[1] Настоящее раскрытие относится к распределенной системе управления данными для интеллектуальных ПЛК (PLC). Различные системы и способы могут применяться в приложениях промышленной автоматизации, а также различных других приложениях, в которых используются интеллектуальные PLC.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[2] Программируемый логический контроллер (PLC) - это специализированная компьютерная система управления, сконфигурированная для исполнения программного обеспечения, которое непрерывно собирает данные о состоянии входных устройств для управления состоянием выходных устройств. PLC обычно включает в себя три основных компонента: процессор (который может включать в себя энергозависимую память), энергозависимую память, содержащую прикладную программу, и один или несколько портов ввода/вывода (I/O) для соединения с другими устройствами в системе автоматизации.
[3] Обычные системы автоматизации следуют пирамидальной структуре, которая требует передачи всех необработанных данных (миллионы точек выборок) от PLC в historian (архив данных) на верхнем уровне (например, уровне SCADA или MES). Продвижение данных на верхний уровень уменьшает разрешение и готовность данных, что, в свою очередь, ограничивает эффективность аналитики для извлечения выводов из поведения PLC и увеличивает запаздывание для вмешательства в процесс управления для оптимизации управления. Способность PLC поддерживать глубокую аналитику данных на основе их привилегированного доступа к данным процесса и логике контроллера в недостаточной степени используется в традиционных системах. Последнее обусловлено статической логикой/конфигурацией контроллера, которая в настоящее время не поддерживает динамические адаптивные изменения или изменения после фазы ввода в действие логики управления, а также не поддерживает осведомленность о данных и контексте другого PLC, когда это необходимо.
[4] Дополнительным недостатком традиционных систем автоматизации является то, что контроллеры на эксплуатационном уровне не поддерживают и не управляют базами знаний. Например, большинство обычных Ethernet-контроллеров соединены со своими главными администраторами, чтобы передавать необработанные данные в системы контролирующего уровня, без осведомленности о данных, знаниях и поведении своих одноранговых узлов, что продвигает процесс принятия решений на верхние уровни. Контекст контроллера не используется для получения выводов на основе более глубокого анализа. Аналитические модели данных в настоящее время строятся на верхних уровнях, где контекстная информация контроллера (например, представление метаданных функциональных блоков, которые могут использоваться для обратного инжиниринга данных) недоступна. Неэффективное принятие решений, недоступность локально хранимых архивных данных ввода/вывода и моделей знаний и аналитических данных на более низком уровне влияет на принятие эффективных решений для управления локальным устройством.
[5] Традиционные системы автоматизации также крайне ограничены в объеме знаний архива данных, которые поддерживаются локально на PLC. В свою очередь, это ограничивает функциональность PLC. Например, обработка в цикле в текущее время не может выполняться, если требуется последние архивные данные (т.е. краткосрочные данные). Это приводит к тому, что вычисления выполняются внешним образом и возвращаются в PLC. Кроме того, отсутствие в PLC локального архива данных ограничивает возможность выполнения аналитики данных в реальном времени, которая поддерживает динамическую адаптацию параметров управления, которые направлены на оптимизацию операций системы.
[6] Кроме того, без локальной информации в PLC и других устройствах уровня управления, является проблематичным, если не невозможным, реализовать эффективные и надежные аналитические решения в условиях эксплуатации в традиционных системах автоматизации. Традиционные решения для аналитики на месте эксплуатации в настоящее время реализуются в виде процессов групповой обработки (серийного производства), поддерживающих ретроспективный анализ прошлого производства (например, прошлых партий). Онлайн-анализ производства возможен только с некоторой задержкой. Поэтому прямое вмешательство в управление на основе анализа часто является непрактичным для критичных по времени процессов.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[7] Варианты осуществления настоящего изобретения обращаются к вышеуказанной проблеме и преодолевают один или несколько из вышеупомянутых изъянов и недостатков путем предоставления способов, систем и устройств, относящихся к распределенной системе хранения, обеспечиваемой устройствами уровня управления, такими как интеллектуальные PLC. Например, описанные здесь методы направлены на решение задачи обеспечения доступности данных локального архива данных (historian) и знания контекстуализации в распределенной инфраструктуре данных путем обеспечения возможности распределения данных и аналитики из распределенной системы в механизм обработки аналитики за время цикла. Описанная здесь технология особенно хорошо подходит для различных приложений промышленной автоматизации, но не ограничивается ими.
[8] Согласно некоторым вариантам осуществления настоящего изобретения, предложена система для хранения данных в промышленной производственной среде, причем система содержит распределенную систему управления данными, сохраненную на множестве устройств интеллектуальных программируемых логических контроллеров. Каждое устройство интеллектуального программируемого логического контроллера содержит энергозависимый считываемый компьютером носитель данных, содержащий область изображения процесса, энергонезависимый считываемый компьютером носитель данных; управляющую программу, сконфигурированную, чтобы предоставлять операционные инструкции на производственный блок; компонент ввода/вывода, сконфигурированный, чтобы обновлять область изображения процесса в течение каждого цикла сканирования данными, ассоциированными с производственным блоком; компонент распределенного управления данными, содержащий экземпляр распределенной системы управления данными; компонент контекстуализации, компонент архива данных и компонент аналитики данных. Компонент контекстуализации сконфигурирован, чтобы генерировать контекстуализированные данные путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации. Компонент исторического архива сконфигурирован, чтобы локально хранить содержимое области изображения процесса и контекстуализированные данные, что делает содержимое доступным в распределенной системе управления данными через компонент распределенного управления данными. Компонент аналитики данных сконфигурирован, чтобы исполнять один или несколько алгоритмов рассуждений для анализа данных, сохраненных в распределенной системе управления данными, с использованием компонента распределенного управления данными.
[9] В некоторых вариантах осуществления, вышеупомянутая система дополнительно включает в себя компонент менеджера знаний, сконфигурированный, чтобы динамически модифицировать один или несколько алгоритмов рассуждений во время выполнения управляющей программы на основе одной или нескольких моделей декларативных знаний. Эти модели декларативных знаний могут содержать, например, онтологии, выраженные с использованием языка описания онтологий (OWL), модель предсказания, выраженную с использованием стандарта языка разметки прогнозного моделирования (PMML) и/или одного или нескольких правил, выраженных с использованием формата обмена правилами (RIF).
[10] В некоторых вариантах осуществления вышеупомянутой системы, алгоритмы рассуждений, используемые компонентом аналитики данных каждого соответствующего устройства интеллектуального программируемого логического контроллера, сконфигурированы на основе одной или нескольких моделей знаний, заданных производителем. Эти модели знаний, заданные производителем, могут включать в себя, например, информацию, относящуюся к одной или нескольким функциональным возможностям множества устройств интеллектуальных программируемых логических контроллеров, диагностические знания, доступные на множестве устройств интеллектуальных программируемых логических контроллеров, и/или информацию о структуре данных, используемую множеством устройств интеллектуальных программируемых логических контроллеров.
[11] Различные признаки вышеупомянутой системы могут быть адаптированы, расширены или усовершенствованы на основе функциональных возможностей обработки аппаратных средств хоста. Например, в некоторых вариантах осуществления, каждое соответствующее устройство интеллектуального программируемого логического контроллера дополнительно содержит один или несколько процессоров, сконфигурированных, чтобы исполнять управляющую программу, и параллельно с исполнением управляющей программы, модифицировать один или несколько алгоритмов рассуждений параллельно с исполнением управляющей программы.
[12] В соответствии с другими вариантами осуществления настоящего изобретения, способ хранения данных в промышленной производственной среде включает в себя исполнение, первым интеллектуальным программируемым логическим контроллером, управляющей программы, сконфигурированной, чтобы предоставлять операционные инструкции на производственный блок на протяжении множества циклов сканирования, и обновление области изображения процесса во время каждого из множества циклов сканирования данными, ассоциированными с производственным блоком. Способ дополнительно включает в себя генерирование, первым интеллектуальным программируемым логическим контроллером, контекстуализированных данных путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации и вставку содержимого области изображения процесса и контекстуализированных данных в локальный энергонезависимый считываемый компьютером носитель на первом интеллектуальном программируемом логическом контроллере. Этот локальный энергонезависимый считываемый компьютером носитель является частью распределенной системы хранения, сохраненной на первом интеллектуальном программируемом логическом контроллере и множестве вторых интеллектуальных программируемых логических контроллеров. Вставка данных, ассоциированных с производственным блоком, в локальный энергонезависимый считываемый компьютером носитель, может быть запущена, например, на основе изменений в операционных инструкциях и данных, ассоциированных с производственным блоком. Первый интеллектуальный программируемый логический контроллер исполняет один или несколько алгоритмов рассуждений для анализа данных, сохраненных в распределенной системе хранения.
[13] Вышеупомянутый способ может иметь дополнительные признаки, усовершенствования или другие модификации в различных вариантах осуществления настоящего изобретения. Например, в некоторых вариантах осуществления, способ дополнительно включает в себя то, что первый интеллектуальный программируемый логический контроллер динамически модифицирует один или несколько алгоритмов рассуждений во время выполнения управляющей программы на основе одной или нескольких моделей декларативных знаний. В некоторых вариантах осуществления вышеупомянутого способа, локальный энергонезависимый считываемый компьютером носитель содержит базу данных NoSQL, которая имеет эквивалентное табличное представление.
[14] Алгоритмы рассуждений, используемые в вышеупомянутом способе, могут быть сконфигурированы, например, на основе одной или нескольких моделей знаний, заданных производителем. Например, эти модели знаний, заданные производителем, могут включать в себя информацию, относящуюся к одной или нескольким функциональным возможностям первого интеллектуального программируемого логического контроллера, диагностические знания, доступные в первом интеллектуальном программируемом логическом контроллере, и/или информацию о структуре данных, используемую первым интеллектуальным программируемым логическим контроллером.
[15] В некоторых вариантах осуществления, вышеупомянутый способ может быть выполнен в параллельной вычислительной среде. Например, в одном варианте осуществления, первый интеллектуальный программируемый логический контроллер исполняет управляющую программу с использованием первого ядра процессора, включенного в первый интеллектуальный программируемый логический контроллер. Алгоритмы рассуждений могут быть динамически модифицированы с использованием второго ядра процессора, включенного в первый интеллектуальный программируемый логический контроллер.
[16] В соответствии с другими вариантами осуществления настоящего изобретения, изделие производства для хранения данных в промышленной производственной среде, содержит не-временный, материальный (осязаемый) считываемый компьютером носитель, содержащий исполняемые компьютером инструкции для выполнения вышеупомянутого способа, с дополнительными признаками, рассмотренными выше, или без них.
