Область техники, к которой относится изобретение
Предлагаемое изобретение относится к области защиты данных, а именно к области способов контроля и обеспечения целостности данных при их обработке.
Уровень техники
В настоящее время перед пользователями различных информационных систем стоят задачи по защите содержащихся и обрабатываемых в них данных. Одной из мер обеспечения защищенности данных, содержащихся и обрабатываемых в информационных системах, является защита их целостности (Методический документ. Меры защиты информации в государственных информационных системах: утв. директором ФСТЭК 11.02.2014 // ФСТЭК России, 2014. - 176 с.).
Особую актуальность решение задачи защиты целостности данных приобретает в процессе функционирования повсеместно создаваемых за рубежом и в нашей стране центров обработки данных при использовании в их составе различных средств обработки с отличающимися структурами построения и принципами работы. Поэтому под термином «средство обработки данных» будем понимать любое электронное устройство, содержащее память для хранения данных, в которую можно загружать данные из внешней среды (источника).
Задача защиты целостности данных является сложной, ввиду своей комплексности, так как включает в себя не только контроль целостности данных, но и ее обеспечение, что подразумевает восстановление данных, целостность которых была нарушена по каким-либо причинам.
Целостность данных нарушается обычно в результате случайных ошибок, а также ошибок, генерируемых посредством преднамеренных воздействий злоумышленника (несанкционированного изменения данных (например, посредством действия вредоносного кода) или выхода из строя части носителя (например, отдельных ячеек, секторов)).
Как правило, задача защиты целостности данных решается с помощью различных способов. Далее для раскрытия сути изобретения приводится краткое описание существующих способов защиты целостности данных.
а) Описание аналогов
Известны способы контроля целостности данных за счет вычисления контрольных сумм и сравнения их с эталонными (Патент РФ №2145727 публ. 20.02.2000, Патент РФ №2467495 публ. 20.11.2012; Патент РФ №2628894 публ. 06.09.2016), а также способы, основанные на применении криптографических методов: ключевое и бесключевое хэширование, средства электронной подписи (Патент РФ №2408071 публ. 27.12.2010; Патент РФ №2500027 публ. 27.11.2013; Заявка на патент РФ №2005113932 публ. 20.01.2007; Заявка на патент РФ №2004110622 публ. 10.10.2007; Заявка на патент РФ №2006116797 публ. 27.01.2008; Заявка на патент РФ №2007141753 публ. 10.09.2010; Заявка на патент РФ №2012107193 публ. 10.10.2013; Заявка на патент РФ №2013149120 публ. 10.05.2015; Заявка на патент РФ №2015152423 публ. 14.06.2017; Кнут, Д.Э. Искусство программирования для ЭВМ. Том 3 сортировка и поиск [Текст] / Д.Э. Кнут. - М.: «Мир», 1978. - 824 с.; Menezes, A.J. Handbook of Applied Cryptography [Текст] / A.J. Menezes, Paul C. van Oorschot, Scott A. Vanstone. - M.: CRC Press, Inc., 1996. - 816 c.; Biham, E. A framework for iterative hash functions. - HAIFA [Текст] / E. Biham, O. Dunkelman. - M.: HAIFA, ePrint Archive, Report 2007/278. - 20 с.; To же [Электронный ресурс]. - Режим доступа: eprint.iacr.org/2007/278.pdf (July, 2007); Wang, X. How to break MD5 and Other Hash Function [Текст] / X. Wang, H. Yu. - M.: EUROCRYPT 2005, LNCS 3494, Springer-Verlag 2005. - C. 19-35; Bellare, M. New Proofs for NMAC and HMAC: Security without Collision-Resistance [Текст] / M. Bellare. - M.: CRYPTO 2006, ePrint Archive, Report 2006/043. - 31 с.; To же [Электронный ресурс]. - Режим доступа: eprint.iacr.org/2006/043.pdf (2006)).
Недостатками данных способов являются:
- отсутствие возможности без ввода дополнительного механизма восстановления данных обеспечить их целостность;
- большое количество криптографических преобразований.
Известны способы обеспечения целостности данных за счет применения различных видов резервирования (с использованием программно-аппаратной или программной реализации технологии RAID (Redundant Array of Independent Disks) (RAID-массивы), методы дублирования, методы избыточного кодирования) (Патент РФ №2406118 публ. 10.04.2007; Патент РФ №2481632 публ. 10.05.2013; Патент РФ №2513725 публ. 20.04.2014; Патент РФ №2598991 публ. 10.10.2016; Патент США №7392458 публ. 24.06.2008; Патент США №7437658 публ. 14.10.2008; Патент США №7600176 публ. 06.10.2009; Заявка на патент США №20090132851 публ. 21.05.2009; Заявка на патент США №20100229033 публ. 09.09.2010; Заявка на патент США №20110114567 публ. 16.06.2011; Заявка на патент США №20110167294 публ. 07.07.2011; Заявка на патент США №20110264949 публ. 27.10.2011; Уоррен, Г. Подсчет битов: алгоритмические трюки для программистов (Hacker's Delight) [Текст] / Г. Уоррен, мл. - М.: «Вильямс», 2007. - 512 с.; Морелос-Сарагоса, Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение [Текст] / Р. Морелос-Сарагоса; перевод с англ. В.Б. Афанасьев. - М.: Техносфера, 2006. - 320 с.; Хемминг, Р.В. Теория кодирования и теория информации [Текст] / Р.В. Хемминг; перевод с англ. - М.: «Радио и связь», 1983. - 176 с.).
