Область техники, к которой относится изобретение
Данное раскрытие относится к кодированию и декодированию данных.
Уровень техники
Описание в разделе "Уровень техники", представленное здесь, предназначено для общего представления контекста раскрытия. Работа упомянутых здесь авторов изобретения, в той степени, как она описана в данном разделе "Уровень техники", а также аспекты описания, которые в других случаях невозможно квалифицировать, как предшествующий уровень техники на время подачи, ни в явном, ни в скрытом виде не допущены, как предшествующий уровень техники в отношении настоящего раскрытия.
Существует несколько систем сжатия и распаковки видеоданных, в которых используется преобразование видеоданных, представленных в области частоты, квантование коэффициентов в области частоты и с последующим применением некоторой формы энтропийного кодирования для квантованных коэффициентов.
Энтропию, в настоящем контексте, можно рассматривать, как представляющую содержание информации, состоящей из символов данных или последовательности символов. Цель энтропийного кодирования состоит в том, чтобы кодировать последовательность символов данных без потерь, используя (в идеале) наименьшее количество битов кодированных данных, которые необходимы для представления информационного содержания этой последовательности символов данных. На практике энтропийное кодирование используется для кодирования квантованных коэффициентов таким образом, что кодированные данные меньше (с точки зрения их количества битов), чем размер данных оригинальных квантованных коэффициентов. Более эффективная обработка энтропийного кодирования приводит к получению меньшего размера выходных данных для того же размера входных данных.
Одна из технологий для энтропийного кодирования видеоданных представляет собой, так называемую, технологию САВАС (контекстно-адаптивное двоичное арифметическое кодирование).
Раскрытие изобретения
Данное раскрытие направлено на обеспечение способа кодирования данных в соответствии с п. 1 формулы изобретения.
Дополнительные соответствующие аспекты и свойства определены в приложенной формуле изобретения.
Следует понимать, что, как представленное выше общее описание, так и следующее подробное описание изобретения являются примерными, но не ограничительными для настоящего раскрытия.
Краткое описание чертежей
Более полное понимание раскрытия и множества присущих ему преимуществ будут скорее достигнуты, по мере его лучшего понимания со ссылкой на следующее подробное описание вариантов осуществления, которое следует рассматривать совместно с приложенными чертежами, на которых:
на фиг. 1 схематично показана система передачи и приема аудио/видео (A/V) данных, с использованием сжатия и распаковки видеоданных;
на фиг. 2 схематично показана система отображения видео с использованием распаковки видеоданных;
на фиг. 3 схематично показана система накопителя аудио/видео данных, с использованием сжатия и распаковки видеоданных;
на фиг. 4 схематично показана видеокамера, в которой используется сжатие видеоданных;
на фиг. 5 схематично представлен общий обзор устройства сжатия и распаковки видеоданных;
на фиг. 6 схематично показано генерирование прогнозируемых изображений;
на фиг. 7 схематично показан наибольший модуль кодирования (LCU);
на фиг. 8 схематично показан ряд из четырех модулей кодирования (CU);
на фиг. 9 и 10 схематично поясняются модули кодирования по фиг. 8, разделенные на меньшие модули кодирования;
на фиг. 11 схематично показан массив модулей прогнозирования (PU);
на фиг. 12 схематично показан массив модулей преобразования (TU);
на фиг. 13 схематично показано частично кодированное изображение;
на фиг. 14 схематично показан набор возможных направлений прогнозирования;
на фиг. 15 схематично показан набор режимов прогнозирования;
на фиг. 16 схематично показано зигзагообразное сканирование;
на фиг. 17 схематично показан энтропийный кодер САВАС;
на фиг. 18А к 18D схематично поясняются аспекты операций кодирования и декодирования САВАС;
на фиг. 19 схематично показан кодер САВАС;
на фиг. 20 схематично показан декодер САВАС;
на фиг. 21 показана схема, представляющая общий обзор системы кодирования;
на фиг. 22 показан график скорости передачи битов, в зависимости от параметра квантования (QP);
на фиг. 23 показан график скорости передачи битов, в зависимости от PSNR зеленого канала, для тестирования шести значений битовой глубины, с включенным режимом пропуска преобразования;
на фиг. 24 показан график скорости передачи битов, в зависимости от PSNR зеленого канала, для тестирования шести значений битовой глубины, с отключенным режимом пропуска преобразования;
на фиг. 25 показан график скорости передачи битов, в зависимости от PSNR зеленого канала, для тестирования шести значений битовой глубины, с матрицами 14 битного преобразования;
на фиг. 26 показан график PSNR, в зависимости от скорости передачи битов, для одной тестовой последовательности, в которой сравнивают матрицы DCT с различной точностью;
на фиг. 27 показан график PSNR, в зависимости от скорости передачи битов, для одной тестовой последовательности, представляющий использование обходного кодирования с фиксированными битами;
на фиг. 28 показана таблица, представляющая примеры профилей кодирования;
на фиг. 29-31 схематично показаны блок-схемы последовательности операций, соответственно, поясняющие версии части обработки САВАС;
на фиг. 32A-F показаны схемы, поясняющими различные схемы выравнивания САВАС;
на фиг. 33-35 схематично показаны блок-схемы последовательности операций, соответственно, поясняющие версии каскада завершения обработки САВАС;
на фиг. 36 показана блок-схема последовательности операций, схематично поясняющая технологию кодирования;
на фиг. 37 показана блок-схема последовательности операций, схематично поясняющая технологию адаптации; и
на фиг. 38 и 39 схематично показаны блок-схемы последовательности операций, поясняющие обработку для выбора динамического диапазона преобразования и параметров точности данных.
Осуществление изобретения
Со ссылкой на чертежи, фиг. 1-4 представлены для схематической иллюстрации устройства или систем, в которых используется устройство сжатия и/или распаковки, которое будет описано ниже совместно с вариантами осуществления.
Все из устройств сжатия и/или распаковки данных, которые будут описаны ниже, могут быть воплощены в аппаратных средствах, в программном обеспечении, могут работать в устройстве обработки данных общего назначения, таком как компьютер общего назначения, как программируемые аппаратные средства, такие как специализированная интегральная микросхема (ASIC) или программируемая пользователем вентильная матрица (FPGA) или как их комбинации. В случаях, когда варианты воплощены с использованием программного обеспечения и/или встроенного программного обеспечения, следует понимать, что такое программное обеспечение и/или встроенное программное обеспечение и непереходные носители информации, считываемые устройством, в которых содержится такое программное обеспечение и/или встроенное программное обеспечение или предусмотрено по-другому, рассматриваются как варианты осуществления.
На фиг. 1 схематично иллюстрируется система передачи и приема аудио/видеоданных, в которой используются сжатие и распаковка видеоданных.
Входной аудио/видеосигнал 10 подают в устройство 20 сжатия видеоданных, которое сжимает, по меньшей мере, видеокомпонент аудио/видеосигнала 10 для передачи по маршруту 30 передачи, такому как кабель, оптическое волокно, беспроводное соединение и т.п. Сжатый сигнал обрабатывается устройством 40 распаковки для получения выходного аудио/видеосигнала 50. Для обратного пути, устройство 60 сжатия сжимает аудио/видеосигнал для передачи вдоль маршрута 30 передачи в устройство 70 распаковки.
Устройство 20 сжатия и устройство 70 распаковки, поэтому, могут формировать один узел линии передачи. Устройство 40 распаковки и устройство 60 распаковки могут формировать другой узел линии передачи. Конечно, в случаях, когда соединение для передачи данных является однонаправленным, только в одном из узлов может потребоваться устройство сжатия, и в другом из узлов может потребоваться только устройство распаковки.
На фиг. 2 схематично иллюстрируется система отображения видео, в которой используется распаковка видеоданных. В частности, сжатый аудио/видеосигнал 100 обрабатывается устройством 110 распаковки для предоставления распакованного сигнала, который может отображаться на дисплее 120. Устройство 110 распаковки может быть воплощено, как интегральная часть дисплея 120, например, оно может быть предусмотрено в том же корпусе, что и устройство дисплея. В качестве альтернативы, устройство 110 распаковки может быть предусмотрено как (например) так называемая телевизионная приставка (STB), следует отметить, что выражение "телевизионная приставка" не подразумевает требование, что такая приставка должна находиться в какой-либо определенной ориентации или положении относительно дисплея 120; это просто термин, используемый в данной области техники для обозначения устройства, которое может быть подключено к дисплею, как периферийное устройство.
На фиг. 3 схематично иллюстрируется система аудио/видео накопителя, в которой используется сжатие и распаковка видеоданных. Входной аудио/видеосигнал 130 поступает в устройство 140 сжатия, которое генерирует сжатый сигнал для сохранения устройством 150 накопителя, такое как устройство магнитного диска, устройство оптического диска, устройство на магнитной ленте, твердотельное устройство накопителя, такое как полупроводниковое запоминающее устройство или другое устройство-накопитель. Для воспроизведения сжатые данные считывают из устройства 150 накопителя и передают в устройство 160 распаковки для распаковки, для представления выходного аудио/видеосигнала 170.
Следует понимать, что сжатый или кодированный сигнал и носитель информации или носитель данных, на котором содержится этот сигнал, рассматриваются как варианты осуществления.
На фиг. 4 схематично иллюстрируется видеокамера, в которой используется сжатие видеоданных. На фиг. 4 и в устройстве 180 захвата изображения, таком как датчик изображения на приборе с зарядовой связью (CCD) и с соответствующими электронными схемами управления и считывания, генерируется видеосигнал, который передают в устройство 190 сжатия. Микрофон (или множество микрофонов) 200 генерируют аудиосигнал, который передают в устройство 190 сжатия. Устройство 190 сжатия генерирует сжатый аудио/видеосигнал 210, который должен быть сохранен и/или передан (в общем показано как схематичный этап 220).
Технологии, которые будут описаны ниже, в основном, относятся к сжатию видеоданных. Следует понимать, что множество существующих технологий могут использоваться для сжатия аудиоданных совместно с технологиями сжатия видеоданных, которые будут описаны ниже, для генерирования сжатого аудио/видеосигнала. В соответствии с этим, отдельное описание сжатия аудиоданных не будет представлено. Следует также понимать, что скорость передачи данных, связанная с видеоданными, в частности, при широковещательной передаче качественных видеоданных, обычно намного выше, чем скорость передачи данных, связанная с аудиоданными (которые сжаты или которые не сжаты). Поэтому, следует понимать, что несжатые аудиоданные могут сопровождать сжатые видеоданные для формирования сжатого аудио/видеосигнала. Кроме того, следует понимать, что хотя настоящие примеры (показанные на фиг. 1-4) относятся к аудио/видеоданным, технологии, которые будут описаны ниже, могут найти использование в системе, которой просто работает с видеоданными (то есть их сжимает, распаковывает, сохраняет, отображает и/или передает). То есть варианты осуществления могут применяться к сжатию видеоданных без необходимости использования любой ассоциированной обработки аудиоданных вообще.
На фиг. 5 представлен схематичный обзор устройства сжатия и распаковки видеоданных.
Последовательные изображения входного видеосигнала 300 подают в сумматор 310 и в блок 320 прогнозирования изображения. Блок 320 прогнозирования изображения будет описан более подробно ниже со ссылкой на фиг. 6. Сумматор 310 фактически выполняет операцию вычитания (отрицательное суммирование), состоящую в том, что он принимает входной видеосигнал 300 на входе "+" и выходной сигнал блока 320 прогнозирования изображения на входе таким образом, прогнозируемое изображение вычитают из входного изображения. Результат состоит в генерировании, так называемого, сигнала 330 остаточного изображения, представляющего разность между фактическими и проектируемым изображениями.
Одна из причин, по которой генерируют сигнал остаточного изображения, состоит в следующем. Технологии кодирования данных, которые будут описаны ниже, то есть технологии, которые применяются в сигнале остаточного изображения, проявляют тенденцию более эффективной работы, когда используется меньше "энергии" в изображении, которое должно быть кодировано. Здесь термин "эффективно" относится к генерированию меньшего количества кодированных данных; для конкретного уровня качества изображения желательно (и считается "эффективным") генерировать как можно меньше данных, насколько это практически возможно. Ссылка на "энергию" в остаточном изображении относится к количеству информации, содержащейся в остаточном изображении. Если бы прогнозируемое изображение было быть идентичным реальному изображению, разность между ними двумя (то есть остаточным изображением) могла бы содержать нулевую информацию (нулевую энергию), и было бы очень легко кодировать его с малым количеством кодированных данных. В общем, если обработка прогнозирования может быть выполнена так, чтобы она работала хорошо, ожидание состоит в том, что остаточные данные изображения будут содержать меньше информации (меньше энергии), чем входное изображение, и таким образом, было бы легче кодировать их в малое количество кодированных данных.
Данные 330 остаточного изображения подают в модуль 340 преобразования, который генерирует представление дискретного косинусного преобразования (DCT) данных остаточного изображения. Сама технология DCT хорошо известна и не будет описана здесь подробно. Однако существуют аспекты технологий, используемые в настоящем устройстве, которые будет описаны более подробно ниже, в частности, относящиеся к выбору различных блоков данных, в которых применяется операция DCT. Они будут описаны ниже со ссылкой на фиг. 7-12.
Следует отметить, что в некоторых вариантах осуществления используется дискретное синусное преобразование (DST) вместо DCT. В других вариантах осуществления может не использоваться никакое преобразование. Это может быть выполнено избирательно таким образом, что фактически выполняется обход этапа преобразования, например, под управлением команды или режима "пропустить преобразование".
Выход модуля 340 преобразования, который представляет собой набор коэффициентов преобразования для каждого преобразованного блока данных изображения, подают в блок 350 квантования. Различные технологии квантования известны в области сжатия видеоданных, в пределах от простого умножения на коэффициент масштабирования квантования, вплоть до применения сложных справочных таблиц под управлением параметра квантования. Общая цель является двойной. Во-первых, обработка квантования уменьшает количество возможных значений преобразованных данных. Во-вторых, обработка квантования может увеличивать вероятность того, что значения преобразованных данных будут равны нулю. Оба из них могут обеспечить более эффективную работу энтропийного кодирования, которая будет описана ниже, при генерировании малых количеств сжатых видеоданных.
Обработка сканирования данных применяется модулем 360 сканирования. Назначение обработки сканирования состоит в том, чтобы изменить порядок квантованных преобразованных данных, с тем, чтобы собрать вместе как можно больше возможных не равных нулю квантованных преобразованных коэффициентов, и, конечно, поэтому, чтобы собрать вместе как можно больше коэффициентов со значением ноль. Эти технологии могут обеспечить эффективное применение, так называемого, кодирования по длинам серий или аналогичных технологий. Таким образом, обработка сканирования включает в себя выбор коэффициентов из квантованных преобразованных данных, и, в частности, из блока коэффициентов, соответствующих блоку данных изображения, которые были преобразованы и квантованы, в соответствии с "порядком сканирования" таким образом, что (а) все коэффициенты будут выбраны однажды, как часть сканирования, и (b) сканирование проявляет тенденцию обеспечения требуемого изменения порядка. Технологии для выбора порядка сканирования будут описаны ниже. Один пример порядка сканирования, который может проявлять тенденцию получения полезных результатов, представляет собой так называемый порядок зигзагообразного сканирования.
Сканированные коэффициенты затем передают в энтропийный кодер (ЕЕ) 370. И снова, можно использовать различные типы энтропийного кодирования. Два примеры, которые будут описаны ниже, представляют собой варианты, так называемой, системы САВАС (контекстно-адаптивное двоичное арифметическое кодирование) и варианты, так называемой, системы CAVLC (контекстно-адаптивное кодирование переменной длины). В общих чертах, САВАС рассматривается, как обеспечивающее лучшую эффективность, и некоторые исследования показали, что оно обеспечивает 10-20% уменьшение количества кодированных выходных данных для сравнимого качества изображений, по сравнению с CAVLC. Однако считается, что CAVLC представляет гораздо меньший уровень сложности (с точки зрения его воплощения), чем САВАС. Технология САВАС будет описана ниже со ссылкой на фиг. 17, и технология CAVLC будет описана со ссылкой на фиг. 18 и 19, представленные ниже.
Следует отметить, что обработка сканирования и обработка энтропийного кодирования представлены как отдельная обработка, но фактически могут быть скомбинированы или могут обрабатываться совместно. То есть считывание данных в энтропийный кодер может происходить в порядке сканирования. Соответствующие принципы применяются к соответствующим обратным процессам, которые будут описаны ниже.
Выход энтропийного кодера 370, вместе с дополнительными данными (упомянутыми выше и/или описанными ниже), например, определение подхода, в соответствии с которым блок 320 прогнозирования сгенерировал прогнозируемое изображение, обеспечивает сжатый выходной видеосигнал 380.
Однако обратный путь также обеспечивается, поскольку операция самого блока 320 прогнозирования зависит от распакованной версии сжатых выходных данных.
Причина этого свойства состоит в следующем. На соответствующем этапе при обработке распаковки (которая будет описана ниже) генерируется распакованная версия остаточных данных. Такие распакованные остаточные данные должны быть добавлены к прогнозируемому изображению для генерирования выходного изображения (поскольку оригинальные остаточные данные представляют собой разность между входным изображением и прогнозируемым изображением). В порядке, в котором эта обработка была сравнима, как между стороной сжатия, так и между стороной распаковки, прогнозируемые изображения, генерируемые блоком 320 прогнозирования, должны быть одинаковыми во время обработки сжатия и во время обработки распаковки. Конечно, при распаковке устройство не имеет доступа к оригинальным входным изображениям, а только к распакованным изображениям. Поэтому, при сжатии, блок 320 прогнозирования основывает свое прогнозирование (по меньшей мере, для кодирования между изображениями) на распакованных версиях сжатых изображений.
Обработка энтропийного кодирования, выполняемая энтропийным кодером 370, рассматривается, как обработка "без потерь", которая состоит в том, что она может быть обратимой, с получением точно таких же данных, которые были изначально поданы в энтропийный кодер 370. Таким образом, обратный путь может быть воплощен перед этапом энтропийного кодирования. Действительно, обработка сканирования, выполняемая модулем 360 сканирования, также рассматривается, как обработка без потерь, но в настоящем варианте осуществления обратный путь 390 представляет собой путь от выхода блока 350 квантования до входа взаимодополняющего обратного блока 420 квантования.
В общих чертах, энтропийный декодер 410, модуль 400 обратного сканирования, блок 420 обратного квантования и модуль 430 обратного преобразования обеспечивает соответствующие обратные функции энтропийного кодера 370, модуля 360 сканирования, блока 350 квантования и модуля преобразования 340. Теперь описание будет продолжаться в отношении обработки сжатия; обработка для распаковки входного сжатого видеосигнала будет описана отдельно ниже.
При обработке сжатия сканированные коэффициенты проходят по обратному пути 390 от блока 350 квантования до блока 420 обратного квантования, который выполняет обратную операцию модуля 360 сканирования. Обработка обратного квантования и обратного преобразования выполняется модулями 420, 430 для генерирования сжатого-распакованного сигнала 440 остаточного изображения.
Сигнал 440 изображения добавляют в сумматоре 450 к выходу блока 320 прогнозирования для генерирования реконструированного выходного изображения 460. Это формирует вход для блока 320 прогнозирования изображения, как будет описано ниже.
Обращаясь теперь к обработке, применяемой для принятого сжатого видеосигнала 470, сигнал подают в энтропийный декодер 410 и из него подают в цепочку из модуля 400 обратного сканирования, блока 420 обратного квантования и модуля 430 обратного преобразования перед добавлением к выходу блока 320 прогнозирования изображения в сумматоре 450. Другими словами, выход 460 сумматора 450 формирует выходной распакованный видеосигнал 480. На практике, дополнительная фильтрация может применяться перед выводом сигнала.
На фиг. 6 схематично иллюстрируется генерирование прогнозируемых изображений, и, в частности, операция блока 320 прогнозирования изображения.
Существует две основные модели прогнозирования: так называемое, прогнозирование внутри изображения и, так называемое, прогнозирование между изображениями или прогнозирование с компенсированным движением (МС).
Прогнозирование внутри изображения основано на прогнозировании содержания блока изображения на данных, находящихся в том же изображении. Это соответствует, так называемому, кодированию I-кадра в других технологиях сжатия видеоданных. В отличие от кодирования I-кадра, где все изображение подвергают кодированию внутри изображения, в настоящих вариантах осуществления выбор между кодированием внутри изображения и между изображениями может быть выполнен на основе от блока к блоку, хотя в других вариантах осуществления выбор все еще выполняется на основе от изображения к изображению.
При прогнозировании с компенсированным движением используется информация о движении, которая пытается определить источник в другом соседнем или расположенном рядом изображении для деталей изображения, которые должны быть кодированы в текущем изображении. В соответствии с этим, в идеальном примере, содержание блока данных изображения в прогнозируемом изображении может кодироваться очень просто, как ссылка (вектор движения), указывающая на соответствующий блок в том же или несколько другом положении в соседнем изображении.
Возвращаясь к фиг. 6, здесь показаны две соседних компоновки прогнозирования изображения (соответствуют прогнозированию внутри изображения и между изображениями), результаты которых выбраны мультиплексором 500 под управлением сигнала 510 режима, для получения блоков прогнозируемого изображения для подачи в сумматоры 310 и 450. Выбор выполняют в зависимости от того, какой из вариантов выбора обеспечивает наименьшую "энергию", (которую, как описано выше, можно рассматривать, как содержание информации, требующей кодирования), и этот вариант выбора передают, как сигналы, в кодер с кодированным выходным потоком данных. Энергия изображения, в этом контексте, может быть детектирована, например, путем выполнения тройного вычитания области двух версий прогнозируемого изображения из входного изображения, возведения в квадрат каждого значение пикселя разностного изображения, суммирования возведенных в квадрат значений, и идентификации, какая из этих двух версий приводит к повышению наименьшего среднеквадратичного значения дифференциального изображения, относящегося к этой области изображения.
Фактическое прогнозирование в системе кодирования внутри изображения выполняется на основе блоков изображения, принимаемых как часть сигнала 460, таким образом, можно сказать, что прогнозирование основано на кодированных -декодированных блоках изображения в порядке, при котором точно такое же прогнозирование может быть выполнено в устройстве распаковки. Однако данные могут быть выведены из входного видеосигнала 300, используя селектор 520 режима внутри изображения, для управления операцией блока 530 прогнозирования внутри изображения.
Для прогнозирования между изображениями блок 540 прогнозирования с компенсированным движением (МС) использует информацию движения, такую как векторы движения, выведенные блоком 550 оценки движения из входного видеосигнала 300. Такие векторы движения применяются для обработанной версии реконструированного изображения 460 с помощью блока 540 прогнозирования компенсированного движения, для генерирования блоков прогнозирования между изображениями.
Обработка, применяемая для сигнала 460, будет описана ниже. Вначале сигнал фильтруют модулем 560 фильтра. Это подразумевает использование фильтра "устранения блоков", который удаляет или, по меньшей мере, проявляет тенденцию уменьшения эффектов обработки на основе блока, выполняемой модулем 340 преобразования, и в ходе последующих операций. Кроме того, применяется фильтр адаптивного контура, используя коэффициенты, выведенные обработкой реконструированного сигнала 460 и входного видеосигнала 300. Фильтр адаптивного контура представляет собой фильтр такого типа, который при использовании известных технологий применяет коэффициенты адаптивного фильтра к данным, которые должны быть отфильтрованы. То есть коэффициенты фильтра могут изменяться в зависимости от различных факторов. Данные, определяющие, какие коэффициенты фильтра следует использовать, включены как часть кодированного выходного потока данных.
Фильтрованный выход из модуля 560 фильтра фактически формирует выходной видеосигнал 480. Его также размещают в буфер в одном или больше накопителях 570 изображения; накопитель последовательных изображений необходим для обработки прогнозирования с компенсированным движением, и, в частности, для генерирования векторов движения. Для экономии в отношении требований к накопителю, сохраненные изображения в накопителях 570 изображения могут содержаться в сжатой форме и затем могут распаковываться для использования при генерировании векторов движения. Для этого конкретного назначения может использоваться любая известная система сжатия/распаковки. Сохраненные изображения пропускают через фильтр 580 интерполяции, который генерирует версию с более высоким разрешением сохраненных изображений; в этом примере промежуточные выборки (подвыборки) генерируют таким образом, что разрешение интерполированного изображения, выводимого, используя фильтр 580 интерполяции, в 8 раз (в каждом измерении) выше, чем у изображений, сохраненных в накопителях 570 изображения. Интерполированные изображения пропускают, как входные изображения в блок 550 оценки движения и также в блок 540 прогнозирования компенсированного движения.
В вариантах осуществления предусмотрен дополнительный необязательный этап, который состоит в том, чтобы умножить значения данных входного видеосигнала на коэффициент, равный четырем, используя умножитель 600 (фактически просто путем сдвига значений данных влево на два бита), и с применением соответствующей операции деления (сдвига вправо на два бита) на выходе устройства, используя делитель или блок 610 сдвига вправо. Таким образом, что сдвиг влево и сдвиг вправо изменяют данные исключительно для внутренней операции устройства. Эта мера может обеспечить дополнительную точность расчетов внутри устройства, влияя на уменьшение ошибок, связанных с округлением данных.
Подход, в соответствии с которым изображение разделяют для обработки сжатия, будет описан ниже. На самом основном уровне, изображение, которое должно быть сжато, рассматривают, как массив блоков выборок. С целью настоящего описания, наибольший такой рассматриваемый блок представляет собой так называемый наибольший модуль 700 кодирования (LCU) (фиг. 7), которая представляет собой квадратный массив из выборок размером 64×64. Здесь описание относится к выборкам яркости. В зависимости от режима цветности, такого как 4:4:4, 4:2:2, 4:2:0 или 4:4:4:4 (GBR "плюс" данные ключа), будет присутствовать разное количество соответствующих выборок цветности, соответствующих блоку яркости.
Будут описаны три основных типа блоков: модули кодирования, модули прогнозирования и модули преобразования. В общих чертах, рекурсивное разделение LCU позволяет разделить входное изображение таким образом, что как размеры блока, так и параметры кодирования блока (такие как режимы прогнозирования или остаточного кодирования) могут быть установлены в соответствии с определенными характеристиками изображения, предназначенного для кодирования.
LCU может быть подразделен на, так называемые, модули кодирования (CU). Модули кодирования всегда квадратные и имеют размер от 8×8 выборок до полного размера LCU 700. Модули кодирования могут быть размещены, как разновидность древовидной структуры, таким образом, что первое подразделение может происходить, как показано на фиг. 8, задавая модули 710 кодирования размером 32×32 выборки; последующие подразделения могут затем происходить на избирательной основе для получения некоторых модулей 720 кодирования размером 16×16 выборок (фиг. 9) и потенциально некоторых модулей 730 кодирования размером 8×8 выборок (фиг. 10). В целом, эта обработка может обеспечивать контекстно-адаптивную древовидную структуру кодирования из блоков CU, каждый из которых может быть настолько большим, как LCU, или настолько малым, как 8×8 выборок. Кодирование выходных видеоданных происходит на основе кодирования единичной структуры.
На фиг. 11 схематично иллюстрируется массив модулей прогнозирования (PU). Модуль прогнозирования представляет собой основной модуль для переноса информации, относящейся к обработке прогнозирования изображения, или, другими словами, дополнительных данных, добавленных к энтропийно кодированным данным остаточного изображения, для формирования выходного видеосигнала из устройства на фиг. 5. В общем, модули прогнозирования не ограничены требованием квадратной формы. Они могут иметь другие формы, в частности, прямоугольную форму, формирующую половину одного из квадратных модулей кодирования, если только модуль кодирования будет больше, чем минимальный размер (8×8). Цель состоит в том, чтобы обеспечить возможность соответствия границы соседних модулей прогнозирования (настолько тесно, насколько это возможно) границе реальных объектов в изображении, таким образом, что разные параметры прогнозирования могут применяться для разных реальных объектов. Каждый модуль кодирования может содержать один или больше модулей прогнозирования.
На фиг. 12 схематично иллюстрируется массив модулей преобразования (TU). Модуль преобразования представляет собой основной модуль обработки квантования и преобразования. Модули преобразования всегда являются квадратными и могут иметь размер от 4×4 вплоть до 32×32 выборки. Каждый модуль кодирования может содержать один или больше модулей преобразования. Акроним SDIP-P на фиг. 12 обозначает, так называемое, разделение прогнозирования внутри изображения на коротком расстоянии. При такой компоновке используются только преобразования размеров, таким образом, что блок 4×N пропускают через N преобразований, и при этом входные данные преобразуют на основе ранее декодированных соседних блоков и ранее декодированных соседних строк в текущем SDIP-P.
Обработка прогнозирования внутри кадра будет описана ниже. В общих чертах, прогнозирование внутри кадров подразумевает генерирование прогнозирования текущего блока (модуля прогнозирования) выборок из ранее кодированных и декодированных выборок в одном и том же изображении. На фиг. 13 схематично иллюстрируется частично кодированное изображение 800. Здесь изображение кодируют на основе от верхнего левого до нижнего правого угла LCU. Пример LCU, кодированного частично, посредством обработки всего изображения, показан, как блок 810. Затушеванная область 820, представленная выше и слева от блока 810, уже была кодирована. Прогнозирование внутри изображения содержания блока 810 может использоваться для любой затушеванной области 820, но не может использовать не затушеванную область ниже нее.
Блок 810 представляет LCU; как описано выше, с целью обработки прогнозирования внутри изображения, и он может быть подразделен на набор меньших модулей прогнозирования. Пример модуля 830 прогнозирования показан в пределах LCU 810.
Прогнозирование внутри изображения учитывает выборки выше и/или слева от текущего LCU 810. Выборки источника, по которым прогнозируют требуемые выборки, могут быть расположены в разных положениях или направлениях относительно текущего модуля прогнозирования в пределах LCU 810. Для определения, какое направление является соответствующим для текущего модуля прогнозирования, результаты испытательного прогнозирования, основанные на каждом направлении-кандидате, сравнивают для того, чтобы определить, какое направление-кандидат приводит к результату, который находится ближе всего к соответствующему блоку входного изображения. Направление-кандидат, обеспечивающее ближайший результат, выбирают, как направление прогнозирования для этого модуля прогнозирования.
Изображение также может быть кодировано на основе "среза". В одном примере срез представляет собой расположенную горизонтально рядом друг с другом группу LCU. Но в более общих чертах, все остаточное изображение может формировать срез, или срез может представлять собой один LCU, или срез может представлять собой ряд LCU, и так далее. Срезы могут обеспечивать некоторую устойчивость к ошибкам, поскольку их кодируют, как независимые модули. Состояния кодера и декодера полностью сбрасывают на границе среза. Например, прогнозирование внутри кадра не выполняется через границы среза; границы среза с этой целью обрабатываются, как границы изображения.
На фиг. 14 схематично иллюстрируется набор возможных направлений прогнозирования (кандидатов). Полный набор из 34 направлений-кандидатов доступен для модуля прогнозирования размером 8×8, 16×16 или 32×32 выборок. Особые случаи размеров модуля прогнозирования размером 4×4 и 64×64 выборки имеют уменьшенный набор направлений-кандидатов, доступный для них (17 направлений-кандидатов и 5 направлений-кандидатов соответственно). Направления определяют путем горизонтального и вертикального смещения относительно текущего положения блока, но их кодируют, как "режимы" прогнозирования, набор из которых показан на фиг. 15. Следует отметить, что так называемый режим DC представляет простое арифметическое среднее окружающих верхней и левой выборок.
На фиг. 16 схематично иллюстрируется зигзагообразное сканирование, которое представляет собой структуру сканирования, которая может применяться модулем 360 сканирования. На фиг. 16 показана структура для примерного блока с коэффициентами преобразования 8×8, при этом коэффициент DC расположен в верхнем левом положении 840 блока, и увеличение горизонтальной и вертикальной пространственных частот, представленных коэффициентами с увеличенными расстояниями вниз и вправо от верхнего левого положения 840.
Следует отметить, что в некоторых вариантах осуществления коэффициенты могут быть сканированы в обратном порядке (с нижнего правого в верхний левый, используя обозначения порядка на фиг. 16). Также следует отметить, что в некоторых вариантах осуществления сканирование может проходить слева направо через некоторые (например, от одного до трех) верхних горизонтальных рядов, перед выполнением зигзага для остальных коэффициентов.
На фиг. 17 схематично иллюстрируется работа энтропийного кодера САВАС.
В контексте адаптивного кодирования такого свойства и в соответствии с вариантами осуществления, бит данных может быть кодирован относительно модели вероятности или контекста, представляющего ожидание или прогнозирование насколько вероятно, что бит данных будет равен единице или нулю. С этой целью для бита входных данных назначают обозначение кода в пределах выбранного одного из двух (или в более общем смысле из множества) взаимно дополняющих поддиапазонов из диапазона значений кода, с соответствующими размерами поддиапазонов (в вариантах осуществления соответствующими пропорциями поддиапазонов относительно наборов значений кода), определенных контекстом (который, в свою очередь, определен переменной контекста, ассоциированной или по-другому сопоставленной с входным значением). Следующий этап состоит в модификации общего диапазона, который можно сказать, представляет собой набор значений кода (предназначенных для использования в отношении следующего бита или значения входных данных) в ответ на назначенное значение кода, и текущий размер выбранного поддиапазона. Если модифицированный диапазон затем меньше, чем пороговое значение, представляющее заданный минимальный размер (например, половину размера оригинального диапазона) тогда его размер увеличивают, например, путем удвоения (сдвига влево) модифицированного диапазона, и такая обработка удвоения может выполняться последовательно (более, чем один раз), если это требуется, до тех пор, пока диапазон не будет иметь, по меньшей мере, заданный минимальный размер. В этот момент бит выходных кодированных данных генерируют для обозначения того, что произошла операция удвоения или увеличения размера (каждого или больше, чем одного). Дополнительный этап должен модифицировать контекст (то есть в вариантах осуществления для модификации переменной контекста) для использования с или в отношении следующего бита или значения входных данных (или в некоторых вариантах осуществления в отношении следующей группы битов данных или значений, которые должны быть кодированы). Это может быть выполнено, используя текущий контекст и идентичность текущего "наиболее вероятного символа" (единицы или нуля, в зависимости от того, какой из них обозначен контекстом, чтобы иметь в данный момент вероятность больше 0,5), как индекс в справочной таблице поиска новых контекстных значений, или как входные значения для соответствующей математической формулы, из которой может быть выведена новая контекстная переменная. Модификация контекстной переменной в вариантах осуществления может увеличить пропорцию набора кодовых значений в поддиапазоне, который был выбран для текущего значения данных.
Кодер САВАС работает в отношении двоичных данных, то есть данных, представленных только этими двумя символами 0 и 1. Кодер использует, так называемую, обработку контекстного моделирования, которая выбирает "контекст" или модель вероятности для последующих данных на основе ранее кодированных данных. Выбор контекста осуществляется детерминистическим образом таким образом, что некоторое определение на основе ранее декодированных данных, может быть выполнено в декодере без необходимости добавления дополнительных данных (устанавливающих контекст) к кодированному потоку данных, подаваемому в декодер.
Как представлено на фиг. 17, входные данные, которые должны быть кодированы, могут быть переданы в двоичный преобразователь 900, если они еще не представлены в двоичной форме; если данные уже находятся в двоичной форме, преобразователь 900 обходят (используя указанный на схеме переключатель 910). В настоящих вариантах осуществления преобразование в двоичную форму фактически выполняется путем выражения квантованных данных коэффициента преобразования, как последовательность двоичных "карт", которые будут дополнительно описаны ниже.
Двоичные данные могут затем обрабатываться в одном из двух путей обработки, в "регулярном" и "обходном" пути (которые схематично показаны, как отдельные пути, но которые в вариантах осуществления, описанных ниже, фактически могут быть воплощены одними и теми же этапами обработки, используя только несколько отличающиеся параметры). В обходном пути используется так называемый обходной кодер 920, в котором не обязательно используется моделирование контекста в той же форме, как и регулярном пути. В некоторых примерах кодирования САВАС такой обходной путь может быть выбран, если существует потребность в особенно быстрой обработке пакетов данных, но в настоящих вариантах осуществления следует отметить два свойства, так называемых, "обходных" данных: во-первых, обходные данные обрабатываются кодером (950, 960) САВАС, используя только фиксированную модель контекста, представляющую вероятность 50%; и во-вторых, обходные данные относятся к определенным категориям данных, один конкретный пример представляет собой данные знака коэффициента. В противном случае выбирается обычный путь с использованием представленной схемы переключателей 930, 940. Это подразумевает то, что данные будут обработаны блоком 950 моделирования контекста, после которого следует механизм 960 кодирования.
