Область техники
[0001] Настоящее техническое решение относится к способу и системе синтеза речи по тексту. В частности, предложены способ и система для вывода синтезированной речи с одним или несколькими выбранными речевыми атрибутами.
Уровень техники
[0002] В системах преобразования текста в речь (от англ. text-to-speech (TTS) - текст-в-речь) часть текста (или аудио текстовый файл) преобразовывается в аудио-речь (или речевой аудио-файл). Такие системы используются в широком диапазоне приложений, например, в электронных играх, устройствах для чтения электронных книг, устройствах, выполненных с возможностью чтения электронных писем, спутниковой навигации, автоматизированных телефонных системах и автоматизированных системах оповещения. Например, некоторые системы мгновенных сообщений (от англ. instant messaging (IM)) используют синтез TTS для преобразования текстового чата в речь. Это может быть очень удобно для людей, которым трудно читать, людям, ведущим машину, или людям, которые просто не хотят отвлекаться от своего занятия, чтобы переключить внимание на окно IM.
[0003] Проблема с синтезом TTS заключается в том, что синтезированная речь может лишиться таких атрибутов как эмоциональность, речевая выразительность, личные особенности диктора. Часто все синтезированные голоса звучат одинаково. Сейчас существует необходимость в том, чтобы голоса таких систем звучали как естественные человеческие голоса.
[0004] В патенте США No. 8,135,591, опубликованном 13 марта 2012 года, раскрыт способ и система обучения системы преобразования текста в речь для использования в области синтеза речи. Способ включает в себя: создание речевой базы аудио-файлов, включающих в себя аудио-файлы, включающие в себя голоса, связанные с конкретной предметной областью, и обладающие различными просодиями; и обучение системы синтеза речи по тексту, с использованием базы данных, посредством выбора аудио-сегментов с просодией на основе по меньшей мере одного диалогового состояния. Система включает в себя процессор, речевую базу аудио-файлов и модули для осуществления способа.
[0005] В патентной заявке США No. 2013/0262119, опубликованной 3 октября 2013 года, раскрыт способ преобразования текста в речь, выполненный с возможностью выводить речь с выбранным голосом диктора и выбранным атрибутом диктора. Способ включает в себя ввод текста; разделение введенного текста на последовательность акустических единиц; выбор диктора для введенного текста; выбор атрибута диктора для введенного текста; преобразование последовательности акустических единиц в последовательность речевых векторов с использованием акустической модели; и вывод последовательности акустических векторов в виде аудио с выбранным голосом диктора и выбранным атрибутом диктора. Акустическая модель включает в себя первый набор параметров, относящихся к голосу диктора, и второй набор параметров, относящихся к атрибутам диктора, причем эти параметры не перекрываются. Выбор голоса диктора включает в себя выбор параметров из первого набора параметров, а выбор атрибута диктора включает в себя выбор параметров из второго набора параметров. Акустическая модель обучается с использованием способа обучения, адаптивного к кластеру (англ. cluster adaptive training method (CAT)), где диктор и атрибуты диктора адаптируются посредством применения весов к параметрам модели, причем параметры модели были организованы в кластеры, и для каждого кластера было создано дерево принятия решений. Описаны варианты осуществления технического решения, где акустическая модель является скрытой марковской моделью (англ. Hidden Markov Model (НММ)).
[0006] В патенте США No. 8,135,591, опубликованном 11 ноября 2014 года, раскрыт способ и система синтеза речи по тексту с персонализированным голосом. Способ включает в себя получение сопроводительного аудио-ввода речи в форме аудио-коммуникации от диктора, осуществившего ввод, и создание набора данных голоса для диктора, осуществившего ввод. Текстовый ввод получен на том же самом устройстве, что приняло аудио-ввод, и текст синтезируется из текстового ввода в синтезированную речь с использованием набора данных голоса для персонализации синтезированной речи, чтобы синтезированная речь звучала как голос диктора, осуществившего ввод. Кроме того, способ включает в себя анализ текстана выразительность и добавление выразительности в синтезированную речь. Аудио-коммуникация может быть частью видео-коммуникации, и аудио-ввод может иметь связанный визуальный ввод изображения диктора, осуществившего ввод. Синтез по тексту может включать в себя предоставление синтезированного изображения, персонализированного так, чтобы оно выглядело как изображение диктора, осуществившего ввод, с добавленными из визуального ввода выражениями.
Раскрытие
[0007] Задачей предлагаемого технического решения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[0008] Одним объектом настоящего технического решения является способ синтеза речи по тексту (англ. text-to-speech synthesis (TTS)), выполненный с возможностью выводить синтезированную речь, обладающую выбранным речевым атрибутом. Способ выполняется на вычислительном устройстве. Способ включает в себя следующие этапы обучения акустической пространственной модели: а) получение обучающих текстовых данных и соответствующих обучающих акустических данных, причем соответствующие обучающие акустические данные являются произнесенным представлением обучающих текстовых данных, и соответствующие обучающие акустические данные связаны с одним или несколькими определенными речевыми атрибутами; б) извлечение одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных; в) извлечение вокодерных характеристик соответствующих обучающих акустических данных, и корреляция вокодерных характеристик с фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами, что, таким образом, создает набор обучающих данных речевых атрибутов; и г) использование глубокой нейронной сети (англ. deep neural network (DNN)) для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных. Глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости, причем акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и обеспечивает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов.
[0009] Способ дополнительно включает в себя следующие этапы TTS с использованием акустической пространственной модели: д) получение текста; е) получение выбора речевого атрибута, причем речевой атрибут обладает весом выбранного атрибута; ж) преобразование текста в синтезированную речь с использованием акустической пространственной модели, причем синтезированная речь обладает выбранным речевым атрибутом; и з) вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом.
[0010] В некоторых вариантах осуществления настоящего технического решения на этапе извлечения одной или нескольких фонетических и лингвистических характеристик из обучающих текстовых данных выполняют разделение обучающих текстовых данных на звуки (англ. phones). В некоторых вариантах осуществления настоящего технического решения на этапе извлечения вокодерных характеристик соответствующих обучающих акустических данных выполняют понижение размерности формы волн соответствующих обучающих акустических данных.
[0011] Один или несколько речевых атрибутов могут быть определены во время этапов обучения. Аналогично, один или несколько речевых атрибутов могут быть определены во время этапов преобразования / синтеза речи. Неограничивающие примеры речевых атрибутов включают в себя: эмоции, пол, интонации, акценты, речевые стили, динамику и личные особенности диктора. В некоторых вариантах осуществления настоящего технического решения определяют и выбирают два или несколько речевых атрибута. Каждый выбранный речевой атрибут обладает соответствующим весом выбранного атрибута. В тех вариантах осуществления настоящего технического решения, где выбирают два или несколько речевых атрибута, выведенная синтезированная речь обладает каждым из двух или несколькими выбранными речевыми атрибутами.
[0012] В некоторых вариантах осуществления настоящего технического решения способ дополнительно включает в себя этапы: получения второго текста; получения второго выбранного речевого атрибута, причем второй выбранный речевой атрибут обладает весом второго выбранного атрибута; преобразование второго текста во вторую синтезированную речь с использованием акустической пространственной модели, причем вторая синтезированная речь обладает вторым выбранным речевым атрибутом; и вывода второй синтезированной речи в виде аудио, обладающего вторым выбранным речевым атрибутом.
[0013] Другим объектом настоящего технического решения является сервер. Сервер включает в себя носитель информации; процессор, функционально соединенный с носителем информации и выполненный с возможностью сохранять объекты на носителе информации. Процессор дополнительно выполнен с возможностью осуществлять: а) получение обучающих текстовых данных и соответствующих обучающих акустических данных, причем соответствующие обучающие акустические данные являются произнесенным представлением обучающих текстовых данных, и соответствующие обучающие акустические данные связаны с одним или несколькими определенными речевыми атрибутами; б) извлечение одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных; в) извлечение вокодерных характеристик соответствующих обучающих акустических данных, и корреляция вокодерных характеристик с фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами, что, таким образом, создает набор обучающих данных речевых атрибутов; и г) использование глубокой нейронной сети (англ. deep neural network (DNN)) для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных, причем глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости, причем акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов.
[0014] Процессор дополнительно выполнен с возможностью осуществлять: д) получение текста; е) получение выбора речевого атрибута, причем речевой атрибут обладает весом выбранного атрибута; ж) преобразование текста в синтезированную речь с использованием акустической пространственной модели, причем синтезированная речь обладает выбранным речевым атрибутом; и з) вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом.
[0015] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данного технического решения. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[0016] В контексте настоящего описания, если конкретно не указано иное, «клиентское устройство» подразумевает под собой электронное устройство, связанное с пользователем и включающее в себя любое аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что компьютерное устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[0017] В контексте настоящего описания, если конкретно не указано иное, «компьютерное устройство» подразумевает под собой любое электронное устройство, выполненное с возможностью работать с программным обеспечением, подходящим к решению соответствующей задачи. Компьютерное устройство может являться сервером, клиентским устройством и так далее.
[0018] В контексте настоящего описания, если конкретно не указано иное, термин «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступными для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[0019] В контексте настоящего описания, если конкретно не указано иное, «информация» включает в себя любую информацию любого типа, включая информацию, которую можно хранить в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (фотографии, видео, звукозаписи, презентации и т.д.), данные (картографические данные, данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[0020] В контексте настоящего описания, если конкретно не указано иное, «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[0021] В контексте настоящего описания, если конкретно не указано иное, термин «носитель информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[0022] В контексте настоящего описания, если конкретно не указано иное, термин «вокодер» подразумевает под собой аудио-процессор, который анализирует речевой ввод с помощью определения характеристических элементов (например, компонентов частоты, компонентов шума и т.д.) аудио-сигнала. В некоторых случаях вокодер может быть использован для синтеза нового аудио-вывода, на основе существующего аудио-образца, с помощью добавления характеристических элементов к существующему аудио-образцу. Другими словами, вокодер может использовать спектр частот одного аудио-образца для модулирования спектра частот другого аудио-образца. «Вокодерные характеристики» подразумевают под собой характеристические элементы аудио-образца, определенные вокодером, например, характеристики формы волн аудио-образца, такие как частота и т.д.
