Перекрестная ссылка на родственные заявки
По этой заявке испрашивается приоритет патентной заявки США №11/389,451, поданной 23 марта 2006 года, которая притязает на приоритет предварительной заявки США №60/748,386, поданной 7 декабря 2005 года.
Предшествующий уровень техники
Общим для множественных потоков многопотокового процесса является совместное использование общих ячеек памяти во время параллельного исполнения. Следовательно, два разных потока многопотокового процесса могут читать и обновлять одну и ту же ячейку памяти, к которой обращается программа. Однако следует предпринимать осторожность, чтобы гарантировать, что один поток не модифицирует значение совместно используемой ячейки, в то время как другой поток находится в середине последовательности операций, которые зависят от этого значения.
Например, предположим, что программа обращается к содержимому двух разных программных объектов, в которых каждый объект представляет количество денег на разных банковских счетах. Первоначально сумма первого счета, равная $10, сохранена по адресу A1 памяти, в то время как сумма второго счета, равная $200, сохранена по адресу A2 памяти. Первый поток банковской программы закодирован, чтобы переводить $100 с A2 на A1, а второй поток закодирован, чтобы вычислить общее количество денежных средств на обоих счетах. Первый поток может начаться добавлением $100 к содержимому A1, обновлением его до $110 и затем перейти к вычитанию $100 из содержимого A2, обновлению его до $100. Однако если второй поток выполняется между этими двумя операциями, то второй поток может вычислить скорее неправильную сумму в $310 для обоих счетов, чем правильную сумму в $210.
Программная транзакционная память предоставляет абстракцию программирования, посредством которой поток может безопасно выполнить последовательность обращений к совместно используемой памяти, позволяющую потоку завершить свою транзакцию без помех от другого потока. Соответственно транзакционные запоминающие устройства могут быть применены в программном обеспечении, чтобы гарантировать, что транзакция, включающая в себя примерные операции добавления и вычитания первого потока, является "атомарной" по отношению к ячейкам A1 и A2 памяти, и поэтому второй поток будет вычислять правильную итоговую сумму на обоих счетах.
Однако существующие подходы осуществления транзакционной памяти в программном обеспечении страдают от проблем, связанных с производительностью. Например, в одном существующем подходе, когда поток обращается к последовательности ячеек памяти в рамках транзакции, этот поток поддерживает отдельный список ячеек памяти и значений, которые он желает прочитать и обновить (т.е. записать) во время транзакции, и затем, в конце транзакции, поток обновляет все эти значения в фактически совместно используемых ячейках памяти. Если во время транзакции поток хочет повторно прочитать или повторно записать в любую ячейку памяти в своем списке, поток должен исследовать запись ячейки памяти в списке, чтобы обратиться к записи, что является медленным с программной точки зрения. Соответственно этот косвенный способ осуществления транзакционной памяти в программном обеспечении страдает от плохой производительности.
Дополнительно, существующие подходы к осуществлению транзакционной памяти в программном обеспечении вводят существенные накладные расходы, включающие в себя необязательные вызовы транзакционной памяти и инструкции ведения записей, вызывающие замедление исполнения программ, особенно, если эти инструкции выполняются неэффективным образом. Дополнительно, действиям по регистрации свойственно в некоторых схемах транзакционной памяти неэффективно ограничивать создание и сохранение записей, которые они создают, что может вызвать излишние затраты памяти, также как и дискового пространства и других системных ресурсов.
Сущность изобретения
Описана система программной транзакционной памяти ("STM"). Система и методика, описанные в данном документе, выполняют оптимизации инструкций программной транзакционной памяти, чтобы достичь эффективной работы. Описан компилятор, который заменяет блоки программной транзакционной памяти инструкциями программной транзакционной памяти и дополнительно декомпозирует эти инструкции на декомпозированные инструкции программной транзакционной памяти. Компилятор использует знание семантики инструкции, чтобы выполнять оптимизации, которые будут недоступны в традиционных системах программной транзакционной памяти. Компилятор дополнительно выполняет высокоуровневые оптимизации кода STM. Некоторые из этих оптимизаций выполняются, чтобы получить преимущество низкоуровневых оптимизаций. Эти высокоуровневые оптимизации включают в себя удаление необязательных модернизаций чтения-для-обновления, перемещение операций STM по вызовам процедур и удаление необязательных операций по новым создаваемым объектам. Дополнительно, код STM оптимизируется, чтобы предоставить строгую атомарность обращений к памяти, записанных вне транзакций.
В одном примере способ компиляции программы, включающей в себя блоки программной транзакционной памяти, описан в вычислительной системе, содержащей процессор и компилятор, сконфигурированный со знанием операций программной транзакционной памяти. Способ содержит оптимизацию программы, чтобы создать оптимизированную программу, содержащую инструкции программной транзакционной памяти, и компиляцию оптимизированной программы.
Данное изложение сущности изобретения предусмотрено для того, чтобы в упрощенной форме представить набор идей, которые дополнительно описываются ниже в подробном описании. Это изложение сущности изобретения не предназначено для того, чтобы идентифицировать ключевые признаки или важнейшие признаки заявляемого предмета изобретения, а также не предназначена для того, чтобы быть использованной в качестве помощи при определении объема заявляемого изобретения.
Дополнительные признаки и преимущества станут очевидными из последующего подробного описания варианта осуществления, которое продолжается со ссылкой на сопровождающие чертежи.
Перечень фигур чертежей
Фиг.1 является блок-схемой компилятора, используемого, чтобы скомпилировать исходный код, содержащий атомарные блоки памяти транзакций.
Фиг.2 является блок-схемой компонентов компилятора на фиг.1.
Фиг.3 является блок-схемой, иллюстрирующей примерный процесс компиляции и выполнения программы, использующей транзакционную память.
Фиг.4 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на фиг.1, для компиляции программы с транзакционной памятью.
Фиг.5 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на фиг.1, для выполнения высокоуровневых оптимизаций программной транзакционной памяти.
Фиг.6 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на Фиг.1, для оптимизации декомпозированных инструкций программной транзакционной памяти во время компиляции.
Фиг.7 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на Фиг.1, для ввода операций для осуществления строгой атомарности.
Фиг.8 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на Фиг.1, для удаления модернизаций чтения-для-обновления.
Фиг.9 является блок-схемой, иллюстрирующей дополнительный примерный процесс, выполняемый компилятором на Фиг.1, для удаления модернизаций чтения-для-обновления.
Фиг.10 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на Фиг.1, для перемещения операций по вызовам процедур.
Фиг.11 является блок-схемой, иллюстрирующей примерный процесс, выполняемый компилятором на Фиг.1, для удаления операций регистрации для новых создаваемых объектов.
Фиг.12 является блок-схемой, иллюстрирующей дополнительный примерный процесс, выполняемый компилятором на Фиг.1, для удаления операций регистрации для новых создаваемых объектов.
Фиг.13 является блок-схемой, содержащей программные модули, использованные во время прогона программы в рабочей среде системы программной транзакционной памяти.
Фиг.14a и 14b являются блок-схемами, иллюстрирующими примерные объекты, использующие универсально используемые слова заголовков.
Фиг.15a и 15b являются блок-схемами, иллюстрирующими примерный объект с изменяющимся моментальным снимком.
Фиг.16 является блок-схемой, иллюстрирующей примерный процесс среды выполнения на Фиг.6 для проверки достоверности объекта с помощью моментальных снимков.
Фиг.17 является блок-схемой, иллюстрирующей примерный процесс среды выполнения на Фиг.6 для модификации моментального снимка объекта, использующего наполненное слово заголовка.
Фиг.18a и 18b являются блок-схемами, иллюстрирующими примеры выполнения транзакций.
Фиг.19a-19c являются блок-схемами, иллюстрирующими дополнительные примеры выполнения транзакций.
Фиг.20 является блок-схемой, иллюстрирующей примерную ассоциативную таблицу, используемую в среде выполнения на Фиг.6 для фильтрации журнала.
Фиг.21 является блок-схемой, иллюстрирующей примерный процесс среды выполнения на Фиг.6 для фильтрации журнальных записей с помощью ассоциативной таблицы на Фиг.13.
Фиг.22 является блок-схемой, иллюстрирующей дополнительный примерный процесс среды выполнения на Фиг.6 для фильтрации журнальных записей с помощью ассоциативной таблицы на Фиг.13.
Фиг.23 является блок-схемой, иллюстрирующей примерный процесс среды выполнения на Фиг.6 для уплотнения журналов во время очистки памяти.
Фиг.24 является блок-схемой, иллюстрирующей дополнительный примерный процесс, выполняемый в среде выполнения на Фиг.6, для уплотнения журналов во время очистки памяти.
Фиг.25 является блок-схемой, иллюстрирующей дополнительный примерный процесс, выполняемый в среде выполнения на Фиг.6, для уплотнения журналов во время очистки памяти.
Фиг.26 является блок-схемой подходящего вычислительного окружения для осуществления технологий данного документа.
Подробное описание
Примеры, иллюстрированные в данном документе, описывают примеры программных и аппаратных систем транзакционной памяти, также как и улучшения в производительности этих систем. В частности, примеры осуществления ниже описывают: декомпозированные операции программных транзакций; использование примитивов STM в промежуточном представлении компилятора ("IR"), чтобы предоставить возможность для оптимизации кода (этот термин объяснен ниже), улучшения компилятора, которые работают так, чтобы улучшить производительность этих примитивов, фильтрацию журнала работы с помощью ассоциативных таблиц и эффективные операции выполнения по каждому объекту. В то время как описания, предоставленные в данном документе, предоставлены в качестве оптимизаций отдельного осуществления программной транзакционной памяти, будет признано, что технологии и системы, описанные в данном документе, могут работать в разных осуществлениях, и необязательно предполагать какое-либо ограничение в осуществлении, производительности или требованиях технологий, описанных в данном документе.
1. Примеры системы программной транзакционной памяти
Атомарные блоки представляют обещанное упрощение проблемы записи параллельных программ. В системах, описанных в данном документе, блок кода обозначается атомарным, и компилятор и исполняющая система обеспечивают то, что операции в блоке, включающие в себя вызовы функций, являются атомарными. Программисту больше не нужно беспокоиться о ручной блокировке, низкоуровневых режимах состязаний или взаимных блокировках. Атомарные блоки могут также обеспечивать восстановление исключений, посредством чего действия со стороны блока откатываются, если исключение прекращает его. Это является значимым даже в однопотоковом приложении: код обработки ошибки часто трудно записать или протестировать. Осуществления атомарных блоков масштабируются на многопроцессорные машины, поскольку они сохраняют параллелизм: атомарные блоки могут выполняться одновременно при условии, что ячейка, обновляемая в одном блоке, не доступна в любом другом месте. Это сохраняет вид совместного использования, разрешенный в традиционном кэше данных.
Технологии, описанные в данном документе, сделаны со ссылкой на осуществление STM, которое тесно объединено с компилятором и исполняющей системой. Одним признаком осуществления является то, что это является STM с прямым обновлением. Это позволяет объектам обновляться непосредственно скорее в динамически распределяемой области памяти, чем работать в частных точных копиях объектов или через дополнительные уровни между ссылкой на объект и содержимым текущего объекта. Это более эффективно для транзакций, которые успешно фиксированы.
Системы и технологии, описанные в данном документе, используют признак осуществления, который предоставляет декомпозированный интерфейс STM. Например, поле obj.field=42 транзакционной памяти разбивается на этапы, которые (a) делают запись о том, что объект обновляется текущим потоком, (b) регистрируют старое значение, которое удерживалось в поле, и (c) сохраняют новое значение 42 в поле. Этот новый замысел позволяет предоставлять классические оптимизации в транзакционных операциях. Например, три этапа в нашем примере управляются отдельно компилятором, и этапы (a) и (b) могут часто подниматься из цикла. В технологиях, описанных в данном документе, декомпозированный интерфейс STM сделан более эффективным посредством использования компилятора с определенным знанием интерфейса STM и семантики, и который может выполнять оптимизации, которые сконфигурированы, чтобы действовать конкретно с этим интерфейсом.
В другом примере системы и технологии, описанные в данном документе, иллюстрируют действия в описанном осуществлении STM посредством эффективных операций с каждым объектом, которые используют объединенный транзакционный контроль версий. Эти осуществления используют объединение транзакционного контроля версий с существующим заголовком объекта. Это отличается от других систем STM, так как эти системы либо используют внешние таблицы записей контроля версий, дополнительные слова заголовков, либо уровни преобразования логических адресов в физические между ссылками на объект и текущим содержимым объекта. Эти подходы вызывают плохую локальность кэша или увеличивают использование пространства. Осуществление, описанное в данном документе, использует наполненное слово заголовка вместе с эффективными инструкциями моментального снимка памяти, которые предоставляют возможность быстрой верификации изменений объекта в то время, когда фиксируется транзакция.
Кроме того, описывается фильтрация журнала выполнения. Фильтрация полезна, так как не все ненужные операции STM могут быть идентифицированы статистически в момент компиляции.
В одном осуществлении примеры, описанные в данном документе, осуществлены в компиляторе Бартока, оптимизирующем компиляторе с предварительным поиском и исполняющей системе для программ на общем промежуточном языке (CIL) с производительностью, конкурирующей с платформой Microsoft.NET. Исполняющая система может быть осуществлена в CIL, включая в себя программы очистки памяти и новую STM.
1.1. Семантика
Технологии, описанные в данном документе, фокусируются на производительности атомарных блоков. Различные осуществления могут отличаться точной семантикой, включающей в себя взаимодействие атомарных блоков с кодом блокировки и объединением операций ввода/вывода с атомарными блоками при продолжении использования этих технологий.
1.2. Допущения проекта
В примерах, описанных в данном документе, сделаны некоторые предположения о том, как будут использоваться атомарные блоки. Они необязательно представляют ограничения в осуществлениях, описанных в данном документе, а вместо этого служат для того, чтобы упростить описание.
Одним предположением является то, что большинство транзакций фиксируются успешно. Это является приемлемым предположением, поскольку, во-первых, использование сохраняющей параллелизм STM означает, что транзакции не будут прекращаться 'спонтанно', или из-за конфликтов, которые программист не может понять (в альтернативных вариантах осуществления конфликты обнаруживаются на основе значений хэш-функции, с которыми могут неожиданно сталкиваться). Предполагается, как часть этого, что программист уже имеет сильный стимул избежать конфликтной ситуации из-за расходов на излишнее перемещение данных между кэшами. Технологии, такие как операции с высокой конкуренцией передачи в очереди обработки, управляемые одним потоком, остаются полезными.
Вторым предположением является то, что операции чтения превышают по численности обновления в атомарных блоках. Это предположение подкрепляется наблюдениями текущих программ и попытками разработать их транзакционные версии. Это акцентирует пользу сохранения накладных расходов на транзакционные операции чтения очень низкими: чтения затрагивают просто регистрацию адреса читаемого объекта и содержимое его слова заголовка.
Конечным предположением является то, что размер транзакции не должен быть ограничен. Это сохраняет композиционность при предложении того, что осуществление STM нужно также масштабировать, когда растет длина транзакций. В этом проекте накладные расходы на пространство растут с величиной объектов, к которым осуществляется обращение в транзакции, а не с числом сделанных обращений. В этих примерах, описанных в данном документе, транзакции неформально называются "короткими" и "длинными". Короткие транзакции, вероятно, работают без необходимости какого-либо распределения памяти посредством STM. Длинными транзакциями являются те, чье выполнение, вероятно, должно охватывать GC-циклы (например, оценку одного из эталонных тестов LISP в версии эталонного теста xlip SPEC95, который был транслирован в C#).
1.3. Пример STM на основе слова
Один традиционный интерфейс для STM на основе слова предоставляет следующие два набора операций:
void TMStart()
void TMAbort()
bool TMCommit()
bool TMIsValid()
word TMRead(addr addr)
void TMWrite(addr addr, word value)
Первый набор используется, чтобы управлять транзакциями: TMStart начинает транзакцию в текущем потоке. TMAbort прерывает транзакцию текущего потока. TMCommit пытается фиксировать транзакцию текущего потока. Если транзакция не может быть фиксирована (например, в одном осуществлении из-за того, что параллельная транзакция обновила одну из ячеек, к которой она обращалась), тогда TMCommit возвращает ложное значение, и текущая транзакция отвергается. Иначе TMCommit возвращает истинное значение, и любые обновления, которые были сделаны во время транзакции, атомарно распространяются на совместно используемую динамическую область памяти. TMIsValid возвращает истинное значение, если и только если транзакция текущего потока может быть фиксирована в момент вызова. Второй набор операций выполняет обращения к данным: TMRead возвращает текущее значение конкретной ячейки или наиболее последнее значение, записанное посредством TMWrite в текущей транзакции.
В одном осуществлении технологий, описанных в данном документе, процесс программирования напрямую с STM автоматизирован за счет наличия обращений компилятора к перезаписываемой памяти в атомарных блоках, чтобы использовать операции STM, и его необходимости формировать специализированные версии вызванных методов, чтобы гарантировать, что TMRead и TMWrite используются для всех обращений к памяти в атомарном блоке.
Проект, описанный выше, страдает от ряда проблем, которые ограничивают его применимость. Следующие примеры кода иллюстрируют это: Пример 1a, показанный ниже, выполняет итерацию по элементам связанного списка между сигнальными узлами this.Head и this.Tail. Он суммирует значения полей узлов и сохраняет результат в this.Sum. Пример 1b иллюстрирует один пример автоматически размещаемых вызовов TMRead и TMWrite для всех обращений к памяти.
Однако несколько проблем производительности могут произойти с этой системой на основе слова. Во-первых, многие осуществления TMRead и TMWrite используют журналы транзакций, которые исследуются по каждой операции TMRead и TMWrite. TMRead должен видеть более ранние сохранения посредством той же транзакции, таким образом, он исследует журнал транзакций, который хранит пробные обновления. Такое исследование не может масштабироваться для поддержки больших транзакций. Производительность зависит от длины журнала транзакций и эффективности структур вспомогательных указателей. Во-вторых, непрозрачные вызовы библиотеки STM препятствуют оптимизации (например, больше невозможно поднимать чтение this.Tail из цикла, так как характер TMRead не известен компилятору). В заключение, монолитные операции TM вызывают повторную работу. Например, повторяющиеся исследования при обращении к полю в цикле.
1.4. STM с декомпозированным прямым доступом
Осуществление STM с декомпозированным прямым доступом, которое используется в примерах, предоставленных выше, обходит эти проблемы. Первая проблема обходится системами проектирования так, что транзакция может выполнять операции чтения и записи непосредственно в динамической области памяти, давая возможность чтению легко видеть предшествующее транзакционное сохранение без какого-либо поиска. Журналы все еще нужны для отката транзакции, который отменяет и отслеживает информацию о версии ячеек, к которым осуществлен доступ. Для коротких транзакций эти журналы являются только дополняемыми. Таким образом, поиск не требуется, невзирая на размер транзакции.
Вторая проблема обходится введением TM-операций своевременно во время компиляции и продолжения фаз последующего анализа и оптимизации, чтобы знать об их семантике. В заключение, третья проблема обходится разбиванием монолитных TM-операций на отдельные этапы так, что повторяющаяся работа может быть отменена. Например, управление журналами транзакций отделяется от фактических обращений к данным, часто позволяя управлению журналом подниматься из циклов.
Этот интерфейс делит операции с транзакционной памятью на четыре набора:
tm_mgr DTMGetTMMgr()
void DTMStart (tm_mgr tx)
void DTMAbort(tm_mgr tx)
bool DTMCommit(tm_mgr tx)
bool DTMIsValid(tm_mgr tx)
void DTMOpenForRead(tm_mgr tx, object obj)
void DTMOpenForUpdate (tm_mgr tx, object obj)
object DTMAddrToSurrogate(tra_mgr tx, addr addr)
void DTMLogFieldStore (tm_mgr tx, object obj, int offset)
void DTMLogAddrStore(tm_mgr tx, addr obj)
Первые два набора являются прямыми, представляя DTMGetTMMgr, чтобы получить менеджер транзакций текущего потока, и, далее, представляя обычные операции управления транзакциями. Третий набор обеспечивает обнаружение конфликтной ситуации: DTMOpenForRead и DTMOpenForUpdate указывают, что к конкретному объекту можно обращаться только в режиме чтения, и что он может быть впоследствии обновлен. Доступ к статическим полям опосредован замещающими объектами, которые хранят информацию о версии от их лица: DTMAddToSurrogate отображает адрес на своего заместителя. Последний набор сохраняет журнал отката, необходимый, чтобы откатить обновления при преждевременном прекращении. DTMLogFieidstore имеет дело с сохранением в поля объектов, а DTMLogAddrstore имеет дело с сохранением по какому-либо адресу.
Вызовы этих операций должны быть корректно упорядочены, чтобы обеспечить атомарность. Существуют три правила: (a) ячейка должна быть открыта для чтения, когда она читается, (b) ячейка должна быть открыта для обновления, когда она обновляется или сохраняет журнал для него, (с) старое значение ячейки должно быть зарегистрировано в журнале перед тем, как оно обновляется. На практике это означает, что вызов в TMRead для поля объекта делится на последовательность DTMGetTMMgr, DTMOpenForRead и затем чтение поля.
TMWrite является последовательностью DTMGetTMMgr, DTMOpenForUpdate, DTMLogAddstore и затем запись поля. Вызов в TMRead для статического поля делится на последовательность DTMGetTMMgr, DTMAddrToSurrogate, DTMOpenForRead и затем чтение статического поля. TMWrite является последовательностью DTMGetTMMgr, DTMAddrToSurrogate, DTMOpenForUpdate, DTMLogAddstore и затем запись статического поля.
Следующие примеры демонстрируют пример использования STM с декомпозированным прямым доступом. Код в примере 1a выполняет итерацию элементов связанного списка между сигнальными узлами this.Head и this.Tail. Он суммирует поля Значения узлов и сохраняет результат в this.Sum. Пример 2 показывает, как Sum может быть осуществлена с помощью STM с декомпозированным прямым доступом.
Пример 1a

