Уровень техники
Настоящее изобретение, в основном, относится к доступу процессора к памяти и, прежде всего, к доступу процессора к блоку данных в памяти элементарным или поблочно-параллельным образом.
Скалярный код основывается на той предпосылке, что выполняющий код центральный процессор (ЦП) получает совместный доступ ко всем байтам переменной программного обеспечения. В типичной архитектуре для ЦП такая предпосылка является оправданной для скалярного кода до тех пор, пока доступ выполняется на границе в памяти, которая является целым кратным к размеру данных, к которым обращаются. Когда скалярный код векторизован компилятором, команды загрузки и сохранения зачастую преобразуются для векторизации команд загрузки и сохранения. Однако векторная команда загрузки и векторная команда сохранения зачастую не имеют никаких гарантий непротиворечивости, или непротиворечивость гарантируется, только если векторная команда загрузки или сохранения находится на границе, которая является размером векторного регистра в ЦП. Для доступов, которые не являются элементарными или поблочно-параллельными, если один ЦП выполняет контрольное считывание данных, а другой ЦП в то же время считывает данные, считывающий данные ЦП может обнаруживать частичные обновления ячеек памяти, содержащие переменные последнего ЦП. Это не является совместимым с семантикой большинства языков программирования или технологиями программирования, такими как безблокировочные структуры данных.
Сущность изобретения
Варианты осуществления включают в себя способы, системы и машиночитаемые носители данных с компьютерными программными продуктами для доступа к данным в памяти. Изобретение может быть реализовано в способе получения доступа к данным в сопряженной с процессором памяти, содержащем: получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти, причем команда обращения к памяти задает первый размер; выявление посредством процессора размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении; выявление посредством процессора наибольшего общего делителя для первого размера и для выявленного размера выравнивания; и получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
Изобретение также может быть реализовано в системе для получения доступа к данным, содержащей память и процессор, сконфигурированный для выполнения способа, содержащего: получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти; выявление размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении; выявление наибольшего общего делителя для первого размера и для размера выравнивания; и получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными наибольшему общему делителю.
Кроме того, изобретение может быть реализовано в машиночитаемом информационном носителе (носителе данных), имеющем сохраненные на нем программные команды, считываемые процессором для принуждения процессора к выполнению способа получения доступа к данным, содержащего: получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти; выявление размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении; выявление наибольшего общего делителя для первого размера и для размера выравнивания; и получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными наибольшему общему делителю.
Далее, изобретение может быть реализовано в способе получения доступа к данным в сопряженной с процессором памяти, содержащем: получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти, причем команда обращения к памяти задает первый размер; выявление посредством процессора размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении; выявление наибольшего общего делителя для первого размера и для выявленного размера выравнивания; и получение доступа к данным первого размера в одной или нескольких группах данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
Изобретение также может быть реализовано в системе для получения доступа к данным, содержащей память и процессор, сконфигурированный для выполнения способа, содержащего: получение команды обращения к памяти для получения доступа к пространству данных с первым размером по адресу в памяти, причем команда обращения к памяти задает первый размер; выявление размера выравнивания адреса; выявление наибольшего общего делителя для первого размера и для выявленного размера выравнивания; и получение доступа к данным первого размера в одной или нескольких группах данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
Краткое описание чертежей
Рассматриваемый в качестве вариантов осуществления объект изобретения, прежде всего, указан и недвусмысленно заявлен в пунктах формулы изобретения в конце технического описания. Упомянутые ранее и другие признаки и преимущества вариантов осуществления являются очевидными из последующего подробного описания, рассматриваемого совместно с сопровождающими чертежами, на которых:
Фиг. 1 показывает участки памяти, имеющие блоки, которые являются естественно выровненными согласно некоторым вариантам осуществления изобретения,
Фиг. 2 изображает участок памяти, к которому получают доступ согласно некоторым вариантам осуществления изобретения,
Фиг. 3 изображает последовательность операций для доступа к памяти согласно некоторым вариантам осуществления изобретения,
Фиг. 4 изображает последовательность операций для доступа к памяти согласно некоторым вариантам осуществления изобретения, и
Фиг. 5 показывает систему для доступа к данным в памяти согласно некоторым вариантам осуществления изобретения.
Подробное описание
Некоторые соглашения по языку программирования требуют параллельного доступа ко всем байтам блока данных (например, типизированной в исходном формате переменной, такой как целочисленная, с плавающей точкой, длинная, двойная и т.д.) в памяти со стороны процессора (например, центрального вычислительного устройства (ЦП)). Параллельный доступ к байтам означает, что получают доступ либо к исходному значению, либо к обновленному значению, но отсутствует возможность получения доступа к какой-либо смеси из этих двух значений. Например, когда блок данных имеет значение «1234», и значение обновляется к «5678», только одно из этих двух значений является правильным значением для выборки. Любое частично обновленное значение (например, «1278» или «5634»), которое может быть результатом получения доступа к блоку данных непараллельным образом, является неправильным значением для выборки. Такое требование параллельного доступа в данном раскрытии называют «параллелизмом блоков». Кроме того, при доступе к памяти термин «поблочно-параллельно» или «поблочно-параллельный» означает, что способ, посредством которого получают доступ к данным в памяти, соответствует параллелизму блоков. Для обычных языков программирования и процессоров, поблочно-параллельный доступ к блоку данных гарантируется только в том случае, когда блок является «естественно выровненным», то есть когда адрес блока соответствует кратному размеру типа данных блока числу.
Полям величиной 2, 4, 8, 16, и 32 байтов дают специальные наименования. Полуслово является группой из двух последовательных байтов. Слово является группой из четырех последовательных байтов. Двойное слово является группой из восьми последовательных байтов. Учетверенное слово является группой из 16 последовательных байтов. Восьмикратное слово является группой из 32 последовательных байтов. Когда адреса памяти обозначают «естественно выровненные» полуслова, слова, двойные слова, учетверенные слова и восьмикратные слова, двоичное представление адреса содержит, соответственно, один, два, три, четыре, или пять самых правых нулевых битов. Полуслово, слово, двойное слово или учетверенное слово в данном раскрытии называют блоком.
Для некоторых команд, которые обращаются к данным в памяти, доступы ко всем байтам в пределах полуслова, слова, двойного слова или учетверенного слова задают таким образом, что они представляются поблочно-параллельными при наблюдении со стороны других процессоров и программ управления работой канала ввода-вывода. Когда задается обращение выборочного типа, для представления в параллельном виде внутри блока, никакой доступ к памяти для блока со стороны другого процессора или программы управления работой канала ввода-вывода не является разрешенным в то время, когда содержащиеся в блоке байты выбираются одним процессором. Когда задается обращение сохраняющего типа, для представления в параллельном виде внутри блока, никакой доступ к блоку, будь то выборочного типа или сохраняющего типа, не является разрешенным для другого процессора или программы управления работой канала ввода-вывода в то время, когда байты в пределах блока сохраняются одним процессором. Согласно обычной архитектуре системы команд, обращения к единственному операнду (например, единственному значению, загруженному в единственный регистр, или единственному используемому командой операнду) имеют параллелизм блоков, соответствующий размеру этого операнда (то есть, размеру данных, к которым получают доступ), если заданный в операнде адрес располагается на целочисленной границе. Если заданный в операнде адрес не располагается на целочисленной границе, операнд является поблочно-параллельным только при его соответствии размеру в один байт.
Для обычных процессоров ко всем восьми битам байта всегда обращаются совместно - это называют параллелизмом байта. Поэтому параллелизм блоков представляет собой различные уровни параллелизма байта. Например, параллелизм блоков для четырехбайтового блока данных могут называть четырехбайтовым параллелизмом. Кроме того, поскольку ко всем четырем байтам четырехбайтового блока данных получают доступ одновременно, как к единому модулю, когда получают доступ к памяти с четырехбайтовым параллелизмом, два двухбайтовых блока данных и четыре однобайтовых блока данных являются, соответственно, параллельными по двум байтам и параллельными по одному байту.
Поблочно-параллельные операции с памятью также называют элементарными операциями относительно обращений к памяти. Обращение к памяти считают поблочно-параллельным, когда ко всем байтам в пределах целочисленного блока получают доступ как к единому с позиции других процессоров модулю. Целочисленный блок является блоком данных, адрес которого является целым кратным длины блока. Целочисленный блок находится на целочисленной границе, то есть адрес первого байта блока располагается на целочисленной границе.
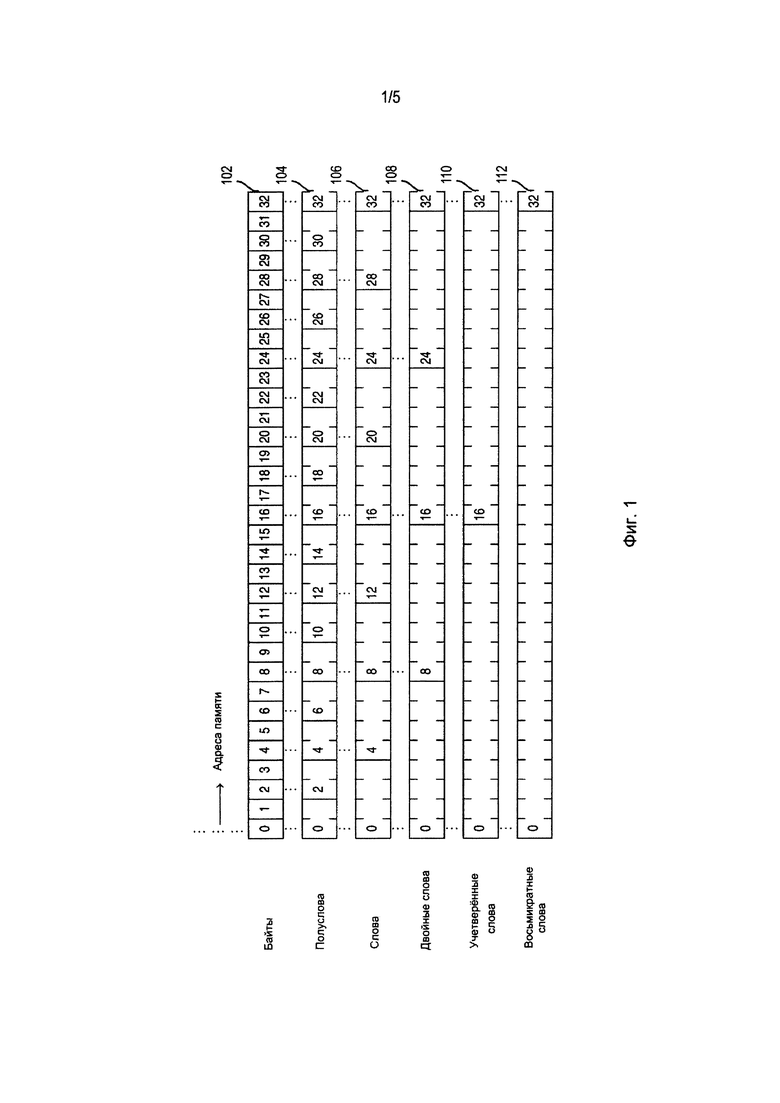
Фиг. 1 показывает участки памяти с адресами, обозначающими «естественно выровненные» блоки. Конкретно, этот чертеж изображает строки 102-112, которые представляют собой, соответственно, «естественно выровненные» полуслова, слова, двойные слова, учетверенные слова и восьмикратные слова. Как показано, память рассматривается как длинная горизонтальная строка битов. Строка битов подразделена на модули по байтам (то есть, по восемь битов). Каждое местоположение байта в памяти идентифицируется уникальным неотрицательным целым числом, которое является адресом этого местоположения байта.
