Область техники, к которой относится изобретение
Предлагаемая технология относится к передающему устройству, способу передачи, приемному устройству и способу приема и, в частности, к передающему устройству, способу передачи, приемному устройству и способу приема, которые могут улучшить доступность для людей с нарушениями зрения.
Уровень техники
В области систем цифрового вещания необходимо обеспечить доступность для людей с нарушениями зрения (например, см. Патентный документ 1).
В частности, в США в 2010 г. был принят «Закон о доступности коммуникаций и видео XXI века» (21st Century Communications and Video Accessibility Act of 2010 (CVAA)) или так называемый «Американский закон о доступности». Федеральная комиссия по связи (Federal Communications Commission (FCC)) на основе этого закона выпустила разнообразные нормативные документы.
Список литературы
Патентный документ
Патентный документ 1: Выложенная заявка на получение патента Японии No. 2009-204711
Раскрытие сущности изобретения
Проблемы, которые должно решать настоящее изобретение
В частности, когда интерфейс пользователя (UI), например, для программной информации представляют людям с нарушениями зрения, текстовую информацию из состава программной информации зачитывают вслух посредством механизма речевого воспроизведения текста (Text То Speech (TTS) engine). Такой подход является типовым способом повышения доступности.
Однако при использовании механизма TTS текстовую информацию совсем не обязательно будет зачитана вслух в соответствии с намерениями производителя этой программной информации. Например, неизвестно, смогут ли люди с нарушениями зрения воспринимать такую информацию, которую воспринимают физически здоровые люди. В свете вышеизложенного, нужна технология, которая позволит надежно произносить вслух слова и тексты так, как этого хотел бы производитель программного обеспечения, чтобы люди с нарушениями зрения могли получать информацию, аналогичную информации, воспринимаемой физически здоровыми людьми.
В свете вышеизложенного, предлагаемая технология позволяет улучшить доступность для людей с нарушениями зрения путем надежного произнесения слов и текстов вслух в соответствии с намерениями производителя программы.
Решение проблем
Передающее устройство согласно первому аспекту предлагаемой технологии содержит: модуль генерирования метаданных для генерирования метаданных, относящихся к произнесению преобразованного в речь текста из состава информации отображения, так что такое произнесение преобразованного в речь текста осуществляется в соответствии с намерениями производителя программного обеспечения; модуль генерирования электронной программной информации, который генерирует электронную программную информацию, содержащую указанные метаданные; и передающий модуль для передачи указанной электронной программы информации приемному устройству, способному представлять информацию отображения на устройство отображения.
Метаданные могут содержать информацию относительно произнесения строки символов, произношение которой не определено однозначно, либо строки символов, произносить которую трудно.
Информация отображения может содержать информацию или иконку контента.
Кроме того, система может содержать модуль получения контента, который получает контент, а передающий модуль может передавать электронную программную информацию вместе с этим контентом с использованием сигнала цифрового вещания.
Указанная электронная программная информация может соответствовать электронной программе передач (Electronic Service Guide (ESG)), определяемой согласно стандарту «Открытый мобильный альянс мобильных вещательных сервисов» (Open Mobile Alliance - Mobile Broadcast Services Enabler Suite (OMA-BCAST)), метаданные могут быть описаны в формате Языка разметки синтеза речи (Speech Synthesis Markup Language (SSML)), а определяемый заранее фрагмент в составе программы ESG может содержать адресную информацию, указывающую адрес, по которому можно получить файл метаданных, описанных в формате языка SSML, или содержание, соответствующее метаданным, описанным в формате языка SSML.
Передающее устройство может представлять собой независимое устройство или может быть выполнено в виде внутреннего блока в составе другого устройства.
Способ передачи согласно первому аспекту предлагаемой технологии соответствует передающему устройству согласно первому аспекту предлагаемой технологии.
В передающем устройстве и при использовании способа передачи согласно первому аспекту предлагаемой технологии генерируют метаданные относительно произнесения преобразованного в речь текста, который считает нужным произнести производитель программ, и генерируют электронную программную информацию, содержащую эти метаданные. Затем сформированную электронную программную информацию передают приемному устройству, способному представлять информацию отображения пользователю.
Приемное устройство согласно второму аспекту предлагаемой технологии содержит: приемный модуль для приема электронной программной информации, указанную электронную программную информацию передает указанное передающее устройство, указанная электронная программная информация содержит метаданные относительно произнесения преобразованного в речь текста из состава информации отображения, произнесение преобразованного в речь текста осуществляется так, как этого хотел бы производитель программы; модуль получения метаданных, который получает метаданные, входящие в состав электронной программной информации; и модуль прочтения вслух преобразованного в речь текста, который зачитывает вслух информацию отображения на основе метаданных.
Метаданные могут содержать информацию относительно произнесения строки символов, произношение которой не определено однозначно, либо строки символов, произносить которую трудно.
Информация отображения может содержать информацию или иконку контента.
Приемный модуль может принимать электронную программную информацию, передаваемую вместе с контентом, в виде сигнала цифрового вещания.
Указанная электронная программная информация может соответствовать программе ESG, определяемой согласно стандарту OMA-BCAST, метаданные могут быть описаны в формате языка SSML, определяемый заранее фрагмент в составе программы ESG может содержать адресную информацию, указывающую адрес, по которому можно получить файл метаданных, описанных в формате языка SSML, или содержание, соответствующее метаданным, описанным в формате языка SSML, а модуль получения метаданных может получать файл метаданных в соответствии с указанной адресной информацией или получать метаданные из этого фрагмента.
Приемное устройство может представлять собой независимое устройство или может быть выполнено в виде внутреннего блока в составе другого устройства.
Способ приема согласно второму аспекту предлагаемой технологии соответствует приемному устройству согласно второму аспекту предлагаемой технологии.
В приемном устройстве и при использовании способа приема согласно второму аспекту предлагаемой технологии принимают электронную программную информацию, содержащую метаданные относительно произнесения преобразованного в речь текста, который считает нужным произнести производитель программ, из состава информации отображения, и переданную от передающего устройства. Затем выделяют метаданные, входящие в состав указанной электронной программной информации, и зачитывают вслух информацию отображения на основе метаданных.
Преимущества настоящего изобретения
Согласно первому аспекту и второму аспекту предлагаемой технологии можно улучшить доступность для людей с нарушениями зрения.
Отметим, что преимущества предлагаемой технологии не обязательно ограничиваются описанными выше эффектами, а могут представлять собой какой-либо из эффектов, рассматриваемых здесь.
Краткое описание чертежей
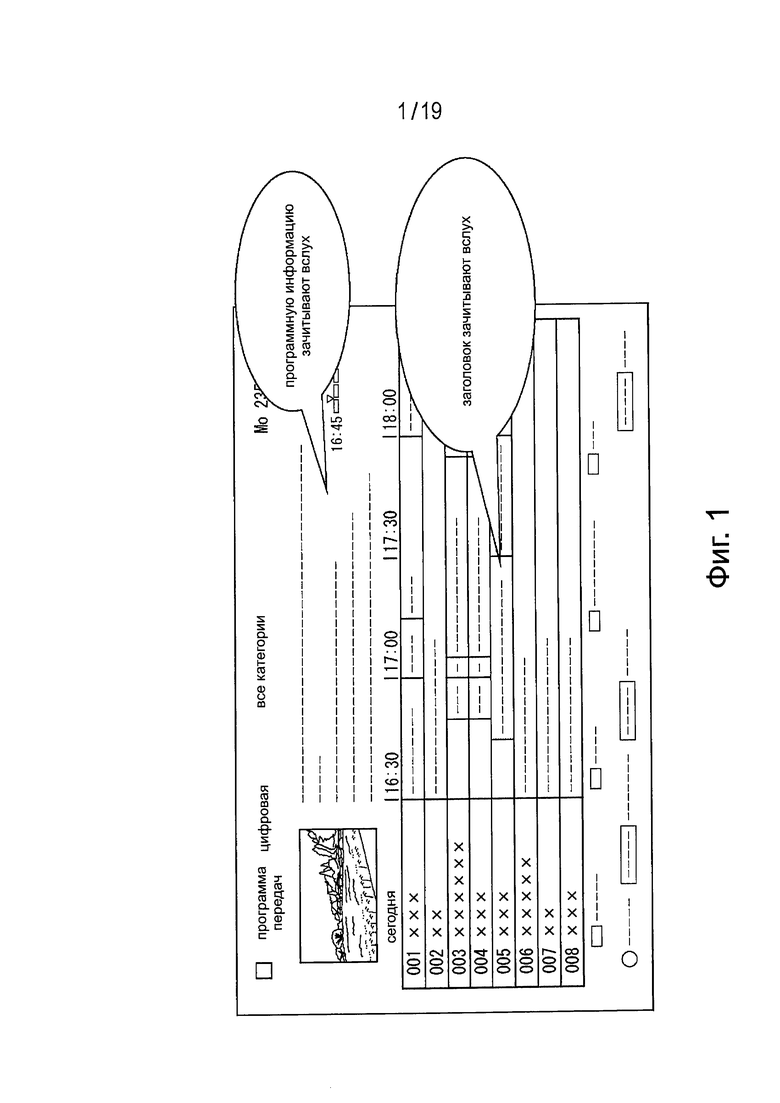
Фиг. 1 представляет диаграмму примера, в котором зачитывают вслух программную информацию и заголовок.
Фиг. 2 представляет диаграмму примера, в котором зачитывают вслух название иконки.
Фиг. 3 представляет пояснительную схему примера, в котором зачитывают вслух текстовую информацию с использованием существующего механизма TTS.
Фиг. 4 представляет пояснительную схему примера, в котором зачитывают вслух текстовую информацию с использованием существующего механизма TTS.
Фиг. 5 представляет пояснительную схему примера, когда зачитывают вслух текстовую информацию с использованием существующего механизма TTS, к которому применяют предлагаемую технологию.
Фиг. 6 представляет пояснительную схему примера, когда зачитывают вслух текстовую информацию с использованием существующего механизма TTS, к которому применяют предлагаемую технологию.
