ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Не применимо.
УРОВЕНЬ ТЕХНИКИ
[0002] 1. Уровень техники и соответствующая область техники
[0003] Вычислительные системы и связанные с ними технологии влияют на многие аспекты общества. Действительно, способность вычислительных систем обрабатывать информацию изменила наш образ жизни и трудовую деятельность. Вычислительные системы теперь повсеместно выполняют множество задач (например, обработку слов, планирование, расчетные операции и т.д.), которые перед появлением вычислительных систем выполнялись вручную. В последнее время, вычислительные системы были связаны друг с другом и с другими электронными устройствами для формирования как проводных, так и беспроводных вычислительных сетей, через которые вычислительные системы и другие электронные устройства могут передавать электронные данные. Таким образом, выполнение многих вычислительных задач распределено по некоторому количеству разных вычислительных систем и/или некоторому количеству разных вычислительных сред.
[0004] В сетях, включая интернет, могут быть использованы поисковые подсистемы для обнаружения информации, представляющей интерес для пользователя. Поисковая подсистема обычно использует поискового агента, который непрерывно автоматически сканирует веб-страницы в сети, такой как интернет, для индексирования контента. Для нахождения контента, пользователь предоставляет один или несколько поисковых терминов для поисковой подсистемы. Поисковая подсистема идентифицирует страницы, которые, как считается, содержат контент, релевантный для одного или нескольких поисковых терминов. Поисковая подсистема, затем, возвращает ссылки на идентифицированные страницы обратно к пользователю. Пользователь может затем выбрать (например, «щелкнуть мышью») ссылку для просмотра контента соответствующей страницы.
[0005] Система поиска структурированных данных (SDSS) подобным образом автоматически сканирует сеть, такую как интернет, для индексирования структурированной информации. Структурированная информация может включать в себя таблицы в реляционной базе данных или HTML-таблицы, извлеченные из веб-страниц. Для нахождения структурированных данных, пользователь предоставляет один или несколько поисковых терминов для SDSS. SDSS идентифицирует структурированные данные, такие как таблица, которые, как считается, содержат контент, релевантный для одного или нескольких поисковых терминов. Поисковая подсистема, затем, возвращает структурированные данные обратно к пользователю. Пользователь может затем интегрировать структурированные данные в свои приложения.
[0006] Для эффективного индексирования структурированных данных, таких как таблица, необходимо по меньшей мере некоторое понимание структурированных данных. Некоторые таблицы в сети могут явно определить свой предметный столбец и заголовки столбцов. SDSS может индексировать эти типы таблиц относительно эффективно. Другие таблицы в сети не могут явно определить свой предметный столбец и/или заголовки столбцов. SDSS может быть неспособной индексировать эти другие типы таблиц.
[0007] Вследствие различий в генерации контента в интернете, значительная часть таблиц в интернете не имеет явно определенного предметного столбца и/или явно определенных заголовков столбцов. Поскольку SDSS может быть неспособной индексировать таблицы, не имеющие явно определенного предметного столбца и/или явно определенных заголовков столбцов, весьма маловероятно возвращение таких таблиц в ответ на пользовательский поиск. Таким образом, для пользователя может оказаться очень трудным нахождение таблиц, которые не имеют явно определенного предметного столбца, и/или которые не имеют явно определенных заголовков столбцов, даже если контент таких таблиц может быть полезным.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0008] Настоящее изобретение распространяется на способы, системы, и компьютерные программные продукты для понимания таблиц для поиска. Аспекты настоящего изобретения включают в себя идентификацию предметного столбца для таблицы, детектирование заголовка столбцов для таблицы с использованием других таблиц и детектирование заголовка столбцов для таблицы с использованием базы знаний.
[0009] Это краткое изложение сущности изобретения приведена для ознакомления в упрощенной форме с подборкой идей изобретения, которые дополнительно описаны ниже в подробном описании. Данное краткое изложение сущности изобретения не предназначено для идентификации ключевых признаков или существенных признаков заявленного изобретения, а также не предназначено для использования для помощи в определении объема заявленного изобретения.
[0010] Дополнительные признаки и преимущества настоящего изобретения будут изложены в нижеследующем описании, и, частично, будут ясны из описания, или могут быть изучены при применении на практике настоящего изобретения. Признаки и преимущества настоящего изобретения могут быть реализованы и получены посредством инструментов и комбинаций, конкретно указанных в прилагаемой формуле изобретения. Эти и другие признаки настоящего изобретения станут более ясными из нижеследующего описания и прилагаемой формулы изобретения, или могут быть изучены при применении на практике настоящего изобретения, изложенного ниже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0011] Для описания способа, в котором упомянутые выше и другие преимущества и признаки настоящего изобретения могут быть получены, более конкретное описание изобретения, кратко описанного выше, будет приведено со ссылкой на конкретные его реализации, которые показаны в прилагаемых чертежах. Следует понимать, что эти чертежи показывают только некоторые реализации настоящего изобретения и, следовательно, не должны рассматриваться как ограничивающие его объем, таким образом, настоящее изобретение будет описано и объяснено с дополнительной конкретикой и подробностями с использованием сопутствующих чертежей, в которых:
[0012] Фиг. 1 показывает иллюстративную вычислительную архитектуру, которая облегчает создание одного или нескольких индексов на основе одного или нескольких наборов данных структурированных данных.
[0013] Фиг. 2 показывает иллюстративную вычислительную архитектуру, которая облегчает идентификацию предметного столбца таблицы.
[0014] Фиг. 3 показывает блок-схему последовательности операций иллюстративного способа для идентификации предметного столбца таблицы.
[0015] Фиг. 4 показывает иллюстративную вычислительную архитектуру, которая облегчает детектирование заголовка столбцов для таблицы.
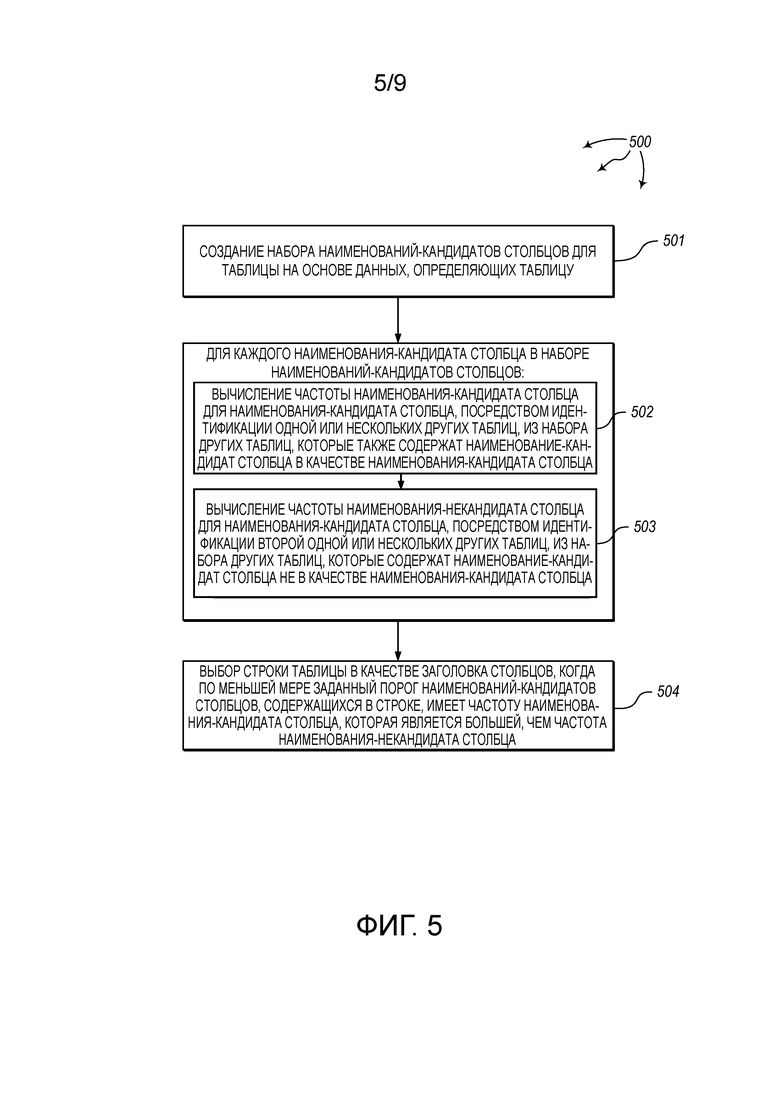
[0016] Фиг. 5 показывает блок-схему последовательности операций иллюстративного способа для детектирования заголовка столбцов для таблицы.
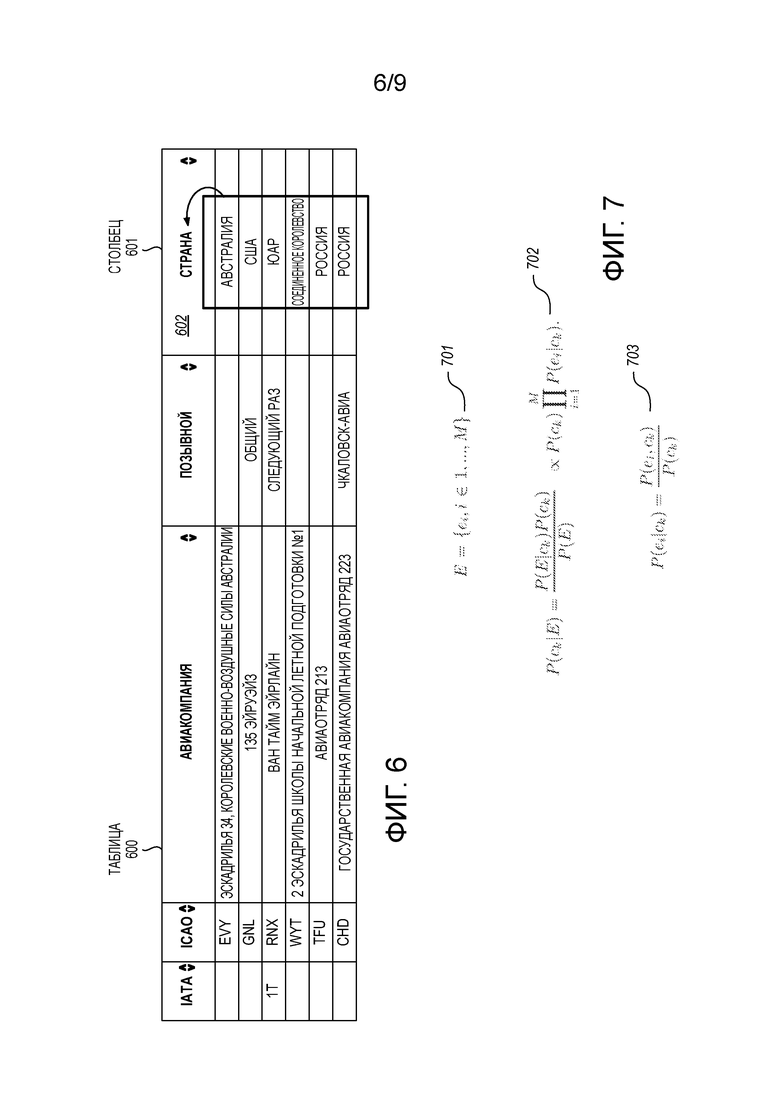
[0017] Фиг. 6 показывает иллюстративную таблицу.
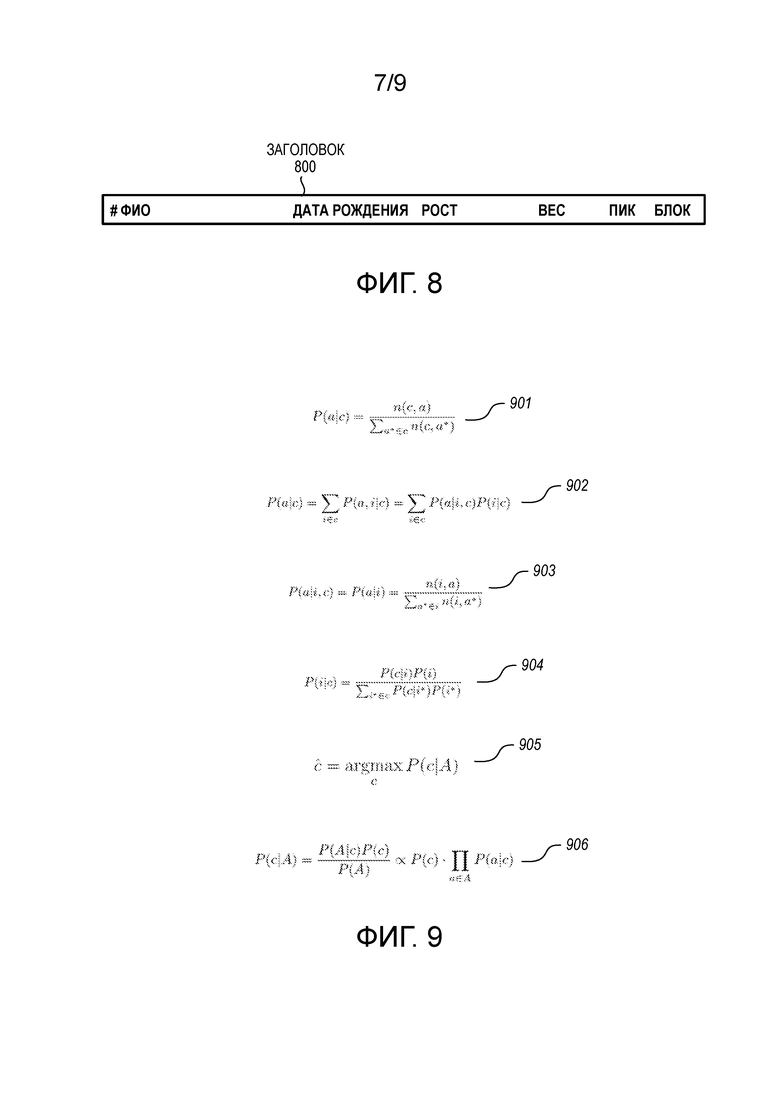
[0018] Фиг. 7 показывает различные уравнения, используемые для логического вывода концептов на основе набора примеров.