[0023] В контексте настоящего описания, если конкретно не указано иное, термин «текст» подразумевает под собой последовательность символов и слов, которые эти символы образуют, причем эта последовательность может быть прочитана человеком. Текст может, в общем случае, быть кодированным в машиночитаемые форматы, например, ASCII. Текст в общем случае отличается от бессимвольных закодированных данных, например, графических изображений в форме растровых изображений, и программного кода. Текст может быть в различных формах, например, он может быть написан или напечатан, например, в виде книги или документа, электронного сообщения, текстового сообщения (например, отправленного в системе мгновенных сообщений) и т.д.
[0024] В контексте настоящего описания, если конкретно не указано иное, термин «акустический» подразумевает под собой звуковую энергию в форме волн, обладающих частотой, в общем случае находящейся в диапазоне, слышимом человеком. «Аудио» подразумевает под собой звук в акустическом диапазоне, слышимом человеком. Термины «речь» и «синтезированная речь» в общем случае используются здесь, подразумевая под собой аудио- или акустические (например, озвученные) представления текста. Акустические данные и аудио-данные могут иметь много различных форм, например, он могут быть записями, песнями и т.д. Акустические данные и аудио-данные могут быть сохранены в файле, например, в MP3 файле, который может быть сжат для хранения или более быстрой передачи.
[0025] В контексте настоящего описания, если конкретно не указано иное, выражение «речевой атрибут» подразумевает под собой характеристики голоса, например, эмоцию, речевой стиль, акцент, личные особенности диктора, интонацию, динамику или отличительные черты диктора (пол, возраст и т.д.) Например, речевой атрибут может быть эмоциями злости, грусти, счастья, нейтральным настроением, взволнованным настроением, приказным тоном, мужским полом, женским полом, пожилым возрастом, молодым возрастом, прерывистостью или плавностью, убыстряющимся темпом, быстрым темпом, громкостью, «нежностью» (англ. - soft), конкретным местным или иностранным акцентом и т.д. Возможно множество речевых атрибутов. Кроме того, речевой атрибут может меняться в непрерывном диапазоне, например, промежуточном между «грустью» и «счастьем», или «грустью» и «злостью».
[0026] В контексте настоящего описания, если конкретно не указано иное, выражение «глубокая нейронная сеть» подразумевает под собой систему программ и структур данных, созданных для приближенного моделирования процессов в человеческом мозге. Глубокие нейронные сети в общем случае включают в себя серию алгоритмов, которые могут идентифицировать лежащие в основе отношения и связи в наборе данных, используя процесс, который имитирует работу человеческого мозга. Расположения и веса связей в наборе данных в общем случае определяют вывод. Глубокая нейронная сеть, таким образом, в общем случае открыта для всех данных ввода или параметров одновременно, во всей их полноте, и, следовательно, способна моделировать их взаимозависимость. В отличие от алгоритмов машинного обучения, которые используют деревья принятия решений и, следовательно, имеют свои ограничения, глубокие нейронные сети не ограничены и, следовательно, подходят для моделирования взаимозависимостей.
[0027] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной передачи данных между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий «второй сервер» обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0028] Каждый вариант осуществления настоящего технического решения преследует по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые объекты данного технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять и другим целям, отдельно не указанным здесь.
[0029] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[0030] Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0031] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с вариантом осуществления настоящего технического решения, не ограничивающим его объем.
[0032] На Фиг. 2 представлена блок-схема способа, выполняемого в системе, изображенной на Фиг. 1, в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[0033] На Фиг. 3 представлена принципиальная схема обучения акустической пространственной модели с помощью исходного текста и акустических данных в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[0034] На Фиг. 4 представлена принципиальная схема синтеза речи по тексту, выполненного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
Осуществление
[0035] На Фиг. 1 представлена схема системы 100, выполненная в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративных примеров настоящего технического решения. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[0036] Система 100 включает в себя сервер 102. Сервер 102 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения, сервер 102 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 102 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 102 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность сервера 102 может быть разделена и может выполняться с помощью нескольких серверов.
[0037] В некоторых вариантах осуществления настоящего технического решения сервер 102 может находиться под контролем и/или управлением поставщика приложения, которое использует синтез речи по тексту (TTS), например, электронной игры, устройства для чтения электронных книг, устройства, выполненного с возможностью чтения электронных писем, спутниковой навигации, автоматизированной телефонной системы и автоматизированной системы оповещения. В альтернативных вариантах осуществления настоящего технического решения сервер 102 может получать доступ к приложению, использующему синтез TTS, предоставляемый сторонними поставщиками. В альтернативных вариантах осуществления настоящего технического решения сервер 102 может находиться под контролем и/или управлением или может получать доступ к поставщику сервисов TTS и других сервисов, включающих в себя TTS.
[0038] Сервер 102 включает в себя носитель 104 информации, который может использоваться сервером 102. В общем случае носитель 104 информации может быть выполнен как носитель любого характера и вида, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. а также их комбинацию.
[0039] Варианты осуществления сервера 102 хорошо известны. Таким образом, достаточно отметить, что сервер 102 включает в себя, среди прочего, интерфейс 109 сетевой связи (например, модем, сетевую карту и тому подобное) для двусторонней связи по сети 110 передачи данных; и процессор 108, соединенный с интерфейсом 109 сетевой передачи данных и носителем 104 информации, причем процессор 108 выполнен с возможностью выполнять различные процедуры, включая те, что описаны ниже. С этой целью процессор 108 может иметь доступ к машиночитаемым инструкциям, хранящимся на носителе 104 информации, выполнение которых инициирует реализацию процессором 108 различных описанных здесь процедур.
[0040] В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, сеть 110 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящего технического решения сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[0041] Носитель 104 информации выполнен с возможностью хранить данные, включая машиночитаемые инструкции и другие данные, включая текстовые данные, аудио-данные, акустические данные и так далее. В некоторых вариантах осуществления настоящего технического решения носитель 104 информации может хранить по меньшей мере часть данных в базе данных 106. В других вариантах осуществления настоящего технического решения носитель 104 информации может хранить по меньшей мере часть данных в любом наборе данных, который отличается от базы данных.
[0042] Носитель 104 информации может хранить машиночитаемые инструкции, которые управляют обновлениями, заполнением и модификациям базы данных 106 и/или другими наборами данных. Более конкретно, машиночитаемые инструкции, хранящиеся на носителе 104 информации могут позволить серверу 102 получить (например, обновить) информацию о текстовых образцах и аудио-образцах по сети 110 передачи данных и сохранить информацию о текстовых образцах и аудио-образцах, включая информацию об их фонетических характеристиках, лингвистических характеристиках, вокодерных характеристиках, речевых атрибутах и т.д. в базе данных 106 и/или других наборах данных.
[0043] Данные, сохраненные на носителе 104 информации (и, более конкретно, по меньшей мере частично, в некоторых вариантах осуществления настоящего технического решения, в базе данных 106), могут включать в себя, среди прочего, текстовые образцы и аудио-образцы любого типа. Неограничивающие примеры текстовых образцов и/или аудио-образцов включают в себя книги, статьи, журналы, электронные сообщения, текстовые сообщения, письменные сообщения, голосовые записи, речи, видео игры, графические материалы, озвученный текст, песни, видео и аудиовизуальные работы.
[0044] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут инициировать получение процессором 108 инструкции на выведение синтезированной речи 440, обладающей выбранным речевым атрибутом 420 (Фиг. 4). Инструкция на выведение синтезированной речи 440, обладающей выбранным речевым атрибутом 420, может быть инструкцией пользователя 121, полученной сервером 102 от клиентского устройства 112, которое будет описано подробнее ниже. Инструкция на выведение синтезированной речи 440, обладающей выбранным речевым атрибутом 420, может быть инструкцией клиентского устройства 112, полученной сервером 102 от клиентского устройства 112. Например, в ответ на запрос пользователя 121 клиентскому устройству 112 прочесть текстовое сообщение вслух, клиентское устройство 112 может отправить серверу 102 соответствующий запрос на предоставление пользователю 121, через модуль 118 вывода и аудио-вывод 140 клиентского устройства 112, вывода входящего текстового сообщения в виде синтезированной речи 440, обладающей выбранным речевым атрибутом 420.
[0045] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать преобразование процессором 108 текста в синтезированную речь 440, с использованием акустической пространственной модели 340, причем синтезированная речь 440 обладает выбранным речевым атрибутом 420. В общем случае, процесс преобразования может быть разбит на две части: процесс обучения, в котором создается акустическая пространственная модель 340 (в общих чертах изображено на Фиг. 3), и «рабочий» процесс, в котором акустическая пространственная модель 340 используется для преобразования полученного текста 410 в синтезированную речь 440, обладающую выбранным речевым атрибутом 420 (в общих чертах изображено на Фиг. 4). Каждая из этих частей будет рассмотрена по очереди.
[0046] В процессе обучения машиночитаемые инструкции, хранящиеся на носителе 104 информации при их исполнении могут инициировать получение процессором 108 обучающих текстовых данных 312 и соответствующих обучающих акустических данных 322. Форма обучающих текстовых данных 312 никак конкретно не ограничена и может быть, например, частью написанного или отпечатанного текста 410 любого типа, например, книгой, статьей, электронным сообщением, текстовым сообщением 410 и так далее. В некоторых вариантах осуществления настоящего технического решения обучающие текстовые данные 312 получены с использованием текстового ввода 130 и модуля 113 ввода. В альтернативных вариантах осуществления настоящего технического решения обучающие текстовые данные 312 получены с использованием второго модуля (не изображен) ввода в сервере (102). Обучающие текстовые данные 312 могут быть получены от клиента электронной почты, устройства чтения электронных книг, системы обмена сообщениями, веб-браузера, или от другого приложения, включающего в себя текст. Альтернативно, текстовые данные 312 могут быть получены от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112). Форма обучающих акустических данных 322 также никак конкретно не ограничена, и может представлять собой, например, запись человека, читающего вслух обучающие текстовые данные 312, записанную речь, пьесу, песню, видео и так далее.
[0047] Обучающие акустические данные 322 являются озвученным (например, аудио) представлением обучающих текстовых данных 312 и связаны с одним или несколькими определенными речевыми атрибутами, причем один или несколько определенных речевых атрибутов описывает характеристики обучающих акустических данных 322. Один или несколько определенных речевых атрибутов никак конкретно не ограничены и могут соответствовать, например, эмоции (злость, счастье, грусть, и т.д.), полу диктора, акценту, интонации, динамике (громкости, «нежности» и т.д.), личным особенностям диктора и т.д. Обучающие акустические данные 322 могут быть получены как любой тип аудио-образца, например, как запись, MP3 и т.д. В некоторых вариантах осуществления настоящего технического решения обучающие акустические данные 322 получены с использованием аудио-ввода (не изображен) и модуля 113 ввода. В альтернативных вариантах осуществления настоящего технического решения обучающие акустические данные 322 получены с использованием второго модуля (не изображен) ввода в сервере (102). Обучающие акустические данные 322 могут быть получены от приложения, включающего в себя аудио-контент. Альтернативно, акустические данные 322 могут быть получены от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112).
[0048] Обучающие текстовые данные 312 и обучающие акустические данные 322 могут происходить из различных источников. Например, обучающие текстовые и/или акустические данные могут быть извлечены из сообщений электронной почты, загруженных с удаленного сервера, и так далее. В некоторых неограничивающих вариантах осуществления настоящего технического решения обучающие текстовые и/или акустические данные сохраняются на носителе 104 информации, например, в базе данных 106. В альтернативных неограничивающих вариантах осуществления настоящего технического решения обучающие текстовые и/или акустические данные получены (например, загружены) сервером 102 с клиентского устройства 112 по сети 110 передачи данных.В других вариантах осуществления настоящего технического решения обучающие текстовые и/или акустические данные извлечены (например, загружены) с внешнего источника (не изображен) по сети 110 передачи данных. В некоторых вариантах осуществления настоящего технического решения обучающие текстовые данные 312 введены пользователем 121 с использованием текстового ввода 130 и модуля 113 ввода. Аналогично, обучающие акустические данные 322 могут быть введены пользователем 121 с помощью аудио-ввода (не изображен), соединенного с модулем 113 ввода.
[0049] В таком варианте осуществления настоящего технического решения сервер 102 запрашивает обучающие текстовые и/или акустические данные у внешнего источника (не изображен), который может являться, например, поставщиком подобных данных. Следует ясно понимать, что источником обучающих текстовых и/или акустических данных может являться любой подходящий источник, например, любое устройство, которое оптически сканирует изображения и преобразует их в цифровые изображения, любое устройство, которое записывает аудио-образцы, и так далее.
[0050] Могут быть получены один или несколько наборов обучающих текстовых данных 312. В некоторых неограничивающих вариантах осуществления могут быть получены два или несколько наборов обучающих текстовых данных 312. В некоторых неограничивающих вариантах осуществления, два или несколько соответствующих наборов обучающих акустических данных 322 могут быть получены для каждого набора полученных обучающих текстовых данных 312, причем каждый набор обучающих акустических данных 322 связан с одним или несколькими определенными речевыми атрибутами. В таких вариантах осуществления каждые обучающие акустические данные могут обладать различными определенными речевыми атрибутами. Например, первые обучающие акустические данные 322 являются озвученным представлением первых обучающих текстовых данных 312 и могут обладать определенными речевыми атрибутами «мужской» и «злой» (т.е. запись первых текстовых данных 312 прочитана вслух сердитым мужчиной), в то время как вторые обучающие акустические данные 322 являются озвученным представлением вторых обучающих текстовых данных 312 и могут обладать определенными речевыми атрибутами «женский», «счастливый» и «молодой» (т.е. запись первых текстовых данных 312 прочитана вслух молодой девушкой, которая очень счастлива). Количество и тип речевых атрибутов определяется независимо от каждых обучающих акустических данных 322.
[0051] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать извлечение процессором 108 одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных 312. Например, в некоторых вариантах осуществления настоящего технического решения может быть инициировано разделение процессором 108 обучающих текстовых данных 312 на звуки, причем звук является минимальным сегментом разговорной речи в языке (а именно гласным или согласным звуком). Как будет понятно специалисту в данной области техники, может быть извлечено множество фонетических и лингвистических характеристик, и для этого существует множество известных способов; ни фонетические характеристики, ни лингвистические характеристики, ни способы их извлечения никак конкретно не ограничены.
[0052] Машиночитаемые инструкции, хранящиеся на носителе 104 информации, при их исполнении могут дополнительно инициировать извлечение процессором 108 вокодерных характеристик соответствующих обучающих акустических данных 322 и корреляцию вокодерных характеристик с одной или несколькими фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами. Таким образом, создают набор обучающих данных речевых атрибутов. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, извлечение вокодерных характеристик обучающих акустических данных включает в себя понижение размерности формы волн соответствующих обучающих акустических данных. Как будет понятно специалисту в данной области техники, извлечение вокодерных характеристик может быть осуществлено с использованием многих различных способов, и используемый способ никак конкретно не ограничен.
[0053] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут также инициировать использование процессором 108 глубокой нейронной сети (deep neural network (DNN)) для определения взаимозависимых факторов между речевыми атрибутами в обучающих данных. Глубокая нейронная сеть (как будет дополнительно описано ниже) создает единственную непрерывную пространственную модель, которая учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов. Реализация глубокой нейронной сети никак конкретно не ограничена. Многие из таких алгоритмов машинного обучения являются известными. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, акустическая пространственная модель, после ее создания, сохраняется на носителе 104 информации, например, в базе данных 106, для будущего использования в «рабочей» части процесса TTS.
[0054] Обучающая часть процесса TTS, таким образом, завершается созданием акустической пространственной модели. Теперь будет описана система «рабочей» части процесса TTS, в которой акустическая пространственная модель используется для трансформации полученного текста в синтезированную речь, обладающую выбранными речевыми атрибутами.
[0055] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать получение процессором 108 текста 410. Как и для обучающих текстовых данных 312, форма и источник текста 410 никак конкретно не ограничены. Текст 410 может быть, например, частью написанного текста любого типа, например, книгой, статьей, электронным сообщением, текстовым сообщением и так далее. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, текст 410 получен с помощью текстового ввода 130 и модуля 113 ввода клиентского устройства 112. Текст 410 может быть получен от клиента электронной почты, устройства чтения электронных книг, системы обмена сообщениями, веб-браузера, или от другого приложения, включающего в себя текстовый контент. Альтернативно, текст 410 может быть введен пользователем 121 с помощью текстового ввода 130. В альтернативных вариантах осуществления настоящего технического решения, не ограничивающих его объем, текст 410 может быть получен от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112).
[0056] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать получение процессором 108 выбора речевого атрибута 420, причем речевой атрибут 420 обладает весом выбранного атрибута. Может быть получен один или несколько речевых атрибутов 420, причем каждый из них обладает одним или несколькими весами выбранного атрибута. Вес выбранного атрибута определяет вес речевого атрибута 420, наличие которого является желательным в синтезированной речи на выходе. Другими словами, синтезированная речь будет обладать взвешенной суммой речевых атрибутов 420. Кроме того, речевой атрибут 420 может меняться в непрерывном диапазоне, например, промежуточном между «грустью» и «счастьем», или «грустью» и «злостью».
[0057] В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, выбранный речевой атрибут 420 получен с помощью модуля 113 ввода клиентского устройства 112. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, выбранный речевой атрибут 420 получен с текстом 410. В альтернативных вариантах осуществления настоящего технического решения текст 410 и выбранный речевой атрибут 420 получены раздельно (например, в различное время, от различных приложений, от различных пользователей, или в различных файлах и т.д.) с помощью модуля 113 ввода. В дополнительных вариантах осуществления настоящего технического решения, не ограничивающих его объем, выбранный речевой атрибут 420 получен с использованием второго модуля (не изображен) ввода в сервере (102).
[0058] Следует ясно понимать, что выбранный речевой атрибут 420 никак конкретно не ограничен и может соответствовать, например, эмоции (злость, счастье, грусть и т.д.), полу диктора, акценту, интонации, динамике, личным особенностям диктора, речевому стилю и т.д., или любой их комбинации.
[0059] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать преобразование процессором 108 текста 410 в синтезированную речь 440, с использованием акустической пространственной модели 340, созданной в процессе обучения. Другими словами, текст 410 и выбранный один или несколько речевых атрибутов 420 вводятся в акустическую пространственную модель 340, которая выводит синтезированную речь, обладающую выбранным речевым атрибутом (как описано подробнее ниже). Следует понимать, что для вывода синтезированной речи могут быть выбраны и использованы любые желаемые речевые атрибуты.
[0060] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать отправку процессором 108 на клиентское устройство 112 инструкции на вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом 420, например, через модуль 118 вывода и аудио-вывод 140 клиентского устройства 112. Инструкция может быть отправлена по сети 110 передачи данных. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, процессор 108 может отправлять инструкцию на вывод синтезированной речи в виде аудио с использованием второго модуля (не изображен) вывода в сервере 102, например, соединенного с интерфейсом 109 сетевого обмена данными и процессором 108. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, инструкция на вывод синтезированной речи через модуль 118 вывода и аудио-вывод 140 клиентского устройства 112 отправляется на клиентское устройство 112 с помощью второго модуля (не изображен) вывода в сервере 102.
[0061] Машиночитаемые инструкции, сохраненные на носителе 104 информации, при их исполнении могут дополнительно инициировать повторение процессором 108 «рабочего» процесса, в котором акустическая пространственная модель 340 используется для преобразования полученного текста 410 в синтезированную речь, обладающую речевыми атрибутами 420, до тех пор, пока все полученные тексты 410 не будут выведены как синтезированная речь, обладающая выбранными речевыми атрибутами 420. Количество текстов 410, которое может быть получено и выведено как синтезированная речь с использованием акустической пространственной модели 340, никак конкретно не ограничено.
[0062] Система 100 также включает в себя клиентское устройство 112. Клиентское устройство 112 обычно связано с пользователем 121. Следует отметить, что тот факт, что клиентское устройство 112 связано с пользователем 121, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного.
[0063] Варианты осуществления клиентского устройства 112 конкретно не ограничены, но в качестве примера клиентского устройства 112 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) или беспроводные устройства передачи данных (смартфоны, планшеты и т.п.).
[0064] Клиентское устройство 112 включает в себя модуль 113 ввода. Реализация модуля 113 ввода никак конкретно не ограничена и будет зависеть от того, какое клиентское устройство 112 используется. Модуль 113 ввода может включать в себя любой механизм предоставления пользовательского ввода процессору 116 клиентского устройства 112. Модуль 113 ввода связан с текстовым вводом 130. Текстовый ввод 130 получает текст. Реализация текстового ввода 130 никак конкретно не ограничена и будет зависеть от того, какое клиентское устройство 112 используется. Текстовый ввод 130 может являться клавиатурой и/или мышью и так далее. Альтернативно, текстовый ввод 130 может быть средствами для получения текстовых данных от внешнего носителя или сети. Текстовый ввод 130 не ограничен конкретными способами ввода или устройствами. Например, он может быть реализован как виртуальная кнопка на сенсорном экране или как физическая кнопка на корпусе электронного устройства. Возможны другие варианты осуществления настоящего технического решения.
