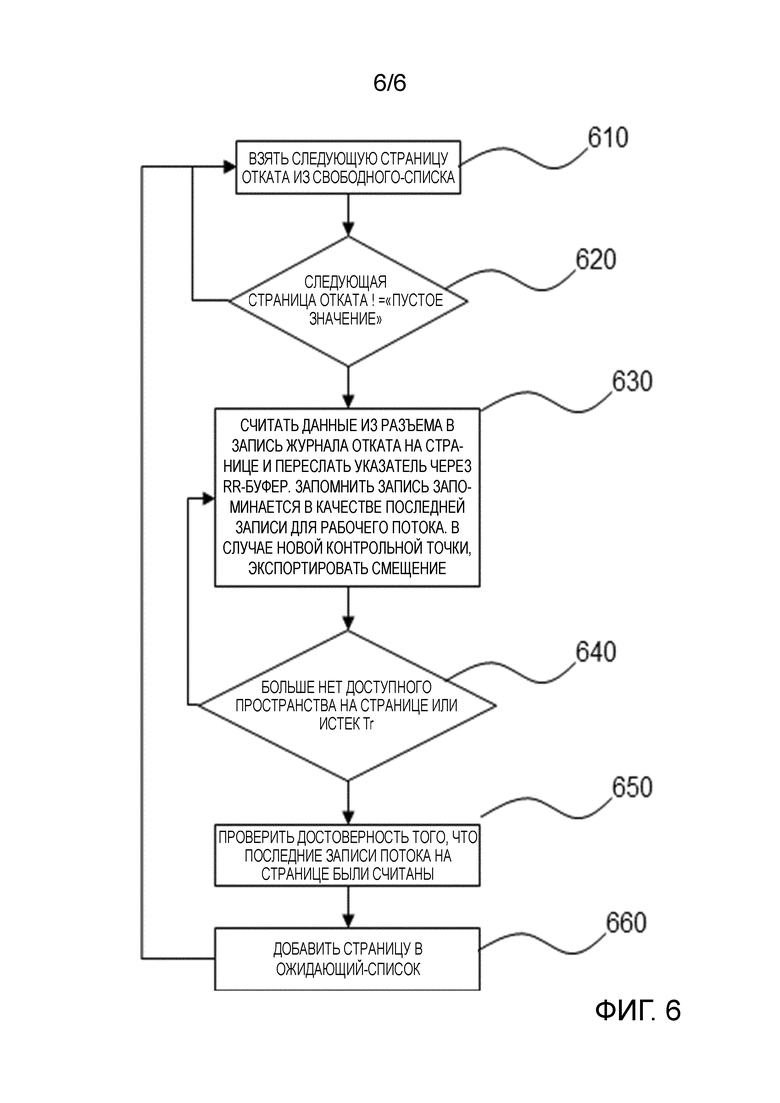
Фиг. 6 показывает блок-схему последовательности операций коммуникационного потока. Коммуникационный поток приватизирует страницу журнала отката из Свободного-Списка. Страница обеспечивает достаточное пространство журнала отката, так что нет необходимости в частом распределении страниц. При наличии необходимого пространства в записи журнала отката, поток считывает запрос операции обновления на странице, запоминает запись в качестве последней записи для соответствующего рабочего потока. После исчерпания пространства или истечения таймера Tr, коммуникационный поток проверяет достоверность того, что все последние записи на странице были считаны. После этого, поток добавляет страницу в Ожидающий-Список и переходит в начало цикла.
