Ссылка на родственные заявки
По настоящей заявке испрашивается приоритет в соответствии с предварительной заявкой на патент США №61/982245, поданной 21 апреля 2014 г.; предварительной заявкой на патент США №61/987407, поданной 1 мая 2014 г.; предварительной заявкой на патент США №62/066514, поданной 21 октября 2014 г.; предварительной заявкой на патент США №62/146188, поданной 10 апреля 2015 г.; предварительной заявкой на патент США №62/147377, поданной 14 апреля 2015 г.; предварительной заявкой на патент США №62/148173, поданной 15 апреля 2015 г., полное содержание этих заявок включено в настоящий документ посредством ссылки для раскрытых в настоящем документе идей.
Область техники, к которой относится настоящее изобретение
Настоящее изобретение в целом относится к способам и системам обнаружения плоидности сегмента хромосомы, а также способам и системам обнаружения однонуклеотидного варианта.
Предшествующий уровень техники настоящего изобретения
Вариация числа копий (CNV) была идентифицирована в качестве основной причины структурных вариаций в геноме, включая в себя как дупликации, так и делеции последовательностей, которые, как правило, находятся в диапазоне длин от 1000 пар оснований (1 т.п.н.) до 20 мегабаз (Мб). Делеции и дупликации хромосомных сегментов или целых хромосом связаны с различными состояниями, такими как восприимчивость или устойчивость к заболеванию.
CNV часто относят к одной из двух основных категорий, основанных на длине пораженной последовательности. Первая категория включает в себя полиморфизмы числа копий (CNP), которые распространены в общей популяции, происходящие с общей частотой более 1%. CNP, как правило, представляют собой небольшие (большинство из них менее 10 т.п.н. в длину) и они часто обогащены генами, которые кодируют белки, важные в детоксикации лекарственных средств и иммунитета. Субпопуляция этих CNP сильно варьирует в отношении числа копий. В результате, различные хромосомы человека могут характеризоваться широким диапазоном числа копий (например, 2, 3, 4, 5 и т.д.) для определенного набора генов. CNP, связанные с генами иммунного ответа, в последнее время были связаны с восприимчивостью к сложным генетическим заболеваниям, включающим в себя псориаз, болезнь Крона и гломерулонефрит.
Второй класс CNV включает в себя относительно редкие варианты, которые намного длиннее, чем CNP, варьирующие в размере от сотен тысяч пар нуклеотидов до более 1 млн пар нуклеотидов в длину. В некоторых случаях эти CNV могут возникать в процессе производства спермы или яйцеклетки, что приводит к конкретному индивидууму, или они, возможно, были переданы в течение всего нескольких поколений внутри семьи. Эти большие и редкие структурные варианты наблюдались непропорционально у субъектов с задержкой умственного развития, задержкой развития, шизофренией и аутизмом. Их появление у таких субъектов приводило к предположению, что большие и редкие CNV могут быть более важны в нейрокогнитивных заболеваниях, по сравнению с другими формами наследственных мутаций, включая в себя однонуклеотидные замены.
Число копий гена может быть изменено в злокачественных клетках. Например, удвоение Chr1p распространено при злокачественной опухоли молочной железы, а число копий EGFR может быть выше нормы при немелкоклеточной злокачественной опухоли легких. Злокачественная опухоль представляет собой одну из основных причин смерти; таким образом, ранняя диагностика и лечение злокачественной опухоли имеет важное значение, так как это может улучшить результат лечения пациента (например, за счет увеличения вероятности ремиссии и продолжительности ремиссии). Ранняя диагностика может также позволить пациенту проходить меньше альтернатив или менее радикальные альтернативы лечению. Многие из современных способов лечения, которые разрушают злокачественные клетки, также влияют на нормальные клетки, приводя к различным возможным побочным эффектам, таким как тошнота, рвота, низкое содержание клеток крови, повышенный риск инфекции, выпадение волос и язвы в слизистых оболочках. Таким образом, желательно раннее обнаружение злокачественных опухолей, так как это может уменьшить количество и/или число воздействий (таких как химиотерапевтические средства или излучение), необходимых для устранения злокачественной опухоли.
Вариация числа копий также была связана с серьезными умственными и физическими недостатками, а также идиопатическим нарушением обучаемости. Неинвазивное пренатальное исследование (NIPT) с использованием внеклеточной ДНК (вкДНК) может быть использовано для обнаружения нарушений, таких как трисомия 13, 18, и 21 плода, триплоидия и анеуплоидии половой хромосомы. Субхромосомные микроделеции, которые также могут приводить к серьезным психическим и физическими недостаткам, представляют собой более сложные для обнаружения из-за их меньшего размера. Восемь из микроделеционных синдромов характеризуются совокупной частотой более чем 1 на 1000, что делает их почти такими же частыми, как аутосомные трисомии плода.
Кроме того, более высокое число копий CCL3L1 было связано с более низкой восприимчивостью к ВИЧ-инфекции, а также низкое число копий FCGR3B (рецептор иммуноглобулина клеточной поверхности CD16) может увеличивать восприимчивость к системной красной волчанке и другим подобным воспалительным аутоиммунным нарушениям.
Таким образом, необходимы улучшенные способы обнаружения делеций и дупликаций сегментов хромосом или целых хромосом. Предпочтительно, чтобы эти способы могли быть использованы для более точной диагностики заболевания или повышенного риска заболевания, такого как злокачественная опухоль, или CNV при развитии плода.
Краткая сущность настоящего изобретения
Согласно иллюстративным вариантам осуществления в настоящем документе предусмотрен способ определения плоидности хромосомного сегмента в образце индивидуума. Способ предусматривает следующие стадии:
a. получение данных о частоте аллелей, содержащих количество каждого аллеля, присутствующего в образце в каждом локусе в совокупности полиморфных локусов на хромосомном сегменте;
b. создание поэтапной аллельной информации для совокупности полиморфных локусов путем оценки фазы данных по частоте аллелей;
c. создание индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных о частоте аллелей;
d. создание совместных вероятностей для совокупности полиморфных локусов с использованием индивидуальных вероятностей и поэтапной аллельной информации; а также
e. выбор, основанный на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную плоидность, тем самым определяющей плоидность хромосомного сегмента.
Согласно одному иллюстративному варианту осуществления способа определения плоидности данные получают с использованием данных о последовательности нуклеиновой кислоты, в особенности высокоэффективных данных о последовательности нуклеиновой кислоты. Согласно некоторым иллюстративным примерам способа определения плоидности, данные о частоте аллелей корректируются на наличие ошибок, прежде чем они используются для создания индивидуальных вероятностей. Согласно конкретным иллюстративным вариантам осуществления ошибки, которые исправляются, включают в себя систематическую ошибку эффективности амплификации аллеля. Согласно другим вариантам осуществления ошибки, которые исправляются, включают в себя загрязнение окружающей среды и загрязнение генотипа. Согласно некоторым вариантам осуществления ошибки, которые исправляются, включают в себя систематическую ошибку амплификации аллелей, загрязнение окружающей среды и загрязнение генотипа.
Согласно некоторым вариантам осуществления способа определения плоидности, индивидуальные вероятности получают с использованием совокупности моделей, как различных состояний плоидности, так и фракций аллельного дисбаланса для совокупности полиморфных локусов. Согласно этим вариантам осуществления и другим вариантам осуществления совместные вероятности получают с учетом взаимосвязи между полиморфными локусами на сегменте хромосомы.
Соответственно, согласно одному иллюстративному варианту осуществления, который сочетает в себе некоторые из этих вариантов осуществления, в настоящем документе предусмотрен способ определения хромосомной плоидности в образце индивидуума, который предусматривает следующие стадии:
a. получение данных о последовательности нуклеиновой кислоты для аллелей в совокупности полиморфных локусов на хромосомном сегменте у индивидуума;
b. обнаружение частот аллелей в совокупности локусов с использованием данных о последовательности нуклеиновой кислоты;
c. коррекции систематических ошибок эффективности амплификации аллелей в обнаруженных частотах аллелей для получения скорректированных частот аллелей для совокупности полиморфных локусов;
d. получение фазированной аллельной информацию для совокупности полиморфных локусов путем оценки фазы данных о последовательности нуклеиновой кислоты;
e. получение индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения скорректированных частот аллели с совокупностью моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов;
f. получение совместных вероятностей для совокупности полиморфных локусов путем комбинирования индивидуальных вероятностей с учетом связи между полиморфными локусами на сегменте хромосомы; а также
g. выбор, основанный на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную анеуплоидию.
Согласно другому аспекту в настоящем документе предусмотрена система обнаружения хромосомной плоидности в образце индивидуума, причем эта система предусматривает:
a. входной процессор, выполненный с возможностью получения данных о частоте аллелей, содержащих количество каждого аллеля, присутствующего в образце в каждом локусе в совокупности полиморфных локусов на хромосомном сегменте;
b. моделирующее устройство, выполненное с возможностью:
I. создавать фазированную аллельную информацию для совокупности полиморфных локусов путем оценки фазы данных о частоте аллелей; а также
II. создавать индивидуальные вероятности частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных о частоте аллелей; а также
III. создавать совместные вероятности для совокупности полиморфных локусов с использованием индивидуальных вероятностей и фазированной аллельной информации; а также
c. менеджер гипотез, выполненный с возможностью выбора, основанного на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную плоидность, тем самым определяя плоидность хромосомного сегмента.
Согласно некоторым вариантам осуществления варианта осуществления этой системы данные о частоте аллелей представляют собой данные, полученные системой для секвенирования нуклеиновой кислоты. Согласно некоторым вариантам осуществления система дополнительно содержит блок для коррекции ошибок, выполненный с возможностью коррекции ошибок в данных о частоте аллелей, причем исправленные данные о частоте аллеля используется моделирующим устройством для получения индивидуальных вероятностей. Согласно некоторым вариантам осуществления блок для коррекции ошибок корректирует систематические ошибки эффективности амплификации аллеля. Согласно некоторым вариантам осуществления моделирующее устройство создает индивидуальные вероятности с использованием множества моделей, как различных состояний плоидности, так и фракций аллельного дисбаланса для совокупности полиморфных локусов. Моделирующее устройство, согласно некоторым иллюстративным вариантам осуществления, создает совместные вероятности, рассматривая связь между полиморфными локусами на сегменте хромосомы.
Согласно одному иллюстративному варианту осуществления в настоящем документе предусмотрена система обнаружения хромосомной плоидности в образце индивидуума, которая предусматривает:
a. входной процессор, выполненный с возможностью приема данных о последовательности нуклеиновой кислоты для аллелей в совокупности полиморфных локусов на сегменте хромосомы у индивидуума и обнаружения частот аллелей в совокупности локусов с использованием данных о последовательности нуклеиновой кислоты;
b. блок коррекции ошибок, выполненный с возможностью коррекции ошибок в обнаруженных частотах аллелей и создания скорректированных частот аллелей для совокупности полиморфных локусов;
c. моделирующее устройство, выполненное с возможностью:
I. получения фазированной аллельной информации для совокупности полиморфных локусов путем оценки фазы данных о последовательности нуклеиновой кислоты;
II. получения индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения фазированной аллельной информации с множеством моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов; а также
III. получения совместных вероятностей для совокупности полиморфных локусов путем объединения индивидуальных вероятностей с учетом относительного расстояния между полиморфными локусами на сегменте хромосомы; а также
d. менеджер гипотез, выполненный с возможностью выбора, основанного на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную анеуплоидию.
Согласно некоторым аспектам в настоящем изобретении предусмотрен способ определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты в образце у индивидуума, предусматривающий
a. анализ образца для определения плоидности в совокупности полиморфных локусов на хромосомном сегменте у индивидуума; а также
b. определение уровня аллельного дисбаланса, присутствующего в полиморфных локусах, на основании определения плоидности, причем аллельный дисбаланс, равный или больший, чем 0,4%, 0,45% или 0,5%, указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце.
Согласно некоторым вариантам осуществления способ определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, кроме того предусматривает обнаружение однонуклеотидного варианта в сайте однонуклеотидной дисперсии в совокупности положений однонуклеотидных дисперсий, причем обнаружение либо аллельного дисбаланса, равного 45% или более, либо обнаружение однонуклеотидного варианта, или и то и другое свидетельствует о присутствии циркулирующих опухолевых нуклеиновых кислот в образце.
Согласно некоторым вариантам осуществления стадия анализа в способе определения того, присутствуют ли циркулирующие опухолевых нуклеиновые кислоты, предусматривает анализ совокупности хромосомных сегментов, про которые известно, что они характеризуются анеуплоидией при злокачественной опухоли. Согласно некоторым вариантам осуществления стадия анализа в способе определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, предусматривает анализ от 1000 до 50000 или от 100 до 1000 полиморфных локусов на плоидность.
Согласно некоторым аспектам в настоящем документе предусмотрены способы обнаружения однонуклеотидных вариантов в образце. Соответственно, в настоящем документе предусмотрен способ определения того, присутствует ли однонуклеотидный вариант в совокупности геномных положений в образце от индивидуума, причем способ предусматривает:
a. для каждого геномного положения получение оценки эффективности и частоты появления ошибок за цикл для ампликона, охватывающего это геномное положение, с использованием обучающего набора данных;
b. получение информации о наблюдаемой нуклеотидной идентичности для каждого геномного положения в образце;
c. определение множества вероятностей процента однонуклеотидных вариантов в результате одной или нескольких реальных мутаций в каждом геномном положении путем сравнения информации о наблюдаемой нуклеотидной идентичности в каждом геномном положении с моделью процентов различных вариантов с использованием оцененной эффективности амплификации и частоты появления ошибок за цикл для каждого геномного положения независимо; а также
d. определение наиболее вероятного реального процента вариантов и доверительного интервала из совокупности вероятностей для каждого геномного положения.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, производят оценку эффективности и частоту появления ошибок за один цикл для множества ампликонов, которые охватывают геномное положение. Например, может быть включено 2, 3, 4, 5, 10, 15, 20, 25, 50, 100 или более ампликонов, которые охватывают геномное положение. Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV предел обнаружения составляет 0,015%, 0,017% или 0,02%.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, информация о наблюдаемой нуклеотидной идентичности содержит наблюдаемое число общих прочтений для каждого геномного положения и наблюдаемое число прочтений вариантных аллелей для каждого геномного положения.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, образец представляет собой образец плазмы, и однонуклеотидный вариант присутствует в циркулирующей опухолевой ДНК образца.
Согласно другому варианту осуществления в настоящем документе предусмотрен способ обнаружения одного или нескольких однонуклеотидных вариантов в исследуемом образце от индивидуума. Способ согласно настоящему варианту осуществления предусматривает следующие стадии:
a. определение медианной частоты вариантных аллелей для множества контрольных образцов от каждого из множества нормальных индивидуумов для каждого положения однонуклеотидного варианта в совокупности положений однонуклеотидных дисперсий на основе результатов, полученных в пробеге секвенирования, чтобы идентифицировать положения выбранного однонуклеотидного варианта, имеющие вариантные частоты медианных аллелей в нормальных образцах ниже порогового значения, и чтобы определить фоновую ошибку для каждого из положений однонуклеотидных вариантов после удаления выпадающих образцов для каждого из положений однонуклеотидных вариантов;
b. определение наблюдаемой глубины средневзвешенного прочтения и дисперсии для выбранных положений однонуклеотидных вариантов для исследуемого образца на основе данных, полученных в пробеге секвенирования для исследуемого образца; а также
c. идентификация с использованием компьютера одного или нескольких положений однонуклеотидных вариантов со статистически значимой глубиной средневзвешенного прочтения в сравнении с фоновой ошибкой для этого положения, тем самым определяя один или несколько однонуклеотидных вариантов.
Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV образец представляет собой образец плазмы, контрольные образцы представляют собой образцы плазмы и обнаруженные один или несколько однонуклеотидных вариантов присутствуют в циркулирующий опухолевой ДНК образца. Согласно некоторым вариантам осуществления этого способа для обнаружения одного или нескольких SNV множество контрольных образцов содержит по меньшей мере 25 образцов. Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV из данных удаляют выбросы, полученные при высокоэффективном пробеге секвенирования, чтобы вычислить наблюдаемую глубину средневзвешенного прочтения, и определяют наблюдаемую дисперсию. Согласно определенным вариантам осуществления этого способа обнаружения одного или нескольких SNV глубина прочтения для каждого положения однонуклеотидного варианта для исследуемого образца составляет по меньшей мере 100 прочтений.
Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV пробег секвенирования предусматривает мультиплексную реакцию амплификации, выполняемую при проведении реакции в условиях ограниченного количества праймеров. Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV предел обнаружения составляет 0,015%, 0,017% или 0,02%.
Согласно одному аспекту настоящее изобретение относится к способу определения того, имеется ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и получение измеренных генетических аллельных данных, содержащих количество каждого аллеля, присутствующего в образце ДНК или РНК из одной или нескольких клеток от индивидуума, для каждого из аллелей в каждом из локусов в совокупности полиморфных локусов. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез с указанием степени превалирования первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума, вычисление (например, вычисление на компьютере) правдоподобия одной или нескольких гипотез, основанных на полученных генетических данных образца и полученных фазированных генетических данных, и выбор гипотезы с наибольшей вероятностью, определяя тем самым степень превышения числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума. Согласно некоторым вариантам осуществления фазированные данные предусматривают прогнозируемые фазированные данные с использованием основанных на популяции частот гаплотипов и/или измеренных фазированных данных (например, фазированных данных, полученных путем измерения образца, содержащего ДНК или РНК от индивидуума или родственника индивидуума).
Согласно одному аспекту в настоящем изобретении предусмотрен способ определения того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, а также получение измеренных генетических аллельных данных, содержащих количество каждого аллеля, присутствующего в образце ДНК или РНК из одной или нескольких клеток от индивидуума для каждого из аллелей в каждом из локусов в совокупности полиморфных локусов. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез с указанием степени превалирования первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума, вычисление для каждой из гипотез ожидаемых генетических данных для множества локусов в образце из полученных фазированных генетических данных, вычисление (например, вычисление на компьютере) совпадения данных между полученными генетическими данными образца и ожидаемыми генетическими данными для образца, ранжирование одной или нескольких гипотез в соответствии с совпадением данных и выбор гипотезы с самым высоким положением при ранжировании, определяя тем самым степень превалирования числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума.
Согласно одному аспекту настоящее изобретение предусматривает способ определения того, наблюдается ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и получение измеренных генетических аллельных данных, содержащих для каждого из аллелей в каждом из локусов в совокупности локусов количество каждого аллеля, присутствующего в образце ДНК или РНК из одной или нескольких клеток-мишеней и одной или нескольких клеток-немишеней от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности одной или нескольких гипотез, определяющих степень превалирования первого гомологичного хромосомного сегмента, вычисление (например, вычисление на компьютере) для каждой из гипотез ожидаемых генетических данных для множества локусов в образце из полученных фазированных генетических данных для одного или нескольких возможных соотношений ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце; вычисление (например, вычисление на компьютере) для каждого возможного соотношения ДНК или РНК и для каждой гипотезы, проверку совпадения данных между полученными генетическими данными образца и ожидаемыми генетическими данными для образца для этого возможного отношение ДНК или РНК и для этой гипотезы; ранжирование одной или нескольких из гипотез, согласно совпадению данных; выбор гипотезы, которая заняла самое высокое место при ранжировании, тем самым определяя степень превалирования числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума.
Согласно одному аспекту настоящее изобретение предусматривает способ определения, существует ли превалирование числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в этом локусе на первом гомологичном хромосомном сегменте каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в этом локусе на втором гомологичном хромосомном сегменте для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и получение измеренных генетических аллельных данных, содержащих количество каждого аллеля, присутствующего в образце ДНК или РНК из одной или нескольких клеток-мишеней и одной или нескольких клеток-немишеней от индивидуума для каждого из аллелей в каждом из локусов в совокупности полиморфных локусов. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, определяющих степень превалирования первого гомологичного хромосомного сегмента, вычисление (например, вычисление на компьютере) для каждой из гипотез ожидаемых генетических данных для множества локусов в образце из полученных фазированных генетических данных для одного или нескольких возможных соотношений ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце; вычисление (например, вычисление на компьютере) для каждого локуса во множестве локусов каждого возможного соотношения ДНК или РНК, а также каждой гипотезы, вероятности того, что гипотеза верна путем сравнения полученных генетических данных образца для данного локуса и ожидаемых генетических данных для этого локуса для этого возможного соотношения ДНК или РНК и для этой гипотезы; определение объединенной вероятности для каждой гипотезы путем объединения вероятностей этой гипотезы для каждого локуса и каждого возможного соотношения, и выбор гипотезы с наибольшей объединенной вероятностью, определяя тем самым степень превалирования числа копий первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления все локусы рассматриваются сразу для вычисления вероятности конкретной гипотезы, и выбирается гипотеза с наибольшей вероятностью.
Согласно одному аспекту в настоящем изобретении предусмотрен способ определения числа копий представляющего интерес хромосомного сегмента в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных по меньшей мере для одного биологического родителя плода, причем фазированные генетические данные предусматривают идентичность присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте в паре гомологичных хромосомных сегментов, которая содержит представляющий интерес хромосомный сегмент. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на представляющем интерес хромосомном сегменте в смешанном образце ДНК или РНК, содержащем эмбриональную ДНК или РНК и материнскую ДНК или РНК от матери плода путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, указывающих на количество копий представляющего интерес хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности одной или нескольких гипотез с указанием, для одного или обоих родителей, количества копий первого гомологичного хромосомного сегмента или его части от родителя в геноме плода, количества копий второго гомологичного хромосомного сегмента или его части от родительского генома плода, а также общего количества копий представляющего интерес хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждой из гипотез, ожидаемых генетических данных для множества локусов в смешанном образце из полученных фазированных генетических данных от родителя(ей); вычисление (например, вычисление на компьютере) совпадения данных между полученными генетическими данными смешанного образца и ожидаемыми генетическими данными для смешанного образца; ранжирование одной или нескольких из гипотез согласно подгонке данных; и выбор гипотезы, которая занимает самую высокую позицию при ранжировании, тем самым определяя количество копий представляющих интерес хромосомных сегментов в геноме плода.
Согласно одному аспекту настоящее изобретение относится к способу определения числа копий хромосомы или представляющего интерес хромосомного сегмента в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных по меньшей мере для одного биологического родителя плода, причем фазированные генетические данные предусматривают идентичность присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у родителя. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в смешанном образце ДНК или РНК, содержащем эмбриональную ДНК или РНК и материнскую ДНК или РНК от матери плода путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, указывающих на число копий представляющей интерес хромосомы или хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает создание (например, создание на компьютере) для каждой из гипотез, распределения вероятности ожидаемого количества каждого аллеля в каждом из множества локусов в смешанном образце из (I) полученных фазированных генетических данных от родителя(ей) и (II) необязательной вероятности одного или нескольких кроссоверов, которые могут происходить во время образования гамет, которые вносят копию представляющей интерес хромосомы или хромосомного сегмента к плоду, вычисление (например, вычисление на компьютере) совпадения для каждой из гипотез между (1) полученными генетическими данными смешанного образца и (2) распределением вероятности ожидаемого количества каждого аллеля в каждом из множества локусов в смешанном образце для этой гипотезы; ранжирование одной или нескольких гипотез согласно совпадению данных и выбор гипотезы, которая занимает самое высокое положение при ранжировании, тем самым определяя количество копий представляющего интерес хромосомного сегмента в геноме плода.
Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для матери плода. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, указывающих на количество копий первого гомологичного хромосомного сегмента или его части от матери в геноме плода, количество копий второго гомологичного хромосомного сегмента или его части от матери в геноме плода, а также общее количество копий представляющего интерес хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает вычисление, для каждой из гипотез, ожидаемых генетических данных для множества локусов в смешанном образце из полученных фазированных генетических данных от матери.
Согласно некоторым вариантам осуществления ожидаемые генетические данные для каждой из гипотез содержат идентичность и количество одного или нескольких аллелей в каждом локусе во множестве локусов от материнской ДНК или РНК и фетальной ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере) ожидаемых генетических данных путем определения доли фетальной ДНК или РНК и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление, для каждого локуса во множестве локусов, ожидаемого количества одного или нескольких аллелей для этого локуса в материнской ДНК или РНК в смешанном образце с использованием идентичности аллеля(ей), присутствующего в этом локусе, в полученных фазированных генетических данных матери и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждого локуса во множестве локусов для каждой гипотезы, ожидаемого количества одного или нескольких аллелей для этого локуса в фетальной ДНК или РНК, унаследованной от матери, в смешанном образце с использованием идентичности аллеля, присутствующего в этом локусе в первом или втором гомологичном хромосомном сегменте от матери, который задается гипотезой, как унаследованный плодом, количества копий первого или второго гомологичного хромосомного сегмента от матери, который задается гипотезой, как унаследованный плодом, а также доли фетальной ДНК или РНК в смешанном образце.
Согласно некоторым вариантам осуществления ожидаемые генетические данные для каждой из гипотез включает в себя идентичность и количество одного или нескольких аллелей в каждом локусе во множестве локусов от материнской ДНК или РНК и фетальной ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление ожидаемых генетических данных путем определения доли фетальной ДНК или РНК и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждого локуса во множестве локусов, ожидаемого количества одного или нескольких аллелей для этого локуса в материнской ДНК или РНК в смешанном образце с использованием идентичности аллеля(ей), присутствующего в этом локусе, в полученных фазированных генетических данных матери и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждого локуса во множестве локусов для каждой гипотезы, ожидаемого количества одного или нескольких аллелей для этого локуса в фетальной ДНК или РНК, унаследованной от матери, в смешанном образце с использованием идентичности аллеля, присутствующего в этом локусе в первом или втором гомологичном хромосомном сегменте от матери, который задается гипотезой, как унаследованный плодом, количества копий первого или второго гомологичного хромосомного сегмента от матери, который задается гипотезой, как унаследованный плодом, идентичности одного или нескольких возможных аллелей в этом локусе в первом или втором гомологичном хромосомном сегменте от отца, который задается гипотезой, как унаследованный плодом, количество копий первого или второго гомологичного хромосомного сегмента от отца, который задается гипотезой, как унаследованный плодом, и доли фетальной ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления частоты популяции используются для предсказания идентичности аллелей в первом или втором гомологичном хромосомном сегменте от отца. Согласно некоторым вариантам осуществления вероятность для каждого из возможных аллелей в каждом локусе в первом или во втором гомологичном хромосомном сегменте от отца считаются одинаковыми.
Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных, как для матери, так и для отца плода. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, указывающих на количество копий первого гомологичного хромосомного сегмента или его части от матери в геноме плода, количество копий второго гомологичной хромосомного сегмента или его части от матери в геноме плода, количество копий первого гомологичного хромосомного сегмента или его части от отца в геноме плода, количество копий второго гомологичного хромосомного сегмента или его части от отца в геноме плода, а также общее количество копий представляющего интерес хромосомного сегмента в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждой из гипотез, ожидаемых генетических данных для множества локусов в смешанном образце из полученных фазированных генетических данных от матери и полученных фазированных генетических данных от отца.
Согласно некоторым вариантам осуществления ожидаемые генетические данные для каждой из гипотез включает в себя идентичность и количество одного или нескольких аллелей в каждом локусе во множестве локусов из материнской ДНК или РНК и фетальной ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление ожидаемых генетических данных путем определения доли фетальной ДНК или РНК и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждого локуса во множестве локусов, ожидаемого количества одного или нескольких аллелей для этого локуса в материнской ДНК или РНК в смешанном образце с использованием идентичности аллеля(ей), присутствующего в этом локусе, в полученных фазированных генетических данных матери и доли материнской ДНК или РНК в смешанном образце. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждого локуса во множестве локусов для каждой гипотезы, ожидаемого количества одного или нескольких аллелей для этого локуса в фетальной ДНК или РНК в смешанном образце с использованием идентичности аллеля, присутствующего в данном локусе в первом или втором гомологичном хромосомном сегменте от матери, который задается гипотезой, как унаследованный плодом, количества копий первого или второго гомологичного хромосомного сегмента от матери, который задается гипотезой, как унаследованный плодом, идентичности аллеля, присутствующего в этом локусе в первом или втором гомологичном хромосомном сегменте от отца, который задается гипотезой, как унаследованный плодом, количества копий первого или второго гомологичного хромосомного сегмента от отца, который задается гипотезой, как унаследованный плодом, и доли фетальной ДНК или РНК в смешанном образце.
Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждой из гипотез, распределения вероятностей ожидаемых генетических данных для множества локусов в смешанном образце из полученных фазированных генетических данных от родителя(ей). Согласно некоторым вариантам осуществления способ предусматривает увеличение вероятности в распределении вероятностей определенного аллеля, присутствующего в первом локусе в смешанном образце, если этот конкретный аллель присутствует в первом гомологичном сегменте у родителя и у родителя наблюдается аллель в близлежащем локусе в первом гомологичном сегменте в полученных генетических данных смешанного образца; или снижение вероятности в распределении вероятностей определенного аллеля, присутствующего в первом локусе в смешанном образце, если этот конкретный аллель присутствует в первом гомологичном сегменте у родителя и у родителя не наблюдается аллель в соседнем локусе в первом гомологичном сегменте в полученных генетических данных смешанного образца. Согласно некоторым вариантам осуществления способ предусматривает увеличение вероятности в распределении вероятностей определенного аллеля, присутствующего во втором локусе в смешанном образце, если этот конкретный аллель присутствует во втором гомологичном сегменте у родителя и у родителя наблюдается аллель в близлежащем локусе во втором гомологичном сегменте в полученных генетических данных смешанного образца; или снижение вероятности в распределении вероятностей определенного аллеля, присутствующего во втором локусе в смешанном образце, если этот конкретный аллель присутствует во втором гомологичном сегменте у родителя и не наблюдается аллель в соседнем локусе во втором гомологичном сегменте у родителя в полученных генетических данных смешанного образца.
Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных, как для матери, так и отца плода. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, задающих количество копий первого гомологичного хромосомного сегмента или его части от матери в геноме плода, количество копий второго гомологичного хромосомного сегмента или его части от матери в геноме плода, количество копий первого гомологичного хромосомного сегмента или его части от отца в геноме плода, количество копий второго гомологичного хромосомного сегмента или его части от отца в геноме плода, а также общее количество копий представляющего интерес хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает вычисление (например, вычисление на компьютере), для каждой из гипотез, распределения вероятностей ожидаемых генетических данных для множества локусов в смешанном образце из полученных фазированных генетических данных от матери и отца. Согласно некоторым вариантам осуществления способ предусматривает увеличение вероятности в распределении вероятностей определенного аллеля, присутствующего в первом локусе в смешанном образце, если этот конкретный аллель присутствует в первом гомологичном сегменте у матери или отца и у этого родителя наблюдается аллель в соседнем локусе в первом гомологичном сегменте в полученных генетических данных смешанного образца; или снижение вероятности в распределении вероятностей определенного аллеля, присутствующего в первом локусе в смешанном образце, если этот конкретный аллель присутствует в первом гомологичном сегменте у матери или отца и у этого родителя не наблюдается аллель в соседнем локусе в первом гомологичном сегменте в полученных генетических данных смешанного образца. Согласно некоторым вариантам осуществления способ предусматривает увеличение вероятности в распределении вероятностей определенного аллеля, присутствующего во втором локусе в смешанном образце, если этот конкретный аллель присутствует во втором гомологичном сегменте у матери или отца и у этого родителя наблюдается аллель в соседнем локусе во втором гомологичном сегменте в полученных генетических данных смешанного образца; или снижение вероятности в распределении вероятностей определенного аллеля, присутствующего во втором локусе в смешанном образце, если этот конкретный аллель присутствует во втором гомологичном сегменте у матери или отца и у этого родителя не наблюдается аллель в соседнем локусе во втором гомологичном сегменте в полученных генетических данных смешанного образца.
Согласно некоторым вариантам осуществления первый локус и локус, который находится рядом с первым локусом, косегрегируют. Согласно некоторым вариантам осуществления второй локус и локус, который находится рядом со вторым локусом, косегрегируют. Согласно некоторым вариантам осуществления не ожидается никаких кроссоверов между первым локусом и локусом, который находится рядом с первым локусом. Согласно некоторым вариантам осуществления не ожидается никаких кроссоверов между вторым локусом и локусом, который находится рядом со вторым локусом. Согласно некоторым вариантам осуществления расстояние между первым локусом и локусом, который находится рядом с первым локусом, составляет менее чем 5 Мб, 1 Мб, 100 т.п.н., 10 т.п.н., 1 т.п.н., 0,1 т.п.н. или 0,01 т.п.н.. Согласно некоторым вариантам осуществления расстояние между вторым локусом и локусом, который находится рядом со вторым локусом, составляет менее чем 5 Мб, 1 Мб, 100 т.п.н., 10 т.п.н., 1 т.п.н., 0,1 т.п.н. или 0,01 т.п.н..
Согласно некоторым вариантам осуществления при образовании гаметы образуются один или несколько кроссоверов, которые вносят копию представляющего интерес хромосомного сегмента к плоду; и кроссовер производит представляющий интерес хромосомный сегмент в геноме плода, который содержит часть первого гомологичного сегмента и часть второго гомологичного сегмента от родителя. Согласно некоторым вариантам осуществления совокупность гипотез включает в себя одну или нескольких гипотез, задающих количество копий представляющего интерес хромосомного сегмента в геноме плода, который содержит часть первого гомологичного сегмента и часть второго гомологичного сегмента от родителя.
Согласно некоторым вариантам осуществления ожидаемые генетические данные смешанного образца содержат ожидаемое количество одного или нескольких аллелей в каждом локусе во множестве локусов в смешанном образце для каждой из гипотез.
Согласно одному аспекту настоящее изобретение относится к способу определения того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме индивидуума (например, в геноме одной или нескольких клеток, вкДНК, вкРНК индивидуума, у которого подозревают наличие злокачественной опухоли, плода или эмбриона) с использованием фазированных генетических данных. Согласно некоторым вариантам осуществления способ предусматривает одновременное или последовательное в любом порядке (I) получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусах на первом гомологичном хромосомном сегменте, (II) получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентичность аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и (III) получение измеренных данных о генетических аллелях, содержащих количество каждого аллеля в каждом из локусов в совокупности полиморфных локусов в образце ДНК или РНК из одной или нескольких клеток от индивидуума или в смешанном образце внеклеточной ДНК или РНК из двух или нескольких генетически различных клеток от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает вычисление аллельных соотношений для одного или нескольких локусов в совокупности полиморфных локусов, которые являются гетерозиготными по меньшей мере в одной клетке, из которой был получен образец. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей в локусе. Согласно некоторым вариантам осуществления способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента посредством сравнения одного или нескольких вычисленных аллельных соотношений для локуса с ожидаемым аллельным соотношением, таким как соотношение, которое ожидается для такого локуса, если первый и второй гомологичные хромосомные сегменты присутствуют в равных пропорциях. Согласно некоторым вариантам осуществления ожидаемое соотношение составляет 0,5 для биаллельных локусов.
Согласно некоторым вариантам осуществления для пренатальной диагностики способ предусматривает одновременное или последовательное в любом порядке (I) получение фазированных генетических данных для первого гомологичного хромосомного сегмента в геноме плода (например, плода, развивающегося у беременной матери), содержащего идентичность аллеля, присутствующего в этом локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, (II) получение фазированных генетических данных для второго гомологичного хромосомного сегмента в геноме плода, содержащего идентичность аллеля, присутствующего в этом локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегмента, и (III) получение данных по измеренным генетическим аллелям, содержащих количество каждого аллеля в каждом из локусов в совокупности полиморфных локусов в смешанном образце ДНК или РНК от матери плода, который содержит фетальную ДНК или РНК и материнскую ДНК или РНК (например, смешанный образец внеклеточной ДНК или РНК, происходящий из образца крови от матери, который содержит фетальную внеклеточную ДНК или РНК, и материнскую внеклеточную ДНК или РНК). Согласно некоторым вариантам осуществления способ предусматривает вычисление аллельных соотношений для одного или нескольких локусов в совокупности полиморфных локусов, которые гетерозиготны у плода и/или гетерозиготны у матери. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса. Согласно некоторым вариантам осуществления способ предусматривает определение, существует ли превышение числа копий первого гомологичного хромосомного сегмента путем сравнения одного или нескольких вычисленных аллельных соотношений для локуса с ожидаемым аллельным соотношением, таким как соотношение, который ожидается для этого локуса, если первый и второй гомологичные хромосомные сегменты присутствуют в равных пропорциях.
Согласно некоторым вариантам осуществления вычисленное аллельное соотношение свидетельствует о превышении числа копий первого гомологичного хромосомного сегмента, если (I) аллельное соотношение для измеряемого количества аллеля, присутствующего в этом локусе на первой гомологичной хромосоме, поделенного на общее измеренное количество всех аллелей для локуса, больше, чем ожидаемое аллельное соотношение для этого локуса, или (II) аллельное соотношение для измеряемого количества аллеля, присутствующего в этом локусе на второй гомологичной хромосоме, поделенного на общее измеренное количество всех аллелей для локуса, меньше, чем ожидаемое аллельное соотношение для этого локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение свидетельствует об отсутствии превышения числа копий первого гомологичного хромосомного сегмента, если (I) аллельное соотношение для измеряемого количества аллеля, присутствующего в этом локусе на первой гомологичной хромосоме, поделенного на общее измеренное количество всех аллелей для локуса, меньше, чем ожидаемое аллельное соотношение для этого локуса или равно ему, или (II) аллельное соотношение для измеряемого количества аллеля, присутствующего в этом локусе на второй гомологичной хромосоме, поделенного на общее измеренное количество всех аллелей для локуса, больше, чем ожидаемое аллельное соотношение для этого локуса или равно ему.
Согласно некоторым вариантам осуществления определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента, предусматривает перечисление совокупности из одной или нескольких гипотез, которые задают степень превышения первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления прогнозируемые аллельные коэффициенты для локусов, которые гетерозиготны по меньшей мере в одной клетке (например, локусов, которые гетерозиготны у плода и/или гетерозиготны у матери), оцениваются для каждой гипотезы с учетом степени превышения, заданной гипотезой. Согласно некоторым вариантам осуществления правдоподобие того, что гипотеза верна, рассчитывается путем сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, и выбирается гипотеза с наибольшим правдоподобием. Согласно некоторым вариантам осуществления ожидаемое распределение статистики критерия вычисляется с использованием прогнозируемых аллельных соотношений для каждой гипотезы. Согласно некоторым вариантам осуществления правдоподобие того, что гипотеза верна, рассчитывается путем сравнения критерия значимости, который рассчитывается с использованием вычисленных аллельных соотношений, с ожидаемым распределением статистики критерия, который рассчитывается с использованием прогнозируемых аллельных соотношений, и выбирается гипотеза с наибольшим правдоподобием. Согласно некоторым вариантам осуществления прогнозируемые аллельные соотношения для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусы, которые являются гетерозиготными у плода и/или гетерозиготными у матери), оцениваются с учетом фазированных генетических данных для первого гомологичного хромосомного сегмента, фазированных генетических данных для второго гомологичного хромосомного сегмента и степени превышения, заданной этой гипотезой. Согласно некоторым вариантам осуществления правдоподобие того, что гипотеза верна, рассчитывается путем сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, и выбирается гипотеза с наибольшим правдоподобием.
Согласно некоторым вариантам осуществления вычисляется отношение ДНК (или РНК) из одной или нескольких клеток-мишеней к общей ДНК (или РНК) в образце. Иллюстративное соотношение представляет собой отношение фетальной ДНК (или РНК) к общей ДНК (или РНК) в образце. Согласно некоторым вариантам осуществления отношение фетальной ДНК к общей ДНК в образце определяют путем измерения количества аллеля в одном или нескольких локусах, в которых у плода содержится аллель, а у матери аллеля нет. Согласно некоторым вариантам осуществления отношение фетальной ДНК к общей ДНК в образце определяют путем измерения разности метилирования между одной или несколькими аллелями матери и плода. Согласно некоторым вариантам осуществления перечисляют совокупность одной или нескольких гипотез, задающих степень превышения первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления прогнозированные аллельные соотношения для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), оцениваются с учетом вычисленного соотношения ДНК или РНК, и степень превышения, заданная этой гипотезой, оценивается для каждой гипотезы. Согласно некоторым вариантам осуществления правдоподобие того, что гипотеза верна, рассчитывается путем сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, и выбирают гипотезу с наибольшим правдоподобием. Согласно некоторым вариантам осуществления ожидаемое распределение статистики критерия, вычисленное с использованием прогнозируемых аллельных соотношений и вычисленного соотношения ДНК или РНК, оценивается для каждой гипотезы. Согласно некоторым вариантам осуществления правдоподобие того, что гипотеза верна, определяется путем сравнения статистики критерия, вычисленной с использованием вычисленных аллельных соотношений и вычисленного соотношения ДНК или РНК с ожидаемым распределением статистики критерия, вычисленного с использованием прогнозируемых аллельных соотношений и вычисленного соотношения ДНК или РНК, и выбирают гипотезу с наибольшим правдоподобием.
Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, задающих степень превышения первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления способ предусматривает оценку, для каждой гипотезы, либо (I) прогнозируемых аллельных соотношений для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), учитывая степень превышения, заданную этой гипотезой, или (II) для одного или нескольких возможных соотношений ДНК или РНК (например соотношений фетальной ДНК или РНК к общей ДНК или РНК в образце) ожидаемого распределения статистики критерия, вычисленного с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК из одной или нескольких клеток-мишеней (например, клеток плода) к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления соответствие данных рассчитывается путем сравнения либо (I) вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, либо (II) статистики критерия, вычисленной с использованием вычисленных аллельных соотношений и возможного соотношения ДНК или РНК, с ожидаемым распределением статистики критерия, рассчитанной с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК. Согласно некоторым вариантам осуществления одну или несколько гипотез ранжируют по соответствию данных и выбирают гипотезу, которая заняла самое высокое положение при ранжировании. Согласно некоторым вариантам осуществления технологию или алгоритм, например, алгоритм поиска, используют для одной или нескольких из следующих стадий: вычисление совпадения данных, ранжирование гипотез или выбор гипотезы, которая заняла самое высокое место при ранжировании. Согласно некоторым вариантам осуществления совпадение данных представляет собой совпадение по бета-биномиальному распределению или совпадение по биномиальному распределению. Согласно некоторым вариантам осуществления технологию или алгоритм выбирают из группы, состоящей из оценки по максимальному правдоподобию, оценки по максимальной апостериорной гипотезе, Байесовского оценивания, динамического оценивания (например, динамического Байесовского оценивания) и EM-оценки. Согласно некоторым вариантам осуществления способ предусматривает применение технологии или алгоритма к полученным генетическим данным и ожидаемым генетическим данным.
Согласно некоторым вариантам осуществления способ предусматривает создание разбиения возможных соотношений (например, соотношений фетальной ДНК или РНК к общей ДНК или РНК в образце) в диапазоне от нижнего предела до верхнего предела для соотношения ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления перечислена совокупность одной или нескольких гипотез, задающих степень превышения первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления способ предусматривает оценку, для каждого из возможных соотношений ДНК или РНК в разбиении и для каждой гипотезы, либо (I) предсказанных аллельных соотношений для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), учитывая возможное соотношение ДНК или РНК и степень превалирования, заданную этой гипотезой, либо (II) ожидаемого распределения статистики критерия, вычисленного с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК. Согласно некоторым вариантам осуществления способ предусматривает вычисление, для каждого из возможных соотношений ДНК или РНК в разбиении и для каждой гипотезы, вероятности того, что гипотеза верна путем сравнения либо (I) вычисленных аллельных соотношений с предсказанными аллельными соотношениями, либо (II) статистики критерия, вычисленной с использованием рассчитанных аллельных соотношений и возможного соотношения ДНК или РНК, с ожидаемым распределением статистики критерия, вычисленной с использованием предсказанных аллельных соотношений и возможного соотношения ДНК или РНК. Согласно некоторым вариантам осуществления совместная вероятность для каждой гипотезы определяется путем объединения вероятностей этой гипотезы для каждого из возможных соотношений в разбиении; и выбирают гипотезу с наибольшей совместной вероятностью. Согласно некоторым вариантам осуществления совместную вероятность для каждой гипотезы определяют путем задавания веса вероятности гипотезы для конкретного возможного соотношения на основе вероятности того, что это возможное соотношение представляет собой правильное соотношение.
Согласно одному аспекту настоящее изобретение предусматривает способ определения числа копий хромосомы или хромосомного сегмента в геноме одной или нескольких клеток у индивидуума с использованием фазированных или нефазированных генетических данных. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в образце путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления образец представляет собой образец ДНК или РНК из одной или нескольких клеток от индивидуума или смешанного образца внеклеточной ДНК от индивидуума, который включает в себя внеклеточную ДНК из двух или нескольких генетически различных клеток. Согласно некоторым вариантам осуществления аллельные соотношения вычисляют для локусов, которые являются гетерозиготными по меньшей мере в одной клетке, из которой был получен образец. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей (например, аллеля на первом гомологичном хромосомном сегменте), деленное на измеренное количество одного или нескольких других аллелей (например, аллеля на втором гомологичном хромосомном сегменте) для локуса. Согласно некоторым вариантам осуществления перечислена совокупность одной или нескольких гипотез, задающих число копий хромосомы или хромосомного сегмента в геноме одной или нескольких клеток. Согласно некоторым вариантам осуществления выбирают гипотезу, которая наиболее вероятна на основании статистики критерия, тем самым определяя число копий хромосомы или хромосомного сегмента в геноме одной или нескольких клеток.
Согласно одному аспекту настоящее изобретение предусматривает способ определения числа копий хромосомы или хромосомного сегмента в геноме плода (например, плода, который развивается у беременной матери) с использованием фазированных или нефазированных генетических данных. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в образце путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления образец представляет собой смешанный образец ДНК, содержащий фетальную ДНК или РНК и материнскую ДНК или РНК от матери плода (например, смешанный образец внеклеточной ДНК или РНК, происходящей из образца крови от матери, который включает в себя внеклеточную ДНК или РНК плода и внеклеточную материнскую ДНК или РНК). Согласно некоторым вариантам осуществления аллельные соотношения вычисляют для локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей (например, аллеля на первом гомологичном хромосомном сегменте), деленное на измеренное количество одного или нескольких других аллелей (например, аллеля на втором гомологичном хромосомном сегменте) для локуса. Согласно некоторым вариантам осуществления перечислена совокупность одной или нескольких гипотез, задающих число копий хромосомы или хромосомного сегмента в геноме плода. Согласно некоторым вариантам осуществления выбирают гипотезу, которая представляет собой наиболее вероятную на основании статистики критерия, тем самым определяя число копий хромосомы или хромосомного сегмента в геноме плода.
Согласно некоторым вариантам осуществления гипотезу выбирают, если вероятность того, что статистика критерия принадлежит к распределению статистики критерия для той гипотезы, находится выше верхнего порога; одну или несколько гипотез отвергают, если вероятность того, что статистика критерия принадлежит распределению статистики критерия для этой гипотезы, ниже нижнего порога; или гипотезу ни выбирают, ни отвергают, если вероятность того, что статистика критерия относится к распределению статистики критерия для этой гипотезы, находится между нижним порогом и верхним порогом, или если вероятность не определена с достаточно высокой степенью достоверности. Согласно некоторым вариантам осуществления превышение числа копий первого гомологичного хромосомного сегмента происходит из-за дупликации первого гомологичного хромосомного сегмента или делеции второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления общее измеренное количество всех аллелей для одного или нескольких локусов сравнивают с эталонным количеством, чтобы определить, происходит ли превышение числа копий первого гомологичного хромосомного сегмента из-за дупликации первого гомологичного хромосомного сегмента или делеции второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления величина разности между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для одного или нескольких локусов используется для определения того, происходит ли превышение числа копий первого гомологичного хромосомного сегмента из-за дупликации первого гомологичного хромосомного сегмента или делеции второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления первый и второй гомологичные хромосомные сегменты определяются как присутствующие в равных пропорциях, если нет превышения числа копий первого гомологичного хромосомного сегмента и нет превышения второго гомологичного хромосомного сегмента (например, в геноме клеток, вкДНК, вкРНК, индивидуума, плода или эмбриона).
Согласно некоторым вариантам осуществления соотношение ДНК из одной или нескольких клеток-мишеней к общей ДНК в образце определяют на основании общего или относительного количества одного или нескольких аллелей в одном или нескольких локусах, для которых генотип клетки-мишени отличается от генотипа клеток-немишеней и для которых ожидается, что клетки-мишени и клетки-немишени будут дисомными. Согласно некоторым вариантам осуществления это соотношение используют, чтобы определить, происходит ли превышение числа копий первого гомологичного хромосомного сегмента из-за дупликации первого гомологичного хромосомного сегмента или делеции второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления соотношение используют для определения количества дополнительных копий хромосомного сегмента или хромосомы, которая дублирована. Согласно некоторым вариантам осуществления фазированные генетические данные включают в себя вероятностные данные. Согласно некоторым вариантам осуществления получение фазированных генетических данных для первого гомологичного хромосомного сегмента и/или второго гомологичного хромосомного сегмента в геноме плода включает в себя получение фазированных генетических данных для первого гомологичного хромосомного сегмента и/или второго гомологичного хромосомного сегмента в геноме одного или обоих биологических родителей плода, и выведение заключения о том, какой гомологичный хромосомный сегмент плода унаследован от одного или обоих биологических родителей. Согласно некоторым вариантам осуществления вероятность одного или нескольких кроссоверов (например, 1, 2, 3 или 4 кроссоверов), которые могут происходить в процессе образования гамет, которые способствуют копированию первого гомологичного хромосомного сегмента или второго гомологичного хромосомного сегмента к плоду, используется для вывода заключения о том, какой гомологичной хромосомный сегмент(ы) плода унаследован от одного или обоих биологических родителей. Согласно некоторым вариантам осуществления фазированные генетические данные для матери и/или отца плода получают с использованием способа, выбранного из группы, состоящей из цифровой ПЦР, выводящий гаплотип с использованием основанной на популяции частоты гаплотипов, гаплотипирования с использованием гаплоидной клетки, такой как сперматозоид или яйцеклетка, гаплотипирования с использованием генетических данных от одного или нескольких ближайших родственников, а также их комбинации. Согласно некоторым вариантам осуществления фазированные генетические данные для индивидуума получают путем фазирования части или всей области, соответствующей делеций или дупликации в образце от индивидуума. Согласно некоторым вариантам осуществления фазированные генетические данные для плода получают путем фазирования части или всей области, соответствующей делеций или дупликации в образце, взятом у плода или матери плода. Согласно некоторым вариантам осуществления получение фазированных генетических данных для первого и второго гомологичного хромосомного сегмента включает в себя определение идентичности аллелей, присутствующих в одном из хромосомных сегментов, и определение идентичности аллелей, присутствующих в другом хромосомном сегменте, путем выведения заключения. Согласно некоторым вариантам осуществления аллели из нефазированных генетических данных, которые не присутствуют в первом гомологичном хромосомном сегменте, присваиваются второму гомологичному хромосомному сегменту. Например, если генотип индивидуума представляет собой (AB, AB) и фазированные данные для индивидуума указывают на то, что первый гаплотип представляет собой (A, A); то можно сделать вывод, что другой гаплотип представляет собой (B, B). Согласно некоторым вариантам осуществления если измеряется только один аллель в локусе, то этот аллель определяется как часть, как первого, так и второго гомологичного хромосомного сегмента (например, если генотип представляет собой AA в локусе, значит оба гаплотипа характеризуются наличием аллеля A). Согласно некоторым вариантам осуществления фазированные генетические данные для индивидуума содержат определение того, происходит ли один или нескольких возможных хромосомных кроссоверов, например, путем определения последовательности горячих точек рекомбинации и, возможно, области, фланкирующей горячие точки рекомбинации. Согласно некоторым вариантам осуществления любая из библиотек праймеров согласно настоящему изобретению используется для обнаружения события рекомбинации, чтобы определить, какие блоки гаплотипов присутствуют в геноме индивидуума.
Согласно некоторым вариантам осуществления способ предусматривает использование модели совместного распределения (например, модель совместного распределения, которая принимает во внимание связь между локусами), выполняя анализ сцепления, использование биномиальной модели распределения, использование бета-биномиальной модели распределения и/или использование вероятности кроссоверов, происходящих во время мейоза, которое привело к гаметам, которые образовали эмбрион, который перерос в плод (например, используя вероятность хромосом, перекрещивающихся в разных положениях в хромосоме, чтобы моделировать зависимость между полиморфными аллелями на представляющей интерес хромосоме или хромосомном сегменте).
Согласно некоторым вариантам осуществления одно или несколько вычисленных аллельных соотношений для вкДНК или вкРНК указывает на соответствующие аллельные соотношения для ДНК или РНК в клетках, из которых была получена вкДНК или вкРНК. Согласно некоторым вариантам осуществления одно или несколько вычисленных аллельных соотношений для вкДНК или вкРНК указывает на соответствующие аллельные соотношения в геноме индивидуума. Согласно некоторым вариантам осуществления аллельное соотношение только вычисляется или только сравнивается с ожидаемым аллельным соотношением, если измеренные генетические данные указывают на то, что более чем один отличный аллель присутствует в этом локусе в образце (например, в образце вкДНК или вкРНК). Согласно некоторым вариантам осуществления аллельное соотношение только вычисляется или только сравнивается с ожидаемым аллельным соотношением, если локус является гетерозиготным по меньшей мере в одной из клеток, из которых был получен образец (например, локусе, который является гетерозиготным у плода и/или гетерозиготным у матери). Согласно некоторым вариантам осуществления аллельное соотношение только вычисляется или только сравнивается с ожидаемым аллельным соотношением, если локус является гетерозиготным у плода. Согласно некоторым вариантам осуществления аллельное соотношение вычисляется и сравнивается с ожидаемым аллельным соотношением для гомозиготного локуса. Например, аллельные соотношения для локусов, которые предсказываются как гомозиготные для конкретного подвергаемого исследованию индивидуума (или как для плода, так и для беременной матери) могут быть проанализированы, чтобы определить уровень шума или ошибок в системе.
Согласно некоторым вариантам осуществления анализируют по меньшей мере 10; 50; 100; 200; 300; 500; 750; 1000; 2000; 3000; 4000 или более локусов (например, SNP) для представляющей интерес хромосомы или хромосомного сегмента. Согласно некоторым вариантам осуществления среднее число локусов (например, SNP) на мегабазу в представляющей интерес хромосоме или хромосомном сегменте составляет по меньшей мере 1; 10; 25; 50; 100; 150; 200; 300; 500; 750; 1000 или более локусов на мегабазу. Согласно некоторым вариантам осуществления среднее число локусов (например, SNP) на мегабазу в представляющей интерес хромосоме или хромосомном сегменте составляет от 1 до 500 локусов на мегабазу, например, от 1 до 50, от 50 до 100, от 100 до 200, от 200 до 400, от 200 до 300 или от 300 до 400 локусов на мегабазу, включительно. Согласно некоторым вариантам осуществления анализируют локусы в нескольких участках потенциальной делеции или дупликации, чтобы повысить чувствительность и/или специфичность определения CNV по сравнению с анализом только 1 локуса или анализом только нескольких локусов, которые находятся рядом друг с другом. Согласно некоторым вариантам осуществления измеряют только два наиболее распространенных аллеля в каждом локусе или используют для определения вычисленного аллельного соотношения. Согласно некоторым вариантам осуществления амплификацию локусов осуществляют с использованием полимеразы (например, ДНК-полимеразы, РНК-полимеразы или обратной транскриптазы) с низкой 5'→3' экзонуклеазной активностью и/или низкой активностью замещения цепей. Согласно некоторым вариантам осуществления измеренные генетические аллельные данные получают посредством (I) секвенирования ДНК или РНК в образце, (II) амплификации ДНК или РНК в образце, а затем секвенирования амплифицированной ДНК, или (II) амплификации ДНК или РНК в образце, лигирования продуктов ПЦР, а затем секвенирования лигированных продуктов. Согласно некоторым вариантам осуществления измеренные генетические аллельные данные получают путем деления ДНК или РНК из образца на множество фракций, добавления другого штрих-кода к ДНК или РНК в каждой фракции (например, таким образом, что все ДНК или РНК в той или иной фракции имеют один и тот же штрих-код), при необходимости амплификации ДНК или РНК со штрих-кодом, объединение фракций, а затем секвенирования ДНК или РНК со штрих-кодом в объединенные фракции. Согласно некоторым вариантам осуществления аллели полиморфных локусов (например, SNP) идентифицируют с использованием одного или нескольких из следующих способов: секвенирование (например, нанопоровое секвенирование или секвенирование Halcyon Molecular), матричный анализ SNP, ПЦР в реальном времени, TaqMan, система для анализа NanostringnCounter®, анализ генотипирования GoldenGate Illumina, который использует дискриминационную ДНК-полимеразу и лигазу, опосредованная лигированием ПЦР или связанные инвертированные зонды (LIP, который также можно назвать зондами предварительной циркуляции, циркулирующими зондами, зондами Padlock или инвертированными молекулярными зондами (MIP)). Согласно некоторым вариантам осуществления два или более (например, 3 или 4) ампликона-мишени лидировали вместе и затем лигированные продукты секвенировали. Согласно некоторым вариантам осуществления измерения для различных аллелей для того же локуса корректируют в отношении различий в метаболизме, апоптозе, гистонах, инактивации и/или амплификации между аллелями (например, различия в эффективности амплификации между различными аллелями одного и того же локуса). Согласно некоторым вариантам осуществления эта корректировка производится до вычисления аллельного соотношения для полученных генетических данных или до сравнения измеренных генетических данных с ожидаемыми генетическими данными.
Согласно некоторым вариантам осуществления способ также предусматривает определение наличия или отсутствия одного или нескольких факторов риска развития заболевания или нарушения. Согласно некоторым вариантам осуществления способ также предусматривает определение наличия или отсутствия одного или нескольких полиморфизмов или мутаций, связанных с заболеванием или нарушением или повышенным риском развития заболевания или нарушения. Согласно некоторым вариантам осуществления способ также предусматривает определение общего содержания вкДНК, вк мДНК, вк нДНК, вкРНК, миРНК или любой их комбинации. Согласно некоторым вариантам осуществления способ предусматривает определение содержания одной или нескольких из представляющих интерес молекул вкДНК, вк мДНК, вк нДНК, вкРНК и/или миРНК, например, молекул с полиморфизмом или мутацией, связанной с заболеванием или нарушением или повышенным риском развития заболевания или нарушения. Согласно некоторым вариантам осуществления определяют долю опухолевой ДНК из общей ДНК (например, долю опухолевой вкДНК из общей вкДНК или долю опухолевой вкДНК с определенной мутацией из общей вкДНК). Согласно некоторым вариантам осуществления эту опухолевую фракцию используют для определения стадии злокачественной опухоли (так как более высокие опухолевые фракции могут быть связаны с более поздней стадией злокачественной опухоли). Согласно некоторым вариантам осуществления способ также предусматривает определение общего содержания ДНК или содержания РНК. Согласно некоторым вариантам осуществления способ предусматривает определение уровня метилирования одной или нескольких представляющих интерес молекул ДНК или РНК, таких, как молекулы с полиморфизмом или мутацией, связанной с заболеванием или нарушением или повышенным риском развития заболевания или нарушения. Согласно некоторым вариантам осуществления способ предусматривает определение наличия или отсутствия изменений в целостности ДНК. Согласно некоторым вариантам осуществления способ также предусматривает определение общего уровня сплайсинга мРНК. Согласно некоторым вариантам осуществления способ предусматривает определение уровня сплайсинга мРНК или обнаружения альтернативного сплайсинга мРНК для одной или нескольких представляющих интерес молекул РНК, таких как молекулы с полиморфизмом или мутацией, связанной с заболеванием или нарушением или повышенным риском развития заболевания или нарушения.
Согласно некоторым вариантам осуществления настоящее изобретение относится к способу обнаружения злокачественного фенотипа у индивидуума, причем злокачественный фенотип характеризуется наличием по меньшей мере одной из множества мутаций. Согласно некоторым вариантам осуществления способ предусматривает получение измерений ДНК или РНК в образце ДНК или РНК из одной или нескольких клеток от индивидуума, у которого в одной или нескольких из клеток подозревается наличие злокачественного фенотипа, и анализ измерений ДНК или РНК для определения, для каждой из мутаций в совокупности мутаций, правдоподобия того, что по меньшей мере одна из клеток характеризуется наличием этой мутации. Согласно некоторым вариантам осуществления способ предусматривает определение того, что индивидуум характеризуется наличием злокачественного фенотипа, если (I) по меньшей мере для одной из мутаций вероятность того, что по меньшей мере одна из клеток содержит эту мутацию, больше, чем пороговое значение, или (II) по меньшей мере для одной из мутаций вероятность того, что по меньшей мере одна из клеток содержит эту мутацию, меньше, чем пороговое значение, и для множества мутаций, совокупное правдоподобие того, что по меньшей мере одна из клеток содержит по меньшей мере одну из мутации больше, чем пороговое значение. Согласно некоторым вариантам осуществления одна или несколько клеток содержат подмножество или все мутации в совокупности мутаций. Согласно некоторым вариантам осуществления подмножество мутаций связано со злокачественной опухолью или повышенным риском развития злокачественной опухоли. Согласно некоторым вариантам осуществления образец включает в себя внеклеточную ДНК или РНК. Согласно некоторым вариантам осуществления измерения ДНК или РНК включают в себя измерения (например, количество каждого аллеля в каждом локусе) в совокупности полиморфных локусов на одной или нескольких представляющих интерес хромосомах или хромосомных сегментах.
Согласно одному аспекту настоящее изобретение относится к способам выбора терапии для лечения, стабилизации или предотвращения заболевания или нарушения у млекопитающего. Согласно некоторым вариантам осуществления способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментов с использованием любого из описанных в настоящем документе способов. Согласно некоторым вариантам осуществления выбирают способ лечения для млекопитающего (например, для лечения заболевания или нарушения, связанного с превалированием первого гомологичного хромосомного сегмента).
Согласно одному аспекту настоящее изобретение относится к способам профилактики, замедления, стабилизации или лечения заболевания или нарушения у млекопитающего. Согласно некоторым вариантам осуществления способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом с использованием любого из описанных в настоящем документе способов. Согласно некоторым вариантам осуществления выбирают способ лечения для млекопитающего (например, для лечения заболевания или нарушения, связанного с превалированием первого гомологичного хромосомного сегмента), а затем вводят лечение млекопитающему.
Согласно некоторым вариантам осуществления лечение, стабилизация или предотвращение заболевания или нарушения предусматривает предотвращение или замедление первоначального или последующего возникновения заболевания или нарушения, увеличение времени выживаемости без признаков заболевания между исчезновением состояния и его рецидивом, стабилизацию или уменьшение неблагоприятного симптома, связанного с состоянием, или ингибирование или стабилизацию прогрессирования состояния. Согласно некоторым вариантам осуществления по меньшей мере 20, 40, 60, 80, 90 или 95% пролеченных субъектов характеризуются полной ремиссией, при которой исчезают все подтверждения состояния. Согласно некоторым вариантам осуществления продолжительность времени, в течение которого субъект выживает после установления диагноза и лечения, составляет по меньшей мере на 20, 40, 60, 80, 100, 200 или даже 500% больше, чем (I) среднее время выживаемости субъекта без лечения или (II) среднее время выживаемости субъекта при другом способе лечения.
Согласно некоторым вариантам осуществления лечение, стабилизация или предотвращение злокачественной опухоли предусматривает уменьшение или стабилизацию размера опухоли (например, доброкачественной или злокачественной опухоли), замедление или предотвращение увеличения размера опухоли, уменьшение или стабилизацию числа опухолевых клеток, увеличение выживаемости без признаков заболевания между исчезновением опухоли и ее повторным появлением, предотвращение начального или последующего возникновения опухоли или уменьшение или стабилизацию неблагоприятного симптома, связанного с опухолью. Согласно одному варианту осуществления количество выживающих злокачественных клеток после лечения составляет по меньшей мере на 10, 20, 40, 60, 80 или 100% ниже, чем начальное число злокачественных клеток, измеренных с использованием любого стандартного анализа. Согласно некоторым вариантам осуществления уменьшение числа злокачественных клеток, вызванное введением терапии согласно настоящему изобретению, по меньшей мере в 2, 5, 10, 20 или в 50 раз больше, чем уменьшение количества незлокачественных клеток. Согласно некоторым вариантам осуществления количество злокачественных клеток, присутствующих после введения терапии, по меньшей мере в 2, 5, 10, 20 или в 50 раз меньше, чем количество злокачественных клеток, присутствующих после введения контроля (например, введения физиологического раствора или буфера). Согласно некоторым вариантам осуществления способы согласно настоящему изобретению приводят к уменьшению на 10, 20, 40, 60, 80 или 100% размера опухоли, как определяли с использованием стандартных способов. Согласно некоторым вариантам осуществления по меньшей мере 10, 20, 40, 60, 80, 90 или 95% подвергнутых лечению субъектов характеризуются полной ремиссией, при которой нет никаких поддающихся обнаружению злокачественных клеток. Согласно некоторым вариантам осуществления злокачественная опухоль не появляется или вновь появляется по меньшей мере через 2, 5, 10, 15 или 20 лет. Согласно некоторым вариантам осуществления продолжительность времени, в течение которого субъект выживает после того, как поставлен диагноз злокачественной опухоли и проведено лечение с применением способа лечения согласно настоящему изобретению, по меньшей мере на 10, 20, 40, 60, 80, 100, 200 или даже 500% больше, чем (I) средняя продолжительность выживания не подвергнутого лечению субъекта или (II) средняя продолжительность выживания подвергнутого другому способу лечения субъекта.
Согласно одному аспекту настоящее изобретение относится к способам стратификации субъектов, участвующих в клиническом испытании лечения, стабилизации или профилактики заболевания или нарушения у млекопитающего. Согласно некоторым вариантам осуществления способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом с использованием любого из описанных в настоящей заявке способов до, во время или после клинических испытаний. Согласно некоторым вариантам осуществления наличие или отсутствие превалирования первого гомологичного хромосомного сегмента в геноме субъекта включает субъекта в подгруппу для клинического исследования.
Согласно некоторым вариантам осуществления заболевание или нарушение выбирают из группы, состоящей из злокачественной опухоли, умственной отсталости, неспособности к обучению (например, идиопатическое нарушение обучаемости), задержки умственного развития, задержки развития, аутизма, нейродегенеративного заболевания или нарушения, шизофрении, физического дефекта, аутоиммунного заболевания или нарушения, системной красной волчанки, псориаза, болезни Крона, гломерулонефрита, ВИЧ-инфекции, СПИДа, а также их комбинации. Согласно некоторым вариантам осуществления заболевание или нарушение выбирают из группы, состоящей из синдрома Ди Георга, синдрома Ди Георга 2, синдрома Ди Георга/VCFS, синдрома Прадера-Вилли, синдрома Ангельмана, синдрома Беквита-Видемана, синдрома делеции 1р36, синдрома делеции 2q37, синдрома делеции 3q29, синдрома делеции 9q34, синдрома делеции 17q21.31, синдрома кошачьего крика, синдрома Якобсена, синдрома Миллер Дикера, синдрома Фелан-МакДермид, синдрома Смита-Магениса, синдрома WAGR, синдрома Вольфа-Хиршхорна, синдрома Уильямса, синдрома Уильямса-Бойрена, синдрома Миллера-Дикера, синдрома Фелан-МакДермид, синдрома Смита-Магениса, синдрома Дауна, синдрома Эдварда, синдрома Патау, синдрома Клайнфельтера, синдрома Тернера, синдрома трисомии по X-хромосоме, синдрома 47,XYY, синдрома Сотоса, а также их комбинации. Согласно некоторым вариантам осуществления способ определяет наличие или отсутствие одной или нескольких из следующих хромосомных аномалий: нуллисомии, моносомии, однородительской дисомии, трисомии, совпадающей трисомии, несовпадающей трисомии, материнской трисомии, отцовской трисомиий, триплоидии, мозаичной тетрасомии, совпадающей тетрасомии, несовпадающей тетрасомии, других анеуплоидий, несбалансированных транслокаций, сбалансированных транслокаций, вставок, делеции, рекомбинаций и их комбинации. Согласно некоторым вариантам осуществления хромосомная аномалия представляет собой любое отклонение в числе копий конкретной хромосомы или хромосомного сегмента из наиболее распространенного числа копий этого сегмента или хромосомы, например, в человеческой соматической клетке, любое отклонение от 2-х копий можно рассматривать как хромосомную аномалию. Согласно некоторым вариантам осуществления способ определяет наличие или отсутствие эуплоидии. Согласно некоторым вариантам осуществления гипотезы числа копий включают в себя одну или большее количество гипотез числа копий для одноплодной беременности. Согласно некоторым вариантам осуществления гипотезы числа копий включают в себя одну или большее количество гипотез числа копий для многоплодной беременности, такой как беременность двойней (например, идентичные или разнояйцевые близнецы или исчезающий близнец). Согласно некоторым вариантам осуществления гипотезы числа копий включают в себя все эуплоидные плоды в многоплодной беременности, все анеуплоидные плоды в многоплодной беременности (например, любую из раскрытых в настоящем документе анеуплоидий) и/или один или несколько эуплоидных плодов в многоплодной беременности и один или несколько анеуплоидных плодов в многоплодной беременности. Согласно некоторым вариантам осуществления гипотезы числа копий включают в себя однояйцевых близнецов (называемых также монозиготными близнецами) или разнояйцевых близнецов (называемые также дизиготными близнецами). Согласно некоторым вариантам осуществления гипотезы числа копий включают в себя молярную беременность, например, полную или частичную молярную беременность. Согласно некоторым вариантам осуществления представляющий интерес хромосомный сегмент представляет собой целую хромосому. Согласно некоторым вариантам осуществления хромосому или хромосомный сегмент выбирают из группы, состоящей из 13-й хромосомы, 18-й хромосомы, 21-й хромосомы, Х-хромосомы, Y-хромосомы их сегментов, а также их комбинации. Согласно некоторым вариантам осуществления первый гомологичный хромосомный сегмент и второй гомологичный хромосомный сегмент представляют собой пару гомологичных хромосомных сегментов, которая содержит представляющий интерес хромосомный сегмент. Согласно некоторым вариантам осуществления первый гомологичный хромосомный сегмент и второй гомологичный хромосомный сегмент представляют собой пару представляющих интерес гомологичных хромосом. Согласно некоторым вариантам осуществления вычисляют достоверность для определения CNV или диагностики заболевания или нарушения.
Согласно некоторым вариантам осуществления делеция представляет собой удаление по меньшей мере 0,01 т.п.н., 0,1 т.п.н., 1 т.п.н., 10 т.п.н., 100 т.п.н., 1 Мб, 2 Мб, 3 Мб, 5 Мб, 10 Мб, 15 Мб, 20 Мб, 30 Мб или 40 Мб. Согласно некоторым вариантам осуществления делеция представляет собой удаление от 1 т.п.н. до 40 Мб, например, от 1 т.п.н. до 100 т.п.н., 100 т.п.н. до 1 Мб, от 1 до 5 Мб, от 5 до 10 Мб, от 10 до 15 Мб, от 15 до 20 Мб, от 20 до 25 Мб, от 25 до 30 Мб или от 30 до 40 Мб, включительно. Согласно некоторым вариантам осуществления одну копию хромосомного сегмента удаляют и одна копия присутствует. Согласно некоторым вариантам осуществления две копии хромосомного сегмента удаляют. Согласно некоторым вариантам осуществления удаляют всю хромосому.
Согласно некоторым вариантам осуществления дупликация представляет собой дупликацию по меньшей мере 0,01 т.п.н., 0,1 т.п.н., 1 т.п.н., 10 т.п.н., 100 т.п.н., 1 Мб, 2 Мб, 3 Мб, 5 Мб, 10 Мб, 15 Мб, 20 Мб, 30 Мб или 40 Мб. Согласно некоторым вариантам осуществления дупликация представляет собой дупликацию от 1 т.п.н. до 40 Мб, например, от 1 т.п.н. до 100 т.п.н., 100 т.п.н. до 1 Мб, от 1 до 5 Мб, от 5 до 10 Мб, от 10 до 15 Мб, от 15 до 20 Мб, от 20 до 25 Мб, от 25 до 30 Мб или от 30 до 40 Мб, включительно. Согласно некоторым вариантам осуществления сегмент хромосомы дублируют один раз. Согласно некоторым вариантам осуществления сегмент хромосомы дублируют более чем один раз, например, 2, 3, 4 или 5 раз. Согласно некоторым вариантам осуществления дублируют всю хромосому. Согласно некоторым вариантам осуществления удаляют область в первом гомологичном сегменте и дублируют ту же область или другую область во второй гомологичном сегменте. Согласно некоторым вариантам осуществления по меньшей мере 50, 60, 70, 80, 90, 95, 96, 98, 99 или 100% исследованных SNV представляют собой трансверсии, а не транзиции.
Согласно некоторым вариантам осуществления образец содержит ДНК и/или РНК из (I) одной или нескольких клеток-мишеней или (II) одной или нескольких клеток-немишеней. Согласно некоторым вариантам осуществления образец представляет собой смешанный образец с ДНК и/или РНК из одной или нескольких клеток-мишеней и одной или нескольких клеток-немишеней. Согласно некоторым вариантам осуществления клетки-мишени представляют собой клетки, которые характеризуются наличием CNV, такой как представляющая интерес делеция или дупликация, и клетки-немишени представляют собой клетки, у которых нет представляющей интерес вариации числа копий. Согласно некоторым вариантам осуществления, в которых одна или несколько клеток-мишеней представляют собой злокачественные клетки, а одна или нескольких клеток-немишеней представляют собой незлокачественные клетки, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких злокачественных клеток. Согласно некоторым вариантам осуществления, в которых одна или несколько клеток-мишеней представляют собой генетически идентичные злокачественные клетки, а одна или нескольких клеток-немишеней представляют собой незлокачественные клетки, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких злокачественных клеток. Согласно некоторым вариантам осуществления, в которых одна или несколько клеток-мишеней представляют собой генетически неидентичные злокачественные клетки, а одна или нескольких клеток-немишеней представляют собой незлокачественные клетки, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких генетически неидентичных злокачественных клеток. Согласно некоторым вариантам осуществления, в которых образец содержит внеклеточную ДНК из смеси одной или нескольких злокачественных клеток и одной или нескольких незлокачественных клеток, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких злокачественных клеток. Согласно некоторым вариантам осуществления, в которых одна или несколько клеток-мишеней представляют собой генетически идентичные фетальные клетки и одна или несколько клеток-немишеней представляют собой материнские клетки, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента плода в геноме фетальной клетки(клеток). Согласно некоторым вариантам осуществления, в которых одна или несколько клеток-мишеней представляют собой генетически неидентичные фетальные клетки и одна или несколько клеток-немишеней представляют собой материнские клетки, способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких генетически неидентичных клеток плода. Поскольку клетки большинства индивидуумов содержат почти идентичный набор ядерной ДНК, термин "клетка-мишень" может быть использован взаимозаменяемо с термином "индивидуум" согласно некоторым вариантам осуществления. Злокачественные клетки имеют генотипы, которые отличаются от индивидуума-хозяина. В этом случае сама злокачественная опухоль может рассматриваться как индивидуум. Кроме того, многие виды злокачественных опухолей представляют собой гетерогенные, что означает, что различные клетки в опухоли генетически отличаются от других клеток в той же опухоли. В этом случае различные генетически идентичные области можно рассматривать различными индивидуумами. Альтернативно, злокачественную опухоль можно рассматривать как единственного индивидуума со смесью клеток с различными геномами. Как правило, клетки-немишени представляют собой эуплоидные, хотя это не обязательно.
Согласно некоторым вариантам осуществления образец получают из образца материнской цельной крови или ее фракции, клеток, выделенных из образца материнской крови, образца амниоцентеза, продуктов плодного образца, образца плацентарной ткани, образца ворсин хориона, образца плацентарной мембраны, образца слизи цервикального канала или образца из плода. Согласно некоторым вариантам осуществления образец содержит внеклеточную ДНК, полученную из образца крови или ее фракции от матери. Согласно некоторым вариантам осуществления образец содержит ядерную ДНК, полученную из смеси клеток плода и материнских клеток. Согласно некоторым вариантам осуществления образец получают из фракции материнской крови, содержащей ядросодержащие клетки, которые были обогащены клетками плода. Согласно некоторым вариантам осуществления образец разделяется на несколько фракций (например, 2, 3, 4 5 или более фракций), каждую из которых анализируют с использованием способа согласно настоящему изобретению. Если каждая фракция дает тот же результат (например, наличие или отсутствие одной или нескольких представляющих интерес CNV), доверительный интервал результатов увеличивается. Разные фракции дают разные результаты, образец может быть повторно проанализирован или другой образец может быть собран от того же субъекта и проанализирован.
Иллюстративные субъекты включают в себя млекопитающих, таких как люди и представляющие ветеринарный интерес млекопитающие. Согласно некоторым вариантам осуществления млекопитающее представляет собой примата (например, человека, мартышку, гориллу, обезьяну, лемуру и т.п.), крупного рогатого скота, лошадь, свинью, представителя собачьих или кошачьих.
Согласно некоторым вариантам осуществления любой из способов предусматривает создание отчета (например, письменного или электронного отчета), раскрывающего результат способа согласно настоящему изобретению (например, наличие или отсутствие делеций или дупликации).
Согласно некоторым вариантам осуществления любой из способов предусматривает произведение клинического действия, основанного на результате способа согласно настоящему изобретению (например, наличии или отсутствии делеций или дупликации). Согласно некоторым вариантам осуществления, в которых эмбрион или плод содержит один или несколько представляющих интерес полиморфизмов или мутаций (таких как CNV), основанных на результате способа согласно настоящему изобретению, клиническое действие предусматривает выполнение дополнительных испытаний (например, исследований для подтверждения наличия полиморфизма или мутации), не имплантацию эмбриона для ЭКО, имплантацию другого эмбриона для ЭКО, прерывание беременности, подготовку к особым потребностям ребенка или подвергание вмешательству, направленному на снижение тяжести фенотипического представления генетического заболевания. Согласно некоторым вариантам осуществления клиническое действие выбирают из группы, состоящей из выполнения УЗИ, амниоцентеза на плоде, амниоцентеза на последующем плоде, который наследует генетический материал от матери и/или отца, биопсии ворсинок хориона на плоде, биопсии ворсинок хориона на последующий плоде, который наследует генетический материал от матери и/или отца, искусственного оплодотворения, предимплантационной генетической диагностики на одном или нескольких эмбрионах, которые наследуют генетический материал от матери и/или отца, кариотипирования на матери, кариотипирования на отце, фетальной эхокардиографии (например, эхокардиографии плода с трисомией 21, 18 или 13, моносомии X или микроделеции) и их комбинации. Согласно некоторым вариантам осуществления клиническое действие выбирают из группы, состоящей из введения гормона роста новорожденному ребенку с моносомией X (например, введение, начиная с ~9 месяцев), введения кальция новорожденному ребенку с делецией 22q (например, синдромом Ди Георга), введения андрогенов, таких как тестостерон, новорожденному ребенку с 47,XXY (например, одну инъекцию в месяц в течение 3-х месяцев 25 мг тестостерона энантата младенцу или ребенку ясельного возраста), выполнения исследования на злокачественную опухоль у женщины с полной или частичной молярной беременностью (например, триплоидным плодом), введения лечения злокачественной опухоли, такого как химиотерапевтическое средство, женщине с полной или частичной молярной беременностью (например, триплоидным плодом), скрининг плода, определенного как плод мужского пола (например, определено, что плод мужского пола с использованием способа согласно настоящему изобретению) на одно или несколько связанных с X-хромосомой генетических нарушений, таких как мышечная дистрофия Дюшенна (DMD), адренолейкодистрофия или гемофилия, выполнение амниоцентеза на плоде мужского пола с повышенным риском развития связанного с Х-хромосомой нарушения, введение дексаметазона женщинам с плодом женского пола (например, определено, что плод женского пола с использованием способа согласно настоящему изобретению) с риском врожденной гиперплазии коры надпочечников, выполнение амниоцентеза на плоде женского пола на риск развития врожденной гиперплазии коры надпочечников, введение убитых вакцин (вместо живых вакцин) или не введение некоторых вакцин рожденному ребенку, который характеризуется наличием (или подозревается в этом) иммунодефицита из-за делеции 22q11.2, выполнение профессиональной и/или физической терапии, выполнение раннего вмешательства в образование, рождение ребенка в центре высокоспециализированной медицинской помощью с NICU и/или имеющего специалистов-педиатров, доступны при родах, поведенческое вмешательство для новорожденного ребенка (например, ребенка с XXX, XXY или XYY), а также их комбинации.
Согласно некоторым вариантам осуществления ультразвуковой или другой скрининг-тест проводится на женщинах, у которых определили наличие многоплодных беременностей (например, близнецов), чтобы определить, действительно ли два или несколько плода представляют собой монохориальные. Монозиготные близнецы представляют собой результат овуляции и оплодотворения одной яйцеклетки с последующим делением зиготы; плацентация может быть дихориальной или монохориальной. Дизиготные близнецы происходят от овуляции и оплодотворения двух яйцеклеток, что обычно приводит к дихориальной плацентации. Монохориональные близнецы характеризуются риском развития синдрома фето-фетальной трансфузии, что может вызвать неравномерное распределение крови между плодами, что приводит к различиям в их росте и развитии, иногда приводит к мертворождению. Таким образом, близнецов, определенных как монозиготные близнецы с использованием способа согласно настоящему изобретению, желательно подвергать исследованию (например, с помощью ультразвука), чтобы определить, представляют ли они собой монохориональных близнецов, и если да, то этих близнецов можно контролировать (например, каждые две недели ультразвук с 16 недель) на наличие признаков синдрома фето-фетальной трансфузии.
Согласно некоторым вариантам осуществления, в которых эмбрион или плод не содержит один или более одного или более представляющих интерес полиморфизмов или мутаций (таких как CNV), основываясь на результате способа согласно настоящему изобретению, клиническое действие включает в себя имплантацию эмбриона для ЭКО или продолжения беременности. Согласно некоторым вариантам осуществления настоящего изобретения клиническое действие представляет собой дополнительное исследование, чтобы подтвердить отсутствие полиморфизма или мутации, выбранной из группы, состоящей из выполнения УЗИ, амниоцентеза, биопсии ворсин хориона, а также их комбинации.
Согласно некоторым вариантам осуществления, в которых индивидуум содержит один или более одного или более полиморфизмов или мутаций (например, полиморфизм или мутацию, связанную с заболеванием или нарушением, таким как злокачественная опухоль или повышенный риск развития заболевания или нарушения, такого как злокачественная опухоль) на основе результата способа согласно настоящему изобретению, клиническое действие включает в себя выполнение дополнительных испытаний или введение одного или нескольких способов лечения для лечения заболевания или нарушения (например, способа лечения злокачественной опухоли, способа лечения конкретного типа злокачественной опухоли или типа мутации индивидуума, у которого ее диагностировали, или любого из описанных в настоящем документе способов лечения). Согласно некоторым вариантам осуществления клиническое действие представляет собой дополнительное исследование, чтобы подтвердить наличие или отсутствие полиморфизма или мутации, выбранной из группы, состоящей из биопсии, хирургии, медицинской визуализации (например, маммография или УЗИ), а также их комбинации.
Согласно некоторым вариантам осуществления дополнительное исследование предусматривает выполнение того же самого или другого способа (например, любого из описанных в настоящем документе способов), чтобы подтвердить наличие или отсутствие полиморфизма или мутации (например, CNV), например, исследование либо второй части того же образца, который был исследован, или другого образца от того же индивидуума (например, той же беременной матери, плода, эмбриона или индивидуума с повышенным риском развития злокачественной опухоли). Согласно некоторым вариантам осуществления дополнительное исследование выполняют для индивидуума, для которого вероятность полиморфизма или мутации (например, CNV) выше порогового значения (например, дополнительное исследование, чтобы подтвердить наличие вероятного полиморфизма или мутации). Согласно некоторым вариантам осуществления дополнительное исследование выполняют для индивидуума, для которого доверительный интервал или z-показатель для определения полиморфизма или мутации (например, CNV) находится выше порогового значения (например, дополнительное исследование, чтобы подтвердить наличие вероятного полиморфизма или мутации). Согласно некоторым вариантам осуществления дополнительное исследование выполняют для индивидуума, для которого доверительный интервал или z-показатель для определения полиморфизма или мутации (например, CNV) находится между минимальным и максимальным пороговыми значениями (например, дополнительное исследование, чтобы увеличить доверительный интервал в том, что первоначальный результат является правильным). Согласно некоторым вариантам осуществления дополнительное исследование выполняют для индивидуума, для которого доверительный интервал для определения наличия или отсутствия полиморфизма или мутации (например, CNV) находится ниже порогового значения (например, результат "без основания" из-за невозможности определить наличие или отсутствие CNV с достаточным доверительным интервалом). Иллюстративный z-показатель вычисляют в публикации Chiu et al. BMJ 2011; 342: c7401 (которая полностью включена в настоящий документ посредством ссылки), в которой 21-я хромосома используется в качестве примера и может быть заменена любой другой хромосомой или хромосомным сегментом в исследуемом образце.
Z-показатель процента хромосомы 21 в совокупности данных исследования = ((процент хромосомы 21 в совокупности данных исследования) - (средний процент 21-й хромосомы в эталонных контролях))/(стандартное отклонение процента хромосомы 21 в эталонных контролях).
Согласно некоторым вариантам осуществления дополнительное исследование выполняют для индивидуума, для которого исходный образец не соответствовал установленным требованиям контроля качества или фетальная фракция или опухолевая фракция были ниже порогового значения. Согласно некоторым вариантам осуществления способ предусматривает выбор индивидуума для проведения дополнительных испытаний на основании результата способа согласно настоящему изобретению, вероятности результата, доверительного интервала результата или Z-показателя; и выполнение дополнительного исследования на индивидууме (например, на том же самом или другом образце). Согласно некоторым вариантам осуществления субъект, которому поставлен диагноз заболевания или нарушения (например, злокачественной опухоли), подвергается повторному исследованию с использованием способа согласно настоящему изобретению или известному исследованию на заболевание или нарушение в различные моменты времени для наблюдения за развитием заболевания или нарушения или ремиссией, или возобновлением заболевания или нарушения.
Согласно одному аспекту настоящее изобретение предоставляет отчет (например, письменный или электронный отчет) с результатом от способа согласно настоящему изобретению (например, наличием или отсутствием делеций или дупликации).