Строка 102 представляет собой память, имеющую блоки однобайтовых данных. Каждый прямоугольник в строке 102 представляет собой блок однобайтовых данных. Содержащееся в каждом прямоугольнике число является смещением байтового блока по отношению к базовому адресу (который соответствует адресу первого элемента, промаркированному смещением 0). К каждому байту можно получить доступ (то есть, выбрать его или сохранить в памяти) с использованием адреса и полученного из него смещения. В некоторых вариантах осуществления память является поблочно-параллельно доступной, по меньшей мере, на уровне байта (то есть, побайтово-параллельной). Кроме того, если адрес первого байта данных, к которым получают доступ, является целочисленной границей для большего размера блока, то доступы к большим блокам также могут быть поблочно-параллельными относительно этого размера блока.
Строка 104 представляет собой память, имеющую блоки двухбайтовых данных, которые являются естественно выровненными. Каждый из двухбайтовых блоков адресуется с помощью кратного двум числа, и таким образом, все двухбайтовые блоки данных являются целочисленными блоками, и к ним может быть получен доступ поблочно-параллельным образом с размером блока в два байта. Аналогично, все четырехбайтовые блоки данных в строке 106, восьмибайтовые блоки данных в строке 108, 16-байтовые блоки данных в строке 110 и 32-байтовые блоки данных в строке 112 являются целочисленными блоками, и доступ к этим блокам данных может быть выполнен поблочно-параллельно по отношению к четырехбайтовым, восьмибайтовым, 16-байтовым и 32-байтовым блокам.
В этом раскрытии размер выравнивания адреса для адреса памяти является размером самого большого целочисленного блока, который может быть адресован по данному адресу, то есть самой большой степенью числа два делителя адреса. Например, размер выравнивания адреса для адреса 96 равняется 32 (то есть, 25), а размер выравнивания адреса для адреса 64 равняется 64 (то есть, 26). В некоторых вариантах осуществления размер выравнивания адреса для адреса получают путем подсчета конечных нулей адреса в двоичном представлении, и последующего возведения числа два в степень из конечных нулей в двоичном представлении, то есть alignment_size (address)=2trailing_zeros(address), где alignment_size () является функцией, берущей адрес в качестве входа и производящей размер выравнивания адреса для входного адреса, а trailing_zeros () является функцией, берущей адрес в качестве входа и производящей число конечных нулей в адресе в двоичном представлении. Например, адресом 96 является 11000002, который имеет пять конечных нулей. Размер выравнивания адреса для адреса 96 поэтому равняется 25 или 32. Адресом 64 является 10000002, который имеет шесть конечных нулей. Размер выравнивания адреса 64 поэтому равняется 26 или 64.
Для обычной команды обращения к памяти параллелизм блоков зависит от того, является ли адрес первого байта блока данных, к которому обращаются, неотъемлемой частью размера обращения к памяти (то есть, является ли адрес первого байта числом, кратным размеру обращения к памяти, или размер выравнивания адреса равен размеру обращения к памяти или превышает его). Это означает, что параллелизм блоков для обычной команды обращения к памяти зависит от того, имеет ли блок данных, к которому обращаются посредством команды, размер выравнивания адреса, совпадающий с размером обращения к памяти. Например, если обычная команда обращения к памяти обращается к восьми байтам данных на восьмибайтовой целочисленной границе (например, адреса 0, 8, 16, 24, и т.д., показанные на участке памяти, представленном строкой 108), это является восьмибайтовым параллелизмом. Однако, если обычная команда обращения к памяти обращается к восьми байтам данных на четырехбайтовой целочисленной границе (например, адреса 4, 12, 20, и т.д., показанные на участке памяти, представленном строкой 106), восьмибайтовый параллелизм не гарантируется. Это вызвано тем, что, когда обычная команда обращения к памяти обращается к восьмибайтовому блоку данных в памяти, выровненной по четырехбайтовым границам, не гарантируется, что два четырехбайтовых блока или четыре двухбайтовых блока не окажутся обновленными другим процессором, в то время как один процессор обращается к восьми байтам.
Когда адрес блока данных, к которому обращаются, не является целочисленным по отношению к размеру обращения к памяти, которая обращается к блоку, обычные архитектуры системы команд гарантируют только однобайтовый параллелизм для такого обращения к памяти, такой как при загрузке в единственный регистр или сохранении в нем, при котором предоставляется один операнд из памяти для команды, которая ожидает операнд памяти, и т.д. Программное обеспечение как таковое может полагаться только на обычное обращение к памяти, предоставляющее параллелизм блоков по размеру обращения к памяти или всего лишь однобайтовый параллелизм. В соответствии с обычными архитектурами системы команд для команд обращения к памяти не гарантируется какого-либо промежуточного уровня параллелизма блоков. Это означает, что, например, когда размер обращения к памяти составляет восемь байтов, а блок данных, к которому обращаются, является выровненным по четырехбайтовой границе или двухбайтовой границе, предоставляется только однобайтовый параллелизм (то есть, параллелизм блоков с размером блока в один байт), поскольку восьмибайтовый параллелизм предоставляется только для восьмибайтовых (двойное слово) обращений на целочисленные восьмибайтовые адреса памяти (то есть, когда адрес является числом, кратным восьмибайтовому размеру данных) или, в противном случае, гарантируется однобайтовый параллелизм.
В современных процессорах доступы к обращениям для широких данных (например, двойное слово, учетверенное слово или восьмикратное слово) обычно могут выполняться на той же скорости, что и обращения к более малым размерам данных. Тем самым, когда для большей области памяти требуется доступ, обработка или копирование, является желательным осуществление доступа, обработки или копирования большой области с помощью команд работы с памятью, приспособленных для доступа, обработки и/или копирования памяти с помощью больших размеров обращений к памяти. Тем самым, например, когда два последовательных слова должны быть скопированы, двухсловные загрузки и двухсловные сохранения могут быть заменены единственной загрузкой двойного слова и единственным сохранением двойного слова и, таким образом, получено удвоение скорости выполнения операции копирования. Когда матрица из 32 двухбайтовых переменных на двухбайтовой границе должна быть скопирована, для завершения копирования требуется 32 загрузки полуслова и 32 сохранения полуслова. На процессоре, реализующем доступы двойного слова, каждая группа из четырех доступов полуслова может быть заменена единственным доступом двойного слова.
Варианты осуществления изобретения предоставляют механизм для копирования последовательности выровненных данных (например, слов) на их целочисленном адресе (например, адресе 1002) с параллелизмом блоков на соответствующем отдельном элементе данных при копировании таких данных с помощью обращений к памяти для размеров данных (например, размеров двойного слова - восемь байтов) больших, чем размер каждого отдельного элемента данных (например, размер слова - четыре байта) на их соответствующей (элементу данных) целочисленной границе, и когда первый отдельный элемент данных на его соответствующей (элементу данных) целочисленной границе (например, адресе 1002) не является выровненным на целочисленной границе большего размера данных (например, адресе 10002), соответствующей размеру обращения, используемому для копирования последовательности элементов данных, выровненных на их целочисленной границе.
Варианты осуществления изобретения предоставляют системы и способы, предоставляющие разные уровни параллелизма блоков также и в том случае, когда адрес блока данных, к которому обращаются, не является неотъемлемой частью размера обращения к памяти. В некоторых вариантах осуществления операнд команды состоит из кратных поблочно-параллельных обращений, каждый блок соответствует блоку на его соответствующей целочисленной границе. Например, когда команда обращения к памяти согласно некоторым вариантам осуществления обращается к восьми байтам данных на четырехбайтовой границе (например, адрес 1002 или 11002, показанные на участке памяти, представленной строкой 106), гарантируется четырехбайтовый параллелизм для каждого четырехбайтового блока, выровненного на целочисленной четырехбайтовой границе. Кроме того, также гарантируется двухбайтовый параллелизм, поскольку он подразумевается гарантируемым четырехбайтовым параллелизмом (то есть, любой блок, выровненный на целочисленной четырехбайтовой границе, также является выровненным на целочисленной двухбайтовой границе, поскольку число четыре является кратным двум). Аналогично, когда команда обращения к памяти имеет размер обращения к памяти 16 байтов в адресе памяти с восьмибайтовой границей (например, адрес 10002 или 110002, показанные на участке памяти, представленной строкой 106), гарантируются восьмибайтовый параллелизм блоков, четырехбайтовый параллелизм блоков, двухбайтовый параллелизм блоков и однобайтовый параллелизм блоков для восьмибайтовых, четырехбайтовых, двухбайтовых и однобайтовых блоков, выровненных по их целочисленной восьмибайтовой, четырехбайтовой, двухбайтовой и однобайтовой блоковой границе, которые содержат 16-байтовый блок. Это означает, что любой восьми- четырех- двух- или однобайтовый блок на его целочисленной границе, содержащей 16-байтовый размер обращения, к которому получают доступ, гарантированно не включает в себя частично обновленное значение.
Размер выравнивания адреса блока данных, к которому обращаются, является только минимальным уровнем байтового параллелизма, который предоставляют процессоры, выполняющие команды обращения к памяти согласно некоторым вариантам осуществления изобретения. Это означает, что в некоторых вариантах осуществления единственный поблочно-параллельный доступ может быть реализован в виде множества доступов во взаимодействии с логикой для обеспечения того, что несколько таких доступов демонстрируют поблочно-параллельную логику работы. В некоторых вариантах осуществления реализовано несколько поблочно-параллельных доступов в качестве одиночного доступа, предоставляющих, по меньшей мере, поблочно-параллельную логику работы для каждого выровненного на целочисленной границе блока указанного множества доступов.
