Область техники
Заявляемое изобретение относится к декодеру аудиосигнала, генерирующему представление сигнала повышающего микширования (апмикс-сигнала), исходя из представления сигнала понижающего микширования (даунмикс-сигнала) и объектно-ориентированной параметрической информации. Реализации данного изобретения относится также к способу генерации представления сигнала повышающего микширования на основании представления сигнала понижающего микширования и объектно-ориентированной параметрической информации. Кроме того, осуществление настоящего изобретения относится к компьютерной программе. Некоторые аппаратные версии представленного изобретения относятся к расширенной системе пространственного кодирования аудиообъекта SAOC Karaoke/Solo („Караоке/Соло").
Уровень техники
Современные акустические системы требуют оптимальной скорости обмена двоичными данными (эффективного битрейта) при передаче и хранении звуковой информации. В дополнение к этому часто требуется озвучивать аудиоконтент с использованием двух и более громкоговорителей, разнесенных в пространстве. В подобных случаях, как правило, желательно, чтобы конфигурация множества динамиков позволяла слушателю позиционно разграничивать различные источники звука или различные составляющие одного источника звука. Это может быть достигнуто за счет соотнесения разных акустических составляющих с индивидуальными громкоговорителями.
Иначе говоря, в технологиях обработки звука, передачи и хранения аудиоданных все возрастающее требование предъявляется к регулированию многоканального контента для совершенствования слухового впечатления. Использование многоканального аудиоконтента способствует значительному улучшению восприятия слушателем. Например, стало доступно создание трехмерного акустического образа, благодаря которому возрастает степень удовлетворенности пользователя развлекательными приложениями. В то же время многоканальный аудиоконтент функционален и в профессиональной среде, например в телеконференцсвязи, где речь говорящего может быть воспроизведена более разборчиво благодаря многоканальному представлению звука. При этом необходимо выбрать оптимальное соотношение качества звука и скорости обмена данными (битрейта) во избежание чрезмерной нагрузки на ресурс за счет многоканальных приложений. Недавно были предложены параметрические средства оптимизации скорости обмена данными при передаче и/или хранении аудиосцен, содержащих множественные аудиообъекты, такие как, кодирование бинаурального сигнала (Тип 1) (см., например, ссылку [ВСС]), кодирование совокупного источника (см., например, ссылку [JSC]) и пространственное кодирование аудиообъекта в формате MPEG (SAOC) (см., например, ссылки [SAOC1], [SAOC2]).
Эти инструментальные средства применяют с целью воссоздания выбранной звуковой сцены перцептуально, а не за счет волнового согласования.
На фиг.8 представлена общая схема подобной системы (здесь - системы пространственного кодирования оудиообъекта SAOC формата MPEG - MPEG SAOC). Система MPEG SAOC 800 на фиг.8 состоит из кодера SAOC 810 и декодера SAOC 820. Кодер SAOC 810 принимает множество сигналов объектов x1-xN, которые могут представлять собой, скажем, сигналы временной области или сигналы частотно-временной области (допустим, в виде набора коэффициентов одного из преобразований Фурье или в виде подполосовых сигналов КЗФ [квадратурно-зеркального фильтра]). Помимо этого, кодер SAOC 810 часто получает коэффициенты понижающего микширования [даунмикс-коэффициенты] d1-dN, соотнесенные с сигналами объектов x1-xN. Отдельные комбинации даунмикс-коэффициентов можно применять для каждого канала микшированного с понижением сигнала [даунмикс-канала]. С помощью кодера SAOC 810 обычно формируют канал микшированного с понижением сигнала, комбинируя сигналы объектов x1-xN в соответствии с присвоенными коэффициентами понижающего микширования d1-dN. Типично, даунмикс-каналов меньше, чем сигналов объектов x1-xN. Предусматривая (хотя бы, приблизительное) разделение (или раздельное преобразование) сигналов объектов на стороне декодера SAOC 820, кодер SAOC 810 генерирует один или более даунмикс-сигналов 812 и сопроводительную служебную информацию 814. Служебная информация 814 отражает характеристики сигналов объектов x1-xN, что обеспечивает объектно-ориентированную обработку на стороне декодера.
Декодер SAOC 820 предусматривает прием одного или более даунмикс-сигналов 812 и сопроводительной служебной информации 814. Кроме того, декодер SAOC 820, как правило, рассчитан на получение от пользователя интерактивной информации и/или управляющей информации 822, в которой описывается желаемый режим воспроизведения [рендеринг]. Так, предположим, информация от пользователя в реальном времени/пользовательские параметры управления 822 могут задавать параметры громкоговорителя и желаемое пространственное расположение объектов-источников сигналов x1-xN. Декодер SAOC 820 предусматривает, например, генерирование множества декодированных сигналов канала повышающего микширования [апмикс-канала] 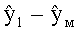 . Сигналы апмикс-канала могут, к примеру, быть привязаны к индивидуальным динамикам многоколоночной системы воспроизведения звука. Декодер SAOC 820 может, в частности, включать в себя разделитель объектов 820а, выполняющий, по крайней мере, приближенную, реконструкцию сигналов объектов x1-xN на основе одного или более микшированных с понижением сигналов 812 и служебной информации 814, обеспечивая в результате воссоздание сигналов объектов 820b. Однако, реконструированные сигналы объектов 820b могут иметь некоторые девиации относительно оригинальных сигналов объектов x1-xN потому, например, что сопроводительная служебная информация 814 не всегда достаточна для адекватного воссоздания исходного материала в силу ограничений по скорости передачи данных. Кроме того, декодер SAOC 820 может иметь в своем составе смеситель [микшер] 820с, способный принимать реконструированные сигналы объектов 820b и информацию обратной связи с пользователем/управляющую информацию пользователя 822 и на их базе генерировать сигналы канала повышающего микширования
. Сигналы апмикс-канала могут, к примеру, быть привязаны к индивидуальным динамикам многоколоночной системы воспроизведения звука. Декодер SAOC 820 может, в частности, включать в себя разделитель объектов 820а, выполняющий, по крайней мере, приближенную, реконструкцию сигналов объектов x1-xN на основе одного или более микшированных с понижением сигналов 812 и служебной информации 814, обеспечивая в результате воссоздание сигналов объектов 820b. Однако, реконструированные сигналы объектов 820b могут иметь некоторые девиации относительно оригинальных сигналов объектов x1-xN потому, например, что сопроводительная служебная информация 814 не всегда достаточна для адекватного воссоздания исходного материала в силу ограничений по скорости передачи данных. Кроме того, декодер SAOC 820 может иметь в своем составе смеситель [микшер] 820с, способный принимать реконструированные сигналы объектов 820b и информацию обратной связи с пользователем/управляющую информацию пользователя 822 и на их базе генерировать сигналы канала повышающего микширования 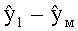 . Смеситель 820 предусматривает задействование интерактивной информации от пользователя/пользовательских управляющих данных 822 для расчета соотношения составляющих индивидуальных реконструируемых сигналов объектов 820b в сигналах апмикс-каналов . Пользовательская интерактивная/управляющая информация 822 может, в частности, включать в себя параметры воспроизведения (называемые также коэффициентами рендеринга), которые определяют соотношение составляющих отдельных сигналов реконструируемых объектов 822 в сигналах каналов повышающего микширования .
. Смеситель 820 предусматривает задействование интерактивной информации от пользователя/пользовательских управляющих данных 822 для расчета соотношения составляющих индивидуальных реконструируемых сигналов объектов 820b в сигналах апмикс-каналов . Пользовательская интерактивная/управляющая информация 822 может, в частности, включать в себя параметры воспроизведения (называемые также коэффициентами рендеринга), которые определяют соотношение составляющих отдельных сигналов реконструируемых объектов 822 в сигналах каналов повышающего микширования .
Здесь следует обратить внимание на то, что при реализации часто разделение объектов, обозначенное на фиг.8 как разделитель объектов 820а, и микширование, обозначенное на фиг.8 как смеситель [микшер] 820с, осуществляют как одну операцию. Для этого рассчитывают сводные параметры, описывающие прямое соотнесение одного или более микшированных с понижением сигналов 812 с сигналами каналов повышающего микширования . Эти параметры могут быть рассчитаны, исходя из служебной информации 814 и пользовательской информации обратной связи/управления 822.
Теперь, со ссылкой на фигуры 9а, 9b и 9с рассмотрим другой вариант реализации устройства, формирующего представления сигнала, микшированного с повышением, на базе представления сигнала, микшированного с понижением, и объектно-ориентированной служебной информации. На фиг.9а дана принципиальная блочная схема системы MPEG SAOC 900, включающей в себя декодер SAOC 920. Декодер SAOC 920 в качестве самостоятельных функциональных блоков содержит декодер объекта 922 и смеситель/рендерер [микшер/рендерер] 926. Декодер объектов 922 генерирует множество восстановленных сигналов объектов 924, опираясь на полученное им представление даунмикс-сигнала (допустим, в виде одного или более сигналов понижающего микширования во временной области или в частотно-временной области) и на объектно-ориентированную сопутствующую информацию (допустим, в виде метаданных объекта). Смеситель/рендерер 924 получает восстановленные сигналы объектов 924, относящиеся к множеству N объектов, и на их основе формирует один или более сигналов апмикс-канала 928. В компоновке SAOC-декодера 920 экстракция сигналов объектов 924 выполняется отдельно от микширования/рендеринга, что позволяет разделить функции декодирования объекта и микширования/рендеринга, однако приводит к относительно высокой вычислительной трудоемкости.
Далее, обратившись к фиг.9b, кратко обсудим еще одно конструктивное решение системы MPEG SAOC 930, куда введен декодер SAOC 950. Декодер SAOC 950 генерирует множество восстановленных сигналов объектов 958, опираясь на полученное им представление даунмикс-сигнала (допустим, в виде одного или более сигналов понижающего микширования) и на объектно-ориентированную служебную информацию (допустим, в виде метаданных объекта). Декодер SAOC 950 представляет собой интегрированный декодер и смеситель/рендерер объекта, выполненный с возможностью генерирования сигналов апмикс-каналов 958 в ходе комбинированного процесса микширования без разделения декодирования и микширования/рендеринга объектов, параметры которого строятся на объектно-ориентированный служебной информации и данных рендеринга. Комбинированный процесс повышающего микширования зависит также от информации понижающего микширования, которая рассматривается как часть объектно-ориентированной служебной информации.
Делая вывод из сказанного, сигналы каналов повышающего микширования 928, 958 могут быть сгенерированы в ходе одноэтапной или двухэтапной операции.
Теперь, обращаясь к фиг.9с, охарактеризуем систему MPEG SAOC 960. Система [пространственного кодирования оудиообъекта] SAOC 960 предпочтительно включает в себя транскодер SAOC в MPEG Surround 980 вместо декодера SAOC.
Преобразователь кода [транскодер] SAOC в MPEG Surround состоит из перекодировщика [транскодера] служебной информации 982, который предназначен для приема объектно-ориентированной служебной информации (предположительно, в форме метаданных объекта) и, факультативно, информации об одном или более даунмикс-сигналов и параметров рендеринга. Перекодировщик служебной информации предназначен также для выработки на базе полученных данных служебной информации формата MPEG Surround (например, в форме битстрима MPEG Surround). Соответственно, транскодер служебной информации 982 выполняет функцию преобразования объектно-ориентированной (параметрической) служебной информации, поступающей от кодера объектов, в служебную (параметрическую) информацию, описывающую каналы с учетом параметров рендеринга и, произвольно, информации о контенте одного или более микшированных с понижением сигналов.
В качестве опции транскодер SAOC в MPEG Surround 980 может выполнять функцию манипулирования одним или более даунмикс-сигналами, описанными, например, посредством представления даунмикс-сигнала с получением видоизмененного [манипуляцией] представления сигнала понижающего микширования 988. Тем не менее, манипулятор даунмикс-сигналом 986 можно не включать в компоновку, в результате чего представление сигнала понижающего микширования 988 на выходе транскодера SAOC в MPEG Surround 980 будет идентичным представлению сигнала понижающего микширования на входе транскодера SAOC в MPEG Surround. Манипулятор даунмикс-сигналом 986 может найти применение, например, когда служебная информация MPEG Surround 984 с привязкой к каналам не позволяет создать желаемое слуховое впечатление на базе представления сигнала понижающего микширования на входе транскодера SAOC в MPEG Surround 980, что может иметь место при некоторых констелляциях [совокупностях факторов] акустического рендеринга.
Следовательно, транскодер SAOC в MPEG Surround 980 формирует представление сигнала понижающего микширования 988 и битстрим формата MPEG Surround 984 таким образом, что множество сигналов каналов повышающего микширования, отображающих аудиообъекты в соответствии с данными рендеринга, вводимыми в транскодер SAOC -MPEG Surround 980, могут быть сгенерированы с помощью декодера MPEG Surround, на который поступают битстрим MPEG Surround 984 и представление даунмикс-сигнала 988.
Из сказанного вытекает, что для декодирования аудиосигналов, закодированных в SAOC, можно применять различные подходы. В некоторых случаях используют декодер SAOC, который генерирует сигналы каналов повышающего микширования (например, сигналы апмикс-каналов 928, 958) на основе представления сигналов понижающего микширования и объектно-ориентированной служебной параметрической информации. Примеры такого подхода приведены на фиг.9а и 9b. В другом случае аудиоданные, закодированные в SAOC, могут быть перекодированы с получением представления сигнала понижающего микширования (например, представления даунмикс-сигнала 988) и сопроводительной информации, специфицирующей канал (например, битстрима MPEG Surround 984, характеризующего канал), которые будут использованы декодером MPEG Surround для выработки необходимых сигналов каналов повышающего микширования.
На фиг.8 показана общая схема системы MPEG SAOC 800, которая предусматривает частотно-избирательную обработку каждого частотного диапазона таким образом, что:
- кодер SAOC микширует с понижением N входных сигналов аудиообъектов x1-xN. Для понижающего монофонического микширования коэффициенты указаны как d1-dN. В дополнение к этому кодер SAOC 810 извлекает служебную информацию 814, описывающую входные аудиообъекты. Для процедуры пространственного кодирования оудиообъекта SAOC в формате MPEG базовым видом сопроводительной информации является соотношение мощностей объектов.
- Микшированный с понижением сигнал (или сигналы) 812 и служебную информацию 814 пересылают и/или вводят в память. Для этого микшированный с понижением аудиосигнал сжимают, используя такие известные аудиокодеры перцептуального типа, как MPEG-1 уровня II или III (также известный как,,.mp3"), как Передовая технология аудиокодирования ААС формата MPEG, или любой другой аудиокодер.
- Концептуальная задача декодера SAOC 820 на приемном конце - восстановить исходный сигнал объекта („дифференцировать объекты"), используя полученную служебную информацию 814 (и, естественно, один или более даунмикс-сигналов 812). Затем, из таких приближенных к оригиналам объектных сигналов (определяемых также как реконструированные сигналы объектов [/ сигналы реконструированных объектов] 820b) микшируют целевую сцену, отображаемую посредством М выходных звуковых каналов (которые, например, могут быть представлены сигналами каналов повышающего микширования ) с приложением матрицы аудиорендеринга. Для монофонического звукового выхода коэффициенты матрицы аудиорендеринга представлены как r1-rN.
- В действительности, сепарация сигналов объекта выполняется редко (или даже никогда не выполняется), поскольку и шаг сепарации (обозначенный как разделитель объектов 820а), и шаг микширования (обозначенный как смеситель 820с), объединены в общую процедуру транскодирования, в результате которой зачастую происходит значительное снижение вычислительной сложности.
Было установлено, что такая схема чрезвычайно эффективна, как с точки зрения скорости передачи данных (когда необходимо передавать только несколько даунмикс-каналов и некоторую служебную информацию вместо N дискретных сигналов аудиообъектов или дискретной системы), так и с точки зрения вычислительной трудоемкости (трудоемкость обработки связана больше с числом выходных каналов, чем с количеством отображаемых аудиообъектов). Дополнительные преимущества пользователя на приемном конце состоят в свободе выбора воспроизводимого акустического образа (моно-, стереофония, охватывающее, виртуализированное [приближенное к реальности] звучание в наушниках и тому подобное) и в возможности непосредственного участия слушателя/слушательницы: матрица аудиорендеринга обеспечивает возможность адаптации звуковой сцены в режиме реального времени к запросам пользователя в соответствии с его/ее вкусами, личными предпочтениями или иными критериями. Например, можно пространственно ощутимо отделять собеседников одной группы в одной части звукового объема от других участников разговора. Такая интерактивность достигается за счет интерфейса пользователя с декодером.
Регулируются относительный уровень и (для немонофонического рендеринга) пространственное положение каждого звукового объекта. Пользователь может выполнять это в режиме реального времени, изменяя положение соответствующего ползунка устройства графического интерфейса пользователя (GUI/ГИП) (например: уровень объекта = +5 дБ, положение объекта = -30°).
Тем не менее, было установлено, что в подобной системе трудно регулировать разнотипные аудиообъекты. В частности, определено, что затруднения касаются разных типов аудиообъектов, например, сопровождаемых разнотипной служебной информацией, если полное количество аудиообъектов, которое будет обработано, не задано заранее. Ввиду описанной ситуации заявляемое изобретение преследует цель представить концепцию вычислительно эффективного и гибкого декодирования аудиосигнала, где аудиосигнал содержит представление сигнала понижающего микширования и объектно-ориентированную параметрическую информацию, описывающую аудиообъекты двух или более разных типов аудиообъектов.
Краткое описание изобретения
Поставленная цель достигается за счет декодера аудиосигнала [аудиодекодера], генерирующего представление сигнала повышающего микширования [представление апмикс-сигнала] на основании представления сигнала понижающего микширования [представления даунмикс-сигнала] и объектно-ориентированной параметрической информации, с помощью способа генерации представления апмикс-сигнала на основании представления даунмикс-сигнала и объектно-ориентированной параметрической информации с применением компьютерной программы, как определено в независимых пунктах формулы изобретения.
Новизной данного изобретения является декодер аудиосигнала для генерации представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и объектно-ориентированной параметрической информации. Декодер аудиосигнала [отличается тем, что] включает в свою конструкцию разделитель объектов, предназначенный для разложения представления сигнала понижающего микширования с получением „первой аудиоинформации", описывающей первый набор из одного или более аудиообъектов первого типа аудиообъектов, и получения „второй аудиоинформации", описывающей второй набор из одного или более аудиообъектов второго типа аудиообъектов, на основе представления сигнала понижающего микширования и с использованием, по меньшей мере, части объектно-ориентированной параметрической информации. Декодер аудиосигнала также включает в свою конструкцию процессор аудиосигналов, предназначенный для приема второй аудиоинформации и обработки второй аудиоинформации, исходя из объектно-ориентированной параметрической информации, с получением обработанной версии второй аудиоинформации. Декодер аудиосигнала наряду с этим включает в свою конструкцию комбинатор (блок сведения) аудиосигнала, предназначенный для объединения первой аудиоинформации с обработанной версией второй аудиоинформации с получением представления сигнала повышающего микширования.
Основная идея представленного изобретения заключается в том, что эффективная обработка различных типов аудиообъектов может быть достигнута по каскадной схеме, которая предусматривает разделение различных типов аудиообъектов за счет использования, по меньшей мере, части объектно-ориентированной параметрической информации на первом этапе обработки с помощью разделителя объектов, и которая предусматривает дополнительную пространственную обработку на втором этапе обработки, который выполняется процессором аудиосигналов, исходя из, по меньшей мере, части объектно-ориентированной параметрической информации.
Установлено, что выделение из представления даунмикс-сигнала второй аудиоинформации, содержащей аудиообъекты второго типа аудиообъектов, может быть выполнено с умеренной трудоемкостью, даже если присутствует большее количество аудиообъектов второго типа аудиообъектов. В дополнение к этому было определено, что пространственная обработка аудиообъектов второго типа может быть произведена эффективно, если вторая аудиоинформация отделена от первой аудиоинформации, описывающей аудиообъекты первого типа.
Кроме того, выявлено, что алгоритм обработки, выполняемый разделителем объектов для того, чтобы отделить первую аудиоинформацию от второй аудиоинформации, может быть реализован со сравнительно небольшой сложностью, если индивидуальная обработка аудиообъектов второго типа будет передана процессору аудиосигналов и не будет выполняться одновременно с сепарацией первой аудиоинформации и второй аудиоинформации. Предпочтительный вариант осуществления декодера аудиосигнала выполнен с возможностью формирования представления сигнала повышающего микширования на основании представления сигнала понижающего микширования, объектно-ориентированной параметрической информации и остаточной (разностной) информации, относящейся к подмножеству аудиообъектов, отображенных в представлении сигнала понижающего микширования. В такой компоновке разделитель объектов выполнен с возможностью разложения представления сигнала понижающего микширования на первую аудиоинформацию, описывающую первую комбинацию из одного или более аудиообъектов (допустим, объектов переднего плана FGO) первого типа аудиообъектов, к которым относится остаточная (разностная) информация, и вторую аудиоинформацию, описывающую вторую комбинацию из одного или более аудиообъектов (скажем, объектов заднего плана BGO) второго типа аудиообъектов, к которым остаточная (разностная) информация не относится, исходя из представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации и остаточной (разностной) информации.
Это конструктивное решение основано на заключении, что особенно точная сепарация первой аудиоинформации, описывающей первую совокупность аудиообъектов первого типа аудиообъектов, и второй аудиоинформации, описывающей вторую совокупность аудиообъектов второго типа аудиообъектов, может быть выполнена путем использования остаточной (разностной) информации в дополнение к объектно-ориентированной параметрической информации. Выявлено, что использование только объектно-ориентированной параметрической информации во многих случаях ведет к искажениям, которые можно существенно снизить или даже полностью устранить благодаря применению остаточной (разностной) информации. Остаточная (разностная) информация описывает, допустим, ожидаемое остаточное искажение после выделения аудиообъекта первого типа аудиообъектов с использованием только объектно-ориентированной параметрической информации. Остаточную информацию обычно оценивает кодер аудиосигнала. С помощью остаточной информации может быть оптимизировано разделение аудиообъектов первого типа и аудиообъектов второго типа.
Это позволяет формировать первую аудиоинформацию и вторую аудиоинформацию с особенно хорошим выделением аудиообъектов первого типа аудиообъектов и аудиообъектов второго типа аудиообъектов, что, в свою очередь, позволяет добиваться высококачественной пространственной обработки аудиообъектов второго типа аудиообъектов при выполнении обработки второй аудиоинформации процессором аудиосигналов.
Таким образом, в предпочтительном варианте осуществления разделитель объектов выполнен с возможностью формирования первой аудиоинформации таким образом, что в ней аудиообъекты первого типа аудиообъектов выделены относительно аудиообъектов второго типа. Кроме того, разделитель объектов выполнен с возможностью формирования второй аудиоинформации таким образом, что в ней аудиообъекты второго типа аудиообъектов выделены относительно аудиообъектов первого типа.
Декодер аудиосигнала отличается тем, что выполняет двухэтапную обработку таким образом, что процессор аудиосигналов обрабатывает вторую аудиоинформацию следом за сепарацией первой аудиоинформации, описывающей первый набор из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации, описывающей второй набор из одного или более аудиообъектов второго типа аудиообъектов. В предпочтительном конструктивном варианте процессор аудиосигналов обрабатывает вторую аудиоинформацию в зависимости от объектно-ориентированной параметрической информации относительно аудиообъектов второго типа аудиообъектов и независимо от объектно-ориентированной параметрической информации относительно аудиообъектов первого типа. Следовательно, возможна раздельная обработка аудиообъектов первого типа аудиообъектов и аудиообъектов второго типа аудиообъектов.
В предпочтительном варианте технического решения разделитель объектов формирует первую аудиоинформацию и вторую аудиоинформацию, используя линейную комбинацию одного или более каналов понижающего микширования и одного или более остаточных каналов. В этом случае разделитель объектов предусматривает расчет параметров линейной комбинации в зависимости от параметров понижающего микширования для аудиообъектов первого типа аудиообъектов и в зависимости от канальных коэффициентов предсказания аудиообъектов первого типа аудиообъектов. При расчете коэффициентов предсказания каналов аудиообъектов первого типа аудиообъектов можно, например, учитывать аудиообъекты второго типа аудиообъектов как один совокупный аудиообъект. В силу этого процесс сепарации можно выполнять с достаточно низкой вычислительной сложностью почти независимо, например, от количества аудиообъектов второго типа аудиообъектов.
В предпочтительной аппаратной версии разделитель объектов предусматривает приложение матрицы аудиорендеринга к первой аудиоинформации с целью отображения сигналов объектов первой аудиоинформации в аудиоканалах представления аудиосигнала повышающего микширования. Это выполнимо благодаря тому, что разделитель объектов выполнен с возможностью экстракции отдельных аудиосигналов, обособленно отображающих аудиообъекты первого типа аудиообъектов. Следовательно, можно спроецировать сигналы объекта первой аудиоинформации непосредственно на аудиоканалы представления апмикс-аудиосигнала. В предпочтительном техническом исполнении аудиопроцессор предназначен для стереофонического преобразования второй аудиоинформации на основании параметров рендеринга, объектно-ориентированных данных ковариации и параметров даунмикса с формированием аудиоканалов представления аудиосигналов повышающего микширования.
Следовательно, стереообработка аудиообъектов второго типа аудиообъектов выполняется отдельно от сортировки аудиообъектов первого типа аудиообъектов и аудиообъектов второго типа аудиообъектов. Таким образом, на эффективность разделения аудиообъектов первого типа и аудиообъектов второго типа стереофоническое преобразование не влияет (или не снижает ее), хотя, как правило, оно приводит к распределению аудиообъектов по множеству аудиоканалов без высокой степени разделения объектов, которое может быть достигнуто, например, с помощью разделителя объектов с использованием остаточной информации. В другом предпочтительном варианте реализации аудиопроцессор предусматривает выполнение последующей обработки (постпроцессинг) второй аудиоинформации в зависимости от параметров рендеринга, объектно-ориентированных данных ковариации и параметров понижающего микширования. Такая форма постпроцессинга обеспечивает пространственную расстановку аудиообъектов второго типа аудиообъектов в композиции аудиосцены. Однако, благодаря каскадному подходу вычислительная трудоемкость для аудиопроцессора сохраняется на достаточно невысоком уровне, так как аудиопроцессор не должен учитывать объектно-ориентированную параметрическую информацию, относящуюся к аудиообъектам первого типа аудиообъектов.
Более того, аудиопроцессор рассчитан на выполнение многих разновидностей обработки, таких, например, как моно-бинауральное преобразование, моностереофоническое преобразование, стерео-бинауральное или стерео-стерео преобразование.
В предпочтительном варианте конструктивного решения разделитель объектов выполнен с возможностью обработки аудиообъектов второго типа, не имеющих сопутствующей остаточной информации, в виде единого аудиообъекта. Более того, процессор аудиосигналов предусматривает учет объектно-ориентированных параметров рендеринга для выверки соотношения компонент объектов второго типа аудиообъектов в структуре представления сигнала повышающего микширования. Таким образом, разделитель объектов воспринимает аудиообъекты второго типа аудиообъектов как один аудиообъект, что существенно снижает вычислительную сложность для разделителя объектов и наряду с этим формирует уникальную остаточную информацию, которая не связана с параметрами рендеринга аудиообъектов второго типа аудиообъектов. В предпочтительном конструктивном варианте разделитель объектов выполнен с возможностью расчета общего показателя разности уровней объектов для множества аудиообъектов второго типа аудиообъектов. Расчет общей разности уровней объектов выполняется разделителем объектов с целью вычисления коэффициентов предсказания каналов. При этом разделитель объектов предусматривает использование коэффициентов предсказания каналов с целью формирования одного или двух аудиоканалов для представления второй аудиоинформации. Чтобы получить обобщенное значение разности уровней объектов разделитель аудиообъектов может эффективно оперировать с аудиообъектами второго типа как с единым аудиообъектом. Разделитель объектов выполнен с возможностью вычисления общего значения разности уровней множества аудиообъектов второго типа аудиообъектов и применения этого общего значения разности уровней объектов для вычисления элементов матрицы детализации энергетического режима. Разделитель объектов использует матрицу детализации энергетического режима для формирования одного или более аудиоканалов представления второй аудиоинформации. И вновь, общее значение разности уровней объектов рационализирует совокупную обработку аудиообъектов второго типа разделителем объектов.