Согласно различным вариантам осуществления реакция удлинения праймера или полимеразная цепная реакция предусматривает добавление одного или нескольких нуклеотидов с помощью полимеразы. Согласно некоторым вариантам осуществления праймеры находятся в растворе. Согласно некоторым вариантам осуществления праймеры находятся в растворе и не иммобилизованы на твердом носителе. Согласно некоторым вариантам осуществления праймеры не представляют собой часть микрочипа. Согласно различным вариантам осуществления реакция удлинения праймера или полимеразная цепная реакции не включает в себя опосредованное лигированием ПЦР. Согласно различным вариантам осуществления реакция удлинения праймера или полимеразная цепная реакция не включает в себя соединение двух праймеров с помощью лигазы. Согласно различным вариантам осуществления праймеры не включают в себя связанные инвертированные зонды (LIP), которые также можно назвать предварительно циркулирующими зондами, циркулирующими зондами, зондами Padlock или зондами молекулярной инверсии (MIP).
Следует понимать, что описанные в настоящем документе аспекты и варианты осуществления настоящего изобретения предусматривают комбинации любых двух или нескольких из аспектов или вариантов осуществления настоящего изобретения.
Определения
Однонуклеотидный полиморфизм (SNP) относится к одному нуклеотиду, который может отличаться между геномами двух представителей одного и того же вида. Использование термина не должно подразумевать никаких ограничений по частоте, с которой происходит каждый вариант.
Последовательность относится к последовательности ДНК или генетической последовательности. Она может относиться к первичной, физической структуре молекулы ДНК или нити у индивидуума. Она может относиться к последовательности нуклеотидов, обнаруженных в этой молекуле ДНК или комплементарной нити к молекуле ДНК. Она может относиться к информации, содержащейся в молекуле ДНК в качестве его представления in silico.
Локус относится к определенной представляющей интерес области на ДНК индивидуума, которая может относиться к SNP, месту возможной вставки или делеции или месту какой-либо другой соответствующей генетической изменчивости. Связанный с заболеванием SNP может также относиться к связанным с заболеванием локусам.
Полиморфный аллель, также "полиморфный локус", относится к аллелю или локусу, где генотип варьирует между индивидуумами в пределах данного вида. Некоторые примеры полиморфных аллелей включают в себя однонуклеотидные полиморфизмы, короткие тандемные повторы, делеции, дупликации и инверсии.
Полиморфный сайт относится к специфическим нуклеотидам, обнаруженным в полиморфной области, которые различаются между индивидуумами.
Мутация относится к изменению в природной или эталонной последовательности нуклеиновой кислоты, такому как вставка, делеция, дупликация, транслокация, замещение, мутация со сдвигом рамки, молчащая мутация, нонсенс-мутация, миссенс-мутация, точечная мутация, транзиция, трансверсия, обратная мутация или микросателлитное изменение. Согласно некоторым вариантам осуществления аминокислотная последовательность, кодируемая последовательностью нуклеиновой кислоты, содержит по меньшей мере одно изменение аминокислоты по сравнению с природной последовательностью.
Аллель относится к генам, которые занимают определенный локус.
Генетические данные, также "генотипические данные", относятся к данным, характеризующим аспекты генома одного или нескольких индивидуумов. Они могут относиться к одному локусу или их совокупности, частичным или целым последовательностям, частичным или целым хромосомам или всему геному. Они могут относиться к идентичности одного или множества нуклеотидов; они могут относиться к совокупности последовательных нуклеотидов или нуклеотидов из разных мест в геноме, или их комбинации. Генотипические данные представляют собой, как правило, in silico, однако, также можно рассматривать физические нуклеотиды в последовательности в виде химически закодированных генетических данных. Генотипические данные могут быть "в", "от", "из" индивидуума(ов). Генотипические данные относятся к выходным измерениям от платформы генотипирования, где эти измерения производятся на генетическом материале.
Генетический материал, также "генетический образец", относится к физической материи, такой как ткань или кровь, от одного или нескольких индивидуумов, содержащих ДНК или РНК.
Доверительный интервал относится к статистической вероятности того, что называемое SNP, аллелем, совокупностью аллелей, определенным количеством копий хромосомы или хромосомного сегмента или диагностикой наличия или отсутствия заболевания, правильно отражает реальное генетическое состояние индивидуума.
Распознавание плоидности, также "распознавание числа копий хромосом" или "распознавание числа копий" (CNC) может относиться к акту определения количества и/или хромосомной идентичности одной или нескольких хромосом или хромосомных сегментов, присутствующих в клетке.
Анеуплоидия относится к состоянию, когда в клетке присутствует неправильное число хромосом (например, неправильное число полных хромосом или неправильное число хромосомных сегментов, например, присутствуют делеции или дупликации хромосомного сегмента). В случае соматической клетки человека она может относиться к случаю, когда клетка не содержит 22 пары аутосомных хромосом и одну пару половых хромосом. В случае человеческой гаметы, она может относиться к случаю, когда клетка не содержит одну из каждой из 23 хромосом. В случае одного типа хромосом, она может относиться к случаю, когда присутствует больше или меньше двух гомологичных, но не идентичных копий хромосом или когда присутствуют две копии хромосомы, которые происходят от одного и того же родителя. Согласно некоторым вариантам осуществления делеция хромосомного сегмента представляет собой микроделецию.
Состояние плоидности относится к количеству и/или хромосомной идентичности одной или нескольких хромосом или хромосомных сегментов в клетке.
Хромосома может относиться к одной копии хромосомы, означая одну молекулу ДНК из 46 находящихся в нормальной соматической клетке; примером является "происходящая от матери хромосома 18''. Хромосома может также относиться к типу хромосом, которых 23 в нормальной человеческой соматической клетке; примером может служить "хромосома 18''.
Хромосомная идентичность может относиться к эталонному номеру хромосомы, т.е. типу хромосомы. Нормальные люди имеют 22 типа пронумерованных аутосомных типов хромосом, а также два типа половых хромосом. Она может также относиться к происходящим от родителей хромосомам. Она может также относиться к определенной хромосоме, унаследованной от родителей. Она может также относиться к другим характерным признакам хромосомы.
Аллельные данные относятся к набору генотипических данных, касающихся совокупности одного или нескольких аллелей. Они могут относиться к фазированным, гаплотипическим данным. Они могут относиться к идентификаторам SNP и они могут относиться к данным последовательности ДНК, включая в себя вставки, делеции, повторы и мутации. Они могут включать в себя родительское происхождение каждого аллеля.
Аллельное состояние относится к фактическому состоянию генов в совокупности одного или нескольких аллелей. Оно может относиться к фактическому состоянию генов, описанному аллельными данными.
Аллельное число относится к количеству последовательностей, которые картируют для конкретного локуса, и если этот локус представляет собой полиморфный, оно относится к числу последовательностей, которые картируют для каждого из аллелей. Если каждый аллель считается в двоичной системе исчисления, то аллельное число будет целым числом. Если аллели считаются в вероятностном смысле, то аллельное число может быть дробным числом.
Вероятность аллельного числа относится к количеству последовательностей, которые вероятно будут картированы в определенном локусе или совокупности аллелей в полиморфном локусе в сочетании с вероятностью картирования. Следует отметить, что аллельные числа эквивалентны вероятностям аллельного числа, где вероятность картирования для каждой подсчитываемой последовательности может быть двоичной (ноль или один). Согласно некоторым вариантам осуществления вероятности аллельного числа могут быть двоичными. Согласно некоторым вариантам осуществления вероятности аллельного числа могут быть установлены, чтобы равняться измерениям ДНК.
Аллельное распределение, или "распределение аллельного числа", относится к относительному количеству каждого аллеля, который присутствует в каждом локусе в совокупности локусов. Аллельное распределение может относиться к индивидууму, к образцу или к совокупности измерений, выполненных на образце. В контексте цифровых измерений аллелей, таких как секвенирование, аллельное распределение относится к количеству или вероятному количеству прочтений, которые отображаются на определенном аллеле для каждого аллеля в совокупности полиморфных локусов. В контексте аналоговых измерений аллелей, таких как матрицы SNP, аллельное распределение относится к аллельной интенсивности и/или соотношениям аллелей. Измерения аллелей могут быть обработаны вероятностно, то есть вероятность того, что данный аллель присутствует для данной считанной последовательности представляет собой фракцию от 0 до 1, или они могут быть обработаны в двоичной системе счисления, то есть, любое считывание рассматривается равным точно нулю или одной копии определенного аллеля.
Профиль аллельного распределения относится к совокупности различных аллельных распределений для различных контекстов, таких как различные родительские контексты. Некоторые профили аллельного распределения могут свидетельствовать о некоторых состояниях плоидности.
Аллельная систематическая ошибка относится к степени, в которой измеренное аллельное соотношение в гетерозиготном локусе отличается от соотношения, которое присутствовало в исходном образце ДНК или РНК. Степень аллельной систематической ошибки в конкретном локусе равна наблюдаемому аллельному соотношению в этом локусе, как измерено, деленному на соотношение аллелей в исходном образце ДНК или РНК в этом локусе. Аллельная систематическая ошибка может быть из-за систематической ошибки амплификации, систематической ошибки очистки или какого-либо другого явления, которое затрагивает различные аллели по-разному.
Аллельный дисбаланс относится к SNV, к доле аномальной ДНК, которую, как правило, измеряют с использованием частоты мутантных аллелей (количество мутантных аллелей в локусе/общее число аллелей в этом локусе). Так как разница между количествами двух гомологов в опухолях аналогично, авторы настоящего изобретения измеряют долю аномальной ДНК для CNV посредством среднего аллельного дисбаланса (AAI), который определяется как |(H1-H2)|/(H1+H2), где Hi представляет собой среднее количество копий гомолога i в образце и Hi/(H1+H2) представляет собой относительную распространенность, или соотношение гомологов, гомолога i. Максимальное соотношение гомологов представляет собой соотношение гомологов более распространенного гомолога.
Анализ частоты исключения из исследования представляет собой процент SNP без прочтений, оцениваемый с использованием всех SNP.
Частота исключения одиночных аллелей (ADO) представляет собой процент SNP с присутствующим только одним аллелем, оцениваемый с использованием только гетерозиготных SNP.
Праймер, также "ПЦР-зонд", относится к одной молекуле нуклеиновой кислоты (например, молекуле ДНК или олигомеру ДНК) или набору молекул нуклеиновых кислот (таких, как молекулы ДНК или олигомеры ДНК), где молекулы идентичны или практически идентичны и где праймер содержит область, которая предназначена для гибридизации с локусом-мишенью (например, полиморфным локусом-мишенью или неполиморфным локусом-мишенью) или с универсальной последовательностью прайминга и может содержать примирующую последовательность, предназначенную для возможности ПЦР-амплификации. Праймер может также содержать молекулярный штрих-код. Праймер может содержать случайную область, которая отличается для каждой отдельной молекулы.
Библиотека праймеров относится к популяции двух или нескольких праймеров. Согласно различным вариантам осуществления библиотека включает в себя по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных праймеров. Согласно различным вариантам осуществления библиотека включает в себя по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных пар праймеров, причем каждая пара праймеров включает в себя прямой тестовый праймер и обратный тестовый праймер, где каждая пара тестовых праймеров гибридизуется с локусом-мишенью. Согласно некоторым вариантам осуществления библиотека праймеров включает в себя по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных отдельных праймеров, каждый из которых гибридизуется с различным локусом-мишенью, причем отдельные праймеры не представляют собой часть пар праймеров. Согласно некоторым вариантам осуществления библиотека содержит, как (I) пару праймеров, так и (II) отдельные праймеры (такие как универсальные праймеры), которые не представляют собой часть пар праймеров.
Различные праймеры относятся к неидентичным праймерам.
Различные пулы относятся к неидентичным пулам.
Различные локусы-мишени относятся к неидентичным локусам-мишеням.
Различные ампликоны относятся к неидентичным ампликонам.
Зонд-гибридная ловушка относится к любой последовательности нуклеиновой кислоты, возможно, модифицированной, которая создается с помощью различных способов, таких как ПЦР или прямой синтез, и предназначена, чтобы быть комплементарной одной нити определенной последовательности ДНК-мишени в образце. Экзогенные зонды-гибридные ловушки могут быть добавлены к подготовленному образцу и гибридизованы с помощью процесса денатурации-повторного отжига с образованием дуплексов экзогенных-эндогенный фрагментов. Эти дуплексы затем могут быть физически отделены от образца с помощью различных средств.
Прочтения последовательностей относятся к данным, представляющим собой измеренную последовательность нуклеотидных оснований, например, с помощью способа клонального секвенирования. Клональное секвенирование может производить данные последовательности, представляющие собой единственную молекулу ДНК или клоны, или кластеры одной исходной молекулы ДНК. Прочтение последовательности также может быть связано с показателем качества в каждом положении основания последовательности, указывающего на вероятность того, что нуклеотид был назван правильно.
Картирование прочтения последовательности представляет собой процесс определения положения прочтения последовательности происхождения в последовательности генома конкретного организма. Положение происхождения прочтений последовательностей основывается на сходстве нуклеотидной последовательности почтения и геномной последовательности.
Сопряженная ошибка копирования, также "сопряженная хромосомная анеуплоидия" (МСА), относится к состоянию анеуплоидии, где одна клетка содержит две одинаковые или почти одинаковые хромосомы. Этот тип анеуплоидии может возникать при образовании половых клеток в мейозе и может упоминаться как мейотическая ошибка нерасхождения. Этот тип ошибки может возникать в митозе. Соответствующая трисомия может относиться к случаю, когда три копии данной хромосомы присутствуют у индивидуума и две из копий являются идентичными.
Несопряженная ошибка копирования, а также "уникальная хромосомная анеуплоидия" (UCA), относится к состоянию анеуплоидии, где одна клетка содержит две хромосомы от одного и того же родителя и они могут быть гомологичны, но не идентичны. Этот тип анеуплоидии может возникнуть во время мейоза и может упоминаться как ошибка мейоза. Несопряженная трисомия может относиться к случаю, когда три копии данной хромосомы присутствуют у индивидуума и две копии от одного и того же родителя, и представляют собой гомологичные, но не идентичные. Следует отметить, что несопряженная трисомия может относиться к случаю, когда присутствуют две гомологичные хромосомы от одного родителя, и где некоторые хромосомные сегменты идентичны, тогда как другие сегменты представляют собой лишь гомологичные.
Гомологичные хромосомы относятся к копиям хромосом, которые содержат один и тот же набор генов, которые обычно разделяются на пары во время мейоза.
Идентичные хромосомы относятся к копиям хромосом, которые содержат один и тот же набор генов и для каждого гена они имеют один и тот же набор аллелей, которые идентичны или почти идентичны.
Исключение аллеля (ADO) относится к ситуации, когда не обнаруживается по меньшей мере одна из пар оснований в совокупности пар оснований из гомологичных хромосом в данном аллеле.
Исключение локуса (LDO) относится к ситуации, когда не обнаруживаются обе пары оснований в совокупности пар оснований из гомологичных хромосом в данном аллеле.
Гомозиготный относится к наличию подобных аллелей, что и соответствующие хромосомные локусы.
Гетерозиготный относится к наличию неодинаковых аллелей в соответствующих хромосомных локусах.
Степень гетерозиготности относится к частоте индивидуумов в популяции, содержащей гетерозиготные аллели в данном локусе. Степень гетерозиготности может также относиться к ожидаемому или измеренному соотношению аллелей в данном локусе у индивидуума или образце ДНК или РНК.
Хромосомная область относится к сегменту хромосомы или полной хромосоме.
Сегмент хромосомы относится к секции хромосомы, которая может варьировать в размере от одной пары оснований до целой хромосомы.
Хромосома относится либо к целой хромосоме, либо сегменту или участку хромосомы.
Копии относятся к количеству копий хромосомного сегмента. Они могут относиться к идентичным копиям или неидентичным, гомологичным копиям хромосомного сегмента, причем различные копии хромосомного сегмента содержат по существу аналогичный набор локусов, и где один или нескольких аллелей различны. Следует отметить, что в некоторых случаях анеуплоидии, таких как ошибки копирования M2, возможно наличие нескольких копий данного хромосомного сегмента, которые идентичны, а также нескольких копий того же хромосомного сегмента, которые не являются идентичными.
Гаплотип относится к комбинации аллелей во множественных локусах, которые, как правило, наследуются вместе на той же самой хромосоме. Гаплотип может относиться только к двум локусам или целой хромосоме в зависимости от количества рекомбинационных событий, произошедших между заданной совокупностью локусов. Гаплотип может также относиться к совокупности SNP на одной хроматиде, которые статистически связаны.
Гаплотипические данные, также "фазированные данные" или "упорядоченные генетические данные" относятся к данным из одной хромосомы или хромосомного сегмента в диплоидном или полиплоидном геноме, например, либо в обособленной материнской, либо отцовской копии хромосомы в диплоидном геноме.
Фазированный относится к акту определения гаплотипических генетических данных индивидуума с учетом неупорядоченных, диплоидных (или полиплоидных) генетических данных. Может относиться к акту определения, какой из двух генов в аллеле для совокупности аллелей, обнаруженных на одной из хромосом, связан с каждой из двух гомологичных хромосом у индивидуума.
Фазированные данные относятся к генетическим данным, в которых был определен один или несколько гаплотипов.
Гипотезы относятся к возможному состоянию, такому как возможная степень превышение количества копий первой гомологичной хромосомы или хромосомного сегмента по сравнению со второй гомологичной хромосомой или хромосомным сегментом, возможному удалению, возможному дублированию, возможному состоянию плоидности при заданном наборе из одной или нескольких хромосом или хромосомных сегментов, возможному аллельному состоянию при заданном наборе из одного или нескольких локусов, возможной отцовской связи или возможной ДНК, РНК, фетальной фракции при заданном наборе из одной или нескольких хромосом или хромосомных сегментов, или набору количеств генетического материала из совокупности локусов. Генетические состояния могут быть необязательно связаны с вероятностями, указывающими на относительную возможность каждого из элементов в гипотезе быть истинным по отношению к другим элементам в гипотезе или относительной возможности гипотезы в целом быть истинной. Совокупность возможностей может содержать один или нескольких элементов.
Гипотеза числа копий, также "гипотеза состояния плоидности", относится к гипотезе, касающейся количества копий хромосомы или хромосомного сегмента у индивидуума. Она может также относиться к гипотезе, касающейся идентичности каждой из хромосом, включая в себя родоначальника происхождения каждой хромосомы, и какая из двух хромосом родителя присутствует у индивидуума. Она может также относиться к гипотезе, касающейся того, какие хромосомы или хромосомные сегменты, если таковые имеются, от родственного индивидуума генетически соответствуют данной хромосоме от индивидуума.
Родственный индивидуум относится к любому индивидууму, который генетически связан с, и, таким образом, разделяет блоки гаплотипов с индивидуумом-мишенью. В одном контексте, родственный индивидуум может быть генетическим родителем индивидуума-мишени или любым генетическим материалом, полученным от родителя, таким как сперма, полярное тело, эмбрион, плод или ребенок. Он может также относиться к родному брату/сестре, родителю или прародителю.
Сиблинг относится к любому индивидууму, чьи генетические родители являются теми же, что и у индивидуума, о котором идет речь. Согласно некоторым вариантам осуществления он может относиться к рожденному ребенку, эмбриону или плоду или одной или нескольким клеткам, происходящим от новорожденного ребенка, эмбриона или плода. Сиблинг может также относиться к гаплоидному индивидууму, который берет свое начало от одного из родителей, например, сперме, полярному телу или любому другому набору гаплотипической генетической материи. Индивидуум может считаться сиблингом самого себя.
Ребенок может относиться к эмбриону, бластомеру или плоду. Следует отметить, что в описанных в настоящем документе вариантах осуществления, описанные принципы в равной мере применимы к индивидуумам, которые представляют собой новорожденного ребенка, плод, зародыш, или набору его клеток. Использование термина "ребенок" может просто быть обозначением индивидуума, упоминаемого как ребенок в качестве генетического потомства родителей.
Фетальный относится к "плоду" или "области плаценты, генетически похожей на плод". У беременной женщины некоторая часть плаценты генетически похожа на плод, а также свободно плавающая ДНК плода, обнаруженная в крови матери, возможно, возникла из части плаценты с генотипом, который соответствует плоду. Следует отметить, что генетическая информация в половине хромосом у плода наследуется от матери к плоду. Согласно некоторым вариантам осуществления ДНК из этих наследуемых по материнской линии хромосом, которые пришли из фетальной клетки, рассматривается как "фетального происхождения", а не "материнского происхождения".
ДНК фетального происхождения относится к ДНК, которая первоначально была частью клетки, генотип которой был по существу эквивалентен таковому у плода.
ДНК материнского происхождения относится к ДНК, которая первоначально была частью клетки, генотип которой был по существу эквивалентен таковому у матери.
Родитель относится к генетической матери или отцу индивидуума. Индивидуум, как правило, имеет двух родителей, мать и отца, хотя это не обязательно может быть в случае, например, генетического или хромосомного химеризма. Родитель может рассматриваться как индивидуум.
Родительский контекст относится к генетическому состоянию данного SNP на каждой из двух соответствующих хромосомах для одного или обоих из двух родителей-мишеней.
Материнская плазма относится к плазменной части крови от женщины, которая беременна.
Клиническое решение относится к любому решению принимать или не принимать меры, результат которых влияет на здоровье или выживание индивидуума. Клиническое решение может также относиться к решению провести дополнительное исследование, чтобы прервать или сохранить беременность, принять меры для смягчения нежелательного фенотипа или принять меры, чтобы подготовиться к фенотипу.
Диагностическое устройство относится к одному или комбинации приборов, предназначенных для выполнения одного или множества аспектов описанных в настоящем документе способов. Согласно одному варианту осуществления диагностическое устройство может быть размещено в точке ухода за пациентами. Согласно одному варианту осуществления диагностическое устройство может выполнять направленную амплификацию с последующим секвенированием. Согласно одному варианту осуществления диагностическое устройство может работать самостоятельно или с помощью технического специалиста.
Основанный на информатике способ относится к способу, который в значительной мере опирается на статистику, чтобы разобраться с большим количеством данных. В контексте пренатальной диагностики, он относится к способу, предназначенному для определения состояния плоидности в одной или нескольких хромосомах или хромосомных сегментах, аллельного состояния в одном или нескольких аллелях или отцовства, статистически выводя наиболее вероятное состояние, а не непосредственное физическое измерение состояния, учитывая большое количество генетических данных, например, из молекулярной матрицы или секвенирования. Согласно одному варианту осуществления настоящего изобретения основанная на информатике техника может представлять собой одну из раскрытых в настоящей патентной заявке. Согласно одному варианту осуществления настоящего изобретения это может быть PARENTAL SUPPORT.
Первичные генетические данные относятся к аналоговым интенсивностным сигналам, которые выводятся с помощью платформы генотипирования. В контексте матриц SNP, первичные генетические данные относятся к сигналам интенсивности до того, как было сделано распознавание генотипа. В контексте секвенирования, первичные генетические данные относятся к аналоговым измерениям, аналогичным хроматограмме, которая выходит из секвенатора перед тем, как была определена идентичность любых пар оснований, и перед тем, как последовательность была картирована в геноме.
Вторичные генетические данные относятся к обработанным генетическим данным, которые выводятся с помощью платформы генотипирования. В контексте матрицы SNP, вторичные генетические данные относятся к аллельным распознаваниям, сделанным с помощью программного обеспечения, связанного с устройством считывания матриц SNP, причем программное обеспечение распознает, присутствует ли в образце данный аллель или нет. В контексте секвенирования, вторичные генетические данные относятся к идентичностям пар оснований последовательностей, которые были определены, а также, возможно, где последовательности были картированы в геном.
Преимущественное обогащение ДНК, которое соответствует локусу, или преимущественное обогащение ДНК в локусе, относится к любому способу, который приводит к более высокому проценту молекул ДНК в смеси ДНК после обогащения, которая соответствует локусу, чем процент молекул ДНК в смеси до обогащения ДНК, которая соответствует локусу. Способ может предусматривать селективную амплификацию молекул ДНК, которые соответствуют локусу. Способ может предусматривать удаление молекул ДНК, которые не соответствуют локусу. Способ может предусматривать комбинацию способов. Степень обогащения определяется как процент молекул ДНК в смеси после обогащения, которые соответствуют локусу, деленный на процент молекул ДНК в смеси до обогащения, которые соответствуют локусу. Преимущественное обогащение может быть осуществлено во множестве локусов. Согласно некоторым вариантам осуществления настоящего изобретения степень обогащения больше, чем 20, 200 или 2000. Когда преимущественное обогащение осуществляется во множестве локусов, степень обогащения может относиться к средней степени обогащения всех локусов в совокупности локусов.
Амплификация относится к способу, который увеличивает количество копий молекулы ДНК или РНК.
Селективная амплификация может относиться к способу, который увеличивает количество копий определенной молекулы ДНК (или РНК) или молекул ДНК (или РНК), которые соответствуют определенной области ДНК (или РНК). Она может также относиться к способу, который увеличивает число копий определенной молекулы-мишени ДНК (или РНК) или области-мишени ДНК (или РНК) в большей степени, чем происходит увеличение молекул-немишеней или областей-немишеней ДНК (или РНК). Селективная амплификация может представлять собой способ преимущественного обогащения.
Универсальная последовательность прайминга относится к последовательности ДНК (или РНК), которая может быть присоединена к популяции молекул-мишеней ДНК (или РНК), например, путем лигирования, ПЦР или опосредованной лигированием ПЦР. После добавления к популяции молекул-мишеней, праймеры, специфичные к универсальным последовательностям прайминга, могут быть использованы для амплификации популяции-мишени с использованием одной пары праймеров для амплификации. Универсальные последовательности прайминга, как правило, не связаны с последовательностями-мишенями.
Универсальные адаптеры или "адаптеры лигирования", или "теги библиотек" представляют собой молекулы нуклеиновых кислот, содержащие универсальную последовательность прайминга, которая может быть ковалентно связана с 5-прайм и 3-прайм концом популяции молекул-мишеней двухцепочечных нуклеиновых кислот. Добавление адаптеров обеспечивает универсальные последовательности прайминга к 5-прайм и 3-прайм концу популяции-мишени, с которой может начинаться ПЦР-амплификация, амплифицируя все молекулы из популяции-мишени с использованием одной пары праймеров для амплификации.
Направленное воздействие относится к способу, используемому для селективной амплификации или иного преимущественного обогащения теми молекулами ДНК (или РНК), которые соответствуют совокупности локусов в смеси ДНК (или РНК).
Модель совместного распределения относится к модели, которая определяет вероятность событий, определенных в терминах нескольких случайных переменных, учитывая множество случайных переменных, определенных на том же вероятностном пространстве, где вероятности переменной связаны между собой. Согласно некоторым вариантам осуществления может быть использован вырожденный случай, когда вероятности переменных не связаны между собой.
Связанный со злокачественной опухолью ген относится к гену, связанному с измененным риском развития злокачественной опухоли или измененным прогнозом для злокачественной опухоли. Иллюстративные связанные со злокачественной опухолью гены, которые вызывают злокачественную опухоль, включают в себя онкогены; гены, которые усиливают клеточную пролиферацию, инвазию или метастаз; гены, которые ингибируют апоптоз, и гены про-ангиогенеза. Связанные со злокачественной опухолью гены, ингибирующие злокачественную опухоль, включают в себя без ограничения гены-супрессоры опухолей; гены, которые ингибируют клеточную пролиферацию, инвазию или метастаз; гены, которые способствуют апоптозу и гены анти-ангиогенеза.
Связанная с эстрогеном злокачественная опухоль относится к злокачественной опухоли, которая модулируется эстрогеном. Примеры связанных с эстрогеном злокачественных опухолей включают в себя без ограничения злокачественную опухоль молочной железы и злокачественную опухоль яичников. Her2 сверхэкспрессируется при многих связанных с эстрогеном злокачественных опухолях (патент США №6165464, который полностью включен в настоящий документ посредством ссылки).
Связанная с андрогеном злокачественная опухоль относится к злокачественной опухоли, которая модулируется андрогеном. Примером связанных с андрогеном видов злокачественных опухолей является злокачественная опухоль предстательной железы.
Более высокий, чем нормальный уровень экспрессии относится к экспрессии мРНК или белка на уровне, который выше, чем средний уровень экспрессии соответствующей молекулы у контрольных субъектов (например, субъектов без заболевания или нарушения, такого как злокачественная опухоль). Согласно различным вариантам осуществления уровень экспрессии по меньшей мере на 20, 40, 50, 75, 90, 100, 200, 500 или даже 1000% выше, чем уровень у контрольных субъектов.
Более низкий, чем нормальный уровень экспрессии относится к экспрессии мРНК или белка на уровне, который ниже, чем средний уровень экспрессии соответствующей молекулы у контрольных субъектов (например, субъектов без заболевания или нарушения, такого как злокачественная опухоль). Согласно различным вариантам осуществления уровень экспрессии по меньшей мере на 20, 40, 50, 75, 90, 95 или 100% ниже, чем уровень у контрольных субъектов. Согласно некоторым вариантам осуществления экспрессия мРНК или белка не обнаруживается.
Модулирование экспрессии или активности относится к увеличению или уменьшению экспрессии или активности, например, последовательности белка или нуклеиновой кислоты, по сравнению с контрольными условиями. Согласно некоторым вариантам осуществления модуляция в экспрессии или активности представляет собой увеличение или уменьшение по меньшей мере на 10, 20, 40, 50, 75, 90, 100, 200, 500 или даже 1000%. Согласно различным вариантам осуществления транскрипция, трансляция, стабильность мРНК или белка или связывание мРНК или белка с другими молекулами in vivo модулируют посредством терапии. Согласно некоторым вариантам осуществления содержание мРНК определяют посредством стандартного анализа Нозерн-блоттинг, а содержание белка определяют с помощью стандартного анализа Вестерн-блоттинг, например, анализов, описанных в настоящем документе, или тех, которые описаны, например, в публикации Ausubel et al. (Current Protocols in Molecular Biology, John Wiley & Sons, New York, July 11, 2013, которая полностью включена в настоящий документ посредством ссылки). Согласно одному варианту осуществления содержание белка определяют путем измерения уровня ферментативной активности с использованием стандартных способов. Согласно другому предпочтительному варианту осуществления содержание мРНК, белка или ферментативная активность равны или менее чем в 20, 10, 5 или 2 раза выше соответствующего уровня в контрольных клетках, которые не экспрессируют функциональную форму белка, например, клетки, гомозиготные по нонсенс-мутации. Согласно еще одному варианту осуществления содержание мРНК, белка или ферментативная активность равны или менее чем в 20, 10, 5 или 2 раза выше соответствующего базального уровня в контрольных клетках, таких как незлокачественные клетки, клеток, которые не подвергались воздействию условий, индуцирующих аномальную пролиферацию клеток или ингибирующих апоптоз, или клеток от субъекта без представляющего интерес заболевания или нарушения.
Доза, достаточная для модулирования экспрессии или активности мРНК или белка, относится к количеству терапии, которое увеличивает или уменьшает экспрессию или активность мРНК или белка при введении субъекту. Согласно некоторым вариантам осуществления для соединения, которое уменьшает экспрессию или активность, модуляция представляет собой снижение экспрессии или активности, которое по меньшей мере на 10%, 30%, 40%, 50%, 75% или на 90% ниже у подвергаемого лечению субъекта, чем у того же субъекта до введения ингибитора или чем у не подвергнутого воздействию контрольного субъекта. Кроме того, согласно некоторым вариантам осуществления для соединения, которое повышает экспрессию или активность, уровень экспрессии или активности мРНК или белка по меньшей мере в 1,5, 2, 3, 5, 10 или 20 раз больше у подвергаемого лечению субъекта, чем у того же субъекта до введения ингибитора или чем у не подвергнутого воздействию контрольного субъекта.
Согласно некоторым вариантам осуществления соединения могут прямо или косвенно модулировать экспрессию или активность мРНК или белка. Например, соединение может косвенно модулировать экспрессию или активность представляющей интерес мРНК или белка путем модуляции экспрессии или активности молекулы (например, нуклеиновой кислоты, белка, сигнальной молекулы, фактора роста, цитокина или хемокина), которая прямо или косвенно влияет на экспрессию или активность представляющей интерес мРНК или белка. Согласно некоторым вариантам осуществления соединения ингибируют деление клеток или индуцируют апоптоз. Эти соединения в терапии могут включать в себя, например, неочищенные или очищенные белки, антитела, синтетические органические молекулы, природные органические молекулы, молекулы нуклеиновых кислот, а также их компоненты. Соединения в комбинированной терапии могут быть введены одновременно или последовательно. Иллюстративные соединения включают в себя ингибиторы сигнальной трансдукции.
Очищенные относится к соединениям, отделенным от других компонентов, которые естественным образом сопровождают их. Как правило, фактор представляет собой по существу чистый, когда он по меньшей мере на 50% по массе свободен от белков, антител и встречающихся в природе органических молекул, с которыми он связан в природе. Согласно некоторым вариантам осуществления фактор представляет собой чистый по меньшей мере на 75%, 90% или 99% по массе. По существу чистый фактор может быть получен путем химического синтеза, выделения фактора из природных источников или производства фактора в рекомбинантной клетке-хозяине, которая в природе не продуцирует фактор. Белки и малые молекулы могут быть очищены специалистом в настоящей области техники с использованием стандартных техник, таких как способы, описанные Ausubel с соавт. (публикация Current Protocols in Molecular Biology, John Wiley & Sons, New York, July 11, 2013, которая полностью включена в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления фактор по меньшей мере в 2, 5 или 10 раз чище, чем исходный материал, что измерено с использованием электрофореза в полиакриламидном геле, колоночной хроматографии, оптической плотности, анализа с помощью ВЭЖХ или вестерн-анализа (Ausubel с соавт., выше). Иллюстративные способы очистки включают в себя иммунопреципитацию, колоночную хроматографию, такую как иммуноаффинную хроматографию, иммунноаффинную очистку магнитными гранулами и пэннинг со связанным с планшетом антителом.
Другие особенности и преимущества настоящего изобретения будут очевидны из следующего подробного описания и формулы изобретения.
Краткое описание чертежей
Патент или файл заявки содержит по меньшей мере один чертеж, выполненный в цвете. Копии настоящего патента или публикации патентной заявки с цветным чертежом(ами) будут предоставлены Управлением по запросу и уплаты необходимой пошлины.
Описанные в настоящее время варианты осуществления будут дополнительно поясняться со ссылкой на прилагаемые графические материалы, на которых подобные структуры относятся к одним и тем же численным величинам на нескольких видах. Показанные графические материалы не обязательно выполнены с соблюдением масштаба, с особым вниманием, вместо этого они размещены для общей иллюстрации принципов раскрытых в настоящее время вариантов осуществления.
Фиг. 1A-1D представляют собой графики, показывающие распределение статистики критерия S, разделенное на Т (количество SNP) ("S/T"), для различных гипотез числа копий для глубины считывания (DOR) 500 и опухолевой фракции 1% для увеличивающегося количества SNP.
Фиг. 2A-2D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 500 и опухолевой фракции 2% для увеличивающегося количества SNP.
Фиг. 3A-3D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 500 и опухолевой фракции 3% для увеличивающегося количества SNP.
Фиг. 4A-4D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 500 и опухолевой фракции 4% для увеличивающегося количества SNP.
Фиг. 5A-5D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 500 и опухолевой фракции 5% для увеличивающегося количества SNP.
Фиг. 6A-6D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 500 и опухолевой фракции 6% для увеличивающегося количества SNP.
Фиг. 7A-7D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 1000 и опухолевой фракции 0,5% для увеличивающегося количества SNP.
Фиг. 8A-8D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 1000 и опухолевой фракции 1% для увеличивающегося количества SNP.
Фиг. 9A-9D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 1000 и опухолевой фракции 2% для увеличивающегося количества SNP.
Фиг. 10A-10D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 1000 и опухолевой фракции 3% для увеличивающегося количества SNP.
Фиг. 11A-11D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 1000 и опухолевой фракции 4% для увеличивающегося количества SNP.
Фиг. 12A-12D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 3000 и опухолевой фракции 0,5% для увеличивающегося количества SNP.
Фиг. 13A-13D представляют собой графики, показывающие распределение S/T для различных гипотез числа копий для DOR 3000 и опухолевой фракции 1% для увеличивающегося количества SNP.
Фиг. 14 представляет собой таблицу с указанием чувствительности и специфичности для обнаружения шести синдромов с микроделециями.
Фиг. 15А-15С представляют собой графические представления эуплоидии. Ось X представляет собой линейное положение отдельных полиморфных локусов вдоль хромосомы, а ось Y представляет собой число считываний аллеля А в виде доли от общих считываний аллелей (А+В). Материнский и фетальный генотипы указаны справа от графиков. Графики содержат цветную маркировку в соответствии с генотипом матери, такую, что красный указывает на материнский генотип АА, синий указывает на материнский генотип ВВ и зеленый указывает на материнский генотип АВ. Фиг. 15А представляет собой график, когда присутствуют две хромосомы и фракция фетальной вкДНК составляет 0%. Этот график представляет собой график от небеременной женщины и, таким образом, представляет собой образец, когда генотип полностью материнский. Аллельные кластеры, таким образом, сосредоточены вокруг 1 (аллели AA), 0,5 (аллели AB) и 0 (аллели BB). Фиг. 15B представляет собой график, когда присутствуют две хромосомы и фетальная фракция составляет 12%. Вклад фетальных аллелей во фракцию считываний аллеля A сдвигает положение некоторых пятен аллеля вверх или вниз вдоль оси Y. Фиг. 15C представляет собой график, когда присутствуют две хромосомы и фетальная фракция составляет 26%. Легко просматривается профиль, включающий в себя две красные и две синие периферийные полосы и трио центральных зеленых полос.
Фиг. 16A и 16B представляют собой графические представления синдрома делеции 22q11.2. Фиг. 16А для материнского носителя делеции 22q11.2 (как указано посредством отсутствия зеленых АВ SNP). Фиг. 16B для унаследованной от родителей делеции 22q11 у плода (как указано посредством наличия одной красной и одной синей периферической полосы). Ось X представляет собой линейное положение SNP, а ось Y указывает на фракцию прочтений аллеля А из всех прочтений. Каждое пятно представляет собой единственный локус SNP.
Фиг. 17 представляет собой графическое представление унаследованного от матери делеционного синдрома кошачьего крика (что указано посредством наличия двух центральных зеленых полос вместо трех зеленых полос). Ось X представляет собой линейное положение SNP, а ось Y указывает на фракцию прочтений аллеля А из всех прочтений. Каждое пятно представляет собой единственный локус SNP.
Фиг. 18 представляет собой графическое представление унаследованного от отца делеционного синдрома Вольфа-Хиршхорна (что указано посредством наличия одной красной и одной синей периферийной полосы). Ось X представляет собой линейное положение SNP, а ось Y указывает на фракцию прочтений аллеля А из всех прочтений. Каждое пятно представляет собой единственный локус SNP.
Фиг. 19A-19D представляют собой графические представления резкого скачка Х-хромосомы в экспериментах, чтобы представить дополнительную копию хромосомы или хромосомного сегмента. На графиках показаны различные количества ДНК от отца, смешанного с ДНК от дочери: 16% ДНК отца (Фиг. 19А), 10% ДНК отца (Фиг. 19B), 1% ДНК отца (Фиг. 19С) и 0,1% ДНК отца (Фиг. 19D). Ось X представляет собой линейное положение SNP на Х-хромосоме, а ось Y обозначает фракцию прочтений аллеля М из всех прочтений (М+R). Каждое пятно представляет собой единственный локус SNP с аллелем М или R.
Фиг. 20А и 20B представляют собой графики относительного числа ложно негативных заключений с использованием данных гаплотипов (Фиг. 20А) и без данных гаплотипов (Фиг. 20B).
Фиг. 21А и 21B представляют собой графики относительного числа ложно позитивных заключений при p=1% с использованием данных гаплотипов (Фиг. 21A) и без данных гаплотипов (Фиг. 21B).
Фиг. 22А и 22B представляют собой графики относительного числа ложно позитивных заключений при p=1,5% с использованием данных гаплотипов (Фиг. 22А) и без данных гаплотипов (Фиг. 22B).
Фиг. 23А и 23B представляют собой графики относительного числа ложно позитивных заключений при p=2% с использованием данных гаплотипов (Фиг. 23А) и без данных гаплотипов (Фиг. 23B).
Фиг. 24А и 24B представляют собой графики относительного числа ложно позитивных заключений при p=2,5% с использованием данных гаплотипов (Фиг. 24А) и без данных гаплотипов (Фиг. 24B).
Фиг. 25А и 25B представляют собой графики относительного числа ложно позитивных заключений при p=3% с использованием данных гаплотипов (Фиг. 25А) и без данных гаплотипов (Фиг. 25B).
Фиг. 26 представляет собой таблицу относительного числа ложно позитивных заключений для первой модели.
Фиг. 27 представляет собой таблицу относительного числа ложно негативных заключений для первой модели.
Фиг. 28А представляет собой график эталонных количеств (количеств одного аллеля, например, аллеля "А"), разделенных на общие количества для этого локуса для нормальной (незлокачественной) клеточной линии.
Фиг. 28B представляет собой график эталонных количеств, разделенных на общие количества для линии клеток злокачественной опухоли с делецией.
Фиг. 28C представляет собой график эталонных количеств, разделенных на общие количества для смеси ДНК из нормальной клеточной линии и клеточной линии злокачественной опухоли.
Фиг. 29 представляет собой график эталонных количеств, разделенных на общие количества для образца плазмы от пациента со злокачественной опухолью молочной железы стадии IIa с опухолевой фракцией, составляющей 4,33% (в котором 4,33% ДНК от опухолевых клеток). Зеленая часть графика представляет собой область, в которой нет CNV. Синяя и красная часть графика представляет собой область, в которой присутствует CNV и есть видимое разделение измеренных аллельных соотношений от ожидаемого аллельного соотношения 0,5. Синее окрашивание указывает на один гаплотип, а красное окрашивание указывает на другой гаплотип. Приблизительно 636 гетерозиготных SNP проанализировали в области CNV.
Фиг. 30 представляет собой график эталонных количеств, разделенных на общие количества для образца плазмы от пациента со злокачественной опухолью молочной железы стадии IIb с опухолевой фракцией, составляющей 0,58%. Зеленая часть графика представляет собой область, в которой нет CNV. Синяя и красная часть графика представляет собой область, в которой присутствует CNV, но нет явно видимого разделения измеренных аллельных соотношений от ожидаемого аллельного соотношения 0,5. Для этого анализа 86 гетерозиготных SNP проанализировали в области CNV.
Фиг. 31А и 31B представляют собой графики, показывающие оценку максимального правдоподобия опухолевой фракции. Оценка максимального правдоподобия указывается пиком на графике и составляет 4,33% на Фиг. 31А и 0,58% на Фиг. 31B.
Фиг. 32А представляет собой сравнение графиков логарифма отношения вероятностей для различных возможных опухолевых фракций для образца с высоким содержанием опухолевой фракции (4,33%) и образца с низким содержанием опухолевой фракции (0,58%). Если логарифм отношения вероятностей меньше 0, то эуплоидная гипотеза более вероятна. Если логарифм отношения вероятностей больше 0, то более вероятно наличие CNV.
Фиг. 32B представляет собой график вероятности делеции, деленной на вероятность отсутствия делеции для различных возможных опухолевых фракций для образца с низким содержанием опухолевой фракции (0,58%).
Фиг. 33 представляет собой график логарифма отношения вероятностей для различных возможных опухолевых фракций для образца с низким содержанием опухолевой фракции (0,58%). Фиг. 33 представляет собой увеличенную версию графика на Фиг. 32А для образца с низким содержанием опухолевой фракции.
Фиг. 34 представляет собой график, на котором показан предел обнаружения для однонуклеотидных вариантов в биопсии опухоли с использованием трех различных способов, описанных в примере 6.
Фиг. 35 представляет собой график, на котором показан предел обнаружения для однонуклеотидных вариантов в образце плазмы с использованием трех различных способов, описанных в примере 6.
Фиг. 36А и 36B представляют собой графики анализа геномной ДНК (Фиг. 36А) или ДНК из одной клетки (Фиг. 36B) с использованием библиотеки из приблизительно 28000 праймеров, предназначенных для обнаружения CNV. Наличие двух центральных полос вместо одной центральной полосы указывает на наличие CNV. Ось X представляет собой линейное положение SNP, а ось Y указывает на фракцию считываний аллеля А из общего числа считываний.
Фиг. 37А и 37B представляют собой графики анализа геномной ДНК (Фиг. 37А) или ДНК из одной клетки (Фиг. 37B) с использованием библиотеки из приблизительно 3000 праймеров, предназначенных для обнаружения CNV. Наличие двух центральных полос вместо одной центральной полосы указывает на наличие CNV. Ось X представляет собой линейное положение SNP, а ось Y указывает на фракцию считываний аллеля А из общего числа считываний.
Фиг. 38 представляет собой график, иллюстрирующий однородность DOR для этих ~3000 локусов.
Фиг. 39 представляет собой таблицу сравнения метрик распознавания ошибок для геномной ДНК и ДНК из одной клетки.
Фиг. 40 представляет собой график частоты появления ошибок для транзиций и трансверсий.
Фиг. 41a-d представляют собой графики чувствительности CoNVERGe, определенные с помощью PlasmArts. (a) Корреляция между вычисленным с помощью CoNVERGe AAI и фактической входной фракцией в образцах PlasmArt с ДНК из делеции 22q11.2 и соответствующих нормальных клеточных линий. (b) Корреляция между вычисленным AAI и фактическим вводом опухолевой ДНК в образцах PlasmArt с ДНК из клеток злокачественной опухоли молочной железы НСС2218 с CNV хромосом 2p и 2q и соответствующих нормальных клеток HCC2218BL, содержащих 0-9,09% фракций опухолевой ДНК. (c) Корреляция между вычисленным AAI и фактическим вводом опухолевой ДНК в образцах PlasmArt с ДНК из клеток злокачественной опухоли молочной железы НСС1954 с CNV хромосом 1p и 1q и соответствующих нормальных клеток HCC1954BL, содержащих 0-5,66% фракции опухолевой ДНК. (d) График аллельных частот для клеток НСС1954, используемых в (с). В (а), (b) и (с) точки данных и столбики ошибок указывают на среднее и стандартное отклонение (SD), соответственно, 3-8 повторов.
На Фиг. 42 представлены подробности относительно иллюстративных включенных в стандарт Plasmart графиков распределений размеров фрагмента в нижней части.
На Фиг. 43 справа представлены результаты от кривой разведения синтетических стандартов цоДНК Plasmart для проверки микроделеционной и злокачественной панелей. На Фиг. 43А; правой панели, показана максимальное правдоподобие опухоли, оценка результатов фракции ДНК в виде диаграммы относительного риска. Фиг. 43B представляет собой диаграмму для обнаружения событий трансверсий. Фиг. 43C представляет собой диаграмму для обнаружения транзиций.
Фиг. 44 представляет собой диаграмму, на которой показаны CNV для различных хромосомных областей, как указано для различных образцов при различных % цоДНК.
Фиг. 45 представляет собой диаграмму, на которой показаны CNV для различных хромосомных областей для различных образцов злокачественной опухоли яичника с различным % содержания цоДНК.
Фиг. 46 представляет собой таблицу, на которой показан процент пациентов со злокачественной опухолью молочной железы или легких с SNV или комбинацией SNV и/или CNV в цоДНК.
Фиг. 47 представляет собой график процента образцов на разных стадиях злокачественной опухоли молочной железы с опухолеспецифическими SNV и/или CNV в плазме и связанную с ним таблицу данных справа.
Фиг. 48 представляет собой график процента образцов на разных подстадиях злокачественной опухоли молочной железы с опухолеспецифическими SNV и/или CNV в плазме и связанную с ним таблицу данных справа.
Фиг. 49 представляет собой график процента образцов злокачественной опухоли легких на разных стадиях с опухолеспецифическими SNV и/или CNV в плазме и связанную с ним таблицу данных справа.
Фиг. 50 представляет собой график процента образцов на разных подстадиях злокачественной опухоли легких с опухолеспецифическими SNV и/или CNV в плазме и связанную с ним таблицу данных справа.
Фиг. 51А представляет собой гистологическое заключение/анамнез для первичных опухолей легких, проанализированных на клональную и субклональную опухолевую гетерогенность. Фиг. 51B представляет собой таблицу из идентичностей VAF биопсий опухолей легких посредством секвенирования всего генома и анализа с помощью AmpliSEQ.
На Фиг. 52 показано применение цоДНК из плазмы, чтобы идентифицировать как клональные и субклональные мутации SNA преодолевают опухолевую гетерогенность.
Фиг. 53 представляет собой таблицу сравнения распознаваний VAF с помощью AmpliSeq и mmPCR-NGS для обнаружения SNV в первичной опухоли, которые были пропущены при AmpliSeq, и мутаций SNV, выявленных в цоДНК из плазмы.
Фиг. 54А представляет собой диаграмму % VAF в первичной опухоли легких. Фиг. 54B представляет собой диаграмму линейной регрессии VAF AmpliSeq против VAF Natera.
Фиг. 55 представляет собой график 1/4 пула реакции ПЦР SNV с участием 84 праймеров, когда концентрация праймера ограничена.
Фиг. 56 представляет собой график 2/4 пула реакции ПЦР SNV с участием 84 праймеров, когда концентрация праймера ограничена
Фиг. 57 представляет собой график 3/4 пула реакции ПЦР SNV с участием 84 праймеров, когда концентрация праймера ограничена
Фиг. 58 представляет собой график 4/4 пула реакции ПЦР SNV с участием 84 праймеров, когда концентрация праймера ограничена
На Фиг. 59 показана диаграмма предела обнаружения (LOD) против глубины прочтений (DOR) для обнаружения мутаций транзиций и трансверсий SNV в реакции ПЦР с участием 84 последовательностей при 15 циклах ПЦР.
На Фиг. 60 показана диаграмма предела обнаружения (LOD) против глубины прочтений (DOR) для обнаружения мутаций транзиций и трансверсий SNV в реакции ПЦР с участием 84 последовательностей при 20 циклах ПЦР.
На Фиг. 61 показана диаграмма предела обнаружения (LOD) против глубины прочтений (DOR) для обнаружения мутаций транзиций и трансверсий SNV в реакции ПЦР с участием 84 последовательностей при 25 циклах ПЦР.
Фиг. 62 представляет собой диаграмму, иллюстрирующую сопоставимые чувствительности между геномными ДНК опухоли и единственной клетки. В верхней части показаны результаты с использованием геномной ДНК опухолевых клеток. В нижней части показаны результаты с использованием геномной ДНК единственной клетки.
На Фиг. 63 показана организация рабочего процесса для анализа CNV в различных типах образцов злокачественной опухоли в мультиплексном анализе ПЦР с большим количеством целевых последовательностей (mmPCR), направленном на SNP - Фиг. 63a. На Фиг. 63b-f приведено сравнение анализа CoNVERGe с микроматричным анализом на клеточных линиях злокачественной опухоли молочной железы против соответствующих нормальных клеточных линий.
На Фиг. 64 приведено сравнение свежемороженых (FF) и FFPE (фиксированных в формалине и залитых в парафин) образцов злокачественных опухолей молочной железы с соответствующими контролями. На Фиг. a-h представлено сравнение анализа CoNVERGe с микроматричным анализом на клеточных линиях злокачественной молочной железы против соответствующих контрольных образцов лейкоцитарных гДНК.
На Фиг. 65 показаны диаграммы частот аллелей для отражения числа копий хромосом с использованием анализа CoNVERGe для обнаружения CNV в одиночных клетках. Фиг. 65а-с представляют собой анализы из трех параллелей отдельных клеток злокачественной опухоли молочной железы. Фиг. 65d представляет собой анализ клеточной линии В-лимфоцитов без CNV в областях-мишенях.
На Фиг. 66 показаны диаграммы частот аллелей для отражения числа копий хромосом с использованием анализа CoNVERGe для обнаружения CNV в реальных образцах плазмы. Фиг. 66а представляет собой образец вкДНК плазмы при злокачественной опухоли молочной железы стадии II и гДНК соответствующей биопсии опухоли. Фиг. 66b представляет собой образец вкДНК плазмы при злокачественной опухоли яичника на поздней стадии и гДНК соответствующей биопсии. Фиг. 66c представляет собой диаграмму, иллюстрирующую опухолевую гетерогенность, как определено с помощью обнаружения CNV на пяти образцах плазмы при злокачественной опухоли яичников на поздней стадии и соответствующих тканей.
На Фиг. 67 показаны положения хромосом и мутационное изменение при злокачественной опухоли молочной железы.
На Фиг. 68 показаны частоты SNP основного (Фиг. 68А) и минорного аллеля (Фиг. 68B), используемые в реакции mmPCR 3168.
На Фиг. 69 показана иллюстративная архитектура системы Х00, применимая для выполнения вариантов осуществления согласно настоящему изобретению.
На Фиг. 70 показана иллюстративная компьютерная система для выполнения вариантов осуществления согласно настоящему изобретению.
В то время как идентифицированные выше графические материалы представляют описанные в настоящее время варианты осуществления, другие варианты осуществления также рассматриваются, как отмечено в обсуждении. Настоящее изобретение представляет иллюстративные варианты осуществления путем представления, а не ограничения. Специалистами в настоящей области техники могут быть разработаны многочисленные другие модификации и варианты осуществления, которые подпадают под объем и сущность принципов, раскрытых в настоящее время вариантов осуществления.
Подробное описание настоящего изобретения
Согласно одному аспекту настоящее изобретение относится, в общем, по меньшей мере частично, к усовершенствованным способам определения наличия или отсутствия вариаций числа копий, таким как делеции или дупликации хромосомных сегментов или целых хромосом. Эти способы особенно применимы для обнаружения небольших делеции или дупликаций, которые бывает трудно обнаружить с высокой специфичностью и чувствительностью с использованием предыдущих способов из-за небольшого объема данных, доступных из соответствующего хромосомного сегмента. Эти способы предусматривают более совершенные аналитические способы, более совершенные способы биоанализа и комбинации улучшенных аналитических способов и биоанализа. Способы согласно настоящему изобретению также могут быть использованы для обнаружения делеции или дупликации, которые присутствуют только у небольшого процента клеток или молекул нуклеиновых кислот, которые исследуют. Это позволяет обнаруживать делеции или дупликации до возникновения заболевания (например, на стадии до злокачественной опухоли) или на ранних стадиях заболевания, например, до накопления большого количества патологических клеток (таких как злокачественные клетки) с делециями или дупликациям. Более точное обнаружение делеции или дупликации, связанных с заболеванием или нарушением, позволяет улучшить способы диагностики, прогнозирования, профилактики, задержки, стабилизации или лечения заболевания или нарушения. Несколько делеции или дупликаций, как известно, связано со злокачественной опухолью или с тяжелыми психическими или физическими недостатками.
Согласно другому аспекту настоящее изобретение относится, в общем, по меньшей мере частично, к усовершенствованным способам обнаружения однонуклеотидных вариаций (SNV). Эти улучшенные способы предусматривают более совершенные аналитические способы, более совершенные способы биоанализа и усовершенствованные способы, которые используют комбинацию улучшенных аналитических способов и биоанализа. Способы согласно некоторым иллюстративным вариантам осуществления используются для обнаружения, диагностики, мониторинга или определения стадии злокачественной опухоли, например, в образцах, где SNV присутствует в очень низких концентрациях, например, менее чем 10%, 5%, 4%, 3%, 2,5%, 2%, 1%, 0,5%, 0,25% или 0,1% по отношению к общему числу нормальных копий локуса SNV, таких как образцы циркулирующих свободных ДНК. Т.е. эти способы согласно некоторым иллюстративным вариантам осуществления особенно хорошо подходят для образцов, где существует относительно низкий процент мутации или варианта по отношению к нормальным полиморфным аллелям, присутствующим для этих генетических локусов. Наконец, в настоящем документе предусмотрены способы, которые сочетают в себе улучшенные способы обнаружения вариаций числа копий с усовершенствованными способами обнаружения однонуклеотидных вариаций.
Успешное лечение таких заболеваний, как злокачественная опухоль, часто основывается на ранней диагностике, правильной постановке стадии заболевания, выборе эффективного терапевтического режима, а также тщательного контроля предотвращения или обнаружения рецидива. Для диагностики злокачественной опухоли, гистологическое исследование материала опухоли, полученного из биопсии ткани, часто считается самым надежным способом. Тем не менее, инвазивный характер основанного на биопсии взятия образца оказался непрактичным для массового скрининга и регулярного наблюдения. Таким образом, настоящие способы имеют преимущество, будучи в состоянии выполняться неинвазивно при желании при относительно низкой стоимости с быстрой скоростью обработки данных. Направленное секвенирование, которое может быть использовано способами согласно настоящему изобретению, требует меньшего количества прочтений, чем секвенирование способом "выстрела из дробового ружья", например, несколько миллионов прочтений вместо 40 миллионов прочтений, тем самым снижая затраты. Мультиплексная ПЦР и секвенирование следующего поколения, которые могут быть использованы, увеличивают пропускную способность и снижают затраты.
Согласно некоторым вариантам осуществления используются способы обнаружения делеции, дупликации или однонуклеотидного варианта у индивидуума. Может быть проанализирован образец от индивидуума, который содержит клетки или нуклеиновые кислоты, в которых подозревается делеция, дупликация или однонуклеотидный вариант. Согласно некоторым вариантам осуществления образец берут из ткани или органа с подозрением на наличие делеции, дупликации или однонуклеотидного варианта, например, клеток или массы с подозрением на злокачественность. Способы согласно настоящему изобретению могут быть использованы для обнаружения делеции, дупликации или однонуклеотидного варианта, которые присутствуют только в одной клетке или небольшом количестве клеток в смеси, содержащей клетки с делецией, дупликацией или однонуклеотидным вариантом или клетки без делеции, дупликации или однонуклеотидного варианта. Согласно некоторым вариантам осуществления анализируют вкДНК или вкРНК из образца крови от индивидуума. Согласно некоторым вариантам осуществления вкДНК или вкРНК секретируется клетками, такими как злокачественные клетки. Согласно некоторым вариантам осуществления вкДНК или вкРНК высвобождается клетками, подвергающимися некрозу или апоптозу, такими как злокачественные клетки. Способы согласно настоящему изобретению могут быть использованы для обнаружения делеции, дупликации или однонуклеотидного варианта, которые присутствуют только в небольшом проценте вкДНК или вкРНК. Согласно некоторым вариантам осуществления исследуют одну или несколько клеток из эмбриона.
Согласно некоторым вариантам осуществления используются способы для неинвазивной или инвазивной пренатальной диагностики плода. Эти способы могут быть использованы, чтобы определить наличие или отсутствие делеции или дупликаций хромосомного сегмента или целой хромосомы, например, делеции или дупликаций, о которых известно, что они связаны с серьезными умственными или физическими нарушениями, пониженной обучаемостью или злокачественной опухолью. Согласно некоторым вариантам осуществления для неинвазивной пренатальной диагностики (NIPT) исследуют клетки, вкДНК или вкРНК из образца крови от беременной матери. Эти способы позволяют обнаружить делецию или дупликацию в клетках, вкДНК или вкРНК от плода, несмотря на большое количество клеток, вкДНК или вкРНК от матери, которые также присутствуют. Согласно некоторым вариантам осуществления для инвазивной пренатальной диагностики исследуют ДНК или РНК из образца от плода (например, CVS или образец амниоцентеза). Даже если образец загрязнен ДНК или РНК от беременной матери, способы могут быть использованы для обнаружения делеции или дупликации в эмбриональной ДНК или РНК.
В дополнение к определению наличия или отсутствия вариации числа копий, при желании могут быть проанализированы один или нескольких других факторов. Эти факторы могут быть использованы для повышения точности диагностики (например, определение наличия или отсутствия злокачественной опухоли или повышенного риска развития злокачественной опухоли, классификация злокачественной опухоли или стадии злокачественной опухоли) или прогноза. Эти факторы также могут быть использованы для выбора конкретной терапии или схемы лечения, которая, вероятно, будет эффективной у субъекта. Иллюстративные факторы включают в себя наличие или отсутствие полиморфизмов или мутации; измененных (увеличенных или уменьшенных) уровней общей или конкретной вкДНК, вкРНК, микроРНК (миРНК); измененной (увеличенной или уменьшенной) опухолевой фракции; измененных (увеличенных или уменьшенных) уровней метилирования, измененной (увеличенной или уменьшенной) целостности ДНК, измененного (увеличенного или уменьшенного) или альтернативного сплайсинга мРНК.
В следующих разделах описаны способы обнаружения делеции или дупликаций с использованием фазированных данных (например, выведенных или измеренных фазированных данных) или нефазированных данных; образцы, которые могут быть проверены; способы подготовки образцов, амплификации и количественного определения; способы фазирования генетических данных; полиморфизмов, мутаций, изменений нуклеиновых кислот, изменений сплайсинга мРНК и изменений содержания нуклеиновых кислот, которые могут быть обнаружены; базы данных с результатами способов, других факторов риска и способов скрининга; злокачественные опухоли, которые могут быть диагностированы или подвергнуты лечению; способы лечения злокачественных опухолей; модели злокачественных опухолей для исследования способов лечения и способы для состава и введения лекарственных средств.
Иллюстративные способы определения плоидности с использованием фазированных данных
Некоторые из способов согласно настоящему изобретению частично основаны на обнаружении того факта, что использование фазированных данных для обнаружения CNV снижает частоту ложноотрицательных и ложноположительных значений по сравнению с использованием нефазированных данных (Фиг. 20А-27). Это улучшение представляет собой наибольшее для образцов с CNV, присутствующими на низких уровнях. Таким образом, фазированные данные повышают точность обнаружения CNV по сравнению с использованием нефазированных данных (например, способы, которые вычисляют аллельные соотношения в одном или нескольких локусах или агрегируют аллельные соотношения, чтобы получить агрегированное значение (например, среднее значение) в хромосоме или хромосомном сегменте без учета того, указывают ли аллельные соотношения в различных локусах на то, что одни и те же или различные гаплотипы присутствуют в ненормальном количестве). Использование фазированных данных позволяет получить более точное определение того, обусловлена ли разница между измеренным и ожидаемым аллельным соотношением шумом или наличием CNV. Например, если разности между измеренным и ожидаемым аллельным соотношением в большинстве или всех локусах в области показывают, что тот же гаплотип превалирует, то CNV, скорее всего, будет присутствовать. Использование связи между аллелями в гаплотипе позволяет определить, соответствуют ли измеренные генетические данные такому же гаплотипу при превалировании (а не случайном шуме). В противоположность этому, если разности между измеренными и ожидаемыми аллельными соотношениями обусловлены только шумом (например, ошибкой эксперимента), то согласно некоторым вариантам осуществления приблизительно в половине случаев первый гаплотип, по всей видимости, превалирует и приблизительно в половине случаев второй гаплотип, по всей видимости, превалирует.
Точность может быть увеличена с учетом связи между SNP и вероятностью кроссоверов, происходящих во время мейоза, которое приводит к гаметам, которые сформировали эмбрион, который перерос в плод. Использование связи при создании ожидаемого распределения измерений аллелей для одной или нескольких гипотез позволяет создавать ожидаемые распределения аллельных измерений, которые соответствуют действительности значительно лучше, чем когда связь не используется. Например, можно представить, что есть два SNP, 1 и 2, расположенные рядом друг с другом, а мать представляет собой A в SNP 1 и A в SNP 2 на одном гомологе, и B в SNP 1 и B в SNP 2 на гомологе два. Если отец представляет собой A для обоих SNP на обоих гомологах и B измеряется для SNP 1 плода, это указывает на то, что гомолог два унаследован плодом, и, следовательно, существует гораздо большая вероятность того, что B присутствует у плода в SNP 2. Модель, которая учитывает связь, может это предсказать, в то время как модель, которая не принимает во внимание связь, не может. С другой стороны, если мать представляет собой АВ в SNP 1 и АВ в соседнем SNP 2, то могут быть использованы две гипотезы, соответствующие материнской трисомии в этом положении - одна с участием нарушения расхождения сестринских хроматид (нерасхождение в мейозе II или митозе на ранних стадиях развития плода), и одна, предполагающая нарушение расхождения гомологичных хромосом (нерасхождение в мейозе I). В случае трисомии нарушения расхождения сестринских хроматид, если плод унаследовал AA от матери в SNP 1, то плод имеет гораздо больше шансов на наследование либо АА, либо BB от матери в SNP 2, но не АВ. В случае нарушение расхождения гомологичных хромосом плод наследует AB от матери в обоих SNP. Гипотезы аллельного распределения, выполненные с помощью способа распознавания CNV, который принимает во внимание связь, может сделать эти предсказания, и, следовательно, соответствует фактическим измерениям аллеля в значительно большей степени, чем способ распознавания CNV, который не принимает во внимание связь.
Согласно некоторым вариантам осуществления фазированные генетические данные используют для определения того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме индивидуума (например, в геноме одной или нескольких клеток или в вкДНК или вкРНК). Иллюстративные превышения включают в себя дупликацию первого гомологичного хромосомного сегмента или делецию второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления не существует превышения, так как первый и второй гомологичные хромосомные сегменты присутствуют в равных пропорциях (например, по одной копии каждого сегмента в диплоидном образце). Согласно некоторым вариантам осуществления вычисленные аллельные соотношения в образце нуклеиновой кислоты сравнивают с ожидаемыми аллельными соотношениями, чтобы определить, существует ли превышение, как описано далее ниже. В настоящем документе фраза "первый гомологичный хромосомный сегмент по сравнению со вторым гомологичным хромосомным сегментом" означает первый гомолог хромосомного сегмента и второй гомолог хромосомного сегмента.
Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентификатор аллеля, присутствующего в этом локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентификатор аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и получение измеренных генетических аллельных данных, содержащих, для каждого из аллелей в каждом из локусов в совокупности полиморфных локусов, количество каждого аллеля, присутствующего в образце ДНК или РНК из одной или нескольких клеток-мишеней и одной или нескольких клеток-немишеней от индивидуума. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, определяющих степень превалирования первого гомологичного хромосомного сегмента; вычисление для каждой из гипотез ожидаемых генетических данных для множества локусов в образце из полученных фазированных генетических данных для одного или нескольких возможных соотношений ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце; вычисление (например, вычисление на компьютере) для каждого возможного соотношения ДНК или РНК и для каждой гипотезы данных, согласующихся между полученными генетическими данными образца и ожидаемыми генетическими данными для образца для этого возможного соотношения ДНК или РНК и для этой гипотезы; ранжирование одной или нескольких гипотез соответственно согласованию данных и выбор гипотезы, которая занимает самое высокое положение при ранжировании, тем самым определяя степень превышения числа копий первого гомологичного хромосомного сегмента в геноме одной или нескольких клеток от индивидуума.
Согласно одному аспекту настоящее изобретение относится к способу определения числа копий представляющей интерес хромосомы или хромосомного сегмента в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных по меньшей мере для одного биологического родителя плода, причем фазированные генетические данные содержат идентификатор присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у родителя. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в смешанном образце ДНК или РНК, содержащем фетальную ДНК или РНК и материнскую ДНК или РНК от матери плода, путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности одной или нескольких гипотез, указывающих на число копий представляющей интерес хромосомы или хромосомного сегмента, присутствующего в геноме плода. Согласно некоторым вариантам осуществления способ предусматривает создание (например, создание на компьютере) для каждой из гипотез распределения вероятности ожидаемого количества каждого аллеля в каждом из множества локусов в смешанном образце из (I) полученных фазированных генетических данных от родителя(ей) и необязательно (II) вероятности одного или нескольких кроссоверов, которые могут происходить при образовании гамет, что вносит вклад в копирование представляющей интерес хромосомы или хромосомного сегмента к плоду; вычисление (например, вычисление на компьютере) согласования для каждой из гипотез между (1) полученными генетическими данными смешанного образца и (2) распределением вероятности ожидаемого количества каждого аллеля в каждом из множества локусов в смешанном образце для этой гипотезы; ранжирования одной или нескольких гипотез в соответствии с согласованием данных и выбор гипотезы, которая занимает самое высокое положение при ранжировании, определяя тем самым число копий представляющего интерес хромосомного сегмента в геноме плода.
Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных с использованием любого из описанных в настоящей заявке способов или любого известного способа. Согласно некоторым вариантам осуществления способ предусматривает одновременное или последовательное в любом порядке (I) получение фазированных генетических данных для первого гомологичного хромосомного сегмента, содержащего идентификатор аллеля, присутствующего в данном локусе на первом гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте, (II) получение фазированных генетических данных для второго гомологичного хромосомного сегмента, содержащего идентификатор аллеля, присутствующего в данном локусе на втором гомологичном хромосомном сегменте, для каждого локуса в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте, и (III) получение измеренных генетических аллельные данных, содержащих количество каждого аллеля в каждом из локусов в совокупности полиморфных локусов в образце ДНК из одной или нескольких клеток от индивидуума.
Согласно некоторым вариантам осуществления способ предусматривает вычисление аллельных соотношений для одного или нескольких локусов в совокупности полиморфных локусов, которые представляют собой гетерозиготные по меньшей мере в одной клетке, из которой был получен образец (например, локусы, которые являются гетерозиготными у плода и/или гетерозиготными у матери). Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей (например, аллеля на первом гомологичном хромосомном сегменте), разделенное на измеренное количество одного или нескольких других аллелей (например, аллеля на втором гомологичном хромосомном сегменте) для локуса. Вычисленные аллельные соотношения могут быть вычислены с использованием любого из описанных в настоящей заявке способов или любого стандартного способа (например, любого математического преобразования вычисленных аллельных соотношений, описанного в настоящем документе).
Согласно некоторым вариантам осуществления способ предусматривает определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента, путем сравнения одного или нескольких вычисленных аллельных соотношений для локуса с аллельным соотношением, которое ожидается для этого локуса, если первый и второй гомологичные хромосомные сегменты присутствуют в равных пропорциях. Согласно некоторым вариантам осуществления ожидаемое аллельное соотношение предполагает, что возможные аллели для локуса характеризуются равной вероятностью присутствия. Согласно некоторым вариантам осуществления, в которых вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса, соответствующее ожидаемое аллельное соотношение составляет 0,5 для биаллельного локуса или 1/3 для триаллельного локуса. Согласно некоторым вариантам осуществления ожидаемое аллельное соотношение является одинаковым для всех локусов, например, 0,5 для всех локусов. Согласно некоторым вариантам осуществления ожидаемое аллельное соотношение предполагает, что возможные аллели для локуса могут иметь различную вероятность присутствия, например, вероятность на основе частоты каждого из аллелей в определенной популяции, к которой принадлежит субъект, например, популяция, на основе происхождения субъекта. Такие аллельные частоты находятся в открытом доступе (смотрите, например, HapMap Project; Perlegen Human Haplotype Project; web at ncbi.nlm.nih.gov/projects/SNP/; Sherry ST, Ward MH, Kholodov M, et al. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 2001 Jan 1; 29(1): 308-11, каждая из которых полностью включена посредством ссылки). Согласно некоторым вариантам осуществления ожидаемое аллельное соотношение представляет собой аллельное соотношение, которое ожидается для конкретного исследуемого индивидуума для конкретной гипотезы, задающей степень превалирования первого гомологичного хромосомного сегмента. Например, ожидаемое аллельное соотношение для конкретного индивидуума может быть определено на основе фазированных или нефазированных генетических данных от индивидуума (например, из образца от индивидуума, который маловероятно будет иметь делецию или дупликацию, например, незлокачественного образца) или данных от одного или нескольких родственников индивидуума. Согласно некоторым вариантам осуществления для пренатальной диагностики ожидаемое аллельное соотношение представляет собой аллельное соотношение, которое ожидается для смешанного образца, который включает в себя ДНК или РНК от беременной матери и плода (например, образец материнской плазмы или сыворотки, который включает в себя вкДНК от матери и вкДНК от плода) для конкретной гипотезы, задающей степень превалирования первого гомологичного хромосомного сегмента. Например, ожидаемое аллельное соотношение для смешанного образца может быть определено на основе генетических данных от матери и предсказанных генетических данных для плода (например, предсказания для аллелей, которые плод, возможно, унаследовали от матери и/или отца). Согласно некоторым вариантам осуществления фазированные или нефазированные генетические данные из образца ДНК или РНК, полученные только от матери (например, лейкоцитарный слой из образца материнской крови), определяют аллели из материнской ДНК или РНК в смешанном образце, а также аллели, которые плод возможно унаследовал от матери (и, таким образом, могут присутствовать в фетальной ДНК или РНК в смешанном образце). Согласно некоторым вариантам осуществления фазированные или нефазированные генетические данные из образца ДНК или РНК только от отца используют, чтобы определить аллели, которые плод возможно унаследовал от отца (и, таким образом, могут присутствовать в фетальной ДНК или РНК в смешанном образце). Ожидаемые аллельные соотношения могут быть вычислены с использованием любого из описанных в настоящей заявке способов или любого стандартного способа (например, любого математического преобразования ожидаемых аллельных соотношений, описанных в настоящем документе) (публикация патента США №2012/0270212, поданная 18 ноября 2011 г., которая полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления вычисленное аллельное соотношение свидетельствует о превышении числа копий первого гомологичного хромосомного сегмента, если (I) аллельное соотношение для измеренного количества аллеля, присутствующего в этом локусе на первой гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, больше, чем ожидаемое аллельное соотношение для этого локуса, или (II) аллельное соотношение для измеренного количества аллеля, присутствующего в этом локусе на второй гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, меньше, чем ожидаемое аллельное соотношение для этого локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение только считается показателем превышения, если оно значительно больше или меньше, чем ожидаемое соотношение для данного локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение представляет собой показатель не превышения числа копий первого гомологичного хромосомного сегмента, если (I) аллельное соотношение для измеренного количества аллеля, присутствующего в этом локусе на первой гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, меньше или равно ожидаемому аллельному соотношению для этого локуса, или (II) аллельное соотношение для измеренного количества аллеля, присутствующего в этом локусе на второй гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, больше или равно ожидаемому аллельному соотношению для этого локуса. Согласно некоторым вариантам осуществления вычисленные отношения, равные соответствующему ожидаемому соотношению, игнорируются (поскольку они указывают на отсутствие превышения).
Согласно различным вариантам осуществления один или нескольких из следующих способов используют для сравнения одного или нескольких вычисленных аллельных соотношений с соответствующим ожидаемым аллельным соотношением(ями). Согласно некоторым вариантам осуществления он определяет, выше или ниже вычисленное аллельное соотношение, чем ожидаемое аллельное соотношение для конкретного локуса независимо от величины разницы. Согласно некоторым вариантам осуществления он определяет величину разницы между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для конкретного локуса независимо от того, выше или ниже вычисленное аллельное соотношение, чем ожидаемое аллельное соотношение. Согласно некоторым вариантам осуществления он определяет, выше или ниже вычисленное аллельное соотношение, чем ожидаемое аллельное соотношение, и величину разницы для конкретного локуса. Согласно некоторым вариантам осуществления он определяет, выше или ниже среднее или средневзвешенное значение вычисленных аллельных соотношений, чем среднее или средневзвешенное значение ожидаемых аллельных соотношений, независимо от величины разницы. Согласно некоторым вариантам осуществления он определяет величину разницы между средним или средневзвешенным значением вычисленных аллельных соотношений и средним или средневзвешенным значением ожидаемых аллельных соотношений, независимо от того, выше или ниже среднее или средневзвешенное вычисленное аллельное соотношение, чем среднее или средневзвешенное значение ожидаемых аллельных соотношений. Согласно некоторым вариантам осуществления он определяет, выше или ниже среднее или средневзвешенное вычисленное аллельное соотношение, чем среднее или средневзвешенное значение ожидаемых аллельных соотношений, и величину разницы. Согласно некоторым вариантам осуществления он определяет среднее или средневзвешенное значение величины разницы между вычисленными аллельными соотношениями и ожидаемыми аллельными соотношениями.
Согласно некоторым вариантам осуществления величина разницы между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для одного или нескольких локусов используется для определения того, превышает ли число копий первого гомологичной хромосомного сегмента из-за дупликации первого гомологичного хромосомного сегмента или делеции второго гомологичного хромосомного сегмента в геноме одной или нескольких клеток.
Согласно некоторым вариантам осуществления превышение числа копий первого гомологичного хромосомного сегмента определяется как присутствующее, если удовлетворяется одно или несколько из следующих условий. Согласно некоторым вариантам осуществления количество вычисленных аллельных соотношений, которое свидетельствует о превышении числа копий первого гомологичного хромосомного сегмента, выше порогового значения. Согласно некоторым вариантам осуществления количество вычисленных аллельных соотношений, которое свидетельствует о превышении числа копий первого гомологичного хромосомного сегмента, ниже порогового значения. Согласно некоторым вариантам осуществления настоящего изобретения величина разницы между вычисленными аллельными соотношениями, которая свидетельствует о превышении числа копий первого гомологичного хромосомного сегмента, и соответствующих ожидаемых аллельных соотношений выше порогового значения. Согласно некоторым вариантам осуществления для всех вычисленных аллельных соотношений, которые свидетельствуют о превалировании, сумма величины разницы между вычисленным аллельным соотношением и соответствующим ожидаемым аллельным соотношением выше порогового значения. Согласно некоторым вариантам осуществления величина разницы между вычисленными аллельными соотношениями, которые свидетельствуют об отсутствии превышения числа копий первого гомологичного хромосомного сегмента, и соответствующими ожидаемыми аллельными соотношениями ниже порогового значения. Согласно некоторым вариантам осуществления среднее или средневзвешенное значение вычисленных аллельных соотношений для измеренного количества аллеля, присутствующего на первой гомологичной хромосоме, деленное на общее отмеренное количество всех аллелей для локуса, больше среднего или средневзвешенного значения ожидаемых аллельных соотношений по меньшей мере на пороговое значение. Согласно некоторым вариантам осуществления среднее или средневзвешенное значение вычисленных аллельных соотношений для измеренного количества аллеля, присутствующего на второй гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, меньше среднего или средневзвешенного значения ожидаемых аллельных соотношений по меньшей мере на пороговое значение. Согласно некоторым вариантам осуществления совпадение данных между вычисленными аллельными соотношениями и аллельными соотношениями, которые прогнозируются для превышения числа копий первого гомологичного хромосомного сегмента, ниже порогового значения (показатель хорошего совпадения данных). Согласно некоторым вариантам осуществления совпадение данных между вычисленными аллельными соотношениями и аллельными соотношениями, которые прогнозируются для отсутствия превышения числа копий первого гомологичного хромосомного сегмента, выше порогового значения (показатель слабого совпадения данных).
Согласно некоторым вариантам осуществления превышение числа копий первого гомологичного хромосомного сегмента определяется как отсутствующее, если выполняется одно или несколько из следующих условий. Согласно некоторым вариантам осуществления количество вычисленных аллельных соотношений, которое свидетельствуют о превышении числа копий первого гомологичного хромосомного сегмента, ниже порогового значения. Согласно некоторым вариантам осуществления количество вычисленных аллельных соотношений, которое свидетельствуют об отсутствии превышения числа копий первого гомологичного хромосомного сегмента, выше порогового значения. Согласно некоторым вариантам осуществления величина разницы между вычисленными аллельными соотношениями, которые свидетельствуют о превышении числа копий первого гомологичного хромосомного сегмента, и соответствующими ожидаемыми аллельными соотношениями ниже порогового значения. Согласно некоторым вариантам осуществления величина разницы между вычисленными аллельными соотношениями, которые свидетельствуют о превышении числа копий первого гомологичного хромосомного сегмента, и соответствующими ожидаемыми аллельными соотношениями, ниже порогового значения. Согласно некоторым вариантам осуществления среднее или средневзвешенное значение вычисленных аллельных соотношений для измеряемого количества аллеля, присутствующего на первой гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса минус среднее или средневзвешенное значение ожидаемых аллельных соотношений, меньше, чем пороговое значение. Согласно некоторым вариантам осуществления среднее или средневзвешенное значение ожидаемых аллельных соотношений минус среднее или средневзвешенное значение вычисленных аллельных соотношений для измеряемого количества аллеля, присутствующего на второй гомологичной хромосоме, деленное на общее измеренное количество всех аллелей для локуса, меньше, чем пороговое значение. Согласно некоторым вариантам осуществления совпадение данных между вычисленными аллельными соотношениями и аллельными соотношениями, которые прогнозируются для превышения числа копий первого гомологичного хромосомного сегмента, выше порогового значения. Согласно некоторым вариантам осуществления совпадение данных между вычисленными аллельными соотношениями и аллельными соотношениями, которые прогнозируются для отсутствия превышения числа копий первого гомологичного хромосомного сегмента, ниже порогового значения. Согласно некоторым вариантам осуществления пороговое значение определяется из эмпирической проверки образцов, про которые известно, что они содержат представляющие интерес CNV, и/или образцов, про которые известно, что они не содержат CNV.
Согласно некоторым вариантам осуществления определение того, существует ли превышение числа копий первого гомологичного хромосомного сегмента, предусматривает перечисление совокупности из одной или нескольких гипотез, определяющих степень превышения первого гомологичного хромосомного сегмента. Иллюстративная гипотеза представляет собой отсутствие превышения, поскольку первый и второй гомологичные хромосомные сегменты присутствуют в равных пропорциях (например, по одной копии каждого сегмента в диплоидном образце). Другие иллюстративные гипотезы включают в себя первый гомологичный хромосомный сегмент, дублированный один или несколько раз (например, 1, 2, 3, 4, 5 или нескольких дополнительных копий первой гомологичной хромосомы по сравнению с числом копий второго гомологичного хромосомного сегмента). Другая иллюстративная гипотеза предусматривает удаление второго гомологичного хромосомного сегмента. Еще одна иллюстративная гипотеза представляет собой удаление, как первого, так и второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления прогнозируемые аллельные соотношения для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусы, которые являются гетерозиготными у плода и/или гетерозиготными у матери), оценивают для каждой гипотезы с учетом степени превышения, заданного данной гипотезой. Согласно некоторым вариантам осуществления вероятность того, что гипотеза верна, вычисляют посредством сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, и выбирают гипотезу с наибольшим правдоподобием.
Согласно некоторым вариантам осуществления ожидаемое распределение статистики критерия вычисляется с использованием предсказанных аллельных соотношений для каждой гипотезы. Согласно некоторым вариантам осуществления вероятность того, что гипотеза верна, рассчитывается путем сравнения статистики критерия, которую рассчитывают с использованием вычисленных аллельных соотношений с ожидаемым распределением статистики критерия, которую рассчитывают с использованием прогнозируемых аллельных соотношений, и выбирают гипотезу с наибольшей вероятностью.
Согласно некоторым вариантам осуществления прогнозируемые аллельные соотношения для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусы, которые являются гетерозиготными у плода и/или гетерозиготными у матери), оценивают с учетом фазированных генетических данных для первого гомологичного хромосомного сегмента, фазированных генетических данных для второго гомологичного хромосомного сегмента, а степень превышение задается этой гипотезой. Согласно некоторым вариантам осуществления вероятность того, что гипотеза верна, рассчитывают путем сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями и выбирают гипотезу с наибольшей вероятностью.
Использование смешанных образцов
Следует понимать, что для многих вариантов осуществления образец представляет собой смешанный образец с ДНК или РНК из одной или нескольких клеток-мишеней и одной или нескольких клеток-немишеней. Согласно некоторым вариантам осуществления клетки-мишени представляют собой клетки, у которых есть CNV, такие как представляющая интерес делеция или дупликация, и клетки-немишени представляют собой клетки, в которых нет представляющей интерес вариации числа копий (например, исследуемая смесь клеток с представляющей интерес делецией или дупликацией и клеток без каких-либо делеции или дупликаций). Согласно некоторым вариантам осуществления клетки-мишени представляют собой клетки, которые связаны с заболеванием или нарушением или повышенным риском развития заболевания или нарушения (например, злокачественные клетки), а клетки-немишени представляют собой клетки, которые не связаны с заболеванием или нарушением или повышенным риском развития заболевания или нарушения (например, незлокачественные клетки). Согласно некоторым вариантам осуществления клетки-мишени характеризуются наличием одинаковых CNV. Согласно некоторым вариантам осуществления две или более клеток-мишеней характеризуются наличием разных CNV. Согласно некоторым вариантам осуществления одна или нескольких клеток-мишеней характеризуются наличием CNV, полиморфизма или мутации, связанной с заболеванием или нарушением или повышенным риском развития заболевания или нарушения, которые не обнаруживаются по меньшей мере в одной другой клетке-мишени. Согласно некоторым таким вариантам осуществления предполагается, что доля клеток, которые связаны с заболеванием или нарушением или повышенным риском развития заболевания или нарушения от общего количества клеток из образца больше или равна доле наиболее частых из этих CNV, полиморфизмов или мутаций в образце. Например, если 6% клеток характеризуются наличием мутации K-ras и 8% клеток характеризуются наличием мутации BRAF, по меньшей мере 8% этих клеток считаются злокачественными.
Согласно некоторым вариантам осуществления вычисляют отношение ДНК (или РНК) из одной или нескольких клеток-мишеней к общей ДНК (или РНК) в образце. Согласно некоторым вариантам осуществления перечисляют совокупность из одной или нескольких гипотез, задающих степень превалирования первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления для каждой гипотезы оценивают прогнозируемые аллельные соотношения для локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), оцениваются с учетом вычисленного соотношения ДНК или РНК и степени превышения, заданной этой гипотезе. Согласно некоторым вариантам осуществления вероятность того, что гипотеза верна, рассчитывается путем сравнения вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, и выбирают гипотезу с наибольшей вероятностью.
Согласно некоторым вариантам осуществления ожидаемое распределение статистики критерия вычисляют с использованием предсказанных аллельных соотношений и оценивают вычисленное отношение ДНК или РНК для каждой гипотезы. Согласно некоторым вариантам осуществления вероятность того, что гипотеза верна, определяют путем сравнения статистики критерия, рассчитанной с использованием вычисленных аллельных соотношений и вычисленного отношения ДНК или РНК с ожидаемым распределением статистики критерия, вычисленной с использованием прогнозируемых аллельных соотношений и вычисленного отношения ДНК или РНК, и выбирают гипотезу с наибольшей вероятностью.
Согласно некоторым вариантам осуществления способ предусматривает перечисление совокупности из одной или нескольких гипотез, задающих степень превалирования первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления настоящего изобретения способ предусматривает оценку, для каждой гипотезы, либо (I) прогнозируемых аллельных соотношений локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), учитывая степень превышения, определяемую этой гипотезой, либо (II) для одного или нескольких возможных соотношений ДНК или РНК, ожидаемого распределения статистики критерия, вычисленного с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления совпадение данных рассчитывают путем сравнения либо (I), вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, либо (II) статистики критерия, рассчитанной с использованием вычисленных аллельных соотношений и возможного соотношения ДНК или РНК, с ожидаемым распределением статистики критерия, вычисленной с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК. Согласно некоторым вариантам осуществления одну или нескольких из гипотез ранжируют по совпадению данных и выбирают гипотезу, которая занимает самое высокое положение при ранжировании. Согласно некоторым вариантам осуществления технику или алгоритм, например, алгоритм поиска, используют для одной или нескольких следующих стадий: вычисление совпадения данных, ранжирование гипотез или выбор гипотезы, которая занимает самое высокое положение при ранжировании. Согласно некоторым вариантам осуществления совпадение данных представляет собой совпадение с бета-биномиальным распределением или совпадение с биномиальным распределением. Согласно некоторым вариантам осуществления технику или алгоритм выбирают из группы, состоящей из оценки по максимуму правдоподобия, оценки с помощью апостериорного максимума, Байесовской оценки, динамической оценки (например, динамической Байесовской оценки) и оценки на основе максимизации ожидания. Согласно некоторым вариантам осуществления способ предусматривает применение техники или алгоритма к полученным генетическим данных и ожидаемым генетическим данным.
