Область техники
Изобретение относится к области вычислительной техники, в частности к системе обработки информации на основе потока данных и к способу вычислений, использующему поток данных.
Предшествующий уровень техники
Вычислительные системы, управляемые потоком данных, известны несколько десятилетий. В различных странах было создано несколько опытных функционирующих образцов, однако до настоящего времени эти системы не нашли широкого применения. Главным недостатком подобных вычислительных систем (ВС) является необходимость иметь ассоциативную память большого объема для хранения промежуточных результатов вычислений.
Известна вычислительная система на основе потока данных, содержащая множество одинаковых исполнительных устройств, множество модулей ассоциативной памяти и два коммутатора, один из которых обеспечивает передачу данных из модулей ассоциативной памяти в исполнительные устройства, другой коммутатор - из исполнительных устройств в модули ассоциативной памяти, а также реализованный в ней способ обработки информации на основе потока данных (см. Optical associative memory for high performance digital computers with nontraditional architectures, V.S.Burtsev and V.B.Fyodorov, Optical Computing and Processing, 1991, volume 1, number 4, pages 275-288).
В модулях ассоциативной памяти известной вычислительной системы информация хранится в виде токенов, каждый их которых представляет структуру данных, состоящую из поля данных и поля ключа. Понятие токена является фундаментальным в вычислительных системах, управляемых потоком данных, и используется при описании подобных систем. Основной операцией в ассоциативной памяти является операция поиска токена, ключ которого совпадает с ключом входящего токена. При успешном поиске из входящего и найденного токенов формируется пара данных, содержащая ключ и два операнда, один из которых взят из входящего токена, а другой - из найденного. На исполнительные устройства информация передается в виде пар данных. Если при операции поиска токен с заданным во входящем токене ключом не был найден, то входящий токен помещается в ассоциативную память и присоединяется к хранящимся токенам.
Модульность ассоциативной памяти позволяет увеличить темп выполнения операций поиска, так как поиск в различных модулях ассоциативной памяти осуществляется одновременно. Распределение токенов по модулям ассоциативной памяти осуществляется с помощью «вычисления хеш-функции», аргументом которой является ключ токена.
Недостатком известной вычислительной системы и реализованного в ней способа является относительно невысокая надежность работы, связанная с возможностью возникновения тупиковых ситуаций («дедлоков») в процессе вычислений.
По технической сущности наиболее близким к предложенным изобретениям является способ обработки информации на основе потока данных, включающий следующие операции:
«обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют структуру данных - «токен» - состоящую из группы разрядов, образующих поле данных, поле контекста и поле ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены;
«вычисление хеш-функции» для сформированного токена, при которой по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен;
«направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена;
«поиск» среди сформированных указанным выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск»,
а также устройство - система обработки информации на основе потока данных, содержащая один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью:
хранить поступающую в него структуру данных - «токен», состоящую из группы разрядов, образующих поле данных, поле контекста и поле ключа,
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена,
запоминать поступающий токен в модулях ассоциативной памяти в случае неудачного поиска;
формировать пару данных из поступающего в ассоциативную память токена и найденного в ассоциативной памяти токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств;
одно или несколько исполнительных устройств, выполненных с возможностью:
выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в паре данных,
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром,
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти,
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией;
первый коммутатор, выполненный с возможностью направлять токены из любого исполнительного устройства в любой модуль ассоциативной памяти, и
второй коммутатор, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти в любое исполнительное устройство (см. патент США №6,370,634, Data flow computer with two switches, Current U.S. Class 712/10, Intern. class G 06 F 015/16 of April 9, 2002).
В этом патенте в разделе «Подробное описание изобретения» (Detailed description of the invention) подробно раскрыто понятие термина - «токен».
Однако при реализации известной вычислительной системы и используемого в ней способа обработки информации возникают проблемы, связанные с возникновением тупиковых ситуаций («дедлоков») при переполнении в процессе вычислений хотя бы одного модуля ассоциативной памяти. Вместе с тем увеличение объема ассоциативной памяти приводит к значительным расходам, так как ассоциативная память значительно превосходит по стоимости обычную память с произвольной выборкой (RAM - random access memory).
Другим недостатком прототипа является отсутствие средств для управления прохождением вычислительного процесса со стороны операционной системы и пользователя, а также отсутствие информации о выполнении во времени тех или иных вычислительных задач. Все это снижает надежность функционирования и функциональные возможности вычислительной системы.
Раскрытие изобретения
Техническим результатом является повышение надежности функционирования при сохранении объема ассоциативной памяти путем повышения достоверности информации процесса обработки и обеспечения контроля за процессами обработки.
Достигается это тем, что в способе обработки информации на основе потока данных, заключающемся в выполнении следующих операций:
«обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют структуру данных - «токен», состоящую из группы разрядов, образующих поле данных, поле контекста и поле ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены;
«вычисление хеш-функции» для сформированного токена, при котором по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен;
«направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена;
«поиск» среди сформированных указанным выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск»,
согласно изобретению в операции «поиск» производят «троичный поиск», при котором каждый бит прикрепленного к токену ключа имеет три состояния: «0», «1» и «неважно», при сравнении ключей входного и хранящегося токенов бит со значением «неважно» в любом из двух ключей считают совпавшим с соответствующим битом оставшегося ключа, при успешном «поиске» из входного и найденного токенов формируют пары данных, количество которых равно количеству найденных токенов при «троичном поиске», каждая из сформированных пар данных содержит результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над всеми сформированными таким образом парами данных выполняют действия, указанные в операции «обработка пары данных»;
осуществляют операцию «запись во вторичную память входного токена», при которой указанный в операции входной токен записывают по адресу, сформированному из ключа токена;
осуществляют операцию «чтение из вторичной памяти» токена, при которой считывают из вторичной памяти токен по адресу, указанному в операции;
осуществляют операцию «запись во вторичную память пары данных», при которой указанную в операции пару данных - токен записывают по адресу, сформированному из ключа пары данных;
осуществляют операцию «чтение из вторичной памяти пары данных», при которой считывают из вторичной памяти пару данных по адресу, указанному в операции;
осуществляют «мониторинг процесса вычислений» и на его основе вырабатывают управляющие токены, которые изменяют алгоритм выбора указанных выше действий над входными токенами и парами данных;
при выполнении операции «обработка пары данных» в троичный ключ токена вводят дополнительные разряды для хранения номера задачи - поле Т, характеризующее некоторый независимый вычислительный процесс,
а при выполнении операции «обработка пары данных» в троичный ключ токена вводят дополнительные разряды для хранения номера подзадачи - поле ST, характеризующее часть независимого вычислительного процесса.
Кроме того, в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «заглушка» и помещают его в одну, в несколько или во все группы хранящихся токенов без выполнения операции «поиск», при этом такой токен оказывает следующее влияние на выполнение операции «троичный поиск»: если ключ очередного входного токена при операции «троичный поиск» совпадает с ключом хранящегося токена, у которого имеется признак «заглушка», то над входным токеном выполняется операция «запись во вторичную память входного токена» и ему приписывают признак «откачанный заглушкой токен», а токен с признаком «заглушка» остается в одной, в нескольких или в каждой группе хранящихся токенов соответственно,
и/или в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «убрать заглушки», в котором все разряды ключа, кроме полей ST и Т, установлены в значение «неважно», разряды в полях ST и Т, характеризующие номера задач и подзадач, токены с признаком «заглушка» для которых должны быть убраны, и помещают управляющий токен в одну, в несколько или во все группы хранящихся токенов, при этом такой токен оказывает следующее влияние на выполнение операции «троичный поиск»: все найденные при выполнении операции «троичный поиск» токены с признаком «заглушка» удаляются соответственно из одной, из нескольких или из всех групп хранящихся токенов, и/или
в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «переместить во вторичную память токены» из одной, из нескольких или из всех групп хранящихся токенов, в указанном управляющем токене все разряды ключа, кроме полей ST и Т, установлены в значение «неважно», разряды в полях ST и Т, характеризующие номера задач и подзадач, токены которых должны быть перемещены во вторичную память, имеют значение «0», «1» или «неважно», при этом управляющий токен вызывает следующие действия:
соответственно в одной, в нескольких или во всех группах хранящихся токенов производят «троичный поиск» токенов, у которых поля ST и Т совпадают с полями ST и Т в управляющем токене;
все найденные токены удаляют соответственно из одной, из нескольких или из всех групп хранящихся токенов и перемещают найденные токены во вторичную память, причем этим токенам присваивают во вторичной памяти признак «откачанные записанные токены», и/или
в операции «мониторинг процесса вычислений» вводят действие «вернуть откачанные записанные токены с указанными значениями полей S и ST», при котором все хранящиеся во вторичной памяти токены с признаком «откачанные записанные токены» с заданными значениями троичных полей S и ST удаляют из вторичной памяти и помещают их в ту группу хранящихся токенов, номер которой определяют путем выполнения операции «вычисление хеш-функции», и/или
в операции «мониторинг процесса вычислений» вводят действие «вернуть откачанные заглушкой токены с указанными значениями полей S и ST», при котором все хранящиеся во вторичной памяти токены с признаком «откачанные заглушкой токены» с заданными значениями троичных полей S и ST удаляют из вторичной памяти и направляют их в качестве входных токенов в операцию «троичный поиск» среди той группы хранящихся токенов, номер которой определяют путем выполнения операции «вычисление хеш-функции», а также
при выполнении операции «обработка пары данных» в токен вводят поле, определяющее кратность N использования такого токена, который называют «токен многократного отклика», рассылают его по всем группам хранящихся токенов, причем в операции «троичный поиск» при нахождении такого токена формируют из него пару данных, как и из обычного токена, уменьшают N на 1, оставляют токен в группе хранящихся токенов, если N>0, и удаляют его из группы, если N=0, реализуя при этом возможности:
выдавать информацию о значении N по запросу из операции «мониторинг процесса вычислений»,
подсчитывать суммарное количество К сформированных с таким токеном пар данных во всех группах хранящихся токенов,
информировать задачу пользователя о ситуации, когда K=N,
формировать токен с заданными значениями полей Т и ST и с признаком «событийный токен» и выдавать его при возникновении ситуации, при которой K=N, независимо от того возникла ли эта ситуация при размещении «токена многократного отклика» в одной группе хранящихся токенов или во всех группах, а также
при формировании токена в него вводят поле, определяющее кратность N использования этого токена, помещают его в группу хранящихся токенов, номер которой определяют при помощи операции «вычисление хеш-функции», а в операции «троичный поиск» при нахождении такого токена формируют из него пару данных, как и из обычного токена, уменьшают значение N на 1, оставляют токен в группе хранящихся токенов, если N>0 и удаляют токен из группы хранящихся токенов, если N=0, а также
при формировании токена в токен вводят поле, определяющее порядковый номер операнда, который прикреплен к токену, а при выполнении операции «троичный поиск» образуют пары данных из токенов, у которых совпадают троичные ключи, а порядковые номера операндов различны.
Поставленный технический результат по второму изобретению достигается тем, что в системе обработки информации на основе потока данных, содержащей:
один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью:
хранить поступающие в него токены, содержащие поле данных и поле ключа,
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена,
запоминать поступающий токен в модулях ассоциативной памяти в случае неудачного поиска;
формировать пару данных из поступающего в ассоциативную память токена и найденного в ассоциативной памяти токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств;
одно или несколько исполнительных устройств, выполненных с возможностью:
выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в паре данных,
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром,
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти,
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией,
первый коммутатор, выполненный с возможностью направлять токены из любого исполнительного устройства в любой модуль ассоциативной памяти, и
второй коммутатор, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти в любое исполнительное устройство,
согласно изобретению введены
вторичная память для временного хранения пар данных и токенов, выполненная с возможностью:
получать токены для хранения из исполнительных устройств и ассоциативной памяти,
получать пары данных на хранение из ассоциативной памяти,
выдавать хранящиеся токены и пары данных в ассоциативную память;
адаптер вторичной памяти, выполненный с возможностью определять место во вторичной памяти для хранения токенов и пар,
и процессор для регулировки степени параллелизма, выполненный с возможностью:
собирать информацию о степени загрузки ассоциативной памяти и исполнительных устройств,
направлять токены из ассоциативной памяти во вторичную память и обратно и
направлять управляющие токены в ассоциативную память,
а каждый модуль ассоциативной памяти выполнен троичным с возможностью
хранить токены с троичными ключами, каждый разряд которых может принимать одно из трех значений: «0», «1» и «неважно», осуществлять «троичный поиск» среди хранящихся токенов токена, троичный ключ которого совпадает с троичным ключом пришедшего токена таким образом, что разряды, в которых записано значение «неважно» в любом из токенов, не участвуют в сравнении, и выдавать в рамках одной операции «троичный поиск» несколько хранящихся в ассоциативной памяти токенов, количество которых равно количеству токенов, найденных при «троичном поиске»,
кроме того, процессор для регулировки параллелизма выполнен с возможностью направлять пары данных из вторичной памяти в исполнительные устройства,
а также каждый модуль ассоциативной памяти содержит двоичную ассоциативную память, которая дополнительно приспособлена
хранить вместе с ключом маску, в которой указаны разряды ключа со значением «неважно», а приходящий токен, кроме обычного вышеописанного ключа, содержит маску, в которой указаны разряды ключа со значением «неважно»,
осуществлять среди хранящихся токенов «троичный поиск» токена с ключом, совпадающим с ключом пришедшего токена таким образом, что разряды хранящихся токенов и/или пришедшего токена, которые закрываются масками, то есть имеют значение «неважно», не участвуют в сравнении,
выдавать в рамках одного троичного поиска несколько хранящихся в ассоциативной памяти токенов, ключ каждого из которых удовлетворяет вышеприведенному критерию «троичного поиска», а также
первый коммутатор выполнен с возможностью принимать токены, приходящие из других аналогичных систем обработки информации и содержащие номер той системы, для которой они предназначены, выявлять токены, предназначенные для системы, к которой относится коммутатор, и направлять выявленные токены в ассоциативную память этой системы, а также
адаптер вторичной памяти выполнен с возможностью различать токены типа «откачанные заглушкой токены», «откачанные записанные токены» и определять место для хранения различных типов токенов во вторичной памяти, а также
каждый модуль ассоциативной памяти содержит несколько исполнительных устройств, каждое из которых предназначено для обработки поступающих из модуля пар данных.
Сущность предлагаемых технических решений заключается в том, что выполнение вычислительной системы вышеописанным образом позволило обеспечить такой режим работы при выполнении операций способа, при котором исключается возникновение тупиковых ситуаций («дедлоков») и появляется возможность получения информации о выполнении этапов вычислительного процесса.
Краткое описание чертежей
На Фиг.1 представлена структурная схема предлагаемой системы обработки информации, на Фиг.2 приведены структуры данных, используемых в предлагаемой системе, на Фиг.3 приведен алгоритм выполнения операции «троичный поиск», на Фиг.4 - пример использования предлагаемой системы в рабочей станции, на Фиг.5 - пример реализации изобретения в многомашинной конфигурации, на Фиг.6 - структура токена, используемого при реализации многомашинной конфигурации.
Лучший вариант осуществления изобретений
Способ обработки информации на основе потока данных заключается в выполнении следующих операций.
Вначале осуществляют операцию «обработка пары данных», представляющую собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют структуру данных - «токен», состоящую из группы разрядов, образующих поле данных, поле контекста и поле ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены.
После этого по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен - «вычисление хеш-функции».
Затем осуществляют операцию «направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена.
После этого осуществляют операцию «поиск» среди сформированных указанным выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск».
Особенностью выполнения предложенного способа является то, что при выполнении операции «поиск» производят действие - «троичный поиск», при котором каждый бит прикрепленного к токену ключа имеет три состояния: «0», «1» и «неважно», при сравнении ключей входного и хранящегося токенов бит со значением «неважно» в любом из двух ключей считают совпавшим с соответствующим битом оставшегося ключа, при успешном «поиске» из входного и найденного токенов формируют пары данных, количество которых равно количеству найденных токенов при этом поиске, каждая из сформированных пар данных содержит результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над всеми сформированными таким образом парами данных выполняют действия, указанные в операции «обработка пары данных».
Кроме того, осуществляют операцию «запись во вторичную память входного токена», при которой указанный в операции входной токен записывают по адресу, сформированному из ключа токена, осуществляют операцию «чтение из вторичной памяти» токена, при которой считывают из вторичной памяти токен по адресу, указанному в операции, осуществляют операцию «запись во вторичную память пары данных», при которой указанную в операции пару данных токен записывают по адресу, сформированному из ключа пары данных, осуществляют операцию «чтение из вторичной памяти пары данных», при которой считывают из вторичной памяти пару данных по адресу, указанному в операции, и осуществляют «мониторинг процесса вычислений» и на его основе вырабатывают управляющие токены, которые изменяют алгоритм выбора указанных выше действий над входными токенами и парами данных.
Следует отметить, что при выполнении операции «обработка пары данных» в ключ токена вводят дополнительные разряды для хранения номера задачи - поле Т, характеризующего некоторый независимый вычислительный процесс, а при выполнении операции «обработка пары данных» в ключ токена вводят дополнительные разряды для хранения номера задачи - поле ST, характеризующего часть независимого вычислительного процесса.
Кроме того, в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «заглушка» и помещают его в одну, в несколько или во все группы хранящихся токенов без выполнения операции «поиск», при этом такой токен оказывает следующее влияние на выполнение операции «троичный поиск»: если ключ очередного входного токена при операции «троичный поиск» совпадает с ключом хранящегося токена, у которого имеется признак «заглушка», то над входным токеном выполняется операция «запись во вторичную память входного токена» и ему приписывают признак «откачанный заглушкой токен», а токен с признаком «заглушка» остается в одной, в нескольких или во всех группах хранящихся токенов соответственно, а в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «убрать заглушки», в котором все разряды ключа, кроме полей ST и Т, установлены в значение «неважно», разряды в полях ST и Т, характеризующие номера задач и подзадач, токены с признаком «заглушка» для которых должны быть убраны, и помещают управляющий токен в одну, в несколько или во все группы хранящихся токенов, при этом такой токен оказывает следующее влияние на выполнение операции «троичный поиск»: все найденные при выполнении операции «троичный поиск» токены с признаком «заглушка» удаляются из одной, из нескольких или из всех групп хранящихся токенов соответственно.
Кроме того, в операции «мониторинг процесса вычислений» вырабатывают управляющий токен с признаком «переместить во вторичную память токены» из одной, из нескольких или из всех групп хранящихся токенов, в указанном управляющем токене все разряды ключа, кроме полей ST и Т, установлены в значение «неважно», разряды в полях ST и Т, характеризующие номера задач и подзадач, токены которых должны быть перемещены во вторичную память, имеют значение «0», «1» или «неважно», при этом управляющий токен вызывает следующие действия: соответственно в одной, в нескольких или во всех группах хранящихся токенов производят «троичный поиск» токенов, у которых поля ST и Т совпадают с полями ST и Т в управляющем токене; все найденные токены удаляют соответственно из одной, из нескольких или из всех групп хранящихся токенов и перемещают найденные токены во вторичную память, причем этим токенам присваивают во вторичной памяти признак «откачанные записанные токены».
Кроме того, в операции «мониторинг процесса вычислений» вводят действие «вернуть откачанные записанные токены с указанными значениями полей S и ST», при котором все хранящиеся во вторичной памяти токены с признаком «откачанные записанные токены» с заданными значениями троичных полей S и ST удаляют из вторичной памяти и помещают их в ту группу хранящихся токенов, номер которой определяют путем выполнения операции «вычисление хеш-функции».
Кроме того, в операции «мониторинг процесса вычислений» вводят действие «вернуть откачанные заглушкой токены с указанными значениями полей S и ST», при котором все хранящиеся во вторичной памяти токены с признаком «откачанные заглушкой токены» с заданными значениями троичных полей S и ST удаляют из вторичной памяти и направляют их в качестве входных токенов в операцию «троичный поиск» среди той группы хранящихся токенов, номер которой определяют путем выполнения операции «вычисление хеш-функции».
Кроме того, при выполнении операции «обработка пары данных» в токен вводят поле, определяющее кратность N использования такого токена, который называют «токен многократного отклика», рассылают его по всем группам хранящихся токенов, причем в операции «троичный поиск» при нахождении такого токена формируют из него пару данных, как и из обычного токена, уменьшают N на 1, оставляют токен в группе хранящихся токенов, если N>0, и удаляют его из группы, если N=0, реализуя при этом возможности:
выдавать информацию о значении N по запросу из операции «мониторинг процесса вычислений»,
подсчитывать суммарное количество К сформированных с таким токеном пар данных во всех группах хранящихся токенов,
информировать задачу пользователя о ситуации, когда K=N,
формировать токен с заданными значениями полей Т и ST и с признаком «событийный токен» и выдавать его при возникновении ситуации, при которой K=N, независимо от того возникла ли эта ситуация при размещении «токена многократного отклика» в одной группе хранящихся токенов или во всех группах.
Кроме того, при формирования токена в него вводят поле, определяющее кратность N использования этого токена, помещают его в группу хранящихся токенов, номер которой определяют при помощи операции «вычисление хеш-функции», а в операции «троичный поиск» при нахождении такого токена формируют из него пару данных, как и из обычного токена, уменьшают значение N на 1, оставляют токен в группе хранящихся токенов, если N>0 и удаляют токен из группы хранящихся токенов, если N=0.
При формировании токена в токен вводят поле, определяющее порядковый номер операнда, который прикреплен к токену, а при выполнении операции «троичный поиск» образуют пары данных из токенов, у которых совпадают троичные ключи, а порядковые номера операндов различны.
Система 1 обработки информации на основе потока данных содержит
один или несколько модулей ассоциативной памяти 2, одно или несколько исполнительных устройств 3, первый коммутатор 4, выполненный с возможностью направлять токены из любого исполнительного устройства 3 в любой модуль ассоциативной памяти 2, и второй коммутатор 5, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти 2 в любое исполнительное устройство 3.
Каждый из модулей ассоциативной памяти 2 выполнен с возможностью хранить поступающие в него токены, содержащие поле данных и поле ключа, отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена, запоминать поступающий токен в модулях ассоциативной памяти 2 в случае неудачного поиска, формировать пару данных из поступающего в ассоциативную память 2 токена и найденного в ней токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств 3.
Каждое исполнительное устройство 3 выполнено с возможностью: выполнять инструкции, хранящиеся в доступной для исполнительного устройства 3 памяти команд по адресам, указанным в паре данных,
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром,
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти,
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией.
Особенностью технического решения на устройство является то, что в систему введены следующие узлы:
вторичная память 6 для временного хранения пар данных и токенов, выполненная с возможностью получать токены для хранения из исполнительных устройств 3 и ассоциативной памяти 2, получать пары данных на хранение из ассоциативной памяти 2 и выдавать в нее хранящиеся токены и пары данных;
адаптер 7 вторичной памяти, выполненный с возможностью определять место во вторичной памяти для хранения токенов и пар,
и процессор 8 для регулировки степени параллелизма, выполненный с возможностью собирать информацию о степени загрузки ассоциативной памяти 2 и исполнительных устройств 3, направлять токены из ассоциативной памяти 2 во вторичную память 6 и обратно и направлять управляющие токены в ассоциативную память 2.
Кроме того, каждый модуль ассоциативной памяти 2 выполнен «троичным» - с возможностью хранить токены с троичными ключами, каждый разряд которых может принимать одно из трех значений: «0», «1» и «неважно», осуществлять «троичный поиск» среди хранящихся токенов токена, троичный ключ которого совпадает с троичным ключом пришедшего токена таким образом, что разряды, в которых записано значение «неважно» в любом из токенов, не участвуют в сравнении, и выдавать в рамках одной операции «троичный поиск» несколько хранящихся в ассоциативной памяти 2 токенов, количество которых равно количеству токенов, найденных при «троичном поиске».
Кроме того, процессор 8 для регулировки параллелизма выполнен с возможностью направлять пары данных из вторичной памяти 6 в исполнительные устройства 3.
Каждый модуль ассоциативной памяти 2 может содержать двоичную ассоциативную память, которая дополнительно приспособлена:
хранить вместе с ключом маску, в которой указаны разряды ключа со значением «неважно», а приходящий токен, кроме обычного вышеупомянутого ключа, содержит маску, в которой указаны разряды ключа со значением «неважно»,
осуществлять среди хранящихся токенов «троичный поиск» токена с ключом, совпадающим с ключом пришедшего токена таким образом, что разряды хранящихся токенов и/или пришедшего токена, которые закрываются масками, то есть имеют значение «неважно», не участвуют в сравнении,
выдавать в рамках одного троичного поиска несколько хранящихся в ассоциативной памяти 2 токенов, ключ каждого из которых удовлетворяет вышеприведенному критерию «троичного поиска».
Первый коммутатор 4 может быть выполнен с возможностью принимать токены, приходящие из других аналогичных систем обработки информации и содержащие номер той системы, для которой они предназначены, выявлять токены, предназначенные для системы, к которой относится коммутатор, и направлять выявленные токены в ассоциативную память этой системы.
Адаптер 7 вторичной памяти выполнен с возможностью различать токены типа «откачанные заглушкой токены», «откачанные записанные токены» и определять место для хранения различных типов токенов во вторичной памяти 6.
Каждый модуль ассоциативной памяти 2 может содержать несколько исполнительных устройств 3, каждое из которых предназначено для обработки поступающих из этого модуля пар данных.
Структура токенов, с которыми оперируют исполнительные устройства 3, и ассоциативная память 2 показаны на Фиг.2.
Здесь поля «Т» и «ST» в токене предназначены для хранения номеров задачи и подзадачи соответственно. Эти поля являются частью ключа токена. В поле «КОДМАСКИ», размер которого совпадает с размером ключа, записываются единицы в те разряды, которые в ключе имеют значение «неважно». В поле «ДАННЫЕ» записывают результат выполненной операции. В поле «КОДОП» закодирован код операции, которая в дальнейшем должна быть выполнена над данными, хранящимися в поле «ДАННЫЕ».
Часть токена, содержащая ключ, имеет поле «An», определяющее адрес команды в памяти команд, доступной из каждого исполнительного устройства 3. Когда пара данных, посланная из ассоциативной памяти 2, приходит в исполнительное устройство, исполнительное устройство читает код операции в паре данных и выполняет соответствующую операцию над двумя операндами, содержащимися в паре данных. Возможен случай, когда выполняется не одна, а несколько операций. Последовательность таких операций в виде команд записана в памяти команд и начинается с команды, адрес которой записан в паре данных. Таким образом, в результате обработки в модуле исполнительных устройств 3 одной пары данных может быть выполнено неограниченное количество команд по программе, записанной в памяти команд.
Поле «Д1/Д2» в токене служит для определения номера операнда, хранящегося в поле «ДАННЫЕ». Если в поле «Д1/Д2» записан «0», то операнд этого токена будет иметь порядковый номер «1» в последующей операции. Если в поле «Д1/Д2» записана «1», то операнд этого токена будет иметь порядковый номер «2» в последующей операции. Таким образом, при операции поиска поиск считается успешным, если найден токен, у которого ключ совпадает с ключом входного токена, а значение в поле «Д1/Д2» найденного токена отличается от значения в поле «Д1/Д2» входного токена. Значение других полей, входящих в ключ, будет указано позднее.
Пара данных, структура которой показана на Фиг.2б, формируется в ассоциативной памяти 2 после выполнения операции поиска токена в том случае, если поиск удачен. Здесь поля «ДАННЫЕ 1», «ДАННЫЕ 2» предназначены для хранения данных, взятых из поля «ДАННЫЕ» входного токена и поля «ДАННЫЕ» найденного токена. При формировании пары данных операнд из токена, у которого значение поля «Д1/Д2» равно «0», записывается в поле «ДАННЫЕ 1», а операнд из другого токена записывается в поле «ДАННЫЕ 2». Значения полей «Т», «ST», «An», «КОНТЕКСТ» в паре данных переписываются из соответствующих полей входного токена.
Для управления степенью параллелизма введены управляющие токены. Для управляющего токена типа «токен-заглушка» имеют значение поля «Т», «ST», соответствующие этим полям биты в поле «КОДМАСКИ». Признак, что этот токен является управляющим, может быть помещен в поле «КОДОП». При необходимости приостановить активность вычислительных процессов, характеризующихся записанными в полях «Т», «ST», «КОДОП» значениями, такой токен с этими значениями в полях «Т», «ST» и в поле «КОДМАСКИ» безусловно добавляется во все группы хранящихся токенов
Алгоритм выполнения операции поиск представлен на Фиг.3. Во вторичной памяти 6 хранение токенов организовано таким образом, что токены с одинаковыми значениями в полях «Т», «ST» сгруппированы вместе. В этом смысле значение полей «Т», «ST» можно рассматривать как виртуальный адрес этой группы токенов, а совокупность всех значений полей «Т», «ST» - как виртуальное адресное пространство. В этом случае можно сказать, что значения полей «Т», «ST», в которых часть разрядов замаскирована, определяют часть виртуального адресного пространства.
Для управляющего токена типа «переместить во вторичную память токены из заданной группы хранящихся токенов» имеют значение поля «Т», «ST», соответствующие эти полям биты в поле «КОДМАСКИ». При необходимости убрать из групп хранящихся токенов токены, характеризующиеся записанными в полях «Т», «ST», «КОДМАСКИ» значениями, токен типа с этими значениями в полях «Т», «ST» и в поле «КОДМАСКИ» выдается на операцию поиска в каждую группу хранящихся токенов. Все найденные в результате такой операции токены (кроме управляющих токенов типа заглушки) удаляются из групп хранящихся токенов и запоминаются во вторичной памяти 6. При этом им присваивается признак «откачанные записанные токены».
Кроме того, для увеличения скорости обработки информации ассоциативная память 2 разделена на собственно запоминающее устройство, в котором хранятся токены и осуществляется их ассоциативный поиск, и буферный регистр готовых пар данных, в котором могут накапливаться сформированные пары данных в том случае, если исполнительные устройства 3 выполняют длительные по времени операции и возникает очередь на обработку пар данных.
Вторичная память 6 разделена на собственно запоминающее устройство, в котором хранятся токены и пары данных, буфер готовых пар данных и буфер для «токенов, откачанных заглушкой».
Предпочтительно, если это возможно, по вычислительной ситуации не передавать токены из ассоциативной памяти 2 во вторичную память 6 или передавать только их часть. Таким образом, процессор 8 регулировки параллелизма может только приостановить какой-либо вычислительный процесс, тем самым несколько сдерживая развитие параллелизма выполняемой задачи в целом, и тем самым предотвратить переполнение ассоциативной памяти 2.
Процессор 8 регулировки параллелизма работает следующим образом. Когда произошло переполнение или ситуация близка к переполнению ассоциативной памяти 2 или ее модуля, если она состоит из нескольких модулей, можно было бы записать во вторичную память 6 токены, которые должны были бы быть записаны в ассоциативную память 2 или в ее модуль. Однако в этом случае производительность ВС была бы значительно уменьшена, поскольку при выполнении операции «поиск» в модуле ассоциативной памяти 2 ключ каждого токена должен сравниваться не только с соответствующими ключами токенов, записанных в модуль ассоциативной памяти 2, но также с соответствующими частями токенов, записанных во вторичную память 6. Выполнение такого сравнения для токенов, хранящихся в обычной памяти с произвольной выборкой, может быть выполнено с использованием специального сравнивающего устройства путем последовательной обработки этих токенов, что значительно медленнее, чем это происходит в ассоциативной памяти 2.
Таким образом, как уже упоминалось, во вторичной памяти 6 предпочтительно хранить только часть токенов, выдаваемых исполнительными устройствами в ассоциативную память 2, а оставшиеся токены подвергать обычным процессам спаривания и хранения в ассоциативной памяти 2. Когда токены хранятся во вторичной памяти 6, они не участвуют в формировании пар данных в ассоциативной памяти 2. Другими словами, обычная обработка данных продолжается только для токенов, которые не хранятся во вторичной памяти 6. Возможны такие ситуации, когда избежать переполнения ассоциативной памяти 2 можно, только переводя токены на хранение во вторичную память 6. Когда условия в ассоциативной памяти 2 позволят, токены возвращаются обратно в ассоциативную память 2 и подвергаются обычному процессу спаривания.
Токены, которые должны быть временно исключены из процесса обработки, то есть токены, которые будут храниться во вторичной памяти 6, определяются динамически. При этом другие токены обеспечивают высокую эффективность в формировании пар данных и буферный регистр готовых пар данных не пустует, что означает, что все модули исполнительных устройств 3 загружены полностью. Это может быть достигнуто путем определения вероятности интенсивности формирования пар данных для различных групп токенов и запуска на обработку токенов, наиболее активных в данный момент. В результате различные группы токенов могут быть временно исключены из обработки и затем возвращены в ассоциативную память 2, когда наступит подходящий момент.
Токены, которые могут быть откачены из ассоциативной памяти 2 во вторичную память 6, определяются по их ключу. В результате токены с заданной частью виртуального адресного пространства хранятся во вторичной памяти 6. Виртуальное адресное пространство токенов определяется ключевой частью токенов, см. Фиг.2а. Выделение виртуального адресного пространства может быть достигнуто с использованием в каждой ключевой части токена еще и кода маски по каждому разряду ключа. Будем называть такую ассоциативную память троичной. В троичной ассоциативной памяти биты в части, адресуемой по содержанию, могут быть либо логическим «0», либо логической «1», но могут также и быть замаскированными. Замаскированный бит также называется незначащим битом. Аналогично, поиск по содержимому может выполняться по ключу, содержащему как нулевые и единичные биты, так и незначащие биты. При обычной ситуации в ВС, то есть при отсутствии риска переполнения ассоциативной памяти 2 или по крайней мере одного модуля в ней, обработка данных происходит без участия вторичной памяти 6. Маски используются пользователем для улучшения эффективности работы системы, например для считывания сразу всех элементов вектора или для работы с токенами кратности «n», о чем будет сказано ниже.
В том случае, если происходит переполнение или ситуация близка к переполнению какого-либо модуля ассоциативной памяти 2, определенная часть виртуального адресного пространства токенов исключается из активного вычислительного процесса при помощи процессора 8 регулировки параллелизма, который формирует и записывает в ассоциативную память 2 токен типа, показанного на Фиг.2а, в котором требуемые биты ключевой части, идентифицирующие желаемую часть виртуального адресного пространства, установлены соответственно в «1» или «0», в то время как все другие биты ключевой части замаскированы. Одновременная рассылка токенов во все модули ассоциативной памяти 2 выполняется специальной операцией (глобальной операцией).
Процессор 8 регулировки параллелизма записывает «токен-заглушку» в ассоциативную память 2. В результате все последующие токены, приходящие в ассоциативную память 2, будут проверяться на совпадение с «заглушкой», как при выполнении обычного шага поиска, как описано выше. Ассоциативная память 2 распознает, что испытуемая пара данных образована «токеном-заглушкой». В результате ассоциативная память 2 не формирует пару данных и не стирает «токен-заглушку» в ассоциативной памяти 2, а вместо этого посылает токен, пришедший вместе с «токеном-заглушкой» во вторичную память 6 в буфер «токенов, откачанных заглушкой». В дальнейшем мы будем называть такие токены «откачанные заглушкой токены». Таким образом, в буфер «токенов, откачанных заглушкой», будут направлены на временное хранение токены, принадлежащие адресному пространству, закрытому этой заглушкой. Позже эти токены могут быть переданы из вторичной памяти 6 в ассоциативную память 2, когда степень занятости ассоциативной памяти 2 позволит это сделать.
В результате ВС может продолжать обрабатывать данные на оставшемся виртуальном адресном пространстве, в то время как выделенная часть виртуального адресного пространства временно исключена из дальнейшей обработки. При этом можно избежать «дэдлоков», так как степень параллелизма обработки уменьшена, а виртуальное адресное пространство ограничено только разрядностью ключа.
В то время, когда заглушка записана в ассоциативную память 2, записанные ранее токены соответствующей части виртуального адресного пространства могут находиться в ассоциативной памяти 2. Так как в этом нет необходимости, эти токены могут быть выгружены из ассоциативной памяти 2, чтобы выделить в ней свободное место. Следовательно, после того как «токен-заглушка» записана в ассоциативную память 2, та же самая «заглушка» используется для выполнения поиска по ключу в ассоциативной памяти 2 путем использования «токена-заглушки» в качестве входного токена. Все токены в ассоциативной памяти 2, принадлежащие части виртуального адресного пространства, определяемой «токеном-заглушкой», будут выгружены из ассоциативной памяти 2 во вторичную память 6. Другими словами, эти токены записываются в буфер для «токенов, откачанных заглушкой» и стираются в ассоциативной памяти 2 путем установки статуса соответствующих местоположений ассоциативной памяти 2 в состояние «свободен». Токены, ранее записанные в ассоциативную память 2, будем называть просто «записанные токены», а «записанные токены», загруженные во вторичную память 6, - «откаченными записанными токенами». Поскольку сама заглушка была предварительно записана в ассоциативную память 2, заглушка также окажется среди совпавших токенов. В отличие от других совпавших токенов ассоциативная память 2 не записывает «токен-заглушку» в буфер для «токенов, откачанных заглушкой».
Позже, когда ассоциативной памяти 2 не будет грозить переполнение, процессор 8 регулировки параллелизма выгружает «откачанные записанные токены» из буфера для «токенов, откачанных заглушкой» или из вторичной памяти 6 и загружает их обратно в ассоциативную память 2 на свободные места, после чего процессор 8 регулировки параллелизма выдает команду для стирания заглушки из всех модулей ассоциативной памяти 2. Процессор 8 регулировки параллелизма посылает последовательно «откачанные заглушкой токены» в ассоциативную память 2 для обработки тем же самым образом, как и токены, поступающие непосредственно из исполнительных устройств 3. Соответствующее место в буфере для «токенов, откачанных заглушкой» или во вторичной памяти 6 становится снова свободным.
Выбор части виртуального адресного пространства токенов с целью временного исключения его из активного вычислительного процесса, чтобы избежать дэдлоков, может производиться различными способами. В частности, некоторые биты контекстной информации ключа токена (см. Фиг.2а) могут быть использованы в ВС, чтобы идентифицировать задачу и, возможно, подзадачу, к которым токен принадлежит, как будет пояснено позднее. Как следствие, процессор регулировки параллелизма 8 может исключить задачи или подзадачи путем использования «токена-заглушки», в которой замаскирован весь ключ, кроме битов, идентифицирующих задачу или подзадачу, которые установлены соответствующим образом. Другая возможность заключается в том, что процессор 8 регулировки параллелизма определяет часть виртуального адресного пространства, используя поле адреса в командной части токена.
Ясно, что когда ассоциативная память 2 содержит множество модулей, описанный способ разгрузки токенов из ассоциативной памяти 2 во вторичную память 6 и загрузки их обратно может быть выполнен процессором 8 регулировки параллелизма на уровне всех модулей или только некоторых, или, например, в одном из них, в котором возникло переполнение или ситуация близка к переполнению.
Если ассоциативная память 2 выдает пары данных быстрее, чем исполнительные устройства 3 могут обрабатывать их, то пары данных должны ожидать, когда исполнительные устройства 3 освободятся. Может так оказаться, что в буферном регистре готовых пар данных нет больше свободного пространства для очередных выдаваемых ассоциативной памяти 2 пар данных. В результате ассоциативная память 2 должна была бы прекратить выдачу пар данных. Как следствие, исполнительные устройства 3 должны прекратить посылать токены в ассоциативную память 2. В результате полностью может остановиться обработка в ВС. Чтобы избежать этой ситуации, создается продолжение буферного регистра готовых пар данных во вторичной памяти в виде буфера готовых пар данных. Таким образом, когда буферный регистр готовых пар данных полон, любые дополнительные пары данных, выдаваемые ассоциативной памятью 2, помещаются в буфер готовых пар данных. Как только место в буферном регистре готовых пар данных освободится, пары данных из буфера готовых пар данных загружаются обратно в буферный регистр готовых пар данных. Это происходит по команде процессора 8 регулировки параллелизма с участием ассоциативной памяти 2. Процессор 8 регулировки параллелизма предпочтительно работает с буфером готовых пар данных по принципу «FIFO». Когда объема вторичной памяти 6 недостаточно, она может быть расширена за счет внешней памяти, например, винчестера, как это делается в известных традиционных системах обработки. В результате для пар данных может быть предоставлено неограниченное пространство при использовании вторичной памяти. Таким образом, из-за ограниченной памяти так называемого кольца: исполнительные устройства 3, коммутатор 4, ассоциативная память 2, коммутатор 5, исполнительные устройства 3 система остановиться не может, «дедлок» по этой причине исключен.
В том случае, если совпавший токен обнаружен в ассоциативной памяти 2, формируется пара данных со структурой, показанной на Фиг.2b. Один из операндов в этой паре данных берется из пришедшего токена, а другой - из совпавшего токена, записанного в ассоциативную память 2. Тот факт, что код операции записан в токены и, как следствие, в пары данных, дает исполнительным устройствам 3 возможность сразу начать выполнение соответствующей операции над операндами в паре данных без считывания его сначала из памяти команд. Таким образом увеличивается скорость обработки. Однако следующие коды операции вместе с командами считываются из памяти команд.
Опишем теперь способ, как процессор 8 регулировки параллелизма исключает из активного вычислительного процесса токены, принадлежащие к определенному виртуальному адресному пространству при необходимости избежать «дэдлоки», из-за того что ассоциативная память 2 или, по крайней мере, один модуль в ней становятся полными. Для этого в каждом токене имеется 2 поля «Т» и «ST», которые характеризуют номер задачи и подзадачи. Задача отличается от подзадачи тем, что подзадачи могут взаимодействовать с задачей, в то время как задачи могут взаимодействовать между собой только через операционную систему (ОС). Другими словами, подзадачи могут взаимодействовать через общее виртуальное адресное пространство, относящееся к задаче, к которой они принадлежат.
Когда ВС выполняет несколько задач, задача, к которой принадлежат токены и пары данных, идентифицируется полем задачи «Т» в токене, структура которого показана на Фиг.2а, и в паре данных, структура которой показана на Фиг.2б. Другими словами, виртуальное адресное пространство токенов разделяется при помощи номера задачи, записанного в ключ токена. Аналогичным образом виртуальное адресное пространство задачи может быть разделено при помощи номера подзадачи, записанного в часть токена, содержащую ключ.
Процессор 8 регулировки параллелизма 8 отслеживает степень занятости свободных местоположений в ассоциативной памяти 2. Когда ассоциативная память 2 приближается к полному заполнению, процессор 8 регулировки параллелизма принимает решение выгрузить часть виртуального адресного пространства токенов в буфер для «токенов, откачанных заглушкой» с целью уменьшить параллелизм в ВС и избежать переполнения ассоциативной памяти 2. Часть виртуального адресного пространства токенов, которая должна быть выгружена, определяется процессором 8 регулировки параллелизма путем выделения по крайней мере одной задачи для выгрузки. Следовательно, процессор 8 регулировки параллелизма формирует и записывает в ассоциативную память 2 «токен-заглушку», основанную на структуре токена, показанного на Фиг.2а, в которой все биты поля ключа, исключая поле задачи «Т», маскируются путем соответствующей установки битов в поле маски. В биты поля задачи «Т» в «токене-заглушке» записывается номер задачи, которая должна быть выгружена. Затем процессор 8 регулировки параллелизма выгружает ранее «записанные токены» этой задачи в буфер для «токенов, откачанных заглушкой», используя этот «токен-заглушку», как уже было описано при рассмотрении Фиг.3. Когда рабочие условия в ассоциативной памяти 2 позволят, процессор 8 регулировки параллелизма загружает обратно выгруженные токены из буфера для «токенов, откачанных заглушкой»в ассоциативную память 2.
Разумеется, процессор 8 регулировки параллелизма имеет возможность выгружать не только одну задачу, но и несколько задач, используя при этом несколько заглушек по одной на каждую задачу. В некоторых случаях также возможно использовать одну заглушку с некоторыми замаскированными маской битами в поле задачи «Т» для выгрузки нескольких задач.
Вместо выгрузки всей задачи процессор 8 регулировки параллелизма может принять решение выгрузить только токены данной подзадачи у задачи. В этом случае процессор 8 регулировки параллелизма формирует заглушку со структурой токена в соответствии с Фиг.2а, в которой все биты поля ключа, кроме поля задачи «Т» и поля подзадачи «ST», замаскированы путем соответствующей установки битов в поле маски. Биты в поле задачи «Т» и в поле подзадачи «ST» в заглушке устанавливаются в соответствии с номером задачи и подзадачи, которая должна быть выгружена.
Как уже упоминалось, в том случае, когда ассоциативная память 2 состоит из нескольких модулей и имеет место неравномерное распределение токенов между модулями, может так случиться, что один или несколько модулей переполнятся, а другие нет, то есть эти другие модули работают в нормальном режиме. В этом случае нет необходимости выгружать токены из всех модулей ассоциативной памяти 2. Достаточно, чтобы процессор 8 регулировки параллелизма выгрузил токены в буфер для «токенов, откачанных заглушкой» из модулей, которые переполнились путем выполнения описанной выше процедуры выгрузки с помощью «заглушек» только для этих модулей. В этом случае выгружается не вся задача или подзадача, а только ее часть, которая использует эти модули ассоциативной памяти 2. Запоминающее устройство вторичной памяти 6 структурируется задачами, подзадачами и типами выгружаемых токенов, то есть токенами, «откачанными с помощью заглушки» и «откачанными записанными токенами» или «откачанными парами».
Случай, при котором ВС выполняет только одну задачу, является частным случаем многозадачного режима работы и разгрузка в буфер для «токенов, откачанных заглушкой» и загрузка обратно из него аналогичны описанным. Но в этом случае можно использовать поле задачи Т для увеличения поля подзадач «ST», что дает возможность увеличить количество подзадач, одновременно выполняющихся в ВС.
Чтобы определить, когда необходима выгрузка задач или подзадач и какие это задачи и подзадачи, а также из каких модулей ассоциативной памяти 2 требуется откачать токены, а также когда возможен возврат токенов из вторичной памяти 6 обратно в ассоциативную память 2 и каких задач и подзадач в первую очередь, процессор 8 регулировки параллелизма использует информацию, получаемую от ассоциативной памяти 2 и от исполнительных устройств 3. К такой информации, которая может быть получена без снижения производительности, относятся:
- процент загрузки исполнительных устройств 3. Так как пары данных выдаются в свободный модуль исполнительных устройств 3, то все модули исполнительных устройств 3 загружены в среднем равномерно и достаточно знать процент загрузки хотя бы одного модуля исполнительных устройств 3 и только в том случае, когда буфер готовых пар данных пуст;
- степень загрузки «записанными» токенами» ассоциативной памяти 2 или каждого модуля по каждой задаче или подзадаче. Необходимо сделать соответствующий множественный отклик с подсчетом количества откликов;
- общая загруженность модуля ассоциативной памяти 2. Информация имеется в каждом модуле ассоциативной памяти 2, т.к. определяется по числу свободных местоположений;
- определение вероятности эффективности работы той или иной откачанной «задачи» или «подзадачи». Определяется отношением «K1/K2», где «K1» - количество «откаченных заглушкой токенов», а «К2» - количество «откаченных записанных токенов».
Кроме того, процессор 8 регулировки параллелизма с некоторым снижением производительности может определять вероятную интенсивность формирования пар данных для задач или подзадач, находящихся в активном вычислительном процессе.
В традиционных системах такой информации нет. Возможность получения такой информации является существенным преимуществом предлагаемого изобретения. Ее получение возможно благодаря использованию ассоциативной памяти 2.
В зависимости от этой информации процессор 8 регулировки параллелизма может обеспечить циркуляцию задач или подзадач между соответствующими модулями ассоциативной памяти 2, буфером для «токенов, откачанных заглушкой» и компонентой запоминающего устройства вторичной памяти 6, в которой происходит хранение информации с целью поддержания наиболее высокой эффективности формирования пар данных, при которой буферный регистр готовых пар данных был бы пуст. Следовательно, процессор 8 регулировки параллелизма должен обеспечить активный вычислительный процесс для задач и подзадач, наиболее эффективно загружающих исполнительные устройства 3 в данный момент времени.
Номера задачи и подзадачи могут быть переиспользованы ОС для других задач или подзадач, которые не выполняются одновременно.
Однако возможен и более сложный способ формирования адресного пространства подзадачи, когда за одной подзадачей закрепляется несколько виртуальных адресных пространств, определяемых несколькими «токенами-заглушками». Принцип работы остается тем же. Отличие состоит в том, что считывание из ассоциативной памяти 2 и передача в буфер готовых пар данных осуществляется при помощи всех закрепленных за подзадачей «токенов-заглушек». С этой целью все закрепленные «токены-заглушки» записываются в ассоциативную память 2. В то же время во вторичной памяти 6 не выделяется отдельных мест для «откачанных отложенных», «откачанных записанных» токенов, относящихся к разным заглушкам, но принадлежащим одной подзадаче.
Мы описали возможность выгружать токены из буфера для «токенов, откачанных заглушкой» на основе задачи или подзадачи, к которым они принадлежат. Но в том случае, когда ВС выполняет только одну задачу, может случиться, что эта единственная задача не может быть разбита на подзадачи на пользовательском уровне, используя поле подзадачи «ST». В том случае, если имеет место переполнение в ассоциативной памяти 2 или хотя бы в одном модуле, тем не менее имеется возможность разделить виртуальное адресное пространство в процессе выполнения задачи на основе поля адреса команды «An» для того, чтобы выгрузить часть виртуального адресного пространства в буфер для «токенов, откачанных заглушкой». В частности, это может быть сделано путем разделения адреса команды на страницы. В этом случае страница, к которой принадлежит токен, может быть определена некоторыми битами в адресе команды в самом поле «An», например старшими битами. Чтобы избежать переполнения ассоциативной памяти 2 или некоторого модуля в ней, процессор 8 регулировки параллелизма выбирает одну или несколько страниц команд, которыми ассоциативная память 2 или ее модуль заняты, и откачивает «записанные токены», имеющие адрес команды, принадлежащий выбранным страницам, в буфере для «токенов, откачанных заглушкой». После этого процессор 8 регулировки параллелизма записывает в ассоциативную память 2 этот токен с маской в виде «токена-заглушки».
Используя ассоциативную память 2 и глобальную операцию, при помощи которой рассылается через переключатель коммутатор 4 одновременно во все модули ассоциативной памяти 2 один и тот же «токен кратности», можно существенно улучшить эффективность выполнения такой типовой вычислительной конструкции, при которой все элементы вектора взаимодействуют с одной и той же скалярной величиной (токеном).
К особенностям работы систем, управляемых потоком данных, относится и то обстоятельство, что время прохождения токена через ассоциативную память 2 неизвестно. Неизвестно также, какой из токенов, которые должны спариться в ассоциативной памяти 2, пришел раньше и запишется в нее, а какой из них при операции «поиск» найдет себе пару данных и не будет записан. Это обстоятельство необходимо учитывать во многих случаях работы систем, управляемых потоком данных, и, в частности, в случае несимметричных в отношении данных операций. Неизвестно, если специально не обозначать данные, какой из двух операндов при выполнении операции вычитания является уменьшаемым, а какой вычитаемым. Поэтому во всех системах подобного типа должен быть введен признак первого или второго данного. В рассматриваемом случае этот признак помечен одним разрядом «Д1/Д2» в токене. Если этот разряд равен «1», то это данное при формировании пары данных устанавливается в поле «ДАННЫЕ 1», в противном случае - в поле «ДАННЫЕ 2».
Это обстоятельство используется в ВС для аппаратной поддержки таких часто встречающихся вычислительных конструкций, как взаимодействие вектора с одной и той же скалярной величиной, т.е. нескольких токенов с одним и тем же токеном без его стирания. Для того чтобы провзаимодействовать какой-либо величине со всеми элементами вектора, обычно необходимо разослать эту величину в «n» виртуальных адресов (ключей), где «n» - размерность вектора. Возможны две реализации этой конструкции вычислительного процесса.
1-я реализация. Все элементы вектора засылаются по одному и тому же виртуальному адресу, следовательно, в один и тот же модуль ассоциативной памяти 2. Делается это с использованием признака «Д1/Д2» в качестве одного из разрядов ключа. Все элементы вектора приходят на один и тот же вход, левый или правый. Для того чтобы они не совпали, необходимо в случае записи токена в модуль ассоциативной памяти 2 изменить «Д1/Д2» на обратную величину, т.е. перевести ее из «1» в «0» либо наоборот. В этом случае все элементы вектора не будут «видеть» друг друга из-за несовпадения по «Д1/Д2». В то же время токен, которому необходимо провзаимодействовать со всеми элементами вектора, имеющими тот же виртуальный адрес (ключ), будет взаимодействовать с «записанными токенами» вектора, так как значение «Д1/Д2» у него противоположное. Он приходит на противоположный вход оператора. Так как этот токен должен провзаимодействовать с «n» элементами вектора, он не должен уничтожаться до тех пор, пока не встретится со всеми токенами вектора. Назовем его «токеном кратности». Если до прихода этого токена записалось «k» элементов вектора, то произойдет так называемый «множественный отклик», в котором все «k» элементов вектора совпадут и образуют пары данных с «токеном кратности». После этого «токен кратности» записывается в ассоциативную память 2 с кратностью «n-k».
Элементы вектора, имеющие кратность «n=1» после взаимодействия с «токеном кратности», стираются в ассоциативной памяти 2, а элементы вектора, пришедшие после записи в ассоциативную память 2 «токена кратности» со значением кратности «n-k», взаимодействуют с ним и образуют пары данных. При этом они уничтожаются, т.к. их кратность «n=1», а из значения «n-k» «токена кратности» вычитается «1» до тех пор, пока «n-k» не станет равным «0». Необходимо отметить, что описанная выше конструкция работает при любой очередности прихода токенов элементов вектора и «токена кратности». Аппаратная поддержка этой вычислительной конструкции дает следующие преимущества:
- не требует формирования и рассылки токена кратности «n»;
- в среднем в «n/2» сокращает число операций «поиск» в ассоциативной памяти 2 за счет множественного отклика;
- не требует очистки ячеек ассоциативной памяти 2 после окончания операции;
- после окончания операции аппаратным способом выдается сообщение пользовательской программе о завершении выполнения этой типовой вычислительной конструкции.
2-й случай. Элементы вектора разбросаны в соответствии с «ХЕШ-функцией» по всем модулям ассоциативной памяти 2 и эти элементы должны провзаимодействовать с токеном кратности n. Вопрос достаточно принципиальный для преодоления модульности ассоциативной памяти 2, т.к. сколько элементов вектора в каком модуле ассоциативной памяти 2 находится неизвестно. Контекст «n» (ключи) токена, могут формироваться во время вычислений, что является отличительной особенностью системы, существенно расширяющей сферу применения предлагаемой ВС. Фактически решается задача предоставления пользователю не модульной, а монолитной ассоциативной памяти 2 с сохранением возможности изменений любых полей ключа в процессе вычислений.
Решение сводится к следующему: во все модули засылается «токен кратности», у которого «n=∞». Это выполняется специальной «глобальной операцией» без учета «хеш-функции», в то время как сама величина кратности n этого токена отсылается в процессор 8 регулировки параллелизма через переключатель коммутатор 4 и записывается с соответствующим ключом в зону памяти, отведенной четвертому, пока не описанному, типу данных. Пока было описано три типа данных, откачанных во вторичную память: «откачанные записанные токены», «откачанные заглушкой отложенные токены» и «пары данных».
Так как в данном случае элементы вектора могут иметь различные виртуальные адреса (ключи), «токен кратности» может совпадать с ними в том случае, если он имеет маску, закрывающую те разряды контекста, по которым различаются элементы данного вектора. В каждом модуле ассоциативной памяти 2 «токен кратности», имеющий «n=∞», выбирает при наличии множественного отклика все ранее пришедшие токены вектора по «ki» элементов вектора (где «ki» - количество откликов в «i»-том модуле ассоциативной памяти 2). С выбранными токенами образуются пары данных и выдаются в исполнительные устройства 3. В отличие от описанного выше случая из «токена кратности» нет необходимости вычитать величину «ki» в каждом модуле, т.к. его «n» равно «∞». Сам «токен кратности» с «n=∞» записывается соответственно в каждый модуль. Величина «кi» фиксируется в каждом модуле в поле «n» каждого токена кратности и выдается в процессор 8 регулировки параллелизма по его запросу.
Далее, по приходу элементов вектора в соответствующий модуль ассоциативной памяти 2 происходят разовые совпадения, при которых образуется пара данных и отправляется в свободное исполнительное устройство 3. Пришедший элемент вектора стирается, а к величине «кi», хранящейся в поле «n» каждого «токена кратности», прибавляется «1». Процессор 8 регулировки параллелизма считывает информацию о том, сколько токенов спарилось с каждым токеном кратности в каждом модуле, и контролирует величину «n-k», являющуюся результатом опроса всех модулей (где 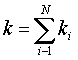 , a «N» количество модулей в ассоциативной памяти 2). Опрос модулей инициирует либо процессор 8 регулировки параллелизма с определенным временным интервалом, либо программа пользователя путем обращения к процессору 8 регулировки параллелизма с помощью засылки специального токена, в котором указывается виртуальный адрес поставки информации.
, a «N» количество модулей в ассоциативной памяти 2). Опрос модулей инициирует либо процессор 8 регулировки параллелизма с определенным временным интервалом, либо программа пользователя путем обращения к процессору 8 регулировки параллелизма с помощью засылки специального токена, в котором указывается виртуальный адрес поставки информации.
Когда величина «n-k» станет равной «0», процессор 8 регулировки параллелизма стирает во всех модулях все «токены кратности» с «n=∞» и сообщает, при необходимости, пользовательской программе, что выполнение этой вычислительной конструкции завершено.
Этот способ используется всегда, когда пользователь работает с группой элементов вектора, разнесенных по модулям, фактически не зная, сколько элементов векторов хранится в каждом модуле ассоциативной памяти 2.
Вышеописанный способ обеспечивает параллельную во времени работу модулей ассоциативной памяти 2 при обработке вектора, сокращает время рассылки и формирования токенов с различными ключами, очищает ячейки после завершения операции, выдает сообщение о завершении выполнения этой вычислительной конструкции, не требует значительных вычислительных ресурсов на реализацию этой конструкции, т.к. многое выполняется на аппаратном уровне, сокращает количество операций поиска в ассоциативной памяти 2 за счет возможности множественных откликов по всем модулям ассоциативной памяти 2.
Необходимо отметить, что программным способом достаточно сложно реализовать эту вычислительную конструкцию, т.к. на уровне пользователя нет данных о размещении векторов по модулям ассоциативной памяти 2 и о времени завершения выполнения этой конструкции в комплексе.
Описанные способы выполнения операций над типовой вычислительной конструкцией взаимодействия вектора с многократно используемой величиной могут быть с небольшими изменениями использованы в программах пользователя и системных программах для получения достаточно полной информации о прохождении вычислительного процесса в ВС по решению поставленной задачи. По завершении реализации типовой конструкции и в первом, и во втором случаях ВС с использованием процессора 8 регулировки параллелизма генерирует токены, оповещающие другие вычислительные процессы о завершении выполнения типовой конструкции. Будем называть такие токены «событийные токены».
В то же время сам вектор может состоять из «событийных токенов» и, таким образом, выполнение типовой конструкции, состоящей из событийных токенов, будет оповещать о выполнении более сложной вычислительной конструкции. Пользователь, опрашивая процессор 8 регулировки параллелизма о выполнении той или иной вычислительной конструкции, может знать фактически степень ее выполнения или процент выполнения. Например, при завершении обработки элементов вектора выдается событийный токен. Если программа написана таким образом, что такой событийный токен является элементом вектора другого событийного токена, то, когда будут выданы все элементы другого событийного токена, будет сформирован новый событийный токен и т.д. Таким образом может быть исключен достаточно неприятный недостаток любой системы, управляемой потоком данных, - отсутствие информации о стадии выполнения задачи и ее подзадач, отдельных программ или даже вычислительных конструкций. В то же время системным программам и программам пользователя дается возможность практически мгновенно приостанавливать прохождение задач, подзадач и отдельных программ с помощью записи «токена-заглушки» либо во все модули одновременно, либо в несколько модулей ассоциативной памяти 2.
Изменения в системе для реализации этого режима состоят в том, что «токен-заглушка» должен будет иметь специальный разряд, выделяющий его из всего множественного отклика, в котором могут быть и «записанные токены». Возможно и другое решение, когда токену типа «токен-заглушка» выделяется специальная зона свободных адресов. Таким образом, используя «токен-заглушку», и пользователь, и операционная система могут регулировать интенсивность прохождения того или иного вычислительного процесса. Пользователь, опрашивая процессор 8 регулировки параллелизма о выполнении той или иной вычислительной конструкции, может знать фактически степень ее выполнения.
Использование «событийных токенов» имеет следующие преимущества:
увеличивается количество хранимых токенов за счет совместной работы ассоциативной памяти 2 со вторичной памятью 6;
увеличивается пропускная способность ассоциативной памяти 2 за счет модульности, которая не сказывается на возможности программирования в виртуальном адресном пространстве;
появляется возможность работы с маской для считывания вектора за одну операцию «троичный поиск», несмотря на модульность ассоциативной памяти 2;
имеется возможность работы с многократно используемым токеном без изменения виртуального адреса;
и пользователь, и ОС имеют информацию о прохождении задачи с точностью до процентов прохождения отдельных подзадач, программ и вычислительных конструкций;
обеспечена возможность регулирования интенсивности прохождения вычислительных процессов за счет приостановки отдельных задач, подзадач и отдельных вычислительных конструкций;
обеспечена возможность динамического изменения всех полей ключа задачи, подзадачи, номера следующей команды, контекста, а также поля маски и хеш-функции, что существенно расширяет возможности программирования на них.
На Фиг.4 показана реализация рабочей станции в соответствии с описанным выше изобретением.
Рабочая станция содержит:
- исполнительные устройства 3 из «64» модулей, ассоциативную память 2 из «64» модулей, вторичную память 6 из «68» модулей, процессор 8 регулировки параллелизма, систему ввода-вывода 9 из «8» микропроцессоров, «HOST» процессор 10, используемый в качестве «HOST» - машины, со своей операционной системой, которая обеспечивает взаимодействие ВС с внешней памятью с помощью операционной системы обычного типа.
«HOST» процессор 10 взаимодействует с пользователями персональных компьютеров PC 12 через локальную сеть 13, подключая их к работе с ВС. В частности, «HOST» процессор 10 может загрузить в ВС начальные входные данные от пользователей, выдавать результаты обработки пользователям через вторичную память 6. «HOST» процессор 10 управляет также обменами между вторичной памятью 6 и модулями внешней памяти 11, используя при этом систему ввода-вывода 9. Может быть предоставлен компилятор для трансляции пользовательских программ, написанных на обычных высокоуровневых языках, таких как «Паскаль» и «Си», в автокод рабочей станции. Внешняя память может быть любого типа, такого как твердый диск, «CD» или «DVD». Имеется соответствующий модуль в системе ввода-вывода 9 для каждого модуля вторичной памяти 6. Как уже было описано, вторичная память 6 используется для хранения пар данных из буферного регистра готовых пар данных и токенов из буфера для «токенов, откачанных заглушкой». Пары данных и токены записываются во вторичную память 6 через адаптер 7 вторичной памяти, который определяет местоположение токенов и пар данных с учетом их полей «Т» и «ST». Из любого модуля ассоциативной памяти 2 данные могут быть записаны в любой модуль вторичной памяти 6, для этого в ней предусмотрен коммутатор модулей вторичной памяти.
Адаптер 7 обеспечивает запись токенов и пар данных во вторичную память, группируя их по задачам и/или подзадачам, к которым они принадлежат, с учетом их типов: «пара данных», «откачанный заглушкой токен», «откачанный записанный токен». Для этого адаптер 7 содержит ряд регистров физических адресов, по одному для каждого типа данных и для задачи и/или подзадачи. Например, допустим, что ВС имеет возможность выполнять «64» задачи и/или подзадачи одновременно. В этом случае часть токена, относящаяся к ключу, содержит «6» битов для идентификации задачи и/или подзадачи. Эти «6» битов находятся в полях «Т» и «ST» для структур токена и пары данных, показанных на Фиг.2а и Фиг.2б соответственно. Так как ВС выгружает «3» типа данных в описанной реализации, то есть «пары данных», «откачанные заглушкой токены», «откачанные записанные токены», ВС содержит «64*3», то есть «192» регистров физического адреса.
Когда пара данных или токен поступают в адаптер 7, выбирается соответствующая группа регистров физических адресов на основе двух битов, идентифицирующих тип данных. На основе «6» битов, идентифицирующих задачу и/или подзадачу, в этой группе выбирается один из «64» регистров физических адресов. Пара данных или токен записываются во вторичную память 6 по физическому адресу, хранящемуся в регистре физического адреса. Далее, соответствующий регистр физического адреса увеличивается на «1» таким образом, чтобы указывать на следующий физический адрес во вторичной памяти 6 для записи следующих данных соответствующего типа, относящихся к этой же задаче и/или подзадаче.
Регистры физического адреса первоначально устанавливаются с помощью процессора 8 регулировки параллелизма перед запуском задачи. Вторичная память 6 может быть организована страничным образом. В этом случае определенная часть битов в регистрах физических адресов идентифицирует страницу, в то время как оставшиеся биты идентифицируют местоположение внутри страницы. Когда «HOST» процессор 10 занимается размещением ресурсов, он указывает процессору 8 регулировки параллелизма адреса страниц для хранения пар данных и откачанных токенов. При инициализации процессор 8 регулировки параллелизма записывает начальный адрес соответствующей пустой страницы в каждый регистр физических адресов. Аналогичным образом, если страница заполнена выгруженными токенами или парами данных, процессор 8 регулировки параллелизма записывает адрес начала другой пустой страницы в соответствующий регистр физического адреса. Далее, процессор 8 регулировки параллелизма соединяет полную страницу с пустой страницей посредством ссылки или таблицы. В результате разбиение вторичной памяти 6 на страницы обеспечивает простыми средствами неограниченный размер буферного регистра готовых пар данных и буфера для «токенов, откачанных заглушкой», т.к. имеется возможность с помощью операционной системы «HOST» - процессора 10 откачать страницы на диск.
Восстановление данных в ассоциативной памяти 2 имеет некоторую особенность, существенно упрощающую этот процесс. Она состоит в том, что и токены, и пары данных могут возвращаться через любой модуль ассоциативной памяти 2, так как пара данных может поступать на любое свободное исполнительное устройство 3, а токен, проходя через коммутатор 4, направляется в соответствие с его «хэш-функцией» на тот модуль ассоциативной памяти 2, который она определяет. В том случае, если токен не имеет «хэш-функции» (первичный ввод данных), она формируется при прохождении токена через коммутатор 4. Принятая на вход коммутатора 4 пара данных, минуя модуль ассоциативной памяти 2, передается на вход коммутатора 5, который передает эту пару данных на свободный модуль исполнительных устройств 3. Принятый на вход коммутатора 4 токен возвращается в соответствии с его «хэш-функцией» в тот же модуль ассоциативной памяти 2, из которого он был откачан.
Производительность такой рабочей станции может достигать от «0.5» до «1» терафлоп при соответствующей аппаратной реализации, в частности, путем использования элементной базы с высокой степенью интеграции для реализации основных устройств ВС, таких как: исполнительные устройства 3, коммутаторы 4, 5, модули ассоциативной памяти 2 и «RISC»-процессора для «HOST» процессора 10 и процессор 8 регулировки параллелизма.
В соответствии с изобретением ВС может быть также использована для реализации персонального компьютера. Фактически персональный компьютер представляет собой минимальную конфигурацию описанной выше рабочей станции. Так, он может иметь меньшее количество исполнительных устройств, меньшее количество модулей ассоциативной памяти 2. Процессор 8 регулировки параллелизма может быть исключен, а его функции могут выполняться программными средствами. «HOST» процессор 10 содержит процессор, на котором выполняется операционная система, а также программы, выполняющие функции процессора 8 регулировки параллелизма. Коммутаторы 4, 5 и коммутатор модулей вторичной памяти могут быть реализованы с использованием «LVDS» линий связи известными методами.
На Фиг.5 показана схематически архитектура многопроцессорной вычислительной системы, обеспечивающая увеличение производительности ВС в целом. Она содержит множество рабочих станций, тип которых описан при рассмотрении Фиг.4, например «64» рабочих станции в рассматриваемом случае. Каждая рабочая станция содержит «128» исполнительных устройств 3 и «128» модулей ассоциативной памяти 2. Рабочие станции объединены в одну систему с помощью, например, коммутатора 16 с использованием оптических линий связи с высокой пропускной способностью, чтобы обеспечить высокую скорость передачи данных порядка сотен Гбит/с. Данные могут передаваться через коммутатор 16 в форме пакетов.
Для работы в многопроцессорной системе, показанной на Фиг.5, структура токена, используемая в рабочей станции, показанная на Фиг.2а, должна быть несколько изменена. Изменение сводится к расширению поля адресации токена путем добавления информации, определяющей номер рабочей станции (поле «PCn» на Фиг.6). Необходимо отметить, что структура пары данных при этом осталась неизменной.
Каждая рабочая станция имеет селектор 15, в который посылаются токены, выдаваемые исполнительными устройствами 3. Если адрес назначения токена находится в той же самой рабочей станции, селектор 15 посылает его на коммутатор 4 этой рабочей станции, который, в свою очередь, посылает его в соответствующий модуль ассоциативной памяти 2 рабочей станции для обычной обработки, как было описано при рассмотрении Фиг.4. Если адрес назначения токена находится в другой рабочей станции, селектор 15 формирует пакет, содержащий токен, и посылает его на другую рабочую станцию через коммутатор 16. Каждая рабочая станция выбирает пакеты токенов в соответствии со своим номером, затем считывает из этого пакета токены и посылает их на коммутатор 4 этой рабочей станции для обычной обработки, как было описано при рассмотрении Фиг.4.
Ввод и вывод данных задачи пользователя может производиться через локальную сеть 17, которая управляет всеми «HOST» машинами всех рабочих станций.
Таким образом, в предложенных технических решениях достигается поставленный технический результат: повышается надежность функционирования при сохранении объема ассоциативной памяти за счет повышения достоверности информации процесса обработки, а также обеспечивается контроль за процессами обработки.
Предложенные технические решения были описаны со ссылкой на предпочтительную реализацию. Однако в пределах области действия изобретений возможны многочисленные изменения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ С ИСПОЛЬЗОВАНИЕМ ПОДХОДА, ОСНОВАННОГО НА УПРАВЛЕНИИ ПОТОКОМ ДАННЫХ, И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2006 |
|
RU2360279C2 |
| ПАРАЛЛЕЛЬНАЯ ПРОЦЕССОРНАЯ СИСТЕМА | 1991 |
|
RU2084953C1 |
| МУЛЬТИСЕРВИСНЫЙ МАРШРУТИЗАТОР | 2019 |
|
RU2710980C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1995 |
|
RU2110089C1 |
| СПОСОБ ОТЛАДКИ ОБУЧЕННОЙ РЕКУРРЕНТНОЙ НЕЙРОННОЙ СЕТИ | 2019 |
|
RU2715024C1 |
| СПОСОБ ЗАШИФРОВАННОЙ СВЯЗИ С ИСПОЛЬЗОВАНИЕМ ДЕЦЕНТРАЛИЗОВАННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ | 2024 |
|
RU2838643C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| Вычислительная система | 1977 |
|
SU692400A1 |
| СИНХРОНИЗАЦИЯ СОСТОЯНИЯ МАРКЕРА | 2019 |
|
RU2792695C2 |
| ВЫЧИСЛИТЕЛЬНАЯ МАШИНА | 1997 |
|
RU2130198C1 |


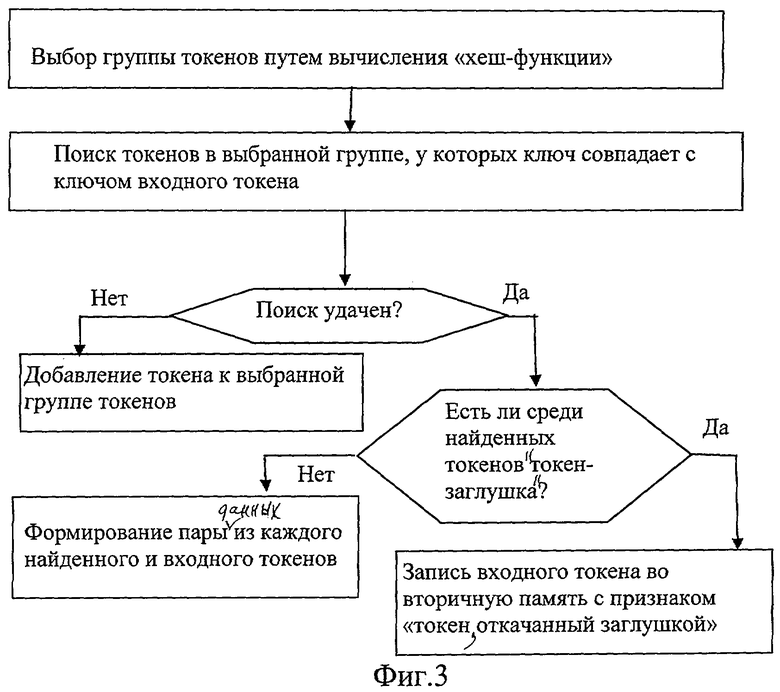
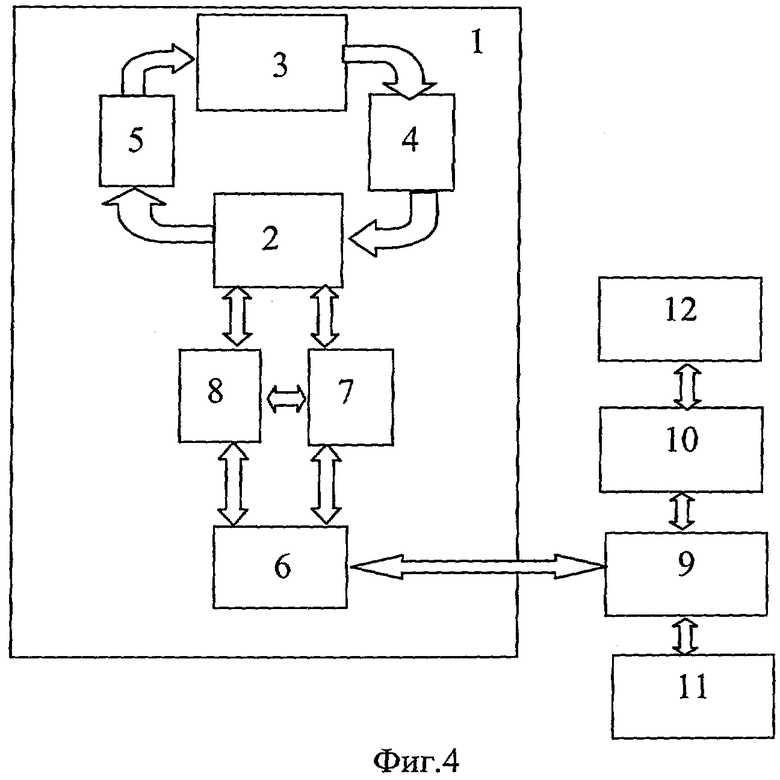


Изобретение относится к области вычислительной техники. Техническим результатом является повышение надежности функционирования при сохранении объема ассоциативной памяти путем повышения достоверности информации процесса обработки и обеспечения контроля за процессами обработки. Указанный результат достигается за счет того, что система содержит один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью хранить поступающую в него структуру данных - «токен», содержащую группу разрядов, образующих поле данных, поле контекста и поле ключа, одно или несколько исполнительных устройств, два коммутатора, вторичную память для временного хранения пар данных и «токенов», адаптер вторичной памяти, процессор для регулировки степени параллелизма. 2 н. и 12 з.п. ф-лы, 6 ил.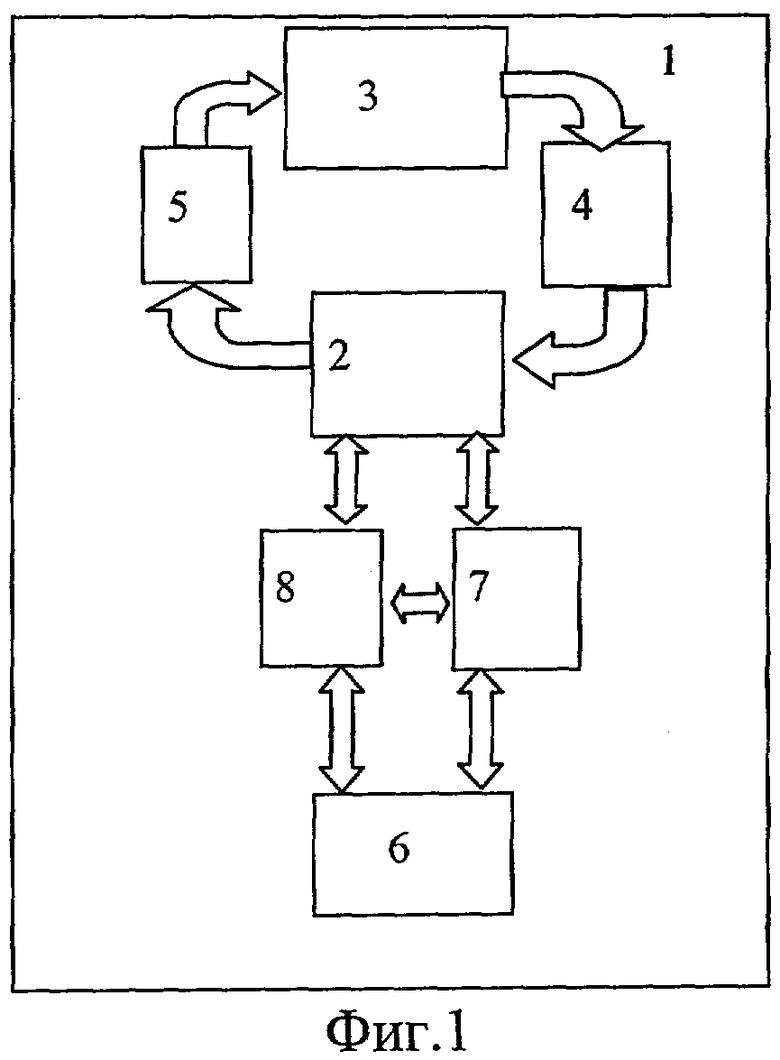
«обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют структуру данных - «токен», состоящую из группы разрядов, образующих поле данных, поле контекста и поле ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены;
по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен - «вычисление хеш-функции»;
«направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена;
«поиск» среди сформированных указанных выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск»,
отличающийся тем, что при выполнении операции «поиск» производят действие «троичный поиск», при котором каждый бит прикрепленного к токену ключа имеет три состояния: «0», «1» и «маскированный», при сравнении ключей входного и хранящегося токенов бит со значением «маскированный» в любом из двух ключей считают совпавшим с соответствующим битом оставшегося ключа, при успешном «поиске» из входного и найденного токенов формируют пары данных, количество которых равно количеству найденных токенов при этом поиске, каждая из сформированных пар данных содержит результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над всеми сформированными таким образом парами данных выполняют действия, указанные в операции «обработка пары данных»;
осуществляют операцию «запись во вторичную память входного токена», при которой указанный в операции входной токен записывают по адресу, сформированному из ключа токена;
осуществляют операцию «чтение из вторичной памяти» токена, при которой считывают из вторичной памяти токен по адресу, указанному в операции;
осуществляют операцию «запись во вторичную память пары данных», при которой указанную в операции пару данных токена записывают по адресу, сформированному из ключа пары данных;
осуществляют операцию «чтение из вторичной памяти пары данных», при которой считывают из вторичной памяти пару данных по адресу, указанному в операции;
осуществляют «мониторинг процесса вычислений» и на его основе вырабатывают управляющие токены, которые изменяют алгоритм выбора указанных выше действий над входными токенами и парами данных;
при выполнении операции «обработка пары данных» в ключ токена вводят дополнительные разряды для хранения номера задачи - поле Т, характеризующего некоторый независимый вычислительный процесс,
а при выполнении операции «обработка пары данных» в ключ токена вводят дополнительные разряды для хранения номера задачи - поле ST, характеризующего часть независимого вычислительного процесса.
соответственно в одной, в нескольких или во всех группах хранящихся токенов производят «троичный поиск» токенов, у которых поля ST и Т совпадают с полями ST и Т в управляющем токене;
все найденные токены удаляют соответственно из одной, из нескольких или из всех групп хранящихся токенов и перемещают найденные токены во вторичную память, причем этим токенам присваивают во вторичной памяти признак «откачанные записанные токены».
выдавать информацию о значении N по запросу из операции «мониторинг процесса вычислений»,
подсчитывать суммарное количество К сформированных с таким токеном пар данных во всех группах хранящихся токенов,
информировать задачу пользователя о ситуации, когда K=N,
формировать токен с заданными значениями полей Т и ST и с признаком «событийный токен» и выдавать его при возникновении ситуации, при которой K=N, независимо от того, возникла ли эта ситуация при размещении «токена многократного отклика» в одной группе хранящихся токенов или во всех группах.
хранить поступающую в него структуру данных - «токен», содержащую группу разрядов, образующих поле данных, поле контекста и поле ключа,
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена,
запоминать поступающий токен в модулях ассоциативной памяти в случае неудачного поиска,
формировать пару данных из поступающего в ассоциативную память токена и найденного в ассоциативной памяти токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств;
одно или несколько исполнительных устройств (3), выполненных с возможностью
выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в ключе пары данных,
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром,
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти,
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией;
первый коммутатор (4), выполненный с возможностью направлять токены из любого исполнительного устройства (3) в любой модуль ассоциативной памяти (2), и
второй коммутатор (5), выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти (2) в любое исполнительное устройство (3),
отличающаяся тем, что введены
вторичная память (6) для временного хранения пар данных и токенов, выполненная с возможностью
получать токены для хранения из исполнительных устройств и ассоциативной памяти,
получать пары данных на хранение из ассоциативной памяти,
выдавать хранящиеся токены и пары данных в ассоциативную память;
адаптер вторичной памяти (7), выполненный с возможностью определять место во вторичной памяти для хранения токенов и пар данных,
и процессор для регулировки степени параллелизма (8), выполненный с возможностью:
собирать информацию о степени загрузки ассоциативной 1 памяти и исполнительных устройств (3),
направлять токены из ассоциативной памяти во вторичную память (6) и обратно и
направлять управляющие токены в ассоциативную память,
а каждый модуль ассоциативной памяти выполнен троичным с возможностью
хранить токены с троичными ключами, каждый разряд которых может принимать одно из трех значений: «0», «1» и «маскированный», осуществлять «троичный поиск» среди хранящихся токенов токена, троичный ключ которого совпадает с троичным ключом пришедшего токена таким образом, что разряды, в которых записано значение «маскированный» в любом из токенов, не участвуют в сравнении, и выдавать в рамках одной операции «троичный поиск» несколько хранящихся в ассоциативной памяти токенов, количество которых равно количеству токенов, найденных при «троичном поиске».
хранить вместе с ключом маску, в которой указаны разряды ключа с значением «маскированный», а приходящий токен кроме ключа содержит маску, в которой указаны разряды ключа с значением «маскированный»,
осуществлять среди хранящихся токенов «троичный поиск» токена с ключом, совпадающим с ключом пришедшего токена таким образом, что разряды хранящихся токенов и/или пришедшего токена, которые закрываются масками, то есть имеют значение «маскированный», не участвуют в сравнении,
выдавать в рамках одного троичного поиска несколько хранящихся в ассоциативной памяти токенов, ключ каждого из которых удовлетворяет вышеприведенному критерию «троичного поиска».
| Вычислительная система | 1977 |
|
SU692400A1 |
| GB 1207105 A1, 30.09.1970 | |||
| DE 3534026 А, 26.03.1987 | |||
| US 4366551 A, 28.12.1982. | |||

