Изобретение относится к заполнению шумом при многоканальном кодировании аудио.
Современные системы кодирования речи/аудио в частотной области, такие как Opus/Celt-кодек IETF[1], MPEG-4 (HE-)AAC[2] или, в частности, MPEG-D xHE-AAC (USAC) [3], предлагают средство кодировать аудиокадры либо с использованием одного длинного преобразования (длинного блока), либо с использованием восьми последовательных коротких преобразований (коротких блоков) в зависимости от временной стационарности сигнала. Помимо этого, для кодирования с низкой скоростью передачи битов эти схемы предоставляют инструментальные средства для того, чтобы восстанавливать частотные коэффициенты канала с использованием псевдослучайного шума или более низких частотных коэффициентов того же канала. В xHE-AAC, эти инструментальные средства известны как заполнение шумом и репликация полос спектра, соответственно.
Тем не менее, для очень тонального или переходного стереофонического ввода, только заполнение шумом и/или репликация полос спектра ограничивают достижимое качество кодирования на очень низких скоростях передачи битов, главным образом поскольку слишком много спектральных коэффициентов обоих каналов должны передаваться явно.
Таким образом, цель заключается в том, чтобы предоставлять принцип для выполнения заполнения шумом при многоканальном кодировании аудио, который обеспечивает более эффективное кодирование, в частности, на очень низких скоростях передачи битов.
Это цель достигается посредством предмета изобретения в прилагаемых независимых пунктах формулы изобретения.
Настоящая заявка основана на таких выявленных сведениях, что при многоканальном кодировании аудио, повышенная эффективность кодирования может достигаться, если заполнение шумом нульквантованных полос коэффициентов масштабирования канала выполняется с использованием источников заполнения шумом, отличных от искусственно сформированной шумовой или спектральной реплики того же канала. В частности, эффективность при многоканальном кодировании аудио может повышаться посредством выполнения заполнения шумом на основе шума, сформированного с использованием спектральных линий из предыдущего кадра или другого канала текущего кадра многоканального аудиосигнала.
Посредством использования спектрально совместно размещенных спектральных линий предыдущего кадра или спектровременно совместно размещенных спектральных линий других каналов многоканального аудиосигнала, можно достигать более удовлетворительного качества восстановленного многоканального аудиосигнала, в частности, на очень низких скоростях передачи битов, на которых необходимость для кодера нульквантовать спектральные линии является близкой к такой ситуации, чтобы нульквантовать полосы коэффициентов масштабирования в целом. Вследствие улучшенного заполнения шумом, кодер в таком случае может, с меньшей потерей качества, выбирать нульквантование большего числа полос коэффициентов масштабирования, за счет этого повышая эффективность кодирования.
В соответствии с вариантом осуществления настоящей заявки, источник для выполнения заполнения шумом частично перекрывается с источником, используемым для выполнения комплекснозначного стереопрогнозирования. В частности, понижающее микширование предыдущего кадра может использоваться в качестве источника для заполнения шумом и совместно использоваться в качестве источника для выполнения или, по меньшей мере, улучшения оценки мнимой части для выполнения комплексного межканального прогнозирования.
В соответствии с вариантами осуществления, существующий многоканальный аудиокодек расширяется обратно совместимым способом таким образом, чтобы передавать в служебных сигналах, на покадровой основе, использование заполнения межканальным шумом. Нижеуказанные конкретные варианты осуществления, например, расширяют xHE-AAC посредством передачи служебных сигналов обратно совместимым способом с передачей служебных сигналов, включающей и выключающей заполнение межканальным шумом с помощью неиспользуемых состояний условно кодированного параметра заполнения шумом.
Преимущественные реализации настоящей заявки являются предметом зависимых пунктов формулы изобретения. Предпочтительные варианты осуществления настоящей заявки описываются ниже со ссылкой на чертежи, на которых:
Фиг. 1 показывает блок-схему параметрического декодера в частотной области согласно варианту осуществления настоящей заявки;
Фиг. 2 показывает принципиальную схему, иллюстрирующую последовательность спектров, формирующих спектрограммы каналов многоканального аудиосигнала, чтобы упрощать понимание описания декодера по фиг. 1;
Фиг. 3 показывает принципиальную схему, иллюстрирующую текущие спектры из спектрограмм, показанных на фиг. 2, для упрощения понимания описания фиг. 1;
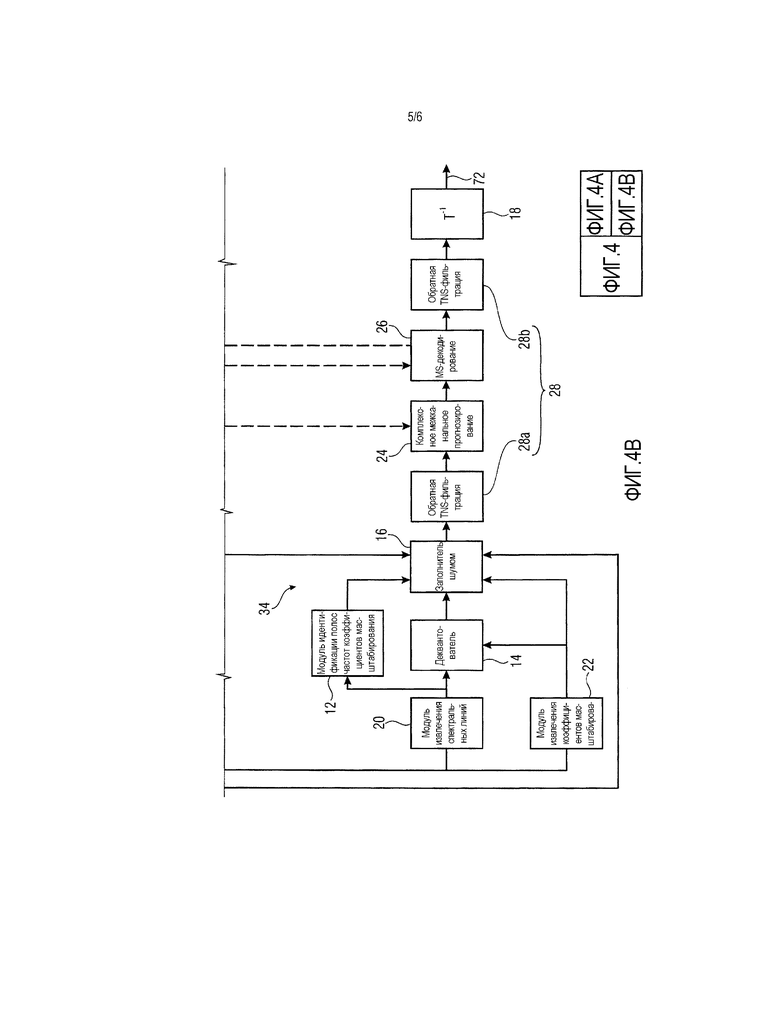
Фиг. 4 показывает блок-схему параметрического аудиодекодера в частотной области в соответствии с альтернативным вариантом осуществления, согласно которому понижающее микширование предыдущего кадра используется в качестве основы для заполнения межканальным шумом; и
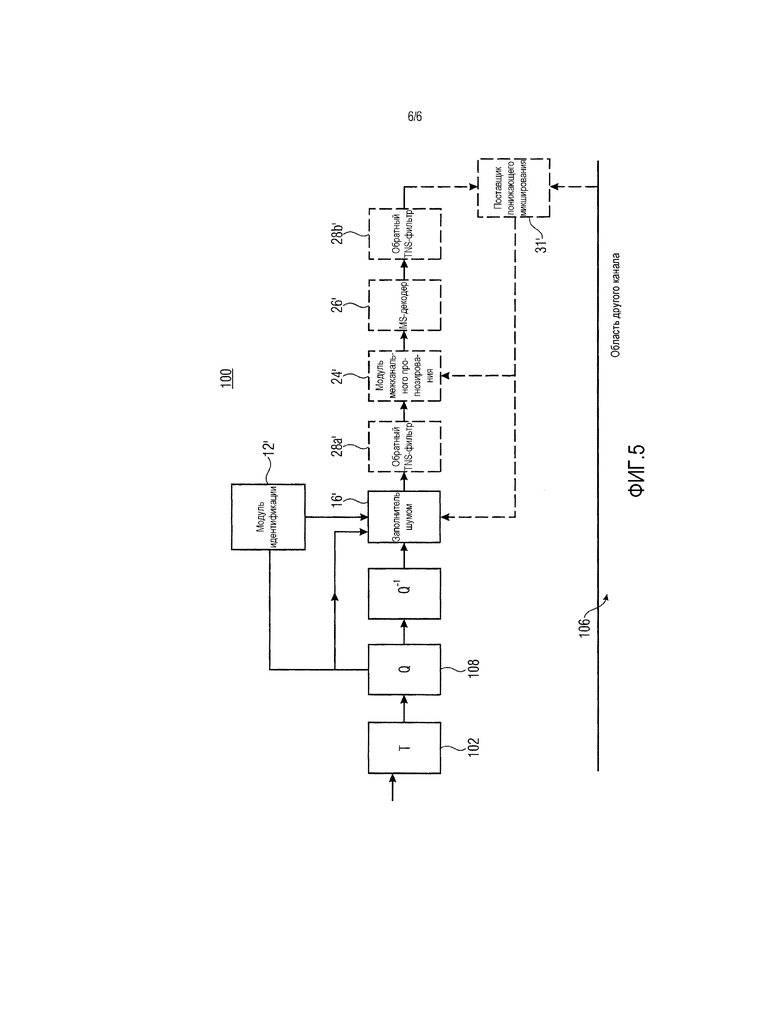
Фиг. 5 показывает блок-схему параметрического аудиокодера в частотной области в соответствии с вариантом осуществления.
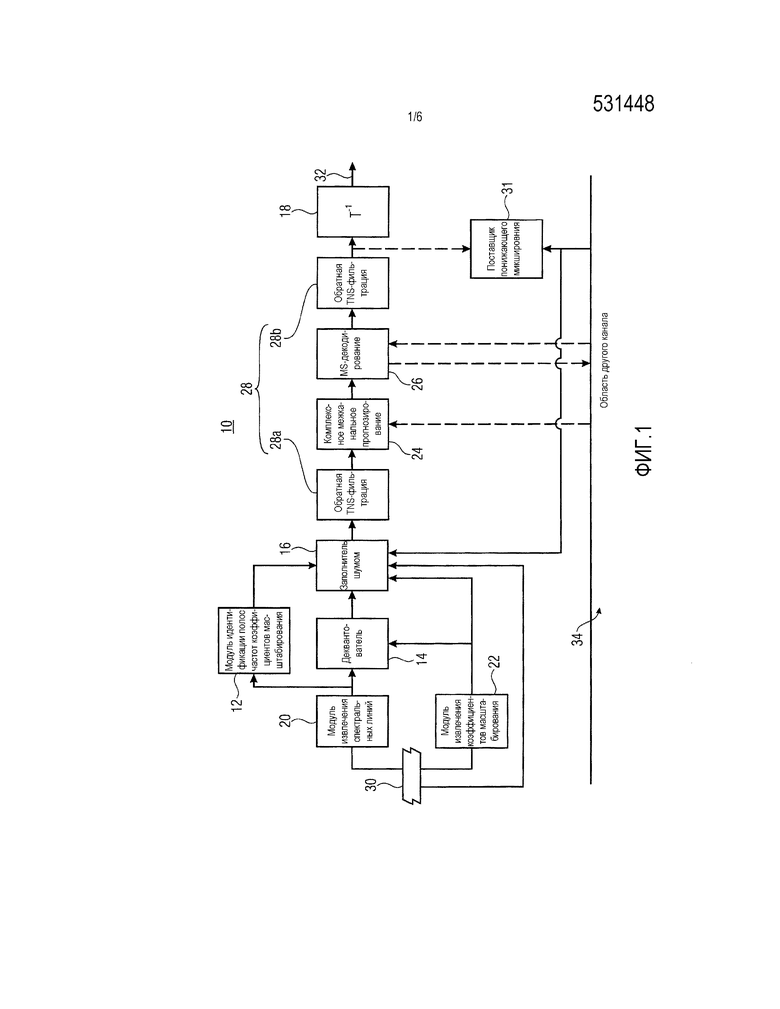
Фиг. 1 показывает аудиодекодер в частотной области в соответствии с вариантом осуществления настоящей заявки. Декодер, в общем, указывается с использованием ссылки с номером 10 и содержит модуль 12 идентификации полос коэффициентов масштабирования, деквантователь 14, заполнитель 16 шумом и обратный преобразователь 18, а также модуль 20 извлечения спектральных линий и модуль 22 извлечения коэффициентов масштабирования. Необязательные дополнительные элементы, которые может содержать декодер 10, охватывают модуль 24 комплексного стереопрогнозирования, MS (средний/боковой) декодер 26 и инструментальное средство фильтра обратного TNS (временного формирования шума), два экземпляра которого 28a и 28b показаны на фиг. 1. Помимо этого, поставщик понижающего микширования показывается и приводится подробнее ниже использования ссылки с номером 30.
Аудиодекодер 10 в частотной области по фиг. 1 представляет собой параметрический декодер, поддерживающий заполнение шумом, согласно которому некоторая нульквантованная полоса коэффициентов масштабирования заполнена шумом с использованием коэффициента масштабирования этой полосы коэффициентов масштабирования в качестве средства управления уровнем шума, заполненного в эту полосу коэффициентов масштабирования. Помимо этого, декодер 10 по фиг. 1 представляет многоканальный аудиодекодер, выполненный с возможностью восстанавливать многоканальный аудиосигнал из входящего потока 30 данных. Тем не менее, фиг. 1 концентрируется на элементах декодера 10, участвующих в восстановлении одного из многоканальных аудиосигналов, кодированных в поток 30 данных, и выводит этот (выходной) канал на выходе 32. Ссылка с номером 34 указывает то, что декодер 10 может содержать дополнительные элементы либо может содержать некоторый конвейерный функциональный контроллер, отвечающий за восстановление других каналов многоканального аудиосигнала, при этом описание, приведенное ниже, указывает то, как восстановление декодера 10 интересующего канала на выходе 32 взаимодействует с декодированием других каналов.
Многоканальный аудиосигнал, представленный посредством потока 30 данных, может содержать два или более каналов. Далее описание вариантов осуществления настоящей заявки концентрируется на стереослучае, в котором многоканальный аудиосигнал содержит только два канала, но в принципе варианты осуществления, приведенные далее, могут легко переноситься на альтернативные варианты осуществления относительно многоканальных аудиосигналов и их кодирования, содержащего более двух каналов.
Как должно становиться очевидным из описания по фиг. 1 ниже, декодер 10 по фиг. 1 представляет собой декодер с преобразованием. Иными словами, согласно декодеру 10, лежащему в основе технологии кодирования, каналы кодируются в области преобразования, к примеру, с использованием перекрывающегося преобразования каналов. Кроме того, в зависимости от создателя аудиосигнала, возникают временные фазы, в течение которых каналы аудиосигнала большей частью представляют такой же аудиоконтент, отклоняющийся друг от друга просто посредством незначительных или детерминированных изменений между собой, таких как различные амплитуды и/или фаза, чтобы представлять аудиосцену, в которой разности между каналами предоставляют виртуальное позиционирование аудиоисточника аудиосцены относительно позиций виртуальных динамиков, ассоциированных с выходными каналами многоканального аудиосигнала. Тем не менее, в некоторых других временных фазах различные каналы аудиосигнала могут быть более или менее декоррелированными между собой и могут даже представлять, например, абсолютно различные аудиоисточники.
Чтобы учитывать возможно изменяющуюся во времени взаимосвязь между каналами аудиосигнала, декодер 10, лежащий в основе аудиокодека по фиг. 1, обеспечивает возможность изменяющегося во времени использования различных показателей для того, чтобы использовать межканальные избыточности. Например, MS-кодирование обеспечивает возможность переключения между представлением левого и правого каналов стереоаудиосигнала как есть или как пары M (средних) и S (боковых) каналов, представляющих понижающее микширование левого и правого каналов и их половинную разность, соответственно. Иными словами, предусмотрены непрерывные (в спектровременном смысле) спектрограммы двух каналов, передаваемых посредством потока 30 данных, но смысл этих (передаваемых) каналов может изменяться во времени и относительно выходных каналов, соответственно.
Комплексное стереопрогнозирование (другое инструментальное средство использования межканальных избыточностей) обеспечивает, в спектральной области, прогнозирование коэффициентов частотной области одного канала или спектральных линий с использованием спектрально совместно размещенных линий другого канала. Ниже описываются дополнительные сведения относительно этого.
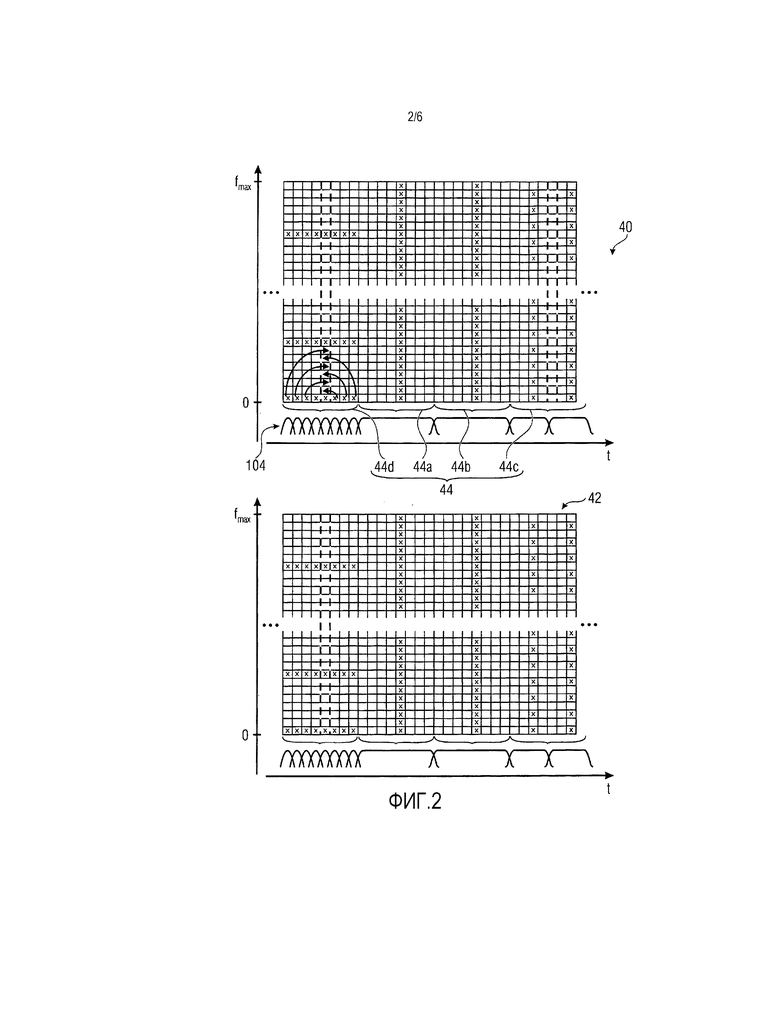
Чтобы упрощать понимание последующего описания фиг. 1 и его показанных компонентов, фиг. 2 показывает, для примерного случая стереоаудиосигнала, представленного посредством потока 30 данных, возможный способ того, как выборочные значения для спектральных линий двух каналов могут кодироваться в поток 30 данных таким образом, чтобы обрабатываться посредством декодера 10 по фиг. 1. В частности, тогда как в верхней половине по фиг. 2 проиллюстрирована спектрограмма 40 первого канала стереоаудиосигнала, нижняя половина по фиг. 2 иллюстрирует спектрограмму 42 другого канала стереоаудиосигнала. С другой стороны, необходимо отметить, что "смысл" спектрограмм 40 и 42 может изменяться во времени вследствие, например, изменяющегося во времени переключения между MS-кодированной областью и не-MS-кодированной областью. Прежде всего, спектрограммы 40 и 42 связаны с M- и S-каналом, соответственно, тогда как во втором случае спектрограммы 40 и 42 связаны с левым и правым каналами. Переключение между MS-кодированной областью и не-MS-кодированной областью может передаваться в служебных сигналах в потоке 30 данных.
Фиг. 2 показывает то, что спектрограммы 40 и 42 могут кодироваться в поток 30 данных с изменяющимся во времени спектровременным разрешением. Например, оба (передаваемых) канала могут, с временным совмещением, подразделяться на последовательность кадров, указываемых с использованием фигурных скобок 44, которые могут быть одинаково длинными и примыкают друг к другу без перекрытия. Как упомянуто выше, спектральное разрешение, с которым спектрограммы 40 и 42 представлены в потоке 30 данных, может изменяться во времени. Предварительно, предполагается, что спектровременное разрешение изменения во времени одинаково для спектрограмм 40 и 42, но расширение этого упрощения также является целесообразным, как должно становиться очевидным из нижеприведенного описания. Изменение спектровременного разрешения, например, передается в служебных сигналах в потоке 30 данных в единицах кадров 44. Иными словами, спектровременное разрешение изменяется в единицах кадров 44. Изменение спектровременного разрешения спектрограмм 40 и 42 достигается посредством переключения длины преобразования и числа преобразований, используемых для того, чтобы описывать спектрограммы 40 и 42 в каждом кадре 44. В примере по фиг. 2, кадры 44a и 44b иллюстрируют кадры, в которых одно длинное преобразование использовано для того, чтобы дискретизировать каналы аудиосигнала, за счет этого приводя к наибольшему спектральному разрешению с одним выборочным значением спектральной линии в расчете на спектральную линию для каждого из таких кадров в расчете на один канал. На фиг. 2, выборочные значения спектральных линий указываются с использованием небольших крестиков в прямоугольниках, при этом прямоугольники, в свою очередь, размещаются в строках и столбцах и должны представлять спектральную временную сетку, причем каждая строка соответствует одной спектральной линии, а каждый столбец соответствует подыинтервалам кадров 44, соответствующих кратчайшим преобразованиям, участвующим в формировании спектрограмм 40 и 42. В частности, фиг. 2 иллюстрирует, например, для кадра 44d то, что кадр альтернативно может подвергаться последовательным преобразованиям меньшей длины, за счет этого получая в результате, для таких кадров, к примеру, кадра 44d, несколько временно последующих спектров с уменьшенным спектральным разрешением. Восемь коротких преобразований примерно использованы для кадра 44d, что приводит к спектровременной дискретизации спектрограмм 40 и 42 в этом кадре 42d, в спектральных линиях, разнесенных друг от друга, так что заполняется только каждая восьмая спектральная линия, но при этом выборочное значение для каждого из восьми окон преобразования на основе кодирования со взвешиванием или преобразований меньшей длины используется для того, чтобы преобразовывать кадр 44d. В качестве иллюстрации, на фиг. 2 показано то, что также должны быть целесообразными другие числа преобразований для кадра, к примеру, использование двух преобразований с длиной преобразования, которая составляет, например, половину от длины преобразования для длинных преобразований для кадров 44a и 44b, за счет этого приводя к дискретизации спектровременной сетки или спектрограмм 40 и 42, причем два выборочных значения спектральных линий получаются для каждой второй спектральной линии, одно из которых связано с начальным преобразованием, а другое - с конечным преобразованием.
Окна преобразования на основе кодирования со взвешиванием для преобразований, на которые подразделяются кадры, проиллюстрированы на фиг. 2 ниже каждой спектрограммы с использованием линий в форме накладывающихся окон кодирования со спектром. Временное перекрытие, например, служит для целей TDAC (подавления наложения спектров во временной области).
Хотя варианты осуществления, подробно описанные ниже, также могут реализовываться другим способом, фиг. 2 иллюстрируют случай, в котором переключение между различными спектровременными разрешениями для отдельных кадров 44 выполняется таким образом, что для каждого кадра 44, идентичное число значений спектральных линий, указываемых посредством небольших крестиков на фиг. 2, в результате получается для спектрограммы 40 и спектрограммы 42, причем разность заключается только в способе, которым линии спектровременно дискретизируют соответствующий спектровременной мозаичный фрагмент, соответствующий надлежащему кадру 44, охватываемому временно в течение времени соответствующего кадра 44 и охватываемому спектрально от нулевой частоты до максимальной частоты fmax.
С использованием стрелок на фиг. 2, фиг. 2 иллюстрирует относительно кадра 44d то, что аналогичные спектры могут получаться для всех кадров 44 посредством подходящего распределения выборочных значений спектральных линий, принадлежащих идентичной спектральной линии, но окнам кодирования с взвешиванием коротких преобразований в одном кадре одного канала, на незанятые (пустые) спектральные линии в этом кадре вплоть до следующей занятой спектральной линии этого кадра. Такие результирующие спектры далее называются "перемеженными спектрами". При перемежении n преобразований одного кадра одного канала, например, спектрально совместно размещенные значения спектральных линий n коротких преобразований идут друг за другом до того, как идет набор из n спектрально совместно размещенных значений спектральных линий n коротких преобразований спектрально последующей спектральной линии. Промежуточная форма перемежения также должна быть целесообразной: вместо перемежения всех коэффициентов спектральных линий одного кадра, должно быть целесообразным перемежать только коэффициенты спектральных линий строгого поднабора коротких преобразований кадра 44d. В любом случае, каждый раз, когда поясняются спектры кадров двух каналов, соответствующих спектрограммам 40 и 42, эти спектры могут означать перемеженные спектры или неперемеженные спектры.
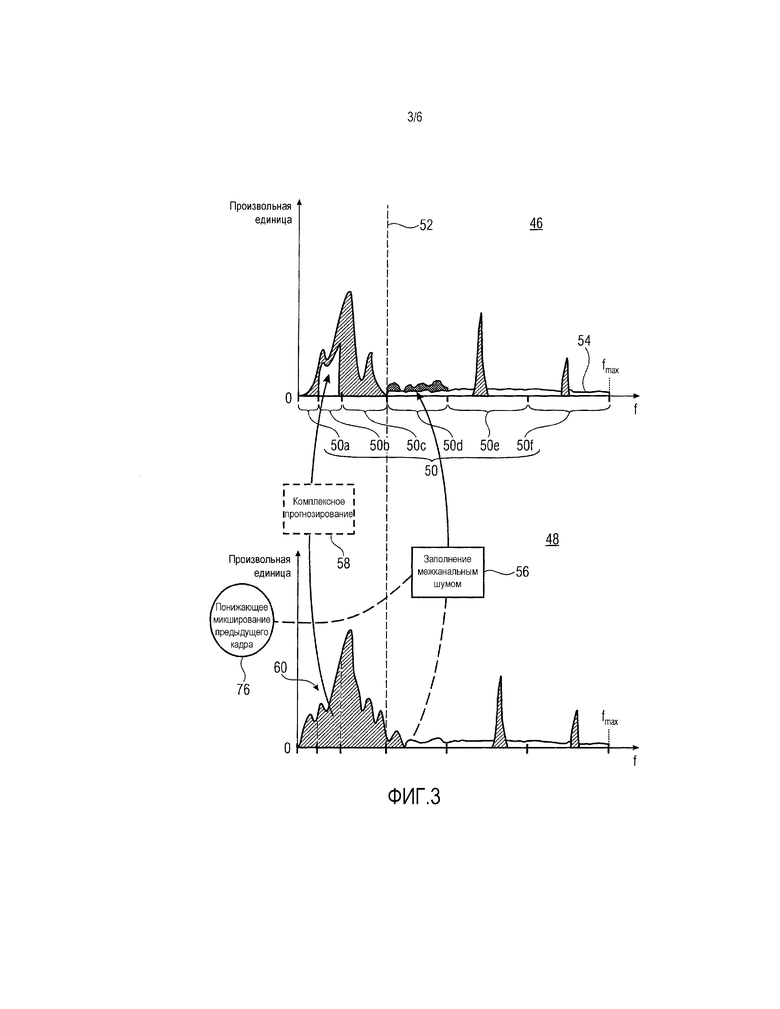
Чтобы эффективно кодировать коэффициенты спектральных линий, представляющие спектрограммы 40 и 42 через поток 30 данных, передаваемый в декодер 10, они квантуются. Чтобы спектровременно управлять шумом квантования, размер шага квантования управляется через коэффициенты масштабирования, которые задаются в некоторой спектровременной сетке. В частности, в каждой последовательности спектров каждой спектрограммы, спектральные линии группируются в спектрально последовательные неперекрывающиеся группы коэффициентов масштабирования. Фиг. 3 показывает спектр 46 спектрограммы 40 в верхней половине и совместный временной спектр 48 из спектрограммы 42. Как показано здесь, спектры 46 и 48 подразделяются на полосы коэффициентов масштабирования вдоль спектральной оси f, с тем чтобы группировать спектральные линии в неперекрывающиеся группы. Полосы коэффициентов масштабирования проиллюстрированы на фиг. 3 с использованием фигурных скобок 50. Для простоты предполагается, что границы между полосами коэффициентов масштабирования совпадают между спектром 46 и 48, но это не должно обязательно иметь место.
Иными словами, посредством кодирования в потоке 30 данных, каждая из спектрограмм 40 и 42 подразделяется на временную последовательность спектров, и каждый из этих спектров спектрально подразделяется на полосы коэффициентов масштабирования, и для каждой полосы коэффициентов масштабирования поток 30 данных кодирует или передает информацию относительно коэффициента масштабирования, соответствующего надлежащей полосе коэффициентов масштабирования. Коэффициенты спектральных линий, попадающие в соответствующую полосу 50 коэффициентов масштабирования, квантуются с использованием соответствующего коэффициента масштабирования либо, что касается декодера 10, могут деквантоваться с использованием коэффициента масштабирования соответствующей полосы коэффициентов масштабирования.
Перед возвращением снова к фиг. 1 и его описанию, в дальнейшем предполагается, что конкретный обрабатываемый канал, т.е. канал, в декодировании которого участвуют конкретные элементы декодера по фиг. 1, отличные от 34, представляет собой передаваемый канал спектрограммы 40, который, как уже указано выше, может представлять один из левого и правого каналов, M-канала или S-канала, с учетом того, что многоканальный аудиосигнал, кодированный в поток 30 данных, представляет собой стереоаудиосигнал.
Хотя модуль 20 извлечения спектральных линий выполнен с возможностью извлекать данные спектральных линий, т.е. коэффициенты спектральных линий для кадров 44 из потока 30 данных, модуль 22 извлечения коэффициентов масштабирования выполнен с возможностью извлекать для каждого кадра 44 соответствующие коэффициенты масштабирования. С этой целью, модули 20 и 22 извлечения могут использовать энтропийное декодирование. В соответствии с вариантом осуществления, модуль 22 извлечения коэффициентов масштабирования выполнен с возможностью последовательно извлекать коэффициенты масштабирования, например, спектр 46 на фиг. 3, т.е. коэффициенты масштабирования полос 50 коэффициентов масштабирования, из потока 30 данных с использованием контекстно-адаптивного энтропийного декодирования. Порядок последовательного декодирования может соответствовать спектральному порядку, заданному для полос коэффициентов масштабирования, идущих, например, от низкой частоты до высокой частоты. Модуль 22 извлечения коэффициентов масштабирования может использовать контекстно-адаптивное энтропийное декодирование и может определять контекст для каждого коэффициента масштабирования в зависимости от уже извлеченных коэффициентов масштабирования в спектральном окружении текущего извлеченного коэффициента масштабирования, к примеру, в зависимости от коэффициента масштабирования непосредственно предшествующей полосы коэффициентов масштабирования. Альтернативно, модуль 22 извлечения коэффициентов масштабирования может прогнозирующе декодировать коэффициенты масштабирования из потока 30 данных, такого как, например, с использованием дифференциального декодирования при прогнозировании текущего декодированного коэффициента масштабирования на основе любого из ранее декодированных коэффициентов масштабирования, к примеру, непосредственно предшествующего коэффициента масштабирования. А именно, этот процесс извлечения коэффициента масштабирования является независимым относительно коэффициента масштабирования, принадлежащего полосе коэффициентов масштабирования, заполненной исключительно посредством нульквантованных спектральных линий либо заполненной посредством спектральных линий, из которых, по меньшей мере, одна квантуется в ненулевое значение. Коэффициент масштабирования, принадлежащий полосе коэффициентов масштабирования, заполненной только посредством нульквантованных спектральных линий, может как служить в качестве основы прогнозирования для последующего декодированного коэффициента масштабирования, который возможно принадлежит полосе коэффициентов масштабирования, заполненной посредством спектральных линий, из которых одна является ненулевой, так и прогнозироваться на основе ранее декодированного коэффициента масштабирования, который возможно принадлежит полосе коэффициентов масштабирования, заполненной посредством спектральных линий, из которых одна является ненулевой.
Только для полноты следует отметить, что модуль 20 извлечения спектральных линий извлекает коэффициенты спектральных линий, с которыми полосы 50 коэффициентов масштабирования заполняются, аналогично использованию, например, энтропийного кодирования и/или прогнозирующего кодирования. Энтропийное кодирование может использовать адаптивность контекста на основе коэффициентов спектральных линий в спектровременном окружении текущего декодированного коэффициента спектральной линии, и аналогично, прогнозирование может представлять собой спектральное прогнозирование, временное прогнозирование или спектровременное прогнозирование, прогнозирующее текущий декодированный коэффициент спектральной линии на основе ранее декодированных коэффициентов спектральных линий в своем спектровременном окружении. Для повышенной эффективности кодирования, модуль 20 извлечения спектральных линий может быть выполнен с возможностью осуществлять декодирование спектральных линий или коэффициентов линий в кортежах, которые собирают или группируют спектральные линии вдоль частотной оси.
Таким образом, на выходе модуля 20 извлечения спектральных линий, предоставляются коэффициенты спектральных линий, такие как, например, в единицах спектров, таких как спектр 46, собирающий, например, все коэффициенты спектральных линий соответствующего кадра, или альтернативно собирающий все коэффициенты спектральных линий некоторых коротких преобразований соответствующего кадра. На выходе модуля 22 извлечения коэффициентов масштабирования, в свою очередь, выводятся соответствующие коэффициенты масштабирования соответствующих спектров.
Модуль 12 идентификации полос коэффициентов масштабирования, а также деквантователь 14 имеют входы спектральных линий, связанные с выходом модуля 20 извлечения спектральных линий, и деквантователь 14 и заполнитель 16 шумом имеют входы коэффициентов масштабирования, связанные с выходом модуля 22 извлечения коэффициентов масштабирования. Модуль 12 идентификации полос коэффициентов масштабирования выполнен с возможностью идентифицировать так называемые нульквантованные полосы коэффициентов масштабирования в текущем спектре 46, т.е. полосы коэффициентов масштабирования, в которых все спектральные линии квантуются в нулевые, к примеру, полосу 50c коэффициентов масштабирования на фиг. 3 и оставшиеся полосы коэффициентов масштабирования спектра, в которых, по меньшей мере, одна спектральная линия квантуется в ненулевую. В частности, на фиг. 3 коэффициенты спектральных линий указываются с использованием областей со штриховкой на фиг. 3. Из него видно, что в спектре 46, все полосы коэффициентов масштабирования, кроме полосы 50b коэффициентов масштабирования, имеют, по меньшей мере, одну спектральную линию, коэффициент спектральной линии которой квантуется в ненулевое значение. Далее должно становиться очевидным, что нульквантованные полосы коэффициентов масштабирования, к примеру, 50d формируют объект заполнения межканальным шумом, подробнее описанного ниже. Перед продолжением описания следует отметить, что модуль 12 идентификации полос коэффициентов масштабирования может ограничивать свою идентификацию только строгим поднабором полос 50 коэффициентов масштабирования, к примеру, полосами коэффициентов масштабирования выше некоторой начальной частоты 52. На фиг. 3, это должно ограничивать процедуру идентификации полосами 50d, 50e и 50f коэффициентов масштабирования.