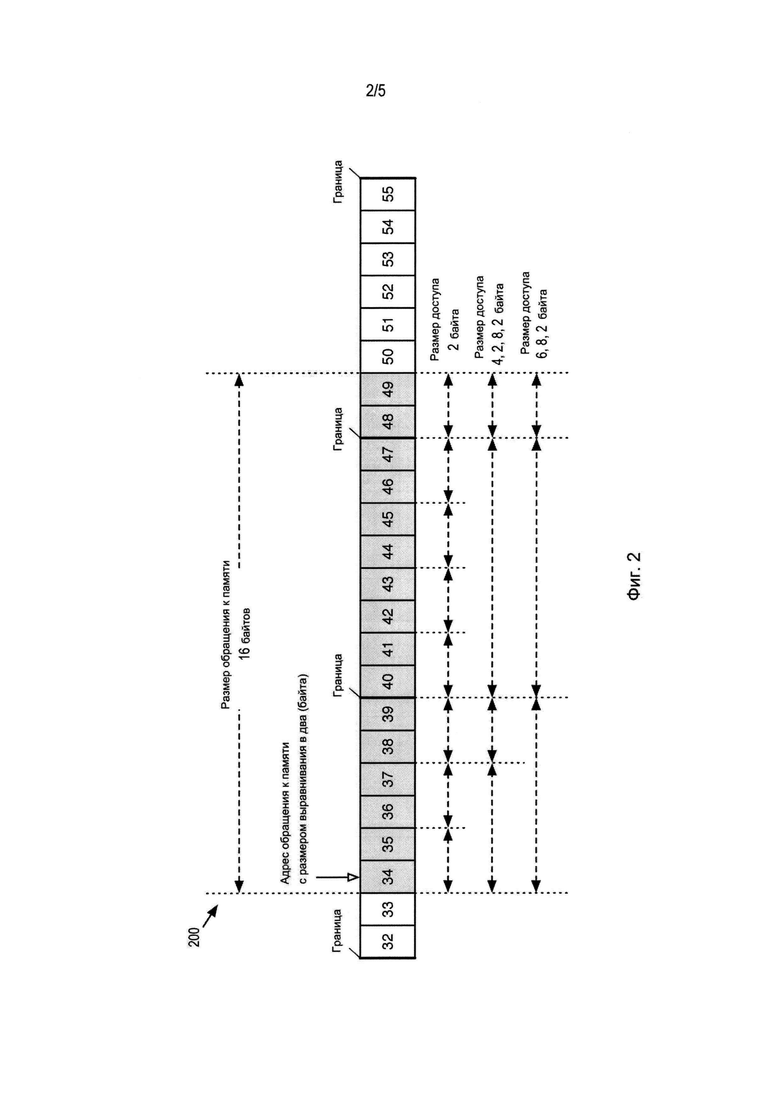
Фиг. 2 изображает участок памяти 200, к которому получают доступ процессоры согласно некоторым вариантам осуществления изобретения. Конкретным образом, этот чертеж показывает участок памяти с адресами от 32 до 55. Память 200 имеет восьмибайтовые границы (например, размер интерфейса кэша). Это означает, что адреса 32, 40 и 48 содержат границы.
В качестве примера, команда обращения к памяти согласно некоторым вариантам осуществления изобретения имеет размер обращения к памяти в 16 байтов (то есть, размер учетверенного слова), и этот блок в 16 байтов имеет адрес 34 (то есть, первый байт блока располагается по адресу 34 в памяти 200). Эти 16 байтов изображены как серые поля на фиг. 2. Выполняющий эту команду обращения к памяти процессор может получать доступ к 16 байтам данных при гарантии двухбайтового параллелизма. Это вызвано тем, что адрес 34 в двоичной форме (то есть, 1000102) имеет один конечный нуль, и поэтому адрес имеет размер выравнивания в два байта.
В некоторых вариантах осуществления процессор может получать доступ к 16 байтам данных в любых размерах групп, которые являются кратными размеру выравнивания до тех пор, пока ни одна из групп не переходит через границу памяти. Например, выполняющий команду процессор может получать доступ к четырем байтам с адресами 34-37, двум байтам с адресами 38 и 39, четырем байтам с адресами 40-43, четырем байтам с адресами 44-47 и двум байтам с адресами 48 и 49. Однако, поскольку получение доступа к каждой группе занимает время и затрагивает производительность, выполняющий команду процессор может получать доступ к этим 16 байтам данных в рамках наименьшего возможного числа доступов при избегании пересечения строк кэша (то есть, адресов 32, 40, 48 в этом примере). Конкретным образом, процессор может получать доступ к первым шести байтам с адресами 34-39 до адреса 40 строки кэша, к следующим восьми байтам с адресами 40-47 до следующего адреса 48 строки кэша и к следующим двум байтам с адресами 48 и 49. Эти три доступа (то есть, шестибайтовый доступ, восьмибайтовый доступ и двухбайтовый доступ) могут быть выполнены в любом порядке таким образом, что получается доступ ко всем 16 байтам.
В отличие от процессора, выполняющего команду обращения к памяти согласно некоторым вариантам осуществления изобретения, процессор, выполняющий обычную команду обращения к памяти, которая обращается к 16 байтам данных в адресе 34 памяти 200, может получать доступ к 16 байтам данных с использованием до 16 однобайтовых доступов. Это вызвано тем, что для обычной команды обращения к памяти адрес 16-байтовых данных не является целочисленным для размера обращения к памяти (то есть, 16 байтов), и поэтому гарантируется только побайтовый параллелизм. В некоторых случаях процессор, выполняющий обычную команду обращения к памяти, должен добавлять бессмысленные байты в байтовых адресах 32, 33 и 50-55 для получения доступа к шестнадцати байтам с адресами 34-49 без провоцирования ошибки выравнивания. Такие дополнительные этапы сказываются на производительности.
Следующие примеры кода задаются на основании типовых команд согласно z/Архитектуре IBM, если не указано иное. Однако для специалистов в данной области техники должны быть понятны способы приспособления примеров в настоящем документе к другой архитектуре, такой как архитектура Power ISA. Система команд семейства серверов System z IBM, известная как система команд z/Архитектуры, формулируется в публикации IBM «z/Архитектура, принципы работы», SA22-7832-09 (10-й выпуск, сентябрь 2012) и включена в настоящий документ путем отсылки в полном объеме. Система команд для серверов Power, известная как Power ISA (архитектура системы команд), формулируется в «Power IS А» (Версия 2.06, редакция В, июль 2010) и включена в настоящий документ путем отсылки в полном объеме.
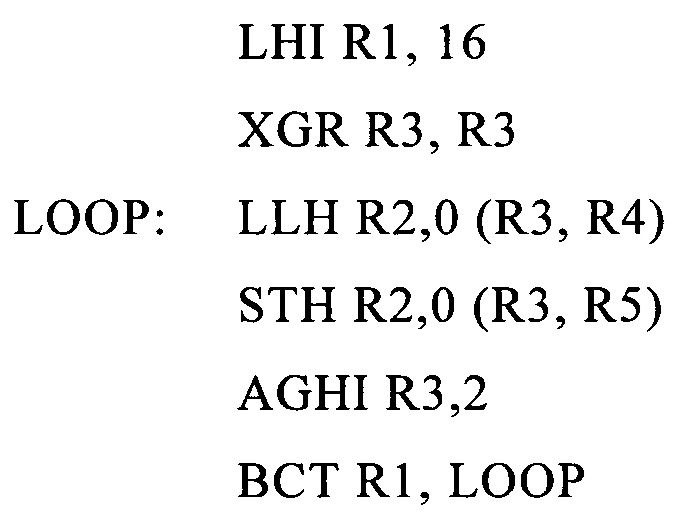
В следующих типовых командах z/Архитектуры (пример 1) показан оператор цикла копирования 16 загрузок и сохранений полуслова:


где LHI является командой LOAD HALFWORD IMMEDIATE (загрузки полуслова с непосредственной адресацией), XGR является командой EXCLUSIVE OR (исключающего ИЛИ), LLH является командой LOAD LOGICAL HALFWORD (загрузки логического полуслова), STH является командой STORE HALFWORD (сохранения полуслова), AGHI является командой ADD HALFWORD IMMEDIATE (добавления полуслова с непосредственной адресацией), ВСТ является командой BRANCH ON COUNT (ветвления на счете), и R1-R5 являются регистрами. Более подробное описание этих команд приведено во введенном выше в состав заявки материале «z/Архитектура, принципы работы».
16 загрузок и сохранений полуслова, показанные в примере 1, могут быть заменены четырьмя загрузками и четырьмя сохранениями регистров двойных слов, что уменьшает время выполнения со времени, соответствующего выполнению 66 команд, ко времени, соответствующего выполнению 18 команд, как показано в следующем примере 2:

Однако пример 1, который основан на копировании 16 полуслов, предлагает двухбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере двум, и однобайтовый параллелизм (то есть, параллелизм блоков с размером блока, соответствующим единственному байту). С другой стороны, показанные в примере 2 команды обычно могут гарантировать учетверенно-словный параллелизм блоков, когда регистры R4 и R5 имеют размер выравнивания адреса, равный, по меньшей мере, учетверенному слову, и побайтовый параллелизм в противном случае. Таким образом, преобразующий команды из примера 1 к примеру 2 программист или компилятор может понизить гарантии параллелизма блоков примера 1 от поблочно-параллельного для полуслова к только лишь побайтово параллельному для адресов, имеющих размер адреса выравнивания меньший учетверенного слова, но, по меньшей мере, равный размеру полуслова. Поэтому программист или компилятор в результате данного, в других случаях, выгодного изменения может ввести нарушение языка программирования или соглашений программирования.
В качестве другого примера, если требуется копирование матрицы 32 двухбайтовых переменных на двухбайтовой границе, для завершения копирования необходимы 32 загрузки полуслова и 32 сохранения полуслова. Если используется загрузка с одним потоком команд и несколькими потоками данных (SIMD), одновременно загружающая 16 байтов согласно некоторым вариантам осуществления этого изобретения, то требуются только две загрузки и два сохранения, что значительно уменьшает время выполнения копирования. Когда такая загрузка SIMD реализуется на процессоре z/Архитектуры, код в примере 3 ниже может быть заменен двумя командами VECTOR LOAD (векторной загрузки), сопровождаемыми двумя командами VECTOR STORE (векторного сохранения) как показано в примере 4 ниже.
Пример 3 показывает оператор цикла копирования 16 загрузок и сохранений полуслова:
Этот оператор цикла копирования может быть заменен всего лишь двумя загрузками и двумя сохранениями векторных регистров, что уменьшает время выполнения со времени, соответствующего выполнению 66 команд, ко времени, соответствующего выполнению четырех команд, как показано в примере 4:
VL V1, 0 (R4)
VST V1, 0 (R5)
VL V1, 16 (R4)
VST V1, 16 (R5)
где VL является командой VECTOR LOAD (векторной загрузки, VST является командой VECTOR STORE (векторного сохранения) и V1 является 5 векторным типом данных.