Пример 1b

Пример 2

2. Оптимизации в процессе компилирования
Секция 2 описывает оптимизацию декомпозированных операций STM с помощью компилятора, который сконфигурирован со знанием операций STM. Следует заметить, что в качестве используемых в данной заявке термины "оптимизировать", "оптимизированный", "оптимизации" и подобные являются терминами области техники, которые, как правило, ссылаются на улучшение без ссылки на какую-либо определенную степень улучшения. Таким образом, в разных сценариях, в то время как "оптимизация" может улучшить один или более аспектов производительности системы или техники, она необязательно требует, чтобы каждый аспект системы или технологии был улучшен. Дополнительно, в различных ситуациях "оптимизация" необязательно подразумевает улучшение какого-либо аспекта до какой-либо определенной минимальной или максимальной степени. Кроме того, в то время как "оптимизированная" система или технология могут показывать улучшение производительности в одной или более областях, она может также показать снижение в производительности в других областях. В заключение, в то время как "оптимизация" может улучшить производительность системы или технологии в некоторых ситуациях, может быть возможно, что она уменьшает производительность в других ситуациях. В определенных обстоятельствах, описанных ниже, в то время как оптимизации будут иметь результатом удаление излишних или ненужных инструкций STM или журнальных записей, возможно предоставление улучшенной производительности, эти оптимизации должны подразумевать, что каждые возможные избыточные или ненужные инструкции будут удалены.
Фиг.1 является блок-схемой, иллюстрирующей один пример компилятора 100, используемого для того, чтобы создать оптимизированную программу 120, использующую программную транзакционную память. В иллюстрированном примере компилятор 100 рассматривается как входной исходный код 110. Как иллюстрировано, исходный код 110 содержит один или более атомарных блоков 115. Как упоминалось выше, в одном осуществлении включение в состав таких атомарных блоков отменяет дополнительное программирование для программиста, желающего использовать STM; эти блоки модифицируются компилятором так, чтобы включать в себя декомпозированные инструкции STM, которые затем оптимизируются. В то время как Фиг.1 иллюстрирует один участок исходного кода, следует принимать во внимание, что это представлено только для упрощения иллюстрирования; технологии и системы, описанные в данном документе, применяются также к множественным файлам исходных кодов, которые компилируются вместе, также как и к исходному коду, который использует уже скомпилированный код. Дополнительно, в различных осуществлениях используются разные кодовые языки, включающие в себя C++, C#, Java, C и другие; также, в различных осуществлениях интерпретируемые языки также могут быть оптимизированы. В иллюстрированном примере эта оптимизация обеспечивается оптимизациями 150 STM, которая интегрирована в компиляторе, дополнительные детали этой интеграции обсуждаются ниже. После компиляции и оптимизации создается оптимизированная программа 120, которая использует программную транзакционную память. Дополнительные детали операций исполнения такой оптимизированной программы описаны более подробно ниже. Дополнительно, в то время как иллюстрированное осуществление показывает компиляцию в исполняемый файл перед выполнением, альтернативные осуществления технологий, описанных в данном документе, могут компилировать и оптимизировать программы непосредственно перед или параллельно с выполнением.
Фиг.2 является блок-схемой, иллюстрирующей примерные компоненты компилятора 100 на Фиг.1. Фиг.2 иллюстрирует примерный путь операции через компилятор. В то время как Фиг.2 иллюстрирует определенные модули отдельно, следует принимать во внимание, что в различных осуществлениях модули могут быть соединены или разделены в различных комбинациях. Путь начинается с первого модуля 220 компилятора, который принимает исходный код 110 и создает из него промежуточное представление 230. В одном осуществлении это IR принимает форму графа управляющего процесса ("CFG"), который позволяет легко управлять им посредством оптимизирующих технологий, описанных в данном документе.
Далее, IR 230 модифицируется модулем 240 оптимизации, чтобы создать оптимизированное IR 250. В этой операции модуля 240 оптимизации традиционные оптимизации в процессе компилирования расширяются с помощью низкоуровневых и высокоуровневых характерных для STM оптимизаций. Примеры таких оптимизаций будут описаны более подробно ниже. В заключение, оптимизированное IR 250 компилируется вторым модулем 260 компилятора в исполняемый код, такой как оптимизированная программа 120 на Фиг.1.
Фиг.3 является блок-схемой примерного процесса 300 компиляции и выполнения программы, использующей STM. В различных осуществлениях этапы иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 320, где принимается исходный код, содержащий блоки транзакционной памяти (такие как атомарные блоки на Фиг.1). В альтернативном осуществлении исходный код может не содержать блоков транзакционной памяти, а вместо этого будет содержать индивидуальные инструкции программной транзакционной памяти, такие как построенные на слове или декомпозированные инструкции, описанные выше. Далее, на этапе 340 этот исходный код компилируется в исполняемую программу. Конкретные примеры компиляции описываются более подробно ниже. В заключение, на этапе 360 исполняемая программа выполняется.
Фиг.4 является блок-схемой примерного процесса 400 компиляции исходного кода, который объединяет блоки транзакционной памяти. Процесс 400 соответствует этапу 340 на Фиг.3. В различных осуществлениях этапы иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 420, где инструкции программной транзакционной памяти вставляются в каждый атомарный блок посредством компилятора 100. В одном осуществлении эта вставка выполняется посредством вставки подходящих основанных на слове STM-инструкций чтения и записи вокруг каждого события чтения или записи в блоке. В другом осуществлении, если программист решает вставить свои собственные STM-инструкции, процесс этапа 420 может быть опущен.
Далее, на этапе 440 основанные на слове STM-инструкции заменяются компилятором 100 на декомпозированные инструкции. В одном осуществлении, если исходный код, принятый компилятором, содержит уже декомпозированные инструкции, процесс этапа 440 пропускается. Дополнительно, в некоторых осуществлениях процессы блоков 420 и 440, в частности, могут быть объединены, чтобы вставить декомпозированные STM-инструкции непосредственно в ответ на прием атомарного блока. Пример 2, выше, иллюстрирует, что часть кода может выглядеть как после работы процесса этапа 440.
В другом осуществлении процесса этапа 440 компилятор дополнительно уменьшает расходы на управление журналом регистрации посредством декомпозиции журнальных операций, предоставляя возможность списания стоимости работы по управлению журналом регистрации по множественным операциям. В частности, в одном осуществлении операции DTMOpen* и DTMLog* начинаются с проверки того, что существует пространство в текущем массиве. Для DTMOpenForRead это только проверка того, что должно быть выполнено в версии кода с быстрым маршрутом. Чтобы амортизировать расходы на эти проверки, компилятор использует новую операцию, EnsureLogMemory, беря целое число, которое указывает, как много сегментов зарезервировать в данном журнале.
Характерные декомпозированные версии операций DTMOpen* и DTMLog* могут, таким образом, предположить, что пространство существует. Чтобы уменьшить регистрацию использования системных ресурсов во время выполнения в одном осуществлении операции EnsureLogMemory не являются аддитивными: две последующие операции резервируют запрошенный максимум, но не полностью. Для простоты, одно осуществление не устанавливает специализированные операции, где зарезервированное пространство потребуется после вызова или возврата. В другом осуществлении резервирования объединяются для всех операций между вызовами в каждом базовом блоке. В другом случае обратный анализ, который используется, чтобы интенсивно зарезервировать пространство заранее, насколько возможно, принуждается останавливаться во всех вызовах и заголовках циклов. Это имеет преимущество объединения большего числа резервирований, но может ввести операции резервирования в маршрутах, которые не требуют их.
На этапе 460 компилятор выполняет высокоуровневые оптимизации STM, включающие в себя введение операций строгой атомарности, перемещения и удаления необязательных STM-операций и удаление журнальных операций для новых создаваемых объектов. Этот процесс описан более подробно ниже. В заключение, на этапе 480 программа оптимизируется, включая в себя инструкции STM. В то время как процесс на Фиг.4 иллюстрирует высокоуровневые операции, за которыми следуют другие оптимизации в блоках 460 и 480, и не иллюстрирует повторение оптимизаций, в некоторых осуществлениях процессы в Фиг.460 и 480 или их подпроцессы могут быть выполнены в другом порядке, чем проиллюстрировано, и могут быть повторены. Одной причиной повторения является то, что определенные оптимизации могут раскрывать возможности для других оптимизаций. Таким образом, может быть желательно повторно выполнить оптимизации, чтобы получить пользу от возможностей, когда они могут возникать.
Фиг.5 является блок-схемой примерного процесса 500 выполнения высокоуровневых оптимизаций по инструкциям STM. Процесс 500 соответствует этапу 460 на Фиг.4. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. В одном осуществлении процесс 500 выполняется перед оптимизациями в процессе компилирования процесса 600, описанного ниже с тем, чтобы операции, добавленные посредством высокоуровневых оптимизаций, могли быть дополнительно оптимизированы компилятором. Процесс начинается на этапе 520, где компилятор вводит операции для строгой атомарности. Далее, на этапе 540 операции для того, чтобы открыть объекты для чтения, за которыми следуют операции, чтобы открыть те же объекты для обновления, заменяются операциями открытия для обновления, чтобы позволить последующее удаление операций открытия во время последующей оптимизации. В одном осуществлении эти операции открытия-для-чтения, за которыми следуют операции открытия-для-обновления, называются модернизациями чтения-для-обновления; процесс этапа 540 удаляет эти модернизации. Далее, на этапе 560, декомпозированные STM-операции перемещаются по вызовам процедур, чтобы предоставить большие оптимизации в процессе на Фиг.6. В заключение, на этапе 580 операции записи в журнал объектов, которые заново создаются в транзакциях, для которых они протоколируются, удаляются, чтобы предотвратить ненужные вызовы операции записи в журнал. Отдельные примеры каждого из этих процессов описаны более подробно ниже относительно Фиг.7-12.
2.1. Оптимизации в процессе компилирования по декомпозированному коду
Фиг.6 является блок-схемой примерного процесса 600 выполнения оптимизаций по инструкциям STM. Процесс 600 соответствует этапу 480 на Фиг.4. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Дополнительно, в то время как иллюстрированное осуществление дает пример, в котором каждое действие выполняется один раз, в альтернативных осуществлениях действия могут повторяться. Таким образом, например, общее действие исключения подвыражения, описанное ниже, может быть выполнено второй раз после того, как были выполнены оптимизации переноса части текста программы. В то время как Фиг.6 не иллюстрирует оптимизацию неSTM-инструкций, это делается ради простоты иллюстрации, и не демонстрирует какого-либо ограничения в процессах, описанных в данном документе.
Процесс начинается на этапе 620, где создаются ограничения по модификации инструкций STM. В одном осуществлении этими ограничениями являются, по меньшей мере, ограничения атомарности, которые основаны на последовательности вызовов. Таким образом, существуют три правила: (a) ячейка должна быть открыта для чтения, когда она считывается, (b) ячейка должна быть открыта для обновления, когда она обновляется или сохраняется запись в журнале для нее, (с) старое значение ячейки должно быть зарегистрировано в журнале перед тем, как она обновляется.
Эти правила могут быть осуществлены с помощью ряда способов. В одном способе компилятор сохраняет данные отслеживания ограничений во время компиляции посредством различных вспомогательных показателей. Поскольку это может быстро усложнить процесс компиляции, в другом осуществлении CFG может быть модифицирован, чтобы предотвратить нарушение ограничений. Одним таким способом является введение зависимостей данных с помощью фиктивных переменных между инструкциями STM, что оказывает влияние на порядок вызовов, создавая фиктивные переменные вывода для инструкций, которые становятся входными переменными для последующих инструкций. Таким образом, IR, которое выглядит как следующее (использующее общие инструкции):
open_for_update (loc);
log_for_update (loc);
write (loc, val);
становится:
dummy1 = open_for_update (loc);
dummy2 = log_for_update (loc, dummy1);
write (loc, val, dummy2);
Далее, на этапе 640 выполняется общее исключение подвыражений ("CSE") по инструкциям STM, за которым следует исключение излишней загрузки памяти по инструкциям на этапе 660 и оптимизация перемещения кода на этапе 680.
В одном примере эти оптимизации могут выполняться по операции DTMGetTMMgr, поскольку она является постоянной и, таким образом, предоставляет возможности для CSE. Подобным образом, поскольку операции DTMOpenForRead, DTMOpenForUpadate, DTMAddrToSurrogate и DTMLog* являются идемпотентными в транзакции, они также подходят для CSE или переноса кода. Одним ограничением по этой оптимизации является то, что перенос кода не может, в одном осуществлении, распространяться за границы транзакции. В другом осуществлении CSE распространяется, чтобы предоставить исключение инструкций DTMOpenForRead, которые имеют место после DTMOpenForUpdate. Эта оптимизация может быть выполнена, поскольку обращение с обновлением относится к категории обращения с чтением.
В других осуществлениях CSE может быть выполнено по операциям между вложенными транзакциями. Таким образом, в одном примере операция DTMOpenForRead во вложенной транзакции относится к категории DTMOpenForRead или DTMOpenForUpdate во внешней транзакции и, таким образом, может быть исключена. В другом осуществлении DTMOpenForUpdate во вложенной транзакции относится к категории DTMOpenForUpdate во внешней транзакции и исключается.
В другом осуществлении операция DTMGetTMMgr может быть осуществлена посредством привлечения менеджера текущей транзакции для потока из объекта Thread по каждому потоку (и создания менеджера транзакций, если необходимо). Компилятор Бартока может, таким образом, также обрабатывать инструкцию GetCurrentThread как постоянную операцию, подверженную переносу кода.
В качестве примера, после выполнения вышеуказанных процессов кода в примере 2 упрощается до следующего, более эффективного кода:
Пример 3

