Настоящее изобретение относится к аудиокодерам, использующим повышающее микширование аудиосигналов.
Многие алгоритмы аудиокодирования предлагают эффективное кодирование или сжатие аудиоданных одного канала, т.е. монофонических сигналов. На основе теории восприятия звука аудиопотоки разделяются на фрагменты, сжимаются или устраняются в случае их нерелевантности, например в РСМ-кодировании аудиосигналов; дублированные фрагменты устраняются.
В качестве следующего шага в кодировании/сжатии стереофонического сигнала используется сходство между его левым и правым каналами.
Однако современные приложения предъявляют новые требования к алгоритмам кодирования аудиосигнала. Например, в телеконференциях, компьютерных играх, музыкальных приложениях и т.д., где несколько частично или полностью не связанных аудиосигналов передаются одновременно. Для обеспечения требуемого низкого битрейта кодирования, а также с целью обеспечения совместимости с низкоскоростными приложениями до последнего времени использовались аудиокодеки, которые выполняли микширование с повышением многоканального аудисигнала в стерео- или даже монофонический сигнал. Например, стандарт MPEG Surround микширует аудиосигналы на входе в кодированный сигнал понижающего микширования (downmix сигнал) методом, установленным данным стандартом. Понижающее микширование выполняется посредством так называемых ОТТ и ТТТ-блоков, которые выполняют микширование двух сигналов в один или трех сигналов в два соответственно. Для микширования более чем трех сигналов используется иерархическая структура из этих блоков. Каждый ОТТ-блок выдает, кроме монофонического downmix сигнала, информацию об уровневой разности между двумя входными каналами, а также параметры межканальной когерентности/взаимной корреляции, определяющие когерентность или кросс-корреляцию между двумя входными каналами. Параметры выдаются вместе с downmix сигналом кодера MPEG Surround в пределах потока данных MPEG Surround. Также каждый ТТТ-блок передает канальные коэффициенты предсказания, обеспечивая восстановление трех входных каналов из результирующего стерео downmix сигнала. Канальные коэффициенты предсказания также передаются как служебная информация в пределах потока данных MPEG Surround. Декодер MPEG Surround выполняет микширование с повышением downmix сигнала с помощью передаваемой служебной информации и восстанавливает исходные каналы, поступившие в кодер MPEG Surround.
Стандарт MPEG Surround не работает со всеми возможными конфигурациями аудиосигналов. Например, декодер MPEG Surround предназначен для восстановления downmix сигнала кодера MPEG Surround таким образом, что входные каналы кодера MPEG Surround восстанавливаются в том виде, как есть. Другими словами, аудиосигнал в стандарте MPEG Surround воспроизводится в той же конфигурации, как он был закодирован.
Однако в некоторых случаях требуется, чтобы конфигурация аудиосигнала была изменена на этапе декодирования.
В связи с этим в настоящий момент разрабатывается стандарт кодирования пространственных аудиообъектов (SAOC). Каждый канал обрабатывается как отдельный объект, после чего все его объекты микшируются в downmix сигнал. Отдельные объекты могут дополнительно содержать индивидуальные звуковые источники, например инструментальные или вокальные треки. В отличие от декодера MPEG Surround SAOC-декодер способен отдельно микшировать downmix сигнал для воспроизведения отдельных объектов в любой акустической конфигурации. Для того чтобы дать возможность SAOC-декодеру восстановить отдельные объекты, закодированные в потоке данных SAOC, внутри битового потока SAOC передается служебная информация о разности уровней объектов и параметрах межобъектной кросс-корреляции (для объектов, формирующих вместе стерео- или многоканальный сигнал). Кроме этого декодер/транскодер SAOC располагает информацией, показывающей, как отдельные объекты микшированы в downmix сигнал. Таким образом, на этапе декодирования возможно восстановление отдельных SAOC-каналов и воспроизведение этих сигналов в любой акустической конфигурации, используя определяемые пользователем параметры воспроизведения.
Несмотря на то, что SAOC-кодек был разработан для индивидуальной обработки аудиообъектов, он не соответствует требованиям некоторых приложений. Например, приложения Караоке требуют полного отделения аудиосигналов заднего плана от аудиосигналов переднего плана. Наоборот, в режиме Соло объекты переднего плана должны быть отделены от объектов заднего плана. Вследствие одинаковой обработки аудиообъектов в стандарте SAOC невозможно полностью удалить объекты заднего плана или объекты переднего плана из downmix сигнала.
Таким образом, задача настоящего изобретения - создать аудиокодек, производящий микширование аудиосигналов с понижением количества каналов и микширование с повышением количества каналов так, чтобы производилось разделение отдельных аудиообъектов, таких как, например, в режимах Караоке/Соло.
Эта задача реализуется при помощи аудиодекодера согласно п.1, метода декодирования согласно п.19 и программы согласно п.20.
Варианты осуществления изобретения показаны на следующих чертежах:
фиг.1 показывает структурную схему устройства SAOC-кодера/декодера, в котором могут быть реализованы варианты настоящего изобретения;
фиг.2 показывает схематическую и иллюстративную диаграмму спектрального изображения монофонического сигнала;
фиг.3 показывает структурную схему аудиодекодера, соответствующего варианту настоящего изобретения;
фиг.4 показывает структурную схему аудиокодера, соответствующего варианту настоящего изобретения;
фиг.5 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло, дополнительный вариант;
фиг.6 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло согласно основному варианту настоящего изобретения;
фиг.7а показывает структурную схему аудиокодера для применения в режиме Караоке/Соло согласно дополнительному варианту изобретения;
фиг.7b показывает структурную схему аудиокодера для применения в режиме Караоке/Соло согласно основному варианту настоящего изобретения;
фиг.8а и b показывает график результатов измерения качества;
фиг.9 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло для сравнительных целей;
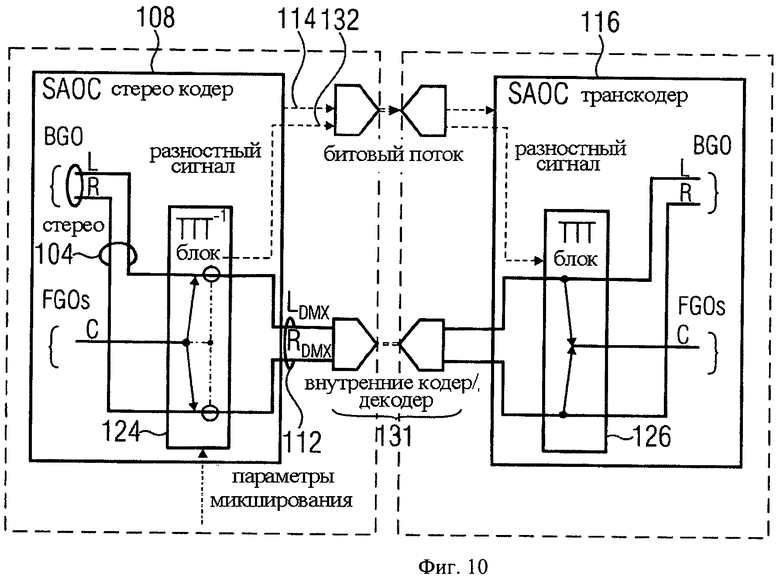
фиг.10 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло согласно основному варианту настоящего изобретения;
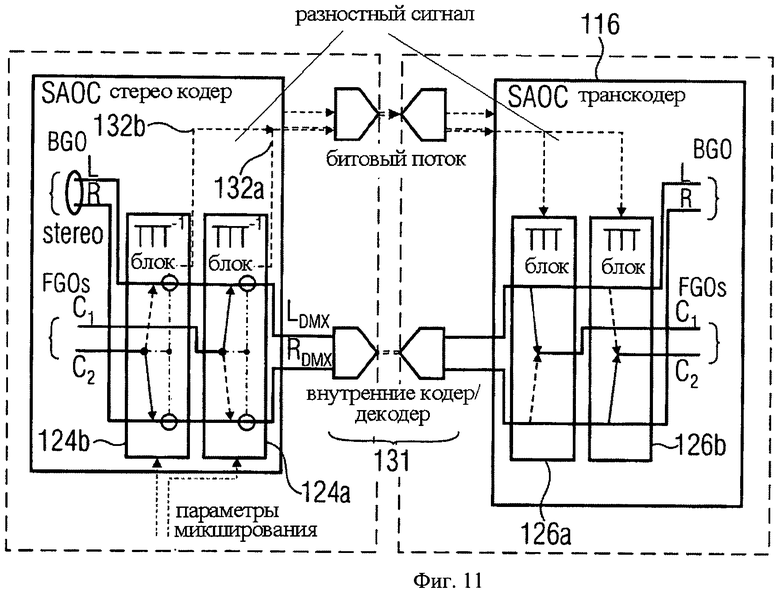
фиг.11 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло согласно усовершенствованному варианту настоящего изобретения;
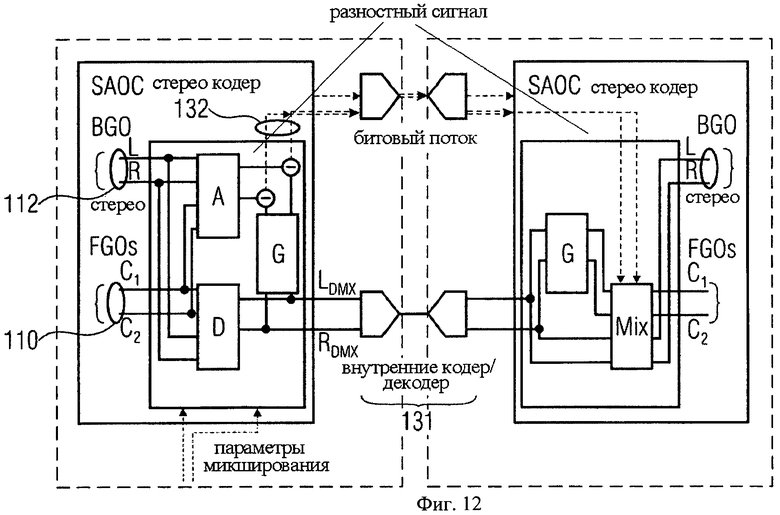
фиг.12 показывает структурную схему устройства аудиокодера/декодера для применения в режиме Караоке/Соло согласно усовершенствованному варианту настоящего изобретения;
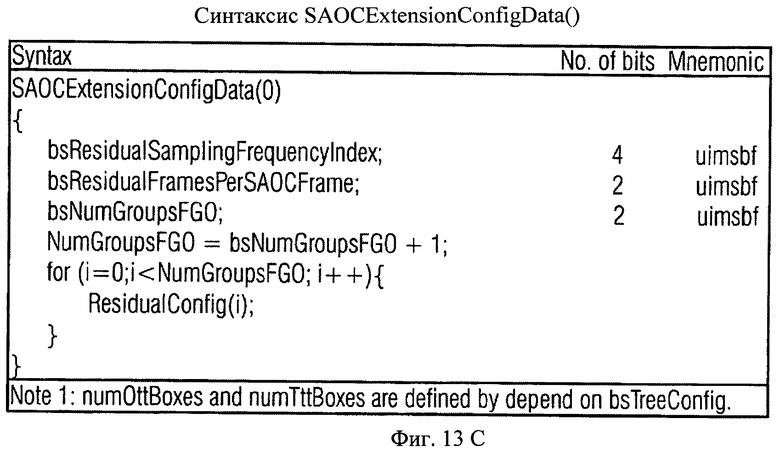
фиг.13а по h показывают таблицы, отражающие возможную структуру битового SAOC-потока, согласно варианту настоящего изобретения;
фиг.14 показывает структурную схему аудиодекодера для применения в режиме Караоке/Соло согласно основному варианту настоящего изобретения;
фиг.15 показывает таблицу, отражающую возможную структуру битового потока SAOC, согласно основному варианту настоящего изобретения.
Для понимания описываемых далее вариантов настоящего изобретения ниже приводится описание SAOC-кодека и передаваемых в битовом SAOC-потоке параметров.
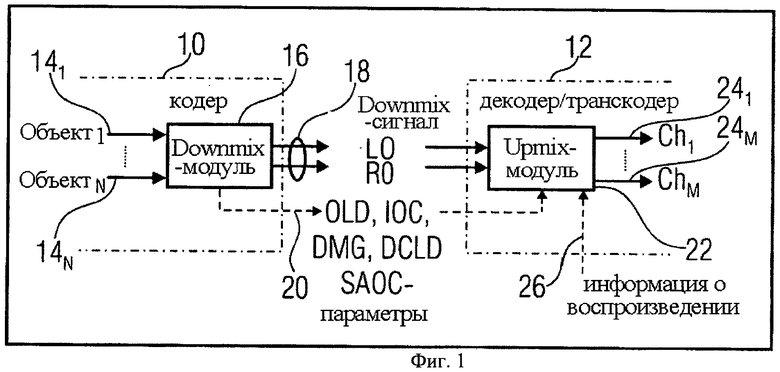
Фиг.1 показывает общую структуру SAOC-кодера 10 и SAOC-декодера 12. SAOC-кодер принимает N входных объектов, т.е. аудиосигналов 141-14N. В частности, кодер 10 содержит модуль, производящий микширование с понижением, 16, который принимает аудиосигналы с 141-14N и микширует их в downmix сигнал 18. На фиг.1 downmix сигнал представлен как стерео downmix сигнал, однако возможен также моно downmix сигнал. Каналы стерео downmix сигнала 18 обозначаются как L0 и R0, в случае моно downmix сигнала - L0. Для того чтобы обеспечить возможность SAOC-декодеру 12 восстановить отдельные объекты 141-14N, модуль 16 передает SAOC-декодеру 12 служебную информацию, содержащую такие SAOC-параметры, как разность уровней объектов (OLD), параметры межобъектной кросс-корреляции (IOC), значения downmix усиления (DMG) и разность уровней downmix каналов (DCLD). Служебная информация 20, содержащая SAOC-параметры, вместе с downmix сигналом 18 формирует выходной поток данных, принимаемый SAOC-декодером 12.
SAOC-декодер 12 содержит модуль повышающего микширования (далее upmix-модуль) 22, который принимает downmix сигнал 18 и служебную информацию 20, с целью восстановления и воспроизведения аудиосигналов 141-14N на определяемой пользователем группе каналов 241-24N, с учетом информации о воспроизведении, переданной в SAOC-декодер 12.
Аудиосигналы 141-14N могут быть переданы в downmix модуль 16 в любой кодируемой области, временной или спектральной. В случае, если аудиосигналы 141-14N передаются в downmix модуль 16 во временной области, например в формате РСМ, downmix модуль 16 использует для увеличения частотного разрешения блок фильтров, например, гибридный QMF-блок (комплекс экспоненциально модулированных фильтров с расширением Найквиста для нижнего частотного диапазона). Это необходимо для того, чтобы передавать сигналы в спектральную область, где аудиосигналы представлены в нескольких поддиапазонах, соответствующих разным спектральным областям, при определенном разрешении блока фильтров. Если аудиосигналы 141-14N уже представлены форматом, ожидаемым модулем понижающего микширования (downmix модулем) 16, нет необходимости выполнять спектральную декомпозицию.
