Область техники, к которой относится изобретение
Варианты осуществления, описанные здесь, в общем, относятся к процессорам. В частности, варианты осуществления, описанные здесь, в общем, относятся к процессорам, имеющим инструкции, которые полезны для транскодирования точек кода переменной длины для знаков Unicode.
Уровень техники
Компьютеры, в принципе, обрабатывают двоичные числа. Обычно они не обрабатывают всевозможного типа буквы, десятичные числа, символы или другие знаки, используемые в разных языках и традициях. Скорее, таким различным буквам, десятичным числам, символам и другим знакам назначают двоичные числа, и их представляют двоичными числами.
Универсальный набор знаков (UCS) представляет собой стандартизированный набор знаков, на котором основаны несколько систем кодирования знаков. UCS определен международным стандартом ISO/IEC 10646, Information technology - Universal multiple-octet coded character set (UCS), вместе с изменениями к этому стандарту. UCS включает в себя большое количество разных знаков, включая в себя буквы, числа, символы, идеограммы, логограммы и другие знаки из наиболее распространенных языков, текстов и традиций мира. Каждый из этих знаков идентифицируется целым числом, которое называется точкой кода знаков.
Стандарт Unicode (Unicode) был разработан совместно с USC. Unicode представляет собой стандарт компьютерной промышленности для соответствующего цифрового кодирования, представления и обработки знаков UCS. В соответствии с последними отчетами Unicode обеспечивает уникальное число для каждого знака, независимо от платформы, независимо от программы, независимо от языка. Unicode в настоящее время используется практически всеми современными компьютерами и серверами, как основа для обработки текста по Интернет.
Unicode может быть воплощен через различные системы кодирования знаков. Одна из обычно используемых систем кодирования представляет собой UTF-8 (8-битный формат преобразования UCS). UTF-8 представляет собой кодирование переменной длины (например, с переменным количеством байтов), которое может представлять собой каждый знак в Unicode. Каждый знак в Unicode представлен между одним и четырьмя байтами. Байты также называются октетами в стандарте Unicode. В UTF-8 используется один байт для представления любого из знаков ASCII. UTF-8 обладает обратной совместимость с ASCII, и знаки имеют одинаковое кодирование, как в ASCII, так и в UTF-8. Другие знаки, не входящие в ASCII, представлены двумя, тремя или четырьмя байтами. По оценке UTF-8 представляет собой самое распространенное кодирование Unicode на веб-страницах во всемирной сети, при этом более половины всех веб-страниц кодируют, используя UTF-8. UTF-8 также широко используется программами электронной почты для отображения и формирования почты. Все чаще UTF-8 также используется для кодирования знаков Unicode в определенных языках программирования, операционных системах, интерфейсах программирования приложения (API) и в программных приложениях.
Другое обычно используемое кодирование представляет собой UTF-16 (16-битный формат преобразования UCS). UTF-16 представляет собой кодирование переменной длины (например, с переменным количеством байтов), которое может представлять каждый знак в Unicode. Каждый знак Unicode представлен либо двумя, или четырьмя байтами. UTF-16 не обладает обратной совместимостью с ASCII. UTF-16 обычно используется, как международная форма Unicode в определенных языках программирования таких, как, например, Java, С# и JavaScript, и в определенных операционных системах. Также используются различные другие известные системы кодирования (например, UTF-2, UTF-32, UTF-1 и т.д.).
Обычно, для того чтобы способствовать обработке в компьютерных системах, UTF-8, UTF-16 или другие кодированные данные, могут быть транскодированы в другой формат, такой как, например, Unicode. Транскодирование представляет непосредственное цифро-цифровое преобразование данных из одной системы кодирования в другую. Такое транскодирование может быть выполнено по разным причинам, таким как, например, для того, чтобы помочь повысить эффективность или скорость обработки данных, для преобразования кодированных данных в формат, используемый программным обеспечением, или в более широко распознаваемый формат и т.д. Часто большое количество обработки требуется для транскодирования содержания веб-страниц, документов, отформатированных с использованием языков разметки, документов XML и т.п., из одной системы кодирования (например, UTF-8) в стандартные знаки Unicode или в другие форматы. Благодаря распространенности такого транскодирования и/или его потенциального влияния на рабочие характеристики, новые и полезные подходы для транскодирования могли бы стать предпочтительными. Краткое описание чертежей
Изобретение будет более понятным при ссылке на следующее описание и приложенные чертежи, которые используются для иллюстрации вариантов осуществления. На чертежах:
на фиг. 1 показана блок-схема варианта осуществления процессора;
на фиг. 2 показана таблица характеристик точек кода переменной длины UTF-8;
на фиг. 3 показана блок-схема варианта осуществления процессора, который во время работы обрабатывает вариант осуществления инструкции определения длины точки упакованного кода переменной длины;
на фиг. 4 показана блок-схема примерного варианта осуществления соответствующей операции определения длины точки упакованного кода переменной длины для точек кода переменной длины UTF-8;
на фиг. 5 показана блок-схема последовательности операций варианта осуществления способа, выполняемого процессором и/или в пределах процессора, в ходе обработки варианта осуществления инструкции определения длины точки упакованного кода переменной длины;
на фиг. 6 показана блок-схема варианта осуществления процессора, который во время работы выполняет или обрабатывает вариант осуществления инструкции выделения битов знака точки упакованного кода переменной длины (например, битов Unicode);
на фиг. 7 показана блок-схема примерного варианта осуществления соответствующих операций выделения битов знака точки упакованного кода UTF-8 (например, битов Unicode) для точек кода UTF-8;
на фиг. 8 показана блок-схема, иллюстрирующая соответствующие способы размещения или упорядочивания наборов выделенных битов Unicode в упакованном элементе данных;
на фиг. 9 показана блок-схема последовательности операций варианта осуществления способа, выполняемого процессором и/или в пределах процессора, в ходе обработки варианта осуществления инструкции выделения битов знака точки упакованного кода переменной длины (например, битов Unicode);
на фиг. 10А показана блок-схема, иллюстрирующая обобщенный формат инструкции, удобный для векторных операций, и его шаблоны инструкции класса А в соответствии с вариантами осуществления изобретения;
на фиг. 10В показана блок-схема, иллюстрирующая обобщенный формат инструкции, удобный для векторных операций, и его шаблоны инструкции класса В в соответствии с вариантами осуществления изобретения;
на фиг. 11А показана блок-схема, иллюстрирующая примерный конкретный формат инструкции, удобный для векторных операций, в соответствии с вариантами осуществления изобретения;
на фиг. 11В представлен конкретный формат инструкции, удобный для векторных операций, который определен в том смысле, что он определяет местоположение, размер, интерпретацию и порядок полей, а также значения для некоторых из этих областей;
на фиг. 11С показана блок-схема, иллюстрирующая поля конкретного формата инструкции, удобного для векторных операций, которые составляют поле индекса регистра в соответствии с одним вариантом выполнения изобретения;
на фиг. 11D показана блок-схема, иллюстрирующая поля конкретного формата инструкции, удобного для векторных операций, которые составляют поле операции приращения в соответствии с одним вариантом выполнения изобретения;
на фиг. 12 показана блок-схема архитектуры регистра в соответствии с одним вариантом выполнения изобретения;
на фиг. 13А показана блок-схема, иллюстрирующая, как примерный конвейер, работающий по порядку, так и примерный конвейер обработки задачи/исполнения, работающий не порядку, с переименованием регистра, в соответствии с вариантами осуществления изобретения;
на фиг. 13В показана блок-схема, иллюстрирующая, как примерный вариант осуществления архитектуры ядра, работающей по порядку, так и пример архитектуры ядра задачи/исполнения не по порядку с переименованием регистра, которое должно быть включено в процессор, в соответствии с вариантами осуществления изобретения;
на фиг. 14А показана блок-схема ядра с одним процессором, вместе с его соединением с сетью взаимного соединения на кристалле и с его локальным поднабором кэш Уровня 2 (L2), в соответствии с вариантами осуществления изобретения;
на фиг. 14В показан расширенный вид в перспективе части ядра процессора по фиг. 14А, в соответствии с вариантами осуществления изобретения;
на фиг. 15 показана блок-схема процессора, который может иметь больше, чем одно ядро, может иметь интегрированный контроллер памяти и может иметь интегрированную графику, в соответствии с вариантами осуществления изобретения;
на фиг. 16 показана блок-схема системы в соответствии с одним вариантом осуществления настоящего изобретение;
на фиг. 17 показана блок-схема первого, более конкретного примера системы, в соответствии с вариантом осуществления настоящего изобретение;
на фиг. 18 показана блок-схема второго, более конкретного примера системы, в соответствии с вариантом осуществления настоящего изобретение;
на фиг. 19 показана блок-схема SoC, в соответствии с вариантом осуществления настоящего изобретение;
на фиг. 20 показана блок-схема, представляющая отличие от использования программного преобразователя инструкции для преобразования двоичных инструкций в наборе инструкций источников в двоичную инструкцию в целевом наборе инструкций, в соответствии с вариантами осуществления изобретения.
Осуществление изобретения
Здесь раскрыты инструкции, используемые для транскодирования точек кода переменной длины данных Unicode, процессоры для исполнения или выполнения инструкций, способы, выполняемые процессорами при исполнении или выполнении инструкций, и системы, в состав которых входит один или больше процессоров для исполнения или выполнения инструкций. В следующем описании, представлено множество конкретных деталей (например, операции/функции конкретной инструкции, комбинации инструкций, форматы кодирования, конфигурации процессора, последовательности операций и т.п.). Однако, варианты осуществления могут быть выполнены на практике без этих конкретных деталей. В других случаях хорошо известные схемы, структуры и технологии не были представлены подробно, чтобы исключить затруднения при понимании описания.
На фиг. 1 показана блок-схема варианта осуществления процессора 100. Процессор представляет вариант осуществления устройства обработки инструкции. В некоторых вариантах осуществления процессор может представлять собой процессор общего назначения (например, микропроцессор общего назначения, такого типа, который часто используется, как центральное процессорное устройство (CPU) в настольных компьютерах, переносных компьютерах и подобных компьютерах). В качестве альтернативы, процессор может представлять собой процессор специального назначения. Примеры соответствующих процессоров специального назначения включают в себя, но не ограничены этим, сетевые процессоры, процессоры передачи данных, криптографические процессоры, графические процессоры, сопроцессоры, встроенные процессоры, цифровые сигнальные процессоры (DSP) и контроллеры (например, микроконтроллеры), которые представляют собой только несколько примеров. Такие процессоры специального назначения также иногда называются аппаратными ускорителями, ускорителями специального назначения и т.п. Процессор может представлять собой любой из различных процессоров со сложным набором команд архитектуры процессора (CISC), различных процессоров с сокращенным набором команд (RISC), различных процессоров с командами большой длины (VLIW), различные гибриды или другие типы процессоров вообще.
Процессор имеет набор 102 инструкций. Инструкции набора инструкций представляют макроинструкции, инструкции языка ассемблера, инструкции машинного уровня или другие инструкции относительно высокого уровня или сигналы управления, в отличие от микроинструкций, микроопераций, или других инструкций относительно низкого уровня или сигналов управления, которые получают в результате декодирования инструкций более высокого уровня или сигналов управления.
В некоторых вариантах осуществления набор инструкций может включать в себя одну или больше инструкций 103, которые используются для транскодирования кодов переменной длины или точек кода для данных Unicode. В некоторых вариантах осуществления инструкции 103, в случае необходимости, включают в себя одну или больше упакованных инструкций 104 определения длины точки кода переменной длины. Упакованные инструкции 104 определения длины точки кода переменной длины могут иметь одну из характеристик, атрибутов или свойств, показанных и описанных дополнительно ниже на фигурах со ссылкой на фиг. 3-5. В некоторых вариантах осуществления инструкции 103, в случае необходимости, могут включать в себя одну или больше инструкций 106 выделения упакованных битов знака точки кода переменной длины (например, битов Unicode). Инструкции 106 выделения упакованных битов знака точки кода переменной длины (например, биты Unicode) могут иметь любую одну из характеристик, атрибутов или свойств, показанных и описанных дополнительно ниже со ссылкой на фиг. 2 и 6-9. В некоторых вариантах осуществления инструкции 103 могут, в случае необходимости, включать в себя, как одну или больше инструкций 104 определения длины точки кода упакованной переменной длины и одну или больше инструкций 106 выделения упакованных битов знака точки кода переменной длины (например, битов Unicode), хотя это и не требуется.
Процессор также включает в себя набор регистров 108 упакованных данных. Регистры упакованных данных, в общем, представляют места расположения на кристалле в накопителе процессора. Регистры упакованных данных работают для сохранения упакованных данных, векторных данных или данных SIMD. Инструкции из набора инструкций (например, инструкции 104 определения длины точки кода упакованной переменной длины и/или инструкции 106 выделения битов Unicode точки кода упакованной переменной длины), могут устанавливать регистры упакованных данных из набора 108 для идентификации операндов (например, операндов источника, операндов места назначения и т.д.). Таким образом, регистры упакованных данных могут быть видимыми для программных средств и/или программиста (возможно, могут быть воплощены с переименованием регистра). Такие регистры иногда называются архитектурно видимыми регистрами или архитектурными регистрами.
Процессор также включает в себя один или больше исполнительных модулей 110. Исполнительный модуль (модули) работают для исполнения или обработки необязательных инструкций 104 определения длины упакованной точки кода переменной длины и/или необязательных инструкций 106 выделения битов Unicode упакованной точки кода переменной длины. В некоторых вариантах осуществления исполнительный модуль (модули) может включать в себя определенную логику (например, определенную схему или другие аппаратные средства, потенциально в комбинации с одним или больше из встроенного программного обеспечения и программного обеспечения) для выполнения инструкций 104, 106.
На фиг. 2 показана таблица характеристик 224 точек кода переменной длины UTF-8. В первом самом левом столбце представлен список множества байтов в точках кода переменной длины UTF-8. Первый ряд соответствует одному байту точек кода UTF-8, второй ряд соответствует двум байтам точек кода UTF-8, третий ряд соответствует трем байтам точек кода UTF-8, и четвертый ряд соответствует четырем байтам точек кода UTF-8. В будущем, возможно, что пять или еще шесть байтов точек кода UTF-8 могут стать более распространенными в UTF-8.
Во втором - четвертом столбцах представлен в виде списка формат из байтов переменной длины точек кода UTF-8. Формат в каждом байте представлен от положения младшего значащего бита справа до положения старшего значащего бита слева. Например, формат байта 1 одного байта точки кода UTF-8 представляет собой Оххххххх. Байт 2 следует после байта 1 (то есть, байт 2 является более значимым), байт 3 следует после байта 2, и байт 4 следует после байта 3. Для двухбайтной точки кода UTF-8 формат байта 1 представляет собой 10ххххх, и формат байта 2 представляет собой 10хххххх. Форматы точек кода UTF-8 из трех и четырех байтов являются такими, как представлено на иллюстрации. В этих форматах биты, которые представляют двоичные единицы (то есть, 1) и нули (то есть, 0) представляют биты 226 сигнатуры, тогда как символ "х" используется в тех битах, которые представляют биты 228 точек кода Unicode. Например, для формата UTF-8 из двух байтов, самые левые три старших значащих бита в байте 1 и самые левые два старших значащих бита в байте 2 представляют собой биты сигнатуры, тогда как все другие биты, представленные "х", представляют собой биты точки кода Unicode.
Биты 226 сигнатуры используются для определения длины точки кода UTF-8 (например, представляет ли она собой точку кода UTF-8 из одного байта, двух байтов, трех байтов или четырех байтов). Например, биты сигнатуры могут использоваться для определения контекста положения точки кода во входном потоке байтов, который может использоваться для определения идентичностей компонента байтов многобайтной точки кода UTF-8. Биты 228 точки кода Unicode можно использовать для определения, путем транскодирования, соответствующего знака Unicode или значения, которое кодировано или представлено точкой кода UTF-8. Таким образом, биты точки кода Unicode могут изменяться с одного знака Unicode на другой.
Точка однобайтового кода UTF-8 имеет один бит сигнатуры в бите 7 и семь битов точек кода Unicode в битах [6:0]. Точка двухбайтового кода UTF-8 имеет пять битов сигнатуры в битах [7:5] и [15:14] и одиннадцать битов точки кода Unicode в битах [4:0] и [13:8]. Точка в трехбайтовом коде UTF-8 имеет восемь битов сигнатуры в битах [7:4], [15:14] и [23:22], и шестнадцать битов точек кода Unicode в битах [3:0], [13:8] и [21:16]. Точка четырехбайтового кода UTF-8 имеет одиннадцать битов сигнатуры в битах [7:3], [15:14], [23:22] и [31:30]. Точка четырехбайтового кода UTF-8 имеет двадцать один бит точки кода Unicode в битах [2:0], [13:8], [21:16] и [29:24].
В соответствии с этим, в UTF-8 так же, как и в других стандартах, используемых для кодирования знаков Unicode, применяют кодирование переменной длины или точки кода (например, различные количества байтов для представления разных знаков Unicode). Кодирование переменной длины или точек кода обычно означает, что процессорам требуется транскодировать или по-другому обработать эти точки кода или потоки байтов в контексте положения, выведенном из одного или больше предыдущего байта (байтов). Такое свойство часто затрудняет выполнение такого транскодирования, используя операции с упакованными данными, векторные операции или операции SIMD. С одной стороны, вычислительные операции или манипуляции необходимые для транскодирования точки кода UTF-8, например, в 32-битное значение Unicode, обычно меняются в зависимости от длины точки кода UTF-8. В результате, границы разделений между точками кода переменной длины (например, точками кода одно, двух, трех и четырехбайтового кода UTF-8) обычно должны быть определены и должны соблюдаться во время обработки SIMD. Существующие наборы инструкций SIMD, в общем, являются неэффективными при удостоверении или определении переменных длин точек кода UTF-8 и других систем кодирования переменной длины. Улучшенные способы определения длины разных точек кода, например, через одиночные инструкции, специально разработанные с этой целью, могут иметь преимущество. Кроме того, гранулярная обработка бита внутри байта и между байтами с неустановившимися структурами от одного байта к следующему, применяемая при транскодировании UTF-8 или других точек кода переменной длины в другие форматы, обычно проявляет тенденцию быть трудновыполнимой в операциях с упакованными данными, в векторных операциях или в операциях SIMD. Улучшенные способы выполнения такой гетерогенной обработки внутри байта и между байтами, используемой во время транскодирования, например, через одиночные инструкции, специально разработанные с этой целью, могут иметь преимущества.
На фиг. 3 показана блок-схема варианта осуществления процессора 300, который во время работы выполняет или обрабатывает вариант осуществления инструкции определения длины точки упакованного кода переменной длины 304. Процессор 300, в случае необходимости, может иметь одну из характеристик или атрибутов процессора по фиг. 1. Например, процессор 300 может представлять собой процессор общего назначения, процессор специального назначения, может иметь архитектуру CISC, RISC, VLIW или другую архитектуру, и т.д. Для предотвращения усложнения описания, такие свойства, которые могут быть одинаковыми или аналогичными, не будут повторяться, а скорее описание будет стремиться к тому, чтобы подчеркивать разные или дополнительные свойства процессора по фиг. 3.
Процессор 300 может принимать инструкцию 304 определения длины точки упакованного кода переменной длины. Например, инструкция может быть принята из модуля выборки инструкции, из очереди инструкций и т.п. Инструкция может представлять макроинструкцию, инструкцию на уровне машинного кода, инструкцию языка ассемблера или другую инструкцию или сигнал управления из набора инструкций процессора. Инструкции могут иметь рабочий код или операционный код. Операционный код может представлять собой множество битов, или одно или больше полей, которые во время работы идентифицируют инструкцию и/или операцию, которая должна быть выполнена (например, операцию определения длины точки упакованного кода переменной длины). Инструкции также могут иметь биты или одно или больше полей для установления одного или больше источников и/или операндов назначения, как дополнительно поясняется ниже.
Представленный процессор включает в себя модуль 312 декодирования инструкции. Модуль декодирования инструкции может также называться модулем декодирования или декодером. Модуль декодирования может принимать и декодировать инструкции относительно высокого уровня или сигналы управления (например, макроинструкции, инструкции на уровне машинного кода, инструкции языка ассемблера и т.д.) и может выводить одну или больше микроинструкций, микроопераций, точек входа микрокода или другие инструкции относительно низкого уровня или сигналы управления, которые отражают, представляют и/или которые выведены из инструкций высокого уровня или сигналов управления. Одна или больше из инструкций низкого уровня или сигналов управления может быть воплощена инструкцией высокого уровня или сигналом управления через одну или больше операций низкого уровня (например, на уровне схемы или на уровне аппаратных средств). Модуль декодирования может быть осуществлен, используя всевозможные механизмы, логику или интегральные схемы, включающие в себя, но без ограничений, постоянные запоминающие устройства для микрокода (ROM), справочные таблицы, воплощения в виде аппаратных средств, массивы программируемой логики (PLA) и другие механизмы, логику или интегральные схемы, используемые для воплощения, модули декодирования, известные в области техники.
В других вариантах осуществления могут использоваться эмулятор инструкции, транслятор, морфер, интерпретатор или другая логика преобразования инструкции. Различные типы логики преобразования инструкции известны в области техники и могут быть воплощены в программных, аппаратных средствах, во встроенном программном обеспечении, или используя их комбинации. Логика преобразования инструкции может принимать инструкцию и может эмулировать, транслировать, выполнять трансформацию, интерпретировать или по-другому преобразовывать инструкцию в одну или больше соответствующие выведенные инструкции или сигналы управления. В других вариантах осуществления могут использоваться, как логика преобразования инструкции, так и модуль декодирования. Например, процессор может иметь логику преобразования инструкции для преобразования принимаемой инструкции машинного кода в одну или больше промежуточных инструкций, и модуль декодирования для декодирования одной или больше промежуточных инструкций в одной или больше инструкциях более низкого уровня, или сигналы управления, выполняемые собственными аппаратными средствами процессора (например, исполнительным модулем). Некоторые или все из логики преобразования инструкции могут быть расположены вне процессора, например, на отдельном кристалле и/или в памяти.
Процессор 300 также включает в себя набор регистров 308 упакованных данных. Каждый из регистров упакованных данных может представлять место расположения для накопителя на кристалле, который во время работы сохраняет упакованные данные, векторные данные или данные SIMD. Регистры упакованных данных могут быть воплощены по-разному в разных микроархитектурах, используя хорошо известные технологии, и не ограничены каким-либо определенным типом схемы. Различные типы регистров пригодны для этого. Примеры соответствующих типов регистров включают в себя, но не ограничены этим, специализированные физические регистры, динамически выделенные физические регистры с использованием переименования регистра, и их комбинацию.
Снова обращаясь к фиг. 3, исполнительный модуль 310 соединен с модулем 312 декодирования и с регистрами 308 упакованных данных. В качестве примера исполнительный модуль может включать в себя функциональный модуль, логический модуль, арифметический логический модуль, цифровую схему для выполнения логических и/или арифметических, и логических операций, и т.п. Исполнительный модуль может принимать одну или больше из декодированных или по-другому преобразованных инструкций или сигналы управления, которые представляют инструкцию 304 определения длины точки упакованного кода переменной длины и/или которые выведены из нее. Исполнительный модуль и/или процессор может включать в себя специфичную или конкретную логику (например, схему или другие аппаратные средства, потенциально скомбинированные со встроенным программным обеспечением и/или программным обеспечением), которая работает для выполнения операции определения длины точки упакованного кода переменной длины в ответ на и/или, как результат инструкции определения длины точки упакованного кода переменной длины (например, в ответ на одну или больше инструкций или сигналы управления, декодированные или по-другому выведенные из него).
В некоторых вариантах осуществления инструкция 304 определения длины точки упакованного кода переменной длины может в явном виде устанавливать (например, через одно или больше полей или набор битов), или по-другому обозначать (например, в скрытом виде обозначать), упакованные данные 314 первого источника. Упакованные данные первого источника могут иметь, по меньшей мере, две точки упакованного кода переменной длины знаков 315 Unicode. В одном конкретном варианте осуществления упакованные данные первого источника могут иметь часть потока непрерывно расположенных переменных точек кодов UTF-8 или кодирования для знаков Unicode, включающие в себя кодовые точки из одного байта, двух байтов, в случае необходимости, трех байтов и, в случае необходимости, четырех байтов, хотя объем изобретения не ограничен этим.
В некоторых вариантах осуществления инструкция определения длины точки упакованного кода переменной длины, в случае необходимости, может в явном виде устанавливать или по-другому обозначать упакованные данные 316 второго источника, хотя это и не требуется. Упакованные данные второго источника могут иметь, по меньшей мере, две структуры упакованной сигнатуры для разных точек кода переменной длины. В качестве альтернативы, вместо требования, чтобы инструкция обозначала упакованные данные второго источника, имеющие две или больше структур упакованной сигнатуры, эти две или больше структуры сигнатуры, в случае необходимости, могут быть сохранены в энергонезависимой памяти на кристалле, такой как, например, постоянное запоминающее устройство (ROM) на кристалле. В некоторых вариантах осуществления может присутствовать другая структура сигнатуры для каждой другой точки возможной длины кода в упакованных данных 314 первого источника. В некоторых вариантах осуществления могут присутствовать, по меньшей мере, две, в случае необходимости, три или, в случае необходимости, четыре или больше разных структур сигнатуры, в зависимости от конкретного подхода к кодированию, и каждая из которых соответствует другой точке кода переменной длины, возможного в упакованных данных 314 первого источника. Такие структуры сигнатуры могут быть, по существу, заранее определенными или могут представлять собой фиксированные значения.
В одном конкретном примерном варианте осуществления, в котором используется UTF-8, может присутствовать структура сигнатуры однобайтового UTF-8 для точки однобайтового кода UTF-8, структура сигнатуры двухбайтового UTF-8 для точки двухбайтового кода UTF-8, в случае необходимости, структура сигнатуры трехбайтового UTF-8 для точки трехбайтового кода UTF-8, и, в случае необходимости, структура сигнатуры четырехбайтового UTF-8 для точки четырехбайтового кода UTF-8, хотя объем изобретения не ограничен этим. Структуры битов сигнатуры, в случае необходимости, могут быть аналогичны тем, которые показаны и описаны выше со ссылкой на фиг. 2. Например, структура сигнатуры для точки однобайтового кода UTF-8 может иметь один бит сигнатуры в бите 7, структура сигнатуры для точки двухбайтового кода UTF-8 может иметь пять битов сигнатуры в битах [7:5] и [15:14], структура сигнатуры для точки трехбайтового кода UTF-8 может иметь восемь битов сигнатуры в битах [7:4], [15:14] и [23:22], и структура сигнатуры для точки четырехбайтового кода UTF-8 может иметь одиннадцать битов сигнатуры в битах [7:3], [15:14], [23:22] и [31:30].
В таблице 1, представленной ниже, перечислены примеры соответствующих структур сигнатуры, представленных в двоичном и шестнадцатеричном обозначениях для точек одно-четырехбайтового кода UTF-8.

В некоторых вариантах осуществления инструкции 304 определения длины точки упакованного кода переменной длины, в случае необходимости, могут иметь непосредственный операнд 318, хотя это и не требуется. Непосредственный операнд может иметь значения длины структур сигнатуры для разных точек кода переменной длины (например, которые представляют собой упакованные данные 316 второго источника). Каждое из значений длины может соответствовать разным структурам сигнатуры. Например, значения длины могут включать в себя или могут обозначать длину один байт, соответствующую структуре сигнатуры в один байт, длину два байта, соответствующую структуре сигнатуры два байта, в случае необходимости, длину три байта, соответствующую структуре сигнатуры три байта и, в случае необходимости, длину четыре байта, соответствующую структуре сигнатуры четыре байта. В других вариантах осуществления только два или только три разных значения длины могут потребоваться для конкретного воплощения. В качестве альтернативы, в других вариантах осуществления, вместо инструкции, для которой требуется непосредственный операнд, значения длины структур сигнатуры, в случае необходимости, могут быть предоставлены по-другому, например, путем сохранения в ROM на одном кристалле или в другой энергонезависимой памяти на кристалле. В качестве другого варианта выбора, значения длины, в случае необходимости, могут предоставляться другим явно установленным или неявно обозначенным операндом источника (например, могут быть предоставлены через скрытый регистр).
В некоторых вариантах осуществления инструкция определения длины точки упакованного кода переменной длины, в случае необходимости, может в явном виде устанавливать или по-другому обозначать место 320 назначения (например, место назначения сохранения), где полученные в результате упакованные данные должны быть сохранены в ответ на инструкцию 304. В некоторых вариантах осуществления полученные в результате упакованные данные могут включать в себя упакованные отрезки подтвержденных точек кода переменной длины или кодирование знаков 321 Unicode.
В некоторых вариантах осуществления исполнительный модуль может определять, соответствует ли часть данных из точек упакованного кода переменной длины знакам 315 Unicode любой из разных структур сигнатуры для разных точек 317 длины кода. Например, исполнительный модуль может сравнивать первый байт из точек упакованного кода UTF-8 переменной длины для знаков 315 Unicode с однобайтовой структурой 317 сигнатуры UTF-8, может сравнивать первые два байта из точек упакованного кода UTF-8 переменной длины знаков 315 Unicode с двухбайтовой структурой 317 сигнатуры UTF-8. В некоторых вариантах осуществления исполнительный модуль может также, в случае необходимости, сравнивать первые три байта из точек упакованного кода UTF-8 переменной длины знаков 315 Unicode с тремя байтами структуры 317 сигнатуры UTF-8 и может дополнительно, в случае необходимости, сравнивать первые четыре байта из точек упакованного кода UTF-8 переменной длины знаков 315 Unicode с четырьмя байтами структуры 317 сигнатуры UTF-8.
Если в определенной точке будет обнаружено соответствие, тогда можно предположить, что длина точки кода UTF-8 переменной длины или точки другого кода переменной длины из первых данных 314 источника была правильно определена. Это иногда называется в данной области техники подтверждением кодовой точки. В некоторых вариантах осуществления исполнительный модуль может затем сохранять подтвержденные или по-другому определенные значения длины для этих точек кода UTF-8 переменной длины или других точек кода в соответствующем положении в месте 320 назначения. Например, первый непрерывный трехбайтовый сегмент из первого источника 314 соответствует трехбайтовой структуре сигнатуры из второго источника 316, затем значение три может быть сохранено или по-другому обозначено в соответствующем положении в месте назначения для обозначения того, что соответствующая точка кода представляет собой точку трехбайтового кода. Такая обработка может повторяться для генерирования результата, который включает в себя упакованные значения длины всех удостоверенных точек кода переменной длины знаков 321 Unicode, которые могут быть удостоверены или по-другому определены в первом источнике 314.
Как показано, в некоторых вариантах осуществления, каждые из упакованных данных 314 первого источника, упакованных данных 316 второго источника и место 320 назначения могут представлять разные регистры упакованных данных. В качестве альтернативы, места расположения памяти или другие места расположения накопителя можно использовать для одного или больше из этих операндов. Например, точки упакованного кода переменной длины знаков 315 Unicode могут быть сохранены в определенном месте положения в памяти. Кроме того, один или больше операндов источников и/или мест назначения могут быть скрыты для инструкции, вместо их явного указания. В качестве другого варианта, один из операндов источника, в случае необходимости, может повторно использоваться в качестве операнда назначения, и полученные в результате упакованные данные могут быть записаны поверх упакованных данных источника. Хотя в некоторых случаях может быть желательно сохранить упакованные данные источника.
Для того, чтобы исключить усложнение описания, был представлен и описан относительно простой процессор 300. В других вариантах осуществления процессор, в случае необходимости, может включать в себя другие хорошо известные компоненты, которые можно видеть в процессорах. Примеры таких компонентов включают в себя, но без ограничений, модуль прогнозирования ветвлений, модуль выборки команды, кэш для инструкции и данных, буферы быстрого преобразования адреса для трансляции инструкции и данных, буферы упреждающей выборки, очереди микроинструкций, последовательности микроинструкций, модуль переименования регистра, модуль планировании инструкции, модули интерфейса шины, кэш второго или более высокого уровня, модуль устранения, другие компоненты, включенные в процессоры, и различные их комбинации. Существует буквально множество разных комбинаций и конфигураций компонентов в процессорах, и варианты осуществления не ограничены какой-либо конкретной их комбинацией или конфигурацией. Варианты осуществления могут быть включены в процессоры, которые имеют множество ядер, логические процессоры или механизмы исполнения, по меньшей мере, один из которых имеет исполнительную логику, действующую для выполнения варианта осуществления по инструкциям, раскрытым здесь.
На фиг. 4 показана блок-схема примерного варианта осуществления соответствующей операции 430 определения длины точки упакованного кода переменной длины для точек кода UTF-8 переменной длины. Операция может выполняться процессором или другим устройством обработки инструкции в ответ на и/или, как результат варианта осуществления инструкции определения длины точки упакованного кода переменной длины.
Инструкция может устанавливать или по-другому обозначать точки 415 упакованного кода UTF-8. Например, точки упакованного кода UTF-8 могут находиться в регистре упакованных данных или в определенном местоположении в памяти, установленном или по-другому обозначенном в инструкции. В представленном варианте осуществления точки упакованного кода UTF-8 имеют ширину 128 битов. В других вариантах осуществления, в случае необходимости, могут использоваться другие значения ширины такие как, например, 64 бита, 256 битов, 1024 бита или некоторые другие значения ширины. 128 битов являются достаточно широкими для размещения шестнадцати байтов. Шестнадцать байтов позволяют сохранять переменное количество точек кода UTF-8 переменной длины, например, каждый из которых имеет от одного до четырех байтов. В представленном примере три байта самого низкого порядка в битах [23:0] сохраняют точку 431 3-байтового кода UTF-8 для символа европейской денежной единицы (€). Четвертый байт в битах [31:24] содержит точку 432 1-байтового кода UTF-8 для знака доллар ($). Пятый и шестой байты в битах [47:32] содержат точку 433 2-байтового кода UTF-8 для знака цент (0). С седьмого по девятый байты в битах [71:48] также содержат точку 434 3-байтового кода UTF-8 для символа европейской валюты. Пятнадцатый и шестнадцатый байты в битах [127:112] содержат неполные два из трех байтов точки 435 3-х байтового кода UTF-8 для знака европейской валюты. Остальной третий байт не может попасть в пределы ограничения по ширине операнда 128-битных упакованных данных, и таким образом, только неполная часть символов представлена (например, в 128-битном регистре).
Инструкция может устанавливать или по-другому обозначать структуры упакованной сигнатуры для точек 417 кода UTF-8 разной длины. В некоторых вариантах осуществления инструкция может устанавливать регистр или другое местоположение в накопителе, имеющем структуры упакованной сигнатуры. В других вариантах осуществления структуры упакованной сигнатуры могут быть сохранены в ROM или в другой энергонезависимой памяти на кристалле. В представленном варианте осуществления показаны четыре разных структуры сигнатуры. В частности, первая структура 436 сигнатуры для однобайтовой точки кода UTF-8 сохранена в самом нижнем порядке 32-битного двойного слова в битах [31:0], вторая структура 437 сигнатуры для точки двухбайтового кода UTF-8 сохранена в следующем после самого низкого порядка 32-битного кодового слова в битах [63:32], третья структура 438 сигнатуры для точки трехбайтового кода UTF-8 сохранена в следующем 32-битном двойном слове самого высокого порядка в битах [95:64], четвертая структура 439 сигнатуры для точки четырехбайтового кода UTF-8 сохранена в 32-битном двойном слове самого высокого порядка в битах [127:96]. Первая структура сигнатуры может иметь нулевое расширение и может иметь в своем байте самого низкого порядка значение "00000000". Вторая структура сигнатуры может иметь нулевое расширение и может иметь в своих двух байтах самого низкого порядка значение "10000000 11000000". Третья структура сигнатуры может иметь нулевое расширение и может иметь в своих трех байтах самого низкого порядка значения "10000000 10000000 11100000". Четвертая структура сигнатуры может иметь нулевое расширение и может иметь в своих четырех байтах самого низкого порядка значения "10000000 10000000 10000000 11110000". Эти структуры сигнатуры, в случае необходимости, также могут быть размещены в любом другом порядке в пределах операндов. Также, в других вариантах осуществления можно использовать только две различные структуры сигнатуры (например, если предполагается использовать только точки одно- и двухбайтового кода UTF-8, но не предполагается использовать точки трех- или четырехбайтового кода UTF-8). Следует отметить, что установленные биты (то есть, бинарные биты) в структурах 417 сигнатуры также можно найти в тех же относительных положениях битов точек 415 кода UTF-8 для той же длины байтов. Например, структура сигнатуры для точки 437 двухбайтового кода UTF-8 имеет установленные биты только в битах [15:14] и [7], и точка 433 двухбайтового кода UTF-8 для знака цент, также имеет установленные биты в битах [15:14] и [7].
В некоторых вариантах осуществления инструкция может устанавливать или по-другому обозначать значения длины структур 419 сигнатуры. В этом варианте осуществления значения длины структур сигнатуры представляют собой один, два, три и четыре байта. В некоторых вариантах осуществления инструкция может иметь непосредственный операнд для предоставления этих значений длины. Например, в одном варианте осуществления, непосредственный операнд может представлять собой 8-битный непосредственный операнд, имеющий четыре 2-битных поля, каждое из которых обозначает одно из значений длины. В некоторых вариантах осуществления может использоваться так называемое соглашение "плюс один", в котором значение ноль в непосредственном операнде может использоваться, для обозначения 1 байта, значение один может использоваться для обозначения 2 байтов, значение два может использоваться для обозначения 3 байтов, и значение три может использоваться для обозначения 4 байтов, хотя это не требуется. Эти значения также, в случае необходимости, могут быть размещены в любых других порядках в пределах непосредственного операнда, если только каждый из них логически соответствует соответствующей структуре сигнатуры. В другом варианте осуществления два разных значения длины могут быть обозначены двумя 2-битными полями 4-битного непосредственного операнда. В других вариантах осуществления значения длины, в случае необходимости, могут быть сохранены в ROM или в другой энергонезависимой памяти на кристалле, вместо предоставления с использованием непосредственного операнда.
В ответ на и/или в результате инструкции, процессор может сравнивать байты из точек 415 упакованного кода UTF-8 с другими упакованными структурами сигнатуры для точек 417 кода UTF-8 разной длины. Например, первый байт в битах [7:0] точек 415 упакованного кода UTF-8 можно сравнивать со структурой 436 сигнатуры для точки 1-байтового кода UTF-8, и может быть определено, что они не соответствуют. Затем первые 2 байта в битах [15:0] точек 415 упакованного кода UTF-8 можно сравнивать со структурой 437 сигнатуры для точки 2-байтового кода UTF-8, и может быть определено, что они не соответствуют. Затем первые 3 байта в битах [23:0] точек 415 упакованного кода UTF-8 можно сравнивать со структурой 438 сигнатуры для точки 3-байтового кода UTF-8, и может быть определено, что они не соответствуют друг другу. Другими словами, может быть определено, что все установленные биты (то есть, двоичные) в структуре 438 сигнатуры также представляют собой установленные биты (то есть, двоичные) в точке 431 3-байтового кода UTF-8. Также можно определить, что биты [31:24] точек 415 упакованного кода UTF-8 представляют точку 1-байтового кода UTF-8 для знака 432 доллара, который соответствует структуре 436 сигнатуры для точки 1-байтового кода UTF-8. Также может быть определено, что биты [47-32] точек 415 упакованного кода UTF-8, которые представляют точку 2-байтового кода UTF-8 для знака 433 цент, соответствуют структуре 437 сигнатуры для точки 2-байтового кода UTF-8. Также может быть определено, что биты [71:48] точек 415 упакованного кода UTF-8, которые представляют точку 3-байтового кода UTF-8 для знака 434 европейской валюты, соответствуют структуре 438 сигнатуры для точки 3-байтового кода UTF-8. В представленном выше описании описан определенный порядок для выполнения этих сравнений, хотя следует понимать, что сравнения могут, в случае необходимости, быть выполнены в любом другом требуемом порядке, и что сравнения могут быть выполнены последовательно, параллельно или частично последовательно и частично параллельно.
Такие определения, что точки кода UTF-8 соответствуют структурам сигнатуры, представляют вариант осуществления для определения значения длины точек кода UTF-8. Значения, представляющие значения длины точек кода UTF-8, могут быть сохранены в упакованных значениях длины удостоверенных точек 421 кода UTF-8. Например, как показано, это может включать в себя сохранение значения, обозначающего длину из 3-байтов 440, соответствующую точке 431 3-байтового кода UTF-8 для первого возникновения символа евро, значение, обозначающее длину 1 байта 441, соответствующего точке 432 1-байтового кода UTF-8 для знака доллар, значение, обозначающее длину 2 байта 442, соответствующую точке 433 2-байтового кода UTF-8 для символа цент, и значение, обозначающее длину 3 байтов 443, соответствующую точке 434 3-байтового кода UTF-8 для второго возникновения символа европейской валюты. Как показано в некоторых вариантах осуществления, значения, представляющие значения длины, в случае необходимости, могут быть сохранены в тех же относительных положениях байта для байтов самого низкого порядка, соответствующих точек кода UTF-8, и все нули, в случае необходимости, могут быть сохранены в тех же относительных положениях байта или в любых более значимых байтах соответствующих точек кода UTF-8, хотя это и не требуется. В других вариантах осуществления, в случае необходимости, могут использоваться другие соглашения. Предпочтительно, такой формат проявляет тенденцию хорошего соответствия для кодирования переменной длины. Если относительно большое количество точек меньшего кода (например, точек 1 -байтового кода) будет включено во входной поток (то есть, первый источник), тогда большие значения длины могут быть сохранены в месте назначения. Например, вплоть до шестнадцати значений длины для шестнадцати соответствующих 1-байтовых знаков (например, точек кода UTF-8 для знаков ASCII) могут быть сохранены в месте назначения.
На фиг. 4 был представлен и описан определенный порядок компоновки байтов точек кода UTF-8. Однако, также возможны другие способы организации или размещения байтов в операндах или регистрах. Также пригодны любые известные обычные способы размещения байтов в точках кода UTF-8.
На фиг. 5 показана блок-схема последовательности операций варианта осуществления способа 550, выполняемого процессором и/или выполняемого в пределах процессора при обработке варианта осуществления инструкции определения длины точки упакованного кода переменной длины. В некоторых вариантах осуществления операция и/или способ на фиг. 5 могут быть выполнены процессором и/или в пределах процессоров, показанных на фиг. 1 и/или фиг. 3. Компоненты, свойства и конкретные дополнительные детали, описанные здесь для процессоров на фиг. 1 и/или фиг. 3 также, в случае необходимости, применяют для операций и/или способа на фиг. 5, который может быть выполнен в вариантах осуществления, используя и/или находясь в пределах таких процессоров. В качестве альтернативы, операции и/или способ по фиг. 5 могут быть выполнены с помощью и/или в пределах аналогичных или других процессоров, или другого устройства. Кроме того, процессоры на фиг. 1 и/или на фиг. 3 могут выполнять операции и/или способы, которые являются такими же как, аналогичными или другими, чем представлены на фиг. 5.
Способ включает в себя: принимают инструкция определения длины точки упакованного кода переменной длины, в блоке 551. В других аспектах инструкция может быть принята в процессоре или в его части (например, в модуле выборки инструкции, в модуле декодирования и т.д.). В различных аспектах инструкция может быть принята из источника, находящегося за пределами кристалла (например, из основной памяти, диска или через взаимное соединение), или из источника, находящегося на кристалле (например, из кэш инструкции). В некоторых вариантах осуществления инструкция определения длины точки упакованного кода переменной длины может в явном виде устанавливать или по-другому обозначать упакованные данные из первого источника, имеющие множество точек упакованного кода переменной длины, каждая из которых представляет знак, и может в явном виде устанавливать или по-другому обозначать местоположения назначения сохранения.
Полученные в результате упакованные данные могут быть сохранения в обозначенном местоположении сохранения назначения в ответ на и/или как результат инструкции определения длины точки упакованного кода переменной длины, в блоке 552. В некоторых вариантах осуществления полученные в результате упакованные данные могут включать в себя значения длины для каждой из множества точек упакованного кода переменной длины. В некоторых вариантах осуществления полученные в результате упакованные данные могут иметь любую из ранее описанных характеристик упакованных длин 321 на фиг. 3 и/или упакованных длин 421 на фиг. 4.
Для того, чтобы дополнительно иллюстрировать определенные концепции, рассмотрим подробный пример варианта осуществления инструкции определения длины точки упакованного кода переменной длины с пневмоником VPVLNCPCLSFL. Формат инструкции может представлять собой VPVLNCPCLSFL DEST, SRC1, SRC2, IMM8. DEST может представлять регистр мета назначения упакованных данных шириной 128 битов. SRC1 может представлять собой регистр упакованных данных шириной 128 битов из первого источника или места в памяти. SRC2 может представлять собой второй регистр упакованных данных шириной 128 битов из второго источника. IMM8 может представлять 8-битный непосредственный операнд.
SRC1 может сохранять часть потока UTF-8, представляющую кодированную последовательность байтов UTF-8. SRC2 может сохранять вплоть до четырех разных структур сигнатуры, соответствующих формату кодирования UTF-8 для каждого из четырех разных значений длины точек кода UTF-8 (например, один, два, три и четыре байта). Например, каждая из этих четырех разных структур сигнатуры может быть сохранена в различных элементах данных 32-битного двойного слова. IMM8 может включать в себя четыре 2-битных поля. Каждое 2-битное поле может представлять кодирование длины соответствующей структуры сигнатуры, например, в соглашении "один плюс", в котором единицу добавляют к длине, кодированной для определения фактической длины байта. Другой вариант осуществления описанной выше инструкции может исключать операнд SRC2 второго источника и непосредственный операнд IMM8, и, вместо этого, может предоставлять структуры сигнатуры, и их соответствующие значения длины через ROM или другую энергонезависимую память на кристалле.
Инструкция может использоваться для удостоверения и определения длины в байтах каждой удостоверенной точки кода UTF-8 из SRC1, и также для идентификации смещения первой неполной точки кода UTF-8 в SRC1. Это смещение может быть полезным для определения начала следующей части кода UTF-8 для обработки (например, с последующей инструкцией). Каждую точку кода из SRC1 можно сравнивать с, по меньшей мере, двумя и вплоть до четырех различными структурами сигнатуры, соответствующими разным значениям длины из SRC2. Если точка кода из SRC1 соответствует структуре сигнатуры из SRC2, тогда положение ведущего байта DEST может сохранять заданное значение длины точки кода, которая равна длине структуры сигнатуры и известной из IMM8 (например, один, два, три или четыре). Если определенная длина точки кода больше, чем единица, все следующие оставшиеся байты точки кода в DEST могут быть заполнены нулями (например, 00000000).
В некоторых вариантах осуществления, если ни одна из четырех структур сигнатуры в SRC2 не соответствует точке кода в SRC1, тогда соответствующий ведущий байт точки кода DEST может, в случае необходимости, быть заполнен всеми единицами (например, 11111111). Это необязательно, но может помочь для маркировки или обозначения недействительных или недостоверных точек кода. Это также может помочь для идентификации смещения первой неполной и/или недействительной точки кода UTF-8 в SRC1 (например, для обработки последующей инструкции). Например, в процессорах архитектуры Intel (ΙΑ), такая идентификация может быть выполнена при использовании инструкции PMOVMSKB. Например, результат PMOVMSKB может быть проверен, и младший значащий установленный бит результата PMOVMSKB может обозначать значение смещения первой неполной и/или недействительной точки кода UTF-8 в SRC1. Если результат PMOVMSKB, выполняемый DEST, равен нулю, тогда все 16 байтов во входном потоке UTF-8 могут рассматриваться, как действительные кодовые точки. В качестве альтернативы, некоторое другое соответствующее распознанное значение, помимо всех единиц (например, 11111111), в таких ситуациях, в случае необходимости, может быть сохранено в DEST. В других вариантах осуществления, в случае необходимости, могут использоваться более широкие или более узкие регистры. Например, в различных вариантах осуществления могут использоваться 64-битные, 256-битные, 512-битные или 1024-битные регистры для SRC1 и/или SRC2 и/или DEST.
Следующий псевдокод представляет другой примерный вариант осуществления соответствующей инструкции определения длины точки упакованного кода переменной длины. В этом псевдокоде Src1 представляет первый источник, имеющий набор или последовательность точек кода UTF-8, Src2 представляет операнд второго источника, имеющий четыре сигнатуры для точек от одного до четырехбайтового кода UTF-8, Imm представляет 8-битный непосредственный операнд, и Dest представляет место назначения. ZeroExt32 представляет нулевое расширение для 32-битной функции.



На фиг. 6 показана блок-схема варианта осуществления процессора 600, который работает для исполнения или обработки варианта осуществления битов инструкции 606 выделения знака точки упакованного кода переменной длины (например, битов Unicode). Процессор 600, в случае необходимости, может иметь любую из характеристик или атрибутов процессора 100 по фиг. 1 и/или процессора 300 на фиг. 3. Например, процессор 600 может представлять собой процессор общего назначения, процессор специального назначения может иметь архитектуру CISC, RISC, VLIW или другую архитектуру, модуль декодирования может быть таким же или аналогичным, и т.д. Для того чтобы не усложнять описание, эти особенности, которые могут быть такими же или аналогичными, не будут повторяться, а скорее в описании просматривается тенденция разъяснять другие или дополнительные свойства процессора 600 на фиг. 6.
Процессор 600 может принимать инструкцию 606 в виде выделения битов знака точки упакованного кода переменной длины (например, биты Unicode). Биты Unicode, предназначенные для выделения, представляют те биты кодирования переменной длины, которые позволяют получить знак Unicode или его значение (например, знак Unicode может быть определен на основе только полного набора битов Unicode, предназначенного для выделения). Биты Unicode представляют вариант осуществления знака или битов данных, которые должны быть выделены, и другие варианты осуществления не ограничены битами Unicode. Инструкция может иметь код операции или опкод, который во время работы идентифицирует инструкцию и/или операцию для выполнения (например, операцию выделения битов Unicode точки упакованного кода переменной длины). Представленный процессор включает в себя модуль 612 декодирования инструкции, который может быть аналогичен или может быть таким же, как модуль 312 декодирования. Как описано ранее, в случае необходимости, может также использоваться логика преобразования инструкции. Процессор 600 также включает в себя набор регистров 608 упакованных данных, который может быть аналогичен или может быть таким же, как регистры 308 упакованных данных. Исполнительный модуль 610 соединен с модулем 312 декодирования и с регистрами 308 упакованных данных. Исполнительный модуль 610 может быть аналогичным или может быть таким же, как и исполнительный модуль 310. Исполнительный модуль и/или процессор может включать в себя определенную или конкретную логику (например, схему или другие аппаратные средства, потенциально скомбинированные со встроенным программным обеспечением и/или программным обеспечением), которое во время работы выполняет операцию выделения битов Unicode точки упакованного кода переменной длины в ответ на и/или в результате инструкции 606 (например, в ответ на одну или больше инструкций или декодированных сигналов управления или по-другому выведенных из инструкции 606).
В некоторых вариантах осуществления инструкция 304 выделения битов знака точки упакованного кода переменной длины (например, биты Unicode) может в явном виде устанавливать (например, через одно или больше полей или набор битов), или по-другому обозначать (например, обозначать в неявном виде), упакованные данные 614 первого источника. Упакованные данные первого источника могут иметь, по меньшей мере, две точки упакованного кода переменной длины в виде знаков 615 Unicode. В одном конкретном варианте осуществления упакованные данные первого источника могут иметь участок потока последовательных точек переменных кодов UTF-8 или могут составлять кодирование для знаков Unicode, включающих в себя однобайтовые, двухбайтовые, в случае необходимости, трехбайтовые и, в случае необходимости, четырехбайтовые кодовые точки, хотя объем изобретения не ограничен этим. В некоторых вариантах осуществления точки 615 упакованного кода переменной длины могут быть аналогичными или могут быть такими же, как и точки 315 упакованного кода переменной длины, используемые для инструкции 304 определения длины точки упакованного кода переменной длины по фиг. 3. Например, та же последовательность точек кода может вначале быть обработана инструкцией 304 на фиг. 3, и затем может быть обработана инструкцией 606 на фиг. 6.
В некоторых вариантах осуществления, инструкция выделения битов знака точки упакованного кода переменной длины (например, биты Unicode) может в явном виде устанавливать или по-другому обозначать упакованные данные 616 второго источника. В некоторых вариантах осуществления упакованные данные второго источника могут иметь две или больше упакованные длины точек удостоверенного кода переменной длины знаков 621 Unicode. Например, в некоторых вариантах осуществления упакованные длины точек удостоверенного кода переменной длины знаков 621 Unicode могут содержать два или больше значения, обозначающие значения длины двух или больше соответствующих точек кода UTF-8, как 1-байтовое, 2-байтовое, или, в случае необходимости, 3-байтовое или 4-байтовое (например, в вариантах осуществления, в которых используются 3-байтовые или 4-байтовые точки кода UTF-8). Например, в варианте осуществления, в котором используется UTF-8, значения упакованной длины точек удостоверенного кода переменной длины знаков Unicode 621 могут содержать значение (например, три), для обозначения длины 3 байта для соответствующей точки кода UTF-8, представляющей символ евро, значение (например, один), для обозначения длины 1 байт, для соответствующей точки кода UTF-8, представляющей знак доллар, и так далее.
В некоторых вариантах осуществления значения 621 упакованной длины могут представлять результат, сохраненный в ответ на вариант осуществления инструкции 104 выделения битов знака точки упакованного кода переменной длины (например, битов Unicode). Таким образом, в некоторых вариантах осуществления результат инструкции 104 может использоваться, как операнд источника инструкцией 606. Например, в некоторых вариантах осуществления, значения 621 упакованной длины могут быть аналогичны или могут быть такими же, как и значения 321 упакованной длины на фиг. 3 и/или значения 421 упакованной длины на фиг. 4. Любые из свойств и характеристик, описанных для значений 321 упакованной длины и/или значения 421 упакованной длины, также, в случае необходимости, применимы к значениям 621 упакованной длины. В качестве альтернативы, другие типы значений упакованной длины удостоверенных точек кода переменной длины знаков 621, в случае необходимости, можно использовать вместо этого, и они не ограничены генерированием инструкции 104 определения длины точки упакованного кода переменной длины. Некоторые варианты осуществления не ограничены знаками Unicode, а скорее могут использовать другие знаки или стандарты. Некоторые варианты осуществления не ограничены UTF-8, а скорее могут использовать другое кодирование переменной длины, помимо UTF-8.
В некоторых вариантах осуществления инструкция 606 выделения битов Unicode точки упакованного кода переменной длины, в случае необходимости, могут в явном виде устанавливать или по-другому обозначать место назначения 620 (например, место назначения накопителя), где полученные в результате упакованные данные должны быть сохранены в ответ на инструкцию 606. В качестве другой опции, один из источников можно повторно использовать, как место назначения, и данные источника могут быть перезаписаны результатом. В некоторых вариантах осуществления упакованные наборы выделенных битов 660 Unicode могут быть сохранены в месте назначения. Каждый набор выделенных упакованных битов Unicode может соответствовать разным соответствующим точкам кода переменной длины из первого источника 614. Каждый набор выделенных битов Unicode может включать в себя или может представлять те биты из соответствующих точек кода переменной длины, которые составляют значение Unicode или другое значение знака/символа. Набор выделенных битов Unicode может быть достаточным сам по себе для определения или транскодирования значения Unicode. В некоторых вариантах осуществления биты Unicode могут быть выделены путем логического вычитания, или по-другому удаления битов сигнатуры из соответствующих точек кода переменной длины, хотя объем изобретения не ограничен этим. Например, одна или больше логических операций может использоваться для удаления структуры сигнатуры из соответствующих точек кода переменной длины. В некоторых вариантах осуществления любая из ранее описанных структур сигнатуры может использоваться с этой целью. В других вариантах осуществления операция выделения отдельных битов на уровне бита может выполняться без таких логических операций, например, используя мультиплексоры и т.д. Следует понимать, что обработка выделения может перемещать, изменять компоновку, может перегруппировать, может выполнять конкатенацию или по-другому может манипулировать с выделенными битами Unicode различными, отличающимися друг от друга способами, если только инструкции и/или наборы инструкций, используемые для обработки выделенных битов Unicode, позволяют понять и использовать такие манипуляции. Без ограничения, такие упакованные наборы выделенных битов Unicode можно впоследствии обрабатывать одной или больше другими инструкциями для преобразования их в значения Unicode или другие форматы знаков.
Как показано, в некоторых вариантах осуществления, каждые из упакованных данных 614 первого источника упакованных данных 616 второго источника, и место 620 назначения могут представлять разный регистр упакованных данных. В качестве альтернативы, расположение в памяти или другие места расположения в накопителе можно использовать для одного или больше из таких операндов. Например, точки упакованного кода переменной длины для знаков 615 Unicode, в случае необходимости, вместо этого, могут быть сохранены в определенном месте расположения в памяти. Кроме того, один или больше операндов источников и/или мест назначения может, в случае необходимости, быть неявным для инструкции, вместо его явного установления. В качестве другого варианта, один из первого и второго операндов источника, в случае необходимости, можно повторно использовать, как операнд места назначения, и полученные в результате упакованные данные могут быть записаны поверх упакованных данных источника.
В некоторых вариантах осуществления количество выделенных 664 точек кода, в случае необходимости, могут также быть сохранены в ответ на и/или как результат инструкции 606 выделения битов Unicode точки упакованного кода переменной длины, хотя это и не требуется. Количество выделенных точек кода может представлять общее количество удостоверенных точек кода в первом операнде 614 источнике, для которого были выделены биты Unicode. Например, если первый операнд источника имеет шестнадцать удостоверенных 1-байтовых точек кода, тогда количество выделенных точек кода также может быть равно шестнадцати. В некоторых вариантах осуществления инструкция может в явном виде устанавливать или в неявном виде обозначать второе место 662 назначения, где количество выделенных точек 664 кода должно быть сохранено. Например, в одном варианте осуществления, инструкция может в неявном виде обозначать регистр общего назначения, хотя объем изобретения не ограничен этим.
На фиг. 7 показана блок-схема примерного варианта осуществления соответствующей операции 766 выделения битов Unicode точек упакованного кода UTF-8, для точек кода UTF-8. Операция может быть выполнена процессором или другим устройством обработки инструкции в ответ на и/или как результат примерного варианта осуществления инструкции выделения битов Unicode точки упакованного кода UTF-8.
Инструкция может устанавливать или по-другому обозначать точки 715 упакованного кода UTF-8. Например, точки упакованного кода UTF-8 могут находиться в регистре упакованных данных или в определенном местоположении памяти, которые установлены или по-другому обозначены инструкцией. В иллюстрируемом варианте осуществления операнд точек упакованного кода UTF-8 имеет ширину 128 битов. В других вариантах осуществления другие значения ширины, в случае необходимости, можно использовать, такие как, например, 64 бита, 256 битов, 1024 бита или некоторые другие значения ширины. Ширина 128 битов имеет шестнадцать байтов. Шестнадцать байтов позволяют сохранить переменное количество точек кода UTF-8 переменной длины, например, каждый из которых имеет от одного до двух байтов, от одного до трех байтов или от одного до четырех байтов, в зависимости от варианта осуществления. В представленном примере три байта самого низкого порядка в битах [23:0] содержат точку 731 3-байтового кода UTF-8 для символа европейской валюты (€). Четвертый байт в битах [31:24] содержит точку 732 1 - байтового кода UTF-8 для символа доллар ($). Пятый и шестой байты в битах [47:32] содержат точку 733 2-байтового кода UTF-8 для знака цент (0). В с седьмого по девятый байтах, в битах [71:48] также содержится точка 734 3-байтового кода UTF-8 для символа европейской валюты. В пятнадцатом и шестнадцатом байтах, в битах [127:112] содержатся неполные два из трех байтов точки 735 3-байтового кода UTF-8 для символа европейской валюты. Оставшийся третий байт не может быть установлен в пределах ограничения ширины 128-битов операнда, и поэтому только неполная часть символа присутствует (например, в 128-битном регистре). Конечно, здесь представлены исключительно примерные типы точек кода.