В предпочтительном конструктивном решении разделитель объектов выполнен с возможностью селективного расчета общего значения межобъектной корреляции аудиообъектов второго типа в зависимости от объектно-ориентированной параметрической информации, если присутствуют два аудиообъекта второго типа аудиообъектов, или установления на ноль значения межобъектной корреляции аудиообъектов второго типа, если присутствует больше или меньше, чем два аудиообъекта второго типа аудиообъектов.
Разделитель объектов использует общее значение межобъектной корреляции аудиообъектов второго типа аудиообъектов с целью формирования одного или более аудиоканалов представления второй аудиоинформации. При данном подходе значение межобъектной корреляции задействуется, если оно доступно с высокой вычислительной эффективностью, то есть, если присутствуют два аудиообъекта второго типа аудиообъектов. В иных случаях расчет значений межобъектной корреляции вычислительно трудоемко. В силу этого, с точки зрения слухового впечатления и вычислительной стоимости был найден целесообразный компромисс, это - установление на ноль значения межобъектной корреляции аудиообъектов второго типа аудиообъектов, когда в наличии имеется больше или меньше двух аудиообъектов второго типа.
В предпочтительном варианте реализации процессор аудиосигналов характеризуется тем, что преобразует вторую аудиоинформацию в зависимости от (по меньшей мере части) объектно-ориентированной параметрической информации с получением преобразованного представления аудиообъектов второго типа аудиообъектов в виде обработанной версии второй аудиоинформации. В этом случае подобное преобразование может быть выполнено независимо от аудиообъектов первого типа аудиообъектов.
В предпочтительной версии исполнения разделитель объектов характеризуется тем, что обрабатывает вторую аудиоинформацию таким образом, что вторая аудиоинформация описывает более двух аудиообъектов второго типа аудиообъектов. Устройства, выполненные в соответствии с изобретением, обеспечивают гибкое регулирование количества аудиообъектов второго типа аудиообъектов, чему в значительной степени способствует каскадная схема обработки.
В предпочтительном конструктивном решении разделитель объектов характеризуется тем, что формирует в виде второй аудиоинформации представление одноканального аудиосигнала или представление двухканального аудиосигнала, отображающее более двух аудиообъектов второго типа аудиообъектов. Выделение одного или двух каналов аудиосигнала разделитель объектов выполняет с низкой вычислительной сложностью. В частности, трудоемкость вычисления для разделителя объектов может сохраняться на значительно более низком уровне, чем в случае, когда разделитель объектов должен обсчитать более двух аудиообъектов второго типа аудиообъектов. Однако, исследования показали, что в вычислительном отношении эффективным представление аудиообъектов второго типа является при использовании одного или двух каналов аудиосигнала.
Процессор аудиосигналов характеризуется тем, что принимает вторую аудиоинформацию и обрабатывает вторую аудиоинформацию, исходя из (по меньшей мере, части) объектно-ориентированной параметрической информации, учитывая объектно-ориентированную параметрическую информацию о более, чем двух аудиообъектах второго типа аудиообъектов. Отсюда следует, что индивидуально-объектную обработку выполняет аудиопроцессор при том, что такую индивидуально-объектную обработку аудиообъектов второго типа аудиообъектов не выполняет разделитель объектов.
В предпочтительном конструктивном решении аудиодекодер выполнен с возможностью извлечения из данных о конфигурации, входящих в состав объектно-ориентированной параметрической информации, суммарного значения количества объектов и значения количества объектов переднего плана. Аудиодекодер также выполнен с возможностью вычисления количества аудиообъектов второго типа аудиообъектов путем расчета разности чисел суммарного количества объектов и объектов переднего плана. Благодаря этому достигается эффективное выведение числа аудиообъектов второго типа аудиообъектов. При этом такой подход обеспечивает высокую степень гибкости в отношении количества аудиообъектов второго типа аудиообъектов.
В предпочтительной аппаратной версии разделитель объектов использует объектно-ориентированную параметрическую информацию о Neao аудиообъектах первого типа аудиообъектов для формирования первой аудиоинформации путем выделения Neao аудиосигналов, представляющих (предпочтительно - индивидуально) Neao аудиообъектов первого типа, и для формирования второй аудиоинформации путем выделения одного или двух аудиосигналов, представляющих N-Neao аудиообъектов второго типа аудиообъектов, обрабатывая эти N-Neao аудиообъектов второго типа как одиночный одноканальный или двухканальный аудиообъект. Процессор аудиосигналов выполнен с возможностью индивидуального преобразования N-Neao аудиообъектов, представленных одним или двумя аудиосигналами из второй аудиоинформации, с использованием объектно-ориентированной параметрической информации о N-Neao аудиообъектах второго типа аудиообъектов. Таким образом, сепарация аудиообъектов первого типа и аудиообъектов второго типа отделена от последующей обработки аудиообъектов второго типа аудиообъектов.
В заявляемом изобретении разработан способ формирования представления сигнала повышающего микширования на основании представления сигнала понижающего микширования и объектно-ориентированной параметрической информации.
Кроме того, заявляемое изобретение реализуется в виде компьютерной программы для осуществления названного способа.
Краткое описание фигур
Конструктивные решения по заявляемому изобретению далее будут рассмотрены со ссылкой на прилагаемые фигуры, где:
на фиг.1 представлена принципиальная блочная схема реализации декодера аудиосигнала в соответствии с данным изобретением;
на фиг.2 представлена принципиальная блочная схема варианта исполнения декодера аудиосигнала в соответствии с данным изобретением;
на фиг.3а и 3b представлены принципиальные блочные схемы разностного процессора, способного выполнять функции сепаратора объектов согласно изобретению;
на фиг.4а-4е представлены принципиальные блочные схемы процессоров аудиосигналов, которые могут быть использованы в декодере аудиосигналов в соответствии с изобретением;
на фиг.4f дана принципиальная блочная схема реализации транскодера SAOC;
на фиг.4g дана принципиальная блочная схема реализации декодера SAOC;
на фиг.5а представлена принципиальная блочная схема реализации декодера аудиосигнала в соответствии с данным изобретением;
на фиг.5b представлена принципиальная блочная схема варианта исполнения декодера аудиосигнала в соответствии с данным изобретением;
на фиг.6а дана таблица моделей тестов на прослушивание;
на фиг.6b дана таблица тестируемых систем;
на фиг.6с дана таблица позиций, испытываемых на прослушивание, и матриц аудиорендеринга;
на фиг.6d графически представлены средние показатели результатов теста на прослушивание звуковоспроизведения типа караоке/соло по методике MUSHRA;
на фиг.6е графически представлены средние показатели результатов теста на прослушивание звуковоспроизведения классического типа по методике MUSHRA;
на фиг.7 представлена блок-схема способа формирования представления сигнала повышающего микширования согласно изобретению;
на фиг.8 показана принципиальная блочная схема стандартной системы MPEG SAOC;
на фиг.9а показана принципиальная блочная схема стандартной системы SAOC с раздельными декодером и микшером;
на фиг.9b показана принципиальная блочная схема стандартной системы SAOC с объединенными декодером и микшером; и
на фиг.9с показана принципиальная блочная схема стандартной системы SAOC с использованием транскодера SAOC в MPEG.
Подробное техническое описание
1. Декодер аудиосигнала на фиг.1
Фиг.1 отображает принципиальную блочную схему конструктивного решения декодера аудиосигнала 100 в соответствии с заявляемым изобретением.
Декодер аудиосигнала 100 предназначен для приема объектно-ориентированной параметрической информации 110 и представления сигнала понижающего микширования (даунмикс-сигнала) 112. Декодер аудиосигнала 100 предназначен для формирования представления сигнала повышающего микширования (апмикс-сигнала) 120 на основании представления сигнала понижающего микширования 772 и объектно-ориентированной параметрической информации 110. Декодер аудиосигнала 100 включает в свою компоновку разделитель объектов 130, предназначенный для разложения даунмикс-сигнала 112 на первую аудиоинформацию 132, описывающую первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и вторую аудиоинформацию 134, описывающую вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, исходя из представления даунмикс-сигнала 112 с использованием, по меньшей мере, части объектно-ориентированной параметрической информации 110. Декодер аудиосигнала 100 также включает в свою компоновку процессор аудиосигнала 140, предназначенный для приема второй аудиоинформации 134 и обработки второй аудиоинформации, исходя из, по меньшей мере, части объектно-ориентированной параметрической информации 112, с формированием на выходе обработанной версии 142 второй аудиоинформации 134. Декодер аудиосигнала 100 также включает в свою компоновку комбинатор аудиосигнала 150, предназначенный для объединения первой аудиоинформации 132 с обработанной версией 142 второй аудиоинформации 134 с формированием на выходе представления сигнала повышающего микширования (апмикс-сигнала) 120.
Декодер аудиосигнала 100 выполнен с возможностью каскадной обработки представления сигнала понижающего микширования, когда даунмикс-сигнал отображает аудиообъекты первого типа аудиообъектов и аудиообъекты второго типа аудиообъектов в смешанном виде.
Осуществляя обработку, разделитель объектов 130 на первом этапе отделяет вторую аудиоинформацию, описывающую вторую комбинацию аудиообъектов второго типа аудиообъектов, от первой аудиоинформации 132, описывающей первую комбинацию аудиообъектов первого типа аудиообъектов, используя объектно-ориентированную параметрическую информацию 110. При этом вторая аудиоинформация 134, как правило, представляет собой аудиоданные (например, одноканальный аудиосигнал или двухканальный аудиосигнал), описывающие аудиообъекты второго типа аудиообъектов в смешанном виде. На втором этапе обработки процессор аудиосигналов 140 обрабатывает вторую аудиоинформацию 134, исходя из объектно-ориентированной параметрической информации. Следовательно, процессор аудиосигналов 140 выполнен с возможностью индивидуально-объектной обработки или отображения аудиообъектов второго типа аудиообъектов, описанных во второй аудиоинформации 134, причем, разделитель объектов 130, как правило, такую обработку не выполняет.
Таким образом, при том, что разделитель объектов 130 преимущественно не задействуется для индивидуальной обработки аудиообъектов второго типа, аудиообъекты второго типа, тем не менее, проходят обязательную индивидуальную обработку (например, воспроизводятся их отличительные признаки) на втором этапе обработки, выполняемом процессором аудиосигналов 140. Отсюда следует, что сепарация аудиообъектов первого типа аудиообъектов и аудиообъектов второго типа аудиообъектов, выполняемая разделителем объектов 130, отделена от индивидуально-объектной обработки аудиообъектов второго типа аудиообъектов, которую в дальнейшем выполняет процессор аудиосигналов 140. Соответственно, обработка, производимая разделителем объектов 130, по существу, независима от количества аудиообъектов второго типа аудиообъектов. Более того, формат (например, одноканальный аудиосигнал или двухканальный аудиосигнал) второй аудиоинформации 134, как правило, не зависит от количества аудиообъектов второго типа аудиообъектов. Из этого следует, что количество аудиообъектов второго типа аудиообъектов может варьироваться без необходимости модификации схемы разделителя объектов 130. Другими словами, аудиообъекты второго типа аудиообъектов обрабатываются как одиночный (например, одноканальный или двухканальный) аудиообъект, для которого разделитель объектов 130 выводит общую объектно-ориентированную параметрическую информацию (например, общий показатель разности уровней объектов для одного или двух аудиоканалов).
Таким образом, как следует из фиг.1, декодер аудиосигнала 100 характеризуется тем, что предусматривает обработку различного количества аудиообъектов второго типа аудиообъектов без необходимости внесения конструктивных изменений в разделитель объектов 130. Более того, разделитель объектов 130 и процессор аудиосигналов 140 могут использовать различные алгоритмы обработки аудиообъектов. Так, в частности, особенно качественная сепарация аудиообъектов достигается разделителем объектов 130 при использовании остаточной информации, которая играет роль служебной информации для совершенствования дифференциации объектов. И наоборот, процессор аудиосигналов 140 может выполнять индивидуально-объектную обработку, не используя остаточную информацию. Например, для акустического отображения различных аудиообъектов процессор аудиосигналов 140 может быть реализован с возможностью выполнения стандартного преобразования аудиосигнала в формате пространственного кодирования аудиообъекта (SAOC).
2. Декодер аудиосигнала на фиг.2
Далее представлено описание одного из конструктивных решений декодера аудиосигнала 200 в соответствии с заявляемым изобретением. Принципиальная блочная схема такого декодера аудиосигнала 200 дана на фиг.2. Аудиодекодер 200 предназначен для приема сигнала понижающего микширования (даунмикс-сигнала) 210, так называемого битстрима SAOC 212, характеристик матрицы аудиорендеринга 214 и в качестве опции - параметров передаточной функция головы слушателя (функции HRTF) 216. Кроме того, аудиодекодер 200 предназначен для формирования выходного сигнала/даунмикс-сигнала в формате MPS 220 и (как опция) битстрима формата MPS [MPEG Surround] 222.
2.1. Входные и выходные сигналы декодера аудиосигнала 200
Ниже дана детализация разновидностей входных и выходных сигналов аудиодекодера 200.
Микшированный с понижением сигнал 210 может представлять собой, допустим, одноканальный или двухканальный аудиосигнал. Даунмикс-сигнал 210, например, может быть извлечен из кодированного представления сигнала понижающего микширования.
Двоичный поток пространственного кодирования аудиообъектов (битстрим SAOC) 212 может, в частности, включать в себя объектно-ориентированную параметрическую информацию. Предположим, битстрим SAOC 212 может содержать данные разности уровней объектов, например, в виде параметров OLD, данные межобъектной корреляции, например, в виде показателей IOC.
Дополнительно битстрим SAOC 212 может содержать информацию о понижающем микшировании, описывающую формирование даунмикс-сигналов в процессе микширования с понижением множества сигналов аудиообъектов. Битстрим SAOC, скажем, может включать в себя такие параметры, как коэффициент усиления при понижающем микшировании DMG и (произвольно) разности уровней каналов понижающего микширования DCLD.
Данные матрицы аудиорендеринга 214, например, могут задавать порядок звукоотображения аудиодекодером различных аудиообъектов. Предположим, информация матрицы аудиорендеринга (звукоотображения) 214 может описывать распределение аудиообъекта по одному или более каналов выходного/MPS даунмикс-сигнала 220.
Диспозитивная параметрическая информация относительно передаточной функции слухового тракта (функции HRTF) 216 может специфицировать передаточную функцию для генерирования бинаурального сигнала для наушников.
Выходной/MPEG-Surround микшированный с понижением сигнал (для краткости также обозначаемый как „выходной/MPS даунмикс-сигнал") 220 представляет один или более аудиоканалов, например, в виде аудиосигнала во временной области или аудиосигнала в частотной области. Происходит формирование представления сигнала повышающего микширования в возможной комбинации с битстримом MPEG-Surround (битстримом MPS) 222, который содержит параметры MPEG Surround, описывающие распределение выходного/MPS даунмикс-сигнала по множеству аудиоканалов.
2.2. Конструкция и функции декодера аудиосигнала 200
Далее более подробно рассмотрена компоновка декодера аудиосигнала 200, реализованного с возможностью выполнять функции транскодера SAOC или функции декодера SAOC. Декодер аудиосигнала 200 включает в свой состав процессор понижающего микширования 230, который даунмикс-сигнал 210 и на его основе генерирует выходной/MPS даунмикс-сигнал 220. Процессор понижающего микширования 230 также принимает, по меньшей мере, часть информации битстрима SAOC 212 и, по меньшей мере, часть информации матрицы аудиорендеринга 214. Дополнительно процессор понижающего микширования 230 может принимать обработанную параметрическую информацию SAOC 240 от процессора параметров 250.
Процессор параметров 250 принимает информацию битстрима SAOC 212, информацию матрицы аудиорендеринга 214 и в качестве опции - параметрические данные передаточной функции слухового тракта 260 и на их базе генерирует битовый поток MPEG Surround 222, несущий параметры формата MPEG Surround (если таковые необходимы, как, например, в случае работы в режиме транскодирования). Дополнительно процессор параметров 250 формирует на выходе обработанную информацию SAOC 240 (если такая обработанная информация SAOC необходима).
Ниже конструкция и функциональные возможности процессора понижающего микширования 230 описаны более детально.
Процессор понижающего микширования 230 включает в свою схему разностный процессор 260, предназначенный для приема даунмикс-сигнала 210 и генерации на его основе первого сигнала аудиообъектов 262, описывающего так называемые „существенные" аудиообъекты (БАО), которые можно рассматривать как аудиообъекты первого типа аудиообъектов. Первый сигнал аудиообъекта может содержать один или более аудиоканалов и может рассматриваться как первая аудиоинформация. Разностный процессор 260 предназначен также для генерации второго сигнала аудиообъекта 264, описывающего аудиообъекты второго типа аудиообъектов, которые могут рассматриваться как вторая аудиоинформация. Второй сигнал аудиообъекта 264 может содержать один или более каналов и, как правило, включает в себя один или два аудиоканала, отображающие множество аудиообъектов. Обычно второй сигнал аудиообъектов может описывать даже больше, чем два аудиообъекта второго типа аудиообъектов.
Процессор понижающего микширования 230, кроме того, включает в свой состав препроцессор понижающего микширования SAOC 270, который принимает второй сигнал аудиообъекта 264 и на его основе генерирует обработанную версию 272 второго сигнала аудиообъекта 264, который может рассматриваться как обработанная версия второй аудиоинформации.
Процессор понижающего микширования 230 также имеет в своем составе комбинатор аудиосигнала 280, предназначенный для приема первого сигнала аудиообъекта 262 и обработанной версии 272 второго сигнала аудиообъекта 264 и для формирования на их основе выходного/MPS даунмикс-сигнала 220, который можно рассматривать отдельно или вместе с (произвольным) соответствующим битстримом MPEG Surround 222 как представление сигнала повышающего микширования.
Далее будут рассмотрены функции отдельных элементов процессора понижающего микширования 230.
Разностный процессор 260 реализован с целью раздельного формирования первого сигнала аудиообъектов 262 и второго сигнала аудиообъектов 264. Для этого разностный процессор 260 может использовать хотя бы часть информации битстрима SAOC 212. Например, разностный процессор 260 выполнен с возможностью оценивания объектно-ориентированной параметрической информации о аудиообъектах первого типа аудиообъектов, то есть - так называемых „существенных аудиообъектах" ЕАО. Кроме того, разностный процессор 260, как правило, выполнен с возможностью извлечения полной информации, описывающей аудиообъекты второго типа аудиообъектов, в частности, так называемые „несущественные аудиообъекты". Разностный процессор 260 предусматривает также оценивание остаточной информации, содержащейся в потоке данных SAOC 212, для сепарации существенных аудиообъектов (ЕАО) (аудиообъектов первого типа аудиообъектов) и несущественных аудиообъектов (аудиообъектов второго типа аудиообъектов). Остаточная информация, например, может содержать в кодированном виде разностный сигнал временной области, который будет использован для особо точного разделения существенных аудиообъектов и несущественных аудиообъектов. В дополнение к этому разностный процессор 260 рассчитан на применение такой опции, как оценивание, по меньшей мере, части информации матрицы аудиорендеринга 214, например, для распределения существенных аудиообъектов по аудиоканалам первого сигнала аудиообъекта 262.
В схему препроцессора понижающего микширования SAOC 270 включен перераспределитель каналов 274, предназначенный для приема одного или более аудиоканалов второго сигнала аудиообъекта 264 и формирования на их основе одного или более (как правило, двух) аудиоканалов преобразованного второго сигнала аудиообъектов 272. В дополнение к этому в схему препроцессора понижающего микширования SAOC 270 введен генератор декоррелированного сигнала 276, предназначенный для приема одного или более аудиоканалов второго сигнала аудиообъекта 264 и генерации на их основе одного или более декоррелированных сигналов 278а, 278b, которые затем суммируют с сигналами, полученными от перераспределителя каналов 274, с формированием обработанной версии 272 второго сигнала аудиообъекта 264.
Другие особенности процессора понижающего микширования SAOC будут рассмотрены ниже.
Комбинатор аудиосигнала 280 предназначен для сведения первого сигнала аудиообъектов 262 с обработанной версией 272 второго сигнала аудиообъектов. С этой целью может быть применено сведение каналов. В результате этого формируется выходной/MPS даунмикс-сигнал 220.
Параметрический процессор 250 реализован с целью подбора (в качестве опции) параметров формата MPEG Surround, составляющих битовый поток MPEG Surround 222 в структуре представления сигнала повышающего микширования, что выполняется на базе потока данных SAOC с учетом информации матрицы аудиорендеринга 214 и, вспомогательно, параметрических показателей функции моделирования восприятия акустической среды HRTF 216. Иными словами, процессор параметров SAOC 252 реализован с целью преобразования объектно-ориентированной параметрической информации, отраженной в данных битстрима SAOC 212, в информацию о параметрах каналов, описываемой битстримом MPEG Surround 222.
Дальше кратко рассмотрим компоновку транскодера/декодера SAOC на фиг.2. Пространственное кодирование аудиообъектов (SAOC) представляет собой алгоритм параметрического кодирования множественных объектов. Он разработан с целью передачи некоторого количества аудиообъектов с аудиосигналом (например, с даунмикс-аудиосигналом 210), разбитым на М каналов. Вместе с таким обратно совместимым микшированным с понижением сигналом передаются параметры объекта (например, с использованием информации битстрима SAOC 212), которые позволяют восстанавливать и оперировать исходными сигналами объекта. Кодер SAOC (здесь не показан) микширует с понижением вводимые в него сигналы объектов и на выходе генерирует параметры этих объектов. Количество объектов, которые могут быть обработаны, в принципе, не ограничено. Параметры объектов квантуют и эффективно кодируют в поток двоичных данных пространственного кодирования аудиообъектов (в битстрим SAOC) 212. Даунмикс-сигнал 210 сжимают и пересылают без необходимости модификации существующих кодеров и информационной инфраструктуры. Параметры объектов, или служебную информацию SAOC, пересылают по низкоскоростному вспомогательному каналу данных, например, со вспомогательной частью данных битового потока понижающего микширования.
На стороне декодера входные объекты реконструируют и распределяют между определенным числом каналов воспроизведения. Параметры рендеринга, содержащие показатели уровня воспроизведения и стереопозиции каждого объекта, могут быть установлены пользователем или извлечены из битстрима SAOC (например, как заданные данные). Данные рендеринга могут изменяться во времени. Сценарии звучания на выходе находятся в диапазоне от монофонического до многоканального (например, в формате 5.1) и не зависят как от количества входных объектов, так и от количества каналов понижающего микширования. Предусматривается также бинауральный рендеринг объектов, включая азимутальные и вертикальные перемещения виртуальных звуковых объектов. В качестве опции предусмотрен интерфейс акустических эффектов, дающий возможность расширенного манипулирования сигналами объектов помимо регулировки уровня и панорамирования.
Сами объекты могут представлять собой монофонические сигналы, стереофонические сигналы, как и многоканальные сигналы (скажем, 5.1 каналов). Типичными конфигурациями понижающего микширования являются моно- и стереофоническая.
Дальше даны пояснения относительно базовой компоновки транскодера/декодера SAOC на фиг.2. Описываемый здесь модуль транскодера/декодера SAOC способен действовать и как автономный декодер, и как перекодировщик (транскодер) из SAOC в битстрим MPEG Surround в зависимости от предполагаемой конфигурации выходного канала. Первый рабочий режим предусматривает такие конфигурации выходного сигнала, как моно, стерео или бинауральную при двух выходных каналах. В этом первом случае модуль SAOC может работать в режиме декодера, а на выходе модуля SAOC будет формироваться импульсно-кодово-модулированный выходной сигнал (ИКМ-вывод). В первом случае декодер формата MPEG Surround не нужен. Скорее, представление сигнала повышающего микширования может содержать только выходной сигнал 220, в то время как битстрим MPEG Surround 222 может быть опущен. Во втором случае выходной сигнал имеет многоканальную конфигурацию с более, чем двумя выходными каналами. Модуль SAOC может работать в режиме транскодера. В этом, втором, случае на выходе модуля SAOC может быть сгенерирован как даунмикс-сигнал 220, так и битстрим MPEG Surround 222, как показано на фиг.2. Можно сделать вывод, что декодер формата MPEG Surround нужен для формирования конечного представления аудиосигнала на выходе громкоговорителей.
Фиг.2 отображает базовую архитектуру транскодера/декодера SAOC. Разностный процессор 216 выбирает существенные аудиообъекты из входящего микшированного с понижением сигнала 210, используя остаточную информацию битстрима SAOC 212. Препроцессор даунмикс-сигнала 270 обрабатывает обычные аудиообъекты (например, не являющиеся существенными аудиообъектами, т.е., аудиообъекты, для которых в битстриме SAOC 212 не содержится разностная информация). Существенные аудиообъекты (представленные первым сигналом аудиообъектов 262) и обработанные обычные аудиообъекты (представленные, например, обработанной версией 272 второго сигнала аудиообъектов 264) сводятся в выходной сигнал 220 при работе в режиме SAOC-декодера или в даунмикс-сигнал MPEG Surround 220 при режиме транскодера SAOC. Детализация блоков обработки дана ниже.
3. Архитектура и функции процессора разностных данных и процессора энергетических режимов
Далее подробно рассмотрен процессор разностных данных, который может, например, выполнять функции разделителя объектов 130 декодера аудиосигнала 100 или разностного процессора 260 декодера аудиосигнала 200. Для этого на фиг.3а и 3b даны принципиальные блочные схемы такого процессора разностных данных 300, который может быть использован место разделителя объектов 130 или разностного процессора 260. Фиг.3а менее детализирована, чем фиг.3b. Тем не менее, приведенное ниже описание применимо как к процессору разностных данных 300 на фиг.3а, так и к процессору разностных данных 380 на фиг.3b.
Процессор разностных данных 300 реализован с целью приема даунмикс-сигнала SAOC 310, который может быть эквивалентным представлению сигнала понижающего микширования 112 на фиг.1 или представлению сигнала понижающего микширования 210 на фиг.2. На основе принятого сигнала процессор разностных данных 300 формирует первую аудиоинформацию 320, описывающую один или более существенных аудиосигналов, которая, допустим, может быть эквивалентной первой аудиоинформации 132 или первому сигналу аудиообъектов 262. Кроме того, процессор разностных данных 300 может сформировать вторую аудиоинформацию 322, описывающую один или более других аудиообъектов (скажем, несущественные аудиообъекты, для которых разностная информация отсутствует), причем, вторая аудиоинформация 322 может быть эквивалентной второй аудиоинформации 134 или второму сигналу аудиообъекта 264.
Процессор разностных данных 300 включает в себя блок 1-B-N/2-B-N (блок OTN/TTN) 330, который принимает даунмикс-сигнал SAOC 310 и который также принимает данные и разности SAOC 332. Наряду с этим, блок 1-B-N/2-B-N 330 формирует сигнал существенных аудиообъектов 334, который описывает существенные аудиообъекты (ЕАО), содержавшиеся в даунмикс-сигнале SAOC 310. Кроме того, блок 1-B-N/2-B-N 330 формирует вторую аудиоинформацию 322. Процессор разностных данных 300 также включает в себя блок рендеринга 340, который принимает сигнал существенного аудиообъекта 334 и данные матрицы аудиорендеринга 342, используя которые формирует первую аудиоинформацию 320.
Далее рассмотрим детали процесса обработки существенных аудиообъектов (процесс ЕАО), выполняемого процессором разностных данных 300.
3.1. Введение в описание действия процессора разностных данных 300
Говоря о функциональных возможностях процессора разностных данных 300, следует обратить внимание на то, что технология SAOC позволяет индивидуально регулировать усиление/ослабление уровней нескольких аудиообъектов без существенного снижения конечного качества звука только в весьма ограниченных пределах. Сценарий специального приложения „караоке" требует полного (или почти полного) подавления определенной части объектов, как правило - ведущего вокала, при сохранении неизменным воспринимаемого качества звукового сопровождения сцены.