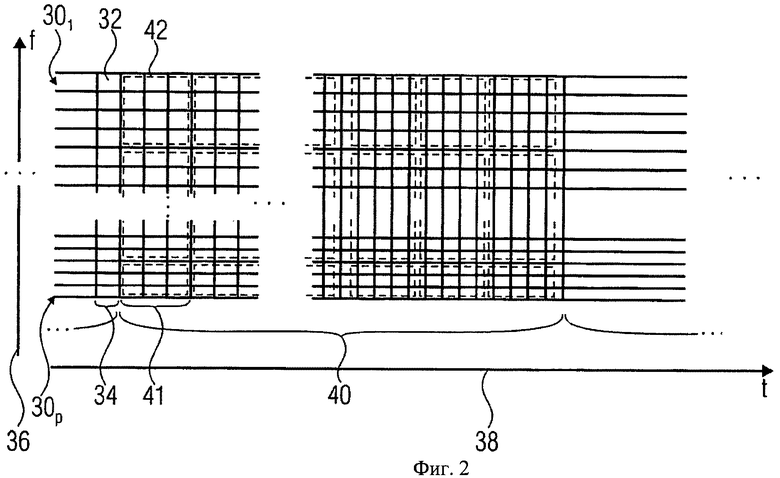
На фиг.2 показан аудиосигнал в указанной выше спектральной области. Как видим, аудиосигнал представлен как множество сигналов различных поддиапазонов. Каждый поддиапазонный сигнал 301-30P состоит из последовательности значений поддиапазонов, которые отображаются модулем 32. Значения поддиапазонов для сигналов 301-30P синхронизированы таким образом, что для каждого последовательного временного слота 34 в блоке фильтров существует значение 32 для каждого поддиапазона.
При отображении на частотной шкале 36 поддиапазонные сигналы 301-30P соотносятся с различными частотными областями, при отображении на временной шкале 38 временные слоты блока фильтров 34 выстраиваются во временную последовательность.
Downmix модуль 16 вычисляет SAOC-параметры входных сигналов 141-14N. Downmix модуль 16 производит данные вычисления в частотно-временном разрешении, которое может быть уменьшено по отношению к исходному частотно-временному разрешению, установленному временными слотами блока фильтров 34 и декомпозицией поддиапазонов. Результаты указываются в служебной информации соответствующими синтаксическими элементами bsFrameLength и bsFreqRes. Например, группы последовательных временных слотов блока 34 могут формировать фрейм 40. Иными словами, аудиосигнал может быть разделен на фреймы, пересекающиеся во времени или следующие друг за другом. В этом случае bsFrameLength определяет количество временных слотов 41, т.е. временной промежуток, в котором SAOC-параметры OLD и IOC вычисляются во фрейме 40; и bsFreqRes определяет количество обрабатываемых частотных диапазонов, для которых вычисляются SAOC-параметры. При таком подходе каждый фрейм разделен на частотно-временные области, показанные на фиг.2 пунктирной линией 42.
Downmix модуль 16 вычисляет SAOC-параметры по следующим формулам. В частности, downmix модуль 16 вычисляет параметр OLD для каждого объекта i следующим образом:
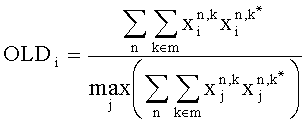
где величина n и индексы k применяются во временных слотах 34, во всех поддиапазонах 30, которые принадлежат определенной частотно-временной области 42. Таким образом, энергии всех значений поддиапазона xi аудиосигнала или объекта суммируются и нормализуются до максимального значения энергии этой области среди всех элементов аудиосигнала.
Далее downmix модуль 16 вычисляет сходные показатели соответствующих частотно-временных областей пары различных входных сигналов 14i-14N. Наряду с тем, что downmix модуль 16 производит вычисления сходных показателей любой пары входных сигналов 14i-14N, он имеет возможность подавлять передачу сходного показателя или ограничивать вычисление сходных показателей аудиосигналов 14i-14N, которые формируют левый и правый каналы общего стереосигнала. Сходным показателем является параметр межобъектной кросс-корреляции IOCij, который вычисляется по формуле:
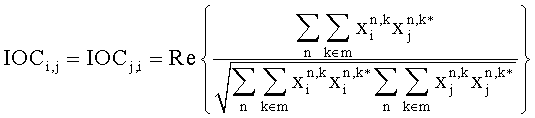
Индексы n и k применяются ко всем значениям поддиапазонов, принадлежащих к определенной частотно-временной области 42, i и j обозначают пару аудиосигналов 14i-14N.
Downmix модуль 16 микширует сигналы 14i-14N с помощью коэффициентов усиления, которые применяются к каждому сигналу 14i-14N, то есть, коэффициент усиления Di применяется к сигналу i, а затем все взвешенные сигналы 14i-14N суммируются для получения микшированного моно downmix сигнала. В случае стерео downmix сигнала, который показан на фиг.1, коэффициент усиления D1,i применяется к сигналу i, а затем все взвешенные сигналы суммируются для получения левого downmix канала L0; коэффициент усиления D2,i применяется к сигналу i, а затем все взвешенные сигналы суммируются для получения правого downmix канала R0.
Настройки микширования передаются в декодер параметрами downmix усиления DMGi; в случае стерео downmix сигнала - параметрами DCLDi (разность уровней downmix каналов).
Параметры downmix усиления вычисляются по формуле:
DMGi=20log10(Di+ε) для моносигнала
 для стереосигнала
для стереосигнала
где ε - число порядка 10-9.
Для вычисления параметров DCLD применяется формула:
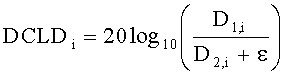
В обычном режиме downmix модуль 16 формирует микшированный сигнал в соответствии с формулой:
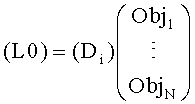 для моносигнала
для моносигнала
или
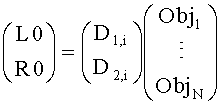 для стереосигнала
для стереосигнала
Таким образом, в вышеуказанных формулах параметры OLD и IOC являются функциями аудиосигналов, а параметры DMG и DCLD - функциями величины D. При этом необходимо отметить, что D может изменяться во времени.
В обычном режиме downmix модуль 16 микширует все сигналы 14i-14N без предпочтений, то есть обрабатывает все объекты одинаково. Upmix-модуль 22 одним вычислением выполняет обратную процедуру и добавляет информацию о воспроизведении, представленной матрицей А, а именно:
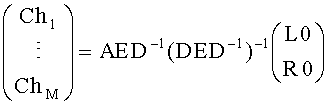
где матрица Е - это функция параметров OLD и IOC. Другими словами, в обычном режиме не проводится классификация объектов 14i-14N на BGO-объекты заднего плана и FGO-объекты переднего плана. Информация о том, какой объект будет представлен на выходе upmix-модуля 22 предоставляется матрицей воспроизведения А. Например, если объект с индексом 1 является левым каналом стереообъекта, объект 2 - правым каналом, объект с индексом 3 - объектом переднего плана матрица воспроизведения А будет следующая:
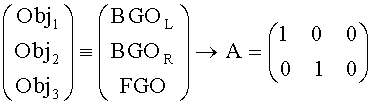
для выходного сигнала типа Караоке
Однако, как указывалось выше, передача FGO-объектов переднего плана и BGO-объектов заднего плана в обычном режиме SAOC-кодека не дает приемлемых результатов.
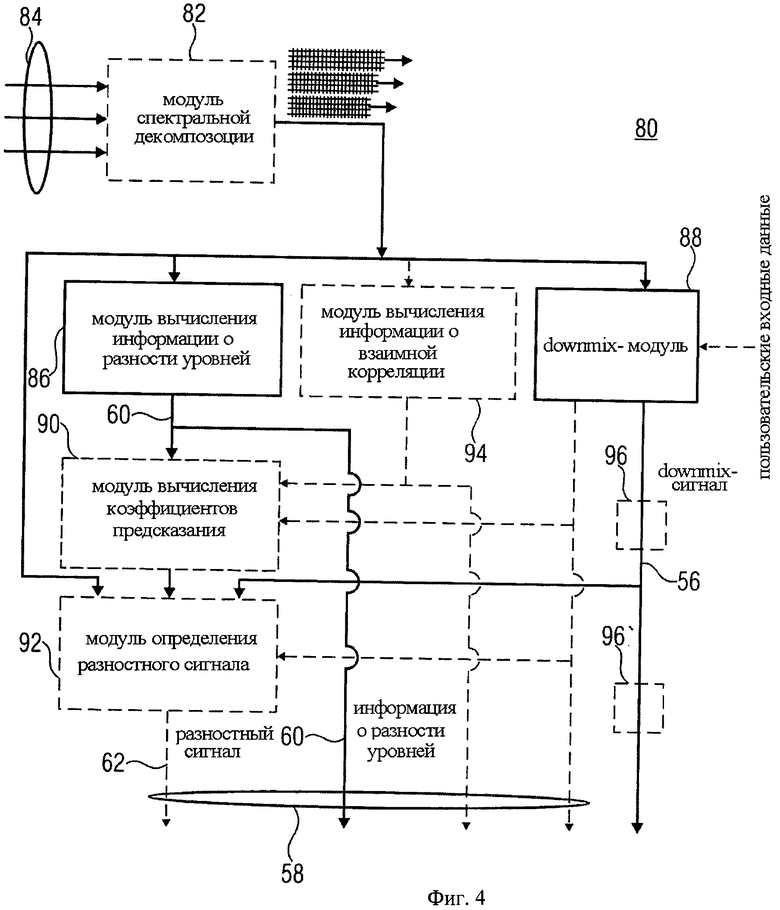
На фиг.3 и 4 представлен вариант настоящего изобретения, который устраняет указанные недостатки. Кодер и декодер, показанные на фиг.3 и 4, обеспечивают функционирование дополнительного, так называемого «усовершенствованного» режима, в который может переключаться SAOC-кодек на фиг.1.
На фиг.3 представлен декодер 50. Декодер 50 содержит модуль 52 для вычисления коэффициентов предсказания и upmix-модуль 54 для восстановления downmix сигнала.
Аудиодекодер 50 на фиг.3 используется для декодирования многоканального аудиосигнала, состоящего из аудиосигнала первого типа и аудиосигнала второго типа. Аудиосигнал первого типа и аудиосигнал второго типа могут быть моно- или стереосигналами соответственно. Например, аудиосигнал первого типа - это объект заднего плана, а аудиосигнал второго типа - это объект переднего плана. Таким образом, варианты изобретения на фиг.3 и фиг.4 не ограничиваются режимами Караоке/Соло. Наоборот, декодер на фиг.3 и кодер на фиг.4 могут успешно применяться в различных приложениях.
Многоканальный аудиосигнал состоит из downmix сигнала 56 и служебной информации 58. Служебная информация 58 содержит информацию об уровне 60, показывающую, например, спектральную энергию аудиосигнала первого типа и аудиосигнала второго типа, например, в первом частотно-временном разрешении 42. В частности, информация об уровне 60 может содержать скалярное значение нормализованной спектральной энергии для каждого объекта и частотно-временной области. Нормализация соотносится с максимальным значением спектральной энергии среди аудиосигналов первого и второго типов в соответствующей частотно-временной области. В результате формируются параметры OLD, содержащие информацию об уровне. Несмотря на то, что указанные ниже варианты изобретения используют параметры OLD, они могут использовать нормализованную спектральную энергию, представленную другими способами.
Служебная информация 58 при необходимости содержит разностный сигнал 62, указывающий на значение разностного уровня во втором частотно-временном разрешении, которое может быть эквивалентным или отличаться от первого частотно-временного разрешения.
Модуль 52 для вычисления коэффициента предсказания функционирует на основе информации об уровне 60. Кроме этого модуль 52 может вычислять коэффициент предсказания далее на основе информации о взаимной корреляции, которая содержится в служебной информации 58. Далее модуль 52 использует информацию об изменяющихся настройках понижающего микширования для последующего вычисления коэффициента предсказания. Коэффициенты предсказания, полученные с помощью модуля 52, необходимы для извлечения или микширования исходных аудиообъектов или аудиосигналов из downmix сигналов 56.
Соответственно, upmix-модуль 54 используется для микширования downmix сигнала 56 на основе коэффициентов предсказания 64, полученных от модуля 52, и при необходимости на основе разностного сигнала 62. При использовании разностного сигнала 62 декодер 50 более эффективно подавляет взаимное влияние каналов разных типов. Upmix-модуль 54 может использовать для микширования изменяющиеся downmix настройки. Upmix-модуль 54 может использовать заданные пользователем входные данные 66 для определения того, какой из восстановленных из downmix сигнала 56 аудиосигнал должен быть передан на выход 68 и в каком объеме. В одном случае пользовательские данные 66 могут сообщить upmix-модулю 54 передать на выход первый сигнал повышающего микширования (upmix-сигнал), который по параметрам приближается к аудиосигналу первого типа. В другом (противоположном) случае, upmix-модуль 54 выдает только второй upmix-сигнал, который приближается к аудиосигналу второго типа. Промежуточные варианты характеризуются смешением обоих upmix-сигналов, которые выводятся на модуль 68.
Фиг.4 показывает вариант аудиокодера, предназначенного для создания многоканального аудиосигнала, декодируемого декодером, представленным на фиг.3. Кодер на фиг.4, который обозначен указателем 80, может содержать модуль 82 для спектрального разложения в случае, если предназначенные для кодирования аудиосигналы 84 находятся за пределами спектральной области. Среди аудиосигналов, в свою очередь, существуют, как минимум, один сигнал первого типа, и, как минимум, один сигнал второго типа. Модуль спектральной декомпозиции 82 сконфигурирован таким образом, чтобы выполнить спектральное разложение каждого сигнала 84, как показано на фиг.2, то есть модуль спектральной декомпозиции 82 раскладывает сигналы 84 с предопределенным частотно-временным разрешением. Модуль 82 может содержать блок фильтров, такой как гибридный QMF блок.
Аудиокодер 80 содержит модуль 86 для вычисления информации об уровне, модуль понижающего микширования (далее downmix модуль) 88, модуль вычисления коэффициентов предсказания 90 (при необходимости), а также модуль определения разностного сигнала 92. Дополнительно кодер 80 может содержать модуль вычисления параметров взаимной корреляции 94. Модуль 86 вычисляет данные об уровне, характеризующие уровень выдаваемых модулем 82 аудиосигналов первого типа и аудиосигналов второго типа в первом частотно-временном разрешении. Downmix модуль 88 микширует аудиосигналы аналогичным образом.
Модуль 88 выдает downmix сигнал 56, а модуль 86 выдает данные об уровне. Модуль вычисления коэффициентов предсказания 90 функционирует аналогично модулю 52, т.е. модуль 90 вычисляет коэффициенты предсказания на основе информации об уровне 60 и выдает коэффициенты предсказания 64 в модуль 92. Модуль 92, в свою очередь, устанавливает разностный сигнал 62 на основе downmix сигнала 56, коэффициентов предсказания 64 и исходных аудиосигналов во втором частотно-временном разрешении, так что результатом восстановления downmix сигнала 56 на основе коэффициентов предсказания 64 и разностного сигнала 62 является первый upmix-сигнал, который приближается по своим характеристикам к аудиосигналу первого типа, и второй аудиосигнал, который приближается к аудиосигналу второго типа. Приближение считается положительным при отсутствии разностного сигнала.
Разностный сигнал 62 (если присутствует) и данные об уровне 60 содержатся в служебной информации 58, которая наряду с downmix сигналом 56 формирует многоканальный аудиосигнал, который декодируется декодером на фиг.3.
Как показано на фиг.4, аналогично фиг.3 модуль 90 (если присутствует) может дополнительно использовать информацию о взаимной корреляции, формируемую модулем 94, и/или изменяющиеся настройки понижающего микширования модулем 88 для вычисления коэффициента предсказания 64. Далее модуль 92, определяющий разностный сигнал 62 (если он присутствует), для его корректного определения может дополнительно использовать выдаваемые модулем 88 изменяющиеся во времени настройки понижающего микширования.
