ОБЛАСТЬ ТЕХНИКИ
[001] Данное техническое решение относится в общем к области вычислительной техники в генетике и микробиологии, а более конкретно, к способу для исследования и интерпретации генетических данных и/или данных о составе микробиоты кишечника человека в области микробиологии, с целью выработки рекомендаций пользователю.
УРОВЕНЬ ТЕХНИКИ
[002] Организм человека является одной из наиболее плотно населенных сред обитания на Земле. Число микроорганизмов, обитающих в такой «биологической системе», насчитывает порядка 100 триллионов бактерий, что значительно превышает общее число эукариотических клеток всех тканей и органов человека. Только 10% клеток организма являются нашими собственными, остальные 90% принадлежат бактериям. Совокупность всех микроорганизмов человека называется микрофлорой или микробиотой, а совокупность их генов - метагеномом. При этом метагеном человека в 100-150 раз больше генома самого человека. Большая часть микроорганизмов приходится на желудочно-кишечный тракт, поэтому его исследование и интерпретация этих данных является очень важной технической задачей. Фактически в настоящий момент формируется представление о микробиоте кишечника как об отдельном органе человеческого организма, что не противоречит исторически сложившемуся определению органа как части организма, представляющей собой эволюционно сложившийся комплекс тканей, объединенный общей функцией, структурной организацией и развитием. При этом человека можно рассматривать как «сверхорганизм», обмен веществ которых обеспечивается четко организованной работой ферментов, кодируемых не только геномом собственно Homo sapiens, но и геномами всех микроорганизмов.
[003] Генетика человека - это врожденные особенности человека, передаваемые через гены, которые представляют собой участки ДНК, несущие информацию о наследственности. Генетика человека часто способствует возникновению наиболее распространенных заболеваний. Нельзя не учитывать наследственные особенности человека в определении образа жизни и режима питания, выборе профессии, занятий каким-то видом спорта и др. Многофакторные заболевания развиваются под действием нескольких факторов, например, таких как экология, образ жизни, физическая активность и наследственность. Соответственно корректируя модифицируемые факторы, мы можем снижать риски. Таким образом, знание о генетических рисках важно для формирования индивидуальных профилактических мер. Многие факторы вызывают нарушения всех процессов в организме и несут за собой развитие различных заболеваний, которые можно предотвратить, исследуя генетические данные человека и формируя рекомендации по факторам: здоровью, питанию, спорту, и в целом образу жизни.
[004] Учитывая большое влияние микробиоты и генетики на здоровье человека, следует продолжать усилия, связанные с их исследованием и интерпретацией.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[005] Данное техническое решение направлено на устранение недостатков, свойственных решениям, известным из уровня техники.
[006] Технической задачей или проблемой, решаемой в данном техническом решении, является формирование рекомендаций по образу жизни, профилактике заболеваний, питанию и физической активности пользователю на основании генетических данных и/или данных о составе микробиоты кишечника.
[007] Техническим результатом, достигаемым при решении вышеуказанной технической проблемы, является повышение точности формирования рекомендаций пользователю на основании учета генетических данных и данных о составе микробиоты кишечника.
[008] Указанный технический результат достигается благодаря реализации системы формирования рекомендаций пользователю на основе генетических данных и/или данных о составе микробиоты кишечника, которая содержит блок получения первичных данных, выполненный с возможностью использования генетических данных пользователя и/или данных о микробиоте кишечника пользователя; блок контроля качества, выполненный с возможностью контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя, полученных блоком получения первичных данных, причем генетические данные включают в себя однонуклеотидные полиморфизмы, а данные о микробиоте включают в себя чтения; блок популяционного анализа генетических данных, выполненный с возможностью определения отцовской и материнской гаплогруппы, популяционного состава генетических данных пользователя; блок таксономического анализа данных о микробиоте, выполненный с возможностью картирования метагеномных чтений на каталог, состоящий из набора последовательностей генов микробов микробиоты кишечника; блок определения риска заболеваний, выполненный с возможностью определения защищенности от заболеваний, а также проверки мутаций на наличие патогенных аллелей и оценки статуса заболеваний; блок определения признаков, выполненный с возможностью определения состояний признаков пользователя путем редукции графа зависимостей признаков; блок формирования рекомендаций для пользователя, выполненный с возможностью формирования рекомендаций пользователю на основании данных блока определения риска заболеваний и блока определения признаков пользователя.
[009] В некоторых вариантах осуществления технического решения данные о микробиоте кишечника пользователя получают в формате FASTQ или FASTA с секвенатора.
[0010] В некоторых вариантах осуществления технического решения генетические данные пользователя получают из кремниевого биочипа посредством сканера биочипов.
[0011] В некоторых вариантах осуществления технического решения генетические данные содержат данные о генотипах однонуклеотидных полиморфизмов пользователя, содержащие полиморфизмы Х- и Y-хромосом.
[0012] В некоторых вариантах осуществления технического решения при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя дополнительно определяет пол пользователя посредством подсчета количества однонуклеотидных полиморфизмов по Х- и по Y-хромосомам.
[0013] В некоторых вариантах осуществления технического решения в случае мужского пола конвертируют однонуклеотидные полиморфизмы в гомозиготном состоянии с Х- и Y-хромосом в однонуклеотидные полиморфизмы в гемизиготном состоянии.
[0014] В некоторых вариантах осуществления технического решения в случае женского пола все однонуклеотидные полиморфизмы с Y-хромосомой отфильтровываются и не попадают в итоговую выборку генетических данных.
[0015] В некоторых вариантах осуществления технического решения при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя отсеивают чтения со средним баллом качества ниже заранее заданного порогового.
[0016] В некоторых вариантах осуществления технического решения при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя с концов чтений удаляет позиции, имеющие низкий балл качества.
[0017] В некоторых вариантах осуществления технического решения при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя отсеивают постороннюю генетическую информацию в чтениях, имеющих биологическое или небиологическое происхождение, возникающую из-за прочтения артефактных последовательностей.
[0018] В некоторых вариантах осуществления технического решения при определении отцовской и материнской гаплогруппы популяционного состава генетических данных определяет отцовскую гаплогруппу на основании дерева мутаций для Y хромосомы и генетических данных пользователя.
[0019] В некоторых вариантах осуществления технического решения при определении отцовской и материнской гаплогруппы популяционного состава генетических данных определяют материнскую гаплогруппу на основании дерева мутаций для митохондрии и генетических данных пользователя.
[0020] В некоторых вариантах осуществления технического решения при определении отцовской и материнской гаплогруппы популяционного состава генетических данных определяют популяционный состав на основании данных о генотипах людей из разных популяций и генетических данных пользователя.
[0021] В некоторых вариантах осуществления технического решения при определении отцовской и материнской гаплогруппы популяционного состава генетических данных на основании генетических данных пользователя, набора унаследованных от неандертальца аллелей в определенных полиморфизмах определяют общее количество неандертальских аллелей.
[0022] В некоторых вариантах осуществления технического решения при классификации по базе данных последовательностей генов 16S рРНК, данная база данных содержит набор геномов бактерий и/или архей, встречающихся в кишечнике пользователя.
[0023] В некоторых вариантах осуществления технического решения при осуществлении анализа данных по микробиоте кишечника определяют относительную представленность микробного генома или вида.
[0024] В некоторых вариантах осуществления технического решения при осуществлении анализа данных по микробиоте кишечника формируют прореженные таблицы представленности по другим таксономическим уровням.
[0025] В некоторых вариантах осуществления технического решения при определении риска возникновения заболеваний оценивают аномальность генетических данных посредством проверки суммарного процента чтений, относящихся к одному из таксонов из списка оппортунистических патогенов.
[0026] В некоторых вариантах осуществления технического решения при определении риска возникновения заболеваний определяют защищенность от заболеваний пользователя по данным о микробиоте на основании референсных данных.