Типичный случай прикладного применения содержит до четырех существенных сигналов аудиообъектов (ЕАО), которые могут отображать, например, два независимых стереофонических объекта (предположим, два отдельных стереообъекта, которые предполагается удалить на стороне декодера).
Следует учитывать, что существенные аудиообъекты улучшенного качества (один или более) (или, точнее, составляющие аудиосигналов, соотнесенные с существенными аудиообъектами) встроены в структуру даунмикс-сигнала SAOC 310. Как правило, составляющие аудиосигнала, соотнесенные с (одним или более) существенными аудиообъектами, смешиваются при понижающем микшировании аудиосигнала на стороне аудиокодера с составляющими аудиосигналов других акустических объектов, не являющихся существенными аудиообъектами. Опять же, необходимо учитывать, что составляющие аудиосигналов множества существенных аудиообъектов обычно, кроме прочего, перекрываются или смешиваются аудиокодером при понижающем микшировании.
3.2. Архитектура SOAC, поддерживающая существенные аудиообъекты
Дальше дана детализация процессора разностных данных 300. Обработка существенного аудиообъекта подразумевает задействование блоков 1-в-N или 2-в-N в зависимости от режима понижающего микширования SAOC. Блок преобразования 1-в-N (OTN) предназначен для сигнала понижающего мономикширования, а блок преобразования 2-в-N (TTN) предназначен для сигнала понижающего стереомикширования 310. Оба эти блока представляют собой унифицированную и расширенную модификацию блока 2-в-2 (блока ТТТ), известного из стандарта ISO/IEC 23003-1:2007. Кодер смешивает ординарные и ЕАО сигналы в сигнал понижающего микширования (даунмикс). Блоки преобразования OTN-1/TTN-1 (блоки обратного преобразования 1-в-N или 2-в-N) используются для генерации и кодирования соответствующих разностных сигналов.
Блоки OTN/TTN 330 восстанавливают ординарные и ЕАО сигналы из даунмикса 310, используя служебную информацию SAOC и встроенные разностные сигналы. Восстановленные ЕАО (описываемые сигналом существенных аудиообъектов 334) вводятся в блок рендеринга 340, который представляет (или формирует), произведение соответствующей матрицы аудиорендеринга (описанной данными матрицы аудиорендеринга 342) и результирующим выходом блока OTN/TTN (1-в-N/2-в-N). Ординарные аудиообъекты (описанные во второй аудиоинформации 322) вводятся в препроцессор понижающего микширования SAOC, например, в препроцессор даунмикс-сигнала SAOC 270, для последующей обработки. На фиг.3a и 3b изображена общая схема конструктивного решения, т.е. архитектура, процессора разностных данных.
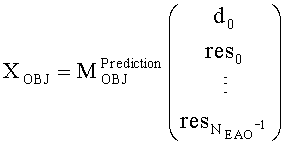
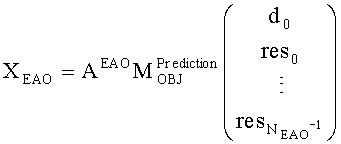
Выходные сигналы 320 322 процессора разностных данных вычисляют как
XOBJ=MOBJXres,
XEAO=AEAOMEAOXres,
где XOBJ представляет даунмикс-сигнал ординарных аудиообъектов (т.е. не ЕАО), а XEAO - преобразованный рендерингом выходной сигнал ЕАО для режима декодирования SAOC или соответствующий даунмикс-сигнал ЕАО для режима транскодирования SAOC.
Процессор разностных данных может работать в режиме предсказания (используя разностную информацию) или в энергетическом режиме (без разностной информации).
Расширенный входной сигнал Xres определяют как:

Здесь, X может обозначать, например, один или более каналов представления сигнала понижающего микширования 310, которые могут передаваться с битстримом, представляющим многоканальный аудиоконтент. res может обозначать один или более разностных сигналов, которые могут быть описаны битовым потоком, представляющим многоканальный аудиоконтент.
Преобразование OTN/TTN представлено матрицей М, а процессор ЕАО - матрицей AEAO.
Матрицу М преобразования OTN/TTN определяют в соответствии с рабочим режимом ЕАО (т.е. - предсказания или энергетическим) как
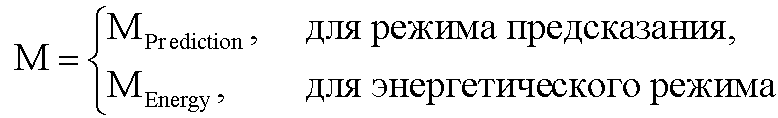
Матрица М преобразования OTN/TTN представлена как
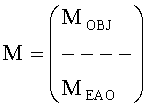 ,
,
где матрица MOBJ относится к ординарным аудиообъектам (т.е. - не ЕАО, а матрица MEAO - к существенным аудиообъектам (ЕАО).
В некоторых реализациях один или более многоканальных объектов заднего плана (МВО) могут быть обработаны процессором разностных данных 300 таким же образом.
Многоканальный объект заднего плана (МВО) представляет собой моно- или стереодаунмикс формата MPS, являющийся частью даунмикс-сигнала SAOC. В противоположность использованию индивидуальных объектов SAOC для каждого канала многоканального сигнала использование МВО позволяет задействовать SAOC для более эффективной обработки многоканального объекта. В случае использования МВО массив протокола SAOC сокращается, поскольку параметры SAOC многоканального объекта заднего плана МВО связаны только с даунмикс-каналами, а не со всеми каналами повышающего микширования.
3.3 Прочие определения
3.3.1 Размерность сигналов и параметров
Далее следует краткое толкование размерности сигналов и параметров, чтобы внести ясность относительно частоты выполнения расчетов.
Аудиосигналы определяют для каждого кванта времени n и каждого гибридного поддиапазона (который может быть частотной подполосой) k. Соответствующие параметры SAOC задают для каждого параметрического кванта времени 1 и полосы преобразования m. Последующее сопоставление гибридной и параметрической областей выполняют согласно таблице А.31 ISO/IEC 23003-1:2007. Таким образом, все вычисления выполняют с учетом некоторых коэффициентов времени/диапазона, а каждая вводимая переменная заключает в себе соответствующие размерности.
Однако, в дальнейшем коэффициенты времени и частотной полосы будут иногда опущены для краткости системы обозначений.
3.3.2 Расчет матрицы AEAO
Матрицу AEAO предварительного рендеринга ЕАО определяют, исходя из количества выходных каналов (т.е. - моно, стерео или бинауральный), как

Матрицу 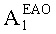 размерностью 1×NEAO и матрицу
размерностью 1×NEAO и матрицу 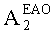 размерностью 2×NEAO определяют как
размерностью 2×NEAO определяют как
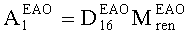 ,
, 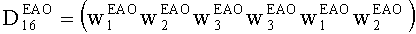 ,
,
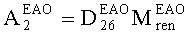 ,
,
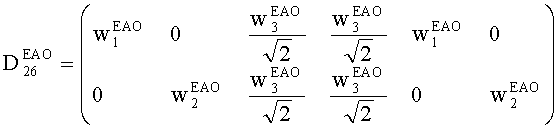 ,
,
где субматрица 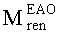 рендеринга соответствует построению ЕАО (и описывает желаемое распределение существенных аудиообъектов между каналами представления сигнала повышающего микширования).
рендеринга соответствует построению ЕАО (и описывает желаемое распределение существенных аудиообъектов между каналами представления сигнала повышающего микширования).
Значения 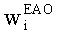 вычисляют в зависимости от данных рендеринга, связанных с существенными аудиообъектами, используя соответствующие элементы ЕАО и применяя уравнения из параграфа 4.2.2.1.
вычисляют в зависимости от данных рендеринга, связанных с существенными аудиообъектами, используя соответствующие элементы ЕАО и применяя уравнения из параграфа 4.2.2.1.
В случае бинаурального рендеринга матрицу 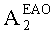 определяют с помощью уравнений, приведенных в параграфе 4.1.2, для которых соответствующая объектная бинауральная матрица аудиорендеринга содержит только элементы, относящиеся к ЕАО.
определяют с помощью уравнений, приведенных в параграфе 4.1.2, для которых соответствующая объектная бинауральная матрица аудиорендеринга содержит только элементы, относящиеся к ЕАО.
3.4 Расчет элементов OTN/TTN в разностном режиме
Дальше рассмотрим, как даунмикс-сигнал SAOC 310, который стандартно включает в себя один или два аудиоканала, проецируют на сигнал существенного аудиообъекта 334, который стандартно включает в себя один или более каналов существенных аудиообъектов, и отображают во второй аудиоинформации 322, которая, как правило, содержит один или два канала ординарных аудиообъектов.
Функциональные возможности блока 1-в-N или блока 2-в-N 330 могут быть реализованы, например путем матричного векторного умножения таким образом, чтобы вектор, описывающий каналы сигнала существенных аудиообъектов 334 и каналы второй аудиоинформации 322, был получен перемножением вектора, описывающего каналы даунмикс-сигнала SAOC 310, и (факультативно) одного или более разностных сигналов с матрицей MPrediction (предсказания) или MEnergy (энергии). Соответственно, определение матрицы MPrediction или MEnergy является важным шагом в выделении первой аудиоинформации 320 и второй аудиоинформации 322 из SAOC-даунмикса 310.
Если обобщить сказанное, процесс повышающего микширования OTN/TTN представлен или матрицей MPrediction для режима предсказания, или матрицей MEnergy для энергетического режима.
Процедура кодирования/декодирования на основе уровня энергии разработана для кодирования даунмикс-сигнала без сохранения формы волны. Таким образом, матрица повышающего микширования OTN/TTN для соответствующего энергетического режима не зависит от специфики формы колебания, а только описывает распределение относительной энергии входных аудиообъектов, что будет подробнее обсуждаться ниже.
3.4.1 Режим предсказания
Для режима предсказания задана матрица MPrediction, активизирующая информацию понижающего микширования из матрицы 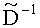 и данные СРС (коэффициентов предсказания канала) из матрицы C:
и данные СРС (коэффициентов предсказания канала) из матрицы C:
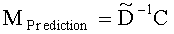 .
.
Что касается нескольких режимов SAOC, расширенная матрица понижающего микширования 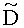 и матрица C коэффициента предсказания канала СРС демонстрируют приведенные ниже размерности и структуры.
и матрица C коэффициента предсказания канала СРС демонстрируют приведенные ниже размерности и структуры.
3.4.1.1 Режим понижающего стереомикширования (TTN):
Для режимов понижающего стереомикширования (TTN) (например, для случая понижающего стереомикширования на основе двух каналов ординарных аудиообъектов и NEAO каналов существенных аудиообъектов) (расширенная) матрица понижающего микширования 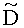 и матрица C коэффициента предсказания канала СРС могут быть образованы следующим образом:
и матрица C коэффициента предсказания канала СРС могут быть образованы следующим образом:
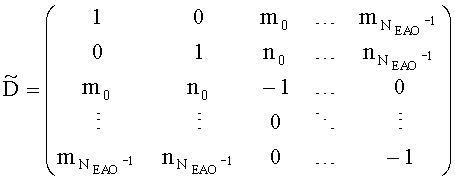
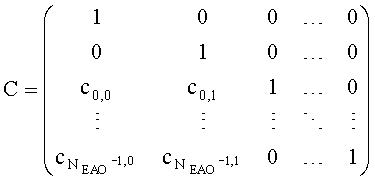
При понижающем стереомикшировании каждый EAOj имеет два СРС - cj,0 и cj,1, формируя матрицу С.
Выходные сигналы процессора разностных данных рассчитывают как
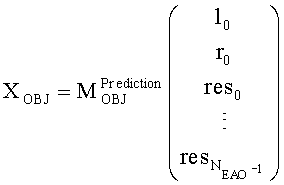
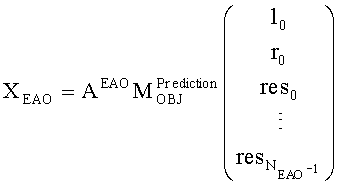
Соответственно, генерируются два сигнала yL, yR (представленные через XOBJ), которые отображают один или два или даже больше двух ординарных аудиообъектов (обозначаемых еще как нерасширяемые аудиообъекты). Кроме того, генерируется NEAO сигналов (представленных через XEAO), отображающих NEAO существенных аудиообъектов. Генерация этих сигналов осуществляется на базе двух даунмикс-сигналов SAOC 10, r0 и NEAO разностных сигналов от res0 до resNEAO-1, что будет закодировано в массиве служебной информации SAOC, например, как часть объектно-ориентированной параметрической информации.
Следует указать на то, что сигналы yL и yR могут быть эквивалентны сигналу 322, и что сигналы с y0,EAO по yNEAO-1, EAO (представленные XEAO) могут быть эквивалентны сигналам 320.
Матрица AEAO является матрицей аудиорендеринга (звукопостроения). Элементы матрицы AEAO могут описывать, например, распределение существенных аудиообъектов по каналам сигнала существенного аудиообъекта 334 (XEAO).
Таким образом, адекватный выбор матрицы AEAO может позволить дополнительно интегрировать функцию блока рендеринга 340 таким образом, что перемножение вектора, описывающего каналы (l0, r0) даунмикс-сигнала SAOC 310, и одного или более разностных сигналов (res0,…,resNEAO-1) с матрицей 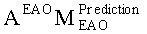 может напрямую дать в результате представление XEAO первой аудиоинформации 320.
может напрямую дать в результате представление XEAO первой аудиоинформации 320.
3.4.1.2 Режимы понижающего мономикширования (OTN):
Дальше описан процесс извлечения сигналов существенных аудиообъектов 320 (или, как вариант, сигналов существенных аудиообъектов 334) и сигнала ординарного аудиообъекта 322 для варианта, где даунмикс-сигнал SAOC 310 состоит только из одного канала.
Для режимов монофонического понижающего микширования (OTN) (например, понижающего мономикширования на базе одного канала ординарных аудиообъектов и NEAO каналов существенных аудиообъектов), (расширенная) матрица понижающего микширования и матрица - CCPC могут быть образованы следующим образом:
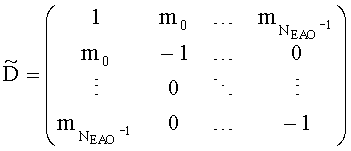
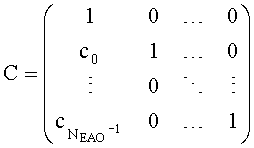
При мономикшировании с понижением один EAOj может быть предсказан только одним коэффициентом C j с формированием матрицы С. Все матричные элементы C j получены, например, из параметров SAOC (скажем, из данных SAOC 322) согласно отношениям, приведенным ниже (в параграфе 3.4.1.4).
Выходные сигналы процессора разностных данных рассчитывают как
Выходной сигнал XOBJ состоит, например, из одного канала, отображающего ординарные аудиообъекты (несущественные аудиообъекты). Выходной сигнал XEAO состоит, например, из одного, двух или даже большего числа каналов, отображающих существенные аудиообъекты (предпочтительно, NEAO каналов, воспроизводящих существенные аудиообъекты). Вновь, названные сигналы эквивалентны сигналам 320, 322.
3.4.1.3 Расчет обратной расширенной матрицы понижающего микширования
Матрица 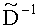 является инверсной относительно расширенной матрицы понижающего микширования
является инверсной относительно расширенной матрицы понижающего микширования 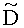 , а C - заключает в себе СРС.
, а C - заключает в себе СРС.
Матрица 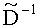 является инверсной относительно расширенной матрицы понижающего микширования
является инверсной относительно расширенной матрицы понижающего микширования 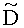 и может быть рассчитана как
и может быть рассчитана как
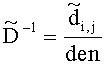 .
.
Элементы 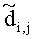 (например, обратной относительно расширенной матрицы понижающего микширования размерностью 6×6) получены с использованием следующих величин:
(например, обратной относительно расширенной матрицы понижающего микширования размерностью 6×6) получены с использованием следующих величин:
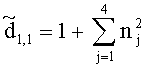
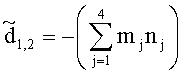 ,
,
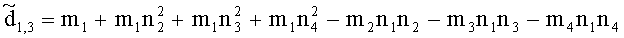 ,
,
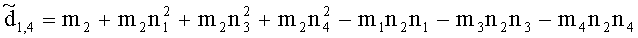 ,
,
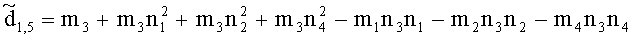 ,
,
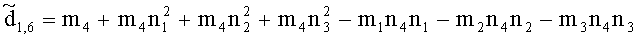 ,
,
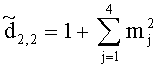 ,
,
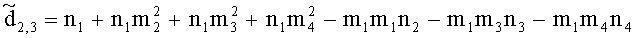 ,
,
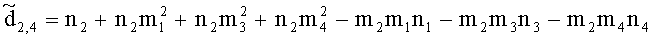 ,
,
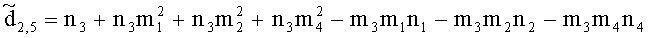 ,
,
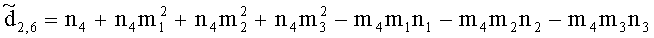 ,
,
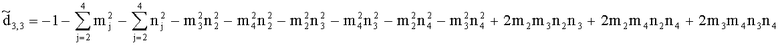
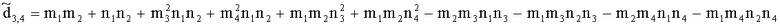 ,
,
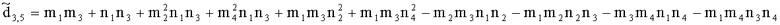 ,
,
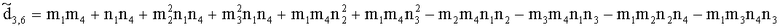 ,
,
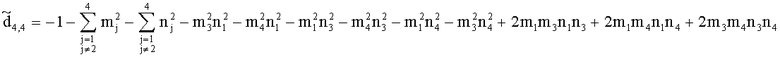 ,
,
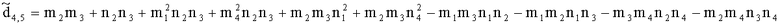 ,
,
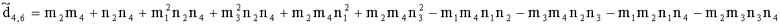 ,
,
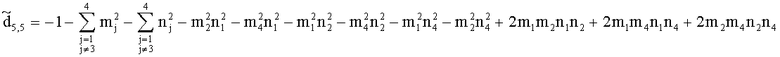 ,
,
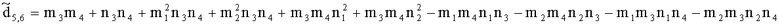 ,
,
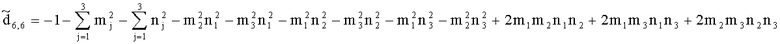 ,
,
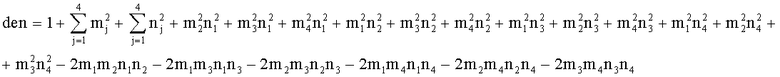 .
.
Коэффициенты mj и nj расширенной матрицы понижающего микширования 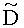 выражают показатели понижающего микширования для каждого EAOj для правого и левого даунмикс-канала как
выражают показатели понижающего микширования для каждого EAOj для правого и левого даунмикс-канала как
mj=d0,EAO(j), nj=d1,EAO(j).
Элементы di,j матрицы D понижающего микширования получают, используя информацию о коэффициентах усиления при понижающем микшировании DMG и (факультативно) информацию о разности уровней каналов понижающего микширования DCLD, которая включена в информацию SAOC 332, представленную, например, объектно-ориентированной параметрической информацией 110 или информацией битстрима SAOC 212.
В случае стереофонического понижающего микширования матрицу D понижающего микширования размерностью 2×N с элементами di,j=(i=0,1; j=0,…,N-1) формируют из DMG (коэффициентов усиления при понижающем микшировании) и параметров DCLD (разности уровней даунмикс-каналов) как
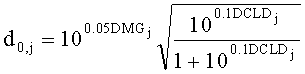 ,
,
В случае монофонического микширования с понижением матрицу понижающего микширования D размерностью 1×N с элементами di,j=(i=0; j=0,…,N-1) образуют из параметров DMG как
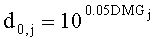 .
.
Здесь „деквантованные" параметры понижающего микширования DMGj и DCLDj извлекают, например, из служебной параметрической информации 110 или из битстрима SAOC 212.
Функция EAO(j) определяет зависимость между коэффициентами каналов входных аудиообъектов и сигналами существенных аудиообъектов ЕАО:
EAO(j)=N-1-j, j=0,…,NEAO-1
3.4.1.4 Расчет матрицы С
Матрица C заключает в себе СРС (коэффициенты предсказания каналов) и формируется из переданных параметров SAOC (т.е. OLD [разности уровней объектов], IOC [межобъектной кросс-когерентности], DMG [коэффициентов усиления при понижающем микшировании] и DCLD [разности уровней даунмикс-каналов]) в виде
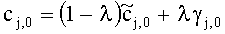 ,
,
Иначе говоря, ограничение коэффициентов предсказания каналов СРС обусловлено приведенными выше уравнениями, которые можно рассматривать как алгоритм упорядочения. Тем не менее, упорядоченные СРС могут быть также получены из значений 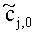 ,
, 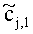 с использованием другого принципа ограничения (алгоритма упорядочения) или могут быть заданы равными величинам
с использованием другого принципа ограничения (алгоритма упорядочения) или могут быть заданы равными величинам 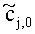 ,
, 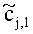 .
.
Необходимо уточнить, что матричные элементы cj,1 (и промежуточные величины, на базе которых вычисляются матричные элементы cj,1) требуются, как правило, только если сигнал понижающего микширования является сигналом стереофонического понижающего микширования.
Коэффициенты СРС ограничены следующими ограничивающими функциями:
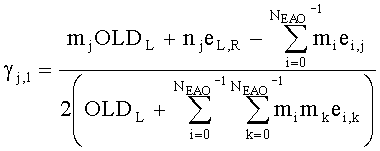 ,
, 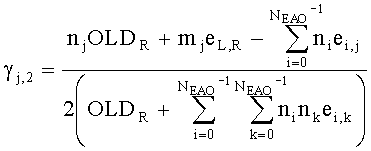
с весовым коэффициентом γ, определяемым как
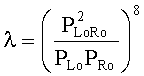 .
.
Для одного выделенного канала ЕАО j=0…NEAO -1 неограниченные СРС оценивают с помощью
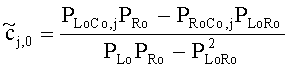 ,
, 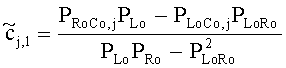 .
.
Показатели величины энергии PLo PRo PLoRo и PRoCo,j рассчитывают следующим образом:
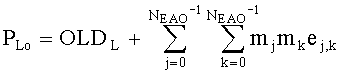 ,
,
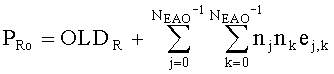 ,
,
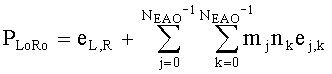 ,
,
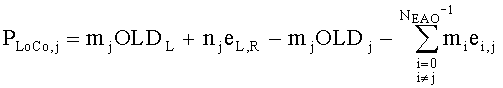 ,
,
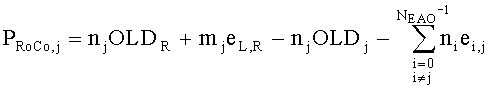 .
.
Ковариационную матрицу ei,j определяют приведенным ниже образом. Матрица ковариации Е размерностью N×N с элементами ei,j представляет аппроксимацию ковариационной матрицы E≈SS* исходного сигнала и формируется из параметров OLD и IOC как
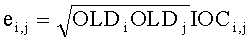 .
.
Здесь деквантованные параметры объектов OLDi, IOCij извлекают, например, из служебной параметрической информации 110 или из битстрима SAOC 212.
Дополнительно eL,R можно извлечь, например, как
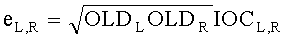 .
.
Параметры OLDL, OLDR и IOCL,R соответствуют ординарным (аудио-) объектам и могут быть получены из данных понижающего микширования:
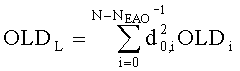 ,
,
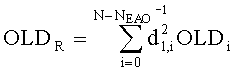 ,
,
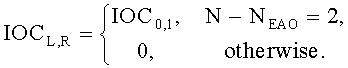
Как можно видеть, два общих значения разности уровней объектов OLDL и OLDR рассчитаны для ординарных аудиообъектов в контексте стереодаунмикс-сигнала (который преимущественно заключает в себе двухканальный сигнал ординарного аудиообъекта). В противоположность этому, только одно общее значение разности уровней объектов OLDL рассчитывают для ординарных аудиообъектов в случае одноканального (монофонического) даунмикс-сигнала (который преимущественно заключает в себе одноканальный сигнал ординарных аудиообъектов).
Можно видеть, что первое (в случае двухканального даунмикс-сигнала) или единственное (в случае одноканального даунмикс-сигнала) общее значение разности уровней объектов OLDL получают путем сложения составляющих ординарных аудиообъектов, имеющих индекс (или индексы) аудиообъектов i, с левым каналом (или единственным каналом) даунмикс-сигнала SAOC 310.
Второе общее значение разности уровней объектов OLDR (используемое в случае двухканального даунмикс-сигнала) получают, путем сложения составляющих ординарных аудиообъектов с индексом (или индексами) аудиообъектов i с правым каналом даунмикс-сигнала SAOC 310.
Составляющая OLDL ординарных аудиообъектов (имеющих индексы аудиообъектов от i=0 до i=N-NEAO-1 в сигнале левого канала (или единственного сигнала канала) даунмикс-сигнала SAOC 710 вычисляют, например, учитывая коэффициент усиления при понижающем микшировании d0,i, описывающий коэффициент усиления при понижающем микшировании, примененный к ординарному аудиообъекту с индексом аудиообъекта i, при формировании сигнала левого канала даунмикс-сигнала SAOC 310, а также - уровень ординарного аудиообъекта с индексом i, который представлен величиной OLDi.
Аналогичным образом общее значение разности уровней объектов OLDR получают, используя коэффициенты понижающего микширования d1,i, описывающие коэффициент усиления понижающего микширования, примененный к ординарному аудиообъекту с индексом аудиообъекта i, при формировании сигнала правого канала даунмикс-сигнала SAOC 310, и данных уровня old), относящихся к ординарному аудиообъекту с индектом аудиообъекта i.
Как видно, уравнения для вычисления величин PLo, PRo, PLoRo, PLoCo,j and PRoCo,j не дают различие между индивидуальными ординарными аудиообъектами, а просто используют общие значения разности уровней объектов OLDL, OLDR, представляя за счет этого ординарные аудиообъекты (имеющие индексы аудиообъекта i) как единый аудиообъект.
Также, показатель межобъектной корреляции IOCL,R, соотнесенный с ординарными аудиообъектами, устанавливается на 0, если в наличии нет двух ординарных аудиообъектов.
Ковариационную матрицу ei,j (и eL,R) определяют следующим образом:
Матрица ковариации Е размерностью N×N с элементами ei,j представляет аппроксимацию ковариационной матрицы исходного сигнала и формируется из параметров OLD и IOC как
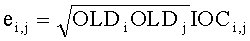 .
.
Например,
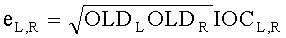 ,
,
где OLDR и OLDR и IOCL,R к рассчитывают, как описано выше. Здесь, деквантованные параметры объектов получают как
OLDi=DOLD(i,l,m), IOCi,j=DIOC(i,j,l,m),
где DOLD and DIOC - матрицы, содержащие параметры разности уровней объектов и параметры межобъектной корреляции.
3.4.2. Энергетический режим
Далее представлен еще один подход к разделению сигналов расширенных аудиообъектов 320 и сигналов ординарных (нерасширенных) аудиообъектов 322, который может применяться в комбинации с аудиокодированием „без сохранения формы волны" даунмикс-каналов SAOC 310.
Иначе говоря, процедура кодирования/декодирования на основе энергии предназначена для кодирования сигнала понижающего микширования без сохранения формы волны. Отсюда следует, что матрица повышающего микширования OTN/TTN (1-в-N/2-в-N) для соответствующего энергетического режима не зависит от особенностей формы сигнала, а лишь описывает распределение относительной энергии входных аудиообъектов.