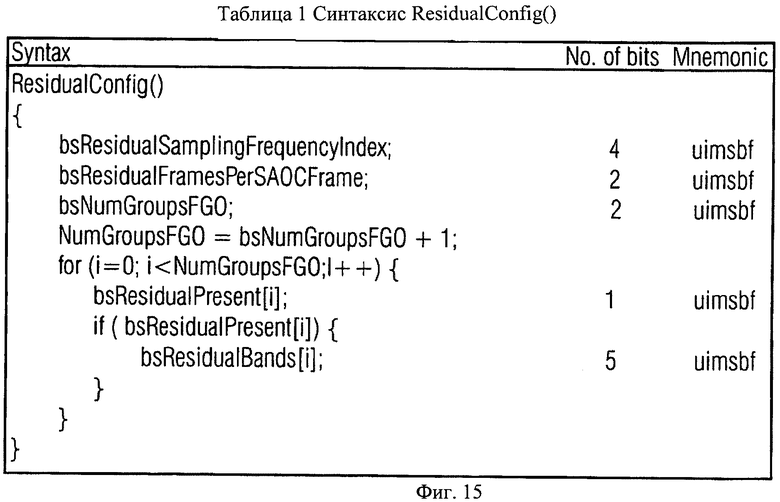
Как отмечалось раннее, аудиосигнал первого типа может быть моно- или стереосигналом. Это касается и аудиосигнала второго типа. Наличие разностного сигнала 62 необязательно. Однако при его наличии он передается в составе служебной информации в том же частотно-временном разрешении, которое использовалось, например, для вычисления информации об уровне либо в другом частотно-временном разрешении. Возможна ситуация, когда передача разностного сигнала может быть ограничена фрагментом спектрального диапазона частотно-временной области 42, для которой передается информация об уровне. Например, частотно-временное разрешение, в котором передается разностный сигнал, может быть представлено в служебной информации 58 посредством синтаксических элементов bsResidualBands и bsResidualFramesPerSAOCFrame. Эти синтаксические элементы могут определять другое сегментирование фрейма на частотно-временные области, чем то, которое приводит к частотно-временной области 42.
Как упоминалось выше, разностный сигнал 62 либо отражает, либо не отражает потерю информации в результате использования внутреннего кодера 96, который иногда используется для кодирования downmix сигнала кодером 80. Как показано на фиг.4, модуль 92 определяет разностный сигнал 62 на основе downmix сигнала, восстанавливаемого из данных на выходе внутреннего кодера 96 или на основе данных на входе кодера 96'. Аналогичным образом аудиодекодер 50 может иметь внутренний декодер 98 для декодирования или декомпрессии downmix сигнала 56.
Способность устанавливать частотно-временное разрешение для вычисления разностного сигнала 62 внутри многоканального аудиосигнала, отличного от частотно-временного разрешения, используемого для вычисления информации об уровне 60, позволяет достичь приемлемого компромисса между качеством аудиосигнала, с одной стороны, и степенью сжатия многоканального сигнала, с другой стороны. В любом случае разностный сигнал 62 позволяет улучшить подавление взаимного влияния одного аудиосигнала на другой внутри первого и второго upmix-сигналов, которые передаются на выход 68 в соответствии с пользовательской информацией 66.
Как будет показано в следующем варианте изобретения, в составе служебной информации может быть передано более одного разностного сигнала 62 в случае, если закодированы более чем один объект переднего плана или аудиосигнал второго типа. Содержание служебной информации позволяет принимать индивидуальное решение о том, передавать ли разностный сигнал 62 для определенного аудиосигнала второго типа или нет. Таким образом, количество разностных сигналов 62 может варьироваться от одного до общего количества аудиосигналов второго типа.
В аудиодекодере на фиг.3 модуль 54 может быть сконфигурирован для вычисления коэффициента предсказания матрицы С, состоящей из коэффициентов предсказания на основе информации об уровне (OLD), а модуль 56 - для извлечения первого upmix-сигнала S1 и/или второго upmix-сигнала S2 из downmix сигнала d в соответствии с формулой
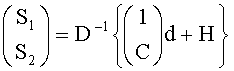
где «1» обозначает - в зависимости от количества каналов downmix сигнала d - скалярную величину или единичную матрицу, D-1 - матрица, определенная содержащимися в служебной информации настройками понижающего микширования, согласно которым аудиосигнал первого типа и аудиосигнал второго типа микшируются в downmix сигнал. Н - величина независимая от d, но зависимая от разностного сигнала, если он присутствует.
Как указано выше, настройки понижающего микширования могут варьироваться по времени и/или по спектральным параметрам. Если аудиосигнал первого типа - это стереосигнал, имеющий первый (L) и второй (R) входные каналы, информация об уровне характеризует нормализованные спектральные энергии первого (L) и второго (R) входных каналов, аудиосигнал второго типа в частотно-временном разрешении 42.
Вышеупомянутые вычисления, согласно которым upmix-модуль 56 производит микширование, представлены формулой:
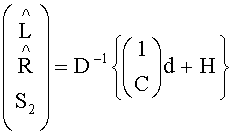
где 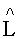 - 1-ый канал первого upmix-сигнала, стремящийся к L,
- 1-ый канал первого upmix-сигнала, стремящийся к L, 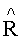 - второй канал первого upmix-сигнала, стремящийся к R; 1 - скалярная величина, если d - моносигнал, или единичная 2×2 матрица, если d - стереосигнал. Если downmix сигнал 56 - это стереоаудиосигнал, имеющий первый (L0) и второй (R0) выходные каналы, вычисления, согласно которым upmix-модуль 56 выполняет микширование, представлены формулой:
- второй канал первого upmix-сигнала, стремящийся к R; 1 - скалярная величина, если d - моносигнал, или единичная 2×2 матрица, если d - стереосигнал. Если downmix сигнал 56 - это стереоаудиосигнал, имеющий первый (L0) и второй (R0) выходные каналы, вычисления, согласно которым upmix-модуль 56 выполняет микширование, представлены формулой:
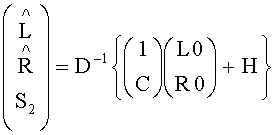
Поскольку величина Н зависит от разностного сигнала res, upmix-модуль 56 выполняет микширование согласно формуле:
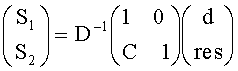
Многоканальный аудиосигнал может содержать множество аудиосигналов второго типа, служебная информация может содержать один разностный сигнал для каждого аудиосигнала второго типа. Параметр разностного разрешения может присутствовать в служебной информации, определяя спектральный диапазон, в котором передается разностный сигнал в составе служебной информации. Он может определять нижнюю и верхнюю границы спектрального диапазона.
Многоканальный аудиосигнал может содержать информацию пространственного воспроизведения для воспроизведения сигнала первого типа в предопределенной конфигурации акустической системы. Иными словами, аудиосигнал первого типа может быть многоканальным MPEG Surround сигналом, смикшированным в стереосигнал.
В дальнейшем будут описаны варианты изобретения, которые используют вышеуказанную передачу разностного сигнала. Необходимо отметить, что термин «объект» часто имеет двойственное значение. Иногда объект обозначает отдельный моно-аудиосигнал. Таким образом, стереообъект может содержать моно-аудиосигнал, который является каналом стереосигнала. Однако в других случаях стереообъект может, на самом деле, обозначать два объекта, а именно правый и левый каналы стереосигнала. Значение термина становится ясным в контексте.
Причиной разработки следующего варианта изобретения послужили недостатки основной технологии стандарта SAOC, выбранного в качестве опорной модели 0 (RM0) в 2007 г. RM0 допускала отдельные манипуляции над звуковыми объектами в части панорамного позиционирования и усиления/ослабления. Особый сценарий был представлен в контексте Караоке-приложений.
В этом случае
- моно-, стерео- или объемная фоновая сцена (далее называемая «фоновый объект», BGO) передается серией определенных SAOC-объектов, которые воспроизводятся без изменений, т.е. каждый входной сигнал воспроизводится через тот же выходной канал без изменения уровня;
- отдельный объект (далее называемый «объект переднего плана», FGO) (чаще всего это ведущий вокал) воспроизводится с изменениями. (FGO обычно находится в середине звуковой сцены и может быть подавлен, т.е. значительно ослаблен для режима Караоке).
Как показывает практика и лежащий в основе технологии принцип, изменение позиции объекта ведет к улучшению качества звука. Манипуляции с уровнем объекта являются более сложными. Как правило, чем выше дополнительное усиление/ослабление сигнала, тем выше вероятность появления побочных эффектов. В этом смысле режим Караоке технически сложен, так как необходимо максимальное (в идеале полное) ослабление FGO-объекта.
Второй вариант использования технологии заключается в способности воспроизводить только FGO-объект без объектов заднего плана/МВО, далее называемый режим «Соло».
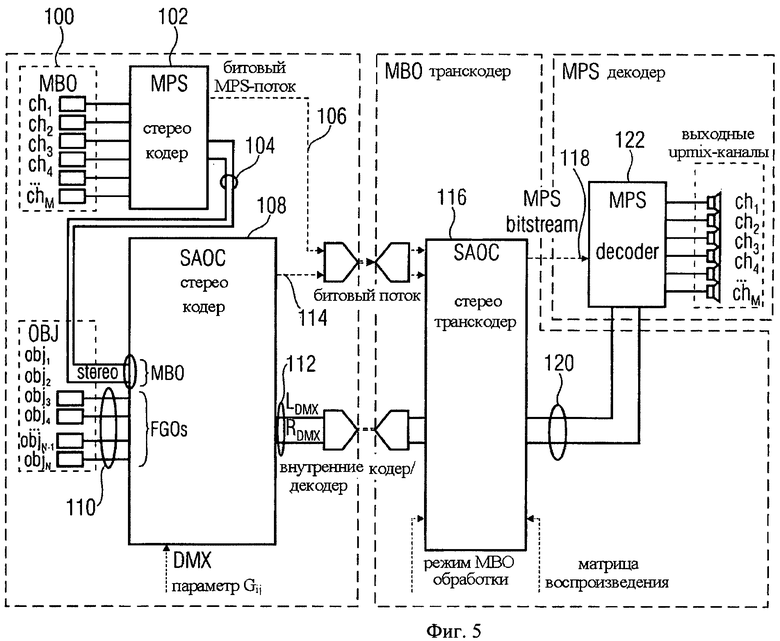
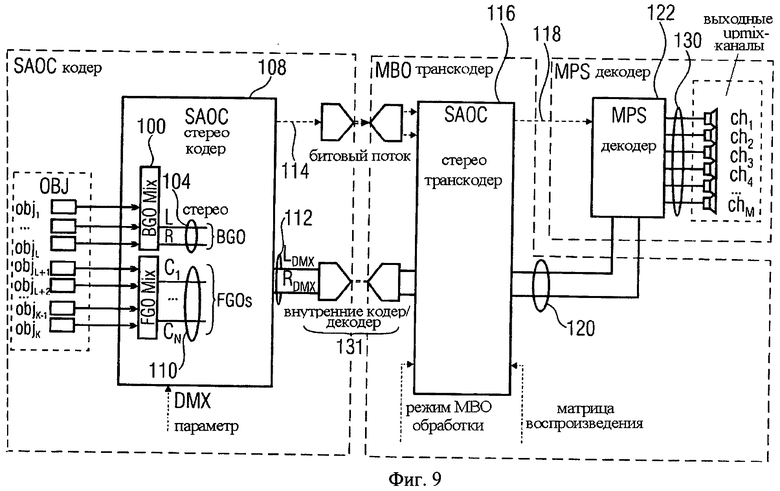
Уже отмечалось, что в случае использования режима Surround Background, он обозначается как мультиканальный объект заднего плана (МВО). Обработка МВО, как показано на фиг.5, происходит следующим образом:
- МВО кодируется с помощью стандартного 5-2-5 MPEG Surround кодера 102. В результате получается стерео МВО downmix сигнал 104 и поток служебной информации МВО MPS;
- МВО downmix сигнал кодируется далее SAOC-кодером 108 как стереообъект (два параметра уровневой разности и параметры межканальной корреляции) совместно с FGO 110 (иногда с несколькими FGO). В итоге получается общий downmix сигнал 112 и поток служебной SAOC-информации 114.
В транскодере 116 предварительно обрабатывается downmix сигнал 112, SAOC- и MPS-потоки служебной информации 106 и 114 преобразовываются в единый выходной MPS-поток служебной информации 118. При этом происходит либо полное подавление FGO- (одного или нескольких), либо подавление МВО-объектов. В итоге полученный downmix сигнал 120 и служебная информация 118 воспроизводятся MPEG Surround декодером 122.
На фиг.5 МВО downmix сигнал 104 и контролируемый сигнал (сигналы) 110 объединены в один стерео downmix сигнал 112. Присутствие аудиосигнала 110 в downmix сигнале затрудняет получение Караоке-версии с высоким качеством звука. Предлагается следующее решение данной проблемы.
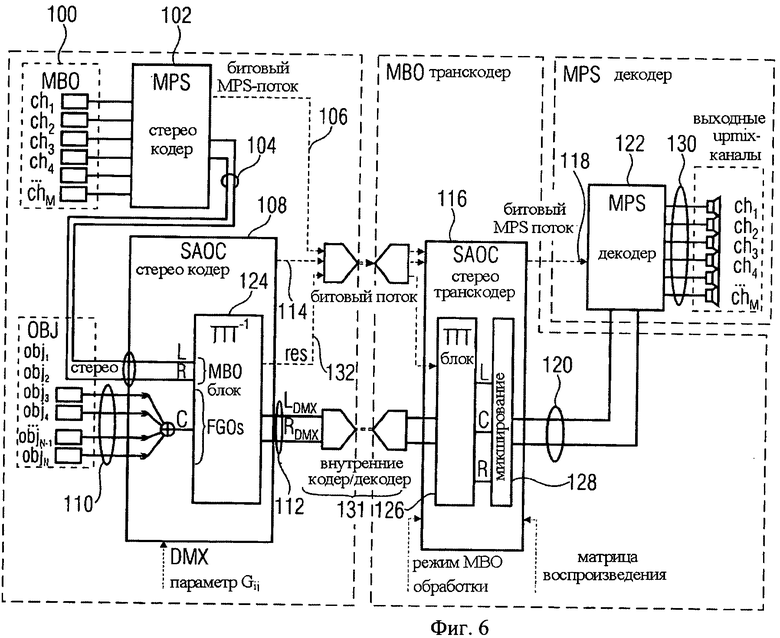
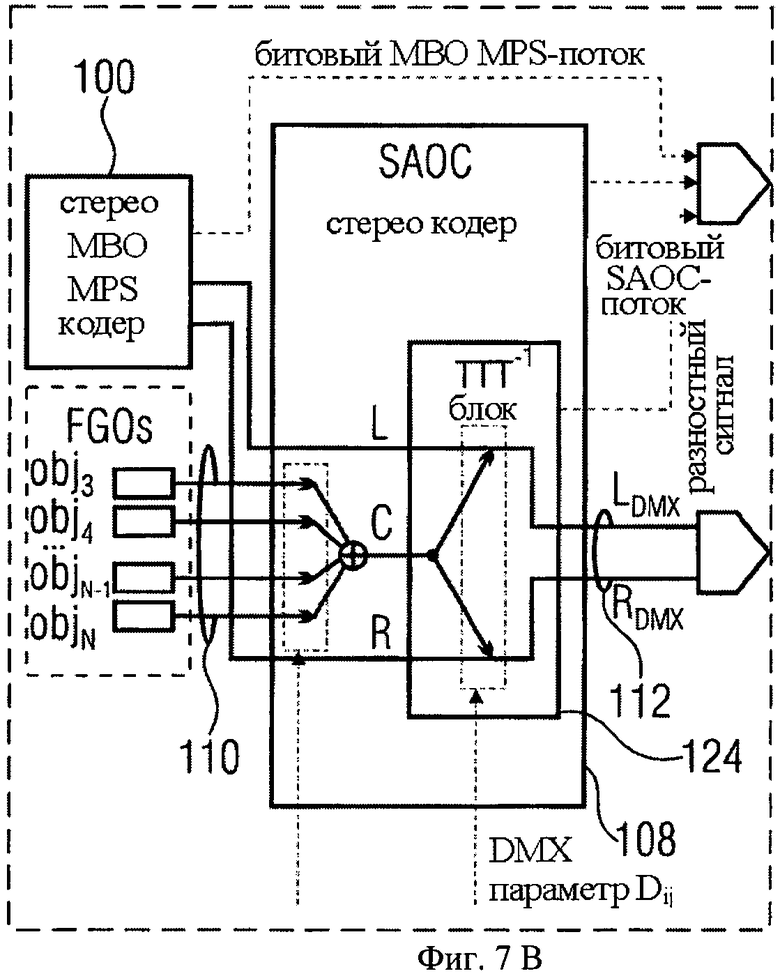
Рассмотрим пример использования варианта изобретения на фиг.6. Допустим, что имеется один FGO-объект (например, один ведущий вокал). SAOC downmix сигнал представляет собой комбинацию BGO и FGO сигналов, т.е. три аудиосигнала смикшированы и переданы с помощью двух downmix каналов. В идеале эти сигналы должны быть разделены в транскодере для того, чтобы получился чистый Караоке-сигнал (т.е. необходимо удалить FGO-сигнал) или воспроизвести чистый Соло-сигнал (т.е. необходимо удалить BGO-сигнал). Эта задача решается с помощью варианта изобретения на фиг.6 при использовании блока кодера «три-в-два» (ТТТ-1) 124, известного в стандарте MPEG Surround, в SAOC-кодере 108 для совмещения BGO- и FGO-сигналов в один SAOC downmix сигнал.