[0027] В некоторых вариантах осуществления технического решения при определении состояния генетического признака осуществляют проверку на наличие циклов в графе зависимостей, и при наличии циклов блок не дает запустить редукцию графа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0028] Признаки и преимущества настоящего технического решения станут очевидными из приведенного ниже подробного описания и прилагаемых чертежей, на которых:
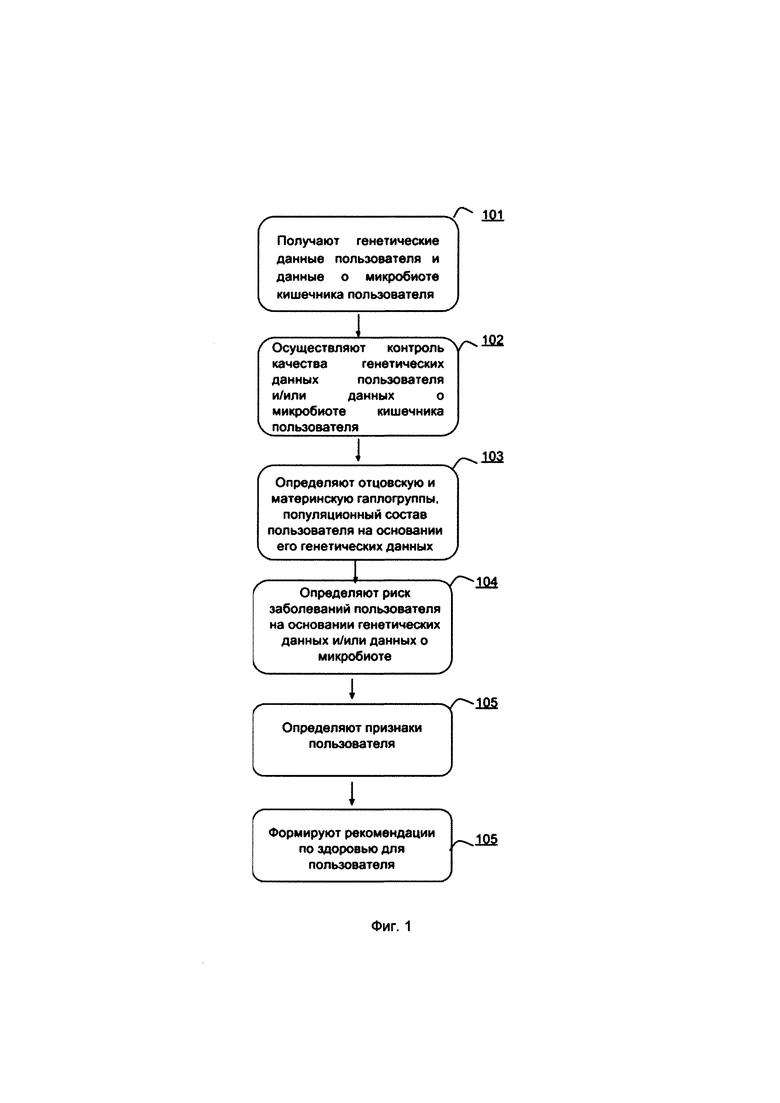
[0029] Фиг. 1 - приведена блок-схема способа формирования рекомендаций пользователю на основе генетических данных и/или данных о составе микробиоты кишечника;
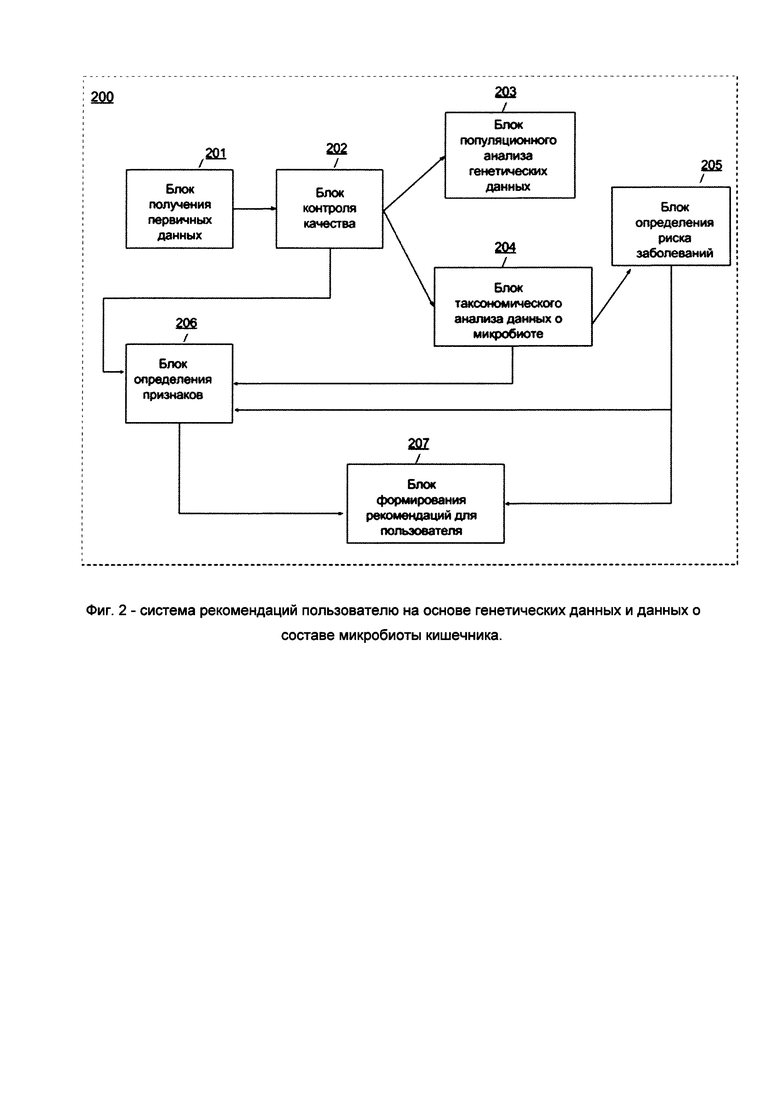
[0030] Фиг. 2 - приведена блок-схема системы формирования рекомендаций пользователю на основе генетических данных и/или данных о составе микробиоты кишечника;
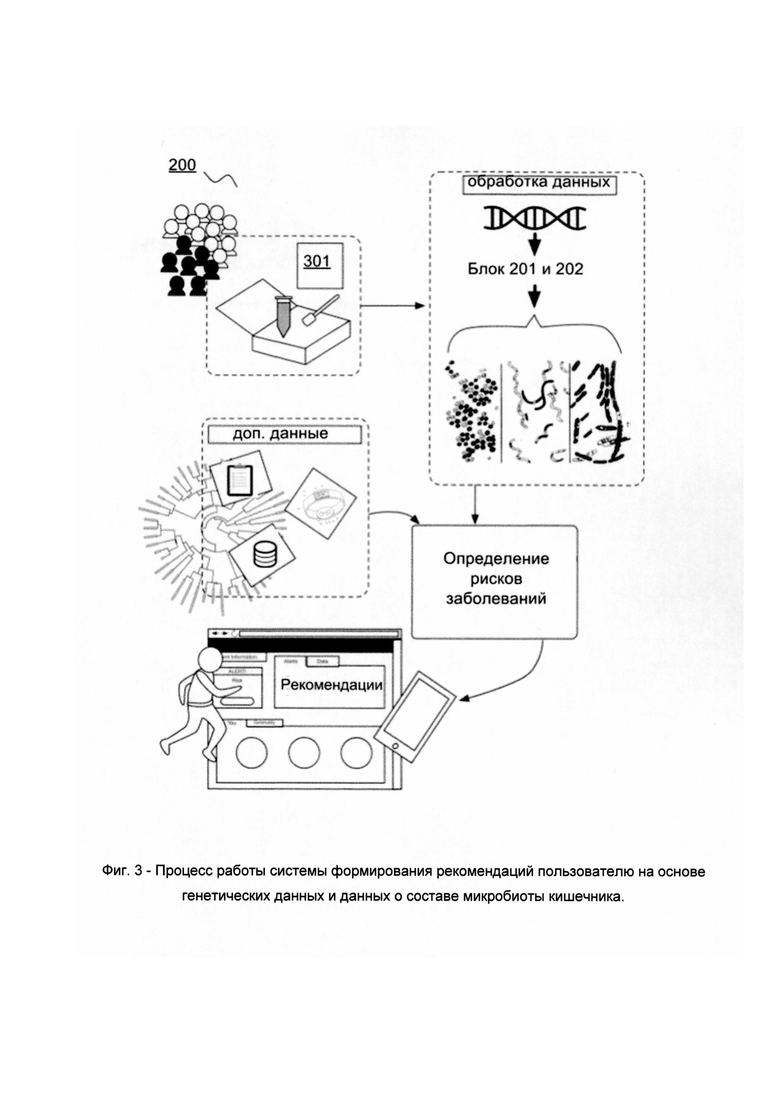
[0031] Фиг. 3 - показан процесс работы системы формирования рекомендаций пользователю на основе генетических данных и/или данных о составе микробиоты кишечника.
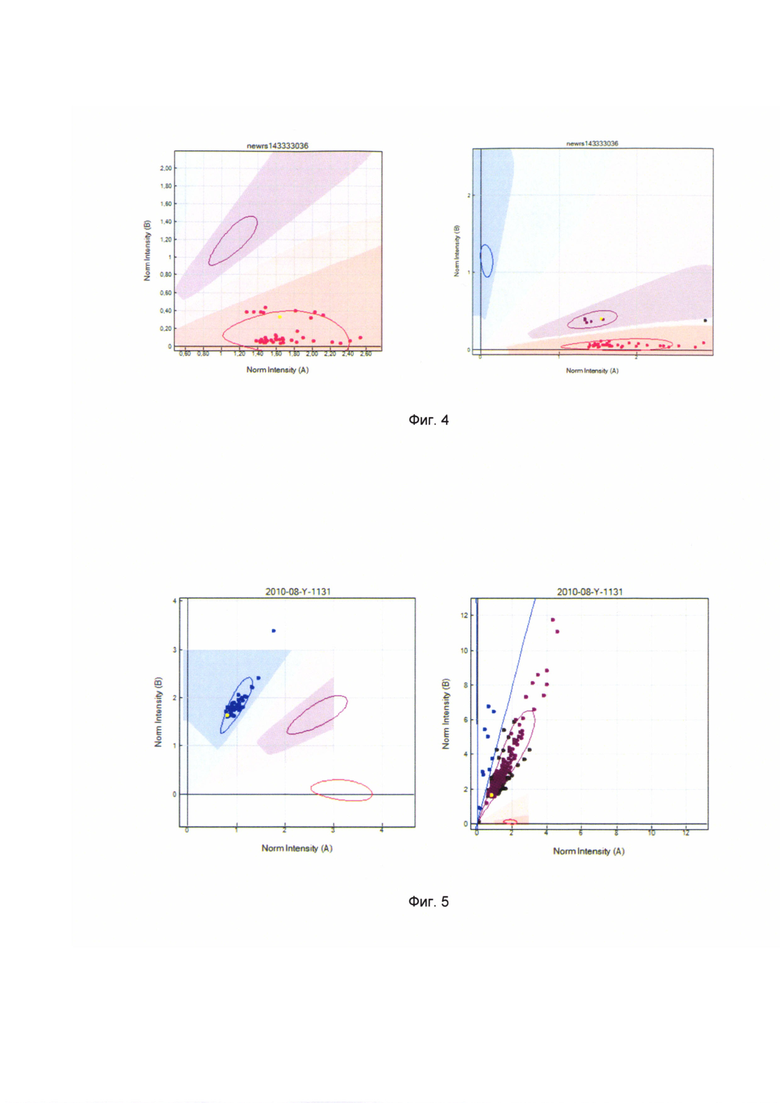
[0032] Фиг. 4 - показан вариант реализации, когда образцы для одних и тех же пользователей имеют разные генотипы.
[0033] Фиг. 5 - показан вариант реализации, когда в зависимости от количества образцов генотип одного и того же пользователя может различаться.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0034] Ниже будут подробно рассмотрены термины и их определения, используемые в описании технического решения.
[0035] В данном изобретении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[0036] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы). Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические приводы.
[0037] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0038] Микробиота (нормальная микрофлора, нормофлора) человека - это совокупность всех микроорганизмов в теле человека.
[0039] Генетические данные - это информация о структуре ДНК, последовательности нуклеотидов ДНК, одно- и олигонуклеотидных изменений в последовательности ДНК, включая все хромосомы конкретного организма. Генетическая информация частично определяет морфологическое строение, рост, развитие, обмен веществ, психический склад, предрасположенность к заболеваниям и генетические пороки организма.
[0040] Однонуклеотидный полиморфизм (ОНП, англ. single nucleotide polymorphism, SNP, произносится как снип) - отличия последовательности ДНК размером в один нуклеотид (А, Т, G или С) в геноме (или в другой сравниваемой последовательности) представителей одного вида или между гомологичными участками гомологичных хромосом.
