УРОВЕНЬ ТЕХНИКИ
[1] Системы автоматического распознавания речи (ASR) конфигурируются для распознавания фрагментов речи, сформулированных пользователями. Точнее говоря, микрофон формирует электрический сигнал в ответ на захват аудио, где аудио включает в себя фрагмент речи. Электрический сигнал обрабатывается для фильтрации шума из аудио и извлечения признаков, которые можно использовать для распознавания фрагмента речи. Хотя за несколько последних лет значительно повысилась производительность (например, скорость и точность) систем ASR, традиционные системы ASR продолжают испытывать трудность, когда рассматриваются большие словари, когда системы ASR не обучены на подходящих обучающих данных, которые представляют конкретные акценты или диалекты, или когда существуют другие субоптимальные условия. Кроме того, системы ASR часто испытывают трудность с распознаванием фрагментов речи, сформулированных в шумных средах, например, когда фрагмент формулируется в шумящем аэропорте, в движущемся автомобиле и т. п.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[2] Нижеследующее является кратким изложением предмета изобретения, который подробнее описывается в этом документе. Данная сущность изобретения не предназначена для ограничения в отношении объема формулы изобретения.
[3] В этом документе описываются технологии, которые упрощают прием страницы для показа на дисплее, страница содержит первый визуальный элемент и второй визуальный элемент на первом расстоянии друг от друга. Страница изменяется для формирования измененной страницы, измененная страница включает в себя первый визуальный элемент и второй визуальный элемент на втором расстоянии друг от друга, где изменение страницы основывается на сходстве произношения между по меньшей мере одним словом, соответствующим первому визуальному элементу, и по меньшей мере одним словом, соответствующим второму визуальному элементу. Затем страница отображается на дисплее.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[4] Фиг. 1 - функциональная блок-схема примерной системы, которая конфигурируется для изменения визуального контента.
[5] Фиг. 2 - функциональная блок-схема примерного компонента генератора макета, который конфигурируется для изменения макета визуального контента.
[6] Фиг. 3 - функциональная блок-схема системы автоматического распознавания речи (ASR), которую можно настраивать на основе оценочного зрительного внимания.
[7] Фиг. 4 иллюстрирует примерное изменение визуального контента, выполненное компонентом генератора макета.
[8] Фиг. 5 иллюстрирует другое примерное изменение визуального контента, выполненное компонентом генератора макета.
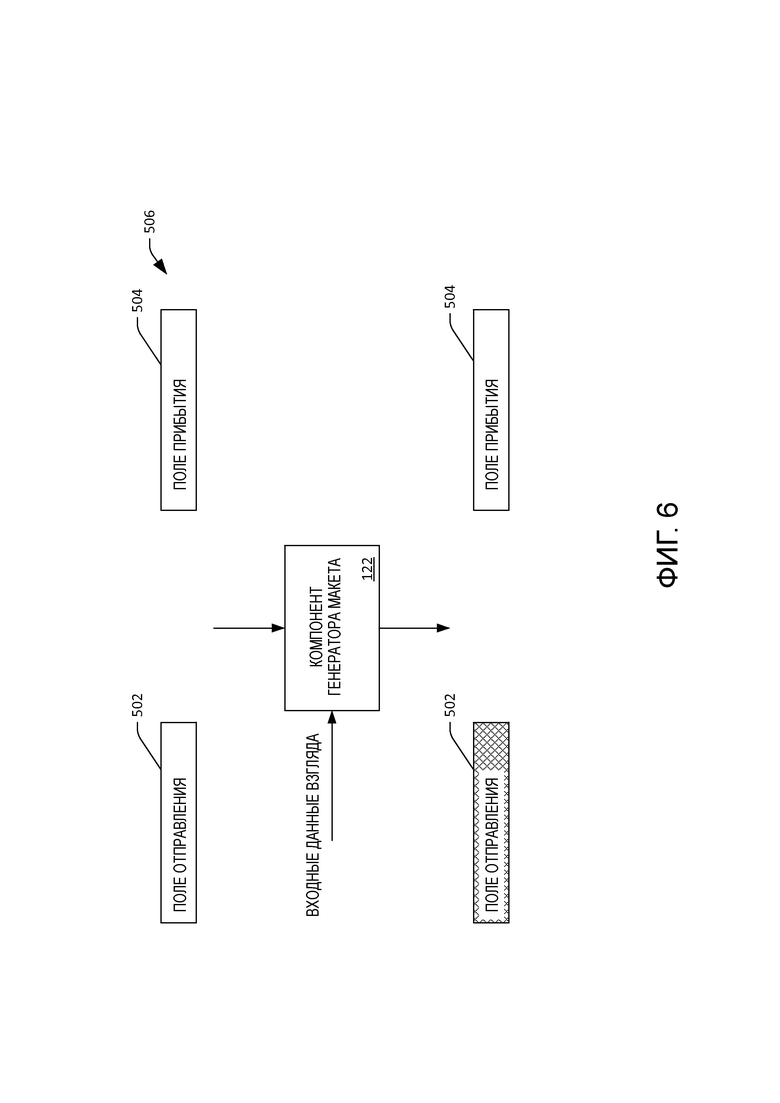
[9] Фиг. 6 иллюстрирует предоставление пользователю графической обратной связи.
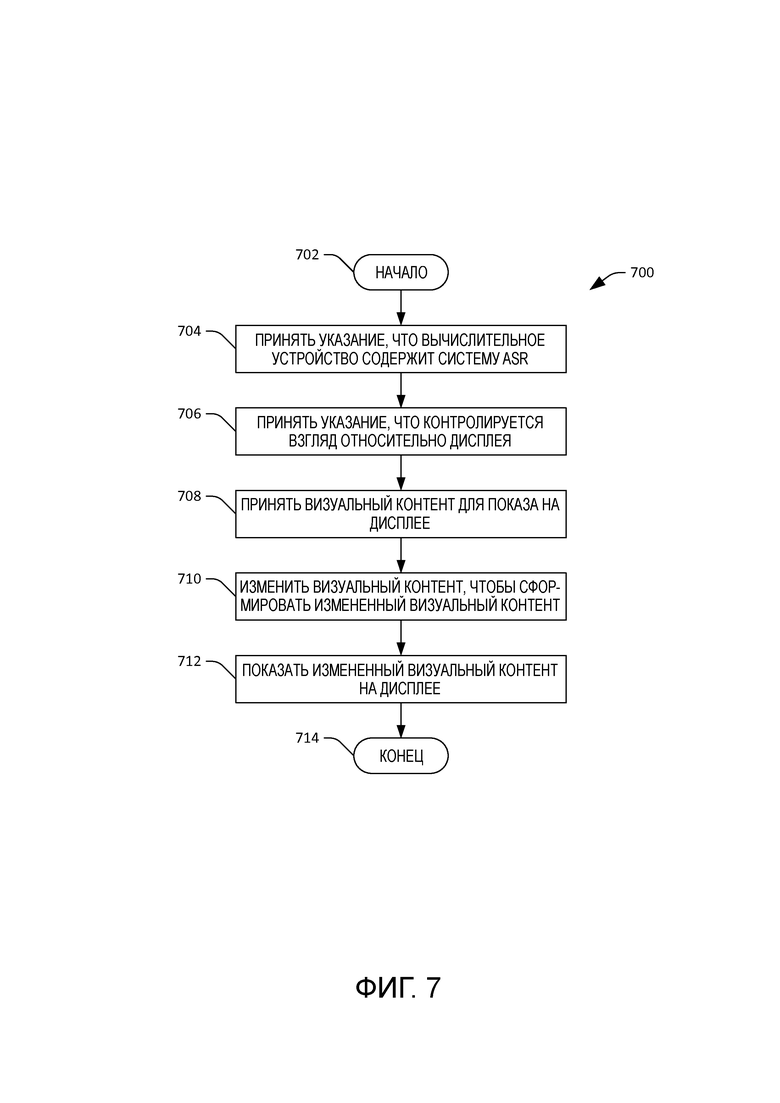
[10] Фиг. 7 - блок-схема алгоритма, иллюстрирующая примерную методологию для изменения визуального контента для устранения неоднозначности того, на что смотрит пользователь.
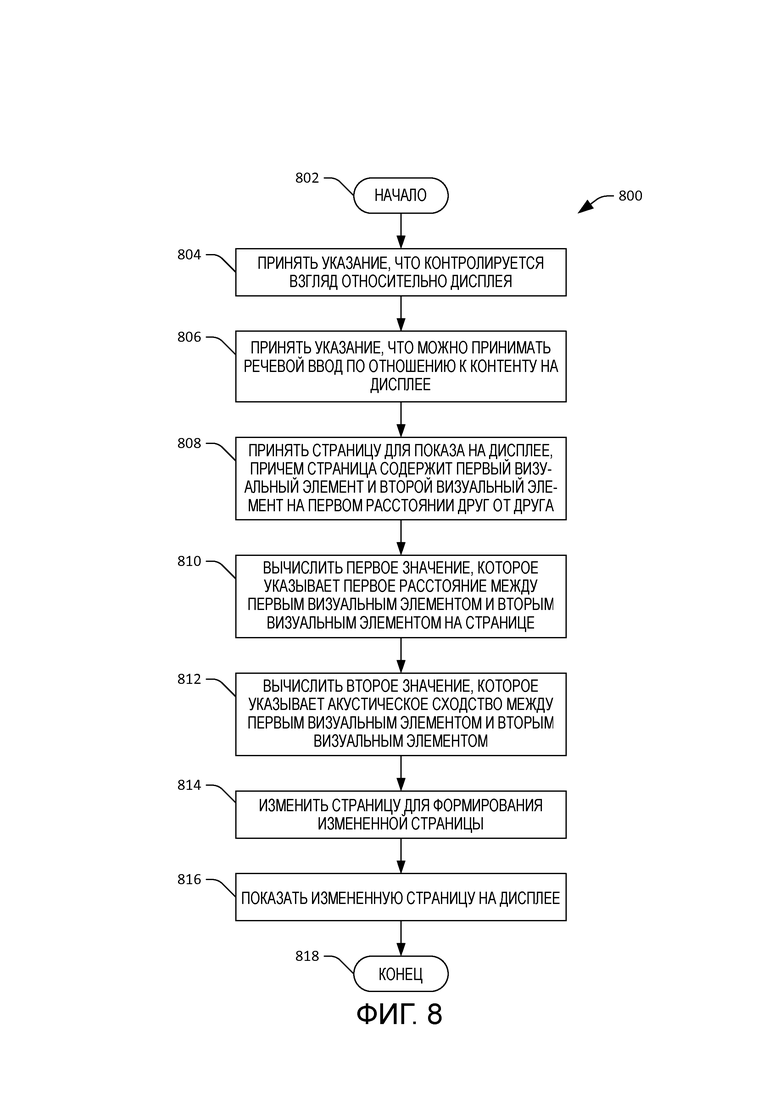
[11] Фиг. 8 - блок-схема алгоритма, которая иллюстрирует примерную методологию для изменения макета визуального контента на основе значения, которое указывает возможность путаницы между элементами в визуальном контенте.
