Область техники, к которой относится изобретение
[1] Настоящая технология в целом относится к страницам результатов поисковой системы и, в частности, к способу и серверу для обучения алгоритма машинного обучения, предназначенного для ранжирования объектов в ответ на запрос.
Уровень техники
[2] Сеть Интернет обеспечивает доступ к разнообразным ресурсам, таким как, видеофайлы, файлы изображений, аудиофайлы или веб-страницы. Для поиска этих ресурсов используются поисковые системы. Например, после получения отправленного пользователем запроса поисковая система способна обнаруживать цифровые изображения, соответствующие информационным потребностям пользователя. Пользовательские запросы могут состоять из одного или нескольких терминов. Поисковая система выбирает и ранжирует результаты поиска в зависимости от их соответствия пользовательскому запросу и/или их важности по сравнению с другими результатами поиска и предоставляет пользователю лучшие результаты поиска.
[3] Для ранжирования результатов поиска на странице результатов поисковой системы (SERP, Search Engine Results Page), формируемой и предоставляемой пользователю, отправившему запрос, используются многие передовые алгоритмы ранжирования.
Раскрытие изобретения
[4] Разработчики настоящей технологии обнаружили определенные технические недостатки, связанные с существующими поисковыми системами.
[5] Согласно первому аспекту настоящей технологии реализован компьютерный способ обучения алгоритма машинного обучения (MLA, Machine Learning Algorithm) ранжированию объектов в ответ на запрос. Алгоритм MLA выполняется сервером, которому доступны объекты и запрос. Обучение включает в себя использование функции метрики качества ранжирования, представляющей собой плоскую или разрывную функцию, для определения оценки эффективности алгоритма MLA. Способ выполняется сервером и включает в себя формирование сервером, выполняющим алгоритм MLA, оценок релевантности для набора обучающих объектов на основе данных, связанных (а) с набором обучающих объектов и (б) с обучающим запросом. Оценки релевантности указывают на ожидаемую релевантность обучающему запросу соответствующего обучающего объекта. Способ включает в себя формирование сервером зашумленных оценок релевантности для набора обучающих объектов путем сочетания оценок релевантности и значений шума. Значения шума формируются на основе шумовой функции с заранее заданным распределением. Способ включает в себя формирование сервером оценки эффективности для алгоритма MLA на основе зашумленных оценок релевантности. Оценка эффективности указывает на качество ранжирования алгоритмом MLA, если обучающие объекты из набора обучающих объектов ранжированы согласно соответствующим зашумленным оценкам релевантности. Способ включает в себя определение сервером величины градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом MLA для объектов этапа использования в ответ на запрос этапа использования. Величина градиента политики определяется на основе сочетания (а) оценки эффективности, (б) оценок релевантности и (в) зашумленных оценок релевантности для набора обучающих объектов. Способ включает в себя применение сервером величины градиента политики при обучении алгоритма MLA ранжированию объектов этапа использования в ответ на запрос этапа использования.
[6] В некоторых вариантах осуществления способа формирование оценки эффективности на основе зашумленных оценок релевантности позволяет определять величину градиента политики.
[7] В некоторых вариантах осуществления способа применение величины градиента политики включает в себя применение сервером взвешенной величины градиента политики при обучении алгоритма MLA. Взвешенный градиент политики определяется в виде сочетания (а) величины градиента политики и (б) заранее заданного весового значения.
[8] В некоторых вариантах осуществления способа алгоритм MLA представляет собой алгоритм на основе дерева решений с набором деревьев решений, а применение величины градиента политики включает в себя формирование сервером дополнительного дерева решений для алгоритма MLA на основе величины градиента политики и/или модификацию сервером по меньшей мере одного дерева решений из набора деревьев решений алгоритма MLA на основе величины градиента политики.
[9] В некоторых вариантах осуществления способа применение величины градиента политики при обучении обеспечивает прямую оптимизацию качества ранжирования алгоритмом MLA.
[10] В некоторых вариантах осуществления способа определение величины градиента политики включает в себя оценивание сервером величины градиента политики с применением способа покоординатной антитетической выборки.
[11] В некоторых вариантах осуществления способа оценивание величины градиента политики с применением способа покоординатной антитетической выборки включает в себя оценивание сервером градиента политики по следующей формуле:
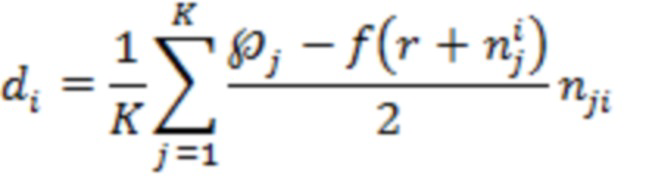
где:
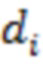 - величина градиента политики для обучающего объекта
- величина градиента политики для обучающего объекта  в наборе обучающих объектов;
в наборе обучающих объектов;
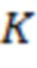 - количество значений зашумленных оценок релевантности;
- количество значений зашумленных оценок релевантности;
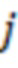 - номер значения зашумленной оценки релевантности;
- номер значения зашумленной оценки релевантности;
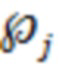 - оценка эффективности для j-го значения зашумленной оценки релевантности;
- оценка эффективности для j-го значения зашумленной оценки релевантности;
 - вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
- вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
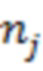 - вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
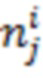 - вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
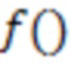 - функция метрики качества ранжирования.
- функция метрики качества ранжирования.
[12] В некоторых вариантах осуществления способа величина градиента политики применяется сервером в автономном режиме.
[13] В некоторых вариантах осуществления способа величина градиента политики применяется сервером до применения алгоритма MLA на этапе использования.
[14] В некоторых вариантах осуществления способа заранее заданное распределение представляет собой распределение Гаусса и/или распределение Коши и/или распределение Лапласа.
[15] В некоторых вариантах осуществления способа функция метрики качества ранжирования представляет собой одну из следующих функций: нормализованный дисконтированный кумулятивный показатель (NDCG, Normalized Discounted Cumulative Gain), ожидаемый взаимный ранг (ERR, Expected Reciprocal Rank), средняя точность (MAP, Mean Average Precision) и средний взаимный ранг (MRR, Mean Reciprocal Rank).
[16] В некоторых вариантах осуществления способа обучающие объекты представляют собой электронные документы, а обучающий запрос представляет собой запрос, ранее отправленный поисковой системе. Поисковая система размещена на сервере.
[17] В некоторых вариантах осуществления способа он дополнительно включает в себя ранжирование сервером объектов этапа использования в ответ на запрос этапа использования и инициирование сервером отображения страницы SERP пользователю, связанному с запросом этапа использования. Страница SERP представляет собой ранжированный список объектов этапа использования.
[18] Согласно второму аспекту настоящей технологии реализован сервер для обучения алгоритма MLA ранжированию объектов в ответ на запрос. Алгоритм MLA выполняется сервером, которому доступны объекты и запрос. Обучение включает в себя использование функции метрики качества ранжирования, представляющей собой плоскую или разрывную функцию, для определения оценки эффективности алгоритма MLA. Сервер способен путем выполнения алгоритма MLA формировать оценки релевантности для набора обучающих объектов на основе данных, связанных (а) с набором обучающих объектов и (б) с обучающим запросом. Оценки релевантности указывают на ожидаемую релевантность обучающему запросу соответствующего обучающего объекта. Сервер способен формировать зашумленные оценки релевантности для набора обучающих объектов путем сочетания оценок релевантности и значений шума. Значения шума формируются на основе шумовой функции с заранее заданным распределением. Сервер способен формировать оценку эффективности для алгоритма MLA на основе зашумленных оценок релевантности. Оценка эффективности указывает на качество ранжирования алгоритмом MLA, если обучающие объекты из набора обучающих объектов ранжированы согласно соответствующим зашумленным оценкам релевантности. Сервер способен определять величину градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом MLA для объектов этапа использования в ответ на запрос этапа использования. Величина градиента политики определяется на основе сочетания (а) оценки эффективности, (б) оценок релевантности и (в) зашумленных оценок релевантности для набора обучающих объектов. Сервер способен применять величину градиента политики при обучении алгоритма MLA ранжированию объектов этапа использования в ответ на запрос этапа использования.
[19] В некоторых вариантах осуществления сервера он способен формировать оценку эффективности на основе зашумленных оценок релевантности, что позволяет определять величину градиента политики.
[20] В некоторых вариантах осуществления изобретения способность сервера применять величины градиента политики включает в себя способность сервера применять взвешенную величину градиента политики при обучении алгоритма MLA. Взвешенный градиент политики определяется в виде сочетания (а) величины градиента политики и (б) заранее заданного весового значения.
[21] В некоторых вариантах осуществления сервера алгоритм MLA представляет собой алгоритм на основе дерева решений с набором деревьев решений, а способность сервера применять величины градиента политики включает в себя способность сервера формировать дополнительное дерево решений для алгоритма MLA на основе величины градиента политики и/или модифицировать по меньшей мере одно дерево решений из набора деревьев решений алгоритма MLA на основе величины градиента политики.
[22] В некоторых вариантах осуществления сервера он способен применять величину градиента политики для обучения, что обеспечивает прямую оптимизацию качества ранжирования алгоритмом MLA.