Однако, в соответствии с обычной архитектурой команд, пример 3, который основан на копировании 16 полуслов, предлагает двухбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере двум, а также однобайтовый 10 параллелизм. С другой стороны, пример 4 обычно может гарантировать учетверенно-словный параллелизм блоков, когда регистры R4 и R5 имеют размер выравнивания адреса, равный, по меньшей мере, учетверенному слову, и побайтовый параллелизм в противном случае. Таким образом, преобразующий команды из примера 3 к примеру 4 программист или компилятор может 15 понизить гарантии параллелизма блоков примера 3 от поблочно-параллельного для полуслова к только лишь побайтово параллельному для адресов, имеющих размер адреса выравнивания меньший учетверенного слова, но, по меньшей мере, равный размеру полуслова. Поэтому программист или компилятор в результате данного, в других случаях, выгодного изменения может ввести 20 нарушение языка программирования или соглашений программирования.
Когда множественные значения матрицы должны быть увеличены на константу, могут быть выполнены подобные преобразования. Конкретным образом, пример 5 ниже показывает оператор цикла добавления для 16 полуслов:

где LH является командой LOAD HALFWORD (загрузки полуслова), АН является командой ADD HALFWORD (добавления полуслова) и R6 и R7 являются регистрами. Этот оператор цикла добавления 16 полуслов может быть заменен всего лишь двумя векторными добавлениями, что уменьшает время выполнения со времени, соответствующего выполнению 83 команд, ко времени, соответствующего выполнению 7 команд, как показано в следующем примере 6:
VLREPH V3, 0 (R6)
VL V1, 0 (R4)
VAH V1, V1, V3
VST V1, 0 (R5)
VL V1, 16 (R4)
VAH V1, V1, V3
VST V2, 16 (R5)
где VLREPH является командой VECTOR LOAD AND REPLICATE (векторной загрузки и копирования), VAH является командой VECTOR ADD HALFWORD (векторного добавления полуслова) и V1-V3 являются векторами.
Пример 5 предоставляет параллелизм блоков для каждого увеличиваемого таким образом полуслова, когда адреса R4 и R5 имеют размер выравнивания адреса, равные по меньшей мере двум, в то время как пример 6 предлагает параллелизм блоков для групп из восьми увеличиваемых таким образом полуслов, когда адреса R4 и R5 имеют размер выравнивания адреса, равный по меньшей мере 16, и только побайтовый параллелизм в противном случае. Таким образом, преобразование от примера 5 к примеру 6 не сохраняет логику работы параллелизма блоков из примера 5.
Следует отметить, что показанные в примерах 4 и 6 векторные команды не являются обычными командами обращения к памяти, но являются новыми командами. Однако эти новые векторные команды не имеют логики работы параллелизма блоков согласно некоторыми вариантами осуществления описанного в настоящем документе изобретения.
Варианты осуществления изобретения предоставляют новые описания команд обращения к памяти, основанные на размере выравнивания адреса для указанного адреса памяти таким образом, что эти команды предоставляют параллелизм блоков для подблоков с размером блока, соответствующим размеру выравнивания адреса, выровненному по данному размеру выравнивания адреса. Следовательно, вышеупомянутые три преобразования кода (от примера 1 к примеру 2, от примера 3 к примеру 4 и от примера 5 к примеру 6) могут быть выполнены на основе новых, измененных описаний команд для команд загрузки и сохранения. Модификация соответствует логике работы параллелизма блоков, описанной в настоящем документе, в то время как логика работы других аспектов выполнения команд остается неизмененной. Для разъяснения, в последующих примерах команд коды операций следующих типовых измененных команд обозначены «m» в начале кода операции.
Оператор цикла копирования полуслова с параллелизмом блоков полуслова может быть выполнен с помощью измененных команд доступа к двойному слову, как показано в следующем примере 7:

В некоторых вариантах осуществления данный код в примере 7 предлагает двухбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере двум, а также однобайтовый параллелизм. Кроме того, в некоторых вариантах осуществления, этот код предлагает четырехбайтовый параллелизм блоков, когда удержанные в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере четырем. Кроме того, в некоторых вариантах осуществления, этот код предлагает восьмибайтовый параллелизм блоков, когда удержанные в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере восьми.
Подобным образом, команды примера 7 могут быть выражены с помощью Power ISA на основе измененных описаний команд Power ISA для команд загрузки и сохранения. Изменение соответствует описанной в настоящем документе логике работы параллелизма блоков, в то время как логика работы других аспектов выполнения команды остается неизмененной, как она задается описанием Power ISA. Вновь для разъяснения, коды операций этих измененных команд обозначаются «m» в начале кода операции в следующих инструкциях примера 7:

где LI является командой LOAD IMMEDIATE (загрузки с непосредственной адресацией, MTCTR является командой MOVE ТО COUNT REGISTER (перехода к регистру счета), XOR является командой EXCLUSIVE OR (исключающего ИЛИ), LDX является командой LOAD DOUBLE WORD (загрузки двойного слова), STDX является командой STORE DOUBLEWORD INDEXED (сохранения индексированного двойного слова), ADDI является командой ADD IMMEDIATE (добавления с непосредственной адресацией), BDNZ является командой перехода и R1-R5 являются регистрами.
Кроме того, оптимизированные команды примера 4 могут быть преобразованы к командам следующего примера 8. Оптимизированный код может быть выполнен с помощью измененных команд следующим образом:
mVL V1, 0 (R4)
mVST V1, 0 (R5)
mVL V1, 16 (R4)
mVST V1, 16 (R5)
В некоторых вариантах осуществления этот код примера 8 предлагает двухбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере двум, а также однобайтовый параллелизм (т.е., параллелизм блоков с размером блока, соответствующим единственному байту). Кроме того, в некоторых вариантах осуществления, этот код предлагает четырехбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере четырем. Кроме того, в некоторых вариантах осуществления, этот код предлагает восьмибайтовый параллелизм блоков, когда удержанные в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере восьми. Кроме того, в некоторых вариантах осуществления, этот код предлагает 16-байтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере 16, если максимальный размер параллелизма блоков для mVL и mVST задан величиной по меньшей мере 16 байтов. В некоторых вариантах осуществления этот код предлагает восьмибайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере 16, если максимальный размер параллелизма блоков для mVL и mVST задан величиной по меньшей мере восемь байтов.
Подобным образом, код примера 7 может быть выражен с помощью измененного описания Power ISA, как показывает следующий пример 8:

Подобным образом, пример 6 может быть выражен в виде следующего примера 9:

В некоторых вариантах осуществления этот код примера 9 предлагает двухбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере двум, а также однобайтовый параллелизм (то есть, параллелизм блоков с размером блока, соответствующим единственному байту). Кроме того, в некоторых вариантах осуществления, этот код предлагает четырехбайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере четырем. Кроме того, в некоторых вариантах осуществления, этот код предлагает восьмибайтовый параллелизм блоков, когда удержанные в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере восьми. Кроме того, в некоторых вариантах осуществления, этот код предлагает 16-байтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере 16, если максимальный размер параллелизма блоков для mVL и mVST задан величиной по меньшей мере 16 байтов. В некоторых вариантах осуществления этот код предлагает восьмибайтовый параллелизм блоков, когда удерживаемые в регистрах R4 и R5 адреса соответствуют размеру выравнивания адреса, равному по меньшей мере 16, если максимальный размер параллелизма блоков для mVL и mVST задан величиной по меньшей мере восемь байтов.
В некоторых вариантах осуществления изменяются существующие команды и коды операций, и не вводится какой-либо новой символики для команд. В других вариантах осуществления новые команды и коды операций вводятся с помощью руководства по параллелизму блоков, основанному на размере выравнивания адреса, описанном в настоящем документе.
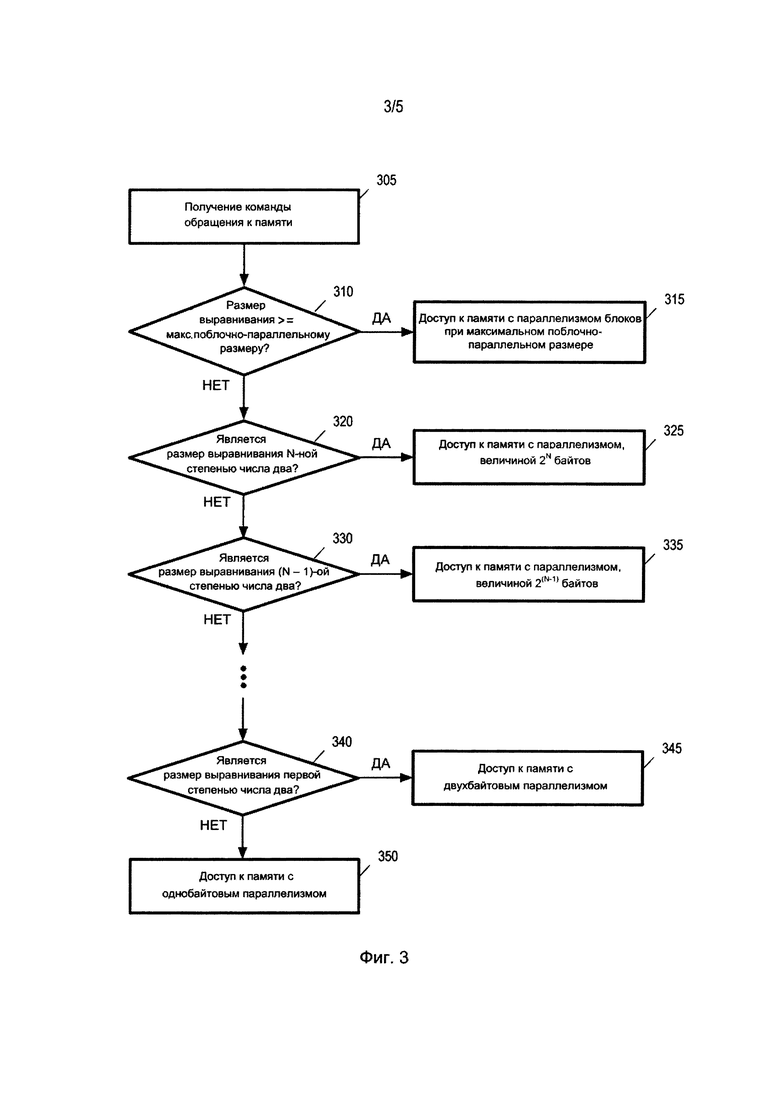
Фиг. 3 изображает последовательность операций для доступа к памяти согласно некоторым вариантам осуществления изобретения. В некоторых вариантах осуществления, процессор (например, ЦП), выполняет последовательность операций, показанную на фиг. 3. В поле 305 процессор получает команду обращения к памяти, которая обращается к блоку данных по адресу в памяти. Команда обращения к памяти включает в себя любую команду, которая обращается к блоку данных в памяти (например, команда, включающая в себя адрес в памяти в виде операнда). Такие команды включают в себя команды загрузки и команды сохранения, а также команды для арифметических операций (например, команды сложения, команды вычитания, команды сравнения и т.д.).
В поле 310 принятия решения процессор факультативно выявляет, имеет ли память, к которой процессор обращается за данными, границу адреса памяти (то есть, размер выравнивания адреса, заданный в команде обращения к памяти), превышающую максимальный поблочно-параллельный размер обращения к памяти (или максимальный размер параллелизма блоков) или равную ему, поддерживаемой командой обращения к памяти, полученной в поле 305. Максимальный размер обращения к памяти для команды задается для всех команд архитектуры системы команд. Максимальный поблочно-параллельный размер обращения к памяти может быть представлен размером обращения к памяти команды или может соответствовать максимальному поблочно-параллельному размеру обращения, заданному для всех команд архитектуры системы команд. В некоторых вариантах осуществления максимальный поблочно-параллельный размер обращения к памяти может быть представлен размером обращение к памяти команды или может соответствовать максимальному поблочно-параллельному размеру обращения, заданному независимо для каждой команды архитектуры системы команд.
В ответ на выявление в поле 310 принятия решения того, что граница адреса памяти не превышает максимальный поблочно-параллельный размер обращения или не равняется ему, процессор переходит к полю 320 принятия решения, которое будет описано далее ниже. В ответ на выявление в поле 310 принятия решения, что граница адреса памяти превышает максимальный поблочно-параллельный размер обращения или равняется ему, процессор переходит к полю 315 для получения доступа к памяти с параллелизмом блоков при максимальном поблочно-параллельном размере обращения к памяти. Например, когда размер обращения к памяти составляет 32 байта, граница адреса памяти составляет 16 байтов, но максимальный поблочно-параллельный размер обращения к памяти составляет восемь байтов, процессор получает доступ к памяти с восьмибайтовым параллелизмом.
В поле 320 принятия решения процессор выявляет, является ли размер выравнивания запрашиваемого адреса памяти N-ной степенью числа два (то есть, 2N), где N является самым большим неотрицательным целым числом, при использовании которого 2N является меньшим, чем размер обращения к памяти, или равным ему. Например, когда размер обращения к памяти составляет 36 байтов, процессор в поле 320 принятия решения выявляет, имеет ли запрашиваемый адрес памяти размер выравнивания 32 байтов (25 байтов). В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти является N-ной степенью числа два, процессор переходит к полю 325 для получения доступа к памяти с параллелизмом, величиной 2N байтов. Например, процессор поблочно-параллельно получает доступ к совместной памяти в 32 байта для получения доступа ко всем 32 байтам, если размер выравнивания адреса памяти составляет 32 байта, и размер обращения к памяти составляет 32 байта. В ответ на выявление того, что запрашиваемое выравнивание адреса памяти не является N-ной степенью числа два, процессор переходит к полю 330. Как описано выше, максимальный поблочно-параллельный размер обращения к памяти может быть задан для одной или нескольких команд. В некоторых вариантах осуществления N задают значение самого большого неотрицательного целого числа, при использовании которого 2N является меньшим, чем поблочно-параллельный размер обращения к памяти, или равным ему, независимо от размера обращения к памяти. Например, команда может предоставлять максимальный поблочно-параллельный размер обращения к памяти величиной восемь байтов. Затем N задают значение три также и в том случае, когда размер обращения к памяти превышает 23.
В поле 330 принятия решения процессор выявляет, является ли запрашиваемый размер выравнивания адреса памяти (N-1)-ой степенью числа два (то есть, 2(N-1). Например, когда размер обращения к памяти составляет 32 байта (25 байтов), процессор в поле 330 выявляет, является ли запрашиваемый размер выравнивания адреса памяти равным 16 байтам (24 байтам). В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти является (N-1)-ой степенью числа два, процессор переходит к полю 335 для получения доступа к памяти с параллелизм 2 величиной 2(N-1) байтов. Например, если размер обращения к памяти составляет 32 байта (25 байтов), процессор получает поблочно-параллельный доступ к 16 байтам (24 байтам) памяти за один раз для получения доступа ко всем 32 байтам.
В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти не равняется (N-1)-ой степени числа два, процессор переходит к полю 340 принятия решения подобным образом до тех пор, пока в поле 340 принятия решения не выявляется, что требуемый размер выравнивания адреса памяти является первой степенью числа два (то есть, 21 байтов). В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти равняется двум, процессор переходит к полю 345 для получения доступа к памяти с двухбайтовым параллелизмом. Например, если размер обращения к памяти составляет 32 байта, процессор поблочно-параллельно получает доступ к памяти по два байта за один раз для получения доступа ко всем 32 байтам. В ответ на выявление в поле 340 принятия решения, что запрашиваемый размер выравнивания адреса памяти не равняется двум, процессор переходит к полю 350 для получения доступа к памяти с однобайтовым параллелизмом. Таким образом, процессор получает доступ к одному байту за один раз для получения доступа ко всем байтам, заданным командой обращения к памяти.
Следует понимать, что в полях от 320 до 350 процессор получает доступ к памяти с параллелизмом блоков в запрашиваемом размере выравнивания адреса памяти, когда требуемый размер выравнивания адреса памяти является меньшим, чем размер обращения к памяти команды обращения к памяти. Это означает, что в некоторых вариантах осуществления выполняющий команду обращения к памяти процессор действует, как будто доступ является поблочно-параллельным по отношению к любой границе, по отношению к которой адрес запрашиваемого блока данных является выровненным (то есть, доступ является поблочно-параллельным при любом размере выравнивания).
В некоторых вариантах осуществления размер обращения к памяти команды обращения к памяти неявно задается посредством, например, кода операции (операционного кода) команды. Это вызвано тем, что код операции команды указывает на тип данных тех данных, к которым обращаются, а также на операцию для выполнения. Альтернативно или дополнительно, в некоторых вариантах осуществления команда обращения к памяти может быть задана для явного задания размера обращения к памяти, например в операнде команды. Например, операнд команды задает самый высокий индексируемый байт для выборки или сохранения. Это позволяет программисту задавать размер обращения к памяти. В некоторых случаях размер обращения к памяти может не быть представленным степенью числа два (например, 10 байтов) и может не соответствовать неявно задаваемому кодом операции размеру обращения к памяти.
Варианты осуществления изобретения предоставляют системы и способы, предоставляющие параллелизм блоков, когда размер обращения к памяти не совпадает с границей адреса запрашиваемой памяти. В некоторых вариантах осуществления, когда размер обращения к памяти задается в команде обращения к памяти, выполняющий команду процессор использует наибольший общий делитель для границы адреса запрашиваемого адреса памяти и для заданного размера обращения к памяти в качестве размера поблочно-параллельного доступа к данным. Например, если адрес операнда команды находится на четырехбайтовой границе, и заданный размер обращения к памяти составляет 10 байтов, доступы к данным представляются по меньшей мере двухбайтово-параллельными с другими процессорами, поскольку число два является наибольшим общим делителем для 10 и для четырех. Это позволяет применять параллельный по данным код, имеющий ту же логику работы, как у скалярного кода, и не повреждающий какую-либо семантику или соглашения языка программирования.
В некоторых вариантах осуществления размер блока параллелизма блоков (то есть, уровень параллелизма блоков, например 2-байтовый параллелизм, 4-байтовый параллелизм, 16-байтовый параллелизм, 32-байтовый параллелизм) получают непосредственно из размера выравнивания адреса. В других вариантах осуществления размер параллелизма блоков поблочно-параллельного доступа основывается как на размере выравнивания адреса, так и на размере обращения к памяти команды. В некоторых таких вариантах осуществления размер блока для поблочно-параллельного доступа является наименьшим значением из числа размера блока параллелизма блоков, полученного непосредственно из выравнивания адреса, и размера обращения к памяти. Во всех других вариантах осуществления размер блока для поблочно-параллельного доступа выявляется посредством самой большой общей степени числа два для размера блока среди размера выравнивания адреса и размера обращения к памяти, как далее показано на фиг. 4.
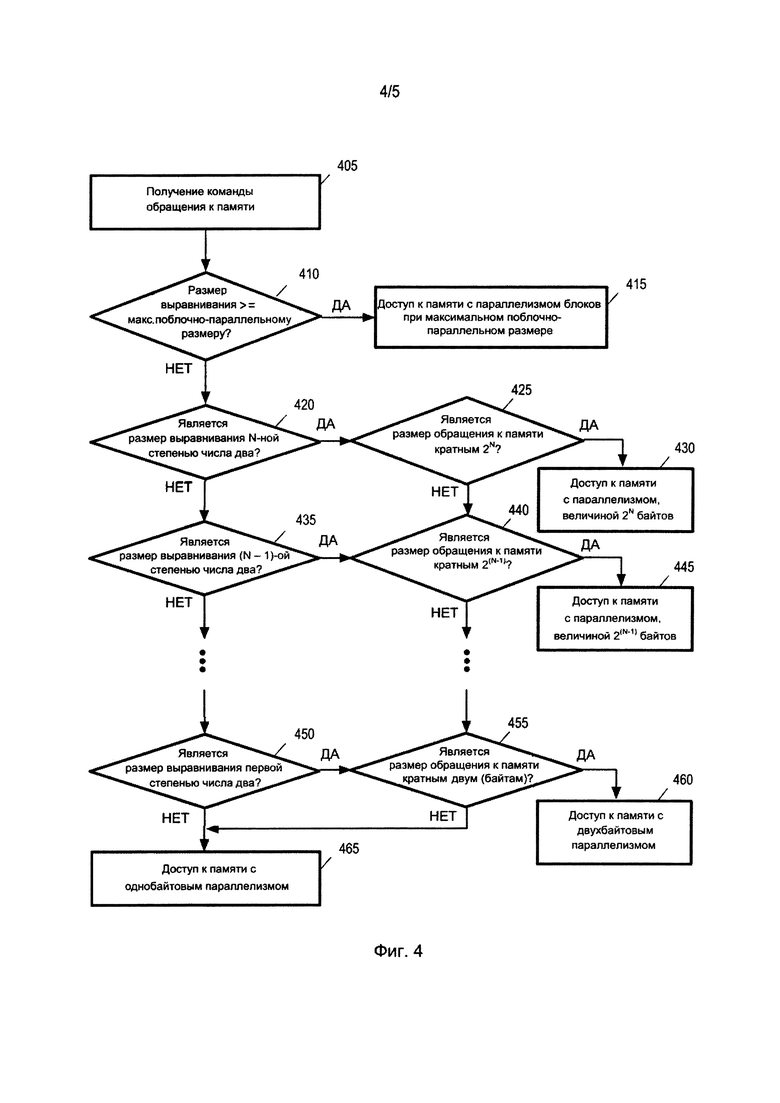
Фиг. 4 изображает последовательность операций для получения доступа к памяти, когда размер блока поблочно-параллельного доступа основывается как на размере выравнивания адреса, так и на размере обращения к памяти команды обращения к памяти. В некоторых вариантах осуществления максимальный размер блока поблочно-параллельного доступа может быть назначен для всех команд посредством архитектуры системы команд или для конкретных команд, которые имеют максимальные размеры параллелизма блоков. Некоторые команды обращения к памяти явным образом задают ссылочный размер памяти, который может не быть представленным степенью числа два. Однако некоторые реализации могут позволить только размеры параллелизма блоков, представленные степенью числа два. В некоторых таких вариантах осуществления процессор (например, ЦП), выполняет последовательность операций, показанную на фиг. 4.
