Область техники, к которой относится изобретение
Предлагаемое изобретение относится к информационным технологиям и может быть использовано для контроля и восстановления целостности данных в многомерных системах хранения на основе применения криптографических хэш-функций и кодов, контролирующих ошибки, к защищаемым блокам данных в условиях ограничений на допустимые затраты ресурса.
Уровень техники
а) Описание аналогов
Известны способы контроля целостности данных за счет применения криптографических методов: ключевое и бесключевое хэширование, средства электронной подписи (Патент на изобретение RUS №26207030, 07.12.2015; Патент на изобретение RUS №2669144, 28.11.2017; Патент на изобретение RUS №2680033, 22.05.2017; Патент на изобретение RUS №2680350, 02.05.2017; Патент на изобретение RUS №2680739, 28.11.2017; Патент на изобретение RUS №2686024, 25.04.2018; Кнут, Д.Э. Искусство программирования для ЭВМ. Том 3. Сортировка и поиск / Д.Э. Кнут. - М.: «Мир», 1978. - 824 с.; Dichenko, S. Two-dimensional control and assurance of data integrity in information systems based on residue number system codes and cryptographic hash functions / S. Dichenko, O. Finko // Integrating Research Agendas and Devising Joint Challenges International Multidisciplinary Symposium ICT Research in Russian Federation and Europe. 2018. P. 139-146; Диченко, С.А. Гибридный крипто-кодовый метод контроля и восстановления целостности данных для защищенных информационно-аналитических систем / С. Диченко, О. Финько // Вопросы кибербезопасности. - 2019. - №6(34). - С. 17-36), для которых характерны три обобщенные схемы применения хэш-функции:
- с вычислением одного общего хэш-кода от к блоков данных (фиг. 1);
- с вычислением по одному хэш-коду от каждого из блоков данных (фиг. 2);
- с построением полносвязной сети хэширования (фиг. 3).
Недостатками данных способов являются:
- для схемы применения хэш-функции с вычислением одного общего хэш-кода от k блоков данных:
- не позволяет после контроля целостности данных выполнить локализацию блока данных с нарушением целостности;
- для схемы применения хэш-функции с вычислением по одному хэш-коду от каждого из блоков данных:
- высокая избыточность контрольной информации при контроле целостности блоков данных, представленных двоичными векторами небольшой размерности;
- для схемы применения хэш-функции с построением полносвязной сети хэширования:
- высокая избыточность контрольной информации при контроле целостности блоков данных, представленных двоичными векторами небольшой размерности;
- в общем виде данная модель не позволяет после контроля целостности данных выполнить локализацию блока данных с нарушением целостности.
Известны способы восстановления целостности данных за счет применения различных видов резервирования (с использованием программно-аппаратной или программной реализации технологии RAID (Redundant Array of Independent Disks) (RAID-массивы), методы дублирования, методы избыточного кодирования) (Патент на изобретение RUS №2406118, 10.04.2007; Патент на изобретение RUS №2481632, 10.05.2013; Патент на изобретение RUS №2513725, 20.04.2014; Патент на изобретение RUS №2598991, 10.10.2016; Патент на изобретение USA №7392458, 24.06.2008; Патент на изобретение USA №7437658, 14.10.2008; Патент на изобретение USA №7600176, 06.10.2009; Уоррен, Г. Подсчет битов: алгоритмические трюки для программистов (Hacker's Delight) / Г. Уоррен, мл. - М.: «Вильямс», 2007. - 512 с.; Морелос-Сарагоса, Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / Р. Морелос-Сарагоса; переводе англ. В.Б. Афанасьев. - М.: Техносфера, 2006. - 320 с.; Хемминг, Р.В. Теория кодирования и теория информации / Р.В. Хемминг; перевод с англ. - М.: «Радио и связь», 1983. - 176 с.).
Недостатками данных способов являются:
- высокая избыточность;
- отсутствие возможности повышения исправляющей способности средств восстановления в условиях ограничений на допустимые затраты ресурса.
б) Описание ближайшего аналога (прототипа)
Наиболее близким по технической сущности к заявленному изобретению (прототипом) является способ двумерного контроля и обеспечения целостности данных (фиг. 4), основанный на осуществлении контроля и восстановления целостности данных, представленных в виде двумерного массива блоков данных фиксированной длины, от элементов строк которого предварительно посредством применения хэш-функции вычисляются эталонные хэш-коды, значения которых в последующем сравниваются со значениями хэш-кодов, вычисляемых уже от проверяемых блоков данных, при запросе на их использование, а к элементам столбцов массива применяется математический аппарат избыточных модулярных кодов (Диченко С.А., Самойленко Д.В., Финько О.А. Способ двумерного контроля и обеспечения целостности данных // Патент на изобретение RUS №2696425, 02.08.2019).
Недостатком известного способа является отсутствие возможности повышения исправляющей способности средств восстановления в условиях ограничений на допустимые затраты ресурса.
Раскрытие изобретения
а) Технический результат, на достижение которого направлено изобретение Целью настоящего изобретения является разработка способа контроля и восстановления целостности многомерных массивов данных на основе применения к защищаемым блокам данных криптографических хэш-функций и математического аппарата избыточных модулярных кодов с возможностью повышения исправляющей способности средств восстановления в условиях ограничений на допустимые затраты ресурса.
б) Совокупность существенных признаков
Поставленная цель достигается тем, что в известном способе двумерного контроля и обеспечения целостности данных, заключающемся в том, что для осуществления контроля целостности блоки данных Mi (i=1, 2, …, n) представляются в виде подблоков фиксированной длины Mi,1, Mi,2, …, Mi,n, от которых предварительно вычисляются эталонные хэш-коды Hi хэш-функции h(Mi), значения которых в последующем сравниваются со значениями хэш-кодов 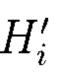 хэш-функции
хэш-функции  вычисляемых уже от проверяемых блоков данных
вычисляемых уже от проверяемых блоков данных  подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, в представленном же способе многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i = j = r = 0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k - 1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов
подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, в представленном же способе многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i = j = r = 0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k - 1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов 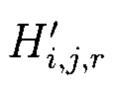 хэш-функции
хэш-функции  вычисляемых уже от проверяемых блоков данных
вычисляемых уже от проверяемых блоков данных  при восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям
при восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям 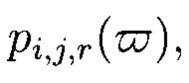 при этом полученный 3-мерный массив данных М[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований
при этом полученный 3-мерный массив данных М[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований 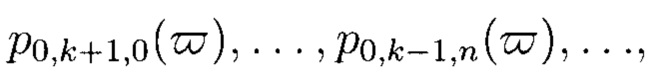
 для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности.
для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности.
Сопоставительный анализ заявленного решения и прототипа показывает, что предлагаемый способ отличается от известного тем, что поставленная цель достигается за счет представления многомерного массива данных размерности k в виде 3-мерного массива данных M[k, k, k], состоящего из k3 блоков данных Mi,j,r, для обнаружения признаков нарушения целостности которых применяется хэш-функция и вычисляются 3k2 хэш-кодов Hi,j,r, которые при восстановлении целостности интерпретируются как элементы GF(2t) и образуют единый суперблок модулярного полиномиального кода, что позволяет повысить исправляющую способность средств восстановления в условиях ограничений на допустимые затраты ресурса.
Контроль и восстановление целостности k3 блоков данных Mi,j,r будет осуществляться за счет вычисления от них 3k2 хэш-кодов Hi,j,r, которые будут интерпретироваться как элементы GF(2t) и образовывать единый суперблок модулярного полиномиального кода, что позволит в момент времени t в условиях ограничений на допустимые затраты ресурса для обнаружения признаков нарушения целостности сравнить значения хэш-кодов Hi,j,r со значениями хэш-кодов  вычисляемых при запросе на использование данных, подлежащих защите, а для восстановления целостности блоков данных Mi,j,г выполнить процедуру реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности. Новым является то, что многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r, которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k - 1 его блоков, при этом свободные блоки массива будут предназначаться для эталонных хэш-кодов Hi,j,r. Новым является то, что для восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям
вычисляемых при запросе на использование данных, подлежащих защите, а для восстановления целостности блоков данных Mi,j,г выполнить процедуру реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности. Новым является то, что многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r, которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k - 1 его блоков, при этом свободные блоки массива будут предназначаться для эталонных хэш-кодов Hi,j,r. Новым является то, что для восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям  Новым является то, что полученный 3-мерный массив данных М[k+1, k+1, k+1], содержащий блоки данных Mi,j,r и эталонные хэш-коды Hi,j,r, будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований, для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, что позволяет повысить вероятность исправления возникающих ошибок, приводящих к нарушению целостности данных, подлежащих защите.
Новым является то, что полученный 3-мерный массив данных М[k+1, k+1, k+1], содержащий блоки данных Mi,j,r и эталонные хэш-коды Hi,j,r, будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований, для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, что позволяет повысить вероятность исправления возникающих ошибок, приводящих к нарушению целостности данных, подлежащих защите.
в) Причинно-следственная связь между признаками и техническим результатом
Благодаря новой совокупности существенных признаков в способе реализована возможность:
- контроля целостности многомерного массива данных с низкой избыточностью контрольной информации;
- локализации блоков данных с признаками нарушения целостности;
- восстановления целостности многомерного массива данных с низкой избыточностью;
- повышения исправляющей способности средств восстановления в условиях ограничений на допустимые затраты ресурса.
Доказательства соответствия заявленного изобретения условиям патентоспособности «новизна» и «изобретательский уровень»
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обуславливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показано:
фиг. 1 - схема применения хэш-функции с вычислением одного общего хэш-кода от k блоков данных;
фиг. 2 - схема применения хэш-функции с вычислением по одному хэш-коду от каждого из блоков данных;
фиг. 3 - схема применения хэш-функции с построением полносвязной сети хэширования;
фиг. 4 - схема, поясняющая порядок контроля и восстановления целостности данных, представленных в виде двумерного массива блоков данных;
фиг. 5 - схема 3-мерного куба, содержащего блоки данных Mi,j,r;
фиг. 6 - порядок расположения в кубе размерности k=3 блоков данных, подлежащих защите, и хэш-кодов;
фиг. 7 - сеть хэширования для обнаружения и локализации 1-кратной ошибки;
фиг. 8 - сеть хэширования для обнаружения и локализации 2-кратных ошибок;
фиг. 9 - зависимости изменения вероятностей Рисп.1, Рисп.2 от размерности k;
фиг. 10 - порядок расположения избыточных блоков данных в соответствии с введенными связями в 3-мерном кубе.
Осуществление изобретения
Многомерный массив данных представляется в виде р-мерного массива, состоящего из элементов Мψ1, …, ψp, где индексы ψ1, …, ψp принимают значения от 1 до ka (а=1, …, р) соответственно. При этом р-мерный массив данных будет содержать k1×k2×…×kp элементов и обозначаться как

Многомерный массив данных M[k1, k2, …, kp] является математическим множеством, имеющим определенную структуру и аксиоматические правила, что позволяет рассматривать его аналогично пространству, а содержащиеся в нем элементы (блоки данных Мψ1, …, ψp) - как точки пространства. Такое пространство будем называть пространством данных.
Пространство данных будет считаться дискретным метрическим пространством, так как содержит в своей структуре точки, представленные элементами массива, изолированными друг от друга в некотором смысле. Внутри многомерного массива данных M[k1, k2, …, kp] все элементы (блоки данных Мψ1, …, ψp) располагаются вдоль абстрактных прямых, параллельных осям координат, на одинаковых расстояниях друг от друга.
Пример 1. 3-мерный массив данных М[k1, k2, k3] может быть представлен в виде 3-мерного куба (фиг. 5), содержащего систему координат с осями: x, y, z, по которым откладываются блоки данных Mi,j,r (i = 0, 1, …, k1 - 1; j = 0, 1, …, k2 - 1; r = 0, 1, …, k3 - 1).
Представим 3-мерный массив данных M[k1, k2, k3] в следующем виде:
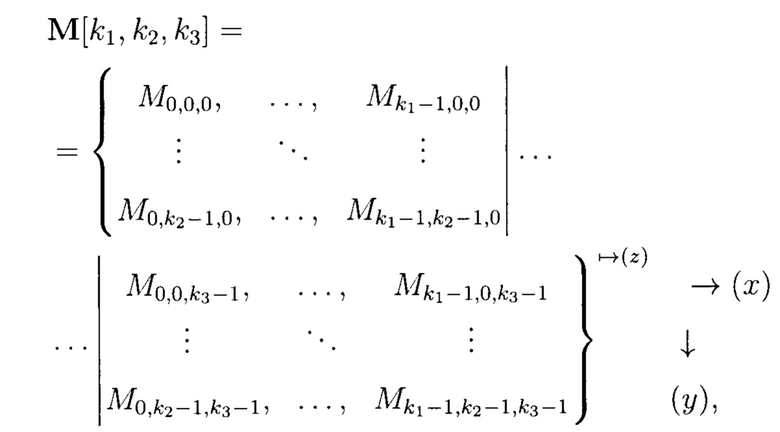
где стрелка « » с индексом (z) показывает порядок представления массива посредством сечений, ориентированных по оси z; стрелки «→» и «↓» с индексами (x) и (у) указывают направления, в которых возрастают соответствующие индексы у элементов массива по осям х и у.
» с индексом (z) показывает порядок представления массива посредством сечений, ориентированных по оси z; стрелки «→» и «↓» с индексами (x) и (у) указывают направления, в которых возрастают соответствующие индексы у элементов массива по осям х и у.
Если все измерения гиперкуба, содержащего блоки данных, будут иметь одинаковые значения (k1 = k2 = … = kp), то он будет являться правильной фигурой, а его размер может быть описан одним числом k, равным количеству блоков данных, расположенных на его ребре. Такой гиперкуб будем называть гиперкубом размерности k.
При этом 3-мерный массив данных М[k, k, k]={Mi,j,r} размерности k с помощью сечений ориентации (z) может быть представлен в следующем виде:

где i, j, r = 0, …, k - 1.
Разместим 3-мерный массив данных (1) размерности k в массиве размерности k+1, представленном 3-х мерным кубом, заполнив при этом от 0 до k - 1 его блоков.
При таком расположении из (k+1)3 блоков 3-мерного куба k3 блоков предназначены для хранения блоков данных, подлежащих защите.
3-мерный массив данных (1) примет вид:

где «0» обозначает свободный для записи блок куба.
Для обнаружения признаков нарушения целостности многомерных массивов данных (блоков данных Mi,j,r (i, j, r = 0, …, k - 1)) применим к элементам массива (2) хэш-функцию h.
Разместим полученные эталонные хэш-коды Hi,j,r (i, j, r = 0, …, k) в свободные для записи блоки куба.
Полученный 3-мерный массив, содержащий блоки данных и хэш-коды, с помощью сечений ориентации (z) может быть представлен в следующем виде:

Таким образом, полученный 3-мерный массив (3) может быть представлен в виде 3-мерного куба, содержащего (k+1)3 блоков, в том числе:
- k3 блоков данных Mi,j,r (i, j, r = 0, …, k - 1), подлежащих защите;
- 3k2 блоков с хэш-кодами Hi,j,r (i, j, r = 0, …, k);
- 3k + 1 свободных для записи блоков.
При этом к каждому блоку данных, подлежащему защите, по трем осям добавляются блоки с вычисленными от них эталонными хэш-кодами, используемыми для обнаружения данных с признаками нарушения целостности.
Под нарушением целостности одного блока данных будем понимать возникновение в нем ошибки, соответственно нарушение целостности q блоков данных определяется возникновением q-кратной ошибки.
Обнаружение блока данных с признаками нарушения целостности выполняется путем сравнения значений предварительно вычисленных от него эталонных хэш-кодов и хэш-кодов, вычисленных при запросе на его использование. В случае несоответствия сравниваемых значений хэш-кодов делается вывод о возникновении ошибки и определяется ее синдром.
Под синдромом ошибки будем понимать двоичное число, полученное при написании символа «0» для каждой выполненной проверки на соответствие значений вычисленного и эталонного хэш-кода и символа «1» при несоответствии сравниваемых значений.
Пример 2. Для контроля целостности многомерных массивов данных разместим в 3-мерном кубе (фиг. 6) блоки данных, подлежащие защите, и соответствующие им хэш-коды.
При этом блоки данных Mi,j,r, подлежащие защите, и вычисленные от них эталонные хэш-коды Hi,j,r интерпретируются как двоичные векторы:

где  g=1, 2, …, t.
g=1, 2, …, t.
Полученный 3-мерный массив с помощью сечений ориентации (х) может быть представлен в следующем виде:

при этом каждый хэш-код вычисляется от двух блоков данных, расположенных с ним в одной строке или одном столбце массива.
Пример 3. Хэш-коды Н002, Н012, Н020, Н021 вычисляются следующим образом:

где «||» - операция конкатенации (объединения).
Построим сеть хэширования (фиг. 7) для обеспечения возможности обнаружения и локализации 1-кратной ошибки.
При этом каждому блоку данных Mi,j,г будет соответствовать неповторяющаяся совокупность из трех хэш-кодов Hi,j,r.
Пример 4. В соответствии с построенной сетью хэширования (фиг. 7) блокам данных М100, М011 соответствуют следующие хэш-коды:
- для М100: Н120, Н102, Н200;
- для М011: H021, H012, Н211,
причем полученные совокупности хэш-кодов для всех блоков данных будут неповторяющимися.
Построим таблицу синдромов ошибок, приводящих к нарушению целостности блока данных Mi,j,r, в которой место ошибки определяется наличием символа «1» в соответствующих столбцах и строках.
Пример 5. Синдромы 1-кратных ошибок, приводящих к нарушению целостности блоков данных [М100] и [М011], представлены в таблице 1.

Сеть хэширования и соответствующая ей таблица синдромов ошибок для обнаружения и локализации q блоков данных с признаками нарушения целостности строятся по аналогичным правилам.
Сеть хэширования для возможности обнаружения и локализации 2-кратных ошибок представлена на фиг. 8.
Пример 6. Синдромы 2-кратных ошибок, приводящих к нарушению целостности блоков данных [М100] и [М110], а также [M001] и [М011], представлены в таблице 2.

Для восстановления целостности многомерных массивов данных блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироватьсяся как элементы GF(2t):


где  g=t - 1, t - 2, …, 0;
g=t - 1, t - 2, …, 0;  - фиктивная переменная.
- фиктивная переменная.
При этом блоки данных и эталонные хэш-коды будут являться наименьшими полиномиальными вычетами по основаниям  таким, что
таким, что

где основания  представлены при помощи сечений ориентации (x);
представлены при помощи сечений ориентации (x);
i1, i2 = 0, 1, …, k; i1 ≠ i2.
При этом

где 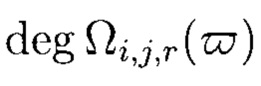 - степень полинома
- степень полинома 
Полученный 3-мерный массив, представленный посредством сечений ориентации (x):

будет рассматриваться как единый суперблок модулярного полиномиального кода (МПК) по системе оснований:

В соответствии с Китайской теоремой об остатках для многочленов, представленных в виде (7) и удовлетворяющих условию (4), и многочленов, представленных в виде (6) таких, что выполняется условие (5), система сравнений:

имеет единственное решение 
Выполним операцию расширения МПК путем введения n - k избыточных оснований:

Получим соответствующие им избыточные вычеты:

Причем выполняется условие (4), а условие (5) примет вид:  Получим расширенный МПК в кольце многочленов:
Получим расширенный МПК в кольце многочленов:

Разместим избыточные блоки данных в свободных для записи ячейках 3-мерного массива, который посредством сечений ориентации (х) может быть представлен в следующем виде:

Полученный 3-мерный массив (10) может быть представлен в виде 3-мерного куба и содержит (n+1)3 блоков, в том числе:
- k3 блоков данных Mi,j,r (i, j, r = 0, …, k - 1), подлежащих защите;
- 3k2 блоков с хэш-кодами Hi,j,r (i, j, r = 0, …, k);
- 3k2(n - k) избыточных блоков данных, а также свободных для записи блоков.
При этом для восстановления целостности k3 + 3k2 блоков данных, подлежащих защите, и вычисленных для контроля целостности данных эталонных хэш-кодов требуется 3k2(n - k) избыточных блоков данных.
Данные, подлежащие защите, представленные в виде (10), отправляются на хранение.
При запросе на использование данных после осуществления контроля их целостности в случае обнаружения ошибки выполняется процедура восстановления целостности данных.
В соответствии с правилами декодирования модулярных кодов (Акушский И.Я., Юдицкий Д.М. Машинная арифметика в остаточных классах. - М.: Советское радио, 1968. - 604 с.) критерием отсутствия обнаруживаемых ошибок в расширенном МПК (9) является выполнение неравенства:
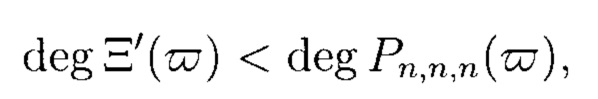
где  - решение системы (8) для
- решение системы (8) для 
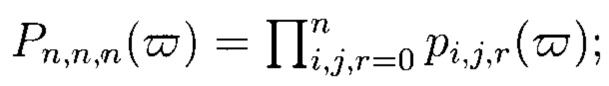 символ «(⋅)'» указывает на возможное нарушение целостности данных.
символ «(⋅)'» указывает на возможное нарушение целостности данных.
Критерий обнаруживаемой ошибки - выполнение неравенства:

Восстановление целостности блока 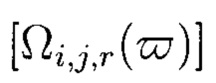 выполняется путем вычисления наименьшего вычета:
выполняется путем вычисления наименьшего вычета:
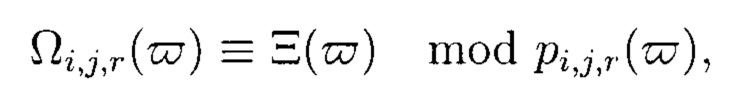
где 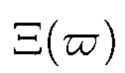 повторно вычислено с учетом исключения искаженного блока данных
повторно вычислено с учетом исключения искаженного блока данных 
В разработанном способе в сравнении с прототипом при ограничениях, наложенных на средства восстановления, в зависимости от размерности к максимальное количество возможных q блоков данных с нарушением целостности в кубе определяется следующим образом:
q=k3.
При этом для восстановления целостности всех искаженных блоков данных потребуется 3k2 избыточных блоков данных. В то же время, в прототипе классическое применение избыточного МПК, при котором исправляется q или менее ошибок, если n - k≥2q, требуется 2k3 избыточных блоков данных.
Зависимости вероятностей Рисп исправления возникающих ошибок представлены на фиг. 9, где - Рисп.1 - вероятность, при применении разработанного способа, Рисп.2 - вероятность, при применении прототипа.
Повышение вероятности исправления возникающих ошибок за счет использования разработанного способа объясняется тем, что n - k избыточных блоков данных используется для восстановления целостности не только  искаженных блоков данных, как при классическом применении избыточного МПК, но и других блоков данных, подлежащих защите, в соответствии с введенными связями в 3-мерном кубе при восстановлении целостности многомерных массивов данных (фиг. 10).
искаженных блоков данных, как при классическом применении избыточного МПК, но и других блоков данных, подлежащих защите, в соответствии с введенными связями в 3-мерном кубе при восстановлении целостности многомерных массивов данных (фиг. 10).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ | 2021 |
|
RU2771236C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ В УСЛОВИЯХ КРИТИЧЕСКОЙ ДЕГРАДАЦИИ СИСТЕМ ИХ ХРАНЕНИЯ | 2023 |
|
RU2828227C1 |
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ НА ОСНОВЕ ПРАВИЛ ПОСТРОЕНИЯ КУБИЧЕСКИХ КОДОВ | 2021 |
|
RU2785800C1 |
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ НА ОСНОВЕ ПРАВИЛ ПОСТРОЕНИЯ ТРЕУГОЛЬНЫХ КОДОВ | 2021 |
|
RU2771146C1 |
| СПОСОБ КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ В УСЛОВИЯХ ДЕГРАДАЦИИ СИСТЕМ ХРАНЕНИЯ | 2022 |
|
RU2801124C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ ПРИ ДЕГРАДАЦИИ МНОГОМЕРНЫХ СИСТЕМ ХРАНЕНИЯ | 2023 |
|
RU2833352C1 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ДАННЫХ С ПОДТВЕРЖДЕННОЙ ЦЕЛОСТНОСТЬЮ | 2021 |
|
RU2771238C1 |
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ ДАННЫХ НА ОСНОВЕ ПРАВИЛ ПОСТРОЕНИЯ ГЕОМЕТРИЧЕСКИХ КОДОВ | 2021 |
|
RU2758194C1 |
| СПОСОБ СТРУКТУРНО-ПАРАМЕТРИЧЕСКОГО СИНТЕЗА КРИПТО-КОДОВЫХ КОНСТРУКЦИЙ ПРИ ВЫНУЖДЕННОМ СОКРАЩЕНИИ МЕРНОСТИ ПРОСТРАНСТВА КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ СТРУКТУРИРОВАННЫХ МАССИВОВ ДАННЫХ | 2022 |
|
RU2801198C1 |
| СПОСОБ ФОРМИРОВАНИЯ КРИПТО-КОДОВЫХ КОНСТРУКЦИЙ В УСЛОВИЯХ СОКРАЩЕНИЯ МЕРНОСТИ ПРОСТРАНСТВА КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ СТРУКТУРИРОВАННЫХ МАССИВОВ ДАННЫХ | 2022 |
|
RU2806539C1 |