Недостатком данных способов является высокая избыточность.
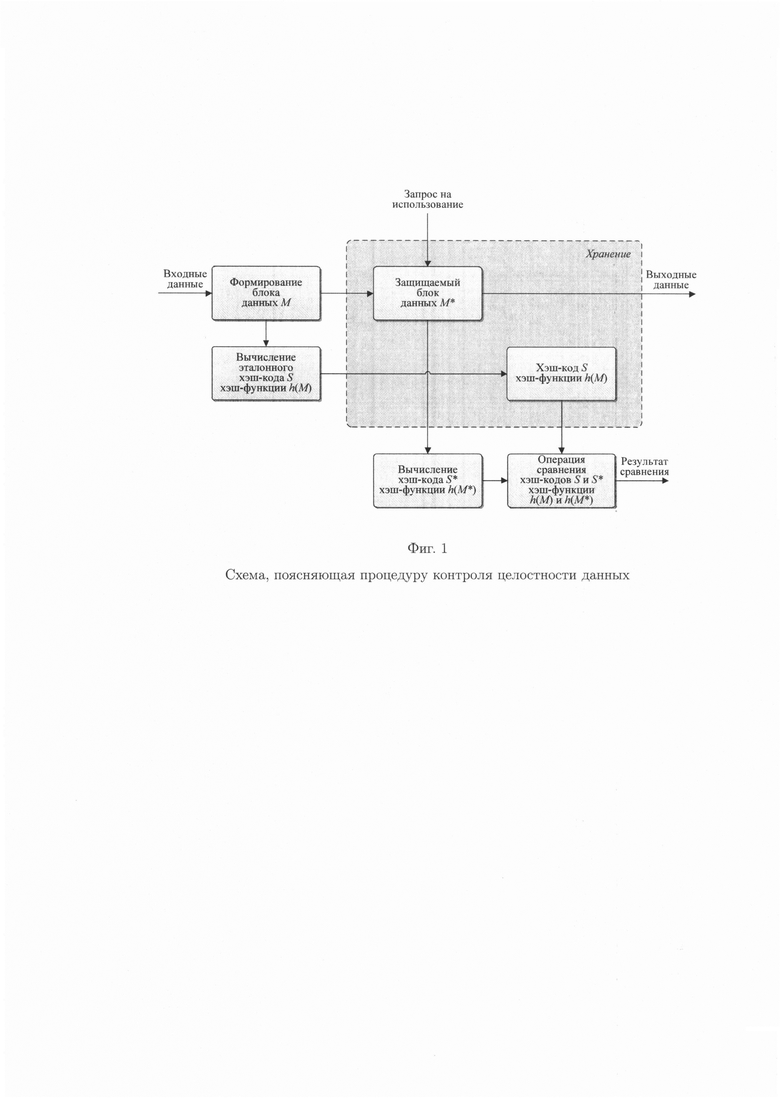
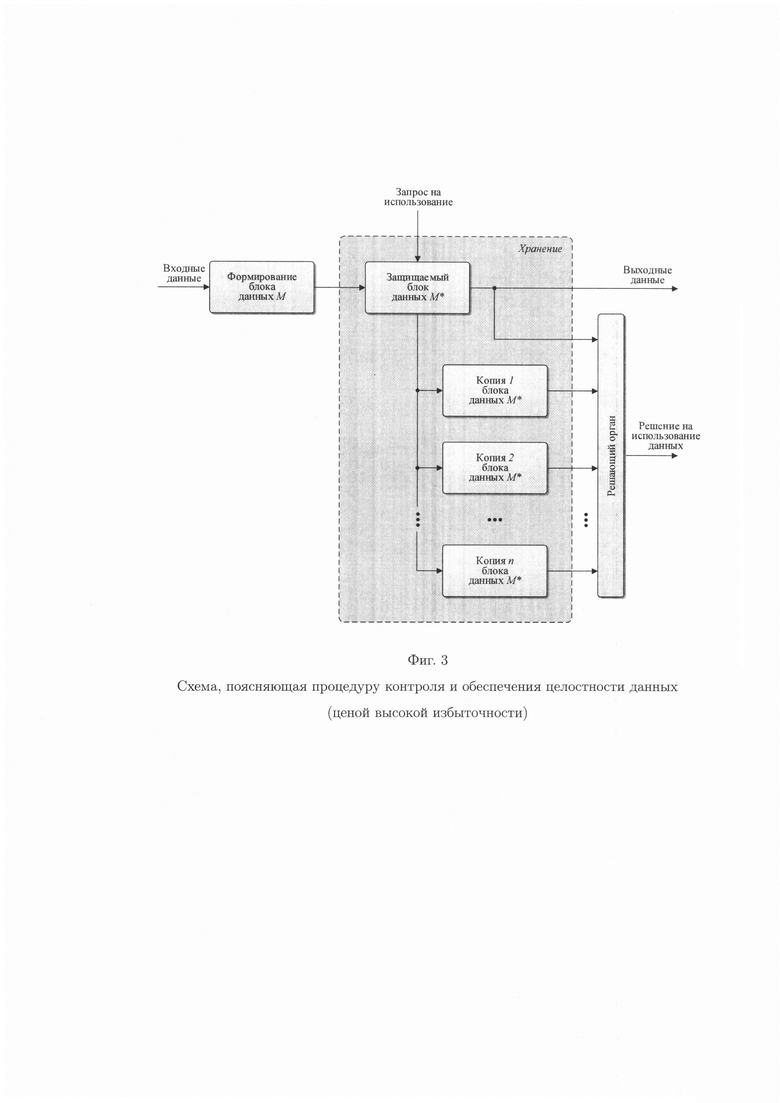
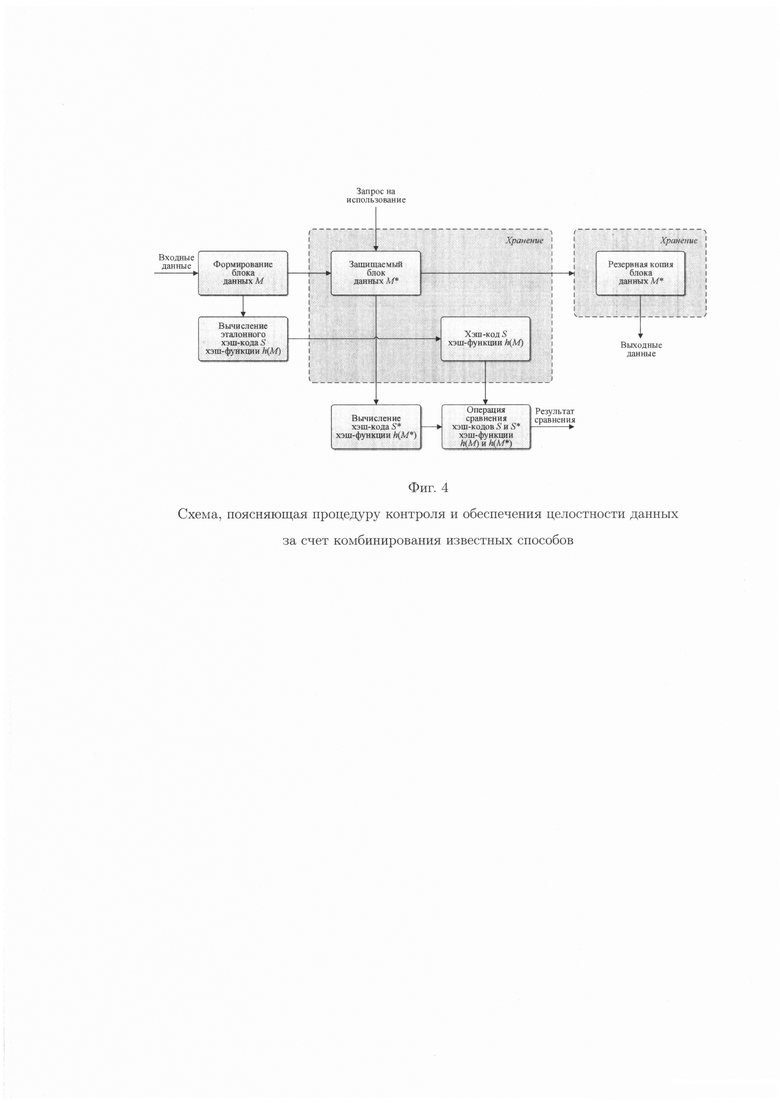
Представленные решения показывают, что часть способов позволяет осуществить контроль целостности данных путем сравнения значений эталонных и вычисляемых хэш-кодов хэш-функции (контрольных сумм) при запросе на использование хранящихся в памяти данных (фиг. 1), однако в них отсутствует механизм их восстановления в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника, что не обеспечивает их целостность. Другие способы, напротив, позволяют обеспечить целостность данных путем их восстановления, к примеру, из резервной копии (фиг. 2), однако практическое их использование без возможности осуществления контроля целостности данных является неэффективным. Отдельные способы позволяют осуществить контроль и обеспечить целостность данных, однако ценной высокой избыточности (фиг. 3). Наиболее популярными являются решения комплексной защиты целостности данных, связанной с одновременным решением задач контроля и обеспечения целостности данных, что достигается за счет последовательного применения сначала криптографического преобразования к данным, а затем применения технологии резервного копирования данных (фиг. 4). При этом, защита целостности данных актуальна как для систем типа RAID, где все носители размещены в одном конструктивном блоке, так и для распределенных систем хранения, то есть для сетевых хранилищ.
Так в Заявке на патент США №20050081048 публ. 14.04.2005 предложен способ защиты данных в RAID-массивах, согласно которому перед записью на RAID-массив (после чтения с RAID-массива) данные шифруются (расшифровываются) специально выделенным устройством, подключенным к PCI-шине. Ключ зашифрования/расшифрования считывается с внешнего запоминающего устройства и/или запрашивается у пользователя.
В Патенте США №7752676 публ. 06.07.2010 предложен способ защиты данных в сетевом хранилище, согласно которому, пользовательский запрос на чтение (запись) данных сначала проходит процедуру авторизации, и только в случае разрешения операции выполняется соответственно расшифрование (шифрование) данных на сетевом хранилище. Ключи зашифрования/расшифрования хранятся на стороне клиента.
Другой вариант комбинированной защиты предложен в Заявке на патент США №20110107103 публ. 05.05.2011, согласно которому данные хранятся в облаке, а модуль шифрования хранится не на стороне клиента, а на стороне провайдера облачного хранилища. Это решение предназначено, как правило, для защиты резервных копий данных в облаке, хотя оригинальные данные хранятся на стороне клиента в исходном виде. При этом для обеспечения защиты данных файл с данными сначала разбивается на части, а затем каждая часть преобразуется с помощью криптографического алгоритма и записывается на один или несколько носителей в облаке. Защита обеспечивается в случае, когда данные утрачиваются на стороне клиента. В этом случае резервная копия восстанавливается из облака.
Недостатком данных способов является отсутствие возможности без ввода дополнительного механизма контроля осуществить проверку правильности (достоверности, безошибочности) данных после восстановления при обеспечении их целостности в случае ее нарушения.
Анализ предшествующего уровня техники и возможностей показывает, что для защиты целостности данных при рассмотрении этого понятия в комплексе необходимо осуществить агрегирование существующих решений. Комбинирование известных способов в одном позволяет осуществить контроль и обеспечить целостность данных.
б) Описание ближайшего аналога (прототипа)
Наиболее близким по технической сущности к заявленному изобретению (прототипом) является способ защиты информации для RAID-массивов, согласно которому перед записью в массив данные разбиваются на несколько сегментов, после чего от данных из каждого сегмента отдельно вычисляются контрольные суммы. Сегменты данных и контрольные суммы далее распределяются по дискам RAID-массива (Патент США №8209551 публ. 26.06.2012).