Согласно некоторым вариантам осуществления способ предусматривает создание разложения возможных соотношений, которые варьируют от нижнего предела до верхнего предела для отношения ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления перечислена совокупность из одной или нескольких гипотез, указывающих на степень превалирования первого гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления способ предусматривает оценку, для каждого из возможных соотношений ДНК или РНК в разложении и для каждой гипотезы, либо (I) прогнозируемых аллельных соотношений локусов, которые являются гетерозиготными по меньшей мере в одной клетке (например, локусов, которые являются гетерозиготными у плода и/или гетерозиготными у матери), учитывая возможное соотношение ДНК или РНК и степень превалирования, определенную этой гипотезой, либо (II) ожидаемого распределения статистики критерия, рассчитанной с использованием прогнозируемых аллельных соотношений и возможного отношения ДНК или РНК. Согласно некоторым вариантам осуществления способ предусматривает вычисление, для каждого из возможных соотношений ДНК или РНК в разложении и для каждой гипотезы, вероятность того, что гипотеза верна путем сравнения либо (I) вычисленных аллельных соотношений с прогнозируемыми аллельными соотношениями, либо (II) статистики критерия, рассчитанной с использованием вычисленных аллельных соотношений и возможного соотношения ДНК или РНК с ожидаемым распределением статистики критерия, рассчитанной с использованием прогнозируемых аллельных соотношений и возможного соотношения ДНК или РНК. Согласно некоторым вариантам осуществления совместную вероятность для каждой гипотезы определяют путем объединения вероятностей этой гипотезы для каждого из возможных соотношений в разложении; и выбирают гипотезу с наибольшей совместной вероятностью. Согласно некоторым вариантам осуществления совместную вероятность для каждой гипотезы определяют путем взвешивания вероятности гипотезы для конкретного возможного соотношения на основе вероятности того, что это возможно соотношение представляет собой правильное соотношение.
Согласно некоторым вариантам осуществления технику, выбранную из группы, состоящей из оценки по максимуму правдоподобия, оценки с помощью апостериорного максимума, Байесовской оценки, динамической оценки (например, динамической Байесовской оценки) и оценки на основе максимизации ожидания, используют для оценки соотношения ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления предполагается, что отношение ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце одинаковое для двух или более (или всех) представляющих интерес CNV. Согласно некоторым вариантам осуществления отношение ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце вычисляют для каждой представляющей интерес CNV.
Иллюстративные способы использования недостаточно фазированных данных
Следует понимать, что для многих вариантов осуществления используются недостаточно фазированные данные. Например, может быть не известно со 100% уверенностью, какой аллель присутствует для одного или нескольких локусов на первом и/или втором гомологичном хромосомном сегменте. Согласно некоторым вариантам осуществления априорные вероятности для возможных гаплотипов индивидуума (например, гаплотипов основанных на популяции частот гаплотипов) используют при вычисления вероятности каждой гипотезы. Согласно некоторым вариантам осуществления априорные вероятности для возможных гаплотипов сглаживаются либо с использованием другого способа для фазирования генетических данных, либо с помощью фазированных данных от других субъектов (например, предыдущих субъектов) для уточнения демографических данных для основанного на информатике фазирования индивидуума.
Согласно некоторым вариантам осуществления фазированные генетические данные содержат вероятностные данные для двух или более возможных совокупностей фазированных генетических данных, причем каждая из возможных совокупностей фазированных данных содержит возможную идентификацию аллеля, присутствующего в каждом локусе во множестве полиморфных локусов на первом гомологичном хромосомном сегменте, и возможную идентификацию аллеля, присутствующего в каждом локусе в совокупности полиморфных локусов на втором гомологичном хромосомном сегменте. Согласно некоторым вариантам осуществления вероятность по меньшей мере для одной из гипотез определяют для каждой из возможных совокупностей фазированных генетических данных. Согласно некоторым вариантам осуществления совместную вероятность для гипотезы определяют путем объединения вероятностей гипотезы для каждой из возможных совокупностей фазированных генетических данных; и выбирают гипотезу с наибольшей совместной вероятностью.
Любой из раскрытых в настоящем документе способов или любой известный способ может быть использован для получения недостаточно фазированных данных (например, использование основанных на популяциях частот гаплотипов для выведения наиболее вероятной фазы) для использования в заявленных способах. Согласно некоторым вариантам осуществления фазированные данные получают путем вероятностного комбинирования гаплотипов небольших сегментов. Например, возможные гаплотипы могут быть определены на основании возможных комбинаций одного гаплотипа из первой области с другим гаплотипом из другой области из той же самой хромосомы. Вероятность того, что отдельные гаплотипы из разных областей представляют собой часть того же, большего блока гаплотипов на той же хромосоме может быть определена с использованием, например, основанных на популяциях частот гаплотипов и/или известных скоростей рекомбинации между различными областями.
Согласно некоторым вариантам осуществления используется тест отвержения одной гипотезы для нулевой гипотезы дисомии. Согласно некоторым вариантам осуществления вычисляется вероятность гипотезы дисомии и гипотеза дисомии отвергается, если вероятность меньше заданного порогового значения (например, менее чем 1 на 1000). Если нулевая гипотеза отвергается, это может происходить из-за ошибок в недостаточно фазированных данных или из-за наличия CNV. Согласно некоторым вариантам осуществления получают более точные фазированные данные (например, фазированные данные от любого из способов молекулярного фазирования, раскрытых в настоящем документе, чтобы получить фактические фазированные данные, а не основанные на биоинформатике предполагаемые фазированные данные). Согласно некоторым вариантам осуществления вероятность гипотезы дисомии пересчитывается с использованием более точных фазированных данных, чтобы определить, должна ли гипотеза дисомии по-прежнему отвергаться. Отвержение этой гипотезы свидетельствует о том, что дупликация или делеция хромосомного сегмента присутствует. При желании, процент ложных срабатываний может быть изменен путем изменения порогового значения.
Дополнительные иллюстративные варианты осуществления для определения плоидности с использованием фазированных данных
Согласно иллюстративным вариантам осуществления в настоящем документе предусмотрен способ определения плоидности хромосомного сегмента в образце индивидуума. Способ предусматривает следующие стадии:
a. получение данных о частотах аллелей, содержащих количество каждого аллеля, присутствующего в образце в каждом локусе в совокупности локусов на хромосомном сегменте;
b. получение фазированной аллельной информации для совокупности локусов путем оценки фазы данных о частотах аллелей;
c. получение индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных по частотам аллелей;
d. получение совместных вероятностей для совокупности полиморфных локусов с использованием отдельных вероятностей и фазированной аллельной информации; а также
e. выбор, основанный на совместных вероятностях, лучшей модели совпадения, указывающей на хромосомную плоидность, тем самым определяя плоидность хромосомного сегмента.
Как описано в настоящем документе, данные о частотах аллелей (также называемые в настоящем документе измеренными генетическими аллельными данными) могут быть получены способами, известными в настоящей области техники. Например, данные могут быть получены с использованием кПЦР или микроматричного анализа. Согласно одному иллюстративному варианту осуществления данные получают с использованием данных о последовательности нуклеиновой кислоты, в особенности, данные о последовательности нуклеиновой кислоты с высокой пропускной способностью.
Согласно некоторым иллюстративным примерам данные о частотах аллелей корректируется на наличие ошибок до того, как они используются для получения индивидуальных вероятностей. Согласно конкретным иллюстративным вариантам осуществления ошибки, которые исправляются, включают в себя систематическую ошибку эффективности амплификации аллелей. Согласно другим вариантам осуществления ошибки, которые исправляются, включают в себя загрязнение окружающей среды и загрязнение генотипа. Согласно некоторым вариантам осуществления ошибки, которые исправляются, включают в себя систематическую ошибку амплификации аллелей, загрязнение окружающей среды и загрязнение генотипа.
Согласно некоторым вариантам осуществления индивидуальные вероятности получают с использованием совокупности моделей, как различных состояний плоидности, так и фракции аллельного дисбаланса для совокупности полиморфных локусов. Согласно этим вариантам осуществления и другим вариантам осуществления совместные вероятности получают с учетом взаимосвязи между полиморфными локусами на хромосомном сегменте.
Соответственно, согласно одному иллюстративному варианту осуществления, который объединяет некоторые из этих вариантов осуществления, в настоящем документе предусмотрен способ определения хромосомной плоидности в образце индивидуума, который предусматривает следующие стадии:
a. получение данных о последовательностях нуклеиновых кислот для аллелей в совокупности локусов в хромосомном сегменте у индивидуума;
b. обнаружение частот аллелей в совокупности локусов с использованием данных о последовательностях нуклеиновых кислот;
c. коррекция систематической ошибки эффективности амплификации аллелей в обнаруженных частотах аллелей для получения скорректированных частот аллелей для совокупности полиморфных локусов;
d. получение фазированной аллельной информации для совокупности полиморфных локусов путем оценки фазы данных о последовательностях нуклеиновых кислот;
e. получение индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения скорректированных частот аллелей с совокупностью моделей различных состояний плоидности и фракций аллельных дисбалансов совокупности полиморфных локусов;
f. получение совместных вероятностей для совокупности локусов путем объединения индивидуальных вероятностей с учетом связи между полиморфными локусами на хромосомном сегменте; а также
g. выбор, основанный на совместных вероятностях, модели наилучшего совпадения, указывающей на хромосомную анеуплоидию.
Как описано в настоящем документе, отдельные вероятности могут быть получены с использованием совокупности моделей или гипотез, как различных состояний плоидности, так и фракций среднего аллельного дисбаланса для множества полиморфных локусов. Например, в особенно иллюстративном примере отдельные вероятности получают путем моделирования состояний плоидности первого гомологичного хромосомного сегмента и второго гомологичного хромосомного сегмента. Состояния плоидности, которые моделируются, включают в себя следующие:
(1) все клетки не содержат делецию или амплификацию первого гомолога или второго гомолога хромосомного сегмента;
(2) по меньшей мере некоторые клетки содержат делецию первого гомолога или амплификацию второго гомолога хромосомного сегмента; а также
(3) по меньшей мере некоторые клетки содержат делецию второго гомолога или амплификацию первого гомолога хромосомного сегмента.
Следует понимать, что вышеуказанные модели также могут быть отнесены к гипотезе, которую используют для ограничения модели. Таким образом, выше представлены 3 гипотезы, которые могут быть использованы.
Смоделированные фракции среднего аллельного дисбаланса могут включать в себя любой диапазон среднего аллельного дисбаланса, который включает в себя фактический средний аллельный дисбаланс хромосомного сегмента. Например, согласно некоторым иллюстративным вариантам осуществления диапазон моделируемого среднего аллельного дисбаланса может быть в пределах от 0, 0,1, 0,2, 0,25, 0,3, 0,4, 0,5, 0,6, 0,75, 1, 2, 2,5, 3, 4 и 5% на нижнем уровне до 1, 2, 2,5, 3, 4, 5, 10, 15, 20, 25, 30, 40, 50, 60, 70 80 90, 95 и 99% на верхнем уровне. Интервалы для моделирования с диапазоном могут представлять собой любой интервал в зависимости от используемой вычислительной мощности и времени, отведенного для анализа. Например, могут быть смоделированы интервалы 0,01, 0,05, 0,02 или 0,1.
Согласно некоторым иллюстративным вариантам осуществления образец характеризуется средним аллельным дисбалансом для хромосомного сегмента от 0,4% до 5%. Согласно некоторым вариантам осуществления средний аллельный дисбаланс представляет собой низкий. Согласно этим вариантам осуществления средний аллельный дисбаланс составляет, как правило, менее чем 10%. Согласно некоторым иллюстративным вариантам осуществления аллельный дисбаланс составляет от 0,25, 0,3, 0,4, 0,5, 0,6, 0,75, 1, 2, 2,5, 3, 4 и 5% на нижнем уровне до 1,2, 2,5, 3, 4 и 5% на верхнем уровне. Согласно другим иллюстративным вариантам осуществления средний аллельный дисбаланс составляет от 0,4, 0,45, 0,5, 0,6, 0,7, 0,8, 0,9 или 1,0% на нижнем уровне до 0,5, 0,6, 0,7, 0,8, 0,9, 1,0, 1,5, 2,0, 3,0, 4,0 или 5,0% на верхнем уровне. Например, средний аллельный дисбаланс образца в иллюстративном примере составляет от 0,45 до 2,5%. В другом примере средний аллельный дисбаланс обнаруживается с чувствительностью 0,45, 0,5, 0,6, 0,8, 0,8, 0,9 или 1,0. Иллюстративный образец с низким аллельным дисбалансом в способах согласно настоящему изобретению включает в себя образцы плазмы от индивидуумов со злокачественной опухолью, содержащих циркулирующую опухолевую ДНК, или образцы плазмы от беременных женщин, содержащих циркулирующую ДНК плода.
Следует понимать, что для SNV долю аномальной ДНК, как правило, измеряют с использованием частоты мутантных аллелей (число мутантных аллелей в локусе/общее число аллелей в этом локусе). Так как разница между количествами двух гомологов в опухолях аналогична, авторы настоящего изобретения измеряли долю аномальной ДНК для CNV с помощью среднего аллельного дисбаланса (AAI), который определяется как |(H1-H2)|/(H1+H2), где Hi представляет собой среднее число копий гомолога i в образце и Hi/(H1+H2) представляет собой относительную распространенность, или отношение гомологов, гомолога i. Максимальное отношение гомологов представляет собой отношение гомологов более распространенного гомолога.
Анализ частоты отсева представляет собой процент SNP без прочтений, оцениваемый с использованием всех SNP. Частота одноаллельного исключения (ADO) представляет собой процент SNP только с одной аллелью, оцениваемый с использованием только гетерозиготных SNP. Доверительный интервал генотипа может быть определен путем сопоставления биномиального распределения с числом прочтений в каждом SNP, которые представляли собой B-аллельные прочтения, и использование статуса плоидности фокальной области SNP, чтобы оценить вероятность каждого генотипа.
Для получения образцов опухолевых тканей, хромосомная анеуплоидия (представлена на примере I этого раздела с помощью CNV) может быть выражена переходами между распределениями частот аллелей. В образцах плазмы, CNV могут быть идентифицированы с помощью алгоритма максимального правдоподобия, который ищет CNV плазмы в тех областях, где опухолевый образец от того же индивидуума также имеет CNV, используя информацию о гаплотипе, выведенную из опухолевого образца. Этот алгоритм может моделировать ожидаемые частоты аллелей во всех соотношениях аллельного дисбаланса в интервалах 0,025% для трех совокупностей гипотез: (1) все клетки представляют собой нормальные (нет аллельного дисбаланса), (2) некоторые/все клетки характеризуются наличием делеции гомолога 1 или амплификации гомолога 2 или (3) некоторые/все клетки характеризуются наличием делеции гомолога 2 или амплификации гомолога 1. Вероятность каждой гипотезы может быть определена в каждом SNP, используя Байесовский классификатор, основанный на бета-биномиальной модели ожидаемых и наблюдаемых частот аллелей во всех гетерозиготных SNP, а затем может быть вычислена совместная вероятность на нескольких SNP, согласно некоторым иллюстративным вариантам осуществления, принимая связь локусов SNP в рассмотрение в качестве примера в настоящем документе. Может быть выбрана гипотеза максимального правдоподобия.
Можно рассмотреть хромосомную область со средним числом копий N в опухоли, и пусть с обозначает фракцию ДНК в плазме, полученную из смеси нормальных и опухолевых клеток в дисомной области. AAI вычисляют следующим образом:
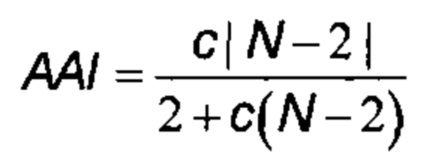
В некоторых иллюстративных примерах данные о частотах аллелей корректируется на наличие ошибок, прежде чем они используются для получения индивидуальных вероятностей. В настоящем документе раскрыты различные типы ошибок и/или коррекция стандартных ошибок. Согласно конкретным иллюстративным вариантам осуществления ошибки, которые корректируются, представляют собой систематические ошибки эффективности аллельной амплификации. Согласно другим вариантам осуществления ошибки, которые корректируются, включают в себя загрязнение окружающей среды и загрязнение генотипа. Согласно некоторым вариантам осуществления ошибки, которые корректируются, включают в себя систематические ошибки аллельной амплификации, загрязнение окружающей среды и загрязнение генотипа.
Следует понимать, что систематические ошибки эффективности аллельной амплификации могут быть определены для аллеля как части экспериментального или лабораторного определения, которое осуществляется на исследуемом образце, или они могут быть определены в разное время с использованием совокупности образцов, которые включают в себя аллель, эффективность которого вычисляется. Загрязнение окружающей среды и загрязнение генотипа, как правило, определяют в том же пробеге, что и анализ исследуемого образца.
Согласно некоторым вариантам осуществления загрязнение окружающей среды и загрязнение генотипа определяют для гомозиготных аллелей в образце. Следует понимать, что для любого данного образца из индивидуума некоторые локусы в образце будут гетерозиготными, а другие будут гомозиготными, даже если локус выбран для анализа по причине того, что он имеет относительно высокую гетерозиготность в популяции. Целесообразно согласно некоторым вариантам осуществления, хотя плоидность хромосомного сегмента может быть определена с использованием гетерозиготных локусов для индивидуума, гомозиготные локусы могут быть использованы для вычисления загрязнения окружающей среды и генотипа.
В некоторых иллюстративных примерах выбор выполняется путем анализа величины разницы между фазированной аллельной информацией и оцененными аллельными частотами, полученными для моделей.
В иллюстративных примерах отдельные вероятности частот аллелей получают на основе бета-биномиальной модели ожидаемых и наблюдаемых частот аллелей в совокупности полиморфных локусов. В иллюстративных примерах индивидуальные вероятности получают с использованием Байесовского классификатора.
Согласно некоторым иллюстративным вариантам осуществления настоящего изобретения данные о последовательности нуклеиновой кислоты получают путем выполнения секвенирования ДНК с высокой пропускной способностью множества копий серии ампликонов, полученных с использованием мультиплексной реакции амплификации, причем каждый ампликон серии ампликонов охватывает по меньшей мере один полиморфный локус совокупности локусов и причем каждый из полимерных локусов совокупности амплифицируется. Согласно некоторым вариантам осуществления мультиплексную реакцию амплификации осуществляют в условиях ограниченного количества праймера по меньшей мере для 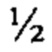 реакций. Согласно некоторым вариантам осуществления ограничивающие концентрации праймера используют в 1/10, 1/5,
реакций. Согласно некоторым вариантам осуществления ограничивающие концентрации праймера используют в 1/10, 1/5, 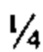 , 1/3, или всех реакциях мультиплексной реакции. В настоящем документе предусмотрены факторы, которые необходимо учитывать для достижения условий ограниченного количества праймера в реакции амплификации, такой как ПЦР.
, 1/3, или всех реакциях мультиплексной реакции. В настоящем документе предусмотрены факторы, которые необходимо учитывать для достижения условий ограниченного количества праймера в реакции амплификации, такой как ПЦР.
Согласно некоторым вариантам осуществления предусмотренные в настоящем документе способы обнаруживают плоидность для нескольких хромосомных сегментов на нескольких хромосомах. Соответственно, хромосомную плоидность в этих вариантах осуществления определяют для совокупности хромосомных сегментов в образце. Для этих вариантов осуществления необходимы более высокоэффективные реакции мультиплексной амплификации. Соответственно, для этих вариантов осуществления мультиплексная реакция амплификации может включать в себя, например, от 2500 до 50000 мультиплексных реакций. Согласно некоторым вариантам осуществления проводят следующие диапазоны мультиплексных реакций: от 100, 200, 250, 500, 1000, 2500, 5000, 10000, 20000, 25000, 50000 на нижнем уровне диапазона и до 200, 250, 500, 1000, 2500, 5000, 10000, 20000, 25000, 50000 и 100000 на верхнем уровне диапазона.
Согласно иллюстративным вариантам осуществления совокупность полиморфных локусов представляет собой совокупность локусов, которые, как известно, обладают высокой гетерозиготностью. Тем не менее, предполагается, что для любого данного индивидуума некоторые из этих локусов будут гомозиготными. Согласно некоторым иллюстративным вариантам осуществления способы по настоящему изобретению используют информацию о последовательности нуклеиновой кислоты, как для гомозиготных, так и гетерозиготных локусов для индивидуума. Гомозиготные локусы индивидуума используются, например, для коррекции ошибок, тогда как гетерозиготные локусы используются для определения аллельного дисбаланса образца. Согласно некоторым вариантам осуществления по меньшей мере 10% полиморфных локусов представляют собой гетерозиготные локусы для индивидуума.
Как описано в настоящем документе, предпочтение отдается для анализа локусов SNP-мишеней, которые, как известно, являются гетерозиготными в популяции. Соответственно, согласно некоторым вариантам осуществления выбирают локусы, в которых по меньшей мере 10, 20, 25, 50, 75, 80, 90, 95, 99 или 100% от полиморфных локусов с известной гетерозиготностью в популяции.
Как описано в настоящем документе, согласно некоторым вариантам осуществления образец представляет собой образец плазмы от беременной особи женского пола.
В некоторых примерах способ дополнительно предусматривает выполнение способа на контрольном образце с известным средним соотношением аллельного дисбаланса. Контроль может характеризоваться средним соотношением аллельного дисбаланса для конкретного аллельного состояния, указывающего на анеуплоидию хромосомного сегмента, от 0,4 до 10%, чтобы имитировать средний аллельный дисбаланс аллеля в образце, который присутствует в таких низких концентрациях, какие можно было бы ожидать для циркулирующей свободной ДНК от плода или из опухоли.
Согласно некоторым вариантам осуществления в качестве контролей используют раскрытые в настоящем документе контроли PlasmArt. Соответственно, согласно некоторым аспектам образец представляет собой образец, полученный способом, предусматривающим фрагментацию образца нуклеиновой кислоты, про которую известно, что она обладает хромосомной анеуплоидией на фрагментах, которые имитируют размер фрагментов ДНК, циркулирующих в плазме человека. Согласно некоторым аспектам используется контроль, который не характеризуется анеуплоидией для хромосомного сегмента.
Согласно иллюстративным вариантам осуществления данные от одного или нескольких контролей могут быть проанализированы в способе вместе с исследуемым образцом. Контроли, например, могут включать в себя различные образцы от индивидуума, который, предположительно, не характеризуется наличием хромосомной анеуплоидии, или образец, который, предположительно, содержит CNV или хромосомную анеуплоидию. Например, когда исследуемый образец представляет собой образец плазмы, в которой предположительно содержится циркулирующая свободная опухолевая ДНК, этот способ может быть также выполнен для контрольного образца из опухоли от субъекта вместе с образцом плазмы. Как раскрыто в настоящем документе, контрольный образец может быть получен путем фрагментации образца ДНК, про который известно, что он не обладает хромосомной анеуплоидией. Такая фрагментация может приводить к образцу ДНК, который имитирует композицию ДНК апоптической клетки, особенно если образец от индивидуума, характеризующегося наличием злокачественной опухоли. Данные от контрольного образца будут увеличивать доверительный интервал обнаружения хромосомной анеуплоидии.
Согласно некоторым вариантам осуществления способов определения плоидности, образец представляет собой образец плазмы от индивидуума, у которого подозревают наличие злокачественной опухоли. Согласно этим вариантам осуществления способ дополнительно предусматривает определение, основанное на выборе того, присутствует ли вариация числа копий в клетках опухоли индивидуума. Для этих вариантов осуществления образец может представлять собой образец плазмы от индивидуума. Для этих вариантов осуществления способ может дополнительно предусматривать определение, основанное на выборе того, присутствует ли у индивидуума злокачественная опухоль.
Эти варианты осуществления для определения плоидности хромосомного сегмента могут дополнительно предусматривать обнаружение однонуклеотидного варианта в положении однонуклеотидной дисперсии в совокупности положений однонуклеотидных дисперсий, причем обнаружение либо хромосомной анеуплоидии, либо однонуклеотидного варианта, либо и того и другого указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце.
Эти варианты осуществления могут дополнительно предусматривать получение информации о гаплотипе хромосомного сегмента для опухоли индивидуума и использование информации о гаплотипе для получения набора моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов.
Как описано в настоящем документе, некоторые варианты осуществления способов определения плоидности могут дополнительно предусматривать удаление исключений из исходных или скорректированных данных о частоте аллелей перед сравнением начальных или скорректированных частот аллелей с множеством моделей. Например, согласно некоторым вариантам осуществления частоты аллельных локусов, которые по меньшей мере на 2 или 3 стандартных отклонения выше или ниже среднего значения для других локусов на хромосомном сегменте, удаляются из данных до их использования для моделирования.
Как уже упоминалось в настоящем документе, следует понимать, что для многих предусмотренных в настоящем документе вариантов осуществления, в том числе для определения плоидности хромосомного сегмента, предпочтительно используют неполностью или полностью фазированные данные. Также следует понимать, что в настоящем документе предусмотрен целый ряд особенностей, которые обеспечивают улучшение по сравнению с известными ранее способами для обнаружения плоидности, и что могут быть использованы многие из различных комбинаций из этих особенностей.
Согласно некоторым вариантам осуществления как показано на Фиг. 69-70, в настоящем документе предусмотрены компьютерные системы и машиночитаемые носители для выполнения любых способов согласно настоящему изобретению. К ним относятся системы и машиночитаемые носители информации для выполнения способов определения плоидности. Соответственно, и в качестве не ограничивающих примеров вариантов осуществления систем для того чтобы продемонстрировать, что любой из способов, приведенных в настоящем документе, может быть выполнен с использованием системы и машиночитаемого носителя с использованием данного раскрытия, согласно другому аспекту в настоящем документе предусмотрена система обнаружения хромосомной плоидности в образце индивидуума, причем эта система содержит:
a. входной процессор, выполненный с возможностью приема данных о частоте аллелей, содержащих количество каждого аллеля, присутствующего в образце в каждом локусе в совокупности локусов на хромосомном сегменте;
b. моделирующее устройство, выполненное с возможностью:
I. получать фазированную аллельную информацию для совокупности полиморфных локусов путем оценки фазы данных о частоте аллелей; а также
II. получать индивидуальные вероятности частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных о частоте аллеля; а также
III. получать совместные вероятности для совокупности полиморфных локусов с использованием индивидуальных вероятностей и фазированной аллельной информации; а также
c. менеджер гипотез, выполненный с возможностью выбора, основанного на совместных вероятностях, модели наилучших совпадений, указывающей на хромосомную плоидность, тем самым определяя плоидность хромосомного сегмента.
Согласно некоторым вариантам осуществления этого варианта осуществления системы данные о частоте аллелей представляют собой данные, полученные системой для секвенирования нуклеиновых кислот. Согласно некоторым вариантам осуществления система дополнительно содержит блок исправления ошибок, выполненный с возможностью исправления ошибок в данных о частоте аллелей, причем исправленные данные о частоте аллелей используются инструментом моделирования для получения индивидуальных вероятностей. Согласно некоторым вариантам осуществления блок коррекции ошибок корректирует стандартные ошибки эффективности амплификации аллеля. Согласно некоторым вариантам осуществления инструмент моделирования получает индивидуальные вероятности, используя совокупность моделей, как различных состояний плоидности, так и фракций аллельного дисбаланса для множества локусов. Инструмент моделирования, согласно некоторым иллюстративным вариантам осуществления, получает совместные вероятности, рассматривая связь между полиморфными локусами на хромосомном сегменте.
Согласно одному иллюстративному варианту осуществления в настоящем документе предусмотрена система обнаружения хромосомной плоидности в образце индивидуума, которая включает в себя следующее:
a. входной процессор, выполненный с возможностью приема данных о последовательности нуклеиновой кислоты для аллелей в совокупности полиморфных локусов на хромосомном сегменте у индивидуума и обнаружения частоты аллелей в совокупности локусов с использованием данных о последовательности нуклеиновой кислоты;
b. блок исправления ошибок, выполненный с возможностью исправления ошибок в обнаруженных частотах аллелей и получения скорректированных частот аллелей для совокупности полиморфных локусов;
c. инструмент моделирования, выполненный с возможностью:
I. получать фазированную аллельную информацию для совокупности локусов путем оценки фазы данных о последовательности нуклеиновой кислоты;
II. получать индивидуальные вероятности частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения фазированной аллельной информации с совокупностью моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов; а также
III. получать совместные вероятности для совокупности полиморфных локусов путем объединения индивидуальных вероятностей с учетом относительного расстояния между полиморфными локусами на хромосомном сегменте; а также
d. менеджер гипотез, выполненный с возможностью выбора на основании совместных вероятностей наиболее подходящей модели, указывающей на хромосомную анеуплоидию.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренная в настоящем документе совокупность полиморфных локусов содержит от 1000 до 50000 полиморфных локусов. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренная в настоящем документе совокупность полиморфных локусов содержит 100 известных гетерозиготных локусов горячих точек. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренная в настоящем документе совокупность полиморфных локусов содержит 100 локусов, которые находятся в пределах горячей точки рекомбинации или в пределах 0,5 т.п.н. от нее.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренная в настоящем документе наиболее подходящая модель анализирует следующие состояния плоидности первого гомологичного хромосомного сегмента и второго гомологичного хромосомного сегмента:
(1) у всех клеток отсутствует делеция или амплификация первого гомолога или второго гомолога хромосомного сегмента;
(2) у некоторых клеток или у всех имеется делеция первого гомолога или амплификация второго гомолога хромосомного сегмента; а также
(3) у некоторых клеток или у всех имеется делеция второго гомолога или амплификация первого гомолога хромосомного сегмента.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренное в настоящем документе исправление ошибок включают в себя исправление систематических ошибок эффективности аллельной амплификации, ошибок загрязнения и/или секвенирования. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренное в настоящем документе загрязнение включает в себя загрязнение окружения и загрязнение генотипа. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренное в настоящем документе загрязнение окружающей среды и загрязнение генотипа определяется на гомозиготных аллелях.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе менеджер гипотез выполнен с возможностью анализировать величину разницы между фазированной аллельной информацией и оцененными аллельными частотами, получаемыми для моделей. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе инструмент моделирования получает индивидуальные вероятности аллельных частот на основе бета-биномиальной модели ожидаемых и наблюдаемых частот аллелей в совокупности полиморфных локусов. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе инструмент моделирования получает индивидуальные вероятности с использованием Байесовского классификатора.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренные в настоящем документе данные о последовательностях нуклеиновых кислот получают путем выполнения секвенирования ДНК с высокой пропускной способностью множества копий серии ампликонов, полученных с использованием мультиплексной реакции амплификации, в которой каждый ампликон из серии ампликонов охватывает по меньшей мере один полиморфный локус совокупности локусов и в которой каждый из полимерных локусов набора амплифицируется. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренную в настоящем документе мультиплексную реакцию амплификации проводят в условиях ограниченного количества праймера по меньшей мере для реакций. Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе образец характеризуется средним аллельным дисбалансом от 0,4% до 5%.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе образец представляет собой образец плазмы от индивидуума с подозрением на злокачественную опухоль, и дополнительно выполнен менеджер гипотез с возможностью определения, на основе наиболее подходящей модели, присутствует ли вариация числа копий в опухолевых клетках индивидуума.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе образец представляет собой образец плазмы от индивидуума, и дополнительно выполнен менеджер гипотез с возможностью определения, на основе наиболее подходящей модели, что злокачественная опухоль присутствует у индивидуума. Согласно этим вариантам осуществления менеджер гипотез может быть дополнительно выполнен с возможностью обнаружения однонуклеотидного варианта в положении однонуклеотидной дисперсии в совокупности положений однонуклеотидных дисперсий, причем обнаружение либо хромосомной анеуплоидий, либо однонуклеотидного варианта, либо и того и другого указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренный в настоящем документе входной процессор дополнительно выполнен с возможностью приема информации о гаплотипе хромосомного сегмента для опухоли индивидуума, а инструмент моделирования выполнен с возможностью использования информации о гаплотипе для формирования совокупности моделей разных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов.
Согласно некоторым иллюстративным вариантам осуществления системы предусмотренное в настоящем документе моделирующее устройство создает модели фракций аллельного дисбаланса в диапазоне от 0% до 25%.
Следует понимать, что любой из предусмотренных в настоящем документе способов может быть выполнен посредством машиночитаемого кода, который хранится на энергонезависимом машиночитаемом носителе. Соответственно, в настоящем документе согласно одному варианту осуществления предусмотрен энергонезависимый машиночитаемый носитель для обнаружения хромосомной плоидности в образце индивидуума, включающий в себя машиночитаемый код, который, когда он выполняется устройством обработки данных, приводит к тому, что устройство обработки данных:
a. принимает данные о частоте аллелей, содержащие количество каждого аллеля, присутствующего в образце в каждом локусе в совокупности полиморфных локусов на хромосомном сегменте;
b. вырабатывает фазированную аллельную информацию для совокупности полиморфных локусов путем оценки фазы данных о частоте аллелей;
c. создает индивидуальные вероятности частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных о частоте аллеля;
d. создает совместные вероятности для совокупности полиморфных локусов с использованием индивидуальных вероятностей и фазированной аллельной информации; а также
e. выбирает, основываясь на совместных вероятностях, наиболее подходящую модель, указывающую на хромосомную плоидность, определяя тем самым плоидность хромосомного сегмента.
Согласно некоторым вариантам осуществления машиночитаемых носителей данные о частотах аллелей получают из данных о последовательности нуклеиновой кислоты. Некоторые варианты осуществления машиночитаемых носителей дополнительно предусматривают исправление ошибок в данных о частоте аллеля и использование исправленных данных о частоте аллеля для получения стадии индивидуальных вероятностей. Согласно определенным вариантам осуществления машиночитаемых носителей ошибки, которые исправляются, представляют собой систематические ошибки эффективности амплификации аллелей. Согласно определенным вариантам осуществления машиночитаемых носителей индивидуальные вероятности получают с использованием совокупности моделей, как различных состояний плоидности, так и фракций с аллельным дисбалансом для множества полиморфных локусов. Согласно некоторым вариантам осуществления машиночитаемых носителей совместные вероятности получают с учетом связи между полиморфными локусам на хромосомном сегменте.
Согласно одному конкретному варианту осуществления в настоящем документе предусмотрен энергонезависимый машиночитаемый носитель для обнаружения хромосомной плоидности в образце индивидуума, содержащий машиночитаемый код, который, когда он выполняется устройством обработки данных, приводит к тому, что устройство обработки данных:
a. принимает данные о последовательности нуклеиновых кислот для аллелей в совокупности полиморфных локусов на хромосомном сегменте у индивидуума;
b. обнаруживает частоты аллелей в совокупности локусов с использованием данных о последовательности нуклеиновой кислоты;
c. корректирует систематические ошибки эффективности амплификации аллелей в обнаруженных частотах аллелей для получения скорректированных частот аллелей для совокупности полиморфных локусов;
d. производит фазированную аллельную информацию для совокупности полиморфных локусов путем оценки фазы данных о последовательности нуклеиновой кислоты;
e. создает индивидуальные вероятности частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения скорректированных частот аллелей с совокупностью моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов;
f. получает совместные вероятности для совокупности полиморфных локусов путем объединения индивидуальных вероятностей с учетом связи между полиморфными локусами на хромосомном сегменте; а также
g. выбирает, основываясь на совместных вероятностях, наиболее подходящую модель, указывающую на хромосомную анеуплоидию.
Согласно некоторым иллюстративным вариантам осуществления машиночитаемых носителей выбор выполняется путем анализа величины разницы между фазированной аллельной информацией и расчетными аллельными частотами, получаемыми для моделей.
Согласно некоторым иллюстративным вариантам осуществления машиночитаемых носителей индивидуальные вероятности частот аллелей создаются на основании бета-биномиальной модели ожидаемой и наблюдаемой частот аллелей в совокупности полиморфных локусов.
Следует понимать, что любой из предусмотренных в настоящем документе вариантов осуществления способа может быть выполнен путем выполнения кода, хранящегося на энергонезависимом машиночитаемом носителе.
Иллюстративные варианты осуществления для обнаружения злокачественной опухоли
Согласно некоторым аспектам в настоящем изобретении предусмотрен способ обнаружения злокачественной опухоли. Понятно, что образец может представлять собой опухолевый образец или жидкий образец, такой как плазма, от индивидуума, у которого подозревают наличие злокачественной опухоли. Эти способы особенно эффективны при выявлении генетических мутаций, таких как однонуклеотидные изменения, такие как SNV, или изменения числа копий, такие как CNV, в образцах с низким уровнем этих генетических изменений в виде доли от общей ДНК в образце. Таким образом, чувствительность для обнаружения ДНК или РНК в образцах злокачественной опухоли представляет собой исключительную. Способы могут комбинировать любые или все из усовершенствований, представленных в настоящем документе, для обнаружения CNV и SNV для достижения этой исключительной чувствительности.
Соответственно, согласно некоторым вариантам осуществления в настоящем документе предусмотрен способ определения того, присутствуют ли в образце у индивидуума циркулирующие опухолевые нуклеиновые кислоты, и энергонезависимый машиночитаемый носитель, содержащий машиночитаемый код, который, при исполнении обрабатывающим устройством, приводит к выполнению способа устройством обработки данных. Способ предусматривает следующие стадии:
c. анализ образца для определения плоидности в совокупности полиморфных локусов на хромосомном сегменте у индивидуума; а также
d. определение уровня среднего аллельного дисбаланса, присутствующего в полиморфных локусах, на основании определения плоидности, причем средний аллельный дисбаланс, равный или больше 0,4%, 0,45%, 0,5%, 0,6%, 0,7%, 0,75%, 0,8%, 0,9% или 1%, свидетельствует о присутствии циркулирующих опухолевых нуклеиновых кислот, таких как цоДНК, в образце.
В некоторых иллюстративных примерах средний аллельный дисбаланс больше, чем 0,4, 0,45 или 0,5%, свидетельствует о наличии цоДНК. Согласно некоторым вариантам осуществления способ определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, дополнительно предусматривает обнаружение однонуклеотидного варианта в сайте однонуклеотидной дисперсии в совокупности положений однонуклеотидных дисперсий, причем обнаружение либо аллельного дисбаланса, равного или большего чем 0,5%, либо обнаружение однонуклеотидного варианта, либо и того и другого указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце. Следует понимать, что любой из способов, предусмотренных для выявления хромосомной плоидности или CNV, может быть использован для определения уровня аллельного дисбаланса, как правило, выражаемый как средний аллельный дисбаланс. Следует понимать, что любой из представленных в настоящем документе способов обнаружения SNV может быть использован для обнаружения единственного нуклеотида для этого аспекта настоящего изобретения.
Согласно некоторым вариантам осуществления способ определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, дополнительно предусматривает выполнения способа на контрольном образце с известным средним отношением аллельного дисбаланса. Контроль, например, может представлять собой образец из опухоли индивидуума. Согласно некоторым вариантам осуществления контроль характеризуется средним аллельным дисбалансом, ожидаемым для образца при анализе. Например, AAI от 0,5% до 5% или соотношение среднего аллельного дисбаланса 0,5%.
Согласно некоторым вариантам осуществления стадия анализа в способе определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, предусматривает анализ совокупности хромосомных сегментов, про которые известно, что они проявляют анеуплоидий при злокачественной опухоли. Согласно некоторым вариантам осуществления стадия анализа в способе определения того, присутствуют ли циркулирующих опухолевых нуклеиновые кислоты, предусматривает анализ от 1000 до 50000 или от 100 до 1000 полиморфных локусов для плоидности. Согласно некоторым вариантам осуществления стадия анализа в способе определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты, предусматривает анализ от 100 до 1000 участков однонуклеотидных вариантов. Например, согласно этим вариантам осуществления стадия анализа может включать в себя выполнение мультиплексной ПЦР для амплификации ампликонов вдоль 1000-50000 полимерных локусов и 100-1000 сайтов однонуклеотидных вариантов. Эта мультиплексная реакция может быть установлена в качестве единственной реакции или в качестве пулов различных совокупностей мультиплексных реакций. Предусмотренные в настоящем документе способы мультиплексной реакции, такие как описанная в настоящем документе мультиплексная ПЦР с большим количеством целевых последовательностей, обеспечивают иллюстративный процесс проведения реакции амплификации, чтобы помочь достичь улучшенного мультиплексирования и, таким образом, уровней чувствительности.
Согласно некоторым вариантам осуществления мультиплексную реакцию ПЦР проводят в условиях ограниченного количества праймера по меньшей мере для 10%, 20%, 25%, 50%, 75%, 90%, 95%, 98%, 99% или 100% реакций. Могут быть использованы улучшенные условия для проведения предусмотренной в настоящем документе мультиплексной реакции с большим количеством целевых последовательностей.
Согласно некоторым аспектам вышеуказанный способ определения того, присутствуют ли циркулирующие опухолевые нуклеиновые кислоты в образце у индивидуума, и все его варианты осуществления могут быть выполнены с системой. В настоящем изобретении предусмотрены идеи относительно конкретных функциональных и структурных особенностей для выполнения способов. В качестве неограничивающего примера система включает в себя следующее:
a. Входной процессор, выполненный с возможностью анализировать данные от образца, для определения плоидности в совокупности полиморфных локусов на хромосомном сегменте у индивидуума; а также
b. Моделирующее устройство, выполненное с возможностью определения уровня аллельного дисбаланса, присутствующего в полиморфных локусах, на основании определения плоидности, причем аллельный дисбаланс, равный 0,5% или больше, свидетельствует о присутствии циркуляции.
Иллюстративные варианты осуществления для обнаружения однонуклеотидных вариантов
Согласно некоторым аспектам в настоящем документе предусмотрены способы обнаружения однонуклеотидных вариантов в образце. Предусмотренные в настоящем документе усовершенствованные способы могут достигать пределов обнаружения в 0,015, 0,017, 0,02, 0,05, 0,1, 0,2, 0,3, 0,4 или 0,5 процентах SNV в образце. Все варианты осуществления для обнаружения SNV могут быть осуществлены с системой. В настоящем изобретении представлены идеи относительно конкретных функциональных и структурных особенностей для выполнения способов. Кроме того, в настоящем документе представлены варианты осуществления, предусматривающие энергонезависимый машиночитаемый носитель, содержащий машиночитаемый код, который, когда выполняется устройством обработки данных, приводит к тому, что устройство обработки данных выполняет способы обнаружения SNV, представленные в настоящем документе.
Соответственно, в настоящем документе согласно одному варианту осуществления предусмотрен способ определения того, присутствует ли в совокупности геномных положений в образце у индивидуума однонуклеотидный вариант, причем способ предусматривает:
a. для каждой геномного положения получение оценки эффективности и частоты появления ошибок за цикл для ампликона, покрывающего это геномное положение, используя обучающий набор данных;
b. получение наблюдаемой информации об идентичности нуклеотидов для каждого геномного положения в образце;
c. определение совокупности вероятностей процента однонуклеотидных вариантов в результате одной или нескольких реальных мутаций в каждом геномном положении, путем сравнения информации о наблюдаемой нуклеотидной идентичности в каждом геномном положении с моделью различных процентов вариантов с использованием оцененной эффективности амплификации и частоты появления ошибок за цикл для каждого геномного положения независимо; а также
d. определение наиболее вероятного реального процента вариантов и доверительного интервала из совокупности вероятностей для каждого геномного положения.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, проводят оценку эффективности и частоты появления ошибок за цикл для набора ампликонов, которые охватывают геномное положение. Например, могут быть включены 2, 3, 4, 5, 10, 15, 20, 25, 50, 100 или более ампликонов, которые охватывают геномное положение.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, наблюдаемая информация о нуклеотидной идентичности предусматривает наблюдаемое общее количество прочтений для каждого геномного положения и наблюдаемое число прочтений аллельных вариантов для каждого геномного положения.
Согласно иллюстративным вариантам осуществления способа определения того, присутствует ли однонуклеотидный вариант, образец представляет собой образец плазмы, и однонуклеотидный вариант присутствует в циркулирующей опухолевой ДНК образца.
Согласно другому варианту осуществления в настоящем документе предусмотрен способ оценки процента однонуклеотидных вариантов, которые присутствуют в образце от индивидуума. Способ предусматривает следующие стадии:
a. в совокупности геномных положений получение оценки эффективности и частоты появления ошибок за цикл для ампликона, охватывающего эти геномные положения, используя обучающий набор данных;
b. получение наблюдаемой информации об идентичности нуклеотидов для каждого геномного положения в образце;
c. получение оценки среднего значения и дисперсии для общего числа молекул, молекул с фоновыми ошибками и молекул с реальными мутациями для пространства поиска, предусматривающего начальный процент молекул с реальными мутациями с использованием эффективности амплификации и частоты появления ошибок за цикл ампликонов; а также
d. определение процентного содержания однонуклеотидных вариантов, присутствующих в образце, в результате реальных мутаций путем определения наиболее вероятного реального процента однонуклеотидных вариантов путем подгонки распределения с использованием расчетных средних значений и дисперсий к наблюдаемой информации о нуклеотидной идентичности в образце.
В иллюстративных примерах данного способа оценки процента однонуклеотидных вариантов, которые присутствуют в образце, образец представляет собой образец плазмы, и однонуклеотидный вариант присутствует в циркулирующей опухолевой ДНК образца.
Набор обучающих данных для этого варианта осуществления настоящего изобретения, как правило, включает в себя образцы от одного или, предпочтительно, группы здоровых индивидуумов. Согласно некоторым иллюстративным вариантам осуществления набор обучающих данных анализируют в тот же день или даже в тот же пробег, что и один или несколько исследуемых образцов. Например, могут быть использованы образцы из группы из 2, 3, 4, 5, 10, 15, 20, 25, 30, 36, 48, 96, 100, 192, 200, 250, 500, 1000 или более здоровых индивидуумов для формирования набора обучающих данных. Там, где данные доступны для большего числа здоровых индивидуумов, например, 96 или более, доверительный интервал возрастает для оценок эффективности амплификации, даже если пробеги выполняются перед выполнением способа для анализируемых образцов. В частоте появления ошибок ПЦР может использоваться информация о последовательности нуклеиновой кислоты, получаемая не только для положения оснований с SNV, но и для всей амплифицированной области вокруг SNV, так как частота ошибок представляет собой на ампликон. Например, использование образцов от 50 индивидуумов и секвенирования ампликона из 20 пар оснований вокруг SNV, данные о частоте ошибок от 1000 считываний оснований могут быть использованы для определения частоты ошибок.
Как правило, эффективность амплификации оценивают путем оценки среднего значения и стандартного отклонения для эффективности амплификации для амплифицируемого сегмента, а затем подгоняют к модели распределения, такой как биномиальное распределение или бета-биномиальное распределение. Частота появления ошибок определяется для реакции ПЦР с известным числом циклов, а затем оценивается частота появления ошибок за один цикл.
Согласно некоторым иллюстративным вариантам осуществления оценка исходных молекул совокупности тестовых данных дополнительно включает в себя обновление оценки эффективности для совокупности тестовых данных с использованием исходного числа молекул, оцененных на стадии (b), если наблюдаемое число считываний значительно отличается от оцененного числа считываний. Тогда оценка может быть обновлена для новой эффективности и/или исходных молекул.
Пространство поиска, используемое для оценки общего количества молекул, молекул с фоновыми ошибками и молекул с реальными мутациями, может включать в себя пространство поиска с 0,1%, 0,2%, 0,25%, 0,5%, 1%, 2,5%, 5%, 10%, 15%, 20%, или 25% на нижнем пределе и 1%, 2%, 2,5%, 5%, 10%, 12,5%, 15%, 20%, 25%, 50%, 75%, 90% или 95% на верхнем пределе копий основания в положении SNV, представляющего собой основание SNV. Более узкие диапазоны, 0,1%, 0,2%, 0,25%, 0,5% или 1% на нижнем пределе и 1%, 2%, 2,5%, 5%, 10%, 12,5% или 15% на верхнем пределе могут быть использованы в иллюстративных примерах для образцов плазмы, где способ представляет собой обнаружение циркулирующей опухолевой ДНК. Более широкие диапазоны используются для опухолевых образцов.
Распределение представляет собой подгон к числу всех ошибочных молекул (фоновая ошибка и реальная мутация) во всех молекулах, чтобы вычислить правдоподобие или вероятность для каждой возможной реальной мутации в пространстве поиска. Такое распределение может представлять собой биномиальное распределение или бета-биномиальное распределение.
Наиболее вероятно, реальную мутацию определяют путем определения процента наиболее вероятной реальной мутации и вычисления доверительного интервала с использованием данных из подгонки распределения. В качестве иллюстративного примера, а не для ограничения клинической интерпретации предусмотренных в настоящем документе способов, если средняя частота мутаций высока, то процент доверительного интервала, который необходим, чтобы сделать положительное определение SNV, ниже. Например, если средняя частота мутаций для SNV в образце с использованием наиболее вероятной гипотезы составляет 5%, а процент доверительного интервала составляет 99%, то будет сделан положительное распознавание SNV. С другой стороны, для этого иллюстративного примера, если средняя частота мутаций для SNV в образце с использованием наиболее вероятной гипотезы составляет 1%, а процент доверительного интервала составляет 50%, то в определенных ситуациях не будет сделано положительное распознавание SNV. Следует понимать, что клиническая интерпретация данных будет представлять собой функцию чувствительности, специфичности, показателя распространенности, а также альтернативной доступности продукта.
Согласно одному иллюстративному варианту осуществления образец представляет собой образец циркулирующей ДНК, такой как образец циркулирующей опухолевой ДНК.
Согласно другому варианту осуществления в настоящем документе предусмотрен способ обнаружения одного или нескольких однонуклеотидных вариантов в исследуемом образце от индивидуума. Способ, согласно настоящему варианту осуществления, предусматривает следующие стадии:
d. определение медианной частоты вариантных аллелей для множества контрольных образцов от каждого из множества нормальных индивидуумов, для каждого положения однонуклеотидного варианта в совокупности положений однонуклеотидных дисперсий, на основе результатов, полученных в пробеге секвенирования, чтобы идентифицировать положения выбранных однонуклеотидных вариантов, характеризующихся вариантными медианными частотами аллелей в нормальных образцах ниже порогового значения, и определение фоновой ошибки для каждого из положений однонуклеотидных вариантов после удаления образцов-выбросов для каждого из положений однонуклеотидных вариантов;
e. определение наблюдаемой глубины считывания средневзвешенного значения и дисперсии для положений выбранных однонуклеотидных вариантов для исследуемого образца на основе данных, полученных в пробеге секвенирования для исследуемого образца; а также
f. идентификация с использованием компьютера одного или нескольких положений однонуклеотидных вариантов со статистически значимой глубиной прочтения средневзвешенного значения по сравнению с фоновой ошибкой для этого положения, тем самым определяя один или несколько однонуклеотидных вариантов.
Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV, образец представляет собой образец плазмы, контрольные образцы представляют собой образцы плазмы и обнаруженный один или несколько однонуклеотидных вариантов присутствует в образце циркулирующей опухолевой ДНК. Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV множество контрольных образцов содержит по меньшей мере 25 образцов. Согласно некоторым иллюстративным вариантам осуществления множество контрольных образцов представляет собой по меньшей мере 5, 10, 15, 20, 25, 50, 75, 100, 200 или 250 образцов на нижнем уровне и 10, 15, 20, 25, 50, 75, 100, 200, 250, 500 и 1000 образцов на верхнем уровне.
Согласно некоторым вариантам осуществления этого способа обнаружения одного или нескольких SNV, выбросы удаляются из данных, полученных в пробеге секвенирования с высокой пропускной способностью, чтобы вычислить наблюдаемую глубину прочтения средневзвешенного и определяют наблюдаемую дисперсию. Согласно определенным вариантам осуществления этого способа обнаружения одного или нескольких SNV глубина прочтения для каждого положения однонуклеотидного варианта для исследуемого образца составляет по меньшей мере 100 прочтений.
Согласно некоторым вариантам осуществления этого способа для обнаружения одного или нескольких SNV, пробег секвенирования предусматривает мультиплексную реакцию амплификации, выполняемую в условиях реакции ограниченного количества праймера. Предусмотренные в настоящем документе усовершенствованные способы выполнения мультиплексных реакций амплификации используются для выполнения этих вариантов осуществления в иллюстративных примерах.
Без ограничения теорией способы настоящего варианта осуществления используют модель фоновых ошибок с использованием образцов нормальной плазмы, которые секвенируют на том же пробеге секвенирования в качестве исследуемого образца, чтобы учесть специфические для пробега артефакты. Шумные положения с нормальными медианными частотами вариантных аллелей выше порогового значения, например, >0,1%, 0,2%, 0,25%, 0,5% 0,75% и 1,0%, при этом удаляются.
Образцы-выбросы итеративно удаляют из модели для учета шума и загрязнения. Для каждого замещения основания каждого геномного локуса вычисляют глубину считывания средневзвешенного значения и стандартного отклонения погрешности. Согласно некоторым иллюстративным вариантам осуществления такие образцы, как опухолевые или внеклеточные образцы плазмы, с положениями однонуклеотидных вариантов по меньшей мере с пороговым количеством считываний, например, по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 250, 500 или 1000 вариантных считываний и Z-показателем больше, чем 2,5, 5, 7,5 или 10 по сравнению с моделью фоновых ошибок согласно некоторым вариантам осуществления, подсчитываются в качестве кандидатной мутации.
Согласно некоторым вариантам осуществления глубина прочтения выше 100, 250, 500, 1000, 2000, 2500, 5000, 10000, 20000, 50000, 25,0000 или 100000 на нижнем уровне диапазона и 2000, 2500, 5000, 7500, 10000, 25000, 50000, 100000, 250000 или 500000 прочтений на верхнем уровне, достигается в пробеге секвенирования для каждого положения однонуклеотидного варианта в совокупности положений однонуклеотидных вариантов. Как правило, пробег секвенирования представляет собой пробег секвенирования с высокой пропускной способностью. Средние или медианные значения, полученные для исследуемых образцов, согласно иллюстративным вариантам осуществления, представляют собой взвешенные по глубине прочтения. Таким образом, вероятность того, что определение вариантного аллеля реально в образце с 1 вариантным аллелем, обнаруженным в 1000 прочтений, представляет собой взвешенное выше, чем образец с 1 вариантным аллелем, обнаруженным в 10000 считываний. Поскольку определения вариантного аллеля (т.е. мутации) не производят со 100% доверительным интервалом, идентифицированный однонуклеотидный вариант можно рассматривать как кандидатный вариант или кандидатную мутацию.
Иллюстративная статистика критерия для анализа фазированных данных
Иллюстративная статистика критерия описана ниже для анализа фазированных данных из образца, представляющего собой смешанный или предположительно смешанный образец, содержащий ДНК или РНК, который получен из двух или нескольких клеток, которые не являются генетически идентичными. Пусть ƒ обозначает представляющую интерес фракцию ДНК или РНК, например, фракцию ДНК или РНК с представляющей интерес CNV или фракцию ДНК или РНК из представляющих интерес клеток, таких как злокачественные клетки. Согласно некоторым вариантам осуществления для пренатальной диагностики, ƒ обозначает долю фетальной ДНК, РНК или клеток в смеси плодовых и материнских ДНК, РНК или клеток. Следует отметить, что она относится к фракции ДНК из представляющих интерес клеток, предполагая, что две копии ДНК даются каждой представляющей интерес клеткой. Она отличается от фракции ДНК из представляющих интерес клеток в сегменте, который удален или дублирован.
Возможные аллельные значения каждого SNP обозначаются A и B. AA, AB, BA и BB используются для обозначения всех возможных упорядоченных пар аллелей. Согласно некоторым вариантам осуществления анализируют SNP с упорядоченными аллелями АВ или ВА. Пусть Ni обозначает число считываний последовательности i-го SNP, a Ai и Bi обозначают число считываний i-го SNP, которые указывают на аллель A и B, соответственно. Предполагается:
Ni=Ai+Bi
Аллельное соотношение Ri определяется:
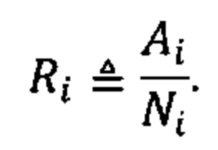
Пусть T обозначает число нацеленных SNP.
Без ограничения общностью некоторые варианты осуществления сосредоточены на одном хромосомном сегменте. Для дополнительной наглядности в настоящем документе фраза "первый гомологичный хромосомный сегмент по сравнению со вторым гомологичным хромосомным сегментом" означает первый гомолог хромосомного сегмента и второй гомолог хромосомного сегмента. Согласно некоторым таким вариантам осуществления все SNP-мишени содержатся в представляющем интерес хромосомном сегменте. Согласно другим вариантам осуществления анализируют несколько хромосомных сегментов на возможные вариации числа копий.
Оценка MAP
В этом способе используют знание фазирования с помощью упорядоченных аллелей для обнаружения делеций или дупликации сегмента-мишени. Для каждого SNP i следует определить
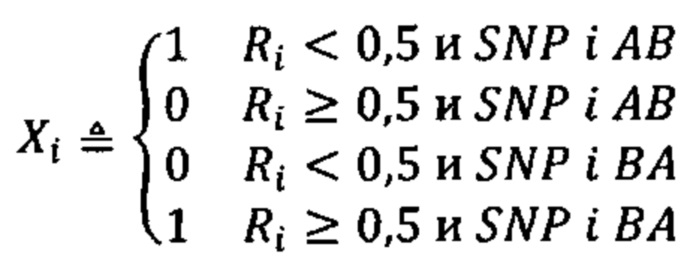
Затем следует определить
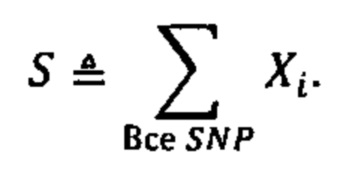
Распределения Xi и S в гипотезах различного числа копий (например, гипотезы дисомии, удаления первого или второго гомолога или дупликации первого или второго гомолога), описаны ниже.
Гипотеза дисомии
Согласно гипотезе того, что сегмент-мишень не удаляется или дуплицируется
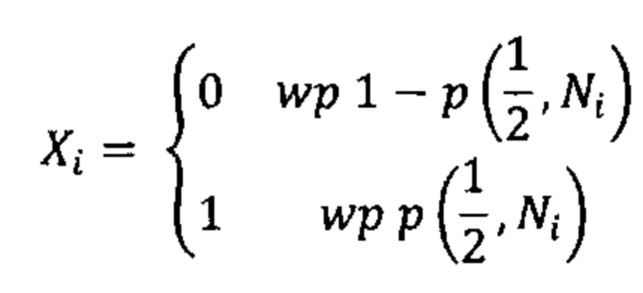
где
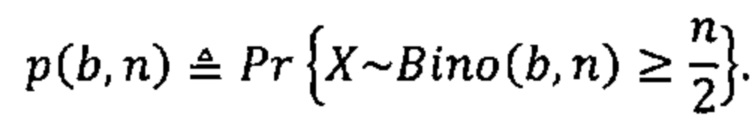
Если предположить постоянную глубину прочтения N, это дает биномиальное распределение S с параметрами
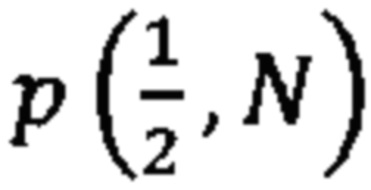 и T.
и T.
Гипотеза удаления
Согласно гипотезе, что первый гомолог удаляется (т.е., SNP АВ становится B и SNP BA становится А), то Ri характеризуется биномиальным распределением с параметрами 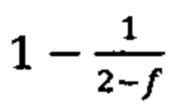 и T для SNP АВ, и
и T для SNP АВ, и 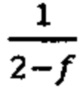 и T для SNP ВА. Следовательно,
и T для SNP ВА. Следовательно,
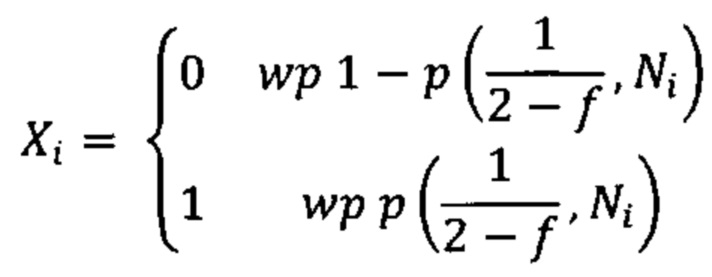
Если предположить постоянную глубину прочтения N, это дает биномиальное распределение S с параметрами
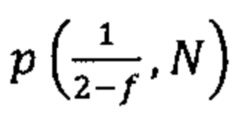 и Т.
и Т.
Согласно гипотезе, что второй гомолог удаляется (т.е., SNP AB становится A и SNP BA становится B), то Ri характеризуется биномиальным распределением с параметрами 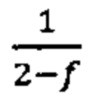 и T для SNP АВ, и
и T для SNP АВ, и 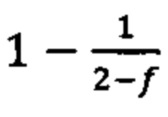 и T для SNP ВА. Следовательно,
и T для SNP ВА. Следовательно,
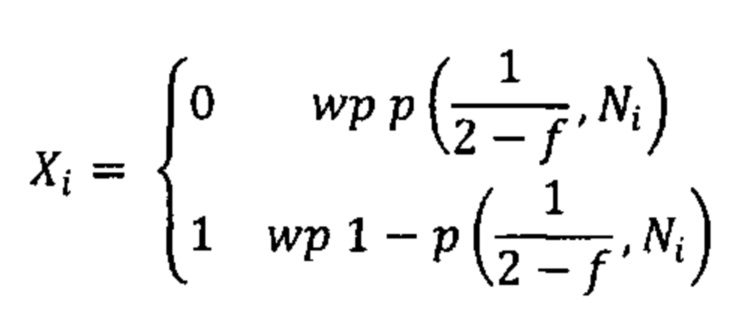
Если предположить постоянную глубину прочтения N, это дает биномиальное распределение S с параметрами
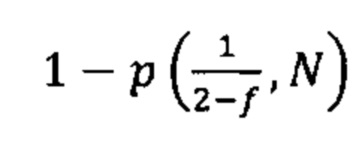 и T.
и T.
Гипотезы дупликации
Согласно гипотезе, что дублируется первый гомолог (т.е., SNP АВ становится ААВ, и SNP ВА становится ВВА), то Ri характеризуется биномиальным распределением с параметрами 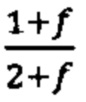 и T для SNP АВ, и
и T для SNP АВ, и 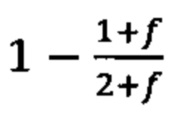 и T для SNP BA. Следовательно,
и T для SNP BA. Следовательно,
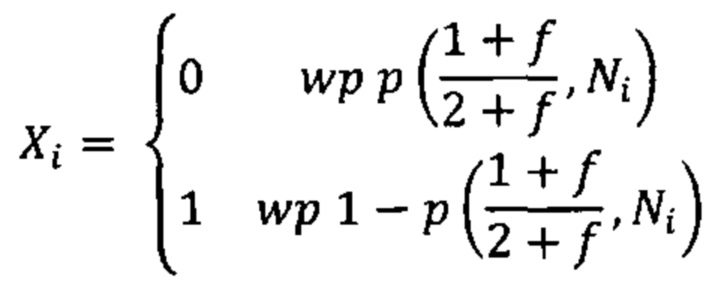
Если предположить постоянную глубину прочтения N, это дает биномиальное распределение S с параметрами
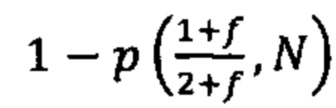 и T.
и T.
Согласно гипотезе, что дублируется второй гомолог (т.е., SNP АВ становится ABB и SNP ВА становится ВАА), то Ri характеризуется биномиальным распределением с параметрами 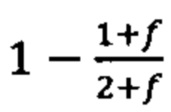 и T для SNP АВ, и
и T для SNP АВ, и 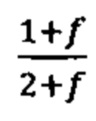 и T для SNP ВА. Следовательно,
и T для SNP ВА. Следовательно,
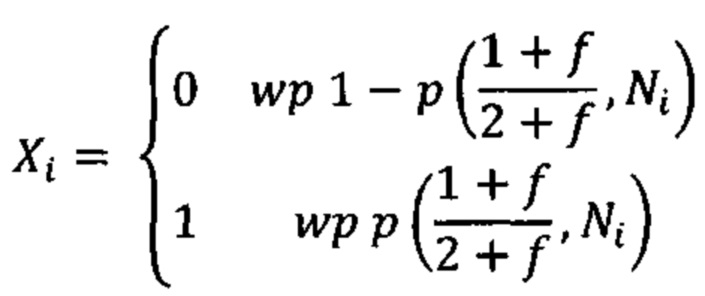
Если предположить постоянную глубину прочтения N, это дает биномиальное распределение с параметрами
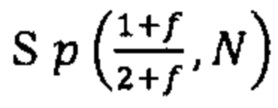 и T.
и T.
Классификация
Как было показано в предыдущих разделах, Xi представляет собой двоичную случайную величину с
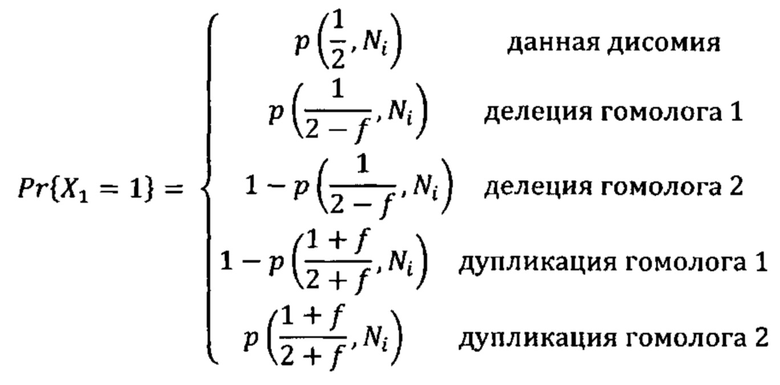
Это позволяет вычислить вероятность статистики критерия S в рамках каждой гипотезы. Может быть вычислена вероятность каждой гипотезы измеренных данных. Согласно некоторым вариантам осуществления выбирают гипотезу с наибольшей вероятностью. При желании, распределение на S можно упростить посредством либо приближения каждого N с постоянной глубиной досягаемости N, либо усечения глубины прочтения до постоянной N. Это упрощение дает
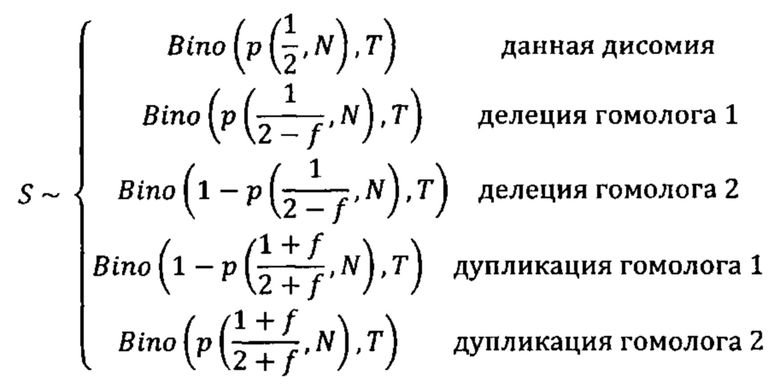
Значение для ƒ может быть оценено путем выбора наиболее вероятного значения измеренных данных ƒ, таких как значение ƒ, которое производит лучшее совпадение данных с использованием алгоритма (например, алгоритма поиска), такого как оценка по максимуму правдоподобия, оценка по апостериорному максимуму или Байесовская оценка. Согласно некоторым вариантам осуществления анализируют множественные хромосомные сегменты, и значение для ƒ оценивают на основе данных для каждого сегмента. Если все клетки-мишени имеют эти дупликации или делеции, расчетные значения для ƒ, основанные на данных для этих различных сегментов, похожи. Согласно некоторым вариантам осуществления ƒ представляет собой измеренную экспериментально, например, путем определения доли ДНК или РНК из злокачественных клеток на основе разницы метилирования (гипометилировании или гиперметилировании) между злокачественными и незлокачественными ДНК или РНК.
Согласно некоторым вариантам осуществления для смешанных образцов нуклеиновых кислот плода и матери, значение ƒ представляет собой фетальную фракцию, то есть долю ДНК (или РНК) плода от общего количества ДНК (или РНК) в образце. Согласно некоторым вариантам осуществления фетальную фракцию определяют путем получения генотипических данных из образца материнской крови (или ее фракции) для совокупности полиморфных локусов по меньшей мере на одной хромосоме, которая, как ожидается, будет дисомической, как у матери, так и плода; создания множества гипотез, каждая из которых соответствует различным возможным фетальным фракциям на хромосоме; построения модели для ожидаемых измерений аллелей в образце крови в совокупности полиморфных локусов на хромосоме для возможных фетальных фракций; вычисления относительной вероятности каждой из гипотез для фетальных фракций с использованием модели и аллельных измерений из образца крови или ее фракции; и определения фетальной фракции в образце крови путем выбора фетальный фракции, соответствующей гипотезе с наибольшей вероятностью. Согласно некоторым вариантам осуществления настоящего изобретения фетальную фракцию определяют путем идентификации тех полиморфных локусов, где мать является гомозиготной по первому аллелю в полиморфном локусе и отец является (I) гетерозиготным по первому аллелю и второму аллелю или (II) гомозиготным по второму аллелю в полиморфном локусе; и использования количества второго аллеля, обнаруженного в образце крови для каждого из идентифицированных полиморфных локусов, для определения фетальной фракции в образце крови (смотрите, например, публикацию патента США №2012/0185176, поданную 29 марта 2012 г., и публикацию патента США №2014/0065621, поданную 13 марта 2013 г., каждая из которых полностью включена в настоящий документ посредством ссылки).
Другой способ определения фетальной фракции предусматривает использование секвенатора ДНК с высокой пропускной способностью для вычисления аллелей в большом числе полиморфных (например, SNP) генетических локусов и моделирование вероятной фетальной фракции (смотрите, например, публикацию патента США №2012/0264121, которая полностью включена в настоящий документ посредством ссылки). Другой способ вычисления фетальной фракции можно найти в публикации Sparks et al., "Noninvasive prenatal detection and selective analysis of cell-free DNA obtained from maternal blood: evaluation for trisomy 21 and trisomy 18," Am J Obstet Gynecol 2012; 206: 319.e1-9, которая полностью включена в настоящий документ посредством ссылки. Согласно некоторым вариантам осуществления фетальную фракцию определяют с использованием анализа метилирования (смотрите, например, патенты США №7754428; 7901884 и 8166382, каждый из которых полностью включен в настоящее описание посредством ссылки), который допускает, что определенные локусы представляют собой метилированные или преимущественно метилированные у плода и те же самые локусы представляют собой неметилированные или преимущественно неметилированные у матери.
Фиг. 1A-13D представляют собой графики, показывающие распределение статистики критерия S, разделенное на T (количество SNP) ("S/T") для различных гипотез числа копий для различной глубины прочтения и опухолевых фракций (где ƒ представляет собой долю опухолевой ДНК из общей ДНК) для увеличивающегося числа SNP.
Отвержение единственной гипотезы
Распределение S для гипотезы дисомии не зависит от ƒ. Таким образом, вероятность измеренных данных можно вычислить для гипотезы дисомии без вычисления ƒ. Тест отвержения единственной гипотезы может быть использован для нулевой гипотезы дисомии. Согласно некоторым вариантам осуществления вычисляется вероятность S согласно гипотезе дисомии, и гипотеза дисомии отвергается, если вероятность меньше заданного порогового значения (например, меньше чем 1 на 1000). Это указывает на то, что присутствует дупликация или делеция хромосомного сегмента. При желании, процент ложно позитивных срабатываний может быть изменен путем изменения порогового значения.
Иллюстративные способы анализа фазированных данных
Ниже описаны иллюстративные способы анализа данных из образца, который известен или подозревается в том, что он представляет собой смешанный образец, содержащий ДНК или РНК, которые возникли из двух или нескольких клеток, которые генетически не идентичны. Согласно некоторым вариантам осуществления используются фазированные данные. Согласно некоторым вариантам осуществления способ предусматривает определение, для каждого вычисленного аллельного соотношения, того, выше ли или ниже ожидаемое аллельное соотношение и величина разницы для конкретного локуса. Согласно некоторым вариантам осуществления распределение правдоподобия вычисляют для аллельного соотношения в локусе для конкретной гипотезы и, чем ближе вычисленное аллельное соотношение к центру распределения правдоподобия, тем более вероятно, что гипотеза верна. Согласно некоторым вариантам осуществления способ предусматривает определение правдоподобия того, что гипотеза верна для каждого локуса. Согласно некоторым вариантам осуществления способ предусматривает определение правдоподобия того, что гипотеза верна для каждого локуса, и объединение вероятностей этой гипотезы для каждого локуса, и выбирают гипотезу с наибольшей совместной вероятностью. Согласно некоторым вариантам осуществления способ предусматривает определение правдоподобия того, что гипотеза верна для каждого локуса и для каждого возможного отношения ДНК или РНК из одной или нескольких клеток-мишеней к общей ДНК или РНК в образце. Согласно некоторым вариантам осуществления совместная вероятность для каждой гипотезы определяется путем объединения вероятностей этой гипотезы для каждого локуса и каждого возможного соотношения, и выбирают гипотезу с наибольшей совместной вероятностью.
Согласно одному варианту осуществления рассматриваются следующие гипотезы: H11 (все клетки нормальные), H10 (наличие клеток только с гомологом 1, следовательно, делецией гомолога 2), H01 (наличие клеток только с гомологом 2, следовательно, делецией гомолога 1), H21 (наличие клеток с дупликацией гомолога 1), H12 (наличие клеток с дупликацией гомолога 2). Для получения фракции ƒ клеток-мишеней, таких как злокачественные клетки или мозаичные клетки (или фракции ДНК или РНК из клеток-мишеней), ожидаемое аллельное соотношение для гетерозиготных (AB или BA) SNP можно найти следующим образом:
Уравнение (1):
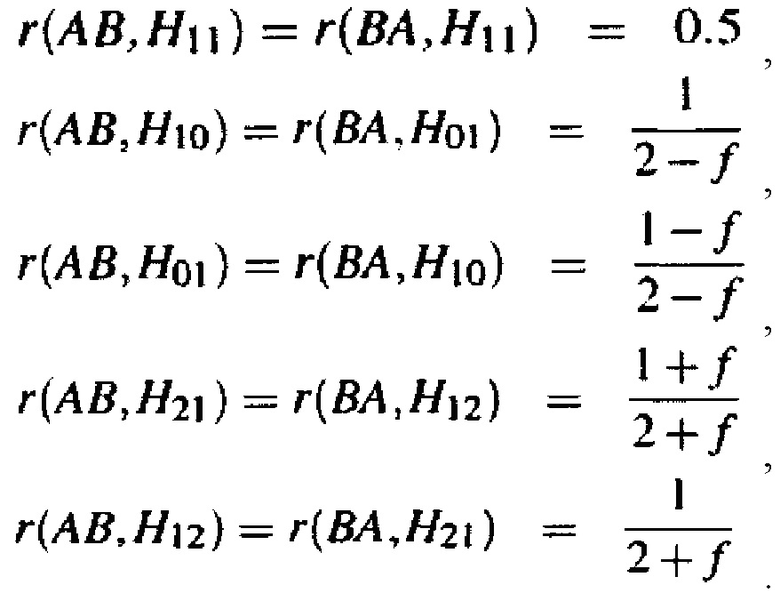
Систематическая ошибка, загрязнение и исправление ошибок секвенирования:
Наблюдение Ds в SNP состоит из числа исходных картированных прочтений с каждым присутствующим аллелем, nA0 и nB0. Тогда можно найти исправленные прочтения nA и nB с использованием ожидаемой систематической ошибки в амплификации аллелей A и B.
Пусть ca для обозначает загрязнения окружающей среды (например, загрязнение от ДНК в воздухе или окружающей среды) и r(ca) обозначает аллельное соотношение для окружающего загрязнителя (который принимается равным 0,5 на начальном этапе). Кроме того, cg обозначает степень генотипированного загрязнения (например, загрязнение от другого образца) и r(cg) представляет собой аллельное соотношение для загрязнителя. Пусть Se(A,B) и Se(B,A) обозначают ошибки секвенирования для распознавания одного аллеля как другого аллеля (например, ошибочного обнаружения аллеля A, когда присутствует аллель B).
Можно найти наблюдаемое аллельное соотношение q(r, ca, r(ca), cg, r(cg), Se(A,B), Se(B,A)) для данного ожидаемого аллельного соотношения r путем исправления для окружающего загрязнения, генотипированного загрязнения и ошибок секвенирования.
Поскольку загрязняющие генотипы неизвестны, популяционные частоты могут быть использованы для нахождения P(r(cg)). Более конкретно, пусть p будет популяционной частотой для одного из аллелей (который может быть назван как эталонный аллель). Тогда P(r(cg)=0)=(1-р)2, P(r(cg)=0)=2р(1-р) и P(r(cg)=0)=p.2 Условное математическое ожидание по r(cg) может быть использовано для определения E[q(r, са, r(ca), cg, r(cg), Se(A,B), Se(B,A))]. Следует отметить, что загрязнения окружающей среды и генотипирования определяют с использованием гомозиготных SNP, следовательно, они не зависят от отсутствия или наличия делеции или дупликаций. Кроме того, при желании можно измерить загрязнение окружающей среды и генотипирования с использованием эталонной хромосомы.
Правдоподобие в каждом SNP:
Уравнение ниже дает вероятность наблюдения данных nA и nB для аллельного соотношения r:
Уравнение (2):
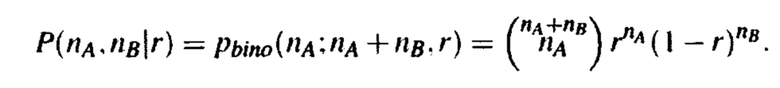
Пусть Ds обозначает данные для SNP. Для каждой гипотезы h∈{H11, H01, H10, H21, H12}, можно позволить r=r(AB,h) или r=r(BA,h) в уравнении (1) и найти условное математическое ожидание по r(cg), чтобы определить наблюдаемое аллельное соотношение E[q(r, са, r(ca), cg, r(cg))]. Тогда, полагая r=E[q(r, ca, r(ca), cg, r(cg), Se(A,B), Se(B,A))] в уравнении (2) можно определить P(Ds|h,ƒ).
Алгоритм поиска:
Согласно некоторым вариантам осуществления SNP с аллельными соотношениями, которые кажутся выпадающими, игнорируются (например, путем игнорирования или устранения SNP с аллельными соотношениями, которые по меньшей мере на 2 или 3 стандартных отклонения выше или ниже среднего значения). Следует отметить, что определенное для этого подхода преимущество состоит в том, что при наличии более высокого процента мозаицизма, изменчивость в аллельных соотношениях может быть высокой, следовательно, это гарантирует, что SNP не будут обрезаны из-за мозаицизма.
Пусть F={ƒ1, …, ƒN} обозначает пространство поиска для процента мозаицизма (например, опухолевой фракции). Можно определить P(Ds|h,ƒ) в каждом SNP s и ƒ∈F, и комбинировать вероятность над всеми SNP.
Алгоритм переходит каждый ƒ для каждой гипотезы. Используя способ поиска, можно сделать вывод, что мозаицизм существует, если существует диапазон F* в ƒ, где доверительный интервал гипотезы делеций или дупликации выше, чем доверительный интервал гипотезы отсутствия делеций и дупликации. Согласно некоторым вариантам осуществления определяют оценку максимального правдоподобия для P(Ds|h,ƒ) в F*. При желании, может быть определено условное математическое ожидание по ƒ∈F*. При желании, может быть определен доверительный интервал для каждой гипотезы.
Дополнительные варианты осуществления:
Согласно некоторым вариантам осуществления используется бета-биномиальное распределение вместо биномиального распределения. Согласно некоторым вариантам осуществления эталонная хромосома или хромосомный сегмент используется для определения специфических для образца параметров бета-биномиала.
Теоретическая производительность с использованием имитационного моделирования:
При желании можно оценить теоретическую производительность алгоритма путем случайного присвоения числа эталонных считываний SNP с заданной глубиной прочтения (DOR). Для нормального случая, используют p=0,5 для параметра биномиальной вероятности, а для делеций или дупликации, p пересматривают соответствующим образом. Иллюстративные входные параметры для каждого моделирования представляют собой следующие: (1) количество SNP S (2) константа DOR D на SNP, (3) p и (4) число экспериментов.
Первый имитационный эксперимент:
Этот эксперимент фокусируется на S ∈ {500, 1000}, D ∈ {500, 1000} и p ∈ {0%, 1%, 2%, 3%, 4%, 5%}. Авторы настоящего изобретения выполнили 1000 имитационных экспериментов в каждой установке (следовательно, 24000 экспериментов с фазой и 24000 без фазы). Авторы настоящего изобретения моделировали число прочтений из биномиального распределения (при желании, могут быть использованы другие распределения). Относительное число ложноположительных срабатываний (в случае p=0%) и относительное число ложноотрицательных срабатываний (в случае p>0%) определяли, как с фазовой информацией, так и без нее. Относительные числа ложноположительных срабатываний приведены на Фиг. 26. Следует отметить, что фазовая информация может быть очень полезной, особенно для S=1000, D=1000. Хотя для S=500, D=500 алгоритм характеризовался наиболее высоким относительным числом ложноположительных срабатываний с поэтапным отказом от условий испытания или без него. Относительное число ложноотрицательных срабатываний приведено на Фиг. 27.
Фазовая информация особенно применима при низких процентах мозаицизма (≤3%). Без фазовой информации наблюдался высокий уровень ложноотрицательных срабатываний при p=1%, потому что доверительный интервал на делеции определяли путем присвоения равных возможностей H10 и H01, и небольшое отклонение в пользу одной из гипотез не достаточно, чтобы компенсировать низкое правдоподобие от другой гипотезы. Это относится и к дупликации также. Следует отметить также, что алгоритм, как представляется, более чувствителен к глубине прочтения по сравнению с количеством SNP. Для получения результатов с фазовой информацией, авторы настоящего изобретения предполагают, что совершенная фазовая информация доступна для большого количества последовательных гетерозиготных SNP. При желании, информация о гаплотипе может быть получена путем вероятностного объединения гаплотипов на более мелких сегментах.
Второй имитационный эксперимент:
Этот эксперимент фокусируется на S ∈ {100, 200, 300, 400, 500}, D ∈ {1000, 2000, 3000, 4000, 5000} и p ∈ {0%, 1%,1,5%, 2%,2,5%, 3%} и 10000 случайных экспериментов при различных параметрах. Относительное число ложноположительных срабатываний (в случае p=0%) и относительное число ложноотрицательных срабатываний (в случае p>0%) определяли, как с фазовой информацией, так и без нее. Относительное число ложноотрицательных срабатываний составляло ниже 10% для D≥3000 и N≥200 с использованием информации о гаплотипе, в то время как та же производительность достигается при D=5000 и N≥400 (Фиг. 20А и 20B). Разница между относительным числом ложноотрицательных срабатываний была особенно заметна для небольших процентов мозаицизма (Фиг. 21А-25B). Например, при p=1%, менее чем 20% относительного числа ложноотрицательных срабатываний никогда не достигается без данных гаплотипов, в то время как оно близко к 0% для N≥300 и D≥3000. При p=3%, относительное число ложноотрицательных срабатываний 0% наблюдается с данными гаплотипов, в то время как N≥300 и D≥3000 необходимо для достижения той же производительности без данных о гаплотипах.
Иллюстративные способы обнаружения делеции и дупликаций без фазированных данных
Согласно некоторым вариантам осуществления нефазированные генетические данные используют для определения, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментов в геноме индивидуума (например, в геноме одной или нескольких клеток или в вкДНК или вкРНК). Согласно некоторым вариантам осуществления используют фазированные генетические данные, но фазирование игнорируется. Согласно некоторым вариантам осуществления образец ДНК или РНК, представляет собой смешанный образец вкДНК или вкРНК от индивидуума, который включает в себя вкДНК или вкРНК из двух или нескольких генетически различных клеток. Согласно некоторым вариантам осуществления в способе используют величину разности между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для каждого из локусов.
Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в образце ДНК или РНК из одной или нескольких клеток от индивидуума путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления аллельные соотношения вычисляют для локусов, которые являются гетерозиготными по меньшей мере в одной клетке, из которой был получен образец (например, локусов, которые гетерозиготны у плода и/или гетерозиготны у матери). Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей, деленное на общее измеренное количество всех аллелей для локуса. Согласно некоторым вариантам осуществления вычисленное аллельное соотношение для конкретного локуса представляет собой измеренное количество одного из аллелей (например, аллеля на первом гомологичном хромосомном сегменте), разделенное на измеренное количество одного или нескольких других аллелей (например, аллеля на втором гомологичном хромосомном сегменте) для локуса. Вычисленные аллельные соотношения и ожидаемые аллельные соотношения могут быть вычислены с использованием любого из способов, описанных в настоящей заявке, или любым стандартным способом (например, как любым математическим преобразованием вычисленных аллельных соотношений или ожидаемых аллельных соотношений, описанных в настоящем документе).
Согласно некоторым вариантам осуществления статистику критерия вычисляют на основании величины разности между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для каждого из локусов. Согласно некоторым вариантам осуществления статистику критерия A вычисляют по следующей формуле
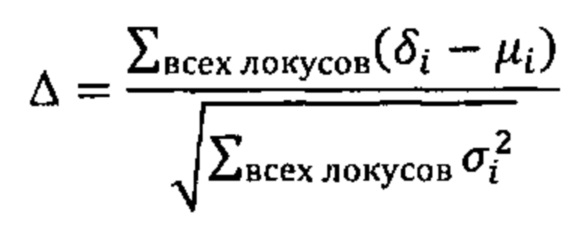
где δi представляет собой величину разности между вычисленным аллельным соотношением и ожидаемым аллельным соотношением для i локусов;
где μi представляет собой среднее значение δi и
где 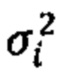 представляет собой стандартное отклонение δi.
представляет собой стандартное отклонение δi.
Например, можно определить δi следующим образом, когда ожидаемое аллельное соотношение составляет 0,5:
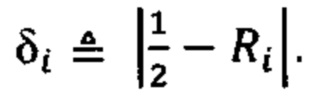
Значения μi и σi можно вычислить с использованием того факта, что Ri представляет собой биномиальную случайную величину. Согласно некоторым вариантам осуществления предполагается, что стандартное отклонение будет одинаковым для всех локусов. Согласно некоторым вариантам осуществления среднее или средневзвешенное значение стандартного отклонения или оценка стандартного отклонения используется для значения . Согласно некоторым вариантам осуществления предполагается, что статистика критерия характеризуется нормальным распределением. Например, центральная предельная теорема вытекает из того, что распределение Δ сходится к стандартному нормальному, поскольку увеличивается число локусов (например, число T SNP).
Согласно некоторым вариантам осуществления перечислена совокупность из одной или нескольких гипотез, задающих число копий хромосомы или хромосомного сегмента в геноме одной или нескольких клеток. Согласно некоторым вариантам осуществления выбирают гипотезу, которая представляет собой наиболее вероятную на основании статистики критерия, тем самым определяя число копий хромосомы или хромосомного сегмента в геноме одной или нескольких клеток. Согласно некоторым вариантам осуществления гипотезу выбирают, если вероятность того, что статистика критерия принадлежит к распределению статистики критерия для этой гипотезы, выше верхнего порога; одну или несколько гипотез отвергают, если вероятность того, что статистика критерия принадлежит к распределению статистики критерия для этой гипотезы, ниже нижнего порога; или гипотезу ни выбирают, ни отвергают, если вероятность того, что статистика критерия относится к распределению статистики критерия для этой гипотезы, между нижним порогом и верхним порогом или если вероятность не определяется с достаточно высоким интервалом достоверности. Согласно некоторым варианта осуществления верхний и/или нижний порог определяют из эмпирического распределения, такого как распределение от обучающих данных (например, образцов с известным числом копий, таких как диплоидные образцы или образцы, у которых известно наличие конкретной делеций или дупликации). Такое эмпирическое распределение может быть использовано для выбора порогового значения для теста отвержения единственной гипотезы.
Следует отметить, что статистика критерия Δ не зависит от S и, следовательно, оба они могут быть использованы независимо друг от друга, если это желательно.
Иллюстративные способы обнаружения делеций и дупликации с использованием аллельного распределения или профилей
Этот раздел включает в себя способы определения того, существует ли превышение числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом. Согласно некоторым вариантам осуществления способ предусматривает перечисление (I) множества гипотез, задающих число копий хромосомы или хромосомного сегмента, которые присутствуют в геноме одной или нескольких клеток (таких как злокачественные клетки) индивидуума, или (II) множества гипотез, задающих степень превышения числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных от индивидуума во множестве полиморфных локусов (например, локусов SNP) на хромосоме или хромосомном сегменте. Согласно некоторым вариантам осуществления создается распределение вероятностей ожидаемых генотипов индивидуума для каждой из гипотез. Согласно некоторым вариантам осуществления вычисляется соответствие между полученными генетическими данными индивидуума и распределением вероятностей ожидаемых генотипов индивидуума. Согласно некоторым вариантам осуществления одну или несколько гипотез ранжируют в соответствии с совпадением данных и выбирают гипотезу, которая занимает самое высокое положение при ранжировании. Согласно некоторым вариантам осуществления технику или алгоритм, например, алгоритм поиска, используют для одной или нескольких из следующих стадий: вычисление совпадения данных, ранжирование гипотез или выбор гипотезы, которая занимает самое высокое положение при ранжировании. Согласно некоторым вариантам осуществления совпадение данных представляет собой совпадение с бета-биномиальным распределением или совпадение с биномиальным распределением. Согласно некоторым вариантам осуществления технику или алгоритм выбирают из группы, состоящей из оценки по максимуму правдоподобия, оценки по апостериорному максимуму, Байесовской оценки, динамической оценки (например, динамической Байесовской оценки) и оценки на основе максимизации ожидания. Согласно некоторым вариантам осуществления способ предусматривает применение техники или алгоритма к полученным генетическим данным и ожидаемым генетическим данным.
Согласно некоторым вариантам осуществления способ предусматривает перечисление (I) множества гипотез, задающих число копий хромосомы или хромосомного сегмента, которые присутствуют в геноме одной или нескольких клеток (таких как злокачественные клетки) индивидуума, или (II) множества гипотез, задающих степень превышения числа копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток индивидуума. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных от индивидуума во множестве полиморфных локусов (например, локусов SNP) на хромосоме или хромосомном сегменте. Согласно некоторым вариантам осуществления генетические данные включают в себя подсчеты аллелей для множества полиморфных локусов. Согласно некоторым вариантам осуществления модель совместного распределения создается для ожидаемых подсчетов аллелей во множестве полиморфных локусов на хромосоме или хромосомном сегменте для каждой гипотезы. Согласно некоторым вариантам осуществления относительная вероятность для одной или нескольких гипотез определяется с использованием модели совместного распределения и подсчетов аллелей, измеренных на образце, и выбирают гипотезу с наибольшей вероятностью.
Согласно некоторым вариантам осуществления распределение или профиль аллелей (например, профиль вычисленных аллельных соотношений) используют для определения наличия или отсутствия CNV, таких как делеция или дупликация. При желании на основе этого профиля может быть определено родительское происхождение CNV. Наследуемая по материнской линии дупликация представляет собой дополнительную копию хромосомного сегмента от матери, а наследуемая по материнской линии делеция представляет собой отсутствие копии хромосомного сегмента от матери, так что присутствует единственная копия хромосомного сегмента от отца. Иллюстративные профили показаны на Фиг. 15A-19D и описаны ниже.
Для того чтобы определить наличие или отсутствие делеции представляющего интерес хромосомного сегмента, алгоритм учитывает распределение подсчетов последовательностей от каждого из двух возможных аллелей в большом количестве SNP на хромосому. Важно отметить, что некоторые варианты осуществления алгоритма используют подход, который не поддается визуализации. Таким образом, для целей иллюстрации, данные отображаются на Фиг. 15А-18 в упрощенном виде как соотношения двух наиболее вероятных аллелей, обозначенных как A и B, таким образом, что соответствующие тенденции могут быть более легко визуализированы. Эта упрощенная иллюстрация не принимает во внимание некоторые из возможных особенностей алгоритма. Например, два варианта осуществления для алгоритма, которые не возможно проиллюстрировать с помощью способа визуализации, который показывает аллельные соотношения, представляют собой: 1) возможность использовать неравновесия по сцеплению, то есть влияние того, что измерение в одном SNP имеет преимущество перед вероятной идентичностью соседних SNP, и 2) использование негауссовских моделей данных, описывающих ожидаемое распределение измерений аллелей в SNP данных характеристик платформы и стандартными ошибками амплификации. Также следует отметить, что упрощенная версия алгоритма учитывает только два наиболее распространенных аллеля в каждом SNP, игнорируя другие возможные аллели.
Представляющие интерес делеции были обнаружены в геномных и материнских образцах крови. Согласно некоторым вариантам осуществления геномные и материнские образцы плазмы анализировали с использованием способа мультиплексной ПЦР и секвенирования, описанного в примере 1. Исследуемые образцы геномной ДНК с синдромом не содержали гетерозиготные SNP в областях-мишенях, подтверждая способность анализов различать моносомию (пораженную) от дисомии (без изменений). Анализ вкДНК из образца материнской крови был в состоянии обнаружить синдром делеции 22q11.2, синдром кошачьего крика и синдром Вольфа-Хиршхорн, а также другие синдромы делеции на Фиг. 14 у плода.
На Фиг. 15А-15С изображены данные, которые указывают на наличие двух хромосом, когда образец представляет собой полностью материнский (не присутствует вкДНК плода, Фиг. 15А), содержит умеренную фетальную фракцию вкДНК 12% (Фиг. 15B) или содержит высокую фетальную фракцию вкДНК 26% (Фиг. 15C). Ось X представляет собой линейное положение отдельных полиморфных локусов по хромосоме, а ось Y представляет собой число прочтений аллеля А в виде доли от всех прочтений аллелей (А+В). Материнские и фетальные генотипы указаны справа от диаграмм. Диаграммы характеризуются цветовой маркировкой в соответствии с генотипом матери, таким образом, что красный указывает на материнский генотип АА, синий указывает на материнский генотип BB, а зеленый указывает на материнский генотип АВ. Следует отметить, что измерения производятся на общей вкДНК, выделенной из материнской крови, и вкДНК включает в себя вкДНК, как матери, так и плода; таким образом, каждое пятно представляет собой сочетание вклада ДНК матери и плода для этого SNP. Таким образом, увеличение доли материнской вкДНК от 0% до 100% будет постепенно смещать некоторые пятна вверх или вниз в пределах диаграмм в зависимости от генотипа матери и плода.
Во всех случаях, обнаруживается, что SNP, которые являются гомозиготными по аллелю A (AA), как у матери, так и плода, плотно связаны с верхним пределом диаграмм, а фракция прочтения A высока, потому что не должно присутствовать никаких аллелей В. И наоборот, обнаруживается, что SNP, которые являются гомозиготными по аллелю В у матери и плода, плотно связаны с нижним пределом диаграмм, поскольку фракция прочтения аллеля A низка, потому что должны быть только аллели B. Пятна, которые не плотно связаны с верхним и нижним пределами диаграмм, представляют собой SNP, для которых мать, плод или оба являются гетерозиготными; эти пятна применимы для идентификации фетальных делеции или дупликаций, но также могут быть информативными для определения отцовского наследования, по сравнению с материнским. Эти пятна сегрегируют на основе, как материнского, так и фетального генотипов и фетальной фракции, а также такое точное положение каждого отдельного пятна вдоль оси Y зависит как от стехиометрии, так и фетальной фракции. Например, локусы, где мать представляет собой АА, а плод - АВ, как ожидается, имеют различную долю прочтений аллелей, и, таким образом, различное положение вдоль оси Y в зависимости от эмбриональной фракции.
На Фиг. 15А представлены данные для небеременной женщины, и, таким образом, она представляет собой образец, когда генотип полностью материнский. Эта модель включает в себя "кластеры" пятен: красный кластер плотно связан с верхней частью диаграммы (SNP, где материнский генотип представляет собой AA), синий кластер тесно связан с нижней частью диаграммы (SNP, где материнский генотип представляет собой BB) и единственный, расположенный в центре зеленый кластер (SNP, где материнский генотип представляет собой АВ). На Фиг. 15B, вклад фетальных аллелей в долю прочтений аллеля А сдвигает положение некоторых пятен аллеля вверх или вниз вдоль оси Y. На Фиг. 15С легко просматривается профиль, включающий в себя две красные и две синие периферические полосы и трио центральных зеленых полос. Три центральные зеленые полосы соответствуют SNP, которые являются гетерозиготными у матери, а также две "периферические" группы сверху (красный) и снизу (синий) диаграммы соответствуют SNP, которые являются гомозиготными у матери.
Анализ носителя делеции 22q11.2 (мать с этой делецией) показан на Фиг. 16А. Носитель делеции не содержит гетерозиготных SNP в этой области, так как носитель характеризуется наличием только одной копии этой области. Таким образом, эта делеция указывает на отсутствие зеленого SNP АВ. Анализ наследуемой по отцовской линии делеции 22q11 у плода показан на Фиг. 16B. Когда плод наследует только одну копию хромосомного сегмента (в случае наследования делеции по отцовской линии, присутствующая у плода копия происходит от матери) и, таким образом, наследует только единственный аллель для каждого локуса в этом сегменте, гетерозиготность плода не возможна. Таким образом, единственными возможными идентификаторами фетальных SNP являются A или B. Следует отметить отсутствие внутренних периферических полос. Для унаследованной по отцовской линии делеций характерный профиль включает в себя две центральные зеленые полосы, которые представляют собой SNP, для которых мать является гетерозиготной, и имеются только единственные периферические красные и синие полосы, которые представляют собой SNP, для которых мать является гомозиготной и которые остаются тесно связанными с верхним и нижним пределами диаграмм (1 и 0), соответственно.
Анализ наследуемого по материнской линии делеционного синдрома кошачьего крика показан на Фиг. 17. Наблюдаются две центральные зеленые полосы вместо трех зеленых полос и есть две красные и две синие периферические полосы. Наследуемая по материнской линии делеция (например, носитель по материнской линии мышечной дистрофии Дюшенна) также может быть обнаружена на основе небольшого количества сигнала в этой области делеций в смешанном образце материнской и фетальной ДНК (например, образца плазмы) из-за того, что как мать, так и плод характеризуются наличием делеций.
Фиг. 18 представляет собой график с унаследованным по отцовской линии делеционным синдромом Вольфа-Хиршхорна, как указано благодаря наличию одной красной и одной синей периферической полосы.
При желании, подобные графики могут быть получены для образца от индивидуума с подозрением на наличие делеций или дупликации, например, CNV, связанной со злокачественной опухолью. На таких графиках, может использоваться следующее цветовое кодирование на основе генотипа клеток без CNV: красный указывает на генотип АА, синий указывает на генотип BB и зеленый указывает на генотип АВ. Согласно некоторым вариантам осуществления для делеций, профиль включает в себя две центральные зеленые полосы, которые представляют собой SNP, для которых индивидуум является гетерозиготным (верхняя зеленая полоса представляет собой АВ из клеток без делеций и A из клеток с делецией, а нижняя зеленая полоса представляет собой АВ из клеток без делеций и В из клеток с делецией), а содержит только единственные периферические красные и синие полосы, которые представляют собой SNP, для которых индивидуум является гомозиготным, и которые остаются тесно связанными с верхним и нижним пределами диаграмм (1 и 0), соответственно. Согласно некоторым вариантам осуществления разделение двух зеленых полос возрастает с увеличением доли клеток, ДНК или РНК с делецией.
Иллюстративные способы идентификации и анализа многоплодных беременностей
Согласно некоторым вариантам осуществления любой из способов согласно настоящему изобретению используют для обнаружения наличия многоплодной беременности, такой как беременности двойней, где по меньшей мере один из плодов генетически отличается от по меньшей мере одного другого плода. Согласно некоторым вариантам осуществления разнояйцевых близнецов идентифицируют на основании наличия двух плодов с различным аллелем, различными аллельными соотношениями или различными аллельными распределениями в некоторых (или всех) исследуемых локусах. Согласно некоторым вариантам осуществления разнояйцевых близнецов идентифицируют посредством определения ожидаемого аллельного соотношения в каждом локусе (например, локусах SNP) для двух плодов, которые могут иметь одинаковые или различные фетальные фракции в образце (например, образце плазмы). Согласно некоторым вариантам осуществления правдоподобие конкретной пары фетальных фракций (где f1 представляет собой фетальную фракцию для плода 1 и f2 представляет собой фетальную фракцию для плода 2) вычисляют с учетом некоторых или всех возможных генотипов двух плодов, обусловлено генотипом и популяционными частотами генотипа матери. Смесь двух фетальных и одного материнского генотипа в сочетании с фетальными фракциями, определяет ожидаемое аллельное соотношение в SNP. Например, если мать представляет собой АА, плод 1 представляет собой АА и плод 2 представляет собой АВ, то общая доля аллеля B в SNP составляет половину от f2. Расчет вероятности спрашивает, насколько хорошо все SNP вместе соответствуют ожидаемым аллельным отношениям, основанным на всех возможных комбинациях фетальных генотипов. Выбирают пару фетальных фракций (f1, f2), которая наилучшим образом соответствует данным. Нет необходимости в вычислении конкретных генотипов плодов; вместо этого, можно, например, рассматривать все возможные генотипы в статистическом сочетании. Согласно некоторым вариантам осуществления, если способ не делает различия между синглтоном и идентичными близнецами, может быть выполнено ультразвуковое исследование, чтобы определить, имеется одноплодная беременность или однояйцевые близнецы. Если УЗИ обнаруживает двойную беременность, можно предположить, что беременность представляет собой беременность однояйцевыми близнецами, потому что беременность двуяйцевыми близнецами была бы обнаружена на основе анализа SNP, рассмотренного выше.
Согласно некоторым вариантам осуществления известно, что беременная женщина характеризуется наличием многоплодной беременности (например, беременности двойней) на основе предварительного исследования, например, ультразвукового исследования. Любой из способов по настоящему изобретению может быть использован для определения того, включает ли многоплодная беременность однояйцевых или двуяйцевых близнецов. Например, измеренные аллельные соотношения можно сравнить с таковыми, которые можно было бы ожидать для однояйцевых близнецов (например, такие же аллельные соотношения как при одноплодной беременности) или для двуяйцевых близнецов (например, вычисление аллельных соотношений, как описано выше). Некоторые однояйцевые близнецы представляют собой монохориальную двойню, которые характеризуются риском развития синдрома фето-фетальной трансфузии. Таким образом, близнецы, определенные как однояйцевые близнецы с использованием способа согласно настоящему изобретению, желательно должны быть исследованы (например, с помощью ультразвука), чтобы определить, являются ли они монохориальной двойней, и если да, то этих близнецов можно контролировать (например, посредством ультразвукового исследования каждые две недели начиная с 16 недель) на наличие признаков синдрома фето-фетальной трансфузии.
Согласно некоторым вариантам осуществления любой из способов согласно настоящему изобретению используют для определения того, представляет ли собой какой-либо из плодов в многоплодной беременности, например, беременности двойней, анеуплоидный. Исследование анеуплоидий для близнецов начинается с оценки фетальных фракций. Согласно некоторым вариантам осуществления выбирают пару фетальных фракций (f1, f2), которая наилучшим образом соответствует данным, как описано выше. Согласно некоторым вариантам осуществления оценку способом максимального правдоподобия выполняют для пары параметров (f1, f2) в диапазоне возможных фетальных фракций. Согласно некоторым вариантам осуществления диапазон f2 составляет от 0 до f1, так как f2 определяется как меньшая фетальная фракция. Учитывая пару (f1, f2), данные правдоподобия вычисляют из аллельных соотношений, наблюдаемых в совокупности локусов, таких как локусы SNP. Согласно некоторым вариантам осуществления данные правдоподобия отражают генотипы матери, отца, если доступны, популяционные частоты, и полученные в результате вероятности генотипов плода. Согласно некоторым вариантам осуществления SNP предполагаются независимыми. Оцененная пара фетальных фракций представляет собой ту, которая производит самое высокое правдоподобие данных. Если f2 равна 0, то данные лучше всего объясняются только одной совокупностью фетальных генотипов, что указывает на однояйцевых близнецов, где f1 представляет собой комбинированную фетальную фракцию. В противном случае f1 и f2 представляют собой оценки отдельных фетальных фракций близнецов. Установив наилучшую оценку (f1, f2), можно прогнозировать общую фракцию аллеля B в плазме для любой комбинации материнского и фетального генотипов, при желании. Не нужно присваивать прочтения отдельных последовательностей отдельным плодам. Исследование плоидности проводят с использованием другой оценки способом максимального правдоподобия, который сравнивает правдоподобность данных двух гипотез. Согласно некоторым вариантам осуществления для однояйцевых близнецов рассматривают гипотезы (I) оба близнеца являются эуплоидными и (II) оба близнеца являются трисомными. Согласно некоторым вариантам осуществления для двуяйцевых близнецов рассматриваются гипотезы (I) оба близнеца являются эуплоидными и (II) по меньшей мере один близнец является трисомным. Гипотезы трисомии для двуяйцевых близнецов основаны на более низкой фетальной фракции, так как трисомия у близнеца с более высокой фетальной фракцией также будет обнаружена. Правдоподобия плоидности вычисляют с использованием способа, который предсказывает ожидаемое число считываний в каждом нацеленном локусе генома, обусловленное гипотезами либо дисомии, либо трисомии. Для эталонной дисомии хромосом требования отсутствуют. Модель дисперсии для ожидаемого числа считываний учитывает производительность отдельных локусов-мишеней, а также корреляцию между локусами (смотрите, например, патент США с серийным №62/008235, поданный 5 июня 2014 г., и патент США с серийным номером 62/032785, поданный 4 августа 2014 г., каждый из которых полностью включен в настоящий документ посредством ссылки). Если меньший близнец характеризуется наличием фетальной фракции f1, способность обнаружить трисомию у этого близнеца эквивалентна способности обнаружить трисомию при одноплодной беременности в той же фетальной фракции. Это объясняется тем, что часть способа, который обнаруживает трисомию согласно некоторым вариантам осуществления, не зависит от генотипов и не различает многоплодную или одноплодную беременность. Он просто ищет увеличенное число прочтений в соответствии с определенной фетальной фракцией.
Согласно некоторым вариантам осуществления способ предусматривает обнаружение наличия близнецов на основании локусов SNP (например, как описано выше). Если близнецы обнаружены, SPN используются для определения фетальной фракции каждого плода (f1, f2), как описано выше. Согласно некоторым вариантам осуществления образцы, которые характеризуются высоким доверительным интервалом обнаружения дисомии, используются для определения систематической ошибки амплификации на основе каждого SNP. Согласно некоторым вариантам осуществления эти образцы с высоким доверительным интервалом обнаружения дисомии анализируют в том же пробеге, что и один или нескольких представляющих интерес образцов. Согласно некоторым вариантам осуществления систематические погрешности амплификации на основе каждого SNP используются для моделирования распределения прочтений для одной или нескольких представляющих интерес хромосом или хромосомных сегментов, таких, как ожидаемая 21-я хромосома, или гипотезы дисомии и трисомии, заданной наименьшей из двух фетальных фракций близнецов. Правдоподобие или вероятность дисомии или трисомии вычисляется с учетом двух моделей и измеренного количества представляющей интерес хромосомы или хромосомного сегмента.
Согласно некоторым вариантам осуществления пороговое значение для распознанной положительной анеуплоидии (например, распознанной трисомии) устанавливается на основании близнеца с меньшей фетальной фракцией. Таким образом, если другой близнец представляет собой положительный или если оба положительны, то общее хромосомное представление точно выше порогового значения.
Иллюстративные способы подсчета/количественные способы Согласно некоторым вариантам осуществления один или несколько способов подсчета (также упоминается как количественные способы) используются для обнаружения одного или нескольких CNS, такие как делеции или дупликации хромосомных сегментов или целых хромосом. Согласно некоторым вариантам осуществления один или несколько способов подсчета используются для определения того, представляет собой превышение числа копий первого гомологичного хромосомного сегмента результат дупликации первого гомологичного хромосомного сегмента или результат делеции второго гомологичного хромосомного сегмента. Согласно некоторым вариантам осуществления один или несколько способов подсчета используются для определения числа дополнительных копий хромосомного сегмента или хромосомы, которая дублируется (например, существует ли 1, 2, 3, 4 или более дополнительных копий). Согласно некоторым вариантам осуществления один или несколько способов подсчета используются для дифференциации образца, который характеризуется многими дупликациями и меньшей опухолевой фракцией из образца с меньшим числом дупликаций и большей опухолевой фракцией. Например, один или несколько способов подсчета могут быть использованы для дифференциации образца с четырьмя дополнительными копиями хромосом и опухолевой фракцией, составляющей 10%, от образца с двумя дополнительными копиями хромосом и опухолевой фракцией 20%. Иллюстративные способы описаны, например, в публикациях патента США №2007/0184467; 2013/0172211 и 2012/0003637; в патентах США №8467976, 7888017; 8008018; 8296076 и 8195415; в патенте США с серийным №62/008235, поданном 5 июня 2014 г., и патенте США с серийным №62/032785, поданном 4 августа 2014 г., каждый из которых полностью включен в настоящий документ посредством ссылки.
Согласно некоторым вариантам осуществления способ подсчета предусматривает подсчет количества основанных на последовательности ДНК прочтений, которые картируют на одну или несколько данных хромосом или хромосомных сегментов. Некоторые такие способы предусматривают создание эталонного значения (предельного значения) для числа считываний последовательностей ДНК, отображенных на определенной хромосоме или хромосомном сегменте, причем число считываний сверх значения представляет собой показатель определенной генетической аномалии.
Согласно некоторым вариантам осуществления общее измеренное количество всех аллелей одного или нескольких локусов (например, общее количество полиморфного или не полиморфного локуса) сравнивается с эталонным количеством. Согласно некоторым вариантам осуществления эталонное количество представляет собой (I) пороговое значение или (II) предполагаемое количество для гипотезы определенного числа копий. Согласно некоторым вариантам осуществления эталонное количество (для отсутствия CNV) представляет собой общее измеренное количество всех аллелей для одного или нескольких локусов, для одной или нескольких хромосом или хромосомных сегментов, про которые известно или предполагается, что у них отсутствует делеция или дупликация. Согласно некоторым вариантам осуществления эталонное количество (для наличия CNV) представляет собой общее измеренное количество всех аллелей для одного или нескольких локусов, для одной или нескольких хромосом или хромосомных сегментов, про которые известно или предполагается, что у них присутствует делеция или дупликация. Согласно некоторым вариантам осуществления эталонное количество представляет собой общей измеренное количество всех аллелей для одного или нескольких локусов, для одной или нескольких эталонных хромосом или хромосомных сегментов. Согласно некоторым вариантам осуществления эталонное количество представляет собой среднее или медианное значения, определенные для двух или более различных хромосом, хромосомных сегментов или разных образцов. Согласно некоторым вариантам осуществления случайное (например, массовое параллельное секвенирование способом выстрела из дробового ружья) или направленное секвенирование используется для определения количества одного или нескольких полиморфных или не полиморфных локусов.
Согласно некоторым вариантам осуществления использования эталонного количества, способ предусматривает (a) измерение количества генетического материала на представляющей интерес хромосоме или хромосомном сегменте; (b) сравнение количества со стадии (a) с эталонным количеством и (c) идентификация на основе сравнения наличия или отсутствия делеции или дупликации.
Согласно некоторым вариантам осуществления использования эталонной хромосомы или хромосомного сегмента, способ предусматривает секвенирование ДНК или РНК из образца, чтобы получить множество тегов последовательностей, выравнивающих по локусам-мишеням. Согласно некоторым вариантам осуществления теги последовательностей характеризуются достаточной длиной, чтобы быть отнесенными к конкретному локусу-мишени (например, 15-100 нуклеотидов в длину); локусы-мишени представляют собой локусы из множества различных хромосом или хромосомных сегментов, которые включают в себя по меньшей мере одну первую хромосому или хромосомный сегмент, подозреваемый в аномальном распределении в образце, и по меньшей мере одну вторую хромосому или хромосомный сегмент, который как предполагают, имеет нормальное распределение в образце. Согласно некоторым вариантам осуществления множество тегов последовательностей назначают соответствующим локусам. Согласно некоторым вариантам осуществления определяется число тегов последовательностей, выравнивающих по локусам-мишеням первой хромосомы или хромосомного сегмента, и число тегов последовательностей выравнивающих по локусам-мишеням второй хромосомы или хромосомного сегмента. Согласно некоторым вариантам осуществления эти числа сравниваются, чтобы определить наличие или отсутствие аномального распределения (например, делеции или дупликации) первой хромосомы или хромосомного сегмента.
Согласно некоторым вариантам осуществления значение ƒ (например, фетальная фракция или опухолевая фракция) используют при определении CNV, например, для сравнения наблюдаемых различий между количеством двух хромосом или хромосомных сегментов с разницей, которую можно было бы ожидать для конкретного типа CNV, принимая во внимание значение ƒ (смотрите, например, публикацию патента США №2012/0190020, публикацию патента США №2012/0190021, публикацию патента США №2012/0190557, публикацию патента США №2012/0191358, каждый из которых полностью включен в настоящий документ посредством ссылки). Например, разница в количестве хромосомного сегмента, которая дублируется у плода, по сравнению с дисомным эталонным хромосомным сегментом в образце крови от матери, несущей плод, возрастает с увеличением фетальной фракции. Кроме того, разница в количестве хромосомного сегмента, которая дублируется в опухоли, по сравнению с дисомным эталонным хромосомным сегментом увеличивается, когда увеличивается фетальная фракция. Согласно некоторым вариантам осуществления способ предусматривает сравнение относительной частоты представляющей интерес хромосомы или хромосомного сегмента с эталонной хромосомой или хромосомным сегментом (например, хромосоме или хромосомному сегменту с ожидаемой или известной дисомией) до значения ƒ, чтобы определить вероятность CNV. Например, разницу в количестве между первой хромосомой или хромосомным сегментом с эталонной хромосомой или хромосомным сегментом можно сравнить с тем, что можно было бы ожидать, учитывая значение ƒ для различных возможных CNV (например, одной или двух дополнительных копий представляющего интерес хромосомного сегмента).
Следующие примеры возможного использования иллюстрируют использование способа подсчета/количественного способа, чтобы различать дупликацию первого гомологичного хромосомного сегмента и делецию второго гомологичного хромосомного сегмента. Если нормальный дисомный геном хозяина рассматривать исходным уровнем, тогда анализ смеси нормальных и злокачественных клеток дает среднюю разницу между исходным уровнем и злокачественной ДНК в смеси. Например, представим случай, когда 10% ДНК в образце происходит из клеток с делецией в области хромосомы, нацеленной с помощью анализа. Согласно некоторым вариантам осуществления количественный подход показывает, что количество прочтений, соответствующих этой области, как ожидается, будет 95% от ожидаемого для нормального образца. Это объясняется тем, что одна из двух хромосомных областей-мишеней в каждой из опухолевых клеток с делецией нацеленной области отсутствует, и, таким образом, общее количество отображения ДНК в этой области составляет 90% (для нормальных клеток) плюс 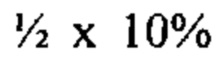 (для опухолевых клеток) = 95%. Альтернативно, согласно некоторым вариантам осуществления аллельный подход показывает, что соотношение аллелей в гетерозиготных локусах в среднем составляет 19:20. Теперь представим случай, когда 10% ДНК в образце происходит от клеток с пятикратной фокусной амплификацией области хромосомы, нацеленной с помощью анализа. Согласно некоторым вариантам осуществления количественный подход показывает, что количество прочтений, соответствующих этой области, как ожидается, будет 125% от того, которое ожидается для нормального образца. Это объясняется тем, что одна из двух хромосомных областей-мишеней в каждой из опухолевых клеток с пятикратной фокальной амплификацией копируется дополнительные пять раз в нацеленной области, и, таким образом, общее количество отображения ДНК в этой области составляет 90% (для нормальных клеток) плюс (2+5)×10%/2 (для опухолевых клеток) = 125%. Альтернативно, согласно некоторым вариантам осуществления аллельный подход показывает, что соотношение аллелей в гетерозиготных локусах составляет в среднем 25:20. Следует отметить, что при использовании только аллельного подхода, пятикратная фокусная амплификация хромосомной области в образце с 10% вкДНК может оказаться такой же, как делеция той же области в образце с 40% вкДНК; в этих двух случаях, гаплотип, который недостаточно представлен в случае делеций, по-видимому, представляет собой гаплотип без CNV в случае с фокусной дупликацией, а гаплотип без CNV в случае делеций, по-видимому, представляет собой превалирующий гаплотип в случае с фокусной дупликацией. Сочетание правдоподобий, полученных посредством этого аллельного подхода, с правдоподобиями, полученными с помощью количественного подхода, проводит различия между этими двумя возможностями.
(для опухолевых клеток) = 95%. Альтернативно, согласно некоторым вариантам осуществления аллельный подход показывает, что соотношение аллелей в гетерозиготных локусах в среднем составляет 19:20. Теперь представим случай, когда 10% ДНК в образце происходит от клеток с пятикратной фокусной амплификацией области хромосомы, нацеленной с помощью анализа. Согласно некоторым вариантам осуществления количественный подход показывает, что количество прочтений, соответствующих этой области, как ожидается, будет 125% от того, которое ожидается для нормального образца. Это объясняется тем, что одна из двух хромосомных областей-мишеней в каждой из опухолевых клеток с пятикратной фокальной амплификацией копируется дополнительные пять раз в нацеленной области, и, таким образом, общее количество отображения ДНК в этой области составляет 90% (для нормальных клеток) плюс (2+5)×10%/2 (для опухолевых клеток) = 125%. Альтернативно, согласно некоторым вариантам осуществления аллельный подход показывает, что соотношение аллелей в гетерозиготных локусах составляет в среднем 25:20. Следует отметить, что при использовании только аллельного подхода, пятикратная фокусная амплификация хромосомной области в образце с 10% вкДНК может оказаться такой же, как делеция той же области в образце с 40% вкДНК; в этих двух случаях, гаплотип, который недостаточно представлен в случае делеций, по-видимому, представляет собой гаплотип без CNV в случае с фокусной дупликацией, а гаплотип без CNV в случае делеций, по-видимому, представляет собой превалирующий гаплотип в случае с фокусной дупликацией. Сочетание правдоподобий, полученных посредством этого аллельного подхода, с правдоподобиями, полученными с помощью количественного подхода, проводит различия между этими двумя возможностями.
Иллюстративные способы подсчета/количественные способы с использованием эталонных образцов
Иллюстративный количественный способ, который использует один или несколько эталонных образцов, описан в патенте США с серийным номером 62/008235, поданном 5 июня 2014 г., и патенте США с серийным номером 62/032785, поданном 4 августа 2014 г., которые полностью включены в настоящий документ посредством ссылки. Согласно некоторым вариантам осуществления один или нескольких эталонных образцов, наиболее вероятно не имеющие каких-либо CNV на одной или нескольких представляющих интерес хромосомах или хромосомных сегментах (например, нормальный образец), идентифицируют путем выбора образцов с самой высокой долей опухолевой ДНК, отбора образцов с Z-показателем ближе всего к нулю, выбора образцов, где данные соответствуют гипотезе, соответствующей отсутствию CNV с наивысшим доверительным интервалом или правдоподобием, выбора образцов с известной нормальностью, выбора образцов от индивидуумов с самым низким правдоподобием наличия злокачественной опухоли (например, характеризующихся небольшим возрастом, мужским полом при скрининге на злокачественную опухоль молочной железы, без семейного анамнеза и т.д.), выбора образцов с наибольшим входным количеством ДНК, выбора образцов с наибольшим отношением сигнал-шум, выбора образцов на основе других критериев, которые, как полагают, коррелируют с правдоподобием наличия злокачественной опухоли, или выбора образцов с использованием некоторой комбинации критерий. После выбора эталонной совокупности, можно сделать предположение о том, что эти случаи представляют собой дисомию, а затем оценить систематическую погрешность на SNP, которая представляет собой специфическую для эксперимента амплификацию, и другие систематические ошибки обработки для каждого локуса. Затем можно использовать эту оценку специфической для эксперимента систематической ошибки для исправления систематической ошибки в измерениях представляющей интерес хромосомы, например, локусов хромосомы 21, и для других хромосомных локусов в зависимости от обстоятельств, для образцов, которые не представляют собой часть подмножества, где дисомия предполагается для хромосомы 21. После исправления систематических погрешностей для этих образцов неизвестной плоидности, данные для этих образцов затем могут быть проанализированы во второй раз с использованием того же или другого способа, чтобы определить, характеризуются ли индивидуумы (например, плоды) наличием трисомии 21. Например, количественный способ может быть использован на оставшемся образце неизвестной плоидности, и Z-показатель может быть вычислен с использованием исправленных измеренных генетических данных на хромосоме 21. Альтернативно, в рамках предварительной оценки состояния плоидности хромосомы 21, может быть вычислена фетальная фракция (или опухолевая фракция для образцов от индивидуума с подозрением на злокачественную опухоль). Доля исправленных прочтений, которая ожидается в случае дисомии (гипотеза дисомии) и доля исправленных прочтений, которая ожидается в случае трисомии (гипотеза трисомии) может быть вычислена для случая с этой фетальной фракцией. Альтернативно, если фетальная фракция не была измерена ранее, совокупность гипотез дисомии и трисомии может быть получена для различных фетальных фракций. Для каждого случая, ожидаемое распределение доли исправленных прочтений можно рассчитать с учетом ожидаемой статистической вариации в выборе и измерении различных локусов ДНК. Наблюдаемую исправленную долю прочтений можно сравнить с распределением ожидаемой доли исправленных прочтений, и может быть вычислено отношение правдоподобия для гипотез дисомии и трисомии для каждого из образцов неизвестной плоидности. Состояние плоидности, связанное с гипотезой с самым высоким вычисленным правдоподобием, может быть выбрано в качестве правильного состояния плоидности.
Согласно некоторым вариантам осуществления может быть выбрано подмножество образцов с достаточно низким правдоподобием наличия злокачественной опухоли, чтобы выступать в качестве контрольной совокупности образцов. Подмножество может представлять собой фиксированное количество или оно может представлять собой переменное количество, которое основано на выборе только тех образцов, которые падают ниже порогового значения. Количественные данные из подмножества образцов могут быть объединены, усреднены или объединены с использованием средневзвешенного, где взвешивание основывается на правдоподобии нормального образца. Количественные данные могут быть использованы для определения статистической ошибки каждого локуса для амплификации секвенирования образцов в данном пакете контрольных образцов. Систематические ошибки на локус могут также включать в себя данные из других партий образцов. Систематические ошибки на локус могут указывать на относительную избыточную или недостаточную амплификацию, которая наблюдается для данного локуса по сравнению с другими локусами, что делает предположение о том, что подмножество образцов не содержит никаких CNV, и что любая наблюдаемая избыточная или недостаточная амплификация представляет собой результат амплификации и/или секвенирования, или другой систематической ошибки. Систематические ошибки на локус могут принимать во внимание содержание GC ампликона. Локусы могут быть сгруппированы в группы локусов с целью вычисления систематической ошибки на локус. После того, как систематическая ошибка на локус было рассчитана для каждого локуса во множестве локусов, данные секвенирования для одного или нескольких образцов, которые не в подгруппе образцов, и необязательно одного или нескольких образцов, которые находятся в подмножестве образцов, могут быть исправлены путем корректировки количественных измерений для каждого локуса, чтобы устранить эффект систематической ошибки в этом локусе. Например, если SNP 1 наблюдался в подгруппе пациентов, характеризующихся глубиной прочтения, которая в два раза больше, чем в среднем, корректировка может включать в себя замену числа прочтений, соответствующих SNP 1 на число, которое в два раза больше. Если исследуемый локус представляет собой SNP, корректировка может включать в себя сокращение числа прочтений, соответствующих каждому из аллелей в этом локусе наполовину. После того как данные секвенирования для каждого из локусов в одном или нескольких образцах были скорректированы, они могут быть проанализированы с использованием способа с целью обнаружения присутствия CNV в одной или нескольких хромосомных областях.
В качестве примера, образец A представляет собой смесь амплифицированной ДНК, происходящей из смеси нормальных и злокачественных клеток, которые анализируют с помощью количественного способа. Ниже показаны иллюстративные возможные данные. Область плеча q на хромосоме 22 встречается только у 90% ожидаемых отображений ДНК в этой области; фокальная область, соответствующая гену HER2, обнаружена у 150% ожидаемых отображений ДНК в этой области и p-плечо хромосомы 5 обнаружено у 105% ожидаемых отображений ДНК в этой области. Клиницист может сделать вывод, что образец содержит делецию области на q-плече на хромосоме 22 и дупликацию гена HER2. Клиницист может сделать вывод, что, так как делеции 22q распространены при злокачественной опухоли молочной железы и что, так как клетки с делецией области 22q на обеих хромосомах, как правило, не выживают, то приблизительно 20% ДНК в образце происходит от клеток с делецией 22q на одной из двух хромосом. Клиницист может также сделать вывод, что если ДНК из смешанного образца, который происходит из опухолевых клеток, происходящих из совокупности генетически опухолевых клеток, у которых область HER2 и области 22q были однородными, то клетки содержали пятикратную дупликацию области HER2.
В качестве примера, образец A также анализируют с использованием аллельного способа. Ниже показаны иллюстративные возможные данные. Два гаплотипа на одной и той же области на плече q на хромосоме 22 присутствуют в соотношении 4:5; два гаплотипа в фокальной области, соответствующие гену HER2, присутствуют в соотношении 1:2; и два гаплотипа на p-плече хромосомы 5 присутствуют в соотношении 20:21. Все остальные исследованные области генома не имеют статистически значимого превышения любого гаплотипа. Клиницист может сделать вывод, что образец содержит ДНК из опухоли с CNV в области 22q, области HER2 и плече 5р. Основываясь на знании того, что делеций 22q очень распространены при злокачественной опухоли молочной железы, и/или количественном анализе, показывающем превышение количества картированной ДНК на область 22q генома, клиницист может сделать вывод о существовании опухоли с делецией 22q. Основываясь на знании того, что амплификации HER2 очень распространены при злокачественной опухоли молочной железы, и/или количественном анализе, показывающем превышение количества картирования ДНК на область HER2 генома, клиницист может сделать вывод о существовании опухоли с амплификацией HER2.
Иллюстративные эталонные хромосомы или хромосомные сегменты
Согласно некоторым вариантам осуществления любой из описанных в настоящем документе способов также выполняется на одной или нескольких эталонных хромосомах или хромосомных сегментах и результаты сравнивают с таковыми для одной или нескольких представляющих интерес хромосом или хромосомных сегментов.
Согласно некоторым вариантам осуществления эталонная хромосома или хромосомный сегмент используют в качестве контроля для того, что можно было бы ожидать при отсутствии CNV. Согласно некоторым вариантам осуществления эталон представляет собой ту же хромосому или хромосомный сегмент из одного или нескольких различных образцов, про которые известно или предполагается, что у них отсутствует делеция или дупликация в этой хромосоме или хромосомном сегменте. Согласно некоторым вариантам осуществления эталон представляет собой другую хромосому или хромосомный сегмент из исследуемого образца, который, как ожидается, будет дисомным. Согласно некоторым вариантам осуществления эталон представляет собой другой сегмент от одной из представляющих интерес хромосом в том же исследуемом образце. Например, эталонным может быть один или несколько сегментов за пределами области потенциальной делеций или дупликации. Наличие эталона на той же самой хромосоме, которая исследуется, избегает изменчивости между разными хромосомами, такими как различия в метаболизме, апоптозе, гистонах, инактивации и/или амплификации между хромосомами. Анализ сегментов без CNV на той же самой исследуемой хромосоме также может быть использован для определения различий в метаболизме, апоптозе, гистонах, инактивации и/или амплификации между гомологами, позволяя определить уровень изменчивости между гомологами в отсутствие CNV для сравнения с результатами от потенциального CNV. Согласно некоторым вариантам осуществления величина разницы между вычисленными и ожидаемыми аллельными соотношениями для потенциального CNV выше, чем соответствующая величина для эталона, тем самым подтверждая наличие CNV.
Согласно некоторым вариантам осуществления эталонную хромосому или хромосомный сегмент используют в качестве контроля для того, что можно было бы ожидать при наличии CNV, такой как определенная представляющая интерес делеция или дупликация. Согласно некоторым вариантам осуществления эталон представляет собой ту же хромосому или хромосомный сегмент из одного или нескольких различных образцов, у которых известно или предполагается наличие делеции или дупликации в этой хромосоме или хромосомном сегменте. Согласно некоторым вариантам осуществления эталон представляет собой другую хромосому или хромосомный сегмент из исследуемого образца, у которого известно или ожидается наличие CNV. Согласно некоторым вариантам осуществления величина разности между вычисленными и ожидаемыми аллельными соотношениями на потенциальную CNV подобна (например, не сильно отличается), в отличие от соответствующей величины для эталона на CNV, тем самым подтверждая наличие CNV. Согласно некоторым вариантам осуществления величина разности между вычисленными и ожидаемыми аллельными соотношениями на потенциальную CNV меньше (например, значительно меньше), чем соответствующая величина для эталона на CNV, тем самым подтверждая отсутствие CNV. Согласно некоторым вариантам осуществления один или несколько локусов, для которых генотип злокачественной клетки (или ДНК или РНК из злокачественной клетки, такой как вкДНК или вкРНК) отличается от генотипа незлокачественной клетки (или ДНК или РНК из незлокачественной клетки, такой как вкДНК или вкРНК), что используют для определения опухолевой фракции. Опухолевая фракция может быть использована, чтобы определить, объясняется ли превышение числа копий первого гомологичного хромосомного сегмента дупликацией первого гомологичного хромосомного сегмента или делецией второго гомологичного хромосомного сегмента. Опухолевая фракция также может быть использована для определения количества дополнительных копий хромосомного сегмента или хромосомы, которая дублируется (например, имеется ли 1, 2, 3, 4 или более дополнительных копий), например, чтобы дифференцировать образец с четырьмя дополнительными копиями хромосом и опухолевой фракцией 10% от образца с двумя дополнительными копиями хромосом и опухолевой фракцией 20%. Опухолевая фракция также может быть использована для определения того, насколько хорошо наблюдаемые данные соответствуют ожидаемым данным на возможные CNV. Согласно некоторым вариантам осуществления степень превышения CNV используется для выбора конкретной терапии или терапевтической схемы лечения для индивидуума. Например, некоторые терапевтические средства эффективны только по меньшей мере для четырех, шести или более копий хромосомного сегмента.
Согласно некоторым вариантам осуществления один или нескольких локусов, используемых для определения опухолевой фракции на эталонной хромосоме или хромосомном сегменте, таком как хромосома или хромосомный сегмент, про который известно или предполагается, что он является дисомным, хромосома или хромосомный сегмент, который редко дублируется или удаляется в злокачественных клетках в целом или при конкретном типе злокачественной опухоли, которая имеется у индивидуума или он подвержен повышенному риску наличия, или хромосома или хромосомный сегмент, который вряд ли будет анеуплоидным (такой сегмент, как ожидается, приведет к клеточной гибели при делеции или дупликации). Согласно некоторым вариантам осуществления любой из способов согласно настоящему изобретению используют для подтверждения того, что эталонная хромосома или хромосомный сегмент является дисомным, как в злокачественных, так и незлокачественных клетках. Согласно некоторым вариантам осуществления используют одну или несколько хромосом или хромосомных сегментов, для которых доверительный интервал для распознавания дисомии высок.
Иллюстративные локусы, которые могут быть использованы для определения опухолевой фракции, включают в себя полиморфизмы или мутации (например, SNP) в злокачественных клетках (или ДНК или РНК, такие как вкДНК или вкРНК из злокачественной клетки), которые не присутствуют в незлокачественной клетке (или ДНК или РНК из незлокачественной клетки) у индивидуума. Согласно некоторым вариантам осуществления опухолевую фракцию определяют путем идентификации тех полиморфных локусов, где злокачественная клетка (или ДНК или РНК из злокачественной клетки) содержит аллель, который отсутствует в незлокачественных клетках (или ДНК или РНК из незлокачественных клеток) в образце (например, образце плазмы или биопсии опухоли) от индивидуума; и использования количества аллеля, уникального для злокачественной клетки в одном или нескольких из идентифицированных полиморфных локусов для определения опухолевой фракции в образце. Согласно некоторым вариантам осуществления незлокачественная клетка представляет собой гомозиготную для первого аллеля в полиморфном локусе, а злокачественная клетка является (I) гетерозиготной по первому аллелю и второму аллелю или (II) гомозиготной по второму аллелю в полиморфном локусе. Согласно некоторым вариантам осуществления незлокачественная клетка является гетерозиготной по первому аллелю и второму аллелю в полиморфном локусе, а злокачественная клетка (I) содержит одну или две копии третьего аллеля в полиморфном локусе. Согласно некоторым вариантам осуществления злокачественные клетки, как предполагается или известно, содержат только одну копию аллеля, который не присутствует в незлокачественных клетках. Например, если генотип незлокачественных клеток представляет собой AA, а злокачественных клеток представляет собой АВ, и 5% сигнала в этом локусе в образце от аллеля B, а 95% от аллеля A, то опухолевая фракция образца составляет 10%. Согласно некоторым вариантам осуществления злокачественные клетки, как предполагается или известно, содержат две копии аллеля, который не присутствует в незлокачественных клетках. Например, если генотип незлокачественных клеток представляет собой АА, а злокачественных клеток представляет собой ВВ, и 5% сигнала в этом локусе в образце от аллеля B, а 95% от аллеля A, опухолевая фракция образца составляет 5%. Согласно некоторым вариантам осуществления множественные локусы, для которых имеют аллель злокачественные клетки, а не незлокачественные клетки, анализируют, чтобы определить, какие из локусов в злокачественных клетках гетерозиготны, а какие гомозиготны. Например, для локусов, в которых незлокачественные клетки представляют собой АА, если сигнал от аллеля B составляет ~5% в некоторых локусах и ~10% в некоторых локусах, то злокачественные клетки считаются гетерозиготными в локусах с ~5% аллелем B и гомозиготными в локусах с ~10% аллелем В (указывая на то, что опухолевая фракция составляет ~10%).
Иллюстративные локусы, которые могут быть использованы для определения опухолевой фракции включают в себя локусы, для которых злокачественная клетка и незлокачественная клетка имеют один общий аллель (такие как локусы, в которых злокачественная клетка представляет собой АВ, а незлокачественная клетка представляет собой BB, или злокачественная клетка представляет собой BB, а незлокачественная клетка представляет собой АВ). Количество сигнала A, количество сигнала B или отношение сигнала A к B в смешанном образце (содержащем ДНК или РНК из злокачественной клетки и незлокачественной клетки) сравнивают с соответствующим значением для (I) образца, содержащего ДНК или РНК, полученные только из злокачественных клеток, или (II) образца, содержащего ДНК или РНК только из незлокачественных клеток. Различие в значениях используют для определения опухолевой фракции смешанного образца.
Согласно некоторым вариантам осуществления локусы, которые могут быть использованы для определения опухолевой фракции, выбираются на основе генотипа (I) образца, содержащего ДНК или РНК только из злокачественных клеток, и/или (II) образца, содержащего ДНК или РНК только из незлокачественных клеток. Согласно некоторым вариантам осуществления локусы выбирают на основе анализа смешанного образца, такие как локусы, для которых абсолютные или относительные количества каждого аллеля отличается от того, что можно было бы ожидать, если бы злокачественные и незлокачественные клетки характеризовались бы одинаковым генотипом в определенном локусе. Например, если злокачественные и незлокачественные клетки характеризуются одинаковым генотипом, можно было бы ожидать, что локусы производили бы сигнал B 0%, если все клетки представляют собой АА, сигнал B 50%, если все клетки представляют собой АВ, или сигнал B 100%, если все клетки представляют собой ВВ. Другие значения для сигнала B показывают, что генотип злокачественных и незлокачественных клеток различается в этом локусе и, таким образом, что локус может быть использован для определения опухолевой фракции.
Согласно некоторым вариантам осуществления опухолевую фракцию, рассчитанную на основании аллелей в одном или нескольких локусов, сравнивают с опухолевой фракцией, рассчитанной с использованием одного или нескольких способов подсчета, раскрытых в настоящем документе.
Иллюстративные способы обнаружения фенотипа или анализа множественных мутаций
Согласно некоторым вариантам осуществления способ предусматривает анализ образца на совокупность мутаций, ассоциированных с заболеванием или нарушением (например, злокачественной опухолью) или повышенным риском развития заболевания или нарушения. Существуют сильные корреляции между событиями в пределах классов (например, классами злокачественных опухолей М или С), которые могут быть использованы для улучшения отношения сигнала к шуму способа и классификации опухолей в различных клинических подмножествах. Например, пограничные результаты для нескольких мутаций (например, нескольких CNV) на одной или нескольких хромосомах или хромосомных сегментах, рассматриваемых совместно, могут представлять собой очень сильный сигнал. Согласно некоторым вариантам осуществления определение наличия или отсутствия представляющих интерес множественных полиморфизмов или мутаций (например, 2, 3, 4, 5, 8, 10, 12, 15 или более) повышает чувствительность и/или специфичность определения наличия или отсутствия заболевания или нарушения, такого как злокачественная опухоль, или повышенный риск развития заболевания или нарушения, такого как злокачественная опухоль. Согласно некоторым вариантам осуществления корреляция между событиями в нескольких хромосомах используется для более серьезной оценки сигнала, по сравнению с оценкой каждого из них по отдельности. Разработка самого способа может быть оптимизирована, чтобы наилучшим образом классифицировать опухоли. Это может быть очень полезным для раннего выявления и скрининга рецидива, где чувствительность к одной конкретной мутации/CNV может иметь первостепенное значение. Согласно некоторым вариантам осуществления эти события не всегда коррелируют, но имеется вероятность их корреляции. Согласно некоторым вариантам осуществления используется формулировка оценки матрицы с матрицей ковариации шума, которая воспроизводит недиагональные термины.
Согласно некоторым вариантам осуществления настоящее изобретение относится к способу обнаружения фенотипа (например, злокачественного фенотипа) у индивидуума, причем фенотип определяется наличием по меньшей мере одной из совокупностей мутаций. Согласно некоторым вариантам осуществления способ предусматривает получение измерений ДНК или РНК в образце ДНК или РНК из одной или нескольких клеток от индивидуума, причем у одной или нескольких из клеток подозревается наличие фенотипа; и анализ измерений ДНК или РНК для определения, для каждой из мутаций в совокупности мутаций, вероятности того, что по меньшей мере одна из клеток содержит эту мутацию. Согласно некоторым вариантам осуществления способ предусматривает определение того, что индивидуум характеризуется наличием фенотипа, если (I) по меньшей мере для одной из мутаций правдоподобие того, что по меньшей мере одна из клеток содержит эти мутации больше, чем пороговое значение, или (II) по меньшей мере для одной из мутаций, правдоподобие того, что по меньшей мере одна из клеток содержит эти мутации меньше, чем пороговое значение, и для множества мутаций, совокупное правдоподобие того, что по меньшей мере одна из клеток содержит по меньшей мере одну из мутаций больше, чем пороговое значение. Согласно некоторым вариантам осуществления одна или нескольких клеток содержат подмножество или все мутации в совокупности мутаций. Согласно некоторым вариантам осуществления подмножество мутаций связано со злокачественной опухолью или повышенным риском развития злокачественной опухоли. Согласно некоторым вариантам осуществления совокупность мутаций включает в себя подмножество или все мутации в классе М злокачественных мутаций (публикация Ciriello, Nat Genet. 45(10): 1127-1133, 2013, doi: 10.1038/ng.2762, которая полностью включена в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления совокупность мутаций включает в себя подмножество или все мутации в классе C злокачественных мутаций (Ciriello, выше). Согласно некоторым вариантам осуществления образец включает в себя внеклеточную ДНК или РНК. Согласно некоторым вариантам осуществления измерения ДНК или РНК включают в себя измерения (например, количество каждого аллеля в каждом локусе) в совокупности полиморфных локусов на одной или нескольких представляющих интерес хромосомах или хромосомных сегментах.
Иллюстративные способы исследования на отцовство или исследования на генетическое родство
Способы согласно настоящему изобретению могут быть использованы для повышения точности исследования на отцовство или других исследований на генетическое родство (смотрите, например, публикацию патента США №2012/0122701, поданную 22 декабря 2011 г., которая полностью включена в настоящий документ посредством ссылки). Например, способ мультиплексной ПЦР может позволить проанализировать тысячи полиморфных локусов (таких как SNP) для использования в алгоритме PARENTAL SUPPORT, описанном в настоящем документе, чтобы определить представляет ли собой предполагаемый отец биологического отца плода. Согласно некоторым вариантам осуществления настоящее изобретение относится к способу для установления того, является ли предполагаемый отец биологическим отцом плода, которого вынашивает беременная мать. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для предполагаемого отца (например, с использованием других описанных в настоящем документе способов для фазирования генетических данных), причем фазированные генетические данные содержат идентификацию присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у предполагаемого отца. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в смешанном образце ДНК, содержащем ДНК плода и ДНК матери от матери плода, путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления способ предусматривает вычисление на компьютере ожидаемых генетических данных для смешанного образца ДНК из фазированных генетических данных для предполагаемого отца; определение на компьютере вероятности того, что предполагаемый отец представляет собой биологического отца плода путем сравнения с получением генетических данных, сделанным на смешанном образце ДНК с ожидаемыми генетическими данными для смешанного образца ДНК; а также установление того, является ли предполагаемый отец биологическим отцом плода с использованием определенной вероятности того, что предполагаемый отец представляет собой биологического отца плода. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для биологической матери плода (например, с использованием другого из способов, описанных в настоящем документе, для фазирования генетических данных), причем фазированные генетические данные содержат идентификацию присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у матери. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для плода (например, с использованием другого из способов, описанных в настоящем документе, для фазирования генетических данных), причем фазированные генетические данные содержат идентификацию присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у плода. Согласно некоторым вариантам осуществления способ предусматривает вычисление на компьютере ожидаемых генетических данных для смешанного образца ДНК с использованием фазированных генетических данных для предполагаемого отца и использованием фазированных генетических данных для матери и/или фазированных генетических данных для плода.
Согласно некоторым вариантам осуществления настоящее изобретение относится к способу установления того, является ли предполагаемый отец биологическим отцом плода, который вынашивает беременная мать. Согласно некоторым вариантам осуществления способ предусматривает получение фазированных генетических данных для предполагаемого отца (например, с использованием другого из способов, описанных в настоящем документе, для фазирования генетических данных), причем фазированные генетические данные содержат идентичность присутствующего аллеля для каждого локуса в совокупности полиморфных локусов на первом гомологичном хромосомном сегменте и втором гомологичном хромосомном сегменте у предполагаемого отца. Согласно некоторым вариантам осуществления способ предусматривает получение генетических данных в совокупности полиморфных локусов на хромосоме или хромосомном сегменте в смешанном образце ДНК, содержащем ДНК плода и ДНК матери, от матери плода путем измерения количества каждого аллеля в каждом локусе. Согласно некоторым вариантам осуществления способ предусматривает идентификацию (I) аллелей, которые присутствуют в ДНК плода, но отсутствуют в материнской ДНК в полиморфных локусах, и/или идентификацию (I) аллелей, которые отсутствуют в ДНК плода и материнской ДНК в полиморфных локусах. Согласно некоторым вариантам осуществления способ предусматривает определение на компьютере вероятности того, что предполагаемый отец представляет собой биологического отца плода; причем определение предусматривает: (1) сравнение (I) аллелей, которые присутствуют в фетальной ДНК, но отсутствуют в материнской ДНК, в полиморфных локусах с (II) аллелями в соответствующих полиморфных локусах в генетическом материале от предполагаемого отца, и/или (2) сравнение (I) аллелей, которые отсутствуют в ДНК плода и ДНК матери в полиморфных локусах, с (II) аллелями в соответствующих полиморфных локусах в генетическом материале от предполагаемого отца; и установление того, является ли предполагаемый отец биологическим отцом плода с использованием определенной вероятности того, что предполагаемый отец представляет собой биологического отца плода.
Согласно некоторым вариантам осуществления описанный выше способ определения того, является ли предполагаемый отец биологическим отцом плода, используется для определения, является ли предполагаемый родственник (например, бабушка или дедушка, родной брат/сестра, тетя или дядя) плода фактическим биологическим родственником плода (например, с использованием генетических данных предполагаемого родственника вместо генетических данных предполагаемого отца).
Иллюстративные комбинации способов
Для повышения точности результатов выполняют два или несколько способов (например, любой из способов согласно настоящему изобретению или любой известный способ) обнаружения наличия или отсутствия CNV. Согласно некоторым вариантам осуществления выполняют один или несколько способов анализа фактора (например, любой из описанных в настоящем документе способов или любой известный способ), указывающих на наличие или отсутствие заболевания или нарушения или повышенный риск развития заболевания или нарушения.
Согласно некоторым вариантам осуществления стандартные математические техники используются для вычисления ковариации и/или корреляции между двумя или более способами. Стандартные математические техники могут быть также использованы для определения совокупной вероятности конкретной гипотезы, основанной на двух или нескольких тестах. Иллюстративные техники включают в себя мета-анализ, комбинированный тест вероятности Фишера для независимых испытаний, способ Брауна для объединения зависимых p-значений с известными ковариациями и метод Коста для комбинирования зависимых p-значений с неизвестными ковариации. В тех случаях, когда правдоподобие определяют первым способом ортогональным путем или путем, который не связан с путем, в котором правдоподобие определяют для второго способа, объединение правдоподобий не вызывает затруднений и может быть сделано путем умножения и нормализации или с использованием формулы, такой как:
Rобъед.=R1R2/[R1R2+(1-R1)(1-R2)]
Rобъед. представляет собой объединенное правдоподобие, а R1 и R2 представляют собой отдельные правдоподобия. Например, если правдоподобие трисомии из способа 1 составляет 90% и правдоподобие трисомии из способа 2 составляет 95%, то объединение выходов из двух способов позволяет клиницисту сделать вывод о том, что плод представляет собой плод с трисомией с вероятностью (0,90)(0,95)/[(0,90)(0,95)+(1-0,90)(1-0,95)]=99,42%. В тех случаях, когда первый и второй способы не представляют собой ортогональные, то есть, где существует корреляция между этими двумя способами, то правдоподобия все еще могут быть объединены.
Иллюстративные способы анализа нескольких факторов или переменных описаны в патенте США №8024128, выданном 20 сентября 2011 г.; публикации США №2007/0027636, поданной 31 июля 2006 г., и в публикации США №2007/0178501, поданной 6 декабря 2006 г., каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно различным вариантам осуществления совместная вероятность конкретной гипотезы или диагноза превышает 80, 85, 90, 92, 94, 96, 98, 99 или 99,9% или больше, чем какая-либо другая пороговая величина.
Предел обнаружения
Согласно некоторым вариантам осуществления предел обнаружения мутации (например, SNV или CNV) способа согласно настоящему изобретению составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее. Согласно некоторым вариантам осуществления предел обнаружения мутации (например, SNV или CNV) способа согласно настоящему изобретению составляет от 15 до 0,005%, например, от 10 до 0,005%, от 10 до 0,01%, от 10 до 0,1%, от 5 до 0,005%, от 5 до 0,01%, от 5 до 0,1%, от 1 до 0,005%, от 1 до 0,01%, от 1 до 0,1%, от 0,5 до 0,005%, от 0,5 до 0,01%, от 0,5 до 0,1% или от 0,1 до 0,01, включительно. Согласно некоторым вариантам осуществления предел обнаружения таков, что обнаруживается (или может быть обнаружена) мутация (например, SNV или CNV), присутствие которой составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее от молекулы ДНК или РНК с этим локусом в образце (например, образце вкДНК или вкРНК). Например, мутация может быть обнаружена, даже если ее присутствие составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее от молекул ДНК или РНК, у которых есть этот локус с мутацией в локусе (вместо, например, версии дикого типа или немутированной версии локуса или иной мутации в этом локусе). Согласно некоторым вариантам осуществления предел обнаружения таков, что обнаруживается (или может быть обнаружена) мутация (например, SNV или CNV), присутствие которой составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее от молекул ДНК или РНК в образце (например, образце вкДНК или вкРНК). Согласно некоторым вариантам осуществления, в которых CNV представляет собой делецию, делеция может быть обнаружена, даже если ее присутствие составляет только 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее молекул ДНК или РНК, которые содержат представляющую интерес область, которая может содержать или не содержать делеции в образце. Согласно некоторым вариантам осуществления, в которых CNV представляет собой делецию, делеция может быть обнаружена, даже если ее присутствие составляет только 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее молекул ДНК или РНК в образце. Согласно некоторым вариантам осуществления, в которых CNV представляет собой дупликацию, дупликация может быть обнаружена, даже если присутствие дополнительно продублированной ДНК или РНК составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее молекул ДНК или РНК, которые содержат представляющую интерес область, которая может быть продублирована или не продублирована в образце. Согласно некоторым вариантам осуществления, в которых CNV представляет собой дупликацию, дупликация может быть обнаружена, даже если присутствие дополнительно продублированной ДНК или РНК составляет 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% или менее молекул ДНК или РНК в образце. В примере 6 приведены иллюстративные способы для вычисления предела обнаружения. Согласно некоторым вариантам осуществления используется способ "LOD-zs5.0-mr5" примера 6.
Иллюстративные образцы
Согласно некоторым вариантам осуществления любого из аспектов настоящего изобретения, образец включает в себя клеточный и/или внеклеточный генетический материал из клеток, в которых подозревается наличие делеции или дупликации, например, клеток, которые подозреваются в злокачественности. Согласно некоторым вариантам осуществления образец содержит любую ткань или биологическую жидкость, предположительно содержащую клетки, ДНК или РНК с делецией или дупликацией, такие как злокачественные клетки, ДНК или РНК. Генетические измерения, используемые в рамках этих способов, могут быть выполнены на любом образце, содержащем ДНК или РНК, например, но без ограничения, на ткани, крови, сыворотке, плазме, моче, волосах, слезах, слюне, коже, ногтях, фекалиях, желчи, лимфе, цервикальной слизи, семенной жидкости или других клетках или материалах, содержащих нуклеиновые кислоты. Образцы могут включать в себя любой тип клеток или ДНК или РНК из любого типа клеток (например, клетки из любого органа или ткани, подозреваемых в злокачественности, или нейронов). Согласно некоторым вариантам осуществления образец включает в себя ядерную и/или митохондриальную ДНК. Согласно некоторым вариантам осуществления образец происходит от любого из раскрытых в настоящем документе индивидуумов-мишеней. Согласно некоторым вариантам осуществления индивидуум-мишень представляет собой рожденного индивидуума, вынашиваемый плод, невынашиваемый плод, например, образец продуктов оплодотворенной яйцеклетки, эмбриона или любого другого индивидуума.
Иллюстративные образцы включают в себя те, которые содержат вкДНК или вкРНК. Согласно некоторым вариантам осуществления вкДНК доступна для анализа, не требуя стадии лизирования клеток. Внеклеточная ДНК может быть получена из различных тканей, таких как ткани, которые находятся в жидкой форме, например, кровь, плазма, лимфа, асцитная жидкость или спинно-мозговая жидкость. В некоторых случаях вкДНК состоит из ДНК, полученной из эмбриональных клеток. В некоторых случаях вкДНК состоит из ДНК, полученной, как из фетальных, так и материнских клеток. В некоторых случаях вкДНК выделяют из плазмы, которая была выделена из цельной крови, которую центрифугировали для удаления клеточного материала. ВкДНК может представлять собой смесь ДНК, полученную из клеток-мишеней (например, злокачественных клеток) и клеток-немишеней (например, незлокачественных клеток).
Согласно некоторым вариантам осуществления образец содержит или предположительно содержит смесь ДНК (или РНК), такую как смесь злокачественной ДНК (или РНК), а также незлокачественной ДНК (или РНК). Согласно некоторым вариантам осуществления по меньшей мере 0,5, 1, 3, 5, 7, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 92, 94, 95, 96, 98, 99 или 100% клеток в образце представляют собой злокачественные клетки. Согласно некоторым вариантам осуществления по меньшей мере 0,5, 1, 3, 5, 7, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 92, 94, 95, 96, 98, 99 или 100% ДНК (например, вкДНК) или РНК (например, вкРНК) в образце происходят из злокачественной клетки (клеток). Согласно различным вариантам осуществления процент клеток в образце, которые представляют собой злокачественные клетки, составляет от 0,5 до 99%, например, от 1 до 95%, от 5 до 95%, от 10 до 90%, от 5 до 70%, от 10 до 70%, от 20 до 90% или от 20 до 70%, включительно. Согласно некоторым вариантам осуществления образец обогащен злокачественными клетками или ДНК или РНК из злокачественных клеток. Согласно некоторым вариантам осуществления в котором образец обогащен злокачественными клетками, по меньшей мере 0,5, 1, 2, 3, 4, 5, 6, 7, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 92, 94, 95, 96, 98, 99 или 100% клеток в обогащенном образце представляют собой злокачественные клетки. Согласно некоторым вариантам осуществления, в которых образец обогащен ДНК или РНК из злокачественных клеток, по меньшей мере 0,5, 1, 2, 3, 4, 5, 6, 7, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 92, 94, 95, 96, 98, 99 или 100% ДНК или РНК в обогащенном образце происходят из злокачественной клетки(ок). Согласно некоторым вариантам осуществления сортировка клеток (например, сортировка флуоресцентно-активированных клеток (FACS)) используется для обогащения злокачественными клетками (публикации Barteneva et. al., Biochim Biophys Acta., 1836(1): 105-22, Aug 2013. doi: 10.1016/j.bbcan.2013.02.004. Epub 2013 Feb 24 и Ibrahim et al., Adv Biochem Eng Biotechnol. 106: 19-39, 2007, каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления любого из аспектов согласно настоящему изобретению образец содержит любую ткань, которая предполагает по меньшей мере частичное фетальное происхождение. Согласно некоторым вариантам осуществления образец включает в себя клеточный и/или внеклеточный генетический материал от плода, загрязняющий клеточный и/или внеклеточный генетический материал (например, генетический материал от матери плода) или их сочетание. Согласно некоторым вариантам осуществления образец содержит клеточный генетический материал от плода, загрязняющий клеточный генетический материал или их комбинацию.
Согласно некоторым вариантам осуществления образец происходит от вынашиваемого плода. Согласно некоторым вариантам осуществления образец происходит от невынашиваемого плода, например, продуктов образца оплодотворенной яйцеклетки или образца из любой ткани плода после гибели плода. Согласно некоторым вариантам осуществления образец представляет собой образец цельной крови матери, клетки, выделенные из образца крови матери, образец плазмы матери, образец сыворотки матери, образец амниоцентеза, образец плацентарной ткани (например, хорионбиопсию, децидуальную или плацентарную мембрану), образец цервикальной слизи или другой образец от плода. Согласно некоторым вариантам осуществления по меньшей мере 3, 5, 7, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 92, 94, 95, 96, 98, 99 или 100% клеток в образце представляют собой материнские клетки. Согласно различным вариантам осуществления процент клеток в образце, которые представляют собой материнские клетки, находится в пределах от 5 до 99%, например, от 10 до 95%, от 20 до 95%, от 30 до 90%, от 30 до 70%, от 40 до 90%, от 40 до 70%, от 50 до 90% или от 50 до 80%, включительно.
Согласно некоторым вариантам осуществления образец обогащен фетальными клетками. Согласно некоторым вариантам осуществления, в которых образец обогащен фетальными клетками, по меньшей мере 0,5, 1, 2, 3, 4, 5, 6, 7% или более клеток в обогащенном образце представляют собой клетки плода. Согласно некоторым вариантам осуществления процент клеток в образце, которые представляют собой клетки плода, составляет от 0,5 до 100%, например, от 1 до 99%, от 5 до 95%, от 10 до 95%, от 10 до 95%, от 20 до 90% или от 30 до 70%, включительно. Согласно некоторым вариантам осуществления образец обогащен ДНК плода. Согласно некоторым вариантам осуществления, в котором образец обогащен ДНК плода, по меньшей мере 0,5, 1, 2, 3, 4, 5, 6, 7% или более ДНК в обогащенном образце представляют собой ДНК плода. Согласно некоторым вариантам осуществления процент ДНК в образце, которые представляют собой ДНК плода, составляет от 0,5 до 100%, например, от 1 до 99%, от 5 до 95%, от 10 до 95%, от 10 до 95%, от 20 до 90% или от 30 до 70%, включительно.
Согласно некоторым вариантам осуществления образец включает в себя единственную клетку или включает в себя ДНК и/или РНК из одной клетки. Согласно некоторым вариантам осуществления множество отдельных клеток (например, по меньшей мере 5, 10, 20, 30, 40 или 50 клеток от того же субъекта или разных субъектов) анализируют параллельно. Согласно некоторым вариантам осуществления клетки от нескольких образцов от того же индивидуума объединяют, что уменьшает объем работ по сравнению с анализом образцов по отдельности. Объединение нескольких образцов может также позволить одновременное исследование нескольких тканей на наличие злокачественной опухоли (которые могут быть использованы для обеспечения или более тщательного скрининга на наличие злокачественной опухоли или чтобы определить, имеются ли злокачественные метастазы в другие ткани).
Согласно некоторым вариантам осуществления образец содержит одну клетку или небольшое число клеток, например, 2, 3, 5, 6, 7, 8, 9 или 10 клеток. Согласно некоторым вариантам осуществления настоящего изобретения образец содержит от 1 до 100, от 100 до 500 или от 500 до 1000 клеток, включительно. Согласно некоторым вариантам осуществления образец содержит от 1 до 10 пикограмм, от 10 до 100 пикограмм, от 100 пикограмм до 1 нанограммов, от 1 до 10 нанограмм, от 10 до 100 нанограмм или 100 нанограмм до 1 микрограмма РНК и/или ДНК, включительно.
Согласно некоторым вариантам осуществления образец заключают в парафиновую пленку. Согласно некоторым вариантам осуществления образец сохраняется с консервантом, таким как формальдегид, и необязательно, заключенным в парафин, что может вызывать сшивание ДНК таким образом, что он становится менее доступным для ПЦР. Согласно некоторым вариантам осуществления образец представляет собой фиксированный в формальдегиде заключенный в парафин (FFPE) образец. Согласно некоторым вариантам осуществления образец представляет собой свежий образец (например, образец, полученный в течение 1 или 2 дней анализа). Согласно некоторым вариантам осуществления образец замораживают перед анализом. Согласно некоторым вариантам осуществления образец представляет собой исторический образец.
Эти образцы могут быть использованы в любом из способов согласно настоящему изобретению.
Иллюстративные способы подготовки образцов
Согласно некоторым вариантам осуществления способ предусматривает выделение или очистку ДНК и/или РНК. Существует целый ряд стандартных процедур, известных в настоящей области техники, для достижения такого конца. Согласно некоторым вариантам осуществления образец может быть центрифугирован для отделения различных слоев. Согласно некоторым вариантам осуществления ДНК или РНК может быть выделена с использованием фильтрации. Согласно некоторым вариантам осуществления подготовка ДНК или РНК может включать в себя амплификацию, сепарацию, очистку с помощью хроматографии, жидкость-жидкостное разделение, выделение, преимущественное обогащение, преимущественную амплификацию, направленную амплификацию или любую из ряда других техник, либо известных в настоящей области техники, либо описанных в настоящем документе. Согласно некоторым вариантам осуществления для выделения ДНК используется РНКаза для разрушения РНК. Согласно некоторым вариантам осуществления для выделения РНК используется ДНКаза (например, ДНКаза I от Invitrogen, Carlsbad, СА, США) для разрушения ДНК. Согласно некоторым вариантам осуществления используется мини набор RNeasy (QIAGEN) для выделения РНК в соответствии с протоколом производителя. Согласно некоторым вариантам осуществления небольшие молекулы РНК выделяют с использованием набора mirVana PARIS (Амбион, Остин, штат Техас, США) в соответствии с протоколом производителя (публикация Gu et al., J. Neurochem. 122: 641-649, 2012, которая полностью включена в настоящий документ посредством ссылки). Концентрация и чистота РНК необязательно может быть определена с использованием Nanovue (GE Healthcare, Piscataway, NJ, США), a целостность РНК необязательно может быть измерена путем использования биоанализатора 2100 (Agilent Technologies, Санта-Клара, Калифорния, США) (публикация Gu et al., J. Neurochem. 122: 641-649, 2012, которая полностью включена в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления TRIZOL или RNAlater (Ambion) используют для стабилизации РНК в процессе хранения.
Согласно некоторым вариантам осуществления добавляют универсальные меченые адаптеры, чтобы получить библиотеку. До лигирования ДНК-образец может быть тупоконечным, а затем одно аденозиновое основание добавляют к 3'-концу. До лигирования ДНК может быть расщеплена с использованием рестриктазы или некоторых других способов расщепления. При лигации 3'-аденозиных фрагментов образца и комплементарного 3'-тирозинового липкого конца адаптора можно повысить эффективность лигации. Согласно некоторым вариантам осуществления лигирование адаптора выполняется с использованием набора для лигирования, найденном в наборе AGILENT SURESELECT. Согласно некоторым вариантам осуществления библиотеку амплифицируют с использованием универсальных праймеров. Согласно одному варианту осуществления амплифицированную библиотеку фракционируют путем сепарации по размеру или с использованием таких продуктов, как гранулы AGENCOURT AMPURE или других подобных способов. Согласно некоторым вариантам осуществления ПЦР-амплификацию используют для амплификации локусов-мишеней. Согласно некоторым вариантам осуществления амплифицированную ДНК секвенируют (например, секвенирование с использованием секвенсора ILLUMINA IIGAX или HiSeq). Согласно некоторым вариантам осуществления амплифицированную ДНК секвенируют с каждого конца амплифицированной ДНК, чтобы уменьшить количество ошибок секвенирования. Если находится ошибка последовательности в конкретном основании при секвенировании с одного конца амплифицированной ДНК, менее вероятно, что будет ошибка последовательности в комплементарном основании при секвенировании с другой стороны амплифицированной ДНК (по сравнению с секвенированием несколько раз с одного и того же конца амплифицированной ДНК).
Согласно некоторым вариантам осуществления амплификацию целого генома (WGA) используют для амплификации образца нуклеиновой кислоты. Существует целый ряд способов, доступных для WGA: опосредованная лигированием ПЦР (LM-PCR), ПЦР с вырожденным олигонуклеотидным праймером (DOP-PCR) и амплификации с множественным вытеснением цепи (MDA). При LM-PCR короткие ДНК-последовательности, называемые адапторы, лигируют с тупоконечной ДНК. Эти адаптеры содержат универсальные последовательности амплификации, которые используют для амплификации ДНК с помощью ПЦР. При DOP-PCR случайные праймеры, которые также содержат универсальные последовательности амплификации, используются в первом раунде отжига и ПЦР. Затем второй раунд ПЦР используется для дальнейшей амплификации последовательностей с универсальными праймерными последовательностями. MDA использует phi-29-полимеразу, которая представляет собой высоко процессивный и неспецифический фермент, который реплицирует ДНК и используется для одноклеточного анализа. Согласно некоторым вариантам осуществления WGA не выполняется.
Согласно некоторым вариантам осуществления селективную амплификацию или обогащение используют для амплификации или обогащения локусов-мишеней. Согласно некоторым вариантам осуществления техника амплификации и/или селективного обогащения может включать в себя такую ПЦР, как опосредованная лигацией ПЦР, захват фрагментов путем гибридизации, инвертируемые молекулярные зонды или другие циркулирующие зонды. Согласно некоторым вариантам осуществления используют количественную ПЦР в режиме реального времени (RT-qPCR), цифровую ПЦР или эмульсионную ПЦР, реакцию достройки по одному аллельному основанию с последующей масс-спектрометрией (публикация Hung et al., J Clin Pathol 62: 308-313, 2009, которая полностью включена в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления захват с помощью гибридизации с гибридными зондами захвата используют для предпочтительного обогащения ДНК. Согласно некоторым вариантам осуществления способы амплификации или селективного обогащения могут включать в себя использование зондов, где, при правильной гибридизации с последовательностью-мишенью, 3'-конец или 5'-конец нуклеотидного зонда отделяют от полиморфного сайта полиморфного аллеля посредством небольшого числа нуклеотидов. Такое отделение снижает преимущественную амплификацию одного аллеля, названную аллельной систематической погрешностью. Это улучшение по сравнению со способами, которые связаны с использованием зондов, где 3'-конец или 5'-конец правильно гибридизированного зонда непосредственно примыкает или находится в непосредственной близости от полиморфного сайта аллеля. Согласно одному варианту осуществления зонды, в которых область гибридизации может содержать или точно содержит полиморфный сайт, исключаются. Полиморфные сайты в сайте гибридизации могут вызывать неравную гибридизацию или ингибировать гибридизацию вообще в некоторых аллелях, приводя к преимущественной амплификации определенных аллелей. Эти варианты осуществления представляют собой улучшения по сравнению с другими способами, которые включают в себя нацеленную амплификацию и/или селективное обогащение в том, что они лучше сохраняют исходные частоты аллелей образца в каждом полиморфном локусе, представляет ли собой образец чистый геномный образец от одного индивидуума или смеси индивидуумов.
Согласно некоторым вариантам осуществления ПЦР (называемую мини-ПЦР) используют для получения очень коротких ампликонов (заявка на патент США №13/683604, поданная 21 ноября 2012 г., публикация заявки США №2013/0123120, заявка на патент США №13/300235, поданная 18 ноября 2011 г., публикация заявки США №2012/0270212, поданная 18 ноября 2011 г. и патент США с серийным №61/994791, поданный 16 мая 2014 г., каждый из которых полностью включен в настоящий документ посредством ссылки). ВкДНК (например, фетальная вкДНК в сыворотке крови матери или некротически или апоптически высвобожденная злокачественная вкДНК) представляет собой сильно фрагментированную. Для фетальной вкДНК размеры фрагментов распределены приблизительно по гауссовому распределению со средним значением 160 п.н., стандартное отклонение 15 п.н., минимальный размер приблизительно 100 п.н., а максимальный размер приблизительно 220 п.н. Полиморфный сайт одного конкретного локуса-мишени может занимать любое положение от начала до конца между различными фрагментами, происходящими из этого локуса. Поскольку фрагменты вкДНК являются короткими, правдоподобие обоих присутствующих участков праймеров и правдоподобие фрагмента длиной L, содержащего участки как прямого, так и обратного праймера, представляет собой отношение длины ампликона к длине фрагмента. В идеальных условиях анализы, в которых ампликон составляет 45, 50, 55, 60, 65 или 70 п.н., будут успешно амплифицировать 72%, 69%, 66%, 63%, 59% или 56%, соответственно, имеющихся в наличии шаблонных молекул фрагментов. Согласно некоторым вариантам осуществления, которые наиболее предпочтительно касаются вкДНК из образцов индивидуумов, у которых подозревается наличие злокачественной опухоли, вкДНК амплифицируют с использованием праймеров, которые дают максимальную длину ампликона 85, 80, 75 или 70 п.н., а согласно некоторым предпочтительным вариантам осуществления 75 п.н., и которые характеризуются температурой плавления от 50 до 65°C, а согласно некоторым предпочтительным вариантам осуществления от 54 до 60,5°C. Длина ампликона представляет собой расстоянием между 5'-концами прямого и обратного примирующих сайтов. Длина ампликона, которая короче, чем те, которые обычно используют в настоящей области техники, может привести к более эффективным измерениям желаемых полиморфных локусов посредством необходимости только коротких прочтений последовательности. Согласно одному варианту осуществления значительная фракция ампликонов составляет менее 100 п.н., менее 90 п.н., менее 80 п.н., менее 70 п.н., менее 65 п.н., менее 60 п.н., менее 55 п.н., менее 50 п.н. или менее 45 п.н..
Согласно некоторым вариантам осуществления амплификацию осуществляют с использованием прямой мультиплексной ПЦР, последовательной ПЦР, вложенной ПЦР, дважды вложенной ПЦР, полуторносторонней вложенной ПЦР, полностью вложенной ПЦР, односторонней полностью вложенной ПЦР, односторонней вложенной ПЦР, полугнездовой ПЦР, трехкратно полу-гнездовой ПЦР, полугнездовую ПЦР, односторонней полугнездовой ПЦР, реверсной полугнездовой ПЦР или односторонней ПЦР, которые описаны в заявке на патент США №13/683604, поданной 21 ноября 2012 г., публикации США №2013/0123120, заявке на патент США №13/300235, поданной 18 ноября 2011 г., публикации США №2012/0270212 и патенте США с серийным №61/994791, поданным 16 мая 2014 г., которые полностью включены в настоящий документ посредством ссылки. Если желательно, любой из этих способов может быть использован для мини-ПЦР.
При необходимости, стадия удлинения ПЦР-амплификации может быть ограничена с точки зрения времени, чтобы уменьшить амплификацию из фрагментов длиной более 200 нуклеотидов, 300 нуклеотидов, 400 нуклеотидов, 500 нуклеотидов или 1000 нуклеотидов. Это может привести к обогащению фрагментированной или более короткой ДНК (такой как фетальная ДНК или ДНК из злокачественных клеток, претерпевших апоптоз или некроз) и улучшению производительности теста.
Согласно некоторым вариантам осуществления используется мультиплексная ПЦР. Согласно некоторым вариантам осуществления способ амплификации локусов-мишеней в образце нуклеиновой кислоты предусматривает (I) контактирование образца нуклеиновой кислоты с библиотекой праймеров, которые одновременно гибридизуют по меньшей мере с 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных локусов-мишеней для получения реакционной смеси; и (II) подвергание реакционной смеси воздействию реакционных условий для достройки праймером (например, условий ПЦР) для производства амплифицированных продуктов, которые включают в себя ампликоны-мишени. Согласно некоторым вариантам осуществления амплифицируют по меньшей мере 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 или 99,5% локусов-мишеней. Согласно различным вариантам осуществления менее чем 60, 50, 40, 30, 20, 10, 5, 4, 3, 2, 1, 0,5, 0,25, 0,1 или 0,05% амплифицированных продуктов представляют собой димеры праймеров. Согласно некоторым вариантам осуществления праймеры находятся в растворе (например, растворенные в жидкой фазе, а не в твердой фазе). Согласно некоторым вариантам осуществления праймеры находятся в растворе и не иммобилизованы на твердом носителе. Согласно некоторым вариантам осуществления праймеры не представляют собой часть микрочипов. Согласно некоторым вариантам осуществления праймеры не включают в себя молекулярные инвертируемые зонды (MIP).
Согласно некоторым вариантам осуществления два или более (например, 3 или 4) ампликона-мишени (такие как ампликоны из раскрытого в настоящем документе способа миниПЦР) лигируют вместе и затем секвенируют лигированные продукты. Объединение нескольких ампликонов в один лигированный продукт повышает эффективность последующей стадии секвенирования. Согласно некоторым вариантам осуществления ампликоны-мишени составляют менее чем 150, 100, 90, 75 или 50 п.н. в длину до лигирования. Селективное обогащение и/или амплификация может включать в себя мечение каждой отдельной молекулы различными метками, молекулярными штрих-кодами, тегами для амплификации и/или тегами для секвенирования. Согласно некоторым вариантам осуществления амплифицированные продукты анализируют с помощью секвенирования (например, секвенирования с высокой пропускной способностью) или путем гибридизации с матрицей, такой как матрица SNP, матрица ILLUMINA INFINIUM или генный чип AFFYMETRIX. Согласно некоторым вариантам осуществления используют секвенирование нанопор, такое как технология секвенирования нанопор, разработанная Genia (смотрите, например, в интернете по адресу geniachip.com/technology~~pobj, который полностью включен в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления используется дуплексное секвенирование (публикация Schmitt et al., "Detection of ultra-rare mutations by next-generation sequencing," Proc Natl Acad Sci USA. 109(36): 14508-14513, 2012, которая полностью включена в настоящий документ посредством ссылки). Такой подход значительно снижает количество ошибок посредством независимого мечения и секвенирования каждой из двух нитей дуплекса ДНК. Поскольку две нити комплементарны, истинные мутации встречаются в том же самом положении в обеих нитях. В отличие от этого, ошибки ПЦР или секвенирования приводят к мутациям только в одной нити и, таким образом, могут считаться технической ошибкой. Согласно некоторым вариантам осуществления способ предусматривает мечение обеих нитей дуплексной ДНК случайной, но комплементарной двухцепочечной нуклеотидной последовательностью, указанной в качестве дуплексного тега. Двухцепочечные теговые последовательности включены в стандартные адапторы секвенирования путем введения сначала одноцепочечной рандомизированной нуклеотидной последовательности в одну адапторную нить, а затем удлинения противоположной нити с помощью ДНК-полимеразы с образованием комплементарного двухцепочечного тега. После лигирования меченых адаптеров к фрагментированной ДНК, индивидуально меченные нити амплифицируют с помощью ПЦР из асимметричных сайтов праймеров на адапторных хвостах и подвергают секвенированию спаренных концов. Согласно некоторым вариантам осуществления образец (например, образец ДНК или РНК) делится на множество фракций, таких как различные лунки (например, лунки WaferGen SmartChip). Деление образца на различные фракции (например, по меньшей мере на 5, 10, 20, 50, 75, 100, 150, 200 или 300 фракций) может увеличить чувствительность анализа, так как процент молекул с мутацией выше в некоторых из лунок, чем в общей выборке. Согласно некоторым вариантам осуществления каждая фракция содержит менее чем 500,400,200,100, 50,20, 10, 5, 2 или 1 молекулу ДНК или РНК. Согласно некоторым вариантам осуществления молекулы в каждой фракции секвенируют по отдельности. Согласно некоторым вариантам осуществления тот же штрих-код (например, случайную или отличную от человеческой последовательность) добавляют ко всем молекулам в той же фракции (например, путем амплификации с праймером, содержащим штрих-код или путем лигирования штрих-кода), а также различные штрих-коды добавляют к молекулам в различных фракциях. Эти молекулы-штрих-коды могут быть объединены и секвенировали вместе. Согласно некоторым вариантам осуществления молекулы амплифицируют перед тем, как они будут объединены и секвенированы, например, с использованием вложенной ПЦР. Согласно некоторым вариантам осуществления используют один прямой и два обратных праймера или два прямых и один обратный праймер.