В поле 405 процессор получает команду обращения к памяти, которая обращается к блоку данных по адресу в памяти. Эта команда обращения к памяти также задает размер данных, к которым обращаются, например, в операнде команды.
В поле 410 принятия решения процессор факультативно выявляет, имеет ли память, к которой процессор обращается за данными, размер выравнивания адреса памяти, превышающий максимальный поблочно-параллельный размер обращения к памяти команды обращения к памяти, полученной в поле 405, или равный ему. В ответ на выявление того, что размер выравнивания адреса памяти не превышает максимальный поблочно-параллельный размер обращения или не равняется ему, процессор переходит к полю 420 принятия решения, которое будет описано далее ниже. В ответ на выявление того, что размер выравнивания адреса памяти превышает максимальный поблочно-параллельный размер обращения или равняется ему, процессор переходит к полю 415 для получения доступа к памяти с параллелизмом блоков при максимальном поблочно-параллельном размере обращения к памяти. Например, когда заданный размер обращения к памяти составляет восемь байтов, и размер выравнивания адреса памяти составляет восемь байтов, но максимальный размер поблочно-параллельного доступа составляет 4 байта, процессор получает доступ к памяти с четырехбайтовым параллелизмом.
В поле 420 принятия решения процессор выявляет, является ли требуемый размер выравнивания адреса памяти N-ной степенью числа два (то есть, 2N), где N является самым большим неотрицательным целым числом, при использовании которого 2N является меньшим, чем заданный размер обращения к памяти, или равным ему. Например, когда заданный размер обращения к памяти составляет десять байтов, процессор в поле 415 выявляет, является ли запрашиваемый адрес памяти выровненным по отношению к восьми (23) байтам. В ответ на выявление в поле 420 принятия решения, что требуемый размер выравнивания адреса памяти не является N-ной степенью числа два, процессор переходит к полю 435 принятия решения, которое будет описано далее ниже.
В ответ на выявление в поле 420 принятия решения, что требуемый размер выравнивания адреса памяти является N-ной степенью числа два, процессор переходит к полю 425 принятия решения для выявления того, является ли заданный размер обращения к памяти кратным N-ной степени числа два. Например, когда заданный размер обращения к памяти составляет десять байтов, процессор в поле 425 принятия решения выявляет, является ли заданный размер обращения к памяти величиной десять кратным восьми байтам. Если заданный размер обращения к памяти не является кратным N-ной степени числа два, процессор переходит к полю 440 принятия решения, которое будет описано далее ниже. Если заданный размер обращения к памяти является N-ной степенью числа два, процессор переходит к полю 430 для получения доступа к памяти с параллелизмом 2N-байтов.
В поле 435 принятия решения процессор выявляет, является ли запрашиваемый размер выравнивания адреса памяти (N-1)-ой степенью числа два (то есть, 2(N-1)). Например, когда размер обращения к памяти составляет десять байтов, процессор в поле 435 принятия решения выявляет, представлен ли запрашиваемый размер выравнивания адреса памяти четырьмя байтами (то есть, 22 байтами). В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти не является (N-1)-ой степенью числа два, процессор переходит к полю 450 принятия решения, которое будет описано далее ниже.
В ответ на выявление в поле 435 принятия решения того, что запрашиваемый размер выравнивания адреса памяти является (N-1)-ой степенью числа два, процессор переходит к полю 440 принятия решения для выявления того, является ли заданный размер обращения к памяти кратным (N-1)-ой степени числа два. Например, когда заданный размер обращения к памяти составляет десять байтов, процессор в поле 440 принятия решения выявляет, является ли заданный размер обращения к памяти величиной десять кратным четырем байтам (22 байтам). Если заданный размер обращения к памяти не является кратным (N-1)-ой степени числа два, процессор переходит к полю 455 принятия решения, которое будет описано далее ниже. Если заданный размер обращения к памяти является (N-1)-ой степенью числа два, процессор переходит к полю 445 для получения доступа к памяти с параллелизмом, величиной 2(N-1) байтов.
В ответ на выявление того, что запрашиваемый размер выравнивания адреса памяти не равняется (N-1)-ой степени числа два, процессор переходит к полю 450 принятия решения подобным образом до тех пор, пока в поле 450 принятия решения не выявляется, что требуемый размер выравнивания адреса памяти является первой степенью числа два (то есть, 21 байтов). В ответ на выявление в поле 450 принятия решения, что запрашиваемый размер выравнивания адреса памяти не равняется двум, процессор в поле 465 получает доступ к памяти с однобайтовым параллелизмом. Таким образом, процессор получает доступ к одному байту за один раз для получения доступа ко всем байтам, заданным командой обращения к памяти.
В ответ на выявление в поле 450 принятия решения, что требуемый размер выравнивания адреса памяти равняется двум, процессор переходит к полю 455 принятия решения для выявления того, является ли заданный размер обращения к памяти кратным двум байтам. Если заданный размер обращения к памяти не является кратным числу два, процессор переходит к полю 465 для получения доступа к памяти с однобайтовым параллелизмом. Если заданный размер обращения к памяти является кратным числу два, процессор переходит к полю 460 для получения доступа к памяти с двухбайтовым параллелизмом. Например, если размер обращения к памяти составляет десять байтов, для получения доступа ко всем десяти байтам процессор получает доступ к памяти по два байта за один раз.
Следует понимать, что в полях от 420 до 465 процессор идентифицирует наибольший общий делитель для запрашиваемого размера выравнивания адреса памяти и для заданного размера обращения к памяти, который исчисляется в числе байтов, и обращается к памяти с параллелизмом блоков, величиной в общий делитель. Например, когда заданный размер обращения к памяти составляет десять байтов, и запрашиваемый размер выравнивания адреса памяти составляет четыре байта, процессор идентифицирует наибольший общий делитель как два байта, и получает доступ к памяти с двухбайтовым параллелизмом (то есть, получает доступ ко всем десяти байтам посредством поблочно-параллельного получения доступа к двум байтам за один раз).
В некоторых вариантах осуществления максимальный размер параллелизма блоков может быть задан для одной или нескольких команд. Например, команда может предоставлять максимальный размер параллелизма блоков в восемь байтов. Затем, в поле 420 принятия решения N задается величиной три также и в том случае, когда заданный размер обращения к памяти превышает 23. В некоторых вариантах осуществления максимальный размер параллелизма блоков относится ко всем командам. В других вариантах осуществления каждая команда может иметь отдельный максимальный размер параллелизма блоков.
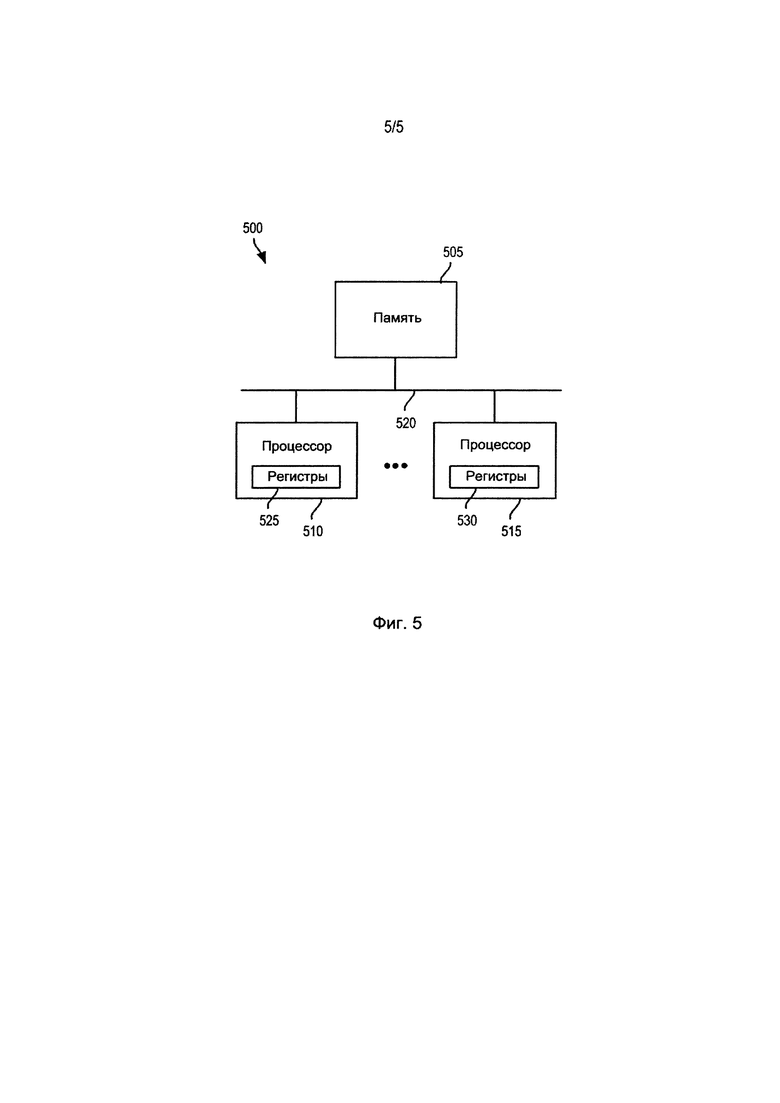
Фиг. 5 показывает систему 500 для получения доступа к данным в памяти согласно некоторым вариантам осуществления изобретения. Конкретным образом, этот чертеж показывает, что система 500 включает в себя память 505 и несколько процессоров 510и515в числе других, не изображенных для простоты иллюстрации и описания компонентов. Память 505 и процессоры 510 и 515 сопряжены друг с другом посредством одной или нескольких шин 520. Процессоры 510 и 515 показаны имеющими, соответственно, регистры 525 и 530, но другие компоненты в пределах процессоров (например, арифметико-логические устройства, управляющие модули, часы, внутренняя шина и т.д.) не изображены для простоты иллюстрации и описания).
В некоторых вариантах осуществления система 500 представляет собой различные окружения параллельной обработки. Например, один из процессоров 510 и 515 может быть представлен векторным процессором, выполняющим векторизованные команды. Один из числа других процессоров может быть представлен скалярным процессором, выполняющим скалярные команды. Векторный процессор и скалярный процессор могут совместно использовать память 505. В качестве другого примера, система 500 может представлять собой многоядерный процессор, в котором процессоры 510 и 515 являются различными ядрами, совместно использующими память 505. В качестве еще одного другого примера, система 500 может представлять собой мэйнфреймовую компьютерную систему, имеющую процессоры 510 и 515, которые производят обработку параллельно.
Как известно из уровня техники, процессор или семейство процессоров (такое как 8086 и х86-семейство или семейство серверов System z IBM) имеет свою собственную систему машинных команд. Например, система команд семейства серверов System z IBM, известная как система команд z/Архитектуры, сформулирована во введенном выше в состав заявки руководстве «z/Архитектура, принципы работы», а система команд серверов Power, известных как Power ISA (архитектура системы команд), сформулирована во введенном выше в состав заявки руководстве «Power ISA». Машинные команды являются конфигурациями битов, которые целенаправленно соответствуют различным операторам машины. В большинстве случаев система команд является специфичной для класса процессоров, использующих одинаковую архитектуру. Большинство команд имеет один или несколько кодов операций, задающих тип исходной команды (такой как арифметическая, обращение к памяти, ветвление и т.д.) и выполняемую операцию (такую как загрузка, сохранение, добавление или сравнение), а также другие поля, которые могут задавать тип операнда (операндов), режима (режимов) адресации, смещения (смещений) адресации или индекса или фактического значения как такового. Таким образом, каждая машинная команда предназначается для выполнения очень специфической задачи, такой как загрузка, ветвление или эксплуатация арифметико-логического устройства (ALU) на модуле данных в регистрах или памяти. Некоторые из этих машинных команд являются командами обращения к памяти, которые обращаются к данным по специфическим адресам в памяти 505 для выборки данных из памяти 530 или регистров, или сохранения данных в них.
Процессоры 510 и 515 могут быть выполненными для выполнения команд обращения к памяти, предоставляющих параллелизм блоков также и в том случае, когда адрес блока данных в пределах памяти 505 не является неотъемлемой частью размера обращения к памяти для команды обращения к памяти. Это означает, что в некоторых вариантах осуществления команды обращения к памяти для процессоров 510 и 515 действуют таким образом, как будто команды являются поблочно-параллельными по отношению к любой границе, по отношению к которой является выровненным блок данных, к которому обращаются. В некоторых вариантах осуществления максимально имеется восьмибайтовый параллелизм. В некоторых вариантах осуществления процессоры идентифицируют наибольший общий делитель для размера выравнивания адреса памяти и для заданного размера обращения к памяти, исчисляемый в числе байтов, и получают доступ к памяти 505 с параллелизмом блоков, величиной в наибольший общий делитель. Тем самым, может быть улучшено функционирование компьютера, включающего в себя процессоры 510 и 515.
Различные варианты осуществления конфигурируют процессоры 510 и 515 различным образом. Например, в некоторых вариантах осуществления, процессоры 510 и 515 могут быть сконфигурированы путем предоставления новых описаний существующим обычным командам обращения к памяти таким образом, что процессоры 510 и 515 при выполнении команд получают доступ к памяти 505 согласно различным вариантам осуществления изобретения. Альтернативно или дополнительно, процессоры 510 и 515 могут быть сконфигурированы путем задания новых команд обращения к памяти, которые получают доступ к памяти 505 согласно различным вариантам осуществления изобретения.
Например, команда обращения к памяти включает в себя векторную команду загрузки, зачастую имеющую 16-байтовое требование по выравниванию. Это означает, что векторная команда загрузки с 16-байтовым требованием по выравниванию, как ожидают, загружает из памяти все 16 байтов 16-байтового блока данных как единый модуль. Когда многопоточный код векторизируется компилятором, например для обеспечения параллельного по данным выполнения, предполагается, что при обновлении первым ЦП одной переменной и считывании ее вторым ЦП, второй ЦП видит полностью измененную переменную, но никогда - смешанные результаты. Действительность блоков не может быть гарантирована с помощью обычных описаний векторной команды загрузки. Поэтому зачастую является затруднительным использование высоких степеней параллелизма данных, также при использовании параллелизма потоков. Это ограничивает потенциальную производительность программного обеспечения и вызывает неполное использование аппаратных средств.
Путем конфигурирования процессоров для получения доступа к памяти согласно различным вариантам осуществления изобретения процессоры могут использовать высокие степени параллелизма данных при использовании параллелизма потоков без потребности во внешнем преобразовании в последовательную форму (например, блокировок). Сконфигурированные согласно вариантам осуществления изобретения процессоры также улучшают производительность программного обеспечения и облегчают использование аппаратных средств. Варианты осуществления изобретения позволяют упаковывать более малоразмерные типы данных в вектор, что позволяет им представляться для других процессоров в качестве работающих с той же семантикой, как если используются скалярные команды. Кроме того, параллелизм блоков обеспечивает более легкую самопараллелизацию кода посредством компиляторов путем ухода от дополнительных ограничений по выравниванию и от потребности в дополнительном коде для обработки участков данных, которые могут оказаться невыровненными.
В некоторых вариантах осуществления изобретения предоставляется способ получения доступа к данным в сопряженной с процессором памяти. Способ получает команду обращения к памяти для доступа к данным первого размера по адресу в памяти. Способ выявляет размер выравнивания адреса. Способ получает доступ к данным первого размера в одной или нескольких группах данных путем поблочно-параллельного доступа к каждой группе данных. Группы данных имеют размеры, которые являются кратными размеру выравнивания. Способ выявляет размер выравнивания путем подсчета числа конечных нулей в адресе в двоичном представлении. Каждая группа данных не превышает по величине предопределенный максимальный размер параллелизма блоков в байтах. В некоторых вариантах осуществления первый размер превышает выявленный размер выравнивания. В некоторых вариантах осуществления первый размер и выявленный размер выравнивания исчисляются в количестве байтов, где первый размер составляет 2А, а выявленный размер выравнивания - 2В, причем А является целым числом, превышающим В, которое является неотрицательным целым числом. В некоторых вариантах осуществления способ выявляет первый размер на основании кода операции команды обращения к памяти. В некоторых вариантах осуществления процессор содержит векторный процессор, а команда обращения к памяти содержит векторную команду.
В некоторых вариантах осуществления изобретения предоставляется способ получения доступа к данным в сопряженной с процессором памяти. Способ получает команду обращения к памяти для доступа к данным первого размера по адресу в памяти. Команда обращения к памяти определяет первый размер. Способ выявляет размер выравнивания адреса. Способ выявляет наибольший общий делитель для первого размера и для выявленного размера выравнивания. Способ получает доступ к данным первого размера в одной или нескольких группах данных. Группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя. В некоторых вариантах осуществления первый размер превышает выявленный размер выравнивания. В некоторых вариантах осуществления первый размер и выявленный размер выравнивания исчисляются в количестве байтов, где первый размер не является размером в виде степени числа два, а выявленный размер выравнивания является размером в виде степени числа два. В некоторых вариантах осуществления способ выявляет первый размер на основании операнда команды обращения к памяти. В некоторых вариантах осуществления процессор содержит векторный процессор, а команда обращения к памяти содержит векторную команду.
Настоящее изобретение может быть представлено системой, способом и/или компьютерным программным продуктом. Компьютерный программный продукт может включать в себя машиночитаемый информационный носитель (или носители), имеющий на нем машиночитаемые программные команды для принуждения процессора к выполнению аспектов настоящего изобретения.
Машиночитаемый информационный носитель может быть представлен материальным устройством, которое способно удерживать и сохранять команды для использования посредством устройства выполнения команд. Машиночитаемый информационный носитель может быть представлен, например, в том числе, но не ограничиваясь, устройством электронной памяти, магнитным запоминающим устройством, оптическим запоминающим устройством, электромагнитным запоминающим устройством, полупроводниковым запоминающим устройством или любой подходящей комбинацией из вышеупомянутого. Неисчерпывающий список более конкретных примеров машиночитаемых информационных носителей включает в себя следующее: портативная компьютерная дискета, жесткий диск, оперативная память (RAM), постоянная память (ROM), стираемая программируемая постоянная память (EPROM или флэш-память), статическая оперативная память (SRAM), переносной компакт-диск для однократной записи данных (CD-ROM), цифровой универсальный диск (DVD), карта памяти, гибкий диск, механически закодированное устройство, такое как перфокарты или выступающие структуры в канавке с записанными на них командами, а также любая подходящая комбинация из вышеупомянутого. Машиночитаемый информационный носитель, как он рассматривается в настоящем документе, не подлежит истолкованию в качестве представленного преходящими сигналами как таковыми, такими как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся через волновод или другие среды передачи (например, проходящие через волоконно-оптический кабель световые импульсы), или передаваемые через провода электрические сигналы.
Машиночитаемые программные команды, описанные в настоящем документе, также могут быть загружены на соответствующие устройства вычисления/обработки от машиночитаемого информационного носителя, или на внешний компьютер или внешнее устройство хранения через сеть, например Интернет, локальную сеть, глобальную сеть и/или беспроводную сеть. Сеть может содержать медные кабели передачи, волокна оптической передачи, беспроводную передачу, маршрутизаторы, брандмауэры, переключения, шлюзы и/или граничные серверы. Карта сетевого адаптера или сетевой интерфейс в каждом устройстве вычисления/обработки получает машиночитаемые программные команды из сети и направляет машиночитаемые программные команды для хранения в машиночитаемый информационный носитель в пределах соответствующего устройства вычисления/обработки.
Машиночитаемые программные команды для выполнения операций настоящего изобретения могут быть представлены командами ассемблера, командами архитектуры системы команд (ISA), машинными командами, машинно-зависимыми командами, микрокодом, командами встроенного программного обеспечения, присваивающими значение состоянию данными, или иным исходным кодом или объектным кодом, записанным на любой комбинации из одного или нескольких языков программирования, включая сюда объектно-ориентированные языки программирования, такие как Smalltalk, С++ и т.п., а также обычные языки процедурного программирования, такие как язык программирования «С» или подобные языки программирования. Машиночитаемые программные команды могут выполняться полностью на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть присоединен к компьютеру пользователя через любой тип сети, включая сюда локальную сеть (LAN) или глобальную сеть (WAN), или присоединение может быть сделано к внешнему компьютеру (например, через Интернет с использованием Интернет-провайдера). В некоторых вариантах осуществления электронные схемы, включающие в себя, например, программируемые логические схемы, программируемые на месте вентильные матрицы (FPGA) или программируемые логические матрицы (PLA) могут выполнять машиночитаемые программные команды посредством использования информации о состоянии машиночитаемых программных команд для настройки электронной схемы с целью выполнения аспектов настоящего изобретения.
Аспекты настоящего изобретения описаны в настоящем документе с отсылками на иллюстрации в виде блок-схем и/или блок-диаграмм для способов, устройств (систем) и компьютерных программных продуктов согласно вариантам осуществления изобретения. Подразумевается, что каждый блок иллюстраций в виде блок-схем и/или блок-диаграмм, а также комбинации блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, может быть реализован посредством машиночитаемых программных команд.
Такие машиночитаемые программные команды могут быть предоставлены процессору универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для образования машины таким образом, что выполняющиеся посредством процессора компьютера или другого программируемого устройства обработки данных команды создают средства для реализации функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы. Такие машиночитаемые программные команды также могут быть сохранены в машиночитаемом информационном носителе, который может управлять компьютером, программируемым устройством обработки данных и/или другими устройствами для их функционирования особым способом таким образом, что сохраняющий на нем команды машиночитаемый информационный носитель представляет собой изделие, содержащее команды, которые реализуют аспекты функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы.
Машиночитаемые программные команды могут также быть загружены в компьютер, другое программируемое устройство обработки данных или другое устройство для принуждения к выполнению на компьютере, другом программируемом устройстве или другом устройстве серии эксплуатационных этапов для получения такого компьютерно-реализованного процесса, что выполняемые на компьютере, другом программируемом устройстве или другом устройстве команды реализуют функции/действия, заданные в блоке или блоках блок-схемы и/или блок-диаграммы.
Блок-схемы и блок-диаграммы на чертежах показывают архитектуру, функциональность и функционирование возможных реализаций систем, способов и компьютерных программных продуктов согласно различным вариантам осуществления настоящего изобретения. В этом отношении каждый блок в блок-схемах или блок-диаграммах может представлять модуль, сегмент или участок команд, который содержит одну или несколько исполнимых команд для реализации указанной логической функции (функций). В некоторых альтернативных реализациях, показанные в блоке функции могут происходить в отличном от приведенного на чертежах порядке. Например, два показанных по очереди блока фактически могут быть выполнены по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от предусмотренной к выполнению функциональности. Необходимо также отметить, что каждый блок на иллюстрациях в виде блок-схем и/или блок-диаграмм, а также в комбинациях блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, может быть реализован посредством основанных на аппаратных средствах систем особого назначения, которые выполняют указанные функции или действия или выполняют комбинации аппаратных и компьютерных команд особого назначения.
Описания различных вариантов осуществления настоящего изобретения были предложены в целях иллюстрации, но не предназначаются для полного охвата или ограничения заявленных вариантов осуществления. Многие модификации и изменения являются очевидными для средних специалистов в области техники без отступления от существа и объема описанных вариантов осуществления. Используемая в настоящем документе терминология выбрана для наилучшего объяснения принципов вариантов осуществления, практического применения или технического улучшения по сравнению с имеющимися в коммерческом доступе технологиями, или для обеспечения другим средним специалистам в области техники возможности понимания описанных в настоящем документе вариантов осуществления.
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности доступа к данным памяти. Способ получения доступа к данным в сопряженной с процессором памяти содержит получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти, причем команда обращения к памяти задает первый размер, выявление посредством процессора размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении, выявление посредством процессора наибольшего общего делителя для первого размера и для выявленного размера выравнивания и получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя. 5 н. и 19 з.п. ф-лы, 5 ил.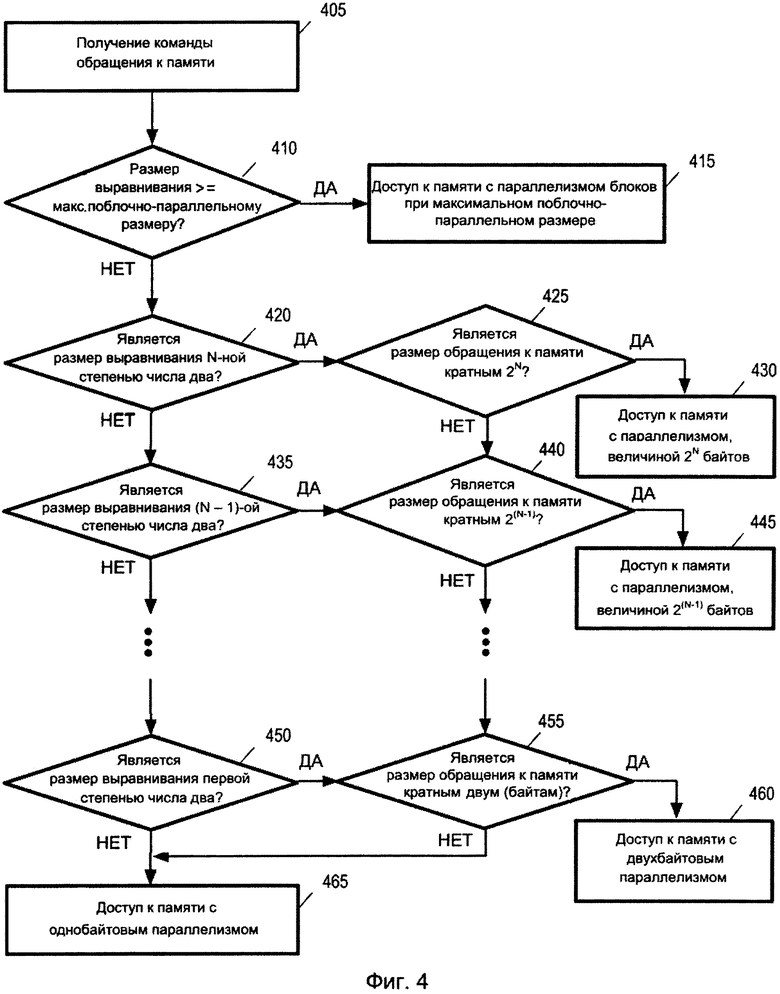
1. Способ получения доступа к данным в сопряженной с процессором памяти, содержащий:
- получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти, причем команда обращения к памяти задает первый размер,
- выявление посредством процессора размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении,
- выявление посредством процессора наибольшего общего делителя для первого размера и для выявленного размера выравнивания и
- получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
2. Способ по п. 1, причем первый размер превышает выявленный размер выравнивания.
3. Способ по п. 1, причем каждая группа данных не превышает предопределенный максимальный размер параллелизма блоков.
4. Способ по п. 1, кроме того, содержащий выявление первого размера на основании кода операции команды обращения к памяти.
5. Способ по п. 1, в котором подсчет числа конечных нулей в адресе в двоичном представлении включает возведение числа два в степень из конечных нулей в двоичном представлении.
6. Система для получения доступа к данным, содержащая память и процессор, сконфигурированный для выполнения способа, содержащего:
- получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти,
- выявление размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении,
- выявление наибольшего общего делителя для первого размера и для размера выравнивания и
- получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными наибольшему общему делителю.
7. Система по п. 6, причем первый размер и выявленный размер выравнивания исчисляются в количестве байтов, причем первый размер составляет 2А, выявленный размер выравнивания - 2В, и причем А является целым числом, превосходящим В, которое является неотрицательным целым числом.
8. Система по п. 6, причем каждая группа данных не превышает предопределенный максимальный размер параллелизма блоков.
9. Система по п. 6, причем процессор содержит векторный процессор, а команда обращения к памяти содержит векторную команду.
10. Система по п. 6, в которой подсчет числа конечных нулей в адресе в двоичном представлении включает возведение числа два в степень из конечных нулей в двоичном представлении.
11. Машиночитаемый информационный носитель, имеющий сохраненные на нем программные команды, считываемые процессором для принуждения процессора к выполнению способа получения доступа к данным, содержащего:
- получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти,
- выявление размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении,
- выявление наибольшего общего делителя для первого размера и для размера выравнивания и
- получение доступа к данным первого размера в одной или нескольких группах данных путем получения поблочно-параллельного доступа к каждой группе данных, причем группы данных имеют размеры, которые являются кратными наибольшему общему делителю.
12. Машиночитаемый информационный носитель по п. 11, причем первый размер превышает выявленный размер выравнивания.
13. Машиночитаемый информационный носитель по п. 11, причем каждая группа данных не превышает предопределенный максимальный размер параллелизма блоков.
14. Машиночитаемый информационный носитель по п. 11, причем способ, кроме того, содержит выявление первого размера на основании кода операции команды обращения к памяти.
15. Способ получения доступа к данным в сопряженной с процессором памяти, содержащий:
- получение команды обращения к памяти для получения доступа к данным первого размера по адресу в памяти, причем команда обращения к памяти задает первый размер,
- выявление посредством процессора размера выравнивания адреса, включающее подсчет числа конечных нулей в адресе в двоичном представлении,
- выявление наибольшего общего делителя для первого размера и для выявленного размера выравнивания и
- получение доступа к данным первого размера в одной или нескольких группах данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
16. Способ по п. 15, причем первый размер превышает выявленный размер выравнивания.
17. Способ по п. 15, причем первый размер и выявленный размер выравнивания исчисляются в количестве байтов, причем первый размер не является размером в виде степени числа два, а выявленный размер выравнивания является размером в виде степени числа два.
18. Способ по п. 15, кроме того, содержащий выявление первого размера на основании операнда команды обращения к памяти.
19. Способ по п. 15, причем получение доступа к данным первого размера выполняется, когда наибольший общий делитель не превышает предопределенный максимальный размер параллелизма блоков.
20. Система для получения доступа к данным, содержащая память и процессор, сконфигурированный для выполнения способа, содержащего:
- получение команды обращения к памяти для получения доступа к пространству данных с первым размером по адресу в памяти, причем команда обращения к памяти задает первый размер,
- выявление размера выравнивания адреса,
- выявление наибольшего общего делителя для первого размера и для выявленного размера выравнивания и
- получение доступа к данным первого размера в одной или нескольких группах данных, причем группы данных имеют размеры, которые являются кратными размеру наибольшего общего делителя.
21. Система по п. 20, причем первый размер превышает выявленный размер выравнивания.
22. Система по п. 20, причем первый размер и выявленный размер выравнивания исчисляются в количестве байтов, причем первый размер не является размером в виде степени числа два, а выявленный размер выравнивания является размером в виде степени числа два.
23. Система по п. 20, кроме того, содержащая выявление первого размера на основании операнда команды обращения к памяти.
24. Система по п. 20, причем процессор содержит векторный процессор, а команда обращения к памяти содержит векторную команду.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ НА ОСНОВЕ ПОТОКА ДАННЫХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2005 |
|
RU2281546C1 |