[0041] Гаплогруппа - группа схожих гаплотипов, имеющих общего предка, у которого произошла мутация, унаследованная всеми потомками (обычно - однонуклеотидный полиморфизм). Термин «гаплогруппа» широко применяется в генетической генеалогии -науке, изучающей генетическую историю человечества, с помощью исследования гаплогрупп Y-хромосомы (Y-ДНК), митохондриальной ДНК (мтДНК) и ГКГ-гаплогруппы.
[0042] Аллели - различные формы (значения) одного и того же гена, расположенные в одинаковых участках (локусах) гомологичных хромосом.
[0043] Секвенирование ДНК - определение последовательности нуклеотидов в молекуле ДНК. Под этим может подразумеваться как амликонное секвенирование (прочтение последовательностей выделенных фрагментов ДНК, полученных в результате ПЦР реакции - таких, как ген 16S рРНК или его фрагменты) и полногеномное секвенирование (прочтение последовательностей всей ДНК, присутствующей в образце).
[0044] Гомозиготное состояние - это такое состояние локуса, при котором аллели в данном локусе идентичны друг другу на гомологичных хромосомах.
[0045] Гетерозиготное состояние - это такое состояние локуса, при котором аллели в данном локусе отличаются друг от друга на гомологичных хромосомах.
[0046] Гемизиготное состояние - это такое состояние локуса, при котором у него отсутствует гомологичный аллель, то есть хромосома, в которой находится данный локус, не имеет гомологичной пары.
[0047] RsID - это обозначение идентификатора индивидуального однонуклеотидного полиморфизма.
[0048] Чтения (риды, reads) - данные, представляющие собой нуклеотидные последовательности фрагментов ДНК, полученные с помощью ДНК-секвенатора.
[0049] FASTA - формат записи последовательностей ДНК.
[0050] Филогенетика или филогенетическая систематика - область биологической систематики, которая занимается выявлением и прояснением эволюционных взаимоотношений среди разных видов жизни на Земле, как современных, так и вымерших.
[0051] α-разнообразие - числовая величина, характеризующая разнообразие микробного сообщества внутри одной ниши. α-разнообразие вычисляется с помощью того или иного алгоритма на основании данных о видовом составе микробиоты.
[0052] β-разнообразие - числовая величина, характеризующая меру различия между 2 микробными сообществами. Это разнообразие между сообществами, показатель степени дифференцированности распределения видов или скорости изменения видового состава, видовой структуры вдоль градиентов среды. Возможный путь определения β-разнообразия - сравнение видового состава различных сообществ. Чем меньше общих видов в сообществах или в разных точках градиента, тем выше В-разнообразие.
[0053] Картирование коротких прочтений - биоинформатический метод анализа результатов секвенирования нового поколения, состоящий в определении позиций в референсной базе геномов или генов, откуда с наибольшей вероятностью могло быть получено каждое конкретное короткое прочтение.
[0054] В результате секвенирования ДНК создается набор чтений. Длина чтения у современных секвенаторов составляет от нескольких сотен до нескольких тысяч нуклеотидов.
[0055] «Золотой стандарт» (эталон, референс) генома - последовательность ДНК в цифровом виде, составленная учеными как общий репрезентативный пример генетического кода того или иного вида живых организмов. В случае человеческого генома, это может быть, например, версия сборки GRChg37 (Genome Reference Consortium human genome 37), которая представляет собой гаплоидный геном с перемежающимися локусами (т.е. изначально сведенные в одну последовательность аллельные варианты могут располагаться на разных хромосомах).
[0056] Таксономия - учение о принципах и практике классификации и систематизации сложноорганизованных иерархически соотносящихся сущностей.
[0057] В некоторых вариантах осуществления способ 100 реализован в системе 200, которая представляет из себя набор блоков, как показано на Фиг. 2. Однако способ 100 может быть альтернативно реализован с использованием любой другой подходящей системы (систем), сконфигурированной для приема и обработки генетических данных пользователей и данных о микробиоте кишечника этих пользователей, в совокупности с другой информацией для создания и обмена данными, полученными из проведенных микробиологических анализов.
[0058] Блок 201 получения первичных данных получает пробы образца по меньшей мере одного пользователя. Вышеуказанные данные получают от пользователя посредством использования набора для отбора проб, включающий контейнер 301 для образцов, как показано на Фиг. 3, имеющий компонент технологического реагента и сконфигурированный для приема образца из места сбора пользователем. Пользователь, находящийся в удаленном месте от блока получения первичных данных, может предоставлять образцы надежным образом. Доставка набора для отбора проб предпочтительно выполняется с использованием службы доставки посылок (например, почтовой службы, службы доставки и т.д.). Дополнительно или альтернативно набор для отбора проб может быть предоставлен непосредственно через устройство, установленное в помещении или на улице, которое предназначено для облегчения приема пробы от пользователя. В других вариантах осуществления набор для отбора проб может быть сдан в клинику или другое медицинское заведение медицинскому лабораторному технику. Однако предоставление набора(-ов) для отбора проб пользователя в блоке 201 получения первичных данных может дополнительно или альтернативно выполняться любым другим подходящим способом.
[0059] Набор(ы) для отбора проб, предусмотренный в блоке 201 получения первичных данных, предпочтительно выполнен с возможностью облегчения приема образцов от пользователей неинвазивным образом. В некоторых вариантах осуществления изобретения неинвазивные способы получения образца от человека могут использовать любой или несколько: проницаемый субстрат (например, тампон, выполненный с возможностью протирать область тела человека, туалетную бумага, губка и т.д.), контейнер (например, флакон, трубка, мешок и т.д.), сконфигурированный для приема образца из области тела пользователя и любого другого подходящего элемента приема (слюна, кал, моча и т.д.). В конкретном примере образцы могут быть собраны неинвазивным образом из одного органа или нескольких, например, таких как нос, кожа, половой орган человека, полость рта и кишечник (например, с использованием тампона и флакона). Однако набор для отбора пробы, предусмотренный в блоке 201 получения первичных данных, может дополнительно или альтернативно быть использован для облегчения приема образцов полуинвазивным способом или инвазивным способом. В некоторых вариантах осуществления инвазивные способы приема образца могут использовать следующие объекты: игла, шприц, биопсийные щипцы, трепан и любой другой подходящий инструмент для сбора образца полуинвазивным или инвазивным способом. В конкретных примерах пробы пользователей могут содержать один или несколько образцов крови, образцов плазмы / сыворотки (например, для экстракции бесклеточной ДНК) и образцов тканей.
[0060] Входные образцы могут представлять из себя образцы (слюна, моча, кал, кровь), которые могут быть обработаны, например, в лаборатории, и из которых получают генетические данные и данные о составе микробиоты кишечника путем секвенирования или генотипирования.
[0061] В некоторых вариантах реализации блок 201 получения первичных данных может получать дополнительные данные, которые будут учитываться при формировании рекомендаций для пользователя, из датчиков, связанных с пользователем (пользователями) (например, датчиков носимых вычислительных устройств, датчиков мобильных устройств, биометрических датчиков, связанных с пользователем и т.д.). Таким образом, блок 201 получения первичных данных может включать в себя получение данных о физической активности пользователя или физическом воздействии на него (например, данные акселерометра и гироскопа с мобильного устройства или носимого вычислительного устройства пользователя), данные об окружающей среде (например, данные о температуре, данные о высоте, данные о климате, данные о параметрах света и т.д.), данные о питании пользователя или данные о диете (например, данные из регистрационных записей о принимаемых пищевых продуктах, данные спектрофотометрического анализа и т.д.), биометрические данные (например, данные, регистрируемые с помощью датчиков в мобильном вычислительном устройстве пользователя), данные о местоположении (например, с использованием датчиков GPS), диагностические данные или любые другие подходящие данные. Дополнительно или альтернативно, дополнительный набор данных может быть получен из данных медицинской записи и/или клинических данных пользователя(ей). В некоторых вариантах реализации дополнительный набор данных может быть получен из одной или нескольких электронных медицинских записей (EHR) пользователя(ей).
[0062] Блок 202 контроля качества на основании проб образца пользователя, полученных в блоке 201 получения первичных данных, получает однонуклеотидные полиморфизмы и чтения пользователя.
[0063] В уровне техники при получении генетических данных бывают несколько типов ошибок. Например, образцы для одних и тех же пользователей имеют разные генотипы, как показано на Фиг. 4. Или, например, в зависимости от количества образцов генотип одного и того же пользователя может различаться (Фиг. 5).
[0064] Чтобы предотвратить вывод неправильных интерпретаций, раньше в уровне техники генетики вручную проверяли, является ли образец правильным, исходя из числа патогенных аллелей для одного однонуклеотидного полиморфизма и показателя интенсивности, что является очень неэффективным.
[0065] При получении однонуклеотидных полиморфизмов, блок 202 контроля качества осуществляет их контроль качества (QC - Quality Control). Данные могут получать из кремниевого биочипа посредством сканера биочипов, на который нанесены небольшие отрезки ДНК - зонды, которые специфически связываются с ДНК пользователя. При успешном связывании к этим данным может присоединяться флюоресцентная метка. Биочипы для генотипирования позволяют проводить SNP-типирование и анализ вариаций числа копий генов, генотипирование образцов для биобанков, таргетное генотипирование. В результате работы сканера биочипа получают информацию о генотипах однонуклеотидных полиморфизмов для конкретного пользователя, содержащую также полиморфизмы с Х- и Y-хромосом. Вышеуказанная информация может в себя включать идентификатор генетического полиморфизма (rsID) и один или два аллеля. Аллель в данном случае - это строка из символов А, Т, G, С, -. Например, данные могут быть представлены в следующем виде:


[0066] На первом шаге определяют пол пользователя посредством подсчета количества однонуклеотидных полиморфизмов по Х- и по Y-хромосомам. В частности осуществляют подсчет доли однонуклеотидных полиморфизмов на Х-хромосоме в гомозиготном состоянии и доли однонуклеотидных полиморфизмов, для которых не удалось осуществить генотипирование, на Y-хромосоме. Для подсчета однонуклеотидных полиморфизмов на Х-хромосоме определяют число однонуклеотидных полиморфизмов на Х-хромосоме в гомозиготном состоянии, общее число однонуклеотидных полиморфизмов на Х-хромосоме, после чего определяют отношение первого числа ко второму. Для подсчета однонуклеотидных полиморфизмов на Y-хромосоме определяют число однонуклеотидных полиморфизмов с неопределенным генотипом, общее число однонуклеотидных полиморфизмов на Y-хромосоме, после чего находят отношение первого числа ко второму.