[23] В некоторых вариантах осуществления изобретения способность сервера определять величину градиента политики включает в себя способность сервера оценивать величины градиента политики с применением способа покоординатной антитетической выборки.
[24] В некоторых вариантах осуществления изобретения способность сервера оценивать величину градиента политики с применением способа покоординатной антитетической выборки включает в себя способность сервера оценивать градиент политики по следующей формуле:
где:
- величина градиента политики для обучающего объекта в наборе обучающих объектов;
- количество значений зашумленных оценок релевантности;
- номер значения зашумленной оценки релевантности;
- оценка эффективности для j-го значения зашумленной оценки релевантности;
- вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
- функция метрики качества ранжирования.
[25] В некоторых вариантах осуществления сервера он способен применять градиент политики в автономном режиме.
[26] В некоторых вариантах осуществления сервера он способен применять градиент политики до применения алгоритма MLA на этапе использования.
[27] В некоторых вариантах осуществления сервера заранее заданное распределение представляет собой распределение Гаусса и/или распределение Коши и/или распределение Лапласа.
[28] В некоторых вариантах осуществления сервера функция метрики качества ранжирования представляет собой одну из следующих функций: показатель NDCG, ранг ERR, точность MAP, ранг MRR.
[29] В некоторых вариантах осуществления сервера обучающие объекты представляют собой электронные документы, а обучающий запрос представляет собой запрос, ранее отправленный поисковой системе. Поисковая система размещена на сервере.
[30] В некоторых вариантах осуществления сервера он дополнительно способен ранжировать объекты этапа использования в ответ на запрос этапа использования и инициировать отображение страницы SERP пользователю, связанному с запросом этапа использования. Страница SERP представляет собой ранжированный список объектов этапа использования.
[31] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[32] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[33] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[34] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[35] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[36] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[37] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[38] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[39] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[40] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[41] На фиг. 1 приведена схема системы, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[42] На фиг. 2 приведено множество компьютерных процедур, используемых сервером с фиг. 1, согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[43] На фиг. 3 представлены данные, хранящиеся в показанном на фиг. 1 репозитории поисковой системы, согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[44] На фиг. 4 приведена схема итерации обучения алгоритма MLA, показанного на фиг. 1, согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[45] На фиг. 5 приведена блок-схема способа обучения алгоритма MLA ранжированию объектов в ответ на запрос согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[46] Кроме того, после описания изобретения приведено Приложение А. Приложение А содержит статью с информацией о некоторых описанных здесь аспектах настоящей технологии и/или о дополнительных аспектах настоящей технологии. Приложение A и информация, составляющая его часть, включены для справки и должны быть удалены из заявки до публикации патента.
Осуществление изобретения
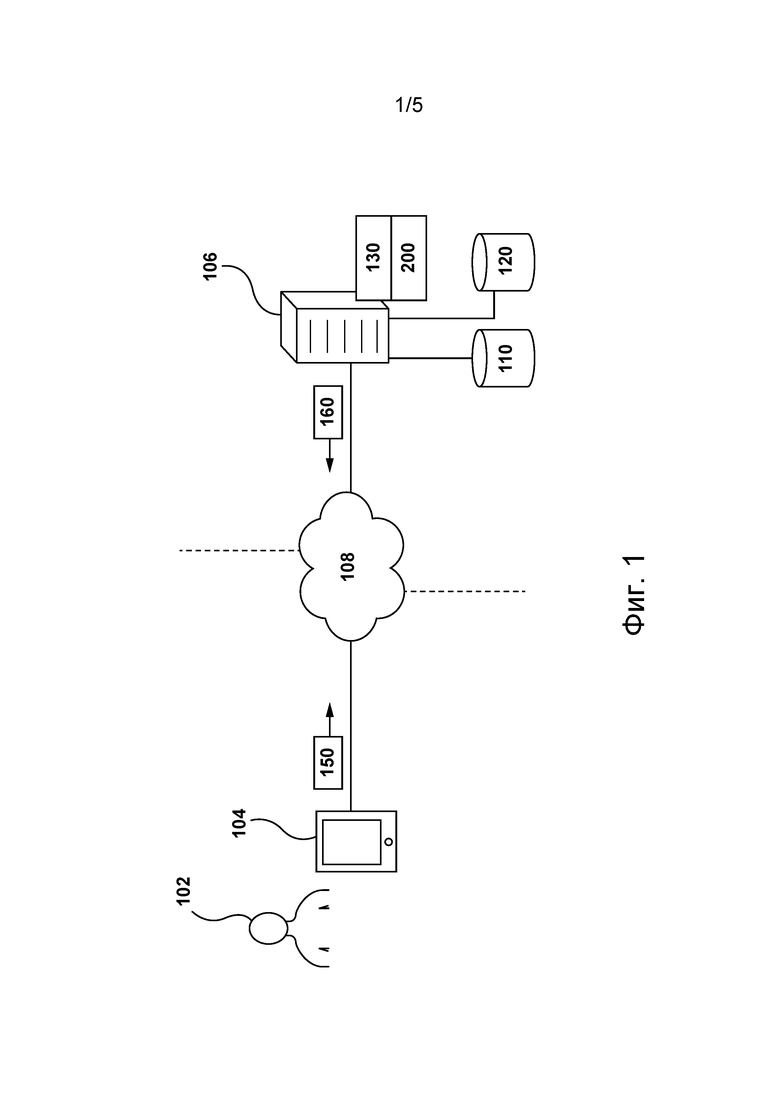
[47] На фиг. 1 представлена схема системы 100 (не показано на фигурах), пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приведены полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это может быть не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой вариант упрощенной реализации настоящей технологии и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[48] В общем случае система 100 способна формировать и предоставлять страницу SERP, содержащую различные результаты поиска, электронному устройству 104 для ее отображения пользователю 102 в ответ на запрос, сделанный пользователем 102. Ниже описаны по меньшей мере некоторые элементы системы 100. Тем не менее, в других вариантах осуществления изобретения элементы, отличные от представленных на фиг. 1, могут входить в состав системы 100 без выхода за границы настоящей технологии.
Электронное устройство
[49] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Электронное устройство 104 иногда может называться клиентским устройством, оконечным устройством, клиентским электронным устройством или просто устройством. Следует отметить, что связь электронного устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[50] На реализацию устройства 104 не накладывается каких-либо особых ограничений. Например, устройство 104 может быть реализовано как персональный компьютер (настольный, ноутбук, нетбук и т.д.), беспроводное устройство связи (смартфон, сотовый телефон, планшет и т.д.) или как сетевое оборудование (маршрутизатор, коммутатор, шлюз и т.д.). Устройство 104 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения. В общем случае браузерное приложение обеспечивает пользователю 102 доступ к одному или нескольким веб-ресурсам. На реализацию браузерного приложения не накладывается каких-либо особых ограничений. Например, браузерное приложение может быть реализовано в виде браузера Yandex™.
[51] В некоторых вариантах осуществления настоящей технологии браузерное приложение, реализованное с использованием устройства 104, позволяет пользователю 102 отправлять поисковые запросы поисковой системе (например, размещенной на сервере 106) и отображать пользователю 102 страницы SERP, соответствующие отправленным запросам. В общем случае поисковая система представляет собой систему, способную получать запросы от множества пользователей, искать информацию, соответствующую полученным запросам, и формировать страницы SERP, содержащие результаты поиска, ранжированные на основе их релевантности полученным запросам. Например, поисковая система может быть реализована в виде поисковой системы YANDEX™, поисковой системы GOOGLE™, поисковой системы YAHOO!™ и т.п.
[52] Например, пользователь 102 может использовать браузерное приложение для ввода или отправки текущего запроса, а устройство 104 может формировать пакет 150 данных запроса, содержащий данные, указывающие на текущий запрос пользователя 102. Предполагается, что множество пакетов данных может быть сформировано множеством устройств системы 100 подобно тому, как устройство 104 формирует пакет 150 данных запроса на основе текущего запроса, введенного или отправленного пользователем 102 в браузерном приложении, без выхода за границы настоящей технологии.
Сеть связи
[53] Устройство 104 подключено к сети 108 связи для доступа к поисковой системе сервера 106. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 108 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 108 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (не пронумерована) между устройством 104 и сетью 108 связи зависит, среди прочего, от реализации устройства 104.
[54] Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где устройство 104 реализовано как беспроводное устройство связи (такое как смартфон), линия связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 реализовано как ноутбук, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
[55] Сеть 108 связи способна передавать, среди прочего, пакет 150 данных запроса от устройства 104 к серверу 106 и пакет 160 данных страницы SERP от сервера 106 к устройству 104. Например, пакет 160 данных страницы SERP может содержать данные, указывающие на страницу SERP, сформированную сервером 106 и содержащую результаты поиска, соответствующие текущему запросу пользователя 102. Ниже более подробно описано формирование сервером 106 пакета 160 данных страницы SERP и самой страницы SERP.
Сервер
[56] Система 100 также содержит сервер 106, который может быть реализован в виде компьютерного сервера. В примере осуществления настоящей технологии сервер 106 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 106 может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 106 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 106 могут быть распределены между несколькими серверами.
