1. ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Варианты осуществления согласно изобретению относятся к преобразователю масштаба времени для обеспечения масштабированной по времени версии входного аудиосигнала.
Дополнительные варианты осуществления согласно изобретению относятся к аудио декодеру для обеспечения декодированного аудио контента на основе входного аудио контента.
Дополнительные варианты осуществления согласно изобретению относятся к способу для обеспечения масштабированной по времени версии входного аудиосигнала.
Дополнительные варианты осуществления согласно изобретению относятся к компьютерной программе для выполнения упомянутого способа.
2. УРОВЕНЬ ТЕХНИКИ
Хранение и передача аудио контента (включая обычный аудио контент, подобный музыкальному контенту, речевому контенту и смешанному обычному аудио/речевому контенту) являются важной областью технического применения. Конкретная проблема обусловлена фактом, что слушатель ожидает непрерывное воспроизведение аудио контентов, без каких-либо прерываний, а также без каких-либо слышимых артефактов, обусловленных хранением и/или передачей аудио контента. В то же время, требуется поддерживать насколько возможно низкими требования к средству хранения и средству передачи данных, чтобы удерживать затраты в рамках допустимого предела.
Проблемы возникают, например, если считывание с носителя данных временно прерывается или задерживается, или если передача между источником данных и приемником данных временно прерывается или задерживается. Например, передача через сеть Интернет не является высоконадежной, поскольку передаваемые по протоколу TCP/IP пакеты могут быть потеряны, и поскольку задержка передачи по сети Интернет может изменяться, например, в зависимости от ситуации с изменяющейся загрузкой интернет-узлов. Однако чтобы иметь удовлетворительное восприятие пользователем, требуется, чтобы имелось непрерывное воспроизведение аудио контента без слышимых "разрывов" (щелчков) или слышимых артефактов. Кроме того, является желательным избегать существенных задержек, которые будут обусловлены буферизацией большого количества аудио информации.
Ввиду вышеизложенного обсуждения, может быть признано, что есть необходимость идеи, которая обеспечивает хорошее качество звучания, даже в случае прерывистого предоставления звуковой информации.
3. РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Осуществление согласно изобретению создает преобразователь масштаба времени для обеспечения масштабированной по времени версии входного аудиосигнала. Преобразователь масштаба времени сконфигурирован для вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Кроме того, преобразователь масштаба времени сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Этот вариант осуществления согласно изобретению основан на идее, что имеются ситуации, в которых масштабирование по времени входного аудиосигнала приводит к существенным слышимым искажениям. Кроме того, вариант осуществления согласно изобретению основан на установлении факта, что механизм управления качеством помогает избегать таких слышимых искажений посредством оценивая, обеспечит ли требуемое масштабирование по времени фактически достаточное качество масштабированной по времени версии входного аудиосигнала. Соответственно, масштабированием по времени управляют не только путем требуемого «растягивания» по времени или «стягивания» по времени, но также и оценивания получаемого качества. Соответственно, является возможным, например, отложить масштабирование по времени, если масштабирование по времени приведет к недопустимо низкому качеству масштабированной по времени версии входного аудиосигнала. Однако, вычислительная оценка (ожидаемого) качества масштабированной по времени версии входного аудиосигнала также может использоваться, чтобы скорректировать какие-либо другие параметры масштабирования по времени. Для заключения, механизм управления качеством, используемый в вышеупомянутом варианте осуществления, помогает уменьшить или предотвратить слышимые артефакты в системе, в которой применяется масштабирование по времени.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован, чтобы выполнять операцию перекрытия-и-сложения, используя первый блок выборок входного аудиосигнала и второй блок выборок входного аудиосигнала (причем, первый блок выборок входного аудиосигнала и второй блок выборок входного аудиосигнала могут быть перекрывающимися или неперекрывающимися блоками выборок, которые принадлежат одному кадру или которые принадлежат различным кадрам). Преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок (например, по сравнению с исходной временной шкалой (осью), связанной с первым блоком выборок и вторым блоком выборок), и для перекрытия-и-сложения первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала. Этот вариант осуществления согласно изобретению основан на установлении факта, что операция перекрытия-и-сложения, использующая первый блок выборок и второй блок выборок, обычно приводит к хорошему масштабированию по времени, причем регулировка сдвига по времени второго блока выборок относительно первого блока выборок позволяет поддерживать искажения достаточно небольшими во многих случаях. Однако также было установлено, что введение дополнительного механизма управления качеством, который проверяет, приводит ли предполагаемое перекрытие-и-сложение первого блока выборок и сдвинутого по времени второго блока выборок фактически к достаточному качеству масштабированной по времени версии входного аудиосигнала, помогает избежать слышимых артефактов с еще большей надежностью. Другими словами, было установлено, что является полезным выполнять проверку качества (на основе оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени) после того, как был идентифицирован требуемый (или эффективный) сдвиг по времени второго блока выборок относительно первого блока выборок, поскольку эта процедура помогает уменьшить или предотвратить слышимые артефакты.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для вычисления или оценивания качества (например, ожидаемого качества) операции перекрытия-и-сложения между первым блоком выборок и сдвинутым по времени вторым блоком выборок, чтобы вычислить или оценить (ожидаемое) качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Было установлено, что качество операции перекрытия-и-сложения фактически имеет сильное влияние на качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для определения сдвига по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства между первым блоком выборок, или порцией первого блока выборок (например, правосторонней порцией, то есть, выборками в конце первого блока выборок), и вторым блоком выборок, или порцией второго блока выборок (например, левосторонней порцией, то есть, выборками в начале второго блока выборок). Эта концепция основана на установлении факта, что определение подобия между первым блоком выборок и сдвинутым по времени вторым блоком выборок обеспечивает оценку качества операции перекрытия-и-сложения, и, следовательно, также обеспечивает значимую оценку качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Кроме того, было установлено, что степень сходства между первым блоком выборок (или правосторонней порцией первого блока выборок) и сдвинутым по времени вторым блоком выборок (или левосторонней порцией сдвинутого по времени второго блока выборок) может быть определена с хорошей точностью, используя умеренную вычислительную сложность.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для определения информации о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, или порцией (например, левосторонней порцией) второго блока выборок, для множества различных сдвигов по времени между первым блоком выборок и вторым блоком выборок, и для определения (пригодного для использования) сдвига по времени, подлежащего использованию для операции перекрытия-и-сложения, на основе информации о степени сходства для множества различных сдвигов по времени. Соответственно, сдвиг по времени второго блока выборок или относительно первого блока выборок может выбираться, чтобы являться приспособленным к аудио контенту. Однако управление качеством, которое включает в себя вычисление или оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, может выполняться после определения (пригодного) сдвига по времени, подлежащего использованию для операции перекрытия-и-сложения. Другими словами, при использовании механизма управления качеством может обеспечиваться, что сдвиг по времени, определенный на основе информации о степени сходства между первым блоком выборок (или порцией первого блока выборок) и вторым блоком выборок (или порцией второго блока выборок) для множества различных сдвигов по времени, фактически приводит к достаточно хорошему качеству звучания. Таким образом, артефакты могут быть уменьшены или предотвращены эффективно.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для определения сдвига по времени второго блока выборок относительно первого блока выборок, каковой сдвиг по времени подлежит использованию для операции перекрытия-и-сложения (если только операция сдвига по времени не отложена в ответ на оценку недостаточного качества), в зависимости от информации целевого сдвига по времени. Другими словами, рассматривают информацию целевого сдвига по времени и делают попытку определить сдвиг по времени второго блока выборок относительно первого блока выборок такой, что упомянутый сдвиг по времени второго блока выборок относительно первого блока выборок является близким к целевому сдвигу по времени, описанному информацией целевого сдвига по времени. Следовательно, может достигаться, что (пригодный) сдвиг по времени, который получают перекрытием-и-сложением первого блока выборок и сдвинутого по времени второго блока выборок, соответствует требованию (заданному информацией целевого сдвига по времени), причем фактическое исполнение операции перекрытия-и-сложения может предотвращаться, если вычисление или оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для вычисления или оценивания качества (например, ожидаемого качество) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала на основе информации о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией (например, левосторонней порцией) второго блока выборок, сдвинутого по времени на определенный сдвиг по времени. Было установлено, что степень сходства между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени, образует хороший критерий для принятия решения, будет ли масштабированная по времени версия входного аудиосигнала, получаемая масштабированием по времени, иметь достаточное качество или нет.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован, для принятия решения, на основе информации о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией (например, левосторонней порцией) второго блока выборок, сдвинутого по времени на определенный сдвиг по времени, выполнять ли масштабирование по времени фактически. Соответственно, определение сдвига по времени, который идентифицирован как пригодный сдвиг по времени, с использованием первого (обычно в вычислительном отношении более простого и не высоконадежного) алгоритма, за которым следует управление качеством, которое основано на информации о степени сходства между первым блоком выборок (или порцией первого блока выборок) и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени (или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени). "Управление качеством" на основе упомянутой информации является обычно более надежным, чем простое определение пригодного сдвига по времени, и поэтому используется, чтобы окончательно принять решение, выполняется ли масштабирование по времени фактически. Таким образом, масштабирование по времени может предотвращаться, если масштабирование по времени приводит к чрезмерным слышимым артефактам (или искажениям).
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получать масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению качества. Преобразователь масштаба времени сконфигурирован для определения сдвига по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, или порцией (например, левосторонней порцией) второго блока выборок. Преобразователь масштаба времени дополнительно сконфигурирован для вычисления или оценивания качества (например, ожидаемого качества) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства, оцениваемой с использованием второй меры подобия, между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией (например, левосторонней порцией) второго блока выборок, сдвинутого по времени на определенный сдвиг по времени. Использование первой меры подобия и второй меры подобия позволяет быстро определять сдвиг по времени второго блока выборок относительно первого блока выборок с умеренной вычислительной сложностью, и также позволяет вычислять или оценивать качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, с высокой точностью. Таким образом, двухэтапная процедура, использующая две различные меры подобия, позволяет объединить сравнительно малую вычислительную сложность на первом этапе с высокой точностью на втором этапе (управления качеством) и позволяет уменьшить или предотвратить слышимые артефакты даже при том, что первая мера подобия, которая обычно в вычислительном отношении является простой, используется для определения (пригодного) сдвига по времени второго блока выборок относительно первых из выборок (причем, это обычно потребует излишне использовать меру подобия высокой вычислительной сложности, подобной второй мере подобия, при определении пригодного сдвига по времени второго блока выборок относительно первого блока выборок).
В предпочтительном варианте осуществления вторая мера подобия в вычислительном отношении является более сложной, чем первая мера подобия. Соответственно, "конечная" проверка качества может выполняться с высокой точностью, тогда как легкое определение сдвига по времени второго блока выборок относительно первого блока выборок может выполняться эффективным образом.
В предпочтительном варианте осуществления первой мерой подобия является взаимная корреляция или нормированная взаимная корреляция или функция разности средних величин или сумма квадратичных ошибок. Предпочтительно, второй мерой подобия является комбинация взаимных корреляций или нормированных взаимных корреляций для множества различных сдвигов по времени. Было установлено, что взаимная корреляция, нормированная взаимная корреляция, функция разности средних величин или сумма квадратичных ошибок позволяют хорошее и эффективное определение (пригодного) сдвига по времени второго блока выборок относительно первого блока выборок. Кроме того, было установлено, что мера подобия, являющаяся комбинацией взаимных корреляций или нормированных взаимных корреляций для множества различных сдвигов по времени, является высоконадежной количественной величиной для численного выражения (вычисления или оценивания) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
В предпочтительном варианте осуществления второй мерой подобия является комбинация взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени. Было установлено, что комбинация взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени позволяет точную оценку качества, поскольку также могут рассматриваться изменения сигнала во времени путем определения корреляции, по меньшей мере, для четырех различных сдвигов по времени. Кроме того, в некоторой степени могут рассматриваться гармоники при использовании взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени. Следовательно, может достигаться особо хорошее оценивание доступного качества.
В предпочтительном варианте осуществления вторая мера подобия является комбинацией первого значения взаимной корреляции и второго значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целочисленное кратное длительности периода основной частоты аудио контента первого блока выборок или второго блока выборок, и третьего значения взаимной корреляции и четвертого значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целочисленное кратное длительности периода основной частоты аудио контента, причем сдвиг по времени, для которого получено первое значение взаимной корреляции, отстоит от сдвига по времени, для которого получено третье значение взаимной корреляции, на нечетное кратное половине длительности периода основной частоты аудио контента. Соответственно, первое значение взаимной корреляции и второе значение взаимной корреляции могут обеспечивать информацию, является ли аудио контент, по меньшей мере, приблизительно стационарным во времени. Подобным образом третье значение взаимной корреляции и четвертое значение взаимной корреляции также обеспечивают информацию, является ли аудио контент, по меньшей мере, приблизительно стационарным во времени. Кроме того, факт, что третье значение взаимной корреляции и четвертое значение взаимной корреляции являются “смещенными во времени” относительно первого значения взаимной корреляции и второго значения взаимной корреляции, позволяет рассмотрение гармоник. Для заключения, вычисление второй меры подобия на основе комбинации первого значения взаимной корреляции, второго значения взаимной корреляции, третьего значения взаимной корреляции и четвертого значения взаимной корреляции привносит высокую точность, и, следовательно, достоверный результат для вычисления (или оценивания) (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
В предпочтительном варианте осуществления вторую меру q подобия получают согласно q=c(p)*c(2*p)+c(3/2*p)*c(1/2*p) или согласно q=c(p)*c(-p)+c(-1/2*p)*c(1/2*p). В вышеупомянутых уравнениях c(p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени (друг относительно друга и относительно исходной временной шкалы) на длительность периода p основной частоты аудио контента первого блока выборок или второго блока выборок. Значение c(2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на 2*p. Значение c(3/2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на 3/2*p. Значение c(1/2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на -1/2*p. Значение c(-p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на -p, и c(-1/2*p) является значением взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на -1/2*p. Было установлено, что использование вышеупомянутых уравнений приводит к особо хорошему и надежному вычислению (или оцениванию) (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для сравнения значения качества, которое основывается на вычислении или оценивании качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, с переменным пороговым значением, для принятия решения, должно ли масштабирование по времени выполняться или нет. Использование переменного порогового значения позволяет адаптировать к ситуации пороговое значение для принятия решения, должно или нет выполняться масштабирование по времени. Соответственно, требования к качеству выполнения масштабирования по времени могут быть повышены в некоторых ситуациях и могут быть понижены в других ситуациях, например, в зависимости от предшествующих операций масштабирования по времени, или любых других характеристик сигнала. Следовательно, значимость принятия решения, выполнять ли масштабирование по времени или нет, может быть дополнительно повышена.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для уменьшения переменного порогового значения, чтобы таким образом снизить требования к качеству в ответ на установление, что качество масштабирования по времени было недостаточным для одного или нескольких предыдущих блоков выборок. Путем уменьшения переменного порогового значения может предотвращаться опускание масштабирования по времени на протяженный период времени, поскольку это может приводить к работе с недогрузкой буфера или с перегрузкой буфера и, следовательно, будет более вредным, чем генерация некоторых артефактов, обусловленных масштабированием по времени. Таким образом, можно избежать проблем, которые будут вызываться чрезмерной задержкой масштабирования по времени.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для повышения переменного порогового значения, чтобы тем самым повысить требования к качеству в ответ на установление, что масштабирование по времени было применено к одному или нескольким предшествующим блокам выборок. Соответственно, может обеспечиваться, что последующие блоки выборок масштабируются по времени только, если может достигаться сравнительно высокий уровень качества (выше чем "нормальный" уровень качества). Напротив, масштабированию по времени последовательности последующих блоков выборок препятствуют, если масштабирование по времени не выполнит сравнительно высокие требования к качеству. Это уместно, поскольку применение масштабирования по времени ко множеству последующих блоков выборок обычно приводит к артефактам, если масштабирование по времени не выполняет сравнительно высокие требования к качеству (которые обычно выше чем требования "нормального" качества, применимые, если только одиночный блок выборок, а не непрерывная последовательность блоков выборок, подлежит масштабированию по времени).
В предпочтительном варианте осуществления преобразователь масштаба времени содержит первый счетчик с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые были масштабированы по времени, поскольку было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Кроме того, преобразователь масштаба времени содержит второй счетчик с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые не были масштабированы по времени, поскольку не было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Преобразователь масштаба времени сконфигурирован для вычисления переменного порогового значения в зависимости от значения первого счетчика и в зависимости от значения второго счетчика. Путем использования первого счетчика с ограниченным интервалом значений и второго счетчика с ограниченным интервалом значений, получают простой механизм для регулировки переменного порогового значения, который позволяет адаптировать переменное пороговое значение к соответственной ситуации, избегая при этом чрезмерно малых или чрезмерно больших значений порогового значения.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован с возможностью добавлять значение, которое пропорционально значению первого счетчика, к начальному пороговому значению, и вычитать значение, которое пропорционально значению второго счетчика, из него, чтобы получать переменное пороговое значение. Путем использования такой концепции переменное пороговое значение можно получать весьма простым образом.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, причем вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала содержит вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться масштабированием по времени. Путем вычисления или оценивания артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться масштабированием по времени, может использоваться значимый критерий для вычисления или оценивания качества, поскольку артефакты обычно будут ухудшать впечатление прослушивания от человека-слушателя.
В предпочтительном варианте осуществления вычислительное оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала содержит вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться операцией перекрытия-и-сложения последующих блоков выборок входного аудиосигнала. Было признано, что операция перекрытия-и-сложения может быть первичным источником артефактов при выполнении масштабирования по времени. Соответственно, было установлено, что эффективным подходом будет вычисление или оценивание артефактов масштабированной по времени версии входного аудиосигнала, которые будут вызываться операцией перекрытия-и-сложения последующих блоков выборок входного аудиосигнала.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован, чтобы вычислять или оценивать (ожидаемое) качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, в зависимости от степени сходства последующих блоков выборок входного аудиосигнала. Было установлено, что масштабирование по времени может обычно выполняться с хорошим качеством, если последующие блоки или выборки входного аудиосигнала содержат сравнительно высокое подобие, и что искажения обычно генерируются масштабированием по времени, если последующие блоки выборок входного аудиосигнала содержат существенные различия.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован, чтобы вычислять или оценивать, имеются ли слышимые артефакты в масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Было установлено, что вычисление или оценивание слышимых артефактов обеспечивает информацию о качестве, которая хорошо адаптирована к впечатлению человека от прослушивания.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован с возможностью отложить масштабирование по времени до последующего кадра или до последующего блока выборок, если вычисление или оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество. Соответственно, является возможным выполнять масштабирование по времени в момент времени, который лучше подходит для масштабирования по времени тем, что генерируется меньше артефактов. Другими словами, путем гибкого выбора момента времени, в который выполняется масштабирование по времени, в зависимости от качества, достигаемого масштабированием по времени, слуховое восприятие масштабированной по времени версии входного аудиосигнала может быть улучшено. Кроме того, эта идея основывается на установлении факта, что небольшая задержка операции масштабирования по времени обычно не несет каких-либо существенных проблем.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован с возможностью отсрочить масштабирование по времени до момента времени, когда масштабирование по времени является менее слышимым, если вычисление или оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество. Соответственно, слуховое восприятие может быть улучшено избеганием слышимых искажений.
Осуществление согласно изобретению создает аудио декодер для обеспечения декодированного аудио контента на основе входного аудио контента. Аудио декодер содержит буфер джиттера, сконфигурированный для буферизации множества аудио кадров, представляющих блоки аудио выборок. Аудио декодер также содержит ядро (базовые средства) декодера, сконфигурированное, чтобы обеспечивать блоки аудио выборок на основе аудио кадров, принимаемых из буфера джиттера. Кроме того, аудио декодер содержит преобразователь масштаба времени на основе выборки, как в общих чертах предоставлено выше. Преобразователь масштаба времени на основе выборки сконфигурирован, чтобы обеспечивать масштабированные по времени блоки аудио выборок на основе блоков аудио выборок, обеспечиваемых ядром декодера. Этот аудио декодер основывается на идее, что преобразователь масштаба времени, который сконфигурирован для масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, хорошо приспособлен для использования в аудио декодере, содержащем буфер джиттера и ядро декодера. Присутствие буфера джиттера позволяет, например, откладывать операцию масштабирования по времени, если вычисление или оценивание (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает, что будет получено плохое качество. Таким образом, преобразователь масштаба времени на основе выборки, который содержит механизм управления качеством, позволяет предотвращать, или, по меньшей мере, уменьшать слышимые артефакты в аудио декодере, содержащем буфер джиттера и ядро декодера.
В предпочтительном варианте осуществления аудио декодер дополнительно содержит управление буфером джиттера. Управление буфером джиттера сконфигурировано, чтобы обеспечивать управляющую информацию для преобразователя масштаба времени на основе выборки, причем управляющая информация указывает, должно ли масштабирование по времени на основе выборки выполняться или нет. Альтернативно, или в дополнение, управляющая информация может указывать требуемую величину изменения масштаба по времени. Соответственно, преобразователем времени на основе выборки можно управлять в зависимости от требований аудио декодера. Например, управление буфером джиттера может выполнять адаптивное к сигналу управление и может выбирать, должно ли масштабирование по времени на основе кадра или масштабирование по времени на основе выборки выполняться адаптивным к сигналу образом. Соответственно, имеется дополнительная степень гибкости. Однако механизм управления качеством преобразователя масштаба времени на основе выборки может, например, отклонять управляющую информацию, обеспечиваемую управлением буфера джиттера, так что масштабирование по времени на основе выборки отменяется (или отключается) даже в случае, в котором управляющая информация, обеспеченная управлением буфера джиттера, указывает, что должно выполняться масштабирование по времени на основе выборки. Таким образом, "интеллектуальный" преобразователь масштаба времени на основе выборки может отклонить управление буфером джиттера, поскольку преобразователь масштаба времени на основе выборки способен получать более подробную информацию о качестве, получаемом масштабированием по времени. Для заключения, преобразователь масштаба времени на основе выборки может направляться управляющей информацией, предоставляемой управлением буфера джиттера, но может тем не менее "отказаться" от масштабирования по времени, если качество будет по существу нарушаться последующей управляющей информацией, обеспечиваемой управлением буфера джиттера, каковое помогает гарантировать удовлетворительное качество звука.
Другое осуществление согласно изобретению создает способ для обеспечения масштабированной по времени версии входного аудиосигнала. Способ содержит вычисление или оценивание качества (например, ожидаемого качества) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Способ дополнительно содержит выполнение масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Этот способ основывается на тех же соображениях, что и вышеупомянутый преобразователь масштаба времени.
Еще один вариант осуществления согласно изобретению создает компьютерную программу для выполнения упомянутого способа, если компьютерная программа исполняется на компьютере. Упомянутая компьютерная программа на тех же соображениях, что и способ, а также буфер джиттера, описанный выше.
4. КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления согласно изобретению затем будут описаны со ссылкой на прилагаемые фигуры чертежей, на которых:
Фиг.1 показывает структурную схему управления буфером джиттера согласно варианту осуществления настоящего изобретения;
Фиг.2 показывает структурную схему преобразователя масштаба времени согласно варианту осуществления настоящего изобретения;
Фиг.3 показывает структурную схему аудио декодера согласно варианту осуществления настоящего изобретения;
Фиг.4 показывает структурную схему аудио декодера согласно другому варианту осуществления настоящего изобретения, причем показано общее представление управления буфером джиттера (JBM);
Фиг.5 показывает псевдо код программы алгоритма для управления уровнем буфера PCM (импульсно-кодово-модулированный формат);
Фиг.6 показывает псевдо код программы алгоритма для вычисления значения задержки и значения смещения от времени приема и отметки времени RTP для пакета RTP;
Фиг.7 показывает псевдо код программы алгоритма для вычисления значений целевой задержки;
Фиг.8 показывает последовательность операций управляющей логики управления буфером джиттера;
Фиг.9 показывает представление структурной схемы модифицированного алгоритма перекрытия-сложения на основе подобия формы сигнала (WSOLA) с управлением качеством;
Фиг. 10 и 10b показывают последовательность операций способа управления преобразователем масштаба времени;
Фиг.11 показывает псевдокод программы алгоритма для управления качеством для масштабирования по времени;
Фиг.12 показывает графическое представление целевой задержки и задержки воспроизведения, которую получают по варианту осуществления согласно настоящему изобретению;
Фиг.13 показывает графическое представление масштабирования по времени, которое выполняется в варианте осуществления согласно настоящему изобретению;
Фиг.14 показывает последовательность операций способа для управления предоставлением декодированного аудио контента на основе входного аудио контента; и
Фиг.15 показывает последовательность операций для обеспечения масштабированной по времени версии входного аудиосигнала согласно варианту осуществления настоящего изобретения.
5. ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
5.1. Управление буфером джиттера по Фиг.1
Фиг.1 показывает структурную схему управления буфером джиттера согласно варианту осуществления настоящего изобретения. Блок (этап) 100 управления буфером джиттера, предназначенный для управления предоставлением декодированного аудио контента на основе входного аудио контента, принимает аудиосигнал 110 или информацию об аудиосигнале (каковая информация может описывать одну или несколько характеристик аудиосигнала, или кадров, или других порций сигнала в аудиосигнале).
Кроме того, блок 100 управления буфером джиттера обеспечивает управляющую информацию (например, управляющий сигнал) 112 для масштабирования на основе кадра. Например, управляющая информация 112 может содержать сигнал активизации (для масштабирования по времени на основе кадра) и/или количественную управляющую информацию (для масштабирования по времени на основе кадра).
Кроме того, блок 100 управления буфером джиттера обеспечивает управляющую информацию (например, управляющий сигнал) 114 для масштабирования по времени на основе выборки. Управляющая информация 114 может, например, содержать сигнал активизации и/или количественную управляющую информацию для масштабирования по времени на основе выборки.
Блок 110 управления буфером джиттера сконфигурирован, чтобы выбирать масштабирование по времени на основе кадра или масштабирование по времени на основе выборки адаптивным к сигналу образом. Соответственно, управление буфером джиттера может быть сконфигурировано для оценивания аудиосигнала или данных аудиосигнала 110 и обеспечения на основе этого управляющей информации 112 и/или управляющей информации 114. Соответственно, принятие решения, используется ли масштабирование по времени на основе кадра или масштабирование по времени на основе выборки, может быть приспособлено к характеристикам аудиосигнала, например, таким образом, что простое в вычислительном отношении масштабирование по времени на основе кадра используется, если ожидается (или оценено) на основе аудиосигнала и/или на основе информации об одной или нескольких характеристиках аудиосигнала, что масштабирование по времени на основе кадра не приводит к существенному ухудшению аудио контента. Напротив, управление буфером джиттера обычно принимает решение использовать масштабирование по времени на основе выборки, если ожидается или оценено (блоком управления буфером джиттера) на основе оценивания характеристик аудиосигнала 110, что требуется масштабирование по времени на основе выборки, чтобы избегать слышимых артефактов при выполнении масштабирования по времени.
Кроме того, следует отметить, что блок 110 управления буфером джиттера может естественно также принимать дополнительную управляющую информацию, например управляющую информацию, указывающую, следует ли выполнять масштабирование по времени или нет.
В последующем будут описаны некоторые необязательные подробности блока 100 управления буфером джиттера. Например, блок 100 управления буфером джиттера может обеспечивать управляющую информацию 112, 114 такую, что аудио кадры удаляют или вставляют для управления глубиной буфера джиттера, когда должно использоваться масштабирование по времени на основе кадра, и такую, что выполняют сдвигаемое по времени перекрытие-и-сложение порций аудиосигнала, когда используется масштабирование по времени на основе выборки. Другими словами, блок 100 управления буфером джиттера может действовать совместно, например, с буфером джиттера (также обозначаемым как буфер де-джиттера в некоторых случаях) и управлять буфером джиттера, чтобы выполнять масштабирование по времени на основе кадра. В этом случае, глубиной буфера джиттера можно управлять путем удаления кадров из буфера джиттера или путем вставки кадров (например, простых кадров, содержащих сигнализацию, что кадр является "неактивным", и что должна использоваться генерация комфортного шума) в буфер джиттера. Кроме того, блок 100 управления буфером джиттера может управлять преобразователем масштаба времени (например, преобразователем масштаба времени на основе выборки), чтобы выполнять сдвигаемое по времени перекрытие-и-сложение порций аудиосигнала.
Контроллер 100 буфера джиттера может быть сконфигурирован для переключения между масштабированием по времени на основе кадра, масштабированием по времени на основе выборки и отключением масштабирования по времени адаптивным к сигналу образом. Другими словами, управление буфером джиттера обычно не только различает масштабирование по времени на основе кадра и масштабирование по времени на основе выборки, но также выбирает состояние, в котором нет масштабирования по времени вовсе. Например, последнее состояние может быть выбрано, если нет необходимости масштабирования по времени, поскольку глубина буфера джиттера находится в рамках допустимого диапазона. В иной формулировке, масштабирование по времени на основе кадра и масштабирование по времени на основе выборки являются обычно не единственными двумя режимами работы, которые могут выбираться блоком управления буфером джиттера.
Блок 100 управления буфером джиттера может также рассматривать информацию глубины буфера джиттера для принятия решения, какой режим работы (например, масштабирование по времени на основе кадра, масштабирование по времени на основе выборки или без масштабирования по времени) должен использоваться. Например, управление буфером джиттера может сравнивать целевое значение, описывающее требуемую глубину буфера джиттера (также обозначаемого как буфер де-джиттера), и фактическое значение, описывающее фактическую глубину буфера джиттера, и выбирать режим работы (масштабирование по времени на основе кадра, масштабирование по времени на основе выборки или без масштабирования по времени) в зависимости от упомянутого сравнения, так что будет выбрано масштабирование по времени на основе кадра или масштабирование по времени на основе выборки для управления глубиной буфера джиттера.
Блок 100 управления буфером джиттера может, например, быть сконфигурирован, чтобы выбирать вставку комфортного шума или удаление комфортного шума, если предшествующий кадр был неактивным (каковое можно, например, узнать из аудиосигнала 110 непосредственно или на основе информации аудиосигнала, подобной, например, флагу SID идентификатора молчания в случае режима прерывистой передачи). Соответственно, блок 100 управления буфером джиттера может сигнализировать на буфер джиттера (также обозначаемый как буфер де-джиттера), что кадр комфортного шума должен быть вставлен, если требуется растягивание по времени, и предшествующий кадр (или текущий кадр) является неактивным. Кроме того, блок 100 управления буфером джиттера может предписать буферу джиттера (или буферу де-джиттера) удалить кадр комфортного шума (например, кадр, содержащий информацию сигнализации, указывающую, что подлежит выполнению генерация комфортного шума), если требуется выполнить стягивание по времени, и предшествующий кадр был неактивным (или текущий кадр является неактивным). Следует отметить, что соответственный кадр может считаться неактивным, когда соответственный кадр несет информацию сигнализации, указывающую генерацию комфортного шума (и обычно не содержит дополнительного закодированного аудио контента). Такая информация сигнализации может, например, принимать форму флага индикации молчания (флага SID) в случае режима прерывистой передачи.
Напротив, блок 100 управления буфером джиттера предпочтительно сконфигурирован, чтобы осуществлять выбор в сдвигаемом по времени перекрытии-и-сложении порций аудиосигнала, если предшествующий кадр был активным (например, если предшествующий кадр не содержал информацию сигнализации, указывающую, что должен генерироваться комфортный шум). Такое сдвигаемое по времени перекрытие-и-сложение порций аудиосигнала обычно позволяет регулировку сдвига по времени между блоками аудио выборок, полученных на основе последующих кадров входной аудиоинформации со сравнительно высоким разрешением (например, с разрешением, которое меньше, чем длина блоков аудио выборок, или которое меньше, чем четверть длины блоков аудио выборок, или которое даже меньше, чем или равно двум аудио выборкам, или которое является величиной в одиночную выборку аудио). Соответственно, выбор основанного на выборке масштабирования по времени позволяет весьма точно настроенное масштабирование по времени, каковое помогает избегать слышимых артефактов для активных кадров.
В случае, что управление буфером джиттера выбирает масштабирование по времени на основе выборки, управление буфером джиттера может также обеспечивать дополнительную управляющую информацию для регулировки или точной настройки масштабирования по времени на основе выборки. Например, блок 100 управления буфером джиттера может быть сконфигурирован для определения, представляет ли блок аудио выборок активную, но являющуюся молчанием порцию аудиосигнала, например порцию аудиосигнала, которая содержит сравнительно малую энергию. В этом случае, то есть, если порция аудиосигнала является "активной" (например, не порция аудиосигнала, для которой используется генерация комфортного шума в аудио декодере, а более детальное декодирование аудио контента), но "являющейся молчанием" (например, в том смысле, что энергия сигнала ниже некоторого порогового значения энергии или даже равна нулю), управление буфером джиттера может обеспечивать управляющую информацию 114 для выбора режима перекрытия-и-сложения, в котором сдвиг по времени между блоком аудио выборок, представляющих являющуюся молчанием (но активную) порцию аудиосигнала, и последующим блоком аудио выборок установлен в предопределенное максимальное значение. Соответственно, преобразователю масштаба времени на основе выборки не требуется идентифицировать надлежащую величину изменения масштаба по времени на основе подробного сравнения последующих блоков аудио выборок, а можно предпочтительнее просто использовать предопределенное максимальное значение для сдвига по времени. Может быть понятно, что "являющаяся молчанием" порция аудиосигнала не будет обычно вызывать существенные артефакты в операции перекрытия-и-сложения независимо от фактического выбора сдвига по времени. Следовательно, управляющая информация 114, обеспеченная блоком управления буфером джиттера, может упростить обработку, подлежащую выполнению преобразователем масштаба времени на основе выборок.
Напротив, если блок 110 управления буфером джиттера обнаруживает, что блок аудио выборок представляет "активную" и не являющуюся молчанием порцию аудиосигнала (например, порцию аудиосигнала, для которой нет генерации комфортного шума, и которая также содержит энергию сигнала, которая выше некоторого порогового значения), управление буфером джиттера обеспечивает управляющую информацию 114, чтобы посредством этого выбрать режим перекрытия-и-сложения, в котором сдвиг по времени между блоками аудио выборок определяют адаптивным к сигналу образом (например, посредством ориентированного на выборки преобразователя масштаба времени и с использованием определения сходных элементов между последующими блоками аудио выборок).
Кроме того, блок 100 управления буфером джиттера может также принимать информацию о фактическом заполнении буфера. Блок 100 управления буфером джиттера может выбирать вставку маскированного кадра (то есть, кадра, который формируют, используя механизм восстановления после потери пакета, например, используя предсказание на основе ранее декодированных кадров) в ответ на определение, что требуется растягивание по времени и что буфер джиттера является пустым. Другими словами, управление буфером джиттера может инициировать обработку исключительной ситуации для случая, в котором в основном будет желательным масштабирование по времени на основе выборки (поскольку предшествующий кадр или текущий кадр является "активным"), но при этом масштабирование по времени на основе выборки (например, с использованием перекрытия-и-сложения) не может выполняться надлежащим образом, поскольку буфер джиттера (или буфер де-джиттера) является пустым. Таким образом, блок 100 управления буфером джиттера может быть сконфигурирован для обеспечения надлежащей управляющей информации 112, 114 даже для исключительных случаев.
Чтобы упростить работу блока 100 управления буфером джиттера, блок 100 управления буфером джиттера может быть сконфигурирован для выбора масштабирования по времени на основе кадра или масштабирования по времени на основе выборки в зависимости от того, используется ли прерывистая передача (также кратко обозначаемая как “DTX”) в сочетании с генерацией комфортного шума (также кратко обозначаемой как “CNG” (comfort noise generation)) в текущий момент. Другими словами, блок 100 управления буфером джиттера может, например, выбрать масштабирование по времени на основе кадра, если на основе аудиосигнала или на основе информации аудиосигнала распознано, что предшествующий кадр (или текущий кадр) является "неактивным" кадром, для которого должна использоваться генерация комфортного шума. Это может быть определено, например, путем оценивания информации сигнализации (например, флага, подобного так называемому флагу “SID”), которая включена в кодированное представление аудиосигнала. Соответственно, управление буфером джиттера может принять решение, что должно использоваться масштабирование по времени на основе кадра, если прерывистая передача в сочетании с генерацией комфортного шума используется в текущий момент, поскольку можно ожидать, что такое масштабирование по времени вызовет только малые слышимые искажения или отсутствие слышимых искажений в этом случае. Напротив, масштабирование по времени на основе выборки может использоваться в противном случае (например, если прерывистая передача в сочетании с генерацией комфортного шума в текущий момент не используется), если только нет каких-либо исключительных условий (подобных, например, пустому буферу джиттера).
Предпочтительно, управление буфером джиттера может выбирать между одним из (по меньшей мере) четырех режимов в случае, что требуется масштабирование по времени. Например, управление буфером джиттера может быть сконфигурировано, чтобы выбирать вставку комфортного шума или удаление комфортного шума для масштабирования по времени, если в текущий момент используется прерывистая передача в сочетании с генерацией комфортного шума. Кроме того, управление буфером джиттера может быть сконфигурировано, чтобы выбирать операцию перекрытия-сложения с использованием предопределенного сдвига по времени, для масштабирования по времени, если текущая порция аудиосигнала является активной, но содержит энергию сигнала, которая меньше чем или равна пороговому значению энергии, и если буфер джиттера не является пустым. Кроме того, управление буфером джиттера может быть сконфигурировано, чтобы выбирать операцию перекрытия-сложения при использовании адаптивного к сигналу сдвига по времени для масштабирования по времени, если текущая порция аудиосигнала является активной и содержит энергию сигнала, которая больше чем или равна пороговому значению энергии, и если буфер джиттера не является пустым. В заключение, управление буфером джиттера может быть сконфигурировано, чтобы выбирать вставку маскированного кадра для масштабирования по времени, если текущая порция аудиосигнала является активной, и если буфер джиттера является пустым. Соответственно, можно видеть, что управление буфером джиттера может быть сконфигурировано, чтобы выбирать масштабирование по времени на основе кадра или масштабирование по времени на основе выборки адаптивным к сигналу образом.
Кроме того, следует отметить, что управление буфером джиттера может быть сконфигурировано, чтобы выбирать операцию перекрытия-и-сложения при использовании адаптивного к сигналу сдвига по времени и механизма управления качеством для масштабирования по времени, если текущая порция аудиосигнала является активной и содержит энергию сигнала, которая больше чем или равна пороговому значению энергии, и если буфер джиттера не является пустым. Другими словами, может иметься дополнительный механизм управления качеством для масштабирования по времени на основе выборки, который дополняет адаптивный к сигналу выбор между масштабированием по времени на основе кадра и масштабированием по времени на основе выборки, который выполняется блоком управления буфером джиттера. Таким образом, может использоваться концепция иерархии, в которой буфер джиттера выполняет начальный выбор между масштабированием по времени на основе кадра и масштабированием по времени на основе выборки, и при этом дополнительный механизм управления качеством реализован, чтобы гарантировать, что масштабирование по времени на основе выборки не приведет к неприемлемому ухудшению качества звучания.
Для заключения, была пояснена основная функциональность блока 100 управления буфером джиттера, и также были пояснены необязательные усовершенствования такового. Кроме того, следует отметить, что блок 100 управления буфером джиттера может быть снабжен любым из признаков и функциональных возможностей, описанными здесь.
5.2. Преобразователь масштаба времени по Фиг.2
Фиг.2 показывает структурную схему преобразователя 200 масштаба времени согласно варианту осуществления настоящего изобретения. Преобразователь 200 масштаба времени сконфигурирован для приема входного аудиосигнала 210 (например, в форме последовательности выборок, обеспечиваемых ядром декодера), и обеспечивает, на основе этого, масштабированную по времени версию 212 входного аудиосигнала. Преобразователь 200 масштаба времени сконфигурирован для вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Эта функциональность может выполняться, например, вычислительным устройством. Кроме того, преобразователь 200 масштаба времени сконфигурирован для выполнения масштабирования по времени входного аудиосигнала 210 в зависимости от результата вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала 212. Эта функциональность может, например, выполняться преобразователем масштаба времени.
Соответственно, преобразователь масштаба времени может выполнять управление качеством, чтобы гарантировать, что предотвращаются чрезмерные ухудшения качества звучания при выполнении масштабирования по времени. Например, преобразователь масштаба времени может быть сконфигурирован для предсказания (или оценивания), на основе входного аудиосигнала, ожидается ли, что предполагаемая операция масштабирования по времени (как, например, операция перекрытия-и-сложения, выполняемая на основе сдвигаемых по времени блоков (аудио) выборок, приведет к достаточно хорошему качеству звучания. Другими словами, преобразователь масштаба времени может быть сконфигурирован для вычисления или оценивания (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, до фактического исполнения масштабирования по времени входного аудиосигнала. С этой целью, преобразователь масштаба времени может, например, сравнивать порции входного аудиосигнала, которые участвуют в операции масштабирования по времени (например, в том, что упомянутые порции входного аудиосигнала подлежат перекрытию и сложению для выполнения посредством этого масштабирования по времени). Для заключения, преобразователь 200 масштаба времени обычно сконфигурирован для проверки, можно ли ожидать, что предполагаемое масштабирование по времени приведет к достаточному качеству звучания масштабированной по времени версии входного аудиосигнала, и решать, выполнять ли масштабирование по времени или нет на основе этого. Альтернативно, преобразователь масштаба времени может адаптировать любой из параметров масштабирования по времени (например, сдвиг по времени между блоками выборок, подлежащих перекрытию и сложению) в зависимости от результата вычислительного оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала.
В последующем будут описаны необязательные усовершенствования преобразователя 200 масштаба времени.
В предпочтительном варианте осуществления преобразователь масштаба времени сконфигурирован для выполнения операции перекрытия-и-сложения с использованием первого блока выборок входного аудиосигнала и второго блока выборок входного аудиосигнала. В этом случае, преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения первого блока выборок и сдвигаемого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала. Например, если требуется стягивание по времени, преобразователь масштаба времени может ввести первое число выборок входного аудиосигнала и обеспечить на основе этого второе число выборок масштабированной по времени версии входного аудиосигнала, причем второе число выборок меньше, чем первое число выборок. Чтобы добиться сокращения числа выборок, первое число выборок может быть разделено на, по меньшей мере, первый блок выборок и второй блок выборок (причем, первый блок выборок и второй блок выборок могут быть перекрывающимися или неперекрывающимися), и первый блок выборок и второй блок выборок могут быть временно сдвинутыми вместе так, чтобы временно сдвинутые версии первого блока выборок и второго блока выборок перекрывались. В области перекрытия между сдвинутой версией(ями) первого блока выборок и второго блока выборок применяется операция перекрытия-и-сложения. Такая операция перекрытия-и-сложения может применяться, не вызывая существенные слышимые искажения, если первый блок выборок и второй блок выборок являются "достаточно" подобными в области перекрытия (в которой выполняется операция перекрытия-и-сложения), и предпочтительно также в окружении перекрывающейся области. Таким образом, посредством перекрытия и сложения порций сигнала, которые первоначально не были перекрывающимися временным образом, добиваются стягивания по времени, поскольку общее число выборок уменьшается на число выборок, которые первоначально не были перекрывающимися (во входном аудиосигнале 210), но которые перекрываются в масштабированной по времени версии 212 входного аудиосигнала.
Наоборот, растягивания по времени можно также добиться, используя такую операцию перекрытия-и-сложения. Например, первый блок выборок и второй блок выборок могут выбираться так, чтобы быть перекрывающимися, и могут содержать первое полное временное расширение. Затем, второй блок выборок можно сдвигать по времени относительно первого блока выборок с тем результатом, что уменьшается перекрытие между первым блоком выборок и вторым блоком выборок. Если сдвигаемый по времени второй блок выборок хорошо подходит к первому блоку выборок, может выполняться перекрытие-и-сложение, причем область перекрытия между первым блоком выборок и сдвигаемой по времени версией второго блока выборок может быть и в терминах числа выборок, и в терминах времени более короткой, чем исходная область перекрытия между первым блоком выборок и вторым блоком выборок. Соответственно, результат операции перекрытия-и-сложения, использующей первый блок выборок и сдвигаемую по времени версию второго блока выборок, может содержать большую временную протяженность (и в терминах времени, и в терминах числа выборок), чем полная протяженность первого блока выборок и второго блока выборок в их исходной форме.
Соответственно, очевидно, что и стягивание по времени, и растягивание по времени можно получить с использованием операции перекрытия-и-сложения, используя первый блок выборок входного аудиосигнала и второй блок выборок входных аудиосигналов, причем второй блок выборок сдвинут по времени относительно первого блока выборок (или при этом и первый блок выборок, и второй блок выборок сдвинуты по времени друг относительно друга).
Предпочтительно, преобразователь 200 масштаба времени сконфигурирован для вычисления или оценивания качества операции перекрытия-и-сложения между первым блоком выборок и сдвигаемой по времени версией второго блока выборок, чтобы вычислять или оценивать (ожидаемое) качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Следует отметить, что имеются обычно какое-либо едва слышимые артефакты, если операцию перекрытия-и-сложения выполняют для порций блоков выборок, которые являются достаточно сходными. В иной формулировке, качество операции перекрытия-и-сложения значительно влияет на (ожидаемое) качество масштабированной по времени версии входных аудиосигналов. Таким образом, оценивание (или вычисление) качества операции перекрытия-и-сложения обеспечивает надежное оценивание (или вычисление) качества масштабированной по времени версии входного аудиосигнала.
Предпочтительно, преобразователь 200 масштаба времени сконфигурирован для определения сдвига по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства между первым блоком выборок или порцией (например, правосторонней порцией) первого блока выборок и сдвигаемым по времени вторым блоком выборок или порцией (например, левосторонней порцией) сдвигаемого по времени второго блока выборок. Другими словами, преобразователь масштаба времени может быть сконфигурирован для определения, какой сдвиг по времени между первым блоком выборок и вторым блоком выборок является наиболее подходящим для получения достаточно хорошего результата перекрытия-и-сложения (или, по меньшей мере, лучшего возможного результата перекрытия-и-сложения). Однако, на добавочном ("управления качеством") этапе может проверяться, способствует ли такой определенный сдвиг по времени второго блока выборок относительно первого блока выборок фактически достаточно хорошему результату перекрытия-и-сложения (или ожидается, что способствует достаточно хорошему результату перекрытия-и-сложения).
Предпочтительно, преобразователь масштаба времени определяет информацию о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок и вторым блоком выборок, или порцией (например, левосторонней порцией) второго блока выборок для множества различных сдвигов по времени между первым блоком выборок и вторым блоком выборок, и определяет (пригодный для использования) сдвиг по времени, который будет использоваться для операции перекрытия-и-сложения, на основе информации о степени сходства для множества различных сдвигов по времени. В иной формулировке, может выполняться поиск лучшего соответствия, причем информацию о степени сходства для различных сдвигов по времени можно сравнивать для нахождения сдвига по времени, для которого можно добиться лучшей степени сходства.
Предпочтительно, преобразователь масштаба времени сконфигурирован для определения сдвига по времени второго блока выборок относительно первого блока выборок, каковой сдвиг по времени должен использоваться для операции перекрытия-и-сложения в зависимости от целевой информации о сдвиге по времени. Другими словами, целевая информация о сдвиге по времени, которая, например, может быть получена на основе оценивания степени заполнения буфера, джиттера и возможно других дополнительных критериев, может рассматриваться (учитываться) при определении, какой сдвиг по времени должен использоваться (например, в качестве пригодного сдвига по времени) для операции перекрытия-и-сложения. Таким образом, перекрытие-и-сложение приспосабливают к требованиям к системе.
В некоторых вариантах осуществления преобразователь масштаба времени может быть сконфигурирован для вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок и вторым блоком выборок, сдвигаемым по времени на определенный (пригодный) сдвиг по времени, или порцию (например, левостороннюю порцию) второго блока выборок, сдвигаемого по времени на определенный (пригодный) сдвиг по времени. Упомянутая информация о степени сходства обеспечивает информацию о (ожидаемом) качестве операции перекрытия-и-сложения и, следовательно, также обеспечивает информацию (по меньшей мере, оценку) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. В некоторых случаях вычисленная или оцененная информация качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, может использоваться для принятия решения, выполняется ли фактически масштабирование по времени или нет (причем, в последнем случае масштабирование по времени может быть отложено). Другими словами, преобразователь масштаба времени может быть сконфигурирован для принятия решения, на основе информации о степени сходства между первым блоком выборок, или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок, сдвигаемым по времени на определенный (пригодный) сдвиг по времени, или порцией (например, левосторонней порцией) второго блока выборок, сдвигаемого по времени на определенный (пригодный) сдвиг по времени, выполняется ли масштабирование по времени фактически (или нет). Таким образом, механизм управления качеством, который оценивает вычисленную или оцененную информацию о качестве масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, может фактически приводить к невыполнению масштабирования по времени (по меньшей мере, для текущего блока или кадра аудио выборок), если ожидается, что масштабирование по времени будет вызывать чрезмерное ухудшение аудио контента.
В некоторых вариантах осуществления различные меры подобия могут использоваться для начального определения (пригодного) сдвига по времени между первым блоком выборок и вторым блоком выборок и для конечного механизма управления качеством. Другими словами, преобразователь масштаба времени может быть сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения первого блока выборок и сдвигаемого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению качества. Преобразователь масштаба времени может быть сконфигурирован для определения (пригодного) сдвига по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок или порцией (например, правосторонней порцией) первого блока выборок, и вторым блоком выборок или порцией (например, левосторонней порцией) второго блока выборок. Кроме того, преобразователь масштаба времени может быть сконфигурирован для вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства, оцениваемой с использованием второй меры подобия, между первым блоком выборок или порцией (например, правосторонней порцией) первого блока выборок и вторым блоком выборок, сдвигаемым по времени на определенный (пригодный) сдвиг по времени, или порцией (например, левосторонней порцией) второго блока выборок, сдвигаемого по времени на определенный (пригодный) сдвиг по времени. Например, вторая мера подобия может быть в вычислительном отношении более сложной, чем первая мера подобия. Такой принцип является полезным, поскольку обычно необходимо вычислять первую меру подобия многократно на одну операцию масштабирования по времени (чтобы определить "пригодный" сдвиг по времени между первым блоком выборок и вторым блоком выборок из множества возможных значений сдвига по времени между первым блоком выборок и вторым блоком выборок). Наоборот, вторая мера подобия обычно требует вычисления только один раз на операцию сдвига по времени, например, в виде "конечной" проверки качества, ожидается ли, что (пригодный) сдвиг по времени, определенный с использованием первой (вычислительно менее сложной) меры качества, приведет к достаточно хорошему качеству звучания. Следовательно, является возможным все еще избежать исполнения перекрытия-и-сложения, если первая мера подобия указывает достаточно хорошее (или, по меньшей мере, достаточное) подобие между первым блоком выборок (или его порцией) и сдвигаемым по времени вторым блоком выборок (или его порцией) для (пригодного) сдвига по времени, но вторая (и обычно более значимая или точная) мера подобия указывает, что масштабирование по времени не приведет к достаточно хорошему качеству звучания. Таким образом, применение управления качеством (использующего вторую меру подобия) помогает избежать слышимых искажений в масштабировании по времени.
Например, первая мера подобия может быть взаимной корреляцией или нормированной взаимной корреляцией, или функцией разности средних величин, или суммой квадратичных ошибок. Такие меры подобия могут быть получены эффективным в вычислительном отношении образом и являются достаточными для нахождения “лучшего соответствия” между первым блоком выборок (или его порцией) и (сдвигаемым по времени) вторым блоком выборок (или его порцией), то есть, определения (пригодного) сдвига по времени. Наоборот, вторая мера подобия может, например, быть комбинацией значений взаимной корреляции или значений нормированной взаимной корреляции для множества различных сдвигов по времени. Такая мера подобия обеспечивает больше точности и помогает рассматривать дополнительные компоненты сигнала (подобные, например, гармоникам) или стационарность аудиосигнала при оценивании (ожидаемого) качества масштабирования по времени. Однако вторая мера подобия в вычислительном отношении требует большего, чем первая мера подобия, так что в вычислительном отношении будет неэффективным применять вторую меру подобия при поиске (пригодного) сдвига по времени.
В последующем будут описаны некоторые необязательные возможности для определения второй меры подобия. В некоторых вариантах осуществления вторая мера подобия может быть комбинацией взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени. Например, вторая мера подобия может быть комбинацией первого значения взаимной корреляции и второго значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целое кратное длительности периода основной частоты аудио контента первого блока выборок или второго блока выборок, и третьего значения взаимной корреляции и четвертого значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целое кратное длительности периода основной частоты аудио контента. Сдвиг по времени, для которого получено первое значение взаимной корреляции, может отстоять от сдвига по времени, для которого получено третье значение взаимной корреляции, на нечетное кратное половине длительности периода основной частоты аудио контента. Если аудио контент (представленный входным аудиосигналом) будет по существу стационарным и с доминированием основной частоты, можно ожидать, что первое значение взаимной корреляции и второе значение взаимной корреляции, которое, например, может быть нормировано, являются оба близкими к единице. Однако поскольку третье значение взаимной корреляции и четвертое значение взаимной корреляции оба получены для сдвигов по времени, которые отстоят на нечетное кратное половине длительности периода основной частоты от сдвигов по времени, для которых получены первое значение взаимной корреляции и второе значение взаимной корреляции, можно ожидать, что третье значение взаимной корреляции и четвертое значение взаимной корреляции являются противоположными по отношению к первому значению взаимной корреляции и второму значению взаимной корреляции в случае, если аудио контент является по существу стационарным и с доминированием основной частоты. Соответственно, значимая комбинация может быть сформирована на основе первого значения взаимной корреляции, второго значения взаимной корреляции, третьего значения взаимной корреляции и четвертого значения взаимной корреляции, которая указывает, является ли аудиосигнал достаточно стационарным и с доминированием основной частоты в (пригодной для использования) области перекрытия-и-сложения.
Следует отметить, что особо значимые меры подобия могут быть получены путем вычисления меры q подобия согласно
q=c(p)*c(2*p)+c(3/2*p)*c(1/2*p)
или согласно
q=c(p)*c(-p)+c(-1/2*p)*c(1/2*p).
В вышеуказанном c(p) - значение взаимной корреляции между первым блоком выборок (или его порцией) и вторым блоком выборок (или его порцией), которые являются сдвигаемыми по времени (например, относительно исходной временной позиции внутри входного аудио контента) на длительность p периода основной частоты аудио контента первого блока выборок и/или второго блока выборок (причем, основная частота аудио контента обычно является по существу идентичной в первом блоке выборок и во втором блоке выборок). Другими словами, значение взаимной корреляции вычисляют на основе блоков выборок, которые взяты из входного аудио контента и дополнительно сдвинуты по времени друг относительно друга на длительность p периода основной частоты входного аудио контента (причем, длительность p периода основной частоты может быть получена, например, на основе оценивания основной частоты, автокорреляции или подобного). Подобным образом c(2*p) является значением взаимной корреляции между первым блоком выборок (или его порцией) и вторым блоком выборок (или его порцией), которые сдвинуты по времени на 2*p. Подобные определения также применяют к c(3/2*p), c(1/2*p), c(-p) и c(-1/2*p), причем аргумент в c(.) обозначает сдвиг по времени.
В последующем будут пояснены некоторые механизмы для принятия решения, должно ли выполняться масштабирование по времени, которое может по выбору применяться в преобразователе 200 масштаба времени. В реализации преобразователь 200 масштаба времени может быть сконфигурирован для сравнения значения качества, которое основано на вычислении или оценивании (ожидаемого) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, с переменным пороговым значением, чтобы решить, должно ли выполняться масштабирование по времени. Соответственно, принятие решения, выполнять ли масштабирование по времени, может также приниматься в зависимости от условий, подобных, например, предыстории, представляющей предшествующие изменения масштаба времени.
Например, преобразователь масштаба времени может быть сконфигурирован для уменьшения переменного порогового значения, чтобы тем самым снизить требование к качеству (которого нужно добиться, чтобы сделать возможным масштабирование по времени), в ответ на установление, что качество масштабирования по времени будет недостаточным для одного или нескольких предшествующих блоков выборок. Соответственно, обеспечивается, что не предотвращается масштабирование по времени для длинной последовательности кадров (или блоков выборок), каковое может вызывать работу с перегрузкой буфера или работу с недогрузкой буфера. Кроме того, преобразователь масштаба времени может быть сконфигурирован для увеличения переменного порогового значения, чтобы тем самым повысить требование к качеству (которого нужно добиться, чтобы сделать возможным масштабирование по времени), в ответ на установление факта, что масштабирование по времени применялось к одному или большему числу предшествующих блоков или выборок. Соответственно, может предотвращаться масштабирование по времени слишком многих последующих блоков или выборок, если только не может быть получено очень хорошее качество (повышенное относительно обычного требования к качеству) масштабирования по времени. Соответственно, можно избегать артефактов, которые будут вызываться, если условия к качеству масштабирования по времени были слишком низкими.
В некоторых вариантах осуществления преобразователь масштаба времени может содержать первый счетчик с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые были масштабированы по времени, поскольку было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Кроме того, преобразователь масштаба времени также может содержать второй счетчик с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые не были масштабированы по времени, поскольку не было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. В этом случае, преобразователь масштаба времени может быть сконфигурирован для вычисления переменного порогового значения в зависимости от значения первого счетчика и в зависимости от значения второго счетчика. Соответственно, "предысторию" масштабирования по времени (а также предысторию "качества") можно рассматривать с умеренным вычислительным усилием.
Например, преобразователь масштаба времени может быть сконфигурирован с возможностью добавлять значение, которое пропорционально значению первого счетчика, к начальному пороговому значению, и вычитать значение, которое пропорционально значению второго счетчика, из него (например, из результата сложения), чтобы получать переменное пороговое значение.
В последующем будут обобщены некоторые важные функциональные возможности, которые могут обеспечиваться в некоторых вариантах осуществления преобразователя 200 масштаба времени. Однако следует отметить, что функциональные возможности, описанные в последующем, не являются существенными функциональными возможностями преобразователя 200 масштаба времени.
В реализации преобразователь масштаба времени может быть сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от результата вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. В этом случае, вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала содержит вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться этим масштабированием по времени. Однако следует отметить, что вычисление или оценивание артефактов могут выполняться косвенным образом, например, путем вычисления качества операции перекрытия-и-сложения. Другими словами, вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала может содержать вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться операцией перекрытия-и-сложения последующих блоков выборок входного аудиосигнала (причем, естественно, некоторый сдвиг по времени может применяться к последующим блокам выборок).
Например, преобразователь масштаба времени может быть сконфигурирован для вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, в зависимости от степени сходства последующих (и возможно перекрывающихся) блоков выборок входного аудиосигнала.
В предпочтительном варианте осуществления преобразователь масштаба времени может быть сконфигурирован для вычисления или оценивания, имеются ли слышимые артефакты в масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Оценивание слышимых артефактов может выполняться косвенным образом, как упомянуто выше.
Как следствие управления качеством, масштабирование по времени может выполняться в моменты времени, которые хорошо подходят для масштабирования по времени, и не допускаться в моменты времени, которые не подходят для масштабирования по времени. Например, преобразователь масштаба времени может быть сконфигурирован, чтобы откладывать масштабирование по времени на последующий кадр или на последующий блок выборок, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество (например, качество, которое ниже некоторого порогового значения качества). Таким образом, масштабирование по времени может выполняться в момент времени, который является более подходящим для масштабирования по времени, так что генерируется меньше артефактов (в частности, слышимых артефактов). Другими словами, преобразователь масштаба времени может быть сконфигурирован, чтобы откладывать масштабирование по времени на момент времени, когда масштабирование по времени является менее слышимым, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество.
Для заключения, преобразователь 200 масштаба времени может быть усовершенствован рядом различных способов, как обсуждено выше.
Кроме того, следует отметить, что преобразователь 200 масштаба времени может дополнительно быть объединен с блоком 100 управления буфером джиттера, причем блок 100 управления буфером джиттера может принимать решение, должно ли использоваться масштабирование по времени на основе выборки, которое обычно выполняется преобразователем 200 масштаба времени, или должно использоваться масштабирование по времени на основе кадра.
5.3. Аудио декодер по Фиг.3
Фиг.3 иллюстрирует структурную схему аудио декодера 300 согласно варианту осуществления настоящего изобретения.
Аудио декодер 300 сконфигурирован для приема входного аудио контента 310, который может рассматриваться в качестве представления входного аудио, и который может, например, быть представлен в форме аудио кадров. Кроме того, аудио декодер 300 обеспечивает, на основе этого, декодированный аудио контент 312, который может, например, быть представлен в форме декодированных аудио выборок. Аудио декодер 300 может, например, содержать буфер 320 джиттера, который сконфигурирован для приема входного аудио контента 310, например, в форме аудио кадров. Буфер 320 джиттера сконфигурирован для буферизации множества аудио кадров, представляющих блоки аудио выборок (причем, одиночный кадр может представлять один или несколько блоков аудио выборок, и при этом аудио выборки, представленные одиночным кадром, могут быть логически подразделены на множество из перекрывающихся или неперекрывающихся блоков аудио выборок). Кроме того, буфер 320 джиттера обеспечивает "буферизованные" аудио кадры 322, причем аудио кадры 322 могут содержать и аудио кадры, включенные во входной аудио контент 310, и аудио кадры, которые формируются или вставляются буфером джиттера (подобные, например, "неактивным" аудио кадрам, содержащим информацию сигнализации, сигнализирующую генерацию комфортного шума). Аудио декодер 300 дополнительно содержит ядро 330 декодера, которое принимает буферизованные аудио кадры 322 из буфера 320 джиттера и которое обеспечивает аудио выборки 332 (например, блоки с аудио выборками, связанными с аудио кадрами) на основе аудио кадров 322, принятых из буфера джиттера. Кроме того, аудио декодер 300 содержит преобразователь 340 масштаба времени на основе выборки, который сконфигурирован для приема аудио выборок 332, обеспеченных ядром 330 декодера, и обеспечения на основе этого масштабированных по времени аудио выборок 342, которые составляют декодированный аудио контент 312. Преобразователь 340 масштаба времени на основе выборки сконфигурирован для обеспечения масштабированных по времени аудио выборок (например, в форме блоков аудио выборок) на основе аудио выборок 332 (то есть, на основе блоков аудио выборок, обеспеченных ядром декодера). Кроме того, аудио декодер может содержать дополнительный блок 350 управления. Блок 350 управления буфером джиттера, который используется в аудио декодере 300, может, например, быть идентичным блоку 100 управления буфером джиттера по Фиг.1. Другими словами, блок 350 управления буфером джиттера может быть сконфигурирован для выбора масштабирования по времени на основе кадра, которое выполняется буфером 320 джиттера, или масштабирования по времени на основе выборки, которое выполняется преобразователем 340 масштаба времени на основе выборки, адаптивным к сигналу образом. Соответственно, блок 350 управления буфером джиттера может принимать входной аудио контент 310 или информацию о входном аудио контенте 310 в виде аудиосигнала 110 или в виде информации об аудиосигнале 110. Кроме того, блок 350 управления буфером джиттера может обеспечивать управляющую информацию 112 (как описано относительно управления буфера джиттера) на буфер 320 джиттера, и блок 350 управления буфером джиттера может обеспечивать управляющую информацию 114, как описано относительно блока 100 управления буфером джиттера, на преобразователь 140 масштаба времени на основе выборки. Соответственно, буфер 320 джиттера может быть сконфигурирован для удаления или вставки аудио кадров для того, чтобы выполнять масштабирование по времени на основе кадра. Кроме того, ядро 330 декодера может быть сконфигурировано для выполнения генерации комфортного шума в ответ на кадр, несущий информацию сигнализации, указывающую генерацию комфортного шума. Соответственно, комфортный шум может генерироваться ядром 330 декодера в ответ на вставку "неактивного" кадра (содержащего информацию сигнализации, указывающую, что должен быть сгенерирован комфортный шум), в буфер 320 джиттера. Другими словами, простая форма масштабирования по времени на основе кадра может эффективно приводить к генерации кадра, содержащего комфортный шум, которая инициирована вставкой "неактивного" кадра в буфер джиттера (каковое может выполняться в ответ на управляющую информацию 112, обеспеченную блоком управления буфером джиттера). Кроме того, ядро декодера может быть сконфигурировано для выполнения "маскирования" в ответ на пустой буфер джиттера. Такое маскирование может содержать генерацию аудио информации для "отсутствующего" кадра (пустой буфер джиттера) на основе аудио информации одного или большего числа кадров, предшествующих отсутствующему аудио кадру. Например, может использоваться предсказание в предположении, что аудио контент отсутствующего аудио кадра является "продолжением" аудио контента одного или большего числа аудио кадров, предшествующих отсутствующему аудио кадру. Однако, любой из принципов маскирования потери кадра, известных в области техники, может использоваться ядром декодера. Следовательно, блок 350 управления буфером джиттера может предписывать буферу 320 джиттера (или ядру 330 декодера) инициировать маскирование в случае, что буфер 320 джиттера работает пустым. Однако ядро декодера может выполнять маскирование даже без явного управляющего сигнала на основании собственных логических возможностей.
Кроме того, следует отметить, что преобразователь 340 масштаба времени на основе выборки может быть эквивалентным преобразователю 200 масштаба времени, описанному относительно Фиг.2. Соответственно, входной аудиосигнал 210 может соответствовать аудио выборкам 332, и масштабированная по времени версия 212 входного аудиосигнала может соответствовать масштабированным по времени аудио выборкам 342. Соответственно, преобразователь 340 масштаба времени может быть сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Преобразователем 340 масштаба времени на основе выборки может управлять блок 350 управления буфером джиттера, причем управляющая информация 114, обеспечиваемая блоком управления буфером джиттера на преобразователь 340 масштаба времени на основе выборки, может указывать, должно ли масштабирование по времени на основе выборки выполняться или нет. Кроме того, управляющая информация 114 может, например, указывать требуемую величину изменения масштаба по времени, подлежащего выполнению поддерживающим выборки преобразователем 340 масштаба времени.
Следует отметить, что преобразователь масштаба времени 300 может быть снабжен любым из признаков и функциональных возможностей, описанных относительно блока 100 управления буфером джиттера и/или относительно преобразователя 200 масштаба времени. Кроме того, аудио декодер 300 также может быть снабжен любыми другими признаками и функциональными возможностями, описанными в документе, например, относительно Фиг.4-15.
5.4. Аудио декодер по Фиг.4
Фиг.4 иллюстрирует структурную схему аудио декодера 400 согласно варианту осуществления настоящего изобретения. Аудио декодер 400 сконфигурирован для приема пакетов 410, которые могут содержать пакетированное представление одного или большего числа аудио кадров. Кроме того, аудио декодер 400 обеспечивает декодированный аудио контент 412, например, в форме аудио выборок. Аудио выборки могут, например, быть представлены в формате “PCM” (то есть, в импульсно-кодовой модулированной форме, например, в форме последовательности цифровых значений, представляющих выборки (отсчеты) формы аудиосигнала).
Аудио декодер 400 содержит разборщик 420, который сконфигурирован для приема пакетов 410 и обеспечения на основе этого восстановленных из пакетов кадров 422. Кроме того, разборщик сконфигурирован для извлечения из пакетов 410 так называемого “флага SID”, который сигнализирует "неактивный" аудио кадр (то есть, аудио кадр, для которого должна использоваться генерация комфортного шума, а не "обычное" подробное декодирование аудио контента). Информация флага SID обозначена позицией 424. Кроме того, разборщик обеспечивает отметку времени по транспортному протоколу реального времени (также обозначаемую как “TS RTP”) и отметку времени поступления (также обозначаемую как “TS поступления”). Информация отметки времени обозначена позицией 426. Кроме того, аудио декодер 400 содержит буфер 430 де-джиттера (также кратко обозначаемый как буфер 430 джиттера), который принимает восстановленные из пакетов кадры 422 от разборщика 420 и который обеспечивает буферизованные кадры 432 (и возможно также вставленные кадры) на ядро 440 декодера. Кроме того, буфер 430 де-джиттера принимает от управляющей логики управляющую информацию 434 для основанного на кадре масштабирования (по времени). Кроме того, буфер 430 де-джиттера предоставляет информацию 436 обратной связи по масштабированию на блок (этап) оценивания задержки воспроизведения. Аудио декодер 400 также содержит преобразователь 450 масштаба времени (также обозначаемый как “TSM”), который принимает декодированные аудио выборки 442 (например, в форме импульсно-кодово-модулированных данных) от ядра 440 декодера, причем ядро 440 декодера обеспечивает декодированные аудио выборки 442 на основе буферизованных или вставленных кадров 432, принятых из буфера 430 де-джиттера. Преобразователь 450 масштаба времени также принимает от управляющей логики управляющую информацию 444 для масштабирования (по времени) на основе выборки и предоставляет информацию 446 обратной связи по масштабированию на блок оценивания задержки воспроизведения. Преобразователь 450 масштаба времени также обеспечивает масштабированные по времени выборки 448, которые могут представлять масштабированный по времени аудио контент в импульсно-кодово-модулированной форме. Аудио декодер 400 также содержит буфер 460 PCM, который принимает масштабированные по времени выборки 448 и буферизует масштабированные по времени выборки 448. Кроме того, буфер 460 PCM обеспечивает буферизованную версию масштабированных по времени выборок 448 в качестве представления декодированного аудио контента 412. Кроме того, буфер 460 PCM может предоставлять информацию задержки 462 на управляющую логику.
Аудио декодер 400 также содержит блок (этап) 470 оценивания целевой задержки, который принимает информацию 424 (например, флаг SID), а также информацию 426 отметки времени, содержащую отметку времени RTP и отметку времени поступления. На основе этой информации блок 470 оценивания целевой задержки предоставляет информацию 472 целевой задержки, которая описывает требуемую задержку, например требуемую задержку, которая будет порождаться буфером 430 де-джиттера, декодером 440, преобразователем 450 масштаба времени и буфером 460 PCM. Например, блок 470 оценивания целевой задержки может вычислять или оценивать информацию 472 целевой задержки с тем, что задержку не выбирают излишне большой, но достаточной, чтобы компенсировать некоторый джиттер пакетов 410. Кроме того, аудио декодер 400 содержит блок 480 оценивания задержки воспроизведения, который сконфигурирован для приема информации 436 обратной связи по масштабированию от буфера 430 де-джиттера и информации 446 обратной связи по масштабированию от преобразователя 460 масштаба времени. Например, информация 436 обратной связи по масштабированию может описывать масштабирование по времени, которое выполняется буфером де-джиттера. Кроме того, информация 446 обратной связи по масштабированию описывает масштабирование по времени, которое выполняется преобразователем 450 масштаба времени. Относительно информации 446 обратной связи по масштабированию, следует отметить, что масштабирование по времени, выполняемое преобразователем 450 масштаба времени, обычно является адаптивным к сигналу, так что фактическое масштабирование по времени, которое описывается информацией 446 обратной связи по масштабированию, может быть отличным от требуемого масштабирования по времени, которое может быть описано информацией 444 основанного на выборке масштабирования. Для заключения, информация 436 обратной связи по масштабированию и информация 446 обратной связи по масштабированию могут описывать фактическое масштабирование по времени, которое может быть отличным от требуемого масштабирования по времени по причине приспосабливаемости к сигналу, обеспечиваемой в соответствии с некоторыми аспектами настоящего изобретения.
Кроме того, аудио декодер 400 также содержит управляющую логику 490, которая выполняет (первичное) управление аудио декодером. Управляющая логика 490 принимает информацию 424 (например, флаг SID) от разборщика 420. Кроме того, управляющая логика 490 принимает информацию 472 целевой задержки от блока 470 оценивания целевой задержки, информацию 482 задержки воспроизведения от блока 480 оценивания задержки воспроизведения (причем информация 482 задержки воспроизведения описывает фактическую задержку, которую получают посредством блока 480 оценивания задержки воспроизведения на основе информации 436 обратной связи по масштабированию и информации 446 обратной связи по масштабированию). Кроме того, управляющая логика 490 (необязательно) принимает информацию 462 задержки от буфера 460 PCM (причем, альтернативно, информация задержки из буфера PCM может быть предопределенной величиной). На основе принятой информации управляющая логика 490 предоставляет информацию 434 масштабирования на основе кадра и информацию 442 масштабирования на основе выборки на буфер 430 де-джиттера и на преобразователь 450 масштаба времени. Соответственно, управляющая логика задает информацию 434 масштабирования на основе кадра и информацию 442 масштабирования на основе выборки в зависимости от информации 472 целевой задержки и информации 482 задержки воспроизведения адаптивным к сигналу образом, рассматривая одну или несколько характеристик аудио контента (подобных, например, вопросу, имеется ли "неактивный" кадр, для которого генерация комфортного шума должна выполняться в соответствии с сигнализацией, которую несет флаг SID).
Следует отметить при этом, что управляющая логика 490 может выполнять некоторые или все из функциональных возможностей блока 100 управления буфером джиттера, причем информация 424 может соответствовать информации 110 относительно аудиосигнала, при этом управляющая информация 112 может соответствовать информации 434 масштабирования на основе кадра, и при этом управляющая информация 114 может соответствовать информации 444 масштабирования на основе выборки. Кроме того, следует отметить, что преобразователь 450 масштаба времени может выполнять некоторые или все из функциональных возможностей преобразователя 200 масштаба времени (или наоборот), причем входной аудиосигнал 210 соответствует декодированным аудио выборкам 442, и при этом масштабированная по времени версия 212 входного аудиосигнала соответствует масштабированным по времени аудио выборкам 448.
Кроме того, следует отметить, что аудио декодер 400 соответствует аудио декодеру 300, так что аудио декодер 300 может выполнять некоторые или все из функциональных возможностей, описанных относительно аудио декодера 400, и наоборот. Буфер 320 джиттера соответствует буферу 430 де-джиттера, ядро 330 декодера соответствует декодеру 440, и преобразователь 340 масштаба времени соответствует блоку 450 масштабирования по времени. Блок 350 управления соответствует управляющей логике 490.
В последующем будут приведены некоторые дополнительные подробности относительно функциональности аудио декодера 400. В частности будет описано предложенное управление буфером джиттера (JBM).
Описывается решение по управлению буфером джиттера (JBM), которое может использоваться, чтобы подавать принятые пакеты 410 с кадрами, содержащими кодированные речевые или аудио данные, в декодер 440, поддерживая при этом непрерывное воспроизведение. В пакетной связи, например, передаче речи по IP-протоколу (VoIP), пакеты (например, пакеты 410) обычно подвергаются переменным временам передачи и теряются в ходе передачи, каковое приводит к джиттеру между моментами поступления и отсутствующим пакетам для приемника (например, приемника, содержащего аудио декодер 400). Следовательно, требуются решения по управлению буфером джиттера и маскированию потери пакетов, чтобы сделать возможным непрерывный выходной сигнал без заминки.
В последующем будет приведено общее представление решения. В случае описанного управления буфером джиттера кодированные данные в принятых RTP пакетах (например, пакетах 410) сначала депакетируют (например, используя разборщик 420) и результирующие кадры (например, кадры 422) с кодированными данными (например, речевыми данными в кодированном кадре AMR-WB) подают в буфер де-джиттера (например, буфер 430 де-джиттера). Когда новые импульсно-кодово-модулированные данные (данные PCM) требуются для воспроизведения, их необходимо сделать доступными посредством декодера (например, посредством декодера 440). С этой целью, кадры (например, кадры 432) извлекают из буфера де-джиттера (например, из буфера 430 де-джиттера). При помощи буфера де-джиттера могут быть компенсированы флуктуации значения времени поступления. Чтобы управлять глубиной буфера, применяется модификация масштаба (шкалы) времени (time scale modification, TSM) (причем, модификация масштаба времени также кратко обозначена масштабированием по времени). Модификация масштаба времени может происходить на основе кодированного кадра (например, в буфере 430 де-джиттера) или в отдельном модуле (например, в преобразователе 450 масштаба времени), позволяя с более тонкой гранулярностью адаптации выходного сигнала PCM (например, выходного сигнала 448 PCM или выходного сигнала 412 PCM).
Вышеописанная концепция иллюстрируется, например, на Фиг.4, которая показывает общее представление управления буфером джиттера. Чтобы управлять глубиной буфера де-джиттера (например, буфера 430 де-джиттера) и, следовательно, также уровнями масштабирования по времени в буфере де-джиттера (например, буфере 430 де-джиттера) и/или модуле TSM (например, в преобразователе 450 масштаба времени), используется управляющая логика (например, управляющая логика 490, которая поддерживается блоком 470 оценивания целевой задержки и блоком 480 оценивания задержки воспроизведения). Она использует информацию о целевой задержке (например, информацию 472) и задержке воспроизведения (например, информацию 482) и факт, используется ли в текущий момент прерывистая передача (DTX) в сочетании с генерацией комфортного шума (CNG) (например, информация 424). Значения задержки формируются, например, от отдельных модулей (например, модулей 470 и 480) для оценивания задержки целевой и воспроизведения, и обеспечивается бит «активный/неактивный» (флаг SID), например, модулем-разборщиком (например, разборщиком 420).
5.4.1. Разборщик
В последующем будет описан разборщик 420. Модуль-разборщик разделяет RTP пакеты 410 на отдельные кадры (блоки доступа) 422. Он также вычисляет отметку времени RTP для всех кадров, которые не являются единственным или первым кадром в пакете. Например, отметка времени, содержащаяся в пакете RTP, назначается его первому кадру. В случае агрегации (то есть, для RTP пакетов, содержащих более чем один единственный кадр), отметку времени для последующих кадров увеличивают на длительность кадра, деленную на масштаб отметок времени RTP. В дополнение к отметке времени RTP, каждый кадр также помечают системным временем, в которое пакет RTP был принят (“отметка времени поступления”). Как можно видеть, информация отметки времени RTP и информация отметки 426 времени поступления может предоставляться, например, на блок 470 оценивания целевой задержки. Модуль-разборщик также определяет, является ли кадр активным или содержит дескриптор вставки молчания (silence insertion descriptor, SID). Следует отметить, что в неактивные периоды только кадры SID принимают в некоторых случаях. Соответственно, информация 424, которая, например, может содержать флаг SID, предоставляется на управляющую логику 490.
5.4.2. Буфер де-джиттера
Модуль 430 буфера де-джиттера сохраняет кадры 422, принятые в(нутри) сети (например, через сеть типа TCP/IP) до момента декодирования (например, декодером 440). Кадры 422 вставляются в очередь, отсортированную в возрастающем порядке отметок времени RTP, чтобы осуществлять отмену (откат) переупорядочения, которое, возможно, произошло в сети. Кадр в головной части очереди может подаваться на декодер 440 и затем удаляется (например, из буфера 430 де-джиттера). Если очередь является пустой, или кадр отсутствует согласно различию отметки времени кадра в головной части (очереди) и ранее считанном кадре, пустой кадр возвращают (например, из буфера 430 де-джиттера на декодер 440), чтобы инициировать маскирование потери пакета (если последний кадр был активным) или генерацию комфортного шума (если последним кадром был “SID” или неактивный) в модуле 440 декодера.
В иной формулировке, декодер 440 может быть сконфигурирован, чтобы генерировать комфортный шум в случае, что в кадре сигнализирована необходимость использования комфортного шума, например, с использованием активного флага “SID”. С другой стороны, декодер также может быть сконфигурирован для выполнения маскирования потери пакета, например, путем обеспечения предсказанных (или экстраполированных) аудио выборок в случае, что предшествующий (последний) кадр был активным (то есть, отключенной генерации комфортного шума), и буфер джиттера работает пустым (так что на декодер 440 пустой кадр предоставляется буфером 430 джиттера).
Модуль 430 буфера де-джиттера также поддерживает масштабирование по времени на основе кадра путем добавления пустого кадра к головной части (например, очереди буфера джиттера) для растягивания по времени или отбрасывания кадра в головной части (например, очереди буфера джиттера) для стягивания по времени. В случае неактивных периодов буфер де-джиттера может действовать, как будто кадры “NO_DATA” были добавлены или удалены.
5.4.3. Модификация масштаба времени (TSM)
В последующем будет описана модификация масштаба времени (TSM), которая также кратко обозначена в документе преобразователем масштаба времени или преобразователем масштаба времени на основе выборки. Модифицированный, ориентированный на пакеты алгоритм WSOLA (перекрытия-сложения на основе подобия формы сигнала) (сравните, например, [Lia01]) с встроенным управлением качеством используется, чтобы выполнять модификацию масштаба времени (кратко обозначаемую как масштабирование по времени) для сигнала. Некоторые подробности можно видеть, например, на Фиг.9, которая будет пояснена ниже. Уровень масштабирования по времени зависит от сигнала; сигналы, которые, если масштабированы, создадут серьезные артефакты, обнаруживают посредством управления качеством, и низкоуровневые сигналы, которые являются близкими к молчанию, масштабируют в наибольшей возможной степени. Сигналы, которые являются хорошо масштабируемыми по времени, подобные периодическим сигналам, масштабируют согласно внутренне выводимому сдвигу. Сдвиг получают выводом из меры подобия, такой как нормированная взаимная корреляция. Вместе с операцией перекрытия-сложения (OLA), конец текущего кадра (также обозначаемый здесь как “второй блок выборок”) сдвигают (например, относительно начала текущего кадра, который здесь также обозначен как “первый блок выборок”), чтобы либо укоротить, либо удлинить кадр.
Как уже упомянуто, дополнительные подробности относительно модификации масштаба времени (TSM) будут описаны ниже, с использованием ссылки на Фиг.9, которая показывает модифицированный WSOLA с управлением качеством, а также с использованием ссылки на Фиг. 10a и 10b и 11.
5.4.4. Буфер PCM
В последующем будет описан буфер PCM. Модуль 450 модификации масштаба времени изменяет длительность кадров PCM, выводимых модулем декодера, с помощью изменяющегося во времени масштаба. Например, 1024 выборки (или 2048 выборок) могут выводиться декодером 440 на один аудио кадр 432. Напротив, переменное число аудио выборок может выводиться преобразователем 450 масштаба времени на один аудио кадр 432 благодаря масштабированию времени на основе выборки. Напротив, звуковая карта громкоговорителя (или, в общем, устройство звукового вывода) обычно предполагает фиксированное кадрирование, например, в 20 мс. Следовательно, используется дополнительный буфер с действием «первым пришел - первым обслужен» (по алгоритму FIFO), чтобы применять фиксированное кадрирование на выходных выборках 448 преобразователя масштаба времени.
Если посмотреть на всю цепочку, этот буфер 460 PCM не создает дополнительную задержку. Скорее задержка лишь совместно используется буфером 430 де-джиттера и буфером 460 PCM. Тем не менее, цель состоит в поддержании числа выборок, сохраняемых в буфере 460 PCM, насколько возможно малым, поскольку это увеличивает число кадров, сохраняемых в буфере 430 де-джиттера, и таким образом снижает вероятность последней потери (причем, декодер маскирует отсутствующий кадр, который принимается позже).
Псевдокод программы, показанный на Фиг.5, иллюстрирует алгоритм для управления уровнем буфера PCM. Как можно видеть из псевдо кода программы по Фиг.5, размер кадра звуковой карты (“soundCardFrameSize”) вычисляют на основе частоты выборки (“sampleRate”), где полагают, в качестве примера, что длительность кадра составляет 20 мс. Соответственно, число выборок на один кадр звуковой карты является известным. Затем, буфер PCM заполняется по декодированию кадров аудио 432 (также обозначаемых как “accessUnit”), пока число выборок в буфере PCM (“pcmBuffer_nReadableSamples()”) более не будет меньше, чем число выборок на один кадр звуковой карты (“soundCardFrameSize”). Сначала, кадр (также обозначаемый как “accessUnit”) получают (или запрашивают) из 430 буфера де-джиттера, как показано в ссылочной позиции 510. Затем, "кадр" аудио выборок получают декодированием кадра 432, запрошенного из буфера де-джиттера, как можно видеть в ссылке 512. Соответственно, получают кадр декодированных аудио выборок (например, обозначаемый позицией 442). Затем, модификацию масштаба времени применяют к кадру декодированных аудио выборок 442, так что получают "кадр" масштабированных по времени аудио выборок 448, каковое можно видеть в ссылочной позиции 514. Следует отметить, что кадр из масштабированных по времени аудио выборок может содержать большее число аудио выборок или меньшее число аудио выборок, чем кадр декодированных аудио выборок 442, вводимых в преобразователь 450 масштаба времени. Затем, кадр масштабированных по времени аудио выборок 448 вставляется в буфер 460 PCM, как можно видеть в ссылочной позиции 516.
Эта процедура повторяется до тех пор, пока достаточное число (масштабированных по времени) аудио выборок не будет иметься в наличии в буфере 460 PCM. Как только достаточное число (масштабированных по времени) выборок имеются в буфере PCM, "кадр" масштабированных по времени аудио выборок (имеющих длину кадра, как требуется устройством воспроизведения звука, подобным звуковой карте) считывается из буфера 460 PCM и пересылается на устройство воспроизведения звука (например, на звуковую карту), как показано в ссылочных позициях 520 и 522.
5.4.5.Оценивание целевой задержки
В последующем будет описано оценивание целевой задержки, которое может выполняться блоком (функцией) 470 оценивания целевой задержки. Целевая задержка указывает требуемую задержку буферизации между моментом времени, когда предшествующий кадр воспроизводился, и временем, когда этот кадр мог быть принят, если бы имел самую низкую задержку передачи в сети по сравнению со всеми кадрами, в текущий момент содержащимися в предыстории модуля 470 оценивания целевой задержки. Чтобы оценивать целевую задержку, используются две различные оценочные функции джиттера, одна долгосрочного и одна краткосрочного оценивания джиттера.
Оценивание долгосрочного джиттера
Для вычисления долгосрочного джиттера может использоваться структура данных FIFO. Отрезок времени, сохраняемый в FIFO, может быть отличным от числа сохраняемых элементов, если используется DTX (режим прерывистой передачи). По этой причине размер окна FIFO ограничивается двояко. Оно может содержать не более чем 500 элементов (эквивалентно 10 секундам при 50 пакетах в секунду), и не более чем отрезок времени в 10 секунд (разность отметок времени RTP между самым новым и самым старым пакетом). Если больше элементов должно быть сохранено, самый старый элемент удаляется. Для каждого RTP пакета, принятого в сети, элемент будет добавляться к FIFO. Элемент содержит три значения: задержку, смещение и отметку времени RTP. Эти значения вычисляют из времени приема (например, представленного отметкой времени поступления) и отметки времени RTP для RTP пакета, как показано в псевдо коде по Фиг.6.
Как можно видеть в ссылочных позициях 610 и 612, разность времен между отметками времени RTP двух пакетов (например, последующих пакетов) вычисляют (выдавая значение “rtpTimeDiff”), и разность между отметками времени двух пакетов (например, последующих пакетов) вычисляют (выдавая значение “rcvTimeDiff”). Кроме того, отметка времени RTP преобразовывается из масштаба (по оси) времени передающего устройства к масштабу (по оси) времени приемного устройства, как можно видеть в ссылочной позиции 614, выдавая “rtpTimeTicks”. Подобным образом разности времени RTP (разность между отметками времени RTP) конвертируются к шкале времени приемника/временной развертке приемного устройства), как можно видеть в ссылочной позиции 616, выдавая “rtpTimeDiff”.
Затем, информация задержки ("задержка") обновляется на основе предыдущей информации задержки, как можно видеть в ссылочной позиции 618. Например, если разность времен для приема (то есть, разность времен, когда пакеты были приняты) больше, чем разность времен RTP (то есть разность между моментами времени, в которые пакеты были посланы), можно заключить, что задержка возросла. Кроме того, вычисляют информацию времени смещения ("смещение"), как можно видеть в ссылочной позиции 620, причем информация времени смещения представляет разность между временем приема (то есть, временем, в которое пакет был принят), и временем, в которое пакет был послан (как задано отметкой времени RTP, преобразованного в шкалу времени приемника). Кроме того, информацию задержки, информацию времени смещения и информацию отметки времени RTP (преобразованного в шкалу времени приемника) добавляют к долгосрочному FIFO, как можно видеть в ссылочной позиции 622.
Затем, некоторая текущая информация сохраняется в качестве "предшествующей" информации для следующей итерации, как можно видеть в ссылочной позиции 624.
Долгосрочный джиттер может быть вычислен в виде разности между максимальным значением задержки, в текущий момент сохраняемым в FIFO, и минимальным значением задержки:
longTermJitter=longTermFifo_getMaxDelay() - longTermFifo_getMinDelay();
Оценивание краткосрочного джиттера
В последующем будет описано оценивание краткосрочного джиттера. Оценивание краткосрочного джиттера делают, например, в два этапа. На первом этапе делается такое же вычисление джиттера, как используется для долгосрочного оценивания, со следующими модификациями: размер окна FIFO ограничен не более чем 50 элементами и отрезком времени не более чем в 1 секунду. Результирующее значение джиттера вычисляют в виде разности между процентильным значением задержки в 94%, в текущий момент сохраняемым в FIFO (три самых высоких значения игнорируются), и минимальным значением задержки:
shortTermJitterTmp=shortTermFifo1_getPercentileDelay (94) - shortTermFifo1_getMinDelay();
На втором этапе сначала различные смещения между краткосрочным и долгосрочным значениями в структурах FIFO компенсируют этим результатом:
shortTermJitterTmp+=shortTermFifo1_getMinOffset();
shortTermJitterTmp-=longTermFifo_getMinOffset();
Этот результат прибавляют к другой структуре FIFO с размером окна не более чем 200 элементов и отрезком времени не более четырех секунд. В заключение, максимальное значение, сохраненное в FIFO, увеличивают до целочисленного множителя размера кадра и используют в качестве краткосрочного джиттера:
shortTermFifo2_add(shortTermJitterTmp);
shortTermJitter=ceil(shortTermFifo2_getMax()/20.f) * 20;
Оценивание целевой задержки по комбинации оценивания долго-/краткосрочного джиттера
Для вычисления целевой задержки (например, информации 472 целевой задержки), оценки долгосрочного и краткосрочного джиттера (например, как определено выше в виде “longTermJitter” и “shortTermJitter”) комбинируют различным образом в зависимости от текущего состояния. Для активных сигналов (или порций сигналов, для которых не используется генерация комфортного шума), интервал (например, задаваемый посредством “targetMin” и “targetMax”) используется в качестве целевой задержки. В ходе DTX и для запуска после DTX, вычисляют два различных значения в качестве целевой задержки (например, “targetDtx” и “targetStartUp”).
Подробности того, каким образом различные значения целевой задержки могут вычисляться, можно видеть, например, на Фиг.7. Как можно видеть в ссылочных позициях 710 и 712, значения “targetMin” и “targetMax”, которые задают область для активных сигналов, вычисляют на основе краткосрочного джиттера (“shortTermJitter”) и долгосрочного джиттера (“longTermJitter”). Вычисление целевой задержки в ходе DTX (“targetDtx”) показано в ссылочной позиции 714, и вычисление значения целевой задержки для запуска (например, после DTX) (“targetStartUp”) показано в ссылочной позиции 716.
5.4.6. Оценивание задержки воспроизведения
В последующем будет описано оценивание задержки воспроизведения, которое может выполняться блоком (функцией) 480 оценивания задержки воспроизведения. Задержка воспроизведения задает задержку буферизации между временем, когда предшествующий кадр воспроизводили, и временем, когда этот кадр мог быть принят, если бы имел самую низкую задержку передачи в сети по сравнению со всеми кадрами, в текущий момент содержащимися в предыстории модуля оценивания целевой задержки. Ее вычисляют в миллисекундах, используя следующую формулу:
playoutDelay=prevPlayoutOffset-longTermFifo_getMinOffset()+pcmBufferDelay;
Переменную “prevPlayoutOffset” повторно вычисляют всякий раз, когда принятый кадр извлекают из модуля 430 буфера де-джиттера, используя текущее системное время в миллисекундах и отметку времени RTP кадра, преобразованную в миллисекунды:
prevPlayoutOffset=sysTime - rtpTimestamp
Для предотвращения, что “prevPlayoutOffset” устареет, если кадр не является доступным, переменную обновляют в случае масштабирования по времени на основе кадра. Для растягивания по времени на основе кадре “prevPlayoutOffset” увеличивают на длительность кадра, и для стягивания по времени на основе кадра “PrevPlayoutOffset” уменьшают на длительность кадра. Переменная “pcmBufferDelay” описывает длительность времени, буферизованную в модуле буфера PCM.
5.4.7 Управляющая логика
В последующем управление (например, управляющая логика 490) будет описано подробно. Однако следует отметить, что управляющая логика 800 по Фиг.8 может быть снабжена любым из признаков и функциональных возможностей, описанных относительно управления 100 буфером джиттера, и наоборот. Кроме того, следует отметить, что управляющая логика 800 может заместить управляющую логику 490 по Фиг.4, но может необязательно содержать дополнительные признаки и функциональные возможности. Кроме того, не требуется, что все из признаков и функциональных возможностей, описанных выше относительно Фиг.4, также присутствуют в управляющей логике 800 по Фиг.8, и наоборот.
Фиг.8 показывает блок-схему управляющей логики 800, которая естественно может быть также реализована аппаратно.
Управляющая логика 800 содержит извлечение 810 кадра для декодирования. Другими словами, кадр выбирают для декодирования, и определяют в последующем, каким образом это декодирование должно выполняться. В проверке 814 проверяют, был ли предшествующий кадр (например, предшествующий кадр, предшествующий кадру, извлеченному для декодирования на этапе 810), активным или нет. Если в проверке 814 устанавливают, что предшествующий кадр был неактивным, выбирают первый путь (ветвь) 820 решения, который используется, чтобы адаптировать неактивный сигнал. Наоборот, если в проверке 814 установлено, что предшествующий кадр был активным, выбирают второй путь (ветвь) 830 решения, который используется, чтобы адаптировать активный сигнал. Первый путь 820 решения содержит определение значения "разрыва" на этапе 840, причем значение разрыва описывает разность между задержкой воспроизведения и целевой задержкой. Кроме того, первый путь 820 решения содержит принятие решения 850 относительно операции масштабирования по времени, подлежащей выполнению, на основе значения разрыва. Второй путь 830 решения содержит выбор 860 масштабирования по времени в зависимости от того, находится ли фактическая задержка воспроизведения в рамках интервала целевой задержки.
В последующем будут описаны дополнительные подробности относительно первого пути 820 решения и второго пути 830 решения.
На этапе 840 первого пути 820 решения выполняется проверка 842, является ли активным следующий кадр. Например, проверка 842 может проверять, является ли кадр, который на этапе 810 извлекают для декодирования, активным или нет. Альтернативно, проверка 842 может проверять, является ли кадр после кадра, извлекаемого на этапе 810 для декодирования, активным или нет. Если в проверке 842 установлено, что следующий кадр не является активным, или что следующий кадр еще не является доступным, то переменную "разрыв" задают на этапе 844 в виде разности между фактической задержкой воспроизведения (задаваемой переменной “playoutDelay”) и целевой задержкой DTX (представленной переменной “targetDtx”), описанной выше в разделе "Оценивание целевой задержки". Напротив, если в проверке 840 установлено, что следующий кадр является активным, переменную "разрыв" устанавливают в разность между задержкой воспроизведения (представленной переменной “playoutDelay”) и целевой задержкой запуска (как определено переменной “targetStartUp”) на этапе 846.
На этапе 850 сначала проверяют, является ли величина переменной "разрыв" больше чем пороговое значение (или равной ему). Это делается в проверке 852. Если установлено, что величина переменной "разрыва" меньше чем пороговое значение (или равна ему), масштабирование по времени не выполняется. Напротив, если в проверке 852 установлено, что величина переменной "разрыв" больше чем пороговое значение (или равна пороговым значениям, в зависимости от реализации), принимают решение, что масштабирование необходимо. В другой проверке 854 проверяют, является ли положительным значение переменной "разрыв" или отрицательным (то есть, является ли переменная "разрыв" больше чем нуль или нет). Если установлено, что значение переменной «разрыв» не более чем нуль (то есть, отрицательное), кадр вставляется в буфер де-джиттера (растягивание по времени на основе кадра на этапе 856), так что выполняется масштабирование по времени на основе кадра. Это может, например, сигнализироваться информацией 434 масштабирования на основе кадра. Напротив, если в проверке 854 установлено, что значение переменной "разрыв" больше чем нуль, то есть, положительно, кадр удаляют из буфера де-джиттера (стягивание по времени на основе кадра на этапе 856), так что выполняется масштабирование по времени на основе кадра. Это может сигнализироваться с использованием информации 434 масштабирования на основе кадра.
В последующем будет описана вторая ветвь 860 решения. В проверке 862 проверяют, является ли задержка воспроизведения больше чем максимальное целевое значение (или равной ему) (то есть, верхнее граничное значение целевого интервала), которое описывается, например, переменной “targetMax”. Если установлено, что задержка воспроизведения больше чем максимальное целевое значение (или равна ему), стягивание по времени выполняется преобразователем 450 масштаба времени (этап 866, стягивание по времени на основе выборки с использованием TSM), так что выполняется масштабирование по времени на основе выборки. Это может сигнализироваться, например, информацией 444 масштабирования на основе выборки. Однако если в проверке 862 установлено, что задержка воспроизведения меньше чем максимальная целевая задержка (или равна ей), выполняют проверку 864, в которой проверяют, является ли задержка воспроизведения меньше чем минимальная целевая задержка (или равна ей), которая описывается, например, переменной “targetMin”. Если установлено, что задержка воспроизведения меньше чем минимальная целевая задержка (или равна ей), растягивание по времени выполняется преобразователем 450 масштаба времени (этап 866, растягивание по времени на основе выборки с использованием TSM), так что выполняется масштабирование по времени на основе выборки. Это может сигнализироваться, например, информацией 444 масштабирования на основе выборки. Однако если в проверке 864 установлено, что задержка воспроизведения не меньше, чем минимальная целевая задержка (или равна ей), масштабирование по времени не выполняется.
Для заключения, модуль управляющей логики (также обозначаемый как управляющая логика для управления буфером джиттера), показанный на Фиг.8, сравнивает фактическую задержку (задержку воспроизведения) с требуемой задержкой (целевой задержкой). В случае значительной разности, он инициирует масштабирование по времени. В условиях комфортного шума (например, когда флаг SID является активным) масштабирование по времени на основе кадра будет инициироваться и исполняться модулем буфера де-джиттера. В условиях активных периодов масштабирование по времени на основе выборки инициируется и исполняется модулем TSM.
Фиг.12 показывает пример для оценивания задержки целевой и воспроизведения. Абсцисса 1210 графического представления 1200 описывает время, и ордината 1212 графического представления 1200 описывает задержку в миллисекундах. Группа из “targetMin” и “targetMax” образует интервал задержки, требуемой модулем оценивания целевой задержки, отслеживающим методом окна джиттер в сети. Задержка воспроизведения "playoutDelay" обычно остается внутри интервала, но адаптация может быть немного задержана по причине адаптивной к сигналу модификации масштаба времени.
Фиг.13 показывает след операций масштаба времени, исполняемых по Фиг.12. Абсцисса 1310 графического изображения 1300 описывает время в секундах, и ордината 1312 описывает масштабирование по времени в миллисекундах. Положительные значения указывают растягивание по времени, отрицательные значения - стягивание масштаба времени в графическом представлении 1300. В условиях пакета оба буфера становятся пустыми только однажды, и один маскированный кадр вставляется для растягивания (плюс 20 миллисекунд в 35 секундах). Для всей прочих адаптаций может использоваться способ масштабирования по времени на основе выборки более высокого качества, который приводит к переменным масштабам по причине адаптивного к сигналу подхода.
Для заключения, целевую задержку динамически приспосабливают в ответ на возрастание джиттера (и также в ответ на уменьшение джиттера) поверх некоторого окна. Когда целевая задержка возрастает или уменьшается, обычно выполняют масштабирование по времени, причем решение о типе масштабирования по времени принимается адаптивным к сигналу образом. При условии, что текущий кадр (или предшествующий кадр) является активным, выполняют масштабирование по времени на основе выборки, причем фактическую задержку основанного на выборке масштабирования по времени приспосабливают адаптивным к сигналу образом, чтобы уменьшить артефакты. Соответственно, обычно имеется не фиксированная величина масштабирования по времени, когда применяется масштабирование по времени на основе выборки. Однако когда буфер джиттера работает пустым, является необходимым (или рекомендуемым) - в качестве исключительной обработки - вставлять маскированный кадр (каковое составляет масштабирование по времени на основе кадра), даже если предшествующий кадр (или текущий кадр) является активным.
5.8. Модификация масштаба времени по Фиг.9
В последующем подробности относительно модификации масштаба времени будут описаны с использованием ссылки на Фиг.9. Следует отметить, что модификация масштаба времени была кратко описана в разделе 5.4.3. Однако модификация масштаба времени, которая может, например, выполняться преобразователем масштаба времени 150, будет описана более подробно в последующем.
Фиг.9 показывает последовательность операций для модифицированного WSOLA с управлением качеством согласно варианту осуществления настоящего изобретения. Следует отметить, что масштабирование 900 времени согласно Фиг.9 может быть дополнено любым из признаков и функциональных возможностей, описанных относительно преобразователя 200 масштаба времени согласно Фиг.2 и наоборот. Кроме того, следует отметить, что масштабирование 900 времени согласно Фиг.9 может соответствовать преобразователю 340 масштаба времени на основе выборки согласно Фиг.3 и преобразователю 450 масштаба времени согласно Фиг.4. Кроме того, масштабирование 900 времени согласно Фиг.9 может заместить масштабирование по времени на основе выборки 866.
Масштабирование 900 времени (или преобразователь масштаба времени, или модификатор преобразователя масштаба времени) принимает декодированные (аудио) выборки 910, например, в импульсно-кодово-модулированной (PCM) форме. Декодированные выборки 910 могут соответствовать декодированным выборкам 442, аудио выборкам 332 или входному аудиосигналу 210. Кроме того, преобразователь 900 масштаба времени принимает управляющую информацию 912, которая может, например, соответствовать информации 444 масштабирования по времени на основе выборки. Управляющая информация 912 может, например, описывать целевой масштаб и/или минимальный размер кадра (например, минимальное число выборок для кадра из аудио выборок 448, подлежащих предоставлению на буфер 460 PCM). Преобразователь 900 масштаба времени содержит переключатель (или выбор) 920, причем принимают решение, на основе информации о целевом масштабе, должно ли выполняться стягивание по времени, должно ли выполняться растягивание по времени, или следует ли не выполнять масштабирование по времени. Например, переключение (или проверка, или выбор) 920 может основываться на информации 444 масштабирования на основе выборки, принятой от управляющей логики 490.
Если на основе информации о целевом масштабе, установлено что масштабирование не подлежит выполнению, то принятые декодированные выборки 910 пересылают в неизмененной форме в качестве выхода преобразователя 900 масштаба времени. Например, декодированные выборки 910 пересылают в неизмененной форме на буфер 460 PCM в виде “масштабированных по времени” выборок 448.
В последующем схема процесса обработки будет описана для случая, что должно выполняться стягивание по времени (каковое может быть установлено проверкой 920 на основе информации о целевом масштабе 912). В случае, что требуется стягивание по времени, выполняется вычисление 930 энергии. В этом вычислении 930 энергии вычисляют энергию блока выборок (например, кадра, содержащего данное число выборок). После вычисления 930 энергии выполняется выбор (или переключение, или проверка) 936. Если установлено, что значение 932 энергии, обеспеченное вычислением 930 энергии, больше чем пороговое значение энергии (или равно ему) (например, пороговому значению Y энергии), то выбирают первый путь 940 обработки, который содержит адаптивное к сигналу определение величины масштабирования по времени, в рамках масштабирования по времени на основе выборки. Напротив, если установлено, что значение 932 энергии, обеспеченное вычислением 930 энергии, меньше чем пороговое значение (или равно ему) (например, пороговое значение Y), то выбирают второй путь 960 обработки, причем фиксированная величина сдвига по времени применяется в масштабировании времени на основе выборки. В первом пути 940 обработки, в котором величину сдвига по времени определяют адаптивным к сигналу образом, оценивание 942 подобия выполняют на основе выборки аудио. Оценивание 942 подобия может рассматривать информацию 944 минимального размера кадра и может предоставлять информацию 946 о наибольшем подобии (или о позиции наибольшего подобия). Другими словами, оценивание 942 подобия может определить, какая позиция (например, какая позиция выборок в рамках блока выборок) лучше всего подходит для операции перекрытия-и-сложения для стягивания по времени. Информация 946 о наибольшем подобии пересылается на блок 950 управления качеством, который вычисляет или оценивает, приведет ли операция перекрытия-и-сложения, использующая информацию 946 о наибольшем подобии, к качеству звучания, которое больше чем пороговое значение качества X (или равно ему) (которое может быть постоянным или которое может быть переменным). Если посредством управления 950 качеством установлено, что качество операции перекрытия-и-сложения (или эквивалентно, масштабированной по времени версии входного аудиосигнала, получаемого операцией перекрытия-и-сложения), будет меньше чем, пороговое значение X качества (или эквивалентно ему), то масштабирование по времени опускают, и немасштабированные аудио выборки выводятся преобразователем 900 масштаба времени. Напротив, если управление 950 качеством устанавливает, что качество операции перекрытия-и-сложения при использовании информации 946 наибольшего подобия (или о позиции наибольшего подобия), будет больше чем или эквивалентно пороговому значению качества X, то выполняется операция 954 перекрытия-и-сложения, причем сдвиг, который применяется в операции перекрытия-и-сложения, описывается информацией 946 о наибольшем подобии (или о позиции наибольшего подобия). Соответственно, масштабированный блок (или кадр) аудио выборок обеспечивается операцией перекрытия-и-сложения.
Блок (или кадр) масштабированных по времени аудио выборок 956 может, например, соответствовать масштабированным по времени выборкам 448. Подобным образом блок (или кадр) немасштабированных аудио выборок 952, которые обеспечиваются, если управление 950 качеством устанавливает, что получаемое качество будет меньше чем или эквивалентно пороговому значению X качества, может также соответствовать “масштабированным по времени” выборкам 448 (причем нет фактически масштабирования по времени в этом случае).
Напротив, если в выборе 936 установлено, что энергия блока (или кадра) входных аудио выборок 910 меньше чем пороговое значение Y энергии (или равно ему), то выполняют операцию перекрытия-и-сложения 962, причем сдвиг, который используется в операции перекрытия-и-сложения, задается минимальным размером кадра (описанным информацией о минимальном размере кадра), и при этом получают блок (или кадр) масштабированных аудио выборок 964, который может соответствовать масштабированным по времени выборкам 448.
Кроме того, следует отметить, что обработка, которая выполняется в случае растягивания по времени, является аналогичной обработке, выполняемой в стягивании по времени с помощью модифицированного перекрытия-сложения на основе подобия формы сигнала.
Для заключения, следует отметить, что различают три различных случая в адаптивном к сигналу масштабировании времени на основе выборки, когда выбрано стягивание по времени или растягивание по времени. Если энергия блока (или кадра) входных аудио выборок содержит сравнительно малую энергию (например, меньше чем (или равно) пороговое значение Y энергии), то выполняют операцию перекрытия-и-сложения для стягивания по времени или растягивания по времени с фиксированным сдвигом по времени (то есть, с фиксированной величиной стягивания по времени или растягивания по времени). Напротив, если энергия блока (или кадр) входных аудио выборок больше чем (или равна) пороговое значение Y энергии), "оптимальную" (также иногда обозначаемую здесь как "пригодная") величину стягивания по времени или растягивания по времени определяют посредством оценивания подобия (оценивание 942 подобия). На последующем этапе управления качеством определяют, было ли получено достаточное качество посредством такой операции перекрытия-и-сложения, используя ранее определенную "оптимальную" величину стягивания по времени или растягивания по времени. Если установлено, что можно добиться достаточного качества, выполняют операцию перекрытия-и-сложения, используя определенную "оптимальную" величину стягивания по времени или растягивания по времени. Если, напротив, установлено, что нельзя добиться достаточного качества, используя операцию перекрытия-и-сложения с использованием используя ранее определенной "оптимальной" величины стягивания по времени или растягивания по времени, стягивание по времени или растягивание по времени опускают (или откладывают до более позднего момента времени, например, до более позднего кадра).
В последующем, будет описана некоторая более подробная информация относительно адаптивного к качеству масштабирования по времени, которое может выполняться преобразователем 900 масштаба времени (или преобразователем 200 масштаба времени, или преобразователем 340 масштаба времени, или преобразователем 450 масштаба времени). Способы масштабирования по времени, использующие перекрытие-и-сложение (OLA), являются широко применяемыми, но в целом не удовлетворяющими результатам адаптивного к сигналу масштабирования по времени. В описанном решении, которое может использоваться в преобразователях масштаба времени, описанных здесь, величина масштабирования по времени зависит не только от позиции, извлеченной оцениванием подобия (например, оцениванием 942 подобия), которая кажется оптимальной для высококачественного масштабирования по времени, но также и ожидаемого качества перекрытия-сложения (например, перекрытия-сложения 954). Следовательно, два этапа управления качеством введены в модуль масштабирования по времени (например, преобразователь 900 масштаба времени или другие преобразователи масштаба времени, описанные здесь), чтобы решать, приведет ли масштабирование по времени к слышимым артефактам. В случае потенциальных артефактов масштабирование по времени откладывают до некоторой точки во времени, где это будет менее слышимым.
Первый этап управления качеством вычисляет объективную меру качества, используя позицию p, извлеченную согласно мере подобия (например, посредством оценивания 942 подобия), в качестве входной. В случае периодического сигнала p будет основной частотой текущего кадра. Нормированную взаимную корреляцию c() вычисляют для позиций p, 2*p, 3/2*p и 1/2*p. Ожидается, что c(p) будет положительным значением, и c(1/2*p) может быть положительным или отрицательным. Для гармонических сигналов знак c(2p) должен также быть положительным, и знак c(3/2*p) должен быть равным знаку c(1/2*p). Это отношение может использоваться, чтобы создать объективную меру q качества:
q=c(p)*c(2*p)+c(3/2*p)*c(1/2*p).
Интервалом значений для q является [-2; +2]. Идеальный гармонический сигнал приведет к q=2, тогда как весьма динамичные и широкополосные сигналы, которые могут создавать слышимые артефакты в ходе масштабирования по времени, выдадут более низкое значение. Вследствие факта, что масштабирование по времени делают на покадровой основе, полный сигнал для вычисления c(2*p) и c(3/2*p) еще может быть недоступным. Однако оценивание также может делаться с рассмотрением прошлых выборок. Следовательно, c(-p) может использоваться вместо c(2*p), и аналогично c(-1/2*p) может использоваться вместо c(3/2*p).
Второй этап управления качеством сравнивает текущее значение объективной меры q качества со значением qMin динамического минимального качества (которое может соответствовать пороговому значению качества X), чтобы определить, должно ли масштабирование по времени применяться к текущему кадру.
Существуют различные намерения, чтобы иметь значение динамического минимального качества: если q имеет малое значение, поскольку сигнал оценивают как плохой для масштабирования по длительному периоду времени, qMin должно снижаться медленно, чтобы гарантировать, что ожидаемое масштабирование все еще исполняется в некоторый момент времени с более низким ожидаемым качеством. С другой стороны, сигналы с высоким значением для q не должны приводить к масштабированию многих кадров подряд, каковое уменьшит качество относительно долгосрочных характеристик сигнала (например, ритма).
Следовательно, используется следующая формула для вычисления динамического минимального qMin качества (которое может, например, быть эквивалентным пороговому значению X качества):
qMin=qMinInitial-(nNotScaled*0,1)+(nScaled*0,2)
qMinInitial - конфигурационное значение для оптимизации между некоторым качеством и задержкой до тех пор, пока кадр не может быть масштабирован с требуемым качеством, для которого значение 1 является хорошим компромиссом. nNotScaled - счетчик кадров, которые не были масштабированы из-за недостаточного качества (q<qMin). nScaled - счетчик числа кадров, которые были масштабированы, поскольку требования к качеству были удовлетворены (q>=qMin). Область значений обоих счетчиков ограничена: они не будут уменьшены до отрицательных значений и не будут увеличены выше назначенного значения, которое устанавливается являющимся 4 по умолчанию (например).
Текущий кадр будет масштабироваться по времени согласно позиции p, если q>=qMin, иначе масштабирование по времени будет отложено до следующего кадра, где это условие удовлетворяется. Псевдокод по Фиг.11 иллюстрирует управление качеством для масштабирования по времени.
Как можно видеть, начальное значение для qMin установлено в 1, причем упомянутое начальное значение обозначено “qMinInitial” (сравните ссылочную позицию 1110). Аналогично максимальное значение счетчика в nScaled (обозначаемое как “переменная qualityRise”) инициализировано в 4, как можно видеть в ссылочной позиции 1112. Максимальное значение счетчика в nNotScaled инициализировано в 4 (переменная “qualityRed”), сравните ссылочную позицию 1114. Затем, информацию позиции p извлекают согласно мере подобия, как можно видеть в ссылочной позиции 1116. Затем, значение q качества вычисляют для позиции, описанной значением p позиции в соответствии с уравнением, которое можно видеть в ссылочной позиции 1116. Пороговое значение qMin качества вычисляют в зависимости от переменной qMinInitial, а также в зависимости от значений nNotScaled и nScaled счетчика, как можно видеть в ссылочной позиции 1118. Как можно видеть, начальное значение qMinInitial для порогового значения qMin качества уменьшается на значение, которое пропорционально значению nNotScaled счетчика, и увеличивается на значение, которое пропорционально значению nScaled. Как можно видеть, максимальные значения для значений nNotScaled и nScaled счетчика, также определяют максимальное увеличение порогового значения qMin качества и максимальное уменьшение порогового значения qMin качества. Затем, выполняется проверка, является ли значение q качества больше чем или равно пороговому значению qMin качества, как можно видеть в ссылочной позиции 1120.
Если это так, выполняется операция перекрытия-сложения, как можно видеть в ссылочной позиции 1122. Кроме того, переменная nNotScaled счетчика уменьшается, причем гарантируется, что упомянутая переменная счетчика не станет отрицательной. Кроме того, переменная счетчика nScaled увеличивается, причем гарантируется, что nScaled не превысит верхнее предельное значение, задаваемое переменной (или константой) qualityRise. Адаптацию переменных счетчиков можно видеть в ссылочных позициях 1124 и 1126.
Напротив, если установлено в сравнении, показанном в ссылочной позиции 1120, что значение q качества меньше чем пороговое значение qMin качества, исполнение операции перекрытия-и-сложения опускается, переменная nNotScaled счетчика увеличивается с принимая во внимание, что переменная nNotScaled счетчика не превысит порог, задаваемый переменной (или константой) qualityRed, и переменная счетчика nScaled уменьшается, принимая во внимание, что переменная счетчика nScaled не станет отрицательной. Адаптация переменных счетчиков для случая, что качество является недостаточным, показывается в ссылочных позициях 1128 и 1130.
5.9. Преобразователь масштаба времени по Фиг. 10a и 10b
В последующем адаптивный к сигналу преобразователь масштаба времени будет пояснен с использованием ссылки на фигуры Фиг. 10 и 10b. Фигуры Фиг. 10 и 10b показывают блок-схему адаптивного к сигналу масштабирования по времени. Следует отметить, что адаптивное к сигналу масштабирование по времени, как показано на Фиг. 10a и 10b может, например, применяться в преобразователе 200 масштаба времени, в преобразователе 340 масштаба времени, в преобразователе 450 масштаба времени или в преобразователе 900 масштаба времени.
Преобразователь 1000 масштаба времени согласно Фиг. 10a и 10b содержит блок 1010 вычисления энергии, в котором вычисляют энергию кадра (или порции, или блока) аудио выборок. Например, блок 1010 вычисления энергии может соответствовать блоку 930 вычисления энергии. Затем, выполняют проверку 1014, в которой проверяют, является ли значение энергии, полученное в вычислении 1010 энергии, больше чем пороговое значение энергии (или равно ему) (которое может, например, быть фиксированным пороговым значением энергии). Если в проверке 1014 устанавливают, что значение энергии, полученное в вычислении 1010 энергии, меньше чем пороговое значение энергии (или равно ему), можно предположить, что достаточное качество можно получить путем операции перекрытия-сложения, и операцию перекрытия-и-сложения выполняют с максимальным сдвигом по времени (чтобы посредством этого получить максимальное масштабирование по времени) на этапе 1018. Напротив, если в проверке 1014 установлено, что значение энергии, полученное в вычислении 1010 энергии, не меньше чем пороговое значение энергии (или равно ему), выполняют поиск наилучшего соответствия сегмента-шаблона внутри области поиска, используя меру подобия. Например, мера подобия может быть взаимной корреляцией, нормированной взаимной корреляцией, функцией разности средних величин или суммой квадратичных ошибок. В последующем будут описаны некоторые подробности относительно этого поиска наилучшего соответствия, и будет также пояснено, каким образом может быть получено растягивание по времени или стягивание по времени.
Ссылка теперь делается на графическое представление в ссылочной позиции 1040. Первое представление 1042 показывает блок (или кадр) выборок, который начинается в момент времени t1 и который заканчивается в момент времени t2. Как можно видеть, блок выборок, который начинается во время t1 и который заканчивается во время t2, может быть разделен логически на первый блок выборок, который начинается во время t1 и который заканчивается во время t3, и второй блок выборок, который начинается во время t4 и который заканчивается во время t2. Однако второй блок выборок затем сдвигается по времени относительно первого блока выборок, каковое можно видеть в ссылочной позиции 1044. Например, в качестве результата первого сдвига по времени, сдвигаемый по времени второй блок выборок начинается во время t4’ и заканчивается во время t2’. Соответственно, имеется временное перекрытие между первым блоком выборок и сдвигаемым по времени вторым блоком выборок между моментами времени t4’ и t3. Однако, как можно видеть, не имеется хорошего соответствия (то есть, нет большого подобия) между первым блоком выборок и сдвинутой по времени версии второго блока выборок, например, в области перекрытия между моментами времени t4’ и t3 (или внутри порции упомянутой области перекрытия между моментами времени t4’ и t3). Другими словами, преобразователь масштаба времени может, например, сдвигать по времени второй блок выборок, как показано в ссылочной позиции 1044, и определять меру подобия для области перекрытия (или для части области перекрытия) между моментами времени t4’ и t3. Кроме того, преобразователь масштаба времени может также применить дополнительный сдвиг по времени ко второму блоку выборок, как показано в ссылочной позиции 1046, так что (дважды) сдвинутая по времени версия второго блока выборок начинается во время t4’’ и заканчивается во время t2’’ (с t2’’>t2’>t2 и аналогично t4’’>t4’>t4). Преобразователь масштаба времени может также определять (количественную) информацию подобия, представляющую подобие между первым блоком выборок и дважды сдвинутой версией второго блока выборок, например, между моментами времени t4’’ и t3 (или, например, внутри порции между моментами времени t4’’ и t3). Соответственно, преобразователь масштаба времени оценивает, для какого временного сдвига сдвигаемой по времени версии второго блока выборок подобие в области перекрытия с первым блоком выборок максимизируется (или, по меньшей мере, больше чем пороговое значение). Соответственно, может быть определен сдвиг по времени, который приводит к “лучшему соответствию” в том, что подобие между первым блоком выборок и сдвигаемой по времени версией второго блока выборок максимизировано (или, по меньшей мере, достаточно велико). Соответственно, если имеется достаточное подобие между первым блоком выборок и дважды сдвинутой по времени версией второго блока выборок внутри временной области перекрытия (например, между моментами времени t4’’ и t3), то можно ожидать с надежностью, определенной используемой мерой подобия, что операция перекрытия-и-сложения, осуществляющая перекрытие-и-сложение первого блока выборок и дважды сдвинутой по времени версией второго блока выборок, приводит к аудиосигналу без существенных слышимых артефактов. Кроме того, следует отметить, что перекрытие-и-сложение между первым блоком выборок и дважды сдвинутой по времени версией второго блока выборок приводит к порции аудиосигнала, которая имеет временную протяженность между моментами времени t1 и t2’’, которая является более длительной, чем "исходный" аудиосигнал, который простирается от времени t1 до времени t2. Соответственно, растягивания по времени можно добиться перекрытием и сложением первого блока выборок и дважды сдвинутой по времени версией второго блока выборок.
Подобным образом стягивания по времени можно добиться, как будет пояснено с использованием ссылки на графическое представление в ссылочной позиции 1050. Как можно видеть в ссылочной позиции 1052, имеется исходный блок (или кадр) выборок, который простирается между моментами времени t11 и t12. Исходный блок (или кадр) выборок может быть разделен, например, на первый блок выборок, который простирается от времени t11 до времени t13, и второй блок выборок, который простирается от времени t13 до времени t12. Второй блок выборок является сдвигаемым по времени влево, как можно видеть в ссылочной позиции 1054. Следовательно, (однократно) сдвинутая по времени версия второго блока выборок начинается во время t13’ и заканчивается во время t12’. Кроме того, имеется временное перекрытие между первым блоком выборок и однократно сдвинутой по времени версией второго блока выборок между моментами времени t13’ и t13. Однако преобразователь масштаба времени может определить (количественную) информацию подобия, представляющую подобие первого блока выборок и (однократно) сдвинутой по времени версией второго блока выборок между моментами времени t13’ и t13 (или для порции времени между моментами времени t13’ и t13), и установить, что подобие не является особенно хорошим. Кроме того, преобразователь масштаба времени может дополнительно сдвигать по времени второй блок выборок, чтобы посредством этого получить дважды сдвинутую по времени версию вторых блоков выборок, которая показана в ссылочной позиции 1056, и которая начинается во время t13’’ и заканчивается во время t12’’. Таким образом, имеется перекрытие между первым блоком выборок и (дважды) сдвинутой по времени версией второго блока выборок между моментами времени t13’’ и t13. Может быть установлено, посредством преобразователя масштаба времени, что (количественная) информация подобия указывает большое подобие между первым блоком выборок и дважды сдвинутой по времени версией второго блока выборок между моментами времени t13’’ и t13. Соответственно, преобразователь масштаба времени может заключить, что операция перекрытия-и-сложения может выполняться с хорошим качеством и менее слышимыми артефактами между первым блоком выборок и дважды сдвинутой по времени версией второго блока выборок (по меньшей мере, с надежностью, обеспечиваемой используемой мерой подобия). Кроме того, трехкратно сдвигаемая по времени версия второго блока выборок, которая показана в ссылочной позиции 1058, также может рассматриваться. Трехкратно сдвигаемая по времени версия второго блока выборок может начинаться во время t13’’’ и заканчиваться как время t12’’’. Однако трехкратно сдвигаемая по времени версия второго блока выборок может не содержать хорошего подобия с первым блоком выборок в области перекрытия между моментами времени t13’’’ и t13, поскольку сдвиг по времени не был подходящим. Следовательно, преобразователь масштаба времени может установить, что дважды сдвинутая по времени версия второго блока выборок содержит лучшее соответствие (лучшее подобие в области перекрытия и/или в окружении области перекрытия и/или в порции области перекрытия) с первым блоком выборок. Соответственно, преобразователь масштаба времени может выполнять перекрытие-и-сложение первого блока выборок и дважды сдвинутой по времени версией второго блока выборок, если дополнительная проверка качества (которая может основываться на второй, более значимой мере подобия) указывает достаточное качество. В результате операции перекрытия-и-сложения получают объединенный блок выборок, который простирается от времени t11 до времени t12’’, и который является по времени более коротким, чем исходный блок выборок от времени t11 до времени t12. Соответственно, стягивание по времени может быть выполнено.
Следует отметить, что вышеуказанные функциональные возможности, которые были описаны с использованием ссылки на графические представления в ссылочных позициях 1040 и 1050, могут выполняться посредством поиска 1030, причем информация о позиции наибольшего подобия обеспечивается в качестве результата поиска лучшего соответствия (причем, информация или значение, описывающие позицию наибольшего подобия, здесь также обозначаются с помощью p). Подобие между первым блоком выборок и сдвигаемой по времени версией второго блока выборок в рамках соответственных областей перекрытия можно определить, используя взаимную корреляцию, используя нормированную взаимную корреляцию, используя функцию разности средних величин или используя сумму квадратичных ошибок.
Как только информация о позиции (p) наибольшего подобия определена, выполняют вычисление 1060 качества соответствия для идентифицированной позиции (p) наибольшего подобия. Это вычисление может выполняться, например, как показано в ссылочной позиции 1116 на Фиг.11. Другими словами, (количественная) информация о качестве соответствия (которая может, например, обозначаться с помощью q) может быть вычислена с использованием комбинации четырех корреляционных значений, которые могут быть получены для различных сдвигов по времени (например, сдвиги по времени p, 2*p, 3/2*p и 1/2*p). Соответственно, (количественная) информация (q), представляющая качество соответствия, может быть получена.
Сделав ссылку теперь на Фиг.10b, выполняется проверка 1064, в которой количественные данные q, описывающие качество соответствия по сравнению с пороговым значением qMin качества. Эта проверка или сравнение 1064 могут оценивать, является ли качество соответствия, представленное переменной q, больше (или равно) переменного порогового значения qMin качества. Если в проверке 1064 установлено, что качество соответствия является достаточным (то есть, больше чем или равно переменному пороговому значению качества), применяют операцию перекрытия-сложения (этап 1068), используя позицию наибольшего подобия (которая описывается, например, переменной p). Соответственно, операция перекрытия-и-сложения выполняется, например, между первым блоком выборок и сдвигаемой по времени версией второго блока выборок, каковое приводит к “лучшему соответствию” (то есть, к наибольшему значению данных подобия). Для дополнительной информации делается ссылка, например, на пояснения, сделанные относительно графического представления 1040 и 1050. Применение перекрытия-и-сложения также показано в ссылочной позиции 1122 на Фиг.11. Кроме того, обновление счетчиков кадров выполняется на этапе 1072. Например, переменную “nNotScaled” счетчика и переменную “nScaled” счетчика, обновляют, например как описано со ссылкой на Фиг.11 в ссылочных позициях 1124 и 1126. Напротив, если в проверке 1064 установлено, что качество соответствия является недостаточным (например, меньшим (или равным) переменному пороговому значению qMin качества), операцию перекрытия-и-сложения отменяют (например, откладывают), каковое обозначено в ссылочной позиции 1076. В этом случае, счетчики кадров также обновляют, как показано на этапе 1080. Обновление счетчиков кадров может выполняться, например, как показано в ссылочных позициях 1128 и 1130 на Фиг.11. Кроме того, преобразователь масштаба времени, описанный со ссылкой на Фиг.10a и 10b, может также вычислять переменное пороговое значение qMin качества, каковое показано в ссылочной позиции 1084. Вычисление переменного порогового значения qMin качества можно выполнять, например, как показано в ссылочной позиции 1118 на Фиг.11.
Для заключения, преобразователь 1000 масштаба времени, функциональные возможности которого были описаны в форме блок-схемы с использованием ссылки на Фиг. 10a и 10b, может выполнять масштабирование по времени на основе выборки, используя механизм управления качеством (этапы 1060-1084).
5.10. Способ по Фиг.14
Фиг.14 иллюстрирует последовательность операций для управления предоставлением декодированного аудио контента на основе входного аудио контента. Способ 1400 по Фиг.14 содержит выбор 1410 масштабирования по времени на основе кадра или масштабирования по времени на основе выборки адаптивным к сигналу образом.
Кроме того, следует отметить, что способ 1400 может быть дополнен любым из признаков и функциональных возможностей, описанными здесь, например, относительно управления буфером джиттера.
5.11. Способ по Фиг.15
Фиг.15 иллюстрирует структурную схему способа 1500 для обеспечения масштабированной по времени версии входного аудиосигнала. Способ содержит вычисление или оценивание 1510 качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Кроме того, способ 1500 содержит выполнение 1520 масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
Способ 1500 может быть дополнен любым из признаков и функциональных возможностей, описанных в документе, например, со ссылкой на преобразователь масштаба времени.
6. Выводы
Для заключения, варианты осуществления согласно изобретению создают способ управления буфером джиттера и устройство для высококачественной речевой и звуковой связи. Способ и устройство могут использоваться совместно с коммуникационными кодеками, такими как разработанные Экспертной группой по вопросам движущегося изображения (MPEG) кодеки ELD (усовершенствованный с низкой задержкой), AMR-W (адаптивный многоскоростной широкополосный), или будущими кодеками. Другими словами, варианты осуществления согласно изобретению создают способ и устройство для компенсации джиттера между поступлениями пакетов в пакетной связи.
Варианты осуществления изобретения могут применяться, например, в технологии, именуемой “3GPP EVS” (расширенные услуги связи Проекта партнерства систем связи 3-го поколения).
В последующем будут кратко описаны некоторые аспекты вариантов осуществления согласно изобретению.
Решение по управлению буфером джиттера, описанное в документе, создает систему, в которой несколько описанных модулей являются доступными и комбинируются описанным выше образом. Кроме того, следует отметить, что аспекты изобретения также относятся к признакам самих модулей.
Важным аспектом настоящего изобретения является адаптивный к сигналу выбор способа масштабирования по времени для адаптивного управления буфером джиттера. Описанное решение объединяет масштабирование по времени на основе кадра и масштабирование по времени на основе выборки в управляющей логике с тем, чтобы объединить преимущества обоих способов. Доступными способами масштабирования по времени являются:
вставка/удаление комфортного шума в DTX
перекрытие-и-сложение (OLA) без корреляции в энергии малого сигнала (например, для кадров с малой энергией сигнала);
WSOLA для активных сигналов;
вставка маскированного кадра для растягивания в случае пустого буфера джиттера.
Описанное в документе решение описывает механизм для объединения способов на основе кадра (вставки/удаления комфортного шума и вставки маскированных кадров для растягивания) со способами на основе выборки (WSOLA для активных сигналов, и несинхронизированное перекрытие-сложение (OLA) для сигналов с малой энергией). На Фиг.8 иллюстрируется управляющая логика, которая выбирает оптимальную технологию для модификации масштаба времени согласно варианту осуществления изобретения.
Согласно дополнительному аспекту, описанному здесь, используются множественные целевые установки для адаптивного управления буфером джиттера. В описанном решении оценивание целевой задержки использует различные критерии оптимизации для вычисления одиночной целевой задержки воспроизведения. Эти критерии приводят к различным целевым установкам сначала, оптимизируемым для высокого качества или малой задержки.
Множественными целевыми установками для вычисления целевой задержки воспроизведения являются:
Качество: избегать последней потери (оценивает джиттер);
Задержка: ограничивать задержку (оценивает джиттер).
(Необязательным) аспектом описанного решения является оптимизировать оценивание целевой задержки с тем, что задержка является ограниченной, но также предотвращаются последние потери, и кроме того в буфере джиттера поддерживается малый резерв для повышения вероятности, что интерполяция сделает возможным высококачественное маскирование ошибок для декодера.
Другой (необязательный) аспект относится к восстановлению маскирования TCX (возбуждение, управляемое кодом преобразования) с помощью последних кадров. Кадры, которые поступают последними, большинством решений по управлению буфером джиттера на настоящее время отбрасываются. Были описаны механизмы для использования последних кадров в декодерах на основе линейного предсказания с возбуждением алгебраическим кодом (ACELP) [Lef03]. Согласно аспекту, такой механизм также используется для кадров, отличных от кадров ACELP, например, кодированных в частотной области кадров, подобных TCX, чтобы способствовать восстановлению состояния декодера в общем. Следовательно, кадры, которые принимают последними и уже маскированными, все еще подаются на декодер, чтобы улучшить восстановление состояния декодера.
Другим важным аспектом согласно настоящему изобретению является адаптивное к качеству масштабирование по времени, которое было описано выше.
Для дополнительного заключения, варианты осуществления согласно настоящему изобретению образуют полное решение по управлению буфером джиттера, которое может использоваться для улучшенного пользовательского восприятия в системах пакетной связи. Было исследование, что представленные решения работают лучше, чем любое другое известное решение по управлению буфером джиттера, известное изобретателям.
7. Альтернативы реализации
Хотя некоторые аспекты были описаны в контексте устройства, понятно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или функции этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока, или элемента, или функции соответствующего устройства. Некоторые или все из этапов способа могут быть исполняемыми (или использующимися) аппаратно-реализованным устройством, подобным, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления один или несколько наиболее важных этапов способа могут исполняться таким устройством.
Предложенный кодированный аудиосигнал может сохраняться в цифровой запоминающей среде или может передаваться в передающей среде, такой как беспроводная передающая среда или проводная передающая среда, например, сеть Интернет.
В зависимости от некоторых требований к реализации, варианты осуществления изобретения могут быть реализованы в виде аппаратных средств или в виде программного обеспечения. Реализацию можно выполнять, используя цифровой носитель данных, например, гибкий диск, цифровой многофункциональный диск DVD, диск по технологии Blu-Ray, компакт-диск (CD), постоянное запоминающее устройство (ПЗУ, ROM), программируемое ПЗУ (PROM), стираемое программируемое ПЗУ (EPROM), электрически-стираемое программируемое ПЗУ (EEPROM) или флэш-память, с наличием сохраненных на них электронно-читаемых управляющих сигналов, которые действуют совместно (или способны к совместному действию) с программируемой компьютерной системой с тем, что выполняется соответственный способ. Следовательно, цифровой носитель данных может быть читаемым компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных с наличием электронно-читаемых управляющих сигналов, которые способны к совместному действию с программируемой компьютерной системой с тем, что выполняется один из способов, описанных в документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с кодом программы, код программы является рабочим для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Код программы может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных здесь, сохраненную на машиночитаемом носителе.
Другими словами, вариантом осуществления нового способа является, следовательно, компьютерная программа с наличием кода программы для выполнения одного из способов, описанных здесь, когда компьютерная программа исполняется на компьютере.
Дополнительным вариантом осуществления новых способов является, следовательно, носитель данных (или цифровой носитель, или читаемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных здесь. Носитель данных, цифровой носитель или носитель с записанными данными являются обычно материальными и/или непромежуточными.
Дополнительным вариантом осуществления нового способа является, следовательно, поток данных или последовательность сигналов, представляющих компьютерную программу выполнения одного из способов, описанных здесь. Поток данных или последовательность сигналов могут, например, быть сконфигурированы с возможностью передаваться через соединение для передачи данных, например через сеть Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, сконфигурированное или приспособленное для выполнения одного из способов, описанных здесь.
Дополнительный вариант осуществления содержит компьютер с установленной на нем компьютерной программой для выполнения одного из способов, описанных здесь.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированные, чтобы передавать на приемник (например, электронным или оптическим способом) компьютерную программу для выполнения одного из способов, описанных здесь. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или подобным. Устройство или система могут, например, содержать файловый сервер для осуществления передачи компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая вентильная матрица) может использоваться, чтобы выполнять некоторые или все из функциональных возможностей способов, описанных здесь. В некоторых вариантах осуществления программируемая вентильная матрица может действовать совместно с микропроцессором для выполнения одного из способов, описанных здесь. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Устройство, описанное здесь, может быть реализовано с использованием аппаратно-реализованного устройства или с использованием компьютера, или с использованием комбинации аппаратно-реализованного устройства и компьютера.
Способы, описанные здесь, могут выполняться с использованием аппаратно-реализованного устройства, или с использованием компьютера, или с использованием комбинации аппаратно-реализованного устройства и компьютера.
Вышеописанные варианты осуществления являются просто пояснительными для принципов настоящего изобретения. Понятно, что модификации и изменения компоновок и подробностей, описанные здесь, будут очевидны другим специалистам в данной области техники. Назначение, следовательно, в том, чтобы ограничиваться только объемом прилагаемой формулы изобретения, а не конкретными подробностями, представленными в качестве описания и пояснения вариантов осуществления в настоящем документе.
Ссылки
[Lia01] Y. J. Liang, N. Faerber, B. Girod: “Adaptive playout scheduling using time-scale modification in packet voice communications”, 2001.
[Lef03] P. Gournay, F. Rousseau, R. Lefebvre: “Improved packet loss recovery using late frames for prediction-based speech coders”, 2003.