[0065] Исключительно как пример и без введения ограничений, в тех вариантах осуществления настоящего технического решения, в которых клиентское устройство 112 реализовано как беспроводное устройство передачи данных (например, смартфон), текстовый ввод 130 может быть выполнен как устройство пользовательского ввода на основе интерференции света. Текстовый ввод 130 в одном примере является устройством восприятия движения пальца/объекта, которым пользователь осуществляет жест и/или на которое нажимает пальцем. Текстовый ввод 130 может идентифицировать/отслеживать жест и/или определять положение пальца пользователя на клиентском 112. В примерах, в которых текстовый ввод 130 выполнен как устройство ввода на основе интерференции света, например, сенсорный экран или мультисенсорный экран, модуль 113 ввода может дополнительно выполнять функции модуля 118 вывода, а именно в вариантах осуществления настоящего технического решения, в которых модуль 118 вывода выполнен как экран (дисплей).
[0066] Модуль 113 ввода также соединен с аудио-вводом (не изображен) для ввода акустических данных. Аудио-ввод никак конкретно не ограничен и может зависеть от того, какое клиентское устройство 112 используется. Например, аудио-ввод может быть микрофоном, записывающим устройством, аудио-ресивером (приемником аудио) и так далее. Альтернативно, аудио-ввод может быть реализован средствами для получения акустических данных от внешнего носителя или сети, например, с кассетной записи, компакт-диска, радио, цифрового аудио источника, файла MP3 и т.д. Аудио-ввод не ограничен никаким конкретным способом ввода или устройством.
[0067] Модуль 113 ввода функционально подключен к процессору 116 и передает сигналы ввода на основе различных форм пользовательского ввода для обработки и анализа процессором 116. В вариантах осуществления настоящего технического решения, где модуль 113 ввода также функционирует как модуль 118 вывода, будучи реализован, например, как экран, модуль 113 ввода также передает сигналы вывода.
[0068] Клиентское устройство 112 дополнительно включает в себя используемый компьютером носитель 114 информации, также упоминаемый как локальная память 114. Локальная память 114 может включать в себя любой тип медиа, включая (но не ограничиваясь) ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. В целом, задачей локальной памяти 114 является хранение машиночитаемых инструкций, а также других данных.
[0069] Клиентское устройство 112 также включает в себя модуль 118 вывода. В некоторых вариантах осуществления настоящего технического решения модуль 118 вывода может быть выполнен как экран. Экран 118 может быть, например, жидкокристаллическим дисплеем (LCD), светодиодным дисплеем (LED), дисплеем на основе интерферометрической модуляции (IMOD) или дисплеем на основе любого другого подходящего технического решения. Экран в целом выполнен с возможностью отображать графический интерфейс пользователя (GUI), который предоставляет простой в использовании графический интерфейс между пользователем 121 клиентского устройства 112 и операционной системой или приложением(ями), установленным(и) на клиентском устройстве 112. В целом графический интерфейс пользователя (GUI) представляет программы, файлы и операционные опции с помощью графических изображений. Модуль 118 вывода также в общем случае выполнен с возможностью отображать другую информацию, например, пользовательские данные и веб-ресурсы на экране. Когда модуль 118 реализован как экран, он может быть реализован как устройство на основе сенсорной модели, например, сенсорный экран. Сенсорный экран является экраном, который определяет наличие и местоположение касаний пользователя. Экран монитора также может быть экраном мультисенсорной или дуальной сенсорной модели, который может идентифицировать наличие, местоположение и движение сенсорного ввода. В примерах, в которых модуль 118 вывода выполнен как устройство на основе сенсорной модели, например, сенсорный экран, или мультисенсорный экран, экран может выполнять функции модуля 113 ввода.
[0070] Модуль 118 вывода дополнительно включает в себя устройство аудио-вывода, например, звуковую карту или внешний адаптер для обработки аудио-данных и устройство для соединения с аудио-выводом 140, причем модуль 118 вывода соединен с аудио-выводом 140. Аудио-вывод 140 может быть, например, прямым аудио-выводом, например, динамиком, наушниками, HDMI аудио, или цифровым выводом, например, файлом с аудиоданными, который может быть отправлен на носитель информации, передан по сети и так далее. Аудио-вывод не ограничен конкретным способом вывода или устройством и может зависеть от того, как выполнено клиентское устройство 112.
[0071] Модуль 118 вывода функционально соединен с процессором 116 и получает от него сигналы. В примерах, в которых модуль 118 вывода выполнен как устройство на основе сенсорной модели, например, сенсорный экран, или мультисенсорный экран, модуль 118 вывода может также передавать сигналы ввода на основе различных форм пользовательского ввода для обработки и анализа процессором 116.
[0072] Клиентское устройство 112 также включает в себя вышеупомянутый процессор 116. Процессор 116 выполнен с возможностью реализовать различные операции в соответствии с машиночитаемым программным кодом. Процессор 116 функционально связан с модулем 113 ввода, локальной памятью 114 и модулем 118 вывода. Процессор 116 выполнен с возможностью иметь доступ к машиночитаемым командам, выполнение которых инициирует реализацию процессором 116 различных процедур.
[0073] В качестве примера, не ограничивающего объем настоящего технического решения, процессор 116, описанный здесь, может получить доступ к машиночитаемым инструкциям, которые, при их исполнении, могут инициировать выполнение процессором 116: вывода синтезированной речи как аудио с помощью модуля 118 вывода; получения от пользователя 121 клиентского устройства 112 с помощью модуля 113 ввода выбора текста и выбранного(ых) речевого(ых) атрибута(ов); отправки клиентским устройством 112 на сервер 102 по сети 110 передачи данных введенных пользователем данных; и получение клиентским устройством 112 от сервера 102 синтезированной речи для вывода с помощью модуля 118 вывода и аудио-вывода 140 клиентского устройства 112.
[0074] Локальная память 114 выполнена с возможностью хранить данные, включая машиночитаемые инструкции и другие данные, включая текстовые и акустические данные. В некоторых вариантах осуществления настоящего технического решения локальная память 114 может хранить по меньшей мере часть данных в базе данных (не изображена). В других вариантах осуществления настоящего технического решения локальная память 114 может хранить по меньшей мере часть данных в любом наборе данных (не изображен), который отличается от базы данных.
[0075] Данные, сохраненные в локальной памяти 114 (и, более конкретно, по меньшей мере частично, в некоторых вариантах осуществления настоящего технического решения, в базе данных) могут включать в себя текстовые и акустические данные любого типа.
[0076] Локальная память 114 может хранить машиночитаемые инструкции, которые управляют обновлениями, заполнением и модификациям базы данных (не изображена) и/или другими наборами данных (не изображены). Более конкретно, машиночитаемые инструкции, хранящиеся в локальной памяти 114, могут позволить клиентскому устройству 112 получить (например, обновить) информацию о текстовых и акустических данных и синтезированной речи по сети 110 передачи данных и сохранить информацию о текстовых и акустических данных и синтезированной речи, включая информацию об их фонетических характеристиках, лингвистических характеристиках, вокодерных характеристиках и речевых атрибутах в базе данных и/или других наборах данных.
[0077] Машиночитаемые инструкции, сохраненные в локальной памяти 114, при их исполнении могут инициировать получение процессором 116 инструкций на осуществление TTS. Инструкция на осуществление TTS может быть получена при выполнении инструкций пользователя 121, полученных клиентским устройством 112, с помощью модуля 113 ввода. Например, в ответ на запрос пользователя 121 прочитать текстовое сообщение вслух, клиентское устройство 112 может отправить на сервер 102 соответствующий запрос на осуществление TTS.
[0078] В некоторых вариантах осуществления настоящего технического решения инструкция на осуществление TTS может быть выполнена на сервере 102, и клиентское устройство 112 передает инструкции на сервер 102. Кроме того, машиночитаемые инструкции, сохраненные в локальной памяти 114, при их исполнении могут инициировать получение процессором 116 от сервера 102, в результате обработки сервером 102, инструкции на вывод синтезированной речи с помощью аудио-вывода 140. Инструкция на вывод синтезированной речи в виде аудио с помощью аудио-вывода 140 может быть получена от сервера 102 по сети 110 передачи данных. В некоторых вариантах осуществления настоящего технического решения инструкция на вывод синтезированной речи в виде аудио с помощью аудио-вывода 140 клиентского устройства 112 может включать в себя инструкцию прочитать входящее текстовое сообщение вслух. Возможно множество других вариантов осуществления настоящего технического решения, которые никак конкретно не ограничены.
[0079] В альтернативных вариантах осуществления настоящего технического решения инструкция на осуществление TTS может быть выполнена локально на клиентском устройстве 112 без соединения с сервером 102.
[0080] Более конкретно, машиночитаемые инструкции, сохраненные в локальной памяти 114, при их исполнении, могут инициировать получение процессором 116 текста, получение одного или нескольких выбранных речевых атрибутов и т.д. В некоторых вариантах осуществления настоящего технического решения инструкция на осуществление TTS может быть инструкциями пользователя 121, введенными с использованием модуля 113 ввода. Например, в ответ на запрос пользователя 121 прочитать текстовое сообщение вслух, клиентское устройство 112 может получать инструкцию на осуществление TTS.
[0081] Машиночитаемые инструкции, сохраненные в локальной памяти 114, при их исполнении могут дополнительно инициировать выполнение процессором 116 других этапов способа TTS, описанных здесь; эти этапы не будут описаны повторно, чтобы избежать излишнего повторения.
[0082] Следует отметить, что клиентское устройство 112 соединено с сетью 110 передачи данных через линию 124 передачи данных. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, сеть 110 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящего технического решения сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п. Клиентское устройство 112 может устанавливать соединения по сети 110 передачи данных с другими устройствами, например, с серверами. Более конкретно, клиентское устройство 112 может устанавливать соединения и взаимодействовать с сервером 102.
[0083] Реализация линии 124 передачи данных не ограничена и будет зависеть оттого, что представляет собой клиентское устройство 112 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящего технического решения в случаях, когда клиентское устройство 112 представляет собой беспроводное устройство связи (например, смартфон), линия 124 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где клиентское устройство 112 представляет собой портативный компьютер, линия 124 передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
[0084] Важно иметь в виду, что варианты реализации клиентского устройства 112, линии 124 передачи данных и сети 110 передачи данных приведены исключительно для наглядности. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления клиентского устройства 112, линии 124 передачи данных и сети 110 передачи данных. То есть, представленные здесь примеры не ограничивают объем настоящего технического решения.
[0085] На Фиг. 2 представлен компьютерный способ 200 синтеза речи по тексту (text-to-speech (TTS)), способ выполняется на компьютерном устройстве (которое может быть клиентским устройством 112 или сервером 102) системы 100 с Фиг. 1.
[0086] Способ 200 начинается на этапах 202-208 обучения акустической пространственной модели, которая используется для TTS в соответствии с вариантами осуществления настоящего технического решения. Для простоты понимания эти этапы описаны с учетом Фиг. 3, на которой представлена принципиальная схема 300 обучения акустической пространственной модели 340 с помощью исходного текста 312 и акустических данных 322 в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[0087] Этап 202 - получение обучающих текстовых данных и соответствующих обучающих акустических данных, причем соответствующие обучающие акустические данные являются произнесенным представлением обучающих текстовых данных, и соответствующие обучающие акустические данные связаны с одним или несколькими определенными речевыми атрибутами.
[0088] Способ 200 начинается на этапе 202, на котором компьютерное устройство, в этом варианте осуществления настоящего технического решения являющееся сервером 102, получает инструкцию на TTS, более конкретно - на вывод синтезированной речи, обладающей выбранным речевым атрибутом.
[0089] Следует иметь в виду, что, хотя способ 200 описан здесь с учетом варианта осуществления настоящего технического решения, в котором компьютерное устройство является сервером 102, это описание представлено здесь исключительно для примера, и способ 200 может быть выполнен с соответствующими изменениями в других вариантах осуществления настоящего технического решения, в котором компьютерное устройство является клиентским устройством 112.
[0090] На этапе 202 получены обучающие текстовые данные 312. Форма обучающих текстовых данных 312 никак конкретно не ограничена. Текст может быть, например, частью написанного текста любого типа, например, книгой, статьей, электронным сообщением, текстовым сообщением и так далее. Обучающие текстовые данные 312 получены с использованием текстового ввода 130 и модуля 113 ввода. Текст может быть получен от клиента электронной почты, устройства чтения электронных книг, системы обмена сообщениями, веб-браузера, или от другого приложения, включающего в себя текстовый контент. Альтернативно, текстовые данные 312 могут быть получены от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112).
[0091] Также получены обучающие акустические данные 322. Обучающие акустические данные 322 являются произнесенным представлением обучающих текстовых данных 312 и никак конкретно не ограничены. Это может быть запись человека, читающего вслух обучающий текст 312, речь, пьеса, песня, видео и так далее.
[0092] Обучающие акустические данные 322 связаны с одним или несколькими определенными речевыми атрибутами 326. Определенные речевые атрибуты 326 никак конкретно не ограничены и могут соответствовать, например, эмоции (злость, счастье, грусть, и т.д.), полу диктора, акценту, интонации, динамике, личным особенностям диктора и т.д. Для каждых полученных обучающих акустических данных 322 определяется одни или несколько атрибутов 326, чтобы дать возможность осуществить корреляцию между вокодерными характеристиками 324 акустических данных 322 и речевыми атрибутами 326 во время обучения акустической пространственной модели 340 (описана ниже).
[0093] Форма обучающих акустических данных 322 никак конкретно не ограничена. Это может быть часть аудио-образца любого типа, например, записи, речи, видео и так далее. Обучающие акустические данные 322 получены с использованием аудио-ввода (не изображен) и модуля 113 ввода. Они могут быть получены от приложения, включающего в себя аудио-контент. Альтернативно, акустические данные 322 могут быть получены от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112).
[0094] Обучающие текстовые данные 312 и обучающие акустические данные 322 могут происходить из различных источников. Например, текстовые и/или акустические данные 312, 322 могут быть извлечены из сообщений электронной почты, загруженных с удаленного сервера, и так далее. В некоторых вариантах осуществления настоящего технического решения текстовые и/или акустические данные 312, 322 сохраняются на носителе 104 информации, например, в базе данных 106. В альтернативных вариантах осуществления настоящего технического решения текстовые и/или акустические данные 312, 322 получены (например, загружены) сервером 102 с клиентского устройства 112 по сети 110 передачи данных. В других вариантах осуществления настоящего технического решения текстовые и/или акустические данные 312, 322 извлечены (например, загружены) с внешнего источника (не изображен) по сети 110 передачи данных.
[0095] В таком варианте осуществления настоящего технического решения сервер 102 запрашивает текстовые и/или акустические данные 312, 322 у внешнего источника (не изображен), который может являться, например, поставщиком подобных данных. В других вариантах осуществления настоящего технического решения источником текстовых и/или акустических данных 312, 322 может являться любой подходящий источник, например, любое устройство, которое оптически сканирует изображения и преобразует их в цифровые изображения, любое устройство, которое записывает аудио-образцы, и так далее.
[0096] Затем способ 200 переходит к этапу 204.
[0097] Этап 204 - извлечение одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных
[0098] Далее, на этапе 204 сервер 102 выполняет этап извлечения одной или нескольких фонетических и лингвистических характеристик 314 обучающих текстовых данных 312. Этот этап схематически показан в первом прямоугольнике 310 на Фиг. 3. Также схематически на Фиг. 3 показаны фонетические и/или лингвистические характеристики 314. Известно множество таких характеристик и способов извлечения таких характеристик, и этот этап никак конкретно не ограничен. Например, в варианте осуществления настоящего технического решения, не ограничивающем его объем, показанном на Фиг. 3, обучающие текстовые данные 312 делятся на звуки, причем звук является минимальным сегментом разговорной речи в языке. Звуки, в общем случае, являются либо гласными, либо согласными, либо их небольшими группами. В некоторых вариантах осуществления настоящего технического решения обучающие текстовые данные 312 могут делиться на фонемы, причем фонема является минимальным сегментом речи, который не может быть заменен другим сегментом без изменения смысла, например, индивидуальная речевая единица для конкретного языка. Как будет понятно специалистам в данной области техники, извлечение фонетических и/или лингвистических характеристик 314 может быть осуществлено с использованием любого известного способа или алгоритма. Используемый способ и определяемые фонетические и/или лингвистические характеристики 314 могут быть выбраны с использованием ряда различных критериев, например, источник текстовых данных 312 и т.д.
[0099] Затем способ 200 переходит к этапу 206.
[00100] Этап 206 - извлечение вокодерных характеристик соответствующих обучающих акустических данных, и корреляция вокодерных характеристик с фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами, что, таким образом, создает набор обучающих данных речевых атрибутов
[00101] Далее, на этапе 206 сервер 102 выполняет этап извлечения вокодерных характеристик 324 обучающих текстовых данных 322. Этот этап схематически показан во втором прямоугольнике 320 на Фиг. 3. Вокодерные характеристики 324 также схематически показаны на Фиг. 3, как и определенные речевые атрибуты 326. Известно множество таких характеристик и способов извлечения таких характеристик, и этот этап никак конкретно не ограничен. Например, в неограничивающем варианте осуществления настоящего технического решения, показанном на Фиг. 3, обучающие акустические данные 322 разделяются на вокодерные характеристики 324. В некоторых вариантах осуществления настоящего технического решения извлечение вокодерных характеристик 324 обучающих акустических данных 322 включает в себя понижение размерности формы волн соответствующих обучающих акустических данных. Как будет понятно специалистам в данной области техники, извлечение вокодерных характеристик 324 может быть осуществлено с использованием любого известного способа или алгоритма. Используемый способ может быть выбран с использованием ряда различных критериев, например, источник акустических данных 322 и т.д.
[00102] Далее, вокодерные характеристики 324 коррелируются с фонетическими и/или лингвистическими характеристиками 314 обучающих текстовых данных 312, определенных на этапе 204 и с одном или несколькими определенными речевыми атрибутами 326, связанными с обучающими акустическими данными 322, и полученными на этапе 202. Фонетические и/или лингвистические характеристики 314, вокодерные характеристики 324, один или несколько речевых атрибутов 326, и корреляции между ними образуют набор обучающих данных (не изображен).
[00103] Затем способ 200 переходит к этапу 208.
[00104] Этап 208 - использование глубокой нейронной сети (англ. deep neural network (DNN)) для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных, причем глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости, и акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов
[00105] На этапе 208 сервер 102 использует глубокую нейронную сеть (DNN) 300 для определения взаимозависимости факторов между речевыми атрибутами 326 в обучающих данных. Глубокая нейронная сеть 330 является алгоритмом машинного обучения, в котором узлы ввода получают ввод, узлы вывода предоставляют вывод, а множество скрытых уровней узлов между узлами ввода и узлами вывода служит для выполнения алгоритма машинного обучения. В отличие от алгоритмов на основе деревьев принятия решений глубокая нейронная сеть 330 учитывает все обучающие данные одновременно и находит взаимосвязи и взаимозависимости между обучающими данными, что дает возможность непрерывного унифицированного моделирования обучающих данных. Известно множество таких глубоких нейронных сетей и способ реализации глубокой нейронной сети 330 никак конкретно не ограничен.
[00106] В неограничивающем варианте осуществления настоящего технического решения, показанном на Фиг. 3, ввод в глубокую нейронную сеть 330 является обучающими данными (не изображены), и вывод из глубокой нейронной сети 330 является акустической пространственной моделью 340. Глубокая нейронная сеть 330, таким образом, создает единственную непрерывную акустическую пространственную модель 340 на основе факторов взаимозависимости между речевыми атрибутами 326, причем акустическая пространственная модель 340, таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов. Акустическая пространственная модель 340 может теперь быть использована на остальных этапах 210-216 способа 200.
[00107] Способ 200 продолжается на этапах 210-216, на которых осуществляется синтез речи по тексту с использованием акустической пространственной модели 340, созданной на этапе 208. Для простоты понимания эти этапы описаны с учетом Фиг. 4, на которой представлена принципиальная схема 400 синтеза речи по тексту (TTS) в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[00108] Этап 210 - получение текста
[00109] На этапе 210 получен текст 410. Как и для обучающих текстовых данных 312, форма текста 410 никак конкретно не ограничена. Текст может быть, например, частью написанного текста любого типа, например, книгой, статьей, электронным сообщением, текстовым сообщением и так далее. Текст 410 получен с использованием текстового ввода 130 и модуля 113 ввода. Текст может быть получен от клиента электронной почты, устройства чтения электронных книг, системы обмена сообщениями, веб-браузера, или от другого приложения, включающего в себя текстовый контент. Альтернативно, текст 410 могут быть получены от операционной системы компьютерного устройства (например, сервера 102 или клиентского устройства 112).