Инструкция также может устанавливать или по-другому обозначать упакованные значения длины удостоверенных точек 721 кода UTF-8. В представленном варианте осуществления операнд точек упакованного кода UTF-8 также имеет ширину 128 битов. В других вариантах осуществления другие значения ширины, в случае необходимости, могут использоваться, такие как, например, 64 бита, 256 битов, 1024 бита или некоторое другое значение ширины. Представленные значения 721 упакованной длины имеют значение, обозначающее длину 3 байта 740, соответствующую точке 731 3-байтового кода UTF-8 для первого возникновения символа евро, значение, обозначающее длину 1 байт 741, соответствующую точке 732 1-байтового кода UTF-8 для знака доллар, значение, обозначающее длину 2 байта, соответствую точке 742 2-байтового кода UTF-8 733 для символа цент, и значение, обозначающего длину 3 байта 743, соответствующее точке 734 3-байтового кода UTF-8 для второго возникновения символа европейской валюты. Как показано, в некоторых вариантах осуществления, значения, представляющие значения длины, в случае необходимости, могут быть сохранены в тех же относительных положениях байта для байтов самого низкого порядка соответствующих точек кода UTF-8, и все нули могут быть, в случае необходимости, сохранены в тех же относительных положениях байтов для любых более значимых байтов соответствующих точек кода UTF-8, хотя это и не требуется. В других вариантах осуществления, в случае необходимости, могут использоваться другие соглашения (например, нули могут быть сохранены в младшем значащем байте (байтах) и значения длины в старшем значащем байте и т.д.). Следует отметить, что в некоторых вариантах осуществления такое же количество байтов используется для упакованных значений 721 длины, как используется для соответствующих точек кода в точках 715 упакованного кода UTF-8 (например, три байта в каждом, два байта в каждом и т.д.).
В ответ на и/или как результат инструкции выделения битов Unicode точек упакованного кода UTF-8, наборы упакованных выделенных битов 760 Unicode могут быть сохранены в установленном или по-другому обозначенном месте назначения. Как показано, в некоторых вариантах осуществления, операнд назначения может представлять собой операнд шириной 512 битов (например, регистр шириной 512 битов, два регистра 256 битов, четыре регистра 128 битов и т.д.). В других вариантах осуществления, в случае необходимости, могут использоваться другие значения ширины. Каждый набор упакованных выделенных битов Unicode может соответствовать другой соответствующей точке кода переменной длины из точек 715 упакованного кода UTF-8. Каждый набор выделенных битов Unicode может включать в себя или может представлять собой те биты соответствующей точки кода переменной длины, которые сопоставляют значение Unicode или другое значение знака/символа. Набор выделенных битов Unicode может быть достаточен сам по себе для определения или транскодирования значения Unicode. В некоторых вариантах осуществления биты Unicode могут быть выделены путем логического вычитания или другого удаления битов сигнатуры и/или структур из соответствующих точек кода переменной длины, хотя объем изобретения не ограничен этим. Например, в некоторых вариантах осуществления, инструкция может обозначать две или больше структуры сигнатуры, соответствующая структура сигнатуры может быть выбрана на основе соответствующей информации длины из значений 721 упакованной длин, и одна или больше логических операций действия могут использоваться для удаления выбранной структуры сигнатуры из соответствующей точки кода переменной длины. Ранее описанные структуры сигнатуры являются соответствующими. В некоторых вариантах осуществления множество структур сигнатуры может быть сохранено в ROM или в другой энергонезависимой памяти на кристалле. В качестве альтернативы, инструкция может устанавливать или может обозначать операнд, имеющий множество структур сигнатуры. В других вариантах осуществления, вместо использования такой структуры сигнатуры, выделения на уровне бита могут быть выполнены аппаратными средствами, например, по линиям передачи, через мультиплексоры и т.д.
И снова обращаясь к фиг. 7, упакованные наборы выделенных битов 760 Unicode включают в себя первый набор выделенных битов 767 Unicode в битах [31:0], которые соответствуют точке 3-байтового кода UTF-8 для первого случая символа 731 евро, и второй набор выделенных битов 768 Unicode в битах [63:32], которые соответствует точке 1-байтового кода UTF-8 для знака 732 доллар. Наборы выделенных битов Unicode также включают в себя третий набор выделенных битов 769 Unicode в битах [95:64], которые соответствуют 2-байтовой точке кода UTF-8 для знака 733 цент, и четвертый набор выделенных битов 770 Unicode в битах [127:96], которые соответствуют 3-байтовой точке кода UTF-8 для второго случая знака 734 евро. На иллюстрации подчеркивание используется для того, чтобы представить, что биты сигнатуры или структуры сигнатуры, так, как они выглядят в точках 715 упакованного кода UTF-8, были удалены из упакованных наборов выделенных битов 731 Unicode. Таким образом, подчеркнутые установленные биты (то есть, двоичные), были преобразованы в подчеркнутые очищенные биты (то есть, двоичный ноль). Другие наборы выделенных битов Unicode также могут быть включены, если существуют другие действительные точки кода UTF-8 в точках 715 упакованного кода UTF-8. Например, вплоть до шестнадцати наборов выделенных битов Unicode, каждый из них сохранен в 32-битном элементе dword 512-битного операнда места назначения, могут быть сохранены в случае, когда упакованные точки 715 кода UTF-8 включают в себя шестнадцать 1-байтовых точек кода UTF. Как показано, в некоторых вариантах осуществления, остаточная ширина операнда назначения может содержать недействительные значения, которые могут представлять собой или могут не представлять собой заданные значения, распознаваемые соответствующими стандартами, как содержащие недействительное значение или недействительные данные (например, не распознанные значения знака Unicode).
На фиг. 8 показана блок-схема, иллюстрирующая соответствующие способы размещения или упорядочивания наборов выделенных битов Unicode в элементе упакованных данных, который может использоваться вариантами осуществления инструкциями/операциями выделения битов Unicode точки упакованного кода переменной длины. Здесь показана точка 3-байтового кода UTF-8 для символа 831 евро. В некоторых вариантах осуществления соответствующий набор выделенных битов Unicode может быть размещен или упорядочен в порядке 872 от младшего к старшему байтам в элементе данных упакованного результата и/или операнда места назначения. Это аналогично подходу, представленному и описанному выше со ссылкой на фиг. 7. В качестве альтернативы, в некоторых вариантах осуществления, соответствующий набор выделенных битов Unicode может быть размещен или упорядочен в порядке 874 от старшего к младшему байтам в элементе упакованного результата и/или операнда места назначения. В некоторых вариантах осуществления такой подход может помочь способствовать последующей обработке, будучи размещенным в формате, который хорошо подходит для определенных инструкций. Однако этот подход не требуется.
На фиг. 9 показана блок-схема последовательности операций варианта осуществления способа 978, выполняемого процессором и/или внутри процессора при обработке варианта осуществления инструкции выделения битов Unicode точки упакованного кода переменной. В некоторых вариантах осуществления операции и/или способ по фиг. 9 могут выполняться процессором и/или внутри процессора по фиг. 1 и/или по фиг. 6. Компоненты, свойства и конкретные необязательные детали, описанные здесь для процессоров на фиг. 1 и/или фиг. 6, также, в случае необходимости, применяются для операций и/или способа на фиг. 9, и эти варианты осуществления могут выполняться процессорами и/или внутри таких процессоров. В качестве альтернативы, операции и/или способ на фиг. 9 могут быть выполнены процессорами и/или внутри аналогичных или других процессоров или других устройств. Кроме того, процессоры на фиг. 1 и/или фиг. 6 могут выполнять операции и/или способы, которые являются такими же, как или аналогичными, или другими, чем те, которые показаны на фиг. 9.
Способ включает в себя: принимают инструкция выделения битов знака точки упакованного кода переменной длины в блоке 979. В различных аспектах инструкция может быть принята в процессоре или его части (например, в модуле выборки инструкции, модуле декодирования и т.д.). В различных аспектах инструкция может быть принята из источника, находящегося вне кристалла (например, из основной памяти, диска или через взаимное соединение), или из источника на кристалле (например, из кэш инструкции). В некоторых вариантах осуществления инструкция выделения битов знака точки упакованного кода переменной длины может в явном виде устанавливать или по-другому обозначать упакованные данные первого источника, имеющие множество точек упакованного кода переменной длины, каждый из которых представляет знак. Инструкция может также в явном виде устанавливать или по-другому обозначать упакованные данные второго источника, имеющие упакованные значения длины удостоверенных точек кода переменной длины из упакованных данных первого источника. Инструкция также может в явном виде устанавливать или по-другому обозначать место положения накопителя места назначения. Это включает в себя, в некоторых случаях, повторное использование одного из источников в качестве места назначения.
Получаемые в результате упакованные данные могут быть сохранены в обозначенном месте положения в накопителе места назначения в ответ на и/или в результате инструкции выделения битов знака точки упакованного кода переменной длины, в блоке 980. В некоторых вариантах осуществления получаемые в результате упакованные данные могут иметь наборы упакованных битов выделенного знака. Каждый набор выделенного знака может соответствовать другой одной из удостоверенных точек кода переменной длины из упакованных данных первого источника. В некоторых вариантах осуществления каждый набор выделенных битов знака может быть достаточным для определения знака, представленного точками кода переменной длины. В некоторых вариантах осуществления полученные в результате упакованные данные могут быть аналогичны или могут быть такими же, как и, в случае необходимости, могут иметь любую из характеристик или свойства упакованных наборов выделенных битов 660 по фиг. 6 и/или упакованных выделенных битов 760 Unicode по фиг. 7.
Для того, чтобы дополнительно иллюстрировать определенные концепции, рассмотрим подробный примерный вариант осуществления инструкции выделения битов Unicode точки упакованного кода UTF-8 с пневмоником VPVLNEXTRD. Формат инструкции может представлять собой VPVLNEXTRD DEST, SRC1, SRC2. DEST может представлять регистр упакованных данных назначения шириной 512 битов. SRC1 может представлять первый регистр упакованных данных источника шириной 128 битов или местоположение в памяти. SRC2 может представлять второй регистр упакованных данных источника шириной 128 битов. Таким образом, в некоторых вариантах осуществления DEST может быть, по меньшей мере, в четыре раза шире, чем каждый из SRC1 и SRC2. SRC1 может содержать часть потока UTF-8, представляющую кодируемую последовательность байта UTF-8. SRC2 может содержать упакованные значения длины, соответствующие удостоверенным точкам кода UTF-8 из SRC1.
Инструкция может использоваться для выделения полей бита Unicode (то есть, тех битов кодирования UTF-8, которые составляют значение Unicode) из каждой удостоверенной точки кода UTF-8 переменной длины в SRC1. Выделенные поля битов Unicode из каждой удостоверенной точки кода UTF-8 в SRC1 могут быть сохранены в разных соответствующих элементах данных в DEST (например, в соответствующем упакованном 32-битном элементе данных dword в DEST). Если значение длины, обозначенное SRC2 (например, по байту в SRC2), составляет от 1 байта до 4 байтов включительно, тогда, в некоторых вариантах осуществления, соответствующие структуры сигнатуры кодирования UTF-8 для той же длины байта могут быть получены, например, из MSROM или другой находящейся на кристалле энергонезависимой памятью. В качестве альтернативы, инструкция может в явном виде устанавливать или в неявном виде обозначать другой операнд источника для обеспечения в структуре сигнатуры кодирования UTF-8. Структура сигнатуры кодирования UTF-8 может использоваться для удаления битов сигнатуры (например, другие биты, чем биты Unicode, которые будут выделены) из соответствующей точки кода UTF-8. Остальные биты Unicode представляют биты Unicode, которые должны быть выделены, и которые достаточны для определения значения Unicode. Такие оставшиеся биты Unicode могут быть сохранены в соответствующем элементе данных, в DEST. Например, в некоторых вариантах осуществления, эти оставшиеся биты Unicode могут быть сохранены в байт-гранулярном порядке возрастания, в пределах соответствующего 32-битного элемента данных dword, хотя объем изобретения не ограничен этим.
В некоторых вариантах осуществления, если длина байта, обозначенная элементом байта в SRC2, больше чем 4 байта (если предположить, что вариант осуществления не поддерживает точки 5-байтового или 6-байтового кода UTF-8), тогда соответствующий 32-битный элемент данных dword в DEST может содержать заданное значение Unicode, представляющее недействительные входные данные. В некоторых вариантах осуществления инструкция может также, в случае необходимости, в явном виде устанавливать или в неявном виде обозначать дополнительный операнд места назначения, где общее количество выделенных точек кода UTF-8 может быть сохранено, в ответ на инструкцию, хотя это и не требуется. В качестве одного конкретного примера, инструкция может в неявном виде обозначать регистр общего назначения для предоставления этого общего количества выделенных точек кода UTF-8, хотя объем изобретения не ограничен этим. В других вариантах осуществления, в случае необходимости, могут использоваться более широкие или более узкие регистры. Например, в различных вариантах осуществления могут использоваться 64-битные, 256-битные или 512-битные регистры для SRC1 и/или SRC2, и регистры в четыре раза шире (или комбинации регистров) могут использоваться, как DEST.
Следующий псевдокод представляет другой примерный вариант осуществления соответствующей инструкции выделения битов Unicode точек упакованного кода UTF-8. В этом псевдокоде Srcl представляет первые 128-битные упакованные данные источника, имеющие часть или последовательность точек кода UTF-8. Src2 представляет вторые 128-битные упакованные данные источника, имеющие значения длины удостоверенных точек кода UTF-8. Dest представляет собой место назначения. В этом псевдокоде операция Switch (K_m) выбирает один из этих четырех случаев на основе значения длины K_m. Символ <<8 представляет сдвиг вправо на 8 битов и т.д. ZeroExt32 представляет 32-битную операцию расширения нулями старшего значащего бита.


В представленном выше описании форматы UTF-8 были выделены из-за их преобладания. Однако другие форматы кодирования переменной длины, помимо UTF-8, могут использоваться вместо этого. Например, можно полностью использовать расширение UTF-8, производные UTF-8, эквиваленты UTF-8, замена для UTF-8 или другие форматы кодирования переменной длины. Кроме того, в представленном выше описании были описаны точки кода от одно- до четырехбайтового кода, из-за их преобладания и охвата большинства знаков и языков, составляющих важность. Однако другие варианты осуществления могут расширить подходы, представленные выше, до точек пяти- или шестибайтового кода, если требуется.
Система команд включает в себя один или больше форматов инструкций. Данный формат инструкции определяет различные поля (количество битов, места расположения битов) для установления, помимо прочего, операции, которая должна быть выполнена (опкод) и операнд (операнды), по которым должна быть выполнена эта операция. Некоторые форматы инструкции дополнительно разбивают путем определения шаблонов инструкции (или подформатов). Например, шаблоны инструкции заданного формата инструкции могут быть определены, как имеющие разные поднаборы полей формата инструкции (включенные в поля обычно в том же порядке, но, по меньшей мере, некоторые имеют другие положения битов, поскольку в них включено меньшее количество полей), и/или определены иметь заданное поле, интерпретируемое по-другому. Таким образом, каждая инструкция ISA выражена, используя заданный формат команды (и, если определен, в заданном одном из шаблонов инструкций этого формата инструкции) и включает в себя поля для установления операции и операндов. Например, примерная инструкция add имеет определенный код операции и формат инструкции, который включает в себя поле кода операции для установления этих полей кода операции и операнда, для выбора операндов (источник 1/место назначения и источник 2); и возникновение такой инструкции add в потоке инструкций будет иметь определенное содержание в полях операнда, которые выбирают определенные операнды. Набор расширений SIMD обозначен, как усовершенствованные векторы расширения (AVX) (AVX1 и AVX2), и использующих схему кодирования вектора расширения (VEX), были выпущены и/или опубликованы (например, см. Intel® 64 and IA-32 Architectures Software Developers Manual, October 2011; and see Intel® Advanced Vector Extensions Programming Reference, June 2011).
Примерные форматы инструкции
Варианты осуществления инструкции (инструкций), описанной здесь, могут быть воплощены в разных форматах. Кроме того, примерные системы, архитектуры и конвейеры обработки определены ниже. Варианты осуществления инструкции (инструкций) могут быть выполнены в таких системах, архитектурах и конвейерах обработки, но не ограничены этими деталями.
Обобщенный формат инструкции, удобный для векторной операции Формат инструкции, удобный для векторной операции, представляет собой формат инструкции, который приспособлен для векторных инструкций (например, существуют некоторые поля, специфичные для векторных операций). В то время, как описаны варианты осуществления, в которых поддерживаются как векторные, так и скалярные операции, используя удобный для векторных операций формат инструкции, в альтернативных вариантах осуществления, в которых используются только векторные операции, используется формат инструкции, удобный для векторных операций.
На фиг. 10A-10В показаны блок-схемы, иллюстрирующие обобщенный формат инструкции, удобный для векторных операций, и его шаблоны инструкции, в соответствии с вариантами осуществления изобретения. На фиг. 10А показа блок-схема, иллюстрирующая обобщенный формат инструкции, удобной для векторной операции и его шаблоны инструкции класса А, в соответствии с вариантами осуществления изобретения; в то время как на фиг. 10В показана блок-схема, иллюстрирующая обобщенный формат инструкции, удобный для векторных операций, и его шаблоны инструкции класса В, в соответствии с вариантами осуществления изобретения. В частности, обобщенный формат 1000 инструкции, удобный для векторных операций, для которого определены шаблоны инструкции класса А и класса В, оба из которых не включают в себя шаблоны инструкции доступа 1005 к памяти и шаблоны инструкции доступа 1020 к памяти. Термин, обобщенный в контексте векторного формата инструкции, удобного для векторных операций, относится формату инструкции, который не привязан к какому-либо конкретному набору инструкций.
В то время как были описаны варианты осуществления изобретения, в которых формат инструкции, удобный для векторных операций, поддерживает следующее: длину (или размер) векторного операнда 64 байта с 32 битами (4 байтами) или 64 бита (8 байтов ширина (или размер) элементов данных (и, таким образом, 64-байтовый вектор состоит либо из 16 элементов размером двойное слово или, в качестве альтернативы, из 8 элементов размером учетверенное слово); длину (или размер) векторного операнда 64 байта с 16 битами (2 байтами) или 8 битами (1 байтом) шириной (или размерами) элемента данных; длину (или размер) векторного операнда 32-байта со значениями 32 бита (4 байта), 64 бита (8 байтов), 16 бита (2 байта), или 8 битов (1 байт) ширины (или размера) элемента данных; и длину (или размер) векторного операнда со значениями 16-байтов со значениями 32 бита (4 байта), 64 бита (8 байтов), 16 битов (2 байта) или 8 битов (1-байт) ширины (или размеры) элемента данных; в альтернативных вариантах осуществления могут поддерживаться большие, меньшие и/или другие размеры векторного операнда (например, векторные операнды 256 байтов) с большими, меньшими или другими значениями ширины элемента данных (например, 128 бита (16 байтов) ширины элемента данных).
Шаблоны инструкции класса А на фиг. 10А включают в себя: 1) в пределах шаблонов инструкции без доступа 1005 к памяти представлено отсутствие доступа к памяти, шаблон инструкции операции 1010 типа полного управления округлением и без доступа к памяти, и шаблон инструкции операции 1015 типа преобразования данных без доступа к памяти; и 2) в пределах шаблонов инструкции 1020 доступа к памяти представлен доступ к памяти, временные 1025 шаблоны инструкции и доступ к памяти, не временные 1030 шаблоны инструкции. Шаблоны инструкции класса В на фиг. 10В включают в себя: 1) в пределах шаблонов инструкции без доступа к памяти 1005 представлено отсутствие доступа к памяти, управление маской записи, шаблон инструкции операции 1012 типа частичного управления округлением и без доступа к памяти, управление маской записи, шаблон инструкции операции 1017 типа vsize; и 2) в пределах шаблонов инструкции доступа 1020 к памяти представлен доступ к памяти, представлен шаблон инструкции управления 1027 маской записи с доступом к памяти.
Обобщенный формат 1000 инструкции, удобной для векторной операции, включает в себя, следующие поля, упомянутые ниже в виде списка в порядке, показанном на фиг. 10A-10В.
Поле 1040 формата - определенное значение (значение идентификатора формата инструкции) в этом поле уникально идентифицируется формат инструкции, удобный для векторной операции, и, таким образом, он сталкивается с инструкциями в формате инструкции, удобном для векторной операции в потоках инструкций. Также, это поле является необязательным в том смысле, что оно не требуется для набора инструкций, который имеет только обобщенный формат инструкций, удобный для векторной операции.
Поле 1042 основной операции - его содержание распознает различные основные операции.
Поле 1044 индекса регистра - его содержание, прямо или через генерирование адресов, устанавливает местоположения операндов источника и места назначения, независимо от того, находятся ли они в регистрах или в памяти. Это включает в себя достаточное количество битов для выбора N регистров из P×Q (например, 32×512, 16×128, 32×1024, 64×1024) файла регистра. В то время, как в одном варианте осуществления N может составлять вплоть до трех источников и один регистр места назначения, альтернативные варианты осуществления могут поддерживать большее или меньшее количество источников и регистров места назначения (например, могут поддерживать вплоть до двух источников, где один из этих источников также действует, как место назначения, могут поддерживать вплоть до трех источников, где один из этих источников также действует, как место назначения, могут поддерживать вплоть до двух источников и одно место назначения).
Поле 1046 модификатора - его содержание распознает возникновение инструкций в обобщенном формате векторной инструкции, которые устанавливают доступ к памяти из тех, которые не имеют этот доступ; то есть, между шаблонами инструкции без доступа 1005 к памяти и шаблонами инструкции с доступом 1020 к памяти. Операции доступа к памяти выполняют считывание и/или запись в иерархии памяти (в некоторых случаях устанавливая адреса источника и/или места назначения, используя значения в регистрах), в то время, как операции без доступа к памяти не выполняют это (например, места источника и назначения представляют собой регистры). В то время, как в одном варианте осуществления такое поле также выбирает между тремя разными способами для выполнения расчетов адреса памяти, в альтернативных вариантах осуществления могут поддерживаться больший, меньший или другие способы для выполнения расчетов адреса памяти.
Поле 1050 операции приращения - его содержание различает, какая одна из множества разных операций должна быть выполнена в дополнение к основной операции. Это поле является специфичным, в зависимости от контекста. В одном варианте осуществления изобретения такое поле разделяют на поле 1068 класса, поле 1052 альфа и поле 1054 бета. Поле 1050 операции приращения позволяет выполнять общие группы операций в одной инструкции вместо 2, 3 или 4 инструкций.
Поле 1060 масштаба - его содержание позволяет масштабировать содержание поля индекса для генерирования адреса памяти (например, для генерирования адреса, в котором используется 2масштаб * индекс + основание).
Поле 1062А перемещения - его содержание используется, как часть генерирования адреса памяти (например, для генерирования адреса, в котором используется 2 масштаб * индекс + основание + смещение).
Поле 1062В фактора перемещения (следует отметить, что 2 поля 1062 сопоставления поля 1062А перемещения непосредственно поверх поля 1062В фактора перемещения обозначают, что одно или другое из них используется) - его содержание используется, как часть генерирования адреса; оно устанавливает фактор смещения, который должен быть масштабирован по размеру доступа (N) к памяти - где N представляет собой количество байтов при доступе к памяти (например, для генерирования адреса, в котором используется 2 масштаб * индекс + основание + масштабированное смещение). Избыточные биты младшего порядка игнорируют и, следовательно, поля коэффициента смещения умножают на общий размер (N) операндов памяти для генерирования конечного смещения, которое должно использоваться при расчете эффективного адреса. Значение N определяют аппаратные средства процессора во время работы на основе полного поля 1074 опкода (описан здесь ниже) и поля 1054С манипуляции с данными. Поле 1062А перемещения и поле 1062В фактора перемещения являются необязательными в том смысле, что они не используются для шаблонов инструкции без доступа 1005 к памяти, и/или в других вариантах осуществления может воплощаться только один или ни один из двух.
Поле 1064 ширины элемента данных - по его содержанию различают, какое одно из множества значений ширины элемента данных следует использовать (в некоторых вариантах осуществления для всех инструкций; в других вариантах осуществления только для некоторых инструкций). Это поле является необязательным в том смысле, что оно не требуется, если только одно значение ширины элемента данных поддерживается, и/или значение ширины элемента данных поддерживается, используя некоторый аспект опкодов.
Поле 1070 маски записи - его содержание управляет на основе положения каждого элемента данных, отражает ли положение этого элемента данных в операнде вектора назначения результат основной операции и операции приращения. Шаблоны инструкции класса А поддерживают слияние - использование маски записи, в то время как шаблоны инструкции класса В поддерживают, как слияние, так и использование маски записи с обнулением. При слиянии векторные маски позволяют защищать любой из элементов в месте назначения от обновления, во время исполнения любой операции (установлено основной операцией и операцией приращения); в другом одном варианте осуществления, сохранение старого значения каждого элемента места назначения, где соответствующий бит маски имеет 0. В отличие от этого, когда маска вектора обнуления позволяет обнулять любой набор элементов в месте назначения во время исполнения любой операции (установленной основной операцией и операцией приращения); в одном варианте осуществления элемент места назначения устанавливают в 0, когда соответствующий бит маски имеет значение 0. Поднабор этих функций представляет собой способность управлять длиной вектора выполняемой операции (то есть, размах элементов модифицируется с первого по последний); однако, нет необходимости, чтобы элементы, которые модифицируют, были последовательными. Таким образом, поле 1070 маски записи позволяет частичные векторные операции, включающие в себя нагрузки, накопители, арифметические, логические операции и т.д. В то время как описаны варианты осуществления изобретения, в которых содержание поля 1070 маски записи выбирает один из множества регистров маски записи, который содержит маску записи, предназначенную для использования (и, таким образом, содержание поля 1070 маски записи опосредованно идентифицирует, что применение этой маски должно быть выполнено), в альтернативных вариантах осуществления, вместо этого или в дополнение, разрешается, чтобы содержание поля 1070 маски записи прямо устанавливало маску, которая должна быть выполнена.
Непосредственное поле 1072 - его содержание позволяет устанавливать непосредственный операнд. Это поле является необязательным в том смысле, что оно не присутствует в варианте осуществления обобщенного формата, удобного для векторной операции, который не поддерживает непосредственный операнд, и оно не присутствует в инструкциях, в которых не используется непосредственный операнд.
Поле 1068 класса - его содержание различает разные классы инструкций. Со ссылкой на фиг. 10А-В, содержание этого поля выбирают между инструкциями класса А и класса В. На фиг. 10А-В используют квадраты с закругленным углом для обозначения, что определенное значение присутствует в поле (например, класс А 1068А и класс В 1068В для поля класса 1068, соответственно, на фиг. 10А-В).
Шаблоны инструкции класса А
В случае шаблонов инструкции без доступа 1005 к памяти класса А поле 1052 альфа интерпретируют, как поле 1052А RS, содержание которого различает, какой один из разных типов операции приращения должен быть выполнен (например, округление 1052А.1 и преобразование 1052А.2 данных, соответственно, установлены для доступа к памяти операции 1010 типа округления и операции 1015 типа преобразования данных без доступа к памяти (шаблоны инструкции)), в то время как поле 1054 бета различает, какие из операций определенного типа 1 должны быть выполнены. В шаблонах инструкции без доступа 1005 к памяти поле 1060 масштаба, поле 1062А перемещения и поле 1062В масштаба смещения не присутствуют.
Шаблоны инструкции без доступа к памяти - операция типа полного управления округлением
В шаблоне инструкции операции 1010 типа полного управления округлением без доступа к памяти поле 1054 бета интерпретируется, как поле 1054А управления округлением, содержание которого обеспечивает статическое округление. В то время, как в описанных вариантах осуществления изобретения поле 1054А управления округлением включает в себя подавление всех полей 1056 (SAE) исключения плавающей точки и поле 1058 управления операцией округления, в альтернативных вариантах осуществления могут поддерживаться и могут кодироваться обе эти концепции в одно и то же поле или могут иметь только одну или другую из этих концепций/полей (например, могут иметь только поле 1058 управления операцией округления).
Поле 1056 SAE - его содержание определяет, следует или нет сделать недействительной отчетность о событии исключения; когда содержание поля 1056 SAE обозначает, что подавление разрешено, заданная инструкция не отчитывается о любом виде флага исключения плавающей точки, и не вызывает какой-либо обработчик исключений плавающей точки.
Поле 1058 управления операцией округления - его содержание различает, какая одна из группы операций округления должна быть выполнена (например, округление вверх, округление вниз, округление в направлении нуля и округление до ближайшего). Таким образом, поле 1058 управления операцией округления позволяет изменять режим округления на основе каждой инструкции. В одном варианте осуществления изобретения, где процессор включает в себя регистр установления инструкциями для установления режимов округления, содержание поля 1050 управления операцией округления замещает это значение в регистре.
Шаблоны инструкции без доступа к памяти - Операция типа преобразования данных
В шаблоне инструкции операции 1015 типа преобразования данных доступа к памяти поля 1054 бета интерпретируется, как поле 1054 В преобразования данных, содержание которого различает, какое одно из множества преобразований данных следует выполнить (например, без преобразования данных, смешанное, с многоадресной передачей).
