Область техники, к которой относится изобретение
[1] Данное изобретение относится к системе управления распределенными данными для интеллектуальных ПЛК. Для приложений, связанных с промышленной автоматизацией, а также других приложений, где используются интеллектуальные ПЛК, применимы различные системы и способы.
УРОВЕНЬ ТЕХНИКИ
[2] Программируемый логический контроллер (ПЛК) представляет собой специализированную компьютерную систему управления, конфигурация которой обеспечивает исполнение программного обеспечения, которое непрерывно собирает данные о состоянии устройств ввода для управления состоянием устройств вывода. В типичном случае, ПЛК включает в себя три основных компонента: процессор (который может включать в себя энергозависимое запоминающее устройство), энергозависимое запоминающее устройство, содержащее прикладную программу, и один или несколько портов ввода-вывода (В-В) для соединения с другими устройствами в системе автоматизации.
[3] ПЛК используются в различных отраслях промышленности для управления технологическими устройствами и другими автоматическими устройствами, которые генерируют большой объем данных в процессе их ежедневной эксплуатации. Эти данные могут включать в себя, например, данные датчиков, параметры исполнительных механизмов и программ управления, а также информацию, связанную с сервисными операциями. Вместе с тем, обычные системы автоматизации и обычные ПЛК, в частности, не в состоянии использовать эти данные в полной мере. Например, в большинстве систем - из-за ограничений аппаратного обеспечения и программного обеспечения - проанализировать и сохранить можно лишь небольшую часть этих данных. Оказываются возможными создание огромных объемов бесполезных данных и пропуск важных точек данных. На более высоких уровнях автоматизации, к неважным данным применимо сжатие, хотя при прохождении по уровням автоматизации важные данные утрачиваются. Более того, даже если предпринимаются попытки предотвращения потери данных, при этом могут предъявляться серьезные требования к остальной части вычислительной инфраструктуры. Например, обработка данных посредством ПЛК может привести к предъявлению высоких требований по пропускной способности сети, а так же емкости запоминающих устройств. Помимо этого, возможна утрата контекста данных, когда эти данные проходят по уровням системы автоматизации. Это вызывает некоторые нежелательные побочные воздействия на систему автоматизации. Например, если аналитическую обработку данных на более высоких уровнях автоматизации проводят на основе данных низкого качества или низкой достоверности, возможна утрата важных данных, обуславливающая неэффективную или неоптимальную работу системы автоматизации.
[4] Недавние достижения в области устройств уровней управления направлены на устранение некоторых несовершенств системы посредством повышенных возможностей хранения и обработки данных в пределах устройства. Вместе с тем, в обычных системах, которые вынуждают устройство уровня управления действовать в рамках парадигмы многоуровневой архитектуры, рассмотренной выше, использование упомянутых возможностей в общем случае оказывается неполным. Соответственно, желательно модифицировать обычную многослойную архитектуру так, чтобы эффективно использовать совокупные вычислительные возможности современных ПЛК.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[5] Варианты осуществления данного изобретения направлены на решение и преодоление одной или нескольких проблем, связанных с вышеупомянутыми изъянами и недостатками, путем разработки способов, систем и аппаратуры, относящихся к системе с распределенной памятью, снабженной устройствами уровней управления, такими, как интеллектуальные ПЛК. Описываемая здесь технология вполне пригодна, в частности, но не в ограничительном смысле, для приложений, связанных с промышленной автоматизацией.
[6] В соответствии с некоторыми вариантами осуществления, система для хранения данных в среде промышленного производства включает в себя распределенную базу данных, хранимую во множестве устройств интеллектуальных программируемых логических контроллеров. Каждое соответственное устройство интеллектуального программируемого логического контроллера включает в себя: энергозависимый машиночитаемый носитель информации, содержащий область образа процесса; энергонезависимый машиночитаемый носитель информации; управляющее приложение; компонент для ввода-вывода; архивный компонент; и компонент для управления распределенными данными.
[7] Конфигурация управляющего приложения в каждом интеллектуальном программируемом логическом контроллере обеспечивает выдачу инструкций по эксплуатации в некоторую единицу технологического оборудования. Конфигурация компонента для ввода-вывода обеспечивает проводимое во время каждого цикла сканирования обновление области образа процесса данными, связанными с этой единицей технологического оборудования. Конфигурация архивного компонента обеспечивает хранение данных системы автоматизации, содержащих инструкции по эксплуатации, и содержимого области образа процесса, на энергонезависимом машиночитаемом носителе информации. Кроме того, в некоторых вариантах осуществления, архивный компонент сжимает данные системы автоматизации перед сохранением содержимого на энергонезависимом машиночитаемом носителе информации. Конфигурация компонента для управления распределенными данными обеспечивает облегчение распределенных операций, подразумевающих использование данных системы автоматизации множеством устройств интеллектуальных программируемых логических контроллеров. В одном варианте осуществления, конфигурация компонента для управления распределенными данными дополнительно обеспечивает разделение данных системы автоматизации на блоки данных перед сохранением данных системы автоматизации на энергонезависимом машиночитаемом носителе информации. Этим блокам данных можно придать размеры, например, в соответствии с некоторым заранее определенным периодом времени.
[8] В каждом соответственном интеллектуальном программируемом логическом контроллере могут быть заключены дополнительные компоненты. Например, в одном варианте осуществления, каждое устройство интеллектуального программируемого логического контроллера включает в себя компонент для контекстуализации, конфигурация которого обеспечивает аннотирование данных, связанных с единицей технологического оборудования, контекстной информацией системы автоматизации для генерирования данных контекстуализации.
[9] Вышеупомянутую систему можно различными путями адаптировать для поддержки разных методологий хранения распределенных файлов. Например, в некоторых вариантах осуществления, каждое соответственное устройство интеллектуального программируемого логического контроллера представляет собой узел данных в кластере системы распределенных файлов, а, по меньшей мере, одно из множества устройств интеллектуальных программируемых логических контроллеров представляет собой узел имен в кластере системы распределенных файлов. В одном варианте осуществления, каждое соответственное устройство интеллектуального программируемого логического контроллера содержит определение ключа шардинга, которое обеспечивает отображение между данными, хранимыми в системе управления распределенными данными, и устройствами интеллектуальных программируемых логических контроллеров. Определение ключа шардинга можно хранить, например, на централизованном сервере, доступном для каждого из множества устройств интеллектуальных программируемых логических контроллеров.
[10] В соответствии с другими вариантами осуществления данного изобретения, способ сохранения данных в среде промышленного производства включает в себя исполнение первым интеллектуальным программируемым логическим контроллером управляющего приложения, конфигурация которого обеспечивает выдачу инструкций по эксплуатации в единицу технологического оборудования на протяжении множества циклов сканирования. Первый интеллектуальный программируемый логический контроллер обновляет область образа процесса во время каждого из множества циклов сканирования данными, связанными с единицей технологического оборудования, и вставляет данные, связанные с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель на первом интеллектуальном программируемом логическом контроллере. Для этого способа, локальный энергонезависимый машиночитаемый носитель представляет собой часть системы с распределенной памятью, хранимой на первом интеллектуальном программируемом логическом контроллере и множестве вторых интеллектуальных программируемых логических контроллеров. Чтобы облегчить хранение, локальный энергонезависимый машиночитаемый носитель может включать в себя, например, базу данных NoSQL которая имеет табличный эквивалентный вид.
[11] Вышеупомянутый способ можно адаптировать и/или улучшить различными дополнительными признаками в разных вариантах осуществления данного изобретения. Например, в некоторых вариантах осуществления, первый интеллектуальный программируемый логический контроллер разделяет данные, связанные с единицей технологического оборудования, на блоки данных (например, такие, которым приданы размеры в соответствии с некоторым заранее определенным периодом времени). В некоторых вариантах осуществления, хранение, по меньшей мере, одного из блоков данных дублируется на одном или нескольких из множества вторых интеллектуально программируемых логических контроллеров. В дополнение к этому, вставление данных, связанных с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель, можно запускать на основе разных событий. Например, в некоторых вариантах осуществления, это вставление запускают на основе изменений, вносимых в инструкции по эксплуатации и данные, связанные с единицей технологического оборудования. В других вариантах осуществления, вставление запускают но основе изменения, вносимого в один или несколько оперативно контролируемых флагов ввода-вывода.
[12] В соответствии еще одним аспектом данного изобретения, изделие промышленного производства для эксплуатации интеллектуального программируемого логического контроллера на протяжении множества циклов сканирования включает в себя непереходный материальный машиночитаемый носитель, хранящий машиночитаемые инструкции для осуществления вышеупомянутого способа, с вышеуказанными дополнительными признаками или без них.
[13] Дополнительные признаки и преимущества изобретения станут очевидными из нижеследующего подробного описания иллюстративных вариантов осуществления, приводимого со ссылками на прилагаемые чертежи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[14] Лучше всего понять вышеизложенные и другие аспекты данного изобретения лучше можно будет из нижеследующего подробного описания, когда его читают в связи с прилагаемым чертежами. С целью иллюстрации изобретения, на чертежах показаны варианты осуществления, предпочтительные в настоящее время; вместе с тем, понятно, что изобретение не ограничивается описываемыми конкретными средствами. Среди чертежей имеются следующие:
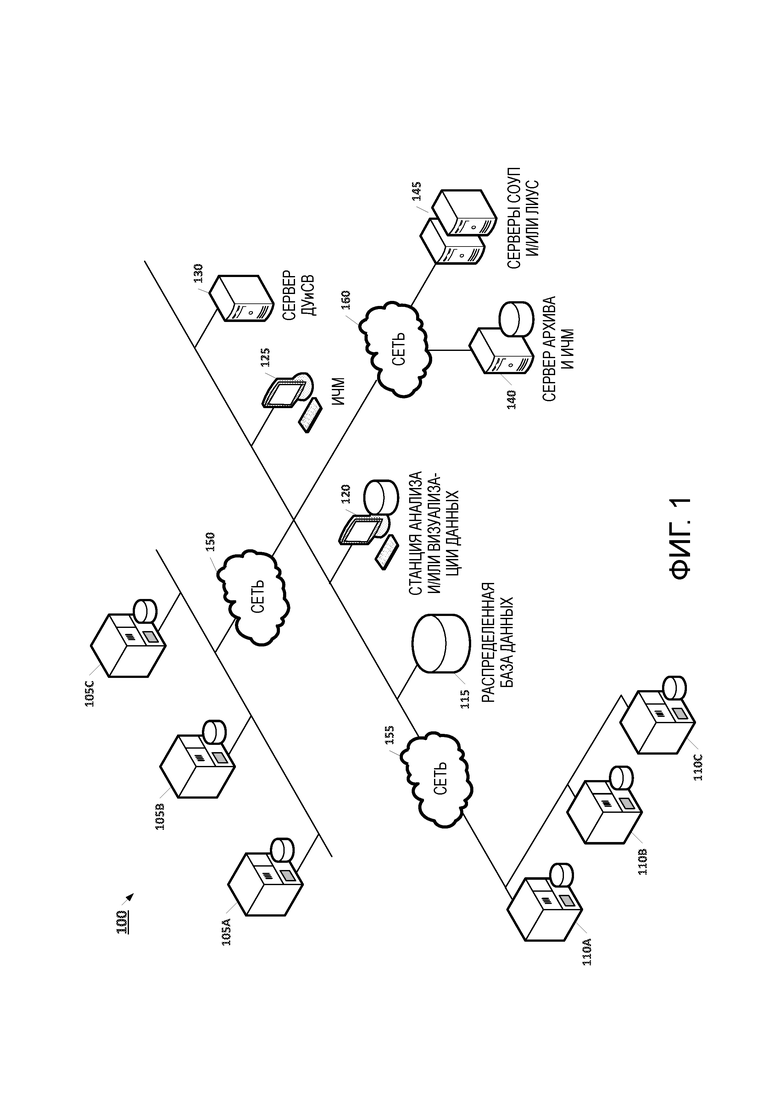
[15] на фиг.1 представлена схема архитектуры, иллюстрирующая систему промышленной автоматизации, где интеллектуальные ПЛК образуют систему управления распределенными данными, предназначенную для данных системы автоматизации, в соответствии с некоторыми вариантами осуществления;
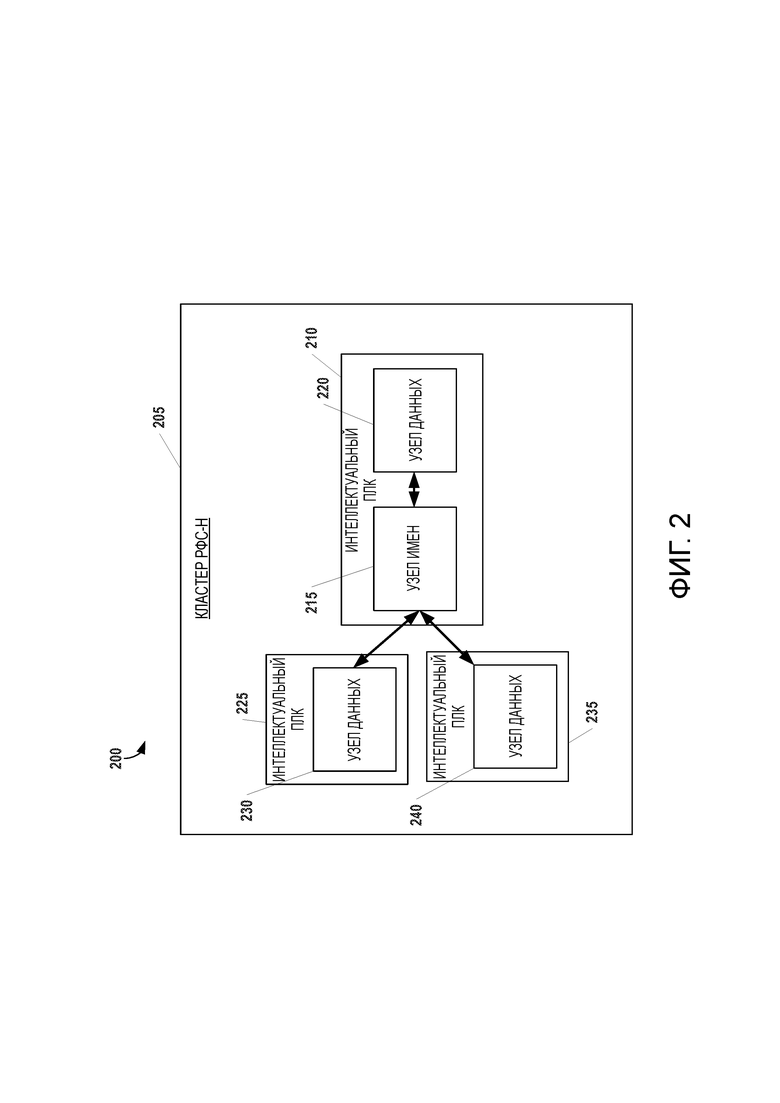
[16] на фиг.2 представлена архитектура распределенной файловой системы, применимая для хранения в системе согласно фиг.1, в соответствии с некоторыми вариантами осуществления;
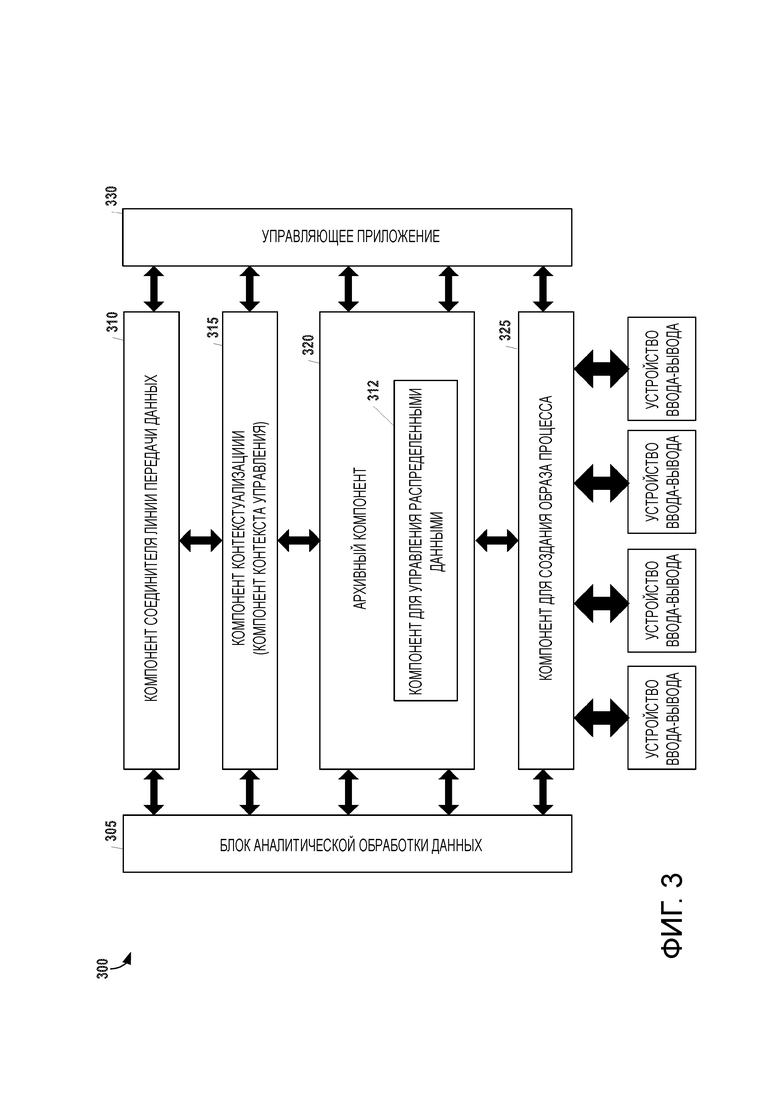
[17] на фиг.3 представлена иллюстрация компонентов системы, входящих в состав интеллектуального ПЛК, в соответствии с некоторыми вариантами осуществления; и
[18] на фиг.4 представлена схема последовательности операций процесса загрузки данных в систему с распределенной памятью, когда данные находятся среде промышленного производства в соответствии с некоторыми вариантами осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
[19] Здесь описываются системы, способы и аппаратура, которые, вообще говоря, относятся к системе с распределенной памятью, воплощаемой во множестве интеллектуальных программируемых логических контроллеров, именуемых здесь «интеллектуальными ПЛК». Короче говоря, каждый интеллектуальный ПЛК включает в себя архивный компонент, который встроен в систему управления распределенными данными. Каждый архивный компонент хранит образ процесса из своего соответственного интеллектуального ПЛК наряду с аналитической, контекстуализационной и другой выдаваемой информацией. В том смысле, в каком он употребляется здесь, термин «система управления распределенными данными» относится к любой системе, которая обеспечивает распределенную память и распределенную обработку (например, посредством отображения и/или восстановления на встроенном уровне) наборов данных на интеллектуальном ПЛК. Таким образом, описываемую здесь систему с распределенной памятью можно воплотить, например, воспользовавшись распределенной файловой системой (например, РФС Hadoop) или системой управления распределенными базами данных (например, MongoDB). С помощью этих систем можно поддерживать уместный распределенный архивный контекст посредством архивных стеков на уровне узлов, и это может быть основой для дальнейшего управления распределенными данными, внедренными аналитическими данными и другими распределенными услугами на основе данных. Описываемые здесь методы можно использовать, например, для обеспечения связного образа во времени, данных (например, данных временного ряда), организации данных, и имен данных по системе промышленной автоматизации и доступа к данным сразу же после их создания.
[20] На фиг.1 представлена схема архитектуры, иллюстрирующая систему 100 промышленной автоматизации, где интеллектуальные ПЛК образуют систему управления распределенными данными, предназначенную для данных системы автоматизации, в соответствии с некоторыми вариантами осуществления. Короче говоря, интеллектуальные ПЛК предоставляют несколько технических особенностей, которые могут присутствовать в различных комбинациях, в соответствии с разными вариантами осуществления. Например, интеллектуальные ПЛК включают в себя эффективный механизм хранения для данных временного ряда (т.е., «архивной» функции) который обеспечивает кратко- и или среднесрочное архивирование данных высокого разрешения, обладающих временными метками. В случае данных высокой достоверности, незначительное количество событий, если они вообще происходят, утрачивается. Для снижения потребностей в хранении и связи, можно использовать эффективные алгоритмы сжатия (например, вариацию «вращающейся двери»). Ниже, со ссылками на фиг.2, интеллектуальный ПЛК рассматривается подробнее. Следует отметить, что на фиг.1 представлен упрощенный общий вид в целом архитектуры, которую можно использовать описываемыми здесь методами. Эту архитектуру можно модифицировать, чтобы она предусматривала дополнительные устройства, которые можно представить, например, в таких практических воплощениях, как, устройства маршрутизации, соединения с дополнительными сетями данных, и т.д.