Другими словами, на этапе 610, страницы берутся из Свободного-Списка до тех пор, пока не будут взяты все страницы, на этапе 620. Данные с разъема считываются в запись журнала отката на странице, и указатель пересылается через буфер, на этапе 630. Дополнительно, на этапе 630 соответствующая запись запоминается в качестве последней записи для рабочего потока. В случае новой контрольной точки, смещение экспортируется. Это повторяется до тех пор, пока больше не останется доступного пространства на странице, или пока не истечет Tr, на этапе 640. На этапе 650, коммуникационный поток проверяет достоверность того, что последние записи на странице были считаны, и добавляет страницу в Ожидающий-Список, на этапе 660.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВОССТАНОВЛЕНИЯ ДАННЫХ В СИСТЕМЕ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ | 2013 |
|
RU2526753C1 |
| ЖУРНАЛИРУЕМОЕ ХРАНЕНИЕ БЕЗ БЛОКИРОВОК ДЛЯ НЕСКОЛЬКИХ СПОСОБОВ ДОСТУПА | 2014 |
|
RU2672719C2 |
| КОРРЕКТНОСТЬ БЕЗ ЗАВИСИМОСТИ ОТ УПОРЯДОЧЕННОСТИ | 2010 |
|
RU2560786C2 |
| ВЫГРУЗКА В ФАЙЛОВОЙ СИСТЕМЕ | 2014 |
|
RU2671049C2 |
| МОДУЛЬ ВИЗУАЛЬНОГО ПРОСМОТРА ЦЕПОЧКИ БЛОКОВ | 2018 |
|
RU2746584C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| ОПТИМИЗАЦИЯ ОПЕРАЦИЙ ПРОГРАММНОЙ ТРАНЗАКЦИОННОЙ ПАМЯТИ | 2006 |
|
RU2433453C2 |
| СПОСОБ, СИСТЕМА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ПРЕДОСТАВЛЕНИЯ УСЛУГ СВЯЗИ МЕЖДУ РЕСУРСАМИ В СЕТЯХ СВЯЗИ И ИНТЕРНЕТ С ЦЕЛЬЮ ПРОВЕДЕНИЯ ТРАНЗАКЦИЙ | 2002 |
|
RU2273107C2 |
| Система и способ идентификации криптографических кошельков на основе анализа транзакций | 2018 |
|
RU2693314C1 |
| МЕХАНИЗМ ЗАПРОСА ПОЗДНЕЙ БЛОКИРОВКИ ДЛЯ ПРОПУСКА АППАРАТНОЙ БЛОКИРОВКИ (HLE) | 2008 |
|
RU2501071C2 |
Изобретение относится к средствам хранения данных. Технический результат заключается в сокращении времени обработки запросов в случае сбоя работы устройства. Устройство (10) хранения данных содержит модуль (100) управления, первый модуль (110) хранения, второй модуль (120) хранения, третий модуль (125) хранения и буфер (130). Первый модуль (110) хранения выполнен с возможностью хранения множества наборов данных. Модуль (100) управления выполнен с возможностью приема запросов на операции, подлежащие выполнению на множестве наборов данных в первом модуле (110) хранения, исполнения принятых запросов и копирования множества наборов данных в первом модуле (120) хранения во второй модуль (120) хранения в заданный момент времени. Модуль управления дополнительно выполнен с возможностью добавления принятых запросов на операции в буфер (130) и сохранения буфера (130) в третьем модуле (125) хранения с помощью средства синхронизации. Устройство хранения данных выполнено с возможностью инициализации множества наборов данных в первом модуле (110) хранения из второго модуля (120) хранения и выполнения операций, соответствующих запросам из третьего модуля (125) хранения, в сценарии восстановления. 13 з.п. ф-лы, 6 ил.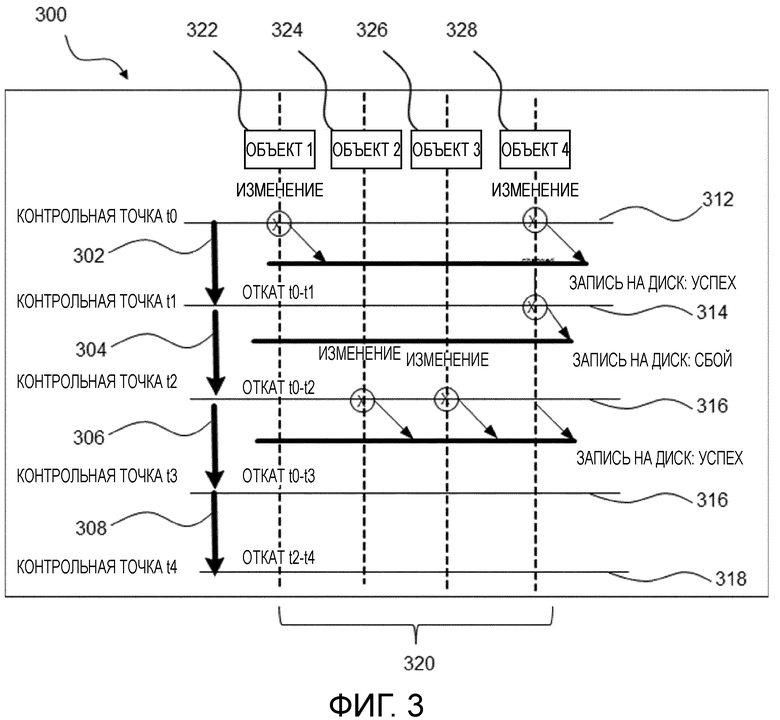
1. Устройство (10) хранения данных, содержащее:
модуль (100) управления;
первый модуль (110) хранения;
второй модуль (120) хранения;
третий модуль (125) хранения и
буфер (130);
причем первый модуль (110) хранения выполнен с возможностью хранения множества наборов данных;
причем модуль (100) управления выполнен с возможностью приема запросов на операции, подлежащие выполнению на множестве наборов данных в первом модуле (110) хранения, исполнения принятых запросов и копирования множества наборов данных в первом модуле (120) хранения во второй модуль (120) хранения в заданный момент времени;
причем модуль управления выполнен с возможностью добавления принятых запросов на операции в буфер (130);
причем модуль управления выполнен с возможностью сохранения буфера (130) в третьем модуле (125) хранения посредством средства синхронизации;
причем устройство хранения данных выполнено с возможностью инициализации множества наборов данных в первом модуле (110) хранения из второго модуля (120) хранения и выполнения операций, соответствующих запросам из третьего модуля (125) хранения, в сценарии восстановления.