Энтропийный кодер, показанный на фиг. 17, кодирует блок данных (то есть, например, данные, соответствующие блоку коэффициентов, относящемуся к блоку остаточного изображения), как единичное значение, если блок сформирован исключительно из данных с нулевым значением. Для каждого блока, который не попадает в эту категорию, то есть для блока, который содержит, по меньшей мере, некоторые ненулевые данные, подготавливают "карту значимости". Карта значимости обозначает, требуется ли для каждого положения в блоке данных, который должен быть кодирован, чтобы соответствующий коэффициент в блоке не был равен нулю. Данные карты значимости, представленные в двоичной форме, сами по себе кодируют, используя САВАС. Использование карты значимости помогает при сжатии, поскольку не требуется кодировать данные для коэффициента с магнитудой, которую карта значимости обозначает, как нулевую. Кроме того, карта значимости может включать в себя специальный код, для обозначения конечного ненулевого коэффициента в блоке, таким образом, что все конечные коэффициенты высокой частоты/нулевого байта в конце строки могут быть исключены из кодирования. После карты значимости в кодируемом потоке битов следуют данные, определяющие значения ненулевых коэффициентов, установленных картой значимости.
Дополнительные уровни данных карты также подготавливают и кодируют, используя САВАС. В качестве примера рассмотрим карту, которая определяет, как двоичное значение (1 = да, 0 = нет), имеют ли данные коэффициента в положении карты, которое карта значимости обозначила, как "не равное нулю", фактически, значение "единица". Другая карта устанавливает, имеют ли данные коэффициента в положении карты, которое карта значимости обозначила, как "не равное нулю", фактически, значение, "два". Дополнительная карта обозначает, для тех положений в карте, для которых карта значимости обозначила, что данные коэффициента "не равны нулю", имеют ли эти данные значение "большее двух". Другая карта обозначает, снова для данных, идентифицированных как "не равные нулю", знак значения данных (используя определенное двоичное обозначение, такое 1 для +, 0 для - или, конечно, используя другой подход для обозначения).
В вариантах осуществления карту значимости и другие карты генерируют из квантованных коэффициентов преобразования, например, с помощью модуля 360 сканирования и подвергают обработке зигзагообразного сканирования (или обработке сканирования, выбранной из зигзагообразного, горизонтального растрового сканирования и вертикального растрового сканирования, в соответствии с режимом прогнозирования внутри кадра) перед выполнением кодирования САВАС.
В некоторых вариантах осуществления энтропийный кодер САВАС HEVC кодирует элементы синтаксиса, используя следующую обработку:
Кодируют местоположение младшего значащего коэффициента (в порядке сканирования) в TU.
Для каждой группы коэффициентов 4×4 (группы обрабатывают в обратном порядке сканирования) кодируют флаг группы значимых коэффициентов, обозначая, содержит или нет эта группа ненулевые коэффициенты. Это не требуется для группы, содержащей младший значащий коэффициент, и, как предполагается, равный 1 для верхней левой группы (содержащей коэффициент DC). Если флаг равен 1, тогда следующие элементы синтаксиса, относящиеся к группе, кодируют немедленно после нее:
Карта значимости:
Для каждого коэффициента в группе кодируют флаг, обозначающий, являются или нет коэффициент значимым (имеет ненулевое значение). Флаг не нужен для коэффициента, обозначенного последним значимым положением.
Карта больше чем единица:
Вплоть до восьми коэффициентов со значением 1 карты значимости (отсчитанных обратно от конца группы), это означает, превышает ли магнитуда 1.
Флаг больше чем два:
Для вплоть до одного коэффициента со значением 1 карты больше чем единица (один ближайший конец группы), он обозначает, превышает ли магнитуда 2.
Биты знака:
Для всех ненулевых коэффициентов биты знака кодируют, как эквивероятностные бины САВАС с последним знаковым битом (в обратном порядке сканирования), возможно, вместо подразумеваемого знака четности, когда используется скрытый бит знака.
Коды перехода:
Для любого коэффициента, магнитуда которого не была полностью описана более ранним элементом синтаксиса, остаток кодируют, как код перехода.
В общих чертах, кодирование САВАС представляет прогнозирование контекста или модель вероятности для следующего бита, который должен быть кодирован, на основе других ранее кодированных данных. Если следующий бит является таким же, как и бит, идентифицированный моделью вероятности, как "наиболее вероятный", тогда кодирование информации о том, что "следующий адрес бита согласуется с моделью вероятности", может быть кодирован с большой эффективностью. Менее эффективно кодировать то, что "следующий бит не согласован с моделью вероятности", таким образом, что вывод контекстных данных является важным для хорошей работы кодера. Термин "адаптивный" означает, что контекст или модели вероятности адаптированы или изменяются во время кодирования при попытке обеспечения хорошего соответствия, как для следующих (пока еще не кодированных) данных.
Используя простую аналогию, в письменном английском языке, буква "U" является относительно нечастой. Но в положении буквы непосредственно после буквы "Q", она, тем не менее, является очень вероятной. Таким образом, модель вероятности может устанавливать вероятность "U", как очень низкое значение, но если текущая буква представляет собой "Q", модель вероятности для "U", как следующей буквы, может быть установлена, как значение с очень высокой вероятностью.
Кодирование САВАС используется, в настоящих компоновках, для карты наименьшей значимости и карт, обозначающих, не равны ли ненулевые значения единице или двум. Обработка обхода, при которой эти варианты осуществления идентичны кодированию САВАС, но с учетом того факта, что модель вероятности является фиксированной и равной распределению вероятности (0,5:0,5) 1-ниц и 0-лей, используется для, по меньшей мере, данных знака и карты, обозначающей, что значение >2. Для этих положений данных, идентифицированных, как >2, может использоваться отдельное, так называемое, кодирование переходом данных, для кодирования фактического значения данных. Это может включать в себя технологию кодирования Голомба-Райса.
Моделирование контекста САВАС и обработка кодирования описаны более подробно в WD4: Working Draft 4 of High-Efficiency Video Coding, JCTVC-F803_d5, Draft ISO/IEC 23008-HEVC; 201x(E) 2011-10-28.
Обработка САВАС далее будет описана несколько более детально.
САВАС, по меньшей мере, в той степени, как оно используется в предложенной системе HEVC, подразумевает вывод "контекста" или модели вероятности в отношении следующего бита, который должен быть кодирован. Контекст, определенный переменной контекста или CV, затем влияет на то, как кодируется бит. В общих чертах, если следующий бит является таким же, как и значение, которое CV определяет, как ожидаемое более вероятное значение, тогда существуют преимущества, связанные с уменьшением количества выходных битов, необходимых для определения бита данных.
Обработка кодирования подразумевает кодирование бита, который должен быть кодирован, на положение в диапазоне значений кода. Диапазон значений кода схематично показан на фиг. 18А, как последовательность соседних целых чисел, продолжающихся от нижнего предела m_Low, до верхнего предела m_high. Разность между этими двумя пределами составляет m_range, где m_range = m_high - m_Low. В соответствии с различными технологиями, которые будут описаны ниже, в основной системе САВАС, m_range ограничено так, что оно находится между 128 и 254; в другом варианте осуществления, используется большее количество битов для представления m_range, m_range может находиться в пределах от 256 до 510. m_Low может представлять собой любое значение. Оно может начинаться с (скажем) нуля, но может изменяться, как часть обработки кодирования, которая будет описана.
Диапазон значений кода, m_range, разделяют на два поддиапазона, с помощью границы 1100, определенной в отношении контекстной переменной следующим образом:
граница = m_Low + (CV * m_range)
Таким образом, контекстная переменная определяет общий диапазон в виде двух взаимодополняющих поддиапазонов или подучастков набора значений кода, пропорции набора, назначенного для каждого поддиапазона, определены переменной CV, один поддиапазон ассоциирован со значением (следующего бита данных) равным нулю, и другой ассоциирован со значением (следующим битом данных) равным единице. Разделение диапазона представляет вероятности, предполагаемые генерированием CV двух значений битов для следующего бита, который должен быть кодирован. Таким образом, если поддиапазон, ассоциированный со значением ноль, меньше, чем половина общего диапазона, это обозначает, что ноль рассматривается менее вероятным, как следующий символ, чем единица.
Существуют различные возможности для определения, какой из подходов в отношении поддиапазонов следует применять для возможных значений битов данных. В одном примере меньшая область диапазона (то есть от m_Low до границы) по согласованию определена, как взаимосвязанная со значением бита данных, равным нулю.
Если больше, чем один бит кодируют за одну операцию, то более, чем два поддиапазона могут быть предусмотрены, как предоставляющие поддиапазон, соответствующий каждому возможному значению входных данных, предназначенных для кодирования.
Кодер и декодер поддерживают запись, в которой значение битов данных является менее вероятным (часто называется "менее вероятным символом" или LPS). CV относится к LPS, таким образом, что CV всегда представляет значение от 0 до 0,5.
Следующий бит теперь отображают на диапазон m_range, как разделенный границей. Это осуществляется детерминистически, как в кодере, так и в декодере, используя технологию, которая будет более подробно описана ниже. Если следующий бит равен 0, определенное значение кода, представляющее положение в пределах поддиапазона от m_Low до границы, назначают для этого бита. Если следующий бит равен 1, конкретное значение кода в поддиапазоне от границы 1100 до m_high назначают для этого бита. Это представляет пример технологии, в соответствии с которой в вариантах осуществления можно выбирать один из множества поддиапазонов набора значений кода, в соответствии со значением текущего входного бита данных, и также пример технологии, с помощью которой в вариантах осуществления можно назначать текущее значение входных данных для значения кода в пределах выбранного поддиапазона.
Нижний предел m_Low и диапазон m_range затем повторно определяют так, чтобы модифицировать набор кодовых значений, в зависимости назначенного значения кода (например, какой поддиапазон назначенного значения кода попадает в него) и размера выбранного поддиапазона. Если только что кодированный бит равен нулю, тогда m_Low остается без изменения, но m_range повторно определяют так, чтобы он был равен m_range * CV. Если только что кодированный бит равен 1, тогда m_Low перемещают в положение границы (m_Low + (CV * m_range)), и m_range повторно определяют, как разность между границей и m_high (то есть (1 CV)*m_range).
После такой модификации выполняют детектирование является ли набор значений кода меньшим, чем заданный минимальный размер (например, m_range составляет, по меньшей мере, 128).
Эти альтернативы схематично представлены на фиг. 18В и 18С.
На фиг. 18В бит данных был равен 1 и, таким образом, m_Low переместили в предыдущее положение границы. Это обеспечивает пересмотренный или модифицированный набор кодовых значений для использования следующего бита в соответствии с последовательностью кодирования. Следует отметить, что в некоторых вариантах осуществления значение CV изменяется для кодирования следующего бита, по меньшей мере, частично, в зависимости от значения только что кодированного бита. Поэтому технология относится к "адаптивным" контекстам. Пересмотренное значение CV используется для генерирования новой границы 1100'.
На фиг. 18С было кодировано значение 0, и, таким образом, m_Low осталось без изменения, но m_high переместилось в предыдущее положение границы. Значение m_range повторно определили или модифицировали, как новые значения m_high-m_Low.
В этом примере это привело к тому, что m_range уменьшилось ниже его минимального допустимого значения (такого как 128). Когда детектируется такой результат, значение m_range повторно нормализуют или увеличивают его размер, что в настоящих вариантах осуществления представлено, как удвоение m_range, то есть сдвиг влево на один бит, такое количество раз, которое необходимо для восстановления m_range до требуемого диапазона 128-256. Пример этого представлен на фиг. 18D, на которой представлен удвоенный диапазон на фиг. 18С так, чтобы он соответствовал требуемым ограничениям. Новый диапазон 1100'' выведен из следующего значения CV и пересмотренного диапазона m_range. Следует отметить, что m_Low аналогично повторно нормализуют или увеличивают его размер всякий раз, когда повторно нормализуют m_range. Это выполняют для того, чтобы поддержать то же отношение между m_Low и m_range.
Всякий раз, когда диапазон требуется умножить на два таким образом, генерируют выходной кодированный бит данных, один для каждого повторно нормализованного этапа.
Таким образом, интервал m_range и нижний предел m_Low последовательно модифицируют и повторно нормализуют, в зависимости от адаптации значений CV (которые могут быть воспроизведены в декодере), и кодированного потока битов. После кодирования последовательности битов полученный в результате интервал и количество этапов повторной нормализации уникально определяют кодированный поток битов. Декодер, в котором известен такой конечный интервал, в принципе, позволяет реконструировать кодированные данные. Однако лежащие в основе этого математические операции демонстрируют, что фактически это не нужно для определения интервала для декодера, но только для определения одного положения в пределах этого интервала. В этом состоит цель назначенного значения кода, которое поддерживают в кодере и передают в декодер при завершении кодирования данных.
Для того, чтобы представить упрощенный пример, рассмотрим пространство вероятности, разделенное на 100 интервалов. В этом случае, m_Low могло бы представлять нижнюю часть пространства вероятности, и 0, и m_Range могли бы представлять его размер, (100). Предположим, для этого примера, что переменная контекста установлена, как 0,5 (как она установлена в отношении обходного пути), таким образом, пространство вероятности должно использоваться для кодирования битов с фиксированной вероятностью 50%. Однако те же принципы применяются, если используются адаптивные значения контекстной переменной, таким образом, что одинаковая обработка адаптации происходит в кодере и в декодере.
Для первого бита каждый символ (0 или 1) мог бы иметь диапазон символа 50, при этом для входного символа 0 назначают (скажем) значения от 0 до 49 включительно, и для входного символа 1 назначают (скажем) значения 50-99 включительно. Если 1 должна представлять собой первый бит, который должен быть кодирован, тогда конечное значение потока должно находиться в диапазоне 50-99, следовательно, m_Low становится равным 50, и m_Range становится равным 50.
Для кодирования второго бита диапазон дополнительно подразделяют на диапазоны символов 25 с входным символом 0, который принимает значения 50-74, и входным символом 1, который принимает значения 75-99. Как можно видеть, не зависимо от того, какой символ будет кодирован, как второй бит, конечное значение все еще находится в пределах от 50 до 99, при сохранении первого бита, но теперь второй бит стал кодированным с тем же номером. Аналогично, если второй бит должен использовать другую вероятностную модель, чем для первого, он все еще не будет влиять на кодирование первого бита, поскольку подразделяемый диапазон все еще простирается от 50 до 99.
Такая обработка продолжается на стороне кодера для каждого входного бита, повторно нормализуя (например, удваивая) m_Range и m_Low каждый раз, когда это необходимо, например, в ответ на падение m_Range ниже 50. В конце обработки кодирования (когда поток завершается) конечное значение записывают в поток.
На стороне декодера конечное значение считывают из потока (отсюда наименование m_Value), скажем, например, значение равно 68. Декодер применяет тот же диапазон символа, разделенный на исходное пространство вероятности, и сравнивает его значение с тем, чтобы определить, в каком диапазоне символов он находится. Видя, что 68 находится в диапазоне 50-99, он декодирует 1, как символ для своего первого бита. Применяя второе разделение диапазона таким же образом, как и кодер, можно видеть, что 68 находится в диапазоне 50-74, и можно декодировать 0, как второй бит, и так далее.
При фактическом воплощении декодер может исключать необходимость поддержания m_Low, выполняемого кодером путем вычитания минимального значения каждого декодированного диапазона символов из m_Value (в данном случае, 50 вычитают из m_Value так, что остается 18). Диапазоны символа затем всегда представляют собой подразделение диапазона от 0 до (m_range - 1) (таким образом, диапазон 50-74 становится диапазоном от 0 до 24).
Важно отметить, что, если бы только два бита должны были бы быть кодированы таким образом, кодер мог бы выбирать любое конечное значение в пределах диапазона 50-74, и все они могли бы быть декодированы в те же самые два бита "10" (единица, после которой следует ноль). Большая точность необходима только, если должны быть кодированы дополнительные биты, и на практике, кодер HEVC всегда мог бы выбрать 50, как нижнюю границу диапазона. В вариантах осуществления, описанных в настоящей заявке, стремятся использовать неиспользуемый диапазон, находя определенные биты, которые, при соответствующей установке, гарантируют, что конечное значение будет правильно декодировано, независимо от того, какие значения составляют оставшиеся биты, освобождая эти оставшиеся биты для переноса другой информации. Например, в примере кодирования выборки, представленном выше, если первая цифра установлена в 6 (или 5), тогда конечное значение всегда должно находиться в пределах диапазона 50-74, независимо от значения второй цифры; следовательно, вторая цифра может использоваться для переноса другой информации.
Как можно видеть, бесконечный поток битов может быть кодирован, используя тот же диапазон вероятности (используя фракции с бесконечной точностью), путем многократного его подразделения. Однако на практике, бесконечная точность, является невозможной, и следует избегать нецелых чисел. С этой целью используется повторная нормализация. Если следует использовать диапазон 50-74 для кодирования третьего бита, каждый из диапазонов символов первоначально должны находиться в интервалах 12,5, но вместо этого, m_Range и m_Low могут быть удвоены (или по-другому умножены на общий множитель) до 50 и 100, соответственно, и диапазоны символа теперь будут представлять собой подразделы диапазона 100-149, то есть по 25 интервалов каждый. Эта операция эквивалентна ретроактивному удвоению размера исходного пространства вероятности от 100 до 200. Поскольку декодер поддерживает тот же m_Range, он может применять повторную нормализацию в то же время, что и кодер.
Контекстная переменная CV определена, как имеющая (в примерном варианте осуществления) 64 возможных состояния, которые последовательно обозначают разные вероятности от нижнего предела (такого как 1%) при CV=63, до 50%-ой вероятности при CV=0.
В адаптивной системе CV изменяется или перемещается от одного бита до следующего в соответствии с различными известными факторами, которые могут быть разными, в зависимости от размера блока данных, который должен быть кодирован. В некоторых случаях могут учитываться, состояние соседства и предыдущие блоки изображения. Таким образом, технологии, описанные здесь, представляют собой примеры модификации контекстной переменной для использования в отношении следующего значения входных данных с тем, чтобы увеличить пропорцию установленных значений кода в поддиапазоне, который был выбран для текущего значения данных.
Функции выбора поддиапазона, назначающие текущий бит для значения кода, модифицирующие набор кодовых обозначений, детектирующие, является ли набор меньшим, чем наименьший размер, и модифицирующие контекстную переменную, все могут выполняться блоком 950 моделирования контекста и механизмом 960 кодирования, действующими вместе. Таким образом, хотя они представлены как отдельные элементы на фиг. 17 для ясности пояснения, они действуют вместе для обеспечения контекстного моделирования и функции кодирования. Однако, для большей ясности, ссылка сделана на фиг. 19, которая более подробно иллюстрирует эти операции и функции.
Назначенное значение кода генерируют из таблицы, которая определяет, для каждого возможного значения CV и каждого возможного значения битов 6 и 7, m_range (учитывая, что бит 8 m_range всегда равны 1, из-за ограничения размера m_range), положение или группу положений, в которых для нового кодированного бита должно быть выделено значение кода в соответствующем поддиапазоне.
На фиг. 19 схематично иллюстрируется кодер САВАС, использующий технологии, описанные выше.
CV инициируют (в случае первого CV) или модифицируют (в случае последующих CV) с помощью модуля 1120 образования CV. Генератор 1130 кода разделяет текущий m_range в соответствии с CV, выбирает поддиапазон и генерирует назначенный код данных в пределах соответствующего sub_range, например, используя упомянутую выше таблицу. Модуль 1140 сброса диапазона сбрасывает m_range такой, как выбранный поддиапазон, для модификации набора кодовых значений, как описано выше. Блок 1150 нормализации детектирует, находится ли полученное в результате значение m_range ниже минимального допустимого значения и, в случае необходимости, повторно нормализует m_range один или больше раз, выводя выходной кодированный бит данных для каждой такой операции повторной нормализации. Как упомянуто, в конце обработки также выводят назначенное значение кода.
В декодере, который схематично показан на фиг. 20, CV инициируют (в случае первого CV) или модифицируют (в случае последующих CV) модулем 1220 вывода CV, который работает так же, как и модуль 1120 в кодере. Модуль 1230 применения кода разделяет текущее m_range, в соответствии с CV, и детектирует, в каком поддиапазоне находится код данных. Модуль 1240 сброса диапазона выполняет сброс m_range в этот выбранный поддиапазон с тем, чтобы модифицировать набор кодовых значений, в зависимости от назначенного кодового обозначения и размера выбранного поддиапазона. В случае необходимости, блок 1250 нормализации повторно нормализует m_range в ответ на принятый бит данных.
Варианты осуществления обеспечивают технологию для завершения потока САВАС. Варианты осуществления будут описаны в контексте примерной системы, в которой диапазон значения кода имеет максимальное значение 512 (вместо 128, как описано выше) и таким образом, он ограничен так, что он находится в верхней половине этого диапазона, то есть от 256 до 510.
Технология может обеспечить потерю в среднем 1,5 бита (то есть намного меньшие потери, чем в предыдущих вызванных технологиях завершения потока). Второй альтернативный способ также представлен, который позволяет получать среднюю потерю 1 бит.Применение этих технологий было рассмотрено так, чтобы они включали в себя завершение потока САВАС до передачи данных IPCM (неразделенных по частоте), и завершение потока для каждого ряда на срез. Эта технология основана на распознавании того, что переменная САВАС может быть установлена в любое значение в пределах правильного диапазона во время завершения. Таким образом, переменная САВАС установлена в значение, которое имеет множество завершающих (младших значащих битов) нулей, таким образом, что, когда значение сбрасывает поток данных, нули могут эффективно игнорироваться.
В текущих технологиях, завершение потока САВАС приводит к тому, что 8 битов будут сброшены в поток данных (то есть они будут потеряны или напрасно затрачены). Иллюстрируется технология с примером, где внутри фреймов завершение потока происходит после каждого LCU или среза изображения (то есть после кодирования группы значений данных, представляющих значения данных, относящиеся к определенной соответствующей подобласти изображения), что позволяет помещать обходные данные коэффициента (коды битов знака/коды перехода) в поток битов, в необработанном формате.
Обработка для завершения потока САВАС применяется в конце каждого среза и перед данными IPCM. В вариантах осуществления в обработке предполагается (для целей этого описания), что вероятность того, что поток должен быть завершен, является фиксированной в среднем на значении 0,54%. (Когда кодируют значение данных (1 или 0), текущее m_range подразделяют на два диапазона символов, представляющих вероятность 1 или 0, соответственно. Для специального "значения" флага конца потока диапазон символа для 1 всегда равен 2. Следовательно, вероятность того, что значение данных равно 1, зависит от значения текущего m_range. В некоторых вариантах осуществления, как описано выше, m_range может изменяться между 256 и 510, таким образом, вероятность завершения, поэтому, изменяется между 2/510 = 0,3922% и 2/256 = 0,7813%).
Для кодера эта обработка представляет собой:
- если поток не следует завершить, диапазон САВАС m_range будет уменьшен на 2, и механизм САВАС будет повторно нормализован на 1 место, если требуется (то есть следует упомянуть, что m_Low и m_range повторно нормализуют); обработка текущего потока САВАС продолжается.
- если поток должен быть завершен, 'm_Low' САВАС последовательно увеличивают на 'диапазон меньший 2', диапазон устанавливают в 2, и механизм САВАС повторно нормализуют на 7 мест, после чего происходит вывод следующей двоичной '1'. Эта обработка эквивалентна повторной нормализации 8 мест, которое повторно нормализуют, принудительно делая нечетным числом.
Возможны случаи, когда описанная выше обработка не является идеальной, то есть случаи, когда вероятность потока является переменной или фиксированной, при более высоком процентном значении, или даже представляет собой достоверный результат (вероятность 1).
Варианты осуществления могут обеспечить способ, в соответствии с которым поток САВАС может быть немедленно завершен, используя только 2 повторных нормализации, с потерей (в среднем) 1,5 бит, и с незначительным влиянием на сложность декодера и кодера. Альтернативный способ также обозначен, который может уменьшить служебные данные до всего лишь 1 бита, но за счет увеличения сложности декодера САВАС. Оба способа могут затем использоваться совместно со стандартной адаптивной контекстной переменной, если существует переменная вероятность завершения, или совместно с фиксированным процентным механизмом (что соответствует неадаптивной контекстной переменной).
Следует отметить, что, как описано выше, m_Low и m_Range повторно нормализуют вместе.
1 Алгоритм
1.1 Способ
Этапы кодера являются следующими:
m_Low = (m_Low + 128)& ~ 127
{или m_Low = (m_Low + 127)& ~ 127}
Выполнить 2 этапа повторной нормализации m_Low и вызвать test_write_out () [записать значение в поток]
Перед кодированием следующего потока САВАС, установить m_Range=510, m_Low=0.
Примечание: & представляет собой операцию AND, и ~ обозначает двоичную инверсию (таким образом, что ~127 представляет собой двоичную инверсию двоичного значения, соответствующего десятичному числу 127, таким образом, что операция AND с двоичной инверсией числа, такого как десятичное число 127 (которое имеет множество младших значащих битов или LSB, равных 1) эквивалентна установке того, что количество LSB полученного в результате значения равно нулю). Функция test_write_out () проверяет, приемлемо ли передать любые биты в верхней части (конец MSB) m_Low в выходной поток, записывая их, если так. В контексте псевдокода, представленного выше, новые биты, сформированные "принудительной повторной нормализацией", будут записаны этой операцией.
Этапы декодера являются следующими:
Отвести обратно входной поток на 7 битов (то есть переместить положение считывания обратно на 7 битов).
Перед декодированием следующего потока САВАС, установить m_Range=0, и считать m_value из потока битов.
Данный способ оказывает слабое влияние на обработку декодера и кодера.
В отношении m_Low следует отметить, что кодер генерирует поток путем многократного суммирования с m_Low. Декодер считывает этот поток, начиная с конечного результата кодера и с многократным вычитанием из него. Декодер вызывает биты, считанные из потока "m_uiValue" (или m_value в примечании к этому описанию), скорее, чем m_Low, и именно они должны быть считаны из потока битов. Это является соответствующим в случае, когда некоторые варианты осуществления требуют, чтобы декодер поддерживал m_Low так же, как и m_uiValue, так, чтобы в нем было известно, что делает кодер. В этом случае m_Low генерируют в декодере точно таким же образом, как и m_Low кодера.
Альтернативный способ
Данный способ увеличивает сложность текущих декодеров, поскольку он требует, чтобы декодер поддерживал m_Low. Если поддержание m_Low требуется в других предложениях, тогда эта дополнительная сложность снова будет минимальной.
Этапы кодера являются следующими:
Let test256 = (m_Low+255)& ~ 255
If (test256 + 256 < m_Low + m_Range)
m_Low = m_test256
Принудительно выполнить 1 этап повторной нормализации m_Low и вызвать test_write_out ().
else (как и раньше)
m_Low = (m_Low + 128)& ~ 127 {или m_Low = (m_Low + 127)& ~ 127}
Принудительно выполнить 2 этапа повторной нормализации m_Low и вызвать test_write_out ().
Перед кодированием следующего потока САВАС установить m_Range=510, m_Low=0.
Этапы декодера являются следующими:
Let test256 = (m_Low + 255)& ~ 255
If (test256 + 256 < m_Low + m_Range)
Вернуть поток обратно на 8 битов
else (как и раньше)
Вернуть обратно поток на 7 битов
Перед декодированием следующего потока САВАС, установить m_Range=0, установить m_Low=0 и считать m_value из потока битов.
Теория
Для кодера САВАС данные, записанные в поток (или помещенные в буфер), соединяют с m_Low, таким образом, что n-битное low обозначает самое меньшее значение, которое может представлять конечный выход. Наибольшее значение, high, представляет собой сумму low и m_Range, переменную, поддерживаемую кодером, так, чтобы она находилась в пределах диапазона от 256 (включительно) до 511 (исключительно). В конце потока любое значение между low (включительно) и high (исключительно) может быть выбрано как конечное выходное значение, без влияния на декодирование. Если декодирование может быть выполнено без зависимости от n LSB значения, тогда n LSB могут быть заменены данными из следующего участка потока битов.
Пусть v будет представлять собой значение между low и high, где n LSB равно 0, и где, если последние n LSB равны 1, полученное в результате значение V все еще может быть меньше, чем high. Поскольку " high - low " составляет, по меньшей мере, 256, тогда всегда будет существовать значение v между low и high, которое имеет, по меньшей мере, 7 LSB, которые равны 0. То есть значение v представляет собой первое значение между low и high, которое может быть разделено на 128 без остатка.
Простейший способ для достижения этого представляет собой стандартную процедуру выравнивания степени 2, а именно:
v=(low+127)&~127
Однако, поскольку диапазон составляет, по меньшей мере, 256, тогда:
v=(low+128)&~127
также достаточно (и приводит к несколько меньшему кодеру).
Для текущей части потока битов кодер мог бы выводит значение 'v', за исключением нижних 7 битов, что достигается путем повторной нормализации m_Low на 2 места. В конце потока битов декодер мог бы считать 7 битов из следующей части потока битов, и, поэтому, был бы вынужден "отвести обратно" поток битов на 7 битов.
Существуют случаи, когда нижние 8 битов не требуются для полного декодирования потока, и простейшую иллюстрацию этого составляет случай, когда "m_Low=0", и это используется в альтернативном алгоритме. В таком альтернативном алгоритме, рассчитывают значение v между low и high с 8 LSB, равными 0, и затем применяют тестирование для проверки, существует ли соответствующее значение V. Обработка принятия решений требует тестирования в отношении low и high, и поскольку декодер должен также принимать то же решение, декодер при этом должен отслеживать m_Low.
В обеих версиях алгоритма кодера существует выбор 7-битного пути, который приводит к другому потоку битов, но все еще может быть декодирован тем же декодером.
Со ссылкой на фиг. 19, описанную выше, модули 1120 и 1130 представляют собой варианты осуществления селектора для выбора одного из множества взаимодополняющих поддиапазонов из набора значений кодов и модуля назначения данных, для назначения текущего входного значения для значения кодов. Модуль 1140 представляет вариант осуществления модуля модификации данных. Модуль 1150 представляет вариант осуществления детектора для детектирования, является ли набор кодовых значений меньшим, чем минимальный размер, и для выполнения других функций этого детектора, соответственно. Модуль 1150 также представляет вариант осуществления блока завершения данных путем выполнения описанной выше функции завершения данных, и который описан ниже, и, в частности, путем принятия решения в отношении того, когда следует завершить поток.
Со ссылкой на фиг. 20, описанную выше, модули 1220, 1230, 1240 и 1250 совместно представляет варианты осуществления контроллера указателя и модуля установки, в том, что они работают так, что они выполняют функцию, описанную выше в отношении этих модулей.
Варианты применения
Возможные варианты применения для этого включают в себя:
1. Завершение для последнего кодированного LCU для среза, в частности, в стиле конфигурации "ряд на срез", где вероятность может быть существенно выше, чем 0,54%; в этой компоновке варианты осуществления могут обеспечивать способ кодирования данных для кодирования последовательных входных значений данных, представляющих видеоданные, способ, содержащий следующие этапы: выбирают один из множества взаимодополняющих поддиапазонов набора значений кода, в соответствии со значением текущего значения входных данных, пропорция поддиапазонов относительно набора значений кода определяется переменной контекста, ассоциированной с этим входным значением данных; назначают текущие значения входных данных для значения кода в пределах выбранного поддиапазона; модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона; детектируют, является ли набор значений кода меньшим, чем заданный минимальный размер, и если это так, последовательно увеличивают размер набора значений кода, до тех пор, пока он не достигнет, по меньшей мере, заданного минимального размера; и выводят кодированный бит данных в ответ на каждую такую операцию по увеличению размера; модифицируют контекстную переменную для использования в отношении следующего бита или значения входных данных, чтобы увеличить пропорцию набора обозначений кода в поддиапазоне, который был выбран для текущего значения данных; и, после кодирования группы значений входных данных, соответствующих набору блоков видеоданных в пределах среза видеоданных, которые кодируют без ссылки на другие видеоданные, прекращают выходные данные путем: установки значения, определяющего конец набора кодовых значений, на значение, имеющее множество младших значащих битов, равных нулю; увеличивают размер набора значений кода; и записывают значения, определяющие конец набора значений кода, в выходные данные.
2. Завершение последнего возможного LCU для среза как завершение после последнего возможного LCU среза представляет собой достоверный результат; при такой компоновке варианты осуществления могут обеспечивать способ кодирования данных для кодирования последовательных значений входных данных, представляющих видеоданные, способ, содержащий следующие этапы: выбирают один из множества взаимодополняющих поддиапазонов набора значений кода в соответствии со значением текущего значения входных данных, пропорции поддиапазонов относительно набора установки значений кода определены контекстной переменной, ассоциированной с этим значением входных данных; назначают текущие значения входных данных для значения кода в пределах выбранного поддиапазона; модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона; детектируют, является ли набор значений кода меньшим, чем заданный минимальный размер, и если это так, последовательно увеличивают размер набора значений кода до тех пор, пока он не будет иметь, по меньшей мере, заданный минимальный размер; и выводят бит кодированных данных в ответ на каждую такую операцию по увеличению размера; модифицируют переменную контекста для использования в отношении следующего бита или значения входных данных, для увеличения пропорции набора значений кода в поддиапазоне, который был выбран для текущего значения данных; и после кодирования группы значений входных данных, представляющих весь срез видеоданных, который кодируют без ссылки на другие видеоданные, завершают выходные данные путем: установки значения, определяющего конец набора значений кода до значения, имеющего множество младших значащих битов, равных нулю; увеличивают размер наборов значений кода; и записывают значения, определяющие конец набора значений кода, в выходные данные.
3. Завершение перед данными IPCM, возможно совместно с контекстной переменной; в этой компоновке варианты осуществления могут обеспечивать способ кодирования данных для кодирования последовательных значений входных данных, представляющих видеоданные, разделенные по частоте, способ, содержащий следующие этапы: выбирают один из множества взаимодополняющих поддиапазонов набора значений кода, в соответствии со значением текущего значения входных данных, пропорции поддиапазонов в отношении набора значений кода определены контекстной переменной, ассоциированной с этим значением входных данных; назначают значения текущих входных данных для значения кода в пределах выбранного поддиапазона; модифицируют набор значений кода, в зависимости от назначенных значений кода и размера выбранного поддиапазона; детектируют, является ли набор значений кода меньшим, чем заданный минимальный размер, и если это так, последовательно увеличивают размер набора значений кода, до тех пор, пока он не достигнет, по меньшей мере, заданного минимального размера; и выводят бит кодированных данных в ответ на каждую такую операцию увеличения размера; модифицируют переменную контекста, для использования в отношении следующего бита или значения входных данных, с тем, чтобы увеличить пропорцию набора значений кода в поддиапазоне, который был выбран для текущего значения данных; и после кодирования группы значений входных данных так, что следующая группа значений данных, которые должны быть кодированы, представляет не разделенные по частоте видеоданные, завершают выходные данные путем: установки значения, определяющего конец набора значений кода до значения, имеющего множество младших значащих битов, равных нулю; увеличивают размер набора значений кода; и записывают значения, определяющие конец набора значений кода, в выходные данные.
