ОПИСАНИЕ
Настоящее изобретение относится к кодированию звуковых сигналов и, в частности, к устройству и способу для стереофонического заполнения при многоканальном кодировании.
Звуковое кодирование является областью сжатия, которая имеет дело с использованием избыточности и относительной энтропии в звуковых сигналах.
В USAC MPEG (например, смотрите [3]), совместное стереофоническое кодирование двух каналов выполняется с использованием комплексного прогноза, MPS 2-1-2 или унифицированного стереофонического звука с ограниченными по полосе или полнополосными остаточными сигналами. MPEG с объемным звучанием (например, смотрите [4]) иерархически объединяет блоки преобразования один в два (OTT) и преобразования два в три (TTT) для совместного кодирования многоканальной звукозаписи с или без передачи остаточных сигналов.
В MPEG-H, четырехканальные элементы иерархически применяют стереофонические блоки 2-1-2 MPS, сопровождаемые блоками комплексного прогноза/ блоками стереофонического кодирования MS, выстраивая дерево повторного микширования 4×4 (например, смотрите [1]).
AC4 (например, смотрите [6]) вводит новые 3-, 4- и 5-канальные элементы, которые предоставляют возможность для повторного микширования передаваемых каналов с помощью переданной матрицы микширования и последующей информации о совместном стереофоническом кодировании. Кроме того, предшествующие публикации предлагают использовать ортогональные преобразования, подобные преобразованию Карунена-Лоэва (KLT) для улучшенного многоканального звукового кодирования (например, смотрите [7]).
Например, в контексте трехмерного воспроизведения звука, каналы громкоговорителей распределены на нескольких уровнях по высоте, давая в результате горизонтальные и вертикальные пары каналов. Совместного кодирования только двух каналов, как определено в USAC, не достаточно для учета пространственных и относящихся к восприятию зависимостей между каналами. MPEG с объемным звучанием применяется на дополнительном этапе предварительной/последующей обработки, остаточные сигналы передаются по отдельности без возможности совместного стереофонического кодирования, например, для использования зависимостей между левым и правым вертикальными остаточными сигналами. В AC-4, введены специализированные N-канальные элементы, которые предоставляют возможность для эффективного кодирования параметров совместного кодирования, но недостаточны для установок с громкоговорителями широкого применения с большим количеством каналов, как предлагаемые для новых создающих эффект присутствия сценариев воспроизведения (7.1+4, 22.2). Четырехканальный элемент MPEG-H также ограничен только 4 каналами и не может динамически применяться к произвольным каналам, но может только к предварительно сконфигурированному и неизменному количеству каналов.
Средство многоканального кодирования MPEG-H предоставляет возможность создания произвольного дерева обособленно кодированных стереофонических блоков, то есть совместно кодированных пар каналов, смотрите [2].
Проблема, которая часто возникает при кодировании звуковых сигналов, вызвана квантованием, например, квантованием спектров. Квантование возможно может приводить к спектральным провалам. Например, все спектральные значения в конкретной полосе частот могут быть установлены в ноль на стороне кодера в результате квантования. Например, точное значение таких спектральных линий до квантования может быть относительно небольшим, и тогда квантование может приводить к ситуации, где спектральные значения всех спектральных линий, например, в пределах конкретной полосы частот, были установлены в ноль. На стороне декодера, при декодировании, это может приводить к нежелательным спектральным провалам.
Современные системы кодирования речевых/звуковых сигналов в частотной области, такие как кодек Opus/Celt IETF [9], MPEG-4 (HE-)AAC [10] или, в частности, MPEG-D xHE-AAC (USAC) [11], предлагают средства для кодирования звуковых кадров с использованием одного длинного преобразования - длинного блока - или восьми последовательных коротких преобразований - коротких блоков - в зависимости от неизменности сигнала во времени. В дополнение, применительно к кодированию для низкой скорости передачи битов, эти схемы предусматривают средство для реконструкции частотных коэффициентов канала с использованием псевдослучайного шума или коэффициентов нижних частот того же самого канала. В xHE-AAC, эти средства известны как шумовое заполнение и репликация спектральных полос, соответственно.
Однако, что касается настоящего тонального или переходного стереофонического входного сигнала, только шумовое заполнение и/или только репликация спектральных полос ограничивают достижимое качество кодирования на очень низких скоростях передачи битов, главным образом, поскольку слишком много спектральных коэффициентов обоих каналов необходимо передавать в явном виде.
Стереофоническое заполнение MPEG-H является параметрическим средством, которое полагается на использование результата понижающего микширования предыдущего кадра для улучшения заполнения спектральных провалов, вызванных квантованием в частотной области. Подобно шумовому заполнению, стереофоническое заполнение действует непосредственно в области МДКП (MDCT, модифицированного дискретного косинусного преобразования) основного кодировщика MPEG-H, смотрите [1], [5], [8].
Однако, использование MPEG с объемным звучанием и стереофонического заполнения в MPEG-H ограничено неизменными элементами пар каналов, а потому, не может использовать меняющиеся во времени межканальные зависимости.
Средство многоканального кодирования (MCT) в MPEG-H предоставляет возможность адаптации к меняющимся межканальным зависимостям, но, вследствие использования одноканальных элементов в типичных рабочих конфигурациях, не дает возможности стереофонического заполнения. Предшествующий уровень техники не раскрывает оптимальные по восприятию способы для формирования результатов понижающего микширования предыдущего кадра в случае меняющихся во времени произвольных пар совместно кодированных каналов. Использование шумового заполнения в качестве замены для стереофонического заполнения в комбинации с MCT для заполнения спектральных провалов привело бы к шумовым артефактам, что особенно касается тональных сигналов.
Цель настоящего изобретения состоит в том, чтобы предложить улучшенные концепции звукового кодирования. Цель настоящего изобретения достигается устройством для декодирования по пункту 1 формулы изобретения, системой по пункту 15 формулы изобретения, способом для декодирования по пункту 17 формулы изобретения и компьютерной программой по пункту 18 формулы изобретения.
Предусмотрено устройство для декодирования кодированного многоканального сигнала текущего кадра для получения трех или более текущих звуковых выходных каналов. Многоканальный процессор приспособлен выбирать два декодированных канала из трех или более декодированных каналов в зависимости от первых многоканальных параметров. Более того, многоканальный процессор приспособлен формировать первую группу из двух или более обработанных каналов на основе упомянутых выбранных каналов. Модуль шумового заполнения приспособлен идентифицировать, применительно к по меньшей мере одному из выбранных каналов, одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формировать смесительный канал с использованием, в зависимости от побочной информации, надлежащего подмножества трех или более предыдущих звуковых выходных каналов, которые были декодированы, и заполнять спектральные линии полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала.
Согласно вариантам осуществления, предусмотрено устройство для декодирования предыдущего кодированного многоканального сигнала предыдущего кадра для получения трех или более предыдущих звуковых выходных каналов, и для декодирования текущего кодированного многоканального сигнала текущего кадра, чтобы получать три или более текущих звуковых выходных каналов.
Устройство содержит интерфейс, канальный декодер, многоканальный процессор для формирования трех или более текущих звуковых выходных каналов и модуль шумового заполнения.
Интерфейс приспособлен принимать текущий кодированный многоканальный сигнал и принимать побочную информацию, содержащую первые многоканальные параметры.
Канальный декодер приспособлен декодировать текущий кодированный многоканальный сигнал текущего кадра для получения набора из трех или более декодированных каналов текущего кадра.
Многоканальный процессор приспособлен выбирать первую выбранную пару двух декодированных каналов из набора из трех или более декодированных каналов в зависимости от первых многоканальных параметров.
Более того, многоканальный процессор приспособлен формировать первую группу из двух или более обработанных каналов на основе упомянутой первой выбранной пары двух декодированных каналов для получения обновленного набора из трех или более декодированных каналов.
Перед тем как многоканальный процессор формирует первую пару из двух или более обработанных каналов на основе упомянутой первой выбранной пары двух декодированных каналов, модуль шумового заполнения приспособлен идентифицировать, применительно к по меньшей мере одному из двух каналов из упомянутой первой выбранной пары двух декодированных каналов, одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формировать смесительный канал с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов, и заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, при этом, модуль шумового заполнения приспособлен выбирать два или более предыдущих звуковых выходных каналов, которые используются для формирования смесительного канала, из трех или более предыдущих звуковых выходных каналов в зависимости от побочной информации.
Конкретная концепция вариантов осуществления, которые могут применяться модулем шумового заполнения, которая задает, каким образом генерировать шум и заполнять шумом, упоминается в качестве стереофонического заполнения.
Более того, предусмотрено устройство для кодирования многоканального сигнала, имеющего по меньшей мере три канала.
Устройство содержит итерационный процессор, являющийся приспособленным рассчитывать, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и для обработки выбранной пары с использованием операции многоканальной обработки, чтобы извлекать начальные многоканальные параметры для выбранной пары и получать первые обработанные каналы.
Итерационный процессор приспособлен выполнять расчет, выбор и обработку на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов, чтобы получать дополнительные многоканальные параметры и вторые обработанные каналы.
Более того, устройство содержит кодер каналов, являющийся приспособленным кодировать каналы, являющиеся результатом итерационной обработки, выполняемой итерационным процессором для получения кодированных каналов.
Более того, устройство содержит выходной интерфейс, являющийся выполненным с возможностью формировать кодированный многоканальный сигнал, имеющий кодированные каналы, начальные многоканальные параметры и дополнительные многоканальные параметры, и имеющий информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным на основе ранее декодированных звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Более того, предусмотрен способ для декодирования предыдущего кодированного многоканального сигнала предыдущего кадра для получения трех или более предыдущих звуковых выходных каналов и для декодирования текущего кодированного многоканального сигнала текущего кадра, чтобы получать три или более текущих звуковых выходных каналов. Способ содержит:
- прием текущего кодированного многоканального сигнала и прием побочной информации, содержащей первые многоканальные параметры;
- декодирование текущего кодированного многоканального сигнала текущего кадра для получения набора из трех или более декодированных каналов текущего кадра;
- выбор первой выбранной пары двух декодированных каналов из набора из трех или более декодированных каналов в зависимости от первых многоканальных параметров;
- формирование первой группы из двух или более обработанных каналов на основе упомянутой первой выбранной пары двух декодированных каналов для получения обновленного набора из трех или более декодированных каналов.
Перед тем, как первая пара из двух или более обработанных сигналов формируется на основе упомянутой первой выбранной пары двух декодированных каналов, проводятся следующие этапы:
- идентификация, применительно к по меньшей мере одному из двух каналов из упомянутой первой выбранной пары, двух декодированных каналов, одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формирование смесительного канала с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов, и заполнение спектральных линий одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, при этом, выбор двух или более предыдущих звуковых выходных каналов, которые используются для формирования смесительного канала, из трех или более предыдущих звуковых выходных каналов проводится в зависимости от побочной информации.
Более того, предусмотрен способ для кодирования многоканального сигнала, имеющего по меньшей мере три канала. Способ содержит:
- расчет, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и обработку выбранной пары с использованием операции многоканальной обработки, чтобы извлекать начальные многоканальные параметры для выбранной пары и получать первые обработанные каналы;
- выполнение расчета, выбора и обработки на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов, чтобы получать дополнительные многоканальные параметры и вторые обработанные каналы;
кодирование каналов, являющихся результатом итерационной обработки, выполненной итерационным процессором, для получения кодированных каналов; а также:
- формирование кодированного многоканального сигнала, имеющего кодированные каналы, начальные многоканальные параметры и дополнительные многоканальные параметры, и имеющего информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным на основе ранее декодированных звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Более того, предусмотрены компьютерные программы, при этом, каждая из компьютерных программ выполнена с возможностью реализовывать один из описанных выше способов, когда приводится в исполнение на компьютере или сигнальном процессоре, так что каждый из описанных выше способов реализуется одной из компьютерных программ.
Более того, предусмотрен кодированный многоканальный сигнал. Кодированный многоканальный сигнал содержит кодированные каналы и многоканальные параметры, и информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, спектральными данными, сформированными на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
В нижеследующем, варианты осуществления настоящего изобретения описаны подробнее со ссылкой на фигуры, на которых:
фиг. 1a показывает устройство для декодирования согласно варианту осуществления;
фиг. 1b показывает устройство для декодирования согласно еще одному варианту осуществления;
фиг. 2 показывает структурную схему параметрического декодера в частотной области согласно варианту осуществления настоящей заявки;
фиг. 3 показывает принципиальную схему, иллюстрирующую последовательность спектров, формирующих спектрограммы каналов многоканального звукового сигнала, для того чтобы облегчить понимание описание декодера по фиг. 2;
фиг. 4 показывает принципиальную схему, иллюстрирующую текущие спектры из спектрограмм, показанных на фиг. 3, ради облегчения понимания описания фиг. 2;
фиг. 5a и 5b показывают структурную схему параметрического декодера звукового сигнала в частотной области в соответствии с альтернативным вариантом осуществления согласно которому результат понижающего микширования предыдущего кадра используется в качестве основы для межканального шумового заполнения;
фиг. 6 показывает структурную схему параметрического кодера звукового сигнала в частотной области в соответствии с вариантом осуществления;
фиг. 7 показывает принципиальную структурную схему устройства для кодирования многоканального сигнала, имеющего по меньшей мере три канала, согласно варианту осуществления;
фиг. 8 показывает принципиальную структурную схему устройства для кодирования многоканального сигнала, имеющего по меньшей мере три канала, согласно варианту осуществления;
Фиг. 9 показывает принципиальную структурную схему стереофонического блока согласно варианту осуществления;
фиг. 10 показывает принципиальную структурную схему устройства для декодирования кодированного многоканального сигнала, имеющего кодированные каналы и по меньшей мере двое многоканальных параметров, согласно варианту осуществления;
фиг. 11 показывает блок-схему последовательности операций способа для кодирования многоканального сигнала, имеющего по меньшей мере три канала, согласно варианту осуществления;
фиг. 12 показывает блок-схему последовательности операций способа для декодирования кодированного многоканального сигнала, имеющего кодированные каналы и по меньшей мере двое многоканальных параметров, согласно варианту осуществления;
фиг. 13 показывает систему согласно варианту осуществления;
фиг. 14 показывает в сценарии (a) формирование комбинационных каналов для первого кадра по сценарию, и в сценарии (b) формирование комбинационных каналов для второго кадра, следующего за первым кадром, согласно варианту осуществления; и
фиг. 15 показывает схему индексации для многоканальных параметров согласно вариантам осуществления.
Равнозначные или эквивалентные элементы или элементы с равнозначными или эквивалентными функциональными возможностями обозначены в нижеследующем описании одинаковыми или эквивалентными номерами ссылок.
В нижеследующем описании, множество подробностей изложены, чтобы обеспечить более полное понимание вариантов осуществления настоящего изобретения. Однако, специалистам в данной области техники будет очевидно, что варианты осуществления настоящего изобретения могут быть осуществлены на практике без этих специфичных подробностей. В других случаях, широко известные конструкции и устройства показаны скорее в виде структурной схемы, чем в подробностях, для того чтобы избежать затенения вариантов осуществления настоящего изобретения. В дополнение, признаки разных вариантов осуществления, описанных в дальнейшем, могут комбинироваться друг с другом, если специально не оговорено иное.
Перед описанием устройства 201 для декодирования по фиг. 1a, в начале описано шумовое заполнение применительно к многоканальному звуковому кодированию. В вариантах осуществления, модуль 220 шумового заполнения по фиг. 1a, например, может быть выполнен с возможностью проводить одну или более технологий, приведенных ниже, которые описаны касательно шумового заполнения для многоканального звукового кодирования.
Фиг. 2 показывает декодер звукового сигнала в частотной области в соответствии с вариантом осуществления настоящей заявки. Декодер указывается в целом с использованием ссылочной позиции 10 и содержит идентификатор 12 полос масштабных коэффициентов, деквантователь 14, шумовой заполнитель 16 и обратный преобразователь 18, а также выделитель 20 спектральных линий и выделитель 22 масштабных коэффициентов. Необязательные дополнительные элементы, которые могли бы содержаться декодером 10, охватывают комплексный стереофонический прогнозатор 24, декодер 26 MS (среднего-побочного каналов) и средство фильтра обратного TNS (временного профилирования шума), два экземпляра 28a и 28b которого показаны на фиг. 2. В дополнение, исполнитель понижающего микширования показан и подробнее изложен ниже с использованием ссылочной позиции 30.
Декодер 10 звукового сигнала в частотной области по фиг. 2 является параметрическим декодером, поддерживающим шумовое заполнение, согласно которому определенная квантованная в ноль полоса масштабных коэффициентов заполняется шумом с использованием масштабного коэффициента такой полосы масштабных коэффициентов, в качестве средства для управления уровнем шума, заполняемого в такой полосе масштабных коэффициентов. Кроме этого, декодер 10 по фиг. 2 представляет собой декодер многоканального звукового сигнала, выполненный с возможностью реконструировать многоканальный звуковой сигнал из входящего потока 30 данных. Однако, фиг. 2 сосредотачивается на элементах 10 декодера, вовлеченных в реконструкцию одного из многоканальных звуковых сигналов, кодированных в поток 30 данных, и который выдает этот (выходной) канал на выходе 32. Ссылочная позиция 34 указывает, что декодер 10 может содержать дополнительные элементы или может содержать некоторый элемент управления работой в конвейерном режиме, ответственный за реконструкцию других каналов многоканального звукового сигнала, при этом, описание, представленное ниже, указывает, каким образом реконструкция интересующего канала декодера 10 на выходе 32 взаимодействует с декодированием других каналов.
Многоканальный звуковой сигнал, представленный потоком 30 данных, может содержать два или более каналов. В последующем, описание вариантов осуществления настоящей заявки сосредотачивается на стереофоническом случае, где многоканальный звуковой сигнал содержит всего лишь два канала, но, в принципе, варианты осуществления, доведенные до сведения в нижеследующем, могут быть без труда перенесены на альтернативные варианты осуществления, относящиеся к многоканальным звуковым сигналам и их кодированию, содержащие более чем два канала.
Как станет яснее из описания по фиг. 2, приведенной ниже, декодер 10 по фиг. 2 является декодером с преобразованием. То есть, согласно технологии кодирования, лежащей в основе декодера 10, каналы закодированы в области преобразования, к примеру, с использованием преобразования с перекрытием каналов. Более того, в зависимости от создателя звукового сигнала, бывают временные фазы, в течение которых каналы звукового сигнала в значительной степени представляют собой один и тот же звуковой контент, отклоняясь друг от друга всего лишь на незначительные или детерминированные изменения между ними, такие как разные амплитуды и/или фазы, для того чтобы представлять собой звуковую сцену, где различия между каналами дают возможность определения виртуального местоположения источника звука звуковой сцены относительно виртуальных положения громкоговорителей, связанных с выходными каналами многоканального звукового сигнала. На некоторых других временных фазах, однако, разные каналы звукового сигнала могут быть некоррелированы друг с другом в большей или меньшей степени и, например, даже могут присутствовать полностью разные источники звука.
Для того чтобы учитывать возможную меняющуюся во времени зависимость между каналами звукового сигнала, аудиокодек, лежащий в основе декодера 10 по фиг. 2 предоставляет возможность меняющегося во времени использования разных мер, чтобы пользоваться межканальной избыточностью. Например, кодирование MS предоставляет возможность для переключения между представлением левого и правого каналов стереофонического звукового сигнала, как они есть или в качестве пары M (среднего) и S (побочного) каналов, представляющих результат понижающего микширования левого и правого каналов и их полуразность, соответственно. То есть, - в спектрально-временном смысле - постоянно есть спектрограммы двух каналов, передаваемых потоком 30 данных, но смысловое содержание этих (передаваемых каналов) может соответственно меняться во времени относительно выходных каналов.
Комплексное стереофоническое прогнозирование - еще одно средство использования межканальной избыточности - дает возможность, в спектральной области, прогнозирования коэффициентов в частотной области или спектральных линий одного канала с использованием спектрально совмещенных линий другого канала. Дополнительные подробности касательно этого описаны ниже.
Для того чтобы облегчить понимание последующего описания фиг. 2 и его компонентов, показанных на ней, фиг. 3, применительно к примерному случаю стереофонического звукового сигнала, представленного потоком 30 данных, показывает возможный способ, как значения отсчетов для спектральных линий двух каналов могли бы кодироваться в поток 30 данных, с тем чтобы обрабатываться декодером 10 по фиг. 2. В частности, в то время как на верхней половине фиг. 3 изображена спектрограмма 40 первого канала стереофонического звукового сигнала, нижняя половина фиг. 3 иллюстрирует спектрограмму 42 другого канала стереофонического звукового сигнала. Вновь, стоит отметить, что «смысловое содержание» спектрограмм 40 и 42 может меняться со временем, например, вследствие меняющегося во времени переключения между кодированной кодом MS областью и кодированной не кодом MS областью. В первом случае, спектрограммы 40 и 42 относятся, соответственно, к каналу M и S, тогда как в последнем случае, спектрограммы 40 и 42 относятся к левому и правому каналам. Переключение между кодированной кодом MS областью и кодированной не кодом MS кодированной областью может сигнализироваться в потоке 30 данных.
Фиг. 3 показывает, что спектрограммы 40 и 42 могут кодироваться в поток 30 данных с меняющимся во времени спектрально-временным разрешением. Например, оба (передаваемых) канала могут быть, выровненным по времени образом, подразделены на последовательность кадров, указанные с использованием фигурных скобок 44, которые могут иметь равную длину и примыкать друг к другу без перекрытия. Как упомянуто только что, спектральное разрешение, с которым спектрограммы 40 и 42 представлены в потоке 30 данных, может меняться во времени. Предварительно, предполагается, что спектрально-временное разрешение изменяется во времени для спектрограмм 40 и 42 одинаково, но расширение этого упрощения также возможно, как станет очевидно из нижеследующего описания. Изменение спектрально-временного разрешения, например, сигнализируется в потоке 30 данных в секциях кадров 44. То есть, спектрально-временное разрешение изменяется в секциях кадров 44. Изменение спектрально-временного разрешения спектрограмм 40 и 42 достигается переключением длины преобразования и количества преобразований, используемых для описания спектрограмм 40 и 42 в каждом кадре 44. В примере по фиг. 3, кадры 44a и 44b представляют собой пример кадров, где преобразование одной длины использовалось, для того чтобы выбирать отсчеты каналов звукового сигнала в нем, тем самым, давая в результате наивысшее спектральное разрешение с одним значением отсчета спектральной линии на каждую спектральную линию для каждого из таких кадров по каждому каналу. На фиг. 3, значения отсчетов спектральных линий указаны с использованием маленьких крестиков внутри ячеек, при этом, ячейки, в свою очередь, скомпонованы в строки и столбцы и будут представлять собой спектральную временную решетку, причем, каждая строка соответствует одной спектральной линии, а каждый столбец соответствует подинтервалам кадров 44, соответствующих кратчайшим преобразованиям, вовлеченным в формирование спектрограмм 40 и 42. В частности, например, фиг. 3 иллюстрирует применительно к кадру 44d, что кадр, в качестве альтернативы может подвергаться следующим друг за другом преобразованиям меньшей длины, тем самым, давая в результате, применительно к таким кадрам, таким как кадр 44d, следующие друг за другом по времени спектры с пониженным спектральным разрешением. Восемь коротких преобразований в качестве примера используются для кадра 44d, давая в результате спектрально-временную выборку отсчетов спектрограмм 40 и 42 в таком кадре 44d, на спектральных линиях, разнесенных друг от друга так, чтобы была занята только каждая восьмая спектральная линия, но со значением отсчета для каждого из восьми окон преобразования или преобразований меньшей длины, используемых для преобразования кадра 44d. В целях иллюстрации, на фиг. 3 показано, что другие количества преобразований для кадра также были бы возможны, такие как использование двух преобразований с длиной преобразования, например, которая имеет значение половины длины преобразования длинных преобразований для кадров 44a и 44b, тем самым, приводя к выборке отсчетов спектрально-временной решетки или спектрограмм 40 и 42, где два значения отсчетов спектральных линий получаются для каждой второй спектральной линии, одно из которых относится к головному преобразованию, а другое к замыкающему преобразованию.
Окна преобразования для преобразований, на которые подразделяются кадры, проиллюстрированы на фиг. 3 под каждой спектрограммой с использованием перекрывающихся подобных селекторному импульсу линий. Временное перекрытие, например, служит для целей TDAC (подавления помех дискретизации во временной области).
Хотя варианты осуществления, дополнительно описанные ниже, также могли бы быть реализованы другим образом, фиг. 3 иллюстрирует случай, где переключение между разными спектрально-временными разрешениями для отдельных кадров 44 выполняется некоторым образом, так чтобы, применительно к каждому кадру 44, одинаковое количество значений спектральных линий, указанных небольшими крестиками на фиг. 3, являлось результатом для спектрограммы 40 и спектрограммы 42, различие состоит только в том, каким образом линии производят спектрально-временную выборку соответственного спектрально-временного фрагмента, соответствующего соответственному кадру 44, растянутого по времени на время соответственного кадра 44 и растянутого спектрально от нулевой частоты до максимальной частоты fmax.
С использованием стрелок на фиг. 3, фиг. 3 иллюстрирует, в отношении кадра 44d, что аналогичные спектры могут быть получены для всех из кадров 44 посредством подходящего распределения значений отсчетов спектральных линий, принадлежащих одной и той же спектральной линии, но окну короткого преобразования в пределах одного кадра одного канала, по незанятым (пустым) спектральным линиям в таком кадре вплоть до следующей занятой спектральной линии того же самого кадра. Такие получающиеся в результате спектры называются «перемежающимися спектрами» в последующем. При перемежении n преобразований одного кадра одного канала, например, значения спектрально совмещенных спектральных линий n коротких преобразований следуют друг за другом до того, как следует набор из n значений спектрально совмещенных спектральных линий n коротких преобразований спектрально последующих спектральных линий. Промежуточная форма перемежения также была бы возможна: вместо перемежения всех коэффициентов спектральных линий одного кадра, было бы возможным перемежать только коэффициенты спектральных линий надлежащего подмножества коротких преобразований кадра 44d. В любом случае, всякий раз, когда обсуждаются спектры кадров двух каналов, соответствующих спектрограммам 40 и 42, эти спектры могут соответствовать перемежающимся спектрам или неперемежающимся спектрам.
Для того чтобы эффективно кодировать коэффициенты спектральных линий, представляющие собой спектрограммы 40 и 42, с помощью потока 30 данных, пропускаемого в декодер 10, вышеупомянутые квантуются. Для того чтобы управлять по спектру и временем шумами квантования, размер шага квантования регулируется посредством масштабных коэффициентов, которые установлены в определенной спектрально-временной решетке. В частности, в пределах каждой последовательности спектров каждой спектрограммы, спектральные линии группируются в спектрально следующие друг за другом неперекрывающиеся группы масштабных коэффициентов. Фиг. 4 показывает спектр 46 спектрограммы 40 в верхней ее половине, а совмещенный по времени спектр 48 вне спектрограммы 42. Как показано в материалах настоящей заявки, спектры 46 и 48 подразделены на полосы масштабных коэффициентов по спектральной оси f, с тем чтобы группировать спектральные линии в неперекрывающиеся группы. Полосы спектральных коэффициентов проиллюстрированы на фиг. 4 с использованием фигурных скобок 50. Ради простоты, предполагается, что границы между полосами масштабных коэффициентов попадают между спектром 46 и 48, но это не обязательно должно иметь место.
То есть, посредством кодирования в потоке 30 данных, каждая из спектрограмм 40 и 42 подразделяется на временную последовательность спектров, и каждый из этих спектров спектрально подразделяется на полосы масштабных коэффициентов, и, применительно к каждой полосе масштабных коэффициентов, поток 30 данных кодирует или сообщает информацию о масштабном коэффициенте, соответствующем соответственной полосе масштабных коэффициентов. Коэффициенты спектральных линий, попадающие в соответственную полосу 50 масштабных коэффициентов, квантуются с использованием соответственного масштабного коэффициента или, покуда рассматривается декодер 10, могут деквантоваться с использованием масштабного коэффициента соответствующей полосы масштабных коэффициентов.
Перед возвращением снова на фиг. 2 и к ее описанию, в нижеследующем будет предполагаться, что специально обработанный канал, то есть, канал, в декодирование которого вовлечены специальные элементы декодера по фиг. 2 кроме 34, является передаваемым каналом спектрограммы 40, который, как уже изложено выше, может представлять собой один из левого и правого каналов, канал M или канал S с допущением, что многоканальный звуковой сигнал, кодированный в поток 30 данных, является стереофоническим звуковым сигналом.
В то время как выделитель 20 спектральных линий выполнен с возможностью извлекать данные спектральных линий, то есть, коэффициенты спектральных линий для кадров 44 из потока 30 данных, выделитель 22 масштабных коэффициентов выполнен с возможностью извлекать, для каждого кадра 44, соответствующие масштабные коэффициенты. С этой целью, выделители 20 и 22 могут использовать энтропийное декодирование. В соответствии с вариантом осуществления, выделитель 22 масштабных коэффициентов выполнен с возможностью последовательно извлекать масштабные коэффициенты, например, спектра 46 на фиг. 4, то есть, масштабные коэффициенты полос 50 масштабных коэффициентов, из данных 30 потока с использованием контекстно адаптивного энтропийного кодирования. Порядок последовательного декодирования может придерживаться спектрального порядка, определенного между полосами масштабных коэффициентов, например, ведущего с низкой частоты на высокую частоту. Выделитель 22 масштабных коэффициентов может использовать контекстно адаптивное энтропийное кодирование и может определять контекст для каждого масштабного коэффициента в зависимости от уже извлеченных масштабных коэффициентов в спектральной окрестности извлекаемого на данный момент масштабного коэффициента, к примеру, в зависимости от масштабного коэффициента непосредственно предшествующей полосы масштабных коэффициентов. В качестве альтернативы, выделитель 22 масштабных коэффициентов, например, может прогнозно декодировать масштабные коэффициенты из потока 30 данных, к примеру, с использованием дифференциального декодирования, тем временем, прогнозируя декодируемый на данный момент масштабный коэффициент на основе каких-нибудь из декодированных ранее масштабных коэффициентов, таких как непосредственно предшествующий таковому. Примечательно, что этот процесс извлечения масштабных коэффициентов инвариантен по отношению к масштабному коэффициенту, принадлежащему полосе масштабных коэффициентов, занятых исключительно квантованными в ноль спектральными линиями или занятых спектральными линиями, среди которых по меньшей мере одна квантована ненулевым значением. Масштабный коэффициент, принадлежащий полосе масштабных коэффициентов, занятых квантованными в ноль спектральными линиями, может служить только в качестве основы прогнозирования для следующего декодируемого масштабного коэффициента, который возможно принадлежит полосе масштабных коэффициентов, занятой спектральными линиями, в числе которых одна ненулевая, и может прогнозироваться на основе декодированного ранее масштабного коэффициента, который возможно принадлежит полосе масштабных коэффициентов, занятой спектральными линиями, среди которых одна ненулевая.
Исключительно ради завершенности, следует отметить, что выделитель 20 спектральных линий извлекает коэффициенты спектральных линий, которыми заняты полосы 50 масштабных коэффициентов, например, подобным образом, с использованием энтропийного кодирования и/или прогнозного кодирования. Энтропийное кодирование может использовать контекстную адаптивность, основанную на коэффициентах спектральных линий в спектрально-временной окрестности декодируемого на данный момент коэффициента спектральной линии, и, подобным образом, прогноз может быть спектральным прогнозом, временным прогнозом или спектрально-временным прогнозом, прогнозирующим декодируемый на данный момент коэффициент спектральной линии на основе декодированных ранее коэффициентов спектральных линий в его спектрально-временной окрестности. Ради повышенной эффективности кодирования, выделитель 20 спектральных линий может быть выполнен с возможностью выполнять декодирование спектральных линий или коэффициентов линий фрагментами данных, которые собирают или группируют спектральные линии по оси частот.
Таким образом, на выходе выделителя 20 спектральных линий, выдаются коэффициенты спектральных линий, например, секциями спектров, таких как спектр 46, например, собирающими все коэффициенты спектральных линий соответствующего кадра или, в качестве альтернативы, собирающими все коэффициенты спектральных линий определенных коротких преобразований соответствующего кадра. На выходе выделителя 22 масштабных коэффициентов, в свою очередь, выводятся соответствующие масштабные коэффициенты соответственных спектров.
Идентификатор 12 полос масштабных коэффициентов, а также деквантователь 14 имеет входы спектральных линий, присоединенные к выходу выделителя 20 спектральных линий, а деквантователь 14 и шумовой заполнитель 16 имеют входы масштабных коэффициентов, присоединенные к выходу выделителя 22 масштабных коэффициентов. Идентификатор 12 полос масштабных коэффициентов выполнен с возможностью идентифицировать так называемые квантованные в ноль полосы масштабных коэффициентов в пределах текущего спектра 46, то есть, полосы масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль, такие как полоса 50c масштабных коэффициентов на фиг. 4, и остальные полосы масштабных коэффициентов спектра, в пределах которых по меньшей мере одна спектральная линия квантована не в ноль. В частности, на фиг. 4, коэффициенты спектральных линий указаны с использованием заштрихованных областей на фиг. 4. По ней видно, что в спектре 46 все полосы масштабных коэффициентов за исключением полосы 50b масштабных коэффициентов имеют по меньшей мере одну спектральную линию, коэффициент спектральной линии которой квантован ненулевым значением. Позднее станет ясно, что квантованные в ноль полосы масштабных коэффициентов, такие как 50d, формирует объект межканального шумового заполнения, дополнительно описанного ниже. Перед возобновлением описания, следует отметить, что идентификатор 12 полос масштабных коэффициентов может ограничивать свое распознавание только надлежащим подмножеством полос 50 масштабных коэффициентов, к примеру, полосами масштабных коэффициентов выше определенной начальной частоты 52. На фиг. 4, это ограничивало бы процедуру идентификации полосами 50d, 50e и 50f масштабных коэффициентов.
Идентификатор 12 полос масштабных коэффициентов информирует шумовой заполнитель 16 о тех полосах масштабных коэффициентов, которые являются квантованными в ноль полосами масштабных коэффициентов. Деквантователь 14 использует масштабные коэффициенты, связанные с входящим спектром 46, с тем чтобы деквантовать или масштабировать коэффициенты спектральных линий у спектральных линий спектра 46 согласно связанным масштабным коэффициентам, то есть, масштабным коэффициентам, связанным с полосами 50 масштабных коэффициентов. В частности, деквантователь 14 деквантует и масштабирует коэффициенты спектральных линий, попадающие в соответствующую полосу масштабных коэффициентов, масштабным коэффициентом, связанным с соответственной полосой масштабных коэффициентов. Фиг. 4 будет интерпретироваться в качестве показывающей результат деквантования спектральных линий.
Шумовой заполнитель 16 получает информацию о квантованных в ноль полосах масштабных коэффициентов, которые формируют объект нижеследующего шумового заполнения, деквантованном спектре, а также масштабных коэффициентах, по меньшей мере, тех полос масштабных коэффициентов, которые идентифицированы в качестве квантованных в ноль полос масштабных коэффициентов, и сигнализацию, полученную из потока 30 данных, касательно текущего кадра, выявляющую, должно ли межканальное шумовое заполнение выполняться для текущего кадра.
Процесс межканального шумового заполнения, описанный в следующем примере, фактически включает в себя два типа шумового заполнения, а именно, вставку нижнего порога 54 шума, относящегося ко всем спектральным линиям, которые были квантованы в ноль, независимо от возможной принадлежности к какой-нибудь квантованной в ноль полосе масштабных коэффициентов, и фактическую процедуру межканального шумового заполнения. Хотя эта комбинация описана в дальнейшем, должно быть подчеркнуто, что вставка нижнего порога шума может быть исключена в соответствии с альтернативным вариантом осуществления. Более того, сигнализация, касающаяся включения и выключения шумового заполнения по отношению к текущему кадру и получаемая из потока 30 данных, могла бы относиться к только к межканальному шумовому заполнению или могла бы управлять комбинацией обеих разновидностей шумового заполнения совместно.
Покуда рассматривается вставка минимального порога шума, шумовой заполнитель 16 мог бы действовать, как изложено ниже. В частности, шумовой заполнитель 16 мог бы применять генерацию искусственного шума, такую как генератор случайных чисел или некоторый другой источник случайности, для того чтобы заполнять спектральные линии, коэффициенты спектральных линий которых имели нулевое значение. Уровень нижнего порога 54 шумов, таким образом вставленного в квантованных в ноль спектральных линиях, мог бы устанавливаться согласно явной сигнализации в потоке 30 данных для текущего кадра или текущего спектра 46. «Уровень» нижнего порога 54 шумов, например, мог бы определяться с использованием среднеквадратического значения (RMS) или измерения энергии.
Вставка нижнего порога шумов, таким образом представляет собой разновидность предварительного заполнения для тех полос масштабных коэффициентов, которые были распознаны в качестве квантованных в ноль, таких как полоса 50d масштабных коэффициентов на фиг. 4. Она также оказывает влияние на другие полосы масштабных коэффициентов вне квантованных в ноль, но последние дополнительно подвергаются следующему межканальному шумовому заполнению. Как описано ниже, процесс межканального шумового заполнения должен заполнять квантованные в ноль полосы масштабных коэффициентов вплоть до уровня, который управляется с помощью масштабного коэффициента соответственной квантованной в ноль полосы масштабных коэффициентов. Последний может использоваться непосредственно для этой цели вследствие того, что все спектральные линии соответственной квантованной в ноль полосы масштабных коэффициентов квантованы в ноль. Тем не менее, поток 30 данных может содержать в себе дополнительную сигнализацию параметра, что касается каждого кадра или каждого спектра 46, который обычно применяется к масштабным коэффициентам или полностью квантованным в ноль полосам масштабных коэффициентов соответствующего кадра или спектра 46 и дает в результате, когда применяется к масштабным коэффициентам квантованных в ноль полос масштабных коэффициентов шумовым заполнителем 16, соответственный уровень заполнения, который индивидуален для квантованных в ноль полос масштабных коэффициентов. То есть, шумовой заполнитель 16 может модифицировать, с использованием одной и той же функции модификации, для каждой квантованной в ноль полосы масштабных коэффициентов спектра 46, масштабный коэффициент соответственной полосы масштабных коэффициентов с использованием только что упомянутого параметра, содержащегося в потоке 30 данных для такого спектра 46 текущего кадра, с тем чтобы добиваться целевого уровня заполнения для соответственной квантованной в ноль полосы масштабных коэффициентов, например, определяющего, в показателях энергии или RMS, уровень, до которого процесс межканального шумового заполнения будет заполнять соответственную квантованную в ноль полосу масштабных коэффициентов (по выбору) добавочным шумом (в дополнение к минимальному порогу 54 шумов).
В частности, для того чтобы выполнять межканальное шумовое заполнение 56, шумовой заполнитель 16 получает спектрально совмещенный участок спектра 48 другого канала, в состоянии, уже в значительной степени или полностью декодированном, и копирует полученный участок спектра 48 в квантованную в ноль полосу масштабных коэффициентов, с которой этот участок был спектрально совмещенным, масштабированный таким образом, чтобы результирующий общий уровень шума в такой квантованной в ноль полосы масштабных коэффициентов - полученный интегрированием по всем спектральным линиям соответственной полосы масштабных коэффициентов - был равен вышеупомянутому целевому уровню заполнения, полученному из масштабного коэффициента квантованной в ноль полосы масштабных коэффициентов. Посредством этого показателя, тональность шума, заполняемого в соответственной квантованной в ноль полосе масштабных коэффициентов, улучшается по сравнению с искусственно генерируемым шумом, таким как формирующий нижний порог 54 шумов, и также является лучшей, чем неуправляемые спектральные копирование/репликация из самых низкочастотных линий в пределах того же самого спектра 46.
Чтобы быть еще более точными, шумовой заполнитель 16 располагает, применительно к текущей полосе, такой как 50d, спектрально совмещенный участок в спектре 48 другого канала, масштабирует его спектральные линии в зависимости от масштабного коэффициента квантованной в ноль полосы 50d масштабных коэффициентов только что описанным образом, по выбору, привлекая некоторый дополнительный параметр коэффициента смещения или шума, содержащийся в потоке 30 данных для текущего кадра или спектра 46, так чтобы результат этого заполнял соответственную квантованную в ноль полосу 50d масштабных коэффициентов вплоть до желательного уровня, который определяется масштабным коэффициентом квантованной в ноль полосы 50d масштабных коэффициентов. В настоящем варианте осуществления, это означает, что заполнение выполняется аддитивным способом относительно нижнего порога 54 шумов.
В соответствии с упрощенным вариантом осуществления, результирующий заполненный шумом спектр 46 подавался бы прямо на вход обратного преобразователя 18, с тем чтобы получать, для каждого окна преобразования, которому принадлежат коэффициенты спектральных линий спектра 46, участок во временной области звукового временного сигнала соответственного канала, после чего (не показано на фиг. 2) процесс сложения с перекрытием может комбинировать эти участки во временной области. То есть, если спектр 46 является неперемеженным спектром, коэффициенты спектральных линий которого принадлежат только одному преобразованию, то обратный преобразователь 18 обуславливает такое преобразование, с тем чтобы давать в результате один участок во временной области, и передний и задний конец которого подвергались бы процессу сложения с перекрытием с предыдущим и последующим участками во временной области, полученными обратным преобразованием предыдущего и последующего обратных преобразований, с тем чтобы, например, осуществлять подавление помех дискретизации во временной области. Однако, если спектр 46 имеет перемежающиеся в нем коэффициенты спектральных линий более чем одного последовательного преобразования, то обратный преобразователь 18 подвергал бы таковой отдельным обратным преобразованиям, с тем чтобы получать одну часть во временной области для каждого обратного преобразования, и, в соответствии с временной очередностью, определенной между ними, эти части во временной области подвергались бы процессу сложения с перекрытием между ними, а также в отношении предыдущих и последующих частей во временной области других спектров или кадров.
Однако, ради полноты, должно быть отмечено, что дополнительная обработка может выполняться над заполненным шумовым заполнением спектром. Как показано на фиг. 2, фильтр обратного TNS может выполнять фильтрацию обратного TNS над заполненным шумовым заполнением спектром. То есть, управляемый с помощью коэффициентов фильтра TNS для текущего кадра или спектра 46, спектр, полученный к настоящему времени, подвергается линейной фильтрации по спектральному направлению.
С или без фильтрации обратного TNS, комплексный стереофонический прогнозатор 24 затем мог бы обрабатывать спектр в качестве прогнозного остатка межканального прогноза. Точнее, межканальный прогнозатор 24 мог бы использовать спектрально совмещенную часть другого канала для прогнозирования спектра 46 или по меньшей подмножества его полос 50 масштабных коэффициентов. Процесс комплексного прогнозирования проиллюстрирован на фиг. 4 пунктирным блоком 58 в связи с полосой 50b масштабных коэффициентов. То есть, поток 30 данных может содержать в себе параметры межканального прогнозирования, например, управляющие тем, какие из полос 50 масштабных коэффициентов будут подвергаться межканальному прогнозированию, а какие не будут прогнозироваться таким образом. Кроме того, параметры межканального прогнозирования в потоке 30 данных дополнительно могут содержать комплексные коэффициенты межканального прогноза, применяемые межканальным прогнозатором 24, с тем чтобы получать результат межканального прогнозирования. Эти коэффициенты могут содержаться в потоке 30 данных отдельно для каждой полосы масштабных коэффициентов или, в качестве альтернативы, каждой группы из одной или более полос масштабных коэффициентов, применительно к которым межканальное прогнозирование введено в действие или сигнализируется приведенным в действие в потоке 30 данных.
Источником межканального прогноза, как указано на фиг. 4, может быть спектр 48 другого канала. Чтобы быть более точными, источник межканального прогноза может быть спектрально совмещенным участком спектра 48, совмещенным с полосой 50b масштабных коэффициентов, подлежащей межканальному прогнозированию, расширенной оценкой ее мнимой частью. Оценка мнимой части может выполняться на основе самого спектрально совмещенного участка 60 спектра 48 и/или может использовать результат понижающего микширования уже декодированных каналов предыдущего кадра, то есть, кадра, непосредственно предшествующего декодируемому на данный момент кадру, которому принадлежит спектр 46. В действительности, межканальный прогнозатор 24 добавляет в полосы масштабных коэффициентов, подлежащие межканальному прогнозированию, такие как полоса 50b масштабных коэффициентов на фиг. 4, прогнозный сигнал, полученный, как только что описано.
Как уже отмечено в предшествующем описании, канал, которому принадлежит спектр 46, может быть кодированным кодом MS каналом или может быть связанным с громкоговорителем каналом, таким как левый или правый канал стереофонического звукового сигнала. Соответственно, по выбору, декодер 26 MS подвергает обусловленный необязательным межканальным прогнозом спектр 46 декодированию MS по той причине, что таковое выполняет, для каждой спектральной линии или спектра 46, сложение или вычитание со спектрально соответствующими спектральными линиями другого канала, соответствующего спектру 48. Например, хотя и не показано на фиг. 2, спектр 48, как показано на фиг. 4, был получен посредством части 34 декодера 10 некоторым образом, аналогичным описанию, заблаговременно приведенному выше в отношении канала, которому принадлежит спектр 46, и модуль 26 декодирования MS, при выполнении декодирования MS, подвергает спектр 46 и 48 сложению по спектральным линиям или вычитанию по спектральным линиям, причем, оба спектра 46 и 48 находятся в одной и той же стадии в линии обработки, означая, что, например, оба были только что получены межканальным прогнозированием, или оба были только что получены шумовым заполнением или фильтрацией обратного TNS.
Следует отметить, что, по выбору, декодирование MS может выполняться некоторым образом, глобально относящимся ко всему спектру 46, или индивидуально приводиться в действие потоком 30 данных, например, в секциях полос 50 масштабных коэффициентов. Другими словами, декодирование MS может включаться или выключаться с использованием соответственной сигнализации в потоке 30 данных, например, секциями кадров или с некоторым более мелким спектрально-временным разрешением, например, таким как отдельно для полос масштабных коэффициентов спектров 46 и/или 48 спектрограмм 40 и/или 42, при этом, предполагается, что определены идентичные границы полос масштабных коэффициентов обоих каналов.
Как проиллюстрировано на фиг. 2, фильтрация обратного TNS посредством фильтра 28 обратного TNS также могла бы выполняться после любой межканальной обработки, такой как межканальное прогнозирование 58 или декодирование MS декодером 26 MS. Такое действие перед, или ниже по потоку от, межканальной обработки могло бы быть неизменным или могло бы управляться с помощью соответственной сигнализации для каждого кадра в потоке 30 данных или на некотором другом уровне детализации. Всякий раз, когда выполняется фильтрация обратного TNS, соответственные коэффициенты фильтра TNS, присутствующие в потоке данных для текущего спектра 46, управляют фильтром TNS, то есть, фильтром линейного прогнозирования, работающим по спектральному направлению, с тем чтобы линейно фильтровать спектр, входящий в соответственные модуль 28a и/или 28b фильтра обратного TNS.
Таким образом, спектр 46, прибывающий на вход обратного преобразователя 18, мог быть подвергнут дополнительной обработке, как только что описано. Вновь не подразумевается, что вышеприведенное описание должно пониматься таким образом, что, одновременно или не одновременно, должны присутствовать все из этих необязательных средств. Эти средства могут присутствовать в декодере 10 частично или совместно.
В любом случае, результирующий спектр на входе обратного преобразователя представляет собой окончательную реконструкцию выходного сигнала канала и формирует основу вышеупомянутого результата понижающего микширования для текущего кадра, которая служит, как описано в отношении комплексного прогноза 58, в качестве основы для возможной оценки мнимой части для следующего кадра, подлежащего декодированию. Дополнительно он может служит в качестве окончательной реконструкции для межканального прогнозирования другого канала, чем тот, к которому относятся элементы кроме 34 на фиг. 2.
Соответственный результат понижающего микширования формируется исполнителем 31 понижающего микширования посредством комбинирования окончательного спектра 46 с соответственным окончательным вариантом спектра 48. Последний объект, то есть, соответственный окончательный вариант спектра 48, формировал основу для комплексного межканального прогнозирования в прогнозаторе 24.
Фиг. 5 показывает альтернативный вариант относительно фиг. 2 ввиду того, что основа для межканального шумового заполнения представлена результатом понижающего микширования спектрально совместной расположенных спектральных линий предыдущего кадра, так что, в необязательном случае использования комплексного межканального прогноза, источник этого комплексного межканального прогнозирования используется дважды, в качестве источника для межканального шумового заполнения, а также в качестве источника для оценки мнимой части комплексного межканального прогноза. Фиг. 5 показывает декодер 10, включающий в себя часть 70, относящуюся к декодированию первого канала, к которому принадлежит спектр 46, а также внутреннюю структуру вышеупомянутой другой части 34, которая вовлечена в декодирование другого канала, содержащего спектр 48. Одна и та же ссылочная позиция использовалась для внутренних элементов части 70 с одной стороны, и 34 с другой стороны. Как может быть видно, конструкция идентична. На выходе 32, выводится один канал стереофонического звукового сигнала, а на выходе обратного преобразователя 18 второй части 34 декодера, получается в результате другой (выходной) канал стереофонического звукового сигнала, причем, этот выход указывается ссылочной позиции 74. Вновь, варианты осуществления, описанные выше, могут быть легко перенесены на случай использования более чем двух каналов.
Исполнитель 31 понижающего микширования совместно используется обеими частями 70 и 34 и принимает совмещенные по времени спектры 48 и 46 спектрограмм 40 и 42, с тем чтобы формировать результат понижающего микширования на основе их, суммируя эти спектры на основе линии за линией, возможно с формированием среднего их значения посредством деления суммы в каждой спектральной линии на количество каналов, подвергнутых понижающему микшированию, то есть, на два в случае по фиг. 5. На выходе исполнителя 31 понижающего микширования, результат понижающего микширования предыдущего кадра получается в результате этого мероприятия. Следует отметить, в этом отношении, что в случае предыдущего кадра, содержащего более чем один спектр в одной из спектрограмм 40 и 42, существуют разные возможности в отношении того, каким образом исполнитель 31 понижающего микширования действует в таком случае. Например, в таком случае, исполнитель 31 понижающего микширования может использовать спектр замыкающих преобразований текущего кадра или может использовать результат перемежения при перемежении всех коэффициентов спектральных линий текущего кадра спектрограммы 40 и 42. Элемент 74 задержки, показанный на фиг. 5 в качестве присоединенного к выходу исполнителя 31 понижающего микширования, показывает, что результат понижающего микширования, таким образом, предусмотренный на выходе исполнителя понижающего микширования, формирует результат понижающего микширования предыдущего кадра 76 (смотрите фиг. 4, что касается межканального шумового заполнения 56 и комплексного прогнозирования 58, соответственно). Таким образом, выход элемента 74 задержки присоединен ко входам межканальных прогнозаторов 24 частей 34 и 70 декодера с одной стороны, и входам шумовых заполнителей 16 частей 70 и 34 декодера с другой стороны.
То есть, несмотря на то, что на фиг. 2, шумовой заполнитель 16 принимает окончательно реконструированный совмещенный по времени спектр 48 другого канала того же самого текущего кадра в качестве основы межканального шумового заполнения, на фиг. 5, взамен выполняется межканальное шумовое заполнение на основе результата понижающего микширования предыдущего кадра, который предоставляется исполнителем 31 понижающего микширования. Способ, которым выполняется межканальное шумовое заполнение, остается прежним. То есть, межканальный шумовой заполнитель 16 выхватывает спектрально совмещенный участок из соответственного спектра у спектра другого канала текущего кадра, в случает по фиг. 2, и в значительной степени или полностью декодированный окончательный спектр получается из предыдущего кадра, представляющий собой результат понижающего микширования предыдущего кадра, в случае по фиг. 5, и прибавляет тот же самый «исходный» участок спектральных линий в пределах полосы масштабных коэффициентов, подлежащей шумовому заполнению, такой как 50d на фиг. 4, масштабированной согласно целевому уровню шума, определенного соответственным масштабным коэффициентом соответственной полосы масштабных коэффициентов.
Подводя итог вышеприведенному обсуждению вариантов осуществления, описывающих межканальное шумовое заполнение в декодере звукового сигнала, читателям, квалифицированным в данной области техники, должно быть очевидно, что, перед прибавлением выхваченного совмещенного спектрально или по времени участка «исходного» спектра к спектральным линиям «целевой» полосы масштабных коэффициентов, определенная предварительная обработка может быть применена к «исходным» спектральным линиям, не отклоняясь от общей концепции межканального заполнения. В частности, может быть полезно применять операцию фильтрации, например, такую как выравнивание спектра или устранение перекоса, к спектральным линиям «исходной» области, подлежащей добавлению в «целевую» полосу масштабных коэффициентов, подобную 50d на фиг. 4, для того чтобы улучшать качество звука процесса межканального шумового заполнения. Подобным образом, и в качестве примера в большой степени (вместо полностью) декодированного спектра, вышеупомянутый «исходный» участок может быть получен из спектра, который еще не был отфильтрован имеющимся в распоряжении фильтра обратного (то есть, синтезирующего) TNS.
Таким образом, вышеприведенные варианты осуществления имели отношение к концепции межканального шумового заполнения. В нижеследующем, описана возможность, каким образом вышеприведенная концепция межканального шумового заполнения может быть встроена в существующий кодек, а именно xHE-AAC, некоторым образом с частичной обратной совместимостью. В частности, в дальнейшем, описана предпочтительная реализация вышеприведенных вариантов осуществления, согласно которым, средство стереофонического заполнения встроено в xHE-AAC на основе аудиокодека способом сигнализации с частичной обратной совместимостью. Посредством использования реализации, дополнительно описанной ниже, применительно к некоторым стереофоническим сигналам, возможно стереофоническое заполнение коэффициентов преобразования в одном из двух каналов в аудиокодеке на основе MPEG-D xHE-AAC (USAC), тем самым, улучшая качество кодирования некоторых звуковых сигналов, особенно на низких скоростях передачи битов. Средство стереофонического заполнения сигнализируется с частично обратной совместимостью, так что унаследованные (т.е. соответствующие прежним версиям) декодеры xHE-AAC могут синтаксически анализировать и декодировать потоки битов без очевидных ошибок или выпадений звукового сигнала. Как уже было описано выше, лучшее общее качество может достигаться, если кодер звукового сигнала может использовать комбинацию декодированных/квантованных ранее коэффициентов двух стереофонических каналов для реконструкции квантованных в ноль (не передаваемых) коэффициентов одного из декодируемых на данный момент каналов. Поэтому, желательно предоставлять возможность такого стереофонического заполнения (из предыдущих в текущие коэффициенты канала) в дополнение к репликации спектральных полос (коэффициентов канала из низких частот в высокие частоты) и шумовому заполнению (из некоррелированного псевдослучайного источника) в кодерах звукового сигнала, в особенности xHE-AAC или кодерах, основанных на нем.
Для предоставления кодированным потокам битов со стереофоническим заполнением возможности читаться и синтаксически анализироваться унаследованными декодерами xHE-AAC, желательное средство стереофонического заполнения будет использоваться некоторым способом с частичной обратной совместимостью: его присутствие не должно побуждать унаследованные декодеры прекращать - или даже не начинать - декодирование. Распознаваемость потока битов инфраструктурой xHE-AAC также может облегчать продвижение на рынке.
Чтобы добиваться вышеупомянутого пожелания частичной обратной совместимости для средства стереофонического заполнения в контексте xHE-AAC или его возможных производных, нижеследующая реализация включает в себя функциональные возможности стереофонического заполнения, а также возможности сигнализировать о таковом с помощью синтаксиса в потоке данных, фактически относящемся к шумовому заполнению. Средство стереофонического заполнения работало бы в соответствии с вышеприведенным описанием. В паре каналов с общей конфигурацией окна, коэффициент квантованной в ноль полосы масштабных коэффициентов, когда введено в действие средство стереофонического заполнения, в качестве альтернативы (или, как описано, в дополнение к) шумовому заполнению, реконструируется суммой или разностью коэффициентов предыдущего кадра в любом одном из двух каналов, предпочтительно, правом канале. Стереофоническое заполнение выполняется аналогично шумовому заполнению. Сигнализация выполнялась бы посредством сигнализации шумового заполнения xHE-AAC. Стереофоническое заполнение передается посредством 8-битной побочной информации шумового заполнения. Это возможно, так как стандарт [3] USAC MPEG-D устанавливает, что все 8 битов передаются, даже если уровень шума, подлежащий применению, имеет значение ноль. В такой ситуации, некоторые из битов шумового заполнения могут повторно использоваться для средства стереофонического заполнения.
Частичная обратная совместимость касательно синтаксического анализа и воспроизведения потока битов унаследованными декодерами xHE-AAC обеспечивается, как изложено ниже. Стереофоническое заполнение сигнализируется с помощью нулевого уровня шума (то есть, всех первых трех битов шумового заполнения, имеющих нулевое значение), сопровождаемого пятью ненулевыми битами (которые традиционно представляют собой компенсацию шума), содержащими в себе побочную информацию для средства стереофонического заполнения, а также отсутствующего уровня шума. Поскольку унаследованный декодер xHE-AAC игнорирует значение 5-битной компенсации шума, если 3-битный уровень шума имеет нулевое значение, наличие сигнализации средства стереофонического заполнения оказывает воздействие на шумовое заполнение только в унаследованном декодере: шумовое заполнение выключено, поскольку первые три бита равны нулю, а оставшаяся часть операции декодирования работает, как намечено. В частности, стереофоническое заполнение не выполняется вследствие того обстоятельства, что оно приводится в действие аналогично процессу шумового заполнения, который выведен из работы. Отсюда, унаследованный декодер по-прежнему предлагает «изящное» декодирование улучшенного потока 30 битов, поскольку, ему не нужно приглушать выходной сигнал или даже аварийно прекращать декодирование по достижению кадра с включенным стереофоническим заполнением. Однако, естественно, он не способен обеспечивать правильную намеченную реконструкцию коэффициентов заполненных стереофоническим заполнением линий, приводя к ухудшенному качеству в находящихся под влиянием кадрах по сравнению с декодированием надлежащим декодером, способным надлежащим образом обращаться с новым средством стереофонического заполнения. Однако, при условии, что средство стереофонического заполнения используется, как намечено, то есть, только на стереофонических входных данных с низкими скоростями передачи битов, качество от декодеров xHE-AAC должно быть лучше, чем если бы поврежденные кадры отбрасывались вследствие подавления шума или приводили бы к другим очевидным ошибкам воспроизведения.
В нижеследующем, представлено подробное описание того, каким образом средство стереофонического заполнения может быть встроено, в качестве расширения, в кодек xHE-AAC.
Когда встроено в стандарт, средство стереофонического заполнения, могло бы быть описано, как изложено ниже. В частности, такое средство стереофонического заполнения (SF) представляло бы собой новое средство в части частотной области (FD) MPEG-H с трехмерным воспроизведением звука. В соответствии с вышеприведенным обсуждением, целью такого средства стереофонического заполнения была бы параметрическая реконструкция спектральных коэффициентов МДКП на низких скоростях передачи битов, аналогичная той, которая уже может достигаться шумовым заполнением согласно разделу 7.2 стандарта, описанного в [3]. Однако, в отличие от шумового заполнения, которое применяет источник псевдослучайного шума для формирования спектральных значений МДКП любого канала FD, SF также имелось бы в распоряжении для реконструкции значений МДКП правого канала совместно кодированной стереофонической пары каналов с использованием результата понижающего микширования левого и правого спектров МДКП предыдущего кадра. SF, в соответствии с реализацией, изложенной ниже, сигнализируется с частичной обратной совместимостью посредством побочной информации шумового заполнения, которая может правильно синтаксически анализироваться унаследованным декодером USAC MPEG-D.
Описание средства могло бы быть следующим. Когда SF является действующим в совместном стереофоническом кадре FD, коэффициенты МДКП пустых (то есть полностью квантованных в ноль) полос масштабных коэффициентов правого (второго) канала, таких как 50d, заменяются суммой или разностью соответствующих декодированных коэффициентов МДКП левого и правого каналов предыдущего кадра (если FD). Если унаследованное шумовое заполнение является действующим для второго канала, псевдослучайные значения также прибавляются к каждому коэффициенту. Результирующие коэффициенты каждой полосы масштабных коэффициентов затем масштабируются, так чтобы RMS (среднеквадратическое значение коэффициентов) каждой полосы соответствовало значению, переданному в качестве масштабного коэффициента такой полосы. Смотрите раздел 7.3 стандарта в [3].
Некоторые эксплуатационные ограничения могли бы быть предусмотрены для использования нового средства SF в стандарте USAC MPEG-D. Например, средство SF может быть пригодным для использования только в правом канале FD из обычной пары каналов FD, то есть, в элементе пары каналов, передающем StereoCoreToolInfo( ) с common_window == 1. Сверх того, вследствие сигнализации с частичной обратной совместимостью, средство SF может быть пригодно для использования, только когда noiseFilling == 1 в синтаксическом контейнере UsacCoreConfig( ). Если любой из каналов в паре находится в core_mode LPD, средство SF может не использоваться, даже если правый канал находится в режиме FD.
Следующие термины и определения используются в дальнейшем, для того чтобы яснее описывать расширение стандарта, как описано в [3].
В частности, покуда рассматриваются элементы данных, вновь введен следующий элемент данных:
stereo_filling двоичный флажковый признак, указывающий, используется ли SF в текущем кадре и канале
Кроме того, введены новые вспомогательные элементы:
noise_offset компенсация шумового заполнения для модификации масштабных коэффициентов квантованных в ноль полос (раздел 7.2)
noise_level уровень шумового заполнения, представляющий собой амплитуду добавленного спектрального шума (раздел 7.2)
downmix_prev[ ] результат понижающего микширования (то есть, сумма или разность) левого и правого каналов предыдущего кадра
sf_index[g][sfb] индекс масштабного коэффициента (то есть, передаваемое целое число) для группы g и полосы sfb окна
Процесс декодирования по стандарту был бы расширен следующим образом. В частности, декодирование кодированного совместным стереофоническим кодированием канала FD введенным в действие средством SF выполняется в течение трех последовательных этапов, как изложено ниже:
Прежде всего, происходило бы декодирование флажкового признака stereo_filling.
stereo_filling не представляет собой независимый элемент потока битов, но извлекается из элементов шумового заполнения, noise_offset и noise_level, в UsacChannelPairElement() и флажкового признака common_window в StereoCoreToolInfo(). Если noiseFilling == 0 или common_window == 0, или текущим каналом является левый (первый) канал в элементе, stereo_filling имеет значение 0, и процесс стереофонического заполнения заканчивается. Иначе,
if ((noiseFilling != 0) && (common_window != 0) && (noise_level == 0)) {
stereo_filling=(noise_offset & 16)/16;
noise_level=(noise_offset & 14)/2;
noise_offset=(noise_offset & 1) * 16;
}
else {
stereo_filling=0;
}
Другими словами, если noise_level == 0, noise_offset содержит в себе флажковый признак stereo_filling, сопровождаемый 4 битами данных шумового заполнения, которые затем перестраиваются. Поскольку эта операция изменяет значения noise_level и noise_offset, необходимо, чтобы она выполнялась перед процессом шумового заполнения из раздела 7.2. Более того, вышеприведенный псевдокод не выполняется в левом (первом) канале UsacChannelPairElement( ) или другого элемента.
Затем, происходил бы расчет downmix_prev.
downmix_prev[ ], результат спектрального понижающего микширования, который должен использоваться для стереофонического заполнения, идентичен dmx_re_prev[ ], используемому для оценки спектра МДКП в комплексном стереофоническом прогнозе (раздел 7.7.2.3). Это означает, что
Все коэффициенты downmix_prev[ ] должны быть нулевыми, если какой-нибудь из каналов кадра или элемент, с которым выполняется понижающее микширование - то есть, кадр перед декодируемым на данный момент - используют core_mode == 1 (LPD), или каналы используют неравные длины преобразования (split_transform == 1 или переключение блоков на window_sequence == EIGHT_SHORT_SEQUENCE только в одном канале), или usacIndependencyFlag == 1.
Все коэффициенты downmix_prev[ ] должны быть нулевыми во время процесса стереофонического заполнения, если длина преобразования канала изменилась с последнего до текущего кадра (то есть, split_transform == 1, которому предшествует split_transform == 0, или window_sequence == EIGHT_SHORT_SEQUENCE, которому предшествует window_sequence != EIGHT_SHORT_SEQUENCE, или соответственно наоборот) в текущем элементе.
Если разбиение преобразования применяется в каналах предыдущего или текущего кадра, downmix_prev[ ] представляет собой результат понижающего микширования перемеженного спектра линия за линией. Для получения более подробной информации, смотрите средство разбиения преобразования.
Если комплексный стереофонический прогноз не используется в текущем кадре и элементе, pred_dir равно 0.
Следовательно, предыдущий результат понижающего микширования должен быть вычислен всего лишь один раз для обоих средств, уменьшая сложность. Единственным различием между downmix_prev[ ] и dmx_re_prev[ ] в разделе 7.7.2 является режим работы, когда комплексное стереофоническое прогнозирование не используется на данный момент, или когда оно является действующим, но use_prev_frame == 0. В таком случае, downmix_prev[ ] вычисляется для декодирования со стереофоническим заполнением согласно разделу 7.7.2.3, даже если dmx_re_prev[ ] не нужен для декодирования с комплексным стереофоническим прогнозом, а потому, является неопределенным/нулевым.
В дальнейшем, выполнялось бы стереофоническое заполнение пустых полос масштабных коэффициентов.
Если stereo_filling == 1, следующая процедура выполняется после процесса шумового заполнения во всех изначально пустых полосах sfb[ ] масштабных коэффициентов ниже max_sfb_ste, то есть, всех полосах, в которых все линии МДКП были квантованы в ноль. Прежде всего, энергии данной sfb[ ] и соответствующих линий в downmix_prev[ ] вычисляются посредством сумм квадратов линий. Таким образом, при условии sfbWidth, содержащем в себе количество линий на каждую sfb[ ],
if (energy[sfb] < sfbWidth[sfb]) { /* уровень шума не максимален, или полоса начинается ниже области шумового заполнения */
facDmx=sqrt((sfbWidth[sfb] -energy[sfb])/energy_dmx[sfb]);
factor=0.0;
/* если предыдущий результат понижающего микширования не пуст, сложить масштабированные линии результата понижающего микширования, так чтобы полоса достигала единичной энергии */
for (index=swb_offset[sfb]; index < swb_offset[sfb+1]; index++) {
spectrum[window][index] += downmix_prev[window][index] * facDmx;
factor += spectrum[window][index] * spectrum[window][index];
}
if ((factor != sfbWidth[sfb]) && (factor > 0)) { /* единичная энергия не достигнута, поэтому, модифицировать полосу */
factor=sqrt(sfbWidth[sfb]/(factor+1e-8));
for (index=swb_offset[sfb]; index < swb_offset[sfb+1]; index++) {
spectrum[window][index] *= factor;
}
}
}
что касается спектра каждого группового окна. Затем, масштабные коэффициенты применяются к результирующему спектру, как в разделе 7.3, причем, масштабные коэффициенты пустых полос обрабатываются подобно обычным масштабным коэффициентам.
Альтернативный вариант для вышеприведенного расширения стандарта xHE-AAC использовал бы способ неявной сигнализации с частичной обратной совместимостью.
Вышеприведенная реализация в структуре кода xHE-AAC описывает подход, который использует один бит в потоке битов для сигнализации об использовании нового средства стереофонического заполнения, содержащийся в stereo_filling, в декодер в соответствии с фиг. 2. Точнее, такая сигнализация (давайте называть ее явной сигнализацией с частичной обратной совместимостью) предоставляет следующим данным унаследованного потока битов - здесь, информации на стороне шумового заполнения - возможность использоваться независимо от сигнализации SF: В настоящем варианте осуществления, данные шумового заполнения не зависят от информации о стереофоническом заполнении, и наоборот. Например, данные шумового заполнения, состоящие из all-zeros (noise_level=noise_offset=0), могут передаваться, в то время как stereo_filling может сигнализировать любое возможное значение (будучи двоичным флажковым признаком, 0 или 1).
В случаях, где строгая независимость между унаследованными и обладающими признаками изобретения данными потока битов не требуется, и обладающий признаками изобретения сигнал является двоичным решением, явная передача бита сигнализации может избегаться, и упомянутое двоичное решение может сигнализироваться посредством присутствия или отсутствия того, что может называться неявной сигнализацией с частичной обратной совместимостью. Вновь беря вышеприведенный вариант осуществления в качестве примера, использование стереофонического заполнения могло бы передаваться посредством простого применения новой сигнализации: Если уровень шума нулевой и, одновременно, noise_offset не равно нулю, флажковый признак stereo_filling устанавливается равным 1. Если оба, noise_level и noise_offset, ненулевые, stereo_filling равен 0. Зависимость этого неявного сигнала от унаследованного сигнала шумового заполнения возникает, когда оба, noise_level и noise_offset, имеют нулевое значение. В этом случае, не ясно, используется ли унаследованная или новая неявная сигнализация SF. Чтобы избежать такой неопределенности, значение stereo_filling должно быть определено заблаговременно. В настоящем примере, уместно определять stereo_filling=0, если данные шумового заполнения состоят из всех нулей, поскольку это то, что сигнализируют унаследованные кодеры без возможности стереофонического заполнения, когда шумовое заполнение не должно применяться в кадре.
Вопросом, который остается решить в случае неявной сигнализации с частичной обратной совместимостью, является то, каким образом одновременно сигнализировать о stereo_filling == 1 и отсутствии шумового заполнения. Как пояснено, данные шумового заполнения не должны быть полностью нулевыми, и если требуется нулевая амплитуда шума, noise_level ((noise_offset & 14)/2, как упомянуто выше) должен равняться 0. Это, в качестве решения, оставляет только noise_offset ((noise_offset & 1)*16, как упомянуто выше) большим, чем 0. Однако, noise_offset учитывается в случае стереофонического заполнения при применении масштабных коэффициентов, даже если noise_level является нулевым. К счастью, кодер может компенсировать то обстоятельство, что нулевая noise_offset могла не быть передаваемым изменением находящихся под влиянием масштабных коэффициентов, так что, при записи потока битов, они содержат в себе смещение, которое аннулируется в декодере с помощью noise_offset. Это предоставляет возможность упомянутой явной сигнализации в вышеприведенном варианте осуществления за счет возможного повышения скорости передачи данных масштабных коэффициентов. Отсюда, сигнализация стереофонического заполнения в псевдокоде по вышеприведенному описанию могла бы быть изменена, как изложено ниже, с использованием сэкономленного бита сигнализации SF для передачи noise_offset двумя битами (4 значениями) вместо 1 бита:
if ((noiseFilling) && (common_window) && (noise_level == 0) && (noise_offset > 0)) {
stereo_filling=1;
noise_level=(noise_offset & 28)/4;
noise_offset=(noise_offset & 3) * 8;
}
else {
stereo_filling=0;
}
Ради полноты, фиг. 6 показывает параметрический кодер звукового сигнала в соответствии с вариантом осуществления настоящей заявки. Прежде всего, кодер по фиг. 6, который в целом указывается с использованием ссылочной позиции 90, содержит преобразователь 92 для выполнения преобразования первоначального неискаженного варианта звукового сигнала, реконструированного на выходе 32 по фиг. 2. Как описано в отношении фиг. 3, преобразование с перекрытием может использоваться с переключением между разными длинами преобразования с соответствующими окнами преобразования в секциях кадров 44. Разная длина преобразования и соответствующие окна преобразования проиллюстрированы на фиг. 3 с использованием ссылочной позиции 104. Некоторым образом, аналогичным фиг. 2, фиг. 6 сосредотачивается на части кодера 90, ответственной за кодирование одного канала из многоканального звукового сигнала, тогда как другая часть области каналов декодера 90 указана в целом с использованием ссылочной позиции 96 на фиг. 6.
На выходе преобразователя 92, спектральные линии и масштабные коэффициенты неквантованы, и еще не произошло по существу никаких потерь при кодировании. Спектрограмма, выдаваемая преобразователем 92, поступает в квантователь 98, который выполнен с возможностью квантовать спектральные линии спектрограммы, выданной преобразователем 91, спектр за спектром, устанавливая и используя предварительные масштабные коэффициенты полос масштабных коэффициентов. То есть, на выходе квантователя 98, получаются в результате предварительные масштабные коэффициенты и соответствующие коэффициенты спектральных линий, и последовательно присоединена цепь шумового заполнителя 16', необязательного фильтра 28a' обратного TNS, межканального прогнозатора 24', декодера 26' MS и фильтра 28b' обратного TNS, с тем чтобы снабжать кодер 90 по фиг. 6 возможностью получать реконструированный окончательный вариант текущего спектра в качестве получаемого на стороне декодера на входе исполнителя понижающего микширования (смотрите фиг. 2). В случае использования межканального прогноза 24' и/или использования межканального шумового заполнения в варианте, формирующем межканальный шум с использованием результата понижающего микширования предыдущего кадра, кодер 90 также содержит исполнитель 31' понижающего микширования, с тем чтобы формировать результат понижающего микширования реконструированных окончательных вариантов спектров каналов многоканального звукового сигнала. Конечно, для экономии вычислений, вместо окончательных, первоначальные неквантованные варианты упомянутых спектров каналов могут использоваться исполнителем 31' понижающего микширования при формировании результата понижающего микширования.
Кодер 90 может использовать информацию о имеющемся в распоряжении реконструированном окончательном варианте спектров, для того чтобы выполнять межкадровое спектральное прогнозирование, такое как вариант выполнения межканального прогнозирования с использованием оценки мнимой части, и/или для того чтобы выполнять управление скоростью передачи, то есть, для того чтобы определять, в контуре управления скоростью, что возможные параметры, окончательно закодированные в потоке 30 данных кодером 90, установлены в оптимальное по скорости/искажению значение.
Например, одним из таких параметров, установленных в таком контуре прогнозирования и/или контуре управления скоростью кодера 90, для каждой квантованной в ноль полосы масштабных коэффициентов, распознанной идентификатором 12', является масштабный коэффициент соответственной полосы масштабных коэффициентов, который был просто предварительно установлен квантователем 98. В контуре управления прогнозированием и/или скоростью кодера 90, масштабный коэффициент квантованных в ноль полос масштабных коэффициентов устанавливается в некоторое оптимальное по психоакустике или по скорости/искажению значение, с тем чтобы определять вышеупомянутый целевой уровень шума, как описано выше, наряду с оптимальным параметром модификации, также передаваемым потоком данных для соответствующего кадра на сторону декодера. Следует отметить, что этот масштабный коэффициент может вычисляться с использованием только спектральных линий спектра и канала, которым он принадлежит (то есть, «целевого» спектра, как описано раньше) или, в качестве альтернативы, может определяться с использованием как спектральных линий «целевого» спектра канала, так и, в дополнение, спектральных линий из предыдущего кадра (то есть, «исходного» спектра, как представлено ранее), полученного из исполнителя 31' понижающего микширования. В частности, для стабилизации целевого уровня шума и снижения флуктуации временного уровня в декодированных звуковых каналах, к которым применено межканальное шумовое заполнение, целевой масштабный коэффициент может вычисляться с использованием зависимости между измерением энергии спектральных линий в «целевой» полосе масштабных коэффициентов и измерением энергии совмещенных спектральных линий в соответствующей «целевой» области. В заключение, как отмечено выше, эта «исходная» область может происходить из реконструированного окончательного варианта другого канала или результата понижающего микширования предыдущего кадра, или, если должна быть уменьшена сложность кодера, первоначальный неквантованный вариант того же самого другого канала или результата понижающего микширования первоначальных вариантов спектров предыдущего кадра.
В нижеследующем, пояснено многоканальное кодирование и многоканальное декодирование согласно вариантам осуществления. В вариантах осуществления, многоканальный процессор 204 устройства 201 для декодирования по фиг. 1a, например, может быть выполнен с возможностью проводить одну или более из технологий, приведенных ниже, которые описаны касательно шумового многоканального декодирования.
Однако, в начале, до описания многоканального декодирования, многоканальное кодирование согласно вариантам осуществления пояснено со ссылкой на фиг. 7 - фиг. 9, а затем, многоканальное декодирование пояснено со ссылкой на фиг. 10 и фиг. 12.
Далее, многоканальное кодирование согласно вариантам осуществления пояснено со ссылкой на фиг. 7 - фиг. 9 и фиг. 11:
Фиг. 7 показывает принципиальную структурную схему устройства 100 (кодера) для кодирования многоканального сигнала 101, имеющего по меньшей мере три канала с CH1 по CH3, согласно варианту осуществления;
Устройство 100 содержит итерационный процессор 102, кодер 104 каналов и выходной интерфейс 106.
Итерационный процессор 102 выполнен с возможностью рассчитывать, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов с CH1 по CH3 для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и для обработки выбранной пары с использованием операции многоканальной обработки, чтобы извлечь многоканальные параметры MCH_PAR1 для выбранной пары и получить первые обработанные каналы P1 и P2. В нижеследующем, такие обработанные каналы P1 и такой обработанный канал P2 также могут указываться ссылкой как комбинационный канал P1 и комбинационный канал P2, соответственно. Кроме того, итерационный процессор 102 выполнен с возможностью выполнять расчет, выбор и обработку на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов P1 или P2, чтобы получить дополнительные многоканальные параметры MCH_PAR2 и вторые обработанные каналы P3 и P4.
Например, как указано на фиг. 7, итерационный процессор 102 может рассчитывать на этапе первой итерации значение межканальной корреляции между первой парой из по меньшей мере трех каналов с CH1 по CH3, первая пара состоит из первого канала CH1 и второго канала CH2, значение межканальной корреляции между второй парой из по меньшей мере трех каналов с CH1 по CH3, вторая пара состоит из второго канала CH2 и третьего канала CH3, и значение межканальной корреляции между третьей парой из по меньшей мере трех каналов с CH1 по CH3, третья пара состоит из первого канала CH1 и третьего канала CH3.
На фиг. 7 предполагается, что, на этапе первой итерации, третья пара, состоящая из первого канала CH1 и третьего канала CH3, содержит наибольшее значение межканальной корреляции, так что итерационный процессор 102 выбирает на этапе первой итерации третью пару, имеющую наибольшее значение межканальной корреляции, и обрабатывает выбранную пару, то есть, третью пару, с использованием операции многоканальной обработки, чтобы извлечь многоканальные параметры MCH_PAR1 для выбранной пары и чтобы получить первые обработанные каналы P1 и P2.
Кроме того, итерационный процессор 102 может быть выполнен с возможностью рассчитывать, на этапе второй итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов с CH1 по CH3 и обработанных каналов P1 и P2, для выбора, на этапе второй итерации, пары, имеющей наибольшее значение межканальной корреляции или имеющей значение выше пороговой величины. В силу этого, итерационный процессор 102 может быть выполнен с возможностью не выбирать выбранную пару по этапу первой итерации на этапе второй итерации (или на любом этапе дополнительной итерации).
Со ссылкой на пример, показанный на фиг. 7, итерационный процессор 102 дополнительно может рассчитывать значение межканальной корреляции между четвертой парой каналов, состоящей из первого канала CH1 и первого обработанного канала P1, значение межканальной корреляции между пятой парой, состоящей из первого канала CH1 и второго обработанного канала P2, значение межканальной корреляции между шестой парой, состоящей из второго канала CH2 и первого обработанного канала P1, значение межканальной корреляции между седьмой парой, состоящей из второго канала CH2 и второго обработанного канала P2, значение межканальной корреляции между восьмой парой, состоящей из третьего канала CH3 и первого обработанного канала P1, значение взаимной корреляции между девятой парой, состоящей из третьего канала CH3 и второго обработанного канала P2, и значение межканальной корреляции между десятой парой, состоящей из первого обработанного канала P1 и второго обработанного канала P2.
На фиг. 7 предполагается, что, на этапе второй итерации, шестая пара, состоящая из второго канала CH2 и первого обработанного канала P1, содержит наибольшее значение межканальной корреляции, так что итерационный процессор 102 выбирает на этапе второй итерации шестую пару и обрабатывает выбранную пару, то есть, шестую пару, с использованием операции многоканальной обработки, чтобы получить многоканальных параметров MCH_PAR2 для выбранной пары и чтобы получить вторые обработанные каналы P3 и P4.
Итерационный процессор 102 может быть выполнен с возможностью выбирать пару, только когда разность уровней пары меньше пороговой величины, пороговая величина является меньшей, чем 40 дБ, 25 дБ, 12 дБ, или меньшей, чем 6 дБ. В силу этого, пороговые величины 25 или 40 дБ соответствуют углам поворота в 3 или 0,5 градусов.
Итерационный процессор 102 может быть выполнен с возможностью рассчитывать нормированные целочисленные значения корреляции, при этом, итерационный процессор 102 может быть выполнен с возможностью выбирать пару, когда целочисленное значение корреляции, например, является большим, чем 0,2 или предпочтительно 0,3.
Кроме того, итерационный процессор 102 может выдавать каналы, являющиеся результатом многоканальной обработки, в кодер 104 каналов. Например, со ссылкой на фиг. 7, итерационный процессор 102 может выдавать третий обработанный канал P3 и четвертый обработанный канал P4, являющиеся результатом многоканальной обработки, выполненной на этапе второй итерации, и второй обработанный канал P2, являющийся результатом многоканальной обработки, выполненной на этапе первой итерации, в кодер 104 каналов. В силу этого, итерационный процессор 102 может выдавать только те обработанные каналы в кодер 104 каналов, которые не обрабатываются (дополнительно) на этапе последующих итераций. Как показано на фиг. 7, первый обработанный канал P1 не выдается в кодер 104 каналов, поскольку он дополнительно обрабатывается на этапе второй итерации.
Кодер 104 каналов может быть выполнен с возможностью кодировать каналы с P2 по P4, являющиеся результатом итерационной обработки (или многоканальной обработки), выполненной итерационным процессором 102, для получения кодированных каналов с E1 по E3.
Например, кодер 104 каналов может быть выполнен с возможностью использовать монофонические кодеры (или монофонические блоки, или монофонические средства) со 120_1 по 120_3 для кодирования каналов с P2 по P4, являющихся результатом итерационной обработки (или многоканальной обработки). Монофонические блоки могут быть выполнены с возможностью кодировать каналы, так чтобы меньшее количество битов требовалось для кодирования канала, имеющего меньшую энергию (или меньшую амплитуду), чем для кодирования канала, имеющего большую энергию (или более высокую амплитуду). Монофонические блоки с 120_1 по 120_3, например, могут быть основанными на преобразовании кодерами звукового сигнала. Кроме того, кодер 104 каналов может быть выполнен с возможностью использовать стереофонические кодеры (например, параметрические стереофонические кодеры или стереофонические кодеры) со 120_1 по 120_3 для кодирования каналов с P2 по P4, являющихся результатом итерационной обработки (или многоканальной обработки).
Выходной интерфейс 106 может быть выполнен с возможностью формировать и кодировать многоканальный сигнал 107, имеющий кодированные каналы с E1 по E3 и многоканальные параметры MCH_PAR1 и MCH_PAR2.
Например, выходной интерфейс 106 может быть выполнен с возможностью формировать кодированный многоканальный сигнал 107 в виде последовательного сигнала или последовательного потока битов, и так чтобы многоканальные параметры MCH_PAR2 находились в кодированном сигнале 107 раньше многоканальных параметров MCH_PAR1. Таким образом, декодер, вариант осуществления которого будет описан позже со ссылкой на фиг. 10, будет принимать многоканальные параметры MCH_PAR2 раньше многоканальных параметров MCH-PAR1.
На фиг. 7, итерационный процессор 102, в качестве примера, выполняет две операции многоканальной обработки, операцию многоканальной обработки на этапе первой итерации и операцию многоканальной обработки на этапе второй итерации. Естественно, итерационный процессор 102 также может выполнять дополнительные операции многоканальной обработки на этапах последующих итераций. В силу этого, итерационный процессор 102 может быть выполнен с возможностью выполнять итерационные этапы до тех пор, пока не достигнут критерий завершения итераций. Критерий завершения итераций может состоять в том, что максимальное количество итерационных этапов равно или больше общего количества каналов многоканального сигнала 102 на два, или при этом, критерием завершения итераций, когда значения межканальной корреляции не имеют значение, большее, чем пороговая величина, является пороговая величина, предпочтительно являющаяся большей, чем 0,2, или пороговая величина, предпочтительно имеющая значение 0,3. В дополнительных вариантах осуществления, критерий завершения итераций может состоять в том, что максимальное количество итерационных этапов равно или больше общего количества каналов многоканального сигнала 102, или при этом, критерием завершения итераций, когда значения межканальной корреляции не имеют значение, большее, чем пороговая величина, пороговая величина предпочтительно является большей, чем 0,2, или пороговая величина предпочтительно имеет значение 0,3.
В целях иллюстрации, операции многоканальной обработки, выполняемые итерационным процессором 102 на этапе первой итерации и этапе второй итерации, в качестве примера, проиллюстрированы на фиг. 7 блоками 110 и 112 обработки. Блоки 110 и 112 обработки могут быть реализованы в аппаратных средствах или программном обеспечении. Блоки 110 и 112 обработки, например, могут быть стереофоническими блоками.
В силу этого, межканальная зависимость сигнала может использоваться посредством иерархического применения известных средств совместного стереофонического кодирования. В противоположность предшествующим подходам MPEG, пары сигналов, подлежащие обработке, не предопределены неизменным трактом сигнала (например, деревом стереофонического кодирования), но могут изменяться динамически, чтобы адаптироваться под характеристики входного сигнала. Входными данными реального стереофонического блока могут быть (1) необработанные каналы, такие как каналы с CH1 по CH3, (2) выходные данные предыдущего стереофонического блока, такие как обработанные сигналы с P1 по P4, или (3) комбинационный канал необработанных каналов и выходных данных предыдущего стереофонического блока.
Обработка внутри стереофонического блока 110 и 112 может быть основанной на прогнозе (подобно блоку комплексного прогноза в USAC) или основанной на KLT/PCA (входные каналы поворачиваются (например, с помощью матрицы поворота 2×2) в кодере для доведения до максимума уплотнение энергии, то есть для концентрации энергии сигнала в одном канале, в декодере повернутые сигналы будут повторно преобразованы в первоначальные направления входного сигнала).
В возможных реализациях кодера 100, (1) кодер рассчитывает межканальную корреляцию между каждой парой каналов и выбирает одну подходящую пару сигналов из входных сигналов и применяет стереофоническое средство к выбранным каналам; (2) кодер повторно рассчитывает межканальную корреляцию между всеми каналами (необработанными каналами, а также обработанными промежуточными выходными каналами) и выбирает одну пригодную пару сигналов из входных сигналов и применяет стереофоническое средство к выбранным каналам; и (3) кодер повторяет этап (2) до тех пор, пока вся межканальная корреляция не находится ниже пороговой величины, или если применяется максимальное количество преобразований.
Как уже упомянуто, пары сигналов, подлежащие обработке кодером 100, или, точнее, итерационным процессором 102, не предопределены неизменным трактом сигнала (например, деревом стереофонического кодирования), но могут динамически изменяться для адаптации к характеристикам входного сигнала. В силу этого, кодер 100 (или итерационный процессор 102) может быть выполнен с возможностью строить стереофоническое дерево в зависимости от по меньшей мере трех каналов с CH1 по CH3 из многоканального (входного) сигнала 101. Другими словами, кодер 100 (или итерационный процессор 102) может быть выполнен с возможностью строить стереофоническое дерево на основе межканальной корреляции (например, рассчитывая, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов с CH1 по CH3, для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или значение выше пороговой величины, и рассчитывая, на этапе второй итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов и обработанных ранее каналов, для выбора, на этапе второй итерации, пары, имеющей наибольшее значение или значение выше пороговой величины). Согласно подходу одного этапа, корреляционная матрица может рассчитываться возможно для каждой итерации, содержащая в себе корреляции всех, возможно обработанных на предыдущих итерациях, каналов.
Как указано выше, итерационный процессор 102 может быть выполнен с возможностью извлекать многоканальные параметры MCH_PAR1 для выбранной пары на этапе первой итерации и получать многоканальные параметры MCH_PAR2 для выбранной пары на этапе второй итерации. Многоканальные параметры MCH_PAR1 могут содержать идентификацию (или индекс) первой пары каналов, идентифицирующую (или сигнализирующую) пару каналов, выбранную на этапе первой итерации, при этом, многоканальные параметры MCH_PAR2 могут содержать в себе идентификацию (или индекс) второй пары каналов, идентифицирующую (или сигнализирующую) пару каналов, выбранную на этапе второй итерации.
В последующем, описана эффективная индексация входных сигналов. Например, пары каналов могут эффективно сигнализироваться с использованием уникального индекса для каждой пары в зависимости от общего количества каналов. Например, индексация пар для шести каналов может быть такой, как показано в следующей таблице:
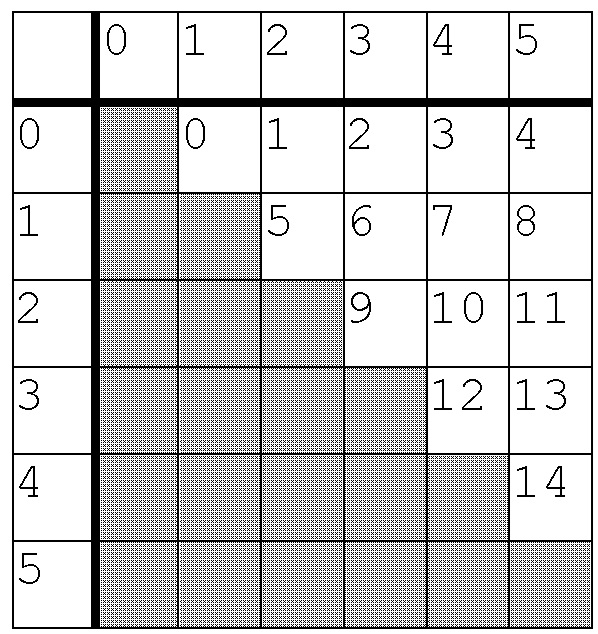
Например, в вышеприведенной таблице, индекс 5 может сигнализировать о паре, состоящей из первого канала и второго канала. Подобным образом, индекс 6 может сигнализировать о паре, состоящей из первого канала и третьего канала.
Общее количество возможных индексов пар каналов для n может быть рассчитано в соответствии с:
numPairs=numChannels*(numChannels-1)/2
Отсюда, количество битов, необходимых для сигнализации одной пары каналов, равно:
numBits=floor(log2(numPairs-1))+1
Кроме того, кодер 100 может использовать маску каналов. Конфигурация многоканального средства может содержать в себе маску каналов, указывающую, применительно к каким каналам является действующим средство. Таким образом, LFE (LFE=каналы низкочастотных эффектов/расширений) может убираться из индексации пар каналов, давая возможность для более эффективного кодирования. Например, что касается структуры 11.1, это уменьшает количество индексов пар каналов с 12*11/2=66 до 11*10/2=55, давая возможность сигнализации 6 битами вместо 7 битов. Этот механизм также может использоваться для исключения каналов, предназначенных для представления монофонических объектов (например, многочисленных речевых дорожек). При декодировании маски каналов (channelMask), карта каналов (channelMap) может формироваться для предоставления возможности переназначения индексов пар каналов на каналы декодера.
Более того, итерационный процессор 102 может быть выполнен с возможностью получать, для первого кадра, множество выбранных указаний пар, при этом, выходной интерфейс 106 может быть выполнен с возможностью включать, в многоканальный сигнал 107, для второго кадра, следующего за первым кадром, индикатор актуальности, указывающий, что второй кадр имеет то же самое множество выбранных указаний пар, что и первый кадр.
Индикатор актуальности или флажковый признак актуального дерева может использоваться для сигнализации, что новое дерево не передается, но будет использоваться последнее стереофоническое дерево. Это может использоваться для избежания многократной передачи одной и той же конфигурации стереофонического дерева, если свойства корреляции каналов остаются неизменными в течение более длительного времени.
Фиг. 8 показывает принципиальную структурную схему стереофонического блока 110, 112. Стереофонический блок 110, 112 содержит входы для первого входного сигнала I1 и второго входного сигнала I2, и выходы для первого выходного сигнала O1 и второго выходного сигнала O2. Как указано на фиг. 8, зависимости выходных сигналов O1 и O2 от входных сигналов I1 и I2 могут быть описаны параметрами с S1 по S4 рассеяния.
Итерационный процессор 102 может использовать (или содержать) стереофонические блоки 110, 112, для того чтобы выполнять операции многоканальной обработки над входными каналами и/или обработанными каналами, для того чтобы получать (дополнительные) обработанные каналы. Например, итерационный процессор 102 может быть выполнен с возможностью использовать основанные на прогнозе или основанные на KLT (преобразовании Карунена-Лоэва) стереофонические блоки 110, 112 поворота широкого применения.
Кодер широкого применения (или стереофонический блок на стороне кодера) может быть выполнен с возможностью кодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения:
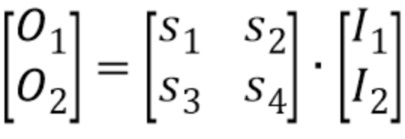 .
.
Декодер широкого применения (или стереофонический блок на стороне декодера) может быть выполнен с возможностью декодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения:
 .
.
Основанный на прогнозе кодер широкого применения (или стереофонический блок на стороне кодера) может быть выполнен с возможностью кодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения
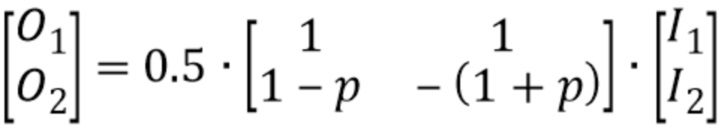 ,
,
в котором p - прогнозный коэффициент.
Основанный на прогнозе декодер (или стереофонический блок на стороне декодера) может быть выполнен с возможностью декодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения:
 .
.
Кодер основанного на KLT поворота (или стереофонический блок на стороне кодера) может быть выполнен с возможностью кодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения:
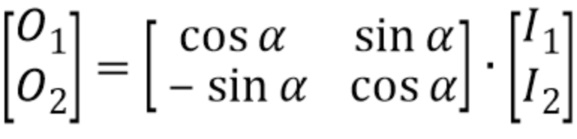 .
.
Декодер основанного на KLT поворота (или стереофонический блок на стороне декодера) может быть выполнен с возможностью декодировать входные сигналы I1 и I2 для получения выходных сигналов O1 и O2 на основе уравнения (обратного поворота):
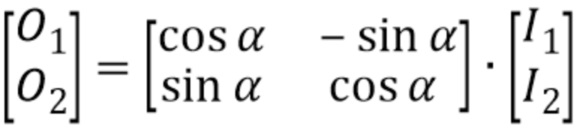 .
.
В нижеследующем описан расчет угла α поворота для основанного на KLT поворота.
Угол поворота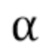 применительно к основанному на KLT повороту может быть определен как:
применительно к основанному на KLT повороту может быть определен как:

причем  являются записями ненормированной корреляционной матрицы, в которой
являются записями ненормированной корреляционной матрицы, в которой  ,
, являются энергиями каналов.
являются энергиями каналов.
Это может быть реализовано с использованием функции atan2 для предоставления возможности проводить различие между отрицательными корреляциями в числителе и отрицательной разностью энергий в знаменателе:
alpha=0,5*atan2(2*correlation[ch1][ch2], (correlation[ch1][ch1] - correlation[ch2][ch2]));
Кроме того, итерационный процессор 102 может быть выполнен с возможностью рассчитывать межканальную корреляцию с использованием кадра каждого канала, содержащего множество полос, так чтобы получалось единое значение межканальной корреляции для множества полос, при этом, итерационный процессор 102 может быть выполнен с возможностью выполнять многоканальную обработку для каждой из множества полос, так чтобы многоканальные параметры получались из каждой из множества полос.
В силу этого, итерационный процессор 102 может быть выполнен с возможностью рассчитывать стереофонические параметры при многоканальной обработке, при этом, итерационный процессор 102 может быть выполнен с возможностью выполнять стереофоническую обработку только в полосах, в которых стереофонический параметр больше квантованной в ноль пороговой величины, определенной стереофоническим квантователем (например, кодером основанного на KLT поворота). Стереофоническими параметрами, например, могут быть MS включен/выключен или углы поворота, или прогнозные коэффициенты).
Например, итерационный процессор 102 может быть выполнен с возможностью рассчитывать углы поворота при многоканальной обработке, при этом, итерационный процессор 102 может быть выполнен с возможностью выполнять обработку поворотом только в полосах, в которых угол поворота больше квантованной в ноль пороговой величины, определенной квантователем угла поворота (например, кодером основанного на KLT поворота).
Таким образом, кодер 100 (или выходной интерфейс 106) может быть выполнен с возможностью передавать информацию о преобразовании/повороте в виде одного параметра для полного спектра (полнополосный блок) или в виде многочисленных зависящих от частоты параметров для частей спектра.
Кодер 100 может быть выполнен с возможностью формировать поток 107 битов на основе следующих таблиц:
Таблица 1 - синтаксис mpegh3daExtElementConfig()
Таблица 21 - синтаксис MCCConfig(),
Таблица 32 - синтаксис MultichannelCodingBoxBandWise()
Таблица 4 - синтаксис MultichannelCodingBoxFullband()
Таблица 5 - синтаксис MultichannelCodingFrame()
Таблица 6 - значение usacExtElementType
Таблица 7 - интерпретация блоков данных для декодирования полезной нагрузки расширения
Фиг. 9 показывает принципиальную структурную схему итерационного процессора 102 согласно варианту осуществления. В варианте осуществления, показанном на фиг. 9, многоканальный сигнал 101 является 5.1-канальным сигналом, имеющим шесть каналов: левый канал L, правый канал R, левый канал Ls объемного звучания, правый канал Rs объемного звучания, центральный канал C и канал LFE низкочастотных эффектов.
Как указано на фиг. 9, канал LFE не обрабатывается итерационным процессором 102. Это могло бы иметь место, поскольку значения межканальной корреляции между каналом LFE и каждым из других пяти каналов L, R, Ls, Rs и C слишком малы, или поскольку маска канала указывает, что не следует обрабатывать канал LFE, что будет предполагаться в последующем.
На этапе первой итерации, итерационный процессор 102 рассчитывает значения межканальной корреляции между каждой парой из пяти каналов L, R, Ls, Rs и C для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины. На фиг. 9 предполагается, что левый канал L и правый канал R имеют наибольшее значение, так что итерационный процессор 102 обрабатывает левый канал L и правый канал R с использованием стереофонического блока 110 (или стереофонического средства), который выполняет операцию многоканальной обработки, чтобы получить первый и второй обработанные каналы P1 и P2.
На этапе второй итерации, итерационный процессор 102 рассчитывает значения межканальной корреляции между каждой парой из пяти каналов L, R, Ls, Rs и C и обработанных каналов P1 и P2 для выбора, на этапе второй итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины. На фиг. 9 предполагается, что левый канал Ls объемного звучания и правый канал Rs объемного звучания имеют наибольшее значение, так что итерационный процессор 102 обрабатывает левый канал Ls объемного звучания и правый канал Rs объемного звучания с использованием стереофонического блока 112 (или стереофонического средства), чтобы получить третий и четвертый обработанные каналы P3 и P4.
На этапе третьей итерации, итерационный процессор 102 рассчитывает значения межканальной корреляции между каждой парой из пяти каналов L, R, Ls, Rs и C и обработанных каналов с P1 по P4 для выбора, на этапе третьей итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины. На фиг. 9 предполагается, что первый обработанный канал P1 и третий обработанный канал P3 имеют наибольшее значение, так что итерационный процессор 102 обрабатывает первый обработанный канал P1 и третий обработанный канал P3 с использованием стереофонического блока 114 (или стереофонического средства), чтобы получить пятый и шестой обработанные каналы P5 и P6.
На этапе четвертой итерации, итерационный процессор 102 рассчитывает значения межканальной корреляции между каждой парой из пяти каналов L, R, Ls, Rs и C и обработанных каналов с P1 по P6 для выбора, на этапе четвертой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины. На фиг. 9 предполагается, что пятый обработанный канал P5 и центральный канал C имеют наибольшее значение, так что итерационный процессор 102 обрабатывает пятый обработанный канал P5 и центральный канал C с использованием стереофонического блока 115 (или стереофонического средства), чтобы получить седьмой и восьмой обработанные каналы P7 и P8.
Стереофонические блоки со 110 по 116 могут быть стереофоническими блоками MS, то есть, средним/побочным стереофоническими блоками, выполненными с возможностью выдавать средний канал и побочный канал. Средний канал может быть суммой входных каналов стереофонического блока, при этом, побочный канал может быть разностью между входными каналами стереофонического блока. Кроме того, стереофонические блоки 110 и 116 могут быть блоками поворота или блоками стереофонического прогноза.
На фиг. 9, первый обработанный канал P1, третий обработанный канал P3 и пятый обработанный канал P5 могут быть средними каналами, при этом, второй обработанный канал P2, четвертый обработанный канал P4 и шестой обработанный канал P6 могут быть побочными каналами.
Кроме того, как указано на фиг. 9, итерационный процессор 102 может быть выполнен с возможностью выполнять расчет, выбор и обработку на этапе второй итерации и, если применимо, на любом этапе дальнейших итераций с использованием входных каналов L, R, Ls, Rs и C и (только) средних каналов P1, P3 и P5 из обработанных каналов. Другими словами, итерационный процессор 102 может быть выполнен с возможностью не использовать побочные каналы P1, P3 и P5 из обработанных каналов при расчете, выборе и обработке на этапе второй итерации и, если применимо, на любом этапе дальнейших итераций.
Фиг. 11 показывает блок-схему последовательности операций способа 300 для кодирования многоканального сигнала, имеющего по меньшей мере три канала. Способ 300 содержит этап 302 расчета, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов, выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и обработки выбранной пары с использованием операции многоканальной обработки, чтобы извлечь многоканальные параметры MCH_PAR1 для выбранной пары и чтобы получить первые обработанные каналы; этап 304 выполнения расчета, выбора и обработки на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов (P1), чтобы получить многоканальные параметры MCH_PAR2 и вторые обработанные каналы; этап 306 кодирования каналов, являющихся результатом итерационной обработки, выполненной итерационным процессором, для получения кодированных каналов; и этап 308 формирования кодированного многоканального сигнала, имеющего кодированные каналы и первые многоканальные параметры MCH_PAR2.
В последующем, пояснено многоканальное декодирование.
Фиг. 10 показывает принципиальную структурную схему устройства 200 (декодера) для декодирования кодированного многоканального сигнала 107, имеющего кодированные каналы с E1 по E3 и по меньшей мере двое многоканальных параметров MCH_PAR1 и MCH_PAR2.
Устройство 200 содержит канальный декодер 202 и многоканальный процессор 204.
Канальный декодер 202 выполнен с возможностью декодировать кодированные каналы с E1 по E3 для получения декодированных каналов в с D1 по D3.
Например, канальный декодер 202 может содержать по меньшей мере три монофонических декодера с 206_1 по 206_3 (или монофонических блока или монофонических средства), при этом, каждый из монофонических декодеров с 206_1 по 206_3 может быть выполнен с возможностью декодировать один из по меньшей мере трех кодированных каналов с E1 по E3, для получения соответственных декодированных каналов с E1 по E3. Монофонические декодеры с 206_1 по 206_3, например, могут быть основанными на преобразовании декодерами звукового сигнала.
Многоканальный процессор 204 выполнен с возможностью выполнять многоканальную обработку с использованием второй пары декодированных каналов, идентифицированных многоканальными параметрами MCH_PAR2, и с использованием многоканальных параметров MCH_PAR2 для получения обработанных каналов, и выполнять дополнительную многоканальную обработку с использованием первой пары каналов, идентифицированных многоканальными параметрами MCH_PAR1, и с использованием многоканальных параметров MCH_PAR1, где первая пара каналов содержит по меньшей мере один обработанный канал.
Как указано на фиг. 10, в качестве примера, многоканальные параметры MCH_PAR2 могут указывать (или сигнализировать), что вторая пара декодированных каналов состоит из первого декодированного канала D1 и второго декодированного канала D2. Таким образом, многоканальный процессор 204 выполняет многоканальную обработку с использованием второй пары декодированных каналов, состоящей из первого декодированного канала D1 и второго декодированного канала D2 (идентифицированных многоканальными параметрами MCH_PAR2), и с использованием многоканальных параметров MCH_PAR2 для получения обработанных каналов P1* и P2*. Многоканальные параметры MCH_PAR1 могут указывать, что первая пара декодированных каналов состоит из первого обработанного канала P1* и третьего декодированного канала D3. Таким образом, многоканальный процессор 204 выполняет дополнительную многоканальную обработку с использованием этой первой пары декодированных каналов, состоящей из первого обработанного канала P1* и третьего декодированного канала D3 (идентифицированных многоканальными параметрами MCH_PAR1), и с использованием многоканальных параметров MCH_PAR1 для получения обработанных каналов P3* и P4*.
Кроме того, многоканальный процессор 204 может выдавать третий обработанный канал P3* в качестве первого канала CH1, четвертый обработанный канал P4* в качестве третьего канала CH3 и второй обработанный канал P2* в качестве второго канала CH2.
Предположим, что декодер 200, показанный на фиг. 10, принимает кодированный многоканальный сигнал 107 из кодера 100, показанного на фиг. 7, первый декодированный канал D1 декодера 200 может быть эквивалентен третьему обработанному каналу P3 кодера 100, при этом второй декодированный канал D2 декодера 200 может быть эквивалентен четвертому обработанному каналу P4 кодера 100, и при этом, третий декодированный канал D3 декодера 200 может быть эквивалентен второму обработанному каналу P2 кодера 100. Кроме того, первый обработанный канал P1* декодера 200 может быть эквивалентным первому обработанному каналу P1 кодера 100.
Кроме того, кодированный многоканальный сигнал 107 может быть последовательным сигналом, при этом многоканальные параметры MCH_PAR2 принимаются в декодере 200 раньше многоканальных параметров MCH_PAR1. В таком случае, многоканальный процессор 204 может быть выполнен с возможностью обрабатывать декодированные каналы в порядке, в котором многоканальные параметры MCH_PAR1 и MCH_PAR2 принимаются декодером. В примере, показанном на фиг. 10, декодер принимает многоканальные параметры MCH_PAR2 раньше многоканальных параметров MCH_PAR1 и, таким образом, выполняет многоканальную обработку с использованием второй пары декодированных каналов (состоящей из первого и второго декодированных каналов D1 и D2), идентифицированных многоканальными параметрами MCH_PAR2, раньше выполнения многоканальной обработки с использованием первой пары декодированных каналов (состоящей из первого обработанного канала P1* и третьего декодированного канала D3), идентифицированных многоканальными параметром MCH_PAR1.
На фиг. 10, многоканальный процессор 204, в качестве примера, выполняет две операции многоканальной обработки. В иллюстративных целях, операции многоканальной обработки, выполняемые многоканальным процессором 204, проиллюстрированы на фиг. 10 блоками 208 и 210 обработки. Блоки 208 и 210 обработки могут быть реализованы в аппаратных средствах или программном обеспечении. Блоки 208 и 210 обработки, например, могут быть стереофоническими блоками, как обсуждено выше со ссылкой на кодер 100, такими как декодеры широкого применения (или стереофонические блоки на стороне декодера), основанные на прогнозе декодеры (или стереофонические блоки на стороне декодера) или декодеры основанного на KLT поворота (или стереофонические блоки на стороне декодера).
Например, кодер 100 может использовать кодеры основанного на KLT поворота (или стереофонические блоки на стороне кодера). В таком случае, кодер 100 может извлекать многоканальные параметры MCH_PAR1 и MCH_PAR2, так чтобы многоканальные параметры MCH_PAR1 и MCH_PAR2 содержали углы поворота. Углы поворота могут кодироваться дифференциально. Поэтому, многоканальный процессор 204 декодера 200 может содержать дифференциальный декодер для дифференциального декодирования дифференциально кодированных углов поворота.
Устройство 200 дополнительно может содержать входной интерфейс 212, выполненный с возможностью принимать и обрабатывать кодированный многоканальный сигнал 107, чтобы выдавать кодированные каналы с E1 по E3 в канальный декодер 202, а многоканальные параметры MCH_PAR1 и MCH_PAR2 в многоканальный процессор 204.
Как уже упомянуто, индикатор актуальности (или флажковый признак актуального дерева) может использоваться для сигнализации, что новое дерево не передано, но будет использоваться последнее стереофоническое дерево. Это может использоваться для избежания многократной передачи одной и той же конфигурации стереофонического дерева, если свойства корреляции каналов остаются неизменными в течение более длительного времени.
Поэтому, когда кодированный многоканальный сигнал 107 содержит, применительно к первому кадру, многоканальные параметры MCH_PAR1 и MCH_PAR2 и, применительно ко второму кадру, следующему за первым кадром, индикатор актуальности, многоканальный процессор 204 может быть выполнен с возможностью выполнять многоканальную обработку или дополнительную многоканальную обработку во втором кадре по отношению к той же самой второй паре или той же самой первой паре каналов, что и используемые в первом кадре.
Многоканальная обработка и дополнительная многоканальная обработка могут содержать стереофоническую обработку с использованием стереофонического параметра, при этом, что касается отдельных полос масштабных коэффициентов или групп полос масштабных коэффициентов декодированных каналов с D1 по D3, первый стереофонический параметр включен в многоканальный параметр MCH_PAR1, а второй стереофонический параметр включен в многоканальный параметр MCH_PAR2. В силу этого, первый стереофонический параметр и второй стереофонический параметр могут иметь одинаковый тип, такой как углы поворота или прогнозные коэффициенты. Естественно, первый стереофонический параметр и второй стереофонический параметр могут иметь разные типы. Например, первым стереофоническим параметром может быть угол поворота, при этом вторым стереофоническим параметром может быть прогнозный коэффициент, или наоборот.
Кроме того, многоканальные параметры MCH_PAR1 и MCH_PAR2 могут содержать маску многоканальной обработки, указывающую, какие полосы масштабных коэффициентов подвергаются многоканальной обработке, а какие полосы масштабных коэффициентов не обрабатываются многоканальной обработкой. В силу этого, многоканальный процессор 204 может быть выполнен с возможностью не выполнять многоканальную обработку в полосах масштабных коэффициентов, указанных маской многоканальной обработки.
Каждые из многоканальных параметров MCH_PAR1 и MCH_PAR2 могут включать в себя идентификацию (или индекс) пары каналов, при этом, многоканальный процессор 204 может быть выполнен с возможностью декодировать идентификацию (или индексы) пар каналов с использованием предопределенного правила кодирования или правила декодирования, указанных в кодированном многоканальном сигнале.
Например, пары каналов могут эффективно сигнализироваться с использованием уникального индекса для каждой пары в зависимости от общего количества каналов, как описано выше со ссылкой на кодер 100.
Кроме того, правило декодирования может быть правилом декодирования Хаффмана, при этом многоканальный процессор 204 может быть выполнен с возможностью выполнять декодирование Хаффмана идентификации пар каналов.
Кодированный многоканальный сигнал 107 дополнительно может содержать индикатор допущения многоканальной обработки, указывающий только подгруппу декодированных каналов, для которых разрешена многоканальная обработка, и указывающий по меньшей мере один декодированный канал, для которого многоканальная обработка не разрешена. В силу этого, многоканальный процессор 204 может быть выполнен с возможностью не выполнять никакую многоканальную обработку применительно к по меньшей мере одному декодированному каналу, для которого многоканальная обработка не разрешена, как указано индикатором допущения многоканальной обработки.
Например, когда многоканальным сигналом является 5.1-канальный сигнал, индикатор допущения многоканальной обработки может указывать, что предоставлена возможность многоканальной обработки только для 5 каналов, то есть, правого канала R, левого канала L, правого канала Rs объемного звучания, левого канала LS объемного звучания и центрального канала C, при этом, многоканальная обработка не разрешена применительно к каналу LFE.
Для процесса декодирования (декодирования индексов пары каналов), может использоваться следующий код на языке C. В силу этого, применительно ко всем парам каналов, необходимо количество каналов с действующей обработкой KLT (nChannels), а также количество пар каналов (numPairs) текущего кадра.
maxNumPairIdx=nChannels*(nChannels-1)/2-1; numBits=floor(log2(maxNumPairIdx)+1;
pairCounter=0;
for (chan1=1; chan1 < nChannels; chan1++) {
for (chan0=0; chan0 < chan1; chan0++) {
if (pairCounter == pairIdx) {
channelPair[0]=chan0;
channelPair[1]=chan1;
return;
}
иначе
pairCounter++;
}
} }
Для декодирования прогнозных коэффициентов применительно к углам не по полосам, может использоваться следующий код на языке C.
for(pair=0; pair<numPairs; pair++) {
mctBandsPerWindow=numMaskBands[pair]/windowsPerFrame;
if(delta_code_time[pair] > 0) {
lastVal=alpha_prev_fullband[pair];
} else {
lastVal=DEFAULT_ALPHA;
}
newAlpha=lastVal+dpcm_alpha[pair][0];
if(newAlpha >= 64) {
newAlpha -= 64;
}
for (band=0; band < numMaskBands; band++){
/* установить все углы в полнополосный угол */
pairAlpha[pair][band]=newAlpha;
/* установить предыдущие углы согласно mctMask */
if(mctMask[pair][band] > 0) {
alpha_prev_frame[pair][band%mctBandsPerWindow]=newAlpha;
}
else {
alpha_prev_frame[pair][band%mctBandsPerWindow]=DEFAULT_ALPHA;
} }
alpha_prev_fullband[pair]=newAlpha;
for(band=bandsPerWindow ; band<MAX_NUM_MC_BANDS; band++) {
alpha_prev_frame[pair][band]=DEFAULT_ALPHA;
}
}
Для декодирования прогнозных коэффициентов применительно к углам KLT не по полосам, может использоваться следующий код на языке C.
for(pair=0; pair<numPairs; pair++) {
mctBandsPerWindow=numMaskBands[pair]/windowsPerFrame;
for(band=0; band<numMaskBands[pair]; band++) {
if(delta_code_time[pair] > 0) {
lastVal=alpha_prev_frame[pair][band%mctBandsPerWindow];
}
else {
if ((band % mctBandsPerWindow) == 0) {
lastVal=DEFAULT_ALPHA;
}
}
if (msMask[pair][band] > 0 ) {
newAlpha=lastVal+dpcm_alpha[pair][band];
if(newAlpha >= 64) {
newAlpha -= 64;
}
pairAlpha[pair][band]=newAlpha;
alpha_prev_frame[pair][band%mctBandsPerWindow]=newAlpha;
lastVal=newAlpha;
}
else {
alpha_prev_frame[pair][band%mctBandsPerWindow]=DEFAULT_ALPHA; /* -45° */
}
/* сбросить полнополосный угол */
alpha_prev_fullband[pair]=DEFAULT_ALPHA;
}
for(band=bandsPerWindow ; band<MAX_NUM_MC_BANDS; band++) {
alpha_prev_frame[pair][band]=DEFAULT_ALPHA;
}
}
Чтобы избежать различий плавающей точки тригонометрических функций на разных платформах, будут использоваться следующие справочные таблицы для преобразования угловых показателей непосредственно в синус/косинус:
tabIndexToSinAlpha[64]={
-1.000000f,-0.998795f,-0.995185f,-0.989177f,-0.980785f,-0.970031f,-0.956940f,-0.941544f,
-0.923880f,-0.903989f,-0.881921f,-0.857729f,-0.831470f,-0.803208f,-0.773010f,-0.740951f,
-0.707107f,-0.671559f,-0.634393f,-0.595699f,-0.555570f,-0.514103f,-0.471397f,-0.427555f,
-0.382683f,-0.336890f,-0.290285f,-0.242980f,-0.195090f,-0.146730f,-0.098017f,-0.049068f,
0.000000f, 0.049068f, 0.098017f, 0.146730f, 0.195090f, 0.242980f, 0.290285f, 0.336890f,
0.382683f, 0.427555f, 0.471397f, 0.514103f, 0.555570f, 0.595699f, 0.634393f, 0.671559f,
0.707107f, 0.740951f, 0.773010f, 0.803208f, 0.831470f, 0.857729f, 0.881921f, 0.903989f,
0.923880f, 0.941544f, 0.956940f, 0.970031f, 0.980785f, 0.989177f, 0.995185f, 0.998795f
};
tabIndexToCosAlpha[64]={
0.000000f, 0.049068f, 0.098017f, 0.146730f, 0.195090f, 0.242980f, 0.290285f, 0.336890f,
0.382683f, 0.427555f, 0.471397f, 0.514103f, 0.555570f, 0.595699f, 0.634393f, 0.671559f,
0.707107f, 0.740951f, 0.773010f, 0.803208f, 0.831470f, 0.857729f, 0.881921f, 0.903989f,
0.923880f, 0.941544f, 0.956940f, 0.970031f, 0.980785f, 0.989177f, 0.995185f, 0.998795f,
1.000000f, 0.998795f, 0.995185f, 0.989177f, 0.980785f, 0.970031f, 0.956940f, 0.941544f,
0.923880f, 0.903989f, 0.881921f, 0.857729f, 0.831470f, 0.803208f, 0.773010f, 0.740951f,
0.707107f, 0.671559f, 0.634393f, 0.595699f, 0.555570f, 0.514103f, 0.471397f, 0.427555f,
0.382683f, 0.336890f, 0.290285f, 0.242980f, 0.195090f, 0.146730f, 0.098017f, 0.049068f
};
Для декодирования многоканального кодирования, следующий код на языке C может использоваться применительно к основанному на повороте KLT подходу.
decode_mct_rotation()
{
for (pair=0; pair < self->numPairs; pair++) {
mctBandOffset=0;
/* обратный поворот MCT */
for (win=0, group=0; group <num_window_groups; group++) {
for (groupwin=0; groupwin < window_group_length[group]; groupwin++, win++) {
*dmx=spectral_data[ch1][win];
*res=spectral_data[ch2][win];
apply_mct_rotation_wrapper(self,dmx,res,&alphaSfb[mctBandOffset], &mctMask[mctBandOffset],mctBandsPerWindow, alpha,
totalSfb,pair,nSamples);
}
mctBandOffset += mctBandsPerWindow;
}
}
}
Что касается обработки по полосам, может использоваться следующий код на языке C.
apply_mct_rotation_wrapper(self, *dmx, *res, *alphaSfb, *mctMask, mctBandsPerWindow, alpha, totalSfb, pair, nSamples)
{
sfb=0;
if (self->MCCSignalingType == 0) {
}
else if (self->MCCSignalingType == 1) {
/* применить полнополосный блок */
if (!self->bHasBandwiseAngles[pair] && !self->bHasMctMask[pair]) {
apply_mct_rotation(dmx, res, alphaSfb[0], nSamples);
}
else {
/* применить обработку по полосам */
for (i=0; i< mctBandsPerWindow; i++) {
if (mctMask[i] == 1) {
startLine=swb_offset [sfb];
stopLine =(sfb+2<totalSfb)? swb_offset [sfb+2]: swb_offset [sfb+1];
nSamples =stopLine-startLine;
apply_mct_rotation(&dmx[startLine], &res[startLine], alphaSfb[i], nSamples);
}
sfb += 2;
/* условие прерывания */
if (sfb >= totalSfb) {
break;
}
}
}
}
else if (self->MCCSignalingType == 2) {
}
else if (self->MCCSignalingType == 3) {
apply_mct_rotation(dmx, res, alpha, nSamples);
}
}
Для применения поворота KLT может использоваться следующий код на языке C.
apply_mct_rotation(*dmx, *res, alpha, nSamples)
{
for (n=0;n<nSamples;n++) {
L= dmx[n] * tabIndexToCosAlpha [alphaIdx] - res[n] * tabIndexToSinAlpha [alphaIdx];
R= dmx[n] * tabIndexToSinAlpha [alphaIdx]+res[n] * tabIndexToCosAlpha [alphaIdx];
dmx[n]=L;
res[n]=R;
}
}
Фиг. 12 показывает блок-схему последовательности операций способа 400 для декодирования кодированного многоканального сигнала, имеющего кодированные каналы и по меньшей мере двое многоканальных параметров MCH_PAR1, MCH_PAR2. Способ 400 содержит этап 402 декодирования кодированных каналов для получения декодированных каналов; и этап 404 выполнения многоканальной обработки с использованием второй пары декодированных каналов, идентифицированных многоканальными параметрами MCH_PAR2, и с использованием многоканальных параметров MCH_PAR2 для получения обработанных каналов, и выполнения дополнительной многоканальной обработки с использованием первой пары каналов, идентифицированных многоканальными параметрами MCH_PAR1, и с использованием многоканальных параметров MCH_PAR1, где первая пара каналов содержит по меньшей мере один обработанный канал.
В последующем пояснено стереофоническое заполнение при многоканальном кодировании согласно вариантам осуществления:
Как уже изложено в общих чертах, нежелательный эффект квантования спектра может состоять в том, что квантование вероятно может приводить к спектральным провалам. Например, все спектральные значения в конкретной полосе частот могут быть установлены в ноль на стороне кодера в результате квантования. Например, точное значение таких спектральных линий до квантования может быть относительно небольшим, и тогда квантование может приводить к ситуации, где спектральные значения всех спектральных линий, например, в пределах конкретной полосы частот, были установлены в ноль. На стороне декодера, при декодировании, это может приводить к нежелательным спектральным провалам.
Средство многоканального кодирования (MCT) в MPEG-H предоставляет возможность адаптации к меняющимся межканальным зависимостям, но, вследствие использования одноканальных элементов в типичных рабочих конфигурациях, не дает возможности стереофонического заполнения.
Как может быть видно на фиг. 14, средство многоканального кодирования комбинирует три или более каналов, которые закодированы иерархическим образом. Однако, способ, как средство многоканального кодирования (MCT) комбинирует разные каналы при кодировании, меняется от кадра к кадру в зависимости от текущих свойств сигнала каналов.
Например, на фиг. 14, в сценарии (a), для формирования первого кадра кодированного звукового сигнала, средство многоканального кодирования (MCT) может комбинировать первый канал Ch1 и второй канал CH2 для получения первого комбинационного канала P1 (обработанного канала) и второго комбинационного канала P2. Затем, средство многоканального кодирования (MCT) может комбинировать первый комбинационный канал P1 и третий канал CH3 для получения третьего комбинационного канала P3 и четвертого комбинационного канала P4. Средство многоканального кодирования (MCT) затем может кодировать второй комбинационный канал P2, третий комбинационный канал P3 и четвертый комбинационный канал P4 для формирования первого кадра.
Затем, например, в сценарии (b) по фиг. 14, для формирования второго кадра кодированного звукового сигнала, следующего (по времени) за первым кадром кодированного звукового сигнала, средство многоканального кодирования (MCT) может комбинировать первый канал CH1′ и третий канал CH3′ для получения первого комбинационного канала P1′ и второго комбинационного канала P2′. Затем, средство многоканального кодирования (MCT) может комбинировать первый комбинационный канал P1′ и второй канал CH2′ для получения третьего комбинационного канала P3′ и четвертого комбинационного канала P4′. Средство многоканального кодирования (MCT) затем может кодировать второй комбинационный канал P2′, третий комбинационный канал P3′ и четвертый комбинационный канал P4′ для формирования второго кадра.
Как может быть видно из фиг. 14, способ, которым были сформированы второй, третий и четвертый комбинационный канал первого кадра в сценарии по фиг. 14(a), значительно отличается от способа, которым были соответственно сформированы второй, третий и четвертый комбинационный канал второго кадра в сценарии по фиг. 14(b), так как разные комбинации каналов использовались для соответственного формирования соответственных комбинационных каналов P2, P3 и P4 и P2′, P3′, P4′.
Среди прочего, варианты осуществления настоящего изобретения основаны на следующих полученных сведениях:
Как может быть видно на фиг. 7 и фиг. 14, комбинационные каналы P3, P4 и P2 (или P2′, P3′ и P4′ в сценарии (b) по фиг. 14) подаются в кодер 104 каналов. Среди прочего, кодер 104 каналов, например, может проводить квантование, так что спектральные значения каналов P2, P3 и P4 могут устанавливаться в ноль вследствие квантования. Спектрально соседние спектральные отсчеты могут кодироваться в виде полосы спектра, при этом, каждая полоса спектра может содержать некоторое количество спектральных отсчетов.
Количество спектральных отсчетов полосы частот может быть разным для разных полос частот. Например, полосы частот в пределах диапазона нижних частот, например, могут содержать меньшее количество спектральных отсчетов (например, 4 спектральных отсчета), чем полосы частот в диапазоне верхних частот, например, который может содержать 16 частотных отсчетов. Например, критические полосы по шкале Барка могут определять используемые полосы частот.
Особенно нежелательная ситуация может возникать, когда все спектральные отсчеты полосы частот были установлены в ноль после квантования. Если может возникнуть такая ситуация, согласно настоящему изобретению, целесообразно проводить стереофоническое заполнение. Более того, настоящее изобретение основано на полученных сведениях, что должен вырабатываться по меньшей мере не только (псевдо-) случайный шум.
Вместо или в дополнение к добавлению (псевдо-) случайного шума, согласно вариантам осуществления настоящего изобретения, например, если, на фиг. 14, в сценарии (b), все спектральные значения полосы частот канала P4′ были установлены в ноль, комбинационный канал, который формировался бы идентичным или аналогичным образом, что и канал P3′, был бы очень удобной основой для формирования шума для заполнения в полосе частот, которая была квантована в ноль.
Однако, согласно вариантам осуществления настоящего изобретения, предпочтительно не использовать спектральные значения комбинационного канала P3′ текущего кадра/текущего момента времени в качестве основы для заполнения полосы частот комбинационного канала P4′, которая содержит только спектральные значения, которые нулевые, так как оба, комбинационный канал P3′, а также комбинационный канал P4′ были сформированы на основе канала P1′ и P2′, и, таким образом, использование комбинационного канала P3′ текущего момента времени привело бы к не более чем панорамированию.
Например, если P3′ является средним каналом из P1′ и P2′ (например, P3′=0,5 * (P1′+P2′) ), и если P4′ является побочным каналом P1′ и P2′ (например, P4′=0,5 * (P1′ - P2′) ), то привнесение, например, ослабленных, спектральных значений P3′ в полосу частот P4′ давало бы в результате всего лишь панорамирование.
Взамен, было бы предпочтительным использование каналов предыдущего момента времени применительно к формированию спектральных значений для заполнения спектральных провалов в текущем комбинационном канале P4′. Согласно полученным сведениям из настоящего изобретения, комбинация каналов предыдущего кадра, которая соответствует комбинационному каналу P3′ текущего кадра, была бы желательной основой для формирования спектральных отсчетов для заполнения спектральных провалов P4′.
Однако, комбинационный канал P3, который был сформирован в сценарии по фиг. 10(a) для предыдущего кадра, не соответствует комбинационному каналу P3′ текущего кадра, так как комбинационный канал P3 предыдущего кадра был сформирован иным образом, нежели комбинационный канал P3′ текущего кадра.
Согласно полученным сведениям из вариантов осуществления настоящего изобретения, приближение комбинационного канала P3′ должно формироваться на основе реконструированных каналов предыдущего кадра на стороне декодера.
Фиг. 10(a) иллюстрирует сценарий кодера, где каналы CH1, CH2 и CH3 кодируются для предыдущего кадра посредством формирования E1, E2 и E3. Декодер принимает каналы E1, E2 и E3 и реконструирует каналы CH1, CH2 и CH3, которые были закодированы. Могла произойти некоторая потеря при кодировании, но, все же, сформированные каналы CH1*, CH2* и CH3*, которые приближенно выражают CH1, CH2 и CH3, будут вполне аналогичны первоначальным каналам CH1, CH2 и CH3, так что CH1* ≈ CH1; CH2* ≈ CH2, и CH3* ≈ CH3. Согласно вариантам осуществления, декодер удерживает каналы CH1*, CH2* и CH3*, сформированные для предыдущего кадра, в буфере для использования их применительно к шумовому заполнению в текущем кадре.
Фиг. 1a, которая иллюстрирует устройство 201 для декодирования согласно вариантам осуществления, далее описана подробнее:
Устройство 201 по фиг. 1a приспособлено декодировать предыдущий кодированный многоканальный сигнал предыдущего кадра для получения трех или более предыдущих звуковых выходных каналов и декодировать текущий кодированный многоканальный сигнал 107 текущего кадра для получения трех или более текущих звуковых выходных каналов.
Устройство 201 содержит интерфейс 212, канальный декодер 202, многоканальный процессор 204 для формирования трех или более текущих звуковых выходных каналов CH1, CH2, CH3 и модуль 220 шумового заполнения.
Интерфейс 212 приспособлен принимать текущий кодированный многоканальный сигнал 107 и принимать побочную информацию, содержащую первые многоканальные параметры MCH_PAR2.
Канальный декодер 202 приспособлен декодировать текущий кодированный многоканальный сигнал текущего кадра для получения набора из трех или более декодированных каналов D1, D2, D3 текущего кадра.
Многоканальный процессор 204 приспособлен выбирать первую выбранную пару двух декодированных каналов D1, D2 из набора из трех или более декодированных каналов D1, D2, D3 в зависимости от первых многоканальных параметров MCH_PAR2.
В качестве примера, это проиллюстрировано на фиг. 1a двумя каналами D1, D2, которые подаются в (необязательный) блок 208 обработки.
Более того, многоканальный процессор 204 приспособлен формировать первую группу из двух или более обработанных каналов P1*, P2* на основе упомянутой первой выбранной пары двух декодированных каналов D1, D2 для получения обновленного набора из трех или более декодированных каналов D3, P1*, P2*.
В примере, где два канала D1 и D2 подаются в (необязательный) блок 208, два обработанных канала P1* и P2* формируются из двух выбранных каналов D1 и D2. Обновленный набор из трех или более декодированных каналов, в таком случае, содержит канал D3, который был оставлен в прежнем состоянии и не был модифицирован, а кроме того, содержит P1* и P2*, которые были сформированы из D1 и D2.
Перед тем как многоканальный процессор 204 формирует первую пару из двух или более обработанных каналов P1*, P2* на основе упомянутой первой выбранной пары двух декодированных каналов D1, D2, модуль 220 шумового заполнения приспособлен идентифицировать, применительно к по меньшей мере одному из двух каналов из упомянутой первой выбранной пары двух декодированных каналов D1, D2, одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формировать смесительный канал с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов, и заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, при этом, модуль 220 шумового заполнения приспособлен выбирать два или более предыдущих звуковых выходных каналов, которые используются для формирования смесительного канала, из трех или более предыдущих звуковых выходных каналов в зависимости от побочной информации.
Таким образом, модуль 220 шумового заполнения анализирует, есть ли полосы частот, которые имеют только спектральные значения, которые нулевые, и более того, заполняет найденные пустые полосы частот сформированным шумом. Например, полоса частот, например, может иметь 4, или 8, или 16 спектральных линий и, когда все спектральные линии полосы частот были квантованы в ноль, тогда модуль 220 шумового заполнения осуществляет заполнение сформированным шумом.
Конкретная концепция вариантов осуществления, которые могут применяться модулем 220 шумового заполнения, которая задает, каким образом формировать шум и заполнять шумом, упоминается в качестве стереофонического заполнения.
В вариантах осуществления по фиг. 1a, модуль 220 шумового заполнения взаимодействует с многоканальным процессором 204. Например, в варианте осуществления, когда модулю шумового заполнения необходимо обработать два канала, например, посредством блока обработки, он подает эти каналы в модуль 220 шумового заполнения, и модуль 220 шумового заполнения проверяет, были ли полосы частот квантованы в ноль, и заполняет такие полосы частот, если обнаружено.
В других вариантах осуществления, проиллюстрированных фиг. 1b, модуль 220 шумового заполнения взаимодействует с канальным декодером 202. Например, еще когда канальный декодер декодирует кодированный многоканальный сигнал для получения трех или более декодированных каналов D1, D2 и D3, модуль шумового заполнения, например, может проверять, были ли полосы частот квантованы в ноль, и, например, заполняет такие полосы частот, если обнаружено. В таком варианте осуществления, многоканальный процессор 204 может быть уверен, что все спектральные провалы уже были закрыты раньше шумовым заполнением.
В дополнительных вариантах осуществления (не показанных), модуль 220 шумового заполнения может взаимодействовать как с канальным декодером так и с многоканальным процессором. Например, когда канальный декодер 202 формирует декодированные каналы D1, D2 и D3, модуль 220 шумового заполнения уже может проверять, были ли полосы частот квантованы в ноль, прямо после того, как канальный декодер 202 сформировал их, но может формировать шум и заполнять соответственные полосы частот, только когда многоканальный процессор 204 реально обрабатывает эти каналы.
Например, случайный шум, дешевая с вычислительной точки зрения операция, может быть вставлен в любые из полос частот, которые были квантованы в ноль, но модуль шумового заполнения может заполнять шумом, который был сформирован из сформированных ранее звуковых выходных каналов, только если они реально обрабатываются многоканальным процессором 204. Однако, в таких вариантах осуществления, перед вставкой случайного шума, должно быть выполнено определение, существуют ли спектральные провалы, перед вставкой случайного шума, и такая информация должна удерживаться в памяти, так как, после вставки случайного шума, соответственные полосы частот имеют спектральные значения, отличные от нуля, поскольку был вставлен случайный шум.
В вариантах осуществления, случайный шум вставляется в полосы частот, которые были квантованы в ноль, в дополнение к шуму, сформированному на основе предыдущих звуковых выходных сигналов.
В некоторых вариантах осуществления, например, интерфейс 212 может быть приспособлен принимать текущий кодированный многоканальный сигнал 107 и принимать побочную информацию, содержащую первые многоканальные параметры MCH_PAR2 и вторые многоканальные параметры MCH_PAR1.
Многоканальный процессор 204, например, может быть приспособлен выбирать вторую выбранную пару двух декодированных каналов P1*, D3 из обновленного набора из трех или более декодированных каналов D3, P1*, P2* в зависимости от вторых многоканальных параметров MCH_PAR1, при этом, по меньшей мере один канал P1* из второй выбранной пары двух декодированных каналов P1*, D3 является одним каналом из первой пары двух или более обработанных каналов P1*, P2*, и
Многоканальный процессор 204, например, может быть приспособлен формировать вторую группу из двух или более обработанных каналов P3*, P4* на основе упомянутой второй выбранной пары двух декодированных каналов P1*, D3 для дальнейшего обновления обновленного набора из трех или более декодированных каналов.
Пример для такого варианта осуществления может быть виден на фиг. 1a и 1b, где (необязательный) блок 210 обработки принимает канал D3 и обработанный канал P1* и обрабатывает их для получения обработанных каналов P3* и P4*, так чтобы дополнительно обновленный набор из трех декодированных каналов содержал P2*, который не был модифицирован блоком 210 обработки, и сформированные P3* и P4*.
Блоки 208 и 210 обработки были помечены на фиг. 1a и фиг. 1b в качестве необязательных. Это должно показать, что, хотя можно использовать блоки 208 и 210 обработки для реализации многоканального процессора 204, существуют различные другие возможности, каким образом полностью реализовать многоканальный процессор 204. Например, вместо использования разных блоков 208, 210 обработки для каждой разной обработки двух (или более) каналов, один и тот же блок обработки может использоваться повторно, или многоканальный процессор 204 может реализовывать обработку двух каналов вообще без использования блоков 208, 210 обработки (в качестве подузлов многоканального процессора 204).
Согласно дополнительному варианту осуществления, многоканальный процессор 204, например, может быть приспособлен формировать первую группу из двух или более обработанных каналов P1*, P2*, формируя первую группу из в точности двух обработанных каналов P1*, P2* на основе упомянутой первой выбранной пары двух декодированных каналов D1, D2. Многоканальный процессор 204, например, может быть приспособлен замещать упомянутую первую выбранную пару двух декодированных каналов D1, D2 в наборе из трех или более декодированных каналов D1, D2, D3 первой группой из в точности двух обработанных каналов P1*, P2* для получения обновленного набора из трех или более декодированных каналов D3, P1*, P2*. Многоканальный процессор 204, например, может быть приспособлен формировать вторую группу из двух или более обработанных каналов P3*, P4*, формируя вторую группу из в точности двух обработанных каналов P3*, P4* на основе упомянутой второй выбранной пары двух декодированных каналов P1*, D3. Более того, многоканальный процессор 204, например, может быть приспособлен замещать упомянутую вторую выбранную пару двух декодированных каналов P1*, D3 в обновленном наборе из трех или более декодированных каналов D3, P1*, P2* второй группой из в точности двух обработанных каналов P3*, P4* для дополнительного обновления обновленного набора из трех или более декодированных каналов.
В таком варианте осуществления, из двух выбранных каналов (например, двух входных каналов блока 208 или 210 обработки), формируются в точности два обработанных канала, и эти в точности два обработанных канала замещают выбранные каналы в наборе из трех или более декодированных каналов. Например, блок 208 обработки многоканального процессора 204 замещает выбранные каналы D1 и D2 каналами P1* и P2*.
Однако, в других вариантах осуществления, повышающее микширование может происходить в устройстве 201 для декодирования, и больше, чем два обработанных канала могут формироваться из двух выбранных каналов, или не все из выбранных каналов могут удаляться из обновленного набора декодированных каналов.
Дополнительная задача состоит в том, чтобы формировать смесительный канал, который используется для формирования шума, формируемого модулем 220 шумового заполнения.
Модуль 220 шумового заполнения, например, может быть приспособлен формировать смесительный канал с использованием в точности двух из трех или более предыдущих звуковых выходных каналов в качестве двух или более из трех или более предыдущих звуковых выходных каналов; при этом, модуль 220 шумового заполнения, например, может быть приспособлен выбирать в точности два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов в зависимости от побочной информации.
Использование только двух из трех или более предыдущих выходных каналов помогает понизить вычислительную сложность расчета смесительного канала.
Однако, в других вариантах осуществления, более чем два канала из предыдущих звуковых выходных каналов используются для формирования смесительного канала, но количество предыдущих звуковых выходных каналов, которые учитываются, меньше общего количества трех или более предыдущих звуковых выходных каналов.
В вариантах осуществления, где учитываются только два из предыдущих выходных каналов, смесительный канал, например, может рассчитываться, как изложено ниже:
В варианте осуществления, модуль 220 шумового заполнения приспособлен формировать смесительный канал с использованием в точности двух предыдущих звуковых выходных каналов на основе формулы
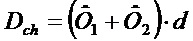 или на основе формулы
или на основе формулы
 ,
,
в которой 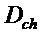 - смесительный канал; при этом
- смесительный канал; при этом  - первый один из в точности двух предыдущих звуковых выходных каналов; при этом,
- первый один из в точности двух предыдущих звуковых выходных каналов; при этом,  - второй один из в точности двух предыдущих звуковых выходных каналов, являющийся отличным от первого одного из в точности двух предыдущих звуковых выходных каналов, и при этом,
- второй один из в точности двух предыдущих звуковых выходных каналов, являющийся отличным от первого одного из в точности двух предыдущих звуковых выходных каналов, и при этом, 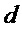 - действительный положительный скаляр.
- действительный положительный скаляр.
В типичных ситуациях, средний канал  может быть пригодным смесительным каналом. Такой подход рассчитывает смесительный канал в качестве среднего канала из двух предыдущих звуковых выходных каналов, которые учитываются.
может быть пригодным смесительным каналом. Такой подход рассчитывает смесительный канал в качестве среднего канала из двух предыдущих звуковых выходных каналов, которые учитываются.
Однако, в некоторых сценариях, смесительный канал, близкий к нулю, может встречаться при применении 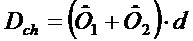 , например, когда
, например, когда  . Тогда, например, может быть предпочтительно использовать
. Тогда, например, может быть предпочтительно использовать 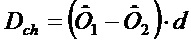 в качестве смесительного сигнала. Таким образом, в таком случае, используется побочный канал (для входных каналов не в фазе).
в качестве смесительного сигнала. Таким образом, в таком случае, используется побочный канал (для входных каналов не в фазе).
Согласно альтернативному подходу, модуль 220 шумового заполнения приспособлен формировать смесительный канал с использованием в точности двух предыдущих звуковых выходных каналов на основе формулы
 или на основе формулы
или на основе формулы

в которой  - смесительный канал, при этом - первый один из в точности двух предыдущих звуковых выходных каналов, при этом, - второй один из в точности двух предыдущих звуковых выходных каналов, являющийся отличным от первого одного из в точности двух предыдущих звуковых выходных каналов, и при этом,
- смесительный канал, при этом - первый один из в точности двух предыдущих звуковых выходных каналов, при этом, - второй один из в точности двух предыдущих звуковых выходных каналов, являющийся отличным от первого одного из в точности двух предыдущих звуковых выходных каналов, и при этом, 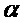 - угол поворота.
- угол поворота.
Такой подход рассчитывает смесительный канал, проводя поворот двух предыдущих звуковых выходных каналов, которые учитываются.
Угол 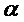 поворота, например, может быть в диапазоне: -90° <
поворота, например, может быть в диапазоне: -90° <  < 90°.
< 90°.
Например, в варианте осуществления, угол поворота может быть в диапазоне: 30° < < 60°.
Вновь, в типичных ситуациях, канал может быть пригодным смесительным каналом. Такой подход рассчитывает смесительный канал в качестве среднего канала из двух предыдущих звуковых выходных каналов, которые учитываются.
Однако, в некоторых сценариях, смесительный канал, близкий к нулю, может встречаться при применении 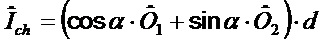 , например, когда
, например, когда  . Тогда, например, может быть предпочтительно использовать в качестве смесительного сигнала.
. Тогда, например, может быть предпочтительно использовать в качестве смесительного сигнала.
Согласно конкретному варианту осуществления, побочная информация, например, может быть текущей побочной информацией, назначаемой в текущий кадр, при этом, интерфейс 212, например, может быть приспособлен принимать предыдущую побочную информацию, назначаемую в предыдущий кадр, при этом, предыдущая побочная информация содержит предыдущий угол; при этом, интерфейс 212, например, может быть приспособлен принимать текущую побочную информацию, содержащую текущий угол, и при этом, модуль 220 шумового заполнения, например, может быть приспособлен использовать текущий угол из текущей побочной информации в качестве угла поворота и приспособлен не использовать предыдущий угол из предыдущей побочной информации в качестве угла поворота.
Таким образом, в таком варианте осуществления, даже если смесительный канал рассчитывается на основе предыдущих звуковых выходных каналов, все же текущий угол, который передается в побочной информации, используется в качестве угла поворота, а не предыдущий принятый угол поворота, хотя смесительный канал рассчитывается на основе предыдущих звуковых выходных каналов, которые были сформированы на основе предыдущего кадра.
Еще один аспект некоторых вариантов осуществления настоящего изобретения относится к масштабным коэффициентам.
Например, полосы частот могут быть полосами масштабных коэффициентов.
Согласно некоторым вариантам осуществления, перед тем как многоканальный процессор 204 формирует первую пару из двух или более обработанных каналов P1*, P2* на основе упомянутой первой выбранной пары двух декодированных каналов D1, D2, модуль 220 шумового заполнения, например, может быть приспособлен идентифицировать, применительно к по меньшей мере одному из двух каналов из упомянутой первой выбранной пары двух декодированных каналов D1, D2, одна или более полос масштабных коэффициентов, являющихся одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и, например, может быть приспособлен формировать смесительный канал с использованием упомянутых двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов, и заполнять спектральные линии одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, в зависимости от масштабного коэффициента каждой из одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль.
В таких вариантах осуществления, масштабный коэффициент, например, может быть назначен на каждую из полос масштабных коэффициентов, и такой масштабный коэффициент учитывается при формировании шума с использованием смесительного канала.
В конкретном варианте осуществления, приемный интерфейс 212, например, может быть выполнен с возможностью принимать масштабный коэффициент каждой из упомянутых одной или более полос масштабных коэффициентов, и масштабный коэффициент каждой из упомянутых одной или более полос масштабных коэффициентов указывает энергию спектральных линий упомянутой полосы масштабных коэффициентов до квантования. Модуль 220 шумового заполнения, например, может быть приспособлен формировать шум для каждой из одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль, так чтобы энергия спектральных линий после добавления шума в одну из полос частот соответствовала энергии, указываемой масштабным коэффициентом для упомянутой полосы масштабных коэффициентов.
Например, смесительный канал может указывать спектральные значения для четырех спектральных линий из полосы масштабных коэффициентов, в которые будет вставлен шум, и этими спектральными значениями, например, могут быть: 0,2; 0,3; 0,5; 0,1.
Энергия такой полосы масштабных коэффициентов смесительного канала, например, может рассчитываться, как изложено ниже:

Однако, масштабный коэффициент для полосы масштабных коэффициентов канала, в котором будет происходить заполнение шумом, например, может иметь значение всего лишь 0,0039.
Например, коэффициент ослабления может рассчитываться, как изложено ниже:

Таким образом, в вышеприведенном примере

В варианте осуществления, каждое из спектральных значений полосы масштабных коэффициентов смесительного канала, который будет использоваться в качестве шума, умножается на коэффициент ослабления:
Таким образом, каждое из четырех спектральных значений полосы масштабных коэффициентов по вышеприведенному примеру, умножается на коэффициент ослабления, и это дает в результате ослабленные спектральные значения:
0,2 ⋅ 0,01=0,002
0,3 ⋅ 0,01=0,003
0,5 ⋅ 0,01=0,005
0,1 ⋅ 0,01=0,001
Эти ослабленные спектральные значения, например, затем могут вставляться в полосу масштабных коэффициентов канала, в котором будет происходить заполнение шумом.
Вышеприведенный пример равным образом применим к логарифмическим значениям посредством замены вышеприведенных операций их соответствующими логарифмическими операциями, например, посредством замены умножения сложением, и т. д.
Более того, в дополнение к описанию конкретных вариантов осуществления, приведенных выше, другие варианты осуществления модуля 220 шумового заполнения применяют одну, некоторые или все концепции, описанные со ссылкой на с фиг. 2 по фиг. 6.
Еще один аспект вариантов осуществления настоящего изобретения относится к вопросу, на каком основании информационные каналы выбираются из предыдущих звуковых выходных каналов для использования, чтобы формировать смесительный канал для получения шума, подлежащего вставке.
Согласно варианту осуществления, устройство в соответствии с модулем 220 шумового заполнения, например, может быть приспособлено выбирать в точности два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов в зависимости от первых многоканальных параметров MCH_PAR2.
Таким образом, в таком варианте осуществления, первые многоканальные параметры, которые управляют тем, какие каналы должны выбираться для обработки, к тому же управляют тем, какие предыдущие звуковые выходные каналы должны использоваться применительно к формированию смесительного канала для формирования шума, подлежащего вставке.
В варианте осуществления, первые многоканальные параметры MCH_PAR2, например, могут указывать два декодированных канала D1, D2 из набора из трех или более декодированных каналов; и многоканальный процессор 204 приспособлен выбирать первую выбранную пару двух декодированных каналов D1, D2 из набора из трех или более декодированных каналов D1, D2, D3, выбирая два декодированных канала D1, D2, указываемых первыми многоканальными параметрами MCH_PAR2. Более того, вторые многоканальные параметры MCH_PAR1, например, могут указывать два декодированных канала P1*, D3 из обновленного набора из трех или более декодированных каналов. Многоканальный процессор 204, например, может быть приспособлен выбирать вторую выбранную пару двух декодированных каналов P1*, D3 из обновленного набора из трех или более декодированных каналов D3, P1*, P2*, выбирая два декодированных канала P1*, D3, указываемых вторыми многоканальными параметрами MCH_PAR1.
Таким образом, в таком варианте осуществления, каналы, которые выбираются для первой обработки, например, обработки блока 208 обработки на фиг. 1a или фиг. 1b, не просто зависят от первых многоканальных параметров MCH_PAR2. Более того, эти два выбранных канала явным образом заданы в первых многоканальных параметрах MCH_PAR2.
Подобным образом, в таком варианте осуществления, каналы, которые выбираются для второй обработки, например, обработки блока 210 обработки на фиг. 1a или фиг. 1b, не просто зависят от вторых многоканальных параметров MCH_PAR1. Более того, эти два выбранных канала явным образом заданы во вторых многоканальных параметрах MCH_PAR1.
Варианты осуществления настоящего изобретения привносят изощренную схему индексации для многоканальных параметров, которая пояснена со ссылкой на фиг. 15.
Фиг. 15 (a) показывает кодирование пяти каналов, а именно, каналов левого, правого, центрального, левого объемного звучания и правого объемного звучания, на стороне кодера. Фиг. 15 (b) показывает декодирование кодированных каналов E0, E1, E2, E3, E4, чтобы реконструировать каналы левый, правый, центральный, левый объемного звучания и правый объемного звучания.
Предполагается, что индекс назначается каждому из пяти каналов, левому, правому, центральному, левому объемного звучания и правому объемного звучания, а именно
Индекс Название канала
0 Левый
1 Правый
2 Центральный
3 Левый объемного звучания
4 Правый объемного звучания
На фиг. 15(a), на стороне кодера, первой операцией, которая проводится, например, может быть микширование канала 0 (левого) и канала 3 (левого объемного звучания) в блоке 192 обработки для получения двух обработанных каналов. Может быть предположено, что один из обработанных каналов является средним каналов, а другой канал является побочным каналом. Однако, также могут применяться другие концепции формирования двух обработанных каналов, например, определение двух обработанных каналов посредством проведения операции поворота.
Далее, два сформированных обработанных канала получают такие же индексы, как индексы каналов, которые использовались для обработки. А именно, первый один из обработанных каналов имеет индекс 0, а второй один из обработанных каналов имеет индекс 3. Определенными многоканальными параметрами для этой обработки, например, могут быть (0; 3).
Второй операцией на стороне кодера, которая проводится, например, может быть микширование канала 1 (правого) и канала 4 (правого объемного звучания) в блоке 194 обработки для получения двух дополнительных обработанных каналов. Вновь, два дополнительных сформированных обработанных канала получают такие же индексы, как индексы каналов, которые использовались для обработки. А именно, первый один из дополнительных обработанных каналов имеет индекс 1, а второй один из обработанных каналов имеет индекс 4. Определенными многоканальными параметрами для этой обработки, например, могут быть (1; 4).
Третьей операцией на стороне кодера, которая проводится, например, может быть микширование обработанного канала 0 и обработанного канала 1 в блоке 196 обработки для получения еще двух обработанных каналов. Вновь, эти два сформированных обработанных канала получают такие же индексы, как индексы каналов, которые использовались для обработки. А именно, первый один из дополнительных обработанных каналов имеет индекс 0, а второй один из обработанных каналов имеет индекс 1. Определенными многоканальными параметрами для этой обработки, например, могут быть (0; 1).
Кодированные каналы E0, E1, E2, E3 и E4 различаются своими индексами, а именно, E0 имеет индекс 0, E1 имеет индекс 1, E2 имеет индекс 2, и т. д.
Три операции на стороне кодера дают в результате три многоканальных параметра:
(0; 3), (1; 4), (0; 1).
Так как устройство для декодирования будет выполнять операции кодера в обратном порядке, порядок многоканальных параметров, например, может быть обращен, при передаче на устройство для декодирования, давая в результате многоканальные параметры:
(0; 1), (1; 4), (0; 3).
Что касается устройства для декодирования, (0; 1) могут упоминаться как первые многоканальные параметры, (1; 4) могут упоминаться как вторые многоканальные параметры, а (0; 3) могут упоминаться как третьи многоканальные параметры.
На стороне декодера, показанной на фиг. 15(b), по приему первых многоканальных параметров (0; 1), устройство для декодирования делает вывод, что, в качестве первой операции обработки на стороне декодера, будут обрабатываться каналы 0 (E0) и 1 (E1). Это проводится в блоке 296 по фиг. 15(b). Оба сформированных обработанных канала наследуют индексы от каналов E0 и E1, которые были использованы для их формирования, и таким образом, сформированные обработанные каналы также имеют индексы 0 и 1.
По приему вторых многоканальных параметров (1; 4), устройство для декодирования делает вывод, что, в качестве второй операции обработки на стороне декодера, будут обрабатываться обработанный каналы 1 и канал 4 (E4). Это проводится в блоке 294 по фиг. 15(b). Оба сформированных обработанных канала наследуют индексы от каналов 1 и 4, которые были использованы для их формирования, и таким образом, сформированные обработанные каналы также имеют индексы 1 и 4.
По приему третьих многоканальных параметров (0; 3), устройство для декодирования делает вывод, что, в качестве третьей операции обработки на стороне декодера, будут обрабатываться обработанный каналы 0 и канал 3 (E3). Это проводится в блоке 292 по фиг. 15(b). Оба сформированных обработанных канала наследуют индексы от каналов 0 и 3, которые были использованы для их формирования, и таким образом, сформированные обработанные каналы также имеют индексы 0 и 3.
В результате обработки устройством для декодирования, реконструируются каналы левый (индекс 0), правый (индекс 1), центральный (индекс 2), левый объемного звучания (индекс 3) и правый объемного звучания (индекс 4).
Давайте предположим, что на стороне декодера, вследствие квантования, все значения канала E1 (индекс 1) в пределах определенной полосы масштабных коэффициентов были квантованы в ноль. Когда устройству для декодирования необходимо проводить обработку в блоке 296, требуется заполненный шумом канал 1 (канал E1).
Как уже изложено в общих чертах, варианты осуществления далее используют два предыдущих звуковых выходных сигнала для заполнения шумом спектрального провала канала 1.
В конкретном варианте осуществления, если канал, с которым будет проводиться операция, имеет полосы масштабных коэффициентом, которые квантованы в ноль, то два предыдущих звуковых выходных канала используются для формирования шума, которые имеют те же номера индексов, что и два канала, с которыми будет проводиться обработка. В примере, если спектральный провал канала 1 выявлен перед обработкой в блоке 296 обработки, то предыдущие звуковые выходные каналы, имеющий индекс 0 (предыдущий левый канал) и имеющий индекс 1 (предыдущий правый канал), используются для формирования шума для заполнения спектрального провала канала 1 на стороне декодера.
Так как индексы единообразно наследуются обработанными каналами, которые являются результатом обработки, может быть предположено, что предыдущие выходные каналы сыграли бы роль в формировании каналов, которые принимают участие в действующей обработке стороны декодера, если бы предыдущие звуковые выходные каналы были текущими звуковыми выходными каналами. Таким образом, можно добиваться хорошей оценки для полосы масштабных коэффициентов, которые были квантованы в ноль.
Согласно вариантам осуществления, устройство, например, может быть приспособлено назначать идентификатор из набора идентификаторов на каждый предыдущий звуковой выходной канал из трех или более предыдущих звуковых выходных каналов, так чтобы каждому предыдущему звуковому выходному каналу из трех или более предыдущих звуковых выходных каналов назначался в точности один идентификатор из набора идентификаторов, и так чтобы каждый идентификатор из набора идентификаторов был назначен в точности на один предыдущий звуковой выходной канал из трех или более предыдущих звуковых выходных каналов. Более того, устройство, например, может быть приспособлено назначать идентификатор из упомянутого набора идентификаторов на каждый канал из набора из трех или более декодированных каналов, так чтобы каждому каналу из набора из трех или более декодированных каналов назначался в точности один идентификатор из набора идентификаторов, и так чтобы каждый идентификатор из набора идентификаторов был назначен в точности на один из набора из трех или более декодированных каналов.
Более того, первые многоканальные параметры MCH_PAR2, например, могут указывать первую пару двух идентификаторов из набора из трех или более идентификаторов. Многоканальный процессор 204, например, может быть приспособлен выбирать первую выбранную пару двух декодированных каналов D1, D2 из набора из трех или более декодированных каналов D1, D2, D3, выбирая два декодированных канала D1, D2, назначаемых двумя идентификаторами из первой пары двух идентификаторов.
Устройство, например, может быть приспособлено назначать первый один из двух идентификаторов из первой пары двух идентификаторов на первый обработанный канал из первой группы из в точности двух обработанных каналов P1*, P2*. Более того, устройство, например, может быть приспособлено назначать второй один из двух идентификаторов из первой пары двух идентификаторов на второй обработанный канал из первой группы из в точности двух обработанных каналов P1*, P2*.
Набор идентификаторов, например, может быть набором индексов, например, набором неотрицательных целых чисел (например, набором, содержащим идентификаторы 0; 1; 2; 3 и 4).
В конкретных вариантах осуществления, вторые многоканальные параметры MCH_PAR1, например, могут указывать вторую пару двух идентификаторов из набора из трех или более идентификаторов. Многоканальный процессор 204, например, может быть приспособлен выбирать вторую выбранную пару двух декодированных каналов P1*, D3 из обновленного набора из трех или более декодированных каналов D3, P1*, P2*, выбирая два декодированных канала D3, P1*, назначаемых двумя идентификаторами из второй пары двух идентификаторов. Более того, устройство, например, может быть приспособлено назначать первый один из двух идентификаторов из второй пары двух идентификаторов на первый обработанный канал из первой группы из в точности двух обработанных каналов P3*, P4*. Кроме того, устройство, например, может быть приспособлено назначать второй один из двух идентификаторов из второй пары двух идентификаторов на второй обработанный канал из первой группы из в точности двух обработанных каналов P3*, P4*.
В конкретном варианте осуществления, первые многоканальные параметры MCH_PAR2, например, могут указывать упомянутую первую пару двух идентификаторов из набора из трех или более идентификаторов. Модуль 220 шумового заполнения, например, может быть приспособлен выбирать в точности два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов, выбирая два предыдущих звуковых выходных канала, назначаемых двумя идентификаторами из упомянутой первой пары двух идентификаторов.
Как уже изложено в общих чертах, фиг. 7 иллюстрирует устройство 100 для кодирования многоканального сигнала 101, имеющего по меньшей мере три канала (CH1:CH3) согласно варианту осуществления.
Устройство содержит итерационный процессор 102, являющийся приспособленным рассчитывать, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов (CH:CH3) для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и для обработки выбранной пары с использованием операции 110, 112 многоканальной обработки, чтобы извлекать начальные многоканальные параметры MCH_PAR1 для выбранной пары и получать первые обработанные каналы P1, P2.
Итерационный процессор 102 приспособлен выполнять расчет, выбор и обработку на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов P1, чтобы получать дополнительные многоканальные параметры MCH_PAR2 и вторые обработанные каналы P3, P4.
Более того, устройство содержит кодер каналов, являющийся приспособленным кодировать каналы (P2:P4), являющиеся результатом итерационной обработки, выполняемой итерационным процессором 104, для получения кодированных каналов (E1:E3).
Кроме того, устройство содержит выходной интерфейс 106, являющийся приспособленным формировать кодированный многоканальный сигнал 107, имеющий кодированные каналы (E1:E3), начальные многоканальные параметры и дополнительные многоканальные параметры MCH_PAR1, MCH_PAR2.
Более того, устройство содержит выходной интерфейс 106, являющийся приспособленным формировать кодированный многоканальный сигнал 107, чтобы содержал информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным на основе ранее декодированных звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Таким образом, устройство для кодирования способно сигнализировать, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Согласно варианту осуществления, каждые из начальных многоканальных параметров и дополнительных многоканальных параметров MCH_PAR1, MCH_PAR2 указывают в точности два канала, каждый один из в точности двух каналов является одним из кодированных каналов (E1:E3) или является одним из первого или второго обработанных каналов P1, P2, P3, P4, или является одним из по меньшей мере трех каналов (CH:CH3).
Выходной интерфейс 106, например, может быть приспособлен формировать кодированный многоканальный сигнал 107, так чтобы информация, указывающая, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, содержала информацию, которая указывает, применительно к каждым одним из начальных и дополнительных многоканальных параметров MCH_PAR1, MCH_PAR2, будет или нет устройство для декодирования, применительно к по меньшей мере одному каналу из в точности двух каналов, которые указаны упомянутыми одними из начальных и дополнительных многоканальных параметров MCH_PAR1, MCH_PAR2, заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, упомянутого по меньшей мере одного канала, спектральными данными, сформированными на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Ниже описаны конкретные варианты осуществления, где такая информация передается с использованием значения hasStereoFilling[pair], которое указывает, будет или нет применяться стереофоническое заполнение в обрабатываемой на данный момент пере каналов MCT.
Фиг. 13 иллюстрирует систему согласно вариантам осуществления.
Система содержит устройство 100 для кодирования, как описано выше, и устройство 201 для декодирования согласно одному из описанных выше вариантов осуществления.
Устройство 201 для декодирования выполнено с возможностью принимать кодированный многоканальный сигнал 107, формируемый устройством 100 для кодирования, из устройства 100 для кодирования.
Кроме того, предусмотрен кодированный многоканальный сигнал 107.
Кодированный многоканальный сигнал содержит
- кодированные каналы (E1:E3), и
- многоканальные параметры MCH_PAR1, MCH_PAR2, и
- информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, спектральными данными, сформированными на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Согласно варианту осуществления, кодированный многоканальный сигнал, например, может содержать, в качестве многоканальных параметров MCH_PAR1, MCH_PAR2, двое или более многоканальных параметров.
Каждые из двух или более многоканальных параметров MCH_PAR1, MCH_PAR2, например, могут указывать в точности два канала, каждый один из в точности двух каналов является одним из кодированных каналов (E1:E3) или является одним из множества обработанных каналов P1, P2, P3, P4, или является одним из по меньшей мере трех первоначальных (например, необработанных) каналов (CH:CH3).
Информация, указывающая, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, например, может содержать информацию, которая указывает, применительно к каждым одним из двух или более многоканальных параметров MCH_PAR1, MCH_PAR2, будет или нет устройство для декодирования, применительно к по меньшей мере одному каналу из в точности двух каналов, которые указаны упомянутыми одними из двух или более многоканальных параметров, заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, упомянутого по меньшей мере одного канала, спектральными данными, сформированными на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
Как уже изложено в общих чертах, ниже описаны конкретные варианты осуществления, где такая информация передается с использованием значения hasStereoFilling[pair], которое указывает, будет или нет применяться стереофоническое заполнение в обрабатываемой на данный момент пере каналов MCT.
В нижеследующем, подробнее описаны общие концепции и конкретные варианты осуществления.
Варианты осуществления реализуют, применительно к режиму параметрического кодирования для малой скорости передачи битов с возможностью перенастройки использования произвольных стереофонических деревьев, комбинацию стереофонического заполнения и MCT.
Межканальные зависимости сигнала используются иерархическим применением известных средств совместного стереофонического кодирования. Что касается меньших скоростей передачи битов, варианты осуществления расширяют MCT использованием обособленных блоков стереофонического кодирования и блоков стереофонического заполнения. Таким образом, полупараметрическое кодирование, например, может применяться к каналам с аналогичным содержимым, то есть к парам каналов с наивысшей корреляцией, тогда как отличающиеся каналы могут кодироваться независимо или с помощью непараметрического представления. Поэтому, синтаксис потока битов MCT расширяется, чтобы быть способным сигнализировать, разрешено ли стереофоническое заполнение, и где оно является действующим.
Варианты осуществления реализуют формирование предыдущего результата понижающего микширования для произвольных пар стереофонического заполнения.
Стереофоническое заполнение полагается на использование результата понижающего микширования предыдущего кадра для улучшения заполнения спектральных провалов, вызванных квантованием в частотной области. Однако, в комбинации с MCT, набору совместно кодированных стереофонических пар теперь предоставлена возможность быть меняющимся во времени. Следовательно, два совместно кодированных канала могли не быть совместно кодированными в предыдущем кадре, то есть, когда изменилась конфигурация дерева.
Для оценки предыдущего результата понижающего микширования, кодированные ранее выходные каналы сохраняются и обрабатываются операцией инверсного стереофонического кодирования. Что касается данного стереофонического блока, это делается с использованием параметров текущего кадра и декодированных выходных каналов предыдущего кадра, соответствующих индексам каналов обрабатываемого стереофонического блока.
Если сигнала предыдущего выходного канала нет в распоряжении, например, вследствие независимого кадра (кадра, который может декодироваться без учета данных предыдущего кадра) или изменения длины преобразования, буфер предыдущего канала соответствующего канала устанавливается в ноль. Таким образом, ненулевое предыдущий результат понижающего микширования будет вычисляться по-прежнему до тех пор, пока имеются в распоряжении по меньшей мере один из сигналов предыдущих каналов.
Если MCT выполнено с возможностью использовать основанные на прогнозе стереофонические блоки, предыдущий результат понижающего микширования рассчитывается с помощью обратной операции MS, как предписано для пар стереофонического заполнения, предпочтительно с использованием одного из следующих двух уравнений на основе флажкового признака направления прогноза (pred_dir в синтаксисе MPEG-H).
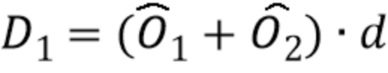
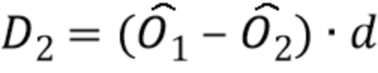 ,
,
где  - произвольная действительная и положительная скалярная величина.
- произвольная действительная и положительная скалярная величина.
Если MCT выполнен с возможностью использовать поворот на основе стереофонических блоков, предыдущий результат понижающего микширования рассчитывается с использованием поворота с инвертированным углом поворота.
Таким образом, для поворота, приведенного в виде:
,
обратный поворот рассчитывается в виде:
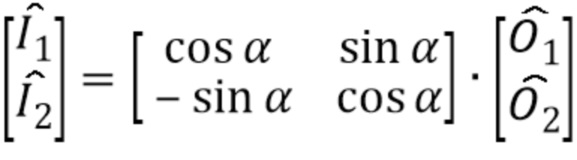
причем  является желательным предыдущим результатом понижающего микширования предыдущих выходных каналов
является желательным предыдущим результатом понижающего микширования предыдущих выходных каналов  и
и  .
.
Варианты осуществления реализуют применение стереофонического заполнения в MCT.
Применение стереофонического заполнения для одиночного стереофонического блока описано в [1], [5]. Что касается одиночного стереофонического блока, стереофоническое заполнение применяется ко второму каналу из данной пары каналов MCT.
Между тем, отличия стереофонического кодирования в комбинации с MCT изложены ниже:
Конфигурация дерева MCT расширена одним битом сигнализации на каждый кадр, чтобы быть способной сигнализировать, разрешено ли стереофоническое заполнение в текущем кадре.
В предпочтительном варианте осуществления, если стереофоническое заполнение разрешено в текущем кадре, один дополнительный бит для ввода в действие стереофонического заполнения в стереофоническом блоке передается для каждого стереофонического блока. Это предпочтительный вариант осуществления, поскольку он предоставляет возможность контроля на стороне кодера над тем, какие блоки должны иметь стереофоническое заполнение, применяемое в декодере.
Во втором варианте осуществления, если стереофоническое заполнение разрешено в текущем кадре, стереофоническое заполнение разрешено во всех стереофонических блоках, и дополнительные биты не передаются для каждого отдельного стереофонического блока. В этом случае, избирательное применение стереофонического заполнения в отдельных блоках MCT управляется декодером.
В нижеследующем описаны дополнительные концепции и подробные варианты осуществления:
Варианты осуществления улучшают качество для многоканальных рабочих точек с малой скоростью передачи битов.
В элементе пары кодированных каналов (CPE) в частотной области (FD), стандарт MPEG-H с трехмерным воспроизведением звука предоставляет возможность использования средства стереофонического заполнения, описанного в подпункте 5.5.5.4.9 из [1], для улучшенного по восприятию заполнения спектральных провалов, вызванных очень грубым квантованием в кодере. Это средство было показано особенно полезным для двухканальной стереозаписи, закодированной на средней и низкой скоростях передачи битов.
Было введено средство многоканального кодирования (MCT), описанное в разделе 7 из [2], которое дает возможность гибких, приспосабливающихся к сигналу определений пар совместно кодированных каналов на покадровой основе для использования меняющихся во времени межканальных зависимостей в многоканальной структуре. Преимущество MCT особенно значимо, когда используется для эффективного динамического совместного кодирования многоканальных структур, где каждый канал находится в своем отдельном одноканальном элементе (SCE), поскольку, в отличие от традиционных конфигураций CPE+SCE (+ LFE), которые должны создаваться априори, оно предоставляет совместному кодированию каналов возможность каскадироваться и/или реконфигурироваться от одного кадра к следующему.
Кодирование многоканального звука объемного звучания без использования CPE на данный момент имеет недостаток, что средство совместного стереофонического кодирования имеется в распоряжении только в CPE - прогнозное кодирование M/S и стереофоническое заполнение - не могут использоваться, что особенно неблагоприятно на средних и низких скоростях передачи битов. MCT может действовать в качестве замены для средства M/S, но замены для средства стереофонического заполнения на данный момент нет в распоряжении.
Варианты осуществления также предоставляют возможность использования средства стереофонического заполнения в пределах пар каналов MCT, расширяя синтаксис потока битов MCT соответственным битом сигнализации и распространяя применение стереофонического заполнения на произвольные пары каналов независимо от их типов элемента канала.
Некоторые варианты осуществления, например, могут реализовывать сигнализацию стереофонического заполнения в MCT, как изложено ниже:
В CPE, использование средства стереофонического заполнения сигнализируется в пределах информации шумового заполнения FD для второго канала, как описано в подпункте 5.5.5.4.9.4 из [1]. При использовании MCT, каждый канал потенциально является «вторым каналом» (вследствие вероятности находящихся на пересечении элементов пар каналов). Поэтому, предлагается явным образом сигнализировать о стереофоническом заполнении посредством дополнительно бита на каждую пару кодированных каналов MCT. Для избежания необходимости этого дополнительного бита, когда стереофоническое заполнение не применяется в какой-нибудь паре каналов определенного экземпляра «дерева» MCT, две зарезервированных на данный момент записи элемента MCTSignalingType element в MultichannelCodingFrame() [2] используются для сигнализации о наличии вышеупомянутого дополнительно бита по каждой паре каналов.
Подробное описание приведено ниже.
Некоторые варианты осуществления, например, могут реализовывать расчет предыдущего результата понижающего микширования, как изложено ниже:
Стереофоническое заполнение в CPE заполняет некоторые «пустые» полосы масштабных коэффициентов второго канала добавлением соответственных коэффициентов МДКП результата понижающего микширования предыдущего кадра, масштабированных согласно соответствующим переданным масштабным коэффициентам полос (которые в противном случае не используются, поскольку упомянутые полосы полностью квантованы в ноль). Процесс взвешенного сложения, управляемый с использованием полос масштабных коэффициентов целевого канала, может идентичным образом применяться в контексте MCT. Однако, исходный спектр для стереофонического заполнения, то есть, результат понижающего микширования предыдущего кадра, должен вычисляться иным образом, чем в пределах CPE, в особенности поскольку конфигурация «дерева» MCT может быть меняющейся во времени.
В MCT, предыдущий результат понижающего микширования может получаться из декодированных выходных каналов последнего кадра (которые сохранены после декодирования MCT) с использованием параметров MCT текущего кадра для данной совместной пары каналов. Применительно к паре, применяющей основанное на прогнозном M/S совместное кодирование, предыдущий результат понижающего микширования равно, как и в стереофоническом заполнении CPE, сумме или разности надлежащих спектров каналов в зависимости от индикатора направления текущего канала. Что касается стереофонической пары, использующей основанное на повороте Карунена-Лоэва совместное кодирование, предыдущий результат понижающего микширования представляет собой обратный поворот, вычисленный по углу(ам) поворота текущего кадра. Вновь, подробное описание приведено ниже.
Оценка сложности показывает, что не ожидается, что стереофоническое заполнение в MCT, являясь средством для средней и низкой скорости передачи битов, увеличит сложность в наихудшем случае, когда измеряется как на низкой/средней, так и высокой скоростях передачи битов. Более того, использование стереофонического заполнения типично соответствует большему количеству спектральных коэффициентов, квантованных в ноль, тем самым, понижая алгоритмическую сложность основанного на контексте арифметического декодера. При условии использования не более N/3 каналов стереофонического заполнения в N-канальной конфигурации объемного звучания и 0,2 дополнительных WMOPS для выполнения стереофонического заполнения, пиковая сложность возрастает всего лишь на 0,4 WMOPS применительно к 5.1 и на 0,8 WMOPS применительно к 11.1 каналам, когда частота выборки кодера имеет значение 48 кГц, а средство IGF работает только выше 12 кГц. Это равносильно менее чем 2% общей сложности декодера.
Варианты осуществления реализуют элемент MultichannelCodingFrame(), как изложено ниже:
(MCTSignalingType == 3)) {
Стереофоническое заполнение в MCT согласно некоторым вариантам осуществления может быть реализовано, как изложено ниже:
Аналогично стереофоническому заполнению для IGF в элементе пары каналов, описанному в подпункте 5.5.5.4.9 из [1], стереофоническое заполнение в средстве многоканального кодирования (MCT) заполняет «пустые» полосы масштабных коэффициентов (которые полностью квантованы в ноль) на или выше начальной частоты шумового заполнения с использованием результата понижающего микширования выходных спектров предыдущего кадра.
Когда стереофоническое заполнение является действующим в паре совместных каналов MCT (hasStereoFilling[pair] ≠ 0 в таблице AMD4.4), все «пустые» полосы масштабных коэффициентов в области шумового заполнения (то есть, начиная с или выше noiseFillingStartOffset) второго канала пары заполняются до определенной целевой энергии с использованием результата понижающего микширования соответствующих выходных спектров (после применения MCT) предыдущего кадра. Это делается после шумового заполнения FD (смотрите подпункт 7.2 в ISO/IEC 23003-3:2012) и перед применением масштабных коэффициентов и совместного стереофонического кодирования MCT. Все выходные спектры после завершенной обработки MCT сохраняются для возможного стереофонического заполнения в следующем кадре.
Эксплуатационные ограничения, например, могут состоять в том, что каскадное выполнение алгоритма стереофонического заполнения (hasStereoFilling[pair] ≠ 0) в пустых полосах второго канала не поддерживается для любой последующей стереофонической пары MCT с hasStereoFilling[pair] ≠ 0, если второй канал является прежним. В элементе пары каналов, действующее стереофоническое заполнение IGF во втором (разностном) канале согласно подпункту 5.5.5.4.9 из [1] обладает приоритетом над - и, таким образом, отменяет - любое последующее применение стереофонического заполнения MCT в том же самом канале того же самого кадра.
Термины и определения, например, могут быть определены, как изложено ниже:
hasStereoFilling[pair] указывает использование стереофонического заполнения в обрабатываемой в данный момент паре каналов MCT
ch1, ch2 индексы каналов в обрабатываемой на данный момент паре каналов MCT
spectral_data[ ][ ] спектральные коэффициенты каналов в обрабатываемой на данный момент паре каналов MCT
spectral_data_prev[ ][ ] выходные спектры после завершенной обработки MCT в предыдущем кадре
downmix_prev[ ][ ] оцененный результат понижающего микширования выходных каналов предыдущего кадра с индексами, заданными обрабатываемой на данный момент парой каналов MCT
num_swb общее количество полос масштабных коэффициентов, смотрите ISO/IEC 23003-3, подпункт 6.2.9.4
ccfl coreCoderFrameLength, длина преобразования, смотрите ISO/IEC 23003-3, подпункт 6.1.
noiseFillingStartOffset начальная линия шумового заполнения, определяемая в зависимости от ccfl в ISO/IEC 23003-3, таблица 109.
igf_WhiteningLevel спектральное выбеливание в IGF, смотрите ISO/IEC 23008-3, подпункт 5.5.5.4.7
seed[ ] источник шумового заполнения, используемый в randomSign(), смотрите ISO/IEC 23003-3, подпункт 7.2.
Применительно к некоторым конкретным вариантам осуществления, процесс декодирования, например, может быть описан, как изложено ниже:
Стереофоническое заполнение MCT выполняется с использованием четырех следующих друг за другом операций, которые описаны в нижеследующем:
Этап 1: Подготовка спектра второго канала для алгоритма стереофонического заполнения.
Если индикатор стереофонического заполнения для данной пары каналов MCT, hasStereoFilling[pair], равен нулю, стереофоническое заполнение не используется, и следующие этапы не выполняются. Иначе, применение масштабного коэффициента отменяется, если он раньше был применен к спектру второго канала пары, spectral_data[ch2].
Этап 2: Формирование спектра предыдущего результата понижающего микширования для данной пары каналов MCT
Предыдущий результат понижающего микширования оценивается по spectral_data_prev[ ][ ] выходных сигналов предыдущего кадра, который был сохранен после применения обработки MCT. Если сигнала предыдущего выходного канала нет в распоряжении, например, вследствие независимого кадра (indepFlag>0), изменения длины преобразования или core_mode == 1, буфер предыдущего канала соответствующего канала будет устанавливаться в ноль.
Что касается прогнозных стереофонических пар, то есть, MCTSignalingType == 0, предыдущий результат понижающего микширования рассчитывается из предыдущих выходных каналов в виде downmix_prev[ ][ ], определенного на этапе 2 подпункта 5.5.5.4.9.4 из [1], в силу чего, spectrum[window][ ] представлен посредством spectral_data[ ][window].
Что касается поворотных стереофонических пар, то есть MCTSignalingType == 1, предыдущий результат понижающего микширования рассчитывается из предыдущих выходных каналов посредством обращения операции поворота, определенной в подпункте 5.5.X.3.7.1 из [2].
apply_mct_rotation_inverse(*R, *L, *dmx, aIdx, nSamples)
{
for (n=0; n<nSamples; n++) {
dmx= L[n] * tabIndexToCosAlpha[aIdx]+R[n] * tabIndexToSinAlpha[aIdx];
}
}
с использованием L=spectral_data_prev[ch1][ ], R=spectral_data_prev[ch2][ ], dmx=downmix_prev[ ] предыдущего кадра и с использованием aIdx, nSamples текущего кадра и пары MCT.
Этап 3: Выполнение алгоритма стереофонического заполнения в пустых полосах второго канала
Стереофоническое заполнение применяется во втором канале пары MCT, как на этапе 3 подпункта 5.5.5.4.9.4 из [1], в силу чего, spectrum[window] представляется посредством
spectral_data[ch2][window] и max_sfb_ste заданы согласно num_swb.
Этап 4: Применение масштабного коэффициента и адаптивная синхронизация источников шумового заполнения.
Как после этапа 3 подпункта 5.5.5.4.9.4 из [1], масштабные коэффициенты применяются к результирующему спектру, как в 7.3 из ISO/IEC 23003-3, причем, масштабные коэффициенты пустых полос обрабатываются аналогично обычным масштабным коэффициентам. В случае, если масштабный коэффициент не определен, например, так как он расположен выше max_sfb, его значение будет равно нулю. Если используется IGF, igf_WhiteningLevel равно 2 в любом из фрагментов второго канала, и оба канала не применяют восемь коротких преобразований, спектральные энергии обоих каналов в паре MCT вычисляются в диапазоне от индекса noiseFillingStartOffset до индекса ccfl/2-1 перед выполнением decode_mct( ). Если вычисленная энергия первого канала более чем в восемь раз больше энергии второго канала, seed[ch2] второго канала устанавливается равным seed[ch1] первого канала.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или элемента, либо признака соответствующего устройства. Некоторые или все из этапов способа могут выполняться посредством (или с использованием) аппаратного устройства, например, подобного микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления, один или более из наиболее важных этапов способа могут выполняться таким устройством.
В зависимости от некоторых требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении, либо по меньшей мере частично в аппаратных средствах или по меньшей мере частично в программном обеспечении. Реализация может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD (цифрового многофункционального диска), диска Blu-Ray, CD (компакт-диска), ПЗУ (постоянного запоминающего устройства, ROM), ППЗУ (программируемого ПЗУ, PROM), СППЗУ (стираемого ППЗУ, EPROM), ЭСППЗУ (электрически стираемого ППЗУ, EEPROM) или памяти FLASH, имеющего электронным образом считываемые сигналы управления, хранимые на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так чтобы выполнялся соответственный способ. Поэтому, цифровой запоминающий носитель может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронным образом считываемые сигналы управления, которые способны к взаимодействию с программируемой компьютерной системой, из условия чтобы выполнялся один из способов, описанных в материалах настоящей заявки.
Вообще, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с управляющей программой, управляющая программа является действующей для выполнения одного из способов, когда компьютерный программный продукт работает на компьютере. Управляющая программа, например, может храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки, хранимую на машиночитаемом носителе.
Поэтому, другими словами, вариант осуществления способа согласно изобретению является компьютерной программой, имеющей управляющую программу для выполнения одного из способов, описанных в материалах настоящей заявки, когда компьютерная программа работает на компьютере.
Поэтому, дополнительным вариантом осуществления способов согласно изобретению является носитель данных (или цифровой запоминающий носитель, или машинно-читаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки. Носитель данных, цифровой запоминающий носитель или записываемый носитель типично являются материальными и/или неэфемерными.
Поэтому, дополнительным вариантом осуществления способа согласно изобретению является поток данных или последовательность сигналов, представляющие собой компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки. Поток данных или последовательность сигналов, например, могут быть приспособлены передаваться через соединение передачи данных, например, через сеть Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненные с возможностью или приспособленные для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненные с возможностью пересылать (например, электронным образом или оптически) компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки, в приемник. Приемник, например, может быть компьютером, мобильным устройством, устройством памяти, или тому подобным. Устройство или система, например, могут содержать файловый сервер для пересылки компьютерной программы на приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех из функциональных возможностей способов, описанных в материалах настоящей заявки. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, для того чтобы выполнять один из способов, описанных в материалах настоящей заявки. Обычно, способы предпочтительно выполняются каким-нибудь аппаратным устройством.
Устройство, описанное в материалах настоящей заявки, может быть реализовано с использованием аппаратного устройства или с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в материалах настоящей заявки, могут выполняться с использованием аппаратного устройства или с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Описанные выше варианты осуществления являются всего лишь иллюстративными применительно к принципам настоящего изобретения. Понятно, что модификации и варианты компоновок и подробностей, описанных в материалах настоящей заявки, будут очевидны специалистам в данной области техники. Поэтому, замысел состоит в том, чтобы ограничиваться только объемом прилагаемой патентной формулой изобретения, а не специфичными подробностями, представленными в качестве описания и пояснения вариантов осуществления, приведенных в материалах настоящей заявки.
Библиографический список
1. ISO/IEC international standard 23008-3:2015, “Information technology – High efficiency coding and media deliverly in heterogeneous environments – Part 3: 3D audio”, март 2015.
2. ISO/IEC amendment 23008-3:2015/PDAM3, “Information technology – High efficiency coding and media delivery in heterogeneous environments – Part 3: 3D audio, Amendment 3: MPEG-H 3D Audio Phase 2”, июль 2015.
3. International Organization for Standardization, ISO/IEC 23003-3:2012, “Information Technology – MPEG audio – Part 3: Unified speech and audio coding,” Geneva, январь 2012.
4. ISO/IEC 23003-1:2007 - Information technology – MPEG audio technologies Part 1: MPEG Surround.
5. C. R. Helmrich, A. Niedermeier, S. Bayer, B. Edler, “Low-Complexity Semi-Parametric Joint-Stereo Audio Transform Coding,” in Proc. EUSIPCO, Nice, сентябрь 2015.
6. ETSI TS 103 190 V1.1.1 (2014-04) – Digital Audio Compression (AC-4) Standard.
7. Yang, Dai and Ai, Hongmei and Kyriakakis, Chris and Kuo, C.-C. Jay, 2001: Adaptive Karhunen-Loeve Transform for Enhanced Multichannel Audio Coding, http://ict.usc.edu/pubs/Adaptive%20Karhunen-Loeve%20Transform%20for %20Enhanced%20Multichannel%20Audio%20Coding.pdf.
8. European Patent Application, Publication EP 2 830 060 A1: “Noise filling in multichannel audio coding”, опубликовано 28 января 2015.
9. Internet Engineering Task Force (IETF), RFC 6716, “Definition of the Opus Audio Codec,” Int. Standard, сентябрь 2012. Доступна онлайн как: http://tools.ietf.org/html/rfc6716.
10. International Organization for Standardization, ISO/IEC 14496-3:2009, “Information Technology – Coding of audio-visual objects – Part 3: Audio”, Geneva, Switzerland, август 2009.
11. M. Neuendorf et al., “MPEG Unified Speech and Audio Coding – The ISO/MPEG Standard for High-Efficiency Audio Coding of All Content Types,” in Proc. 132nd AES Con¬vention, Budapest, Hungary, апрель 2012. Также должна появиться в Journal of the AES, 2013.
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ ОБРАБОТКИ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ С ИСПОЛЬЗОВАНИЕМ КОМПЛЕКСНОГО ПРЕДСКАЗАНИЯ | 2011 |
|
RU2577195C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА | 2016 |
|
RU2711055C2 |
| УСТРОЙСТВО И СПОСОБ ОЦЕНИВАНИЯ МЕЖКАНАЛЬНОЙ РАЗНИЦЫ ВО ВРЕМЕНИ | 2017 |
|
RU2711513C1 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПАРАМЕТРА ШИРОКОПОЛОСНОГО ВЫРАВНИВАНИЯ И МНОЖЕСТВА ПАРАМЕТРОВ УЗКОПОЛОСНОГО ВЫРАВНИВАНИЯ | 2017 |
|
RU2704733C1 |
| ЗАПОЛНЕНИЕ ШУМОМ ПРИ МНОГОКАНАЛЬНОМ КОДИРОВАНИИ АУДИО | 2014 |
|
RU2661776C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ МНОГОКАНАЛЬНОГО ВЫХОДНОГО СИГНАЛА | 2005 |
|
RU2361185C2 |
| ИНТЕГРАЦИЯ МЕТОДИК РЕКОНСТРУКЦИИ ВЫСОКИХ ЧАСТОТ С СОКРАЩЕННОЙ ЗАДЕРЖКОЙ ПОСТОБРАБОТКИ | 2019 |
|
RU2832544C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА И АУДИОДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2680195C1 |
| ИНТЕГРАЦИЯ МЕТОДИК РЕКОНСТРУКЦИИ ВЫСОКИХ ЧАСТОТ ЗВУКА | 2019 |
|
RU2792114C2 |







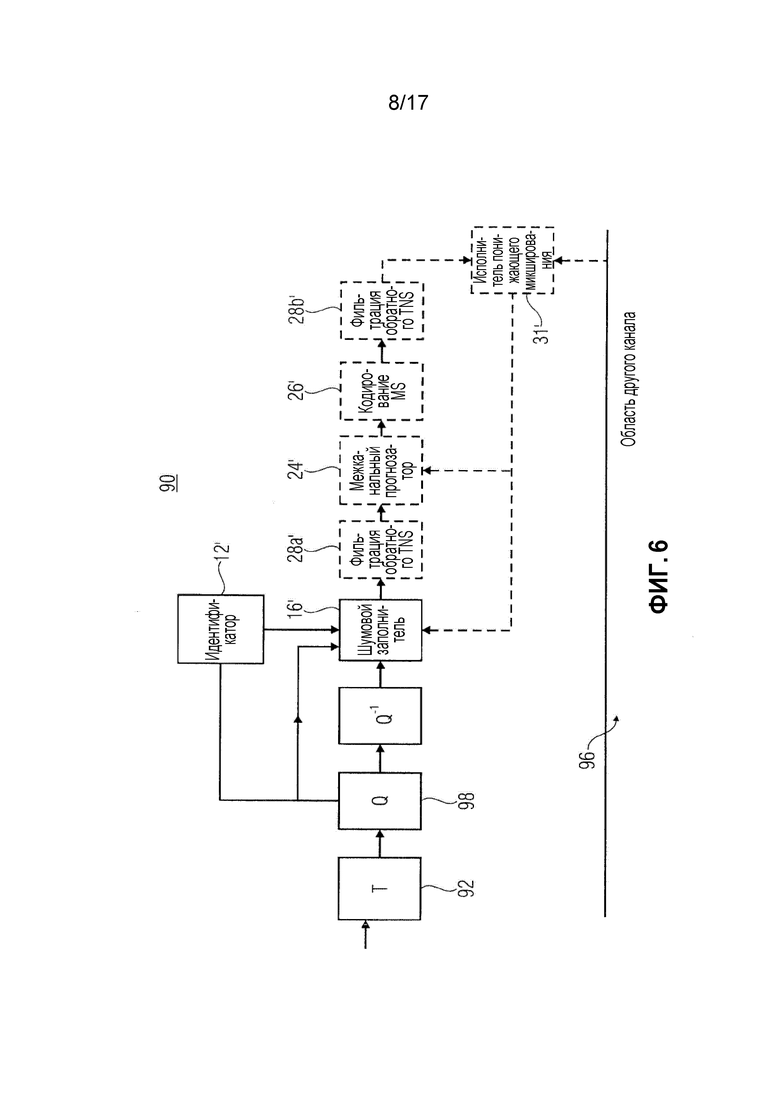
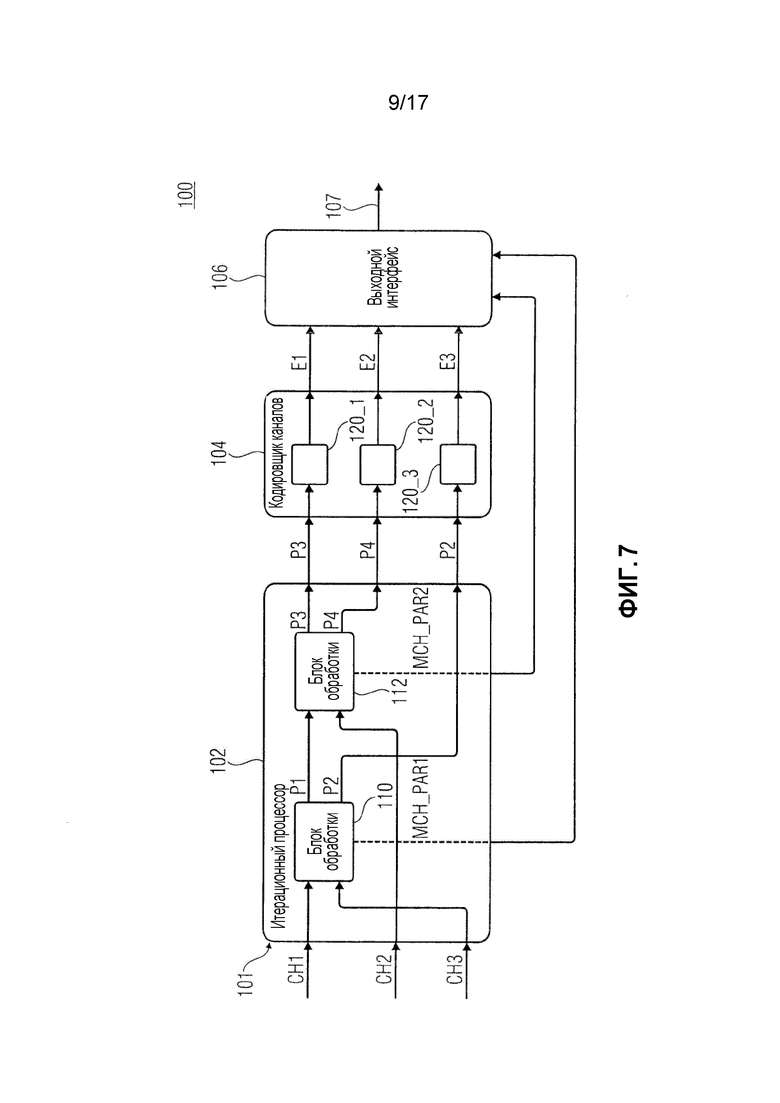
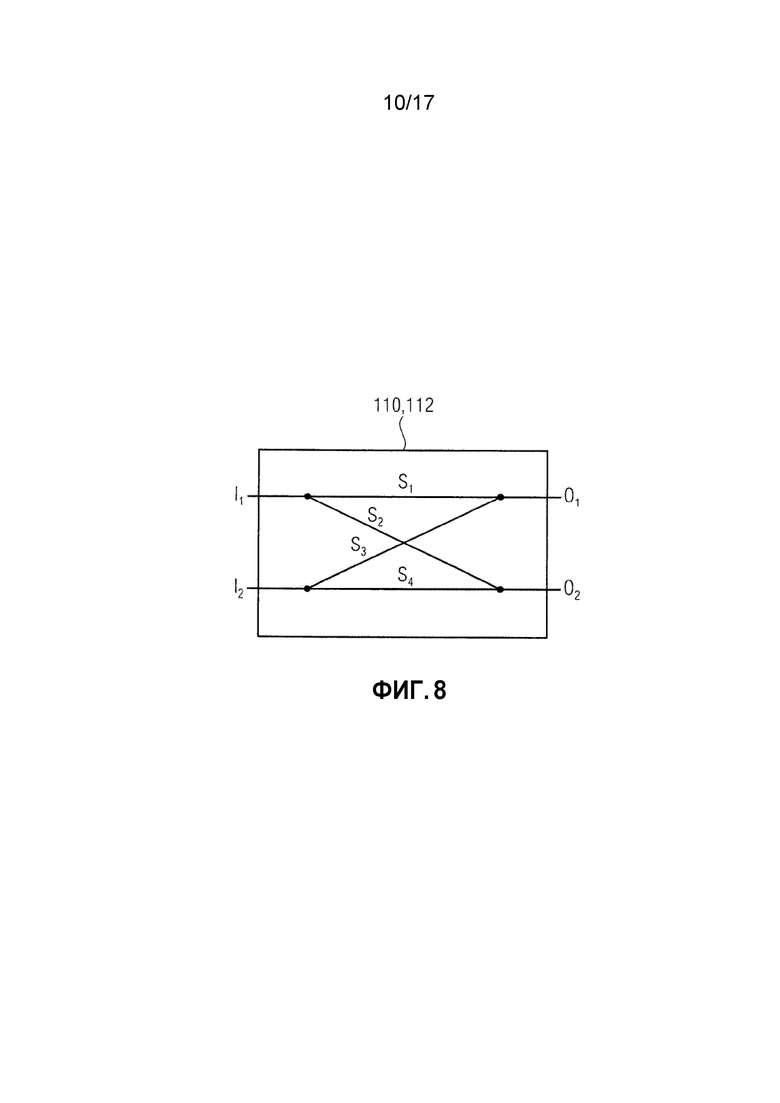
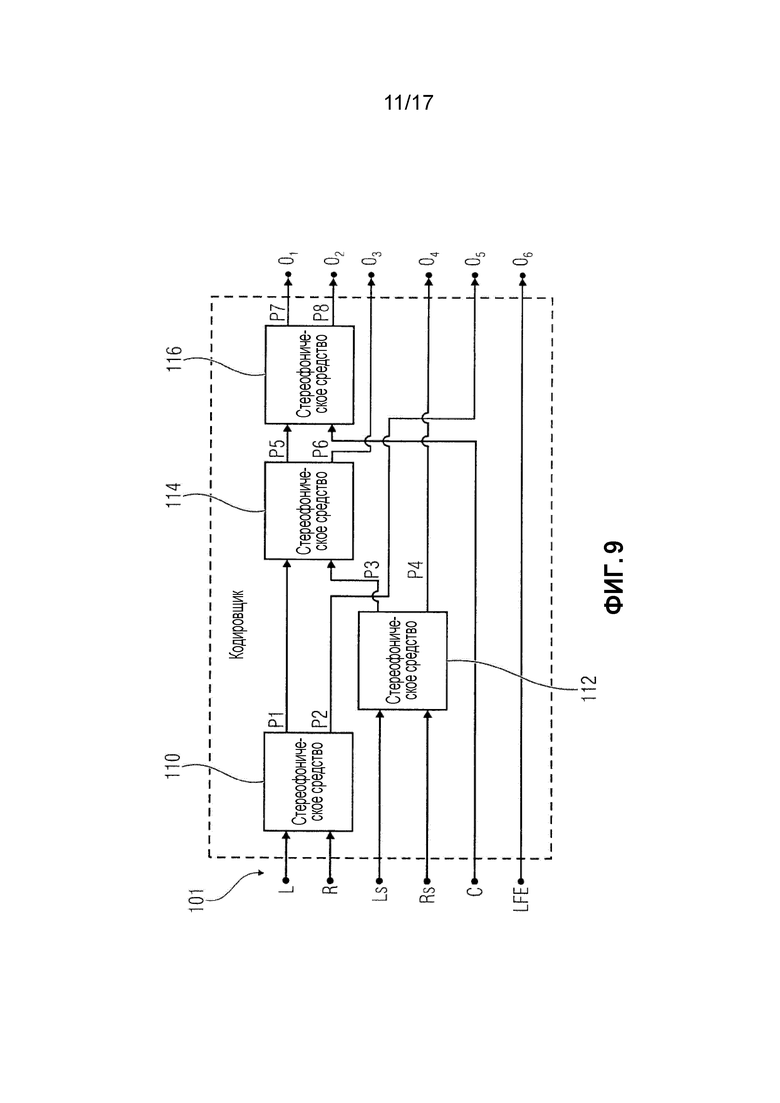
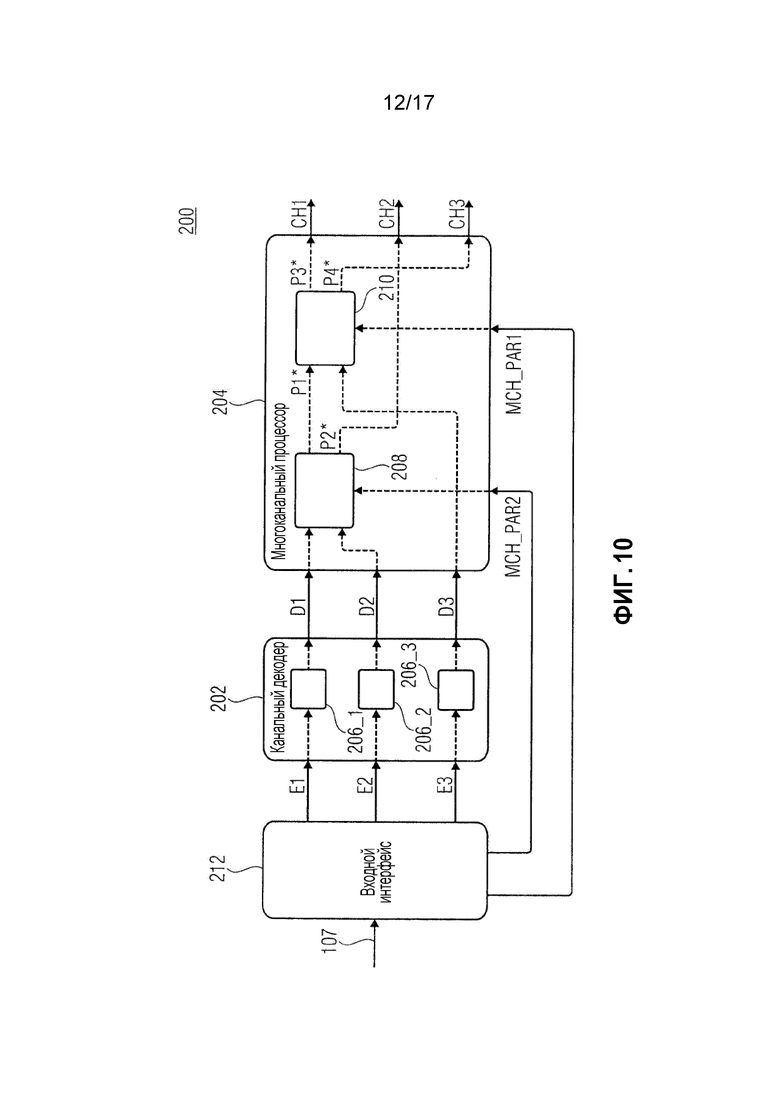
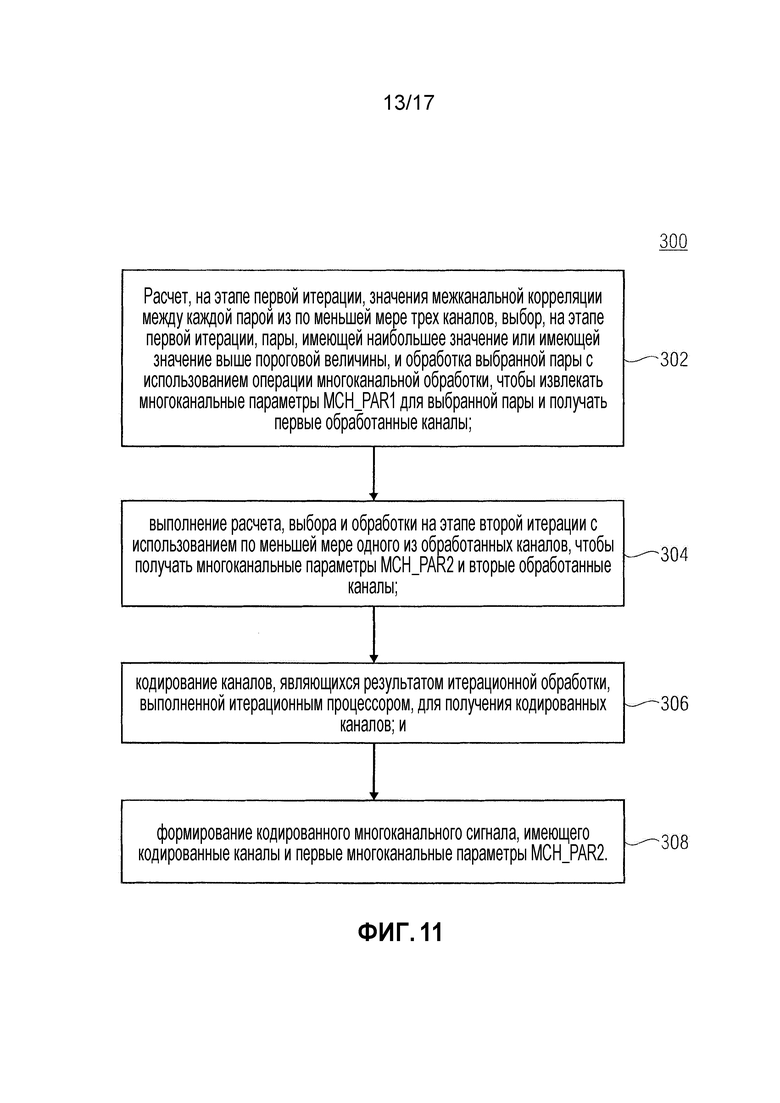

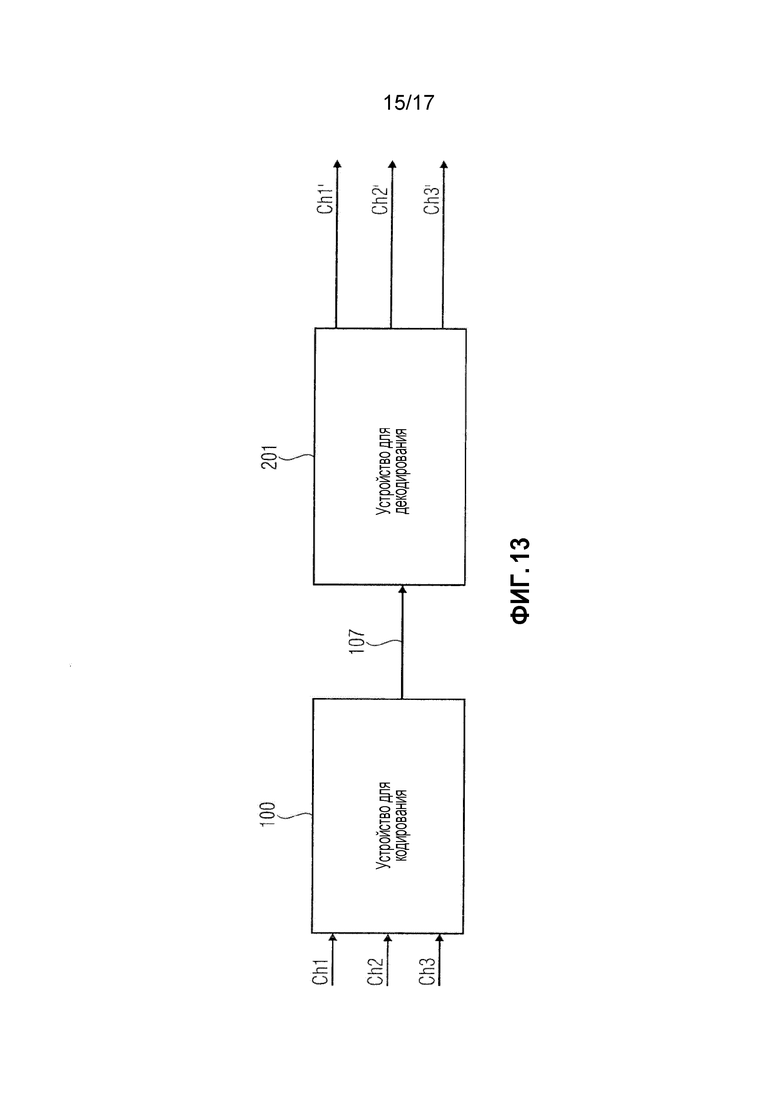


Изобретение относится к области обработки аудиоданных. Технический результат заключается в повышении точности обработки аудиоданных. Технический результат достигается за счет формирования первой группы из двух или более обработанных каналов на основе первой выбранной пары двух декодированных каналов для получения обновленного набора из трех или более декодированных каналов; при этом, перед тем, как первая группа из двух или более обработанных сигналов формируется на основе первой выбранной пары двух декодированных каналов, выполняются следующие этапы, на которых: идентифицируют, применительно к по меньшей мере одному из двух каналов из первой выбранной пары двух декодированных каналов, одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формируют смесительный канал с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов и заполняют спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала. 4 н. и 14 з.п. ф-лы, 17 ил.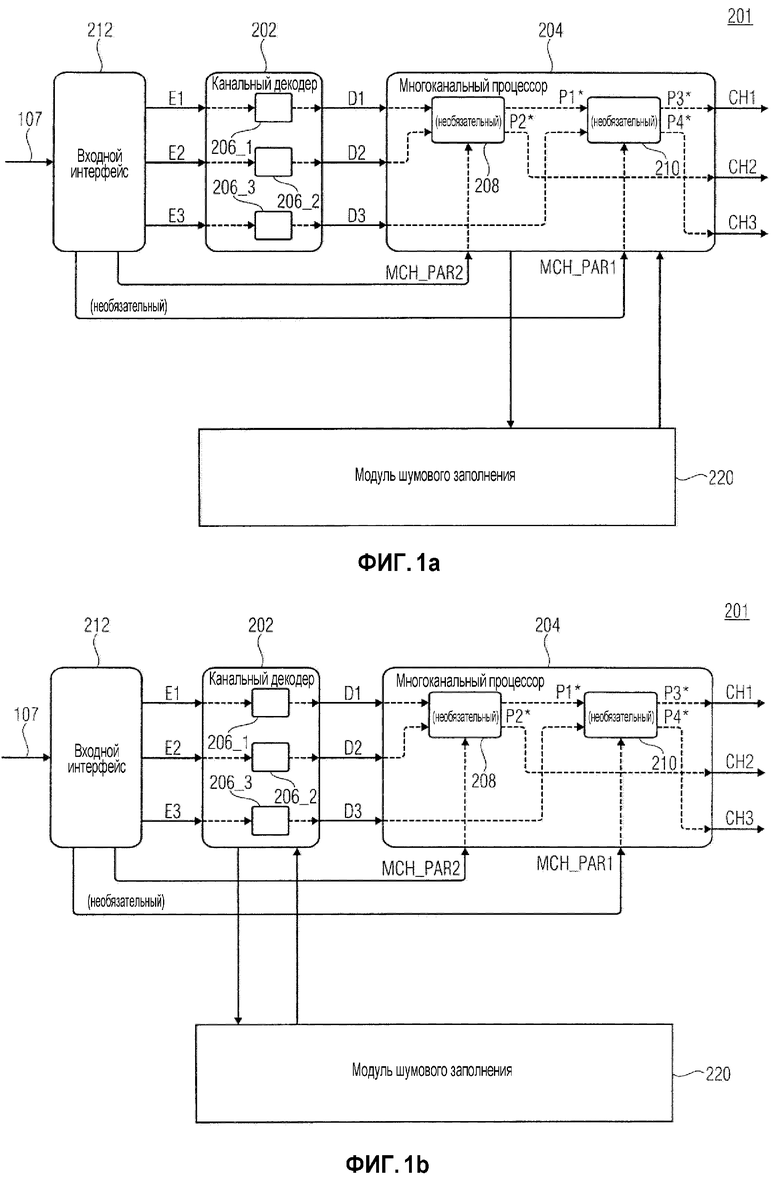
1. Устройство (201) для декодирования предыдущего кодированного многоканального сигнала предыдущего кадра, чтобы получить три или более предыдущих звуковых выходных каналов, и для декодирования текущего кодированного многоканального сигнала (107) текущего кадра, чтобы получить три или более текущих звуковых выходных каналов,
при этом устройство (201) содержит интерфейс (212), канальный декодер (202), многоканальный процессор (204) для формирования трех или более текущих звуковых выходных каналов и модуль (220) шумового заполнения,
при этом интерфейс (212) выполнен с возможностью принимать текущий кодированный многоканальный сигнал (107) и принимать побочную информацию, содержащую первые многоканальные параметры (MCH_PAR2),
при этом канальный декодер (202) выполнен с возможностью декодировать текущий кодированный многоканальный сигнал текущего кадра для получения набора из трех или более декодированных каналов (D1, D2, D3) текущего кадра,