[17] Дополнительные признаки и преимущества изобретения будут очевидны из последующего подробного описания иллюстративных вариантов осуществления, которое излагается со ссылками на прилагаемые чертежи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[18] Вышеизложенные и другие аспекты настоящего изобретения поясняются в последующем подробном описании со ссылками на прилагаемые чертежи. В целях иллюстрации изобретения, на чертежах показаны варианты осуществления, которые в настоящее время являются предпочтительными, однако следует понимать, что изобретение не ограничивается конкретным раскрытым инструментарием. На чертежах представлены следующие фигуры:
[19] Фиг. 1 представляет схему архитектуры, иллюстрирующую промышленную систему автоматизации, в которой интеллектуальные устройства образуют распределенную систему управления данными (DDMS) для данных системы автоматизации в соответствии с некоторыми вариантами осуществления;
[20] Фиг. 2 представляет концептуальное представление интеллектуального PLC в соответствии с некоторыми вариантами осуществления;
[21] Фиг. 3 представляет иллюстрацию архитектуры DDMS для распределенного управления данными и знаниями, а также распределенной аналитики в соответствии с некоторыми вариантами осуществления;
[22] Фиг. 4 представляет концептуальное представление того, как информация может передаваться в узел DDMS и из него, в соответствии с некоторыми вариантами осуществления;
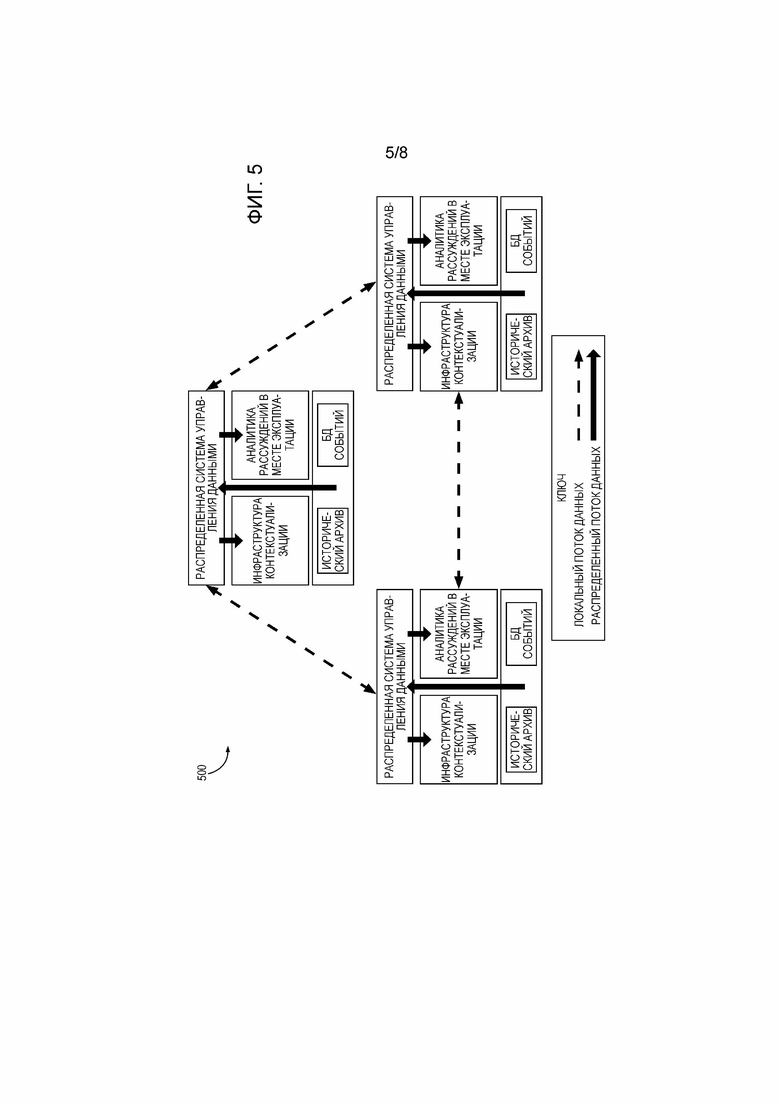
[23] Фиг. 5 представляет дополнительную иллюстрацию того, как экземпляр узла DDMS поддерживает крупномасштабную передачу данных в/из распределенной инфраструктуры данных, в соответствии с некоторыми вариантами осуществления;
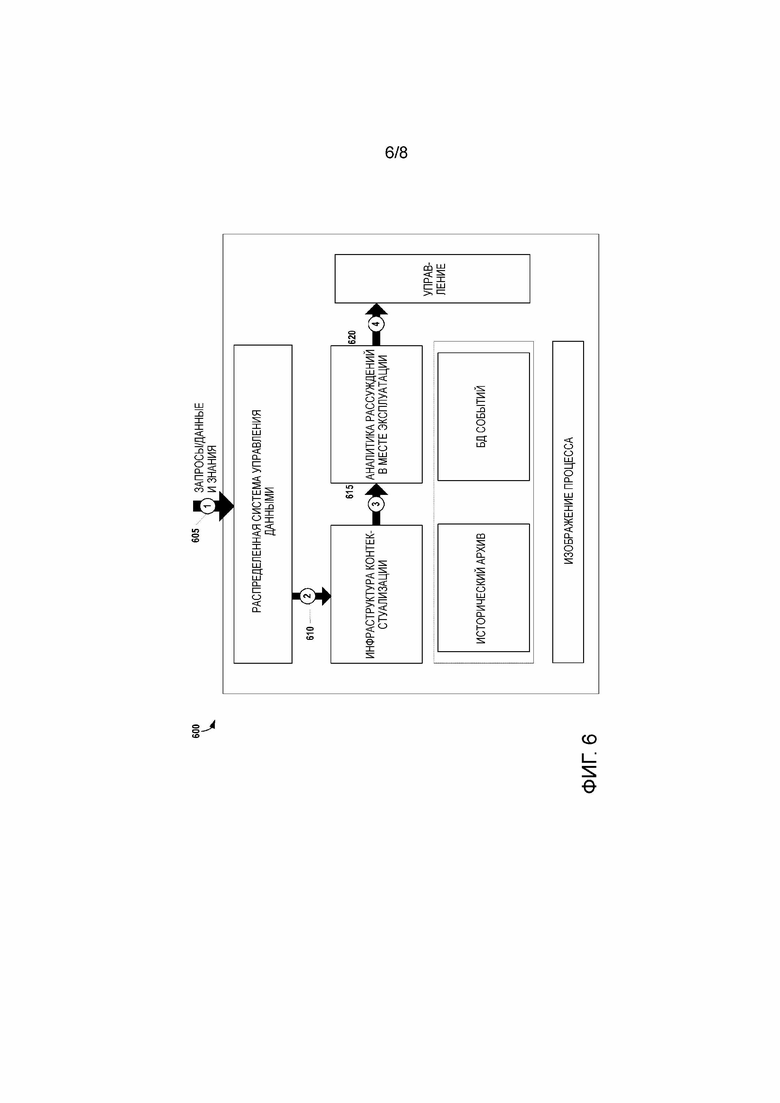
[24] Фиг. 6 представляет пример обновления логического правила интеллектуального PLC, запускаемого внешним устройством или приложением, в соответствии с некоторыми вариантами осуществления;
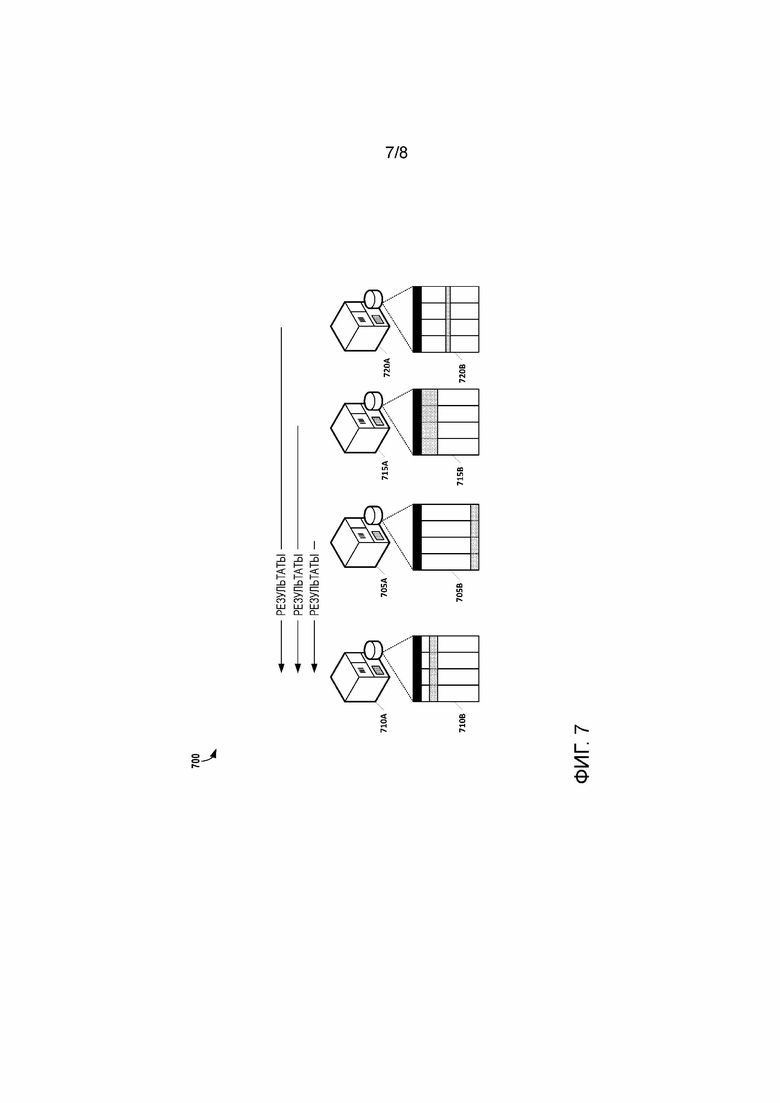
[25] Фиг. 7 представляет иллюстрацию того, как может быть реализован доступ к сегментированным данным в инфраструктуре DDMS, в соответствии с некоторыми вариантами осуществления; и
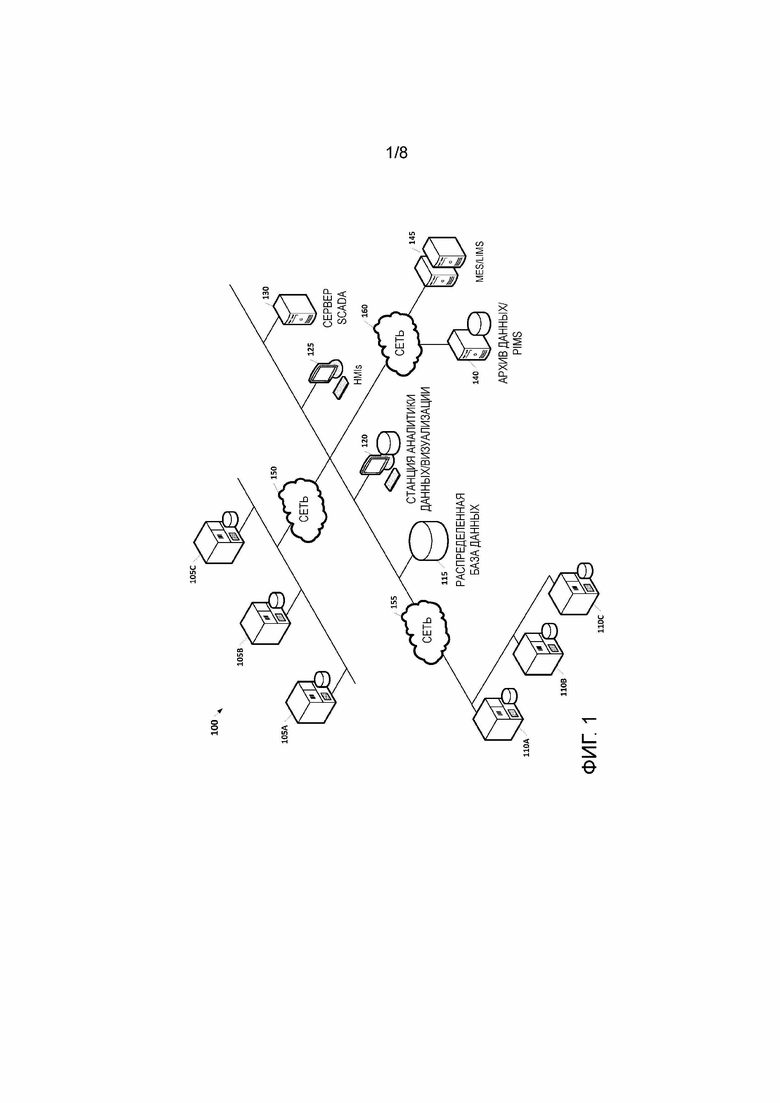
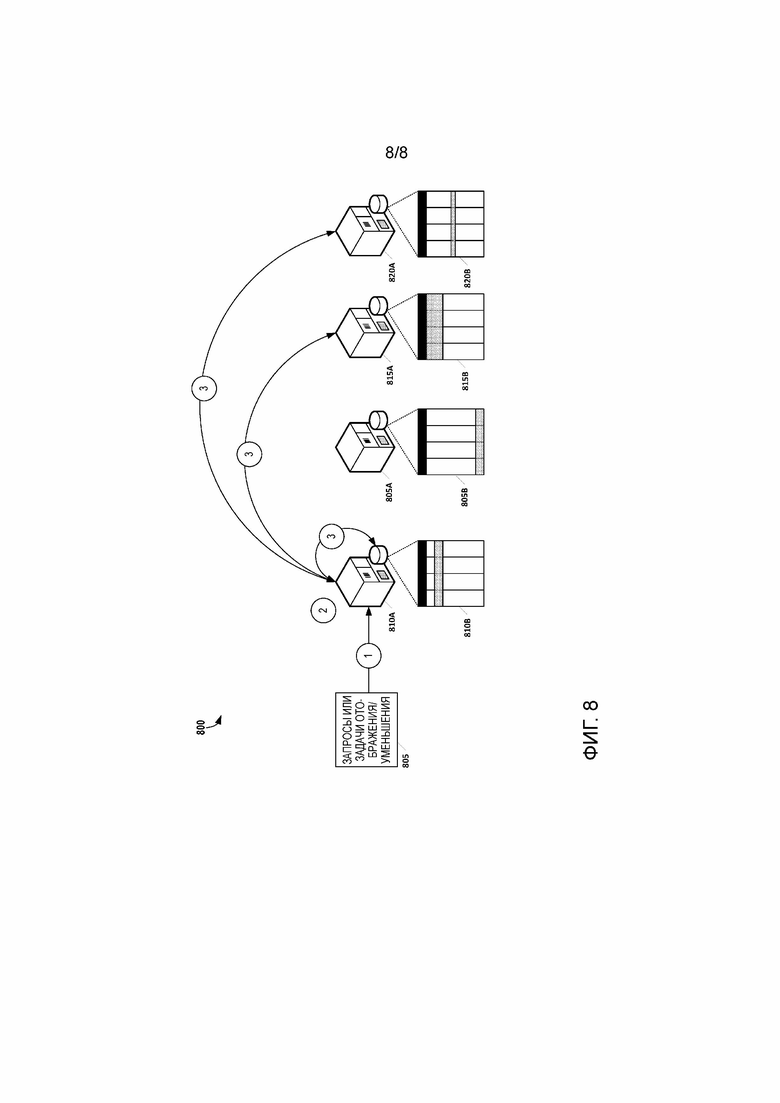
[26] Фиг. 8 показывает трехэтапный процесс для извлечения и обработки данных в распределенной системе управления данными в соответствии с некоторыми вариантами осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[27] Здесь описаны системы, способы и устройства, которые относятся, в общем, к распределенной системе хранения, реализованной на множестве интеллектуальных программируемых логических контроллеров, называемых здесь ʺинтеллектуальными PLCʺ. В соответствии с различными вариантами осуществления, описанными здесь, интеллектуальный PLC представляет собой узел в кластере неоднородных узлов, который реализует одну из нескольких ролей (например, управление, высокопроизводительный сбор данных и т.д.) и извлекает данные из других узлов по мере необходимости для выполнения встроенной аналитики на уровне, невозможном в традиционных системах MES. Кроме того, интеллектуальный PLC может извлекать локальное знание или знание из других узлов. Эта способность в сочетании с локальным архивом данных и моделями знаний и функциональными возможностями рассуждений, а также аналитикой в условиях эксплуатации открывает двери для мощной управляемой знаниями распределенной аналитики на кластере, поэтому делает кластер интеллектуальных PLC мощным механизмом хранения данных в реальном времени, хранения знаний, аналитики и интерфейса для всего процесса автоматизации. Интеллектуальный PLC может с выгодой использовать технологии распределенных данных и аналитики для определения систем управления с (1) повышенной функциональностью на основе истинной аналитики в месте эксплуатации, (2) повышенной гибкостью при конфигурировании, добавлении, настройке, изменении и удалении компонентов и (3) быстрой установкой, расширением существующих функций и возможностями развития. Все вышеперечисленное резко сокращает количество людей и опыта людей, необходимых для установки, эксплуатации, оптимизации, мониторинга, диагностики, а также обучения, необходимого для выполнения этих функций. Способы, описанные здесь, могут быть использованы, например, для обеспечения когерентного отображения времени, данных (например, данных временных рядов), организации данных и имен данных в промышленной системе автоматизации и обеспечения доступности данных немедленно по мере их создания.
[28] Фиг. 1 представляет схему архитектуры, иллюстрирующую промышленную систему 100 автоматизации, где интеллектуальные устройства образуют распределенную систему управления данными (DDMS) для данных системы автоматизации в соответствии с некоторыми вариантами осуществления. DDMS можно определить как распределенную базу данных и знаний, содержащую информацию о процессе, наверху которой находится уровень аналитики данных. Распределение существует по кластеру узлов. Каждый экземпляр DDMS хостирует роли клиента и сервера, один из которых может быть активирован в соответствии с ролью экземпляра DDMS в определенное время. Обычно узел, который запускает процесс, действует как клиент, а остальные узлы, которые обрабатывают или хранят данные, действуют как серверы. Однако узел может действовать как клиент и сервер одновременно и выполнять один или несколько процессов за раз, что может варьироваться в зависимости от текущих потребностей обработки и рабочей нагрузки.
[29] В примере на фиг. 1, каждый узел DDMS является интеллектуальным PLC. Вкратце, интеллектуальный PLC предоставляет несколько технических признаков, которые могут присутствовать в различных комбинациях в соответствии с различными вариантами осуществления. Например, интеллектуальный PLC включает в себя эффективный механизм хранения данных временных рядов (т.е. функцию ʺhistorianʺ - архива данных), которая позволяет осуществлять краткосрочное/среднесрочное архивирование данных с высоким разрешением с временной меткой. При наличии данных высокой достоверности, мало событий теряется, если это вообще имеет место. Эффективные алгоритмы сжатия (например, вариант алгоритма ʺвращающейся двериʺ (swinging door)) могут использоваться для уменьшения требований к хранению и связи. Интеллектуальный PLC более подробно обсуждается ниже со ссылкой на фиг. 2. Следует отметить, что фиг. 1 представляет собой высокоуровневый, упрощенный общий вид архитектуры, которая может использоваться с описанными здесь способами. Эта архитектура может быть модифицирована для включения дополнительных устройств, которые могут присутствовать в реальных реализациях, например, устройств маршрутизации, соединений с дополнительными сетями передачи данных и т.д.
[30] Следует отметить, что, хотя узлы DDMS на фиг. 1 являются интеллектуальными PLC, настоящее изобретение не ограничено как таковое. Другие варианты осуществления DDMS могут включать в себя узлы, которые являются другими интеллектуальными устройствами, которые удовлетворяют некоторым минимальным вычислительным требованиям (например, совместимой операционной системе, памяти и диску) для хостирования экземпляра DDMS. Кроме того, следует отметить, что архитектура, представленная на фиг. 1, не включает в себя никакого главного или центрального узла.
[31] Распределенное управление данными может быть реализовано в промышленной системе 100 автоматизации с использованием различных методов в различных вариантах осуществления. В некоторых вариантах осуществления, распределенная файловая система (DFS) используется для хранения данных на устройствах, сгенерированных интеллектуальными PLC 105A, 105B, 105C, 110A, 110B и 110C. DFS предлагает возможность быстрого масштабирования с точки зрения вычислительной мощности и хранения при очень низкой сопоставимой стоимости относительно распределенной системы баз данных. Таким образом, для приложений, которые включают в себя множество параллелизуемых операций обработки, DFS может обеспечить более эффективное решение для распределенного хранения данных. В других вариантах осуществления, интеллектуальные PLC используются для реализации надежной распределенной системы управления базами данных, которая обеспечивает такие свойства, как атомарность, согласованность, изолированность и долговечность, которые могут быть использованы вместе с функциональными возможностями масштабирования и обработки. Это может обеспечить уровень управления данными, который поддерживает запросы SQL-подобным образом, как абстрагирование доступа к секционированным данным на многих узлах, а также функции, которые могут использовать с выгодой обработку данных локально на узлах, где находятся данные (т.е. локальность данных).
[32] В примере на фиг. 1, узлы распределенной системы управления данными, используемые промышленной системой 100 автоматизации, включают в себя интеллектуальные PLC 105А, 105В, 105С, 110А, 110В и 110С. Хотя фиг. 1 показывает только шесть интеллектуальных PLC, следует понимать, что любое количество интеллектуальных PLC может использоваться с описанными здесь методами. Таким образом, распределенная система управления данными, поддерживаемая архитектурой, представленной на фиг. 1, может динамически расширяться и сокращаться за счет добавления или удаления вычислительных ресурсов в зависимости от потребностей системы. Кроме того, емкость хранения распределенной системы управления данными может быть увеличена путем добавления специализированных или стандартных аппаратных ресурсов (например, серверных стоек, дополнительных контроллеров). Например, как объяснено более подробно ниже, в некоторых вариантах осуществления, сервер распределенной базы данных 115 добавляется в качестве узла распределенной системы управления данными для обеспечения долговременного хранения данных, хранящихся на интеллектуальных PLC 105А, 105В, 105С, 110A, 110В и 110C. Узлы могут быть добавлены в распределенную систему управления данными с использованием любой технологии, общеизвестной в данной области техники. Например, в некоторых вариантах осуществления, новые устройства могут быть развернуты с функциональностью для осуществления связи с распределенной системой управления данными. В других вариантах осуществления, такая функциональность может быть дистанционно загружена на новое или существующее устройство, например, используя технологию рассылки посредством выполнения сценария.
[33] Каждый интеллектуальный PLC 105 A, 105B, 105C, 110А, 110В и 11°C содержит компонент распределенного управления данными. В некоторых вариантах осуществления, компонент распределенного управления данными, включенный в каждый интеллектуальный PLC, способен сохранять данные, полученные от контроллера через один и тот же интерфейс, в совместно используемую память или файловую систему. Например, как более подробно описано ниже в отношении фиг. 3, каждый интеллектуальный PLC 105A, 105B, 105C, 110A, 110B и 11°C содержит встроенный архив данных (historian) процесса, который имеет локальное представление имен, значений и организации данных, исторически (хронологически) архивированных локальным образом. Используя компонент распределенного управления данными, данные, генерируемые каждым соответствующим архивом данных, могут совместно использоваться в системе 100.
[34] Данные, хранящиеся в каждом интеллектуальном PLC 105А, 105В, 105С, 110А, 110В и 110С, могут потребляться клиентскими приложениями, которые исполняются внутри контроллеров или на любом устройстве, которое имеет доступ к распределенной системе управления данными, обеспеченной системой 100, показанной на фиг. 1. В дополнение к хранению, каждый интеллектуальный PLC 105A, 105B, 105C, 110A, 110В и 11°C может также включать в себя сервисы управления кластерами и механизм обработки, который позволяет выполнять такие задачи, как распределенное хранение и коммуникация, а также распределенная обработка и координация.
[35] Метод, используемый для определения местоположения и управления данными на интеллектуальных PLC 105А, 105B, 105C, 110A, 110В и 110С, может варьироваться в зависимости от того, как реализовано распределенное хранилище. Например, в вариантах осуществления, в которых DFS, например Hadoop DFS, используется для распределенного хранения, один или несколько из интеллектуальных PLC 105A, 105B, 105C, 110A, 110B и 11°C служат в качестве ʺузла именʺ. Каждый узел имен управляет деревом каталогов всех файлов в DFS и отслеживает, где в системе 100 сохранены данные файла. Клиентские приложения могут осуществлять связь с узлом имен, чтобы найти файл или выполнить операции над файлом (добавление, копирование, перемещение, удаление и т.д.). Узел имен отвечает на успешные запросы, возвращая список релевантных устройств, где хранятся данные. Следует отметить, что узел имен является единственной точкой отказа для DFS. Таким образом, в некоторых вариантах осуществления, множественные узлы имен могут использоваться для обеспечения избыточности.
[36] В вариантах осуществления, в которых система управления распределенной базой данных используется для реализации распределенного хранилища, данные могут храниться на интеллектуальных PLC 105А, 105В, 105С, 110А, 110В и 11°C с использованием методов шардинга (сегментирования базы данных между разными физическими серверами, т.е. на уровне ресурса). Как хорошо известно в данной области техники, шардинг представляет собой стратегию, используемую распределенной базой данных для поиска ее секционированных (партицированных, т.е. разбитых на логические части) данных. Этот механизм часто используется для поддержки развертываний с наборами данных, для которых требуются операции распределения и высокой пропускной способности. Это делается с помощью определения ключа шардинга, которое является критерием, используемым для разделения данных между контроллерами. Отображение шардинга может храниться на конкретном экземпляре сервера или внутри каждого контроллера. В обоих случаях, информация шардинга доступна для всех устройств. Каждое устройство-держатель ключа шардинга может координировать процесс передачи данных с другими одноранговыми узлами, поскольку метаданные шардинга содержат отображение данных/местоположения контроллера. Таким образом, распределенная система управления данными (например, реализованная с использованием интеллектуальных PLC 105А, 105В, 105С, 110А, 110В и 110С) может обеспечить параллелизацию и низкий трафик данных по сети.
[37] Интеллектуальные PLC 105A, 105B, 105C, 110A, 110В и 11°C могут осуществлять связь друг с другом посредством сетевого соединения с использованием стандартных протоколов сетевого взаимодействия (например, TCP, RPC и т.д.). Такая связь может использоваться, например, для реализации задач распределенной выборки данных и распределенной обработки. В обоих случаях, процесс может быть инициирован с любого контроллера, а последний будет запускать новые соединения с другими контроллерами, которые хранят необходимые данные. Отметим, что широковещательные сообщения не нужно отправлять по разным сетям, так как только контроллеры, которые имеют запрошенные данные, принимаются в качестве целевых координатором (например, контроллером, который запустил задачу выборки данных или распределенной обработки/задачу Map Reduce (сокращения отображения)), исключая ненужный сетевой трафик. Кроме того, если обработка является задачей распределенной обработки, то никакие данные не будут передаваться по сети, кроме результатов обработки. Это достигается путем отправки вычислительного кода и его исполнения на контроллере, который содержит данные, представляющие интерес.
[38] В дополнение к осуществлению связи с друг другом, интеллектуальные PLC 105А, 105В, 105С, 110A, 110B и 11°C могут также осуществлять связь с любыми другими клиентами TCP, Open Database Connectivity (открытого механизма взаимодействия с базами данных, ODBC) и/или OPC Unified Architecture (унифицированной архитектуры, UA), такими как распределенная база данных 115, станция 120 аналитики данных/визуализации, один или несколько человеко-машинных интерфейсов 125 (HMI), сервер SCADA 130, сервер архива данных /PIM 140 и серверы 145, ассоциированные с Manufacturing Execution Systems (системами управления производством, MES) и/или Laboratory Information Management Systems (системами управления лабораторной информацией, LIMS). Каждый компонент архитектуры может быть подключен с использованием локальной интрасети (например, реализованной через Ethernet) и одну или несколько интерсетей 150, 155, 160.
[39] Распределенная база данных 115 представляет собой сервер хранения большой емкости, который хранит данные, которые больше не доступны на интеллектуальных PLC 105A, 105B, 105C, 110A, 110B и 110С. Эти данные по-прежнему доступны для распределенной системы управления данными и ведут себя подобно другому распределенному узлу в системе. Распределенная база данных 115 может быть реализована, например, с использованием NoSQL, как масштабируемое и быстродействующее хранилище данных, которое может обеспечивать в реальном времени распределенный доступ к долгосрочным данным. Она может включать в себя ODBC коннектор, аналогично другим конфигурациям реляционной базы данных.
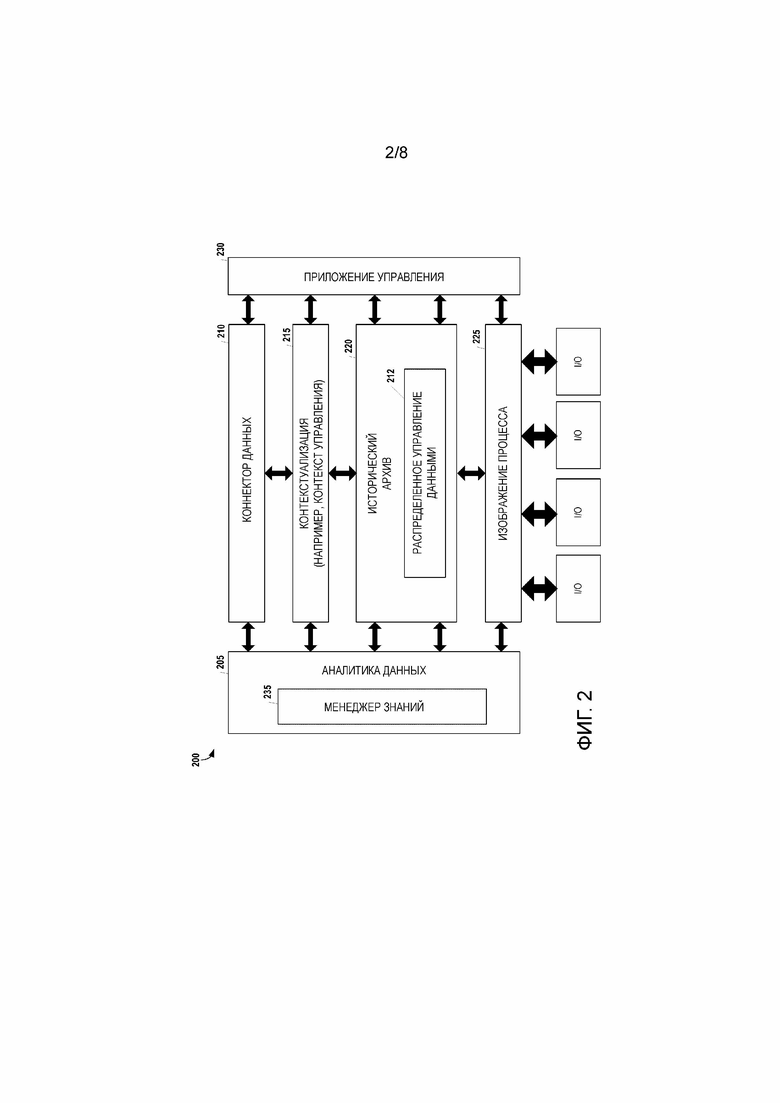
[40] Любая клиентская станция в промышленной системе 100 автоматизации может вводить алгоритмы из хранилища алгоритмов в один или несколько интеллектуальных PLC 105A, 105B, 105C, 110А, 110В и 110С. Интеллектуальные PLC 105A, 105B, 105C, 110A, 110В и 11°C могут исполнять алгоритм распределенным образом (на нескольких контроллерах), а затем агрегировать и отправлять результаты на клиентскую станцию. В примере на фиг. 1, станция 120 аналитики данных/визуализации содержит также хранилище приложений/алгоритмов, которые могут загружаться и исполняться на интеллектуальных PLC 105A, 105B, 105C, 110A, 110В и 110С. Кроме того, в некоторых вариантах осуществления, человеко-машинные интерфейсы 125 (HMI), расположенные по всему производственному оборудованию, могут использоваться для доступа к распределенной системе управления данными либо непосредственно, либо через станцию 120 аналитики данных/визуализации. В некоторых вариантах осуществления, станция 120 аналитики данных/визуализации может включать в себя графический пользовательский интерфейс (GUI), сконфигурированный, чтобы принимать запросы на данные, хранящиеся в приложениях распределенной системы управления данными, и/или отображать визуализации, относящиеся к данным, хранящимся в распределенной системе баз данных. Подобная функциональность также может быть доступна на HMI 125 или других компонентах системы.
[41] Распределенная система управления данными, обеспечиваемая интеллектуальными PLC 105А, 105B, 105C, 110A, 110B и 110C, взаимодействует с существующими компонентами инфраструктуры автоматизации. Например, сервер Supervisory Control and Data Acquisition (диспетчерского управления и сбора данных, SCADA) 130 может связывать и извлекать распределенные данные из интеллектуальных PLC 105A, 105B, 105C, 110A, 110B и 110C, а также других компонентов системы (например, распределенной базы данных 115) с использованием клиентов OPC UA и/или ODBC. Аналогично, сервер архива данных /PIM 140 и серверы, ассоциированные с MES/LIM 145, могут получать доступ к данным в распределенной системе управления данными без существенных изменений или вообще без изменений существующих операций. С учетом времени и ресурсов, эти компоненты более высокого уровня могут быть модифицированы для более эффективной работы с компонентом распределенного управления данными, включенным в каждый из интеллектуальных PLC 105A, 105B, 105C, 110A, 110В и 110C.
[42] Архитектура DDMS, показанная на фиг. 1, может поддерживать большое количество интеллектуальных PLC. Как обсуждалось выше, каждый интеллектуальный PLC (или, в более общем плане, узел) хостирует экземпляр DDMS. Этот экземпляр предоставляет функциональные возможности распределенного хранения и обработки контроллерам, которые могут осуществлять связь друг с другом и с клиентскими или инжиниринговыми станциями, чтобы, например: организовать и индексировать локальные данные и знания, чтобы поддерживать общую когерентность данных и знаний и знать, где что находится; хронологически архивировать результаты аналитической задачи на основе локального архива данных в каждом PLC; обновлять распределенное долговременное хранилище или локальное хранилище для кеширования; обновлять знания и конфигурации интеллектуальных PLC (правила, параметры, настройки кластера, пороги и т.д.); исполнять задачи анализа данных, то есть локальные вычисления или распределенные вычисления; и осуществлять выборку распределенных или локальных данных и извлекать результаты, необходимые для ответа на запросы.
[43] На фиг. 2 представлен концептуальный вид интеллектуального PLC 200 в соответствии с некоторыми вариантами осуществления. Компонент 225 изображения процесса представляет собой область памяти в энергозависимой системной памяти CPU контроллера, которая обновляется в каждом цикле обработки/сканирования на основе данных, ассоциированных с производственными устройствами (например, вводов и выводов подключенных устройств ввода/вывода (I/O)). На каждом этапе обработки, приложение 230 управления считывает компонент 225 изображения процесса, исполняет развернутую логику приложения и записывает результаты обратно в компонент 225 изображения процесса.
[44] Продолжая со ссылкой на фиг. 2, изображение процесса каждого цикла считывается и постоянно сохраняется локально на энергонезависимом физическом носителе хранения компонентом архива (Historian) 220 данных. Кроме того, компонент данных 220 данных может дополнительно хранить контекстную информацию, относящуюся к данным изображения процесса (описано ниже в отношении компонента 215 контекстуализации). Компонент архива данных 220 может быть сконфигурирован для развертывания алгоритмов сжатия данных для уменьшения объема данных и предоставления приложениям доступа к изображениям прошлых процессов. Данные могут храниться либо в течение фиксированного временного окна, либо онлайн-алгоритмы используются для реализации эвристики динамического кэширования. Как часть компонента архива данных 220, интеллектуальные алгоритмы генерации данных могут непрерывно анализировать изображение процесса и контекст, чтобы корректировать параметры генерации данных (например, частоту дискретизации) подсоединенных I/O. Например, для быстро изменяющихся сигналов датчика может быть выбрана высокая частота дискретизации, тогда как для медленно изменяющихся сигналов датчика достаточна более низкая частота дискретизации.
[45] Компонент 212 распределенного управления данными позволяет интеллектуальному PLC 200 работать как экземпляр распределенной системы управления данными или распределенной файловой системы (см., например, фиг. 1). Используя компонент 212 распределенного управления данными, интеллектуальный PLC может совместно использовать данные, сгенерированные компонентом архива 220 данных, с другими устройствами, работающими в промышленной системе автоматизации. Таким образом, историческое, контекстуальное и аналитическое представление системы интеллектуального PLC 200 может использоваться совместно с контроллерами и другими устройствами с использованием алгоритма параллельной распределенной обработки. Например, компонент архива 220 данных имеет локальное представление имен, значений и организации данных, хронологически архивированных локально интеллектуальным PLC 200. Используя компонент 212 распределенного управления данными, это представление системы автоматизации может использоваться совместно.
[46] Для вариантов осуществления, где DFS используется для хранения, компонент 212 распределенного управления данными будет встроенным процессом, обеспечивающим подходящую функциональность DFS. Например, в вариантах осуществления, которые используют ранее упомянутую Hadoop DFS, компонент 212 распределенного управления данными может быть программным обеспечением, которое позволяет интеллектуальному PLC 200 работать как узел данных в кластере. Таким образом, компонент 212 распределенного управления данными может использоваться для форматирования и организации блоков архивных данных в порции данных, которые могут быть переданы, реплицированы и обработаны по всему кластеру. В некоторых вариантах осуществления, компонент 212 распределенного управления данными может также использоваться для получения от узлов имен адресов других узлов данных, где вновь созданная порция данных должна быть реплицирована без преобразования для хранения или вычисления. В других вариантах осуществления, компонент 212 распределенного управления данными может быть сконфигурирован таким образом, что интеллектуальный PLC 200 функционирует как узел имен для кластера, а адреса хранятся локально. После получения адресов, компонент 212 распределенного управления данными может использоваться для автономного управления передачей данных порции архивных данных на другие узлы в кластере. Используя компонент 212 распределенного управления данными, интеллектуальный PLC 200 и другие подобные устройства в среде автоматизации могут реализовывать стек архива данных как алгоритм параллельной распределенной обработки, где каждый встроенный архив данных процессов на узле обладает вышеуказанной функциональностью.
[47] В вариантах осуществления, где распределенная система управления данными используется для распределения хранения по всей системе, компонент 212 распределенного управления данными может быть реализован с использованием различных систем баз данных, общеизвестных в данной области техники. Например, в некоторых вариантах осуществления, данные, хранящиеся в каждом контроллере, хранятся в базе данных NoSQL, которая имеет эквивалентную табличную структуру. Как понятно из уровня техники, термин ʺNoSQLʺ используется для определения класса хранилищ данных, которые не являются реляционными по своей структуре. Существуют различные типы баз данных NoSQL, которые обычно группируются в соответствии с базовой моделью данных. Эти группировки могут включать в себя базы данных, которые используют модели данных на основе столбцов (например, Cassandra), модели данных на основе документов (например, MongoDB), модели данных на основе ключевых значений (например, Redis) и/или модели данных на основе графов (например, Allego). Любой тип базы данных NoSQL может использоваться для реализации различных вариантов осуществления, описанных здесь. В некоторых вариантах осуществления, архивные данные хранятся в распределенной системе управления данными в блоке специфического для данных формата базы данных и организации, которая оптимизирована для распределенной сетки (связной архитектуры, ʺтканиʺ) данных. Размер каждого блока может быть определен, например, на основе требуемой временной гранулярности данных или максимального количества переменных, подлежащих отслеживанию.
[48] Продолжая со ссылкой на фиг. 2, компонент 205 аналитики данных сконфигурирован для исполнения одного или нескольких алгоритмов рассуждений для анализа данных, хранящихся в распределенной системе управления данными, с использованием компонента 212 распределенного управления данными. В компонент 206 аналитики данных могут быть включены различные алгоритмы анализа данных. Например, в некоторых вариантах осуществления, эти алгоритмы включают в себя один или несколько из алгоритмов кластеризации, классификации, рассуждений на основе логики и статистического анализа. Более того, алгоритмы могут быть заданы с помощью модели, которая может быть развернута во время выполнения на устройстве. Компонент 205 аналитики данных может также включать в себя различные аналитические модели и специальные алгоритмы для интерпретации этих моделей. Результаты, сгенерированные компонентом 205 аналитики данных, могут быть сохранены в компоненте архива данных 220, записаны обратно в компонент 225 изображения процесса и/или предоставлены на внешние компоненты через компонент 210 коннектора данных. Таким образом, интеллектуальный PLC можно рассматривать как устройство для предоставления распределенной аналитики на другие устройства в системе автоматизации.
[49] Компонент 205 аналитики данных содержит компонент 235 менеджера знаний, который сконфигурирован, чтобы динамически модифицировать алгоритмы рассуждений, используемые компонентом 205 аналитики данных во время выполнения приложения 230 управления, на основе одной или нескольких моделей декларативных знаний. В некоторых вариантах осуществления, интеллектуальный PLC 200 содержит один или несколько процессоров (не показаны на фиг. 2), которые сконфигурированы, чтобы исполнять приложение 230 управления и, параллельно с исполнением приложения 230 управления, модифицировать один или несколько алгоритмов рассуждений. Параллелизация может быть реализована путем распределения задач по нескольким процессорам (или процессорным ядрам) на основе информации о приоритете. Например, один или несколько процессоров могут быть выделены для высокоприоритетных процессов, таких как исполнение приложения 230 управления, в то время как другие процессоры выделяются для процессов с более низким приоритетом, включая модификации алгоритмов рассуждений.
[50] Различные типы моделей декларативных знаний, общеизвестные в данной области техники, могут использоваться с компонентом 235 менеджера знаний. Например, в некоторых вариантах осуществления, модели декларативных знаний содержат онтологии, выраженные с использованием языка описания онтологий (OWL). Модели могут быть выражены, например, с использованием стандарта языка разметки прогнозного моделирования (PMML) и/или с использованием стандарта формата обмена правилами (RIF). Индивидуальные модели знаний могут быть типовыми по характеру, проприетарными, заданными производителем или любой их комбинацией.
[51] Как отмечено выше, интеллектуальный PLC 200 включает в себя компонент 212 распределенного управления данными, который позволяет интеллектуальному PLC 200 работать в качестве экземпляра распределенной системы управления данными. Чтобы использовать с выгодой коллективные знания системы, в некоторых вариантах осуществления, больше моделей знаний, используемых с компонентом 235 менеджера знаний, могут содержать информацию, такую как функциональные возможности устройств, работающих в распределенной системе управления данными, диагностические знания, доступные на каждом устройстве в распределенной системе управления данными, и/или информацию о структуре данных, используемую распределенной системой управления данными.
[52] В некоторых вариантах осуществления, алгоритмы рассуждений, используемые компонентом 235 менеджера знаний, сконфигурированы на основе одной или нескольких моделей знаний, заданных производителем. Каждая модель знаний, заданная производителем, может включать в себя, например, информацию, относящуюся к функциональным возможностям интеллектуального PLC 200, диагностические знания, доступные в интеллектуальном PLC 200, и/или информацию о структуре данных, используемую интеллектуальным PLC 200.
[53] Компонент 215 контекстуализации сконфигурирован, чтобы генерировать контекстуализированные данные путем аннотирования содержимого компонента 225 изображения процесса контекстной информацией системы автоматизации для облегчения ее последующей интерпретации. Контекстная информация, как используется здесь, может включать в себя любую информацию, которая описывает значение данных. Например, контекст данных в системах автоматизации может включать в себя информацию об устройстве, которое генерировало данные (например, датчик), о структуре системы автоматизации (например, топологию предприятия), о рабочем режиме системы (например, время простоя), о программном обеспечении автоматизации и его статусе во время генерирования данных и/или о продукте/партии, которые производились во время генерирования данных. Компонент 215 контекстуализации сконфигурирован, чтобы предоставлять данные на любой из других компонентов для более специфических потребностей обработки. Контекстная информация, генерируемая компонентом 215 контекстуализации, может не ограничиваться структурой активов (оборудования), но может также включать в себя знания управления, специфическую для продукта информацию, информацию о процессе, информацию о событиях и, возможно, другие аспекты, такие как внешние события, подобные метеорологической информации. Некоторая контекстная информация может быть импортирована из инструментов инжиниринга (например, Siemens Totally Integrated Automation tools). Кроме того, в некоторых вариантах осуществления, компонент 215 контекстуализации обеспечивает семантическую контекстуализацию. Контекст может быть представлен стандартным языком моделирования (например, Web Ontology Language (язык описания веб-онтологий), Resource Description Framework (среда описания ресурса)), где формально определяется значение языковых конструкций. Контекстуализация данных с помощью этих стандартов семантического моделирования позволяет приложениям бизнес-аналитики автоматически понимать и интерпретировать данные, предоставленные системой автоматизации, без усилий ручного конфигурирования.
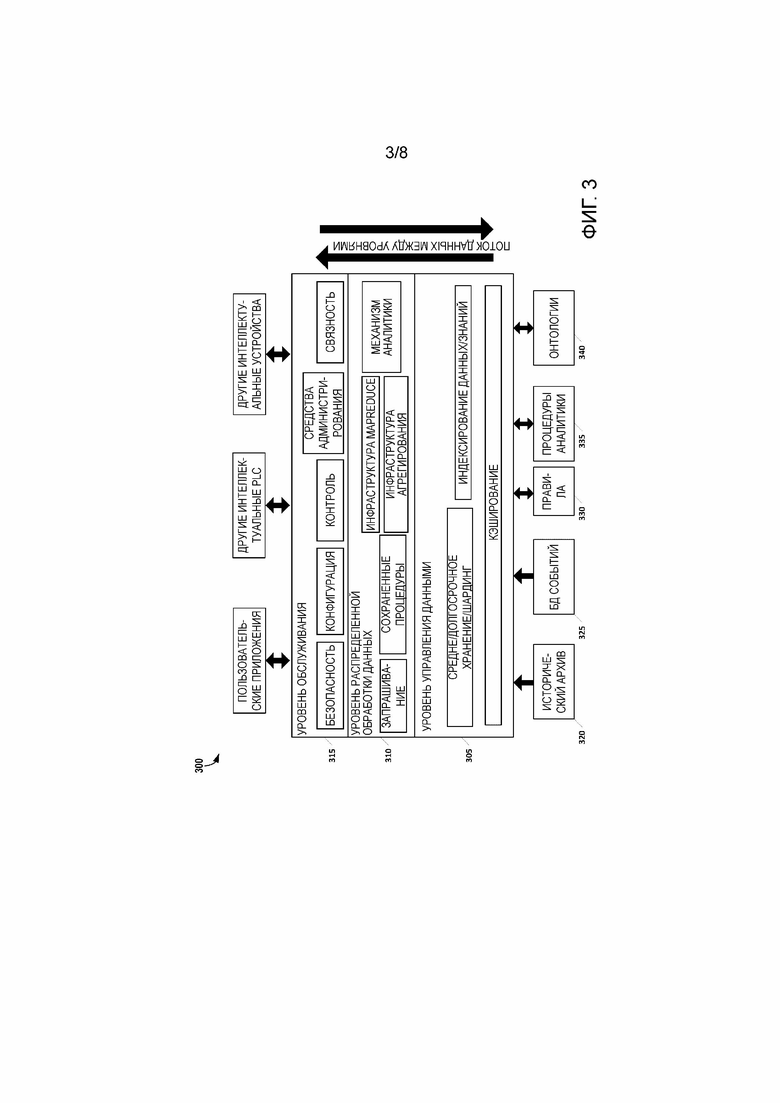
[54] Любые данные, захваченные или сгенерированные компонентами интеллектуального PLC 200, могут быть предоставлены на внешние компоненты через компонент 210 коннектора данных. Таким образом, например, интеллектуальный PLC может осуществлять связь с узлами имен для получения адресов других узлов данных, где вновь созданный блок данных архива данных может быть реплицирован без преобразования для хранения или вычисления. Кроме того, используя базовую технологию связной архитектуры (сетки), устройство может автономно управлять своей передачей данных. В некоторых вариантах осуществления, компонент 210 коннектора данных доставляет данные посредством методологии ʺpushʺ (продвижения) (то есть, активно передает данные на внешний компонент). В других вариантах осуществления, методология ʺpullʺ (извлечения) может использоваться, когда данные запрашиваются внешним компонентом. Кроме того, в некоторых вариантах осуществления, технологии ʺpushʺ и ʺpullʺ могут быть объединены таким образом, что интеллектуальный PLC сконфигурирован для обработки обеих форм передачи данных.
[55] В некоторых вариантах осуществления, интеллектуальный PLC 200 может включать в себя функциональность мониторинга для хранения информации о процессе и контроллере в распределенной базе данных с использованием компонента 212 распределенного управления данными. Кроме того, контекстная информация из компонента 215 контекстуализации может контролироваться и использоваться для получения более глубоких аналитических выводов. Это может выполняться путем обнаружения изменений в поведениях процесса посредством подпрограмм, которые раскрывают метаинформацию о логике интеллектуального PLC 200, которая может использоваться в качестве ввода для дальнейших усовершенствований логики управления. Доступ к логике интеллектуального PLC 200 и мониторинг потоков данных более низкого уровня способствует обнаружению на ранней стадии неправильных конфигураций контроллера.
[56] Дополнительные примеры признаков интеллектуального PLC, которые могут использоваться во взаимосвязи с различными вариантами осуществления, приведены в патентной заявке США № 14/467,125 поданной 25/08/2014 и озаглавленной ʺINTELLIGENT PROGRAMMABLE LOGIC CONTROLLERʺ; патентной заявке РСТ № PCT/US14/63105, поданной 30/10/2014 и озаглавленной ʺUSING SOFT-SENSORS IN A PROGRAMMABLE LOGIC CONTROLLERʺ; патентной заявке РСТ № PCT/US14/62796, поданной 29/10/2014 и озаглавленной ʺSYSTEM AND METHOD FOR AUTOMATIC COMPRESSION ALGORITHM SELECTION AND PARAMETER TUNING BASED ON CONTROL KNOWLEDGEʺ. Каждая из вышеупомянутых заявок включена во всей своей полноте в настоящий документ посредством ссылки.
[57] На фиг. 3 представлена иллюстрация архитектуры 300 DDMS для распределенного управления данными и знаниями, а также распределенной аналитики в соответствии с некоторыми вариантами осуществления. Архитектура DDMS разделяет функциональность на три концептуальных уровня: уровень 305 управления данными, уровень 310 распределенной обработки данных и уровень 315 обслуживания. Функциональность, представленная на фиг. 3, может быть обеспечена, например, различными компонентами интеллектуального PLC 200, показанного на фиг. 2.
[58] Уровень 305 управления данными связан с хранением и операционными возможностями в связи с данными и знаниями, предоставляя функции для организации и индексирования данных и знаний, кеширования и шардинга. Данные из архива (Historian) 320 данных и базы данных 325 событий относятся к реальному времени и могут рассматриваться как кэш для хранилища DDMS. Формат локальных данных регистрируется на узле DDMS, позволяющем осуществлять доступ к данным и обработку в отношении локальных данных. Модели знаний (актив, продукт, процесс, управление и т.д.) обновляются на каждом узле DDMS, позволяющем осуществлять доступ к локальным знаниям. Релевантные диагностические знания (описания правил и аналитики) также будут загружаться на узлы DDMS. Изменения будут автоматически распространяться на все интеллектуальные PLC в кластере, используя возможности распределенного хранения и версификации DDMS. Операционные возможности также могут предоставляться как часть DDMS, например, несколько версий данных могут сосуществовать в одном экземпляре базы данных.
[59] Уровень 305 управления данными тесно связан с локальным архивом 320 данных так, что обеспечивается передача аналитических результатов в цикле из локальных процедур аналитики 335 в локальные узлы системы DDMS. В то же время информация, которая производится вне процедур аналитики 335 (даже вне PLC), может быть сделана доступной для процедур аналитики 335, что позволяет использовать обогащенную контекстуализацию на уровне PLC. Более того, процедуры аналитики 335 могут понимать контекстное сопоставление для ближайших контроллеров. Локальные правила 330 и онтологии 340 могут использоваться для настройки процедур аналитики 335 и других процессов для среды автоматизации.
[60] Уровень 310 распределенной обработки данных предлагает инструментальные средства аналитики в месте эксплуатации и осуществления запросов, которые могут исполняться в отношении распределенных данных, включая использование аналитических механизмов, таких как, например, R и/или JavaScript. В некоторых вариантах осуществления, эти инструментальные средства доступны внешним образом через уровень 315 обслуживания и могут исполняться на локальных данных (одиночного интеллектуального PLC) или распределенных данных (множества интеллектуальных PLC), что обеспечивает локальную обработку, которая позволяет избежать нежелательного сетевого трафика и способствует созданию более масштабируемой инфраструктуры.
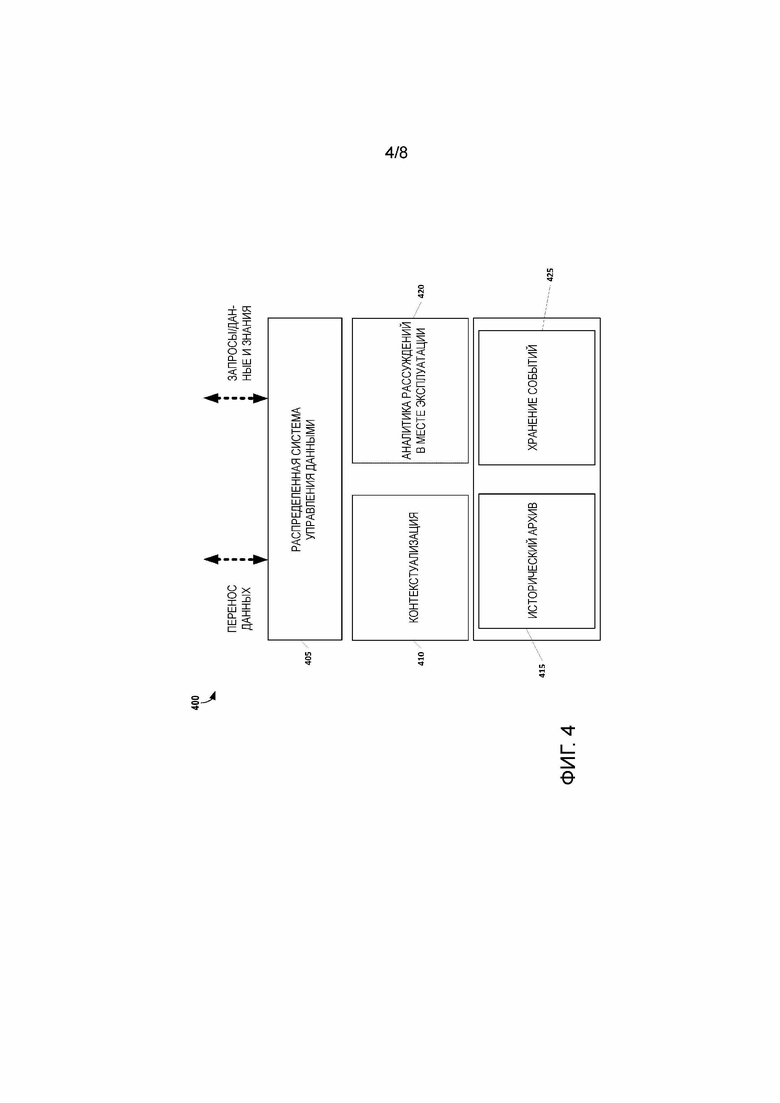
[61] Уровень 315 обслуживания сконфигурирован для обеспечения связности, доступности и безопасности на платформе DDMS, поэтому внешние приложения и устройства могут использовать возможности обработки и управления данными платформы. Доступ к платформе может осуществляться непосредственно с помощью стандартных языков запросов, таких как SQL/SPARQL, или с использованием клиентских инструментов, таких как ODBC, OPC UA, Mongo API, которые обеспечивают интероперабельность на интеллектуальных PLC и расширяют доступ к распределенным данным с внешних устройств и приложений. Любой тип данных, который находится в DDMS, может храниться в зашифрованном формате. Эта стратегия добавляет еще один уровень безопасности к платформе DDMS, гарантируя, что конфиденциальные данные будут надлежащим образом защищены от неавторизованного доступа. Кроме того, для повышения производительности, сжатие при хранении может быть также включено для оптимизации использования пространства хранения.
[62] Как отмечено выше, архитектура 300 DDMS, показанная на фиг. 3, вводит соединение между локальным архивом 320 данных и DDMS, что, в свою очередь, обеспечивает возможность того, что аналитика почти реального времени будет выполняться вне среды в цикле. Соединение может быть реализовано как один направленный канал между архивом данных и DDMS. Через этот канал архив 320 данных может продвигать данные в DDMS (например, в другие узлы) на основе логики, определенной посредством DDMS. Эта логика может включать, например, синхронизированные события, квоты емкости или хронологически архивированные результаты из механизма аналитики в цикле. Соединение между DDMS и механизмом аналитики в месте эксплуатации также может быть однонаправленным в некоторых вариантах осуществления и служить цели перемещения аналитической и контекстной информации из DDMS в механизм аналитики в цикле. Кроме того, DDMS может продвигать новые или обновленные модели знаний.
[63] Новые узлы DDMS могут добавляться путем динамического реконфигурирования инфраструктуры интеллектуального PLC (т.е. кластера DDMS). Как следствие, интеллектуальные PLC могут быть введены, заменены или удалены, не оказывая влияния на существующий базис автоматизации эксплуатационного уровня. Кроме того, следует отметить, что архитектура 300 DDMS является горизонтально масштабируемой, поскольку она применима к количеству интеллектуальных PLC в пределах от одного до нескольких тысяч контроллеров. Добавление узлов в схему распределенной базы данных эквивалентно добавлению большего количества данных в общую разделенную (партиционированную) таблицу. Новые добавленные данные становятся доступными для других контроллеров в сети, как только они загружаются в свою собственную базу данных (контроллера).
[64] На фиг. 4 представлен концептуальный вид 400 того, как информация может быть передана в узел DDMS и из него в соответствии с некоторыми вариантами осуществления. Следует отметить, что многие элементы, показанные на фиг. 4, аналогичны тем, которые представлены интеллектуальным PLC 200 на фиг. 2. На фиг. 4, эти элементы организованы функционально, чтобы выделить основные признаки узла DDMS, связанные с передачей данных в интеллектуальный PLC и из него. DDMS 405 отвечает за индексирование и версификацию данных и знаний для распределенного хранения данных и организует всю информацию (локальную и глобальную) во множество совокупностей на каждый интеллектуальный PLC, таких как совокупность данных временных рядов, совокупность знаний для каждой модели (например, активы, продукт, события, управление и т.д.) и другие совокупности данных. Структура и содержимое совокупности могут модифицироваться с течением времени, например, динамически расширяться в зависимости от того, как используются данные, или сжиматься, отказываясь от требования сохранять некоторые данные. Простейшим примером является поток данных из сенсорных данных (захваченных модулями I/O) на DDMS. Сначала вводы и выводы обрабатываются посредством PLC. Затем данные временных рядов регистрируются в экземпляре базы данных локального узла, так что к ним можно получать доступ извне распределенным образом. Возможно, поднаборы данных являются сегментированными (шардированными) в совокупностях других PLC из того же кластера. Шардинг обсуждается более подробно ниже со ссылкой на фиг. 7 и 8.
[65] На фиг. 4, DDMS 405 представляет собой интерфейс узла данных для локальных необработанных или обработанных данных, событий, кэшированных данных, знаний и концентратор для определения гибкой аналитики поверх этих элементов в сочетании с аналогичными такими элементами, существующими в распределенной системе. Его функции оболочки определены для эффективного решения типичных случаев использования, таких как, без ограничения указанным, передача данных или результатов в узел и из узла, запросы и передача знаний, при индексировании встроенных данных и знаний в распределенной системе и версификации данных и знаний для обеспечения согласованности и когерентности.
[66] Фиг. 4 показывает дополнительную функциональность, которая с выгодой использует данные, сохраненные в распределенной системе. Функциональность контекстуализации 410 используется для контекстуализации локальных данных с использованием знаний, сохраненных в распределенной системе. Аналогично, функциональность аналитики рассуждений в месте эксплуатации, 420, может использоваться для применения алгоритмов рассуждений к данным, сохраненным в распределенной системе.
[67] Функциональность архива 415 данных используется как внутренний источник данных, в то время как внешними источниками данных и знаний являются узлы кластера DDMS. Функциональность о архива 415 данных использует локальную емкость хранения для данных краткосрочных и среднесрочных процессов обработки. Для поддержки долговременного хранения данных (например, для архивирования, анализа многолетних данных и/или регулятивных целей) может быть предоставлен выделенный экземпляр DDMS (не показан на фиг. 4), который поддерживает большие объемы данных и по-прежнему является частью распределенной инфраструктуры данных, как и другой экземпляр DDMS.
[68] Как показано на фиг. 4, результаты аналитики, генерируемые функциональностью аналитики рассуждений в месте эксплуатации, 420, также могут быть хронологически упорядочены функциональностью архива 415 данных. Локальное кратко/среднесрочное хранение данных архива данных организовано, проиндексировано и сегментировано для распределенного хранения данных глобально экземпляром узла DDMS. Результаты аналитики в месте эксплуатации (например, мягких (программируемых) датчиков) также могут представлять временные ряды данных. Структура и содержимое соответствующей совокупности могут модифицироваться с течением времени; тем не менее регистрация данных в DDMS 405 выполняется автоматически, как только данные будут хронологически архивированы. Например, результаты задачи аналитики в месте эксплуатации, которая выполняет вычисления (например, энергопотребления) каждую секунду, могут периодически (например, каждый час или сутки) переноситься на экземпляр DDMS, делая результаты доступными для других интеллектуальных PLC, а также для внешних инструментов автоматизации (например, SCADA, инструментальных средств инжиниринга, MES). Если события генерируются с помощью функциональности аналитики рассуждений в месте эксплуатации, 420, функциональность хранения событий, 425, на интеллектуальном PLC может быть сконфигурирована, чтобы хранить события в локальной базе данных. Как и данные архива данных, после того, как события сохранены, они могут запрашиваться внешними компонентами (например, через DDMS 405) с помощью функциональности аналитики рассуждений в месте эксплуатации, 420, для дальнейшей аналитики (например, для выполнения анализа основных причин).
[69] На фиг. 5 представлена дополнительная иллюстрация 500 того, как экземпляр узла DDMS поддерживает большую передачу данных на/от распределенной инфраструктуры данных (например, экземпляр DDMS долгосрочного хранения) в соответствии с некоторыми вариантами осуществления. Коммуникация между узлами DDMS может происходить, по существу, для задач выборки данных и распределенной обработки. В обоих случаях, процесс может быть инициирован с любого узла, а последний запускает новые соединения с другими узлами, которые хранят данные выборки. В некоторых вариантах осуществления, только узлы, которые запрашиваются для предоставления данных, инициируются координатором (т.е. контроллером, который запускал задачу выборки данных или распределенной обработки), тем самым устраняя ненужный сетевой трафик.
[70] На фиг. 6 приведен пример 600 обновления логического правила интеллектуального PLC, запускаемого внешним устройством или приложением, в соответствии с некоторыми вариантами осуществления. Начиная с этапа 605, принимается обновление правил, инициированное экспертом процесса. Данные могут также поступать из внешних источников, таких как контроллеры и клиентские приложения, работающие на любом устройстве, которое поддерживает и предоставляется для соединения с кластером интеллектуального PLC. На этапе 610 обновляются правила в контекстной базе знаний через один или несколько интерфейсов управления данными. Затем, на этапе 615, правила используются в цикле встроенной аналитикой. Затем, на этапе 620, вновь созданные/обновленные правила применяются к I/O интеллектуального PLC в соответствии с логикой PLC. Пример 600, показанный на фиг. 6 может быть адаптирован для минимизации изменений в интеллектуальном PLC. Например, в одном варианте осуществления, внешнее приложение запускает обновление правил и параметров, на которые ссылается аналитика PLC в месте эксплуатации, результаты чего позволяют изменять поведение управления PLC без необходимости изменения логики PLC.
[71] На фиг. 7 представлена иллюстрация 700 того, как доступ к сегментированным данным может быть реализован через инфраструктуру DDMS в соответствии с некоторыми вариантами осуществления. Шардинг или горизонтальное разбиение представляет собой механизм, который часто используется для поддержки развертываний с наборами данных, которые требуют операций распределения и высокой пропускной способности. Например, на фиг. 7, имеются четыре контроллера 705A, 710A, 715A и 720A, которые хранят поднаборы 705B, 710B, 715B и 720B данных, соответственно. Контроллер 710A инициировал действие, которое требует, чтобы другие контроллеры 705A, 715A и 720A отправляли свои соответствующие поднаборы данных. Используя полученную информацию, контроллер 710A может воссоздать исходный поднабор данных и выполнить операцию с данными.
[72] Разбиение выполняется с использованием определения ключа шардинга, который является критерием, используемым для разделения данных между контроллерами 705A, 710A, 715A и 720A. Отображение шардинга (сегментирования) может быть сохранено конкретным экземпляром сервера или внутри каждого контроллера из контроллеров 705A, 710A, 715A и 720A. В обоих случаях, информация шардинга одинаково доступна для каждого из контроллеров 705A, 710A, 715A и 720A. Каждое устройство-держатель ключа шардинга может координировать процесс передачи данных с другими одноранговыми узлами, поскольку метаданные шардинга содержат отображение местоположения данных/контроллера. Шардинг позволяет децентрализовать принятие решений на уровне управления.
[73] DDMS отвечает за явное установление того, какие данные хранятся локально или удаленно в кластере, поскольку распределенные источники данных могут быть внутренними или внешними по отношению к границе данного контроллера. Для каждой совокупности, к которой необходимо получать доступ в глобальном масштабе, указывается индекс шардинга, который будет предоставлять местоположение сегментированных данных в кластере. Сегментированные метаданные, используемые для доступа к распределенным данным, хранятся локально на каждом интеллектуальном PLC, поэтому каждый PLC может эффективно находить сегментированную информацию. В дополнение к индексам шардинга, файловая система хранения для каждой базы данных может предоставлять внутренние механизмы индексирования, которые ускоряют обработку сканирования для ответов на запросы, в частности, для временных рядов. В качестве механизма согласования, база данных может применять уникальные ключи и также может переопределять предыдущие значения, если регистр соответствует существующим значениям контроллера, тега и временной метки.
[74] На фиг. 8 показан трехэтапный процесс 800 для извлечения и обработки данных в распределенной системе управления данными в соответствии с некоторыми вариантами осуществления настоящего изобретения. Процесс 800 начинается как запросы или задачи отображения/уменьшения, 805, которые исполняют команду на произвольном контроллере. Запросы на данные могут выдаваться любыми контроллерами, позволяя исполнять ситуативные запросы, предварительно определенные запросы, а также вычислять формулы на основе тегов контроллера. Задачи отображения/уменьшения в реляционной базе данных выполняются в распределенной базе данных, которая может содержать сегментированные данные. Эти задачи распределяют задания между узлами, таким образом, поддерживая параллельную обработку. Затем агрегированные результаты возвращаются и сохраняются для дальнейшего исследования. Кроме того, другая обработка может также выполняться на стороне клиента (например, агрегация конечных результатов, извлекаемых из диапазона узлов). Все задачи и результаты запроса будут доступны клиенту в понятном готовом к использованию формате, таком как табличный, csv или изображение.
[75] В примере на фиг. 8, этот первый этап показан как ʺ1ʺ, и произвольный контроллер является контроллером 810A. Запросы или задачи 805 отображения/уменьшения, исполняющие эту команду, могут быть запущены, например, клиентской машиной или любым другим контроллером в системе. На втором этапе (показанном как ʺ2ʺ на фиг. 8) контроллер 810A выполняет поиск местоположения данных (либо используя локальные данные, либо посредством коммуникации с сервером, хранящим информацию шардинга). Основываясь на результатах этого поиска, на третьем этапе (показанном как ʺ3ʺ на фиг. 8) контроллер 810A обменивается сообщениями с контроллерами 815A и 820A для сбора их поднаборов 815B и 820B данных, соответственно. Кроме того, в этом примере, контроллер 810A находит часть запрошенных данных в своем собственном поднаборе 805B данных и соответственно извлекает эти данные. Отметим, что контроллер 805A не нуждается в запросе каких-либо данных из контроллера 810А, потому что поднабор 810B данных, хранящийся в контроллере 810A, не требуется для ответа на исходные запросы. После того как контролер 810A извлек данные из своего собственного хранилища данных и других контроллеров 815A и 820A, контроллер 810A обрабатывает собранные данные для исполнения команды, первоначально принятой на первом этапе процесса 800.
[76] Как показано на фиг. 8, латентность данных может быть автоматически уменьшена путем приближения запросов и задач обработки к данным вследствие вышеупомянутых возможностей обработки. В этом примере, только результаты или обработанные данные передаются по сети. Передача необработанных данных необходима только при некоторых ограниченных обстоятельствах, таких как анализ корреляции данных.
[77] Чтобы проиллюстрировать значение распределенной системы, описанной здесь, рассмотрим ее реализацию в контексте операционной среды автоматизации OEM. Эту среду можно оптимизировать с помощью интегрированной системы, которая обеспечивает масштабируемое в высокой полосе пропускания измерение (с использованием датчиков вибрации), сохранение данных, анализ шпиндельного узла и сообщение результатов шпиндельного узла в масштабе производственного цеха. Для захвата новых измерений вибрации в систему может быть добавлен интеллектуальный PLC, который обменивается сообщениями с датчиками, и данными которого можно управлять локально или посредством другого интеллектуального PLC. С точки зрения управления данными и обработки данных, это выглядит как расширение контроллера, который уже осуществляет управление и мониторинг неисправного механизма. Нет необходимости извлекать данные из системы, чтобы анализировать результаты, создаваемые новыми датчиками. Вместо этого экспертный алгоритм процесса, встроенный в интеллектуальный PLC и управляемый знаниями о процессе, активах и продукте, может анализировать вновь собранные измерения датчика с помощью уже существующего процесса на той же платформе. Результаты диагностики могут просматриваться с помощью любого инструментального средства визуализации данных или аналитики. Как следствие, нет необходимости в извлечении данных процесса из PLC на уровень MES/SCADA для выполнения анализа неисправностей на внешних процессорах, поскольку вновь контролируемые данные будут автоматически доступны для распределенной системы с множеством PLC.
[78] Процессоры, описанные здесь как используемые встроенными контроллерами, могут включать в себя один или несколько центральных процессорных блоков (CPU), графических процессорных блоков (GPU) или любой другой процессор, известный в данной области техники. В общем случае, процессор, как используется здесь, представляет собой устройство для исполнения машиночитаемых инструкций, хранящихся на считываемом компьютером носителе, для выполнения задач и может содержать любое одно или комбинацию аппаратных средств и встроенного программного обеспечения. Процессор может также содержать память, хранящую машиночитаемые инструкции, исполняемые для выполнения задач. Процессор воздействует на информацию посредством манипулирования, анализа, модификации, преобразования или передачи информации для использования исполняемой процедурой или информационным устройством и/или посредством маршрутизации информации на устройство вывода. Процессор может использовать или включать в себя функциональные возможности, например, компьютера, контроллера или микропроцессора и конфигурироваться с использованием исполняемых инструкций для выполнения функций специального назначения, не выполняемых компьютером общего назначения. Процессор может быть связан (электрически и/или как содержащий исполняемые компоненты) с любым другим процессором, обеспечивающим взаимодействие и/или информационный обмен между ними. Процессор или генератор пользовательского интерфейса представляет собой известный элемент, содержащий электронную схему или программное обеспечение, или комбинацию того и другого для формирования отображаемых изображений или их частей. Пользовательский интерфейс содержит одно или несколько отображаемых изображений, которые позволяют пользователю взаимодействовать с процессором или другим устройством.
[79] Различные устройства, описанные здесь, включая, без ограничения, встроенные контроллеры и связанную вычислительную инфраструктуру, могут включать в себя по меньшей мере один считываемый компьютером носитель или память для хранения инструкций, запрограммированных в соответствии с вариантами осуществления изобретения, и для хранения структур данных, таблиц, записей или других данных, описанных здесь. Используемый здесь термин ʺсчитываемый компьютером носительʺ относится к любому носителю, который участвует в предоставлении инструкций на один или несколько процессоров для исполнения. Считываемый компьютером носитель может принимать множество форм, включая, без ограничения указанным, не-временные, энергонезависимые носители, энергозависимые носители и среды передачи. Неограничивающие примеры энергонезависимых носителей включают в себя оптические диски, твердотельные накопители, магнитные диски и магнитооптические диски. Неограничивающие примеры энергозависимых носителей включают в себя динамическую память. Неограничивающие примеры среды передачи включают в себя коаксиальные кабели, медный провод и волоконную оптику, включая провода, составляющие системную шину. Среды передачи могут также принимать форму акустических или световых волн, например, генерируемых при радиоволновой и инфракрасной передаче данных.
[80] Исполняемое приложение, как используется здесь, содержит коды или машиночитаемые инструкции для конфигурирования процессора, чтобы реализовывать предопределенные функции, такие как функции операционной системы, системы сбора контекстных данных или другой системы обработки информации, например, в ответ на пользовательскую команду или ввод. Исполняемая процедура представляет собой сегмент кода или машиночитаемой инструкции, подпрограмму или другую отдельную секцию кода или часть исполняемого приложения для выполнения одного или нескольких конкретных процессов. Эти процессы могут включать в себя прием входных данных и/или параметров, выполнение операций над принятыми входными данными и/или выполнение функций в ответ на принятые входные параметры и предоставление результирующих выходных данных и/или параметров.
[81] Графический пользовательский интерфейс (GUI), как используется здесь, содержит одно или несколько отображаемых изображений, генерируемых процессором отображения и обеспечивающих взаимодействие пользователя с процессором или другим устройством и ассоциированными функциями сбора и обработки данных. GUI также включает в себя исполняемую процедуру или исполняемое приложение. Исполняемая процедура или исполняемое приложение конфигурирует процессор отображения, чтобы генерировать сигналы, представляющие отображаемые изображения GUI. Эти сигналы подаются на устройство отображения, которое отображает изображение для просмотра пользователем. Процессор, под управлением исполняемой процедуры или исполняемого приложения, манипулирует отображаемыми изображениями GUI в ответ на сигналы, полученные от устройств ввода. Таким образом, пользователь может взаимодействовать с отображаемым изображением с помощью устройств ввода, обеспечивая пользовательское взаимодействие с процессором или другим устройством.
[82] Функции и этапы процессов, описанные в настоящем документе, могут выполняться автоматически, полностью или частично в ответ на команду пользователя. Действие (включающее в себя этап), выполняемое автоматически, выполняется в ответ на одну или несколько исполняемых инструкций или операцию устройства без прямого инициирования действия пользователем.
[83] Система и процессы, показанные на чертежах, не являются исключительными. Другие системы, процессы и меню могут быть получены в соответствии с принципами изобретения для достижения тех же целей. Хотя настоящее изобретение описано со ссылкой на конкретные варианты осуществления, следует понимать, что варианты осуществления и вариации, показанные и описанные в настоящем документе, предназначены только для иллюстрации. Модификации представленной структуры могут быть выполнены специалистами в данной области техники без отклонения от объема изобретения. Как описано здесь, различные системы, подсистемы, агенты, менеджеры и процессы могут быть реализованы с использованием аппаратных компонентов, программных компонентов и/или их комбинаций. Ни один элемент пункта формулы изобретения в настоящем документе не должен толковаться в соответствии с положениями 35 U.S.C. 112, шестой абзац, если только этот элемент явно не указан с использованием фразы ʺсредство дляʺ.
Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении доступности данных локального архива данных в распределенной инфраструктуре данных. Система хранения данных в промышленной производственной среде содержит распределенную систему управления данными, сохраненную на множестве устройств интеллектуальных программируемых логических контроллеров, каждое из которых содержит: энергозависимый и энергонезависимый считываемые компьютером носители данных; управляющую программу; компонент ввода/вывода; компонент распределенного управления данными; компонент контекстуализации для генерирования контекстуализированных данных путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации, компонент архива данных для локального сохранения содержимого области изображения процесса и контекстуализированных данных и обеспечения доступа к содержимому в распределенной системе управления данными через компонент распределенного управления данными и компонент аналитики данных для исполнения одного или нескольких алгоритмов рассуждений для анализа данных с использованием компонента управления распределенными данными. 3 н. и 17 з.п. ф-лы, 8 ил.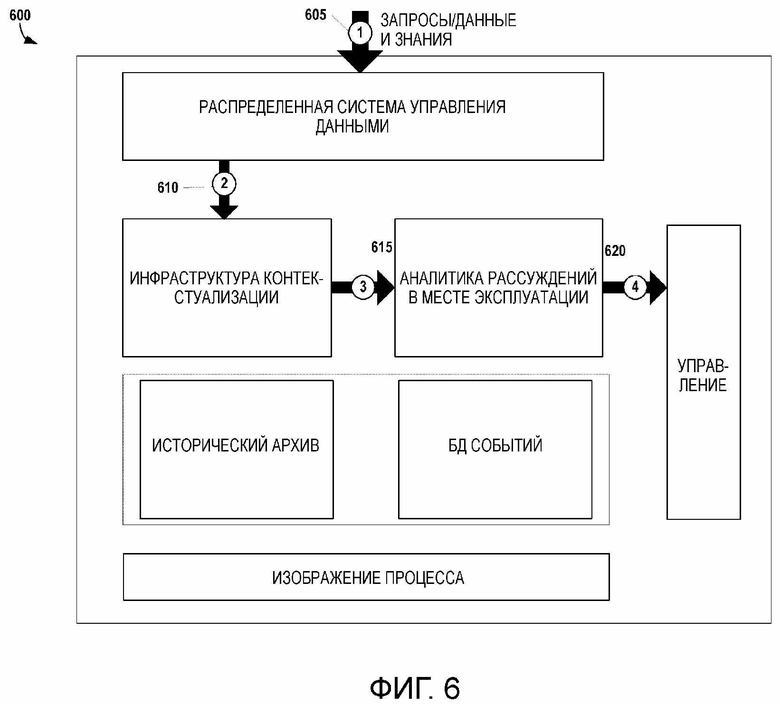
1. Система хранения данных в промышленной производственной среде, причем система содержит:
распределенную систему управления данными, сохраненную на множестве устройств интеллектуальных программируемых логических контроллеров, причем каждое соответствующее устройство интеллектуального программируемого логического контроллера содержит:
энергозависимый считываемый компьютером носитель данных, содержащий область изображения процесса;
энергонезависимый считываемый компьютером носитель данных;
управляющую программу, сконфигурированную с возможностью предоставления операционных инструкций на производственный блок;
компонент ввода/вывода, сконфигурированный с возможностью обновления области изображения процесса во время каждого цикла сканирования на основе данных, ассоциированных с производственным блоком;
компонент распределенного управления данными, содержащий экземпляр распределенной системы управления данными;
компонент контекстуализации, сконфигурированный с возможностью генерирования контекстуализированных данных путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации,
компонент архива данных, сконфигурированный с возможностью локального сохранения содержимого области изображения процесса и контекстуализированных данных, и который обеспечивает доступ к содержимому в распределенной системе управления данными через компонент распределенного управления данными, и
компонент аналитики данных, сконфигурированный с возможностью исполнять один или нескольких алгоритмов рассуждений для анализа данных, сохраненных в распределенной системе управления данными, с использованием компонента управления распределенными данными.
2. Система по п. 1, в которой каждое соответствующее устройство интеллектуального программируемого логического контроллера дополнительно содержит:
компонент менеджера знаний, сконфигурированный с возможностью динамически модифицировать один или несколько алгоритмов рассуждений во время выполнения управляющей программы на основе одной или нескольких моделей декларативных знаний.
3. Система по п. 2, в которой одна или несколько моделей декларативных знаний, используемых компонентом контекстуализации каждого соответствующего устройства интеллектуального программируемого логического контроллера, содержат онтологии, выраженные с использованием языка описания онтологий (OWL).
4. Система по п. 2, в которой одна или несколько моделей декларативных знаний, используемых компонентом контекстуализации каждого соответствующего устройства интеллектуального программируемого логического контроллера, содержат модель предсказания, выраженную с использованием стандарта языка разметки прогнозного моделирования (PMML).
5. Система по п. 2, в которой одна или несколько моделей декларативных знаний, используемых компонентом контекстуализации каждого соответствующего устройства интеллектуального программируемого логического контроллера, содержат одно или несколько правил, выраженных с использованием стандарта формата обмена правилами (RIF).
6. Система по п. 1, в которой один или несколько алгоритмов рассуждений, используемых компонентом аналитики данных каждого соответствующего устройства интеллектуального программируемого логического контроллера, сконфигурированы на основе одной или нескольких моделей знаний, заданных производителем.
7. Система по п. 6, в которой одна или несколько моделей знаний, заданных производителем, содержат информацию, относящуюся к одной или нескольким функциональным возможностям множества устройств интеллектуальных программируемых логических контроллеров, диагностические знания, доступные на множестве устройств интеллектуальных программируемых логических контроллеров, и/или информацию о структуре данных, используемую множеством устройств интеллектуальных программируемых логических контроллеров.
8. Система по п. 1, в которой каждое соответствующее устройство интеллектуального программируемого логического контроллера дополнительно содержит:
один или несколько процессоров, сконфигурированных с возможностью исполнять управляющую программу и, параллельно с исполнением управляющей программы, модифицировать один или несколько алгоритмов рассуждений параллельно с исполнением управляющей программы.
9. Система по п. 1, в которой энергонезависимый считываемый компьютером носитель данных, включенный в каждое соответствующее устройство интеллектуального программируемого логического контроллера, содержит базу данных NoSQL, которая имеет эквивалентное табличное представление.
10. Способ хранения данных в промышленной производственной среде, причем способ содержит:
исполнение, первым интеллектуальным программируемым логическим контроллером, управляющей программы, сконфигурированной с возможностью предоставлять операционные инструкции на производственный блок на протяжении множества циклов сканирования;
обновление, первым интеллектуальным программируемым логическим контроллером, области изображения процесса во время каждого из множества циклов сканирования на основе данных, ассоциированных с производственным блоком;
генерирование, первым интеллектуальным программируемым логическим контроллером, контекстуализированных данных путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации;
вставку, первым интеллектуальным программируемым логическим контроллером, содержимого области изображения процесса и контекстуализированных данных в локальный энергонезависимый считываемый компьютером носитель на первом интеллектуальном программируемом логическом контроллере, причем локальный энергонезависимый считываемый компьютером носитель является частью распределенной системы хранения, сохраненной на первом интеллектуальном программируемом логическом контроллере и множестве вторых интеллектуальных программируемых логических контроллеров; и
исполнение, первым интеллектуальным программируемым логическим контроллером, одного или нескольких алгоритмов рассуждений для анализа данных, сохраненных в распределенной системе хранения.
11. Способ по п. 10, дополнительно содержащий:
динамическое модифицирование, первым интеллектуальным программируемым логическим контроллером, одного или нескольких алгоритмов рассуждений во время выполнения управляющей программы на основе одной или нескольких моделей декларативных знаний.
12. Способ по п. 11, в котором одна или несколько моделей декларативных знаний содержат онтологии, выраженные с использованием языка описания онтологий (OWL).
13. Способ по п. 11, в котором одна или несколько моделей декларативных знаний содержат модель предсказания, выраженную с использованием стандарта языка разметки прогнозного моделирования (PMML).
14. Способ по п. 11, в котором одна или несколько моделей декларативных знаний содержат одно или несколько правил, выраженных с использованием стандарта формата обмена правилами (RIF).
15. Способ по п. 10, в котором локальный энергонезависимый считываемый компьютером носитель содержит базу данных NoSQL, которая имеет эквивалентное табличное представление.
16. Способ по п. 15, в котором вставка данных, ассоциированных с производственным блоком, в локальный энергонезависимый считываемый компьютером носитель запускается на основе изменений в операционных инструкциях и данных, ассоциированных с производственным блоком.
17. Способ по п. 10, в котором один или несколько алгоритмов рассуждений сконфигурированы на основе одной или нескольких моделей знаний, заданных производителем.
18. Способ по п. 17, в котором одна или несколько моделей знаний, заданных производителем, содержат информацию, относящуюся к одной или нескольким функциональным возможностям первого интеллектуального программируемого логического контроллера, диагностические знания, доступные на первом интеллектуальном программируемом логическом контроллере, и/или информацию о структуре данных, используемую первым интеллектуальным программируемым логическим контроллером.
19. Способ по п. 10, дополнительно содержащий:
исполнение, первым интеллектуальным программируемым логическим контроллером, управляющей программы с использованием первого ядра процессора, включенного в первый интеллектуальный программируемый логический контроллер,
причем один или несколько алгоритмов рассуждений динамически модифицируются с использованием второго ядра процессора, включенного в первый интеллектуальный программируемый логический контроллер.
20. Считываемый компьютером носитель, содержащий исполняемые компьютером инструкции для выполнения способа, содержащего:
исполнение управляющей программы, сконфигурированной, чтобы предоставлять операционные инструкции на производственный блок на протяжении множества циклов сканирования;
обновление области изображения процесса во время каждого из множества циклов сканирования на основе данных, ассоциированных с производственным блоком;
генерирование контекстуализированных данных путем аннотирования содержимого области изображения процесса контекстной информацией системы автоматизации;
вставку содержимого области изображения процесса и контекстуализированных данных в локальный энергонезависимый считываемый компьютером носитель, причем локальный энергонезависимый считываемый компьютером носитель является частью распределенной системы хранения; и
исполнение одного или нескольких алгоритмов рассуждений для анализа данных, сохраненных в распределенной системе хранения.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| EP 1895740 A2, 05.03.2008 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| RU 2013116386 A, 10.05.2015. | |||