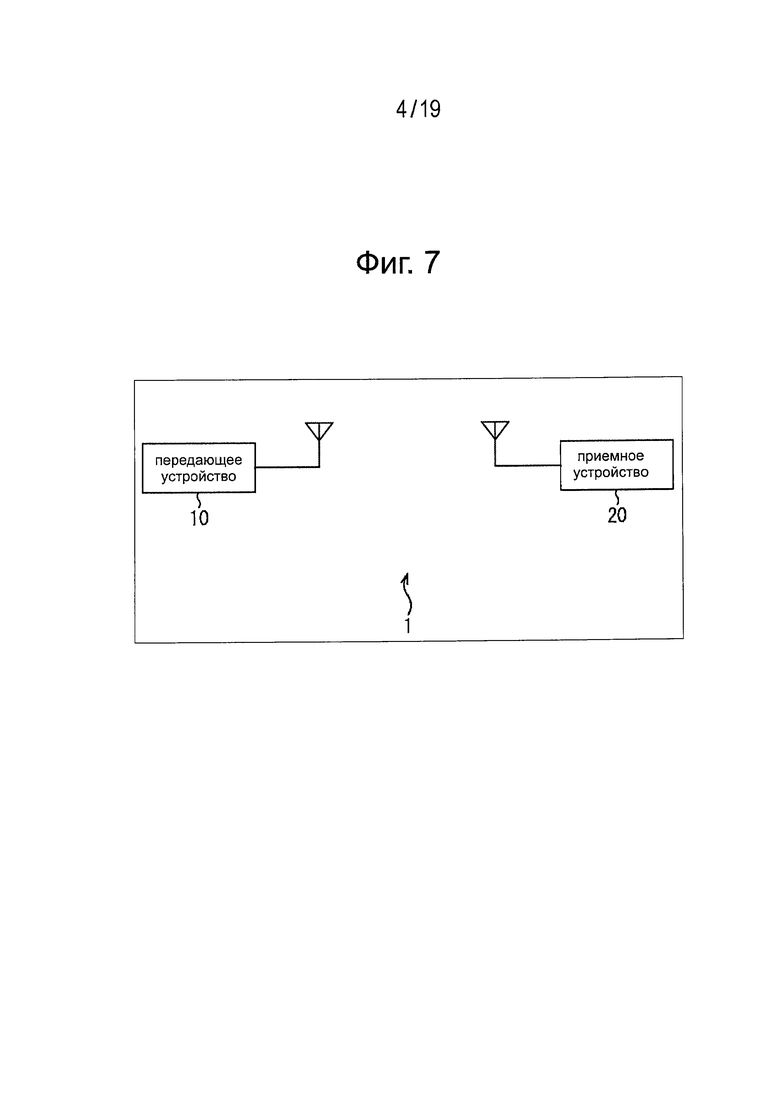
Фиг. 7 представляет схему примера конфигурации системы вещания, к которой применяют предлагаемую технологию.
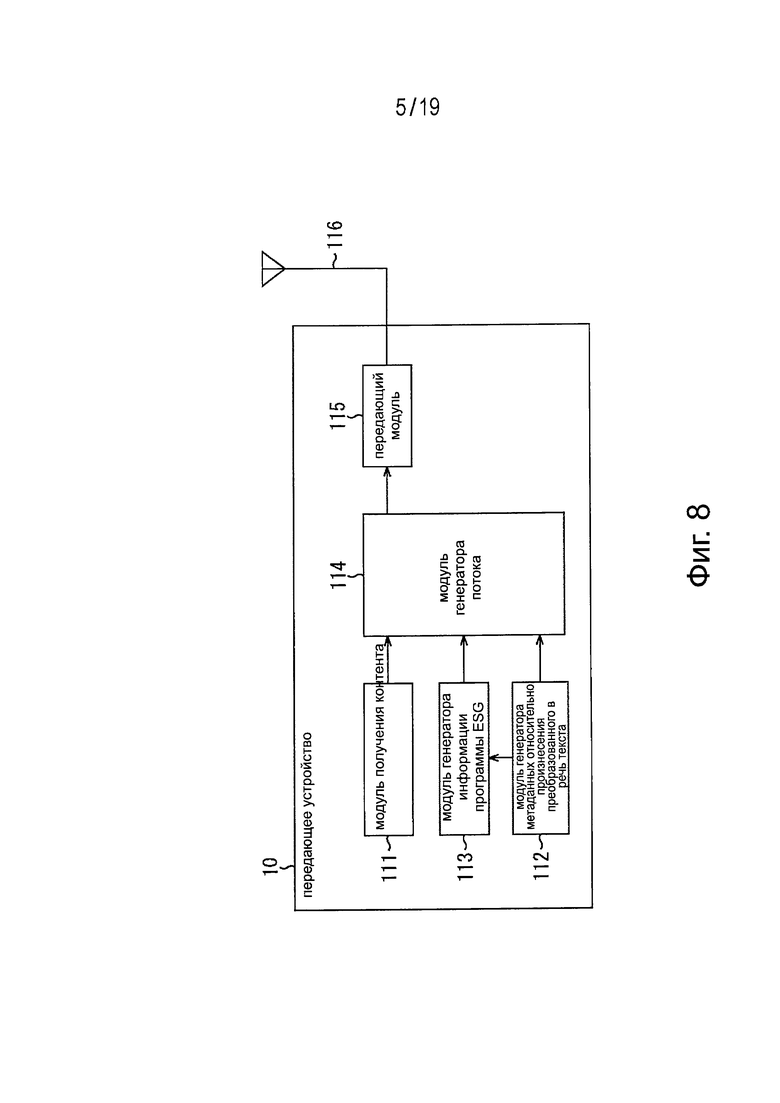
Фиг. 8 представляет схему примера конфигурации передающего устройства, к которому применяют предлагаемую технологию.
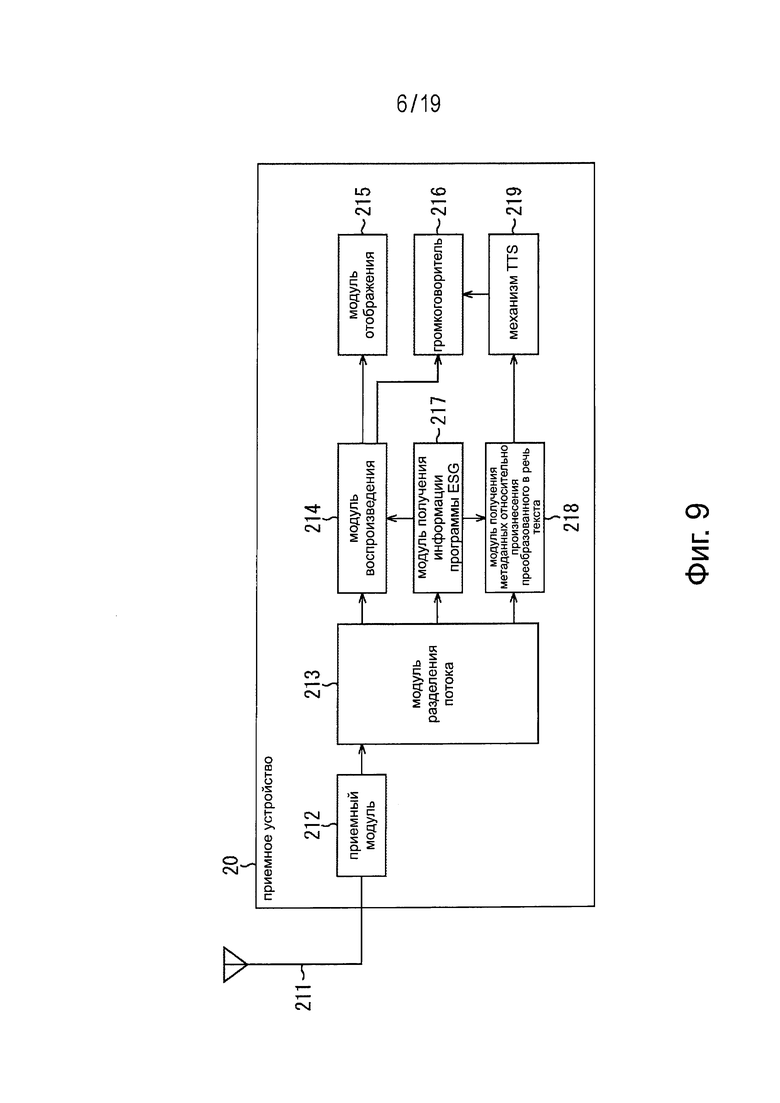
Фиг. 9 представляет схему примера конфигурации приемного устройства, к которому применяют предлагаемую технологию.
Фиг. 10 представляет схему примера конфигурации программы ESG.
Фиг. 11 представляет схему примера конфигурации фрагмента «Сервис» программы ESG.
Фиг. 12 представляет схему примера конфигурации фрагмента «Контент» программы ESG.
Фиг. 13 представляет схему примера конфигурации расширенной программы ESG.
Фиг. 14 представляет схему другого примера конфигурации расширенной программы ESG.
Фиг. 15 представляет подробную схему конфигурации элемента PhoneticInfoURI.
Фиг. 16 представляет подробную схему конфигурации элемента PhoneticInfo.
Фиг. 17 представляет схему примера описания субэлемента в формате языка SSML.
Фиг. 18 представляет схему примера описания фонемного элемента в формате языка SSML.
Фиг. 19 представляет схему примера описания аудио элемента в формате языка SSML.
Фиг. 20 представляет пример логической схемы процесса передачи.
Фиг. 21 представляет пример логической схемы процесса приема.
Фиг. 22 представляет схему примера конфигурации компьютера.
Осуществление изобретения
Варианты предлагаемой технологии будут далее описаны со ссылками на прилагаемые чертежи. Отметим, что эти варианты будут рассмотрены в следующем порядке.
1. Очерк метаданных относительно произнесения преобразованного в речь текста согласно предлагаемой технологии
2. Конфигурация системы
3. Структура метаданных относительно произнесения преобразованного в речь текста с расширением в составе программы ESG
4. Пример описания метаданных относительно произнесения преобразованного в речь текста
5. Логическая схема процесса, выполняемого в каждом устройстве
6. Примеры вариантов
7. Конфигурация компьютера
1. Очерк метаданных относительно произнесения преобразованного в речь текста согласно предлагаемой технологии
Среди совокупности нормативных документов Федеральной комиссии по связи, относящихся к Американскому закону о доступности, стандарты, относящиеся к интерфейсу пользователя, (FCC Report & Order (FCC 13-138) released October 31, 2013. C.F.R. Title 47 §79.107, 108) требуют, чтобы интерфейсы пользователя в приемнике, способном представлять пользователю на дисплее видеопрограммы, таком как телевизор, были доступны для людей с нарушениями зрения.
В частности, когда на дисплее зрителю представлен экран электронной программы передач (Electronic Service Guide (ESG)), а именно, экран программы ESG, как показано на Фиг. 1, например, зачитывают вслух программную информацию и заголовок. Это может предоставить информацию, необходимую, чтобы люди с нарушениями зрения могли выбрать станцию, передающую нужную вещательную программу.
В качестве альтернативы, когда на дисплее представлен экран меню, как показано на Фиг. 2, например, сведения о контенте сервиса, обозначенного каждой иконкой, зачитывают вслух. Это может предоставить сведения о контенте людям с нарушениями зрения.
Как описано выше, информацию относительно интерфейса пользователя, представленного на дисплее, зачитывают вслух. Это позволяет людям с нарушениями зрения получать информацию относительно интерфейса пользователя и осуществлять различные операции с приемником.
При этом, информацию о канале или программную информацию для выбора станции, передающей вещательную программу, сообщают в виде информации программы ESG от передатчика, например, вещательной станции, приемникам. Информация программы ESG содержит главным образом текстовую информацию или данные логотипов. Затем приемник генерирует и представляет на дисплее экран ESG для выбора станции, передающей вещательную программу, на основе информации программы ESG.
Как описано выше, когда на дисплее представлен экран программы ESG, необходимо обеспечить доступность интерфейса пользователя для людей с нарушениями зрения и, например, зачитать вслух название или программную информацию. В таком случае текстовую информацию заголовка или программную информацию зачитывают вслух обычно посредством механизма речевого воспроизведения текста (Text То Speech (TTS) engine). Механизм TTS представляет собой речевой синтезатор (Text То Speech Synthesizer), который может искусственно создавать человеческий голос на основе текстовой информации.
Однако механизм TTS не обязательно зачитывает вслух текстовую информацию так, как это соответствует намерению производителя интерфейса пользователя. Неизвестно, смогут ли люди с нарушениями зрения воспринимать такую информацию, которую воспринимают физически здоровые люди.
В частности, например, когда текстовая информация представляет собой "AAA", как показано на Фиг. 3, текстовая информация может быть произнесена в виде "три А" или "А А А". Произношение здесь не определено однозначно. Таким образом, механизму TTS трудно определить, как именно следует зачитывать эту текстовую информацию вслух. В результате весьма вероятно, что текстовая информация не будет зачитана вслух именно так, как этого хотел бы производитель.
В качестве альтернативы, например, когда текстовая информация имеет вид "Caius College", как показано на Фиг. 4, эта текстовая информация представляет собой имя собственное, которое трудно произнести. Таким образом, для механизма TTS трудно определить, как именно следует произносить эту текстовую информацию при зачитывании ее вслух. В результате весьма вероятно, что текстовая информация не будет зачитана вслух именно так, как этого хотел бы производитель.
Когда произношение текстовой информацию не определено однозначно или когда текстовая информация представляет собой, например, имя собственное, трудное для произнесения, как описано выше, есть вероятность, что эта текстовая информация не будет зачитана вслух именно так, как этого хотел бы производитель. Таким образом, есть необходимость в создании способа, с использованием которого обеспечивается надежное произнесение текстов именно так, как этого хотел бы производитель, а люди с нарушениями зрения смогут получать информацию, аналогичную информации, получаемой физически здоровыми людьми.
В свете вышеизложенного, согласно предлагаемой технологии информацию о произнесении преобразованного в речь текста так, как этого хотел бы производитель, (далее, обозначаемую как «метаданные относительно произнесения преобразованного в речь текста») передают механизму TTS, так что этот механизм TTS сможет произносить слова голосом так, как этого хотел бы производитель, с целью произносить преобразованный в речь текст для зачитывания дисплейной информации, например, интерфейса пользователя, вслух. Отметим, что метаданные относительно произнесения преобразованного в речь текста могут быть включены в состав информации программы ESG.
В частности, как показано на Фиг. 5, например, когда текстовая информация имеет вид "AAA", в качестве метаданных относительно произнесения преобразованного в речь текста механизму TTS передают сигнал «три А» ("triple А"), указывающий, как следует произносить эту текстовую информацию. Это позволяет механизму TTS зачитывать вслух эту текстовую информацию как «три А» на основе указанных метаданных относительно произнесения преобразованного в речь текста.
Другими словами, когда вводят текстовую информацию "AAA", механизм TTS, показанный на Фиг. 3, не определяет, какой именно вариант произношения - «три А» или «А А А» является правильным. С другой стороны, как показано на Фиг. 5, в механизм TTS в качестве метаданных относительно произнесения преобразованного в речь текста вводят «три А», так что механизм TTS может прочитать вслух «три А» в соответствии с метаданными относительно произнесения преобразованного в речь текста. Таким образом, произнесение преобразованного в речь текста осуществляется именно так, как этого хотел бы производитель.
В качестве альтернативы, например, когда текстовая информация имеет вид "Caius College", в качестве метаданных относительно произнесения преобразованного в речь текста механизму TTS, как показано на Фиг. 6, передают информацию о фонемах из состава текстовой информации. Это позволяет механизму TTS зачитать эту текстовую информацию вслух в виде «кейс колледж» ("keys college") на основе указанных метаданных относительно произнесения преобразованного в речь текста.
Другими словами, когда введена текстовая информация "Caius College", механизм TTS, показанный на Фиг. 4, не в состоянии определить, как именно следует произносить эту текстовую информацию, поскольку указанная текстовая информация представляет собой имя собственное, трудное для произнесения. С другой стороны, как показано на Фиг. 6, в механизм TTS в качестве метаданных относительно произнесения преобразованного в речь текста вводят фонемную информацию, так что этот механизм TTS может зачитать рассматриваемую текстовую информацию вслух в виде «кейс колледж» ("keys college") согласно указанным метаданным относительно произнесения преобразованного в речь. Таким образом, произнесение преобразованного в речь текста осуществляется именно так, как этого хотел бы производитель.
Передача метаданных относительно произнесения преобразованного в речь текста механизму TTS, как это описано выше, позволяет уверенно зачитывать вслух текстовую информацию именно так, как этого хотел бы производитель, даже если, например, вид произнесения этой текстовой информации не определен однозначно, либо если эта текстовая информация представляет собой имя собственное, трудное для произнесения. Это позволяет людям с нарушениями зрения получать информацию, аналогичную информации, получаемой физически здоровыми людьми.
2. Конфигурация системы
Пример конфигурации вещательной системы
На Фиг. 7 представлена схема примера конфигурации вещательной системы, к которой применима предлагаемая технология.
Вещательная система 1 предоставляет контент, например, вещательную программу и может сделать дисплейную информацию, например, интерфейса пользователя доступной для людей с нарушениями зрения. Эта вещательная система 1 содержит передающее устройство 10 и приемное устройство 20.
Передающим устройством 10 управляет, например, вещательная станция, предоставляющая сервис цифрового наземного вещания. Это передающее устройство 10 передает контент, например, вещательной программы посредством сигнала цифрового вещания. Более того, передающее устройство 10 генерирует информацию программы ESG, содержащую метаданные относительно произнесения преобразованного в речь текста, встраивает информацию программы ESG в сигнал цифрового вещания и передает этот сигнал цифрового вещания.
Приемное устройство 20 содержит, например, телевизионный приемник или приставку, и такое устройство установлено, например, дома у каждого пользователя. Это приемное устройство 20 принимает сигнал цифрового вещания, передачу которого осуществляет передающее устройство 10, и передает на выход видео и голосовую составляющие контента, например, вещательной программы.
Более того, приемное устройство 20 содержит механизм TTS для зачитывания дисплейной информации, например, интерфейса пользователя, вслух на основе метаданных относительно произнесения преобразованного в речь текста из состава информации в программе ESG, когда дисплейная информация интерфейса пользователя представлена на дисплее.
В этой конфигурации механизм TTS зачитывает вслух информацию отображения, такую как текстовая информация, в соответствии с метаданными относительно произнесения преобразованного в речь текста. Таким образом, дисплейную информацию зачитывают вслух именно так, как этого хотел бы производитель, даже если, например, произношение текстовой информации не определено однозначно или если текстовая информация представляет собой имя собственное, трудное для произнесения.
Отметим, что вещательная система 1, показанная на Фиг. 7, содержит передающее устройство 10. Однако в нескольких вещательных станциях могут быть установлены несколько передающих устройств 10 соответственно. Аналогично, вещательная система 1, показанная на Фиг. 7, содержит приемное устройство 20. Однако в нескольких домах пользователей установлены несколько приемных устройств 20, соответственно.
Пример конфигурации передающее устройство
На Фиг. 8 представлена схема примера конфигурации передающего устройства, показанного на Фиг. 7.
На Фиг. 8 показано, что передающее устройство 10 содержит модуль 111 получения контента, модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста, модуль 113 генератора информации программы ESG, модуль 114 генератора потока и передающий модуль 115.
Модуль 111 получения контента принимает контент, например, вещательной программы и передает этот контент в модуль 114 генератора потока. Более того, модуль 111 получения контента может обрабатывать контенты, например, в процессе кодирования контента или в процессе преобразования формата.
Отметим, что контент, например, получают из запоминающего устройства для записанных контентов в соответствии с моментами времени вещательной передачи контентов по программе или получают из студии или из какого-либо пункта, откуда происходит вещание в прямом эфире.
Модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста генерирует метаданные относительно произнесения преобразованного в речь текста, например, в соответствии с инструкциями от производителя интерфейса пользователя и передает сформированные метаданные относительно произнесения преобразованного в речь текста в модуль 113 генератора информации программы ESG. Отметим, что, например, в качестве таких метаданных относительно произнесения преобразованного в речь текста генерируют информацию, указывающую, как произносить текстовую информацию, когда такое произнесение не определено однозначно, или фонемную информацию, когда текстовая информация представляет собой имя собственное, трудное для произнесения.
В рассматриваемом примере имеются два типа метаданных относительно произнесения преобразованного в речь текста, сохраняемых в составе информации программы ESG. Один тип представляет собой данные, описывающие адресную информацию для получения метаданных относительно произнесения преобразованного в речь текста, а другой тип представляет собой данные, описывающие содержание метаданных относительно произнесения преобразованного в речь текста. Когда метаданные относительно произнесения преобразованного в речь текста описывают адресную информацию, содержание метаданных относительно произнесения преобразованного в речь текста записано в файле, получаемом в соответствии с этой адресной информацией (далее называется «файл метаданных относительно произнесения преобразованного в речь текста»).
Другими словами, когда модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста генерирует такие метаданные относительно произнесения преобразованного в речь текста, содержащие адресную информацию, и передает эти метаданные относительно произнесения преобразованного в речь текста модулю 113 генератора информации программы ESG, этот модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста генерирует файл метаданных относительно произнесения преобразованного в речь текста, который должен быть получен в соответствии с указанной адресной информацией, и передает этот файл метаданных относительно произнесения преобразованного в речь текста в модуль 114 генератора потока. С другой стороны, когда метаданные относительно произнесения преобразованного в речь текста представляют собой содержание метаданных относительно произнесения преобразованного в речь текста, модулю 112 генератора метаданных относительно произнесения преобразованного в речь текста не нужно генерировать файл метаданных относительно произнесения преобразованного в речь текста, так что этот модуль только передает сформированные им метаданные относительно произнесения преобразованного в речь текста в модуль 113 генератора информации программы ESG.
Указанный модуль 113 генератора информации программы ESG генерирует информацию программы ESG в качестве информации о канале для выбора станции, передающей нужный контент, например, вещательную программу. Более того, модуль 113 генератора информации программы ESG сохраняет (помещает) метаданные относительно произнесения преобразованного в речь текста, поступающие от модуля 112 генератора метаданных относительно произнесения преобразованного в речь текста, в составе информации программы ESG. Этот модуль 113 генератора информации программы ESG передает информацию программы ESG, содержащую метаданные относительно произнесения преобразованного в речь текста, в модуль 114 генератора потока.
Этот модуль 114 генератора потока формирует поток данных в соответствии с заданным стандартом на основе данных контента, поступающих от модуля 111 получения контента, и информации программы ESG, поступающей от модуля 113 генератора информации программы ESG, и передает этот сформированный поток в передающий модуль 115.
В качестве альтернативы, когда метаданные относительно произнесения преобразованного в речь текста, встроенные в состав информации программы ESG, поступающей от модуля 113 генератора информации программы ESG, содержат адресную информацию, в модуль 114 генератора потока от модуля 112 генератора метаданных относительно произнесения преобразованного в речь текста передают файл метаданных относительно произнесения преобразованного в речь текста. В этом случае модуль 114 генератора потока формирует поток в соответствии с заданным стандартом на основе данных контента, поступающих от модуля 111 получения контента, указанного файла метаданных относительно произнесения преобразованного в речь текста, поступившего от модуля 112 генератора метаданных относительно произнесения преобразованного в речь текста, и информации программы ESG, поступившей от модуля 113 генератора информации программы ESG.
Передающий модуль 115 обрабатывает поток, поступивший от модуля 114 генератора потока, например, посредством цифровой модуляции, и передает этот поток в виде сигнала цифрового вещания через антенну 116.
Отметим, что все функциональные блоки из состава передающего устройства 10, показанного на Фиг. 8, не обязательно размещены в одном и том же устройстве. По меньшей мере некоторые из этих функциональных блоков могут быть собраны в устройстве, независимом от других функциональных блоков. Например, модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста или модуль 113 генератора информации программы ESG могут быть реализованы в виде функции сервера в сети Интернет. Например, передающее устройство 10 получает и обрабатывает метаданные относительно произнесения преобразованного в речь текста или информацию программы ESG, поступающие от сервера.
Пример конфигурации приемного устройства
На Фиг. 9 представлена схема примера конфигурации приемного устройства, показанного на Фиг. 7.
На Фиг. 9 показано, что приемное устройство 20 содержит приемный модуль 212, модуль 213 разделения потока, модуль 214 воспроизведения, модуль 215 отображения, громкоговоритель 216, модуль 217 получения информации программы ESG, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста и механизм 219 TTS.
Приемный модуль 212 обрабатывает сигнал цифрового вещания, принимаемый антенной 211, например, посредством декодирования и передает поток, получаемый в процессе декодирования, в модуль 213 разделения потока.
Этот модуль 213 разделения потока выделяет данные контента и информацию программы ESG от потока, поступающего от приемного модуля 212, и передает данные контента в модуль 214 воспроизведения, а информацию программы ESG в модуль 217 получения информации программы ESG.
Модуль 214 воспроизведения представляет изображение контента на экране модуля 215 отображения на основе данных контента, поступающих от модуля 213 разделения потока, и воспроизводит голосовую часть контента через громкоговоритель 216. Таким образом, происходит воспроизведение контента, например, вещательной программы.
Модуль 217 получения информации программы ESG получает информацию программы ESG, выделенную модулем 213 разделения потока. Например, когда пользователь дает приемному устройству 20 команду представить на дисплее экран программы ESG, модуль 217 получения информации программы ESG передает информацию программы ESG в модуль 214 воспроизведения. Этот модуль 214 воспроизведения генерирует экран программы ESG на основе информации программы ESG, поступившей от модуля 217 получения информации программы ESG, и представляет экран программы ESG на модуле 215 отображения.
Кроме того, модуль 217 получения информации программы ESG передает метаданные относительно произнесения преобразованного в речь текста, входящие в состав информации программы ESG, в модуль 218 получения метаданных относительно произнесения преобразованного в речь текста. Этот модуль 218 получения метаданных относительно произнесения преобразованного в речь текста получает такие метаданные относительно произнесения преобразованного в речь текста, поступающие от модуля 217 получения информации программы ESG.
В этом примере, как описано выше, имеются два типа метаданных относительно произнесения преобразованного в речь текста, а именно данные, описывающие адресную информацию для получения метаданных относительно произнесения преобразованного в речь текста, и данные, описывающие содержание метаданных относительно произнесения преобразованного в речь текста.
Другими словами, когда метаданные относительно произнесения преобразованного в речь текста содержат адресную информацию, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста получает файл метаданных относительно произнесения преобразованного в речь текста из потока, разделенного посредством модуля 213 разделения потока, на основе входящей в поток адресной информации и передает метаданные относительно произнесения преобразованного в речь текста, представляющие собой содержание, выделенное из полученного файла метаданных относительно произнесения преобразованного в речь текста, механизму 219 TTS. С другой стороны, когда метаданные относительно произнесения преобразованного в речь текста представляют собой содержание, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста передает такие метаданные относительно произнесения преобразованного в речь текста механизму 219 TTS без какой-либо дополнительной обработки.
Механизм 219 TTS зачитывает информацию отображения, например, интерфейса пользователя вслух на основе метаданных относительно произнесения преобразованного в речь текста, поступающих от модуля 218 получения метаданных относительно произнесения преобразованного в речь текста, и воспроизводит голос через громкоговоритель 216.
Например, на модуле 215 отображения представлен экран программы ESG, а заголовок или программную информацию нужно зачитать вслух, чтобы текстовая информация стала доступна для людей с нарушениями зрения. Однако произнесение текстовой информации не определено однозначно. В таком примере, механизм 219 TTS позволяет зачитывать текстовую информацию так, как этого хотел бы производитель, в соответствии с метаданными относительно произнесения преобразованного в речь текста. Это позволяет людям с нарушениями зрения получать информацию, аналогичную информации, получаемой физически здоровыми людьми.
Отметим, что на Фиг. 9 показано, что дисплейный модуль 215 и громкоговоритель 216 находятся в составе приемного устройства 20. Однако дисплейный модуль 215 и громкоговоритель 216 могут быть реализованы в виде другого внешнего устройства.
3. Структура метаданных относительно произнесения преобразованного в речь текста с расширением в составе программы ESG
Далее, информация программы ESG, в которой записаны метаданные относительно произнесения преобразованного в речь текста, будет описана подробно. Отметим, что спецификации электронной программы передач (Electronic Service Guide (ESG)) сформулированы Открытым мобильным альянсом (Open Mobile Alliance (ОМА)), который является организацией для разработки стандартов для мобильных телефонов. Информация программы ESG, в которой записаны метаданные относительно произнесения преобразованного в речь текста, также соответствует требованиям к программе ESG, изложенным в стандарте OMA-Mobile Broadcast Services Enabler Suite (OMA-BCAST).
Конфигурация программы ESG
На Фиг. 10 представлена схема примера конфигурации программы ESG. Отметим, что каждая из линий, соединяющих фрагменты на Фиг. 10, показывает перекрестных связи между соединенными фрагментами.
На Фиг. 10 показано, что программа ESG содержит фрагменты, имеющие различное назначение, и разделена на четыре группы - группу «Административная» (Administrative), группу «Оплата» (Provisioning), группу «Ядро» (Core) и группу «Доступ» (Access), в соответствии с назначением каждого фрагмента.
Группа «Административная» представляет собой группу, содержащую основные сведения, необходимые для приема информации программы ESG. Группа «Административная» содержит дескриптор "ServiceGuideDeliveryDescriptor". Этот дескриптор "ServiceGuideDeliveryDescriptor" предоставляет информацию о канале, по которому могут быть приняты фрагменты программы передач, информацию для планирования и сведения о расписании передач в этом канале и информацию для обновления приемному устройству 20. Это позволяет приемному устройству 20 принимать только необходимую информацию программы ESG в правильное время.
Группа «Оплата» представляет собой группу, предоставляющую информацию об оплате приема сервиса. Группа «Оплата» содержит фрагменты «Предмет покупки» (Purchase Item), «Данные о покупке» (Purchase Data) и «Канал покупки» (Purchase Channel). Фрагмент «Предмет покупки» содержит информацию об оплате относительно одного сервиса или группы сервисов. Фрагмент «Данные о покупке» содержит информацию, указывающую способ, каким пользователь может оплатить приобретаемые им сервисы. Фрагмент «Канал покупки» содержит информацию о системе, в которой пользователь может реально приобрести сервис.
Отметим, что метаданные относительно произнесения преобразованного в речь текста или адресную информацию, указывающую адрес, по которому можно получить метаданные относительно произнесения преобразованного в речь текста, можно записать в каждом из фрагментов - «Предмет покупки», «Данные о покупке» и «Канал покупки». Способ записи метаданных относительно произнесения преобразованного в речь текста в каждом из фрагментов - «Предмет покупки», «Данные о покупке» и «Канал покупки», будет описан ниже со ссылками на Фиг. 13.
Группа «Ядро» представляет собой группу, передающую информацию о сервисе. Группа «Ядро» содержит фрагменты «Сервис» (Service), «Расписание» (Schedule), и «Контент» (Content). Фрагмент «Сервис» передает метаданные, содержащие контент канального сервиса и управляющую информацию, относящуюся к контенту этого канального сервиса. Фрагмент «Расписание» передает метаданные, содержащие расписание доставки контента и управляющую информацию, относящуюся к расписанию доставки контента. Фрагмент «Контент» передает метаданные, содержащие контент сервиса и управляющую информацию, относящуюся к контенту сервиса.
Отметим, что метаданные относительно произнесения преобразованного в речь текста или адресная информация, указывающая адрес, по которому можно получить метаданные относительно произнесения преобразованного в речь текста, могут быть записаны в каждом из фрагментов «Сервис» и «Контент». На Фиг. 11 показан пример конфигурации фрагмента «Сервис». На Фиг. 12 показан пример конфигурации фрагмента «Контент». Способ записи метаданных относительно произнесения преобразованного в речь текста в каждом из фрагментов «Сервис» и «Контент» будет описан ниже со ссылками на Фиг. 13.
Группа «Доступ» представляет собой группу, передающую информацию о доступе к сервису, указывающую способ приема сервиса из группы «Ядро» и конкретную информацию о сеансе, в котором передают контент сервиса. Группа «Доступ» позволяет приемному устройству 20 получить доступ к сервису. Эта группа «Доступ» содержит фрагменты «Доступ» (Access) и «Описание сеанса» (Session Description).
Фрагмент «Доступ» из группы «Доступ» предлагает способ, позволяющий приемному устройству 20 осуществить доступ к некоторым дополнительным сервисам на основе некоего сервиса путем предложения нескольких способов доступа к сервису. Фрагмент «Описание сеанса» содержит информацию о сеансе, относящуюся к сервису, передаваемому в процессе доступа, определяемом согласно фрагменту «Доступ».
В дополнение к этим четырем группам программа ESG содержит фрагмент «Данные для предварительного просмотра» (Preview Data) и фрагмент «Данные интерактивности» (Interactivity Data). Фрагмент «Данные для предварительного просмотра» предлагает предварительный вид или иконку для сервиса и контента. Фрагмент «Данные интерактивности» предлагает метаданные относительно приложения, работающего с этим сервисом и контентом.
Отметим, что метаданные относительно произнесения преобразованного в речь текста или адресная информация, указывающая адрес, по которому можно получить метаданные относительно произнесения преобразованного в речь текста, может быть записана во фрагменте «Данные для предварительного просмотра». Способ записи метаданных относительно произнесения преобразованного в речь текста во фрагменте «Данные для предварительного просмотра» будет описан ниже со ссылками на Фиг. 14.
Пример конфигурации расширенной программы ESG
На Фиг. 13 представлена схема примера конфигурации программы ESG, расширенной для записи метаданных относительно произнесения преобразованного в речь текста или адресной информации, указывающей адрес, по которому можно получить метаданные относительно произнесения преобразованного в речь текста. Отметим, что на Фиг. 13 показано, что из всей совокупности фрагментов, входящих в состав программы ESG, расширены фрагмент «Сервис», фрагмент «Контент», фрагмент «Предмет покупки», фрагмент «Данные о покупке» и фрагмент «Канал покупки».
Другими словами, расширенные фрагменты содержат элемент «Название» (Name) и элемент «Описание» (Description). Таким образом, каждый фрагмент расширен путем добавления элемента PhoneticInfoURI или элемента PhoneticInfo к элементу «Название» и элементу «Описание». Отметим, что элемент PhoneticInfoURI или элемент PhoneticInfo может быть добавлен к элементу PrivateExt расширенного фрагмента.
На Фиг. 13 показано, что наименование фрагмента контента указано в элементе «Название». Элемент «Название» содержит элемент PhoneticInfoURI, элемент PhoneticInfo и атрибут «Тип» (Type) в качестве «дочерних» элементов.
Адресная информация для получения метаданных относительно произнесения преобразованного в речь текста указана в элементе PhoneticInfoURI. Атрибут «Тип» используется совместно с элементом PhoneticInfoURI в качестве пары. Информация о типе, указывающая тип метаданных относительно произнесения преобразованного в речь текста, указана в атрибуте «Тип».
Например, в качестве адресной информации назначен «Унифицированный идентификатор ресурса» (Uniform Resource Identifier (URI)). В качестве альтернативы, например, когда файл метаданных относительно произнесения преобразованного в речь текста передают в сеансе протокола доставки файлов однонаправленным транспортом (File Delivery over Unidirectional Transport (FLUTE)), назначают адресную информацию для получения файла метаданных относительно произнесения преобразованного в речь текста, передаваемого в ходе сеанса по протоколу FLUTE. Отметим, что метаданные относительно произнесения преобразованного в речь текста могут быть описаны на Языке разметки синтеза речи (Speech Synthesis Markup Language (SSML)), представляющем собой язык разметки синтеза голоса.
Содержание метаданных относительно произнесения преобразованного в речь текста описано в элементе PhoneticInfo. Например, содержание метаданных относительно произнесения преобразованного в речь текста описано на языке SSML. Атрибут «Тип» используется совместно с элементом PhoneticInfo в качестве пары. Информация о типе, указывающая тип метаданных относительно произнесения преобразованного в речь текста, назначена в атрибуте «Тип».
Отметим, что когда "1…N" обозначено в качестве числа появлений (Кардинальности) на Фиг. 13, рассматриваемый элемент или атрибут назначают один раз или более. Когда "0…N" обозначено в качестве числа появлений (Кардинальности), произвольно определяют, назначить ли рассматриваемый элемент или атрибут один раз или более. В качестве альтернативы, когда "0…1" обозначено в качестве числа появлений (Кардинальности), произвольно определяют, назначен ли рассматриваемый элемент или атрибут.
Соответственно, элемент PhoneticInfoURI, элемент PhoneticInfo и атрибут «Тип», которые представляют собой дочерние элементы относительно элемента «Название», являются элементами или атрибутом, служащими в качестве опций. Таким образом, в программу могут быть введены не только какой-либо один из элементов - элемент PhoneticInfoURI или элемент PhoneticInfo, но также возможен вариант, когда введены оба элемента - элемент PhoneticInfoURI и элемент PhoneticInfo.
Более того, элемент «Описание» (Description), показанный на Фиг. 13, содержит элемент PhoneticInfoURI, элемент PhoneticInfo и атрибут «Тип» в качестве дочерних элементов. Другими словами, дочерние элементы для элемента «Описание» аналогичны дочерним элементам для элемента «Название».
В частности, адресную информацию для получения метаданных относительно произнесения преобразованного в речь текста назначают в элементе PhoneticInfoURI. Атрибут «Тип» используют вместе с элементом PhoneticInfoURI в виде пары. Информацию о типе, указывающую тип метаданных относительно произнесения преобразованного в речь текста назначают в атрибуте «Тип». Далее, содержание метаданных относительно произнесения преобразованного в речь текста описывают в элементе PhoneticInfo. Атрибут «Тип» используют совместно с элементом PhoneticInfo в качестве пары. Информация о типе, указывающая тип метаданных относительно произнесения преобразованного в речь текста, назначена в атрибуте «Тип».
Отметим, что, как и для элемента PhoneticInfoURI и элемента PhoneticInfo, являющихся дочерними элементами для элемента «Описание», здесь могут быть введены не только какой-либо один из элементов - элемент PhoneticInfoURI или элемент PhoneticInfo, но также возможен вариант, когда введены оба элемента - элемент PhoneticInfoURI и элемент PhoneticInfo.
На Фиг. 14 представлена схема другой конфигурации программы ESG, расширенной для записи метаданных относительно произнесения преобразованного в речь текста или адресной информации, указывающей адрес, по которому можно получить метаданные относительно произнесения преобразованного в речь текста. Отметим, что на Фиг. 14 представлен расширенный фрагмент «Данные для предварительного просмотра» из совокупности фрагментов, входящих в состав программы ESG.
Другими словами, этот фрагмент «Данные для предварительного просмотра» содержит элемент «Изображение» (Picture), так что фрагмент «Данные для предварительного просмотра» расширен таким образом, что к атрибуту relativePreference (относительное предпочтение) из состава элемента «Изображение» добавлен элемент PhoneticInfoURI или элемент PhoneticInfo. Отметим, что элемент PhoneticInfoURI или элемент PhoneticInfo могут быть добавлены к элементу PrivateExt в составе фрагмента «Данные для предварительного просмотра».
На Фиг. 14 показано, что вид предварительного просмотра и иконка для сервиса и контента определены в элементе «Изображение». Элемент «Изображение» содержит элемент PhoneticInfoURI, элемент PhoneticInfo и атрибут «Тип» в качестве дочерних элементов. Другими словами, дочерние элементы для элемента «Изображение» аналогичны дочерним элементам для элемента «Название» и дочерним элементам для элемента «Описание», которые рассмотрены выше.
В частности, адресная информация для получения метаданных относительно произнесения преобразованного в речь текста указана в элементе PhoneticInfoURI. Атрибут «Тип» используется совместно с элементом PhoneticInfoURI в качестве пары. В атрибуте «Тип» приведена информация о типе, обозначающая тип метаданных относительно произнесения преобразованного в речь текста. Кроме того, содержание метаданных относительно произнесения преобразованного в речь текста описано в элементе PhoneticInfo. Атрибут «Тип» используется совместно с элементом PhoneticInfo в качестве пары. В атрибуте «Тип» приведена информация о типе, обозначающая тип метаданных относительно произнесения преобразованного в речь текста.
Отметим, что, как и для элемента PhoneticInfoURI и элемента PhoneticInfo, являющихся дочерними элементами для элемента «Изображение», здесь могут быть введены не только какой-либо один из элементов - элемент PhoneticInfoURI или элемент PhoneticInfo, но также возможен вариант, когда введены оба элемента - элемент PhoneticInfoURI и элемент PhoneticInfo.
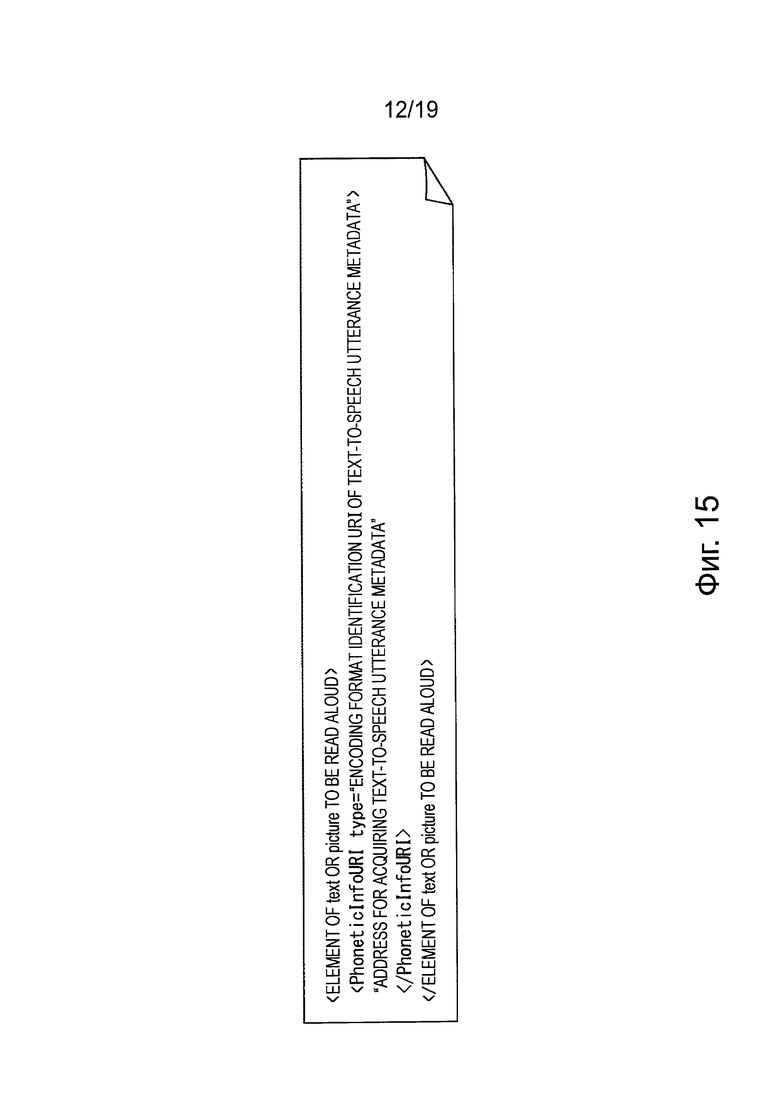
Пример конфигурации элемента PhoneticInfoURI
На Фиг. 15 представлена подробная схема конфигурации элемента PhoneticInfoURI в составе расширенной программы ESG.
Элемент PhoneticInfoURI, показанный на Фиг. 15 описан в качестве дочернего элемента в составе элемента «Название» или элемента «Описание», например, для фрагмента «Сервис» или в качестве дочерних элементов относительно элемента «Изображение» в составе фрагмента «Данные для предварительного просмотра». Адресная информация для получения метаданных относительно произнесения преобразованного в речь текста указана в элементе PhoneticInfoURI.
Кроме того, идентификатор URI для формата кодирования метаданных относительно произнесения преобразованного в речь текста указан в качестве атрибута типа для элемента PhoneticInfoURI.
Например, файл метаданных относительно произнесения преобразованного в речь текста передают в сеансе FLUTE, и таким образом, адресная информация для получения файла метаданных относительно произнесения преобразованного в речь текста, передаваемого в сеансе FLUTE, указана в элементе PhoneticInfoURI.
Пример конфигурации элемента PhoneticInfo
На Фиг. 16 представлена схема подробной конфигурации элемента PhoneticInfo в расширенной программе ESG.
На Фиг. 16 показано, что элемент PhoneticInfo описан в качестве дочернего элемента для элемента «Название» или элемента «Описание», например, в составе фрагмента «Сервис» или в качестве дочернего элемента для элемента «Изображение» в составе фрагмента «Данные для предварительного просмотра». В элементе PhoneticInfo описано содержание метаданных относительно произнесения преобразованного в речь текста.
Кроме того, идентификатор URI для формата кодирования метаданных относительно произнесения преобразованного в речь текста указан в качестве атрибута типа для элемента PhoneticInfo.
Например, содержание метаданных относительно произнесения преобразованного в речь текста описано на языке SSML, иными словами, на языке разметки синтеза речи, и сохранено в качестве текстовой информации между маркером (тегом) старта и маркером окончания в составе элемента PhoneticInfo.
Отметим, что по меньшей мере один из элементов - элемент PhoneticInfoURI и/или элемент PhoneticInfo, описаны в составе расширенного фрагмента в программе ESG. Кроме того, метаданные относительно произнесения преобразованного в речь текста описаны посредством элемента PhoneticInfoURI или элемента PhoneticInfo, и потому иногда называются «объект PhoneticInfo».
4. Пример описания метаданных относительно произнесения преобразованного в речь текста
Как описано выше, метаданные относительно произнесения преобразованного в речь текста смогут быть описаны, например, на языке SSML, иными словами, на языке разметки синтеза речи. Язык SSML рекомендован Консорциумом всемирной паутины (World Wide Web Consortium (W3C)) с целью позволить использовать функцию синтеза речи более высокого качества. Использование языка SSML позволяет строго и подходящим образом управлять элементами, необходимыми для синтеза речи, такими как произношение, громкость и ритм. Далее пример описания документа в формате языка SSML будет рассмотрен со ссылками на Фиг. 17-19.
Субэлемент
На Фиг. 17 представлена схема примера описания субэлемента в формате языка SSML.
Рассматриваемый субэлемент используется для замены одной текстовой информации на другую текстовую информацию. Текстовая информация для произнесения преобразованного в речь текста указана в атрибуте «Псевдоним». Например, как показано на Фиг. 17, текстовую информацию "W3C" заменяют на текстовую информацию "World Wide Web Consortium" для произнесения преобразованного в речь текста и зачитывания его вслух.
Использование этого субэлемента позволяет обозначить информацию, указывающую произношение текстовой информации, например, когда произношение этой текстовой информации не определено однозначно.
Фонемный элемент
На Фиг. 18 представлена схема примера описания фонемного элемента в формате языка SSML.
Фонемный элемент используется для того, чтобы дать вариант произношения, транскрибированный посредством фонемного/фонетического алфавита, для описываемой текстовой информации. В фонемном элементе могут быть указаны атрибут «Алфавит» и атрибут «Фонетика» (ph). Фонетические символы фонемного/фонетического алфавита указаны в атрибуте «Алфавит». Строка символов фонем/фонемного/фонетического алфавита указана в атрибуте «Фонетика». Например, на Фиг. 18, произношение текстовой информации "La vita е bella" указано в атрибуте «Фонетика». Отметим, что маркер "ipa", вписанный в атрибут «Алфавит», указывает, что фонетические символы соответствуют символам чтения международного фонетического алфавита (International Phonetic Alphabet (IPA)).
Использование фонемного элемента позволяет назначить, например, фонемную информацию для текстовой информации, например, когда текстовая информация представляет собой имя собственное, трудное для произношения.
Аудио элемент
На Фиг. 19 представлена схема примера описания аудио элемента в формате языка SSML.
Аудио элемент используется для передачи на выход (воспроизведения) встроенной речи или синтезированной речи из состава аудио файла. В аудио элементе может быть указан атрибут «src». В этом атрибуте «src» указан Унифицированный идентификатор ресурса (Uniform Resource Identifier (URI)) для рассматриваемого аудио файла. Например, как показано на Фиг. 19, текстовую информацию "What city do you want to fly from?" зачитывают вслух путем воспроизведения аудио файла "prompt.au", указанного в атрибуте «src».
Использование аудио элемента позволяет воспроизводить, например, записанный аудио файл и тем самым позволяет предоставлять речевую информацию людям с нарушениями зрения в таком виде, как этого хотел бы производитель интерфейса пользователя.
Отметим, что эти субэлемент, фонемный элемент и аудио элемент, рассмотренные выше, являются примерами описания метаданных относительно произнесения преобразованного в речь текста в формате SSML. Для описания может быть также использован какой-либо другой элемент или атрибут в формате SSML. В качестве альтернативы, метаданные относительно произнесения преобразованного в речь текста могут быть описаны, например, на каком-либо другом языке разметки, отличном от формата SSML.
5. Логическая схема процесса, выполняемого в каждом устройстве
Далее будут описаны процессы, происходящие в передающем устройстве 10 и приемном устройстве 20, входящих в состав вещательной системе 1, показанной на Фиг. 7.
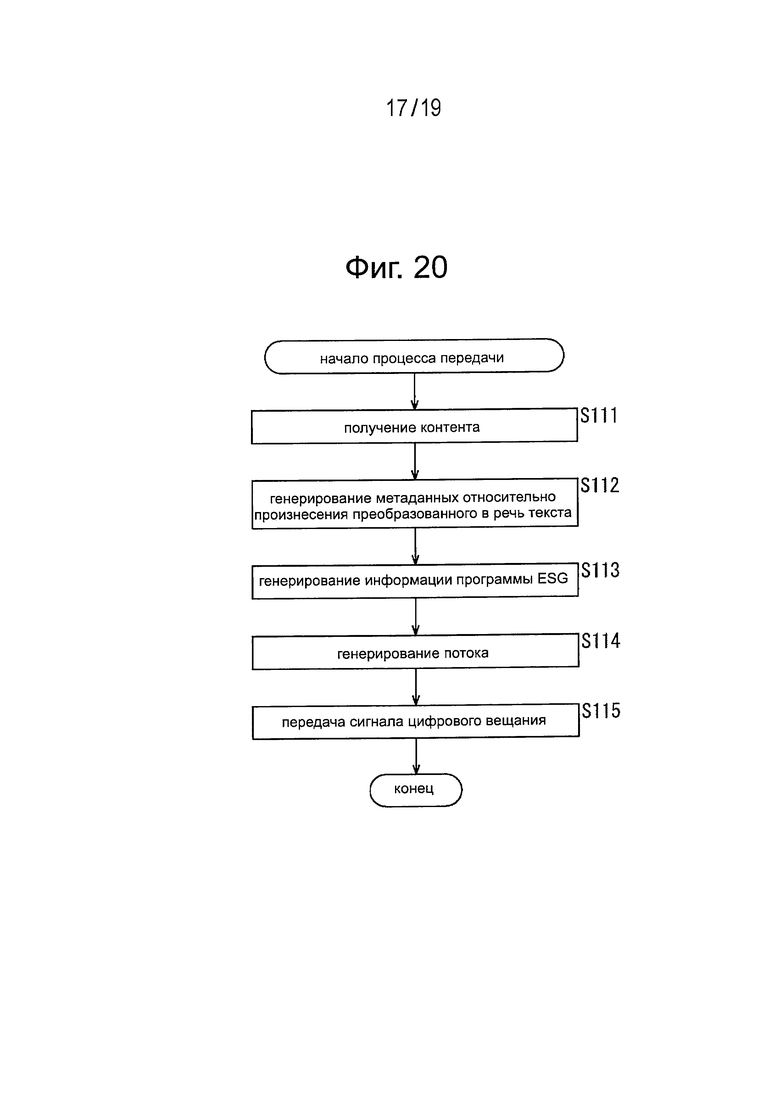
Процесс передачи
Сначала последовательность операций процесса передачи, происходящего в передающем устройстве 10, показанном на Фиг. 7, будет описана со ссылками на логическую схему, представленную на Фиг. 20.
На этапе S111, модуль 111 получения контента принимает контент, например, вещательной программы и передает этот контент в модуль 114 генератора потока.
На этапе S112, модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста генерирует метаданные относительно произнесения преобразованного в речь текста, например, в соответствии с инструкциями от производителя интерфейса пользователя и передает метаданные относительно произнесения преобразованного в речь текста в модуль 113 генератора информации программы ESG.
Отметим, что когда модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста формирует метаданные относительно произнесения преобразованного в речь текста, содержащие адресную информацию, и передает эти сформированные метаданные относительно произнесения преобразованного в речь текста в модуль 113 генератора информации программы ESG, этот модуль 112 генератора метаданных относительно произнесения преобразованного в речь текста генерирует файл метаданных относительно произнесения преобразованного в речь текста, который должен быть получен в соответствии с адресной информацией, и передает этот файл метаданных относительно произнесения преобразованного в речь текста в модуль 114 генератора потока.
На этапе S113 модуль 113 генератора информации программы ESG формирует информацию Программы ESG на основе метаданных относительно произнесения преобразованного в речь текста, поступающих от модуля 112 генератора метаданных относительно произнесения преобразованного в речь текста, и передает информацию программы ESG в модуль 114 генератора потока.
На этапе S114, модуль 114 генератора потока формирует поток в соответствии с заданным стандартом на основе данных контента, поступающих от модуля 111 получения контента, и информации программы ESG, поступающей от модуля 113 генератора информации программы ESG, и передает этот сформированный им поток в передающий модуль 115.