Здесь FGO является источником «центрального» канала блока ТТТ-1 124, а BGO 104 - источником «правого/левого» каналов блока ТТТ-1. Транскодер 116 может производить аппроксимацию BGO-объектов 104 с помощью декодирующего блока «два-в-три» (ТТТ) 126, известного в стандарте MPEG Surround, т.е. выходные «левый/правый» элементы ТТТ L/R выполняют аппроксимацию BGO, в то время как «центральный» выход ТТТ выполняет аппроксимацию FGO 110.
При сравнении варианта на фиг.6 с вариантом кодера и декодера на фиг.3 и 4 указатель 104 соответствует аудиосигналу первого типа из множества аудиосигналов 84, модуль 82 содержит MPS-кодер 102, указатель 110 соответствует аудиосигналам второго типа из множества аудиосигналов 84, блок ТТТ-1 124 выполняет функции модулей 88-92, в то время как функциональные возможности модулей 86 и 94 обеспечиваются SAOC-кодером 108; указатель 112 соответствует указателю 56; указатель 114 соответствует служебной информации 58 за исключением разностного сигнала 62; ТТТ-блок 126 выполняет функции модулей 52 и 54, при этом модуль 54 выполняет функции блока микширования 128. Сигнал 120 соответствует сигналу на выходе модуля 68. Фиг.6 также показывает тракт 131 для передачи downmix сигнала из SAOC-кодера 108 в SAOC-транскодер 116. Тракт 131 внутренних кодера/декодера соответствует опциональным внутренним кодеру 96 и декодеру 98. Как показано на фиг.6, тракт 131 внутренних кодера/декодера также может кодировать/сжимать сигнал служебной информации, передаваемой от кодера 108 в транскодер 116.
Преимущества введения ТТТ-блока на фиг.6 объясняются следующим:
- при передаче выходных каналов «левый/правый» L/R ТТТ-блока в MPS-микшер 120 (передача битового потока МВО MPS 106 в поток 118) финальным MPS-декодером воспроизводится только МВО-объект. Это соответствует режиму «Караоке»;
- при передаче выходого канала «центральный» С ТТТ-блока в левый и правый MPS downmix сигналы 120 (получение обычного битового MPS-потока, который воспроизводит FGO с необходимым уровнем и позицией), финальным MPS-декодером 122 воспроизводится только FGO-объект. Это соответствует режиму «Соло».
Обработка трех выходных сигналов L.R.C ТТТ-блока осуществляется в блоке микширования 128 SAOC-транскодера 116.
Структура процесса, представленная на фиг.6, обеспечивает ряд очевидных преимуществ по сравнению с фиг.5:
- принцип работы обеспечивает структурное разделение МВО(100)- и PGO(110)-сигналов;
- структура ТТТ-блока 126 обеспечивает наилучшее восстановление трех сигналов L.R.C. на основе формы сигнала. Таким образом, окончательные выходные MPS-сигналы 130 сформированы на основе не только энергетического взвешивания (и декорреляции) downmix сигналов, но также становятся ближе по форме сигнала, благодаря ТТТ-обработке;
- в связи с применением MPEG Surround ТТТ-блока становится возможным повышение точности восстановления при использовании разностного кодирования. Таким образом, значительное улучшение качества восстановления может достигаться увеличением ширины полосы и битовой скорости разностного сигнала 132, формируемого на выходе ТТТ-1-блока и используемого ТТТ-блоком для микширования. В идеальном случае интерференция между объектами заднего и объектами переднего планов может быть полностью исключена.
Структура процесса, представленная на фиг.6, имеет следующие характеристики:
- Двойственность Караоке/Соло режима: Подход, представленный на фиг.6, позволяет реализовать как режим Караоке, так и режим Соло с применением тех же технических средств. SAOC параметры могут применяться в обоих режимах.
- Улучшение качества: Качество Караоке/Соло сигнала может быть при необходимости улучшено посредством управления количеством разностной информации о кодировании, используемой в ТТТ-блоке. Например, могут быть использованы параметры bsResidualSamplingFrequencyIndex, bsResidualBands и bsResidualFramesPerSAOCFrame.
- Позиционирование FGO-объектов в downmix сигнале: При использовании ТТТ-блока в соответствии со спецификацией MPEG Surround FGO всегда размещается в средней позиции между левым и правым downmix каналами. Для большей гибкости в выборе местоположения применяется обобщенный ТТТ-блок, который допускает асимметричное расположение относительно центра между входным и выходным каналами;
- Множественные FGO-объекты: В описанной выше конфигурации присутствовал только один FGO-объект (что соответствует основному случаю применения). Однако предлагаемая методика позволяет совместить несколько FGO-объектов, при этом необходимо использовать одну или комбинацию следующих схем:
- сгруппированные FGO: как показано на фиг.6, сигнал, находящийся в центре ТТТ-блока между входным и выходным каналами, может представлять собой сумму нескольких FGO-сигналов, а не один сигнал. Эти FGO-сигналы могут быть расположены независимо друг от друга в многоканальном выходном сигнале 130 (однако максимальное качество достигается, когда они упорядочены). Они занимают общее положение в стерео downmix сигнале 112, при этом присутствует только один разностный сигнал 132. В любом случае интерференция между МВО (задним планом) и контролируемыми объектами исключается (при этом интерференция между контролируемыми объектами сохраняется).
- каскадные FGO: Ограничение позиционирования FGO-сигнала в downmix сигнале 112 снимается при использовании метода, показанного на фиг.6. Множественные FGO-объекты могут располагаться каскадом в несколько ступеней в представленной ТТТ-структуре, каждая ступень соответствует одному FGO и производит один разностный кодирующий поток. В этом случае интерференция максимально устраняется между FGO-объектами. Этот вариант требует более высокой битовой скорости (битрейта), чем при использовании сгруппированных FGO-объектов.
- служебная SAOC-информация: в формате MPEG Surround служебная информация, соответствующая ТТТ-блоку, представляет собой пару канальных коэффициентов предсказания (СРС). В отличие от MPEG Surround SAOC-параметризация и сценарий МВО/Караоке передают объектные энергии для каждого объекта и интерсигнальную корреляцию между 2-мя каналами МВО downmix сигнала (т.е. параметрическую информацию для стереообъекта). Для минимизации количества изменений в параметрической информации (для случая обычного, неусовершенствованного режима Караоке/Соло), а следовательно, и формата битового потока, коэффициенты предсказания СРС могут быть вычислены на основе энергий downmix сигналов (МВО и FGO) и интерсигнальной корреляции МВО стерео downmix объекта. Поэтому нет необходимости изменять или расширять объем передаваемой параметрической информации, так как коэффициенты предсказания СРС могут быть вычислены в SAOC-транскодере 116 на основе передаваемых SAOC-параметров. Таким образом, в случае использования усовершенствованного режима Караоке/Соло битовый поток также может быть декодирован обычным декодером (без разностного кодирования) без учета разностных данных.
Итак, вариант, представленный на фиг.6, направлен на усовершенствование воспроизведения некоторых выбранных объектов (или сцен без этих объектов) и расширение возможностей существующего метода SAOC-кодирования, используя стереомикширование с понижением следующим образом:
- в обычном режиме доля каждого объектного сигнала представлена его составляющими в downmix матрице (для левого и правого downmix каналов, соответственно). Далее, все взвешенные доли левого и правого downmix каналов суммируются с целью формирования окончательных левого и правого downmix каналов;
- в усовершенствованном режиме Караоке/Соло все доли объектов разделены на две группы, одна из которых формируют объект переднего плана (FGO), а другая - объект заднего плана (BGO). Доли FGO-группы суммируются в моно downmix сигнал, доли BGO-группы суммируются в стерео downmix сигнал, и далее они вместе суммируются с помощью обобщенного ТТТ-блока кодера для формирования общего SAOC стерео downmix сигнала.
Таким образом, обычное суммирование заменено «ТТТ-суммированием» (которое может быть при необходимости каскадным).
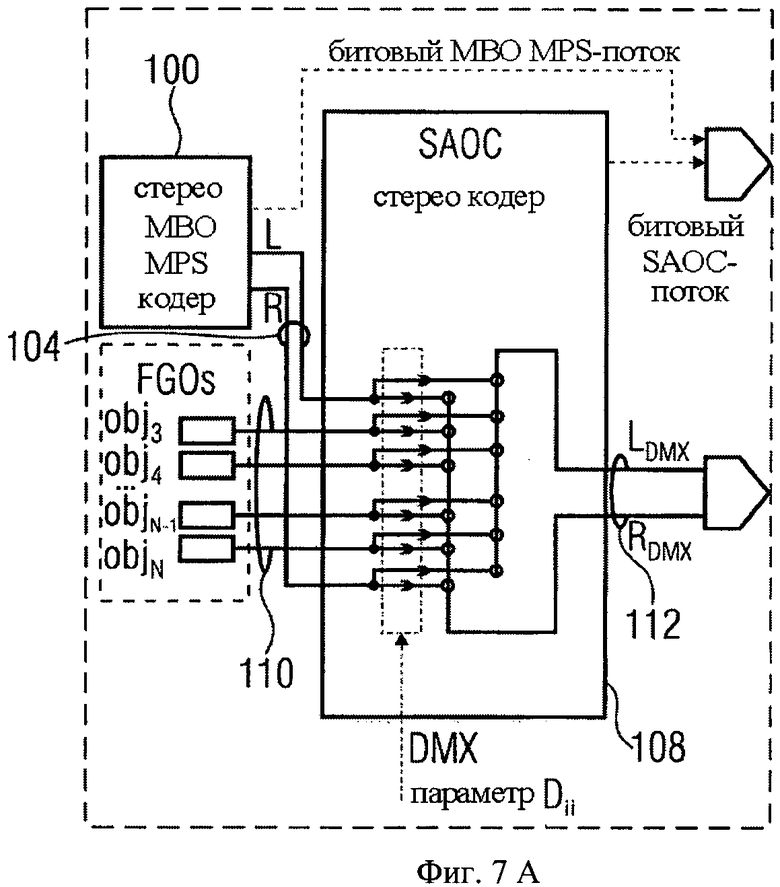
Разница между обычным и усовершенствованным режимами SAOC-кодера проиллюстрирована на фиг.7а и 7b. На фиг.7а показан обычный режим, на фиг.7b - усовершенствованный. Как видно, в обычном режиме SAOC-кодер 108 использует вышеуказанные DMX-параметры Dij для взвешивания объектов j и добавления взвешенных объектов j в SAOC-канал i, т.е. L0 или R0. В случае усовершенствованного режима, показанного на фиг.6, необходим только вектор DMX-параметров Di, а именно DMX-параметры Di, показывающие, как формировать взвешенную сумму FGO-объектов 110, получая центральный канал С для блока ТТТ1 124, и DMX-параметры Di, сообщающие блоку ТТТ-1, как распределить центральный канал С между левым и правым МВО каналами, формируя соответственно LDMX RDMX.
К сожалению, обработка сигнала, показанная на фиг.6, кодеками (HE-AAC/SBR), не сохраняющими форму сигнала, оказывается недостаточно качественной. Решением этой проблемы может быть использование ТТТ-режима, основанного на энергии сигналов для НЕ-ААС и высоких частот.
Вариант изобретения, соответствующий этой проблеме, представлен ниже.
Возможный формат битового потока для каскадной организации ТТТ может быть следующим.
Дополнение к битовому SAOC-потоку, которое может быть при необходимости пропущено в случае «обычного режима декодирования» представлено ниже:
numTTTs int
for (ttt=0; ttt<numTTTs; ttt++)
{no_TTT_obj[ttt] int
TTT_bandwidth[ttt];
TTT_residual_stream [ttt]
}
Что касается сложности и требований к памяти, можно констатировать
следующее. Как следует из предыдущих объяснений, усовершенствованный режим Караоке/Соло (фиг.6) получается при добавлении ступеней одного ключевого элемента в каждый кодер и декодер/транскодер, т.е. обобщенный ТТТ-1/ТТТ элемент. Оба элемента идентичны по сложности в отношении обычных «центрированных» ТТТ аналогов (изменения в значениях коэффициентов на сложность не влияют). Для основного приложения (один FGO-объект представляет собой ведущий вокал) достаточно одного ТТТ-блока.
Влияние этой дополнительной структуры на сложность системы MPEG Surround может быть оценено при анализе структуры всего MPEG Surround декодера, который для случая, релевантного стереосигналу (конфигурация 5-2-5), состоит из одного ТТТ-блока и двух ОТТ-блоков. Дополнительная функциональность достигается приемлемой ценой в смысле вычислительной сложности и потребления памяти (заметим, что ключевые элементы, использующие разностное кодирование, в среднем, не более сложны, чем их аналоги, которые содержат декорреляторы).
Расширение базовой модели MPEG SAOC на фиг.6 обеспечивает улучшение качества аудиосигнала для специальных Караоке-приложений в режимах Соло или Без звука. Необходимо отметить, что фиг.5, 6, 7 относятся к случаю, когда МВО является сценой заднего плана, или BGO является моно- или стереообъектом.
Как показывает практика, нижеследующие условия улучшают качество выходного аудиосигнала для Соло- и Караоке-приложений:
- RM0 (базовая модель).
- Усовершенствованный режим (res 0) (без разностного кодирования).
- Усовершенствованный режим (res 6) (с разностным кодированием в 6 самых низких гибридных QMF диапазонах).
- Усовершенствованный режим (res 12) (с разностным кодированием в 12 самых низких гибридных QMF диапазонах).
- Усовершенствованный режим (res 24) (с разностным кодированием в 24 самых низких гибридных QMF диапазонах).
- Скрытый уровень.
- Нижний уровень (точка отсчета ограничена диапазоном 3.5 кГц). Битовая скорость для предлагаемого усовершенствованного режима аналогична RM0, если используется без разностного кодирования. Все остальные усовершенствованные режимы требуют порядка 10 кбит/сек для каждых 6 полос разностного кодирования.
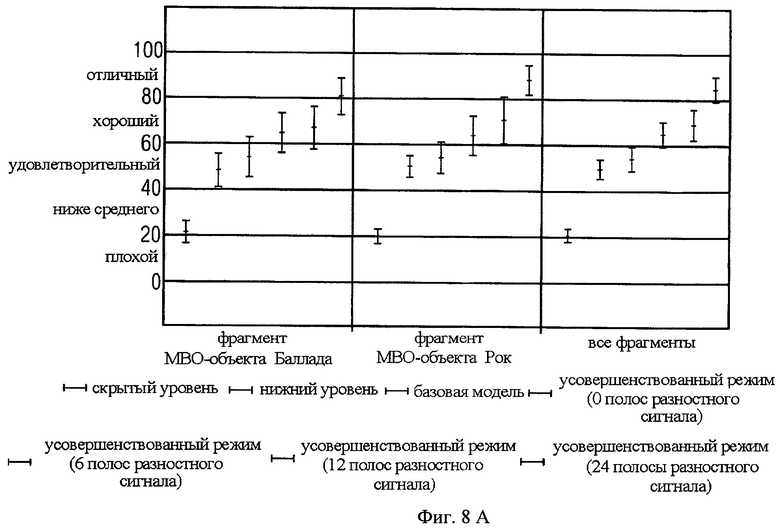
Фиг.8а показывает результаты теста 10 фрагментов в режиме Без звука/Караоке. Предложенное решение имеет средний MUSHRA-показатель, который всегда выше, чем RM0. Показатель увеличивается с каждым дополнительным шагом разностного кодирования. Значительное преимущество по сравнению с RM0 наблюдается при режиме с 6 или более полосами разностного кодирования.
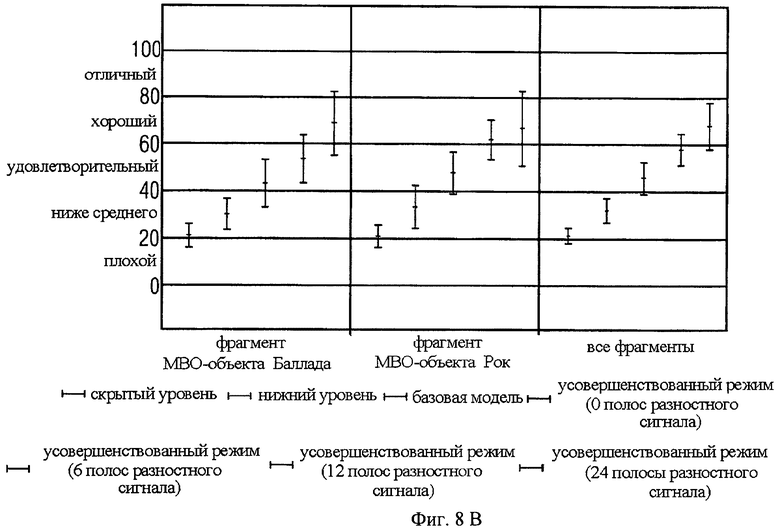
Результаты теста для режима Соло с 9 фрагментами на фиг.8b демонстрируют преимущества для предложенного решения. Средний MUSHRA-показатель значительно увеличивается при добавлении разностного кодирования. Разница между усовершенствованным режимом с 24 полосами разностного кодирования и без них составляет почти 50 единиц.
В итоге в приложении Караоке хорошее качество достигается при битовой скорости на 10 кбит/сек выше, чем для RM0. Значительное улучшение качества обеспечивается при превышении битовой скорости RM0 на 40 кбит/сек. В реальных приложениях, где определена минимальная скорость, предложенный усовершенствованный режим позволяет использовать разницу между текущей скоростью и максимальной скоростью для разностного кодирования. Таким образом достигается максимально возможное качество звука. Дальнейшее улучшение представленных экспериментальных результатов возможно благодаря более эффективному использованию битовой скорости для разностного кодирования: в то время, когда обычные настройки используют разностное кодирование от DC до определенной верхней границы частоты, усовершенствованный режим использует только биты частотного диапазона, которые соответствуют разделению FGO и объектов заднего плана.
В дальнейшем описании представлен усовершенствованный вариант технологии SAOC для Караоке-приложений, а именно дополнительные варианты приложения усовершенствованного режима Караоке/Соло для обработки многоканальной сцены для стандарта MPEG SAOC.
В отличие от FGO-объектов, которые воспроизводятся с изменениями, МВО-сигналы должны воспроизводиться без изменений, т.е. каждый сигнал входного канала воспроизводится через соответствующий выходной канал без изменения уровня.
Следовательно, предварительная обработка МВО-сигналов кодером MPEG Surround состоит в извлечении стерео downmix сигнала, который служит объектом заднего плана для последующих стадий преобразований в режиме Караоке/Соло с помощью SAOC-кодера, МВО-транскодера и MPS-декодера. Фиг.9 демонстрирует общую схему.
Как видим, согласно схеме кодера режима Караоке/Соло входные объекты классифицируются на стереообъекты заднего плана (BGO) 104 и объекты переднего плана (FGO) 110.
Если в режиме RM0 преобразование сценариев происходит в рамках системы SOAC кодера/транскодера, усовершенствованный вариант на фиг.6 дополнительно применяет базовый блок структуры MPEG Surround. Объединение ТТТ-1 блока в кодере и соответствующего ТТТ-блока транскодера улучшает воспроизведение звука, если требуется значительное усиление/ослабление аудиообъекта.
Расширенная структура имеет следующие основные характеристики:
- лучшее разделение сигнала благодаря применению разностного сигнала (в сравнении с RM0);
- гибкое позиционирование сигнала, являющегося центральным входом (т.е. FGO) ТТТ1 -блока за счет расширения характеристик микширования.
Так как непосредственное применение ТТТ-блока включает три входных сигнала со стороны кодера, фиг.6 показывает обработку FGO-объектов как моносигналов (см. также фиг.10). На фиг.6 также указывается обработка мультиканальных FGO-сигналов, что более подробно описывается в следующем разделе.
Фиг.10 представляет улучшенный режим фиг.6: комбинация всех FGO-объектов направляется в центральный канал ТТТ-1 блока.
При DGO моно down mix сигнале, как показано на фиг.6 и 10, конфигурация ТТТ-1 блока кодера содержит FGO-объекты, являющиеся источником центрального входа, и BGO-объекты, являющиеся источником правого и левого входа. Соответствующая симметричная матрица может быть представлена следующим образом:
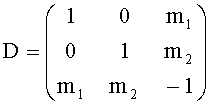 , которая показывает downmix сигнал (L0 R0)Т.
, которая показывает downmix сигнал (L0 R0)Т.
Сигнал F0 представлен следующим образом:
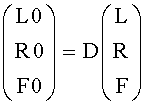
Третий сигнал, полученный с помощью этой линейной системы, устраняется, но при этом может быть восстановлен на стороне транскодера путем объединения двух коэффициентов предсказания C1 и С2 (СРС) согласно формуле:
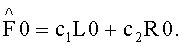
Обратный процесс транскодирования представлен формулой:
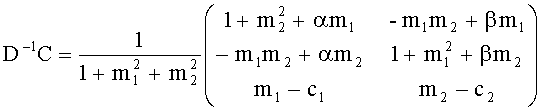
Параметры М1 и М2 соответствуют выражениям:
m1=cos(µ) and m2=sin(µ),
где µ отвечает за панорамирование FGO-объектов в общем ТТТ downmix сигнале (L0 R0)Т. Коэффициенты предсказания C1 и C2, необходимые для ТТТ upmix-модуля на стороне транскодера, могут быть определены с помощью передаваемых SAOC-параметров, т.е. уровневой разницы объектов (OLD) для всех входных аудиообъектов и межобъектной корреляции (IOC) для BGO downmix сигнала (МВО). Вследствие независимости FGO- и BGO-сигналов для определения СРС-коэффициентов применяется следующая формула:
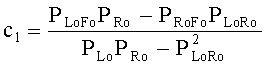 ,
, 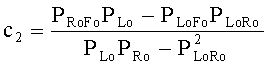
Переменные PLo, PRo, PLoRo, PLoFo и PRoFo рассчитываются как показано ниже, где параметры OLDL, OLDR и IOCLR соответствуют BGO, a OLDF соответствует FGO:
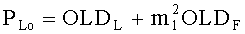
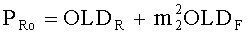 ,
,
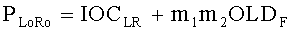 ,
,
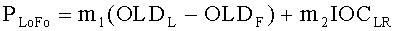 ,
,
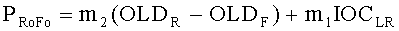 .
.
Ошибка, добавленная применением СРС-коэффициентов, представлена разностным сигналом 132, который передается в пределах битового потока следующим образом:
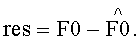
В некоторых приложениях невозможно объединение всех FGO-объектов в один моно downmix сигнал. Такое ограничение преодолевается следующим образом. FGO-объекты разделяются на две или более независимые группы с различным положением и/или разным уровнем ослабления в передаваемом стерео downmix сигнале. Так, каскадная структура, показанная на фиг.11, предполагает два или более последовательных ТТТ-1-блоков 124а, 124b, которые выполняют последовательное извлечение downmix сигналов из всех групп FGO-объектов F1, F2 на стороне кодера до тех пор, пока не будет получен требуемый стерео downmix сигнал 112. Каждый ТТТ-1-блок 124а, 124b на фиг.11 (или, как минимум, несколько блоков) устанавливают разностные сигналы 132а, 132b, которые соответствуют определенному этапу или блоку ТТТ-1 124а, 124b.
Транскодер, наоборот, выполняет последовательное микширование с повышением, используя ряд связанных ТТТ-блоков 126а, b, объединяя соответствующие СРС-коэффициенты и разностные сигналы. Порядок обработки FGO-объектов определяется кодером и должен учитываться транскодером.
Далее описывается математический аппарат, применяемый в двухуровневой каскадной структуре на фиг.11. В целях упрощения, но при этом сохраняя общую схему, далее рассматривается каскадная структура, состоящая из ТТТ-блоков, как показано на фиг.11. Две симметричные матрицы аналогичны матрице FGO моно downmix сигнала, но применяются к соответствующим сигналам:
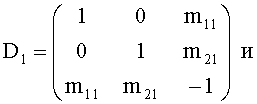
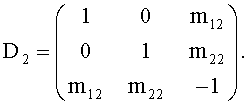
В этом случае появляются две группы СРС-коэффициентов в результате восстановления сигнала:
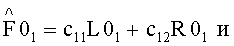
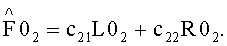
Обратный процесс представлен следующими выражениями:
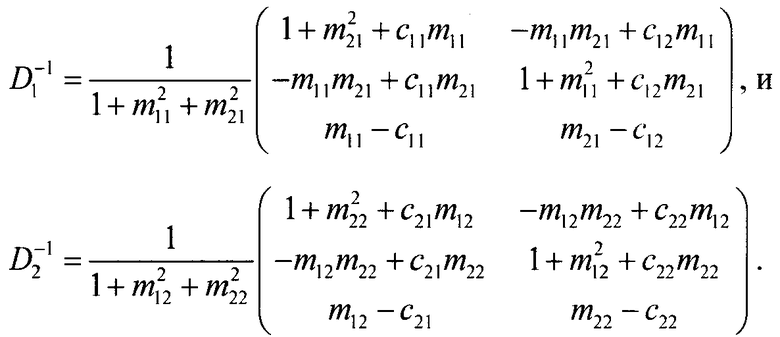
В случае двухступенчатой каскадной структуры она состоит из одного стерео FGO-объекта, в котором левый и правый каналы суммируются с соответствующими каналами BGO при µ1=0 и 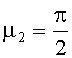 :
:
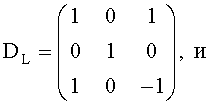
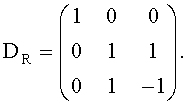
Для такого способа панорамирования, исключающего межобъектную корреляцию, т.е. OLDLR=0, вычисление двух групп СРС-коэффициентов упрощается до:
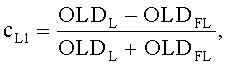
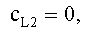
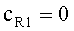 ,
, 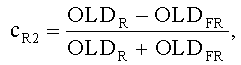
где OLDFL и OLDFR обозначают параметры OLD левого и правого FGO сигналов соответственно.
Общий случай N-ступенчатой каскадной структуры относится к многоканальному FGO downmix сигналу:
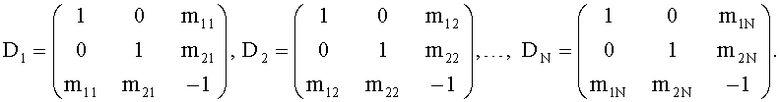
где каждая ступень имеет собственный СРС-коэффициент и разностный сигнал.
Обратное преобразование со стороны транскодера представлено нижеследующими выражениями:
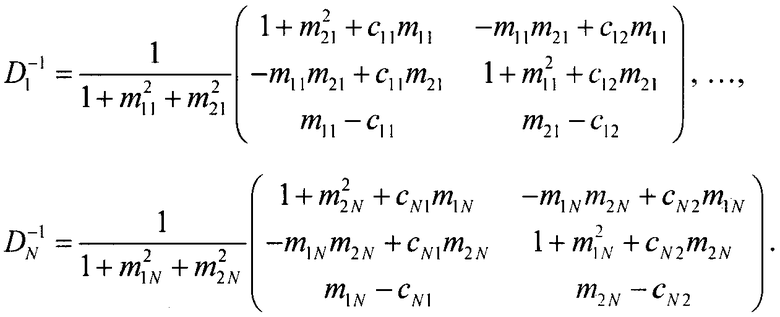
Для того чтобы исключить необходимость сохранения ТТТ-блоков, каскадная структура может быть преобразована в параллельную путем реорганизации N матриц в единую симметричную TTN-матрицу, которую можно представить следующим образом:
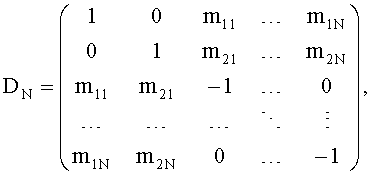
где первые две строки матрицы обозначают стерео downmix сигнал. Термин TTN (два-в-N) относится к процессу микширования с повышением на стороне транскодера.
Используя данное описание, матрица стерео FGO-сигнала может преобразовываться следующим образом:
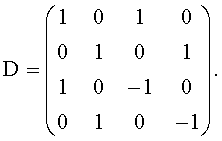
Здесь применялось преобразование 2-в-4 (TTF). В данном случае представлен TTF-блок.
Также возможно выделить TTF-структуру при повторном использовании модуля предварительной обработки SAOC стереосигнала.
Для случая N=4 становится возможным применение структуры TTF (2-в-4), которая повторно использует части существующей SAOC системы.
Этот процесс описывается в следующем параграфе.