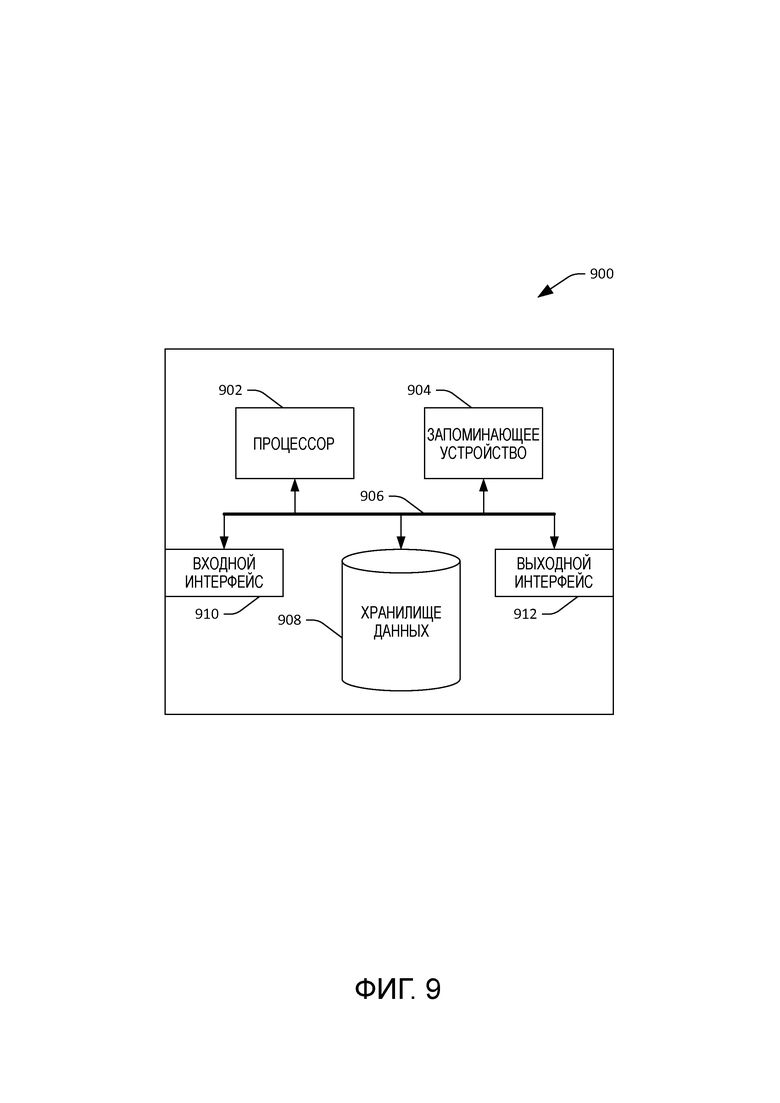
[12] Фиг. 9 - примерная вычислительная система.
ПОДРОБНОЕ ОПИСАНИЕ
[13] Различные технологии, имеющие отношение к изменению визуального контента, описываются сейчас со ссылкой на чертежи, в которых одинаковые номера ссылок используются для ссылки на одинаковые элементы по всему описанию. В нижеследующем описании для целей пояснения излагаются многочисленные характерные подробности, чтобы обеспечить всестороннее понимание одного или нескольких аспектов. Тем не менее может быть очевидным, что такой аспект (аспекты) можно применять на практике без этих характерных подробностей. В иных случаях широко известные структуры и устройства показываются в виде блок-схемы, чтобы облегчить описание одного или нескольких аспектов. Кроме того, нужно понимать, что функциональные возможности, которые описываются как выполняемые некоторыми компонентами системы, могут выполняться несколькими компонентами. Аналогичным образом, например, компонент может конфигурироваться для выполнения функциональных возможностей, которые описываются как выполняемые несколькими компонентами.
[14] Кроме того, термин "или" имеет целью обозначать включающее "или", а не исключающее "или". То есть, пока не указано иное или не ясно из контекста, фраза "X применяет A или B" имеет целью обозначать любую из естественных включающих перестановок. То есть фраза "X применяет A или B" выполняется любым из следующих случаев: X применяет A; X применяет B; или X применяет как A, так и B. К тому же при использовании в этой заявке и прилагаемой формуле изобретения единственное число следует в целом толковать означающим "один или несколько", пока не указано иное или из контекста не станет ясно, что предписывается форма единственного числа.
[15] Кроме того, при использовании в данном документе термины "компонент" и "система" предназначены для включения в себя машиночитаемого хранилища данных, которое снабжается исполняемыми компьютером командами, которые побуждают выполнение некоторых функциональных возможностей при их исполнении процессором. Исполняемые компьютером команды могут включать в себя процедуру, функцию или т. п. Также нужно понимать, что компонент или систему можно расположить на одном устройстве или распределить по нескольким устройствам. Кроме того, при использовании в данном документе термин "примерный" имеет целью обозначать "служащий в качестве иллюстрации или примера чего-либо" и не имеет целью указывать предпочтение.
[16] В этом документе описываются различные технологии, имеющие отношение к изменению визуального контента на дисплее для устранения неоднозначности у намерения пользователя, когда пользователь формулирует фрагмент речи. Устранение неоднозначности у намерения пользователя включает в себя распознавание фрагмента речи, сформулированного пользователем, вместе с визуальным контентом, показанным на дисплее (с течением времени). Дисплей конфигурируется для показа визуального контента, где визуальный контент может быть текстом, изображениями, полями (заполняемыми полями форм), видео, кнопками, ниспадающими списками и т. п. или включать их в себя. Соответственно, визуальный контент можно включать в страницу, которую подлежит показу на дисплее, например веб-страницу или страницу приложения (например, приложения обработки текстов, приложения показа слайдов и т. п.).
[17] Контролируется зрительное внимание пользователя относительно дисплея. Например, у дисплея может быть камера (например, камера RGB (красный, зеленый, синий цвета) и/или камера глубины) возле него или встроенная в него. Камера выводит сигналы (например, изображения), которые можно анализировать для определения положения и ориентации головы, что используется, в свою очередь, для предположения зрительного внимания (например, направления взгляда) пользователя. В другом примере изображения можно анализировать, чтобы идентифицировать части глаза, например зрачок, радужную оболочку, роговицу и т. п., и на основе идентифицированных частей глаза можно предположить зрительное внимание.
[18] Микрофон конфигурируется для формирования сигналов, которые указывают аудио в среде возле дисплея. Аудио может включать в себя фрагменты речи пользователя, и выведенные микрофоном сигналы могут предоставляться в систему ASR, которая конфигурируется для распознавания фрагментов речи. Описанные в этом документе технологии упрощают использование зрительного внимания для устранения неоднозначности у намерения пользователя, когда пользователь формулирует фрагменты речи. Однако, так как определение зрительного внимания может быть весьма неточным, аспекты, подробнее описанные в этом документе, относятся к изменению визуального контента для показа на дисплее, где это изменение совершается для устранения неоднозначности визуальных элементов, наблюдаемых пользователем.
[19] В соответствии с примером показываемый на дисплее визуальный контент может включать в себя первую последовательность слов и вторую последовательность слов, где первая последовательность слов некоторым образом похожа до степени смешения на вторую последовательность слов. Например, первая последовательность слов может быть акустически похожа на вторую последовательность слов. В другом примере первая последовательность слов и вторая последовательность слов могут быть похожи тематически. Визуальный контент можно анализировать, и можно формировать баллы для пар визуальных элементов, где баллы указывают возможность путаницы (например, с точки зрения системы ASR) между визуальными элементами в паре. Например, акустическое сходство можно оценивать в баллах на основе сравнения произношений слов. На основе баллов можно изменять визуальный контент, где изменение визуального контента может включать в себя изменение расстояния между визуальными элементами в визуальном контенте.
[20] Продолжая с изложенным выше примером, балл, вычисленный для пары из первой последовательности слов и второй последовательности слов, может указывать, что две последовательности слов похожи до степени смешения и могут быть источником неоднозначности для системы ASR. На основе балла визуальный контент можно изменить так, что первая последовательность слов располагается дальше от второй последовательности слов. Затем этот измененный визуальный контент можно показать на дисплее. Когда пользователь смотрит на дисплей, можно контролировать зрительное внимание пользователя, и на основе контролируемого зрительного внимания можно установить (с некоторой вероятностью), что пользователь смотрит на первую последовательность слов, а не на вторую последовательность слов. Тогда систему ASR можно настроить на основе первой последовательности слов. Другими словами, текущий контекст пользователя (например, на что пользователь смотрит на дисплее) используется для настройки системы ASR, способствуя улучшенному распознаванию предстоящих фрагментов. Таким образом, изменение визуального контента совершается для устранения неоднозначности того, на что смотрит пользователь, что используется, в свою очередь, для настройки системы ASR.
[21] В другом примере может предоставляться подсказка относительно показанного на дисплее визуального элемента, где подсказка информирует пользователя, что пользователя считают сосредоточившимся на визуальном элементе. Подсказка может быть аудиоподсказкой, пиктограммой (например, указателем мыши), выделением визуального элемента и т. п. Поэтому, когда пользователь формулирует фрагмент речи, пользователь может знать, что система ASR настраивается на основе визуального элемента. Для дополнительного содействия в устранении неоднозначности того, на какой визуальный элемент или элементы смотрит пользователь, также можно распознавать жесты. Например, в дополнение к отслеживанию зрительного внимания захваченные камерой изображения можно анализировать для идентификации того, куда пользователь ориентирован, кивает и т. п., что может применяться, в свою очередь, для идентификации визуального элемента, на котором сосредоточен пользователь.
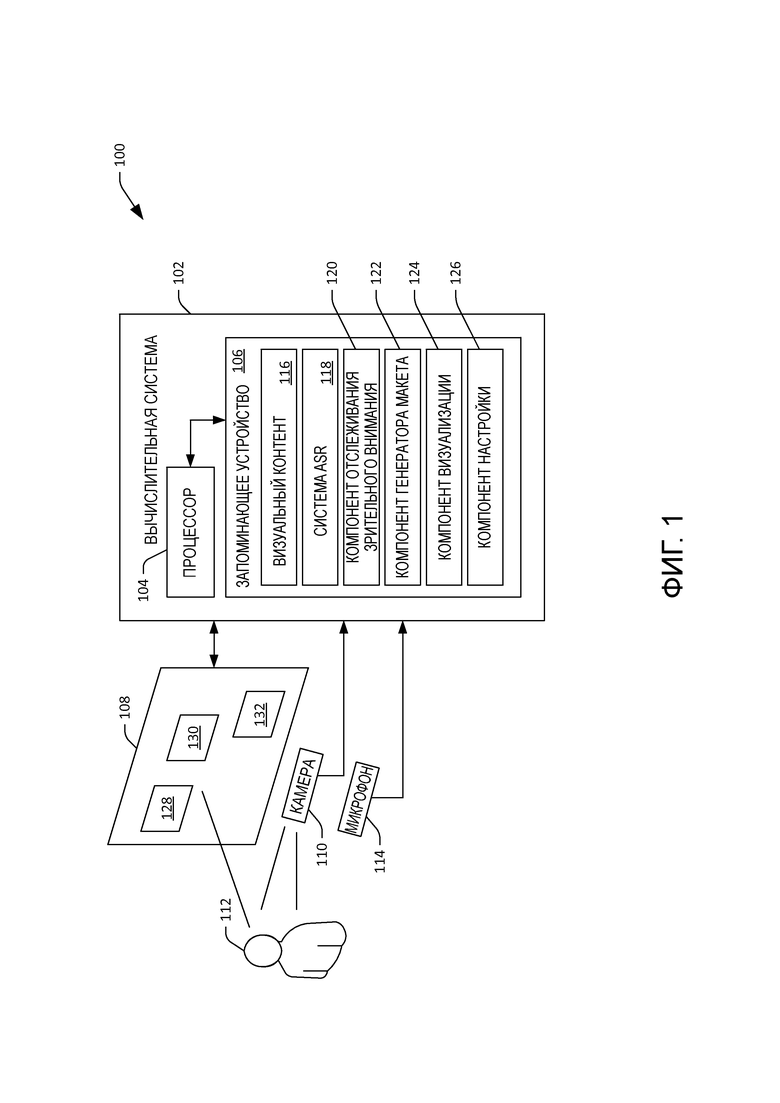
[22] Теперь со ссылкой на фиг. 1 иллюстрируется примерная система 100, которая облегчает изменение показанного на дисплее визуального контента, где изменение визуального контента совершается для устранения неоднозначности у намерения пользователя, формулирующего фрагменты речи. Система 100 включает в себя вычислительную систему 102, которая может быть, но не ограничивается, настольным вычислительным устройством, переносным вычислительным устройством, мобильным вычислительным устройством (например, мобильным телефоном или планшетным вычислительным устройством), игровой видеоприставкой, телевизионной приставкой, телевизором и т. п. В других примерах вычислительная система 102 может быть рассредоточена по нескольким вычислительным устройствам. Более того, по меньшей мере часть вычислительной системы 102 может включаться в центр обработки данных. Вычислительная система 102 включает в себя процессор 104 и запоминающее устройство 106, где запоминающее устройство 106 содержит компоненты и/или системы, которые исполняются процессором 104. Такие компоненты и системы будут подробнее описываться ниже.
