Область техники, к которой относится изобретение
Настоящее изобретение относится к области компьютерных систем, а более точно к способам, системам и компьютерным программным продуктам для создания структур базы данных и для сохранения данных в ответ на атрибуты, ассоциативно связанные с типами данных, в частности с типами данных .NET.
УРОВЕНЬ ТЕХНИКИ
Существует много разных систем и инструментальных средств, которые могут быть использованы для сохранения данных. Хранение данных может включать в себя, например, использование инструментальных средств баз данных, которые сконфигурированы, чтобы предоставить программисту возможность выбирать разные типы структур баз данных для сохранения данных, основываясь на осознанных потребностях. Одно из таких инструментальных средств включает в себя Access, хотя также существуют и другие, которые хранят данные в соответствии с базой данных Jet SQL. Должно быть принято во внимание, однако, что, несмотря на этот пример, существуют различные другие типы инструментальных средств хранения данных для множества разных типов реляционных баз данных.
Одна из проблем с существующими инструментальными средствами баз данных, однако, состоит в том, что они требуют от программистов обладания относительно глубокими знаниями о базах данных и о том, как база данных могла бы быть создана и организована для того, чтобы обеспечивать наилучшую производительность для отдельной реализации, для которой они являются созданными. Например, программисту потребуется идентифицировать различные типы таблиц, выделяемую память и другие структуры хранения, которые должны быть предусмотрены для базы данных.
Однако, в виду того, что потребности в хранимых данных могут изменяться, существующая парадигма для создания структур баз данных отчасти ограничена. В частности, создание баз данных, основанное на известных потребностях в хранении данных, и ограниченное знание программистов о том, как наилучшим образом удовлетворить эти потребности, может чрезмерно ограничить использование базы данных и препятствовать базе данных в том, чтобы быть легко настроенной, чтобы удовлетворять различным потребностям в будущем.
В частности, база данных может быть необходима, чтобы хранить разные типы данных из разных систем, которые не известны заранее или несовместимы с установленной базой данных на момент времени, когда база данных создается. Структурам установленной базы данных может потребоваться также обеспечивать гибкость, которая должна быть использована для разных типов реляционных баз данных, безусловно, исключая SQL (язык структурированных запросов). Существующие технологии, однако, не обеспечивают эту гибкость без необходимости переписывать монолитный код, определяющий базу данных.
Еще одна проблема, встречающаяся при сохранении объектов в реляционных базах данных, заключается в том, что программистам трудно преобразовывать иерархии классов при сохранении объектов в реляционных базах данных и, таким образом, чтобы не оказывать негативного влияния на эффективность хранения, когда к объектам данных осуществляется доступ в последующее время. Например, если многочисленные типы классов соответствуют одному и тому же базовому классу, может не иметь смысла хранить каждый из отдельных классов в единой монолитной структуре базы данных. Более того, может не иметь смысла хранить каждый из отдельных классов полностью раздельно в разных структурах. Оба из этих примеров могут создавать проблемы неэффективности во время последующих запросов данных.
Следовательно, требуется общий подход к хранению произвольных структур данных и извлечения их по требованию и без существенной зависимости от лежащей в основе структуры хранения данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение, в целом, относится к способам, системам и компьютерным программным продуктам, которые предлагают общий механизм для сохранения объектов данных в базах данных и без существенной зависимости от лежащего в основе хранилища данных или его правил, или признаков. Взамен настоящее изобретение предусматривает изменение парадигмы в технологиях хранения данных. В частности, вместо того, чтобы полагаться на специальные знания программиста, чтобы узнать, как могла бы выглядеть структура базы данных для получения желаемых результатов, настоящее изобретение сосредотачивается на том, для чего данные будут использованы и, соответственно, создает оптимизированную базу данных для обеспечения желаемых результатов.
Согласно одному из вариантов осуществления типы данных определены и дополнены программистом атрибутами, которые подсказывают, для чего соответствующие данные будут использованы, и без программиста, определяющего структуру базы данных, которая будет использована для хранения данных. После этого база данных динамически создается для удовлетворения потребностей, подсказанных дополненными атрибутами. В частности, создается некоторое количество различных таблиц в соответствии с запланированными потребностями для осуществления доступа к данным. В соответствии с некоторыми вариантами осуществления структуры и таблицы базы данных создаются таким образом, чтобы минимизировать дублирующее хранение данных и увеличить производительность базы данных, чтобы удовлетворять запланированным потребностям, осуществлять доступ к данным. Такое создание таблиц базы данных прозрачно для программиста, которому не нужно иметь какие-либо специальные знания, относящиеся к различным типам структур данных или баз данных. Взамен программист может разрабатывать код, который всего лишь идентифицирует типы данных на основании известных потребностей осуществлять доступ к соответствующим данным.
Если в дальнейшем потребности осуществлять доступ к данным изменяются, типы данных могут быть модифицированы или удалены, и новые типы данных могут быть созданы, что позволит лежащей в основе структуре базы данных быть динамически обновленной соответственно, и не требуя от монолитного фрагмента кода, соответствующего базе данных, быть модифицированным на всем протяжении. Другими словами, настоящее изобретение предусматривает средство для предоставления возможности модульного создания структур базы данных.
Дополнительные признаки и преимущества изобретения будут изложены в описании, которое следует, и частично будут очевидны из описания или могут быть изучены при осуществлении изобретения на практике. Признаки и преимущества изобретения могут быть реализованы и получены посредством инструментальных средств и комбинаций, подробно раскрытых в прилагаемой формуле изобретения. Эти и другие признаки настоящего изобретения станут более полно видны из последующего описания и приложенных формул или могут быть изучены при осуществлении изобретения на практике, как изложено ниже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для того чтобы описать образ действий, при котором вышеперечисленные и другие преимущества и признаки изобретения могут быть получены, более конкретное описание изобретения, кратко описанного выше, будет воспроизведено со ссылкой на отдельные варианты осуществления, проиллюстрированные на прилагаемых чертежах. Понимая, что эти чертежи изображают только типичные варианты осуществления изобретения, и следовательно, не должны рассматриваться ограничивающими его объем, изобретение будет описано и разъяснено с дополнительной спецификой и детализацией посредством использования сопроводительных чертежей, на которых:
Фиг.1А, 1В, 1С и 1D иллюстрируют набор таблиц типов, которые могут быть созданы в одной отдельной реализации в соответствии с дополнениями, присоединенными к соответствующим типам данных;
Фиг.2А и 2В иллюстрируют другой набор таблиц, который может быть создан в одной отдельной реализации в соответствии с дополнениями, присоединенными к соответствующим типам данных;
Фиг.3 иллюстрирует блок-схему алгоритма, соответствующую способам для сохранения данных согласно одному из вариантов осуществления изобретения;
Фиг.4 иллюстрирует один вариант осуществления пригодной вычислительной среды, в которой способы изобретения могут быть осуществлены на практике.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение распространяется как на способы, так и на системы для сохранения данных и для создания соответствующих структур базы данных. Варианты осуществления настоящего изобретения могут содержать компьютер специального назначения или общего назначения, в том числе, различные компьютерные аппаратные средства, как обсуждено более подробно ниже.
Как описано в материалах настоящей заявки, варианты осуществления изобретения включают в себя способы, в которых типы данных дополняются атрибутами, на основании планируемого использования данных и без требования каких-либо специальных знаний касательно того, как будут создаваться структуры базы данных для сохранения данных. Соответствующие таблицы хранения базы данных затем создаются в соответствии с потребностями, как определено дополненными типами данных. Таблицы могут затем быть заполнены соответствующими данными и запрошены соответствующими приложениями. Будет принято во внимание, что, поскольку создание структур базы данных основано на планируемом использовании данных и является исключающим какие-либо требования к знанию баз данных, структуры базы данных создаются, чтобы оптимизировать производительность базы данных, несмотря на какой-либо недостаток знаний, которыми программист может обладать касательно баз данных и структур баз данных. Также будет принято во внимание, что это представляет изменение парадигмы и усовершенствование сверх прежних технических систем для создания структур баз данных.
Варианты осуществления в пределах объема настоящего изобретения также включают в себя машиночитаемые носители для переноса или содержания машиноисполняемых инструкций или структур данных, сохраненных на них. Такими машиночитаемыми носителями могут быть любые имеющиеся в распоряжении носители, к которым может быть осуществлен доступ компьютером общего назначения или специального назначения. В качестве примера, но не ограничения, такие машиночитаемые носители могут содержать ОЗУ (оперативное запоминающее устройство, RAM), ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое и программируемое запоминающее устройство, EEPROM), CD-ROM (ПЗУ на компакт-диске) или другие оптические дисковые накопители, магнитные дисковые накопители или другие магнитные запоминающие устройства, или любые другие носители, которые могут быть использованы для переноса или хранения желаемого средства программного кода в виде машиноисполняемых инструкций или структур данных, к которым может быть осуществлен доступ компьютером общего назначения или специального назначения. Когда информация переносится или предоставляется по сети или другому соединению передачи данных (как проводному, беспроводному, так и комбинации проводного или беспроводного) на компьютер, компьютер, по существу, рассматривает соединение как машиночитаемый носитель. Таким образом, любое такое соединение, по сути, обозначает машиночитаемый носитель. Комбинации выше приведенного также должны быть включены в объем машиночитаемых носителей. Машиноисполняемые инструкции содержат, например, инструкции и данные, которые заставляют компьютер общего назначения или компьютер специального назначения, или устройство обработки данных специального назначения выполнять определенную функцию или группу функций.
Долговременное хранилище для типов и экземпляров данных .NET.
Согласно одному из вариантов осуществления изобретения, долговременное хранилище типов и экземпляров данных .NET обеспечивается соответствующими модулями, чтобы сделать возможным создание структур базы данных, таких как, но не в качестве ограничения, таблицы баз данных, в ответ на дополнения, которые размещены в типах данных, определенных в во время программирования.
Дополнения, которые размещены в типах данных, могут меняться в соответствии с любой потребностью или пожеланием. Далее будут предоставлены некоторые примеры, чтобы проиллюстрировать, как дополнения могут быть присоединены к типам данных в сегментах кода, написанных программистом, и таким образом, что они могут в дальнейшем быть использованы, чтобы управлять созданием структур баз данных, даже если программист не обладает какими-либо специальными знаниями о структурах базы данных, которые впоследствии будут созданы.