Согласно некоторым вариантам осуществления обнаруживается (или может быть обнаружена) мутация (такая как SNV или CNV), которая присутствует менее чем в 10, 5, 2, 1, 0,5, 0,1, 0,05, 0,01 или 0,005% молекул ДНК или РНК в образце (например, образце вкДНК или вкРНК). Согласно некоторым вариантам осуществления обнаруживается (или может быть обнаружена) мутация (такая как SNV или CNV), которая присутствует менее чем в 1000, 500, 100, 50, 20, 10, 5, 4, 3 или 2 исходных молекулах ДНК или РНК (до амплификации) в образце (например, образце вкДНК или вкРНК из, например, образца крови). Согласно некоторым вариантам осуществления обнаруживается (или может быть обнаружена) мутация (такая как SNV или CNV), которая присутствует только в 1 исходной молекуле ДНК или РНК (до амплификации) в образце (например, образце вкДНК или вкРНК, например, из образца крови).
Например, если предел обнаружения мутации (например, однонуклеотидного варианта (SNV)) составляет 0,1%, значит мутация, присутствующая в 0,01%, может быть обнаружена путем деления фракции на множество фракций, таких как 100 лунок. Большинство лунок не содержат никаких копий мутации. Для несколько лунок с мутацией, мутация находится в гораздо более высоком проценте прочтений. В одном примере существует 20000 первоначальных копий ДНК из локуса-мишени и две из этих копий включают в себя представляющий интерес SNV. Если образец разделен на 100 лунок, 98 скважин содержат SNV, а 2 лунки содержат SNV в 0,5%. ДНК в каждой лунке может быть со штрих-кодом, амплифицирована, объединена с ДНК из других лунок и секвенирована. Лунки без SNV могут быть использованы для измерения фоновой частоты ошибок амплификации/секвенирования, чтобы определить, выше ли фонового уровня шума сигнал от лунок-выбросов.
Согласно некоторым вариантам осуществления амплифицированные продукты обнаруживают с помощью матрицы, например, матрицы, особенно микроматрицы с зондами к одной или нескольким представляющим интерес хромосомам (например, хромосоме 13, 18, 21, X, Y или любой их комбинации). Будет понятно, что, например, может быть использован коммерчески доступная микроматрица обнаружения SNP, такая как, например, анализ генотипирования Illumina (Сан-Диего, Калифорния) GoldenGate, DASL, Infmium или CytoSNP-12 или микроматричный продукт обнаружения SNP от Affymetrix, такой как микрочип OncoScan. Согласно некоторым вариантам осуществления фазированные генетические данные для одного или обоих биологических родителей эмбриона или плода используют для повышения точности анализа массива данных от одной клетки.
Согласно некоторым вариантам осуществления, включающим в себя секвенирование, глубина прочтений представляет собой число прочтений секвенирования, которые картированы для данного локуса. Глубина прочтений может быть нормализована по отношению к общему числу прочтений. Согласно некоторым вариантам осуществления для глубины прочтений образца, глубина прочтения представляет собой среднюю глубину прочтения нацеленных локусов. Согласно некоторым вариантам осуществления для глубины прочтений локуса, глубина прочтений представляет собой число прочтений, измеренных посредством секвенсорного картирования в этот локус. В общем случае, чем больше глубина прочтения локуса, тем ближе соотношение аллелей в локусе, как правило, представляет собой соотношение аллелей в исходном образце ДНК. Глубина прочтений может быть выражена различными способами, включая в себя без ограничения процент или долю. Так, например, в высокопараллельном секвенатре ДНК, таком как Illumina HISEQ, который, например, производит последовательность из 1 миллиона клонов, секвенирование одного локуса 3000 раз приводит к глубине прочтения 3000 прочтений в этом локусе. Доля прочтений в этом локусе составляет 3000, деленные на 1 млн всех прочтений, или 0,3% от общего количества прочтений.
Согласно некоторым вариантам осуществления получают аллельные данные, причем данные включают в себя аллельные количественное измерения, указывающие на число копий определенного аллеля полиморфного локуса. Согласно некоторым вариантам осуществления аллельные данные включают в себя количественные измерения, указывающие на число копий каждого из аллелей, наблюдаемых в полиморфном локусе. Как правило, количественные измерения получают для всех возможных аллелей представляющего интерес полиморфного локуса. Например, любой из описанных в предыдущих параграфах способов для определения аллеля для локуса SNP или SNV, например, микроматричный анализ, кПЦР, секвенирование ДНК, такое как высоко эффективное секвенирование ДНК, может быть использован для создания количественных измерений числа копий определенного аллеля полиморфного локуса. Это количественное измерение упоминается в настоящем документе как данные о частоте аллелей или измеренные генетические аллельные данные. Способы с использованием аллельных данных иногда называют количественными аллельными способами; в отличие от количественных способов, которые используют исключительно количественные данные из неполиморфных локусов или из полиморфных локусов, но без учета аллельной идентичности. Когда аллельные данные измеряют с помощью секвенирования с высокой пропускной способностью, аллельные данные, как правило, включают в себя число прочтений каждого аллельного картирования в представляющий интерес локус.
Согласно некоторым вариантам осуществления получают неаллельные данные, причем неаллельные данные включают в себя количественное измерение(я), указывающее на число копий конкретного локуса. Локус может быть полиморфным или неполиморфным. Согласно некоторым вариантам осуществления, когда локус является неполиморфным, неаллельные данные не содержат информацию об относительном или абсолютном количестве отдельных аллелей, которые могут присутствовать в этом локусе. Способы, использующие только неаллельные данные (то есть, количественные данные от неполиморфных аллелей или количественные данные от полиморфных локусов, но безотносительно к аллельной идентичности каждого фрагмента), называются количественными способами. Как правило, количественные измерения получают для всех возможных аллелей представляющего интерес полиморфного локуса, с одним значением, связанным с измеряемым количеством для всех аллелей в этом локусе, в общей сложности. Неаллельные данные для полиморфного локуса могут быть получены путем суммирования количественных аллельных данных для каждого аллеля в этом локусе. Когда аллельные данные измеряют с использованием высокопроизводительного секвенирования, неаллельные данные, как правило, включают в себя число прочтений картирования в представляющий интерес локус. Измерения при секвенировании могут указать на относительное и/или абсолютное число каждого из аллелей, присутствующих в локусе, и неаллельные данные включают в себя сумму прочтений, независимо от аллельной идентичности, отображающей в локусе. Согласно некоторым вариантам осуществления такой же набор измерений при секвенировании может быть использован для получения, как аллельных данных, так и неаллельных данных. Согласно некоторым вариантам осуществления аллельные данные используют в качестве части способа определения числа копий в представляющей интерес хромосоме, и получаемые неаллельные данные могут быть использованы как часть другого способа определения числа копий в представляющей интерес хромосоме. Согласно некоторым вариантам осуществления эти два способа представляют собой статистически ортогональные и объединяются, чтобы дать более точное определение числа копий в представляющей интерес хромосоме.
Согласно некоторым вариантам осуществления получение генетических данных включает в себя (I) получение информации о последовательности ДНК с помощью лабораторных способов, например, путем использования автоматизированного секвенатора ДНК с высокой пропускной способностью, или (II) получение информации, которая была ранее получена посредством лабораторных способов, причем информация передается в электронном виде, например, с помощью компьютера через интернет или с помощью электронного переноса от устройства секвенирования.
Дополнительные иллюстративные способы подготовки, амплификации и количественного определения образцов описаны в заявке на патент США №13/683604, поданной 21 ноября 2012 г. (публикации США №2013/0123120 и патенте США с серийным №61/994791, поданном 16 мая 2014 г., который полностью включен в настоящий документ посредством ссылки). Эти способы могут быть использованы для анализа любого из раскрытых в настоящем описании образцов.
Иллюстративные способы количественной оценки внеклеточной ДНК При желании, это количество или концентрация вкДНК или вкРНК могут быть измерены с использованием стандартных способов. Согласно некоторым вариантам осуществления определяют количество или концентрацию внеклеточной митохондриальной ДНК (вк мДНК). Согласно некоторым вариантам осуществления определяют количество или концентрацию внеклеточной ДНК, которая происходит от ядерной ДНК (вк яДНК). Согласно некоторым вариантам осуществления количество или концентрацию вк мДНК и вк яДНК определяют одновременно.
Согласно некоторым вариантам осуществления кПЦР используют для измерения вк яДНК и/или вк мДНК (публикация Kohler et al. "Levels of plasma circulating cell free nuclear and mitochondrial DNA as potential biomarkers for breast tumors." Mol Cancer 8: 105, 2009, 8: doi: 10.1186/1476-4598-8-105, которая полностью включена в настоящий документе посредством ссылки). Например, один или несколько локусов из вк яДНК (например, глицеральдегид-3-фосфатдегидрогеназы, GAPDH) и один или несколько локусов из вк мДНК (АТФазы 8, МТАТР 8) могут быть измерены с использованием мультиплексной кПЦР. Согласно некоторым вариантам осуществления флуоресцентно меченную ПЦР используют для измерения вк яДНК и/или вк мДНК (публикация Schwarzenbach et al., "Evaluation of cell-free tumour DNA and RNA in patients with breast cancer and benign breast disease." Mol Biosys 7: 2848-2854, 2011, которая полностью включена в настоящее описание посредством ссылки). Если это желательно, то распределение нормальности данных может быть определено с использованием стандартных способов, таких как тест Шапиро-Уилка. Если это желательно, содержание вк яДНК и вк мДНК можно сравнить с использованием стандартных способов, таких как тест Манна-Уитни-U. Согласно некоторым вариантам осуществления содержание вк яДНК и вк мДНК сравнивают с другими установленными прогностическими факторами с использованием стандартных способов, таких как тесты Манна-Уитни-U или Крускала-Уоллиса.
Иллюстративные способы амплификации, количественного определения и анализа РНК
Любой из следующих иллюстративных способов может быть использован для амплификации и необязательного количественного определения РНК, например, вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, микроРНК, митохондриальной РНК, рРНК или тРНК. Согласно некоторым вариантам осуществления миРНК представляет собой любую из молекул миРНК, перечисленных в базе данных, miRBase, доступной в интернете по адресу mirbase.org, который полностью включен в настоящий документ посредством ссылки. Иллюстративные молекулы миРНК включают в себя miR-509; miR-21 и miR-146a.
Согласно некоторым вариантам осуществления мультиплексную амплификацию лигированных зондов с обратной транскриптазой (ОТ-ММПУ) используют для амплификации РНК. Согласно некоторым вариантам осуществления каждая совокупность гибридизирующих зондов состоит из двух коротких синтетических олигонуклеотидов, охватывающих SNP и один олигонуклеотид (публикации Li et al., Arch Gynecol Obstet. "Development of noninvasive prenatal diagnosis of trisomy 21 by RT-MLPA with a new set of SNP markers," July 5, 2013, DOI10.1007/s00404-013-2926-5; Schouten et al. "Relative quantification of 40 nucleic acid sequences by multiplex ligation-dependent probe amplification." Nucleic Acids Res 30: e57, 2002; Deng et al. (2011) "Noninvasive prenatal diagnosis of trisomy 21 by reverse transcriptase multiplex ligation-dependent probe amplification," Clin, Chem. Lab Med. 49: 641-646, 2011, каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления РНК амплифицируют посредством ПЦР с обратной транскриптазой. Согласно некоторым вариантам осуществления РНК амплифицируют посредством ПЦР в реальном времени с обратной транскриптазой, например, ранее описанная одностадийная ПЦР в реальном времени с обратной транскриптазой с SYBRGREENI (публикации Li et al., Arch Gynecol Obstet. "Development of noninvasive prenatal diagnosis of trisomy 21 by RT-MLPA with a new set of SNP markers," July 5, 2013, DOI10.1007/s00404-013-2926-5; Loetal., "Plasmaplacental RNA allelic ratio permits noninvasive prenatal chromosomal aneuploidydetection, "NatMed13: 218-223, 2007; Tsuietal., Systematic micro-array based identification of placental mRNA in maternal plasma: towards non-invasive prenatal gene expression profiling. J Med Genet 41: 461-467, 2004; Gu et al., J. Neurochem. 122: 641-649, 2012, каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления микроматричный анализ используют для обнаружения РНК. Например, микроматрица миРНК человека от компании Agilent Technologies может быть использована в соответствии с протоколом производителя. Вкратце, выделенную РНК дефосфорилируют и сшивают с pCp-Cy3. Меченую РНК очищают и гибридизуют с матрицами миРНК, содержащими зонды для зрелых миРНК человека на основе Sanger miRBase релиз 14.0. Матрицы промывают и сканируют с использованием сканера микроматриц (G2565BA, Agilent Technologies). Интенсивность каждого гибридизационного сигнала оценивают с помощью программного обеспечения Agilent v9.5.3. Мечение, гибридизация и сканирование могут быть выполнены в соответствии с протоколами в системе микроматричного анализа компании миРНК Agilent (публикация Gu et al., J. Neurochem. 122: 641-649, 2012, которая полностью включена в настоящий документе посредством ссылки).
Согласно некоторым вариантам осуществления анализ TaqMan используется для обнаружения РНК. Иллюстративный анализ представляет собой панель матрицы микроРНК человека TaqMan версии 1.0 (ранний доступ) (Applied Biosystems), которая содержит 157 анализов микроРНК TaqMan, включая в себя соответствующие праймеры обратной транскрипции, ПЦР-праймеры и зонд TaqMan (публикация Chim et al., "Detection and characterization of placental microRNAs in maternal plasma," Clin Chem. 54(3): 482-90, 2008, которая полностью включена в настоящий документ посредством ссылки).
При желании профиль сплайсинга мРНК одной или нескольких мРНК можно определить с помощью стандартных способов (публикация Fackenthall and Godley, Disease Models & Mechanisms 1: 37-42, 2008, doi: 10.1242/dmm.000331, которая полностью включена в настоящий документ посредством ссылки). Например, микроматрицы с высокой плотностью записи и/или секвенирование ДНК с высокой пропускной способностью могут быть использованы для обнаружения вариантов сплайсинга мРНК.
Согласно некоторым вариантам осуществления секвенирование всего транскриптома способом выстрела из дробового ружья или микроматричный анализ используют для измерения транскриптома.
Иллюстративные способы амплификации
Также были разработаны усовершенствованные способы ПЦР-амплификации, которые сводят к минимуму или предотвращают помехи из-за амплификации ближайших или прилегающих локусов-мишеней в том же реакционном объеме (например, часть мультиплексной реакции ПЦР образца, которая одновременно амплифицирует все локусы-мишени). Эти способы могут быть использованы для одновременной амплификации ближайших или прилегающих локусов-мишеней, которые быстрее и дешевле, чем разделение близлежащих локусов-мишеней в различных реакционных объемах так, чтобы они могли быть амплифицированы по отдельности во избежание помех.
Согласно некоторым вариантам осуществления амплификацию локусов-мишеней осуществляют с использованием полимеразы (например, ДНК-полимеразы, РНК-полимеразы или обратной транскриптазы) с низкой экзонуклеазной активностью 5'→3' и/или низкой активностью замещения цепи. Согласно некоторым вариантам осуществления низкий уровень экзонуклеазы 5'→3' уменьшает или предотвращает деградацию соседнего праймера (например, непродленного праймера или праймера, который содержал один или несколько нуклеотидов, добавленных в процессе удлинения праймера). Согласно некоторым вариантам осуществления настоящего изобретения низкий уровень активности замещения цепи снижает или предотвращает смещение соседнего праймера (например, непродленного праймера или праймера, который содержал один или несколько нуклеотидов, добавленных в процессе удлинения праймера). Согласно некоторым вариантам осуществления амплифицируют локусы-мишени, которые примыкают друг к другу (например, нет оснований между локусами-мишенями) или расположены рядом (например, локусы находятся в пределах 50, 40, 30, 20, 15, 10, 9, 8, 7, 6, 5, 4, 3, 2 или 1 основания). Согласно некоторым вариантам осуществления настоящего изобретения 3'-конец одного локуса находится в пределах 50, 40, 30, 20, 15, 10, 9, 8, 7, 6, 5, 4, 3, 2 или 1 основания 5'-конца следующего по направлению транскрипции локуса.
Согласно некоторым вариантам осуществления амплифицируют по меньшей мере 100, 200, 500, 750, 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных локусов-мишеней, например, путем одновременной амплификации в одном реакционном объеме Согласно некоторым вариантам осуществления по меньшей мере 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 или 99,5% амплифицированных продуктов представляют собой ампликоны-мишени. Согласно различным вариантам осуществления количество амплифицированных продуктов, которые представляют собой ампликоны-мишени, составляет от 50 до 99,5%, например, от 60 до 99%, от 70 до 98%, от 80 до 98%, от 90 до 99,5% или от 95 до 99,5%, включительно. Согласно некоторым вариантам осуществления амплифицируют по меньшей мере 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 или 99,5% локусов-мишеней (например, амплифицируют по меньшей мере в 5, 10, 20, 30, 50 или в 100 раз больше по сравнению с количеством до амплификации), например, путем одновременной амплификации в одном реакционном объеме. Согласно различным вариантам осуществления количество локусов-мишеней, которые амплифицируют (например, амплифицируют по меньшей мере в 5, 10, 20, 30, 50 или 100 раз больше по сравнению с количеством до амплификации), составляет от 50 до 99,5%, например, от 60 до 99%, от 70 до 98%, от 80 до 99%, от 90 до 99,5%, от 95 до 99,9% или от 98 до 99,99%, включительно. Согласно некоторым вариантам осуществления производят меньше ампликонов-немишеней, например, меньшее количество ампликонов, образованных из прямого праймера из первой пары праймеров и обратного праймера из второй пары праймеров. Такие нежелательные ампликоны-немишени могут быть получены с использованием известных ранее способов амплификации, если, например, обратный праймер из первой пары праймеров и/или прямой праймер из второй пары праймеров распадается и/или смещается.
Согласно некоторым вариантам осуществления эти способы делают более длительным время, которое можно использовать для удлинения, так как полимераза, связываемая с удлиняющимся праймером, менее вероятно, деградирует и/или сместится на соседний праймер (например, на следующий праймер ниже по ходу транскрипции), учитывая низкую экзонуклеазную активность 5'→3' и/или низкую активность замещения цепи полимеразы. Согласно различным вариантам осуществления условия реакции (например, время удлинения и температура) используют таким образом, что скорость удлинения полимеразы позволяет числу нуклеотидов, которые добавляют к удлиняемому праймеру, составлять 80, 90, 95, 100, 110, 120, 130, 140, 150, 175 или 200% или больше от числа нуклеотидов между 3'-концом сайта связывания праймера и 5'-концом следующего по ходу транскрипции сайта связывания праймера на той же нити.
Согласно некоторым вариантам осуществления ДНК-полимеразу используют, чтобы производить ампликоны ДНК с использованием ДНК в качестве шаблона. Согласно некоторым вариантам осуществления РНК-полимеразу используют, чтобы производить ампликоны РНК с использованием ДНК в качестве шаблона. Согласно некоторым вариантам осуществления обратную транскриптазу используют для получения ампликонов кДНК с использованием РНК в качестве шаблона.
Согласно некоторым вариантам осуществления низкий уровень 5'→3' экзонуклеазы полимеразы составляет менее 80, 70, 60, 50, 40, 30, 20, 10, 5, 1 или 0,1% от активности того же самого количества полимеразы Thermus aquaticus (полимераза "Taq", которая представляет собой обычно используемую ДНК-полимеразу из термофильной бактерии, PDB1BGX, EC 2.7.7.7, Murali et al., "Crystal structure of Taq DNA polymerase in complex with an inhibitory Fab: the Fab is directed against an intermediate in the helix-coil dynamics of the enzyme," Proc. Natl. Acad. Sci. USA 95: 12562-12567, 1998, которая полностью включена в настоящий документ посредством ссылки) в тех же условиях. Согласно некоторым вариантам осуществления низкий уровень активности замещения цепи полимеразы составляет менее 80, 70, 60, 50, 40, 30, 20, 10, 5, 1 или 0,1% от активности того же количества Taq-полимеразы при тех же самых условиях.
Согласно некоторым вариантам осуществления полимераза представляет собой ДНК-полимеразу PUSHION, такую как ДНК-полимеразу PHUSION High Fidelity (M0530S, New England Biolabs, Inc.) или ДНК-полимеразу PHUSION Hot Start Flex (M0535S, New England BioLabs, Inc.; Frey and Suppman BioChemica. 2: 34-35, 1995; Chester and Marshak Analytical Biochemistry. 209: 284-290, 1993, каждая из которых полностью включена в настоящий документ посредством ссылки). ДНК-полимераза PHUSION представляет собой подобный Pyrococcus фермент, слитый с усиливающим процессивность доменом. ДНК-полимераза PHUSION обладает 5'→3' полимеразной активностью и 3'→5' экзонуклеазной активностью и образует тупоконечные продукты. ДНК-полимераза PHUSION характеризуется отсутствием 5'→3' экзонуклеазной активности и активности замещения цепи.
Согласно некоторым вариантам осуществления полимераза представляет собой ДНК-полимеразу Q5®, такую как ДНК-полимераза Q5® High-Fidelity (M0491S, New England Biolabs, Inc.) или ДНК-полимераза Q5® Hot Start High-Fidelity (M0493S, New England BioLabs, Inc.). ДНК-полимераза Q5® High-Fidelity представляет собой высокоточную, термостабильную ДНК-полимеразу с 3'→5' экзонуклеазной активностью, слитую с повышающим процессивность доменом Sso7d. ДНК-полимераза Q5® High-Fidelity характеризуется отсутствием 5'→3' экзонуклеазной активности и активности замещения цепи.
Согласно некоторым вариантам осуществления полимераза представляет собой ДНК-полимеразу T4 (M0203S, New England Biolabs, Inc.; Tabor and Struh. (1989). "DNA-Dependent DNA Polymerases," In Ausebel et al. (Ed.), Current Protocols in Molecular Biology. 3.5.10-3.5.12. New York: John Wiley & Sons, Inc., 1989; Sambrook et al. Molecular Cloning: A Laboratory Manual. (2nd ed.), 5.44-5.47. Cold Spring Harbor: Cold Spring Harbor Laboratory Press, 1989, каждая из которых полностью включена в настоящий документ посредством ссылки). ДНК-полимераза T4 катализирует синтез ДНК в направлении 5'→3' и требует наличия шаблона и праймера. Этот фермент обладает 3'→5' экзонуклеазной активностью, которая гораздо более активна, чем обнаруженная у ДНК-полимеразы I. ДНК-полимераза Т4 характеризуется отсутствием 5'→3' экзонуклеазной активности и активности замещения цепи.
Согласно некоторым вариантам осуществления полимераза представляет собой ДНК-полимеразу Sulfolobus IV (M0327S, New England Biolabs, Inc.; (Boudsocq,. et al. (2001). Nucleic Acids Res., 29: 4607-4616, 2001; McDonald, et al. (2006). Nucleic Acids Res., 34: 1102-1111, 2006, каждая из которых полностью включена в настоящий документ посредством ссылки). ДНК-полимераза Sulfolobus IV представляет собой термостабильную обходящую повреждения ДНК-полимеразу Y-семейства, которая эффективно синтезирует ДНК при различных повреждениях ДНК-матрицы (публикация McDonald, J.P. et al. (2006). Nucleic Acids Res.,. 34, 1102-1111, которая полностью включена в настоящий документ посредством ссылки). ДНК полимераза Sulfolobus IV характеризуется отсутствием 5'→3' экзонуклеазной активности и активности замещения цепи.
Согласно некоторым вариантам осуществления, если праймер связывается с областью с SNP, праймер может связываться и амплифицировать различные аллели с различной эффективностью или может связываться и амплифицировать только один аллель. Для гетерозиготных субъектов один из аллелей может не быть амплифицирован с помощью праймера. Согласно некоторым вариантам осуществления праймер предназначен для каждого аллеля. Например, если существуют два аллеля (например, биаллельный SNP), тогда могут быть использованы два праймера для связывания с тем же положением локуса-мишени (например, прямой праймер для связывания аллеля "A" и прямой праймер для связывания аллеля "B"). Стандартные способы, такие как база данных dbSNP, могут быть использованы для определения местоположения известных SNP, таких как горячие точки SNP, которые характеризуются высокой степенью гетерозиготности.
Согласно некоторым вариантам осуществления ампликоны близки по размеру. Согласно некоторым вариантам осуществления диапазон длины ампликонов-мишеней составляет менее 100, 75, 50, 25, 15, 10 или 5 нуклеотидов. Согласно некоторым вариантам осуществления (например, амплификация локусов-мишеней в фрагментированной ДНК или РНК) длина ампликонов-мишеней составляет от 50 до 100 нуклеотидов, например, от 60 до 80 нуклеотидов или от 60 до 75 нуклеотидов, включительно. Согласно некоторым вариантам осуществления (например, амплификация нескольких локусов-мишеней на протяжении экзона или гена) длина ампликонов-мишеней составляет от 100 до 500 нуклеотидов, например, от 150 до 450 нуклеотидов, от 200 до 400 нуклеотидов, от 200 до 300 нуклеотидов или от 300 до 400 нуклеотидов, включительно.
Согласно некоторым вариантам осуществления множественные локусы-мишени одновременно амплифицируют с использованием пары праймеров, которая включает в себя прямой и обратный праймер для каждого подлежащего амплификации локуса-мишени в этом объеме реакционной смеси. Согласно некоторым вариантам осуществления один раунд ПЦР выполняют с помощью одного праймера на локус-мишень, а затем второй раунд ПЦР проводят с парой праймеров на локус-мишень. Например, первый раунд ПЦР может быть выполнен с одним праймером на локус-мишень таким образом, что все праймеры связываются той же цепью (например, с использованием прямого праймера для каждого локуса-мишени). Это позволяет ПЦР амплифицировать линейным образом и уменьшать или устранять систематические погрешности амплификации между ампликонами из-за различий в последовательности или длине. Согласно некоторым вариантам осуществления ампликоны затем амплифицируют с использованием прямого и обратного праймера для каждого локуса-мишени.
Иллюстративные способы разработки праймеров
При желании мультиплексная ПЦР может быть выполнена с использованием праймеров с пониженным правдоподобием образования димеров праймеров. В частности, высоко мультиплексная ПЦР может часто приводить к получению очень высокой доли ДНК-продукта, который образуется из бесполезных побочных реакций, таких как образование димера праймера. Согласно одному варианту осуществления конкретные праймеры, которые наиболее вероятно вызывают бесполезные побочные реакции, могут быть удалены из библиотеки праймеров, чтобы получить библиотеку праймеров, которая приведет к большей доли амплифицированной ДНК, которая локализована в геноме. Стадия удаления проблемных праймеров, то есть тех праймеров, которые более вероятно образуют димеры, неожиданно сделала возможными чрезвычайно высокие уровни мультиплексирования ПЦР для последующего анализа с помощью секвенирования.
Существуют несколько способов выбора праймеров для библиотеки, где сведено к минимуму количество не картированного димера праймера или других праймерных продуктов. Эмпирические данные указывают на то, что небольшое количество "плохих" праймеров ответственно за большое количество побочных некартированных димеров праймеров. Удаление этих "плохих" праймеров может увеличивать процент прочтений последовательности, которые локализованы в локусах-мишенях. Один из способов определить "плохие" праймеры заключается в том, чтобы посмотреть на секвенируемые данные ДНК, которая была амплифицирована посредством нацеленной амплификации; эти димеры праймеров, которые видны с наибольшей частотой, могут быть удалены, чтобы дать библиотеку праймеров, которая значительно менее вероятно приведет к побочному ДНК-продукту, который не связан с геномом. Существуют также общедоступные программы, которые могут вычислять энергию связывания различных комбинаций праймеров, и удаление тех, у которых наибольшая энергия связи, также даст библиотеку праймеров, которая значительно менее вероятно приведет к побочному ДНК-продукту, который не связан с геномом.
Согласно некоторым вариантам осуществления для выбора праймеров, начальная библиотека потенциальных праймеров создается путем разработки одного или нескольких праймеров или пар праймеров к потенциальным локусам-мишеням. Совокупность потенциальных локусов-мишеней (например, SNP) можно выбирать на основе общедоступной информации о требуемых параметрах для локусов-мишеней, таких как частота SNP в пределах популяции-мишени или степень гетерозиготности SNP. Согласно одному варианту осуществления ПЦР-праймеры могут быть сконструированы с использованием программы Primer3 (в интернете по адресу primer3.sourceforge.net; libprimer3 релиз 2.2.3, который полностью включен в настоящий документ посредством ссылки). При желании, праймеры могут быть разработаны, чтобы подвергать отжигу в пределах определенного диапазона температур отжига, характеризоваться определенным диапазоном содержания GC, характеризоваться определенным диапазоном размеров, производить ампликоны-мишени в определенном диапазоне размеров и/или иметь другие характеристики параметров. Начало с нескольких праймеров или пар праймеров на потенциальный локус-мишень увеличивает вероятность того, что праймер или пара премьеров будет оставаться в библиотеке для большинства или всех локусов-мишеней. Согласно одному варианту осуществления критерии выбора могут потребовать, чтобы по меньшей мере одна пара праймеров на локус-мишень оставалась в библиотеке. Таким образом, большинство или все локусы-мишени будут амплифицированы при использовании окончательной библиотеки праймеров. Это желательно для приложений, таких как скрининг на делеций или дупликации при большом количестве положений в геноме или скрининг на большое число последовательностей (таких как полиморфизмы или другие мутации), связанных с заболеванием или повышенным риском развития заболевания. Если пара праймеров из библиотеки будет производить ампликон-мишень, который перекрывается с ампликоном-мишенью произведенным другой парой праймеров, одна из пар праймеров может быть удалена из библиотеки, чтобы не создавать помех.
Согласно некоторым вариантам осуществления "балл нежелательности" (более высокий балл, представляющий наименьшую желательность) вычисляется (например, вычисление на компьютере) для большей части или всех возможных комбинаций двух праймеров из библиотеки праймеров-кандидатов. Согласно различным вариантам осуществления балл нежелательности рассчитывают по меньшей мере для 80, 90, 95, 98, 99 или 99,5% от возможных комбинаций праймеров-кандидатов в библиотеке. Каждый балл нежелательности основан, по меньшей мере частично, на правдоподобности образования димеров между двумя праймерами-кандидатами. При желании, балл нежелательности также может быть основан на одном или нескольких других параметрах, выбранных из группы, состоящей из степени гетерозиготности локуса-мишени, распространенности заболевания, связанного с последовательностью (например, полиморфизмом) в локусе-мишени, пенетрантности заболевания, связанной с последовательностью (например, полиморфизмом) в локусе-мишени, специфичностью праймера-кандидата к локусу-мишени, размера праймера-кандидата, температуры плавления ампликона-мишени, содержания GC ампликона-мишени, эффективности амплификации ампликона-мишени, размера ампликона-мишени и расстояния от центра горячей точки рекомбинации. Согласно некоторым вариантам осуществления специфичность праймера-кандидата к локусу-мишени предусматривает правдоподобие того, что праймер-кандидат будет связываться с нецелевой последовательностью путем связывания и амплификации локуса отличного от локуса-мишени, который он должен амлифицировать. Согласно некоторым вариантам осуществления один или нескольких или все праймеры-кандидаты, которые связываются с нецелевой последовательностью, удаляются из библиотеки. Согласно некоторым вариантам осуществления, чтобы увеличить число праймеров-кандидатов, из которых производят выбор, праймеры-кандидаты, которые могут связываться с нецелевой последовательностью не удаляются из библиотеки. Если учитывается несколько факторов, балл нежелательности может быть рассчитан на основе средневзвешенного значения различных параметров. Параметрам могут быть присвоены различные веса в зависимости от их важности для конкретного применения, в котором праймеры будут использоваться. Согласно некоторым вариантам осуществления праймер с наивысшим баллом нежелательности удаляется из библиотеки. Если удаляемый праймер является представителем пары праймеров, которая гибридизуется с одним локусом-мишенью, то другой представитель пары праймеров может быть удален из библиотеки. Процесс удаления праймеров может повторяться по желанию. Согласно некоторым вариантам осуществления способ выбора выполняется до тех пор, пока баллы нежелательности для комбинаций праймеров-кандидатов, оставшихся в библиотеке, не станут все равны или ниже минимального порога. Согласно некоторым вариантам осуществления способ выбора выполняется до тех пор, пока число праймеров-кандидатов, оставшихся в библиотеке, не снижается до требуемого числа.
Согласно различным вариантам осуществления после того, как вычисляются баллы нежелательности, праймер-кандидат, который представляет собой часть самого большого числа комбинаций двух праймеров-кандидатов с баллом нежелательности выше первого минимального порога, удаляется из библиотеки. Эта стадия игнорирует взаимодействия, равные или ниже первого минимального порогового значения, так как эти взаимодействия представляют собой менее значительные. Если удаляемый праймер является представителем пары праймеров, которая гибридизуется с одним локусом-мишенью, то другой представитель пары праймеров может быть удален из библиотеки. Процесс удаления праймеров может повторяться по желанию. Согласно некоторым вариантам осуществления способ выбора выполняется до тех пор, пока баллы нежелательности для комбинаций праймеров-кандидатов, оставшихся в библиотеке, не станут все равны или ниже первого минимального порога. Если число праймеров-кандидатов, оставшихся в библиотеке, выше, чем желательно, число праймеров может быть уменьшено путем уменьшения первого минимального порога до более низкого второго минимального порога и повторен процесс удаления праймеров. Если количество праймеров-кандидатов, оставшихся в библиотеке, ниже, чем это желательно, способ может быть продолжен за счет увеличения первого минимального порога до более высокого второго минимального порога и повторен процесс удаления праймеров с использованием первоначальной библиотеки праймеров-кандидатов, таким образом, позволяя большему количеству праймеров-кандидатов остаться в библиотеке. Согласно некоторым вариантам осуществления способ выбора выполняется до тех пор, пока баллы нежелательности для комбинаций праймеров-кандидатов, оставшихся в библиотеке, не станут все равны или ниже второго минимального порогового значения, или пока число праймеров-кандидатов, оставшихся в библиотеке, не снизится до требуемого числа.
При желании пары праймеров, которые производят ампликон-мишень, который перекрывает ампликон-мишень, произведенный другой парой праймеров, можно разделить на отдельные реакции амплификации. Множественные реакции ПЦР-амплификации могут быть желательны для применений, в которых желательно проанализировать все потенциальные локусы-мишени (вместо пропуска потенциальных локусов-мишеней из анализа вследствие перекрывания ампликонов-мишеней).
Эти способы выбора сводят к минимуму количество праймеров-кандидатов, которые должны были быть удалены из библиотеки, чтобы достичь желаемого снижения димеров праймера. Удаляя меньшее число праймеров-кандидатов из библиотеки, больше (или все) локусов-мишеней может быть амплифицировано с использованием полученной библиотеки праймеров.
Мультиплексирование большого числа праймеров накладывает значительное ограничение на анализы, которые могут быть включены. Анализы, которые непреднамеренно взаимодействуют, приводят к побочным продуктам амплификации. Ограничения размера в миниПЦР может привести к дальнейшим ограничениям. Согласно одному варианту осуществления можно начать с очень большого числа потенциальных SNP-мишеней (от приблизительно 500 до более чем 1 миллиона) и попытаться разработать праймеры для амплификации каждого SNP. Там, где праймеры могут быть разработаны, можно попытаться идентифицировать пары праймеров, вероятно способные образовывать ложные продукты путем вычисления вероятности образования ложных дуплексов праймеров между всеми возможными парами праймеров с использованием опубликованных термодинамических параметров для образования дуплекса ДНК. Взаимодействия праймеров могут быть ранжированы по оценочной функции, связанной с взаимодействием, и праймеры с наихудшими оценками взаимодействия устраняют, пока число требуемых праймеров не будет выполнено. В тех случаях, когда SNP, вероятно, являющиеся гетерозиготными, наиболее применимы, можно также ранжировать список анализов и выбрать наиболее совместимые с гетерозиготностью анализы. Эксперименты подтвердили, что праймеры с высокими баллами взаимодействия, скорее всего, образуют димеры праймеров. При высоком мультиплексировании не представляется возможным устранить все ложные взаимодействия, но важным является удаление праймеров или пар праймеров с самыми высокими баллами взаимодействия in silico, так как они могут доминировать над целой реакцией, что значительно ограничивает амплификацию от намеченных мишеней. Авторы настоящего изобретения выполнили эту процедуру для создания мультиплекса наборов праймеров до 10000 праймеров, а в некоторых случаях и больше. Улучшение благодаря этой процедуре представляет собой существенное, что делает возможной амплификацию более чем 80%, более чем 90%, более чем 95%, более чем 98% и даже более чем 99% продуктов-мишеней, что определено с помощью секвенирования всех продуктов ПЦР, по сравнению с 10% в результате реакции, в которой худшие праймеры не были удалены. В сочетании с частичным полугнездовым подходом, как описано выше, более чем 90% и даже более чем 95% ампликонов могут отображаться на нацеленных последовательностях.
Следует отметить, что существуют и другие способы определения того, какие ПЦР-зонды, вероятно, будут образовывать димеры. Согласно одному варианту осуществления анализа пула ДНК, который был амплифицирован с использованием неоптимизированного набора праймеров, может быть достаточно, чтобы определить проблемные праймеры. Например, анализ может быть сделан с помощью секвенирования, и те димеры, которые присутствуют в наибольшем количестве, определяются как те, которые, скорее всего, образуют димеры и могут быть удалены. Согласно одному варианту осуществления способ разработки праймеров может быть использован в сочетании с описанным в настоящем документе способом мини-ПЦР.
Применение тегов на праймерах может привести к снижению амплификации и секвенирования продуктов димеров праймеров. Согласно некоторым вариантам осуществления праймер содержит внутреннюю область, которая образует структуру петли с тегом. Согласно конкретным вариантам осуществления праймеры включают в себя 5'-область, специфичную для локуса-мишени, внутреннюю область, которая не специфична для локуса-мишени и образует петлевую структуру, и 3'-область, которая специфична для локуса-мишени. Согласно некоторым вариантам осуществления петлевая область может находиться между двумя связующими областями, где две области связывания предназначены для связывания с соприкасающимися или соседними областями ДНК-шаблона. Согласно различным вариантам осуществления длина 3'-области составляет по меньшей мере 7 нуклеотидов. Согласно некоторым вариантам осуществления длина 3'-области составляет от 7 до 20 нуклеотидов, например, от 7 до 15 нуклеотидов или от 7 до 10 нуклеотидов, включительно. Согласно различным вариантам осуществления праймеры включают в себя 5'-область, которая не специфична для локуса-мишени (например, тег или сайт связывания универсального праймера), за которым следует область, которая специфична к локусу-мишени, внутренняя область, которая не специфична к локусу-мишени и образует петлевую структуру, и 3'-область, которая специфична к локусу-мишени. Ter-праймеры могут быть использованы для сокращения необходимых специфичных к мишени последовательностей до менее 20, менее 15, менее 12 и даже менее 10 пар оснований. Это может быть непрогнозируемо при стандартной конструкции праймера, когда последовательность-мишень фрагментируется в пределах сайта связывания праймера или он может быть разработан в дизайн праймера. Преимущества этого способа включают в себя следующие: он увеличивает количество анализов, которые могут быть разработаны для определенной максимальной длины ампликонов и укорачивает "неинформативное" секвенирование последовательности праймера. Он также может быть использован в сочетании с внутренним мечением.
Согласно одному варианту осуществления относительное количество непродуктивных продуктов в мультиплексированной нацеленной ПЦР-амплификации может быть уменьшено за счет повышения температуры отжига. В тех случаях, когда амплифицируют библиотеки с тем же тегом, что и специфические праймеры-мишени, температура отжига может быть увеличена по сравнению с геномной ДНК, так как метки будут способствовать связыванию праймеров. Согласно некоторым вариантам осуществления используются уменьшенные концентрации праймеров, при необходимости вместе с более длительным временем отжига. Согласно некоторым вариантам осуществления время отжига может быть более чем 3 минуты, более чем 5 минут, более чем 8 минут, более чем 10 минут, более чем 15 минут, более чем 20 минут, более чем 30 минут, более чем 60 минут, более чем 120 минут, более чем 240 минут, более чем 480 минут и даже более чем 960 минут. Согласно некоторым иллюстративным вариантам осуществления более длительный отжиг используют вместе с уменьшенными концентрациями праймера. Согласно различным вариантам осуществления используют более длительное, чем обычное время удлинения, например, более чем 3, 5, 8, 10 или 15 минут. Согласно некоторым вариантам осуществления концентрации праймера составляют 50 нМ, 20 нМ, 10 нМ, 5 нМ, 1 нМ и ниже 1 нМ. Это, на удивление, приводит к устойчивой производительности высоко мультиплексированных реакций, например, реакций с участием 1000, 2000, 5000, 10000, 20000, 50000 и даже 100000 последовательностей. Согласно одному варианту осуществления при амплификации используется один, два, три, четыре или пять циклов пробега с длительным временем отжига, с последующими ПЦР-циклами с более обычным временем отжига с мечеными праймерами.
Для выбора положений-мишеней можно начать с пула дизайнов пар праймеров-кандидатов и создать термодинамическую модель потенциально отрицательных взаимодействий между парами праймеров, а затем использовать эту модель для устранения дизайнов, которые несовместимы с другими дизайнами в пуле.
Согласно одному варианту осуществления настоящее изобретение относится к способу уменьшения числа локусов-мишеней (например, локусов, которые могут содержать полиморфизм или мутацию, связанную с заболеванием или нарушением или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль) и/или увеличения нагрузки заболевания, которое обнаруживают (например, увеличение числа полиморфизмов или мутаций, которые обнаруживают). Согласно некоторым вариантам осуществления способ предусматривает ранжирование (например, ранжирование от высшего к низшему) локусов по частоте или повторяемости полиморфизма или мутации (например, однонуклеотидной вариации, вставки или делеции, или любой из других вариаций, описанных в настоящем документе) в каждом локусе у пациентов с заболеванием или нарушением, таким как злокачественная опухоль. Согласно некоторым вариантам осуществления ПЦР-праймеры предназначены для некоторых или всех локусов. При выборе ПЦР-праймеров для библиотеки праймеров, праймеры к локусам, которые имеют более высокую частоту или повторяемость (более высокий рейтинг локусов) имеют преимущество по сравнению с более низкой частотой или повторяемостью (низкий рейтинг локусов). Согласно некоторым вариантам осуществления этот параметр включен в качестве одного из параметров в расчете баллов нежелательности, описанных в настоящем документе. При желании праймеры (например, праймеры к локусам с высоким рейтингом), которые несовместимы с другими конструкциями в библиотеке, могут быть включены в другую библиотеку/пул ПЦР. Согласно некоторым вариантам осуществления несколько библиотек/пулов (например, 2, 3, 4, 5 или более) используются в отдельных ПЦР-реакциях, с тем, чтобы амплифицировать все (или большинство) локусы, представленные всеми библиотеками/пулами. Согласно некоторым вариантам осуществления этот способ продолжают, пока достаточное количество праймеров не включат в одну или несколько библиотек/пулов, таким образом, что праймеры, в совокупности, делают возможным захват пораженности требуемым заболеванием или нарушением (например, путем обнаружения не менее 80, 85, 90, 95 или 99% пораженности заболеванием).
Иллюстративные библиотеки праймеров
Согласно одному аспекту настоящее изобретение относится библиотекам праймеров, таких как праймеры, выбранные из библиотеки праймеров-кандидатов с использованием любого из способов согласно настоящему изобретению. Согласно некоторым вариантам осуществления библиотека включает в себя праймеры, которые одновременно гибридизуются (или способны к одновременной гибридизации) или которые одновременно амплифицируют (или способны к одновременной амплификации) по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7,500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных локусов-мишеней в одном объеме реакционной смеси. Согласно различным вариантам осуществления библиотека включает в себя праймеры, которые одновременно амплифицируют (или способны к одновременной амплификации) от 100 до 500; от 500 до 1000; от 1000 до 2000; от 2000 до 5000; от 5000 до 7500; от 7500 до 10000; от 10000 до 20000; от 20000 до 25000; от 25000 до 30000; от 30000 до 40000; от 40000 до 50000; от 50000 до 75000; или от 75000 до 100000 различных локусов в одном объеме реакционной смеси, включительно. Согласно различным вариантам осуществления библиотека включает в себя праймеры, которые одновременно амплифицируют (или способны к одновременной амплификации) от 1000 до 100000 различных локусов-мишеней в одном объеме реакционной смеси, например, от 1000 до 50000; от 1000 до 30000; от 1000 до 20000; от 1000 до 10000; от 2000 до 30000; от 2000 до 20000; от 2000 до 10000; от 5000 до 30000; от 5000 до 20000 или от 5000 до 10000 различных локусов-мишеней, включительно. Согласно некоторым вариантам осуществления библиотека включает в себя праймеры, которые одновременно амплифицируют (или способны к одновременной амплификации) локусы-мишени в таком одном реакционном объеме, что менее чем 60, 40, 30, 20, 10, 5, 4, 3, 2, 1, 0,5, 0,25, 0,1 или 0,5% амплифицированньгх продуктов представляют собой димеры праймеров. Согласно различным вариантам осуществления количество амплифицированных продуктов, которые представляют собой димеры праймеров, составляет от 0,5 до 60%, например, от 0,1 до 40%, от 0,1 до 20%, от 0,25 до 20%, от 0,25 до 10%, от 0,5 до 20%, от 0,5 до 10%, от 1 до 20%, или от 1 до 10%, включительно. Согласно некоторым вариантам осуществления праймеры одновременно амплифицируют (или способны к одновременной амплификации) локусы-мишени в одном объеме реакционной смеси таким образом, что по меньшей мере 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 или 99,5% амплифицированных продуктов представляют собой ампликоны-мишени. Согласно различным вариантам осуществления количество амплифицированных продуктов, которые представляют собой ампликоны-мишени, составляет от 50 до 99,5%, например, от 60 до 99%, от 70 до 98%, от 80 до 98%, от 90 до 99,5% или от 95 до 99,5%, включительно. Согласно некоторым вариантам осуществления праймеры одновременно амплифицируют (или способны к одновременной амплификации) локусы-мишени в одном объеме реакционной смеси таким образом, что по меньшей мере 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 или 99,5% нацеленных локусов амплифицируются (например, амплифицируются по меньшей мере в 5, 10, 20, 30, 50 или 100 раз по сравнению с количеством до амплификации). Согласно различным вариантам осуществления количество локусов-мишеней, которые амплифицируются (например, амплифицируются по меньшей мере в 5, 10, 20, 30, 50 или 100 раз по сравнению с количеством до амплификации), составляет от 50 до 99,5%, например, от 60 до 99%, от 70 до 98%, от 80 до 99%, от 90 до 99,5%, от 95 до 99,9% или от 98 до 99,99%, включительно. Согласно некоторым вариантам осуществления библиотека праймеров включает в себя по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 пар праймеров, причем каждая пара праймеров включает в себя прямой исследуемый праймер и обратный исследуемый праймер, где каждая пара исследуемых праймеров гибридизует с локусом-мишенью. Согласно некоторым вариантам осуществления библиотека праймеров включает в себя по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 отдельных праймеров, каждый из которых гибридизует с различным локусом-мишенью, причем отдельные праймеры не представляют собой часть пар праймеров.
Согласно различным вариантам осуществления концентрация каждого праймера составляет менее 100, 75, 50, 25, 20, 10, 5, 2 или 1 нМ или менее 500, 100, 10 или 1 мкМ. Согласно различным вариантам осуществления концентрация каждого праймера составляет от 1 мкМ до 100 нМ, например от 1 мкМ до 1 нМ, от 1 до 75 нМ, от 2 до 50 нМ или от 5 до 50 нМ, включительно. Согласно различным вариантам осуществления содержание GC праймеров составляет от 30 до 80%, например, от 40 до 70% или от 50 до 60%, включительно. Согласно некоторым вариантам осуществления диапазон содержания GC праймеров составляет менее 30, 20, 10 или 5%. Согласно некоторым вариантам осуществления диапазон содержания GC праймеров составляет от 5 до 30%, например, от 5 до 20% или от 5 до 10%, включительно. Согласно некоторым вариантам осуществления температура плавления (Tm) исследуемых праймеров составляет от 40 до 80°C, например, от 50 до 70°C, от 55 до 65°C или от 57 до 60,5°C, включительно. Согласно некоторым вариантам осуществления Tm вычисляют с использованием программы Primer3 (libprimer3 релиз 2.2.3) с использованием встроенных параметров SantaLucia (в интернете по адресу primer3.sourceforge.net). Согласно некоторым вариантам осуществления диапазон температуры плавления праймеров составляет менее чем 15, 10, 5, 3 или 1°C. Согласно некоторым вариантам осуществления диапазон температуры плавления праймеров составляет от 1 до 15°C, например, от 1 до 10°C, от 1 до 5°C или от 1 до 3°C, включительно. Согласно некоторым вариантам осуществления длина праймеров составляет от 15 до 100 нуклеотидов, например, от 15 до 75 нуклеотидов, от 15 до 40 нуклеотидов, от 17 до 35 нуклеотидов, от 18 до 30 нуклеотидов или от 20 до 65 нуклеотидов, включительно. Согласно некоторым вариантам осуществления диапазон длин праймеров составляет менее чем 50, 40, 30, 20, 10 или 5 нуклеотидов. Согласно некоторым вариантам осуществления диапазон длин праймеров составляет от 5 до 50 нуклеотидов, например, от 5 до 40 нуклеотидов, от 5 до 20 нуклеотидов или от 5 до 10 нуклеотидов, включительно. Согласно некоторым вариантам осуществления длина ампликонов-мишеней составляет от 50 до 100 нуклеотидов, например, от 60 до 80 нуклеотидов или от 60 до 75 нуклеотидов, включительно. Согласно некоторым вариантам осуществления диапазон длин ампликонов-мишеней составляет менее 50, 25, 15, 10 или 5 нуклеотидов. Согласно некоторым вариантам осуществления диапазон длин ампликонов-мишеней составляет от 5 до 50 нуклеотидов, например, от 5 до 25 нуклеотидов, от 5 до 15 нуклеотидов или от 5 до 10 нуклеотидов, включительно. Согласно некоторым вариантам осуществления библиотека не содержит микрочип. Согласно некоторым вариантам осуществления библиотека содержит микрочип.
Согласно некоторым вариантам осуществления некоторые (например, по меньшей мере 80, 90 или 95%) или все из адаптеров или праймеров включают в себя одну или несколько связей между смежными нуклеотидами отличную, от встречающейся в природе фосфодиэфирной связи. Примеры таких связей включают в себя фосфорамидные, фосфоротиоатные и фосфородитиоатные связи. Согласно некоторым вариантам осуществления некоторые (например, по меньшей мере 80, 90 или 95%) или все из адаптеров или праймеров включают в себя тиофосфат (например, монотиофосфат) между последним 3' нуклеотидом и предпоследним 3' нуклеотидом. Согласно некоторым вариантам осуществления некоторые (например, по меньшей мере 80, 90 или 95%) или все из адаптеров или праймеров включают в себя тиофосфат (например, монотиофосфат) между последними 2, 3, 4 или 5 нуклеотидами на 3'-конце. Согласно некоторым вариантам осуществления некоторые (например, по меньшей мере 80, 90 или 95%) или все из адаптеров или праймеров включают в себя тиофосфат (например, монотиофосфат) между по меньшей мере 1, 2, 3, 4 или 5 нуклеотидами из последних 10 нуклеотидов на 3'-конце. Согласно некоторым вариантам осуществления такие праймеры, менее вероятно будут расщепляться или деградировать. Согласно некоторым вариантам осуществления праймеры не содержат сайт расщепления ферментом (например, сайт расщепления протеазой).
Дополнительные иллюстративные способы мультиплексной ПЦР и библиотеки описаны в заявке на патент США №13/683604, поданной 21 ноября 2012 г. (публикация США №2013/0123120) и патенте США с серийным номером 61/994791, поданном 16 мая 2014 г., каждый из которых полностью включен в настоящий документ посредством ссылки). Эти способы и библиотеки могут быть использованы для анализа любого из образцов, раскрытых в настоящем документе, и для применения в любом из способов согласно настоящему изобретению.
Иллюстративные библиотеки праймеров для обнаружения рекомбинации
Согласно некоторым вариантам осуществления праймеры в библиотеке праймеров предназначены для определения того, действительно ли рекомбинация происходит в одной или нескольких известных горячих точках рекомбинации (например, кроссоверы между гомологичными хромосомами человека). Знание о том, какие кроссоверы произошли между хромосомами, позволяет определять более точные фазированные генетические данные для индивидуума. Горячие точки рекомбинации представляют собой локальные области хромосом, в которых имеют тенденцию концентрироваться события рекомбинации. Часто они находятся по бокам "холодных точек", областей с более низкой, чем средняя частота рекомбинации. Горячие точки рекомбинации, как правило, разделяют подобную морфологию и составляют приблизительно от 1 до 2 т.п.н. в длину. Распределение горячих точек положительно коррелирует с содержанием GC и повторяющимся распределением элементов. Частично вырожденный 13-мерный мотив CCNCCNTNNCCNC играет важную роль в некоторой активности горячих точек. Было показано, что белок "цинковый палец", называемый PRDM9, связывается с этим мотивом и инициирует рекомбинацию в этом положении. Среднее расстояние между центрами горячих точек рекомбинации, как сообщается, составляет ~80 т.п.н. Согласно некоторым вариантам осуществления расстояние между центрами горячих точек рекомбинации колеблется в пределах от ~3 т.п.н. до ~100 т.п.н. Общедоступные базы данных включают в себя большое количество известных горячих точек рекомбинации человека, такие как базы данных HUMHOT и Международный проект HapMap (смотрите, например, публикации Nishant et al., "HUMHOT: a database of human meiotic recombination hot spots," Nucleic Acids Research, 34: D25-D28, 2006, Database issue; Mackiewicz et al., "Distribution of Recombination Hotspots in the Human Genome - A Comparison of Computer Simulations with Real Data" PLoS ONE 8(6): e65272, doi: 10.1371/journal.pone.0065272 и в интернете по адресу hapmap.ncbi.nlm.nih.gov/downloads/index.html.en, каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления праймеры в библиотеке праймеров сгруппированы в горячих точках рекомбинации или вблизи них (например, известные горячие точки рекомбинации человека). Согласно некоторым вариантам осуществления соответствующие ампликоны используют для определения последовательности внутри горячих точек рекомбинации или вблизи них, чтобы определить, происходит или нет рекомбинация в этой конкретной горячей точке (например, представляет ли собой последовательность ампликона ожидаемую последовательность, если рекомбинация произошла, или ожидаемую последовательность, если рекомбинация не произошла). Согласно некоторым вариантам осуществления праймеры предназначены для амплификации части или всей горячей точки рекомбинации (и необязательно последовательности, фланкирующей горячую точку рекомбинации). Согласно некоторым вариантам осуществления секвенирование длинных прочтений (например, секвенирование с использованием Moleculo Technology, разработанной Illumina, для секвенирования до ~10 т.п.н.) или секвенирование спаренных концов используется для части или всей последовательности горячей точки рекомбинации. Знание того, произошло ли событие рекомбинации или нет, может быть использовано для определения того, какие блоки гаплотипов фланкируют горячую точку. При желании, наличие определенных блоков гаплотипов может быть подтверждено с использованием праймеров, специфичных к областям внутри блоков гаплотипа. Согласно некоторым вариантам осуществления предполагается, что нет кроссоверов между известными горячими точками рекомбинации. Согласно некоторым вариантам осуществления праймеры в библиотеке праймеров сгруппированы на концах хромосом или вблизи них. Например, такие праймеры могут быть использованы для определения того, присутствует или нет конкретное плечо или часть в конце хромосомы. Согласно некоторым вариантам осуществления праймеры в библиотеке праймеров сгруппированы в горячих точках рекомбинации или вблизи них и на концах хромосом или вблизи них.
Согласно некоторым вариантам осуществления библиотека праймеров включает в себя один или несколько праймеров (например, по меньшей мере 5, 10, 50; 100; 200; 500; 750; 1000, 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000 или 50000 различных праймеров или различных пар праймеров), которые специфичны к горячей точке рекомбинации (например, известная горячая точка рекомбинации человека) и/или специфичны к области вблизи горячей точки рекомбинации (например, в пределах 10, 8, 5, 3, 2, 1 или 0,5 т.п.н. 5' или 3' конца горячей точки рекомбинации). Согласно некоторым вариантам осуществления по меньшей мере 1, 5, 10, 20, 40, 60, 80, 100 или 150 различных праймеров (или пар праймеров) специфичны к той же горячей точке рекомбинации или специфичны к области вблизи горячей точки рекомбинации. Согласно некоторым вариантам осуществления по меньшей мере 1,5, 10, 20, 40, 60, 80, 100 или 150 различных праймеров (или пар праймеров) специфичны к области между горячими точками рекомбинации (например, область, которая маловероятно претерпевает рекомбинацию); эти праймеры могут быть использованы для подтверждения наличия блоков гаплотипов (таких, как те, которые можно было бы ожидать в зависимости от того, произошла или нет рекомбинация). Согласно некоторым вариантам осуществления по меньшей мере 10, 20, 30, 40, 50, 60, 70, 80 или 90% праймеров в библиотеке праймеров специфичны к горячей точке рекомбинации и/или специфичны к области вблизи горячей точки рекомбинации (например, в пределах 10, 8, 5, 3, 2, 1 или 0,5 т.п.н. 5' или 3' конца горячей точки рекомбинации). Согласно некоторым вариантам осуществления библиотеку праймеров используют для определения того, произошла или нет рекомбинация в 5; 10; 50; 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000 или 50000 или более различных горячих точках рекомбинации (такие как известные горячие точки рекомбинации человека). Согласно некоторым вариантам осуществления области, на которые направленно воздействуют праймеры к горячей точке рекомбинации или соседней области, приблизительно равномерно распределены вдоль той части генома. Согласно некоторым вариантам осуществления по меньшей мере 1,5, 10, 20, 40, 60, 80, 100 или 150 различных праймеров (или пар праймеров) специфичны к области на конце хромосомы или вблизи нее (такой как область, в 20, 10, 5, 1, 0,5, 0,1, 0,01 или 0,001 Мб от конца хромосомы). Согласно некоторым вариантам осуществления по меньшей мере 10, 20, 30, 40, 50, 60, 70, 80 или 90% из праймеров в библиотеке праймеров специфичны к области на конце хромосомы или вблизи нее (например, области в пределах 20, 10, 5, 1, 0,5, 0,1, 0,01 или 0,001 Мб от конца хромосомы). Согласно некоторым вариантам осуществления по меньшей мере 1, 5, 10, 20, 40, 60, 80, 100 или 150 различных праймеров (или пар праймеров) специфичны к области в пределах потенциальной микроделеции в хромосоме. Согласно некоторым вариантам осуществления по меньшей мере 10, 20, 30, 40, 50, 60, 70, 80 или 90% праймеров в библиотеке праймеров специфичны к области в пределах потенциальной микроделеции в хромосоме. Согласно некоторым вариантам осуществления по меньшей мере 10, 20, 30, 40, 50, 60, 70, 80 или 90% праймеров в библиотеке праймеров специфичны к горячей точке рекомбинации, области вблизи горячей точки рекомбинации, области на конце хромосомы или возле нее или области в пределах потенциальной микроделеции в хромосоме.
Иллюстративные наборы
Согласно одному аспекту в настоящем изобретении предусмотрен набор, такой как набор для амплификации локусов-мишеней в образце нуклеиновой кислоты, для обнаружения делеций и/или дупликаций хромосомных сегментов или целых хромосом с использованием любого из описанных в настоящем документе способов. Согласно некоторым вариантам осуществления набор может включать в себя любую из библиотек праймеров согласно настоящему изобретению. Согласно одному варианту осуществления набор содержит множество внутренних прямых праймеров и, необязательно, множество внутренних обратных праймеров, и, необязательно, внешние прямые праймеры и внешние обратные праймеры, где каждый из праймеров разработан для гибридизации с областью ДНК, расположенной непосредственно выше против хода транскрипции и/или ниже по ходу транскрипции от одного из сайтов-мишеней (например, полиморфных сайтов) на хромосоме(ах)-мишени(ях) или хромосомном сегменте(ах)-мишени(ях) и, необязательно, дополнительных хромосомах или хромосомных сегментах. Согласно некоторым вариантам осуществления набор включает в себя инструкции по использованию библиотеки праймеров для амплификации локусов-мишеней, например, для обнаружения одной или нескольких делеции и/или дупликаций одного или нескольких хромосомных сегментов или целых хромосом с использованием любого из описанных в настоящем документе способов.
Согласно некоторым вариантам осуществления наборы по настоящему изобретению обеспечивают пары праймеров для обнаружения хромосомной анеуплоидии и определения CNV, например, пары праймеров для мультиплексных реакций с большим количеством целевых последовательностей для обнаружения хромосомной анеуплоидии, такой как CNV (CoNVERGe) (генотипически раскрытые события вариантов числа копий) и/или SNV. Согласно этим вариантам осуществления наборы могут включать в себя по меньшей мере от 100, 200, 250, 300, 500, 1000, 2000, 2500, 3000, 5000, 10000, 20000, 25000, 28000, 50000 или 75000 до не более чем 200, 250, 300, 500, 1000, 2000, 2500, 3000, 5000, 10000, 20000, 25000, 28000, 50000, 75000 или 100000 пар праймеров, которые поставляются вместе. Пары праймеров могут содержаться в одном сосуде, например, в виде одной пробирки или коробки или нескольких пробирок или коробок. Согласно некоторым вариантам осуществления пары праймеров предварительно квалифицируются коммерческим поставщиком услуг и продаются вместе и, согласно другим вариантам осуществления, клиент выбирает пользовательские гены-мишени и/или праймеры, а коммерческий поставщик производит и поставляет пул праймеров клиенту или в одной пробирке, или во множестве пробирок. Согласно некоторым иллюстративным вариантам осуществления наборы включают в себя праймеры для обнаружения как CNV, так и SNV, особенно CNV и SNV, известные как коррелирующие по меньшей мере с одним типом злокачественной опухоли.
Наборы для обнаружения циркулирующей ДНК в соответствии с некоторыми вариантами осуществления настоящего изобретения включают в себя стандарты и/или контроли для обнаружения циркуляции ДНК. Например, согласно некоторым вариантам осуществления стандарты и/или контроли продаются и, возможно, поставляются и упаковываются вместе с праймерами, используемыми для проведения описанных в настоящем документе реакций амплификации, такие как праймеры для выполнения CoNVERGe. Согласно некоторым вариантам осуществления контроли включают в себя полинуклеотиды, такие как ДНК, включающие в себя выделенную геномную ДНК, которая проявляет одну или несколько хромосомных анеуплоидии, таких как CNV, и/или включает в себя один или несколько SNV. Согласно некоторым вариантам осуществления стандарты и/или контроли называются стандартами PlasmArt и включают в себя полинуклеотиды, характеризующиеся идентичностью последовательности с областями генома, про которые известно, что они обладают CNV, особенно при некоторых наследственных заболеваниях, а также при некоторых патологических состояниях, таких как злокачественная опухоль, а также распределением размера, которое отражает, что фрагменты вкДНК естественно обнаруживаются в плазме крови. Иллюстративные способы изготовления стандартов PlasmArt представлены в приведенных в настоящем документе примерах. В общем, геномную ДНК из источника, про который известно, что он характеризуется хромосомной анеуплоидией, выделяют, фрагментируют, очищают и выбирают размер.
Соответственно, искусственные стандарты полинуклеотидных вкДНК и/или контроли могут быть получены с помощью добавления выделенных полинуклеотидных образцов, полученных, как сформулировано выше, в образцы ДНК, заведомо не обладающие хромосомной анеуплоидией и/или SNV, в концентрациях, аналогичных тем, которые наблюдались для вкДНК in vivo, например, от 0,01% до 20%, от 0,1 до 15% или от 0,4 до 10% ДНК в этой жидкости. Эти стандарты/контроли могут быть использованы в качестве контролей для анализа проектирования, определения характеристик, разработки и/или оценки, а также в качестве стандартов контроля во время исследования, таких как исследование злокачественной опухоли, выполняемое в лаборатории CLIA, и/или в качестве стандартов, включенных только в исследовательское применение или диагностические тест-наборы.
Примерные способы нормализации/коррекции
Согласно некоторым вариантам осуществления измерения для различных локусов, хромосомных сегментов или хромосом корректируются с учетом систематической ошибки, например, систематической ошибки из-за различий в содержании GC или систематической ошибки из-за других различий в эффективности амплификации, или корректируются с учетом ошибок секвенирования. Согласно некоторым вариантам осуществления измерения для различных аллелей для того же локуса корректируются с учетом различий в метаболизме, апоптозе, гистонах, инактивации и/или амплификации между аллелями. Согласно некоторым вариантам осуществления измерения для различных аллелей для того же локуса в РНК корректируются с учетом различий в скоростях транскрипции или стабильности между различными аллелями РНК.
Иллюстративные способы фазирования генетических данных
Согласно некоторым вариантам осуществления генетические данные фазируют с использованием способов, описанных в настоящем документе, или любых известных способов фазирования генетических данных (смотрите, например, публикацию РСТ № WO 2009/105531, поданную 9 февраля 2009 г., и публикацию РСТ № WO 2010/017214, поданную 4 августа 2009 г., публикацию США №2013/0123120, поданную 21 ноября 2012 г.; публикацию США №2011/0033862, поданную 7 октября 2010 г., публикацию США №2011/0033862, поданную 19 августа 2010 г.; публикацию США №2011/0178719, поданную 3 февраля 2011 г.; патент США №8515679, поданный 17 марта 2008 г.; публикацию США №2007/0184467, поданную 22 ноября 2006 г.; публикацию США №2008/0243398, поданную 17 марта 2008 г., и патент США с серийным номером 61/994791, поданный 16 мая 2014 г., каждый из которых полностью включен в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления фазу определяют для одной или нескольких областей, которые точно или предположительно содержат представляющую интерес CNV. Согласно некоторым вариантам осуществления фазу также определяют для одной или нескольких областей, фланкирующих область(и) CNV и/или для одной или нескольких эталонных областей. Согласно одному варианту осуществления генетические данные индивидуума (например, индивидуума, исследуемого с использованием способов согласно настоящему изобретению, или родственника вынашиваемого плода или эмбриона, такого как родитель плода или эмбриона) фазируют путем логического вывода посредством измерения ткани от индивидуума, который является гаплоидным, например, путем измерения одного или нескольких сперматозоидов или яйцеклеток. Согласно одному варианту осуществления генетические данные индивидуума фазируют путем логического вывода с использованием измеренных генотипических данных одного или нескольких родственников первой степени, таких как родители индивидуума (например, сперма от отца индивидуума) или братьев и сестер.
Согласно одному варианту осуществления генетические данные индивидуума фазируют путем разбавления, где ДНК или РНК разводят в одной или множестве лунок, например, с использованием цифровой ПЦР. Согласно некоторым вариантам осуществления ДНК или РНК разводят до точки, где, как ожидается, будет не больше, чем приблизительно одна копия каждого гаплотипа в каждой лунке, а затем измеряют ДНК или РНК в одной или нескольких лунках. Согласно некоторым вариантам осуществления клетки останавливают в фазе митоза, когда хромосомы представляют собой плотные пучки, и используют микрожидкости, чтобы помещать отдельные хромосомы в отдельные лунки. Поскольку ДНК или РНК разводят, то маловероятно, что более чем один гаплотип будет находиться в той же фракции (или пробирке). Таким образом, может быть эффективной одна молекула ДНК в пробирке, что позволяет определить гаплотип на одной молекуле ДНК или РНК. Согласно некоторым вариантам осуществления способ предусматривает деление образца ДНК или РНК на множество фракций, таким образом, что по меньшей мере одна из фракций включает в себя одну хромосому или один хромосомный сегмент из пары хромосом, и генотипирование (например, определение наличия двух или нескольких полиморфных локусов) образца ДНК или РНК по меньшей мере в одной из фракций, тем самым определяя гаплотип. Согласно некоторым вариантам осуществления генотипирование включает в себя секвенирование (например, секвенирование способом выстрела из дробового оружия или секвенирование одной молекулы) матрицы SNP для обнаружения полиморфных локусов, или мультиплексную ПЦР. Согласно некоторым вариантам осуществления генотипирование предусматривает использование матрицы SNP для обнаружения полиморфных локусов, таких как по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных полиморфных локусов. Согласно некоторым вариантам осуществления генотипирование предусматривает использование мультиплексной ПЦР. Согласно некоторым вариантам осуществления способ предусматривает контактирование образца во фракции с библиотекой праймеров, которые одновременно гибридизуются по меньшей мере с 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различными полиморфными локусами (например, SNP) с получением реакционной смеси; и подверганию реакционной смеси воздействию условий реакции удлинения праймера для получения продуктов амплификации, которые измеряются с помощью секвенатора с высокой пропускной способностью, для получения данных секвенирования. Согласно некоторым вариантам осуществления секвенируют РНК (например, мРНК). Поскольку мРНК содержит только экзоны, секвенирование мРНК позволяет определить аллель для полиморфных локусов (например, SNP) на большом расстоянии в геноме, например, несколько мегабаз. Согласно некоторым вариантам осуществления гаплотип индивидуума определяют с помощью сортировки хромосом. Иллюстративный способ сортировки хромосом предусматривает остановку клеток на фазе митоза, когда хромосомы находятся в плотном пучке, и с помощью микрожидкостей помещение отдельных хромосом в отдельные лунки. Другой способ предусматривает сбор одиночных хромосом с помощью FACS-опосредованной однохромосомной сортировки. Стандартные способы (такие как секвенирование или матричный анализ) могут быть использованы для идентификации аллелей на одной хромосоме, чтобы определить гаплотип индивидуума.
Согласно некоторым вариантам осуществления гаплотип индивидуума определяют посредством секвенирования длинных прочтений, например, с использованием технологии Moleculo, разработанной Illumina. Согласно некоторым вариантам осуществления стадия получения библиотеки предусматривает деление ДНК на фрагменты, такие как фрагменты размером ~10 т.п.н., разведение фрагментов и размещение их в лунки (таким образом, что приблизительно 3000 фрагментов находятся в одной лунке), амплификацию фрагментов в каждой лунке посредством ПЦР длинных фрагментов и нарезания на короткие фрагменты и штриховое кодирование фрагментов, а также объединение фрагментов со штрих-кодами из каждой лунки вместе, чтобы секвенировать их всех. После секвенирования вычислительные стадии предусматривают разделение прочтений из каждой лунки на основе прикрепленных штрих-кодов и группирование их во фрагменты, сборку фрагментов в их перекрывающихся гетерозиготных SNV в блоки гаплотипов и фазирование блоков статистически на основе фазированной эталонной панели, и производство длинных контигов гаплотипов.
Согласно некоторым вариантам осуществления гаплотип индивидуума определяют с использованием данных от родственника индивидуума. Согласно некоторым вариантам осуществления матрицу SNP используют для определения наличия по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных полиморфных локусов в образце ДНК или РНК от индивидуума и родственника индивидуума. Согласно некоторым вариантам осуществления способ предусматривает контактирование образца ДНК от индивидуума и/или родственника индивидуума с библиотекой праймеров, которые одновременно гибридизуются по меньшей мере с 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различными полиморфными локусами (например, SNP), с получением реакционной смеси; и подвергание реакционной смеси воздействию условий реакции удлинения праймера для получения продуктов амплификации, которые измеряются с помощью секвенсора с высокой пропускной способностью для получения данных секвенирования.
Согласно одному варианту осуществления генетические данные индивидуума фазируют с помощью компьютерной программы, которая использует основанные на популяции частоты гаплотипов, чтобы сделать вывод о наиболее вероятной фазе, например, основанное на HapMap фазирование. Например, наборы гаплоидных данных могут быть выведены непосредственно из диплоидных данных с использованием статистических способов, которые используют известные блоки гаплотипов в общей популяции (например, те, которые создаются для общественного проекта HapMap и для проекта человеческого гаплотипа Perlegen). Блок гаплотипа представляет собой по существу ряд коррелированных аллелей, которые происходят неоднократно в различных популяциях. Так как эти блоки гаплотипов часто представляют собой древние и общие, они могут быть использованы для прогнозирования гаплотипов от диплоидных генотипов. Публично доступные алгоритмы выполнения этой задачи включают в себя подход несовершенной филогении, Байесовские подходы, основанные на сопряженных априорных вероятностях и априорных вероятностях из популяционной генетики. Некоторые из этих алгоритмов используют скрытую модель Маркова.
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных генотипов, например, алгоритма, который использует кластеризацию локализованного гаплотипа (смотрите, например, публикацию Browning and Browning, "Rapid and Accurate Haplotype Phasing and Missing-Data Inference for Whole-Genome Association Studies By Use of Localized Haplotype Clustering" Am J Hum Genet. Nov 2007; 81(5): 1084-1097, которая полностью включена в настоящий документе посредством ссылки). Иллюстративная программа представляет собой Beagle версии: 3.3.2 или версии 4 (доступна в интернете по адресу hfaculty.washington.edu/browning/beagle/beagle.html~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных генотипов, например, алгоритм, который использует распад неравновесного сцепления с расстоянием, порядком и расстоянием между генотипированными маркерами, условной подстановкой недостающих данных, оценками частоты рекомбинации или их комбинации (смотрите, например, публикацию Stephens and Scheet, "Accounting for Decay of Linkage Disequilibrium in Haplotype Inference and Missing-Data Imputation" Am. J. Hum. Genet. 76: 449-462, 2005, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой PHASE v.2.1 или v2.1.1. (доступна в интернете по адресу stephenslab.uchicago.edu/software.html~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционного генотипа, например, алгоритма, который позволяет кластерной принадлежности непрерывно изменяться вдоль хромосомы согласно скрытой Марковской модели. Такой подход представляет собой гибкий, что делает возможными, как профили "типа блока" неравновесного сцепления, так и постепенное снижение в неравновесном сцеплении с расстоянием (смотрите, например, публикацию Scheet and Stephens, "A fast and f1exible statistical model for large-scale population genotype data: applications to inferring missing genotypes and haplotypic phase." Am J Hum Genet, 78: 629-644, 2006, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой fastPHASE (доступна в интернете по адресу stephenslab.uchicago.edu/software.html~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием способа подстановок генотипа, например, способа, который использует один или несколько из следующих эталонных наборов данных: набор данных HapMap, наборы данных контролей, генотипированных на нескольких чипах SNP, и плотно типизированные образцы из проекта геномов 1000. Иллюстративный подход представляет собой гибкую структуру моделирования, которая повышает точность и объединяет информацию по нескольким эталонным панелям (смотрите, например, публикацию Howie, Donnelly, and Marchini (2009) "A f1exible and accurate genotype imputation method for the next generation of genome-wide association studies." PLoS Genetics 5(6): e1000529, 2009, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой IMPUTE или IMPUTE версии 2 (также известная как IMPUTE2) (доступна в интернете по адресу atmathgen.stats.ox.ac.uk/impute/impute_v2.html, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который делает вывод о гаплотипах, например, алгоритма, который делает вывод о гаплотипах под генетической моделью коалесценции с рекомбинацией, как, например, разработанная Stephens PHASE v2.1. Основные алгоритмические усовершенствования опираются на использование бинарных деревьев для представления набора потенциальных гаплотипов для каждого индивидуума. Эти представления бинарного дерева: (1) ускоряют вычисления апостериорных вероятностей гаплотипов, избегая избыточных операций, выполняемых в PHASE v2.1, и (2) преодолевают экспоненциальный аспект вывода о проблеме гаплотипов с помощью смарт-разведки наиболее вероятных путей (т.е. гаплотипов) в бинарных деревьях (смотрите, например, публикацию Delaneau, Coulonges and Zagury, "Shape-IT: new rapid and accurate algorithm for haplotype inference," BMC Bioinformatics 9: 540, 2008 doi: 10.1186/1471-2105-9-540, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой SHAPEIT (доступна в интернете по адресу atmathgen.stats.ox.ac.uk/genetics_software/shapeit/shapeit.html, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционных генотипов, например, алгоритма, который использует частоты гаплотипов-фрагментов для получения основанных на эмпирических вероятностей для более длинных гаплотипов. Согласно некоторым вариантам осуществления алгоритм реконструирует гаплотипы таким образом, что они характеризуются максимальной локальной когерентностью (смотрите, например, публикацию Eronen, Geerts, and Toivonen, "HaploRec: Efficient and accurate large-scale reconstruction of haplotypes, "BMC Bioinformatics 7: 542, 2006, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой HaploRec, например, HaploRec версии 2.3. (доступна в интернете по адресу cs.helsinki.fi/group/genetics/haplotyping.html~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционных генотипов, например, алгоритма, который использует стратегию разложения-сшивания и основанный на максимизации ожидания алгоритм (смотрите, например, публикацию Qin, Niu, and Liu, "Partition-Ligation-Expectation-Maximization Algorithm for Haplotype Inference with Single-Nucleotide Polymorphisms," Am J Hum Genet. 71(5): 1242-1247, 2002, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой PL-EM (доступна в интернете по адресу people.fas.harvard.edu/~junliu/plem/click.html~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционных генотипов, например, алгоритма одновременного фазирования генотипов в гаплотипы и блочное разделение. Согласно некоторым вариантам осуществления используется алгоритм максимизации ожидания (смотрите, например, публикацию Kimmel and Shamir,"GERBIL: Genotype Resolution and Block Identification Using Likelihood, "Proceedings of the National Academy of Sciences of the United States of America (PNAS) 102: 158-162, 2005, которая полностью включена в настоящий документе посредством ссылки). Иллюстративная программа представляет собой GERBIL, которая доступна как часть программы GEVALT версии 2 (доступна в интернете по адресу acgt.cs.tau.ac.il/gevalt/, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционных генотипов, например, алгоритма, который использует EM-алгоритм для расчета оценок ML частот гаплотипов данных измерений генотипов, которые не определяют фазу. Алгоритм также учитывает некоторое отсутствие измерений генотипа (за счет, например, неудачной ПЦР). Он также позволяет множественные условные подстановки отдельных гаплотипов (смотрите, например, публикацию Clayton, D. (2002), "SNPHAP: A Program for Estimating Frequencies of Large Haplotypes of SNPs", которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой SNPHAP (доступна в интернете по адресу gene.cimr.cam.ac.uk/clayton/software/snphap.txt, который полностью включен в настоящий документ посредством ссылки).
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием алгоритма, который оценивает гаплотипы из данных популяционных генотипов, например, алгоритма для вывода гаплотипов на основе статистических данных генотипов, собранных для пар SNP. Это программное обеспечение может быть использовано для сравнительно точного фазирования большого количества длинных последовательностей генома, например, полученных из массивов ДНК. Иллюстративная программа принимает матрицу генотипа в качестве входных данных и выдает соответствующую матрицу гаплотипа (смотрите, например, публикацию Brinza and Zelikovsky, "2SNP: scalable phasing based on 2-SNP haplotypes," Bioinformatics. 22(3): 371-3, 2006, которая полностью включена в настоящий документ посредством ссылки). Иллюстративная программа представляет собой 2SNP (доступна в интернете по адресу alla.cs.gsu.edu/~software/2SNP~~pobj, который полностью включен в настоящий документ посредством ссылки).
Согласно различным вариантам осуществления генетические данные индивидуума фазируют с использованием данных о вероятности хромосом перекрещиваться в разных положениях хромосомы или хромосомного сегмента (например, с использованием данных о рекомбинации, таких как те, которые можно найти в базе данных HapMap для создания балла риска рекомбинации для любого интервала) для моделирования зависимости между полиморфными аллелями на хромосоме или хромосомном сегменте. Согласно некоторым вариантам осуществления подсчеты аллелей в полиморфных локусах вычисляют на компьютере на основе данных секвенирования или данных микроматричного анализа SNP. Согласно некоторым вариантам осуществления создают множество гипотез, каждая из которых относится к различным возможным состояниям хромосомы или хромосомного сегмента (например, превышение количества копий первого гомологичного хромосомного сегмента по сравнению со вторым гомологичным хромосомным сегментом в геноме одной или нескольких клеток от индивидуума, дублирование первого гомологичного хромосомного сегмента, делеция второго гомологичного хромосомного сегмента или равное представление первого и второго гомологичных хромосомных сегментов) (например, создание на компьютере); для каждой гипотезы строят (например, строительство на компьютере) модель (например, модель совместного распределения) для ожидаемых подсчетов аллелей в полиморфных локусах на хромосоме; определяют относительную вероятность каждой из гипотез (например, определение на компьютере) с помощью модели совместного распределения и подсчетов аллелей; и выбирают гипотезу с наибольшей вероятностью. Согласно некоторым вариантам осуществления построение модели совместного распределения для подсчета аллелей и стадию определения относительной вероятности каждой гипотезы выполняют с использованием способа, который не требует использования эталонной хромосомы.
Согласно одному варианту осуществления генетические данные индивидуума фазируют с использованием генетических данных одного или нескольких родственников индивидуума (например, одного или нескольких из родителей, братьев, сестер, детей, плодов, эмбрионов, бабушек и дедушек, дядей, тетей или кузенов). Согласно одному варианту осуществления генетические данные человека фазируют с использованием генетических данных одного или нескольких генетических потомков индивидуума (например, 1, 2, 3 или больше потомков), например, эмбриона, плода, новорожденных детей или образца выкидыша. Согласно одному варианту осуществления генетические данные родителя (например, родителя вынашиваемого плода или эмбриона) фазируют с использованием фазированных гаплотипических данных для другого родителя вместе с нефазированными генетическими данными одного или нескольких генетических потомков родителей.
Согласно некоторым вариантам осуществления образец (например, биопсия, такая как опухолевая биопсия, образец крови, образец плазмы, образец сыворотки или другой образец, который вероятно содержит главным образом или только клетки, ДНК или РНК с представляющими интерес CNV) от индивидуума (например, индивидуума, у которого подозревается наличие злокачественной опухоли, плода или эмбриона) анализируют для определения фазы для одной или нескольких областей, которые точно или предположительно содержат представляющие интерес CNV (например, делецию или дупликацию). Согласно некоторым вариантам осуществления образец содержит высокую опухолевую фракцию (например, 30, 40, 50, 60, 70, 80, 90, 95, 98, 99 или 100%). Согласно некоторым вариантам осуществления образец (например, образец цельной крови матери, клетки, выделенные из образца крови матери, образец плазмы матери, образец сыворотки матери, образец амниоцентеза, образец плацентарной ткани (например, хориона, децидуальной или плацентарной мембраны), образец цервикальной слизи, ткань плода после гибели плода, другой образец из плода или другой образец, который вероятно содержит в основном или только клетки, ДНК или РНК с представляющими интерес CNV) от плода или беременной матери плода анализируют для определения фазы для одной или нескольких областей, которые точно или предположительно содержат представляющие интерес CNV (например, делецию или дупликацию). Согласно некоторым вариантам осуществления образец содержит высокую эмбриональную фракцию (например, 25, 30, 40, 50, 60, 70, 80, 90, 95, 98, 99 или 100%).
Согласно некоторым вариантам осуществления образец характеризуется гаплотипическим дисбалансом или любой анеуплоидией. Согласно некоторым вариантам осуществления образец включает в себя любую смесь двух типов ДНК, где два типа характеризуются различными соотношениями двух гаплотипов и разделяют по меньшей мере один гаплотип. Например, в фетально-материнском случае, мать представляет собой 1:1, а плод 1:0 (плюс отцовский гаплотип). Например, в случае опухоли, нормальная ткань представляет собой 1:1, а опухолевая ткань представляет собой 1:0 или 1:2, 1:3, 1:4 и т.д. Согласно некоторым вариантам осуществления анализируют по меньшей мере 10; 100; 500; 1000; 2000; 3000; 5000; 8000 или 10000 полиморфных локусов для определения фазы аллелей в некоторых или всех локусах. Согласно некоторым вариантам осуществления образец получают из клетки или ткани, которая была обработана, чтобы стать анеуплоидной, например, анеуплоидия, индуцированная длительным культивированием клеток.
Согласно некоторым вариантам осуществления большой процент или вся ДНК или РНК в образце содержат представляющую интерес CNV. Согласно некоторым вариантам осуществления отношение ДНК или РНК из одной или нескольких клеток-мишеней, которые содержат представляющую интерес CNV, к общей ДНК или РНК в образце составляет по меньшей мере 80, 85, 90, 95 или 100%. Для образцов с делецией, только один гаплотип присутствует для клеток (или ДНК, или РНК) с делецией. Этот первый гаплотип может быть определен с помощью стандартных способов определения идентичности аллелей, присутствующих в области делеции. В образцах, содержащих только клетки (или ДНК, или РНК) с делецией, будет только сигнал от первого гаплотипа, который присутствует в этих клетках. В образцах, которые также содержат небольшое количество клеток (или ДНК, или РНК) без делеции (например, небольшое количество незлокачественных клеток), слабый сигнал от второго гаплотипа в этих клетках (или ДНК, или РНК) может быть проигнорирован. Второй гаплотип, который присутствует в других клетках, ДНК или РНК от индивидуума, у которого отсутствует делеция, может быть определен с помощью логического вывода. Например, если генотип клеток от индивидуума без делеции представляет собой (AB, AB) и фазированные данные для индивидуума указывают на то, что первый гаплотип представляет собой (A, A); то можно сделать вывод, что другой гаплотип представляет собой (B, B).
Для получения образцов, в которых присутствуют, как клетки (или ДНК, или РНК) с делецией, так и клетки (или ДНК, или РНК) без делеции, фаза по-прежнему может быть определена. Например, могут быть созданы диаграммы, аналогичные показанным на Фиг. 18 или 29, в которой ось X представляет собой линейное положение отдельных локусов по хромосоме, а ось Y представляет собой число прочтений аллеля А в виде доли от общего числа (А+В) прочтений аллелей. Согласно некоторым вариантам осуществления для делеции, профиль включает в себя две центральные полосы, которые представляют собой SNP, для которых индивидуум является гетерозиготным (верхняя полоса представляет собой АВ из клеток без делеции и A из клеток с делецией, а нижняя полоса представляет собой АВ из клеток без делеции и B из клеток с делецией). Согласно некоторым вариантам осуществления разделение этих двух полос возрастает с увеличением доли клеток, ДНК или РНК с делецией. Таким образом, идентичность аллелей A может быть использована для определения первого гаплотипа, а идентичность аллелей B может быть использована для определения второго гаплотипа.
Для образцов с дупликацией, дополнительная копия гаплотипа присутствует для клеток (или ДНК, или РНК) с дупликацией. Этот гаплотип дублированной области может быть определен с использованием стандартных способов для определения идентичности аллелей, присутствующих в увеличенном количестве в области дупликации, или гаплотип области, который не дублируется, может быть определен с использованием стандартных способов для определения идентичности аллелей, присутствующих в уменьшенном количестве. После того, как один гаплотип определен, другой гаплотип может быть определен с помощью логического вывода.
Для получения образцов, в которых присутствуют, как клетки (или ДНК, или РНК) с дупликацией, так и клетки (или ДНК, или РНК) без дупликации, фаза по-прежнему может быть определена с использованием способа, аналогичного тому, который описан выше для делеции. Например, могут быть созданы графики, аналогичные показанным на Фиг. 18 или 29, в которых ось X представляет собой линейное положение отдельных локусов по хромосоме, а ось Y представляет собой число прочтений аллеля А в виде доли от общего числа (А+В) прочтений аллелей. Согласно некоторым вариантам осуществления для делеции профиль включает в себя две центральные полосы, которые представляют собой SNP, для которых индивидуум является гетерозиготным (верхняя полоса представляет собой АВ из клеток без дупликации и ААВ из клеток с дупликацией, а нижняя полоса представляет собой АВ из клеток без дупликации и ABB из клетки с дупликацией). Согласно некоторым вариантам осуществления разделение этих двух полос возрастает с увеличением доли клеток, ДНК или РНК с дупликацией. Таким образом, идентичность аллелей A может быть использована для определения первого гаплотипа, а идентичность аллелей B может быть использована для определения второго гаплотипа. Согласно некоторым вариантам осуществления фазу одной или нескольких областей CNV (например, фазу по меньшей мере 50, 60, 70, 80, 90, 95 или 100% полиморфных локусов в области, которую измеряли) определяют для образца (например, опухолевой биопсии или образца плазмы) от индивидуума, у которого известно наличие злокачественной опухоли, и используют для анализа последующих образцов от того же индивидуума, чтобы контролировать прогрессирование злокачественной опухоли (например, контроль за ремиссией или рецидивом злокачественной опухоли). Согласно некоторым вариантам осуществления образец с высокой опухолевой фракцией (например, опухолевая биопсия или образец плазмы от индивидуума с высокой опухолевой нагрузкой) используют для получения фазированной данных, которые используются для анализа последующих образцов с более низкой опухолевой фракцией (например, образца плазмы от индивидуума, проходящего курс лечения злокачественной опухоли или в стадии ремиссии).
Согласно другому варианту осуществления для пренатальной диагностики, фазированные родительские гаплотипические данные обнаруживают наличие более чем одного гомолога от отца, подразумевая, что генетический материал от более чем одного плода присутствует в образце материнской крови. Сосредоточив внимание на хромосомах, которые, как ожидается, будут эуплоидными у плода, можно было бы исключить возможность того, что плод поражен трисомией. Кроме того, можно определить, является ли ДНК плода не от нынешнего отца.
Согласно некоторым вариантам осуществления два или более из описанных в настоящем документе способов используют для фазирования генетических данных индивидуума. Согласно некоторым вариантам осуществления используется как способ биоинформатики (например, использование основанных на популяции частот гаплотипов, чтобы сделать вывод о наиболее вероятной фазе), так и способ молекулярной биологии (например, любой из раскрытых в настоящем документе способов молекулярного фазирования, чтобы получить фактические фазированные данные, а не основанные на биоинформатике выведенные фазированные данные). Согласно некоторым вариантам осуществления фазированные данные от других субъектов (например, предыдущих субъектов) используют для уточнения популяционных данных. Например, фазированные данные от других субъектов могут быть добавлены к популяционным данным для расчета априорных вероятностей для возможных гаплотипов для другого субъекта. Согласно некоторым вариантам осуществления фазированные данные от других субъектов (например, предыдущих субъектов) используют для расчета априорных вероятностей для возможных гаплотипов для другого субъекта.
Согласно некоторым вариантам осуществления могут быть использованы вероятностные данные. Например, в связи с вероятностным характером представления молекул ДНК в образце, а также различными статистическими погрешностями амплификации и измерений, относительное число молекул ДНК, измеренных от двух разных локусов или от различных аллелей в данном локусе, не всегда является типичным показателем относительного числа молекул в смеси или у индивидуума. При попытке определить генотип нормального диплоидного индивидуума в данном локусе на аутосомной хромосоме путем секвенирования ДНК из плазмы индивидуума, можно было бы ожидать, либо наличие только одного аллеля (гомозиготное), либо равное количество двух аллелей (гетерозиготное). Если, в этом аллеле наблюдалось десять молекул аллеля A и наблюдалось две молекулы аллеля B, то не будет понятно, индивидуум был гомозиготным в локусе, а две молекулы аллеля B были обусловлены шумом или загрязнением, или индивидуум был гетерозиготным, а меньшее число молекул аллеля В было обусловлено случайной, статистической вариацией числа молекул ДНК в плазме, систематической ошибкой амплификации, загрязнением или любым количеством других причин. В этом случае может быть вычислена вероятность того, что индивидуум был гомозиготным, и соответствующая вероятность того, что индивидуум был гетерозиготным, и эти вероятностные генотипы могут быть использованы в дальнейших вычислениях.
Следует отметить, что при заданном аллельном соотношении, правдоподобие того, что соотношение близко представляет собой отношение молекул ДНК у индивидуума больше, чем больше число молекул, которые наблюдают. Например, если бы было измерено 100 молекул A и 100 молекул В, правдоподобие того, что фактическое соотношение составляло 50%, значительно больше, чем если бы было измерено 10 молекул A и 10 молекул B. Согласно одному варианту осуществления Байесовскую теорию в сочетании с детальной моделью данных используют для определения правдоподобия того, что конкретная гипотеза верна для данного наблюдения. Например, при рассмотрении двух гипотез - одна соответствует трисомному индивидууму, а вторая соответствует дисомному индивидууму - тогда вероятность правильности дисомной гипотезы была бы значительно выше, для случая, когда наблюдали 100 молекул каждого из двух аллелей, по сравнению со случаем, когда наблюдали 10 молекул каждого из двух аллелей. По мере того как данные становятся шумными из-за систематической ошибки, загрязнения или какого-либо другого источника шума, или по мере того, как число наблюдений в данном локусе уменьшается, вероятность истинности гипотезы максимального правдоподобия для наблюдаемых данных падает. На практике, можно собрать вместе вероятности по многим локусам, чтобы увеличить достоверный интервал, с которым гипотеза максимального правдоподобия может быть определена как правильная гипотеза. Согласно некоторым вариантам осуществления вероятности просто собирают вместе без учета рекомбинации. Согласно некоторым вариантам осуществления вычисления учитывают кроссоверы.
Согласно одному варианту осуществления вероятностно фазированные данные используют в определении вариации числа копий. Согласно некоторым вариантам осуществления вероятностно фазированные данные представляют собой основанные на популяции данные о частотах блоков гаплотипов из источника данных, например, базы данных HapMap. Согласно некоторым вариантам осуществления вероятностно фазированные данные представляют собой гаплотипические данные, полученные с помощью молекулярного способа, например, фазирования путем разбавления, где отдельные сегменты хромосом разводят до одной молекулы на реакцию, но где из-за стохаистического шума идентичности гаплотипов не могут быть абсолютно известны. Согласно некоторым вариантам осуществления вероятностно фазированные данные представляют собой гаплотипические данные, полученные с помощью молекулярного способа, где идентичности гаплотипов могут быть известны с высокой степенью достоверности.
Если представить гипотетический случай, где врач хотел бы определить, имеются ли у индивидуума некоторые клетки в организме, которые содержат делению на определенном хромосомном сегменте путем измерения ДНК плазмы от индивидуума. Врач может использовать знания того, что, если все клетки, из которых происходит ДНК плазмы, были диплоидными и с одним и тем же генотипом, то для гетерозиготных локусов, относительное число молекул ДНК, наблюдаемое для каждого из двух аллелей, будет попадать в одно распределение, которое сосредоточено на 50% аллеля A и 50% аллеля B. Тем не менее, если доля клеток, из которых возникла ДНК плазмы, содержала делецию в определенном хромосомном сегменте, тогда для гетерозиготных локусов можно было бы ожидать, что относительное число молекул ДНК, наблюдаемое для каждого из двух аллелей, разделялось бы на два распределения, одно с центром в точке выше 50% аллеля A для локусов, где была делеция хромосомного сегмента, содержащего аллель B, и одно с центром ниже 50% для локусов, где произошла делеция хромосомного сегмента, содержащего аллель A. Чем большая доля клеток, из которых возникла ДНК плазмы, содержит делецию, тем дальше от 50% будут эти два распределения.
В этом гипотетическом случае можно представить клинициста, который хочет определить, имеется ли у индивидуума делеция хромосомной области в части клеток в организме. Клиницист может собрать кровь у индивидуума в вакутейнер или пробирку для сбора крови другого типа, центрифугировать кровь и выделить слой плазмы. Клиницист может выделить ДНК из плазмы крови, обогатить ДНК на нацеленные локусы, возможно, за счет нацеленной или другой амплификации, способов захвата локуса, обогащения размера или другие способов обогащения. Клиницист может анализировать, например, путем измерения числа аллелей в совокупности SNP, другими словами путем получения данных о частоте аллелей, обогащенной и/или амплифицированной ДНК с использованием такого анализа, как кПЦР, секвенирование, микроматричный анализ или другие способы, которые измеряют количество ДНК в образце. Авторы настоящего изобретения будут рассматривать анализ данных для случая, когда клиницист амплифицировал внеклеточную ДНК плазмы с использованием способа нацеленной амплификации, а затем секвенировал амплифицированную ДНК, чтобы получить следующие иллюстративные возможные данные в шести SNP, обнаруженных на хромосомном сегменте, что свидетельствует о злокачественной опухоли, где индивидуум был гетерозиготным по этим SNP:
SNP 1: 460 прочтений аллеля A; 540 прочтений аллеля B (46% A)
SNP 2: 530 прочтений аллеля A; 470 прочтений аллеля B (53% А)
SNP 3: 40 прочтений аллеля A; 60 прочтений аллеля B (40% А)
SNP 4: 46 прочтений аллеля A; 54 прочтения аллеля B (46% А)
SNP 5: 520 прочтений аллеля A; 480 прочтений аллеля B (52% А)
SNP 6: 200 прочтений аллеля A; 200 прочтений аллеля B (50% А)
Из этого набора данных может быть трудно провести различие между случаем, когда индивидуум является нормальным со всеми дисомическими клетками или когда индивидуум может характеризоваться наличием злокачественной опухоли с некоторой части клеток, ДНК, внесших вклад во внеклеточную ДНК, обнаруженную в плазме с делецией или дупликацией на хромосоме. Например, две гипотезы с максимальным правдоподобием могут быть такими, что индивидуум характеризуется наличием делеции в этом хромосомном сегменте с опухолевой фракцией 6%, а удаленный хромосомный сегмент характеризуется генотипом шести полиморфизмов (А,В,А,А,В,В) или (А,В,А,А,В,А). В этом представлении генотипа индивидуума над набором SNP, первая буква в скобках соответствует генотипу гаплотипа для SNP 1, вторая - для SNP 2 и т.д.
Если используется способ определения гаплотипа индивидуума в этом хромосомном сегменте и обнаруживается, что гаплотип для одной из двух хромосом представляет собой (А,В,А,А,В,В), то это согласуется с гипотезой максимального правдоподобия, и вычисленное правдоподобие, что индивидуум содержит делецию в этом сегменте и, следовательно, может характеризоваться наличием злокачественных или предшественников злокачественных клеток, будет значительно увеличено. С другой стороны, если было обнаружено, что индивидуум характеризуется наличием гаплотипа (А,А,А,А,А,А), то правдоподобие того, что индивидуум содержит делецию в этом хромосомной сегменте, будет значительно уменьшено, и, возможно, правдоподобие гипотезы отсутствия делеции будет выше (фактические значения правдоподобия будут зависеть от других параметров, таких как измеренный шум в системе, среди прочего).
Существует много способов определить гаплотип индивидуума, многие из которых описаны в настоящем документе. Неполный список приведен в настоящем документе и не претендует на исчерпывающий характер. Одним из способов является биологический способ, в котором отдельные молекулы ДНК разводят до приблизительно одной молекулы от каждой хромосомной области в любом заданном объеме реакционной смеси, а затем такие способы, как секвенирование, используют для измерения генотипа. Другой способ основан на информатике, где популяционные данные о различных гаплотипах в сочетании с их частотой могут быть использованы в вероятностной форме. Другой способ заключается в измерении диплоидных данных индивидуума вместе с одним или множеством родственных индивидуумов, которые, как предполагается, разделяют блоки гаплотипов с индивидуумом, и подведение логического вывода о блоках гаплотипов. Другой способ заключается в том, чтобы взять образец ткани с высокой концентрацией удаленного или дублированного сегмента и определить гаплотип, основанный на аллельном дисбалансе, например, измерениях генотипа из образца опухолевой ткани с делецией может быть использован для определения фазированных данных для этой области с делецией, и эти данные затем могут быть использованы для определения, не появилась ли повторно злокачественная опухоль после резекции.
На практике, как правило, измеряют более 20 SNP, более 50 SNP, более 100 SNP, более 500 SNP, более 1000 SNP или более 5000 SNP на данном хромосомном сегменте.
Иллюстративные способы фазирования, предсказания аллельных соотношений и восстановления фетальных генетических данных
Согласно одному аспекту настоящее изобретение относится к способам определения одного или нескольких гаплотипов плода. Согласно различным вариантам осуществления этот способ позволяет определить, какой из полиморфных локусов (например, SNP) унаследован плодом, и реконструировать гомологи (в том числе и события рекомбинации), которые присутствуют у плода (и, таким образом, интерполировать последовательность между полиморфных локусов). При желании, по существу, весь геном плода может быть реконструирован. Если существует некоторая оставшаяся неоднозначность в геноме плода (например, в интервалах с кроссовером), эта неоднозначность может быть сведена к минимуму, при желании, с помощью анализа дополнительных полиморфных локусов. Согласно различным вариантам осуществления полиморфные локусы выбирают так, чтобы охватывать одну или несколько хромосом с такой плотностью, чтобы уменьшить любую неоднозначность до желательного уровня. Этот способ имеет важное применение для обнаружения полиморфизмов или других представляющих интерес мутаций (например, делеций или дупликаций) у плода, так как он делает возможным их обнаружение на основании сцепления (например, наличие сцепленных полиморфных локусов в фетальном геноме), а не направляя обнаружения полиморфизма или другой представляющей интерес мутации в фетальном геноме. Например, если один из родителей представляет собой носителя мутации, связанной с кистозным фиброзом (CF), образец нуклеиновой кислоты, который включает в себя материнскую ДНК от матери плода и фетальную ДНК от плода, может быть проанализирован, чтобы определить, включает ли ДНК плода гаплотип, содержащий мутацию CF. В частности, полиморфные локусы могут быть проанализированы, чтобы определить, содержит ли ДНК плода гаплотип, содержащий мутацию CF, без обнаружения самой мутации CF в фетальной ДНК. Это полезно для скрининга на одну или несколько мутаций, таких как связанных с заболеванием, без необходимости непосредственного обнаружения мутаций.
Согласно некоторым вариантам осуществления способ предусматривает определение родительского гаплотипа (например, гаплотипа матери или отца плода), например, с использованием любого из описанных в настоящем документе способов. Согласно некоторым вариантам осуществления это определение производят без использования данных от родственника матери или отца. Согласно некоторым вариантам осуществления родительский гаплотип определяют с использованием подхода разбавления с последующим генотипированием или секвенированием SNP, как описано в настоящем документе. Согласно некоторым вариантам осуществления гаплотип матери (или отца) определяют с помощью любого из описанных в настоящем документе способов с использованием данных от родственника матери (или отца). Согласно некоторым вариантам осуществления гаплотип определяют как для отца, так и для матери.
Этот данные о родительском гаплотипе могут быть использованы для определения того, унаследовал ли плод родительский гаплотип. Согласно некоторым вариантам осуществления образец нуклеиновой кислоты, которая включает в себя материнскую ДНК от матери плода и фетальную ДНК от плода анализируют с использованием матрицы SNP, чтобы обнаружить по меньшей мере 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных полиморфных локусов. Согласно некоторым вариантам осуществления образец нуклеиновой кислоты, который включает в себя материнскую ДНК от матери плода и фетальную ДНК от плода, анализируют путем приведения в контакт образца с библиотекой праймеров, которые одновременно гибридизуют по меньшей мере с 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различными полиморфными локусами (например, SNP) для получения реакционной смеси. Согласно некоторым вариантам осуществления реакционную смесь подвергают воздействию условий реакции для удлинения праймера для получения продуктов амплификации. Согласно некоторым вариантам осуществления амплифицированные продукты измеряют посредством секвенатора с высокой пропускной способностью для получения данных секвенирования.
Согласно различным вариантам осуществления фетальный гаплотип определяют с использованием данных о вероятности пересечения хромосом в разных местах в хромосоме или хромосомном сегменте (например, с использованием таких данных о рекомбинации, которые могут быть обнаружены в базе данных HapMap, чтобы создать оценку риска рекомбинации для любого интервала), чтобы моделировать зависимость между полиморфными аллелями на хромосоме или хромосомном сегменте, как описано выше. Согласно некоторым вариантам осуществления способ учитывает физическое расстояние от SNP (например, SNP, фланкирующие представляющий интерес ген или мутацию) и данные рекомбинации от положения конкретных правдоподобий рекомбинации, и данные, наблюдаемые от генетических измерений материнской плазмы, чтобы получить наиболее вероятный генотип плода. Тогда может быть выполнен PARENTAL SUPPORT™ на нацеленной последовательности или данных матрицы SPN, полученных от этих SNP, чтобы определить, какие гомологи были унаследованы плодом от обоих родителей (смотрите, например, заявку на патент США №11/603406 (публикация США №20070184467), заявку на патент США №12/076348 (публикация США №20080243398), заявку на патент США №13/110685 (публикация США №2011/0288780), заявку РСТ PCT/US09/52730 (публикация РСТ WO/2010/017214) и заявку РСТ PCT/US10/050824 (публикация РСТ WO/2011/041485), заявку на патент США №13/300235 (публикация США №2012/0270212), заявку на патент США №13/335043 (публикация США №2012/0122701), заявку на патент США №13/683604 и заявку на патент США №13/780022, каждая из которых полностью включена в настоящий документ посредством ссылки).
В обобщенном примере, где возможные аллели в одном локусе представляют собой A и B; установление идентичности A или B к конкретным аллелям представляет собой произвольное. Родительские генотипы для конкретного SNP, называемые генетическими контекстами, выражаются в виде материнского генотипа|отцовского генотипа. Таким образом, если мать является гомозиготной, а отец - гетерозиготен, это будет представлено как АА|АВ. Точно так же, если оба родителя являются гомозиготными по тому же аллелю, родительские генотипы будут представлены в виде АА|АА. Кроме того, плод никогда не будет иметь состояний АВ или ВВ, и число прочтений последовательности с аллелем B будет низким, и, следовательно, могут быть использованы для определения ответов шума анализа и платформы генотипирования, в том числе и такие эффекты, как загрязнение низкого уровня ДНК и ошибки секвенирования; эти ответы шума полезны для моделирования ожидаемых профилей генетических данных. Существует только пять возможных материнских|отцовских генетических контекстов: АА|АА, АА|АВ, АВ|АА, АВ|АВ и АА|ВВ; другие контексты эквивалентны по симметрии. SNP, где родители являются гомозиготными по одному и тому же аллелю, представляют собой информативные только для определения уровней шума и загрязнения. SNP, где родители не являются гомозиготными по одному и тому же аллелю, представляют собой информативные при определении фетальной фракции и подсчет числа копий.
Пусть NA,i и NB,i представляют собой число прочтений каждого аллеля в SNP i и пусть Ci представляет собой родительский генетический контекст в этом локусе. Набор данных для конкретной хромосомы представлена NAB={NA,i, NB,i}=1…N и C={Ci}, i=1…N. Для восстановления части или всего фетального генома, при желании можно определить, характеризуется ли плод анеуплоидией (например, отсутствующей или дополнительной копией хромосомы или хромосомного сегмента). Для каждой отдельной хромосомы или исследуемой хромосомы, пусть H представляет собой набор из одной или нескольких гипотез для общего числа хромосом, родительского происхождения каждой хромосомы и положений на родительских хромосомах, где произошла рекомбинация во время образования половых клеток, которые были оплодотворены для получения ребенка. Вероятность гипотезы P(H) может быть вычислена с использованием данных из базы данных HapMap и априорной информации, связанной с каждым из состояний плоидности.
Кроме того, пусть F представляет собой фетальную фракцию вкДНК в образце. Принимая во внимание множество возможных H, C и F, можно вычислить вероятность NAB, P(NAB|H,F,C), основанную на моделировании источников шума платформы молекулярного анализа и секвенирования. Цель состоит в том, чтобы найти гипотезу Н и фетальную фракцию F, которая максимизирует P(H,F|NAB). Используя стандартные Байесовские статистические способы и предполагая равномерное распределение вероятностей для F от 0 до 1, то это можно переписать в терминах максимизации вероятности P(NAB|H,F,C)P(H) для H и F, все из которых могут теперь быть вычислены. Вероятность всех гипотез, связанных с определенным числом копий и фетальной фракцией, например, трисомия и F=10%, но охватывающие все возможные происхождения родительских хромосом и расположения кроссоверов, суммируются. Гипотезу числа копий с самой высокой вероятностью выбирают в качестве результата исследования, фетальная фракция, связанная с этой гипотезой, показывает фетальную фракцию, и вероятность, связанная с этой гипотезой, представляет собой расчетную точность результата.
Согласно некоторым вариантам осуществления алгоритм использует моделирование in silico для создания очень большого числа наборов гипотетических данных секвенирования, которые могут возникнуть в результате возможных фетальных профилей генетического наследования, параметров образца и артефактов амплификации и измерения способа. Более конкретно, алгоритм сначала использует родительские генотипы при большом количестве SNP и данные о частоте кроссоверов из базы данных HapMap, чтобы прогнозировать возможные фетальные генотипы. Затем он предсказывает ожидаемые профили данных для данных секвенирования, которые будут измерены из смешанных образцов, происходящих от матери, несущей плод, с каждым из возможных генотипов плода и с учетом различных параметров, включающих в себя фетальную фракцию, ожидаемый профиль глубины прочтения, эквиваленты фетального генома, присутствующие в образце, ожидаемые статистические погрешности амплификации в каждом из SNP, а также число параметров шума. Модель данных описывает, как ожидается, что данные секвенирования или матричного анализа SNP появятся для каждой из этих гипотез с учетом особого набора параметров. Выбирают гипотезу с наилучшим совпадением данных между этим смоделированными данными и измеренными данными.
При желании, ожидаемые аллельные соотношения могут быть вычислены для ДНК или РНК из плода с использованием результатов того, какие гаплотипы были унаследованы плодом. Ожидаемые аллельные соотношения также могут быть рассчитаны для смешанного образца, содержащего нуклеиновые кислоты, как от матери, так и от плода (эти аллельные соотношения указывают на то, что ожидается для измерения общего количества каждого аллеля, включая в себя количество аллеля, как от материнских нуклеиновых кислот, так и от эмбриональных нуклеиновых кислот в образце). Ожидаемые аллельные соотношения можно вычислить для различных гипотез, определяющих степень превышения первого гомологичного хромосомного сегмента.
Согласно некоторым вариантам осуществления способ предусматривает определение того, характеризуется ли плод одним или несколькими из следующих состояний: муковисцидоз, болезнь Хантингтона, ломкая Х-хромосома, таласемия, мышечная дистрофия (например, мышечная дистрофия Дюшенна), болезнь Альцгеймера, анемия Фанкони, болезнь Гоше, муколипидоз IV, болезнь Нимана-Пика, болезнь Тея-Сакса, серповидно-клеточная анемия, болезнь Паркинсона, торсионная дистония и злокачественная опухоль. Согласно некоторым вариантам осуществления фетальный гаплотип определяют для одной или нескольких хромосом, взятых из группы, состоящей из хромосом 13, 18, 21, X и Y. Согласно некоторым вариантам осуществления фетальный гаплотип определяют для всех фетальных хромосом. Согласно различным вариантам осуществления способ определяет по существу весь геном плода. Согласно некоторым вариантам осуществления гаплотип определяется по меньшей мере на 30, 40, 50, 60, 70, 80, 90 или 95% генома плода. Согласно некоторым вариантам осуществления определение гаплотипа плода включает в себя информацию о том, какие аллели присутствуют по меньшей мере для 100; 200; 500; 750; 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных полиморфных локусов. Согласно некоторым вариантам осуществления этот способ используется для определения гаплотипа или аллельных соотношения для эмбриона.
Иллюстративные способы прогнозирования аллельных соотношений Иллюстративные способы описаны ниже для расчета ожидаемых аллельных соотношений для образца. В таблице 1 приведены ожидаемые аллельные соотношения для смешанного образца (например, образца крови матери), содержащего нуклеиновые кислоты, как от матери, так и плода. Эти ожидаемые аллельные соотношения указывают на то, что ожидается для измерения общего количества каждого аллеля, включая в себя количество аллелей, как из материнских нуклеиновых кислот, так и фетальных нуклеиновых кислот в смешанном образце. В качестве примера, мать является гетерозиготной в двух соседних локусах, которые, как ожидается, разделяются (например, два локуса, для которых не ожидается хромосомных кроссоверов между локусами). Таким образом, мать представляет собой (AB,AB). Если представить, что фазированные данные для матери указывают на то, что для одного гаплотипа она представляет собой (A,A); то для другого гаплотипа можно сделать вывод, что она представляет собой (B,B). В таблице 1 приведены ожидаемые аллельные соотношения для различных гипотез, где фетальная фракция составляет 20%. Для этого примера, не предполагается знание отцовских данных и предполагается, что степень гетерозиготности составляет 50%. Ожидаемые аллельные соотношения приведены в пересчете (ожидаемая доля прочтений A / общее число прочтений) для каждого из двух SNP. Эти коэффициенты рассчитываются как с использованием материнских фазированных данных (знание того, что один гаплотип представляет собой (A,A), а один - (B,B)), так и без использования материнских фазированных данных. Таблица 1 включает в себя различные гипотезы для числа копий хромосомного сегмента у плода от каждого родителя.
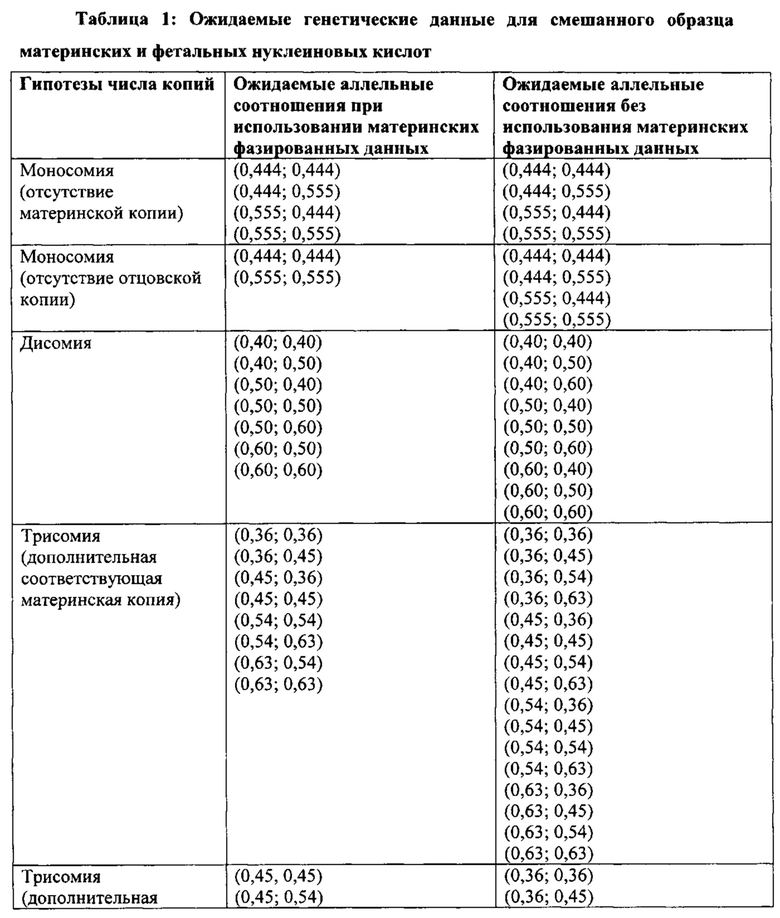
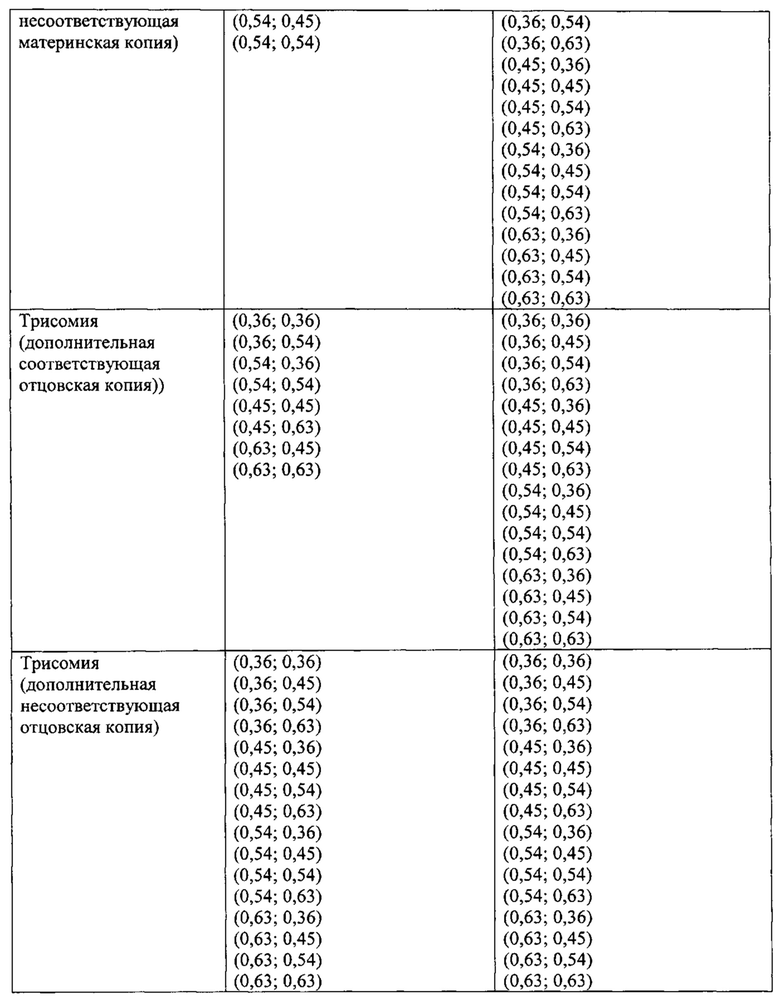
В дополнение к тому факту, что использование фазированных данных сокращает число возможных ожидаемых аллельных соотношений, оно также изменяет предварительное правдоподобие каждого из ожидаемых аллельных соотношений таким образом, что результат максимального правдоподобия скорее всего будет правильным. Исключение ожидаемых аллельных соотношений или гипотез, которые не возможны, повышает вероятность того, что будет выбрана правильная гипотеза. В качестве примера, можно предположить, что измеренное аллельное соотношение составляет (0,41, 0,59). Без использования фазированных данных, можно было бы предположить, что гипотеза с максимальным правдоподобием представляет собой гипотезу дисомии (учитывая сходство измеренных аллельных отношений с числом ожидаемых аллельных соотношений (0,40, 0,60) для дисомии). Тем не менее, с использованием фазированных данных можно исключить (0,40, 0,60) в качестве ожидаемых аллельных соотношений для гипотезы дисомии и можно выбрать гипотезу трисомии, как более вероятную.
Полагая, что измеренные аллельные соотношения представляют собой (0,4, 0,4). Без любой информации о гаплотипе вероятность материнской делеций в каждом SNP будет представлять собой 0,5×P (A удален) + 0,5×P (B удален). Поэтому, хотя это выглядит как A удален (отсутствует у плода), правдоподобие удаления будет представлять собой среднее из двух. Для получения достаточно высокой эмбриональной фракции, еще можно определить наиболее вероятную гипотезу. Для достаточно низкой эмбриональной фракции, усреднение может работать против гипотезы делеций. Однако с информацией о гаплотипе вероятность удаления гомолога 1, P (A удален), больше, и будет соответствовать измеренным данным лучше. При желании также могут быть рассмотрены вероятности кроссоверов между двумя л оку сами.
В дополнительном иллюстративном примере совместных правдоподобий с использованием фазированных данных, рассматривают два последовательных SNP s1 и s2, a D1 и D2 обозначают данные аллелей в этих SNP. В настоящем документе авторы настоящего изобретения приводят пример того, как объединить правдоподобия для этих двух SNP. Пусть c обозначает правдоподобие того, что два последовательных гетерозиготных SNP имеют один и тот же аллель в том же гомологе (т.е. оба SNP представляют собой АВ или оба SNP представляют собой ВА). Следовательно 1-е представляет собой вероятность того, что один SNP представляет собой АВ, а другой представляет собой BA. Например, можно рассмотреть гипотезу H10 и значение аллельного дисбаланса f. Во-первых, предполагают, что все правдоподобия вычисляют с предположением того, что все SNP представляют собой либо АВ, либо ВА. Затем, можно объединить правдоподобия в двух следующих друг за другом SNP следующим образом:
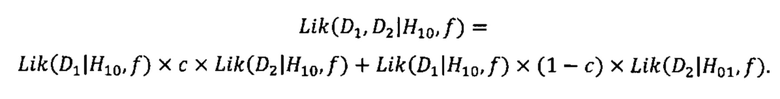
Можно сделать это рекурсивно, чтобы определить совместное правдоподобие Lik(D1, …, DN|H10, ƒ) для всех SNP.
Иллюстративные мутации
Иллюстративные мутации, связанные с заболеванием или нарушением, таким как злокачественная опухоль или повышенный риск развития (например, выше нормального уровня риска) заболевания или нарушения, такого как злокачественная опухоль, включают в себя однонуклеотидные варианты (SNV), множественные нуклеотидные мутации, делеции (например, делеция области от 2 до 30 миллионов пар нуклеотидов), дупликации или тандемные повторы. Согласно некоторым вариантам осуществления мутация происходит в ДНК, например, вкДНК, внеклеточной митохондриальной ДНК (вк мДНК), внеклеточной ДНК, которая происходит из ядерной ДНК (вк нДНК), клеточной ДНК или митохондриальной ДНК. Согласно некоторым вариантам осуществления мутация происходит в РНК, например, вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК. Согласно некоторым вариантам осуществления мутация присутствует с более высокой частотой у субъектов с заболеванием или нарушением (например, злокачественной опухолью), чем у субъектов без заболевания или нарушения (например, злокачественной опухоли). Согласно некоторым вариантам осуществления мутация представляет собой признак злокачественной опухоли, например, болезнетворная мутация. Согласно некоторым вариантам осуществления мутация представляет собой драйверную мутацию, которая играет роль причины в развитии этого заболевания или нарушения. Согласно некоторым вариантам осуществления мутация не играет роль причины в развитии этого заболевания или нарушения. Например, при некоторых видах злокачественных опухолей накапливаются множественные мутации, но некоторые из них не являются мутациями, вызывающими заболевания. Мутации (такие, как те, которые присутствуют с более высокой частотой у субъектов с заболеванием или нарушением, чем у субъектов без заболевания или нарушения), которые не вызывают заболевание, все равно могут быть полезными для диагностики заболевания или нарушения. Согласно некоторым вариантам осуществления мутация представляет собой потерю гетерозиготности (LOH) в одном или нескольких микросателитах.
Согласно некоторым вариантам осуществления субъект подвергают скринингу на один из нескольких полиморфизмов или мутаций, наличие которых у субъекта известно (например, для проверки на предмет их наличия, изменения количества клеток, ДНК или РНК с этими полиморфизмами или мутациями, или ремиссии злокачественной опухоли или повторное появление). Согласно некоторым вариантам осуществления субъект подвергают скринингу на один из нескольких полиморфизмов или мутаций, риск появления которых у субъекта известен (например, субъекта, у которого есть родственник с полиморфизмом или мутацией). Согласно некоторым вариантам осуществления субъект подвергают скринингу на панель полиморфизмов или мутаций, связанных с заболеванием или нарушением, таким как злокачественная опухоль (например, по меньшей мере 5, 10, 50, 100, 200, 300, 500, 750, 1000, 1500, 2000 или 5000 полиморфизмов или мутаций).
Много вариантов кодирования, связанных со злокачественной опухолью, описаны в публикации Abaan et al., "The Exomes of the NCI-60 Panel: A Genomic Resource for Cancer Biology and Systems Pharmacology", Cancer Research, July 15, 2013 и в интернете по адресу dtp.nci.nih.gov/branches/btb/characterizationNCI60.html~~pobj, каждый из которых полностью включен в настоящий документ посредством ссылки). Панель клеточных линий злокачественной опухоли NCI-60 человека состоит из 60 различных клеточных линий, представляющих собой злокачественные опухоли легких, толстой кишки, головного мозга, яичников, молочной железы, предстательной железы и почек, а также лейкемии и меланомы. Генетические вариации, которые были идентифицированы в этих клеточных линиях, состояли из двух типов: вариантов типа I, которые находятся в нормальной популяции, а также вариантов типа II, которые представляют собой специфические к злокачественной опухоли.
Иллюстративные полиморфизмы или мутации (такие как делеции или дупликации) находятся в одном или нескольких из следующих генов: ТР53, PTEN, PIK3CA, АРС, EGFR, NRAS, NF2, FBXW7, ERBBs, ATAD5, KRAS, BRAF, VEGF, EGFR, HER2, ALK, р53, BRCA, BRCA1, BRCA2, SETD2, LRP1B, PBRM, SPTA1, DNMT3A, ARID1A, GRIN2A, TRRAP, STAG2, EPHA3/5/7, POLE, SYNE1, C20orf80, CSMD1, CTNNB1, ERBB2. FBXW7, KIT, MUC4, ATM, CDH1, DDX11, DDX12, DSPP, EPPK1, FAM186A, GNAS, HRNR, KRTAP4-11, MAP2K4, MLL3, NRAS, RBI, SMAD4, TTN, ABCC9, ACVR1B, ADAM29, ADAMTS19, AGAP10, AKT1, AMBN, AMPD2, ANKRD30A, ANKRD40, APOBR, AR, BIRC6, BMP2, BRAT1, BTNL8, C12orf4, C1QTNF7, C20orf186, CAPRIN2, CBWD1, CCDC30, CCDC93, CD5L, CDC27, CDC42BPA, CDH9, CDKN2A, CHD8, CHEK2, CHRNA9, CIZ1, CLSPN, CNTN6, COL14A1, CREBBP, CROCC, CTSF, CYP1A2, DCLK1, DHDDS, DHX32, DKK2, DLEC1, DNAH14, DNAH5, DNAH9, DNASE1L3, DUSP16, DYNC2H1, ECT2, EFHB, RRN3P2, TRIM49B, TUBB8P5, EPHA7, ERBB3, ERCC6, FAM21A, FAM21C, FCGBP, FGFR2, F1G2, F1T1, FOLR2, FRYL, FSCB, GAB1, GABRA4, GABRP, GH2, GOLGA6L1, GPHB5, GPR32, GPX5, GTF3C3, HECW1, HIST1H3B, HLA-A, HRAS, HS3ST1, HS6ST1, HSPD1, IDH1, JAK2, KDM5B, KIAA0528, KRT15, KRT38, KRTAP21-1, KRTAP4-5, KRTAP4-7, KRTAP5-4, KRTAP5-5, LAMA4, LATS1, LMF1, LPAR4, LPPR4, LRRFIP1, LUM, LYST, MAP2K1, MARCH1, MARCO, MB21D2, MEGF10, MMP16, MORC1, MRE11A, MTMR3, MUC12, MUC17, MUC2, MUC20, NBPF10, NBPF20, NEK1, NFE2L2, NLRP4, NOTCH2, NRK, NUP93, OBSCN, OR11H1, OR2B11, OR2M4, OR4Q3, OR5D13, OR8I2, OXSM, PIK3R1, PPP2R5C, PRAME, PRF1, PRG4, PRPF19, PTH2, PTPRC, PTPRJ, RAC1, RAD50, RBM12, RGPD3, RGS22, ROR1, RP11-671M22.1, RP13-996F3.4, RP1L1, RSBN1L, RYR3, SAMD3, SCN3A, SEC31A, SF1, SF3B1, SLC25A2, SLC44A1, SLC4A11, SMAD2, SPTA1, ST6GAL2, STK11, SZT2, TAF1L, TAX1BP1, TBP, TGFBI, TIF1, TMEM14B, TMEM74, TPTE, TRAPPC8, TRPS1, TXNDC6, USP32, UTP20, VASN, VPS72, WASH3P, WWTR1, XPO1, ZFHX4, ZMIZ1, ZNF167, ZNF436, ZNF492, ZNF598, ZRSR2, ABL1, AKT2, AKT3, ARAF, ARFRP1, ARID2, ASXL1, ATR, ATRX, AURKA, AURKB, AXL, BAP1, BARD1, BCL2, BCL2L2, BCL6, BCOR, BCORL1, BLM, BRIP1, ВТК, CARD11, CBFB, CBL, CCND1, CCND2, CCND3, CCNE1, CD79A, CD79B, CDC73, CDK12, CDK4, CDK6, CDK8, CDKN1B, CDKN2B, CDKN2C, СЕВРА, CHEK1, CIC, CRKL, CRLF2, CSF1R, CTCF, CTNNA1, DAXX, DDR2, DOT1L, EMSY (C11orf30), EP300, ЕРНАЗ, EPHA5, EPHB1, ERBB4, ERG, ESR1, EZH2, FAM123B (WTX), FAM46C, FANCA, FANCC, FANCD2, FANCE, FANCF, FANCG, FANCL, FGF10, FGF14, FGF19, FGF23, FGF3, FGF4, FGF6, FGFR1, FGFR2, FGFR3, FGFR4, F1T3, F1T4, FOXL2, GATA1, GATA2, GATA3, GID4 (C17orf39), GNA11, GNA13, GNAQ, GNAS, GPR124, GSK3B, HGF, IDH1, IDH2, IGF1R, IKBKE, IKZF1, IL7R, INHBA, IRF4, IRS2, JAK1, JAK3, JUN, KAT6A (MYST3), KDM5A, KDM5C, KDM6A, KDR, KEAP1, KLHL6, MAP2K2, MAP2K4, MAP3K1, MCL1, MDM2, MDM4, MED12, MEF2B, MEN1, MET, MITF, MLH1, MLL, MLL2, MPL, MSH2, MSH6, MTOR, MUTYH, MYC, MYCL1, MYCN, MYD88, NF1, NFKBIA, NKX2-1, NOTCH1, NPM1, NRAS, NTRK1, NTRK2, NTRK3, PAK3, PALB2, PAX5, PBRM1, PDGFRA, PDGFRB, PDK1, PIK3CG, PIK3R2, PPP2R1A, PRDM1, PRKAR1A, PRKDC, PTCH1, PTPN11, RAD51, RAF1, RARA, RET, RICTOR, RNF43, RPTOR, RUNX1, SMARCA4, SMARCB1, SMO, SOCS1, SOX10, SOX2, SPEN, SPOP, SRC, STAT4, SUFU, TET2, TGFBR2, TNFAIP3, TNFRSF14, TOPI, TP53, TSC1, TSC2, TSHR, VHL, WISP3, WT1, ZNF217, ZNF703, а также их комбинации (публикации Su et al., J Mol Diagn 2011, 13: 74-84; DOI: 10.1016/j.jmoldx.2010.11.010 и Abaan et al., "The Exomes of the NCI-60 Panel: A Genomic Resource for Cancer Biology and Systems Pharmacology", Cancer Research, July 15, 2013, каждая из которых полностью включена в настоящий документ посредством ссылки). Согласно некоторым вариантам осуществления дупликация представляет собой дупликацию хромосомы 1р ("Chr1p"), связанную со злокачественной опухолью молочной железы. Согласно некоторым вариантам осуществления один или несколько полиморфизмов или мутаций происходят в BRAF, например, мутация V600E. Согласно некоторым вариантам осуществления один или несколько полиморфизмов или мутаций происходят в K-ras. Согласно некоторым вариантам осуществления наблюдается сочетание одного или нескольких полиморфизмов или мутаций в K-ras и APC. Согласно некоторым вариантам осуществления наблюдается сочетание одного или нескольких полиморфизмов или мутаций в K-ras и p53. Согласно некоторым вариантам осуществления наблюдается сочетание одного или нескольких полиморфизмов или мутаций в APC и p53. Согласно некоторым вариантам осуществления наблюдается сочетание одного или нескольких полиморфизмов или мутации в K-ras, APC и р53. Согласно некоторым вариантам осуществления наблюдается сочетание одного или нескольких полиморфизмов или мутаций в K-ras и EGFR. Иллюстративные полиморфизмы или мутации находятся в одной или нескольких из следующих микроРНК: miR-15a, miR-16-1, miR-23a, miR-23b, miR-24-1, miR-24-2, miR-27a, miR-27b, miR-29b-2, miR-29c, miR-146, miR-155, miR-221, miR-222 and miR-223 (публикация Calin et al. "A microRNA signature associated with prognosis and progression in chronic lymphocytic leukemia." N Engl J Med 353: 1793-801, 2005, которая полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления делеция представляет собой делецию по меньшей мере 0,01 т.п.н., 0,1 т.п.н., 1 т.п.н., 10 т.п.н., 100 т.п.н., 1 Мб, 2 Мб, 3 Мб, 5 Мб, 10 Мб, 15 Мб, 20 Мб, 30 Мб или 40 Мб. Согласно некоторым вариантам осуществления делеция представляет собой делецию от 1 т.п.н. до 40 Мб, например, от 1 т.п.н. до 100 т.п.н., от 100 т.п.н. до 1 Мб, от 1 до 5 Мб, от 5 до 10 Мб, от 10 до 15 Мб, от 15 до 20 Мб, от 20 до 25 Мб, от 25 до 30 Мб или от 30 до 40 Мб, включительно.
Согласно некоторым вариантам осуществления дупликация представляет собой дупликацию по меньшей мере 0,01 т.п.н., 0,1 т.п.н., 1 т.п.н., 10 т.п.н., 100 т.п.н., 1 Мб, 2 Мб, 3 Мб, 5 Мб, 10 Мб, 15 Мб, 20 Мб, 30 Мб или 40 Мб. Согласно некоторым вариантам осуществления дупликация представляет собой дупликацию от 1 т.п.н. до 40 Мб, например, от 1 т.п.н. до 100 т.п.н., 100 т.п.н. до 1 Мб, от 1 до 5 Мб, от 5 до 10 Мб, от 10 до 15 Мб, от 15 до 20 Мб, от 20 до 25 Мб, 25 до 30 Мб или от 30 до 40 Мб, включительно.
Согласно некоторым вариантам осуществления тандемный повтор представляет собой повторение от 2 до 60 нуклеотидов, например, от 2 до 6, от 7 до 10, от 10 до 20, от 20 до 30, от 30 до 40, от 40 до 50 или от 50 до 60 лет нуклеотидов, включительно. Согласно некоторым вариантам осуществления тандемный повтор представляет собой повторение 2 нуклеотидов (динуклеотидный повтор). Согласно некоторым вариантам осуществления тандемный повтор представляет собой повторение 3 нуклеотидов (тринуклеотидный повтор).
Согласно некоторым вариантам осуществления полиморфизм или мутация представляют собой прогностические. Иллюстративные прогностические мутации включают в себя мутации K-ras, например, мутации K-ras, которые представляют собой показатели послеоперационного рецидива заболевания при злокачественной опухоли толстой и прямой кишок (публикации Ryan et al. "A prospective study of circulating mutant KRAS2 in the serum of patients with colorectal neoplasia: strong prognostic indicator in postoperative follow up," Gut 52: 101-108, 2003 и Lecomte T et al. Detection of free-circulating tumor-associated DNA in plasma of colorectal cancer patients and its association with prognosis," Int J Cancer 100: 542-548, 2002, каждая из которых полностью включена в настоящий документ посредством ссылки).
Согласно некоторым вариантам осуществления полиморфизм или мутация связана с измененным ответом на конкретный способ лечения (например, увеличенная или уменьшенная эффективность или побочные эффекты). Примеры включают в себя мутации K-ras, связанные с уменьшенным ответом на основанное на EGFR лечение при немелкоклеточной злокачественной опухоли легкого (публикация Wang et al. "Potential clinical significance of a plasma-based KRAS mutation analysis in patients with advanced non-small cell lung cancer," Clin Cane Res 16: 1324-1330, 2010, которая полностью включена в настоящий документ посредством ссылки).
K-ras представляет собой онкоген, который активируется при многих видах злокачественных опухолей. Иллюстративные мутации K-ras представляют собой мутации в кодонах 12, 13 и 61. Мутации K-ras вкДНК были идентифицированы при злокачественных опухолях поджелудочной железы, легких, толстой кишки, мочевого пузыря и желудка (публикация F1eischhacker & Schmidt "Circulating nucleic acids (CNAs) and caner - a survey," Biochim Biophys Acta 1775: 181-232, 2007, которая полностью включена в настоящий документе посредством ссылки).
p53 представляет собой опухолевый супрессор, который мутирует при многих злокачественных опухолях и способствует опухолевой прогрессии (публикация Levine & Oren "The first 30 years of p53: growing ever more complex. Nature Rev Cancer," 9: 749-758, 2009, которая полностью включена в настоящий документе посредством ссылки). Могут мутировать многие другие кодоны, такие как Ser249. Мутации р53 вкДНК были идентифицированы при злокачественных опухолях молочной железы, легких, яичников, мочевого пузыря, желудка, поджелудочной железы, толстой и прямой кишок, кишечника и печени (публикация F1eischhacker & Schmidt "Circulating nucleic acids (CNAs) and caner - a survey," Biochim Biophys Acta 1775: 181-232, 2007, которая полностью включена в настоящий документ посредством ссылки).
BRAF представляет собой онкоген ниже по ходу транскрипции от Ras. Мутации BRAF были идентифицированы в глиальном новообразовании, меланоме, злокачественных опухолях щитовидной железы и легких (публикации Dias-Santagata et al. BRAF V600E mutations are common in pleomorphic xanthoastrocytoma: diagnostic and therapeutic implications. PLOS ONE 2011; 6: e17948, 2011; Shinozaki et al. Utility of circulating B-RAF DNA mutation in serum for monitoring melanoma patients receiving biochemotherapy. Clin Cane Res 13: 2068-2074, 2007 и Board et al. Detection of BRAF mutations in the tumor and serum of patients enrolled in the AZD6244 (ARRY-142886) advanced melanoma phase II study. Brit J Cane 2009; 101: 1724-1730, каждая из которых полностью включена в настоящий документ посредством ссылки). Мутация BRAFV600E происходит, например, в опухолях меланомы, и чаще встречается на более поздних стадиях. Мутация V600E была обнаружена в вкДНК.
EGFR способствует пролиферации клеток и неправильно регулируется при многих видах злокачественных опухолей (публикации Downward J. Targeting RAS signalling pathways in cancer therapy. Nature Rev Cancer 3: 11-22, 2003 и Levine & Oren "The first 30 years of p53: growing ever more complex. Nature Rev Cancer," 9: 749-758, 2009, которые полностью включены в настоящий документе посредством ссылки). Иллюстративные мутации EGFR включают в себя мутации в экзонах 18-21, которые были идентифицированы у пациентов со злокачественными опухолями легких. Мутации EGFR вкДНК были идентифицированы у пациентов со злокачественными опухолями легких (публикация Jia et al. "Prediction of epidermal growth factor receptor mutations in the plasma/pleural effusion to efficacy of gefitinib treatment in advanced non-small cell lung cancer," J Cane Res Clin Oncol 2010; 136: 1341-1347, 2010, которая полностью включена в настоящий документ посредством ссылки).
Иллюстративные полиморфизмы или мутации, связанные со злокачественной опухолью молочной железы включают в себя LOH в микросателлитах (публикация Kohler et al. "Levels of plasma circulating cell free nuclear and mitochondrial DNA as potential biomarkers for breast tumors," Mol Cancer 8: doi: 10.1186/1476-4598-8-105, 2009, которая полностью включена в настоящий документе посредством ссылки), мутации р53 (например, мутации в экзонах 5-8) (публикация Garcia et al. "Extracellular tumor DNA in plasma and overall survival in breast cancer patients," Genes, Chromosomes & Cancer 45: 692-701, 2006, которая полностью включена в настоящий документе посредством ссылки), HER2 (публикация Sorensen et al. "Circulating HER2 DNA after trastuzumab treatment predicts survival and response in breast cancer," Anticancer Res30: 2463-2468, 2010, которая полностью включена в настоящий документ посредством ссылки), полиморфизмы или мутации PIK3CA, MED1 и GAS6 (публикация Murtaza et al. "Non-invasive analysis of acquired resistance to cancer therapy by sequencing of plasma DNA," Nature 2013; doi: 10.1038/naturel2065, 2013, которая полностью включена в настоящий документ посредством ссылки).
Повышение содержания вкДНК и LOH связано с уменьшением выживаемости в целом и без признаков заболевания. Мутации р53 (экзоны 5-8) связаны со снижением общей выживаемости. Сниженные циркулирующие уровни HER2 вкДНК связаны с лучшим ответом на направленное на HER2 лечение у HER2-положительных субъектов с опухолью молочной железы. Активация мутации в PIK3CA, усечение MED1 и мутация сплайсинга в GAS6 приводит к резистентности к лечению.
Иллюстративные полиморфизмы или мутации, связанные со злокачественной опухолью толстой и прямой кишок, включают в себя мутации р53, APC, K-ras и тимидилатсинтазы и метилирование гена p16 (публикации Wang et al. "Molecular detection of APC, K-ras, and p53 mutations in the serum of colorectal cancer patients as circulating biomarkers," World J Surg 28: 721-726, 2004; Ryan et al. "A prospective study of circulating mutant KRAS2 in the serum of patients with colorectal neoplasia: strong prognostic indicator in postoperative follow up," Gut 52: 101-108, 2003; Lecomte et al. "Detection of free-circulating tumor-associated DNA in plasma of colorectal cancer patients and its association with prognosis," Int J Cancer 100: 542-548, 2002; Schwarzenbach et al. "Molecular analysis of the polymorphisms of thymidylate synthase on cell-free circulating DNA in blood of patients with advanced colorectal carcinoma," Int J Cancer 127: 881-888, 2009, каждая из которых полностью включена в настоящий документ посредством ссылки). Послеоперационное обнаружение мутаций K-ras в сыворотке крови представляет собой сильный прогностический фактор повторного проявления заболевания. Обнаружение мутаций K-ras и метилирования гена р16 связано с уменьшением выживаемости и увеличением повторного появления заболевания. Обнаружение мутаций K-ras, АРС и/или р53 связано с рецидивом и/или метастазами. Полиморфизмы (в том числе LOH, SNP, тандемные повторы вариабельного числа и делеция) в гене тимидилатсинтазе (мишень основанных на фторпиримидине химиотерапии) с использованием вкДНК могут быть связаны с ответом на лечение.
Иллюстративные полиморфизмы или мутации, связанные со злокачественной опухолью легких (например, немелкоклеточным раком легких), включают в себя мутации K-ras (например, мутации в кодоне 12) и EGFR. Иллюстративные прогностические мутации включают в себя мутации EGFR (делеция экзона 19 или мутация экзона 21), связанные с увеличенной выживаемостью в целом и без прогрессирования заболевания, а мутации K-ras (в кодонах 12 и 13) связаны со снижением выживаемости без прогрессирования (публикации Jian et al. "Prediction of epidermal growth factor receptor mutations in the plasma/pleural effusion to efficacy of gefitinib treatment in advanced non-small cell lung cancer," J Cane Res Clin Oncol 136: 1341-1347, 2010; Wang et al. "Potential clinical significance of a plasma-based KRAS mutation analysis in patients with advanced non-small cell lung cancer," Clin Cane Res 16: 1324-1330, 2010, каждая из которых полностью включена в настоящий документ посредством ссылки). Иллюстративные полиморфизмы или мутации, указывающие на реакцию на лечение, включают в себя мутации EGFR (делецию экзона 19 или мутацию экзона 21), которые улучшают реакцию на лечение, и мутации K-ras (кодоны 12 и 13), которые снижают реакцию на лечение. В EFGR была идентифицирована придающая стойкость мутация (публикация Murtaza et al. "Non-invasive analysis of acquired resistance to cancer therapy by sequencing of plasma DNA," Nature doi: 10.1038/naturel2065, 2013, которая полностью включена в настоящий документ посредством ссылки).
Иллюстративные полиморфизмы или мутации, связанные с меланомой (например, увеальной меланомой), включают в себя мутации в GNAQ, GNA11, BRAF и р53. Иллюстративные мутации GNAQ и GNA11 включают в себя мутации R183 и Q209. Мутации Q209 в GNAQ или GNA11 связаны с метастазами в кости. Мутации V600E BRAF могут быть обнаружены у пациентов с метастатической меланомой/меланомой на поздней стадии. V600E BRAF представляет собой показатель инвазивной меланомы. Наличие мутации V600E BRAF после химиотерапии связано с отсутствием ответа на лечение.
Иллюстративные полиморфизмы или мутации, связанные с панкреатическими карциномами, включают в себя мутации в K-ras и p53 (например, Ser249 р53). Ser249 р53 также связан с инфекцией гепатита B и гепатоцеллюлярной карциномой, а также злокачественной опухолью яичников и неходжкинской лимфомой.
Даже полиморфизмы или мутации, которые присутствуют в низких частотах в образце, могут быть обнаружены с помощью способов согласно настоящему изобретению. Например, полиморфизм или мутацию, которая присутствует с частотой 1 на миллион, можно наблюдать 10 раз, выполняя 10000000 прочтений секвенирования. При желании число операций прочтения секвенирования может быть изменено в зависимости от уровня желаемой чувствительности. Согласно некоторым вариантам осуществления образец повторно анализируют или другой образец от субъекта анализируют с помощью большего числа прочтений секвенирования для улучшения чувствительности. Например, если не обнаруживаются или обнаруживается только небольшое число (например, 1, 2, 3, 4 или 5) полиморфизмов или мутаций, которые связаны со злокачественной опухолью или повышенным риском развития злокачественной опухоли, образец повторно анализируют или исследуют другой образец.
Согласно некоторым вариантам осуществления множественные полиморфизмы или мутации необходимы для злокачественной опухоли или для метастатической злокачественной опухоли. В таких случаях скрининг для множественных полиморфизмов или мутаций повышает способность точно диагностировать злокачественную опухоль или метастатическую злокачественную опухоль. Согласно некоторым вариантам осуществления, когда субъект характеризуется наличием подгруппы множеств полиморфизмов или мутаций, которые необходимы для злокачественной опухоли или метастатической злокачественной опухоли, субъект может быть повторно подвергнут скринингу, чтобы увидеть, приобретает ли субъект дополнительные мутации.
Согласно некоторым вариантам осуществления, в которых множественные полиморфизмы или мутации необходимы для злокачественной опухоли или метастатической злокачественной опухоли, частоту каждого полиморфизма или мутации можно сравнить, чтобы увидеть, происходят ли они со сходными частотами. Например, если две мутации необходимы для злокачественной опухоли (обозначаемые "А" и "В"), некоторые клетки не будут содержать ни одной, некоторые клетки будут с A, некоторые - с B, а некоторые - с A и B. Если A и B наблюдаются со схожей частотой, субъект, более вероятно, содержит некоторые клетки как с A, так и B. Если у наблюдаемых A и B неодинаковые частоты, субъект, более вероятно, содержит различные клеточные популяции.
Согласно некоторым вариантам осуществления, в которых множество полиморфизмов или мутаций необходимо для злокачественной опухоли или метастатической злокачественной опухоли, число или идентичность таких полиморфизмов или мутаций, которые присутствуют у субъекта, могут быть использованы, чтобы предсказать, насколько вероятно или скоро субъект, скорее всего, будет характеризоваться наличием заболевания или нарушения. Согласно некоторым вариантам осуществления, в которых полиморфизмы или мутации, как правило, происходят в определенном порядке, субъект может периодически проверяться, чтобы увидеть, не приобрел субъект другие полиморфизмы или мутации.
Согласно некоторым вариантам осуществления определение наличия или отсутствия множественных полиморфизмов или мутаций (например, 2, 3, 4, 5, 8, 10, 12, 15 или более) повышает чувствительность и/или специфичность определения наличия или отсутствия заболевания или нарушения, такого как злокачественная опухоль, или повышенного риска развития заболевания или нарушения, такого как злокачественная опухоль.
Согласно некоторым вариантам осуществления полиморфизм(ы) или мутацию(и) обнаруживают непосредственно. Согласно некоторым вариантам осуществления полиморфизм(ы) или мутацию(и) обнаруживают косвенно путем обнаружения одной или нескольких последовательностей (например, полиморфного локуса, такого как SNP), которые связаны с полиморфизмом или мутацией.
Иллюстративные изменения нуклеиновых кислот
Согласно некоторым вариантам осуществления существует изменение целостности РНК или ДНК (например, изменение размера фрагментированных вкРНК или вкДНК или изменение нуклеосомного состава), что связано с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль. Согласно некоторым вариантам осуществления существует изменение в паттерне метилирования РНК или ДНК, который связан с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль (например, гиперметилирование генов-супрессоров опухолей). Например, было предположено, что метилирование островков CpG в промоторной области генов-супрессоров опухолей запускает местный сайленсинг гена. Аномальное метилирование гена-супрессора опухоли р16 происходит у субъектов со злокачественными опухолями печени, легких и молочной железы. Другие часто метилированные гены-супрессоры опухолей, включающие в себя АРС, белок 1А семейства связанных с Ras доменов (RASSF1A), глутатион-8-трансферазу P1 (GSTP1) и DAPK, были обнаружены при различных типах злокачественных опухолей, например, карциноме носоглотки, злокачественной опухоли толстой и прямой кишок, злокачественной опухоли легкого, злокачественной опухоли пищевода, злокачественной опухоли предстательной железы, злокачественной опухоли мочевого пузыря, меланоме и остром лейкозе. Метилирование некоторых генов-супрессоров опухолей, таких как p16, было описано в качестве раннего события в образовании злокачественной опухоли, и, таким образом, применимо для раннего скрининга злокачественной опухоли.
Согласно некоторым вариантам осуществления бисульфитная перегруппировка или основанная на небисульфите стратегия с использованием чувствительного к метилированию расщеплению фермента рестрикции используется для определения паттерна метилирования (публикация Hung et al., J Clin Pathol 62: 308-313, 2009, которая полностью включена в настоящий документ посредством ссылки). При бисульфитной перегруппировке метилированные цитозины остаются в виде цитозинов, в то время как неметилированные цитозины преобразуются в урацилы. Чувствительные к метилированию ферменты рестрикции (например, BstUI) расщепляют неметилированные последовательности ДНК в определенных сайтах распознавания (например, 5'-CG ∨ CG-3' для BstUI), в то время как метилированные последовательности остаются нетронутыми. Согласно некоторым вариантам осуществления обнаруживаются интактные метилированные последовательности. Согласно некоторым вариантам осуществления праймеры типа "петля на стебле" используют для избирательной амплификации расщепленных ферментом рестрикции неметилированных фрагментов без совместной амплификации неферментно-расщепленной метилированной ДНК.
Иллюстративные изменения в сплайсинге мРНК
Согласно некоторым вариантам осуществления изменение в сплайсинге мРНК связано с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль. Согласно некоторым вариантам осуществления изменение в сплайсинге мРНК происходит в одной или нескольких из следующих нуклеиновых кислот, связанных со злокачественной опухолью или повышенным риском развития злокачественной опухоли: DNMT3B, BRCA1, KLF6, Ron или Gemin5. Согласно некоторым вариантам осуществления обнаруженный вариант сплайсинга мРНК связан с заболеванием или нарушением, таким как злокачественная опухоль. Согласно некоторым вариантам осуществления множественные варианты сплайсинга мРНК производятся здоровыми клетками (например, незлокачественными клетками), а изменение относительных количеств вариантов сплайсинга мРНК связано с заболеванием или нарушением, таким как злокачественная опухоль. Согласно некоторым вариантам осуществления изменение в сплайсинге мРНК обусловлено изменением последовательности мРНК (например, мутацией в сплайс-сайте), изменением в уровнях фактора сплайсинга, изменением в количестве доступного фактора сплайсинга (например, уменьшение количества доступного фактора сплайсинга за счет связывания фактора сплайсинга с повтором), измененной регуляцией сплайсинга или микроокружением опухоли.
Реакция сплайсинга осуществляется мультибелковым-РНК-комплексом, названным сплайсосомой (публикация Fackenthall and Godley, Disease Models & Mechanisms 1: 37-42, 2008, doi: 10.1242/dmm.000331, которая полностью включена в настоящий документ посредством ссылки). Сплайсосома распознает границы интрона-экзона и удаляет промежуточные интроны с помощью двух реакций переэтерификации, которые приводят к сшиванию двух соседних экзонов. Верность этой реакции должна быть точной, потому что если сшивание происходит неправильно, нормальный белок-кодирующий потенциал может быть поставлен под угрозу. Например, в тех случаях, когда пропуск экзона сохраняет рамку считывания триплетных кодонов, задающих идентичность и порядок аминокислот в процессе трансляции, мРНК альтернативного сплайсинга может задавать белок, который испытывает недостаток важных аминокислотных остатков. Чаще всего, пропуск экзона будет нарушать трансляционную рамку считывания, приводя к преждевременным стоп-кодонам. Эти мРНК, как правило, деградируют по меньшей мере на 90% с помощью процесса, известного как нонсенс-опосредованная деградация мРНК, что снижает правдоподобие того, что такие дефектные сообщения будут аккумулироваться для получения укороченных белковых продуктов. Если мРНК с нарушенным сплайсингом избегают этого пути, тогда производятся укороченные, мутировавшие или нестабильные белки.
Альтернативный сплайсинг представляет собой средство экспрессии нескольких или многих различных транскриптов из той же геномной ДНК и представляет собой результат включения подмножества доступных экзонов для конкретного белка. Путем исключения одного или нескольких экзонов, некоторые домены белков могут быть потеряны из кодируемого белка, что может привести к потере или усилению функции белка. Были описано несколько типов альтернативного сплайсинга: пропуск экзона; альтернативные 5' или 3' сайты сплайсинга; взаимоисключающие экзоны и, гораздо реже, удержание интронов. Другие сравнили количество альтернативного сплайсинга при злокачественной опухоли по сравнению с нормальными клетками, используя биоинформационный подход, и определили, что злокачественные опухоли демонстрируют более низкие уровни альтернативного сплайсинга, чем нормальные клетки. Кроме того, распределение типов событий альтернативного сплайсинга различалось у злокачественных клеток по сравнению с нормальными клетками. Злокачественные клетки демонстрировали меньше пропусков экзонов, но больший выбор альтернативных 5' и 3' сайтов сплайсинга и удержания интрона, чем нормальные клетки. Когда исследовали феномен экзонизации (использование последовательностей экзонов, которые используются главным образом в других тканях, в виде интронов), гены, ассоциированные с экзонизацией в злокачественных клетках, были преимущественно связаны с процессингом мРНК, что указывает на прямую связь между злокачественными клетками и получением аберрантных форм сплайсинга мРНК.
Иллюстративные изменения в содержании ДНК или РНК
Согласно некоторым вариантам осуществления существует изменение в общем количестве или концентрации одного или нескольких типов ДНК (например, вкДНК, вк мДНК, вк яДНК, клеточной ДНК или митохондриальной ДНК) или РНК (вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК). Согласно некоторым вариантам осуществления существует изменение в количестве или концентрации одной или нескольких специфических молекул ДНК (например, вкДНК, вк мДНК, вк яДНК, клеточной ДНК или митохондриальной ДНК) или РНК (вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК). Согласно некоторым вариантам осуществления один аллель экспрессируется в большей степени, чем другой аллель представляющего интерес локуса. Иллюстративные миРНК представляют собой короткие молекулы РНК длиной 20-22 нуклеотида, которые регулируют экспрессию гена. Согласно некоторым вариантам осуществления существует изменение в транскриптоме, такое как изменение идентичности или количества одной или нескольких молекул РНК.
Согласно некоторым вариантам осуществления увеличение общего количества или концентрации вкДНК или вкРНК связано с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль. Согласно некоторым вариантам осуществления общая концентрация типа ДНК (например, вкДНК, вк мДНК, вк яДНК, клеточной ДНК или митохондриальной ДНК) или РНК (вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК) увеличивается по меньшей мере в 2, 3, 4, 5, 6, 7, 8, 9, 10 раз или более, по сравнению с общей концентрацией этого типа ДНК или РНК у здоровых (например, без злокачественной опухоли) субъектов. Согласно некоторым вариантам осуществления общая концентрация вкДНК от 75 до 100 нг/мл, от 100 до 150 нг/мл, от 150 до 200 нг/мл, от 200 до 300 нг/мл, от 300 до 400 нг/мл, от 400 до 600 нг/мл, от 600 до 800 нг/мл, от 800 до 1000 нг/мл, включительно, или в общей сложности концентрация вкДНК более 100 нг, мл, например более чем 200, 300, 400, 500, 600, 700, 800, 900 или 1000 нг/мл представляет собой показатель наличия злокачественной опухоли, повышенного риска развития злокачественной опухоли, повышенного риска для опухоли быть злокачественной, а не доброкачественной, сниженной вероятности злокачественной опухоли перейти в ремиссию или более худшего прогноза для злокачественной опухоли. Согласно некоторым вариантам осуществления количество типа ДНК (например, вкДНК, вк мДНК, вк яДНК, клеточной ДНК или митохондриальной ДНК) или РНК (вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК), содержащей один или нескольких полиморфизмов/мутаций (например, делеции или дупликаций), связанных с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль, составляет по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 18, 20 или 25% от общего количества этого типа ДНК или РНК. Согласно некоторым вариантам осуществления по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 18, 20 или 25% от общего количества типа ДНК (например, вкДНК, вк мДНК, вк яДНК, клеточной ДНК или митохондриальной ДНК) или РНК (вкРНК, клеточной РНК, цитоплазматической РНК, кодирующей цитоплазматической РНК, некодирующей цитоплазматической РНК, мРНК, миРНК, митохондриальной РНК, рРНК или тРНК) содержит определенный полиморфизм или мутацию (например, делецию или дупликацию), связанную с заболеванием или нарушением, таким как злокачественная опухоль, или повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль.
Согласно некоторым вариантам осуществления вкДНК инкапсулируется. Согласно некоторым вариантам осуществления вкДНК не инкапсулируются.
Согласно некоторым вариантам осуществления определяется фракция опухолевой ДНК из общей ДНК (например, фракция опухолевой вкДНК из общей вкДНК или фракция опухолевой вкДНК с определенной мутацией из общей вкДНК). Согласно некоторым вариантам осуществления может быть определена фракция опухолевой ДНК для множества мутаций, где мутации могут представлять собой однонуклеотидные варианты, варианты числа копий, дифференциальное метилирование или их комбинации. Согласно некоторым вариантам осуществления средняя опухолевая фракция, рассчитанная для одной или совокупности мутаций с самой высокой вычисленной опухолевой фракцией, принимается в качестве фактической опухолевой фракции в образце. Согласно некоторым вариантам осуществления среднюю опухолевую фракцию, рассчитанную для всех мутаций, берут в качестве фактической опухолевой фракции в образце. Согласно некоторым вариантам осуществления эта опухолевая фракция используется для стадии злокачественной опухоли (так как более высокие опухолевые фракции могут быть связаны с более поздней стадией злокачественной опухоли). Согласно некоторым вариантам осуществления опухолевую фракцию используют для определения размера злокачественной опухоли, так как более крупные опухоли могут быть соотнесены с фракцией опухолевой ДНК в плазме. Согласно некоторым вариантам осуществления опухолевую фракцию используют для получения размера части опухоли, в которой имеется одна или множество мутаций, так как может быть корреляция между измеренной опухолевой фракцией в образце плазмы и размером ткани с заданным генотипом мутации(й). Например, размер ткани с заданным генотипом мутации(й) может быть соотнесен с фракцией опухолевой ДНК, которая может быть вычислена путем фокусирования на этой конкретной мутации(ях).
Иллюстративные базы данных
Настоящее изобретение также включает в себя базы данных, содержащие один или несколько результатов от способа согласно настоящему изобретению. Например, база данных может включать в себя записи с любой информацией для одного или нескольких субъектов: любые идентифицированные полиморфизмы/мутации (такие как CNV), любую известную связь полиморфизмов/мутаций с заболеванием или нарушением или повышенным риском развития заболевания или нарушения, влияние полиморфизмов/мутаций на уровень экспрессии или активности кодируемой мРНК или белка, фракция ДНК, РНК или клеток, связанная с заболеванием или нарушением (например, ДНК, РНК или клетки, характеризующиеся наличием полиморфизма/мутации, связанной с заболеванием или нарушением) из общего количества ДНК, РНК или клеток в образце, источник образца, используемый для идентификации полиморфизмов/мутаций (например, образец крови или образец из определенной ткани), количество пораженных клеток, результаты позже повторенных испытаний (например, повторение исследования, чтобы контролировать прогрессирование или ремиссию заболевания или нарушения), результаты других исследований на заболевание или нарушение, тип заболевания или нарушения у субъекта, которому был поставлен диагноз, вводимое лечение(я), ответ на такое лечение(я), побочные эффекты такого лечения(й), симптомы (например, симптомы, связанные с заболеванием или нарушением), длительность и количество ремиссий, продолжительность выживания (например, период времени от первоначального исследования до смерти или продолжительность времени с момента постановки диагноза до смерти), причина смерти, а также их комбинации.
Согласно некоторым вариантам осуществления база данных включает в себя записи с любой из следующей информации для одного или нескольких субъектов: любые идентифицированные полиморфизмы/мутации, любая известная связь полиморфизма/мутаций со злокачественной опухолью или повышенным риском развития злокачественной опухоли, влияние полиморфизма/мутации на уровень экспрессии или активности кодируемой мРНК или белка, фракция злокачественной ДНК, РНК или клеток из общей ДНК, РНК или клеток в образце, источник образца, используемый для идентификации полиморфизмов/мутации (например, образец крови или образец из определенной ткани), количество злокачественных клеток, размер опухоли(ей), результаты более поздних повторений исследований (например, повторение исследования, чтобы контролировать прогрессирование или ремиссию злокачественной опухоли), результаты других исследований на злокачественную опухоль, тип злокачественной опухоли у субъекта, которому был поставлен диагноз, вводимое лечение(я), ответ на такое лечение(я), побочные эффекты такого лечения(й), симптомы (например, симптомы, связанные со злокачественной опухолью), продолжительность и количество ремиссий, продолжительность выживания (например, промежуток времени от первоначального испытания до смерти или продолжительность времени с момента постановки диагноза злокачественной опухоли до смерти), причины смерти, а также их комбинации. Согласно некоторым вариантам осуществления настоящего изобретения ответ на лечение включает в себя любое из следующих действий: уменьшение или стабилизацию размера опухоли (например, доброкачественной или злокачественной опухоли), замедление или предотвращение увеличения размера опухоли, уменьшение или стабилизацию числа опухолевых клеток, увеличение времени выживаемости без признаков заболевания между исчезновением опухоли и ее повторным появлением, предотвращение первоначального или последующего возникновения опухоли, уменьшение или стабилизацию неблагоприятного симптома, связанного с опухолью, или их комбинации. Согласно некоторым вариантам осуществления включены результаты одного или нескольких других исследований на наличие заболевания или нарушения, такого как злокачественная опухоль, например, результаты из скрининговых исследований, медицинской визуализации или микроскопического исследования образца ткани.
Согласно одному такому аспекту настоящее изобретение охватывает электронную базу данных, включающую в себя по меньшей мере 5, 10, 102, 103, 104, 105, 106, 107, 108 или более записей. Согласно некоторым вариантам осуществления база данных содержит записи по меньшей мере от 5, 10, 102, 103, 104, 105, 106, 107, 108 или более различных субъектов.
Согласно другому аспекту настоящее изобретение охватывает компьютер, содержащий базу данных согласно настоящему изобретению и пользовательский интерфейс. Согласно некоторым вариантам осуществления пользовательский интерфейс способен отображать часть или всю информацию, содержащуюся в одной или нескольких записях. Согласно некоторым вариантам осуществления пользовательский интерфейс способен отображать (I) один или несколько видов злокачественной опухоли, которые были идентифицированы как содержащие полиморфизм или мутацию, записи которых хранятся в компьютере, (II) один или несколько полиморфизмов или мутаций, которые были идентифицированы в конкретном типе злокачественной опухоли, записи которых хранятся в компьютере, (III) прогностическую информацию для конкретного типа злокачественной опухоли или конкретного полиморфизма или мутации, запись которой сохраняется в компьютере (IV) одно или несколько соединений или другие виды лечения, применимые для злокачественной опухоли с полиморфизмом или мутацией, записи которых хранятся в компьютере, (V) одно или несколько соединений, которые модулируют экспрессию или активность мРНК или белка, записи которых хранятся в компьютере, и (VI) одну или несколько молекул мРНК или белков, экспрессия или активность которых модулируется соединением, запись которого хранится в компьютере. Внутренние компоненты компьютера, как правило, включают в себя процессор, соединенный с памятью. Внешние компоненты, как правило, включают в себя запоминающее устройство, например, жесткий диск; пользовательские устройства ввода, например, клавиатуру и мышь; дисплей, например, монитор; и, возможно, сеть, связанную с возможностью подключения компьютерной системы к другим компьютерам, чтобы позволить обмен данными и задачами обработки. Программы могут быть загружены в память этой системы во время работы.
Согласно другому аспекту настоящее изобретение относится к реализуемому компьютером процессу, который включает в себя одну или нескольких стадий любого из способов согласно настоящему изобретению.
Иллюстративные факторы риска
Согласно некоторым вариантам осуществления субъект также оценивается на один или нескольких факторов риска развития заболевания или нарушения, такого как злокачественная опухоль. Иллюстративные факторы риска включают в себя семейный анамнез в отношении заболевания или нарушения, образ жизни (например, курение и воздействие канцерогенов) и уровень одного или нескольких гормонов или сывороточных белков (например, альфа-фетопротеин (АФП) при злокачественной опухоли печени, карциноэмбриональный антиген (СЕА) при злокачественной опухоли толстой и прямой кишок или простат-специфический антиген (ПСА) при злокачественной опухоли предстательной железы). Согласно некоторым вариантам осуществления размер и/или количество опухолей измеряют и используют при определении прогноза субъекта или выбора лечения субъекта.
Иллюстративные способы скрининга
При необходимости, может быть подтверждено наличие или отсутствие заболевания или нарушения, такого как злокачественная опухоль, или такое заболевание или нарушение, как злокачественная опухоль, может быть классифицировано с использованием любого стандартного способа. Например, заболевание или нарушение, такое как злокачественная опухоль, может быть обнаружено посредством ряда способов, включающих в себя наличие определенных признаков и симптомов, биопсии опухоли, скрининг-теста или медицинской визуализации (например, маммографии или УЗИ). После того, как возможная злокачественная опухоль обнаружена, она может быть диагностирована с помощью микроскопического исследования образца ткани. Согласно некоторым вариантам осуществления субъект, которому поставлен диагноз, подвергается повторному исследованию с использованием способа согласно настоящему изобретению или известного исследования на заболевание или нарушение, в различные моменты времени, чтобы следить за прогрессированием заболевания или нарушения, или ремиссией или рецидивом заболевания или нарушения.
Иллюстративные злокачественные опухоли
Иллюстративные злокачественные опухоли, которые могут быть диагностированы, прогнозированы, стабилизированы, обработаны или предотвращены с помощью любого из способов согласно настоящему изобретению, включают в себя солидные опухоли, карциномы, саркомы, лимфомы, лейкозы, эмбрионально-клеточные опухоли или бластомы. Согласно различным вариантам осуществления злокачественная опухоль представляет собой острый лимфобластный лейкоз, острый миелобластный лейкоз, адренокортикальную карциному, связанную со СПИДом злокачественную опухоль, связанную со СПИДом лимфому, анальную злокачественную опухоль, злокачественную опухоль аппендикса, астроцитому (например, мозжечка у детей или астроцитому головного мозга), базально-клеточную карциному, злокачественную опухоль желчных протоков (например, внепеченочную злокачественную опухоль желчных протоков), злокачественную опухоль мочевого пузыря, опухоль кости (например, остеосаркому или злокачественную фиброзную гистиоцитому), глиому ствола головного мозга, злокачественную опухоль мозга (например, астроцитому мозжечка, астроцитому головного мозга/злокачественную глиому, эпендимо, медуллобластому, супратенториально примитивные нейроэктодермальные опухоли или глиому зрительного пути и гипоталамическую), глиобластому, злокачественную опухоль молочной железы, бронхиальную аденому или карциноид, лимфому Беркитта, карциноидную опухоль (например, детскую или желудочно-кишечного тракта карциноидную опухоль), карциному центральной нервной системы, лимфому, астроцитому мозжечка или злокачественную глиому (например, детскую мозжечковую астроцитому или злокачественную глиому), злокачественную опухоль шейки матки, детскую злокачественную опухоль, хронический лимфолейкоз, хронический миелолейкоз, хронические миелопролиферативные заболевания, злокачественную опухоль толстой кишки, кожную T-клеточную лимфому, десмопластическую мелкокруглоклеточную опухоль, злокачественную опухоль эндометрия, эпендимому, злокачественную опухоль пищевода, саркому Юинга, опухоль семейства опухолей Юинга, экстракраниальную эмбрионально-клеточную опухоль (например, детскую экстракраниальную эмбрионально-клеточную опухоль), внегонадную эмбрионально-клеточную опухоль, злокачественную опухоль глаза (например, внутриглазная меланома или ретинобластома глаза), злокачественную опухоль желчного пузыря, злокачественную опухоль желудка, карциноидную опухоль желудочно-кишечного тракта, желудочно-кишечную стромальную опухоль, эмбрионально-клеточную опухоль (например, экстракраниальную, внегонадную или эмбрионально-клеточную опухоль яичников), гестационную трофобластическую опухоль, глиому (например, ствола мозга, детскую астроцитому головного мозга или детскую глиому зрительного пути и гипоталамическую), карциноид желудка, лейкоз ворсистых клеток, злокачественную опухоль головы и шеи, злокачественную опухоль сердца, гепатоцеллюлярную (печени) злокачественную опухоль, лимфому Ходжкина, гипофарингеальную злокачественную опухоль, гипоталамическую глиому и глиому зрительного пути (например, детскую глиому зрительного пути), карциному островковых клеток (например, карциному эндокринных или панкреатических островковых клеток), саркому Капоши, злокачественную опухоль почки, злокачественную опухоль гортани, лейкоз (например, острый лимфобластный, острый миелоидный, хронический лимфоцитарный, хронический миелобластный или лейкоз ворсистых клеток), злокачественную опухоль губ или ротовой полости, липосаркому, злокачественную опухоль печени (например, немелкоклеточную или мелкоклеточную злокачественную опухоль), злокачественную опухоль легкого, лимфому (например, связанную со СПИДом лимфому, Беркитта, T-клеточную кожи, лимфому Ходжкина, неходжкинскую или центральной нервной системы), макроглобулинемию (например, макроглобулинемию Вальденстрема, злокачественную фиброзную гистиоцитому кости или остеосаркому, медуллобластому (например, детскую медуллобластому), меланому, карциному клеток Меркеля, мезотелиому (например, взрослую или детскую мезотелиому), метастатическую плоскоклеточную злокачественную опухоль шеи неизвестного происхождения, злокачественную опухоль ротовой полости, синдром множественной эндокринной неоплазии (например, синдром детской множественной эндокринной неоплазии), множественную миелому или новообразование плазмоцитов, грибовидный микоз, миелодиспластический синдром, миелодиспластические или миелопролиферативные заболевания, миелолейкоз (например, хронический миелолейкоз), миелолейкоз (например, взрослый острый или детский острой миелоидный лейкоз), миелопролиферативное нарушение (например, хроническое миелопролиферативное нарушение), злокачественную опухоль носовой полости или придаточных пазух, карциному носоглотки, нейробластому, злокачественную опухоль полости рта, злокачественную опухоль ротоглотки, остеосаркому или злокачественную фиброзную гистиоцитому кости, злокачественную опухоль яичников, эпителиальную злокачественную опухоль яичников, эмбрионально-клеточную опухоль яичников, пограничную опухоль яичников, злокачественную опухоль поджелудочной железы (например, злокачественную опухоль островковых клеток поджелудочной железы), злокачественную опухоль придаточных пазух носа или носовой полости, паратиреоидную злокачественную опухоль, злокачественную опухоль полового члена, глоточную злокачественную опухоль, феохромоцитому, шишковидную астроцитому, шишковидную герминому, пинеобластому или супратенториальную примитивную нейроэктодермальную опухоль (например, детскую пинеобластому или супратенториальную примитивную нейроэктодермальную опухоль), аденому гипофиза, неоплазию плазматических клеток, плевролегочную бластому, первичную лимфому центральной нервной системы, злокачественную опухоль прямой кишки, почечно-клеточную карциному, злокачественную опухоль почечной лоханки или мочеточника (например, переходно-клеточную злокачественную опухоль почечной лоханки или мочеточника, ретинобластому, рабдомиосаркому (например, детскую рабдомиосаркому), злокачественную опухоль слюнной железы, саркому (например, саркому в семействе опухолей Юинга, саркому мягких тканей или саркому матки), синдром Сезари, злокачественную опухоль кожи (например, немеланому, меланому или злокачественную опухоль клеток Меркеля кожи), злокачественную опухоль тонкой кишки, плоскоклеточную карциному, супратенториальную примитивную нейроэктодермальную опухоль (например, детскую супратенториальную примитивную нейроэктодермальную опухоль), T-клеточную лимфому (например, кожную T-клеточную лимфому), злокачественную опухоль яичек, злокачественную опухоль горла, тимому (например, детскую тимому), тимому или карциному вилочковой железы, злокачественную опухоль щитовидной железы (например, злокачественную опухоль щитовидной железы у детей), трофобластическую опухоль (например, гестационную трофобластическую опухоль), карциному неизвестной первичной локализации (например, карциному неизвестной первичной локализации у взрослых или детей), злокачественную опухоль мочеиспускательного канала (например, злокачественную опухоль эндометрия матки), саркому матки, злокачественную опухоль влагалища, глиому зрительного пути или гипоталамуса (например, глиому зрительного пути или гипоталамуса у детей), злокачественную опухоль вульвы, макроглобулинемию Вальденстрема или опухоль Вильмса (например, опухоль Вильмса у детей). Согласно различным вариантам осуществления у злокачественной опухоли присутствуют или отсутствуют метастазы.
Злокачественная опухоль может представлять собой связанную или зависимую от гормонов злокачественную опухоль или может не быть таковой (например, связанная с эстрогеном или андрогеном злокачественная опухоль). Доброкачественные опухоли или злокачественные опухоли могут быть диагностированы, прогнозируемы, стабилизированы, подвергнуты лечению или предотвращены с использованием способов и/или композиций согласно настоящему изобретению.
Согласно некоторым вариантам осуществления субъект характеризуется наличием синдрома злокачественной опухоли. Синдром злокачественной опухоли представляет собой генетическое заболевание, в котором генетические мутации в одном или нескольких генах предрасполагают пораженных индивидуумов к развитию злокачественных опухолей, а также могут привести к раннему началу этих злокачественных опухолей. Синдромы злокачественных опухолей часто показывают не только высокий пожизненный риск развития злокачественной опухоли, но и развитие нескольких независимых первичных опухолей. Многие из этих синдромов вызываются мутациями в генах-супрессорах опухолей, генах, которые участвуют в защите клетки от превращения в злокачественную. Другие гены, которые могут быть затронуты, представляют собой гены репарации ДНК, онкогены и гены, участвующие в производстве кровеносных сосудов (ангиогенезе). Типичные примеры наследственных синдромов злокачественной опухоли представляют собой наследственный синдром злокачественной опухоли молочной железы и яичников и наследственную неполипозную злокачественную опухоль толстой кишки (синдром Линча).
Согласно некоторым вариантам осуществления субъекту с одним или несколькими полиморфизмами или мутациями в K-ras, р53, BRA, EGFR или HER2 вводят лечение, которое направленно воздействует на K-ras, р53, BRA, EGFR или HER2, соответственно.
Способы согласно настоящему изобретения могут быть в целом применимы к лечению злокачественных или доброкачественных опухолей любого типа клеток, тканей или органов.
Иллюстративные способы лечения
При необходимости, любое лечение для стабилизации, лечения или профилактики заболевания или нарушения, такого как злокачественная опухоль, или повышенный риск развития заболевания или нарушения, такого как злокачественная опухоль, можно вводить субъекту (например, субъекту, идентифицированному как субъект со злокачественной опухолью или повышенным риском развития злокачественной опухоли, с помощью любого из способов согласно настоящему изобретению). Согласно различным вариантам осуществления лечение представляет собой известный способ лечения или сочетание способов лечения заболевания или нарушения, такого как злокачественная опухоль, например, лечение направленно воздействующими цитотоксическими средствами, иммунотерапия, гормональная терапия, лучевая терапия, хирургическое удаление злокачественных клеток или клеток, которые могут стать злокачественными, трансплантация стволовых клеток, трансплантация костного мозга, фотодинамическая терапия, паллиативное лечение или их комбинация. Согласно некоторым вариантам осуществления лечение (например, профилактическое лекарство) используется для предотвращения, задержки или уменьшения тяжести заболевания или нарушения, такого как злокачественная опухоль, у субъекта с повышенным риском развития заболевания или нарушения, такого как злокачественная опухоль.
Согласно некоторым вариантам осуществления прицельная терапия представляет собой лечение, которое направленно воздействует на специфические для злокачественной опухоли гены, белки или окружающие ткани, которые способствуют росту и выживанию злокачественной опухоли. Этот тип лечения блокирует рост и распространение злокачественных клеток, ограничивая при этом повреждение нормальных клеток, как правило, приводя к меньшим количествам побочных эффектов, чем другие лекарственные средства против злокачественной опухоли.
Одним из наиболее успешных подходов является направленное воздействие на ангиогенез, рост новых кровеносных сосудов вокруг опухоли. Прицельные способы лечения, такие как бевацизумаб (авастин), леналидомид (ревлимид), сорафениб (нексавар), сунитинибом (сутент) и талидомид (таломид), мешают ангиогенезу. Другим примером может служить использование лечения, мишенью которого является HER2, например, трастузумаб или лапатиниб, для злокачественных опухолей, которые сверхэкспрессируют HER2 (например, некоторые злокачественные опухоли молочной железы). Согласно некоторым вариантам осуществления моноклональное антитело используется для блокирования конкретной мишени на внешней стороне злокачественной клетки. Примеры включают в себя алемтузумаб (кампат-1Н), бевацизумаб, цетуксимаб (эрбитукс), панитумумаб (вектибикс), пертузумаб (омнитарг), ритуксимаб (ритуксан) и трастузумаб. Согласно некоторым вариантам осуществления моноклональное антитело тозитумомаб (бексар) используется для доставки радиоактивного излучения к опухоли. Согласно некоторым вариантам осуществления пероральная небольшая молекула ингибирует процесс развития злокачественной опухоли внутри злокачественной клетки. Примеры включают в себя дазатиниб (сприцел), эрлотиниб (тарцева), гефитиниб (пресса), иматиниб (гливек), лапатиниб (тикерб), нилотиниб (тасигна), сорафениб, сунитиниб и темсиролимус (торизел). Согласно некоторым вариантам осуществления ингибитор протеасом, (например, лекарственное средство от множественной миеломы, бортезомиб (велкейд)) нарушает специализированные белки, называемые ферментами, которые расщепляют другие белки в клетке.
Согласно некоторым вариантам осуществления иммунотерапия предназначена для повышения естественных защитных сил организма для борьбы со злокачественной опухолью. Иллюстративные виды иммунотерапии представляют собой применение материалов, производимых либо в организме, либо в лаборатории, чтобы поддержать, направленно воздействовать или восстанавливать функцию иммунной системы.
Согласно некоторым вариантам осуществления гормональная терапия лечит злокачественную опухоль за счет снижения количеств гормонов в организме. Некоторые типы злокачественной опухоли, включающие в себя злокачественную опухоль молочной железы и некоторых видов злокачественной опухоли предстательной железы, растут и распространяются только в присутствии природных химических веществ в организме, называемых гормонами. Согласно различным вариантам осуществления гормональная терапия используется для лечения злокачественной опухоли предстательной железы, молочной железы, щитовидной железы и репродуктивной системы.
Согласно некоторым вариантам осуществления лечение предусматривает трансплантацию стволовых клеток, при которой патологический костный мозг замещается высокоспециализированными клетками, называемыми гемопоэтические стволовые клетки. Гемопоэтические стволовые клетки обнаруживают, как в крови, так и в костном мозге.
Согласно некоторым вариантам осуществления лечение предусматривает фотодинамическую терапию, при которой используются специальные лекарственные средства, называемые фотосенсибилизирующие средства, наряду со светом, чтобы убить злокачественные клетки. Эти лекарственные средства работают после того, как они были активированы определенными видами света.
Согласно некоторым вариантам осуществления лечение предусматривает хирургическое удаление злокачественных клеток или клеток, которые могут стать злокачественными (например, лампектомия или мастэктомия). Например, женщина с мутацией гена восприимчивости к злокачественной опухоли молочной железы (мутация гена BRCA1 или BRCA2) может уменьшить риск развития злокачественной опухоли молочной железы и злокачественной опухоли яичников посредством снижающего риск удаления придатков матки (удаления маточных труб и яичников) и/или снижающей риск двусторонней мастэктомии (удаления обеих молочных желез). Лазеры, которые представляют собой очень мощные, точные лучи света, могут быть использованы вместо лезвий (скальпелей) для очень тщательной хирургической работы, включая в себя и лечение некоторых видов злокачественных опухолей.
В дополнение к лечению, чтобы замедлить, остановить или исключить злокачественную опухоль (также называемому направленное на заболевание лечение), важная часть лечения злокачественной опухоли представляет собой облегчение симптомов и побочных эффектов, таких как боль и тошнота, у субъекта. Оно предусматривает поддержку субъекта в физических, эмоциональных и социальных потребностях, подход под названием паллиативное или поддерживающее лечение. Люди часто получают направленное на заболевание лечение и лечение для облегчения симптомов одновременно.
Иллюстративные лекарственные средства включают в себя следующие: актиномицин D, адцетрис, адриамицин, алдеслейкин, алемтузумаб, алимта, амсидин, амсакрин, анастрозол, аредия, аримидекс, аромазин, аспарагиназа, авастин, бевацизумаб, бикалутамид, блеомицин, бондронат, бонефос, бортезомибом, бузилвекс, бусульфан, кампто, капецитабин, карбоплатин, кармустин, касодекс, цетуксимаб, чимакс, хлорамбуцил, циметидин, цисплатин, кладрибин, клодроната, клофарабин, кразантаспаза, циклофосфамид, ципротерона ацетат, ципростат, цитарабин, цитоксан, дакарбозин, дактиномицин, дазатиниб, даунорубицин, дексаметазон, диэтилстилбестрол, доцетаксел, доксорубицин, дрогенил, эмцит, эпирубицин, эпозин, эрбитукс, эрлотиниб, эстрацит, эстрамустин, этопофос, этопозид, эволтра, экземестан, фарестон, фемара, филграстим, флудара, флударабин, фторурацил, флутамид, гефинитиб, гемцитабин, гемзар, глеевек, депо гонапептила, гозерелин, галавен, герцептин, гикамтин, гидроксикарбамид, ибандроновая кислота, ибритумомаб, идаруцибин, ифосфомид, интерферон, иматиниб мезилат, иресса, иринотекана, джевтана, ланвис, лапатиниб, летрозол, лейкеран, лейпрорелин, лейстат, ломустин, кэмпас, мабтера, мегаце, мегестрол, метотрексат, митоксантрон, митомицин, мутулан, милеран, навелбин, нейласта, нейпоген, нексавар, нипент, нолвадекс D, novantron, онковин, паклитаксел, памидронат, PCV, пеметрексед, пентостатин, перджета, прокарбазин, провенге, преднизолон, прострап, ралтитрексед, ритуксимаб, сприцел, сорафениб, солтамокс, стрептозоцин, стильбоэстрон, стимувакс, сунитинибом, сутент, таблоид, тагамет, тамофен, тамоксифен, тарцева, таксол, таксотир, тегафур с урацилом, темодал, темозоломид, талидомид, тиоплекс, тиотепа, тиогуанин, томудекс, топотекан, торемифен, трастузумаб, третиноин, треосульфан, триэтилентиофосфорамид, трипторелин, тиверб, уфторал, велкейд, вепезид, везаноид, винкристин, винорелбин, ксалкори, кселода, ервой, зактима, занозар, заведос, зевелин, золадекс, золедронат, зомета, золедроновая кислота и зитига.
Для субъектов, которые экспрессируют, как мутантную форму (например, связанную со злокачественной опухолью форму), так и форму дикого типа (например, не связанную со злокачественной опухолью форму) мРНК или белка, лечение предпочтительно ингибирует экспрессию или активность мутантной формы по меньшей мере в 2, 5, 10 или в 20 раз больше, чем он ингибирует экспрессию или активность формы дикого типа. Одновременное или последовательное применение нескольких терапевтических средств может значительно снизить заболеваемость злокачественной опухолью и уменьшить количество подвергнутых лечению злокачественных опухолей, которые становятся устойчивыми к лечению. Кроме того, терапевтические средства, которые используются в качестве части комбинированной терапии, могут потребовать более низкой дозы для лечения злокачественной опухоли, соответствующей дозы, необходимой, когда терапевтические средства используют по отдельности. Низкая доза каждого соединения в комбинированной терапии снижает тяжесть потенциальных неблагоприятных побочных эффектов от соединений.
Согласно некоторым вариантам осуществления субъект, у которого идентифицирован повышенный риск развития злокачественной опухоли, может (согласно настоящему изобретению или любым стандартным способом) избегать конкретных факторов риска или внести изменения в образ жизни, чтобы уменьшить любой дополнительный риск развития злокачественной опухоли.
Согласно некоторым вариантам осуществления полиморфизмы, мутации, факторы риска или любая их комбинация используются для выбора схемы лечения для субъекта. Согласно некоторым вариантам осуществления большая доза или большее количество воздействий выбирается для субъекта с большим риском развития злокачественной опухоли или с плохим прогнозом.
Другие соединения для включения в индивидуальную или комбинированную терапию
При необходимости могут быть идентифицированы дополнительные соединения для стабилизации, лечения или профилактики заболевания или нарушения, такого как злокачественная опухоль, или повышенного риска развития заболевания или нарушения, такого как злокачественная опухоль, из больших библиотек, как природного продукта, так и синтетических (или полусинтетических) экстрактов, или химических библиотек в соответствии со способами, известными в настоящей области техники. Специалистам в настоящей области техники или разработки и развития лекарственных средств поймут, что точный источник исследуемых экстрактов или соединений не имеет решающего значения для способов согласно настоящему изобретению. Соответственно, практически любое количество химических экстрактов или соединений может быть подвергнуто скринингу на их воздействие на клетки от конкретного типа злокачественной опухоли или от конкретного субъекта или скринингу на их влияние на активность или экспрессию связанных со злокачественной опухолью молекул (например, связанные со злокачественной опухолью молекулы, которые характеризуются известной измененной активностью или экспрессией в конкретном типе злокачественной опухоли). Когда оказывается, что неочищенный экстракт модулирует активность или экспрессию связанной со злокачественной опухолью молекулы, может быть выполнен дополнительное фракционирование экстракта положительного вывода, чтобы выделить химическую составляющую, ответственную за наблюдаемый эффект, с использованием способов, известных в настоящей области техники.
Иллюстративные анализы и животные модели для исследования способов лечения
При желании, один или несколько из раскрытых в настоящем документе способов лечения могут быть исследованы в отношении их воздействия на заболевание или нарушение, такое как злокачественная опухоль, с использованием линии клеток (например, линии клеток с одной или несколькими из мутаций, идентифицированных у субъекта, которому был поставлен диагноз злокачественная опухоль, или с повышенным риском развития злокачественной опухоли, с использованием способов согласно настоящему изобретению) или животной модели заболевания или нарушения, например, модели SCID мыши (публикация Jain et al., Tumor Models In Cancer Research, ed. Teicher, Humana Press Inc., Totowa, N.J., pp. 647-671, 2001, которая полностью включена в настоящий документ посредством ссылки). Кроме того, существует множество стандартных анализов и животных моделей, которые могут быть использованы для определения эффективности конкретных способов лечения для стабилизации, лечения или профилактики заболевания или нарушения, такого как злокачественная опухоль, или повышенного риска развития заболевания или нарушения, такого как злокачественная опухоль. Способы лечения также могут быть исследованы в стандартных клинических испытаниях на людях.
Для выбора предпочтительного способа лечения для конкретного субъекта, соединения могут быть исследованы в отношении их влияния на экспрессию или активность на одном или нескольких генов, которые мутируют у субъекта. Например, способность соединения модулировать экспрессию определенных молекул мРНК или белка может быть обнаружена с помощью стандартного нозерн-, вестерн- или микроматричного анализов. Согласно некоторым вариантам осуществления один или несколько соединений выбирают таким образом, чтобы (I) ингибировать экспрессию или активность молекулы мРНК или белка, которые способствуют развитию злокачественной опухоли, которые экспрессируются на более высоком по отношению к нормальному уровне или характеризуются более высоким, чем нормальный уровень активности у субъекта (такие, как в образце, взятом у субъекта), или (II) содействовать экспрессии или активности молекул мРНК или белков, которые ингибируют злокачественную опухоль, которые экспрессируются на более низком уровне, чем обычно, или характеризуются более низким, чем нормальный уровень активности у субъекта. Индивидуальная или комбинированная терапия (I) модулирует наибольшее количество молекул мРНК или белков, которые содержат мутации, связанные со злокачественной опухолью у субъекта, и (II) модулирует наименьшее количество молекул мРНК или белков, которые не содержат мутаций, связанных со злокачественной опухолью у субъекта. Согласно некоторым вариантам осуществления выбранная индивидуальная или комбинированная терапия характеризуется высокой эффективностью лекарственного средства и производит мало, если таковые имеются, неблагоприятных побочных эффектов.
В качестве альтернативы к описанному выше специфическому к субъекту анализу могут быть использованы ДНК-чипы для сравнения экспрессии молекул мРНК в определенном типе злокачественной опухоли на ранней или поздней стадии (например, злокачественные клетки молочной железы) для экспрессии в нормальной ткани (публикации Marrack et al., Current Opinion in Immunology 12, 206-209, 2000; Harkin, Oncologist. 5: 501-507, 2000; Pelizzari et al., Nucleic Acids Res. 28(22): 4577-4581, 2000, каждая из которых полностью включена в настоящий документ посредством ссылки). На основе этого анализа может быть выбрана индивидуальная или комбинированная терапия для пациентов с этим типом злокачественной опухоли, чтобы модулировать экспрессию мРНК или белков, которые характеризуются измененной экспрессией в этом типе злокачественной опухоли.
В дополнение к использованию для выбора способа лечения для конкретного субъекта или группы субъектов, профилирование экспрессии может быть использовано для мониторинга изменений в экспрессии мРНК и/или белка, которые происходят во время лечения. Например, профилирование экспрессии может быть использовано для определения того, вернулась ли экспрессия генов, связанных со злокачественной опухолью, к нормальному уровню. Если нет, то доза одного или нескольких соединений при лечении может быть изменена для увеличения или уменьшения влияния лечения на уровни экспрессии соответствующего связанного со злокачественной опухолью гена(ов). Кроме того, этот анализ может быть использован, чтобы определить, влияет ли способ лечения на экспрессию других генов (например, генов, которые связаны с неблагоприятными побочными эффектами). При желании, доза или состав терапии может быть изменен, чтобы предотвратить или уменьшить нежелательные побочные эффекты.
Иллюстративные составы и способы введения
Для стабилизации, лечения или профилактики заболевания или нарушения, такого как злокачественная опухоль, или повышенного риска развития заболевания или нарушения, такого как злокачественная опухоль, композиция может быть приготовлена и введена с использованием любого способа, известного специалистам в настоящей области техники (смотрите, например, патенты США №8389578 и 8389557, каждый из которых полностью включен в настоящий документ посредством ссылки). Общие способы приготовления и введения можно найти в публикации "Remington: The Science and Practice of Pharmacy," 21st Edition, Ed. David Troy, 2006, Lippincott Williams & Wilkins, Philadelphia, Pa., которая полностью включена в настоящий документ посредством ссылки. Жидкости, взвеси, таблетки, капсулы, пилюли, порошки, гранулы, гели, мази, суппозитории, инъекции, средства для ингаляции и аэрозоли представляют собой примеры таких композиций. В качестве примера, модифицированный или с замедленным высвобождением пероральный состав может быть получен с использованием дополнительных способов, известных в настоящей области техники. Например, подходящая форма с замедленным высвобождением активного ингредиента может представлять собой матричную таблетку или капсульную композицию. Подходящие образующие матрицу материалы включают в себя, например, воски (например, карнаубский, пчелиный воск, парафин, церезин, шеллак, жирные кислоты и жирные спирты), масла, гидрированные масла или жиры (например, закаленное рапсовое масло, касторовое масло, говяжий жир, пальмовое масло и масло соевых бобов) и полимеры (например, гидроксипропилцеллюлозу, поливинилпирролидон, гидроксипропилметилцеллюлозу, целлюлозу и полиэтиленгликоль). Другие подходящие матричные материалы для таблетирования представляют собой микрокристаллическую целлюлозу, порошкообразную целлюлозу, гидроксипропилметилцеллюлозу, этилцеллюлозу, с другими носителями и наполнителями. Таблетки также могут содержать гранулы, покрытые оболочкой порошки или микросферы. Таблетки также могут быть многослойными. По желанию, готовая таблетка может быть с покрытием или без покрытия.
Типичные пути введения таких композиций включают в себя без ограничения пероральный, сублингвальный, буккальный, местный, трансдермальный, ингаляционный, парентеральный (например, подкожная, внутривенная, внутримышечная инъекция или инфузия), ректальный, вагинальный и назальный. Согласно предпочтительным вариантам осуществления лекарственные средства вводят с использованием устройства пролонгированного действия.
Композиции согласно настоящему изобретению составляют таким образом, чтобы позволить активному ингредиенту(ам), содержащемуся в нем, быть биодоступным после введения композиции. Композиции могут принимать форму одной или нескольких доз. Композиции могут содержать 1, 2, 3, 4 или более активных ингредиентов и необязательно могут содержать 1, 2, 3, 4 или более неактивных ингредиентов.
Альтернативные варианты осуществления
Любой из описанных в настоящем документе способов может включать в себя вывод данных в физическом формате, например, на экране компьютера или на бумажной распечатке. Любой из способов согласно настоящему изобретению может быть объединен с выводом из практических данных в формате, на основании которого может действовать врач. Некоторые из вариантов осуществления, описанных в настоящем документе, для определения генетических данных, относящихся к индивидууму-мишени, могут быть объединены с уведомлением о потенциальной хромосомной аномалии (например, делеции или дупликации) или ее отсутствии, необязательно в сочетании с решением о прерывании беременности или не прерывании ее в контексте пренатальной диагностики. Некоторые из вариантов осуществления, описанных в настоящем документе, могут быть объединены с выводом из практических данных и выполнением клинического решения, которое приводит к клиническому лечению, или исполнение клинического решения не вступает в действие.
Согласно некоторым вариантам осуществления в настоящем документе описан способ для создания отчета, раскрывающего результат какого-либо способа согласно настоящему изобретению (например, наличие или отсутствие делеции или дупликации). Отчет может быть получен с результатом от способа согласно настоящему изобретению, и он может быть отправлен к врачу в электронном виде, отображен на устройстве вывода (например, цифровой отчет) или врачу может быть доставлен письменный отчет (например, распечатанный отчет). Кроме того, описанные способы могут быть объединены с фактическим исполнением клинического решения, которое приводит к клиническому лечению, или исполнение клинического решения может не вступать в действие.
Согласно некоторым вариантам осуществления в настоящем изобретении предусмотрены реагенты, наборы, а также способы и компьютерные системы и компьютерные носители с закодированными инструкциями для выполнения таких способов для обнаружения, как CNV, так и SNV из того же образца, с использованием способов мультиплексной ПЦР, раскрытых в настоящем документе. Согласно некоторым предпочтительным вариантам осуществления образец представляет собой образец одной клетки или образец плазмы, предположительно содержащей циркулирующую опухолевую ДНК. Эти варианты осуществления пользуются преимуществом открытия того, что посредством исследуемых образцов ДНК из отдельных клеток или плазмы на CNV и SNV с использованием раскрытых в настоящем документе высокочувствительных способов мультиплексной ПЦР может быть достигнуто улучшенное обнаружение злокачественной опухоли, по сравнению с исследованием только на CNV, или SNV по отдельности, особенно для злокачественных опухолей, проявляющих CNV, таких как злокачественной опухоли молочной железы, яичников и легких. Способы согласно некоторым иллюстративным вариантам осуществления для анализа CNV исследуют на 50-100000 или 50-10000, или 50-1000 SNP, и для анализа SNV исследуют на 50-1000 SNV или на 50-500 SNV, или на 50-250 SNV. Предусмотренные в настоящем документе способы обнаружения CNV и/или SNV в плазме субъектов, подозреваемых в наличии злокачественной опухоли, включая в себя, например, злокачественной опухоли, при которой известно проявление CNV и SNV, такие как злокачественная опухоль молочной железы, легких и яичников, обеспечивают преимущество обнаружения CNV и/или SNV из опухолей, которые часто состоят из популяций гетерогенных злокачественных клеток с точки зрения генетических композиций. Таким образом, традиционные способы, которые сосредоточены на анализе только определенных областей опухолей, могут часто пропускать CNV или SNV, которые присутствуют в клетках и в других областях опухоли. Образцы плазмы действуют как жидкие биопсии, которые могут быть исследованы для обнаружения любого из CNV и/или SNV, которые присутствуют только в субпопуляции опухолевых клеток.
Иллюстративная компьютерная архитектура
На Фиг. 69 показана иллюстративная архитектура системы Х00, применимая для выполнения вариантов осуществления согласно настоящему изобретению. Архитектура системы Х00 включает в себя платформу для анализа Х08, подключенную к одной или нескольким лабораторным информационным системам ("LIS") Х04. Как показано на Фиг. 69, платформа для анализа Х08 может быть подключена к LIS Х04 через сеть Х02. Сеть Х02 может включать в себя одну или нескольких сетей одной или нескольких типов сетей, включая в себя любую комбинацию LAN, WAN, сети Интернет и т.д. Сеть Х02 может охватывать соединения между любыми или всеми компонентами в архитектуре системы Х00. Платформа для анализа Х08 может альтернативно или дополнительно быть подключена непосредственно к LIS Х06. Согласно одному варианту осуществления платформа для анализа Х08 анализирует генетические данные, предоставленные LIS Х04 в модели "программное обеспечение как сервис", где LIS Х04 представляет собой независимую LIS, в то время как платформа для анализа Х08 анализирует предоставленные LIS ХОбгенетические данные в модели в полном объеме или собственной разработки, где LIS Х06 и платформа для анализа Х08 контролируются той же стороной. Согласно варианту осуществления, где платформа для анализа Х08 представляет собой предоставляющую информацию по сети Х02, платформа для анализа Х08 может быть сервером.
Согласно одному иллюстративному варианту осуществления лабораторная информационная система Х04 включает в себя одно или несколько государственных или частных учреждений, которые собирают, управляют и/или хранят генетические данные. Специалисту в соответствующей области техники будет понятно, что способы и стандарты для обеспечения генетических данных, известны и могут быть реализованы с использованием различных способов обеспечения информационной безопасности и политики, например, имя пользователя/пароль, безопасность на транспортном уровне (TLS), протокол безопасных соединений (SSL) и/или другие криптографические протоколы, обеспечивающие безопасность связи.
Согласно иллюстративному варианту осуществления архитектура системы Х00 работает как сервис-ориентированная архитектура и использует модель клиент-сервер, которая будет понятна специалисту в соответствующей области техники, чтобы включить различные формы взаимодействия и связи между LIS Х04 и платформой для анализа Х08. Архитектура системы Х00 может быть распределена по различным типам сетей Х02 и/или может работать как облачная вычислительная архитектура. Облачная вычислительная архитектура может включать в себя любой тип распределенной архитектуры сети. В качестве примера, а не ограничения, облачная архитектура применима для предоставления программного обеспечения в виде услуги (SaaS), инфраструктуры в виде услуги (IaaS), платформы в виде услуги (PaaS), сети в виде услуги (HAAH), данных в виде услуги (DaaS), базы данных в виде услуги (DBaaS), бэкэнда в виде услуги (BaaS), тестовой среды в виде услуги (TEaaS), API в виде услуги (APIaaS), платформы интеграции в виде услуги (IPaaS) и т.д.
В иллюстративном варианте осуществления LIS Х04 и Х06 каждая включает в себя компьютер, устройство, интерфейс и т.д. или любую их подсистему. LIS Х04 и Х06 могут включать в себя операционную систему (ОС), приложения, установленные для выполнения различных функций, таких как, например, доступ к данным и/или навигацию, сделанными доступными локально, в памяти и/или по сети Х02. Согласно одному варианту осуществления LIS Х04 получает доступ к платформе для анализа Х08 через интерфейс прикладного программирования ("API"). LIS Х04 может также включать в себя одно или несколько собственных приложений, которые могут работать независимо друг от друга из API.
Согласно иллюстративному варианту осуществления платформа для анализа Х08 включает в себя одно или несколько из следующего: входной процессор Х12, менеджер гипотез X14, моделирующее устройство X16, блока исправления ошибок X18, блок машинного обучения Х20 и выходной процессор X18. Входной процессор X12 принимает и обрабатывает входные сигналы от LIS Х04 и/или Х06. Обработка может включать в себя без ограничения такие операции, как синтаксический анализ, перекодирование, перевод, адаптирование или иной способ обработки любого входа, полученного от LIS Х04 и/или Х06. Входы могут быть получены с помощью одного или нескольких потоков, подачи новостей, баз данных или других источников данных, таких, которые могут быть сделаны доступными посредством LIS Х04 и Х06. Ошибки в данных могут быть исправлены с помощью блока коррекции ошибок X18 посредством выполнения описанных выше механизмов коррекции ошибок.
Согласно иллюстративному варианту осуществления менеджер гипотезы Х14 выполнен с возможностью принимать входные сигналы, передаваемые от входного процессора X12 в виде готового к исполнению в соответствии с гипотезами для генетического анализа, которые представлены в качестве моделей и/или алгоритмов. Такие модели и/или алгоритмы могут быть использованы устройством для моделирования X16 для получения вероятностей, например, на основе динамической, в реальном масштабе времени и/или исторических статистических данных или других показателей. Данные, используемые для получения и заполнения таких моделей и/или алгоритмов стратегии доступны для менеджера гипотез X14 через, например, источник генетических данных X10. Источник генетических данных X10 может включать в себя, например, секвенатор нуклеиновых кислот. Менеджер гипотез X14 может быть сконфигурирован так, чтобы формулировать гипотезы, основанные, например, на переменных, необходимых для заполнения своих моделей и/или алгоритмов. Модели и/или алгоритмы, однажды загруженные, могут быть использованы устройством для моделирования X16 для создания одной или нескольких гипотез, как описано выше. Менеджер гипотез X14 может выбрать определенное значение, диапазон значений или оценку, основанную на наиболее вероятной гипотезе, в качестве выходного сигнала, как описано выше. Устройство для моделирования X16 может работать в соответствии с моделями и/или алгоритмами, обученных блоком машинного обучения Х20. Например, блок машинного обучения Х20 может разрабатывать такие модели и/или алгоритмы путем применения алгоритма классификации, как описано выше, для набора обучающей базы данных (не показаны). Согласно некоторым вариантам осуществления блок машинного обучения анализирует один или несколько контрольных образцов, чтобы создавать наборы обучающих данных, применимых в способах обнаружения SNV, представленных в настоящем документе.
После того, как менеджер гипотез X14 определил конкретный выход, такой выход может быть возвращен к конкретной LIS 104 или 106, запрашивающей информацию с помощью выходного процессора Х22.
Различные аспекты настоящего раскрытия могут быть реализованы на вычислительном устройстве с помощью программного обеспечения, встроенного программного обеспечения, аппаратных средств или их комбинации. На Фиг. 70 показан пример компьютерной системы Y00, в котором рассматриваемые варианты осуществления или их части могут быть реализованы в виде машиночитаемого кода. Различные варианты осуществления описаны в терминах данного примера компьютерной системы Y00.
Задачи обработки в варианте осуществления на Фиг. 70 выполняются одним или несколькими процессорами Y02. Тем не менее, следует отметить, что в настоящем документе могут быть использованы различные типы технологии обработки, включая в себя программируемые логические матрицы (PLA), интегральные схемы прикладной ориентации (ASIC), многоядерные процессоры, множественные процессоры или распределенные процессоры. Дополнительные специализированные ресурсы обработки, такие как графика, мультимедиа или математические возможности обработки могут быть также использованы для оказания помощи в определенных задачах обработки. Эти ресурсы обработки могут представлять собой аппаратные средства, программное обеспечение или соответствующую их комбинацию. Например, один или несколько процессоров Y02 может представлять собой графический процессор (GPU). Согласно одному варианту осуществления GPU представляет собой процессор, который представляет собой специализированную электронную схему, предназначенную для быстрой обработки математически сложных приложений на электронных устройствах. GPU может характеризоваться высокопараллельной структурой, которая эффективна для параллельной обработки больших массивов данных, таких как требующие значительных математических расчетов данные. Альтернативно или дополнительно, один или несколько процессоров Y02 могут представлять собой специальную параллельную обработку без оптимизации графики, например, параллельные процессоры, выполняющие требующие значительных математических расчетов функции, описанные в настоящем документе. Один или несколько процессоров Y02 могут включать в себя ускоритель обработки (например, DSP или другой процессор специального назначения).
Компьютерная система Y00 также включает в себя основную память Y30 и может также включать в себя вторичную память Y40. Основная память Y30 может представлять собой энергозависимую память или энергонезависимую память и делиться на каналы. Вторичная память Y40 может включать в себя, например, энергонезависимую память, такую как накопитель на жестком диске Y50, сменное устройство памяти Y60 и/или карту памяти. Сменное устройство памяти Y60 может содержать дисковод, лентопротяжный механизм, накопитель на оптическом диске, флэш-память или тому подобное. Сменное устройство памяти Y60 считывает и/или записывает на блок сменной памяти Y70 хорошо известным способом. Блок сменной памяти Y70 может содержать дискету, магнитную ленту, оптический диск и т.д., который считывается и записывается в виде сменного устройства памяти Y60. Как будет понятно специалистам в настоящей области техники, блок сменной памяти Y70 включает в себя используемый компьютером носитель для хранения, на котором хранится компьютерное программное обеспечение и/или данные.
Согласно альтернативным вариантам осуществления вторичная память Y40 может включать в себя другие аналогичные средства, позволяющие компьютерным программам или другим инструкциям загружаться в компьютерную систему Y00. Такие средства могут включать в себя, например, блок сменной памяти Y70 и интерфейс (не показан). Примеры таких средств могут включать в себя картридж программ и картриджный интерфейс (например, найденный в видеоигровых устройствах), съемную микросхему памяти (например, EPROM или PROM) и соответствующее гнездо, а также другие блоки сменной памяти Y70 и интерфейсы, которые позволяют передавать программное обеспечение и данные с блоков сменной памяти Y70 к компьютерной системе Y00.
Компьютерная система Y00 может также включать в себя контроллер памяти Y75. Контроллер памяти Y75 контролирует доступ к данным главной памяти Y30 и вторичной памяти Y40. Согласно некоторым вариантам осуществления контроллер памяти Y75 может быть внешним по отношению к процессору Y10, как показано на Фиг. 70. Согласно другим вариантам осуществления контроллер памяти Y75 может также представлять собой непосредственную часть процессора Y10. Например, многие процессоры AMDTM и IntelTM используют интегрированные контроллеры памяти, которые представляют собой часть одного и того же чипа в виде процессора Y10 (не показан на Фиг. 70).
Компьютерная система Y00 может также включать в себя коммуникационный и сетевой интерфейс Y80. Коммуникационный и сетевой интерфейс Y80 позволяет передавать программное обеспечение и данные между компьютерной системой Y00 и внешними устройствами. Коммуникационный и сетевой интерфейс Y80 может включать в себя модем, коммуникационный порт, слот PCMCIA и карту или тому подобное. Программное обеспечение и данные, передаваемые через коммуникационный и сетевой интерфейс Y80, передаются в виде сигналов, которые могут быть электронными, электромагнитными, оптическими или другими сигналами, способными быть полученными посредством коммуникационного и сетевого интерфейса Y80. Эти сигналы обеспечиваются коммуникационным и сетевым интерфейсом Y80 с помощью коммуникационного пути Y85. Коммуникационный путь Y85 несет сигналы и может быть реализован с использованием провода или кабеля, волоконно-оптического кабеля, телефонной линии, соединения сотового телефон, соединения RF или других коммуникационных каналов.
Коммуникационный и сетевой интерфейс Y80 позволяет компьютерной системе Y00 обмениваться данными по коммуникационным сетям или средам, таким как LAN, WAN, интернет и т.д. Коммуникационный и сетевой интерфейс Y80 может взаимодействовать с удаленными сайтами или сетями через проводные или беспроводные соединения.
В настоящем документе термины "носитель компьютерной программы", "приемлемый для компьютера носитель" и "энергонезависимый носитель" в целом относятся к материальным носителям, таким как блок сменной памяти Y70, сменное устройство памяти Y60 и жесткий диск, установленный в дисководе для жесткого диска Y50. Сигналы, передаваемые по коммуникационному пути Y85, могут также воплощать логику, описанную в настоящем документе. Носитель компьютерной программы и приемлемый для компьютера носитель могут также относиться к такой памяти, как основная память Y30 и вторичная память Y40, которые могут быть полупроводниками памяти (например, DRAM и т.д.). Эти компьютерные программные продукты представляют собой средства для предоставления программного обеспечения для компьютерной системы Y00.
Компьютерные программы (также называемые логической частью компьютерного управления) хранятся в главной памяти Y30 и/или вторичной памяти Y40. Компьютерные программы также могут быть получены с помощью коммуникационного и сетевого интерфейса Y80. Такие компьютерные программы, при исполнении, позволяют компьютерной системе Y00 реализовать варианты осуществления, описанные в настоящем документе. В частности, компьютерные программы при исполнении позволяют процессору Y10 реализовать раскрытые процессы. Соответственно, такие компьютерные программы представляют собой контроллеры компьютерной системы Y00. Там, где варианты осуществления реализуются с использованием программного обеспечения, программное обеспечение может храниться в компьютерном программном продукте и загружаться в компьютерную систему Y00 с использованием сменного устройства памяти Y60, интерфейсов, жесткого диска Y50 или коммуникационного и сетевого интерфейса Y80, например.
Компьютерная система Y00 может также включать в себя устройства входа/выхода/дисплея Y90, например, клавиатуры, мониторы, устройства управления курсором, сенсорные экраны и т.д.
Следует отметить, что моделирование, синтез и/или изготовление различных вариантов осуществления может быть выполнено, в частности, за счет использования машиночитаемого кода, включающего в себя общие языки программирования (например, C или C++), языки описания аппаратных средств (HDL), такие как, например, Verilog HDL, VHDL, Altera HDL (AHDL) или другие доступные средства программирования. Этот машиночитаемый код может быть расположен на любом приемлемом для компьютера носителе, включающем в себя полупроводник, магнитный диск, оптический диск (например, CD-ROM, DVD-ROM). Таким образом, код может быть передан по коммуникационным сетям, включающим в себя Интернет.
Варианты осуществления также направлены на компьютерные программные продукты, содержащие программное обеспечение, хранящееся на любом приемлемом для компьютера носителе. Такое программное обеспечение при выполнении в одном или нескольких устройствах обработки данных заставляет устройство(а) обработки данных действовать, как описано в настоящем документе. Варианты осуществления используют любой приемлемый для компьютера или машиночитаемый носитель и любой приемлемый для компьютера или машиночитаемый носитель данных, известный в настоящее время или в будущем. Примеры приемлемых для компьютера или машиночитаемых носителей включают в себя без ограничения первичные запоминающие устройства (например, любой тип оперативной памяти), вторичные запоминающие устройства (например, жесткие диски, дискеты, CD-ROM, ZIP диски, ленты, магнитные запоминающие устройства, оптические запоминающие устройства, MEMS, нано-технологические запоминающие устройства и т.д.) и коммуникационные носители (например, проводные и беспроводные коммуникационные сети, локальные сети, глобальные сети, интранет и т.д.). Приемлемые для компьютера или считываемые компьютером носители могут включать в себя любую форму энергозависимых (которые включают в себя сигналы) или энергонезависимых (которые исключают сигналы) носителей. Энергонезависимые носители включают в себя, в качестве не ограничивающего примера, вышеупомянутые физические запоминающие устройства (например, первичные и вторичные запоминающие устройства).
Следует понимать, что любой из раскрытых в настоящем документе вариантов осуществления может быть использован в сочетании с любым другим раскрытым в настоящем документе вариантом осуществления.
Экспериментальная часть
Раскрытые в настоящее время варианты осуществления описаны в следующих примерах, которые приведены для облегчения понимания раскрытия и не должны быть истолкованы как ограничивающие каким-либо образом объем настоящего изобретения, который определен формулой изобретения, которая следует далее. Следующие примеры выдвигаются таким образом, чтобы обеспечить обычным специалистам в настоящей области техники полное раскрытие и описание того, как использовать описанные варианты осуществления, и не предназначены для ограничения объема раскрытия, а также не предназначены для представления того, что приведенные ниже эксперименты являются всеми или только выполненными экспериментами. Были предприняты усилия для обеспечения точности в отношении используемых чисел (например, количеств, температуры и т.д.), но некоторые экспериментальные ошибки и отклонения должны учитываться. Если не указано иное, части представляют собой части по объему, а температура представлена в градусах Цельсия. Следует понимать, что вариации в описанных способах могут быть сделаны без изменения фундаментальных аспектов, для иллюстрации которых предназначены эксперименты.
Пример 1
Иллюстративные способы подготовки образца и амплификации описаны в заявке на патент США №13/683604, поданной 21 ноября 2012 г.; публикации США №2013/0123120 и патенте США с серийным номером 61/994791, поданном 16 мая 2014 г., который полностью включен в настоящий документ посредством ссылки. Эти способы могут быть использованы для анализа любого из раскрытых в настоящем документе образцов.
В одном эксперименте образцы плазмы готовили и амплифицировали с использованием полугнездового протокола с одновременным участием 19488 последовательностей. Образцы готовили следующим образом: до 20 мл крови центрифугировали для выделения лейкоцитарной пленки и плазмы. Геномную ДНК в образце крови получали из лейкоцитарной пленки. Геномная ДНК также может быть получена из образца слюны. Внеклеточную ДНК в плазме выделяли с использованием набора QIAGEN CIRCULATING NUCLEIC ACID и элюировали в 50 мкл буфера ТЕ в соответствии с инструкциями изготовителя. Универсальные адаптеры для лигирования добавляли к концу каждой молекулы в 40 мкл очищенной ДНК плазмы и библиотеки амплифицировали в течение 9 циклов с использованием специфических к адаптеру праймеров. Библиотеки очищали с помощью гранул AGENCOURT AMPURE и элюировали в 50 мкл буфера для суспензии ДНК.
6 мкл ДНК амплифицировали посредством 15 циклов STAR 1 (95°C в течение 10 мин для первоначальной активации полимеразы, затем 15 циклов при температуре 96°C в течение 30 секунд, 65°C в течение 1 мин; 58°C в течение 6 мин, 60°C в течение 8 мин, 65°C в течение 4 мин и 72°C в течение 30 секунд, а также окончательное удлинение при температуре 72°C в течение 2 мин) с использованием концентрации праймеров 7,5 нМ 19488 специфичных для мишени меченных обратных праймеров и специфичного к одной библиотеки адаптеров прямого праймера в концентрации 500 нМ.
Протокол полугнездовой ПЦР включал в себя вторую амплификацию разведения продукта STAR 1 в течение 15 циклов (STAR 2) (95°C в течение 10 мин для первоначальной активации полимеразы, затем 15 циклов при температуре 95°C в течение 30 секунд; 65°C в течение 1 мин; 60°C в течение 5 мин, 65°C в течение 5 мин и 72°C в течение 30 секунд, и окончательное удлинение при температуре 72°C в течение 2 мин) с использованием концентрации обратных тегов 1000 нМ и концентрации 20 нМ для каждого из 19488 специфических к мишени прямых праймеров.
Аликвоту продуктов STAR 2 затем амплифицировали с помощью стандартной ПЦР в течение 12 циклов с 1 мкМ специфичных к тегам прямых праймеров и обратных праймеров со штрих-кодами для создания библиотек секвенирования со штрих-кодами. Аликвоту каждой библиотеки смешивали с библиотеками различных штрих-кодов и очищали с использованием центрифужной колонки.
Таким образом, 19488 праймеров использовали в однолуночных реакциях; праймеры разрабатывали для направленного воздействия на SNP, найденные на хромосомах 1,2, 13, 18, 21, X и Y. Ампликоны затем секвенировали с использованием секвенатора ILLUMINA GAIIX. При желании число прочтений секвенирования может быть увеличено, чтобы увеличить число нацеленных SNP, которые амплифицируют и секвенируют.
Соответствующие образцы геномной ДНК амплифицировали с использованием полунездовой ПЦР с 19488 внешних прямых праймеров и помеченных обратных праймеров в концентрации 7,5 нМ в STAR 1. Условия термоциклирования и состав STAR 2 и штрихкодирующая ПЦР были такими же, как и для полугнездового протокола.
Пример 2
Иллюстративные способы выбора праймеров описаны в заявке на патент США №13/683604, поданной 21 ноября 2012 г. (публикация США №2013/0123120), и патенте США с серийным номером 61/994,791, поданном 16 мая 2014 г., который полностью включен в настоящий документ посредством ссылки. Эти способы могут быть использованы для анализа любого из раскрытых в настоящем документе образцов.
Следующий эксперимент демонстрирует иллюстративный способ разработки и выбора библиотеки праймеров, которые могут быть использованы в любом из способов мультиплексной ПЦР согласно настоящему изобретению. Цель состоит в том, чтобы выбрать праймеры из исходной библиотеки праймеров-кандидатов, которые могут быть использованы для одновременной амплификации большого числа локусов-мишеней (или подмножества локусов-мишеней) в одном реакционном объеме. Для начальной совокупности потенциальных локусов-мишеней праймеры не должны быть разработаны или выбраны для каждого локуса-мишени. Предпочтительно, чтобы праймеры разрабатывали и выбирали для большей части наиболее желательных локусов-мишеней.
Стадия 1
Совокупность потенциальных локусов-мишеней (таких, как SNP) отбирали на основании публично доступной информации о требуемых параметрах для локусов-мишеней, таких как частота SNP в пределах популяции-мишени или степень гетерозиготности SNP (в сети интернет по адресу ncbi.nlm.nih.gov/projects/SNP/; публикации Sherry ST, Ward МН, Kholodov М, et al. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 2001 Jan 1; 29(1): 308-11, каждая из которых полностью включена посредством ссылки). Для каждого локуса-кандидата разрабатывали одну или несколько пар праймеров ПЦР с использованием программы Primer3 (в сети интернет по адресу primer3.sourceforge.net; libprimer3 релиз 2.2.3, который полностью включен в настоящий документ посредством ссылки). Если не было никаких подходящих разработок для ПЦР-праймеров для конкретного локуса-мишени, то тогда этот локус-мишень исключали из дальнейшего рассмотрения.
При желании, "балл локуса-мишени" (более высокий балл представляет более высокую желательность) можно рассчитать для большинства или всех локусов-мишеней, например, балл локуса-мишени, вычисленный на основе средневзвешенного значения различных желаемых параметров для локусов-мишеней. В качестве параметров могут быть назначены различные веса в зависимости от их важности для конкретного применения, для которого праймеры будут использоваться. Иллюстративные параметры включают в себя степень гетерозиготности локуса-мишени, распространенность заболевания, связанного с последовательностью (например, полиморфизмом) локуса-мишени, пенетрантность заболевания, связанного с последовательностью (например, полиморфизмом) локуса-мишени, специфичность праймера(ов)-кандидата, используемого для амплификации локуса-мишени, размер праймера(ов)-кандидата, используемого для амплификации локуса-мишени, а также размер ампликона-мишени. Согласно некоторым вариантам осуществления специфичность праймера-кандидата к локусу-мишени включает в себя правдоподобие того, что праймер-кандидат будет неспецифически связываться путем связывания и амплификации локуса, отличного от локуса-мишени, для амплификации которого он был разработан. Согласно некоторым вариантам осуществления один или несколько или все праймеры кандидаты, которые неспецифически связываются, удаляют из библиотеки.
Стадия 2
Балл термодинамического взаимодействия рассчитывали между каждым праймером и всеми праймерами для всех других локусов-мишеней со стадии 1 (смотрите, например, публикации Allawi, Н.T. & SantaLucia, J., Jr. (1998), "Thermodynamics of Internal C-T Mismatches in DNA", Nucleic Acids Res. 26, 2694-2701; Peyret, N., Seneviratne, P.A., Allawi, H.T. & SantaLucia, J., Jr. (1999), "Nearest-Neighbor Thermodynamics and NMR of DNA Sequences with Internal A-A, C-C, G-G, and T-T Mismatches", Biochemistry 38, 3468-3477; Allawi, H.T. & SantaLucia, J., Jr. (1998), "Nearest-Neighbor Thermodynamics of Internal A-C Mismatches in DNA: Sequence Dependence and pH Effects", Biochemistry 37, 9435-9444.; Allawi, H.T. & SantaLucia, J., Jr. (1998), "Nearest Neighbor Thermodynamic Parameters for Internal G-A Mismatches in DNA", Biochemistry 37, 2170-2179 и Allawi, H.T. & SantaLucia, J., Jr. (1997), "Thermodynamics and NMR of Internal G-T Mismatches in DNA", Biochemistry 36, 10581-10594; MultiPLX 2.1 (Kaplinski L, Andreson R, Puurand T, Remm M. MultiPLX: automatic grouping and evaluation of PCR primers. Bioinformatics. 2005 Apr 15; 21 (8): 1701-2, каждая из которых полностью включена в настоящий документ посредством ссылки). Эта стадия приводила к 2D-матрице баллов взаимодействия. Баллы взаимодействия предсказывали правдоподобие праймеров-димеров с участием двух взаимодействующих праймеров. Балл рассчитывали следующим образом:
interaction_score = max(-deltaG_2, 0,8*(-deltaG_1)),
где deltaG_2 = энергия Гиббса (энергия, необходимая для разрушения димера) для димера, который представляет собой удлиняемый с помощью ПЦР на обоих концах, т.е. 3'-конец каждого праймера подвергается отжигу с другим праймером; а также deltaG_1 = энергия Гиббса для димера, который представляет собой удлиняемый с помощью ПЦР по меньшей мере на одном конце.
Стадия 3:
Для каждого локуса-мишени, если существует более одного дизайна пары праймеров, тогда один дизайн выбирали с помощью следующего способа:
1. Для каждого дизайна пары праймеров для локуса необходимо найти наихудший (самый высокий) балл взаимодействия для двух праймеров в этом дизайне и всех праймеров из всех дизайнов для всех других локусов-мишеней.
2. Необходимо выбрать дизайн с самым лучшим (самым низким) наихудшим баллом взаимодействия.
Стадия 4
Граф строили таким образом, чтобы каждый узел представлял собой один локус и связанный с ним дизайн пары праймера (например, проблема максимальной группировки). Одно ребро создавали между каждой парой узлов. Вес назначали каждому ребру, равному наихудшему (самому высокому) баллу взаимодействия между праймерами, связанными с двумя узлами, соединенными ребром.
Стадия 5
При желании, для каждой пары дизайнов для двух разных локусов-мишеней, где один из праймеров из одного дизайна и один из праймеров из другого дизайна будут подвергать отжигу для перекрывания областей-мишеней, добавляли дополнительное ребро между узлами для двух дизайнов. Вес этих ребер устанавливали равным самому высокому весу, назначенному на стадии 4. Таким образом, стадия 5 предотвращает библиотеку от наличия праймеров, которые гибридизуются с перекрыванием областей-мишеней и, таким образом, мешают друг другу в ходе мультиплексной ПЦР-реакции.
Стадия 6
Начальный порог балла взаимодействия рассчитывали следующим образом:
weight_threshold = max(edge_weight) - 0,05 * (max(edge_weight) - min(edge_weight)),
где
max(edge_weight) представляет собой максимальный вес ребра в графе; а также
min(edge_weight) представляет собой минимальный вес ребра в графе.
Начальные связи для порогового значения были установлены следующим образом:
max_weight_threshold = max(edge_weight)
min_weight_threshold = min(edge_weight)
Стадия 7
Строили новый граф, состоящий из той же совокупности узлов, что и граф из стадии 5, только с включением ребер с весами, которые превышают weight_threshold. Таким образом, стадия игнорирует взаимодействия с баллами, равными или ниже weight_threshold.
Стадия 8
Узлы (и все ребра, соединенные с удаленными узлами) удаляли из графа, полученного на стадии 7, пока не осталось никаких ребер. Узлы удаляли с повторным применением следующей процедуры:
1. Найти узел с высокой степенью (наибольшее число ребер). Если их больше одного, то выбрать один произвольно.
2. Определить совокупность узлов, состоящих из узла, выбранного выше, и всех соединенных с ним узлов, за исключением любых узлов, которые имеют степень меньше, чем узел, выбранный выше.
3. Выбрать узел из совокупности, которая характеризуется самый низким баллом локуса-мишени (более низкий балл, представляющий меньшую желательность), начиная со стадии 1. Удалить этот узел из графа.
Стадия 9
Если число остающихся в графе узлов удовлетворяет требуемому числу локусов-мишеней для пула мультиплексных ПЦР (в пределах приемлемого допуска), то способ продолжается на стадии 10.
Если было слишком много или слишком мало остающихся в графике узлов, то проводили бинарный поиск, чтобы определить, какие пороговые значения будут приводить к желаемому числу узлов, остающихся в графах. Если было слишком много узлов в графе, тогда пороговые значения веса корректировали следующим образом:
max_weight_threshold = weight_threshold
В противном случае (если существует два узла в графе), то пороговые значения веса корректировали следующим образом:
min_weight_threshold = weight_threshold
Затем порог веса регулировали следующим образом:
weight_threshold = (max_weight_threshold + min_weight_threshold)/2
Стадии 7-9 повторяли.
Стадия 10
Дизайны пар праймеров, связанные с узлами, остающимися в графе, выбирали для библиотеки праймеров. Эта библиотека праймеров может быть использована в любом из способов согласно настоящему изобретению.
При желании этот способ разработки и выбора праймеров может быть выполнен для библиотек праймеров, в которых только один праймер (вместо пары праймеров) используется для амплификации локуса-мишени. В этом случае узел представляет собой один праймер на локус-мишень (а не пару праймеров).
Пример 3
При желании, способы согласно настоящему изобретению могут быть исследованы, чтобы оценить их способность обнаруживать делецию или дупликацию хромосомы или хромосомного сегмента. Проводили следующий эксперимент, чтобы продемонстрировать обнаружение превалирования X-хромосомы или сегмента из X-хромосомы, унаследованного от отца, по сравнению с X-хромосомой или X хромосомным сегментом от матери. Этот анализ предназначен для имитации делеции или дупликации хромосомы или хромосомного сегмента. Различные количества ДНК от отца (с половыми хромосомами XY) смешивали с ДНК от дочери (с половыми хромосомами XX) отца для анализа излишка Х-хромосомы от отца (Фиг. 19A-19D).
ДНК из клеточных линий отца и дочери экстрагировали и количественно определяли с использованием Qubit. Использовали клеточную линию AG16782, CAG16782-2-F отца и клеточную линию AG16777, CAG16777-2-P дочери. Чтобы определить гаплотип отца для Х-хромосомы, обнаруживали SNP, которые присутствуют на Х-хромосоме, но не на Y-хромосоме, таким образом, чтобы наблюдался сигнал от Х-хромосомы отца, но не Y-хромосомы. Дочь унаследовала этот гаплотип от отца. Гаплотип от другой Х-хромосомы у дочери был унаследован от ее матери. Этот гаплотип от матери может быть определен путем назначения SNP в ДНК из клеточной линии дочери, которые не были унаследованного от отца, гаплотипу от матери.
Для того чтобы определить, может ли быть обнаружено доминирование X-хромосомы от отца, различные количества ДНК из клеточной линии отца смешивали с ДНК из клеточной линии дочери. Общий ввод ДНК составлял приблизительно 75 нг (~25 тыс. копий) геномной ДНК. Приблизительно 3456 SNP амплифицировали с использованием прямой мультиплексной ПЦР для анализов X и Y хромосом. Амплифицированные продукты секвенировали с использованием 50 п.н. одного пробега секвенирования с 7 п.н. штрих-кодов с использованием режима Rapid/HT. Число прочтений составляло приблизительно 10 тыс. на SNP.
Как показано на Фиг. 19A-19D, могла быть обнаружена мозаичность из ДНК отца. Эти данные свидетельствуют о том, что могут быть обнаружены хромосомные сегменты или целые хромосомы, которые доминируют.
Все патенты, заявки на патенты и опубликованные ссылки, приведенные в настоящем документе, полностью включены посредством ссылки. Хотя способы настоящего раскрытия были описаны в связи с конкретными вариантами осуществления, следует понимать, что возможна дальнейшая модификация. Кроме того, эта заявка предназначена для охвата любых вариаций, применений или адаптации способов согласно настоящему изобретению, включая в себя такие отклонения от настоящего изобретения, которые находятся в пределах известной или обычной практики в настоящей области техники, к которым относятся способы настоящего раскрытия, и которые попадают в пределы объема приложенной формулы изобретения. Любые из вариантов осуществления настоящего изобретения могут быть выполнены посредством анализа ДНК и/или РНК в образце. Например, любой из способов, описанных в настоящем документе для ДНК, может быть легко адаптирован для РНК, например, путем включения стадии обратной транскрипции, чтобы преобразовать РНК в ДНК.
Пример 4
В этом примере описан иллюстративный способ для неинвазивного основанного на внеклеточной опухолевой ДНК выявления связанных со злокачественной опухолью молочной железы вариаций числа копий. Скрининг злокачественной опухоли молочной железы включает в себя маммографию, которая приводит к большому числу ложно позитивных заключений и пропускает некоторые виды злокачественной опухоли. Анализ полученной из опухоли циркулирующей внеклеточной ДНК (цоДНК) для связанных со злокачественной опухолью CNV может позволить более ранний, безопасный и более точный скрининг. Основанный на SNP подход с использованием мультиплексной ПЦР с большим количеством целевых последовательностей (mmPCR) использовали для скрининга CNV в цоДНК, выделенной из плазмы пациентов со злокачественной опухолью молочной железы. Анализ ммПЦР был разработан для направленного воздействия на 3168 SNP на хромосомах 1, 2 и 22, которые часто характеризуются наличием CNV при злокачественной опухоли (например, 49% образцов злокачественной опухоли молочной железы характеризуются наличием делеции 22q). Проанализировали шесть образцов плазмы от пациентов со злокачественной опухолью молочной железы - один на стадии IIa, четыре на стадии IIb и один на стадии IIIb. Каждый образец характеризовался наличием CNV на одной или нескольких хромосомах-мишенях. Анализ идентифицировал CNV во всех шести образцах плазмы, включая в себя один образец стадии IIb, который был правильно распознан во фракции цоДНК 0,58% (Фиг. 30, 31B, 32A, 32B и 33); обнаружение требовало только 86 гетерозиготных SNP. Образец стадии IIa также был правильно распознан во фракции цоДНК 4,33% с использованием приблизительно 636 гетерозиготных SNP (Фиг. 29, 31А и 32А). Это свидетельствует о том, что как фокальные CNV, так и CNV целого плеча хромосомы, общие при злокачественной опухоли, можно легко обнаружить.
Для дополнительной оценки чувствительности, 22 искусственные смеси, содержащие 3 Мб CNV 22q из злокачественной клеточной линии, смешивали с ДНК из нормальной клеточной линии (5:95) для имитации фракции цоДНК в диапазоне от 0,43% до 7,35% (Фиг. 28А-28С). Способ правильно обнаружил CNV в 100% этих образцов. Таким образом, искусственные полинуклеотидные стандарты/контроли вкДНК могут быть получены с помощью внесения выделенных полинуклеотидных образцов, которые включают в себя фрагментированные полинуклеотидные смеси, созданные источниками не-вкДНК, про которые известно, что они обладают CNV, такие как опухолевые клеточные линии, в другие образцы ДНК в концентрациях, аналогичных тем, которые наблюдались для вкДНК in vivo, например, от 0,01% до 20%, от 0,1 до 15% или от 0,4 до 10% ДНК в этой жидкости. Эти стандарты/контроли могут быть использованы в качестве контролей для разработки анализа, определения характеристик, разработки и/или оценки, а также в качестве стандартов контроля качества во время исследования, например, исследования злокачественной опухоли, выполняемого в лаборатории CLIA, и/или в качестве стандартов, включенных только для применения в исследовательских целях или только в диагностических тест-наборах. Важно отметить, что во многих видах злокачественных опухолей - в том числе злокачественных опухолей молочной железы и яичников - CNV более распространены по сравнению с точечными мутациями. Все вместе это поддерживает то, что этот основанный на SNP подход mmPCR предлагает экономически эффективный, неинвазивный способ обнаружения этих видов злокачественной опухоли.
Пример 5
В этом примере описан иллюстративный способ обнаружения вариаций числа копий в образцах злокачественной опухоли молочной железы с использованием меченной SNP мультиплексной ПЦР с большим количеством целевых последовательностей. Оценка CNV в опухолевых тканях, как правило, включает в себя микроматричный анализ SNP или aCGH. Эти способы обладают высокой разрешающей способностью для целого генома, но требуют большого количества исходного материала, имеют высокие фиксированные затраты и не работают хорошо на фиксированных формальдегидом погруженных в парафин (FFPE) образцах. Для этого примера, ПЦР с нацеленными SNP с участием 28000 последовательностей с использованием следующего поколения секвенирования (NGS) использовали для направленного воздействия на 1p, 1Q, 2Р, 2Q, 4р16, 5р15, 7q11, 15Q, 17р, 22q11, 22q13 и хромосомы 13, 18, 21 и X для обнаружение CNV в образцах злокачественной опухоли молочной железы. Точность проверяли на 96 образцах с анеуплоидиями или микроделециями. Чувствительность одиночных молекул оценивали на основе анализа отдельных клеток. Из 17 проанализированных образцов злокачественной опухоли молочной железы (15 свежемороженых и 2 FFPE опухолевых тканей, 5 пар соответствующих опухолевых и нормальных клеточных линий), у 16 (в том числе и FFPE) наблюдались с полные или частичные CNV в 1-15 мишенях (в среднем 7,8); наблюдалось свидетельство гетерогенности опухоли. Три ткани с одной CNV характеризовались наличием дупликации 1q, наиболее частой цитогенетической аномалией при злокачественной опухоли молочной железы. Наиболее частые области с CNV представляли собой 1q, 7Р и 22q1. Только одна опухолевая ткань (с 9 CNV) содержала область с LOH; эта LOH была также обнаружена в соседней предполагаемо нормальной ткани, в которой не было остальных 8 CNV. В отличие от этого, 5 или более областей с LOH и высоким общим количеством CNV (в среднем 12,8) были обнаружены в клеточных линиях. Таким образом, мультиплексная ПЦР с большим количеством последовательностей предлагает экономичный высоко пропускной подход к целенаправленному исследованию CNV и применим к труднодоступным для анализа образцам, таким как ткани FFPE.
Пример 6
Этот пример показывает иллюстративные способы вычисления предела обнаружения для любого из способов согласно настоящему изобретению. Эти способы использовали для вычисления предела обнаружения для однонуклеотидных вариантов (SNV) в биопсии опухоли (Фиг. 34) и образце плазмы (Фиг. 35).
Первый способ (обозначенный "LOD-mr5" на Фиг. 34 и 35) вычисляет предел обнаружения на основе минимума из 5 прочтений, выбираемых в качестве минимального количества раз для SNV, наблюдаемого в данных секвенирования, чтобы иметь достаточную уверенность в том, SNV на самом деле присутствует. Предел обнаружения основан на том, выше ли наблюдаемая глубина прочтения (DOR) этого минимума 5. Серые линии на Фиг. 34 и 35 показывают SNV, для которых предел обнаружения ограничивается DOR. В этих случаях было измерено недостаточно прочтений, чтобы достигнуть предела ошибки анализа. При желании, предел обнаружения может быть улучшен (что приводит к снижению числового значения) для этих SNV за счет увеличения DOR.
Второй способ (обозначенный "LOD-zs5.0" на Фиг. 34 и 35) вычисляет предел обнаружения, основанный на Z-показателе. Z-показатель представляет собой число стандартных отклонений, когда наблюдаемый процент ошибок находится далеко от фоновой средней ошибки. При желании, выпадения могут быть удалены, a Z-показатель может быть пересчитан, и этот процесс может повторяться. Окончательное взвешенное среднее значение и стандартное отклонение частоты ошибок используются для расчета Z-показателя. Среднее взвешивается посредством DOR, так как точность выше, когда DOR выше.
Для иллюстративного расчета Z-показателя, используемого для этого примера, фоновая средняя ошибка и стандартное отклонение рассчитывали из всех других образцов того же пробега секвенирования, взвешенных по их глубине прочтения, для каждой геномного локуса и типа замещения. Образцы не рассматривали в фоновом распределении, если они были в 5 стандартных отклонениях от фонового значения. Оранжевые линии на Фиг. 34 и 35 показывают SNV, для которых предел обнаружения ограничивается частотой ошибок. Для этих SNV принимали достаточные прочтения для достижения минимума 5 прочтений, а предел обнаружения ограничивали частотой ошибок. При желании, предел обнаружения может быть улучшен за счет оптимизации анализа, чтобы уменьшить частоту появления ошибок.
Третий способ (обозначенный "LOD-zs5.0-mr5" на Фиг. 34 и 35) вычисляет предел обнаружения на основе максимального значения двух указанных выше показателей.
Для анализа образца опухоли, показанного на Фиг. 34, средний предел обнаружения составлял 0,36%, а медианный предел обнаружения составлял 0,28%. Число DOR ограниченных (серые линии) SNV составляло 934. Число частоты ошибок ограниченных (оранжевые линии) SNV составляло 738.
Для анализа кДНК в образце плазмы, показанном на Фиг. 35, средний предел обнаружения составлял 0,24%, а медианный предел обнаружения составлял 0,09%. Число DOR ограниченных (серые линии) SNV составляло 732. Число частоты ошибок ограниченных (оранжевые линии) SNV составляло 921.
Пример 7
Этот пример иллюстрирует обнаружение CNV и SNV из той же единственной клетки. Были использованы следующие библиотеки праймеров: библиотека из ~28000 праймеров для обнаружения CNV, библиотека из ~3000 праймеров для обнаружения CNV и библиотека праймеров для обнаружения SNV. Для анализа одной клетки, клетки серийно разбавляли до тех пор, пока не было 3 или 4 клетки на каплю. Отдельную клетку отбирали пипеткой и помещали в пробирку для ПЦР. Клетку лизировали с использованием протеазы K, соли и DTT с использованием следующих условий: 56°C в течение 20 минут, 95°C в течение 10 минут, а затем поддерживали температуру 4°C. Для анализа геномной ДНК, ДНК из той же самой клеточной линии в качестве анализируемой одной клетки либо приобретали, либо получали путем выращивания клеток и экстракции ДНК.
Для амплификации с библиотекой из ~28000 праймеров использовали следующие условия ПЦР: объем реакционной смеси 40 мкл, 7,5 нМ каждого праймера и 2-кратный мастер-микс (ММ). Согласно некоторым вариантам осуществления набор для мультиплексной ПЦР QIAGEN используется для мастер-микса (каталог QIAGEN №206143, смотрите, например, информацию, доступную в интернете по адресу qiagen.com/products/catalog/assay-technologies/end-point-pcr-and-rt-pcr-reagents/qiagen-multiplex-pcr-kit, который полностью включен в настоящий документе посредством ссылки). Набор включает в себя 2-кратный мастер-микс для мультиплексной ПЦР QIAGEN (обеспечивающий конечную концентрацию 3 мМ MgCl2, 3×0,85 мл), 5-кратный Q-раствор (1×2,0 мл) и воду без РНКазы (2×1,7 мл). Мастер-микс (ММ) мультиплексной ПЦР QIAGEN содержит комбинацию KCl и (NH4)2SO4, а также добавку ПЦР, фактор MP, что увеличивает локальную концентрацию праймеров в шаблоне. Фактор MP стабилизирует специфически связывающие праймеры, что позволяет эффективное удлинение праймера с помощью, например, ДНК-полимеразы HotStarTaq. ДНК-полимераза HotStarTaq представляет собой модифицированную форму ДНК-полимеразы Taq и не обладает полимеразной активностью при температуре окружающей среды. Следующие условия термоциклирования использовали для первого раунда ПЦР: 95°C в течение 10 минут; 25 циклов при температуре 96°C в течение 30 секунд, 65°C в течение 29 мин и 72°C в течение 30 секунд, а затем 72°C в течение 2 мин и поддерживать температуру 4°C. Для второго раунда ПЦР использовали 10 мкл реакционного объема, 1-кратный ММ и 5 нМ каждого праймера. Использовали следующие условия термоциклирования: 95°C в течение 15 минут; 25 циклов при температуре 94°C в течение 30 секунд, 65°C в течение 1 минуты, 60°C в течение 5 минут, 65°C в течение 5 минут и 72°C в течение 30 секунд; а затем 72°C в течение 2 минут и поддерживали температуру 4°C.
Для библиотеки из ~3000 праймеров иллюстративные условия реакции включают в себя реакционный объем 10 мкл, 2-кратный ММ, 70 мМ ТМАС и 2 нМ каждого праймера. Для библиотеки праймеров для обнаружения SNV, иллюстративные условия реакции включают в себя реакционный объем 10 мкл, 2-кратный ММ, 4 мМ ЭДТА и 7,5 нМ каждого праймера. Иллюстративные условия термоциклирования включают в себя 95°C в течение 15 минут, 20 циклов при температуре 94°C в течение 30 секунд, 65°C в течение 15 минут и 72°C в течение 30 секунд; а затем 72°C в течение 2 минут и поддержание температуры 4°C.
Амплифицированные продукты подвергали штрих-кодированию. Один пробег секвенирования проводили с приблизительно равным числом прочтений на образец.
На Фиг. 36А и 36B показаны результаты анализа геномной ДНК (Фиг. 36А) или ДНК из одной клетки (Фиг. 36B) с использованием библиотеки приблизительно из 28000 праймеров, предназначенных для обнаружения CNV. Приблизительно 4 миллиона прочтений измеряли в образце. Наличие двух центральных полос вместо одной центральной полосы указывает на наличие CNV. Для трех образцов ДНК из одной клетки, процент картированных прочтений составлял 89,9%, 94,0% и 93,4%, соответственно. Для двух образцов геномной ДНК процент картированных прочтений составлял 99,1% для каждого образца.
На Фиг. 37А и 37B показаны результаты анализа геномной ДНК (Фиг. 37А) или ДНК из одной клетки (Фиг. 37B) с использованием библиотеки приблизительно из 3000 праймеров, предназначенных для обнаружения CNV. Приблизительно 1,2 миллиона прочтений измеряли в образце. Наличие двух центральных полос вместо одной центральной полосы указывает на наличие CNV. Для трех образцов ДНК из одной клетки процент картированных прочтений составлял 98,2%, 98,2% и 97,9%, соответственно. Для двух образцов геномной ДНК процент картированных прочтений составлял 98,8% для каждого образца. На Фиг. 38 показана однородность в DOR для этих ~3000 локусов.
Для распознавания SNV процент распознавания истинных положительных мутаций был похож на таковой для ДНК из одной клетки и геномной ДНК. График процента распознавания для истинных положительных мутаций для одиночных клеток на оси y против таковых для геномной ДНК на оси X приводил к подбору кривой y=1,0076x-0,3088 с R2=0,9834. На Фиг. 39 показаны аналогичные показатели распознавания ошибок для геномной ДНК и ДНК из единственной клетки. На Фиг. 40 показано, что частота появления ошибок для обнаружения транзиций была больше, чем для обнаружения трансверсий, что указывает на то, что может быть желательным выбор для обнаружения трансверсий, а не транзиций, когда это возможно.
Пример 8
Этот пример подтверждает способ мультиплексной ПЦР с большим количеством целевых последовательностей для определения раскрытой в настоящем документе хромосомной анеуплоидии и CNV, названный CoNVERGe (выявляемые генотипически варианты числа копий), а также дополнительно иллюстрирует развитие и использование стандартов "PlasmArt" для ПЦР образцов цоДНК. Стандарты PlasmArt включают в себя полинуклеотиды, характеризующиеся идентичностью последовательности к областям генома, про которые известно, что они обладают CNV, и распределением по размерам, которое отражает таковое фрагментов вкДНК, обнаруженное в естественных условиях в плазме.
Сбор образцов
Клеточные линии злокачественной опухоли молочной железы человека (НСС38, НСС1143, НСС1395, НСС1937, НСС1954 и НСС2218) и соответствующие нормальные клеточные линии (HCC38BL, HCC1143BL, HCC1395BL, HCC1937BL, HCC1954BL и HCC2218BL) получали из Американской коллекции типовых культур (АТСС). Клеточные линии В-лимфоцитов с трисомией 21 (AG 16777) и спаренные отец/ребенок синдрома Ди Георга (DGS) (GM10383 и GM10382, соответственно) были из Coriell Cell Repository (Камден, штат Нью-Джерси). Клетки GM10382 содержат только отцовскую область 22q11.2.
Авторы настоящего изобретения закупали опухолевые ткани от 16 пациентов со злокачественной опухолью молочной железы, включая в себя 11 свежезамороженных (FF) образцов из Geneticist (Глендейл, Калифорния) и пять фиксированных формалином погруженных в парафин (FFPE) образцов из North Shore-LIJ (Manhasset, Нью-Йорк). Авторы настоящего изобретения приобрели соответствующие образцы лейкоцитарной пленки для восьми пациентов и подобранные образцы плазмы девяти пациентов. FF опухолевые ткани и соответствующие образцы лейкоцитарной пленки и плазмы от пяти пациентов со злокачественной опухолью яичников были из North Shore-Lij. Для восьми FF образцов опухоли молочной железы резецировали срезы ткани для анализа. Для сбора образцов получали утверждения Экспертным советом организации из Northshore/Lij IRB и Национального комитета по этике медицинского университета Харькова, а информированное согласие получали от всех субъектов.
Образцы крови собирали в пробирки с ЭДТА. Циркулирующие опухолевые ДНК выделяли из 1 мл плазмы с использованием набора для циркулирующих нуклеиновых кислот QIAamp (Qiagen, Valencia, СА).
Для того чтобы получить стандарты PlasmArt в соответствии с одним иллюстративным способом, во-первых, 9×106 клеток лизировали посредством гипотонического буфера для лизиса (20 мМ Трис-Cl (pH 7,5), 10 мМ NaCl и 3 мМ MgCl2) в течение 15 мин на льду. Затем добавляли 10% IGEPAL СА-630 (Sigma, St. Louis, MO) до конечной концентрации 0,5%. После центрифугирования при 3000 g в течение 10 мин при температуре 4°C осажденные ядра ресуспендировали в 1-кратном микрококковом нуклеазном (MNase) буфере (New England Biolabs, Ipswich, MA) перед добавлением 1000 ед MNase (New England Biolabs), а затем инкубировали в течение 5 мин при температуре 37°C. Реакции останавливали добавлением ЭДТА до конечной концентрации 15 мМ. Нерасщепленный хроматин удаляли центрифугированием при 2000 g в течение 1 мин. Фрагментированную ДНК очищали с использованием набора DNA Clean & Concentrator™-500 (Zymo Research, Irvine, CA). Мононуклеосомную ДНК, полученную путем расщепления MNase, также очищали и селектировали по размеру с использованием магнитных гранул AMPure XP (Beckman Coulter, Brea, СА). Фрагменты ДНК классифицировали по размеру и количественно определяли посредством чипа Bioanalyzer DNA 1000 (Agilent, Санта-Клара, Калифорния).
Для моделирования цоДНК при различных концентрациях, различные фракции PlasmArts из злокачественных клеток НСС1954 и НСС2218 смешивали с таковыми из соответствующей нормальной клеточной линии (HCC1954BL и HCC2218BL, соответственно). Анализировали три образца каждой концентрации. Аналогичным образом, для моделирования аллельных дисбалансов в ДНК плазмы в фокальной области размером 3,5 Мб, авторы настоящего изобретения получали PlasmArts из смесей ДНК, содержащих различные соотношения ДНК от ребенка с материнской делецией 22q11.2 и ДНК от отца. Образцы, содержащие только ДНК отца, использовали в качестве отрицательного контроля. Анализировали восемь образцов каждой концентрации.
Таким образом, для оценки чувствительности и воспроизводимости CoNVERGe, особенно, когда доля аномальной ДНК для CNV или среднее значение аллельного дисбаланса (AAI) является низким, авторы настоящего изобретения использовали его для обнаружения CNV в смесях ДНК, состоящих из ранее охарактеризованного аномального образца, введенного в соответствующий нормальный образец. Смеси состояли из искусственной вкДНК, названной "PlasmArt", с распределением по размерам фрагментов, приблизительно равным натуральной вкДНК (смотрите выше). На Фиг. 42 графически показано распределение по размерам иллюстративного PlasmArt, полученного из злокачественной клеточной линии, в сравнении с распределением по размерам вкДНК, глядя на CNV на плечах хромосом 1p, 1q, 2р и 2q. В первой паре образец опухолевой ДНК сына, содержащий фокальную делецию CNV размером 3 Мб в области 22q11.2, вводили в совпавший нормальный образец от отца в пределах 0-1,5% от общей вкДНК (Фиг. 41а). CoNVERGe воспроизводимо идентифицировала CNV, соответствующие известной аномальности с оценочной AAI >0,35% в смесях AAI ≥0,5% +/- 0,2%, не удалось обнаружить CNV в 6/8 повторах в 0,25% аномальной ДНК, и сообщала о значении ≤0,05% для всех восьми образцов отрицательного контроля. Значения AAI по оценкам CoNVERGe показали высокую линейность (R2=0,940) и воспроизводимость (дисперсия ошибки = 0,087). Анализ был чувствителен к различным уровням амплификации в пределах того же образца. На основании этих данных консервативный порог обнаружения AAI 0,45% может быть использован для последующих анализов. С использованием этого предельного уровня выполняли еще один эксперимент, в котором синтетическую цоДНК Plasmart обрабатывали известными концентрациями для создания синтетической злокачественной плазмы от приблизительно 0,5% до приблизительно 3,5%. Отрицательную плазму также включали в качестве контроля. Все из синтетических злокачественных образцов плазмы получали оценки выше 0,45%, а показание для отрицательной плазмы было значительно ниже 0,45% (Фиг. 43А-С). На Фиг. 43А; на правой панели показано максимальное правдоподобие опухоли, оценка результатов фракции ДНК в виде графика отношения шансов. На Фиг. 43B представлен график для обнаружения событий трансверсии. На фигуре 43C показан график для обнаружения событий транзиции.
Также оценивали два дополнительных титрования PlasmArt, полученные из пар соответствующих опухолевых образцов и образцов нормальных клеточных линий и имеющих CNV на хромосоме 1 или хромосоме 2 (Фиг. 41b, 41c). Среди отрицательных контролей все значения были <0,45%, и высокую линейность (R2=0,952 для НСС1954 1p, R2=0,993 для НСС1954 1Q, R2=0,977 для НСС2218 2р, R2=0,967 для НСС2218 2q) и воспроизводимость (дисперсия ошибки = 0,190 для НСС1954 1p, 0,029 для НСС1954 1Q, 0,250 для НСС2218 2р и 0,350 для НСС2218 2q) наблюдали между известным входным количеством ДНК и рассчитанным с помощью CoNVERGe. Разница в наклонах регрессии для областей 1р и 1q одной пары образцов коррелирует с относительной разницей в числе копий, наблюдаемой в B-аллельных частотах (BAF) областей 1р и 1q того же образца, демонстрируя относительную точность оценки AAI, вычисленную с помощью CoNVERGe (Фиг. 41c, 41d).
Схема работы для обработки образцов показана на Фиг. 63. CoNVERge применяется к различным источникам образцов, включая FFPE, свежемороженые, одноклеточные, контроль Germline и вкДНК. Авторы настоящего изобретения применили CoNVERGe к шести клеточным линиям злокачественной опухоли молочной железы человека и соответствующим нормальным клеточным линиям, чтобы оценить, может ли он обнаружить соматические CNV. CNV на уровне плечей и фокальные CNV присутствовали во всех шести опухолевых клеточных линиях, но отсутствовали в соответствующих нормальных клеточных линиях, за исключением хромосомы 2 в НСС1143, в которой нормальная клеточная линия демонстрирует отклонение от коэффициентов гомологов 1:1 (Фиг. 63b). Для подтверждения этих результатов на другой платформе, авторы настоящего изобретения провели микроматричный анализ CytoSNP-12, которые производил стабильные результаты для всех образцов (Фиг. 63d, 63е). Кроме того, максимальные коэффициенты гомологов для CNV, идентифицированные с помощью CoNVERGe и микроматричного анализа CytoSNP-12, проявляли сильную линейную корреляцию (R2=0,987, p<0,001) (Фиг. 63f).
Далее авторы настоящего изобретения применили CoNVERGe к свежемороженым (FF) (Фиг. 64а) и фиксированным формалином заключенным в парафин (FFPE) образцам ткани опухоли молочной железы (Фиг. 64b, 64d). В обоих типах образцов присутствовали несколько CNV на уровне плеча и фокальные, однако, никаких CNV не обнаружили в ДНК из соответствующих образцов лейкоцитарной пленки. Результаты CoNVERGe тесно коррелировали с таковыми от микроматричных анализов тех же образцов (Фиг. 64e-h; R2=0,909, p<0,001 для CytoSNP-12 в FF, R2=0,992, p<0,001 для OncoScan в FFPE). 64e-h также производит устойчивые результаты на небольших количествах ДНК, извлеченной из образцов лазерной захватывающей микродиссекции (LCM), для которых микроматричные способы не подходят.
Обнаружение CNV в отдельных клетках с помощью CoNVERGe
Для того чтобы проверить пределы применимости этого подхода mmPCR, авторы настоящего изобретения выделяли отдельные клетки из шести вышеупомянутых злокачественных клеточных линий и из клеточной линии В-лимфоцитов, в которых не было никаких CNV в областях-мишенях. Профили CNV этих одноклеточных экспериментов согласовывались между тремя повторами и с таковыми из геномной ДНК (гДНК), извлеченной из массивного образца из приблизительно 20000 клеток (Фиг. 65). На основе числа SNP без прочтений секвенирования, в среднем процент отсева анализа для объемных образцов составлял 0,48% (диапазон: 0,41-0,60%), что обусловлено либо синтезом, либо нарушением в конструкции анализа. Для одиночных клеток, наблюдаемый дополнительный средний процент отсева в анализе составлял 0,39% (диапазон: 0,19-0,67%). Для анализов отдельных клеток, которые не выпадают (не произошло, т.е. нет отсева при анализе), средний коэффициент одного ADO, рассчитанный с использованием гетерозиготных SNP, составил 0,05% (диапазон: 0,00-0,43%). Кроме того, процент SNP с генотипами с высокими доверительными интервалами (т.е. генотипы SNP, определенные доверительным интервалом, составляющим по меньшей мере 98%) был одинаковый, как для одной клетки, так и объемных образцов, и генотип в одноклеточных образцах соответствовал таковому в объемном образце (в среднем на 99,52%, диапазон: 92,63-100,00%).
В отдельных клетках частоты аллелей, как ожидается, будут непосредственно отражать числа копий хромосом, в отличие от опухолевых образцов, где это может быть искажено загрязнением ТН и неопухолевыми клетками. BAF 1/n и (n-1)/n указывают на n копий хромосом в области. Числа хромосомных копий указывают на графики частот аллелей, как для одноклеточных, так и соответствующих гДНК образцов (Фиг. 65).
Применение CoNVERGe к образцам плазмы
Для того чтобы исследовать способность CoNVERGe обнаруживать CNV в реальных образцах плазмы, авторы настоящего изобретения применяли свой подход к вкДНК, спаренной с соответствующей опухолевой биопсией от каждого из двух пациентов со злокачественной опухолью молочной железы на II стадии и пяти пациентов со злокачественной опухолью яичников на поздней стадии. У всех семи пациентов CNV обнаруживали, как в FF опухолевых тканях, так и в соответствующих образцах плазмы (Фиг. 66). На Фиг. 67 представлен список мутаций SNV при злокачественной опухоли молочной железы. В общей сложности 32 CNV, на уровне AAI ≥0,45%, были обнаружены в семи образцах плазмы (диапазон: AAI 0,48-12,99%) на протяжении пяти проанализированных областей, которые составляют около 20% генома. Следует отметить, что наличие CNV в плазме не может быть подтверждено из-за отсутствия альтернативных ортогональных способов.
Хотя оценки AAI могут коррелировать с BAF в опухоли, прямая пропорциональность не обязательно ожидается из-за гетерогенности опухоли. Например, в образце ВС5 (Фиг. 66а) овалы в верхнем левом углу области на Фиг. 66а указывают на области, которые характеризуются BAF, совместимым с N=11; сочетание этого с расчетом AAI из образца плазмы приводит к оценкам для с 2,33% и 2,67% для двух областей. Оценка c с использованием других областей в образце дает значения от 4,46% до 9,53%, что явно демонстрирует наличие опухолевой гетерогенности.
Эти данные свидетельствуют о том, что CNV могут быть обнаружены в плазме в значительной доле образцов, а также позволяют предположить, что более превалирующая CNV находится в пределах опухоли, и тем более вероятно, будет наблюдаться в вкДНК. Кроме того, CoNVERGe обнаруживал CNV из жидкой биопсии, которая, возможно, иначе была бы незамеченной при традиционной биопсии опухоли.
Пример 9
В этом примере предусмотрена подробная информация относительно иллюстративных способов получения образцов, используемых для анализа CoNVERGe различных типов образцов.
Одноклеточный протокол CNV для ПЦР с участие 28000 последовательностей
Мультиплексная ПЦР позволяет проводить одновременную амплификацию многих мишеней в одной реакции. Целевые SNP идентифицировали в каждой области генома с 10% минимальной частотой аллелей малой популяции (1000 данных Genomes Project; релиз 30 апреля 2012 г.). Для каждого SNP разрабатывали несколько полугнездовых праймеров, чтобы получить ампликон с максимальной длиной 75 пар нуклеотидов, а температуру плавления от 54 до 60,5°C. Оценки взаимодействия праймеров рассчитывали для всех возможных комбинаций праймеров; праймеры с высокими баллами устраняли, чтобы уменьшить вероятность образования димерного продукта праймера. Анализы ПЦР кандидатов ранжировали и выбирали на основе целевой частоты SNP минорного аллеля, наблюдаемой степени гетерозиготности (из dbSNP), присутствия в HapMap и длины ампликона.
В некоторых экспериментах получали одноклеточные образцы и амплифицировали с использованием протокола mmPCR с одновременным участием 28000 последовательностей. Образцы готовили следующим образом: для анализа одной клетки, клетки серийно разбавляли до 3 или 4 клеток в капле. Отдельную клетку отбирали пипеткой и помещали в пробирку для ПЦР. Клетку лизировали с использованием протеазы K, соли и DTT с использованием следующих условий: 56°C в течение 20 мин, 95°C в течение 10 мин, а затем поддерживали температуру 4°C. Для анализа геномной ДНК, ДНК из той же клеточной линии, что и анализируемая одна клетка, либо приобретали, либо получали путем выращивания клеток и экстракции ДНК. ДНК амплифицировали в объеме реакционной смеси, содержащей 40 мкл мастер-микс Qiagen mp-PCR (2-кратная конечная концентрация мастер-микса), концентрация праймера 7,5 нМ для 28 тыс. пар праймеров, имеющих полугнезовые праймеры Rev при следующих условиях: 95°C в течение 10 мин, 25-кратно [96°C 30 сек, 65°C 29 мин, 72°C 30 сек], 72°C в течение 2 мин, поддерживание температуры 4°C. Продукт амплификации разводили 1:200 в воде и 2 мкл добавляли к STAR 2 (объем реакционной смеси 10 мкл) 1-кратному ММ, концентрация праймера составляла 5 нМ и ПЦР проводили с использованием полугнездового внутреннего прямого праймера и специфичного к метке обратного праймера: 95°C в течение 15 мин, 25-кратно [94°C 30 сек, 65°C 1 мин, 60°C 5 мин, 65°C 5 мин, 72°C 30 сек], 72°C 2 мин, поддержание температуры 4°C.