[0067] В случае совпадения определения пола по Х- и по Y-хромосомам итоговый пол однозначно определен. В случае, если по X определился мужчина, а по Y - женщина, то результатом является Х0 - признак синдрома Тернера; если наоборот - то признак синдрома Клайнфельтера. В некоторых вариантах осуществления в случае несовпадения определения пола по Х- и Y-хромосомам производится дополнительная проверка образца на брак, так как с высокой долей вероятности речь идет именно о браке, а не об указанных двух синдромах.
[0068] После определения пола блоком 202 контроля качества на этапе контроля качества в случае мужского пола однонуклеотидные полиморфизмы в гомозиготном состоянии с X-и Y-хромосомами конвертируются в однонуклеотидные полиморфизмы в гемизиготном состоянии; при этом гетерозиготные однонуклеотидные полиморфизмы с X и Y-хромосомами отфильтровываются и не попадают в итоговую выборку генетических данных. В случае женского пола все однонуклеотидные полиморфизмы с Y-хромосомой отфильтровываются и не попадают в итоговую выборку генетических данных. Под конвертацией в данном техническом решении понимается удаление одного аллеля из пары.
[0069] Также блок 201 получения первичных данных получает данные в результате секвенирования последовательностей микробных генов 16S рРНК микробиоты кишечника. В некоторых вариантах осуществления блок 201 получения первичных данных получает файлы секвенирования в формате FASTQ или FASTA, полученные с секвенатора, по одному файлу на каждый образец. Предпочтительно может применяться ампликонное секвенирование, но также может применяться полногеномное секвенирование (WGS).
[0070] В процессе секвенирования, заключительным этапом запуска секвенатора является нахождение нуклеотидов (англ. base calling) - преобразование промежуточных "сырых" (внутренних) сигналов прибора (изображений, спектров, карт интенсивности) во множество чтений, сопровождаемых баллами качества (по одному баллу для каждой нуклеотидной позиции). Чтения состоят из четырех символов нуклеотидов (А, С, G и Т), а также служебного символа N или ".", или "?", обозначающего полную неопределенность относительно значения в данной позиции (секвенатор не может определить нуклеотид), например в виде "GCAAAAAACTTACCCCGGAACAGGCCGAGCAGATCAAAACGCTACTGCAATACAGACCATCAAGCACCAACTCCCNNNCGTAGNNNNNNTATGTTNNNNG". С точки зрения биоинформатического анализа важнейшими являются следующие характеристики чтений: во-первых, какой длины получатся чтения, во-вторых, какие в них могут быть ошибки и как часто. Приборный балл качества (англ. quality value) - величина, характеризующая вероятность отсутствия ошибки в данной позиции, вычисляемая секвенатором исходя из качества сигнала:
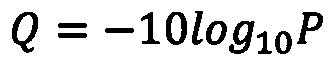
[0071] где Р - вероятность ошибки в данной позиции. В разных вариантах осуществления чтения и их баллы качества могут генерироваться в виде двух файлов для каждого образца (формат FASTA) либо объединены в единый файл (формат FASTQ); при этом с целью экономии дискового пространства данные текстовые представления могут быть переведены в двоичный формат.
[0072] Для ускорения расчетов, файлы размером, например, более 500 МБ формата FASTQ прореживаются до, например, 89951 чтений (это количество чтений в среднем соответствует размеру файла в 500 МБ при длине ридов 250 нуклеотидов). Начиная с некоторого значения увеличение глубины секвенирования слабо влияет на получаемый видовой состав микробиоты.
[0073] Блок 202 контроля качества осуществляет отсеивание чтений со средним баллом качества ниже заранее заданного порогового. В других вариантах осуществления с концов чтений могут адаптивно удаляться позиции, имеющие низкий балл качества (например, последовательно удаляются все нуклеотиды с 5' к 3' концу до тех пор, пока не встретится позиция с баллом качества, превышающим фиксированный порог). Дополнительно блок 202 контроля качества отсеивает постороннюю генетическую информацию в чтениях, имеющих небиологическое происхождение, возникающую из-за прочтения артефактных последовательностей, возникающих в ходе неправильной химической модификации исходной ДНК.
[0074] При выполнении процесса контроля качества блок 202 контроля качества может использовать вычислительные методы (например, статистические методы, методы машинного обучения, методы искусственного интеллекта, методы биоинформатики и т.д.).
[0075] Затем блок 202 контроля качества передает список однонуклеотидных полиморфизмов пользователя с координатами (хромосома и ее позиция) и генотипом пользователя в блок 203 популяционного анализа генетических данных.
[0076] Гаплогруппы бывают двух типов: материнская гаплогруппа и отцовская гаплогруппа.
[0077] В блоке 203 популяционного анализа генетических данных сначала определяют отцовскую гаплогруппу на основании дерева мутаций для Y-хромосомы и генетических данных пользователя. Дерево мутаций может быть представлено, например, в формате XML. Генетические данные пользователя содержат список однонуклеотидных полиморфизмов с координатами (хромосома и позиция) и генотипом пользователя. Дерево мутаций для Y-хромосомы содержит мутации, характерные для каждой гаплогруппы (позиция - полиморфизм).
[0078] Структура данных и способ расчета для материнской гаплогруппы совпадает с отцовской, за исключением того, что материнская гаплогруппа рассчитывается по SNP (однонуклеотидным полиморфизмам) с МТ-хромосомы, а отцовская гаплогруппа рассчитывается по SNP (однонуклеотидным полиморфизмам) с Y-хромосомы. В результате для мужчин вычисляется и отцовская и материнская гаплогруппы, а для женщин только материнская гаплогруппа.
[0079] Каждая гаплогруппа, кроме изначальной, имеет одну родительскую гаплогруппу, и одну или несколько дочерних. Каждая гаплогруппа имеет конечный список определяющих мутаций. Таким образом, образуется дерево гаплогрупп, где ребра определяются наборами мутаций.
[0080] Блок 203 популяционного анализа генетических данных при определении отцовской гаплогруппы использует дерево мутаций, генетические данные пользователя и работает следующим образом:
[0081] определяет количество вхождений каждого полиморфизма в дерево мутаций (например, A123G встречается 3 раза в дереве, Т456С встречается в дереве 22 раза);
70. сохраняет отдельно максимально возможное количество вхождений полиморфизма в дерево (получается число, например 30);
[0082] оценивает каждый полиморфизм по формуле: максимальное число вхождений какого-либо полиморфизма (определенное на предыдущем шаге) минус количество вхождений данного полиморфизма в дерево. Это значение является весом полиморфизма;
[0083] находит совпадения полиморфизмов между образцом (пользовательские данные) и каждой гаплогруппой;
[0084] находит несовпадения полиморфизмов между образцом (пользовательские данные) и каждой гаплогруппой. В контексте данного технического решения несовпадающий полиморфизм - это такой полиморфизм, при котором мутация является обратной указанной. Например, если в дереве мутаций находится мутация А12345С, а у пользователя генотип А, то блок 203 популяционного анализа генетических данных определяет, что это не совпадающий полиморфизм.
[0085] если в дереве мутаций находится мутация А12345С, а у пользователя генотип не С и не А, то блок 203 популяционного анализа генетических данных отображает мутацию на комплементарную цепочку и получается T12345G. На данном шаге меняется обозначение аллелей на комплементарные, то есть меняются аллели так, как будто они были на FWD цепочке, а стали на REV.
[0086] определяет количество совпавших и не совпавших полиморфизмов для каждой гаплогруппы;
[0087] оценивает гаплогруппу (которая является элементом дерева мутаций) по формуле: сумма весов совпавших полиморфизмов минус сумма весов не совпавших полиморфизмов;
[0088] находит такой путь по дереву мутаций, чтобы сумма оценок гаплогрупп была максимальна. Конечная гаплогруппа в таком пути и будет являться искомой отцовской гаплогруппой.
[0089] Аналогично, блок 203 популяционного анализа генетических данных определяет материнскую гаплогруппу, однако на основании дерева мутаций для митохондрии и генетических данных пользователя. мтДНК хранит дерево мутаций - устойчивые генетические маркеры (гаплогруппы), которые повторяются у всех потомков. Дерево образуется так: маркеры возникают во время мутаций и накапливаются в мтДНК. Есть возможность проследить отношение родства различных популяций по количеству совпадающих маркеров - чем больше маркеров совпадает, тем ближе родство. Если маркеры после определенной мутации не совпадают, можно сказать, когда популяции разошлись.
[0090] Далее блок 203 популяционного анализа генетических данных определяет популяционный состав пользователя на основании данных о генотипах людей из разных популяций, списка однонуклеотидных полиморфизмов с координатами (хромосома и позиция) и генотипом пользователя.
[0091] Блок 203 популяционного анализа генетических данных определяет популяционный состав посредством применения метода главных компонент. Каждый генетический образец из базы геномов для популяций разбивается на отрезки, состоящие из определенного количества однонуклеотидных полиморфизмов, следующих в геноме друг за другом последовательно. Для каждого отрезка образца определяется вектор методом главных компонент.
[0092] Аналогично, определяется вектор методом главных компонент для каждого отрезка входного образца.
[0093] Каждый отрезок образца относится в итоге к определенной популяции путем сравнения с векторами, определенными ранее.
[0094] Доля популяции рассчитывается как количество отрезков образца, отнесенных к этой популяции, поделенное на общее число отрезков образца.
[0095] В некоторых вариантах осуществления изобретения может использоваться метод главных компонент для разложения образца на вектор из 12 популяционных компонент, причем на вход подается образец целиком.
[0096] В некоторых вариантах осуществления блок 203 популяционного анализа генетических данных на основании списка однонуклеотидных полиморфизмов с координатами (хромосома и позиция) и генотипа пользователя, набора унаследованных от неандертальца аллелей в определенных полиморфизмах определяет общее количество неандертальских аллелей в образце следующим образом: если неандертальская аллель в гомозиготном состоянии, тогда +2 к результату, если неандертальская аллель в гетерозиготном состоянии, тогда +1 к результату, иначе +0. Изначально набор унаследованных от неандертальца аллелей может быть разделен на три части по популяциям: ASN, EUR и EURASN и в итоге слит в один набор. Далее, позиции на хромосоме переводятся из 37 в 38 сборок генома.