Стандарт SAOC описывает процесс предварительной обработки стерео downmix сигнала для режима транскодирования стерео-в-стерео. При этом выходной стереосигнал Y вычисляется из входного стереосигнала Х совместно с декодированным Xd:
Y=GModX+P2Xd
Декоррелированный компонент Xd представляет собой синтетическую репрезентацию частей исходного сигнала, который был исключен в процессе кодирования. В соответствии с фиг.12 декоррелированный сигнал заменяется подходящим сгенерированным кодером разностным сигналом 132 для определенного частотного диапазона. Перечень представлен ниже:
-D - 2×N downmix матрица
- А - 2×N матрица воспроизведения
- Е - модель N×N ковариации входных объектов S
- Gmod - (соответствует G на фиг.12) upmix-матрица предсказания 2×2
Заметим, что Gmod является функцией D, А и Е. Для вычисления разностного сигнала Xres необходимо сымитировать процесс декодирования в кодере, т.е. определить Gmod. В общем случае А неизвестна, но в конкретном случае Караоке-режима (например, с одним стереообъектом заднего плана и одним стереообъектом переднего плана N=4) допускается, что
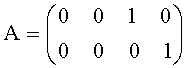
что соответствует воспроизведению только BGO-объекта.
Для вычисления объекта переднего плана восстановленный объект заднего плана вычитается из downmix сигнала X. Этот процесс и окончательное воспроизведение выполняется в блоке “mix”. Подробное описание представлено ниже.
Матрица воспроизведения А устанавливается следующим образом:
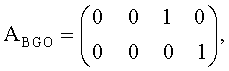
где предполагается, что два первых столбца представляют два канала FGO, а следующие два столбца - два канала ВGO.
BGO и FGO стереовыходы вычисляются в соответствии со следующими формулами:
YBGO=GModX+Xres,
а взвешивающая downmix матрица определяется как:
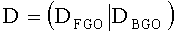 ,
,
где
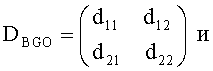
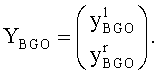
FGO-объект может быть определен как:
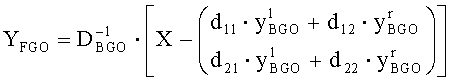 .
.
Это может быть упрощено до:
YFGO=X-YBGO
для downmix матрицы
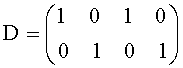
Xres является разностными сигналами, полученными вышеуказанным методом. Необходимо отметить, что декоррелированные сигналы не добавляются.
Финальный выход Y определяется следующим выражением:
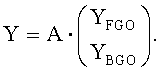
Вышеописанные варианты могут применяться, если вместо стерео FGO используется моно FGO-сигнал. Процесс преобразования в этом случае изменяется следующим образом:
Матрица воспроизведения А устанавливается как:
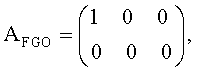
где принимается, что первый столбец представляет моно FGO, а следующие столбцы - два канала В GO.
BGO и FGO стереовыход вычисляется в соответствии со следующими формулами:
YFGO=GModX+Xres,
а взвешивающая downmix матрица D определяется как:
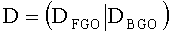 , где
, где
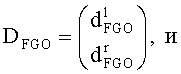
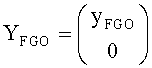
BGO-объект может быть определен как:
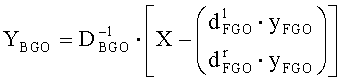
Как пример, это может быть упрощено до
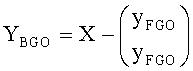
Для downmix матрицы
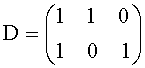
Xres является разностным сигналом, полученным вышеописанным способом. Необходимо отметить, что декоррелированные сигналы не учитывались. Финальный выход Y определялся следующим выражением:
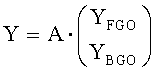
Для обработки более чем 4-х объектов вышеописанные варианты будут расширены путем объединения параллельных этапов ступеней обработки, как это было описано ранее.
Вышеописанные варианты представили детальное описание усовершенствованного режима Караоке/Соло для случаев многоканальной FGO аудиосцены.
Это обобщение предназначено расширить класс Караоке-приложений, для которых качество звука базовых MPEG SAOC-моделей может быть улучшено применением усовершенствованного режима Караоке/Соло. Улучшение достигается введением общей TTN-структуры в часть SAOC-кодера, где выполняется микширование с понижением, и соответствующего аналога в SAOC-MPS транскодер. Применение разностных сигналов улучшило результат.
Фиг.13a-13h показывают возможные структуры служебной информации битового SAOC-потока в соответствии с вариантом настоящего изобретения.
После описания некоторых вариантов усовершенствованного режима SAOC-кодека необходимо отметить, что некоторые варианты касаются приложений, где аудиовход SAOC-кодера содержит не только обычный моно- или стереосигнал, но и многоканальные объекты. Это было подробно описано со ссылкой на фиг.5-7b. Такой многоканальный объект заднего плана МВО может рассматриваться как сложная звуковая сцена, состоящая из неопределенного количества источников звука, для которых не требуется реализация контролируемого воспроизведения. По отдельности эти аудиоисточники не могут быть эффективно обработаны в системе SAOC-кодирования/декодирования. Однако концепция SAOC-кодирования может быть расширена для обработки комплексных входных объектов, например МВО-каналов, совместно с обычными SAOC аудиообъектами. Таким образом, в вышеуказанных вариантах на фиг.5-7b, допускается, что MPEG Surround кодер объединяется с SAOC-кодером, что обозначено пунктирной линией вокруг SAOC-кодера 108 и MPS-кодера 100.
Результирующий downmix сигнал 104 является входным стереообъектом для SAOC-кодера 108. Вместе с контролируемым SAOC-объектом 110 они составляют стерео downmix сигнал 112, который передается в транскодер. Что касается параметров, то битовый MPS-поток 106 и битовый SAOC-поток 114 поступают в SAOC-транскодер 116, который в зависимости от сценария МВО-приложения обеспечивает необходимый битовый MPS-поток 118 для MPEG Surround декодера 122. Эта задача решается с использованием информации о воспроизведении или матрицы воспроизведения и с применением предварительной downmix обработки с целью преобразования downmix сигнала 112 в downmix сигнал 122 для MPS-декодера 122.
Следующий вариант для усовершенствованного режима Караоке/Соло описан ниже. Он допускает отдельные манипуляции над аудиообъектами в плане усиления/ослабления их уровня без значительного ухудшения качества звука.
Особый сценарий Караоке-приложения требует полного подавления некоторых аудиообъектов, обычно ведущего вокала (в дальнейшем называемого FGO), сохраняя при этом качество звука объектов заднего плана. Он также обеспечивает возможность воспроизведения отдельных FGO-сигналов без воспроизведения сцены заднего плана (BGO); участие пользователя в плане панорамирования не требуется. Этот сценарий называется режимом Соло. Типовой случай применения содержит стерео BGO-сигнал и до 4-х FGO-сигналов, которые, например, могут представлять два независимых стереообъекта.
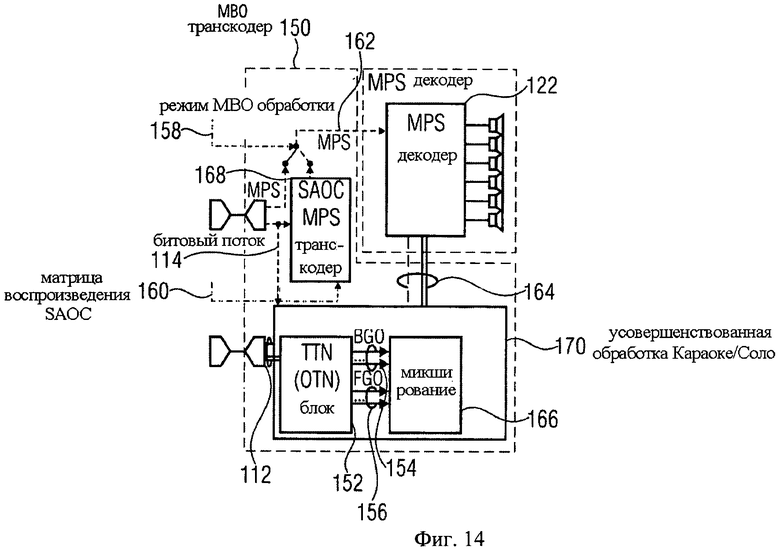
В соответствии с этим вариантом и фиг.14 усовершенствованный Караоке/Соло транскодер 150 содержит либо TTN (2-B-N), либо OTN (1-в-N) блок 152, которые представляют улучшенную модификацию ТТТ-блока, известного в стандарте MPEG Surround. Выбор необходимого элемента зависит от количества передаваемых downmix каналов, т.е. TTN-блок предназначен для стерео downmix сигнала, в то время как для моно downmix сигнала применяется OTN-блок. Соответствующий TTN-1 или OTN-1 блок SAOC-кодера объединяет BGO- и FGO-сигналы в общий SAOC стерео или моно downmix сигнал 112 и генерирует битовый поток 114.
Предварительное позиционирование отдельных FGO-сигналов в downmix сигнале 112 поддерживается всеми элементами, т.е. TTN или OTN 152.
На стороне транскодера BGO-сигнал 154 или любая комбинация FGO-сигналов 156 (в зависимости от внешне заданного режима работы 158) восстанавливается из downmix сигнала 112 при помощи TTN или OTN 152 с применением служебной SAOC-информации 114 и при необходимости содержащихся разностных сигналов.
Восстановленные аудиообъекты 154/156 и информация о воспроизведении 160 используются для создания битового потока 162 MPEG Surround и соответствующего предварительного downmix сигнала 164. Блок микширования 166 выполняет обработку downmix сигнала 112 для получения входного MPS downmix сигнала 164; MPS-транскодер 168 отвечает за транскодирование SAOC-параметров 114 в MPS-параметры 162. TTN/OTN-блок 152 и блок микширования 166 совместно выполняют обработку в усовершенствованном режиме Караоке/Соло 170, что соответствует модулям 52, 54 на фиг.3. При этом модуль 54 совмещает функцию блока микширования.
МВО может преобразовываться таким же образом, т.е. подвергаться предварительной обработке MPEG Surround-кодером, который выделяет моно или стерео downmix сигнал, который, в свою очередь, является BGO-объектом на входе SAOC-кодера. В этом случае для транскодера необходим дополнительный битовый MPEG Surround-поток, наряду с битовым SAOC-потоком.
Далее представлены вычисления, производимые TTN/OTN-блоками. TTN/OTN-матрица выражается в первом частотно-временном разрешении 42; М - это результат 2-х матриц:
M=D-1C,
где D-1 содержит информацию о downmix сигнале (downmix информация) и С -содержит СРС-коэффициенты предсказания для каждого FGO-канала. С вычисляется с помощью модуля 52 и блока 152 соответственно. D-1 вычисляется и применяется вместе с матрицей С для SAOC downmix сигнала модулем 54 и блоком 152. Вычисление производится следующим образом:
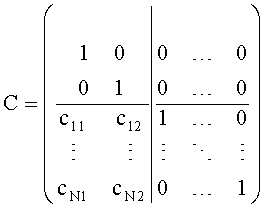
для TTN-блока, т.е. стерео downmix сигнала и
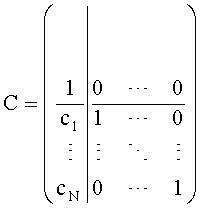
для OTN-блока, т.е. моно downmix сигнала.
Коэффициенты предсказания СРС определяются на основе SAOC-параметров OLD, IOC, DMG, DCLD. Для одного FGO-канала j коэффициенты СРС вычисляются следующим образом:
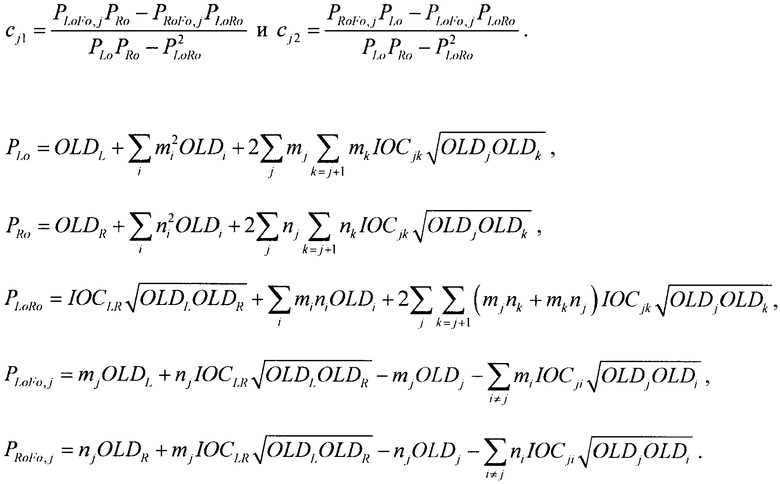
Параметры OLDR, OLDL и IOCLR соответствуют BGO-объектам, а остальные параметры - FGO-объектам.
Коэффициенты mj и nj обозначают параметры микширования с понижением для левого и правого downmix каналов каждого FGO. Они рассчитываются из параметра усиления DMG и параметра уровневой разности downmix каналов DCLD.
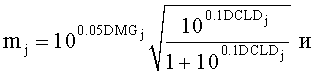
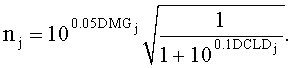
По отношению к OTN-блоку вычисление второго СРС-коэффициента cj2 становится избыточным.
Для восстановления двух групп BGO- и FGO-объектов параметры кодирования используются как обратная матрица к downmix матрице D, которая расширена для определения линейной комбинации для сигналов F01-F0N, т.е.
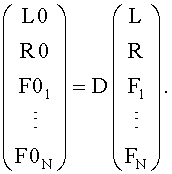
Далее представлен процесс микширования на стороне кодера:
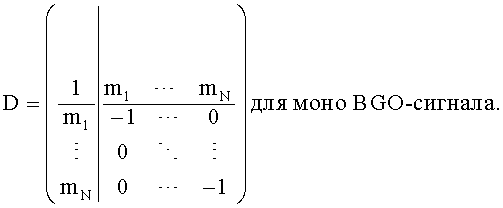
Внутри TTN-1-блока расширенная downmix матрица представлена следующим образом
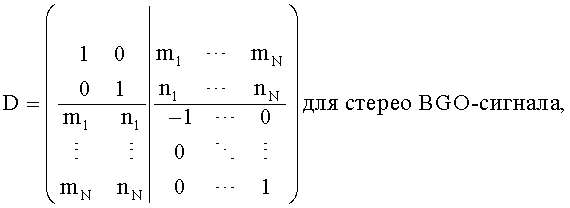
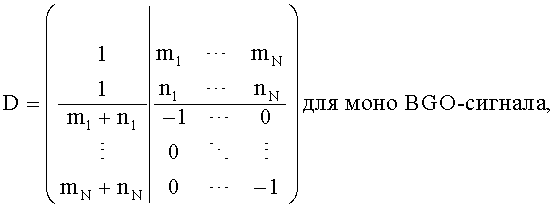
а для OTN-1-блока расширенная downmix матрица соответствует:
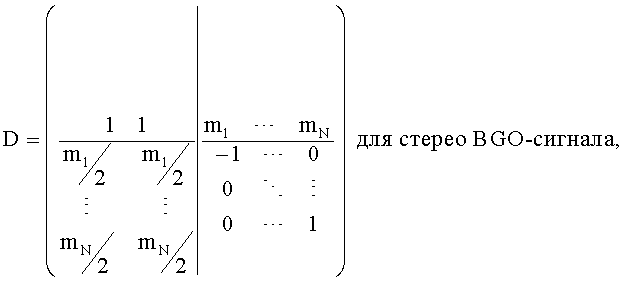
Выход TTN/OTN-блока формирует:
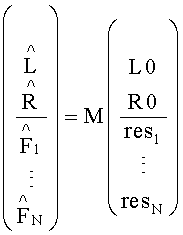 для стерео BGO и стерео downmix сигнала.