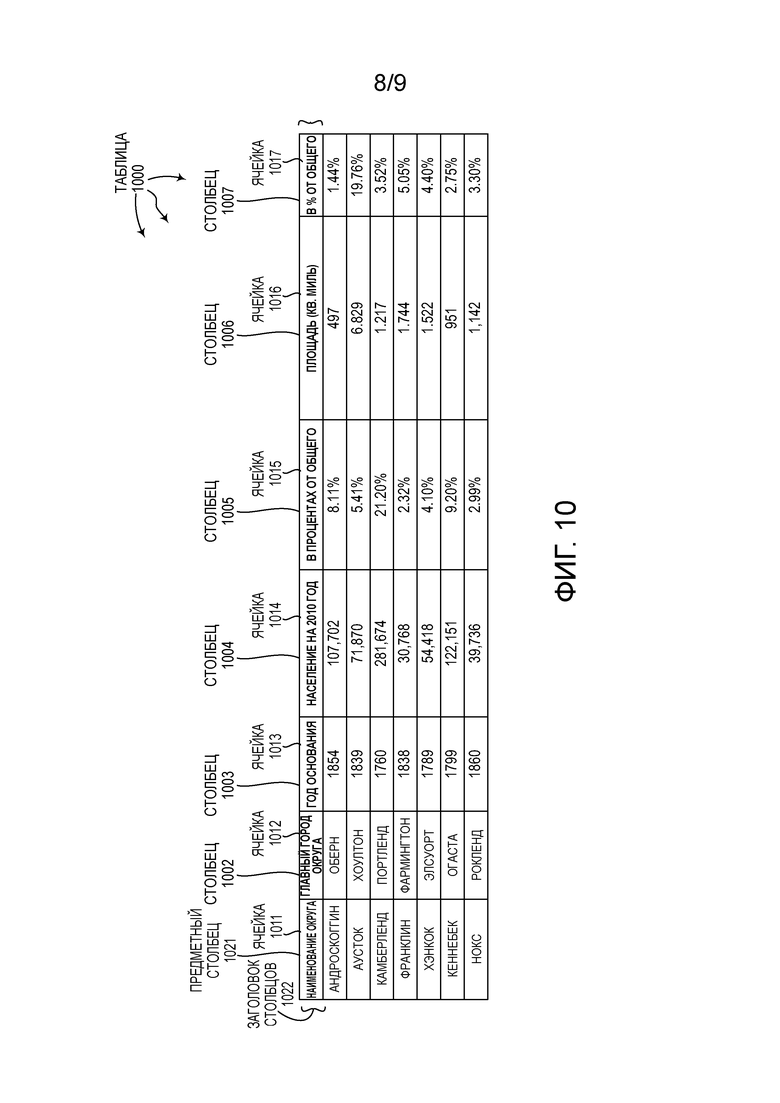
[0019] Фиг. 8 показывает иллюстративную строку заголовка.
[0020] Фиг. 9 показывает различные уравнения, используемые для вычисления оценок типичности для извлеченных атрибутов.
[0021] Фиг. 10 показывает иллюстративную таблицу.
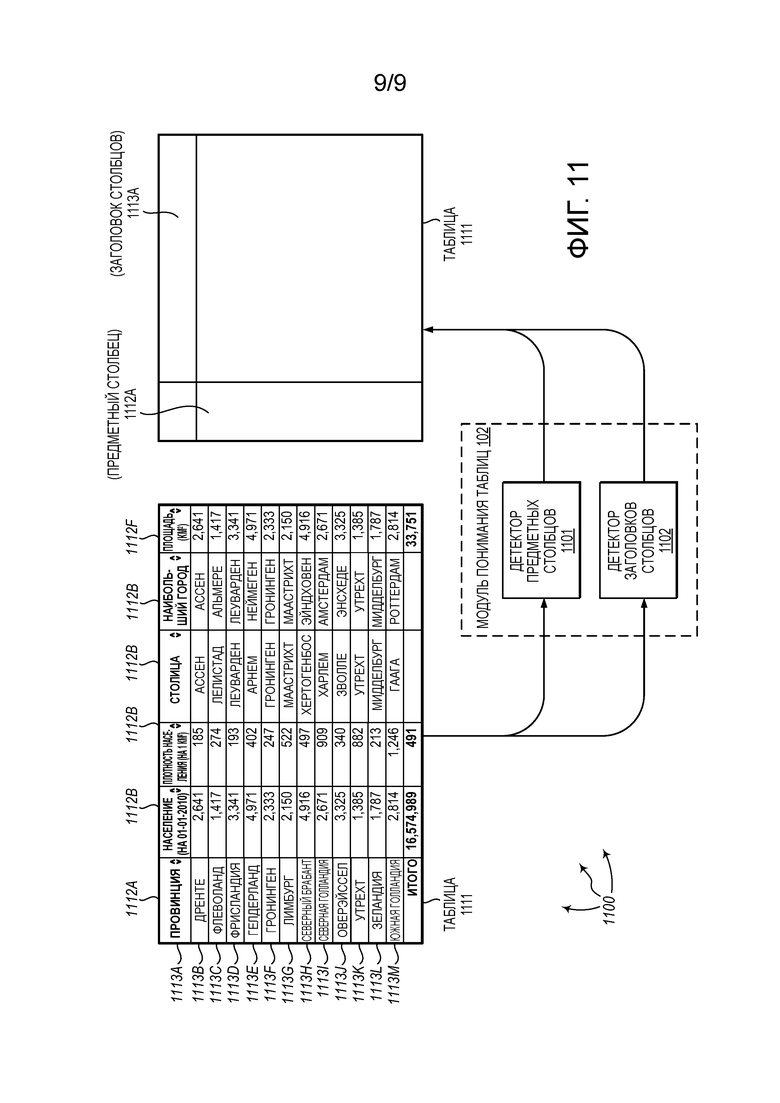
[0022] Фиг. 11 показывает иллюстративную архитектуру, которая облегчает понимание таблицы.
ПОДРОБНОЕ ОПИСАНИЕ
[0023] Настоящее изобретение распространяется на способы, системы и компьютерные программные продукты для понимания таблиц для поиска. Аспекты настоящего изобретения включают в себя идентификацию предметного столбца для таблицы, детектирование заголовка столбцов для таблицы с использованием других таблиц, и детектирование заголовка столбцов для таблицы с использованием базы знаний.
[0024] Реализации настоящего изобретения могут содержать или использовать компьютер общего назначения или специального назначения, включающий в себя компьютерное аппаратное обеспечение, такое как, например, один или несколько процессоров и системную память, как описано более подробно ниже. Реализации в пределах объема настоящего изобретения также включают в себя физические и другие машиночитаемые среды для переноса или запоминания исполняемых компьютерами команд и/или структур данных. Такие машиночитаемые среды могут быть любыми доступными средами, к которым может осуществлять доступ вычислительная система общего назначения или специального назначения. Машиночитаемые среды, которые запоминают исполняемые компьютерами команды, являются машиночитаемыми запоминающими средами (устройствами). Машиночитаемые среды, которые переносят исполняемые компьютерами команды, являются средами передачи данных. Таким образом, в качестве примера, а не ограничения, реализации настоящего изобретения могут содержать по меньшей мере два отчетливо отличающихся вида машиночитаемых сред: машиночитаемые запоминающие среды (устройства) и среды передачи данных.
[0025] Машиночитаемые запоминающие среды (устройства) включают в себя RAM, ROM, EEPROM, CD-ROM, твердотельные накопители (SSD) (например, на основе RAM), флэш-память, память на фазовых переходах (PCM), другие типы памяти, другие запоминающие устройства на оптических дисках, запоминающие устройства на магнитных дисках или другие магнитные запоминающие устройства, или любую другую среду, которая может быть использована для запоминания необходимого средства программного кода в форме исполняемых компьютером команд или структур данных, и к которой может быть осуществлен доступ посредством компьютера общего назначения или специального назначения.
[0026] «Сеть» определена как один или несколько каналов передачи данных, которые обеспечивают транспортировку электронных данных между вычислительными системами и/или модулями и/или другими электронными устройствами. Когда информация передается или обеспечивается через сеть или другое коммуникационное соединение (либо фиксированное, либо беспроводное, либо комбинацию фиксированного или беспроводного) с компьютером, компьютер, собственно, рассматривает это соединение как среду передачи данных. Среды передачи данных включают в себя сеть и/или каналы передачи данных, которые могут быть использованы для переноса необходимого средства программного кода в форме исполняемых компьютером команд или структур данных, и к которым может быть осуществлен доступ посредством компьютера общего назначения или специального назначения. Комбинации вышеупомянутого также должны быть включены в пределы объема машиночитаемых сред.
[0027] Далее, после достижения различных компонентов вычислительной системы, средство программного кода в форме исполняемых компьютером команд или структур данных может быть передано автоматически из сред передачи данных в машиночитаемые запоминающие среды (устройства) (или наоборот). Например, исполняемые компьютером команды или структуры данных, принятые через сеть или канал передачи данных, могут быть буферизованы в RAM в пределах модуля сетевого интерфейса (например, "NIC"), и, затем, в конечном счете, переданы к RAM вычислительной системы и/или к менее энергозависимым машиночитаемым запоминающим средам (устройствам) в вычислительной системе. Таким образом, следует понимать, что машиночитаемые запоминающие среды (устройства) могут быть включены в компоненты вычислительной системы, которые также (или даже в первую очередь) используют среды передачи данных.
[0028] Исполняемые компьютером команды содержат, например, команды и данные, которые, при исполнении в процессоре, обеспечивают выполнение компьютером общего назначения, компьютером специального назначения, или специальным обрабатывающим устройством некоторой функции или группы функций. Исполняемые компьютером команды могут быть, например, командами двоичного, промежуточного формата, такими как язык ассемблера, или даже исходный код. Хотя объект изобретения был описан на языке, специфическом для структурных признаков и/или методологических действий, следует понимать, что объем изобретения, определяемый прилагаемой формулой изобретения, не обязательно ограничен описанными признаками или действиями, описанными выше. Напротив, описанные признаки и действия раскрыты как иллюстративные формы реализации формулы изобретения.
[0029] Специалистам в данной области техники следует понимать, что настоящее изобретение может применяться на практике в сетевых вычислительных средах со многими типами конфигураций вычислительных систем, включающих в себя персональные компьютеры, настольные компьютеры, компактные портативные компьютеры, процессоры сообщений, ручные устройства, многопроцессорные системы, бытовую электронику на основе микропроцессоров или программируемую бытовую электронику, сетевые PC, миникомпьютеры, компьютеры-мэйнфреймы, мобильные телефоны, PDA, планшеты, пейджеры, маршрутизаторы, коммутаторы, и т.п. Настоящее изобретение может также применяться на практике в распределенных системных средах, где выполняют задачи локальные и удаленные вычислительные системы, которые связаны (либо фиксированными каналами передачи данных, либо беспроводными каналами передачи данных, либо комбинацией фиксированных и беспроводных каналов передачи данных) через сеть. В распределенной системной среде, программные модули могут быть расположены как в локальных, так и в удаленных запоминающих устройствах.
[0030] Настоящее изобретение может быть также реализовано в средах облачных вычислений. В этом описании и нижеследующей формуле изобретения, «облачные вычисления» определены как модель для обеспечения сетевого доступа по требованию к совместно используемому объединению конфигурируемых вычислительных ресурсов. Например, облачные вычисления могут быть использованы в месте торговли для предложения повсеместного и удобного доступа по требованию к совместно используемому объединению конфигурируемых вычислительных ресурсов. Совместно используемое объединение конфигурируемых вычислительных ресурсов может быть быстро обеспечено посредством виртуализации и освобождено с небольшим объемом работ по управлению или небольшим взаимодействием с поставщиком услуг и, затем, может быть оценено соответствующим образом.
[0031] Модель облачных вычислений может быть составлена из различных характеристик, таких как, например, самообслуживание по требованию, широкий сетевой доступ, объединение ресурсов, способность к быстрой адаптации, измеряемая услуга и т.д. Модель облачных вычислений может также обеспечить различные модели услуг, такие как, например, программное обеспечение в качестве услуги (SaaS), платформа в качестве услуги (PaaS), и инфраструктура в качестве услуги (IaaS). Модель облачных вычислений может быть также развернута с использованием разных моделей развертывания, таких как частная облачная среда, коллективная облачная среда, публичная облачная среда, гибридная облачная среда, и т.д. В этом описании и в формуле изобретения, «среда облачных вычислений» является средой, в которой используются облачные вычисления.