Более того, обсуждаемая здесь концепция, называемая еще концепцией „энергетического режима", может использоваться без обмена информацией разностного сигнала. И вновь, ординарные аудиообъекты (несущественные аудиообъекты) обрабатывают как одиночный одноканальный или двухканальный аудиообъект, имеющий один или два общих значения разности уровней объектов OLDL, OLDR.
Для работы в энергетическом режиме матрицу MEnergy определяют, используя информацию понижающего микширования и разницу уровней объектов OLD, что будет пояснено дальше.
3.4.2.1. Энергетический режим для режимов понижающего стереомикширования (TTN)
В стереоформате (например, при стереофоническом понижающем микшировании на базе двух каналов ординарных (нерасширенных) аудиообъектов и NEAO каналов существенных (расширенных) аудиообъектов) матрицы  и
и 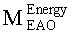 образуют из соответствующих межобъектных разниц уровней OLD в соответствии с
образуют из соответствующих межобъектных разниц уровней OLD в соответствии с
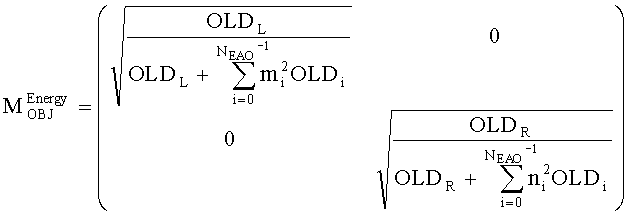
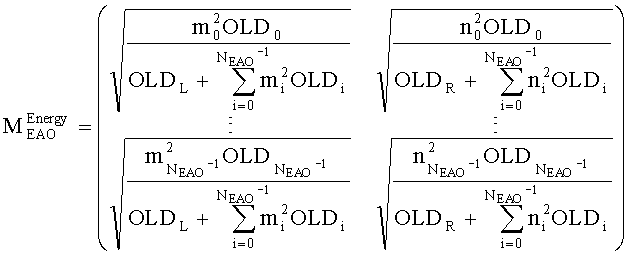
Выходные сигналы процессора разностных данных рассчитывают как
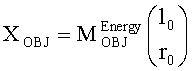 ,
,
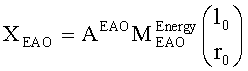 .
.
Сигналы yL, yR, представленные сигналом XOBJ, отображают ординарные аудиообъекты (и могут быть эквивалентными сигналу 322), а сигналы с y0,EAO по yNEAO-1,EAO, представленные сигналом XEAO, отображают существенные аудиообъекты (и могут быть эквивалентны сигналу 334 или сигналу 320).
При необходимости повышающего мономикширования стереодаунмикс-сигнала выполняют преобразование 2-в-1, используя, например, препроцессор 270 для обработки двухканального сигнала XOBJ.
3.4.2.2. Энергетический режим для режимов понижающего мономикширования (OTN)
Для моноформата (например, при монофоническом понижающем микшировании на базе одного канала ординарных аудиообъектов и NEAO каналов расширенных аудиообъектов) формируют матрицы 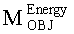 и
и 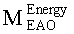 из соответствующих OLD в соответствии с
из соответствующих OLD в соответствии с
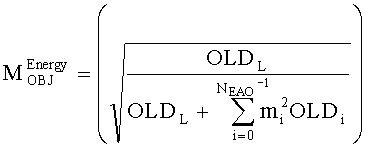 ,
,
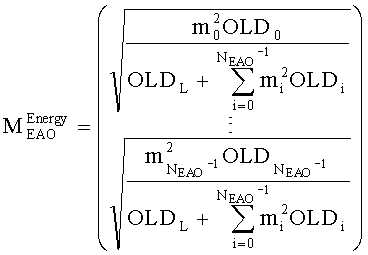 .
.
Выходные сигналы процессора разностных данных рассчитывают как
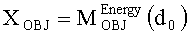 ,
,
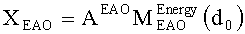 .
.
Одиночный канал ординарных аудиообъектов 322 (представленный через XOBJ) и NEAO каналов существенных аудиообъектов 320 (представленных через XEAO) могут быть сформированы приложением матриц 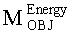 и
и 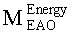 к представлению одноканального даунмикс-сигнала SAOC 310 (представленного здесь через d0).
к представлению одноканального даунмикс-сигнала SAOC 310 (представленного здесь через d0).
При необходимости получения двухканального (стерео) сигнала повышающего микширования из одноканального (моно) даунмикс-сигнала выполняют преобразование 1-в-2, используя, например, препроцессор 270 для обработки одноканального сигнала XOBJ.
4. Архитектура и действие препроцессора понижающего микширования SAOC
Далее описывается работа препроцессора понижающего микширования SAOC 270 в ряде режимов декодирования и в ряде режимов транскодирования.
4.1 Работа в режимах декодирования
4.1.1 Введение
Ниже рассмотрен способ генерации выходного сигнала на основе параметров SAOC и данных панорамирования (или параметров рендеринга) по каждому аудиообъекту. На фиг.4g изображен декодер SAOC 495, состоящий из процессора параметров SAOC 496 и процессора понижающего микширования (даунмикс-процессора) 497.
Декодер SAOC 495 может быть использован для обработки ординарных аудиообъектов и поэтому выполнен с возможностью приема в качестве сигнала понижающего микширования 497а второго сигнала аудиообъектов 264 или сигнала ординарных аудиообъектов 322 или второй аудиоинформации 134. Соответственно, даунмикс-процессор 497 может генерировать на выходе 497b обработанную версию 272 второго сигнала аудиообъекта 264 или обработанную версию 142 второй аудиоинформации 134. Следовательно, процессор понижающего микширования 497 может выполнять роль препроцессора понижающего микширования SAOC 270 или роль процессора аудиосигналов 140.
Процессор параметров SAOC 496 может выполнять роль процессора параметров SAOC 252 и, следовательно, формирует информацию понижающего микширования 496а.
4.1.2 Процессор понижающего микширования
Далее дана детализация процессора понижающего микширования (даунмикс-процессора), который является компонентом процессора аудиосигналов 140 и который обозначен как „препроцессор понижающего микширования SAOC" 270 в компоновке на фиг.2, а также который обозначен ссылкой 497 в составе декодера SAOC 495.
При работе системы пространственного кодирования аудиообъекта SAOC в режиме декодера выходной сигнал 142, 272, 497b даунмикс-процессора (представленный в гибридной области QMF/КЗФ [квадратурно-зеркального фильтра]) вводят в соответствующий синтезирующий банк фильтров (не показанный на фиг.1 и 2), как предписано в стандарте ISO/IEC 23003-1:2007, получая на выходе конечный сигнал РСМ/ИКМ [импульсно-кодовой модуляции]. Тем не менее, выходной сигнал 142, 272, 497b даунмикс-процессора обычно совмещен с одним или несколькими аудиосигналами 132, 262, представляющими расширенные аудиообъекты. Такое совмещение может происходить до ввода в соответствующий банк фильтров синтеза (таким образом, что в банк фильтров синтеза вводят комбинированный сигнал, объединяющий выходной сигнал даунмикс-процессора и один или более сигналов, отображающих существенные аудиообъекты). В другом случае выходной сигнал процессора понижающего микширования может быть совмещен с одним или более аудиосигналов, отображающих существенные аудиообъекты, только после обработки синтезирующим банком фильтров. В силу этого сигнал повышающего микширования 120, 220 может быть представлен или в области КЗФ, или в области ИКМ (или иметь любое другое сообразное представление). Микширование с понижением может включать в себя, например, монофоническое преобразование, стереофоническое преобразование и при необходимости - последующее бинауральное преобразование.
Выходной сигнал Х даунмикс-процессора 270, 497 (обозначенный также ссылками 142, 272, 497b) рассчитывают из монодаунмикс-сигнала Х (также обозначенного 134, 264, 497а) и декоррелированного монодаунмикс-сигнала как
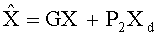 .
.
Декоррелированный монодаунмикс-сигнал Xd вычисляют как
Xd=decorrFunc(X).
Декоррелированные сигналы Xd генерирует декоррелятор, описанный в 23003-1:2007 ISO/IEC, подпункт 6.6.2. Следуя предложенной схеме согласно таблицам с А.26 по А.29 стандарта ISO/IEC 23003-1:2007, конфигурацию bsDecorrConfig == 0 следует использовать с коэффициентом декоррелятора x=8. Отсюда, decorrFunc() обозначает процесс декорреляции:
 .
.
Для генерации на выходе бинаурального сигнала к даунмикс-сигналу Х (и Xd) применяют параметры повышающего микширования G и P2, полученные из данных SAOC, информацию рендеринга и параметры функции HRTF с формированием на выходе бинаурального сигнала 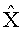 , см. базовую схему даунмикс-процессора на фиг.2, ссылка 270.
, см. базовую схему даунмикс-процессора на фиг.2, ссылка 270.
Целевая матрица бинаурального аудиорендеринга Al,m размерностью 2×N состоит из элементов 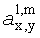 . Каждый элемент
. Каждый элемент 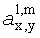 получают на базе параметров HRTF и матрицы аудиорендеринга
получают на базе параметров HRTF и матрицы аудиорендеринга 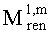 с элементами
с элементами 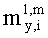 , используя, например, процессора параметров SAOC. Объектная матрица бинаурального рендеринга Al,m выражает отношение между всеми объектами входного аудиосигнала и желательным бинауральным выходом.
, используя, например, процессора параметров SAOC. Объектная матрица бинаурального рендеринга Al,m выражает отношение между всеми объектами входного аудиосигнала и желательным бинауральным выходом.
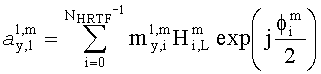 ,
, 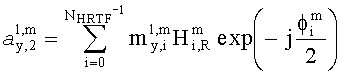 .
.
Параметры HRTF получают из 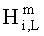 ,
, 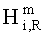 и
и 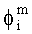 для каждой полосы преобразования m. Пространственные координаты, описываемые параметрами передаточной функции слухового тракта HRTF, характеризуются индексом i. Эти параметры специфицированы в стандарте ISO/IEC 23003-1:2007.
для каждой полосы преобразования m. Пространственные координаты, описываемые параметрами передаточной функции слухового тракта HRTF, характеризуются индексом i. Эти параметры специфицированы в стандарте ISO/IEC 23003-1:2007.
4.1.2.1 Обзор
Ниже дан обзор процесса понижающего микширования со ссылкой на фиг.4а и 4b, на которых схематически представлен этот процесс, выполнение которого предусмотрено с помощью процессоре аудиосигналов 140, или процессора параметров SAOC 252 в комбинации с препроцессором понижающего микширования SAOC 270, или процессора параметров SAOC 496 в комбинации с даунмикс-процессором 497.
Теперь обратимся к фиг.4а, где процессор понижающего микширования (даунмикс-процессор) принимает на входе матрицу М аудиорендеринга, показатели разности уровней объектов OLD, данные межобъектной корреляции IOC, значения коэффициентов усиления при понижающем микшировании DMG и (факультативно) значения разности уровней даунмикс-каналов DCLD. Даунмикс-процессор 400 в процессе понижающего микширования в соответствии с фиг.4а генерирует матрицу аудиорендеринга А на базе матрицы аудиорендеринга М, задействуя, например, регулятор параметров и матричное преобразование М-в-А. Кроме того, вырабатываются элементы матрицы ковариации Е, исходя из информации о разности уровней объектов OLD и межобъектной корреляции IOC, например, как рассматривалось выше. Аналогичным образом вырабатываются элементы матрицы понижающего микширования D, исходя из информации о коэффициентах усиления при понижающем микшировании DMG и разности уровней даунмикс-каналов DCLD.
Элементы f желаемой ковариационной матрицы F формируются в зависимости от матрицы аудиорендеринга А и матрицы ковариации Е. Кроме того, в зависимости от матрицы ковариации Е и матрицы понижающего микширования D (или в зависимости от их элементов) генерируется скалярная величина ν.
Значения коэффициентов усиления PL, PR для двух каналов находят в зависимости от элементов желаемой ковариационной матрицы F и скалярной величины ν . Значение межканальной разности фаз φC также получают в зависимости от элементов f желаемой ковариационной матрицы F. Угол поворота α тоже получают, исходя из элементов f желаемой ковариационной матрицы F, учитывая, например, константу с. Дополнительно второй угол поворота β находят, например, исходя из коэффициентов усиления каналов PL, PR и первого угла поворота α. Элементы матрицы G рассчитывают, например, в зависимости от значений коэффициентов усиления PL, PR двух каналов, а также в зависимости от разности фаз каналов φC и, вспомогательно, от углов поворота α, β. Подобно этому элементы матрицы Р2 определяют на основе некоторых или всех названных показателей PL, PR, φc, α, β.
Дальше описано, как матрица G и/или матрица Р2 (или их элементы), которые процессор понижающего микширования задействует так, как рассматривалось выше, могут быть сгенерированы для различных режимов преобразования.
4.1.2.2 Режим преобразования моноформата в бинауральный „x-1-b"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены одноканальным даунмикс-сигналом 134, 264, 322, 497а и где желателен бинауральный рендеринг.
Параметры Gl,m и 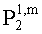 повышающего микширования рассчитывают как
повышающего микширования рассчитывают как
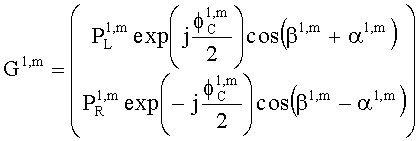 ,
,
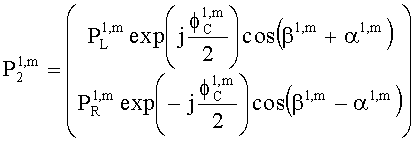 .
.
Коэффициенты усиления  и
и 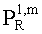 для левого и правого выходных каналов выглядят как
для левого и правого выходных каналов выглядят как
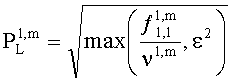 ,
, 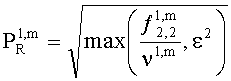 .
.
Желаемая ковариационная матрица Fl,m размерностью 2×2 с элементами 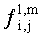 дана как
дана как
Fl,m=Al,mEl,m(Al,m)*
Скаляр v вычисляют как
νl,m=DlEl,m(Dl)*+ε2.
Межканальная разность фаз 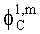 дана как
дана как
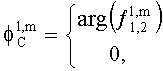 ,
, 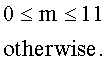 ,
, 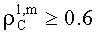 ,
,
Межканальную когерентность 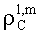 вычисляют как
вычисляют как
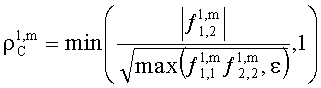 .
.
Углы поворота αl,m и βl,m получают как
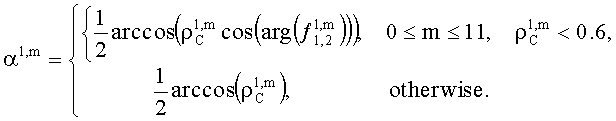
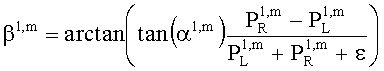 .
.
4.1.2.3 Режим преобразования моно-в-стерео „х-1-2"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены одноканальным сигналом 134,264,222 и где желателен стереорендеринг.
В случае генерации стереовыхода может быть задействован режим преобразования "x-1-b" без использования информации о HRTF. Это может быть выполнено путем извлечения всех элементов 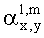 матрицы аудиорендеринга A с получением:
матрицы аудиорендеринга A с получением:
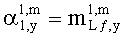 ,
, 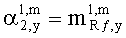 .
.
4.1.2.4 Режим преобразования моно-в-моно „х-1-1"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены каналом сигнала 134, 264, 322, 497а и где желателен двухканальный рендеринг ординарных аудиообъектов.
В случае генерации моновыхода "x-1-2" может быть применен режим преобразования со следующими элементами:
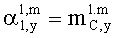 ,
, 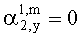
4.1.2.5 Режим преобразования стереоформата в бинауральный „x-2-b"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены двухканальным сигналом 134, 264, 322,497а и где желателен бинауральный рендеринг ординарных аудиообъектов.
Параметры Gl,m и 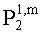 повышающего микширования рассчитывают как
повышающего микширования рассчитывают как
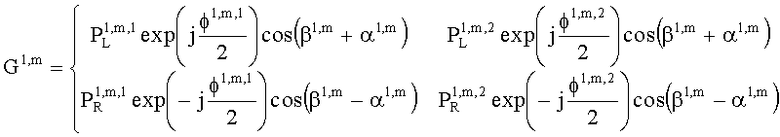 ,
,
Соответствующими коэффициентами усиления 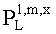 ,
, 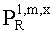 и
и 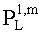 ,
, 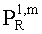 для левого и правого выходных каналов будут
для левого и правого выходных каналов будут
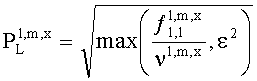 ,
, 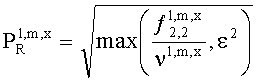 ,
,
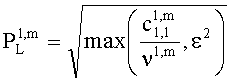 ,
, 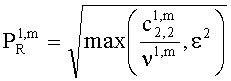 .
.
Желаемая ковариационная матрица Fl,m,x размерности 2×2 с элементами 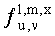 дана как
дана как
Fl,m,x=Al,mEl,m,x(Al,m)*
Матрицу ковариации Cl,m размерности 2×2 с элементами 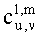 "сухого" бинаурального сигнала оценивают как
"сухого" бинаурального сигнала оценивают как
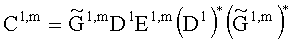 ,
,
где
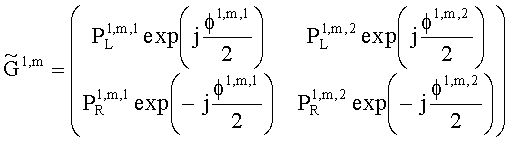 .
.
Соответствующие скаляры νl,m,x и νl,m вычисляют как
νl,m,x=Dl,xEl,m(Dl,x)*+ε2, νl,m=(Dl,1+Dl,2)El,m(Dl,1+Dl,2)*+ε2.
Матрица понижающего микширования Dl,x размерностью 1×N с элементами 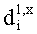 может быть найдена как
может быть найдена как
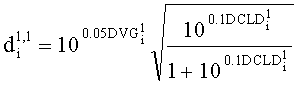 ,
,
Матрица Dl понижающего стереомикширования размерностью 2×N с элементами 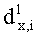 может быть найдена как
может быть найдена как
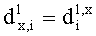 .
.
Матрицу El,m,x с элементами  выводят из следующего отношения
выводят из следующего отношения
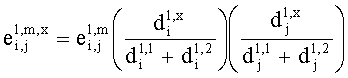 .
.
Разности фаз между каналами  получают в виде
получают в виде
 .
.
Показатели межканальной корреляции ICC 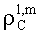 и
и 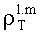 рассчитывают как
рассчитывают как
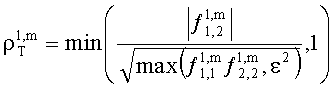 ,
, 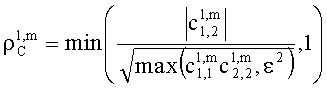 .
.
Углы поворота αl,m и βl,m получают как
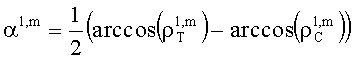 ,
, 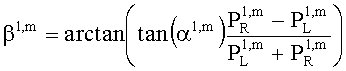 .
.
4.1.2.6 Режим преобразования стерео-в-стерео „х-2-2"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены двухканальным (стерео) сигналом 134, 264, 322, 497а и где желателен двухканальный (стерео) рендеринг.
В случае генерации стереовыхода напрямую применяют предварительную стереообработку, описанную ниже в параграфе 4.2.2.3.
4.1. 2.7 Режим преобразования стерео-в-моно „х-2-1"
Ниже рассмотрен режим преобразования, где ординарные аудиообъекты представлены двухканальным (стерео) сигналом 134, 264, 322, 497а и где желателен одноканальный (моно) рендеринг.
В случае генерации моновыхода применяют предварительную стереообработку с одним активным элементом матрицы аудиорендеринга, как описано ниже в параграфе
4.2.2.3.
4.1.2.8 Заключение
Выше, со ссылкой на фиг.4а и 4b был описан процесс преобразования, который может быть приложен к одноканальному или двухканальному сигналу 134, 264, 322, 497а, представляющему ординарные аудиообъекты после разделения расширенных аудиообъектов и ординарных аудиообъектов. Фигуры 4а и 4b иллюстрируют процесс цифровой обработки сигнала, отличаясь между собой введением дополнительных операций настройки параметров на различных ступенях преобразования.
4.2. Работа в режимах транскодирования
4.2.1 Введение
Далее изложены особенности интегрирования параметров SAOC и информации о панорамировании (или спецификаций рендеринга), связанной с каждым аудиообъектом (или, предпочтительно, с каждым ординарным аудиообъектом) в стандартном совместимом битстриме формата MPEG Surround (битстриме MPS).
Транскодер (кодопреобразователь) пространственного кодирования аудиообъектов SAOC 490 изображен на фиг.4f и состоит из процессора параметров SAOC 491 и процессора понижающего микширования (даунмикс-процессора) 492, выполняющего стереофоническое понижающее микширование.
Транскодер SAOC 490 может, например, выполнять функции процессора аудиосигналов 140. В другом случае, транскодер SAOC 490 может принять на себя функции препроцессора понижающего микширования SAOC 270, работая во взаимодействии с процессором параметров SAOC 252.
Например, процессор параметров SAOC 491 может принимать битстрим SAOC 491 а, который является эквивалентом объектно-ориентированной параметрической информации 110 или битстриму SAOC 212. Кроме того, процессор параметров SAOC 491 может принимать параметры матрицы аудиорендеринга 49 lb, которые могут быть включены в объектно-ориентированную параметрическую информацию 110 или которые могут быть эквивалентом информации матрицы аудиорендеринга 214. Процессор параметров SAOC 491 может также формировать информацию о понижающем микшировании 491 с для даунмикс-процессора 492, которая может представлять собой эквивалент информации 240. Более того, процессор параметров SAOC 491 может генерировать битстрим MPEG Surround (или параметрический битстрим MPEG Surround) 491d, содержащий информацию о параметрах охватывающего звучания, совместимых со стандартом MPEG Surround. Битстрим MPEG Surround 491d может, например, быть составляющей обработанной версии 142 второй аудиоинформации, или, например, элементом или замещением битстрима MPS 222.
Процессор понижающего микширования (даунмикс-процессор) 492 выполнен с возможностью приема даунмикс-сигнала 492а, который преимущественно является одноканальным или двухканальным сигналом понижающего микширования и который преимущественно эквивалентен второй аудиоинформации 134 или второму сигналу аудиообъекта 264, 322. Даунмикс-процессор 492 выполнен с возможностью также генерировать сигнал даунмикс-сигнал MPEG Surround 492b, который является эквивалентным (или составляющей) обработанная версия 142 второй аудиоинформации 134, или эквивалентным (или составляющей) обработанной версии 272 второго сигнала аудиообъекта 264.
Однако, существуют разные способы комбинирования даунмикс-сигнала в формате MPEG Surround 492b с сигналом расширенных аудиообъектов 132, 262. Сведение может выполняться в области MPEG Surround.
Однако, возможен вариант, при котором представление ординарных аудиообъектов в формате MPEG Surround, включающее в себя параметрический битстрим MPEG Surround 49 Id и даунмикс-сигнал MPEG Surround 492b, может быть трансформировано декодером MPEG Surround обратно в многоканальное представление во временной области или многоканальное представление в частотной области (индивидуально отображающее разные аудиоканалы) и в последующем совмещено с сигналами существенных аудиообъектов.
Следует обратить внимание на то, что режимы транскодирования включают в себя как один или более видов моно понижающего микширования, так и один или более видов стерео понижающего микширования. Тем не менее, в дальнейшем будет рассматриваться только стереофонический режим понижающего микширования в силу того, что преобразование сигналов ординарных аудиообъектов для понижающего стереомикширования представляет большую сложность.
4.2.2 Микширование с понижением в режиме стереофонического понижающего микширования („х-2-5")
4.2.2.1 Введение
В этом параграфе дано описание режима транскодирования SAOC при понижающем стереомикшировании.
Параметры объектов (OLD - разность уровней объектов, IOC - межобъектная корреляция, DMG - коэффициент усиления при понижающем микшировании и DCLD - разность уровней даунмикс-каналов), взятые из потока двоичных данных пространственного кодирования аудиообъекта SAOC перекодируются в пространственные (преимущественно, соотнесенные с каналами) параметры (CLD -разность уровней каналов, ICC - межканальная корреляция, СРС - коэффициент предсказания канала) для битстрима MPEG Surround в соответствии с информацией, специфицирующей рендеринг. Понижающее микширование модифицируется в соответствии с параметрами объектов и матрицей аудиорендеринга.
Теперь, обратившись к фигурам 4с, 4d и 4е, сделаем обзор осуществляемых преобразований, в особенности, модификаций, производимых в процессе понижающего микширования.
На фиг.4с отображена блок-схема модификаций, вносимых в процессе преобразования сигнала понижающего микширования, например, 134, 264, 322, 492а, отображающего один или, предпочтительно, более ординарных аудиообъектов. На фиг.4с, 4d и 4е видно, что для преобразования принимают данные матрицы аудиорендеринга Mren, коэффициентов усиления при понижающем микшировании DMG, разностей уровней даунмикс-каналов DCLD, разностей уровней объектов OLD и межобъектной корреляции IOC. Параметры матрицы аудиорендеринга произвольно могут быть скорректированы, как показано на фиг.4 с.Элементы матрицы D понижающего микширования вырабатывают, исходя из данных коэффициентов усиления при понижающем микшировании DMG и разности уровней даунмикс-каналов DCLD. Элементы матрицы когерентности Е получают на основе показателей разности уровней объектов OLD и межобъектной корреляции IOC. Дополнительно на базе матрицы понижающего микширования D и матрицы когерентности Е или на базе их элементов может быть сгенерирована матрица J. Далее, на основе матрицы аудиорендеринга Mren матрицы понижающего микширования D, матрицы когерентности Е и матрицы J может быть сформирована матрица С3. Матрица G может быть получена в зависимости от матрицы DTTT, которая может иметь заранее заданные элементы, а также - в зависимости от матрицы С3. Матрица G факультативно подлежать модификации с получением модифицированной матрицы Gmod. Матрица G или ее модифицированная версия Gmod могут быть использованы для формирования обработанной версии 142, 272, 492b второй аудиоинформации 134, 264 из второй аудиоинформации 134, 264, 492а (где при разработке второй аудиоинформации 134, 264 вводят X, и где при разработке ее обработанной версии 142, 272 вводят  .
.
Далее будет обсуждена процедура рендеринга энергии объектов, выполняемая с целью получения параметров формата MPEG Surround. Также, будет описана предварительная стереообработка, выполняемая с целью получения обработанной версии 142, 272, 492b второй аудиоинформации 134, 264, 492а, описывающей ординарные аудиообъекты.
4.2.2.2 Рендеринг энергии объектов
Транскодер (кодопреобразователь) рассчитывает параметры для MPS-декодера в соответствии с заданным аудиорендерингом согласно описанию матрицей аудиорендеринга Mren. Объектная ковариация шести каналов определяется с помощью F
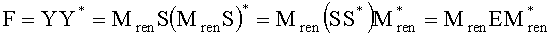 .
.
Процесс кодопреобразования умозрительно может быть разделен на две части. В одной части выполняются построения трехканального рендеринга, касающиеся левого, правого и среднего каналов. На этом этапе определяют параметры модификации понижающего микширования, а также параметры предсказания для блока ТТТ для декодера MPS. В другой части определяют параметры CLD и ICC построения фронтального и окружающих каналов (ОТТ, левого фронтального - левого охватывающего, правого фронтального - правого охватывающего).
4.2.2.2.1 Рендеринг левого, правого и центрального каналов
На этом этапе определяют пространственные параметры, отвечающие за акустическое построение (рендеринг) левого и правого каналов и относящиеся к фронтальному и охватывающему сигналам. Эти параметры описывают матрицу предсказания блока ТТТ для MPS-декодирования CTTT (параметры СРС для декодера) и матрицу G преобразования понижающего микширования. CTTT представляет собой матрицу предсказания объектного аудиорендеринга, исходя из модифицированного даунмикса 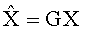 :
:
 .
.
A3 - приведенная матрица аудиорендеринга размерностью 3×N, описывающая акустическое построение левого, правого и центрального каналов, соответственно. Ее формируют как A3=D36Mren с матрицей D36 частичного понижающего микширования с 6 до 3 каналов, определяемой как
 .
.
Веса wp, p=1,2,3 частичного понижающего микширования корректируют так, что энергия wp(y2p-1+y2p) равна сумме энергий 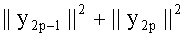 до предельного коэффициента.
до предельного коэффициента.
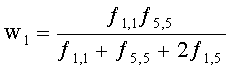 ,
, 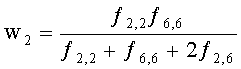 , w3=0.5,
, w3=0.5,
где ƒi,j обозначают элементы F. Для оценивания желаемой матрицы предсказания CTTT и матрицы G предварительного преобразования понижающего микширования определим матрицу предсказания C3 размерностью 3×2, дающую в результате заданный аудиорендеринг
C3≈A3S.
Такую матрицу получаем, принимая во внимание нормальные уравнения
C3(DED*)≈A3ED*.
Решение нормальных уравнений дает наилучшее согласование формы волны для целевого выходного сигнала с учетом модели ковариации объектов. Теперь G и CTTT получаем решением системы уравнений
CTTTG=C3.
Во избежание проблем с числами при вычислении член J=(DED*)-1 модифицируют.
Сначала собственные числа λ1,2, принадлежащие J, рассчитывают, решая det(J-λ1,2I)=0
Собственные числа упорядочивают в нисходящем (λ1≥λ2) порядке, а собственный вектор, соответствующий большему собственному числу, рассчитывают согласно уравнению, данному выше. Предполагается, что он лежит в положительной плоскости х (первый элемент должен быть положительным). Второй собственный вектор получают из первого поворотом на 90 градусов:
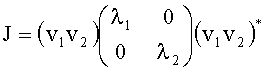 .
.
Взвешивающую матрицу рассчитывают из матрицы понижающего микширования D и матрицы предсказания C3 W=(D diag(C3)). Поскольку CTTT является функцией параметров c1 and c2 предсказания MPS (как определено в стандарте ISO/IEC 23003-1:2007), CTTTG=C3 переписывают следующим образом, находя стационарную точку или точки функции,
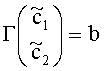 ,
,
при Г=(DTTTC3)W(DTTTC3)* и b=GWC3v,
где 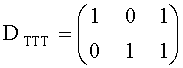 и v=(1 1 -1).
и v=(1 1 -1).
Если Г не обеспечивает уникальное решение (det(Г)<10-3), выбирают точку, ближайшую к результирующей точке прохода ТТТ. В качестве первого шага выбирают ряд i матрицы Г γ=[γi,1 γi,2], где элементы содержат наибольшую энергию так, что
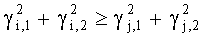 , j=1,2.
, j=1,2.
Затем решение определяют таким образом, что
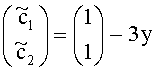 с
с 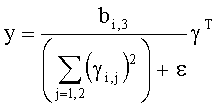 .
.
Если полученное решение для 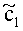 и
и 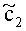 находится вне диапазона допустимых значений коэффициентов предсказания, определяемого как
находится вне диапазона допустимых значений коэффициентов предсказания, определяемого как  (по спецификации стандарта ISO/IEC 23003-1:2007),
(по спецификации стандарта ISO/IEC 23003-1:2007), 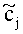 следует рассчитывать согласно нижеприведенному. Сначала определяют точечное множество xp как:
следует рассчитывать согласно нижеприведенному. Сначала определяют точечное множество xp как:
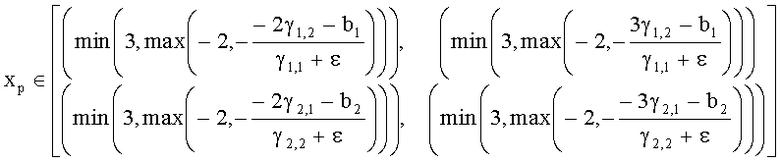 ,
,
и функцию расстояния,
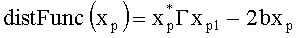 .
.
Затем определяют параметры предсказания, исходя из:
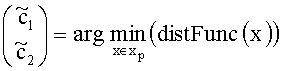 .
.
Параметры предсказания имеют ограничения:
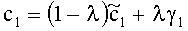 ,
, 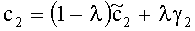 ,
,
где λ, γ1 и γ2 определяются как
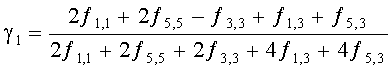 ,
, 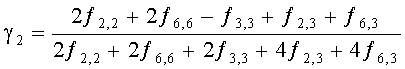 ,
,
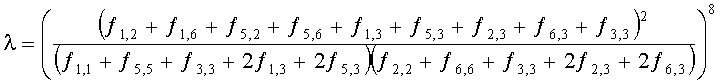 .
.
Для декодера MPS коэффициенты предсказания канала СРС и соответствующая 1ССттт вычисляют следующим образом:
DCPC_1=c1(l,m), DCPC_2=c2(l,m) и 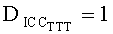 .
.
4.2.2.2.2 Аудиорендеринг фронтального и охватывающих каналов
Параметры распределения акустического объема (аудиорендеринга) между каналами переднего плана и флангового охвата могут быть рассчитаны непосредственно из целевой ковариационной матрицы F
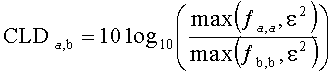 ,
, 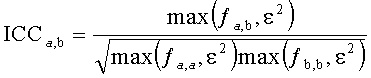 ,
,
при (a,b) = (1,2) и (3,4).
Параметры формата MPS определяют в виде
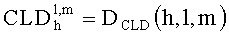 и
и 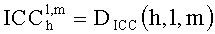 ,
,
для каждого блока h ОТТ.
4.2.2.3 Стереопроцессинг
Дальше будет описано стереофоническое преобразование сигнала ординарного аудиообъекта 134 в 64, 322. Стереопроцессинг (стереопреобразование) применяют для формирования общего представления 142, 272 на базе двухканального отображения ординарных аудиообъектов.
Стереодаунмикс-отображение X, представленное сигналами ординарных аудиообъектов 134, 264, 492а, преобразуют в модифицированный даунмикс-сигнал, представленный обработанными сигналами ординарных аудиообъектов 142, 272:
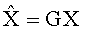 ,
,
где
G=DTTTC3=DTTTMrenED*J
Конечный выходной стереосигнал транскодера SAOC 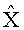 формируют, смешивая Х с компонентой декоррелированного сигнала, следуя:
формируют, смешивая Х с компонентой декоррелированного сигнала, следуя:
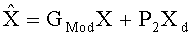 ,
,
где декоррелированный сигнал Xd рассчитывают, как описано выше, а матрицы смешивания GMod и P2 - как показано ниже.
Сначала определяют матрицу ошибок рендеринга повышающего микширования как
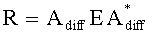 ,
,
где
Adiff=DTTTA3-GD,
и, кроме этого, определяют матрицу ковариации предсказанного сигнала  как
как
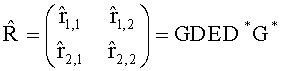
Затем, может быть вычислен вектор усиления gvec:
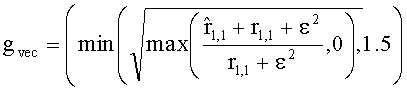
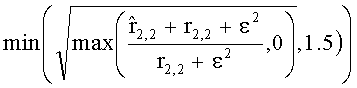 ,
,
при этом матрица смешивания GMod представляется как:
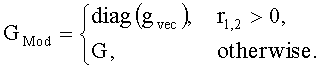
Аналогично дается матрица смешивания P2:
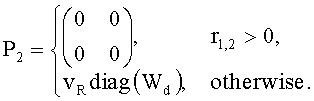
Для выведения vR и Wd необходимо решить характеристическое уравнение R: det(R-λ1,2I)=0, дающее характеристические значения λ1 и λ2.
Соответствующие собственные векторы R vR1 и vR2 могут быть вычислены путем решения системы уравнений:
(R-λ1,2I)vR1,R2=0.
Собственные числа упорядочивают в нисходящем (λ1≥λ2) порядке, а собственный вектор, соответствующий большему собственному числу, рассчитывают согласно уравнению, данному выше. Предполагается, что он лежит в положительной плоскости х (первый элемент должен быть положительным). Второй собственный вектор получают из первого поворотом на 90 градусов:
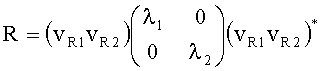 .
.
Объединение P1=(1 1)G, Rd может быть вычислено в соответствии с:
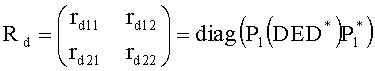 ,
,
что дает
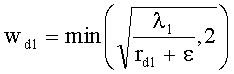 ,
, 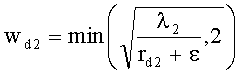
и, наконец, матрицу смешивания
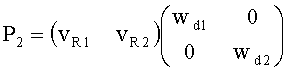 .
.
4.2.2.4 Дуальный режим
Для верхнего диапазона частот транскодер SAOC предусматривает альтернативную схему расчета матриц смешивания P1, P2 и матрицы предсказания C3. Применение такой альтернативной схемы особенно целесообразно для сигналов понижающего микширования, где верхняя полоса частот закодирована с использованием алгоритма кодирования без сохранения формы волны, например, при репликации спектральных полос SBR в высокоэффективном усовершенствованном методе кодирования звука ААС.
Для верхних параметрических диапазонов, определяемых bsTttBandsLow≤pb<numBands, матрицы P1, P2 и C3 должны быть рассчитаны в соответствии с альтернативной схемой, описанной ниже:
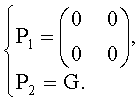
Определим энергию понижающего микширования и целевые векторы энергии, соответственно:
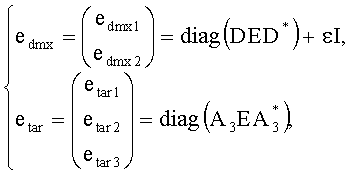
и вспомогательную матрицу
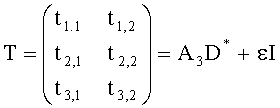
После этого вычислим вектор усиления
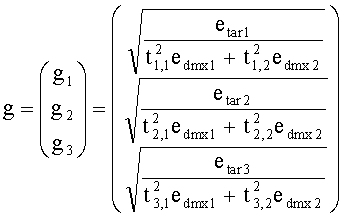 ,
,
который в итоге дает новую матрицу предсказания
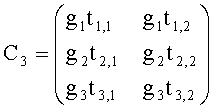 .
.
5. Интегрированные EKS SAOC - режим декодирования/транскодирования, кодер на фиг.10 и системы на фиг.5а, 5b
Ниже дано краткое описание интегрированного алгоритма преобразования EKS SAOC. Предлагается предпочтительная „комбинированная EKS SAOC" процедура обработки сигнала, встроенная в каскадную схему, при которой преобразование EKS интегрировано в стандартную последовательность пространственного декодирования/транскодирования SAOC.
5.1. Кодер аудиосигнала в контексте фиг.5
На первом этапе с помощью переменной битстрима „bsNumGroupsFGO" выделяют объекты, предназначенные для преобразования в EKS (расширенном формате караоке/соло) в качестве объектов переднего плана (FGO), и определяют их количество NFGO (также обозначаемое как NEAO). Указанная переменная битстрима может быть, например, включена в битстрим SAOC, как описано выше.
Для генерации нужного битстрима (кодером аудиосигнала) параметры всех входных объектов Nobj переупорядочивают таким образом, чтобы объекты переднего плана FGO в каждом случае содержали последние NFGO (или NEAO) параметров, например, OLDi для [Nobj-NFGO≤i≤Nobj-1].
Из остающихся объектов, например, заднего плана BGO или несущественных (нерасширенных) аудиообъектов, генерируют сигнал понижающего микширования в „стандартном формате SAOC", который одновременно служит фоновым объектом BGO. Затем, объект заднего плана и объекты переднего плана микшируют с понижением в формате EKS, и из каждого фронтального объекта извлекают разностную (остаточную) информацию. Благодаря такой процедуре нет необходимости вводить дополнительные шаги преобразования. Следовательно, не требуется изменение синтаксиса битстрима.
Другими словами, на стороне кодера несущественные аудиообъекты отделяют от существенных аудиообъектов. Формируют одноканальный или двухканальный микшированный с понижением сигнал ординарных аудиообъектов, который отображает ординарные аудиообъекты (нерасширенные/несущественные аудиообъекты), куда могут входить один, два или более ординарных аудиообъектов (несущественных аудиообъектов). Затем, одноканальный или двухканальный даунмикс-сигнал ординарного аудиообъекта совмещают с сигналами одного или более существенных аудиообъектов (которые могут быть, например одно- или двухканальными сигналами) с получением совокупного сигнала понижающего микширования (который может быть, например, одно- или двухканальным сигналом понижающего микширования), в котором сведены аудиосигналы существенных аудиообъектов и даунмикс-сигнала ординарного аудиообъекта.
Далее кратко описана базовая компоновка кодера каскадного типа согласно изобретению со ссылкой на принципиальную блочную схему реализации кодера SAOC 1000 на фиг.10. Кодер SAOC 1000 имеет в своем составе первый понижающий микшер SAOC 1010, который, как правило, не выводит разностную информацию. Понижающий микшер SAOC 1010 предназначен для приема множества сигналов ординарных (нерасширенных) аудиообъектов NFGO 1012. Кроме того, понижающий микшер SAOC 1010 предназначен для генерации на базе ординарных аудиообъектов 1012 даунмикс-сигнала ординарного аудиообъекта 1014, в котором, исходя из параметров понижающего микширования, сведены сигналы ординарных аудиообъектов 1012. Наряду с этим понижающий микшер SAOC 1010 формирует информацию SAOC 1016 об ординарных аудиообъектах, описывающую сигналы ординарных оудиообъектов и процедуру микширования с понижением (даунмикс). Например, информация SAOC об ординарных аудиообъектах 1016 может содержать коэффициенты усиления при понижающем микшировании DMG и разность уровней даунмикс-каналов DCLD, описывающие понижающее микширование, выполненное понижающим микшером SAOC 1010. Одновременно информация SAOC об ординарных аудиообъектах 1016 может включать в себя данные разницы уровней объектов и показатели межобъектной корреляции, отражающие взаимное соотношение между ординарными аудиообъектами, отображенными в сигнале ординарных аудиообъектов 1012.
Далее, кодер 1000 включает в свой состав второй понижающий микшер SAOC 1020, стандартно предназначенный для формирования разностной (остаточной) информации. Второй понижающий микшер SAOC 1020 предпочтительно предназначен для приема одного или более сигналов существенных (расширенных) аудиообъектов 1022, а также для приема даунмикс-сигнала ординарного аудиообъекта 1014.
Второй понижающий микшер SAOC 1020 также предназначенный для выработки совокупного даунмикс-сигнала SAOC 1024 на базе сигналов существенных аудиообъектов 1022 и микшированного с понижением сигнала ординарного аудиообъекта 1014. При выработке совокупного даунмикс-сигнала SAOC второй понижающий микшер SAOC 1020 обрабатывает микшированный с понижением сигнал ординарного аудиообъекта 1014 как один одноканальный или двухканальный сигнал одного аудиообъекта.
Кроме того, второй понижающий микшер SAOC 1020 предусматривает формирование информации SAOC о существенных аудиообъектах, отражающей, в частности, значения разности уровней даунмикс-каналов DCLD, связанные с существенными аудиообъектами, значения разности уровней объектов OLD, связанные с существенными аудиообъектами, и показатели межобъектной корреляции IOC, связанные с существенными аудиообъектами. В дополнение к этому, второй понижающий микшер SAOC 1020 реализован с возможностью формирования относящейся к каждому из существенных аудиообъектов разностной информации, которая описывает различие между исходным индивидуальным сигналом существенного аудиообъекта и ожидаемым индивидуальным сигналом существенного аудиообъекта, извлеченным из сигнала понижающего микширования с использованием информации о понижающем микшировании DMG, DCLD и информации о аудиообъектах OLD, IOC.
Аудиокодер 1000 полностью совместим с описанным здесь аудиодекодером.
5.2. Декодер аудиосигнала на фиг.5а
Далее рассмотрена базовая схема интегрированного декодера EK.S SAOC 500 на основе принципиальной блочной схемы, представленной на фиг.5а.
Аудиодекодер 500, показанный на фиг.5а, реализован с целью приема микшированного с понижением сигнала 510, информации битстрима SAOC 512 и данных матрицы аудиорендеринга 514. Аудиодекодер 500 включает в свою конструкцию модуль расширенного преобразования караоке/соло и рендеринга фронтальных объектов 520, предназначенный для генерации первого сигнала аудиообъектов 562, который отображает результат рендеринга фронтальных объектов, и генерации второго сигнала аудиообъектов 564, который отображает объекты заднего плана (фоновые). Объектами переднего плана могут быть, предположим, так называемые „существенные аудиообъекты", а объектами заднего плана - допустим, „ординарные, или несущественные, аудиообъекты". Кроме того, аудиодекодер 500 включает в свою конструкцию блок стандартного декодирования SAOC 570, предназначенный для приема второго сигнала аудиообъектов 564 и генерации на его основе обработанной версии 572 второго сигнала аудиообъектов 564. Также, аудиодекодер 500 включает в свою конструкцию комбинатор (блок сведения) 580, предназначенный для сведения первого сигнала аудиообъекта 562 и обработанной версии 572 второго сигнала аудиообъекта 564 с формированием выходного сигнала 520.
Ниже дана детализация функциональных возможностей аудиодекодера 500. На стороне декодера/транскодера SAOC процесс повышающего микширования в конечном итоге представляет собой алгоритм каскадного типа, где первым шагом является расширенное преобразование караоке/соло (преобразование EKS), в ходе которого сигнал понижающего микширования разлагают на фоновый объект (BGO) и фронтальные объекты (FGO). Необходимые показатели различия уровней объектов (OLD) и корреляции между объектами (IOC) для фонового объекта выводят из информации об объекте и о понижающем микшировании (которая в обеих формах представляет собой объектно-ориентированную параметрическую информацию, и которую в обеих формах обычно включают в битстрим SAOC):
,
,
Одновременно, этот шаг (выполняемый, как правило, модулем преобразования EKS и рендеринга фронтальных объектов 520) включает в себя построение соответствий фронтальным объектам в каналах конечного выходного сигнала (таким образом, чтобы, например, первый сигнал аудиообъектов 562 был многоканальным сигналом, отображающим каждый из объектов переднего плана по одному или более каналов). Объект заднего плана (как правило, включающий в себя множество так называемых „ординарных аудиообъектов") соотносят с соответствующими выходными каналами в процессе стандартного декодирования SAOC (или в некоторых случаях, как вариант, в процессе транскодирования SAOC). Этот процесс может выполняться, например, стандартным декодером SAOC 570. На стадии конечного микширования (например, с использованием блока сведения (комбинатора) 580) на выходе формируют желаемую композицию сигналов объектов переднего плана и сигналов объектов звукового фона.
Эта интегрированная система EKS SAOC представляет собой сочетание всех преимуществ стандартной системы пространственного кодирования аудиообъектов SAOC и расширенного режима караоке/соло EKS в ее среде. Этот подход обеспечивает соответствие предложенной системы требованиям функциональности и эффективности без изменения характеристик битстрима как для классических (со сбалансированным рендерингом), так и для экстремальных (с рендерингом типа карааоке/соло) сценариев воспроизведения звука.
5.3. Унифицированная схема на фиг.5b
Дальше дается краткое описание унифицированной компоновки интегрированной системы EKS SAOC 590 со ссылкой на принципиальную блочную схему на фиг.5b. Комбинированную систему EKS SAOC 590 на фиг.5b можно также рассматривать как аудиодекодер.
Комбинированная система EKS SAOC 590 интегрирована с целью приема даунмикс-сигнала 510а, информации битстрима SAOC 512а и данных матрицы аудиорендеринга 514а. Кроме того, комбинированная система EKS SAOC 590 интегрирована для генерации на базе указанной информации выходного сигнала 520а.
Интегрированная система EKS SAOC 590 включает в свой состав блок SAOC-преобразования I ступени 520а, в который вводят даунмикс-сигнал 510а, информацию битстрима SAOC 512а (или, по меньшей мере, ее часть) и данные матрицы аудиорендеринга 514а (или, по меньшей мере, их часть). В частности, в блок SAOC-преобразования I ступени 520а вводят значения разности уровней объектов первой ступени (OLD). Блок SAOC-преобразования I ступени 520а генерирует один или более сигналов 5б2а, отображающих первую комбинацию объектов (например, аудиообъектов первого типа аудиообъектов). Блок SAOC-преобразования I ступени 520а также генерирует один или более сигналов, отображающих вторую совокупность объектов.
Кроме того, интегрированная система EKS SAOC включает в свой состав блок SAOC-преобразования II ступени 570а, предназначенный для приема одно или более сигналов 5б4а, отображающих вторую совокупность объектов, и для генерации на основе этих объектов одного или более сигналов 572а, представляющих третье сочетание объектов, для чего задействуются разности уровней объектов второй ступени, содержащиеся в информации битстрима SAOC 512а, а также, по меньшей мере, часть данных матрицы аудиорендеринга 514а. Интегрированная система EKS SAOC также включает в свой состав блок сведения (комбинатор) 580а, который может представлять собой, например, сумматор, предназначенный для формирования выходных сигналов 520а путем сведения одного или более сигналов 5б2а, описывающих первый набор объектов, и одного или более сигналов 570а, описывающих третий набор объектов (где третий набор объектов может быть обработанной версией второго набора объектов).
Обобщая сказанное, можно заключить, что на фиг.5b в унифицированной форме представлена реализация базовой компоновки устройства, относящегося к изобретению, показанного на фиг.5а.
6. Перцептуальная оценка интегрированной схемы преобразования EKS SAOC
6.1 Методика, оборудование и объекты тестирования
Эти субъективные тесты на прослушивание проводились в акустически изолированной студии, специально предназначенной для высококачественного прослушивания. Воспроизведение осуществлялось с использованием головных телефонов (STAX SR Lambda Pro с конвертером Lake-People D/A и монитором STAX SRM). Тестирование проводилось по методике, соответствующей стандартным процедурам проверочных испытаний пространственного звука, на основе метода „множественного раздражителя со скрытыми базисом и привязками" (MUSHRA) для субъективной оценки промежуточного качества звука (см. [7]).
В тестировании участвовало в общей сложности восемь слушателей. Все субъекты могут быть оценены как опытные слушатели. Согласно методике MUSHRA слушатели получили задание сравнивать все режимы тестирования с эталоном. Режимы тестирования были автоматически рандомизированы для каждого объекта испытаний и для каждого слушателя. Субъективные ответные реакции регистрировались с помощью компьютерной программы MUSHRA по шкале в диапазоне от 0 до 100. Разрешалось мгновенное переключение между объектами испытания. Тест MUSHRA проводился с целью оценки перцепционного воздействия рассматриваемых режимов SAOC и предложенной системы, описанной в таблице на фиг.6а, где отражен ход испытания на прослушивание.
Соответствующие сигналы понижающего микширования были закодированы с использованием корневого кодера ААС при битрейте 128 кбит/с. Для оценки воспринимаемого качества выходного сигнала, генерируемого предлагаемой интегрированной системой EKS SAOC, было проведено сравнение ее со стандартной системой SAOC RM (эталонной моделью системы SAOC) и со стандартным режимом EKS (расширенным режимом караоке-соло) по двум разным тест-сценариям рендеринга, описанным в таблице испытываемых систем на фиг.6b.
Для стандартного режима EKS и предложенной интегрированной системы EKS SAOC было применено остаточное кодирование с битрейтом 20 кбит/с.Следует обратить внимание на то, что перед фактическим выполнением процедуры кодирования/ декодирования для обычного режима EKS необходимо генерировать стереофонический фоновый объект (BGO), поскольку этот режим имеет ограничения по количеству и типу вводимых объектов.
Аудиоматериалы и соответствующие параметры понижающего микширования и рендеринга для тестирования на прослушивание отбирались из предложений по телефонному запросу (CfP), как описано в публикации [2]. Соответствующие данные для прикладных сценариев рендеринга „караоке" и „классический" отображены в таблице объектов слухового тестирования и матриц аудиорендеринга на фиг.6с.
6.2 Результаты теста на прослушивание
Краткий анализ результатов тестирования на слух графически представлен на фиг.6d и 6е, где на фиг.6d отражены средние баллы MUSHRA для теста на прослушивание результатов рендеринга по типу караоке/соло, а на фиг.6е даны средние баллы MUSHRA для теста на прослушивание рендеринга классического образца. Отрезки диаграммы отображают среднюю оценку по MUSHRA всех слушателей за каждый объект тестирования и статистическое среднее значение по всем оцененным объектам с учетом соотнесенных 95%-ных доверительных интервалов.
На основе результатов проведенного тестирования на прослушивание могут быть сделаны приведенные ниже выводы.
На фиг.6d сопоставлены стандартный режим EKS и интегрированная система EKS SAOC для приложений типа караоке. Для всех объектов испытания существенная разница (в статистическом плане) качественных показателей между этими двумя системами не наблюдалась. Их этого наблюдения следует, что интегрированная система EKS SAOC может эффективно использовать разностную информацию для преобразований в режиме EKS. Можно также заметить, что характеристики традиционной системы SAOC (без разности) ниже обеих других систем.
На фиг.6е сопоставлены стандартная традиционная система SAOC и интегрированная система EKS SAOC для реализации классических сценариев рендеринга. Для всех объектов тестирования рабочие характеристики этих двух систем статистически одинаковы. Это демонстрирует надлежащие функциональные возможности интегрированной системы EKS SAOC для классического сценария рендеринга.
Отсюда следует, что предложенная объединенная система, работающая в интегрированном режиме EKS и стандартного SAOC, сохраняет преимущества субъективно воспринимаемого качества звучания при соответствующих типах аудиорендеринга.
Принимая во внимание тот факт, что заявляемая интегрированная система EKS SAOC больше не имеет ограничения, связанные с объектом BGO, а обладает гибкой адаптивностью к режимам рендеринга стандартного SAOC и может использовать равный с ним битстрим для любого типа рендеринга, можно считать целесообразным введение этой системы в стандарт MPEG SAOC.
7. Способ по алгоритму на фиг.7
Ниже, с обращением к блок-схеме на фиг.7 рассмотрен способ формирования представления сигнала повышающего микширования (апмикс-сигнала) на безе представления сигнала понижающего микширования и объектно-ориентированной параметрической информации.
Способ 700 включает в себя шаг 710, состоящий в декомпозиции представления сигнала понижающего микширования, выведении первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и выведении второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, исходя из представления сигнала понижающего микширования и, по меньшей мере, части объектно-ориентированной параметрической информации. Способ 700 также включает в себя шаг 720, состоящий в обработке второй аудиоинформации на основании объектно-ориентированной параметрической информации с выведением обработанной версии второй аудиоинформации.
Способ 700 далее включает в себя шаг 730, заключающийся в объединении первой аудиоинформации с обработанной версией второй аудиоинформации с формированием представления сигнала повышающего микширования.
Способ 700 согласно фиг.7 может быть расширен за счет любых рабочих характеристик и функциональных возможностей, относящихся к изобретению и рассмотренных в данной заявке. Кроме того, способ 700 обеспечивает реализацию обсуждавшихся здесь преимуществ устройства, являющегося предметом изобретения.
8. Альтернативные конструктивные решения
Несмотря на то, что здесь в основном рассматривается оборудование с точки зрения его технического устройства, понятно, что аспекты материальной части тесно связаны с описанием соответствующих способов ее применения, и какое-либо изделие или блок соответствуют особенностям метода или технологической операции. Аналогично, рассматриваемые технологии и рабочие операции непосредственно связаны с соответствующим машинным оборудованием и его элементной базой. Некоторые или все шаги предлагаемого способа могут быть выполнены с использованием аппаратных средств, таких, например, как микропроцессор, программируемый компьютер или электронная схема. В некоторых случаях осуществления одна или больше ответственных операций, составляющих данный способ, могут быть выполнены таким устройством.