[23] Система 100 дополнительно включает в себя дисплей 108, который осуществляет связь с вычислительной системой 102. Хотя дисплей 108 иллюстрируется как отдельный от вычислительной системы 102, в другом примере дисплей 108 может составлять одно целое с вычислительной системой 102. Таким образом, например, дисплей 108 может быть дисплеем мобильного вычислительного устройства, дисплеем переносного вычислительного устройства, дисплеем телевизора и т. п. В другом примере дисплей 108 может быть проекционным дисплеем.
[24] Система 100 дополнительно содержит камеру 110, которая может быть камерой RGB (красный, зеленый, синий цвета), камерой оттенков серого и/или камерой глубины. Камера 110 конфигурируется для захвата изображений пользователя 112 (по меньшей мере его головы), когда пользователь 112 смотрит на визуальный контент, показанный на дисплее 108. Система 100 также включает в себя микрофон 114, который располагается вблизи от пользователя 112 и/или дисплея 108 и поэтому конфигурируется для захвата фрагментов речи, формулируемых пользователем 112. Хотя камера 110 и микрофон 114 иллюстрируются на фиг. 1 как отдельные от дисплея 108 и/или вычислительной системы 102, нужно понимать, что камера 110 и/или микрофон 114 могут быть встроены в дисплей 108 и/или вычислительную систему 102.
[25] Запоминающее устройство 106 в вычислительной системе 102 может включать в себя визуальный контент 116, который подлежит показу на дисплее 108. В примере визуальный контент 116 можно включать в веб-страницу. Соответственно, визуальный контент 116 может включать в себя текст, изображения, видео, анимацию или т. п. В другом примере визуальный контент 116 может конфигурироваться для отображения исполняемым компьютером приложением, например приложением обработки текстов, приложением электронных таблиц, приложением показа слайдов, видеопроигрывателем или т. п. В еще одном примере визуальный контент 116 может быть видеопрограммой, рекламным объявлением, частью видеоигры или другим подходящим визуальным контентом. Визуальный контент 116 может включать в себя несколько визуальных элементов, например слова, последовательности слов, изображения, видеоклипы и т. п. Визуальный контент 116 может иметь первый макет, и элементы могут включаться в визуальный контент 116 в соответствии с первым макетом.
[26] Запоминающее устройство 106 также включает в себя систему 118 автоматического распознавания речи (ASR), которая конфигурируется для распознавания фрагментов речи, сформулированных пользователем 112, на основе вывода из микрофона 114. Запоминающее устройство 106 также включает в себя компонент 120 отслеживания зрительного внимания, который конфигурируется для идентификации направления взгляда пользователя 112 на основе изображений (RGB и/или изображений глубины), выведенных камерой 110. В примере компонент 120 отслеживания зрительного внимания может идентифицировать положение и поворот головы пользователя 112, и компонент отслеживания зрительного внимания может предполагать, на чем сосредоточился пользователь 112 (например, направление взгляда пользователя 112), на основе положения и поворота головы пользователя 112. В другом примере компонент 120 отслеживания зрительного внимания может анализировать изображения, выведенные камерой 110, и может идентифицировать глаза пользователя 112 на таких изображениях. Например, компонент 120 отслеживания взгляда может идентифицировать элементы глаза, например зрачок, радужную оболочку и/или роговицу, и может предполагать направление взгляда пользователя 112 на основе обнаруженных местоположений таких элементов глаза (например, совместно с положением и поворотом головы).
[27] Полагая, что местоположение камеры 110 относительно дисплея 108 известно по меньшей мере приблизительно, и местоположение пользователя 112 относительно дисплея 108 известно по меньшей мере приблизительно, компонент 120 отслеживания зрительного внимания может оценивать наблюдаемую пользователем 112 область на дисплее 108 (например, с некоторой подходящей вероятностью). Точность компонента 120 отслеживания зрительного внимания относительно дисплея 108 может определяться во время фазы калибровки (например, во время производства или во время фактического использования). Такая точность может зависеть от конструктива дисплея 108 (например, размера дисплея), разрешения камеры 110 (камеры глубины или RGB), возможностей процессора 104, размера запоминающего устройства 106 и т. п. Точность компонента 120 отслеживания зрительного внимания может учитывать границы (размер) идентифицируемой области, где пользователь 112 может смотреть на любые визуальные элементы в той области.
[28] Запоминающее устройство 106 может дополнительно включать в себя компонент 122 генератора макета, который особенно хорошо подходит для включения в вычислительные устройства, которые поддерживают как ASR, так и контроль зрительного внимания. Компонент 122 генератора макета конфигурируется для изменения визуального контента 116 для создания измененного визуального контента (который также может называться "новым" визуальным контентом), где компонент 122 генератора макета выполняет такое изменение перед инициированием показа визуального контента 116 на дисплее 108. Компонент 122 генератора макета выполняет такое изменение для устранения неоднозначности у намерения пользователя 112, когда пользователь 112 смотрит на дисплей 108 и/или иным образом взаимодействует с дисплеем (например, выдавая фрагменты речи относительно показанного на дисплее контента).
[29] Как правило, компонент 122 генератора макета принимает указание, что вычислительная система 102 поддерживает контроль зрительного внимания. Компонент 122 генератора макета при необходимости может принять указание, что вычислительная система 102 содержит систему 118 ASR. Компонент 122 генератора макета принимает визуальный контент 116, который подлежит показу на дисплее 108, и изменяет такой визуальный контент для формирования измененного (нового) визуального контента перед инициированием показа визуального контента 116 на дисплее 108. Компонент 122 генератора макета изменяет визуальный контент 116 на основе элементов в визуальном контенте 116 (которые подробнее будут описываться ниже), первого макета визуального контента 116 и вышеуказанной точности компонента 120 отслеживания зрительного внимания.
[30] Говоря подробнее об изменении визуального контента 116 на основе элементов в нем, компонент 122 генератора макета может принимать визуальный контент 116 и может идентифицировать элементы в нем. Компонент 122 генератора макета может вычислять расстояния между элементами и может вычислять значение для пары элементов, которое указывает неоднозначность между элементами в паре по отношению к системе 118 ASR. Например, первый макет визуального контента 116 может включать в себя две последовательности слов в непосредственной близости друг к другу, чьи произношения похожи друг на друга, потенциально затрудняя, таким образом, устранение неоднозначности между двумя последовательностями слов для системы 118 ASR, когда одна из таких последовательностей произносится пользователем 112. Компонент 122 генератора макета может изменить визуальный контент 116 для формирования измененного визуального контента, где измененный визуальный контент имеет второй макет, и во втором макете две последовательности слов расставляются дальше друг от друга (или разделяются другим контентом). Поэтому компонент 122 генератора макета изменил визуальный контент 116, чтобы расставить последовательности слов с похожими произношениями дальше друг от друга.
[31] В другом примере компонент 122 генератора макета может изменить визуальный контент 116 путем изменения масштаба визуального контента 116. То есть визуальный контент 116 может иметь масштаб, назначенный ему по умолчанию. Компонент 122 генератора макета может анализировать визуальный контент 116 и идентифицировать элементы в нем, которые находятся в непосредственной близости друг к другу и могут быть некоторым образом неоднозначными для системы 118 ASR. Компонент 122 генератора макета может "увеличить масштаб" визуального контента в конкретном местоположении, так что элементы при показе на дисплее 108 располагаются дальше друг от друга.
[32] Запоминающее устройство 106 также включает в себя компонент 124 визуализации, который показывает измененный визуальный контент на дисплее 108, где измененный визуальный контент может быть просмотрен пользователем 112. Запоминающее устройство 106 дополнительно включает в себя компонент 126 настройки, который настраивает систему 118 ASR на основе контекста просмотра у пользователя 112 (например, на основе вывода компонента 120 отслеживания зрительного внимания). Настройка системы 118 ASR включает в себя 1) изменение весов в моделях в системе 118 ASR на основе контекста просмотра у пользователя; 2) взвешивание вывода системы 118 ASR; и 3) изменение весов в моделях в системе 118 ASR и взвешивание вывода системы 118 ASR.
[33] Теперь излагается работа системы 100, когда пользователь 112 смотрит на дисплей 108. Пользователь 112 располагается для просмотра дисплея 108. Запоминающее устройство 106 включает в себя визуальный контент 116, который подлежит показу пользователю 112 на дисплее 108. Когда вычислительная система 102 поддерживает отслеживание зрительного внимания и содержит систему 118 ASR, можно запустить компонент 122 генератора макета, чтобы проанализировать визуальный контент 116 на предмет изменения. Компонент 122 генератора макета принимает визуальный контент 116 и ищет в визуальном контенте 116 элементы, которые могут вызывать неоднозначность по отношению к системе 118 ASR, когда пользователь 112 формулирует фрагменты речи по меньшей мере относительно одного из таких элементов. Например, компонент 122 генератора макета может идентифицировать акустически сходные слова или последовательности слов, элементы, которые похожи тематически, заполняемые поля форм в непосредственной близости друг к другу, кнопки в непосредственной близости друг к другу и т. п.
[34] В соответствии с примером компонент 122 генератора макета может применять модель "пружинного матраса", в которой элементы в визуальном контенте 116 соединяются "пружинами", которые расталкивают или сближают их на основе возможной неоднозначности по отношению к системе 118 ASR. Расстояние, на которое нужно расставить друг от друга неоднозначные элементы, может зависеть от точности компонента 120 отслеживания зрительного внимания (например, чем точнее возможность отслеживания зрительного внимания, тем на меньшее расстояние нужно расставить неоднозначные элементы, тогда как неоднозначные элементы расставляются дальше, когда точность отслеживания зрительного внимания уменьшается). Перестановка элементов в визуальном контенте 116 может быть особенно полезна, когда элементы являются заполняемыми полями форм, так как система 118 ASR может использовать разные модели языка для разных заполняемых полей форм соответственно. Таким образом, два заполняемых поля форм, ассоциированные с двумя разными моделями языка, можно расставить дальше с помощью компонента 122 генератора макета.
[35] Компонент 124 визуализации визуализирует на дисплее 108 измененный визуальный контент (измененный компонентом 122 генератора макета). В показанном на фиг. 1 примере измененный визуальный контент может включать в себя элементы 128, 130 и 132. В визуальном контенте 116 элементы 128 и 132 могут находиться рядом друг с другом. Однако компонент 122 генератора макета может установить, что элементы 128 и 132 могут вызывать неоднозначность по отношению к системе 118 ASR (например, система 118 ASR может испытывать трудность с идентификацией, к какому из элементов 128 или 132 обращается пользователь 112, формулируя фрагменты речи). Поэтому компонент 122 генератора макета изменил визуальный контент 116 так, что элементы 128 и 132 расставляются дальше друг от друга.
[36] Компонент 120 отслеживания зрительного внимания принимает изображения от камеры 110 и оценивает, например, направление взгляда пользователя 112 на основе изображений, выведенных камерой 110. Так как можно оценить направление взгляда пользователя 112, можно сформировать оценку того, на какой из элементов 128-132 смотрит пользователь 112 (если вообще смотрит). В соответствии с примером, когда компонент 120 отслеживания зрительного внимания оценивает, что пользователь 112 смотрит на конкретный элемент, компонент 122 генератора макета может формировать вывод, который указывает пользователю 112, что компонент 120 отслеживания зрительного внимания оценил, что пользователь 112 смотрит на конкретный элемент. Вывод, сформированный компонентом 122 генератора макета, может быть слышимым выводом, добавлением пиктограммы поверх конкретного элемента (например, курсора), выделением конкретного элемента и т. п.
[37] Компонент 126 настройки может принимать указание о том, на какой из элементов 128-132 смотрит пользователь 112. В ответ на прием этого указания компонент 126 настройки может настроить систему 118 ASR на основе элемента на дисплее 108, наблюдаемого пользователем 112 (который определен компонентом 120 отслеживания зрительного внимания). Например, компонент настройки может изменить веса в акустической модели, модели лексикона и/или модели языка в системе 118 ASR на основе элемента, определенного как наблюдаемого пользователем 112. Дополнительно или в качестве альтернативы компонент 126 настройки может выбирать выводы (возможно, неизмененной) системы 118 ASR на основе элемента, определенного как наблюдаемого пользователем 112. Компонент 126 настройки может взвешивать выводы системы 118 ASR для разных контекстов. В другом примере компонент 126 настройки может использовать правила для выбора вывода системы 118 ASR (например, когда пользователь 112 смотрит на заполняемое поле формы, которое сконфигурировано для приема названия города, правило может выбрать название города из возможных выводов системы 118 ASR). Фактически, компонент 126 настройки настраивает систему 118 ASR на основе контекста - на что смотрит пользователь 112, посредством этого способствуя повышению вероятности, что система 118 ASR правильно распознает фрагменты речи пользователя 112.
[38] Когда пользователь 112 формулирует фрагмент речи, микрофон 114 может захватывать такой фрагмент речи и выводить сигнал, который представляет фрагмент речи. Система 118 ASR, настроенная компонентом 126 настройки, может распознавать фрагмент речи на основе сигнала, выведенного микрофоном 114. Возможность точно определять, на что смотрит пользователь 112, увеличивается путем изменения визуального контента 116, выполняемого компонентом 122 генератора макета. Таким образом, система 100 поддерживает изменение визуального контента 116, так что потенциально неоднозначные элементы расставляются достаточно далеко, чтобы облегчить установление различия между наблюдаемыми элементами для компонента 120 отслеживания зрительного внимания. Компонент 122 генератора макета может выполнять эту операцию автоматически, принимая во внимание точность компонента 120 отслеживания зрительного внимания, а также элементы и макет визуального контента 116. Кроме того, так как компонент 120 отслеживания зрительного внимания может знать о том, на что смотрит пользователь 112, можно прийти к заключению о том, о чем будет говорить пользователь 112. Эта информация может предоставляться системе 118 ASR, помогая системе 118 ASR в понимании намерения пользователя 112. Поэтому, например, когда элемент 132 является заполняемым полем формы для приема города назначения, и компонент 120 отслеживания зрительного внимания определяет, что пользователь 112 смотрит на такое заполняемое поле формы, то компонент 126 настройки может ожидать, что пользователь 112 выдаст фрагмент речи, который включает в себя название города или аэропорта. Соответственно, компонент 126 настройки может изменить модель языка у системы 118 ASR, чтобы придать большой вес названиям городов и/или аэропортов.
[39] Хотя этот пример обсудил изменение визуального контента 116 во время визуализации, описанные в этом документе идеи также хорошо подходят для изменения визуального контента во время создания. Например, проектировщик может сформировать макет для веб-страницы, а компонент 122 генератора макета может принять этот макет. Затем компонент 122 генератора макета может внести изменения в макет и показать изменения проектировщику (который может решить принять или отклонить предложенные изменения макета). Снова компонент 122 генератора макета может внести эти изменения макета, чтобы помочь системе 118 ASR в распознавании фрагментов речи, сформулированных зрителями веб-страницы.
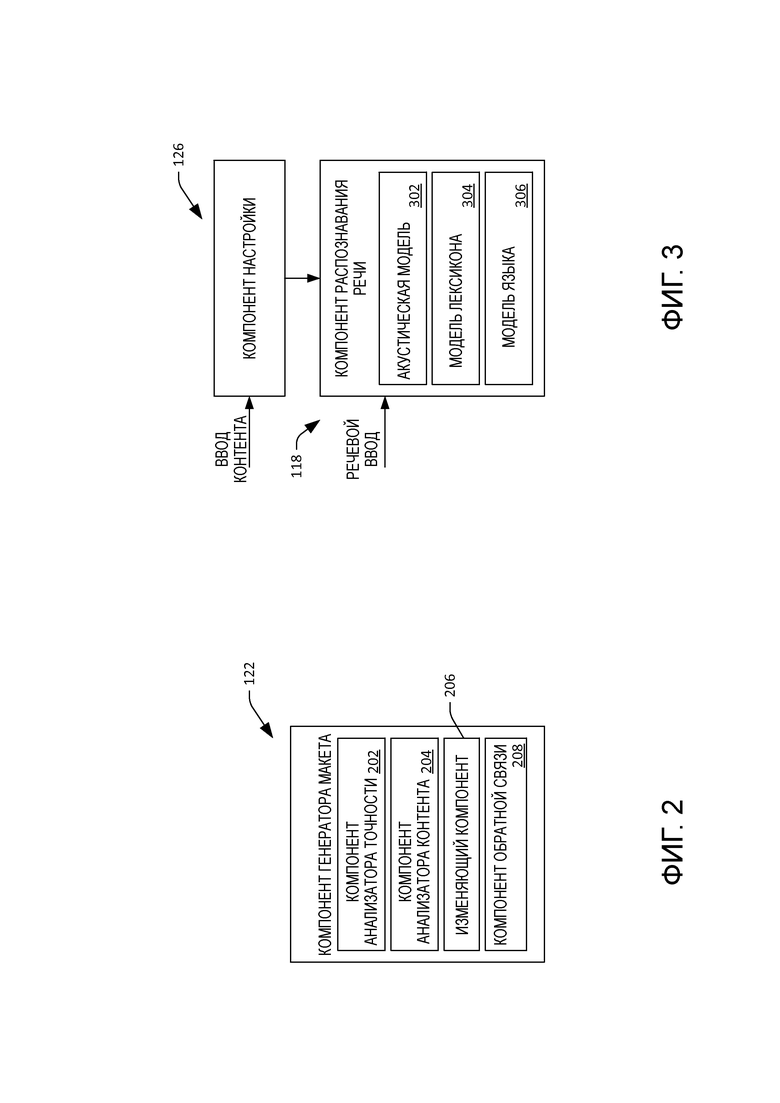
[40] В соответствии с еще одним примером в дополнение к контролю зрительного внимания запоминающее устройство 106 может включать в себя компонент (не показан), который конфигурируется для распознавания жестов, например, указывающего на элемент пользователя 112. Сочетание распознавания того, куда пользователь 112 указывает и куда пользователь 112 смотрит на дисплее 108, может использоваться для предположения, что интересует пользователя 112, и предположения, что пользователь 112 собирается сказать следующим. Таким образом, компонент 126 настройки может настраивать систему 118 ASR на основе того, что предполагается интересующим пользователя 112.
[41] Кроме того, хотя описанные в этом документе аспекты описаны относительно системы 118 ASR, нужно понимать, что изменение макета, которое описано выше, может использоваться в других контекстах. Например, разработаны персональные цифровые помощники, которые конфигурируются для предугадывания пожеланий пользователей компьютера, так что персональный цифровой помощник может, например, предоставлять данные пользователю без приема фрагмента речи от пользователя. Визуальный контент можно изменять для уменьшения неоднозначности по отношению к тому, на что пользователь смотрит на дисплее, и персональный цифровой помощник может предоставлять контент с использованием измененного макета. Например, визуальный контент 116 может включать в себя два элемента: первый элемент, который представляет итальянский ресторан, и второй элемент, который представляет итальянский фестиваль. Компонент 122 генератора макета может расставить два элемента дальше друг от друга; соответственно, когда распознается, что пользователь 112 смотрит на первый элемент, персональный цифровой помощник может показать меню для ресторана либо может спросить у пользователя 112, желает ли пользователь забронировать место в ресторане. В отличие от этого, когда распознается, что пользователь 112 смотрит на второй элемент, персональный цифровой помощник может показать время и местоположение фестиваля на дисплее 108.
[42] Поэтому можно установить, что система 100 поддерживает средство для изменения визуального контента 116 на основе возможной неоднозначности с точки зрения системы 118 ASR между по меньшей мере одним словом, соответствующим первому визуальному элементу, и по меньшей мере одним словом, соответствующим второму визуальному элементу в визуальном контенте. В примере возможная неоднозначность может основываться на сходстве произношения между по меньшей мере одним словом, соответствующим первому визуальному элементу, и по меньшей мере одним словом, соответствующим второму визуальному элементу. В другом примере возможная неоднозначность может основываться на сходстве между соответствующими типами визуальных элементов (например, оба визуальных элемента являются заполняемыми полями форм). Система 100 дополнительно поддерживает средство для отображения измененного визуального контента, где изменилось расстояние между первым визуальным элементом и вторым визуальным элементом.
[43] Ссылаясь теперь на фиг. 2, иллюстрируется функциональная блок-схема компонента 122 генератора макета. Компонент 122 генератора макета включает в себя компонент 202 анализатора точности. Компонент 202 анализатора точности конфигурируется для определения точности компонента 120 отслеживания взгляда при определении направления взгляда (на основе изображений, выведенных камерой 110). Например, компонент 202 анализатора точности может определять точность на основе размера дисплея 108, разрешения камеры 110, возможностей обработки у процессора 104, размера запоминающего устройства 106, расстояния пользователя 112 от дисплея 108 и т. п. В соответствии с примером компонент 202 анализатора точности может идентифицировать величину ошибки, соответствующей определениям направления взгляда, выполненным компонентом 120 отслеживания взгляда. Например, компонент 202 анализатора точности может выводить распределение вероятностей по пикселям дисплея 108 в зависимости от положения на дисплее 108, которое определяется как положение, на которое смотрит пользователь 112 (например, компонентом 120 отслеживания взгляда).
[44] Компонент 122 генератора макета также включает в себя компонент 204 анализатора контента, который анализирует элементы в визуальном контенте 116. В частности, как указывалось выше, компонент 204 анализатора контента может идентифицировать элементы в визуальном контенте 116, которые могут вызывать неоднозначность с точки зрения системы 118 ASR (и/или персонального цифрового помощника). Например, визуальный контент 116 может включать в себя два заполняемых поля форм в непосредственной близости друг к другу, которые могут вызывать неоднозначность с точки зрения системы 118 ASR. В другом примере изображения, которые включают в себя или ссылаются на объекты, которые обладают некоторым граничным сходством, могут вызывать неоднозначность с точки зрения системы 118 ASR. В еще одном примере два слова или две последовательности слов, которые акустически похожи, могут вызывать неоднозначность с точки зрения системы 118 ASR. В еще одном примере изображения, слова или последовательности слов, которые тематически похожи, могут вызывать неоднозначность с точки зрения системы 118 ASR.
[45] Соответственно, компонент 204 анализатора контента в соответствии с изложенными выше примерами может идентифицировать элементы в визуальном контенте 116, которые могут вызывать неоднозначность с точки зрения системы 118 ASR. Таким образом, компонент 204 анализатора контента может идентифицировать похожие элементы (например, заполняемые поля форм) в визуальном контенте 116, которые находятся в относительно непосредственной близости друг к другу. Кроме того, компонент 204 анализатора контента может вычислять значение, указывающее сходство в произношении между словами или последовательностями, упоминаемыми в визуальном контенте 116. Например, произношения слов могут представляться с помощью вектора значений, и может применяться основанный на расстоянии алгоритм для вычисления расстояния между векторами. Также компонент 204 анализатора контента может идентифицировать элементы в визуальном контенте 116, которые тематически похожи друг на друга. Кроме того, компонент 204 анализатора контента может идентифицировать изображения в визуальном контенте 116, которые ссылаются на объекты или изображают объекты, которые могут вызывать неоднозначность с точки зрения системы 118 ASR. Например, компонент 204 анализатора контента может включать в себя или осуществлять связь с системой, которая выполняет распознавание объектов на изображениях, где такое распознавание может основываться на сигнатурах изображений (например, цветовых сигнатурах, градиентных сигнатурах и т. п.). В примере визуальный контент 116 может содержать первое изображение, которое включает в себя или ссылается на автомобиль, и может содержать второе изображение, которое включает в себя или ссылается на звезду. Компонент 204 анализатора контента может вывести указание, что два изображения могут вызывать неоднозначность с точки зрения системы 118 ASR из-за сходства между произношением "car" (автомобиль) и "star" (звезда).
[46] Как указывалось выше, компонент 204 анализатора контента может использовать основанный на расстоянии алгоритм для вычисления значения расстояния для пары элементов, где значение расстояния указывает сходство между элементами (и таким образом, указывает возможную неоднозначность). Такой основанный на расстоянии алгоритм может хорошо подходить для случаев, где элементы (или произношения элементов) можно представить с помощью векторов, и расстояние между векторами можно использовать для определения (акустического) сходства между словами или последовательностями слов, сходства между изображениями и т. п. Что касается определения того, что два элемента тематически похожи, то компонент 204 анализатора контента может иметь доступ к назначенным элементам темам (например, с помощью поисковой системы). Когда обнаруживается, что два элемента относятся к некой теме, компонент 204 анализатора контента может формировать вывод, который указывает, что два элемента тематически похожи. Компонент 204 анализатора контента также может анализировать метаданные в визуальном контенте 116. Например, изображения и веб-страницы часто содержат внедренные в них метаданные, и компонент 204 анализатора контента может сравнивать метаданные, назначенные элементам в визуальном контенте 116. Затем компонент 204 анализатора контента на основе сравнения метаданных может выводить значение, указывающее сходство между элементами.
[47] Компонент 122 генератора макета дополнительно содержит изменяющий компонент 206, который изменяет визуальный контент 116 на основе 1) информации о точности, выведенной компонентом 202 анализатора точности; и 2) значений сходства (например, значения возможности путаницы) для пар элементов, выведенных компонентом 204 анализатора контента. Например, когда компонент 202 анализатора точности определяет, что компонент 120 отслеживания зрительного внимания имеет высокую точность, то изменяющему компоненту 206 не нужно значительно изменять положения элементов в визуальном контенте 116, даже когда компонент 204 анализатора контента определяет, что два элемента в визуальном контенте 116 очень похожи (и соответственно, могут вызывать неоднозначность с точки зрения системы 118 ASR). В другом примере, когда компонент 120 отслеживания зрительного внимания менее точен, и компонент 204 анализатора контента идентифицирует два элемента, которые вызывают неоднозначность с точки зрения системы 118 ASR, изменяющий компонент 206 может изменить визуальный контент 116 так, что два элемента размещаются дальше друг от друга в измененном визуальном контенте.
[48] Компонент 122 генератора макета также может включать в себя компонент 208 обратной связи, который предоставляет пользователю 112 обратную связь о том, что компонент 120 отслеживания зрительного внимания идентифицировал в качестве элемента, наблюдаемого пользователем 112. Например, когда компонент 120 отслеживания зрительного внимания устанавливает, что пользователь 112 смотрит на конкретный элемент, компонент 208 обратной связи может формировать обратную связь, которая информирует пользователя 112, что система 118 ASR настраивается на предположение ввода на основе такого элемента. Вывод может быть слышимым, где слышимый вывод информирует пользователя 112 об элементе, про который компонент 120 отслеживания зрительного внимания установил, что на него смотрит пользователь 112. В другом примере компонент 208 обратной связи может отображать пиктограмму, например указатель мыши, на элементе. В еще одном примере элемент можно выделять. Выделение элементов может быть особенно полезным, когда измененный визуальный контент включает в себя заполняемые поля форм. Выделение заполняемого поля формы укажет пользователю 112 тип контента, который система 118 ASR предполагает принять от пользователя 112. Например, если заполняемое поле формы соответствует отправлению рейса, то заполняемое поле формы может выделяться, указывая пользователю 112, что система 118 ASR предполагает принять название местоположения (город, код аэропорта и т. п.).
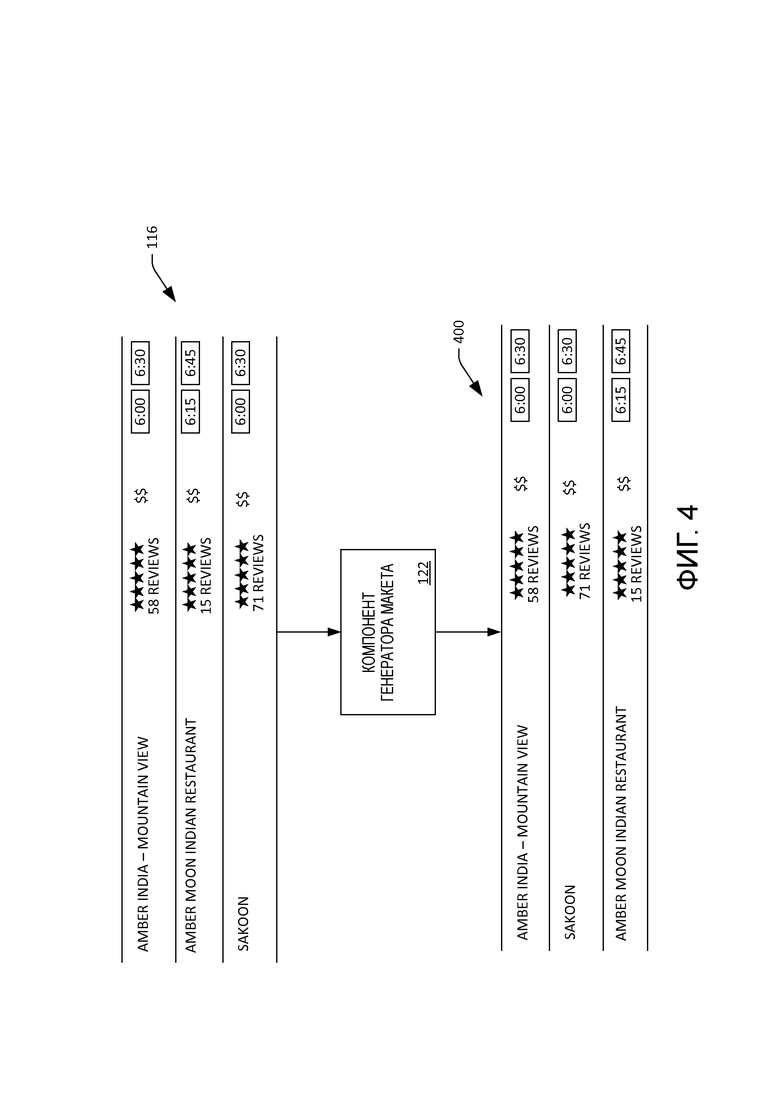
[49] Теперь со ссылкой на фиг. 3 иллюстрируется функциональная блок-схема системы 118 ASR и компонента 126 настройки. Система 118 ASR включает в себя акустическую модель 302, модель 304 лексикона и модель 306 языка. Акустическая модель 302 моделирует звуки (фоны), издаваемые людьми. Модель 304 лексикона моделирует последовательности звуков, обычно слова на конкретном языке. Модель 306 языка моделирует последовательности слов на конкретном языке. Каждая из моделей 302-306 имеет назначенные ей веса, где веса указывают вероятности наблюдения того, что моделируется (например, на основе, возможно, предыдущих наблюдений). Однако в некоторых случаях может быть желательно изменить веса для разных контекстов.
[50] Компонент 120 отслеживания зрительного внимания может предоставлять контекстную информацию (например, что интересует пользователя на дисплее 108) на основе определенного направления взгляда. Компонент 126 настройки может принимать указание того, на что пользователь 112 смотрит в настоящее время или смотрел в последнее время, и может настраивать систему 118 ASR на основе такого указания. Например, компонент 126 настройки может настраивать веса у одной или нескольких моделей 302-306 на основе того, на что пользователь смотрит в настоящее время или смотрел в последнее время. Например, когда пользователь 112 пристально смотрит на заполняемое поле формы для города отправления, модель 304 языка и/или модель 306 лексикона можно настроить для назначения больших весов словам и последовательностям слов, соответствующим местоположениям (например, городам с аэропортами и/или кодам аэропортов). В другом примере, когда компонент 120 отслеживания зрительного внимания определяет, что пользователь 112 смотрит на элемент, который характеризует конкретный ресторан, компонент 126 настройки может принять этот контекст и обновить одну или несколько моделей 302-306 системы 118 ASR, чтобы система 118 ASR с большей вероятностью распознавала пищевые продукты во фрагменте речи пользователя 112.
[51] Кроме того, как упоминалось выше, компонент 126 настройки вместо изменения весов, назначенных моделям 302-306, или в дополнение к изменению весов, назначенных моделям 302-306, может выбирать вывод системы 118 ASR на основе принятого от компонента 120 отслеживания зрительного внимания указания о том, на что смотрит пользователь 112. Например, система 118 ASR может выводить распределение вероятностей по возможным словам и/или последовательностям слов. Компонент 126 настройки может выбирать слово или последовательность слов на основе указания, принятого от компонента 120 отслеживания взгляда, даже когда слово или последовательность слов не является наиболее вероятным словом либо последовательностью слов.
[52] Ссылаясь теперь на фиг. 4, иллюстрируется примерное изменение визуального контента, которое может выполняться компонентом 122 генератора макета. В этом примере визуальный контент 116 включает в себя три элемента: 1) последовательность слов "Amber India - Mountain View", 2) последовательность слов "Amber Moon Indian Restaurant" и 3) слово "Sakoon". Компонент 204 анализатора контента может определить, что элементы 1 и 2 похожи друг на друга, но элемент 3 не похож ни на элемент 1, ни на элемент 2. Соответственно, компонент 122 генератора макета может изменить визуальный контент 116 для формирования измененного визуального контента 400, который включает в себя те же три элемента, но размещенные во втором макете. В частности, вместо элементов 1 и 2 рядом друг с другом элемент 3 располагается между элементом 1 и элементом 2. Этот измененный визуальный контент 400 помогает компоненту 120 отслеживания зрительного внимания устранить неоднозначность между тем, когда пользователь 112 смотрит на элемент 1, и тем, когда пользователь 112 смотрит на элемент 2. Соответственно, когда пользователь 112 смотрит, например, на элемент 1 и заявляет "make reservations for Amber India", систему 118 ASR можно настроить для лучшего выявления намерения пользователя 112.
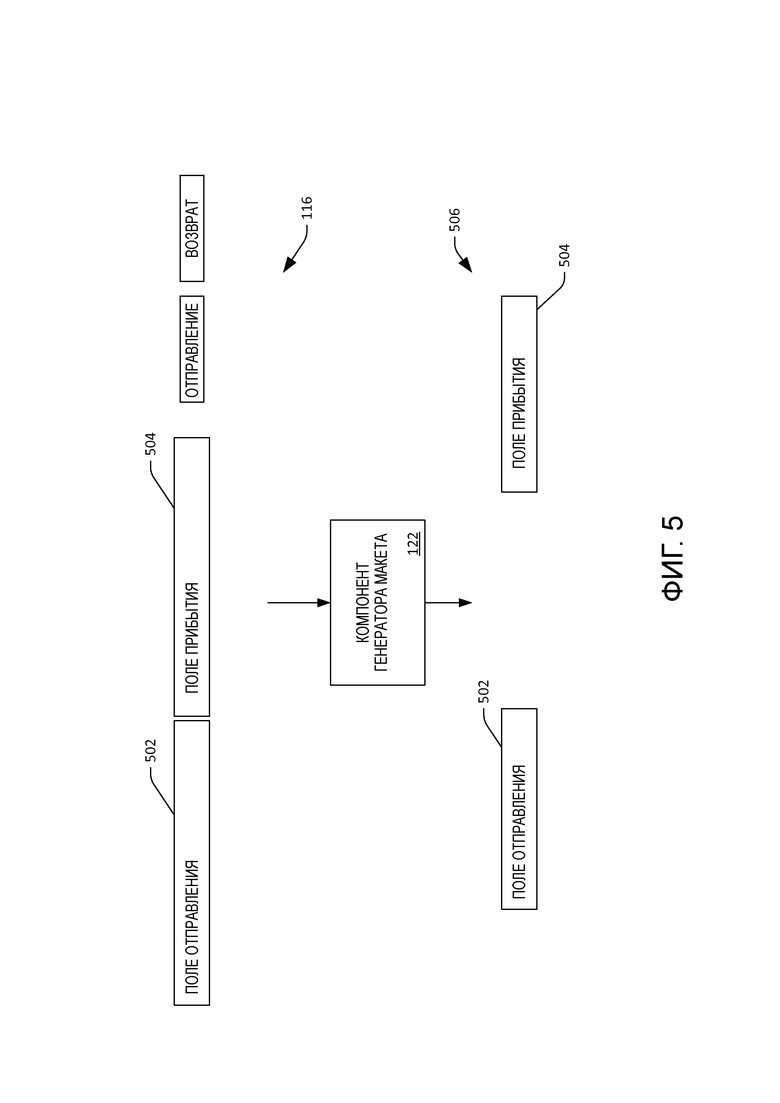
[53] Теперь со ссылкой на фиг. 5 иллюстрируется другое примерное изменение визуального контента, которое может выполняться компонентом 122 генератора макета. В этом примере визуальный контент 116 включает в себя два элемента; первое заполняемое поле 502 формы, которое сконфигурировано для приема города отправления, и второе заполняемое поле 504 формы, которое сконфигурировано для приема города прибытия. В визуальном контенте 116 первый элемент 502 находится в непосредственной близости ко второму элементу 504. Соответственно, когда пользователь смотрит на первый элемент 502 либо на второй элемент 504, компонент 120 отслеживания взгляда может не суметь установить с подходящей достоверностью, на какой из элементов 502 или 504 фактически смотрит пользователь 112.
[54] Таким образом, компонент 122 генератора макета может изменить визуальный контент 116 для создания измененного визуального макета 506, где первый элемент 502 и второй элемент 504 находятся на расстоянии друг от друга. То есть в визуальном контенте 116 первый элемент 502 находится на первом расстоянии от второго элемента 504, тогда как в измененном визуальном контенте 506 первый элемент 502 находится на втором расстоянии от второго элемента 504, причем второе расстояние больше первого расстояния. В этом примере пользователь 112 может затем посмотреть на первый элемент 502, и компонент 120 отслеживания взгляда со сравнительно высокой достоверностью может установить, что пользователь 112 смотрит на первый элемент 502 (а не на второй элемент 504). Когда пользователь 112 произносит название города отправления или код аэропорта, система 118 ASR может распознать город отправления или аэропорт, произнесенный пользователем 112, и первый элемент 502 можно заполнить городом или аэропортом, произнесенным пользователем 112 (а не второй элемент 504).
[55] Обращаясь теперь к фиг. 6, иллюстрируется другое примерное изменение визуального контента, которое может выполняться компонентом 122 генератора макета. В этом примере компонент 122 генератора макета принимает измененный визуальный контент 506, который включает в себя первый элемент 502 и второй элемент 504. Компонент 122 генератора макета также может принимать входные данные взгляда, которые идентифицированы компонентом 120 отслеживания взгляда. В ответ на прием входных данных взгляда компонент 122 генератора макета может предоставить вывод, который информирует пользователя 112 о том, какой из элементов 502 или 504 компонент 120 отслеживания взгляда оценил, что на него смотрит пользователь 112. В этом примере оценивается, что пользователь 112 смотрит на первый элемент 502, и соответственно, выделяется первый элемент 502. Тогда пользователь 112 может предполагать, что когда он формулирует фрагмент речи, такой фрагмент речи будет введен в элемент 502 (а не в элемент 504).
[56] Фиг. 7-8 иллюстрируют примерные методологии, относящиеся к изменению визуального контента с целью настройки системы ASR. Хотя методологии показываются и описываются как ряд действий, которые выполняются в некой последовательности, нужно понимать и принимать во внимание, что методологии не ограничиваются порядком той последовательности. Например, некоторые действия могут происходить в ином порядке, нежели описывается в этом документе. К тому же действие может происходить одновременно с другим действием. Кроме того, в некоторых случаях не все действия могут быть необходимы для реализации описанной в этом документе методологии.
[57] Кроме того, описанные в этом документе действия могут быть исполняемыми компьютером командами, которые можно реализовать одним или несколькими процессорами и/или сохранить на машиночитаемом носителе или носителях. Исполняемые компьютером команды могут включать в себя процедуру, подпрограмму, программы, поток исполнения и/или т. п. Более того, результаты действий в методологиях можно сохранять на машиночитаемом носителе, отображать на устройстве отображения и/или т. п.
[58] Ссылаясь теперь на фиг. 7, иллюстрируется примерная методология 700 для изменения визуального контента. Методология 700 начинается с этапа 702, и на этапе 704 принимается указание, что вычислительное устройство содержит систему ASR. На этапе 706 принимается указание, что контролируется зрительное внимание относительно дисплея, и на этапе 708 принимается визуальный контент для показа на дисплее.
[59] На этапе 710 перед инициированием показа визуального контента на дисплее визуальный контент изменяется, чтобы сформировать измененный визуальный контент. Это изменение основывается на указании, что вычислительное устройство содержит систему ASR, и указании, что контролируется зрительное внимание относительно дисплея. Как указано выше, изменение может включать в себя изменение макета визуального контента для формирования второго макета. В другом примере такое изменение может включать в себя изменение масштаба по умолчанию для визуального контента. На этапе 712 измененный визуальный контент показывают на дисплее. После этого, например, можно оценивать взгляд зрителя дисплея, и систему ASR можно настроить на основе того, что идентифицируется как наблюдаемое зрителем. Методология 700 завершается на этапе 714.
[60] Ссылаясь теперь на фиг. 8, иллюстрируется другая примерная методология 800 для изменения визуального контента. Методология 800 начинается с этапа 802, и на этапе 804 принимается указание, что зрительное внимание контролируется относительно дисплея. На этапе 806 принимается указание, что можно принимать речевой ввод по отношению к контенту на дисплее. На этапе 808 принимается страница для показа на дисплее, где страница содержит первый визуальный элемент и второй визуальный элемент на первом расстоянии друг от друга. Например, страница может быть веб-страницей, хотя методология 800 этим не ограничивается.
[61] На этапе 810 вычисляется первое значение, которое указывает первое расстояние между первым визуальным элементом и вторым визуальным элементом на странице. Как указывалось ранее, первый визуальный элемент и второй визуальный элемент могут быть соответственно первым словом или последовательностью слов и вторым словом или последовательностью слов. В другом примере первый визуальный элемент и второй визуальный элемент могут быть соответственно первым и вторым заполняемыми полями форм. Более того, первый визуальный элемент и второй визуальный элемент могут быть соответственно первым и вторым изображениями. Элемент также может быть сочетанием этих типов элементов (или других элементов).
[62] На этапе 812 вычисляется второе значение, где второе значение указывает акустическое сходство между первым визуальным элементом и вторым визуальным элементом. На этапе 814 страница изменяется для формирования измененной страницы, где измененная страница включает в себя первый визуальный элемент и второй визуальный элемент на втором расстоянии друг от друга. Кроме того, изменение страницы на этапе 814 основывается на первом значении и втором значении, вычисленных соответственно на этапах 810 и 812. На этапе 816 измененную страницу показывают на дисплее. Методология 800 заканчивается на этапе 818.
[63] Теперь излагаются различные примеры.
[64] Пример 1: Способ, исполняемый вычислительным устройством, содержащий: прием визуального контента для показа на дисплее; изменение визуального контента перед инициированием показа визуального контента на дисплее для формирования нового визуального контента на основе того, что: вычислительное устройство поддерживает автоматическое распознавание речи (ASR); и вычислительное устройство поддерживает контроль зрительного внимания; и инициирование показа нового визуального контента на дисплее в ответ на изменение визуального контента.
[65] Пример 2: Способ в соответствии с примером 1, в котором визуальный контент имеет первый макет, и в котором изменение визуального контента для формирования нового визуального контента содержит преобразование первого макета во второй макет.
[66] Пример 3: Способ в соответствии с примером 1, в котором первый макет включает в себя первый элемент и второй элемент с первым расстоянием между ними, и в котором изменение визуального контента для формирования нового визуального контента содержит изменение расстояния между первым элементом и вторым элементом так, что во втором макете второе расстояние отделяет первый элемент от второго элемента.
[67] Пример 4: Способ в соответствии с примером 1, в котором первый элемент содержит первое слово или последовательность слов, второй элемент содержит второе слово или последовательность слов, при этом способ дополнительно содержит: вычисление значения, указывающего акустическое сходство между первым словом или последовательностью слов и вторым словом или последовательностью слов; и изменение визуального контента для формирования измененного визуального контента на основе значения, указывающего акустическое сходство между первым словом или последовательностью слов и вторым словом или последовательностью слов.
[68] Пример 5: Способ в соответствии с любым из примеров 1-4, в котором визуальный контент имеет первый масштаб, и в котором изменение визуального контента для формирования нового визуального контента содержит изменение первого масштаба на второй масштаб.
[69] Пример 6: Способ в соответствии с любым из примеров 1-5, дополнительно содержащий прием изображений, которые включают в себя зрителя дисплея; идентификацию наблюдаемого элемента в новом визуальном контенте, показанном на дисплее, на основе изображений; и настройку системы ASR на основе идентификации элемента.
[70] Пример 7: Способ в соответствии с любым из примеров 1-6, дополнительно содержащий прием сигнала от микрофона, причем сигнал представляет фрагмент речи; и распознавание фрагмента речи в ответ на настройку системы ASR.
[71] Пример 8: Способ в соответствии с примером 1, дополнительно содержащий прием сигналов, которые включают в себя зрителя дисплея; оценивание на основе сигналов, что наблюдается элемент в новом визуальном контенте; и формирование вывода, который указывает, что элемент оценен как наблюдаемый, в ответ на оценивание, что элемент наблюдается.
[72] Пример 9: Способ в соответствии с примером 8, в котором формирование вывода содержит назначение визуального индикатора элементу в измененном визуальном контенте.
[73] Пример 10: Способ в соответствии с любым из примеров 8-9, в котором элемент является заполняемым полем формы.
[74] Пример 11: Способ в соответствии с любым из примеров 1-10, в котором визуальный контент содержит первое заполняемое поле формы и второе заполняемое поле формы, и изменение визуального контента для формирования нового визуального контента содержит перестановку по меньшей мере одного из первого заполняемого поля формы или второго заполняемого поля формы так, что первое заполняемое поле формы располагается дальше от второго заполняемого поля формы.
[75] Пример 12: Вычислительное устройство, содержащее: процессор; и запоминающее устройство, которое содержит множество компонентов, которые исполняются процессором, причем множество компонентов содержит: компонент генератора макета, который принимает визуальный контент, который подлежит показу на дисплее, причем визуальный контент имеет первый макет, компонент генератора макета перед показом визуального контента на дисплее изменяет визуальный контент так, что визуальный контент, когда изменен, имеет второй макет, компонент генератора макета изменяет визуальный контент на основе зрительного внимания, отслеживаемого относительно дисплея, где второй макет отличается от первого макета; и компонент визуализации в связи с компонентом генератора макета, причем компонент визуализации визуализирует визуальный контент со вторым макетом для показа на дисплее.
[76] Пример 13: Вычислительное устройство в соответствии с примером 12, причем множество компонентов дополнительно содержит: компонент отслеживания взгляда, который принимает изображения от камеры, компонент отслеживания взгляда идентифицирует направление взгляда на основе изображений, компонент отслеживания взгляда оценивает элемент, наблюдаемый на дисплее, на основе направления взгляда, где компонент генератора макета инициирует показ на дисплее графических данных, которые указывают, что элемент оценивается как наблюдаемый.
[77] Пример 14: Вычислительное устройство в соответствии с примером 13, в котором элемент является заполняемым полем формы, а графические данные являются выделением заполняемого поля формы.
[78] Пример 15: Вычислительное устройство в соответствии с любым из примеров 12-14, в котором множество компонентов дополнительно содержит компонент отслеживания взгляда, который принимает изображения от камеры, компонент отслеживания взгляда идентифицирует направление взгляда на основе изображений, компонент отслеживания взгляда оценивает элемент, наблюдаемый на дисплее, на основе направления взгляда, запоминающее устройство дополнительно содержит систему автоматического распознавания речи (ASR), которая исполняется процессором, система ASR сконфигурирована для приема аудиосигнала и распознавания фрагмента речи в аудиосигнале, система распознавания речи распознает фрагмент речи на основе элемента, оцененного компонентом отслеживания взгляда как наблюдаемого.
[79] Пример 16: Вычислительное устройство в соответствии с примером 15, причем множество компонентов дополнительно содержит компонент настройки, который настраивает систему ASR на основе элемента, оцененного компонентом отслеживания взгляда как наблюдаемого.
[80] Пример 17: Вычислительное устройство в соответствии с любым из примеров 12-16, в котором первый макет включает в себя первый элемент и второй элемент, которые находятся в первых положениях друг относительно друга, и в котором второй макет включает в себя первый элемент и второй элемент во вторых положениях друг относительно друга.
[81] Пример 18: Вычислительное устройство в соответствии с примером 17, в котором компонент генератора макета изменяет визуальный контент на основе значения, указывающего акустическое сходство между первым элементом и вторым элементом.
[82] Пример 19: Вычислительное устройство в соответствии с любым из примеров 12-18, причем визуальный контент включен в веб-страницу, которая подлежит отображению на дисплее.
[83] Пример 20: Машиночитаемый носитель информации, содержащий команды, которые при исполнении процессором побуждают процессор выполнить действия, содержащие: прием страницы для показа на дисплее, причем страница содержит первый визуальный элемент и второй визуальный элемент на первом расстоянии друг от друга; изменение страницы для формирования измененной страницы, причем измененная страница включает в себя первый визуальный элемент и второй визуальный элемент на втором расстоянии друг от друга, изменение страницы основывается на сходстве произношения между по меньшей мере одним словом, соответствующим первому визуальному элементу, и по меньшей мере одним словом, соответствующим второму визуальному элементу; и отображение измененной страницы на дисплее.
[84] Пример 21: Вычислительная система, которая описывается в этом документе, где вычислительная система содержит: средство для выполнения отслеживания зрительного внимания; средство для выполнения автоматического распознавания речи; и средство для изменения графического макета страницы на основе средства для выполнения отслеживания зрительного внимания и средства для выполнения автоматического распознавания речи.
[85] Ссылаясь теперь на фиг. 9, приводится высокоуровневая иллюстрация примерного вычислительного устройства 900, которое может использоваться в соответствии с системами и методологиями, раскрытыми в этом документе. Например, вычислительное устройство 900 может использоваться в системе, которая поддерживает отслеживание зрительного внимания. В качестве другого примера вычислительное устройство 900 может использоваться в системе, которая поддерживает ASR. Вычислительное устройство 900 включает в себя по меньшей мере один процессор 902, который исполняет команды, которые хранятся в запоминающем устройстве 904. Команды могут быть, например, командами для реализации функциональных возможностей, описанных как осуществляемых одним или несколькими рассмотренными выше компонентами, или командами для реализации одного или нескольких описанных выше способов. Процессор 902 может обращаться к запоминающему устройству 904 посредством системной шины 906. В дополнение к хранению исполняемых команд запоминающее устройство 904 также может хранить визуальный контент, фрагменты речи и т. п.
[86] Вычислительное устройство 900 дополнительно включает в себя хранилище 908 данных, которое доступно процессору 902 посредством системной шины 906. Хранилище 908 данных может включать в себя исполняемые команды, визуальный контент, фрагменты речи и т. п. Вычислительное устройство 900 также включает в себя входной интерфейс 910, который позволяет внешним устройствам осуществлять связь с вычислительным устройством 900. Например, входной интерфейс 910 может использоваться для приема команд от внешнего компьютерного устройства, от пользователя и т. п. Вычислительное устройство 900 также включает в себя выходной интерфейс 912, который сопрягает вычислительное устройство 900 с одним или несколькими внешними устройствами. Например, вычислительное устройство 900 может отображать текст, изображения и т. п. посредством выходного интерфейса 912.
[87] Предполагается, что внешние устройства, которые осуществляют связь с вычислительным устройством 900 через входной интерфейс 910 и выходной интерфейс 912, можно включить в среду, которая предоставляет практически любой тип интерфейса пользователя, с которым может взаимодействовать пользователь. Примеры типов интерфейса пользователя включают в себя графические интерфейсы пользователя, естественные интерфейсы пользователя и так далее. Например, графический интерфейс пользователя может принимать ввод от пользователя, применяющего такое устройство (устройства) ввода, как клавиатура, мышь, пульт дистанционного управления или т. п., и предоставлять вывод на таком устройстве вывода, как дисплей. Кроме того, естественный интерфейс пользователя может дать пользователю возможность взаимодействовать с вычислительным устройством 900 без ограничений, накладываемых устройством ввода, например клавиатурами, мышами, пультами дистанционного управления и т. п. Точнее, естественный интерфейс пользователя может опираться на распознавание речи, распознавание касания и пера, распознавание жестов на экране и рядом с экраном, жесты в воздухе, отслеживание движений головы и глаз, голос и речь, зрение, касание, жесты, искусственный интеллект и так далее.
[88] Более того, хотя и проиллюстрировано в виде одиночной системы, нужно понимать, что вычислительное устройство 900 может быть распределенной системой. Таким образом, например, несколько устройств могут осуществлять связь посредством сетевого соединения и могут вместе выполнять задачи, описанные как выполняемые вычислительным устройством 900.
[89] Различные функции, описанные в этом документе, могут быть реализованы в аппаратных средствах, программном обеспечении или любом их сочетании. При реализации в программном обеспечении функции могут храниться или передаваться в виде одной или нескольких команд либо кода на машиночитаемом носителе. Машиночитаемые носители включают в себя машиночитаемые носители информации. Машиночитаемые носители информации могут быть любыми доступными носителями информации, к которым можно обращаться с помощью компьютера. В качестве примера, а не ограничения, такие машиночитаемые носители информации могут быть выполнены в виде RAM, ROM, EEPROM, компакт-диска или другого накопителя на оптических дисках, накопителя на магнитных дисках или других магнитных запоминающих устройств, либо любого другого носителя, который может использоваться для перемещения или хранения необходимого программного кода в виде команд или структур данных, и к которому [носителю] можно обращаться с помощью компьютера. Диски при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и диск Blu-ray (BD), где магнитные диски обычно воспроизводят данные магнитным способом, а оптические диски обычно воспроизводят данные оптически с помощью лазеров. Кроме того, распространяемый сигнал не включается в область машиночитаемых носителей информации. Машиночитаемые носители также включают в себя средства связи, включающие любой носитель, который способствует переносу компьютерной программы из одного места в другое. Соединение, например, может быть средством связи. Например, если программное обеспечение передается с веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, например ИК-связи, радиочастотной связи и СВЧ-связи, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, например ИК-связь, радиочастотная связь и СВЧ-связь, включаются в определение средства связи. Сочетания вышеперечисленного также следует включить в область машиночитаемых носителей.