В случае шаблонов инструкции доступа 1020 к памяти класса А поле 1052 альфа интерпретируется, как поле 1052В подсказки на замещение, содержание которого различает, какая одна из подсказок на замещение должна использоваться (на фиг. 10А, временная 1052В.1 и невременная 1052В.2, соответственно установлены для доступа к памяти, временный 1025 шаблон инструкции и невременный 1030 шаблон инструкции без доступа к памяти), в то время как поле 1054 бета интерпретируется, как поле 1054С манипуляции с данными, содержание которого различает, какая одна из множества операций манипуляции с данными (также известными как примитивы) должна быть выполнена (например, без манипуляций; многоадресная передача; преобразование вверх источника; и преобразование вниз места назначения). Шаблоны инструкции доступа 1020 к памяти включают в себя поле 1060 масштаба, и, в случае необходимости, поле 1062А перемещения или поле 1062В масштаба смещения.
Инструкции векторной памяти выполняют векторные нагрузки из и сохранение вектора в памяти, с поддержкой преобразования. Как и в регулярных векторных инструкциях, данные переноса инструкции векторной памяти из/в память, в виде элементов данных для каждого элемента в элементах, которые фактически передают, диктуются содержанием векторной маски, которую выбирают, как маску записи.
Шаблоны инструкции доступа к памяти - временные
Временные данные представляют собой данные, которые, вероятно, будут повторно использованы достаточно скоро, чтобы использовать кэширование. Они, однако, представляют подсказку и разные процессоры могут воплощать их по-разному, включая в себя полное игнорирование подсказки.
Шаблоны инструкции доступа к памяти - не временные
Не временные данные представляют собой данные, уникальные для их достаточно скорого повторного использования с тем, чтобы пользоваться кэшированием в кэш 1 уровня и для замещения должен быть задан приоритет. Они, однако, представляют собой подсказку, и разные процессоры могут воплощать их по-разному, включая в себя полное игнорирование этой подсказки.
Шаблоны инструкции класса В
В случае шаблонов инструкции по классу В альфа-поле 1052 интерпретируется как поле 1052С управления (Z) маской записи, содержание которого различает, следует ли выполнить слияние или обнуление маски записи, управляемой полем 1070 маски записи.
В случае шаблонов инструкции без доступа 1005 к памяти класса В часть бета-поля 1054 интерпретируется, как поле 1057А RL, содержание которого различает, какой одни из разных типов операции приращения следует выполнить (например, округление 1057А.1 и определение векторной длины (VSIZE) 1057А.2, соответственно, установлены без доступа к памяти управления маской записи, шаблон инструкции 1012 операции типа управления частичным округлением и управление маской записи без доступа к памяти, шаблон инструкции операции 1017 типа VSIZE), в то время как остальное бета-поле 1054 различает, какие из операций установленного типа 1 следует выполнить. В шаблонах инструкции без доступа 1005 к памяти поле 1060 масштаба, поле 1062А перемещения и поле 1062 В масштаба перемещения не присутствуют.
В случае шаблона инструкции операции 1010 типа управлении частичного округления управления маской записи без доступа к памяти, остальная часть бета-поля 1054 интерпретируется, как поле 1059А операции округления, и отчетность о событии исключения отключена (данная инструкция не передает отчет о каком-либо флаге исключения с плавающей точкой, и не вызывает какой-либо обработчик исключений плавающей точки).
Поле 1059А управления операцией округления - так же, как и поле 1058 управления операцией округления, его содержание различает, какую одну из группы операций округления следует выполнить (например, округление с повышением, округление с понижением, округление в направлении нуля и округление к ближайшему). Таким образом, поле 1059А управления операцией округления позволяет изменять режим округления на основе для каждой инструкции. В одном варианте осуществления изобретения, в случае, когда процессор включает в себя регистр управления, для установления режимов округления, содержание поля 1050 управления операцией округления замещает это значение регистра.
При отсутствии доступа к памяти, маска записи управляет шаблоном инструкции 1017 операции типа VSIZE, остальная часть бета-поля 1054 интерпретируется, как поле 1059 В длины вектора, содержание которого различает, какое одно из множества значений длины вектора данных следует выполнить (например, 128, 256 или 512 байтов).
В случае шаблона инструкции доступа 1020 к памяти по классу В часть бета-поля 1054 интерпретируется, как поле 1057В многоадресной передачи, содержание которого различает, следует или нет выполнить операцию манипуляции с данными типа многоадресной передачи, в то время как остальную часть бета-поля 1054 интерпретируют, как поле 1059В длины вектора. Шаблоны инструкции доступа 1020 к памяти включают в себя поле 1060 масштаба, и, в случае необходимости, поле 1062А шкалы или поле 1062В шкалы перемещения.
Что касается обобщенного формата 1000 инструкции, удобного для векторной операции, показано полное поле 1074 опкода, включающее в себя поле 1040 формата, поле 1042 основной операции и поле 1064 ширины элемента данных. В то время, как показан один вариант осуществления, где полное поле 1074 опкода включает в себя все эти поля, полное поле 1074 опкода включает в себя меньше чем все эти поля в вариантах осуществления, не все из которых поддерживаются. Полное поле 1074 опкода обеспечивает код операции (опкод).
Поле 1050 операции приращения, поле 1064 ширины элемента данных, и поле 1070 маски записи позволяют устанавливать эти свойства на основе для каждой инструкции в обобщенном формате инструкции, удобном для векторной операции.
Комбинация поля маски записи и поля ширины элемента данных формирует отпечатанные инструкции в том виде, что они позволяют применять маску на основе разных значений ширины элемента данных.
Различные шаблоны инструкции, которые можно найти в пределах класса А и класса В, являются полезными в разных ситуациях. В некоторых вариантах осуществления изобретения разные процессоры или разные ядра в процессоре могут поддерживать только класс А, только класс В или оба класса. Например, ядро высокой производительности общего назначения, работающее не по порядку, предназначенное для расчетов общего назначения, может поддерживать только класс В, ядро, предназначенное, в основном, для графических и/или научных (высокая производительность) вычислений может поддерживать только класс А, и ядро, предназначенное для обоих из них, может поддерживать оба из них (конечно, такое ядро, имеет некоторую смесь шаблонов и инструкций и обоих классов, но не все шаблоны и инструкции из обоих классов находятся в пределах сферы применения изобретения). Кроме того, один процессор может включать в себя множество ядер, все из которых поддерживают один и тот же класс или в котором разные ядра поддерживают разные классы. Например, в процессоре с отдельными графическими ядрами и ядрами общего назначения одно из графических ядер, предназначенное, в основном, для графических и/или научных вычислений, может поддерживать только класс А, в то время как одно или больше из ядер общего назначения может представлять собой ядро общего назначения с высокой производительностью, с исполнением не по порядку и с переименованием регистра, предназначенного для вычислений общего назначения, которое поддерживает только класс В. Другой процессор, который не имеет отдельное графическое ядро, может включать в себя на одно больше ядер общего назначения, работающих по порядку, или работающих не по порядку, которые поддерживают как класс А, так и класс В. Конечно, свойства из одного класса также могут быть воплощены в другом классе в других вариантах осуществления изобретения. Программы, записанные на языке высокого уровня, могут быть помещены (например, как компилированные в нужное время или статически компилированные) в разнообразие различных исполняемых форм, включающих в себя: 1) форму, имеющую только инструкции класса (классов), поддерживаемых целевым процессором для исполнения; или 2) форму, имеющую альтернативные процедуры, записанные, используя разные комбинации инструкций всех классов и имеющие код потока управления, который выбирает процедуры для исполнения на основе инструкций, поддерживаемых процессором, которые в настоящее время исполняет код.
Примерный формат специфичной инструкции, удобной для исполнения векторной операции
На фиг. 11А показана блок-схема, иллюстрирующая примерный формат специфичной инструкции, удобной для векторной операции, в соответствии с вариантами осуществления изобретения. На фиг. 11В показан формат 1100 специфичной инструкции, удобной для векторной операции, которая является специфичной в том смысле, что она устанавливает местоположение, размер, интерпретацию и порядок полей, а также значения для некоторых из этих полей. Формат 1100 специфичной инструкции, удобной для векторной операции, может использоваться для расширения набора инструкций х86, и, таким образом, некоторые из полей являются аналогичными или такими же, как используются в существующем наборе инструкций х86 и их расширениях (например, AVX). Этот формат остается соответствующим полю кодирования с префиксом, полю реального байта опкода, полю MOD R/M, полю SIB, полю перемещения и полям непосредственного операнда существующего набора инструкций х86 с расширениями. Здесь представлены поля были с фиг. 10, на которой иллюстрируются поля с фиг. 11А.
Следует понимать, что, хотя варианты осуществления изобретения описаны со ссылкой на формат 1100 специфичной инструкции, удобной для векторной операции в контексте формата 1000 обобщенной инструкции, удобной для векторной операции с целью иллюстрации, изобретение не ограничено форматом 1100 специфичной инструкции, удобной для векторной операции, за исключением в случая, когда это заявлено в формуле изобретения. Например, формат 1000 обобщенной инструкции, удобной для векторной операции предусматривает множество возможных размеров для разных полей, в то время как формат 1100 специфичной инструкции, удобной для векторной операции, показан как имеющий поля со специфичными размерами. В качестве специфичного примера, в то время, как поле 1064 ширины элемента данных показано как однобитовое поле в формате 1100 специфичной инструкции, удобной для векторной операции, изобретение не ограничено (то есть, формат 1000 обобщенной инструкции, удобной для векторной операции предусматривает другие размеры поля 1064 ширины элемента данных).
Формат 1000 обобщенной инструкции, удобной для векторной операции, включает в себя следующие поля, упомянутые ниже в порядке, показанном на фиг. 11А.
EVEX префикс (байты 0-3) 1102 - кодировано в четырехбайтовой форме.
Поле 1040 формата (EVEX байт 0, биты [7:0]) - первый байт (байт 0 EVEX) представляет собой поле 1040 формата, и содержит 0×62 (уникальное значение, используемое для различения формата инструкции, удобной для векторной операции в одном варианте осуществления изобретения).
Вторые четыре байты (Байты 1-3 EVEX) включают в себя множество полей битов, обеспечивающих определенную способность.
Поле 1105 REX (Байт 1 EVEX, биты [7-5]) - состоит из поля битов EVEX.R (EVEX байт 1, бит [7] - R), поле битов EVEX.X (байт 1 EVEX, бит [6] - X), и байт 1 1057 ВЕХ, бит [5] - В). Поля битов EVEX.R, EVEX.X и EVEX.B обеспечивают ту же функцию, как и соответствующие поля битов VEX, и ИХ кодируют, используя форму дополнения до 1. То есть, ZMM0 кодируется как 1111В, ZMM15 кодируется как 0000 В. Другие поля инструкций кодируют нижние три бита индексов регистра, как известно в данной области техники (rrr, xxx и bbb), таким образом, что Rrrr, Хххх и Bbbb могут быть сформированы путем суммирования EVEX.R, EVEX.X и EVEX.B.
Поле REX' 1010 - оно представляет собой первую часть поля 1010 REX' и представляет собой поле бита EVEX.R' (Байт 1 EVEX, бит [4] - R'), который используется для кодирования либо верхних 16 или нижних 16 из расширенного 32 наборов регистров. В одном варианте осуществления изобретения этот бит, вместе с другими, как обозначено ниже, сохранен в инвертированном формате бита, для его различения (в хорошо известном 32-битном режиме х86) из инструкции BOUND, реальный байт опкода которой составляет 62, но при этом не приемлем в поле MOD R/M (описано ниже) со значением 11 в поле MOD; альтернативные варианты осуществления изобретения не содержат этот и другие обозначенные биты ниже в инвертированном формате. Значение 1 используется для кодирования нижних 16 регистров. Другими словами, R'Rrrr сформировано путем комбинирования EVEX.R', EVEX.R и других RRR из других полей.
Поле 1115 карты опкода (байт EVEX 1, биты [3:0] - mrnmm) - его содержание кодирует подразумеваемый ведущий байт опкода (OF, OF 38 или OF 3).
Поле 1064 ширины элемента данных (байт EVEX 2, бит [7] - W) - представлен обозначением EVEX.W. EVEX.W используется для определения гранулярности (размера) типа данных (либо 32-битные элементы данных, или 64-битные элементы данных).
EVEX.VVW 1120 (Байт 2 EVEX, биты [6:3]-vvvv) - роль EVEX.vvvv может включать в себя следующее: 1) EVEX.vvvv кодирует первый операнд регистра источника, установленный в инвертированной (дополняющей до 1) форме, и он является действительным для инструкций с 2 или больше операндами источника; 2) EVEX.vvvv кодирует операнд регистра места назначения, установленный в форме, дополняющей до 1 для определенных сдвигов вектора; или 3) EVEX.vvvv не кодирует какой-либо операнд, поле зарезервировано и должно содержать 1111b. Таким образом, поле 1120 EVEX.vvvv кодирует 4 бита низкого разряда первого спецификатора регистра источника, сохраненного в инвертированной (дополняющей до 1) форме. В зависимости от инструкции дополнительное другое поле бита EVEX используется для расширения размера спецификатора до 32 регистров.
Поле класса EVEX.U 1068 (байт 2 EVEX, бит [2]-U) - Если EVEX.U=0, это обозначает класс А или EVEX.U0; если EVEX.U=1, это обозначает класс В или EVEX.U 1.
Поле 1125 кодирования префикса (байт 2 EVEX, биты [1:0] - рр) - предусматривает дополнительные биты для поля основной операции. В дополнение к предоставлению поддержки для наследуемых инструкций S SE в формате префикса EVEX это также имеет преимущество представления в компактной форме префикса SIMD (вместо требования байта для выражения префикса SIMD, префикс EVEX требует только 2 бита). В одном варианте осуществления, для поддержки наследуемых инструкций S SE, которые используют префикс SIMD (66Н, F2H, F3H) как в наследуемом формате, так и в формате префикса EVEX, такие наследуемые префиксы SIMD кодируют в поле кодирования префикса SIMD; и во время исполнения расширяют в наследуемый префикс SIMD перед предоставлением в PLA декодера (таким образом, PLA может исполнить как наследуемый формат, так и формат Ε VEX этих наследуемых инструкций без модификации). Хотя более новые инструкции могут использовать содержание поля кодирования префикса EVEX непосредственно, как расширение опкода, некоторые варианты осуществления расширяют аналогичным образом для соответствия, но позволяют устанавливать другие значения для этих наследуемых префиксов SIMD. Альтернативный вариант осуществления может по-другому скомпоновать PLA для поддержки кодирования 2-битного префикса SIMD, и, таким образом, не требует расширения.
Поле 1052 альфа (байт EVEX 3, бит [7] - ЕН; также известны как EVEX.EH, EVEX.rs, EVEX.RL, EVEX.write управления маской записи и EVEX.N; также представленные с) - как описано выше, это поле является специфичным для контекста.
Бета-поле 1054 (байт 3 EVEX, биты [6:4]-SSS, также известные как EVEX.S2-0, EVEX.r2-o, EVEX.rr1, EVEX.LLO, EVEX.LLB; также представленные с РРР) - как описано выше, это поле является специфичным для контекста.
Поле 1010 REX' - оно представляет собой остаток поля REX' и представляет собой поле бита EVEX.V (Байт 3 EVEX, бит [3] - V'), который может использоваться для кодирования либо верхних 16, или нижних 16 из расширенного 32 набора регистров. Этот бит сохранен в инвертированном формате бита. Значение 1 используется для кодирования нижних 16 регистров. Другими словами, V'VVVV формируется путем комбинирования EVEX.V', EVEX.vvvv.
Поле 1070 маски записи (байт 3 EVEX, биты [2:0]-kkk) - его содержание устанавливает индекс регистра в регистрах маски записи, как описано выше. В одном варианте осуществления изобретения конкретное значение EVEX.kkk=000 имеет специальное поведение, подразумевающее, что маска записи не используется для определенной инструкции (это может быть воплощено различными способами, включая в себя использование маски записи, которая аппаратно выполнена для всех из них или для аппаратных средств, которые обходят аппаратные средства, устанавливающие маску).
Поле 1130 реального опкода (Байт 4) также известно, как байт опкода. Часть опкода установлена в этом поле.
Поле 1140 MOD R/M (Байт 5) включает в себя поле 1142 MOD, поле 1144 Reg и поле 1146 R/M. Как описано выше, контекст поля 1142 MOD различает между операциями с доступом к памяти и без доступа к памяти. Роль поля 1144 Reg может быть сведена к двум ситуациям: кодирование либо операнда регистра или места назначения, или операнда регистра источника, или может рассматриваться, как расширение опкода и может не использоваться для кодирования какого-либо операнда инструкции. Роль поля 1146 R/M может включать в себя следующее: кодирование операнда инструкции, который ссылается на адрес в памяти, либо кодирование либо операнда регистра назначения, или операнда регистра источника.
Байт, шкала, индекс основания (SIB) (Байт 6) - как описано выше, содержания поля 1050 шкалы используются для генерирования адреса в памяти. SIB.xxx 1154 и SIB.bbb 1156 - на содержание этих полей была ранее сделана ссылка в отношении индексов Хххх и Bbbb регистра.
Поле 1062А перемещения (Байты 7-10) - когда поле 1142 MOD содержит 10, байты 7-10 представляют собой поле 1062А перемещения, и оно работает так же, как и наследуемое 32-битное перемещением (disp32) и работает при байтовой гранулярности.
Поле 1062 В фактора перемещения (Байт 7) - когда поле 1142 MOD содержит 01, байт 7, представляет собой поле 1062 В фактора перемещения. Местоположение этого поля является таким же, как и у установленной наследуемой инструкции х86 перемещения на 8 бит (disp8), которое работает при байтовой гранулярности. Поскольку disp8 расширено с добавлением знака, оно может выполнять адресацию только между -128 и 127 байтами смещения; в том, что касается линий кэш байта 64, disp8 использует 8 битов, которые можно установить только в четыре реально полезных значения -128,-64, 0 и 64; поскольку часто требуется больший диапазон, используют disp32; однако, disp32 требует 4 байтов. В отличие от disp8 и disp32, поле 1062 В фактора перемещения представляет собой реинтерпретацию disp8; когда используют поле 1062 В поля фактора перемещения, фактическое перемещение определяют по содержанию поля фактора перемещения, умноженного на размер доступа (N) к операнду памяти. Такой тип перемещения называется disp8*N. Это уменьшает среднюю длину инструкции (один байт используется для перемещения, но с на много большим диапазоном). Такое сжатое перемещение основано на предположении, что эффективное перемещение является кратным для гранулярности адреса памяти, и, следовательно, избыточные биты низкого порядка смещения адреса не требуется кодировать. Другими словами, поле 1062 В фактора перемещения заменяет наследуемый набор инструкций х86 при 8-битном перемещении. Таким образом, поле 1062 В фактора перемещения кодируют так же, как и набор инструкций х86 8-битного перемещения (таким образом, не происходят какие-либо изменения в правилах ModRM/правилах кодирования SIB) с единственным исключением, что в disp8 перегружают для disp8*N. Другими словами, отсутствуют какие-либо изменения в правилах кодирования или в значениях длины кодирования, но только в интерпретации значения перемещения аппаратными средствами (которые должны масштабировать перемещение по размеру операнда памяти, для получения смещения адреса, выраженного в байтах).
Непосредственное поле 1072 работает, как описано выше.
Поле полного опкода
На фиг. 11В показана блок-схема, иллюстрирующая поля формата 1100 специфичной инструкции, удобного для векторной операции, которые составляют полное поле 1074 опкода, в соответствии с одним вариантом осуществления изобретения. В частности, полное поле 1074 опкода включает в себя поле 1040 формата, поле 1042 основной операции и поле 1064 ширины (W) элемента данных. Поле 1042 основной операции включает в себя поле 1125 кодирования префикса, поле 1115 отображения опкода, и поле 1130 реального опкода.
Поле индекса регистра
На фиг. 11С показана блок-схема, иллюстрирующая поля формата 1100 специфичной инструкции, удобного для векторной операции, которые составляют поле 1044 индекса регистра, в соответствии с одним вариантом осуществления изобретения. В частности, поле 1044 индекса регистра включает в себя поле 1105 REX, поле 1110 REX', поле 1144 MODR/M.reg, поле 1146 MODR/M.r/m, поле 1120 WW, поле 1154 ххх и поле 1156 bbb.
Поле операции приращения
На фиг. 11D показана блок-схема, иллюстрирующая поля формата 1100 специфичной инструкции, удобного для векторной операции, которые составляют поле 1050 операции приращения, в соответствии с одним вариантом осуществления изобретения. Когда поле 1068 класса (U) содержит 0, оно обозначается, как EVEX.U0 (класс А 1068А); когда оно содержит 1, оно обозначает EVEX.U1 (класс В 1068В). Когда U=0 и в поле 1142 MOD содержится 11 (что обозначает операцию с отсутствием доступа к памяти), альфа-поле 1052 (байт 3 EVEX, бит [7] - ЕН) интерпретируется, как поле 1052А. Когда поле 1052A RS содержит 1 (округление 1052А.1), бета-поле 1054 (байт 3 EVEX, биты [6:4] - SSS) интерпретируется как поле 1054А управления округлением. Поле 1054А управления округлением включает в себя однобитное поле 1056 SAE и двухбитное поле 1058 операции округления. Когда поле 1052А RS содержит 0 (преобразование 1052А.2 данных), бета-поле 1054 (байт 3 EVEX, биты [6:4] - SSS) интерпретируется, как трехбитное поле 1054 В преобразования данных. Когда U=0 и поле 1142 MOD содержит 00, 01 или 10 (что обозначает операции с доступом к памяти), альфа-поле 1052 (байт 3 EVEX, бит [7] - ЕН) интерпретируется, как поле 1052 В подсказки на замещения (ЕН), и бета-поле 1054 (байт 3 EVEX, биты [6:4] - SSS) интерпретируется как трехбитное поле 1054С манипуляции с битами данных.
Когда U=1, альфа-поле 1052 (байт 3 EVEX, бит [7] - ЕН) интерпретируется, как поле 1052С управления (Z) маской записи. Когда U=1 и поле 1142 MOD содержит 11 (что обозначает операцию без доступа к памяти), часть бета-поля 1054 (байт 3 EVEX, бит [4] -So) интерпретируется как поле 1057А RL; то, когда оно содержит 1 (округление 1057А.1) остальное бета-поле 1054 (байт 3 EVEX, бит [6-5] - S21), интерпретируется, как поле 1059А операции округления, в то время как, когда поле RL 1057А содержит 0 (VSIZE 1057. А2), остальное бета-поле 1054 (байт EVEX 3, бит [6-5] - S2 - 1) интерпретируется, как поле 1059 В вектора длины (байт 3 EVEX, бит [6-5] - Li_0). То, когда U=1 и поле 1142 MOD содержат 00, 01 или 10 (что обозначает операцию с доступом к памяти), бета-поле 1054 (байт 3 EVEX, биты [6:4] - SSS) интерпретируется, как поле 1059 В длины вектора (байт 3 EVEX, биты [6-5] - Li_0) и поле 1057 В многоадресной передачи (байт 3 EVEX, бит [4] - В).
Пример архитектуры регистра
На фиг. 12 показана блок-схема архитектуры 1200 регистра в соответствии с одним вариантом осуществления изобретения. В представленном варианте осуществления существуют 32 векторных регистра 1210, которые имеют ширину 512 битов; эти регистры обозначены как zmm0 - zmm31. 256 битов младшего порядка младших 16 регистров zmm накладывают на регистры ymm0 - 16. 128 битов младшего порядка из младших 16 регистров zmm (128 битов младшего порядка регистров ymm) перегружают в регистры xmm0 - 15. Формат 1100 специфичной инструкции, удобный для векторной операции, работает в этом перегруженном файле регистра, как представлено в показанной ниже таблице.
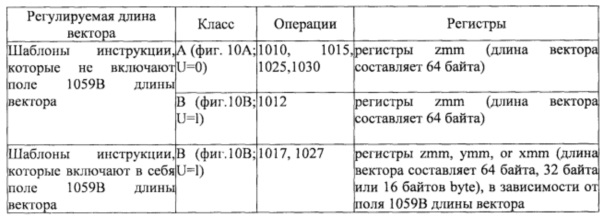
Другими словами, поле 1059 В длины вектора выбирает между максимальной длиной и одним или больше другими более короткими значениями длины, где каждое из более короткого значения длины составляет половину длины предшествующей длины; и шаблоны инструкций без поля длины 1059В вектора работает по максимальной длине вектора. Кроме того, в одном варианте осуществления, шаблоны инструкции класса В формата 1100 специфичной инструкции, удобного для векторной операции работают с упакованными или скалярными данными с плавающей точкой одиночной/двойной точности, и представляют собой упакованные или скалярные целочисленные данные. Скалярные операции представляют собой операции, выполняемые для положения элемента данных самого младшего порядка в регистре zmm/ymm/xmm; для положения элемента данных более высокого порядка, либо их оставляют такими же, как они были перед инструкцией, или обнуляют, в зависимости от варианта осуществления.
Регистры 1215 маски записи - в представленном варианте осуществления, существуют 8 регистров маски записи (kО - к7), каждый размером 64 бита. В альтернативном варианте осуществления, регистры 1215 маски записи имеют размер 16 битов. Как было описано выше, в одном варианте осуществления изобретения, регистр маски вектора kО не может использоваться, как маска записи во время кодирования, которое обычно обозначало бы, что kО используется для маски записи, он выбирает аппаратную маску записи, такую как OxFFFF, эффективно отключая установку маски записи для этой инструкции.
Регистры 1225 общего назначения - в представленном варианте осуществления существуют шестнадцать 64-битных регистров общего назначения, которые используются вместе с существующими способами х86 адресации для адресации операндов памяти. Эти регистры обозначаются по наименованиям RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP и R8-R15.
Файл 1245 скалярного регистра стека упакован с плавающей точкой (стек х87), по которому переименовывают файл 1250 регистра некодированного, упакованного целого числа ММХ - в представленном варианте осуществления стек х87 представляет собой восьмиэлементный стек, используемый для выполнения скалярных операций с плавающей точкой для 32/64/80-битных данных с плавающей точкой, используя расширение набора инструкций х87; в то время, как регистры ММХ используются для выполнения операции для упакованных целочисленных 64-битных данных, а также для операндов удержания для некоторых операций, выполняемых между регистрами ХММ и ММХ.
Альтернативные варианты осуществления изобретения могут использовать более широкие или более узкие регистры. В случае необходимости, альтернативные варианты осуществления изобретения могут использовать большее, меньшее или другое количество файлов регистров и регистров.
Примерная архитектура кода, процессора и компьютерной архитектуры
Ядра процессора могут быть воплощены по-разному для разных назначений и в разных процессорах. Например, воплощения в таких ядрах могут включать в себя: 1) ядро общего назначения, работающее по порядку, предназначенное для вычислений общего назначения; 2) высокопроизводительное ядро общего назначения, работающее не по порядку, предназначенное для вычислений общего назначения; 3) ядро специального назначения, предназначенное, в основном, для графических и/или научных (высокая пропускная способность) вычислений. Воплощения разных процессоров могут включать в себя: 1) CPU, включающее в себя одно или больше ядер, работающих по порядку, общего назначения, предназначенных для расчетов общего назначения, и/или одно или больше ядер, работающих не по порядку, общего назначения, предназначенных для вычислений общего назначения; и 2) сопроцессор, включающий в себя одно или больше ядер специального назначения, в основном, предназначенных для графики и/или научных вычислений (высокая пропускная способность). Такие разные процессоры приводят к разным архитектурам компьютерной системы, которые могут включать в себя: 1) сопроцессор на отдельном от CPU кристалле; 2) сопроцессор на отдельном кристалле в том же корпусе, что и CPU; 3) сопроцессор на том же кристалле, что и CPU (в этом случае, такой сопроцессор иногда называется логикой специального назначения, такой как интегрированная логика для графических и/или научных (высокая пропускная способность) вычислений, или ядрами специального назначения); и 4) система на кристалле, которая может включать в себя на том же кристалле описанное CPU (иногда называется ядром (ядрами) приложения или процессором (процессорами) приложения), описанный выше сопроцессор, и дополнительные функции. Примерные архитектуры кода описаны далее, после чего следуют описания примерных процессоров и архитектур компьютера.
Примеры архитектуры ядра
Блок-схема ядра, работающая по порядку и не по порядку
На фиг. 13А показана блок-схема, иллюстрирующая, как пример конвейера обработки, работающего по порядку, так и пример конвейера обработки задачи/исполнения, работающего не порядку, с переименованием регистра, в соответствии с вариантами осуществления изобретения. На фиг. 13В показана блок-схема, иллюстрирующая, как примерный вариант осуществления архитектуры ядра, работающего по порядку, так и пример архитектуры ядра задачи/исполнения не по порядку с переименованием регистра, которое должно быть включено в процессор в соответствии с вариантами осуществления изобретения. Прямоугольники, вычерченные сплошными линиями на фиг. 13А-В, иллюстрируют конвейер обработки, работающий по порядку, и ядро, работающее по порядку, в то время как необязательное добавление прямоугольников, вычерченных пунктирными линиями, иллюстрируют конвейер обработки и ядро задачи/исполнения не по порядку, с переименованием регистра. Учитывая, что аспект работы по порядку представляет собой поднабор аспекта работы не по порядку, будет описан аспект работы не по порядку.
На фиг. 13А, конвейер 1300 обработки процессора включает в себя этап 1302 выборки, этап 1304 декодирования длины, этап 1306 декодирования, этап 1308 выделения, этап 1310 переименования, этап 1312 планирования (также известный как диспетчеризация или задача), этап 1314 считывания регистра/считывания памяти, исполнительный этап 1316, этап 1318 обратной записи/записи в память, этап 1322 обработки исключения и этап 1324 фиксации операции.
На фиг. 13В показано ядро 1390 процессора, включающее в себя модуль 1330 предварительной обработки, соединенный с модулем 1350 исполнительного механизма, и оба они соединены с модулем 1370 памяти. Ядро 1390 может представлять собой вычислительное ядро с сокращенным набором команд (RISC), ядро со сложным набором команд (CISC), ядро с командными словами очень большой длины (VLIW) или ядро гибридного или альтернативного типа. В качестве еще одной, другой опции, ядро 1390 может представлять собой ядро специального назначения, такое как, например, сетевое ядро или ядро передачи данных, механизм сжатия, ядро сопроцессора, ядро графической обработки для вычислений общего назначения (GPGPU), графическое ядро и т.п.
Модуль 1330 предварительной обработки включает в себя модуль 1332 прогнозирования ветвления, соединенный с модулем 1334 кэш инструкции, который соединен с буфером 1336 быстрого одновременного параллельного поиска трансляции инструкции (TLB), который соединен с модулем 1338 выборки инструкции, который соединен с модулем 1340 декодирования. Модуль 1340 декодирования (или декодер) может декодировать инструкции и генерировать, как выход, одну или больше микроопераций, точек входа в микрокод, микроинструкций, других инструкций или других сигналов управления, которые декодируют из, или которые по-другому отражают, или которые выводят из оригинальных инструкций. Модуль 1340 декодирования может быть воплощен, используя всевозможные механизмы. Примеры соответствующих механизмов включают в себя, но не ограничены этим, справочные таблицы воплощения в виде аппаратных средств, массивы программируемой логики (PLA), постоянные запоминающие устройства (ROM) микрокода и т.д. В одном варианте осуществления ядро 1390 включает в себя ROM микрокода или другой носитель, в котором содержится микрокод для определенных макроинструкций (например, в модуле 1340 декодирования, или по-другому в пределах модуля 1330 предварительной обработки). Модуль 1340 декодирования соединен с модулем 1352 переименования/распределителя в модуле 1350 исполнительного механизма.
Модуль 1350 исполнительного механизма включает в себя модуль 1352 переименования/распределителя, соединенный с модулем 1354 завершения инструкции и набором из одного или больше модуля (модулей) 1356 планировщика. Модуль (модули) 1356 планировщика представляет любое количество разных планировщиков, включая в себя станции резервирования, окно центральной инструкции и т.д. Модуль (модули) 1356 планировщика соединен с модулем (модулями) 1358 файла (файлов) физического регистра. Каждый из модулей 1358 файла (файлов) физического регистра представляет один или больше файлов физического регистра, причем разные файлы такого типа содержат один или больше разных типов данных, таких как скалярное целое число, скалярное число в плавающей точкой, упакованное целое число, упакованное число с плавающей точкой, векторное целое число, векторное число в плавающей точкой, статус (например, указатель инструкций, который представляет собой адрес следующей инструкции, предназначенной для исполнения) и т.д. В одном варианте осуществления модуль 1358 файла (файлов) физического регистра содержит модуль векторных регистров, модуль регистра маски записи и модуль скалярных регистров. Эти модули регистра могут предоставлять регистры архитектурного вектора, регистры маски вектора и регистры общего назначения. Модуль (модули) 1358 файла (файлов) физического регистра замещается модулем 1354 завершения операции, для представления различных путей, в которых могут быть воплощены переименование регистра и исполнение не по порядку (например, используя буфер (буферы) изменения порядка и файл (файлы) регистра завершения операции; используя будущий файл (файлы), буфер (буферы) предыстории и файл (файлы) регистра завершения операции; используя карты регистра и общие фонды регистров; и т.д.). Модуль 1354 завершения операции и модуль (модули) 1358 файла (файлов) физического регистра соединены с исполнительным кластером (кластерами) 1360. Исполнительный кластер (кластеры) 1360 включает в себя набор из одного или больше исполнительных модулей 1362 и набор из одного или больше модулей 1364 доступа к памяти. Исполнительный модуль 1362 может выполнять различные операции (например, сдвиги, суммирование, вычитание, умножение) и для различных типов данных (например, скалярных данных с плавающей точкой, упакованных целых чисел, упакованных чисел с плавающей точкой, векторного целого числа, векторного числа с плавающей точкой). В то время как некоторые варианты осуществления могут включать в себя множество исполнительных модулей, специально предназначенных для определенных функций или наборов функций, другие варианты осуществления могут включать в себя только один исполнительный модуль или множество исполнительных модулей, все из которых выполняют все функции. Модуль (модули) 1356 планировщика, модуль (модули) 1358 файла (файлов) физического регистра и исполнительный кластер (кластеры) 1360 показаны, как, возможно, присутствующие во множественном числе, поскольку в определенных вариантах осуществления формируются отдельные конвейеры обработки данных для определенных типов данных/операций (например, конвейер обработки скалярного целого числа, конвейер обработки скалярного числа с плавающей точкой/ упакованного целого числа/упакованного числа с плавающей точкой/ векторного целого числа/векторного числа с плавающей точкой и/или конвейер обработки с доступом к памяти, каждый из которых имеет свой собственный модуль планировщика, модуль файла (файлов) физического регистра и/или исполнительный кластер - и в случае отдельного конвейера обработки с доступом к памяти, воплощены определенные варианты осуществления, в которых только исполнительный кластер этого конвейера обработки имеет модуль (модули) 1364 доступа к памяти). Следует также понимать, что в случаях, когда используются отдельные конвейеры обработки, один или больше из таких конвейеров обработки может представлять собой конвейер задачи/исполнения, работающий не по порядку, и остальные работают по порядку.
Набор модулей 1364 доступа к памяти соединен с модулем 1370 памяти, который включает в себя модуль 1372 данных TLB, соединенный с модулем 1374 кэш-данных, соединенный с модулем 1376 кэш уровня 2 (L2). В одном примерном варианте осуществления модули 1364 доступа к памяти могут включать в себя модуль загрузки, модуль адреса сохранения и модуль данных сохранения, каждый из которых соединен с модулем 1372 данных TLB в модуле 1370 памяти. Модуль 1334 кэш - инструкции дополнительно соединен с модулем 1376 кэш уровня 2 (L2) в модуле 1370 памяти. Модуль 1376 кэш L2 соединен с одним или больше другими уровнями кэш и, в конечном итоге, с основной памятью.
В качестве примера, пример архитектуры ядра задачи/исполнения не по порядку с переименованием регистра может воплощать конвейер 1300 обработки следующим образом: 1) выборка 1338 инструкции выполняет этапы 1302 и 1304 выборки и декодирования длины; 2) модуль 1340 декодирования выполняет этап 1306 декодирования; 3) модуль 1352 переименования/распределителя выполняет этап 1308 распределения и этап 1310 переименования; 4) модуль (модули) 1356 планировщика выполняет этап 1312 планирования; 5) модуль (модули) 1358 файла (файлов) физического регистра и модуль 1370 памяти выполняют этап 1314 считывания регистра/считывания памяти; исполнительный кластер 1360 выполняет этап 1316 исполнения; 6) модуль 1370 памяти и модуль (модули) 1358 файла (файлов) физического регистра выполняют этап 1318 обратной записи/записи в памяти; 7) различные модули могут быть вовлечены в этап 1322 обработки исключений; и 8) модуль 1354 завершения операции и модуль (модули) 1358 файла (файлов) физического регистра выполняют этап 1324 фиксации транзакции.
Ядро 1390 может поддерживать одну или больше инструкций (например, набор инструкций х86 (с некоторыми расширениями, которые были добавлены в более новых версиях); набор инструкций MIPS компании MIPS Technologies of Sunnyvale, CA; набор инструкций ARM (с дополнительными необязательными расширениями, такими как NEON) of ARM Holdings of Sunnyvale, CA) компании, включая в себя инструкцию (инструкции), описанные здесь. В одном варианте осуществления ядро 1390 включает в себя логику для поддержки расширения набора инструкций упакованных данных (например, AVX1, AVX2), разрешая, таким образом, выполнение операций, используемых множеством мультимедийных приложений, используя упакованные данные.
Следует понимать, что ядро может поддерживать многопоточную обработку (исполняя два или больше параллельных набора операций или потоков), и может выполнять это различными путями, включая в себя многопоточную обработку с нарезкой времени, одновременную многопоточную обработку (когда одно физическое ядро обеспечивает логическое ядро для каждого из потоков обработки, которое физическое ядро одновременно подвергает многопоточной обработке), или их комбинацию (например, выборку с нарезкой времени и декодирование, и одновременную многопоточную обработку после этого, такую как в технологии Intel® Hyperthreading).
В то время как переименование регистра описано в контексте исполнения не по порядку, следует понимать, что переименование регистра может использоваться в архитектуре, работающей по порядку. В то время как представленный вариант осуществления процессора также включает в себя отдельную инструкцию и модули 1334/1374 кэш-данных и совместно использует модуль 1376 кэш L2, альтернативные варианты осуществления могут иметь одиночный внутренний кэш, как для инструкций, так и для данных, такой как, например, внутренний кэш Уровня 1 (LI), или множество уровней внутреннего кэш. В некоторых вариантах осуществления система может включать в себя комбинацию внутреннего кэш и внешнего кэш, который является внешним для ядра и/или процессора. В качестве альтернативы, все из кэш могут быть внешними для ядра и/или процессора.
Конкретный пример архитектуры ядра, работающего не по порядку
На фиг. 14А-В иллюстрируется блок-схема более конкретного примера архитектуры ядра, работающего не по порядку, и такое ядро может представлять собой ядро из нескольких логических блоков (включая в себя другие ядра того же типа и/или других типов) на микросхеме. Логические блоки сообщаются между собой через сеть взаимного соединения с широкой полосой пропускания (например, кольцевую сеть) с некоторой фиксированной функциональной логикой, интерфейсами I/O памяти, и другой необходимой логикой I/O, в зависимости от приложения.
На фиг. 14А показана блок-схема ядра с одним процессором, вместе с его соединением с сетью 1402 взаимного соединения на кристалле и с его локальным поднабором кэш 1404 уровня 2 (L2), в соответствии с вариантами осуществления изобретения. В одном варианте осуществления, декодер 1400 инструкции поддерживает набор инструкций х86 с расширением набора инструкций упакованных данных. Кэш 1406 L1 обеспечивает доступ с малой задержкой к памяти кэш в скалярных и векторных модулях. В то время, как в одном варианте осуществления (для упрощения конструкции), скалярный модуль 1408 и векторный модуль 1410 использует разные наборы регистров (соответственно, скалярные регистры 1412 и векторные регистры 1414) и данные, передаваемые между ними, записывают в памяти и затем считывают обратно из кэш 1406 уровня 1 (L1), в альтернативных вариантах осуществления изобретения может использоваться другой подход (например, использование одного набора регистров или может включать в себя путь передачи данных, который позволяет передавать данные между двумя файлами регистра, без записи и обратного считывания).
Локальный поднабор кэш 1404 L2 представляет собой часть глобального кэш L2, который разделен на отдельные локальные поднаборы, по одному на ядро процессора. Каждое ядро процессора имеет путь прямого доступа к его собственному локальному поднабору кэш 1404 L2. Данные, считываемые ядром процессора, сохраняют в его поднаборе 1404 кэш L2, и к ним может быть быстро обеспечен доступ, параллельно с другими ядрами процессора, которые обращаются к своим собственным локальным поднаборам кэш L2. Данные, записанные ядром процессора, содержатся в его собственном поднаборе 1404 кэш L2, и их передают из других поднаборов, в случае необходимости. Кольцевая сеть обеспечивает когерентность для совместно используемых данных. Кольцевая сеть является двунаправленной, обеспечивает возможность для агентов, таких как ядра процессора, кэш L2 и другие логические блоки сообщаться друг с другом в пределах микросхемы. Каждый кольцевой путь передачи данных составляет ширину 1012 битов в каждом направлении.
На фиг. 14В показан расширенный вид в перспективе части ядра процессора по фиг. 14А в соответствии с вариантами осуществления изобретения. Фиг. 14В включает в себя кэш 1406А данных L1, которая представляет собой часть кэш 1404 L1, а также более подробное считывание векторного модуля 1410 и векторных регистров 1414. В частности, векторный модуль 1410 представляет собой модуль обработки вектора (VPU) шириной 16 (см. ALU 1428 шириной 16), который исполняет одну или больше из инструкций с целым числом, числом с плавающей точкой одиночной точности и числом с плавающей точкой двойной точности. VPU поддерживает настройку по адресам входных данных регистра, используя модуль 1420 настройки по адресам, цифровое преобразование, используя модули 1422А-В цифрового преобразования и репликацию с модулем 1424 репликации по входу в память. Регистры 1426 маски записи обеспечивают возможность предиката, в результате чего происходит запись вектора.
Процессор с интегрированным контроллером памяти и графикой
На фиг. 15 показана блок-схема процессора 1500, который может иметь более, чем одно ядро, может иметь интегрированный контроллер памяти, и может иметь интегрированную графику, в соответствии с вариантами осуществления изобретения. Прямоугольники, вычерченные сплошными линиями на фиг. 15, иллюстрируют процессор 1500 с одним ядром 1502А, системным агентом 1510, набором из одного или больше модулей 1516 контроллера шины, в то время как необязательное добавление прямоугольника из пунктирных иллюстрирует дополнительный процессор 1500 с множеством ядер 1502A-N, набор из одного или больше модуля (модулей) 1514 контроллера интегрированной памяти в модуле 1510 системного агента и логику 1508 специального назначения.
Таким образом, разные варианты осуществления процессора 1500 могут включать в себя: 1) CPU с логикой 1508 специального назначения, который представляет собой интегрированную логику графики и/или научной (с высокой пропускной способностью) логикой (которая может включать в себя одно или больше ядер), и ядра 1502A-N, которые представляют собой одно или больше ядер общего назначения (например, ядер, работающих по порядку общего назначения, ядер, работающих не по порядку общего назначения, комбинацию из этих двух ядер); 2) сопроцессор с ядрами 1502A-N представляет собой большое количество ядер специального назначения, в основном, предназначенных для графической и/или научной (высокая пропускная способность) обработки; и 3) сопроцессор с ядрами 1502A-N, который представляет собой большое количество ядер, работающих не по порядку общего назначения. Таким образом, процессор 1500 может представлять собой процессор общего назначения, сопроцессор или процессор специального назначения, такой как, например, сетевой процессор или процессор передачи данных, механизм сжатия, графический процессор, GPGPU (модуль графической обработки общего назначения), сопроцессор с высокой пропускной способностью и множеством интегрированных ядер (MIC) (включающий в себя 30 или больше ядер), встроенный процессор и т.п. Процессор может быть воплощен в одной или больше микросхемах. Процессор 1500 может представлять собой часть подложки и/или может быть воплощен на одной или больше подложках, используя любое количество технологий обработки, таких как, например, BiCMOS, CMOS или NMOS.
Иерархия памяти включает в себя один или больше уровней кэш в пределах ядер, наборов из одного или больше модулей 1506 совместно используемых кэш, и внешнюю память (не показана), соединенную с набором интегрированных модулей 1514 контроллера памяти. Набор совместно используемых модулей 1506 кэш может включать в себя один или больше кэш среднего уровня, такого как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или других уровней кэш, кэш последнего уровня (LLC) и/или их комбинации. В то время как в одном варианте осуществления модуль 1512 взаимного соединения на основе кольца взаимно соединяет интегрированную графическую логику 1508, набор совместно используемых модулей 1506 кэш, и модуль 1510 системного агента/модуль (модули) 1514 контроллера интегрированной памяти, альтернативные варианты осуществления могут использовать любое количество известных технологий, для взаимного соединения таких модулей. В одном варианте осуществления когерентность поддерживается между одним или больше модулями 1506 кэш и ядрами 1502-A-N.
В некоторых вариантах осуществления одно или больше из ядер 1502A-N выполнены с возможностью многопоточной обработки. Системный агент 1510 включает в себя такие координирующие компоненты и выполняющие операции ядра 1502A-N. Модуль 1510 системного агента может включать в себя, например, модуль управления питанием (PCU) и модуль дисплея. PCU может представлять собой или может включать в себя логику и компоненты, необходимые для регулировки состояния питания ядер 1502А-N и интегрированной графической логики 1508. Модуль отображения предназначен для управления одним или больше из подключенных внешних устройств отображения.
Ядра 1502A-N могут быть гомогенными или гетерогенными с точки зрения набора инструкций архитектуры; то есть, два или больше ядер 1502A-N могут быть выполнены с возможностью выполнения одного и того же набора инструкций, в то время как другие могут быть выполнены с возможностью исполнения только поднабора этого набора инструкций или другого поднабора инструкций.
Примерные архитектуры компьютера
На фиг. 16-19 показаны блок-схемы примерных архитектур компьютера. Также пригодны другие конструкции системы и конфигурации, известные в области техники для переносных компьютеров, настольных компьютеров, портативных компьютеров, карманных персональных компьютеров, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, цифровых сигнальных процессоров (DSP), графических устройств, устройств видеоигр, телевизионных приставок, микроконтроллеров, сотовых телефонов, портативных мультимедийных проигрывателей, партий портативных устройств и различных других электронных устройств. В общем, огромное разнообразие систем или электронных устройств, выполненных с возможностью встройки в них процессора и/или другой исполнительной логики, как раскрыто здесь, в общем, являются пригодными.
Далее, на фиг. 16, показана блок-схема системы 1600, в соответствии с одним вариантом осуществления настоящего изобретения. Система 1600 может включать в себя один или больше процессоров 1610, 1615, которые соединены с концентратором 1620 контроллера. В одном варианте осуществления концентратор 1620 контроллера включает в себя концентратор 1690 контроллера графической памяти (GMCH) и концентратор 1650 ввода-вывода (ЮН) (который может находиться на отдельных микросхемах); GMCH 1690 включает в себя память и графические контроллеры, с которыми соединена память 1640 и сопроцессор 1645; IOН 1650 соединяет устройства 1660 ввода-вывода (I/O) с GMCH1690. В качестве альтернативы, один или оба из контроллеров памяти и графических контроллеров интегрированы в пределах процессора (как описано здесь), с памятью 1640 и сопроцессором 1645 и соединены непосредственно с процессором 1610 и концентратором 1620 контроллера на одной микросхеме с IOН 1650.
Необязательное свойство дополнительных процессоров 1615 обозначено на фиг. 16 пунктирными линиями. Каждый процессор 1610, 1615 может включать в себя одно или больше из ядер обработки, описанных здесь, и может представлять собой некоторую версию процессора 1500.
Память 1640 может, например, представлять собой динамическое оперативное запоминающее устройство (DRAM), память с изменением фазы (РСМ) или комбинацию этих двух подходов. Для, по меньшей мере, одного варианта осуществления концентратор 1620 контроллера сообщается с процессором (процессорами) 1610, 1615 через многоточечную шину, такую как системная шина (FSB), интерфейс "из точку-в-точку", такой как взаимное соединение QuickPath (QPI), или аналогичное соединение 1695.
В одном варианте осуществления сопроцессор 1645 представляет собой процессор специального назначения, такой как, например, процессор MIC с высокой пропускной способностью, сетевой процессор или процессор передачи данных, механизм сжатия, графический процессор, GPGPU, встроенный процессор и т.п. В одном варианте осуществления шина 1620 контроллера может включать в себя интегрированный графический акселератор.
Могут существовать множество различий между физическими ресурсами 1610, 1615 в отношении спектра измеряемых характеристик, включая в себя архитектурные, микроархитектурные, тепловые характеристики, характеристики потребления питания и т.п.
В одном варианте осуществления процессор 1610 исполняет инструкции, которые управляют операциями по обработке данных общего типа. Инструкции могут быть встроены в инструкции сопроцессора. Процессор 1610 распознает эти инструкции сопроцессора, как инструкции такого типа, которые должны быть выполнены присоединенным сопроцессором 1645. В соответствии с этим, процессор 1610 генерирует такие инструкции сопроцессора (или сигналы управления, представляющие инструкции сопроцессора) по шине сопроцессора или по другому взаимному соединению, с сопроцессором 1645. Сопроцессор (сопроцессоры) 1645 принимает и исполняет принятые инструкции сопроцессора.
Далее, на фиг. 17, показана блок-схема первого, более конкретного примера системы 1700, в соответствии с вариантом осуществления настоящего изобретения. Как показано на фиг. 17, многопроцессорная система 1700 представляет собой систему взаимного соединения из точки в точку, и включает в себя первый процессор 1770 и второй процессор 1780, соединенные через взаимное соединение 1750 из точки в точку. Каждый из процессоров 1770 и 1780 может представлять собой некоторую версию процессора 1500. В одном варианте осуществления изобретения процессоры 1770 и 1780, соответственно, представляют собой процессоры 1610 и 1615, в то время, как сопроцессор 1738 представляет собой сопроцессор 1645. В другом варианте осуществления процессоры 1770 и 1780 представляют собой, соответственно, процессор 1610 и сопроцессор 1645.
Процессоры 1770 и 1780 показаны, как включающие в себя модули 1772 и 1782 интегрированного контроллера памяти (IMC), соответственно. Процессор 1770 также включает в себя, как часть своих модулей контроллера шины, интерфейсы 1776 и 1778 "из точки-в-точку" (Р-Р); аналогично, второй процессор 1780 включает в себя интерфейсы 1786 и 1788 Р-Р. Процессоры 1770, 1780 могут выполнять обмен информацией через интерфейс 1750 схемы "из точки-в-точку" (Р-Р), используя схемы интерфейса Р-Р 1778, 1788. Как показано на фиг. 17, IMC 1772 и 1782 соединяют процессоры с соответствующей памятью, а именно, с памятью 1732 и памятью 1734, которые могут представлять собой часть основной памяти, локально соединенной с соответствующими процессорами.
Процессоры 1770, 1780 могут выполнять обмен информацией с набором 1790 микросхем через индивидуальные интерфейсы 1752, 1754 Р-Р, используя схемы 1776, 1794, 1786, 1798 интерфейса из точки-в-точку. Набор 1790 микросхем, в случае необходимости, может выполнять обмен информацией с сопроцессором 1738 через интерфейс 1739 высокой производительности. В одном варианте осуществления сопроцессор 1738 представляет собой процессор специального назначения, такой как, например, процессор MIC с высокой пропускной способностью, сетевой процессор или процессор передачи данных, механизм сжатия, графический процессор, GPGPU, встроенный процессор и т.п.
Совместно используемый кэш (не показан) может быть включен либо в процессор, или за пределами обоих процессоров, но все же может быть соединен с процессорами через взаимное соединение Р-Р, таким образом, что любая или обе информации локального процессоров может быть сохранена в совместно используемом кэш, если процессор переведен в режим малого потребления энергии.
Набор 1790 микросхем может быть соединен с первой шиной 1716 через интерфейс 1796. В одном варианте осуществления первая шина 1716 может представлять собой шину межсоединения периферийных компонентов (PCI), или такую шину, как шина PCI Express, или другую шину межсоединения I/O третьего поколения, хотя объем настоящего изобретения не ограничен этим.
Как показано на фиг. 17, различные устройства 1714 I/O могут быть соединены с первой шиной 1716, вместе с мостом 1718 шины, который соединяет первую шину 1716 со второй шиной 1720. В одном варианте осуществления, один или больше из дополнительного процессора (процессоров) 1715, таких как сопроцессоры, процессоры MIC с высокой пропускной способностью, GPGPU, ускорители (такие как, например, графические ускорители или модуль (модули) цифровой обработки сигналов (DSP)), программируемые пользователем вентильные матрицы или любой другой процессор соединены с первой шиной 1716. В одном варианте осуществления вторая шина 1720 может представлять собой шину с малым количеством выводов (LPC). Различные устройства могут быть соединены со второй шиной 1720, включающей в себя, например, клавиатуру и/или "мышь" 1722, устройство 1727 передачи данных и модуль 1728 накопитель, такой как привод диска, или другое устройство накопитель с большим объемом памяти, которое может включать в себя инструкции/код и данные 1730, в одном варианте осуществления. Кроме того, аудио I/O 1724 может быть соединен со второй шиной 1720. Следует отметить, что возможны другие архитектуры. Например, вместо архитектуры "из точки-в-точку" по фиг. 17, система может быть воплощена, как многоточечная шина или другая такая архитектура.
Теперь на фиг. 18 показана блок-схема второго, более конкретного примера системы 1800, в соответствии с вариантом осуществления настоящего изобретения. Одинаковые элементы на фиг. 17 и 18 обозначены одинаковыми номерами ссылочных позиций, и определенные аспекты фиг. 17 были исключены на фиг. 18 для того, чтобы исключить усложнения других аспектов фиг. 18.
На фиг. 18 иллюстрируется, что процессоры 1770, 1780 могут включать в себя интегрированную память и логику 1772 и 1782 управления ("CL") I/O, соответственно. Таким образом, CL 1772, 1782 включают в себя модули контроллера интегрированной памяти и включают в себя логику управления I/O. На фиг. 18 иллюстрируется, что не только память 1732, 1734 соединена с CL 1772, 1782, но также и что устройства 1814 I/O также соединены с логикой 1772, 1782 управления. Наследуемые устройства 1815 I/O соединены с набором 1790 микросхем.
Далее, на фиг. 19, показана блок-схема SoC 1900, в соответствии с вариантом осуществления настоящего изобретения. Аналогичные элементы на фиг. 15 обозначены такими же номерами ссылочной позиции. Кроме того, прямоугольники, представленные пунктирными линиями, представляют необязательные свойства более усовершенствованных SoC. На фиг. 19 модуль (модули) 1902 взаимного соединения соединен с: процессором 1910 приложения, который включает в себя набор из одного или больше ядер 202A-N, и модулем (модулями) 1506 совместно используемого кэш; модуль 1510 системного агента; модуль (модули) 1516 контроллера шины; модуль (модули) 1514 контроллера интегрированной памяти; набор из одного или больше сопроцессоров 1920, который может включать в себя интегрированную логику графики, процессор изображения, аудиопроцессор и видеопроцессор; модуль 1930 статического оперативного запоминающего устройства (SRAM); модуль 1932 прямого доступа к памяти (DMA); и модуль 1940 отображения для подключения одного или больше внешних устройств отображения. В одном варианте осуществления, сопроцессор (сопроцессоры) 1920 включают в себя процессор специального назначения, такой как, например, сетевой процессор или процессор передачи данных, механизм сжатия, GPGPU, процессор MIC с высокой пропускной способностью, встроенный процессор и т.п.
Варианты осуществления механизмов, раскрытых здесь, могут быть воплощены в аппаратных средствах, программном обеспечении, в виде встроенного программного обеспечения или используя комбинацию таких подходов к воплощению. Варианты осуществления изобретения могут быть воплощены, как компьютерные программы или программный код, исполняемый в программируемых системах, содержащих, по меньшей мере, один процессор, систему накопителя (включающую в себя энергозависимую и энергонезависимую память и/или элементы накопителя), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода.
Программный код, такой как код 1730, показанный на фиг. 17, может применяться для ввода инструкций для выполнения функций, описанных здесь, и может генерировать выходную информацию. Выходная информация может применяться для одного или больше выходных устройств известным образом. Для назначения данной заявки система обработки включает в себя любую систему, которая имеет процессор, такой как, например; цифровой сигнальный процессор (DSP), микроконтроллер, специализированную интегральную схему (ASIC) или микропроцессор.
Программный код может быть воплощен, используя процедурный или объектно-ориентированный язык программирования высокого уровня для обмена данными с системой обработки. Программный код также может быть воплощен в виде Ассемблера или машинного языка, если требуется. Фактически, описанные здесь механизмы не ограничены по объему каким-либо конкретным языком программирования. В любом случае, язык может представлять собой компилируемый или интерпретируемый язык.
В одном или больше аспектах, по меньшей мере, один вариант осуществления может быть воплощен с использованием репрезентативных инструкций, сохраненных на считываемом устройством носителе информации, который представляет различную логику внутри процессора, которая при считывании ее устройством обеспечивает составление устройством логики для выполнения технологий, описанных здесь. Такие представления, известные как "IP ядра", могут быть сохранены на физическом, считываемом устройством носителе информации и могут быть переданы различным потребителям или в производственные предприятия для загрузки в изготавливаемые устройства, которые фактически составляют логику или процессор.
Такие считываемые устройством носители - накопители могут включать в себя, без ограничений, непереходящие, физические компоновки изделий, изготовленных или сформированных машиной или устройством, включая в себя носители - накопители, такие как жесткие диски, любой другой тип диска, включая в себя гибкие диски, оптические диски, постоянное запоминающее устройство на компакт-дисках (CD-ROM), перезаписываемый компактный диск (CD-RW) и магнитооптические диски, полупроводниковые устройства, такие как постоянные запоминающие устройства (ROM), оперативное запоминающее устройство (RAM), такое как динамическое оперативное запоминающее устройство (DRAM), статическое оперативное запоминающее устройство (SRAM), стираемое программируемое постоянное запоминающее устройство (EPROM), память типа флэш, электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), память с изменением фазы (РСМ), магнитные или оптические карты, или любой другой тип носителя, пригодный для сохранения электронных инструкций.
В соответствии с этим, варианты осуществления изобретения также включают в себя энергонезависимые, физические считываемые устройством носители информации, содержащие инструкции или содержащие расчетные данные, такие, как данные на языке описания аппаратного обеспечения (HDL), который определяет структуры, схемы, устройства, процессоры и/или элементы системы, описанные здесь. Такие варианты осуществления также могут называться программными продуктами.
Эмуляция (включая в себя двоичную трансляцию, трансформацию кода и т.д.)
В некоторых случаях, преобразователь инструкции может использоваться для преобразования инструкции из набора инструкций источника в набор целевых инструкций. Например, преобразователь инструкции может транслировать (например, используя статическую двоичную трансляцию, динамическую двоичную трансляцию, включая в себя динамическую компиляцию), трансформировать, эмулировать или по-другому преобразовывать инструкцию в одну или больше других инструкций, которые предназначены для обработки ядром. Преобразователь инструкции может быть воплощен в программных средствах, аппаратных средствах, в виде встроенного программного обеспечения или используя их комбинации. Преобразователь инструкции может быть встроен в процессоре, может находиться за пределами процессора или может составлять часть внутри процессора и часть за пределами процессора.
На фиг. 20 показана блок-схема, которая представляет отличие от использования программного преобразователя инструкции, для преобразования двоичных инструкций в наборе инструкций источников, в двоичную инструкцию в целевом наборе инструкций, в соответствии с вариантами осуществления изобретения. В представленном варианте осуществления преобразователь инструкции представляет собой преобразователь программной инструкцией, хотя, в качестве альтернативы, преобразователь инструкции может быть воплощен в виде программного средства, встроенного программного обеспечения, аппаратных средств или используя различные их комбинации. На фиг. 20 представлена программа на языке 2002 высокого уровня, которая может быть скомпилирована, используя компилятор 2004 х86, для генерирования двоичного кода 2006 х86, который может быть в исходном виде выполнен процессором, по меньшей мере, с одним ядром 2016 с набором инструкций х86. Процессор, по меньшей мере, с одним ядром 2016 с набором инструкций х86 представляет собой любой процессор, который может выполнять, по существу, одни и те же функции, что и процессор Intel, по меньшей мере, с одним ядром с набором инструкций х86, благодаря совместимости исполнения или другой обработки (1) существенной части набора инструкций ядра набора инструкций х86 Intel или (2) версии в виде объектного кода приложений или другого программного обеспечения, предназначенного для работы в процессоре Intel, по меньшей мере, с одним ядром набора инструкций х86, для достижения, по существу, того же результата, что и у процессора Intel, по меньшей мере, одним ядром набора инструкций х86. Компилятор 2004 х86 представляет собой компилятор, который может работать для генерирования двоичного кода 2006 х86 (например, объектного кода), который с помощью или без дополнительной обработки сборки может быть выполнен в процессоре, по меньшей мере, с одним ядром 2016 набора инструкций х86. Аналогично, на фиг. 20 показана программа на языке 2002 высокого уровня, который может быть скомпилирован, используя альтернативный компилятор 2008 альтернативного набора инструкций для генерирования двоичного кода 2010 альтернативного набора, который может быть исходно выполнен процессором, по меньшей мере, одним ядром 2014 набора инструкций х86 (например, процессором с ядрами, которые исполняют набор инструкций MIPS производства MIPS Technologies of Sunnyvale, CA и/или которые исполняют набор инструкций ARM производства ARM Holdings of Sunnyvale, СА). Преобразователь 2012 инструкции используется для преобразования двоичного кода 2006 х86 в код, который может быть исходно выполнен процессором без ядра 2014 набора инструкций х86. Такой преобразованный код, вряд ли, будет таким же, как и двоичный код 2010 альтернативного набора инструкций, поскольку преобразователь инструкции, способный на это, трудно выполнить; однако, преобразованный код будет выполнять общую операцию и будет составлен из инструкций из альтернативного набора инструкций. Таким образом, преобразователь 2012 инструкции представляет программное обеспечение, встроенное программное обеспечение, аппаратные средства или их комбинацию, которые в результате эмуляции, моделирования или любой другой обработки, позволяют выполнять двоичный код 2006 х86 процессором или другим электронным устройством, которое не имеет процессор или ядро с набором инструкций х86,.
Компоненты, свойства и детали, описанные для любой из фиг. 2 или 4, также, в случае необходимости, могут использоваться для любой одной из фиг. 1, 3 и 5. Компоненты, свойства и детали, описанные для любой из фиг. 2, 7 или 9, также, в случае необходимости, можно использовать для любой одной из фиг. 6 или 9. Кроме того, компоненты, свойства и детали, описанные здесь для любого одного из устройства, могут также, в случае необходимости, использоваться для любого из способов, описанных здесь, которые в вариантах осуществления могут быть выполнены таким устройством и/или с его использованием.
В описании и в формуле изобретения, использовались термины "соединенный" и/или "связанный", наряду с их производными. Следует понимать, что эти термины не предназначены для использования в качестве синонимов друг друга. Скорее в конкретных вариантах осуществления, "соединенный" может использоваться для обозначения того, что два или больше элемента находятся в непосредственном прямом или электрическом контакте друг с другом. "Связанный" может означать, что два или больше элемента находятся в прямом физическом или электрическом контакте. Однако, "связанный" может также означать, что два или больше элемента не находятся в непосредственном контакте друг с другом, но все еще сотрудничают или взаимодействуют друг с другом. Например, исполнительный модуль может быть соединен с регистром или модулем декодирования через один или больше промежуточных компонентов. На фигуре стрелки используются для представления соединений и связи.
В описании и формуле изобретения также может использоваться термин "логика". Используемый здесь термин логика может включать в себя аппаратные средства, встроенное программное обеспечение, программное обеспечение или различные их комбинации. Примеры логики включают в себя интегральные схемы, специализированные интегральные схемы, аналоговые схемы, цифровые схемы, программируемые логические устройства, устройства памяти, включающие в себя инструкции, и т.д. В некоторых вариантах осуществления аппаратная логика может включать в себя транзисторы и/или логические элементы, наряду с другими компонентами схем. В некоторых вариантах осуществления логика может быть воплощена как компонент, модуль или другой модуль.
В представленном выше описании были представлены конкретные детали для того, чтобы обеспечить полное понимание вариантов осуществления. Однако, другие варианты осуществления могут быть выполнены на практике без некоторых из этих конкретных деталей. Объем изобретения не следует определять по конкретным примерам, представленным выше, но только по представленной ниже формуле изобретения. В других случаях хорошо известные схемы, структуры, устройства и операции были представлены в форме блок-схем или без деталей, для того, исключить усложнение понимания описания.
Различные операции и способы были описаны выше. Некоторые из способов были описаны в относительно основной форме в виде блок-схем последовательности операций, но операции, в случае необходимости, могут быть добавлены к и/или исключены из способов. Например, дополнительные детали микроархитектуры могут быть добавлены к описанным способам инструкций обработки. Кроме того, в то время как операции были описаны в определенном порядке, в соответствии с примерными вариантами осуществления, этот конкретный порядок является примерным. Альтернативные варианты осуществления, в случае необходимости, выполняют операции в другом порядке, комбинируют некоторые операции, накладывают определенные операции и т.д.
Определенные операции могут быть выполнены аппаратными компонентами, или могут быть воплощены в виде машинно-исполняемых или исполняемых схемой инструкций, которые могут использоваться для обеспечения и/или получения результата в устройстве, схеме или в аппаратном компоненте (например, в части процессора, в процессоре, в схемах и т.д.), запрограммированном инструкциями, выполняющими операции. Операции могут также, в случае необходимости, быть выполнены, используя комбинацию аппаратного и программного обеспечения. Процессор, машинная схема или аппаратное средства могут включать в себя определенную или конкретную схему, или другую логику (например, аппаратные средства, потенциально комбинированные со встроенным программным обеспечением и/или программным обеспечением), которые работают для исполнения и/или обработки инструкции и сохранения результата в ответ на эти инструкции.
Некоторые варианты осуществления включают в себя изделие (например, компьютерный программный продукт), который включает в себя считываемый устройством носитель информации. Носитель информации может включать в себя механизм, который обеспечивает, например, сохраняет информацию в форме, которая может быть считана устройством. Считываемый устройством носитель информации может обеспечивать, или на нем можно сохранять инструкции или последовательность инструкций, которые, если и/или когда их исполняет устройство, могут во время работы обеспечить выполнение устройством и/или получение результата в устройстве, выполняющем одну из операций, способов или технологий, раскрытых здесь. Считываемый устройством носитель информации может обеспечивать, например, сохранение одного или больше из вариантов осуществления инструкций, раскрытых здесь.
В некоторых вариантах осуществления считываемый устройством носитель информации может включать в себя физический и/или энергонезависимый считаемый устройством накопитель информации. Например, физический и/или энергонезависимый считаемый устройством носитель-накопитель может включать в себя гибкий диск, оптический носитель информации, оптический диск, оптическое устройство накопителя данных, CD-ROM, магнитный диск, магнитооптический диск, постоянное запоминающее устройство (ROM), программируемое ROM (PROM), стираемое и программируемое ROM (EPROM) электрически стираемое и программируемое ROM (EEPROM), оперативное запоминающее устройство (RAM), статическое RAM (SRAM), динамическое RAM (DRAM), память типа флэш, память с изменением фазы, материал, сохраняющий данные с изменением фазы, энергонезависимую память, энергонезависимое устройство - накопитель данных, непереходящую память, непереходящее устройство - накопитель данных и т.п. Непереходящий считываемый устройством носитель-накопитель не состоит временно распространяющегося сигнала.
Примеры соответствующих устройств включают в себя, но не ограничены этим, процессоры общего назначения, процессоры специального назначения, устройство обработки инструкции, цифровые логические схемы, интегральные схемы и т.п. Тем не менее, другие примеры соответствующих устройств включают в себя компьютерные устройства и другие электронные устройства, в которые встроены такие процессоры, устройство обработки инструкции, цифровые логические схемы или интегральные схемы. Примеры таких компьютерных устройств и электронных устройств включают в себя, но без ограничений, настольные компьютеры, переносные компьютеры, компьютеры-ноутбуки, планшетные компьютеры, нетбуки, смартфоны, сотовые телефоны, серверы, сетевые устройства (например, маршрутизаторы и коммутаторы). Мобильные интернет-устройства (MID), мультимедийные проигрыватели, интеллектуальные телевизоры, бытовые электронные устройства с управлением через компьютерную сеть, телевизионные приставки и видеоигровые контроллеры.
В данном описании ссылки на "один вариант осуществления", "вариант осуществления", "один или больше вариантов осуществления", "некоторые варианты осуществления", например, обозначают, что конкретное свойство может быть включено в практику изобретения, но это не обязательно требуется. Аналогично, в описании различные свойства иногда сгруппированы вместе в одном варианте осуществления, на фигуре или в ее описании, с целью упрощения раскрытия и для того, чтобы способствовать пониманию различных изобретательских аспектов. Данный способ раскрытия, однако, не следует интерпретировать, как отражающий намерения, состоящие в том, что изобретение требует больше свойств, чем в явно выраженном виде представлено в каждом пункте формулы изобретения. Скорее, как отражено в следующей формуле изобретения, изобретательские аспекты содержатся в менее, чем во всех свойствах одного раскрытого варианта осуществления. Таким образом, формула изобретения, следующая после "Подробного описания изобретения" здесь в явном виде встроена в данное подробное описание изобретения, и каждый пункт формулы изобретения является самостоятельным, как отдельный вариант осуществления изобретения.
Примеры вариантов осуществления
Следующие примеры относятся к дополнительным вариантам осуществления. Особенности этих примеров могут использоваться везде в одном или больше вариантах осуществления.
Пример 1 направлен на обеспечение процессора, включающего в себя множество регистров упакованных данных, и модуль декодирования для декодирования инструкции определения длины точки упакованного кода переменной длины. Инструкция определения длины точки упакованного кода переменной длины предназначена для обозначения упакованных данных первого источника, которые должны иметь множество точек упакованного кода переменной длины, каждая из которых должна представлять знак. Инструкция определения длины точки упакованного кода переменной длины также должна указывать местоположение в накопителе. Процессор также включает в себя исполнительный модуль, соединенный с модулем декодирования, и регистрами упакованных данных. Исполнительный модуль, в ответ на инструкцию определения длины точки упакованного кода переменной длины, предназначен для сохранения полученных в результате упакованных данных в обозначенном месте назначения в накопителе, полученные в результате упакованные данные должны иметь длину для каждой из множества точек упакованного кода переменной длины.
Пример 2 включает в себя процессор по Примеру 1, в случае необходимости, с инструкцией, которая должна указывать упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8.
Пример 3 включает в себя процессор по Примеру 1, в случае необходимости, в котором инструкция должна указывать множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода переменной длины.
Пример 4 включает в себя процессор по Примеру 3, в котором исполнительный модуль, в ответ на инструкцию, должен определять, что данная точка кода переменной длины соответствует данной структуре сигнатуры, путем сравнения данной точки кода переменной длины с каждой из множества структур сигнатуры, и в котором исполнительный модуль, в ответ на инструкцию, должен сохранять значение длины, соответствующее данной структуре сигнатуры для данной точки кода переменной длины в месте назначения в накопителе.
Пример 5 включает в себя процессор по Примеру 3, в котором инструкция предназначена для обозначения упакованных данных второго источника, которые должны иметь множество структур сигнатуры, и в которых инструкция должна иметь непосредственный операнд для обозначения множества значений длины, каждое из которых соответствует одной из множества структур сигнатуры.
Пример 6 включает в себя процессор по Примеру 5, в котором множество структур сигнатуры должны включать в себя четыре разных структуры сигнатуры, и в котором непосредственный операнд должен иметь четыре поля, каждое из которых должно обозначать соответствующее значение длины разных одной из четырех структур сигнатуры.
Пример 7 включает в себя процессор по Примеру 3, в котором структуры сигнатуры должны быть сохранены в энергонезависимой памяти процессора, которая не является архитектурным регистром.
Пример 8 включает в себя процессор по любому из предыдущих Примеров, в случае необходимости, в котором исполнительный модуль, в ответ на инструкцию, должен сохранять каждое значение длины в байте, который должен находиться в том же относительном положении бита в месте назначения накопителя, как и младший значащий байт соответствующей точки кода переменной длины в упакованных данных первого источника.
Пример 9 включает в себя процессор по Примеру 8, в котором исполнительный модуль, в ответ на инструкцию, должен сохранять значение длины, указывающее три байта в заданном байте, который должен находиться в том же относительном положении бита, в месте назначения накопителя, как и младший значащий байт соответствующей трехбайтовой кодовой точки в упакованных данных первого источника, и должен сохранять все нули в двух более значащих последовательных байтах, которые должны быть более значимыми, чем заданный байт в месте назначения накопителя.
Пример 10 включает в себя процессор по любому из предыдущего Примера, в случае необходимости в котором исполнительный модуль, в ответ на инструкцию, должен сохранять все двоичные единицы в байтах в тех же относительных положениях битов в месте назначения накопителя, как и байты неполных или недействительных точек кода переменной длины упакованных данных первого источника.
Пример 11 направлен на способ, выполняемый процессором. Способ включает в себя этапы, на которых принимают инструкцию определения длины точки упакованного кода переменной длины. Инструкция определения длины точки упакованного кода переменной длины обозначает упакованные данные первого источника, имеющие множество точек упакованного кода переменной длины, каждая из которых представляет знак, и указывает место назначения в накопителе. Способ включает в себя этапы, на которых: сохраняют полученные в результате упакованные данные в указанном месте назначения в накопителе, в ответ на инструкцию определения длины точки упакованного кода переменной длины. Полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины.
Пример 12 включает в себя способ по Примеру 11, в случае необходимости, в котором прием включает в себя этап, на котором: принимают инструкцию, указывающую упакованные данные первого источника, имеющие множество упакованных точек кода UTF-8.
Пример 13 включает в себя способ по Примеру 11, в котором в случае необходимости, прием включает в себя подэтап, на котором: принимают инструкцию, указывающую множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода переменной длины.
Пример 14 включает в себя способ по Примеру 13, дополнительно, в случае необходимости, включает в себя этап, на котором определяют, что заданная точка кода переменной длины соответствует заданной структуре сигнатуры, путем сравнения заданной точки кода переменной длины с каждой из множества структур сигнатуры. Способ, в случае необходимости, также может включать в себя этап, на котором сохраняют значения длины, соответствующие заданной структуре сигнатуры для заданной точки кода переменной длины в месте назначения в накопителе.
Пример 15 включает в себя способ по Примеру 13, в котором этап приема включает в себя подэтап, на котором принимают инструкцию, указывающую упакованные данные второго источника, имеющие множество структур сигнатуры. Инструкция, в случае необходимости, может иметь непосредственный операнд, указывающий множество значений длины, каждое из которых соответствует одной из множества структур сигнатуры.
Пример 16 включает в себя способ по Примеру 15, в который множество структур сигнатуры включают в себя четыре разных структуры сигнатуры. В случае необходимости, каждая из четырех разных структур сигнатуры может быть сохранена в другом 32-битном элементе данных упакованных данных второго источника, которые имеют, по меньшей мере, ширину 128 битов. В случае необходимости, непосредственный операнд может иметь четыре поля, каждое из которых соответствует другой одной из четырех структур сигнатуры, для указания соответствующего значения длины.
Пример 17 включает в себя способ по Примеру 13, в котором этап приема включает в себя подэтап, на котором принимают инструкцию, указывающую структуру сигнатуры, каждая из которых сохранена в энергонезависимой памяти на кристалле процессора.
Пример 18 включает в себя способ по любому из предыдущих Примеров, в случае необходимости, в котором этап сохранения включает в себя сохранение каждого значения длины в байт, расположенный в том же относительном положении бита, в месте назначения накопителя, как младший значащий байт соответствующей точки кода переменной длины в упакованных данных первого источника.
Пример 19 включает в себя способ по Примеру 18, в котором этап сохранения включает в себя сохранение значений длины, указывающих два байта в заданном байте, то есть, в том же относительном положении бита в месте назначения накопителя, что и младший значащий байт соответствующей двухбайтовой точки кода в упакованных данных первого источника. В случае необходимости, все нули могут быть сохранены в более значащем последовательном байте, который является более значащим, чем заданный байт в месте назначения накопителя.
Пример 20 включает в себя способ по любому из предыдущих Примеров, в случае необходимости, в котором этап сохранения включает в себя подэтап, на котором сохраняют все единицы в байтах, в тех же относительных положениях бита в месте назначения накопителя, что и байты неполных или недействительных точек кода переменной длины упакованных данных первого источника.
Пример 21 включает в себя способ по Примеру 20, дополнительно, в случае необходимости, включающий в себя этап, на котором выполняют одну или более из других инструкций, для определения положения старшего значащего байта, содержащего все единицы, и указывающего неполную точку кода переменной длины. Заданное положение старшего значащего байта, в случае необходимости, можно использовать для загрузки другой непрерывной части точек кода переменной длины.
Пример 22 представляет собой систему обработки инструкции, включающую в себя взаимное соединение, процессор, соединенный с взаимным соединением, и динамическое оперативное запоминающее устройство (DRAM), соединенное с взаимным соединением. DRAM предназначено для сохранения алгоритма транскодирования, имеющего инструкция определения длины точки упакованного кода переменной длины. Инструкция определения длины точки упакованного кода переменной длины предназначена для указания упакованных данных первого источника, которые должны иметь множество точек упакованного кода переменной длины, каждая из которых должна представлять знак. Инструкция определения длины точки упакованного кода переменной длины предназначена для обозначения места назначения в накопителе. Инструкция определения длины точки упакованного кода переменной длины, если она выполняется процессором, должна во время работы обеспечивать выполнение процессором операций, включающих в себя сохранение полученных в результате упакованных данных, в обозначенном месте назначения накопителя, полученные в результате упакованные данные должны иметь длину для каждой из множества точек упакованного кода переменной длины.
Пример 23 включает в себя систему по Примеру 22, в которой инструкция должна указывать упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8. В случае необходимости, инструкция может обозначать множество структур сигнатуры, каждая из которых должна соответствовать одному из разных значений длины точек кода UTF-8.
Пример 24 направлен на изделие, включающее в себя энергонезависимый считываемый устройством носитель - накопитель. Считываемый устройством носитель - накопитель содержит инструкцию определения длины точки упакованного кода переменной длины. Инструкция определения длины точки упакованного кода переменной длины может указывать упакованные данные первого источника, которые должны иметь множество точек упакованного кода переменной длины, каждая из которых должна представлять знак. Инструкция определения длины точки упакованного кода переменной длины может обозначать место назначения в накопителе. Инструкция определения длины точки упакованного кода, если она исполняется устройством, должна обеспечивать выполнение устройством операций, включающих в себя сохранение полученных в результате упакованных данных в обозначенном месте назначения в накопителе, полученные в результате упакованные данные должны иметь длину для каждой из множества точек упакованного кода переменной длины.
Пример 25 включает в себя изделие по Примеру 24, в котором инструкция должна указывать упакованные данные первого источника, которые должны включать в себя точки кода UTF-8. В случае необходимости, инструкция может указывать множество структур сигнатуры, каждая из которых должна соответствовать одному из разных значений длин точек кода UTF-8.
Пример 26 направлен на способ, выполняемый процессором. Способ включает в себя этапы, на которых: принимают инструкцию выделения битов знака точки упакованного кода переменной длины. Инструкция выделения битов знака точки упакованного кода переменной длины должна обозначать упакованные данные первого источника, имеющие множество точек упакованного кода переменной длины, каждая из которых представляет знак. Инструкция также должна обозначать упакованные данные второго источника, имеющие упакованные значения длины удостоверенных точек упакованного кода переменной длины из упакованных данных первого источника, и указывающие места назначения в накопителе. Способ включает в себя этапы, на которых: сохраняют полученные в результате упакованные данные в обозначенном месте назначения в накопителе в ответ на инструкцию выделения битов знака точки упакованного кода переменной длины. Полученные в результате упакованные данные имеют упакованные наборы выделенных битов знака. Каждый набор выделенных битов знака, соответствующий другой из удостоверенных точек кода переменной длины из упакованных данных первого источника. Каждый набор выделенных битов знака может быть достаточным для определения знака, представленного точками кода переменной длины.
Пример 27 включает в себя способ по Примеру 26, в котором этап приема включает в себя подэтапы, на которых: принимают инструкцию, указывающую упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8.
Пример 28 включает в себя способ по Примеру 26, в котором этап приема включает в себя подэтап, на котором принимают инструкцию, указывающую множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода переменной длины.
Пример 29 включает в себя способ по Примеру 28, дополнительно, в случае необходимости, включающий в себя этап, на котором выбирают структуры сигнатуры для заданной точки кода переменной длины из упакованных данных первого источника, используя значения длины, соответствующие заданной точке кода переменной длины из упакованных данных второго источника. Способ может также, в случае необходимости, включать в себя этапы, на которых: удаляют биты сигнатуры из заданной точки кода переменной длины, выполняя логическую операцию для заданной точки кода переменной длины и выбранной структуры сигнатуры.
Пример 30 включает в себя способ по Примеру 28, в котором этап приема включает в себя подэтап, на котором принимают инструкцию, указывающую структуры сигнатуры, которые содержатся в энергонезависимой памяти процессора.
Пример 31 включает в себя способ по любому из предыдущих Примеров, в котором этап приема включает в себя подэтапы, на которых: принимают инструкцию, указывающую место назначения в накопителе, которое в четыре раза шире по количеству битов, чем упакованные данные первого источника. В случае необходимости, каждый из наборов выделенных битов знака может быть сохранен в 32 битах места назначения накопителя.
Пример 32 включает в себя способ по любому предыдущих Примеров, в случае необходимости, в котором упакованные данные первого источника представляют собой по меньшей мере 128 битов, и место назначения в накопителе содержит, по меньшей мере, 512 битов.
Пример 33 включает в себя способ по любому из предыдущих Примеров, в котором прием включает в себя: принимают инструкцию, обозначающую второе место назначения накопителя, и дополнительно включающую в себя сохранение количества удостоверенных точек кода переменной длины, выделенных во втором месте назначения накопителя.
Пример 34 направлен на считываемый устройством носитель - накопитель, содержащий инструкции, которые при их исполнении устройством должны обеспечивать выполнение устройством способа по любому из примеров 13-21.
Пример 35 направлен на устройство для выполнения способа по любому из примеров 13-21.
Пример 36 направлен на устройство, включающее в себя средство для выполнения способа по любому из примеров 13-21.
Пример 37 направлен на считываемый устройством носитель - накопитель, содержащий инструкции, которые при их исполнении устройством должны обеспечить выполнение устройством способа по любому из примеров 26-33.
Пример 38 направлен на устройство для выполнения способа по любому из примеров 26-33.
Пример 39 направлен на устройство, включающее в себя средство для выполнения способа по любому из примеров 26-33.
Пример 40 направлен на устройство для исполнения инструкции, по существу, как описано здесь.
Пример 41 направлен на устройство, включающее в себя средство для исполнения инструкции, по существу, как описано здесь.