2.2. Высокоуровневые оптимизации STM
2.2.1. Реализация строгой атомарности
Технологии, описанные выше, могут использоваться, чтобы построить "атомарные" блоки, в которых обращения к памяти в одном атомарном блоке происходят неделимо по отношению к обращениям во втором атомарном блоке. Однако "атомарный" блок, выполняемый одним потоком, может не появляться для выполнения неделимым образом, когда второй поток выполняет конфликтующее обращение к памяти без использования "атомарного" блока. Проекты с этим признаком могут быть упомянуты для того, чтобы предоставлять "слабую атомарность".
Одно осуществление технологий, описанных в данном документе, относится к тому, как предоставить "строгую атомарность", в которой атомарные блоки предстают для выполнения неделимым образом по отношению ко всем обращениям к памяти, а не только тем, которые сделаны в других атомарных блоках.
Основное осуществление распространяется на STM, описанное выше, с поддержкой строгой атомарности посредством (a) идентификации всех обращений к совместно используемой памяти, которые происходят вне какого-либо атомарного блока, (b) перезаписи их в качестве коротких атомарных блоков.
Например, предположим, что программа читает содержимое поля "o1.x" и сохраняет результат в поле "o2.x". Это первоначально будет представлено двумя инструкциями в промежуточном представлении (IR) компилятора:
L1:
t1 = getfield<x>(o1)
L2:
putfield<x>(o2, t1)
Базовая реализация развертывает это в код, такой как:
L1:
DTMStart (tm)
DTMOpenForRead(tm, o1)
t1=getfield<x>(o1)
DTMCommit(tm) // C1
L2:
DTMStart(tm)
DTMOpenForUpdate(tm, o2)
logfield<x>(o2)
putfield<x>(o2, tl)
DTMCommit(tm) // C2
(В некоторых осуществлениях фактически записанный код является более сложным, поскольку он также должен включать в себя маршруты кода, чтобы повторно выполнить транзакции из L1 или L2, если существует конфликтная ситуация во время операций фиксации C1 или C2. Точные детали этого кода будут отличаться в зависимости от того, как STM-операции представлены в IR).
Основная форма будет обеспечивать строгую атомарность, но она будет выполняться плохо из-за дополнительных расходов на операции запуска транзакции, фиксации транзакции, открытия для чтения, открытия для обновления и записи в журнал поверх расходов на обращения к оригинальному полю.
Чтобы увеличить эффективность, в то время как все еще обеспечивается осуществление строгой атомарности, одно осуществление технологий, описанных в данном документе, использует специализированные операции IR, чтобы ускорить производительность коротких транзакций, которые обращаются только к одной ячейке памяти.
Существуют два случая для рассмотрения: транзакции, которые читают из одной ячейки, и транзакции, которые обновляют одну ячейку (включающие в себя транзакции, которые выполняют операции чтение-модификация-запись в одну ячейку). Оба случая затрагивают проверку STM-слова, которое описано более подробно ниже. Первый случай представлен в расширенном IR посредством (a) чтения STM-слова для связного объекта, (b) чтения поля, (c) повторного чтения STM-слова и проверки того, что прочитанное значение соответствует тому, что в (a), и что значение не указывает, что было параллельное, конфликтующее обращение. Второй случай представлен в расширенном IR посредством (a) обновления STM-слова для связного объекта, указания, что он подвергнут нетранзакционному обновлению, (b) обновления поля, (c) обновлении STM-слова еще раз, указания, что он больше не подвержен нетранзакционному обновлению. Таким образом, IR для примера выглядит как следующее:
L1:
S1 = openoneobjforread(o1)
t1 = getfield<x>(o1)
if (!checkoneobj(o1, s1)) goto L1
L2:
s2 = openoneobjforupdate(o2)
putfield<x>(o2, t1)
commitoneobj(o2, s2)
Это осуществление предполагает два отличия от осуществления STM, описанного выше. Первым является то, что в отличие от осуществления STM, описанного выше, временное хранилище основано скорее на локальных переменных, чем на журналах транзакций. Это означает, что переменные могут быть выделены в регистрах процессора, чтобы сделать быстрым доступ к ним. Вторым отличием является то, что транзакция, начинающаяся в L2, не может быть прервана, и, таким образом, необязательно регистрировать в журнале значение, которое перезаписано в "o2.x".
Еще в одном осуществлении строгой атомарности компилятор выполняет дополнительную оптимизацию, чтобы ограничить число полей, которые должны быть расширены в этом способе. В одном примере компилятор выполняет основанный на типе анализ, чтобы идентифицировать все поля, которые могут быть записаны в атомарном блоке. К любым другим полям, к которым гарантировано никогда не будет производиться доступ в атомарных блоках, доступ может быть непосредственным, и, таким образом, не потребуется вставка операций строгой атомарности вокруг них.
Фиг.7 является блок-схемой примерного процесса 700 введения операций для того, чтобы осуществить строгую атомарность. Процесс 700 соответствует этапу 520 на Фиг.5. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 710, где выполняется анализ типа, чтобы определить поля, к которым может быть осуществлен доступ в атомарном блоке. Как описано выше, в одном осуществлении это выполняется, чтобы избежать ненужной вставки операций строгой атомарности в отношении обращений к памяти, которые не могут вызывать конфликт. Далее, на этапе 720 определяется обращение к памяти в программе, которое может обратиться к полю, содержащемуся в атомарном блоке, с помощью полей, определенных на этапе 710. В альтернативном осуществлении процесс этапа 710 может быть пропущен, и процесс этапа 720 может разместить каждое обращение к памяти вне атомарных блоков для вставки операций строгой атомарности.
Далее, процесс продолжается до этапа 725 принятия решения, где компилятор определяет, является ли обращение, размещенное на этапе 720, чтением или обращением для обновления. Если обращение является чтением, процесс продолжается на этапе 730, где инструкция открытия-для-чтения вставляется перед обращением. В одном осуществлении эта инструкция сконфигурирована, чтобы блокировать, пока она способна принимать STM-слово, и, таким образом, гарантировать, что обращение к памяти может правильно прочитать поле, к которому осуществляется обращение. В другом осуществлении операция не блокируется, а создается цикл после обращения к памяти, если обращение к памяти не подтверждено. Далее, на этапе 740 инструкция проверки вставляется после обращения к памяти, чтобы гарантировать, что по ходу обращения по чтению STM-слово не указывает изменения в читаемом поле. В осуществлении, предоставленном выше, это сделано посредством приема STM-слова на этапе 730 и передачи STM-слова в операцию проверки на этапе 740; это также создает зависимость данных, которая предохраняет оптимизацию кода от переупорядочивания порядка операций строгой атомарности.
Если, однако, этап 725 определяет, что обращение является обновлением, процесс продолжается на этапе 750, где инструкция открытия-для-обновления вставляется перед обращением. В одном осуществлении эта инструкция сконфигурирована, чтобы модифицировать STM-слово из объекта, к которому осуществляется обращение, чтобы предотвратить другие обращения, таким образом, обеспечивая строгую атомарность. Далее, на этапе 760, инструкция фиксации вставляется после обращения к памяти, чтобы фиксировать обновление, выполненное при обращении к памяти. В одном осуществлении номер версии объекта, к которому осуществлено обращение, изменяется. В другом - нет. Далее, на этапе 765 принятия решения, компилятор определяет, существуют ли дополнительные неатомарные обращения к памяти. Если так, процесс повторяется. Если нет, процесс заканчивается.
2.2.2. Удаление модернизаций чтение-для-обновления
Другая высокоуровневая оптимизация, выполненная различными осуществлениями компилятора STM, существует, чтобы избежать ненужной записи в журнал, которая происходит, когда за операцией DTMOpenForRead следует операция DTMOpenForUpdate. Одним предположением проекта, присущим технологиям, описанным в данном документе, является то, что чтения являются более общими, чем записи, вот почему эти технологии используют отдельные операции DTMOpenForUpdate и DTMOpenForRead; инструкция открытие-для-чтения способна выполниться более быстро. Однако иногда объекты считываются и затем записываются (каноническим примером является "obj.field++). В этом случае IR с операциями открытия будет выглядеть приблизительно так:
DTMOpenForRead(obj);
t = obj.field;
t = t + 1;
DTMOpenForUpdate(obj);
DTMLogFieldStore(obj, offsetof(obj.field));
obj.field = t;
Если программа достигает точки открытия-для-чтения, можно увидеть, что она будет искать точку открытия-для-обновления, игнорируя исключения в данный момент. Так как открытие-для-обновления относится к категории открытия-для-чтения того же объекта, операция открытие-для-чтения тратится впустую. Это известно в одном осуществлении как модернизация чтение-для-обновления. Будет более эффективным просто выполнить операцию открытия-для-обновления раньше:
DTMOpenForUpdate(obj);
t = obj.field;
t = t+1;
DTMLogFieldStore(obj, offsetof(obj.field));
obj.field = t;
Таким образом, в одном осуществлении компилятор удаляет модернизации чтение-для-обновления, когда они находятся. Как правило, это может управляться компилятором в базовом блоке посредством прямого анализа потока данных, обновления операций DTMOpenForRead, если за ними следует DTMOpenForUpdate. В другом общем случае операции DTMOpenForUpdate просто вставляются в начало всех базовых блоков, из которых все неисключающие маршруты выполняют одинаковую DTMOpenForUpdate (без мешающих сохранений в затронутые переменные). CSE затем пытается исключить лишние операции DTMOpenForUpdate, также как и какие-либо последующие операции DTMOpenForRead по одному и тому же объекту.
Фиг.8 является блок-схемой примерного процесса 800 для удаления ненужных модернизаций чтения-для-обновления. Процесс 800 соответствует этапу 540 на Фиг.5. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 810, где компилятор идентифицирует операции открытия-для-чтения, за которыми всегда следуют операции открытия-для-обновления по той же ссылке. Отметим, что, в то время как примеры в данном документе используют указатели объектов, описанные технологии исключения ненужных модернизаций чтения-для-обновления также осуществляют удаление внутренних указателей и статических полей. Компилятору нужно определить, что операции открытия существуют по одному и тому же объекту (или замещающему объекту в случае осуществления статических полей).
В одном осуществлении анализ требует, чтобы ссылка на объект или внутренний указатель были одной и той же локальной переменной, и чтобы переменная не обновлялась между операциями. В то время как это осуществление может избежать удаления модернизации по присваиванию, другие осуществления также анализируют присваивания. В другом осуществлении статические поля (или переменные) управляются по операциям открытия замещающих объектов, что позволяет удалять модернизации между двумя разными статическими полями, когда один замещающий объект контролирует все статические поля. Примерный процесс процесса этапа 810 будет описан более подробно ниже со ссылкой на Фиг.9.
Далее, на этапе 820, операции открытия-для-чтения, которые были идентифицированы на этапе 810, заменяются операциями открытия-для-обновления по той же ссылке. Затем, на этапе 820, излишние операции открытия-для-обновления удаляются. В одном осуществлении это не выполняется непосредственно после процесса этапа 820, а вместо этого выполняется посредством оптимизаций в процессе компилирования, описанных для Фиг.6, таких как CSE.
Первое примерное осуществление анализа удаления чтения-для-модернизации удаляет модернизации в базовых блоках. Таким образом, компилятор просматривает каждый базовый блок во всей программе и сканирует каждый, чтобы найти операции открытия-для-чтения. Когда найдена первая, компилятор сканирует вперед, отыскивая операцию открытия-для-обновления или присваивания переменных, указывающих на открытый объект. Если первой находится открытие-для-обновления, тогда компилятор преобразует открытие-для-чтения в операцию открытия-для-обновления и удаляет оригинальное открытие-для-обновления. Если переменная обновлена, этот поиск отменяется. В альтернативном осуществлении компилятор может сканировать в обратном направлении от операций открытия для обновления, чтобы найти операции открытия-для-чтения.
Фиг.9 является блок-схемой второго примерного процесса 900 удаления идентификации операций открытия-для-чтения, которые всегда относятся к группе операций открытия-для-обновления. Процесс 900 соответствует этапу 810 на Фиг.8. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены.
Процесс на Фиг.9 использует стандартный обратный анализ потока данных. В этом анализе компилятор вычисляет в каждой точке программы набор объектов, которые точно будут открыты для обновления в будущем. В различных осуществлениях процесс на Фиг.9 выполняется для каждого из базовых блоков в программе или для поднаборов базовых блоков. Процесс начинается на этапе 910, где наборы создаются в пределах базового блока, чтобы содержать указания объектов, которые точно обновлены. На этапе 920 все переменные в базовом блоке добавляются в набор. Затем, на этапе 930, анализ инструкций в базовом блоке начинается изучением последней инструкции на этапе. На этапе 935 принятия решения компилятор рассматривает форму инструкции. Если инструкция является присваиванием (например, "x=..."), на этапе 940 переменная присваивания удаляется из набора. Если инструкцией является инструкция открытия-для-обновления, однако, на этапе 950 переменная, открытая инструкцией, добавляется в набор.
В любом случае, или если существует инструкция другого типа, компилятор переходит к этапу 955 принятия решения, где он определяет, существуют ли дополнительные инструкции в базовом блоке. Если так, на этапе 960 компилятор переходит назад по графу управляющего процесса и находит следующую инструкцию в графе управляющего процесса, и процесс повторяется. Когда компилятор определяет на этапе 955 принятия решения, что не существует больше инструкций, достигается начало базового блока. Когда компилятор достигает начала блока, на этапе 970 он ищет предшественников блока (т.е. блоки, которые могут перейти к текущему блоку) и перекрещивает набор с наборами, сохраненными в конце каждого из этих предшественников. В одном осуществлении процесс на Фиг.9 повторяется до тех пор, пока ничто уже не будет изменяться, предоставляя текущий набор в конце каждого блока. Компилятор может идти назад по блоку, обновляющему набор тем же способом, чтобы получить набор для каждой точки программы.
В этот момент переменные в наборе "должны быть открыты для обновления в будущем" идентифицируются в целях этапа 810. Затем, в одном осуществлении, операции открытия-для-обновления добавляются для каждой из этих переменных, позволяя CSE удалить излишние операции открытия-для-обновления позже. В другом осуществлении частичная чрезмерность ("PRE") используется вместо агрессивного добавления инструкций открытия-для-обновления, за которыми следует CSE-оптимизация. Это является более общим решением и может производить код с меньшим числом инструкций открытия по тем же маршрутам.
В одном осуществлении анализы, описанные выше, предполагают, что исключения не возбуждаются, и, таким образом, игнорируют границы исключения и вычисляют наборы объектов, которые точно будут открыты для обновления в будущем, задавая то, что ни одно исключение не брошено. Это происходит потому, что исключения не являются общим случаем. Эта потеря точности не влияет на правильность. Однако альтернативные варианты осуществления могут быть расширены, чтобы принимать во внимание границы исключения, чтобы произвести точные результаты.
Дополнительно, в альтернативных осуществлениях анализы, описанные выше, могут быть модифицированы, чтобы игнорировать другие участки кода. Это может быть сделано посредством использования эвристических процедур, которые указывают, что игнорированный код выполняется относительно редко по сравнению с кодом, который анализируется. В одном осуществлении эти эвристические процедуры определены статически; в другом они определяются из информации профиля.
В качестве примера, после выполнения вышеуказанных процедур код в примере 3 упрощается до следующего, более эффективного кода:
Пример 3.1

2.2.3. Операции перемещения в присутствии вызовов процедур
Многие существующие оптимизации в процессе компилирования могут только сравнивать, исключать и перемещать код в функциях, так как технологии, как правило, слишком дорогостоящи, чтобы применяться к графу по всей программе. Однако посредством высокоуровневой STM-оптимизации перемещения STM-операций сквозь границы процедур такие оптимизации могут выполняться более эффективно.
В качестве примера приведен код:

ясно, что Foo всегда будет открывать объект, указанный по ссылке его параметром, для обновления. Вызывающая программа для Foo может также открыть этот объект (как выше) или может вызывать Foo в цикле (или ряд других случаев). Однако вызов процедуры предотвращает анализ/оптимизацию действий Foo с кодом в вызывающей программе. Эта оптимизация перемещает операцию открытия через барьер вызова, чтобы создать больше возможностей для других оптимизаций. CSE является очевидным кандидатом, так как вызывающая программа может уже сделать операцию, которая перемещается в нее. Другие, нехарактерные для транзакций оптимизации могут также быть улучшены (например, если тот же объект повторно передается в функцию в цикле, тогда открытие может быть поднято из цикла).
В одном примере эта оптимизация осуществляется для операций DTMGetTMMgr и DTMOpenFor*. В альтернативных осуществлениях оптимизация может быть выполнена для других операций, которые должны произойти, если вызывается метод. Дополнительно, в альтернативных осуществлениях, оптимизация может быть выполнена по операциям, которые будут обычно выполняться, если вызывается метод, жертвуя точностью и производительностью в необычных случаях для более лучшей производительности в общих случаях без потери цельности. В одном осуществлении компилятор выполняет оптимизацию по невиртуальным (так называемым "прямым") вызовам; это включает в себя виртуальные вызовы, которые были "девиртуализированы" (например, определено, что существует только одна цель вызова, и виртуальный вызов заменяется прямым).
Фиг.10 является блок-схемой примерного процесса 1000 для оптимизации STM-операций посредством их перемещения через границы метода. Процесс 1000 соответствует этапу 560 на Фиг.5. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 1010, где размещаются методы, которые содержат операции, которые могут быть перемещены за границы метода. Далее, на этапе 1020, метод клонируется, чтобы создать версию метода, которая позволяет операции выполняться вне метода. Если операция дает результат, процесс этапа 1020 также добавляет аргумент к клонированному методу, так что результат может быть передан ему.
Далее, на этапе 1030, операция перемещается из клонированного метода в одно или более мест вызова метода. В альтернативном осуществлении скорее, чем именно клонирование метода и перемещение операции, клонированный метод создается без перемещенной операции. Затем, в заключение, на этапе 1040, вызовы к оригинальному методу заменяются клонированным методом. В одном осуществлении замененных вызовов включаются дополнительные аргументы, которые используются клонированными методами. Примеры этих дополнительных аргументов показаны ниже.
В другом осуществлении замещения вызовов компилятор сохраняет набор методов, которые были клонированы, и отображение этих методов на их клонированные (специализированные) версии. Компилятор затем сканирует все методы в программе снова, чтобы заменить вызовы. В некоторых случаях технология исключает оригинальную версию функции полностью. В некоторых случаях, однако (например, если взят адрес функции), все еще будут существовать вызовы в неспециализированную версию, и они не могут быть удалены.
Разные операции будут заставлять способы клонироваться разными способами. В одном примере, если способ содержит GetTxMgr, компилятор клонирует способ, добавляет лишний параметр, чтобы принять менеджер транзакций, и заменяет все случаи GetTxMgr этим параметром.

В этом примере вызовы метода заменяются вызовами клонированного метода с дополнительным аргументом, содержащим менеджер транзакции:

В другом примере вместо одной характеристики, чтобы отслеживать и создавать специализированный клон, основанный на (менеджере транзакции), существует множество характеристик (каждый параметр и каждый статический заместитель). Например,

В этом примере компилятор будет, вероятно, создавать специализированную версию, которая предполагает, что вызывающая программа откроет obj1 и obj3 соответствующим образом (а не обязательно obj2). В одном осуществлении это делается посредством выполнения анализа "должен быть открыт для обновления в некоторый момент в будущем", описанного выше как часть процесса этапа 1010. Здесь анализ отслеживает только параметры и статических заместителей, но также распространяется на выполнение операций "открытие-для-чтения", также как и "открытие-для-обновления". Компилятор затем анализирует наборы в корне функции. Если они не пустые, тогда компилятор клонирует метод, за исключением указанного выше, для перемещения соответствующих операций открытия вокруг вместо этого. Компилятор хранит клонированную функцию, чьи параметры исключены, чтобы быть открытыми (либо для чтения, либо для обновления) для других оптимизаций, для просмотра.
2.2.4. Сокращение операций записи в журнал для новых создаваемых объектов
Конечная высокоуровневая оптимизация служит для того, чтобы сократить число операций записи в журнал, удаляя в транзакции операции записи в журнал для объектов, которые заново создаются в транзакции. В частности, не нужно сохранять информацию об откате в журнале для объектов, которые никогда не выйдут из транзакции, в которой они созданы. Вот почему информация в журнале отката для такого объекта используется только, если транзакция отменяется, в этот момент объект будет удален так или иначе.
По существу, оптимизация служит, чтобы идентифицировать переменные, которые всегда привязаны к объектам, которые были выделены после начала транзакции, и затем, чтобы удалить операции записи в журнал по этим объектам. Таким образом, Фиг.11 иллюстрирует блок-схему примерного процесса 1100 для удаления операций записи в журнал для новых создаваемых объектов. Процесс 1100 соответствует этапу 580 на Фиг.5. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены.
Процесс начинается на этапе 1110, где компилятор идентифицирует переменные, которые всегда привязаны к объектам, которые заново создаются в своей транзакции. В различных осуществлениях процесс этапа 1110 выполняется так, чтобы принимать информацию о переменных в разных наборах точек программы в компилируемой программе. Таким образом, анализ этапа 1110 может быть выполнен, чтобы узнать информацию о ссылках в отдельной точке, небольшом интервале кода, или по всему времени жизни переменной в транзакции.
После этого анализа, на этапе 1120, компилятор удаляет операции отката в журнале, которые действуют по этим переменным, и процесс заканчивается. В одном осуществлении компилятор выполняет процесс этапа 1120, заменяя STM-операции, которые обращаются к динамической области памяти, специальными расширенными версиями операций, чьи разбиения не включают в себя операции записи в журнал. В другом осуществлении компилятор выполняет процессы на Фиг.11 после разбиения STM-операции, чтобы явно удалить декомпозированные операции записи в журнал.
Процесс этапа 1110 классифицируется от простого к сложному в зависимости от кода, который анализируется. В одном примере код, такой как:
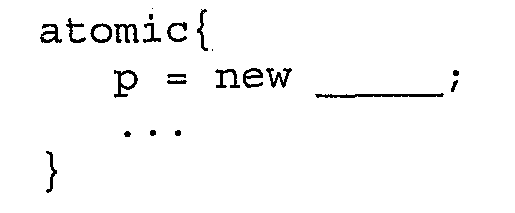
означает, что p всегда известен, чтобы ссылаться на новый создаваемый объект в атомарном блоке транзакции. Таким образом, безопасно удалить операции записи в журнал, которые работают с p. Однако часть кода, такого как:

не легко предоставляет информацию о том, всегда ли p ссылается на новые создаваемые объекты. Таким образом, компилятор должен выполнить анализ, чтобы идентифицировать, являются ли переменные подходящими для удаления записи в журнале или нет.
В одном осуществлении компилятор использует битовые векторы, которые используют вектор в каждой точке программы, который указывает, известна ли переменная, чтобы точно найти по ссылке новый создаваемый объект. В то время как это осуществление будет правильно идентифицировать ссылки для каждой из операций записи в журнал, которые могут быть удалены, это, как правило, является медленным и подразумевает большое использование памяти. В другом осуществлении битовые векторы могут предоставлять краткую информацию для большой подсекции кода, такого как базовый блок. Это осуществление может быть все еще медленным для межпроцедурного анализа.
В качестве альтернативы в одном осуществлении компилятор использует чувствительный к потоку межпроцедурный анализ, чтобы идентифицировать переменные, которые всегда привязаны к объектам, которые были выделены после начала транзакции. Фиг.12 иллюстрирует блок-схему такого примерного процесса 1200. Процесс 1200 соответствует этапу 1110 на Фиг.11. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. В иллюстрированном осуществлении процесс 1200 выполняется по каждому базовому блоку в транзакции.
Процесс, иллюстрированный на Фиг.12, выполняется по каждой функции всей программы, чтобы параллельно построить и разрешить граф зависимости. Для каждой функции процесс начинается на этапе 1210, где создается отображение от переменных по типу объекта к структурным элементам или узлам в графе зависимости. Отображение представляет типы значений, которые могут быть присвоены переменной в любой момент на этапе. В одном осуществлении структура имеет в себе три элемента: "Старый", который представляет переменные, которые ссылаются на объекты, которые не могут быть новыми создаваемыми, "Новый", который представляет переменные, которые ссылаются на объекты, которые должны быть заново созданы, и "Неизвестный" для переменных, для которых нет информации. На этапе 1220 все значения в отображении установлены в "Неизвестные". Далее, на этапе 1230, компилятор перемещается вперед по базовому блоку, чтобы изучить первую операцию на этапе. На этапе 1235 принятия решения компилятор определяет, какой тип операции изучается. Если операция является выделением объекта, на этапе 1240 компилятор добавляет элемент "Новый" в карту соответствия для присваиваемой переменной. Если операция является присвоением, заменой или вызовом процедуры, тогда на этапе 1250 компилятор распространяет структурные значения между переменными. Таким образом, присваивания и распределения распространяют свое абстрактное значение переменной присваивания. Вызовы распространяют абстрактные значения в формальные вызовы и из возвращаемого значения. Если, однако, операция является чем-то отличным от вышеописанных случаев, на этапе 1260 структура модифицируется, чтобы представить элемент "Старый" для переменных, которым назначена операция. В одном осуществлении анализ также рассматривает объекты, выделенные в зафиксированной субтранзакции текущей транзакции как являющиеся новыми создаваемыми.
Компилятор затем распространяет информацию вперед для отображения от локальных переменных в структурные значения или символы графа и повторяет процесс в функции до тех пор, пока не будет достигнута фиксированная точка. Таким образом, на этапе 1265 принятия решения компилятор определяет, достигнута ли точка объединения, такая как закрытие выражения ЕСЛИ (IF). Если точка объединения была достигнута, на этапе 1270 структурные значения из предшествующих блоков на точечной основе пересекаются с существующим отображением для текущего блока. В целях анализа в качестве начала функции рассматривается точка объединения из всех участков ее вызова. В любом случае процесс переходит к этапу 1275 принятия решения, где он определяет, существуют ли еще операции для изучения. Если так, процесс повторяется на этапе 1235 принятия решения. Если нет, процесс заканчивается. Этот процесс может вызвать распространение по графу в переменные из других функций. После того как процесс был выполнен по каждому базовому блоку в транзакции, для тех переменных, которые были обозначены как "Новые", операции их записи в журнал могут быть удалены. Отслеживание зависимости означает, что в различных осуществлениях функции могут быть обработаны в разных порядках. Это также означает, что функция не должна быть анализирована второй раз, если определена новая вызывающая программа или программы функции.
3. Примеры оптимизации выполнения
В этом разрезе описывается осуществление STM c декомпозированным прямым доступом. В общих чертах, транзакция использует точную двухфазную фиксацию для обновлений и записывает номера версий для объектов, которые она считывает, так, что она может обнаружить конфликтующие обновления. Журнал отката используется для восстановления после конфликта или взаимной блокировки. Одна оптимизация затрагивает расширение формата объекта, чтобы поддерживать номера версий, использованные операцией фиксации, также как и быструю технологию определения изменений в объекте на основе этого расширения. Также описывается фильтрация выполнения записей в журналах транзакционной памяти.
3.1. Атомарные операции фиксации
Расширение структуры объекта понимается в контексте атомарной операции фиксации в осуществлении STM, описанном в данном документе. В одном примере атомарной фиксации вызывается DTMStart, объекты открываются для чтения и обновления, а фиксация заканчивается вызовом DTMCommit, чтобы попытаться выполнить эти обращения атомарно.
Внутренне операция фиксации начинается попыткой проверить объекты, которые были открыты для чтения. Это гарантирует, что обновления не были сделаны в них другими транзакциями после того, как они были открыты. Если проверка заканчивается неудачей, обнаруживается конфликт: обновления транзакции откатываются, и объекты, которые она открыла для обновления, закрываются, после чего они могут быть открыты другими транзакциями. Если проверка заканчивается успешно, тогда транзакция выполняется без конфликтов: объекты, которые она открыла для обновления, закрываются, сохраняя обновления.
Процесс проверки проверяет, что не было конфликтующих обновлений в объектах, которые транзакция прочитала в течение интервала времени от вызова команды DTMOpenForRead до утверждения. Удерживание объектов открытыми для обновления предотвращает конфликты в течение интервала времени от вызова команды DTMOpenForUpdate до закрытия объектов в журнале STM. Следовательно, не существует конфликтующего обращения к любому из объектов, открытых во время пересечения этих интервалов времени; транзакция может считаться атомарной только перед тем, как начнется проверка.
3.2. Среда выполнения
Фиг.13 является блок-схемой, иллюстрирующей пример объектов и программных модулей, которые работают, чтобы оптимизировать производительность STM во время выполнения в среде 1300 выполнения. В то время как Фиг.13 иллюстрирует частные модули отдельно, следует принимать во внимание, что в различных осуществлениях модули могут быть объединены или разделены в различных комбинациях или могут работать как части других структур выполнения программного обеспечения, которые не иллюстрируются. Фиг.13 иллюстрирует объект 1310, функционирующий в среде выполнения вместе с наполненным основанным на слове заголовком 1315. Работа объекта с его наполненным основанным на слове заголовком будет описана в следующем разделе. Фиг.13 также иллюстрирует модуль 1320 подтверждения чтения и модуль 1330 закрытия обновления объекта для осуществления процедур подтверждения и закрытия осуществления STM, как описано выше. Отдельные аспекты этих модулей относительно объектов в среде выполнения описываются в данном документе. Фиг.13 дополнительно иллюстрирует ассоциативную таблицу 1350 фильтрации, которая в некоторых осуществлениях фильтрует и предотвращает ненужные записи от регистрации в различных комбинациях журнала 1360 отката, журнала 1370 обновленных объектов и журнала 1380 прочитанных объектов. Отдельные осуществления этого процесса фильтрации описываются более подробно ниже. В заключение Фиг.13 иллюстрирует модуль 1390 очистки памяти, который служит для того, чтобы освобождать объекты, когда они больше не доступны в выполняющейся программе, и чтобы уплотнять журналы STM во время очистки памяти. Отдельные осуществления этого модуля очистки памяти описываются ниже.
3.3. Структура объекта
Этот раздел описывает примеры структур, используемых, чтобы поддерживать проверку только читаемых объектов и операции открытия и закрытия по объектам, которые обновляются. В одном осуществлении STM использует две абстрактных сущности по каждому объекту в целях операций по объекту. STM-слово, использованное, чтобы согласовывать, какая транзакция имеет объект, открытый для обновления, и моментальный снимок STM, используемый в коде с быстрым маршрутом, чтобы обнаружить конфликтующие обновления в объектах, которые читает транзакция. Примеры операций, использующих эти структуры данных, являются следующими:
word GetSTMWord(Object o)
bool OpenSTMWord(Object o, word prev, word next)
void CloseSTMWord(Object o, word next)
snapshot GetSTMSnapshot(Object o)
word SnapshotToWord(snapshot s)
STM-слово объекта имеет два поля. Одно - это единичный бит, который указывает, открыт или нет объект в настоящее время для обновления какой-либо транзакцией. Если установлен, тогда остаток слова идентифицирует саму транзакцию. Иначе остаток слова хранит номер версии. OpenSTMWord выполняет атомарное сравнение-и-обмен по STM-слову (от предыдущего к следующему). CloseSTMWord обновляет слово до конкретного значения.
Фиг.14a и 14b иллюстрируют пример осуществления STM-слов в объектах. Иллюстрированное осуществление использует факт того, что среда выполнения Бартока ассоциативно связывает одно универсально используемое слово заголовка с каждым объектом, когда предоставляется то, что объект находится в памяти, используя это, чтобы ассоциативно связать блокировки синхронизации и хэш-коды (никакой из которых не является компонентами технологий STM, описанных в данном документе) с объектами. На Фиг.14a и 14b это универсально используемое слово заголовка расширяется с помощью дополнительного состояния, чтобы хранить STM-слово объектов, которые всегда были открыты для обновления в транзакции. Таким образом, на Фиг.14a объект 1400 содержит универсально используемое слово 1410 заголовка, которое содержит указатель 1413 типа значения, которое сохранено в нем, за которым следует фактическое STM-слово 1418. Использование указателя 1413 позволяет универсально используемому слову использоваться для хэш-кодов и блокировок посредством использования разных значений указателя. В одном осуществлении предполагается, что если указатель 1413 для объекта указывает, что блокировка или хэш-код сохраняется в слове, пока еще не существует STM-слова для объекта. Как также иллюстрирует Фиг.14a, STM-слово 1418 может иметь два типа значений, как описано выше. В примере 1420 STM-слово содержит бит, который указывает, что объект 1400 не открыт для обновления, и, таким образом, остаток слова хранит номер версии. В примере 1430 STM-слово содержит бит, который указывает, что объект открыт для обновления, таким образом, STM-слово идентифицировало транзакцию, которая имеет открытый объект для обновления.
В другом осуществлении, если универсально используемое слово необходимо больше чем для одной из этих целей (например, для хэш-кода и STM-слова), тогда оно наполняется, и внешняя структура хранит слово блокировки объекта, хэш-код и STM-слово. Таким образом, на Фиг.14b объект 1450 иллюстрируется как использующий наполненное слово заголовка. Указатель 1465 универсально используемого слова объекта содержит значение, которое указывает, что слово заголовка было наполнено, и остающееся значение 1460 универсально используемого слова содержит адрес памяти для структуры наполненного слова заголовка. Таким образом, на Фиг.14b универсально используемое слово указывает на структуру 1470 наполненного слова заголовка, которая содержит слово блокировки, хэш-код и STM-слово.
В противоположность STM-слову моментальный снимок STM объекта предоставляет подсказку о транзакционном состоянии объекта. В одном осуществлении среда выполнения гарантирует, что моментальный снимок изменяется всякий раз, когда вызывается closeSTMWord по объекту - то есть всякий раз, когда поток освобождает доступ для обновления к объекту. Это предоставляет достаточную информацию, чтобы обнаруживать конфликты.
Один способ гарантировать это - осуществление моментального снимка STM в качестве значения универсально используемого слова объекта. Очевидно, это осуществление означает, что моментальный снимок будет изменяться, когда STM-слово сохраняется непосредственно в универсально используемом слове. Однако оно не обязательно будет изменяться, когда используется наполненное слово заголовка. В одном осуществлении моментальный снимок для объектов, использующих наполненные слова заголовков, может отслеживать до конца и исследовать наполненное слово заголовка для каждого объекта. Однако существует неэффективная практика, которая существует в неравенствах с целью создания инструкций быстрого моментального снимка. Таким образом, в другом осуществлении, если универсально используемое слово было наполнено, тогда CloseSTMWord создает новую наполненную структуру и копирует содержимое предыдущей структуры в нее. Это позволяет моментальному снимку STM всегда осуществляться в качестве значения универсально используемого слова объекта при сохранении быстроты.
Фиг.15a и 15b иллюстрируют эффекты такого осуществления CloseSTMWord. На Фиг.15a объект 1500 иллюстрируется перед выполнением CloseSTMWord. Объект 1500 использует наполненное слово 1520 заголовка и хранит адрес наполненного слова 1520 заголовка в своем универсально используемом слове 1510 заголовка. Фиг.15b иллюстрирует изменения в объекте и памяти выполнения после выполнения CloseSTMWord. После выполнения создается новая структура 1540 наполненного слова заголовка, и адрес, сохраненный в универсально используемом слове 1510 заголовка, изменяется. Это означает, что моментальный снимок, который содержит значение универсально используемого слова 1510, изменился в результате закрытия.
Фиг.16 является блок-схемой примерного процесса 1600 для выполнения подтверждения с помощью моментальных снимков объекта. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 1620, где данные моментального снимка записываются для объекта. В одном осуществлении эта запись выполняется, когда объект открывается для чтения. Далее, на этапе 1640, модуль 1320 подтверждения чтения записывает второй моментальный снимок для объекта в момент подтверждения во время операции фиксации. На этапе 1660 принятия решения модуль сравнивает два моментальных снимка, чтобы видеть, идентичны ли они. Если они совпадают, процесс продолжается на этапе 1670, где транзакции позволяется продолжиться с процедурами фиксации/отмены, которые имеют преимущество в том факте, что моментальный снимок не изменяется, чтобы выполнить тесты по быстрому маршруту. Если моментальные снимки не совпадают, на этапе 1680 модуль 1320 подтверждения чтения выполняет процедуры фиксации/отмены, которые не могут использовать существование совпадающих моментальных снимков, чтобы определить, может ли транзакции быть фиксирована или отменена, и процесс заканчивается. В одном осуществлении эти два разных набора процедур известны как процедуры по быстрому маршруту и по медленному маршруту.
Ключевая разница между процессами этапа 1670 и 1680 в том, что процессы для этапа 1670 могут избежать ненужных тестов или обращений к памяти из-за знания того, что моментальный снимок не изменялся, и, таким образом, могут выполняться более быстро, чем тесты этапа 1680. В различных осуществлениях точная природа этих тестов может зависеть от природы лежащего в основе осуществления транзакционной памяти. Например, в одном осуществлении, описанном ниже в коде Примера 6, код выполняет подтверждение, где двум совпадающим моментальным снимкам нужно проверить только одно STM-слово, чтобы определить, владеет ли им транзакция, и если что, транзакция является такой же, что и подтверждающаяся в настоящее время. В противоположность, когда моментальные снимки не совпадают в этом примере, второе STM-слово может быть найдено, также как и элемент обновления в определенных обстоятельствах. Эти дополнительные обращения к памяти, также как и дополнительные сравнения, которые выполняются по ним, означает, что это осуществление этапа 1680, как правило, медленнее, чем соответствующее осуществление этапа 1670.
Фиг.17 является блок-схемой примерного процесса 1700 для модификации объекта с помощью наполненного слова заголовка. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 1720, где объект модифицируется. В одном осуществлении это может быть из-за инструкции обновления STM. В другом осуществлении наполненное слово заголовка объекта само может быть модифицировано либо в слове блокировки, либо хэш-коде. Далее, на этапе 1740, модуль 1330 закрытия обновления объекта, отвечающий на инструкцию закрытия, создает новое заполненное слово заголовка. Процесс продолжается на этапе 1760, где модуль копирует информацию из старого слова заголовка в новое слово заголовка. Затем, на этапе 1780, модуль 630 закрытия обновления заголовка модифицирует универсально используемое слово заголовка объекта, чтобы указывать на новое наполненное слово заголовка.
В заключение, на этапе 1790, если имеет место очистка памяти, старое наполненное слово заголовка остается на месте до восстановления программы 1390 очистки памяти. Модуль закрытия обновления объекта делает это, чтобы предотвратить сценарий, где второе изменение делается в объекте в другом потоке, и третье наполненное слово заголовка записывается в память, восстановленную из первого наполненного слова заголовка. Если это произошло в то время, как транзакция читает открытый объект, моментальный снимок объекта может получиться не измененным в момент фиксации, даже если он был изменен дважды. Это может позволить транзакции выполнять чтение, чтобы фиксироваться, когда она должна быть отменена, из-за двух модификаций по объекту. В одном осуществлении процесс этапа 1790 выполняется посредством оставления объекта на месте до такого момента времени, когда он безопасно может восстановить объект, в одном примере это делается, когда нет транзакций, имеющих объект, открытый для чтения.
4. Примеры записи в журнал и фиксации в STM
4.1. Примеры структуры журналов STM
Каждый поток имеет отдельный менеджер транзакций с тремя журналами. Журнал прочитанных объектов и журнал обновленных объектов отслеживают объекты, которые транзакция открыла для чтения или для обновления. Журнал откатов отслеживает обновления, которые должны быть отменены при прерывании. Все журналы записываются последовательно, и в них никогда не выполняется поиск. Отдельные журналы используются, поскольку записи в них имеют различные форматы и поскольку в ходе фиксации система требует проводить итерацию для записей различных типов по очереди. Каждый журнал организуется в список массивов записей, так что они могут увеличиваться без копирования.
Фиг.18a, 18b и 19a-c иллюстрируют структуру журналов с помощью примерного списка из примера 2a. Фиг.18a показывает начальное состояние списка, хранящего один режим со значением 10. Предполагается, что универсально используемые слова объектов используются для того, чтобы хранить STM-слова - в этом случае объекты имеют версии 90 и 100. В проиллюстрированных примерах Фиг.18a, 18b и 19a-c значения из двух цифр в правой части STM-слова соответствуют индикаторам Фиг.14a, 14b, 15a и 15b.
Одна операция из примера 3 раскрывает это для обновления, используя openSTMWord для того, чтобы атомарно заменять номер версии с указателем на новую запись в журнале обновленных объектов. Один пример псевдокода приводится как пример 4:
Пример 4


Фиг.18b иллюстрирует этот результат. Отметим, что в проиллюстрированном осуществлении поле "сдвиг в участке журнала" используется в ходе очистки памяти как быстрый способ отображать внутренний указатель на журнал (к примеру, из узла List на Фиг.18b), чтобы ссылаться на массив записей журнала, хранящих его.
Пример суммирования списка продолжается, чтобы открывать каждый узел списка для чтения. DTM делает это непосредственно: для каждого объекта ссылка на объект и его текущий моментальный снимок STM регистрируется. Пример 5 показывает пример этого в псевдокоде:
Пример 5

Фиг.19a иллюстрирует запись журнала, которую создает. Не предпринимается попыток обнаруживать конфликты после проектного допущения о том, что конфликты редки, так что преимущества их раннего окружения перевешиваются посредством затрат на проверку.
После прочтения узлов списков конечный этап состоит в том, чтобы обновлять поле Sum. DTMLogFieldStore записывает в перезаписанное значение запись журнала отката, как показано на Фиг.19b. Псевдокод для этого опускается, так как на конкретную используемую запись оказывает влияние поддержка очистки памяти в системе Бартока, используемой в одном осуществлении; другие конструкции являются подходящими в других системах. Запись журнала отката записывает адрес перезаписанного значения как пару (объект, смещение). Это предотвращает применение внутренних указателей, которые затратно обрабатывать в некоторых программах очистки памяти. Запись также различает между хранилищами скаляров и ссылочных типов. Эта информация типа требуется в некоторых программах очистки памяти. В завершение она записывает перезаписанное значение. В другом осуществлении более короткая запись журнала из двух слов может быть использована, которая содержит только адрес и перезаписанное слово, за счет большей работы в ходе очистки памяти.
4.2. Примеры процедур фиксации
Предусмотрено две фазы DTMCommit в описываемых в данном документе осуществлениях: первая проверяет конфликтующие обновления в объектах, открытых для чтения, а вторая закрывает объекты, которые открыты для обновления. Нет необходимости закрывать объекты для чтения явно, поскольку этот факт записывается только в персональных для потоков журналах транзакций.
Пример 6, приведенный ниже, показывает структуру validateReadobject. Предусмотрено большое число случаев в псевдокоде, но общая конструкция четче, если рассматривается как разделение случаев в отношении операций в интерфейсе DTM. Случаи V1, V2 и V3 ниже указывают, что конфликта не произошло:
- V1 - объект не открыт для обновления в любой точки в ходе транзакции.
- V2 - объект открыт для обновления посредством текущей транзакции на всю продолжительность.
- V3 - объект первоначально не открыт для обновления, и текущая транзакция была следующей транзакцией, чтобы открыть его для обновления.
- V4 - объект открыт для обновления посредством другой транзакции на всю продолжительность.
- V5 - объект первоначально не открыт для обновления, и другая транзакция была следующей транзакцией, чтобы открыть его для обновления.
Эти случаи отмечены в примерном псевдокоде. Некоторые происходят несколько раз, поскольку полезно различать между событиями, когда тест, выполненный для моментального снимка STM, завершается ошибкой вследствие фактического конфликта, и когда он завершается ошибкой без конфликта (к примеру, поскольку моментальный снимок STM изменился, когда универсально используемое слово объекта стало наполненным).
Пример 6


Пример 7 иллюстрирует операцию closeupdatedobject, используемую для того, чтобы закрывать объект, который открыт для обновления.
Пример 7

Фиг.19c показывает результирующее обновление в структуре списка, при этом новый номер версии 91 помещается в заголовок списка объекта.
Можно наблюдать, что при 29 битах, доступных для номера версии, можно получить примерно 500M различных версий. Проиллюстрированная конструкция делает безопасным для номеров версий переполнение до тех пор, пока номер версии не будет повторно использован в том же объекте, когда выполняющаяся транзакция имеет объект, открытый для чтения; проблема A-B-A, дающая возможность транзакции чтения фиксироваться успешно без обнаружения того, чтобы может быть примерно 500M обновлений номера.
Для корректности в одном осуществлении это предотвращается посредством (a) выполнения очистки памяти, по меньшей мере, один раз каждые 500M транзакций, и (b) проверки выполняющихся транзакций при каждой очистке памяти. Запись в журнале прочитанных объектов является допустимой только в том случае, если зарегистрированный номер версии совпадает с текущим: результат заключается в том, что каждая очистка памяти "сбрасывает часы" 500M транзакций без необходимости просматривать каждый объект для того, чтобы обновить номер версии.
5. Фильтрация журнала выполнения
Этот раздел описывает технологию выполнения для того, чтобы фильтровать копии с помощью схемы вероятностного хэширования, чтобы фильтровать копии из журнала прочитанных объектов и журнала отката. Фильтрация журнала, в общем, является полезной, поскольку a) журнал может занимать значительное пространство, истощая системные ресурсы, и b) после того как конкретная ячейка памяти зарегистрирована как записанная или прочитанная, нет необходимости в дополнительном ведении журнала. Это обусловлено тем, что в ходе проверки единственной информацией, требуемой из журнала прочитанных объектов, является мгновенный снимок STM-объекта до транзакции, а единственной информацией, требуемой из журнала отката, является значение обновленных ячеек памяти до транзакции. Поскольку это не изменяется в рамках транзакции, только одна запись журнала требуется для данной ячейки памяти на транзакцию.
В осуществлении раздела 4 необязательно фильтровать записи в журнале обновленных объектов. Это обусловлено тем, что DTMOpenForUpdate не разрешает копиям записей журнала быть создаваемыми для одного заголовка обновленного объекта в рамках одной транзакции. В других осуществлениях эти копии могут быть созданы и, следовательно, могут быть фильтрованы.
В общем, фильтр поддерживает две операции. Первая операция "фильтрация" возвращает истинное значение, если указанное слово должно присутствовать в фильтре. Она возвращает ложное значение, если указанное слово может не присутствовать в фильтре, добавляя слово в фильтр, как она это делает. Поэтому такой фильтр выступает в качестве вероятностного набора, который допускает ошибочные отказы при поиске (т.е. можно заявить, что слова не находятся в фильтре, когда фактически они находятся, но нельзя заявлять, что слово находится в фильтре, когда оно фактически не находится). Вторая операция, "очистка", удаляет все слова в фильтре.
В контексте программной транзакционной памяти (STM) фильтр может быть использован для того, чтобы уменьшать количество раз, когда содержимое одного слова записывается в один из журналов транзакций, которые содержит STM.
5.2. Примеры фильтрации таблицы хэширования
Схема фильтрации, описанная в данном документе, вероятностно обнаруживает копии запросов регистрации в журнал прочитанных объектов и журнал отката с помощью ассоциативно связанной таблицы. Хотя осуществления, описанные в данном документе, приводятся со ссылкой на таблицу хэширования, следует признавать, что в альтернативных осуществлениях технологии и системы фильтрации могут использовать другие осуществления ассоциативной таблицы. Одно осуществление использует таблицы на потоке, которые сопоставляют хэш адреса сведениях по самой последней операции регистрации, связанной с адресами с данным хэшем.
Можно отметить, что в одном осуществлении только одна ассоциативная таблица требуется для того, чтобы фильтровать журналы прочитанных объектов и отката. Сохранения в журнал прочитанных объектов используют адрес слова заголовка объекта, тогда как сохранения в журнал отката используют адрес регистрируемого слова. Поскольку эти наборы адресов являются раздельными, одна таблица не продемонстрирует конфликты доступов прочитанных объектов и обновления и, таким образом, может быть использована для обоих журналов.
Фиг.20 иллюстрирует структуру таблицы. Фиг.20 иллюстрирует ассоциативную таблицу, осуществленную как таблица 2000 хэширования. Как иллюстрирует Фиг.20, каждая запись в таблице 2000 хэширования содержит адрес 2020 памяти и номер 2030 транзакции. Записи организуются посредством последовательностей номеров 2010 сегментов.
В одном осуществлении хэш-код, который идентифицирует номер сегмента для конкретного адреса памяти, поступает посредством разделения адреса на индекс хэша и тег. Таким образом, в этом осуществлении хэш-функция просто использует некоторые из самых младших битов из слова W, чтобы выбрать сегмент S для того, чтобы использовать в таблице. Биты в слове W, следовательно, могут рассматриваться как разделенные на 2 части: самые младшие биты являются хэш-кодом, который может выступать для того, чтобы идентифицировать сегмент, который использовать, а оставшиеся выступают в качестве тега, чтобы уникально идентифицировать адрес. Например, слово 0x1000 должно иметь тег-1 сегмент-0, слово 0x1001 должно иметь тег-1 сегмент -1, слово 0x2000 должно иметь тег-2 сегмент-0, слово 0x2001 должно иметь тег-2 сегмент-1 и т.п. В альтернативных осуществлениях используют другие схемы хэширования.
Дополнительно, хотя таблица 2000 хэширования показывает номер транзакции как отдельный от адреса памяти, в различных осуществлениях номер транзакции комбинируется с адресом памяти, к примеру, с использованием операции XOR. Операция XOR используется в одном осуществлении, поскольку это относительно быстрая операция, и ее откат не может быть выполнен посредством последующей XOR. В альтернативных осуществлениях другие способы записи номера транзакции используются, к примеру, замена младших битов в адресе памяти на номер транзакции или использование операции сложения вместо операции XOR. Они полезны в том, что каждый из них совместно использует то свойство, что для двух адресов a1 и a2, которые указывают на один хэш-код, и двух номеров транзакции t1 и t2, op(a1, t1) равно op(a2, t2) только в том случае, когда a1=a2 и t1=t2. Это свойство предоставляет уверенность в том, что вставленные комбинированные значения являются уникальными для конкретного адреса и номера транзакции, из которой они созданы.
Применение номера транзакции, который является локальным для потока, заключается в том, чтобы не допустить путаницы записи, записанной посредством более ранней транзакции, с записью, относящейся к текущей транзакции. Идентификатор номера транзакции позволяет таблице быть очищаемой только тогда, когда биты, используемые для последовательности номеров транзакций, переполняются. В одном осуществлении таблица очищается единожды каждый раз, когда последовательность номеров транзакций переполняется, что предотвращает конфликты в таблицы посредством недопущения использования одного номера транзакции двумя записями, сформированными из различных транзакций. В другом осуществлении один сегмент в таблице очищается на транзакцию; в некоторых осуществлениях прибавление небольших дополнительных данных к каждой транзакции может быть предпочтительнее прибавления случайных значительных дополнительных данных. В других случаях предпочтительно осуществлять всю очистку таблицы сразу.
Фиг.21 является блок-схемой, иллюстрирующей примерный процесс 2100 фильтрации журнальных записей. В различных осуществлениях этапы иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс начинается на этапе 2110, где счетчик транзакций обновляется в начале текущей транзакции. Этот счетчик предоставляет номер транзакции, который используется в таблице хэширования. Затем на этапе 2115 принятия решения определяется то, достигнут ли предел счетчика транзакций. В одном осуществлении этот предел определяется посредством переполнения числа битов, выделенных счетчику. В других предел может быть основан на ограничениях памяти или может быть выбран так, чтобы точно настраивать производительность таблицы хэширования. Если предел не достигнут, на этапе 2140 адрес, который должен быть зарегистрирован, фильтруется посредством таблицы хэширования. Наоборот, если пределом был счетчик, сброшенный на этапе 2120, и таблица очищена на этапе 2130, то на этапе 2140 адрес, который должен быть зарегистрирован, фильтруется посредством таблицы хэширования.
Фиг.22 является блок-схемой, иллюстрирующей примерный процесс 2200 фильтрации журнальных записей. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. В различных осуществлениях процесс 2200 соответствует процессу этапа 2140 процесса 2100. Процесс 2200 начинается на этапе 2210, где адрес хэшируется, чтобы найти надлежащую запись таблицы хэширования. Затем на этапе 2220 адрес, который должен быть фильтрован, подвергается операции XOR с текущим номером транзакции (принятым из счетчика транзакций). В одном осуществлении хэширование выполняется так, как описано выше, посредством разделения адреса на хэш-код и значение тега.
Процесс далее переходит к этапу 2225 принятия решения, на котором значение записи хэша проверяется на соответствие результату XOR. Если они совпадают, то нет необходимости в доступе к памяти журнала, и на этапе 2230 запись в журнал не выполняется. Тем не менее, если они не совпадают, то на этапе 2240 результат XOR записывается в запись таблицы хэширования, и на этапе 2250 запись записывается в журнал.
5.3. Фильтрация журнала выполнения для новых создаваемых объектов
В одном осуществлении система STM и методики, описанные в данном документе, идентифицируют объекты, создаваемые посредством текущей транзакции, чтобы не допустить записи каких-либо записей журнала отката для них. Это предоставляет резервирование в том случае, если статический анализ времени компилятора, описанный выше, пропускает или не может удалить конкретные операции журнала для новых создаваемых объектов. Эта технология выполнения является безопасной, поскольку объекты обрабатываются, если текущая транзакция прерывается. В одном осуществления это выполняется с помощью версии DTMOpenForUpdate, которая специализирована для того, чтобы работать для новых создаваемых объектов, и посредством записи этой операцией указанного значения STM-слова, чтобы помечать объект как транзакционно созданный.
6. Примеры очистки памяти
В общем, очистка памяти (GC) предоставляет механизм автоматического определения того, когда объект памяти может быть освобожден, поскольку он более не требуется посредством какого-либо потока в программе. Очистка памяти встроена во множество современных языков программирования и формирует часть инфраструктуры Microsoft.NET.
Данный раздел описывает различные осуществления интеграции GC в технологии STM, описанные выше. Тем не менее, такая интеграция не является простой. Чтобы проиллюстрировать эту проблему, рассмотрим следующий пример:

Предположим для целей примера то, что вычисления, выполняемые на E1 и E2, достаточно усложнены для того, чтобы GC требовалась им, чтобы выполняться без полного расхода памяти. Кроме того, предположим, что LargeTemporaryObject, привязанный к t1, используется только в E1, и аналогично, LargeTemporaryObject, привязанный к t2, используется только в E2. Если приводится в исполнение без "атомарного" этапа, то пространство, занимаемое посредством t1, может быть восстановлено после того, как E1 завершилась.
Этот пример не может быть приведен в исполнение с существующими системами транзакционной памяти и GC. В этих системах возникает одна из двух проблем:
1. Некоторые GC без поддержки TM инструктируют всем транзакциям памяти быть прерванными, когда возникает GC. Для этих систем вычисления, такие как E1 и E2, никогда могут не выполняться в атомарном блоке.
2. Другие GC без поддержки TM инструктируют объектам быть сохраненными в течение большего времени, чем для наших GC с поддержкой TM. В этих системах пример может выполняться успешно, но t1 и t2 сохраняются до самого конца атомарного блока, даже если GC возникает в ходе E2, в течение которого известно, что t1 далее не нужен.
В одном осуществлении эти проблемы разрешаются посредством GC с поддержкой TM, которые (a) дают возможность GC возникать, пока потоки находятся в середине исполнения атомарных блоков, и (b) дают возможность GC восстанавливать объекты, которые гарантированно не потребуются, посредством программы независимо от того, завершается атомарный блок успешно или он должен быть повторно выполнен.
В различных осуществлениях технологии очистки памяти включают в себя технологии для использования в осуществлениях атомарных транзакционных блоков для идентификации объектов, созданных в рамках текущего атомарного блока. Осуществления также включают в себя технологии для идентификации того, какие объекты, упоминаемые ссылкой посредством структур данных STM, гарантированно не потребуются посредством программы. Наконец, осуществления GC включают в себя технологии для идентификации того, какие записи в структурах данных TM не требуются для будущего выполнения программы.
Хотя нижеследующее описание основывается, в частности, на системе, описанной выше, описанные в данном документе осуществления не ограничены этой настройкой; они могут быть использованы с другими формами транзакционной памяти, возможно, в том числе аппаратной транзакционной памятью.
Осуществления, описанные в данном документе, описываются со ссылкой на программу очистки памяти с останавливающим отслеживанием, например программу очистки памяти с пометкой вариаций или программу очистки памяти с копированием. Тем не менее, это служит для простоты пояснения, и осуществления не ограничены этой настройкой; известные подходы могут быть использованы для того, чтобы интегрировать с другими технологиями очистки памяти STM, такими как формирующая очистка памяти, согласующаяся очистка памяти или параллельная очистка памяти. В одному осуществления STM интегрирована с формирующей очисткой памяти.
На высоком уровне операция GC с останавливающим отслеживанием может быть обобщена как следующая процедура. Сначала остановка всех прикладных потоков в приложении ("потоки-мутаторы", как их иногда называют). Затем просмотр каждого из "корней", посредством которых потоки-мутаторы первоначально осуществляют доступ к объектам, обеспечивая то, что объекты, упоминаемые ссылкой из этих корней, сохраняются после очистки. (Корни включают в себя сохраненное содержимое регистров выполняющихся потоков-мутаторов процессора, объектные ссылки на стеки потоков и объектные ссылки, видимые для этих потоков посредством статических полей программы.) Таким образом сохраненные объекты часто упоминаются как "серые", а остальные объекты первоначально упоминаются как "белые". Затем для каждого серого объекта просмотр объектных ссылок, которые он содержит. Все белые объекты, которые идентифицируют эти ссылки, по очереди помечаются серым, и после того как все ссылки в сером объекте просмотрены, объект помечается черным. Повторение этого этапа до тех пор, пока не остается серых объектов. Все белые объекты, которые остаются, считаются мусором, и пространство, которое они занимают, может быть сделано доступным потокам-мутаторам для перераспределения. В завершение перезапуск потоков-мутаторов. В нижеприведенном примере серые объекты упоминаются как "просмотренные" объекты, тогда как известные белые объекты являются "недостижимыми".
В одном осуществлении интеграции STM с GC все транзакции прерываются при запуске GC. Это имеет очевидные недостатки. В другом осуществлении GC рассматривает структуры данных STM как часть корней потоков-мутаторов, тем самым просматривая объекты на основе их упоминания ссылками посредством записей в журналах. В этом осуществления ссылки на объекты из некоторых журналов считаются "сильными ссылками", которые требуют от GC сохранять память, достижимую посредством них.
Хотя это осуществление предоставляет некоторую степень интеграции между STM-системой и GC, в другом осуществлении предоставляется большая степень интеграции. Фиг.23 - это блок-схема примерного процесса 2300, выполняемого посредством модуля 1390 очистки памяти для осуществления очистки памяти в STM-системе. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. В проиллюстрированных ниже процедурах GC может применять специальное знание STM для того, чтобы освобождать объекты и записи журналов, когда больше нельзя их использовать, а также уплотнять журналы посредством удаления избыточных записей. В одном осуществлении процесс на Фиг.23 выполняется вместо этапа в типичной вышеприведенной процедуре GC просмотра каждой из объектных ссылок посещаемого объекта. В альтернативных осуществлениях процесс Фиг.23 может быть интегрирован в другие общие процедуры GC.
В некоторых осуществлениях процесс по Фиг.23 распознает две особенности журналов в STM-системе. Первое - это журналы, которые идентифицируют объекты, к которым текущая транзакция попыталась осуществить доступ. Журналы этого типа в различных осуществлениях включают в себя ссылки на объекты, к которым осуществляется доступ в журналах прочитанных объектов, обновленных объектов и отката, в осуществлениях, описанных в статье PLDI. В одной терминологии некоторые ссылки на объекты из этих журналов считаются "слабыми ссылками", означая то, что GC восстанавливает память, используемую объектами, которые являются недостижимыми за исключением этих слабых ссылок. Другим свойством, обнаруживаемым посредством GC при выполнении этого процесса, являются журналы, которые идентифицируют объектные ссылки, которые восстанавливаются в памяти при фиксации или при прерывании транзакции. Журналы этого типа включают в себя старые значения в журналах отката. Эти ссылки и этих журналов упоминаются в некоторой терминологии как "строгие ссылки". В отношении вышесказанного "строгие ссылки" требуют от GC сохранять память, достижимую посредством них.
Процесс начинается на этапе 2310, где GC-модуль 1390 просматривает объекты, указываемые ссылкой посредством поля "предыдущее значение" каждой записи в журналах 1360 отката, тем самым не допуская рассматривания этих объектов как недостижимых и не допуская их восстановление в том случае, если текущая транзакция прерывается. Затем на этапе 2320 конкретные записи специальных случаев удаляются из журналов. Пример этого процесса удаления подробнее описан ниже со ссылкой на Фиг.24.
Процесс переходит к этапу 2325, на котором GC-модуль просматривает объектные ссылки, содержащиеся в каждом уже просмотренном объекте, чтобы просмотреть все достижимые объекты и добиться конечного набора недостижимых ссылок. Затем на этапе 2330 GC-модуль анализирует записи в журнале 1380 прочитанных объектов, которые ссылаются на недостижимые объекты. На этапе 2335 принятия решения GC-модуль определяет для каждой записи то, есть конфликтующий параллельный доступ к объекту, указываемому ссылкой посредством записи. В одном осуществлении GC делает это посредством определения для каждой записи того, совпадает ли номер версии в записи с номером версии объекта. Если совпадает, запись просто освобождается из журнала на этапе 2350, поскольку запись является текущей, а объект является недостижимым. Тем не менее, если номера версий не совпадают, текущая транзакция является недопустимой. В этой точке сам GC-модуль прерывает транзакцию на этапе 2340, удаляя все записи журналов для транзакции. В альтернативном осуществлении конкретные проверки и процессы этапов 2335, 2340 и 2350 могут быть опущены, записи для известных недостижимых объектов освобождаются из журнала прочитанных объектов без анализа, и другие системы выполнения STM, на которых основываются в том, чтобы определять то, следует или нет прерывать транзакцию.
Затем на этапе 2360 GC-модуль анализирует записи в журнале 1370 обновленных объектов и освобождает все записи, которые ссылаются на объекты, которые недостижимы. После этого на этапе 2370 тот же процесс выполняется для записей в журнале 1360 отката. В завершение на этапе 2380 GC-модуль продолжает так, чтобы освободить все оставшиеся недостижимые объекты.
Расширения осуществлений используют специальные случаи для того, чтобы удалять дополнительные записи из STM-журналов. Фиг.24 - это блок-схема, иллюстрирующая один такой примерный процесс 2400, выполняемый посредством модуля 1390 очистки памяти для удаления записей журнала специальных случаев. Процесс Фиг.24 соответствует этапу 2320 на Фиг.23. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Хотя описание в данном документе поясняет эти расширения как последовательные этапы, которые являются частью процессов процесса 2400 и этапа 2320, следует признавать, что в определенных обстоятельствах процессы Фиг.24 могут быть использованы независимо друг от друга, и в некоторых случаях независимо от базового осуществления (например, чтобы уплотнять журналы в моменты времени, отличные от GC), и что быстрое осуществление может комбинировать части одного или более из этих этапов, чтобы уменьшать число раз, когда записи в журналах должны быть просмотрены.
Процесс 2400 начинается на этапе 2410, на котором, если активна только одна транзакция, G-модуль 1390 сразу откатывает и удаляет записи из журнала 1360 отката, которые ссылаются на недостижимые объекты. На этапе 2420 GC-модуль анализирует журнал 1380 прочитанных объектов и журнал 1360 отката и удаляет записи из этих журналов, если записи ссылаются на недостижимые объекты, которые созданы в рамках текущего транзакционного блока. GC-модуль 1390 выполняет это, поскольку если объект создан после того, когда транзакция начата, и теперь является недостижимым, он теряется вне зависимости от того, фиксируется или нет транзакция. В одном осуществлении записи журналов для недостижимых объектов, которые созданы в субтранзакциях текущей транзакции, также удаляются.
На этапе 2430 для каждой записи в журнале прочитанных объектов объект, на который ссылается объект, анализируется, и если объект уже находится в журнале обновленных объектов, и номера контроля версий журналов прочитанных объектов и журналов обновленных объектов совпадают для объекта, запись журнала прочитанных объектов может быть удалена. Этот процесс может идентифицировать как то, когда объект сначала добавлен в журнал прочитанных объектов, так и то, когда объект сначала добавлен в журнал обновленных объектов. В любом случае GC служит для того, чтобы удалять отнесенные к одной категории записи журнала прочитанных объектов.
На этапе 2440 GC-модуль 1390 удаляет копии записей из журнала прочитанных объектов в осуществлениях STM, которые разрешают копии записей. Примерный процесс удаления копий записей журнала прочитанных объектов описан ниже со ссылкой на Фиг.25. На этапе 2450 затем GC-модуль 1390 анализирует записи в журнале отката и сравнивает "предыдущее значение" в журнале с текущим значением зарегистрированной ячейки памяти. Ели они совпадают, значение не изменилось, и нет причин хранить запись журнала отката, так что GC-модуль 1390 удаляет эти записи.
Фиг.25 - это блок-схема, иллюстрирующая один такой примерный процесс 2500, выполняемый посредством модуля 1390 очистки памяти для удаления копий записей журнала прочитанных объектов. Процесс Фиг.25 соответствует этапу 2440 на Фиг.24. В различных осуществлениях блоки иллюстрированного процесса могут быть объединены, разделены на подэтапы или опущены. Процесс по Фиг.25 использует преимущество того факта, что запись журнала прочитанных объектов записывает только то, что объект открыт для чтения в рамках текущей транзакции. Это делает несколько записей для одного объекта ненужными, и таким образом, выгодно удалить эти записи в ходе GC.
Процесс по Фиг.25 использует преимущество одного флага бита считывания, который хранится для каждого объекта в ходе очистки памяти. В одном осуществлении этот флаг хранится посредством системы выполнения аналогично тому, как хранится STM-слово. В другом осуществлении GC-модуль 1390 хранит флаги для каждого объекта в ходе GC. Процесс начинается на этапе 2510, где GC-модуль 1390 начинает уплотнение журнала прочитанных объектов с первой записи в журнале. Далее на этапе 2520 объект, на который ссылается текущий анализированный объект, анализируется. На этапе 2525 GC-модуль 1390 определяет то, имеет ли объект прочитанный бит заданным. Если нет, текущая запись считается первой записью для объекта. Таким образом, на этапе 2530 прочитанный бит задается, и запись не трогается. Тем не менее, если GC-модуль 1390 определяет то, что прочитанный бит ранее задан на этапе 2540, модуль удаляет текущую запись, поскольку она не нужна для предыдущей записи объекта. В одном осуществлении данное удаление выполняется вместо копирования записей, которые хранятся, в ячейки записей, которые удаляются. В других осуществлениях записи не удаляются, а просто освобождаются там, где находятся. Процесс далее переходит к этапу 2545 принятия решения, на котором модуль определяет то, существуют ли дополнительные записи в журнале прочитанных объектов. Если так, процесс продолжается. Если нет, процесс заканчивается.
7. Вычислительное окружение
Вышеописанные технологии программной транзакционной памяти могут быть выполнены на одном из множества вычислительных устройств. Технологии могут быть реализованы в аппаратной схеме, а также в программном обеспечении, выполняющемся в компьютере или другом вычислительном окружении, такое как показанное на Фиг.16.
Фиг.26 иллюстрирует обобщенный пример подходящего вычислительного окружения (2600), в котором могут быть реализованы описанные варианты осуществления. Вычислительное окружение (2600) не предназначено для того, чтобы налагать какое-либо ограничение на область использования или функциональность изобретения, поскольку настоящее изобретение может быть реализовано в различных вычислительных окружениях общего или специального назначения.
Ссылаясь на Фиг.26, вычислительное окружение (2600) включает в себя, по меньшей мере, один процессор (2610) и память (2620). На Фиг.26 эта самая базовая конфигурация (2630) показана пунктирной линией. Процессор (2610) приводит в исполнение машиноисполняемые инструкции и может быть реальным или виртуальным процессором. В многопроцессорной системе несколько процессоров приводят в исполнение машиноисполняемые инструкции, чтобы повысить вычислительную мощность. Памятью 2620 может быть энергозависимая память (к примеру, регистры, кэш, RAM), энергонезависимая память (к примеру, ROM, EPPROM, флэш-память и т.д.) или какое-либо их сочетание. Память (2620) хранит программное обеспечение (2680), осуществляющее описанные технологии.
Вычислительное окружение может иметь дополнительные признаки. Например, вычислительное окружение (2600) включает в себя устройство (2640) хранения, устройства (2650) ввода, одно или более устройств (2660) вывода и одно или более подключений (2670) связи. Механизм межкомпонентного соединения (не показан), такой как шина, контроллер или сеть, соединяет между собой компоненты вычислительного окружения (2600). Типично программное обеспечение операционной системы (не показано) предоставляет операционное окружение для другого программного обеспечения, приводимого в исполнение в вычислительном окружении (2600), и координирует действия компонентов вычислительного окружения (2600).
Устройство (2640) хранения может быть съемным или стационарным и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, CD-RW, DVD или любой другой носитель, который может быть использован, чтобы сохранять информацию, и к которому можно осуществлять доступ в рамках вычислительного окружения (2600). Устройство (2640) хранения хранит инструкции для программного обеспечения (2680), осуществляющего описанные технологии.
Устройством (2650) ввода может быть устройство сенсорного ввода, такое как клавиатура, мышь, перо или шаровой манипулятор, устройство голосового ввода, устройство сканирования или другое устройство, которое предоставляет ввод в вычислительное окружение (2600). Для аудио устройством (2650) ввода может быть звуковая плата или аналогичное устройство, которое принимает ввод звука в аналоговой или цифровой форме, либо устройство считывания CD-ROM, которое предоставляет выборки аудио вычислительному окружению. Устройством (2660) вывода может быть дисплей, принтер, динамик, пишущее устройство CD-RW или другое устройство, которое предоставляет вывод из вычислительного окружения (2600).
Подключения (2670) связи обеспечивают обмен данными по среде обмена данными с другим вычислительным объектом. Среда обмена данными передает информацию, такую как машиноисполняемые инструкции, сжатую аудио- и видеоинформацию или другие данные в модулированном информационном сигнале. Модулированный сигнал данных - это сигнал, который имеет одну или более характеристик, установленных или изменяемых таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, среда обмена данными включает в себя проводные или беспроводные методики, реализованные с помощью электрического, оптического, радиочастотного, инфракрасного, акустического или другого оборудования связи.
Методики, описанные в данном документе, могут быть описаны в общем контексте машиночитаемых носителей. Машиночитаемые носители - это любые доступные носители, к которым можно осуществлять доступ в вычислительном окружении. В качестве примера, а не ограничения, в вычислительном окружении (2600) машиночитаемые носители включают в себя память (2620), устройство (2640) хранения, среду обмена данными и комбинации любых вышеозначенных элементов.
Методики в данном документе могут быть описаны в общем контексте машиноисполняемых инструкций, таких как включенные в программные модули, приводимые в исполнение в вычислительном окружении для целевого реального или виртуального процессора. В общем, программные модули включают в себя процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Функциональность программных модулей может быть комбинирована или разделена между программными модулями, как требуется в различных вариантах осуществления. Машиноисполняемые инструкции для программных модулей могут быть приводимы в исполнение в локальном или распределенном вычислительном окружении.
Для целей представления подробное описание использует такие термины, как "определить", "сформировать", "сравнить" и "записать", чтобы описывать операции компьютера в вычислительном окружении. Эти термины являются высокоуровневыми абстракциями для операций, выполняемых компьютером, и не должны путаться с действиями, выполняемыми человеком. Фактические операции компьютером, соответствующие этим терминам, различаются в зависимости от осуществления.
В свете множества возможных вариаций описываемого в данном документе предмета изобретения, мы заявляем в качестве изобретения все подобные варианты осуществления, которые могут подпадать под область применения нижеследующей формулы изобретения и ее эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСШИРЕНИЕ СОГЛАСУЮЩЕГО ПРОТОКОЛА ДЛЯ ИНДИКАЦИИ СОСТОЯНИЯ ТРАНЗАКЦИИ | 2015 |
|
RU2665306C2 |
| ЖУРНАЛИРУЕМОЕ ХРАНЕНИЕ БЕЗ БЛОКИРОВОК ДЛЯ НЕСКОЛЬКИХ СПОСОБОВ ДОСТУПА | 2014 |
|
RU2672719C2 |
| ПОРЯДОК ФИКСАЦИИ ПРОГРАММНЫХ ТРАНЗАКЦИЙ И УПРАВЛЕНИЕ КОНФЛИКТАМИ | 2007 |
|
RU2439663C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УСОВЕРШЕНСТВОВАННЫХ ТЕХНОЛОГИЙ ПРОПУСКА БЛОКИРОВКИ | 2014 |
|
RU2595925C2 |
| МЕХАНИЗМ ЗАПРОСА ПОЗДНЕЙ БЛОКИРОВКИ ДЛЯ ПРОПУСКА АППАРАТНОЙ БЛОКИРОВКИ (HLE) | 2008 |
|
RU2501071C2 |
| КОНТЕЙНЕРНОЕ РАЗВЕРТЫВАНИЕ МИКРОСЕРВИСОВ НА ОСНОВЕ МОНОЛИТНЫХ УНАСЛЕДОВАННЫХ ПРИЛОЖЕНИЙ | 2017 |
|
RU2733507C1 |
| ОБРАБОТКА ТРАНЗАКЦИЙ ДЛЯ ДЕЙСТВИЙ С ПОБОЧНЫМ ЭФФЕКТОМ В ТРАНЗАКЦИОННОЙ ПАМЯТИ | 2009 |
|
RU2510977C2 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ДАННЫХ В СИСТЕМЕ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ | 2013 |
|
RU2526753C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| ТРАНЗАКЦИОННАЯ ИЗОЛИРОВАННАЯ СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2458385C2 |