[00110] Способ 200 затем переходит к выполнению этапа 212.
[00111] Этап 212 - получение выбора речевого атрибута, причем речевой атрибут обладает весом выбранного атрибута
[00112] На этапе 212 получен выбор речевого атрибута 420. Может быть выбран и получен один или несколько речевых атрибутов 420. Речевой атрибут 420 никак конкретно не ограничен и может соответствовать, например, эмоции (злость, счастье, грусть, и т.д.), полу диктора, акценту, интонации, динамике, личным особенностям диктора, речевому стилю и т.д. Для каждых полученных обучающих акустических данных 322 определяется одни или несколько атрибутов 326, чтобы дать возможность осуществить корреляцию между вокодерными характеристиками 324 акустических данных 322 и речевыми атрибутами 326 во время обучения акустической пространственной модели 340 (описана ниже).
[00113] Каждый речевой атрибут 326 обладает весом выбранного атрибута (не изображен). Вес выбранного атрибута определяет вес речевого атрибута, наличие которого является желательным в синтезированной речи 440. Вес применяется для каждого речевого атрибута 326, и синтезированная речь 440 на выходе обладает взвешенной суммой речевых атрибутов. Будет очевидно, что, в варианте осуществления настоящего технического решения, не ограничивающим его объем, в котором выбран только один речевой атрибут 420, вес выбранного атрибута для единственного речевого атрибута 420 обязательно равен 1 (или 100%). В альтернативных вариантах осуществления настоящего технического решения, в которых получено два или несколько речевых атрибута 420, причем каждый выбранный атрибут 420 обладает весом выбранного атрибута, синтезированная речь 440 на выходе будет обладать взвешенной суммой двух или более выбранных речевых атрибутов 420.
[00114] Выбор речевого атрибута 420 получен с помощью модуля 113 ввода. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, он может быть получен вместе с текстом 410 с помощью текстового ввода 130. В альтернативных вариантах осуществления настоящего технического решения текст 410 и речевой атрибут 420 получены раздельно (например, в различное время, от различных приложений, от различных пользователей, или в различных файлах и т.д.) с помощью модуля 113 ввода.
[00115] Этап 214 - преобразование текста в синтезированную речь с использованием акустической пространственной модели, причем синтезированная речь обладает выбранным речевым атрибутом.
[00116] На этапе 214 текст 410 и один или несколько речевых атрибутов 420 вводятся в акустическую пространственную модель 340. Акустическая пространственная модель 340 преобразует текст в синтезированную речь 440. Синтезированная речь 440 обладает воспринимаемыми характеристиками 430. Воспринимаемые характеристики 430 соответствуют вокодерным или аудио-характеристикам синтезированной речи 440, которые воспринимаются как соответствующие выбранному(ым) речевому(ым) атрибуту(ам) 420. Например, когда выбирается речевой атрибут «злой», синтезированная речь 440 обладает формой волны, частотные характеристики которой (в этом примере частотные характеристики являются воспринимаемыми характеристиками 430) воспроизводят звук, который воспринимается как «злой», и синтезированная речь 440, следовательно, обладает выбранным речевым атрибутом «злой».
[00117] Этап 216 - вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом.
[00118] Способ 200 завершается на этапе 216, на котором синтезированная речь 440 выводится в виде аудио, обладающего выбранным(и) речевым(и) атрибутом(ами) 420. Как описано выше относительно этапа 214, синтезированная речь 440, воспроизведенная акустической пространственной моделью 340, обладает воспринимаемыми характеристиками 430, причем воспринимаемые характеристики 430 воспроизводят звук, обладающий выбранным(и) речевым(и) атрибутом(ами) 420.
[00119] В некоторых вариантах осуществления настоящего технического решения, когда компьютерное устройство является сервером 102 (как в варианте осуществления настоящего технического решения, изображенном здесь), способ 200 может дополнительно включать в себя этап (не изображен) отправки на клиентское устройство 112 инструкции на вывод синтезированной речи 440 с помощью модуля 118 вывода и аудио вывода 140 клиентского устройства 112. В некоторых вариантах осуществления настоящего технического решения инструкция на вывод синтезированной речи 440 с помощью аудио вывода 140 клиентского устройства 112 включает в себя инструкцию на чтение вслух текстового сообщения, полученного на клиентском устройстве 112, пользователю 121, и, таким образом, пользователю 121 не требуется смотреть на клиентское устройство 112 для получения текстового сообщения. Например, инструкция на вывод синтезированной речи 440 на клиентском устройстве 112 может быть частью инструкции на чтение текстового сообщения. В таком случае текст 410, полученный на этапе 210, может также быть частью инструкции на преобразование входящих текстовых сообщений в аудио. Возможно множество альтернативных вариантов осуществления настоящего технического решения. Например, инструкция на вывод синтезированной речи 440 на клиентском устройстве может быть частью инструкции на чтение вслух электронной книги; сообщения электронной почты; текста, который пользователь 121 ввел, - чтобы проверить точность текста и так далее.
[00120] В некоторых вариантах осуществления настоящего технического решения, когда компьютерное устройство является сервером 102 (как в варианте осуществления настоящего технического решения, изображенном здесь), способ 200 может дополнительно включать в себя этап (не изображен) вывода синтезированной речи 440 с помощью второго модуля вывода (не изображен). Второй модуль вывода (не изображен) может, например, быть частью сервера 102, например, он может быть соединен с интерфейсом 109 сетевого обмена данными и процессором 108. В некоторых вариантах осуществления настоящего технического решения, инструкция на вывод синтезированной речи 440 через модуль 118 вывода и аудио-вывод 140 клиентского устройства 112 отправляется на клиентское устройство 112 с помощью второго модуля (не изображен) вывода в сервере 102.
[00121] В альтернативных вариантах осуществления настоящего технического решения, когда компьютерное устройство является клиентским устройством 112, способ 200 может дополнительно включать в себя этап вывода синтезированной речи 440 с помощью модуля 118 вывода и аудио-вывода 140 клиентского устройства 112. В некоторых вариантах осуществления настоящего технического решения инструкция на вывод синтезированной речи 440 с помощью аудио вывода 140 клиентского устройства 112 включает в себя инструкцию на чтение вслух текстового сообщения, полученного на клиентском устройстве 112, пользователю 121, и, таким образом, пользователю 121 не требуется смотреть на клиентское устройство 112 для получения текстового сообщения. Например, инструкция на вывод синтезированной речи 440 на клиентском устройстве 112 может быть частью инструкции на чтение текстового сообщения. В таком случае текст 410, полученный на этапе 210, может также быть частью инструкции на преобразование входящих текстовых сообщений в аудио. Возможно множество альтернативных вариантов осуществления настоящего технического решения. Например, инструкция на вывод синтезированной речи 440 на клиентском устройстве 112 может быть частью инструкции на чтение вслух электронной книги; сообщения электронной почты; текста, который пользователь 121 ввел, - чтобы проверить точность текста и так далее.
[00122] В некоторых вариантах осуществления настоящего технического решения способ 200 завершается после этапа 216. Например, если полученный текст 410 был выведен как синтезированная речь 440, то способ 200 завершается после этапа 216. В альтернативных вариантах осуществления настоящего технического решения этапы 210-216 могут повторяться. Например, может быть получен второй текст (не изображен) вместе со вторым выбором одного или нескольких речевых атрибутов (не изображены). В данном случае второй текст преобразуется во вторую синтезированную речь (не изображена) с использованием акустической пространственной модели 340, причем вторая синтезированная речь обладает вторым выбранным одним или несколькими речевыми атрибутами, и вторая синтезированная речь выводится как аудио, обладающее вторым выбранным одним или несколькими речевыми атрибутами. Этапы 210-216 могут повторяться, пока все желаемые тексты не будут преобразованы в синтезированную речь, обладающую выбранным одним или несколькими речевыми атрибутами. В таких вариантах осуществления настоящего технического решения способ, следовательно, является рекурсивным, повторно преобразуя тексты в синтезированную речь и выводя синтезированную речь как аудио, пока каждый желаемый текст не будет преобразован и выведен.
[00123] Некоторые из описанных выше этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы/получены с помощью оптических средств (например, опто-волоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00124] Некоторые технические эффекты неограничивающих вариантов осуществления настоящего технического решения могут включать предоставление пользователю быстроисполнимого, эффективного, многофункционального и/или доступного способа синтеза речи в текст. В некоторых вариантах осуществления настоящее техническое решение позволяет предоставить TTS с выбираемым программным образом голосом. Например, в некоторых вариантах осуществления настоящее техническое решение может быть выведена синтезированная речь, обладающая любой комбинацией выбранных речевых атрибутов. В таких вариантах осуществления настоящего технического решения оно может быть адаптивным и многофункциональным, позволяя выводить выбираемый программным образом голос. В некоторых вариантах осуществления настоящего технического решения комбинация речевых атрибутов выбирается независимо от речевых атрибутов в обучающих акустических данных. Например, предположим, что первые обучающие акустические данные, обладающие речевыми атрибутами «злой мужской» и вторые обучающие акустические данные, обладающие речевыми атрибутами «молодой женский счастливый» получены во время обучения акустической пространственной модели; однако, могут быть выбраны речевые атрибуты «злой» и «женский», и может быть выведена синтезированная речь, обладающая атрибутами «злой женский». Кроме того, могут быть выбраны произвольные веса для каждого речевого атрибута, в зависимости от желаемых голосовых характеристик в синтезированной речи. В некоторых вариантах осуществления настоящего технического решения синтезированная речь может быть выведена, даже если во время обучения не было получено соответствующих обучающих акустических данных с выбранными атрибутами. Более того, текст, преобразованный в синтезированную речь, не должен в обязательном порядке соответствовать обучающим текстовым данным, и текст может быть преобразован в синтезированную речь даже в случае, если для этого текста не было получено соответствующих акустических данных во время процесса обучения. По меньшей мере некоторые технические эффекты достигаются с помощью акустической модели, которая основывается на взаимозависимостях атрибутов акустических данных. В некоторых вариантах осуществления настоящее техническое решение может предоставить синтезированную речь, которая звучит как естественный человеческий голос, обладающий выбранными речевыми атрибутами.
[00125] Важно иметь в виду, что варианты осуществления настоящего технического решения могут быть реализованы с проявлением и других технических результатов.
[00126] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Приведенное описание представлено только в качестве примера и не имеет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
[00127] Таким образом, с одной точки зрения, варианты осуществления настоящего технического решения можно изложить следующим образом, структурированно, пронумерованными пунктами:
[00128] ПУНКТ 1. Способ синтеза речи по тексту (англ. text-to-speech synthesis (TTS)), выполненный с возможностью выводить синтезированную речь (440), обладающую выбранным речевым атрибутом (420), способ выполняется на компьютерном устройстве, способ включает в себя этапы:
[00129] а) получение обучающих текстовых данных (312) и соответствующих обучающих акустических данных (322), причем соответствующие обучающие акустические данные (322) являются произнесенным представлением обучающих текстовых данных (312), и соответствующие обучающие акустические данные (322) связаны с одним или несколькими определенными речевыми атрибутами (326);
[00130] б) извлечение одной или нескольких фонетических и лингвистических характеристик (314) обучающих текстовых данных (312);
[00131] в) извлечение вокодерных характеристик (324) соответствующих обучающих акустических данных (322), и корреляция вокодерных характеристик (324) с фонетическими и лингвистическими характеристиками (314) обучающих текстовых данных (312) и с одним или несколькими определенными речевыми атрибутами (326), что, таким образом, создает набор обучающих данных речевых атрибутов;
[00132] г) использование глубокой нейронной сети (330) (англ. deep neural network (DNN)) для определения факторов взаимозависимости между речевыми атрибутами (326) в обучающих данных, причем глубокая нейронная сеть (330) создает единственную непрерывную акустическую пространственную модель (340) на основе факторов взаимозависимости, и акустическая пространственная модель (340), таким образом, учитывает множество взаимозависимых речевых атрибутов и обеспечивает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов;
[00133] д) получение текста (410);
[00134] е) получение выбора речевого атрибута (420), причем речевой атрибут (420) обладает весом выбранного атрибута;
[00135] ж) преобразование текста (410) в синтезированную речь (440) с использованием акустической пространственной модели (340), причем синтезированная речь (440) обладает выбранным речевым атрибутом (420); и
[00136] з) вывод синтезированной речи (440) в виде аудио, обладающего выбранным речевым атрибутом (420).
[00137] ПУНКТ 2. Способ по п. 1, в котором на этапе извлечения одной или нескольких фонетических и лингвистических характеристик (314) из обучающих текстовых данных (312) выполняют разделение обучающих текстовых данных (312) на звуки (англ. phones).
[00138] ПУНКТ 3. Способ по п. 1 или 2, в котором на этапе извлечения вокодерных характеристик (324) обучающих акустических данных (322) выполняют понижение размерности формы волн соответствующих обучающих акустических данных (322).
[00139] ПУНКТ 4. Способ по любому из пп. 1-3, в котором один или несколько определенных речевых атрибута (326) является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
[00140] ПУНКТ 5. Способ по любому из пп. 1-4, в котором выбранный речевой атрибут (420) является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
[00141] ПУНКТ 6. Способ по любому из пп. 1-5, в котором получен выбор двух или нескольких речевых атрибутов (420), причем каждый выбранный речевой атрибут (420) обладает соответствующим весом выбранного атрибута, и выведенная синтезированная речь (440) обладает каждым из двух или несколькими выбранными речевыми атрибутами (420).
[00142] ПУНКТ 7. Способ по любому из пп. 1-6, дополнительно включающий в себя этапы: получения второго текста; получения второго выбранного речевого атрибута, причем второй выбранный речевой атрибут обладает весом второго выбранного атрибута; преобразование второго текста во вторую синтезированную речь с использованием акустической пространственной модели (340), причем вторая синтезированная речь обладает вторым выбранным речевым атрибутом; и вывода второй синтезированной речи в виде аудио, обладающего вторым выбранным речевым атрибутом.
[00143] ПУНКТ 8. Сервер (102), включающий в себя:
[00144] носитель (104) информации;
[00145] процессор (108), функционально соединенный с носителем (104) информации, причем процессор (108) выполнен с возможностью сохранять объекты на носителе (104) информации; процессор (108) также выполнен с возможностью осуществлять:
[00146] а) получение обучающих текстовых данных (312) и соответствующих обучающих акустических данных (322), причем соответствующие обучающие акустические данные (322) являются произнесенным представлением обучающих текстовых данных (312), и соответствующие обучающие акустические данные (322) связаны с одним или несколькими определенными речевыми атрибутами (326);
[00147] б) извлечение одной или нескольких фонетических и лингвистических характеристик (314) обучающих текстовых данных (312);
[00148] в) извлечение вокодерных характеристик (324) соответствующих обучающих акустических данных (322), и корреляцию вокодерных характеристик (324) с фонетическими и лингвистическими характеристиками (314) обучающих текстовых данных (312) и с одним или несколькими определенными речевыми атрибутами (326), что, таким образом, создает набор обучающих данных речевых атрибутов;
[00149] г) использование глубокой нейронной сети (330) (англ. deep neural network (DNN)) для определения факторов взаимозависимости между речевыми атрибутами (326) в обучающих данных, причем глубокая нейронная сеть (330) создает единственную непрерывную акустическую пространственную модель (340) на основе факторов взаимозависимости, и акустическая пространственная модель (340), таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов;
[00150] д) получение текста (410);
[00151] е) получение выбора речевого атрибута (420), причем речевой атрибут (420) обладает весом выбранного атрибута;
[00152] ж) преобразование текста (410) в синтезированную речь (440) с использованием акустической пространственной модели (340), причем синтезированная речь (440) обладает выбранным речевым атрибутом (420); и
[00153] з) вывод синтезированной речи (440) в виде аудио, обладающего выбранным речевым атрибутом (420).
[00154] ПУНКТ 9. Сервер по п. 8, в котором при извлечении одной или нескольких фонетических и лингвистических характеристик (314) из обучающих текстовых данных (312) процессор выполнен с возможностью разделения обучающих текстовых данных (312) на звуки (англ. phones).
[00155] ПУНКТ 10. Сервер по п. 8 или 9, в котором при извлечении вокодерных характеристик (324) обучающих акустических данных (322) процессор выполнен с возможностью понижения размерности формы волн соответствующих обучающих акустических данных (322).
[00156] ПУНКТ 11. Сервер по любому из пп. 8-10, в котором один или несколько определенных речевых атрибута (326) является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
[00157] ПУНКТ 12. Сервер по любому из пп. 8-11, в котором выбранный речевой атрибут (420) является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
[00158] ПУНКТ 13. Сервер по любому из пп. 8-12, в котором процессор (108) дополнительно выполнен с возможностью получать выбор двух или нескольких речевых атрибутов (420), причем каждый выбранный речевой атрибут (420) обладает соответствующим весом выбранного атрибута, и выводить синтезированную речь (440), обладающую каждым из двух или несколькими выбранными речевыми атрибутами (420).
[00159] ПУНКТ 14. Сервер по любому из пп. 8-13, в котором процессор (108) дополнительно выполнен с возможностью осуществлять: получение второго текста; получение второго выбранного речевого атрибута, причем второй выбранный речевой атрибут обладает весом второго выбранного атрибута; преобразование второго текста во вторую синтезированную речь с использованием акустической пространственной модели (340), причем вторая синтезированная речь обладает вторым выбранным речевым атрибутом; и вывод второй синтезированной речи в виде аудио, обладающего вторым выбранным речевым атрибутом.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ синтеза речи с передачей достоверного интонирования клонируемого образца | 2020 |
|
RU2754920C1 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| Способ и система для синтеза речи из текста | 2017 |
|