4. Завершение потока, для предотвращения слишком длительное времени продолжения механизма "ожидающих выполнения битов"; в такой компоновке варианты осуществления могут обеспечить способ кодирования данных для кодирования последовательных значений входных данных, способ, содержащий следующие этапы: выбирают один из множества взаимодополняющих поддиапазонов из набора значений кода, в соответствии со значением текущего значения входных данных, пропорции поддиапазонов в отношении набора значений кода, определяемые переменной контекста, ассоциированной с этими значениями входных данных; назначают для текущего значения входных данных значения кода в пределах выбранного поддиапазона; модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона; детектируют, является ли набор значений кода меньшим, чем заданный минимальный размер, и если это так, последовательно увеличивают размер набора значений кода до тех пор, пока он не будет иметь, по меньшей мере, заданный минимальный размер; и выводят бит кодированных данных в ответ на каждую такую операцию увеличения размера; модифицируют переменную контекста для использования в отношении следующего значения битов входных данных таким образом, что увеличивается пропорция набора значений кода в поддиапазоне, который был выбран для текущего значения данных; детектируют, превышает ли набор значений данных, которые должны быть кодированы, используя другую технологию кодирования, заданный размер, и если это так, завершают выходные данные путем: установки значения, определяющего конец набора значений кода в значение, имеющее множество младших значащих битов, равных нулю; увеличивают размер набора значений кода; и записывают значения, определяющие конец набора значений кода, в выходные данные.
Следующая часть описания относится к расширению операций кодеров и декодеров, таких, как те, которые были описаны выше, до операций с более высоким разрешением видеоизображения и, соответственно, более низкими (включая в себя отрицательные) значениями QP. Низкие рабочие значения QP могут потребоваться, если кодек действительно должен поддерживать большую битовую глубину. Будут описаны возможные источники ошибок, которые могут быть вызваны внутренними ограничениями точности, присутствующим в кодерах и декодерах, таких как определены HEVC. Некоторые изменения в отношении этих значений точности могут уменьшить ошибки и, таким образом, могут расширить рабочий диапазон HEVC. Кроме того, представлены изменения в энтропийном кодировании.
Во время подачи настоящей заявки в HEVC Версия 1 описан 8 и 10-битный кодек; Версия 2 должна включать операции с 12 и 14 битами. Хотя тестовая демонстрация программного обеспечения была записана как позволяющая использовать значения глубины входных данных битов до 14, возможности кодека кодировать 14 битов не обязательно соответствуют способу, в соответствии с которым кодек обрабатывает данные с разрешением 8 или 10 битов. В некоторых случаях внутренняя обработка может вводить шумы, которые могут привести к эффективной потере разрешения. Например, если отношение пикового сигнала к шумам (PSNR) для входных данных 14-битов будет настолько низким, что младшие значащие два бита эффективно уменьшаются до уровня шума, тогда кодек эффективно работает только с 12-битным разрешением. Поэтому целесообразно устанавливать в качестве цели систему, имеющую внутренние рабочие функции, которые позволяют использовать входные данные с более высоким разрешением (например, входные данные с разрешением 12 или 14 битов), без ввода слишком больших шумов, ошибок или других артефактов для уменьшения эффективного (полезного) разрешения выходных данных на существенную величину.
Термин "битовая глубина" и переменная bitDepth используются здесь для обозначения разрешения входных данных и/или (в соответствии с текстовым контекстом) обработки данных, выполняемой в кодеке (последняя также называется "внутренней битовой глубиной", используя терминологию демонстрационной модели программного обеспечения HEVC). Например, для обработки 14-ти битовых данных bitDepth=14.
В контексте 8-ми и 10-ти битного кодека описаны параметры квантования (QP) в положительном диапазоне (QP>0). Однако для каждого дополнительного бита (превышающего 8 битов) в разрешающей способности входных данных, минимальное допустимое значение QP (minQP) может быть на 6 меньше, чем 0, или другими словами:
minQP = -6 * (bitDepth - 8)
Переменная "PSNR" или пиковое значение SNR определена как функция среднеквадратичной ошибки (MSE) и битовой глубины:
PSNR = 10 * log10(((2bitDepth) - 1)2 / MSE)
Как можно видеть на фиг. 23, которая будет описана ниже, независимо от того, каково значение битовой глубины обработки в примерном варианте осуществления кодека, общая тенденция состоит в том, что кривая PSNR имеет пик на уровне 90 дБ; для более отрицательных значений QP (QP соответствует пику кривой PSNR), характеристики PSNR фактически уменьшаются.
Используя уравнение для PSNR, можно вывести следующую таблицу значений PSNR для заданных значений глубины битов и MSE:
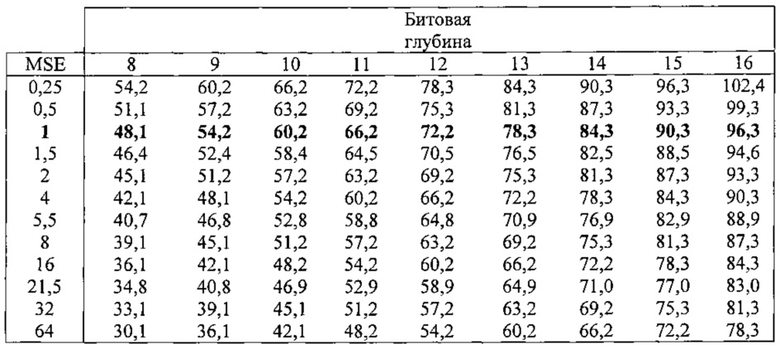
Если 14-битовый кодек способен достичь только PSNR 72,2 дБ, тогда каждое выходное значение будет точным только в пределах диапазона ±4 соответствующего оригинального значения. Два младших значащих бита, поэтому, представляют собой эффективный шум, таким образом, что кодек в действительности эквивалентен 12-ти битному кодеку с двумя дополнительными случайными битами, добавленными на выходе. (Важно отметить, что этот анализ основан на усреднениях, и что фактически, в некоторых частях изображения, может быть достигнуто лучшее или худшее качество, чем это среднее значение).
Расширяя этот аргумент, при сравнении PSNR, используя такой исключительно численный способ, можно подумать, что наилучшая система, поэтому, фактически будет представлять собой 8-ми битную систему с кодированием без потерь, которая позволяет достичь бесконечного значения PSNR (MSE=0). Однако при этом не учитываются потери при исходном округлении или усечении видеоизображения из n битов (где n в исходном варианте выше, чем 8) до 8 битов. Такой подход может быть обобщен, в соответствии со следующими примерами:
- Если (n-1)-битная система без потерь была доступна для кодирования n-битных данных, тогда на выходе наблюдаемое n-битное MSE могло бы представлять собой (0+12)/2=0,5.
Если (n-2)-битная система без потерь была доступна для кодирования n-битных данных, тогда на выходе наблюдаемое n-битное MSE могло бы составлять (0+12+22+12)/4=1,5.
- Если (n-3)-битная система без потерь была доступна для кодирования n-битных данных, тогда на выходе наблюдаемое n-битное MSE могло бы составлять (0+12+22+32+42+32+22+12)/8=5,5.
- Если (n-4)-битная система без потерь была доступна для кодирования n-битных данных, тогда на выходе наблюдаемое n-битное MSE могло бы составлять:
(0+12+22+32+42+52+62+72+82+72+62+52+42+32+22+12)/16=21,5.
Поэтому, возвращаясь к конкретному примеру, если 14-ти битная система не достигает значения MSE 21,5 или меньше (эквивалентно 71,0 дБ), и если значение битов 10-битной системы, работающей без потерь, было аналогичным, тогда, с точки зрения цифровой обработки, эффективно кодируются только 10 битов.
Рассмотрим (n-r)-битную систему с потерями и с низкой битовой глубиной с MSE 'm'. Если эта система используется для кодирования n-битных данных с большей битовой глубиной, то ее MSE, поэтому, будет задано величиной (2r)2m.
Например, для (n-1)-битной системы с потерями, MSE в n-битной системе могло бы составлять 4 m; для (n-2)-битной системы с потерями MSE в n-битной системе могло бы составлять 16 m; для (n-3)-битной системы с потерями MSE в n-битной системе могло бы составлять 64 m; и для (n-4)-битной системы с потерями MSE в n-битной системе могло бы составлять 256 m.
Поэтому, для случая, когда системы с малой битовой глубиной с потерями кодируют данные с большей битовой глубиной (n-битной), они обычно теряют основную составляющую для MSE, наблюдаемого в области n-бит, таким образом, что простые показатели PSNR могут использоваться как прямое сравнение качества.
Воплощение кодера HEVC (во время подачи заявки) имело пики на уровне 90 дБ (как показано на фиг. 23); это можно рассматривать соответствующим для кодирования 11-битных данных, но в этой рабочей точке, ниже будет рассмотрен вопрос, можно ли достичь дальнейшего улучшения.
Во-первых, будут описаны потенциальные источники ошибки.
Основная система HEVC (версия 1) была разработана для 8 и 10 битных операций. По мере увеличения количества битов, внутренняя точность частей системы может стать значимой, как потенциальный источник ошибок, шумов или артефактов, приводящих к эффективной потере общего разрешения.
Упрощенная схематичная диаграмма, иллюстрирующая поток данных через кодер таких типов, как описаны выше, такой как кодер HEVC, показана на фиг. 21. Назначение обобщения обработки в форме, показанной на фиг. 21, состоит в том, чтобы обозначить потенциальные ограничения в отношении рабочего разрешения в системе. Следует отметить, что, по этой причине, не все функции кодера показаны на фиг. 21. Следует отметить также, что на фиг. 21 представлен пример устройства для кодирования значения входных данных набора данных (которые могут представлять собой значения видеоданных). Кроме того, следует отметить, что (как описано выше) технологии, используемые на прямом пути кодирования, таком, как показан на фиг. 21, также можно использовать на взаимодополняющем обратном пути декодирования кодера и также можно использовать на прямом пути декодирования декодера.
Входные данные 1300 определенной глубины битов подают на этап 1310 прогнозирования, который выполняет либо прогнозирование внутри изображения, либо прогнозирование между изображениями, и вычитает спрогнозированную версию из фактического входного изображения, генерируя остаточные данные 1320 определенной битовой глубины. Таким образом, этап 1300, в общем, соответствует пунктам 320 и 310 на фиг. 5.
Остаточные данные 1320 преобразуют по частоте на этапе 1330 преобразования, который подразумевает выполнение множества этапов обработки преобразования (обозначены как этап 1 и этап 2), соответствующих умножению левой и правой матрицы в уравнении преобразования 2D, и выполняется в соответствии с одним или больше наборами матрицы 1340 преобразования (преобразования могут быть воплощены с помощью обработки умножения матриц), имеющих определенное разрешение. Максимальный динамический диапазон 1350 при обработке преобразования, называемый MAX_TR_DYNAMIC_RANGE, применяется для расчетов, используемых при этой обработке. Выход этапа преобразования установлен из коэффициентов 1360 преобразования в соответствии с MAX_TR_DYNAMIC_RANGE. Этап 1330 преобразования, в общем, соответствует модулю 340 преобразования на фиг. 5.
Коэффициенты 1360 затем передают на этап 1370 квантования, который, в общем, соответствует блоку 350 квантования по фиг. 5. Этап квантования может использовать механизм множественного сдвига под управлением коэффициентов квантования и списков 1380 масштабирования, включая в себя ограничения до максимального динамического диапазона ENTROPY_CODING_DYNAMIC_RANGE (который в вариантах осуществления является таким же, как MAX_TR_DYNAMIC_RANGE). Выход этапа квантования представляет собой набор 1390 квантованных коэффициентов, в соответствии с ENTROPY_CODING_DYNAMIC_RANGE, который затем (в полном кодере, который не показан здесь) передают на этап энтропийного кодирования, такой, как представлен модулем 360 сканирования и энтропийным кодером 370 на фиг. 5.
Используя обозначение, введенное в отношении фиг. 21, основные источники шумов, возникающих при расчетах, игнорируя (с целью данного описания) шумы, вызванные различными вариантами прогнозирования и RQT (остаточное квадро-дерево) и обработкой принятия решения в отношении RDOQ (оптимизированное квантование случайного искажения) в HEVC, описанном ниже:
Значения коэффициента матрицы преобразования
В идеале, обратное преобразование, применяемое для преобразованных коэффициентов, приводит к воспроизведению исходных входных значений. Однако это ограничено целочисленной природой расчетов. В HEVC матричные коэффициенты преобразования имеют 6 фракционных битов (то есть они имеют неотъемлемый присущий им сдвиг влево, равный 6).
Результаты сдвига до MAX_TR_DYNAMIC_RANGE после каждого этапа преобразования
Прямое преобразование приводит к получению значений, которые имеют размер bitDepth + log2(size) битов. После первого этапа преобразования ширина коэффициентов в битах должна составлять, по меньшей мере, bitDepth + log2(size) (хотя дополнительные биты помогают поддерживать большую точность). Однако в HEVC эти промежуточные значения сдвинуты при преобразовании вперед (только кодер) таким образом, что они никогда не превышают MAX_TR_DYNAMIC_RANGE; то же самое относится ко второму этапу. При обратном преобразовании значения на выходе каждого этапа обрезают до MAX_TR_DYNAMIC_RANGE.
Если, MAX_TR_DYNAMIC_RANGE будет меньше, чем bitDepth + log2(size), то значения из прямого преобразования фактически будут сдвинуты влево (вместо вправо) на этапе квантования, и затем будут обрезаны до 15 битного (ENTROPY_CODING_DYNAMIC_RANGE). Фактически, если ENTROPY_CODING_DYNAMIC_RANGE будет меньше, чем bitDepth + log2(size) + 1, то происходит обрезка сигнала, когда QP будет меньше, чем (4 - (6 * (bitDepth - 8))).
В HEVC, MAX_TR_DYNAMIC_RANGE (и ENTROPY_CODING_DYNAMIC_RANGE равный 15 используется вплоть для операций с 10 битами, хотя коэффициенты в блоках 32×32 могут быть обрезаны для QP<-8. Кроме того, отсутствие запаса для внутренней точности также может вводить ошибки для низких значений QP.
Шумы, добавляемые во время квантования
Хотя блок квантования и блок обратного квантования кодера и декодера добавляют шумы, дополнительные шумы при квантовании могут быть непреднамеренно добавлены при применении списков масштабирования, и поэтому коэффициенты квантования, определенные в массивах 'quantScales' и 'invQuantScales', не обязательно являются идеальными обратными величинами.
Эффект точности матрицы преобразования и MAX_TR_DYNAMIC_RANGE описан ниже.
Эмпирические данные были получены в результате анализа (используя так называемый профиль внутреннего кодирования) при кодировании пяти видеопоследовательностей из, так называемого, тестового набора SVT (1920×1080 50р при 16 битах, масштабируемых до видеоданных 4 K). Из этих последовательностей только первые 150 кадров использовались при испытаниях. Шестая последовательность, называемая Traffic_RGB (2560×1600 20р при 12 битах) определена тестовыми условиями стандарта Range Extension, применяемыми для HEVC на время подачи настоящей заявки.
В эмпирических тестах, если битовая глубина файла (входных данных) была меньше, чем внутренняя тестируемая битовая глубина (входная битовая глубина кодека), тогда в выборках выполняли набивку (LSB устанавливали в 0); если битовая глубина файла составляла больше, чем внутренняя битовая глубина, выборки масштабировали и округляли.
В представленном ниже описании bitDepth используют, скорее, для описания внутренней битовой глубины, чем битовой глубины входных данных. Рассматривают системы с внутренней битовой глубиной (bitDepth) вплоть до 16.
На фиг. 22 показан график зависимости скорости передачи битов от параметра квантования (QP), который схематично иллюстрирует эмпирические рабочие характеристики системы кодера по фиг. 21 для множества значений битовой глубины. На фиг. 23 показан график PSNR для зеленого канала (на основе того, что легче получить эмпирические данные для одного канала, и зеленый представляет собой канал, который в наибольшей степени способствует восприятию зрителем выходного видеоизображения), в зависимости от QP. Графики на фиг. 22 сформированы из составных данных для обработки 16 битов (QP от -48 до -26), 14 битов (QP от -24 до -14), 12 битов (QP от -12 до -2), 10 битов (QP от 0 до 10) и 8 битов (QP от 12 до 22). Вертикальные линии 1400 схематично обозначают точки, в которых изменяется битовая глубина. Множество кривых на фиг. 22 соответствуют результатам, полученным с разными соответствующими последовательностями тестирования.
На фиг. 22 показано, что скорость передачи битов, в общем, изменяется монотонно с изменением QP.
Как показано на фиг. 23, PSNR для bitDepth=8 и bitDepth=10 резко увеличивается при значении QPs 4 и меньше (самые правые три точки данных на каждой кривой). При значении QP 4, делитель квантования для 8 битов равен 1 (QP равен -8 для 10 битов), оставляя несоответствие между DCT и IDСТ, и между коэффициентами квантования и деквантования, как единственные вероятные источники ошибки. Поскольку в системе проявляется тенденция в направлении обработки без потерь, MSE приближается к нулю и выбросы SNR вверх на фиг. 24 представляют график PSNR в зависимости от скорости битов, для одной тестовой последовательности, в серии разных внутренних значений битовой глубины (8, 10, 12, 14, 16). Эти пять кривых практически точно накладываются друг на друга на большей части их диапазона и, таким образом, их нельзя просто различать.
10-битная система в той же рабочей точке имеет ошибки, в основном, в двух младших значащих битах, что означает, что она также приближается к обработке без потерь, если учитывать только 8-битную точность, но как обозначено повсеместно в этом описании, также следует учитывать действие преобразования 10-битных видеоданных в 8-битные видеоданные. Это добавляет MSE 1,5, которое скрыто (то есть не показано в явном виде как результат этих эмпирических тестов, но все еще приводит к более высокому общему значению SNR), при учете более низкой точности.
В системах, которые не ограничены внутренней точностью в отношении пикового значения SNR, это увеличение в направлении обработки без потерь можно видеть для каждого значения bitDepth по мере падения QP (4 - (6 * (bitDepth - 8))). Это показано на фиг. 25, на которой представлен график PSNR зеленого канала, в зависимости от скорости битов, для диапазона значений битовой глубины (8, 10, 12, 14, 16) при MAX_TR_DYNAMIC_RANGE=21, ENTROIPY_CODING_DYNAMIC_RANGE=21 и 14-ти битных матрицах преобразования, при отключенном RDOQ и при отключенном пропуске преобразования. Пять кривых накладываются друг на друга за исключением участков 1420 (на 8-ми битной кривой), 1430 (на 10-ти битной кривой), 1440 (на 12-ти битной кривой), 1450 (на 14-ти битной кривой) и 1460 (на 16-ти битной кривой). Также можно видеть, что для того же количества битов существенно большие значения SNR могут достигнуты, чем в случае, показанном на фиг. 24.
Эмпирические результаты показали, что в вариантах осуществления настоящего раскрытия, точность матрицы преобразования должна составлять, по меньшей мере, bitDepth - 2. На фиг. 26 показан график зависимости PSNR от скорости битов для зеленого канала в одной тестовой последовательности с bitDepth=10 и MAX_TR_DYNAMIC_RANGE=17, при сравнении различных матриц DCT различной точности.
В вариантах осуществления MAX_TR_DYNAMIC_RANGE должен составлять, по меньшей мере, на 5 (что представляет собой минимальное значение log2(size)) больше, чем bitDepth. Дополнительная точность была показана для дополнительного повышения эффективности кодирования.
В вариантах осуществления ENTROPY_CODING_DYNAMIC_RANGE должен быть, по меньшей мере, на 6 больше, чем bitDepth (на 1 меньше для фактора "квантования", применяемого QP, чем (4 - (6 * (bitDepth - 8))) плюс 5 для максимального значения log2(size)). В других вариантах осуществления, в случае, когда ограничение сигнала для наименьших значений QP не составляет проблему, тогда ENTROPY_CODING_DYNAMIC_RANGE должен быть, по меньшей мере, на 5 (минимальное значение log2(size)) больше, чем bitDepth.
Для 16-битной системы точность матрицы преобразования должна быть установлена равной 14, MAX_TR_DYNAMIC_RANGE должен быть установлен в 21, и ENTROPY_CODING_DYNAMIC_RANGE должен быть установлен в 22. Поскольку получение большей внутренней точности редко рассматривается как вредное, эти параметры также были тестированы при разных значениях bitDepth, приводя к результатам, которые демонстрируют, что для одинакового количества битов может быть достигнуто существенно более высокое значение SNR, и что система повышенной точности имеет рабочие точки PSNR/MSE, которые пригодны для bitDepth вплоть до 16.
Если расширения диапазона предназначены для получения одного нового профиля для всех битов глубины, тогда описанная выше система пригодна для использования. Однако, если разные профили должны быть описаны для разных максимальных значений bitDepth, тогда может быть полезно иметь разные значения параметра для уменьшения сложности аппаратных средств в системе, в которой не требуются наивысшие профили. В некоторых вариантах осуществления разные профили могут определять разные значения для точности матрицы преобразования, MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE.
В других вариантах осуществления профиль мог бы обеспечить возможность выбора кодером некоторых или всех значений точности матриц преобразования, MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE из списка разрешенных значений (при этом стоимость воплощения представляет собой критерий выбора), или функцией дополнительной информации, такой как bitDepth. Однако это могло бы потребовать множества наборов матриц преобразования, если точность матрицы преобразования должна изменяться, и по этой причине в дополнительных вариантах осуществления только точность матрицы преобразования определена для профиля, и при этом точность матрицы преобразования соответствует рекомендованному значению для максимальной битовой глубины, для которой разработан профиль. Набор возможных профилей предложен ниже со ссылкой на фиг. 28.
Примеры значений точности матрицы преобразования,
MAX_TR_DYNAMIC_RANGE, ENTROPY_CODING_DYNAMIC_RANGE и bitDepth показаны в представленной ниже таблице:

В таблице значения, помеченные  , обрезают до минимума 15 в соответствии с текущим описанием HEVC. Значения, помеченные
, обрезают до минимума 15 в соответствии с текущим описанием HEVC. Значения, помеченные  и
и  больше, чем установлены для текущего описания HEVC, и они составляют 15 и 6, соответственно.
больше, чем установлены для текущего описания HEVC, и они составляют 15 и 6, соответственно.
Если должны использоваться разные профили, тогда в вариантах осуществления раскрытия эти спецификации могут использоваться как минимальные (следует отметить, что версия HEVC 1 в 10-битной системе не вполне удовлетворяет этим целевым значениям). Использование значений, которые меньше, чем эти обозначенные минимумы, возможно, хотя это приведет к деградации PSNR для более высоких значений скорости битов (для меньших значений QP).
В соответствии с этим, представленная выше таблица является примером компоновки, в которой точность и/или динамический диапазон одного или больше из этапов кодирования (и взаимодополняющего декодирования) установлены в соответствии с битовой глубиной видеоданных.
В некоторых вариантах осуществления, однако, данные яркости и цветности могут иметь разные значения битовой глубины.
В соответствии с этим, в таких ситуациях, хотя значения точности и/или динамического диапазона могут быть установлены по-разному (как между данными яркости и цветности), таким образом, один набор значений применяется для данных яркости и другой, потенциально отличающийся набор значений, применяется для данных цветности, в вариантах осуществления настоящего раскрытия этот момент обрабатывается по-другому.
В некоторых вариантах осуществления распознается, что было бы предпочтительным, с точки зрения эффективности воплощения, использовать одинаковые значения точности и/или динамического диапазона как для данных яркости, так и для данных цветности, все еще поддерживая возможность изменения этих значений, в соответствии с битовой глубиной. Использование одинаковых параметров между данными яркости и цветности позволяет устанавливать один путь кодирования для данных яркости и цветности, исключая необходимость установки вплоть до (либо в программном, или в аппаратном воплощении) двух разных, по-отдельности программируемых или управляемых путей.
Выбор, какой из наборов параметров следует использовать, может быть выполнен в соответствии с определенным правилом. Например, могут быть выбраны параметры, относящиеся к данным яркости. В качестве альтернативы, и обеспечивая улучшенную гибкость при работе, могут быть выбраны параметры в соответствии с видеокомпонентом (например, яркостью, цветностью), имеющим наибольшую битовую глубину видеокомпонента. Таким образом, например, используя представленную выше таблицу, если битовая глубина яркости составляет (скажем) 16, и битовая глубина цветности составляет (скажем) 14, тогда колонка параметров, относящихся к битовой глубине 16, может использоваться для обработки яркости и цветности.
Битовая глубина и/или взаимосвязь битовой глубины с параметрами, описанная выше, и/или с индексом в таблице параметров, такой, как показана выше, могут быть определены одним или больше "наборами параметров" видеоданных. На самом высоком уровне находится набор параметров видеоданных (VPS), после которого следует (на более низком уровне, в соответствии с большей гранулярностью) набор параметра последовательности (SPS), где последовательность содержит одно или больше изображений, набор параметра изображения (PPS) и набор параметра среза, где изображение содержит один или больше срезов. Взаимосвязи или значения битов глубины или точности, и/или значения динамического диапазона могут быть определены по любому из них, но в некоторых вариантах осуществления они могут быть определены SPS.
В соответствии с этим в описанных выше вариантах осуществления значения точности и/или динамического диапазона для одного или больше этапов кодирования установлены так, чтобы они изменялись в соответствии с битовой глубиной видеоданных, таким образом, что если битовая глубина отличается между видеокомпонентами (например, между данными яркости и цветности), тогда используется заданное правило для выбранных одних значений набора точности и/или динамического диапазона для использования со всеми видеокомпонентами. Аналогичный подход применяется в отношении данных изображения (вместо видеоданных). Аналогичные принципы применяются в кодере и в декодере. В соответствии с этим, такие компоновки также могут обеспечить пример компоновки, в которой для входных или выходных данных изображения, имеющих компоненты изображения с разной битовой глубиной, выбирают один набор максимального динамического диапазона и/или точности данных матриц преобразования для использования со всеми компонентами изображения.
В некоторых вариантах осуществления один набор максимального динамического диапазона и/или точности данных матриц преобразования выбирают, как те значения, которые относятся к тому одному из компонентов изображения, который имеет наибольшую битовую глубину.
Следует отметить, что на стороне декодера и на обратном пути от кодера в некоторых вариантах осуществления можно использовать тот же (один, или оба из них) максимальный динамический диапазон и/или точность данных матриц преобразования, которые используются на стороне кодера. В других вариантах осуществления точность данных обратных матриц преобразования (на стороне декодера) установлена для заданного значения, такого как 6.
Примеры этих компоновок будут дополнительно описаны ниже со ссылкой на фиг. 38 и 39.
Теперь система САВАС, как описано выше, обеспечивает пример использования технологии кодирования, в которой применяется выбор одного из множества взаимодополняющих поддиапазонов наборов значений кодов, в соответствии с текущим значением входных данных, набор значений кода определен по переменной диапазона, назначая текущее значение входных данных для значения кода в пределах выбранного поддиапазона, модифицируя набор значений кода в зависимости от назначенного значения кода и размера выбранного поддиапазона и детектируя, является ли переменная диапазона, определяющая набор значений кода, меньшей, чем заданный минимальный размер, и если это так, последовательно увеличивают переменную диапазона так, чтобы увеличить размер набора значений кода до тех пор, пока он не составит, по меньшей мере, заданный минимальный размер; и выводят бит кодированных данных в ответ на каждую такую операцию увеличения размера. В вариантах осуществления пропорции поддиапазонов относительно набора значений кода определены контекстной переменной, ассоциированной со значением входных данных. Варианты осуществления компоновки САВАС включают в себя: после кодирования значения входных данных модифицируют переменную контекста для использования в отношении следующего значения входных данных, для увеличения пропорции установленных значений кода в поддиапазоне, который был выбран для текущего значения входных данных.
Также, как описано выше, в некоторых вариантах осуществления энтропийный кодер HEVC САВАС кодирует элементы синтаксиса, используя следующую обработку:
Кодируют местоположение младшего значащего коэффициента (в порядке сканирования) TU.
Для каждой группы коэффициентов 4×4 (группы обрабатываются в обратном порядке сканирования), кодируют флаг группы значимых коэффициентов, обозначающий, содержит или нет группа ненулевые коэффициенты. Это не требуется для группы, содержащей младший значащий коэффициент, и предполагается, что он равен 1 для верхней левой группы (содержащей коэффициент DC). Если флаг равен 1, тогда следующие элементы синтаксиса, относящиеся к группе, кодируют немедленно после нее: карту значимости; карту "больше, чем один"; флаг "больше, чем два"; биты знака; и коды перехода.
Такая компоновка схематично представлена на фиг. 29. На этапе 1500 кодер САВАС проверяет, содержит ли текущая группа младший значащий коэффициент. Если это так, обработка заканчивается. Если нет, обработка переходит на этап 1510, на котором кодер проверяет, является ли текущая группа верхней левой группой, содержащей коэффициент DC. Если это так, управление переходит на этап 1530. Если нет, на этапе 1520 кодер детектирует, содержит ли текущая группа ненулевые коэффициенты. Если нет, обработка заканчивается. Если это так, тогда на этапе 1530 генерируют карту значимости. На этапе 1540 генерируют карту а>1, которая обозначает для 8 коэффициентов со значением 1 карты значимости, отсчитанным в обратном порядке от конца группы, является ли магнитуда большей чем 1. На этапе 1550 генерируют карту а>2. Вплоть до 1 коэффициента со значением >1 карты 1 (ближайшим к концу группы), это обозначает, превышает ли магнитуда 2. На этапе 1560 генерируют знаковые биты, и, на этапе 1570, генерируют коды перехода для любого коэффициента, магнитуда которого не была полностью описана более ранним элементом синтаксиса (то есть данными, генерируемыми на любом из этапов 1530-1560).
Для 16-битной, 14-битной или даже 12-битной системы в рабочей точке, где MSE меньше, чем 1 (обычно QP составляют -34, -22 и -10, соответственно), система обычно выполняет очень малое сжатие (для 16 битов, она фактически расширяет исходные данные). Коэффициенты, в общем, представляют собой большие числа, и, поэтому, они почти всегда кодируются, как коды перехода. По этой причине два предложенных изменения были выполнены для энтропийного кодера, для обеспечения больших значений битовой глубины, путем помещения фиксированного количества LSB, BF в битовый поток для каждого коэффициента. В основном, эти схемы позволяют для текущего энтропийного кодера HEVC САВАС, который было разработан для 8 и 10-битных операций, работать при оригинальном значении bitDepth, для которого он был разработан, путем эффективного преобразования системы с большей величиной битов, такой как 16-ти битная, в системе с меньшим количеством битов, такой как 10-ти битная, используя альтернативный путь для дополнительной точности. Эффективность используемого способа разделения увеличивается, поскольку значения системы с низким значением битов прогнозируются в существенно большей степени, и, поэтому, они пригодны для кодирования с более сложными схемами кодирования, тогда как дополнительная точность, требуемая для системы с большим количеством битов, является менее прогнозируемой и, поэтому, в меньшей степени поддается сжатию и является менее эффективной. Например, 16-битная система может конфигурировать BF так, что он становится равным 8.
Использование фиксированных схем битов обозначено в потоке битов кодером, и когда используется эта схема, средство для определения количества фиксированных битов может быть обозначено кодером для декодера. Такое средство может представлять собой либо непосредственное кодирование числа, или обозначение, как вывести значение BF из параметров, присутствующих в потоке битов (включая в себя QP, битовую глубину и/или профиль), уже кодированных в битовом потоке, или используя их комбинации. Кодер также может иметь вариант выбора разных значений BF для разных изображений, срезов и CU, используя одно и то же средство, или путем обозначения треугольных значений дельта для значения BF, выведенного для последовательности, изображения, среза или предшествующего CU. Значение BF также может быть задано так, чтобы оно отличалось для разных размеров блока модуля преобразования, разных типов прогнозирования (между изображениями/внутри изображения), и для разных каналов цветности, где свойство видеоданных источника могло бы управлять кодером при выборе разных параметров.
Пример вывода BF на основе QP может быть представлен следующим выражением:
BF = max(0, int(QP / -6))
Пример вывода для BF на основе битовой глубины может быть представлен следующим образом:
BF = bitDepth - 8
Пример вывода для BF на основе размера блока модуля преобразования и QP:
BF = max(0, int(QP / -6) + 2 - log2(размера))
Различные значения BF могут быть определены в кодере, используя предварительную компоновку кодера (пробную), или могут быть сконфигурированы так, чтобы они следовали заданным правилам.
Вариант 1 энтропийного кодирования
Для того, чтобы обеспечить возможность обработки при больших значениях битовой глубины, обработка энтропийного кодера HEVC изменяется на следующую для количества фиксированных битов BF, которое меньше, чем bitDepth:
Кодируют местоположение младшего значащего коэффициента (в порядке сканирования) в TU.
Для каждой группы коэффициентов 4×4 (группы обрабатывают в обратном порядке сканирования), каждый коэффициент С разделяют на старшую значащую часть CMSB и на младшую значащую часть CLSB, где CMSB = abs(C) >> BF
CLSB = abs(C) - (CMSB << BF),
и BF представляет собой количество фиксированных битов, которые должны использоваться, как определено для потока битов.
Генерирование CMSB и CLSB, как описано выше, представляет собой пример (в отношении технологии кодирования последовательности значений данных) генерирования из исходных значений данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных значения представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет остальные младшие значащие биты этого значения.
Кодируют флаг группы значимых коэффициентов, обозначающий, содержит или нет группа ненулевые значения CMSB. Это требуется для группы, содержащей младшие значащие коэффициенты, и предполагается, что флаг равен 1 для верхней левой группы (содержащей коэффициент DC). Если флаг равен 1, тогда следующие элементы синтаксиса, относящиеся к группе, кодируют непосредственно после него:
Карта значимости:
Для каждого коэффициента в группе кодируют флаг, обозначающий, является или нет значение CMSB значащим (имеет ненулевое значение). Флаг кодируют для коэффициента, обозначенного младшим значащим положением.
Карта "Больше, чем один":
Вплоть до восьми коэффициентов со значением 1 карты значимости (отсчитанный в обратном порядке от конца группы), это обозначает, является ли CMSB больше, чем 1.
Флаг "Больше, чем два":
Вплоть до одного коэффициента со значением 1 карты "больше, чем один" (единица, ближайшая к концу группы), это обозначает, является ли CMSB больше, чем 2.
Фиксированные биты:
Для каждого коэффициента в группе значение CLSB кодируют как обходные данные, используя равновероятные бины САВАС.
Биты знака:
Для всех ненулевых коэффициентов биты знака кодируют как равновероятные бины САВАС, с последним значащим битом (в обратном порядке сканирования), который, возможно, вместо этого, выведен из значения четности, когда используется скрытие бита знака.
Коды перехода:
Для любого коэффициента, магнитуда которого не была полностью описана более ранним элементом синтаксиса, остальное кодируется как код перехода.
Однако в случае, когда флаг группы значимого коэффициента равен 0, тогда следующие элементы синтаксиса, относящиеся к группе, кодируют непосредственно после него:
Фиксированные биты:
Для каждого коэффициента в группе значение CLSB кодируют как равновероятные бины САВАС.
Биты знака:
Для всех ненулевых коэффициентов биты знака кодируют как равновероятные бины САВАС с последним значащим битом (в обратном порядке сканирования), возможно, вместо вывода из знака четности, когда используется сокрытие бита знака.
Генерирование одной или больше из этих карт и флагов представляет пример генерирования одного или больше наборов данных, обозначающих положения относительно массива значений, частей старших значащих данных с заданными магнитудами. Кодирование одной или больше карт, используя САВАС, предусматривает пример кодирования наборов данных для выходного потока данных, используя двоичное кодирование. Кодирование других данных, используя равновероятные бины САВАС, предусматривает пример включения данных, определяющих младшие значащие части потока выходных данных, или (используя другую терминологию) пример включения данных, определяющих части младших значащих битов, в выходной поток данных, содержит кодирование частей младших значащих данных, используя арифметическое кодирование, в котором символы, представляющие части младших значащих данных, кодируют в соответствии с соответствующими пропорциями диапазона значений кодирования, в котором соответствующие пропорции диапазона значений кодирования для каждого из символов, которые описывают части младших значащих данных, имеют равный размер. В качестве альтернативы для равновероятностного кодирования САВАС, однако, этап включения данных, определяющих младшие значащие части, в поток выходных данных может содержать непосредственное включение части младших значащих данных в поток выходных данных в качестве необработанных данных.
Вариант осуществления данного раскрытия изменяет интерпретацию флага группы значимого коэффициента для обозначения, является ли какой-либо из коэффициентов ненулевым (а не только их эквиваленты CMSB). В этом случае группа коэффициента, содержащая последний коэффициент в обратном порядке сканирования, не обязательно должна быть обозначена (как в случае, если бы она была равна 1), и дополнительные элементы синтаксиса не обязательно должны быть кодированы, когда флаг группы значимых коэффициентов равен 0. Это представляет собой пример, в соответствии с которым карта значимости содержит флаг данных, обозначающий положение, в соответствии с заданным упорядочиванием массива значений, последней из частей наиболее значимых данных, имеющих ненулевое значение.
Последняя компоновка схематично представлена на фиг. 30, которая во многом соответствует фиг. 29. При сравнении двух чертежей, можно видеть, что фиг. 30 не имеет эквивалента этапа 1500 на фиг. 29, что соответствующего тому факту, что обработка происходит даже для группы, содержащей последний значащий коэффициент. Этапы 1610 и 1620, в общем, соответствуют этапам 1510 и 1520 на фиг. 29. Во вновь введенном этапе 1625 коэффициенты разделены на части MSB и LSB, как описано выше. Этапы 1630, 1640 и 1650, в общем, соответствуют соответствующим этапам 1530, 1540 и 1550 на фиг. 29, за исключением того, что они действуют только на части MSB разделенных коэффициентов. Вновь введенный этап 1655 содержит кодирование частей LSB разделенных коэффициентов, как фиксированных битов, как описано выше. Этапы 1660 и 1670, в общем, соответствуют этапам 1560 и 1570 на фиг. 29.
Эта модификация может эффективно формировать систему, где энтропийный кодер САВАС работает с оригинальным bitDepth, для которой он был разработан, для выбора BF так, что количество MSB, равное конструктивной битовой глубине кодера, пропускают через кодирование САВАС, при этом LSB большей битовой глубины (которая является наименее предсказуемой и, поэтому, наименее сжимаемой) кодируют с обходом. Например, если кодер представляет собой кодер с битовой глубиной 8 или 10, BF может быть равно 8 или 10. Это обеспечивает пример системы, в которой последовательность значений данных представляет данные изображения, имеющие битовую глубину данных изображения; и способ содержит установку количества битов, которые должны использоваться как множество старших значащих битов, в каждой части старших значащих данных, которая должна быть равна битовой глубине данных изображения.
Как описано выше, технологии могут (в некоторых вариантах осуществления) применяться для компоновок, в которых последовательность значений данных содержит последовательность коэффициентов изображения, преобразованных по частоте. Однако могут использоваться другие типы данных (такие как аудиоданные или просто цифровые данные). Результаты такого предложения можно видеть на фиг. 27, на которой показан график PSNR в зависимости от QP для одной тестовой последовательности с точностью матрицы DCT и набором MAX_TR_DYNAMIC_RANGE, в соответствии с битовой глубиной, представляющей эквивалентные операции с (кривая 1680) и без (кривая 1690) кодирования фиксированного бита с обходом. Экономия скорости битов для системы с фиксированными битами (относительно системы без фиксированных битов) изменяется от 5% при QP равном 0 до 37% при QP -48. Оптимальное значение BF будет зависеть от последовательности. Пример BF составляет 8 или 10, как описано выше.
Вариант 2 осуществления энтропийного кодирования
В аналогичной схеме в других вариантах осуществления применяется множество тех же этапов обработки, но в ней сохраняется исходная функциональность карты значимости, где значение флага, равное 0, обозначает значение коэффициента, равное 0 (вместо значения 0 (как представлено в Варианте 1 осуществления энтропийного кодирования) для части MSB коэффициента). Это может быть более полезным при рассмотрении (обычно плавного) генерируемого компьютером видеоизображения (где ожидается, что нули встречаются чаще). Такой вариант осуществления энтропийного кодирования содержит следующие этапы обработки для множества фиксированных битов BF, которое меньше, чем bitDepth:
Кодируют местоположение младшего значащего коэффициента (в порядке сканирования) в TU.
Для каждой группы коэффициентов 4×4 (группы обрабатывают в обратном порядке сканирования) кодируют флаг группы значащего коэффициента, обозначающий, содержит или нет эта группа ненулевые коэффициенты. Это не требуется для группы, содержащей последний значащий коэффициент, и предполагается, что он равен 1 для верхней левой группы (содержащей коэффициент DC). Если флаг равен 1, то каждый коэффициент С разделяют на старшую значащую часть CMSB и младшую значащую часть CLSB, где
CMSB = (abs(C)-1) >> BF
и
CLSB = (abs(C) - 1) - (CMSB << BF)
Генерирование CMSB и CLSB, как описано, представляет пример (в отношении технологии для кодирования последовательности значений данных) генерирования из входных значений данных соответствующих взаимодополняющих частей старших значащих данных и частей младших значащих данных, таким образом, что часть старших значащих данных этого значения представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения.
Следующие элементы синтаксиса, относящиеся к группе, кодируют непосредственно после этого:
Карта значимости:
Для каждого коэффициента в группе кодируют флаг, обозначающий, является или нет коэффициент С значимым (имеет ненулевое значение). Флаг не нужен для коэффициента, обозначенного последним значимым положением.
Карта "Больше, чем один":
Для вплоть до восьми коэффициентов со значением 1 карты значимости (подсчитан в обратном порядке от конца группы) это обозначает, является ли CMSB большим чем или равным 1.
Флаг "Больше, чем два":
Для вплоть до одного коэффициента со значением 1 карты "больше чем один" (единица, ближайшая к концу группы), это обозначает, является ли CMSB большим чем или равным 2.
Биты знака:
Для всех ненулевых коэффициентов биты знака кодируют как равновероятностные бины САВАС, возможно с последним значащим битом (в обратном порядке сканирования) вместо вывода знака четности, когда используется скрытые бита знака.
Фиксированные биты:
Для каждого ненулевого коэффициента в группе кодируют значение CLSB.
Коды перехода:
Для любого коэффициента, магнитуда которого не была полностью описана более ранним элементом синтаксиса, остаток кодируют как код перехода.
Генерирование одной или больше из этих карт и флагов представляет собой пример генерирования одного или больше наборов данных, обозначающих положения, относительно массива значений, частей старших значащих данных с заданными магнитудами. Кодирование одной или больше карт, используя САВАС, предусматривает пример кодирования наборов данных для выходного потока данных, используя двоичное кодирование. Кодирование других данных, используя равновероятностные бины САВАС, предусматривает пример включения данных, определяющих младшие значащие части выходного потока данных.
Следует отметить, что существуют различные варианты выбора для порядка этих различных компонентов данных в выходном потоке. Например, со ссылкой на биты знака, фиксированные биты и коды перехода, порядок для группы (скажем) n коэффициентов (где n может быть равно, например, 16) может быть следующим:
n × биты знака, затем n × наборы фиксированных битов, затем n × коды перехода; или
n × биты знака, затем n × (коды перехода и фиксированные байты для одного коэффициента).
Такая компоновка схематично представлена в виде блок-схемы последовательности операций на фиг. 31. Здесь этапы, 1700…1770 соответствует соответствующим этапам на фиг. 31 и 32 следующим образом, до тех пор, пока не будет идентифицирована разность. Следует отметить, что этап 1755 следует после этапа 1760 на фиг. 31 (аналогично этап 1655 предшествует этапу 1660 на фиг. 30).
Этап 1700 соответствует, в общем, этапу 1500 на фиг. 29. Если это не представляет собой группу, содержащую последний значащий коэффициент, управление переходит на этап 1710. Этапы 1710 и 1720 соответствуют этапам 1610 и 1620 на фиг. 30. Коэффициенты разделены на этапах 1725, в соответствии с этапом 1625 на фиг. 30. Однако на этапах 1730, в отличие от компоновки на этапе 1630, описанной выше, все коэффициенты (игнорируя время, в которое выполняется разделение на этапе 1725), используются при выводе карты значения. Этапы 1740 и 1750 действуют только для части MSB коэффициентов разделения и соответствуют функции этапам 1640 и 1650. За исключением факта, что упорядочивание этапов иллюстрируется (в качестве примера) несколько по-другому на фиг. 32 и 33, этапы 1755, 1760 и 1770 соответствует функциональности этапов 1655, 1660 и 1670.
Результаты сравнения этих двух вариантов осуществления энтропийного кодирования можно видеть на фиг. 28. На фиг. 28 показан график, иллюстрирующий для каждой из шести тестовых последовательностей процент улучшения скорости битов для варианта 2 осуществления энтропийного кодирования относительно результатов, достигаемых (с в остальном идентичными параметрами) в варианте 1 осуществления энтропийного кодирования.
Вариант 2 осуществления энтропийного кодирования показал, на 1% меньшую эффективность в среднем для некоторого исходного материала, чем Вариант 1 осуществления энтропийного кодирования для отрицательных QP, что приводит к росту приблизительно на 3% для положительных QP. Однако для некоторого другого исходного материала наблюдается противоположное из-за увеличенного количества нулей в коэффициентах. В варианте осуществления кодер также может быть выполнен с возможностью выбирать любой способ энтропийного кодирования и передавать сигнал в декодер о своем выборе.
Поскольку экономия для положительного QP является малой по сравнению с экономией для отрицательных QP, модификации энтропийного кодирования могут быть включены только, когда QP является отрицательным. Учитывая, что Вариант 1 осуществления энтропийного кодирования проявляет экономию битов вплоть до 37% для отрицательных QP, существует небольшое различие между двумя вариантами осуществления энтропийного кодирования в их рабочих точках, по сравнению с системой без модификации энтропийного кодирования.
В соответствии с этим в примерных вариантах осуществления, в которых коэффициенты входного изображения, преобразованные по частоте, представляют собой квантованные коэффициенты входного изображения, преобразованные по частоте, в соответствии с параметром переменного квантования, выбранным из диапазона доступных параметров квантования, технологии могут содержать кодирование массива коэффициентов входного изображения, преобразованного по частоте, в соответствии с частями старших значащих данных и частями младших значащих данных для коэффициентов, полученных, используя параметр квантования в первом заданном поддиапазоне диапазона доступных параметров квантования; и для коэффициентов, полученных, используя параметр квантования не в первом заданном поддиапазоне диапазона доступных параметров квантования, кодирование массива коэффициентов входного изображения, преобразованных по частоте таким образом, что количество битов в каждой части старших значащих данных равно количеству битов этого коэффициента, и соответствующая часть младших значащих данных не содержит биты.
Поскольку количество кодируемых данных несколько больше, чем наблюдается для стандартных рабочих точек HEVC версии 1, дополнительный этап применяется или может применяться для обеих предложенных систем, и действительно, система, где ранее предложенные системы не могут использоваться, или их не разрешено использовать, будут описаны в связи с дополнительными вариантами осуществления раскрытия.
Дополнительный этап обеспечивает побитное выравнивание потока САВАС перед кодированием обходных данных для каждой группы коэффициентов. Это позволяет более быстро (и параллельно) декодировать обходные данные, поскольку значения теперь могут быть считаны непосредственно из потока, устраняя требование длительного разделения при декодировании обходных бинов.
Один механизм для достижения этого состоит в применении способа завершения САВАС, ранее представленного выше.
Однако в варианте осуществления, описываемом теперь, вместо завершения потока битов, состояние САВАС выравнивают по границе битов.
В вариантах осуществления набор значений кода САВАС содержит значения от 0 до верхнего значения, определенного переменной диапазона, верхнее значение находится между заданным минимальным размером (например, 256) и вторым заданным значением (например, 510).
Для битового выравнивания потока m_Range просто устанавливают на значение 256, как в кодере, так и в декодере. Это существенно упрощает обработку кодирования и декодирования, позволяя непосредственно считывать двоичные данные из m_Value в форме ряда, и, поэтому, множество битов за раз могут быть одновременно обработаны декодером.
Следует отметить, что действие установки m_Range на значение 256 приводит к потере, в среднем, 0,5 бита (если m_Range уже было равно 256, потери не возникают; если m_Range было равно 510, тогда будет потерян приблизительно 1 бит; среднее значение по всем действительным значениям m_Range, поэтому, составляет 0,5 бита).
Множество способов можно использовать для уменьшения потерь или потенциальных затрат, возникающих в связи с этими технологиями. На фиг. 33-35 схематично показаны блок-схемы последовательности операций, соответственно иллюстрирующие версии каскада завершения обработки САВАС, которые выполняются кодером САВАС.
В соответствии с фиг. 33 можно выбрать, следует или нет использовать выравнивание битов, в зависимости от оценки ожидаемого количества данных, кодированных с обходом (например, на основе множества флагов "больше единицы", равных 1). Если ожидается мало данных кодированных с обходом, выравнивание по битам является дорогостоящим (поскольку здесь теряется в среднем 0,5 бита для каждого выравнивания), и также ненужным, поскольку скорость передачи битов, вероятно, будет ниже. В соответствии с этим, на фиг. 33, этап 1800 включает в себя детектирование оценки количества данных, кодированных с обходом, путем детектирования количества флагов >1, которые были установлены, и путем сравнения этого количества с пороговым значением Thr. Если оценка превышает пороговое значение Thr, тогда управление переходит на этап 1810, на котором выбирают режим выравнивания битов. В противном случае, управление переходит на этап 1820, на котором выбирают режим "без выравнивание битов". Этапы на фиг. 33, например, для каждой подгруппы могут повторяться в каждом TU. Это обеспечивает пример кодирования данных, представляющих коэффициенты, которые не представлены набором данных, как обходные данные; детектируя количество обходных данных, ассоциированное с текущим массивом; и применяя этап установки, если количество обходных данных превышает пороговое значение, но не применяя этап установки в противном случае.
На фиг. 34, вместо кодирования обходных данных в конце каждой группы коэффициентов, все обходные данные для TU могут быть кодированы вместе после данных бина САВАС для TU. Потеря, поэтому, составляет 0,5 бита для кодированного TU, вместо 0,5 битов для группы коэффициентов. В соответствии с этим, на этапе 1830 на фиг. 34 применяют тестирование для детектирования, находится ли текущая группа в конце кодирования TU. Если это не так, тогда выравнивание бита не применяют (схематично обозначено как этап 1840), и управление возвращается на этап 1830. Таким образом, если это так, затем применяется выравнивание битов на этапе 1850. Это предусматривает пример компоновки, при которой значения входных данных представляют данные изображения; и при которой данные изображения кодируют как модули преобразования, содержащие множество массивов коэффициентов, способ, содержащий: применяют этап установки в конце кодирования модуля преобразования.
Такой механизм выравнивания также может использоваться перед другими или всеми данными в потоке, которые кодируют с равновероятностным механизмом, который, хотя он может снизить эффективность, может упростить кодирование потока.
В качестве альтернативного выравнивания, как представлено на фиг. 35, m_Range может быть установлен в одно из множества N заданных значений, чем просто в значение 256 (например, можно выравнивать по значению 384 для половины бита). Поскольку значение выравнивания должно быть меньше чем или равно исходному значению m_Range (поскольку диапазон не может быть увеличен по-другому, кроме как используя повторную нормализацию), выравнивание в соответствии с потерями составляет затем (0,5/N) для равномерно разнесенных значений. Такой способ может все еще требовать разделения других значений, кроме 256, но знаменатель может быть известен заранее, и, таким образом, деление можно оценить, используя справочную таблицу. В соответствии с этим, на этапе 1860 (в котором применяется ситуация с выравниванием битов) детектируют значение m_range, и на этапе 1870 выровненное значение выбирают в соответствии с m_range для использования при обработке выравнивания битов.
В качестве дополнительного улучшения такого альтернативного способа выравнивания, бин (или бины) непосредственно следующий после выравнивания, может быть кодирован, используя (неравные) диапазоны символов, которые представляют собой степени двух. Таким образом, все требования для разделения последующих бинов могут быть устранены без какой-либо дополнительной потери сверх (0,5/N) эффективности битов.
Например, при выравнивании по 384, диапазоны символов для [0, 1] для следующего бина могут быть установлены как [256, 128]:
Если кодируется 0, m_Range устанавливают в 256, что составляет стоимость кодирования бина 0,5 битов.
Если кодируется 1, m_Range устанавливают в 128 (и 256 добавляют к значению m_Value), и систему повторно нормализуют (и снова, m_Range становится равным 256), что делает стоимость кодирования бина 1,5 битов.
Поскольку 0 и 1 ожидаются с равной вероятностью, средняя стоимость кодирования бина, непосредственно следующего после выравнивания, все еще составляет 1 бит. Для случая, когда N=2, и две точки выравнивания представляют собой 256 и 384, способ может состоять в выборе наибольшей точки выравнивания, которая меньше чем или равна текущему m_Range. Если точка выравнивания равна 256, тогда m_Range просто устанавливают равным 256 для выравнивания механизма САВАС; если точка выравнивания равна 384, тогда требуется описанная выше обработка, которая может потребовать кодирования одного символа.
Это представлено на фиг. 32А и В, и дополнительный пример для значения N-4 показан на фиг. 32С-32F.
Для иллюстрации преимуществ выравнивания механизма САВАС, способ для декодирования равновероятностного (ЕР) бина без такого этапа выравнивания может быть выражен следующим образом:
if (m_Value> = m_Range/2)
декодированное значение ЕР равно 1.
Последовательное уменьшение m_Value m_Range/2 else
декодированное значение ЕР равно 0.
then считать следующий бит из потока битов:
m_Value = (m_Value*2) + next_bit_in_stream
Рабочий пример тогда может быть представлен следующим образом:
let m_Range = 458 и m_Value = 303, и предположим, что следующие два бита в потоке битов равны 1
цикл 1:
m_Value>=229, таким образом, что следующее кодированное значение ЕР равно 1. m_Value=74
then считать следующий бит из потока битов: m_Value = 74 * 2 + 1 = 149
цикл 2:
m_Value<229, таким образом, значение ЕР равно 0 (m_Value без изменений)
then считать следующий бит из потока битов: m_Value = 149 * 2 + 1 = 299
Декодированные равновероятностные бины являются эквивалентными одному этапу длинного разделения, и может потребоваться арифметика для тестирования неравности. Для декодирования двух бинов, затем эта примерная обработка может использоваться дважды, воплощая двухэтапную обработку длинного разделения.
Однако, если применяется этап выравнивания, полученный в результате m_Range представляет собой наибольшую действительную степень 2 (такую как 256 для 9-битного энтропийного кодера HEVC САВАС), тогда описанная выше обработка упрощается
кодированное значение ЕР представляет собой старший значащий бит значения m_Value.
Обновить m_Value путем обработки его, как сдвигового регистра, со сдвигом следующего бита в младшее значащее положение.
Следовательно, m_Value, по существу, становится сдвиговым регистром, и бины ЕР считывают из старшего значащего положения, в то время, как поток битов сдвигается в младшее значащее положение. Поэтому, множество битов ЕР могут быть считаны путем простого сдвига большего количества битов из верхней части m_Value.
Рабочий пример этого случая выравнивания представляет собой:
Let m_Range=256, m_Value=189, и следующие два бита в потоке битов равны 1
цикл 1:
Следующее кодированное значение ЕР представляет собой бит 7 m_Value, который равен 1.
Обновить m_Value путем сдвига наружу бита 7 и сдвига внутрь 1 из потока битов в младшее значащее положение: m_Value становится равным 123.
цикл 2:
Следующее кодированное значение ЕР представляет собой бит 7 m_Value, который равен 0.
Обновить m_Value путем сдвига наружу бита 7 и сдвига внутрь 1 из потока битов в младшее значащее положение: m_Value становится равным 247.
Количество точек выравнивания, N, которые выбраны, можно рассматривать как компромисс между сложностью воплощения и битовой стоимостью выравнивания. Для рабочей точки, где существует множество бинов ЕР для каждой точки выравнивания, тогда их потеря будет менее значимой, и может быть достаточно системы выравнивания с меньшим количеством точек. И, наоборот, для рабочих точек, где существует меньшее количество бинов ЕР для точки выравнивания, тогда потери являются более существенными, и система выравнивания с большим количеством точек может быть предпочтительной; для некоторых рабочих точек может быть предпочтительным полное отключение алгоритма выравнивания. Кодер и, поэтому, поток битов может обозначать количество точек выравнивания, которые должны использоваться декодером, которые можно выбрать в соответствии с рабочей точкой для этой части потока данных. Такое обозначенное количество, в качестве альтернативы, может быть выведено из другой информации, присутствующей в потоке битов, таком как профиль или уровень.
Используя множество положений выравнивания, в простом случае, где положения выравнивания представляют собой просто 256 и 384:
Для выравнивания,
if m_Range<384, просто установить m_Range=256, и см.
представленный выше рабочий пример для декодирования.
else
установить m_Range=384, и следующая обработка
используется для кодирования следующего бина ЕР:
m_Range = 384 = 256 + 128.
Назначить диапазон символа 256 для значения 0
и 128 для значения 1, для следующего бина ЕР, предназначенного для кодирования.
If m_Value>=256, then (операция тестирования битов MSB)
следующее значение ЕР равно 1.
m_Value-=256 (фактически операция очистки бита),
m_Range=128.
Повторная нормализация (поскольку m_Range<256):
m_Range=256
m_Value = (m_Value * 2) + next_bit_in_stream
else
следующее значение ЕР равно 0.
m_Range=256.
Затем, m_Range=256, и представленная выше простая обработка
может использоваться для всех последующих бинов ЕР.
Результаты для Варианта 1 осуществления энтропийного кодирования с механизмами выравнивания битов САВАС, описанными только что, показаны на фиг. 29, на которой представлен график различия скорости битов, в зависимости от QP, для шести последовательностей с и без механизмов выравнивания битов для N=1. Положительная разность скорости битов (по вертикальной оси) обозначает, что система с выравниванием битов генерирует более высокую скорость передачи битов, чем схема без механизма выравнивания битов. Разность скорости битов для каждой последовательности составляет приблизительно 0,5 раз числа тысяч групп коэффициентов в секунду (трафик составляет 2560×1600 30р=11520, все другие составляют 1920×1080 50р=9720).
Технологии выравнивания, описанные выше, представляют собой следующее: после кодирования группы входных значений данных, устанавливают переменную диапазона для значения, выбранного из заданного поднабора доступных значений переменных диапазона, каждое значение поднабора, имеющее, по меньшей мере, один младший значащий бит, равный нулю. Поднабор может включать в себя минимальный размер (пример, 256). Поднабор может содержать два или больше значения между заданным минимальным размером (таким как 256) и вторым заданным значением (таким как 510). Значение может быть выбрано в соответствии с текущим значением переменной диапазона. Варианты осуществления включают в себя выбор определенного значения из поднабора, если текущее значение переменной диапазона составляет между этим конкретным значением и значением, меньшим, чем следующее более высокое значение в поднаборе (как показано, например, на фиг. 32A-32F). В конкретном примере поднабор доступных значений содержит набор, состоящий из 256, 320, 384 и 448; этап установки переменной диапазона содержит установку значения из поднабора, в соответствии с текущим значением значения переменной диапазона, таким образом, что переменную диапазона устанавливают равной 256, если текущее значение переменной диапазона составляет от 256 до 319, переменную диапазона устанавливают равной 320, если текущее значение переменной диапазона составляет от 320 до 383, переменную диапазона устанавливают равной 384, если текущее значение переменной диапазона составляет от 384 до 447, и переменную диапазона устанавливают равной 448, если текущее значение переменной диапазона составляет от 448 до 510. В другом примере этап установки переменной диапазона содержит выбор значения из поднабора, в соответствии с текущим значением переменной диапазона, таким образом, что переменная диапазона была установлена равной 256, если текущее значение переменной диапазона находится от 256 до 383, и переменную диапазона устанавливают равной 384, если текущее значение переменной диапазона находится между 384 и 510.
Варианты выбора, представленные на фиг. 30, предложены как профили.
Если требуется только высокий профиль (профили) для поддержки bitDepth вплоть до 14, тогда точность коэффициента матрицы преобразования, MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE предложено устанавливать как значения 12, 19 и 20, соответственно.
В дополнение к этим профилям могут быть определены профили главный/распакованный только для прогнозирования внутри изображения, но поскольку декодер, работающий только внутри изображения, является существенно менее сложным, чем декодер, работающий как внутри, так и между изображения, здесь был описан только высокий профиль, работающий внутри изображения.
Аналогичным образом, профили распакованный/высокий могут быть определены для кодирования неподвижных изображений и различных форматов цветности.
В более низких профилях может потребоваться использовать ту же точность матрицы, MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE, которая использовалась более высокими профилями, в противном случае, потоки битов, формируемые двумя профилями, не будут соответствовать.
Различные варианты выбора будут описаны ниже:
Вариант 1 выбора
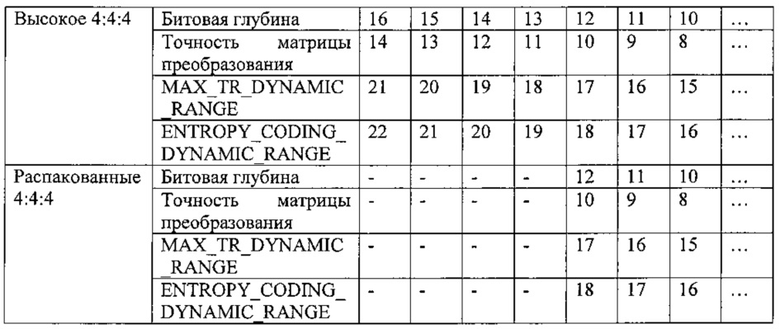
В этом варианте выбора битовая глубина будет диктовать точность матрицы преобразования MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE. Это означает, что декодер, который может потребоваться для поддержки битовой глубины, вплоть до 16, может потребоваться для обработки 13-битных данных с другим набором матриц, и внутренняя точность может быть ограничена только до 18 битов для MAX_TR_DYNAMIC_RANGE, хотя декодер может иметь возможность поддержки вплоть до 21. Однако 12-битные данные, кодированные с использованием высокого профиля, могут быть декодированы декодером, который является соответствующим на более низком профиле.
Вариант 2 выбора
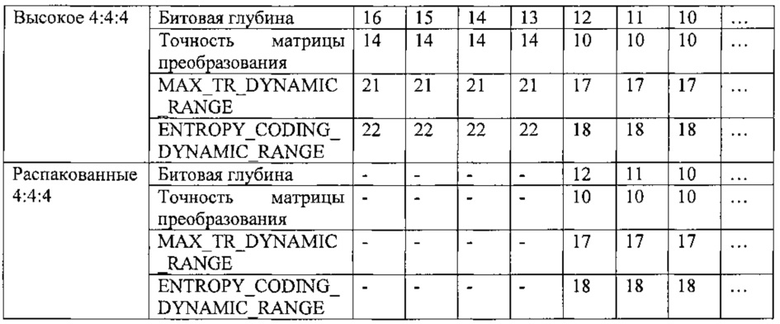
В этом варианте выбора параметры бита для накладывающихся значений глубины бита определяют, используя более низкий профиль, делая, таким образом, возможным декодирование 12-битных данных, кодированных с использованием высокого профиля, используя декодер, соответствующий распакованному профилю. Кроме того, внутренняя точность 13-битных данных может быть такой же, как и для 16-битных данных. Кроме того, несколько значений точности матрицы может потребоваться поддерживать по сравнению с Вариантом 1 выбора.
В настоящем контексте может быть сохранен один набор значений матриц преобразования и все другие значения, выведенные из него.
Следует отметить, что, если матрица преобразования имеет исходную точность 14 битов, в общем, меньшая точность может быть выведена при делении на два и округлении.
Используя это общее правило для вывода матриц более низкой точности из матриц более высокой точности можно получить следующее:
Пример 1
Вариант 1 выбора: Высокий 4:4:4 Определить точность матрицы преобразования = 14
Вывести точность матрицы преобразования = 13… из 14
Распакованный 4:4:4 Определить точность матрицы преобразования = 14
Вывести точность матрицы преобразования = 10… из 14
то есть сохранить с "Высокой" точностью.
Пример 2
Вариант 1 выбора: Высокий 4:4:4 Определить точность матрицы преобразования = 10
Вывести точность матрицы преобразования = 14… из 10
Распакованный 4:4:4 Определить точность матрицы преобразования = 10
Вывести точность матрицы преобразования = 10… из 14
то есть сохранить с "Распакованной" точностью.
Для лучшего качества более предпочтительным является "Пример 1". Однако Пример 2 может привести к уменьшенным требованиям к накопителю.
Примечание - альтернатива, конечно, состоит в сохранении набора матриц преобразования для каждого значения точности. Правила "Пример 1" и "Пример 2" также могут использоваться для "Варианта 2 выбора ".
Поскольку цель состоит в увеличении качества и также в разделении на профили, возникнут ошибки масштабирования, если каждый набор матриц преобразования будет выведен из одного набора с одной точностью.
В случае "Примера 1" система выполняет масштабирование с уменьшением матриц преобразования из 14 битов, и в случае "Примера 2" система выполняет масштабирование с уменьшением матриц преобразования из 10 битов.
Вариант 3 выбора
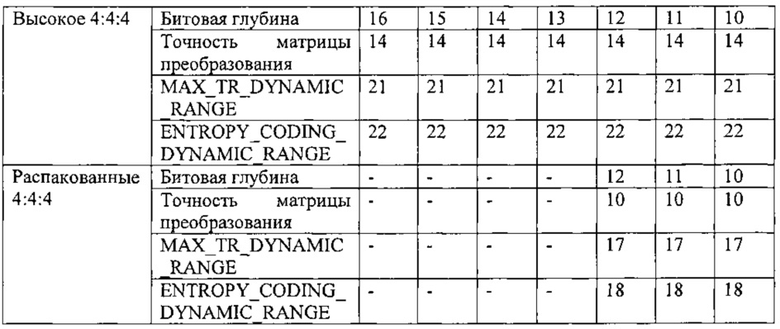
То есть битовые глубины для 12 битных видеоданных могут кодированы либо как "Высокое 4:4:4" или "Распакованные 4:4:4", хотя только декодер высокого разрешения 4:4:4 может быть способным декодировать потоки, кодированные с использованием схемы высокое 4:4:4.
Вариант 4 выбора
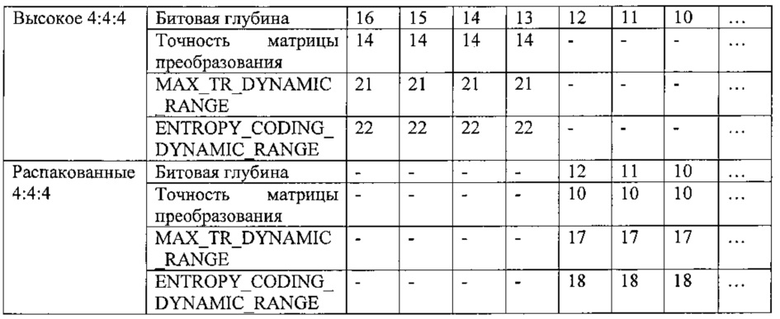
То есть профиль "Высокое 4:4:4" должен поддерживать более низкий профиль "Распакованные 4:4:4" в таком "Варианте 4 выбора", при этом существует только один вариант выбора, как кодировать 12-ти битные видеоданные.
Вариант выбора 5
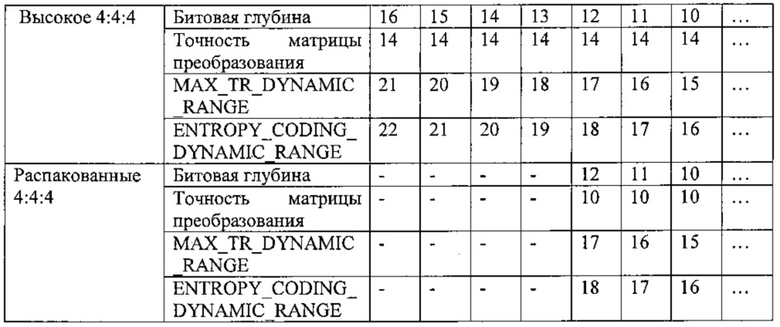
В этом варианте выбора точность матрицы ограничена до значения 1 на профиль, что уменьшает служебные издержки для кодера. Кроме того, MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE определяются значениями битовой глубины, и, поэтому, для кодера, которому требуется кодировать только 13-битные данные, могло бы потребоваться включать служебные издержки на воплощение, используя дополнительную точность внутренних расчетов.
Вариант 6 выбора
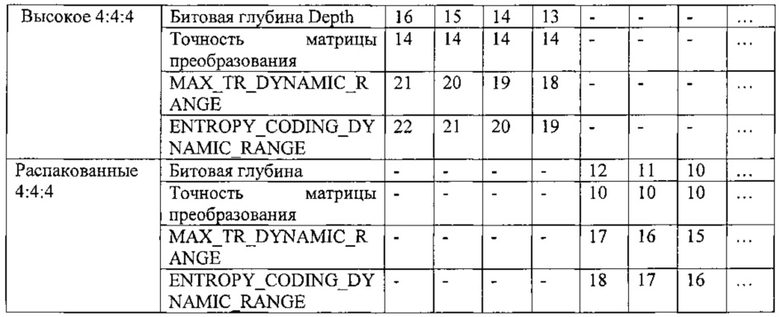
Вариант 6 выбора аналогичен Варианту 5 выбора, но в случае, когда только распакованные профили определены для кодирования 12-битных данных.
В общем, предложенные изменения, в соответствии с различными вариантами осуществления настоящего раскрытия, состоят в следующем:
Использовать, по меньшей мере, один дополнительный набор матриц преобразования для более высокой точности.
Предпочтительно иметь один набор для всех значений более высокой точности, для упрощения многопрофильных кодеров/декодеров.
Предложенные матрицы преобразования предусмотрены для преобразования значений точности 7-14 матрицы - см. представленное ниже описание.
Предполагается использовать матрицы преобразования с точностью 14 битов, поскольку они будут соответствовать 16-битным типам данных для программного обеспечения и будут обеспечивать достаточную точность для обеспечения будущей распаковки для 16-битных видеоданных.
Выбор точности матрицы преобразования можно было бы сконфигурировать по глубине битов входных данных и профилю, или, в качестве альтернативы, он мог бы быть определен параметрами, установленными на уровне последовательности, изображения или среза.
MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE (то есть скажем, один или они оба из них) могут быть изменены для более высокой точности.
Множество значений MAX_TR_DYNAMIC_RANGE и ENTROPY_CODING_DYNAMIC_RANGE не должны представлять проблему для многопрофильных кодеров/декодеров.
Предполагается вывести MAX_TR_DYNAMIC_RANGE = bitDepth + 5 и ENTROPY_CODING_DYNAMIC_RANGE = bitDepth + 6.
Использование MAX_TR_DYNAMIC_RANGE = bitDepth + 5 может соответствовать множеству ситуаций и типов видеоматериала. Однако возможная потребность в вариации этого подхода будет описана ниже.
Эмпирические тесты показали, что в некоторых случаях, для поднабора последовательностей видеоданных, в частности, в некоторых видеопоследовательностях, имеющих низкий уровень шумов, использование MAX_TR_DYNAMIC_RANGE = bitDepth + 5 приводит к росту кривой отклика (учитывая взаимосвязь между выходной скоростью битов и параметром квантования), которая не является монотонной.
Обычно такая кривая отклика не является монотонной, как между выходной скоростью битов и параметром квантования, таким образом, что более грубое квантование приводит к меньшей выходной скорости битов, и менее грубое квантование приводит к более высокой выходной скорости битов. Такая монотонная взаимосвязь формирует основу алгоритмов управления скоростью, таким образом, что система управления скоростью регулирует параметр квантования для поддержания выходной скорости передачи битов в требуемом диапазоне или в пределах требуемого порогового значения.
Но в некоторых случаях использования MAX_TR_DYNAMIC_RANGE = bitDepth + 5, определили, что монотонная взаимосвязь разрывается таким образом, что, например, изменение менее грубого квантования фактически может привести к росту более низкой выходной скорости битов, или даже к тому, что могут существовать два возможных значения SNR изображения для определенной выходной скорости передачи битов. Такие отклонения могут привести к тому, что в алгоритме управления скоростью будет трудно или даже невозможно получить требуемую скорость передачи битов.
В эмпирических тестах определили, что такие проблемы могут быть преодолены, используя MAX_TR_DYNAMIC_RANGE = bitDepth + 6. В соответствии с этим в некоторых вариантах осуществления используется эта взаимосвязь между MAX_TR_DYNAMIC_RANGE и bitDepth.
В конкретном примере матрицы 32×32 DCT обработка DCT проявляет тенденцию требования, чтобы обеспечивалось log2 (32) битов точности по сравнению с bitDepth, которая определяет, что связано с тем, каким образом выводится значение bitDepth+5. Однако обработка квантования может добавлять эквивалентный или другой бит точности. Существенно лучшие результаты могут быть получены, по меньшей мере, для некоторого видеоматериала, если этот дополнительный бит предусмотрен, как дополнительная точность при обработке DCT.
Однако при эмпирическом тестировании также было определено, что эта проблема и, соответственно, решение использования MAX_TR_DYNAMIC_RANGE = bitDepth + 6, соответствует только большим значениям размеров матрицы DCT. Преимущество использования других взаимосвязей между MAX_TR_DYNAMIC_RANGE и bitDepth может состоять в том, что это исключает ненужную служебную обработку в случаях, когда не требуется дополнительная точность.
В частности, в настоящих примерах, представленная выше задача и предложенное решение, в частности, соответствуют размерам матрицы 32×32 DCT. Для матриц меньшего размера может использоваться взаимосвязь MAX_TR_DYNAMIC_RANGE = bitDepth + 5.
В более общем случае, адаптивная вариация взаимосвязи между MAX_TR_DYNAMIC_RANGE и bitDepth может использоваться таким образом, что смещение (значение, которое добавляют к битовой глубине, для генерирования MAX_TR_DYNAMIC_RANGE) изменяется в соответствии с размером матрицы. Таким образом, MAX_TR_DYNAMIC_RANGE = bitDepth + смещение, где смещение представляет собой функцию размера матрицы. В примере значения смещения могут быть выбраны следующим образом:
В другом примере может использоваться прогрессивная взаимосвязь для распознавания потребности в большей точности при больших размерах матриц, в то время как более низкая точность может использоваться при меньшем размере матрицы:
Взаимосвязь между смещением и размером матрицы должна быть такой же, как и между обратным путем кодера (декодирование) и путем декодирования декодера. Поэтому существует потребность в установлении или передаче взаимосвязи, как между этими тремя областями технологии.
В примере взаимосвязь может быть установлена как заранее определенная, жестко кодированная взаимосвязь в кодере и в декодере.
В другом примере взаимосвязь может быть передана в явном виде как часть (или в ассоциации с кодированными видеоданными.
В другом примере взаимосвязь может быть выведена как в кодере, так и в декодере в результате идентификации "профиля", ассоциированного с кодированными видеоданными. Здесь, как описано повсеместно в этом описании, профиль представляет собой показатель набора параметров, используемых для кодирования или декодирования видеоданных. Отображение между обозначением профиля и фактическими параметрами, установленными идентификацией этого профиля, предварительно сохраняют как в кодере, так и в декодере. Идентификация профиля может осуществляться, например, как часть кодированных данных.
В общем, однако, значения смещение (которое в некоторых примерах называется вторым смещением) зависит от размера матриц преобразования.
Так же, как и в отношении точности матрицы преобразования, выбор MAX_TR_DYNAMIC_RANGE и/или ENTROPY_CODING_DYNAMIC_RANGE может быть сконфигурирован по битовой глубине входных данных и профилю, или, в качестве альтернативы, может быть определен по параметрам, установленным на уровне последовательности, изображения или среза (возможно, те же параметры, как и в случае, когда выбирают матрицы DCT).
Такие компоновки предусматривают примеры входных данных изображения, преобразованных по частоте, для генерирования массива коэффициентов входного изображения, преобразованных по частоте, при обработке умножения матрицы, в соответствии с максимальным динамическим диапазоном преобразованных данных, и используя матрицы преобразования, имеющие определенную точность данных; и для выбора максимального динамического диапазона и/или точности данных матриц преобразования в соответствии с битовой глубиной входных данных изображения.
В вариантах осуществления точность данных матриц преобразования может быть установлена как первое количество битов смещения (такое как 2), меньшее, чем битовая глубина входных данных изображения; и максимальный динамический диапазон преобразованных данных может быть установлен как второе число битов смещения (такое как 5), которое больше, чем битовая глубина входных данных изображения.
Энтропийное кодирование может быть изменено так, чтобы оно включало в себя некоторую обработку с фиксированным битом (см. Варианты 1 и 2 осуществления энтропийного кодирования) для увеличения сжатия при низких значениях QP.
Присутствие фиксированных битов можно конфигурировать на уровне последовательности.
Количество фиксированных битов BF может быть сконфигурировано в последовательности, в изображении (хотя это трудно, поскольку в наборе параметров изображения отсутствуют установки уровня последовательности), на уровне среза или CU (возможно, путем передачи в виде сигналов значения дельта от количества фиксированных битов для предыдущей последовательности/изображения/среза/CU, родительского объекта или определения профиля).
Энтропийное кодирование может изменяться так, что оно будет включать в себя выравнивание бита САВАС, для того, чтобы обеспечить выделение обходных битов из потока без использования длительного деления (также может быть предпочтительным для применения одного или больше из упомянутых выше способов уменьшения потерь битов).
Варианты осуществления настоящего раскрытия, поэтому, направлены на повышение внутренней точности так, чтобы соответствовать требованиям мандата расширений диапазона для обеспечения больших значений битовой глубины, используя HEVC. Изучали различные источники ошибок, и были выработаны рекомендации. Кроме того, были представлены изменения по улучшению эффективности кодирования, и также были представлены изменения для улучшения значения пропускной способности.
Матрицы преобразования с увеличенной точностью
В этой части представлено подробное описание матриц преобразования на различных уровнях точности.
4×4 DST
Матрица преобразования имеет форму:

где значения в решетке определены точностью коэффициента матрицы в соответствии со следующей таблицей (6-битная версия 1 HEVC значений матрицы, включена для сравнения):
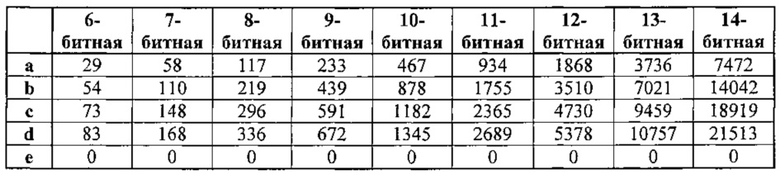
Комбинированная матрица DCT
Для простоты воплощения может быть описана одиночная матрица М32 32×32 DCT, из которой выводят каждую матрицу меньшего размера MN DCT с размером N×N, используя подвыборку (как пример вывода матриц преобразования с требуемой точностью данных из соответствующих матриц преобразования источника с другой точностью данных), в соответствии со следующим:
MN [х] [у] = М32 [х] [(2 (5 - log2 (N))) у] для х, у=0 … (N-1).
Комбинированная матрица М32 имеет следующую форму:

со значениями решетки, определенными точностью коэффициента матрицы, в соответствии со следующей таблицей (6-битная версия 1 HEVC значений матрицы, включена для сравнения):
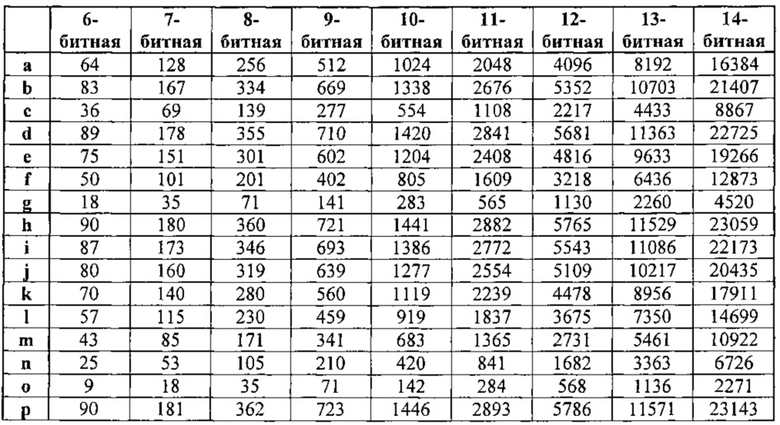
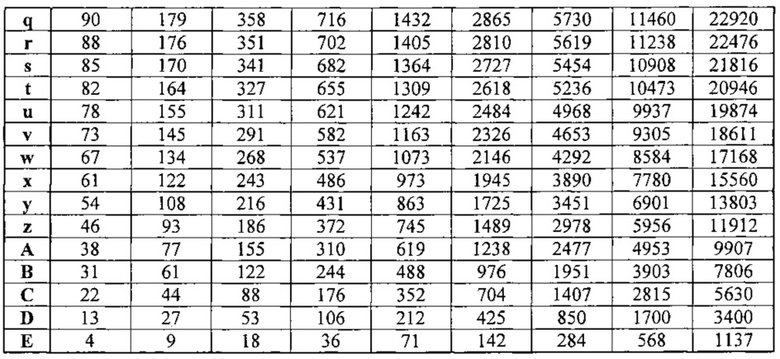
Для информации, здесь представлены матрицы DCT меньшего размера, выведенные из матрицы 32×32. Значения в каждой ячейке решетки определены точностью коэффициента матрицы в соответствии с представленной выше таблицей.
4×4 DCT
Матрица М4 определена как первые 4 коэффициента каждого 8-ого ряда комбинированной матрицы М32.
8×8 DCT
Матрица М8 определена как первые 8 коэффициентов каждого 4-ого ряда комбинированной матрицы М32.

16×16 DCT
Матрица M16 определена как первые 16 коэффициентов каждого четного ряда комбинированной матрицы М32.

Другие технологии, относящиеся к вариантам осуществления кодирования фиксированного бита или соответствующие им технологии будут описаны со ссылкой на фиг. 36 и 37.
Вначале, однако, будут описаны технологии, используемые для кодирования кодов перехода.
Так называемое кодирование Голомба Райса кодирует значение v как унарный кодированный префикс (переменное количество 1, после которых следует 0 или наоборот), после которого следует k битов суффикса.
Пусть prefix_length составляет общее количество 1 в унарно кодированном префиксе. Пусть К представляет собой значение младших значащих к битов.
v = (prefix_length << k) + K
(где << n обозначает сдвиг влево на n битов; аналогичное обозначение >> n представляет сдвиг вправо на n битов),
Общее количество битов равно prefix_length + 1 + k.
Далее будут описаны, так называемые, экспоненциальные коды Голомба порядка k. В таких кодах число, которое должно быть кодировано, разделяют на унарно кодированный префикс переменной длины и суффикс переменной длины. Количество битов суффикса = prefix_length+k. Здесь prefix_length снова представляет собой количество 1 в унарном коде.
Общее количество битов в коде = prefix_length + 1 + prefix_length + k.
Пусть K представляет собой значение последних k битов.
Когда prefix_length равно 0, v будет равно К.
Когда prefix_length равно 1, v будет находиться между (1<<k)+K и (3<<k)+K и (исключительно)
Когда prefix_length равно 2, v будет находиться между (3<<k)+K и (7<<k)+K и (исключительно)
Когда prefix_length равно 3, v будет между (7<<k)+K и (15<<k)+K и (исключительно)
Поэтому v = ((2^prefix_length)-1) << k) + суффикс
В HEVC используются как коды Голомба-Райса, так и экспоненциальные коды Голомба. Если prefïx_length меньше чем три, код интерпретируется как код Голомба-Райса. Однако, если prefix_length больше чем или равен 3, код интерпретируется как экспоненциальный код Голомба порядка к.
Префикс (в любой системе) представляет собой пример унарного кода. Суффикс представляет собой пример неунарного кода. Эти две системы представляют собой примеры кода переменной длины, состоящего из двух частей.
В этом случае значение prefix_length, используемое для декодирования экспоненциального кода Голомба, уменьшается на 3, и значение, получаемое в результате операции декодирования, увеличивается на (3<<k), поскольку это представляет собой наименьшее значение, которое не может быть представлено, используя код Голомба-Райса.
Значение "k", используемое для кодов перехода HEVC и перехода-перехода, меняется. Для каждой группы из 16 коэффициентов значение к начинается с 0, и увеличивается всякий раз, когда магнитуда значения коэффициента больше, чем 3<<k. В ответ на такую ситуацию выполняют последовательное увеличение k (то есть в ответ на магнитуду текущего значения данных) до максимального значения 4. Следует отметить, что описание относится к магнитудам коэффициентов, поскольку бит знака, представляющий знак коэффициента, передают отдельно.
На фиг. 36 показана схематичная блок-схема последовательности операций, иллюстрирующая обработку для генерирования кодов перехода, как описано выше. Несколько из этапов блок-схемы последовательности операций аналогичны тем, которые были описаны ранее, и не будут снова описаны подробно.
Способ работы в отношении группы значений данных, содержащих (например) последовательность преобразованных по частоте коэффициентов изображения, или ненулевых элементов этой последовательности, или ненулевых составляющих этой последовательности, где магнитуда каждого значения данных была уменьшена на 1 (в этом последнем случае карта значимости может быть вначале сгенерирована таким образом, что каждый коэффициент уменьшается на 1 перед дополнительной обработкой, поскольку карта значимости рассчитывается для значения 1).
На этапе 2000 устанавливают исходное значение k. В нормальной системе HEVC к первоначально устанавливают в 0. Этапы 2010, 2020, 2030, 2040, 2050 и 2060 соответствуют аналогичным этапам в блок-схемах последовательности операций на фиг. 29-31 и не будут дополнительно описаны здесь. Следует отметить, что на фиг. 29-31, а также на фиг. 36, в некоторых примерных вариантах осуществления HEVC, не все карты должны быть сгенерированы для каждого коэффициента. Например, в пределах группы (скажем) из 16 коэффициентов, могут присутствовать один или больше коэффициентов, для которых не генерируются некоторые карты.
На этапе 2070, если требуется код перехода, его генерируют на основе текущего значения k, используя только что описанные технологии. В частности, коэффициент, для которого требуется использование кода перехода, вначале обрабатывают, используя карту значимости и, в случае необходимости, одну или больше других карт. Следует отметить, что в случае коэффициента, для которого требуется кодирование перехода, любая из карт >1 и>2 значимости, которая используется, будет помечена флагом как "1". Это связано с тем, что любой коэффициент, для которого требуется кодирование перехода, по определению является большим, чем значение, которое может быть кодировано, используя любые карты, доступные в отношении этого коэффициента.
Код перехода требуется, если текущее значение данных не было полностью кодировано. Здесь термин "полностью" кодированный означает, что значение данных меньше уже кодированных (используя карты или карты вместе с фиксированными битами, например) значений равно нулю. Другими словами, значение данных является полностью кодированным по уже сгенерированным компонентам, если остаточное количество этого значения данных, учитывая эти компоненты, равно нулю.
Таким образом, можно сделать вывод, что в примере коэффициента карты значимости и карты >1 и>2 являются доступными, каждая из них может быть помечена флагом как "значимая", ">1" и ">2" в отношении этого коэффициента.
Это означает (в данном примере), что коэффициент должен быть равным, по меньшей мере, 3.
Поэтому, значение 3 можно вычесть из коэффициента перед кодированием выхода, без потери информации. Значение 3 (или в более общем случае, переменная base_level, которая обозначает цифровой диапазон, который определен картами, которые применяются для этого коэффициента) повторно устанавливается при декодировании.
Если принять значение коэффициента 15 десятичное (1111 двоичное), в качестве примера, карта значимости равна "1" карта >1 равна "1", и карта >2 равна "1". Значение base_level равно 3. Base_level вычитают из значения коэффициента, для получения значения 12 десятичное (1100 двоичное), которое передают для кодирования перехода.
Значение k (см. выше) теперь определяет количество битов суффикса. Биты суффикса получают из младших значащих битов значения коэффициента после вычитания base_level. Если (например) k=2, тогда два младших значащих бита оставшегося значения 1100 обрабатывают, как биты суффикса, при этом следует отметить, что биты суффикса в этом примере равны 00. Оставшиеся биты (11 в этом примере) обрабатывают путем кодирования, как префикс.
Таким образом, обработка, ассоциированная с кодированием выхода, включает в себя:
генерируют одну или больше карт, определяющих один или больше младших значащих битов коэффициентов таким образом, что (если требуется код перехода) коэффициент должен иметь значение, по меньшей мере, base_level;
вычитают base_level из коэффициента;
кодируют младшие значащие k битов оставшейся части коэффициента, как биты суффикса; и
кодируют оставшиеся старшие значащие биты оставшейся части коэффициента, как префикс.
Затем, используя тест, описанный выше, если значение k требуется изменить, изменение воплощают на этапе 2080 и новое значение k предоставляют для следующей операции на этапе 2070.
Модификация технологии кода перехода которая может обеспечить аналогичный эффект для пользователя фиксированных битов (фиг. 30 и 31), состоит в том, чтобы применить смещение для значения k, определяющее количество битов суффикса, используемых в коде перехода.
Например, значение к в системе HEVC имеет диапазон от 0 до 4, и переход (в отношении группы коэффициентов) от начальной точки 0 до максимального значения 4. В вариантах осуществления настоящей технологии смещение добавляют к этому значению k. Например, смещение может быть заранее определено как значение param_offset, такое как 3, таким образом, что существующая технология для изменения k, при в кодировании группы коэффициентов, вместо изменения к от k=0 до k=4, изменяет его от k = param_offset до k = 4 + param_offset.
Значение param_offset может быть заранее определено, например, между кодером и декодером.
Или значение param_offset может быть передано из кодера и декодера, например, как часть потока, изображения, среза или заголовка блока (такого как TU).
Или значение param_offset может быть выведено в кодере и декодере как заданная функция битовой глубины видеоданных, такая как (например):
for bit_depth≤10, param_offset=0
for bit_depth>10, param_offset=bit_depth-10
Или значение param_offset может быть выведено в кодере и декодере как заданная функция степени квантования (Qp), применяемая для блока или группы коэффициентов;
Или значение param_offset может быть зависимым (например, заданным образом) от одного или больше: какие видеокомпоненты кодируют, размера блока, режима (например, без потерь или с потерями), типа изображения и так далее.
Или значение param_offset может быть выведено в кодере и в декодере на адаптивной основе, принимая заданную начальную точку или начальную точку, переданную в заголовке, или начальную точку, выведенную из (например) bit_depth. Пример такой адаптивной обработки будет описан ниже со ссылкой на фиг. 37.
Или может применяться больше чем один из этих критериев. В частности, в случае, когда значение param_offset зависит от другого параметра (такого как размер блока) и его адаптивно изменяют, как описано со ссылкой на фиг. 37, представленную ниже, тогда адаптивная вариация может применяться отдельно для каждого возможного значения param_offset (то есть отдельно для каждого размера блока).
Следует отметить, что любая или все из этих зависимостей могут применяться в отношении количества фиксированных битов, используемых в компоновках по фиг. 30 и 31.
При сравнении этой модифицированной технологии и технологий фиксированных битов, описанной выше со ссылкой на фиг. 30 и 31, можно видеть, что:
(a) в технологии фиксированных битов на фиг. 30 и 31 коэффициент разделяют на более значащие и менее значащие части перед генерированием любой из карт, одну или больше карт затем генерируют из старшей значимой части, и младшую значащую часть непосредственно кодируют (или по-другому обрабатывают, как описано выше); но
(b) при генерировании кодов перехода, используя param_offset, одну или больше карт вначале генерируют и затем оставшуюся часть значения коэффициента (меньшую, чем значение base_level) обрабатывают либо как суффикс или как префикс, с границей между суффиксом и префиксом, в зависимости от k + param_offset, и суффиксом, представляющим младший значащий бит (биты) оставшейся части.
В любом случае, параметр (параметры), ассоциированный с кодированием фиксированного бита, или значением param_offset, может изменяться адаптивным образом. Пример того, как это может быть выполнено, будет теперь описан со ссылкой на фиг. 37. На фиг. 37 аналогичные технологии могут применяться либо для множества фиксированных битов (обозначены как "NFB" на фиг. 37, и с обозначением количества битов младшей значащей части, выведенной на этапе 1625 или 1725 на фиг. 30 и 31, соответственно) или для значения param_offset (сокращенно представлено как "смещение" на фиг. 37) из представленного выше описания.
В следующем описании примерной компоновки предполагается, что адаптацию смещения или значения NFB выполняют на основе от среза к срезу. Следует отметить, что срез может быть определен в пределах семейства HEVC систем, как любой от LCU и до целого изображения, но фундаментальное свойство среза состоит в том то, что его кодирование выполняется независимо от кодирования, применяемого для любого другого среза, таким образом, что индивидуальный срез может быть декодирован независимо от другого среза. Конечно, однако, адаптация может происходить на основе от блока к блоку или от изображения к изображению.
Следует отметить, что обработка на фиг. 37 происходит в кодере и также, во взаимодополняющей форме декодирования, происходит в декодере, таким образом, что значение переменной смещения/NFB идентично отслеживается как между кодером и декодером.
На этапе 2100 начинается обработка среза.
На этапе 2110 выполняют сброс значения смещения/NFB. При этом может использоваться сброс значения до фиксированного значения, такого как 0. В альтернативной компоновке значение может быть сброшено до исходного значения, выведенного из конечного значения переменной смещения/NFB в отношении одного или больше предыдущих срезов. В таком случае, для поддержания возможности декодировать каждый срез независимо, варианты осуществления настоящей технологии обеспечивают показатель исходного значения переменной смещения/NFB в заголовке среза. Следует отметить, что доступны все возможные технологии для получения такого исходного значения. Например, начальное значение переменной смещения/NFB может быть установлено в 0, если конечное значение этой переменной для предыдущего среза не превышает 2, и может быть установлено равным 1 в других случаях. Аналогичная компоновка может применяться для среднего конечного значения переменной, полученной из всех срезов, относящихся к предыдущему изображению. Специалист в данной области будет понимать, что доступны различные другие возможности. Конечно, если используется заданное начальное значение, тогда либо оно может быть согласовано заранее, используя стандартное определение, применимое для кодера и декодера, или заданное начальное значение может быть установлено в потоке или заголовке изображения.
Что касается данных заголовка, флаг может быть включен в поток, изображение или заголовок среза для обозначения, происходит ли обработка адаптации по фиг. 37 в отношении этого потока, изображения или среза.
На этапе 2120, начинается обработка первого модуля преобразования (TU). Обработка среза переходит на основе от TU к TU, как описано ранее.
На этапе 2130 три дополнительных переменных сбрасывают, на этот раз в 0. Эти переменные называются "under" (ниже), "over" (выше) и "total" (сумма). Назначение этих переменных будет описано ниже.
В пределах TU каждый коэффициент кодируют по очереди. На этапе 2140 кодируют следующий коэффициент. Кодирование коэффициента может выполняться в соответствии с блок-схемой последовательности операций на фиг. 30/31 или в соответствии с блок-схемой последовательности операций на фиг. 36, и в каждом случае используется смещение или значение NFB, применимое на этом этапе обработки. Конечно, для первого коэффициента, который должен быть кодирован, значение смещения/NFB равно значению, которое установлено на этапе 2110. Для последующих коэффициентов используется текущее значение смещения/NFB.
Тест применяют в отношении результата кодирования этапа 2140. В зависимости от результата тестирования обработка переходит на этап 2150, 2160 или 2170, или непосредственно на этап 2180. Вначале будет описан тест. Следует отметить, что тест несколько отличается, в зависимости от того, используется ли система с фиксированными битами, представленная на фиг. 30/31, или система param_offset, представленная на фиг. 37 и в соответствующем описании.
Тест с фиксированными битами
В случае системы с фиксированными битами, всякий раз, когда кодируется набор фиксированных битов (выполняется ли этап 1655, или этап 1755), выполняется последовательное приращение переменной "total". В соответствии с этим, переменная "total" относится к количеству случаев, после того как переменная была сброшена в последний раз, в которых были кодированы фиксированные биты.
Тест затем выводит переменную remaining_magnitude, которая определена как часть магнитуды коэффициента, который не кодируют, как фиксированные биты, таким образом, что:
remaining_magnitude = (magnitude - 1) >> NFB
Другое значение, base_level, определено (как описано выше) как наибольшая магнитуда, которая может быть описана без использования кода перехода. Здесь следует отметить, что конкретный коэффициент может иметь один, два или три флага или входа в карту, кодируемых в отношении этого коэффициента. Таким образом:
if коэффициент имеет флаг а>2, base_level=3; else
if коэффициент имеет флаг а>1, base_level=2; else
base_level=1
Значение remaining_magnitude затем тестируют в отношении base_level.
Если ((remaining_magnitude >> 1) ≥ base_level), тогда выполняют последовательное приращение переменной "under". На фиг. 37 это соответствует этапу 2150. Лежащее в основе значение этого этапа состоит в том, что так называемый отрицательный выброс был детектирован таким образом, что количество фиксированных битов (NFB) не было достаточным для кодирования текущего коэффициента. Значимость сдвига вправо (>> 1) при тестировании состоит в том, что отрицательный выброс помечается флагами только, как заслуживающий внимания отрицательный выброс, если в переменной NFB не хватает два или больше бита.
Аналогично, если ((NFB>0) AND ((remaining_magnitude << 1) ≤ 0)), тогда выполняют последовательное приращение переменной "over". На фиг. 37 это соответствует этапу 2160. Лежащее в основе значение этого этапа состоит в том, что положительный выброс детектируется, если, даже когда фиксированных битов на один меньше (детектировано по сдвигу <<1 в выражении, представленном выше), компонент фиксированного бита мог бы иметь возможность кодирования всей магнитуды коэффициента. Другими словами, количество фиксированных битов является значимым при превышении числа, требуемого для кодирования этого коэффициента.
Следует понимать, что различные параметры, используемые в этих тестах, в частности, количество применяемых сдвигов бита, могут изменяться в соответствии со способностью к конструированию умозрительного специалиста в данной области техники.
Если - не выполняется ни тест по отрицательному выбросу, ни тест по положительному выбросу, но кодируются фиксированные биты, тогда управление переходит на этап 2170, на котором выполняют последовательное приращение только переменной "total".
Для полноты отмечается, что управление переходит непосредственно на этап 2180 на фиг. 37, где операция с фиксированными битами не разрешена, таким образом, что изменения выполняют для любой из переменных: "under", "over" и "total".
Тест Param_Offset
В случае системы, основанной на param_offset, лежащие в основе принципы аналогичны, но некоторые из деталей несколько отличаются от описанных выше.
Выполняют последовательное приращение переменной "total" всякий раз, когда кодируется значение перехода.
Значение коэффициента тестируют в отношении параметра k, который, как описано выше, определен таким образом, чтобы учесть эффект смещения param_offset.
If (коэффициент > (3 << k)) then выполняют последовательное приращение переменной "under". Это соответствует этапу 2150 на фиг. 37 и обозначает ситуацию отрицательного выброса, как описано выше. Другими словами, переменная k, учитывающая param_offset, была недостаточна для кодирования кода перехода, как суффикса.
Другими словами, если ((коэффициент * 3) < (1 << k)) then выполняют последовательное приращение переменной "over". Это соответствует этапу 2160 на фиг. 37. Это представляет ситуацию положительного выброса, при которой для переменной k, учитывая param_offset, предоставляют больше битов суффикса, чем требовалось для кодирования кода перехода.
Если не выполняется тестирование ни для отрицательного выброса, ни для положительного выброса, но кодируют код перехода, управление переходит на этап 2170, на котором выполняют последовательное приращение только переменной "total".
И снова следует отметить, что управление переходит непосредственно на этап 2180 на фиг. 37, где кодируют код перехода таким образом, что не выполняют какие-либо изменения для любых из переменных: "under", "over" и "total".
Следует отметить, что при любом наборе тестов проверяют, является ли отрицательный выброс или положительный выброс существенным, путем проверки, мог ли произойти отрицательный выброс или положительный выброс, если NFB или param_offset было еще выше, или еще ниже, соответственно. Но этот дополнительный запас не требуется - в тестах может быть просто установлено "произошел ли отрицательный (положительный) выброс?"
На этапе 2180, если доступен другой коэффициент для кодирования в TU, тогда управление возвращается на этап 2140. В противном случае, управление переходит на этап 2190, который выполняется в конце каждого TU, но перед кодированием следующего TU. На этом этапе 2190, переменная смещения/NFB потенциально адаптивно изменяется в соответствии с переменными "under", "over" и "total". Здесь та же адаптация применяется либо для значения смещения, или для значения NFB, таким образом, что:
if ((under * 4) > total, значение смещения/NFB последовательно увеличивают на (1); и
if ((over * 2) > total, значение смещения/NFB последовательно уменьшают на (1) при учете, что минимальное значение равно 0.
Следует отметить, что, если оба теста будут проведены в отношении одного TU, то значение NFB или param_offset останется таким же.
Следует отметить, что разделение на срезы и затем на TU не является существенным - любая группа значений (которая даже может не представлять собой значения видеоданных), может обрабатываться, таким образом, и может быть подразделена на поднаборы вместо разделения на TU в этом описании.
Это эквивалентно последовательному приращению смещения/NFB, если возникает больше чем 25% отрицательных выбросов, но последовательному уменьшению значения смещения/NFB, если наблюдается больше, чем 50% положительных выбросов. Таким образом, пропорция, используемое для тестирования отрицательных выбросов, ниже, чем пропорция, используемая для тестирования положительных выбросов. Причина такой асимметрии состоит в том, что отрицательные выбросы генерируют больше неэффективности, чем положительные выбросы, из-за природы способов кодирования перехода, используемых в случае отрицательных выбросов. Следует понимать, однако, что могут использоваться одинаковые пороговые значения, или могут использоваться разные значения.
И, наконец, на этапе 2200, если существует другое TU в срезе, тогда управление возвращается на этап 2120. Если другие TU отсутствуют в срезе, тогда управление возвращается на этап 2100. Следует отметить, что, как описано выше, в случае необходимости, начальная точка для смещения/NFB может быть установлена (для использования в следующем случае этапа 2120 для следующего или будущего среза) на основе результатов, полученных во время обработки кодирования, которая была только что закончена.
Взаимодополняющие этапы выполняются на стороне декодирования (или на стороне декодирования кодера). Например, способ декодирования может содержать: декодируют первую часть каждого значения данных из одного или больше наборов данных, обозначающих первые части заданных диапазонов магнитуды, и кодированные для входного потока данных, используя двоичное кодирование; декодируют вторую часть, по меньшей мере, значений данных, не полностью кодированных этими наборами данных, количество битов второй части, зависит от значения n, где n представляет собой целое число, данные, определяющие второй участок, включенный в поток входных данных, и если значение данных не было полностью декодировано соответствующими первым и вторым участками, декодируют оставшийся третий участок значения данных из потока входных данных; обнаруживают для поднабора из двух или больше значений данных, (i) количество случаев значений данных, для которых третий участок был кодирован, и если все еще требуется, используется более высокое значение n, и (ii) количество случаев значений данных, для которых был кодирован второй участок, но значение n было таким, что значение данных могло быть полностью кодировано первым и вторым участками, используя нижнее значение n; и после декодирования поднабора значений данных, изменяют n для использования в отношении последовательных значений данных в соответствии с результатами этапа обнаружения.
Описанные выше этапы могут быть выполнены энтропийным кодером 370 и энтропийным декодером 410 (в случае обработки кодирования) или только энтропийным декодером 410 (в случае обработки декодирования). Обработка могут быть воплощена в аппаратных средствах, в программном обеспечении, в программируемых аппаратных средствах и т.п. Следует отметить, что энтропийный кодер 370 может поэтому действовать как кодер, генератор, устройство обнаружения и процессор для воплощения способов кодирования. Энтропийный декодер 410 может, соответственно, действовать как один или больше декодеров, устройств обнаружения и процессоров для воплощения описанной здесь технологии декодирования.
Соответственно, описанные выше компоновки, представляют примеры способа декодирования данных для декодирования группы (например, среза) значений данных (например, данных изображения), способ, содержащий этапы:
декодируют первую часть каждого значения данных из одного или больше наборов данных (например, карт) обозначающих первые части заданных диапазонов магнитуды и кодируемых в поток входных данных, используя двоичное кодирование;
декодируют вторую часть, по меньшей мере, тех значений данных, не полностью кодируемых наборами данных, количество битов второй части зависит от значения n, где n представляет собой целое число, данные, определяющие вторую часть, включены в поток входных данных, и, если значение данных не было полностью декодировано соответствующими первой и второй частями, декодируют оставшуюся третью часть значений данных из потока входных данных (здесь, например, вторая часть может представлять фиксированные биты или часть суффикса; значение n может представлять количество фиксированных битов или длину суффикса (при кодировании Голомба-Райса) или порядок экспоненциального кодирования Голомба, как описано выше; третья часть может представлять собой префикс в системе Голомба-Райса или в экспоненциальной системе Голомба, или код перехода с фиксированными битами);
обнаруживают для поднабора из двух или больше значений данных, (i) количество (например, для переменной "under") случаев значений данных, для которых была кодирована третья часть, и если все еще требуется, используется более высокое значение n, и (ii) количество (например, для переменной "under") случаев значений данных, для которых была кодирована вторая часть, но значение n было таким, что значение данных могло быть полностью кодировано первой и второй частями, используя меньшее значение n; и
после декодирования поднабора значений данных, изменяют (например, выполняют последовательное приращение или последовательное уменьшение) n для использования в отношении следующих значений данных, в соответствии с результатами этапа обнаружения.
Переменная "total" представляет пример обнаруженного суммарного количества случаев в отношении этих поднаборов значений данных, для которых была кодирована вторая часть.
Описанные выше варианты осуществления также представляют пример способа кодирования данных для кодирования массива значений данных, в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, код перехода содержащий унарно кодированную часть и неунарно кодированную часть, способ, содержащий этапы:
устанавливают параметры кодирования (например, param_offset), определяющие минимальное количество битов неунарно кодированной части (в системе Голомба-Райса или в экспоненциальный системе Голомба к определяет минимальную длину суффикса или порядок), параметр кодирования находится между значением 0 и заданным верхним пределом;
суммируют значения смещения (param_offset в примерах) 1 или больше с параметром кодирования для определения размера части минимальных значащих данных;
генерируют один или больше наборов данных (например, карту значимости, наборы >1, >2) обозначающих для положений, относящихся к массиву значений данных, значения данных заданных диапазонов магнитуды, чтобы кодировать значение, по меньшей мере, одного младшего значащего бита каждого значения данных;
генерируют из, по меньшей мере, части каждого значения данных, которое не было кодировано одним или больше наборами данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных таким образом, что, часть старших значащих данных значения представляет ноль или больше старших значащих битов этой части, и соответствующая часть младших значащих данных зависит от количества младших значащих битов этой части, количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных;
кодируют наборы данных в поток выходных данных (например, как двоичные кодированные данные);
кодируют части старших значащих данных в поток выходных данных (например, как префикс); и
кодируют младшие значащие части в поток выходных данных (например, как суффикс).
Следует отметить, что описанная выше обработка может быть выполнена (в некоторых вариантах осуществления) после генерирования карты значимости так, чтобы значения данных (для которых была выполнена обработка) могли бы быть сгенерированы из соответствующих входных значений путем: генерирования дополнительного набора данных, дополнительный набор данных имеет карту значимости, обозначающую положения относительно массива входных значений, ненулевых входных значений; и вычитания 1 из каждого входного значения для генерирования соответствующих значений данных.
На фиг. 38 и 39 схематично показаны блок-схемы последовательности операций, поясняющие обработку для выбора динамического диапазона преобразования и параметров точности данных.
Как показано на фиг. 38 и как описано выше, на этапе 2410 параметры, такие как максимальный динамический диапазон и/или точность данных матрицы преобразования, выбирают в соответствии с битовой глубиной каждого изображения или видеокомпонента. На этапе 2410, для входных или выходных данных изображения, имеющих изображения или компоненты видеоданных с различной битовой глубиной, выбирают один набор максимального динамического диапазона и/или точности данных матрицы преобразования для использования со всеми видеокомпонентами или компонентами изображения.
Как показано на фиг. 39, этап 2420 аналогичен этапу 2410, но включает в себя дополнительные особенности, в соответствии с которыми выбирают один набор максимального динамического диапазона и/или точности данных матрицы преобразования как значения, относящиеся к этому одному из изображения или видеокомпонентов, имеющему наибольшую битовую глубину.
Варианты осуществления раскрытия могут работать в отношении последовательности значений входных данных, в зависимости от массива преобразованных по частоте коэффициентов входного изображения.