[0097] В некоторых вариантах осуществления при полногеномном (WGS) профилировании состава микробиоты блок 204 таксономического анализа данных о микробиоте картирует метагеномные чтения на неизбыточный каталог, состоящий из представительного набора геномов микробов кишечника. В данный каталог могут входить геномы бактерий, а также архей, встречающихся в кишечнике пользователя. Данный каталог может быть выработан на основании общедоступных крупных баз данных, а также автоматического анализа публикаций, имеющихся в уровне техники. В некоторых вариантах реализации расширяют набор референсных геномов, что позволяет регулярно добавлять новые опубликованные геномы. Результат картирования может быть сохранен в файле формата ВАМ. В некоторых вариантах осуществления для каждого генома определяют суммарную длину картировавшихся на него чтений (глубина покрытия).
[0098] При полногеномном анализе микробиоты относительная представленность генома далее может определяться блоком 204 таксономического анализа данных о микробиоте путем нормализации покрытия на длину генома и общую длину картировавшихся чтений:
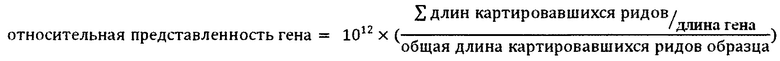
[0099] При анализе микробиоты с помощью 16S рРНК секвенирования после предварительной обработки, блок 204 таксономического анализа данных о микробиоте осуществляет количественный таксономический анализ данных путем определения, к какой известной бактерии принадлежит каждое чтение 16S рРНК (или его фрагмента) и как можно охарактеризовать чтения от неизвестных бактерий. Поиск осуществляется с применением стратегии поиска на основании шаблона (англ. reference-based). Таксономическая классификация опирается на базовое понятие операционной таксономической единицы (ОТЕ, англ. operational taxonomic unit, OTU) - определение бактериального вида на основании одной лишь последовательности 16S рРНК. Набор чтений гена 16S рРНК (или его региона) сопоставляется с представительной базой последовательностей данного гена. Каждое чтение относится к той таксономической единице, с которой он обладает высокой степенью сходства. В случае нескольких совпадений возможно случайное назначение чтения одной из этих ОТЕ. В базе каждая запись является представительной последовательностью соответствующего ОТЕ, полученного ранее в результате кластерного анализа. В то время как порог сходства можно варьировать, традиционно в метагеномных исследованиях используется значение 97% сходства как эвристическая оценка степени сходства 16S рРНК внутри одного бактериального вида. Однако данное значение не является абсолютным: с одной стороны, и в пределах одного бактериального вида могут встречаться бактерии с сильно различающимися последовательностями этого гена, с другой стороны, у двух разных видов могут быть идентичные последовательности (например, Escherichia и Shigella).
[00100] В данном техническом решении могут применяться в некоторых вариантах осуществления две другие основные стратегии идентификации ОТЕ, известные из уровня техники: поиск de novo и гибридный подход (сочетающий элементы поиска на основании шаблона и поиска de novo).
[00101] Накопленные последовательности по 16S рРНК секвенированию микробиоты сводятся в объединенные базы данных и филогенетически аннотируются. Среди наиболее используемых баз данных в уровне техники Greengenes (курируемая база полных последовательностей гена 16S рРНК), SILVA (включает последовательности не только 16S, но и 18S, 23S/28S для эукариот), RDP (аннотация менее унифицирована, но объем выше, чем у Greengenes).
[00102] В результате обработки набора метагеномов в формате 16S рРНК получается таблица относительной представленности, которая отражает количество чтений, отнесенных к каждой таксономической единице (ОТЕ) из базы данных для каждого образца. Прореженная таблица относительной представленности может определяться по следующему принципу:
a. Если суммарное число чтений для образца по каждой таксономической единице меньше порогового значения (например, 5000), такой образец исключается из дальнейшего анализа как не подходящий по качеству и подлежащий повторному секвенированию.
b. Если суммарное число чтений для образца по каждой таксономической единице больше или равно пороговому значению (например, 5000), то число чтений для каждой таксономической единицы пропорционально нормируется таким образом, чтобы суммарное число чтений для образца стало равно пороговому значению (например, 5000).
[00103] В некоторых вариантах осуществления относительная представленность нормируется. Для этого для каждого образца суммируется количество его чтений, которые успешно откартировались на референсную базу. Нормированная представленность для каждого таксона рассчитывается как количество чтений, отнесенных к этому таксону для данного образца, деленное на общую сумму откартированных чтений для этого образца и помноженное на 100%. Из полученных значений нормированной представленности составляется нормированная таблица представленности, содержащая процент чтений, отнесенных к каждому таксону из базы данных для каждого образца.
[00104] Из непрореженных таблиц относительной представленности по OTU блок 204 таксономического анализа формирует прореженные таблицы представленности по другим таксономическим уровням (родам, семействам и т.п.). Для каждого таксономического уровня применяется следующий способ:
a. Количество чтений в образце для всех OTU, которые относятся к данному таксономическому уровню, суммируются;
b. Из полученных сумм составляется таблица представленности для данного таксономического уровня.
[00105] Далее на основании прореженной таблицы представленности (таблица, которая отражает количество чтений, отнесенных к каждому таксону одного из таксономических уровней для каждого образца) оценивается относительная представленность групп микробных генов.
[00106] Для этого прореженную таблицу представленности нормализуют на число копий 16S рРНК. Для этого количество чтений, отнесенных к каждому из таксонов для каждого образца, делят на оценочное количество копий гена 16S рРНК, характерное для данного таксона.
[00107] Затем для каждого гена определяют его представленность для каждого образца следующим образом: используя существующую таблицы наличия тех или иных метаболических путей и/или групп генов в них входящих в различных микроорганизмах, для каждого образца составляется таблица представленности групп генов (ЕС) и метаболических путей, которая пропорциональная представленности микроорганизмам, в которых эти гены/метаболические пути содержатся.
[00108] В итоге из получившихся сумм составляется таблица представленности генов в каждом образце.
[00109] Таксономический профиль популяции микробных сообществ по 16S рРНК, полученный блоком 204 таксономического анализа, применяется для оценки важных характеристик популяции пользователя: альфа- и бета-разнообразия. Они являются численными величинами, характеризующими разнообразие одиночного микробного сообщества и различие между двумя сообществами, соответственно. Чем больше чтений на образец будет секвенировано, тем больше различных видов будет найдено, причем с увеличением числа чтений происходит насыщение; для сообщества низкой сложности оно будет происходить быстрее, чем для сложного; поэтому при вычислении альфа-разнообразия учитывается число чтений на образец. Среди наиболее широко применяемых оценивателей альфа-разнообразия может применяться в данном техническом решении филогенетическое разнообразие (пропорционально доле дерева жизни, которую покрывает собой сообщество), а также индексы Спао 1 и АСЕ.
[00110] Предварительно осуществляется фильтрация малопредставленных таксонов - например, по следующему принципу: оставляются таксоны, представленность которых превышает 0,2% от общей микробной представленности не менее чем в 10% образцах.
[00111] Далее на основании нормированной таблицы представленности, содержащейся в блоке 204 таксономического анализа, блок 205 определения риска заболеваний предварительно осуществляет предобработку и оценивает аномальность состава микробиоты в образце. Для каждого образца проверяется суммарный процент чтений, относящихся к каждому из таксонов из списка оппортунистических патогенов. Образец, в котором суммарный процент превышает фиксированный - например, 20% -считается аномальным. В некоторых вариантах осуществления учитывается процентная доля отдельно взятых таксонов из списка, в том числе с возможностью взвешивания их вкладов в оценку аномальности. В некоторых вариантах осуществления дополнительно для каждого образца проверяется процент чтений, относящихся к роду бифидобактерий. Образец, в котором этот процент превышает фиксированный - например, 50% - считается аномальным. В некоторых вариантах осуществления относительные представленности таксонов для каждого образца могут просматриваться экспертом на предмет обнаружения нетипичной представленности ряда выделенных таксонов, в том числе условно патогенных. На основании суждения эксперта и/или результатов работы алгоритмов машинного обучения образец также может считаться аномальным. Образцы, признанные аномальными, исключаются из дальнейшего анализа. Пользователям, которым принадлежали эти образцы, высылается уведомление о нетипичном составе микробиоты.
[00112] Затем на основании нормированной таблицы представленности и базы данных связей бактерий и болезней, блок 205 определения риска заболеваний определяет защищенность от заболеваний пользователя по данным о микробиоте.
[00113] Предварительно из микробиотных образцов популяционной выборки создается так называемый контекст - референсные данные для сравнения - следующим образом.
[00114] Для каждой бактерии (рода или иного таксона) рассчитывается набор фиксированных перцентилей по представленности - например, 33%- и 67%-перцентили. Иначе говоря, получают два порога представленности: треть образцов из популяционной выборки имеет меньшую представленность по данной бактерии, чем меньший порог; а треть образцов из популяционной выборки имеет большую представленность по данной бактерии, чем больший порог.
[00115] В некоторых вариантах реализации пороговые значения для перцентилей могут быть заранее вычислены на основании результатов статистического анализа относительной представленности таксона у пациентов с данным заболеванием (или лиц с повышенным риском данного заболевания) по сравнению со здоровыми индивидами.
[00116] Для каждого образца блок 205 определения риска заболеваний определяет его защищенность от каждой болезни. Каждому заболеванию заранее сопоставлен список прямо или обратно ассоциированных с ним микробных таксонов (биомаркеров). Далее образцу по данной болезни выставляется величина защищенности, которая может быть рассчитана по следующим правилам:
[00117] Для данного образца каждому микроорганизму (таксону) из числа биомаркеров данного заболевания присваивается значение 0, N(k) или М(k) (где k - номер биомаркера, a N(k) и М(k) - специфичные для данного биомаркера данного заболевания константы) по следующим правилам:
i. Если данная бактерия не содержится в данном образце, этой бактерии присваивается число 0.
ii. Если представленность данной бактерии в данном образце ниже верхнего и выше нижнего перцентиля, этой бактерии присваивается число 0.
iii. Если данная бактерия по данным о связи бактерий и болезней не влияет на данную болезнь, этой бактерии присваивается число 0.
iv. Если представленность данной бактерии в данном образце превышает верхний перцентиль и, по данным таблицы связей бактерий и болезней, положительно ассоциирована с этим заболеванием, этой бактерии присваивается число -М(k).
v. Если представленность данной бактерии в данном образце ниже нижнего перцентиля и, по данным о связи бактерий и болезней, положительно ассоциирована с этим заболеванием, этой бактерии присваивается число N(k).
vi. Если представленность данной бактерии в данном образце выше верхнего перцентиля и, по данным о связи бактерий и болезней, отрицательно ассоциирована с этим заболеванием, этой бактерии присваивается число 1.
vii. Если представленность данной бактерии в данном образце ниже нижнего перцентиля и, по данным о связи бактерий и болезней, отрицательно ассоциирована с этим заболеванием, этой бактерии присваивается число -1.
[00118] В некоторых примерных вариантах реализации для всех биомаркеров (k=1,…) N(k)=M(k)=1.
[00119] Данному образцу присваивается величина защищенности от данной болезни, равное сумме величин, присвоенных бактериям-биомаркерам на предыдущем шаге.
[00120] Для каждой болезни рассчитываются фиксированные перцентили по защищенности, например, 33%- и 67%-перцентили. Иначе говоря, получаются два порога защищенности: треть образцов из популяционной выборки имеет меньшую защищенность по данной болезни, чем меньший порог; а треть образцов из популяционной выборки имеет большую защищенность по данной болезни, чем больший порог.
[00121] Затем шкалированная величина защищенности для пользователя определяется блоком 205 определения риска заболеваний так:
[00122] Для каждой болезни рассчитывается величина защищенности микробиотой по способу, описанному выше при анализе контекста.
[00123] Затем защищенность для пользователя шкалируется по следующему правилу:
a. Нижний перцентиль защищенности от данного заболевания, вычисленный по контексту, принимается в новой шкале за 0;
b. Верхний перцентиль защищенности от данного заболевания, вычисленный по контексту, принимается в новой шкале за 10;
c. Значение защищенности пользователя пропорционально нормализуется по новой шкале.
[00124] Если значение защищенности по новой шкале меньше 4, ему присваивается значение 4. Полученное значение является уровнем защищенности образца от данной болезни.
[00125] В других вариантах осуществления технического решения могут быть использованы иные перцентили. Также каждый таксон может иметь свой индивидуальный вес, складывающийся из оценки его влияния на признак и его представленности в конкретном образце, отличный от 1, -1 или 0.
[00126] В рекомендациях для пользователя предлагается повысить относительную представленность бактерий, которые отрицательно ассоциированы с болезнью и имеют низкую (ненулевую) и/или нормальную представленность (лежат между верхним и нижним перцентилем), а также если они не являются положительно ассоциированными с другими болезнями.
[00127] В некоторых вариантах осуществления блок 205 определения риска заболеваний определяет состав наследственных моногенных заболеваний. Для этого может быть использован список мутаций и патогенных аллелей для наследственных заболеваний. Эти данные содержат информацию только о патогенных мутациях. Образец пользователя содержит идентификатор мутации и генотипы.
[00128] Блок 205 определения риска заболеваний проверяет каждую мутацию на наличие патогенной аллели и оценивает статус заболевания, например следующим образом:
a. 0 - нет патогенной аллели;
b. 1 - одна и только одна мутация с одной патогенной аллелью;
c. 2 - одна и более мутаций с обеими патогенными аллелями;
d. 3 - две и более мутаций с одной патогенной аллелью (составная гетерозигота);
[00129] Для одного заболевания, в одном образце могут быть первые три случая одновременно, порядок назначения: 2>3>1.
[00130] В уровне техники существует следующие типы наследования мутаций: аутосомно-рецессивный (AR), аутосомно-доминантный (AD), Х-сцепленный рецессивный (XR), Х-сцепленный доминантный (XD), Y-сцепленный (Y), митохондриальный (МТ).
[00131] В случае оценки статуса заболевания как 2 (одна и более мутаций с обеими патогенными аллелями) или 3 (две и более мутаций с одной патогенной аллелью), порядок назначения итогового типа наследования при комбинации AD и AR - AD следующий AR - AD>AR; при комбинации XD и XR - XD>XR. В итоге на выходе блок 205 определения риска заболеваний выдает статус заболевания с типом наследования.
[00132] В некоторых вариантах осуществления блок 205 определения риска заболеваний может ранжировать пользователей на основании полученных данных (индивидуальные данные, полученные в результате расчета рисков, а также данные метагеномного анализа). Для каждого заболевания блок 205 определения риска заболеваний ранжирует всех пользователей по величине показателя относительного риска и делит их, например, на пять групп таким образом, чтобы первая группа включала 10% пользователей, вторая - 20%, третья - 40%, четвертая - 20%, пятая - 10%.
[00133] Далее блок 205 определения риска заболеваний формирует например следующее распределение пользователей по группам риска:
1. Высокий риск - от 0-го до 10-го перцентиля
2. Повышенный риск - от 10-го до 30-го перцентиля
3. Средний риск - от 30-го до 70-го перцентиля
4. Умеренный риск - от 70-го до 90-го перцентиля
5. Низкий риск - от 90-го до 100-го перцентиля
[00134] По результатам метагеномного анализа, как было показано выше, блок 205 определения риска заболеваний определяет степень защищенности организма от развития некоторых заболеваний. Уровень защищенности может выражаться в целых числах по шкале от 0 до 10. Блок 205 определения риска заболеваний использует следующие принципы включения данных о степени защищенности микробиотой в ранжирование рисков по генетике:
- 0-5 баллов - пользователь перемещается на группу риска выше, чем группа, определившаяся по результатам расчета рисков (но не выше первой);
- 6-7 баллов - группа риска остается неизменной;
- 8-10 баллов - пользователь перемещается на группу риска ниже, чем группа, определившаяся по результатам расчета рисков (но не ниже пятой).
[00135] В случае, если пользователь сдавал только тест микробиоты (генетические данные не учитываются), распределение рисков может выглядеть следующим образом:
1. Высокий риск - от 0 до 3 баллов;
2. Повышенный риск - от 4 до 5 баллов;
3. Средний риск - от 6 до 7 баллов;
4. Умеренный риск - от 8 до 9 баллов;
5. Низкий риск - 10 баллов.
[00136] Специалисту в данной области техники очевидно, что способ ранжирования и количество баллов является примерным, а не ограничивающим и не влияет на сущность технического решения.
[00137] В некоторых вариантах осуществления при расчете риска может быть сделано допущение, что все факторы (внешние и генетические) независимы друг от друга. Для определения риска заболевания может использоваться логистическая модель, отправной точкой в которой считается средняя встречаемость заболевания в популяции и учитываются вклады внешних и генетических факторов риска.
[00138] Для генетических факторов риска численные значения вклада могут быть извлечены из исследований типа широкогеномный поиск ассоциаций (GWAS) по данному заболеванию. Например, для такого заболевания как "сахарный диабет 2 типа" это исследование Morris, А.Р. et al., 2012. Large-scale association analysis provides insights into the genetic architecture and pathophysiology of type 2 diabetes. Nature Genetics, 44(9), pp. 981-990.
[00139] Для внешних факторов риска используются источники информации, где показана связь между тем или иным фактором риска и риском развития данного заболевания. Например, для сахарного диабета это могут быть следующие факторы и статьи:




[00140] В некоторых вариантах осуществления определяют по составу образца микробиоты относительную представленность групп генов согласно номенклатуре ЕС (Enzyme commission number), входящих в состав метаболического пути синтеза масляной кислоты. Их представленность соотносится с контекстными данными, и каждой группе генов назначается балл по способу, аналогичному описанному выше для расчета защищенности от заболеваний. Контекстные данные представленности микроорганизмов содержат распределение представленности прокариотических микроорганизмов, значения для 33% и 67% перцентилей. Далее определяется определяется балл от 4 до 10 и это будет являться баллом синтеза масляной кислоты. В том случае, если этот балл менее порогового значения, находятся те таксоны, которые потенциально несут в своем геноме те группы генов, которые на первом шаге оказались не представлены (попали ниже 33%-перцентиля), и проверяется их представленность по контекстным данным. Если эти таксоны также попали ниже 33%-перцентиля, то они используются в дальнейшем при формировании рекомендаций пользователю.
[00141] В других вариантах осуществления происходит определение представленности групп генов ЕС в образце, входящих в состав пути синтеза витаминов, для каждого в отдельности из числа витаминов В1, В2, ВЗ, В5, В6, В7, В9, К. Их представленность соотносится с контекстными данными, каждому ЕС назначается балл по способу, аналогичному в пункте 116. Далее считается средний балл по всем витаминам и целое от него будет являться баллом синтеза витамина. В том случае если этот балл менее порогового значения, находятся те микроорганизмы, которые потенциально обладают в своем геноме теми ЕС, которые на первом шаге оказались недопредставленны (попали в 33%), и проверяется их представленность по контекстным данным. Если эти микроорганизмы также попали в 33%, то они используются в дальнейшем способе рекомендаций для пользователя.
[00142] В некоторых вариантах реализации может быть использована другая номенклатура микробных функциональных групп генов - например, KEGG Orthology groups или группы генов из базы MetaCyc.
[00143] В других вариантах осуществления происходит определение потенциала расщепления для каждого типа пищевого волокна из заранее заданного набора. Производится оценка суммы представленности относительно контекстных данных тех микроорганизмов, для которых из базы данных ассоциаций известно, что они способны их расщеплять. Если их суммарная представленность попадает в 33%, алгоритм решает, что потенциал расщепления этого волокна низок. Для каждого волокна рассчитывается балл от 4 до 10 в зависимости от значения их суммарной представленности. Суммарный потенциал расщепления волокон считается как целое среднее значение баллов по всем пищевым волокнам.
[00144] В некоторых вариантах осуществления блок 202 контроля качества передает генетические данные в блок 206 определения признаков пользователя. Признак (trait) в генетической терминологии - это измеряемая характеристика пользователя. Признак может быть получен из заполненного пользователем опросника, генетического теста, носимых гаджетов, медкарты и т.д.
[00145] Примеры признаков пользователя:
- непереносимость лактозы (дискретные состояния: есть предрасположенность, нет предрасположенности, неизвестно);
- возраст (непрерывное состояние: 30 лет, 49 лет и т.д.);
- активность CYP2D6 (дискретные состояния: ультрабыстрый метаболизатор, нормальный метаболизатор, плохой метаболизатор);
- риск ожирения (непрерывное состояние: риск 50%, риск 43,4% и т.д.).
[00146] В некоторых вариантах осуществления признаки могут быть объединены в группы по наследственным заболеваниям, реакции на лекарства, признакам по питанию, признакам по спорту, гаплотипам.
[00147] В зависимости от типа признака пользователя, признак может иметь два или более возможных состояний (states). В некоторых вариантах осуществления состояния могут быть дискретными или непрерывными, но не одновременно для одного признака. Пока признак не рассчитан для пользователя он имеет неопределенное состояние. В некоторых вариантах осуществления признак пользователя зависит от состояний других признаков. Все возможные комбинации состояний зависимостей составляют область определения признака.
[00148] Признаки могут быть изменяемыми (потребление кофе), неизменяемыми (активность CYP2D6, статус фенилкетонурии) и условно изменяемыми (некоторые риски), которые зависят от изменяемых признаков.
[00149] Признак может иметь срок давности, спустя который он будет инвалидирован, то есть перейдет в неопределенное состояние. Например, концентрация холестерина в крови по результатам анализа будет действительна в течение года, а затем признак вернется в состояние неопределенного признака пользователя.
[00150] Изменяемые и условно изменяемые признаки хранят историю изменений своего состояния, в том числе при инвалидации по истечении срока давности.
[00151] Так как признаки могут ссылаться на другие признаки в своей интерпретации, при наполнении системы признаками блок 206 определения признаков образует направленный граф зависимостей между признаками. Узлы графа, которые ни на что не ссылаются, - это узлы исходных данных (мутаций, ответов на вопросы, микробиоты). Все остальные узлы напрямую или опосредованно зависят от узлов исходных данных.
[00152] Блок 206 определения признаков пользователя осуществляет определение состояний признаков для конкретного пользователя путем редукции графа, начиная с узлов исходных данных.
[00153] Если какой-то из признаков изменил свое состояние, например, пользователь по-другому ответил на вопрос в опроснике, все зависимые от опросника признаки будут пересчитаны, т.е. обновлены. Пересчет одних признаков вызовет пересчет других, пока не будет достигнут конец графа зависимостей.
[00154] Перед определением состояния признака блок 206 определения признаков осуществляет проверку на наличие циклов в графе зависимостей, и при наличии циклов блок 206 не дает запустить редукцию графа.
[00155] На основании показателя по меньшей мере одного признака, состояния данного признака и генетических данных (однонуклеотидный полиморфизм, пол и т.д.), блок 206 определения признаков может сформулировать интерпретацию для пользователя (по спорту, по питанию, по личным качествам и т.д., не ограничиваясь) например в следующем виде:

[00156] В некоторых вариантах осуществления блок 206 определения признаков определяет признак пользователя по питанию на основании данных микробиоты. Для этого используются результаты расчета защищенности от заболеваний, потенциала к расщеплению пищевых волокон, синтеза короткоцепочечных жирных кислот, синтеза витаминов, а также база данных ассоциаций между продуктами питания и представителями кишечной микробиоты. Данная база данных формируется с использованием алгоритмов машинного анализа текста совместно с ручным наполнением на основании фактов о продуктах, прием которых положительно ассоциирован с теми или иными микроорганизмами, обитающих в кишечнике человека.
[00157] Если итоговый балл по одному из данных (например, защищенность от заболеваний) меньше заранее заданного порогового значения, то из базы данных ассоциаций берутся те продукты питания, которые ассоциированы с ростом тех микроорганизмов, представленность которых оказалась недостаточной. Чем чаще рекомендуется тот или иной продукт для данного пользователя по результатам различных алгоритмов, тем выше его ранг и вероятность его рекомендации для пользователя.
[00158] Блок 207 формирования рекомендаций для пользователя выполнен с возможностью формирования рекомендации пользователю на основании данных блока 205 определения риска заболеваний и блока 206 определения признаков пользователя.
[00159] На вход данному блоку подаются индивидуальные данные, полученные в результате определения признаков, рисков и статусов носительства заболеваний, а также данные метагеномного анализа с других блоков системы.
[00160] Работа блока 207 формирования рекомендаций для пользователя основана на выполнении условия, приводящего к выдаче результата. Условие является сочетанием простых логических операций над входными данными. Результатом является текст рекомендации, направленный на то, чтобы побудить пользователя к выполнению определенного набора действий. Рекомендации в некоторых вариантах осуществления делятся на следующие группы:
- рекомендации по нежелательным видам нагрузки;
- рекомендации по изменению образа жизни;
- рекомендации по изменению приема в пищу тех или иных продуктов питания или их групп;
- рекомендации по посещению врача.
[00161] Группа рекомендаций по продуктам питания выдается с учетом как данных генотипирования, так и данных состава микробиоты кишечника или одного варианта.
[00162] В некоторых вариантах осуществления блок 207 формирования рекомендаций для пользователя формирует рекомендации по снижению риска, рекомендации по самодиагностике, рекомендации по обращению к врачу, рекомендации по признакам.
[00163] При формировании рекомендаций по снижению риска заболевания необходимым условием отображения рекомендаций является повышенный риск заболевания.
[00164] Рекомендация побуждает перейти из одного состояния признака в другое. То есть рекомендация относится к собственно признаку. Признак может иметь массив рекомендаций, размер которого равен количеству заданных переходов между разными состояниями. Сам переход может произойти только тогда, когда меняются исходные данные пользователя, затрагивающие данный признак, и выполняется переинтерпретация.
[00165] Переход может иметь дополнительные условия, при которых он будет осуществлен. Например, пол пользователя может влиять на выдачу рекомендации.
[00166] Наличие определенного состояния какого-либо признака, определенного блоком 206 определения признаков может требовать определенное состояние другого признака, то есть, существует требователь и требуемое состояние. У каждого из состояний, среди которых предстоит выбрать целевое, есть вес, который складывается из весов всех требователей. В том случае, если требуемое состояние отличается от текущего, начинает работать переход и выдается рекомендация, побуждающая пользователя совершить этот переход. Выбор рекомендации, которую нужно дать пользователю, зависит от того, какое из требуемых состояний признака перевешивает.
[00167] Если у пользователя повышенный риск заболевания, ему выдаются рекомендации по коррекции изменяемых внешних факторов риска, которые у него находятся в состоянии, повышающем риск. Например, для сахарного диабета рекомендации могут выглядеть так:
"Пейте кофе каждый день.
Следует ежедневно включать в свой рацион кофе, не превышая, однако, допустимую для вас норму.
Включите в свой ежедневный рацион фрукты
Рекомендуется употреблять фрукты каждый день. Они богаты клетчаткой и полезными витаминами и микроэлементами.
Рекомендуется употреблять продукты, богатые витамином Е
[00168] Следует увеличить поступление в организм токоферола с пищей. Витамин Е является мощным антиоксидантом, необходим для мышечной ткани и иммунной системы".
[00169] Более подробно, сформированные рекомендации в блоке 207 формирования рекомендаций для пользователя могут включать в себя предоставление уведомлений пользователю относительно рекомендуемых терапевтических мер и/или других вариантов действий в отношении целей, связанных со здоровьем. Уведомления о рекомендациях могут предоставляться отдельному лицу посредством электронного устройства (например, персонального компьютера, мобильного устройства, планшета, смарт-часов и т.д.), причем с отображением в графическом интерфейсе пользователя (GUI). Рекомендации могут отображаться в приложении, веб-интерфейс в личном кабинете пользователя, в смс-сообщении или PUSH-уведомлении. В одном примере реализации веб-интерфейс персонального компьютера или ноутбука, связанный с пользователем, может предоставлять пользователю доступ к учетной записи пользователя, в котором учетная запись пользователя включает информацию о данных пользователя, подробную информацию о генетических данных и данных о составе микробиоты кишечника, а также уведомления о рекомендациях, сгенерированных в блоке 207 формирования рекомендаций. В другом варианте реализации приложение, выполняемое на персональном электронном устройстве (например, смартфон, смарт-часы, интеллектуальное устройство на голове), может быть сконфигурировано для предоставления уведомлений (например, на дисплее или звуковым образом и т.д.), в отношении рекомендаций, полученных с помощью блока 207 формирования рекомендаций. Уведомления могут дополнительно или альтернативно предоставляться непосредственно через человека, связанного с пользователем системы (например, смотритель, супруг, медицинский работник и т.д.). В некоторых дополнительных вариантах реализации уведомления могут дополнительно или альтернативно быть предоставлены человеку (например, специалисту в области здравоохранения), связанному с пользователем, в котором человек может влиять на осуществление рекомендаций (например, посредством рецепта, путем проведения терапевтического сеанса и т.д.). Однако рекомендации и уведомления о них могут быть предоставлены пользователю системы любым другим подходящим способом.
[00170] Хотя варианты осуществления описаны в связи с иллюстративной вычислительной системной средой, они могут быть реализованы с помощью многочисленных других вычислительных системных сред, конфигураций и устройств общего и специального назначения.
[00171] Примеры известных вычислительных систем, сред и/или конфигураций, которые могут являться подходящими для использования с аспектами изобретения, включают в себя, но без ограничения, мобильные вычислительные устройства, персональные компьютеры, серверные компьютеры, карманные устройства или ноутбуки, многопроцессорные системы, игровые консоли, системы на основе микропроцессоров, телеприставки, программируемую бытовую электронику, мобильные телефоны, сетевые персональные компьютеры, миникомпьютеры, суперкомпьютеры, распределенные вычислительные среды, которые включают в себя любые из упомянутых выше систем или устройств (например, фитнес-браслеты), и т.п. Такие системы или устройства могут принимать данные от пользователя в любом виде, в том числе от устройств ввода данных, таких как клавиатура или указательное устройство, через жестовый ввод и/или через речевой ввод.
[00172] Варианты осуществления изобретения могут быть описаны в общем контексте исполняемых с помощью компьютера команд, таких как программные модули или блоки, исполняемые одним или несколькими компьютерами или другими устройствами. Исполняемые с помощью компьютера команды могут быть организованы в один или несколько исполняемых с помощью компьютера компонентов или модулей. Обычно программные модули включают в себя, но без ограничения, подпрограммы, программы, объекты, компоненты и структуры данных, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Аспекты изобретения могут быть реализованы с помощью любого количества и любой организации таких компонентов или модулей. Например, аспекты изобретения не ограничены конкретными исполняемыми с помощью компьютера командами или конкретными компонентами или модулями, проиллюстрированными на фигурах и описанными здесь. Другие варианты осуществления изобретения могут включать в себя другие исполняемые с помощью компьютера команды или компоненты, имеющие большую или меньшую функциональность, чем проиллюстрированная и описанная здесь.
[00173] Аспекты изобретения преобразовывают компьютер общего назначения в вычислительную систему специального назначения, выполненную с возможностью интерпретировать генетические данные пользователя и данные о составе микробиоты кишечника.
[00174] Следует понимать, что различные способы, описанные в данном документе, могут быть реализованы вместе с аппаратным или программным обеспечением или, при необходимости, с их комбинацией. Поэтому, способы и система данного предмета изобретения, или некоторые аспекты или части такового, могут содержать программный код (т.е., инструкции), реализованные в материальном носителе, таком как гибкие дискеты, CD-ROM, накопители на жестких магнитных дисках, облачные хранилища или любые другие носители информации, при этом, когда программный код загружается и выполняется машиной, такой как компьютер, машина становится устройством для применения предмета изобретения. В случае выполнения программного кода на программируемых компьютерах, вычислительное устройство, в основном, содержит процессор, носитель информации доступный для чтения процессором (включая энергозависимую и энергонезависимую память и/или элементы памяти), по меньшей мере одно устройство ввода, и по меньшей мере одно устройство вывода. Одна или более программ может реализовывать или использовать процессы, описанные вместе с настоящим раскрытым предметом изобретения, например, посредством использования прикладного программного интерфейса (API), повторно используемых элементов управления, и тому подобного. Такие программы могут быть реализованы при помощи высокоуровневого процедурного или объектно-ориентированного языка программирования для обмена данными с компьютерной системой. Однако, при необходимости, программа(ы) могут быть реализованы на ассемблере, или машинном языке программирования. В любом случае, язык программирования может быть компилируемым или интерпретируемым языком, и это может быть комбинироваться с аппаратными реализациями.
[00175] Несмотря на то что предмет изобретения был описан специфическим языком структурных особенностей и/или методологических функций, является понятным, что предмет изобретения получил определение в прилагаемых пунктах формулы патента, и нет необходимости ограничивать описанные выше характерные особенности или функции. В значительной степени, описанные выше характерные особенности и функции раскрываются как типовые разновидности реализации формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОЦЕНКИ РИСКА ЗАБОЛЕВАНИЯ У ПОЛЬЗОВАТЕЛЯ НА ОСНОВАНИИ ГЕНЕТИЧЕСКИХ ДАННЫХ И ДАННЫХ О СОСТАВЕ МИКРОБИОТЫ КИШЕЧНИКА | 2018 |
|
RU2699517C2 |
| СПОСОБ И СИСТЕМА ОТСЛЕЖИВАНИЯ РАЦИОНА И ФОРМИРОВАНИЯ ЗАКЛЮЧЕНИЯ О КАЧЕСТВЕ ПИТАНИЯ И/ИЛИ ИНДИВИДУАЛЬНЫХ РЕКОМЕНДАЦИЙ ПО ПИТАНИЮ | 2019 |
|
RU2721234C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ИНДИВИДУАЛЬНОГО РАЦИОНА ПРОДУКТОВ ПИТАНИЯ ПОСЛЕ ПЕРЕСАДКИ МИКРОБИОТЫ | 2018 |
|
RU2699283C1 |
| СПОСОБ И СИСТЕМА КОРРЕКЦИИ НЕЖЕЛАТЕЛЬНЫХ КОВАРИАЦИОННЫХ ЭФФЕКТОВ В МИКРОБИОМНЫХ ДАННЫХ | 2019 |
|
RU2742003C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ИНДИВИДУАЛЬНЫХ РЕКОМЕНДАЦИЙ ПО ДИЕТЕ НА ОСНОВАНИИ АНАЛИЗА СОСТАВА МИКРОБИОТЫ | 2019 |
|
RU2724498C1 |
| ОБНАРУЖЕНИЕ МУТАЦИЙ И ПЛОИДНОСТИ В ХРОМОСОМНЫХ СЕГМЕНТАХ | 2015 |
|
RU2717641C2 |
| СПОСОБ, ТЕСТ-СИСТЕМА И ПРАЙМЕРЫ ДЛЯ ОПРЕДЕЛЕНИЯ ГАПЛОГРУПП Y-ХРОМОСОМЫ ЧЕЛОВЕКА | 2013 |
|
RU2558231C2 |
| ОПРЕДЕЛЕНИЕ ФЕНОТИПА НА ОСНОВЕ НЕПОЛНЫХ ГЕНЕТИЧЕСКИХ ДАННЫХ | 2020 |
|
RU2754884C2 |
| СПОСОБЫ ВЫЯВЛЕНИЯ И МОНИТОРИНГА РАКА ПУТЕМ ПЕРСОНАЛИЗИРОВАННОГО ВЫЯВЛЕНИЯ ЦИРКУЛИРУЮЩЕЙ ОПУХОЛЕВОЙ ДНК | 2019 |
|
RU2811503C2 |
| Система обработки данных полногеномного секвенирования | 2023 |
|
RU2804535C1 |
Данное техническое решение относится к медицине. Предложен компьютерно-реализованный способ подготовки рекомендаций для пользователя, основанный на получении и использовании генетических данных пользователя и данных о микробиоте кишечника пользователя, а также набора генетических и внешних факторов риска возникновения заболеваний, причем генетические данные включают в себя однонуклеотидные полиморфизмы, а данные о микробиоте включают в себя чтения. Технический результат - повышение точности рекомендаций пользователю на основании его генетических данных и данных о составе микробиоты кишечника. 15 з.п. ф-лы, 5 ил.
1. Компьютерно-реализованный способ подготовки рекомендаций для пользователя на основе его генетических данных и данных о составе микробиоты кишечника, включающий следующие шаги:
- получают генетические данные пользователя из кремниевого биочипа, данные о микробиоте кишечника пользователя из секвенатора путем генотипирования и секвенирования биологических образцов пользователя, а также набор генетических и внешних факторов риска возникновения заболеваний, причем генетические данные включают в себя однонуклеотидные полиморфизмы, а данные о микробиоте включают в себя чтения;
- осуществляют контроль качества генетических данных пользователя и данных о микробиоте кишечника пользователя, полученных из биочипа;
- осуществляют анализ данных о микробиоте кишечника посредством определения, к какому микроорганизму принадлежит каждое чтение 16S рРНК и как характеризуются чтения от неизвестных микроорганизмов, в результате чего получают нормированную таблицу представленности микроорганизмов в биологическом образце пользователя;
- определяют риск возникновения заболеваний на основании генетических данных пользователя, генетических и внешних факторов риска, защищенность от заболеваний на основании нормированной таблицы представленности микроорганизмов и базы данных связей микроорганизмов и болезней;
- формируют граф зависимостей между собой генетических признаков пользователя на основании его генетических данных после контроля их качества;
- определяют состояния генетических признаков пользователя путем редукции графа зависимостей признаков, сформированного на предыдущем шаге, причем если состояние по меньшей мере одного генетического признака изменилось с предыдущей проверки, все зависимые от него признаки обновляются;
- формируют рекомендации для пользователя, связанные с конкретными генетическими признаками, на основании определенного риска возникновения заболеваний, защищенности от заболеваний и состояния генетических признаков пользователя, которые отображают на электронном устройстве.
2. Способ по п. 1, характеризующийся тем, что данные о микробиоте кишечника пользователя получают в формате FASTQ или FASTA с секвенатора.
3. Способ по п. 1, характеризующийся тем, что генетические данные пользователя получают из кремниевого биочипа посредством сканера биочипов.
4. Способ по п. 3, характеризующийся тем, что генетические данные содержат данные о генотипах однонуклеотидных полиморфизмов пользователя, содержащие полиморфизмы Х- и Y-хромосом.
5. Способ по п. 1, характеризующийся тем, что при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя дополнительно определяет пол пользователя посредством подсчета количества однонуклеотидных полиморфизмов по Х- и по Y-хромосомам.
6. Способ по п. 5, характеризующийся тем, что в случае мужского пола конвертируют однонуклеотидные полиморфизмы в гомозиготном состоянии с Х- и Y-хромосом в однонуклеотидные полиморфизмы в гемизиготном состоянии.
7. Способ по п. 5, характеризующийся тем, что в случае женского пола все однонуклеотидные полиморфизмы с Y-хромосомой отфильтровываются и не попадают в итоговую выборку генетических данных.
8. Способ по п. 1, характеризующийся тем, что при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя отсеивают чтения со средним баллом качества ниже заранее заданного порогового.
9. Способ по п. 1, характеризующийся тем, что при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя с концов чтений удаляет позиции, имеющие низкий балл качества.
10. Способ по п. 1, характеризующийся тем, что при осуществлении контроля качества генетических данных пользователя и данных о микробиоте кишечника пользователя отсеивают постороннюю генетическую информацию в чтениях, имеющих биологическое или небиологическое происхождение, возникающую из-за прочтения артефактных последовательностей.
11. Способ по п. 1, характеризующийся тем, что при классификации по базе данных последовательностей генов 16S рРНК, данная база данных содержит набор геномов бактерий и/или архей, встречающихся в кишечнике пользователя.
12. Способ по п. 1, характеризующийся тем, что при осуществлении анализа данных по микробиоте кишечника определяют относительную представленность микробного генома или вида.
13. Способ по п. 1, характеризующийся тем, что при осуществлении анализа данных по микробиоте кишечника формируют прореженные таблицы представленности по другим таксономическим уровням.
14. Способ по п. 1, характеризующийся тем, что при определении риска возникновения заболеваний оценивают аномальность генетических данных посредством проверки суммарного процента чтений, относящихся к одному из таксонов из списка оппортунистических патогенов.
15. Способ по п. 1, характеризующийся тем, что при определении риска возникновения заболеваний определяют защищенность от заболеваний пользователя по данным о микробиоте на основании референсных данных.
16. Способ по п. 1, характеризующийся тем, что при определении состояния генетического признака осуществляют проверку на наличие циклов в графе зависимостей, и при наличии циклов блок не дает запустить редукцию графа.
| Токарный резец | 1924 |
|
SU2016A1 |
| DEURENBERG RUUD H | |||
| et al | |||
| "Application of next generation sequencing in clinical microbiology and infection prevention." Journal of biotechnology, 2017 (Available online 29 December 2016), 243: 16-24 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ ДИАГНОСТИКИ СОСТОЯНИЯ МИКРОБИОТЫ КИШЕЧНИКА НА ФОНЕ ЭРАДИКАЦИОННОЙ ТЕРАПИИ HELICOBACTER PYLORI И ЕГО ПРИМЕНЕНИЕ | 2015 |
|
RU2616280C1 |
| EP 3012760 A1, 27.04.2016 | |||
| КОСТРЮКОВА Е | |||
| С | |||
| и др., "Вариабельность относительного содержания геномной ДНК человека при метагеномном анализе микробиоты кишечника." Биомедицинская химия, 2014, 60(6): 695-701. | |||