RU2692051C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ТЕКСТОВОГО ПРЕДСТАВЛЕНИЯ ФРАГМЕНТА УСТНОЙ РЕЧИ ПОЛЬЗОВАТЕЛЯ | 2019 |
|
RU2731334C1 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ОПРЕДЕЛЕНИЯ НАМЕРЕНИЯ, СВЯЗАННОГО С ПРОИЗНЕСЕННЫМ ВЫСКАЗЫВАНИЕМ ПОЛЬЗОВАТЕЛЯ | 2018 |
|
RU2711153C2 |
| Способ транскрибирования речи по цифровым сигналам с низкоскоростным кодированием | 2023 |
|
RU2801621C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| ПОВТОРНОЕ РАСПОЗНАВАНИЕ РЕЧИ С ВНЕШНИМИ ИСТОЧНИКАМИ ДАННЫХ | 2016 |
|
RU2688277C1 |
| СПОСОБ ПЕРЕОЗВУЧИВАНИЯ АУДИОМАТЕРИАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2012 |
|
RU2510954C2 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |


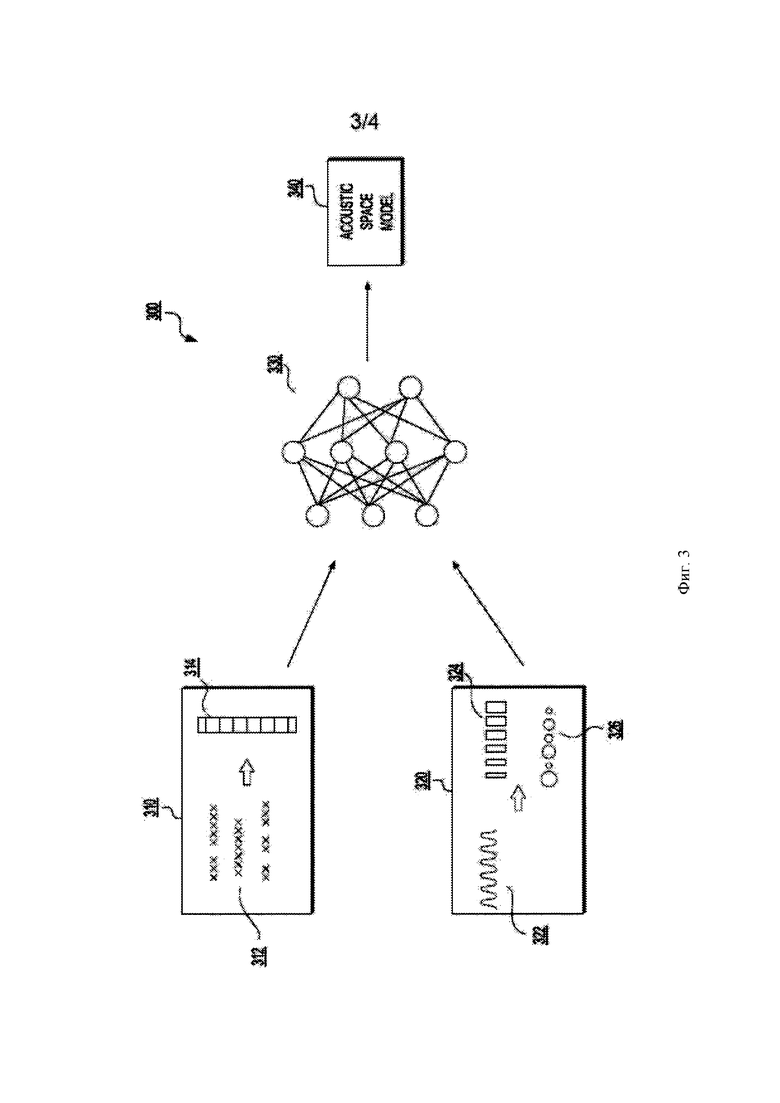
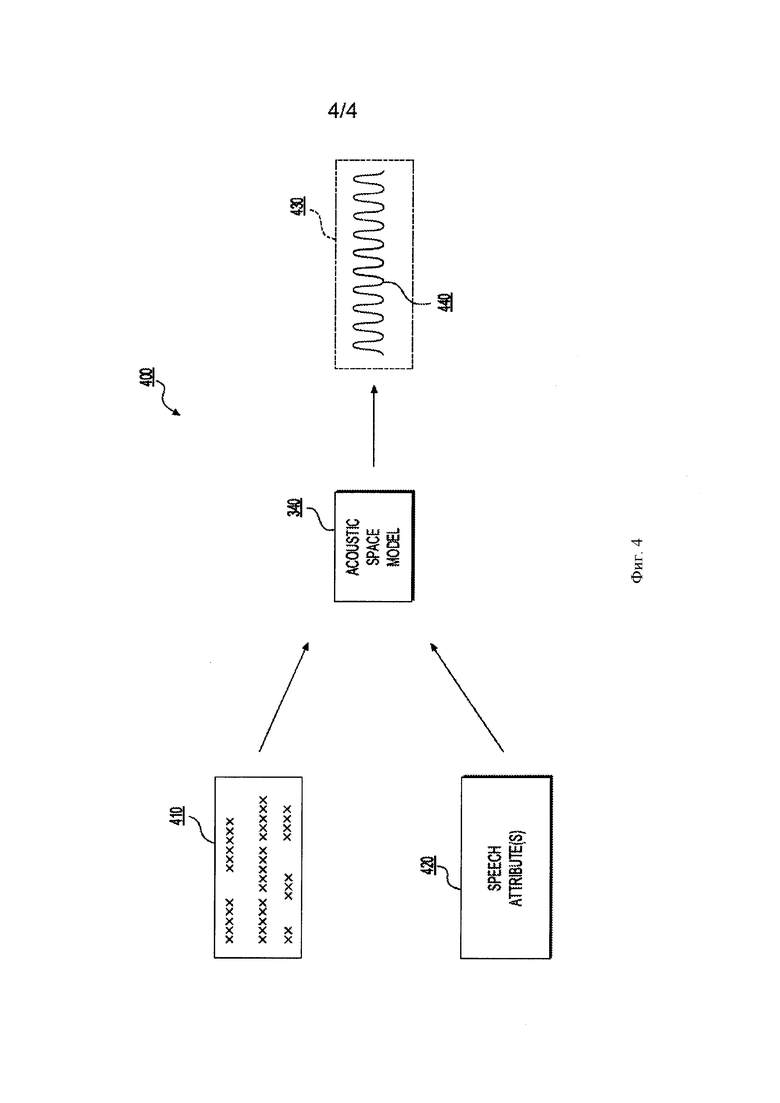
Изобретение относится к средствам синтеза речи по тексту. Технический результат заключается в повышении естественности человеческого голоса в синтезированной речи. Акустическая пространственная модель обучается на основе обучающих данных речевых атрибутов с использованием глубокой нейронной сети для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных. Глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости. Акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов. Далее происходит получение текста; получение выбора одного или нескольких речевых атрибутов, причем каждый речевой атрибут обладает весом выбранного атрибута. Текст преобразуется в синтезированную речь с использованием акустической пространственной модели, и синтезированная речь обладает выбранным речевым атрибутом. Синтезированная речь выводится в виде аудио, обладающего выбранным речевым атрибутом. 2 н. и 12 з.п. ф-лы, 4 ил.
1. Способ синтеза речи по тексту, выполненный с возможностью выводить синтезированную речь, обладающую выбранным речевым атрибутом, способ выполняется на компьютерном устройстве, способ включает в себя этапы:
- получение обучающих текстовых данных и соответствующих обучающих акустических данных, причем соответствующие обучающие акустические данные являются произнесенным представлением обучающих текстовых данных, и соответствующие обучающие акустические данные связаны с одним или несколькими определенными речевыми атрибутами;
- извлечение одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных;
- извлечение вокодерных характеристик соответствующих обучающих акустических данных, и корреляция вокодерных характеристик с фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами, что, таким образом, создает набор обучающих данных речевых атрибутов;
- использование глубокой нейронной сети для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных, причем глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости, и акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и обеспечивает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов;
- получение текста;
- получение выбора речевого атрибута, причем речевой атрибут обладает весом выбранного атрибута;
- преобразование текста в синтезированную речь с использованием акустической пространственной модели, причем синтезированная речь обладает выбранным речевым атрибутом;
- вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом.
2. Способ по п. 1, в котором на этапе указанного извлечения одной или нескольких фонетических и лингвистических характеристик из обучающих текстовых данных выполняют разделение обучающих текстовых данных на звуки.
3. Способ по п. 1, в котором на этапе указанного извлечения вокодерных характеристик обучающих акустических данных выполняют понижение размерности формы волн соответствующих обучающих акустических данных.
4. Способ по п. 1, в котором указанный один или несколько определенных речевых атрибутов является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
5. Способ по п. 1, в котором указанный выбранный речевой атрибут является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
6. Способ по п. 1, в котором получают выбор двух или нескольких речевых атрибутов, причем каждый выбранный речевой атрибут обладает соответствующим весом выбранного атрибута, и выведенная синтезированная речь обладает каждым из двух или несколькими выбранными речевыми атрибутами.
7. Способ по п. 1, дополнительно включающий в себя этапы: получения второго текста; получения второго выбранного речевого атрибута, причем второй выбранный речевой атрибут обладает весом второго выбранного атрибута; преобразование второго текста во вторую синтезированную речь с использованием указанной акустической пространственной модели, причем вторая синтезированная речь обладает вторым выбранным речевым атрибутом; и вывода второй синтезированной речи в виде аудио, обладающего вторым выбранным речевым атрибутом.
8. Сервер включает в себя:
носитель информации;
процессор, функционально соединенный с носителем информации, причем процессор выполнен с возможностью сохранять объекты на носителе информации; процессор также выполнен с возможностью осуществлять:
- получение обучающих текстовых данных и соответствующих обучающих акустических данных, причем соответствующие обучающие акустические данные являются произнесенным представлением обучающих текстовых данных, и соответствующие обучающие акустические данные связаны с одним или несколькими определенными речевыми атрибутами;
- извлечение одной или нескольких фонетических и лингвистических характеристик обучающих текстовых данных;
- извлечение вокодерных характеристик соответствующих обучающих акустических данных, и корреляция вокодерных характеристик с фонетическими и лингвистическими характеристиками обучающих текстовых данных и с одним или несколькими определенными речевыми атрибутами, что, таким образом, создает набор обучающих данных речевых атрибутов;
- использование глубокой нейронной сети для определения факторов взаимозависимости между речевыми атрибутами в обучающих данных, причем глубокая нейронная сеть создает единственную непрерывную акустическую пространственную модель на основе факторов взаимозависимости, и акустическая пространственная модель, таким образом, учитывает множество взаимозависимых речевых атрибутов и дает возможность моделировать непрерывный спектр взаимозависимых речевых атрибутов;
- получение текста;
- получение выбора речевого атрибута, причем речевой атрибут обладает весом выбранного атрибута;
- преобразование текста в синтезированную речь с использованием акустической пространственной модели, причем синтезированная речь обладает выбранным речевым атрибутом;
- вывод синтезированной речи в виде аудио, обладающего выбранным речевым атрибутом.
9. Сервер по п. 8, в котором при указанном извлечении одной или нескольких фонетических и лингвистических характеристик из обучающих текстовых данных процессор выполнен с возможностью осуществлять разделение обучающих текстовых данных на звуки (англ. phones).
10. Сервер по п. 8, в котором при указанном извлечении вокодерных характеристик обучающих акустических данных процессор выполнен с возможностью понижения размерности формы волн соответствующих обучающих акустических данных.
11. Сервер по п. 8, в котором указанный один или несколько определенных речевых атрибутов является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
12. Сервер по п. 8, в котором указанный выбранный речевой атрибут является эмоцией, полом, интонацией, акцентом, речевым стилем, динамикой, или личными особенностями диктора.
13. Сервер по п. 8, в котором процессор дополнительно выполнен с возможностью получать выбор двух или нескольких речевых атрибутов, причем каждый выбранный речевой атрибут обладает соответствующим весом выбранного атрибута, и выводить синтезированную речь, обладающую каждым из двух или несколькими выбранными речевыми атрибутами.
14. Сервер по п. 8, в котором процессор дополнительно выполнен с возможностью осуществлять: получение второго текста; получение второго выбранного речевого атрибута, причем второй выбранный речевой атрибут обладает весом второго выбранного атрибута; преобразование второго текста во вторую синтезированную речь с использованием указанной акустической пространственной модели, причем вторая синтезированная речь обладает вторым выбранным речевым атрибутом; и вывод второй синтезированной речи в виде аудио, обладающего вторым выбранным речевым атрибутом.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ АНАЛИЗА И СИНТЕЗА РЕЧИ | 2005 |
|
RU2296377C2 |
| СПОСОБ КОМПИЛЯЦИОННОГО ФОНЕМНОГО СИНТЕЗА РУССКОЙ РЕЧИ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2005 |
|
RU2298234C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |