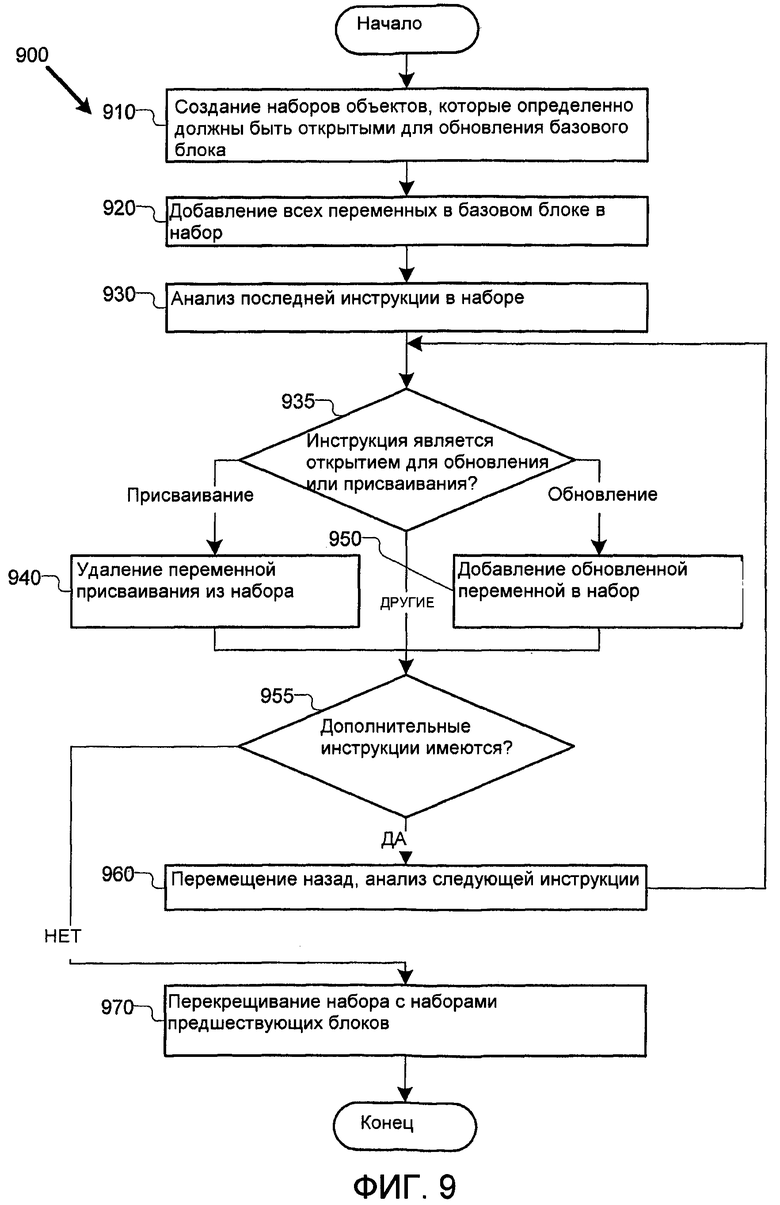

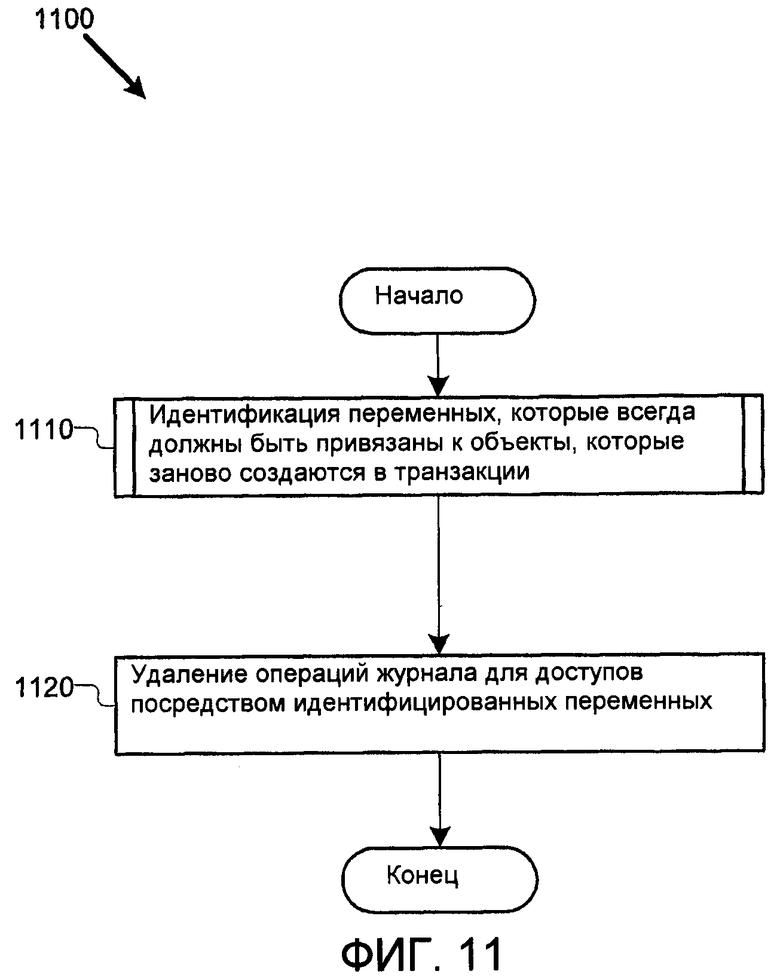

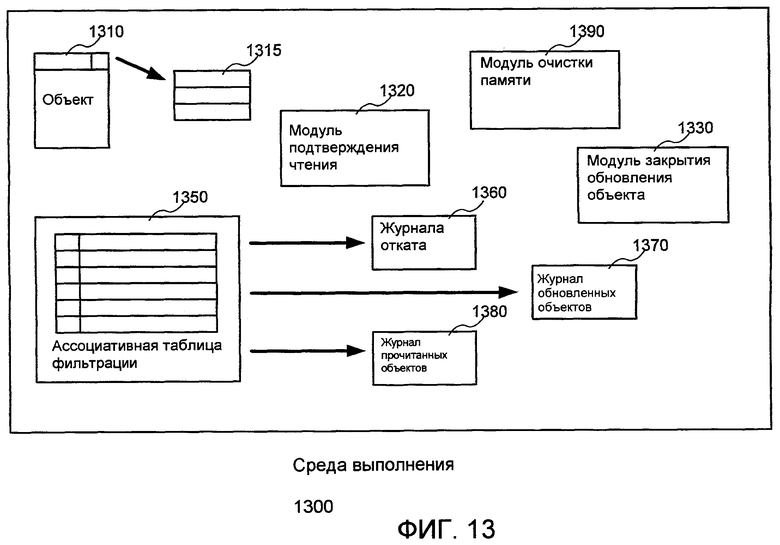

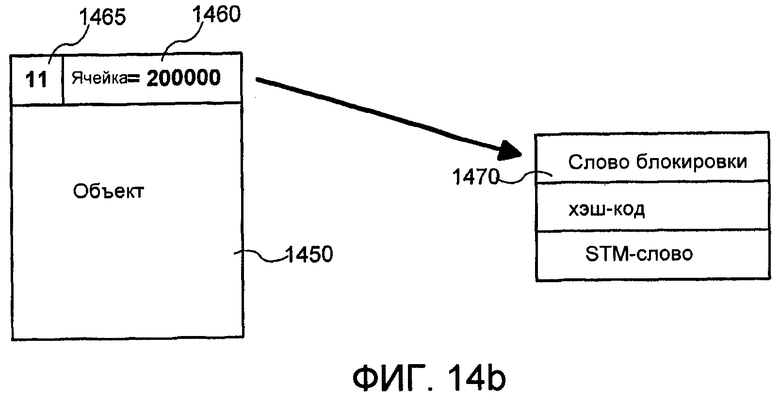













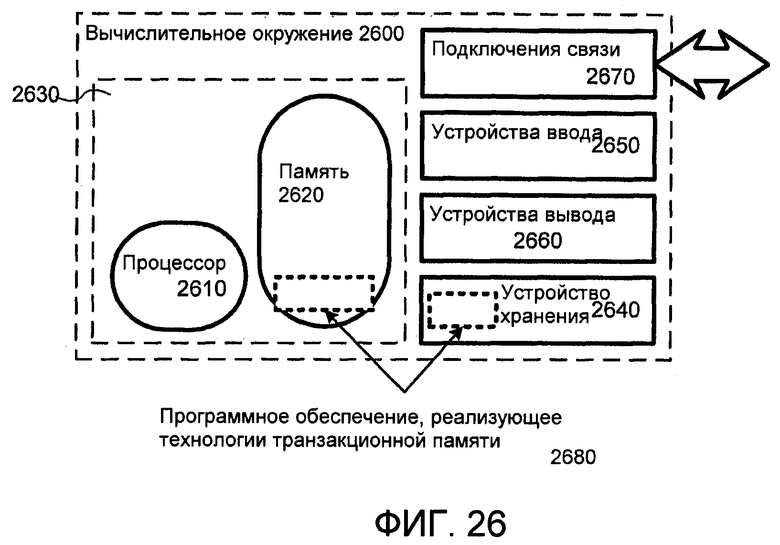
Изобретение относится к системам программной транзакционной памяти. Технический результат заключается в увеличении оптимизации компилирования программ за счет оптимизации инструкций программной транзакционной памяти. Блоки программной транзакционной памяти заменяются инструкциями программной транзакционной памяти, которые затем дополнительно декомпозируются на декомпозированные инструкции программной транзакционной памяти. Декомпозированные инструкции позволяют компилятору со знанием семантики инструкций выполнять оптимизации, которые будут недоступны в традиционных системах программной транзакционной памяти. Выполняются высокоуровневые оптимизации программной транзакционной памяти, такие как перемещение кода по вызовам процедур, добавление операций, чтобы предоставлять строгую атомарность, удаление необязательных модернизаций чтения-для-обновления и удаление операций по новым создаваемым объектам. 39 з.п. ф-лы, 31 ил.
1. Реализуемый в компьютерной системе, содержащей процессор и компилятор, сконфигурированный со знанием операций программной транзакционной памяти, способ компиляции программы, включающей в себя блоки программной транзакционной памяти, при этом способ содержит этапы, на которых:
оптимизируют (460) программу, чтобы создать оптимизированную программу, содержащую инструкции программной транзакционной памяти, причем при оптимизации программы:
вставляют в программу декомпозированные инструкции программной транзакционной памяти в блоки программной транзакционной памяти и
выполняют оптимизации в отношении программы, чтобы создать оптимизированную программу, так что по меньшей мере одна из этих оптимизаций сконфигурирована так, чтобы работать в отношении декомпозированных инструкций программной транзакционной памяти,
при этом при выполнении оптимизаций выполняют процедуру общего исключения подвыражений, которая модифицирована так, чтобы работать в отношении декомпозированных инструкций программной транзакционной памяти с тем, чтобы исключалась инструкция открытия объекта для чтения, которая имеет место после инструкции открытия объекта для обновления в рамках той же транзакции; и
компилируют (340) оптимизированную программу.
2. Способ по п.1, в котором процедура общего исключения подвыражений модифицирована так, что избыточные чтения и записи по адресам памяти и избыточные журналы для адресов памяти в рамках транзакции удаляются.
3. Способ по п.2, в котором процедура общего исключения подвыражений дополнительно модифицирована так, что чтения и записи в первой транзакции исключаются, если они сделаны избыточными посредством чтений и записей во второй транзакции, причем первая транзакция вложена во вторую транзакцию.
4. Способ по п.1, в котором при выполнении оптимизаций выполняют оптимизацию переноса части кода.
5. Способ по п.1, в котором при выполнении оптимизаций дополняют по меньшей мере одну операцию нетранзакционной памяти, которая осуществляет доступ к объекту вне транзакции памяти, одной или более операциями транзакционной памяти, которые обеспечивают атомарность между доступами транзакционной памяти к этому объекту и операцией нетранзакционной памяти.
6. Способ по п.5, в котором при дополнении операции нетранзакционной памяти:
вставляют операцию открытия до операции нетранзакционной памяти, которая открывает упомянутый объект для доступа со стороны операции нетранзакционной памяти; и
вставляют операцию фиксации после операции нетранзакционной памяти, которая определяет, был ли конфликтующий доступ к упомянутому объекту в ходе выполнения операции нетранзакционной памяти.
7. Способ по п.6, в котором:
операция нетранзакционной памяти - это операция считывания;
операция открытия сконфигурирована так, чтобы извлекать индикатор состояния упомянутого объекта до выполнения операции нетранзакционной памяти; и
операция фиксации сконфигурирована так, чтобы:
извлекать индикатор состояния упомянутого объекта после выполнения операции нетранзакционной памяти и
если состояние упомянутого объекта указывает конфликтующий доступ, вызывать выполнение операций открытия, чтения и фиксации в цикле до тех пор, пока чтение не станет возможным.
8. Способ по п.6, в котором:
операция нетранзакционной памяти - это операция записи;
операция открытия сконфигурирована так, чтобы получать доступ на запись к упомянутому объекту; и
операция фиксации сконфигурирована так, чтобы фиксировать запись, выполненную в упомянутый объект.
9. Способ по п.6, в котором команды открытия и фиксации используют синхронизацию по упомянутому объекту, чтобы гарантировать то, что операция нетранзакционной памяти выполняется атомарно.
10. Способ по п.6, в котором команда открытия блокируется до тех пор, пока она не сможет открыть упомянутый объект для доступа.
11. Способ по п.5, дополнительно содержащий этап, на котором идентифицируют одну или более операций памяти, которые осуществляют доступ к объектам вне транзакций памяти.
12. Способ по п.11, в котором при идентификации одной или более операций памяти:
анализируют доступы транзакционной памяти, чтобы определять поля, к которым может осуществляться доступ посредством операций транзакционной памяти в ходе исполнения программного обеспечения;
идентифицируют одну или более операций нетранзакционной памяти, которые осуществляют доступ к полям, к которым может осуществляться доступ посредством операций нетранзакционной памяти.
13. Способ по п.12, в котором для любого поля, к которому гарантированно не осуществляется доступ посредством операций транзакционной памяти, дополнение операций нетранзакционной памяти, которые осуществляют доступ к этому полю, исключается.
14. Способ по п.13, в котором, при дополнении операции нетранзакционной памяти, которая осуществляет доступ к объекту вне транзакции памяти, одной или более операциями транзакционной памяти, вставляют атомарные блоки транзакций памяти вокруг операции нетранзакционной памяти.
15. Способ по п.1, в котором при выполнении оптимизаций:
идентифицируют ссылки на объекты, которые всегда привязываются к новым создаваемым объектам в транзакциях в наборе программных точек; и
предотвращают операции программной транзакционной памяти в отношении объектов, достигнутых посредством идентифицированных ссылок, причем эти операции не имеют эффекта вне транзакций.
16. Способ по п.15, в котором идентификация ссылок на объекты, которые всегда привязываются к новым создаваемым объектам в транзакциях в наборе программных точек, осуществляется в рамках вызовов процедур.
17. Способ по п.16, в котором при идентификации ссылок на объекты, которые всегда привязываются к новым создаваемым объектам в наборе программных точек, выполняют прямой анализ потоков данных в программе.
18. Способ по п.17, в котором при прямом анализе потоков данных сохраняют структуру данных для каждого базового блока, которая представляет в ячейке базового блока для каждой переменной в базовом блоке то, известно ли, что переменная всегда должна выделяться новым создаваемым объектам, возможно может быть выделена объекту, созданному вне транзакции, либо что информация неизвестна для переменной.
19. Способ по п.18, в котором структура данных содержит привязку из каждой ссылки на данные, хранимые для каждой ссылки, при этом данные, хранимые для каждой ссылки, содержат обновляемую секцию, содержащую структурное значение и зависимости между ссылками.
20. Способ по п.19, в котором при сохранении структуры данных распространяют информацию, используя зависимости между ссылками, по обновляемым секциям структурных значений по мере того, как анализ потоков данных выполняется.
21. Способ по п.20, в котором при распространении информации распространяют информацию в непривязанные переменные в привязке от переменных к обновляемым секциям структурных значений, до того как операторы программы для этих непривязанных значений будут проанализированы.
22. Способ по п.15, в котором при предотвращении операций программной транзакционной памяти в отношении объектов, достигнутых посредством идентифицированных ссылок, причем эти операции не имеют эффекта вне транзакций, заменяют, для каждой ссылки, операции обновления по ссылке на операции обновления, которые, когда декомпозированы на декомпозированные операции программной транзакционной памяти, не включают в себя операции журнала обновлений.
23. Способ по п.15, в котором при предотвращении операций программной транзакционной памяти в отношении объектов, достигнутых посредством идентифицированных ссылок, причем эти операции не имеют эффекта вне транзакций, удаляют, после того как операции программной транзакционной памяти декомпозированы на декомпозированные операции программной транзакционной памяти, декомпозированные операции журнала, которые работают через идентифицированные ссылки.
24. Способ по п.15, дополнительно содержащий этап, на котором определяют то, какие из идентифицированных ссылок направлены на объекты, которые недоступны после транзакции, при этом при предотвращении операций программной транзакционной памяти в отношении объектов, достигнутых посредством идентифицированных ссылок, причем эти операции не имеют эффекта вне транзакций, удаляют операции программной транзакционной памяти открытия объектов для чтения или обновления через идентифицированные ссылки.
25. Способ по п.1, в котором при выполнении оптимизаций:
находят инструкцию программной транзакционной памяти открытия ссылки для чтения, за которой, как известно, должна следовать первая инструкция программной транзакционной памяти открытия ссылки для обновления в ходе исполнения; и
заменяют инструкцию открытия ссылки для чтения на вторую инструкцию открытия ссылки для обновления.
26. Способ по п.25, дополнительно содержащий этап, на котором удаляют первую инструкцию открытия ссылки для обновления.
27. Способ по п.26, в котором при удалении первой инструкции используют общее исключение подвыражений, чтобы удалять избыточные инструкции, в том числе первую инструкцию.
28. Способ по п.25, в котором программное обеспечение представляется посредством графа управляющего процесса, и способ выполняется по этому графу управляющего процесса.
29. Способ по п.28, в котором при нахождении инструкции открытия ссылки для чтения выполняют для базовых блоков в графе управляющего процесса этапы, на которых:
идентифицируют инструкцию открытия ссылки для чтения;
записывают эту ссылку;
сканируют вперед по базовому блоку от идентифицированной инструкции; когда назначение ссылке обнаружено, прекращают сканирование идентифицированной инструкции; и
когда инструкция открытия ссылки для обновления обнаружена, переходят к выполнению замены на идентифицированную инструкцию.
30. Способ по п.28, в котором при нахождении инструкции открытия ссылки для чтения выполняют для базовых блоков в графе управляющего процесса этапы, на которых:
идентифицируют инструкцию открытия ссылки для обновления;
записывают эту ссылку;
сканируют назад по базовому блоку от идентифицированной инструкции;
когда обнаружено назначение ссылке, прекращают сканирование идентифицированной инструкции; и
когда обнаружена инструкция открытия ссылки для чтения, переходят к выполнению замены на обнаруженную инструкцию открытия ссылки для чтения.
31. Способ по п.28, в котором при нахождении инструкции открытия ссылки для чтения выполняют анализ потоков данных, при котором осуществляют поиск по границам базовых блоков на предмет инструкций открытия ссылки для чтения, которые сделаны избыточными посредством инструкций открытия ссылки для обновления.
32. Способ по п.31, в котором при выполнении анализа потоков данных:
сохраняют набор переменных на границе каждого базового блока в графе управляющего процесса, которые, как известно, ссылаются на ссылки, которые открыты для обновления;
для каждого базового блока:
сканируют назад по графу управляющего процесса;
когда инструкция открытия ссылки для обновления обнаружена для конкретной переменной, добавляют эту переменную в набор переменных для базового блока;
когда определение обнаружено для конкретной переменной, удаляют эту переменную из набора переменных для базового блока;
когда начало базового блока обнаружено, перекрещивают набор переменных для базового блока с наборами переменных, сохраненных в конце базовых блоков, которые приводят непосредственно к базовому блоку;
повторяют процесс до тех пор, пока стабильный набор переменных не будет создан для каждого базового блока; и
для каждого базового блока рассматривают инструкции открытия ссылок, на которые ссылается набор переменных для базового блока, для чтения в качестве избыточных инструкций.
33. Способ по п.1, в котором при выполнении оптимизаций:
идентифицируют одну или более процедур в программе, которые содержат одну или более операций программной транзакционной памяти, которые могут быть оптимизированы вне этих процедур;
создают для каждой из упомянутых одной или более процедур клонированную версию этой процедуры, которая допускает вызов операций программной транзакционной памяти, которые могут быть оптимизированы вне клонированной версии;
перемещают упомянутые одну или более операций программной транзакционной памяти, которые могут быть оптимизированы вне этих процедур; и
заменяют вызовы каждой из упомянутых одной или более процедур на вызовы ее клонированной версии.
34. Способ по п.33, дополнительно содержащий этап, на котором оптимизируют программу посредством удаления избыточностей среди упомянутых одной или более операций программной транзакционной памяти, которые могут быть оптимизированы.
35. Способ по п.34, в котором при оптимизации программы выполняют общее исключение подвыражений для программы.
36. Способ по п.34, в котором упомянутые одна или более операций программной транзакционной памяти, которые могут быть оптимизированы, содержат операции получения менеджера транзакций.
37. Способ по п.36, в котором клонированные версии процедур, содержащие операции получения менеджера транзакций, содержат процедуры, которые принимают экземпляры менеджера транзакций в качестве входных данных.
38. Способ по п.34, в котором упомянутые одна или более операций программной транзакционной памяти, которые могут быть оптимизированы, содержат операции открытия ссылок для чтения или обновления, причем эти ссылки передаются в процедуры в качестве входных данных.
39. Способ по п.38, в котором клонированные версии процедур, содержащих операции открытия ссылок для чтения или обновления, содержат процедуры, которые основываются на ссылках, открываемых до того, как вызываются эти процедуры.
40. Способ по п.39, в котором при создании клонированных версий процедур, содержащих операции открытия ссылок для чтения или обновления, выполняют обратный анализ потоков данных, чтобы определять, какие процедуры содержат операции открытия ссылок для чтения или обновления для ссылок, которые известны в началах этих процедур.
| СПОСОБ ПОЛУЧЕНИЯ ОБЪЕКТНОГО КОДА | 2000 |
|
RU2206119C2 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6622300 В1, 16.09.2003 | |||
| US 6505291 B1, 07.01.2003. | |||

