ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ПАТЕНТНЫЕ ЗАЯВКИ
[0001] Эта заявка заявляет приоритет предварительной заявки США № 62/679517, поданной 1 июня 2018 г., и предварительной заявки США № 62/840986, поданной 30 апреля 2019 г., включенные посредством ссылки в данный документ во всей своей полноте.
УРОВЕНЬ ТЕХНИКИ
[0002] Для поиска, разработки и коммерческого производства новых классов лекарственных средств могут потребоваться десятилетия и миллиардные инвестиции в научно-исследовательские работы. Исследования показывают, что кандидаты новых целевых лекарственных средств, основанные на доказательствах генетики человека, обладают существенно более высокой вероятностью успеха. В связи с этим для подкрепления ассортиментов лекарственных средств, находящихся в разработке, были созданы обширные генетические базы данных. Такие обширные генетические базы данных содержат данные о последовательностях ДНК от более чем 250000 индивидуумов, связанные с электронными медицинскими картами, в которых идентифицирующая личность информация удалена. Высокопроизводительные процессы обработки данных были разработаны для проверки ассоциаций между всеми генетическими мутациями и признаками заболеваний. В результате были получены большие объемы данных, включающих генотипы, признаки здоровья и их ассоциации. Хотя такие массивные объемы данных предоставляют беспрецедентную возможность получить новые представления о терапии, такой объем данных создал ряд задач на пути оправдания надежд, возлагаемых на большие данные и геномику в поиске лекарственных средств. В число основных задач включены проблемы модернизации, проблемы интеграции данных, проблемы масштабируемости и децентрализованная аналитическая обработка данных. Модернизация: большая часть программных средств для анализа генома спроектирована для работы на отдельных машинах и они функционируют со специализированными форматами плоских файлов, в которых часто отсутствует четкая схема данных. Интеграция данных: необработанные генетические и фенотипические данные являются рассредоточенными и хранятся в разных специализированных форматах сжатых файлов, которые с трудом поддаются интеграции. Масштабируемость: быстро растущие объемы данных усложняют выполнение запросов или преобразование данных. Децентрализованная аналитическая обработка данных: отсутствие унифицированного механизма для обработки больших данных, который обеспечивает совместно используемые API и общую базу кодов.
[0003] Таким образом, в данной области техники существует потребность в эффективных интегрированных представлениях данных для матриц генотипа и фенотипа, а также результатов их ассоциаций, масштабируемых производственных ETL потоках с разбиением данных и схемами индексирования для осуществления запросов по миллиардам результатов ассоциаций и процессах анализа данных для ноутбука, которые обладают одинаковой внутренней инфраструктурой, обеспечивающих достаточную гибкость и абстракцию для того, чтобы позволять выполнять вычисления пользователям всех уровней.
СУТЬ ИЗОБРЕТЕНИЯ
[0004] Следует понимать, что и последующее общее описание, и последующее подробное описание являются лишь иллюстративными и пояснительными, но не являются ограничивающими.
[0005] В одном варианте осуществления описан способ, который предусматривает прием данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт. Способ также предусматривает генерирование на основе данных о генотипе матрицы генотипов, где матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов. Способ дополнительно предусматривает генерирование на основе данных о фенотипе матрицы количественных признаков, где матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов. Способ дополнительно предусматривает генерирование на основе данных о фенотипе матрицы двоичных признаков; где матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов. Способ предусматривает присоединение по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков. Способ также предусматривает присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, где индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор. Способ дополнительно предусматривает генерирование структуры данных в виде n-кортежа на основе менеджера идентификаторов матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Способ также предусматривает определение матрицы генотипов, основанной на разреженных векторах, на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупности строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов. Способ также предусматривает определение матрицы количественных признаков, основанной на разреженных векторах, на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков. Способ дополнительно предусматривает определение матрицы двоичных признаков, основанной на разреженных векторах, на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого индивидуума из совокупности и совокупность строк для каждого генотипа из совокупности, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков. Способ дополнительно предусматривает выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах. Дополнительно способ предусматривает обработку одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
[0006] В одном варианте осуществления описан способ, который предусматривает прием данных о генотипе и данных о фенотипе для совокупности индивидуумов. Способ также предусматривает генерирование одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков. Способ дополнительно предусматривает присваивание посредством менеджера идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов. Способ дополнительно предусматривает генерирование на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа. Дополнительно способ предусматривает определение на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах. Способ также предусматривает обработку одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
[0007] В одном варианте осуществления описана система, которая содержит матричную систему, менеджер идентификаторов и матричную систему, основанную на разреженных векторах. Матричная система приспособлена к приему данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт. Матричная система также приспособлена к генерированию на основе данных о генотипе матрицы генотипов, где матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов. Матричная система дополнительно приспособлена к генерированию на основе данных о фенотипе матрицы количественных признаков, где матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов. Дополнительно матричная система приспособлена к генерированию на основе данных о фенотипе матрицы двоичных признаков; где матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов. Матричная система дополнительно приспособлена к присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков. Менеджер идентификаторов приспособлен к присваиванию глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, где одному индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор. Матричная система, основанная на разреженных векторах, приспособлена к генерированию на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Матричная система, основанная на разреженных векторах, также приспособлена к определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов матрицы генотипов, основанной на разреженных векторах, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов. Матричная система, основанная на разреженных векторах, также приспособлена к определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков матрицы количественных признаков, основанной на разреженных векторах, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков. Дополнительно матричная система, основанная на разреженных векторах, приспособлена к определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков матрицы двоичных признаков, основанной на разреженных векторах, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков. Матричная система, основанная на разреженных векторах, также приспособлена к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах. Матричная система, основанная на разреженных векторах, также приспособлена к обработке одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
[0008] В другом варианте осуществления описана система, которая содержит матричную систему, менеджер идентификаторов и матричную систему, основанную на разреженных векторах. Матричная система приспособлена к приему данных о генотипе и данные о фенотипе для совокупности индивидуумов. Матричная система также приспособлена к генерированию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков. Менеджер идентификаторов приспособлен к присваиванию глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов. Матричная система, основанная на разреженных векторах, приспособлена к генерированию на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа. Матричная система, основанная на разреженных векторах, также приспособлена к определению на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах. Дополнительно матричная система, основанная на разреженных векторах, приспособлена к обработке одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
[0009] В одном варианте осуществления описано устройство, приспособленное к приему одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, где матрица генотипов, матрица количественных признаков или матрица двоичных признаков основаны на одном или более из данных о генотипе или данных о фенотипе для совокупности фенотипов. Устройство также приспособлено к присваиванию посредством менеджера идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов. Устройство также приспособлено к генерированию на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа. Устройство также приспособлено к определению на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах. Дополнительно устройство приспособлено к обработке одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
[0010] В одном варианте осуществления описан машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к вызову приема одной или более компьютерными системами данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами на основе данных о генотипе матрицы генотипов, где матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами на основе данных о фенотипе матрицы количественных признаков, где матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами на основе данных о фенотипе матрицы двоичных признаков, где матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов. Выполняемые процессором команды также приспособлены к инициации присоединения одной или более компьютерными системами по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков. Выполняемые процессором команды также приспособлены к инициации присваивания одной или более компьютерными системами посредством менеджера идентификаторов, глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, где одному индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами на основе менеджера идентификаторов матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Выполняемые процессором команды также приспособлены к инициации определения одной или более компьютерными системами на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов матрицы генотипов, основанной на разреженных векторах, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов. Выполняемые процессором команды также приспособлены к инициации определения одной или более компьютерными системами на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков матрицы количественных признаков, основанной на разреженных векторах, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупности строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков. Выполняемые процессором команды также приспособлены к инициации определения одной или более компьютерными системами на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков матрицы двоичных признаков, основанной на разреженных векторах, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков. Выполняемые процессором команды также приспособлены к инициации выравнивания одной или более компьютерными системами согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах. Дополнительно выполняемые процессором команды приспособлены к инициации обработки одной или более компьютерными системами запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
[0011] В другом варианте осуществления описан машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации приема одной или более компьютерными системами данных о генотипе и данных о фенотипе для совокупности индивидуумов. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков. Выполняемые процессором команды также приспособлены к инициации присваивания одной или более компьютерными системами посредством менеджера идентификаторов, глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов. Выполняемые процессором команды также приспособлены к инициации генерирования одной или более компьютерными системами на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа. Выполняемые процессором команды также приспособлены к инициации определения одной или более компьютерными системами на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах. Дополнительно выполняемые процессором команды приспособлены к инициации обработки одной или более компьютерными системами одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
[0012] В одном варианте осуществления описан способ, который предусматривает прием запроса на выполнение сравнения данных, где запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM), определение совокупности рабочих модулей для выполнения сравнения данных, разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM, предоставление каждому из совокупности рабочих модулей одного раздела GM из совокупности разделов GM, где каждый из совокупности рабочих модулей принимает разный раздел GM, разбиение на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM, предоставление каждому из совокупности рабочих модулей первого раздела TM из одного или более разделов TM и в результате этого инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, где каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM.
[0013] В одном варианте осуществления описан способ, который предусматривает прием запроса на выполнение сравнения данных, где запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM), определение совокупности рабочих модулей для выполнения сравнения данных, разбиение на основе совокупности рабочих модулей матрицы признаков на совокупность разделов TM, предоставление каждому из совокупности рабочих модулей одного раздела TM из совокупности разделов TM, где каждый из совокупности рабочих модулей принимает разный раздел TM, разбиение на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM, предоставление каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM и в результате этого инициацию выполнения сравнения данных каждым рабочим модулем из совокупности рабочих модулей, где каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM.
[0014] В одном варианте осуществления описан способ, который предусматривает прием запроса на выполнение сравнения данных, где запрос осуществляет идентификацию совокупности признаков из матрицы признаков (TM) для сравнения с совокупностью генотипов из матрицы генотипов (GM), определение совокупности рабочих модулей для выполнения сравнения данных, разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM, предоставление каждому из совокупности рабочих модулей одного раздела GM из совокупности разделов GM, где каждый из совокупности рабочих модулей принимает разный раздел GM, разбиение на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM, генерирование на основе некоторого количества из совокупности разделов TM очередности обработки, где очередность обработки указывает порядок обработки по меньшей мере первого раздела TM и второго раздела TM, предоставление каждому из совокупности рабочих модулей первого раздела TM, в результате этого инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, где каждый рабочий модуль из совокупности рабочих модулей сравнивает первый раздел TM с разделом GM, прием от первого рабочего модуля из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, и предоставление на основе очереди обработки второго раздела TM первому рабочему модулю.
[0015] В одном варианте осуществления описан способ, который предусматривает генерирование на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, где совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики, осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип, осуществление запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип, предоставление каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов, за счет чего каждым рабочим модулем из совокупности рабочих модулей выполняется определение того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов, и если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициирование выполнения рабочим модулем статистического анализа.
[0016] Дополнительные преимущества будут частично изложены в нижеследующем описании или могут быть получены в ходе реализации на практике. Преимущества будут реализованы и достигнуты посредством признаков и комбинаций, конкретно изложенных в прилагаемой формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0017] Прилагаемые графические материалы, которые включены в настоящее описание и составляют его часть, иллюстрируют варианты осуществления и вместе с описанием служат для пояснения принципов способов и систем:
на фигуре 1 представлена в качестве примера операционная среда;
на фигуре 2 проиллюстрирована совокупность системных компонентов и структур данных, приспособленных к выполнению способов;
на фигуре 3 проиллюстрирована совокупность системных компонентов и структур данных, приспособленных к выполнению способов;
на фигуре 4 проиллюстрированы в качестве примера матричные структуры данных и их представления, основанные на разреженных векторах;
на фигуре 5 проиллюстрированы в качестве примера матричные структуры данных и их представления, основанные на разреженных векторах;
на фигуре 6 проиллюстрирована совокупность системных компонентов и структур данных, приспособленных к выполнению способов;
на фигуре 7 проиллюстрированы в качестве примера матричные структуры данных и их представления, основанные на разреженных векторах;
на фигуре 8 проиллюстрирована совокупность системных компонентов и структур данных, приспособленных к выполнению способов;
на фигуре 9 проиллюстрирована совокупность системных компонентов и структур данных, приспособленных к выполнению способов;
на фигуре 10 представлены в качестве примера способ ETL для преобразования одной или более матриц в представления, основанные на разреженных векторах, и варианты их использования;
на фигуре 11 проиллюстрировано время обработки для операций;
на фигуре 12 проиллюстрирована в качестве примера распределенная среда обработки;
на фигуре 13 проиллюстрирована в качестве примера распределенная среда обработки;
на фигуре 14 проиллюстрирована в качестве примера таблица сопряженности;
на фигуре 15 проиллюстрирована в качестве примера каркасная структура данных;
на фигуре 16 проиллюстрирована в качестве примера распределенная среда обработки;
на фигуре 17 проиллюстрирован в качестве примера каскадный подход к анализу данных;
на фигуре 18 представлена в качестве примера операционная среда;
на фигуре 19 проиллюстрирован в качестве примера способ;
на фигуре 20 проиллюстрирован в качестве примера способ;
на фигуре 21 проиллюстрирован в качестве примера способ;
на фигуре 22 проиллюстрирована временная и пространственная сложность для способа, показанного на фиг. 21, по сравнению с традиционной системой в качестве функций числа процедур регрессии;
на фигуре 23 проиллюстрировано масштабирование производительности в виде функции размера кластера для способа, показанного на фигуре 21, по сравнению с традиционной системой;
на фигуре 24 проиллюстрирован в качестве примера способ;
на фигуре 25 проиллюстрирован в качестве примера способ и
на фигуре 26 проиллюстрирован в качестве примера способ.
ПОДРОБНОЕ ОПИСАНИЕ
[0018] Прежде чем настоящие способы и системы будут раскрыты и описаны, необходимо понять, что эти способы и системы не ограничиваются конкретными способами, конкретными компонентами или конкретными вариантами реализации. Также необходимо понимать, что терминология, используемая в данном документе, представлена только с целью описания конкретных вариантов осуществления и не подразумевается как ограничивающая.
[0019] Используемые в описании и прилагаемой формуле настоящего изобретения формы единственного числа включают обозначаемый объект и во множественном числе, если в контексте явно не указано иначе. В данном документе диапазоны могут быть выражены как от «приблизительно» одного определенного значения и/или до «приблизительно» другого определенного значения. Если указан такой диапазон, другой вариант осуществления включает от одного определенного значения и/или до другого определенного значения. Подобным образом, если значения выражены в виде приближений с использованием предшествующего слова «приблизительно», будет понятно, что определенное значение образует другой вариант осуществления. Также будет понятно, что конечные точки каждого из диапазонов являются значимыми как в отношении другой конечной точки, так и независимо от другой конечной точки.
[0020] «Необязательный» или «необязательно» означает, что описанное далее событие или обстоятельство может происходить или не происходить, и что описание включает случаи, при которых указанное событие или обстоятельство имеет место, и случаи, при которых оно не происходит.
[0021] По всему описанию и формуле данного документа слово «содержать» и варианты этого слова, такие как «содержащий» и «содержит», означает «включающий без ограничения», и оно не предназначено для исключения, например, других компонентов, целых чисел или стадий. Выражение «примерный» означает «пример» и не предназначено для указания предпочтительного или оптимального варианта осуществления. Выражение «такой как» используется не в ограничительном смысле, а в пояснительных целях.
[0022] Понятно, что способы и системы не ограничиваются конкретными описанными методологией, протоколами и реагентами, поскольку они могут варьироваться. Также следует понимать, что используемая в данном документе терминология предназначена только для описания конкретных вариантов осуществления и не предназначена для ограничения объема способов и системы по настоящему ограничению, которые будут ограничены только прилагаемой формулой изобретения.
[0023] Если не определено иначе, все технические и научные термины, используемые в данном документе, имеют те же значения, которые обычно понимаются специалистом в данной области техники, к которой относятся способы и системы. Хотя при практическом осуществлении или испытании способа и композиций по настоящему изобретению можно использовать любые способы и материалы, подобные или эквивалентные описанным в данном документе, описаны только особенно предпочтительные способы, устройства и материалы. Публикации, цитируемые в данном документе, и материалы, в отношении которых они цитируются, тем самым специально включены посредством ссылки. Ничего в данном документе не должно истолковываться как признание того, что способы и системы по настоящему изобретению не должны предшествовать такому раскрытию на основании предшествующего изобретения. Не допускается, что какие-либо ссылки составляют предшествующий уровень техники. Обсуждение ссылок указывает на то, что заявляют их авторы, и заявители оставляют за собой право оспорить точность и актуальность цитируемых документов. Будет четко понятно, что хотя в данном документе ссылаются на ряд публикаций, такая ссылка не является признанием того, что какой-либо из данных документов составляет часть общих знаний в данной области техники.
[0024] В данном документе раскрываются компоненты, которые можно применять для реализации указанных способов и систем. В данном документе раскрываются и эти, и другие компоненты, и понятно, что при раскрытии комбинаций, подмножеств, взаимодействий, групп и т. д. этих компонентов, несмотря на то, что конкретная ссылка на каждую из различных отдельных и совокупных комбинаций и их перестановки может не быть явно описана в данном документе, каждая из них конкретно предполагается и описывается в данном документе в отношении всех способов и систем. Данное применимо ко всем вариантам осуществления данной заявки, в том числе стадиям в способах. Таким образом, если существует ряд дополнительных стадий, которые можно осуществить, понятно, что каждая из этих дополнительных стадий может быть выполнена с любым конкретным вариантом осуществления или комбинацией вариантов осуществления способов.
[0025] Способы и системы по настоящему изобретению будет проще понять, обратившись к нижеследующему подробному описанию предпочтительных вариантов осуществления и примерам, включенным в них, а также к фигурам и их предыдущему и последующему описанию.
[0026] Способы и системы могут принимать форму исключительно аппаратного варианта осуществления, исключительно программного варианта осуществления или варианта осуществления, сочетающего программные и аппаратные варианты осуществления. Кроме того, способы и системы могут принимать форму компьютерного программного продукта на машиночитаемом носителе данных, имеющем машиночитаемые программные команды (например, компьютерное программное обеспечение), реализованное на носителе данных. Более конкретно, способы и системы по настоящему изобретению могут принимать форму компьютерного программного обеспечения, реализуемого через интернет. Может использоваться любой подходящий машиночитаемый носитель данных, в том числе жесткие диски, CD-ROM, оптические запоминающие устройства или магнитные запоминающие устройства.
[0027] Варианты осуществления способов и систем описаны ниже со ссылкой на структурные схемы и блок-схемы способов, систем, устройств и компьютерных программных продуктов. Будет понятно, что каждый блок иллюстраций структурных схем и блок-схем и комбинации блоков на иллюстрациях структурных схем и блок-схем соответственно могут быть реализованы посредством компьютерных программных команд. Данные компьютерные программные команды могут быть загружены на компьютер общего назначения, компьютер специализированного назначения или другое программируемое устройство обработки данных, представляющее собой машину, в результате чего команды, выполняемые на компьютере или другом программируемом устройстве обработки данных, создают средства для реализации функций, указанных в блоке или блоках блок-схемы.
[0028] Эти компьютерные программные команды также могут храниться в машиночитаемой памяти, которая может управлять компьютером или другим программируемым устройством обработки данных для выполнения их функций конкретным образом, за счет чего команды, хранящиеся в машиночитаемой памяти, обеспечивают получение готового изделия, включая машиночитаемые команды, для реализации функции, указанной в блоке или блоках блок-схемы. Компьютерные программные команды также могут быть загружены на компьютер или другое программируемое устройство обработки данных для того, чтобы инициировать выполнение последовательности рабочих стадий на компьютере или другом программируемом устройстве с получением реализуемого на компьютере процесса, в результате чего команды, выполняемые на компьютере или другом программируемом устройстве, обеспечивают стадии для реализации функций, указанных в блоке или блоках блок-схемы.
[0029] Соответственно, блоки иллюстраций структурных схем и блок-схем поддерживают комбинации средств для выполнения указанных функций, комбинации стадий для выполнения указанных функций и средства, представленные программными командами, для выполнения указанных функций. Также будет понятно, что каждый блок иллюстраций структурных схем и блок-схем и комбинации блоков на иллюстрациях структурных схем и блок-схем могут быть реализованы посредством аппаратных компьютерных систем специализированного назначения, которые выполняют указанные функции или стадии, или комбинаций аппаратных средств специализированного назначения и компьютерных команд.
[0030] Технология секвенирования ДНК нового поколения позволяет выполнять генетические исследования в большом масштабе. Способы и системы могут использовать клиническую информацию и биологические данные без идентификации личности для ассоциаций, имеющих медицинскую значимость. Способы и системы могут содержать высокопроизводительную платформу для нахождения и проверки генетических факторов, которые вызывают ряд заболеваний или влияют на них, включая заболевания, в отношении которых существуют серьезные неудовлетворенные потребности в сфере медицины.
[0031] На фиг. 1 представлены различные варианты осуществления приведенной в качестве примера среды 100, в которой могут работать способы и системы по настоящему изобретению. Способы по настоящему изобретению могут использоваться в различных типах сетей и систем, в которых применяется как цифровое, так и аналоговое оборудование. Подразумевается, что настоящее является функциональным описанием и что соответствующие функции могут быть выполнены посредством программного обеспечения, аппаратного обеспечения или комбинации программного и аппаратного обеспечения.
[0032] Среда 100 может содержать локальный центр 102 данных/обработки. Локальный центр 102 данных/обработки может содержать одну или более сетей, таких как локальная вычислительная сеть, для содействия связи между одним или более вычислительными устройствами. Одно или более вычислительных устройств могут быть использованы для хранения, обработки, анализа, выдачи и/или визуализации биологических данных. Среда 100 может необязательно предусматривать поставщика 104 медицинских данных. Поставщик 104 медицинских данных может предусматривать один или более источников биологических данных. Например, поставщик 104 медицинских данных может предусматривать одну или более систем здравоохранения с доступом к медицинской информации для одного или более пациентов. Медицинская информация может содержать, например, историю болезни, профессиональные медицинские наблюдения и замечания, лабораторные отчеты, диагнозы, врачебные назначения, рецепты, показатели жизненно важных функций, водный баланс, параметры дыхательной функции, показатели крови, электрокардиограммы, рентгеновские исследования, данные КТ-сканирования, данные МРТ, результаты лабораторных исследований, диагнозы, прогнозы, оценки, записи о приеме и выписке и регистрационную информацию пациента. Поставщик 104 медицинских данных может содержать одну или более сетей, таких как локальная вычислительная сеть, для содействия связи между одним или более вычислительными устройствами. Одно или более вычислительных устройств могут быть использованы для хранения, обработки, анализа, выдачи и/или визуализации медицинской информации. Поставщик 104 медицинских данных может исключать идентифицирующие личность данные из медицинской информации и предоставлять медицинскую информацию без идентификации личности в локальный центр 102 данных/обработки. Медицинская информация без идентификации личности может содержать уникальный идентификатор для каждого пациента, чтобы отличать медицинскую информацию одного пациента от другого пациента с сохранением при этом медицинской информации в статусе без идентификации личности. Медицинская информация без идентификации личности препятствует связывание личности пациента с его или ее конкретной медицинской информацией. Локальный центр 102 данных/обработки может анализировать медицинскую информацию без идентификации личности, чтобы присваивать один или более фенотипов каждому пациенту (например, путем присваивания кодов согласно «ICD» Международной классификации болезней и/или «CPT» Современной врачебной терминологии по процедурам).
[0033] Среда 100 может предусматривать учреждение 106 для секвенирования NGS. Учреждение 106 для секвенирования NGS может содержать один или более секвенаторов (например, Illumina HiSeq 2500, Pacific Biosciences PacBio RS II). Один или более секвенаторов могут быть приспособлены к секвенированию экзома, полному секвенированию экзома, секвенированию РНК и/или полному секвенированию генома, целевому секвенированию. В одном варианте осуществления поставщик 104 медицинских данных может предоставлять биологические образцы от пациентов, связанные с медицинской информацией без идентификации личности. Уникальный идентификатор может быть использован для сохранения связи между биологическим образцом и медицинской информацией без идентификации личности, которая соответствует биологическому образцу. Учреждение 106 для секвенирования NGS может осуществлять секвенирование экзома каждого пациента с использованием биологического образца. Для хранения биологических образцов перед секвенированием в учреждении 106 для секвенирования NGS может иметься биобанк (например, от компании «Liconic Instruments»). Биологические образцы могут быть получены в пробирках (каждая пробирка связана с пациентом), каждая пробирка может содержать штрихкод (или другой идентификатор), который можно сканировать, чтобы автоматически загружать образцы в локальный центр 102 данных/обработки. В учреждении 106 для секвенирования NGS может располагаться один или более роботов для применения в одной или более фазах секвенирования, чтобы обеспечивать однородные данные и фактически беспрерывную работу. Таким образом, в учреждении 106 для секвенирования NGS можно секвенировать десятки тысяч экзомов в год. В одном варианте осуществления учреждение 106 для секвенирования NGS характеризуется функциональной способностью к секвенированию по меньшей мере 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000, 11000 или 12000 полных экзомов в месяц.
[0034] Биологические данные (например, необработанные данные секвенирования), сгенерированные в учреждении 106 для секвенирования NGS, могут быть переданы в локальный центр 102 данных/обработки, который затем передает биологические данные в удаленный центр 108 данных/обработки. Удаленный центр 108 данных/обработки может содержать облачные хранилище данных и центр обработки, содержащие одно или более вычислительных устройств. Локальный центр 102 данных/обработки и учреждение 106 для секвенирования NGS могут обмениваться данными с удаленным центром 108 данных/обработки непосредственно посредством одной или более волоконных линий с высокой пропускной способностью, хотя предусматриваются и другие системы обмена данными (например, интернет). В одном варианте осуществления удаленный центр 108 данных/обработки может предусматривать систему третьей стороны, например Amazon Web Services (DNAnexus). Удаленный центр 108 данных/обработки может облегчать автоматизацию стадий анализа и позволяет совместно использовать данные с одним или более взаимодействующими партнерами 110. После приема биологических данных из локального центра 102 данных/обработки удаленный центр 108 данных/обработки может выполнять автоматизированную последовательность стадий конвейерных обработок данных для первичного и вторичного анализа данных с использованием биоинформационных инструментов с получением в результате файлов аннотированных вариантов для каждого образца. Результаты такого анализа данных (например, генотипа) могут быть переданы обратно в локальный центр 102 данных/обработки и, например, интегрированы в лабораторную информационно-управляющую систему (LIMS), которая может быть сконфигурирована для поддержания статуса каждого биологического образца.
[0035] Локальный центр 102 данных/обработки затем может использовать биологические данные (например, о генотипе), полученные посредством учреждения 106 для секвенирования NGS и удаленного центра 108 данных/обработки, в сочетании с медицинской информацией без идентификации личности (включая идентифицированные фенотипы), чтобы идентифицировать ассоциации между генотипами и фенотипами. Например, локальный центр 102 данных/обработки может использовать подход с первенством фенотипа, при котором определяют фенотип, который может обладать терапевтическим потенциалом в определенной группе заболеваний, например крайние значения липидов крови для сердечно-сосудистого заболевания. Другим примером является исследования у пациентов с ожирением для идентификации индивидуумов, которые оказываются защищенными от типичного набора сопутствующих патологий. Другой подход заключается в том, чтобы начинать с исследования генотипа и некоторой гипотезы, например, о том, что ген X играет некоторую роль в возникновении заболевания Y или в защите от него.
[0036] В одном варианте осуществления один или более взаимодействующих партнеров 110 могут осуществлять доступ к некоторым или ко всем биологическим данным и/или медицинской информации без идентификации личности по сети, такой как интернет 112.
[0037] В одном варианте осуществления, представленном на фиг. 2, раскрыта система 200. Система 200 может содержать высокопроизводительную схему 205 конвейерной обработки данных, которая может быть выполнена в одном или более из локального центра 102 данных/обработки и/или удаленного центра 108 данных/обработки. Высокопроизводительная схема 205 конвейерной обработки данных может работать на одной или более из матрицы 201 генотипов (GT), матрицы 202 количественных признаков (QT), матрицы 203 двоичных признаков (BT) и/или матрицы 204 метаданных образцов (SM). Некоторые или все из матрицы 201 генотипов, матрицы 202 количественных признаков, матрицы 203 двоичных признаков и/или матрицы 204 метаданных образцов могут быть объединены в одну матрицу. Например, матрицы двоичных и количественных признаков могут быть объединены в одну «матрицу признаков». Более того, все матричные схемы спроектированы так, чтобы поддерживать интеграцию, например, одну матрицу генотипы+признаки+метаданные. Некоторые или все из матрицы 204 метаданных образцов могут быть присоединены к одной или более из матрицы 201 генотипов, матрицы 202 количественных признаков и/или матрицы 203 двоичных признаков. Матрица 204 метаданных образцов может содержать данные, относящиеся к одной или более аннотациям (двоичные, категориальные или непрерывные), которые могут включать 1) ковариаты в моделях исследования корреляций генотип/фенотип и 2) отметки для определения подмножеств образцов. В качестве примера матрица 204 метаданных образцов может содержать аннотации для возраста, пола, генетически определенных предков, генотипических основных компонентов, показателей качества секвенирования и/или их комбинации. Аннотации могут содержать числовые аннотации, но не символьные строки. Может быть установлено цифровое отображение, например женщина=1, мужчина=2. Отображение декодирования/кодирования может быть сохранено (например, в виде столбца в матрице) таким образом, что каждую строку можно перекодировать как соответствующую символьную строку.
[0038] Матрица 201 генотипов, матрица 202 количественных признаков, матрица 203 двоичных признаков и/или матрица 204 метаданных образцов могут быть получены полностью или частично из хранилища 207 данных и/или файловой системы 220. В хранилище 207 данных могут храниться данные, полученные от одного или более из поставщика 104 медицинских данных, учреждения 106 для секвенирования NGS, локального центра 102 данных/обработки и/или удаленного центра 108 данных/обработки. Высокопроизводительная схема 205 конвейерной обработки данных может выполнять автоматизированную последовательность стадий конвейерной обработки данных для первичного и вторичного анализа данных для некоторых или всех данных, содержащихся в одной или более из матрицы 201 генотипов, матрицы 202 количественных признаков, матрицы 203 двоичных признаков и/или матрицы 204 метаданных образцов с использованием биоинформационных инструментов, результаты которого могут быть сохранены в матрице 206 результатов.
[0039] Система 200 может быть приспособлена к генерированию матрицы 201 генотипов. Например, система 200 может быть приспособлена к генерированию матрицы 201 генотипов посредством одного или более из оценки качества данных последовательности, выравнивания ридов на референтный геном, идентификации вариантов, аннотации вариантов, идентификации фенотипа, идентификации ассоциаций вариант-фенотип, визуализации данных и/или их комбинаций.
[0040] Система 200 может быть сконфигурирована для функционального аннотирования одного или более генетических вариантов. Система 200 также может быть приспособлена к хранению, анализу и/или приему одного или более генетических вариантов. Один или более генетических вариантов могут быть аннотированы из данных о последовательности (например, необработанных данных о последовательности), полученных от одного или более пациентов (субъектов). Например, один или более генетических вариантов могут быть аннотированы от каждого из по меньшей мере 100000, 200000, 300000, 400000 или 500000 субъектов. Результатом функционального аннотирования одного или более генетических вариантов является генерирование данных о генетических вариантах. В качестве примера данные о генетических вариантах могут содержать один или более файлов в формате Variant Call Format (VCF). Файл VCF представляет собой текстовый формат файла для представления SNP, вставки/делеции и/или распознанных структурных вариаций. Варианты оценивают по их функциональному влиянию на транскрипты/гены и идентифицируют кандидатов с потенциальной мутацией с потерей функции (pLoF). Варианты затем могут быть аннотированы с использованием разнообразных инструментов для аннотации.
[0041] Система 200 может быть оснащена одним или более компонентами для выполнения функциональной аннотации одного или более генетических вариантов. Например, компонентом идентификации вариантов, компонентом выравнивания, компонентом распознания вариантов, компонентом аннотации вариантов, компонентом функционального предсказания и/или их комбинациями.
[0042] Компонент идентификации вариантов может оценивать качество необработанных данных о последовательности (например, ридов) и/или отмечать двойные риды (например, артефакты ПЦР). На необработанные данные о последовательности, сгенерированные учреждением 106 для секвенирования NGS и/или сохраненные в хранилище 207 данных, могут оказывать отрицательное влияние артефакты последовательности, такие как ошибки распознания оснований, вставки/делеции, риды неудовлетворительного качества и/или контаминация адаптора.
[0043] После того, как данные о последовательности (например, риды) были обработаны, компонент идентификации вариантов может использовать компонент выравнивания, чтобы выравнивать данные о последовательности (например, риды) на существующий референтный геном, например, GRCh38, который является новейшей версией стандартной референтной сборки человеческих последовательностей. В отличие от других последовательностей GRCh38 представляет не геномную последовательность одного индивидуума, а создана из референтных последовательностей разных индивидуумов. Могут использоваться и другие референтные геномы. Могут быть использованы любые алгоритмы/программы выравнивания, например, Burrow-Wheeler (BWA), BWA MEM, Bowtie/Bowtie2, MAQ, mrFAST, Novoalign, SOAP, SSAHA2, Stampy и/или YOABS. Компонент выравнивания может генерировать карту выравнивания последовательностей (SAM) и/или двоичную карту выравнивания (BAM). SAM представляет собой формат выравнивания для хранения ридов, выровненных с референтными последовательностями, тогда как BAM является сжатой двоичной версией SAM. Файл BAM является компактным и индексируемым представлением выравниваний нуклеотидных последовательностей.
[0044] После того как данные последовательности (например, риды) были выровнены, компонент идентификации вариантов может идентифицировать (например, распознавать) один или более вариантов. Инструменты для полногеномной идентификации вариантов могут быть сгруппированы в четыре категории: (i) выявители зародышевой линии, (ii) соматические выявители, (iii) идентификация вариантов числа копий (CNV) и (iv) идентификация структурной вариации (SV). Инструменты для идентификации крупных структурных модификаций можно разделить на те, которые находят варианты CNV, и те, которые находят другие вариации SV, такие как инверсии, транслокации или крупные вставки/делеции. Варианты CNV могут быть определены при исследованиях как с полногеномным секвенированием, так и с полногеномным секвенированием экзома. Неограничивающие примеры таких инструментов включают без ограничения CASAVA, GATK, SAMtools, CLAMMS, SomaticSniper, SNVer, VarScan 2, CNVnator, CONTRA, ExomeCNV, RDXplorer, BreakDancer, Breakpointer, CLEVER, GASVPro и SVMerge.
[0045] Компонент аннотации вариантов может быть приспособлен к определению и приписыванию функциональной информации идентифицированным вариантам. Компонент аннотации вариантов может быть приспособлен к распределению каждого варианта по категориям с учетом взаимосвязи варианта с кодирующими последовательностями в геноме и того, как вариант может изменять кодирующую последовательность и влиять на генный продукт. Компонент аннотации вариантов может быть приспособлен к аннотированию мультинуклеотидных полиморфизмов (MNP). Компонент аннотации вариантов может быть приспособлен к измерению консервативности последовательности. Компонент аннотации вариантов может быть приспособлен к предсказанию влияния варианта на структуру и функцию белка. Компонент аннотации вариантов также может быть приспособлен к обеспечению ссылок баз данных на различные с открытым доступом базы данных вариантов, такие как dbSNP. Результатом компонента аннотации вариантов может быть классификация на приемлемые и вредные мутации и/или балл, отражающий вероятность вредного воздействия. Компонент аннотации вариантов может использовать компонент функционального предсказания, такой как SnpEff, Combined Annotation Dependent Depletion (CADD), ANNOVAR, AnnTools, NGS-SNP, анализатор вариантов последовательности (SVA), сервер аннотаций «SeattleSeq», VARIANT, предсказатель влияния вариантов (VEP) и/или их комбинации.
[0046] Генетический вариант может быть представлен в формате Variant Call Format (VCF) несколькими разными способами. Несогласующееся представление вариантов между выявителями и анализами вариантов будут увеличивать расхождения между ними и усложнять фильтрование вариантов и удаление дубликатов. Нормализация вариантов может быть выполнена перед приемом данных системой 200 и/или системой 210, основанной на разреженных векторах. Нормализация вариантов также может применяться ко всем аннотациям, основанным на вариантах, чтобы минимизировать несоответствия между внутренними данными и внешними ресурсами аннотаций.
[0047] В качестве результата компонента идентификации вариантов и компонента аннотации вариантов система 200 может содержать идентификацию и функциональную аннотацию вариантов, полученных из данных о последовательности, сгенерированных учреждением 106 для секвенирования NGS. Миллионы вариантов могут быть идентифицированы и аннотированы (например, SNP, вставки/делеции, сдвиги рамки, усечения, несмысловые и/или смысловые) для сотен тысяч пациентов (субъектов). Идентификация и функциональная аннотация вариантов может быть получена от субъектов секвенирования (a) в общей совокупности, например, совокупности субъектов, которые нуждаются в помощи медицинской системы, в которой поддерживаются детальные продолжительные электронные истории болезней субъектов, (b) в семье, страдающей генетическим заболеванием, и (c) в популяции основателей.
[0048] На фиг. 2 показано, что результаты идентификации и/или аннотации функциональных вариантов могут быть сохранены в виде данных в матричной структуре данных. Матричная структура данных может содержать матрицу 201 генотипов. Матрица 201 генотипов может содержать совокупность столбцов, где каждый столбец представляет индивидуума (например, субъекта). Матрица 201 генотипов может содержать совокупность строк, где каждая строка представляет вариант (сайт). Пересечение строки и столбца в матрице 201 генотипов представляет один или более генотипов. Матрица 201 генотипов может быть сгенерирована из множества данных о генотипе, включая без ограничения SNP, вставки/делеции, CNV и сложные гетерозиготы (CHET), определенные по результатам секвенирования экзома, SNP и вставки/делеции из массивов генотипирования, части из импутированных данных и/или их комбинаций. Матрица 201 генотипов может быть сохранена полностью или частично в файловой системе 220. Файловая система 220 может представлять собой любую подходящую файловую систему, включая файловые системы с локальным и/или сетевым доступом.
[0049] Система 200 может быть приспособлена к генерированию матрицы 202 количественных признаков и/или матрицы 203 двоичных признаков. Например, система 200 может быть приспособлена к генерированию матрицу 202 количественных признаков и/или матрицу 203 двоичных признаков посредством определения, сохранения, анализа и/или приема одного или более фенотипов для пациента (субъекта). Результатом определения одного или более фенотипов является генерирование фенотипических данных. Фенотипические данные могут быть определены из совокупности категорий фенотипов.
[0050] Система 200 может содержать один или более компонентов для определения одного или более фенотипов для пациента. Фенотип может представлять собой наблюдаемое физическое или биохимическое выражение конкретного признака или гена в организме, такое как заболевание, состояние, биохимическая характеристика, физиологическая характеристика, телосложение, основанное на генетической информации и влиянии внешней среды. Фенотип может включать измеримые биологические (физиологические, биохимические и анатомические признаки), поведенческие (психометрический паттерн) или когнитивные маркеры, которые чаще встречаются у индивидуумов с некоторым заболеванием или состоянием, чем в общей совокупности.
[0051] В одном варианте осуществления система 200 может быть приспособлена к генерированию матрицы 203 двоичных признаков путем анализа медицинской информации без идентификации личности для идентификации одного или более кодов, присвоенных пациенту в медицинской информации без идентификации личности. Один или более кодов могут представлять собой, например, коды Международной классификации болезней (ICD-9, ICD-9-CM, ICD-10), коды Систематизированной номенклатуры медицины-клинической терминологии (SNOMED CT), коды Системы унифицированного медицинского языка (UMLS), коды RxNorm, коды Современной врачебной терминологии по процедурам (CPT), коды Логических названий и коды идентификаторов исследований (LOINC), коды MedDRA, названия лекарственных средств и/или коды для оплаты медицинских услуг. Один или более кодов основаны на контролируемой терминологии и присвоены конкретным диагнозам и медицинским процедурам. Система 200 может идентифицировать наличие (или отсутствие) одного или более кодов, определять фенотип(ы), ассоциированные с одним или более кодами, и присваивать фенотип(ы) пациенту, связанному с медицинской информацией без идентификации личности посредством уникального идентификатора.
[0052] Как показано на фиг. 2, результаты анализа двоичных признаков могут быть сохранены в виде данных в матричной структуре данных. Матричная структура данных может предусматривать матрицу 203 двоичных признаков. Матрица 203 двоичных признаков может содержать совокупность строк, где каждая строка представляет индивидуума (например, субъекта). Пересечение строки и столбца в матрице двоичных признаков 203 представляет статус предрасположенности/отсутствия предрасположенности у индивидуума (например, диабетический или недиабетический). В одном варианте осуществления каждый столбец/признак матрицы 203 двоичных признаков может быть присвоен узлу в иерархии фенотипов, построенной из UMLS, ICD, SNOMED или других иерархических представлений фенотипов. Это позволяет группировать связанные признаки/фенотипы или измерительное сходство между признаками/фенотипами. Матрица 203 двоичных признаков может быть сгенерирована из множества данных о фенотипе, включая без ограничения электронные истории болезней, статус больного/контрольного для исследований фенотип-зависимых заболеваний или выведенные признаки, которые представляют фенотип с задействованными трансформациями или агрегированиями, такими как операция подмножества, объединение нескольких фенотипов и/или применение эвристик к необработанной информации о фенотипе для присвоения индивидууму статуса больного/контрольного/неизвестного. Матрица 203 двоичных признаков может быть сохранена полностью или частично в файловой системе 220. Файловая система 220 может представлять собой любую подходящую файловую систему, включая файловые системы с локальным и/или сетевым доступом.
[0053] В одном варианте осуществления система 200 может быть приспособлена к генерированию матрицы 202 количественных признаков путем анализа медицинской информации без идентификации личности для идентификации непрерывных переменных и присваивания фенотипа на основе идентифицированной непрерывной переменной. Непрерывная переменная может предусматривать физиологический показатель, который может включать одно или более значений из диапазона значений. Например, глюкоза крови, частота сердечных сокращений и/или любые данные лабораторных анализов. Система 200 может идентифицировать такие непрерывные переменные, использовать идентифицированные непрерывные переменные применительно к предварительно определенной шкале классификации для идентифицированных непрерывных переменных и присваивать фенотип(ы) пациенту, связанному с медицинской информацией без идентификации личности посредством уникального идентификатора. Матрица 202 количественных признаков может быть сохранена полностью или частично в файловой системе 220. Файловая система 220 может представлять собой любую подходящую файловую систему, включая файловые системы с локальным и/или сетевым доступом.
[0054] На фиг. 2 показано, что результаты анализа количественных признаков могут быть сохранены в виде данных в матричной структуре данных. Матричная структура данных может предусматривать матрицу 202 количественных признаков. Матрица 202 количественных признаков может содержать совокупность строк, где каждая строка представляет индивидуума (например, субъекта). Пересечение строки и столбца в матрице 202 количественных признаков представляет значение количественного признака для индивидуума (например, уровень LDL). В некоторых вариантах осуществления значение количественного признака для индивидуума может быть равным нулю. Например, в случае, если лабораторный анализ содержит возможное значение 0, значение количественного признака, связанное с лабораторным анализом, будет равным 0. В некоторых вариантах осуществления значение количественного признака для индивидуума может быть равным NULL (например, в случае отсутствия данных). Например, данные, связанные с количественным признаком для индивидуума, могут отсутствовать. В одном варианте осуществления каждый столбец/признак матрицы 202 количественных признаков может быть присвоен узлу в иерархии фенотипов, построенной из UMLS, ICD, SNOMED или других иерархических представлений фенотипов. Это позволяет группировать связанные признаки/фенотипы или измерительное сходство между признаками/фенотипами. Матрица 202 количественных признаков может быть сгенерирована из множества данных о фенотипе, включая без ограничения электронные истории болезней, статус больного/контрольного индивидуума для исследований фенотип-зависимых заболеваний или выведенные признаки, которые представляют фенотип с задействованными трансформациями или агрегированиями, такими как операция подмножества, объединение нескольких фенотипов, логарифмическое преобразование или эмпирическое приближение модели к наблюдаемому распределению необработанного клинического показателя и создание обратного преобразования к нормальному распределению, с исключением локального фона и/или на основании ранга, с выгодными свойствами для проверки ассоциаций, например согласующегося с нормальным распределением. Матрица 202 количественных признаков может быть сохранена полностью или частично в файловой системе 220. Файловая система 220 может представлять собой любую подходящую файловую систему, включая файловые системы с локальным и/или сетевым доступом.
[0055] Высокопроизводительная схема 205 конвейерной обработки данных системы 200 может быть приспособлена к генерированию матрицы 206 результатов путем определения, сохранения, анализа и/или приема одной или более ассоциаций между одним или более генетическими вариантами в данных о генетических вариантах, представленных в матрице 201 генотипов, и одним или более фенотипами в фенотипических данных, представленных в матрице 202 количественных признаков и/или матрице двоичных признаков 203.
[0056] Система 200 может быть приспособлена к генерированию результатов ассоциации генетический вариант-фенотип и/или результатов ассоциации ген-фенотип с новыми результатами, автоматически вычисляемыми при каждом фиксировании генетических данных (количество субъектов, для которых проводится секвенирование). Факторы, учитываемые в количестве результатов ассоциации генетический вариант-фенотип и/или ассоциации ген-фенотип, которые могут быть сгенерированы, включают количество генов и/или генетических вариантов, количество фенотипов и количество реализуемых статистических исследований или моделей. Следовательно, система 200 является хорошо масштабируемой. В одном варианте осуществления анализ результата ассоциации генетический вариант-фенотип и/или результата ассоциации ген-фенотип для требуемого количества генов и/или генетических вариантов, требуемого количества фенотипов и количества используемых статистических тестов и моделей.
[0057] На фиг. 2 показано, что результаты анализа ассоциаций между одним или более генетическими вариантами в данных о генетических вариантах, представленных в матрице 201 генотипов, и одним или более фенотипами в фенотипических данных, представленных в матрице 202 количественных признаков и/или матрице 203 двоичных признаков, могут представлять собой сохраненные данные в матричной структуре данных. Матричная структура данных может содержать матрицу 206 результатов. Матрица 206 результатов может представлять собой файл с результатами канала высокой пропускной способности (HTP) с ассоциациями генотип/фенотип. Матрица 206 результатов может содержать совокупность столбцов, где каждый столбец представляет компонент ассоциации генотип/фенотип, включая без ограничения генетический локус (или производный маркер, такой как генная нагрузка), фенотип (или производный признак), способ проверки (например, линейная регрессия с аддитивной генетической моделью), сводную статистику и аннотации этих компонентов, такие как названия ассоциированных генов и прогнозирования влияния мутации. Матрица 206 результатов может содержать совокупность строк, где каждая строка представляет один результат проверки ассоциации генотип/фенотип. Пересечение строки и столбца в матрице 206 результатов представляет один компонент одного результата проверки ассоциации генотип/фенотип. Матрица 206 результатов может быть сохранена полностью или частично в файловой системе 220. Файловая система 220 может представлять собой любую подходящую файловую систему, включая файловые системы с локальным и/или сетевым доступом.
[0058] Система 200 может быть приспособлена к генерированию, хранению и индексированию результатов из матрицы 206 результатов. Например, результаты могут быть проиндексированы по варианту(-ам), результаты могут быть проиндексированы по фенотипу(-ам) и/или их комбинациям. Система 200 может быть приспособлена к выполнению добычи данных, методик искусственного интеллекта (например, машинного обучения) и/или аналитического прогнозирования. Система 200 может генерировать и хранить визуальное отображение, например, манхэттенский график, на котором показаны варианты по оси x и значимость по оси y.
[0059] Способы и системы, раскрытые ранее, предоставляют высокопроизводительные схемы конвейерной обработки для проверки ассоциаций между некоторыми или всеми генетическими мутациями и признаками заболеваний. В результате системы хранят и обрабатывают обширные объемы данных, охватывающих генотипы, фенотипы и их ассоциации. Хотя эти массивные объемы данных предоставляют беспрецедентную возможность получать новые терапевтические представления, раскрываются дополнительные технологические усовершенствования, которые улучшают как эффективность, так и способность систем обрабатывать и хранить большие данные. Получаемые в результате технологические усовершенствования способствуют усовершенствованиям в другой технологической области, а именно в геномике и поиске лекарственных средств. Одним примером конкретной технологической задачи, решаемой системами по настоящему изобретению, является то, что большая часть программных средств для анализа генома спроектирована для работы на отдельных машинах и они функционируют со специализированными форматами плоских файлов, в которых часто отсутствует четкая схема данных. Другой пример технологической задачи, решаемой посредством данных систем, относится к интеграции данных, причем необработанные генетические и фенотипические данные являются децентрализованными и хранятся в разных обычных форматах сжатых файлов, которые сложно интегрировать. Другой пример технологической задачи, решаемой посредством данных систем, относится к масштабируемости, причем объемы данных быстро растут, что усложняет выполнение запросов или преобразование данных. Другой пример технологической задачи, решаемой настоящими системами, относится к децентрализованной аналитической обработке данных, поскольку существует недостаток унифицированной программы обработки больших данных, которая предоставляет совместно используемые прикладные программные интерфейсы (API) и общую базу кодов.
[0060] Для устранения этих и других технических ограничений представленная на фиг. 2 система 210, основанная на разреженных векторах, облегчает интеграцию клинических и генетических данных и обеспечивает расширенные функциональные возможности запросов и аналитические возможности. Система 210, основанная на разреженных векторах, обеспечивает эффективные, интегрированные представления данных для матриц генотипов и фенотипов, а также результатов их ассоциаций. Система 210, основанная на разреженных векторах, осуществляет реализацию масштабируемого производства рабочих потоков извлечения-преобразования-загрузки (ETL) и создает настраиваемую схему разбиения и индексирования данных для выполнения запросов к по меньшей мере десяткам миллиардов результатов ассоциаций; в результате данная настраиваемая схема разбиения и индексирования данных сокращает время ответа на запрос от ~30 минут до менее 5 секунд. Система 210, основанная на разреженных векторах, осуществляет реализацию производственных процессов на основе ноутбука, которые обладают одинаковой внутренней инфраструктурой, обеспечивая достаточную гибкость и абстракцию для того, чтобы позволять выполнять вычисления пользователям всех уровней.
[0061] На фиг. 2 показано, что система 200 находится в сообщении с системой 210, основанной на разреженных векторах. Система 210, основанная на разреженных векторах, не заменяет систему 200, а скорее обменивается данными с системой 200. Система 210, основанная на разреженных векторах, может хранить данные о генотипе, данные о количественных признаках, данные о двоичных признаках и/или метаданные образцов в соответствующих матричных структурах данных (включая файловую систему 220). Соответственно, система 210, основанная на разреженных векторах, может содержать одну или более из матрицы 211 генотипов, основанной на разреженных векторах, матрицы 212 количественных признаков, основанной на разреженных векторах, матрицы 213 двоичных признаков, основанной на разреженных векторах, матрицы 214 метаданных образцов и/или матрицы 216 результатов.
[0062] В одном варианте осуществления матрица 211 генотипов, основанная на разреженных векторах, матрица 212 количественных признаков, основанная на разреженных векторах, и матрица 213 двоичных признаков, основанная на разреженных векторах, могут представлять собой матрицы, основанные на разреженных векторах, матрицы 201 генотипов, матрицы 202 количественных признаков и матрицы 203 двоичных признаков соответственно. Типичный вектор имеет ряд операндов в конкретном порядке, например, A0, A1, A2, A3. . . , An. Разреженный вектор представляет собой вектор, в котором значения определенных заданных операндов удалены. Обычно удаляют операнды, имеющие значение 0, около 0, или в которых данные отсутствуют. Остальные операнды последовательно соединяют или упаковывают для более эффективного хранения в памяти и извлечения из нее. Например, предположим, что операнды A2, A3 и A8 заданного вектора имеют значение, равное нулю. Разреженный вектор этого вектора в памяти будет выглядеть как A1, A4, A5, A6, A7, A9, . . . до An.
[0063] В качестве примера 0 может быть удаленным значением в матрице генотипов 211, основанной на разреженных векторах. Отсутствующие данные могут быть удаленным значением в матрице 212 количественных признаков, основанной на разреженных векторах, и/или матрице 213 двоичных признаков, основанной на разреженных векторах. В одном варианте осуществления разреженный вектор может быть выбран динамически на основе наиболее частого значения в векторе. В другом варианте осуществления разреженный вектор может быть сохранен в отличающихся структурах данных, которые представляют такую же информацию. Например, структура данных отображения может иметь:
значение 1: A0, A1, A5
значение 2: A3, A6
значение 3: A7.
Структура данных отображения является разреженной, поскольку A2 и A4 не закодированы, но это значение представлено только один раз, а именно это значение содержится в списке индексов образца.
[0064] Матрица 211 генотипов, основанная на разреженных векторах, может содержать один столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы 201 генотипов. Пересечение строки и столбца в матрице 211 генотипов, основанной на разреженных векторах, представляет один или более генотипов. Матрица 211 генотипов, основанная на разреженных векторах, не ограничена однонуклеотидными полиморфизмами (SNP). Строка может идентифицировать любой генетический маркер, который может быть представлен вектором значений, описывающим статус носителя маркера для ряда индивидуумов. Это может включать вставки, делеции, варианты числа копий, структурные варианты и т. д. и может представлять данные с любой платформы генотипирования (например, полную последовательность экзома, полную последовательность генома, массивы генотипирования и т. д.). Она также может представлять маркеры генотипа, которые являются агрегациями нескольких отдельных генотипов, включая генотипические баллы риска и наборы сложных гетерозиготных мутаций.
[0065] Матрица 212 количественных признаков, основанная на разреженных векторах, может содержать один столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности количественных признаков, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы 202 количественных признаков. Пересечение строки и столбца в матрице 202 количественных признаков представляет значение количественного признака для индивидуума (например, уровень LDL). Значение количественного признака для индивидуума может быть равным нулю. Например, лабораторный анализ может включать возможное значение, равное 0. В некоторых вариантах осуществления значение количественного признака для индивидуума может быть равным NULL (например, в случае отсутствия данных). Например, данные, связанные с количественным признаком для индивидуума, могут отсутствовать. Соответственно, модифицированный подход с разреженными векторами используют для представления значений в матрице 212 количественных признаков, основанной на разреженных векторах. Как правило, значение, равное нулю, было бы исключено из представления, основанного на разреженных векторах, однако в матрице 202 количественных признаков нуль (и даже NULL) могут быть действительными значениями.
[0066] Матрица 213 двоичных признаков, основанная на разреженных векторах, может содержать один столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности двоичных признаков, где по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы 203 двоичных признаков.
[0067] В другом варианте осуществления матрица 202 количественных признаков и матрица 203 двоичных признаков могут быть представлены как одна матрица 301 признаков, основанная на разреженных векторах (как показано на фиг. 3).
[0068] Хотя матрица 202 количественных признаков и матрица 203 двоичных признаков содержат строки, относящиеся к индивидуумам, соответствующие представления, основанные на разреженных векторах, содержат столбцы, относящиеся к индивидуумам. Такая организация данных в матрицах позволяет укладывать в стек/выравнивать матрицы на основе индивидуумов, представляемых столбцами для всех типов данных. Матрица 211 генотипов, основанная на разреженных векторах, матрица 212 количественных признаков, основанная на разреженных векторах, и матрица 213 двоичных признаков, основанная на разреженных векторах, могут быть уложены в стек (например, выровнены) с учетом индивидуумов. В системе 200 интегрирование информации о носителях конкретной комбинации генотипа и фенотипа требует определения подмножества индивидуумов, представленных в обеих матрицах (пересечения множеств), и сопоставления для каждого образца от индивидуума в подмножестве значения генотипа со значением фенотипа. В одном варианте осуществления это операция O(n log n), допуская, что списки не были предварительно выровнены. Между тем, в системе 210, основанной на разреженных векторах, столбцы для каждой матрицы в когорте создают идентичными (одно и то же подмножество представлено в том же порядке), в результате чего данная операция взятия подмножества и сопоставления больше не требуется. Таким образом, разреженное представление никогда не следует распаковывать и сами идентификаторы образцов не нужно хранить в векторе (только номер столбца). Это обеспечивает эффективность в отношении памяти и вычислений. Система 200 хранит единственное табличное отображение каждого идентификатора образца на его номер (идентификатор) столбца в когорте, но и также глобальный номер (идентификатор) столбца, который позволяет объединять векторы из разных когорт без необходимости переназначать индексы столбцов.
[0069] Матрица 216 результатов может представлять собой файл или набор файлов с результатами канала высокой пропускной способности (HTP) с ассоциациями генотип/фенотип. Матрица 216 результатов может содержать совокупность столбцов, где каждый столбец представляет компонент ассоциации генотип/фенотип, включая без ограничения генетический локус (или производный маркер, такой как генная нагрузка), фенотип (или производный признак), способ проверки (например, линейная регрессия с аддитивной генетической моделью), сводную статистику и аннотации этих компонентов, такие как названия ассоциированных генов и прогнозирования влияния мутации. Матрица 216 результатов может содержать совокупность строк, где каждая строка представляет один результат проверки ассоциации генотип/фенотип. Пересечение строки и столбца в матрице 216 результатов представляет один компонент одного результата проверки ассоциации генотип/фенотип. Матрица 216 результатов может быть сохранена полностью или частично в файловой системе 220.
[0070] Матрица 206 результатов может содержать необработанные (например, текстовые) файлы результатов, которые не были разбиты на разделы и/или проиндексированы, тогда как матрица 216 результатов может содержать файлы с результатами, которые разбиты на разделы для быстрых геномных запросов по диапазону. Матрица 216 результатов может также содержать уплотненные файлы (например, в целом меньше файлов, но каждый файл может быть больше, что в результате обеспечивает более быстрые операции чтения). Матрица 216 результатов может содержать файлы, которые хранятся в паркетном формате (столбчатое хранилище => более быстрый доступ к столбцам).
[0071] Матрица 214 метаданных образцов может содержать данные, относящиеся к одной или более аннотациям (двоичные, категориальные или непрерывные), которые могут включать 1) ковариаты в моделях исследования корреляций генотип/фенотип и 2) отметки для определения подмножеств образцов. В качестве примера матрица 214 метаданных образцов может содержать аннотации для возраста, пола, генетически определенных предков, генотипических основных компонентов, показателей качества секвенирования и/или их комбинации. Аннотации могут содержать числовые аннотации, но не символьные строки. Может быть установлено цифровое отображение, например женщина=1, мужчина=2. Отображение декодирования/кодирования может быть сохранено (например, в виде столбца в матрице) таким образом, что каждую строку можно перекодировать как соответствующую символьную строку.
[0072] Система 210, основанная на разреженных векторах, может содержать менеджер 217 идентификаторов (ID). Менеджер 217 ID позволяет преобразовывать ID каждого образца в когорте в уникальный численный ID (идентификатор когорты), соответствующий номеру столбца в относящейся к когорте матрице (идентификаторы ID в диапазоне 1-N, где имеется N образцов в когорте) и одновременно в уникальный численный ID (глобальный идентификатор), соответствующий номеру столбца в глобальной матрице, которая является объединением матриц из совокупности когорт (идентификаторы ID в диапазоне 1-X, где в заданный момент времени имеется X уникальных образцов во всех когортах и X >= N). Лежащие в основе биологические данные, из которых генерируют матрицы, получают от одной или более когорт индивидуумов. Индивидууму в когорте может быть присвоен идентификатор, который уникальным образом идентифицирует индивидуума в когорте (например, ID когорты). ID когорты можно называть идентификатором вектора. Однако если получается так, что один индивидуум является частью нескольких когорт, то двум или более записям об этом индивидууме может быть присвоен один и тот же глобальный ID. В качестве примера, но не ограничения, первой когорте из 50000 индивидуумов может быть присвоен идентификатор из диапазона от «субъект_00001» до «субъект_50000». Однако включение данных из второй когорты может идентифицировать подмножество индивидуумов, содержащихся в первой когорте. Система может быть приспособлена к использованию одного и того же глобального ID или присваивания уникального глобального ID противоречивому образцу, в зависимости от того, желательно или нет объединять их записи (например, если информация о фенотипе является одинаковой). Таким образом, менеджер 217 ID может быть приспособлен к непрерывному наращиванию присваиваемых ID_когорты по когортам. Продолжая предыдущий пример, включение биологических данных для второй когорты из 50000 индивидуумов, которая также содержит «субъект_00001», приведет к присваиванию новым индивидуумам глобальных идентификаторов, начинающихся с 50001, но для «субъекта_00001» глобальный ID может быть равен 1 или 50001 в зависимости от настроек системы по работе с дубликатами. В любом случае идентификаторы когорты для новой когорты начинаются с 1 и заканчиваются на 50000. Менеджер 217 ID может быть приспособлен к присваиванию уникального глобального идентификатора каждому индивидууму.
[0073] В некоторых вариантах осуществления ID_когорты может служить уникальным глобальным идентификатором. Уникальный глобальный идентификатор может идентифицировать субъектов уникальным образом по всем когортам. Дополнительно менеджер 217 ID может определять и поддерживать связь нескольких ID когорты, которые могут быть связаны с одним индивидуумом (например, в том случае, если индивидуум находится в более чем одной когорте). Менеджер 217 ID позволяет автоматически интегрировать выполненные в разреженных векторах представления генотипа, фенотипа или матриц метаданных из нескольких когорт и разных типов анализов (например, по одному маркеру, генной нагрузке, CNV и т. д.) посредством использования глобального ID. При существующей инфраструктуре эти операции объединения потребовали бы существенной работы вручную с необработанными матричными файлами, которые в дополнение к наличию несовместимых представлений данных могут иметь противоречивые или несоответствующие идентификаторы ID образца, которые необходимо интегрировать.
[0074] Система 210, основанная на разреженных векторах, может содержать менеджер 218 матричного преобразования. Менеджер матричного преобразования может быть может быть приспособлен к получению «стандартных» матриц (например, 201, 202, 203), перестановке «стандартных» матриц (например, основанных на разреженных векторах матрицы 211, 212, 213) и/или графическому представлению любой из «стандартных» матриц (например, 201, 202, 203) или основанных на разреженных векторах матриц (например, 211, 212, 213). Менеджер 218 матричного преобразования может быть приспособлен к сканированию «стандартных» матриц (например, 201, 202, 203) и генерированию представления 222 в виде n-кортежа. Представление 222 в виде n-кортежа может содержать любое количество кортежей, которое может быть продиктовано лежащими в основе матрицами. В одном варианте осуществления представление 222 в виде n-кортежа также может содержать необработанные метаданные. Представление 222 в виде n-кортежа может быть приспособлено к содержанию только одного элемента ячейки матрицы и/или данных, относящихся к нему, в противоположность всему вектору строки матрицы. В ходе работы менеджер матричного преобразования может выполнять процесс извлечения-преобразования-загрузки, посредством которого матрицы 201, 202 и/или 203 отслеживают в отношении новых записей. Например, к матрицам 201, 202 и/или 203 могут быть добавлены данные для новой когорты, запуская выполнение менеджером 218 матричного преобразования процесса ETL. При определении того, что существует новая запись, менеджер 218 матричного преобразования в сочетании с менеджером 217 ID может генерировать одно или более представлений в виде n-кортежа и генерировать одну или более из матриц 211, 212 и/или 213, основанных на разреженных векторах (и/или присоединять к ним новую запись). Извлечение-преобразование-загрузка могут выполняться на непрерывной, автоматической и/или регулярно запланированной временной основе.
[0075] Для целей иллюстрации настоящее описание будет основано на представлении в виде 3-кортежа («структура данных в виде тройки»). Структура данных в виде тройки может быть таблицей. Структура данных в виде тройки может быть сгенерирована путем сканирования матрицы 201 генотипов, матрицы 202 количественных признаков, матрицы 203 двоичных признаков и/или матрицы 204 метаданных образцов. Структура данных в виде тройки может быть сгенерирована для каждой из матрицы 201 генотипов, матрицы 202 количественных признаков и/или матрицы 203 двоичных признаков. В некоторых вариантах осуществления одна структура данных в виде тройки может быть сгенерирована совместно для обеих из матрицы 202 количественных признаков и матрицы 203 двоичных признаков. В одном варианте осуществления менеджер 218 матричного преобразования может сканировать подмножества одной или более из матрицы 201 генотипов, матрицы 202 количественных признаков и/или матрицы 203 двоичных признаков. Структура данных в виде тройки может содержать идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Идентификатор столбца может содержать один или более из ID когорты и/или глобального ID. Идентификатор строки может содержать любые данные, необходимые для идентификации строки в одной или более из матрицы 211 генотипов, основанной на разреженных векторах, матрицы 212 количественных признаков, основанной на разреженных векторах, и/или матрицы 213 двоичных признаков, основанной на разреженных векторах. Идентификатор столбца может содержать идентификатор вектора для индивидуума, сгенерированный менеджером 217 ID. Например, структура данных в виде тройки может содержать (id_строки, id_столбца, значение).
[0076] Структура данных в виде тройки может быть сгенерирована для каждого индивидуума, для каждого геномного локуса в матрице 201 генотипов. Например, структура данных в виде тройки, полученная из матрицы 201 генотипов, может содержать идентификатор строки «хромосома:положение:референт:альтернатива», идентификатор столбца содержит ID когорты, глобальный ID или сходное название образца от индивидуума, а значение представляет количество альтернативных аллелей, которые несет индивидуум для этого варианта.
[0077] Другая приведенная в качестве примера структура данных в виде тройки, полученная из матрицы 201 генотипов, может содержать идентификатор строки «хромосома:геномный_диапазон:референт:альтернатива». Геномный_диапазон может быть выражен как начальное положение и конечное положение. Приведенная в качестве примера структура данных в виде тройки может быть выражена как («хромосома:положение:референт:альтернатива», «субъект_00002», 1), где идентификатор столбца представляет собой идентификатор вектора «субъект_00002», идентификатор строки представляет собой «хромосома:положение:референт:альтернатива», а значение равно «1».
[0078] Структура данных в виде тройки может быть сгенерирована для каждого индивидуума и для каждого признака в матрице 202 количественных признаков. Например, структура данных в виде тройки, полученная из матрицы 202 количественных признаков, может содержать («идентификатор_вектора, признак, значение»). Например, структура данных в виде тройки, полученная из матрицы 202 количественных признаков, может содержать («субъект_00002, Max LDL-C, 78»).
[0079] Структура данных в виде тройки может быть сгенерирована для каждого индивидуума и для каждого признака в матрице 203 двоичных признаков. Например, структура данных в виде тройки, полученная из матрицы 203 двоичных признаков, может содержать («идентификатор_вектора, признак, значение»). Например, структура данных в виде тройки, полученная из матрицы 203 двоичных признаков, может содержать («субъект_000002, ишемическая болезнь сердца, 1»). Например, значение 1 для ишемической болезни сердца может указывать на то, что у индивидуума имеется ишемическая болезнь сердца, а значение 0 указывало бы на отсутствие ишемической болезни сердца, или же данные могли бы отсутствовать.
[0080] Система 210, основанная на разреженных векторах, может генерировать матрицы 211, 212 и 213, основанные на разреженных векторах, на основе структур данных в виде тройки. На фиг. 4 проиллюстрированы приведенная в качестве примера матрица 202 количественных признаков, структура 222 данных в виде тройки, полученная из нее, и приведенная в качестве примера матрица 212 количественных признаков, основанная на разреженных векторах, сгенерированная из структуры 222 данных в виде тройки. На фиг. 5 проиллюстрированы приведенная в качестве примера матрица 203 двоичных признаков, структура 222 данных в виде тройки, полученная из нее, и приведенная в качестве примера матрица 213 двоичных признаков, основанная на разреженных векторах, сгенерированная из структуры 222 данных в виде тройки. Матрицы, основанные на разреженных векторах, не будут содержать записей, связанных с выбранным разреженным значением (представлены как пустое пространство на фиг. 4 и фиг. 5).
[0081] Для генерирования матрицы с использованием структуры данных в виде тройки система 210, основанная на разреженных векторах, может считывать первую позицию строки в структуре данных в виде тройки и определять, представлено ли уже значение из первой позиции как заголовок строки в матрице. Если значение из первой позиции еще не представлено как заголовок строки в матрице, система 210, основанная на разреженных векторах, может присваивать значение из первой позиции заголовку строки матрицы и переходить к считыванию второй позиции строки в структуре данных в виде тройки. Если значение из первой позиции уже представлено как заголовок строки в матрице, система 210, основанная на разреженных векторах, может идентифицировать заголовок строки и переходить к считыванию второй позиции строки в структуре данных в виде тройки. Система 210, основанная на разреженных векторах, может определять, представлено ли уже значение из второй позиции как заголовок столбца в матрице. Если значение из второй позиции еще не представлено как заголовок столбца в матрице, система 210, основанная на разреженных векторах, может присваивать значение из второй позиции заголовку столбца матрицы и переходить к считыванию третьей позиции строки в структуре данных в виде тройки. Если значение из второй позиции уже представлено как заголовок столбца в матрице, система 210, основанная на разреженных векторах, может идентифицировать заголовок столбца матрицы и переходить к считыванию третьей позиции строки в структуре данных в виде тройки. Система 210, основанная на разреженных векторах, присваивает третью позицию как значение, находящееся на пересечении только что созданных и/или идентифицированных столбца и строки в матрице. Система 210, основанная на разреженных векторах, может повторять этот процесс для каждой строки структуры данных в виде тройки до тех пор, пока не будут считаны все строки структуры данных в виде тройки.
[0082] Для генерирования матриц 211, 212 и 213, основанных на разреженных векторах, некоторое значение может быть определено как «разреженное значение» для каждого типа матрицы. В некоторых вариантах осуществления это значение может представлять собой нулевое значение или ненулевое значение. В некоторых вариантах осуществления разреженное значение не сохраняется, а скорее выводится по отсутствию сохраненных данных. Это сводит к минимуму объем хранилища данных и улучшает потребление дискового пространства и памяти компьютера. Например, что касается матрицы 211 генотипов, основанной на разреженных векторах, наиболее распространенным значением является гомозиготный референт (например, равное 0 значение), поэтому использование гомозиготного референта в качестве разреженного значения обеспечивает улучшенное сжатие данных. В качестве еще одного примера, что касается матрицы 212 количественных признаков, основанной на разреженных векторах, и матрицы 213 двоичных признаков, основанной на разреженных векторах, «неопределенное» значение (например, отсутствие данных о фенотипе) может использоваться как разреженное значение, поскольку такие индивидуумы обычно исключаются из последующих анализов. Одним из факторов, влияющих на выбор разреженного значения, является идентификация того, какое значение приведет к максимальному/оптимальному сжатию. Другие факторы, влияющие на выбор разреженного значения, включают вычислительную сложность распаковки (например, уплотнения) разреженного значения и выполнения таких операций, как операция с подмножеством.
[0083] Для генерирования матрицы, основанной на разреженных векторах, с использованием структуры данных в виде тройки система 210, основанная на разреженных векторах, может считывать первую позицию строки в структуре данных в виде тройки и определять, представлено ли уже значение из первой позиции как заголовок столбца в матрице, основанной на разреженных векторах. Если значение из первой позиции еще не представлено как заголовок столбца в матрице, основанной на разреженных векторах, система 210, основанная на разреженных векторах, может присваивать значение из первой позиции заголовку столбца матрицы, основанной на разреженных векторах, и переходить к считыванию второй позиции строки в структуре данных в виде тройки. Если значение из первой позиции уже представлено как заголовок столбца в матрице, основанной на разреженных векторах, система 210, основанная на разреженных векторах, может идентифицировать заголовок столбца и переходить к считыванию второй позиции строки в структуре данных в виде тройки. Система 210, основанная на разреженных векторах, может определять, представлено ли уже значение из второй позиции как заголовок строки в матрице, основанной на разреженных векторах. Если значение из второго положения еще не представлено как заголовок строки в матрице, основанной на разреженных векторах, система 210, основанная на разреженных векторах, может присваивать значение из второй позиции заголовку строки матрицы, основанной на разреженных векторах, и переходить к считыванию третьего положения строки в структуре данных в виде тройки. Если значение из второй позиции уже представлено как заголовок строки в матрице, основанной на разреженных векторах, система 210, основанная на разреженных векторах, может идентифицировать заголовок строки матрицы и переходить к считыванию третьей позиции строки в структуре данных в виде тройки. Система 200 может считывать третью позицию строки в структуре данных в виде тройки и присваивать третью позицию как значение, находящееся на пересечении только что созданных и/или идентифицированных столбца и строки в матрице, основанной на разреженных векторах. Система 210, основанная на разреженных векторах, может повторять этот процесс для каждой строки структуры данных в виде тройки до тех пор, пока не будут считаны все строки структуры данных в виде тройки.
[0084] В одном варианте осуществления система 200 и/или система 210, основанная на разреженных векторах, могут охватывать единственную когорту или совокупность когорт. Каждая когорта может иметь матрицу генотипов, матрицу количественных признаков, матрицу двоичных признаков и матрицу метаданных образцов или подмножество этих матриц, где ID когорты менеджера ID поддерживает унифицированные номера столбцов для всех типов матриц, которые являются независимыми для одной когорты. На фиг. 6 показано, что в случае наличия более одной когорты, лежащие в их основе матрицы (например, матрицы 211, основанные на разреженных векторах), могут быть объединены в одну суперматрицу (например, главную матрицу 601 генотипов, основанную на разреженных векторах), объединяющую строки и столбцы из лежащих в основе матриц с использованием номеров столбцов, соответствующих глобальному ID. Процесс объединения может реализовываться разными способами, например посредством операций объединения или пересечения. При объединении все строки всех подматриц сохраняются в суперматрице (например, посредством объединения по идентификаторам строк). При пересечении в суперматрице сохраняются только строки, представленные во всех подматрицах (например, посредством пересечения по идентификаторам строк). Кроме того, строки из подматриц, имеющие одинаковый ID после операции объединения или пересечения, могут или быть объединены в одну строку с соединением отдельных векторов, или же они могут быть сохранены как отдельные строки с единственными копиями отдельных векторов.
[0085] В одном варианте осуществления с данными, связанными с одной или более когортами, может быть выполнена функция агрегирования, чтобы генерировать агрегированную матрицу генотипов, основанную на разреженных векторах. К исходной матрице генотипов, основанной на разреженных векторах, такой как главная матрица 601 генотипов, основанная на разреженных векторах, можно делать запросы по одному или более генам. Например, запрос может быть по всем субъектам из всех когорт, у которых имеется мутация с потерей функции в PCSK9. В запросе можно использовать, например, один или более булевых операторов, таких как OR, AND, NOT, XOR и т. д. Например, запрос может быть по всем субъектам из всех когорт, у которых имеется мутация с потерей функции в PCSK9 или APOE. В запросе можно идентифицировать строки исходной матрицы генотипов, основанной на разреженных векторах, которая удовлетворяет запросу. Идентифицированные строки могут быть собраны в новую производную матрицу генотипов, основанную на разреженных векторах (например, агрегированную матрицу генотипов). Которая возвращает одного или более субъектов, удовлетворяющих запросу, из двух или более когорт. Например, главная матрица 601 генотипов, основанная на разреженных векторах, может получать запросы и возвращать каждую строку, которая содержит разреженный вектор для субъекта, у которого имеется мутация с потерей функции в гене, по которому делают запрос. Агрегированная матрица генотипов может быть сгенерирована на основе результатов запросов к исходной матрице генотипов.
[0086] Для примера рассмотрим приведенную в качестве примера исходную матрицу генотипов, основанную на разреженных векторах, которая описывает мутации с потерей функции (1-n) для PCSK9 в трех когортах (когорта 1 состоит из образцов 1-50000, когорта 2 состоит из образцов 50001-60000; и когорта 3 состоит из образцов 60001-100000):
(1-50000)
(50001-60000)
(600001-100000)
ID образца 59000
ID образца 13000
[0087] Приведенный в качестве примера запрос на агрегирование всех субъектов, у которых имеется мутация с потерей функции в PCSK9, из всех когорт даст в результате агрегированную матрицу генотипов, основанную на разреженных векторах:
Агрегированная матрица генотипов, основанная на разреженных векторах, также может быть обработана и/или проанализирована отдельно или в сочетании с одной или более другими матрицами (например, дополнительными матрицами генотипов, основанными на разреженных векторах, матрицами признаков, основанными на разреженных векторах, и/или матрицами метаданных образцов).
[0088] В одном варианте осуществления менеджер 218 матричного преобразования может сканировать подмножества одной или более из матрицы 201 генотипов, матрицы 202 количественных признаков и/или матрицы 203 двоичных признаков. Например, в системе 200 может существовать совокупность матриц 201 генотипов. Совокупность матриц 201 генотипов может быть просканирована, структуры данных в виде тройки могут быть сгенерированы, а затем использованы для создания единой матрицы 211 генотипов, основанной на разреженных векторах. Например, единая матрица 201 генотипов может быть получена из подмножества так, чтобы включать только женщин в матрице 211 генотипов, основанной на разреженных векторах. Структуры данных в виде тройки могут быть сгенерированы для каждой из совокупности матриц 201 генотипов, а затем быть использованы с фильтром для сборки фильтрованной матрицы 211 генотипов, основанной на разреженных векторах. Фильтр может быть по одному или более значений из любых значений, на которых основаны матрицы.
[0089] В одном варианте осуществления одна или более из матриц 201, 202, 203, одна или более из матриц 211, 212, 213, основанных на разреженных векторах, одна или более из матрицы 204 метаданных образцов, матрицы 214 метаданных образцов, одна или более из матрицы 206 результатов и/или матрицы 216 результатов могут быть сохранены как файлы данных в файловой системе 220. Файловая система 220 может быть приспособлена к разбивке сохраненных данных на разделы равным или относительно равным образом, существенно улучшая производительность параллельных вычислений и требования к памяти, гарантируя, что машины, работающие одновременно, имеют схожие объемы работ для выполнения и поэтому завершают их за схожее количество времени. Если данные не разбиты на разделы равномерно, то для завершения всей работы может потребоваться существенно больше времени, поскольку одна задача занимает, например, 95% всех данных. В крайних случаях машины со слишком большим объемом данных могут даже расходовать всю память и давать сбой. Таким образом, настоящее изобретение также характеризуется, например, способом разбиения на разделы, основанным на местоположении в геноме. При заданных наборе входных данных, размере целевого файла и количестве файлов, которые необходимо назначать каждому разделу, можно определить количество отдельных записей данных (например, рядов) из набора данных, которые будут примерно удовлетворять размеру целевого файла. Разбиение высшего уровня может быть применено по хромосоме, чтобы гарантировать, что разделы не охватывают несколько хромосом. Тогда относительно каждой хромосомы количество выходных файлов, которые необходимо генерировать, можно определить на основе оцененного количества записей на один целевой файл, разделенного на количество записей, представленных о хромосоме. Записи могут быть просканированы для определения внутренних границ диапазонов, которые будут разбивать данные на требуемое количество смежных неперекрывающихся интервалов, каждый из которых будет соответствовать одному выходному файлу. Если требуемое количество файлов на раздел диапазона превышает 1, собственно интервалы (выходные файлы) могут быть сгруппированы в смежные интервалы соседствующих диапазонов и может быть назначен новый раздел сверхдиапазона с границами, равными минимальной и максимальной координатам поддиапазонов, которые он охватывает. Сперва можно определить сверхдиапазоны, имея требуемое количество поддиапазонов, на которые необходимо разбивать, для выходных файлов, а отдельные файлы в пределах раздела сверхдиапазона можно разбить аналогичным образом на следующей стадии. Если сверхдиапазон предварительно рассчитан, несколько выходных файлов для сверхдиапазона можно разбить на куски в случайной последовательности, которые не являются смежными. Собственно выходные файлы могут быть или в случайном порядке упорядочены, или организованы таким способом (например, отсортированы по геномной координате), который повышает скорости доступа для запросов, которые должны считывать данные, назначенные для файла. Файлы могут быть сжатыми. Каждый раздел может содержать один или более файлов и/или один или более каталогов. Каталоги могут быть названы так, чтобы соответствовать хромосомным разделам. Файлы данных, сохраненные в каталоге, могут быть названы так, чтобы соответствовать хромосоме, ассоциируемой с каталогом, который содержит эти файлы данных. Названия каталогов и/или файлов данных также могут включать геномный диапазон. Таким образом, поиск по названию гена может включать определение хромосомы, которая содержит данное название и требуемые координаты. Каталог, который соответствует хромосоме, может быть определен, и подкаталог (подкаталоги), который соответствует (соответствуют) геномному (геномным) диапазону (диапазонам), перекрывающемуся (перекрывающимся) с координатами запрашиваемого гена, может (могут) быть эффективно извлечен(ы). Разделы предпочтительно генерируют так, чтобы поддерживать разделы относительно равного размера с учетом количества хранимых данных. Могут быть случаи, когда определенные геномные локусы имеют больший объем ассоциированных данных, чем другие геномные локусы. В этом случае значения длины диапазонов в системе геномных координат, соответствующие каждому разделу, могут быть соответственно откорректированы. Благодаря способу разбиения запросы к матрице 216 результатов, которая может содержать десятки миллиардов строк, можно сократить с 30 минут до менее чем 5 секунд.
[0090] В работе система, основанная на разреженных векторах, может принимать данные о генотипе, данные о фенотипе и/или метаданные для совокупности индивидуумов (например, субъектов), генерировать одну или более из матрицы генотипов, матрицы количественных признаков и/или матрицы двоичных признаков, присваивать глобальный идентификатор и идентификатор вектора каждому из совокупности индивидуумов (например, присвоение может выполнять менеджер идентификаторов), генерировать матрицу генотипов, матрицу количественных признаков и матрицу двоичных признаков, структуру данных в виде n-кортежа, определять матрицу генотипов, основанную на разреженных векторах, матрицу количественных признаков, основанную на разреженных векторах, и/или матрицу двоичных признаков, основанную на разреженных векторах, и обрабатывать один или более запросов к матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и/или матрице двоичных признаков, основанной на разреженных векторах.
[0091] Совокупность индивидуумов может быть частью когорты. Совокупность индивидуумов может быть частью нескольких когорт. В некоторых случаях один или более индивидуумов будут входить в более чем одну когорту. В некоторых случаях данные о фенотипе субъекта могут быть получены из медицинских записей. Чтобы получить единое значение для фенотипа (например, обозначение больной/контрольный для двоичного признака или единичного измерения холестерина LDL), сводная статистика и/или эвристика используются применительно к одному или последовательности измерений и/или диагнозов для отнесения индивидуумов к носителям или к не являющимся носителями двоичного фенотипа или к единственному репрезентативному значению для количественного признака (например, максимальному зарегистрированному в течение жизни уровню холестерина LDL). В одном варианте осуществления сводная статистика и/или эвристика могут давать количественное значение, представляющее вероятность того, что у субъекта имеется двоичный фенотип. Эти процессы позволяют создать матрицу фенотипов, имеющую двоичные, категориальные или количественные значения, представляющие совокупность необработанной клинической информации.
[0092] Матрица генотипов может быть сгенерирована на основе данных о генотипе. Чтобы гарантировать, что одни и те же генетические варианты, наблюдаемые у нескольких индивидуумов и/или нескольких когорт, кодируются аналогичным образом, что позволяет их идентификаторам строк быть одинаковыми, варианты, распознанные из схемы секвенирования, могут быть нормализованы до стандартного кодирования. Матрица генотипов может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов. Матрица количественных признаков может быть сгенерирована на основе данных о фенотипе. Матрица количественных признаков может содержать столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов. Матрица двоичных признаков может быть сгенерирована на основе данных о фенотипе. Матрица двоичных признаков может содержать столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов. В одном варианте осуществления по меньшей мере часть матрицы метаданных может быть присоединена к каждой из матрицы количественных признаков и матрицы двоичных признаков. Матрица метаданных может содержать, например, данные, относящиеся к одной или более аннотациям (двоичные, категориальные или непрерывные), которые могут включать 1) ковариаты в моделях исследования корреляций генотип/фенотип и 2) отметки для определения подмножеств образцов. В качестве примера матрица метаданных образцов может содержать аннотации для возраста, пола, генетически определенных предков, генотипических основных компонентов, показателей качества секвенирования и/или их комбинации. Аннотации могут содержать числовые аннотации, но не символьные строки. Может быть установлено цифровое отображение, например женщина=1, мужчина=2. Отображение декодирования/кодирования может быть сохранено (например, в виде столбца в матрице) таким образом, что каждую строку можно перекодировать как соответствующую символьную строку.
[0093] Индивидууму могут быть присвоены более одного идентификатора вектора и только один глобальный идентификатор.
[0094] Структура данных в виде n-кортежа может содержать любое количество кортежей, например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше кортежей. В одном варианте осуществления структура данных в виде n-кортежа может содержать 3 кортежа и называться тройкой. Структура данных в виде n-кортежа может содержать идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Идентификатор строки может содержать следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива. Идентификатор столбца может содержать идентификатор когорты и/или глобальный идентификатор.
[0095] Матрицу генотипов, основанную на разреженных векторах, можно определить на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов. Матрица генотипов, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец может содержать разреженный вектор, представляющий одно или более значений матрицы генотипов. Матрица количественных признаков, основанная на разреженных векторах, может быть определена на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков. Матрица количественных признаков, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец может содержать разреженный вектор, представляющий одно или более значений матрицы количественных признаков. Матрица двоичных признаков, основанная на разреженных векторах, может быть определена на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков. Матрица двоичных признаков, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
[0096] Для определения матриц, основанных на разреженных векторах, одно значение может быть определено как «разреженное значение» для каждого типа матрицы. В некоторых вариантах осуществления значение может представлять собой ненулевое значение. Например, разреженный вектор, представляющий одно или более значений матрицы генотипов, может содержать структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, у которого имеется ненулевое значение в строке матрицы генотипов. Разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков. Разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, у которого имеется ненулевое значение в столбце матрицы двоичных признаков. Разреженные векторы, представляющие одно или более значений матрицы генотипов или матрицы количественных признаков, могут быть приспособлены к отбрасыванию значений, равных 0 (нулю). Разреженный вектор, представляющий одно или более значений матрицы количественных признаков, может быть приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
[0097] В некоторых вариантах осуществления разреженное значение не сохраняется, а скорее выводится по отсутствию сохраненных данных. Это сводит к минимуму объем хранилища данных и улучшает потребление дискового пространства и памяти компьютера. Например, что касается матрицы генотипов, основанной на разреженных векторах, наиболее распространенным значением является гомозиготный референт (например, равное 0 значение), поэтому использование гомозиготного референта в качестве разреженного значения обеспечивает улучшенное сжатие данных. В качестве еще одного примера, что касается матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, «неопределенное» значение (например, отсутствие данных о фенотипе) может использоваться как разреженное значение, поскольку такие индивидуумы обычно исключаются из последующих анализов. Одним из факторов, влияющих на выбор разреженного значения, является идентификация того, какое значение приведет к максимальному/оптимальному сжатию. Другие факторы, влияющие на выбор разреженного значения, включают вычислительную сложность распаковки (например, уплотнения) разреженного значения и выполнения таких операций, как операция с подмножеством.
[0098] В одном варианте осуществления обработка одного или более запросов может предусматривать выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах. Соответственно, могут быть обработаны один или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и матрице двоичных признаков, основанной на разреженных векторах. Обработка одного или более запросов может предусматривать прием ввода запроса и определение присутствия или отсутствия данных в матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и/или матрице двоичных признаков, основанной на разреженных векторах, которые «соответствуют» вводу запроса. Определение соответствия вводу запроса может предусматривать идентификацию идентичного соответствия или частичного соответствия. Обработка одного или более запросов может предусматривать некоторые или все из способов, описанных в данном документе, включая, например, способы, описанные применительно к фиг. 21 - фиг. 24.
[0099] Дополнительные данные о генотипе и дополнительные данные о фенотипе могут быть приняты для дополнительной совокупности индивидуумов. Идентификатор вектора (идентификатор когорты) может быть присвоен каждому индивидууму в совокупности индивидуумов и глобальный идентификатор - каждому индивидууму в совокупности индивидуумов. Менеджер идентификаторов может осуществлять идентификацию каждого индивидуума, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, и может присваивать один и тот же глобальный идентификатор каждому повторяющемуся индивидууму, но разные идентификаторы вектора (идентификаторы когорты). В некоторых вариантах осуществления индивидууму может быть присвоено более одного глобального идентификатора.
[00100] По меньшей мере часть дополнительных данных о генотипе может быть добавлена к матрице генотипов, по меньшей мере часть дополнительных данных о фенотипе может быть добавлена к матрице количественных признаков, по меньшей мере часть дополнительных данных о фенотипе может быть добавлена к матрице количественных признаков и/или по меньшей мере часть матрицы метаданных может быть повторно присоединена к каждой из матрицы количественных признаков и матрицы двоичных признаков. Эта функциональность позволяет создавать производные матрицы, которые могут включать всех индивидуумов или их подмножество из одной или более когорт, которые можно в совокупности анализировать. Поскольку количество возможных комбинаций индивидуумов для включения в производные матрицы является экспоненциальным, предварительное вычисление этих производных матриц является нетривиальным и ограничивающим.
[00101] В одном варианте осуществления матрица результатов ассоциации может быть сгенерирована на основе одной или более из матрицы генотипов, матрицы количественных признаков и/или матрицы двоичных признаков. Матрица результатов ассоциации может быть разбита. Разбиение матрицы результатов ассоциации может предусматривать генерирование структуры данных в виде каталога для каждой из совокупности хромосом, разделение матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону и сохранение на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
[00102] После того как матрицы 211, 212 и 213, основанные на разреженных векторах, были сгенерированы и сохранены, высокопроизводительная схема 205 конвейерной обработки данных может выполнять автоматизированную последовательность стадий схемы конвейерной обработки для первичного и вторичного анализа данных для некоторых или всех данных, содержащихся в одной или более из матрицы 211 генотипов, основанной на разреженных векторах, матрицы 212 количественных признаков, основанной на разреженных векторах, и/или матрицы 213 двоичных признаков, основанной на разреженных векторах, с использованием биоинформационных инструментов, результаты которого могут быть сохранены в матрице 216 результатов.
[00103] Путем генерирования матриц 211, 212 и 213, основанных на разреженных векторах, и матрицы 214 метаданных, имеющих совместимые схемы, многие вторичные операции с этими данными упрощаются. Например, часто требуется создать собственные фенотипы или генотипы, которые происходят из некоторого сочетания фенотипов или генотипов в лежащих в основе матрицах. Это может включать создание собственного двоичного фенотипа с использованием существующего двоичного признака в качестве отправной точки, но затем используется количественный признак (например, лабораторное значение) для уточнения статуса больного/контрольного. В другом варианте осуществления может быть создан собственный двоичный признак, который влияет на носителей с конкретной мутацией или без нее (например, болезнь Альцгеймера без известной мутации APOE4, являющейся фактором риска). В качестве альтернативы собственный генотип может быть получен из совокупности отдельных вариантов, например, суммирования значений встречаемости аллелей двух известных вариантов риска для создания генотипа с баллами риска. Все эти операции могут быть определены путем осуществления запроса к различным строкам из матриц 211, 212 и 213, основанных на разреженных векторах, и/или матрицы 214 метаданных. Агрегация строк, возвращаемых из запроса, может осуществляться посредством разных способов, включая определение функции агрегации, которая работает с последовательностью разреженных векторов. В качестве альтернативы может быть желательным сперва преобразовать разреженные векторы в их плотное представление, используя транспонирование и осуществляя считывание в стандартный инструмент для анализа нераспределенных данных, например R. В этом случае возвращенные строки разреженных векторов собирают в единую машину, осуществляют расширение до плотных векторов (например, разреженные значения обратно добавляют), и транспонируют так, что индивидуумы представляют строки, а различные идентификаторы разреженных векторов становятся столбцами. Затем это представление можно проанализировать посредством традиционных инструментов для исследовательских целей, где точная логика агрегации требует проверки и ручных манипуляций.
[00104] На фиг. 7 показано, что запросы могут быть выполнены к одной или более из матриц 211, 212 и 213, основанных на разреженных векторах. Например, может быть обработан единый запрос ко всем матрицам. Поскольку матрицы, основанные на разреженных векторах, 211, 212 и 213, могут быть уложены в стек/выровнены, запрос может быстро определять и генерировать структуру 701 данных запроса. Структура 701 данных запроса может содержать все строки из матриц 211, 212 и 213, основанных на разреженных векторах, соответствующие конкретному запросу. В матрице 214 метаданных образцов можно запросить любые подходящие метаданные. Соответствующие строки из матриц 211, 212 и 213, основанных на разреженных векторах, и любые подходящие метаданные могут быть собраны в структуру 701 данных запроса.
[00105] Как показано на фиг. 8 и фиг. 9, система 210, основанная на разреженных векторах, может обрабатывать любой результат сравнения структуры 701 данных запроса с матрицей 216 результатов. Обработанный результат может быть преобразован в файл данных, приспособленный для ввода в высокопроизводительную схему 205 конвейерной обработки данных системы 200. Высокопроизводительная схема 205 конвейерной обработки данных может обрабатывать входные данные и возвращать любые результаты в матрицу 206 результатов и/или матрицу 216 результатов. Результаты могут также быть сохранены в соответствующей файловой системе 220.
[00106] Матрица 216 результатов может содержать результаты ассоциации генотип/фенотип, полученные непосредственно из высокопроизводительной схемы 205 конвейерной обработки данных или из результатов процесса контроля качества, который предоставляет дополнительные показатели об отдельных ассоциациях и/или фильтрует ассоциации, которые полагают низкокачественными. Следовательно, система 210, основанная на разреженных векторах, может задействовать внутренний процесс контроля качества применительно к результатам, которые не прошли контроль качества (QC) или когда QC необходимо провести повторно. Система 210, основанная на разреженных векторах, может включать в себя распределенные, масштабируемые реализации стандартных процедур QC, такие как расчеты для лямбда GC, корректирования p-значения, значений встречаемости в ячейках таблицы сопряженности и неравновесия по сцеплению, а также функциональные возможности для генерирования визуализаций, таких как графики Q-Q, манхэттенские графики, графики PheWAS. Дополнительно может потребоваться аннотация результатов различной информацией. Например, варианты можно аннотировать ближайшими генами, и фенотипы можно аннотировать их родительскими терминами в онтологии ICD10. Система 210, основанная на разреженных векторах, может получать эти аннотации из различных источников, включая без ограничения матрицы 211, 212 и 213 генотипов и фенотипов, основанные на разреженных векторах, доступ к которым может осуществляться посредством операции соединения.
[00107] Результаты ассоциации, которые формируют матрицу 216 результатов, могут быть получены из одного рабочего цикла высокопроизводительной схемы 205 конвейерной обработки данных (или ее эквивалента), из последовательности рабочих циклов высокопроизводительной схемы 205 конвейерной обработки данных или из непрерывного цикла работы высокопроизводительной схемы 205 конвейерной обработки данных, которая генерирует отдельные результаты в реальном времени. Последние случаи использования требуют, чтобы лежащая в основе матрица 216 результатов имела возможность для присоединения, при которой сама матрица может динамически расти, и операции с матрицей (например, контроль качества, определенные схемы разбиения и выполнение запросов) могут быть спроектированы так, чтобы работать без предположения о полной, предварительно рассчитанной, статической матрице результатов.
[00108] Чтобы эффективно обрабатывать растущую матрицу 216 результатов, несколько классов операций могут быть определены на строках матрицы результатов на основе зависимостей строк относительно других строк в матрице 216 результатов. В простейшей форме имеются независимые операции, которые работают в рамках строки и не имеют зависимостей от других строк, такие как применение пороговых значений к показателям в одном из столбцов строки (например, порог p-значения). Затем осуществляются операции, которые зависят от подмножества результатов из матрицы 216 результатов, такие как лямбда GC, графики Q-Q и определенные корректировки p-значения, и которые требуют наблюдения за распределением p-значения по всем вариантам для комбинации одной когорты, фенотипа, модели и типа варианта. Наконец, осуществляются операции, которые требуют всей матрицы 216 результатов, такие как способ 1900 разбиения (показан на фиг. 19), который обеспечивает оптимальную производительность запросов на основе геномного местоположения на снимке матрицы 216 результатов. Поскольку матрица 216 результатов может состоять из сотен миллиардов строк, присоединение новых результатов может быть очень медленной и затратной операцией. Для усовершенствования его функции зависимости новых данных могут быть определены заранее, чтобы свести к минимуму объем данных, который необходимо обрабатывать на каждой стадии ETL. Это позволяет повторно использовать промежуточные результаты предыдущих процесса(-ов) ETL, предотвращая повторное вычисления больших объемов данных в ходе обновления матрицы результатов. Данный процесс представлен на фиг. 10. На фиг. 11 проиллюстрировано время обработки для операций над матрицей 206 результатов с использованием системы 200 по сравнению со временем обработки для операций над матрицей 216 результатов с использованием браузера результатов системы 210. Как показано, система 200 не способна к выполнению операций над миллиардами записей менее чем за день, а в большинстве случаев ей бы потребовались недели, если не месяцы, для выполнения операций, которые система 210 может выполнять за секунды, минуты или часы.
[00109] В одном варианте осуществления высокопроизводительная схема 205 конвейерной обработки данных или дополнительная высокопроизводительная схема конвейерной обработки данных (не показана) может быть приспособлена к выполнению операции над матрицами 211, 212 и 213, основанными на разреженных векторах, и над матрицей 214 метаданных. Для выполнения одной проверки ассоциации генотип/фенотип с ковариатами или без них система 210, основанная на разреженных векторах, может выполнять декартово произведение матрицы 211 генотипов, основанной на разреженных векторах, и матриц 212/213 фенотипов, основанных на разреженных векторах, и присоединять необходимые надлежащие метаданные 214 образцов как ковариаты. Декартово произведение может быть выполнено путем копирования и/или отправки отдельных строк, разделов или полной копии одной матрицы во все отдельные строки, разделы или полные копии другой матрицы. В одном варианте осуществления может потребоваться преобразование разреженных векторов в более сжатую структуру данных перед умножением, чтобы уменьшить сетевые издержки при получении декартова произведения. Для уменьшения количества проводимых проверок можно использовать фильтрование применительно к матрице 211 генотипов, основанной на разреженных векторах, и матрицам 212/213 фенотипов, основанным на разреженных векторах, и/или получаемой в результате объединенной структуре данных, на основании особой логики, например с применением порогового значения частоты встречаемости минорного аллеля в генотипе или минимальных значений встречаемости в пороговом значении в ячейках в пороговом значении таблицы статистической структуры изучаемой популяции. После фильтрования объединенная структура данных может иметь один разреженный вектор генотипов, один разреженный вектор фенотипов и от нуля до множества разреженных векторов метаданных. Выполнение проверки ассоциации на этих векторах может включать в себя подсчет встречаемости комбинаций разных значений генотип/фенотип или выполнение регрессии на объединенных векторах. Тесты на выявление ассоциаций могут требовать преобразования разреженных векторов в альтернативное представления, такое как плотный вектор.
[00110] На фиг. 12 показана приведенная для примера конфигурация высокопроизводительной схемы 205 конвейерной обработки данных. В одном варианте осуществления высокопроизводительная схема 205 конвейерной обработки данных может быть приспособлена к выполнению анализа одного или более типов, включающего одну или более из матрицы 211 генотипов, основанной на разреженных векторах, матрицы 301, основанной на разреженных векторах, матрицы 214 метаданных образцов, матрицы 216 результатов, их совокупностей и/или их комбинаций. В одном варианте осуществления высокопроизводительная схема 205 конвейерной обработки данных может выполнять, например, полногеномный поиск ассоциаций (GWAS), полнофеномный поиск ассоциаций (PheWAS), анализ сцепления, исследование ассоциаций генетической нагрузки, исследование ассоциаций с полигенной оценкой риска, исследование корреляции фенотип-фенотип, оценку наследуемости фенотипа, исследование ассоциаций многих генотипов со многими фенотипами и т. д. Высокопроизводительная схема 205 конвейерной обработки данных может быть использована для определения ассоциации одного или более генотипов с одним или более фенотипами. Высокопроизводительная схема 205 конвейерной обработки данных может быть использована для определения статистически значимой корреляции между одним или более генотипами и одним или более фенотипами. Например, изменчивость в вариациях SNP (генотип) может быть проверена по сравнению с изменчивостью в вариации фенотипа, и если ассоциация является значимой на основе выбранных статистического критерия и порогового p-значения, то можно утверждать, что SNP является ассоциированным. Высокопроизводительная схема 205 конвейерной обработки данных может быть использована для выполнения тестов для выявления ассоциаций, таких как сравнение «всех со всеми», при котором сравнивают все генотипы со всеми фенотипами, сравнение «один со всеми», при котором сравнивают один генотип со всеми фенотипами, сравнение «все с одним», при котором сравнивают все генотипы с одним фенотипом, и/или сравнение «один или более с одним или более», при котором сравнивают один или более генотипов с одним или более фенотипами. В одном варианте осуществления выполняемый анализ может дополнительно предусматривать ковариационный анализ (например, курение, потребление алкоголя и т. п.). Определение таких ассоциаций, как правило, включает одну или более крупных когорт субъектов, что дает большие объемы данных о генотипе и большие объемы данных о фенотипе. Большие наборы данных подвергают специальному рассмотрению, например, в том числе обработке «больших данных», которые измеряются миллионами, миллиардами SNP и т. п. В качестве примера одна матрица, основанная на разреженных векторах, содержащая более ~100 миллионов вариантов (строк) с более 500000 индивидуумов (столбцов), может иметь размер файла приблизительно 15 терабайт сжатых данных. Одна матрица, основанная на разреженных векторах, может быть распределена, например, по 35000 файлов на основе способа 1900 разбиения на диапазоны, как описано для фиг. 19. Результаты анализа всех относительно всех могут исчисляться триллионами. Распределение одной матрицы, основанной на разреженных векторах, по многим файлам способствует эффективной обработке.
[00111] Тесты для выявления ассоциаций, выполняемые посредством высокопроизводительной схемы 205 конвейерной обработки данных, могут идентифицировать совокупность субъектов, демонстрирующих фенотипический признак, и совокупность субъектов, которые не демонстрируют этот фенотипический признак. Генетические вариации (например, проявления SNP), которые проявляются у популяции субъектов, имеющих фенотипический признак, и которые не проявляются в контрольной популяции, могут характеризоваться корреляцией с данным фенотипическим признаком. После того как генетические вариации идентифицированы как коррелирующие с фенотипическим признаком, геномы субъектов, которые обладают потенциалом к развитию данного фенотипического признака, могут быть подвергнуты скринингу для определения проявления или отсутствия проявления генетической вариации в геномах у субъектов, чтобы установить, существует ли вероятность, что у данных субъектов в итоге разовьется данный фенотипический признак. Например, такой генетический скрининг может быть использован для субъектов, у которых существует риск развития конкретного заболевания. Также это может быть использовано при внутриутробном скрининге, чтобы идентифицировать, является ли плод пораженным заболеванием или предрасположенным к его развитию. Идентификация корреляции между присутствием генетической вариации у субъекта и итоговым развитием заболевания (фенотипического признака) у субъекта является особенно полезной для идентификации средств терапевтического воздействия, которые с некоторой вероятностью будут эффективны для субъекта, раннего назначения средств терапевтического воздействия, инициирования изменений в образе жизни (например, сокращение потребления содержащей холестерин или жирной пищи во избежание сердечно-сосудистого заболевания у субъектов, имеющих предрасположенность к такому заболеванию, которая превышает нормальную) или тщательного мониторинга субъекта на предмет развития рака или другого заболевания. Тесты для выявления ассоциаций, выполняемые посредством высокопроизводительной схемы 205 конвейерной обработки данных, могут указывать на то, что генетический маркер коррелирует со статусом заболевания. Идентифицированные ассоциации могут быть использованы для прогресса усилий в поиске лекарственных средств путем предоставления новых мишеней и/или новых доказательств для обоснования уже существующих мишеней.
[00112] Высокопроизводительная схема 205 конвейерной обработки данных может содержать распределенную или сетевую вычислительную среду 1200. Используемая в данном документе распределенная вычислительная среда 1200 обычно относится к использованию совокупности распределенных разнородных вычислительных ресурсов (например, узлов), которые могут быть разнесены по совместно используемым сетям и/или географическим областям, выполнения вычислительных задач или запросов, которые могут быть весьма большими. На фиг. 12 показан ведущий узел 1201, который может представлять собой одно или более вычислительных устройств или одну или более виртуальных машин, функционирующих на вычислительном устройстве, в сообщении с совокупностью рабочих узлов (рабочим узлом 1202A, рабочим узлом 1202B, рабочим узлом 1202C и рабочим узлом 1202N), которые могут представлять собой одно или более вычислительных устройств или одну или более виртуальных машин, функционирующих на вычислительном устройстве. В качестве примера совокупность рабочих узлов может предусматривать распределенный кластер вычислительных устройств и/или кластер виртуальных машин, функционирующих на одном или более вычислительных устройствах. Например, «вычислительный» или «серверный» парк (например, вычислительное облако) может предусматривать укомплектованных вычислительных устройств (например, каждое с находящимися на нем устройствами ЦПУ, памятью, хранилищами, блоками питания, сетевыми платами и т. п.), которые подключены к одной или более сетям (например, LAN, WAN, интернет) посредством сетевой (сетевых) платы (плат). Различные в корне отличающиеся вычислительные устройства могут быть организованы и находиться под управлением таким образом, чтобы образовывать одну большую интегрированную вычислительную систему. Тогда единая интегрированная система может обрабатывать задачи и процессы, эффективная обработка которых является слишком большой и сложной для любого отдельного вычислительного устройства.
[00113] Ресурсы распределенной вычислительной среды 1200 могут быть развернуты для обработки запрашиваемых задач (которые могут быть далее подразделены на отдельные работы) по одной или более сетям. Такие задачи и работы могут принимать многие формы, например конкретных приложений, которые подлежат исполнению, задач, которые подлежат выполнению, и т. д. Использование распределенной вычислительной среды 1200 может в результате обеспечить уменьшение затрат на владение, совокупную и повышенную эффективность вычислительных ресурсов, связанных с обработкой и хранением данных, и предоставить возможности виртуальной организации для приложений и совместного использования данных.
[00114] Громадные объемы заданий могут быть переданы в распределенную вычислительную среду 1200 со связанными соглашениями об уровне услуг (SLA) и другими политиками и ограничениями. В вычислительной облачной среде распределенная вычислительная среда 1200 может быть приспособлена к предоставлению вычислительной мощности для заинтересованных пользователей более гибким способом, посредством которого объем ресурсов, выделяемых указанным пользователю или группе, увеличивают и уменьшают в зависимости от потребности. В связи с этим пользователь платит за ресурсы, которые потребляются или выделяются по факту.
[00115] Центральной частью распределенной вычислительной среды 1200 является планировщик распределенных ресурсов (например, ведущий узел 1201). Ведущий узел 1201 может быть приспособлен к оценке всех доступных ресурсов (например, обрабатывающей способности, доступной памяти и т. п.) относительно запрашиваемых объемов использования ресурсов от поступающих задач (а также существующих SLA, политик, ограничений и т. п.) в качестве части построения расписания выполнения задач (например, эти задачи обладают приоритетом в отношении ресурсов совокупности рабочих узлов 1202A - 1202N относительно других задач). Другие критерии также могут заставлять некоторые задачи ожидать более позднего выполнения, например SLA, которые задают календарное время или другие ограничения, которые могут быть удовлетворены только в более позднее время. Ведущий узел 1201 может быть приспособлен к предоставлению некоторого количества узлов из совокупности рабочих узлов 1202A - 1202N, которое является необходимым или требуемым для выполнения задачи.
[00116] В одном варианте осуществления распределенная вычислительная среда 1200 может применять модель ценообразования, которая распределяет цены/плату за потребляемые ресурсы среди пользователей согласно конкретной денежной сумме за единицу времени в связи с конкретным типом ресурса (например, с пользователя может быть снято 0,10$ за час работы ЦПУ, сети, запоминающего устройства или других использованных услуг или ресурсов). Прямым результатом такой модели ценообразования является то, что избыточное и недостаточное предоставление может быть затратным и неэффективным. Избыточное предоставление может возникать в том случае, когда слишком много рабочих узлов предоставляется для обработки элемента рабочей нагрузки и ресурсы вынуждены бездействовать. С пользователя будет продолжаться взиматься плата за предоставляемые ресурсы несмотря на их состояние бездействия. Недостаточное предоставление может быть отражено в производительности предоставленных рабочих узлов и может привести к увеличению задержки элементов рабочей нагрузки. Ведущий узел 1201 приспособлен к поддержанию баланса между работающими элементами рабочей нагрузки и интервалами времени так, чтобы предоставленные рабочие узлы не были перегруженными и ресурсы не были недостаточно использованными.
[00117] Планировщик распределенных ресурсов (например, ведущий узел 1201) может принимать запросы на выполнение задачи, разделять задачи на меньшие рабочие элементы (работы), выбирать рабочие узлы для каждой работы, отправлять задачи на выбранные рабочие узлы, принимать результаты с каждого одного рабочего узла и возвращать консолидированный результат отправителю запроса. Ведущий узел 1201 таким образом приспособлен к разделению заданного элемента рабочей нагрузки на дискретные задачи и выдавать эти задачи (и любые необходимые данные) на совокупность рабочих узлов 1202A - 1202N для выполнения. В том случае, если ведущий узел выдает задачи совокупности рабочих узлов 1202A - 1202N несбалансированно, некоторые рабочие узлы могут завершать назначенные задачи раньше других рабочих узлов. Благодаря указанной модели ценообразования рабочий узел, который завершил назначенную задачу, будет оставаться бездействующим (и накапливать затраты/плату пользователя) до тех пор, пока остальные рабочие узлы не завершат назначенные задачи, чтобы полностью закончить обработку элемента рабочей нагрузки. Таким образом, несбалансированное назначение задач совокупности рабочих узлов 1202A - 1202N может привести к увеличению платы, взимаемой с пользователей за бездействующие рабочие узлы или бездействующие виртуальные экземпляры.
[00118] Распределенная вычислительная среда 1200 приспособлена к минимизации неэффективного использования ресурсов рабочих узлов во время выполнения работ, полученных из задачи. Целью ведущего узла 1201 является разделение задач на работы и назначение работ таким образом, чтобы все рабочие узлы заканчивали обработку назначенных работ примерно в одно и то же время. В одном варианте осуществления задача может представлять собой анализ всех относительно всех, при котором сравнивают все генотипы в матрице 211 генотипов, основанной на разреженных векторах, со всеми признаками в матрице 301 признаков, основанной на разреженных векторах. В одном варианте осуществления задача может представлять собой анализ одного относительно всех, при котором сравнивают один генотип в матрице 211 генотипов, основанной на разреженных векторах, со всеми признаками в матрице 301 признаков, основанной на разреженных векторах. В одном варианте осуществления задача может представлять собой анализ всех относительно одного, при котором сравнивают все генотипы в матрице 211 генотипов, основанной на разреженных векторах, с одним признаком в матрице 301 признаков, основанной на разреженных векторах.
[00119] На фиг. 12 показано, что матрица 211 генотипов, основанная на разреженных векторах, может содержать совокупность разделов, описанных ранее. Совокупность разделов матрицы 211 генотипов, основанной на разреженных векторах, может содержать раздел GM_1, раздел GM_2, раздел GM_3 и/или раздел GM_n. Матрица 301 признаков, основанная на разреженных векторах, может содержать совокупность разделов, описанных ранее. Совокупность разделов матрицы 301 признаков, основанной на разреженных векторах, может содержать раздел TM_1, раздел TM_2, раздел TM_3 и/или раздел TM_n. Совокупность разделов матрицы 211 генотипов, основанной на разреженных векторах, и совокупность разделов матрицы 301, основанной на разреженных векторах, могут храниться в файловой системе 220. Ведущий узел 1201 и совокупность рабочих узлов 1202A - 1202N показаны в виде приспособленных к выполнению анализа всех относительно всех, сравнивая все генотипы в матрице 211 генотипов, основанной на разреженных векторах, со всеми признаками в матрице 301 признаков, основанной на разреженных векторах.
[00120] В одном варианте осуществления ведущий узел 1201 назначает совокупность разделов матрицы 211 генотипов, основанной на разреженных векторах, и совокупность разделов матрицы 301 признаков, основанной на разреженных векторах, совокупности рабочих узлов 1202A - 1202N, чтобы минимизировать «перетасовку данных». Для достижения требуемых свойств разделов данных при перетасовке данных проводят подготовку данных для параллельной обработки на будущих стадиях. На стадии перетасовки данных может происходить реорганизация и перераспределение данных в соответствующие разделы и/или на соответствующие рабочие узлы. Однако перетасовка данных склонна к вызову затратных сетевых и дисковых операций ввода и вывода (I/O), поскольку она охватывает все данные.
[00121] В одном варианте осуществления, чтобы минимизировать перетасовку данных, ведущий узел 1201 может определять на основе атрибута рабочего узла (такого как скорость обработки, память и т. п.), какому рабочему модулю из совокупности рабочих узлов 1202A - 1202N присваивать каждый из совокупности разделов матрицы 211 генотипов, основанной на разреженных векторах. В одном варианте осуществления ведущий узел 1201 может присваивать более одного раздела одному рабочему узлу. В одном варианте осуществления ведущий узел 1201 может определять, что матрицу 211 генотипов, основанную на разреженных векторах, следует разбить иначе, чтобы обеспечить более эффективное использование доступных рабочих узлов. Например, совокупность разделов матрицы 211 генотипов, основанной на разреженных векторах, может быть слишком большой для того, чтобы один или более рабочих узлов 1202A - 1202N обработали их своевременно. Тогда ведущий узел 1201 может запрашивать и/или инициировать иное разбиение матрицы 211 генотипов, основанной на разреженных векторах, чтобы генерировать размеры разделов, более подходящие для обработки рабочими узлами 1202A - 1202N. Например, способ 1900 разбиения на диапазоны, показанный на фиг. 19, может осуществлять вставку строки из одного и того же геномного местоположения в один и тот же файл. Такое разбиение по диапазонам может поддерживать эффективную обработку для запроса, основанного на диапазоне, но может быть менее подходящим для анализа всех относительно всех, поскольку некоторые геномные местоположения (например, область HLA) являются более плотными, чем другие (например, векторы являются менее разреженными), и для их обработки потребуется больше времени. Для анализа всех относительно всех ведущий узел 1201 может запрашивать и/или вызывать такое разбиение матрицы 211 генотипов, основанной на разреженных векторах, чтобы получаемые в результате разделы были сбалансированы по плотности распределения с целью сбалансировать время обработки.
[00122] В одном варианте осуществления, чтобы минимизировать перетасовку данных, ведущий узел 1201 может быть снабжен совокупностью ведущих экземпляров. На фиг. 12 показано, что ведущий узел 1201 может быть снабжен ведущим экземпляром M_1, ведущим экземпляром M_2, ведущим экземпляром M_3 и ведущим экземпляром M_N. Каждый ведущий экземпляр может быть приспособлен к координации выполнения подзадачи. Ведущий узел 1201 может быть приспособлен к принятию задачи, разделению задачи на совокупность подзадач и разделению каждой подзадачи на совокупность работ, подлежащих выполнению рабочими узлами 1202A - 1202N. Ведущий узел 1201 может генерировать очередь 1203 и присваивать участок очереди, связанный с подзадачей, каждому из ведущих экземпляров.
[00123] В одном варианте осуществления задача может выполнять анализ всех относительно всех. Задача может заключаться в сравнении разделов TM_1 - TM_N с разделами GM_1 - GM_N. Как описано ранее, раздел может представлять собой набор строк. Используемое в данном документе сравнение раздела с другим разделом может предусматривать сравнение одной или более строк одного раздела с одной или более строками другого раздела. В простейшем варианте осуществления сравнения данных (один генотип с одним фенотипом) сравнение может представлять собой просто сравнение строки со строкой, а не сравнение целого раздела с целым разделом. Задача может быть разделена на подзадачи, где каждая подзадача осуществляет сравнение одного раздела матрицы 301 признаков, основанной на разреженных векторах, с совокупностью разделов матрицы 211 генотипов, основанной на разреженных векторах. Подзадачи могут состоять в том, чтобы сравнить раздел TM_1 с разделами GM_1 - GM_N, сравнить раздел TM_2 с разделами GM_1 - GM_N, сравнить раздел TM_3 с разделами GM_1 - GM_N и сравнить раздел TM_N с разделами GM_1 - GM_N. Альтернативно каждая подзадача может осуществлять сравнение одного раздела матрицы 211 генотипов, основанной на разреженных векторах, с совокупностью разделов матрицы 301 признаков, основанной на разреженных векторах. Каждая подзадача может быть разделена на работы, где каждая работа отражает обработку, необходимую для выполнения подзадачи. Для подзадачи, заключающейся в сравнении раздела TM_1 с совокупностью разделов GM_1 - GM_N, работы могут заключаться в сравнении раздела TM_1 с разделом GM_1, сравнении раздела TM_1 с разделом GM_2, сравнении раздела TM_1 с разделом GM_3 и сравнении раздела TM_1 с разделом GM_N. Таким образом, каждый ведущий экземпляр M_1-M_N может быть приспособлен к выполнении подзадачи, извлеченной из очереди 1203, путем назначения работ из подзадачи рабочим узлам 1202A - 1202N.
[00124] Ведущий узел 1201 (например, посредством ведущих экземпляров M_1 - M_N) может предоставлять (или инициировать предоставление другой системой) каждому из совокупности рабочих узлов 1202A - 1202N один раздел из совокупности разделов матрицы 211 генотипов, основанной на разреженных векторах. Ведущий узел 1201 может инициировать получение совокупностью рабочих узлов 1202A - 1202N присвоенного раздела из файловой системы 220 и/или может инициировать отправку файловой системой 220 разделов на совокупность рабочих узлов 1202A - 1202N. В одном варианте осуществления каждый раздел из совокупности разделов матрицы 211 генотипов, основанной на разреженных векторах, расположенный на каждом рабочем узле, является уникальным. В одном варианте осуществления каждый раздел из совокупности разделов матрицы 211 генотипов, основанной на разреженных векторах, расположенный на каждом рабочем узле, может не быть уникальным. Ведущий узел 1201 или другой узел может предоставлять каждый раздел из совокупности разделов матрицы 211 генотипов, основанной на разреженных векторах, на каждый рабочий узел из совокупности рабочих узлов 1202A - 1202N.
[00125] На фиг. 12 показано, что ведущий экземпляр M_1 посредством очереди 1203 связан с подзадачей сравнения раздела TM_1 с разделами GM_1-GM_N. Соответственно, ведущий экземпляр M_1 предоставляет (или инициирует предоставление другой системой) рабочему узлу 1202A раздел GM_1, рабочему узлу 1202B раздел GM_2, рабочему узлу 1202C раздел GM_3и рабочему узлу 1202N раздел GM_N. Ведущий экземпляр M_1 предоставляет каждому из рабочих узлов 1202A - 1202N раздел TM_1. Ведущий экземпляр M_1 инициирует выполнение каждым из рабочих узлов 1202A - 1202N сравнения раздела TM_1 с соответствующим разделом генотипа, хранящимся на рабочем узле.
[00126] Когда рабочий узел завершает назначенную работу, могут быть выданы результаты. Результаты могут быть выданы на ведущий узел 1201, в файловую систему 210 и/или другие системы. Когда рабочий узел завершает выделенную работу, ведущий узел 1201 может инициировать посредством очереди 1203 назначение другим ведущим экземпляром работы уже бездействующему рабочему узлу. На фиг. 13 показано, что рабочий узел 1202A выполняет работу по сравнению раздела TM_1 с разделом GM_1 и предоставляет вывод 1301. Рабочие узлы 1202A обычно остаются бездействующими, пока остальные рабочие узлы не выполнят назначенные работы. Однако ведущий узел 1201 может инициировать посредством очереди 1203 назначение ведущим экземпляром M_2 работы из другой подзадачи (например, сравнить TM_2 с разделами GM_1-GM_N) рабочему узлу 1202A, пока другие рабочие узлы продолжают обрабатывать работы из исходной подзадачи (например, сравнивать TM_1 с разделами GM_1-GM_N). Соответственно, ведущий экземпляр M_2 предоставляет (или инициирует предоставление другой системой) рабочему узлу 1202A раздел TM_1 и инициирует выполнение рабочим узлом 1202A сравнения раздела TM_2 с разделом GM_1, сохраненным на рабочем узле 1202A. Когда остальные рабочие узлы завершают назначенные работы, связанные со сравнением TM_1 с соответствующими разделами генотипа, ведущий узел 1201 может инициировать назначение ведущим экземпляром M_2 работы для подзадачи, которая заключается в сравнении TM_2 с разделами GM_1-GM_N, рабочим узлам, когда рабочие узлы завершают исходные работы. Ведущий узел 1201 посредством очереди 1203 и ведущих экземпляров M_2 - M_N, может продолжать назначать новые работы из других подзадач рабочим узлам, когда рабочие узлы завершают работы из текущих подзадач. Такое управление работами позволяет избежать ненужных затрат и напрасно затраченных вычислительных ресурсов посредством размещения данных и назначения работ, минимизируя бездействующие ресурсы и перетасовку данных.
[00127] Распределенная вычислительная среда 1200 также может быть приспособлена к выполнению анализа одного относительно всех и всех относительно одного. Как описано выше, подзадача, такая как сравнение раздела TM_1 с разделами GM_1, GM_2, GM_3, GM_N, будет предоставлять результаты для сравнения одного (или более) признаков со всеми генотипами. В другом примере, чтобы сравнивать один (или более) генотипов со всеми признаками, каждому рабочему узлу может быть предоставлен уникальный раздел (TM_1, TM_2, TM_3, TM_N) матрицы 301 признаков, основанной на разреженных векторах, а затем раздел (например, GM_1, GM_2, GM_3 или GM_4), содержащий один или более генотипов, из матрицы 211 генотипов, основанной на разреженных векторах, может быть отправлен на каждый из рабочих узлов для сравнения с соответствующим разделом признаков, сохраненным на рабочих узлах.
[00128] Каждая подзадача, запущенная на рабочем узле, будет выполнять сравнения одного или более разреженных векторов генотипов, содержащихся в разделе GM, с одним или более разреженными векторами признаков, содержащимися в разделе TM, вместе с любыми метаданными образцов. Каждое сравнение в рамках подзадачи может выдавать одну или более данных сводной статистики, соответствующих сравнению разреженного (разреженных) вектора(-ов) генотипов и разреженного (разреженных) вектора(-ов) признаков, включающих без ограничения значения встречаемости, показатели распределения, статистические показатели ассоциации, их сочетания и т. п. В одном варианте осуществления, когда завершены все работы для всех подзадач, выход из всех подзадач и рабочих узлов необязательно может быть объединен, перетасован, приведен в компактную форму, подвергнут комбинации данных операций и т. п. Одно сравнение строки в разделе GM со строкой в разделе TM дает одну или более строк таблицы каркасов (например, каркасной структуры данных, более подробно описанной ниже). Сравнение одного раздела GM с одним разделом TM может генерировать один или более выходных файлов, содержащих строки для таблицы каркасов (например, каркасной структуры данных, более подробно описанной ниже) для этого сравнения на уровне разделов. Каждый рабочий узел может создавать множество выходных файлов меньшего размера со строками таблицы каркасов на основе сравнений, указанных подзадачами. После завершения работы совокупность файлов, сгенерированных рабочими узлами, может представлять полную выходную таблицу каркасов (например, каркасную структуру данных, более подробно описанную ниже).
[00129] На фиг. 14 показана в качестве примера таблица 1400 сопряженности для иллюстративных фенотипа и генотипа (SNP, варианта и т. д.), представленная, например, конкретным идентификатором строки «хромосома:положение:референт:альтернатива». Таблица 1400 сопряженности состоит из значений встречаемости субъектов. Данные для каждого генотипа с минорным аллелем «a» и мажорным аллелем «A» могут быть представлены как значения встречаемости статуса заболевания по встречаемости генотипов (например, a - a, A - a, и A - A). Таким образом, столбцы указывают генотип референтный аллель - референтный аллель, генотип референтный аллель - альтернативный аллель, генотип альтернативный аллель - альтернативный аллель и «не распознано» (данные отсутствуют или они сомнительны). Строки указывают на то, был ли субъект из популяции с заболеванием (с заболеванием сердца) или из контрольной популяции (без заболевания сердца).
[00130] Таблица 1400 сопряженности может быть использована для определения того, имеют ли значения встречаемости генотипов статистически значимую разницу между популяцией с заболеванием и контрольной популяцией. Проверки генетической ассоциации могут быть выполнены отдельно для каждого отдельного генотипа с генерированием сводной статистики. Согласно нулевой гипотезе об отсутствии ассоциации с заболеванием ожидается, что относительные частоты аллеля или генотипа будут одинаковыми в группе больных и в контрольной группе. Проверка ассоциации, таким образом, осуществляется посредством критерия χ2 для независимости строк и столбцов таблицы сопряженности. При традиционной проверке по критерию χ2 для ассоциации на основе таблицы сопряженности 2 × 3 значений встречаемости генотипов в группе с заболеванием и контрольной группе можно полагать, что каждый из генотипов имеет независимую ассоциацию с заболеванием и получаемая в результате проверка генотипической ассоциации характеризуется 2 степенями свободы (d.f.). Способы анализа таблицы сопряженности делают возможными альтернативные модели пенетрантности благодаря суммированию значений встречаемости разными способами. Пенетрантность относится к риску возникновения заболевания у заданного индивидуума. Генотип-специфические значения пенетрантности отражают риск возникновения заболевания с учетом генотипа. Например, для проверки доминантной модели пенетрантности, в которой любое количество копий аллеля A повышает риск возникновения заболевания, таблица сопряженности может быть сведена к таблице 2 × 2 значений встречаемости генотипов A/A против объединенных и a/A, и a/a. Для проверки рецессивной модели пенетрантности, в которой две копии аллеля A требуются для любого повышенного риска, таблица сопряженности сводится к значениям встречаемости генотипа a/a против объединенной встречаемости обоих генотипов a/A и A/A. Альтернативно любая модель пенетрантности, задающая некоторый вид тренда для риска с увеличением количества аллелей A, для которой все из аддитивной, доминантной и рецессивной моделей являются примерами, может оцениваться с использованием теста тренда Кохрана-Армитажа. В другом примере тест тренда Кохрана-Армитажа является способом направления тестов по критерию χ2 к этим более узким альтернативам. Мощность может быть улучшена при условии, что риски возникновения заболевания, связанные с генотипом a/A, являются промежуточными между связанными с генотипами a/a и A/A. В еще одном примере проверки ассоциации могут также быть проведены посредством методов соотношения правдоподобий (LR), в которых заключение основывается на правдоподобии того, что данные, соответствующие генотипу, получат статус заболевания. Правдоподобие наблюдаемых данных при предложенной модели ассоциации заболевания сравнивают с правдоподобием наблюдаемых данных при нулевой модели отсутствия ассоциации; при высоком значении LR нулевую гипотезу обычно отвергают. Все модели заболеваний могут быть проверены посредством LR-методик. Для больших выборок можно показать, что методы χ2 и LR являются эквивалентными при нулевой гипотезе. В качестве еще одного примера точный критерий Фишера является еще одной проверкой статистической значимости, которая может быть использована при анализе таблицы 1400 сопряженности.
[00131] Хотя таблица 1400 сопряженности может предоставить указание того, является ли ассоциация между генотипом и фенотипом статистически значимой, таблица 1400 сопряженности может быть асимметрична из-за ковариат. Такое искажение представляет тип отклонения в статистическом анализе, который возникает, когда существует фактор, имеющий причинную связь с результатом исследования (например, статусом больной-контрольный) независимо от представляющего основной интерес фактора (например, генотипа в заданном локусе) и связанный с переменной этого фактора, но не являющийся следствием переменной этого фактора. Могут существовать ковариаты, которые вносят вклад в такое искажение. Ковариаты включают любую переменную, отличную от основного фактора, представляющего интерес, которая с некоторой вероятностью может прогнозировать результат исследования; при этом ковариаты включают искажающие переменные, которые в дополнение к прогнозированию переменной результата связаны с фактором. Когда возникает необходимость включения дополнительных ковариат для обработки сложных признаков, используют более сложные модели логической регрессии для ассоциации. Примерами этого являются ситуации, в которых риск возникновения заболевания может быть изменен ковариатами, например, влияниями окружающей среды, такими как эпидемиологические факторы риска (например, курение и пол), клиническими переменными (например, тяжесть заболевания и возраст проявления) и стратификацией популяции (например, основные компоненты, захватывающие вариант вследствие отличающейся наследственности), или взаимодействующими и совместными эффектами других маркерных локусов. В моделях логической регрессии логарифм вероятности возникновения заболевания является переменной отклика, а линейные (аддитивные) комбинации объясняющих переменных (переменные генотипов и любые ковариаты) входят в модель в качестве ее предикторов. Для подходящих линейных предикторов коэффициенты регрессии, подобранные в логистической регрессии, представляют логарифм OR для ассоциации гена с заболеванием, описанной выше.
[00132] В одном варианте осуществления описана каркасная структура данных для определения того, следует ли применять более сложные модели, которые изначально являются вычислительно и финансово более дорогостоящими при выполнении в распределенной вычислительной среде 1200. На фиг. 15 показан пример каркасной структуры 1500 данных. Каркасная структура 1500 данных содержит столбец для идентификатора генотипа, столбец для идентификатора признака, таблицу 1400 сопряженности для соответствующих идентификатора генотипа и идентификатора признака и сводную статистику, определенную из таблицы 1400 сопряженности. В одном варианте осуществления каркасная структура 1500 данных может содержать один или более дополнительных столбцов, таких как, например, рецессивная/доминантная/аддитивная модель, критерии подмножества, исходная когорта, их комбинации и т. п. Каркасной структуре 1500 данных может быть присвоен уникальный идентификатор каркаса. Как описано ранее, однократное сравнение строки в разделе GM со строкой в разделе TM дает одну или более строк каркасной структуры 1500 данных. Сравнение одного раздела GM с одним разделом TM может генерировать один или более выходных файлов, содержащих строки для каркасной структуры 1500 данных для этого сравнения на уровне разделов. Каждый рабочий узел может создавать много выходных файлов меньшего размера со строками каркасной структуры 1500 данных на основе сравнений, указанных подзадачами. После завершения работы совокупность файлов, сгенерированных рабочими узлами, может представлять полный вывод каркасной структуры 1500 данных.
[00133] В одном варианте осуществления результаты анализа, выполненного рабочими узлами, могут быть предоставлены в качестве входных данных в матрицу 216 результатов. Как описано ранее, матрица 216 результатов может просматриваться браузером результатов. Результаты анализа, выполненного рабочими узлами, могут использоваться для генерирования отчетов, фигур, справок и т. п., выделяющих интересующие результаты. Результаты анализа, выполненного рабочими узлами, могут использоваться для идентификации «приоритетных» ассоциаций (например, по p-значению), новых ассоциаций, не наблюдавшихся ранее, ассоциаций, связанных с определенных заболеванием или интересующим геном, манхэттенских графиков и т. п. Таким образом, браузер результатов может использоваться в качестве инструмента, позволяющего делать такие типы представлений данных в процессе работы на основе пользовательских запросов.
[00134] Можно осуществить запрос к каркасной структуре 1500 данных, чтобы определить, следует ли выполнять более сложные операции для использования сложных моделей анализа применительно к базовым данным. В зависимости от конечного размера анализируемых данных и сложности модели анализа применение модели анализа может занять недели для обработки сотен рабочих узлов. Запросы могут выполняться для того, чтобы уменьшить объем данных, вводимых в более сложные модели анализа, и сократить за счет этого время обработки и/или количество рабочих узлов. Например, результат анализа всех относительно всех может дать большой объем данных результата из сравнения сотен миллиардов комбинаций генотип/фенотип. Многие данные результатов недостаточно коррелированы, чтобы гарантировать дальнейший анализ с использованием более сложной статистической модели. Например, использование точки отсечения p-значения, равного 0,05, из таблицы каркасов теоретически снижает количество необходимых последующих сравнений на 95%, поэтому время выполнения также может быть сокращено на 95%, обеспечивая значительную экономию затрат и времени, когда каждое отдельное сравнение занимает секунды или доли секунды для вычисления. Использование сложной модели анализа применительно ко всем данным результата анализа всех относительно всех требует больших вычислительных и финансовых затрат при выполнении в распределенной вычислительной среде 1200. Чтобы снизить сложность и стоимость, каркасная структура 1500 данных может использоваться для генерирования подмножества данных, с которыми можно выполнять более сложные операции. Запрос к каркасной структуре 1500 данных может быть осуществлен посредством одного или более из идентификатора генотипа, идентификатора признака, любого значения встречаемости, содержащегося в таблице 1400 сопряженности, сводной статистики, их комбинаций и т. п. Запрос к таблице 1400 сопряженности может быть осуществлен для идентификации строк, которые удовлетворяют пороговому значению встречаемости генотипов. Запрос сводной статистики может быть осуществлен для идентификации строк, которые удовлетворяют пороговому значению сводной статистики. Например, сводная статистика может предусматривать р-значение. Применительно к каркасной структуре 1500 данных каркаса может использоваться запрос, чтобы идентифицировать те строки, которые удовлетворяют заданной пороговой величине p-значения. В качестве дополнительного примера применительно к каркасной структуре 1500 данных может использоваться запрос, чтобы идентифицировать те строки, которые удовлетворяют заданному пороговому значению встречаемости генотипов. В дополнительном примере применительно к каркасной структуре 1500 данных может использоваться запрос, чтобы идентифицировать те строки, которые удовлетворяют как пороговой величине p-значения, так и заданному пороговому значению встречаемости генотипов.
[00135] На фиг. 16 показано, что ведущий узел 1201 может быть приспособлен к генерированию таблицы 1400 сопряженности и/или каркасной структуры 1500 данных. Ведущий узел 1201 может быть снабжен одним или более запросами 1601 для использования применительно к каркасной структуре 1500 данных после того, как она была сгенерирована, для отфильтровывания строк, которые не удовлетворяют одному или более запросам 1601. Затем применительно к результатам 1602 запроса может быть использована более сложная модель. Таким образом, ведущий узел 1201 может использовать каркасную структуру 1500 данных, чтобы выборочно уменьшить объем данных, на основе которых можно реализовывать модели анализа с более интенсивными вычислениями. Ведущий узел 1201 может автоматически инициировать выполнение задачи по использованию более сложной модели анализа применительно к сокращенному набору данных. Ведущий узел 1201 может быть приспособлен к использованию каскадного подхода применительно к запуску еще более интенсивных моделей анализа с еще более сокращенными наборами данных. После завершения любой сложной модели анализа результаты применения модели могут быть запрошены для дальнейшего автоматического сокращения набора данных и автоматического запуска следующей сложной модели анализа.
[00136] На фиг. 17 показан каскадный подход для анализа данных, при этом ведущий узел 1201 может запросить, чтобы рабочие узлы 1202A - 1202N проанализировали матрицы генотипов, основанные на разреженных векторах, и матрицы признаков, основанные на разреженных векторах, для генерирования каркасной структуры 1500 данных, как это описано в данном документе (например, анализ всех относительно всех). Ведущий узел 1201 может сгенерировать задачу 1701 для рабочих узлов 1202A - 1202N, чтобы использовать первую модель анализа (модель 1) применительно к результатам в каркасной структуре 1500 данных (например, точный критерий Фишера) и присоединить 1702 результаты к каркасной структуре 1500 данных.
[00137] Ведущий узел 1201 может осуществлять запрос 1703 к каркасной структуре 1500 данных на основе значения (например, статистического значения), чтобы определить результаты, которые являются статистически значимыми, на основе первой модели анализа. Например, ведущий узел 1201 может запросить любые результаты с p-значением, которое < 0,05. Результат 1704 запроса может представлять собой первые идентификаторы строк (например, идентификаторы строк генотипов и идентификаторы строк признаков), которые удовлетворяют запросу 1703. Ведущий узел 1201 может осуществлять запрос к совокупности разделов (TM_1, TM_2, TM_3, TM_N) матрицы 301 признаков, основанной на разреженных векторах, чтобы идентифицировать, какие разделы содержат идентификаторы строк признаков из первых идентификаторов строк, полученных путем осуществления запроса к каркасной структуре 1500 данных. В одном варианте осуществления ведущий узел 1201 может дополнительно осуществлять запрос к совокупности разделов (GM_1, GM_2, GM_3, GM_N) матрицы 301 генотипов, основанной на разреженных векторах, чтобы идентифицировать, какие разделы содержат идентификаторы строк генотипов из первых идентификаторов строк, полученных путем осуществления запроса к каркасной структуре 1500 данных. Затем ведущий узел 1201 может нацеливаться только на те рабочие узлы, которые содержат раздел матрицы 301 генотипов, основанной на разреженных векторах, который имеет отношение к анализу.
[00138] Затем ведущий узел 1201 может сгенерировать задачу 1705 для использования второй модели анализа (модели 2) совокупностью рабочих узлов 1202A - 1202N применительно к данным, идентифицированным первыми идентификаторами строк. Вторая модель анализа может быть более сложной и/или потребовать более интенсивных вычислений, чем первая модель анализа. Ведущий узел 1201 может использовать очередь 1203 и/или один или более ведущих экземпляров M_1 - M_N по мере необходимости. Ведущий узел 1201 может предоставлять или инициировать идентифицированный раздел (идентифицированные разделы) матрицы 301 признаков, основанной на разреженных векторах (или инициировать их предоставление другой системой), каждому из совокупности рабочих узлов 1202A - 1202N. Ведущий узел 1201 может также предоставлять идентификаторы строк генотипов из первых идентификаторов строк, полученных путем осуществления запроса к каркасной структуре 1500 данных, каждому из совокупности рабочих узлов 1202A - 1202N. Таким образом, каждый рабочий узел может осуществлять запрос к соответствующему разделу генотипа, хранящемуся локально, чтобы определить, обладает ли рабочий узел данными, относящимися к любому из идентификаторов строк генотипов. Если рабочий узел определяет, что соответствующий раздел генотипа, хранящийся локально, не содержит ни одного из принятых идентификаторов строк генотипов, то рабочий узел может перейти в режим ожидания, принять другую работу или может быть деинициализирован. Если рабочий узел определяет, что соответствующий раздел генотипа, хранящийся локально, содержит один или более из принятых идентификаторов строк генотипов, то рабочий узел может перейти к выполнению второй модели анализа с использованием принятых раздела признака и раздела генотипа. Для этого сравнения может потребоваться несколько дорогостоящих в плане вычислений операций, включая, в частности, создание плотной версии разреженного вектора со всеми индивидуумами, имеющими значение, объединение векторов в одну или более матриц в памяти, выполнение матричных операций и/или подпрограмм линейной алгебры и обмен данными между процессами (например, если векторы представлены на Scala или Java, но модель написана на C++ или R, процессы должны отправлять данные туда и обратно). Рабочие узлы могут генерировать результаты вследствие применения второй модели анализа. Рабочие узлы могут выводить результаты второй модели анализа. Результаты всех рабочих узлов могут быть объединены. Результаты рабочих узлов могут быть присоединены 1706 к каркасной структуре 1500 данных. Таким образом, можно снова осуществить запрос к обновленной каркасной структуре 1500 данных на присутствие недавно сгенерированных результатов, чтобы дополнительно сократить набор данных для дальнейшего анализа.
[00139] На фиг. 17 показано, что способ каскадного анализа данных может переходить к тому, что ведущий узел 1201 осуществляет запрос 1707 к каркасной структуре 1500 данных на основе значения (например, статистического значения), чтобы определить результаты, которые являются статистически значимыми, на основе второй модели анализа. Результат 1708 запроса может представлять собой вторые идентификаторы строк (например, идентификаторы строк генотипов и идентификаторы строк признаков), которые удовлетворяют запросу 1707. Ведущий узел 1201 может сгенерировать задачу 1709 для использования третьей модели анализа (модели 3) совокупностью рабочих узлов 1202A - 1202N, применительно к данным, идентифицированным вторыми идентификаторами строк. Третья модель анализа может быть более сложной и/или требовать более интенсивных вычислений, чем первая и/или вторая модели анализа. Рабочие узлы могут использовать третью модель анализа применительно к разделу (разделам) признаков и разделу (разделам) генотипов, как описано выше, и могут выводить результаты третьей модели анализа. Результаты всех рабочих узлов могут быть объединены. Результаты рабочих узлов могут быть присоединены 1710 к каркасной структуре 1500 данных.
[00140] Способ каскадного анализа данных может переходить к тому, что ведущий узел 1201 осуществляет запрос 1711 к каркасной структуре 1500 данных на основе значения (например, статистического значения), чтобы определить результаты, которые являются статистически значимыми, на основе третьей модели анализа. Результат 1712 запроса может представлять собой третьи идентификаторы строк (например, идентификаторы строк генотипов и идентификаторы строк признаков), которые удовлетворяют запросу 1711. Ведущий узел 1201 может сгенерировать задачу 1713 для использования четвертой модели анализа (модели 4) совокупностью рабочих узлов 1202A - 1202N, применительно к данным, идентифицированным третьими идентификаторами строк. Четвертая модель анализа может быть более сложной и/или требовать более интенсивных вычислений, чем первая, вторая и/или третья модели анализа. Рабочие узлы могут использовать четвертую модель анализа применительно к разделу (разделам) признаков и разделу (разделам) генотипов, как это описано выше, и могут выводить результаты третьей модели анализа. Результаты всех рабочих узлов могут быть объединены. Результаты рабочих узлов могут быть присоединены 1714 к каркасной структуре 1500 данных.
[00141] Способ каскадного анализа данных может переходить к последующему применению способов анализа, фильтрованию наборов данных на основе способов анализа и применению более сложных и/или требующих более интенсивных вычислений способов анализа. В одном варианте осуществления результаты анализа, выполненного рабочими узлами, могут быть предоставлены в качестве входных данных в матрицу 216 результатов.
[00142] В приведенном в качестве примера варианте осуществления способы и системы могут быть реализованы на компьютере 2001, как проиллюстрировано на фиг. 18 и описано ниже. Аналогичным образом в способах и системах может использоваться один или более компьютеров для выполнения одной или более функций в одном или более местоположениях. На фиг. 18 показана структурная схема, иллюстрирующая приведенную в качестве примера операционную среду для выполнения способов. Эта приведенная в качестве примера операционная среда является лишь примером операционной среды и не предполагает каких-либо ограничений в отношении объема применения или функциональности архитектуры операционной среды. Также не следует истолковывать операционную среду как имеющую какие-либо зависимость или требование, относящиеся к любому из компонентов или их комбинациям, показанных в приведенной в качестве примера операционной среде.
[00143] Способы и системы по настоящему изобретению могут функционировать с многочисленными другими средами или конфигурациями вычислительных систем общего назначения или специализированного назначения. Примеры вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с системами и способами, включают без ограничения персональные компьютеры, серверные компьютеры, портативные компьютеры и многопроцессорные системы. Дополнительные примеры включают компьютерные приставки, программируемую бытовую электротехнику, сетевые персональные компьютеры, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые содержат любые из указанных выше систем или устройств.
[00144] Обработка согласно способам и системам по настоящему изобретению может выполняться посредством компонентов программного обеспечения. Системы и способы могут быть описаны в общем контексте выполняемых компьютером команд, таких как программные модули, выполняемые одним или более компьютерами или другими устройствами. Как правило, программные модули включают вычислительный код, процедуры, программы, объекты, компоненты, структуры данных и т. д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Способы также можно осуществлять на практике посредством сетевых и распределенных вычислительных сред, в которых задачи выполняются устройствами удаленной обработки, которые связаны посредством сети связи. В распределенной вычислительной среде программные модули могут быть расположены как на локальных, так и на удаленных компьютерных носителях информации, включая запоминающие устройства.
[00145] Обработка согласно способам и системам может выполняться посредством инфраструктуры кластерных вычислений, такой как APACHE SPARK. В одном варианте осуществления инфраструктура кластерных вычислений может предоставлять интерфейс прикладного программирования, основанный на устойчивом распределенном наборе данных (RDD). RDD может содержать доступное только для чтения мультимножество элементов данных, распределенных по кластеру компьютеров или других устройств обработки. В одном варианте осуществления кластер реализован с одним или более допустимыми сбоями. В одном варианте осуществления инфраструктура кластерных вычислений может включать диспетчер кластера, управляющий производительностью каждого устройства в кластере, и распределенную систему хранения.
[00146] В одном варианте осуществления инфраструктура кластерных вычислений может реализовать интерфейс прикладного программирования (API), основанный на абстракции RDD. В одном варианте осуществления API может обеспечивать функции диспетчеризации распределенных задач, планирования и/или ввода/вывода (I/O). В одном варианте осуществления API может отражать функциональную модель программирования/модель программирования высшего порядка. Например, программа может вызывать параллельные операции, такие как сопоставление, фильтрация или сокращение в RDD, передавая функцию в планировщик, который затем планирует исполнение функции параллельно в кластере. В одном варианте осуществления такие операции могут принимать RDD как ввод и создавать новый RDD как вывод. В одном варианте осуществления отказоустойчивость может быть достигнута путем отслеживания последовательности операций для создания каждого RDD, что позволяет восстановить RDD в случае потери данных.
[00147] В одном варианте осуществления инфраструктура кластерных вычислений может реализовывать абстракцию данных, которая обеспечивает поддержку структурированных и полуструктурированных данных, также называемых «кадрами данных». В одном варианте осуществления инфраструктура кластерных вычислений может реализовывать специфичный для предметной области язык для управления кадрами данных, закодированными в заданном языке программирования или формате. В одном варианте осуществления это может облегчить осуществление запросов на языке структурированных запросов (SQL).
[00148] В одном варианте осуществления инфраструктура кластерных вычислений может выполнять потоковую передачу аналитических данных для приема данных пакетами или частями и осуществление преобразований RDD для этих пакетов данных. Это позволяет использовать тот же набор кодов приложения, который написан для пакетных аналитических данных, для потоковой передачи аналитических данных, что способствует лямбда-архитектуре. В другом варианте осуществления данные могут обрабатываться постадийно, а не партиями. В одном варианте осуществления инфраструктура кластерных вычислений может включать инфраструктуру распределенного машинного обучения. Потоковая передача обеспечивает масштабируемую, высокопроизводительную, отказоустойчивую потоковую обработку потоков данных в реальном времени. Данные могут быть получены из многих источников и могут обрабатываться с использованием сложных алгоритмов (например, алгоритмов, выраженных посредством высокоуровневых функций, таких как, в частности, отображение, уменьшение, объединение и финитная взвешивающая функция). И наконец, обработанные данные могут быть отправлены в файловые системы, базы данных и оперативные информационные панели. В одном варианте осуществления один или более алгоритмов машинного обучения и/или обработки графов могут выполняться для потоков данных.
[00149] В одном варианте осуществления инфраструктура кластерных вычислений может принимать потоки входных данных в реальном времени и разделять данные на пакеты, которые затем обрабатываются для генерирования окончательного потока результатов в пакетах. Потоковая передача обеспечивает высокоуровневую абстракцию, называемую дискретизированным потоком или DStream, которая представляет непрерывный поток данных. DStream могут быть получены либо из потоков входных данных из источников, либо путем задействования высокоуровневых операций к другим DStream. Внутри DStream может быть представлен в виде последовательности устойчивых распределенных наборов данных (RDD). Устойчивый распределенный набор данных (RDD) представляет неизменяемую, разбитую совокупность элементов, с которыми можно работать параллельно.
[00150] Кроме того, системы и способы могут быть реализованы посредством вычислительного устройства в виде компьютера 1801. Компоненты компьютера 1801 могут предусматривать без ограничения один или более процессоров 1803, системную память 1812 и системную шину 1813, которая соединяет различные компоненты системы, в том числе один или более процессоров 1803 с системной памятью 1812. Система может использовать параллельную вычислительную обработку.
[00151] Системная шина 1813 представляет собой один или более из нескольких возможных типов шинных структур, в том числе шину запоминающего устройство или контроллер запоминающего устройства, периферийную шину, ускоренный графический порт или локальную шину с использованием любой из совокупности шинных архитектур. Шина 1813 и все шины, указанные в данном описании, могут быть также реализованы посредством проводного или беспроводного сетевого соединения, и каждая из подсистем, в том числе один или более процессоров 1803, запоминающее устройство 1804 большой емкости, операционная система 1805, программное обеспечение 1806, данные 1807, сетевой адаптер 1808, системная память 1812, интерфейс 1810 ввода/вывода, графический адаптер 1809, устройство 1811 отображения и интерфейс 1802 «человек-машина», может находиться в пределах одного или более удаленных вычислительных устройств 1814a, b,c, находящихся в физически отделенных местоположениях, соединенных посредством шин данного типа, в результате чего реализуется полностью распределенная система.
[00152] Компьютер 1801, как правило, содержит ряд различных машиночитаемых носителей. Приведенные в качестве примера считываемые носители могут представлять собой любые доступные носители, доступ к которым осуществляется посредством компьютера 1801, и они предусматривают, например, без ограничения как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. Системное запоминающее устройство 1812 содержит машиночитаемые носители в виде энергозависимого запоминающего устройства, такого как запоминающее устройство с произвольным доступом (RAM), и/или энергонезависимого запоминающего устройства, такого как запоминающее устройство с постоянным доступом (ROM). Системная память 1812, как правило, содержит данные, как, например, данные 1807, и/или программные модули, как, например, операционная система 1805 и программное обеспечение 1806, которые непосредственно доступны для одного или более процессоров 1803 и/или в данный момент подвергаются обработке с их помощью. Данные 1807 могут содержать, например, одно или более из матрицы 201 генотипов, матрицы 202 количественных признаков, матрицы 203 двоичных признаков, метаданных 204 образцов, матрицы 206 результатов, матрицы 211 генотипов, основанной на разреженных векторах, матрицы 212 количественных признаков, основанной на разреженных векторах, матрицы 213 двоичных признаков, основанной на разреженных векторах, метаданных 214 образцов, матрицы 216 результатов, матрицы 301 признаков, основанной на разреженных векторах, таблицы 1400 сопряженности, каркасной структуры 1500, их разделов, их комбинаций и т. п. Данные 1807 могут быть разбиты, например, согласно способу 1900 разбиения (показанному на фиг. 19). Способ 1900 разбиения может предусматривать генерирование согласованных размеров разделов (например, для предотвращения асимметрии) и создание разделов в диапазоне размеров от ~100 Мбайт до 2 Гбайт для повышения производительности чтения. Данные 1807 могут храниться на вычислительном устройстве 1801 или могут храниться распределенным образом на удаленных вычислительных устройствах 1814a, b,c.
[00153] В другом варианте осуществления компьютер 1801 также может содержать другие съемные/несъемные энергозависимые/энергонезависимые компьютерные носители информации. В качестве примера на фиг. 18 проиллюстрировано запоминающее устройство 1804 большой емкости, которое может обеспечивать энергонезависимое хранение программного кода, машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 1801. Например, без ограничения запоминающее устройство 1804 большой емкости может представлять собой жесткий диск, съемный магнитный диск, съемный оптический диск, магнитные кассеты или другие магнитные запоминающие устройства, карты флеш-памяти, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое запоминающее устройство, блоки оперативной памяти (RAM), блоки постоянной памяти (ROM) и/или электрически стираемое программируемое постоянное запоминающее устройство (EEPROM).
[00154] Необязательно любое количество программных модулей может храниться на запоминающем устройстве 1804 большой емкости, в том числе в качестве примера операционная система 1805 и программное обеспечение 1806. Каждое из операционной системы 1805 и программного обеспечения 1806 (или какой-либо их комбинации) может содержать элементы программ и программное обеспечение 1806. Данные 1807 также могут храниться на запоминающем устройстве 1804 большой емкости. Данные 1807 могут храниться в любой из одной или более баз данных. Примеры таких баз данных включают DB2®, MICROSOFT® Access, MICROSOFT® SQL Server, ORACLE® и/или MYSQL®, POSTGRESQL®. Базы данных могут быть централизованными или распределенными между несколькими системами.
[00155] В другом варианте осуществления пользователь может вводить инструкции и информацию в компьютер 1801 посредством устройства ввода данных (не показано). Примеры таких устройств ввода данных включают без ограничения клавиатуру, указательное устройство (например, «мышь»), микрофон, джойстик, сканер, устройства тактильного ввода, как, например, перчатки и/или другие покрывающие тело предметы. Эти и другие устройства ввода данных могут быть соединены с одним или более процессорами 1803 посредством интерфейса 1802 «человек-машина», которые соединены с системной шиной 1813, но могут быть соединены посредством другого интерфейса и шинных структур, таких как параллельный порт, игровой порт, порт IEEE 1394 (также называемый портом Firewire), последовательный порт или универсальная последовательная шина (USB).
[00156] В еще одном варианте осуществления устройство 1811 отображения также может быть соединено с системной шиной 1813 посредством интерфейса, такого как графический адаптер 1809. Подразумевается, что компьютер 1801 может иметь более одного графического адаптера 1809, и компьютер 1801 может иметь более одного устройства 1811 отображения. Например, устройство отображения может представлять собой монитор, LCD (жидкокристаллический дисплей) или проектор. В дополнение к устройству 1811 отображения другие периферийные устройства вывода могут предусматривать такие компоненты, как громкоговорители (не показаны) и принтер (не показан), которые могут быть соединены с компьютером 1801 посредством интерфейса 1810 ввода/вывода. Любые стадия и/или результат способов могут быть выведены в любой форме на устройство вывода. Такой выводимый результат может быть представлен в любой форме визуального представления, в том числе без ограничения в текстовой, графической, анимационной, звуковой и/или тактильной формах. Дисплей 1811 и компьютер 1801 могут быть частью одного устройства или отдельными устройствами.
[00157] Компьютер 1801 может функционировать в сетевой среде с использованием логических соединений с одним или более удаленными вычислительными устройствами 1814a, b,c. В качестве примера удаленное вычислительное устройство может представлять собой персональный компьютер, портативный компьютер, смартфон, сервер, маршрутизатор, сетевой компьютер, одноранговое устройство или другой общий узел сети и т. д. Логические соединения между компьютером 1801 и удаленным вычислительным устройством 1814a, b,c могут быть установлены посредством сети 1815, такой как локальная вычислительная сеть (LAN) и/или общая глобальная вычислительная сеть (WAN). Такие сетевые соединения могут быть осуществлены посредством сетевого адаптера 1808. Сетевой адаптер 1808 может быть реализован как в проводной, так и в беспроводной средах. В одном варианте осуществления системная память 1812 может хранить один или более объектов, доступных для одного или более удаленных вычислительных устройств 1814a, b,c по сети 1815. Таким образом, компьютер 1801 может служить в качестве облачного хранилища объектов. В другом варианте осуществления одно или более из одного или более удаленных вычислительных устройств 1814a, b,c могут хранить один или более объектов, доступных для компьютера 1801 и/или другого из одного или более удаленных вычислительных устройств 1814a, b,c. Таким образом, одно или более удаленных вычислительных устройств 1814a, b,c также могут служить в качестве облачного хранилища объектов.
[00158] В целях иллюстрации прикладные программы и другие выполняемые компоненты программ, как, например, операционная система 1805, проиллюстрированы в настоящем документе в виде дискретных блоков, хотя понятно, что такие программы и компоненты находятся в различные моменты времени в разных запоминающих компонентах вычислительного устройства 1801 и их исполнение реализуется одним или более процессорами 1803 компьютера. В одном варианте осуществления по меньшей мере часть программного обеспечения 1806 и/или данных 1807 может храниться на и/или выполняться в одном или более из вычислительного устройства 1801, удаленных вычислительных устройств 1814a, b,c и/или их комбинаций. Таким образом, использование программного обеспечения 1806 и/или данных 1807 может быть реализовано в пределах среды облачных вычислений, вследствие чего доступ к программному обеспечению 1806 и/или данным 1807 можно получать по сети 1815 (например, сети интернет). Более того, в варианте осуществления данные 1807 можно синхронизировать между одним или более из вычислительного устройства 1801, удаленных вычислительных устройств 1814a, b,c, и/или их комбинаций.
[00159] Вариант реализации программного обеспечения 1806 может храниться на энергонезависимых машиночитаемых носителях или передаваться посредством какого-либо их типа. Любой из способов можно выполнять посредством машиночитаемых команд, реализованных на машиночитаемых носителях. Машиночитаемые носители могут представлять собой любые доступные носители, доступ к которым может быть получен посредством компьютера. В качестве примера и без ограничения машиночитаемые носители могут предусматривать «компьютерные носители информации» и «средства связи». «Компьютерные носители информации» включают энергозависимые и энергонезависимые съемные и несъемные носители, реализованные посредством любых способов или технологии хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Приведенные в качестве примера компьютерные носители информации включают без ограничения RAM, ROM, EEPROM, флеш-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитных дисках, или другие магнитные запоминающие устройства, или любой другой носитель, который можно использовать для хранения требуемой информации, и доступ к которым может быть получен посредством компьютера.
[00160] Программное обеспечение 1806 может быть приспособлено к выполнению некоторых или всех стадий способов, раскрытых в данном документе. В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к определению ассоциации одного или более генов или одного или более генетических вариантов с одним или более фенотипами посредством осуществления доступа к генетическим данным, осуществления доступа к фенотипическим данным и выполнения статистического анализа ассоциации одного или более генов или одного или более генетических вариантов с одним или более фенотипами. В одном варианте осуществления один или более фенотипов представляют собой один или более двоичных фенотипов. В другом варианте осуществления один или более фенотипов представляют собой один или более количественных фенотипов. Неограничивающие примеры статистического анализа включают точный критерий Фишера, линейную смешанную модель, линейную смешанную модель Болта, логистическую регрессию, регрессию Ферта, общую модель регрессии и линейную регрессию.
[00161] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к визуализации результатов ассоциации генетический вариант-фенотип посредством осуществления доступа к генетическим данным, осуществления доступа к фенотипическим данным, и выполнения статистического анализа ассоциации одного или более генов или одного или более генетических вариантов с одним или более фенотипами, и визуализации одного или более результатов ассоциации генетический вариант-фенотип. В одном варианте осуществления результаты визуализируются в представлении GWAS. В другом варианте осуществления результаты визуализируются в представлении GWAS как манхэттенский график. В другом варианте осуществления манхэттенский график представляет собой динамический график. В другом варианте осуществления результаты визуализируются в представлении PheWas. В другом варианте осуществления результаты визуализируются в представлении PheWAS как график в стиле PHEHATTAN. В другом варианте осуществления график в стиле PHEHATTAN представляет собой динамический график.
[00162] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к разбиению данных. Программное обеспечение 1806 может быть приспособлено к выполнению способа 1900 разбиения, показанного на фиг. 19. Способ 1900 разбиения может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. Способ 1900 разбиения может быть основан на местоположении в геноме. При заданных наборе входных данных, размере целевого файла и количестве файлов, которые необходимо назначать каждому разделу, способ 1900 разбиения может включать определение количества отдельных записей данных (например, рядов) из набора данных, которые будут примерно удовлетворять размеру целевого файла, на стадии 1902. Способ 1900 разбиения может сначала включать применение разбиения высшего уровня по хромосоме, чтобы гарантировать, что разделы не охватывают несколько хромосом. Тогда относительно каждой хромосомы способ 1900 разбиения может предусматривать определение количества выходных файлов для генерирования на основе оцененного количества записей на один целевой файл, разделенного на количество записей, представленных по хромосоме, на стадии 1904. Способ 1900 разбиения может затем предусматривать сканирование записей для определения внутренних границ диапазонов, которые будут разбивать данные на требуемое количество смежных неперекрывающихся интервалов, каждый из которых будет соответствовать одному выходному файлу, на стадии 1906. Если требуемое количество файлов на раздел диапазона превышает 1, собственно интервалы (выходные файлы) могут быть сгруппированы в смежные интервалы соседствующих диапазонов на стадии 1908, и может быть назначен новый раздел сверхдиапазона с границами, равными минимальной и максимальной координатам поддиапазонов, которые он охватывает, на стадии 1910. Сперва можно определить сверхдиапазоны, имея требуемое количество поддиапазонов, на которые необходимо разбивать, для выходных файлов, а отдельные файлы в пределах раздела сверхдиапазона можно разбить аналогичным образом на следующей стадии. Если сверхдиапазон предварительно рассчитан, несколько выходных файлов для сверхдиапазона можно разбить на куски в случайной последовательности, которые не являются смежными. Собственно выходные файлы могут быть или в случайном порядке упорядочены, или организованы таким способом (например, отсортированы по геномной координате), который повышает скорости доступа для запросов, которые должны считывать данные, назначенные для файла. Файлы могут быть сжатыми. Каждый раздел может содержать один или более файлов и/или один или более каталогов. Каталоги могут быть названы так, чтобы соответствовать хромосомным разделам. Файлы данных, сохраненные в каталоге, могут быть названы так, чтобы соответствовать хромосоме, ассоциируемой с каталогом, который содержит эти файлы данных. Названия каталогов и/или файлов данных также могут включать геномный диапазон. Таким образом, поиск по названию гена может включать определение хромосомы, которая содержит данное название и требуемые координаты. Каталог, который соответствует хромосоме, может быть определен, и подкаталог (подкаталоги), который соответствует (соответствуют) геномному (геномным) диапазону (диапазонам), перекрывающемуся (перекрывающимся) с координатами запрашиваемого гена, может (могут) быть эффективно извлечен(ы). Разделы предпочтительно генерируют так, чтобы поддерживать разделы относительно равного размера с учетом количества хранимых данных. Могут быть случаи, когда определенные геномные локусы имеют больший объем ассоциированных данных, чем другие геномные локусы. В этом случае значения длины диапазонов в системе геномных координат, соответствующие каждому разделу, могут быть соответственно откорректированы. Благодаря способу разбиения запросы к матрице 216 результатов, которая может содержать десятки миллиардов строк, можно сократить с 30 минут до менее чем 5 секунд.
[00163] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к генерированию матриц, основанных на разреженных векторах, и/или осуществлению запроса к ним. Программное обеспечение 1806 может быть приспособлено к выполнению способа 2000, показанного на фиг. 20. Способ 2000 может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. В ходе работы система 210, основанная на разреженных векторах, может выполнять способ 2000, предусматривающий прием на стадии 2002 данных о генотипе, данных о фенотипе и/или метаданных для совокупности индивидуумов (например, субъектов). Совокупность индивидуумов может быть частью когорты. Совокупность индивидуумов может быть частью нескольких когорт. В некоторых случаях один или более индивидуумов будут входить в более чем одну когорту. В некоторых случаях данные о фенотипе субъекта могут быть получены из медицинских записей. Чтобы получить единое значение для фенотипа (например, обозначение больной/контрольный для двоичного признака или единичного измерения холестерина LDL), сводная статистика и/или эвристика используются применительно к одному или последовательности измерений и/или диагнозов для отнесения индивидуумов к носителям или к не являющимся носителями двоичного фенотипа или к единственному репрезентативному значению для количественного признака (например, максимальному зарегистрированному в течение жизни уровню холестерина LDL). В одном варианте осуществления сводная статистика и/или эвристика могут давать количественное значение, представляющее вероятность того, что у субъекта имеется двоичный фенотип. Эти процессы позволяют создать матрицу фенотипов, имеющую двоичные, категориальные или количественные значения, представляющие совокупность необработанной клинической информации.
[00164] Способ 2000 может предусматривать генерирование на стадии 2004 одной или более из матрицы генотипов, матрицы количественных признаков и/или матрицы двоичных признаков. Матрица генотипов может быть сгенерирована на основе данных о генотипе. Чтобы гарантировать, что одни и те же генетические варианты, наблюдаемые у нескольких индивидуумов и/или нескольких когорт, кодируются аналогичным образом, что позволяет их идентификаторам строк быть одинаковыми, варианты, распознанные из схемы секвенирования, могут быть нормализованы до стандартного кодирования. Матрица генотипов может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов. Матрица количественных признаков может быть сгенерирована на основе данных о фенотипе. Матрица количественных признаков может содержать столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов. Матрица двоичных признаков может быть сгенерирована на основе данных о фенотипе. Матрица двоичных признаков может содержать столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов. Способ 2000 может дополнительно предусматривать присоединение по меньшей мере части матрицы метаданных к каждой из матрицы количественных признаков и матрицы двоичных признаков. Матрица метаданных может содержать, например, данные, относящиеся к одной или более аннотациям (двоичные, категориальные или непрерывные), которые могут включать 1) ковариаты в моделях исследования корреляций генотип/фенотип и 2) отметки для определения подмножеств образцов. В качестве примера матрица метаданных образцов может содержать аннотации для возраста, пола, генетически определенных предков, генотипических основных компонентов, показателей качества секвенирования и/или их комбинации. Аннотации могут содержать числовые аннотации, но не символьные строки. Может быть установлено цифровое отображение, например женщина=1, мужчина=2. Отображение декодирования/кодирования может быть сохранено (например, в виде столбца в матрице) таким образом, что каждую строку можно перекодировать как соответствующую символьную строку.
[00165] Способ 2000 может предусматривать присваивание на стадии 2006 посредством менеджера идентификаторов глобального идентификатора и идентификатора вектора каждому из совокупности индивидуумов. Индивидууму могут быть присвоены более одного идентификатора вектора и только один глобальный идентификатор.
[00166] Способ 2000 может предусматривать генерирование на стадии 2008 на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа. Структура данных в виде n-кортежа может содержать любое количество кортежей, например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше кортежей. В одном варианте осуществления структура данных в виде n-кортежа может содержать 3 кортежа и называться тройкой. Структура данных в виде n-кортежа может содержать идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца. Идентификатор строки может содержать следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива. Идентификатор столбца может содержать идентификатор когорты и/или глобальный идентификатор.
[00167] Способ 2000 может предусматривать определение на стадии 2010 матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и/или матрицы двоичных признаков, основанной на разреженных векторах. Матрицу генотипов, основанную на разреженных векторах, можно определить на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов. Матрица генотипов, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец может содержать разреженный вектор, представляющий одно или более значений матрицы генотипов. Матрица количественных признаков, основанная на разреженных векторах, может быть определена на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков. Матрица количественных признаков, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец может содержать разреженный вектор, представляющий одно или более значений матрицы количественных признаков. Матрица двоичных признаков, основанная на разреженных векторах, может быть определена на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков. Матрица двоичных признаков, основанная на разреженных векторах, может содержать столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов. По меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
[00168] Для определения матриц, основанных на разреженных векторах, одно значение может быть определено как «разреженное значение» для каждого типа матрицы. В некоторых вариантах осуществления значение может представлять собой ненулевое значение. Например, разреженный вектор, представляющий одно или более значений матрицы генотипов, может содержать структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, у которого имеется ненулевое значение в строке матрицы генотипов. Разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков. Разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора вектора (идентификатора когорты), ассоциированного с индивидуумом, у которого имеется ненулевое значение в столбце матрицы двоичных признаков. Разреженные векторы, представляющие одно или более значений матрицы генотипов или матрицы количественных признаков, могут быть приспособлены к отбрасыванию значений, равных 0 (нулю). Разреженный вектор, представляющий одно или более значений матрицы количественных признаков, может быть приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
[00169] В некоторых вариантах осуществления разреженное значение не сохраняется, а скорее выводится по отсутствию сохраненных данных. Это сводит к минимуму объем хранилища данных и улучшает потребление дискового пространства и памяти компьютера. Например, что касается матрицы генотипов, основанной на разреженных векторах, наиболее распространенным значением является гомозиготный референт (например, равное 0 значение), поэтому использование гомозиготного референта в качестве разреженного значения обеспечивает улучшенное сжатие данных. В качестве еще одного примера, что касается матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, «неопределенное» значение (например, отсутствие данных о фенотипе) может использоваться как разреженное значение, поскольку такие индивидуумы обычно исключаются из последующих анализов. Одним из факторов, влияющих на выбор разреженного значения, является идентификация того, какое значение приведет к максимальному/оптимальному сжатию. Другие факторы, влияющие на выбор разреженного значения, включают вычислительную сложность распаковки (например, уплотнения) разреженного значения и выполнения таких операций, как операция с подмножеством.
[00170] Способ 2000 может включать обработку на этапе 2012 одного или более запросов к матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и/или матрице двоичных признаков, основанной на разреженных векторах. В одном варианте осуществления обработка одного или более запросов может предусматривать выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах. Соответственно, могут быть обработаны один или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и матрице двоичных признаков, основанной на разреженных векторах. Обработка одного или более запросов может предусматривать прием ввода запроса и определение присутствия или отсутствия данных в матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, и/или матрице двоичных признаков, основанной на разреженных векторах, которые «соответствуют» вводу запроса. Определение соответствия вводу запроса может предусматривать идентификацию идентичного соответствия или частичного соответствия. Обработка одного или более запросов может предусматривать некоторые или все из способов, описанных в данном документе, включая, например, способы, описанные применительно к фиг. 21 - фиг. 24.
[00171] Способ 2000 может дополнительно предусматривать прием дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов. Способ 2000 может дополнительно предусматривать присваивание менеджером идентификаторов идентификатора вектора (идентификатора когорты) каждому индивидууму в совокупности индивидуумов и глобальный идентификатор - каждому индивидууму в совокупности индивидуумов. Менеджер идентификаторов может осуществлять идентификацию каждого индивидуума, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, и может присваивать один и тот же глобальный идентификатор каждому повторяющемуся индивидууму, но разные идентификаторы вектора (идентификаторы когорты). В некоторых вариантах осуществления индивидууму может быть присвоено более одного глобального идентификатора.
[00172] Способ 2000 может дополнительно предусматривать добавление по меньшей мере части дополнительных данных о генотипе в матрицу генотипов, добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков, добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков и повторное присоединение по меньшей мере части матрицы метаданных к каждой из матрицы количественных признаков и матрицы двоичных признаков. Эта функциональность позволяет создавать производные матрицы, которые могут включать всех индивидуумов или их подмножество из одной или более когорт, которые можно в совокупности анализировать. Поскольку количество возможных комбинаций индивидуумов для включения в производные матрицы является экспоненциальным, предварительное вычисление этих производных матриц является нетривиальным и ограничивающим.
[00173] Способ 2000 может дополнительно предусматривать генерирование на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации. Способ 2000 может дополнительно предусматривать разбиение матрицы результатов ассоциации. Разбиение матрицы результатов ассоциации может предусматривать генерирование структуры данных в виде каталога для каждой из совокупности хромосом, разделение матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону и сохранение на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
[00174] После того как матрицы 211, 212 и 213, основанные на разреженных векторах, были сгенерированы и сохранены, высокопроизводительная схема 205 конвейерной обработки данных может выполнять автоматизированную последовательность стадий схемы конвейерной обработки для первичного и вторичного анализа данных для некоторых или всех данных, содержащихся в одной или более из матрицы 211 генотипов, основанной на разреженных векторах, матрицы 212 количественных признаков, основанной на разреженных векторах, и/или матрицы 213 двоичных признаков, основанной на разреженных векторах, с использованием биоинформационных инструментов, результаты которого могут быть сохранены в матрице 216 результатов.
[00175] Путем генерирования матриц 211, 212 и 213, основанных на разреженных векторах, и матрицы 214 метаданных, имеющих совместимые схемы, многие вторичные операции с этими данными упрощаются. Например, часто требуется создать собственные фенотипы или генотипы, которые происходят из некоторого сочетания фенотипов или генотипов в лежащих в основе матрицах. Это может включать создание собственного двоичного фенотипа с использованием существующего двоичного признака в качестве отправной точки, но затем используется количественный признак (например, лабораторное значение) для уточнения статуса больного/контрольного. В другом варианте осуществления может быть создан собственный двоичный признак, который влияет на носителей с конкретной мутацией или без нее (например, болезнь Альцгеймера без известной мутации APOE4, являющейся фактором риска). В качестве альтернативы собственный генотип может быть получен из совокупности отдельных вариантов, например, суммирования значений встречаемости аллелей двух известных вариантов риска для создания генотипа с баллами риска. Все эти операции могут быть определены путем осуществления запроса к различным строкам из матриц 211, 212 и 213, основанных на разреженных векторах, и/или матрицы 214 метаданных. Агрегация строк, возвращаемых из запроса, может осуществляться посредством разных способов, включая определение функции агрегации, которая работает с последовательностью разреженных векторов. В качестве альтернативы может быть желательным сперва преобразовать разреженные векторы в их плотное представление, используя транспонирование и осуществляя считывание в стандартный инструмент для анализа нераспределенных данных, например R. В этом случае возвращенные строки разреженных векторов собирают в единую машину, осуществляют расширение до плотных векторов (например, разреженные значения обратно добавляют), и транспонируют так, что индивидуумы представляют строки, а различные идентификаторы разреженных векторов становятся столбцами. Затем это представление можно проанализировать посредством традиционных инструментов для исследовательских целей, где точная логика агрегации требует проверки и ручных манипуляций.
[00176] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к выполнению анализа всех относительно всех (всех генотипов по отношению ко всем фенотипам), анализа всех относительно одного (всех генотипов по отношению к одному фенотипу) или анализа всех относительно одного или более (всех генотипов по отношению к одному или более фенотипам). Программное обеспечение 1806 может быть приспособлено к выполнению способа 2100, показанного на фиг. 21. Способ 2100 может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. Способ 2100 может предусматривать прием запроса на выполнение сравнения данных на стадии 2102. Сравнение данных может представлять собой анализ всех относительно всех, анализ всех относительно одного или анализ всех относительно одного или более. Запрос может осуществлять идентификацию одного или более признаков из матрицы признаков (TM) (например, матрицы 301 признаков, основанной на разреженных векторах) для сравнения с одним или более генотипами из матрицы генотипов (GM) (например, матрицы 211 генотипов, основанной на разреженных векторах). В одном варианте осуществления матрица генотипов содержит агрегированную матрицу генотипов.
[00177] Способ 2100 может предусматривать определение совокупности рабочих модулей (например, совокупности рабочих узлов 1202A - 1202N) для выполнения сравнения данных на стадии 2104. Способ 2100 может предусматривать разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM на стадии 2106. В одном варианте осуществления матрица генотипов является предварительно разбитой. Способ 2100 может предусматривать предоставление каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM на стадии 2108. В одном варианте осуществления каждый из совокупности рабочих модулей принимает разный раздел GM. В одном варианте осуществления каждый из совокупности рабочих модулей принимает один или более разделов GM. Способ 2100 может предусматривать разбиение на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM на стадии 2110. В одном варианте осуществления матрица признаков является предварительно разбитой. Способ 2100 может предусматривать предоставление каждому из совокупности рабочих модулей первого раздела TM из одного или более разделов TM на стадии 2112. Способ 2100 может предусматривать инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных на стадии 2114. В одном варианте осуществления каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM. Результат сравнения данных может содержать одну или более ассоциаций признак-генотип.
[00178] Способ 2100 может дополнительно предусматривать прием указания от каждого рабочего модуля из совокупности рабочих модулей о том, что сравнение данных завершено, предоставление на основе указаний каждому из совокупности рабочих модулей второго раздела TM и обеспечение выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела TM с разделом GM.
[00179] Способ 2100 может дополнительно предусматривать прием указания от рабочего модуля из совокупности рабочих модулей о том, что рабочий модуль завершил сравнение данных с первым разделом TM, предоставление на основе указания рабочему модулю из совокупности рабочих модулей второго раздела TM и инициацию выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом TM.
[00180] Способ 2100 может дополнительно предусматривать прием от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных. Результат сравнения данных может содержать одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом. Одно или более значений встречаемости субъектов могут предусматривать значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC). Способ 2100 может дополнительно предусматривать генерирование на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков. Таблица сопряженности может содержать строку для субъектов с заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца. Способ 2100 может дополнительно предусматривать оценивание сводной статистики на основе таблицы сопряженности. Сводная статистика может предусматривать точный критерий Фишера.
[00181] Способ 2100 может дополнительно предусматривать определение идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками, определение идентификатора признака (TID) для каждого из идентифицированных одного или более признаков и генерирование каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, где совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики. Способ 2100 может дополнительно предусматривать осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и осуществление запроса к совокупности разделов TM для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип. Осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип может быть основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
[00182] Способ 2100 может дополнительно предусматривать предоставление каждому рабочему модулю из совокупности рабочих модулей третьего раздела TM, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов. Способ 2100 может дополнительно предусматривать инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов, если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициирование извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа, инициирование уплотнения рабочим модулем разреженного вектора и инициирование выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора. Статистический анализ может предусматривать одно или более из логистической регрессии или линейной регрессии.
[00183] Способ 2100 может дополнительно предусматривать осуществление запроса к исходной матрице генотипов на основе совокупности генов с использованием одного или более булевых операторов и генерирование на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
[00184] На фиг. 22 и фиг. 23 проиллюстрированы результаты контрольных тестов, которые демонстрируют преимущества в вычислительной производительности раскрытых способов по сравнению с традиционными стратегиями. Результаты контрольных тестов показывают меньшее время вычисления и более эффективное использование памяти (и то, и другое дает финансовое преимущество, поскольку узлы можно использовать в течение меньшего периода времени, и можно использовать узлы с меньшим объемом памяти).
[00185] Чтобы продемонстрировать преимущества раскрытого способа 2100 по сравнению с традиционной реализацией (например, базовой реализацией на основе APACHE SPARK, называемой в данном документе Native Spark), два способа сравнивались с использованием линейной регрессии со случайно сгенерированными признаками и метками в качестве иллюстративного случая использования.
[00186] На фиг. 22 проиллюстрированы результаты контрольных тестов для времени выполнения и требований к памяти. Имеются по меньшей мере два технологических усовершенствования, реализованных посредством способа 2100, по сравнению с Native Spark. Первое технологическое усовершенствование заключается в требованиях к ресурсам для выполнения задач по анализу эквивалентных размеров. На фиг. 22 проиллюстрированы зависимость требуемых времени выполнения и памяти от размера задачи по анализу, что измерено по количеству выполненных регрессий. По реализации всех задач способ 2100 значительно превосходит Native Spark как по времени выполнения, так и по требованиям к памяти. Что еще более важно, по мере увеличения размера задач время выполнения для способа 2100 увеличивается линейно, в то время как время выполнения для Native Spark показывает степенной рост. Требования к памяти для обоих способов демонстрируют сублинейный рост, но скорость роста намного ниже для способа 2100.
[00187] На фиг. 23 проиллюстрировано масштабирование производительности в зависимости от размера кластера. Второе технологическое усовершенствование способа 2100 по сравнению с Native Spark заключается в оптимальном использовании ресурсов кластера. Одним из основных преимуществ Apache Spark является то, что задачи по анализу можно ускорить за счет использования более крупного кластера с большим количеством ресурсов, и в идеальном случае кластер, который в два раза больше, выполнит задачу вдвое быстрее. Однако если реализация задачи неоптимальна, выигрыш во времени выполнения может быть непропорциональным увеличению размера кластера. В этом случае более крупный кластер увеличивает эксплуатационные расходы, не обеспечивая при этом соразмерных преимуществ в производительности. На фиг. 23 показана скорость выполнения задачи, измеряемая количеством регрессий в секунду, в зависимости от размера кластера, измеренного количеством ядер. Для способа 2100 масштабирование производительности относительно размера кластера является линейным и составляет почти 1 к 1 на большей части области размеров кластера. Для сравнения производительность Native Spark практически не меняется, поскольку размер кластера увеличивается на большей части области и начинает улучшаться только между 32 и 64 ядрами. Соответственно, раскрытые способы представляют технологические усовершенствования по сравнению с традиционными системами для анализа данных.
[00188] В варианте осуществления программное обеспечение 1806 может быть приспособлено к выполнению анализа одного относительно всех (одного генотипа по отношению ко всем фенотипам) или анализа одного или более относительно всех (одного или более генотипов по отношению ко всем фенотипам). Программное обеспечение 1806 может быть приспособлено к выполнению способа 2400, показанного на фиг. 24. Способ 2400 может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. Способ 2400 может предусматривать прием запроса на выполнение сравнения данных на стадии 2402. Сравнение данных может представлять собой анализ одного относительно всех или анализ одного или более относительно всех. Запрос может осуществлять идентификацию одного или более признаков из матрицы признаков (TM) (например, матрицы 301 признаков, основанной на разреженных векторах) для сравнения с одним или более генотипами из матрицы генотипов (GM) (например, матрицы 211 генотипов, основанной на разреженных векторах). В одном варианте осуществления матрица генотипов содержит агрегированную матрицу генотипов.
[00189] Способ 2400 может предусматривать определение совокупности рабочих модулей (например, совокупности рабочих узлов 1202A - 1202N) для выполнения сравнения данных на стадии 2404. Способ 2400 может предусматривать разбиение на основе совокупности рабочих матрицы признаков на совокупность разделов TM на стадии 2406. В одном варианте осуществления матрица признаков является предварительно разбитой. Способ 2400 может предусматривать предоставление каждому из совокупности рабочих модулей раздела TM из совокупности разделов TM на стадии 2408. В одном варианте осуществления каждый из совокупности рабочих модулей принимает разный раздел TM. В одном варианте осуществления каждый из совокупности рабочих модулей принимает один или более разделов TM. Способ 2400 может предусматривать разбиение на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM на стадии 2410. В одном варианте осуществления матрица генотипов является предварительно разбитой. Способ 2400 может предусматривать предоставление каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM на стадии 2412. Способ 2400 может предусматривать инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных на стадии 2414. В одном варианте осуществления каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM. Результат сравнения данных может содержать одну или более ассоциаций признак-генотип.
[00190] Способ 2400 может дополнительно предусматривать прием указания от каждого рабочего модуля из совокупности рабочих модулей о том, что сравнение данных завершено, предоставление на основе указаний каждому из совокупности рабочих модулей второго раздела GM и инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела GM с разделом TM.
[00191] Способ 2400 может дополнительно предусматривать прием указания от рабочего модуля из совокупности рабочих модулей о том, что рабочий модуль завершил сравнение данных с первым разделом GM, предоставление на основе указания рабочему модулю из совокупности рабочих модулей второго раздела GM и инициацию выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом GM.
[00192] Способ 2400 может дополнительно предусматривать прием от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных. Результат сравнения данных может содержать одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом. Одно или более значений встречаемости субъектов могут предусматривать значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC). Способ 2400 может дополнительно предусматривать генерирование на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков. Таблица сопряженности может содержать строку для субъектов с заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца. Способ 2400 может дополнительно предусматривать оценивание сводной статистики на основе таблицы сопряженности. Сводная статистика может предусматривать точный критерий Фишера.
[00193] Способ 2400 может дополнительно предусматривать определение идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками, определение идентификатора признака (TID) для каждого из идентифицированных одного или более признаков и генерирование каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, где совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики. Способ 2400 может дополнительно предусматривать осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и осуществление запроса к совокупности разделов GM для определения разделов GM, содержащих генотип из совокупности ассоциаций кандидатный признак-генотип. Осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип может быть основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
[00194] Способ 2400 может дополнительно предусматривать предоставление каждому рабочему модулю из совокупности рабочих модулей третьего раздела GM, содержащего генотип из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов признаков. Способ 2400 может дополнительно предусматривать инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел ТM рабочего модуля идентификатор признака из списка идентификаторов признаков, если раздел ТM рабочего модуля содержит идентификатор признака из списка идентификаторов признаков, инициацию извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором признака, инициацию уплотнения рабочим модулем разреженного вектора и инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора. Статистический анализ может предусматривать одно или более из логистической регрессии или линейной регрессии.
[00195] Способ 2400 может дополнительно предусматривать осуществление запроса к исходной матрице генотипов на основе совокупности генов с использованием одного или более булевых операторов и генерирование на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
[00196] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к выполнению анализа всех относительно всех (всех генотипов по отношению ко всем фенотипам) или анализа совокупности относительно совокупности (совокупности генотипов по отношению к совокупности фенотипов). Программное обеспечение 1806 может быть приспособлено к выполнению способа 2500, показанного на фиг. 25. Способ 2500 может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. Способ 2500 может предусматривать прием запроса на выполнение сравнения данных на стадии 2502. Сравнение данных может представлять собой анализ всех относительно всех или анализ совокупности относительно совокупности. Запрос может осуществлять идентификацию совокупности признаков из матрицы признаков (TM) (например, матрицы 301 признаков, основанной на разреженных векторах) для сравнения с совокупностью генотипов из матрицы генотипов (GM) (например, матрицы 211 генотипов, основанной на разреженных векторах). В одном варианте осуществления матрица генотипов содержит агрегированную матрицу генотипов.
[00197] Способ 2500 может предусматривать определение совокупности рабочих модулей (например, совокупности рабочих узлов 1202A - 1202N) для выполнения сравнения данных на стадии 2504. Способ 2500 может предусматривать разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM на стадии 2506. Способ 2500 может предусматривать предоставление каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM на стадии 2508. Каждый из совокупности рабочих модулей может принимать разный раздел GM. Каждый из совокупности рабочих узлов может принимать один или более разделов GM. Способ 2500 может предусматривать разбиение на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM на стадии 2510. Способ 2500 может предусматривать генерирование на основе некоторого количества из совокупности разделов TM очереди обработки (например, очереди 1203) на стадии 2512. Очередность обработки может указывать порядок обработки по меньшей мере первого раздела TM и второго раздела TM. Первый раздел TM может быть ассоциирован с первой задачей распределенной обработки, и второй раздел TM ассоциируют со второй задачей распределенной обработки. Способ 2500 может предусматривать предоставление каждому из совокупности рабочих модулей первого раздела TM на стадии 2514. Способ 2500 может предусматривать инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных на стадии 2516. Каждый рабочий из совокупности рабочих модулей может осуществлять сравнение первого раздела TM с разделом GM. Способ 2500 может предусматривать прием от первого рабочего из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, на стадии 2518. Способ 2500 может предусматривать предоставление на основе очередности обработки второго раздела TM первому рабочему модулю на стадии 2520. Указание о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, могут быть приняты тогда, когда второй рабочий модуль из совокупности рабочих модулей приступает к выполнению сравнения данных с первым разделом TM.
[00198] Способ 2500 может дополнительно предусматривать создание экземпляра ведущего экземпляра для каждого раздела TM из совокупности разделов TM. Первый ведущий экземпляр может быть ассоциирован с первой задачей распределенной обработки, и второй ведущий экземпляр ассоциируют со второй задачей распределенной обработки. Предоставление первого раздела TM может предусматривать предоставление первым ведущим экземпляром первого раздела TM. Предоставление второго раздела TM первому рабочему модулю может предусматривать предоставление вторым ведущим экземпляром второго раздела TM первому рабочему модулю.
[00199] В одном варианте осуществления программное обеспечение 1806 может быть приспособлено к выполнению статистического анализа возрастающей сложности сокращенного набора данных. Программное обеспечение 1806 может быть приспособлено к выполнению способа 2600, показанного на фиг. 26. Способ 2600 может быть выполнен полностью или частично одним ведущим узлом (например, ведущим узлом 1201), одним ведущим экземпляром, совокупностью ведущих узлов и/или совокупностью ведущих экземпляров. Способ 2600 может предусматривать генерирование на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных (например, каркасной структуры 1500 данных) на стадии 2602. Каркасная структура данных может содержать совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности (например, таблицу 1400 сопряженности) для столбца ассоциированного признака и столбец сводной статистики.
[00200] Способ 2600 может предусматривать осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип на стадии 2604. Осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип может быть основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом. Способ 2600 может предусматривать осуществление запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип, на стадии 2606. Способ 2600 может предусматривать предоставление каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов на стадии 2608. В одном варианте осуществления каждый из совокупности рабочих модулей принимает один или более разделов TM. Способ 2600 может предусматривать инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит (содержат) ли раздел (разделы) GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов, на стадии 2610. Способ 2600 может предусматривать следующее: если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициирование выполнения рабочим модулем статистического анализа на стадии 2612. Результат статистического анализа может содержать показатель статистической значимости одной или более ассоциаций кандидатный признак-генотип из совокупности ассоциаций кандидатный признак-генотип.
[00201] Способ 2600 может дополнительно предусматривать следующее: если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициирование извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа; инициирование уплотнения рабочим модулем разреженного вектора; и при этом инициирование выполненное рабочим модулем статистического анализа предусматривает инициирование выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора. Статистический анализ может предусматривать одно или более из логистической регрессии или линейной регрессии
[00202] В способах и системах по настоящему изобретению могут использоваться контролируемые и неконтролируемые методики искусственного интеллекта, такие как машинное обучение и итеративное обучение. Примеры таких методик включают без ограничения экспертные системы, рассуждение на основе аналогичных случаев, Байесовские сети, кластерный анализ, поиск информации, поиск документов, сетевой анализ, анализ правил ассоциации, поведенческий искусственный интеллект, нейронные сети, системы на основе нечеткой логики, эволюционное вычисление (например, генетические алгоритмы), роевый интеллект (например, алгоритмы муравьиной колонии) и гибридные интеллектуальные системы (например, экспертные правила вывода, полученные посредством нейронной сети, или продукционные правила, полученные в результате статистического обучения).
[00203] Система и способы по настоящему изобретению облегчают исследование биологического пути (путей), который (которые) имеет (имеют) отношение к фенотипу, идентифицированному как ассоциированный с генетическим вариантом. Биологический путь может быть исследован подробно, например, в поддержку разработки лекарств, чтобы определить предполагаемую биологическую мишень для фармакологического вмешательства. Такое исследование может включать биохимическое, молекулярно-биологическое, физиологическое, фармакологическое и компьютерное исследования.
[00204] В одном варианте осуществления предполагаемой биологической мишенью является полипептид, кодируемый геном, который содержит вариант, идентифицированный в ассоциации генетический вариант-фенотип. В другом варианте осуществления предполагаемой биологической мишенью является молекула (например, рецептор, кофактор или полипептидный компонент более крупного полипептидного комплекса), которая связывается с полипептидом, кодируемым геном, который содержит вариант, идентифицированный в ассоциации генетический вариант-фенотип.
[00205] В другом варианте осуществления предполагаемой биологической мишенью является ген, который содержит вариант, идентифицированный в ассоциации генетический вариант-фенотип.
[00206] Способы и системы по настоящему изобретению также облегчают идентификацию терапевтической молекулы, которая связывается с предполагаемой биологической мишенью, обсуждаемой непосредственно выше. Неограничивающие примеры подходящей терапевтической молекулы включают пептиды и полипептиды, которые специфически связываются с предполагаемой биологической мишенью, например, антителом или его фрагментом, и малые химические молекулы. Например, кандидатная терапевтическая молекула может быть протестирована на связывание с предполагаемой биологической мишенью в подходящем скрининговом исследовании.
[00207] Способы и системы по настоящему изобретению также облегчают идентификацию терапевтических способов воздействия на экспрессию гена, который содержит вариант, идентифицированный в ассоциации генетический вариант-фенотип. Неограничивающие примеры подходящих терапевтических способов включают редактирование генома, генную терапию, сайленсинг РНК и использование миРНК.
[00208] Способы и системы по настоящему изобретению также облегчают выявление диагностических способов и инструментов, которые используют идентификацию ассоциации генетический вариант-фенотип.
[00209] Способы и системы по настоящему изобретению также облегчают конструирование генетических конструкций (например, вектора экспрессии) и клеточных линий, которые используют идентификацию ассоциации генетический вариант-фенотип.
[00210] Способы и системы по настоящему изобретению также облегчают конструирование нокаутных и трансгенных грызунов, например, мышей. Генетически модифицированные клетки животных, отличных от человека, и эмбриональные стволовые (ES) клетки могут быть получены с использованием любого подходящего способа. Например, такие генетически модифицированные ES-клетки животного, отличного от человека, могут быть получены с использованием технологии VELOCIGENE®, которая описана в патентах США №№ 6586251, 6596541, 7105148 и в публикации Valenzuela et al., Nat Biotech 2003; 21: 652, при этом каждый из этих документов включен посредством ссылки.
[00211] Хотя способы и системы были описаны в связи с предпочтительными вариантами осуществления и конкретными примерами, не предполагается, что объем ограничивается конкретными изложенными вариантами осуществления, поскольку варианты осуществления в данном документе предназначены во всех отношениях для иллюстрации, а не ограничения.
[00212] Если четко не указано иное, ни в коей мере не предполагается, что любой способ, изложенный в данном документе, должен истолковываться как требующий выполнения его стадий в конкретном порядке. Соответственно, если в пункте формулы изобретения, в котором заявляется способ, в действительности не указан порядок выполнения его стадий, или в формуле изобретения или описании иным образом конкретно не указано, что стадии должны ограничиваться конкретным порядком, то ни в коей мере не предполагается, что порядок таким образом выводится из контекста. Это справедливо для любого возможного неявного основания для интерпретации, в том числе: вопросов логики в отношении порядка стадий или последовательности выполнения технологических операций; общеупотребительного значения, полученного на основе грамматической конструкции или пунктуации; числа или типа вариантов осуществления, описанных в описании.
[00213] Могут быть внесены различные модификации и вариации, не выходящие за рамки объема и сущности. Другие варианты осуществления станут очевидными из рассмотрения описания и практической реализации, раскрытых в данном документе. Предполагается, что описание и примеры следует рассматривать только как приведенные в качестве примера, при этом истинные объем и сущность указаны в следующей формуле изобретения.
Иллюстративные варианты осуществления
Вариант осуществления 1. Способ, предусматривающий:
прием данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт;
генерирование на основе данных о генотипе матрицы генотипов, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов;
генерирование на основе данных о фенотипе матрицы количественных признаков, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов;
генерирование на основе данных о фенотипе матрицы двоичных признаков; при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов;
присоединение по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков;
присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор;
генерирование на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа, при этом структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца;
определение на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов матрицы генотипов, основанной на разреженных векторах, при этом матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов;
определение на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков матрицы количественных признаков, основанной на разреженных векторах, при этом матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков;
определение на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков матрицы двоичных признаков, основанной на разреженных векторах, при этом матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков;
выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах; и
обработку одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
Вариант осуществления 2. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 3. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 4. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 5. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 6. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 7. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 8. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 9. Способ согласно варианту осуществления 1, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 10. Способ согласно варианту осуществления 1, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 11. Способ согласно варианту осуществления 1, дополнительно предусматривающий прием дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 12. Способ согласно варианту осуществления 11, дополнительно предусматривающий:
присваивание менеджером идентификаторов идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 13. Способ согласно варианту осуществления 12, дополнительно предусматривающий:
добавление по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
повторное присоединение по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 14. Способ согласно варианту осуществления 1, дополнительно предусматривающий генерирование на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 15. Способ согласно варианту осуществления 14, дополнительно предусматривающий разбиение матрицы результатов ассоциации.
Вариант осуществления 16. Способ согласно варианту осуществления 15, где разбиение матрицы результатов ассоциации предусматривает:
генерирование структуры данных в виде каталога для каждой из совокупности хромосом;
разделение матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранение на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 17. Способ согласно варианту осуществления 1, дополнительно предусматривающий очистку и согласование одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 18. Способ согласно варианту осуществления 1, где генерирование на основе данных о генотипе матрицы генотипов предусматривает интеграцию одного или более источников данных о генотипе.
Вариант осуществления 19. Способ согласно варианту осуществления 18, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 20. Способ согласно варианту осуществления 1, где генерирование на основе данных о фенотипе матрицы количественных признаков предусматривает генерирование матрицы количественных признаков по результатам нескольких исследований.
Вариант осуществления 21. Способ согласно варианту осуществления 1, где генерирование на основе данных о фенотипе матрицы двоичных признаков предусматривает генерирование матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 22. Способ согласно варианту осуществления 1, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 23. Способ согласно варианту осуществления 1, где выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, основано на одном или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 24. Способ, предусматривающий:
прием данных о генотипе и данных о фенотипе для совокупности индивидуумов;
генерирование одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков;
присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов;
генерирование на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
определение на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; и
обработку одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 25. Способ согласно варианту осуществления 24, где матрица генотипов основана на данных о генотипе, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов.
Вариант осуществления 26. Способ согласно варианту осуществления 24, где матрица количественных признаков основана на данных о фенотипе, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов.
Вариант осуществления 27. Способ согласно варианту осуществления 24, где матрица двоичных признаков основана на данных о фенотипе, при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов
Вариант осуществления 28. Способ согласно варианту осуществления 24, дополнительно предусматривающий присоединение по меньшей мере части матрицы метаданных к одной или более из матрицы генотипов, количественной матрицы и матрицы двоичных признаков.
Вариант осуществления 29. Способ согласно варианту осуществления 24, где индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 30. Способ согласно варианту осуществления 24, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца.
Вариант осуществления 31. Способ согласно варианту осуществления 24, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов.
Вариант осуществления 32. Способ согласно варианту осуществления 31, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков.
Вариант осуществления 33. Способ согласно варианту осуществления 32, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
Вариант осуществления 34. Способ согласно варианту осуществления 33, дополнительно предусматривающий выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 35. Способ согласно варианту осуществления 31, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 36. Способ согласно варианту осуществления 31, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 37. Способ согласно варианту осуществления 32, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 38. Способ согласно варианту осуществления 33, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 39. Способ согласно варианту осуществления 31, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 40. Способ согласно варианту осуществления 32, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 41. Способ согласно варианту осуществления 33, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 42. Способ согласно варианту осуществления 32, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 43. Способ согласно варианту осуществления 30, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 44. Способ согласно варианту осуществления 24, дополнительно предусматривающий прием дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 45. Способ согласно варианту осуществления 44, дополнительно предусматривающий:
присваивание менеджером идентификаторов идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 46. Способ согласно варианту осуществления 45, дополнительно предусматривающий:
добавление по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
присоединение по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 47. Способ согласно варианту осуществления 24, дополнительно предусматривающий генерирование на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 48. Способ согласно варианту осуществления 47, дополнительно предусматривающий разбиение матрицы результатов ассоциации.
Вариант осуществления 49. Способ согласно варианту осуществления 48, где разбиение матрицы результатов ассоциации предусматривает:
генерирование структуры данных в виде каталога для каждой из совокупности хромосом;
разделение матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранение на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 50. Способ согласно варианту осуществления 24, дополнительно предусматривающий очистку и согласование одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 51. Способ согласно варианту осуществления 24, где генерирование матрицы генотипов предусматривает интеграцию одного или более источников данных о генотипе.
Вариант осуществления 52. Способ согласно варианту осуществления 51, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 53. Способ согласно варианту осуществления 24, где генерирование матрицы количественных признаков предусматривает генерирование матрицы количественных признаков по результатам нескольких исследований.
Вариант осуществления 54. Способ согласно варианту осуществления 24, где генерирование матрицы двоичных признаков предусматривает генерирование матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 55. Способ согласно варианту осуществления 28, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 56. Способ согласно варианту осуществления 34, где выравнивание согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, основано на одном или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 57. Система, содержащая:
матричную систему, приспособленную к
приему данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт;
генерированию на основе данных о генотипе матрицы генотипов, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов;
генерированию на основе данных о фенотипе матрицы количественных признаков, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов;
генерированию на основе данных о фенотипе матрицы двоичных признаков; при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов;
присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков;
менеджер идентификаторов, приспособленный к присваиванию глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор; и
матричную систему, основанную на разреженных векторах, приспособленную к
генерированию на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа, при этом структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца;
определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов матрицы генотипов, основанной на разреженных векторах, при этом матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов;
определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков матрицы количественных признаков, основанной на разреженных векторах, при этом матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков;
определению на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков матрицы двоичных признаков, основанной на разреженных векторах, при этом матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков;
выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах; и
обработке одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
Вариант осуществления 58. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 59. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 60. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 61. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 62. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 63. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 64. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 65. Система согласно варианту осуществления 57, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 66. Система согласно варианту осуществления 57, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 67. Система согласно варианту осуществления 57, где матричная система дополнительно приспособлена к приему дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 68. Система согласно варианту осуществления 67, где менеджер идентификаторов дополнительно приспособлен к:
присваиванию идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваиванию глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 69. Система согласно варианту осуществления 68, где матричная система дополнительно приспособлена к:
добавлению по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
повторному присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 70. Система согласно варианту осуществления 26, где матричная система дополнительно приспособлена к генерированию на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 71. Система согласно варианту осуществления 70, где матричная система дополнительно приспособлена к разбиению матрицы результатов ассоциации.
Вариант осуществления 72. Система согласно варианту осуществления 71, где матричная система, дополнительно приспособленная к разбиению матрицы результатов ассоциации, дополнительно приспособлена к:
генерированию структуры данных в виде каталога для каждой из совокупности хромосом;
разделению матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранению на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 73. Система согласно варианту осуществления 57, где матричная система дополнительно приспособлена к очистке и согласованию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 74. Система согласно варианту осуществления 57, где матричная система, приспособленная к генерированию на основе данных о генотипе матрицы генотипов, дополнительно приспособлена к интеграции одного или более источников данных о генотипе.
Вариант осуществления 75. Система согласно варианту осуществления 74, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 76. Система согласно варианту осуществления 57, где матричная система, приспособленная к генерированию на основе данных о фенотипе матрицы количественных признаков, дополнительно приспособлена к генерированию матрицы количественных признаков по результатам нескольких исследований.
Вариант осуществления 77. Система согласно варианту осуществления 57, где матричная система, приспособленная к генерированию на основе данных о фенотипе матрицы двоичных признаков, дополнительно приспособлена к генерированию матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 78. Система согласно варианту осуществления 57, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 79. Система согласно варианту осуществления 57, где матричная система, основанная на разреженных векторах, приспособлена к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, на основе одного или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 80. Система, содержащая:
матричную систему, приспособленную к
приему данных о генотипе и данных о фенотипе для совокупности индивидуумов;
генерированию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков;
менеджер идентификаторов, приспособленный к присваивания глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов; и матричную систему, основанную на разреженных векторах, приспособленную к
генерированию на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
определению на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; и
обработке одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 81. Система согласно варианту осуществления 80, где матрица генотипов основана на данных о генотипе, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов.
Вариант осуществления 82. Система согласно варианту осуществления 80, где матрица количественных признаков основана на данных о фенотипе, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов.
Вариант осуществления 83. Система согласно варианту осуществления 80, где матрица двоичных признаков основана на данных о фенотипе, при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов
Вариант осуществления 84. Система согласно варианту осуществления 80, где матричная система дополнительно приспособлена к присоединению по меньшей мере части матрицы метаданных к одной или более из матрицы генотипов, количественной матрицы и матрицы двоичных признаков.
Вариант осуществления 85. Система согласно варианту осуществления 80, где индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 86. Система согласно варианту осуществления 80, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца.
Вариант осуществления 87. Система согласно варианту осуществления 80, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов.
Вариант осуществления 88. Система согласно варианту осуществления 87, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков.
Вариант осуществления 89. Система согласно варианту осуществления 88, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
Вариант осуществления 90. Система согласно варианту осуществления 89, где матричная система, основанная на разреженных векторах, дополнительно приспособлена к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 91. Система согласно варианту осуществления 87, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 92. Система согласно варианту осуществления 87, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 93. Система согласно варианту осуществления 88, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 94. Система согласно варианту осуществления 89, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 95. Система согласно варианту осуществления 87, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 96. Система согласно варианту осуществления 88, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 97. Система согласно варианту осуществления 89, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 98. Система согласно варианту осуществления 88, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 99. Система согласно варианту осуществления 86, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 100. Система согласно варианту осуществления 80, где матричная система дополнительно приспособлена к приему дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 101. Система согласно варианту осуществления 100, где менеджер идентификаторов дополнительно приспособлен к:
присваиванию идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваиванию глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 102. Система согласно варианту осуществления 101, где матричная система дополнительно приспособлена к:
добавлению по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 103. Система согласно варианту осуществления 80, где матричная система дополнительно приспособлена к генерированию на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 104. Система согласно варианту осуществления 103, где матричная система дополнительно приспособлена к разбиению матрицы результатов ассоциации.
Вариант осуществления 105. Система согласно варианту осуществления 104, где матричная система, приспособленная к разбиению матрицы результатов ассоциации, дополнительно приспособлена к:
генерированию структуры данных в виде каталога для каждой из совокупности хромосом;
разделению матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранению на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 106. Система согласно варианту осуществления 80, где матричная система дополнительно приспособлена к очистке и согласованию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 107. Система согласно варианту осуществления 80, где матричная система, приспособленная к генерированию матрицы генотипов, дополнительно приспособлена к интеграции одного или более источников данных о генотипе.
Вариант осуществления 108. Система согласно варианту осуществления 107, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 109. Система согласно варианту осуществления 80, где матричная система, приспособленная к генерированию матрицы количественных признаков, дополнительно приспособлена к генерированию матрицы количественных признаков по нескольким исследованиям.
Вариант осуществления 110. Система согласно варианту осуществления 80, где матричная система, приспособленная к генерированию матрицы двоичных признаков, дополнительно приспособлена к генерированию матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 111. Система согласно варианту осуществления 84, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 112. Система согласно варианту осуществления 90, где матричная система, основанная на разреженных векторах, дополнительно приспособлена к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, на основе одного или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 113. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, при этом матрица генотипов, матрица количественных признаков или матрица двоичных признаков основаны на одном или более из данных о генотипе или данных о фенотипе для совокупности индивидуумов;
присваивания менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов;
генерирования на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
определения на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; и
обработки одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 114. Устройство согласно варианту осуществления 113, где матрица генотипов основана на данных о генотипе, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов.
Вариант осуществления 115. Устройство согласно варианту осуществления 113, где матрица количественных признаков основана на данных о фенотипе, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов.
Вариант осуществления 116. Устройство согласно варианту осуществления 113, где матрица двоичных признаков основана на данных о фенотипе, при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов
Вариант осуществления 117. Устройство согласно варианту осуществления 113, дополнительно приспособленное к присоединению по меньшей мере части матрицы метаданных к одной или более из матрицы генотипов, количественной матрицы и матрицы двоичных признаков.
Вариант осуществления 118. Устройство согласно варианту осуществления 113, где индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 119. Устройство согласно варианту осуществления 113, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца.
Вариант осуществления 120. Устройство согласно варианту осуществления 113, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов.
Вариант осуществления 121. Устройство согласно варианту осуществления 120, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков.
Вариант осуществления 122. Устройство согласно варианту осуществления 121, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
Вариант осуществления 123. Устройство согласно варианту осуществления 122, дополнительно приспособленное к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 124. Устройство согласно варианту осуществления 120, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 125. Устройство согласно варианту осуществления 120, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 126. Устройство согласно варианту осуществления 121, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 127. Устройство согласно варианту осуществления 122, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 128. Устройство согласно варианту осуществления 120, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 129. Устройство согласно варианту осуществления 121, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 130. Устройство согласно варианту осуществления 122, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 131. Устройство согласно варианту осуществления 121, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 132. Устройство согласно варианту осуществления 119, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 133. Устройство согласно варианту осуществления 113, дополнительно приспособленное к приему дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 134. Устройство согласно варианту осуществления 133, дополнительно приспособленное к:
присваиванию менеджером идентификаторов идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваиванию менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 135. Устройство согласно варианту осуществления 134, дополнительно приспособленное к:
добавлению по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 136. Устройство согласно варианту осуществления 113, дополнительно приспособленное к генерированию на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 137. Устройство согласно варианту осуществления 136, дополнительно приспособленное к разбиению матрицы результатов ассоциации.
Вариант осуществления 138. Устройство согласно варианту осуществления 137, дополнительно приспособленное к:
генерированию структуры данных в виде каталога для каждой из совокупности хромосом;
разделению матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранению на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 139. Устройство согласно варианту осуществления 113, дополнительно приспособленное к очистке и согласованию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 140. Устройство согласно варианту осуществления 113, приспособленное к генерированию матрицы генотипов, которое дополнительно приспособлено к интеграции одного или более источников данных о генотипе.
Вариант осуществления 141. Устройство согласно варианту осуществления 140, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 142. Устройство согласно варианту осуществления 113, приспособленное к генерированию матрицы количественных признаков, которое дополнительно приспособлено к генерированию матрицы количественных признаков по результатам нескольких исследований.
Вариант осуществления 143. Устройство согласно варианту осуществления 113, приспособленное к генерированию матрицы двоичных признаков, которое дополнительно приспособлено к генерированию матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 144. Устройство согласно варианту осуществления 117, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 145. Устройство согласно варианту осуществления 123, приспособленное к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, на основе одного или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 146. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема данных о генотипе и данных о фенотипе для совокупности индивидуумов из совокупности когорт;
генерирования на основе данных о генотипе матрицы генотипов, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов;
генерирования на основе данных о фенотипе матрицы количественных признаков, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов;
генерирования на основе данных о фенотипе матрицы двоичных признаков; при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов;
присоединения по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков;
присваивания менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор;
генерирования на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа, при этом структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца;
определения на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы генотипов матрицы генотипов, основанной на разреженных векторах, при этом матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов;
определения на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы количественных признаков матрицы количественных признаков, основанной на разреженных векторах, при этом матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков;
определения на основе структуры данных в виде n-кортежа, менеджера идентификаторов и матрицы двоичных признаков матрицы двоичных признаков, основанной на разреженных векторах, при этом матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков;
выравнивания согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах; и
обработки одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных.
Вариант осуществления 147. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 148. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 149. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 150. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 151. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 152. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 153. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 154. Машиночитаемый носитель согласно варианту осуществления 146, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 155. Машиночитаемый носитель согласно варианту осуществления 31, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 156. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
приема дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 157. Машиночитаемый носитель согласно варианту осуществления 156, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
присваивания менеджером идентификаторов идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваивания менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 158. Машиночитаемый носитель согласно варианту осуществления 157, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
добавления по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавления по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавления по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
повторного присоединения по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 159. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
генерирования на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 160. Машиночитаемый носитель согласно варианту осуществления 159, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
разбиения матрицы результатов ассоциации.
Вариант осуществления 161. Машиночитаемый носитель согласно варианту осуществления 160, где выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами разбиения матрицы результатов ассоциации, дополнительно содержат выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
генерирования структуры данных в виде каталога для каждой из совокупности хромосом;
разделения матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранения на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 162. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
очистки и согласования одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 163. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами генерирования на основе данных о генотипе матрицы генотипов, дополнительно содержат выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
интеграции одного или более источников данных о генотипе.
Вариант осуществления 164. Машиночитаемый носитель согласно варианту осуществления 163, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 165. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами генерирования на основе данных о фенотипе матрицы количественных признаков, дополнительно содержат выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
генерирования матрицы количественных признаков по результатам нескольких исследований.
Вариант осуществления 166. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами генерирования на основе данных о фенотипе матрицы двоичных признаков, дополнительно содержат выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
генерирования матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 167. Машиночитаемый носитель согласно варианту осуществления 146, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 168. Машиночитаемый носитель согласно варианту осуществления 146, где выполняемые процессором команды приспособлены к инициации выполнения одной или более компьютерными системами выравнивания согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, на основе одного или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 169. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема данных о генотипе и данных о фенотипе для совокупности индивидуумов;
генерирования одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков;
присваивания менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из совокупности индивидуумов;
генерирования на основе менеджера идентификаторов, матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
определения на основе менеджера идентификаторов и структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; и
обработки одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 170. Машиночитаемый носитель согласно варианту осуществления 169, где матрица генотипов основана на данных о генотипе, при этом матрица генотипов содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности вариантов.
Вариант осуществления 171. Машиночитаемый носитель согласно варианту осуществления 169, где матрица количественных признаков основана на данных о фенотипе, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности индивидуумов.
Вариант осуществления 172. Машиночитаемый носитель согласно варианту осуществления 169, где матрица двоичных признаков основана на данных о фенотипе, при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности индивидуумов.
Вариант осуществления 173. Машиночитаемый носитель согласно варианту осуществления 169, дополнительно приспособленный к инициации выполнения одной или более компьютерными системами присоединения по меньшей мере части матрицы метаданных к одной или более из матрицы генотипов, количественной матрицы и матрицы двоичных признаков.
Вариант осуществления 174. Машиночитаемый носитель согласно варианту осуществления 169, где индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 175. Машиночитаемый носитель согласно варианту осуществления 169, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца.
Вариант осуществления 176. Машиночитаемый носитель согласно варианту осуществления 169, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов.
Вариант осуществления 177. Машиночитаемый носитель согласно варианту осуществления 176, где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков.
Вариант осуществления 178. Машиночитаемый носитель согласно варианту осуществления 177, где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности индивидуумов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
Вариант осуществления 179. Машиночитаемый носитель согласно варианту осуществления 178, где выполняемые процессором команды дополнительно приспособлены к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах.
Вариант осуществления 180. Машиночитаемый носитель согласно варианту осуществления 176, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в строке матрицы генотипов.
Вариант осуществления 181. Машиночитаемый носитель согласно варианту осуществления 176, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит гомозиготный референт.
Вариант осуществления 182. Машиночитаемый носитель согласно варианту осуществления 177, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
Вариант осуществления 183. Машиночитаемый носитель согласно варианту осуществления 178, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с индивидуумом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
Вариант осуществления 184. Машиночитаемый носитель согласно варианту осуществления 176, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю).
Вариант осуществления 185. Машиночитаемый носитель согласно варианту осуществления 177, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к допуску значения, равного 0 (нулю), и отбрасыванию значений NULL.
Вариант осуществления 186. Машиночитаемый носитель согласно варианту осуществления 178, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
Вариант осуществления 187. Машиночитаемый носитель согласно варианту осуществления 176, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение.
Вариант осуществления 188. Машиночитаемый носитель согласно варианту осуществления 175, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
Вариант осуществления 189. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды дополнительно приспособлены к приему дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности индивидуумов.
Вариант осуществления 190. Машиночитаемый носитель согласно варианту осуществления 189, где выполняемые процессором команды дополнительно приспособлены к:
присваиванию менеджером идентификаторов идентификатора когорты каждому индивидууму, который является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов; и
присваиванию менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из индивидуумов, который не является общим для совокупности индивидуумов и дополнительной совокупности индивидуумов, при этом индивидууму могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор.
Вариант осуществления 191. Машиночитаемый носитель согласно варианту осуществления 190, где выполняемые процессором команды дополнительно приспособлены к:
добавлению по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавлению по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
присоединению по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
Вариант осуществления 192. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды дополнительно приспособлены к генерированию на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
Вариант осуществления 193. Машиночитаемый носитель согласно варианту осуществления 192, где выполняемые процессором команды дополнительно приспособлены к разбиению матрицы результатов ассоциации.
Вариант осуществления 194. Машиночитаемый носитель согласно варианту осуществления 193, где выполняемые процессором команды, приспособленные к разбиению матрицы результатов ассоциации, дополнительно приспособлены к:
генерированию структуры данных в виде каталога для каждой из совокупности хромосом;
разделению матрицы результатов ассоциации на совокупность файлов согласно геномному диапазону; и
сохранению на основе геномного диапазона и совокупности хромосом совокупности файлов в структурах данных в виде каталогов.
Вариант осуществления 195. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды дополнительно приспособлены к очистке и согласованию одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков.
Вариант осуществления 196. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды, приспособленные к генерированию матрицы генотипов, дополнительно приспособлены к интеграции одного или более источников данных о генотипе.
Вариант осуществления 197. Машиночитаемый носитель согласно варианту осуществления 196, где один или более источников данных о генотипе содержат одно или более из SNP, вставок/делеций, CNV и сложных гетерозигот (CHET), определенных по результатам секвенирования экзома, SNP и вставок/делеций из массивов генотипирования или частей из импутированных данных.
Вариант осуществления 198. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды, приспособлены к генерированию матрицы количественных признаков, дополнительно приспособлены к генерированию матрицы количественных признаков по нескольким исследованиям.
Вариант осуществления 199. Машиночитаемый носитель согласно варианту осуществления 169, где выполняемые процессором команды, приспособленные к генерированию матрицы двоичных признаков, дополнительно приспособлены к генерированию матрицы двоичных признаков по результатам нескольких исследований.
Вариант осуществления 200. Машиночитаемый носитель согласно варианту осуществления 173, где матрица метаданных содержит один или более двоичных признаков или количественных признаков, которые являются ковариатами в модели для исследований корреляции генотип-фенотип, и при этом они являются категориальными.
Вариант осуществления 201. Машиночитаемый носитель согласно варианту осуществления 179, где выполняемые процессором команды приспособлены к выравниванию согласно столбцу матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах, на основе одного или более из глобальных идентификаторов или идентификаторов когорты.
Вариант осуществления 202. Способы согласно вариантам осуществления 1 и 24, где обработка одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных предусматривает способы согласно вариантам осуществления 206-256.
Вариант осуществления 203. Системы согласно вариантам осуществления 57 и 80, где обработка одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных предусматривает системы согласно вариантам осуществления 359-409.
Вариант осуществления 204. Устройство согласно варианту осуществления 113, где обработка одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных предусматривает устройства согласно вариантам осуществления 257-307.
Вариант осуществления 205. Машиночитаемые носители согласно вариантам осуществления 146 и 169, где обработка одного или более запросов к выровненным матрице генотипов, основанной на разреженных векторах, матрице количественных признаков, основанной на разреженных векторах, матрице двоичных признаков, основанной на разреженных векторах, или матрице метаданных предусматривает способы согласно вариантам осуществления 308-358.
Вариант осуществления 206. Способ, предусматривающий:
прием запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определение совокупности рабочих модулей для выполнения сравнения данных;
разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставление каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиение на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM;
предоставление каждому из совокупности рабочих модулей первого раздела TM из одного или более разделов TM; и
инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM.
Вариант осуществления 207. Способ согласно варианту осуществления 206, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 208. Способ согласно варианту осуществления 206, дополнительно предусматривающий:
прием указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставление на основе указаний каждому из совокупности рабочих модулей второго раздела TM; и
инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела TM с разделом GM.
Вариант осуществления 209. Способ согласно варианту осуществления 206, дополнительно предусматривающий:
прием указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом TM;
предоставление на основе указания рабочему модулю из совокупности рабочих модулей второго раздела TM; и
инициацию выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом TM.
Вариант осуществления 210. Способ согласно варианту осуществления 206, дополнительно предусматривающий прием от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 211. Способ согласно варианту осуществления 210, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 212. Способ согласно варианту осуществления 211, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 213. Способ согласно варианту осуществления 212, дополнительно предусматривающий генерирование на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 214. Способ согласно варианту осуществления 213, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 215. Способ согласно варианту осуществления 213, дополнительно предусматривающий оценивание сводной статистики на основе таблицы сопряженности.
Вариант осуществления 216. Способ согласно варианту осуществления 215, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 217. Способ согласно варианту осуществления 212, дополнительно предусматривающий:
определение идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определение идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерирование каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 218. Способ согласно варианту осуществления 217, дополнительно предусматривающий:
осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществление запроса к совокупности разделов TM для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 219. Способ согласно варианту осуществления 218, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 220. Способ согласно варианту осуществления 218, дополнительно предусматривающий:
предоставление каждому рабочему модулю из совокупности рабочих модулей третьего раздела TM, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов.
Вариант осуществления 221. Способ согласно варианту осуществления 220, дополнительно предусматривающий:
инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициацию извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициацию уплотнения рабочим модулем разреженного вектора; и
инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 222. Способ согласно варианту осуществления 221, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 223. Способ согласно варианту осуществления 206, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 224. Способ согласно варианту осуществления 223, дополнительно предусматривающий:
осуществление запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов; и
генерирование на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 225. Способ, предусматривающий:
прием запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определение совокупности рабочих модулей для выполнения сравнения данных;
разбиение на основе совокупности рабочих модулей матрицы признаков на совокупность разделов TM;
предоставление каждому из совокупности рабочих модулей раздела TM из совокупности разделов TM, при этом каждый из совокупности рабочих модулей принимает разный раздел TM;
разбиение на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM;
предоставление каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM; и
инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM.
Вариант осуществления 226. Способ согласно варианту осуществления 225, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 227. Способ согласно варианту осуществления 225, дополнительно предусматривающий:
прием указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставление на основе указаний каждому из совокупности рабочих модулей второго раздела GM; и
инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела GM с разделом TM.
Вариант осуществления 228. Способ согласно варианту осуществления 225, дополнительно предусматривающий:
прием указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом GM;
предоставление на основе указания рабочему модулю из совокупности рабочих модулей второго раздела GM; и
инициацию выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом GM.
Вариант осуществления 229. Способ согласно варианту осуществления 225, дополнительно предусматривающий прием от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 230. Способ согласно варианту осуществления 228, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 231. Способ согласно варианту осуществления 230, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 232. Способ согласно варианту осуществления 231, дополнительно предусматривающий генерирование на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 233. Способ согласно варианту осуществления 232, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 234. Способ согласно варианту осуществления 232, дополнительно предусматривающий оценивание сводной статистики на основе таблицы сопряженности.
Вариант осуществления 235. Способ согласно варианту осуществления 234, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 236. Способ согласно варианту осуществления 231, дополнительно предусматривающий:
определение идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определение идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерирование каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 237. Способ согласно варианту осуществления 236, дополнительно предусматривающий:
осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществление запроса к совокупности разделов GM для определения разделов GM, содержащих генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 238. Способ согласно варианту осуществления 237, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 239. Способ согласно варианту осуществления 237, дополнительно предусматривающий:
предоставление каждому рабочему модулю из совокупности рабочих модулей третьего раздела GM, содержащего генотип из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов признаков.
Вариант осуществления 240. Способ согласно варианту осуществления 239, дополнительно предусматривающий:
инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел TM рабочего модуля идентификатор признака из списка идентификаторов признаков; и
если раздел TM рабочего модуля содержит идентификатор признака из списка идентификаторов признаков, инициацию извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором признака;
инициацию уплотнения рабочим модулем разреженного вектора; и
инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 241. Способ согласно варианту осуществления 240, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 242. Способ согласно варианту осуществления 225, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 243. Способ согласно варианту осуществления 242, дополнительно предусматривающий:
осуществление запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерирование на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 244. Способ, предусматривающий:
прием запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию совокупности признаков из матрицы признаков (TM) для сравнения с совокупностью генотипов из матрицы генотипов (GM);
определение совокупности рабочих модулей для выполнения сравнения данных;
разбиение на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставление каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиение на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM;
генерирование на основе некоторого количества из совокупности разделов TM очередности обработки, при этом очередность обработки указывает порядок обработки по меньшей мере первого раздела TM и второго раздела TM;
предоставление каждому из совокупности рабочих модулей первого раздела TM;
инициацию выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM;
прием от первого рабочего модуля из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM; и
предоставление на основе очереди обработки второго раздела TM первому рабочему модулю.
Вариант осуществления 245. Способ согласно варианту осуществления 244, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 246. Способ согласно варианту осуществления 244, где указание о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, принимают тогда, когда второй рабочий модуль из совокупности рабочих модулей приступает к выполнению сравнения данных с первым разделом TM.
Вариант осуществления 247. Способ согласно варианту осуществления 244, где первый раздел TM ассоциируют с первой задачей распределенной обработки, и второй раздел TM ассоциируют со второй задачей распределенной обработки.
Вариант осуществления 248. Способ согласно варианту осуществления 244, дополнительно предусматривающий создание экземпляра ведущего экземпляра для каждого раздела TM из совокупности разделов TM.
Вариант осуществления 249. Способ согласно варианту осуществления 248, где первый ведущий экземпляр ассоциируют с первой задачей распределенной обработки, и второй ведущий экземпляр ассоциируют со второй задачей распределенной обработки.
Вариант осуществления 250. Способ согласно варианту осуществления 249, где предоставление первого раздела TM предусматривает предоставление первым ведущим экземпляром первого раздела TM.
Вариант осуществления 251. Способ согласно варианту осуществления 250, где предоставление второго раздела TM первому рабочему модулю предусматривает предоставление вторым ведущим экземпляром второго раздела TM первому рабочему модулю.
Вариант осуществления 252. Способ, предусматривающий:
генерирование на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики;
осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип;
осуществление запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип;
предоставление каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов;
инициацию определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициацию выполнения рабочим модулем статистического анализа.
Вариант осуществления 253. Способ согласно варианту осуществления 252, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 254. Способ согласно варианту осуществления 252, дополнительно предусматривающий:
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициацию извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициацию уплотнения рабочим модулем разреженного вектора; и
где инициация выполнения рабочим модулем статистического анализа предусматривает инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 255. Способ согласно варианту осуществления 254, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 256. Способ согласно варианту осуществления 252, где результат статистического анализа содержит показатель статистической значимости одной или более ассоциаций кандидатный признак-генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 257. Устройство, приспособленное к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставлению каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиению на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM;
предоставлению каждому из совокупности рабочих модулей первого раздела TM из одного или более разделов TM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM.
Вариант осуществления 258. Устройство согласно варианту осуществления 257, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 259. Устройство согласно варианту осуществления 257, где устройство дополнительно приспособлено к:
приему указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставлению на основе указаний каждому из совокупности рабочих модулей второго раздела TM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела TM с разделом GM.
Вариант осуществления 260. Устройство согласно варианту осуществления 257, где устройство дополнительно приспособлено к:
приему указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом TM;
предоставлению на основе указания рабочему модулю из совокупности рабочих модулей второго раздела TM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом TM.
Вариант осуществления 261. Устройство согласно варианту осуществления 257, где устройство дополнительно приспособлено к приему от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 262. Устройство согласно варианту осуществления 261, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 263. Устройство согласно варианту осуществления 262, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 264. Устройство согласно варианту осуществления 263, где устройство дополнительно приспособлено к генерированию на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 265. Устройство согласно варианту осуществления 264, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 266. Устройство согласно варианту осуществления 264, где устройство дополнительно приспособлено к оцениванию сводной статистики на основе таблицы сопряженности.
Вариант осуществления 267. Устройство согласно варианту осуществления 266, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 268. Устройство согласно варианту осуществления 263, где устройство дополнительно приспособлено к:
определению идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определению идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерированию каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 269. Устройство согласно варианту осуществления 268, где устройство дополнительно приспособлено к:
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществлению запроса к совокупности разделов TM для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 270. Устройство согласно варианту осуществления 269, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 271. Устройство согласно варианту осуществления 269, где устройство дополнительно приспособлено к:
предоставлению каждому рабочему модулю из совокупности рабочих модулей третьего раздела TM, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов.
Вариант осуществления 272. Устройство согласно варианту осуществления 271, где устройство дополнительно приспособлено к:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 273. Устройство согласно варианту осуществления 272, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 274. Устройство согласно варианту осуществления 258, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 275. Устройство согласно варианту осуществления 274, где устройство дополнительно приспособлено к:
осуществлению запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерированию на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 276. Устройство, приспособленное к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы признаков на совокупность разделов TM;
предоставлению каждому из совокупности рабочих модулей раздела TM из совокупности разделов TM, при этом каждый из совокупности рабочих модулей принимает разный раздел TM;
разбиению на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM;
предоставлению каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM.
Вариант осуществления 277. Устройство согласно варианту осуществления 276, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 278. Устройство согласно варианту осуществления 276, где устройство дополнительно приспособлено к:
приему указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставлению на основе указаний каждому из совокупности рабочих модулей второго раздела GM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела GM с разделом TM.
Вариант осуществления 279. Устройство согласно варианту осуществления 276, где устройство дополнительно приспособлено к:
приему указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом GM;
предоставлению на основе указания рабочему модулю из совокупности рабочих модулей второго раздела GM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом GM.
Вариант осуществления 280. Устройство согласно варианту осуществления 276, где устройство дополнительно приспособлено к приему от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 281. Устройство согласно варианту осуществления 280, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 282. Устройство согласно варианту осуществления 281, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 283. Устройство согласно варианту осуществления 282, где устройство дополнительно приспособлено к генерированию на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 284. Устройство согласно варианту осуществления 283, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 285. Устройство согласно варианту осуществления 283, где устройство дополнительно приспособлено к оцениванию сводной статистики на основе таблицы сопряженности.
Вариант осуществления 286. Устройство согласно варианту осуществления 285, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 287. Устройство согласно варианту осуществления 281, где устройство дополнительно приспособлено к:
определению идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определению идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерированию каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 288. Устройство согласно варианту осуществления 287, где устройство дополнительно приспособлено к:
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществлению запроса к совокупности разделов GM для определения разделов GM, содержащих генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 289. Устройство согласно варианту осуществления 288, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 290. Устройство согласно варианту осуществления 288, где устройство дополнительно приспособлено к:
предоставлению каждому рабочему модулю из совокупности рабочих модулей третьего раздела GM, содержащего генотип из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов признаков.
Вариант осуществления 291. Устройство согласно варианту осуществления 290, где устройство дополнительно приспособлено к:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел TM рабочего модуля идентификатор признака из списка идентификаторов признаков; и
если раздел TM рабочего модуля содержит идентификатор признака из списка идентификаторов признаков, инициацию извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором признака;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 292. Устройство согласно варианту осуществления 291, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 293. Устройство согласно варианту осуществления 285, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 294. Устройство согласно варианту осуществления 293, где устройство дополнительно приспособлено к:
осуществлению запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерированию на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 295. Устройство, приспособленное к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию совокупности признаков из матрицы признаков (TM) для сравнения с совокупностью генотипов из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставлению каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиению на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM;
генерированию на основе некоторого количества из совокупности разделов TM очередности обработки, при этом очередность обработки указывает порядок обработки по меньшей мере первого раздела TM и второго раздела TM;
предоставлению каждому из совокупности рабочих модулей первого раздела TM;
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM;
приему от первого рабочего модуля из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM; и
предоставлению на основе очереди обработки второго раздела TM первому рабочему модулю.
Вариант осуществления 296. Устройство согласно варианту осуществления 295, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 297. Устройство согласно варианту осуществления 295, где указание о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, принимается тогда, когда второй рабочий модуль из совокупности рабочих модулей приступает к выполнению сравнения данных с первым разделом TM.
Вариант осуществления 298. Устройство согласно варианту осуществления 295, где первый раздел TM ассоциирован с первой задачей распределенной обработки, и второй раздел TM ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 299. Устройство согласно варианту осуществления 295, где устройство дополнительно приспособлено к созданию экземпляра ведущего экземпляра для каждого раздела TM из совокупности разделов TM.
Вариант осуществления 300. Устройство согласно варианту осуществления 299, где первый ведущий экземпляр ассоциирован с первой задачей распределенной обработки, и второй ведущий экземпляр ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 301. Устройство согласно варианту осуществления 300, где предоставление первого раздела TM предусматривает предоставление первым ведущим экземпляром первого раздела TM.
Вариант осуществления 302. Устройство согласно варианту осуществления 301, где предоставление второго раздела TM первому рабочему модулю предусматривает предоставление вторым ведущим экземпляром второго раздела TM первому рабочему модулю.
Вариант осуществления 303. Устройство, приспособленное к:
генерированию на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики;
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип;
осуществлению запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип;
предоставлению каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов;
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации выполнения рабочим модулем статистического анализа.
Вариант осуществления 304. Устройство согласно варианту осуществления 303, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 305. Устройство согласно варианту осуществления 303, где устройство дополнительно приспособлено к:
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
где инициация выполнения рабочим модулем статистического анализа предусматривает инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 306. Устройство согласно варианту осуществления 305, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 307. Устройство согласно варианту осуществления 305, где результат статистического анализа содержит показатель статистической значимости одной или более ассоциаций кандидатный признак-генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 308. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определения совокупности рабочих модулей для выполнения сравнения данных;
разбиения на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставления каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиения на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM;
предоставления каждому из совокупности рабочих модулей первого раздела TM из одного или более разделов TM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM.
Вариант осуществления 309. Машиночитаемый носитель согласно варианту осуществления 308, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 310. Машиночитаемый носитель согласно варианту осуществления 308, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
приема указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставления на основе указаний каждому из совокупности рабочих модулей второго раздела TM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела TM с разделом GM.
Вариант осуществления 311. Машиночитаемый носитель согласно варианту осуществления 308, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
приема указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом ТM;
предоставления на основе указания рабочему модулю из совокупности рабочих модулей второго раздела TM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом TM.
Вариант осуществления 312. Машиночитаемый носитель согласно варианту осуществления 308, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами приема от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 313. Машиночитаемый носитель согласно варианту осуществления 312, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 314. Машиночитаемый носитель согласно варианту осуществления 313, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 315. Машиночитаемый носитель согласно варианту осуществления 314, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами генерирования на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 316. Машиночитаемый носитель согласно варианту осуществления 315, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 317. Машиночитаемый носитель согласно варианту осуществления 315, где выполняемые процессором команды дополнительно приспособлены к обеспечению выполнения одной или более компьютерными системами оценивания сводной статистики на основе таблицы сопряженности.
Вариант осуществления 318. Машиночитаемый носитель согласно варианту осуществления 317, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 319. Машиночитаемый носитель согласно варианту осуществления 314, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
определения идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определения идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерирования каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 320. Машиночитаемый носитель согласно варианту осуществления 318, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
осуществления запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществления запроса к совокупности разделов TM для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 321. Машиночитаемый носитель согласно варианту осуществления 320, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 322. Машиночитаемый носитель согласно варианту осуществления 320, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
предоставления каждому рабочему модулю из совокупности рабочих модулей третьего раздела TM, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов.
Вариант осуществления 323. Машиночитаемый носитель согласно варианту осуществления 322, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 324. Машиночитаемый носитель согласно варианту осуществления 323, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 325. Машиночитаемый носитель согласно варианту осуществления 324, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 326. Машиночитаемый носитель согласно варианту осуществления 325, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
осуществления запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерирования на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 327. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определения совокупности рабочих модулей для выполнения сравнения данных;
разбиения на основе совокупности рабочих модулей матрицы признаков на совокупность разделов TM;
предоставления каждому из совокупности рабочих модулей раздела TM из совокупности разделов TM, при этом каждый из совокупности рабочих модулей принимает разный раздел TM;
разбиения на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM;
предоставления каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM.
Вариант осуществления 328. Машиночитаемый носитель согласно варианту осуществления 327, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 329. Машиночитаемый носитель согласно варианту осуществления 327, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
приема указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставления на основе указаний каждому из совокупности рабочих модулей второго раздела GM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела GM с разделом TM.
Вариант осуществления 330. Машиночитаемый носитель согласно варианту осуществления 327, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
приема указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом GM;
предоставления на основе указания рабочему модулю из совокупности рабочих модулей второго раздела GM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом GM.
Вариант осуществления 331. Машиночитаемый носитель согласно варианту осуществления 327, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами приема от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 332. Машиночитаемый носитель согласно варианту осуществления 331, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 333. Машиночитаемый носитель согласно варианту осуществления 332, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 334. Машиночитаемый носитель согласно варианту осуществления 333, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами генерирования на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 335. Машиночитаемый носитель согласно варианту осуществления 334, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 336. Машиночитаемый носитель согласно варианту осуществления 334, где выполняемые процессором команды дополнительно приспособлены к обеспечению выполнения одной или более компьютерными системами оценивания сводной статистики на основе таблицы сопряженности.
Вариант осуществления 337. Машиночитаемый носитель согласно варианту осуществления 336, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 338. Машиночитаемый носитель согласно варианту осуществления 332, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
определения идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определения идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерирования каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 339. Машиночитаемый носитель согласно варианту осуществления 338, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
осуществления запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществления запроса к совокупности разделов GM для определения разделов GM, содержащих генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 340. Машиночитаемый носитель согласно варианту осуществления 339, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 341. Машиночитаемый носитель согласно варианту осуществления 339, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
предоставления каждому рабочему модулю из совокупности рабочих модулей третьего раздела GM, содержащего генотип из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов признаков.
Вариант осуществления 342. Машиночитаемый носитель согласно варианту осуществления 341, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел TM рабочего модуля идентификатор признака из списка идентификаторов признаков; и
если раздел TM рабочего модуля содержит идентификатор признака из списка идентификаторов признаков, инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором признака;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 343. Машиночитаемый носитель согласно варианту осуществления 342, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 344. Машиночитаемый носитель согласно варианту осуществления 336, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 345. Машиночитаемый носитель согласно варианту осуществления 344, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
осуществления запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерирования на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 346. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
приема запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию совокупности признаков из матрицы признаков (TM) для сравнения с совокупностью генотипов из матрицы генотипов (GM);
определения совокупности рабочих модулей для выполнения сравнения данных;
разбиения на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставления каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиения на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM;
генерирования на основе некоторого количества из совокупности разделов TM очередности обработки, при этом очередность обработки указывает порядок обработки по меньшей мере первого раздела TM и второго раздела TM;
предоставления каждому из совокупности рабочих модулей первого раздела TM;
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM;
приема от первого рабочего модуля из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM; и
предоставления на основе очереди обработки второго раздела TM первому рабочему модулю.
Вариант осуществления 347. Машиночитаемый носитель согласно варианту осуществления 346, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 348. Машиночитаемый носитель согласно варианту осуществления 346, где указание о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, принимается тогда, когда второй рабочий модуль из совокупности рабочих модулей приступает к выполнению сравнения данных с первым разделом TM.
Вариант осуществления 349. Машиночитаемый носитель согласно варианту осуществления 346, где первый раздел TM ассоциирован с первой задачей распределенной обработки, и второй раздел TM ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 350. Машиночитаемый носитель согласно варианту осуществления 346, где выполняемые процессором команды дополнительно приспособлены к инициации создания одной или более компьютерными системами экземпляра ведущего экземпляра для каждого раздела TM из совокупности разделов TM.
Вариант осуществления 351. Машиночитаемый носитель согласно варианту осуществления 350, где первый ведущий экземпляр ассоциирован с первой задачей распределенной обработки, и второй ведущий экземпляр ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 352. Машиночитаемый носитель согласно варианту осуществления 351, где предоставление первого раздела TM предусматривает предоставление первым ведущим экземпляром первого раздела TM.
Вариант осуществления 353. Машиночитаемый носитель согласно варианту осуществления 352, где предоставление второго раздела TM первому рабочему модулю предусматривает предоставление вторым ведущим экземпляром второго раздела TM первому рабочему модулю.
Вариант осуществления 354. Машиночитаемый носитель, содержащий выполняемые процессором команды, приспособленные к инициации выполнения одной или более компьютерными системами следующего:
генерирования на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики;
осуществления запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип;
осуществления запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип;
предоставления каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов;
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации выполнения рабочим модулем статистического анализа.
Вариант осуществления 355. Машиночитаемый носитель согласно варианту осуществления 354, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 356. Машиночитаемый носитель согласно варианту осуществления 354, где выполняемые процессором команды дополнительно приспособлены к инициации выполнения одной или более компьютерными системами следующего:
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
где инициация выполнения рабочим модулем статистического анализа предусматривает инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 357. Машиночитаемый носитель согласно варианту осуществления 356, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 358. Машиночитаемый носитель согласно варианту осуществления 356, где результат статистического анализа содержит показатель статистической значимости одной или более ассоциаций кандидатный признак-генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 359. Система, содержащая:
ведущий узел, находящийся в связи с совокупностью рабочих узлов, при этом ведущий узел приспособлен к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставлению каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиению на основе идентифицированных одного или более признаков матрицы признаков на один или более разделов TM;
предоставлению каждому из совокупности рабочих модулей первого раздела ТM из одного или более разделов ТM;
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела ТM с разделом GM; и
при этом каждый рабочий узел из совокупности рабочих узлов приспособлен к:
приему раздела GM из совокупности разделов GM;
приему первого раздела TM из одного или более разделов TM; и
выполнению сравнения данных путем сравнения первого раздела TM с разделом GM.
Вариант осуществления 360. Система согласно варианту осуществления 359, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 361. Система согласно варианту осуществления 359, где ведущий узел дополнительно приспособлен к:
приему указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставлению на основе указаний каждому из совокупности рабочих модулей второго раздела TM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела TM с разделом GM.
Вариант осуществления 362. Система согласно варианту осуществления 359, где ведущий узел дополнительно приспособлен к:
приему указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом ТM;
предоставлению на основе указания рабочему модулю из совокупности рабочих модулей второго раздела TM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом TM.
Вариант осуществления 363. Система согласно варианту осуществления 359, где ведущий узел дополнительно приспособлен к приему от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 364. Система согласно варианту осуществления 363, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 365. Система согласно варианту осуществления 364, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 366. Система согласно варианту осуществления 365, где ведущий узел дополнительно приспособлен к генерированию на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 367. Система согласно варианту осуществления 366, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 368. Система согласно варианту осуществления 366, где ведущий узел дополнительно приспособлен к оцениванию сводной статистики на основе таблицы сопряженности.
Вариант осуществления 369. Система согласно варианту осуществления 368, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 370. Система согласно варианту осуществления 365, где ведущий узел дополнительно приспособлен к:
определению идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определению идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерированию каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 371. Система согласно варианту осуществления 369, где ведущий узел дополнительно приспособлен к:
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществлению запроса к совокупности разделов TM для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 372. Система согласно варианту осуществления 371, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 373. Система согласно варианту осуществления 371, где ведущий узел дополнительно приспособлен к:
предоставлению каждому рабочему модулю из совокупности рабочих модулей третьего раздела TM, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов.
Вариант осуществления 374. Система согласно варианту осуществления 373, где ведущий узел дополнительно приспособлен к:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 375. Система согласно варианту осуществления 374, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 376. Система согласно варианту осуществления 375, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 377. Система согласно варианту осуществления 376, где ведущий узел дополнительно приспособлен к:
осуществлению запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерированию на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 378. Система, содержащая:
ведущий узел, находящийся в связи с совокупностью рабочих узлов, при этом ведущий узел приспособлен к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM) для сравнения с одним или более генотипами из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы признаков на совокупность разделов TM;
предоставлению каждому из совокупности рабочих модулей раздела TM из совокупности разделов TM, при этом каждый из совокупности рабочих модулей принимает разный раздел TM;
разбиению на основе идентифицированных одного или более генотипов матрицы генотипов на один или более разделов GM;
предоставлению каждому из совокупности рабочих модулей первого раздела GM из одного или более разделов GM;
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела GM с разделом TM; и
при этом каждый рабочий узел из совокупности рабочих узлов приспособлен к:
приему раздела TM из совокупности разделов TM;
приему первого раздела GM из одного или более разделов GM; и
выполнению сравнения данных путем сравнения первого раздела GM с разделом TM.
Вариант осуществления 379. Система согласно варианту осуществления 378, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 380. Система согласно варианту осуществления 378, где ведущий узел дополнительно приспособлен к:
приему указания от каждого рабочего модуля из совокупности рабочих модулей о завершении сравнения данных;
предоставлению на основе указаний каждому из совокупности рабочих модулей второго раздела GM; и
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение второго раздела GM с разделом TM.
Вариант осуществления 381. Система согласно варианту осуществления 378, где ведущий узел дополнительно приспособлен к:
приему указания от рабочего модуля из совокупности рабочих модулей о завершении рабочим модулем сравнения данных с первым разделом GM;
предоставлению на основе указания рабочему модулю из совокупности рабочих модулей второго раздела GM; и
инициации выполнения рабочим модулем из совокупности рабочих модулей сравнения данных со вторым разделом GM.
Вариант осуществления 382. Система согласно варианту осуществления 378, где ведущий узел дополнительно приспособлен к приему от каждого рабочего модуля из совокупности рабочих модулей результата сравнения данных.
Вариант осуществления 383. Система согласно варианту осуществления 382, где результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
Вариант осуществления 384. Система согласно варианту осуществления 383, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «не определенным» генотипом (NC).
Вариант осуществления 385. Система согласно варианту осуществления 384, где ведущий узел дополнительно приспособлен к генерированию на основе одного или более значений встречаемости субъектов таблицы сопряженности для каждого из идентифицированных одного или более признаков.
Вариант осуществления 386. Система согласно варианту осуществления 384, где таблица сопряженности содержит строку для субъектов c заболеванием, и строку для контрольных субъектов, и столбец для генотипа RR, генотипа RA, генотипа AA и генотипа NC, при этом пересечение строки и столбца дает значение встречаемости субъектов, репрезентативных для строки и столбца.
Вариант осуществления 387. Система согласно варианту осуществления 384, где ведущий узел дополнительно приспособлен к оцениванию сводной статистики на основе таблицы сопряженности.
Вариант осуществления 388. Система согласно варианту осуществления 387, где сводная статистика предусматривает точный критерий Фишера.
Вариант осуществления 389. Система согласно варианту осуществления 387, где ведущий узел дополнительно приспособлен к:
определению идентификатора генотипа (GID) для каждого из одного или более генотипов, ассоциированных с идентифицированными одним или более признаками;
определению идентификатора признака (TID) для каждого из идентифицированных одного или более признаков; и
генерированию каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики.
Вариант осуществления 390. Система согласно варианту осуществления 389, где ведущий узел дополнительно приспособлен к:
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип и
осуществлению запроса к совокупности разделов GM для определения разделов GM, содержащих генотип из совокупности ассоциаций кандидатный признак-генотип.
Вариант осуществления 391. Система согласно варианту осуществления 390, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 392. Система согласно варианту осуществления 390, где ведущий узел дополнительно приспособлен к:
предоставлению каждому рабочему модулю из совокупности рабочих модулей третьего раздела GM, содержащего генотип из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов признаков.
Вариант осуществления 393. Система согласно варианту осуществления 392, где ведущий узел дополнительно приспособлен к:
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел TM рабочего модуля идентификатор признака из списка идентификаторов признаков; и
если раздел TM рабочего модуля содержит идентификатор признака из списка идентификаторов признаков, инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором признака;
инициации уплотнения рабочим модулем разреженного вектора; и
инициации выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 394. Система согласно варианту осуществления 393, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 395. Система согласно варианту осуществления 387, где матрица генотипов содержит агрегированную матрицу генотипов.
Вариант осуществления 396. Система согласно варианту осуществления 395, где ведущий узел дополнительно приспособлен к:
осуществлению запроса к исходной матрице генотипов на основе совокупности генов с применением одного или более булевых операторов и
генерированию на основе результатов осуществления запроса к исходной матрице генотипов агрегированной матрицы генотипов.
Вариант осуществления 397. Система, содержащая:
ведущий узел, находящийся в связи с совокупностью рабочих узлов, при этом ведущий узел приспособлен к:
приему запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию совокупности признаков из матрицы признаков (TM) для сравнения с совокупностью генотипов из матрицы генотипов (GM);
определению совокупности рабочих модулей для выполнения сравнения данных;
разбиению на основе совокупности рабочих модулей матрицы генотипов на совокупность разделов GM;
предоставлению каждому из совокупности рабочих модулей раздела GM из совокупности разделов GM, при этом каждый из совокупности рабочих модулей принимает разный раздел GM;
разбиению на основе идентифицированной совокупности признаков матрицы признаков на совокупность разделов TM;
генерированию на основе некоторого количества из совокупности разделов TM очередности обработки, при этом очередность обработки указывает порядок обработки по меньшей мере первого раздела TM и второго раздела TM;
предоставлению каждому из совокупности рабочих модулей первого раздела TM;
инициации выполнения каждым рабочим модулем из совокупности рабочих модулей сравнения данных, при этом каждый рабочий модуль из совокупности рабочих модулей осуществляет сравнение первого раздела TM с разделом GM;
приему от первого рабочего модуля из совокупности рабочих модулей указания о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM;
предоставлению на основе очереди обработки второго раздела TM первому рабочему модулю; и
при этом каждый рабочий узел из совокупности рабочих узлов приспособлен к:
приему раздела GM из совокупности разделов GM;
приему первого раздела TM из одного или более разделов TM;
выполнению сравнения данных путем сравнения первого раздела TM с разделом GM;
предоставлению указания о том, что сравнение данных с первым разделом TM завершено; и
приему второго раздела TM из одного или более разделов TM.
Вариант осуществления 398. Система согласно варианту осуществления 397, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
Вариант осуществления 399. Система согласно варианту осуществления 397, где указание о том, что первый рабочий модуль завершил сравнение данных с первым разделом TM, принимается тогда, когда второй рабочий модуль из совокупности рабочих модулей приступает к выполнению сравнения данных с первым разделом TM.
Вариант осуществления 400. Система согласно варианту осуществления 397, где первый раздел TM ассоциирован с первой задачей распределенной обработки, и второй раздел TM ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 401. Система согласно варианту осуществления 397, где ведущий узел дополнительно приспособлен к созданию экземпляра ведущего экземпляра для каждого раздела TM из совокупности разделов TM.
Вариант осуществления 402. Система согласно варианту осуществления 401, где первый ведущий экземпляр ассоциирован с первой задачей распределенной обработки, и второй ведущий экземпляр ассоциирован со второй задачей распределенной обработки.
Вариант осуществления 403. Система согласно варианту осуществления 402, где предоставление первого раздела TM предусматривает предоставление первым ведущим экземпляром первого раздела TM.
Вариант осуществления 404. Система согласно варианту осуществления 403, где предоставление второго раздела TM первому рабочему модулю предусматривает предоставление вторым ведущим экземпляром второго раздела TM первому рабочему модулю.
Вариант осуществления 405. Система, содержащая:
ведущий узел, находящийся в связи с совокупностью рабочих узлов, при этом ведущий узел приспособлен к:
генерированию на основе по меньшей мере части матрицы признаков (TM) и по меньшей мере части матрицы генотипов (GM) каркасной структуры данных, содержащей совокупность строк и совокупность столбцов, при этом совокупность столбцов содержит столбец идентификатора генотипа, идентификатор признака из столбца ассоциированного признака, таблицу сопряженности для столбца ассоциированного признака и столбец сводной статистики;
осуществлению запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип;
осуществлению запроса к совокупности разделов TM матрицы признаков для определения разделов TM, содержащих признак из совокупности ассоциаций кандидатный признак-генотип;
предоставлению каждому рабочему модулю из совокупности рабочих модулей раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов;
инициации определения каждым рабочим модулем из совокупности рабочих модулей того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов;
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, к инициации выполнения рабочим модулем статистического анализа; и
при этом каждый рабочий узел из совокупности рабочих узлов приспособлен к:
приему раздела TM матрицы признаков, содержащего признак из совокупности ассоциаций кандидатный признак-генотип, и списка идентификаторов генотипов;
определению того, содержит ли раздел GM рабочего модуля идентификатор генотипа из списка идентификаторов генотипов; и,
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, выполнению статистического анализа.
Вариант осуществления 406. Система согласно варианту осуществления 405, где осуществление запроса к каркасной структуре данных для идентификации совокупности ассоциаций кандидатный признак-генотип основано на столбце сводной статистики, одном или более значениях встречаемости субъектов или и на том, и на другом.
Вариант осуществления 407. Система согласно варианту осуществления 405, где ведущий узел дополнительно приспособлен к:
если раздел GM рабочего модуля содержит идентификатор генотипа из списка идентификаторов генотипов, инициации извлечения рабочим модулем разреженного вектора, ассоциированного с идентификатором генотипа;
инициации уплотнения рабочим модулем разреженного вектора; и
где инициация выполнения рабочим модулем статистического анализа предусматривает инициацию выполнения рабочим модулем статистического анализа на основе уплотненного разреженного вектора.
Вариант осуществления 408. Система согласно варианту осуществления 407, где статистический анализ предусматривает одну или более из логистической регрессии или линейной регрессии.
Вариант осуществления 409. Система согласно варианту осуществления 407, где результат статистического анализа содержит показатель статистической значимости одной или более ассоциаций кандидатный признак-генотип из совокупности ассоциаций кандидатный признак-генотип.
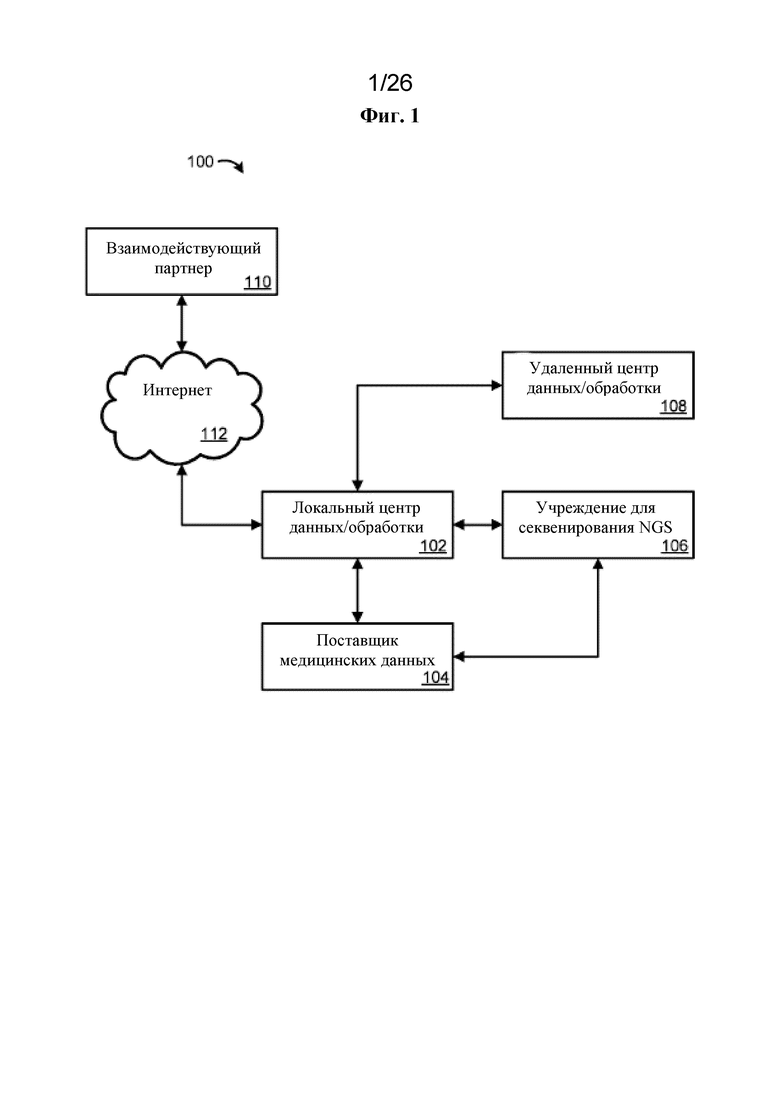
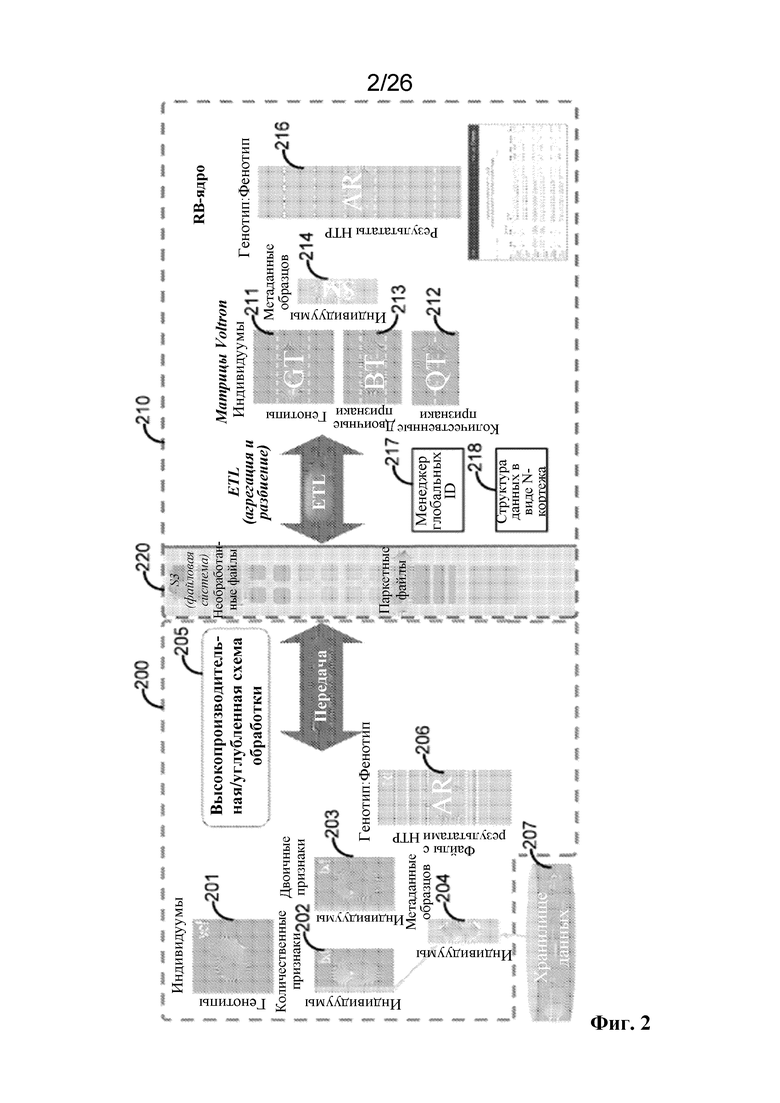
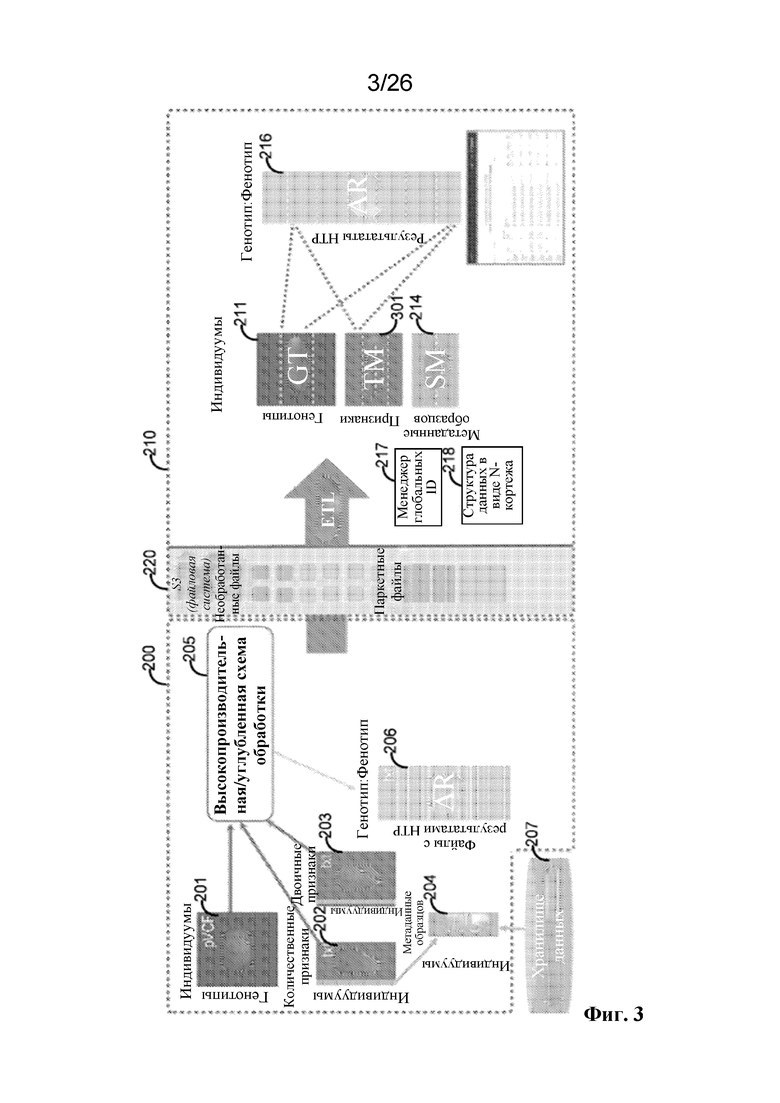
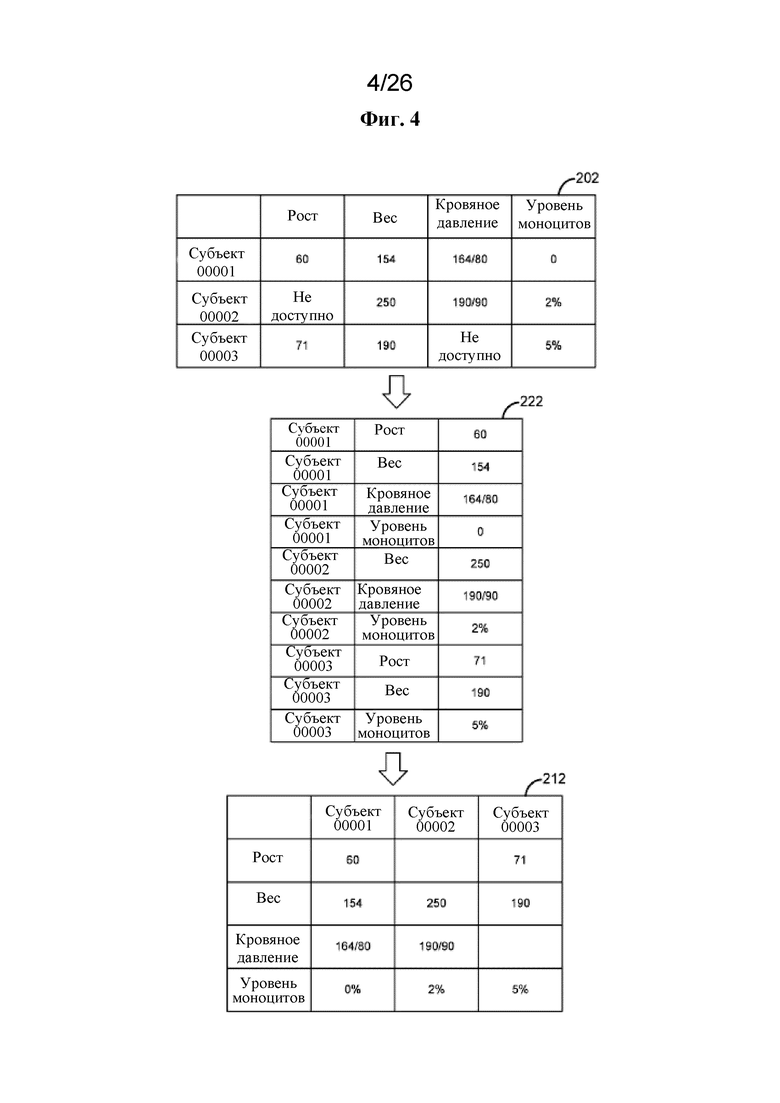
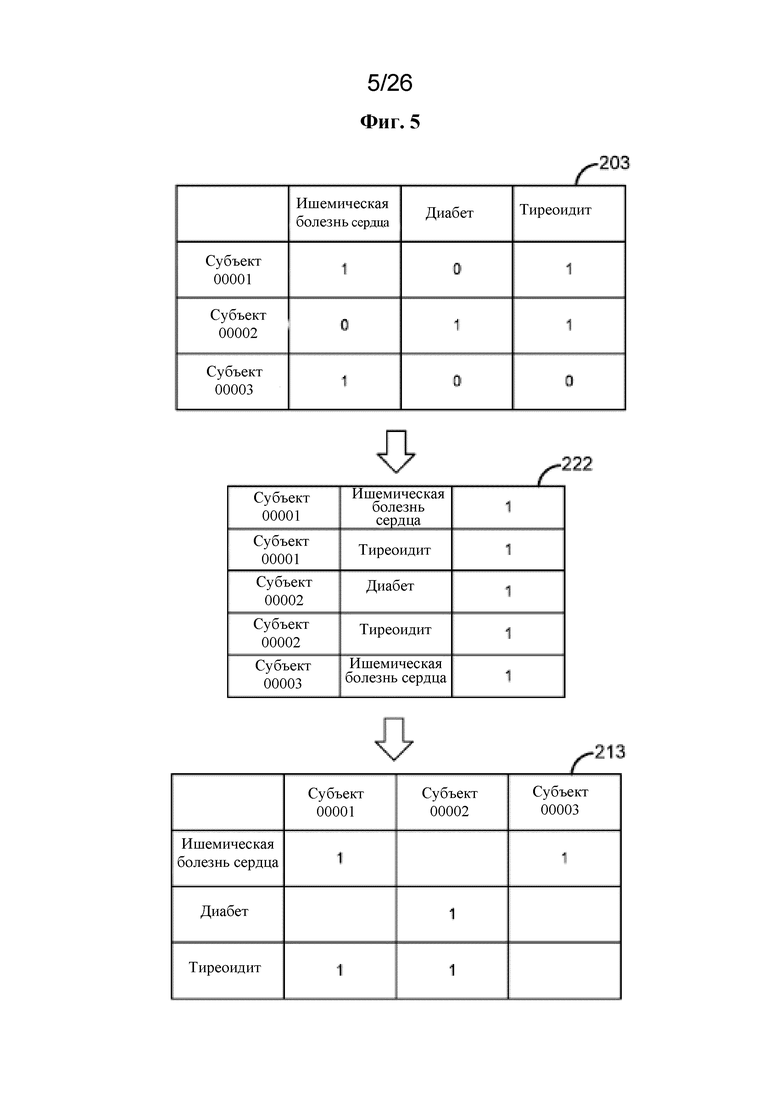
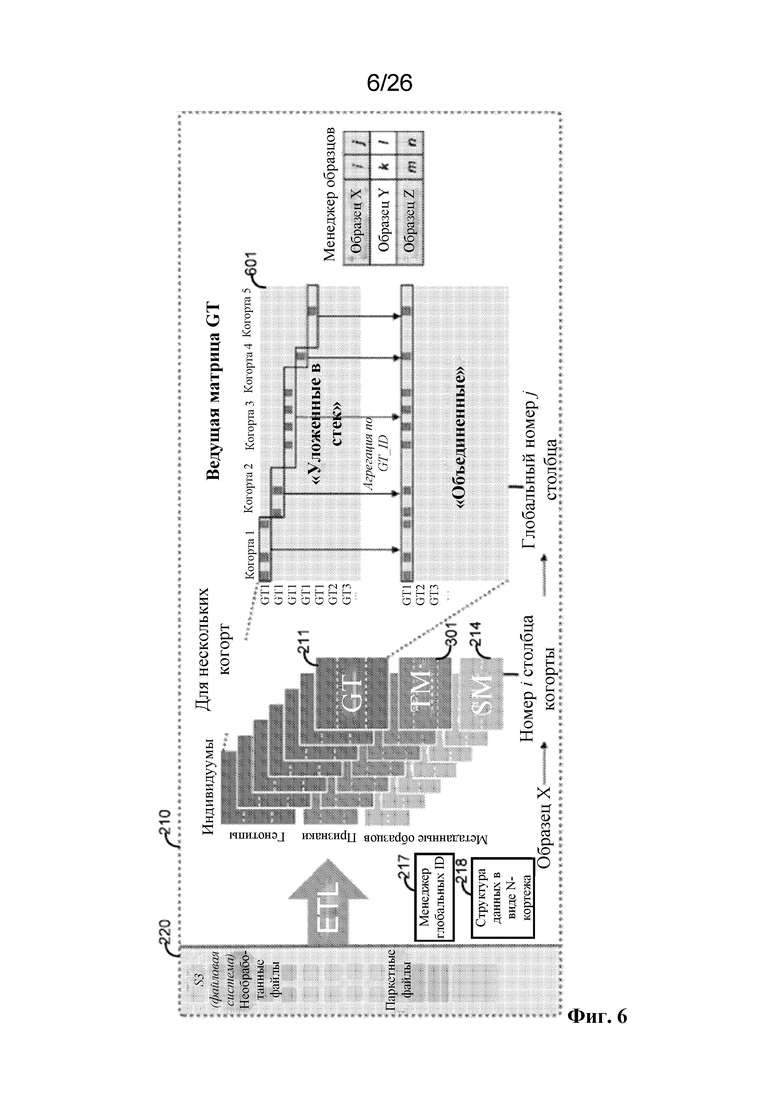



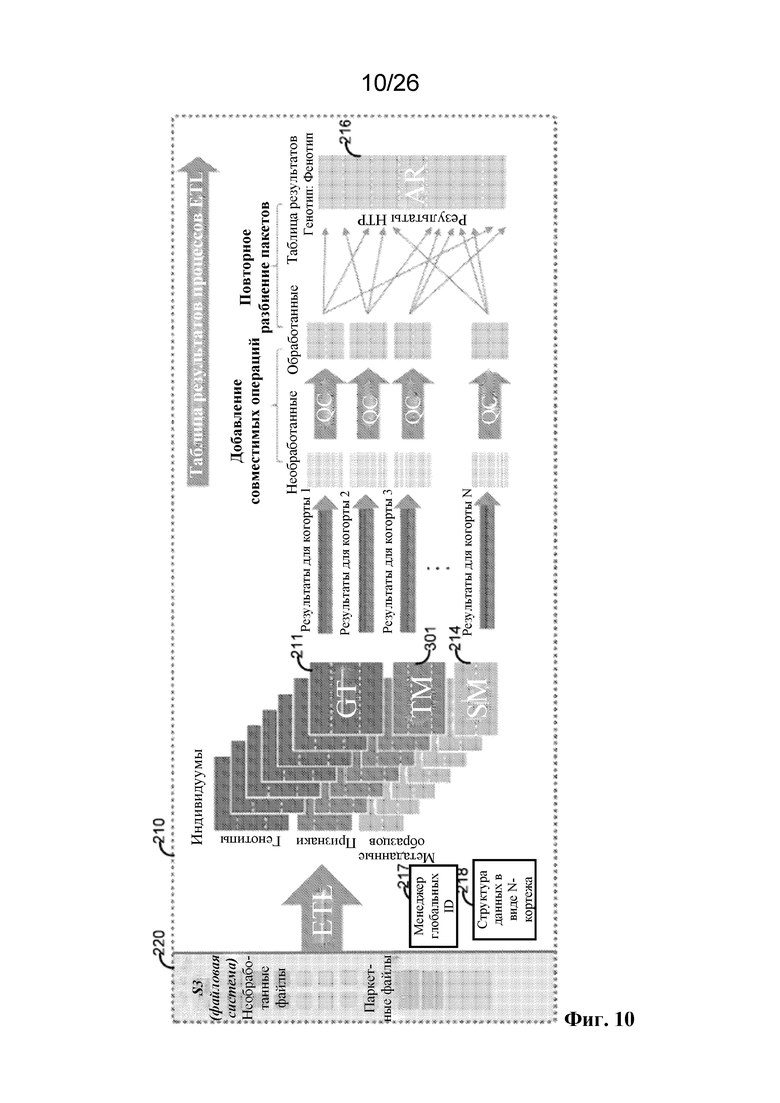
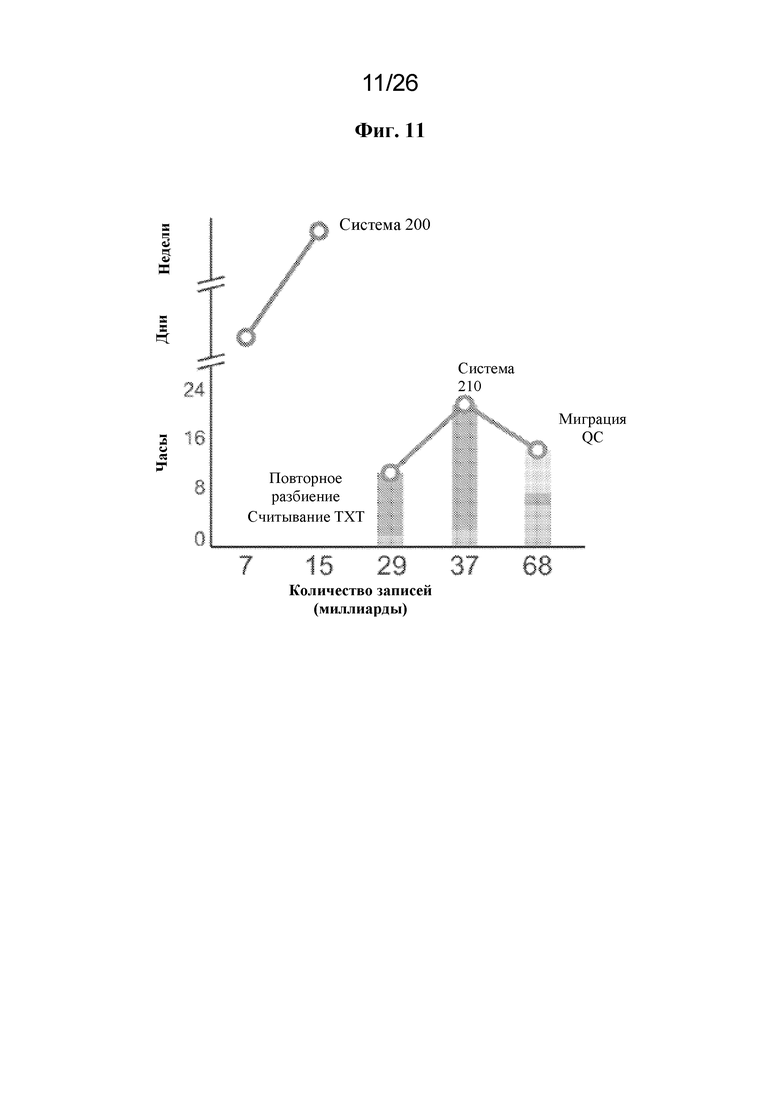
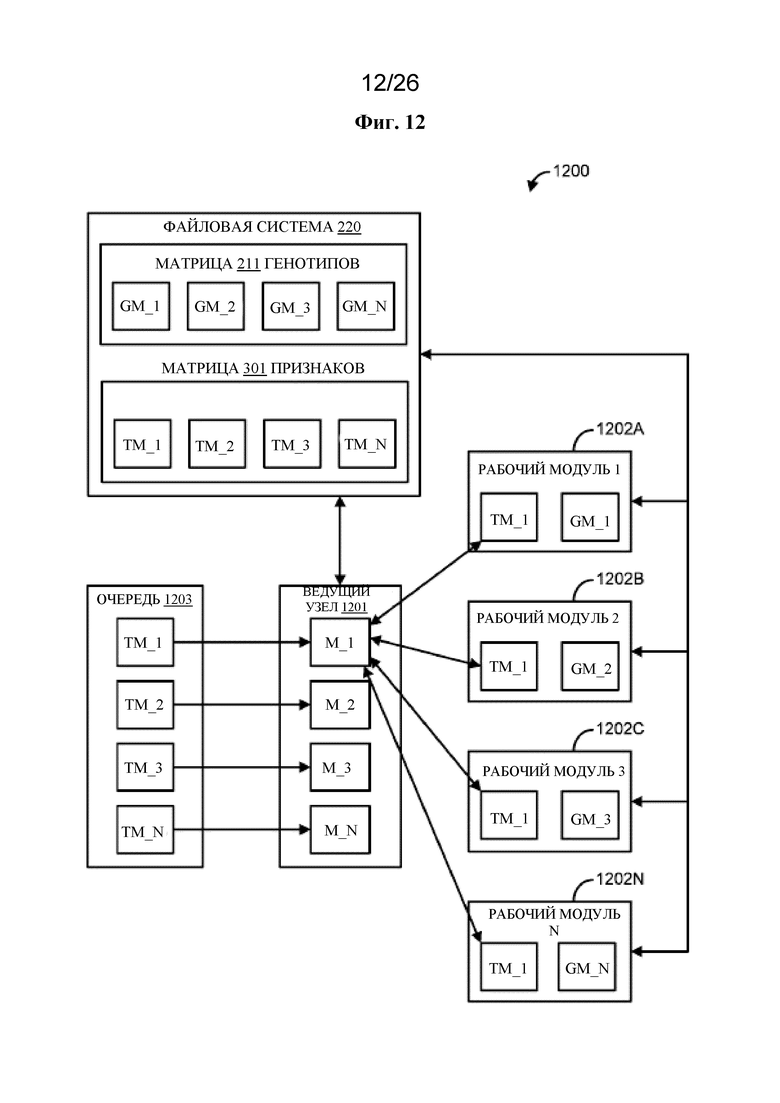
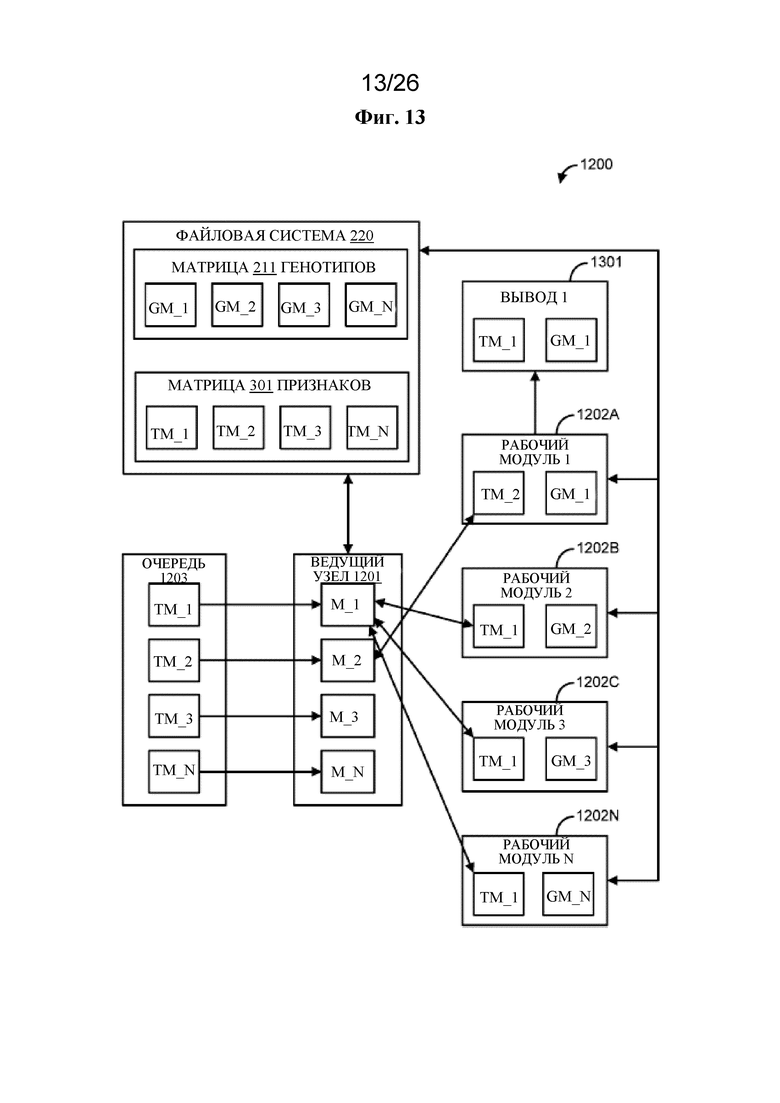
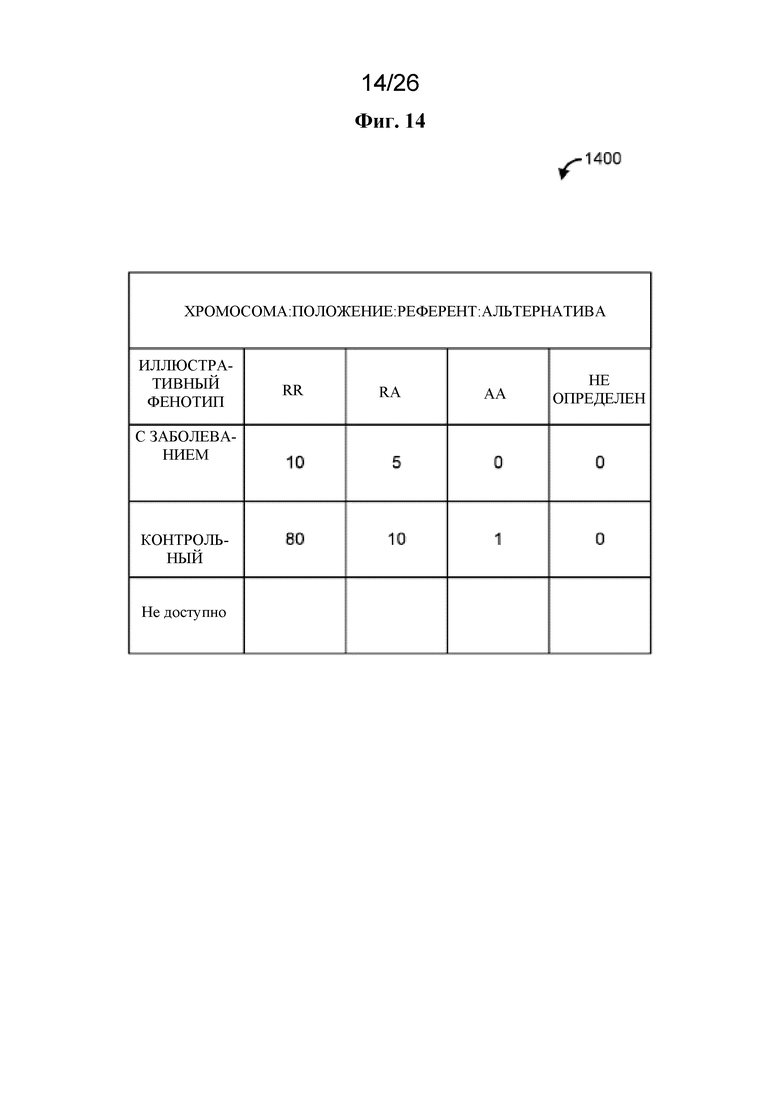
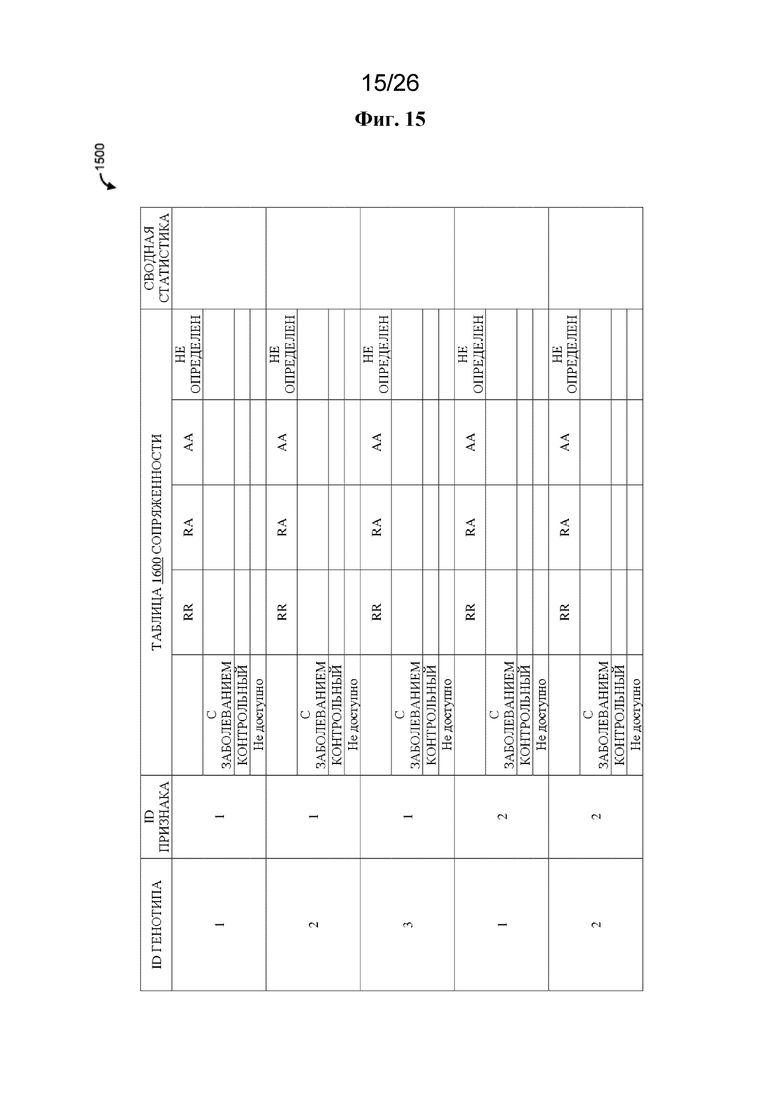
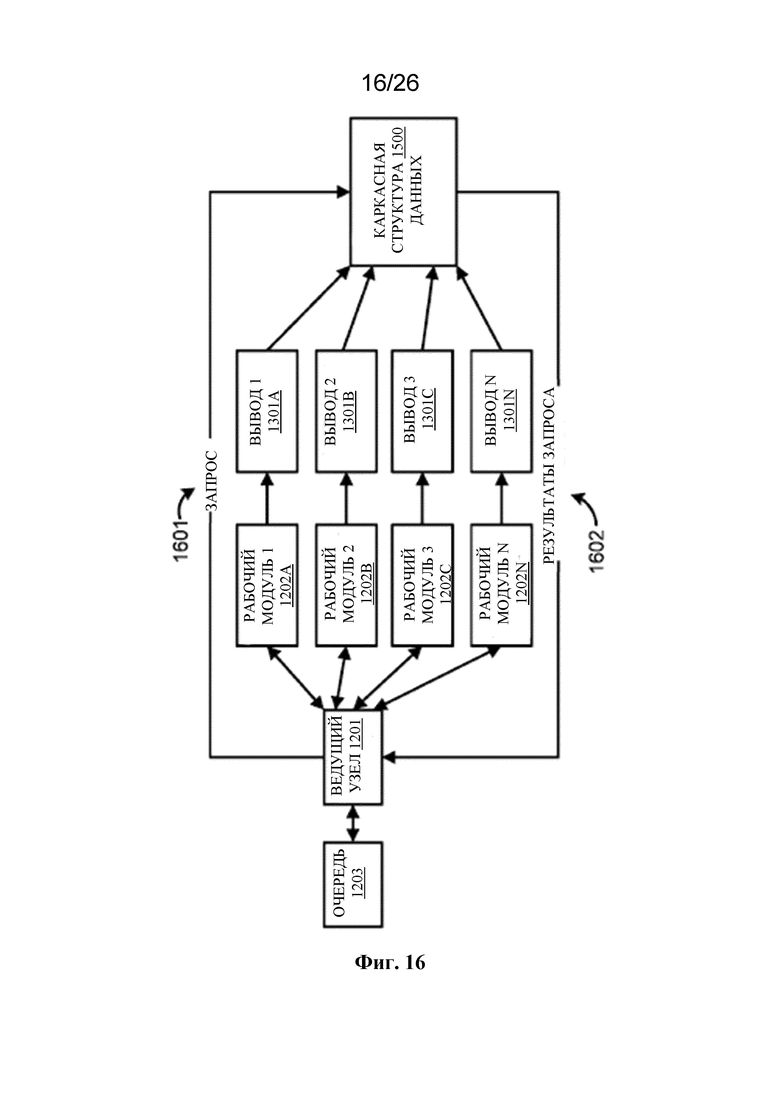
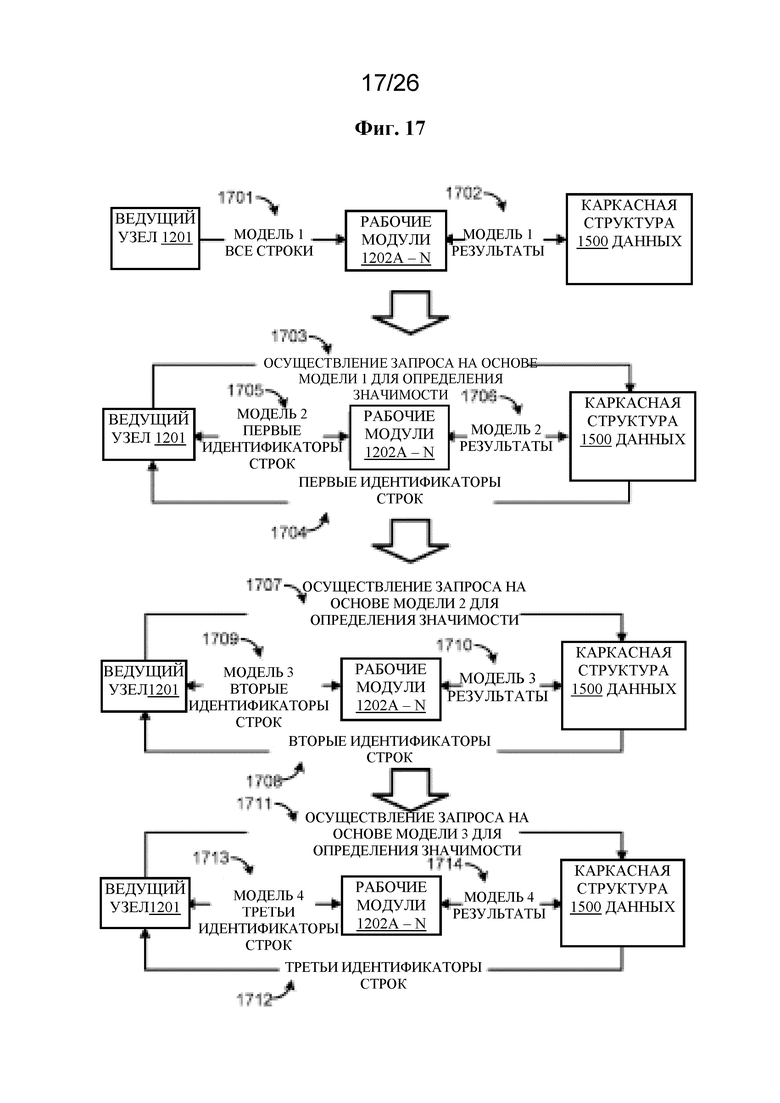
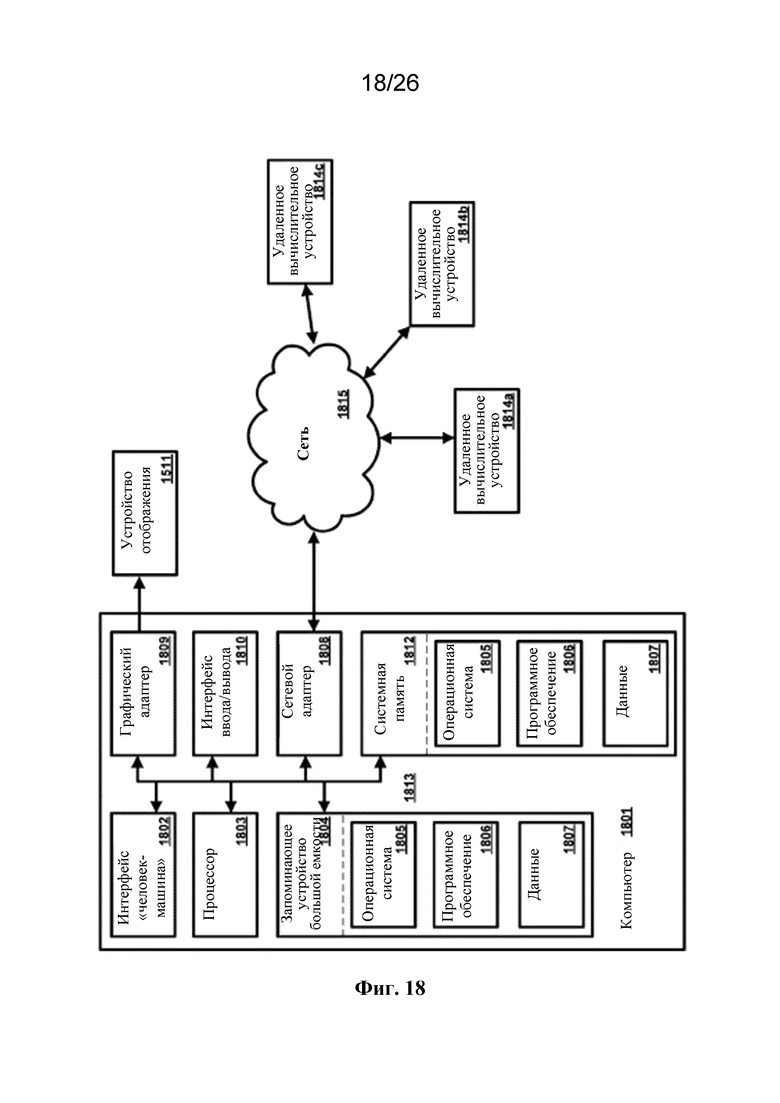
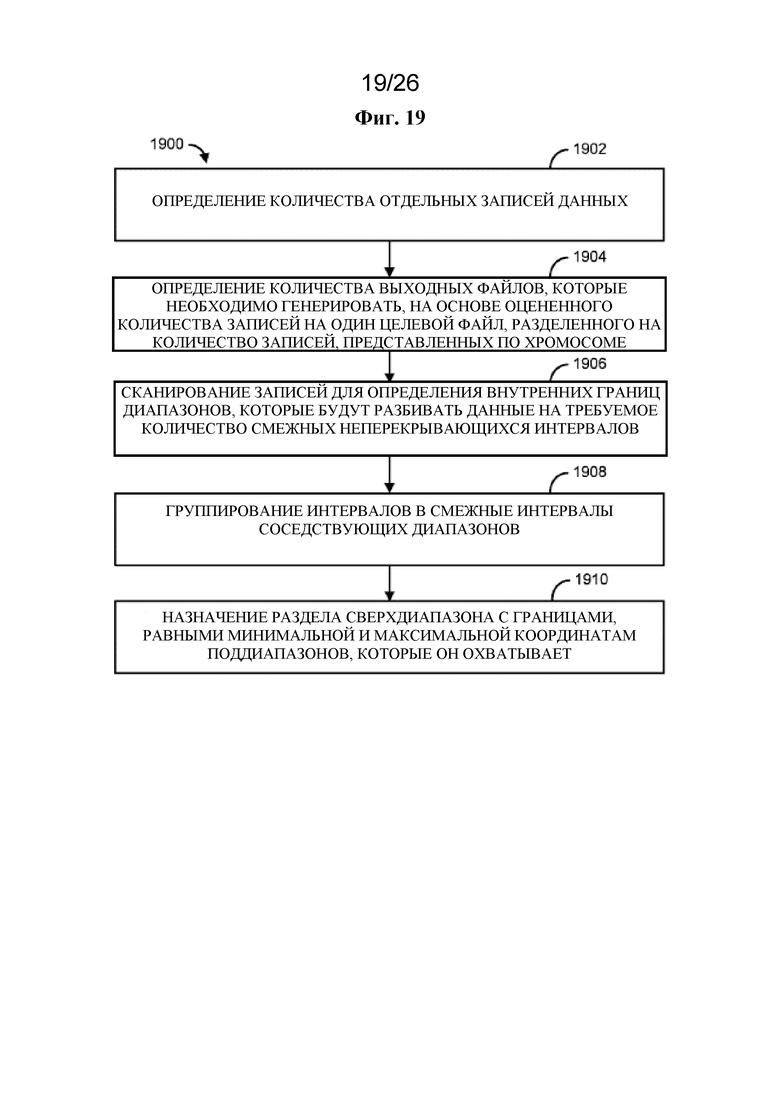
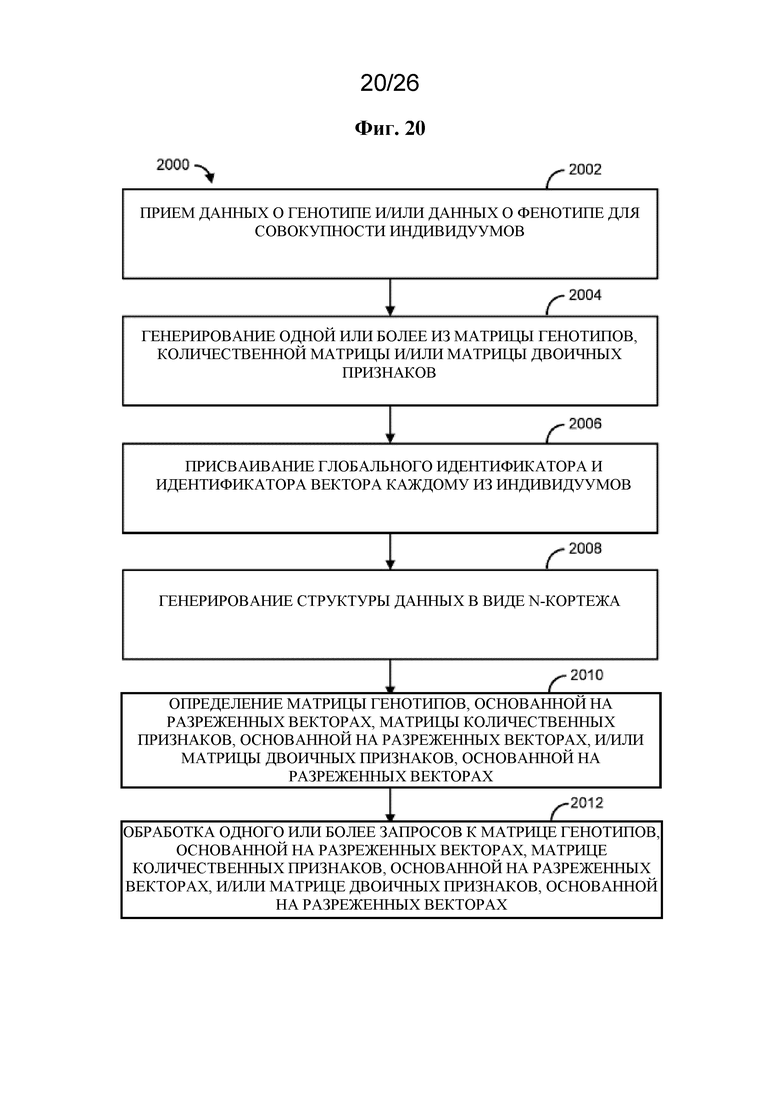
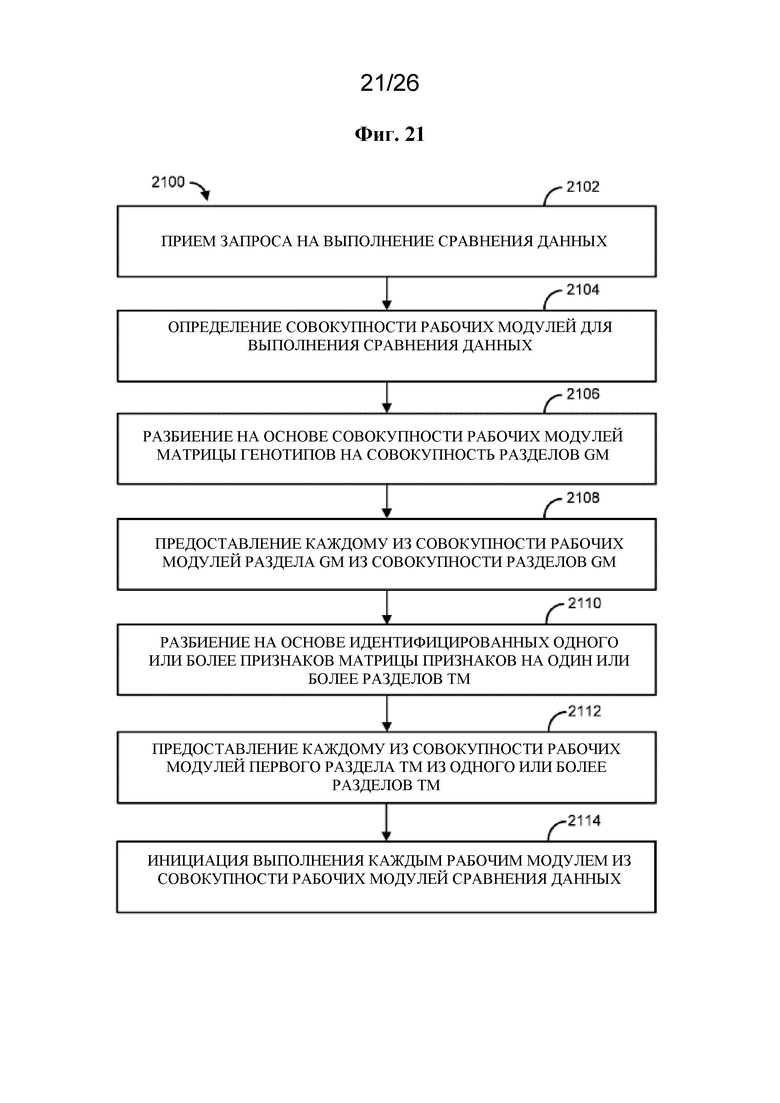
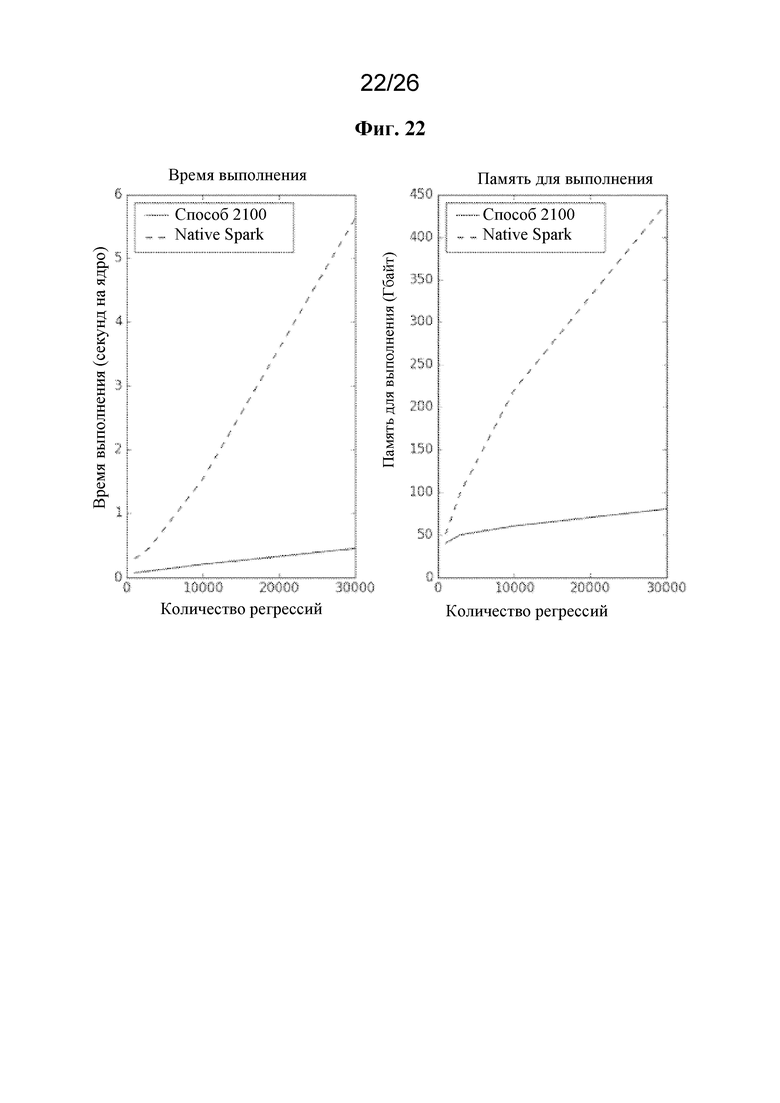
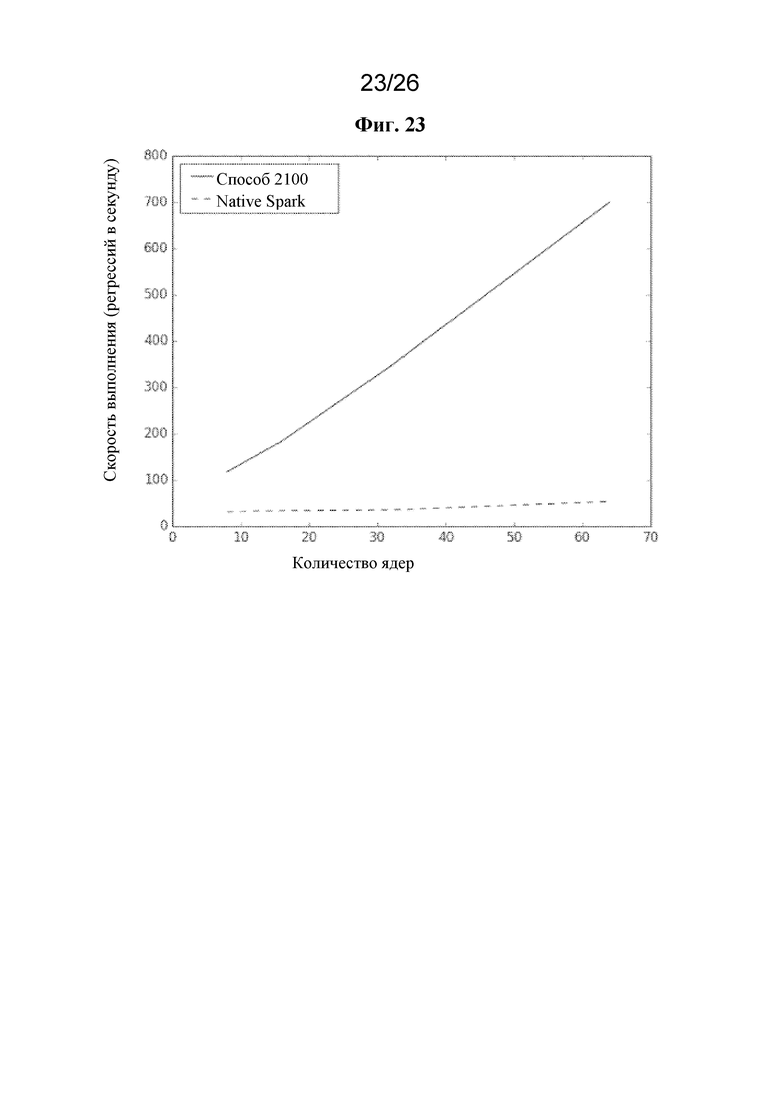
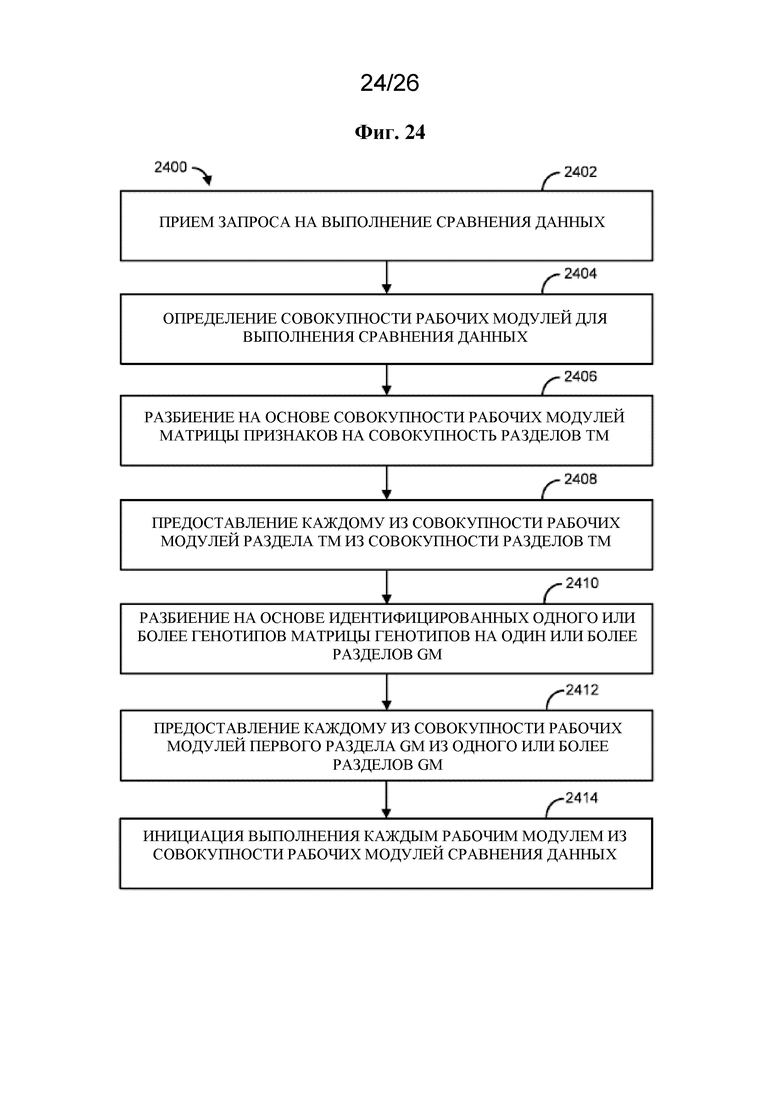
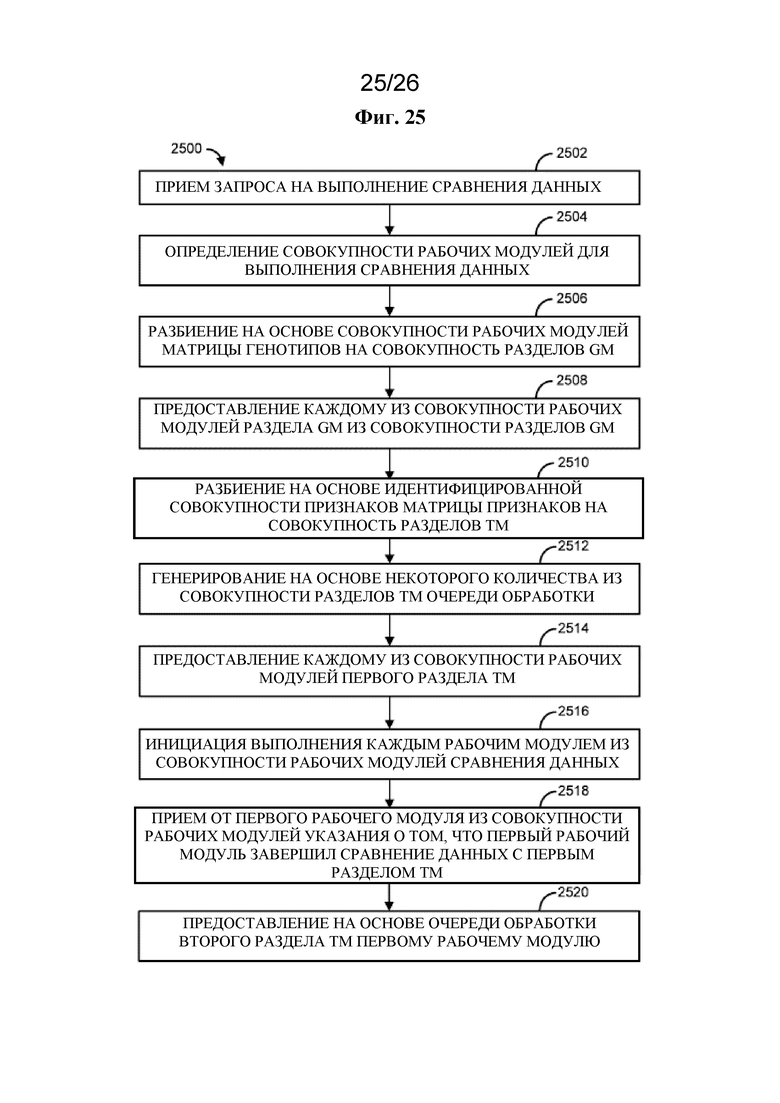
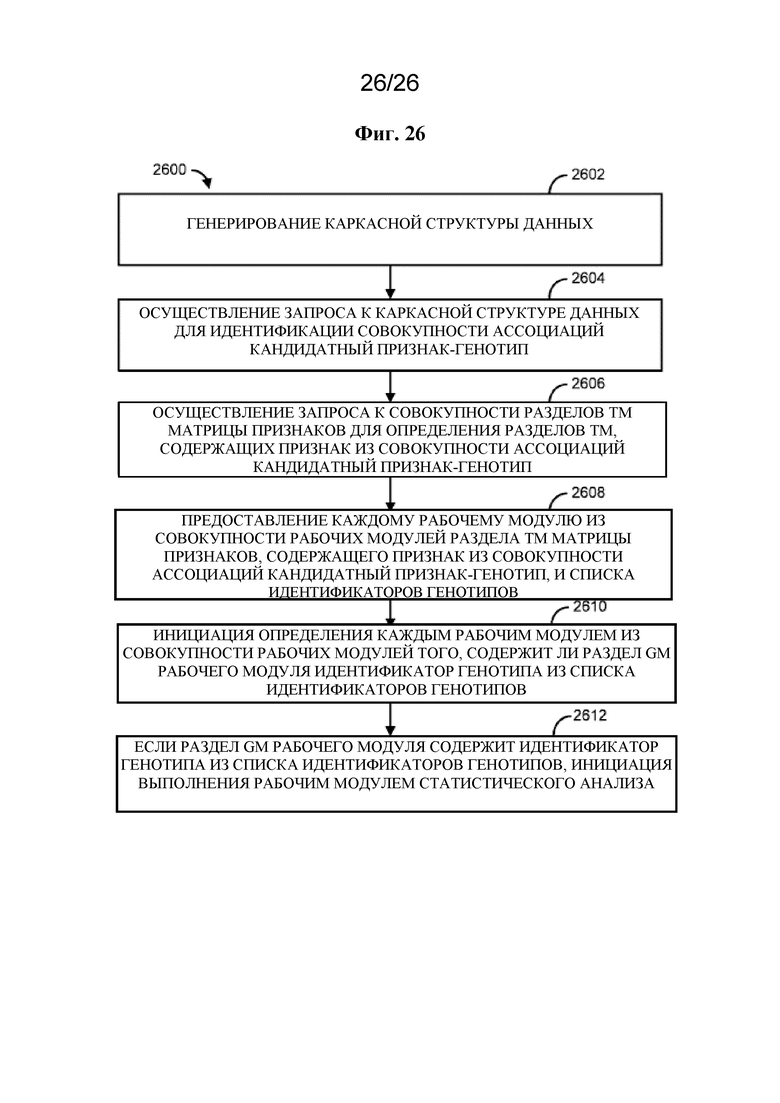
Изобретение относится к биотехнологии. Описан способ исследования биологического образца от пациента на предмет ассоциаций между генетическими мутациями и признаками заболеваний, предусматривающий: генерирование на основе данных о генотипе и данных о фенотипе для совокупности субъектов матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков; генерирование на основе матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа; определение на основе структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; получение биологического образца от пациента; обработку биологического образца секвенатором для получения генетических мутаций и обработку одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах, при этом один или более запросов содержит полученные генетические мутации и при этом данная обработка определяет ассоциацию между полученными генетическими мутациями и одним или более признаками заболевания. Представлена система для исследования биологического образца от пациента на предмет ассоциаций между генетическими мутациями и признаками заболеваний. Изобретение позволяет определять ассоциацию между полученными генетическими мутациями и одним или более признаками заболевания. 2 н. и 16 з.п. ф-лы, 26 ил.
1. Способ исследования биологического образца от пациента на предмет ассоциаций между генетическими мутациями и признаками заболеваний, предусматривающий:
генерирование на основе данных о генотипе и данных о фенотипе для совокупности субъектов матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков;
генерирование на основе матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
определение на основе структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах;
получение биологического образца от пациента;
обработку биологического образца секвенатором для получения генетических мутаций; и
обработку одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах, при этом один или более запросов содержит полученные генетические мутации и при этом данная обработка определяет ассоциацию между полученными генетическими мутациями и одним или более признаками заболевания.
2. Способ по п. 1,
где матрица количественных признаков основана на данных о фенотипе, при этом матрица количественных признаков содержит столбец для каждого из совокупности количественных признаков и совокупность строк для каждого из совокупности субъектов, и
где матрица двоичных признаков основана на данных о фенотипе, при этом матрица двоичных признаков содержит столбец для каждого из совокупности двоичных признаков и совокупность строк для каждого из совокупности субъектов.
3. Способ по п. 1, где структура данных в виде n-кортежа содержит идентификатор строки для строки, идентификатор столбца для столбца и значение, появляющееся на пересечении строки и столбца.
4. Способ по п. 3, где идентификатор строки содержит следующее: хромосома:положение:референт:альтернатива или хромосома:диапазон:референт:альтернатива, и при этом идентификатор столбца содержит идентификатор когорты.
5. Способ по п. 4, где матрица генотипов, основанная на разреженных векторах, содержит столбец для каждого из совокупности субъектов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы генотипов,
где матрица количественных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности субъектов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы количественных признаков, и
где матрица двоичных признаков, основанная на разреженных векторах, содержит столбец для каждого из совокупности субъектов и совокупность строк для каждого из совокупности генотипов, при этом по меньшей мере один столбец содержит разреженный вектор, представляющий одно или более значений матрицы двоичных признаков.
6. Способ по п. 5, дополнительно предусматривающий выравнивание, согласно столбцу, матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, и матрицы двоичных признаков, основанной на разреженных векторах.
7. Способ по п. 5, где разреженный вектор, представляющий одно или более значений матрицы генотипов, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с субъектом, который имеет ненулевое значение в строке матрицы генотипов.
8. Способ по п. 5, где разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с субъектом, который имеет значение, не равное NULL, в столбце матрицы количественных признаков.
9. Способ по п. 5, где разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит структуру данных, имеющую столбец для каждого идентификатора когорты, ассоциированного с субъектом, который имеет ненулевое значение в столбце матрицы двоичных признаков.
10. Способ по п. 5, где разреженный вектор, представляющий одно или более значений матрицы генотипов или матрицы количественных признаков, приспособлен к отбрасыванию значений, равных 0 (нулю), при этом разреженный вектор, представляющий одно или более значений матрицы количественных признаков, приспособлен к разрешению значения, равного 0 (нулю), и к отбрасыванию значений NULL, при этом разреженный вектор, представляющий одно или более значений матрицы количественных признаков, содержит неопределенное значение, и при этом разреженный вектор, представляющий одно или более значений матрицы двоичных признаков, содержит неопределенное значение.
11. Способ по п. 1, дополнительно предусматривающий:
прием дополнительных данных о генотипе и дополнительных данных о фенотипе для дополнительной совокупности субъектов;
присваивание менеджером идентификаторов идентификатора когорты каждому субъекту, который является общим для совокупности субъектов и дополнительной совокупности субъектов; и
присваивание менеджером идентификаторов глобального идентификатора и идентификатора когорты каждому из субъектов, который не является общим для совокупности субъектов и дополнительной совокупности субъектов, при этом субъекту могут быть присвоены более одного идентификатора когорты и только один глобальный идентификатор;
добавление по меньшей мере части дополнительных данных о генотипе в матрицу генотипов;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков;
добавление по меньшей мере части дополнительных данных о фенотипе в матрицу количественных признаков; и
присоединение по меньшей мере части матрицы метаданных к каждой из матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков.
12. Способ по п. 1, дополнительно предусматривающий генерирование на основе одной или более из матрицы генотипов, матрицы количественных признаков или матрицы двоичных признаков, матрицы результатов ассоциации.
13. Способ по п. 12, дополнительно предусматривающий разбиение матрицы результатов ассоциации.
14. Способ по п. 1, где обработка одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах, предусматривает:
прием запроса на выполнение сравнения данных, при этом запрос осуществляет идентификацию одного или более признаков из матрицы признаков (TM), основанной на разреженных векторах, для сравнения с одним или более генотипами из матрицы генотипов (GM), основанной на разреженных векторах, при этом матрица признаков, основанная на разреженных векторах, содержит по меньшей мере часть матрицы количественных признаков, основанной на разреженных векторах, и по меньшей мере часть матрицы двоичных признаков, основанной на разреженных векторах;
инициацию выполнения одним или более вычислительными устройствами сравнения данных, при этом одно или более вычислительных устройств сравнивает матрицу признаков, основанную на разреженных векторах, с матрицей генотипов, основанной на разреженных векторах.
15. Способ по п. 14, где результат сравнения данных содержит одну или более ассоциаций признак-генотип.
16. Способ по п. 14, дополнительно предусматривающий прием от одного или более вычислительных устройств результата сравнения данных, при этом результат сравнения данных содержит одно или более значений встречаемости субъектов, обладающих как признаком, так и генотипом.
17. Способ по п. 16, где одно или более значений встречаемости субъектов предусматривают значение встречаемости субъектов, обладающих генотипом референтный аллель-референтный аллель (RR), генотипом референтный аллель-альтернативный аллель (RA), генотипом альтернативный аллель-альтернативный аллель (AA) или «неопределенным» генотипом (NC).
18. Система для исследования биологического образца от пациента на предмет ассоциаций между генетическими мутациями и признаками заболеваний, содержащая:
секвенатор, выполненный с возможностью обработки биологического образца для получения генетических мутаций; и
вычислительное устройство, выполненное с возможностью:
a) генерирования на основе данных о генотипе и данных о фенотипе для совокупности субъектов матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков;
b) генерирования на основе матрицы генотипов, матрицы количественных признаков и матрицы двоичных признаков структуры данных в виде n-кортежа;
c) определения на основе структуры данных в виде n-кортежа одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах; и
d) обработки одного или более запросов к одной или более из матрицы генотипов, основанной на разреженных векторах, матрицы количественных признаков, основанной на разреженных векторах, или матрицы двоичных признаков, основанной на разреженных векторах, при этом один или более запросов содержит полученные генетические мутации и при этом данная обработка определяет ассоциацию между полученными генетическими мутациями и одним или более признаками заболевания.
| JIANLONG QI ET AL, "kruX: matrix-based non-parametric eQTL discovery", BMC BIOINFORMATICS, BIOMED CENTRAL, LONDON, GB,Vol | |||
| Прибор для нагревания перетягиваемых бандажей подвижного состава | 1917 |
|
SU15A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| HASSAN FOROUGHI ASL, "eQTL mapping and inherited risk enrichment analysis : a systems biology approach for coronary artery disease", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 | |||