Варианты осуществления, описанные выше, определены следующими пронумерованными пунктами:
[1] Способ кодирования данных для кодирования последовательности значений данных, содержащий этапы, на которых:
генерируют из исходных значений данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных значения представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет остальные младшие значащие биты этого значения;
генерируют один или более наборов данных, указывающих положения относительно массива значений, частей старших значащих данных с заданными магнитудами;
кодируют наборы данных в выходной поток данных, используя двоичное кодирование; и
включают данные, определяющие младшие значащие части в выходной поток данных.
[2] Способ по [1], в котором один из наборов данных представляет собой карту значимости, указывающую положения относительно массива значений данных, частей старших значащих данных, которые не равны нулю.
[3] Способ по [2], в котором карта значимости содержит флаг данных, указывающий положения, в соответствии с заданным упорядочиванием массива значений по меньшей мере частей старших значащих данных, имеющих ненулевое значение.
[4] Способ по [2] или [3], в котором наборы данных содержат:
карту больше, чем один, указывающую положения относительно массива значений, частей старших значащих данных, которые больше 1; и
карту больше, чем два, указывающую положения, относящиеся к массиву значений, частей старших значащих данных, которые больше 2.
[5] Способ по [1], в котором наборы данных содержат:
карту больше, чем один, указывающую положения относительно массива значений, частей старших значащих данных, которые больше чем или равны 1; и
карту больше, чем два, указывающую положения, относящиеся к массиву значений, частей старших значащих данных, которые больше чем или равны 2.
[6] Способ по [5], содержащий этап генерирования дополнительного набора данных, дополнительный набор данных представляет собой карту значимости, указывающую положения относительно массива значений из ненулевых значений.
[7] Способ по [6], в котором карта значимости содержит флаг данных, указывающий положения, в соответствии с заданным упорядочиванием массива значений, последних из значений, имеющих ненулевое значение.
[8] Способ по любому из [1]-[7], в котором этап включения данных, указывающих части младших значащих данных в выходной поток данных, содержит подэтап, на котором кодируют части младших значащих данных, используя арифметическое кодирование, в котором символы, представляющие части младших значащих данных, кодируют в соответствии с соответствующими пропорциями диапазона значений кодирования, при этом соответствующие пропорции диапазона значений кодирования для каждого из символов, которые описывают часть младших значащий данных, имеют равный размер.
[9] Способ по любому из [1]-[7], в котором этап включения данных, определяющих младшие значащие части, в выходной поток данных, содержит подэтап, на котором осуществляют непосредственное включение частей младших значащих данных в выходной поток данных, в качестве необработанных данных.
[10] Способ по любому из [1]-[9], в котором:
последовательность значений данных представляет данные изображения, имеющие глубину битов данных изображения; и
способ содержит этапы, на которых устанавливают количество битов, подлежащих использованию в качестве множества старших значащих битов в каждой части старших значащих данных, которые равны битовой глубине данных изображения.
[11] Способ по любому из [1]-[10], в котором последовательность значений данных содержит последовательность коэффициентов изображения, преобразованных по частоте.
[12]. Способ по [1], в котором коэффициенты входного изображения, преобразованные по частоте, представляют собой квантованные коэффициенты входного изображения, преобразованные по частоте, в соответствии с переменным параметром квантования, выбранным из диапазона доступных параметров квантования, при этом способ дополнительно содержит этапы, на которых:
кодируют массив преобразованных по частоте коэффициентов входного изображения, в соответствии с частями старших значащих данных и частями младших значащих данных для коэффициентов, полученных, используя параметр квантования в первом заданном поддиапазоне диапазона доступных параметров квантования; и
для коэффициентов, полученных используя параметр квантования не в первом заданном поддиапазоне диапазона доступных параметров квантования, кодируют массив преобразованных по частоте коэффициентов входного изображения таким образом, что количество битов в каждой части старших значащих данных равно количеству битов этого коэффициента, и соответствующая часть младших значащих данных не содержит биты.
[13] Способ по [11] или [12], содержащий этапы, на которых:
преобразуют по частоте входные данные изображения для генерирования массива преобразованных по частоте коэффициентов входного изображения, с использованием обработки умножения матрицы, в соответствии с максимальным динамическим диапазоном преобразованных данных и используя матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[14] Способ по [13], в котором этап выбора содержит подэтапы, на которых:
устанавливают точность данных матрицы преобразования на первое смещенное число битов меньшее, чем битовая глубина входных данных изображения; и
устанавливают максимальный динамический диапазон преобразованных данных на второе смещенное число битов большее, чем битовая глубина входных данных изображения.
[15] Способ по [14], в котором первое количество битов смещения равно 2, а второе количество битов смещения равно 5.
[16] Способ по любому из [13]-[15], содержащий этап, на котором:
выводят матрицы преобразования с требуемой точностью данных из соответствующих исходных матриц преобразования с разной точностью данных.
[17] Способ по любому из [1]-[16], в котором этап кодирования содержит подэтапы, на которых:
выбирают один из множества взаимодополняющих поддиапазонов набора значений кода, в соответствии со значением текущего значения входных данных набора данных для кодирования, при этом набор значений кода определяют по переменной диапазона;
назначают текущие значения входных данных для значения кода в пределах выбранного поддиапазона;
модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона;
обнаруживают, является ли переменная диапазона, определяющая набор значений кода, меньшей, чем заданный минимальный размер, и если это так, последовательно увеличивают переменную диапазона, так, чтобы увеличить размер набора значений кода до тех пор, пока он не будет иметь, по меньшей мере, заданный минимальный размер; и выводят кодированный бит данных в ответ на каждую такую операцию увеличения размера; и
после кодирования группы значений входных данных устанавливают переменную диапазона на значение, выбранное из заданного поднабора доступных диапазона переменных значений, каждое значение в поднаборе, имеющее по меньшей мере один младший значащий бит, равный нулю.
[18] Способ по [17], в котором:
пропорции поддиапазонов относительно набора значений кода определяют по контекстной переменной, ассоциированной с входным значением данных.
[19]. Способ по [18], содержащий этап, на котором:
после кодирования значения данных, модифицируют контекстную переменную для использования в отношении следующего значения входных данных для увеличения пропорции набора кодовых обозначений в поддиапазоне, выбранном для текущего значения данных.
[20] Способ по любому из [17]-[19], в котором:
набор значений кода содержит значения от 0 до верхнего значения, определенного переменной диапазона, при этом верхнее значение находится между 256 и 510.
[21] Способ по [20], в котором:
поднабор доступных значений переменной диапазона содержит значение 256.
[22] Способ по [20], в котором:
поднабор доступных значений содержит набор, состоящий из 256 и 384;
этап установки переменной диапазона содержит подэтап, на котором выбирают значение из поднабора в соответствии с текущим значением переменной диапазона, так, что переменную диапазона устанавливают равной 256, если текущее значение переменной диапазона находится между 256 и 383, и переменную диапазона устанавливают равной 384, если текущее значение переменной диапазона находится между 384 и 510.
[23] Способ по [20], в котором:
поднабор доступных значений содержит набор, состоящий из 256, 320, 384 и 448;
этап установки переменной диапазона содержит выбор значения из поднабора, в соответствии с текущим значением переменной диапазона, так, что переменную диапазона устанавливают равной 256, если текущее значение переменной диапазона находится между 256 и 319, переменную диапазона устанавливают равной 320, если текущее значение переменной диапазона находится между 320 и 383, переменную диапазону устанавливают равной 384, если текущее значение переменной диапазона находится между 384 и 447, и переменную диапазона устанавливают равной 448, если текущее значение переменной диапазона находится между 448 и 510.
[24] Способ по любому из [17]-[23], содержащий этапы, на которых:
кодируют значения, представляющие данные, которые не представлены в наборе данных, как обходные данные;
обнаруживают количество обходных данных, ассоциированное с текущим массивом; и
применяют этап установки, если количество обходных данных превышает пороговую величину, но не применяют этап установки в других случаях.
[25] Способ по любому из [17]-[24], в котором данные кодируют, как модули преобразования, содержащие множество массивов значений данных, при этом способ содержит этап, на котором применяют этап установки в конце кодирования модуля преобразования.
[26] Способ кодирования данных изображения, содержащий этапы, на которых:
преобразуют по частоте входные данные изображения для генерирования массива коэффициентов преобразованного по частоте входного изображения, с использованием обработки умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и с использованием матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[27] Данные изображения кодируют способом кодирования по любому из [1]-[26].
[28] Носитель данных, на котором содержатся видеоданные по [17].
[29] Способ декодирования данных, предназначенный для декодирования данных, для получения массива значений данных, содержащий этапы, на которых:
отделяют, от входного потока данных, части младших значащих данных для значений данных и один или более наборов кодированных данных;
декодируют наборы данных для генерирования частей старших значащих данных для значений данных, с использованием двоичного декодирования; и
комбинируют части старших значащих данных и части младших значащих данных, для формирования значений данных, так, что, для значения данных, соответствующая часть старших значащих данных представляет множество старших значащих битов этого значения данных, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения данных.
[30] Способ декодирования данных изображения, содержащий этапы, на которых:
выполняют преобразование по частоте входных, преобразованных по частоте данных изображения для генерирования массива выходных данных изображения, с использованием обработки умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и с использованием матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной выходных данных изображения.
[31] Компьютерное программное обеспечение, которое при исполнении компьютером, обеспечивает выполнение компьютером способа по любому из [1]-[30].
[32] Энергонезависимый считываемый устройством носитель информации, хранящий компьютерное программное обеспечение по [31].
[33] Устройство кодирования данных для кодирования последовательности значений данных, содержащее:
генератор, выполненный с возможностью генерирования из значений входных данных соответствующих взаимодополняющих частей старших значащих данных и частей младших значащих данных, так, что часть старших значащих данных с определенным значением представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения, и выполненный с возможностью генерировать один или больше наборов данных, указывающих положения относительно массива значений частей старших значащих данных с заданной магнитудой; и
кодер, выполненный с возможностью кодирования наборов данных выходного потока данных с использованием двоичного кодирования, и включения данных, определяющих младшие значащие части в выходной поток данных.
[34] Устройство кодирования данных для кодирования данных изображения, устройство содержащее:
преобразователь частоты, выполненный с возможностью преобразование по частоте входных данных изображения для генерирования массива преобразованных по частоте коэффициентов входного изображения, используя обработку умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных и используя матрицы преобразования, имеющие определенную точность данных; и
селектор, выполненный с возможностью выбора максимального динамического диапазона и/или точности данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[35] Устройство декодирования данных, предназначенное для декодирования данных, для обеспечения массива значений данных, устройство, содержащее следующие этапы:
разделитель данных, выполненный с возможностью отделения из входного потока данных частей младших значащих данных для значений данных и одного или более наборов кодированных данных;
декодер, выполненный с возможностью декодирования наборов данных для генерирования частей старших значащих данных для значений данных с использованием двоичного декодирования; и
объединитель, выполненный с возможностью объединения частей старших значащих данных и частей младших значащих данных для формирования значения данных так, что для значения данных соответствующая часть старших значащих данных представляет множество старших значащих битов этого значения данных, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения данных.
[36] Устройство декодирования данных изображения, содержащее:
преобразователь частоты, выполненный с возможностью преобразования по частоте входных преобразованных по частоте данных изображения для генерирования массива выходных данных изображения, с использованием обработки умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и используя матрицы преобразования, имеющие определенную точность данных; и
селектор, выполненный с возможностью выбора максимального динамического диапазона и/или точности данных матриц преобразования, в соответствии с битовой глубиной данных выходного изображения.
[37] Устройство захвата, преобразования отображения и/или сохранения видеоданных, содержащее устройство по любому из [33]-[36].
Дополнительные варианты осуществления определены в следующих пронумерованных пунктах:
[1] Способ кодирования данных для значения входных данных набора данных, предназначенного для кодирования, содержащий этапы, на которых:
выбирают один из множества взаимодополняющих поддиапазонов набора значений кода, в соответствии со значением текущего значения входных данных, набор значений кода определен переменной диапазона;
назначают текущие значения входных данных для значения кода в пределах выбранного поддиапазона;
модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона;
обнаруживают, является ли переменная диапазона, определяющая набор значений кода, меньшей, чем заданный минимальный размер, и, если это так, последовательно увеличивают переменный диапазон так, чтобы увеличивать размер набора значений кода до тех пор, пока он не примет по меньшей мере заданный минимальный размер; и выводят кодированный бит данных в ответ на каждую такую операцию увеличения размера; и
после кодирования группы значений входных данных, устанавливают переменную диапазона до значения, выбранного из заданного поднабора доступных значений переменного диапазона, каждое значение в поднаборе, имеющее, по меньшей мере, один младший значащий бит, равный нулю.
[2] Способ по [1], в котором:
пропорции поддиапазонов относительно набора значений кода определены переменной контекста, ассоциированной со значением входных данных.
[3] Способ по [2], содержащий этап, на котором:
после кодирования значения входных данных модифицируют контекстную переменную для использования в отношении следующего значения входных данных, с тем, чтобы увеличить пропорцию наборов значений кода в поддиапазоне, который был выбран для текущего значения входных данных.
[4] Способ по любому из [1]-[3], в котором:
набор значений кода содержит значения от 0 до верхнего значения, определенного переменной диапазона, верхнее значение находится между заданным минимальным размером и вторыми заданными значениями.
[5] Способ по [4], в котором заданный минимальный размер составляет 256 и второе заданное значение равно 510.
[6] Способ по любому из [1]-[5], в котором;
поднабор доступных значений переменной диапазона содержит заданный минимальный размер.
[7] Способ по любому из [1]-[5], в котором поднабор содержит два или больше значения между заданным минимальным размером и вторым заданным значением.
[8] Способ по [7], в котором этап установки содержит выбор значения из поднабора в соответствии с текущим значением переменной диапазона.
[9] Способ по [8], в котором этап установки содержит выбор конкретного значения из поднабора, если текущее значение переменной диапазона между этим конкретным значением и значением, меньшим, чем следующее наибольшее значение в поднаборе.
[10] Способ по любому из [1]-[9], содержащий этапы, на которых:
кодируют данные, представляющие коэффициенты, которые не представлены набором данных, как обходные данные;
обнаруживают количество обходных данных, ассоциированных с текущим массивом; и
применяют этап установки, если количество обходных данных превышает пороговое значение, при этом в остальных случаях не применяют этап установки.
[11] Способ по любому из [1]-[10], в котором:
значения входных данных представляют данные изображения;
данные изображения кодируют, как модули преобразования, содержащие множество массивов коэффициентов, при этом способ содержит этап, на котором применяют этап установки в конце кодирования модуля преобразования.
[12] Данные кодируют способом кодирования по любому из [1]-[11].
[13] Носитель данных, содержащий видеоданные по [12].
[14] Устройство кодирования данных, предназначенное для кодирования значений входных данных набора данных, предназначенных для кодирования, содержащее:
селектор, выполненный с возможностью выбора одного из множества взаимодополняющих поддиапазонов из набора кодовых обозначений, в соответствии со значением текущего значения входных данных, при этом набор кодовых обозначений, определенных переменной диапазона, и назначения текущего значения входных данных для кодового значения в пределах выбранного поддиапазона;
модификатор, выполненный с возможностью модификации набора значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона;
устройство обнаружения, выполненное с возможностью обнаружения, является ли переменная диапазона, определяющая набор значений кода, меньшей, чем заданный минимальный размер, и если это так, последовательного увеличения переменной диапазона для увеличения размера набора значений кода до тех пор, пока он не будет иметь, по меньшей мере, заданный минимальный размер; и вывода бита кодированных данных в ответ на каждую такую операцию увеличения размера; и
установщик переменной диапазона, выполненный с возможностью, после кодирования группы значений входных данных, установки переменной диапазона в значение, выбранное из заданного поднабора доступных значений переменных диапазона, каждое значение в поднаборе, имеющее, по меньшей мере, один младший значащий бит, равный нулю.
[15] Устройство захвата, преобразования и/или сохранения видеоданных, содержащее устройство по [14].
Дополнительные варианты осуществления определены следующими пронумерованными пунктами:
[1] Способ кодирования данных для кодирования массива значений данных, содержащий этапы, на которых:
генерируют из исходных значений данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных значения представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет остальные младшие значащие биты этого значения;
генерируют один или более наборов данных, указывающих положения относительно массива значений, частей старших значащих данных с заданными магнитудами;
кодируют наборы данных в выходной поток данных, используя двоичное кодирование; и
включают данные, указывающие младшие значащие части в выходной поток данных.
[2] Способ по [1], в котором один из наборов данных представляет собой карту значимости, указывающую положения относительно массива значений данных, частей старших значащих данных, которые не равны нулю.
[3] Способ по [2], в котором карта значимости содержит флаг данных, указывающий положения, в соответствии с заданным упорядочиванием массива значений по меньшей мере частей старших значащих данных, имеющих ненулевое значение.
[4] Способ по [2] или [3], в котором наборы данных содержат:
карту больше, чем один, указывающую положения относительно массива значений, частей старших значащих данных, которые больше 1; и
карту больше, чем два, указывающую положения, относящиеся к массиву значений, частей старших значащих данных, которые больше 2.
[5] Способ по [1], в котором наборы данных содержат:
карту больше, чем один, указывающую положения относительно массива значений, частей старших значащих данных, которые больше чем или равны 1; и
карту больше, чем два, указывающую положения, относящиеся к массиву значений, частей старших значащих данных, которые больше чем или равны 2.
[6] Способ по [5], содержащий этап генерирования значений данных из соответствующих входных значений путем:
генерирования дополнительного набора данных, дополнительный набор данных представляет собой карту значимости, указывающую положения относительно массива значений из ненулевых значений; и
вычитания 1 из каждого входного значения для генерирования соответствующего значения данных.
[7] Способ по [5] или [6], в котором карта значимости содержит флаг данных, указывающий положения, в соответствии с заданным упорядочиванием массива значений, последних из значений, имеющих ненулевое значение.
[8] Способ по любому из [1]-[7], в котором этап включения данных, определяющих части младших значащих данных в выходной поток данных, содержит подэтапы, на которых кодируют части младших значащих данных, с использованием арифметического кодирования, при этом символы, представляющие части младших значащих данных, кодируют в соответствии с соответствующими пропорциями диапазона значений кодирования, в котором соответствующие пропорции диапазона значений кодирования для каждого из символов, которые описывают часть младших значащий данных, имеют равный размер.
[9] Способ по любому из [1]-[8], в котором этап включения данных, определяющих младшие значащие части, в выходной поток данных, содержит непосредственное включение частей младших значащих данных в выходной поток данных, в качестве необработанных данных.
[10] Способ по любому из [1]-[9], в котором:
последовательность значений данных представляет данные изображения, имеющие глубину битов данных изображения; при этом
способ содержит этап, на котором устанавливают количество битов, подлежащих использованию в качестве множества старших значащих битов в каждой части старших значащих данных, равных битовой глубине данных изображения.
[11] Способ по любому из [1]-[10], в котором последовательность значений данных содержит последовательность коэффициентов изображения, преобразованных по частоте.
[12] Способ по [11], в котором коэффициенты входного изображения, преобразованные по частоте, представляют собой квантованные коэффициенты входного изображения, преобразованные по частоте, в соответствии с переменным параметром квантования, выбранным из диапазона доступных параметров квантования, при этом способ содержит этапы, на которых:
кодируют массив преобразованных по частоте коэффициентов входного изображения, в соответствии с частями старших значащих данных и частями младших значащих данных для коэффициентов, полученных с использованием параметра квантования в первом заданном поддиапазоне диапазона доступных параметров квантования; и
для коэффициентов, полученных используя параметр квантования не в первом заданном поддиапазоне диапазона доступных параметров квантования, кодируют массив преобразованных по частоте коэффициентов входного изображения так, что количество битов в каждой части старших значащих данных равно количеству битов этого коэффициента, и соответствующая часть младших значащих данных не содержит биты.
[13] Способ по [11], содержащий этапы, на которых:
преобразуют по частоте входные данные изображения для генерирования массива преобразованных по частоте коэффициентов входного изображения, используя обработку умножения матрицы, в соответствии с максимальным динамическим диапазоном преобразованных данных и используя матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[14] Способ по [13], в котором этап выбора содержит подэтапы, на которых:
устанавливают точность данных матрицы преобразования на первое смещенное число битов меньше, чем битовая глубина входных данных изображения; и
устанавливают максимальный динамический диапазон преобразованных данных на второе смещенное число битов больше, чем битовая глубина входных данных изображения.
[15] Способ по [14], в котором первое количество битов смещения равно 2 и второе количество битов смещения равно 5.
[16] Способ по [14], в котором первое количество битов смещения равно 2 и второе количество битов смещения равно 6.
[17] Способ по [14], в котором второе количество битов смещения зависит от размера матрицы в матрицах преобразования.
[18] Способ по любому из [13]-[17], содержащий этап, на котором:
выводят матрицы преобразования с требуемой точностью данных из соответствующих исходных матриц преобразования с разной точностью данных.
[19] Способ кодирования данных для кодирования массива значений данных, как наборов данных и кодов перехода для значений, не кодированных наборами данных, код перехода, содержащий унарно кодированную часть и неунарно кодированную часть, при этом способ содержит этапы, на которых:
устанавливают параметр кодирования, определяющий минимальное количество битов неунарной кодированной части, параметр кодирования находится между 0 и заданным верхним пределом;
добавляют значения смещения, равные 1 или больше, к параметру кодирования, для определения минимального размера части младших значащих данных;
генерируют один или более наборов данных, указывающих положения относительно массива значений данных, для значений данных заданных диапазонов магнитуды, с тем, чтобы кодировать значение по меньшей мере одного младшего значащего бита каждого значения данных;
генерируют, из по меньшей мере части каждого значения данных, не кодированных одним или больше наборами данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных с определенным значением, представляет ноль или больше старших значащих битов этой части, и соответствующая часть младших значащих данных представляет количество младших значащих битов этой части, количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных;
кодируют наборы данных в выходной поток данных;
кодируют части старших значащих данных в выходной поток данных; и
кодируют части младших значащих данных в выходной поток данных.
[20] Способ по [19], в котором:
этап кодирования частей старших значащих данных в выходной поток данных содержит кодирование частей старших значащих данных в выходной поток, используя унарный код; и
этап кодирования младших значащих частей выходного потока данных содержит кодирование младших значащих частей в выходной поток данных, используя неунарный код.
[21] Способ по [19] или [20], в котором этап кодирования наборов данных в выходной поток данных содержит этап, на котором кодируют наборы данных в выходной поток данных, используя двоичный код.
[22] Способ по любому из [19]-[21], в котором этап установки содержит последовательное приращение параметра кодирования, в зависимости от магнитуды текущего значения данных в массиве.
[23] Способ по любому из [20]-[22], в котором этапы кодирования части старших значащих данных и части младших значащих данных содержат подэтапы, на которых: кодируют часть старших значащих данных и часть младших значащих данных, используя код Голомба-Райса или экспоненциальный код Голомба.
[24] Способ по [23], в котором:
длина суффикса кода Голомба-Райса равна минимальному размеру части младших значащих данных; и
экспоненциальный код Голомба имеет порядок, равный минимальному размеру части младших значащих данных.
[25] Способ по любому из [19]-[24], содержащий этап генерирования значения смещения, в зависимости от параметра значений массива данных.
[26] Способ по [26], в котором параметр массива значений данных содержит одно или более из:
количества значений данных в массиве;
типа данных, представленных значениями данных;
параметра квантования, применимого к массиву значений данных; и
режима кодирования.
[27] Способ по любому из [19]-[26], содержащий этап, включающий в себя данные в заголовке данных, определяющем значение смещения.
[28] Способ по [1], в котором этап кодирования содержит:
выбирают один из множества взаимодополняющих поддиапазонов набора значений кода, в соответствии со значением текущего значения входных данных набора данных для кодирования набора значений кода, определенных переменной диапазона;
назначают текущие значения входных данных для значения кода в пределах выбранного поддиапазона;
модифицируют набор значений кода, в зависимости от назначенного значения кода и размера выбранного поддиапазона;
обнаруживают, является ли переменная диапазона, определяющая набор значений кода, меньшей, чем заданный минимальный размер и, если это так, последовательно выполняют последовательное приращение переменной диапазона, так, чтобы увеличить размер набора значений кода, пока он не будет иметь по меньшей мере заданный минимальный размер; и выводят кодированный бит данных в ответ на каждую такую операцию увеличения размера; и
после кодирования группы значений входных данных, устанавливают переменную диапазона на значение, выбранное из заданного поднабора доступных значений переменных диапазона, каждое значение в поднаборе, имеющее по меньшей мере один младший значащий бит, равный нулю.
[29] Способ по [29], в котором:
пропорции поддиапазонов относительно набора значений кода определены переменной контекста, ассоциированной со значением входных данных.
[30] Способ по [29], содержащий следующий этап:
после кодирования значения данных, модифицируют контекстную переменную для использования в отношении следующего значения входных данных, с тем, чтобы увеличить пропорцию набора кодовых обозначений в поддиапазоне, который был выбран для текущего значения данных.
[31] Способ по любому из [28]-[30], в котором:
набор значений кода содержит значения от 0 до верхнего значения, определенного переменной диапазона, верхнее значение находится между 256 и 510.
[32] Способ по [301], в котором:
поднабор доступных значений переменной диапазона содержит значение 256.
[33] Способ по [31], в котором:
поднабор доступных значений содержит набор, состоящий из 256 и 384, при этом
этап установки переменной диапазона содержит подэтап выбора значения из поднабора в соответствии с текущим значением переменной диапазона, таким образом, что переменную диапазона устанавливают равной 256, если текущее значение переменной диапазона находится между 256 и 383, и переменную диапазона устанавливают равной 384, если текущее значение переменной диапазона находится между 384 и 510.
[34] Способ по [31], в котором:
поднабор доступных значений содержит набор, состоящий из 256, 320, 384 и 448, при этом
этап установки переменной диапазона содержит подэтап выбора значения из поднабора, в соответствии с текущим значением переменной диапазона, таким образом, что переменную диапазона устанавливают равной 256, если текущее значение переменной диапазона находится между 256 и 319, переменную диапазона устанавливают равной 320, если текущее значение переменной диапазона находится между 320 и 383, переменную диапазону устанавливают равной 384, если текущее значение переменной диапазона находится между 384 и 447, и переменную диапазона устанавливают равной 448, если текущее значение переменной диапазона находится между 448 и 510.
[35] Способ по любому из [28]-[34], содержащий этапы, на которых:
кодируют значения, представляющие данные, которые не представлены в наборе данных, как обходные данные;
обнаруживают количество обходных данных, ассоциированное с текущим массивом; и
применяют этап установки, если количество обходных данных превышает пороговую величину, при этом не применяют этап установки в других случаях.
[36] Способ по любому из [28]-[35], в котором данные кодируют, как модули преобразования, содержащие множество массивов значений данных, при этом способ содержит этапы, на которых: применяют этап установки в конце кодирования модуля преобразования.
[37] Способ кодирования данных изображения, содержащий этапы, на которых:
преобразуют по частоте входные данные изображения для генерирования массива коэффициентов преобразованного по частоте входного изображения, используя обработку умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и используя матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[38] Способ по [37], в котором, для входных данных изображения, имеющих компоненты изображения с разной битовой глубиной, этап выбора содержит подэтап, на котором выбирают один набор максимального динамического диапазона и/или точности данных матриц преобразования для использования всех компонентов изображения.
[39] Способ по [38], в котором этап выбора содержит подэтап, на котором выбирают, в качестве одного набора из максимального динамического диапазона и/или точности данных матриц преобразования, те значения, которые относятся к одному из компонентов изображения, имеющему наибольшую глубину битов.
[40] Данные изображения кодируют способом кодирования по любому из [1]-[39].
[41] Носитель данных, содержащий данные изображения по [40].
[42] Способ декодирования данных для декодирования данных, для получения массива значений данных, содержащий этапы, на которых:
отделяют, от входного потока данных, части младших значащих данных для значений данных и один или более наборов кодированных данных;
декодируют наборы данных для генерирования частей старших значащих данных для значений данных, используя двоичное декодирование; и
комбинируют части старших значащих данных и части младших значащих данных, для формирования значений данных, так, что, для значения данных, соответствующая часть старших значащих данных представляет множество старших значащих битов этого значения данных, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения данных.
[43] Способ декодирования данных, предназначенный для декодирования входных данных, для предоставления массива значений данных, входные данные кодируют, как наборы данных, и коды перехода для значений, не кодированных набором данных, код перехода, содержащий унарно кодированный участок и неунарно кодированный участок, способ, содержащий следующие этапы:
устанавливают параметр кодирования, определяющий минимальное количество битов неунарно кодированного участка, кодированный параметр находится между 0 и заданным верхним пределом;
добавляют значения смещения, равные 1 или больше, к параметрам кодирования, таким образом, чтобы определить минимальный размер части младших значащих данных;
декодируют один или более наборов данных, указывающих положения относительно массива значений данных, для значений данных заданных диапазонов магнитуды, для декодирования значения по меньшей мере одного младшего значащего бита каждого значения данных;
декодируют по меньшей мере часть каждого значения данных, не кодированного одним или более наборами данных из унарно кодированного участка и неунарно кодированного участка, соответственно взаимодополняющих части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных значения представляет ноль или больше старших значащих битов этого участка, и соответствующая часть младших значащих данных представляет количество младших значащих битов этой части, количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных.
[44] Способ декодирования данных изображения, содержащий этапы, на которых:
выполняют преобразование по частоте входных, преобразованных по частоте данных изображения для генерирования массива выходных данных изображения, используя обработку умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и используя матрицы преобразования, имеющие определенную точность данных; и
выбирают максимальный динамический диапазон и/или точность данных матриц преобразования, в соответствии с битовой глубиной выходных данных изображения.
[45] Способ по [44], в котором, для входных данных изображения, имеющих компоненты изображения с разной битовой глубиной, этап выбора содержит подэтап, на котором выбирают один набор максимального динамического диапазона и/или точности данных матриц преобразования для использования всех компонентов изображения.
[46] Способ по [45], в котором этап выбора содержит подэтап, на котором выбирают, в качестве одного набора из максимального динамического диапазона и/или точности данных матриц преобразования, те значения, которые относятся к одному из компонентов изображения, имеющему наибольшую глубину битов.
[47] Компьютерное программное обеспечение, которое при исполнение компьютером, обеспечивает выполнение компьютером способа по любому из [1]-[39] и [42] - [46].
[48] Энергонезависимый, считываемый устройством носитель информации, на котором содержится компьютерное программное обеспечение, по [47].
[49] Устройство кодирования данных для кодирования последовательности значений данных, содержащее:
генератор, выполненный с возможностью генерирования из значений входных данных соответствующих взаимодополняющих частей старших значащих данных и частей младших значащих данных, таким образом, что часть старших значащих данных с определенным значением представляет множество старших значащих битов этого значения, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения, и выполненный с возможностью генерировать один или больше наборов данных, обозначающих положения относительно массива значений частей старших значащих данных с заданной магнитудой; и
кодер, выполненный с возможностью кодирования наборов данных выходного потока данных, используя двоичное кодирование, и включения данных, определяющих младшие значащие части в выходной поток данных.
[50] Устройство кодирования данных для кодирования массива значений данных, как наборов данных и кодов перехода для значений, не кодированных наборами данных, код перехода, содержащий унарный кодированный участок и неунарный кодированный участок, при этом устройство содержит:
процессор, выполненный с возможностью:
установки параметров кодирования, определяющих минимальное количество битов неунарного кодированного участка, параметр кодирования находится между 0 и заданным верхним пределом;
добавления значения смещения, равного 1 или больше, к параметру кодирования, для определения минимального размера части младших значащих данных;
генерирования одного или более наборов данных, указывающих положения относительно массива значений данных, значений данных заданных диапазонов магнитуды для кодирования значения по меньшей мере одного младшего значащего бита каждого значения данных; и
генерирования из по меньшей мере части каждого значения данных, не кодированной одним или более наборами данных, соответствующих взаимодополняющих частей старших значащих данных и частей младших значащих данных, так, что часть старших значащих данных с определенным значением представляет ноль или больше старших значащих битов этой части, и соответствующая часть младших значащих данных представляет количество младших значащих битов этой части, количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных;
и кодер, выполненный с возможностью:
кодировать наборы данных в выходной поток данных;
кодировать части старших значащих данных в выходной поток данных; и
кодировать младшие значащие части в выходной поток данных.
[51] Устройство кодирования данных для кодирования данных изображения, содержащее:
преобразователь частоты, выполненный с возможностью преобразования по частоте входных данных изображения для генерирования массива преобразованных по частоте коэффициентов входного изображения, используя обработку умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных и используя матрицы преобразования, имеющие определенную точность данных; и
селектор, выполненный с возможностью выбора максимального динамического диапазона и/или точности данных матриц преобразования, в соответствии с битовой глубиной входных данных изображения.
[52] Устройство по [51], в котором для входных данных изображения, имеющих компоненты изображения с разными битовыми глубинами, селектор выполнен с возможностью выбора одного набора из максимального динамического диапазона и/или точности данных матриц преобразования для использования со всеми компонентами изображения.
[53] Устройство по [52], в котором селектор выполнен с возможностью выбора, в качестве одного набора из максимального динамического диапазона и/или точности данных матриц преобразования, тех значений, которые относятся к одному из компонентов изображения, имеющих наибольшую битовую глубину.
[54] Устройство декодирования данных для декодирования данных, для обеспечения массива значений данных, устройство, содержащее следующие этапы:
устройство разделения данных, выполненный с возможностью выделения, из потока входных данных, частей младших значащих данных для значений данных и одного или больше наборов кодированных данных;
декодер, выполненный с возможностью декодирования наборов данных для генерирования частей старших значащих данных, для значений данных, используя двоичное декодирование; и
объединитель, выполненный с возможностью объединения частей старших данных и частей младших значащих данных для формирования значений данных, так, что для значения данных, соответствующая часть старших значащих данных представляет множество старших значащих битов этого значения данных, и соответствующая часть младших значащих данных представляет оставшиеся младшие значащие биты этого значения данных.
[55] Устройство декодирования данных для декодирования входных данных для обеспечения массива значений данных, входные данные кодируют, как наборы данных и коды перехода для значений, не кодированных наборами данных, код перехода, содержащий унарную кодированную часть и неунарную кодированную часть, при этом устройство содержит:
процессор, во время работы выполненный с возможностью установки параметров кодирования, определяющих минимальное количество битов неунарной кодированной части, параметр кодирования находится между 0 и заданным верхним пределом; суммирования значения смещения, равного 1 или больше, с параметром кодирования для определения минимального размера части младших значащих данных; декодирования одного или больше наборов данных, обозначающих положения, относительно массива значений данных, значений данных заданных диапазонов магнитуды для декодирования значения, по меньшей мере, одного младшего значащего бита каждого значения данных; и для декодирования, по меньшей мере, части каждого значения данных, не кодированного одним или больше наборами данных из унарной кодированной части и неунарной кодированной части, соответственно, взаимодополняющих части старших значащих данных и части младших значащих данных, таким образом, что часть старших значащих данных значения представляет ноль или больше старших значащих битов этой части, и, соответственно, часть младших значащих данных представляет число младших значащих битов этой части, число младших значащих битов больше чем или равно минимальному размеру части младших значащих данных.
[56] Устройство декодирования данных изображения, содержащее:
преобразователь частоты, выполненный с возможностью преобразования по частоте входных преобразованных по частоте данных изображения для генерирования массива выходных данных изображения, используя обработку умножения матриц, в соответствии с максимальным динамическим диапазоном преобразованных данных, и используя матрицы преобразования, имеющие определенную точность данных; и
селектор, выполненный с возможностью выбора максимального динамического диапазона и/или точности данных матриц преобразования, в соответствии с битовой глубиной данных выходного изображения.
[57] Устройство по [56], в котором для входных данных изображения, имеющих компоненты изображения разной битовой глубины, селектор выполнен с возможностью выбора одного набора максимального динамического диапазона и/или точности данных матрицы преобразования для использования со всеми компонентами изображения.
[58] Устройство по [57], в котором селектор выполнен с возможностью выбора, в качестве одного набора максимального динамического диапазона и/или точности данных матриц преобразования, тех значений, которые относятся к одному из компонентов изображения, имеющих наибольшую битовую глубину.
[59] Устройство захвата, передачи, отображения и/или сохранения видеоданных, содержащее устройство по любому из [49]-[58].
Как отмечено выше, следует понимать, что свойства устройства в представленных выше пунктах могут быть воплощены соответствующими свойствами кодера или декодера, как описано выше.
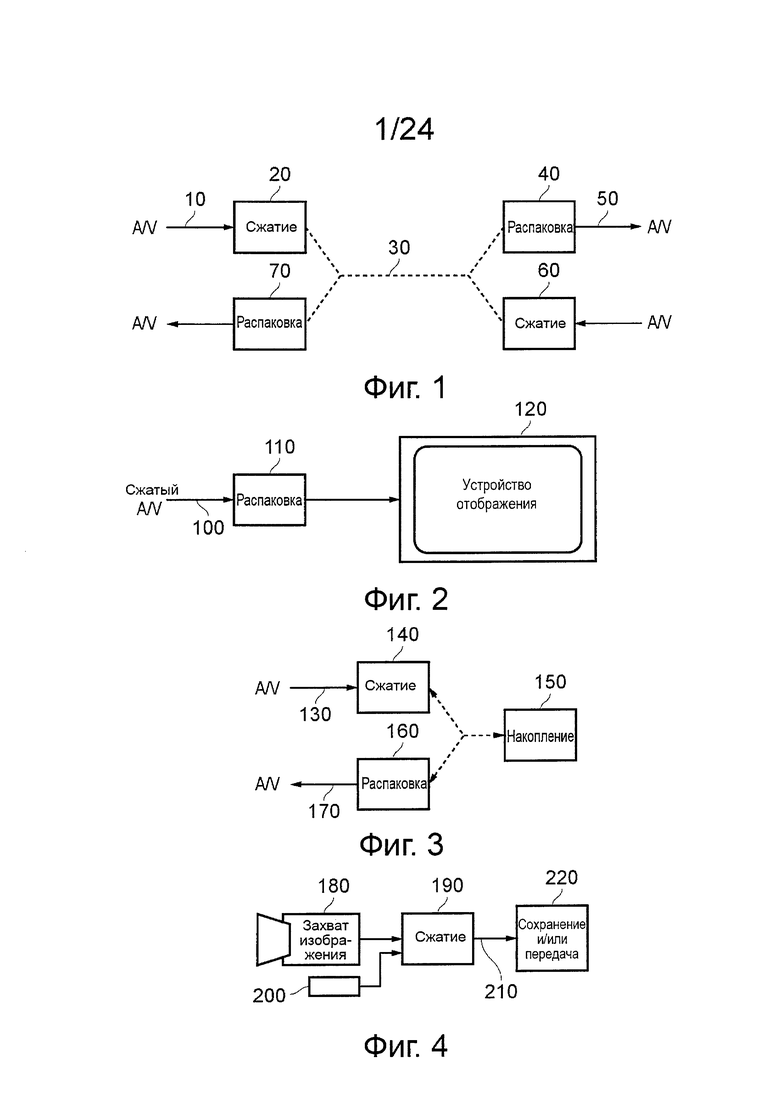
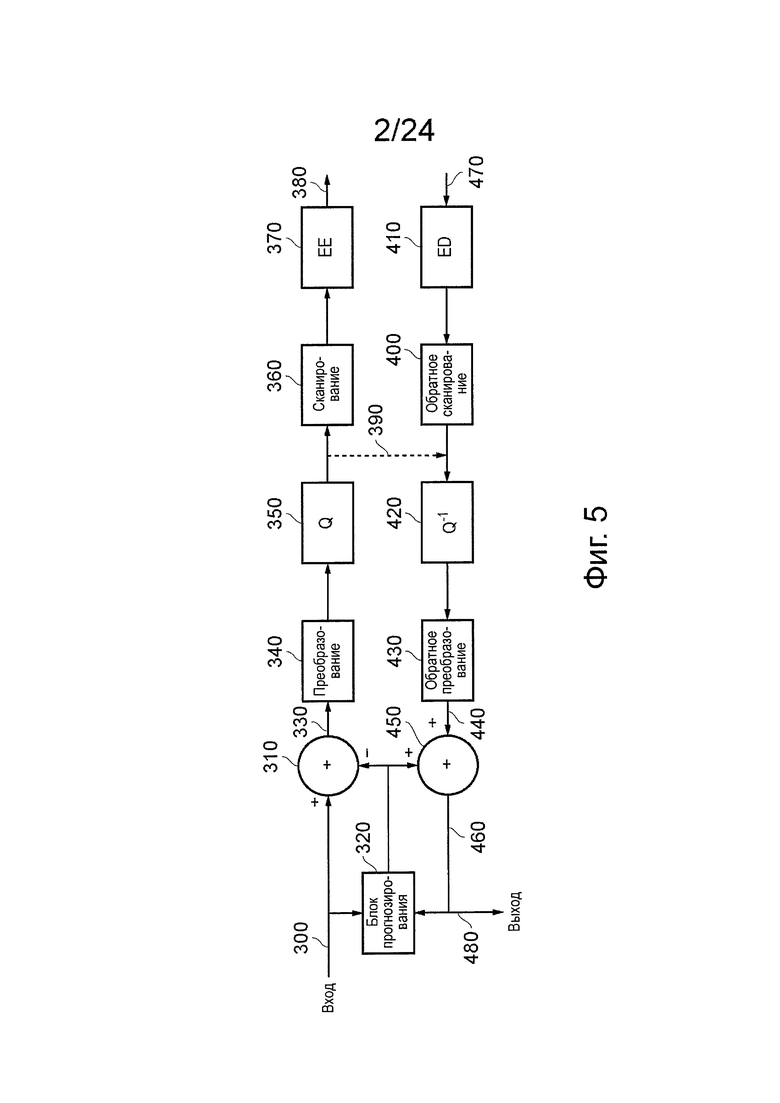
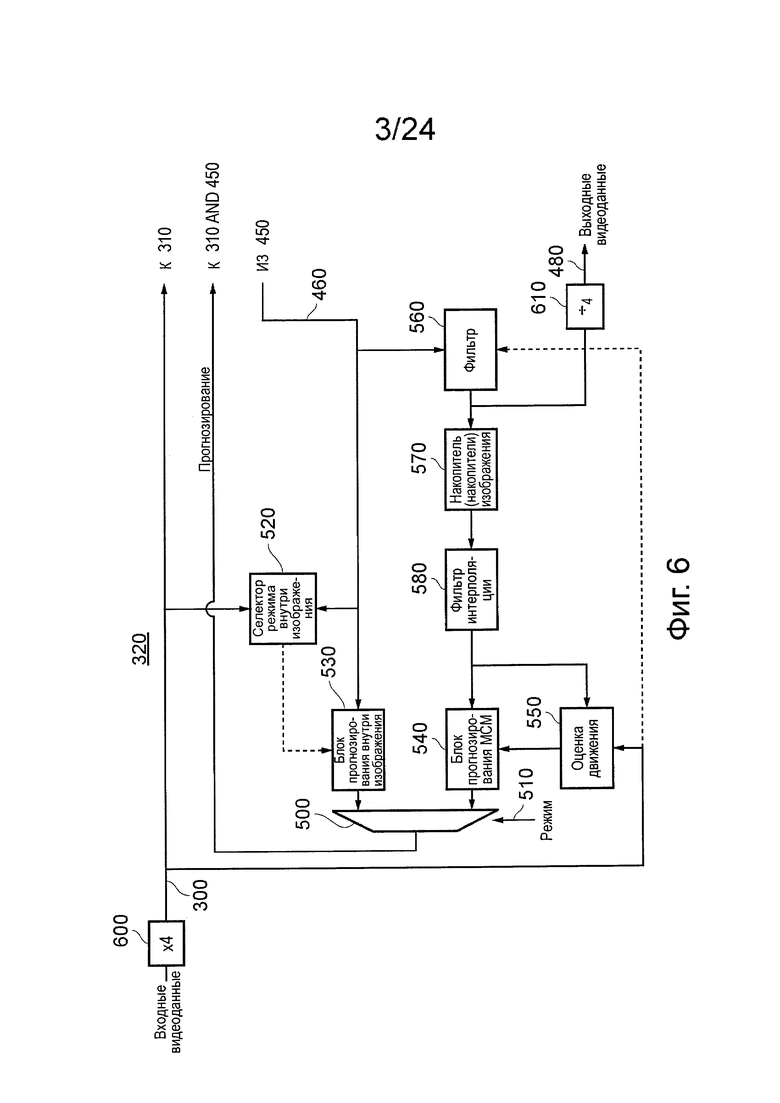
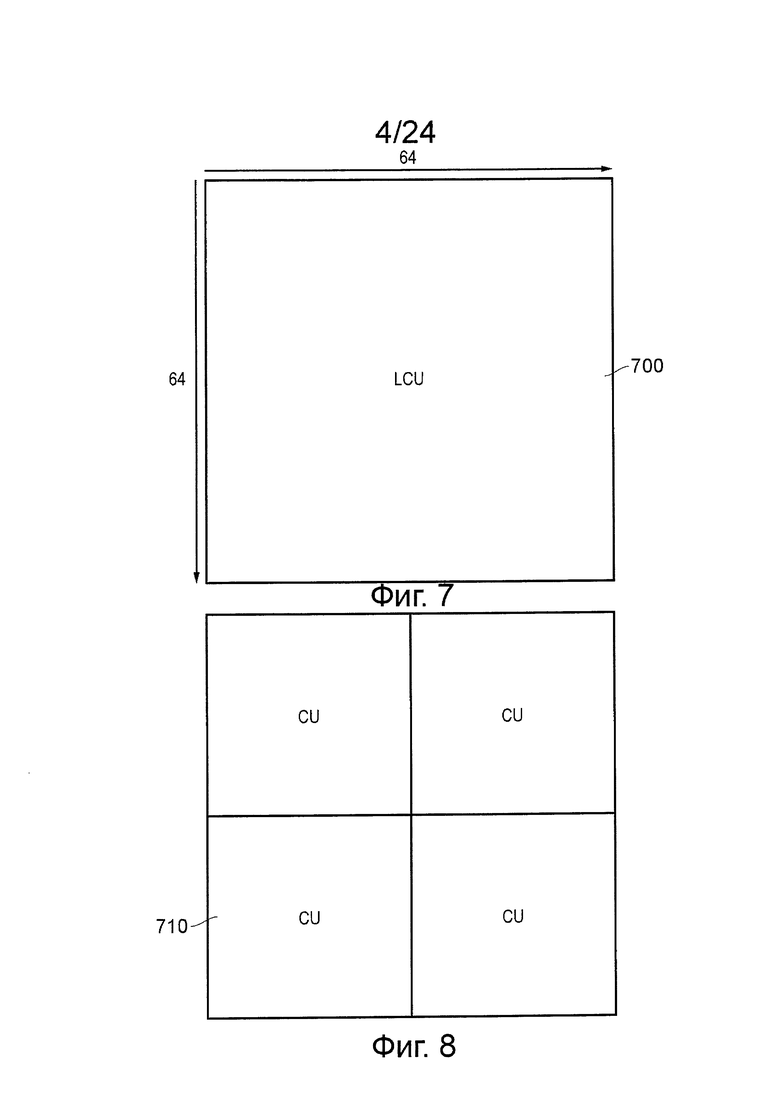
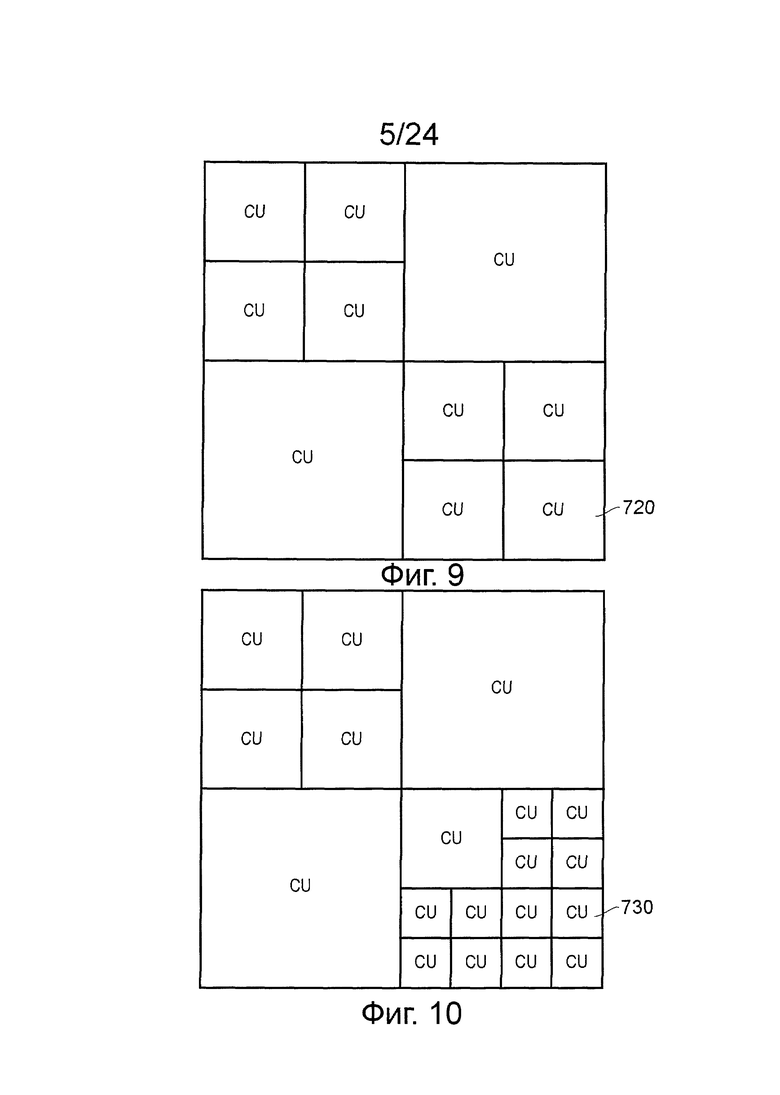
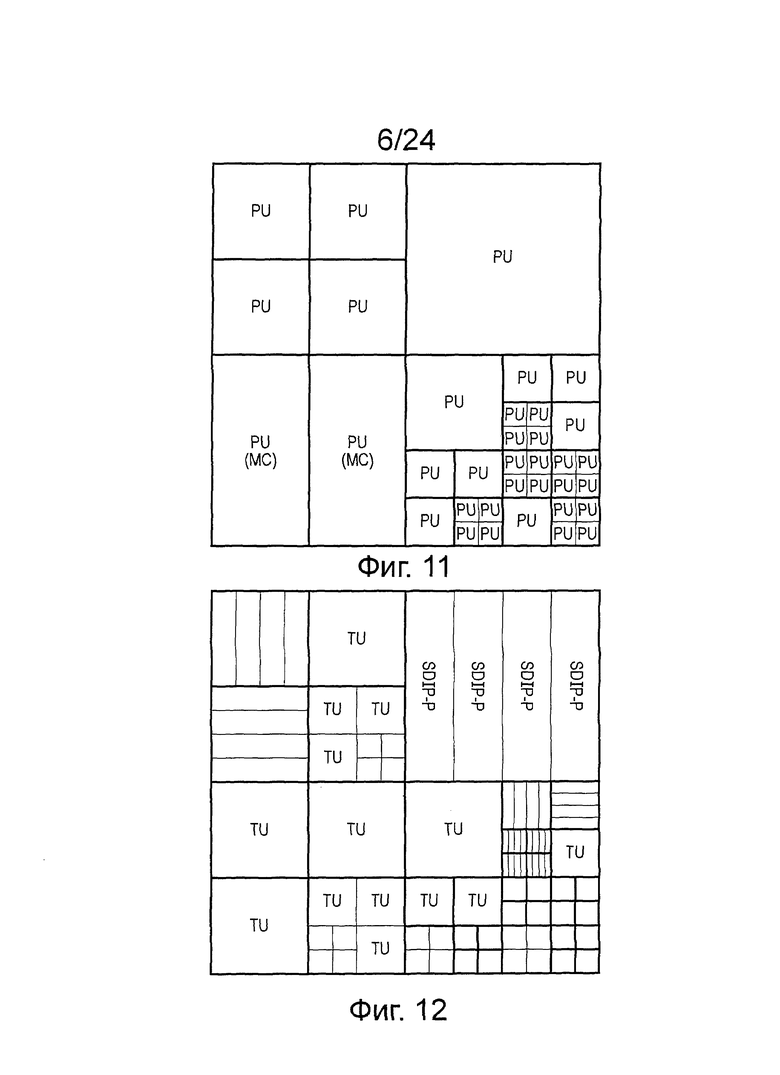
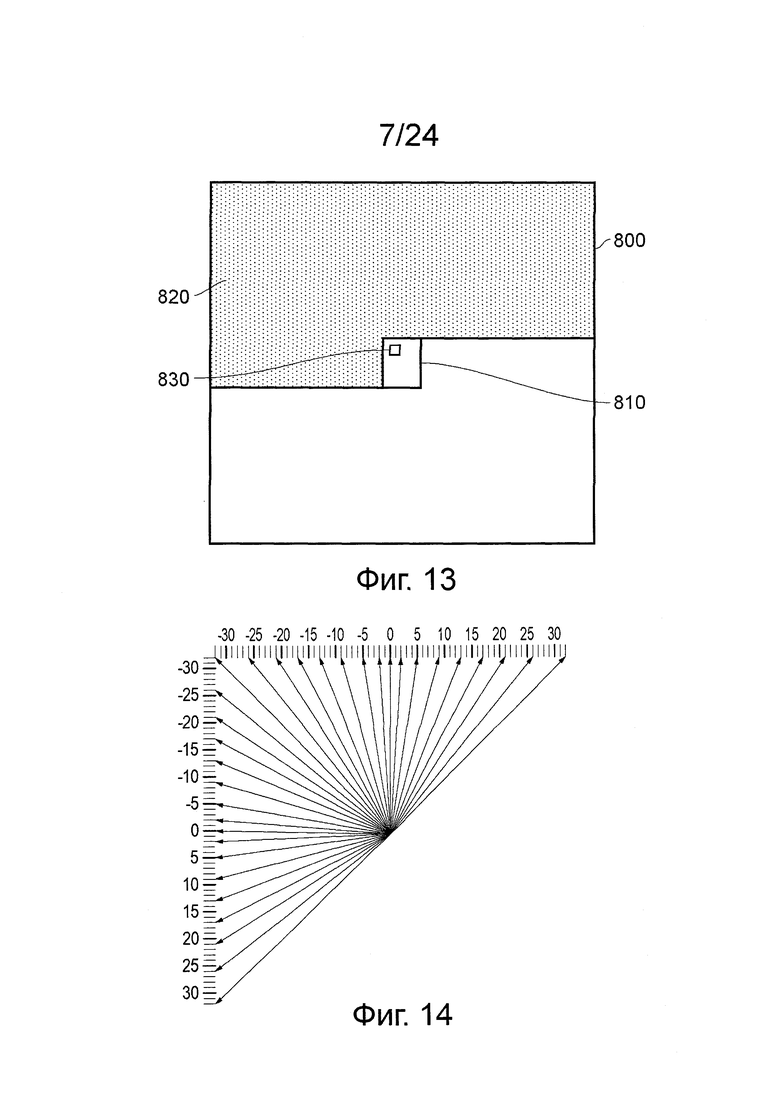
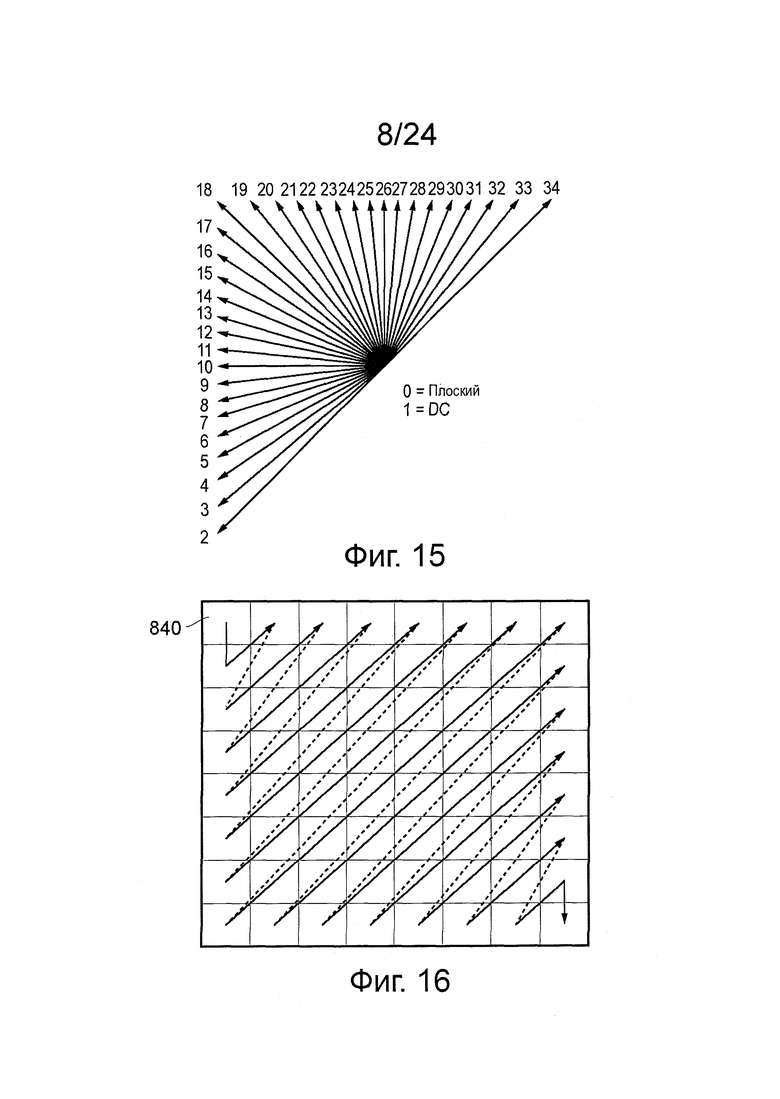
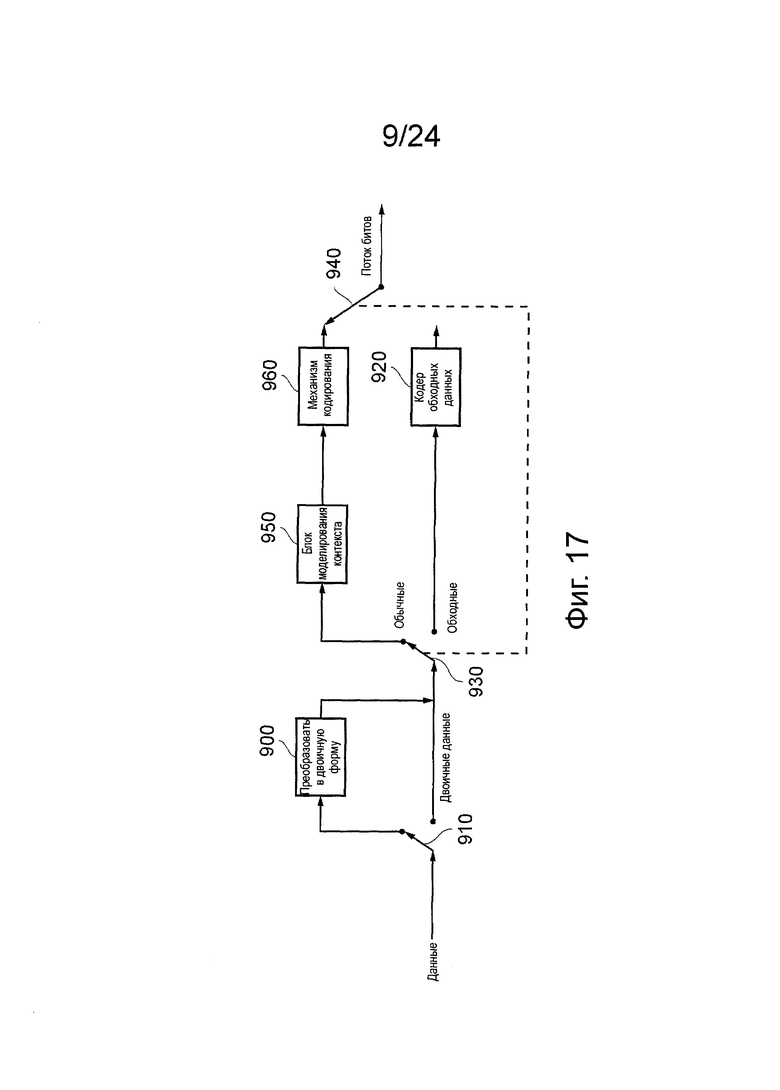
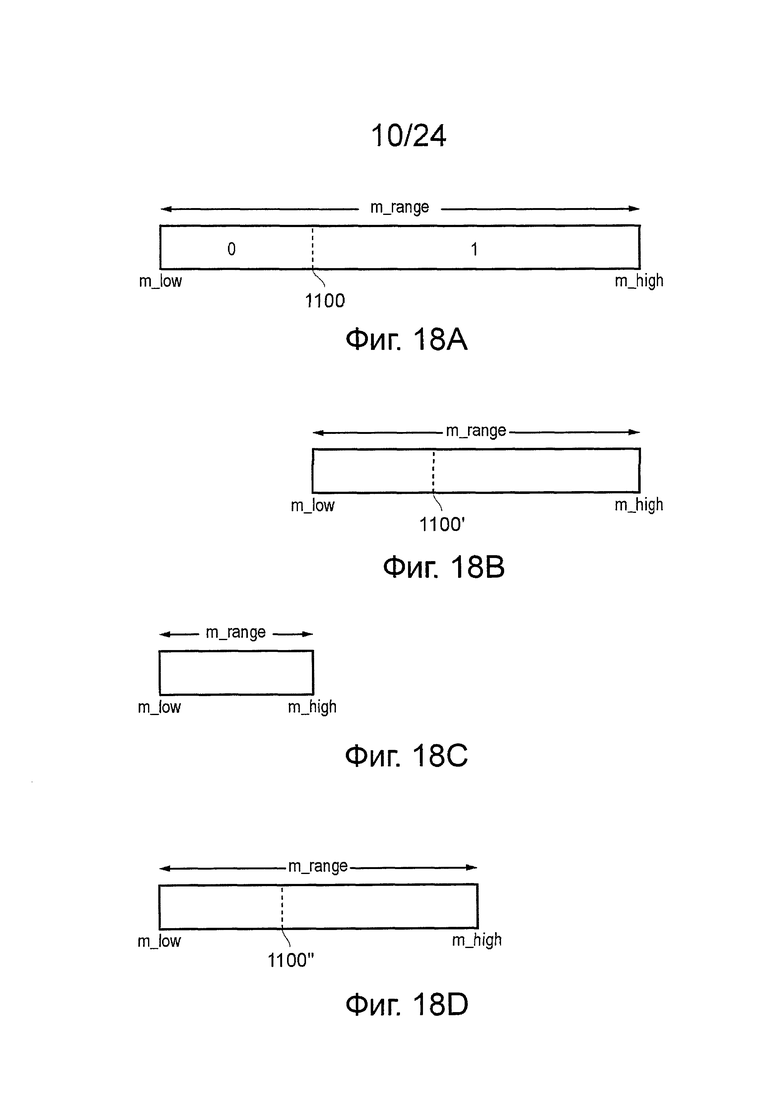
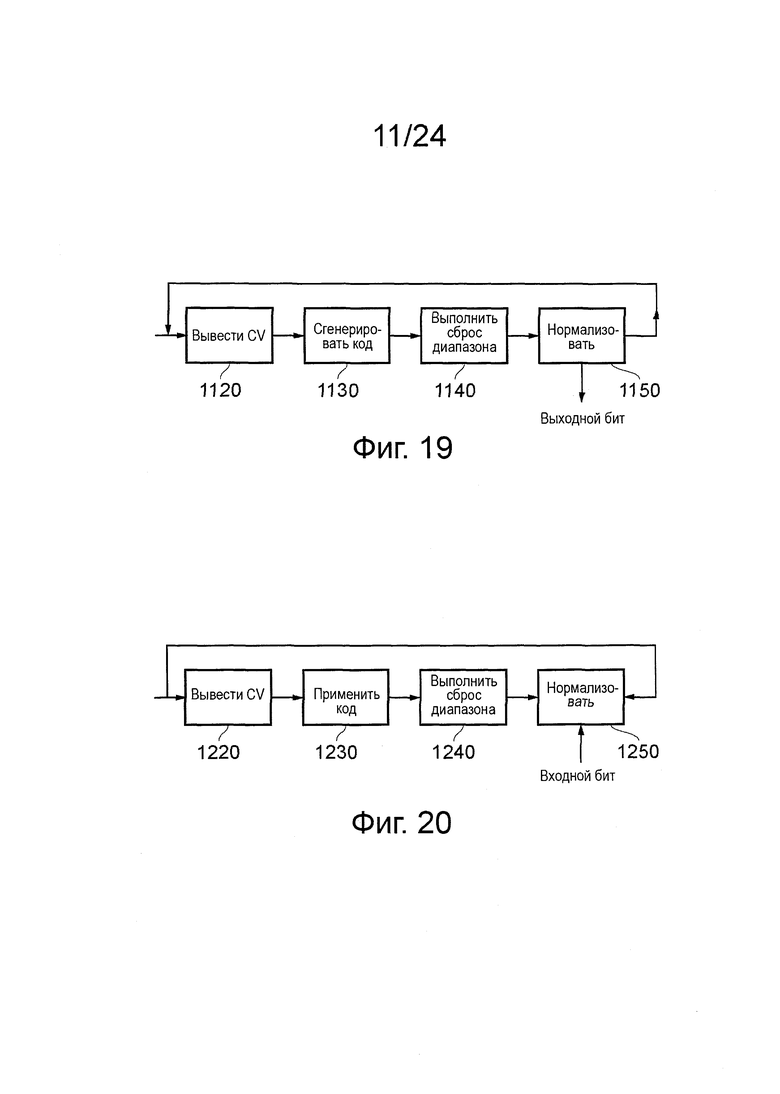
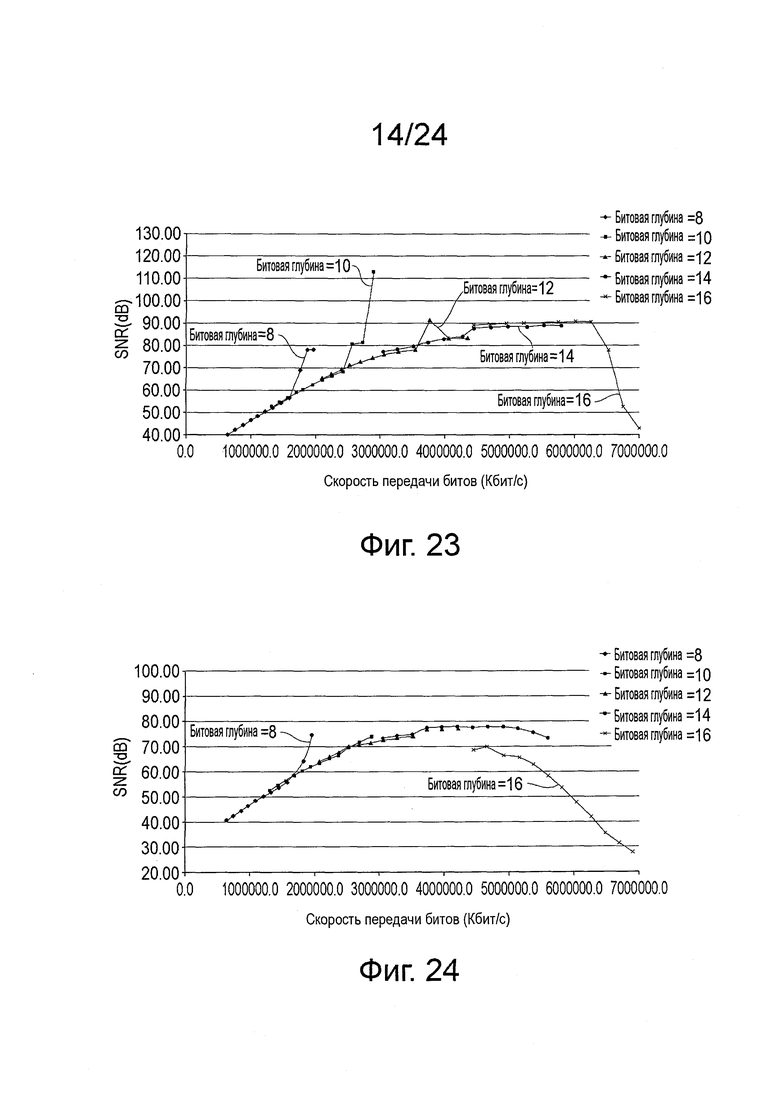
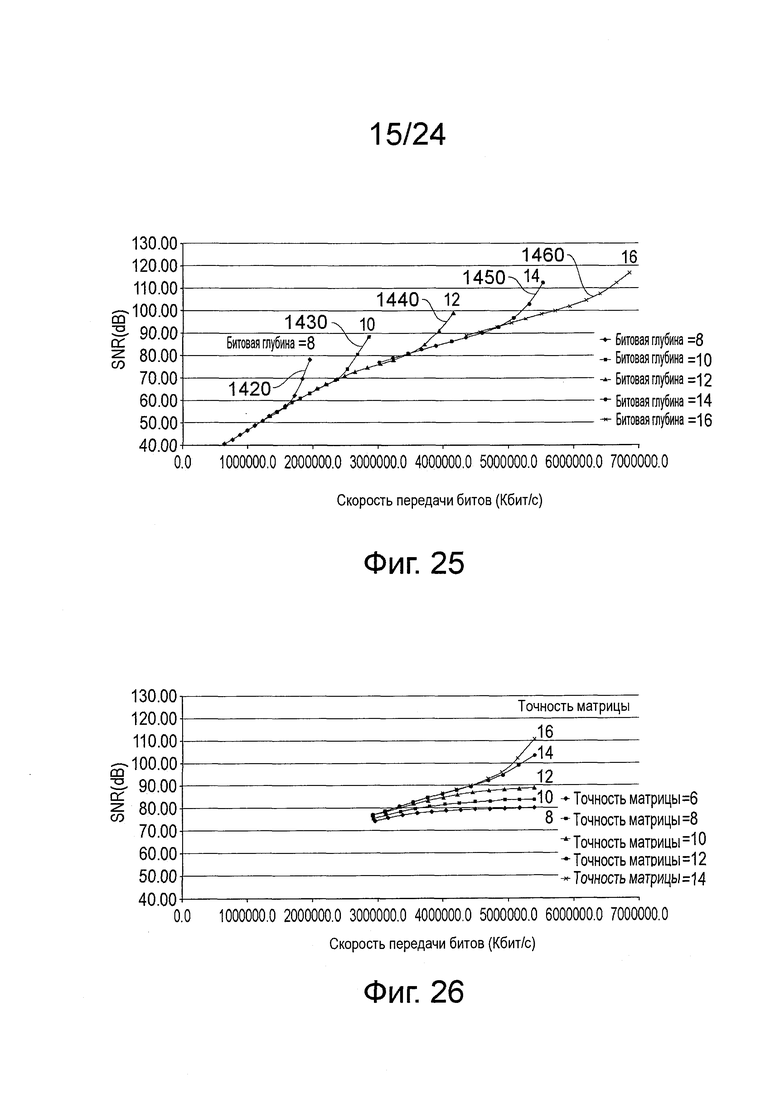
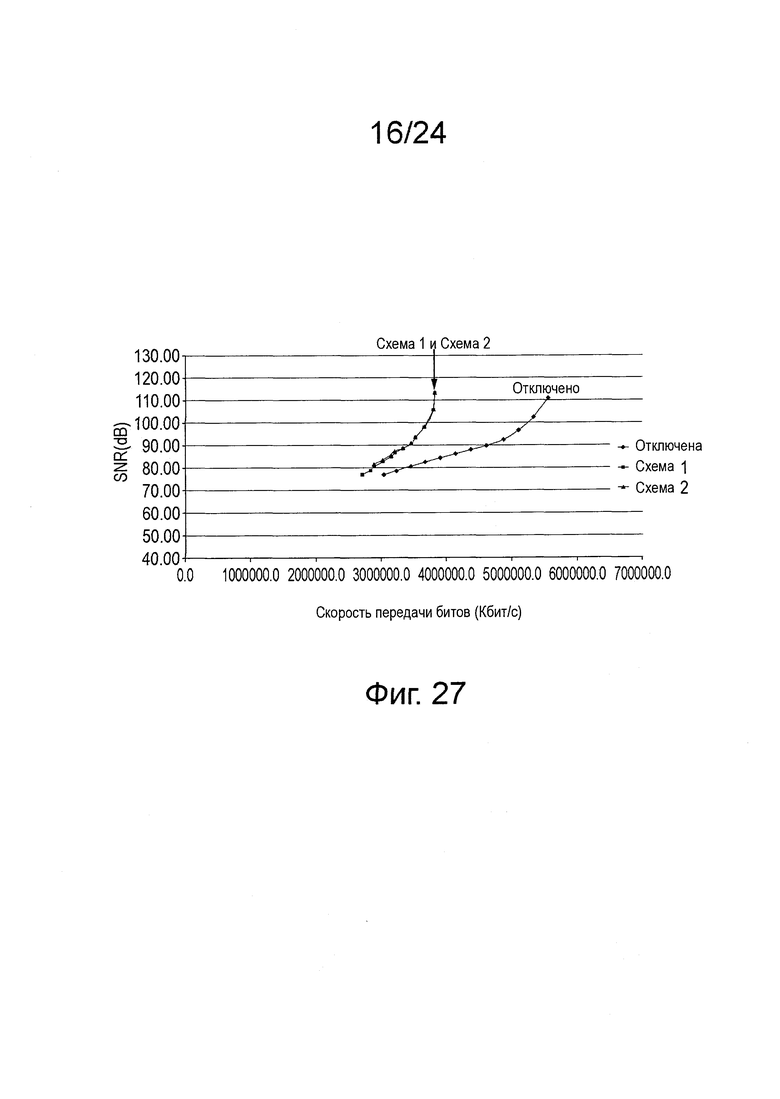
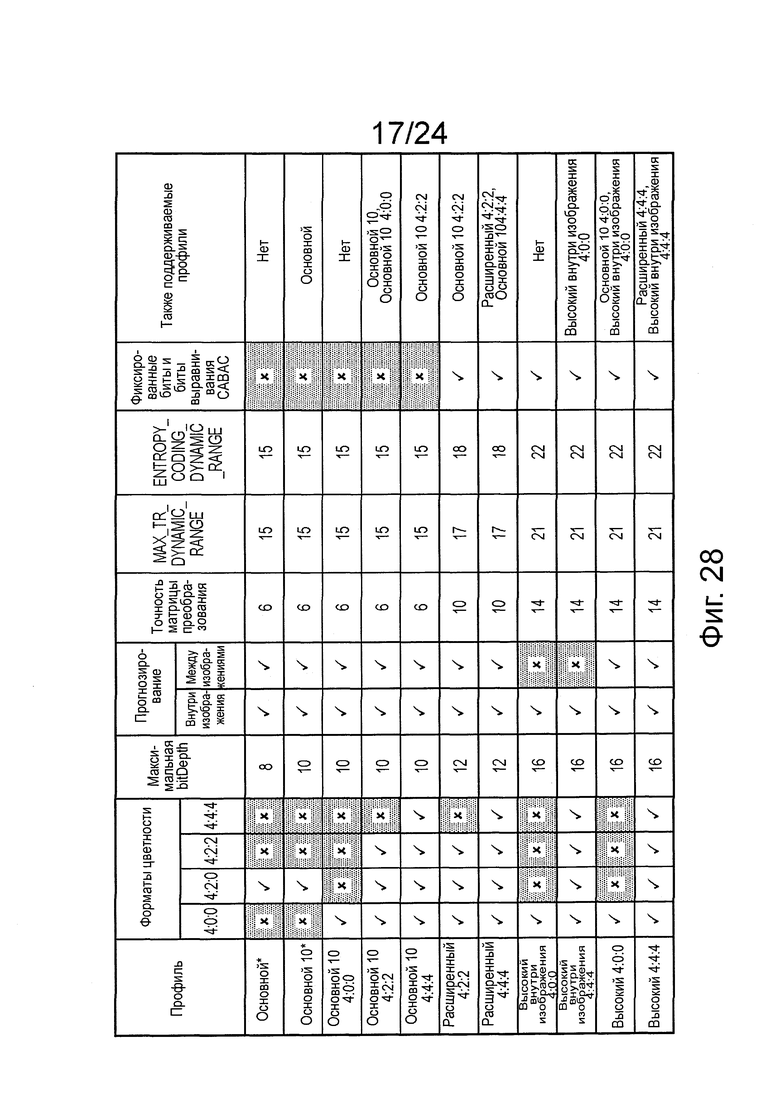
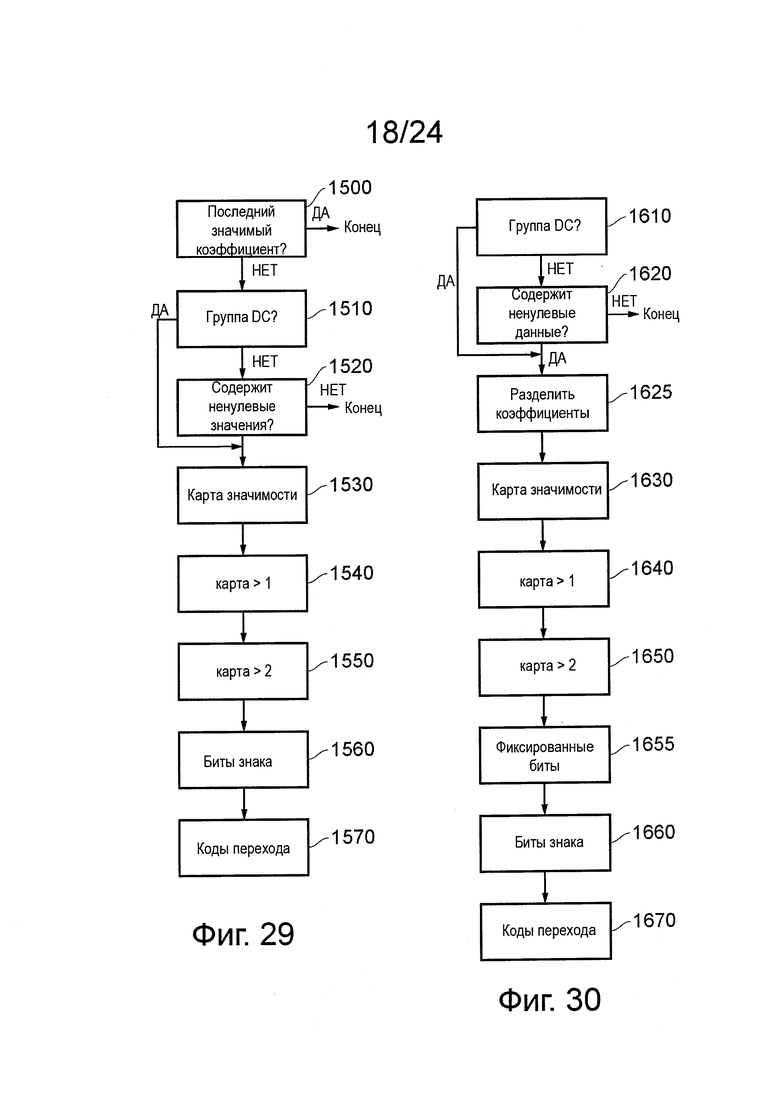
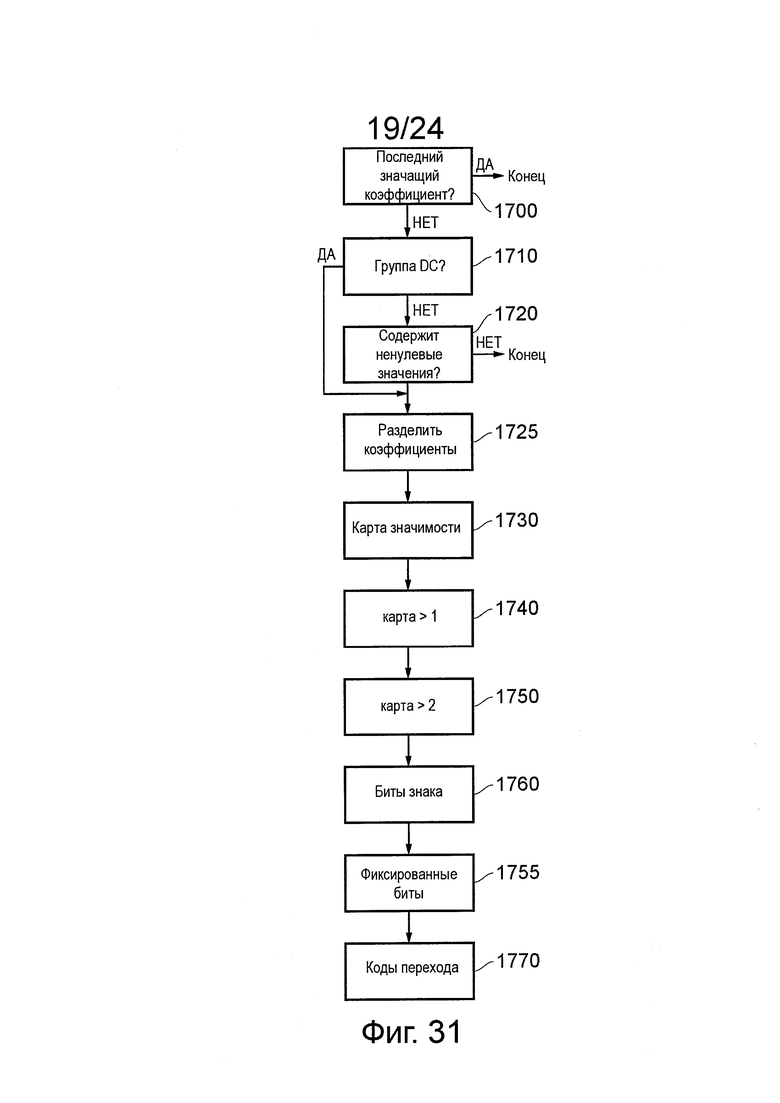
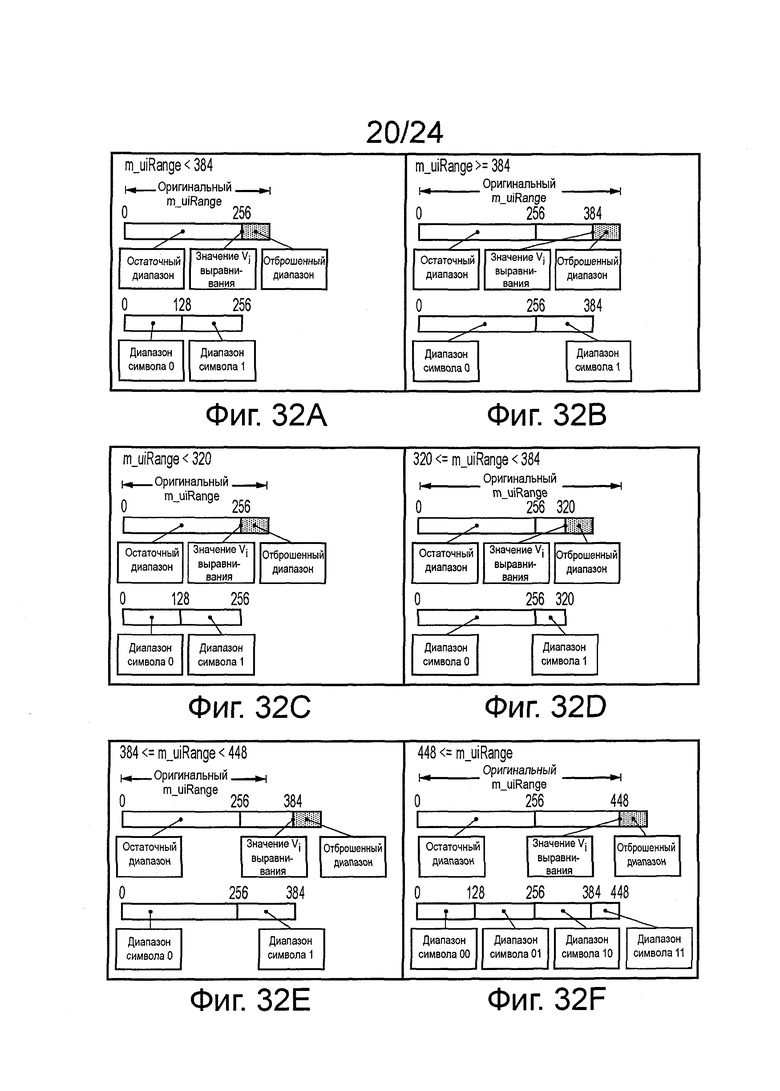
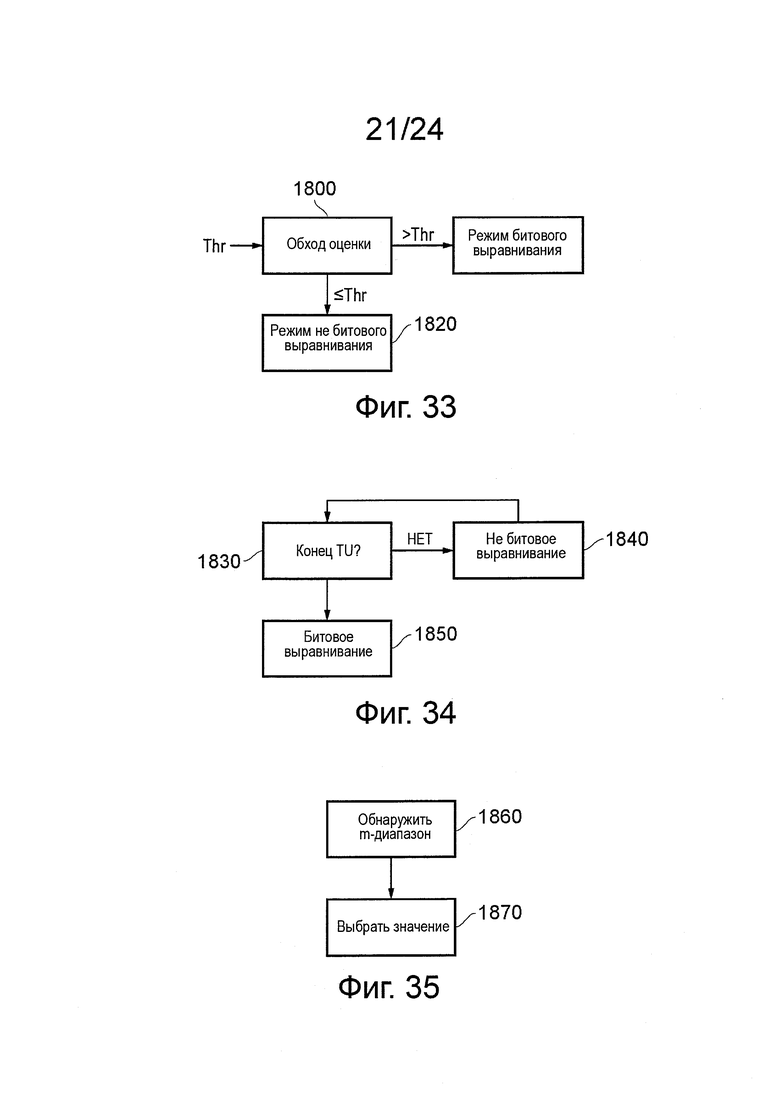
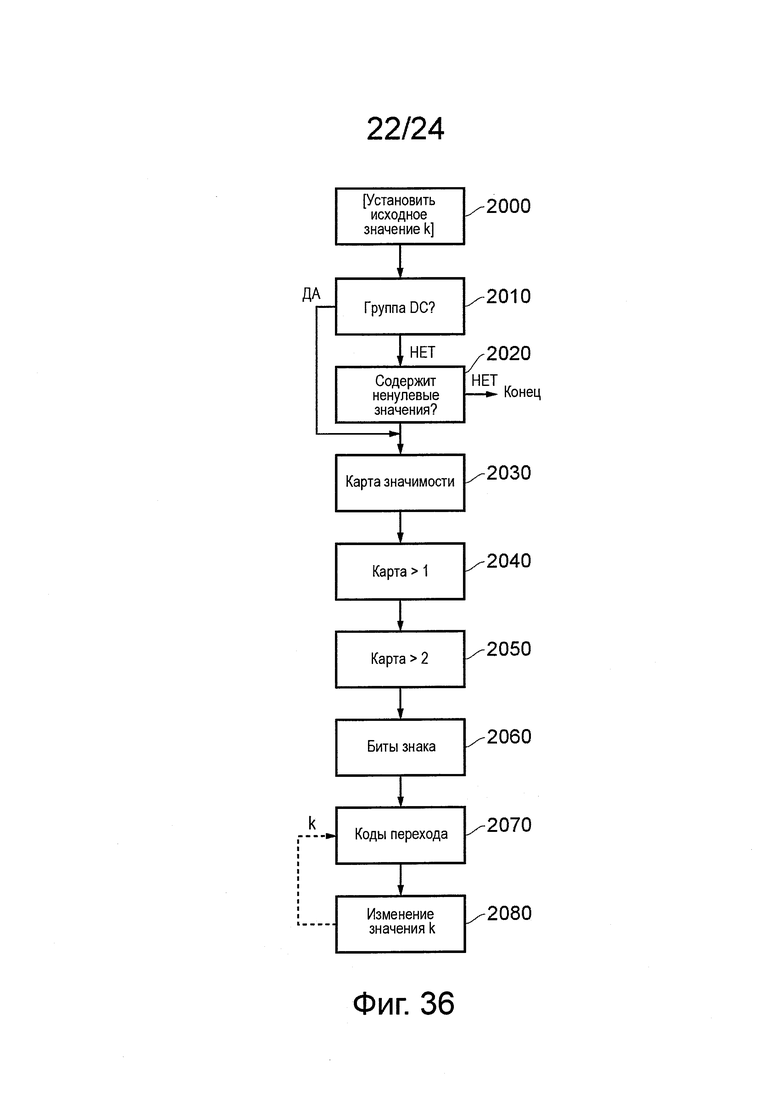
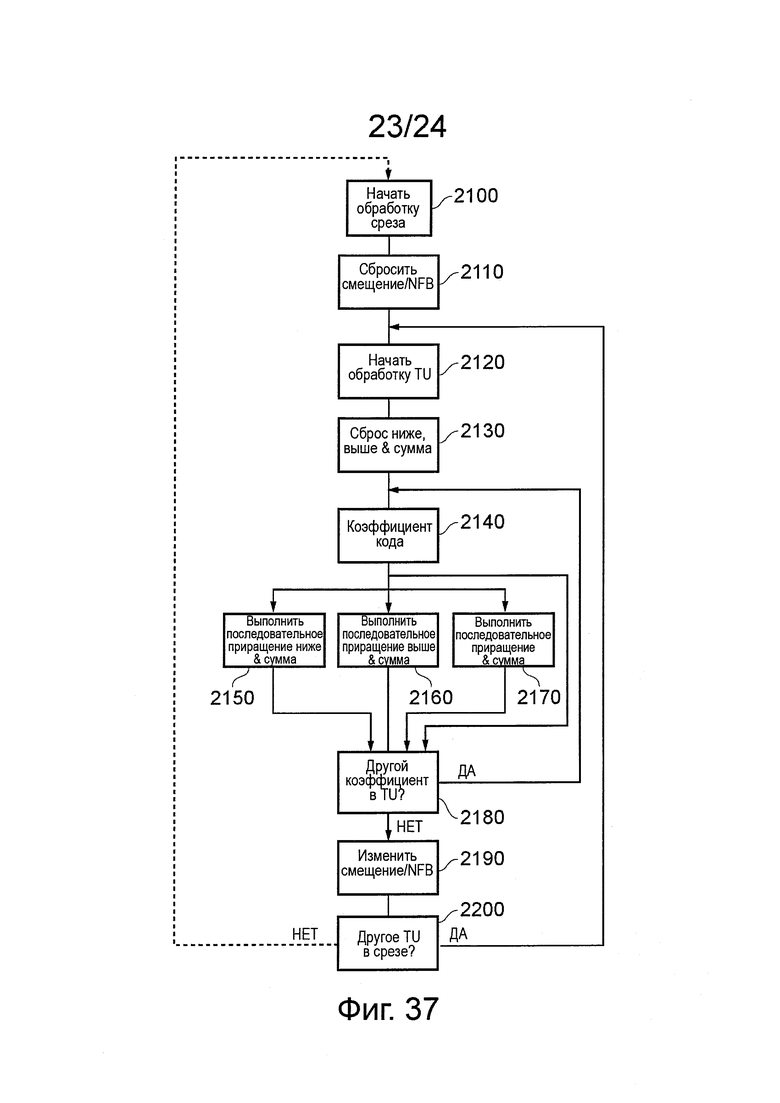
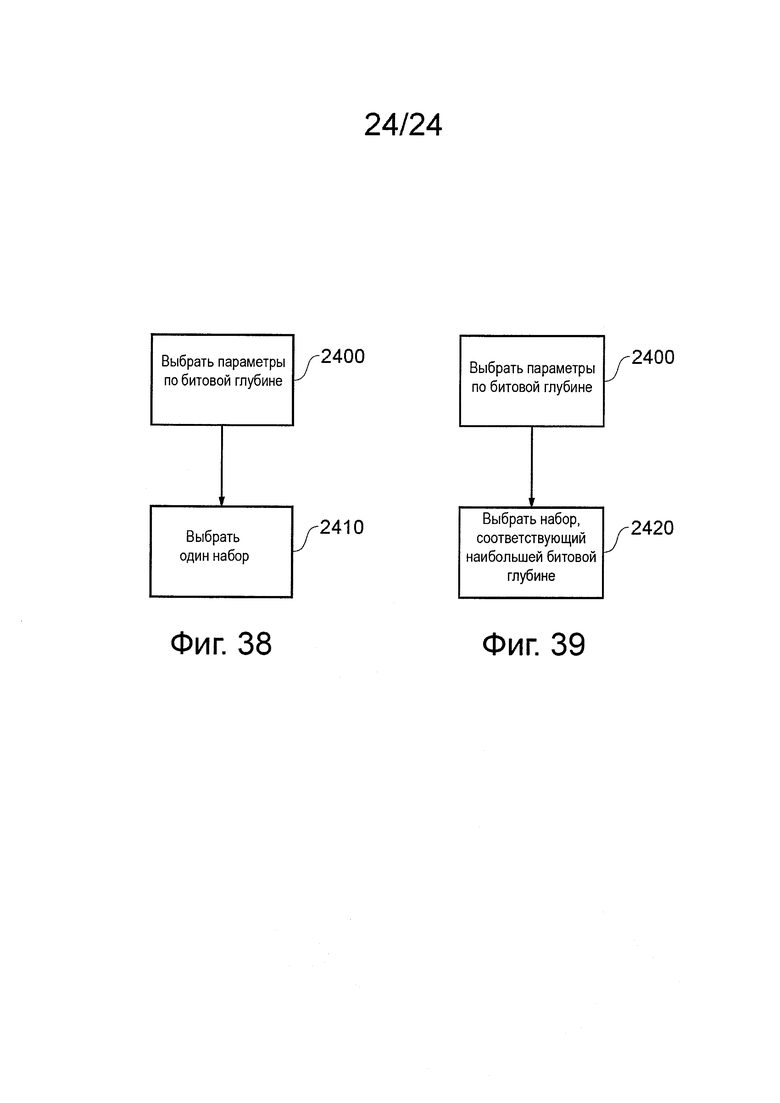
Изобретение относится к вычислительной технике. Технический результат заключается в генерировании меньшего количества кодированных данных. Способ кодирования данных для кодирования массива значений данных, в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, при этом код перехода содержит унарно кодированную часть и неунарно кодированную часть, в котором устанавливают параметр кодирования, определяющий минимальное количество битов неунарной кодированной части, где параметр кодирования находится между 0 и заданным верхним пределом; добавляют значения смещения, равные 1 или больше, к параметру кодирования, для определения минимального размера части младших значащих данных; генерируют один или больше наборов данных, указывающих положения относительно массива значений данных, для значений данных заданных диапазонов магнитуды, для кодирования значения по меньшей мере одного младшего значащего бита каждого значения данных; генерируют, из по меньшей мере части каждого значения данных, не кодированных одним или более наборами данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных; кодируют наборы данных в выходной поток данных. 7 н. и 8 з.п. ф-лы, 47 ил., 13 табл.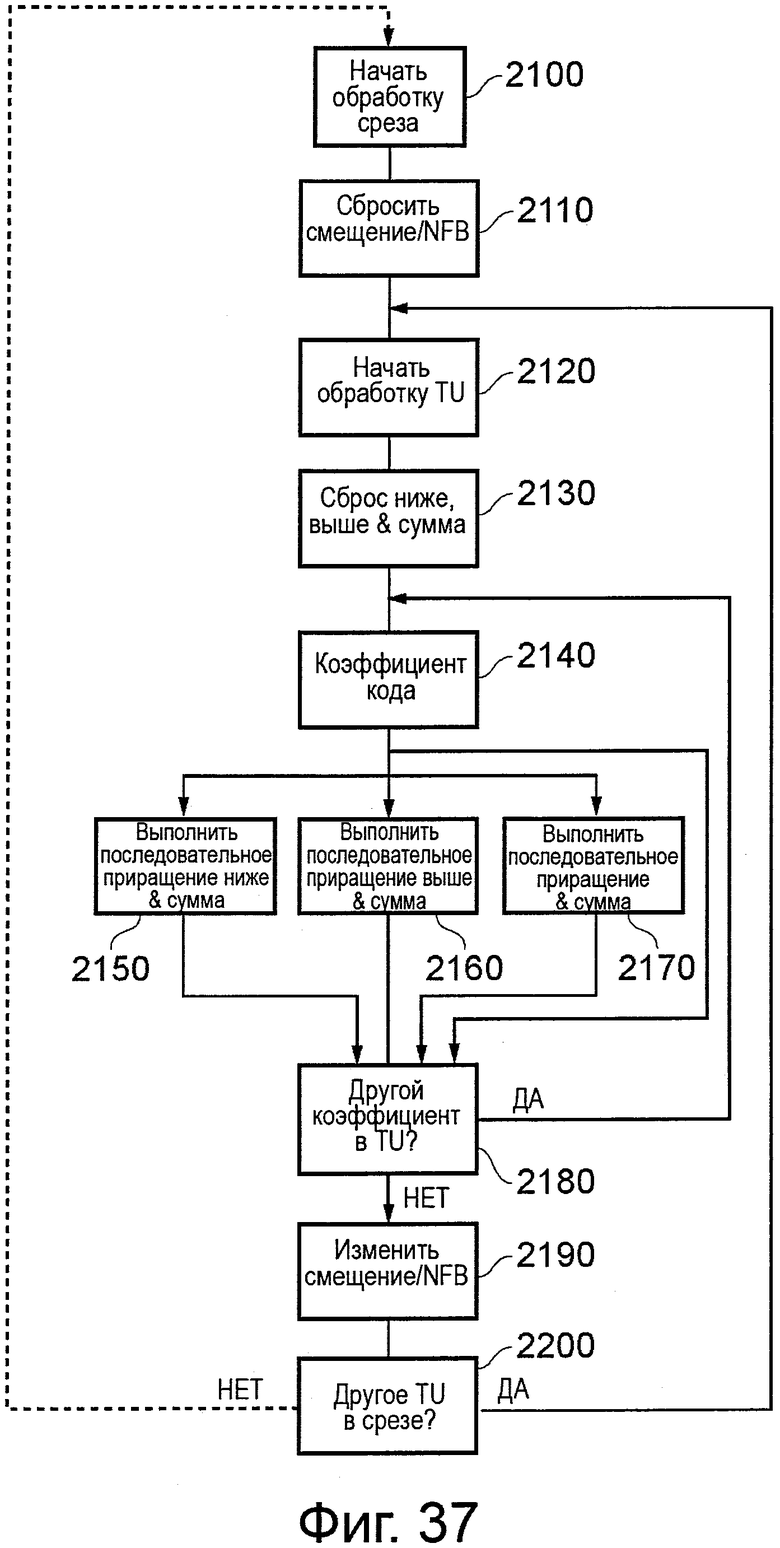
1. Способ кодирования данных для кодирования массива значений данных, в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, при этом код перехода содержит унарно кодированную часть и неунарно кодированную часть, содержащий этапы, на которых:
устанавливают параметр кодирования, определяющий минимальное количество битов неунарной кодированной части, при этом параметр кодирования находится между 0 и заданным верхним пределом;
добавляют значения смещения, равные 1 или больше, к параметру кодирования, для определения минимального размера части младших значащих данных;
генерируют один или больше наборов данных, указывающих положения относительно массива значений данных, для значений данных заданных диапазонов магнитуды, для кодирования значения по меньшей мере одного младшего значащего бита каждого значения данных;
генерируют, из по меньшей мере части каждого значения данных, не кодированных одним или более наборами данных, соответствующие взаимодополняющие части старших значащих данных и части младших значащих данных, так, что часть старших значащих данных с определенным значением, представляет ноль или более старших значащих битов указанной части, а соответствующая часть младших значащих данных представляет количество младших значащих битов указанной части, при этом количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных;
кодируют наборы данных в выходной поток данных;
кодируют части старших значащих данных в выходной поток данных; и
кодируют части младших значащих данных в выходной поток данных.
2. Способ по п. 1, в котором:
этап кодирования частей старших значащих данных в выходной поток данных содержит подэтап, на котором осуществляют кодирование частей старших значащих данных в выходной поток, с использованием унарного кода; а
этап кодирования младших значащих частей выходного потока данных содержит подэтап, на котором осуществляют кодирование младших значащих частей в выходной поток данных, с использованием неунарного кода.
3. Способ по п. 1, в котором этап кодирования наборов данных в выходной поток данных содержит подэтап, на котором кодируют наборы данных в выходной поток данных, с использованием двоичного кода.
4. Способ по п. 1, в котором этап установки содержит последовательное приращение параметра кодирования, в зависимости от магнитуды текущего значения данных в массиве.
5. Способ по п. 2, в котором этапы кодирования части старших значащих данных и части младших значащих данных содержат подэтапы, на которых кодируют часть старших значащих данных и часть младших значащих данных с использованием кода Голомба-Райса или экспоненциального кода Голомба.
6. Способ по п. 5, в котором:
длина суффикса кода Голомба-Райса равна минимальному размеру части младших значащих данных; а
экспоненциальный код Голомба имеет порядок, равный минимальному размеру части младших значащих данных.
7. Способ по п. 1, содержащий этап, на котором генерируют значение смещения, в зависимости от параметра значений массива данных.
8. Способ по п. 7, в котором параметр массива значений данных содержит одно или более из:
количества значений данных в массиве;
типа данных, представленных значениями данных;
параметра квантования, применимого к массиву значений данных; и
режима кодирования.