[57] В целом, сервер 106 может управляться и/или администрироваться поставщиком услуг поисковой системы (не показан), таким как оператор поисковой системы (например, поисковой системы Yandex™). В связи с этим, как описано ранее, поисковая система может быть размещена на сервере 106. Сервер 106 может выполнять один или несколько информационных поисков в ответ на запросы, отправленные пользователями поисковой системы.
[58] Сервер 106 способен выполнять по меньшей мере некоторые процедуры из множества 200 компьютерных процедур, описанных ниже со ссылкой на фиг. 2. В других вариантах осуществления изобретения сервер 106 может выполнять также дополнительные компьютерные процедуры, помимо неисчерпывающим образом представленных на фиг. 2 процедур, без выхода за границы настоящей технологии.
[59] Сервер 106 может выполнять процедуру 202 обнаружения объектов, обычно используемую сервером 106 для обнаружения цифровых объектов, доступных через сеть 108 связи. Например, сервер 106 может выполнять приложение обходчика, посещающее сетевые ресурсы, доступные через сеть 108 связи, и загружающее их для дальнейшей обработки.
[60] На характер цифровых объектов, которые сервер 106 способен посещать и загружать, не накладывается каких-либо особых ограничений. Например, описанные здесь цифровые объекты могут быть цифровыми документами, представляющими собой веб-страницы, доступные через сеть 108 связи. В другом примере описанные здесь цифровые объекты могут представлять собой цифровые изображения, цифровые звукозаписи, цифровые видеоматериалы и цифровые медиа-файлы других видов.
[61] Следует отметить, что в контексте настоящего описания цифровые объекты для простоты называются цифровыми документами или просто документами. Тем не менее, предполагается, что описанные здесь концепции могут применяться в отношении цифровых объектов других видов, подобно тому, как они применяются для цифровых документов, без выхода за границы настоящей технологии.
[62] Сервер 106 также может выполнять процедуру 204 индексации, которая обычно применяется сервером 106 для построения и/или поддержания структур индексации, используемых поисковой системой при выполнении поисков. Например, сервер 106 способен создавать и/или поддерживать инвертированный индекс.
[63] На реализацию инвертированного индекса в настоящей технологии не накладывается каких-либо особых ограничений. Например, инвертированный индекс в основном содержит несколько списков вхождений (posting lists), каждый из которых связан с соответствующим доступным для поиска термином. Каждое вхождение в списке вхождений содержит данные некоторого типа, которые указывают на документ, содержащий доступный для поиска термин, связанный с этим списком вхождений, и опционально некоторые дополнительные данные. Вкратце, каждый список вхождений соответствует доступному для поиска термину и содержит ряд вхождений, указывающих на каждый обнаруженный документ, содержащий по меньшей мере одно вхождение этого термина для поиска.
[64] Следует отметить, что в состав вхождения также могут быть включены дополнительные данные, например, количество вхождений доступного для поиска термина в документе, указание на появление поискового термина в заголовке документа и т.д. Разумеется, что эти дополнительные данные могут различаться в зависимости от конкретной поисковой системы, в том числе, от различных вариантов осуществления настоящей технологии.
[65] Доступные для поиска термины обычно, но не обязательно, представляют собой слова или другие последовательности символов. Поисковая система обычно способна обрабатывать практически все слова на нескольких различных языках, а также имена собственные, числа, символы и т.д. Часто используемому слову может соответствовать список вхождений, содержащий миллиард вхождений (или даже больше). В некоторых вариантах осуществления настоящей технологии поисковый запрос может представлять собой графический поисковый запрос для поиска подобных изображений. В других вариантах осуществления изобретения поисковый запрос также может представлять собой звуковой поисковый запрос для поиска цифровой звукозаписи, содержащей звук из запроса.
[66] Сервер 106 также может выполнять процедуру 206 запрашивания, обычно используемую сервером 106 для определения документов, которые могут содержать некоторую часть запроса, отправленного поисковой системе. Например, когда запрос (такой как текущий запрос пользователя 102) принят сервером 106 поисковой системы, сервер 106 может разделить этот запрос на множество доступных для поиска терминов. Затем сервер 106 может обратиться к инвертированному индексу и определить списки вхождений, связанные с по меньшей мере одним термином из множества доступных для поиска терминов. В результате сервер 106 может получить доступ к по меньшей мере некоторым вхождениям из определенных таким образом списков вхождений и определить по меньшей мере некоторые документы, которые могут содержать по меньшей мере некоторые термины из множества доступных для поиска терминов из запроса.
[67] Сервер 106 также может выполнять процедуру 208 оценивания релевантности, которая обычно используется для оценивания релевантности документа запросу. Например, сервер 106 может реализовывать алгоритм 130 MLA (см. фиг. 1 и 2), обученный оцениванию релевантности документа запросу.
[68] В целом, алгоритм 130 MLA может оценивать релевантность документа запросу, среди прочего, на основе (а) признаков документа (например, данных, связанных с документом) и (б) признаков запроса (например, данных, связанных с запросом). Ниже со ссылками на фиг. 4 описаны обучение и последующее использование алгоритма 130 MLA для оценивания релевантности документа запросу.
[69] Следует отметить, что в некоторых вариантах осуществления настоящей технологии в результате выполнения процедуры 208 оценивания релевантности сервер 106 способен ранжировать документы, один относительно другого, на основе соответствующих оценок релевантности (сформированных алгоритмом 130 MLA), указывающих на ожидаемую релевантность соответствующих документов запросу.
[70] Ранжирование документов в ответ на запрос представляет собой сложную задачу. В данной области техники оно обычно называется задачей обучения ранжированию (L2R, Learning-to-Rank). Качество алгоритма, который может использоваться сервером 106 для ранжирования, традиционно измеряется с использованием выходных данных так называемой функции метрики качества ранжирования. Например, после использования алгоритма для ранжирования документов функция метрики качества ранжирования применяется для определения оценки эффективности, которая представляет собой меру, указывающую на качество ранжирования алгоритмом, использованным для ранжирования документов (например, путем сравнения ранжированного таким образом списка документов с действительными данными об этих документах).
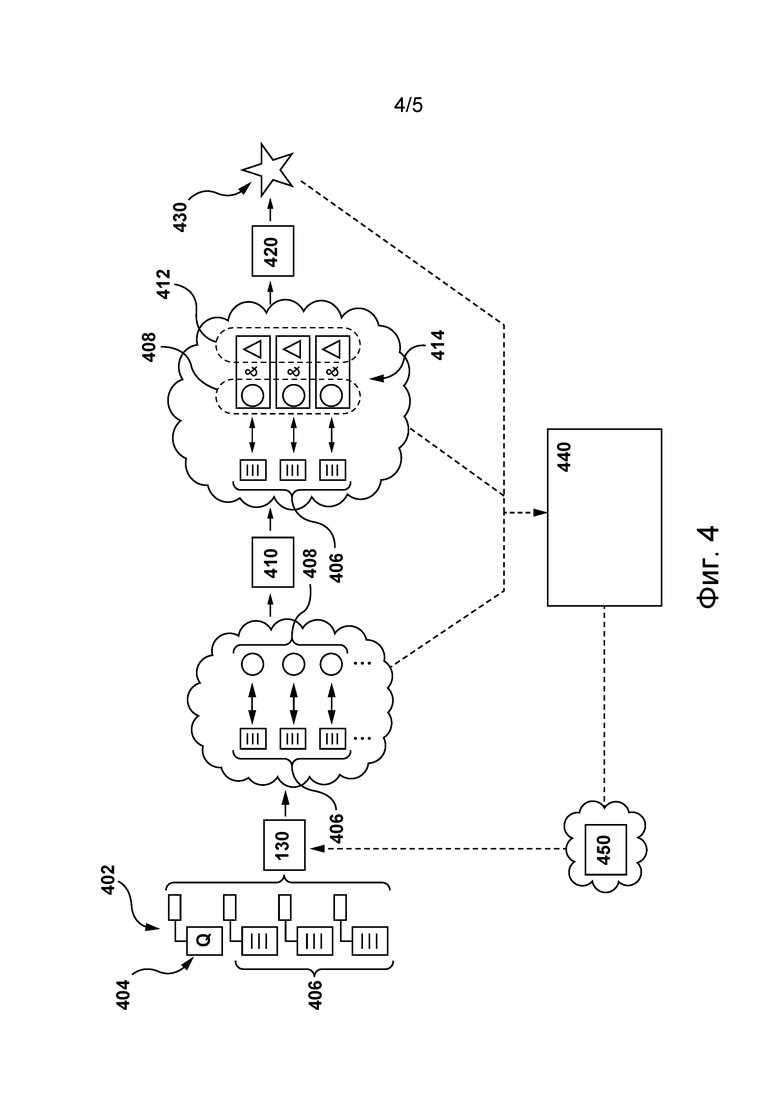
[71] Например, среди прочего, могут использоваться следующие функции метрики качества ранжирования:
- нормализованный дисконтированный кумулятивный показатель (NDCG);
- ожидаемый взаимный ранг (ERR);
- средняя точность (MAP);
- средний взаимный ранг (MRR).
[72] Можно сказать, что функция метрики качества ранжирования может применяться в отношении ранжированного по релевантности списка документов (оценки релевантности которых определены с использованием данного алгоритма), а полученная в результате такого применения оценка эффективности в известном смысле фиксирует полезность документов, ранжированных в таком порядке, для пользователя, отправившего запрос поисковой системе.
[73] Вкратце, задача L2R может быть переформулирована в виде задачи оптимизации функции метрики качества ранжирования. Иными словами, цель заключается в обучении алгоритма формированию оценок релевантности для документов таким образом, чтобы при ранжировании этих документов на основе соответствующих оценок релевантности оценка эффективности (определенная с применением функции метрики качества ранжирования в отношении ранжированного по релевантности списка документов) была оптимизирована.
[74] В по меньшей мере некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали способы и системы для обучения алгоритма 130 MLA формированию оценок релевантности для документов (которые затем должны быть ранжированы на основе этих оценок релевантности) таким образом, чтобы оптимизировать качество ранжирования алгоритмами 130 MLA.
[75] Такая оптимизация представляет собой сложную задачу, поскольку оценки эффективности, полученные с применением функции метрики качества ранжирования, зависят от рангов документов, которые сами определяются путем упорядочивания документов на основе предполагаемых оценок релевантности (например, выходных данных алгоритма). Иными словами, от алгоритма требуется оценивание релевантности документов запросу, но он обучен на информации, получаемой на основе порядка, в котором эти документы ранжированы согласно ожидаемой релевантности. В результате функции метрики качества ранжирования оказываются или плоскими, или разрывными и, следовательно, не являются ни выпуклыми, ни гладкими.
[76] Чтобы лучше проиллюстрировать эти свойства функций метрики качества ранжирования можно предположить, что алгоритм формирует оценки релевантности для набора документов и затем из этих документов на основе соответствующих оценок релевантности формируется первый ранжированный список документов. Когда функция метрики качества ранжирования применяется в отношении первого ранжированного списка документов, формируется первая оценка эффективности.
[77] Далее можно предположить, что алгоритм формирует незначительно отличающиеся (или в целом схожие) оценки релевантности для набора документов и что затем из этих документов на основе этих незначительно отличающихся (или в целом схожих) оценок релевантности формируется второй ранжированный список документов.
[78] Вследствие незначительного отличия оценок релевантности соответствующих документов по меньшей мере некоторые документы могут иметь различные ранги в первом ранжированном списке документов и во втором ранжированном списке документов. Тем не менее, когда функция метрики качества ранжирования применяется в отношении второго ранжированного списка документов, вторая оценка эффективности, сформированная для второго ранжированного списка документов, может значительно отличаться от первой оценки эффективности, несмотря на то, что сами оценки релевантности для документов в первом и во втором ранжированных списках документов (определенные с использованием данного алгоритма) в целом схожи.
[79] Для оптимизации качества ранжирования алгоритмами, используемыми для ранжирования документов на основе ожидаемой релевантности, могут применяться различные подходы, обычно соответствующие одному из следующих классов: поточечные, попарные и списочные. Например, для оптимизации качества ранжирования алгоритмов, используемых для ранжирования документов на основе ожидаемой релевантности, среди прочего, могут применяться следующие алгоритмы: алгоритм LambdaMART, алгоритм NDCG-Loss2++, алгоритм SoftRank и т.п.
[80] Разработчики настоящей технологии установили, что существующие алгоритмы, пригодные для оптимизации качества ранжирования алгоритмов, используемых при ранжировании документов на основе ожидаемой релевантности, имеют ряд недостатков. Некоторые из этих недостатков более подробно описаны в вышеупомянутой приложенной статье «Прямая оптимизация метрик качества ранжирования с использованием стохастической аппроксимации».
[81] В по меньшей мере некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали способы и системы для подхода, который в отличие от, например, алгоритмов LambdaMART, LambdaLoss и SoftRank, обеспечивает прямую оптимизацию любой меры качества ранжирования (оценок эффективности, определенных с использованием функции метрики качества ранжирования). Предполагается, что в по меньшей мере некоторых вариантах осуществления настоящей технологии этот подход может применяться сервером 106 на этапе обучения алгоритма 130 MLA. Ниже более подробно описано выполнение сервером 106 этапа обучения алгоритма 130 MLA согласно этому новому подходу.
[82] Сервер 106 также может выполнять процедуру 210 формирования страницы SERP, которая обычно используется для инициирования отображения релевантной информации пользователю 102 в ответ на текущий запрос. Например, при выполнении процедуры 210 формирования страницы SERP сервер 106 может формировать страницу SERP, содержащую несколько результатов поиска, представляющих документы, ранжированные на основе их оценок релевантности. Иными словами, сервер 106 может формировать страницу SERP так, чтобы включенные в нее результаты поиска представляли соответствующие документы и были ранжированы в том же порядке, что и документы, ранжированные на основе их ожидаемой релевантности текущему запросу.
Репозиторий данных поисковой системы
[83] Как показано на фиг. 1, сервер 106 имеет доступ к репозиторию 110 данных поисковой системы. В целом, репозиторий 110 данных поисковой системы способен хранить информацию, связанную с поисковой системой сервера 106. Несмотря на то, что репозиторий 110 данных поисковой системы показан на фиг. 1 в виде элемента, отдельного от сервера 106, предполагается, что репозиторий 110 данных поисковой системы может входить в состав сервера 106.
[84] Например, репозиторий 110 данных поисковой системы может хранить информацию о ранее выполненных поисковой системой поисках. В другом примере репозиторий 110 данных поисковой системы может хранить информацию о ранее отправленных серверу 106 запросах и о документах, предоставленных поисковой системой сервера 106 в качестве результатов поиска.
[85] Предполагается, что репозиторий 110 данных поисковой системы может хранить данные запроса, связанные с соответствующими запросами. Данные запроса, связанные с запросом, могут быть различных видов и на них не накладывается каких-либо ограничений. Например, репозиторий 110 данных поисковой системы может хранить данные запроса для соответствующих запросов, включая в качестве неограничивающих примеров:
- популярность запроса;
- частоту отправки запроса;
- количество «кликов», связанных с запросом;
- указания на другие отправленные запросы, связанные с запросом;
- указания на документы, связанные с запросом;
- другие статистические данные, связанные с запросом;
- текст, связанный с запросом;
- количество символов в запросе;
- другие присущие запросу характеристики.
[86] Как описано ниже, по меньшей мере некоторые данные запроса могут быть использованы сервером 106 при обучении алгоритма 130 MLA для выполнения процедуры 208 оценивания релевантности.
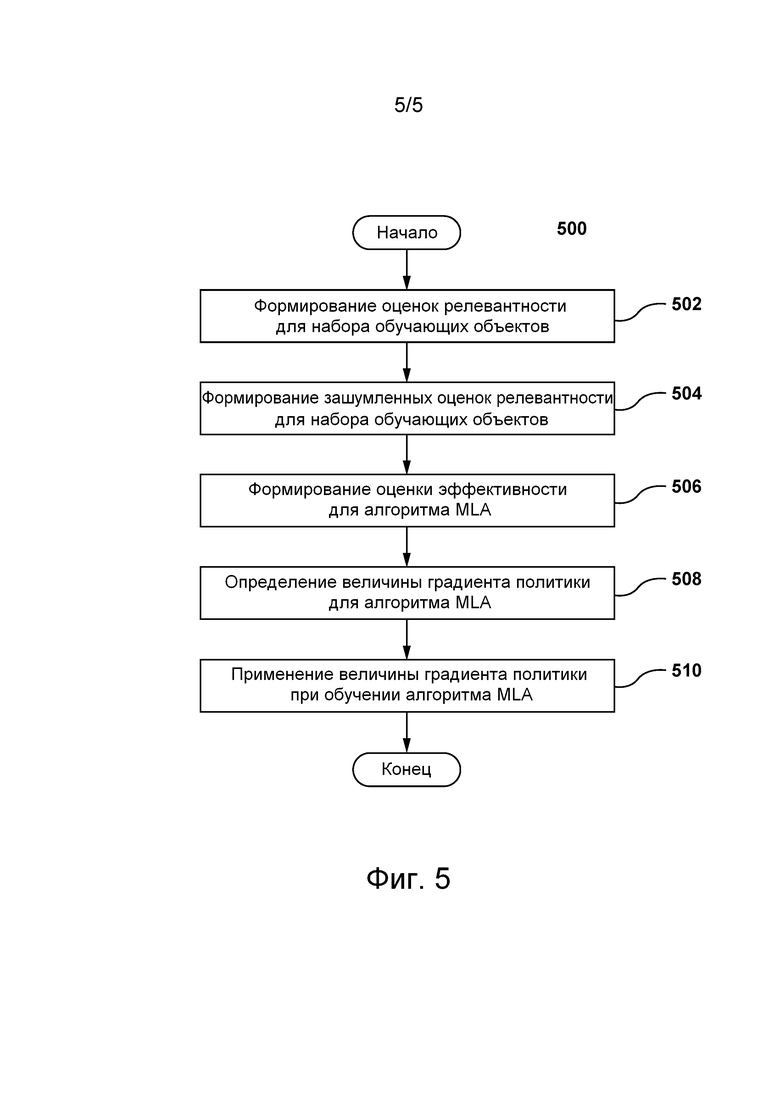
[87] Репозиторий 110 данных поисковой системы также может хранить данные документа, связанные с соответствующими документами. Данные документа, связанные с документом, могут быть различных видов и на них не накладывается каких-либо ограничений. Например, репозиторий 110 данных поисковой системы может хранить данные документа для соответствующих документов, включая в качестве неограничивающих примеров:
- популярность документа;
- коэффициент «кликов» для документа;
- время на «клик», связанное с документом;
- указания на другие документы, связанные с документом;
- указания на запросы, связанные с документом;
- другие статистические данные, связанные с документом;
- текст, связанный с документом;
- объем памяти, занимаемой документом;
- другие присущие документу характеристики.
[88] Как описано ниже, по меньшей мере некоторые данные документа могут быть использованы сервером 106 при обучении алгоритма 130 MLA для выполнения процедуры 208 оценивания релевантности.
[89] Предполагается, что репозиторий 110 данных поисковой системы может также хранить информацию в виде пар запрос-документ. Например, как показано на фиг. 3, репозиторий 110 данных поисковой системы может хранить большое количество пар запрос-документ, подобных паре 300 запрос-документ. Пара 300 запрос-документ содержит запрос 302 и документ 304. В частности, запрос 302 может представлять собой ранее отправленный серверу 106 запрос, а документ 304 может представлять собой документ, ранее представленный поисковой системой в ответ на запрос 302.
[90] Как описано выше, репозиторий 110 данных поисковой системы может хранить данные запроса, связанные с соответствующими запросами, и данные документа, связанные с соответствующими документами. Например, репозиторий 110 данных поисковой системы может хранить запрос 302 в сочетании с данными 306 запроса и может хранить документ 304 в сочетании с данными 308 документа.
[91] Также предполагается, что репозиторий 110 данных поисковой системы может хранить дополнительные данные (в дополнение к показанным на фиг. 3) в сочетании с парой запрос-документ без выхода за границы настоящей технологии. Например, репозиторий 110 данных поисковой системы может хранить в сочетании с парой 300 запрос-документ дополнительные данные, указывающие на зависящую от пары информацию, среди прочего, такую как количество появлений документа 304 в качестве результата поиска в ответ на запрос 302.
[92] Сервер 106 может использовать информацию, хранящуюся в репозитории 110 данных поисковой системы, в качестве обучающих данных для обучения алгоритма 130 MLA. Также предполагается, что сервер 106 может использовать информацию, хранящуюся в репозитории 110 данных поисковой системы, на этапе использования алгоритма 130 MLA. Ниже более подробно описано использование сервером 106 информации, хранящейся в репозитории 110 данных поисковой системы.
Рабочий репозиторий
[93] Как показано на фиг. 1, серверу 106 доступен рабочий репозиторий 120. В целом, рабочий репозиторий 120 может использоваться сервером 106 для временного или постоянного хранения информации, определенной или сформированной сервером 106 во время его работы, для последующего ее использования. Несмотря на то, что рабочий репозиторий 120 показан на фиг. 1 в виде элемента, отдельного от сервера 106 и от репозитория 110 данных поисковой системы, это не обязательно для всех вариантов осуществления настоящей технологии. Например, предполагается, что рабочий репозиторий 120 может входить в состав сервера 106.
[94] Рабочий репозиторий 120 может использоваться сервером 106 для временного или постоянного хранения данных, сформированных на этапе обучения алгоритма 130 MLA и на этапе использования алгоритма 130 MLA. Ниже более подробно описан вид данных, формируемых на этапе обучения и на этапе использования алгоритма 130 MLA.
Обзор алгоритмов MLA, алгоритмы MLA на основе дерева решений и градиентный бустинг
[95] Известно много различных видов алгоритмов MLA. В целом, существуют алгоритмы MLA трех видов: основанные на обучении с учителем, основанные на обучении без учителя и основанные на обучении с подкреплением.
[96] Процесс обучения с учителем для алгоритма MLA основан на целевой выходной переменной (или зависимой переменной), которая должна прогнозироваться на основе набора предикторов (независимых переменных). С использованием этого набора переменных алгоритм MLA (во время обучения) формирует функцию, которая преобразует входные данные в требуемые выходные данные. Процесс обучения продолжается до достижения алгоритмом MLA требуемого уровня точности на проверочных данных. В качестве примеров алгоритмов MLA, основанных на обучении с учителем, можно привести регрессию, дерево решений, случайный лес, логистическую регрессию и т.д.
[97] В целом, алгоритм MLA на основе дерева решений представляет собой пример алгоритма MLA на основе обучения с учителем. Алгоритмы MLA этого вида используют дерево решений (в качестве прогнозирующей модели) для перехода от наблюдений за элементом (представленных ветвями) к заключениям относительно целевого значения элемента (представленным листьями). Модели деревьев, где целевая переменная может принимать дискретный набор значений, называются классификационными деревьями. В этих древовидных структурах листья представляют собой метки класса, а ветви представляют собой конъюкции признаков, приводящих к этим меткам классов. Деревья решений, где целевая переменная может принимать непрерывные значения (обычно действительные числа) называются регрессионными деревьями.
[98] Чтобы алгоритм MLA на основе дерева решений работал, он должен быть «построен» или обучен с использованием обучающего набора объектов, содержащего большое количество обучающих объектов (таких как документы, события и т.п.). Предполагается, что в некоторых вариантах осуществления настоящей технологии алгоритм 130 MLA может быть реализован в виде алгоритма MLA на основе дерева решений.
[99] Ниже описан один из возможных способов обучения алгоритма MLA на основе дерева решений.
[100] Градиентный бустинг представляет собой один из подходов к построению алгоритма MLA на основе дерева решений, с использованием которых формируется прогнозирующая модель в виде ансамбля деревьев. Ансамбль деревьев строится поэтапно. Каждое последующее дерево решений в ансамбле деревьев решений фокусирует обучение на тех итерациях предыдущего дерева решений, которые были «слабыми учениками» на предыдущей итерации (или на нескольких предыдущих итерациях) ансамбля деревьев решений (т.е. были связанны с неудовлетворительным прогнозом или с большой ошибкой).
[101] В целом, бустинг представляет собой способ, нацеленный на повышение качества прогнозирования алгоритмом MLA. В этом сценарии система использует прогноз не одного обученного алгоритма (одного дерева решений), а большого количества обученных алгоритмов (ансамбля деревьев решений) и принимает окончательное решение на основе нескольких результатов прогнозирования этими алгоритмами.
[102] При бустинге деревьев решений алгоритм MLA сначала строит первое дерево, затем второе дерево, улучшающее результат прогнозирования первого дерева, затем третье дерево, улучшающее результат прогнозирования первых двух деревьев, и т.д. Таким образом, алгоритм MLA в известном смысле создает ансамбль деревьев решений, где каждое последующее дерево лучше предыдущего, в частности, ориентируясь на «слабых учеников» предыдущих итераций деревьев решений. Иными словами, каждое дерево строится на том же обучающем наборе обучающих объектов, тем не менее, обучающие объекты, для которых первое дерево допустило «ошибки» при прогнозировании, имеют приоритет при построении второго дерева и т.д. Эти «проблемные» обучающие объекты (для которых на предыдущих итерациях деревьев решений получались менее точные прогнозы) взвешиваются с бóльшими весовыми коэффициентами по сравнению с объектами, где предыдущее дерево обеспечило удовлетворительный прогноз.
[103] Следует отметить, что в некоторых вариантах осуществления изобретения сервер 106 может использовать различные алгоритмы при обучении алгоритма 130 MLA (например, построение деревьев). В частности, сервер 106 может использовать жадный алгоритм при построении деревьев алгоритма MLA. Предполагается, что в по меньшей мере некоторых вариантах осуществления настоящей технологии алгоритм 130 MLA может быть реализован в виде алгоритма на основе дерева решений с градиентным бустингом (GBDT, Gradient Boosted Decision Tree).
[104] Ниже более подробно описано обучение сервером 106 алгоритма 130 MLA.
Этап обучения алгоритма MLA
[105] На фиг. 4 представлена схема итерации 400 (не показано на фигурах) обучения алгоритма 130 MLA. Следует отметить, что, несмотря на то, что ниже описана лишь одна итерация обучения алгоритма 130 MLA, на этапе обучения алгоритма 130 MLA сервер 106 может выполнять большое количество итераций обучения подобно выполнению итерации 400 обучения.
[106] Во время итерации 400 обучения сервер 106 способен водить обучающие данные 402 в алгоритм 130 MLA.
[107] Обучающие данные 402 содержат данные, связанные с обучающим запросом 404, и данные, связанные с набором 406 обучающих документов. Например, сервер 106 может получать данные, связанные с обучающим запросом 404 (например, набор признаков, связанных с обучающим запросом 404), и данные, связанные с набором 406 обучающих документов (например, набор признаков, связанных с соответствующим документом из набора 406 обучающих документов), из репозитория 110 данных поисковой системы.
[108] После ввода сервером 106 обучающих данных 402 алгоритм 130 MLA способен формировать оценки релевантности для набора 406 обучающих документов. Например, алгоритм 130 MLA может формировать набор 408 оценок релевантности, включая оценку релевантности для соответствующего документа из набора 406 обучающих документов.
[109] Следует отметить, что, как описано выше, оценка релевантности из набора оценок релевантности указывает на ожидаемую релевантность обучающему запросу 404 соответствующего обучающего документа из набора 406 обучающих документов.
[110] При выполнении итерации обучения алгоритма 130 MLA сервер 106 также может выполнять шумовую функцию 410. В целом, сервер 106 может применять шумовую функцию 410 для формирования значений шума с заранее заданным распределением для набора 408 оценок релевантности. Иными словами, сервер 106 может формировать значения шума для набора 408 оценок релевантности на основе шумовой функции 410 с заранее заданным распределением.
[111] Следует отметить, что распределение шумовой функции 410 может быть заранее задано оператором поисковой системы. Например, заранее заданное распределение шумовой функции 410 может быть по меньшей мере одним из следующего:
- распределение Гаусса,
- распределение Коши, и
- распределение Лапласа.
[112] Вкратце, с применением алгоритма 130 MLA и шумовой функции 410 сервер 106 способен формировать для набора 406 обучающих документов (а) набор 408 оценок релевантности и (б) набор 412 значений шума.
[113] Можно сказать, что в по меньшей мере некоторых вариантах осуществления изобретения сервер 106 может формировать зашумленные оценки релевантности для обучающих документов путем сочетания соответствующих оценок релевантности и соответствующих значений шума. Например, сервер 106 может формировать набор 414 зашумленных оценок релевантности для набора 406 обучающих документов, при этом зашумленная оценка релевантности из набора 414 зашумленных оценок релевантности представляет собой сочетание соответствующей оценки релевантности (полученной от алгоритма 130 MLA) и соответствующего значения шума (полученного т шумовой функции 410).
[114] При выполнении итерации обучения, как описано выше, сервер 106 также может выполнять функцию метрики качества ранжирования. Например, сервер 106 может использовать функцию 420 метрики качества ранжирования для формирования оценки 430 эффективности на основе набора 414 зашумленных оценок релевантности.
[115] Следует отметить, что, как описано выше, оценка 430 эффективности указывает на качество ранжирования алгоритмом 130 MLA, если обучающие документы из набора 406 обучающих документов ранжированы согласно соответствующим зашумленным оценкам релевантности из набора 414 зашумленных оценок релевантности.
[116] После формирования оценки 430 эффективности для алгоритма 130 MLA сервер 106 может применять процедуру 440 определения градиента политики. В целом, процедура 440 определения градиента политики предназначена для определения величины градиента политики, которая должна использоваться для корректировки алгоритма 130 MLA (например, с использованием градиентного бустинга) с целью улучшения оценивания релевантности обучающих документов на следующей итерации обучения или документов этапа использования на этапе использования алгоритма 130 MLA. В частности, путем выполнения процедуры 440 определения градиента политики сервер 106 способен определять величину 450 градиента политики на основе сочетания (а) оценки 430 эффективности, (б) оценок 408 релевантности и (в) зашумленных оценок 414 релевантности для набора 406 обучающих документов.
[117] Разработчики настоящей технологии установили, что формирование оценки 430 эффективности на основе набора 414 зашумленных оценок релевантности, а не набора 408 оценок релевантности, позволяет определять величину 450 градиента политики. Можно сказать, что внесение шума в набор 408 оценок релевантности позволяет, в известном смысле, «сгладить» функцию 420 метрики качества ранжирования и, следовательно, позволяет рассчитать величину градиента политики.
[118] Как описано выше, функция 420 метрики качества ранжирования представляет собой плоскую или разрывную функцию и, следовательно, расчет величины градиента политики такой функции невозможен, если эта функция не сглажена, как в данном случае, путем внесения шума в набор 408 оценок релевантности.
[119] В некоторых вариантах осуществления настоящей технологии предполагается, что использование для формирования оценки 430 эффективности набора 414 зашумленных оценок релевантности вместо набора 408 оценок релевантности позволяет сгладить функцию 420 метрики качества ранжирования.
[120] Процедура 440 определения градиента политики может выполняться сервером 106 различными способами. Это означает, что сервер 106 может использовать различные методики для определения величины 450 градиента политики.
[121] В первом варианте осуществления изобретения сервер 106 при выполнении процедуры 440 определения градиента политики может применять способ покоординатной антитетической выборки для определения величины 450 градиента политики. Например, сервер 106 для определения величины 450 градиента политики может использовать уравнения (1)…(4):
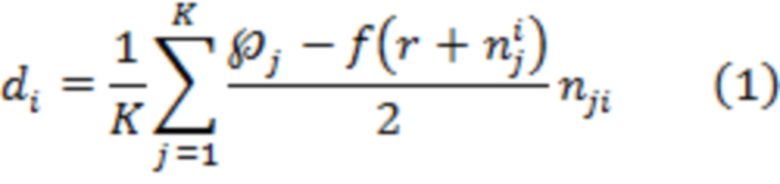
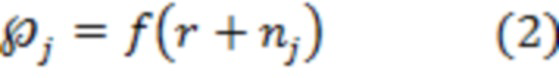
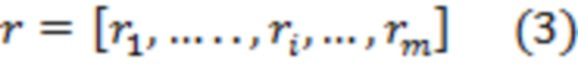
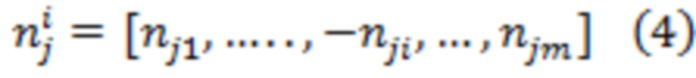
где:
- величина 450 градиента политики для документа ;
- количество значений зашумленных оценок релевантности (например, в некоторых случаях может быть равно 1);
- номер значения зашумленной оценки релевантности (в частности, в некоторых случаях может использоваться лишь одно значение);
- оценка эффективности для j-го значения зашумленной оценки релевантности;
- вектор, представляющий собой набор 408 оценок релевантности для документов, включая документ ;
- вектор, представляющий собой набор 412 значений шума для документов, включая документ , и для значения ;
- вектор, представляющий собой набор 412 значений шума для документов, включая документ , где знак величины шума для документа и для значения (например, 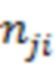 ) инвертирован (например, отрицательный знак);
) инвертирован (например, отрицательный знак);
- функция 420 метрики качества ранжирования.
[122] После определения сервером 106 величины 450 градиента политики с использованием процедуры 440 определения градиента политики сервер 106 может применять величину 450 градиента политики при обучении алгоритма 130 MLA.
[123] В некоторых вариантах осуществления изобретения сервер 106 может применять взвешенную величину градиента политики при обучении алгоритма 130 MLA. Например, взвешенная величина градиента политики может быть определена сервером 106 в виде сочетания величины 450 градиента политики и заранее заданного весового значения.
[124] В некоторых вариантах осуществления изобретения взвешенная величина градиента политики может быть определена сервером 106 в виде гиперпараметра, представляющего собой параметр, значение которого задается до начала процесса обучения. В этом случае взвешенная величина градиента политики может быть определена на основе исчерпывающего поиска, основанного на заранее заданном контрольном наборе.
[125] В некоторых вариантах осуществления изобретения, где алгоритм 130 MLA представляет собой алгоритм на основе дерева решений, например, алгоритм на основе GBDT, сервер 106, применяющий величину 450 градиента политики (или взвешенную величину градиента политики), может формировать дополнительное дерево решений для алгоритма 130 MLA на основе величины 450 градиента политики (или взвешенной величины градиента политики).
[126] Тем не менее, в других вариантах осуществления изобретения сервер 106, применяющий величину 450 градиента политики (или взвешенную величину градиента политики), может модифицировать существующее дерево решений для алгоритма 130 MLA на основе величины 450 градиента политики (или взвешенной величины градиента политики).
[127] Можно сказать, что такое применение величины 450 градиента политики (или взвешенной величины градиента политики) для обучения алгоритма 130 MLA обеспечивает прямую оптимизацию качества ранжирования алгоритмами 130 MLA.
[128] Предполагается, что сервер 106 может применять величину 450 градиента политики (или взвешенную величину градиента политики) для обучения алгоритма 130 MLA в автономном режиме. Предполагается, что сервер 106 может применять величину 450 градиента политики (или взвешенную величину градиента политики) до применения алгоритма 130 MLA на этапе использования. Ниже описано применение алгоритма 130 MLA сервером 106 на этапе использования.
Этап использования алгоритма MLA
[129] Когда алгоритм 130 MLA обучен, сервер 106 может применять алгоритм 130 MLA на этапе его использования. Например, сервер 106 может применять алгоритм 130 MLA в интерактивном режиме, т.е. во время работы поисковой системы с целью предоставления страниц SERP в ответ на запросы, подобные пакету 150 данных запроса (см. фиг. 1).
[130] После получения сервером 106 пакета 150 данных запроса сервер 106 может выполнять по меньшей мере некоторые процедуры из множества 200 компьютерных процедур (см. фиг. 2). Например, сервер 106 может выполнять процедуру 206 запрашивания, процедуру 208 оценивания релевантности и процедуру 210 формирования страницы SERP.
[131] В качестве иллюстрации можно сказать, что сервер 106 может выполнять процедуру 206 запрашивания для определения документов, которые могут содержать некоторую часть запроса, отправленного поисковой системе с использованием пакета 150 данных запроса. По сути, сервер 106 может определять документы этапа использования (объекты этапа использования) в ответ на запрос этапа использования (текущий запрос, полученный с использованием пакета 150 данных запроса).
[132] После определения документов этапа использования сервер 106 может выполнять процедуру 208 оценивания релевантности, когда обученный алгоритм 130 MLA применяется на этапе его использования с целью (а) формирования оценок релевантности для документов этапа использования, которые указывают на соответствующую релевантность запросу этапа использования, и (б) ранжирования документов этапа использования в ответ на запрос этапа использования на основе сформированных таким образом оценок релевантности.
[133] После такого ранжирования сервером 106 документов этапа использования с применением алгоритма 130 MLA сервер 106 может выполнять процедуру 210 формирования страницы SERP для инициирования отображения релевантной информации пользователю 102 в ответ на текущий запрос. Например, сервер 106 может сформировать страницу SERP (в частности, электронный документ, представляющий собой страницу SERP), которая содержит несколько результатов поиска, представляющих документы, ранжированные при выполнении предыдущей компьютерной процедуры.
[134] Затем сервер 106 может сформировать пакет 160 данных страницы SERP (см. фиг. 1), содержащий данные в виде электронного документа, представляющего собой страницу SERP, и данные, используемые для инициирования отображения страницы SERP на электронном устройстве 104, на основе электронного документа, включенного в пакет 160 данных страницы SERP. Таким образом, страница SERP, отображаемая пользователю 102, содержит список документов этапа использования, ранжированных сервером 106 с использованием алгоритма 130 MLA.
Компьютерный способ
[135] На фиг. 5 представлена блок-схема компьютерного способа 500 обучения алгоритма 130 MLA ранжированию объектов в ответ на запрос. В некоторых вариантах осуществления настоящей технологии компьютерный способ 500 может выполняться сервером 106 (см. фиг. 1). Ниже более подробно описаны различные шаги способа 500.
Шаг 502: формирование оценок релевантности для набора обучающих объектов.
[136] Способ 500 начинается с шага 502, на котором сервер 106 может применять алгоритм 130 MLA с целью формирования набора 408 оценок релевантности для набора 406 обучающих документов. Как описано выше и показано на фиг. 4, алгоритм 130 MLA способен формировать набор 408 оценок релевантности для набора 406 обучающих документов на основе данных, связанных (а) с набором 406 обучающих документов и (б) с обучающим запросом 404. Следует отметить, что оценки релевантности из набора 408 оценок релевантности указывают на ожидаемую релевантность обучающему запросу 404 соответствующего обучающего документа из набора 406 обучающих документов.
[137] Как описано выше, алгоритм 130 MLA может формировать оценки релевантности для обучающих объектов, отличных от электронных документов. Это означает, что обучающие объекты, используемые при обучении алгоритма 130 MLA могут, среди прочего, представлять собой электронные документы, а обучающий запрос 404 может представлять собой запрос, ранее отправленный поисковой системе, размещенной на сервере 106.
Шаг 504: формирование зашумленных оценок релевантности для набора обучающих объектов.
[138] Способ 500 продолжается на шаге 504, на котором сервер 106 может формировать набор 414 зашумленных оценок релевантности для набора 406 обучающих документов.
[139] С этой целью в некоторых вариантах осуществления изобретения сервер 106 может использовать шумовую функцию 410 для формирования набора 412 значений шума. Таким образом, в некоторых вариантах осуществления изобретения сервер 106 может формировать набор 414 зашумленных оценок релевантности путем объединения набора 408 оценок релевантности и набора 412 значений шума, как показано на фиг. 4.
[140] Следует отметить, что шумовая функция 410 имеет заранее заданное распределение, которое может представлять собой распределение Гаусса и/или распределение Коши и/или распределение Лапласа.
Шаг 506: формирование оценки эффективности для алгоритма MLA.
[141] Способ 500 продолжается на шаге 506, на котором сервер 106 может формировать оценку 430 эффективности для алгоритма 130 MLA на основе набора 414 зашумленных оценок релевантности. Следует отметить, что оценка 430 эффективности указывает на качество ранжирования алгоритмами 130 MLA, если обучающие документы из набора 406 обучающих документов ранжированы согласно соответствующим зашумленным оценкам релевантности из набора 414 зашумленных оценок релевантности.
[142] Предполагается, что сервер 106 может формировать оценку 430 эффективности с использованием функции 420 метрики качества ранжирования. Функция метрики качества ранжирования представляет собой плоскую или разрывную функцию. Как описано выше, в некоторых вариантах осуществления изобретения функция 420 метрики качества ранжирования представляет собой одну из следующих функций: показатель NDCG, ранг ERR, точность MAP и ранг MRR.
[143] Также предполагается, что в других вариантах осуществления изобретения формирование сервером 106 оценки 430 эффективности на основе набора 414 зашумленных оценок релевантности (а не на основе набора 408 оценок релевантности) позволяет определять величину 450 градиента политики на следующем шаге способа 500.
Шаг 508: определение величины градиента политики для алгоритма MLA.
[144] Способ 500 продолжается на шаге 508, на котором сервер 106 может определять величину 450 градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом 130 MLA для документов этапа использования (и/или объектов этапа использования других видов) в ответ на запрос этапа использования.
[145] Предполагается, что на шаге 508 сервер 106 может выполнять процедуру 440 определения градиента политики. В целом, процедура 440 определения градиента политики предназначена для определения величины 450 градиента политики, которое должно использоваться для корректировки алгоритма 130 MLA (например, с использованием градиентного бустинга) с целью улучшения оценивания релевантности обучающих документов на следующей итерации обучения или улучшения оценивания документов этапа использования на этапе использования алгоритма 130 MLA. Например, путем выполнения процедуры 440 определения градиента политики сервер 106 может определять величину 450 градиента политики на основе сочетания (а) оценки 430 эффективности, (б) оценок 408 релевантности и (в) зашумленных оценок 414 релевантности для набора 406 обучающих документов, как описано выше.
[146] В по меньшей мере некоторых вариантах осуществления настоящей технологии сервер 106 может определять величину 450 градиента политики путем оценивания с использованием способа покоординатной антитетической выборки, т.е. сервер 106 может оценивать величину 450 градиента политики с применением способа покоординатной антитетической выборки. Например, сервер 106 может оценивать величину 450 градиента политики согласно уравнению (1).
Шаг 510: применение величины градиента политики при обучении алгоритма MLA.
[147] Способ 500 продолжается на шаге 510, на котором сервер 106 может применять величину 450 градиента политики при обучении алгоритма 130 MLA ранжированию документов этапа использования в ответ на запрос этапа использования.
[148] В некоторых вариантах осуществления изобретения сервер 106 может применять для обучения алгоритма 130 MLA взвешенную величину градиента политики, которая представляет собой сочетание (а) величины 450 градиента политики и (б) заранее заданного весового значения, как описано выше.
[149] Как описано выше, алгоритм 130 MLA может представлять собой алгоритм на основе дерева решений с набором деревьев решений. В этом случае сервер 106, применяющий величину 450 градиента политики, может (а) формировать дополнительное дерево решений для алгоритма 130 MLA на основе величины 450 градиента политики и/или (б) модифицировать по меньшей мере одно дерево решений из набора деревьев решений алгоритма 130 MLA на основе величины 450 градиента политики.
[150] Предполагается, что сервер 106, применяющий величину 450 градиента политики при обучении алгоритма 130 MLA, может выполнять прямую оптимизацию качества ранжирования алгоритмами 130 MLA. Кроме того, сервер 106 может применять величину 450 градиента политики в автономном режиме. Сервер 106 также может применять величину 450 градиента политики до применения алгоритма 130 MLA на этапе его использования.
[151] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |

Изобретение относится к вычислительной технике. Технический результат заключается в оптимизации качества ранжирования объектов алгоритмом машинного обучения в ответ на поисковый запрос. Компьютерный способ обучения алгоритма машинного обучения ранжированию объектов в ответ на запрос, выполняемого сервером, которому доступны объекты и запрос, при этом способ включает в себя: формирование оценок релевантности для набора обучающих объектов на основе данных, связанных с набором обучающих объектов и с обучающим запросом; формирование зашумленных оценок релевантности для набора обучающих объектов путем сочетания оценок релевантности и значений шума; формирование оценки эффективности для алгоритма MLA на основе зашумленных оценок релевантности; определение величины градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом MLA для объектов этапа использования в ответ на запрос этапа использования; и применение величины градиента политики при обучении алгоритма MLA ранжированию объектов этапа использования в ответ на запрос этапа использования. 2 н. и 24 з.п. ф-лы, 5 ил.