[0032] В этом описании и в нижеследующей формуле изобретения, «таблица» определена как набор информационных элементов (значений), использующих модель вертикальных столбцов и горизонтальных строк. Каждое пересечение строки и столбца представляет собой ячейку. Строки могут быть идентифицированы значениями, появляющимися в заданном подмножестве столбцов, например, могут быть идентифицированы в виде ключевого индекса. Таблицы могут быть найдены в базах данных, в веб-страницах, в выбранных наборах данных, захваченных из изображений (например, с виртуальных аудиторных досок), могут быть найдены в других файлах (например, файлах переносимого формата документов (PDF)), или могут быть найдены в других источниках, и т.д. Аспекты настоящего изобретения могут быть использованы для понимания таблиц из любых из этих источников.
[0033] Один или несколько столбцов таблицы могут быть предметными столбцами. Предметный столбец содержит наименования объектов, информация о которых находится в таблице. Другие столбцы в таблице представляют отношения или характеристики объектов в предметном столбце. Предметный столбец может рассматриваться как аппроксимирующий ключ.
[0034] Строка таблицы может быть заголовком столбцов. Заголовок столбцов для таблицы содержит наименования столбцов таблицы.
[0035] С краткой ссылкой на фиг. 10, фиг. 10 показывает таблицу 1000. Таблица 1000 имеет предметный столбец 1021 «наименование округа» и заголовок 1022 столбцов.
[0036] Аспекты настоящего изобретения включают в себя идентификацию предметного столбца для таблицы, детектирование заголовка столбцов для таблицы с использованием других таблиц, и детектирование заголовка столбцов с использованием базы знаний.
[0037] Архитектура создания индекса
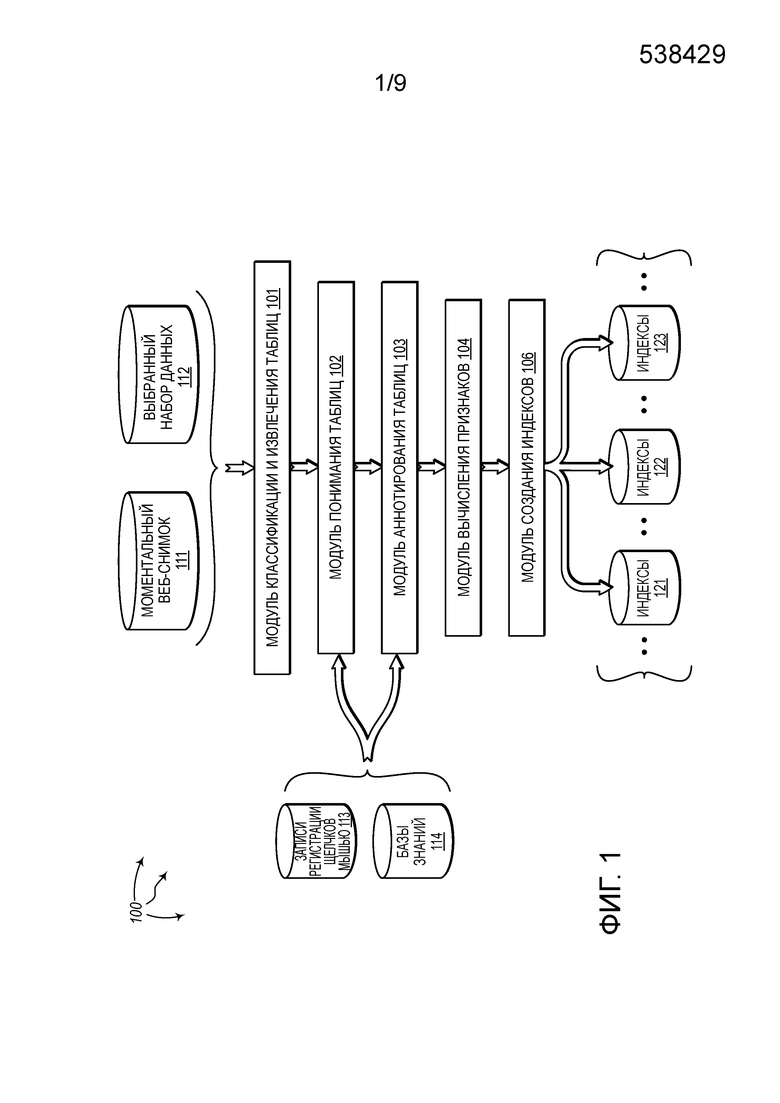
[0038] Фиг. 1 показывает иллюстративную вычислительную архитектуру 100, которая облегчает создание одного или нескольких индексов на основе одного или нескольких наборов данных структурированных данных. Со ссылкой на фиг. 1, вычислительная архитектура 100 включает в себя модуль 101 классификации и извлечения таблиц, модуль 102 понимания таблиц, модуль 103 аннотирования таблиц, модуль 104 вычисления признаков, модуль 106 создания индексов, моментальный веб-снимок 111, выбранный набор 112 данных, записи 113 регистрации щелчков мышью, базы 114 знаний, и индексы 121, 122 и 123. Модуль 101 классификации и извлечения таблиц, модуль 102 понимания таблиц, модуль 103 аннотирования таблиц, модуль 104 вычисления признаков, модуль 106 создания индексов, моментальный веб-снимок 111, выбранный набор 112 данных, записи 113 регистрации щелчков мышью, базы 114 знаний, и индексы 121, 122 и 123 могут быть соединены друг с другом через сеть (или могут быть ее частью), такую как, например, локальная сеть (LAN), глобальная сеть (WAN), и даже интернет. Таким образом, модуль 101 классификации и извлечения таблиц, модуль 102 понимания таблиц, модуль 103 аннотирования таблиц, модуль 104 вычисления признаков, модуль 106 создания индексов, моментальный веб-снимок 111, выбранный набор 112 данных, записи 113 регистрации щелчков (кликов) мышью, и базы 114 знаний, и индексы 121, 122 и 123, а также любые другие присоединенные вычислительные системы и их компоненты, могут создавать связанные с сообщениями данные и обмениваться связанными с сообщениями данными (например, с использованием дейтаграмм интернет-протокола (IP) или других протоколов более высокого уровня, которые используют IP-дейтаграммы, таких как протокол управления передачей данных (TCP), протокол передачи гипертекста (HTTP), простой протокол передачи почты (SMTP), и т.д., или с использованием других недейтаграммных протоколов) через сеть.
[0039] В общем, вычислительная архитектура 100 может эффективно использовать моментальный веб-снимок 111, и, возможно, также один или несколько выбранных наборов 112 данных, для создания одного или нескольких индексов 121, 122 и 123. Вычислительная архитектура 100 может извлечь таблицы (например, веб-таблицы) из моментального веб-снимка 111 и/или одного или нескольких выбранных наборов 112 данных, может понять и аннотировать извлеченные таблицы, и может создать один или несколько индексов 121, 122 и 123 на основе понимания/аннотирования таблиц. Индексы 121, 122 и 123 могут быть, затем, использованы компонентом обслуживания индексов для извлечения возможных результатов пользовательских запросов, а также для классифицирования подходящих результирующих таблиц (таблиц-кандидатов) на основе релевантности. Индексы 121, 122 и 123 могут быть индексами разных типов, такими как, например, индекс отображения строки, который отображает маркеры для идентификаторов и содержит обратные частоты документов маркеров, ключевое слово (инвертированное) или индекс признака, которые могут быть использованы для извлечения высоко оцениваемых таблиц для пользовательских запросов, или индекс контента таблицы, который может быть использован для генерации изображений предварительного просмотра/ фрагментов для извлекаемых таблиц, а также для выборки полных таблиц по запросу.
[0040] В пределах вычислительной архитектуры 100, модуль 101 классификации и извлечения таблиц может принять моментальный веб-снимок 111 и/или выбранный набор 112 данных в качестве входных данных. Моментальный веб-снимок 111 может включать в себя таблицы (например, веб-таблицы) в формате языка разметки гипертекста (HTML). Выбранный набор 112 данных может включать в себя таблицы в специфическом для сайта формате, как, например, данные с сайта data.gov или данные Всемирного банка. Моментальный веб-снимок 111 и выбранный набор 112 данных могут быть созданы с использованием объединителей и/или поисковых агентов, которые анализируют сайты, понимают формат этих сайтов и извлекают таблицы. Например, моментальный веб-снимок 111 может быть создан на основе анализа интернета. Таким образом, моментальный веб-снимок 111 может включать в себя веб-таблицы. Веб-таблицы могут быть реляционными или нереляционными. Некоторые таблицы могут явно определить предметный столбец и заголовки столбцов. Другие таблицы могут не иметь явного определения предметного столбца и/или заголовков столбцов.
[0041] Модуль 101 классификации и извлечения таблиц может извлекать таблицы из моментального веб-снимка 111 и/или выбранного набора 112 данных. Модуль 101 классификации и извлечения таблиц может отфильтровать таблицы, не представляющие ценности, как, например, таблицы, используемые в навигационных/компоновочных целях. На основе любых оставшихся таблиц, модуль 101 классификации и извлечения таблиц может классифицировать таблицы как реляционные и/или нереляционные таблицы. В одном аспекте, модуль 101 классификации и извлечения таблиц также фильтрует нереляционные таблицы. Модуль 101 классификации и извлечения таблиц может выдать таблицы (например, реляционные таблицы) для использования другими модулями в вычислительной архитектуре 100.
[0042] Записи 113 регистрации щелчков мышью могут включать в себя информацию о выборе ссылок («щелчки мышью»), зарегистрированную для множества сетевых пользователей. Для интернета, записи 113 регистрации щелчков мышью могут включать в себя информацию о выборе ссылок для большего множества пользователей. Базы 114 знаний могут включать в себя разные классы баз знаний. Один класс баз знаний может содержать структурированную информацию об объектах и/или отношениях между объектами, такими как, например, веб-таблицы в моментальном веб-снимке 111 и/или выбранном наборе 112 данных. Например, база знаний может включать в себя информацию об объектах таблицы, включающую в себя: наименования объектов, типы объектов, атрибуты объектов, и значения для атрибутов объектов. Другим классом баз знаний являются базы знаний, извлекаемые из веб-документов (например, с использованием текстовых шаблонов).
[0043] Модуль 102 понимания таблиц может принимать таблицы (например, веб-таблицы, реляционные таблицы, и т.д.), извлеченные модулем 101 классификации и извлечения таблиц, в качестве входных данных. Модуль 102 понимания таблиц может использовать различные алгоритмы понимания разных таблиц для понимания таблиц. Некоторые таблицы могут не иметь явно определенных предметных столбцов и/или явно определенных заголовков столбцов. По существу, алгоритмы понимания таблиц могут быть выполнены с возможностью идентификации предметных столбцов для таблиц и/или детектирования заголовков столбцов для таблиц, когда таблицы явно не определяют такую информацию. Модуль 102 понимания таблиц может использовать записи 113 регистрации щелчков мышью и базы 114 знаний для помощи в понимании таблиц. Модуль 102 понимания таблиц может выдать идентифицированные предметные столбцы и детектированные заголовки столбцов для таблиц.
[0044] Модуль 103 аннотирования таблиц может принимать таблицы (например, веб-таблицы, реляционные таблицы, и т.д.), извлеченные модулем 101 классификации и извлечения таблиц. Модуль 103 аннотирования таблиц может также принимать идентифицированные предметные столбцы и детектированные заголовки столбцов для таблиц (например, от модуля 102 понимания таблиц). Модуль 103 аннотирования таблиц может использовать различные алгоритмы аннотирования разных таблиц для аннотирования таблиц с использованием релевантного контента, связь которого с таблицами явно не определена. Например, на веб-странице, содержащей таблицу, контент в пределах тегов <table> и </table> (например, значения ячеек и наименования столбцов) могут быть полезными для поддержки поисков по ключевым словам и поисков для нахождения данных.
[0045] Однако, может также существовать дополнительный контент, полезный для поддержки поисков по ключевым словам и поисков для нахождения данных, который не находится в пределах тегов <table> и </table>. Например, дополнительный контент может быть на веб-странице за пределами тегов <table> и </table>, дополнительный контент может быть в других веб-страницах, содержащих ссылки на данную веб-страницу, дополнительный контент может быть в данных записей регистрации щелчков мышью, и т.д. По существу, алгоритмы аннотирования таблиц могут быть выполнены с возможностью идентификации этого дополнительного контента и аннотирования соответствующих таблиц с использованием дополнительного контента. Затем, модуль 106 создания индексов может сгенерировать инвертированный индекс посредством этого дополнительного контента, а также контента в пределах тегов <table> и </table>.
[0046] Модуль 103 аннотирования таблиц может использовать записи 113 регистрации щелчков мышью и базы 114 знаний для помощи в идентификации дополнительного контента и аннотировании соответствующих таблиц с использованием дополнительного контента. Модуль 103 аннотирования таблиц может выдать таблицы, аннотированные с использованием соответствующего дополнительного контента.
[0047] Модуль 104 вычисления признаков может принимать таблицы (например, веб-таблицы, реляционные таблицы, и т.д.). Модуль 104 вычисления признаков может использовать различные алгоритмы вычисления признаков для вычисления (статических) признаков таблиц. Вычисленные (статические) признаки могут быть использованы для классифицирования. Например, модуль 104 вычисления признаков может вычислить статические (т.е., независимые от запросов) признаки веб-таблиц для использования в релевантном классифицировании. Классифицирование может быть использовано для помощи в выявлении лучших (например, более авторитетных, более популярных, или более релевантных) веб-таблиц, когда многие таблицы удовлетворяют поисковому запросу. Модуль 104 вычисления признаков может выдать вычисленные (статические) признаки для таблиц.