Отметим, что когда метаданные относительно произнесения преобразованного в речь текста, входящие в состав информации программы ESG, поступающей от модуля 113 генератора информации программы ESG, содержат адресную информацию, модуль 114 генератора потока формирует поток в соответствии с заданным стандартом на основе файла метаданных относительно произнесения преобразованного в речь текста, поступающего от модуля 112 генератора метаданных относительно произнесения преобразованного в речь текста, в дополнение к данным контента и информации программы ESG и направляет этот сформированный поток передающему модулю 115.
На этапе S115, передающий модуль 115 обрабатывает поток, поступающий от модуля 114 генератора потока, например, посредством цифровой модуляции и передает этот поток в виде сигнала цифрового вещания через антенну 116.
Выше был описан процесс передачи. В ходе этого процесса передачи генерируют метаданные относительно произнесения преобразованного в речь текста применительно к произнесению преобразованного в речь текста из состава дисплейной информации, например, интерфейса пользователя таким образом, как этого хотел бы производитель интерфейса, и генерируют информацию программы ESG, содержащую эти метаданные относительно произнесения преобразованного в речь текста. Затем эту информацию программы ESG, содержащую метаданные относительно произнесения преобразованного в речь текста, передают вместе с контентом.
Этот процесс позволяет механизму 219 TTS в составе приемного устройства 20 зачитывать вслух дисплейную информацию на основе метаданных относительно произнесения преобразованного в речь текста. Таким образом, например, даже если произношение текстовой информации не определено однозначно или если эта текстовая информация представляет собой имя собственное, трудное для произнесения, рассматриваемую текстовую информацию можно уверенно зачитать вслух так, как этого хотел бы производитель. В результате, люди с нарушениями зрения смогут получать информацию, аналогичную информации, воспринимаемой физически здоровыми людьми.
Процесс приема
Далее последовательность операций процесса приема, происходящего в приемном устройстве 20, показанном на Фиг. 7, будет описана со ссылками на логическую схему, представленную на Фиг. 21.
На этапе S211, приемный модуль 212 осуществляет прием сигнала цифрового вещания, передаваемого через антенну 211 от передающего устройства 10. Кроме того, приемный модуль 212 обрабатывает сигнал цифрового вещания, например, посредством демодуляции и передает поток, генерируемый в результате такой обработки, в модуль 213 разделения потока.
На этапе S212, модуль 213 разделения потока выделяет данные контента и информацию программы ESG из потока, поступающего от приемного модуля 212, и передает данные контента в модуль 214 воспроизведения, а информацию программы ESG в модуль 217 получения информации программы ESG.
На этапе S213, модуль 217 получения информации программы ESG принимает информацию программы ESG, поступающую от модуля 213 разделения потока. Например, когда пользователь дает приемному устройству 20 команду представить на дисплее экран программы ESG, модуль 217 получения информации программы ESG передает полученную им информацию программы ESG в модуль 214 воспроизведения. Кроме того, модуль 217 получения информации программы ESG передает метаданные относительно произнесения преобразованного в речь текста, входящего в состав информации программы ESG, в модуль 218 получения метаданных относительно произнесения преобразованного в речь текста.
На этапе S214, модуль 214 воспроизведения генерирует экран программы ESG на основе информации программы ESG, поступающей от модуля 217 получения информации программы ESG, и представляет этот экран программы ESG посредством своего дисплейного модуля 215.
На этапе S215, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста получает метаданные относительно произнесения преобразованного в речь текста, поступающие от модуля 217 получения информации программы ESG.
Когда метаданные относительно произнесения преобразованного в речь текста содержат адресную информацию на этом этапе, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста получает файл метаданных относительно произнесения преобразованного в речь текста из потока, разделенного посредством модуля 213 разделения потока, на основе адресной информации и передает метаданные относительно произнесения преобразованного в речь текста, в состав которых входит содержание, полученное из принятого файла метаданных относительно произнесения преобразованного в речь текста, механизму 219 TTS. С другой стороны, когда в состав метаданных относительно произнесения преобразованного в речь текста входит содержание, модуль 218 получения метаданных относительно произнесения преобразованного в речь текста передает метаданные относительно произнесения преобразованного в речь текста без какой-либо обработки механизму 219 TTS.
На этапе S216, механизм 219 TTS зачитывает дисплейную информацию, например, интерфейса пользователя, вслух на основе метаданных относительно произнесения преобразованного в речь текста, поступающих от модуля 218 получения метаданных относительно произнесения преобразованного в речь текста, и воспроизводит звук, соответствующий дисплейной информации, через громкоговоритель 216.
В этом примере, когда экран программы ESG представлен на дисплейном модуле 215 и нужно зачитать вслух название или программную информацию, чтобы сделать экран программы ESG доступным для людей с нарушениями зрения, однако, например, произношение текстовой информации не определено однозначно в процессе на этапе S214, механизм 219 TTS следует метаданным относительно произнесения преобразованного в речь текста для зачитывания вслух текстовой информации таким образом, как этого хотел бы производитель.
Выше был описан процесс приема. В ходе этого процесса приема получают информацию программы ESG, которая содержит метаданные относительно произнесения преобразованного в речь текста применительно к произнесению преобразованного в речь текста из состава дисплейной информации таким образом, как этого хотел бы производитель интерфейса, и передачу которой осуществляет передающее устройство 10. После этого, получают метаданные относительно произнесения преобразованного в речь текста, входящего в состав информации программы ESG. Затем зачитывают дисплейную информацию, например, интерфейса пользователя, вслух на основе метаданных относительно произнесения преобразованного в речь текста.
Этот процесс позволяет механизму 219 TTS зачитывать дисплейную информацию вслух на основе метаданных относительно произнесения преобразованного в речь текста. Таким образом, например, когда произношение текстовой информации не определено однозначно или когда текстовая информация представляет собой имя собственное, трудное для произнесения, эту информацию можно зачитать вслух именно так, как этого хотел бы производитель. В результате, людей с нарушениями зрения смогут получать информацию, аналогичную информации, воспринимаемой физически здоровыми людьми.
6. Примеры вариантов
Когда метаданные относительно произнесения преобразованного в речь текста содержат адресную информацию, файл метаданных относительно произнесения преобразованного в речь текста, переданный в сеансе FLUTE, в вариантах, описанных выше, получают в соответствии с адресной информацией. Однако файл метаданных относительно произнесения преобразованного в речь текста может быть доставлен от сервера через Интернет. В таком случае, например, в качестве адресной информации указывают универсальный указатель ресурса (Uniform Resource Locator (URL)) этого сервера.
В описанном выше варианте в качестве электронной программной информации была рассмотрена программа ESG согласно стандарту OMA-BCAST. Предлагаемая технология может быть применена, например, к электронной программе передач (Electronic Program Guide (EPG)) или к другой электронной программной информации. Кроме того, электронная программная информация, такая как информация программы ESG, может быть доставлена от сервера через Интернет и принята посредством приемного устройства 20.
7. Конфигурация компьютера
Последовательность процессов, описанных выше, может быть осуществлена либо аппаратно, либо программно. При выполнении этих процессов посредством программного обеспечения соответствующие программы инсталлируют на компьютере. На Фиг. 22 представлена схема примера конфигурации аппаратуры компьютера, выполняющего указанную последовательность процессов в соответствии с программой.
В компьютере 900 центральный процессор (Central Processing Unit (CPU)) 901, постоянное запоминающее устройство (ПЗУ (Read Only Memory (ROM))) 902 и запоминающее устройство с произвольной выборкой (ЗУПВ (Random Access Memory (RAM))) 903 соединены одно с другим посредством шины 904. С этой шиной 904 соединен также интерфейс 905 ввода/вывода. С этим интерфейсом ввода/вывода соединены устройство 906 ввода, устройство 907 вывода, запоминающее устройство 908, модуль 909 связи и привод 910 накопителей данных.
Устройство 906 ввода содержит, например, клавиатуру, мышь и микрофон. Устройство 907 вывода содержит, например, дисплей и громкоговоритель. Запоминающее устройство 908 представляет собой, например, жесткий диск или энергонезависимое запоминающее устройство. Модуль 909 связи содержит, например, сетевой интерфейс. Привод 910 накопителя данных приводит в действие и управляет сменным носителем 911 информации, таким как магнитный диск, оптический диск, магнитооптический диск или полупроводниковое запоминающее устройство.
В компьютере 900, имеющем описанную выше конфигурацию, процессор CPU 901 загружает программу, хранящуюся в ROM 902 или в запоминающем устройстве 908, через интерфейс 905 и шину 904 в RAM 903 и выполняет эту программу. В результате этого выполнения процессор осуществляет указанную последовательность процессов.
Программа, выполняемая компьютером 900 (процессор CPU 901), может быть записана на сменном носителе 911, например, в качестве носителя пакета программ и предоставлена пользователю. В качестве альтернативы, программа может быть передана через проводную или беспроводную сеть связи, такую как локальная сеть связи, Интернет или система цифрового спутникового вещания.
Компьютер 900 может инсталлировать программу через интерфейс 905 ввода/вывода в записывающем устройстве 908 путем присоединения сменного носителя 911 с приводом 910. В качестве альтернативы, программа может быть принята модулем 909 связи по проводной или беспроводной линии передачи и инсталлирована в запоминающем устройстве 908. В качестве альтернативы, программа может быть предварительно инсталлирована в ROM 902 или в запоминающем устройстве 908.
Здесь, процессы, осуществляемые компьютером в соответствии с программой, не обязательно должны быть выполнены хронологически в порядке, указанном в логической схеме. Другими словами, процессы, осуществляемые компьютером в соответствии с программой, могут представлять собой процессы, выполняемые параллельно или по отдельности (например, параллельная обработка или обработка объектов). Кроме того, программа может выполняться одним компьютером (процессором) или посредством децентрализованной обработки с использованием нескольким компьютером.
Отметим, что спектр возможных вариантов предлагаемой технологии не ограничивается описанными выше вариантами, так что эти варианты могут быть различным образом изменены, не отклоняясь от сущности предлагаемой технологии.
В качестве альтернативы, предлагаемая технология может иметь следующую конфигурацию.
(1) Передающее устройство, содержащее:
модуль генерирования метаданных для генерирования метаданных относительно произнесения преобразованного в речь текста из состава информации отображения, так что произнесение преобразованного в речь текста осуществляется так, как этого хотел бы производитель;
модуль генерирования электронной программной информации для генерирования электронной программной информации, содержащей указанные метаданные; и
передающий модуль для передачи электронной программной информации приемному устройству, выполненному с возможностью представления информации отображения пользователю.
(2) Передающее устройство по п. (1), в котором метаданные содержат информацию относительно произнесения строки символов, произношение которой не определено однозначно, либо строки символов, произносить которую трудно.
(3) Передающее устройство по п. (1) или (2), в котором информация отображения содержит информацию или иконку контента.
(4) Передающее устройство по п. (3), дополнительно содержащее:
модуль получения контента для приема контента, при этом
передающий модуль осуществляет передачи электронной программной информации вместе с контентом с использованием сигнала цифрового вещания.