Изобретение относится к способу контроля и восстановления целостности многомерных массивов данных. Технический результат заключается в обеспечении контроля целостности данных. В способе для осуществления контроля целостности блоки данных Mi (i=1, 2, …, n) представляются в виде подблоков фиксированной длины Mi,l, Mi,2, …, Mi,n, от которых предварительно вычисляются эталонные хэш-коды Hi хэш-функции h(Mi), значения которых в последующем сравниваются со значениями хэш-кодов  хэш-функции
хэш-функции 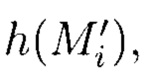 вычисляемых уже от проверяемых блоков данных
вычисляемых уже от проверяемых блоков данных 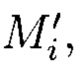 подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, при этом многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i=j=r=0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k-1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов
подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, при этом многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i=j=r=0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k-1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов  хэш-функции
хэш-функции  вычисляемых уже от проверяемых блоков данных при
вычисляемых уже от проверяемых блоков данных при 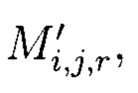 восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям
восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям 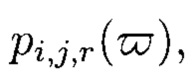 при этом полученный 3-мерный массив данных M[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований
при этом полученный 3-мерный массив данных M[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований 
 для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности. 10 ил.
для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности. 10 ил.
Способ контроля и восстановления целостности многомерных массивов данных, заключающийся в том, что для осуществления контроля целостности блоки данных Mi (i=1, 2, …, n) представляются в виде подблоков фиксированной длины Mi,l, Mi,2, …, Mi,n, от которых предварительно вычисляются эталонные хэш-коды Hi хэш-функции h(Mi), значения которых в последующем сравниваются со значениями хэш-кодов 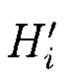 хэш-функции
хэш-функции  вычисляемых уже от проверяемых блоков данных
вычисляемых уже от проверяемых блоков данных  подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, отличающийся тем, что многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i=j=r=0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k-1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов
подблоки которых также являются подблоками блоков данных Mj (j=1, 2, …, n), которые для восстановления целостности данных в случае ее нарушения формируются по правилам, аналогичным правилам построения избыточных модулярных кодов, обеспечивая при этом для подблоков M1,j, M2,j, …, Mn,j, которые являются информационной группой n подблоков, предназначенной для однозначного восстановления блоков данных Mj в случае нарушения их целостности, вычисление контрольной группы (k - n) подблоков Mn+1,j, Mn+2,j, …, Mk,j, дополнительно вводимой для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mj без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений подблока [Mi,j] с возникшей ошибкой, отличающийся тем, что многомерный массив данных размерности к представляется в виде 3-мерного массива данных М[k, k, k], состоящего из k3 блоков данных Mi,j,r (i=j=r=0, 1, …, k - 1), которые для контроля целостности будут размещаться в массиве размерности k+1, заполняя при этом от 0 до k-1 его блоков, к которым для обнаружения признаков нарушения целостности применяется хэш-функция h, при этом вычисленные хэш-коды Hi,j,r (i, j, r = 0, …, k) будут размещаться в 3k2 свободных блоках массива и являться эталонными, значения которых при запросе на использование данных сравниваются со значениями хэш-кодов 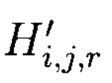 хэш-функции
хэш-функции  вычисляемых уже от проверяемых блоков данных при
вычисляемых уже от проверяемых блоков данных при  восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям
восстановлении целостности блоки данных Mi,j,r, подлежащие защите, а также вычисленные от них эталонные хэш-коды Hi,j,r будут интерпретироваться как элементы GF(2t) и являться наименьшими полиномиальными вычетами по основаниям  при этом полученный 3-мерный массив данных M[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований
при этом полученный 3-мерный массив данных M[k+1, k+1, k+1] будет рассматриваться как единый суперблок модулярного полиномиального кода, над которым выполняется операция расширения путем введения n - k избыточных оснований 
 для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности.
для которых вычисляются соответствующие им 3k2(n - k) избыточных вычетов, дополнительно вводимых для коррекции ошибки, в случае возникновения которой восстановление блоков данных Mi,j,r без ущерба для однозначности их представления осуществляется посредством реконфигурации системы путем исключения из вычислений блока данных с признаками нарушения целостности.
| СПОСОБ ДВУМЕРНОГО КОНТРОЛЯ И ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2018 |
|
RU2696425C1 |
| СПОСОБ КОНТРОЛЯ И ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2017 |
|
RU2680739C1 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2017 |
|
RU2680350C2 |
| СПОСОБ И УСТРОЙСТВО ИМИТОУСТОЙЧИВОЙ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО КАНАЛАМ СВЯЗИ | 2017 |
|
RU2669144C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ | 2017 |
|
RU2680033C2 |
| СПОСОБ И УСТРОЙСТВО МНОГОМЕРНОЙ ИМИТОУСТОЙЧИВОЙ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО КАНАЛАМ СВЯЗИ | 2018 |
|
RU2686024C1 |
| US 20100031060 A1, 04.02.2010 | |||
| US 20110107103 A1, 05.05.2011 | |||
| WO 2017168159 A1, 05.10.2017 | |||
| EP 3591563 A1, 08.01.2020. | |||