9. Способ по п. 1, содержащий этап, на котором включают данные в заголовок данных, определяющих значение смещения.
10. Способ декодирования данных для декодирования входных данных, для предоставления массива значений данных, при этом входные данные кодируют, в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, причем код перехода содержит унарно кодированный участок и неунарно кодированный участок, а способ содержит этапы, на которых:
устанавливают параметр кодирования, определяющий минимальное количество битов неунарно кодированного участка, причем кодированный параметр находится между 0 и заданным верхним пределом;
добавляют значения смещения, равные 1 или более, к параметрам кодирования так, чтобы определить минимальный размер части младших значащих данных;
декодируют один или более наборов данных, указывающих положения относительно массива значений данных, для значений данных заданных диапазонов магнитуды, для декодирования значения по меньшей мере одного младшего значащего бита каждого значения данных;
декодируют по меньшей мере часть каждого значения данных, не кодированного одним или более наборами данных из унарно кодированного участка и неунарно кодированного участка, соответственно взаимодополняющих части старших значащих данных и части младших значащих данных, так, что часть старших значащих данных значения представляет ноль или более старших значащих битов указанного участка и соответствующая часть младших значащих данных представляет количество младших значащих битов указанной части, при этом количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных.
11. Устройство кодирования данных для кодирования массива значений данных, в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, при этом код перехода содержит унарный кодированный участок и неунарный кодированный участок, а устройство содержит:
процессор, выполненный с возможностью:
установки параметров кодирования, определяющих минимальное количество битов неунарного кодированного участка, при этом параметр кодирования находится между 0 и заданным верхним пределом;
добавления значения смещения, равного 1 или более, к параметру кодирования для определения минимального размера части младших значащих данных;
генерирования одного или более наборов данных, указывающих положения относительно массива значений данных, значений данных заданных диапазонов магнитуды для кодирования значения по меньшей мере одного младшего значащего бита каждого значения данных; и
генерирования из по меньшей мере части каждого значения данных, не кодированной одним или более наборами данных, соответствующих взаимодополняющих частей старших значащих данных и частей младших значащих данных, так, что часть старших значащих данных с определенным значением представляет ноль или больше старших значащих битов указанной части и соответствующая часть младших значащих данных представляет количество младших значащих битов указанной части, при этом количество младших значащих битов больше чем или равно минимальному размеру части младших значащих данных;
и схему кодирования, выполненную с возможностью:
кодирования наборов данных в выходной поток данных;
кодирования части старших значащих данных в выходной поток данных; и
кодирования части младших значащих данных в выходной поток данных.
12. Устройство декодирования данных для декодирования входных данных для обеспечения массива значений данных, при этом входные данные кодируют в качестве наборов данных и кодов перехода для значений, не кодированных наборами данных, причем коды перехода содержат унарную кодированную часть и неунарную кодированную часть, а устройство содержит:
процессор, выполненный с возможностью установки параметров кодирования, определяющих минимальное количество битов неунарной кодированной части, при этом параметр кодирования находится между 0 и заданным верхним пределом; суммирования значения смещения, равного 1 или более, с параметром кодирования для определения минимального размера части младших значащих данных; декодирования одного или больше наборов данных, обозначающих положения, относительно массива значений данных, значений данных заданных диапазонов магнитуды для декодирования значения, по меньшей мере, одного младшего значащего бита каждого значения данных; и для декодирования, по меньшей мере, части каждого значения данных, не кодированного одним или больше наборами данных из унарной кодированной части и неунарной кодированной части соответственно, взаимодополняющих части старших значащих данных и части младших значащих данных, так, что часть старших значащих данных значения представляет ноль или более старших значащих битов указанной части и, соответственно, часть младших значащих данных представляет число младших значащих битов указанной части, при этом число младших значащих битов больше чем или равно минимальному размеру части младших значащих данных.
13. Устройство обработки данных, характеризующееся тем, что выполнено с возможностью захвата, преобразования, отображения и/или сохранения видеоданных, содержащее устройство по п. 11.
14. Энергонезависимый машиночитаемый носитель информации, хранящий команды компьютерной программы, вызывающие, при исполнении компьютером, выполнение компьютером способа по п. 1.
15. Энергонезависимый машиночитаемый носитель информации, хранящий команды компьютерной программы, вызывающие, при исполнении компьютером, выполнение компьютером способа по п. 10.
| V | |||
| SEREGIN et al | |||
| "Binarisation modification for last position coding", JCTVC-F375 (version 3), опубл | |||
| Устройство для электрической сигнализации | 1918 |
|
SU16A1 |
| J | |||
| SOLE et al | |||
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |
| Устройство для электрической сигнализации | 1918 |
|
SU16A1 |
| US 7796065 B2, 14.09.2010 | |||
| US 6396422 B1, 28.05.2002 | |||
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КОДИРОВАНИЯ ЗНАЧИМЫХ КОЭФФИЦИЕНТОВ ПРИ ВИДЕОСЖАТИИ | 2007 |
|
RU2406256C2 |