[21] Управление распределенными данными можно воплотить посредством системы 100 промышленной автоматизации, пользуясь разными методами в разных вариантах осуществления. В некоторых вариантах осуществления, для хранения данных с помощью устройств, образуемых интеллектуальными ПЛК 105A, 105B, 105C, 110A, 110B и 110C, используют распределенную файловую систему (РФС). РФС делает возможным быстрое масштабирование в контексте вычислительных возможностей и хранения при затратах, весьма низких по сравнению с системой распределенных баз данных. Таким образом, для приложений, которые предусматривают многочисленные параллелизуемые операции обработки, РФС может обеспечить более эффективное решение для данных распределенной памяти. В других вариантах осуществления, для воплощения стойкой к внешним воздействиям системы управления распределенными базами данных, обеспечивающей свойства, подобные атомарности, непротиворечивости, изолированности и долговечности, которые можно использовать, наряду с масштабируемостью и возможностями обработки, которые тоже можно использовать, применяют интеллектуальные ПЛК. Это может обеспечить уровень управления данными, который поддерживает запрашивание, подобное осуществляемому на языке структурированных запросов (SQL), как абстракцию доступа к данным, распределенным по разделам, во многих узлах, а также функции, которые могут позволить извлечь выгоду и из обработки данных локально в узлах, где эти данные остаются (т.е., поддерживать локальность данных).
[22] В примере согласно фиг.1, узлы системы управления распределенными данными, которая применяется системой 100 промышленной автоматизации включают в себя интеллектуальные ПЛК 105A, 105B, 105C, 110A, 110B и 110C. Хотя на фиг.1 показаны только шесть интеллектуальных ПЛК, следует понять, что описываемыми здесь методами можно использовать любое число интеллектуальных ПЛК. Таким образом, систему управления распределенными данными, поддерживаемую архитектурой, представленной на фиг.1, можно динамически наращивать и сокращать, добавляя или удаляя вычислительные ресурсы в зависимости от потребностей системы. Кроме того, емкость памяти системы управления распределенными данными можно увеличить, добавляя специально выделяемые или широко применяемые ресурсы аппаратного обеспечения (например, стойки серверов, дополнительные контроллеры). Например, как подробнее поясняется ниже, в некоторых вариантах осуществления, в качестве узла системы управления распределенными данными добавляют сервер распределенной базы 115 данных, чтобы обеспечить долгосрочное хранение данных, хранимых на интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C.
[23] Каждый интеллектуальный ПЛК 105A, 105B, 105C, 110A, 110B и 110C содержит компонент для управления распределенными данными. В некоторых вариантах осуществления, компонент для управления распределенными данными, входящий в состав каждого интеллектуального ПЛК, выполнен с возможностью хранения данных, поступающих из контроллера через один и тот же интерфейс в совместно используемое запоминающее устройство, или в файловой системе. Например, как подробнее рассматривается ниже со ссылками на фиг.3, каждый интеллектуальный ПЛК 105A, 105B, 105C, 110A, 110B и 110C содержит архив вложенных процессов, который имеет локальное представление имен, значений и данных организации, архивированных локально. С помощью компонента для управления распределенными данными, можно обеспечить совместное использование данных, генерируемых каждым соответственным архивом, по всей системе 100.
[24] Данными, хранимыми в каждом интеллектуальном ПЛК 105A, 105B, 105C, 110A, 110B и 110C, могут пользовать клиентские приложения, которые запущены внутри контроллеров или на любом устройстве, имеющем доступ к системе управления распределенными данными, обеспечиваемой системой 100, показанной на фиг.1. Помимо хранения, каждый интеллектуальный ПЛК 105A, 105B, 105C, 110A, 110B и 110C также может предусматривать услуги управления кластерами и наличие ядра процессора, которое обеспечивает решение таких задач, как распределенная память и связь, а так же распределенная обработка и координация.
[25] Метод, применяемый для локализации данных и управления ими на интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C, можно изменять в соответствии с тем, как воплощается распределенная память. Например, в вариантах осуществления, где для получения распределенной памяти используют РФС, такую, как Hadoop, один или несколько интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C служат в качестве «узла имен». Каждый узел имен управляет деревом каталогов всех файлов в РФС и отслеживает, где по всей системе 100 хранятся данные файлов. Клиентские приложения могут осуществлять связь с узлом имен для локализации некоторого файла или для проведения операций над этим файлом (добавление, копирование, перемещение, стирание, и т.д.). Узел имен реагирует на успешные запросы, возвращая список релевантных устройств, где хранятся данные. Следует отметить, что для РФС узел имен представляет собой единственное уязвимое звено. Таким образом, в некоторых вариантах осуществления, можно использовать несколько узлов имен, чтобы обеспечить избыточность.
[26] В вариантах осуществления, где систему управления распределенными базами данных используют для воплощения распределенной памяти, хранение данных в интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C возможно с помощью методов шардинга. В данной области техники понимается, что шардинг представляет собой стратегию использований распределенной базы данных для локализации ее разделенных данных. Этот механизм зачастую используют для поддержки развертываний наборами данных, которые требуют распределения и высокопроизводительных операций. Его воплощают посредством определения ключа шардинга, которое дает критерии, используемые для разделения данных между контроллерами. Отображение шардинга можно хранить с помощью некоторого конкретного экземпляра сервера или внутри каждого контроллера. В обоих случаях, информация шардинга доступна всем устройствам. Каждое устройство-держатель ключа шардинга может координировать процесс передачи данных с другими одноранговыми узлами, поскольку отображение местонахождения контроллера и/или данных хранится в метаданных шардинга. Таким образом, система управления распределенными данными (такая, как воплощенная с помощью интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C) может обеспечить распараллеливание и низкий трафик данных через сеть.
[27] Интеллектуальные ПЛК 105A, 105B, 105C, 110A, 110B, и 110C могут осуществлять связь друг с другом через сетевое соединение с использованием стандартных сетевых протоколов (например, TCP, RPC, и т.д.). Такую связь можно использовать, например, чтобы реализовать на практике задачи выборки распределенных данных и распределенной обработки. В обоих случаях, инициировать процесс можно с любого контроллера, а последний запустит новые соединения с другими контроллерами, которые хранят необходимые данные. Отметим, что посылать сообщения оповещения через различные сети не нужно, так как координатор (например, контроллер, который начал решать задачу выборки данных или распределенной обработки, либо выполнять задание «отображение-свертка») намечает лишь контроллеры, которые имеют запрашиваемые данные, исключая ненужный сетевой трафик. Помимо этого, если обработка представляет собой решение задачи распределенной обработки, то - за исключением результатов обработки - данные через сеть пропускаться не будут. Это достигается путем посылки кода вычисления и исполнения его в контроллере, который хранит данные, представляющие интерес.
[28] Помимо осуществления связи друг с другом, интеллектуальные ПЛК 105A, 105B, 105C, 110A, 110B и 110C также могут осуществлять связь с любыми другими клиентами, поддерживающими протокол управления передачей данных (TCP), имеющими архитектуру открытых средств связи с базами данных (ODBC) и/или унифицированную архитектуру, которую разработал консорциум OPC Foundation (и которой соответствует аббревиатура OPC UA), такими как распределенная база 115 данных, станция 120 анализа и/или визуализации данных, один или несколько интерфейсов 125 «человек - машина» (ИЧМ), обозначенных позицией 125, сервер 130 диспетчерского управления и сбора данных (ДУиСВ), сервер 140 архива и ИЧМ, а также серверы 145, связанные с системами оперативного управления производством (СОУП) и/или лабораторными информационно-управляющими системами (ЛИУС). Каждый компонент архитектуры можно подсоединить с помощью корпоративной локальной сети (воплощаемой, например, посредством Ethernet) и одной или нескольких объединенных сетей 150, 155, 160.
[29] Распределенная база 115 данных представляет собой сервер с памятью большой емкости, хранящий данные, которые в дальнейшем недоступны в интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C. Эти данные по-прежнему доступны для системы управления распределенными данными и ведут себя подобно тем, которые находятся в другом распределенном узле в системе. Распределенную базу 115 данных можно воплотить, например, воспользовавшись такой нереляционной базой данных, как NoSQL, являющейся масштабируемым и быстродействующим хранилищем данных, которое может обеспечить долгосрочный доступ к данным в реальном масштабе времени. Она может предусматривать наличие соединителя, соответствующего архитектуре ODBC, аналогично другим конфигурациям реляционных баз данных.
[30] Любая станция-клиент в системе 100 промышленной автоматизации может вводить алгоритмы из хранилища алгоритмов в один или несколько интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C. Интеллектуальные ПЛК 105A, 105B, 105C, 110A, 110B и 110C могут исполнять алгоритм распределенным образом (т.е., исполнение возможно в нескольких контроллерах), потом агрегировать и посылать результаты станции-клиенту. В примере согласно фиг.1, на станции 120 анализа и/или визуализации данных также находится хранилище приложений и/или алгоритмов, которое можно обновлять, а исполнять их можно в интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C. Кроме того, в некоторых вариантах осуществления, для доступа в систему управления распределенными данными, либо непосредственно, либо через станцию 120 анализа и/или визуализации данных, можно использовать интерфейсы «человек-машина» (ИЧМ), обозначенные позицией 125 и распределенные по производственным мощностям. В некоторых вариантах осуществления, станция 120 анализа и/или визуализации данных может включать в себя графический интерфейс пользователя (ГИП), конфигурация которого обеспечивает, например, прием запросов на получение данных, хранимых в системе управления распределенными данными приложений, и/или визуализаций отображений, связанных с данными, хранимыми по всей системе распределенных баз данных. Аналогичные функциональные возможности также могут быть доступными в ГИП 125 или других компонентах системы.
[31] Система управления распределенными данными, обеспечиваемая интеллектуальными ПЛК 105A, 105B, 105C, 110A, 110B и 110C, совместима с компонентами существующей инфраструктуры автоматизации. Например, сервер 130 диспетчерского управления и сбора данных (ДУиСВ) может подавать и выдавать распределенные данные, получаемые из интеллектуальных ПЛК 105A, 105B, 105C, 110A, 110B и 110C, а так же других компонентов системы (например, распределенной базы 115 данных), с помощью клиентов, имеющих архитектуру OPC UA и/или ODBC. Аналогичным образом, сервер 140 архива и ИЧМ, а также СОУП- и/или ЛИУС-серверы 145 могут осуществлять доступ к данным по всей системе управления распределенными данными, при условии незначительной модификации их существующих операций или без нее. Когда время и ресурсы позволяют, эти компоненты более высокого уровня можно модифицировать для более эффективной работы, при этом каждый интеллектуальный ПЛК 105A, 105B, 105C, 110A, 110B и 110C включает в себя компонент для управления распределенными данными.
[32] На фиг.2 представлена архитектура 200 РФС, применимая для хранения в системе 100, в соответствии с некоторыми вариантами осуществления. В этом примере, для хранения используется распределенная файловая система Hadoop (РФС-H). В соответствии с понятиями, принятыми в данной области техники, РФС-H разделяет большие наборы клиентских данных (в типичном случае - размером порядка терабайтов) на меньшие блоки данных (в типичном случае - 64 мегабайт), причем каждый блок данных хранится в более чем одном узле данных, чтобы обеспечить их высокую доступность. РФС-H содержит взаимосвязанные кластеры узлов, каждый из которых хранит файлы и каталоги. В примере согласно фиг.2 показан один кластер 205. Вместе с тем, следует понять, что архитектуру 200 РФС можно изменять пропорционально любому числу кластеров. Кластер 205 включает в себя три интеллектуальных ПЛК 210, 225 и 235. Каждый из этих трех интеллектуальных ПЛК 210, 225 и 235 включает в себя узел данных. С помощью блочного протокола, специфичного для РФС-H, эти узлы 220, 230 и 240 данных работают с локальным архивным компонентом в каждом интеллектуальном ПЛК для сохранения данных системы автоматизации. В дополнение к этому, узлы 220, 230 и 240 данных могут осуществлять связь для перебалансировки данных, перемещения и копирования данных, а также поддержания высокой степени репликации.
[33] Продолжая ссылаться на фиг.2, отмечаем, что интеллектуальный ПЛК 210 в этом примере действует как сервер для кластера 205. Он включает в себя узел 215 имен, который управляет пространством имен файловой системы посредством таких операций, как открывание, закрывание, переименование файлов, и т.д. В дополнение к этому, узел имен отображает блоки данных в узлы в кластере 205 и регулирует доступ к файлам. Узел 215 имен также может выдавать в другие узлы в кластере 205 инструкции, связанные с созданием, стиранием и репликацией данных.
[34] Для отображения заданий параллельных вычислений в узлы 220, 230, 240 данных и последующего восстановления возвращаемых промежуточных результатов в конечный результат можно использовать фреймворк параллельной обработки для системы Hadoop. Архитектура 200 РФС включает в себя службу демона (не показанную на фиг.2) для предоставления и отслеживания задания MapReduce (отображения-свертки). Как понимается в данной области техники, MapReduce представляет собой модель программирования, предназначенную для обработки и генерирования наборов данных с помощью параллельного распределенного алгоритма, применяемого на распределенной системе, такой, как изображенная на фиг.2. В некоторых вариантах осуществления, этот демон исполняется на одном интеллектуальных ПЛК 210, 225, и 235. В других вариантах осуществления, исполнение демона возможно на отдельном вычислительном устройстве, которое соединено с интеллектуальными ПЛК 210, 225 и 235 через компьютерную сеть. Безотносительно ее воплощения, службу демона можно использовать, например, для осуществления методов распределенного анализа и других операций на данных автоматизации, хранимых архивным компонентом каждого из интеллектуальных ПЛК 210, 225 и 235.
[35] На фиг.3 представлено концептуальное изображение интеллектуального ПЛК 300 в соответствии с некоторыми вариантами осуществления. Компонент 325 для создания образа процесса представляет собой область памяти в энергозависимой системной памяти центрального процессора (ЦП) контроллера, которую обновляют в каждом цикле обработки или сканирования на основе данных, связанных с технологическими устройствами (например - с входами и выходами подсоединенных устройств ввода-вывода). На каждом этапе обработки, управляющее приложение 330 считывает компонент 325 для создания образа процесса, исполняет развернутую логику приложения и записывает результаты обратно в компонент 325 для создания образа процесса.
[36] Продолжая ссылаться на фиг.3, отмечаем, что образ процесса согласно каждому циклу считывается и постоянно сохраняется на энергонезависимом материальном носителе информации посредством архивного компонента 320. В некоторых вариантах осуществления, конфигурация этого архивного компонента 320 обеспечивает алгоритмы сжатия развернутых данных для сокращения объема данных и обеспечение приложениям доступа к прошлым образам процесса. Можно либо хранить данные в течение фиксированного временного окна, либо использовать онлайн-алгоритмы для реализации эвристики динамичного кэширования. Как часть архивного компонента 320, интеллектуальные алгоритмы генерирования данных могут обеспечивать непрерывный анализ образа процесса и контекста для коррекции параметров генерирования данных (например - частоты дискретизации) подсоединенных устройств ввода-вывода. Например, для быстро меняющихся сигналов датчиков можно выбрать высокую скорость дискретизации, а для медленно меняющихся сигналов датчиков можно выбрать более низкую скорость дискретизации.
[37] Блок 305 аналитической обработки данных содержит набор алгоритмов анализа данных, которые обрабатывают текущий или прошлый образы процесса (запрашиваемые из архивного компонента). В блоке 305 аналитической обработки данных могут быть заключены различные алгоритмы анализа данных. Например, в некоторых вариантах осуществления, эти алгоритмы включают в себя один или несколько алгоритмов кластеризации, классификации, логического обоснования и статистического анализа. Кроме того, можно задавать алгоритмы посредством модели, которую можно разворачивать во время исполнения на устройстве. Блок 305 аналитической обработки данных также может предусматривать различные аналитические модели и специализированные алгоритмы для интерпретации этих моделей. Результаты, генерируемые блоком 305 аналитической обработки данных, можно хранить в архивном компоненте 320, записывать обратно в компонент 325 для создания образа процесса и/или выдавать во внешние компоненты через компонент 310 соединителя линии передачи данных. Таким образом, интеллектуальный ПЛК можно рассматривать как устройство для выдачи результатов аналитической обработки данных в другие устройства в системе автоматизации.
[38] Компонент 315 для контекстуализации аннотирует поступающие данные контекстной информацией, чтобы облегчить их последующую интерпретацию. В том смысле, в каком он употребляется здесь, термин «контекстная информация», может включать в себя любую информацию, которая описывает смысл данных. Например, контекстные данные в автоматизированных системах может включать в себя информацию об устройстве, которое генерировало данные (например, о датчике), о структуре системы автоматизации (например, о топологии некоторой установки), о рабочем режиме системы (например, о событии простоя), о программном обеспечении автоматизации и статусе во время генерирования данных и/или об изделии или партии, изготовленном или изготовленной во время генерирования данных. Конфигурация компонента для контекстуализации обеспечивает выдачу данных в любой из других компонентов для более специфичных потребностей обработки. Контекстную информацию, генерируемую компонентом 315 для контекстуализации, можно и не ограничивать структурой активов, а можно включать в нее также знания об управлении, информацию, специфичную для изделий, информацию о событиях и - потенциально - другие аспекты таких внешних событий, подобные информации о погоде. Некоторую контекстную информацию можно импортировать из инструментальных приложений (например, из средств полностью интегрированной автоматизации от фирмы Siemens). Кроме того, в некоторых вариантах осуществления, компонент 315 для контекстуализации обеспечивает семантическую контекстуализацию. Контекст можно представить на стандартном языке моделирования (например, на языке описания онтологий для семантической паутины (языке Web-онтологий) или языке системы описания ресурсов (стандарта RDF)), где смысл конструкций языка охарактеризован формально. Контекстуализация данных с помощью этих семантических стандартов моделирования дает возможность автоматического осмысления и интерпретации бизнес-приложений, связанных с аналитической обработкой данных, выдаваемых из системы автоматизации, без затраты усилий на конфигурирование вручную.
[39] Компонент 312 для управления распределенными данными позволяет интеллектуальному ПЛК 300 работать как часть системы управления распределенными данными (см., например, на фиг.1) или распределенной файловой системы (см., например, на фиг.2). С помощью компонента 312 для управления распределенными данными, интеллектуальный ПЛК может использовать данные, генерируемые архивным компонентом 320 (или другими компонентами, показанными на фиг.3), совместно с другими устройствами, работающими в системе промышленной автоматизации. Таким образом, предназначенные для архивного, контекстуального, аналитического обзора системы интеллектуального ПЛК 300 можно использовать совместно с контроллерами и другими устройствами, пользуясь параллельным алгоритмом распределенной обработки. Например, архивный компонент 320 имеет локальный обзор имен, смысла и организации данных, локально архивированных интеллектуальным ПЛК 300. С помощью компонента 312 для управления распределенными данными, можно обеспечить совместное использование этого обзора системы автоматизации.