[0048] Модуль 104 вычисления признаков может быть использован с аннотированными или неаннотированными таблицами. Когда модуль 104 вычисления признаков принимает аннотированные таблицы, различные алгоритмы вычисления признаков могут использовать дополнительный контент, содержащийся в аннотациях, для вычисления (статических) признаков.
[0049] Модуль 106 создания индексов может принимать таблицы (например, веб-таблицы, реляционные таблицы, и т.д.). Модуль 106 создания индексов может использовать различные алгоритмы создания индексов для создания одного или нескольких из индексов 121, 122, и 123 на основе принятых таблиц. Модуль 106 создания индексов может принимать аннотированные или неаннотированные таблицы. Когда модуль 106 создания индексов принимает аннотированные таблицы, различные алгоритмы создания индексов могут использовать дополнительный контент, содержащийся в аннотациях, при создании индексов. Модуль 106 создания индексов может также осуществлять доступ к вычисленным (статическим) признакам для таблиц. Когда модуль 106 создания индексов осуществляет доступ к вычисленным (статическим) признакам для таблиц, различные алгоритмы создания индексов могут использовать вычисленные (статические) признаки при создании индексов.
[0050] Индексы могут быть, затем, использованы для облегчения поисков, включая поиски по ключевым словам и поиски данных для нахождения данных. Поиски по ключевым словам включают в себя ввод пользователем запроса по ключевым словам, такого как «африканские страны gdp», в поисковую подсистему (или другую подобную систему или модуль). Поисковая подсистема (или другая подобная система или модуль) возвращает список классифицированных таблиц, которые соответствующим образом удовлетворяют информации, необходимой для пользователя. Поиски данных для нахождения данных включают в себя задание пользователем набора объектов (например, из электронной таблицы) и, необязательно, дополнительных ключевых слов для поисковой подсистемы (или другой подобной системы или модуля). Поисковая подсистема (или другая подобная система или модуль) возвращает таблицы, содержащие запрошенную информацию для заданного набора объектов.
[0051] Идентификация предметного столбца
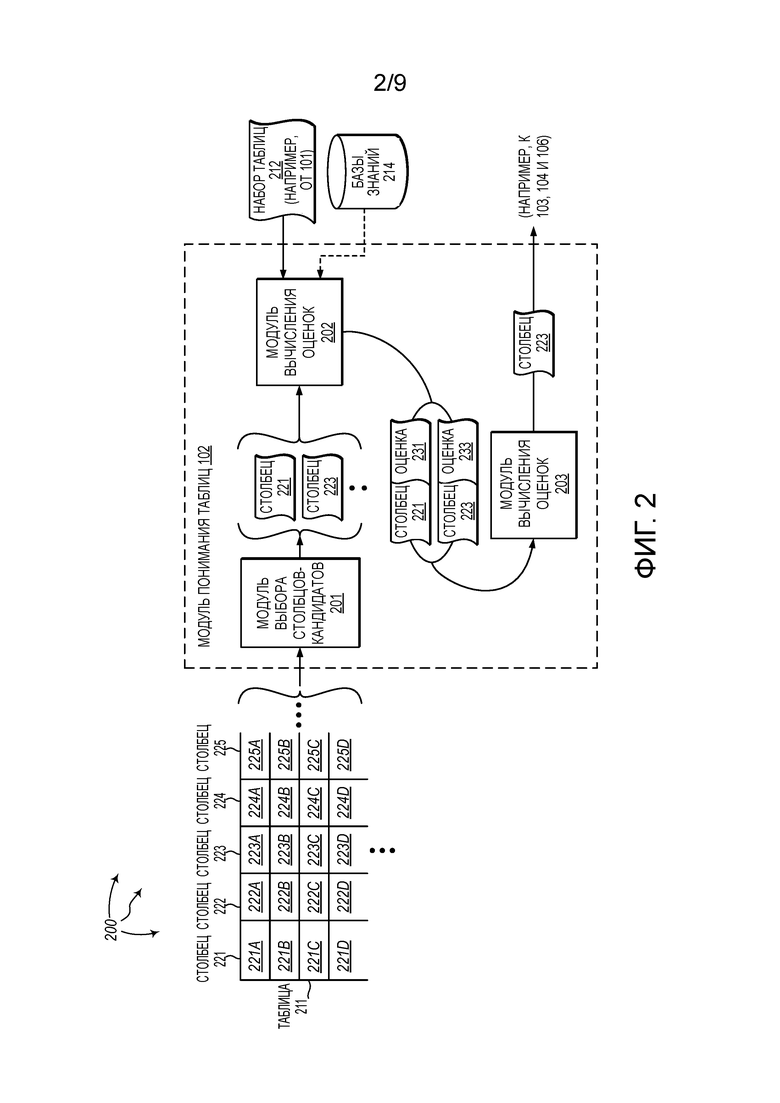
[0052] Фиг. 2 показывает иллюстративную вычислительную архитектуру 200, которая облегчает идентификацию предметного столбца таблицы. Со ссылкой на фиг. 2, вычислительная архитектура 200 включает в себя модуль 201 выбора столбцов-кандидатов, модуль 202 вычисления оценок, и модуль 203 выбора предметных столбцов. Модуль 201 выбора столбцов-кандидатов, модуль 202 вычисления оценок, и модуль 203 выбора предметных столбцов могут быть соединены друг с другом через сеть (или могут быть ее частью), такую как, например, локальная сеть (LAN), глобальная сеть (WAN), и даже интернет. Таким образом, модуль 201 выбора столбцов-кандидатов, модуль 202 вычисления оценок, и модуль 203 выбора предметных столбцов, а также любые другие присоединенные вычислительные системы и их компоненты, могут создавать связанные с сообщениями данные и обмениваться связанными с сообщениями данными (например, с использованием дейтаграмм интернет-протокола (IP) или других протоколов более высокого уровня, которые используют IP-дейтаграммы, таких как протокол управления передачей данных (TCP), протокол передачи гипертекста (HTTP), простой протокол передачи почты (SMTP) и т.д., или с использованием других недейтаграммных протоколов) через сеть.
[0053] Модуль 201 выбора столбцов-кандидатов, модуль 202 вычисления оценок, и модуль 203 выбора предметных столбцов могут быть включены в модуль 102 понимания таблиц. Альтернативно, модуль 201 выбора столбцов-кандидатов, модуль 202 вычисления оценок, и модуль 203 выбора предметных столбцов могут функционировать за пределами модуля 102 понимания таблиц.
[0054] Модуль 201 выбора столбцов-кандидатов выполнен с возможностью приема таблицы (например, веб-таблицы) и выбора одного или нескольких столбцов таблицы в качестве подходящих предметных столбцов (предметных столбцов-кандидатов). Модуль 201 выбора кандидатов может выбрать столбец в качестве предметного столбца-кандидата на основе одного или нескольких аргументов для выбора. Модуль 201 выбора столбцов-кандидатов может учитывать, как другие множественные столбцы отделяют некоторый столбец от левой части таблицы. По меньшей мере для некоторых таблиц, самый левый столбец часто является предметным столбцом.
[0055] Модуль 201 выбора столбцов-кандидатов может учитывать, является ли столбец числовым или нечисловым столбцом. По меньшей мере для некоторых таблиц, предметный столбец часто является нечисловым. По существу, модуль выбора столбцов-кандидатов может учитывать, является ли столбец числовым или нечисловым. Модуль 201 выбора столбцов-кандидатов может вычислить оценку того, является ли столбец числовым или нет. Предшествующие и конечные маркеры могут быть удалены из значений для столбца. Например, столбец информацией о доходах или цене может содержать $ или mil в качестве предшествующих/ конечных маркеров. Эти маркеры могут быть удалены для экспонирования характерных данных. Для столбца, может быть вычислена доля количества ячеек, которые являются числовыми. Например, если столбец имеет 100 ячеек и 80 ячеек имеют значения, которые являются числовыми, то тогда 80% ячеек являются числовыми. Столбцы, которые, как определено, имеют долю числовых ячеек, большую заданного порога, могут быть исключены из дальнейшего рассмотрения в качестве предметного столбца.
[0056] Таким образом, для нечислового столбца, модуль 201 выбора столбцов-кандидатов может учитывать, какие другие множественные столбцы отделяют столбец от левой части таблицы.
[0057] Модуль 201 выбора столбцов-кандидатов может учитывать определенность значений ячеек в столбце. По меньшей мере для некоторых таблиц, предметные столбцы являются аппроксимирующими ключами (т.е., предметные столбцы содержат, главным образом, определенные значения, но могут содержать некоторые дубликаты). Несколько разных мер определенности могут быть учтены для столбца, включая отношение количества определенных значений ячеек к общему количеству ячеек, количество случаев наиболее повторяемого значения, и т.д.
[0058] Модуль 202 вычисления оценок выполнен с возможностью определения того, как часто значения в возможном столбце совместно встречаются в предметных столбцах в других таблицах. По меньшей мере для некоторых таблиц, столбцы таблиц являются характеристиками/ отношениями объектов в предметном столбце. Например, столбец для столичного города может быть характеристикой государства/ может относиться к государству в соответствующем предметном столбце. По существу, значения в правильном предметном столбце могут совместно встречаться с наименованиями столбцов более часто, по сравнению со значениями в не-предметных столбцах.
[0059] Модуль 202 вычисления оценок может вычислить оценку столбца для каждого столбца-кандидата. В одном аспекте, модуль 202 вычисления оценок выбирает N (например, три) самых левых нечисловых столбцов, которые превышают заданный порог определенности (например, 0.7), в качестве предметных столбцов-кандидатов. Для каждого предметного столбца-кандидата, модуль 202 вычисления оценок вычисляет, сколько раз каждое значение в предметном столбце-кандидате встречается с каждым наименованием столбца в наборе (множестве) других таблиц. Для каждого значения/ наименования столбца, количество случаев совместной встречаемости делят на количество случаев встречаемости этого значения в наборе (множестве) других таблиц для получения доли случаев совместной встречаемости. Например, если значение встречается в предметном столбце в 50 таблицах и всего встречается в 500 таблицах, то доля случаев совместной встречаемости составляет 50/500=0.1 (или 10%).
[0060] Модуль 202 вычисления оценок может использовать долю случаев совместной встречаемости для каждого значения в столбце для вычисления оценки столбца для столбца. Например, V1, V2, …, Vn могут представлять набор значений в столбце. C1, C2, …, Cm могут быть наименованиями столбцов. Таким образом, f(Vi,Cj) представляет долю случаев совместной встречаемости таблиц, возможно, содержащих Vi в предметном столбце, где Cj является наименованием столбца. Одна или несколько агрегатных функций могут быть использованы для вычисления оценки столбца для некоторого столбца на основе всех f(Vi, Cj) для этого столбца. Некоторые значения и наименования столбцов могут быть конечными значениями/ наименованиями столбцов, так что даже небольшое количество значений/ наименований столбцов с большей f(Vi, Cj) может способствовать более высокой общей оценке. Одна агрегатная функция вычисляет оценку столбца для столбца посредством нахождения среднего значения заданного наибольшего количества долей случаев совместной встречаемости для столбца.
[0061] Альтернативно или в комбинации, модуль 202 вычисления оценок может также учитывать совместную встречаемость объектов в таблице (например, веб-таблице) и наименований столбцов в базе знаний. Столбцы таблицы (например, веб-таблицы) являются характеристиками/ отношениями объектов в предметном столбце. По существу, наименования столбцов могут встречаться в пределах одного и того же концепта / одного и того же типа в базе знаний. Модуль 202 вычисления оценок может вычислить оценку концепта для любого потенциального концепта (т.е. концепта, который перекрывается с объектами), которая имеет перекрытие с объектами и наименованиями столбцов. Может быть выбран столбец с наиболее подходящей (например, высшей) оценкой концепта.
[0062] Модуль 202 вычисления оценок может также использовать базу знаний для определения того, имеют ли значения наименования предметного столбца-кандидата атрибуты в базе знаний, которые соответствуют таблице. Атрибуты базы знаний, соответствующие таблице, могут быть использованы для идентификации множественных предметных столбцов в таблице. Например, модуль 202 вычисления оценок может изучить отношения атрибутов объектов в пределах таблицы. А именно, таблица может иметь информацию о штатах, еще может иметь столбец «здание законодательного собрания штата» и рядом со столбцом «здание законодательного собрания штата» может иметь столбец населения, которое является населением столицы (причем может быть другой столбец для населения штата).
[0063] Модуль 203 выбора предметных столбцов выполнен с возможностью приема оценок столбцов и/или концептов для столбцов. На основе принятых оценок, модуль 203 выбора предметных столбцов может выбрать один или несколько столбцов в качестве предметных столбцов. Например, на основе оценки столбца и/или оценки концепта, модуль 203 выбора предметных столбцов может классифицировать столбец в качестве предметного столбца или в качестве не-предметного столбца.