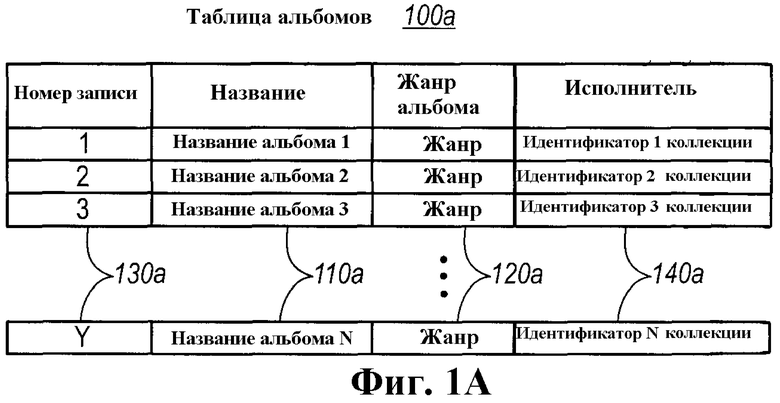
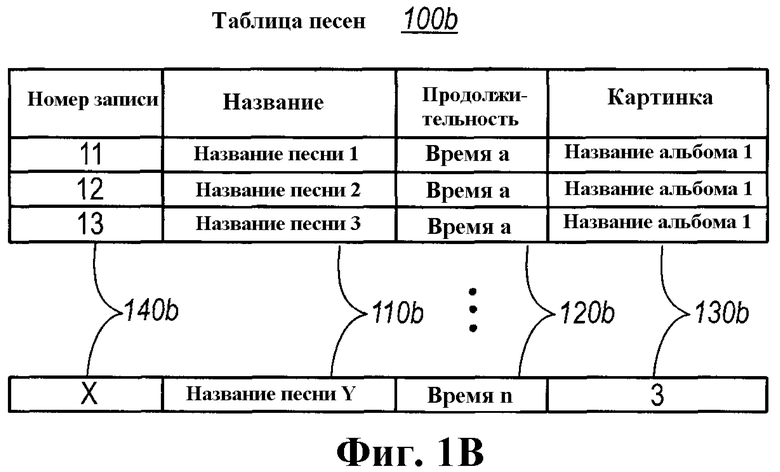
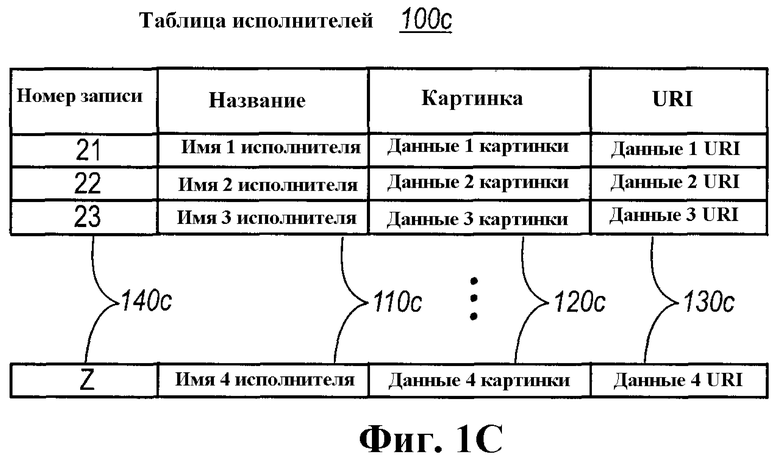
В первом примере альбомы описаны в качестве типа класса, который включает в себя название, жанр альбома, список исполнителей и список песен. Каждая из песен также идентифицирована как тип класса, содержащий название, продолжительность и альбом. В заключение, исполнитель идентифицирован в качестве типа класса, который включает в себя имя, картинку и URI (универсальный указатель ресурса) странички Фан-клуба.
class Album {
String title;
Byte[] albumArt;
//Следующее не дополненное поле коллекции показывает, что
//данный исполнитель может быть указан ссылкой многими
//альбомами, и данный альбом может ссылаться на многих исполнителей.
//В терминах базы данных это отношение многие-ко-многим
Artist[] artists;
//Атрибут CLSIBackPointer следующего поля указывает, что
//Коллекция песен принадлежит экземпляру альбома, и
//что поле альбома в типе песни служит
//обратным указателем на владеющий альбом.
//В терминах базы данных это отношение один-ко-многим
[CLSIBackPointer(album)]
Song[] songs;
}
class Song {
//Атрибут CLSIIndex в следующем поле указывает, что оно
//могло бы быть индексировано для эффективности выполнения запросов.
CLSIIndex]
string title;
int duration;
//Следующее поле служит в качестве обратного указателя,
//указываемого ссылкой коллекцией песен в вышеприведенном
//типе Album (альбома).
//В терминах базы данных это первичный внешний ключ.
Album album;
}
class Artist {
//Атрибут CLSIIndex attribute в следующем поле указывает,
//что оно могло бы быть индексировано для эффективности опроса.
[CLSIIndex]
String Name;
Byte[] picture;
Uri fanPage;
}
Как дополнительно отражено предшествующим примером, некоторые из объектов данных, соответствующие типам классов, дополнены специальными атрибутами. Например, атрибут [CLSIBackPointer(album)] указывает, что поле или объект альбома (album), содержит обратный указатель на множество различных песен, которые могут быть ассоциированы с одним и тем альбомом. Это будет описано более подробно ниже, со ссылкой на фиг.1.
Другое дополнение, которое показано, включает в себя атрибут [CLSIIndex], ассоциативно связанный с классом артиста (artist), который указывает, что он мог бы быть способен быть запрошенным. Одной из причин для этого дополнения является повышение производительности базы данных. В частности, если известно, что база данных будет допускать выполнение запросов определенных выражений, может быть полезным указывать, какие выражения планируется запрашивать. При этом когда структуры данных создаются, они могут быть созданы таким образом, чтобы оптимизировать поиск выражений, которые заведомо должны быть запрошены, как описано более подробно ниже.
Далее внимание направлено на фиг.1A-1D, которые иллюстрируют определенные структуры базы данных, содержащие таблицы базы данных, которые могут быть созданы согласно способам изобретения, и основаны на типах данных и дополнениях, определенных в коде, который предусмотрен для модулей долговременного хранения.
Как показано, были созданы четыре таблицы. Первая таблица, таблица 100a альбомов, соответствует типу альбома (album), идентифицированному в примере, приведенном выше, и включает в себя поля 110a названий, поля 120a жанра, вместе со столбцом 130a номера записи и столбцом 140a исполнителей, указанными ссылкой ниже. Эти различные поля соответствуют объектам, предусмотренным в коде, описанном выше.
Отдельная таблица 100b песен также включает в себя соответствующие поля (110b, 120b, 130b) для названий, продолжительности и альбома соответственно, как определено кодом. Поле 120b продолжительности может включать в себя любые данные продолжительности времени, соответствующие песне, которой они принадлежат.
Таблица 100с исполнителей включает в себя поле 110с имени, поле 120с картинки и 130c поле URI, соответствующие описанию класса исполнителя (artist) в примере, представленном выше. Поле 120с картинки может включать в себя указатель, например, на графическое изображение, соответствующее исполнителю, а поле 130c URI может включать в себя ссылку на документ или веб-страницу, соответствующую исполнителю, такую, как страничка Фан-клуба.
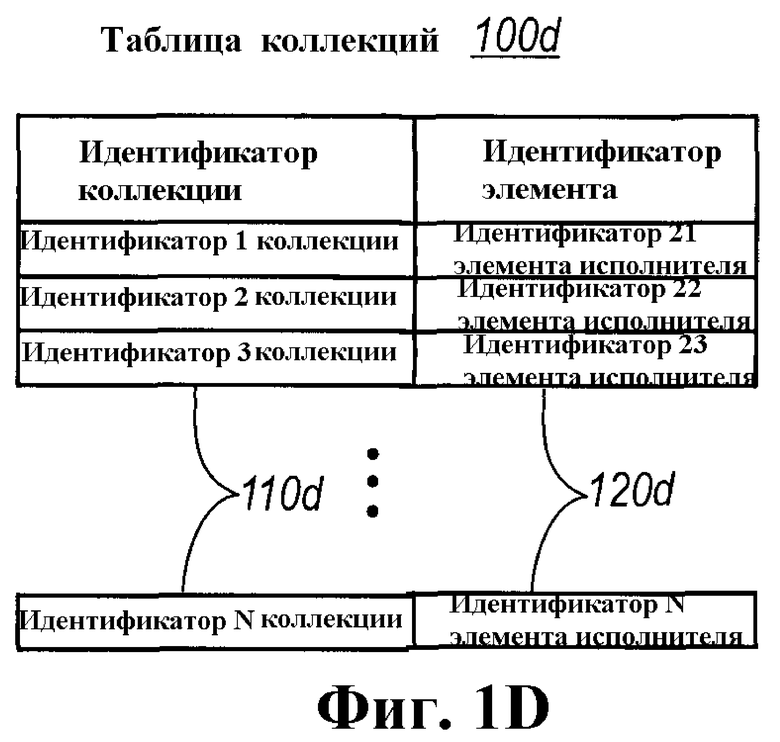
В заключение, предоставлена таблица 100d коллекций, которая включает в себя два столбца, оба определенные для удержания уникальных идентичностей. Первый столбец 110d представляет идентичность коллекции и указан полями экземпляров, ссылающихся на нее, в этом случае, альбомов из таблицы 100а альбомов. Второй столбец 120d представляет идентичность экземпляра, который является частью коллекции, в этом случае исполнителей. Таким образом, одиночная коллекция будет иметь столько строк в таблице коллекций, сколько экземпляров она содержит, но все такие строки имеют ту же самую уникальную идентичность, идентифицирующую данную коллекцию. Соответственно, поля указателей на коллекции могут быть представлены размещением уникальной идентичности строки, представляющей экземпляр коллекции. Это подразумевает, что каждая отдельная коллекция исполнителей, указываемая объектом альбома, будет представлена в таблице коллекций в виде одной или более строк со вторым столбцом каждой строки, указывающим на строку в таблице исполнителей. Например, в представленном примере, коллекция ID1 (которая ассоциируется с альбомом 1) связана с элементом 21 исполнителя и элементом 23 исполнителя. Идентификаторы (ID) коллекций также идентифицированы в таблице 100а альбомов для перекрестной ссылки.
Когда поле наименования типа исполнителя (artist) снабжено атрибутами, в качестве уникального идентификатора, с соответствующими дополнениями, как описано выше, имя исполнителя может представлять уникальную идентичность в таблице коллекций, которая может указывать на строки в таблице исполнителей. Однако, если поле имени типа исполнителя не снабжено атрибутами в качестве уникального идентификатора, указатель, взамен, будет указывать обратно на идентификаторы соответствующей таблицы исполнителей, вместо имени исполнителя. В представленном примере это сделано с использованием номера записи.
Будет принято во внимание, что, поскольку типы поля названия класса песни и поля имени класса исполнителя дополнены атрибутом [CLSIIndex], структуры базы данных (например, таблицы), соответствующие классам песни и исполнителя, построены таким образом, что они могут быть быстро отсортированы и запрошены по столбцам названия и имени соответственно, без необходимости базе данных запрашивать все строки, хранящиеся в соответствующих таблицах базы данных.
Таблица базы данных, ассоциативно связанная с данным классом, может включать в себя скрытые номера 130а, 140b, 140c записей, например, которые предоставляют уникальный идентификатор для каждой строки в таблице.
Во время поиска выражения или объекта база данных может последовательно искать по всем записям, основываясь на номерах 130а записей. Однако, если поле класса было предварительно идентифицировано и дополнено атрибутом, таким как атрибут [CLSIIndex], указывающим что запланировано, чтобы он был запрошен, то может быть создана соответствующая структура индексных данных по столбцам, соответствующим снабженным атрибутами полям, таким, как столбец названий таблицы песен и столбец имен таблицы исполнителей, так что они могут быть отсортированы (по алфавиту или любым другим образом), чтобы оптимизировать поиск. Соответственно, запрос может быть оптимизирован и без программиста, обязанного строить структуру данных посредством специальных знаний о базах данных.