Модуль 12 идентификации полос коэффициентов масштабирования информирует заполнитель 16 шумом в отношении тех полос коэффициентов масштабирования, которые представляют собой нульквантованные полосы коэффициентов масштабирования. Деквантователь 14 использует коэффициенты масштабирования, ассоциированные с входящим спектром 46, для того чтобы деквантовать или масштабировать коэффициенты спектральных линий для спектральных линий спектра 46 согласно ассоциированным коэффициентам масштабирования, т.е. коэффициентам масштабирования, ассоциированным с полосами 50 коэффициентов масштабирования. В частности, деквантователь 14 деквантует и масштабирует коэффициенты спектральных линий, попадающие в соответствующую полосу коэффициентов масштабирования, с помощью коэффициента масштабирования, ассоциированного с соответствующей полосой коэффициентов масштабирования. Фиг. 3 должен интерпретироваться как показывающий результат деквантования спектральных линий.
Заполнитель 16 шумом получает информацию относительно нульквантованных полос коэффициентов масштабирования, которые формируют объект следующего заполнения шумом, деквантованного спектра, а также коэффициентов масштабирования, по меньшей мере, тех полос коэффициентов масштабирования, идентифицированных в качестве нульквантованных полос коэффициентов масштабирования, а также передачи служебных сигналов, полученной из потока 30 данных для текущего кадра, раскрывающей то, должно или нет выполняться заполнение межканальным шумом для текущего кадра.
Процесс заполнения межканальным шумом, описанный в нижеприведенном примере, фактически заключает в себе два типа заполнения шумом, а именно, вставку минимального уровня 54 шума, связанного со всеми спектральными линиями, квантованными до нуля независимо от их потенциального членства в любой нульквантованной полосе коэффициентов масштабирования, и фактическую процедуру заполнения межканальным шумом. Хотя эта комбинация описывается в дальнейшем в этом документе, следует подчеркнуть, что вставка минимального уровня шума может опускаться в соответствии с альтернативным вариантом осуществления. Кроме того, передача служебных сигналов относительно включения и отключения заполнения шумом, связанного с текущим кадром и полученного из потока 30 данных, может быть связана только с заполнением межканальным шумом либо может совместно управлять комбинацией обоих типов заполнения шумом.
Что касается вставки минимального уровня шума, заполнитель 16 шумом может работать следующим образом. В частности, заполнитель 16 шумом может использовать формирование искусственного шума, к примеру, генератор псевдослучайных чисел или некоторый другой источник случайности, для того чтобы заполнять спектральные линии, коэффициенты спектральных линий которых являются нулевыми. "Уровень" минимального уровня 54 шума, вставленного таким способом в нульквантованных спектральных линиях, может задаваться согласно явной передаче служебных сигналов в потоке 30 данных для текущего кадра или текущего спектра 46. "Уровень" минимального уровня 54 шума может определяться с использованием, например, среднеквадратичного значения (RMS) или энергетического показателя.
Таким образом, вставка минимального уровня шума представляет вид предварительного заполнения для тех полос коэффициентов масштабирования, идентифицированных в качестве нульквантованных, к примеру, для полосы 50d коэффициентов масштабирования на фиг. 3. Она также влияет на другие полосы коэффициентов масштабирования за пределами нульквантованных полос коэффициентов масштабирования, но последние дополнительно подвергаются следующему заполнению межканальным шумом. Как описано ниже, процесс заполнения межканальным шумом должен заполнять нульквантованные полосы коэффициентов масштабирования вплоть до уровня, который управляется через коэффициент масштабирования соответствующей нульквантованной полосы коэффициентов масштабирования. Он может быть непосредственно использован с этой целью вследствие квантования до нуля всех спектральных линий соответствующей нульквантованной полосы коэффициентов масштабирования. Тем не менее, поток 30 данных может содержать дополнительную передачу в служебных сигналах параметра для каждого кадра или каждого спектра 46, который обычно применяется к коэффициентам масштабирования всех нульквантованных полос коэффициентов масштабирования соответствующего кадра или спектра 46, и приводит, когда применяется к коэффициентам масштабирования нульквантованных полос коэффициентов масштабирования посредством заполнителя 16 шумом, к соответствующему уровню заполнения, который является отдельным для нульквантованных полос коэффициентов масштабирования. Иными словами, заполнитель 16 шумом может модифицировать, с использованием идентичной функции модификации, для каждой нульквантованной полосы коэффициентов масштабирования спектра 46, коэффициент масштабирования соответствующей полосы коэффициентов масштабирования с использованием вышеуказанного параметра, содержащегося в потоке 30 данных для этого спектра 46 текущего кадра, с тем чтобы получать целевой уровень заполнения для соответствующего измерения нульквантованной полосы коэффициентов масштабирования, с точки зрения энергии или RMS, например, уровень, вплоть до которого процесс заполнения межканальным шумом должен заполнять соответствующую нульквантованную полосу коэффициентов масштабирования (необязательно) дополнительным шумом (в дополнение к минимальному уровню 54 шума).
В частности, чтобы выполнять заполнение 56 межканальным шумом, заполнитель 16 шумом получает спектрально совместно размещенную часть спектра другого канала 48, в состоянии уже значительно или полностью декодированном, и копирует полученную часть спектра 48 в нульквантованную полосу коэффициентов масштабирования, с которой эта часть спектрально совместно размещена, масштабированную таким образом, что результирующий общий уровень шума в этой нульквантованной полосе коэффициентов масштабирования, извлекаемый посредством интегрирования по спектральным линиям соответствующей полосы коэффициентов масштабирования, равен вышеуказанному целевому уровню заполнения, полученному из коэффициента масштабирования нульквантованной полосы коэффициентов масштабирования. Посредством этого показателя, тональность шума, заполненного в соответствующую нульквантованную полосу коэффициентов масштабирования, улучшается по сравнению с искусственно сформированным шумом, к примеру, искусственно сформированным шумом, формирующим основу минимального уровня 54 шума, и также лучше, чем неуправляемое спектральное копирование/репликация из очень низкочастотных линий в идентичном спектре 46.
Еще точнее, заполнитель 16 шумом находит, для текущей полосы, к примеру, 50d, спектрально совместно размещенную часть в спектре 48 другого канала, масштабирует ее спектральные линии в зависимости от коэффициента масштабирования нульквантованной полосы 50d коэффициентов масштабирования вышеописанным способом, заключающим в себе, необязательно, некоторый дополнительный параметр коэффициента смещения или шума, содержащийся в потоке 30 данных для текущего кадра или спектра 46, так что его результат заполняет соответствующую нульквантованную полосу 50d коэффициентов масштабирования вплоть до требуемого уровня, как задано посредством коэффициента масштабирования нульквантованной полосы 50d коэффициентов масштабирования. В настоящем варианте осуществления, это означает то, что заполнение выполняется аддитивным способом относительно минимального уровня 54 шума.
В соответствии с упрощенным вариантом осуществления, результирующий заполненный шумом спектр 46 непосредственно должен вводиться на вход обратного преобразователя 18, с тем чтобы получать, для каждого окна преобразования на основе кодирования со взвешиванием, которому принадлежат коэффициенты спектральных линий спектра 46, часть временного аудиосигнала соответствующего канала, после чего (не показано на фиг. 1) процесс суммирования с перекрытием может комбинировать эти части временной области. Иными словами, если спектр 46 представляет собой неперемеженный спектр, коэффициенты спектральных линий которого принадлежат только одному преобразованию, то обратный преобразователь 18 подвергает этому преобразованию таким образом, чтобы приводить к одной части временной области, и предшествующие и задние концы которого должны подвергаться процессу суммирования с перекрытием с предшествующими и задними частями временной области, полученными посредством обратного преобразования предшествующих и последующих обратных преобразований, с тем чтобы реализовывать, например, подавление наложения спектров во временной области. Тем не менее, если спектр 46 имеет перемеженные коэффициенты спектральных линий более одного последовательного преобразования, то обратный преобразователь 18 должен подвергать их отдельным обратным преобразованиям, с тем чтобы получать одну часть временной области в расчете на обратное преобразование, и в соответствии с временным порядком, заданным между собой, эти части временной области должны подвергаться процессу суммирования с перекрытием между ними, а также относительно предшествующих и последующих частей временной области других спектров или кадров.
Тем не менее, для полноты следует отметить, что последующая обработка может выполняться для заполненного шумом спектра. Как показано на фиг. 1, обратный TNS-фильтр может выполнять обратную TNS-фильтрацию для заполненного шумом спектра. Иными словами, с управлением через коэффициенты TNS-фильтрации для текущего кадра или спектра 46, спектр, полученный ранее, подвергается линейной фильтрации вдоль спектрального направления.
С или без обратной TNS-фильтрации, модуль 24 комплексного стереопрогнозирования затем может трактовать спектр в качестве остатка прогнозирования для межканального прогнозирования. Более конкретно, модуль 24 межканального прогнозирования может использовать спектрально совместно размещенную часть другого канала для того, чтобы прогнозировать спектр 46 или, по меньшей мере, его поднабор полос 50 коэффициентов масштабирования. Процесс комплексного прогнозирования проиллюстрирован на фиг. 3 с помощью пунктирного прямоугольника 58 относительно полосы 50b коэффициентов масштабирования. Иными словами, поток 30 данных может содержать параметры межканального прогнозирования, управляющие, например, тем, какая из полос 50 коэффициентов масштабирования должна быть межканально прогнозирована, а какая не должна быть прогнозирована таким способом. Дополнительно, параметры межканального прогнозирования в потоке 30 данных дополнительно могут содержать коэффициенты комплексного межканального прогнозирования, применяемые посредством модуля 24 межканального прогнозирования для того, чтобы получать результат межканального прогнозирования. Эти коэффициенты могут содержаться в потоке 30 данных по отдельности для каждой полосы коэффициентов масштабирования, или альтернативно, каждой группы из одной или более полос коэффициентов масштабирования, для которых межканальное прогнозирование активируется или передается в служебных сигналах как активированное в потоке 30 данных.
Источник межканального прогнозирования, как указано на фиг. 3, может представлять собой спектр 48 другого канала. Если точнее, источник межканального прогнозирования может представлять собой спектрально совместно размещенную часть спектра 48, совместно размещенную с полосой 50b коэффициентов масштабирования, которая должна быть межканально прогнозирована, расширенную посредством оценки ее мнимой части. Оценка мнимой части может выполняться на основе спектрально совместно размещенной части 60 самого спектра 48 и/или может использовать понижающее микширование уже декодированных каналов предыдущего кадра, т.е. кадра, непосредственно предшествующего текущему декодированному кадру, которому принадлежит спектр 46. Фактически, модуль 24 межканального прогнозирования суммирует с полосами коэффициентов масштабирования, которые должны быть межканально прогнозированы, к примеру, с полосой 50b коэффициентов масштабирования на фиг. 3, сигнал прогнозирования, полученный так, как описано выше.
Как уже отмечено в вышеприведенном описании, канал, которому принадлежит спектр 46, может представлять собой MS-кодированный канал либо может представлять собой связанный с громкоговорителем канал, такой как левый или правый канал стереоаудиосигнала. Соответственно, необязательно MS-декодер 26 подвергает необязательный межканально прогнозированный спектр 46 MS-декодированию, так что он выполняет, в расчете на спектральную линию или спектр 46, суммирование или вычитание со спектрально соответствующими спектральными линиями другого канала, соответствующего спектру 48. Например, хотя не показано на фиг. 1, спектр 48, как показано на фиг. 3, получен посредством части 34 декодера 10 способом, аналогичным описанию, приведенным выше относительно канала, которому принадлежит спектр 46, и модуль 26 MS-декодирования, при выполнении MS-декодирования, подвергает спектры 46 и 48 суммированию на основе спектральных линий или вычитанию на основе спектральных линий, причем оба спектра 46 и 48, находятся на одном каскаде в линии обработки, что означает то, что оба из них только что получены, например, посредством межканального прогнозирования, или оба из них только что получены посредством заполнения шумом или обратной TNS-фильтрации.
Следует отметить, что, необязательно, MS-декодирование может выполняться способом, глобальным относительно целого спектра 46, или отдельно активируемым посредством потока 30 данных в единицах, например, полос 50 коэффициентов масштабирования. Другими словами, MS-декодирование может включаться или выключаться с использованием соответствующей передачи служебных сигналов в потоке 30 данных, в единицах, например, кадров или некоторого более точного спектровременного разрешения, как, например, по отдельности для полос коэффициентов масштабирования спектров 46 и/или 48 из спектрограмм 40 и/или 42, при этом предполагается, что задаются идентичные границы полос коэффициентов масштабирования обоих каналов.
Как проиллюстрировано на фиг. 1, обратная TNS-фильтрация посредством обратного TNS-фильтра 28 также может выполняться после межканальной обработки, такой как межканальное прогнозирование 58 или MS-декодирование посредством MS-декодера 26. Производительность до или после межканальной обработки может быть фиксированной либо может управляться через соответствующую передачу служебных сигналов для каждого кадра в потоке 30 данных или на некотором другом уровне детализации. Каждый раз, когда выполняется обратная TNS-фильтрация, соответствующие коэффициенты TNS-фильтрации, присутствующие в потоке данных для текущего спектра 46, управляют TNS-фильтром, т.е. линейным прогнозным фильтром, выполняющимся вдоль спектрального направления, таким образом, чтобы линейно фильтровать спектр, входящий в соответствующий модуль 28a и/или 28b обратного TNS-фильтра.
Таким образом, спектр 46, поступающий на вход обратного преобразователя 18, возможно, подвергнут последующей обработке, как описано выше. С другой стороны, вышеприведенное описание не должно пониматься таким образом, что все эти необязательные инструментальные средства должны присутствовать, одновременно или нет. Эти инструментальные средства могут присутствовать в декодере 10 частично или совместно.
В любом случае, результирующий спектр на входе обратного преобразователя представляет конечное восстановление выходного сигнала канала и формирует основу вышеуказанного понижающего микширования для текущего кадра, который служит, как описано относительно комплексного прогнозирования 58, в качестве основы для потенциальной оценки мнимой части для следующего кадра, который должен декодироваться. Он дополнительно может служить в качестве конечного восстановления для межканального прогнозирования другого канала, отличного от канала, с которым связаны элементы, помимо 34 на фиг. 1.
Соответствующее понижающее микширование формируется посредством поставщика 31 понижающего микширования посредством комбинирования этого конечного спектра 46 с соответствующей окончательной версией спектра 48. Второй объект, т.е. соответствующая окончательная версия спектра 48, формирует основу для комплексного межканального прогнозирования в модуле 24 прогнозирования.
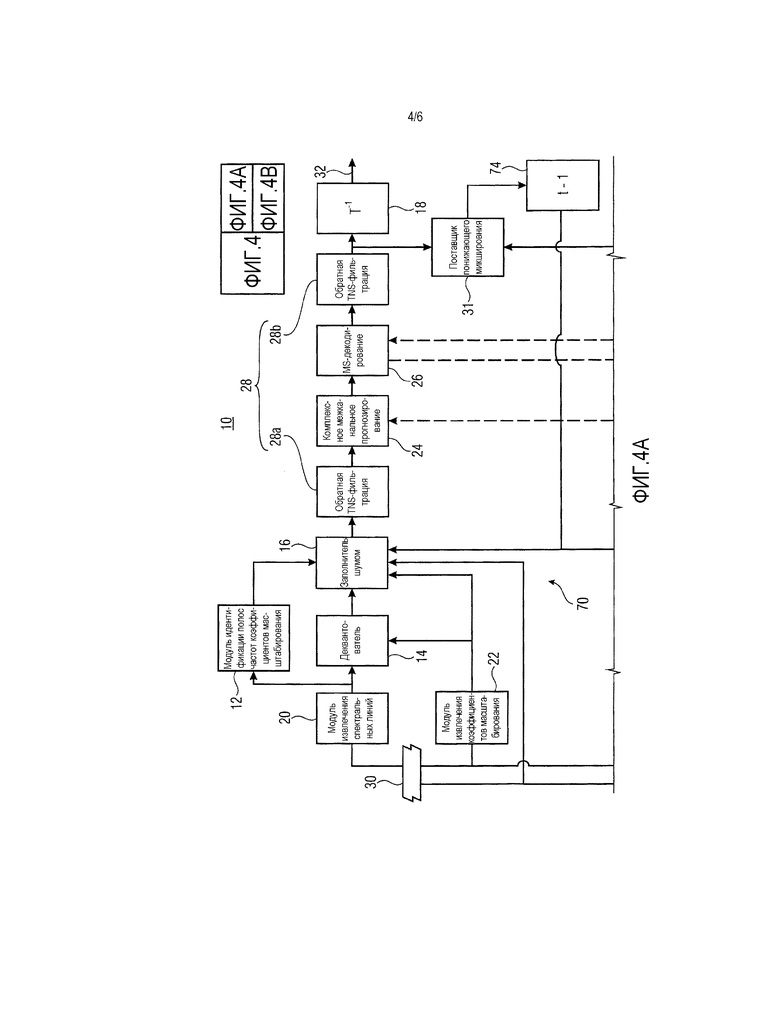
Фиг. 4 показывает альтернативу относительно фиг. 1 в той мере, в какой основа для заполнения межканальным шумом представлена посредством понижающего микширования спектрально совместно размещенных спектральных линий предыдущего кадра, так что, в необязательном случае использования комплексного межканального прогнозирования, источник этого комплексного межканального прогнозирования используется два раза, в качестве источника для заполнения межканальным шумом, а также источника для оценки мнимой части в комплексном межканальном прогнозировании. Фиг. 4 показывает декодер 10, включающий в себя часть 70, связанную с декодированием первого канала, которому принадлежит спектр 46, а также внутреннюю структуру вышеуказанной другой части 34, которая участвует в декодировании другого канала, содержащего спектр 48. Идентичная ссылка с номером использована для внутренних элементов части 70, с одной стороны, и 34, с другой стороны. Как можно видеть, структура является идентичной. На выходе 32 выводится один канал стереоаудиосигнала, а на выходе обратного преобразователя 18 части 34 второго декодера, в результате получается другой (выходной) канал стереоаудиосигнала, причем этот выход указывается посредством ссылки с номером 74. С другой стороны, варианты осуществления, описанные выше, могут легко переноситься на случай использования более двух каналов.
Поставщик 31 понижающего микширования совместно используется посредством обеих частей 70 и 34 и принимает временно совместно размещенные спектры 48 и 46 спектрограмм 40 и 42 для того, чтобы формировать понижающее микширование на их основе посредством суммирования этих спектров на спектральной линии посредством основы спектральной линии, потенциально с формированием среднего из них посредством деления суммы в каждой спектральной линии на низведенное число каналов, т.е. на два в случае фиг. 4. На выходе поставщика 31 понижающего микширования понижающее микширование предыдущего кадра получается в результате посредством этого показателя. В этом отношении следует отметить, что в случае предыдущего кадра, содержащего более одного спектра в любой из спектрограмм 40 и 42, существуют различные варианты в отношении того, как поставщик 31 понижающего микширования работает в этом случае. Например, в этом случае поставщик 31 понижающего микширования может использовать спектр конечных преобразований текущего кадра или может использовать результат перемежения для перемежения всех коэффициентов спектральных линий текущего кадра спектрограммы 40 и 42. Элемент 74 задержки, показанный на фиг. 4 как соединенный с выходом поставщика 31 понижающего микширования, показывает то, что понижающее микширование, предоставленное таким способом на выходе поставщика 31 понижающего микширования, формирует понижающее микширование предыдущего кадра 76 (см. фиг. 3 относительно заполнения 56 межканальным шумом и комплексного прогнозирования 58, соответственно). Таким образом, выход элемента 74 задержки соединяется с входами модулей 24 межканального прогнозирования частей 34 и 70 декодера, с одной стороны, и входами заполнителей 16 шумом частей 70 и 34 декодера, с другой стороны.
Иными словами, тогда как на фиг. 1, заполнитель 16 шумом принимает окончательный восстановленный временно совместно размещенный спектр 48 другой канал идентичного текущего кадра в качестве основы заполнения межканальным шумом на фиг. 4, заполнение межканальным шумом выполняется вместо этого на основе понижающего микширования предыдущего кадра в соответствии с поставщиком 31 понижающего микширования. Способ, которым выполняется заполнение межканальным шумом, остается идентичным. Иными словами, заполнитель 16 межканальным шумом захватывает спектрально совместно размещенную часть из соответствующего спектра для спектра другого канала текущего кадра, в случае фиг. 1, и значительно или полностью декодированного конечного спектра, полученного из предыдущего кадра, представляющего понижающее микширование предыдущего кадра, в случае фиг. 4, и суммирует идентичную "исходную" часть со спектральными линиями в полосе коэффициентов масштабирования, которая должна заполняться шумом, к примеру, 50d на фиг. 3, масштабируемыми согласно целевому уровню шума, определенному посредством коэффициента масштабирования соответствующей полосы коэффициентов масштабирования.
Завершая вышеприведенное пояснение вариантов осуществления, описывающих заполнение межканальным шумом в аудиодекодере, для специалистов в данной области техники должно быть очевидным, что перед суммированием захваченной спектрально или временно совместно размещенной части "исходного" спектра со спектральными линиями "целевой" полосы коэффициентов масштабирования, некоторая предварительная обработка может применяться к "исходным" спектральным линиям без отступления от общего принципа межканального заполнения. В частности, может быть преимущественным применять операцию фильтрации, такую как, например, спектральное сглаживание или наклонное удаление, к спектральным линиям "исходной" области, которые должны суммироваться с "целевой" полосой коэффициентов масштабирования, такой как 50d на фиг. 3, с тем чтобы повышать качество звука для процесса заполнения межканальным шумом. Аналогично и в качестве примера значительно (а не полностью) декодированного спектра, вышеуказанная "исходная" часть может получаться из спектра, который еще не фильтрован посредством доступного обратного (т.е. синтетического) TNS-фильтра.
Таким образом, вышеописанные варианты осуществления относятся к принципу заполнения межканальным шумом. Далее описывается вариант того, как вышеуказанный принцип заполнения межканальным шумом может быть встроен в существующий кодек, а именно, в xHE-AAC, полуобратно совместимым способом. В частности, в дальнейшем описывается предпочтительная реализация вышеописанных вариантов осуществления, согласно которой инструментальное средство стереозаполнения встроено в аудиокодек на основе xHE-AAC полуобратно совместимым способом передачи служебных сигналов. Посредством использования реализации, подробнее описанной ниже, для некоторых стереосигналов, стереозаполнение коэффициентов преобразования в любом из двух каналов в аудиокодеке на основе MPEG-D xHE-AAC (USAC) является целесообразным, за счет этого повышая качество кодирования некоторых аудиосигналов, в частности, на низких скоростях передачи битов. Инструментальное средство стереозаполнения передается в служебных сигналах полуобратно совместимо таким образом, что унаследованные xHE-AAC-декодеры могут синтаксически анализировать и декодировать потоки битов без очевидных аудиоошибок или выпадений сигнала. Как уже описано выше, лучшее общее качество может достигаться, если аудиокодер может использовать комбинацию ранее декодированных/квантованных коэффициентов из двух стереоканалов для того, чтобы восстанавливать нульквантованные (непередаваемые) коэффициенты любого из текущих декодированных каналов. Следовательно, желательно обеспечивать возможность такого стереозаполнения (от предыдущих к текущим канальным коэффициентам) в дополнение к репликации полос спектра (от низко- до высокочастотных канальных коэффициентов) и заполнению шумом (из некоррелированного псевдослучайного источника) в аудиокодерах, в частности, в xHE-AAC или кодерах на его основе.
Чтобы обеспечивать возможность считывания и синтаксического анализа кодированных потоков битов со стереозаполнением посредством унаследованных xHE-AAC-декодеров, требуемое инструментальное средство стереозаполнения должно использоваться полуобратно совместимым способом: его присутствие не должно инструктировать унаследованным декодерам прекращать (или даже не начинать) декодирование. Возможность считывания потока битов посредством xHE-AAC-инфраструктуры также позволяет упрощать распространение на рынке.
Чтобы достигать вышеуказанной необходимости полуобратной совместимости для инструментального средства стереозаполнения в контексте xHE-AAC или ее потенциальных производных, следующая реализация заключает в себе функциональность стереозаполнения, а также способность передавать в служебных сигналах ее через синтаксис в потоке данных, фактически связанном с заполнением шумом. Инструментальное средство стереозаполнения работает в соответствии с вышеприведенным описанием. В канальной паре с конфигурацией общих окон кодирования с взвешиванием, коэффициент нульквантованной полосы коэффициентов масштабирования, когда инструментальное средство стереозаполнения активируется, в качестве альтернативы (или, как описано, помимо этого) заполнению шумом, восстанавливается посредством суммы или разности коэффициентов предыдущего кадра в любом из двух каналов, предпочтительно в правом канале. Стереозаполнение выполняется аналогично заполнению шумом. Передача служебных сигналов должна выполняться через передачу служебных сигналов заполнения шумом согласно xHE-AAC. Стереозаполнение передается посредством 8-битовой вспомогательной информации заполнения шумом. Это является целесообразным, поскольку MPEG-D USAC-стандарт [4] утверждает, что все 8 битов передаются, даже если уровень шума, который должен применяться, является нулевым. В этой ситуации, некоторые биты заполнения шумом могут быть многократно использованы для инструментального средства стереозаполнения.
Полуобратная совместимость относительно синтаксического анализа и воспроизведения потоков битов посредством унаследованных xHE-AAC-декодеров обеспечивается следующим образом. Стереозаполнение передается в служебных сигналах через уровень шума в нуль (т.е. первые три бита заполнения шумом, все из которых имеют значение в нуль), а затем следуют пять ненулевых битов (которые традиционно представляют смещение шума), содержащих вспомогательную информацию для инструментального средства стереозаполнения, а также пропущенного уровня шума. Поскольку унаследованный xHE-AAC-декодер игнорирует значение 5-битового смещения шума, если 3-битовый уровень шума является нулевым, присутствие передачи служебных сигналов инструментального средства стереозаполнения имеет влияние только на заполнение шумом в унаследованном декодере: заполнение шумом выключается, поскольку первые три бита являются нулевыми, и оставшаяся часть операции декодирования выполняется требуемым образом. В частности, стереозаполнение не выполняется вследствие того факта, что оно работает аналогично процессу заполнения шумом, который деактивирован. Следовательно, унаследованный декодер по-прежнему предлагает "корректное" декодирование усовершенствованного потока 30 битов, поскольку он не должен подавлять выходной сигнал или даже прерывать декодирование после достижения кадра с включенным стереозаполнением. Тем не менее, естественно, это не позволяет предоставлять корректное, намеченное восстановление стереозаполненных коэффициентов линий, что приводит к ухудшенному качеству в затрагиваемых кадрах по сравнению с декодированием посредством надлежащего декодера, допускающего надлежащее взаимодействие с новым инструментальным средством стереозаполнения. Тем не менее, при условии, что инструментальное средство стереозаполнения используется требуемым образом, т.е. только на стереовходе на низких скоростях передачи битов, качество через xHE-AAC-декодеры должно быть лучше, чем если затрагиваемые кадры выпадают вследствие подавления или приводят к другим очевидным ошибкам воспроизведения.
Далее представлено подробное описание в отношении того, как инструментальное средство стереозаполнения может быть встроено, в качестве расширения, в xHE-AAC-кодек.
Когда встроено в стандарт, инструментальное средство стереозаполнения может описываться следующим образом. В частности, такое инструментальное средство стереозаполнения (SF) должно представлять новое инструментальное средство в части частотной области (FD) трехмерного MPEG-H-аудио. В соответствии с вышеприведенным пояснением, цель такого инструментального средства стереозаполнения должна состоять в параметрическом восстановлении спектральных MDCT-коэффициентов на низких скоростях передачи битов аналогично тому, что уже может достигаться с помощью заполнения шумом согласно разделу 7.2 стандарта, описанного в [4]. Тем не менее, в отличие от заполнения шумом, которое использует источник псевдослучайного шума для формирования спектральных MDCT-значений любого FD-канала, SF также должен быть доступен для того, чтобы восстанавливать MDCT-значения правого канала объединенно кодированной стереопары каналов с использованием понижающего микширования левого и правого MDCT-спектров предыдущего кадра. SF, в соответствии с реализацией, изложенной ниже, передается в служебных сигналах полуобратно совместимо посредством вспомогательной информации заполнения шумом, которая может быть синтаксически проанализирована корректно посредством унаследованного MPEG-D USAC-декодера.
Описание инструментального средства может заключаться в следующем. Когда SF является активным в объединенном стерео-FD-кадре, MDCT-коэффициенты пустых (т.е. полностью нульквантованных) полос коэффициентов масштабирования правого (второго) канала, к примеру, 50d, заменены посредством суммы или разности MDCT-коэффициентов соответствующих декодированных левого и правого каналов предыдущего кадра (если FD). Если унаследованное заполнение шумом является активным для второго канала, псевдослучайные значения также суммируются с каждым коэффициентом. Результирующие коэффициенты каждой полосы коэффициентов масштабирования затем масштабируются таким образом, что RMS (корень среднего квадрата коэффициента) каждой полосы совпадает со значением, передаваемым посредством коэффициента масштабирования этой полосы. См. раздел 7.3 из стандарта в [4].
Некоторые функциональные ограничения могут быть предусмотрены для использования нового инструментального SF-средства в MPEG-D USAC-стандарте. Например, инструментальное SF-средство может быть доступным для использования только в правом FD-канале общей FD-канальной пары, т.е. в элементе канальной пары, передающем StereoCoreToolInfo с common_window==1. Кроме того, вследствие полуобратно совместимой передачи служебных сигналов, инструментальное SF-средство может быть доступным для использования только тогда, когда noiseFilling==1 в синтаксическом контейнере UsacCoreConfig( ). Если любой из каналов в паре находится в LPD core_mode, инструментальное SF-средство не может использоваться, даже если правый канал находится в FD-режиме.
Следующие термины и определения используются далее для того, чтобы более понятно описывать расширение стандарта, как описано в [4].
В частности, что касается элементов данных, заново вводится следующий элемент данных:
stereo_filling - двоичный флаг, указывающий то, используется или нет SF в текущем кадре и канале,
Дополнительно, вводятся новые вспомогательные элементы:
noise_offset - смещение заполнения шумом, чтобы модифицировать коэффициенты масштабирования нульквантованных полос (раздел 7.2),
noise_level - уровень заполнения шумом, представляющий амплитуду добавленного спектрального шума (раздел 7.2),
downmix_prev[] - понижающее микширование (т.е. сумма или разность) левого и правого каналов предыдущего кадра
sf_index[g][sfb] - индекс коэффициента масштабирования (т.е. передаваемое целое число) для группы g окон кодирования со взвешиванием и полосы sfb
Процесс декодирования стандарта должен быть расширен следующим образом. В частности, декодирование объединенно стереокодированного FD-канала с активацией инструментального SF-средства выполняется на трех последовательных этапах следующим образом:
Во-первых, должно осуществляться декодирование флага stereo_filling.
Stereo_filling не представляет независимый элемент потока битов, но извлекается из элементов заполнения шумом, noise_offset и noise_level, в UsacChannelPairElement() и флаге common_window в StereoCoreToolInfo(). Если noiseFilling==0 или common_window==0, или текущий канал является левым (первым) каналом в элементе, stereo_filling равен 0, и процесс стереозаполнения завершается. Иначе:
if ((noiseFilling !=0) andand (common_window !=0) andand (noise_level==0)) {
stereo_filling=(noise_offset and 16)/16;
noise_level=(noise_offset and 14)/2;
noise_offset=(noise_offset and 1) * 16;
}
else {
stereo_filling=0;
}
Другими словами, если noise_level==0, noise_offset содержит флаг stereo_filling, после которого следуют 4 бита данных заполнения шумом, которые затем перекомпонованы. Поскольку эта операция изменяет значения noise_level и noise_offset, она должна выполняться перед процессом заполнения шумом из раздела 7.2. Кроме того, вышеприведенный псевдокод не выполняется в левом (первом) канале UsacChannelPairElement( ) или любого другого элемента.
Затем должно осуществляться вычисление downmix_prev.
- downmix_prev[], спектральное понижающее микширование, которое должно использоваться для стереозаполнения, является идентичным dmx_re_prev[], используемому для оценки MDST-спектра в комплексном стереопрогнозировании (раздел 7.7.2.3). Это означает то, что:
- Все коэффициенты downmix_prev[] должны быть нулевыми, если какой-либо из каналов кадра и элемента, с помощью которого выполняется понижающее микширование (т.е. кадра перед текущим декодированным кадром), использует core_mode==1 (LPD), либо каналы используют неравные длины преобразования (split_transform==1 или блочное переключение на window_sequence==EIGHT_SHORT_SEQUENCE только в одном канале), либо usacIndependencyFlag==1.
- Все коэффициенты downmix_prev[] должны быть нулевыми в ходе процесса стерео заполнения, если длина преобразования канала изменена от последнего до текущего кадра (т.е. split_transform==1, которому предшествует split_transform==0, либо window_sequence==EIGHT_SHORT_SEQUENCE, которому предшествует window_sequence!=EIGHT_SHORT_SEQUENCE, или наоборот) в текущем элементе.
Если разбиение преобразования применяется в каналах предыдущего или текущего кадра, downmix_prev[] представляет полинейно перемеженное спектральное понижающее микширование. Для получения подробностей следует обратиться к инструментальному средству разбиения преобразования.
Если комплексное стереопрогнозирование не используется в текущем кадре, и элемент pred_dir равен 0.
Следовательно, предыдущее понижающее микширование должно вычисляться только один раз для обоих инструментальных средств, снижая сложность. Единственным отличием между downmix_prev[] и dmx_re_prev[] в разделе 7.7.2 является поведение, когда комплексное стереопрогнозирование в данный момент не используется, либо когда он является активным, но use_prev_frame==0. В этом случае, downmix_prev[] вычисляется для декодирования на основе стереозаполнения согласно разделу 7.7.2.3, даже если dmx_re_prev[] не требуется для декодирования комплексного стереопрогнозирования и в силу этого является неопределенным/нулевым.
После этого должно выполняться стереозаполнение пустых полос коэффициентов масштабирования.
Если stereo_filling==1, следующая процедура выполняется после процесса заполнения шумом во всех первоначально пустых полосах sfb[] коэффициентов масштабирования ниже max_sfb_ste, т.е. во всех полосах, в которых квантованы до нуля все MDCT-линии. Во-первых, энергии данного sfb[] и соответствующих линий в downmix_prev[] вычисляются через суммы квадратов линий. Затем с учетом sfbWidth, содержащего определенное число линий в расчете на sfb[]:
if (energy[sfb]<sfbWidth[sfb]) {/*уровень шума не является максимальным, или полоса начинается ниже области заполнения шумом*/
facDmx=sqrt((sfbWidth[sfb]-energy[sfb])/energy_dmx[sfb]);
factor=0.0;
/*если предыдущее понижающее микширование не является пустым, суммирование масштабированных линий понижающего микширования таким образом, что полоса достигает единичной энергии*/
for (index=swb_offset[sfb]; index<swb_offset[sfb+1]; index++) {
spectrum[window][index]+=downmix_prev[window][index]*facDmx;
factor+=spectrum[window][index]*spectrum[window][index];
}
if ((factor !=sfbWidth[sfb]) andand (factor>0)) {/*единичная энергия не достигнута, следовательно, модификация полосы */
factor=sqrt(sfbWidth[sfb]/(factor+1e-8));
for (index=swb_offset[sfb]; index<swb_offset[sfb+1]; index++) {
spectrum[window][index]*=factor;
}
}
}
для спектра каждого окна кодирования со спектром группы. Затем коэффициенты масштабирования применяются к результирующему спектру, как указано в разделе 7.3, причем коэффициенты масштабирования пустых полос обрабатываются как обычные коэффициенты масштабирования.
Альтернатива вышеуказанному расширению xHE-AAC-стандарта должна использовать неявный полуобратно совместимый способ передачи служебных сигналов.
Вышеуказанная реализация в инфраструктуре xHE-AAC-кода описывает подход, который использует один бит в потоке битов для того, чтобы передавать в служебных сигнала использование нового инструментального средства стереозаполнения, содержащегося в stereo_filling, в декодер в соответствии с фиг. 1. Более точно, такая передача служебных сигналов (можно назвать ее "явной полуобратно совместимой передачей служебных сигналов") обеспечивает возможность использования следующих унаследованных данных потоков битов (здесь вспомогательной информации заполнения шумом) независимо от передачи служебных SF-сигналов. В настоящем варианте осуществления, данные заполнения шумом не зависят от информации стереозаполнения, и наоборот. Например, могут передаваться данные заполнения шумом, состоящие из всех нулей (noise_level=noise_offset=0), тогда как stereo_filling может передавать в служебных сигналах любое возможное значение (представляющее собой двоичный флаг, 0 или 1).
В случаях, если строгая независимость между унаследованными и изобретаемыми данными потоков битов не требуется, и изобретаемый сигнал является двоичным решением, явная передача служебного бита может исключаться, и упомянутое двоичное решение может передаваться в служебных сигналах посредством присутствия или отсутствия того, что может называться неявной полуобратно совместимой передачей служебных сигналов. Если снова рассматривать вышеописанного варианта осуществления в качестве примера, использование стереозаполнения может передаваться посредством простого использования новой передачи служебных сигналов: Если noise_level является нулевым и, одновременно, noise_offset не является нулевым, флаг stereo_filling задается равным 1. Если как noise_level, так и noise_offset не являются нулевыми, stereo_filling равен 0. Зависимость этого неявного сигнала от унаследованного сигнала заполнения шумом возникает, когда как noise_level, так и noise_offset являются нулевыми. В этом случае, непонятно то, используется унаследованная или новая неявная передача служебных SF-сигналов. Чтобы исключать такую неоднозначность, значение stereo_filling должно задаваться заранее. В настоящем примере, целесообразно задавать stereo_filling=0, если данные заполнения шумом состоят из всех нулей, поскольку именно это унаследованные кодеры без поддержки стереозаполнения передают в служебных сигналах то, когда заполнение шумом не должно применяться в кадре.
Проблема, которая по-прежнему должна быть решена в случае неявной полуобратно совместимой передачи служебных сигналов, заключается в том, как передавать в служебных сигналах stereo_filling==1 и не передавать в служебных сигналах заполнение шумом одновременно. Как поясняется, данные заполнения шумом не должны быть всеми нулями, и если запрашивается абсолютная величина шума в нуль, noise_level ((noise_offset and 14)/2, как упомянуто выше) должен быть равным 0. Это оставляет только noise_offset ((noise_offset and 1)*16, как упомянуто выше), больший 0, в качестве решения. Тем не менее, noise_offset рассматривается в случае стереозаполнения при применении коэффициентов масштабирования, даже если noise_level является нулевым. К счастью, кодер может компенсировать тот факт, что noise_offset в нуль не может быть передаваемым посредством изменения затрагиваемых коэффициентов масштабирования таким образом, что при записи потока битов, они содержат смещение, которое отменено в декодере через noise_offset. Это обеспечивает возможность упомянутой неявной передачи служебных сигналов в вышеописанном варианте осуществления за счет потенциального повышения скорости передачи данных коэффициентов масштабирования. Следовательно, передача служебных сигналов стереозаполнения в псевдокоде вышеприведенного описания может изменяться следующим образом, с использованием сэкономленного бита передачи служебных SF-сигналов, чтобы передавать noise_offset с 2 битами (4 значениями) вместо 1 бита:
if ((noiseFilling) andand (common_window) andand (noise_level==0) andand (noise_offset>0)) {
stereo_filling=1;
noise_level=(noise_offset and 28)/4;
noise_offset=(noise_offset and 3)*8;
}
else {
stereo_filling=0;
}
Для полноты, фиг. 5 показывает параметрический аудиокодер в соответствии с вариантом осуществления настоящей заявки. Во-первых, кодер по фиг. 5, который, в общем, указывается с использованием ссылки с номером 100, содержит модуль 102 преобразования для выполнения преобразования исходной, неискаженной версии аудиосигнала, восстановленного на выходе 32 по фиг. 1. Как описано относительно фиг. 2, перекрывающееся преобразование может использоваться с переключением между различными длинами преобразования с соответствующими окнами преобразования на основе кодирования со взвешиванием в единицах кадров 44. Различная длина преобразования и соответствующие окна преобразования на основе кодирования со взвешиванием проиллюстрированы на фиг. 2 с использованием ссылки с номером 104. Способом, аналогичным фиг. 1, фиг. 5 концентрируется на части декодера 100, отвечающей за кодирование одного канала многоканального аудиосигнала, тогда как часть области другого канала декодера 100, в общем, указывается с использованием ссылки с номером 106 на фиг. 5.
На выходе модуля 102 преобразования спектральные линии и коэффициенты масштабирования являются неквантованными, и фактически потери кодирования еще не возникают. Спектрограмма, выводимая посредством модуля 102 преобразования, поступает в квантователь 108, который выполнен с возможностью квантовать спектральные линии спектрограммы, выводимой посредством модуля 102 преобразования, поспектрово, задавать и использовать предварительные коэффициенты масштабирования полос коэффициентов масштабирования. Иными словами, на выходе квантователя 108 в результате получаются предварительные коэффициенты масштабирования и соответствующие коэффициенты спектральных линий, и последовательность из заполнителя 16' шумом, необязательного обратного TNS-фильтра 28a', модуля 24' межканального прогнозирования, MS-декодера 26' и обратного TNS-фильтра 28b' последовательно соединяется, с тем чтобы предоставлять для кодера 100 по фиг. 5 возможность получать восстановленную окончательную версию текущего спектра, получаемого на стороне декодера на входе поставщика понижающего микширования (см. фиг. 1). В случае использования межканального прогнозирования 24' и/или использования заполнения межканальным шумом в версии, формирующей межканальный шум с использованием понижающего микширования предыдущего кадра, кодер 100 также содержит поставщик 31' понижающего микширования для того, чтобы формировать понижающее микширование восстановленных окончательных версий спектров каналов многоканального аудиосигнала. Конечно, с тем чтобы снижать объем вычислений, вместо окончательных, могут использоваться исходные неквантованные версии упомянутых спектров каналов посредством поставщика 31' понижающего микширования при формировании понижающего микширования.
Кодер 100 может использовать информацию относительно доступной восстановленной окончательной версии спектров, чтобы выполнять межкадровое спектральное прогнозирование, к примеру, вышеуказанной возможной версии выполнения межканального прогнозирования с использованием оценки мнимой части и/или чтобы выполнять управление скоростью, т.е. чтобы определять в контуре управления скоростью то, что возможные параметры, в итоге кодированные в поток 30 данных посредством кодера 100, задаются в смысле оптимального искажения в зависимости от скорости передачи.
Например, один такой набор параметров в таком контуре прогнозирования и/или контуре управления скоростью кодера 100, для каждой нульквантованной полосы коэффициентов масштабирования, идентифицированной посредством модуля 12' идентификации, является коэффициентом масштабирования соответствующей полосы коэффициентов масштабирования, который просто предварительно задан посредством квантователя 108. В контуре прогнозирования и/или управления скоростью кодера 100, коэффициент масштабирования нульквантованных полос коэффициентов масштабирования задается в некотором смысле психоакустически оптимального искажения в зависимости от скорости передачи, с тем чтобы определять вышеуказанный целевой уровень шума, вместе, как описано выше, с необязательным параметром модификации, также передаваемым посредством потока данных для соответствующего кадра на сторону декодера. Следует отметить, что этот коэффициент масштабирования может вычисляться с использованием только спектральных линий спектра и канала, которому он принадлежит (т.е. "целевого" спектра, как описано выше), либо альтернативно, может определяться с использованием как спектральных линий "целевого" спектра канала, так и, помимо этого, спектральных линий спектра другого канала или спектра понижающего микширования из предыдущего кадра (т.е. "исходного" спектра, как представлено выше), полученного из поставщика 31' понижающего микширования. В частности, чтобы стабилизировать целевой уровень шума и уменьшать временные флуктуации уровня в декодированных аудиоканалах, к которым применяется заполнение межканальным шумом, целевой коэффициент масштабирования может вычисляться с использованием отношения между энергетическим показателем спектральных линий в "целевой" полосе коэффициентов масштабирования и энергетическим показателем совместно размещенных спектральных линий в соответствующей "исходной" области. В завершение, как отмечено выше, эта "исходная" область может исходить из восстановленной, окончательной версии другого канала или понижающего микширования предыдущего кадра, либо если сложность кодера должна уменьшаться, исходной неквантованной версии идентичного другого канала или понижающего микширования исходных неквантованных версий спектров предыдущего кадра.
В зависимости от некоторых требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного средства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] Internet Engineering Task Force (IETF), RFC 6716, "Definition of the Opus Audio Codec", Int. Standard, сентябрь 2012 года. Доступно по адресу: http://tools.ietf.org/html/rfc6716.
[2] International Organization for Standardization, ISO/IEC 14496-3:2009, "Information Technology - Coding of audio-visual objects - Part 3: Audio ", Женева, Швейцария, август 2009 года.
[3] M. Neuendorf et al. "MPEG Unified Speech and Audio Coding-The ISO/MPEG Standard for High-Efficiency Audio Coding of All Content Types", in Proc. 132nd AES Convention, Будапешт, Венгрия, апрель 2012 года. Также содержится в Journal of the AES, 2013 год.
[4] International Organization for Standardization, ISO/IEC 23003-3:2012, "Information Technology - MPEG audio - Part 3: Unified speech and audio coding ", Женева, январь 2012 года.
Изобретение относится к средствам для заполнения шумом при многоканальном кодировании аудио. Технический результат заключается в повышении эффективности кодирования на низких скоростях передачи битов. Идентифицируют первые полосы коэффициентов масштабирования спектра первого канала текущего кадра многоканального аудиосигнала, в которых все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую. Заполняют спектральные линии в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала, с регулированием уровня шума с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования. Деквантуют спектральные линии во вторых полосах коэффициентов масштабирования с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования. 10 н. и 18 з.п. ф-лы, 6 ил.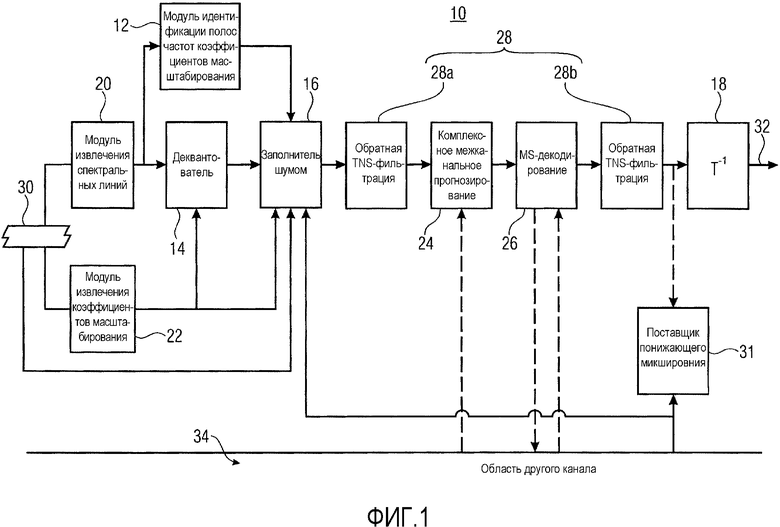
1. Параметрический аудиодекодер в частотной области, выполненный с возможностью:
- идентификации (12) первых полос коэффициентов масштабирования спектра первого канала текущего кадра многоканального аудиосигнала, в которых все спектральные линии квантуются в нулевые, и вторых полос коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую;
- заполнения (16) спектральных линий в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- деквантования (14) спектральных линий во вторых полосах коэффициентов масштабирования с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования; и
- обратного преобразования (18) спектра, полученного из первых полос коэффициентов масштабирования, заполненных шумом, уровень которого регулируется с использованием коэффициентов масштабирования первых полос коэффициентов масштабирования и вторых полос коэффициентов масштабирования, деквантованных с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, с тем чтобы получать часть временной области первого канала многоканального аудиосигнала.
2. Параметрический аудиодекодер в частотной области по п. 1, дополнительно выполненный с возможностью, при заполнении:
- регулирования уровня совместно размещенной части спектра понижающего микширования предыдущего кадра, спектрально совместно размещенного с предварительно определенной полосой коэффициентов масштабирования, с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования, и суммирования совместно размещенной части, имеющей отрегулированный уровень, с предварительно определенной полосой коэффициентов масштабирования.
3. Параметрический аудиодекодер в частотной области по п. 2, дополнительно выполненный с возможностью прогнозирования поднабора полос коэффициентов масштабирования из другого канала или понижающего микширования текущего кадра, чтобы получать межканальное прогнозирование и использовать предварительно определенную полосу коэффициентов масштабирования, заполненную шумом и вторыми полосами коэффициентов масштабирования, деквантованными с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, в качестве остатка прогнозирования для межканального прогнозирования, чтобы получать спектр.
4. Параметрический аудиодекодер в частотной области по п. 3, дополнительно выполненный с возможностью, при прогнозировании поднабора полос коэффициентов масштабирования, выполнения оценки мнимой части другого канала или понижающего микширования текущего кадра с использованием спектра понижающего микширования предыдущего кадра.
5. Параметрический аудиодекодер в частотной области по п. 1, в котором первый канал и другой канал подвергаются MS-кодированию в потоке данных, и параметрический аудиодекодер в частотной области выполнен с возможностью подвергать спектр MS-декодированию.
6. Параметрический аудиодекодер в частотной области по п. 1, дополнительно выполненный с возможностью последовательного извлечения коэффициентов масштабирования первых и вторых полос коэффициентов масштабирования из потока данных с использованием контекстно-адаптивного энтропийного декодирования с определением контекстов в зависимости от и/или с использованием прогнозирующего декодирования со спектральным прогнозированием в зависимости от уже извлеченных коэффициентов масштабирования в спектральном окружении текущего извлеченного коэффициента масштабирования, причем коэффициенты масштабирования спектрально размещены согласно спектральному порядку из первых и вторых полос коэффициентов масштабирования.
7. Параметрический аудиодекодер в частотной области по п. 1, дополнительно сконфигурированный таким образом, что шум дополнительно формируется с использованием псевдослучайного или случайного шума.
8. Параметрический аудиодекодер в частотной области по п. 7, дополнительно выполненный с возможностью регулирования уровня псевдослучайного или случайного шума одинаково для первых полос коэффициентов масштабирования, согласно параметру шума, передаваемому в служебных сигналах в потоке данных для текущего кадра.
9. Параметрический аудиодекодер в частотной области по п. 1, дополнительно выполненный с возможностью одинакового модифицирования коэффициентов масштабирования первых полос коэффициентов масштабирования относительно коэффициентов масштабирования вторых полос коэффициентов масштабирования с использованием параметра модификации, передаваемого в служебных сигналах в потоке данных для текущего кадра.
10. Параметрический аудиокодер в частотной области, выполненный с возможностью:
- квантования спектральных линий спектра первого канала текущего кадра многоканального аудиосигнала с использованием предварительных коэффициентов масштабирования полос коэффициентов масштабирования в спектре;
- идентификации первых полос коэффициентов масштабирования в спектре, в котором все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую,
- в контуре прогнозирования и/или управления скоростью:
- заполнения спектральных линий в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием фактического коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования; и
- передачи в служебных сигналах фактического коэффициента масштабирования для предварительно определенной полосы коэффициентов масштабирования вместо предварительного коэффициента масштабирования.
11. Параметрический аудиокодер в частотной области по п. 10, дополнительно выполненный с возможностью вычисления фактического коэффициента масштабирования для предварительно определенной полосы коэффициентов масштабирования на основе уровня неквантованной версии спектральных линий спектра первого канала в предварительно определенной полосе коэффициентов масштабирования и дополнительно на основе спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала или спектральных линий другого канала текущего кадра многоканального аудиосигнала.
12. Параметрический аудиодекодер в частотной области, выполненный с возможностью:
- идентификации (12) первых полос коэффициентов масштабирования спектра первого канала текущего кадра многоканального аудиосигнала, в которых все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую;
- заполнения (16) спектральных линий в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий другого канала текущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- деквантования (14) спектральных линий во вторых полосах коэффициентов масштабирования с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования; и
- обратного преобразования (18) спектра, полученного из первых полос коэффициентов масштабирования, заполненных шумом, уровень которого регулируется с использованием коэффициентов масштабирования первых полос коэффициентов масштабирования и вторых полос коэффициентов масштабирования, деквантованных с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, с тем чтобы получать часть временной области первого канала многоканального аудиосигнала.
13. Параметрический аудиодекодер в частотной области по п. 12, дополнительно выполненный с возможностью, при заполнении:
регулирования уровня совместно размещенной части спектра понижающего микширования предыдущего кадра, спектрально совместно размещенного с предварительно определенной полосой коэффициентов масштабирования, с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования, и суммировать совместно размещенную часть, имеющую отрегулированный уровень, с предварительно определенной полосой коэффициентов масштабирования.
14. Параметрический аудиодекодер в частотной области по п. 13, дополнительно выполненный с возможностью прогнозирования поднабора полос коэффициентов масштабирования из другого канала или понижающего микширования текущего кадра, чтобы получать межканальное прогнозирование и использовать предварительно определенную полосу коэффициентов масштабирования, заполненную шумом и вторыми полосами коэффициентов масштабирования, деквантованными с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, в качестве остатка прогнозирования для межканального прогнозирования, чтобы получать спектр.
15. Параметрический аудиодекодер в частотной области по п. 14, дополнительно выполненный с возможностью, при прогнозировании поднабора полос коэффициентов масштабирования, выполнения оценки мнимой части другого канала или понижающего микширования текущего кадра с использованием спектра понижающего микширования предыдущего кадра.
16. Параметрический аудиодекодер в частотной области по п. 12, в котором первый канал и другой канал подвергаются MS-кодированию в потоке данных, и параметрический аудиодекодер в частотной области выполнен с возможностью подвергать спектр MS-декодированию.
17. Параметрический аудиодекодер в частотной области по п. 12, дополнительно выполненный с возможностью последовательного извлечения коэффициентов масштабирования первых и вторых полос коэффициентов масштабирования из потока данных с использованием контекстно-адаптивного энтропийного декодирования с определением контекстов в зависимости от и/или с использованием прогнозирующего декодирования со спектральным прогнозированием в зависимости от уже извлеченных коэффициентов масштабирования в спектральном окружении текущего извлеченного коэффициента масштабирования, причем коэффициенты масштабирования спектрально размещены согласно спектральному порядку из первых и вторых полос коэффициентов масштабирования.
18. Параметрический аудиодекодер в частотной области по п. 12, дополнительно сконфигурированный таким образом, что шум дополнительно формируется с использованием псевдослучайного или случайного шума.
19. Параметрический аудиодекодер в частотной области по п. 18, дополнительно выполненный с возможностью регулирования уровня псевдослучайного или случайного шума одинаково для первых полос коэффициентов масштабирования, согласно параметру шума, передаваемому в служебных сигналах в потоке данных для текущего кадра.
20. Параметрический аудиодекодер в частотной области по п. 12, дополнительно выполненный с возможностью одинаково модифицировать коэффициенты масштабирования первых полос коэффициентов масштабирования относительно коэффициентов масштабирования вторых полос коэффициентов масштабирования с использованием параметра модификации, передаваемого в служебных сигналах в потоке данных для текущего кадра.
21. Параметрический аудиокодер в частотной области, выполненный с возможностью:
- квантования спектральных линий спектра первого канала текущего кадра многоканального аудиосигнала с использованием предварительных коэффициентов масштабирования полос коэффициентов масштабирования в спектре;
- идентификации первых полос коэффициентов масштабирования в спектре, в котором все спектральные линии квантуются в нулевые, и вторых полос коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую,
- в контуре прогнозирования и/или управления скоростью:
- заполнения спектральных линий в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий другого канала текущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием фактического коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования; и
- передачи в служебных сигналах фактического коэффициента масштабирования для предварительно определенной полосы коэффициентов масштабирования вместо предварительного коэффициента масштабирования.
22. Параметрический аудиокодер в частотной области по п. 21, дополнительно выполненный с возможностью вычисления фактического коэффициента масштабирования для предварительно определенной полосы коэффициентов масштабирования на основе уровня неквантованной версии спектральных линий спектра первого канала в предварительно определенной полосе коэффициентов масштабирования и дополнительно на основе спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала или спектральных линий другого канала текущего кадра многоканального аудиосигнала.
23. Способ параметрического декодирования аудио частотной области, содержащий этапы, на которых:
- идентифицируют первые полосы коэффициентов масштабирования спектра первого канала текущего кадра многоканального аудиосигнала, в которых все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую;
- заполняют спектральные линии в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием
- спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- деквантуют спектральные линии во вторых полосах коэффициентов масштабирования с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования; и
- обратно преобразуют спектр, полученный из первых полос коэффициентов масштабирования, заполненных шумом, уровень которого регулируется с использованием коэффициентов масштабирования первых полос коэффициентов масштабирования и вторых полос коэффициентов масштабирования, деквантованных с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, с тем чтобы получать часть временной области первого канала многоканального аудиосигнала.
24. Способ параметрического кодирования аудио в частотной области, содержащий этапы, на которых:
- квантуют спектральные линии спектра первого канала текущего кадра многоканального аудиосигнала с использованием предварительных коэффициентов масштабирования полос коэффициентов масштабирования в спектре;
- идентифицируют первые полосы коэффициентов масштабирования в спектре, в котором все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую,
- в контуре прогнозирования и/или управления скоростью
- заполняют спектральные линии в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий понижающего микширования предыдущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием фактического коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- передают в служебных сигналах фактический коэффициент масштабирования для предварительно определенной полосы коэффициентов масштабирования вместо предварительного коэффициента масштабирования.
25. Способ параметрического декодирования аудио частотной области, содержащий этапы, на которых:
- идентифицируют первые полосы коэффициентов масштабирования спектра первого канала текущего кадра многоканального аудиосигнала, в которых все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую;
- заполняют спектральные линии в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий другого канала текущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- деквантуют спектральные линии во вторых полосах коэффициентов масштабирования с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования; и
- обратно преобразуют спектр, полученный из первых полос коэффициентов масштабирования, заполненных шумом, уровень которого регулируется с использованием коэффициентов масштабирования первых полос коэффициентов масштабирования и вторых полос коэффициентов масштабирования, деквантованных с использованием коэффициентов масштабирования вторых полос коэффициентов масштабирования, с тем чтобы получать часть временной области первого канала многоканального аудиосигнала.
26. Способ параметрического кодирования аудио в частотной области, содержащий этапы, на которых:
- квантуют спектральные линии спектра первого канала текущего кадра многоканального аудиосигнала с использованием предварительных коэффициентов масштабирования полос коэффициентов масштабирования в спектре;
- идентифицируют первые полосы коэффициентов масштабирования в спектре, в котором все спектральные линии квантуются в нулевые, и вторые полосы коэффициентов масштабирования спектра, в которых по меньшей мере одна спектральная линия квантуется в ненулевую,
- в контуре прогнозирования и/или управления скоростью:
- заполняют спектральные линии в предварительно определенной полосе коэффициентов масштабирования первых полос коэффициентов масштабирования шумом, сформированным с использованием:
- спектральных линий другого канала текущего кадра многоканального аудиосигнала,
- с регулированием уровня шума с использованием фактического коэффициента масштабирования предварительно определенной полосы коэффициентов масштабирования;
- передают в служебных сигналах фактический коэффициент масштабирования для предварительно определенной полосы коэффициентов масштабирования вместо предварительного коэффициента масштабирования.
27. Компьютерно-читаемый носитель данных, содержащий сохраненную на нем компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по любому из пп. 23 или 25.
28. Компьютерно-читаемый носитель данных, содержащий сохраненную на нем компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по любому из пп. 24 или 26.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| RU 2011104006 A, 20.08.2012. | |||