для стерео BGO и стерео downmix сигнала.
В случае, когда BGO или downmix сигнал являются моносигналами, линейная система соответственно изменяется.
Разностный сигнал res - если присутствует - соответствует FGO-объекту и, если не передается SAOC-потоком, например, вследствие того, что находится за пределами разностного частотного диапазона, или, если указывается, что для FGO-объекта i разностный сигнал не передается совсем, res равен 0. 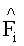 представляет собой восстановленный upmix-сигнал, приближающийся по параметрам к FGO-объекту i. После вычисления он может быть пропущен через блок синтетических фильтров для получения временной области, аналогичной версии FGO-объекта, полученной РСМ-кодированием. L0 и R0 обозначают каналы SAOC downmix сигнала, которые доступны в более высоком частотно-временном разрешении по сравнению с разрешением, лежащим в основе индексов n и k.
представляет собой восстановленный upmix-сигнал, приближающийся по параметрам к FGO-объекту i. После вычисления он может быть пропущен через блок синтетических фильтров для получения временной области, аналогичной версии FGO-объекта, полученной РСМ-кодированием. L0 и R0 обозначают каналы SAOC downmix сигнала, которые доступны в более высоком частотно-временном разрешении по сравнению с разрешением, лежащим в основе индексов n и k. 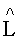 и
и 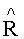 являются восстановленными upmix-сигналами, которые по своим параметрам приближаются к левому и правому каналам BGO-объекта. Вместе со служебным битовым MPS-потоком они могут быть воспроизведены на исходном количестве каналов.
являются восстановленными upmix-сигналами, которые по своим параметрам приближаются к левому и правому каналам BGO-объекта. Вместе со служебным битовым MPS-потоком они могут быть воспроизведены на исходном количестве каналов.
Согласно следующему варианту изобретения TTN-матрица используется в режиме, функционирующем на основе энергии сигнала.
Процедура кодирования/декодирования на основе энергии сигнала создана для не сохраняющего форму сигнала кодирования downmix сигнала. Таким образом, TTN upmix-матрица для соответствующего энергетического режима не опирается на форму сигнала, а только описывает относительное распределение энергии входных аудиообъектов. Элементы матрицы Menergy определяются из соответствующих OLD-параметров:
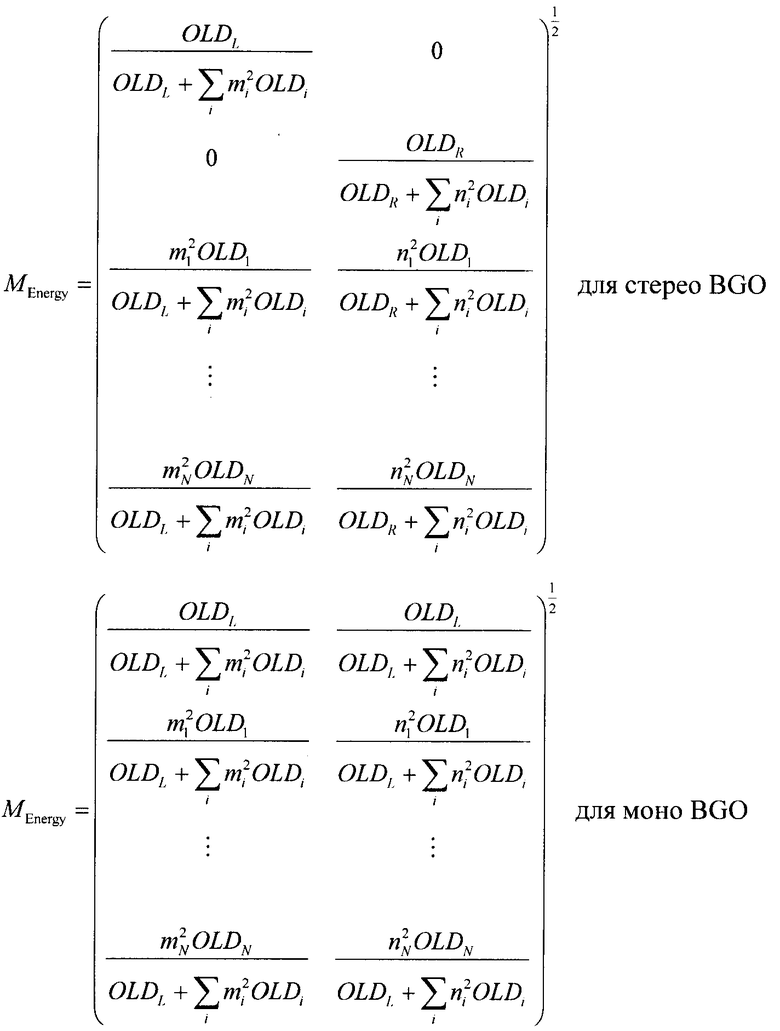
так, что выход TTN-блока формирует:
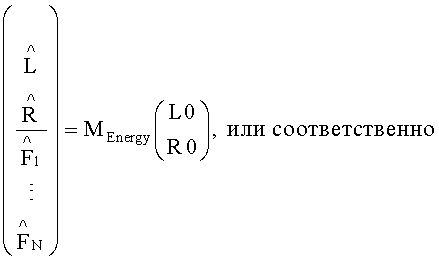
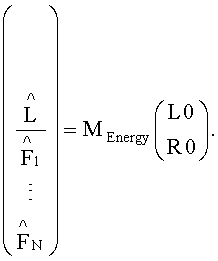
Соответственно, для моно downmix сигнала матрица Menergy превращается в:
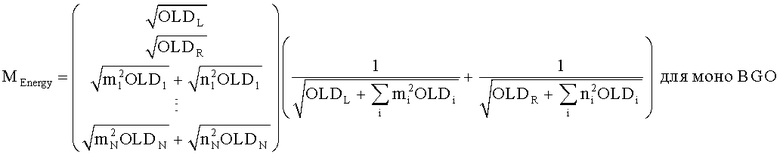
для стерео BGO и
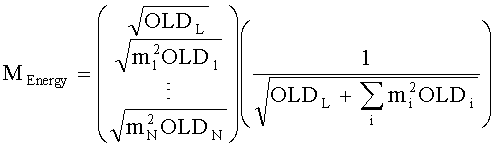 для моно BGO
для моно BGO
Таким образом, на выходе OTN-блока имеем:
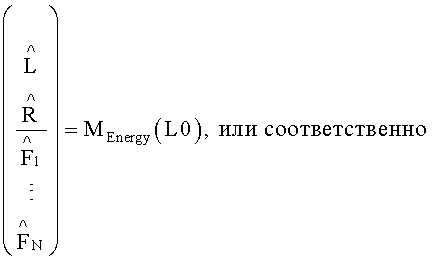
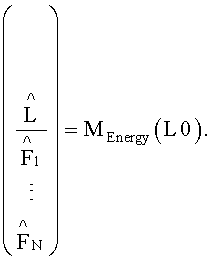
Таким образом, согласно вышеуказанному варианту разделение всех объектов 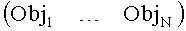 на BGO- и FGO-объекты осуществляется на стороне кодера. BGO-объект может представлять собой моно (L) или стерео
на BGO- и FGO-объекты осуществляется на стороне кодера. BGO-объект может представлять собой моно (L) или стерео  объект.
объект.
Процесс микширования BGO-объекта в downmix сигнал является типичным. Что касается FGO-объектов, то их количество теоретически не ограничено. Однако для большинства приложений оптимальным количеством является 4 FGO-объекта. Возможны любые комбинации моно- и стереообъектов. Посредством параметров mi (взвешивание в левом/моно downmix сигнале) и ni (взвешивание в правом downmix сигнале) FGO downmix сигнал изменяется во времени и по частоте. Как следствие, downmix сигнал может быть как моно (L0), так и стерео 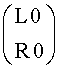 .
.
Сигналы 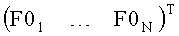 не передаются в декодер/транскодер, они предсказываются на стороне декодера посредством вышеуказанных СРС-коэффициентов.
не передаются в декодер/транскодер, они предсказываются на стороне декодера посредством вышеуказанных СРС-коэффициентов.
В этой связи отметим, что разностные сигналы res могут быть проигнорированы декодером или могут отсутствовать, т.е. они необязательны. В случае отсутствия разностного сигнала декодер 52, например, предсказывает виртуальные сигналы, опираясь только на СРС-коэффициенты, согласно формуле:
стерео downmix
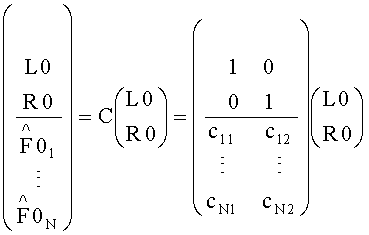
моно downmix
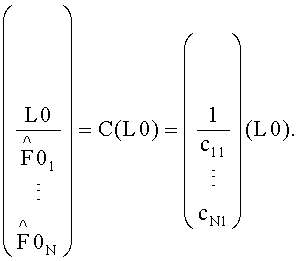
Тогда BGO и/или FGO определяются, например, с помощью модуля 52 путем инверсии одной из четырех возможных линейных комбинаций кодера:
например 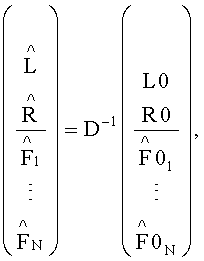
где D-1 - функция параметров DMG и DCLD.
Итак, TTN(OTN)-блок 152, игнорирующий разностный сигнал, производит следующие вычисления:
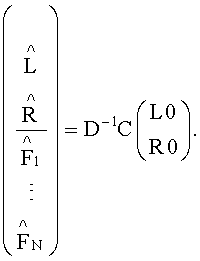
Заметим, что инверсия матрицы D может быть получена напрямую в случае, если матрица D является квадратной матрицей. Если матрица D не является квадратной ее инверсия будет псевдоинверсией, т.е. pinv(D)=D∗(DD∗)-1 или pinv(D)=(D∗D)-1D∗. В любом случае инверсная матрица к матрице D существует.
Наконец, фиг.15 показывает дальнейшую возможность введения в служебную информацию данных для передачи разностного сигнала. В соответствии с такой организацией данных служебная информация содержит bsResidualSamplingFrequencyIndex, т.е. индекс таблицы, устанавливающей соответствие, например, с частотным разрешением. В противном случае разрешение может быть предопределенным, таким как разрешение блока фильтров или разрешение параметра. Далее служебная информация содержит bsResidualFramesPerSAOCFrame, определяющий временное разрешение, в котором передается разностный сигнал. Служебная информация также содержит параметр BsNumGroupsFGO, который отображает количество FGO-объектов. Для каждого FGO-объекта передается определенный элемент bsResidualPresent, сообщающий о том, передается ли для соответствующего FGO-объекта разностный сигнал или нет. Если присутствует разностный сигнал, параметр bsResidualBands показывает количество спектральных полос, для которых передаются разностные значения.
В зависимости от конкретного варианта изобретения изобретенные методы кодирования/декодирования могут быть реализованы на уровне аппаратного или программного обеспечения, поэтому настоящее изобретение касается также компьютерных программ, которые могут храниться на таких носителях информации, как CD, диске или любом другом. Настоящее изобретение является программой, имеющей программный код, исполняемый на компьютере, что позволяет реализовать изобретенные методы кодирования или декодирования, описанные на вышеуказанных фигурах.







Изобретение относится к аудиокодерам, использующим повышающее микширование аудиосигналов. Техническим результатом является возможность разделения отдельных аудиообъектов при микшировании аудиосигналов с понижением количества каналов и с повышением количества каналов. Указанный результат достигается тем, что аудиодекодер для декодирования многообъектного аудиосигнала содержит модуль для вычисления коэффициента предсказания матрицы С, состоящей из коэффициентов предсказания на основе информации о разности уровней объектов (OLD); а также средство для повышающего микширования на основе коэффициентов предсказания для получения первого upmix аудиосигнала, стремящегося к аудиосигналу первого типа, и/или второго upmix аудиосигнала, стремящегося к аудиосигналу второго типа. При этом многообъектный аудиосигнал содержит закодированные аудиосигналы первого типа и второго типа; многоканальный аудиосигнал состоит из downmix сигнала 112 и служебной информации, служебная информация содержит информацию об уровне аудиосигнала первого типа и аудиосигнала второго типа в первом предопределенном частотно-временном разрешении. 3 н. и 17 з.п. ф-лы, 24 ил.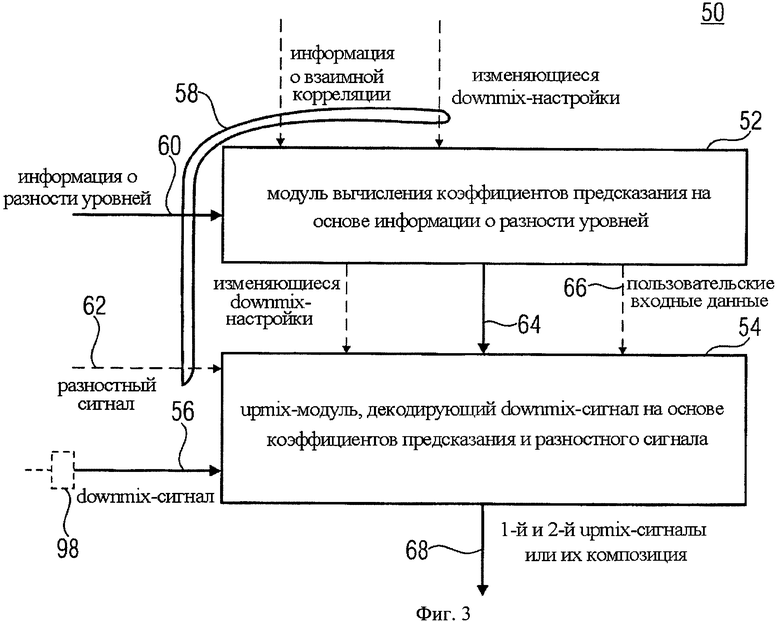
1. Аудиодекодер для декодирования многообъектного аудиосигнала, содержащего закодированные аудиосигналы первого типа и второго типа; многоканальный аудиосигнал состоит из downmix сигнала 112 и служебной информации, служебная информация содержит информацию об уровне аудиосигнала первого типа и аудиосигнала второго типа в первом предопределенном частотно-временном разрешении, характеризующийся тем, что он содержит модуль для вычисления коэффициента предсказания матрицы С, состоящей из коэффициентов предсказания на основе информации о разности уровней объектов (OLD); а также средство для повышающего микширования на основе коэффициентов предсказания для получения первого upmix аудиосигнала, стремящегося к аудиосигналу первого типа, и/или второго upmix аудиосигнала, стремящегося к аудиосигналу второго типа; средство для повышающего микширования сконфигурированы с возможностью выделения первого upmix сигнала S1 и/или второго upmix сигнала S2 из downmix сигнала d в соответствии с формулой
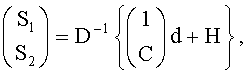
где 1 означает, в зависимости от количества каналов d, скалярную величину или единичную матрицу,
D-1 - матрица, определенная исключительно настройками понижающего микширования, содержащимися в служебной информации, в соответствии с которыми аудиосигнал первого типа и аудиосигнал второго типа микшируются в downmix сигнал,
Н - величина, независимая от d, но зависимая от разностного сигнала res, характеризующего значение разностного уровня во втором частотно-временном разрешении, которое может быть равным или отличаться от первого частотно-временного разрешения.
2. Аудиодекодер по п.1, характеризующийся тем, что настройки понижающего микширования, содержащиеся в служебной информации, изменяются во времени.
3. Аудиодекодер согласно п.1, характеризующийся тем, что настройки понижающего микширования отображают взвешивание downmix сигнала в процессе микширования на основе аудиосигнала первого типа и аудиосигнала второго типа.
4. Аудиодекодер по п.1, характеризующийся тем, что аудиосигнал первого типа является стереосигналом, имеющим первый и второй входные каналы, или моно аудиосигналом, имеющим один входной канал, в котором информация об уровне аудиосигнала показывает разницу между первым входным каналом, вторым входным каналом и аудиосигналом второго типа соответственно в первом частотно-временном разрешении, при этом служебная информация содержит данные о взаимной корреляции, определяющие уровневые сходства между первым и вторым входными каналами в третьем частотно-временном разрешении, средство для вычислений сконфигурировано с возможностью осуществления дальнейших вычислений на основе данных о взаимной корреляции.
5. Аудиодекодер по п.4, характеризующийся тем, что в нем частотно-временное разрешение первого и третьего порядка определяется общим синтаксическим элементом, который отображается в служебной информации.
6. Аудиодекодер по п.4, характеризующийся тем, что модуль, производящий микширование с повышением, функционирует согласно формуле:
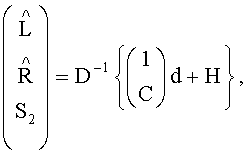
где L - первый канал первого upmix сигнала, стремящийся к первому входному каналу аудиоканала первого типа, R - второй канал первого upmix сигнала, стремящийся ко второму входному каналу аудиоканала первого типа.
7. Аудиодекодер по п.6, характеризующийся тем, что в нем downmix сигнал является стереоаудиосигналом, имеющим первый входной канал L0 и второй выходной канал R0, а модуль, выполняющий микширование с повышением, функционирует согласно формуле:
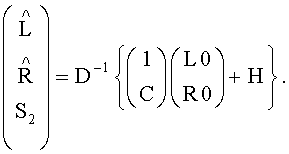
8. Аудиодекодер по п.6, характеризующийся тем, что в нем downmix сигнал является моноаудиосигналом.
9. Аудиодекодер по п.4, характеризующийся тем, что в нем downmix сигнал и аудиосигнал первого типа являются моносигналами.
10. Аудиодекодер по п.1, характеризующийся тем, что в нем служебная информация содержит разностный сигнал res, который указывает на разницу уровней при втором частотно-временном разрешении, а модуль, выполняющий микширование с повышением, функционирует согласно формуле:
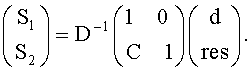
11. Аудиодекодер по п.10, характеризующийся тем, что в нем многоканальный сигнал содержит множество аудиосигналов второго типа, служебная информация содержит разностный сигнал для каждого сигнала второго типа.
12. Аудиодекодер по п.1, характеризующийся тем, что в нем второе частотно-временное разрешение соотносится с первым частотно-временным разрешением посредством показателя разностного разрешения, который содержится в служебной информации, при этом он содержит модуль, который позволяет определить показатель разностного разрешения на основе служебной информации.
13. Аудиодекодер по п.12, характеризующийся тем, что в нем показатель разностного разрешения определяет спектральный диапазон, в котором передается разностный сигнал в составе служебной информации.
14. Аудиодекодер по п.13, характеризующийся тем, что в нем показатель разностного разрешения определяет нижний и верхний пределы спектрального диапазона.
15. Аудиодекодер по п.1, характеризующийся тем, что в нем модуль СРС (коэфициент предсказания каналов) производит вычисление коэффициентов предсказания канала 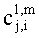 для каждой частотной/временной области (l, n) в первом частотно-временом разрешении для каждого выходного канала i downmix сигнала и для каждого канала j аудиосигнала второго типа согласно формуле:
для каждой частотной/временной области (l, n) в первом частотно-временом разрешении для каждого выходного канала i downmix сигнала и для каждого канала j аудиосигнала второго типа согласно формуле:
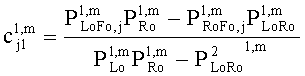 и
и 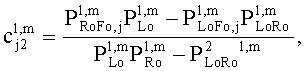
где 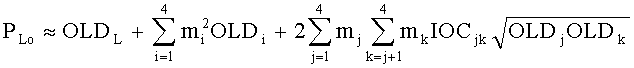 ,
,
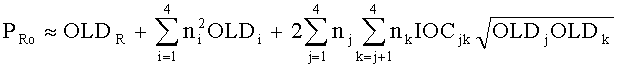 ,
,
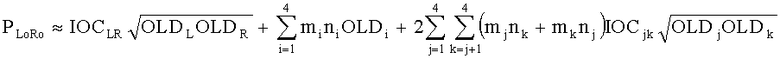 ,
,
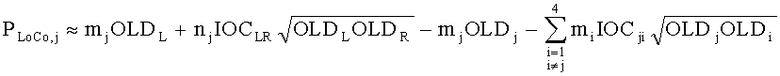 ,
,
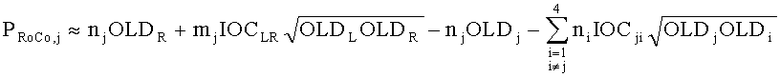 ,
,
где OLDL обозначает нормализованную спектральную энергию первого входного канала аудиосигнала первого типа в соответствующей частотно-временной области, OLDR обозначает нормализованную спектральную энергию второго входного канала аудиосигнала первого типа в соответствующей частотно-временной области, IOCLR обозначает информацию о взаимной корреляции, которая определяет сходство спектральной энергии между первым и вторым входными каналами в пределах соответствующей частотно-временной области, если аудиосигнал первого типа является стереосигналом, или OLDL обозначает нормализованную спектральную энергию аудиосигнала первого типа в соответствующей частотно-временной области, и OLDR, IOCLR равны нулю, если аудиосигнал первого типа является моносигналом;
OLDj обозначает нормализованную спектральную энергию канала j аудиосигнала S второго типа в соответствующей частотно-временной области, IOCij обозначает информацию о взаимной корреляции, которая определяет сходство спектральной энергии между каналами I и j аудиосигнала S второго типа в пределах соответствующей частотно-временной области при:
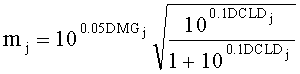 и
и 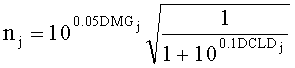 ,
,
где DCLD и DMG - настройки понижающего микширования,
модуль, производящий микширование с повышением, выделяет первый upmix сигнал S1 и/или второй upmix сигнал(ы) S2,1 из downmix сигнала d и разностного сигнала resi каждую секунду второго upmix сигнала S2,1 по формуле:
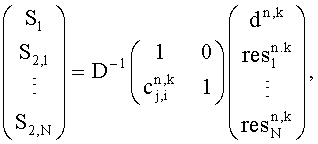
где 1 слева вверху обозначает, в зависимости от количества каналов dnk, скалярную величину или единичную матрицу; 1 справа внизу обозначает единичную матрицу величины N; 0 обозначает нулевой вектор или матрицу, которые также зависят от количества каналов dn,k; D-1 - матрица, определяемая настройками понижающего микширования, согласно которым аудиосигнал первого типа и аудиосигнал второго типа микшируются в downmix сигнал, который содержится в служебной информации; dn,k и 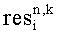 обозначают соответственно downmix сигнал и разностный сигнал для второго upmix сигнала S2,1 в частотно-временной области (n, k);
обозначают соответственно downmix сигнал и разностный сигнал для второго upmix сигнала S2,1 в частотно-временной области (n, k); 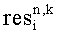 не содержится в служебной информации и равен нулю.
не содержится в служебной информации и равен нулю.
16. Аудиодекодер по п.15, характеризующийся тем, что в нем D-1 - обратное преобразование от
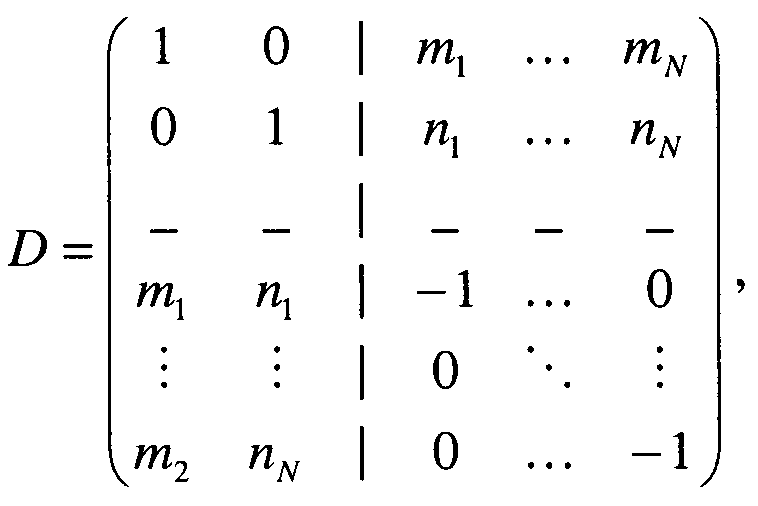 если downmix сигнал является стереосигналом и S1 является стереосигналом,
если downmix сигнал является стереосигналом и S1 является стереосигналом,
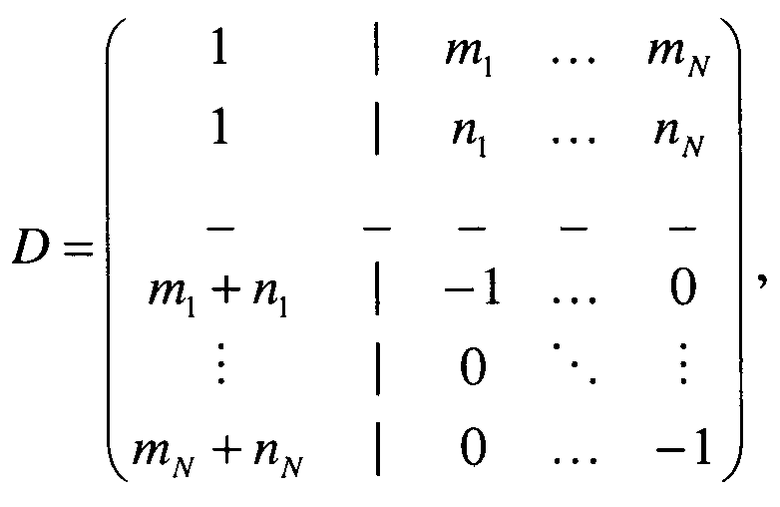 если downmix сигнал является стереосигналом и S1 является моносигналом,
если downmix сигнал является стереосигналом и S1 является моносигналом,
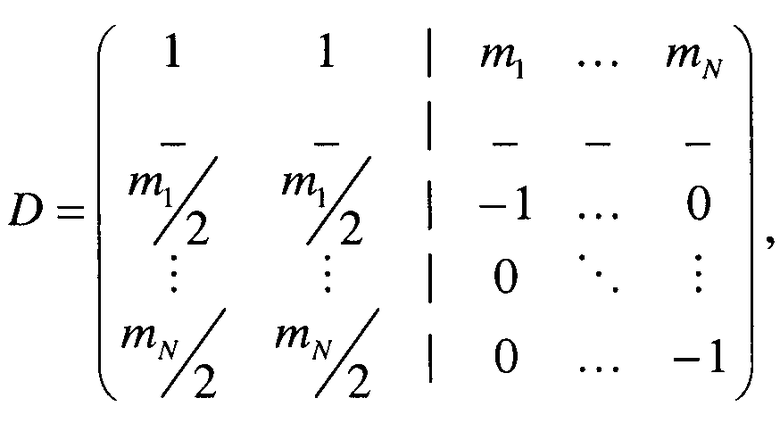 если downmix сигнал является моносигналом и S1 является стереосигналом,
если downmix сигнал является моносигналом и S1 является стереосигналом,
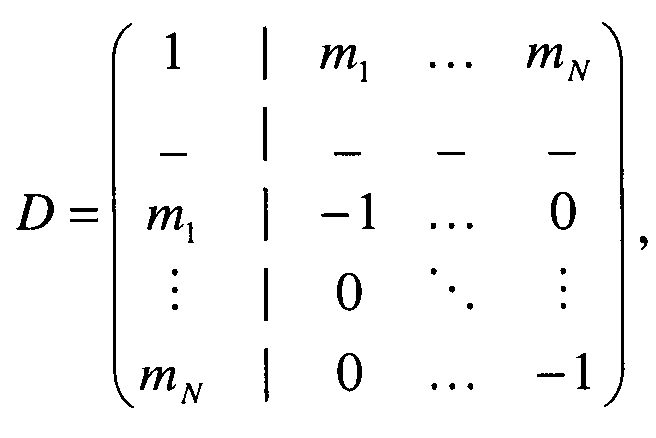 если downmix сигнал является моносигналом и S1 является моносигналом.
если downmix сигнал является моносигналом и S1 является моносигналом.
17. Аудиодекодер по п.1, характеризующийся тем, что в нем многообъектный сигнал содержит данные о пространственном воспроизведении для пространственного воспроизведения аудиосигнала первого типа в условиях определенной конфигурации акустической системы.
18. Аудиодекодер согласно п.1, характеризующийся тем, что модуль микширования с повышением производит пространственное воспроизведение первого upmix сигнала, отделенного от второго upmix сигнала; воспроизведение второго upmix сигнала, отделенного от первого upmix сигнала; или микширует первый upmix сигнал и второй upmix сигнал и воспроизводит их при установленной конфигурации акустической системы.
19. Способ декодирования многоканального аудиосигнала, включающего закодированные аудиосигнал первого типа и аудиосигнал второго типа; многообъектный аудиосигнал состоит из downmix сигнала (112) и служебной информации; служебная информация содержит данные об уровне аудиосигнала первого типа и аудиосигнала второго типа при первом частотно-временном разрешении, характеризующийся тем, что включает вычисление коэффициента прогнозирования матрицы С, состоящей из коэффициентов предсказания на основе информации о разности уровней объектов; микширование с повышением downmix сигнала на основе коэффициента прогнозирования для получения первого upmix сигнала, приближающегося к аудиосигналу первого типа и/или получения второго upmix сигнала, приближающегося к аудиосигналу второго типа; при микшировании с повышением выделяется первый upmix сигнал S1 и/или второй upmix сигнал S2 из downmix сигнала d согласно формуле:
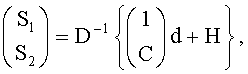
где 1 означает, в зависимости от количества каналов d, скалярную величину или единичную матрицу,
D-1 - матрица, определенная исключительно настройками понижающего микширования, содержащимися в служебной информации, в соответствии с которыми аудиосигнал первого типа и аудиосигнал второго типа микшируются в downmix сигнал, Н - величина, независимая от d, но зависимая от разностного сигнала res, характеризующего значение разностного уровня во втором частотно-временном разрешении, которое может быть равным или отличаться от первого частотно-временного разрешения.
20. Компьютерочитаемый носитель информации с сохраненной на нем компьютерной программой, имеющей программный код для осуществления способа по п.19, когда она исполняется на компьютере.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Устройство для упаковки сыпучих материалов в тару | 1989 |
|
SU1768451A1 |
| RU 2005123984 А, 27.01.2006. | |||