Относящийся к изобретению кодированный аудиосигнал может быть сохранен в цифровой запоминающей среде или может быть транслирован в среде передачи информации, такой как беспроводная передающая среда или проводная передающая среда, например, Интернет.
В зависимости от конечного назначения и особенностей практического применения изобретение может быть реализовано в аппаратных или программных средствах. В реализации могу быть применены такие цифровые носители информации, как гибкий диск, DVD, „Блю-рей", CD, ПЗУ, ППЗУ, программируемое ПЗУ, СППЗУ или ФЛЭШ-память, содержащие электронно-считываемые управляющие сигналы, которые взаимодействуют (или совместимы) с программируемой компьютерной системой таким образом, что предлагаемый способ может быть осуществлен. Следовательно, цифровая среда хранения данных может быть читаемой компьютером.
Некоторые варианты конструкции согласно данному изобретению имеют в своем составе носитель информации, содержащий электронно считываемые сигналы управления, совместимый с программируемой компьютерной системой и способный участвовать в реализации одного из описанных здесь способов.
В целом данное изобретение может быть реализовано как компьютерный программный продукт с кодом программы, обеспечивающим осуществление одного из предлагаемых способов при условии, что компьютерный программный продукт используется с применением компьютера. Код программы может, например, храниться на машиночитаемом носителе.
Различные варианты реализации включают в себя компьютерную программу, хранящуюся на машиночитаемом носителе, для осуществления одного из описанных здесь способов.
Таким образом, формулируя иначе, относящийся к изобретению способ осуществляется с помощью компьютерной программы, имеющей код программы, обеспечивающий реализацию одного из описанных здесь способов, если компьютерную программу выполняют с использованием компьютера.
Далее, следовательно, техническое исполнение изобретенного способа включает в себя носитель данных (либо цифровой накопитель информации, либо читаемую компьютером среду), содержащий записанную на нем компьютерную программу, предназначенную для осуществления одного из способов, описанных здесь. Носитель данных, цифровая среда хранения или средства записи информации, как правило, представляют собой материальные предметы и/или не подлежат передаче средствами связи.
Отсюда следует, что реализация изобретения подразумевает наличие потока данных или последовательности сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов могут быть рассчитаны на передачу через средства связи, например, Интернет.
Кроме того, реализация включает в себя аппаратные средства, например, компьютер или программируемое логическое устройство, предназначенные или приспособленные для осуществления одного из описанных здесь способов.
Далее, для технического исполнения требуется компьютер с установленной на нем компьютерной программой для осуществления одного из описанных здесь способов.
Некоторые версии конструкции для реализации одной или всех функциональных возможностей описанных здесь способов могут потребовать применения программируемого логического устройства (например, полевой программируемой матрицы логических элементов). В зависимости от назначения версии базовый матричный кристалл может сочетаться с микропроцессором с целью осуществления одного из описанных здесь способов. Как правило, описываемые способы могут быть реализованы с использованием любого аппаратного средства.
Описанные выше конструктивные решения являются только иллюстрациями основных принципов настоящего изобретения. Подразумевается, что для специалистов в данной области возможность внесения изменений и усовершенствований в компоновку и элементы описанной конструкции очевидна. В силу этого, представленные здесь описания и пояснения вариантов реализации изобретения ограничиваются только рамками патентных требований, а не конкретными деталями.
9. Выводы
Теперь, подведем краткий итог некоторых аспектов и преимуществ интегрированной системы EKS SAOC в соответствии с настоящим изобретением. При воспроизведении звука по сценариям „караоке" и „соло" режим преобразования EKS SAOC поддерживает как воссоздание объектов заднего и переднего планов, так и произвольно смикшированное сочетание (согласно матрице аудиорендеринга) этих групп объектов.
Причем, первый режим рассматривается как главная цель преобразования EKS, последний обеспечивает дополнительную адаптивность.
Обобщение функциональных возможностей EKS привело к заключению о целесообразности приложения усилий к объединению EKS со стандартным алгоритмом преобразования SAOC с построением единой интегрированной системы. В такой интегрированной системе заложены следующие потенциальные преимущества:
- единая дружественная компоновка схемы кодирования/транскодирования SAOC;
- единый битстрим для EKS и для стандартного SAOC;
- отсутствие ограничений по количеству входных аудиообъектов, содержащих фоновые объекты (BGO), благодаря чему отсутствует необходимость генерации объекта заднего плана до этапа кодирования SAOC; и
- поддержка остаточного кодирования для фронтальных объектов, что оптимизирует качество восприятия в настраиваемых режимах воспроизведения караоке/соло.
Эти преимущества могут быть реализованы в заявляемой здесь интегрированной системе.
Список литературы
[1] ISO/IEC JTC1/SC29/WG11 (MPEG), Document N8853, "Call for Proposals on Spatial Audio Object Coding", 79th MPEG Meeting, Marrakech, January 2007.
[2] ISO/IEC JTC1/SC29/WG11 (MPEG), Document N9099, "Final Spatial Audio Object Coding Evaluation Procedures and Criterion", 80th MPEG Meeting, San Jose, April 2007.
[3] ISO/IEC JTC1/SC29/WG11 (MPEG), Document N9250, "Report on Spatial Audio Object Coding RMO Selection", 81st MPEG Meeting, Lausanne, July 2007.
[4] ISO/IEC JTC1/SC29/WG11 (MPEG), Document M15123, "Information and Verification Results for CE on Karaoke/Solo system improving the performance of MPEG SAOC RMO", 83rd MPEG Meeting, Antalya, Turkey, January 2008.
[5] ISO/IEC JTC1/SC29/WG11 (MPEG), Document N10659, "Study on ISO/IEC 23003-2:200x Spatial Audio Object Coding (SAOC)", 88th MPEG Meeting, Maui, USA, April 2009.
[6] ISO/IEC JTC1/SC29/WG11 (MPEG), Document M10660, "Status and Workplan on SAOC Core Experiments", 88th MPEG Meeting, Maui, USA, April 2009.
[7] EBU Technical recommendation: "MUSHRA-EBU Method for Subjective Listening Tests of Intermediate Audio Quality", Doc. B/AIM022, October 1999.
[8] ISO/IEC 23003-1:2007, Information technology - MPEG audio technologies - Part 1: MPEG Surround.
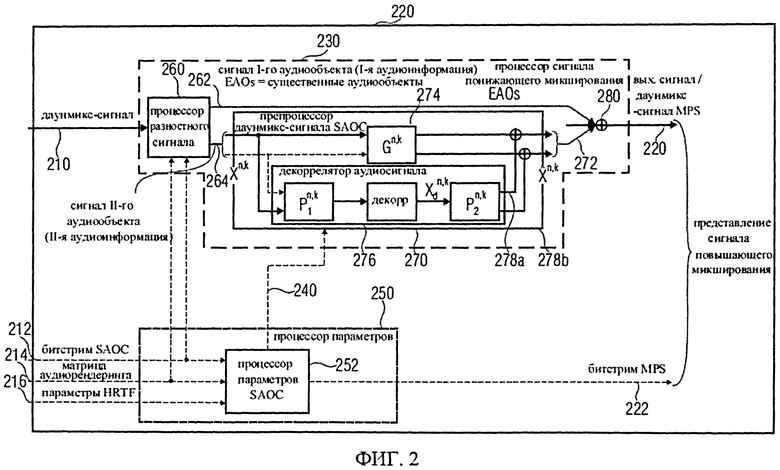
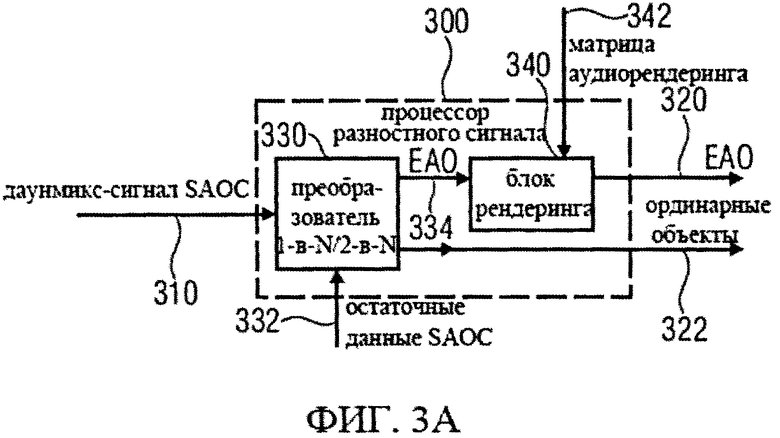
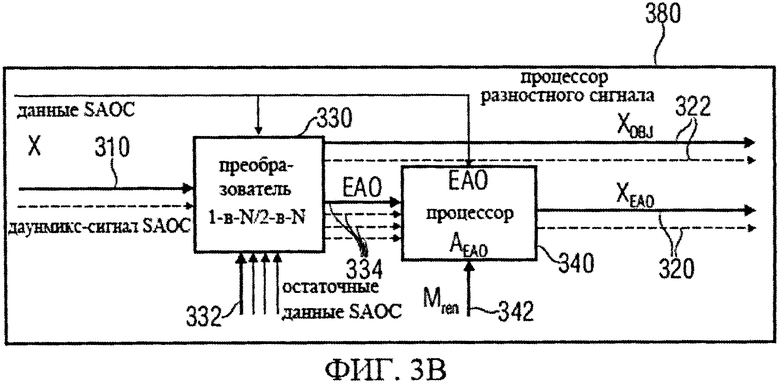
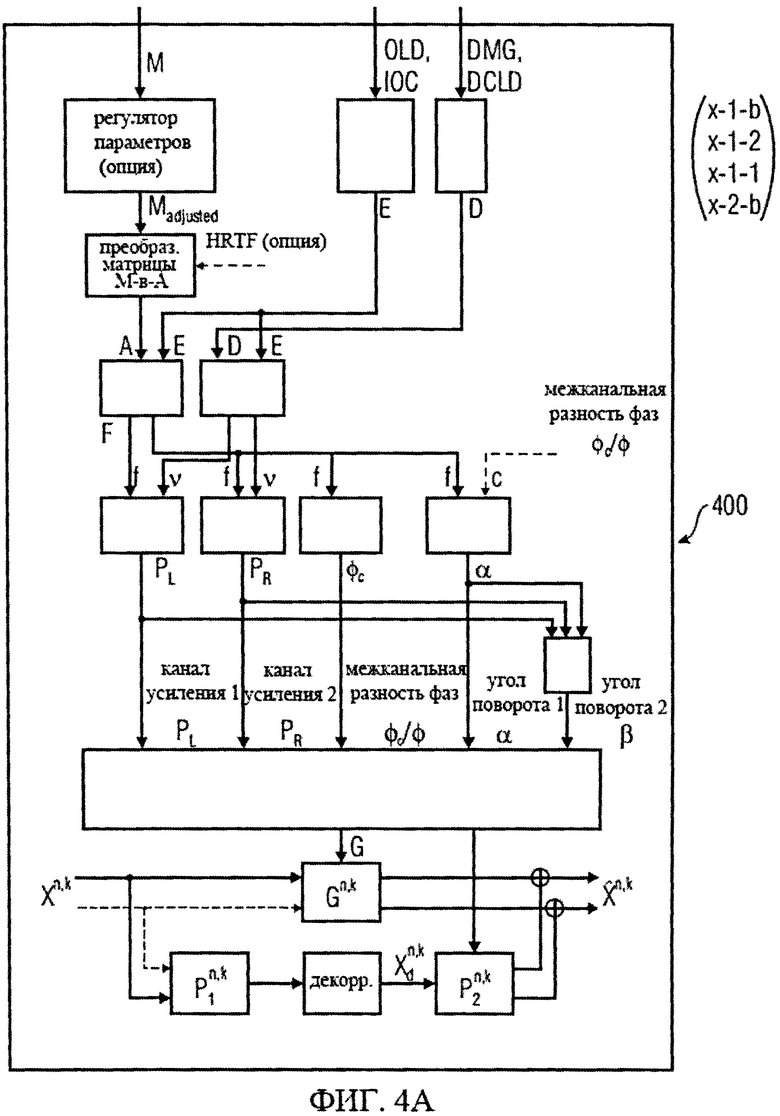
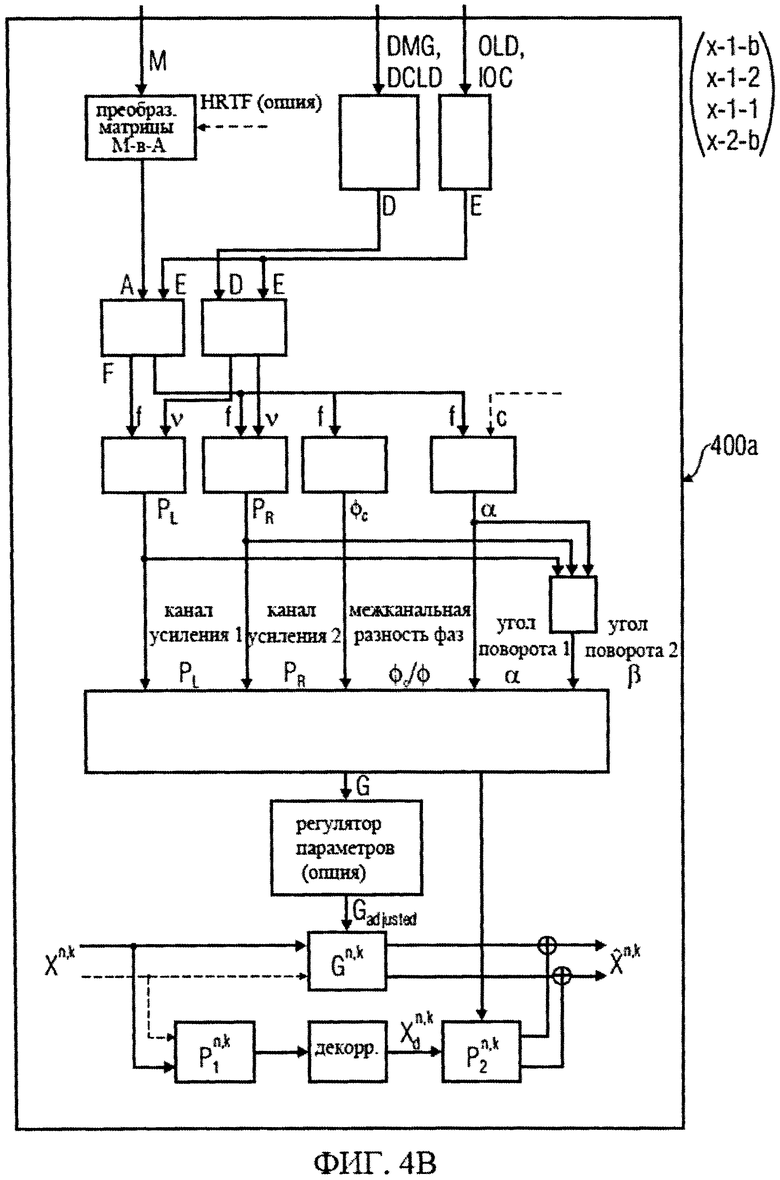
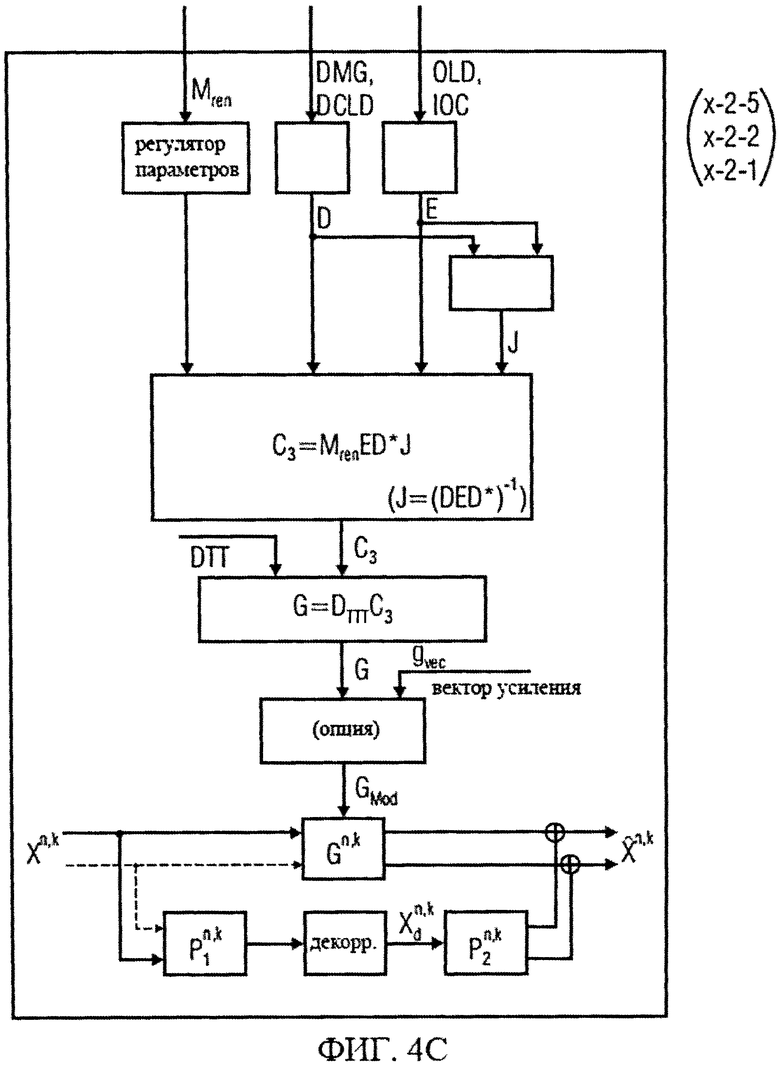
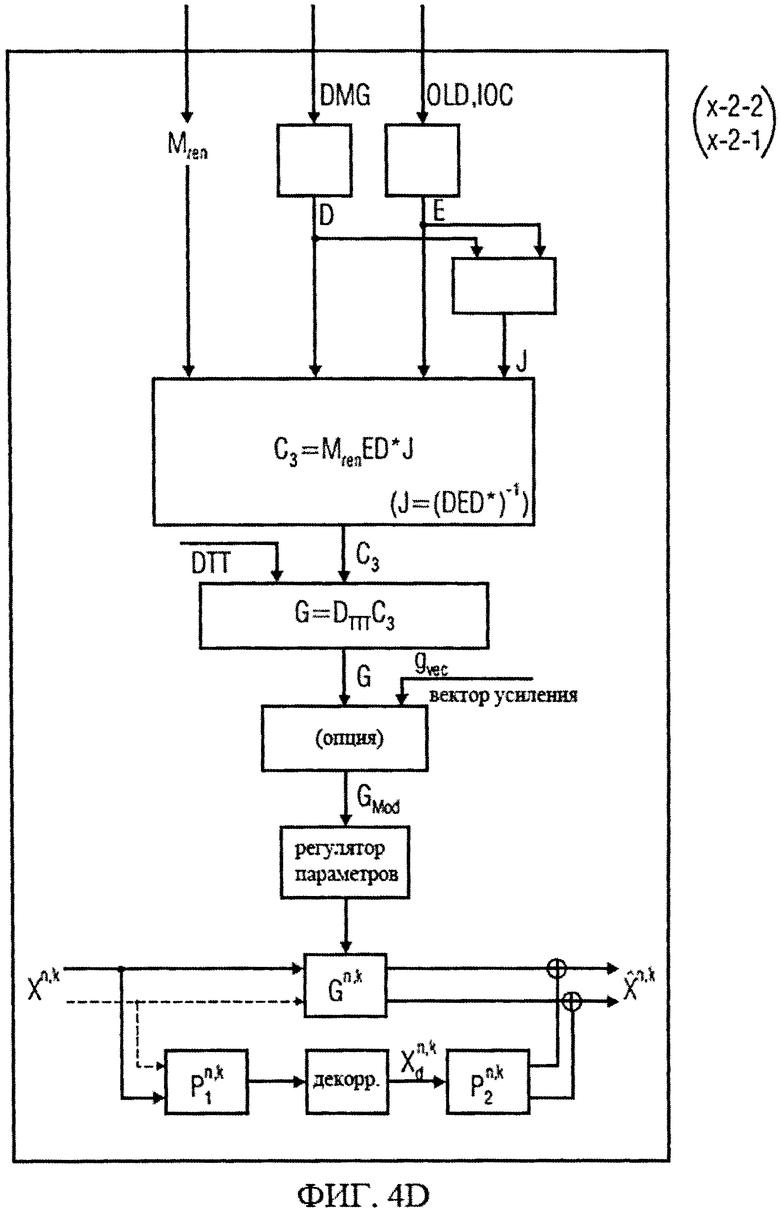
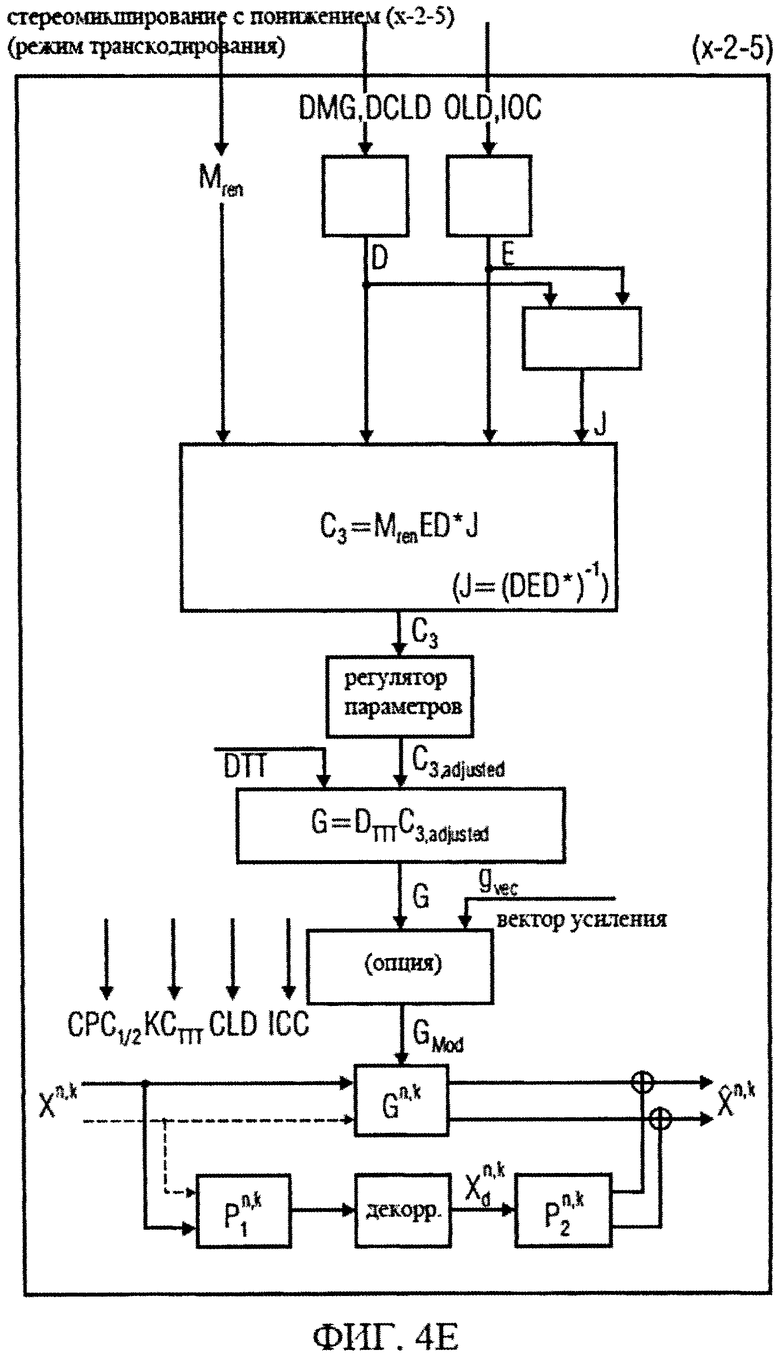
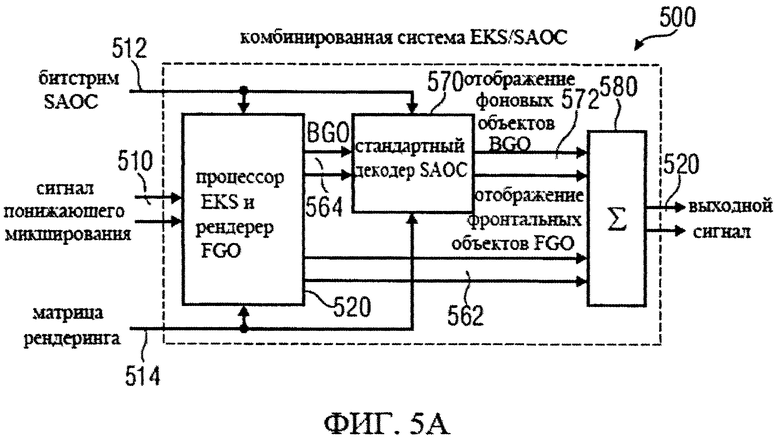
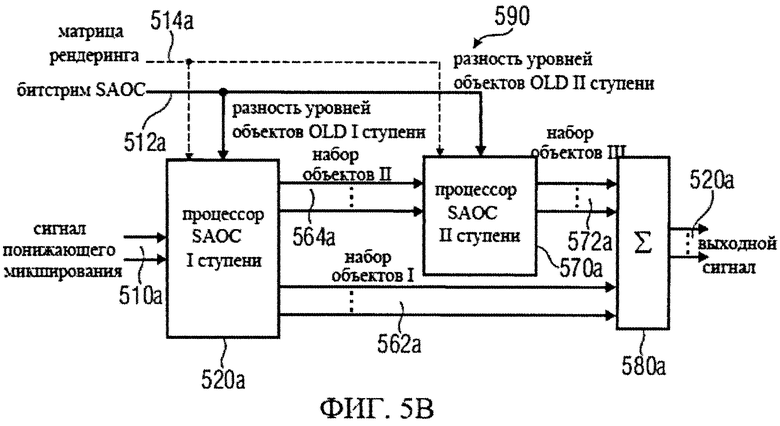

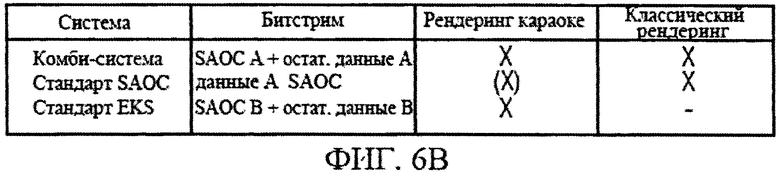

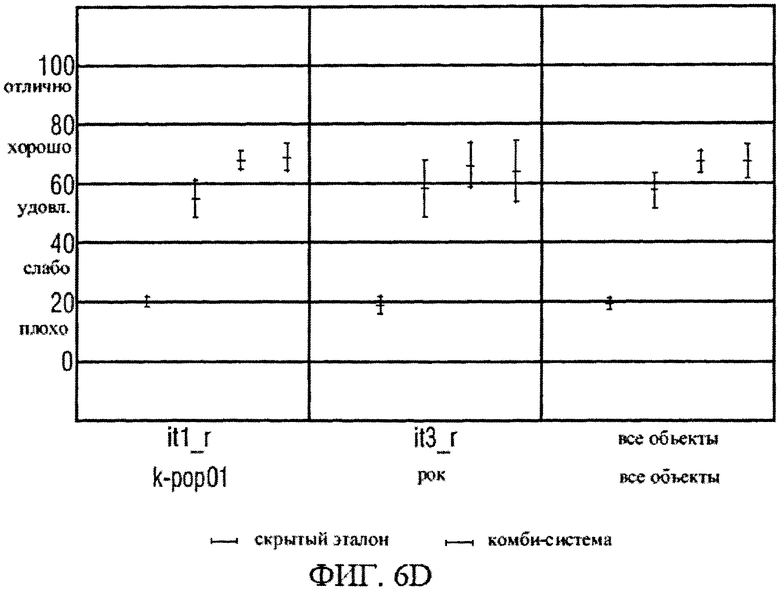
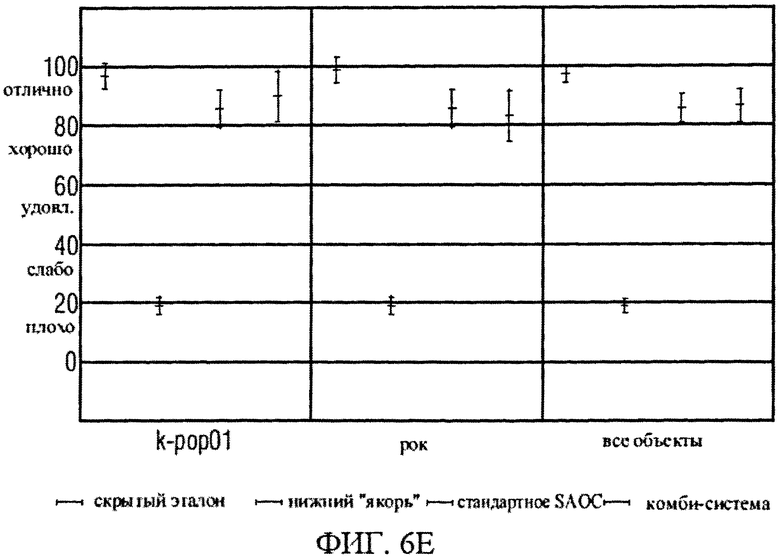
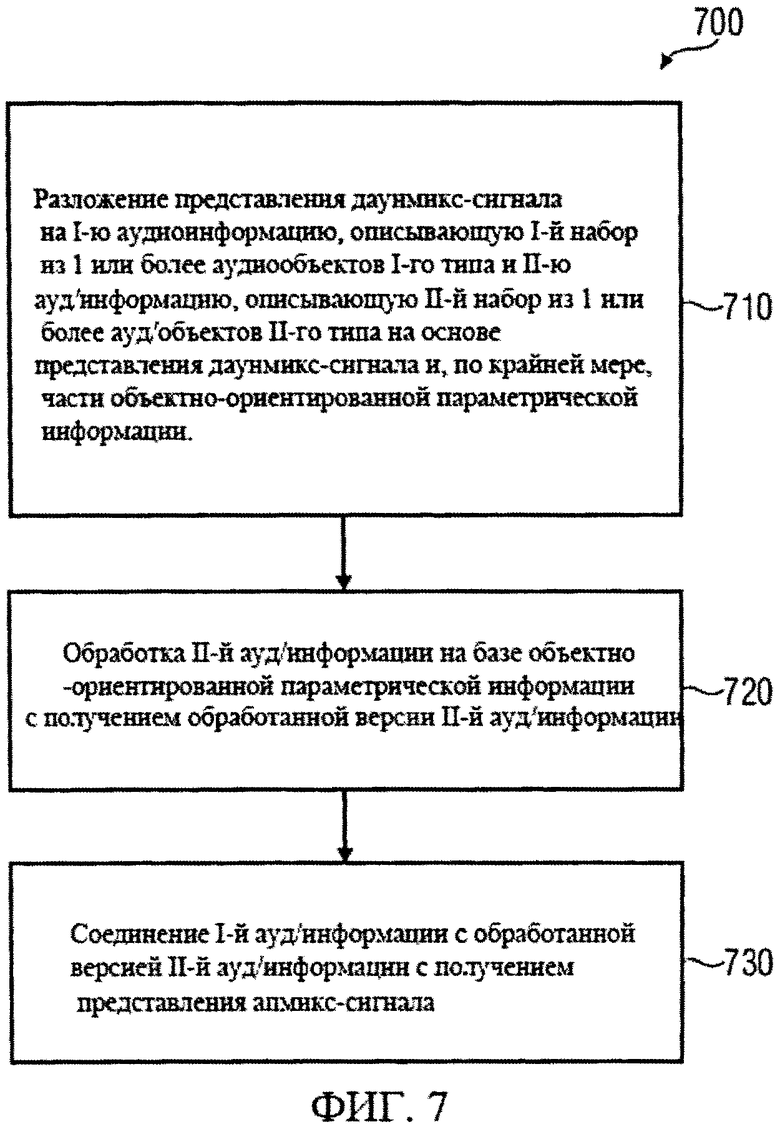
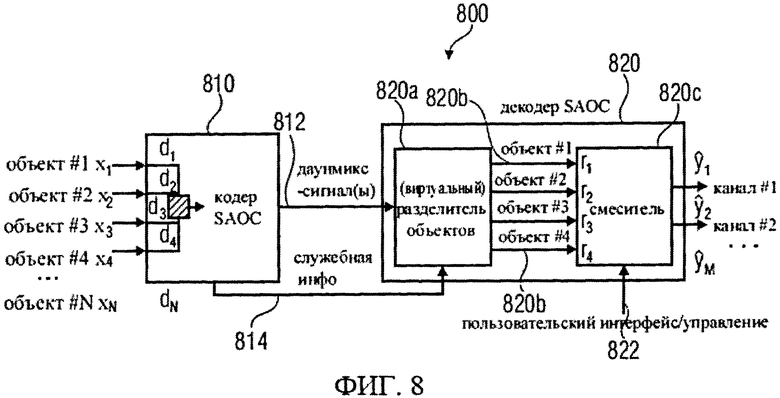
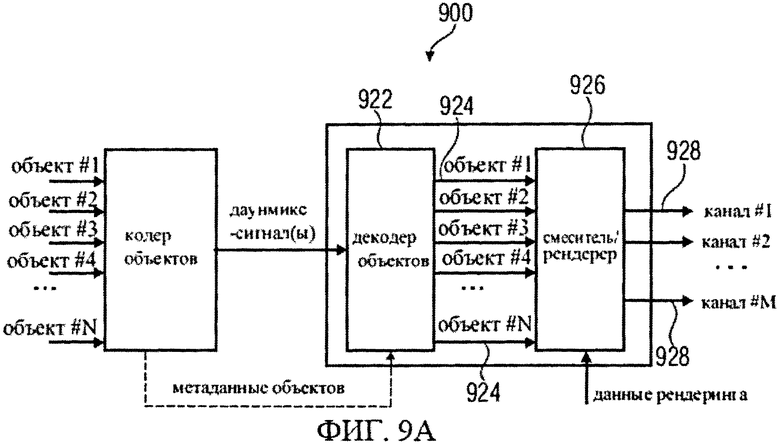
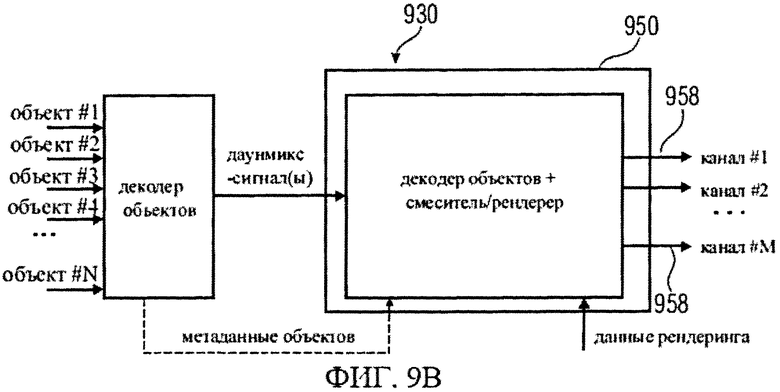
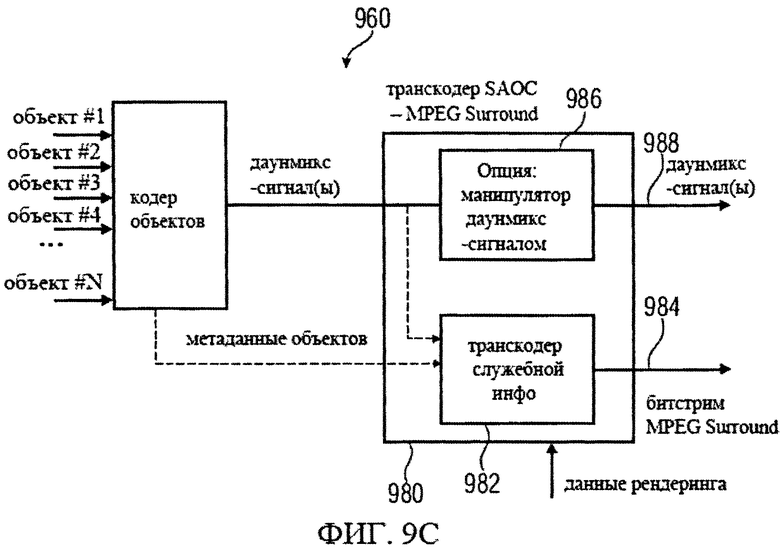
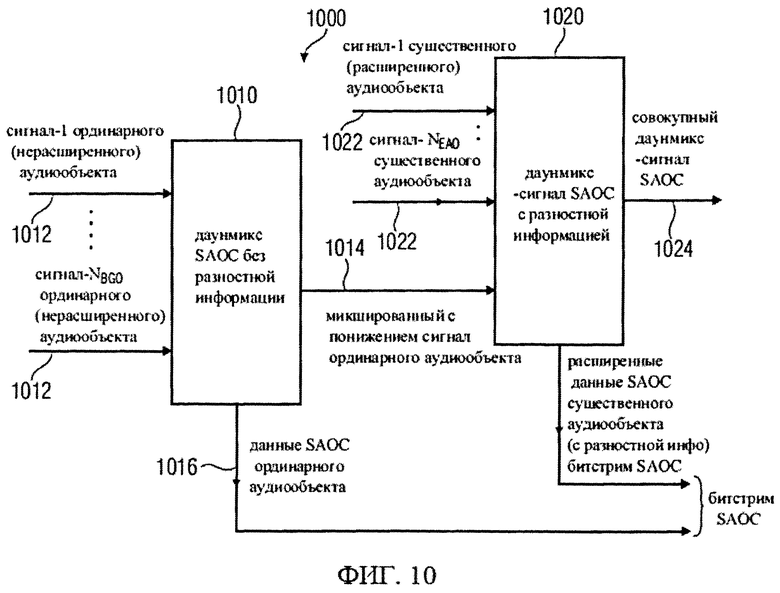
Изобретение относится к декодеру аудиосигнала, генерирующему на выходе представление сигнала повышающего микширования на базе представления сигнала понижающего микширования и объектно-ориентированной параметрической информации. Технический результат - повышение точности воспроизведения аудиосигналов. Для этого декодер аудиосигнала содержит разделитель объектов, предназначенный для разложения представления сигнала понижающего микширования на первую аудиоинформацию, описывающую первую комбинацию из одного или более аудиообъектов первого типа, и вторую аудиоинформацию, описывающую вторую комбинацию из одного или более аудиообъектов второго типа, в зависимости от представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации, процессор аудиосигналов, предназначенный для приема второй аудиоинформации и обработки второй аудиоинформации, исходя из объектно-ориентированной параметрической информации, с получением обработанной версии второй аудиоинформации, комбинатор аудиосигнала, выполняющий объединение первой аудиоинформации с обработанной версией второй аудиоинформации с формированием на выходе представления сигнала повышающего микширования. 12 н. и 27 з.п. ф-лы, 22 ил.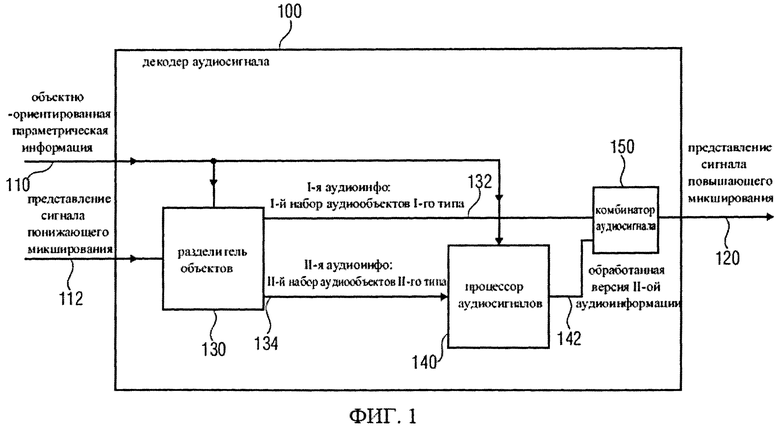
1. Декодер аудиосигнала (100; 200; 500; 590), формирующий представление сигнала повышающего микширования на основе представления сигнала понижающего микширования (112; 210; 510; 510а), объектно-ориентированной параметрической информации (110; 212; 512; 512а), включающий разделитель объектов (130; 260; 520; 520а), предназначенный для разложения представления сигнала понижающего микширования с извлечением первой аудиоинформации (132; 262; 562; 562а), описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации (134; 264; 564; 564а), описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на базе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации; при этом вторая аудиоинформация описывает аудиообъекты второго типа аудиообъектов в совокупном виде; процессор аудиосигналов, предназначенный для приема второй аудиоинформации (134; 264; 564; 564а) и обработки второй аудиоинформации, исходя из объектно-ориентированной параметрической информации, с получением обработанной версии (142; 272; 572; 572а) второй аудиоинформации; и комбинатор аудиосигнала (150; 280; 580; 580а), предназначенный для сведения первой аудиоинформации и обработанной версии второй аудиоинформации с формированием представления сигнала повышающего микширования; имея в своем составе названные компоненты, декодер аудиосигнала формирует представление сигнала повышающего микширования, исходя из разностной информации, относящейся к подмножеству аудиообъектов, отображенных в представлении сигнала понижающего микширования; в составе декодера аудиосигнала разделитель объектов предназначен для разложения представления сигнала понижающего микширования с извлечением первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, к которым относится разностная информация, и извлечением второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, к которым разностная информация не относится, исходя из представления сигнала понижающего микширования и с использованием разностной информации; и в составе декодера аудиосигнала процессор аудиосигналов обрабатывает вторую аудиоинформацию, выполняя индивидуальную обработку аудиообъектов второго типа аудиообъектов, учитывая объектно-ориентированную параметрическую информацию, относящуюся к более чем двум аудиообъектам второго типа; и при этом остаточная информация описывает остаточное искажение, ожидаемое в случае, если аудиообъект первого типа аудиообъектов выделен только с использованием объектно-ориентированной параметрической информации.
2. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов предназначен для выделения из первой аудиоинформации одного или более аудиообъектов первого типа аудиообъектов, более существенных по сравнению с аудиообъектами второго типа аудиообъектов в структуре первой аудиоинформации, и в составе которого разделитель объектов предназначен для выделения из второй аудиоинформации аудиообъектов второго типа аудиообъектов, более значимых относительно аудиообъектов первого типа аудиообъектов в структуре второй аудиоинформации.
3. Декодер аудиосигнала (100; 200; 500; 570) по п. 1, в составе которого процессор аудиосигналов обрабатывает вторую аудиоинформацию (134; 264; 564; 564а) в зависимости от объектно-ориентированной параметрической информации (110; 212; 512; 512а), относящейся к аудиообъектам второго типа аудиообъектов, и независимо от объектно-ориентированной параметрической информации (110; 212; 512; 512а), относящейся к аудиообъектам первого типа аудиообъектов.
4. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов предназначен для извлечения первой аудиоинформации (132; 262; 562; 562а, XEAO) и второй аудиоинформации (134; 264; 564; 564а, XOBJ) с использованием линейной комбинации одного или более каналов представления сигнала понижающего микширования и одного или более разностных каналов; при этом разделитель объектов в составе аудиодекодера вычисляет параметры для построения линейной комбинации, исходя из параметров понижающего микширования аудиообъектов первого типа аудиообъектов (m0…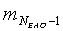 ; n0…
; n0…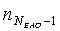 ) и с учетом коэффициентов предсказания каналов (cj,0, cj,1) аудиообъектов первого типа.
) и с учетом коэффициентов предсказания каналов (cj,0, cj,1) аудиообъектов первого типа.
5. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию в соответствии с
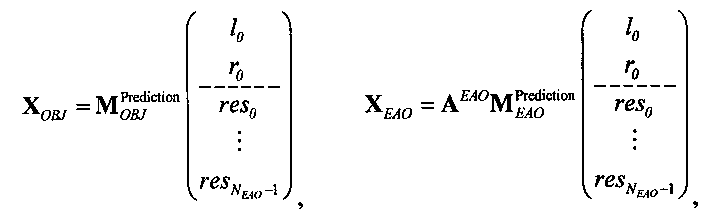
где матрица предсказания
где
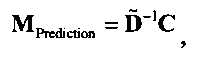
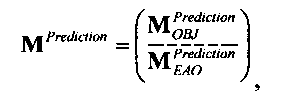
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где 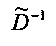 представляет матрицу, обратную расширенной матрице понижающего микширования;
представляет матрицу, обратную расширенной матрице понижающего микширования;
где С описывает матрицу, представляющую множество коэффициентов предсказания каналов 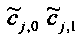 ;
;
где l0 и r0 обозначают каналы представления сигнала понижающего микширования;
где показатели с res0 до resN
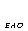 -1 обозначают разностные каналы; и
-1 обозначают разностные каналы; и
где AEAO - матрица предварительного рендеринга ЕАО, элементы которой описывают распределение существенных аудиообъектов по каналам сигнала существенных аудиообъектов XEAO;
также в составе которого разделитель объектов рассчитывает обратную матрицу понижающего микширования 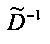 как инверсную расширенной матрице понижающего микширования
как инверсную расширенной матрице понижающего микширования 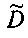 , которая определяется как
, которая определяется как
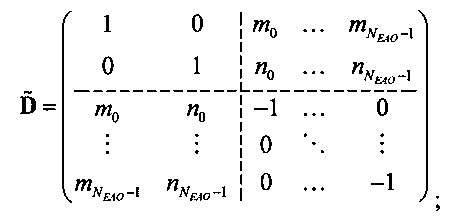
в составе которого разделитель объектов формирует матрицу С как
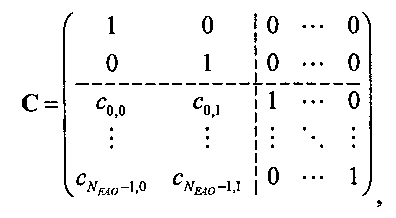
где m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где n0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
также в составе декодера аудиосигнала разделитель объектов рассчитывает коэффициенты предсказания 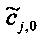 и
и 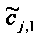 как
как
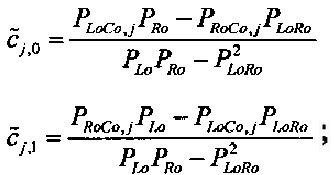
и в составе которого разделитель объектов выводит коэффициенты ограничения предсказания cj,0 и cj,1 из коэффициентов предсказания 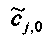 и
и 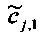 с использованием алгоритма ограничения или использует коэффициенты предсказания
с использованием алгоритма ограничения или использует коэффициенты предсказания 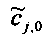 и
и 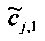 как коэффициенты предсказания cj,0 и cj,1;
как коэффициенты предсказания cj,0 и cj,1;
где показатели уровней энергии PLo, PRo, PLoRo, PLoCoj и PRoCoj определяются как
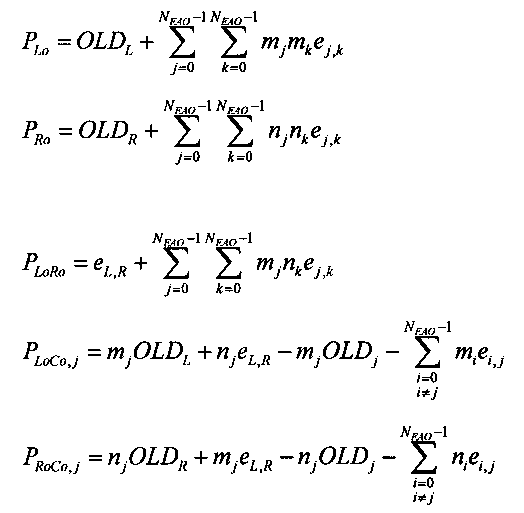
при этом параметры OLDL, OLDR и IOCL,R соответствуют аудиообъектам второго типа аудиообъектов и определяются следующим образом
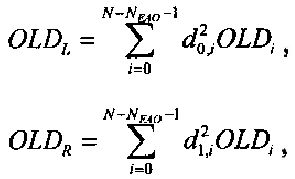
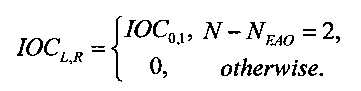
где d0,i и d1,i - показатели понижающего микширования, связанные с аудиообъектами второго типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где N - общее количество аудиообъектов;
где NEAO - количество аудиообъектов первого типа;
где IOC0,1 - показатель межобъектной корреляции пары аудиообъектов второго типа;
где ei,j и eL,R - показатели ковариации, полученные из показателей разности уровней объектов и параметров межобъектной корреляции; и
где ei,j связаны с парой аудиообъектов первого типа аудиообъекта, а eL,R связаны с парой аудиообъектов второго типа аудиообъектов.
6. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию, исходя из
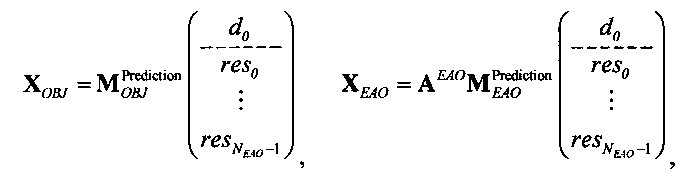
где матрица предсказания
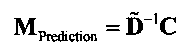
где XOBJ представляет канал второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где  представляет матрицу, обратную расширенной матрице понижающего микширования;
представляет матрицу, обратную расширенной матрице понижающего микширования;
где С описывает матрицу, представляющую множество коэффициентов предсказания каналов  ,
,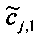 ;
;
где d0 обозначает канал представления сигнала понижающего микширования; и
где показатели с res0 по resN
-1 представляют разностные каналы; и
где AEAO - матрица предварительного рендеринга ЕАО.
7. Декодер аудиосигнала по п. 6, в составе которого разделитель объектов рассчитывает обратную матрицу понижающего микширования 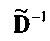 , инверсную расширенной матрице понижающего микширования
, инверсную расширенной матрице понижающего микширования 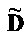 , определяемой как
, определяемой как
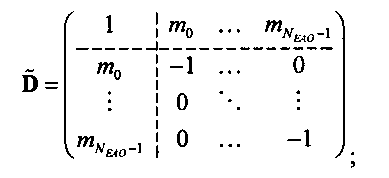
в составе которого разделитель объектов формирует матрицу С как
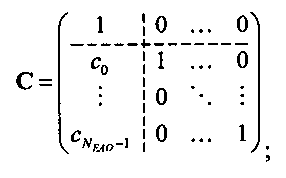
где показатели с m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов.
8. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию, исходя из
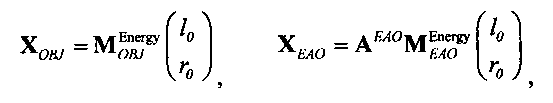
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
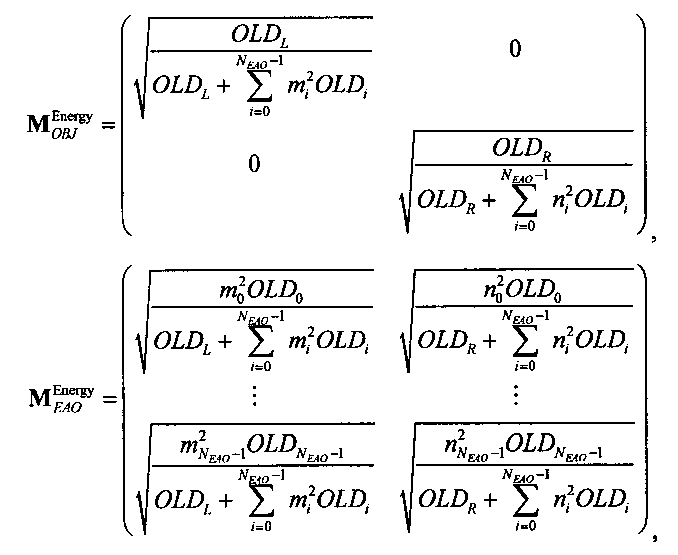
где m0 до - показатели понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где 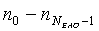 - показатели понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
- показатели понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам первого типа аудиообъектов;
где OLDL и OLDR - общие значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов; и
где AEAO - матрица предварительного рендеринга ЕАО.
9. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию в соответствии с
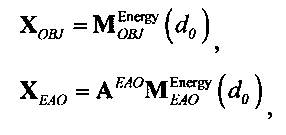
где XOBJ представляет канал второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
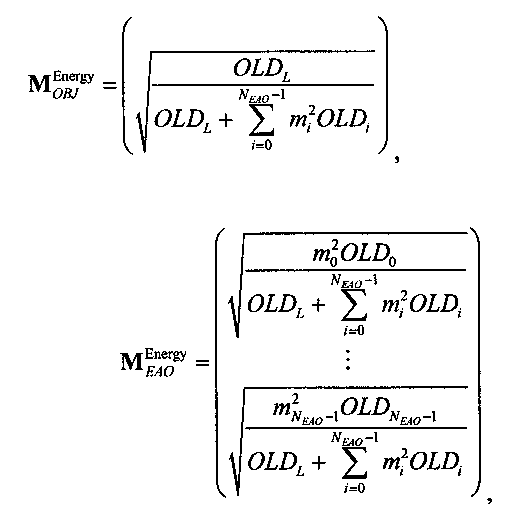
где m0 до - показатели понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам первого типа аудиообъектов;
где OLDL - общее значение разности уровней объектов, связанное с аудиообъектами второго типа аудиообъектов; и
где AEAO - матрица предварительного рендеринга ЕАО;
где матрицы 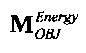 и
и 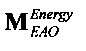 прилагают к представлению d0 единого даунмикс-сигнала SAOC.
прилагают к представлению d0 единого даунмикс-сигнала SAOC.
10. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого разделитель объектов предназначен для приложения матрицы аудиорендеринга к первой аудиоинформации (132; 262; 562; 562а) с целью отображения сигналов объектов первой аудиоинформации в аудиоканалах представления аудиосигнала повышающего микширования (120; 220, 222; 562; 562а).
11. Декодер аудиосигнала (100; 200; 500; 590) по п. 1, в составе которого процессор аудиосигналов (140; 270; 570; 570а) выполняет предварительную стереообработку второй аудиоинформации (134; 264; 564; 564а) на основе информации по рендерингу (Mren), объектно-ориентированных данных ковариации (Е), параметров понижающего микширования (D) с образованием аудиоканалов обработанной версии второй аудиоинформации.
12. Декодер аудиосигнала (100; 200; 500; 590) по п. 11, в составе которого процессор аудиосигналов (140; 270; 570; 570а) выполняет стереообработку с целью распределения оцененной составляющей аудиообъекта (ED*JX) второй аудиоинформации (134; 264; 564; 564а) по множеству каналов представления аудиосигнала повышающего микширования, исходя из характеристик рендеринга и ковариации.
13. Декодер аудиосигнала по п. 11, в составе которого процессор аудиосигналов суммирует составляющую (Р2Х2) декоррелированного аудиосигнала, рассчитанную из одного или более аудиоканалов второй аудиоинформации, со второй аудиоинформацией или с информацией, выделенной из второй аудиоинформации, на основании данных об ошибке рендеринга повышающего микширования (R) и одного или более значений коэффициентов масштабирования интенсивности декоррелированного сигнала (wd1, wd2).
14. Декодер аудиосигнала по п. 1, в составе которого процессор аудиосигналов (140; 270; 570; 570а) выполняет последующую обработку второй аудиоинформации (134; 264; 564; 564а) в зависимости от параметров рендеринга (А), объектно-ориентированных показателей ковариации (Е) и данных понижающего микширования (D).