при этом многоканальный процессор (204) выполнен с возможностью выбирать первую выбранную пару двух декодированных каналов (D1, D2) из набора из трех или более декодированных каналов (D1, D2, D3) в зависимости от первых многоканальных параметров (MCH_PAR2),
при этом многоканальный процессор (204) выполнен с возможностью формировать первую группу из двух или более обработанных каналов (P1*, P2*) на основе первой выбранной пары двух декодированных каналов (D1, D2) для получения обновленного набора из трех или более декодированных каналов (D3, P1*, P2*),
при этом модуль (220) шумового заполнения выполнен с возможностью, перед тем как многоканальный процессор (204) формирует первую группу из двух или более обработанных каналов (P1*, P2*) на основе первой выбранной пары двух декодированных каналов (D1, D2), идентифицировать, применительно к по меньшей мере одному из двух каналов из первой выбранной пары двух декодированных каналов (D1, D2), одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формировать смесительный канал с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов, и заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, при этом модуль (220) шумового заполнения выполнен с возможностью выбирать два или более предыдущих звуковых выходных каналов, которые используются для формирования смесительного канала, из трех или более предыдущих звуковых выходных каналов в зависимости от побочной информации.
2. Устройство (201) по п. 1,
в котором модуль (220) шумового заполнения выполнен с возможностью формировать смесительный канал с использованием ровно двух предыдущих звуковых выходных каналов из трех или более предыдущих звуковых выходных каналов в качестве упомянутых двух или более из трех или более предыдущих звуковых выходных каналов;
при этом модуль (220) шумового заполнения выполнен с возможностью выбирать эти ровно два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов в зависимости от побочной информации.
3. Устройство (201) по п. 2, в котором модуль (220) шумового заполнения выполнен с возможностью формировать смесительный канал с использованием ровно двух предыдущих звуковых выходных каналов на основе формулы
 или на основе формулы
или на основе формулы
 ,
,
где
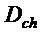 - смесительный канал,
- смесительный канал,
 - первый из упомянутых ровно двух предыдущих звуковых выходных каналов,
- первый из упомянутых ровно двух предыдущих звуковых выходных каналов,
 - второй из упомянутых ровно двух предыдущих звуковых выходных каналов, отличающийся от первого из этих ровно двух предыдущих звуковых выходных каналов, и
- второй из упомянутых ровно двух предыдущих звуковых выходных каналов, отличающийся от первого из этих ровно двух предыдущих звуковых выходных каналов, и
 - действительный положительный скаляр.
- действительный положительный скаляр.
4. Устройство (201) по п. 2, в котором модуль (220) шумового заполнения выполнен с возможностью формировать смесительный канал с использованием ровно двух предыдущих звуковых выходных каналов на основе формулы
 или на основе формулы
или на основе формулы
 ,
,
где
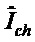 - смесительный канал,
- смесительный канал,
- первый из упомянутых ровно двух предыдущих звуковых выходных каналов,
- второй из упомянутых ровно двух предыдущих звуковых выходных каналов, отличающийся от первого из этих ровно двух предыдущих звуковых выходных каналов, и
 - угол поворота канала.
- угол поворота канала.
5. Устройство (201) по п. 4,
в котором побочная информация является текущей побочной информацией, назначенной текущему кадру,
при этом интерфейс (212) выполнен с возможностью принимать предыдущую побочную информацию, назначенную предыдущему кадру, причем предыдущая побочная информация содержит предыдущий угол поворота канала,
при этом интерфейс (212) выполнен с возможностью принимать текущую побочную информацию, содержащую текущий угол поворота канала, и
при этом модуль (220) шумового заполнения выполнен с возможностью использовать текущий угол поворота канала текущей побочной информации в качестве угла поворота канала и не использовать предыдущий угол поворота канала предыдущей побочной информации в качестве угла поворота канала.
6. Устройство (201) по п. 2, в котором модуль (220) шумового заполнения выполнен с возможностью выбирать ровно два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов в зависимости от первых многоканальных параметров (MCH_PAR2).
7. Устройство (201) по п. 2,
в котором интерфейс (212) выполнен с возможностью принимать текущий кодированный многоканальный сигнал (107) и принимать побочную информацию, содержащую первые многоканальные параметры (MCH_PAR2) и вторые многоканальные параметры (MCH_PAR1),
при этом многоканальный процессор (204) выполнен с возможностью выбирать вторую выбранную пару двух декодированных каналов (P1*, D3) из обновленного набора из трех или более декодированных каналов (D3, P1*, P2*) в зависимости от вторых многоканальных параметров (MCH_PAR1), причем по меньшей мере один канал (P1*) из второй выбранной пары двух декодированных каналов (P1*, D3) является одним каналом из первой группы из двух или более обработанных каналов (P1*, P2*), и
при этом многоканальный процессор (204) выполнен с возможностью формировать вторую группу из двух или более обработанных каналов (P3*, P4*) на основе второй выбранной пары двух декодированных каналов (P1*, D3) для дополнительного обновления обновленного набора из трех или более декодированных каналов.
8. Устройство (201) по п. 7,
в котором многоканальный процессор (204) выполнен с возможностью формировать первую группу из двух или более обработанных каналов (P1*, P2*) посредством формирования первой группы из ровно двух обработанных каналов (P1*, P2*) на основе первой выбранной пары двух декодированных каналов (D1, D2);
при этом многоканальный процессор (204) выполнен с возможностью замещать первую выбранную пару двух декодированных каналов (D1, D2) в наборе из трех или более декодированных каналов (D1, D2, D3) первой группой из ровно двух обработанных каналов (P1*, P2*) для получения обновленного набора из трех или более декодированных каналов (D3, P1*, P2*);
при этом многоканальный процессор (204) выполнен с возможностью формировать вторую группу из двух или более обработанных каналов (P3*, P4*) посредством формирования второй группы из ровно двух обработанных каналов (P3*, P4*) на основе второй выбранной пары двух декодированных каналов (P1*, D3), и
при этом многоканальный процессор (204) выполнен с возможностью замещать вторую выбранную пару двух декодированных каналов (P1*, D3) в обновленном наборе из трех или более декодированных каналов (D3, P1*, P2*) второй группой из ровно двух обработанных каналов (P3*, P4*) для дополнительного обновления обновленного набора из трех или более декодированных каналов.
9. Устройство (201) по п. 8,
в котором первые многоканальные параметры (MCH_PAR2) указывают два декодированных канала (D1, D2) из набора из трех или более декодированных каналов;
при этом многоканальный процессор (204) выполнен с возможностью выбирать первую выбранную пару двух декодированных каналов (D1, D2) из набора из трех или более декодированных каналов (D1, D2, D3) посредством выбора двух декодированных каналов (D1, D2), указываемых первыми многоканальными параметрами (MCH_PAR2);
при этом вторые многоканальные параметры (MCH_PAR1) указывают два декодированных канала (P1*, D3) из обновленного набора из трех или более декодированных каналов;
при этом многоканальный процессор (204) выполнен с возможностью выбирать вторую выбранную пару двух декодированных каналов (P1*, D3) из обновленного набора из трех или более декодированных каналов (D3, P1*, P2*) посредством выбора двух декодированных каналов (P1*, D3), указываемых вторыми многоканальными параметрами (MCH_PAR1).
10. Устройство (201) по п. 9,
при этом устройство (201) выполнено с возможностью назначать идентификатор из набора идентификаторов каждому предыдущему звуковому выходному каналу из трех или более предыдущих звуковых выходных каналов, так чтобы каждому предыдущему звуковому входному каналу из трех или более предыдущих звуковых выходных каналов назначался ровно один идентификатор из набора идентификаторов и так чтобы каждый идентификатор из набора идентификаторов был назначен ровно одному предыдущему звуковому выходному каналу из трех или более предыдущих звуковых выходных каналов,
при этом устройство (201) выполнено с возможностью назначать идентификатор из набора идентификаторов каждому каналу из набора из трех или более декодированных каналов (D1, D2, D3), так чтобы каждому каналу из набора из трех или более декодированных каналов назначался ровно один идентификатор из набора идентификаторов и так чтобы каждый идентификатор из набора идентификаторов был назначен ровно одному из набора из трех или более декодированных каналов (D1, D2, D3),
при этом первые многоканальные параметры (MCH_PAR2) указывают первую пару двух идентификаторов из набора из трех или более идентификаторов,
при этом многоканальный процессор (204) выполнен с возможностью выбирать первую выбранную пару двух декодированных каналов (D1, D2) из набора из трех или более декодированных каналов (D1, D2, D3) посредством выбора двух декодированных каналов (D1, D2), которым назначены два идентификатора из первой пары двух идентификаторов;
при этом устройство (201) выполнено с возможностью назначать первый один из двух идентификаторов из первой пары двух идентификаторов первому обработанному каналу из первой группы из ровно двух обработанных каналов (P1*, P2*), и при этом устройство (201) выполнено с возможностью назначать второй один из двух идентификаторов из первой пары двух идентификаторов второму обработанному каналу из первой группы из ровно двух обработанных каналов (P1*, P2*).
11. Устройство (201) по п. 10,
в котором вторые многоканальные параметры (MCH_PAR1) указывают вторую пару двух идентификаторов,
при этом многоканальный процессор (204) выполнен с возможностью выбирать вторую выбранную пару двух декодированных каналов (P1*, D3) из обновленного набора из трех или более декодированных каналов (D3, P1*, P2*) посредством выбора двух декодированных каналов (D3, P1*), которым назначены два идентификатора из второй пары двух идентификаторов;
при этом устройство (201) выполнено с возможностью назначать первый один из двух идентификаторов из первой пары двух идентификаторов первому обработанному каналу из второй группы из ровно двух обработанных каналов (P3*, P4*), и при этом устройство (201) выполнено с возможностью назначать второй один из двух идентификаторов из второй пары двух идентификаторов второму обработанному каналу из второй группы из ровно двух обработанных каналов (P3*, P4*).
12. Устройство (201) по п. 10,
в котором первые многоканальные параметры (MCH_PAR2) указывают упомянутую первую пару двух идентификаторов из набора из трех или более идентификаторов, и
при этом модуль (220) шумового заполнения выполнен с возможностью выбирать ровно два предыдущих звуковых выходных канала из трех или более предыдущих звуковых выходных каналов посредством выбора двух предыдущих звуковых выходных каналов, которым назначены два идентификатора из упомянутой первой пары двух идентификаторов.
13. Устройство (201) по п. 1, в котором модуль (220) шумового заполнения выполнен с возможностью, перед тем как многоканальный процессор (204) формирует первую группу из двух или более обработанных каналов (P1*, P2*) на основе первой выбранной пары двух декодированных каналов (D1, D2), идентифицировать, применительно к по меньшей мере одному из двух каналов из первой выбранной пары двух декодированных каналов (D1, D2), одну или более полос масштабных коэффициентов, являющихся одной или более полосами частот, в пределах которых все спектральные линии квантованы в ноль, и формировать смесительный канал с использованием упомянутых двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов и заполнять спектральные линии одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, в зависимости от масштабного коэффициента каждой из одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль.
14. Устройство (201) по п. 13,
в котором приемный интерфейс (212) выполнен с возможностью принимать масштабный коэффициент каждой из упомянутых одной или более полос масштабных коэффициентов, и
при этом масштабный коэффициент каждой из этих одной или более полос масштабных коэффициентов указывает энергию спектральных линий данной полосы масштабных коэффициентов до квантования, и
при этом модуль (220) шумового заполнения выполнен с возможностью формировать шум для каждой из одной или более полос масштабных коэффициентов, в пределах которых все спектральные линии квантованы в ноль, так чтобы энергия спектральных линий после добавления шума в одну из полос частот соответствовала энергии, указываемой масштабным коэффициентом для данной полосы масштабных коэффициентов.
15. Система для декодирования предыдущего кодированного многоканального сигнала предыдущего кадра, чтобы получить три или более предыдущих звуковых выходных каналов, и для декодирования текущего кодированного многоканального сигнала текущего кадра, чтобы получить три или более текущих звуковых выходных каналов, при этом система содержит:
устройство (100) для кодирования многоканального сигнала (101), имеющего по меньшей мере три канала (CH1:CH3), и
устройство (201) для декодирования по п. 1,
при этом устройство (201) для декодирования выполнено с возможностью принимать кодированный многоканальный сигнал (107), формируемый устройством (100) для кодирования, из устройства (100) для кодирования,
при этом устройство (100) для кодирования многоканального сигнала (101) содержит:
итерационный процессор (102), выполненный с возможностью рассчитывать, на этапе первой итерации, значения межканальной корреляции между каждой парой из по меньшей мере трех каналов (CH:CH3) для выбора, на этапе первой итерации, пары, имеющей наибольшее значение или имеющей значение выше пороговой величины, и для обработки выбранной пары с использованием операции (110, 112) многоканальной обработки, чтобы извлечь начальные многоканальные параметры (MCH_PAR1) для выбранной пары и получить первые обработанные каналы (P1, P2), при этом итерационный процессор (102) выполнен с возможностью осуществлять упомянутые расчет, выбор и обработку на этапе второй итерации с использованием по меньшей мере одного из обработанных каналов (P1), чтобы получать дополнительные многоканальные параметры (MCH_PAR2) и вторые обработанные каналы (P3, P4);
кодер каналов, выполненный с возможностью кодировать каналы (P2:P4), являющиеся результатом итерационной обработки, выполняемой итерационным процессором (104), для получения кодированных каналов (E1:E3); и
выходной интерфейс (106), выполненный с возможностью формировать кодированный многоканальный сигнал (107), имеющий кодированные каналы (E1:E3), начальные многоканальные параметры и дополнительные многоканальные параметры (MCH_PAR1, MCH_PAR2) и имеющий информацию, указывающую, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным на основе ранее декодированных звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
16. Система по п. 15,
при этом каждые из начальных многоканальных параметров и дополнительных многоканальных параметров (MCH_PAR1, MCH_PAR2) указывают ровно два канала, причем каждый один из этих ровно двух каналов является одним из кодированных каналов (E1:E3), либо является одним из первого и второго обработанных каналов (P1, P2, P3, P4), либо является одним из упомянутых по меньшей мере трех каналов (CH:CH3), и
при этом выходной интерфейс (106) устройства (100) для кодирования многоканального сигнала (101) выполнен с возможностью формировать кодированный многоканальный сигнал (107), так чтобы информация, указывающая, будет или нет устройство для декодирования заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, содержала информацию, которая указывает, применительно к каждым одним из начальных и дополнительных многоканальных параметров (MCH_PAR1, MCH_PAR2), будет или нет устройство для декодирования, применительно к по меньшей мере одному каналу из ровно двух каналов, которые указаны упомянутыми одними из начальных и дополнительных многоканальных параметров (MCH_PAR1, MCH_PAR2), заполнять спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, упомянутого по меньшей мере одного канала, спектральными данными, сформированными на основе декодированных ранее звуковых выходных каналов, которые были декодированы ранее устройством для декодирования.
17. Способ декодирования предыдущего кодированного многоканального сигнала предыдущего кадра, чтобы получить три или более предыдущих звуковых выходных каналов, и для декодирования текущего кодированного многоканального сигнала (107) текущего кадра, чтобы получить три или более текущих звуковых выходных каналов, при этом способ содержит этапы, на которых:
принимают текущий кодированный многоканальный сигнал (107) и принимают побочную информацию, содержащую первые многоканальные параметры (MCH_PAR2);
декодируют текущий кодированный многоканальный сигнал текущего кадра для получения набора из трех или более декодированных каналов (D1, D2, D3) текущего кадра;
выбирают первую выбранную пару двух декодированных каналов (D1, D2) из набора из трех или более декодированных каналов (D1, D2, D3) в зависимости от первых многоканальных параметров (MCH_PAR2);
формируют первую группу из двух или более обработанных каналов (P1*, P2*) на основе первой выбранной пары двух декодированных каналов (D1, D2) для получения обновленного набора из трех или более декодированных каналов (D3, P1*, P2*);
при этом, перед тем, как первая группа из двух или более обработанных сигналов (P1*, P2*) формируется на основе первой выбранной пары двух декодированных каналов (D1, D2), выполняются следующие этапы, на которых:
идентифицируют, применительно к по меньшей мере одному из двух каналов из первой выбранной пары двух декодированных каналов (D1, D2), одну или более полос частот, в пределах которых все спектральные линии квантованы в ноль, и формируют смесительный канал с использованием двух или более, но не всех, из трех или более предыдущих звуковых выходных каналов и заполняют спектральные линии одной или более полос частот, в пределах которых все спектральные линии квантованы в ноль, шумом, сформированным с использованием спектральных линий смесительного канала, при этом выбор двух или более предыдущих звуковых выходных каналов, которые используются для формирования смесительного канала, из трех или более предыдущих звуковых выходных каналов проводится в зависимости от побочной информации.
18. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 17 при ее исполнении на компьютере или сигнальном процессоре.
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ СИГНАЛА | 2007 |
|
RU2406164C2 |
| СТЕРЕОФОНИЧЕСКОЕ КОДИРОВАНИЕ НА ОСНОВЕ MDCT С КОМПЛЕКСНЫМ ПРЕДСКАЗАНИЕМ | 2011 |
|
RU2554844C2 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ повышения защищенности информации в сетях подвижной радиотелефонной связи | 2023 |
|
RU2830060C1 |