[90] В качестве альтернативы или дополнительно функциональные возможности, описанные в этом документе, могут по меньшей мере частично выполняться одним или несколькими компонентами аппаратной логики. Например, и без ограничения, пояснительные типы компонентов аппаратной логики, которые можно использовать, включают в себя программируемые пользователем вентильные матрицы (FPGA), специализированные интегральные схемы (ASIC), стандартные части специализированной ИС (ASSP), системы на кристалле (SOC), сложные программируемые логические устройства (CPLD) и т. п.
[91] То, что описано выше, включает в себя примеры одного или нескольких вариантов осуществления. Конечно, невозможно описать каждое мыслимое изменение и переделку вышеприведенных устройств или методологий в целях описания вышеупомянутых аспектов, однако средний специалист в данной области техники может признать, что допустимы многие дополнительные изменения и перестановки различных аспектов. Соответственно, описанные аспекты предназначены для охвата всех таких переделок, изменений и вариаций, которые входят в сущность и объем прилагаемой формулы изобретения. Кроме того, в случае, когда термин "включает в себя" используется либо в описании подробностей, либо в формуле изобретения, такой термин предназначен быть включающим в некотором смысле аналогично термину "содержащий", поскольку "содержащий" интерпретируется, когда применяется в качестве переходного слова в формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНТЕКСТНЫЕ ДЕЙСТВИЯ В ГОЛОСОВОМ ПОЛЬЗОВАТЕЛЬСКОМ ИНТЕРФЕЙСЕ | 2015 |
|
RU2701129C2 |
| ИЗУЧЕНИЕ И ИСПОЛЬЗОВАНИЕ КОНТЕКСТНЫХ ПРАВИЛ ИЗВЛЕЧЕНИЯ КОНТЕНТА ДЛЯ УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ ЗАПРОСОВ | 2015 |
|
RU2701110C2 |
| ПРОСМОТР ИНФОРМАЦИИ СОЦИАЛЬНЫХ СЕТЕЙ | 2010 |
|
RU2571593C2 |
| ВЫБОР ЭЛЕМЕНТОВ ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА ПОСРЕДСТВОМ ПОЗИЦИОННОГО СИГНАЛА | 2014 |
|
RU2676244C2 |
| РЕКОМЕНДАЦИИ ПО КОНТЕНТУ НА ОСНОВАНИИ ПРОСМОТРОВОЙ ИНФОРМАЦИИ | 2009 |
|
RU2541191C2 |
| ОПРЕДЕЛЕНИЕ ПОИСКОВЫХ ЗАПРОСОВ ДЛЯ ПОЛУЧЕНИЯ ИНФОРМАЦИИ В ПРОЦЕССЕ ПОЛЬЗОВАТЕЛЬСКОГО ВОСПРИЯТИЯ СОБЫТИЯ | 2017 |
|
RU2731837C1 |
| Способ и система для предоставления рекомендуемого элемента цифрового контента | 2019 |
|
RU2746872C1 |
| НАЗНАЧЕНИЕ ЯЧЕЕК В СИСТЕМАХ ПРЕДОСТАВЛЕНИЯ ИНФОРМАЦИИ НА ОСНОВЕ ВЫБОРА МЕСТОПОЛОЖЕНИЯ | 2010 |
|
RU2544986C2 |
| ВЗАИМОДЕЙСТВИЕ ЦИФРОВОГО ПЕРСОНАЛЬНОГО ПОМОЩНИКА С ПОДРАЖАНИЯМИ И ПОЛНОФУНКЦИОНАЛЬНЫМИ МУЛЬТИМЕДИА В ОТВЕТАХ | 2015 |
|
RU2682023C1 |
| ОРИЕНТАЦИЯ И ВИЗУАЛИЗАЦИЯ ВИРТУАЛЬНОГО ОБЪЕКТА | 2014 |
|
RU2670784C9 |
Изобретение относится к области вычислительной техники для изменения визуального контента. Технический результат заключается в повышении точности изменения визуального контента. Технический результат достигается за счет того, что: вычислительное устройство поддерживает автоматическое распознавание речи; вычислительное устройство поддерживает контроль зрительного внимания; и инициируют показ нового визуального контента на дисплее в ответ на изменение визуального контента; при этом визуальный контент имеет первый макет, и при этом этап, на котором изменяют визуальный контент для формирования нового визуального контента, содержит этап, на котором преобразуют первый макет во второй макет; и при этом первый макет включает в себя первый элемент и второй элемент с первым расстоянием между ними, и при этом этап, на котором изменяют визуальный контент для формирования нового визуального контента, содержит этап, на котором меняют расстояние между первым элементом и вторым элементом так, что во втором макете второе расстояние отделяет первый элемент от второго элемента. 2 н. и 10 з.п. ф-лы, 9 ил.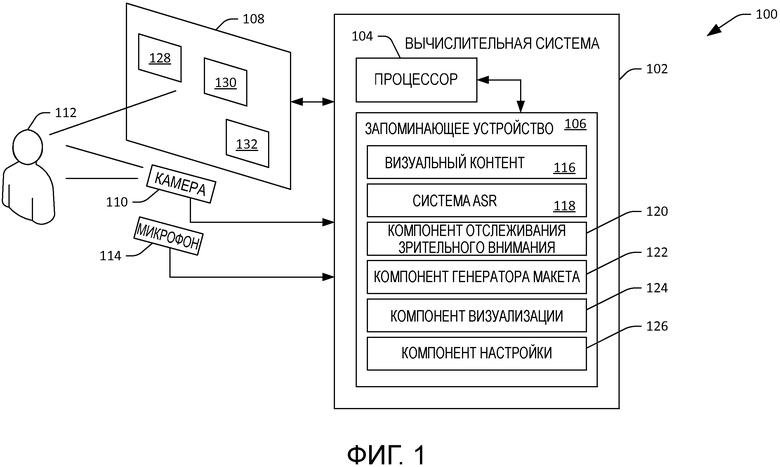
1. Способ изменения визуального контента, исполняемый вычислительным устройством, содержащий этапы, на которых:
принимают визуальный контент для показа на дисплее;
изменяют визуальный контент, перед инициированием показа визуального контента на дисплее, для формирования нового визуального контента на основе того, что:
вычислительное устройство поддерживает автоматическое распознавание речи (ASR); и
вычислительное устройство поддерживает контроль зрительного внимания; и
инициируют показ нового визуального контента на дисплее в ответ на изменение визуального контента;
при этом визуальный контент имеет первый макет, и при этом этап, на котором изменяют визуальный контент для формирования нового визуального контента, содержит этап, на котором преобразуют первый макет во второй макет; и
при этом первый макет включает в себя первый элемент и второй элемент с первым расстоянием между ними, и при этом этап, на котором изменяют визуальный контент для формирования нового визуального контента, содержит этап, на котором меняют расстояние между первым элементом и вторым элементом так, что во втором макете второе расстояние отделяет первый элемент от второго элемента.
2. Способ по п. 1, при этом первый элемент содержит первое слово или последовательность слов, второй элемент содержит второе слово или последовательность слов, при этом способ дополнительно содержит этапы, на которых:
вычисляют значение, указывающее акустическое сходство между первым словом или последовательностью слов и вторым словом или последовательностью слов; и
изменяют визуальный контент для формирования измененного визуального контента на основе значения, указывающего акустическое сходство между первым словом или последовательностью слов и вторым словом или последовательностью слов.
3. Способ по п. 1, дополнительно содержащий этапы, на которых:
принимают изображения, которые включают в себя зрителя дисплея;
идентифицируют наблюдаемый элемент в новом визуальном контенте, показанном на дисплее, на основе изображений; и
настраивают систему ASR на основе идентификации элемента.
4. Способ по п. 1, дополнительно содержащий этапы, на которых:
принимают сигналы, которые включают в себя зрителя дисплея;
оценивают на основе сигналов, что наблюдается элемент в новом визуальном контенте; и
формируют вывод, который указывает, что элемент оценен как наблюдаемый, в ответ на оценивание, что элемент наблюдается.
5. Способ по п. 4, при этом этап, на котором формируют вывод, содержит этап, на котором назначают визуальный индикатор элементу в измененном визуальном контенте.
6. Способ по п. 1, при этом визуальный контент содержит первое заполняемое поле формы и второе заполняемое поле формы, и этап, на котором изменяют визуальный контент для формирования нового визуального контента, содержит этап, на котором переставляют по меньшей мере одно из первого заполняемого поля формы или второго заполняемого поля формы так, что первое заполняемое поле формы располагается дальше от второго заполняемого поля формы.
7. Вычислительная система, поддерживающая автоматическое распознавание речи, содержащая:
процессор; и
запоминающее устройство, которое содержит множество компонентов, которые исполняются процессором, причем множество компонентов содержит:
компонент генератора макета, который принимает визуальный контент, который подлежит показу на дисплее, причем визуальный контент имеет первый макет, компонент генератора макета перед показом визуального контента на дисплее изменяет визуальный контент так, что визуальный контент, когда изменен, имеет второй макет, компонент генератора макета изменяет визуальный контент на основе зрительного внимания, отслеживаемого относительно дисплея, при этом второй макет отличается от первого макета; и
компонент визуализации в связи с компонентом генератора макета, причем компонент визуализации визуализирует визуальный контент со вторым макетом для показа на дисплее;
при этом первый макет включает в себя первый элемент и второй элемент, которые находятся в первых положениях относительно друг друга, и при этом второй макет включает в себя первый элемент и второй элемент во вторых положениях относительно друг друга.
8. Вычислительная система по п. 7, причем множество компонентов дополнительно содержит:
компонент отслеживания взгляда, который принимает изображения от камеры, компонент отслеживания взгляда идентифицирует направление взгляда на основе изображений, компонент отслеживания взгляда оценивает элемент, наблюдаемый на дисплее, на основе направления взгляда, при этом компонент генератора макета инициирует показ на дисплее графических данных, которые указывают, что элемент оценивается как наблюдаемый.
9. Вычислительная система по п. 8, при этом элемент является заполняемым полем формы, а графические данные являются выделением заполняемого поля формы.
10. Вычислительная система по п. 7, при этом множество компонентов дополнительно содержит компонент отслеживания взгляда, который принимает изображения от камеры, компонент отслеживания взгляда идентифицирует направление взгляда на основе изображений, компонент отслеживания взгляда оценивает элемент, наблюдаемый на дисплее, на основе направления взгляда, запоминающее устройство дополнительно содержит систему автоматического распознавания речи (ASR), которая исполняется процессором, система ASR сконфигурирована для приема аудиосигнала и распознавания фрагмента речи в аудиосигнале, система распознавания речи распознает фрагмент речи на основе элемента, оцененного компонентом отслеживания взгляда в качестве наблюдаемого.
11. Вычислительная система по п. 10, причем множество компонентов дополнительно содержит компонент настройки, который настраивает систему ASR на основе элемента, оцененного компонентом отслеживания взгляда в качестве наблюдаемого.
12. Вычислительная система по п. 7, причем визуальный контент включен в веб-страницу, которая подлежит отображению на дисплее.
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОГО ГЕНЕРИРОВАНИЯ СВОДКИ МНОЖЕСТВА ИЗОБРАЖЕНИЙ | 2007 |
|
RU2440606C2 |
| ПОСЛЕДОВАТЕЛЬНЫЙ МУЛЬТИМОДАЛЬНЫЙ ВВОД | 2004 |
|
RU2355044C2 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 6741791 B1, 25.05.2004. | |||