Также дополнение обратного указателя, ассоциативно связанного с полем песни в классе альбома, указывает, что коллекция песен принадлежит экземпляру альбома, и что поле альбома в типе песни служит в качестве обратного указателя на владеющий альбом. Соответственно, песни, принадлежащие данному альбому, могут быть идентифицированы запросом таблицы песен со столбцом альбома, идентифицирующим данный альбом. И наоборот, столбец альбома может быть использован, чтобы идентифицировать альбом, которому принадлежат данные песни. После этого идентифицированный альбом может быть использован, чтобы идентифицировать другую информацию, соответствующую исполнителям альбома, с использованием других таблиц (например, 100с).
Таким образом, таблица 100b песен может быть опрошена независимо от таблицы 100а альбомов, так что таблица 100а альбомов не должна хранить информацию о продолжительности каждой из песен, перечисленных в таблице 100b песен. Будет принято во внимание, что это может улучшить производительность при опросе таблицы 100а альбомов. Более того, опрос таблицы 100b песен может быть также оптимизирован исключением необходимости хранить всю информацию о жанре и имени исполнителя, связанную с альбомом, которому она принадлежит. Это происходит из-за того, что перекрестные ссылки между таблицами могут легко предоставить всю необходимую информацию.
Далее будет предоставлен другой пример касательно заказчиков заказов на покупку, чтобы еще показать дополнительные типы дополнений. Тем не менее, будет принято во внимание, что этот пример, также, как и предыдущий пример, являются только иллюстративными и поэтому не должны быть истолкованы как ограничивающие изобретение в отношении типов структур баз данных, которые могут быть созданы, или типов дополняющих атрибутов, которые могут быть использованы.
В следующем примере создаются классы заказчиков (customer) и заказов на покупку (PurchaseOrder).
class Customer {
//Атрибут CLSIIndex в следующем поле указывает, что оно
//могло бы быть индексировано для эффективности запроса
[CLSIIndex]
String name;
//Атрибут CLSIIdentity в следующем поле указывает, что оно
//служит в качестве поля идентичности для этого класса.
//В терминах базы данных это поле является уникальным
//ключом для этого типа
[CLSIIdentity]
string phoneNumber;
//Атрибут CLSISingleRef в следующем поле указывает, что
//только оно может указывать ссылкой на экземпляр адреса.
//В терминах базы данных оно предполагает отношение 1:1
//между экземплярами заказчика и адреса.
[CLSISingleRef]
Address address;
//Атрибут CLSIBackPointer в следующем поле указывает, что
//коллекция заказов принадлежит экземпляру заказчика и что
//поле заказчика в типе PurchaseOrder служит в качестве
//обратного указателя на владеющий экземпляр заказчика.
//В терминах базы данных это отношение один-ко-многим.
[CLSIBackPointer(customer)]
PurchaseOrder[] orders;
}
class PurchaseOrder {
//Следующее поле служит обратным указателем, указываемого
//ссылкой полем коллекции заказов в вышеприведенном типе
//заказчика. В терминах базы данных это защищенный внешний ключ.
Customer customer;
string itemDescription;
int skuID;
}
abstract class Address {
string street;
string city;
}
class USAddress : Address {
string state;
int zip;
}
В предыдущем примере представлены некоторые дополнительные атрибуты. Например, предоставлен дополняющий поле телефонного номера класса заказчика атрибут [CLSIIdentity], чтобы указывать, что номер телефона может представлять уникальный ключ для типа заказчика.
Также предоставлен атрибут [CLSISingleRef] полю адреса класса заказчика, чтобы указывать, что запланировано существование отношения один-к-одному между заказчиком и адресом заказчика.
Другой атрибут, содержащий [CLSIBackPointer (customer)], дополняется в поле заказа класса заказчика. Этот атрибут указывает, что запланировано, что заказы служат в качестве обратного указателя на заказчиков, делающих заказы. Это может быть более ясно понято при рассмотрении примеров, предоставленных на фиг.2.
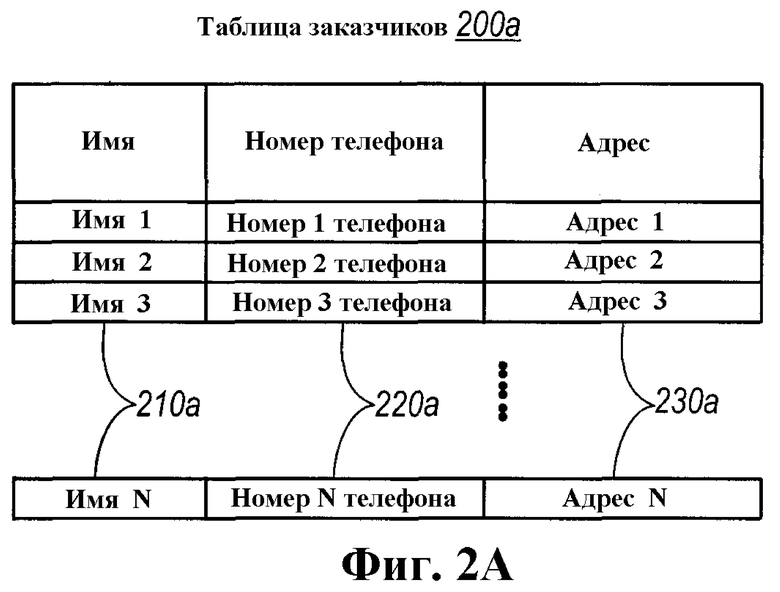
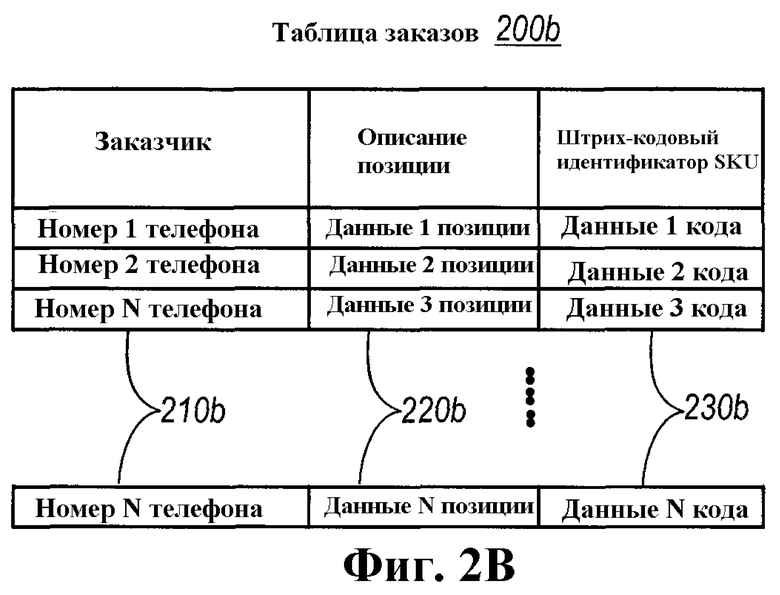
Как показано на фиг.2А и 2В, таблица 200а заказчиков и таблица 200b заказов создаются вместе с соответствующими полями (210а, 220а, 230а) и (220а, 220b, 230b), соответственно, которые определены выше в иллюстративном сегменте кода. Эти таблицы 200а и 200b были созданы, также как и таблицы 100а, 100b и 100с, согласно определениям и дополнительным атрибутам, предусмотренным в сегментах кода, и без каких-либо специальных знаний касательно того, как построены структуры базы данных. Взамен всего лишь определения и дополнительные атрибуты требуются, чтобы предоставить подсказки в отношении того, для чего записанные данные будут использоваться, или как потребуется осуществлять к ним доступ или запрашивать.
В предыдущем примере дополнение атрибута [CLSIIdentity] предусмотрено, чтобы указывать, что соответствующее поле, телефонный номер, может представлять уникальный ключ для типа заказчика. Это может быть полезным, например, чтобы минимизировать требования хранения записи специального номера 130а записи (фиг.1) для каждой строки в таблице. В частности, поле, дополненное атрибутом [CLSIIdentity], может быть использовано в качестве уникального идентификатора для каждой соответствующей строки. Как показано на фиг.2, где номера 220а телефонов используются, чтобы представлять заказчиков в таблице 200b заказов.
В других вариантах осуществления комбинации полей также могут быть дополнены атрибутом [CLSIIdentity], с тем чтобы комбинация полей могла представлять уникальный идентификатор для строки.
Атрибут [CLSISingleRef], определенный выше, также предусмотрен для поля адреса класса заказчика, чтобы указывать, что запланировано существование отношения один-к-одному между заказчиком и адресом заказчика. В этом смысле, поле 230а адреса заказчика может быть заполнено строкой действительного адреса, соответствующего заказчику, или может, в качестве альтернативы, указывать на данные адреса, сохраненные в другой таблице.
Атрибут обратного указателя, [CLSIBackPointer (customer)], в целом описанный выше, был также дополнен в поле заказа для типа класса заказчика в последнем примере. Соответственно, как описано в ссылке на фиг.1, обратный указатель позволяет заказчику, зарегистрированному в таблице заказов, ссылаться обратно на таблицу 200а заказчиков. Соответственно, не является необходимым, чтобы единственная таблица поддерживала каждый из элементов данных, соответствующих заказчику, а также заказам заказчика. Взамен, подробное описание позиции, являющейся заказываемой, и соответствующий SKU-код могут быть поддержаны отдельно от таблицы 200а заказчиков и подвергнуты доступу, когда требуется, посредством отыскивания заказчика, соответствующего заказу. Будет принято во внимание, что это может улучшить производительность базы данных в соответствии с запланированными потребностями базы данных, как описано выше. Даже более важно, что программист не обязан знать или понимать, как таблицы базы данных должны быть созданы. Взамен, программисту всего лишь требуется знать, каково запланированное использование данных.
Предшествующий пример также иллюстрирует, как типы классов могут быть скомпонованы в различные иерархии. В частности, предшествующий пример идентифицирует базовый класс адреса (address), и класс адреса в США (USaddress), который соответствует базовому классу адреса. Это может быть полезным, например, для создания раздельных таблиц или других структур базы данных, которые могут хранить релевантные данные, соответствующие разным классификациям иерархии.
Хотя таблицы для классов адреса в настоящий момент не проиллюстрированы, можно представить себе, как может быть создана таблица группового базового класса для адресов, которая будет включать в себя различные столбцы для хранения информации группового адреса, который является групповым для многих различных типов адресов, таких, как штат, название улицы, адресный номер, и т.д. Подклассы могут затем быть сохранены в специализированных таблицах или других структурах, которые включают в себя более специфичные данные адреса, которые могут не быть релевантными для всех адресов. Например, в приложении всемирного справочника, не все нации будут включать в себя почтовые индексы. К тому же адреса в Соединенных Штатах могут не включать в себя адресные коды и другую информацию, ассоциированную с иностранными адресами. В таких ситуациях каждая из различных таблиц региональных адресов может включать в себя специализированную информацию, которая не является существенной для всех объектов адреса, и при этом по-прежнему предоставляя возможность быстрого доступа к групповой адресной информации из таблицы базового класса.
Как и в предыдущих примерах, касающихся перекрестных ссылок, также будет принято во внимание, что таблицы базовых классов (например, таблица базового класса адреса) могут быть связаны перекрестными ссылками с таблицами подклассов (например, таблицей класса региона). Эта технология может быть использована, чтобы создавать иерархические уровни различной глубины между таблицами классов и подклассов.
Далее внимание будет направлено на блок-схему 300 алгоритма, проиллюстрированную на фиг.3, которая показывает один из способов для реализации изобретения. Как показано, способ включает в себя идентификацию данных, которые должны быть сохранены (310). В этом рассмотрении данные выражения указывают ссылкой на типы данных, которые должны быть сохранены. Эта идентификация может происходить, когда код, который идентифицирует типы данных, представлен модулям долговременного хранения данных (не показаны), которые хранятся на машиночитаемых носителях.
Затем делается определение относительно того, какая схема базы данных (например, структура базы данных) должна быть использована для хранения данных (320). Это определение производится автоматически в ответ на идентификацию дополнений, ассоциативно связанных с типами данных, как описано выше. В частности, программисту нет необходимости иметь какое-либо специальное понимание относительно того, какие структуры данных должны быть созданы или как они могут быть выбраны или созданы с использованием инструментального средства сохранения базы данных. Взамен настоящее изобретение предусматривает автоматическое создание структур данных, на основании дополнений, ассоциативно связанных с типами данных, определенными в коде, при этом дополнения отражают запланированное использование или доступ к данным.
Затем определяется (330), существуют ли соответствующие структуры базы данных. Если нет, они создаются (340). Например, фиг.1 и 2 показывают определенные варианты реализации таблиц, которые могут быть созданы. Эти таблицы, однако, не должны быть истолкованы как ограничивающие объем изобретения. Создание (340) структур базы данных может A включать в себя создание таблицы базы данных, и наполнение таблицы, по меньшей мере, некоторыми столбцами, идентифицированными соответствующими полями в коде, как описано и показано выше со ссылкой на фиг.1 и 2.
Создание (340) структур базы данных может также включать в себя создание многочисленных таблиц, соответствующих типу данных. Таблицы, которые могут быть созданы, могут включать в себя, например, таблицу типов, которая определяет типы, идентифицированные в коде, и которая идентифицирует каждую из соответствующих таблиц базы данных. Эта таблица и другие подобные таблицы более подробно описаны ниже. Любое количество таблиц базовых классов и подклассов также могут быть созданы после определения того, что не существует подходящая структура базы данных для хранения типа данных.
После того как надлежащие структуры базы данных (например, таблицы) созданы, способ, проиллюстрированный на фиг.3, включает в себя получение (350) объектов данных, которые должны быть сохранены. Это может быть выполнено, например, во время существования одного экземпляра или через промежуток времени, и из любого количества связанных или отдельных баз данных и приложений. Как только объекты данных получены (350), определяется (360), были ли уже объекты данных сохранены. Это может быть выполнено, например, посредством проверки соответствующих таблиц, в частности, когда одно из соответствующих полей было дополнено атрибутом [CLSIIdentity], который указывает, что не будет двух одинаковых составляющих, если они не имеют одно и то же значение в соответствующем дополненном поле/полях. Соответственно, если другая составляющая имеет то же значение в соответствующем дополненном поле/полях, может быть определено, что составляющая уже была принята, и новые данные являются либо дубликатом, либо обновлением для уже принятых. При уменьшении дублирующей составляющей объектов данных, емкость хранилища и требования к обработке запросов могут быть минимизированы.
В одном из вариантов осуществления атрибут идентичности применен к полям, чтобы указывать, является ли поле частью первичного ключа. Согласно этому варианту осуществления атрибут идентичности применяется, по меньшей мере, к одному полю в классе, который формирует корень иерархии долговременных классов, так что, по меньшей мере, одно поле используется для идентификации первичного ключа, который может быть использован, как описано выше, чтобы избежать дублированного хранения.
Следующий элемент проиллюстрированного способа включает в себя запись (370) объектов данных, если они еще не были записаны. Это может включать в себя запись любой части объектов данных в одну или более таблиц базы данных, как показано выше, или любым другим образом. Это также может включать в себя запись производных объектов данных в таблицы базы данных. Это также может включать в себя запись указателей в таблицы баз данных, которые указывают на фактические данные, сохраненные в другом месте.
В других вариантах осуществления способы изобретения могут также включать в себя модификацию данных (380), которые уже найдены хранящимися в структурах базы данных. Например, если обновления в отношении данных были произведены после того, как они были в последний раз сохранены, может быть полезным обновить данные. Во избежание того, чтобы обновленные данные были сохраненными раздельно и независимо от более старых данных, и тем самым использовали дорогостоящее пространство хранилища, могут быть использованы первичные ключи, чтобы определять, что данные являются теми же самыми и должны быть модифицированы или переписаны. Иначе запись будет выдавать устаревшую информацию, когда она позднее извлекается обратно в объект. Использование уникального ключа для предотвращения дублированного хранения также является благоприятным для избежания выдачи различных наборов информации для одной и той же сущности в ответ на запросы данных.
Хотя предыдущие примеры предоставлены со ссылкой на структуры базы данных, содержащие таблицы базы данных, будет принято во внимание, что объем изобретения также распространяется на другие варианты осуществления, к примеру, варианты осуществления, в которых структуры баз данных содержат XML-файлы или другие структуры хранения.
Объем изобретения также распространяется на варианты осуществления, в которых хранилище данных является массивом или словарем. Например, массив может быть сконфигурирован подобно коллекциям, описанным выше и в материалах настоящей заявки, посредством предоставления двух дополнительных элементов данных или наборов для разных столбцов, соответствующих количеству измерений массива и упорядочиванию измерений.
В сущности, изобретение, которое может быть сохранено и реализовано на одном или более машиночитаемых носителей, содержащих машиноисполняемые инструкции для реализации способов, описанных выше, иногда указывается в материалах настоящей заявки как долговременное хранилище или долговременное хранилище для типов и экземпляров данных .NET. Как описано, долговременное хранилище предлагает групповой механизм для сериализации структур данных в базы данных, тем самым предоставляя решение для некоторого количества служб, которым требуется групповой способ, чтобы произвольно хранить структуры данных и извлекать их по требованию.
Несмотря на то, что долговременное хранилище основано на функциональных возможностях, предусмотренных CLR (рабочим циклом общего языка), может быть возможным подключать различные источники данных, подчиненные хранилищу. Также модель данных, используемая этим изобретением, основанная на типах данных .NET, не должна рассматриваться в качестве ограничивающей объем изобретения, поскольку альтернативные модели данных, такие как основанные на Java, также могут быть поддержаны.
Некоторые интересные варианты и дополнительные детали, касающиеся изобретения, будут приведены далее в последующем описании.
В исходном положении каркас долговременного хранилища может быть описан как состоящий из следующих элементов: ObjectStore (хранилище объектов), которое обеспечивает базовые функциональные возможности для сериализации десериализации структуры данных по отношению к источнику данных. ObjectStore может допускать контекст, в котором следует работать. Производные формы от ObjectStore обеспечивают своеобразную реализацию, в которой источник данных, ассоциативно связанный с ObjectStore, является базой данных SQL или XML-файлом. Также определены классы, относящиеся к конкретной реализации хранилища для идентификатора записи, контекста хранения и т.д. Также применены атрибуты сериализации. Несколько заказных атрибутов определены, как описано в материалах настоящей заявки, с тем чтобы разработчики службы могли задавать некоторую дополнительную информацию в полях. StoreService (служба хранилища) является службой ServiceBus (шина службы), которая предоставляет единственную точку контакта клиентам для сохранения объектов в лежащей в основе базе данных.
Каркас гарантирует, что множественные ссылки на один и тот же объект в номограмме или коллекции сохраняются только один раз. Ссылки на один и тот же объект через множественные номограммы также должны разрешаться по отношению к одной и той же записи в хранилище. Чтобы гарантировать это, классам требуется точно определять поля, которые составляют их уникальный идентификатор.
Когда происходит десериализация, и номограмма или коллекция объектов выстраиваются из сохраненной записи, каждый объект должен быть создан только один раз. Но объектным ссылкам не требуется разрешаться по отношению к одному и тому же объекту через многочисленные вызовы десериализации, если только они не определены принадлежащими к одному и тому же контексту.
Далее внимание специально направляется на ObjectStore, каковой является компонентом, который обрабатывает запросы на сохранение и извлечение данных. Примерные программные методы и код, соответствующие ObjectStore, будут приведены далее.
Конструктор: ObjectStore является начальной точкой механизма хранения. Необязательный параметр StoreContext (контекст хранилища) используется, чтобы устанавливать стадию для извлечения и сохранения. Если контекст не предоставлен, StoreContext инициализируется значениями по умолчанию.
Write: Этот метод предоставляет вызывающему возможность сохранить объект о. Объект о может быть простого типа, структурой, классом или коллекцией. Метод Write возвращает уникальный RecordID (идентификатор записи), если объект был сохранен. В противном случае он возвращает null или выдает исключение StoreException.
Read: Этот метод строит заданный объектом RecordID и тип объекта. Перегруженный вариант возвращает коллекцию объектов, основанную на предписанном критерии.
Delete: Этот метод удаляет заданные объектом RecordID и тип объекта. Перегруженный вариант удаляет объекты, основываясь на предписанном критерии. Параметр указывает, должны ли ссылки на другие объекты отслеживаться рекурсивно. Может происходить каскадирование операций удаления, если счетчики ссылок на внутренние объекты станут 0 в результате уничтожения внешнего объекта.
Описание типа:
abstract class ObjectStore
{
ObjectStore();
ObjectStore(StoreContext context);
RecordID Write (object o);
object Read(Type t, RecordID id);
object[] Read(Type t, Query criteria);
bool Delete(Type t, RecordID id, bool recurse);
bool Delete(Type t, Query criteria, bool recurse);
}
abstract class RecordID
{
}
abstract class StoreContext
{
}
class StoreException : Exception
{
}
Далее внимание направляется на некоторые примеры заказных атрибутов, включая атрибуты сериализации и действия по ссылке. Далее будет приведен примерный код, соответствующий некоторым атрибутам.
Атрибуты сериализации
SerializableAttribute и NonSerializableAttribute указывают, может или нет экземпляр типа быть сериализован. Storeability (сохраняемость) и serializability (сериализуемость) интерпретируются как родственные понятия. Storeability трактуется как сериализация в файл или хранилище данных.
CLSIIdentityAttribute
Как упомянуто выше, CLSIIdentityAttribute является заказным атрибутом, который применяется к полям, чтобы указывать, является ли поле частью первичного ключа. CLSIIdentityAttribute должен быть применен, по меньшей мере, к одному полю класса, который формирует корень иерархии долговременных классов.
[AttributeUsage(AttributeTargets.Field)]
public sealed class CLSIIdentityAttribute : Attribute
{
}
ReferentialActionAttribute
ReferentiaiActionAttribute является заказным атрибутом, который применяется к ссылочным полям, чтобы указывать действия, которые должны быть предприняты, если адресуемый объект удаляется.
[AttributeUsage{AttributeTargets.Field)]
public sealed class ReferentialActionAttribute : Attribute
{
ReferentialActionAttribute(ReferentialAction a);
}
enum ReferentialAction
{
NoAction//указанный ссылкой объект не может быть удален до тех пор, пока этот объект не удален
Cascade//указанный ссылкой объект будет удален, и этот объект также будет удален
SetNull//указанный ссылкой объект уничтожен, а ссылка на него установлена в нуль (null)
}
Другие атрибуты были описаны выше при ссылке на фиг.1 и 2, в соответствующих примерах.
Далее внимание направляется на SqlStore (SQL-хранилище), каковой является компонентом, который обрабатывает запросы сохранения и извлечения по отношению к базе данных SQL. SqlStore выполняет связывание базы данных, преобразует вызовы Read и Write в понимаемые посредством DataAdapter (адаптером данных) и т.д. Далее будут приведены примерные методы и код, соответствующие SqlStore.
Конструктор: SqlStore является стартовой точкой механизма SQL-хранилища. Необязательный параметр StoreContext используется, чтобы устанавливать стадию для извлечения и записи данных. Если контекст не предоставлен, StoreContext инициализируется значениями по умолчанию.
a) _database (наименование базы данных): установлено в "ServiceBus" («Шина службы»)
b) _varMaxLength: установлено в 1024
Write: Этот метод предоставляет вызывающему возможность сохранять объект о. Объект о может быть простого типа, структурой, классом или коллекцией. Метод Write возвращает уникальный SqlRecordID, если объект был сохранен или уже существует. В противном случае, он возвращает null или выдает исключение StoreException.
Read: Этот метод строит объект по данному RecordID.
VarMaxLength: Это свойство задает максимальную длину, которая должна быть использована при определении SQL-типов varchar и varbinary. Значение по умолчанию - 1024.
Описание типа:
class SqlStore : ObjectStore
{
SqlStore ();
SqlStore(SqlStoreContext context);
SqlDataAdapter DataAdapter {get;}
SqlConnection DbConnection {get;}
uint VarMaxLength {get; set;}
}
class SqiRecordID : RecordID
{
int64 _ID;
}
class SqlStoreContext : Storecontext
{
string _databaseName;
IDataAdapter _dataAdapter;
uint _varMaxLength;
}
class StoreException : Exception
{
}
Хотя изобретение может быть осуществлено на практике во многих различных средах и с различными реляционными базами данных, последующий пример иллюстрирует некоторые из действий, привлекаемых при сохранении объекта в базе данных SQL. В частности, сохранение объекта включает следующие действия в базе данных SQL:
а) Создание таблицы: SQL-таблица, которая равнозначна типу объекта, создается, если необходимо. Если нет, SQL-таблица, в которой объект должен быть сохранен, идентифицируется.
b) Как только SQL-таблица, соответствующая объекту, имеется в распоряжении, поля, составляющие первичный ключ, используются для проверки того, был ли уже объект сохранен в таблице. Если строка уже существует, она обновляется текущим объектом, иначе создается новая запись.
c) Поля экземпляра объекта, которые сериализуемы, сохраняются. На основании типов членов объекта, и, рекурсивно, их членов, большое количество SQL-таблиц создается, если необходимо.
Далее будут представлены примеры различных таблиц, которые могут быть созданы.
ObjectTypeTable
ObjectTypeTabie является SQL-таблицей, которая сопоставляет XmlTypeName CLR-класса/структуры наименованию таблицы источника данных. Для каждой SQL-таблицы, которая создана в процессе записи, в ObjectTypeTable создается составляющая.
OBJECTTYPETABLE
(
objectTypeID SqlRecordID,
objectTypeName varchar(n),
SqlTableName varchar(128),
rootTypeID SqlRecordID,
baseTypeID SqlRecordID,
lastObjectID SqlRecordID
)
objectTypeID: уникальный идентификатор, данный каждому перечисленному типу.
objectTypeName: Полностью уточненное имя, которое может быть использовано для поисков. XmlTypeName вместо AssemblyQualifiedName может быть использован, с тем чтобы тип без изменений полей от варианта к варианту мог быть разрешен тому же самому наименованию типа данных.
sqlTableName: Задает наименование таблице, соответствующей CLR-типу.
rootTypeID: Задает корень иерархии долговременных классов. Этот корневой класс должен иметь первичные ключи, предписанные пользователем. Уникальный идентификатор генерируется для каждой новой строки в этой корневой таблице и будет повторно использован во всех таблицах производных классов по цепи иерархии классов.
baseTypeID: Задает идентификатор базового класса. Будет равен нулю (null) для корня иерархии долговременных классов.
lastObjectID: Задает SqlRecordID последней строки, добавленной в SQL-таблицу, соответствующую этому CLR-типу.
ObjectBaseTypeTable
ObjectBaseTypeTable - SQL-таблица, которая поддерживает отношения базового класса классов. Для каждой SQL-таблицы, которая создана, в процессе сохранения, в ObjectBaseTypeTable создаются одна или более составляющих. Если тип А является базовым классом для класса B, то составляющая содержит строку с A в качестве источника.
Эта таблица полезна во время запросов.
enum Relationship
{
Root=1, // источник является корневым классом для адресата
Ancestor=2, // источник не является непосредственным базовым классом для адресата
Parent=3, // источник является непосредственным базовым классом для адресата
}
EXEC sp_addtype Relationship, tinyint, 'NOT NULL'
OBJECTBASETYPETABLE
(
srcObjectTypeID SqlRecordID,
destObjectTypeID SqlRecordID,
relationship Relationship,
)
srcObjectTypeID: тип, который является источником отношения.
destObjectTypeID: тип, который является адресатом отношения.
relationship: отношение между источником и адресатом.
ObjectArrayTable
ObjectArrayrable является SQL-таблицей, которая содержит элементы, составляющие какой-либо массив. Здесь хранятся элементы всех экземпляров массива.
OBJECTARRAYTABLE
(
objCollectionID SqlRecordID,
elemIndex int,
elemObjID SqlRecordID,
elemTypeID SqlRecordID
)
objCollectionID: уникальный идентификатор, данный каждому перечисленному экземпляру массива.
elemIndex: индекс элемента в пределах массива.
elemObjID: идентификатор записи объекта элемента.
elemTypeID: задает тип объекта элемента. Это поможет локализовать таблицу, в которой сохранен элемент.
ObjectDictionaryTable
ObjectDictionaryTabie - SQL-таблица, которая содержит элементы, составляющие какой-либо словарь. Элементы всех экземпляров словаря хранятся здесь. Заметим, что настоящий ключ и объекты элементов хранятся в SQL-таблицах, соответствующих их CLR-типам.
OBJECTDICTIONARYTABLE
(
objCollectionID SqlRecordID,
elemKeyID SqlRecordID,
elemObjID SqlRecordID,
eiemTypeID SqlRecordID
)
objCollectionID: уникальный идентификатор, данный каждому перечисленному экземпляру словаря.
elemKeyID: идентификатор записи ключа объекта.
elemObjID: идентификатор записи объекта элемента.
elemTypeID: задает тип объекта элемента. Это поможет при локализации таблицы, в которой сохранен элемент.
Далее внимание будет направлено на соответствие CLR-типов. В частности, каждый тип класса сохраняется в виде отдельной SQL-таблицы. Значение каждого поля в экземпляре класса сохраняется в качестве значений столбца в SQL-таблице.
Таблица объекта является эквивалентом типа класса или структуры и создается «на лету», когда встречается первый объект этого типа. Тип экземпляра объекта используется всякий раз, когда доступен, в противном случае используется объявленный тип объекта. То есть, если объект является пустым (null), используется объявленный тип.
Подтип класса преобразуется в SQL-таблицу, содержащую поля производного класса с дополнительными столбцами SqlRecordId, которые должны ссылаться на SQL-запись, соответствующую значению экземпляра корневого класса. Цепочка долговременных классов сохраняется в ObjectTypeTable.
Корневая таблица содержит в себе дополнительный столбец, задающий действующий тип экземпляра. Таблица корневого объекта будет также содержать два столбца для подсчета ссылок. Они будут полезны во время удаления, а также управления циклическими номограммами. Один счетчик ссылок отслеживает, поступал ли объект в качестве корня номограммы объектов (этот счетчик имеет только два значения - 0 и 1), другой счетчик ссылок поддерживает общее количество объектов, ссылающихся на этот объект. Строка будет уничтожена, если оба счетчика станут нулевыми.
Тип первичного ключа таблицы определяется из заказных атрибутов типа объекта. Заказной атрибут, задающий первичный ключ, может быть установлен для одного или более полей типа. Корневой долговременный класс должен содержать, по меньшей мере, одно поле, которое имеет этот атрибут. SqlStore также добавляет SqlRecordId к определению таблицы, которая будет содержать в себе уникальный идентификатор, который сгенерирован автоматически. Этот идентификатор является 64-битным числом, уникальным в пределах SQL-таблицы, и будет определен как альтернативный ключ. SqlRecordId будет всегда использоваться как внешний ключ во внутренних объектах, которые ссылаются на этот объект, даже в случаях, когда первичный ключ был задан явным образом.
Все поля, составляющие первичный ключ, должны быть сериализуемыми членами корневого долговременного класса. В противном случае, чтобы проверить, был ли уже объект сохранен, в первую очередь должен быть получен SqlRecordId ссылочных полей в первичном ключе. Заметим, что это рекурсивный процесс, поскольку ссылочные поля сами могут содержать в себе ссылочные поля в своих первичных ключах. Следующий параграф предоставляет пример этого.
Например, class Media
{
[uniqueKey]
MediaId id;
[uniqueKey]
string location;
string artist;
}
class MediaId
{
string libId;
int objId;
}
Media a;
Здесь, для того чтобы определить, был ли уже сохранен объект "a", нам необходимо запросить SqlRecordId из таблицы MediaId, соответствующей a.id. Поскольку мы обладаем этим, мы можем запросить из таблицы Media первичный ключ, заданный SqlRecordId и значениями местоположения.
Класс, который не имеет полей, преобразуется в SQL-таблицу с одним столбцом, которым является SqlRecordId. Далее будут приведены примеры.
<ROOT TABLENAME>
(
objID SqlRecordID UNIQUE,
objectTypeID SqlRecordID REFERENCES OBJECTTYPETABLE(objectTypeID),
refCount int,
rootRefCount bit,
<field> <type>,
<field> <type>,
<field> SqlRecordID REFERENCES <REF ROOT TABLENAME>(objID),
...
CONSTRAINT PK_<ROOT TABLENAME> PRIMARY KEY {<field>, <field>...)
)
<DERIVED TABLENAME>
(
ObjID SqlRecordID REFERENCES <ROOT TABLENAME>(objID)
<field> <type>,
<field> <type>,
<field> SqlRecordID REFERENCES <REF ROOT TABLENAME>(ObjID)
…
)
например,
class A
{
...
}
[Serializable]
class В : A
{
[UniqueKey]
int fb1;
[UniqueKey]
int fb2;
int fb3;
}
[Serializable]
class C : В
{
int fc1;
}
Созданы следующие SQL-таблицы:
BTABLE
(
objID SqlRecordId UNIQUE,
objectTypeID SqlRecordID REFERENCES OBJECTTYPETABLE(objectTypeID),
refCount int,
rootRefCount bit,
fb1 int,
fb2 int,
fb3 int,
CONSTRAINT PK_BTABLE PRIMARY KEY (fb1, fb2)
)
CTABLE
(
objID SqlRecordId REFERENCES BTABLE(objID),
fc1 int
)
Заданы
В b = new B;
С c = new C;
Предположим, идентификатор объекта (objID) b равен 1, а идентификатор объекта c равен 2. При этом строка с идентификатором 1 появится в BTABLE, в то время как строка с идентификатором 2 появится в BTABLE и CTABLE.
Член класса, который типизирован как тип класса, будет преобразован в столбец SqlRecordId в SQL-таблице, созданной для включающего класса. Ограничение внешнего ключа наложено на этот столбец. Это возможно, хотя экземпляры подтипов типа внутреннего класса также могут быть представлены в экземпляре включающего класса, поскольку все идентификаторы являются уникальными на уровне корневого класса. Столбцы счетчика ссылки (RefCount) и корневого счетчика ссылки (rootRefCount) указываемой ссылкой записи поддерживаются должным образом.
Член класса является обнуляемым, если он классового типа и не является частью первичного ключа. Члены, которые являются простыми типами и структурами, обнуляемыми не являются. В определении SQL-таблицы, обнуляемые поля определяются как nullable.
Когда экземпляры классов A и В содержат ссылки друг на друга, в номограмме объектов A и В сохраняются только один раз. A и В должны содержать SqlRecordId друг друга. Следует пример:
[Serializable]
class A
{
[UniqueKey]
int fa1;
int fa2;
X fa3;
}
[Serializable]
class X
{
[UniqueKey]
int fx1;
}
Создаются следующие SQL-таблицы:
ATABLE
(
objID SqlRecordId UNIQUE,
objectTypeID SqlRecordID REFERENCES OBJECTTYPETABLE(objectTypeID),
fa1 int NOT NULL,
fa2 int NOT NULL,
fa3 SqlRecordId REFERENCES XTABLE(objID) NULL,
CONSTRAINT PK_BTABLE PRIMARY KEY (fa1)
)
XTABLE
(
objID SqlRecordId UNIQUE,
fx1 int
CONSTRAINT PK_BTABLE PRIMARY KEY (fx1)
)
В одном из вариантов осуществления тип структуры преобразуется как отдельная таблица с полями. Несмотря на то, что CLR-структура является типом значения (value), создается независимая таблица, чтобы оптимизировать случай множественных ссылок в блочную структуру. Структуры интерпретируются в точности как классы, не имеющие цепочек наследования.
Значение каждого поля в экземпляре структуры сохраняется как столбец в таблице. Член класса или структуры который имеет тип структуры, будет преобразовываться в колонку SqlRecordId SQL-таблицы, созданной для класса.
Во втором варианте осуществления члены класса, типизированные как структуры, сохраняются в той же таблице, созданной для включающего класса, с наименованиями столбцов, которые соответствуют членам типа структуры, снабженные префиксом наименования члена класса, типизированного как тип структуры во включающем классе.
В третьем варианте осуществления члены члена класса, типизированные как типы структуры, сохраняются в качестве определяемого пользователем типа (User Defined Type - UDT) в таблице, созданной для включающего класса.
Объект, который имеет простой тип, преобразуется в качестве таблицы простого типа. Таблица простого типа содержит в себе два столбца - столбец SqlRecordId и столбец для простого типа. Согласно одному из вариантов осуществления выборочное извлечение и удаление объектов простых типов не поддерживается.
Член класса или структуры, который имеет простой тип, преобразуется в качестве колонки в SQL-таблице, как изложено ниже. Значением столбца является значение простого типа.
Массив завершается уникальным SqlRecordId и сохраняется в ObjectArrayTable в виде множества строк, соответствующих его элементам. Каждая строка в этой таблице будет содержать в себе SqlRecordId экземпляра массива и индекс элемента. Действующие элементы сохранены в таблицах, соответствующих типам их экземпляров. Если массив является членом класса, SqlRecordId массива сохраняется во включающем классе.
Список массива (ArrayList), очередь (Queue): интерпретируются аналогично массивам и сохраняются в таблице
ObjectArrayTable.
Хэш-таблица (HashTable): интерпретируются подобно массивам, но сохраняются в таблице ObjectDictionaryTable. Каждая строка в этой таблице будет содержать в себе SqlRecordId экземпляра элемента и ключ элемента.
ИЗВЛЕЧЕНИЕ И ЗАПРАШИВАНИЕ ОБЪЕКТОВ
Объект может быть извлечен двумя способами: (1) c использованием его SqlRecordID и типа; и (2) с использованием критерия выбора и типа. Тип может быть любым типом в иерархии постоянных классов от корневого до действующего типа объекта. Если SqlRecordID задан и тип не является коллекцией, чтобы его извлечь, могут быть выполнены следующие этапы:
a) Найти таблицу типа объекта и получить наименование корневой таблицы для типа.
b) Получить действующий тип объекта.
c) Получить наименование таблицы для экземпляра из таблицы типа объекта.
d) Получить строку из SQL-таблицы.
e) Получить полностью уточненное наименования CLR-типа из наименования таблицы.
f) Создать объект полученного CLR-типа с использованием констpуктора по умолчанию (предполагается, что постоянный объект должен иметь конструктор по умолчанию).
g) Если CLR-тип является простым типом, присвоить значение непосредственно.
h) Если CLR-тип является классом или структурой, присвоить полям объекта поля строки. Для простых полей присвоить непосредственно; для других полей рекурсивно следовать идентификатору записи и извлекать указываемый ссылкой объект. Заметим, что указываемый ссылкой объект сам может быть классом, структурой или коллекцией.
i) Отследить, что объект создан только один раз во время сериализации номограммы объекта.
Если задан SqlRecordID и тип является коллекцией, для его извлечения могут быть реализованы следующие этапы:
a) Получить количество строк в соответствующей таблице коллекции с идентификатором, заданным в качестве идентификатора коллекции. Создать столько элементов в коллекции, сколько в ней строк.
b) Следовать правилу извлечения объектов, рекурсивно для каждого элемента.
Извлечение объектов, задав запрос, может быть более сложным и может включать в себя:
a) Следовать правилам преобразования запроса и перевести запрос на SQL.
b) Исполнить запрос и получить согласующиеся строки в SQL-таблице типа.
c) Следовать правилам извлечения объекта для каждой строки.
Объект может быть удален двумя способами: (1) с использованием его SqlRecordID и типа, и (2) с использованием критерия выбора и типа. Тип может быть любым типом в иерархии постоянных классов от корневого до действующего типа объекта. Если SqlRecordID задан и тип не является коллекцией, для удаления объекта могут быть выполнены следующие этапы:
a) Получить идентификатор корневой таблицы из типа объекта.
b) Получить строку в корневой таблице. Уменьшить на единицу корневой счетчик ссылок.
c) Получить действующий тип объекта. Следовать цепочке иерархии и идти через поля каждой строки, соответствующей объекту, и получать идентификаторы непростых полей записей.
d) Для каждого из непростого полей получить идентификатор указанной ссылкой таблицы. Уменьшить на единицу доступный счетчик ссылок указанной ссылкой строки. Рекурсивно обходить внутренние непростые поля и применять те же правила. Удалить указанную ссылкой строку, если оба счетчика ссылок будут сброшены в 0.
e) Удалить исходную строку, если оба ее счетчика ссылок, корневой и имеющийся в распоряжении, равны 0.
Этапы c, d должны быть выполнены, только если параметр recurse установлен в true. Если SqlRecordID задан, и тип является коллекцией, для удаления объекта могут быть реализованы следующие этапы:
a) Получать строки в соответствующей таблице коллекции с заданным идентификатором в качестве идентификаторм коллекции.
b) Рекурсивно следовать правилам удаления объекта для каждого элемента.
Удаление объектов, задав запрос, может быть более сложным и может включать в себя следующее:
a) Следовать правилам преобразования запроса и перевести запрос на SQL.
b) Исполнить запрос и получить согласующиеся строки в SQL-таблице типа.
c) Следовать правилам удаления объекта для каждой строки.
На основании вышеизложенного, также будет принято во внимание, что разнообразные типы запросов могут быть также выполнены над данными, сохраненными в структурах базы данных и таблицах, описанных выше. Далее будут приведены некоторые, не ограничивающие примеры запросов, которые могут быть выполнены в примерах, описанных при ссылке на фиг.1 и 2. Например, чтобы извлечь заказы от заказчиков, проживающих по почтовому индексу 98074, запрос XPATH может выглядеть до некоторой степени подобно следующему: /Customers[typeof (address) == USAddress && address.zip = 98074]/orders. Более того, чтобы извлечь адреса заказчиков, которые имеют, по меньшей мере, один неоплаченный заказ, запрос XPATH мог бы выглядеть до некоторой степени подобно следующему: /Customers[Count(orders) > 0]/address. Подобным образом, для извлечения альбомов "Sting" с, по меньшей мере, одной песней, запрос XPATH мог бы выглядеть до некоторой степени подобно следующему: /Albums[Exists(artists, name == "Sting") && count(songs) > 0]. Для извлечения песен альбома, названного Groovy, запрос XPATH мог бы выглядеть до некоторой степени подобно следующему: /Albums[title == "Groovy"]/songs. В заключение, чтобы извлечь альбомы, содержащие в себе песню, названную "Whenever," запрос XPATH мог бы выглядеть до некоторой степени подобно следующему: /Songs[title == "Whenever"]/album.
Несмотря на предшествующие подробности и примеры реализации, которые были представлены в материалах настоящей заявки, будет принято во внимание, что объем настоящего изобретения свободно расширяется до любого способа, системы или компьютерного программного продукта, в которых таблицы или другие структуры данных создаются в ответ на атрибуты и другие дополнения, ассоциативно связанные с объектами и полями классов, и типами данных, которые должны быть сохранены. Такой способ для создания механизма базы данных для сохранения данных не полагается на специальные знания программиста касательно баз данных, но скорее только на знание запланированного использования данных. Это представляет усовершенствование сверх технических систем предшествующего уровня техники, таких как Access другие инструментальные средства баз данных, которые требуют от программистов понимать, как должна быть структурирована база данных, которую они желают видеть.
Настоящее изобретение также позволяет механизму базы данных быть масштабируемым и способным взаимодействовать со многими различными форматами данных и системами реляционных баз данных. Соответственно, будет принято во внимание, что изобретение может быть осуществлено на практике в различных вычислительных средах. Далее следует один из примеров подходящей вычислительной среды, в которой изобретение может быть осуществлено на практике.
ВЫЧИСЛИТЕЛЬНАЯ СРЕДА
Способы, которые были описаны выше, могут быть выполнены с использованием любого количества вычислительных модулей и систем, и сетевых вычислительных сред с различными конфигурациями, включая персональные компьютеры, «карманные» устройства, многопроцессорные системы, основанную на микропроцессоре или программируемую бытовую электронную аппаратуру, сетевые ПК (персональные компьютеры, PC), мини-компьютеры, универсальные вычислительные машины и подобное. Изобретение также может быть реализовано на практике в распределенных вычислительных средах, в которых задачи выполняются локальными и удаленными вычислительными устройствами, которые связаны (проводными линиями связи, беспроводными линиями связи или комбинацией проводных и беспроводных линий связи) через сеть связи. В распределенной вычислительной среде программные модули могут быть размещены на локальных и удаленных запоминающих устройствах хранения.
Со ссылкой на фиг.4 типичная система для реализации изобретения включает в себя вычислительное устройство общего назначения в виде известного компьютера 420, включающий в себя блок 421 обработки данных (процессор), системную память 422, и системную шину 423, которая соединяет различные системные компоненты, в том числе системную память 422, с блоком 421 обработки данных. Системная шина 423 может быть любой из нескольких типов шинных структур, включая шину памяти, или контроллер памяти, периферийную шину и локальную шину, с использованием любой из многообразия шинных архитектур. Системная память включает в себя постоянное запоминающее устройство (ПЗУ, ROM) 424 и оперативное запоминающее устройство (ОЗУ, RAM) 425. Базовая система 426 ввода/вывода (BIOS), содержащая в себе базовые процедуры, которые помогают передавать информацию между элементами в компьютер 420, к примеру, во время запуска, может быть сохранена в ПЗУ 424.
Компьютер 420 также может включать в себя накопитель 427 на жестких магнитных дисках для считывания и записи на жесткий магнитный диск 439, магнитный дисковод 428 для считывания и записи на сменный магнитный диск 429 и оптический дисковод 430 для считывания и записи на сменный оптический диск 431, такой как CD-ROM (ПЗУ на компакт диске), DVD-ROM (ПЗУ на универсальном цифровом диске) или другой оптический носитель. Накопитель 427 на жестких магнитных дисках, магнитный дисковод 428 и оптический дисковод 430 подключены к системной шине 423 посредством интерфейса 432 накопителя на жестких дисках, интерфейса 433 магнитного дисковода и интерфейса 434 оптического дисковода, соответственно. Накопители и дисководы и ассоциированные с ними машиночитаемые носители обеспечивают энергонезависимое хранение машиноисполняемых инструкций, структур данных, программных модулей и других данных для компьютера 420. Хотя иллюстративная среда, описываемая в материалах настоящей заявки, использует жесткий магнитный диск 439, сменный магнитный диск 429 и съемный оптический диск 431, могут быть использованы другие типы машиночитаемых носителей, в том числе магнитные дискеты, карты флэш-памяти, цифровые универсальные диски, картриджи Бернулли, ОЗУ, ПЗУ, и тому подобное.
Средство программного кода, содержащее один и более программных модулей, может быть сохранено на жестком диске 439, магнитном диске 429, оптическом диске 431, ПЗУ 424 или ОЗУ 425, в том числе операционная система 435, одна или более прикладных программ 436, другие программные модули 437 и данные 438 программ. Пользователь может вводить команды и информацию в компьютер 420 посредством клавиатуры 440, указательного устройства 442 или других устройств ввода (не показаны), таких как микрофон, джойстик, игровая панель, спутниковая антенна, сканер и тому подобное. Эти и другие устройства ввода часто подключены к блоку 421 обработки данных через интерфейс 446 последовательного порта, присоединенный к системной шине 423. В качестве альтернативы устройства ввода могут быть подключены другими интерфейсами, такими как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 447 или другое устройство отображения также подключен к системной шине 423 через интерфейс, такой как видеоадаптер 448. В дополнение к монитору персональный компьютер в типичном случае включает в себя другие периферийные устройства вывода (не показаны), такие как динамики и принтеры.
Компьютер 420 может работать в сетевой среде, используя логические соединения с одним и более удаленным компьютерам, таким как удаленные компьютеры 449a и 449b. Каждым из удаленных компьютеров 449a и 449b может быть другой персональный компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой общий узел сети, и в типичном случае включает в себя многие или все из элементов, описанных выше относительно компьютера 420, несмотря на то, что только запоминающие устройства 450a и 450b памяти, и ассоциированные с ними прикладные программы 436a и 436b были проиллюстрированы на фиг.4. Логические соединения, показанные на фиг.4, включают в себя локальную сеть (LAN) 451 и глобальную сеть (WAN) 452, которые представлены здесь в качестве примера, но не ограничения. Такие сетевые среды являются обычными для офисных или корпоративных компьютерных сетей, сетей интранет и Интернет.
При использовании в сетевой среде LAN, компьютер 420 присоединен к локальной сети 451 через сетевой интерфейс или адаптер 453. При использовании в сетевой среде WAN, компьютер 420 может включать в себя модем 454, беспроводную линию связи или другое средство для установления связи через глобальную сетью 452, такую как Интернет. Модем 454, который может быть внутренним или внешним, подключен к системной шине 423 через интерфейс 446 последовательного порта. В сетевой среде программные модули, показанные относительно компьютера 420, или их части могут сохранены в удаленном устройстве, запоминающем устройстве памяти. Будет принято во внимание, что показанные сетевые соединения являются иллюстративными, и другие средства для установления связи через глобальную сеть 452 могут быть использованы.
Настоящее изобретение может быть осуществлено в других специфических формах, не отходя от его сущности или существенных признаков. Описанные варианты осуществления должны быть рассмотрены во всех отношениях только как иллюстративные, а не ограничивающие. Объем изобретения, таким образом, определяется прилагаемой формулой изобретения, а не предшествующим описанием. Все изменения, попадающие под содержание и область эквивалентности формулы изобретения, должны быть включены в объем притязаний.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| РАСШИРЯЕМЫЙ ЯЗЫК ЗАПРОСОВ С ПОДДЕРЖКОЙ ДЛЯ РАСШИРЕНИЯ ТИПОВ ДАННЫХ | 2007 |
|
RU2434276C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ ДАННЫХ ГРАФОВ | 2012 |
|
RU2605387C2 |
| МОДЕЛИРОВАНИЕ ОТНОШЕНИЙ | 2006 |
|
RU2421784C2 |
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| МЕХАНИЗМЫ ОБНАРУЖИВАЕМОСТИ И ПЕРЕЧИСЛЕНИЯ В ИЕРАРХИЧЕСКИ ЗАЩИЩЕННОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2408070C2 |
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
Изобретение относится к компьютерным системам, а именно к способам, системам и компьютерным программным продуктам для создания структур баз данных и для сохранения данных в ответ на атрибуты. Техническим результатом является обеспечение оптимизации подхода к хранению произвольных структур данных. Предоставлен общий механизм для сохранения объектов данных в базах данных без существенной зависимости от лежащего в основе хранилища данных. Вместо обращения к экспертизе программиста, чтобы узнать, как структура базы данных могла бы выглядеть, типы данных определены и дополнены программистом атрибутами, которые подсказывают, для чего соответствующие данные будут использованы, и без определения программистом структуры базы данных, которая будет использоваться для хранения данных. После этого база данных создается динамически, чтобы удовлетворять потребностям, предлагаемым дополненными атрибутами. В частности, некоторое количество различных таблиц создаются в соответствии с запланированными потребностями для осуществления доступа к данным. При выполнении этого может быть создана оптимизированная база данных, чтобы обеспечивать желаемые результаты, без требования от программиста обладать любыми специальными знаниями касательно баз данных и соответствующих схем баз данных. 2 н. и 42 з.п. ф-лы, 8 ил.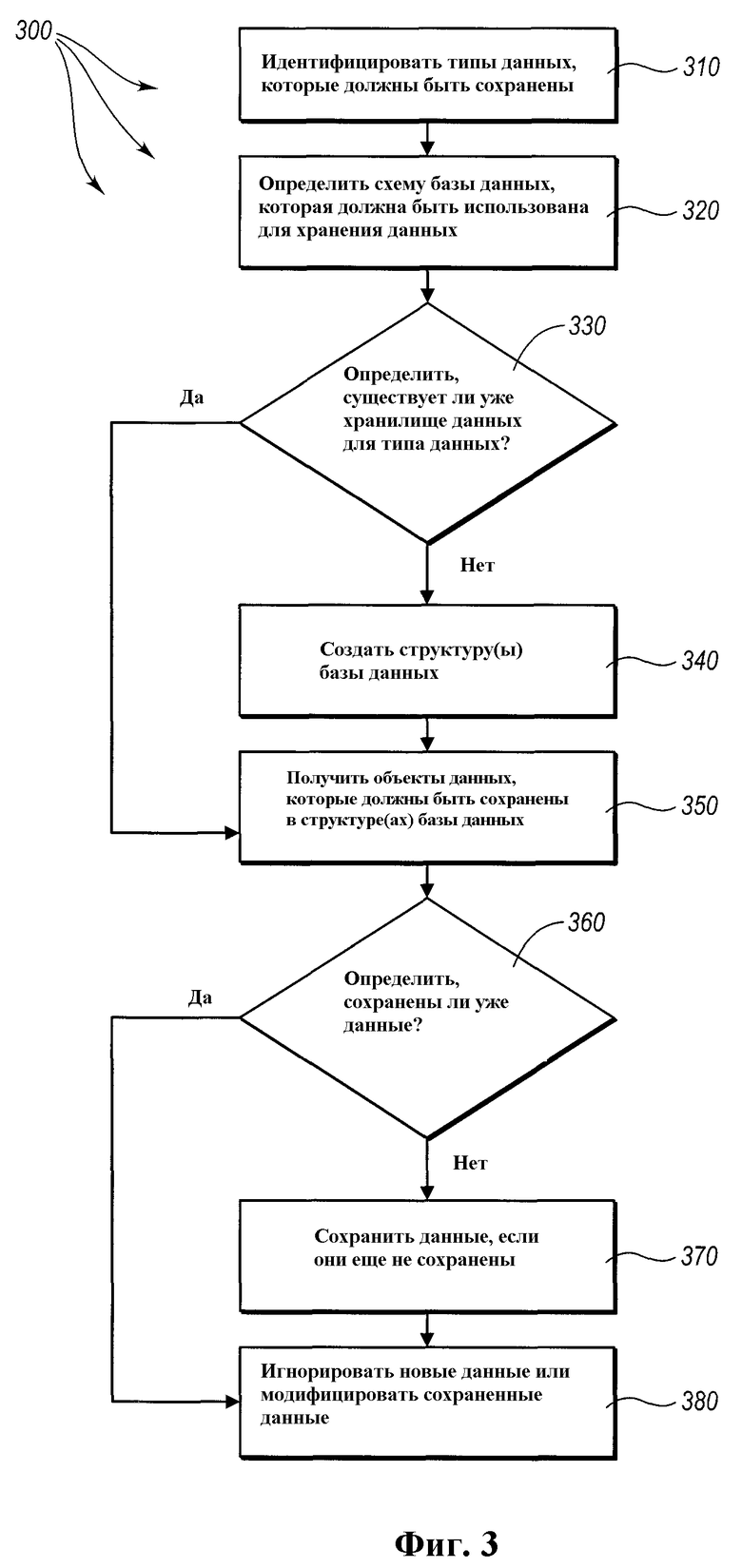
1. Способ динамического определения структуры базы данных и создания долговременного хранилища данных для хранения объектов одного и более типов данных, способ содержит этапы, на которых:
принимают сегмент программного кода, который включает в себя определение одного или более типов данных и по меньшей мере одно дополнение, ассоциативно связанное в программном коде с по меньшей мере одним из типов данных, причем по меньшей мере одно дополнение отражает предназначенное использование или доступ к ассоциативно связанному типу данных;
идентифицируют по меньшей мере одно дополнение, ассоциативно связанное с по меньшей мере одним из типов данных, причем по меньшей мере одно дополнение содержит:
по меньшей мере один атрибут идентичности, применяемый к по меньшей мере одному полю в классе, который формирует корень иерархии, и который указывает, что тип данных должен представлять уникальный ключ в пределах базы данных; и
по меньшей мере одно из:
атрибута индекса, указывающего, что должна иметься возможность осуществления запроса по ассоциативно связанному типу данных;
атрибута обратного указателя, указывающего, что между указанным вторым типом данных и упомянутым типом данных существует отношение один-ко-многим;
атрибута единой ссылки, указывающего, что между экземплярами упомянутого типа данных и указанным вторым типом данных существует отношение один-к-одному;
на основании каждого из определений одного или более типов данных и по меньшей мере одного дополнения определяют структуру базы данных, которая должна быть использована для хранения данных, соответствующих одному или более типов данных;
определяют, существует ли хранилище данных;
при определении, что хранилище данных не существует, создают хранилище данных.
2. Способ по п.1, в котором хранилище данных создается без приема специальных входных данных, определяющих хранилище данных, иных, чем дополнения и определения одного или более типов данных.
3. Способ по п.1, в котором определение схемы для хранилища данных, которая должна быть использована, заключается в том, что определяют схему, которая будет оптимизировать запросы типа данных и данных, хранящихся в пределах хранилища данных.
4. Способ по п.1, в котором создание хранилища данных содержит создание одной или более таблиц базы данных.
5. Способ по п.4, в котором создание одной и более таблиц базы данных заключается в том, что наполняют одну или более таблиц базы данных по меньшей мере некоторыми полями, идентифицированными соответствующими полями в коде.
6. Способ по п.4, в котором создание одной и более таблиц базы данных заключается в том, что создают таблицу базы данных базового класса и по меньшей мере одну таблицу базы данных подкласса, которая связана перекрестными ссылками с таблицей базы данных базового класса.
7. Способ по п.4, который также содержит этап, на котором создают таблицу типов, которая определяет типы, идентифицированные в коде, и которая идентифицирует каждую из соответствующих таблиц базы данных.
8. Способ по п.1, в котором создание хранилища данных содержит создание одного или более XML-файлов.
9. Способ по п.1, в котором другую таблицу базы данных создают для каждого типа, определенного в коде.
10. Способ по п.1, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что поле по меньшей мере одного типа данных могло бы быть индексированным.
11. Способ по п.1, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что одно или более полей по меньшей мере одного типа данных могли бы быть уникальным ключом для типа.
12. Способ по п.1, в котором по меньшей мере одно дополнение включает в себя атрибут, который задает отношение один-к-одному.
13. Способ по п.1, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что поле по меньшей мере одного типа данных могло бы быть обратным указателем на объекты в другой структуре данных.
14. Способ по п.1, в котором по меньшей мере одно поле, определенное в коде, соответствующее по меньшей мере одному типу данных, не дополнено, и при этом отсутствие дополнения указывает, что может существовать отношение один-ко-многим.
15. Способ по п.1, в котором хранилище данных содержит одно из словаря, коллекции и массива.
16. Способ по п.1, дополнительно содержащий этапы, на которых:
принимают данные, которые должны быть сохранены в структуре данных;
определяют, сохранены ли уже данные, включая проверку соответствующих таблиц и проверку каждого поля, дополненного атрибутом идентичности;
при определении, что данные еще не сохранены, сохраняют данные в структуре данных в соответствии с дополнениями и описаниями, предусмотренными в коде; и
при определении, что данные уже сохранены, определяют указатели на уже сохраненные данные и записывают указатели для указания на данные, сохраненные в другом местоположении.
17. Способ по п.16, в котором структура данных создается без приема специальных входных данных, определяющих структуру данных, иных, чем дополнения и определения одного или более типов данных.
18. Способ по п.16, в котором определение того, что данные еще не сохранены, заключается в том, что проверяют уникальное поле идентичности, определенное дополнениями в данных, и удостоверяются, что уникальное поле идентичности в данных еще не существует в пределах структуры данных.
19. Способ по п.16, в котором определение схемы, которая должна быть использована, заключается в том, что определяют схему, которая будет оптимизировать запрос типа данных и данных, хранящихся в структуре данных.
20. Способ по п.16, в котором схема хранилища данных, соответствующая типам данных, содержит одну и более таблиц базы данных.
21. Способ по п.20, в котором сохранение данных в таблице базы данных заключается в том, что заполняют таблицу по меньшей мере некоторыми из данных и таким образом, чтобы оптимизировать запрос данных в дальнейшем.
22. Способ по п.16, в котором при определении, что данные уже сохранены, способ также включает в себя этап, на котором модифицируют данные.
23. Машиночитаемый носитель, содержащий машиноисполняемые инструкции для реализации способа динамического определения структуры базы данных и создания долговременного хранилища данных для хранения объектов одного или более типов данных, способ содержит этапы на которых:
принимают сегмент программного кода, который включает в себя определение одного или более типов данных и по меньшей мере одно дополнение, ассоциативно связанное в программном коде с по меньшей мере одним из типов данных, причем по меньшей мере одно дополнение отражает предназначенное использование или доступ к ассоциативно связанному типу данных;
идентифицируют по меньшей мере одно дополнение, ассоциативно связанное с по меньшей мере одним из типов данных, причем по меньшей мере одно дополнение содержит:
по меньшей мере один атрибут идентичности, применяемый к по меньшей мере одному полю в классе, который формирует корень иерархии, и который указывает, что тип данных должен представлять уникальный ключ в пределах базы данных; и
по меньшей мере одно из:
атрибута индекса, указывающего, что должна иметься возможность осуществления запроса по ассоциативно связанному типу данных;
атрибута обратного указателя, указывающего, что между указанным вторым типом данных и упомянутым типом данных существует отношение один-ко-многим;
атрибута единой ссылки, указывающего, что между экземплярами упомянутого типа данных и указанным вторым типом данных существует отношение один-к-одному;
на основании каждого из определений одного или более типов данных и по меньшей мере одного дополнения определяют структуру базы данных, которая должна быть использована для хранения данных, соответствующих одному или более типов данных;
определяют, существует ли хранилище данных;
при определении, что хранилище данных не существует, создают хранилище данных.
24. Машиночитаемый носитель по п.23, в котором структура данных создается без приема специальных входных данных, определяющих хранилище данных, иных, чем дополнения и определения одного или более типов данных.
25. Машиночитаемый носитель по п.23, в котором определение структуры данных, которая должна быть использована, включает в себя определение схемы, которая будет оптимизировать запрос типа данных и данных, хранимых в хранилище данных.
26. Машиночитаемый носитель по п.23, в котором создание хранилища данных содержит создание одной или более таблиц базы данных.
27. Машиночитаемый носитель по п.26, в котором создание таблицы базы данных включает в себя наполнение таблицы по меньшей мере некоторыми полями, идентифицированными соответствующими полями в коде.
28. Машиночитаемый носитель по п.26, в котором создание одной или более таблиц базы данных включает в себя создание таблицы базы данных базового класса и по меньшей мере одну таблицу базы данных подкласса, которая связана перекрестными ссылками с таблицей базы данных базового класса.
29. Машиночитаемый носитель по п.23, в котором способ также содержит этап, на котором: создают таблицу типов, которая определяет типы, идентифицированные в коде, и которая идентифицирует каждую из соответствующих таблиц базы данных.
30. Машиночитаемый носитель по п.23, в котором другая таблица базы данных создается для каждого типа, определенного в коде.
31. Машиночитаемый носитель по п.23, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что поле по меньшей мере одного типа данных могло бы быть индексировано.
32. Машиночитаемый носитель по п.23, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что поле по меньшей мере одного типа данных могло бы быть уникальным ключом для типа.
33. Машиночитаемый носитель по п.23, в котором по меньшей мере одно дополнение включает в себя атрибут, который задает отношение один-к-одному.
34. Машиночитаемый носитель по п.23, в котором по меньшей мере одно дополнение включает в себя атрибут, который предписывает, что поле по меньшей мере одного типа данных могло бы быть обратным указателем на объекты в другой структуре данных.
35. Машиночитаемый носитель по п.23, в котором по меньшей мере одно поле, определенное в коде, соответствующем по меньшей мере одному типу данных, не дополнено, и в котором отсутствие дополнения указывает, что могло бы существовать отношение один-ко-многим.
36. Машиночитаемый носитель по п.23, в котором создание хранилища данных содержит создание одного или более XML-файлов.
37. Машиночитаемый носитель по п.23, в котором хранилище данных содержит одно из словаря, коллекции и массива.
38. Машиночитаемый носитель по п.23, дополнительно содержащий инструкции для реализации этапов, на которых:
принимают данные, которые должны быть сохранены в структуре данных;
определяют, сохранены ли уже данные, включая проверку соответствующих таблиц и проверку каждого поля, дополненного атрибутом идентичности;
при определении, что данные еще не сохранены, сохраняют данные в структуре данных в соответствии с дополнениями и описаниями, предусмотренными в коде; и
при определении, что данные уже сохранены, определяют указатели на уже сохраненные данные и записывают указатели для указания на данные, сохраненные в другом местоположении.
39. Машиночитаемый носитель по п.38, в котором одна или более структур данных создаются без приема специальных входных данных, определяющих одну или более структуру данных, иных, чем дополнения и определения одного или более типов данных.
40. Машиночитаемый носитель по п.38, в котором определение того, что данные еще не сохранены, включает в себя проверку уникального поля идентичности, определенного дополнениями в данных, и удостоверение в том, что уникальное поле идентичности в данных еще не существует в пределах одной или более структурах данных.
41. Машиночитаемый носитель по п.38, в котором определение того, существует ли одна или более структур данных, включает в себя определение структуры данных, которая будет оптимизировать запрос хранимых типа данных и данных.
42. Машиночитаемый носитель по п.38, в котором структура данных содержит одну или более таблиц базы данных.
43. Машиночитаемый носитель по п.42, в котором сохранение данных в одной или более таблиц базы данных включает в себя заполнение одной или более таблиц по меньшей мере некоторыми данными и таким образом, чтобы оптимизировать запрос данных в дальнейшем.
44. Машиночитаемый носитель по п.38, в котором при определении, что данные уже сохранены, способ также включает в себя модификацию данных.
| US 5878411 А, 02.03.1997 | |||
| US 5557794 А, 17.09.1996 | |||
| Лучковая пила | 1930 |
|
SU22250A1 |