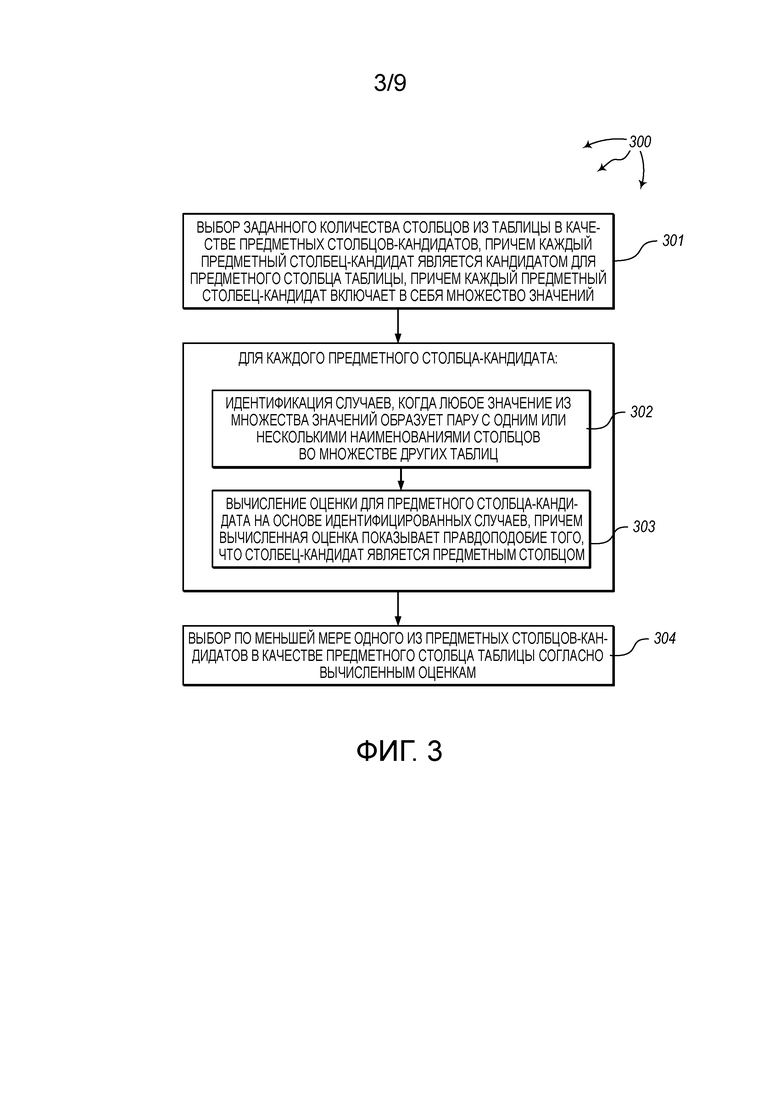
[0064] Фиг. 3 показывает блок-схему последовательности операций иллюстративного способа 300 для идентификации предметного столбца таблицы. Способ 300 будет описан в отношении компонентов и данных вычислительной архитектуры 200.
[0065] Способ 300 включает в себя выбор заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов, причем предметный столбец-кандидат является кандидатом для предметного столбца таблицы, причем каждый предметный столбец-кандидат включает в себя множество значений (301). Например, модуль 201 выбора столбцов-кандидатов может осуществлять доступ к таблице 211 (например, веб-таблице). Как показано, таблица 211 включает в себя столбцы 221, 222, 223, 224, 225, и т.д. Каждый столбец включает в себя множество значений. Столбец 221 включает в себя значения 221A, 221B, 221C, 221D, и т.д. Столбец 222 включает в себя значения 222A, 222B, 222C, 222D, и т.д. Столбец 223 включает в себя значения 223A, 223B, 223C, 223D, и т.д. Столбец 224 включает в себя значения 224A, 224B, 224C, 224D, и т.д. Столбец 225 включает в себя значения 225A, 225B, 225C, 225D, и т.д.
[0066] Модуль 201 выбора столбцов-кандидатов может выбрать столбцы 221 и 223 в качестве предметных столбцов-кандидатов. Например, столбцы 221 и 223 могут быть в пределах самых левых N нечисловых столбцов таблицы 211, и значения в столбцах 221 и 223 могут также удовлетворять порогу определенности. Модуль 201 выбора столбцов-кандидатов может отправить столбцы 221 и 223 к модулю 202 вычисления оценок. С другой стороны, столбец 222 может быть числовым столбцом, и/или значения в столбце 222 могут не быть достаточно определенными. По существу, столбец 222 не рассматривается в качестве предметного столбца-кандидата.
[0067] Модуль 202 вычисления оценок может принять столбцы 221 и 223 от модуля 201 выбора столбцов-кандидатов.
[0068] Способ 300 включает в себя, для каждого предметного столбца-кандидата, идентификацию случаев, когда какое-либо значение из множества значений образует пару с одним или несколькими наименованиями столбцов во множестве других таблиц (302). Например, для столбца 221, модуль 202 вычисления оценок может идентифицировать любые случаи, когда значения 221A, 221B, 221C, 221D, и т.д., образуют пары с наименованиями столбцов в любой из таблиц в наборе 212 таблиц. Подобным образом, для столбца 223, модуль 202 вычисления оценок может идентифицировать любые случаи, когда значения 223A, 223B, 223C, 223D, и т.д., образуют пары с наименованиями столбцов в любой из таблиц в наборе 212 таблиц. В одном аспекте, набор 212 таблиц содержит множество реляционных веб-таблиц.
[0069] Способ 300 включает в себя, для каждого предметного столбца-кандидата, вычисление оценки для предметного столбца-кандидата на основе идентифицированных случаев встречаемости, причем вычисленная оценка указывает на правдоподобие того, что столбец-кандидат является предметным столбцом (303). Например, модуль 202 вычисления оценок может вычислить оценку 231 для столбца 221 и может вычислить оценку 233 для столбца 223.
[0070] В некоторых аспектах, или альтернативно и/или в комбинации, модуль 202 вычисления оценок учитывает случай, когда значения столбцов 221 и 223 имеют объекты в пределах одного и того же концепта/типа в базе 214 знаний, при вычислении оценок 231 и 233, соответственно.
[0071] Модуль 202 вычисления оценок может отправить столбец 221/ оценку 231 и столбец 223/ оценку 233 к модулю 203 выбора предметных столбцов. Модуль 203 выбора предметных столбцов может принимать столбец 221/ оценку 231 и столбец 223/ оценку 233 от модуля 202 вычисления оценок.
[0072] Способ 300 включает в себя выбор по меньшей мере одного из предметных столбцов-кандидатов в качестве предметного столбца таблицы, согласно вычисленным оценкам (304). Например, модуль 203 выбора предметных столбцов может классифицировать столбец 223 в качестве предметного столбца, согласно оценкам 231 и 233. Информация о выборе столбца 223 в качестве предметного столбца может быть отправлена к одному или нескольким из модуля 203 выбора предметных столбцов, модуля 104 вычисления признаков, и модуля 106 создания индексов.
[0073] В некоторых реализациях, идентифицируют множество предметных столбцов. Например, таблица может включать в себя множественные способы для ссылки на предмет таблицы, например, на разных языках, с использованием сокращений, и т.д. Также возможно, что предметный столбец разделен на множественные столбцы, такие как, например, имя и фамилия.
[0074] Для детектирования предметного столбца, может быть также эффективно использована совместная встречаемость пар наименований столбцов в корпусе веб-таблиц. Если пары наименований столбцов для предметного столбца-кандидата встречаются с некоторой регулярностью, то существует повышенная вероятность того, что это предметный столбец, и того, что это атрибут, который относится к этому предмету. Подобным образом могут быть также учтены фактические значения ячеек.
[0075] По существу, идентификация предметного столбца является полезной, поскольку затем может быть определено, что другие столбцы являются атрибутами для предметного столбца. Пользователь может осуществить поиск конкретных атрибутов. Когда пользователь имеет свою собственную таблицу, детектирование предметного столбца может быть выполнено для поисков данных для нахождения данных. Например, пользователь может работать с электронной таблицей, связанной с конкретным предметом. Пользователь может ввести «добавить население» для осуществления поиска таблиц, которые покрывают конкретный предмет, и получения населения.
[0076] Детектирование заголовков столбцов с использованием таблиц
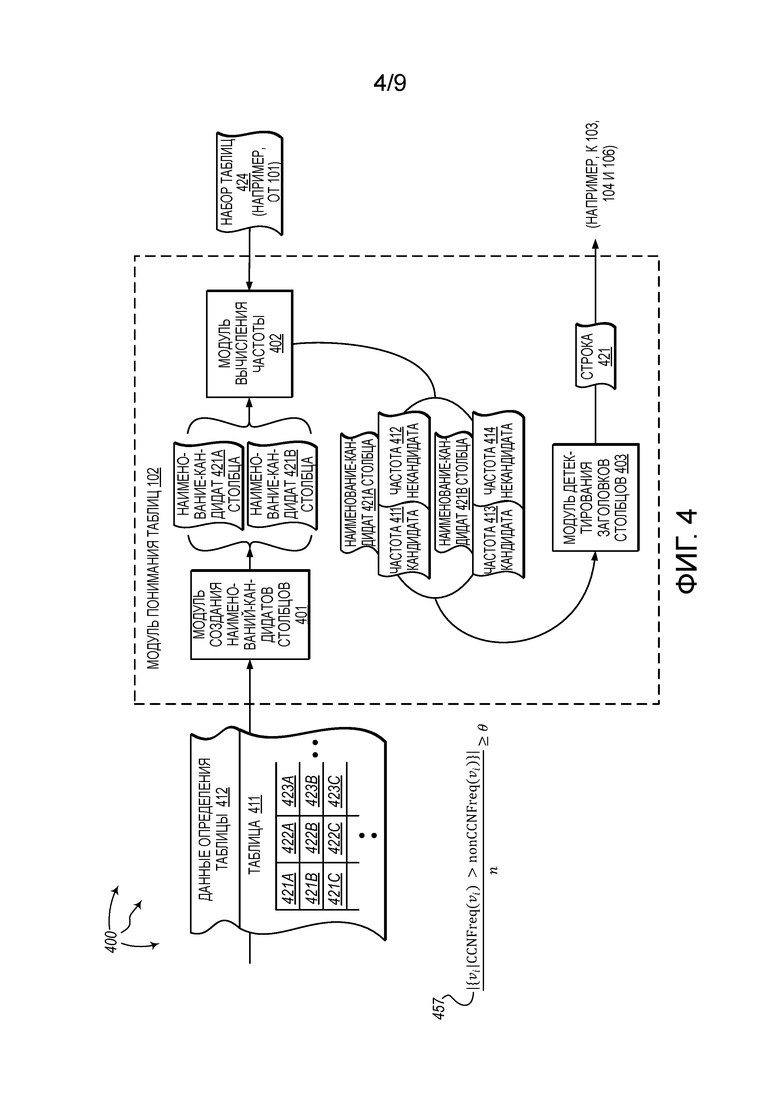
[0077] Фиг. 4 показывает иллюстративную вычислительную архитектуру 400, которая облегчает детектирование заголовка столбцов для таблицы. Со ссылкой на фиг. 4, вычислительная архитектура 400 включает в себя модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов. Модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов могут быть соединены друг с другом через сеть (или могут быть ее частью), такую как, например, локальная сеть (LAN), глобальная сеть (WAN), и даже интернет. Таким образом, модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов, а также любые другие присоединенные вычислительные системы и их компоненты, могут создавать связанные с сообщениями данные и обмениваться связанными с сообщениями данными (например, с использованием дейтаграмм интернет-протокола (IP) или других протоколов более высокого уровня, которые используют IP-дейтаграммы, таких как протокол управления передачей данных (TCP), протокол передачи гипертекста (HTTP), простой протокол передачи почты (SMTP), и т.д., или с использованием других недейтаграммных протоколов) через сеть.
[0078] Модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов могут быть включены в модуль 102 понимания таблиц. Альтернативно, модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов могут функционировать за пределами модуля 102 понимания таблиц.
[0079] Модуль 401 создания наименований-кандидатов столбцов выполнен с возможностью создания наименований-кандидатов столбцов на основе данных определения таблиц. Данные определения таблиц могут включать в себя данные, определяющие таблицу, а также данные, полученные из таблицы. Модуль 401 создания наименований-кандидатов столбцов может создавать набор наименований-кандидатов столбцов, включающий в себя наименования столбцов, которые встречаются в определенном заголовке столбца (например, в пределах тегов <th> или <thead> языка разметки гипертекста (HTML)), и/или наименования столбцов, которые встречаются в первой строке данных в таблице.
[0080] Модуль 402 вычисления частоты может быть выполнен с возможностью вычисления частот встречаемости для каждой строки, которая встречается либо в качестве наименования столбца, либо в качестве значения ячейки в любой таблице (например, в наборе 424 таблиц). Модуль 402 вычисления частоты может вычислить количество таблиц, которые содержат строку в качестве наименования-кандидата столбца (CCNFreq), и количество таблиц, которые, содержат строку в ином качестве (т.е., не в качестве наименования-кандидата столбца) (Не-CCNFreq (Non-CCNFreq)).
[0081] Модуль 403 детектирования заголовков столбцов может быть выполнен с возможностью детектирования строки таблицы в качестве заголовка столбцов на основе CCNFreq и Не-CCNFreq для строк в таблице. Например, когда строки (значения) в первой строке данных имеют более высокие CCNFreq, чем Не-CCNFreq, первая строка с большей вероятностью является заголовком столбцов.
[0082] Более конкретно, например, V1, V2, …, Vn могут представлять значения в первой строке данных таблицы. CCNFreq(Vi) указывает на количество таблиц, в которых Vi встречается либо в качестве явного заголовка столбцов (например, в пределах <th> или <thead>), либо в качестве первой строки данных (например, когда заголовок столбцов явно не определен). Не-CCNFreq(Vi) указывает на количество таблиц, в которых Vi встречается не в явном заголовке или не в качестве первой строки данных. Строка может быть выбрана в качестве заголовка столбцов, когда доля значений Vi, для которых CCNFreq(Vi) > Не-CCNFreq(Vi), превышает заданный порог (например, 0.5). В некоторых аспектах, модуль 403 детектирования заголовков столбцов выбирает заголовок столбцов согласно уравнению 457. В уравнении 457, Θ может изменяться в зависимости от определенности, связанной с детектированием заголовка столбцов.
[0083] Модуль 403 детектирования заголовков столбцов может также учитывать, имеет ли таблица явно определенные наименования столбцов и/или являются ли какие-либо из значений V1, V2, …, Vn числовыми. Если таблица имеет явно определенные наименования столбцов, то строки, содержащие наименования, отличные от явно определенных наименований столбцов, с меньшей вероятностью являются заголовками столбцов. Подобным образом, если строка содержит числовые значения, то эта строка с меньшей вероятностью являются заголовком столбцов.
[0084] Частоты отдельных маркеров в ячейке-кандидате могут быть также учтены. В одном аспекте, модуль 402 вычисления частоты может быть выполнен с возможностью вычисления частот встречаемости для каждого маркера в строках (например, наименованиях-кандидатах столбцов), которые встречаются либо в качестве наименования столбца, либо в качестве значения ячейки в любой таблице (например, в наборе 424 таблиц). Например, маркеры «ср.» («среднее» («Avg.»)) и «количество осадков» («Rainfall») могут быть идентифицированы из строки «ср. количество осадков». Частоты для «ср.» и «количество осадков» могут быть вычислены отдельно, поскольку эти маркеры могут встречаться в других местах. Например, «количество осадков» может встречаться само по себе в качестве наименования столбца. «Ср.» может встречаться в наименовании столбца «ср. температура».
[0085] Модуль 402 вычисления частоты может также реализовать соответствующие агрегатные функции на основе частот уровня маркеров.
[0086] Модуль 403 детектирования заголовков столбцов может быть выполнен с возможностью детектирования строки таблицы в качестве заголовка столбцов на основе CCNFreq и Не-CCNFreq для маркеров в таблице.
[0087] Фиг. 5 показывает блок-схему последовательности операций иллюстративного способа 500 для детектирования заголовка столбцов для таблицы. Способ 500 будет описан в отношении компонентов и данных вычислительной архитектуры 400.
[0088] Способ 500 включает в себя создание набора наименований-кандидатов столбцов для таблицы на основе данных, определяющих таблицу (501). Например, модуль 401 создания наименований-кандидатов столбцов может принять таблицу 411 и определение 412 таблицы. Определение 412 таблицы может определять некоторые характеристики таблицы 411. Как показано, таблица 411 включает в себя строки 421 (первая строка), 422, 423, и т.д. Каждая строка содержит значения, которые являются потенциальными наименованиями столбцов. Строка 421 включает в себя значения 421A, 421B, 421C, и т.д. Строка 422 включает в себя значения 422A, 422B, 422C, и т.д. Строка 423 включает в себя значения 423A, 423B, 423C, и т.д.
[0089] На основе определения 412 таблицы, модуль 401 создания наименований-кандидатов столбцов может определить, что наименования столбцов не являются явно определенными для таблицы 411. По существу, модуль 401 создания наименований-кандидатов столбцов может создать набор наименований-кандидатов столбцов на основе значений строки 421 (первой строки). Например, модуль 401 создания наименований-кандидатов столбцов может создать наименование-кандидат 421А столбца, наименование-кандидат 421В столбца, и т.д.
[0090] Модуль 401 создания наименований-кандидатов столбцов может отправить наименование-кандидат 421А столбца, наименование-кандидат 421В столбца, и т.д., к модулю 402 вычисления частоты. Модуль 402 вычисления частоты может принять наименование-кандидат 421А столбца, наименование-кандидат 421В столбца, и т.д., от модуля 401 создания наименований-кандидатов столбцов.
[0091] Способ 500 включает в себя, для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов, вычисление частоты наименования-кандидата столбца для данного наименования-кандидата столбца посредством идентификации одной или нескольких других таблиц, из набора других таблиц, которые также содержат данное наименование-кандидат столбца в качестве наименования-кандидата столбца (502). Например, модуль 402 вычисления частоты может вычислить частоту 411 кандидата для наименования-кандидата 421А столбца, может вычислить частоту 413 кандидата для наименования-кандидата 421В столбца, и т.д. Для вычисления частоты 411 кандидата, модуль 402 частоты может идентифицировать одну или несколько таблиц из набора 424 таблиц (например, набора веб-таблиц), которые также содержат наименование-кандидат 421А столбца в качестве столбца-кандидата. Подобным образом, для вычисления частоты 413 кандидата, модуль 402 частоты может идентифицировать одну или несколько таблиц из набора 424 таблиц (например, набора веб-таблиц), которые также содержат наименование-кандидат 421В столбца в качестве столбца-кандидата. Подобные вычисления могут быть выполнены для вычисления частот кандидатов для других наименований-кандидатов столбцов (т.е., других значений в строке 421).
[0092] Способ 500 включает в себя, для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов, вычисление частоты наименования-некандидата столбца для данного наименования-кандидата столбца посредством идентификации второй одной или нескольких других таблиц, из набора других таблиц, которые содержат данное наименование-кандидат столбца не в качестве наименования-кандидата столбца (503). Например, модуль 402 вычисления частоты может вычислить частоту 412 некандидата для наименования-кандидата 421А столбца, может вычислить частоту 414 некандидата для наименования-кандидата 421В столбца, и т.д. Для вычисления частоты 412 некандидата, модуль 402 частоты может идентифицировать одну или несколько таблиц из набора 424 таблиц, которые содержат наименование-кандидат 421А столбца, но не в качестве наименования-кандидата столбца. Подобным образом, для вычисления частоты 413 некандидата, модуль 402 частоты может идентифицировать одну или несколько таблиц из набора 424 таблиц (например, набора веб-таблиц), которые также содержат наименование-кандидат 421В столбца, но не в качестве наименования-кандидата столбца. Подобные вычисления могут быть выполнены для вычисления частот некандидатов для других наименований-кандидатов столбцов (т.е., других значений в строке 421).
[0093] Модуль 402 вычисления частоты может отправить наименование-кандидат 421А столбца вместе с частотой 411 кандидата и частотой 412 некандидата к модулю 403 детектирования заголовков столбцов. Подобным образом, модуль 402 вычисления частоты может отправить наименование-кандидат 421В столбца вместе с частотой 413 кандидата и частотой 414 некандидата к модулю 403 детектирования заголовков столбцов. Модуль 403 детектирования заголовков столбцов может принять наименование-кандидат 421А столбца вместе с частотой 411 кандидата и частотой 412 некандидата от модуля 402 вычисления частоты. Подобным образом, модуль 403 детектирования заголовков столбцов может принять наименование-кандидат 421В столбца вместе с частотой 413 кандидата и частотой 414 некандидата от модуля 402 вычисления частоты. Модуль 403 детектирования заголовков столбцов может также осуществить доступ к данным 412 определения таблицы и к таблице 411.
[0094] Способ 500 включает в себя выбор строки таблицы в качестве заголовка столбцов, когда по меньшей мере заданный порог наименований-кандидатов столбцов, содержащихся в строке, имеет частоту наименования-кандидата столбца, которая больше, чем частота наименования-некандидата столбца (504). Например, модуль 403 детектирования заголовков столбцов может детектировать строку 421 в качестве заголовка столбцов таблицы 411. Модуль 403 детектирования заголовков столбцов может определить, что заданный порог наименований-кандидатов столбцов (например, 5) в строке 421 имеет частоту кандидата, которая больше, чем частота некандидата. Например, для наименования-кандидата 421А столбца, модуль 403 детектирования заголовков столбцов может определить, что частота 411 кандидата является большей, чем частота 412 некандидата. Подобным образом, для наименования-кандидата 421В столбца, модуль 403 детектирования заголовков столбцов может определить, что частота 413 кандидата является большей, чем частота 414 некандидата.
Детектирование заголовков столбцов с использованием базы знаний
[0095] А. Использование концептуализации для детектирования того, является ли заголовок корректным
[0096] Заголовки столбцов могут быть детектированы, и/или детектирование заголовков столбцов может быть улучшено (например, увеличена достоверность выбора строки в качестве заголовка столбцов), с использованием базы знаний. В общем, концепты могут быть получены посредством логического вывода на основе наборов примеров, и это может называться «концептуализацией». Концептуализация может быть основана на базе знаний. В некоторых аспектах, концептуализация используется для определения того, является ли заголовок корректным. Обращаясь к фиг. 6, фиг. 6 показывает иллюстративную таблицу 600 (например, веб-таблицу). В таблице 600, заголовок 602 столбца «страна» может быть логически выведен на основе значений Австралия, США, ЮАР, и т.д. По существу, заголовок 602 столбца является гиперонимом или концептом значений в столбце 601. Таким образом, заголовок 602 столбца «страна» является, вероятно, корректным заголовком столбца.
[0097] Обращаясь к фиг. 7, фиг. 7 показывает различные уравнения, используемые для получения концептов на основе набора примеров. База знаний (например, из баз 114 знаний) может включать в себя десятки миллионов пар концепт-пример. Уравнение 701 представляет набор обнаруженных примеров. Для обнаруженных примеров, набор наиболее характерных концептов, описывающих примеры, может быть рассмотрен абстрактно. Вероятность концептов может быть оценена с использованием наивной байесовской модели, показанной в уравнении 702. В уравнении 702, ck является концептом и, как показано в уравнении 703, P(ei,ck) пропорционально совместной встречаемости примеров и концептов, и P(ck), приблизительно, пропорционально обнаруженной частоте ck. В уравнении 702, использовано сглаживание Лапласа для фильтрации шума и введения различий концептов.
[0098] На основе уравнений 701, 702, и 703, концепт с большей апостериорной вероятностью оценивается как более вероятный концепт для описания обнаруженных примеров. Например, если даны примеры «Китай», «Россия», «Индия», и «США», то в качестве концепта может быть предложена «страна». Однако, если даны «Китай», «Индия» и «Россия», то в качестве концепта может быть предложена «страна с развивающимся рынком».
[0099] B. Использование технологий атрибутных данных и атрибутной концептуализации
[0100] Строка заголовка, содержащая наименования, может содержать более вероятные наименования столбцов, которые могут относиться к одному и тому же концепта. Обращаясь к фиг. 8, фиг. 8 показывает иллюстративный заголовок 800 столбцов. Наименования столбцов заголовка 800 столбцов могут относиться к одному и тому же концепта.
[0101] В общем, наименования столбцов могут быть извлечены из заголовка столбцов для генерации списка наименований столбцов. Затем, может быть определено, могут ли наименования столбцов быть концептуализированы в одном и том же гиперониме. Синтаксические шаблоны для извлечения атрибутов на основе концептов и на основе примеров могут быть использованы в отношении веб-корпуса для обработки документов и извлечения атрибутов. Синтаксический шаблон для извлечения на основе концепта может быть представлен следующим образом: 〈а〉 из 〈с〉 (the 〈а〉 of (the/a/an) 〈с〉 [is]). Синтаксический шаблон для извлечения на основе примера может быть представлен следующим образом: 〈а〉 из 〈i〉 (the 〈а〉 of (the/a/an) 〈i〉 [is]).
[0102] В синтаксических шаблонах, 〈а〉 является целевым атрибутом, который должен быть получен из текстов, которые соответствуют синтаксическим шаблонам, 〈с〉 является концептом, для которой атрибуты должны быть получены, и 〈i〉 является примером (подконцептом или объектом) в концепте 〈с〉. Как 〈с〉, так и 〈i〉 могут быть формой семантической сети базы знаний. Например, рассмотрим нахождение атрибутов для концепта 〈с〉=вино. Из предложения «… кислотность вина является существенным компонентом вина …», 〈а〉=кислотность является атрибутом-кандидатом вина. Кроме того, из предложения «вкус бордо является …», 〈а〉=вкус является атрибутом «бордо». Из базы знаний может быть определено, что «бордо» является примером концепта вина. Таким образом, 〈а〉=вкус также является атрибутом-кандидатом вина.
[0103] С использованием списка атрибутов, может быть определено, насколько важным и/или насколько типичным является каждый атрибут для концепта. По существу, могут быть вычислены оценки типичности для атрибутов. Более конкретно:
P(c|a) означает, насколько типичной является концепт с для данного атрибута а.
P(a|c) означает, насколько типичным является атрибут а для данного концепта с.
[0104] Для вычисления оценок типичности, могут быть рассмотрены два случая: атрибуты из извлечения на основе концепта и атрибуты из извлечений на основе примера.
[0105] Фиг. 9 показывает различные уравнения, используемые для вычисления оценок типичности для извлеченных атрибутов. Для извлечения на основе концепта, может быть получен список атрибутов с форматом (c, a, n(c, a)). Группируя этот список относительно с, может быть определен список атрибутов, обнаруженных относительно с, и их частотное распределение. С использованием этой информации, может быть получена оценка типичности P(a|c), как показано в уравнении 901.
[0106] Для извлечения на основе примера, может быть получен один или несколько списков атрибутов с форматом (c, a, n(c, a)). Все разные списки на основе примеров могут быть получены из разных корпусов данных, таких как, например, веб-документы, записи регистрации запросов, и база знаний, соответственно. Отдельная оценка типичности может быть вычислена на основе каждого из разных списков на основе примеров. Отдельные оценки типичности для списков на основе примеров могут быть, затем, агрегированы с использованием оценки типичности для списка на основе концепта. Для соединения шаблона на основе примера с концептом, P(a|c) может быть разложена, как показано в уравнении 902.
[0107] С использованием разложения в уравнении 902, P(a|i,c) и P(i|c) могут быть вычислены для определения оценки типичности. Например, рассмотрим шаблон на основе примера «возраст Джорджа Вашингтона». Шаблон на основе примера может содействовать оцениванию типичности возраста для концепта «президент», зная, что «Джордж Вашингтон» является примером концепта «президент». В уравнении 902, P(a|i,c) количественно оценивает типичность атрибута «возраст» для «Джорджа Вашингтона», когда его базовым концептом является «президент», в то время как P(i|c) представляет, насколько характерным является «Джордж Вашингтон» для концепта «президент».
[0108] При этом упрощающем допущении, P(a|i,c) может быть вычислена, как показано в уравнении 903, а P(i|c) может быть вычислена, как показано в уравнении 904. На основе уравнений 903 и 904, P(c|i) может быть получена из базы знаний. P(c|i) представляет, насколько вероятным является концепт с для данного примера i. P(c|i)=1, если пара концепт-пример обнаружена в базе знаний, и P(c|i)=0 в ином случае.
[0109] С использованием оценок типичности, машина может быть использована для выполнения этого логического вывода. А именно, для нахождения более вероятного концепта на основе набора атрибутов. Например, для нахождения более вероятного концепта с^, как показано в уравнении 905, где А является последовательностью атрибутов. Вероятность концептов может быть оценена с использованием наивной байесовской модели, как показано в уравнении 906.
[0110] C. Использование эвристических правил для детектирования заголовка столбцов.
[0111] Эвристические правила могут быть также использованы для детектирования заголовка столбцов. Например, когда тип ячейки строки заголовка отличается от типа ячейки других ячеек, строка заголовка более вероятно является заголовком наименований столбцов. Обращаясь к фиг. 10, фиг. 10 показывает иллюстративную таблицу 1000 (например, веб-таблицу). В таблице 1000, ячейки 1013, 1014, 1015, 1016, и 1017 являются строками, а значения в других ячейках столбцов 1003, 1004, 1005, 1005, и 1007 являются числами. Таким образом, ячейки 1013, 1014, 1015, 1016, и 1017 более вероятно являются частью заголовка столбцов (т.е., заголовка 1022 столбцов). По существу, можно идентифицировать заголовок 1022 столбцов в качестве заголовка столбцов, даже если эта строка не является явно определенной в качестве заголовка столбцов.
[0112] Длина и/или количество маркеров в ячейке по отношению к длине и/или количеству маркеров в других ячейках в столбце может также учитываться. Например, ячейка 1011 включает в себя два маркера «округ» и «наименование». Другие ячейки в предметном столбце 1021 содержат один маркер. Подобным образом, ячейка 1012 включает в себя два маркера «округ» и «главный город». Другие ячейки в предметном столбце 1002 содержат один маркер. По существу, ячейки 1011 и 1012 более вероятно являются частью заголовка столбцов (например, заголовка 1022 столбцов).
[0113] Может также учитываться, суммируется ли контент одной ячейки и других ячеек в столбце с теми или иными регулярными выражениями. Например, столбец 1013 содержит значения ячеек «год основания», «1854», «1839», «1760», и т.д. Однако, «год основания» суммируется с минимальным регулярным выражением, отличным от минимального регулярного выражения, суммирующегося с каждым из «1854», «1839», «1760», и т.д. Таким образом, ячейка 1013, вероятно, является частью заголовка столбцов (например, заголовка 1022 столбцов).
[0114] В другом примере, столбец может содержать значения ячеек «номер социального страхования» («SocialSecNo»), «123-45-678», «345-67-8901», «678-90-1234». Все ячейки имеют одинаковое количество символов. Однако, «номер социального страхования» суммируется с минимальным регулярным выражением, отличным от минимального регулярного выражения, суммирующегося с каждым из «123-45-678», «345-67-8901», «678-90-1234». По существу, ячейка, содержащая «номер социального страхования», более вероятно, является частью заголовка столбцов.
[0115] Многострочные заголовки столбцов
[0116] Аспекты настоящего изобретения могут быть использованы для детектирования многострочных заголовков столбцов. Например, некоторые таблицы имеют строку заголовка, повторяемую через каждое определенное страничное количество строк. Другие таблицы используют множественные строки заголовков, причем одна строка является более общей, а другая строка является более конкретной. Например, таблица может иметь строку со значением ячейки «температура», охватывающим первый и второй столбцы. Таблица может иметь другую строку со значением ячейки «ср.» в первом столбце и «максимальная» во втором столбце. Модуль 401 создания наименований-кандидатов столбцов, модуль 402 вычисления частоты, и модуль 403 детектирования заголовков столбцов могут быть выполнены с возможностью детектирования множественных строк заголовков для таблицы.
[0117] Понимание таблиц
[0118] Фиг. 11 показывает иллюстративную архитектуру 1100, которая облегчает понимание таблицы. Со ссылкой на фиг. 11, вычислительная архитектура 1100 включает в себя детектор 1101 предметных столбцов и детектор 1102 заголовков столбцов. Детектор 1101 предметных столбцов и детектор 1102 заголовков столбцов могут быть соединены друг с другом через сеть (или могут быть ее частью), такую как, например, локальная сеть (LAN), глобальная сеть (WAN), и даже интернет. Таким образом, детектор 1101 предметных столбцов и детектор 1102 заголовков столбцов, а также любые другие присоединенные вычислительные системы и их компоненты, могут создавать связанные с сообщениями данные и обмениваться связанными с сообщениями данными (например, с использованием дейтаграмм интернет-протокола (IP) или других протоколов более высокого уровня, которые используют IP-дейтаграммы, таких как протокол управления передачей данных (TCP), протокол передачи гипертекста (HTTP), простой протокол передачи почты (SMTP), и т.д., или с использованием других недейтаграммных протоколов) через сеть.
[0119] В общем, детектор 1101 предметных столбцов может детектировать один или несколько предметных столбцов таблицы. Для детектирования одного или нескольких предметных столбцов, детектор 1101 предметных столбцов может реализовать один или несколько модулей вычислительной архитектуры 200 и может использовать любые соответствующие описанные алгоритмы. В общем, детектор 1102 заголовков столбцов выполнен с возможностью детектирования заголовка столбцов таблицы. Для детектирования заголовка столбцов, детектор 1102 заголовков столбцов может реализовать один или несколько модулей вычислительной архитектуры 400 и может использовать любые соответствующие описанные алгоритмы.
[0120] Детектор 1101 предметных столбцов и детектор 1102 заголовков столбцов могут быть включены в модуль 102 понимания таблиц. Альтернативно, детектор 1101 предметных столбцов и детектор 1102 заголовков столбцов могут функционировать за пределами модуля 102 понимания таблиц.
[0121] Как показано, таблица 1111 (например, веб-таблица) включает в себя столбцы 1112A-1112F и строки 1113A-1113M. Каждый из детектора 1101 предметных столбцов и детектора 1102 заголовков столбцов может осуществлять доступ к таблице 1111.
[0122] Детектор 1101 предметных столбцов может детектировать предметный столбец таблицы 1111. Для определения предметного столбца таблицы 1111, детектор 1101 предметных столбцов может учитывать столбцы 1112A, 1112D, и 1112E (3 самые левые нечисловые столбцы). С использованием любого из описанных алгоритмов, детектор 1101 предметных столбцов может вычислить оценку для каждого из столбцов 1112A, 1112D, и 1112E. Например, оценка столбца может быть вычислена на основе совместной встречаемости значений таблицы с наименованиями столбцов в других таблицах, и/или совместной встречаемости объектов таблицы и наименований столбцов в базе знаний. На основе вычисленных оценок, из столбцов 1112A, 1112B, и 1112E, может быть детектирован столбец в качестве предметного столбца для таблицы 1111. Например, столбец 1112А может быть выбран в качестве предметного столбца для таблицы 1111.
[0123] Детектор 1102 заголовков столбцов может детектировать строку заголовка таблицы 1111. Для детектирования заголовка столбцов для таблицы 1111, детектор 1102 заголовков столбцов может использовать любые из описанных алгоритмов, такие как, например, алгоритм детектирования заголовков столбцов с использованием веб-таблиц, алгоритм детектирования заголовков столбцов с использованием базы знаний, концептуализации, эвристики, и т.д., для детектирования строки таблицы 1111 в качестве заголовка столбцов. Например, детектор 1102 заголовков столбцов может создать набор наименований-кандидатов столбцов для таблицы 1111 на основе данных, определяющих таблицу 1111. Детектор 1102 заголовков столбцов может вычислить частоты наименований столбцов и частоты наименований-некандидатов столбцов, для каждого наименования-кандидата столбца. Детектор 1102 заголовков столбцов может выбрать строку таблиц 1111 в качестве заголовка столбцов на основе вычисленных частот. Например, строка 1113А может быть детектирована в качестве заголовка столбцов для таблицы 1111.
[0124] Реализации настоящего изобретения могут быть использованы в системе поиска структурированных данных (SDSS), которая индексирует структурированную информацию, такую как таблицы, в реляционной базе данных или HTML-таблицах, извлеченных из веб-страниц, и обеспечивает пользователям возможность осуществления поиска в структурированной информации (таблицах). SDSS может индексировать и обеспечивать множественные поисковые механизмы для структурированной информации. Одним поисковым механизмом является поиск по ключевым словам, где пользователь предоставляет запрос по ключевым словам, такой как «африканские страны gdp», для SDSS. SDSS возвращает классифицированный список таблиц, которые соответствующим образом удовлетворяют потребность пользователя в информации. Другим механизмом является поиск данных для нахождения данных, где пользователь задает набор объектов (например, присутствующих в электронной таблице) и, необязательно, дополнительные ключевые слова для SDSS. SDSS возвращает таблицы, которые содержат запрашиваемую информацию для этого набора объектов.
[0125] Настоящее изобретение может быть реализовано в других конкретных формах, не выходя за рамки своей сущности или существенных характеристик. Описанные реализации должны во всех отношениях рассматриваться как иллюстрации, а не ограничения. Объем настоящего изобретения определяется, таким образом, прилагаемой формулой изобретения, а не предшествующим описанием. Все изменения, которые попадают в пределы смысла и диапазона эквивалентности формулы изобретения, должны быть включены в пределы ее объема.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ТЕКСТ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2607976C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СОЗДАНИЕ ЗАПРОСОВ ДЛЯ ВЫПОЛНЕНИЯ ПО МНОГОМЕРНЫМ СТРУКТУРАМ ДАННЫХ | 2014 |
|
RU2679977C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| Способ обнаружения обучающих данных для машинного обучения компьютерной системы промышленного интернета вещей с питанием от перезаряжаемой батареи | 2023 |
|
RU2819568C1 |
| ДОЛГОВРЕМЕННОЕ ХРАНИЛИЩЕ ТИПОВ И ЭКЗЕМПЛЯРОВ ДАННЫХ .NET | 2005 |
|
RU2400803C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПРИНЯТИЯ ПРАВОВОГО РЕШЕНИЯ | 2019 |
|
RU2732071C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ТРАНСФОРМАЦИЙ МАТРИЦ, ОСНОВАННЫХ НА РАЗРЕЖЕННЫХ ВЕКТОРАХ | 2019 |
|
RU2764557C1 |
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении эффективности детектирования одного или более предметных столбцов таблицы. Технический результат достигается за счет выбора заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов, причем каждый предметный столбец-кандидат является потенциально подходящим для правильного предметного столбца таблицы, при этом каждый предметный столбец-кандидат включает в себя множество значений; для каждого предметного столбца-кандидата: определения совместной встречаемости для значений в предметном столбце-кандидате, включая определение того, как часто значения в предметном столбце-кандидате также встречаются в правильных предметных столбцах в множестве других таблиц, вычисления оценки для предметного столбца-кандидата на основе упомянутой определенной совместной встречаемости, причем вычисленная оценка показывает правдоподобие того, что предметный столбец-кандидат является правильным предметным столбцом; и классификации предметного столбеца-кандидата в качестве одного из правильного предметного столбца таблицы и непредметного столбца таблицы на основе вычисленной оценки для предметного столбца-кандидата. 6 н. и 27 з.п. ф-лы, 11 ил.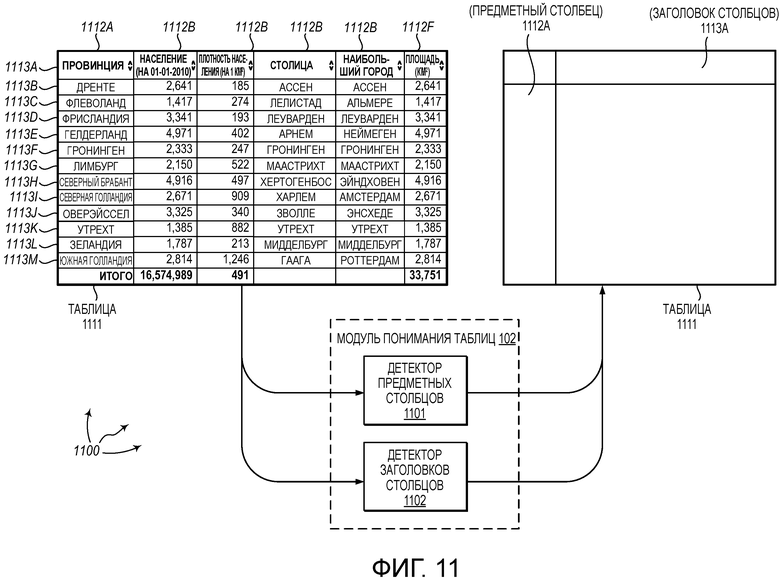
1. Способ детектирования одного или более предметных столбцов таблицы, содержащий этапы, на которых:
выбирают заданное количество столбцов из таблицы в качестве предметных столбцов-кандидатов, причем каждый предметный столбец-кандидат является потенциально подходящим для правильного предметного столбца таблицы, при этом каждый предметный столбец-кандидат включает в себя множество значений; для каждого предметного столбца-кандидата:
определяют совместную встречаемость для значений в предметном столбце-кандидате, включая определение того, как часто значения в предметном столбце-кандидате также встречаются в правильных предметных столбцах в множестве других таблиц,
вычисляют оценку для предметного столбца-кандидата на основе упомянутой определенной совместной встречаемости, причем вычисленная оценка показывает правдоподобие того, что предметный столбец-кандидат является правильным предметным столбцом; и
классифицируют предметный столбец-кандидат в качестве одного из правильного предметного столбца таблицы и непредметного столбца таблицы на основе вычисленной оценки для предметного столбца-кандидата.
2. Способ по п. 1, в котором при упомянутом выборе заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов выбирают заданное количество самых левых столбцов таблицы в качестве предметных столбцов-кандидатов.
3. Способ по п. 2, в котором при упомянутом выборе заданного количества самых левых столбцов таблицы в качестве предметных столбцов-кандидатов выбирают заданное количество самых левых нечисловых столбцов таблицы в качестве предметных столбцов-кандидатов.
4. Способ по п. 1, в котором при упомянутом выборе заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов выбирают заданное количество столбцов из таблицы в качестве предметных столбцов-кандидатов на основе определенности значений ячеек в заданном количестве столбцов.
5. Способ по п. 1, в котором при упомянутом выборе заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов выбирают заданное количество столбцов из одного из реляционной таблицы и веб-таблицы.
6. Способ по п. 1, в котором упомянутое определение совместной встречаемости для значений в предметном столбце-кандидате содержит этап, на котором вычисляют долю случаев совместной встречаемости для каждого значения в предметном столбце-кандидате, каковая доля случаев совместной встречаемости показывает то, как часто это значение встречается в правильных предметных столбцах упомянутого множества других таблиц по отношению к тому, как часто данное значение встречается по всему упомянутому множеству других таблиц.
7. Способ по п. 1, в котором упомянутое вычисление оценки для предметного столбца-кандидата содержит этап, на котором вычисляют оценку для предметного столбца-кандидата исходя из доли случаев совместной встречаемости для каждого значения, каковая доля случаев совместной встречаемости показывает то, как часто это значение встречается в правильных предметных столбцах упомянутого множества других таблиц по отношению к тому, как часто данное значение встречается по всему упомянутому множеству других таблиц.
8. Способ по п. 1, в котором упомянутое вычисление оценки для предметного столбца-кандидата содержит этап, на котором вычисляют оценку для предметного столбца-кандидата на основе встречаемости значений в базе знаний.
9. Реализуемый в вычислительной системе способ детектирования заголовка столбцов для таблицы, включающей в себя одну или более строк, содержащий этапы, на которых:
создают набор наименований-кандидатов столбцов для таблицы на основе данных, определяющих таблицу;
для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов:
вычисляют частоту наименования-кандидата столбца для этого наименования-кандидата столбца посредством
идентификации одной или более других таблиц из набора других таблиц, которые также содержат данное наименование-кандидат столбца в качестве наименования-кандидата столбца, и
вычисляют частоту наименования-некандидата столбца для упомянутого наименования-кандидата столбца посредством идентификации вторых одной или более других таблиц из упомянутого набора других таблиц, которые содержат это наименование-кандидат столбца не в качестве наименования-кандидата столбца; и
выбирают строку таблицы в качестве заголовка столбцов, когда, по меньшей мере, заданное пороговое количество наименований-кандидатов столбцов, содержащихся в этой строке, имеют частоту наименования-кандидата столбца, которая является большей, чем частота наименования-некандидата столбца.
10. Способ по п. 9, дополнительно содержащий, перед созданием набора наименований-кандидатов столбцов, этап, на котором определяют, что данные, определяющие таблицу, не определяют явно заголовок столбцов.
11. Способ по п. 10, в котором при упомянутом определении того, что данные, определяющие таблицу, не определяют явно заголовок столбцов, определяют, что данные, определяющие таблицу, не включают в себя тег <th> языка разметки гипертекста (HTML) и не включают в себя тег <thread> языка разметки гипертекста (HTML).
12. Способ по п. 9, дополнительно содержащий, перед созданием набора наименований-кандидатов столбцов, этап, на котором определяют, что таблица не имеет явно определенного заголовка столбцов.
13. Способ по п. 9, в котором при упомянутом создании набора наименований-кандидатов столбцов для таблицы создают набор наименований-кандидатов столбцов для таблицы из наименований столбцов, включенных в первую строку таблицы.
14. Способ по п. 9, в котором при упомянутом создании набора наименований-кандидатов столбцов для таблицы создают набор наименований-кандидатов столбцов для реляционной веб-таблицы.
15. Способ по п. 9, в котором при упомянутом выборе строки таблицы в качестве заголовка столбцов выбирают первую строку таблицы в качестве заголовка столбцов.
16. Способ по п. 9, дополнительно содержащий логический вывод того, что по меньшей мере один столбец выбранной строки является гиперонимом значений ячеек, содержащихся в этом по меньшей мере одном столбце.
17. Реализуемый в вычислительной системе способ детектирования заголовка столбцов для таблицы, включающей в себя одну или более строк, содержащий этапы, на которых:
создают набор наименований-кандидатов столбцов для таблицы;
для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов вычисляют частоту наименования-кандидата столбца для этого наименования-кандидата столбца посредством идентификации одной или более других таблиц из набора других таблиц, которые также содержат данное наименование-кандидат столбца в качестве наименования-кандидата столбца,
посредством логического вывода получают, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в этом столбце, на основе значений ячеек, содержащихся в данном столбце; и
выбирают строку, содержащую упомянутый столбец, в качестве заголовка столбцов для таблицы на основе упомянутого логического вывода и частот наименований-кандидатов столбцов для наименований-кандидатов столбцов в строке.
18. Способ по п. 17, в котором при упомянутом логическом выводе того, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в столбце, посредством логического вывода получают, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в столбце, путем обращения к базе знаний.
19. Способ по п. 18, в котором при упомянутом логическом выводе того, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в столбце, путем обращения к базе знаний извлекают один или более атрибутов концептов и один или более атрибутов примеров из базы знаний.
20. Способ по п. 18, дополнительно содержащий, перед выбором строки, содержащей столбец, в качестве заголовка столбцов для таблицы, этап, на котором определяют для другого столбца, включенного в набор наименований-кандидатов столбцов, что тип ячеек заголовка столбцов и тип ячеек других ячеек в столбце различаются.
21. Вычислительная система, выполненная с возможностью детектирования одного или более предметных столбцов таблицы, при этом система содержит:
один или более процессоров;
системную память, подключенную к одному или более процессорам, причем в системной памяти хранятся инструкции, которые являются исполняемыми одним или более процессорами, каковые инструкции, при их исполнении одним или более процессорами, предписывают вычислительной системе:
выбирать заданное количество столбцов из таблицы в качестве предметных столбцов-кандидатов, причем каждый предметный столбец-кандидат является потенциально подходящим для правильного предметного столбца таблицы, при этом каждый предметный столбец-кандидат включает в себя множество значений; для каждого предметного столбца-кандидата:
определять совместную встречаемость для значений в предметном столбце-кандидате, включая определение того, как часто значения в предметном столбце-кандидате также встречаются в правильных предметных столбцах в множестве других таблиц,
вычислять оценку для предметного столбца-кандидата на основе упомянутой определенной совместной встречаемости, причем вычисленная оценка показывает правдоподобие того, что предметный столбец-кандидат является правильным предметным столбцом; и
классифицировать предметный столбец-кандидат в
качестве одного из правильного предметного столбца таблицы и непредметного столбца таблицы на основе вычисленной оценки для предметного столбца-кандидата.
22. Система по п. 21, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для выбора заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов, исполняют хранящиеся в системной памяти инструкции для выбора заданного количества самых левых столбцов таблицы в качестве предметных столбцов-кандидатов.
23. Система по п. 21, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для выбора заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов, исполняют хранящиеся в системной памяти инструкции для выбора заданного количества столбцов из таблицы в качестве предметных столбцов-кандидатов на основе определенности значений ячеек в заданном количестве столбцов.
24. Система по п. 21, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для вычисления оценки для предметного столбца-кандидата, исполняют хранящиеся в системной памяти инструкции для вычисления оценки для предметного столбца-кандидата исходя из доли случаев совместной встречаемости для каждого значения, каковая доля случаев совместной встречаемости показывает то, как часто это значение встречается в правильных предметных столбцах упомянутого множества других таблиц по отношению к тому, как часто данное значение встречается по всему упомянутому множеству других таблиц.
25. Система по п. 21, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для вычисления оценки для предметного столбца-кандидата, исполняют хранящиеся в системной памяти инструкции для вычисления оценки для предметного столбца-кандидата на основе встречаемости значений в базе знаний.
26. Вычислительная система, выполненная с возможностью детектирования заголовка столбцов для таблицы, при этом система содержит:
один или более процессоров;
системную память, подключенную к одному или более процессорам, причем в системной памяти хранятся инструкции, которые являются исполняемыми одним или более процессорами, каковые инструкции, при их исполнении одним или более процессорами, предписывают вычислительной системе:
создавать набор наименований-кандидатов столбцов для таблицы на основе данных, определяющих таблицу;
для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов:
вычислять частоту наименования-кандидата столбца для этого наименования-кандидата столбца посредством
идентификации одной или более других таблиц из набора других таблиц, которые также содержат данное наименование-кандидат столбца в качестве наименования-кандидата столбца, и
вычислять частоту наименования-некандидата столбца для упомянутого наименования-кандидата столбца посредством идентификации вторых одной или более других таблиц из набора других таблиц, которые содержат это наименование-кандидат столбца не в качестве наименования-кандидата столбца; и
выбирать строку таблицы в качестве заголовка столбцов, когда, по меньшей мере, заданное пороговое количество наименований-кандидатов столбцов, содержащихся в строке, имеют частоту наименования-кандидата столбца, которая является большей, чем частота наименования-некандидата столбца.
27. Система по п. 26, в которой один или более процессоров дополнительно исполняют хранящиеся в системной памяти инструкции для того, чтобы, перед созданием набора наименований-кандидатов столбцов, определять, что таблица не имеет явно определенного заголовка столбцов.
28. Система по п. 26, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для создания набора наименований-кандидатов столбцов для таблицы, исполняют хранящиеся в системной памяти инструкции для создания набора наименований-кандидатов столбцов для таблицы из наименований столбцов, включенных в первую строку таблицы.
29. Система по п. 26, в которой один или более процессоров дополнительно исполняют хранящиеся в системной памяти инструкции для логического вывода того, что по меньшей мере один столбец выбранной строки является гиперонимом значений ячеек, содержащихся в этом по меньшей мере одном столбце.
30. Вычислительная система, выполненная с возможностью детектирования заголовка столбцов для таблицы, включающей в себя одну или более строк, при этом система содержит:
один или более процессоров;
системную память, подключенную к одному или более процессорам, причем в системной памяти хранятся инструкции, которые являются исполняемыми одним или более процессорами, каковые инструкции, при их исполнении одним или более процессорами, предписывают вычислительной системе:
создавать набор наименований-кандидатов столбцов для таблицы;
для каждого наименования-кандидата столбца в наборе наименований-кандидатов столбцов вычислять частоту наименования-кандидата столбца для этого наименования-кандидата столбца посредством идентификации одной или более других таблиц из набора других таблиц, которые также содержат данное наименование-кандидат столбца в качестве наименования-кандидата столбца,
посредством логического вывода получать, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в этом столбце, на основе значений ячеек, содержащихся в данном столбце; и
выбирать строку, содержащую упомянутый столбец, в качестве заголовка столбцов для таблицы на основе упомянутого логического вывода и частот наименований-кандидатов столбцов для наименований-кандидатов столбцов в строке.
31. Система по п. 30, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для логического вывода того, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в столбце, исполняют хранящиеся в системной памяти инструкции для логического вывода того, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в этом столбце, путем обращения к базе знаний.
32. Система по п. 30, в которой один или более процессоров, исполняя инструкции, хранящиеся в системной памяти, для логического вывода того, что столбец, включенный в набор наименований-кандидатов столбцов, является гиперонимом значений ячеек, содержащихся в столбце, исполняют хранящиеся в системной памяти инструкции для извлечения одного или более атрибутов концептов и одного или более атрибутов примеров из базы знаний.
33. Система по п. 30, в которой один или более процессоров дополнительно исполняют хранящиеся в системной памяти инструкции для того, чтобы перед выбором строки, содержащей столбец, в качестве заголовка столбцов для таблицы, определять для другого столбца, включенного в набор наименований-кандидатов столбцов, что тип ячеек заголовка столбцов и тип ячеек других ячеек в этом столбце различаются.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| EP 2728493 A1, 07.05.2014 | |||
| УСОВЕРШЕНСТВОВАННЫЙ СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ДОКУМЕНТОВ, WEB-САЙТОВ И Т.П., ИМЕЮЩИХ СВОЙСТВА ЗАЩИТЫ | 2008 |
|
RU2433472C2 |