Недостатком известного способа является отсутствие процедуры проверки правильности (достоверности, безошибочности) данных после восстановления при обеспечении их целостности в случае ее нарушения.
Раскрытие изобретения
а) Технический результат, на достижение которого направлено изобретение
Целью настоящего изобретения является разработка способа двумерного контроля и обеспечения целостности данных с возможностью проверки их достоверности после восстановления в случае нарушения их целостности в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника.
б) Совокупность существенных признаков
Поставленная цель достигается тем, что в известном способе защиты информации, заключающемся в том, что целостность данных обеспечивается за счет их резервирования с использованием технологии RAID, при которой для осуществления контроля целостности данных перед записью в массив блок данных М разбивается на несколько подблоков m1, …, mn; часть из которых шифруется, а часть остается в открытом виде, после чего от шифрованных и нешифрованных подблоков данных вычисляются контрольные суммы, которые вместе с подблоками m1, …, mn распределяются по дискам RAID-массива, в представленном же способе для осуществления контроля целостности блоки данных Mi (i=1, 2, …, n) представляются в виде подблоков фиксированной длины mi,1, mi,2, …, mi,n количество которых в блоке данных соответствует числу самих блоков данных, подлежащих защите. От блоков данных Mi предварительно вычисляются эталонные хэш-коды Si хэш-функции h(Mi), значения которых в последующем сравниваются со значениями хэш-кодов 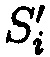 хэш-функции
хэш-функции 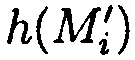 , вычисляемых уже от проверяемых блоков данных
, вычисляемых уже от проверяемых блоков данных 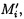 подблоки которых также являются подблоками блоков данных
подблоки которых также являются подблоками блоков данных 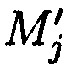 (j=1, 2, …, n), которые для обеспечения целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков m1,j, m2,j, …, mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных
(j=1, 2, …, n), которые для обеспечения целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков m1,j, m2,j, …, mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных 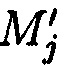 в случае нарушения их целостности, вычисление контрольной группы (k-n) подблоков mn+1,j, mn+2,j, …, mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных
в случае нарушения их целостности, вычисление контрольной группы (k-n) подблоков mn+1,j, mn+2,j, …, mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных 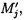 без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока
без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока 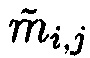 с возникшей ошибкой, после чего от полученного результата вычисляется подблок mi,j взамен ранее исключенного, после восстановления данных осуществляется проверка их достоверности путем сравнения значений вычисленных хэш-кодов
с возникшей ошибкой, после чего от полученного результата вычисляется подблок mi,j взамен ранее исключенного, после восстановления данных осуществляется проверка их достоверности путем сравнения значений вычисленных хэш-кодов 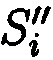 хэш-функции
хэш-функции 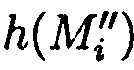 уже от восстановленных блоков данных
уже от восстановленных блоков данных 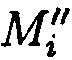 со значениями предварительно вычисленных эталонных хэш-кодов Si хеш-функции h(Mi) от первоначальных блоков данных Mi.
со значениями предварительно вычисленных эталонных хэш-кодов Si хеш-функции h(Mi) от первоначальных блоков данных Mi.
Сопоставительный анализ заявленного решения с прототипом показывает, что предлагаемый способ отличается от известного тем, что поставленная цель достигается за счет контроля целостности данных путем сравнения значений предварительно вычисленных эталонных хэш-кодов хэш-функции от первоначальных блоков данных со значениями вычисленных хэш-кодов хэш-функции от проверяемых блоков данных, подблоки которых для обеспечения целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, что позволяет восстановить данные, то есть обеспечить их целостность в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника, для проверки достоверности данных после восстановления осуществляется сравнение значений хэш-кодов хэш-функции уже от восстановленных блоков данных со значениями предварительно вычисленных эталонных хэш-кодов хэш-функции от первоначальных блоков данных.
Контроль целостности блоков данных Mi будет осуществляться путем сравнения значений предварительно вычисленных от них эталонных хэш-кодов Si хэш-функции h(Mi) со значениями хэш-кодов 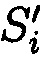 хэш-функции
хэш-функции 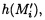 вычисленных уже от проверяемых блоков данных
вычисленных уже от проверяемых блоков данных 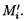 При нарушении целостности данных в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника (в результате преднамеренного несанкционированного изменения данных (например, посредством действия вредоносного кода) или выхода из строя части носителя (например, отдельных ячеек, секторов)) в момент времени t будет осуществляться восстановление блоков данных
При нарушении целостности данных в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника (в результате преднамеренного несанкционированного изменения данных (например, посредством действия вредоносного кода) или выхода из строя части носителя (например, отдельных ячеек, секторов)) в момент времени t будет осуществляться восстановление блоков данных 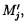 то есть обеспечение их целостности за счет особого построения его подблоков mi,j, которые на подготовительном этапе были сформированы по правилам, аналогичным правилам построения избыточных модулярных кодов. Коррекция возникающей ошибки будет осуществляться по известным правилам, применяемым при использовании кодов в модулярной арифметики (МА) (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.). Проверка достоверности данных после восстановления будет осуществляться путем сравнения значений предварительно вычисленных эталонных хэш-кодов Si хэш-функции h(Mi) от первоначальных блоков данных Mi со значениями хэш-кодов
то есть обеспечение их целостности за счет особого построения его подблоков mi,j, которые на подготовительном этапе были сформированы по правилам, аналогичным правилам построения избыточных модулярных кодов. Коррекция возникающей ошибки будет осуществляться по известным правилам, применяемым при использовании кодов в модулярной арифметики (МА) (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.). Проверка достоверности данных после восстановления будет осуществляться путем сравнения значений предварительно вычисленных эталонных хэш-кодов Si хэш-функции h(Mi) от первоначальных блоков данных Mi со значениями хэш-кодов 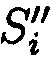 хэш-функции
хэш-функции 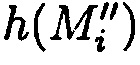 уже от восстановленных блоков данных
уже от восстановленных блоков данных 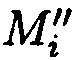 . Новым является то, что в предлагаемом способе получение совокупностей подблоков m1,j, m2,j, …, mn,j, mn+1,j, …, mk,j интерпретируется как построение избыточного модулярного кода, что позволяет обнаружить возникающую ошибку на любой стадии их обработки (при условии, что кратность гарантированно обнаруживаемой ошибки tобн=dmin-1, где dmin - минимальное кодовое расстояние). Новым является то, что восстановление блоков данных
. Новым является то, что в предлагаемом способе получение совокупностей подблоков m1,j, m2,j, …, mn,j, mn+1,j, …, mk,j интерпретируется как построение избыточного модулярного кода, что позволяет обнаружить возникающую ошибку на любой стадии их обработки (при условии, что кратность гарантированно обнаруживаемой ошибки tобн=dmin-1, где dmin - минимальное кодовое расстояние). Новым является то, что восстановление блоков данных 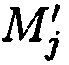 в случае нарушения их целостности возможно путем исключения из процесса восстановления любых r подблоков без ущерба для однозначности их представления (где r=k-n - количество дополнительных подблоков), вследствие чего система подблоков блоков данных
в случае нарушения их целостности возможно путем исключения из процесса восстановления любых r подблоков без ущерба для однозначности их представления (где r=k-n - количество дополнительных подблоков), вследствие чего система подблоков блоков данных 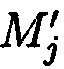 будет интерпретироваться как несистематический или неразделимый код (где каждая разрядная цифра несет часть информации о числе, включая и избыточные символы, а также любые из r разрядных цифр можно считать избыточными символами), после чего вычисляется подблок mi,j взамен ранее исключенного подблока
будет интерпретироваться как несистематический или неразделимый код (где каждая разрядная цифра несет часть информации о числе, включая и избыточные символы, а также любые из r разрядных цифр можно считать избыточными символами), после чего вычисляется подблок mi,j взамен ранее исключенного подблока 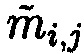 с обнаруженной ошибкой. Новым является то, что сравнение значений предварительно вычисленных эталонных хэш-кодов Si хэш-функции h(Mi) от первоначальных блоков данных Mi в отличие от способа-прототипа позволяет не только осуществить контроль целостности данных, путем их сравнения со значениями хэш-кодов
с обнаруженной ошибкой. Новым является то, что сравнение значений предварительно вычисленных эталонных хэш-кодов Si хэш-функции h(Mi) от первоначальных блоков данных Mi в отличие от способа-прототипа позволяет не только осуществить контроль целостности данных, путем их сравнения со значениями хэш-кодов  хэш-функции от проверяемых блоков данных
хэш-функции от проверяемых блоков данных 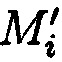 , но и выполнить проверку достоверность данных после восстановления при обеспечении их целостности при их сравнении со значениями хэш-кодов
, но и выполнить проверку достоверность данных после восстановления при обеспечении их целостности при их сравнении со значениями хэш-кодов 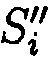 хэш-функции
хэш-функции 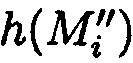 уже от восстановленных блоков данных
уже от восстановленных блоков данных 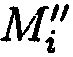 .
.
в) Причинно-следственная связь между признаками и техническим результатом
Благодаря новой совокупности существенных признаков в способе реализована возможность:
- обнаружения возникающей ошибки в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника;
- коррекции обнаруженной ошибки;
- восстановления первоначальных блоков данных в случае нарушения их целостности посредством осуществления реконфигурации системы путем исключения из вычислений подблока с возникшей ошибкой, после чего вычисление нового подблока взамен ранее исключенного;
- проверки достоверности данных после восстановления при обеспечении их целостности в случае ее нарушения.
Доказательства соответствия заявленного изобретения условиям патентоспособности «новизна» и «изобретательский уровень»
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обуславливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показано:
фиг. 1 - схема, поясняющая процедуру контроля целостности данных;
фиг. 2 - схема, поясняющая процедуру восстановления данных из резервной копии;
фиг. 3 - схема, поясняющая процедуру контроля и обеспечения целостности данных (ценной высокой избыточности);
фиг. 4 - схема, поясняющая процедуру контроля и обеспечения целостности данных за счет комбинирования известных способов;
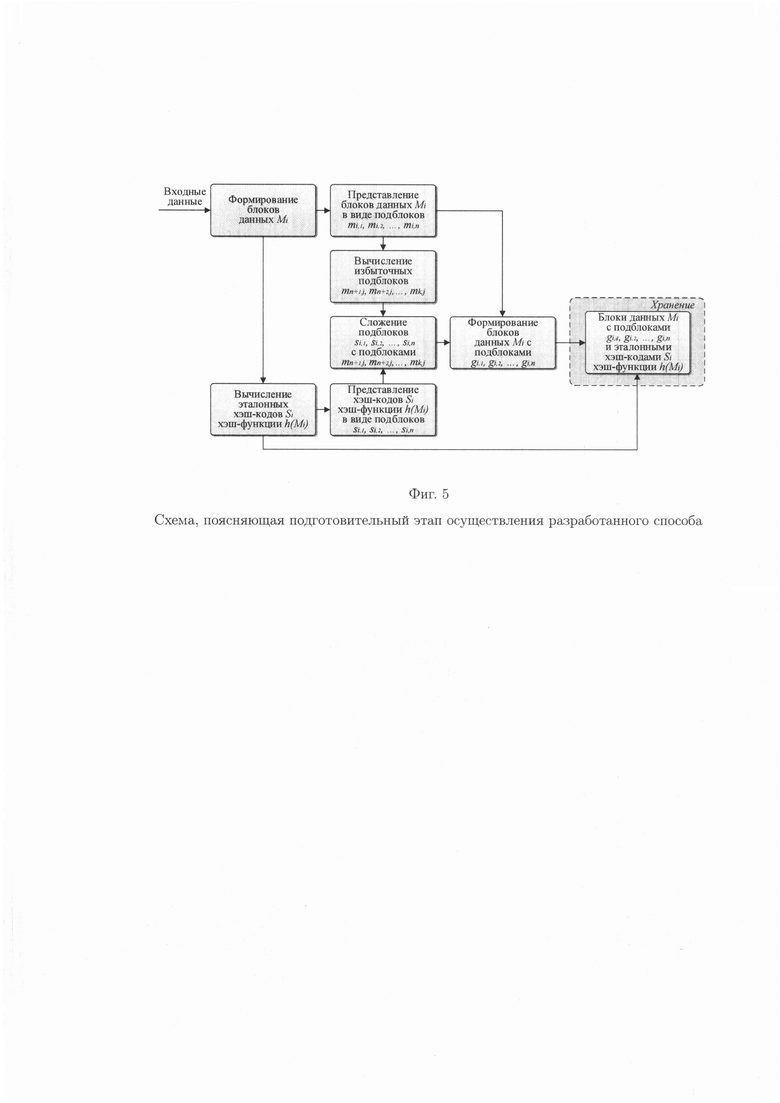
фиг. 5 - схема, поясняющая подготовительный этап осуществления разработанного способа;
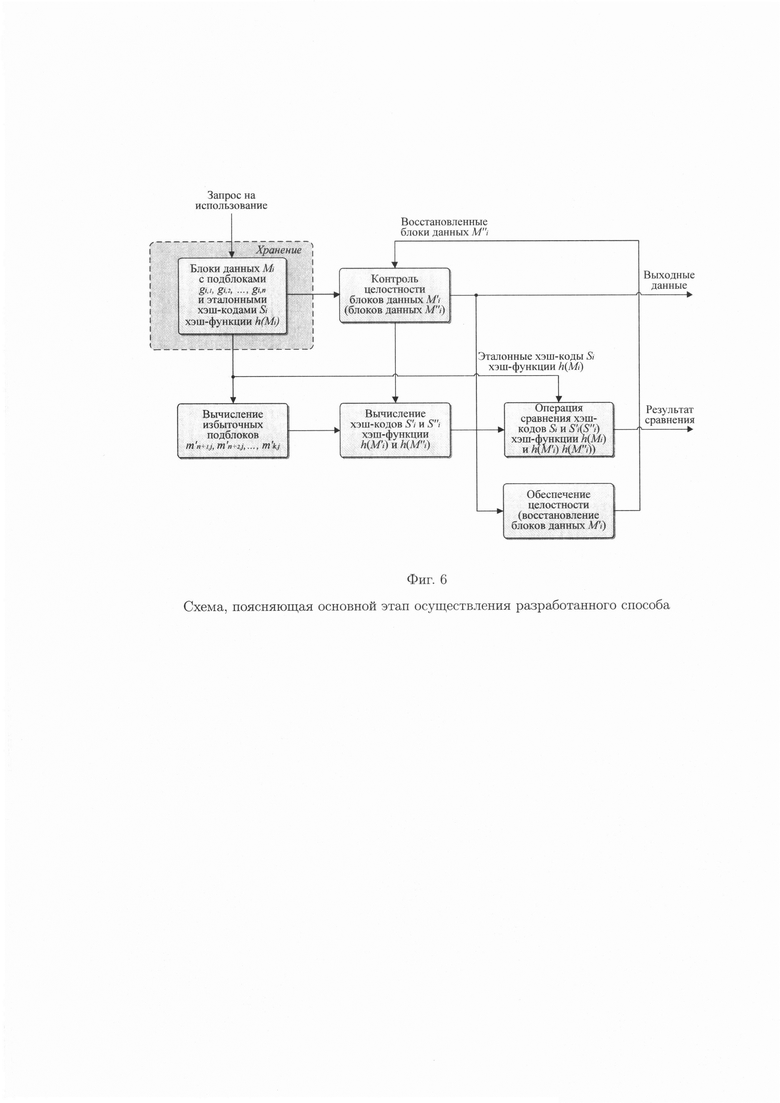
фиг. 6 - схема, поясняющая основной этап осуществления разработанного способа;
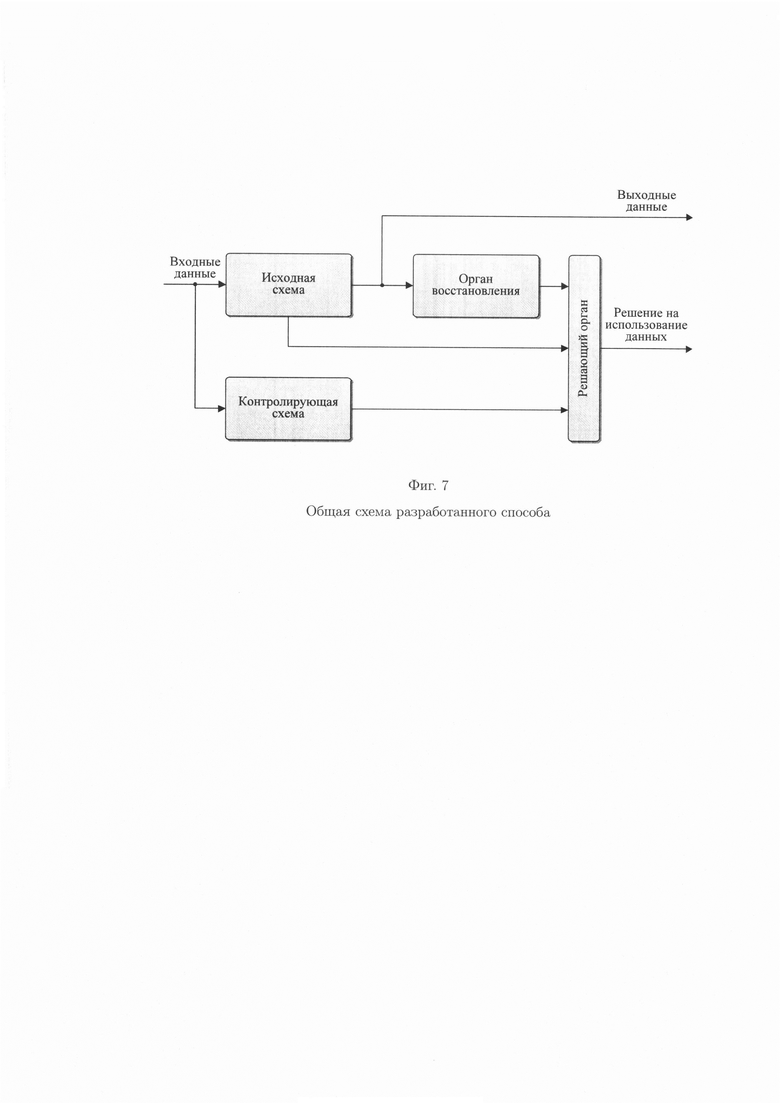
фиг. 7 - общая схема разработанного способа.
Осуществление изобретения
Возможность реализации заявленного способа объясняется следующим.
Для осуществления контроля и обеспечения целостности данных блоки данных Mi (i=1, 2, …, n), подлежащие защите, представляются в виде подблоков фиксированной длины Mi={mi,1||mi,2||…||mi,n}, где || - операция конкатенации, n - количество блоков данных Mi, подлежащих защите, а также подблоков фиксированной длины в каждом рассматриваемом блоке данных Mi. Причем длина блоков данных Mi определяется действующим государственным стандартом (ГОСТ Р 34.11-2012. Информационная технология. Криптографическая защита информации. Функция хэширования) и равняется 512 бит.
Получим матрицу W:
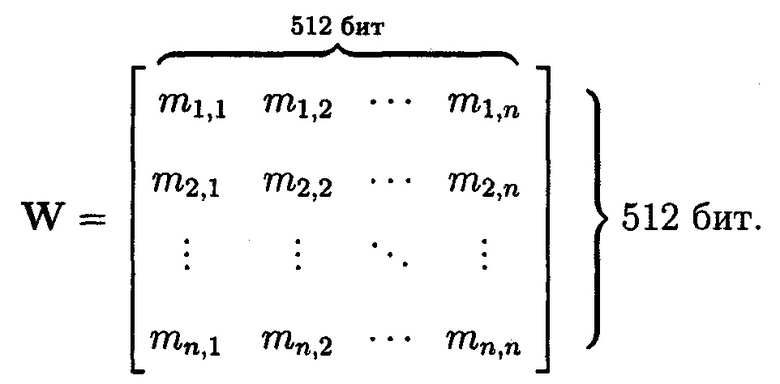
Пример 1
При представлении блоков данных Mi подблоками mi,1, mi,2, …, mi,n размером по 64 бит их количество будет равняться n=8.
Матрица W примет вид:

На подготовительном этапе разработанного способа к блокам данных М, применяется хэш-функция.
В соответствии с международным (ИСО/МЭК 14888-1: 2008. Информационные технологии. Методы защиты. Цифровые подписи с дополнением. Часть 1. Общие положения) и государственным (ГОСТ Р 34.11-2012. Информационная технология. Криптографическая защита информации. Функция хэширования) стандартами определим:
Определение 1. Под хэш-функцией h понимается функция, отображающая блоки бит М∈(0,1)* в строки бит фиксированной длины S∈(0,1)q:h(M)=S, где «( )*» - произвольный размер блока бит, «(
)*» - произвольный размер блока бит, «( )q» - фиксированный размер блока бит, q∈N, и удовлетворяющая следующим свойствам:
)q» - фиксированный размер блока бит, q∈N, и удовлетворяющая следующим свойствам:
- по данному значению хэш-функции S∈(0,1)q сложно вычислить исходные данные М∈(0,1)*, отображаемые в это значение;
- для заданных исходных данных М1∈(0,1)* сложно вычислить другие исходные данные M2∈(0,1)*, отображаемые в то же значение хэш-функции, то есть h(M1)=h(М2), где М1≠М2;
- сложно вычислить какую-либо пару исходных данных (М1, М2), где М1≠М2, Mt∈(0,1)*, t=1, 2, отображаемых в одно и то же значение хэш-функции, то есть h(M1)=h(M2).
Определение 2. Под хэш-кодом понимается строка бит S∈(0,1)q, являющаяся выходным результатом хэш-функции h.
Определение 3. Строки бит М∈(0,1)*, которые хэш-функция h отображает в хэш-код S∈(0,1)q, будут называться блоком данных.
Полученные хэш-коды Si хэш-функции h(Mi) от блоков данных Mi будут являться эталонными, получим матрицу 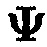 :
:
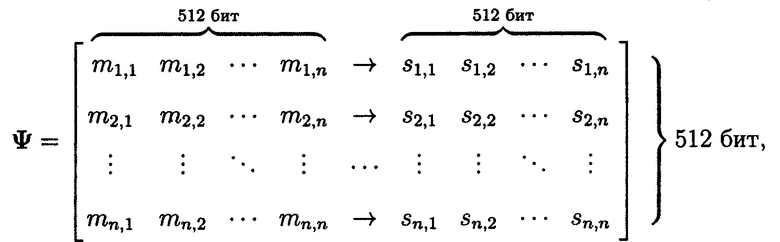
где Si=h(Mi), Si={si,1||si,2||…||si,n}.
Пример 2
В таблице 1 представлены вычисленные в соответствии с ГОСТ Р 34.11-2012 хэш-коды Si хэш-функции h(Mi) от произвольных блоков данных Mi (строки бит представлены в 16-ричной системе счисления).

Далее рассматриваются блоки данных Mj (j=1, 2, …, n), представленные подблоками m1,1, m2,1, …, mn,1; m1,2, m2,2, …, mn,2; …; m1,n, m2,n, …, mn,n. Подблоки mi,j рассматриваемых блоков данных Mj интерпретируются как наименьшие неотрицательные вычеты по сгенерированным, упорядоченным по величине, взаимно простым модулям pi,j, и образуют информационный суперблок модулярного кода (МК).
После операции расширения формируются избыточные подблоки mn+1,1, mn+2,1, …, mk,1; mn+1,2, mn+2,2, …, mk,2; …; mn+1,n, mn+2,n, …, mk,n, совокупность которых, а также подблоки, образующие информационный суперблок МК, образуют кодовый вектор МК.
Получим матрицу 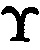 с избыточными подблоками кодового вектора МК:
с избыточными подблоками кодового вектора МК:

Выполняется сложение i-х подблоков хэш-кодов Si с j-ми избыточными подблоками блоков данных 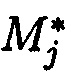 кодового вектора МК:
кодового вектора МК:
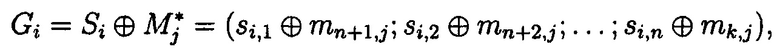
где Si=[si,1 si,2 … si,n], 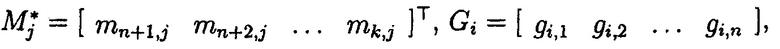 i=j, знаком «
i=j, знаком « » обозначается суммирование в поле Галуа GF(2).
» обозначается суммирование в поле Галуа GF(2).
Матрица  примет вид:
примет вид:
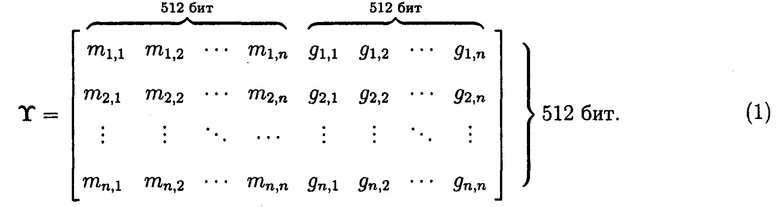
По окончанию подготовительного этапа разработанного способа (фиг. 5) данные, подлежащие хранению, представляются в виде (1), что позволит осуществить контроль и обеспечить их целостность.
При запросе на использование данных (основной этап), находящихся на хранении, осуществляется контроль их целостности. Для этого выполняется операция расширения информационного суперблока МК, при этом формируются избыточные подблоки  , блоков данных
, блоков данных  кодового вектора МК, где «
кодового вектора МК, где « » обозначает, что при хранении данных в подблоках
» обозначает, что при хранении данных в подблоках  блоков данных
блоков данных  могли произойти изменения.
могли произойти изменения.
Матрица  с избыточными подблоками кодового вектора МК примет вид:
с избыточными подблоками кодового вектора МК примет вид:
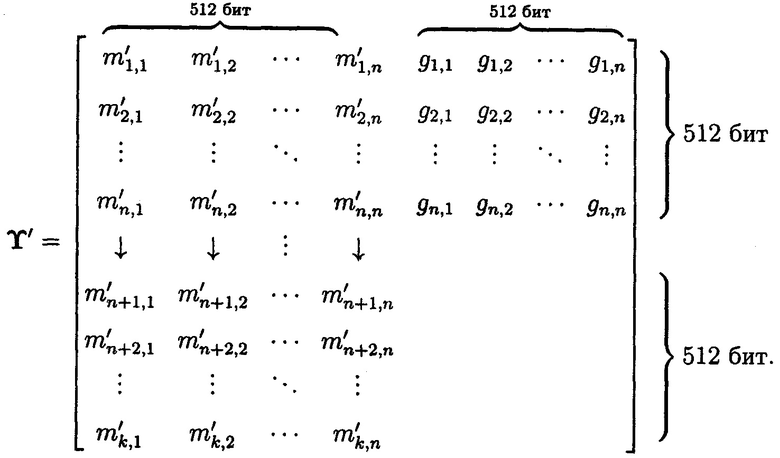
Выполняется обратное преобразование:
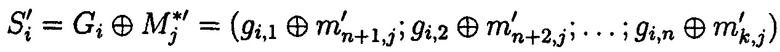
где 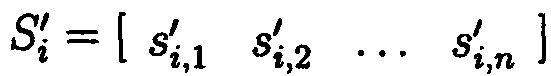
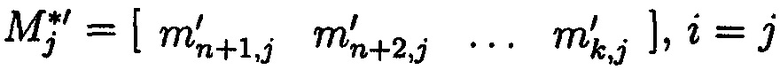
Выполняется сравнение значений полученных хэш-кодов 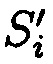 хэш-функции
хэш-функции 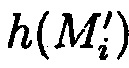 со значениями ранее вычисленных эталонных хэш-кодов Si хэш-функции h(Mi), по результатом которого делается вывод:
со значениями ранее вычисленных эталонных хэш-кодов Si хэш-функции h(Mi), по результатом которого делается вывод:
- об отсутствии нарушения целостности данных, при 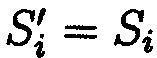 ;
;
- о нарушении целостности данных, при 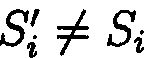
При несоответствии значений сравниваемых между собой хэш-кодов хэш-функции, что будет характеризоваться возникновением ошибки (нарушением целостности) в хранящихся данных, производится ее локализация.
Локализация обнаруженной ошибки (подблока 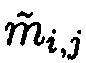 с нарушением целостности) выполняется первоначально по строкам матрицы
с нарушением целостности) выполняется первоначально по строкам матрицы 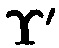 (определяется i-й блок данных с нарушением целостности, в который входит подблок
(определяется i-й блок данных с нарушением целостности, в который входит подблок 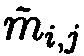 ), а затем по столбцам (определяется j-й блок данных с нарушением целостности, в который входит подблок
), а затем по столбцам (определяется j-й блок данных с нарушением целостности, в который входит подблок 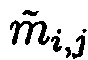 ).
).
Блок данных 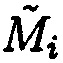 с нарушением целостности, подблоки которого располагаются по строке матрицы
с нарушением целостности, подблоки которого располагаются по строке матрицы 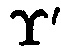 , определяется по результатам сравнения значений вычисленных и эталонных хэш-кодов хэш-функции. Блок данных
, определяется по результатам сравнения значений вычисленных и эталонных хэш-кодов хэш-функции. Блок данных 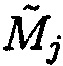 с нарушением целостности, подблоки которого располагаются по столбцу матрицы
с нарушением целостности, подблоки которого располагаются по столбцу матрицы 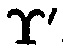 , определяется посредством математического аппарата избыточных модулярных кодов, основанного на фундаментальных положениях Китайской теоремы об остатках.
, определяется посредством математического аппарата избыточных модулярных кодов, основанного на фундаментальных положениях Китайской теоремы об остатках.
В соответствии с математическим аппаратом МА, при котором проверяемый блок данных Mj будет интерпретироваться как целое неотрицательное число Aj, однозначно представленное набором остатков по основаниям MA p1,j, p2,j, …, pn,j<Pn+1,j<…<Pk,j:
Aj=(α1,j, α2,j, …, αn,j, αn+1,j, …, αk,j)MA,
где Pn,j=p1,jp2,j … pn,j>Aj; 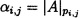 ;
; 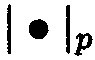 - наименьший неотрицательный вычет числа «
- наименьший неотрицательный вычет числа « » по модулю р; p1,j, p2,j, …, pn,j<pn+1,j<…<pk,j - попарно простые; i=1, 2, …, n; j=1, 2, …, n, n+1, …, k (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.; Торгашев, В.А. Система остаточных классов и надежность ЦВМ [Текст] / В.А. Торгашев. - М.: Советское радио, 1973. - 120 с.).
» по модулю р; p1,j, p2,j, …, pn,j<pn+1,j<…<pk,j - попарно простые; i=1, 2, …, n; j=1, 2, …, n, n+1, …, k (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.; Торгашев, В.А. Система остаточных классов и надежность ЦВМ [Текст] / В.А. Торгашев. - М.: Советское радио, 1973. - 120 с.).
Полученные остатки αi,j будут интерпретироваться как подблоки mi,j блока данных Mj, то есть остатки MA α1,j, α2,j, …, αn,j будут интерпретироваться как подблоки m1,j, m2,j, …, mn,j и считаться информационными (информационной группой n подблоков), а αn+1,j, …, αk,j - интерпретироваться как подблоки mn+1,j, …, mk,j и считаться контрольными (избыточными) (контрольной (избыточной) группой (k-n) подблоков). Сама МА является в этом случае расширенной, где Pk,j=Pn,jpn+1,j…pk,j, и охватывает полное множество состояний, представляемых всеми k вычетами. Эта область будет являться полным диапазоном МА [0, Pk,j) и состоять из рабочего диапазона [0, Pn,j), где Pn,j=p1,jp2,j…pn,j, определяемого неизбыточными основаниями МА (подблоками m1,j, m2,j, …, mn,j), и диапазона [Pn,j, Pk,j), определяемого избыточными основаниями МА (подблоками mn+1, …, mk) и представляющего недопустимую область. Это означает, что операции над числом Aj выполняются в диапазоне [0, Pk,j), и если результат операции МА выходит за пределы Pn,j, то следует вывод об ошибке вычислений. Проверка этого правила позволяет локализовать ошибку в блоке данных 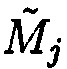 матрицы
матрицы 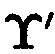 .
.
Пример 3
Выберем систему оснований р1=2, р2=3, р3=5, р4=7, для которой рабочий диапазон равен Р4=p1p2p3p4=2⋅3⋅5⋅7=210. Введем контрольные основания р5=11, р6=13, тогда полный диапазон определяется как Р6=P4p5p6=210⋅11⋅13=30030.
Вычислим ортогональные базисы системы:
B1=(1,0,0,0,0,0)=15015; В2=(0,1,0,0,0,0)=20020; В3=(0,0,1,0,0,0)=6006;
В4=(0,0,0,1,0,0)=25740; В5=(0,0,0,0,1,0)=16380; В6=(0,0,0,0,0,1)=6930.
Дано число А=(1,2,2,3,6,4)=17. Вместо него при обработке данных получили. Ã=(1,2,2,3,1,4) Для локализации ошибки вычисляем величину числа 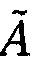 :
:
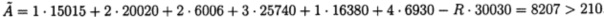 .
.
Полученное число является неправильным 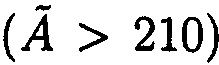 , что свидетельствует об ошибке при обработке данных. В результате локализации определили, что ошибочна цифра
, что свидетельствует об ошибке при обработке данных. В результате локализации определили, что ошибочна цифра 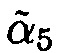 по основанию р5=11.
по основанию р5=11.
После определения блоков данных 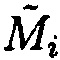 и
и 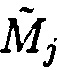 с нарушением целостности принимается решение о том, что в подблоке
с нарушением целостности принимается решение о том, что в подблоке 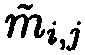 , находящемся на пересечении локализованных строки и столбца матрицы
, находящемся на пересечении локализованных строки и столбца матрицы 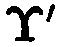 , произошла ошибка (нарушение целостности данных).
, произошла ошибка (нарушение целостности данных).
После локализации ошибки (нахождения подблока 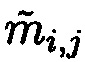 с нарушением целостности) производится операция реконфигурации, возможность выполнения которой обеспечивается посредством математического аппарата избыточных модулярных кодов, в частности, следующей теоремы:
с нарушением целостности) производится операция реконфигурации, возможность выполнения которой обеспечивается посредством математического аппарата избыточных модулярных кодов, в частности, следующей теоремы:
Теорема 1. Пусть основания p1, p2, …, pw, pw+1 МА удовлетворяют условию pi<pw+1 (i=1, 2, …, w) и пусть А=(α1, α2, …, αi, …, αw, αw+1) - правильное число. Тогда величина числа А не изменится, если представлять его в системе оснований, из которой изъято основание pi (то есть если в представлении А зачеркнуть цифру αi).
Доказательство. Неравенство 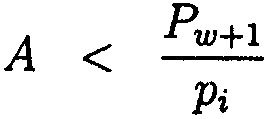 тождественно следующему неравенству А<р1р2, …, pi-1 pi+1, …, pw+1 и, следовательно, число А может быть единственным образом представлено своими остатками по этим основаниям (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.).
тождественно следующему неравенству А<р1р2, …, pi-1 pi+1, …, pw+1 и, следовательно, число А может быть единственным образом представлено своими остатками по этим основаниям (Акушский, И.Я. Машинная арифметика в остаточных классах [Текст] / И.Я. Акушский, Д.И. Юдицкий. - М.: Советское радио, 1968. - 440 с.).
Операция реконфигурации выполняется вычислением А* из системы
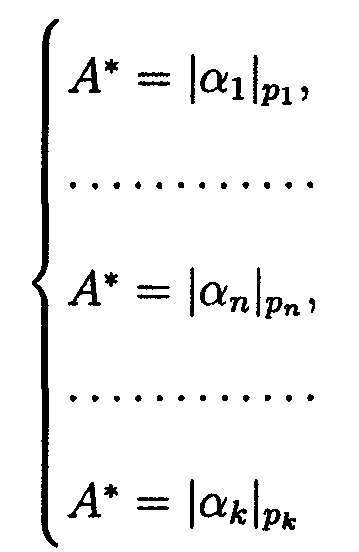
по «правильным» основаниям МА:
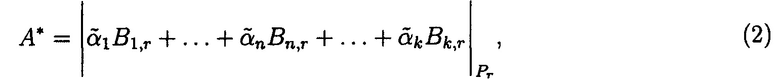
где 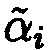 - ошибочный остаток; Bi,r - ортогональные базисы; i=r=1, …, n, …, k; i≠r;
- ошибочный остаток; Bi,r - ортогональные базисы; i=r=1, …, n, …, k; i≠r; 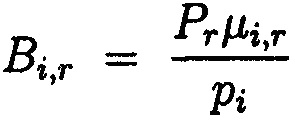 ;
; 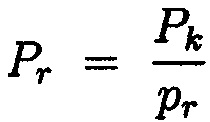 ; μi,r подбирается так, чтобы имело место следующее сравнение:
; μi,r подбирается так, чтобы имело место следующее сравнение: 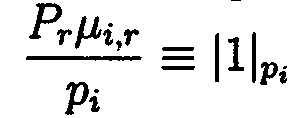
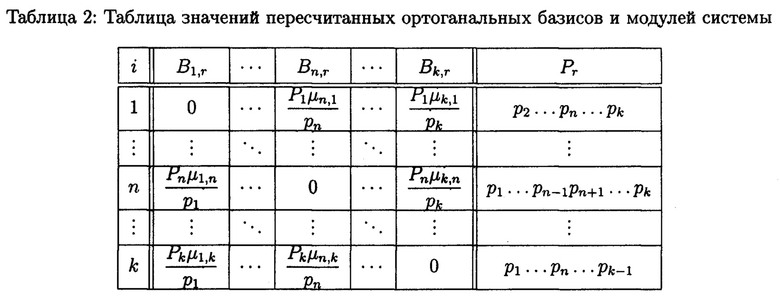
Составляется таблица 2, содержащая значения ортогональных базисов и модулей системы при условии возникновения однократной ошибки по каждому основанию МА соответственно.
После вычисления А* по правильным основаниям системы вычисляется αi взамен ранее исключенного из вычисления ошибочного остатка 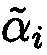 :
:

Пример 4
В соответствии с (2) вычислим А* (исходные данные из Примера 3), используя таблицу 2, получим
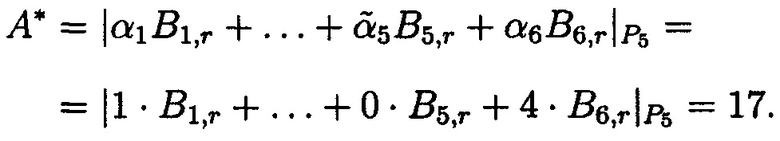
В соответствии с (3) вычислим αi, получим
αi=|A*|pi=|17|11=6.
При выполнении реконфигурации с учетом обнаружения и локализации двухкратной ошибки по двум основаниям системы А* вычисляется следующим образом:
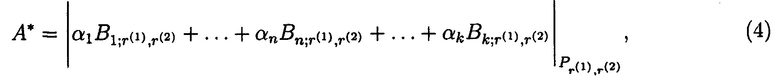
где 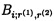 - ортогональный базис; i, r(1), r(2)=1, 2, …, n, …, k; i≠r(1)≠r(2);
- ортогональный базис; i, r(1), r(2)=1, 2, …, n, …, k; i≠r(1)≠r(2); 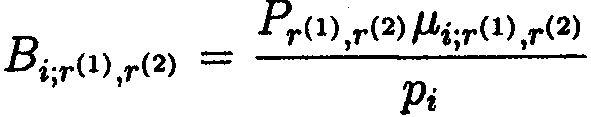 ;
;  ;
; 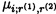 - целое положительное число (вес ортогонального базиса); подбирается так, чтобы имело место следующее сравнение:
- целое положительное число (вес ортогонального базиса); подбирается так, чтобы имело место следующее сравнение: 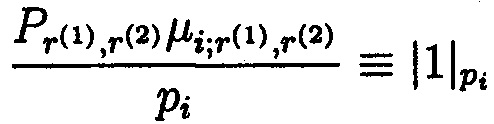 .
.
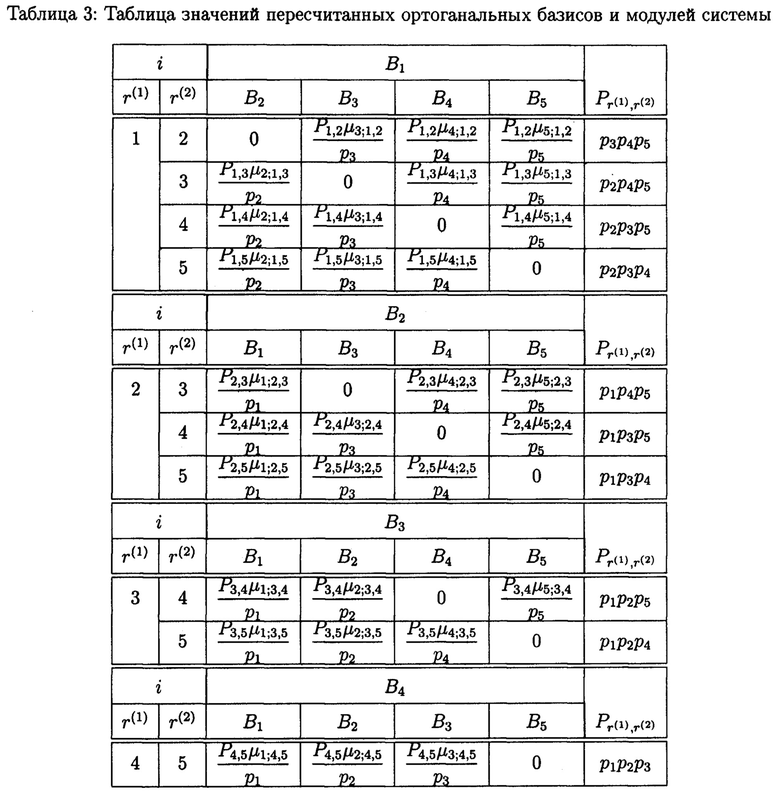
Для реализации (4) предварительно составляется таблица 3, содержащая значения пересчитанных ортоганальных базисов и модулей системы (включающей пять оснований) для условия возникновения двукратной ошибки по двум различным основаниям системы.
Так как кратность ошибки равна двум, а общее количество возможных ошибок равно количеству модулей системы (по условию равно пяти), то для вычисления количества возможных сочетаний ошибок необходимо использовать биномиальные коэффициенты:
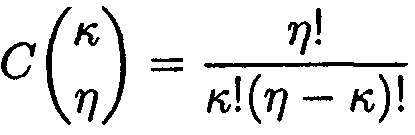
где η - общее количество возможных ошибок, 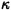 - кратность ошибки.
- кратность ошибки.
Для рассматриваемого случая 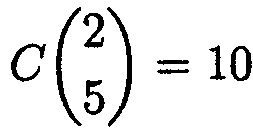 .
.
Таким образом, целостность блока данных Mi была обеспечена, путем осуществления контроля и восстановления подблока данных  с нарушением целостности.
с нарушением целостности.
Выполнение проверки правильности (достоверности, безошибочности) данных после восстановления при обеспечении их целостности в случае ее нарушения осуществляется путем сравнения значения предварительно вычисленного эталонного хэш-кода Si хэш-функции h(Mi) от блока данных Mi со значением вычисленного хэш-кода 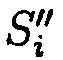 хэш-функции
хэш-функции 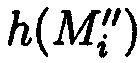 уже от восстановленного блока данных
уже от восстановленного блока данных 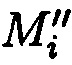 (фиг. 6).
(фиг. 6).
Общая схема разработанного способа двумерного контроля и обеспечения целостности данных представлена на рисунке (фиг. 7).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОНТРОЛЯ И ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2017 |
|
RU2680739C1 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ДАННЫХ С ПОДТВЕРЖДЕННОЙ ЦЕЛОСТНОСТЬЮ | 2021 |
|
RU2771238C1 |
| СПОСОБ КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ | 2021 |
|
RU2771208C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ ПРИ ДЕГРАДАЦИИ МНОГОМЕРНЫХ СИСТЕМ ХРАНЕНИЯ | 2023 |
|
RU2833352C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2017 |
|
RU2680033C2 |
| СПОСОБ МНОГОУРОВНЕВОГО КОНТРОЛЯ И ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2019 |
|
RU2707940C1 |
| СПОСОБ КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ В УСЛОВИЯХ ДЕГРАДАЦИИ СИСТЕМ ХРАНЕНИЯ | 2022 |
|
RU2801124C1 |
| СПОСОБ КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ ОДНОМЕРНЫХ МАССИВОВ ДАННЫХ НА ОСНОВЕ КОМПЛЕКСИРОВАНИЯ КРИПТОГРАФИЧЕСКИХ МЕТОДОВ И МЕТОДОВ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ | 2022 |
|
RU2786617C1 |
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ | 2021 |
|
RU2771236C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ В УСЛОВИЯХ КРИТИЧЕСКОЙ ДЕГРАДАЦИИ СИСТЕМ ИХ ХРАНЕНИЯ | 2023 |
|
RU2828227C1 |

Изобретение относится к области защиты данных, а именно к контролю и обеспечению целостности данных при их обработке. Технический результат – обеспечение возможности проверки достоверности данных после восстановления в случае нарушения целостности. Способ двумерного контроля и обеспечения целостности данных заключается в том, что путем сравнения значений предварительно вычисленных эталонных хэш-кодов хэш-функции от блоков данных, подлежащих защите, со значениями вычисленных хэш-кодов хэш-функции от проверяемых блоков данных, подблоки которых формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, что позволяет восстановить данные в случае нарушения их целостности, то есть обеспечить их целостность в условиях как случайных ошибок, так и ошибок, генерируемых посредством преднамеренных воздействий злоумышленника, для проверки достоверности данных после восстановления осуществляется сравнение значений хэш-кодов хэш-функции уже от восстановленного блока данных со значениями предварительно вычисленного хэш-кода хэш-функции от первоначального блока данных. 7 ил., 3 табл.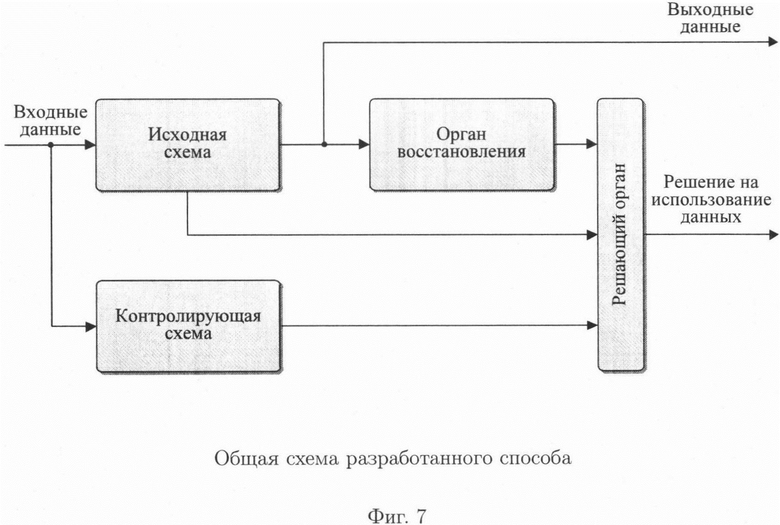
Способ двумерного контроля и обеспечения целостности данных, заключающийся в том, что целостность данных обеспечивается за счет их резервирования с использованием технологии RAID, при которой для осуществления контроля целостности данных перед записью в массив блок данных М разбивается на несколько подблоков m1, …, mn; часть из которых шифруется, а часть остается в открытом виде, после чего от шифрованных и нешифрованных подблоков данных вычисляются контрольные суммы, которые вместе с подблоками m1, …, mn распределяются по дискам RAID-массива, отличающийся тем, что для осуществления контроля целостности блоки данных Mi (i=1, 2, …, n) представляются в виде подблоков фиксированной длины mi,1, mi,2, …, mi,n, количество которых в блоке данных соответствует числу самих блоков данных, подлежащих защите. От блоков данных Mi предварительно вычисляются эталонные хэш-коды Si хэш-функции h(Mi), значения которых в последующем сравниваются со значениями хэш-кодов 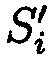 хэш-функции
хэш-функции 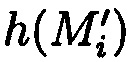 , вычисляемых уже от проверяемых блоков данных
, вычисляемых уже от проверяемых блоков данных 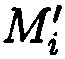 , подблоки которых также являются подблоками блоков данных
, подблоки которых также являются подблоками блоков данных 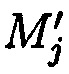 (j=1, 2, …, n), которые для обеспечения целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков m1,j, m2,j, …, mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных
(j=1, 2, …, n), которые для обеспечения целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков m1,j, m2,j, …, mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных 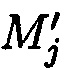 в случае нарушения их целостности, вычисление контрольной группы (k-n) подблоков mn+1,j, mn+2,j, …, mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных
в случае нарушения их целостности, вычисление контрольной группы (k-n) подблоков mn+1,j, mn+2,j, …, mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных 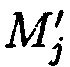 , без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока
, без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока 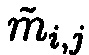 с возникшей ошибкой, после чего от полученного результата вычисляется подблок mi,j взамен ранее исключенного, после восстановления данных осуществляется проверка их достоверности путем сравнения значений вычисленных хэш-кодов
с возникшей ошибкой, после чего от полученного результата вычисляется подблок mi,j взамен ранее исключенного, после восстановления данных осуществляется проверка их достоверности путем сравнения значений вычисленных хэш-кодов 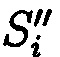 хэш-функции
хэш-функции 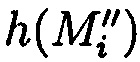 уже от восстановленных блоков данных
уже от восстановленных блоков данных 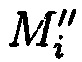 со значениями предварительно вычисленных эталонных хэш-кодов Si хеш-функции h(Mi) от первоначальных блоков данных Mi.
со значениями предварительно вычисленных эталонных хэш-кодов Si хеш-функции h(Mi) от первоначальных блоков данных Mi.
| US 8209551 B2, 26.06.2012 | |||
| US 8375223 B2, 12.02.2013 | |||
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ ДАННЫХ В ИНФОРМАЦИОННО-ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМАХ | 2016 |
|
RU2628894C1 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ЗАПИСЕЙ В ЗАПОМИНАЮЩЕМ УСТРОЙСТВЕ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2012 |
|
RU2502124C1 |