1. Компьютерный способ обучения алгоритма машинного обучения (MLA) ранжированию объектов в ответ на запрос, выполняемого сервером, которому доступны объекты и запрос, при этом обучение включает в себя использование функции метрики качества ранжирования, представляющей собой плоскую или разрывную функцию, для определения оценки эффективности алгоритма MLA, а способ выполняется сервером и включает в себя:
- формирование сервером, выполняющим алгоритм MLA, оценок релевантности для набора обучающих объектов на основе данных, связанных (а) с набором обучающих объектов и (б) с обучающим запросом, при этом оценки релевантности указывают на ожидаемую релевантность обучающему запросу соответствующего обучающего объекта;
- формирование сервером зашумленных оценок релевантности для набора обучающих объектов путем сочетания оценок релевантности и значений шума, сформированных на основе шумовой функции с заранее заданным распределением;
- формирование сервером оценки эффективности для алгоритма MLA на основе зашумленных оценок релевантности, при этом оценка эффективности указывает на качество ранжирования алгоритмом MLA, если обучающие объекты из набора обучающих объектов ранжированы согласно соответствующим зашумленным оценкам релевантности;
- определение сервером величины градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом MLA для объектов этапа использования в ответ на запрос этапа использования, при этом величина градиента политики определяется на основе сочетания (а) оценки эффективности, (б) оценок релевантности и (в) зашумленных оценок релевантности для набора обучающих объектов; и
- применение сервером величины градиента политики при обучении алгоритма MLA ранжированию объектов этапа использования в ответ на запрос этапа использования.
2. Способ по п. 1, отличающийся тем, что формирование оценки эффективности на основе зашумленных оценок релевантности позволяет определять величину градиента политики.
3. Способ по п. 1, отличающийся тем, что применение величины градиента политики включает в себя применение сервером взвешенной величины градиента политики при обучении алгоритма MLA, при этом взвешенный градиент политики определяется в виде сочетания (а) величины градиента политики и (б) заранее заданного весового значения.
4. Способ по п. 1, отличающийся тем, что алгоритм MLA представляет собой алгоритм на основе дерева решений с набором деревьев решений, а применение величины градиента политики включает в себя формирование сервером дополнительного дерева решений для алгоритма MLA на основе величины градиента политики и/или модификацию сервером по меньшей мере одного дерева решений из набора деревьев решений алгоритма MLA на основе величины градиента политики.
5. Способ по п. 1, отличающийся тем, что применение величины градиента политики для обучения обеспечивает прямую оптимизацию качества ранжирования алгоритмом MLA.
6. Способ по п. 1, отличающийся тем, что определение величины градиента политики включает в себя оценивание сервером величины градиента политики с применением способа покоординатной антитетической выборки.
7. Способ по п. 6, отличающийся тем, что оценивание величины градиента политики с применением способа покоординатной антитетической выборки включает в себя оценивание сервером градиента политики по следующей формуле:
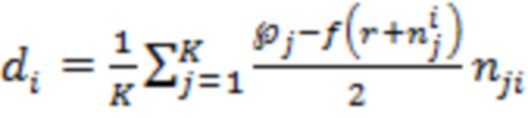 ,
,
где 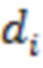 - величина градиента политики для обучающего объекта
- величина градиента политики для обучающего объекта 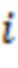 в наборе обучающих объектов;
в наборе обучающих объектов;
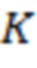 - количество значений зашумленных оценок релевантности;
- количество значений зашумленных оценок релевантности;
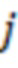 - номер значения зашумленной оценки релевантности;
- номер значения зашумленной оценки релевантности;
 - оценка эффективности для j-го значения зашумленной оценки релевантности;
- оценка эффективности для j-го значения зашумленной оценки релевантности;
 - вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
- вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
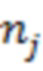 - вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
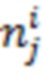 - вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
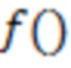 - функция метрики качества ранжирования.
- функция метрики качества ранжирования.
8. Способ по п. 1, отличающийся тем, что величина градиента политики применяется сервером в автономном режиме.
9. Способ по п. 1, отличающийся тем, что величина градиента политики применяется сервером до применения алгоритма MLA на этапе использования.
10. Способ по п. 1, отличающийся тем, что заранее заданное распределение представляет собой распределение Гаусса, и/или распределение Коши, и/или распределение Лапласа.
11. Способ по п. 1, отличающийся тем, что функция метрики качества ранжирования представляет собой одно из следующего:
- нормализованный дисконтированный кумулятивный показатель (NDCG);
- ожидаемый взаимный ранг (ERR);
- средняя точность (MAP); и
- средний взаимный ранг (MRR).
12. Способ по п. 1, отличающийся тем, что обучающие объекты представляют собой электронные документы, а обучающий запрос представляет собой запрос, ранее отправленный поисковой системе, размещенной на сервере.
13. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- ранжирование сервером объектов этапа использования в ответ на запрос этапа использования; и
- инициирование сервером отображения пользователю, связанному с запросом этапа использования, страницы результатов поисковой системы (SERP), содержащей ранжированный список объектов этапа использования.
14. Сервер для обучения алгоритма машинного обучения (MLA) ранжированию объектов в ответ на запрос, при этом обучение включает в себя использование функции метрики качества ранжирования, представляющей собой плоскую или разрывную функцию, для определения оценки эффективности алгоритма MLA, выполняемого сервером, которому доступны объекты и запрос и который выполнен с возможностью:
- формирования, путем выполнения алгоритма MLA, оценок релевантности для набора обучающих объектов на основе данных, связанных (а) с набором обучающих объектов и (б) с обучающим запросом, при этом оценки релевантности указывают на ожидаемую релевантность обучающему запросу соответствующего обучающего объекта;
- формирования зашумленных оценок релевантности для набора обучающих объектов путем сочетания оценок релевантности и значений шума, сформированных на основе шумовой функции с заранее заданным распределением;
- формирования оценки эффективности для алгоритма MLA на основе зашумленных оценок релевантности, при этом оценка эффективности указывает на качество ранжирования алгоритмом MLA, если обучающие объекты из набора обучающих объектов ранжированы согласно соответствующим зашумленным оценкам релевантности;
- определения величины градиента политики для корректировки оценок релевантности, которые должны быть сформированы алгоритмом MLA для объектов этапа использования в ответ на запрос этапа использования, при этом величина градиента политики определяется на основе сочетания (а) оценки эффективности, (б) оценок релевантности и (в) зашумленных оценок релевантности для набора обучающих объектов; и
- применения величины градиента политики при обучении алгоритма MLA ранжированию объектов этапа использования в ответ на запрос этапа использования.
15. Сервер по п. 14, отличающийся тем, что формирование оценки эффективности на основе зашумленных оценок релевантности позволяет определять величину градиента политики.
16. Сервер по п. 14, отличающийся тем, что для применения величины градиента политики сервер способен применять взвешенную величину градиента политики при обучении алгоритма MLA, при этом взвешенный градиент политики определяется в виде сочетания (а) величины градиента политики и (б) заранее заданного весового значения.
17. Сервер по п. 14, отличающийся тем, что алгоритм MLA представляет собой алгоритм на основе дерева решений с набором деревьев решений, а для применения величины градиента политики сервер способен формировать дополнительное дерево решений для алгоритма MLA на основе величины градиента политики и/или модифицировать по меньшей мере одно дерево решений из набора деревьев решений алгоритма MLA на основе величины градиента политики.
18. Сервер по п. 14, отличающийся тем, что применение величины градиента политики для обучения обеспечивает прямую оптимизацию качества ранжирования алгоритмом MLA.
19. Сервер по п. 14, отличающийся тем, что для определения величины градиента политики сервер способен оценивать величину градиента политики с применением способа покоординатной антитетической выборки.
20. Сервер по п. 19, отличающийся тем, что для оценивания величины градиента политики с применением способа покоординатной антитетической выборки сервер способен оценивать градиент политики по следующей формуле:
,
где - величина градиента политики для обучающего объекта в наборе обучающих объектов;
- количество значений зашумленных оценок релевантности;
- номер значения зашумленной оценки релевантности;
- оценка эффективности для j-го значения зашумленной оценки релевантности;
- вектор, представляющий собой набор оценок релевантности для набора обучающих объектов, включая обучающий объект ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , и для значения ;
- вектор, представляющий собой набор значений шума для набора обучающих объектов, включая обучающий объект , где знак значения шума для обучающего объекта и для значения инвертирован; и
- функция метрики качества ранжирования.
21. Сервер по п. 14, отличающийся тем, что он выполнен с возможностью применения градиента политики в автономном режиме.
22. Сервер по п. 14, отличающийся тем, что он выполнен с возможностью применения градиента политики до применения алгоритма MLA на этапе использования.
23. Сервер по п. 14, отличающийся тем, что заранее заданное распределение представляет собой распределение Гаусса, и/или распределение Коши, и/или распределение Лапласа.
24. Сервер по п. 14, отличающийся тем, что функция метрики качества ранжирования представляет собой одно из следующего:
- нормализованный дисконтированный кумулятивный показатель (NDCG);
- ожидаемый взаимный ранг (ERR);
- средняя точность (MAP); и
- средний взаимный ранг (MRR).
25. Сервер по п. 14, отличающийся тем, что обучающие объекты представляют собой электронные документы, а обучающий запрос представляет собой запрос, ранее отправленный поисковой системе, размещенной на сервере.
26. Сервер по п. 14, отличающийся тем, что он дополнительно выполнен с возможностью:
- ранжирования объектов этапа использования в ответ на запрос этапа использования; и
- инициирования отображения пользователю, связанному с запросом этапа использования, страницы SERP, содержащей ранжированный список объектов этапа использования.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |