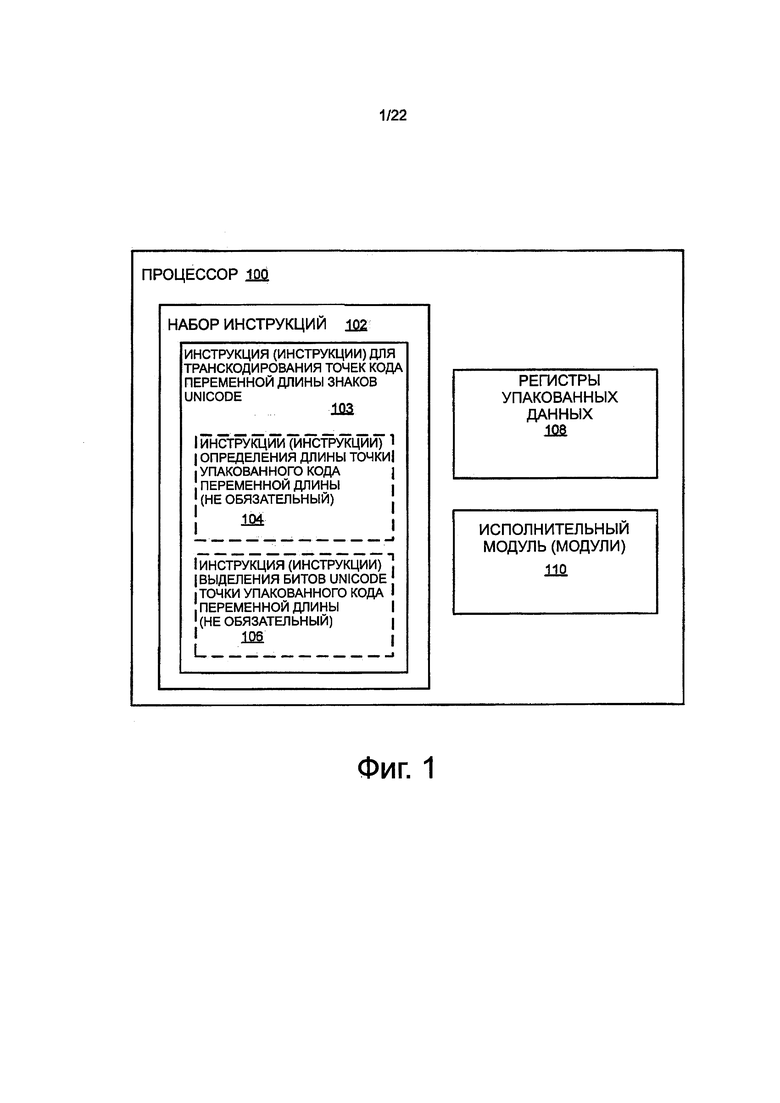
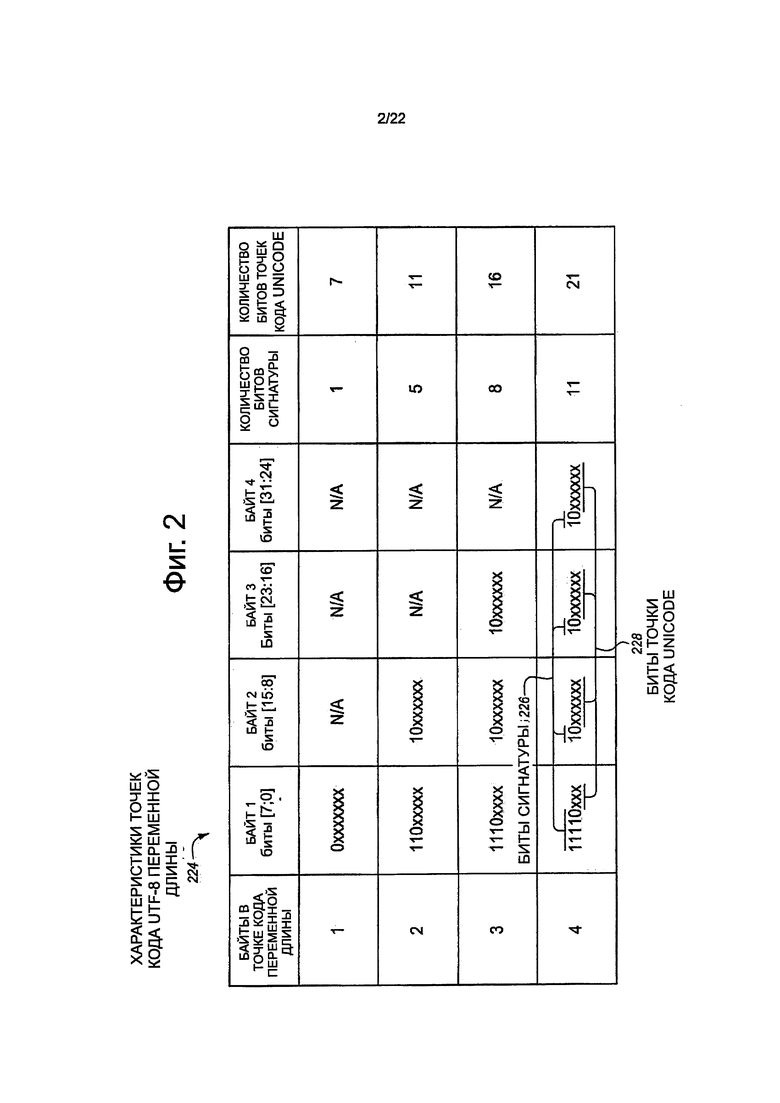
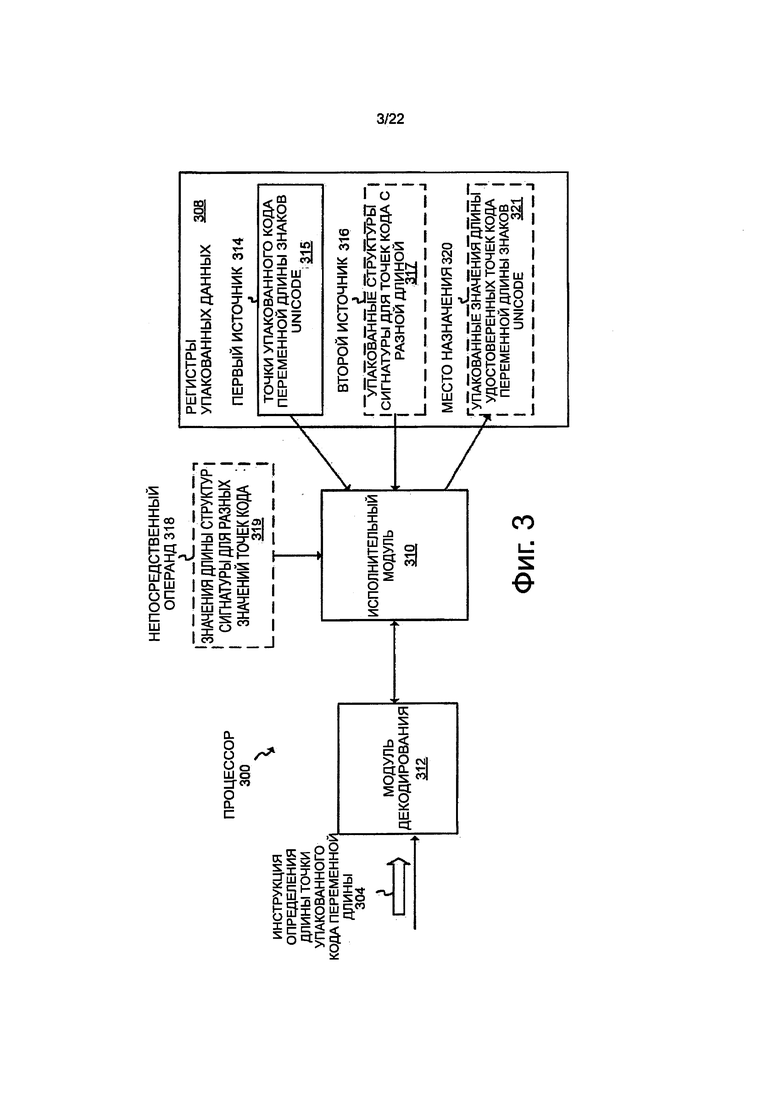
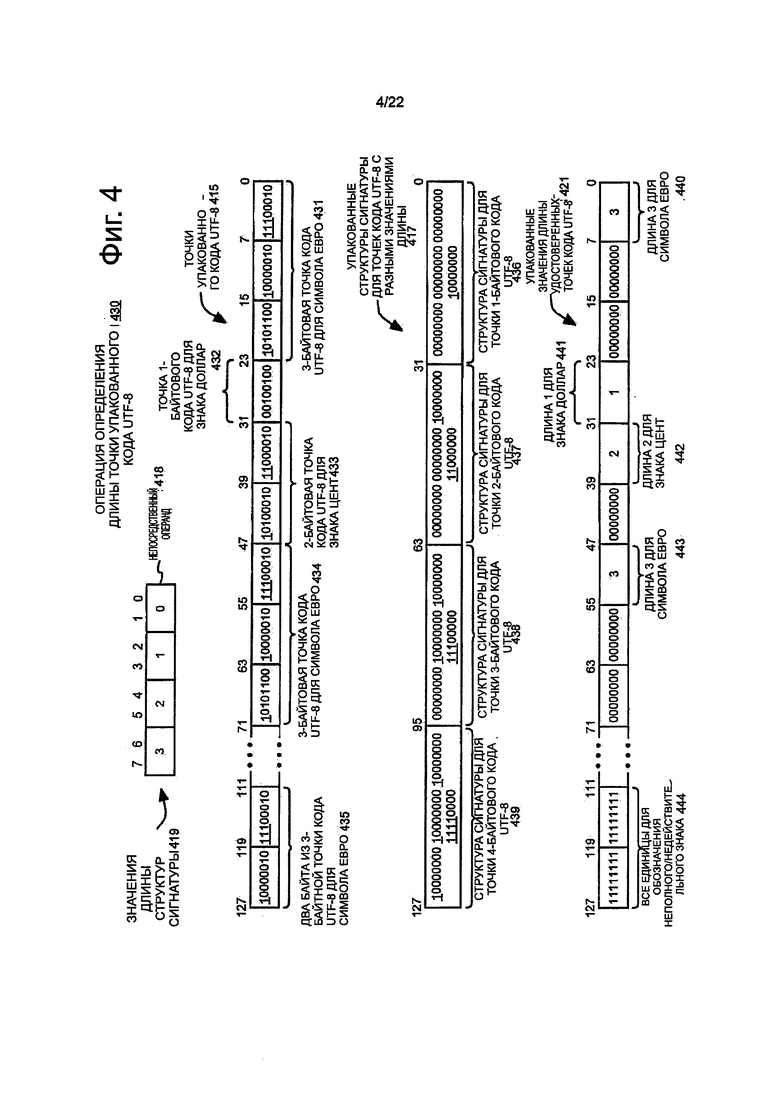

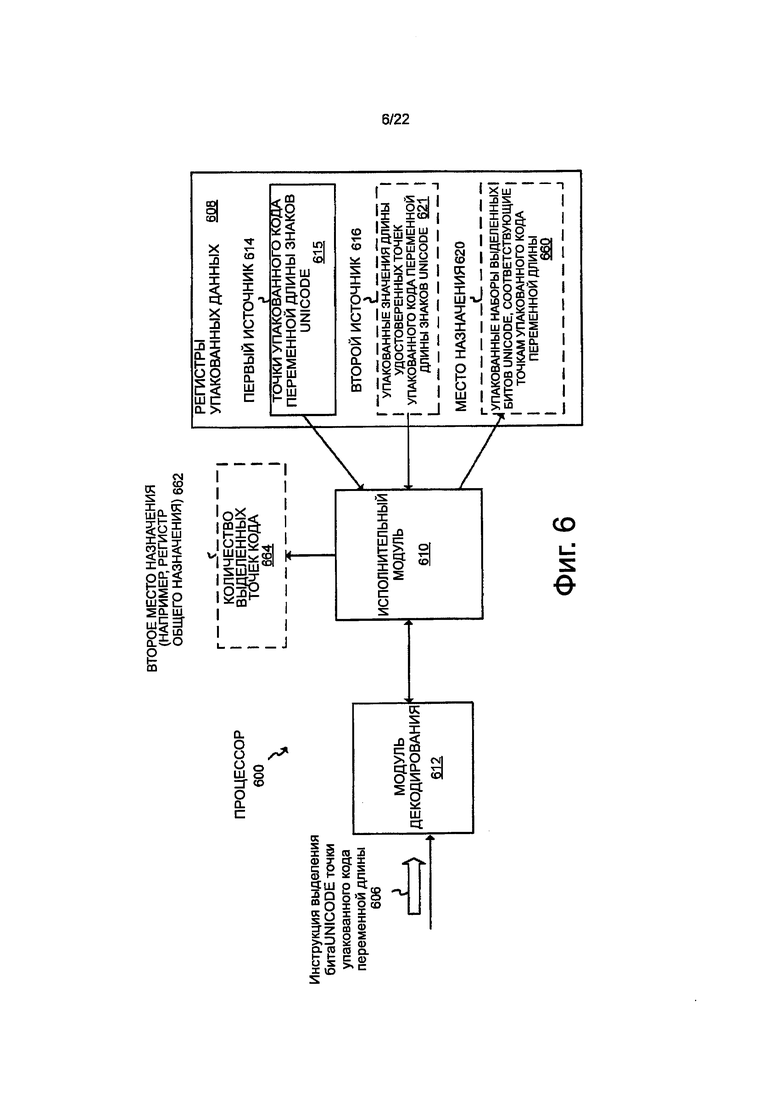
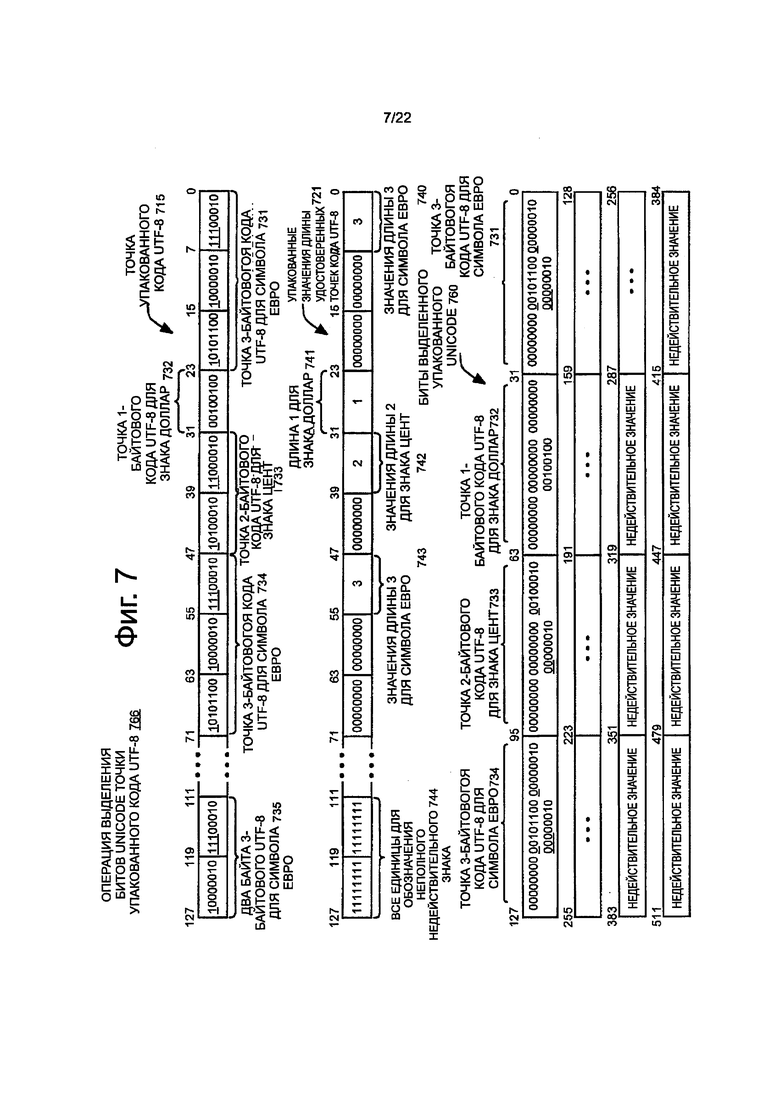
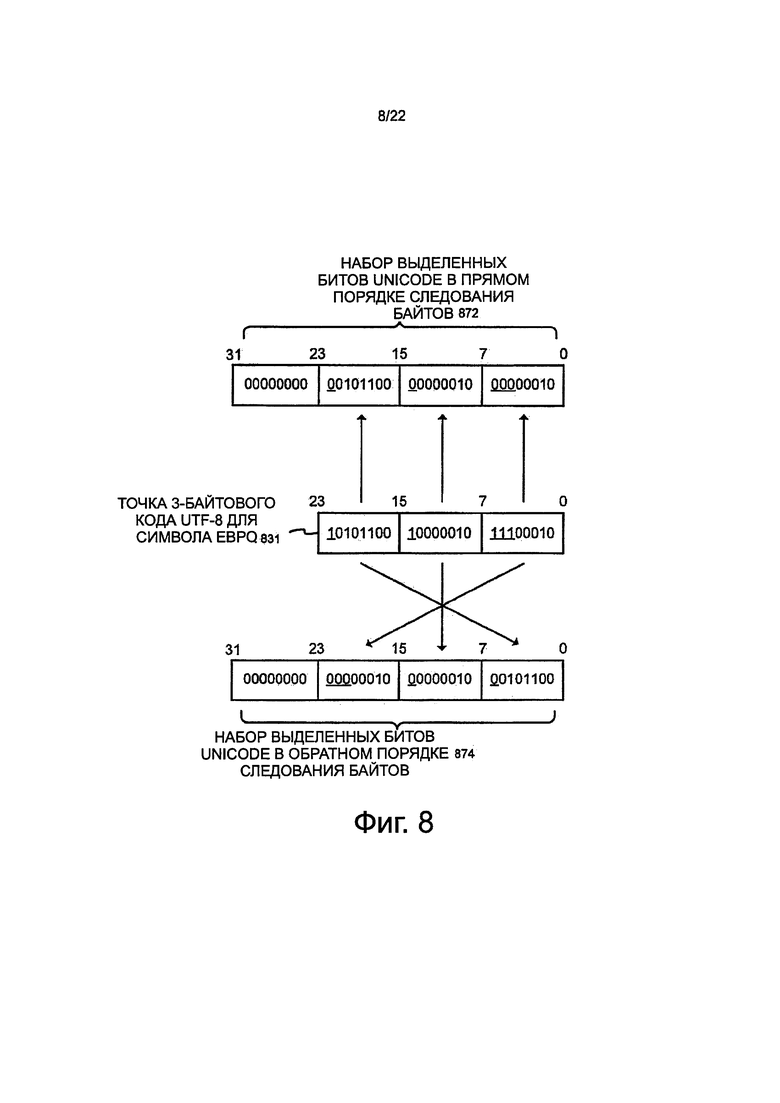
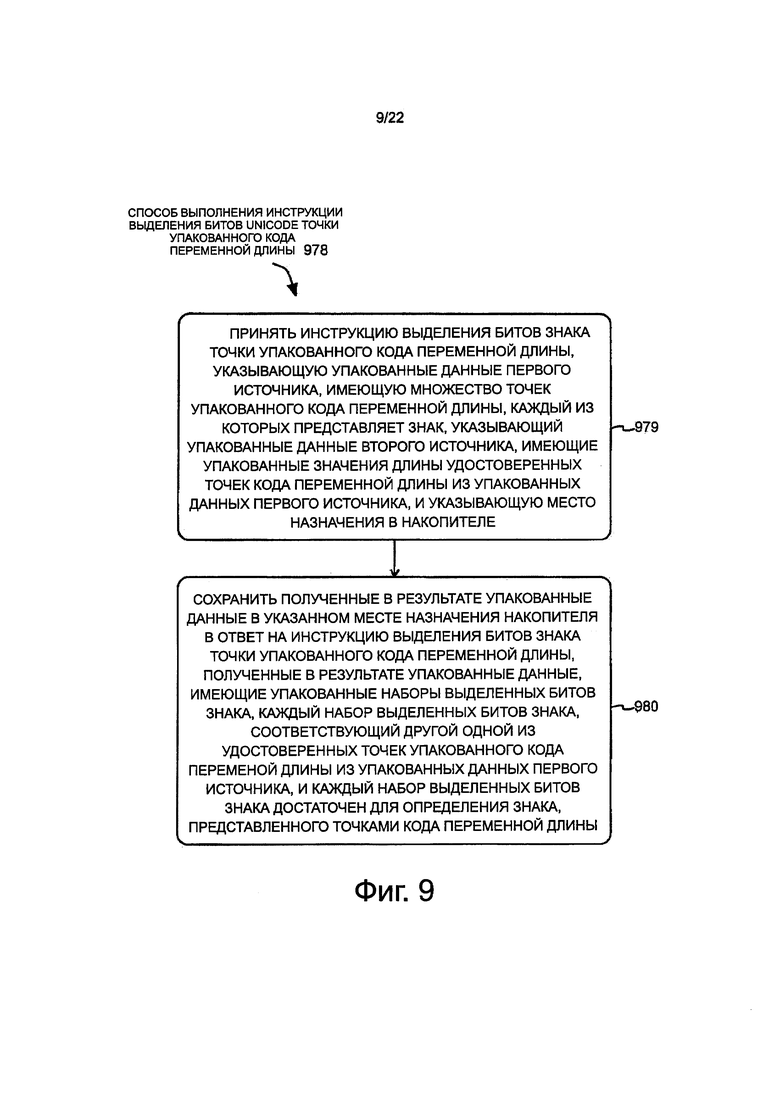
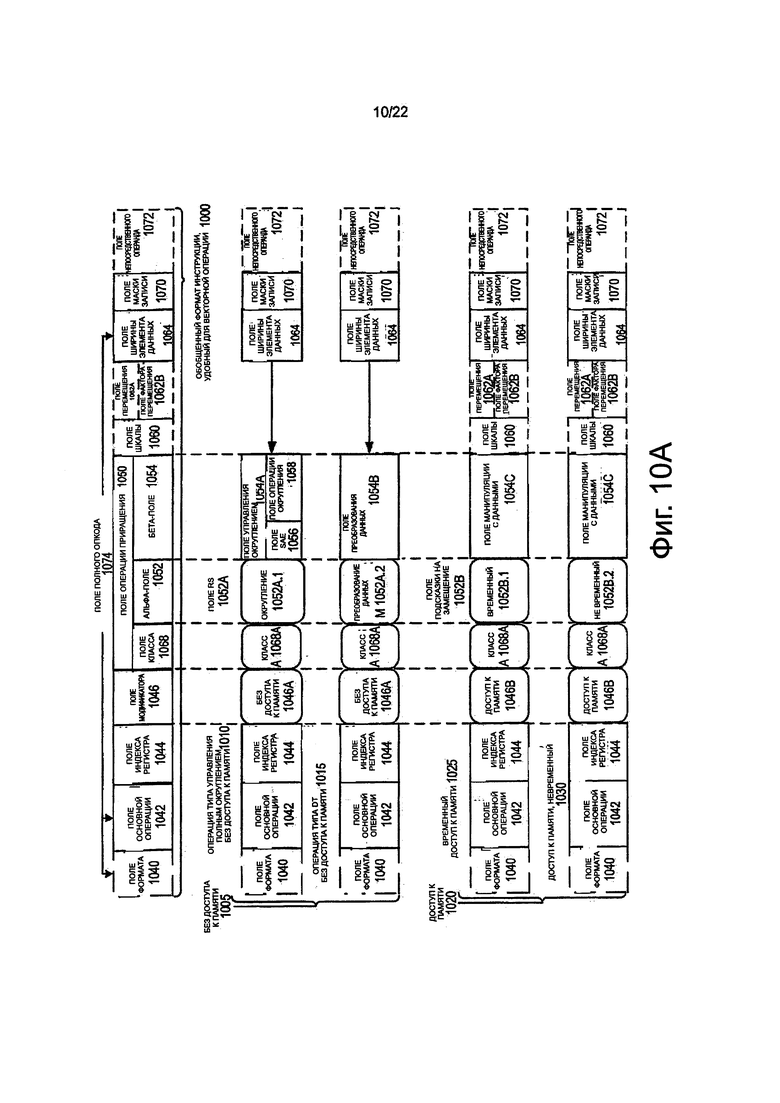
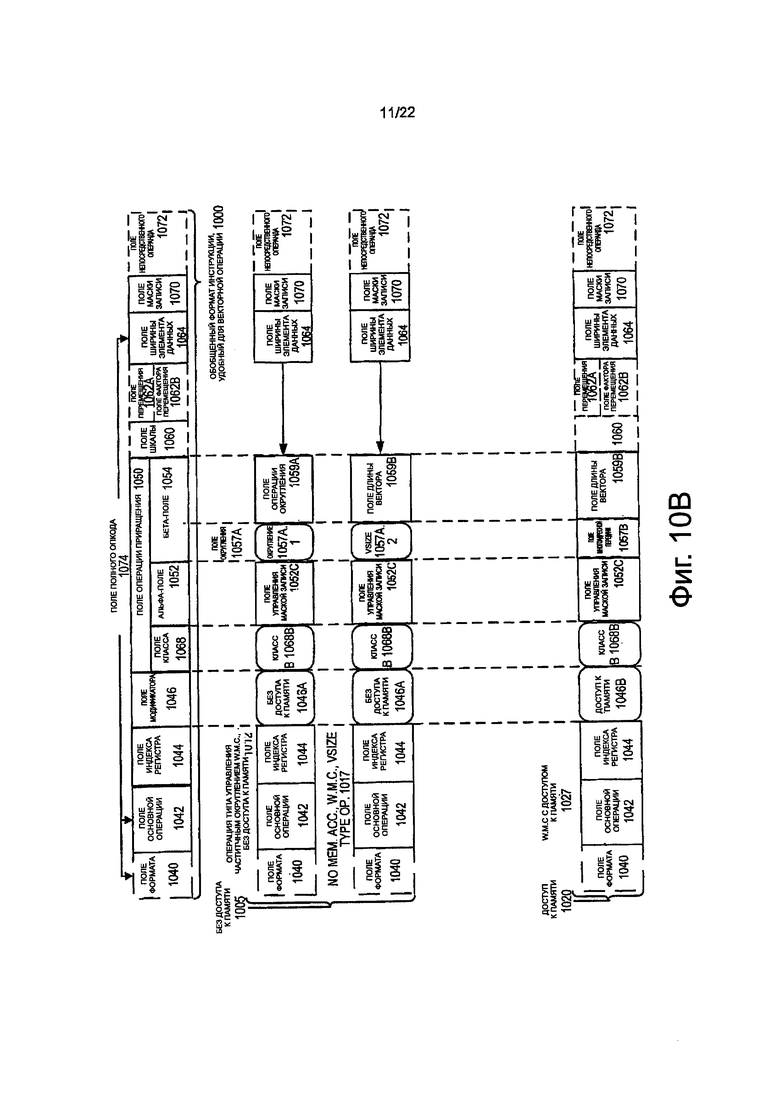
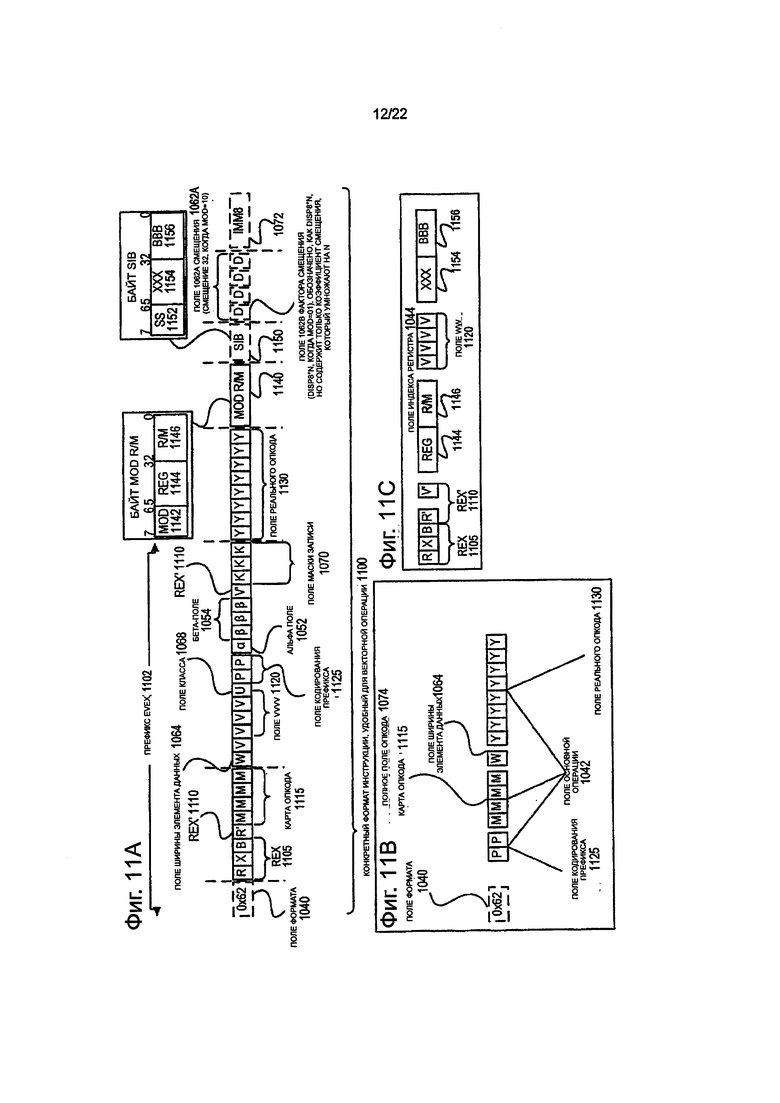
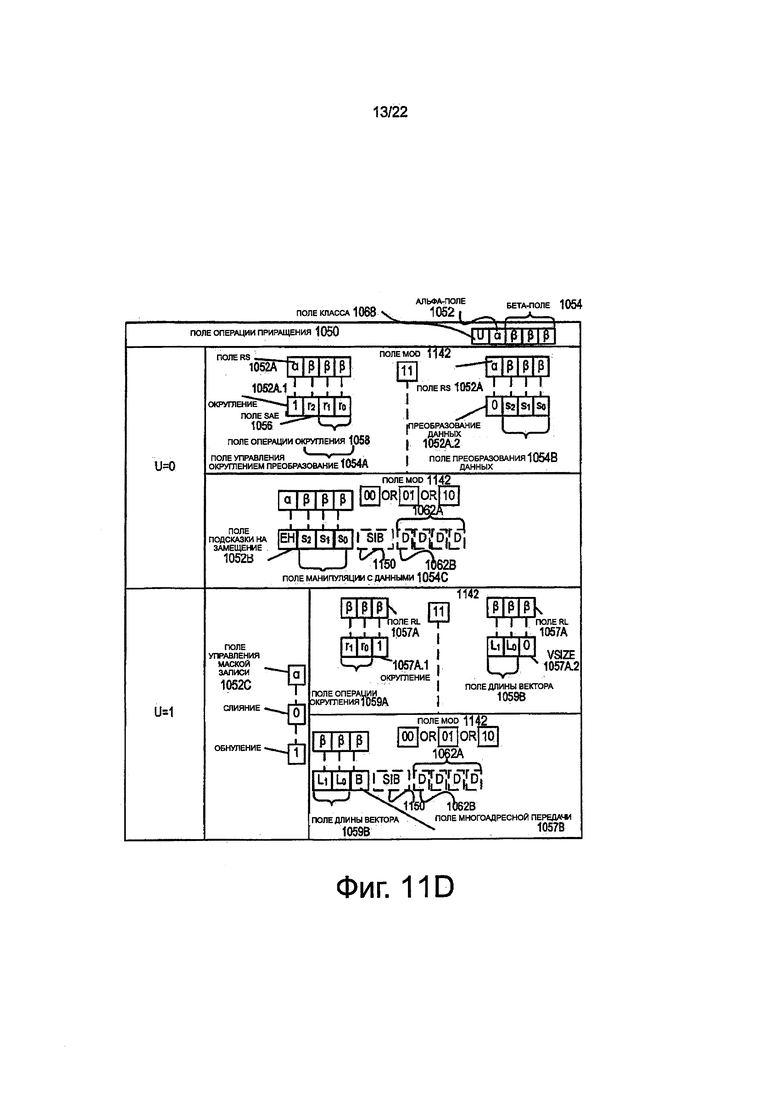
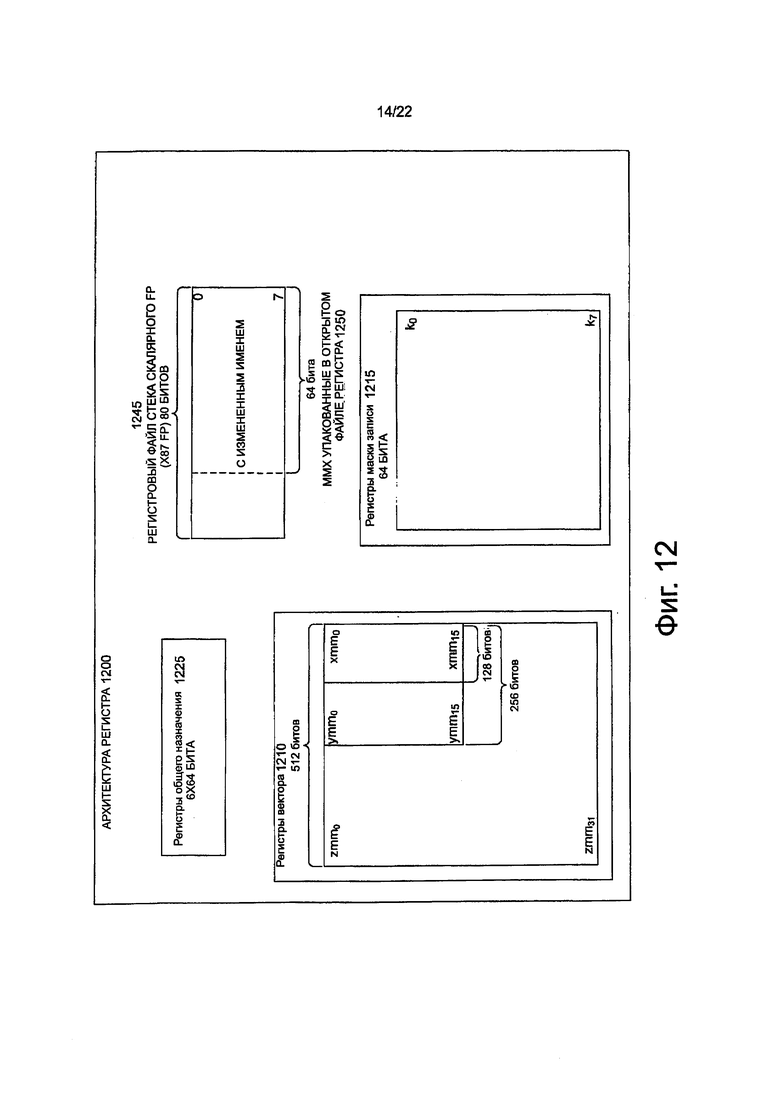
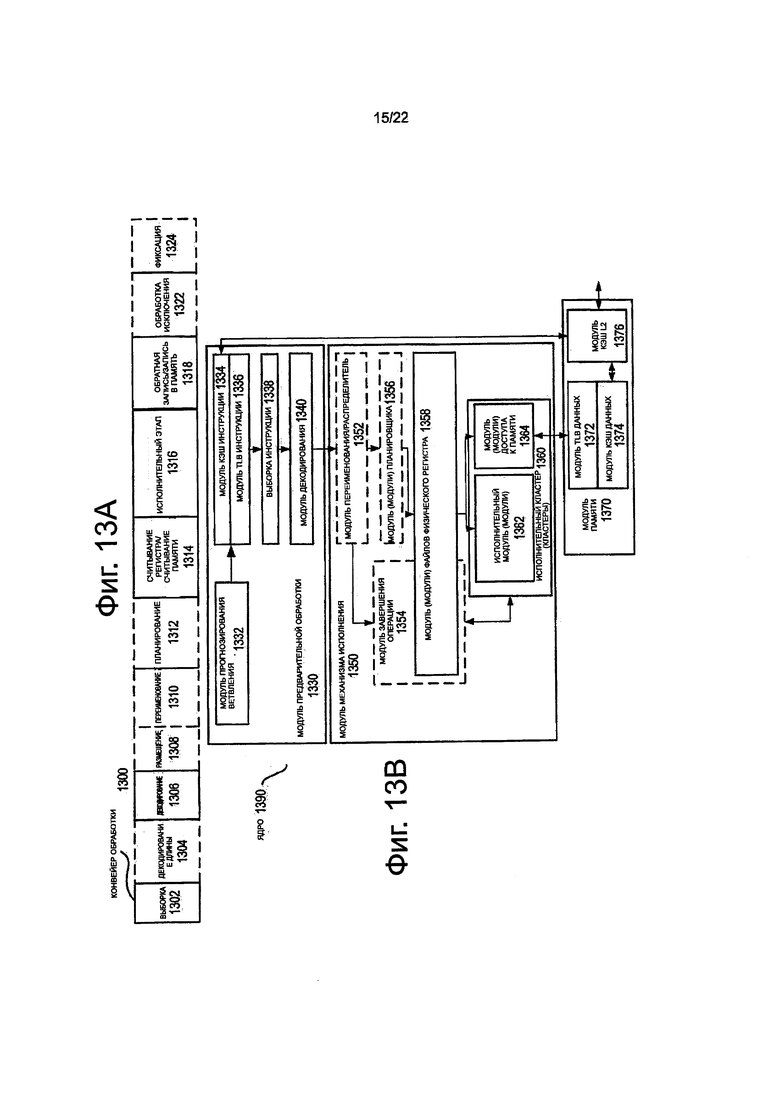
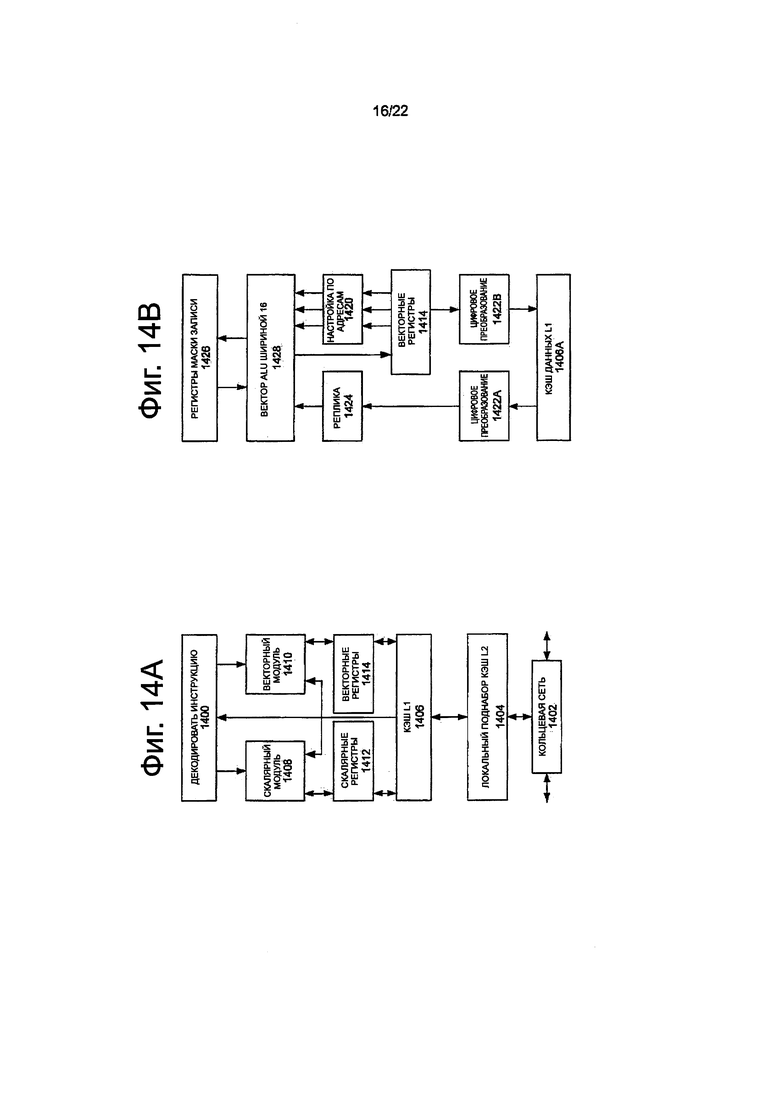
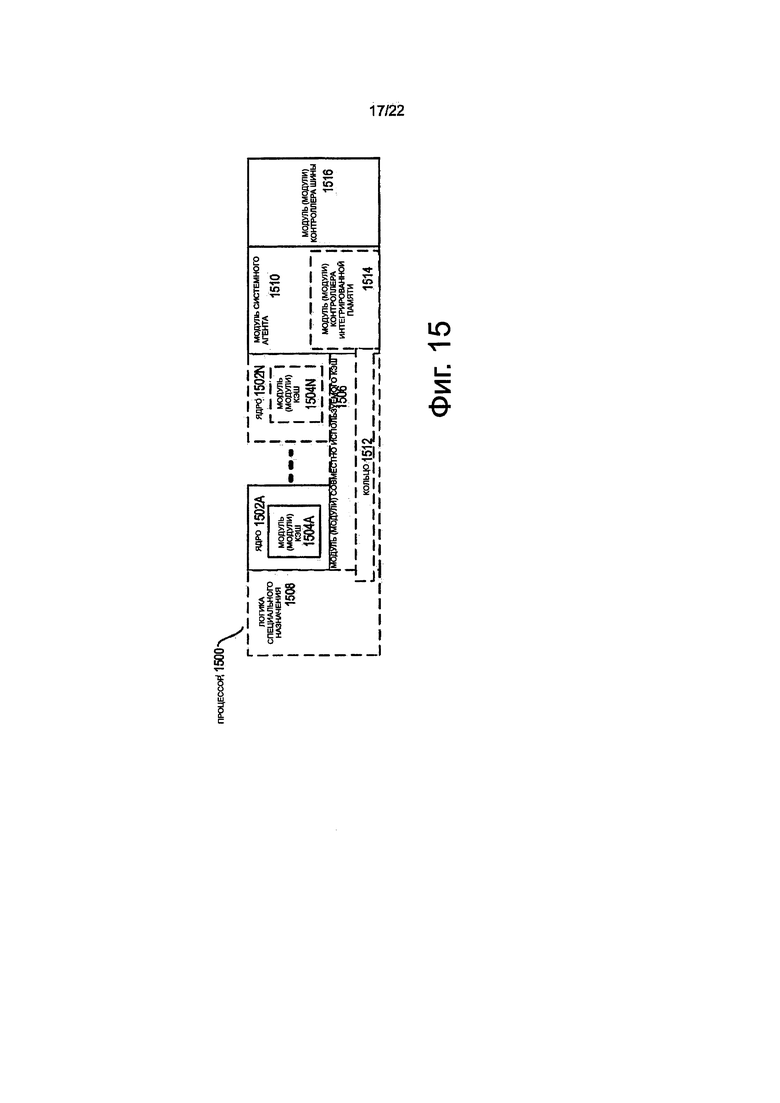
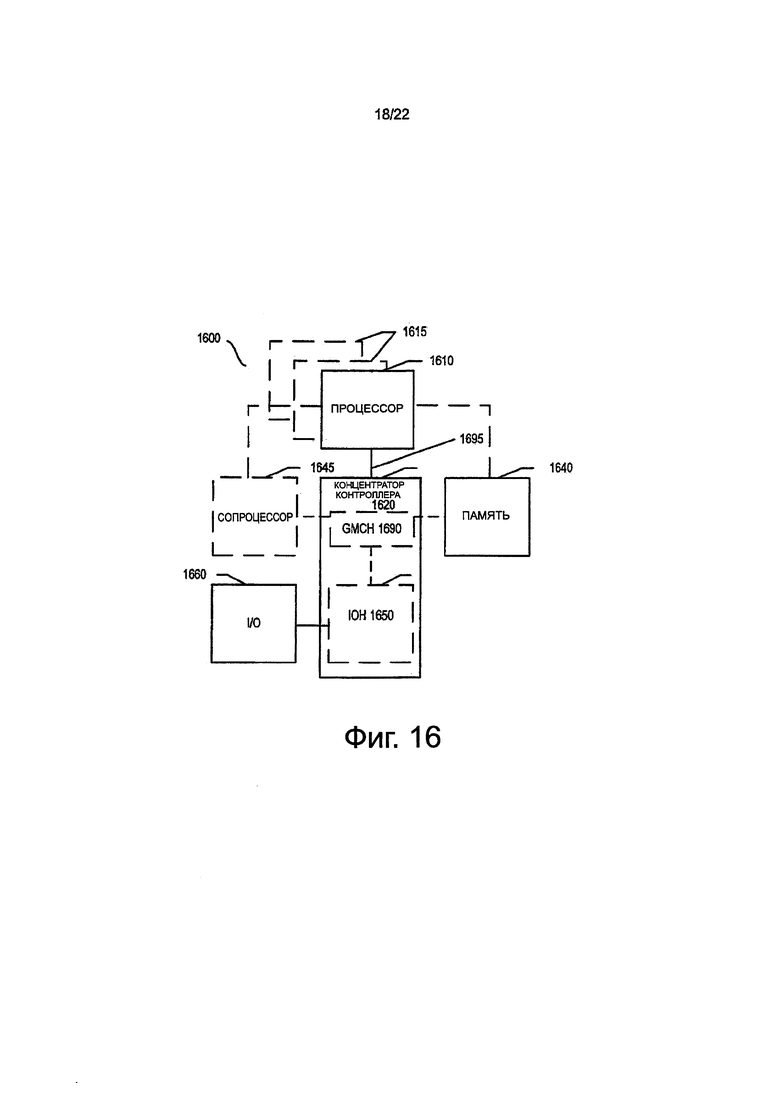
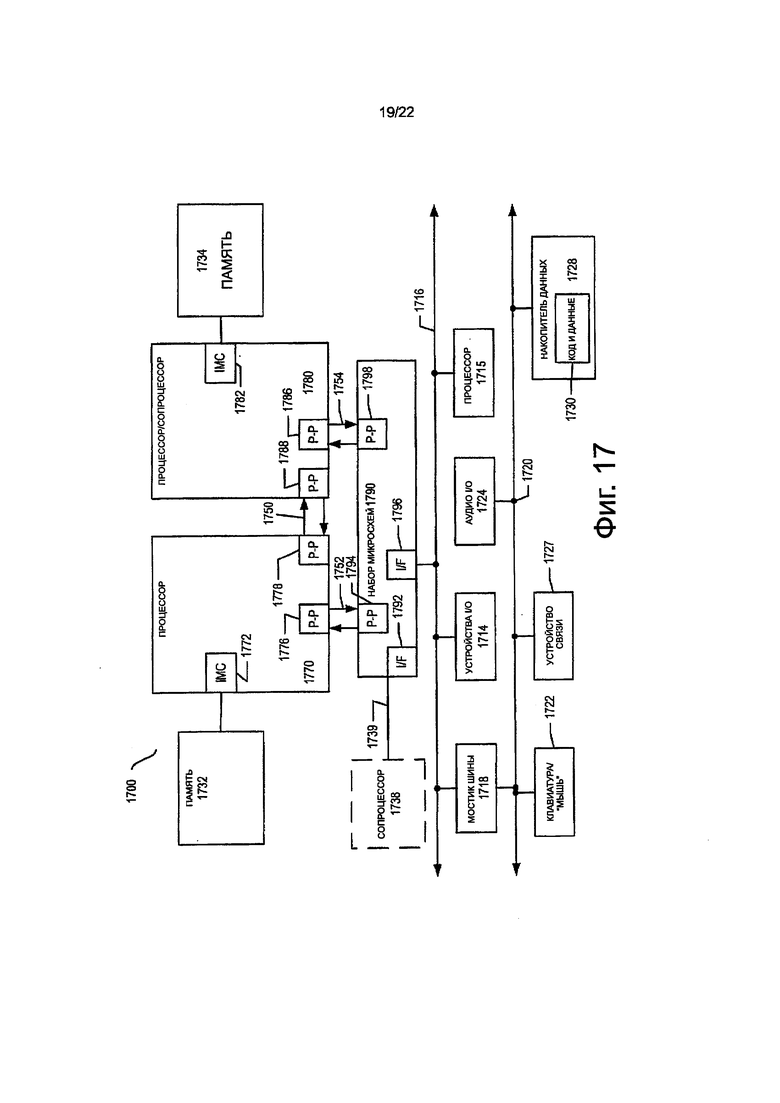

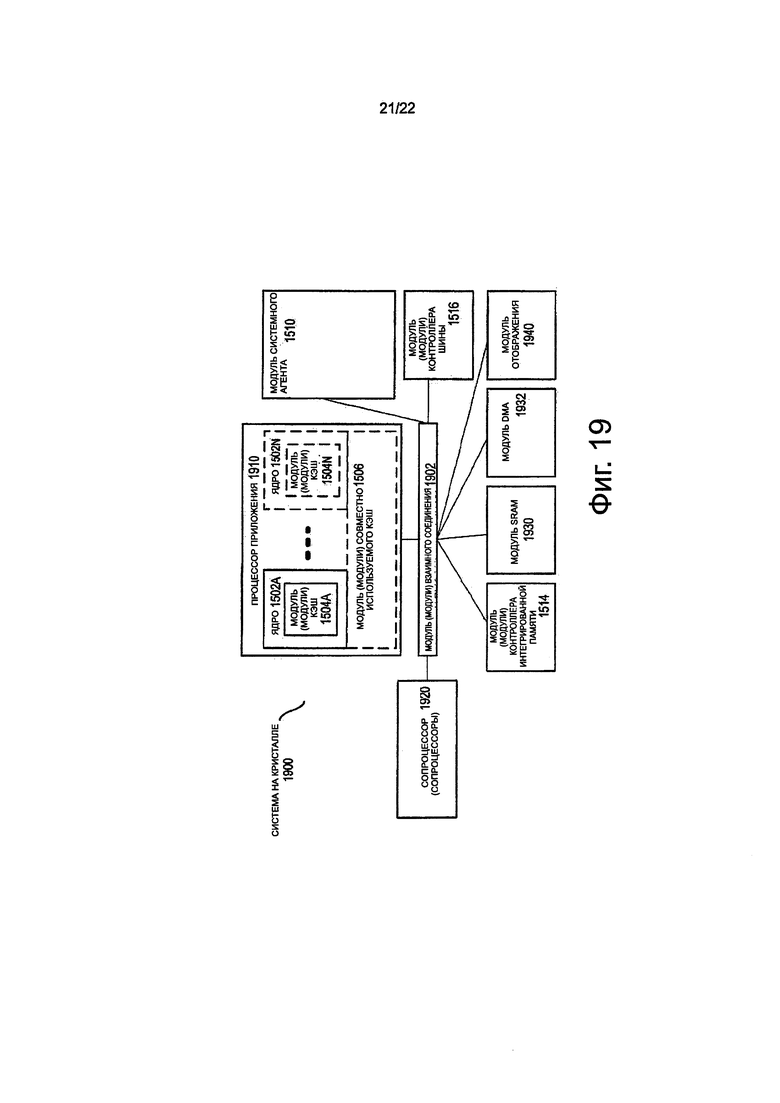
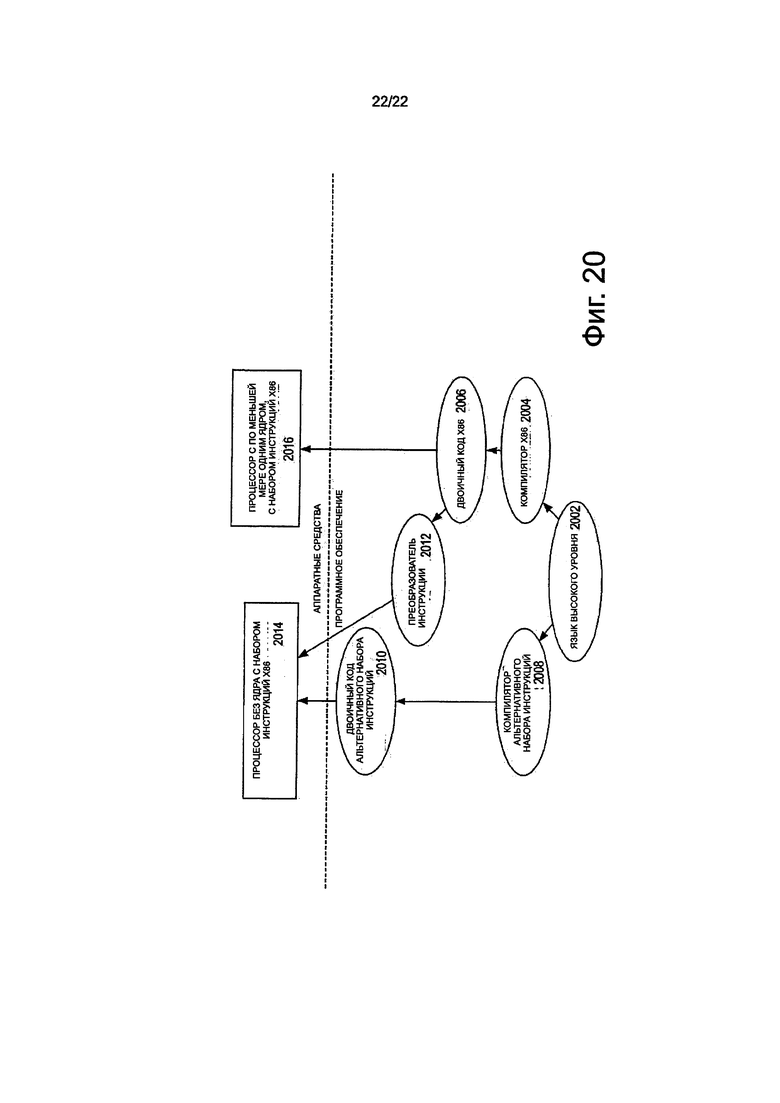
Группа изобретений относится к процессорам и может быть использована для транскодирования точек кода переменной длины для знаков Unicode. Техническим результатом является обеспечение обработки инструкций. Устройство содержит множество регистров упакованных данных; и модуль декодирования для декодирования инструкции определения длины точки упакованного кода переменной длины, которая предназначена для указания упакованных данных первого источника, имеющих множество точек упакованного кода переменной длины, каждая из которых представляет знак и указывает местоположение в накопителе; и исполнительный модуль, соединенный с модулем декодирования и регистрами упакованных данных, выполненный с возможностью сохранения в ответ на инструкцию определения длины точки упакованного кода переменной длины полученных в результате упакованных данных в указанном местоположении, в накопителе, при этом полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины, при этом исполнительный модуль выполнен с возможностью сохранения, в ответ на инструкцию, каждого значения длины в байте, расположенном в том же относительном положении бита в месте назначения накопителя, как и младший значащий байт соответствующей точки кода переменной длины в упакованных данных первого источника. 4 н. и 19 з.п. ф-лы, 26 ил.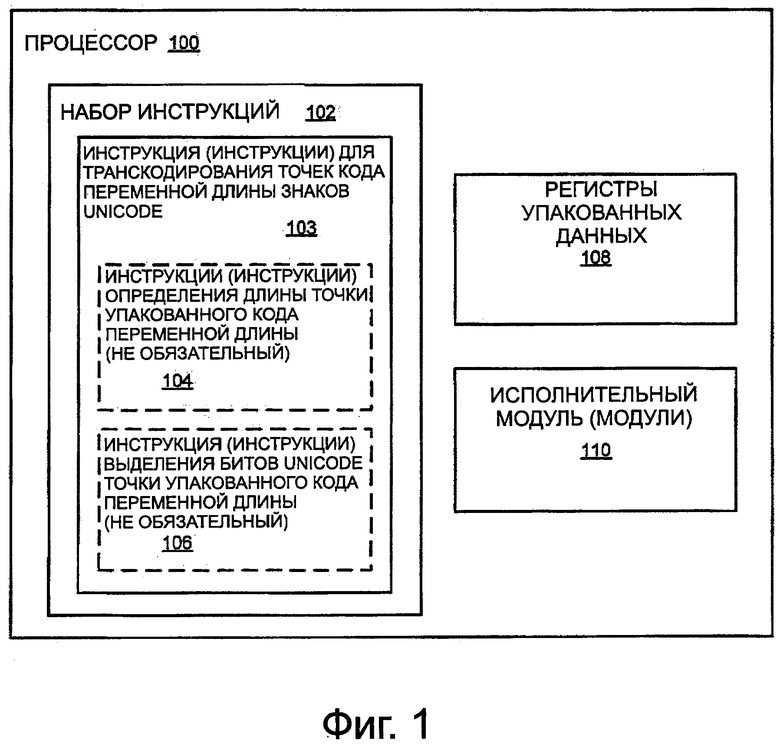
1. Процессор, содержащий:
множество регистров упакованных данных; и
модуль декодирования для декодирования инструкции определения длины точки упакованного кода переменной длины, при этом инструкция определения длины точки упакованного кода переменной длины предназначена для указания упакованных данных первого источника, имеющих множество точек упакованного кода переменной длины, каждая из которых представляет знак, дополнительно инструкция определения длины точки упакованного кода переменной длины указывает местоположение в накопителе; и
исполнительный модуль, соединенный с модулем декодирования, и регистрами упакованных данных, при этом исполнительный модуль выполнен с возможностью сохранения в ответ на инструкцию определения длины точки упакованного кода переменной длины полученных в результате упакованных данных в указанном местоположении, в накопителе, при этом полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины, при этом
исполнительный модуль выполнен с возможностью сохранения, в ответ на инструкцию, каждого значения длины в байте, расположенном в том же относительном положении бита в месте назначения накопителя, как и младший значащий байт соответствующей точки кода переменной длины в упакованных данных первого источника.
2. Процессор по п. 1, в котором инструкция указывает упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8.
3. Процессор по п. 1, в котором инструкция указывает множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода переменной длины.
4. Процессор по п. 3, в котором исполнительный модуль выполнен с возможностью определения, в ответ на инструкцию, что данная точка кода переменной длины соответствует данной структуре сигнатуры, посредством сравнения данной точки кода переменной длины с каждой из множества структур сигнатуры, при этом исполнительный модуль выполнен с возможностью сохранения, в ответ на инструкцию, значения длины, соответствующего данной структуре сигнатуры для данной точки кода переменной длины в месте назначения в накопителе.
5. Процессор по п. 3, в котором инструкция предназначена для указания упакованных данных второго источника, имеющих множество структур сигнатуры, при этом инструкция имеет непосредственный операнд для указания множества значений длины, каждое из которых соответствует одной из множества структур сигнатуры.
6. Процессор по п. 5, в котором множество структур сигнатуры включает в себя четыре разные структуры сигнатуры, а непосредственный операнд имеет четыре поля, каждое из которых указывает соответствующее значение длины разных одной из четырех структур сигнатуры.
7. Процессор по п. 3, в котором структуры сигнатуры подлежат сохранению в энергонезависимой памяти процессора, не являющейся архитектурным регистром.
8. Процессор по п. 1, в котором исполнительный модуль выполнен с возможностью сохранения, в ответ на инструкцию, значения длины, обозначающего три байта в заданном байте, расположенном в том же относительном положении бита, в месте назначения накопителя, как и младший значащий байт соответствующей трехбайтовой кодовой точки в упакованных данных первого источника, и сохранения всех нулей в двух более значащих последовательных байтах, которые должны быть более значимыми, чем заданный байт в месте назначения накопителя.
9. Процессор по п. 1, в котором исполнительный модуль выполнен с возможностью сохранения, в ответ на инструкцию, все двоичные единицы в байтах в тех же относительных положениях битов в месте назначения накопителя, как и байты неполных или недействительных точек кода переменной длины упакованных данных первого источника.
10. Способ обработки инструкции, выполняемый процессором, содержащий этапы, на которых:
принимают инструкцию определения длины точки упакованного кода переменной длины, при этом инструкция определения длины точки упакованного кода переменной длины указывает упакованные данные первого источника, имеющие множество точек упакованного кода переменной длины, каждая из которых представляет знак, и указывает место назначения в накопителе; и
сохраняют полученные в результате упакованные данные в указанном месте назначения в накопителе, в ответ на инструкцию определения длины точки упакованного кода переменной длины, при этом полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины; при этом
этап сохранения содержит подэтап, на котором сохраняют каждое значение длины в байт, расположенный в том же относительном положении бита, в месте назначения накопителя, в качестве младшего значащего байта соответствующей точки кода переменной длины в упакованных данных первого источника.
11. Способ по п. 10, в котором этап приема содержит подэтап, на котором принимают инструкцию, указывающую упакованные данные первого источника, имеющие множество упакованных точек кода UTF-8.
12. Способ по п. 10, в котором этап приема содержит подэтап, на котором принимают инструкцию, указывающую множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода переменной длины.
13. Способ по п. 12, дополнительно содержащий этапы, на которых:
определяют, что заданная точка кода переменной длины соответствует заданной структуре сигнатуры, посредством сравнения заданной точки кода переменной длины с каждой из множества структур сигнатуры; и
сохраняют значения длины, соответствующие заданной структуре сигнатуры для заданной точки кода переменной длины в месте назначения в накопителе.
14. Способ по п. 12, в котором этап приема содержит подэтап, на котором
принимают инструкцию, указывающую упакованные данные второго источника, имеющие множество структур сигнатуры; и имеющую непосредственный операнд, указывающий множество значений длины, каждое из которых соответствует одной из множества структур сигнатуры.
15. Способ по п. 14, в котором множество структур сигнатуры включает в себя четыре разные структуры сигнатуры, при этом каждая из четырех разных структур сигнатуры хранится в отдельном 32-битном элементе данных упакованных данных второго источника, имеющих ширину по меньшей мере 128 битов, причем непосредственный операнд имеет четыре поля, каждое из которых соответствует отдельной одной из четырех структур сигнатуры, для указания соответствующего значения длины.
16. Способ по п. 12, в котором этап приема содержит подэтап, на котором принимают инструкцию, указывающую структуру сигнатуры, каждая из которых сохранена в энергонезависимой памяти на кристалле процессора.
17. Способ по п. 10, в котором этап сохранения содержит подэтап, на котором сохраняют значения длины, указывающие два байта в заданном байте, то есть в том же относительном положении бита в месте назначения накопителя, что и младший значащий байт соответствующей двухбайтовой точке кода в упакованных данных первого источника, и сохраняют все нули в более значащем последовательном байте, являющемся более значащим, чем заданный байт в месте назначения накопителя.
18. Способ по п. 10, в котором этап сохранения содержит подэтап, на котором сохраняют все единицы в байтах, в тех же относительных положениях бита в месте назначения накопителя, что и байты неполных или недействительных точек кода переменной длины упакованных данных первого источника.
19. Способ по п. 18, дополнительно содержащий этапы, на которых
выполняют одну или более из других инструкций для определения положения старшего значащего байта, содержащего все единицы, и указывающего неполную точку кода переменной длины; и используют заданное положение старшего значащего байта, в случае необходимости, для загрузки другой непрерывной части точек кода переменной длины.
20. Система обработки инструкции, содержащая:
взаимное соединение;
процессор, соединенный с взаимным соединением; и
динамическое оперативное запоминающее устройство (DRAM), соединенное с взаимным соединением, DRAM содержит алгоритм транскодирования, имеющий инструкцию определения длины точки упакованного кода переменной длины, при этом инструкция определения длины точки упакованного кода переменной длины предназначена для указания упакованных данных первого источника, имеющих множество точек упакованного кода переменной длины, каждая из которых представляет знак, и инструкцию определения длины точки упакованного кода переменной длины для указания места назначения в накопителе, причем инструкция определения длины точки упакованного кода переменной длины, при ее выполнении процессором, обеспечивает во время работы выполнение процессором операций, содержащих этап, на котором:
сохраняют полученные в результате упакованные данные в указанном месте назначения накопителя, причем полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины; причем
этап сохранения содержит подэтап, на котором сохраняют каждое значение длины в байт, расположенный в том же относительном положении бита, в месте назначения накопителя, в качестве младшего значащего байта соответствующей точки кода переменной длины в упакованных данных первого источника.
21. Система по п. 20, в которой инструкция указывает упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8, при этом инструкции указывают множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода UTF-8.
22. Энергонезависимый машиночитаемый носитель, хранящий инструкции определения длины точки упакованного кода переменной длины, причем инструкции определения длины точки упакованного кода переменной длины выполнены с возможностью указания упакованных данных первого источника, имеющих множество точек упакованного кода переменной длины, каждая из которых представляет знак, дополнительно инструкция определения длины точки упакованного кода переменной длины указывает местоположение в накопителе, при этом при выполнении инструкций определения длины точки упакованного кода переменной длины компьютером указанные инструкции вызывают выполнение компьютером этапа, на котором:
сохраняют полученные в результате упакованные данные в указанном месте назначения накопителя, причем полученные в результате упакованные данные имеют длину для каждой из множества точек упакованного кода переменной длины; при этом
этап сохранения содержит подэтап, на котором сохраняют каждое значение длины в байт, расположенный в том же относительном положении бита, в месте назначения накопителя, в качестве младшего значащего байта соответствующей точки кода переменной длины в упакованных данных первого источника.
23. Энергонезависимый машиночитаемый носитель по п. 22, в котором инструкции, указывающие упакованные данные первого источника, имеющие множество точек упакованного кода UTF-8, при этом инструкции указывают множество структур сигнатуры, каждая из которых соответствует одному из разных значений длины точек кода UTF-8.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ВВОД ДАННЫХ ПРИ ИСПОЛЬЗОВАНИИ GUI-ИНТЕРФЕЙСА | 2000 |
|
RU2267151C2 |