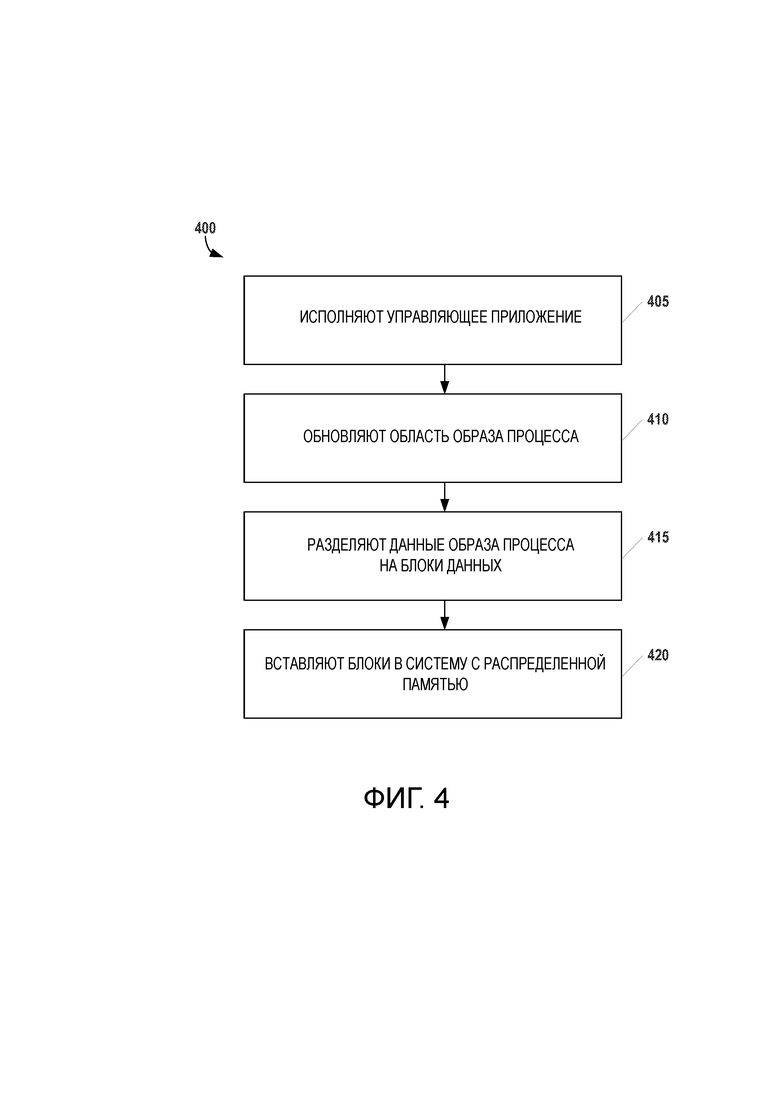
[40] Для вариантов осуществления, где для хранения используют РФС, компонент 312 для управления распределенными данными будет представлять собой вложенный процесс, обеспечивающий подходящие функциональные возможности РФС. Например, в вариантах осуществления, где используется вышеупомянутая РФС Hadoop, компонент 312 для управления распределенными данными может представлять собой программное обеспечение, которое позволяет интеллектуальному ПЛК 300 работать как узел данных в пределах кластера (см. фиг.2). Как таковой, компонент 312 для управления распределенными данными можно использовать для форматирования и организации блоков архивных данных с получением порций данных, которые можно передавать, реплицировать и обрабатывать по всему кластеру. В некоторых вариантах осуществления, компонент 312 для управления распределенными данными также можно использовать для того, чтобы получить из узла имен адреса других узлов данных, где надлежит реплицировать порцию данных без преобразования для хранения и вычислений. В других вариантах осуществления, компоненту 312 для управления распределенными данными можно придать такую конфигурацию, что интеллектуальный ПЛК 300 будет функционировать как узел имен для кластера, и станет возможным локальное хранение адресов. Сразу же после получения адресов, компонент 312 для управления распределенными данными можно использовать для автономного управления передачей данных - порции архивных данных - в другие узлы в кластере. Используя компонент 312 для управления распределенными данными, интеллектуальный ПЛК 300 и другие аналогичные устройства в среде автоматизации могут воплотить стек архива как параллельный алгоритм распределенной обработки, где архив каждого вложенного процесса в узле обладает вышеупомянутыми функциональными возможностями.
[41] В вариантах осуществления, где систему управления распределенными данными используют для распределенного хранения по всей системе, компонент 312 для управления распределенными данными можно воплотить с помощью различных систем баз данных, вообще говоря, известных в данной области техники. Например, в некоторых вариантах осуществления, данные, хранимые в каждом контроллере, хранят в базе данных NoSQL, которая имеет табличную эквивалентную структуру. Как понимается в данной области техники, термин «NoSQL» употребляют, чтобы определить класс хранилищ данных, которые по своему техническому исполнению являются нереляционными. Существуют различные типы баз данных NoSQL, которые, вообще говоря, можно группировать в соответствии с лежащей в их основе моделью данных. Эти группировки могут включать в себя базы данных, в которых используются модели данных на основе столбцов (например, Cassandra), модели данных на основе документов (например, MongoDB), модели данных на основе пары «ключ - значение» (например, Redis) и/или модели данных на основе графов (например, Allego). Для воплощения различных вариантов осуществления, описываемых здесь, можно использовать любой тип базы данных NoSQL. В некоторых вариантах осуществления, архивные данные хранятся по всей системе управления распределенными данными в блоке формата базы данных, специфичного для данных, имеющей организацию, которая оптимизирована для структуры распределенных данных. Размер каждого блока можно задать, например, на основе желаемого временного разбиения данных или максимального числа переменных, которые нужно отслеживать.
[42] Любые данные, захватываемые или генерируемые компонентами интеллектуального ПЛК 300, могут быть выданы во внешние компоненты через компонент 310 соединителя линии передачи данных. Таким образом, интеллектуальный ПЛК может осуществлять связь, например, с узлами имен для получения адресов других узлов данных, где вновь создаваемый блок архивных данных можно реплицировать без преобразования для хранения или вычислений. Кроме того, с помощью базовой технологии информационной структуры, устройство может автономно управлять передачей своих данных. В некоторых вариантах осуществления, компонент 310 соединителя линии передачи данных обеспечивает подачу данных посредством методологии выталкивания (т.е., активной посылки данных во внешний компонент). В других вариантах осуществления, можно использовать методологию вытягивания (при осуществлении которой данные запрашиваются внешним компонентом). В дополнение к этому, методологии выталкивания и вытягивания можно в некоторых вариантах осуществления объединять таким образом, что конфигурация интеллектуальное ПЛК обеспечит манипулирование обеими формами передачи данных.
[43] Дополнительные примеры особенностей интеллектуальных ПЛК, которые можно использовать в сочетании с разными вариантами осуществления, представлены в: поданной 25 августа 2014 г. под названием ʺINTELLIGENT PROGRAMMABLE LOGIC CONTROLLERʺ («ИНТЕЛЛЕКТУАЛЬНЫЙ ПРОГРАММИРУЕМЫЙ ЛОГИЧЕСКИЙ КОНТРОЛЛЕР») заявке № 14/467125 на патент США; поданной 30 октября 2014 г. под названием ʺUSING SOFT-SENSORS IN A PROGRAMMABLE LOGIC CONTROLLERʺ («ПРИМЕНЕНИЕ ПРОГРАММИРУЕМЫХ ДАТЧИКОВ В ПРОГРАММИРУЕМОМ ЛОГИЧЕСКОМ КОНТРОЛЛЕРЕ») заявке № PCT/US14/62796 по Договору о патентной кооперации; поданной 29 октября 2014 г. под названием ʺSYSTEM AND METHOD FOR AUTOMATIC COMPRESSION ALGORITHM SELECTION AND PARAMETER TUNING BASED ON CONTROL KNOWLEDGEʺ («СИСТЕМА И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ АВТОМАТИЧЕСКОГО АЛГОРИТМА СЖАТИЯ И НАСТРОЙКИ ПАРАМЕТРОВ НА ОСНОВЕ ЗНАНИЙ ОБ УПРАВЛЕНИИ») заявке № PCT/US14/63105 на патент по Договору о патентной кооперации. Каждая из этих заявок во всей ее полноте включена сюда посредством ссылки.
[44] На фиг.4 представлена схема последовательности операций процесса 400 загрузки данных в систему с распределенной памятью в среде промышленного производства в соответствии с некоторыми вариантами осуществления. Этот процесс можно проводить, например, посредством архивного компонента, исполняемого на каждом интеллектуальном ПЛК в среде промышленного производства. Как показано на фиг.3, каждый интеллектуальный ПЛК исполняет управляющее приложение, которое включает в себя инструкции по эксплуатации для единицы технологического оборудования. На этапе 405, эти инструкции сохраняются каждым соответственным интеллектуальным ПЛК. Далее, на этапе 410, каждый интеллектуальный ПЛК обновляет свой соответственный образ процесса данными, связанными с соответствующей ему единицей технологического оборудования. Затем, на этапе 415, разделяют данные, связанные с единицей технологического оборудования, на один или несколько блоков данных, размеры которых позволяют, например, охватывать заранее определенный период времени (например, 5 мс). Организация и формат этих блоков могут быть основаны на требованиях, предъявляемых к базовой системе распределенной памяти.
[45] На этапе 420, каждый интеллектуальный ПЛК вставляет свой соответственный один или несколько блоков данных в локальный энергонезависимый машиночитаемый носитель (например, твердотельное запоминающее устройство), которое является частью системы с распределенной памятью. Это вставление может быть основано, например, на внесении изменений в инструкции по эксплуатации и данные, связанные с единицей технологического оборудования, и/или внесении изменений в один или несколько оперативно контролируемых флагов ввода-вывода. Сразу же после вставления блоков данных в систему с распределенной памятью, их можно реплицировать таким образом, что в разных интеллектуальных ПЛК будут храниться многочисленные копии упомянутых блоков.
[46] В этот момент, интеллектуальные ПЛК могут оперировать данными, хранимыми в системе с распределенной памятью. Например, в одном варианте осуществления, один интеллектуальный ПЛК (или подсоединенный сервер) может принимать запрос на обработку и определять один или несколько других интеллектуальных ПЛК, которые хранят части распределенной базы данных и должны реагировать на зарос. Далее, интеллектуальный ПЛК может затем передавать инструкцию по обработке или ответ на данные в каждый из этих других интеллектуальных ПЛК. Информацию, принимаемую из этих интеллектуальных ПЛК, можно затем агрегировать с целью предоставления ответа на исходный запрос.
[47] Пользуясь методами управления распределенными данными, можно - вместе с тем - минимизировать или исключить необходимость транспортировки данных в реальном масштабе времени в некоторую центральную ячейку. Таким образом, можно сделать доступной обрабатывающую логику, где генерируются данные. Кроме того, методы анализа распределенных данных могут дать интеллектуальным ПЛК возможность учиться друг у друга за счет генерирования и распределения знаний по всей системе. Описываемую здесь технологию можно использовать, например, для воплощения распределенной аналитической платформы на более низком уровне в рамках архитектуры промышленных вычислений с помощью концепции управления распределенными данными для интеллектуальных ПЛК.
[48] Такие описываемые здесь процессоры, как используемые интеллектуальными ПЛК, могут включать в себя один или несколько центральных процессоров (ЦП), графические процессоры (ГП) или любой другой процессор, известный в данной области техники. В более общем смысле, используемый в предлагаемой системе процессор представляет собой устройство для исполнения машиночитаемых инструкций, хранимых на машиночитаемом носителе, для решения задач и может содержать любое из аппаратного обеспечения или программного обеспечения, или их комбинацию. Процессор также может содержать запоминающее устройство, хранящее машиночитаемые инструкции, исполняемые для выполнения задач. Процессор воздействует на информацию посредством манипулирования информацией, ее анализа, модификации, преобразования и передачи с целью использования какой-либо исполняемой процедурой или информационным устройством, и/или посредством маршрутизации информации в устройство вывода. Процессор может использовать функциональные возможности, например, компьютера, контроллера или микропроцессора, или обладать этими возможностями, и его можно кондиционировать с помощью исполняемых инструкций для выполнения функций специального назначения, не выполняемых компьютером общего назначения. Процессор можно связать (электрически и/или как содержащий исполняемые компоненты) с любым другим процессором, гарантируя взаимодействие и/или осуществление связи между ними. Процессор или генератор интерфейса пользователя представляет собой известный элемент, содержащий электронные схемы или программное обеспечение иди комбинацию их обоих для генерирования отображаемых изображений или их участков. Интерфейс пользователя содержит одно или несколько отображаемых изображений, дающих пользователю возможность взаимодействовать с процессором или другим устройством.
[49] Различные описанные здесь устройства, включающие в себя - но не в ограничительном смысле - интеллектуальные ПЛК и связанную с ними вычислительную инфраструктуру, могут содержать, по меньшей мере, один машиночитаемый носитель или запоминающее устройство для хранения инструкций, запрограммированных в соответствии с вариантами осуществления изобретения, и для заключения на нем структур данных, таблиц, записей или других описанных здесь данных. В том смысле, в каком он употребляется здесь, термин «машиночитаемый носитель» относится к любому носителю, который принимает участие в выдаче инструкций в один или несколько процессоров для исполнения. Машиночитаемый носитель может принимать многие формы, включая - но не в ограничительном смысле - непереходные энергонезависимые носители, энергозависимые носители и среды передачи. Неограничительные примеры энергонезависимых носителей включают в себя оптические диски, твердотельные накопители, магнитные диски и магнитооптические диски. Неограничительные примеры энергозависимых носителей включают в себя динамическое запоминающее устройство. Неограничительные примеры сред передачи включают в себя коаксиальные кабели, медный провод и волоконную оптику, включая провода, которые образуют системную шину. Среды передачи также могут принимать форму акустических или световых волн, таких, как генерируемые во время передачи сообщений посредством радиоволн и данных инфракрасных датчиков.
[50] В том смысле, в котором исполняемое приложение используется здесь, оно содержит код или машиночитаемые инструкции для кондиционирования процессора с целью воплощения заранее определенных функций, таких, как функции операционной системы, системы сбора контекстных данных или другой системы обработки информации, например, в ответ на команду пользователя или пользовательский ввод. Исполняемая процедура представляет собой сегмент кода или машиночитаемой инструкции, подпрограммы или другого отличающегося участка кода или части исполняемого приложения для осуществления одного или нескольких конкретных процессов. Эти процессы могут включать в себя прием данных и/или параметров ввода, проведение операций с принимаемыми данными ввода и/или выполнение функций в ответ на принимаемые параметры ввода и предоставление данных и/или параметров вывода, получаемых в результате.
[51] В том смысле, в котором он используется в предлагаемом решении, графический интерфейс пользователя (ГИП) содержит одно или несколько отображаемых изображений, генерируемых дисплейным процессором и позволяющим пользователю взаимодействовать с процессором или другим устройством, и обладает функциями получения и обработки связанных данных. ГИП также включает в себя исполняемую процедуру или исполняемое приложение. Исполняемая процедура или исполняемое приложение кондиционирует дисплейный процессор с целью генерирования сигналов представляющих отображаемые изображения ГИП. Эти сигналы подаются в дисплейное устройство, которое отображает изображение для просмотра пользователем. Под управлением исполняемой процедуры и исполняемого приложения, процессор манипулирует отображаемыми изображениями ГИП в ответ на сигналы, принимаемые из устройства ввода. Таким образом, пользователь может взаимодействовать с отображаемым изображением с помощью устройства ввода, что дает пользователю возможность взаимодействовать с процессором или другим устройством.
[52] Функции и этапы процесса, описанные здесь, можно реализовать автоматически - полностью или частично - в ответ на команду пользователя. Действие (включая этап), реализуемое автоматически, проводится в ответ на одну или несколько исполняемых инструкций или операцию устройства, не предусматривая при этом непосредственное инициирование действия пользователем.
Система и процессы, соответствующие чертежам, не являются исключительными. В соответствии с принципами изобретения, для решения тех же задач можно разработать другие системы, процессы и меню. Хотя это изобретение описано со ссылками на конкретные варианты осуществления, понятно, что показанные и описанные здесь варианты осуществления и их разновидности приведены лишь в иллюстративных целях. Специалисты в данной области техники смогут модифицировать предложенную конструкцию в рамках объема притязаний. В том смысле, в котором они описаны здесь, различные системы, подсистемы, вещества, устройства управления и процессы можно воплотить с помощью компонентов аппаратного обеспечения, компонентов программного обеспечения и/или их комбинаций. Ни один заявляемый здесь элемент не следует считать подпадающим под действие положений шестого абзаца параграфа 112 раздела 35 Кодекса законов США, если этот элемент не охарактеризован непосредственно словосочетанием «средство для».
Изобретение относится к управлению распределенными данными. Система промышленной автоматизации для хранения данных в среде промышленного производства содержит систему управления распределенными данными, хранимую во множестве устройств интеллектуальных программируемых логических контроллеров. Каждое соответствующее устройство контроллера содержит энергозависимый машиночитаемый носитель информации, управляющее приложение, компонент ввода-вывода, архивный компонент и компонент для управления распределенными данными. Компонент для управления распределенными данными разделяет данные системы автоматизации на множество блоков данных перед сохранением данных системы автоматизации на энергонезависимом машиночитаемом носителе информации. Повышается эффективность использования вычислительных возможностей. 3 н. и 14 з.п. ф-лы, 4 ил.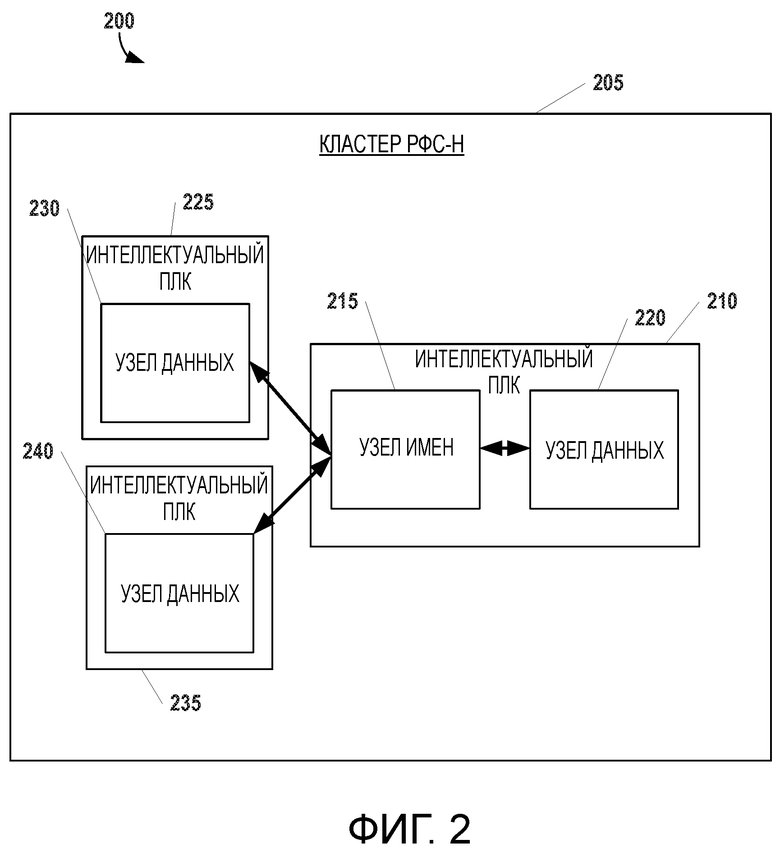
1. Система (100) промышленной автоматизации для хранения данных в среде промышленного производства, причем система (100) содержит:
систему управления распределенными данными, хранимую во множестве устройств (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуальных программируемых логических контроллеров, причем каждое соответствующее устройство (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуального программируемого логического контроллера содержит:
энергозависимый машиночитаемый носитель информации, содержащий область образа процесса;
энергонезависимый машиночитаемый носитель информации;
управляющее приложение (330), выполненное с возможностью предоставления инструкций по эксплуатации в единицу технологического оборудования;
компонент ввода-вывода, выполненный с возможностью обновления области образа процесса данными, связанными с единицей технологического оборудования, во время каждого цикла сканирования каждого соответствующего устройства (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуального программируемого логического контроллера;
архивный компонент (320), выполненный с возможностью сохранения данных системы автоматизации, содержащих инструкции по эксплуатации, и содержимого области образа процесса, на энергонезависимом машиночитаемом носителе информации; и
компонент (312) для управления распределенными данными, выполненный с возможностью обеспечения распределенных операций, с использованием данных системы автоматизации посредством множества устройств (105A, 105B, 105C, 110A, 110B, 110C, 210,225, 235, 300) интеллектуальных программируемых логических контроллеров,
причем компонент (312) для управления распределенными данными, содержащийся в каждом из множества устройств (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуальных программируемых логических контроллеров, дополнительно выполнен с возможностью:
разделения данных системы автоматизации на множество блоков данных перед сохранением данных системы автоматизации на энергонезависимом машиночитаемом носителе информации.
2. Система по п.1, в которой каждому из блоков данных приданы размеры в соответствии с заранее определенным периодом времени.
3. Система по п.1, в которой каждое соответствующее устройство (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуального программируемого логического контроллера дополнительно содержит:
компонент (315) контекстуализации, выполненный с возможностью аннотирования данных, связанных с единицей технологического оборудования, контекстной информацией системы автоматизации для генерирования данных контекстуализации.
4. Система по п.3, в которой данные системы автоматизации дополнительно включают в себя данные контекстуализации.
5. Система по п.1, в которой архивный компонент (320), содержащийся в каждом из множества устройств (105A, 105B, 105C, 110A, 110B, 110C, 210,225, 235, 300) интеллектуальных программируемых логических контроллеров, дополнительно выполнен с возможностью:
сжатия данных системы автоматизации перед сохранением содержимого на энергонезависимом машиночитаемом носителе информации.
6. Система по п.1, в которой каждое соответственное устройство (105A, 105B, 105C, 110A, 110B, 110C, 210,225, 235, 300) интеллектуального программируемого логического контроллера представляет собой узел данных в кластере распределенной файловой системы, а, по меньшей мере, одно из множества устройств (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуальных программируемых логических контроллеров представляет собой узел имен в кластере распределенной файловой системы.
7. Система по п.1, в которой каждое соответственное устройство (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуального программируемого логического контроллера содержит:
определение ключа шардинга, которое обеспечивает отображение между данными, хранимыми в системе управления распределенными данными, и множеством устройств (105A, 105B, 105C, 110A, 110B, 110C, 210, 225, 235, 300) интеллектуальных программируемых логических контроллеров.
8. Система по п.7, дополнительно содержащая:
централизованный сервер, доступный для каждого из множества устройств (105A, 105B, 105C, 110A, 110B, 110C, 210,225, 235, 300) интеллектуальных программируемых логических контроллеров и выполненный с возможностью хранения определения ключа шардинга.
9. Способ (400) сохранения данных в среде промышленного производства, причем способ содержит этапы, на которых:
исполняют (405) - посредством первого интеллектуального программируемого логического контроллера - управляющее приложение, сконфигурованное с возможностью предоставления инструкций по эксплуатации в единицу технологического оборудования на протяжении множества циклов сканирования первого интеллектуального программируемого логического контроллера;
обновляют (410) - посредством первого интеллектуального программируемого логического контроллера - область образа процесса данными, связанными с единицей технологического оборудования, во время каждого из множества циклов сканирования первого интеллектуального программируемого логического контроллера; и
вставляют (420) - посредством первого интеллектуального программируемого логического контроллера - данные, связанные с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель на первом интеллектуальном программируемом логическом контроллере,
причем энергонезависимый машиночитаемый носитель представляет собой часть системы с распределенной памятью, хранимой на первом интеллектуальном программируемом логическом контроллере и множестве вторых интеллектуальных программируемых логических контроллеров,
причем перед вставкой данных, связанных с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель в первом интеллектуальном программируемом логическом контроллере, разделяют (415) данные, связанные с единицей технологического оборудования, на множество блоков данных.
10. Способ по п.9, в котором каждому из множества блоков придан размер в соответствии с заранее определенным периодом времени.
11. Способ по п.9, дополнительно содержащий этап, на котором:
реплицируют сохранения, по меньшей мере, одного из множества блоков данных на одном или нескольких из множества вторых интеллектуальных программируемых логических контроллеров.
12. Способ по п.9, в котором локальный энергонезависимый машиночитаемый носитель содержит базу данных NoSQL, которая имеет табличный эквивалентный вид.
13. Способ по п.12, в котором вставление данных, связанных с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель, запускают на основе изменений, вносимых в инструкции по эксплуатации, и данных, связанных с единицей технологического оборудования.
14. Способ по п.12, в котором вставление данных, связанных с единицей технологического оборудования, в локальный энергонезависимый машиночитаемый носитель запускают на основе изменения одного или нескольких флагов ввода-вывода.
15. Интеллектуальный программируемый логический контроллер, содержащий непереходный материальный машиночитаемый носитель, хранящий машиночитаемые инструкции для осуществления способа, содержащего этапы, на которых:
создают область образа процесса на энергонезависимом машиночитаемом носителе информации, приводимом в действие в интеллектуальном программируемом логическом контроллере;
обновляют область образа процесса на протяжении каждого цикла сканирования интеллектуального программируемого логического контроллера содержимым области образа процесса, включающим в себя данные, связанные с единицей технологического оборудования; и
сохраняют содержимое области образа процесса на протяжении каждого цикла сканирования интеллектуального программируемого логического контроллера на энергонезависимом машиночитаемом носителе информации, приводимом в действие в интеллектуальном программируемом логическом контроллере,
причем энергонезависимый машиночитаемый носитель информации представляет собой часть распределенной файловой системы, занимающей интеллектуальный программируемый логический контроллер, и множество дополнительных интеллектуальных программируемых логических контроллеров,
причем содержимое области образа процесса разделяют на множество блоков данных, распределенных по интеллектуальному программируемому логическому контроллеру и множеству дополнительных интеллектуальных программируемых логических контроллеров.
16. Контроллер по п.15, предусматривающий репликацию сохранения одного или нескольких из множества блоков данных на интеллектуальном программируемом логическом контроллере и множестве дополнительных интеллектуальных программируемых логических контроллеров.
17. Контроллер по п.16, в котором способ дополнительно содержит:
прием запроса на аналитическую информацию, соответствующую данным образа процесса;
создание множества заданий параллельной обработки;
распределение множества заданий параллельной обработки на интеллектуальный программируемый логический контроллер и множество дополнительных интеллектуальных программируемых логических контроллеров;
прием результатов из интеллектуального программируемого логического контроллера и множества дополнительных интеллектуальных программируемых логических контроллеров в ответ на распределение множества заданий параллельной обработки; и
агрегирование результатов для выдачи ответа на запрос на аналитическую информацию.
| US 2006259160 A1, 16.11.2006 | |||
| US 2014277604 A1, 18.09.2014 | |||
| US 2015074672 A1, 12.03.2015 | |||
| US 2015169650 A1, 18.06.2015. |