(5) Передающее устройство по любому из (1)-(4), в котором
электронная программная информация соответствует электронной программе передач (Electronic Service Guide (ESG)) согласно стандарту Open Mobile Alliance - Mobile Broadcast Services Enabler Suite (OMA-BCAST),
метаданные записаны в формате языка разметки синтеза речи (Speech Synthesis Markup Language (SSML)), a
заданный фрагмент из состава программы ESG содержит адресную информацию, указывающую адрес, по которому можно получить файл метаданных, записанный в формате SSML, или содержание метаданных, записанный в формате SSML.
(6) Способ передачи, в соответствии с которым передающее устройство осуществляет процесс, содержащий этапы, на которых:
генерируют метаданные относительно произнесения преобразованного в речь текста из состава информации отображения, так что произнесение преобразованного в речь текста осуществляется так, как этого хотел бы производитель;
генерируют электронную программную информацию, содержащую указанные метаданные; и
передают электронную программную информацию приемному устройству, выполненному с возможностью представления указанной информации отображения пользователю.
(7) Приемное устройство, содержащее:
приемный модуль для приема электронной программной информации, так что указанную электронную программную информацию передают посредством передающего устройства, причем рассматриваемая электронная программная информация содержит метаданные относительно произнесения преобразованного в речь текста из состава информации отображения, так что произнесение преобразованного в речь текста осуществляется так, как этого хотел бы производитель;
модуль получения метаданных для приема метаданных, входящих в состав электронной программной информации; и
модуль прочтения вслух преобразованного в речь текста для чтения дисплейной информации вслух на основе метаданных.
(8) Приемное устройство по (7), где метаданные содержат информацию относительно произнесения строки символов, произношение которой не определено однозначно, либо строки символов, произносить которую трудно.
(9) Приемное устройство по (7) или (8), где информация отображения содержит информацию или иконку контента.
(10) Приемное устройство по (9), в котором приемный модуль осуществляет прием электронной программной информации, передаваемой вместе с контентом в виде сигнала цифрового вещания.
(11) Приемное устройство по любому из (7)-(10), в котором
электронная программная информация соответствует программе ESG согласно стандарту OMA-BCAST,
метаданные записаны в формате языка SSML,
заданный фрагмент из состава программы ESG содержит адресную информацию, указывающую адрес, по которому можно получить файл метаданных, записанный в формате SSML, или содержание метаданных, записанное в формате SSML, и
модуль получения метаданных принимает файл метаданных в соответствии с адресной информацией или получает метаданные из указанного фрагмента.
(12) Способ приема, в соответствии с которым приемное устройство осуществляет процесс, содержащий этапы, на которых:
принимают электронную программную информацию, так что эту электронную программную информацию передают посредством передающего устройства, рассматриваемая электронная программная информация содержит метаданные относительно произнесения преобразованного в речь текста из состава дисплейной информации, так что произнесение преобразованного в речь текста осуществляется так, как этого хотел бы производитель;
получают метаданных, входящих в состав электронной программной информации; и
зачитывают информацию отображения вслух на основе указанных метаданных.
Список позиционных обозначений
1 Вещательная система
10 Передающее устройство
20 Приемное устройство
111 Модуль получения контента
112 Модуль генератора метаданных относительно произнесения преобразованного в речь текста
113 Модуль генератора информации программы ESG
114 Модуль генератора потока
115 Модуль отображения
212 Приемный модуль
213 Модуль разделения потока
214 Модуль воспроизведения
215 Модуль отображения
216 Громкоговоритель
217 Модуль получения информации программы ESG
218 Модуль получения метаданных относительно произнесения преобразованного в речь текста
219 Механизм TTS
900 Компьютер
901 Центральный процессор CPU













Изобретение относится к передающему/приемному устройству, которое может повысить доступность услуг электронной программной информации (ESG) для людей с нарушением зрения. Техническим результатом является обеспечение возможности достоверности и надежности произношения вслух слов и текстов так, как этого хотел бы производитель программного обеспечения, чтобы люди с нарушениями зрения могли получать информацию, аналогичную информации, воспринимаемой физически здоровыми людьми. Предложено передающее устройство, содержащее модуль генерирования метаданных относительно произнесения преобразованного в речь текста для генерирования метаданных относительно произнесения преобразованного в речь текста из состава информации отображения, так что произнесение преобразованного в речь текста осуществляется, как задумано производителем; модуль генерирования электронной программной информации для генерирования электронной программной информации, содержащей указанные метаданные относительно произнесения преобразованного в речь текста; и передающий модуль для передачи электронной программной информации приемному устройству, выполненному с возможностью отображения информации пользователю. Предлагаемая технология может быть применена, например, к передатчику, способному передавать сигнал цифрового телевизионного вещания. 4 н. и 8 з.п. ф-лы, 22 ил. 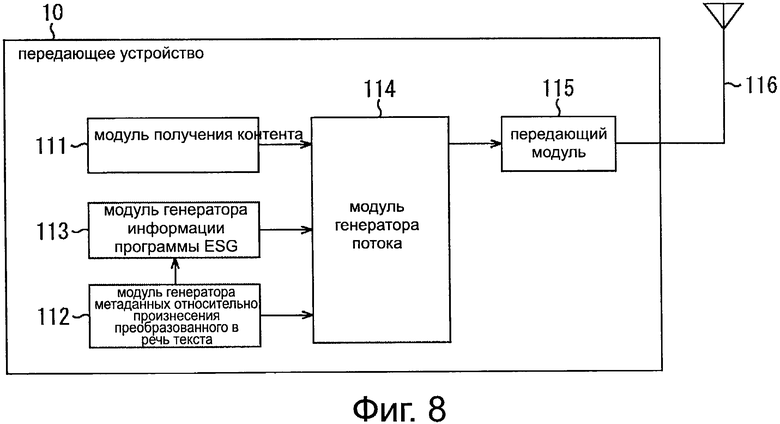
1. Передающее устройство, содержащее:
модуль генерирования метаданных для генерирования метаданных относительно произношения преобразованного в речь текста из состава информации отображения, при этом метаданные о произношении преобразованного в речь текста выполнены с возможностью вызова прочтения вслух информации отображения модулем прочтения вслух преобразованного в речь текста принимающего устройства, выполненного с возможностью отображения информации отображения, с произношением, задуманным производителем;
модуль генерирования электронной программной информации для генерирования электронной программной информации в широковещательной программе и вставки указанных метаданных в электронную программную информацию; и
передающий модуль для передачи электронной программной информации, содержащей метаданные, указанному приемному устройству.
2. Передающее устройство по п. 1, в котором метаданные содержат информацию относительно произношения строки символов, произношение которой не определено однозначно, либо имя собственное.
3. Передающее устройство по п. 2, в котором информация отображения содержит текстовую информацию или иконку контента.
4. Передающее устройство по п. 3, дополнительно содержащее:
модуль получения контента, выполненный с возможностью приема контента, при этом
передающий модуль выполнен с возможностью передачи электронной программной информации вместе с контентом с использованием сигнала цифрового вещания.
5. Передающее устройство по п. 1, в котором
электронная программная информация соответствует электронной программе передач (ESG) согласно стандарту Открытый Мобильный Альянс – Сертификация Мобильных Широковещательных Служб (OMA-BCAST),
метаданные записаны в формате языка разметки синтеза речи (SSML) и
заданный фрагмент из состава программы ESG содержит адресную информацию, указывающую адрес, по которому можно получить файл метаданных, описанный в формате SSML, или содержание метаданных, описанное в формате SSML.
6. Способ передачи, вызывающий выполнение передающим устройством, этапов, на которых:
генерируют метаданные относительно произношения преобразованного в речь текста из состава информации отображения, при этом метаданные о произношении преобразованного в речь текста выполнены с возможностью вызова прочтения вслух информации отображения модулем прочтения вслух преобразованного в речь текста принимающего устройства, выполненного с возможностью отображения информации отображения, с произношением, задуманным производителем;
генерируют электронную программную информацию в широковещательной программе и вставляют указанные метаданные в электронную программную информацию; и
передают электронную программную информацию, содержащую метаданные, указанному приемному устройству.
7. Приемное устройство, содержащее:
приемный модуль для приема, в широковещательной передаче, электронной программной информации при передаче электронной программной информации передающим устройством, причем указанная электронная программная информация содержит метаданные относительно произношения преобразованного в речь текста из состава информации отображения;
модуль получения метаданных для получения метаданных, содержащихся в электронной программной информации; и
модуль прочтения вслух преобразованного в речь текста для зачитывания информации отображения вслух, при этом метаданные о произношении преобразованного в речь текста выполнены с возможностью вызова прочтения вслух, на основе указанных метаданных, информации отображения модулем прочтения вслух преобразованного в речь текста с произношением, задуманным производителем.
8. Приемное устройство по п. 7, в котором метаданные содержат информацию относительно произношения строки символов, произношение которой не определено однозначно, либо имя собственное.
9. Приемное устройство по п. 8, в котором информация отображения содержит текстовую информацию или иконку контента.
10. Приемное устройство по п. 9, в котором приемный модуль выполнен с возможностью приема электронной программной информации, передаваемой вместе с контентом в виде сигнала цифрового вещания.
11. Приемное устройство по п. 7, в котором
электронная программная информация соответствует программе ESG согласно стандарту OMA-BCAST,
метаданные записаны в формате языка SSML,
заданный фрагмент из состава программы ESG содержит адресную информацию, указывающую адрес, по которому можно получить файл метаданных, записанный в формате SSML, или содержание метаданных, записанное в формате SSML, а
модуль получения метаданных выполнен с возможностью получения файла метаданных в соответствии с адресной информацией или получения метаданных из указанного фрагмента.
12. Способ приема, вызывающий выполнение приемным устройством этапов, на которых:
принимают, в широковещательной передаче, электронную программную информацию при передаче указанной программной информации передающим устройством, причем указанная электронная программная информация содержит метаданные относительно произношения преобразованного в речь текста из состава информации отображения;
получают метаданные, входящие в состав электронной программной информации; и
зачитывают информацию отображения вслух, при этом метаданные о произношении преобразованного в речь текста выполнены с возможностью вызова прочтения вслух, на основе указанных метаданных, информации отображения, модулем прочтения вслух преобразованного в речь текста, с произношением, задуманным производителем.
| US 2012016675 A1, 2012-01-19 | |||
| US 7610546 B1, 2009-10-27 | |||
| JP 2001022374 A, 2001-01-26 | |||
| JP 2006100892 A, 2006-04-13 | |||
| TAYLOR P | |||
| et al, SSML: A speech synthesis markup language, SPEECH COMMUNICAT, ELSEVIER SCIENCE PUBLISHERS, Amsterdam, vol | |||
| Выбрасывающий ячеистый аппарат для рядовых сеялок | 1922 |
|
SU21A1 |