15. Декодер аудиосигнала по п. 14, в составе которого процессор аудиосигналов преобразует из моноформата в бинауральный вторую аудиоинформацию для распределения одного канал второй аудиоинформации по двум каналам представления сигнала повышающего микширования с учетом передаточной функции органов слуха.
16. Декодер аудиосигнала по п. 14, в составе которого процессор аудиосигналов выполняет преобразование моно-в-стерео второй аудиоинформации для распределения одного канала второй аудиоинформации по двум каналам представления сигнала повышающего микширования.
17. Декодер аудиосигнала по п. 14, в составе которого процессор аудиосигналов преобразует вторую аудиоинформацию из стереоформата в бинауральный для распределения двух каналов второй аудиоинформации по двум каналам представления сигнала повышающего микширования с учетом передаточной функции слухового тракта.
18. Декодер аудиосигнала по п. 14, в составе которого процессор аудиосигналов выполняет преобразование стерео-в-стерео второй аудиоинформации для распределения двух каналов второй аудиоинформации по двум каналам представления сигнала повышающего микширования.
19. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов обрабатывает аудиообъекты второго типа аудиообъектов, с которыми не соотнесена разностная информация, как единый аудиообъект; и в составе которого процессор аудиосигналов (140; 270; 570; 570а) на базе объектно-ориентированных параметров рендеринга, соотнесенных с аудиообъектами второго типа аудиообъектов, корректирует распределение составляющих аудиообъектов второго типа в представлении сигнала повышающего микширования.
20. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов находит одно или два общих значения разности уровней объектов (OLDL, OLDR) для множества аудиообъектов второго типа аудиообъектов и в составе которого разделитель объектов использует общее значение разности уровней объектов для расчета коэффициентов предсказания каналов (СРС); а также в составе которого разделитель объектов использует коэффициенты предсказания каналов для формирования одного или двух аудиоканалов представления второй аудиоинформации.
21. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов находит одно или два общих значения разности уровней объектов (OLDL, OLDR) для множества аудиообъектов второго типа аудиообъектов, и в составе которого разделитель объектов использует общее значение разности уровней объектов для расчета элементов матрицы (М); и в составе которого разделитель объектов использует матрицу (М) формирования одного или более аудиоканалов представления второй аудиоинформации.
22. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов выборочно находит общее значение корреляции между объектами (IOCL,R) второго типа, исходя из объектно-ориентированной параметрической информации, если определено наличие двух аудиообъектов второго типа аудиообъектов, и устанавливает значение корреляции между объектами второго типа на ноль, если установлено, что присутствует больше или меньше двух аудиообъектов второго типа аудиообъектов; и в составе которого разделитель объектов использует общий показатель межобъектной корреляции для вычисления элементов матрицы (М); а также в составе которого разделитель объектов использует общий показатель корреляции между объектами второго типа для формирования одного или более аудиоканалов представления второй аудиоинформации.
23. Декодер аудиосигнала по п. 1, в составе которого процессор аудиосигналов выполняет рендеринг второй аудиоинформации на основе объектно-ориентированной параметрической информации с формированием представления аудиообъектов второго типа аудиообъектов в виде преобразованной рендерингом версии второй аудиоинформации.
24. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов формирует вторую аудиоинформацию таким образом, что она описывает больше чем два аудиообъекта второго типа аудиообъектов.
25. Декодер аудиосигнала по п. 24, в составе которого разделитель объектов формирует в виде второй аудиоинформации представление одноканального аудиосигнала или представление двухканального аудиосигнала, отображающее более двух аудиообъектов второго типа аудиообъектов.
26. Декодер аудиосигнала по п. 1, в составе которого процессор аудиосигналов принимает вторую аудиоинформацию и обрабатывает ее в соответствии с объектно-ориентированной параметрической информацией, относящейся более чем к двум аудиообъектам второго типа аудиообъектов.
27. Декодер аудиосигнала по п. 1, который характеризуется тем, что извлекает информацию об общем количестве объектов (bsNumObjects) и информацию о количестве фронтальных объектов (bsNumGroupsFGO) из информации о конфигурации (SAOCSpecificConfig) в составе объектно-ориентированной параметрической информации, и тем, что определяет количество аудиообъектов второго типа аудиообъектов, находя разность между общим количеством объектов и количеством фронтальных объектов.
28. Декодер аудиосигнала по п. 1, в составе которого разделитель объектов использует объектно-ориентированную параметрическую информацию, относящуюся к NEAO аудиообъектов первого типа аудиообъектов, для формирования в виде первой аудиоинформации NEAO аудиосигналов (XEAO), представляющих NEAO аудиообъектов первого типа аудиообъектов, и для формирования в виде второй аудиоинформации одного или двух аудиосигналов (XOBJ), представляющих N-NEAO аудиообъектов второго типа аудиообъектов, обрабатывая N-NEAO аудиообъектов второго типа как один одноканальный или двухканальный аудиообъект; и в составе которого процессор аудиосигналов выполняет индивидуальный рендеринг N-NEAO аудиообъектов, представленных одним или двумя аудиосигналами второй аудиоинформации, используя объектно-ориентированную параметрическую информацию, относящуюся к N-NEAO аудиообъектам второго типа аудиообъектов.
29. Способ формирования представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и объектно-ориентированной параметрической информации, включающий в себя: разложение представления сигнала понижающего микширования с извлечением первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и извлечением второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на основе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации, при этом вторая аудиоинформация описывает аудиообъекты второго типа аудиообъектов в совокупном виде; и обработку второй аудиоинформации в зависимости от объектно-ориентированной параметрической информации с получением обработанной версии второй аудиоинформации; и сведение первой аудиоинформации с обработанной версией второй аудиоинформации с формированием представления сигнала повышающего микширования; при этом представление сигнала повышающего микширования формируют в зависимости от остаточной информации, относящейся к подмножеству аудиообъектов, отображенных в представлении сигнала понижающего микширования, при этом представление сигнала понижающего микширования разлагают, исходя из представления сигнала понижающего микширования с использованием остаточной информации, на первую аудиоинформацию, описывающую первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, к которым относится остаточная информация, и вторую аудиоинформацию, описывающую вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, к которым разностная информация не относится; при этом выполняют индивидуальную обработку аудиообъектов второго типа, учитывая объектно-ориентированную параметрическую информацию, относящуюся к более чем двум аудиообъектам второго типа аудиообъектов; и при этом остаточная информация описывает остаточное искажение, ожидаемое в случае, если аудиообъект первого типа аудиообъектов выделен только с использованием объектно-ориентированной параметрической информации.
30. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 29 при условии ее выполнения с использованием вычислительной техники.
31. Декодер аудиосигнала (100; 200; 500; 590), формирующий представление сигнала повышающего микширования на основе представления сигнала понижающего микширования (112; 210; 510; 510а), объектно-ориентированной параметрической информации (110; 212; 512; 512а), включающий в свою конструкцию: разделитель объектов (130; 260; 520; 520а), предназначенный для разложения представления сигнала понижающего микширования с извлечением первой аудиоинформации (132; 262; 562; 562а), описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации (134; 264; 564; 564а), описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на базе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации; комбинатор аудиосигнала (150; 280; 580; 580а), предназначенный для сведения первой аудиоинформации и обработанной версии второй аудиоинформации с формированием представления сигнала повышающего микширования; комбинатор аудиосигнала (150; 280; 580; 580а), предназначенный для сведения первой аудиоинформации и обработанной версии второй аудиоинформации с формированием представления сигнала повышающего микширования; разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию в соответствии с
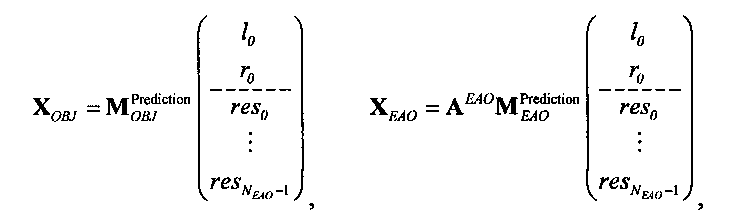
где
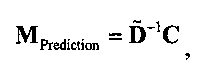
где
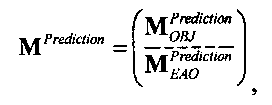
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где  представляет матрицу, обратную расширенной матрице понижающего микширования;
представляет матрицу, обратную расширенной матрице понижающего микширования;
где С описывает матрицу, представляющую множество коэффициентов предсказания каналов 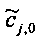 ,
, 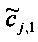 ;
;
где l0 и r0 обозначают каналы представления сигнала понижающего микширования;
где показатели от res0 до resN
-1 обозначают разностные каналы; и
где AEAO - матрица предварительного рендеринга ЕАО, элементы которой описывают распределение существенных аудиообъектов по каналам сигнала существенных аудиообъектов XEAO;
также в составе которого разделитель объектов рассчитывает обратную матрицу понижающего микширования 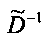 как инверсную расширенной матрице понижающего микширования
как инверсную расширенной матрице понижающего микширования 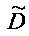 , которая определяется как
, которая определяется как
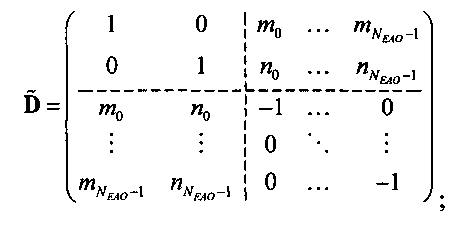
в составе которого разделитель объектов формирует матрицу С как
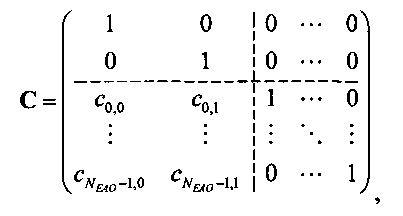
где от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где от n0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
также в составе декодера аудиосигнала разделитель объектов рассчитывает коэффициенты предсказания 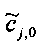 и
и 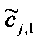 как
как
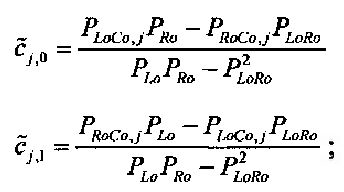
и в составе которого разделитель объектов выводит коэффициенты ограничения предсказания cj,0 и cj,1 из коэффициентов предсказания 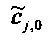 и
и 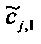 с использованием алгоритма ограничения, или использует коэффициенты предсказания
с использованием алгоритма ограничения, или использует коэффициенты предсказания 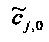 и
и 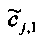 как коэффициенты предсказания cj,0 и cj,1;
как коэффициенты предсказания cj,0 и cj,1;
где показатели уровней энергии PLo, PRo, PLoRo, PLoCoj и PRoCoj определяются как
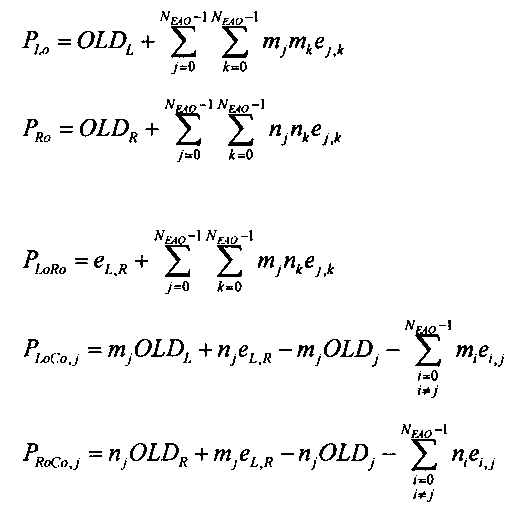
при этом параметры OLDL, OLDR и IOCL,R соответствуют аудиообъектам второго типа аудиообъектов и определяются следующим образом
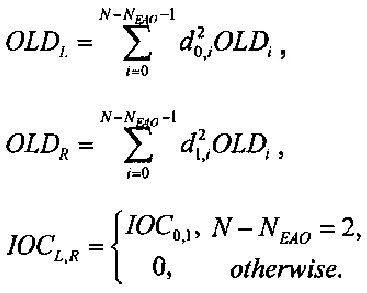
где d0,i и d1,i - показатели понижающего микширования, связанные с аудиообъектами второго типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где N - общее количество аудиообъектов;
где NEAO - количество аудиообъектов первого типа;
где IOC0,1 - показатель межобъектной корреляции пары аудиообъектов второго типа;
где ei,j и eL,R - показатели ковариации, полученные из показателей разности уровней объектов и параметров межобъектной корреляции; и
где ei,j связаны с парой аудиообъектов первого типа аудиообъекта, а eL,R связаны с парой аудиообъектов второго типа аудиообъектов.
32. Декодер аудиосигнала (100; 200; 500; 590), формирующий представление сигнала повышающего микширования на основе представления сигнала понижающего микширования (112; 210; 510; 510а), объектно-ориентированной параметрической информации (110; 212; 512; 512а), включающий в свою конструкцию: разделитель объектов (130; 260; 520; 520а), предназначенный для разложения представления сигнала понижающего микширования с извлечением первой аудиоинформации (132; 262; 562; 562а), описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации (134; 264; 564; 564а), описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на базе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации; процессор аудиосигналов, предназначенный для приема второй аудиоинформации (134; 264; 564; 564а) и обработки второй аудиоинформации, исходя из объектно-ориентированной параметрической информации, с получением обработанной версии (142; 272; 572; 572а) второй аудиоинформации; и комбинатор аудиосигнала (150; 280; 580; 580а), предназначенный для сведения первой аудиоинформации и обработанной версии второй аудиоинформации с формированием представления сигнала повышающего микширования;
где разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию в соответствии с
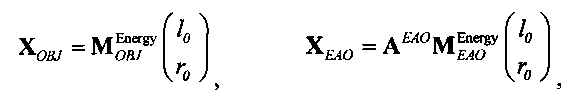
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
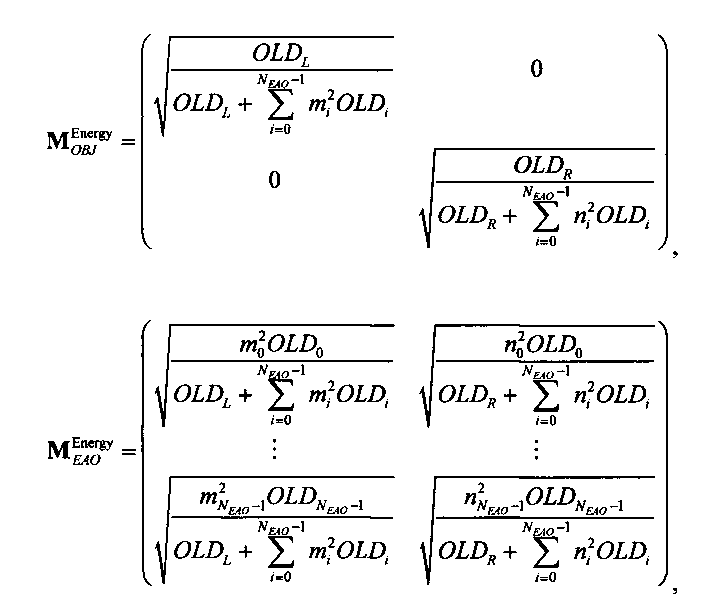
где показатели от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где показатели от n0 по  - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
- значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где OLDL, и OLDR - общие значения разности уровней аудиообъектов второго типа; и
где AEAO - матрица предварительного рендеринга ЕАО.
33. Декодер аудиосигнала (100; 200; 500; 590), формирующий представление сигнала повышающего микширования на основе представления сигнала понижающего микширования (112; 210; 510; 510а), объектно-ориентированной параметрической информации (110; 212; 512; 512а), включающий в свою конструкцию: разделитель объектов (130; 260; 520; 520а), предназначенный для разложения представления сигнала понижающего микширования с извлечением первой аудиоинформации (132; 262; 562; 562а), описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации (134; 264; 564; 564а), описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на базе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации; процессор аудиосигналов, предназначенный для приема второй аудиоинформации (134;264; 564; 564а) и обработки второй аудиоинформации, исходя из объектно-ориентированной параметрической информации, с получением обработанной версии (142; 272; 572; 572а) второй аудиоинформации; и комбинатор аудиосигнала (150; 280; 580; 580а), предназначенный для сведения первой аудиоинформации и обработанной версии второй аудиоинформации с формированием представления сигнала повышающего микширования; где разделитель объектов извлекает первую аудиоинформацию и вторую аудиоинформацию в соответствии с
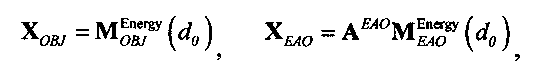
где XOBJ представляет канал второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
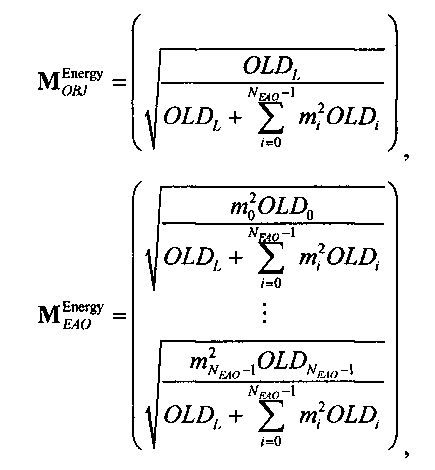
где показатели от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где OLDL - общее значение разности уровней аудиообъектов второго типа аудиообъектов; и
где AEAO - матрица предварительного рендеринга ЕАО;
где матрицы 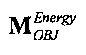 и
и 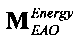 прилагают к представлению d0 единого даунмикс-сигнала SAOC.
прилагают к представлению d0 единого даунмикс-сигнала SAOC.
34. Способ формирования представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и бъектно-ориентированной параметрической информации, включающий в себя: разложение представления сигнала понижающего микширования с извлечением первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и извлечением второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на основе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации, при этом вторая аудиоинформация описывает аудиообъекты второго типа аудиообъектов в совокупном виде; и обработку второй аудиоинформации в зависимости от объектно-ориентированной параметрической информации с получением обработанной версии второй аудиоинформации; и сведение первой аудиоинформации с обработанной версией второй аудиоинформации с формированием представления сигнала повышающего микширования; при этом первую аудиоинформацию и вторую аудиоинформацию извлекают согласно
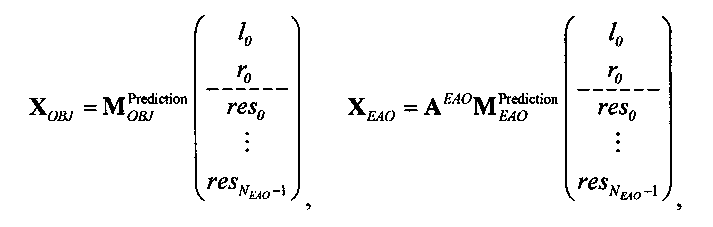
где
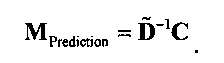
где
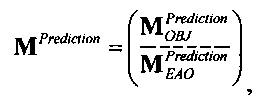
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где 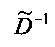 представляет матрицу, обратную расширенной матрице понижающего микширования;
представляет матрицу, обратную расширенной матрице понижающего микширования;
где С описывает матрицу, представляющую множество коэффициентов предсказания каналов 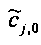 ,
, 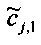 ;
;
где l0 и r0 обозначают каналы представления сигнала понижающего микширования;
где показатели от res0 по resN
-1 обозначают разностные каналы; и
где AEAO - матрица предварительного рендеринга ЕАО, элементы которой описывают распределение существенных (расширенных) аудиообъектов по каналам сигнала существенных аудиообъектов XEAO;
также в составе которого разделитель объектов рассчитывает обратную матрицу понижающего микширования 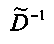 как инверсную расширенной матрице понижающего микширования
как инверсную расширенной матрице понижающего микширования 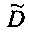 , которая определяется как
, которая определяется как
где матрицу С строят как
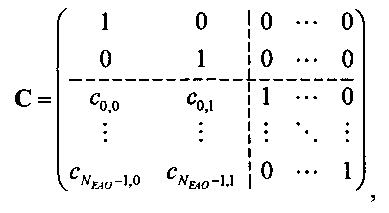
где показатели от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где показатели от n0 по - значения понижающего микширования, относящиеся к аудиообъектам первого типа аудиообъектов;
при этом коэффициенты предсказания 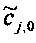 и
и 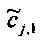 вычисляют как
вычисляют как
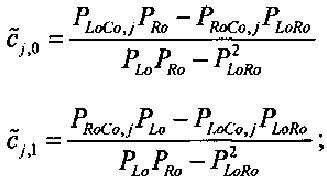
и где коэффициенты ограничения предсказания cj,0 и cj,1 выводят из коэффициентов предсказания 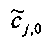 и
и 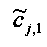 , используя алгоритм ограничения, или коэффициенты предсказания
, используя алгоритм ограничения, или коэффициенты предсказания 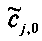 и
и 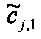 используют как коэффициенты предсказания cj,0 и cj,1;
используют как коэффициенты предсказания cj,0 и cj,1;
где показатели уровней энергии PLo, PRo, PLoRo, PLoCo,j и PRoCo,j определяют как
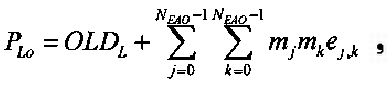
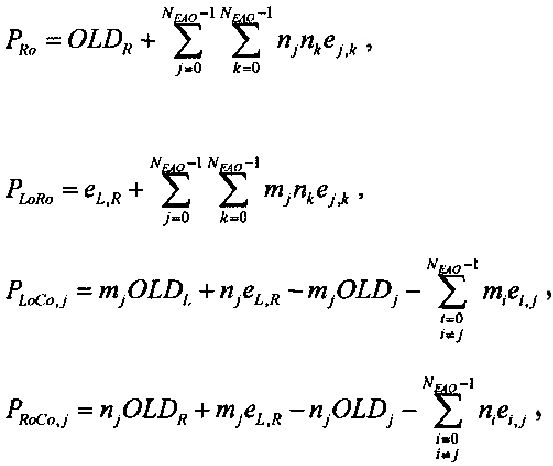
при этом параметры OLDL, OLDR и IOCL,R соответствуют аудиообъектам второго типа аудиообъектов и их определяют следующим образом:
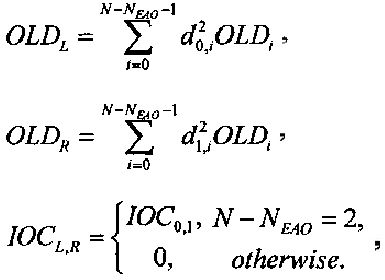
где d0,i и d1,i - показатели понижающего микширования, связанные с аудиообъектами второго типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где N - общее количество аудиообъектов;
где NEAO - количество аудиообъектов первого типа;
где IOC0,1 - показатель межобъектной корреляции пары аудиообъектов второго типа;
где ei,j и eL,R - показатели ковариации, полученные из показателей разности уровней объектов и параметров межобъектной корреляции; и
где ei,j связаны с парой аудиообъектов первого типа аудиообъекта, а eL,R связаны с парой аудиообъектов второго типа аудиообъектов.
35. Способ формирования представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и объектно-ориентированной параметрической информации, включающий в себя: разложение представления сигнала понижающего микширования с извлечением первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, исходя из представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации; обработку второй аудиоинформации в зависимости от объектно-ориентированной параметрической информации с получением обработанной версии второй аудиоинформации; и сведение первой аудиоинформации с обработанной версией второй аудиоинформации с формированием представления сигнала повышающего микширования; при этом первую аудиоинформацию и вторую аудиоинформацию извлекают, следуя выражениям
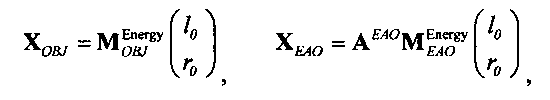
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
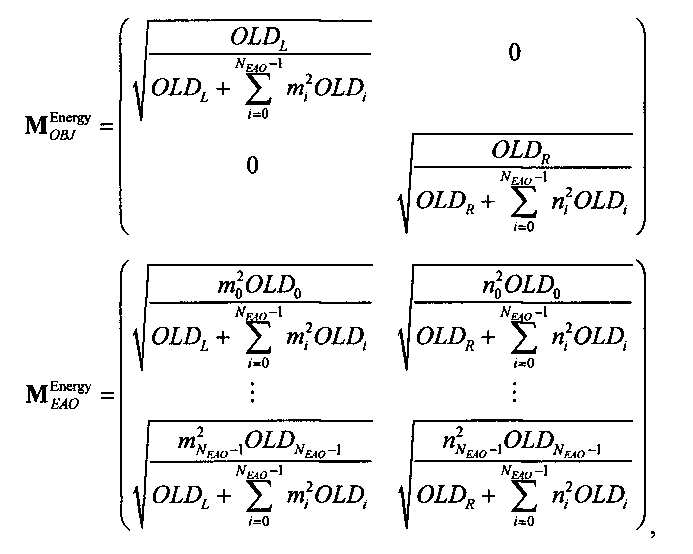
где показатели от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где показатели от n0 по - значения понижающего микширования, относящиеся к аудиообъектам первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где OLDL и OLDR - общие значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов; и
где AEAO - матрица предварительного рендеринга ЕАО.
36. Способ формирования представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и объектно-ориентированной параметрической информации, включающий в себя: разложение представления сигнала понижающего микширования с извлечением первой аудиоинформации, описывающей первую комбинацию из одного или более аудиообъектов первого типа аудиообъектов, и извлечением второй аудиоинформации, описывающей вторую комбинацию из одного или более аудиообъектов второго типа аудиообъектов, на основе представления сигнала понижающего микширования с использованием, по меньшей мере, части объектно-ориентированной параметрической информации, при этом вторая аудиоинформация описывает аудиообъекты второго типа аудиообъектов в совокупном виде; и обработку второй аудиоинформации в зависимости от объектно-ориентированной параметрической информации с получением обработанной версии второй аудиоинформации; и сведение первой аудиоинформации с обработанной версией второй аудиоинформации с формированием представления сигнала повышающего микширования; при этом первую аудиоинформацию и вторую аудиоинформацию извлекают, следуя выражениям
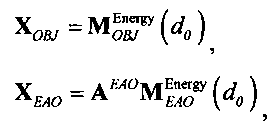
где XOBJ представляет каналы второй аудиоинформации;
где XEAO представляет сигналы объектов первой аудиоинформации;
где
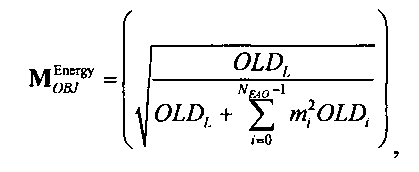
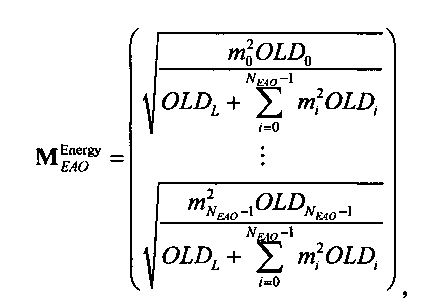
где показатели от m0 по - значения понижающего микширования, связанные с аудиообъектами первого типа аудиообъектов;
где OLDi - значения разности уровней объектов, относящиеся к аудиообъектам второго типа аудиообъектов;
где OLDL - общее значение разности уровней объектов, относящееся к аудиообъектам второго типа аудиообъектов; и
где AEAO - матрица предварительного рендеринга ЕАО;
где матрицы 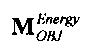 и
и 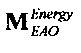 применяют к представлению d0 единого даунмикс-сигнала SAOC.
применяют к представлению d0 единого даунмикс-сигнала SAOC.
37. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 34 при условии ее выполнения с использованием вычислительной техники.
38. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 35 при условии ее выполнения с использованием вычислительной техники.
39. Машиночитаемый носитель информации с записанной на него компьютерной программой для осуществления способа по п. 36 при условии ее выполнения с использованием вычислительной техники.