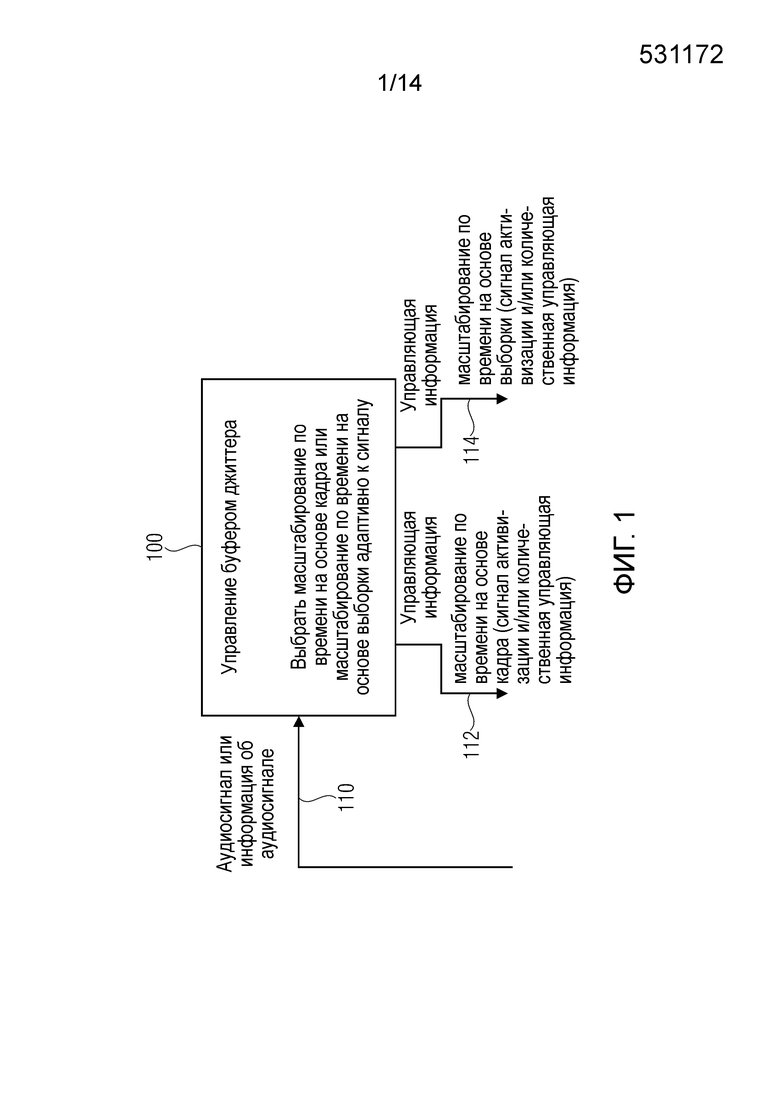
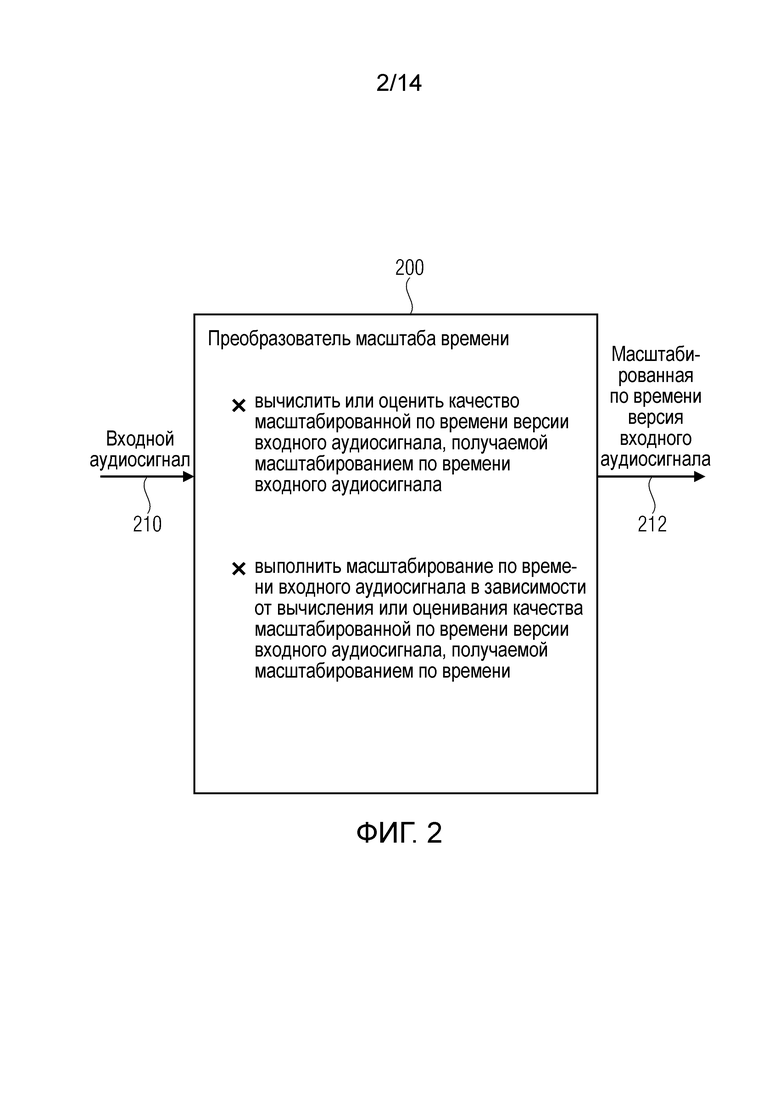
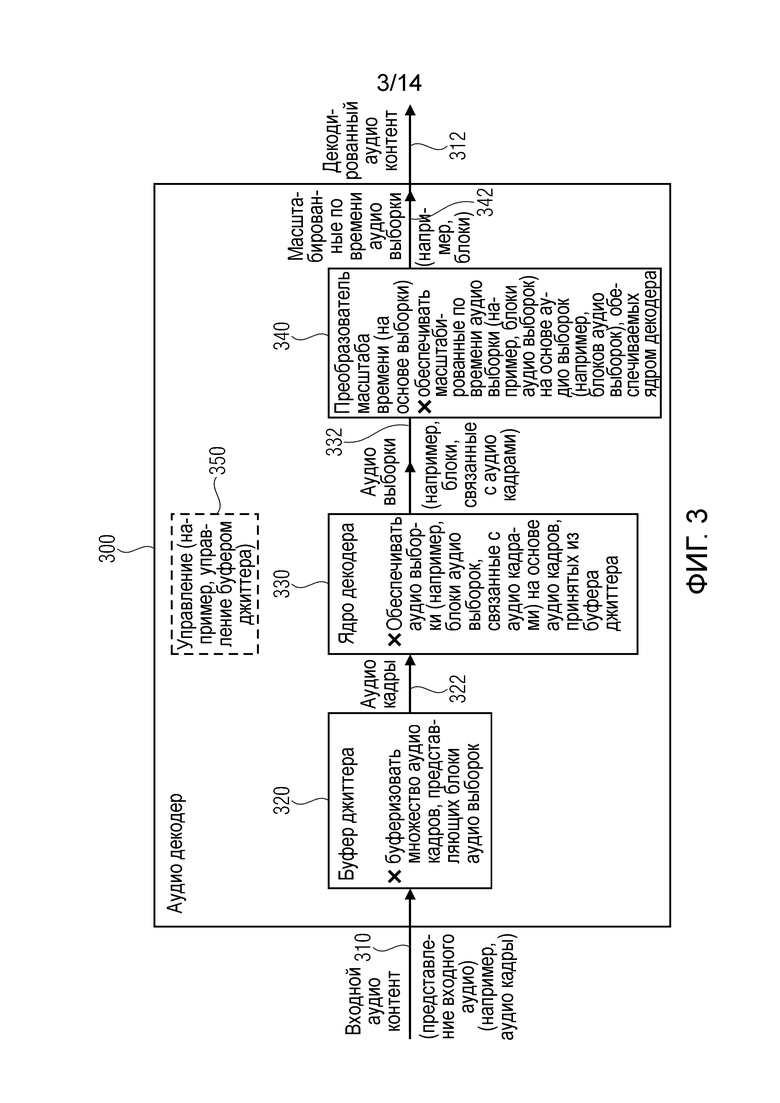
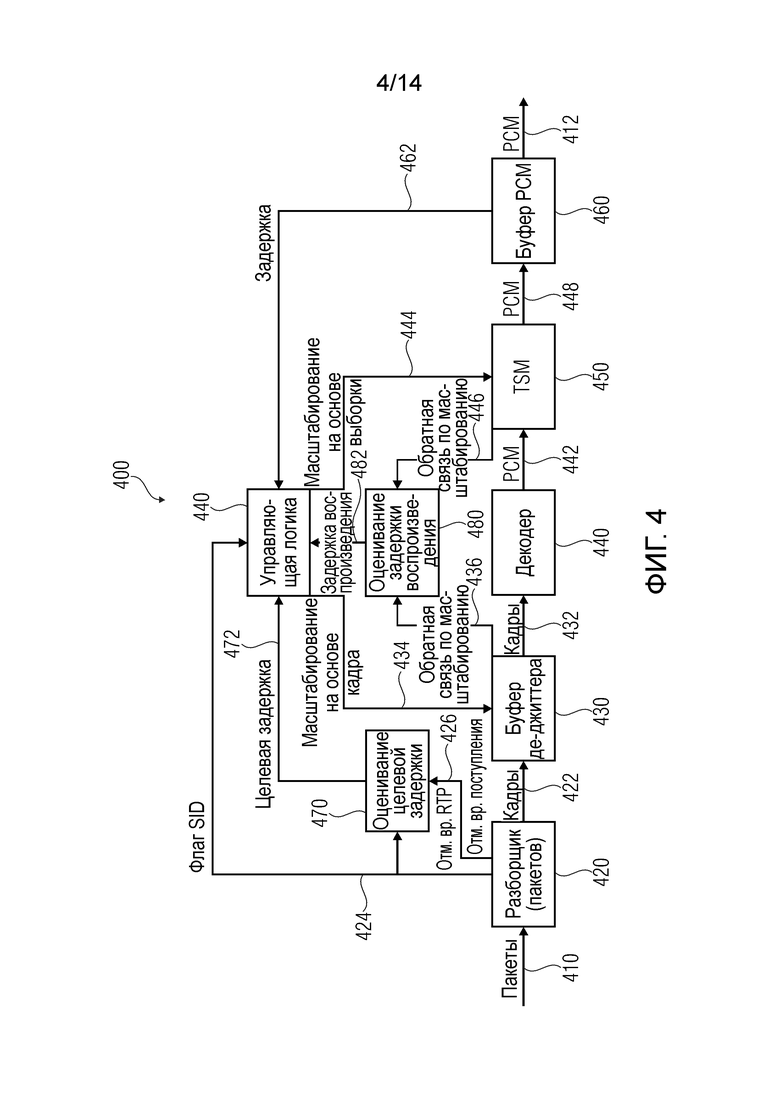

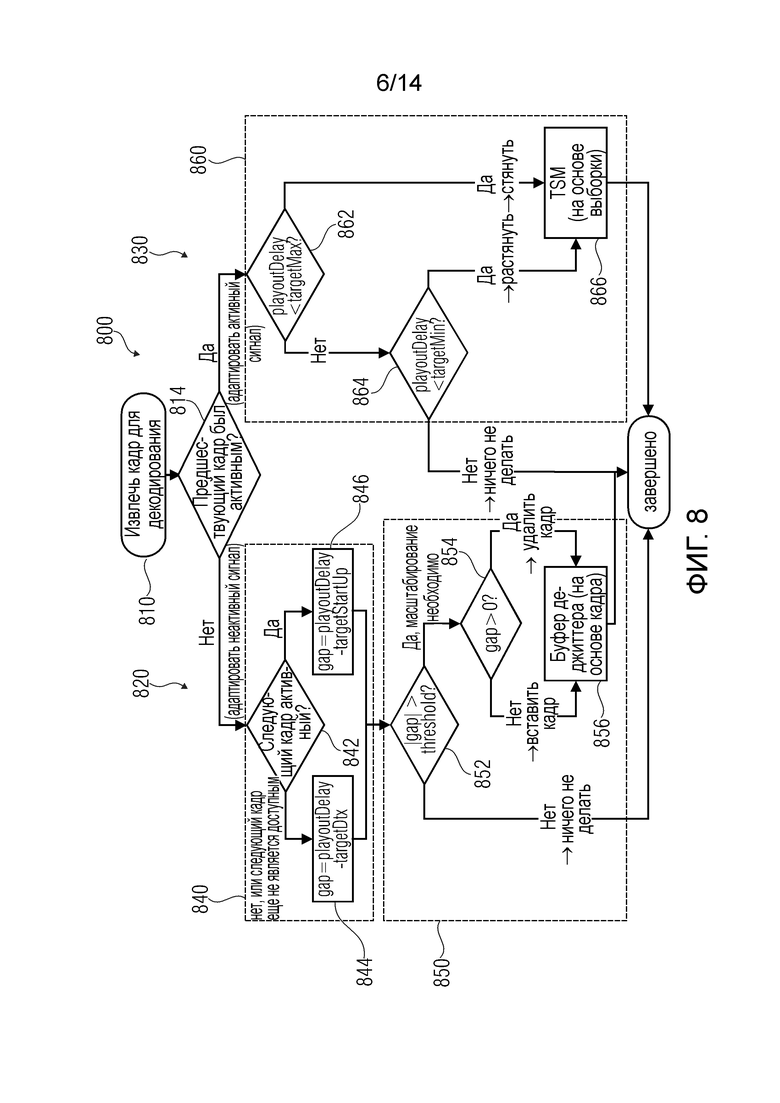
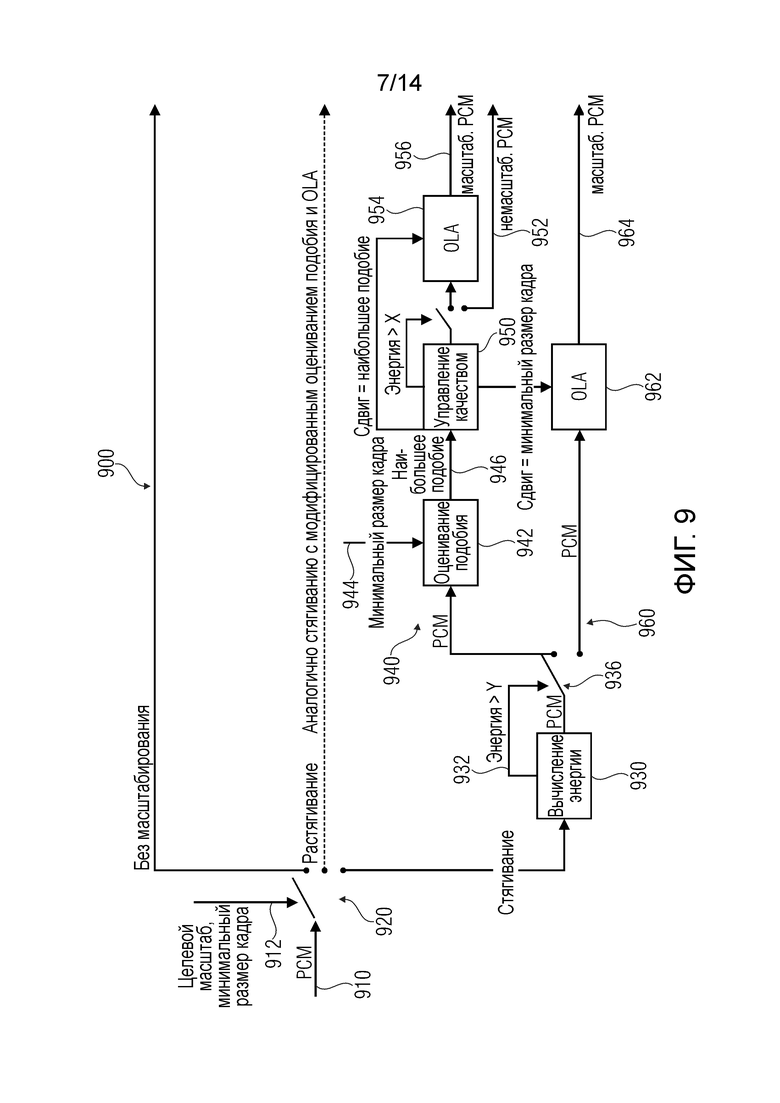
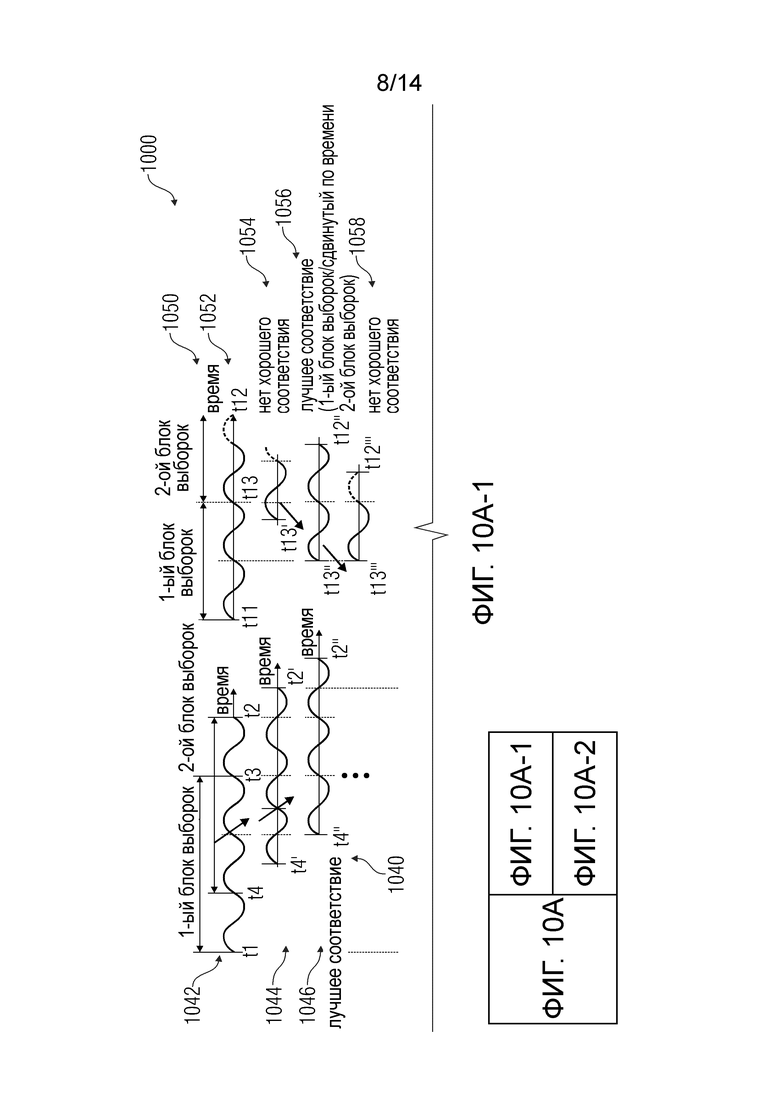
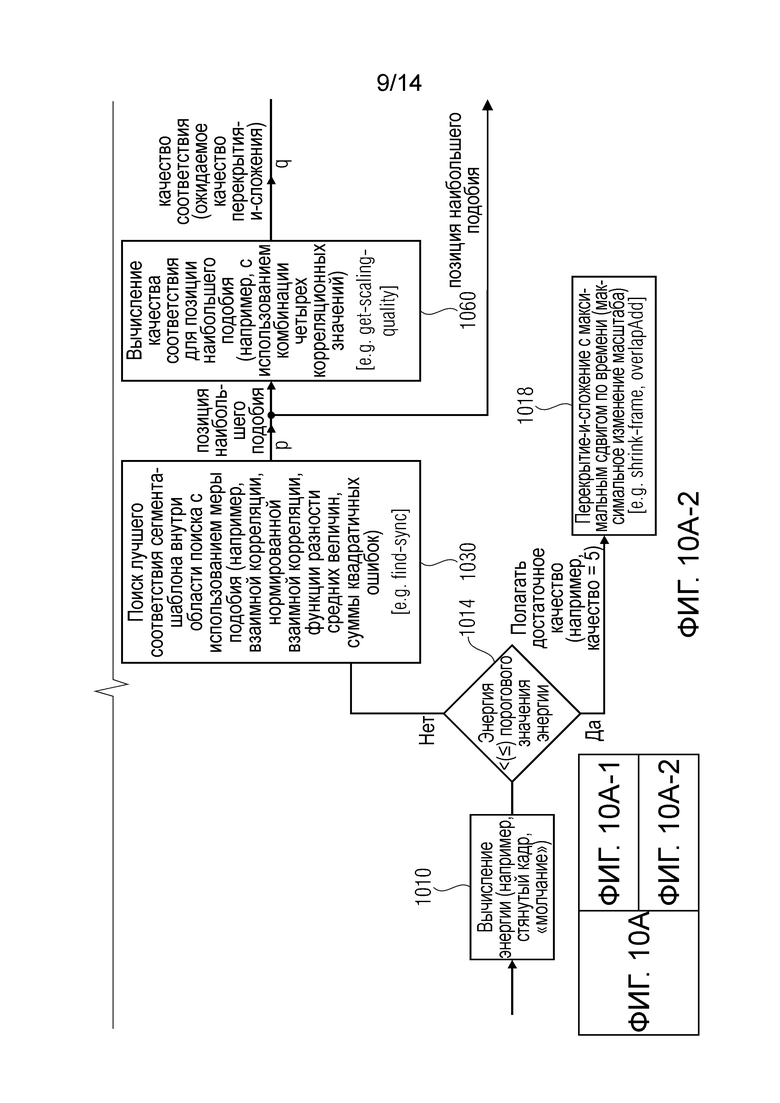
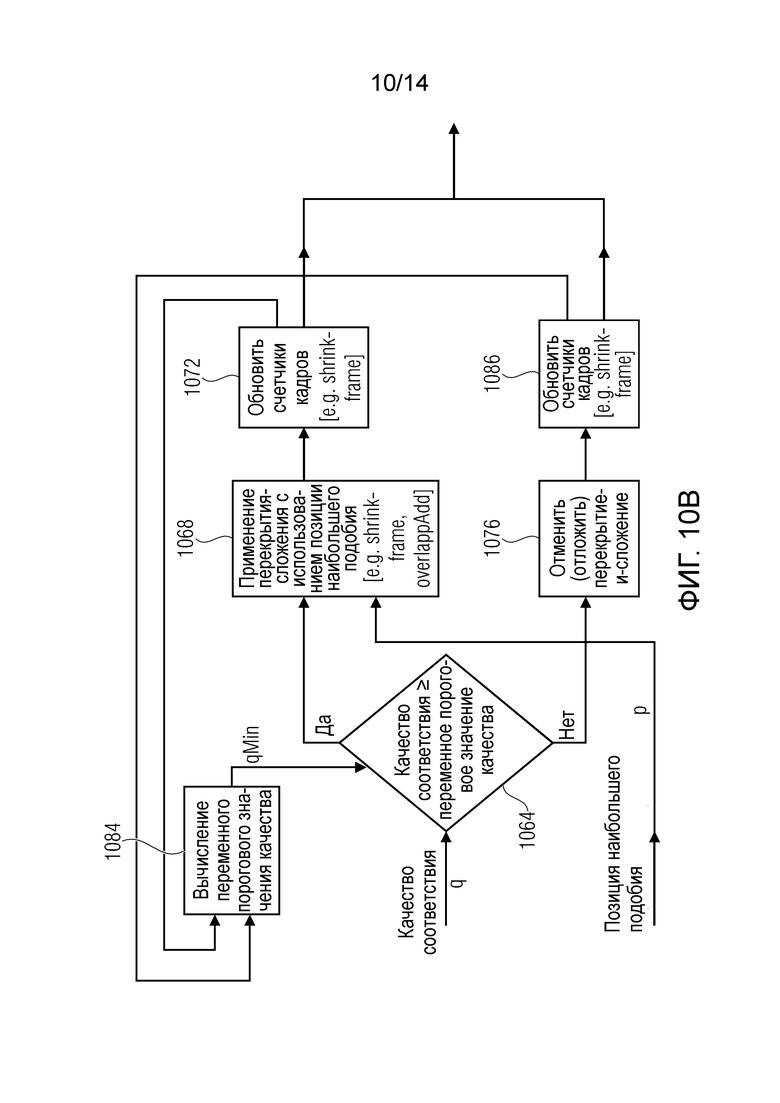

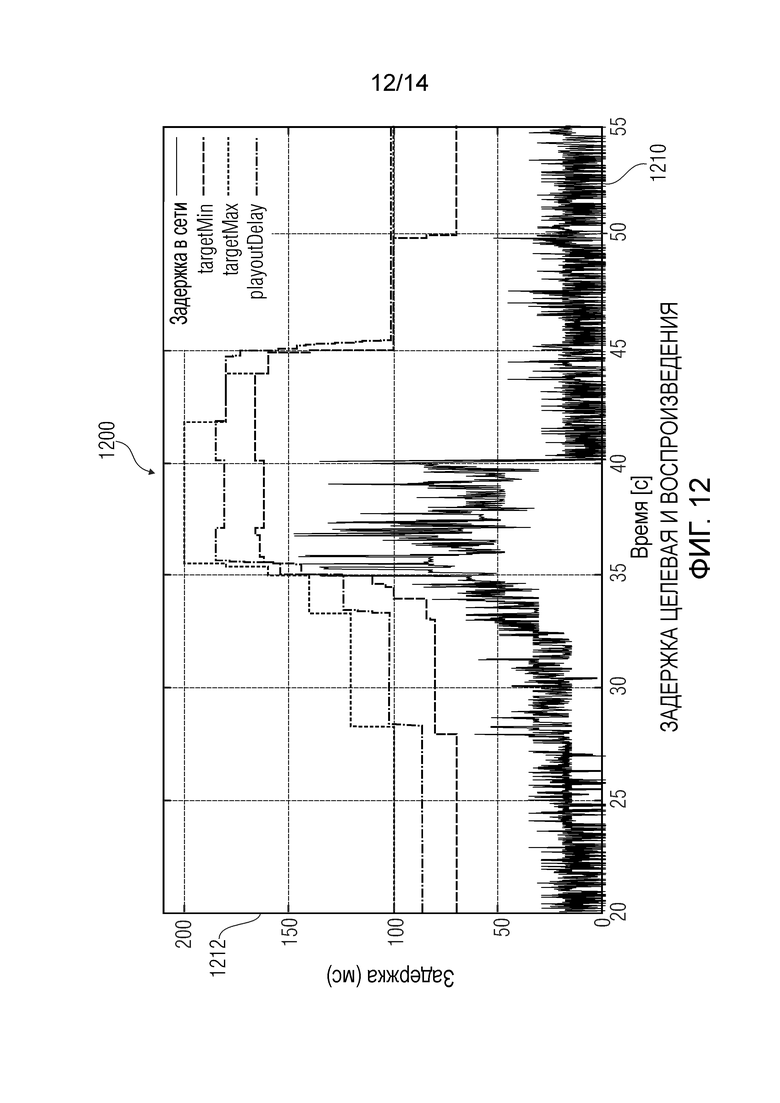
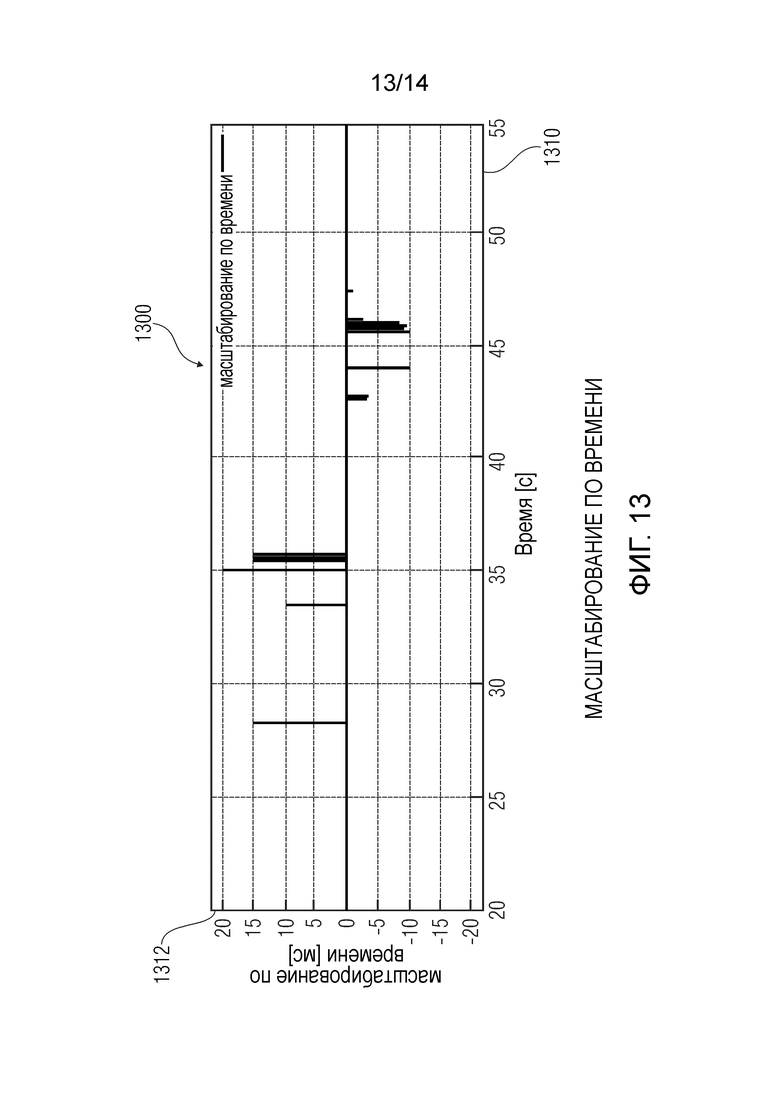
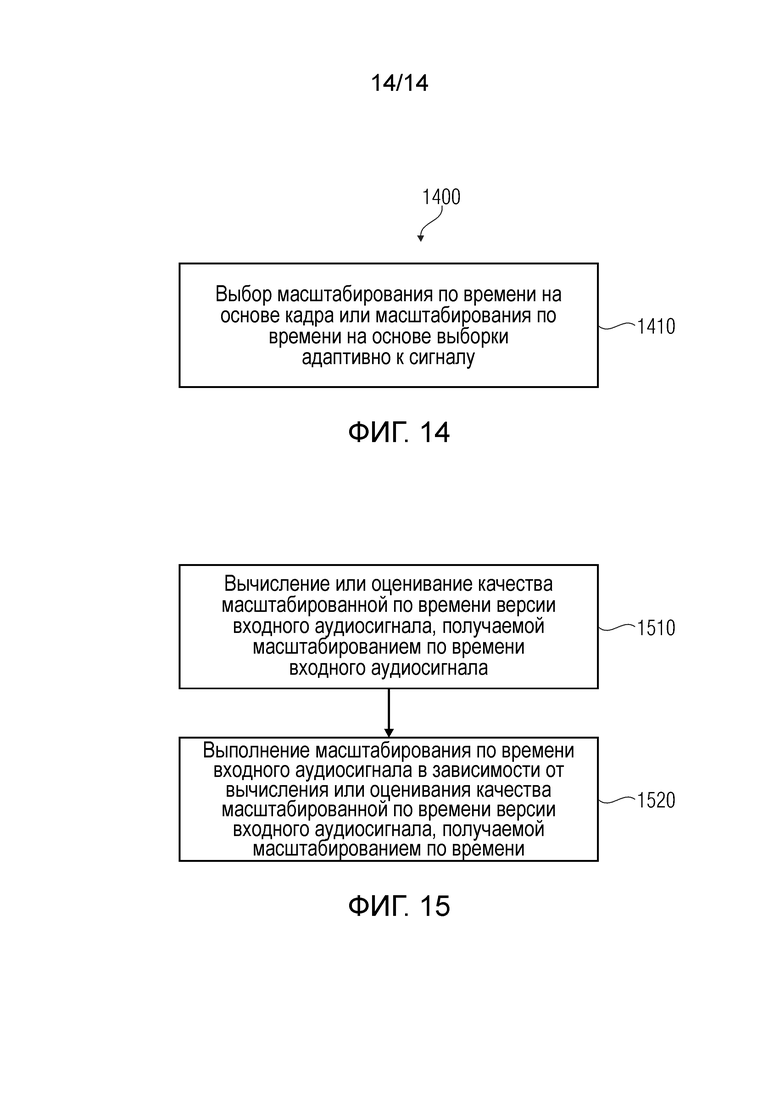
Изобретение относится к области кодирования и декодирования аудиосигналов. Технический результат – повышение качества звучания масштабированной по времени версии входного аудиосигнала. Преобразователь масштаба времени для обеспечения масштабированной по времени версии входного аудиосигнала сконфигурирован, чтобы вычислять или оценивать качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала. Преобразователь масштаба времени сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени. Аудио декодер содержит такой преобразователь масштаба времени. 10 н. и 26 з.п. ф-лы, 15 ил.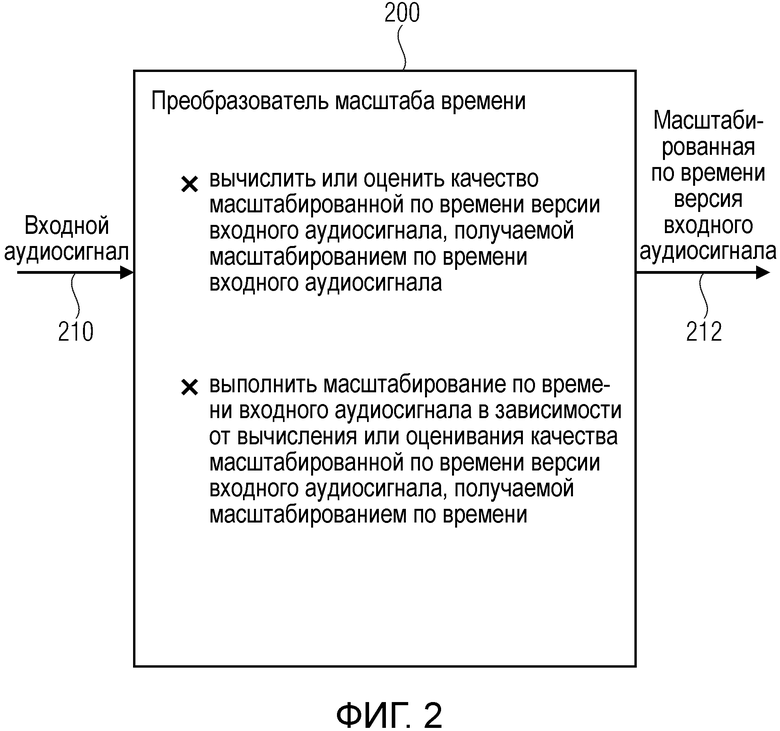
1. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени для обеспечения масштабированной по времени версии (212; 312; 448; 956) входного аудиосигнала (210; 332; 442; 910),
причем преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом преобразователь масштаба времени сконфигурирован для выполнения (954; 1068) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени,
при этом преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения (954; 1068) первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению (qmin) качества; и
при этом преобразователь масштаба времени сконфигурирован для определения сдвига (p) по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, или порцией второго блока выборок,
при этом определенный сдвиг (p) по времени является информацией, описывающей позицию наибольшего подобия; и
при этом преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства, оцененной с использованием второй меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым на определенный сдвиг по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени.
2. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован для выполнения операции (954; 1068) перекрытия-и-сложения при использовании первого блока выборок входного аудиосигнала и второго блока выборок входного аудиосигнала,
причем преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала.
3. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.2, в котором преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества операции перекрытия-и-сложения между первым блоком выборок и сдвинутым по времени вторым блоком выборок, чтобы вычислять или оценивать качество масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени.
4. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.2, в котором преобразователь масштаба времени сконфигурирован для определения (942; 1030) сдвига (p) по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, или порцией второго блока выборок.
5. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.4, в котором преобразователь масштаба времени сконфигурирован для определения информации о степени сходства между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, или порцией второго блока выборок, для множества различных сдвигов по времени между первым блоком выборок и вторым блоком выборок и для определения сдвига (p) по времени, подлежащего использованию для операции перекрытия-и-сложения, на основе информации о степени сходства для множества различных сдвигов по времени.
6. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.4, в котором преобразователь масштаба времени сконфигурирован для определения сдвига (p) по времени второго блока выборок относительно первого блока выборок, каковой сдвиг по времени подлежит использованию для операции перекрытия-и-сложения, в зависимости от информации целевого сдвига по времени.
7. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.4, в котором преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг (p) по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг (p) по времени.
8. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.7, в котором преобразователь масштаба времени сконфигурирован для принятия решения (1064), на основе информации о степени сходства между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг (p) по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг (p) по времени, выполняется ли масштабирование по времени фактически.
9. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором вторая мера (q) подобия является в вычислительном отношении более сложной, чем первая мера подобия.
10. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором первая мера подобия является взаимной корреляцией, или нормированной взаимной корреляцией, или функцией разности средних величин, или суммой квадратичных ошибок, и при этом вторая мера (q) подобия является комбинацией взаимных корреляций или нормированных взаимных корреляций для множества различных сдвигов по времени.
11. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором вторая мера (q) подобия является комбинацией взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени.
12. Преобразователь масштаба времени по п.11, в котором вторая мера (q) подобия является комбинацией первого значения взаимной корреляции и второго значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целочисленное кратное длительности периода (p) основной частоты аудио контента первого блока выборок или второго блока выборок, и третьего значения взаимной корреляции и четвертого значения взаимной корреляции, которые получают для сдвигов по времени, которые отстоят на целочисленное кратное длительности периода (p) основной частоты аудио контента,
причем сдвиг по времени, для которого получают первое значение взаимной корреляции, отстоит от сдвига по времени, для которого получают третье значение взаимной корреляции, на нечетное кратное половине длительности (p) периода основной частоты аудио контента.
13. Преобразователь масштаба времени по п.1, в котором вторую меру q подобия получают согласно
q=c(p)*c(2*p)+c(3/2*p)*c(1/2*p)
или согласно
q=c(p)*c(-p)+c(-1/2*p)*c(1/2*p),
причем c(p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на длительность p периода основной частоты аудио контента первого блока выборок или второго блока выборок;
причем c(2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на 2*p;
причем c(3/2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на 3/2*p;
причем c(1/2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на 1/2*p;
причем c(-p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на -p; и
причем c(-1/2*p) - значение взаимной корреляции между первым блоком выборок и вторым блоком выборок, которые сдвинуты по времени на -1/2*p.
14. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован для сравнения (1064) значения (q) качества, которое основано на вычислении или оценивании качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, с переменным пороговым значением (qmin), чтобы принимать решение, должно ли масштабирование по времени выполняться или нет.
15. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.14, в котором преобразователь масштаба времени сконфигурирован для уменьшения переменного порогового значения (qmin), чтобы таким образом снизить требования к качеству, в ответ на установление, что качество масштабирования по времени было недостаточным для одного или нескольких предшествующих блоков выборок.
16. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.14 или 15, в котором преобразователь масштаба времени сконфигурирован для повышения переменного порогового значения (qmin), чтобы таким образом повысить требования к качеству, в ответ на установление факта, что масштабирование по времени было применено к одному или нескольким предшествующим блокам выборок.
17. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.14, в котором преобразователь масштаба времени содержит первый счетчик (nScaled) с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые были масштабированы по времени, поскольку было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, и
при этом преобразователь масштаба времени содержит второй счетчик (nNotScaled) с ограниченным интервалом значений для подсчета числа блоков выборок или числа кадров, которые не были масштабированы по времени, поскольку не было достигнуто соответственное требование к качеству масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени; и
при этом преобразователь масштаба времени сконфигурирован для вычисления переменного порогового значения (qmin) в зависимости от значения первого счетчика (nScaled) и в зависимости от значения второго счетчика (nNotScaled).
18. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.17, в котором преобразователь масштаба времени сконфигурирован, чтобы добавлять значение, которое пропорционально значению первого счетчика (nScaled), к начальному пороговому значению и вычитать значение, которое пропорционально значению второго счетчика (nNotScaled), из него, чтобы получать переменное пороговое значение (qmin).
19. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован для выполнения масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, причем вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала содержит вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться масштабированием по времени.
20. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.19, в котором вычисление или оценивание (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала содержит вычисление или оценивание артефактов в масштабированной по времени версии входного аудиосигнала, которые будут вызываться операцией (954; 1068) перекрытия-и-сложения последующих блоков выборок входного аудиосигнала.
21. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, в зависимости от степени сходства последующих блоков выборок входного аудиосигнала.
22. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован для вычисления или оценивания, имеются ли слышимые артефакты в масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала.
23. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени по п.1, в котором преобразователь масштаба времени сконфигурирован с возможностью отложить (1076) масштабирование по времени до последующего кадра или до последующего блока выборок, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество.
24. Преобразователь масштаба времени (200; 340; 450; 866; 900; 1000) по п.1, в котором преобразователь масштаба времени сконфигурирован с возможностью отложить масштабирование по времени до момента времени, когда масштабирование по времени является менее слышимым, если вычисление или оценивание качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает недостаточное качество.
25. Преобразователь масштаба времени по п.1, в котором вторая мера подобия обеспечивает более высокую точность, чем первая мера подобия.
26. Преобразователь масштаба времени по п.1, в котором первая мера подобия является взаимной корреляцией, или нормированной взаимной корреляцией, или функцией разности средних величин, или суммой квадратичных ошибок.
27. Преобразователь масштаба времени (200; 340; 450; 866; 900; 1000) для обеспечения масштабированной по времени версии (212; 312; 448; 956) входного аудиосигнала (210; 332; 442; 910),
причем преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом преобразователь масштаба времени сконфигурирован для выполнения (954; 1068) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени;
при этом преобразователь масштаба времени сконфигурирован для сравнения (1064) значения (q) качества, которое основано на вычислении или оценивании качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, с переменным пороговым значением (qmin) для принятия решения, должно ли масштабирование по времени выполняться или нет;
при этом преобразователь масштаба времени сконфигурирован для повышения переменного порогового значения (qmin), чтобы таким образом повысить требования к качеству, в ответ на установление факта, что масштабирование по времени было применено к одному или нескольким предшествующим блокам выборок, с тем, чтобы гарантировать, что последующие блоки выборок масштабируются по времени, только если может достигаться сравнительно высокий уровень качества, более высокий, чем нормальный уровень качества.
28. Аудио декодер (300) для обеспечения декодированного аудио контента (312) на основе входного аудио контента (310), при этом аудио декодер содержит:
буфер (320) джиттера, сконфигурированный для буферизации множества аудио кадров, представляющих блоки аудио выборок;
ядро (330) декодера, сконфигурированное для обеспечения блоков аудио выборок (332) на основе аудио кадров (322), принимаемых из буфера джиттера;
преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени на основе выборки по одному из пп.1-27, в котором преобразователь масштаба времени на основе выборки сконфигурирован, чтобы обеспечивать масштабированные по времени блоки аудио выборок (342) на основе блоков аудио выборок (332), обеспечиваемых ядром декодера.
29. Аудио декодер (300) по п.28, при этом аудио декодер дополнительно содержит управление (100; 350; 490; 800) буфером джиттера,
причем управление буфером джиттера сконфигурировано для предоставления управляющей информации (114; 444) на преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени на основе выборки, при этом управляющая информация указывает, должно ли масштабирование по времени на основе выборки выполняться или нет, и/или при этом управляющая информация указывает требуемую величину изменения масштаба по времени.
30. Способ (1500) обеспечения масштабированной по времени версии входного аудиосигнала,
причем способ содержит вычисление или оценивание (1510) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом способ содержит выполнение (1520) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени,
при этом способ содержит сдвиг по времени второго блока выборок относительно первого блока выборок и перекрытие-и-сложение (954; 1068) первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению (qmin) качества; и
при этом способ содержит определение сдвига (p) по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, или порцией второго блока выборок; и
при этом определенный сдвиг по времени является информацией, описывающей позицию наибольшего подобия,
при этом способ содержит вычисление или оценивание (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства, оцениваемой с использованием второй меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени.
31. Способ (1500) обеспечения масштабированной по времени версии входного аудиосигнала,
причем способ содержит вычисление или оценивание (1510) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом способ содержит выполнение (1520) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени,
при этом способ содержит сравнение (1064) значения (q) качества, которое основано на вычислении или оценивании качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, с переменным пороговым значением (qmin) для принятия решения, должно ли масштабирование по времени выполняться или нет;
при этом способ содержит повышение переменного порогового значения (qmin), чтобы таким образом повысить требование к качеству в ответ на установление факта, что масштабирование по времени было применено к одному или нескольким предшествующим блокам выборок с тем, чтобы гарантировать, что последующие блоки выборок масштабируются по времени, только если может достигаться сравнительно высокий уровень качества, более высокий, чем нормальный уровень качества.
32. Носитель данных, содержащий компьютерную программу для выполнения способа по п.30, когда компьютерная программа исполняется на компьютере.
33. Носитель данных, содержащий компьютерную программу для выполнения способа по п.31, когда компьютерная программа исполняется на компьютере.
34. Преобразователь (200; 340; 450; 866; 900; 1000) масштаба времени для обеспечения масштабированной по времени версии (212; 312; 448; 956) входного аудиосигнала (210; 332; 442; 910),
причем преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом преобразователь масштаба времени сконфигурирован для выполнения (954; 1068) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени;
при этом преобразователь масштаба времени сконфигурирован для сдвига по времени второго блока выборок относительно первого блока выборок и для перекрытия-и-сложения (954; 1068) первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению (qmin) качества; и
при этом преобразователь масштаба времени сконфигурирован для определения сдвига (р) по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок или порцией первого блока выборок и вторым блоком выборок или порцией второго блока выборок; и
при этом преобразователь масштаба времени сконфигурирован для вычисления или оценивания (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, на основе информации о степени сходства, оцененной с использованием второй меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени;
при этом первая мера подобия является взаимной корреляцией или нормированной взаимной корреляцией, или функцией разности средних величин, или суммой квадратичных ошибок, и
при этом вторая мера (q) подобия является комбинацией взаимных корреляций или нормированных взаимных корреляций для множества различных сдвигов по времени; или
при этом вторая мера (q) подобия является комбинацией взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени.
35. Способ (1500) обеспечения масштабированной по времени версии входного аудиосигнала,
причем способ содержит вычисление или оценивание (1510) качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала, и
при этом способ содержит выполнение (1520) масштабирования по времени входного аудиосигнала в зависимости от вычисления или оценивания качества масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени;
при этом способ содержит сдвиг по времени второго блока выборок относительно первого блока выборок и перекрытие-и-сложение (954; 1068) первого блока выборок и сдвинутого по времени второго блока выборок, чтобы посредством этого получить масштабированную по времени версию входного аудиосигнала, если вычисление или оценивание качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени, указывает качество, которое больше чем или равно пороговому значению (qmin) качества; и
при этом способ содержит определение сдвига (p) по времени второго блока выборок относительно первого блока выборок в зависимости от определения степени сходства, оцененной с использованием первой меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, или порцией второго блока выборок; и
при этом способ содержит вычисление или оценивание (950; 1060) качества (q) масштабированной по времени версии входного аудиосигнала, получаемой масштабированием по времени входного аудиосигнала на основе информации о степени сходства, оцененной с использованием второй меры подобия, между первым блоком выборок, или порцией первого блока выборок, и вторым блоком выборок, сдвинутым по времени на определенный сдвиг по времени, или порцией второго блока выборок, сдвинутого по времени на определенный сдвиг по времени;
причем первая мера подобия является взаимной корреляцией или нормированной взаимной корреляцией, или функцией разности средних величин, или суммой квадратичных ошибок, и
при этом вторая мера (q) подобия является комбинацией взаимной корреляции или нормированных взаимных корреляций для множества различных сдвигов по времени; или
при этом вторая мера (q) подобия является комбинацией взаимных корреляций, по меньшей мере, для четырех различных сдвигов по времени.
36. Носитель данных, содержащий компьютерную программу для выполнения способа по п.35, если компьютерная программа исполняется на компьютере.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| ИНТЕЛЛЕКТУАЛЬНЫЙ СПОСОБ, СИСТЕМА И УЗЕЛ ОГРАНИЧЕНИЯ АУДИО | 2007 |
|
RU2398361C2 |
| УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2483366C2 |
| РАСЧЕТ И РЕГУЛИРОВКА ВОСПРИНИМАЕМОЙ ГРОМКОСТИ И/ИЛИ ВОСПРИНИМАЕМОГО СПЕКТРАЛЬНОГО БАЛАНСА ЗВУКОВОГО СИГНАЛА | 2007 |
|
RU2426180C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 7548853 B2, 16.06.2009 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