2. Устройство хранения данных по п. 1, в котором второй модуль (120) хранения выполнен с возможностью содержания постоянной копии согласованного состояния множества наборов данных, во время множества заданных моментов времени, из первого модуля (110) хранения.
3. Устройство хранения данных по п. 1, в котором модуль (100) управления выполнен с возможностью приема запросов на операции, подлежащие выполнению на множестве наборов данных в первом модуле (110) хранения, исполнения принятых запросов и копирования множества наборов данных в первом модуле (120) хранения во второй модуль (120) хранения во время множества последовательных заданных моментов времени.
4. Устройство хранения данных по п. 1, в котором буфер является круговым буфером.
5. Устройство хранения данных по п. 1, в котором буфер (130) выполнен с возможностью использования одних и тех же ячеек буфера для добавления принятых запросов на операции, подлежащие выполнению на первом модуле (110) хранения, и для обновления третьего модуля (125) хранения.
6. Устройство хранения данных по п. 1, в котором модуль (100) управления выполнен с возможностью маркировки запросов на операции, выполняемые на наборах данных в первом модуле хранения, которые были использованы для обновления третьего модуля хранения.
7. Устройство хранения данных по п. 1, в котором модуль (100) управления выполнен с возможностью повторного обновления наборов данных во втором модуле хранения.
8. Устройство хранения данных по п. 1, в котором модуль (100) управления выполнен с возможностью верификации того, является ли обновление наборов данных во втором модуле хранения успешным, и немаркировки соответствующих запросов, как обновленных, во втором модуле хранения, в случае, когда обновление не является успешным.
9. Устройство хранения данных по п. 1, в котором устройство (10) хранения данных выполнено с возможностью обновления только тех наборов данных во втором модуле хранения, на которых была выполнена операция в первом модуле хранения.
10. Устройство хранения данных по п. 1, в котором первый модуль хранения является непостоянным модулем хранения.
11. Устройство хранения данных по п. 1, в котором третий модуль хранения является постоянным модулем хранения.
12. Устройство хранения данных по п. 1, в котором первый модуль (110) хранения выполнен с возможностью назначения множества наборов данных для множества групп наборов данных;
причем устройство хранения данных содержит множество буферов (130);
причем каждый из множества буферов назначен для одной группы наборов данных, соответственно.
13. Устройство хранения данных по п. 1, причем устройство хранения данных выполнено с возможностью восстановления множества наборов данных в первом модуле хранения на основе наборов данных второго модуля хранения и запросов, содержащихся в третьем модуле хранения.
14. Устройство хранения данных по п. 13, в котором только эти запросы, содержащиеся в третьем модуле хранения, применяются к наборам данных в первом модуле хранения, которые не были обновлены во втором модуле хранения.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 6490594 B1, 03.12.2002 | |||
| US 5864849 A, 26.01.1999 | |||
| СПОСОБ ЗАПИСИ ДАННЫХ В ЭНЕРГОНЕЗАВИСИМОЕ ЗАПОМИНАЮЩЕЕ УСТРОЙСТВО, СПОСОБ ИСПОЛЬЗОВАНИЯ УСТРОЙСТВА НА ИНТЕГРАЛЬНЫХ СХЕМАХ, УСТРОЙСТВО НА ИНТЕГРАЛЬНЫХ СХЕМАХ | 1994 |
|
RU2146399C1 |
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| US 7577806 B2, 18.08.2009. | |||