Теги и штрих-коды полных последовательностей прикрепляли к продуктам амплификации и амплифицировали в течение 9 циклов с использованием специфических к адаптерам праймеров. До секвенирования продукт библиотеки со штрих-кодами собирали, очищали с помощью набора для очистки с помощью ПЦР QIAquick (Qiagen) и количественно оценивали с использованием набора для анализа QubitdsDNA BR (Life Technologies). Ампликоны секвенировали с использованием секвенатора Illumina HiSeq 2500.
Выделение ДНК из образца крови/плазмы
Образцы крови собирали в пробирки с ЭДТА. Образец цельной крови центрифугировали и разделяли на три слоя: верхний слой, 55% образца крови, представлял собой плазму и содержал внеклеточную ДНК (вкДНК); средний лейкоцитарный слой содержали лейкоциты, содержащие ДНК, <1% от общего числа; и нижний слой, 45% от собранного образца крови, содержал эритроциты, ДНК не присутствовала в этой фракции, поскольку эритроциты являются безъядерными. Циркулирующую опухолевую ДНК выделяли по меньшей мере из 1 мл плазмы с использованием набора для циркулирующих нуклеиновых кислот QIAamp, QIA-Amp (Qiagen, Valencia, CA), в соответствии с протоколом изготовления.
Протокол для CNV плазмы с участием 3168 последовательностей для 1p, 1q, 2р, 2q и 22q11 хромосом
Библиотеки ДНК плазмы получали и амплифицировали с использованием протокола mmPCR с участием 3168 последовательностей. Образцы готовили следующим образом: до 20 мл крови центрифугировали для выделения лейкоцитарного слоя и плазмы. Выполняли извлечение из плазмы вкДНК и подготовку библиотеки. ДНК элюировали в 50 мкл TE буфера. Исходные данные для mmPCR представляли собой 6,7 мкл амплифицированной и очищенной библиотеки плазмы Natera в вводном количестве приблизительно 1200 нг. ДНК в плазме амплифицировали в реакционном объеме 20 мкл, содержащем мастер-микс для мультиплексной ПЦР Qiagen (2-кратная конечная концентрация мастер-микса), 2 нМ меченного праймера (всего 12,7 мкМ) в пулах 3168 праймеров и проводили ПЦР амплификацию: 95°C в течение 10 мин, 25-кратно [96°C 30 сек, 65°C 20 мин, 72°C 30 сек], 72°C в течение 2 мин, поддерживание температуры 4°C. Продукт амплификации разбавляли 1:2000 в воде и добавляли 1 мкл к штрих-кодирующей ПЦР в объеме реакционной смеси 10 мкл. Штрих-коды присоединяли к продуктам амплификации посредством ПЦР-амплификации на протяжении 12 циклов с использованием специфических к меткам праймеров. Продукты из нескольких образцов собирают и затем очищают с помощью набора для очистки ПЦР QIAquick (Qiagen) и элюируют в 50 мкл буфера для суспензии ДНК. Образцы секвенируют с помощью NGS, как описано для одноклеточного протокола CNV для ПЦР с участием 28000 последовательностей.
Панель осуществимости SNV злокачественной опухоли молочной железы из плазмы
вкДНК из образцов крови пациентов со злокачественной опухолью молочной железы получали и амплифицировали с использованием 336 пар праймеров, которые были распределены на четыре пула по 84 пары. Библиотеки плазмы Natera получали, как описано для протокола CNV плазмы для 3168 последовательностей для хромосом 1p, 1q, 2р, 2q и 22q11. ДНК элюировали в буфере ТЕ объемом 50 мкл. Входные данные для mPCR представляли собой 2,5 мкл амплифицированной и очищенной библиотеки плазмы Natera при входном количестве приблизительно 600 нг. На Фиг. 68А-В представлены частоты основного и минорного аллеля SNP, используемые в реакции mmPCR с участием 3168 последовательностей. Ось X представляет собой число SNP, слева направо, для 1q, 1р, 2д, 2Р и 22q хромосом. SNP отбирали из карты 1000 Genomes для людей, Group 19 и dbSNP для выбора мишени, но только SNP от 1000 Genomes использовали для скрининга на частоты минорных аллелей. ДНК плазмы амплифицировали в четырех параллельных реакциях с пулами 84 праймеров, объемом реакционной смеси 10 мкл, содержащей мастер-микс mp-PCR Qiagen (2-кратная конечная конц. ММ), 4 мМ ЭДТА, 7,5 нМ концентрации праймера (всего 1,26 мкМ) и проводили ПЦР-амплификацию: 95°C 15 мин, 25-кратно [94°C 30 сек, 65°C 15 мин, 72°C 30 сек], 72°C 2 мин, поддерживание температуры 4°C. Продукт амплификации из 4-подпулов каждый разводили 1:200 в воде и 1 мкл добавляли в реакционную смесь штрих-кодирующей ПЦР в объеме реакционной смеси 10 мкл, содержащей мастер-микс Q5 HS HF (1-кратная конечная) и 1 мкМ каждого праймера для штрих-кодирования и каждый из пулов амплифицировали в следующей реакции: 98°C в течение 1 мин, 25 раз [98°C 10 сек, 70°C 10 сек, 60°C 30 сек, 65°C 15 сек, 72°C 15 сек], 72°C 2 мин, поддержание температуры 4°C. Библиотеки очищали с набором для очистки с помощью ПЦР QIAquick (Qiagen) и элюировали в 50 мкл буфера для суспензии ДНК. Образцы секвенировали посредством секвенирования спаренных концов.
Пример 10
В этом примере приводится подробная информация относительно некоторых иллюстративных способов анализа данных секвенирования для идентификации SNV.
СПОСОБ 1 SNV: Для данного варианта осуществления модель фоновой ошибки конструировали с использованием обычных образцов плазмы, которые секвенировали на том же пробеге секвенирования для учета специфических для пробега артефактов. Согласно некоторым вариантам осуществления 5, 10, 15, 20, 25, 30, 40, 50, 100, 150, 200, 250 или более 250 образцов нормальной плазмы анализировали на том же пробеге секвенирования. Согласно некоторым иллюстративным вариантам осуществления 20, 25, 40 или 50 нормальных образцы плазмы анализировали на том же пробеге секвенирования. Шумные положения с нормальной медианной частотой аллельных вариантов выше, чем предельный уровень, удаляют. Например, этот предельный уровень согласно некоторым вариантам осуществления составляет >0,1%, 0,2%, 0,25%, 0,5%, 1%, 2%, 5% или 10%. Согласно некоторым иллюстративным вариантам осуществления шумные положения с нормальной медианной частотой вариантов аллелей больше, чем 0,5%, удаляют. Образцы-выбросы итеративно удаляли из модели для учета шума и загрязнения. Согласно некоторым вариантам осуществления образцы с Z-показателем больше, чем 5, 6, 7, 8, 9 или 10, исключали из анализа данных. Для каждой замены основания каждого локуса генома рассчитывали глубину средневзвешенного считывания и стандартное отклонение погрешности. Положения образцов опухоли или бесклеточной плазмы по меньшей мере с 5 вариантными прочтениями и Z-показателем 10 против модели фоновой ошибки были названы как мутация-кандидат.
СПОСОБ 2 SNV: Для этого варианта осуществления авторы настоящего изобретения стремятся определить однонуклеотидные варианты (SNV) с использованием данных цоДНК плазмы. Авторы настоящего изобретения моделируют процесс ПЦР как стохастический процесс, оценивают параметры с использованием обучающего набора данных и делают окончательное распознавание SNV с использованием отдельного набора тестирования. Основная идея заключается в определении распространения ошибки в нескольких циклах ПЦР, вычислении среднего и дисперсии фоновой ошибки и дифференцировании фоновой ошибки от реальных мутаций.
Следующие параметры оцениваются для каждого основания:
p = эффективность (вероятность того, что каждое прочтение воспроизводится в каждом цикле)
pe - частота появления ошибок за один цикл для мутации типа e (вероятность того, что произошла ошибка типа e)
X0 = начальное число молекул
Поскольку прочтение воспроизводится в течение процесса ПЦР, тем больше ошибок происходят. Следовательно, профиль ошибок прочтений определяется степенью отделения от первоначального прочтения. Авторы настоящего изобретения имеют в виду прочтение, как k-ю генерацию, если оно прошло через k воспроизведений, пока не было произведено.
Авторы настоящего изобретения определяют следующие переменные для каждого основания:
Xij = число прочтений генерации i, произведенное в цикле j ПЦР
Yij = общее число прочтений генерации i в конце цикла j
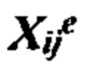 = число прочтений генерации i с мутацией e, произведенное в цикле j ПЦР
= число прочтений генерации i с мутацией e, произведенное в цикле j ПЦР
Кроме того, в дополнение к нормальным молекулам X0, если существуют дополнительные молекулы 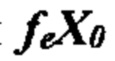 с мутацией е в начале процесса ПЦР (следовательно
с мутацией е в начале процесса ПЦР (следовательно 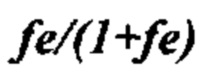 будет долей мутантных молекул в исходной смеси).
будет долей мутантных молекул в исходной смеси).
С учетом общего числа прочтений генерации i-1 в цикле j-1, число прочтений генерации i, производимое в цикле j, характеризуется биномиальным распределением с размером образца Yi-1,j-1 и параметром вероятности p. Следовательно, E(Xij,|Yi-1,j-1,p)=pYi-1,j-1 и Var(Xij,|Yi-1,j-1,p)=p(1-p)Yi-1,j-1.
Также имеется 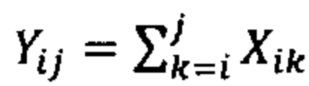 . Следовательно, с помощью рекурсии, моделирования или подобных способов можно определить E(Xij,). Точно так же можно определить Var(Xij)=E(Var(Xij,|p))+Var(E(Xij,|p)) с использованием распределения p.
. Следовательно, с помощью рекурсии, моделирования или подобных способов можно определить E(Xij,). Точно так же можно определить Var(Xij)=E(Var(Xij,|p))+Var(E(Xij,|p)) с использованием распределения p.
И, наконец, E(Xije|Yi-1,j-1,ре)=peYi-1,j-1 и Var(Xije|Yi-1,j-1,р)=pe(1-pe)Yi-1,j-1, и их можно использовать, чтобы вычислить 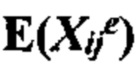 и
и 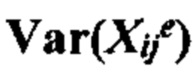 .
.
20.
6+.2 Алгоритм
Алгоритм начинается с оценки эффективности и частоты появления ошибок за один цикл с использованием обучающего набора. Пусть n обозначает общее число циклов ПЦР.
Количество прочтений Pb в каждом основании b может быть приближено к (1+pb)nX0, где pb представляет собой эффективность в основании b. Тогда (Rb/X0)1/n можно использоваться для приблизительного расчета 1+pb. Тогда можно определить среднее значение и стандартную вариацию pb во всех обучающих образцах для оценки параметров распределения вероятностей (например, нормального, бета или аналогичного распределения) для каждого основания.
Точно так же число ошибочных e прочтений 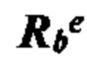 в каждом основании b может быть использовано для оценки pe. После определения среднего значения и стандартного отклонения частоты ошибок во всех обучающих образцах, авторы настоящего изобретения аппроксимируют ее распределение вероятностей (например, нормальное, бета- или подобное распределение), параметры которой оцениваются с использованием этого среднего значения и значения стандартного отклонения.
в каждом основании b может быть использовано для оценки pe. После определения среднего значения и стандартного отклонения частоты ошибок во всех обучающих образцах, авторы настоящего изобретения аппроксимируют ее распределение вероятностей (например, нормальное, бета- или подобное распределение), параметры которой оцениваются с использованием этого среднего значения и значения стандартного отклонения.
Далее, для данных исследования, авторы настоящего изобретения оценивают начальную копию в каждом основании как 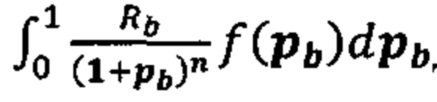 , где f(.) представляет собой оценочное распределение из обучающего набора.
, где f(.) представляет собой оценочное распределение из обучающего набора.
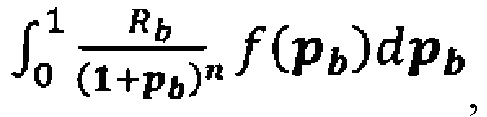 где f(.) представляет собой оценочное распределение из обучающего набора.
где f(.) представляет собой оценочное распределение из обучающего набора.
Таким образом, авторы настоящего изобретения оценили параметры, которые будут использоваться в стохастическом процессе. Затем, используя эти оценки, авторы настоящего изобретения могут оценить среднее значение и дисперсию молекул, созданных в каждом цикле (следует понимать, что авторы настоящего изобретения делают это отдельно для нормальных молекул, ошибочных молекул и молекул с мутациями).
Наконец, с помощью вероятностного способа (например, максимального правдоподобия или аналогичных способов), авторы настоящего изобретения могут определить лучшее значение  , которое соответствует распределению ошибочных, мутировавших и нормальных молекул. Более конкретно, авторы настоящего изобретения оценивают ожидаемое отношение ошибочных молекул к общему количеству молекул при различных значениях в финальных прочтениях и определяют правдоподобие своих данных для каждого из этих значений, а затем выбирают значение с наибольшим правдоподобием.
, которое соответствует распределению ошибочных, мутировавших и нормальных молекул. Более конкретно, авторы настоящего изобретения оценивают ожидаемое отношение ошибочных молекул к общему количеству молекул при различных значениях в финальных прочтениях и определяют правдоподобие своих данных для каждого из этих значений, а затем выбирают значение с наибольшим правдоподобием.
Согласно некоторым вариантам осуществления способ 2 выше выполняют следующим образом:
a) Оценить эффективность ПЦР и частоту появления ошибок за цикл с использованием набора обучающих данных;
b) Оценить ряд исходных молекул для набора данных исследования в каждом основании с использованием распределения эффективности, оцененной на стадии (а);
c) В случае необходимости, обновить оценку эффективности для набора данных исследования с использованием исходного числа молекул, оцененного на стадии (b);
d) Оценить среднее значение и дисперсию для общего числа молекул, молекул с фоновыми ошибками и молекул с реальными мутациями (для пространства поиска, состоящего из начального процента молекул с реальными мутациями) с использованием данных набора исследования и параметров, оцененных на стадиях (а), (b) и (с);
e) Сопоставить распределение с числом всех молекул с ошибками (фоновыми ошибками и реальными мутациями) во всех молекулах и вычислить правдоподобие для процента каждой реальной мутации в пространстве поиска; а также
f) Определить процент наиболее вероятной реальной мутации и вычислить доверительный интервал с использованием данных на стадии (е).
Пример 11
В этом примере представлены результаты, использующие способы мультиплексной ПЦР CoNVERGe, предусмотренные в настоящем документе, для обнаружения злокачественной опухоли путем обнаружения CNV в циркулирующей ДНК. Использовали протокол CNV плазмы для 3168 пар праймеров для хромосом 1р, 1Q, 2Р, 2д и 22q11, предусмотренных в настоящем документе. Анализировали плазму от 21 пациента со злокачественной опухолью молочной железы (стадия I-IIIB). Результаты, показанные на Фиг. 44, демонстрируют, что CNV были обнаружены во всех образцах с использованием AAI >= 0,45% и требовали всего лишь 62 гетерозиготных SNP. Аналогичный протокол использовали для анализа плазмы от пациентов со злокачественной опухолью яичников. Используя предельный уровень 0,45%, частота обнаружения злокачественной опухоли яичников достигала 100%, как это показано на Фиг. 45. Каждый из пяти образцов также характеризовался наличием соответствующего опухолевого образца.
Пример 12
Этот пример показывает, что значительное улучшение в способности обнаружить злокачественную опухоль достигается путем исследования плазмы на наличие CNV и SNV. CNV и SNV обнаруживали с использованием способов, предусмотренных в приведенных выше примерах. Образцы готовили в соответствии с соответствующими протоколами в примере 9. SNV идентифицировали с использованием способа SNV 1 выше. Как показано на Фиг. 46, чувствительность обнаружения злокачественной опухоли молочной железы и легких значительно улучшена путем анализа плазмы от пациентов со злокачественной опухолью на стадии I-III как на CNV, так и на SNV, по сравнению с исследованием только на SNV. Анализ SNV обнаруживает 71% случаев злокачественной опухоли в образцах плазмы. Однако, анализируя наличие SNV и/или CNV, уровень обнаружения поднимается до 83% для злокачественной опухоли молочной железы и до 92% для злокачественной опухоли легких в анализируемых популяциях пациентов. Если учесть все SNV и CNV, которые были идентифицированы в наборах данных TCGA и COSMIC, ожидаемая диагностическая нагрузка была бы больше, чем 97% для злокачественной опухоли молочной железы и >98% для злокачественной опухоли легких.
Дальнейший анализ проводили на образцах от 41 пациента с различными стадиями злокачественной опухоли с использованием способов подготовки образцов плазмы, предоставленных в примере 9, и способе 1 SNV, указанном выше. Как показано на Фиг. 47, при анализе на CNV и SNV в циркулирующей опухолевой ДНК от пациентов со злокачественной опухолью молочной железы обнаруживали 60% на стадии I, 88% на стадии II и 100% на стадии III злокачественной опухоли молочной железы с использованием предела количественного определения цоДНК 0,2% для SNV и цоДНК 0,45% для CNV. Как показано на Фиг. 48, при анализе на CNV и SNV в цоДНК и просмотре 41 образца пациентов с различными стадиями злокачественной опухоли молочной железы, обнаруживали 60% на стадии I, 100% на стадии II, 90% на стадии IIA, 80% на стадии IIB и 100% на стадии III, IIIA и IIIB злокачественной опухоли молочной железы с использованием предела количественного определения 0,2% цоДНК для SNV и 0,45% цоДНК для CNV. Как показано на Фиг. 49, при анализе на CNV и SNV в 24 образцах циркулирующей опухолевой ДНК от пациентов со злокачественной опухолью легких определяли 88% на стадии I, 100% на стадии II и 100% на стадия III злокачественной опухоли легких, используя предел количественного определения 0,2% цоДНК для SNV и 0,45% цоДНК для CNV. Как показано на Фиг. 50, при анализе на CNV и SNV в цоДНК и просмотре 24 образцов пациентов со злокачественными опухолями легких на различных стадиях, 100% степень обнаружения была достигнута для всех стадиях, за исключением степени обнаружения 82%, достигнутой для пациентов со злокачественной опухолью легких на стадии IB, с использованием предела количественного определения 0,2% цоДНК для SNV и 0,45% цоДНК для CNV.
Пример 13
Этот пример демонстрирует, что обнаружение SNV в цоДНК преодолевает ограничения в идентификации вариантных аллелей в образцах биопсии из-за опухолевой гетерогенности. Образцы TRACER трех пациентов с немелкоклеточным раком легких и одного пациента с аденокарциномой легкого, для которых были собраны биопсии опухолей и соответствующие дооперационные образцы плазмы крови, использовали для анализа опухолевой гетерогенности. Образцы получали из центра передового опыта по исследованию злокачественной опухоли легкого UK, Университетского колледжа Лондонского института злокачественной опухоли, Лондон WC1E 6 ВТ, Великобритания. Образцы представляли собой первичные образцы злокачественной опухоли легких для анализа на мутации SNV. У каждого пациента брали от двух до трех образцов из различных областей всего злокачественного легкого (Фиг. 51A). Каждый образец биопсии анализировали посредством секвенирования всего экзома (Illumina HiSeq200; Illumina, San Diego, СА), с последующим секвенированием AmpliSeq® (Ion Torrent, South San Francisco, СА) на PGM® для идентификации базовой клональной гетерогенности. После секвенирования и анализов на SNV, частоту вариантных аллелей (VAF) определяли для каждого образца биопсии (Фиг. 51B).
Образцы плазмы от каждого из четырех пациентов использовали для выделения цоДНК и идентификации, как клональных, так и субклональных мутаций SNV в плазме, чтобы преодолеть опухолевую гетерогенность (Фиг. 52). Клональные популяции характеризовались аллельными распознаваниями VAF во всех проанализированных образцах биопсии и в плазме, в то время, как субклональные популяции характеризовались аллельными распознаваниями VAF по меньшей мере в одном образце биопсии, но не всех образцах биопсии. Плазму рассматривают как совокупного представителя SNV, обнаруженной в цоДНК каждого пациента. Не все SNV, идентифицированные путем секвенирования, были в состоянии характеризоваться соответствующими разработанными анализами ПЦР.
Для сравнения способов анализа AmpliSeq (Swanton) и mmPCR/NGS для идентификации опухолевой гетерогенности, Natera разработали анализы ПЦР для каждой мутации SNV для обнаружения VAF цоДНК, как в биопсиях, так и соответствующей цоДНК из плазмы (Фиг. 53). Пустые клетки представляют собой отсутствие доступных образцов для биопсии, и нулевое значение означает отсутствие обнаруженных VAF. Следующие 11 генов первоначально идентифицировали как отрицательные (ложное распознавание VAF) посредством AmpliSeq FP или FN анализов, но были распознаны правильно с помощью анализов Natera TP или TN и способов анализа mmPCR/NGS: L12: CYFIP1, FAT1, MLLT4 и RASA1; L13: HERC4, JAK2, MSH2, MTOR и PLCG2; L15: GABRG1; L17: TRIM67. Удивительно, но когда исходные данные секвенирования AmpliSeq перепроверили, эти результаты были подтверждены. Файлы секвенирования исходных данных AmpliSeq показали, что данные были ниже порогового значения, обнаруживаемого PGM или Illumina. Данные идентифицировали 16/38 вариантов, обнаруженных в плазме, и в нескольких образцах биопсии пациентов L12 наблюдались преобладающие клоновые мутации L12: BRIP1, CARS, FAT1, MLLT4, NFE2L2, ТР53, ТР53, а также у пациентов L13: EGFR, EGFR, ТР53 и L15: KDM6A, ROS1. Были найдены еще два пациента, чтобы было в общей сложности четыре варианта субклональных мутаций в плазме: L12: CIC, KDM6A и L17; NF1, TRIM67. Эти результаты представлены на Фиг. 54А, которая представляет собой диаграмму с усиками среднего VAF для каждого образца, перечисленного на Фиг. 53 по каждому способу анализа, и Фиг. 54B представляет собой прямое сравнение, представленное диаграммой линейной регрессии каждого среднего образца VAF анализа.
Пример 14
Этот пример показывает, что при использовании низких концентраций праймеров таким образом, чтобы количество праймера представляло собой лимитирующий реагент в мультиплексной ПЦР в рабочем процессе, после которого следует секвенирование следующего поколения, однородность плотности прочтений и, следовательно, пределы обнаружения в пуле реакций амплификации улучшаются. Некоторые эксперименты проводили для CNV плазмы с использованием панели с участием 3168 последовательностей в соответствии с примером 9 выше, за исключением того, что общий объем реакционной смеси составлял 10 мкл вместо 20 мкл. Кроме того, ПЦР проводили в течение 15, 20 или 25 циклов. Другие эксперименты проводили с использованием четырех пулов с участием 84 последовательностей на образцах злокачественной опухоли молочной железы в соответствии с протоколом примера 9 за исключением того, что концентрации праймеров составляли 2 нМ и ПЦР-амплификацию проводили в течение 15, 20 или 25 циклов.
Без ограничения теорией полагают, что праймер, ограничивающий мультиплексную ПЦР, обеспечивает улучшенную однородность глубины прочтения для мультиплексной ПЦР перед секвенированием с множеством прочтений, таким как секвенирование на системе Illumina HiSeq или MiSeq или на система Ion Torrent PGM или Proton, на основе следующих соображений: Если некоторые из амплификации в мультиплексной ПЦР характеризуются более низкой эффективностью, чем другие, то с нормальной мультиплексной ПЦР авторы настоящего изобретения придут в конечном итоге к широкому диапазону значений глубины прочтения ("DOR"). Однако, если количество праймера ограничено, и мультиплексная ПЦР зациклена большее число раз, чем это необходимо, чтобы исчерпать праймер, то более эффективные амплификации будут останавливать удвоение (потому что у них больше нет праймеров для использования), а менее эффективные будет продолжать удваиваться, это приведет к более схожему количеству продукта амплификации для всех продуктов амплификации. Это приведет к гораздо более равномерному распределению DOR.
Следующие вычисления используются для определения количества циклов, которые необходимы для заданного количества праймера и исходной матрицы нуклеиновой кислоты:
Пусть заданный начальный уровень входной ДНК: 100 тыс копий каждой мишени (10∧5, это легко достигается с помощью амплифицированной библиотеки)
Пусть используется 2 нМ каждого праймера в качестве иллюстративной концентрации, хотя другие концентрации, такие как, например, 0,2, 0,5, 1, 1,5, 2, 2,5, 5, или 10 нМ, могут работать тоже.
Вычисление числа молекул праймера для каждого праймера: 2*10∧-9 (молярная концентрация, 2 нМ) x 10*10∧-6 (объем реакционный смеси, 10 мкл) X 6*10∧23 (число молекул на моль, число Авогадро) = 12*10∧9
Вычисление количества амплификации, необходимое, чтобы израсходовать все праймеры: 12*10∧9 (число молекул праймера) / 10∧5 (число копий каждой мишени) = 12*10∧4
Вычисление количества циклов, необходимого для достижения этого количества амплификации, предполагая 100% эффективность в каждом цикле: log2 (12*10∧4) = 17 циклов. (log2, потому что в каждом цикле количество копий удваивается).
Таким образом, для этих условий (100 тыс. входных копий, 2 нМ праймеров, объем реакционной смеси 10 мкл, исходя из 100% эффективности ПЦР в каждом цикле), праймеры будут расходоваться через 17 циклов ПЦР.
Тем не менее, ключевое предположение заключается в том, что некоторые из продуктов не характеризуются 100% эффективностью, поэтому без измерения их эффективности (что так или иначе практически осуществимо только для небольшого числа из них) потребление праймеров заняло бы более 17 циклов.
На Фиг. 55-58 показаны результаты для четырех пулов с участием 84 праймеров ПЦР SNV. Для каждого из пулов авторы настоящего изобретения наблюдали повышенную эффективность DOR с увеличением циклов от 15-20 до 25. Аналогичные результаты были получены в экспериментах с использованием панели с участием 3168 последовательностей (Фиг. 59-61). Предел обнаружения уменьшался (т.е. чувствительность SNV увеличивалась) с увеличением глубины прочтения. Кроме того, чувствительность была последовательно лучше при обнаружении трансверсий, чем транзиций. Вполне вероятно, что дополнительное увеличение эффективности DOR может быть получено с помощью дополнительных циклов при использовании ограничивающей праймерами мультиплексной ПЦР перед секвенированием с множеством прочтений.
Таким образом, согласно одному аспекту в настоящем документе предусмотрен способ амплификации множества локусов-мишеней в образце нуклеиновой кислоты, который предусматривает: (I) контактирование образца нуклеиновой кислоты с библиотекой праймеров и другими компонентами реакции удлинения праймера, чтобы обеспечить реакционную смесь, причем относительное количество каждого праймера в реакционной смеси по сравнению с другими компонентами реакции удлинения праймера создает реакцию, в которой праймеры присутствуют в ограниченной концентрации, и причем праймеры гибридизуются с множеством различных локусов-мишеней; и (II) подвергание реакционной смеси воздействию условий реакции удлинения праймера в течение достаточного количества циклов для потребления или истощения праймеров в библиотеке праймеров, для производства продуктов амплификации, которые включают в себя ампликоны-мишени. Например, множество различных локусов-мишеней может включать в себя по меньшей мере 2, 3, 5, 10, 25, 50, 100, 200, 250, 500, 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000 или 100000 различных локусов-мишеней, и по большей мере 50, 100, 200, 250, 500, 1000; 2000; 5000; 7500; 10000; 20000; 25000; 30000; 40000; 50000; 75000; 100000, 200000, 250000, 500000 и 1000000 различных локусов-мишеней для получения реакционной смеси.
Способ согласно иллюстративным вариантам осуществления предусматривает определение количества праймера, которое будет ограничивающим скорость количеством. Этот расчет, как правило, включает в себя оценку и/или определение количества молекул-мишеней и включает в себя анализ и/или определение количества выполненных циклов амплификации. Например, согласно иллюстративным вариантам осуществления концентрация каждого праймера составляет менее 100, 75, 50, 25, 10, 5, 2, 1, 0,5, 0,25, 0,2 или 0,1 нМ. Согласно различным вариантам осуществления содержание GC праймеров составляет от 30 до 80%, например, от 40 до 70% или от 50 до 60%, включительно. Согласно некоторым вариантам осуществления диапазон содержания GC (например, максимальное содержание GC минус минимальное содержание GC, такое как 80%-60% = диапазон 20%) праймеров, составляет менее 30, 20, 10 или 5%. Согласно некоторым вариантам осуществления температура плавления (Tm) праймеров составляет от 40 до 80°C, например, от 50 до 70°C, от 55 до 65°C или от 57 до 60,5°C, включительно. Согласно некоторым вариантам осуществления диапазон температур плавления праймеров составляет менее 20, 15, 10, 5, 3 или 1°C. Согласно некоторым вариантам осуществления длина праймеров составляет от 15 до 100 нуклеотидов, например, от 15 до 75 нуклеотидов, от 15 до 40 нуклеотидов, от 17 до 35 нуклеотидов, от 18 до 30 нуклеотидов, от 20 до 65 нуклеотидов, включительно. Согласно некоторым вариантам осуществления праймеры включают в себя тег, который не является специфическим к мишени, такой как тег, который образует внутреннюю петлевую структуру. Согласно некоторым вариантам осуществления тег находится между двумя ДНК-связывающими областями. Согласно различным вариантам осуществления праймеры включают в себя 5'-область, специфичную к локусу-мишени, внутреннюю область, которая не специфична к локусу-мишени и образует петлевую структуру, и 3'-область, который специфична к локусу-мишени. Согласно различным вариантам осуществления длина 3'-области составляет по меньшей мере 7 нуклеотидов. Согласно некоторым вариантам осуществления длина 3'-области составляет от 7 до 20 нуклеотидов, например, от 7 до 15 нуклеотидов или от 7 до 10 нуклеотидов, включительно. Согласно различным вариантам осуществления тест-праймеры включают в себя 5'-область, которая не специфична к локусу-мишени (например, тег или универсальный связывающий праймер сайт), за которым следует область, который специфична к локусу-мишени, внутреннюю область, которая не специфична к локусу-мишени и образует петлевую структуру, и 3'-область, которая специфична к локусу-мишени. Согласно некоторым вариантам осуществления диапазон длин праймеров составляет менее 50, 40, 30, 20, 10 или 5 нуклеотидов. Согласно некоторым вариантам осуществления длина ампликонов-мишеней составляет от 50 до 100 нуклеотидов, например, от 60 до 80 нуклеотидов или от 60 до 75 нуклеотидов, включительно. Согласно некоторым вариантам осуществления диапазон длины ампликонов-мишеней составляет менее 100, 75, 50, 25, 15, 10 или 5 нуклеотидов.
Согласно различным вариантам осуществления любого из аспектов настоящего изобретения, условия реакции удлинения праймера представляют собой условия полимеразной цепной реакции (ПЦР). Согласно различным вариантам осуществления длительность стадии отжига составляет больше, чем 3, 5, 8, 10 или 15 минут, но меньше, чем 240, 120, 60 или 30 минут. Согласно различным вариантам осуществления длительность стадии удлинения составляет больше, чем 3, 5, 8, 10 или 15 минут, но меньше, чем 240, 120, 60 или 30 минут.
Пример 15
Этот пример демонстрирует способность способов обнаружения SNV согласно настоящему изобретению идентифицировать мозаицизм в одноклеточном анализе, также называемом одномолекулярным анализом. На Фиг. 62 показаны результаты мультиплексной ПЦР геномной ДНК опухолевых клеток и поступлений отдельных клеток/молекул с использованием набора из 28 тыс. праймеров в соответствии с одноклеточным способом с использованием 28 тыс. праймеров, представленным в примере 9. С использованием этого способа более 85% прочтений были картированы - более 4,7 млн прочтений (около 167 прочтений на мишень). На нижней части фигуры показано, что среди клеток наблюдался мозаицизм.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ВЫСОКОМУЛЬТИПЛЕКСНОЙ ПЦР | 2012 |
|
RU2650790C2 |
| СПОСОБЫ НЕИНВАЗИВНОГО ПРЕНАТАЛЬНОГО УСТАНОВЛЕНИЯ ПЛОИДНОСТИ | 2011 |
|
RU2671980C2 |
| СПОСОБЫ ВЫЯВЛЕНИЯ И МОНИТОРИНГА РАКА ПУТЕМ ПЕРСОНАЛИЗИРОВАННОГО ВЫЯВЛЕНИЯ ЦИРКУЛИРУЮЩЕЙ ОПУХОЛЕВОЙ ДНК | 2019 |
|
RU2811503C2 |
| СПОСОБЫ НЕИНВАЗИВНОГО ПРЕНАТАЛЬНОГО УСТАНОВЛЕНИЯ ОТЦОВСТВА | 2011 |
|
RU2620959C2 |
| УЛУЧШЕННЫЙ СПОСОБ И НАБОР ДЛЯ ОПРЕДЕЛЕНИЯ ТЯЖЕСТИ И ПРОГРЕССИРОВАНИЯ ПЕРИОДОНТАЛЬНОГО ЗАБОЛЕВАНИЯ | 2011 |
|
RU2664431C2 |
| ГЕНЕТИЧЕСКИЕ ПОЛИМОРФИЗМЫ ПРИ ВОЗРАСТНОЙ ДЕГЕНЕРАЦИИ ЖЕЛТОГО ПЯТНА | 2010 |
|
RU2546008C2 |
| ГЕНЕТИЧЕСКИЙ ЛОКУС, АССОЦИИРОВАННЫЙ С ГНИЛЬЮ КОРНЯ И СТЕБЛЯ, ОБУСЛОВЛЕННОЙ PHYTOPHTHORA, У СОИ | 2016 |
|
RU2748688C2 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ГАПЛОТИПИЧЕСКОГО ПОЛИМОРФИЗМА УЧАСТКА АУТОСОМНОЙ ДНК ИНДИВИДУУМА | 2010 |
|
RU2432398C1 |
| МОЛЕКУЛЯРНЫЕ МАРКЕРЫ, АССОЦИИРОВАННЫЕ С УСТОЙЧИВОСТЬЮ ПОДСОЛНЕЧНИКА К OROBANCHE | 2018 |
|
RU2776361C2 |
| ГЕН MTS, МУТАЦИИ ДАННОГО ГЕНА И СПОСОБЫ ДИАГНОСТИКИ ЗЛОКАЧЕСТВЕННЫХ ОПУХОЛЕЙ С ИСПОЛЬЗОВАНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ ГЕНА MTS | 1995 |
|
RU2164419C2 |
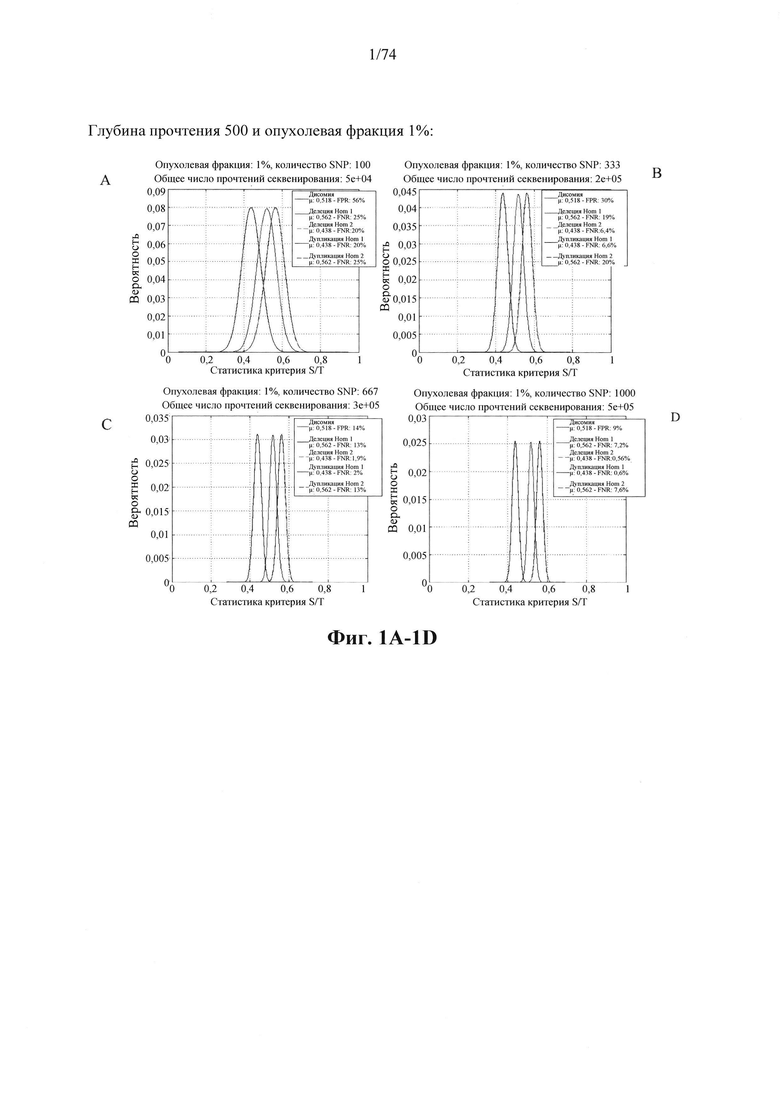
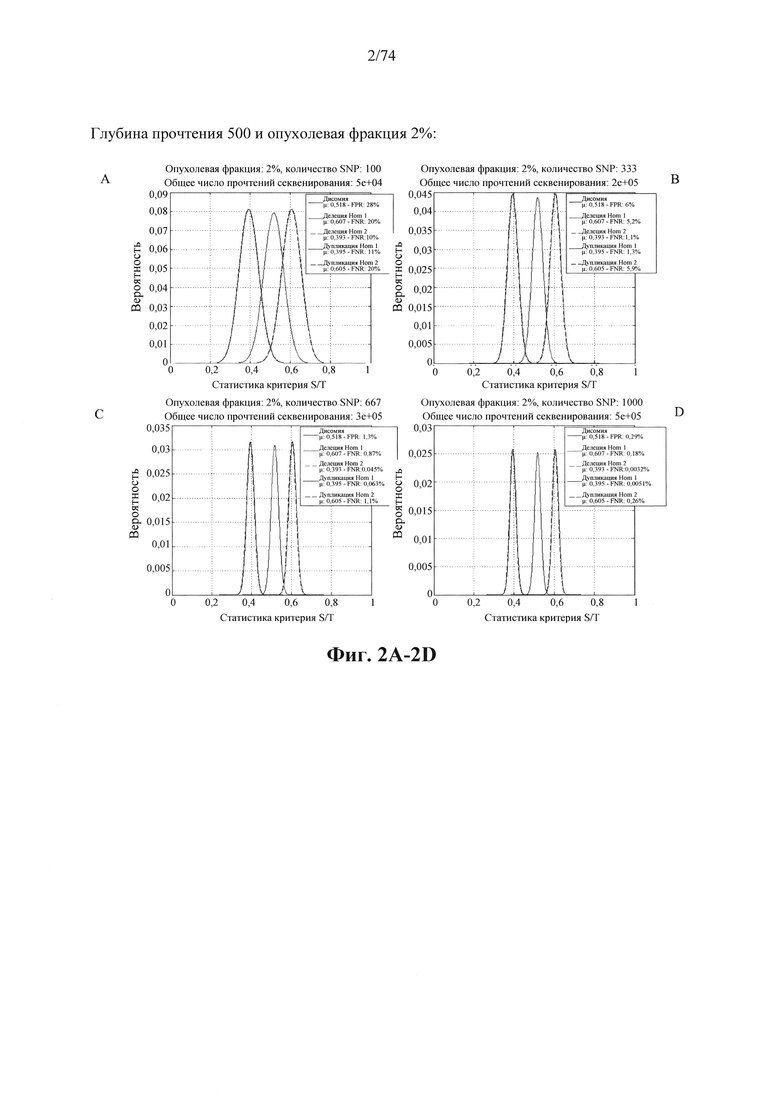
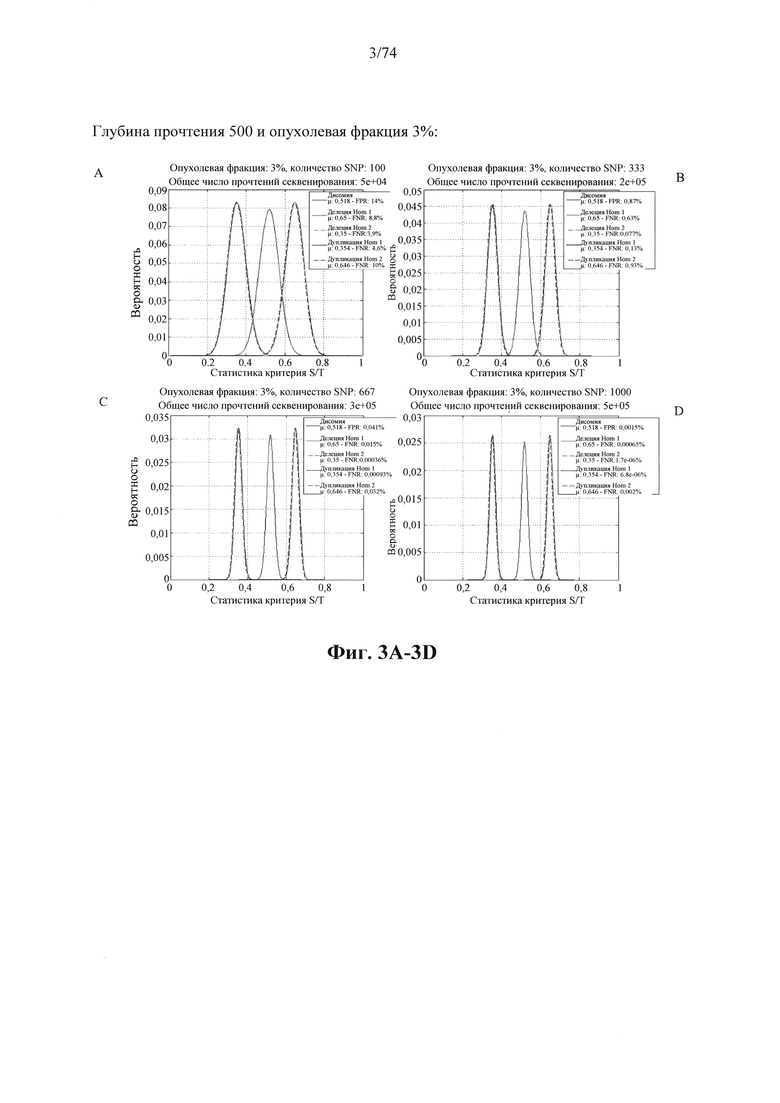
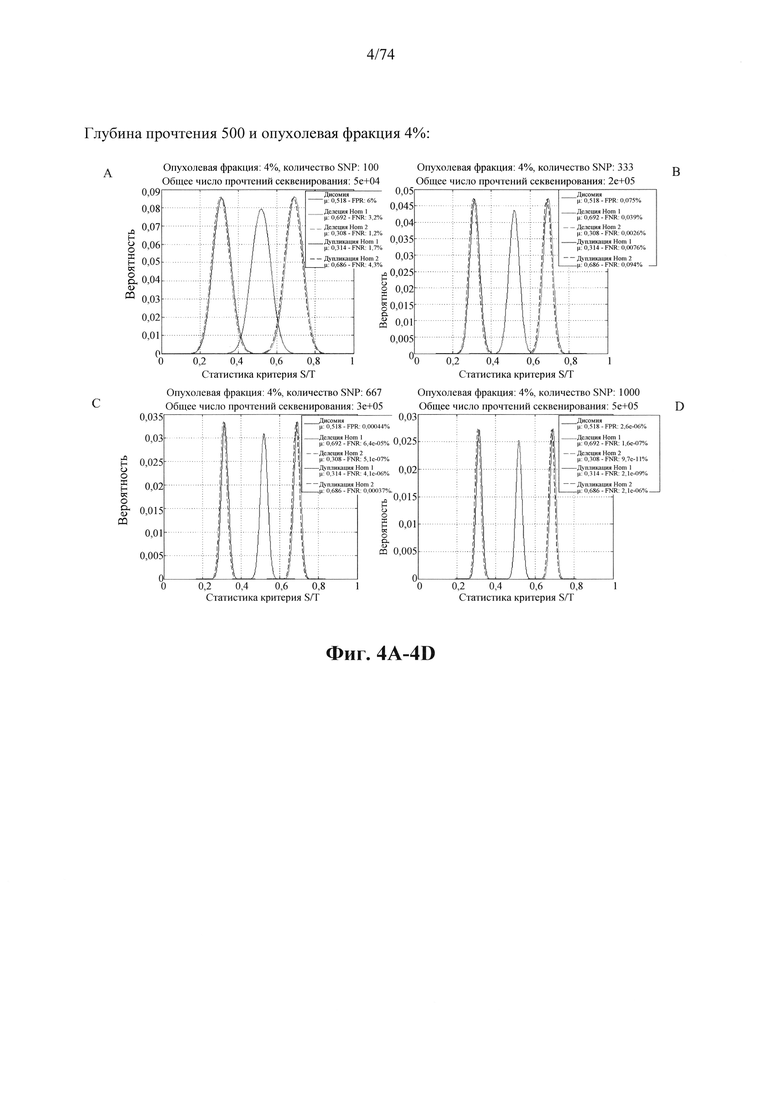
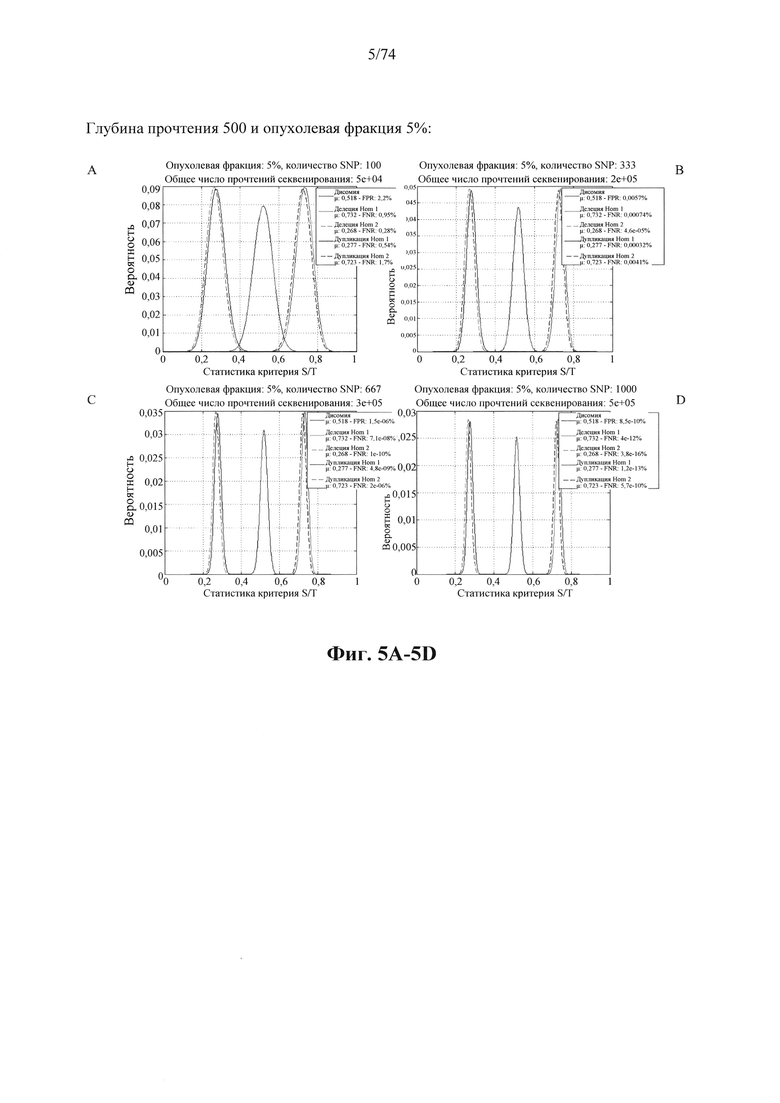
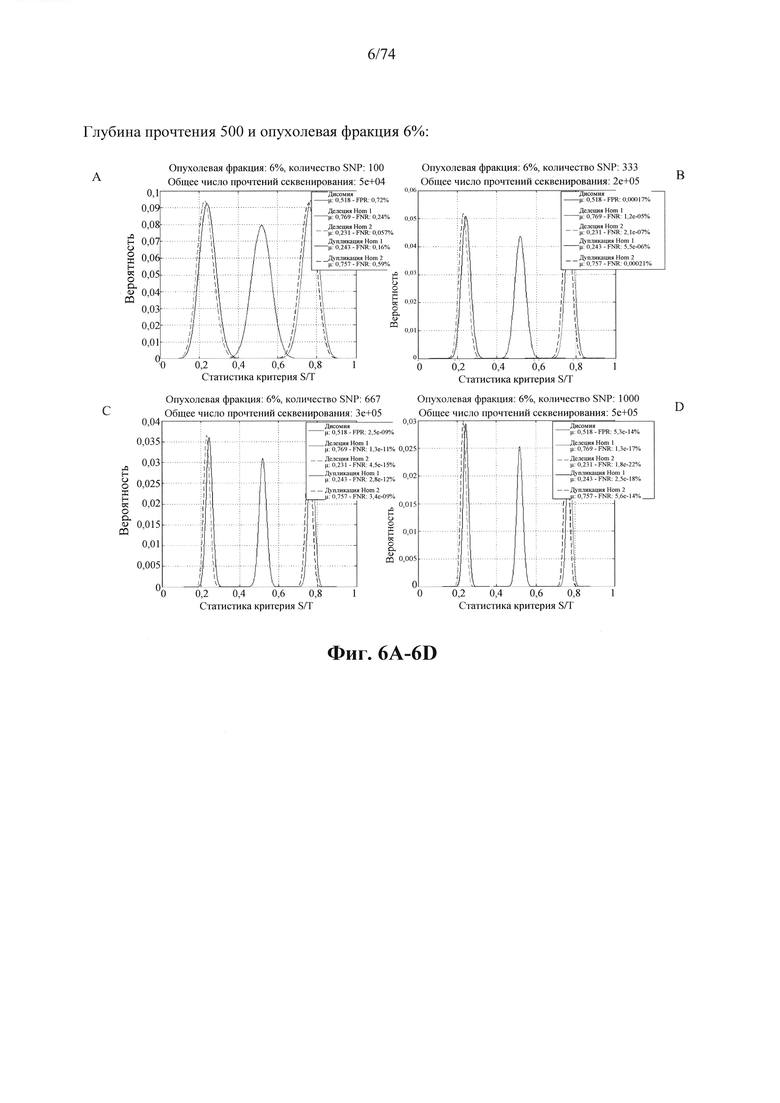
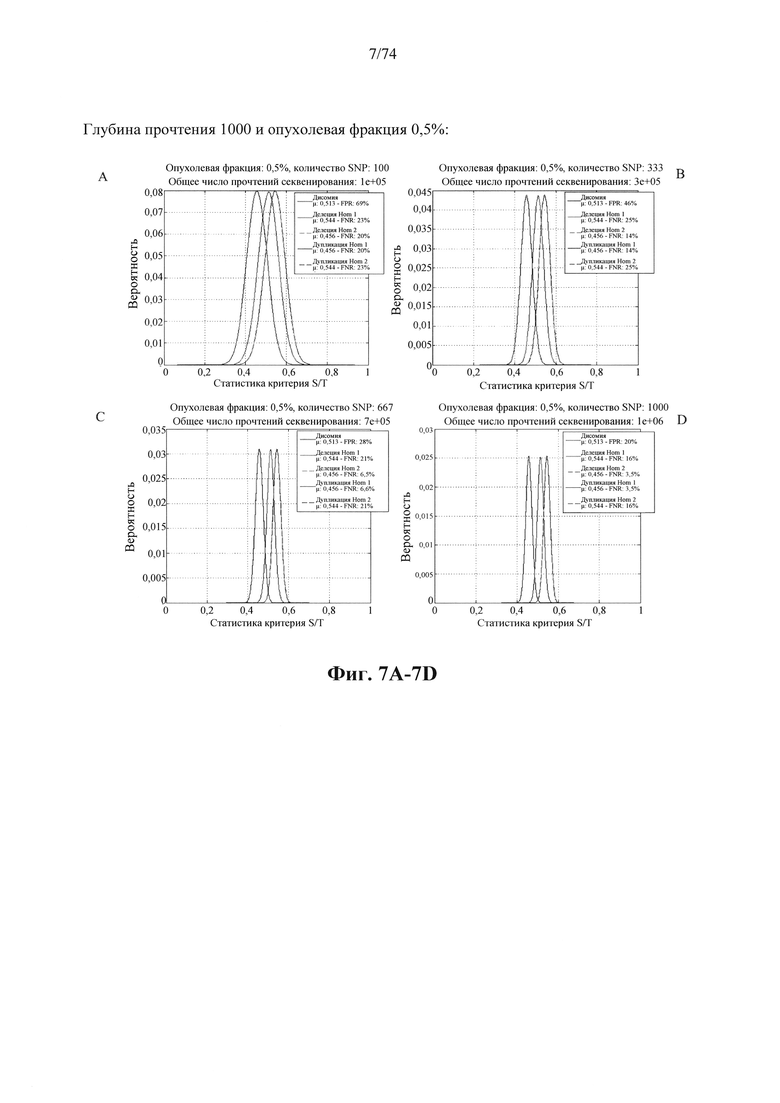
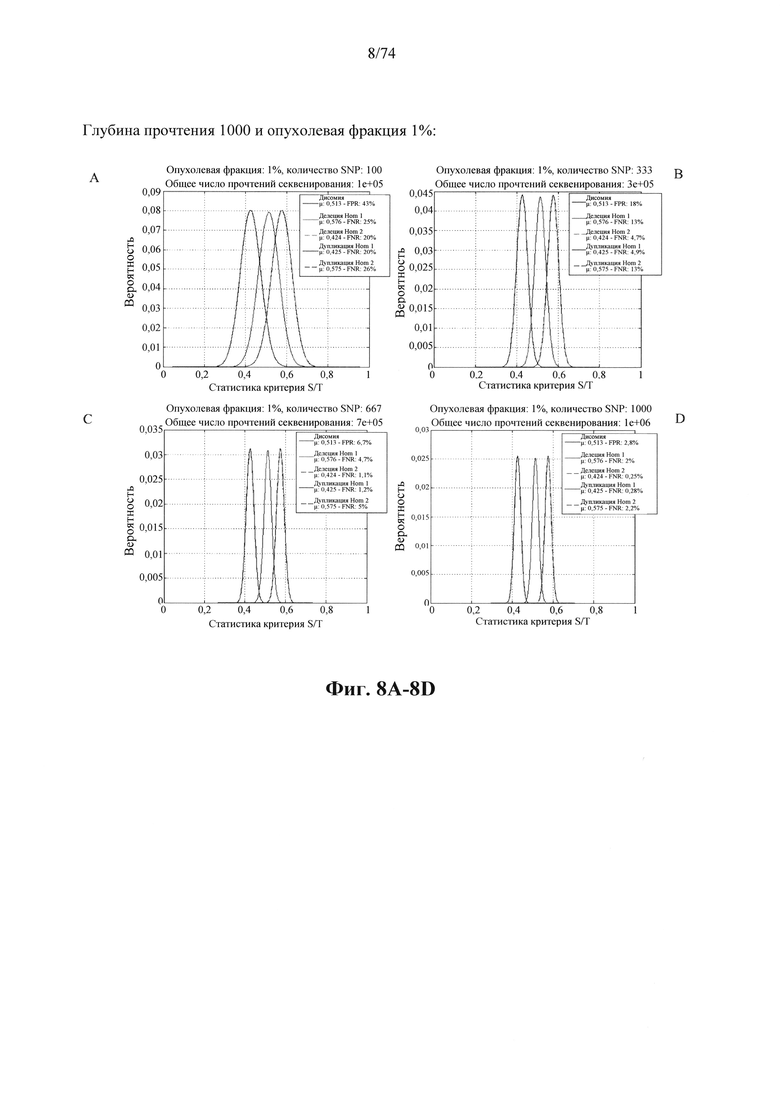
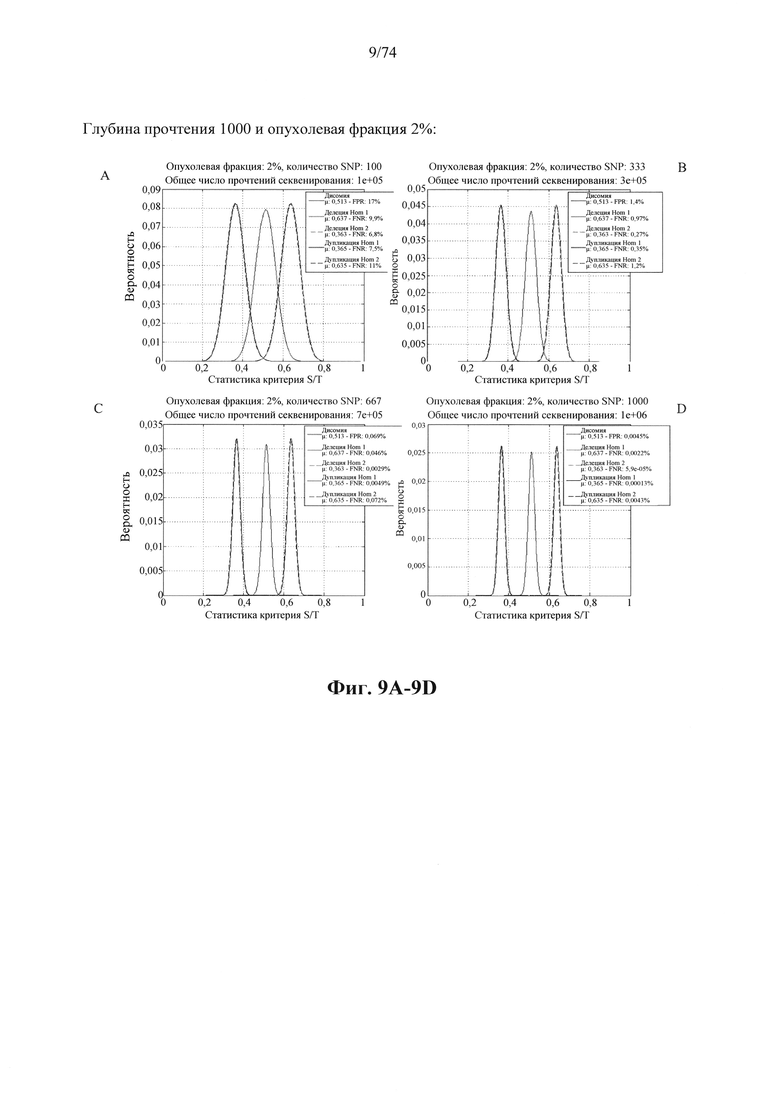
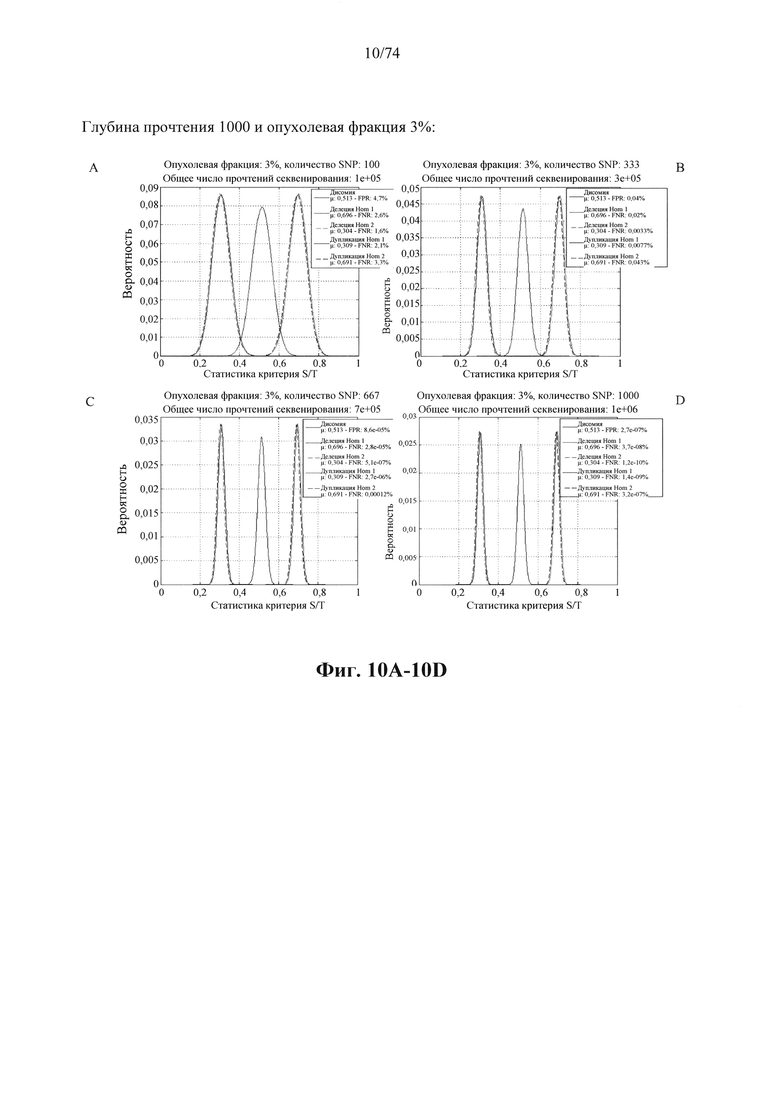
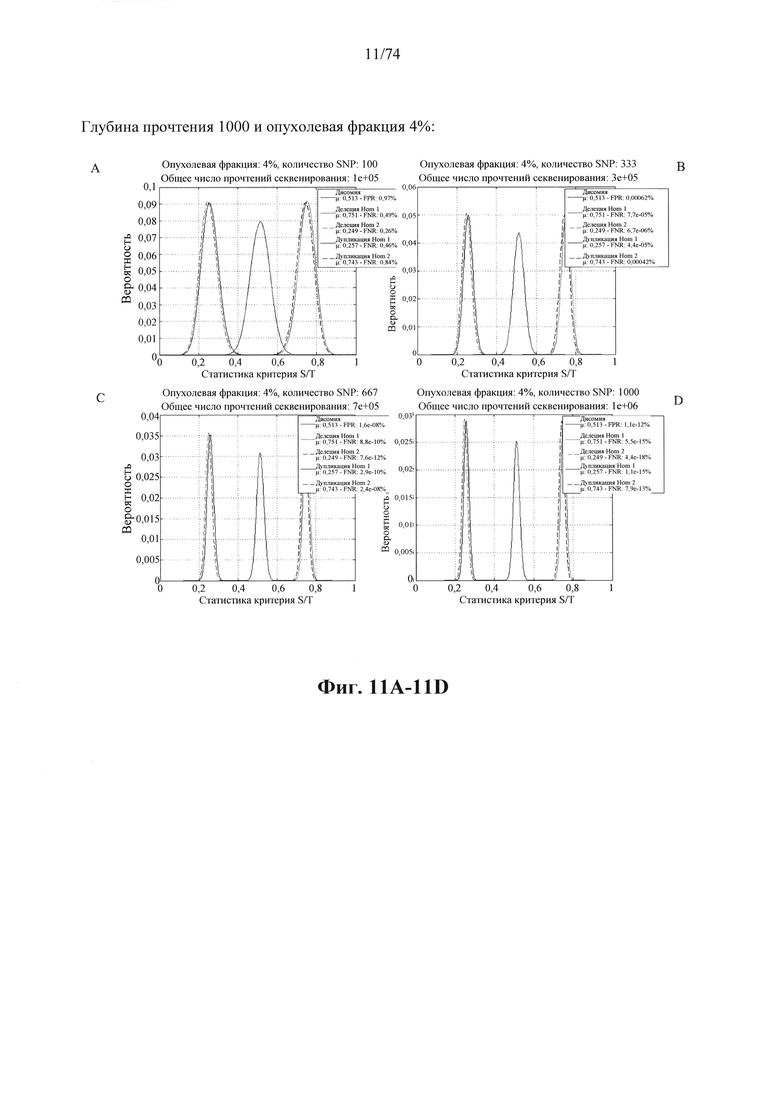
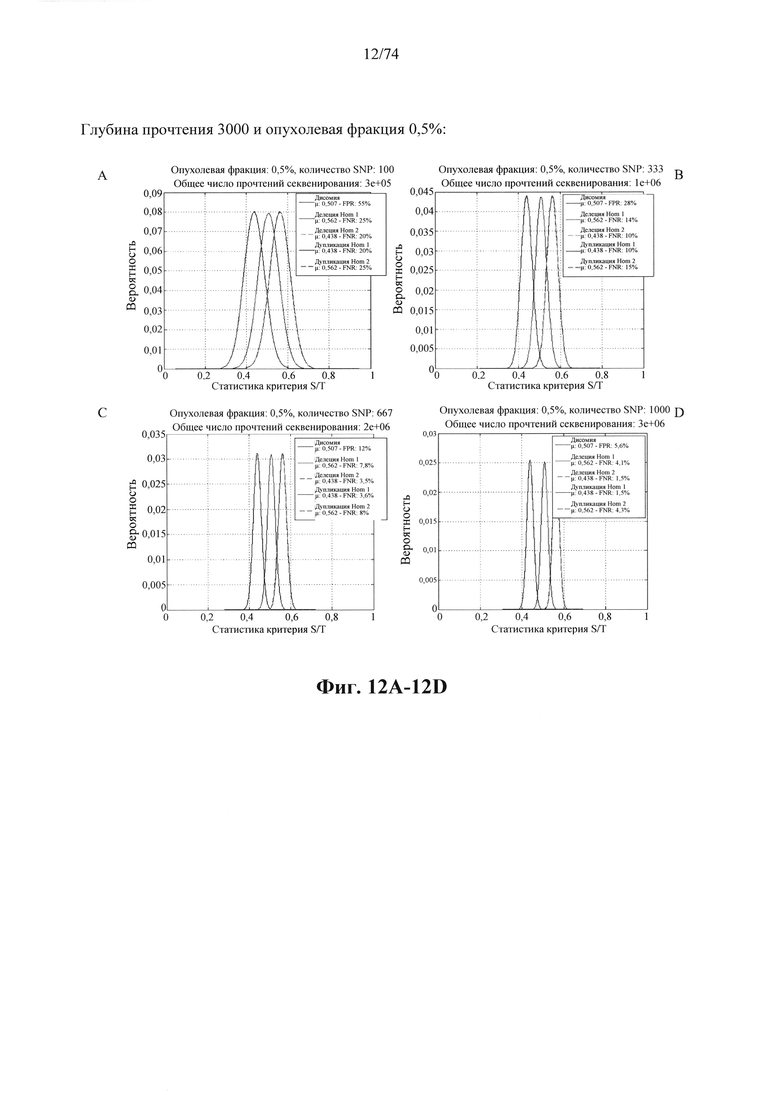
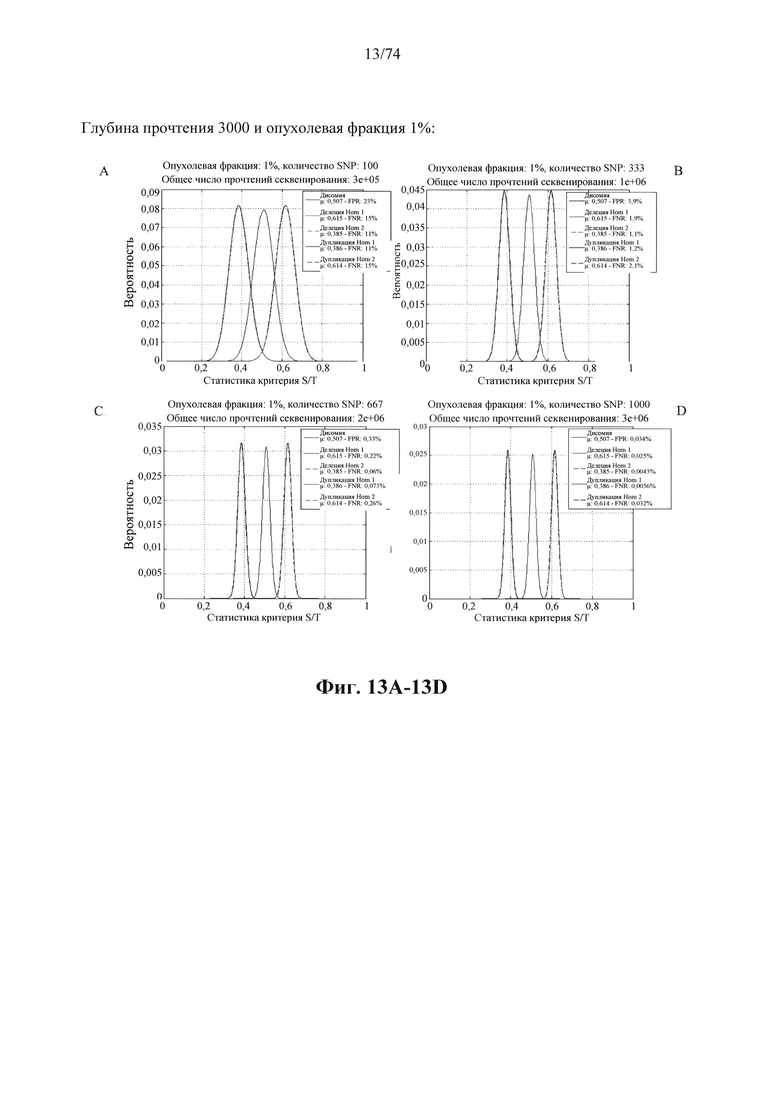
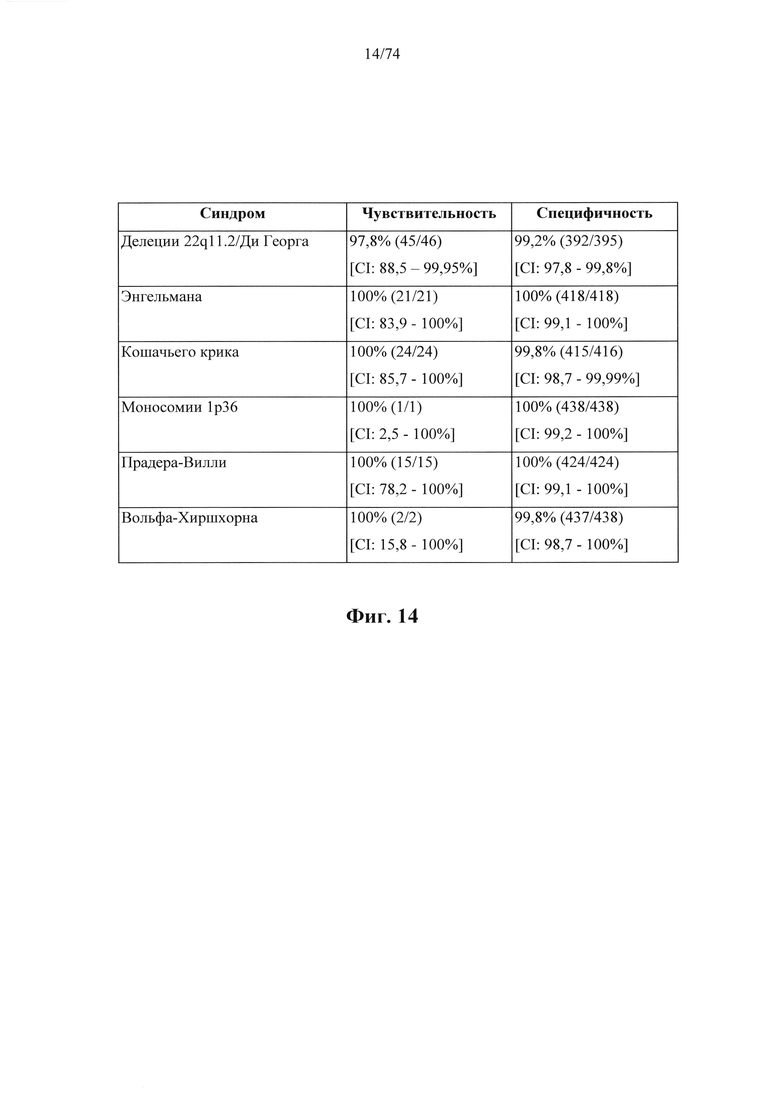
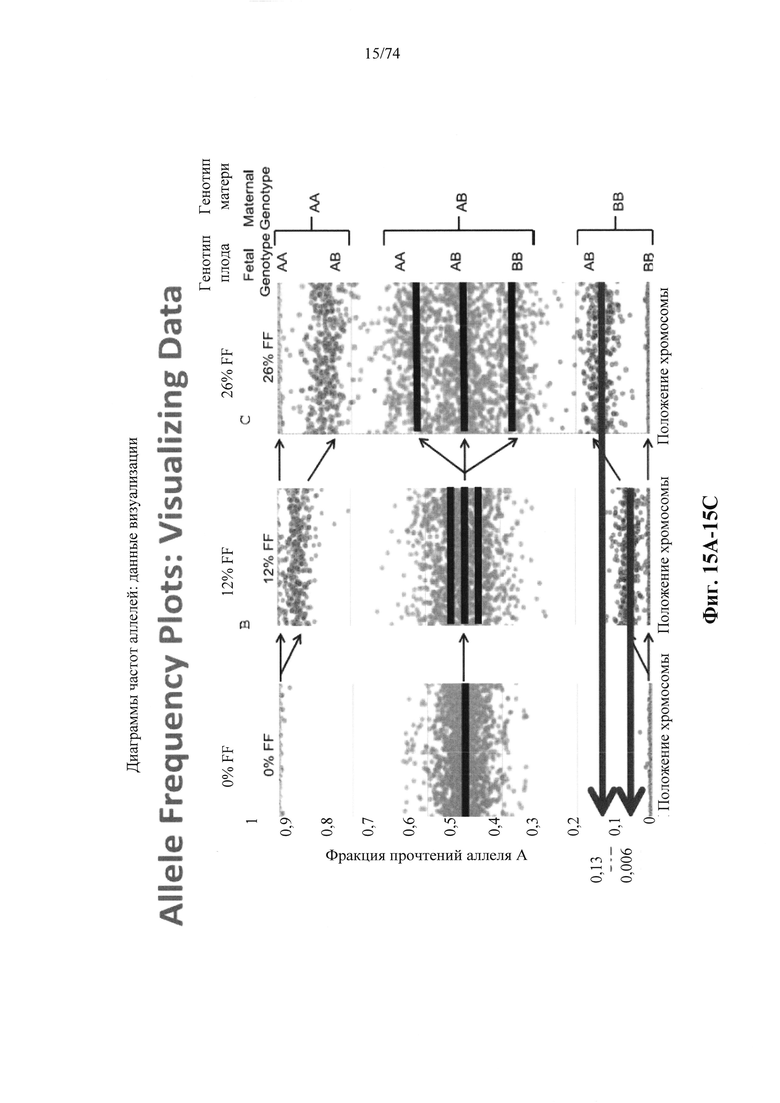
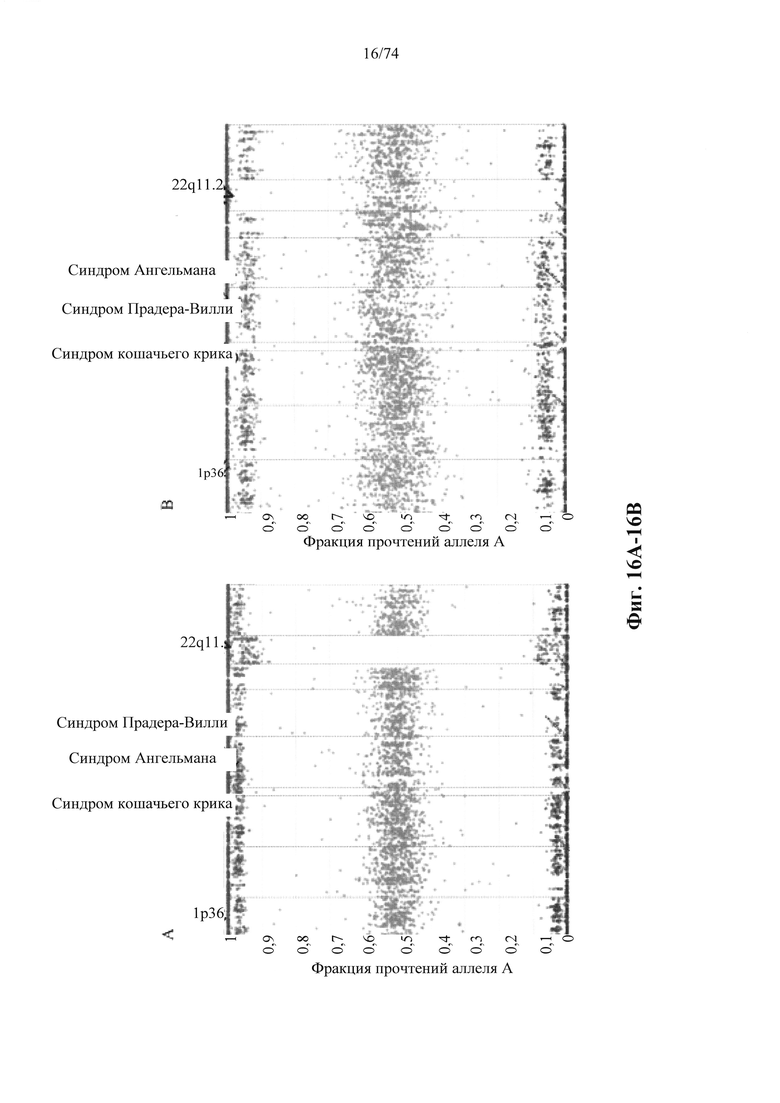
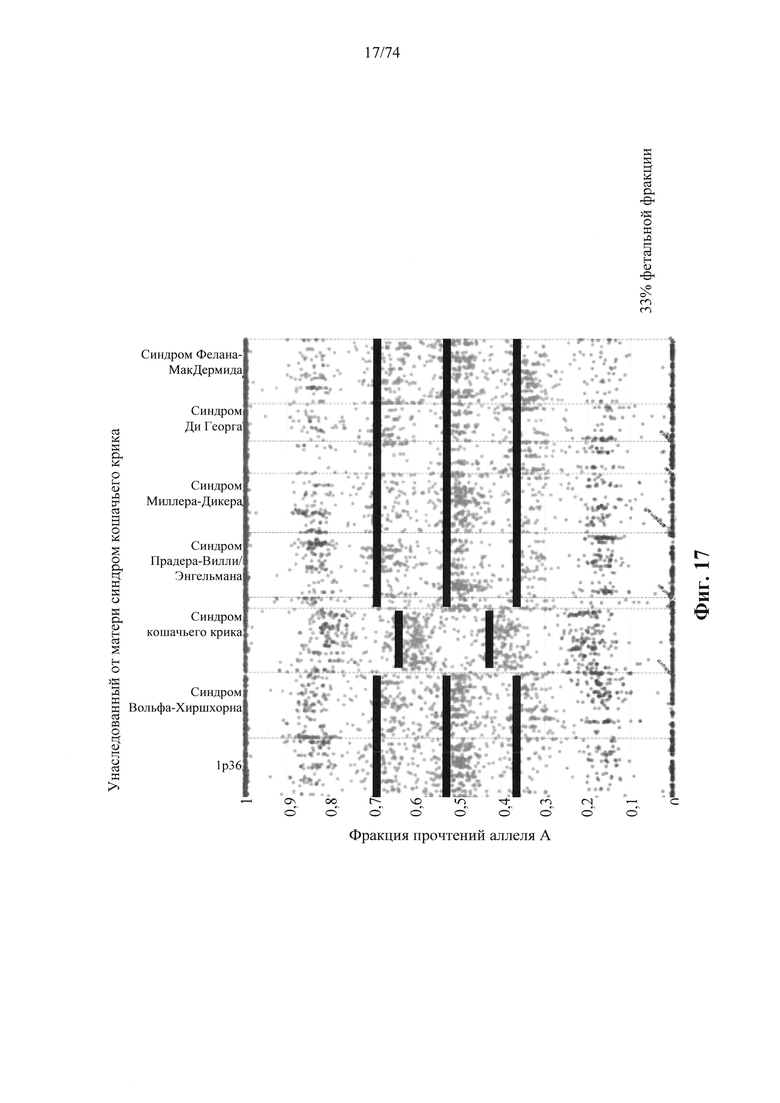
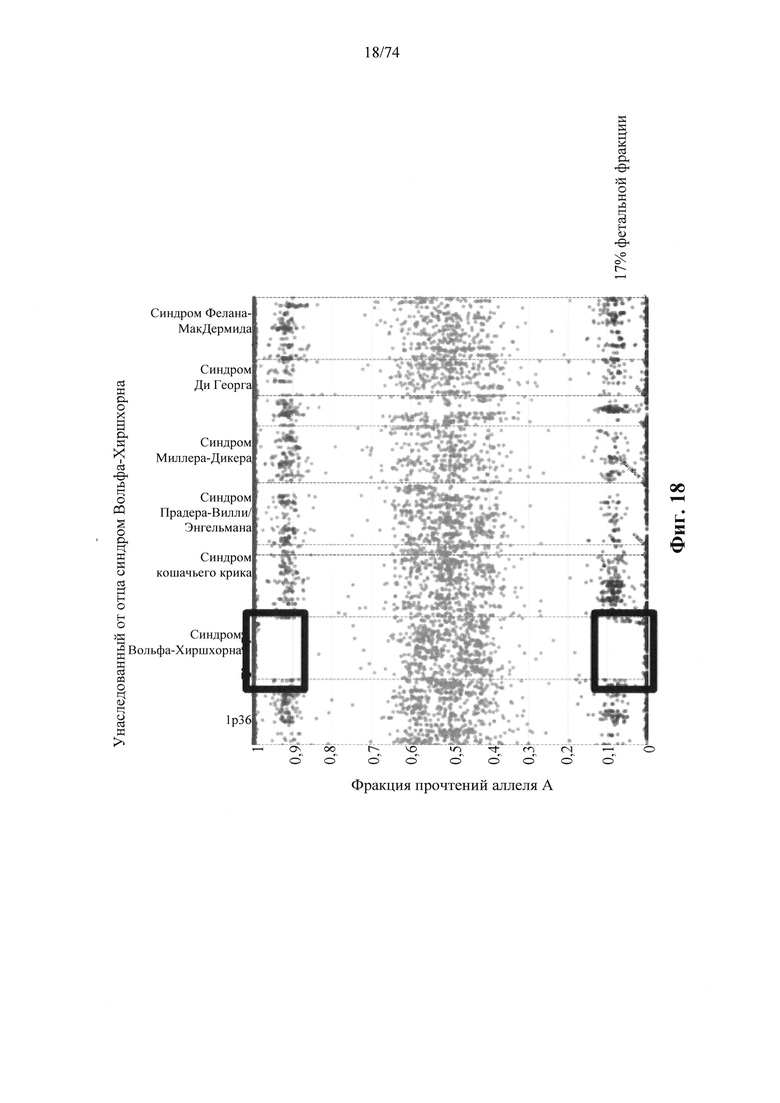

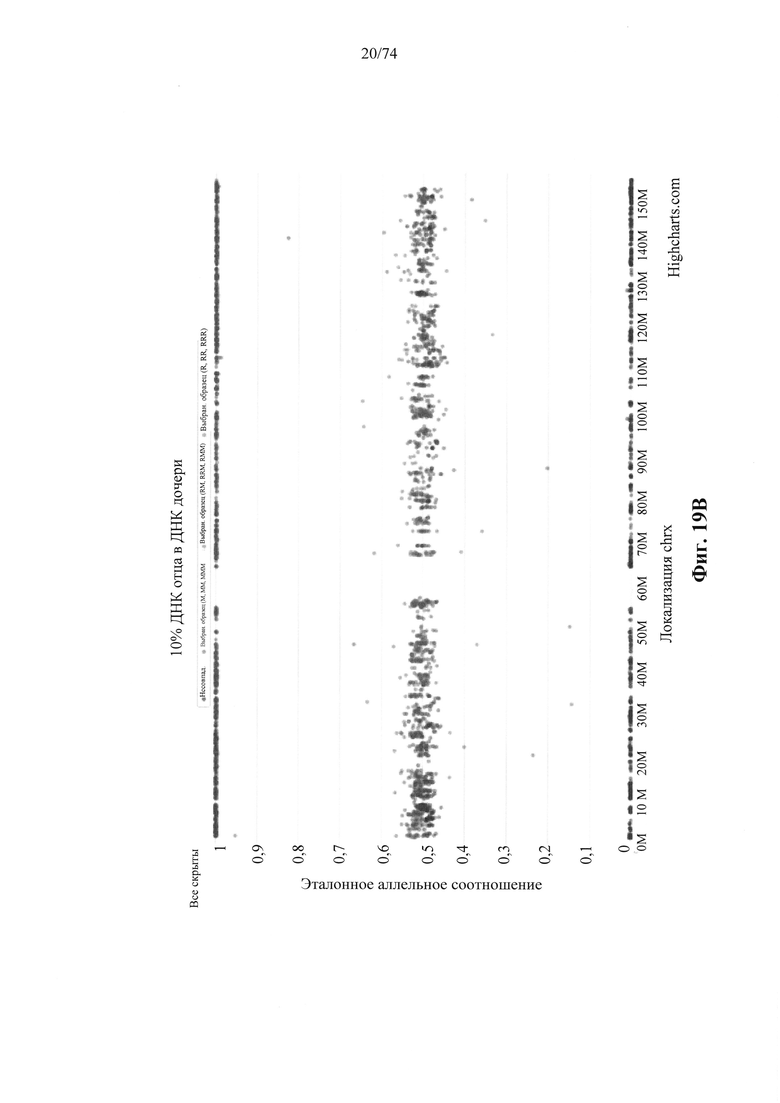


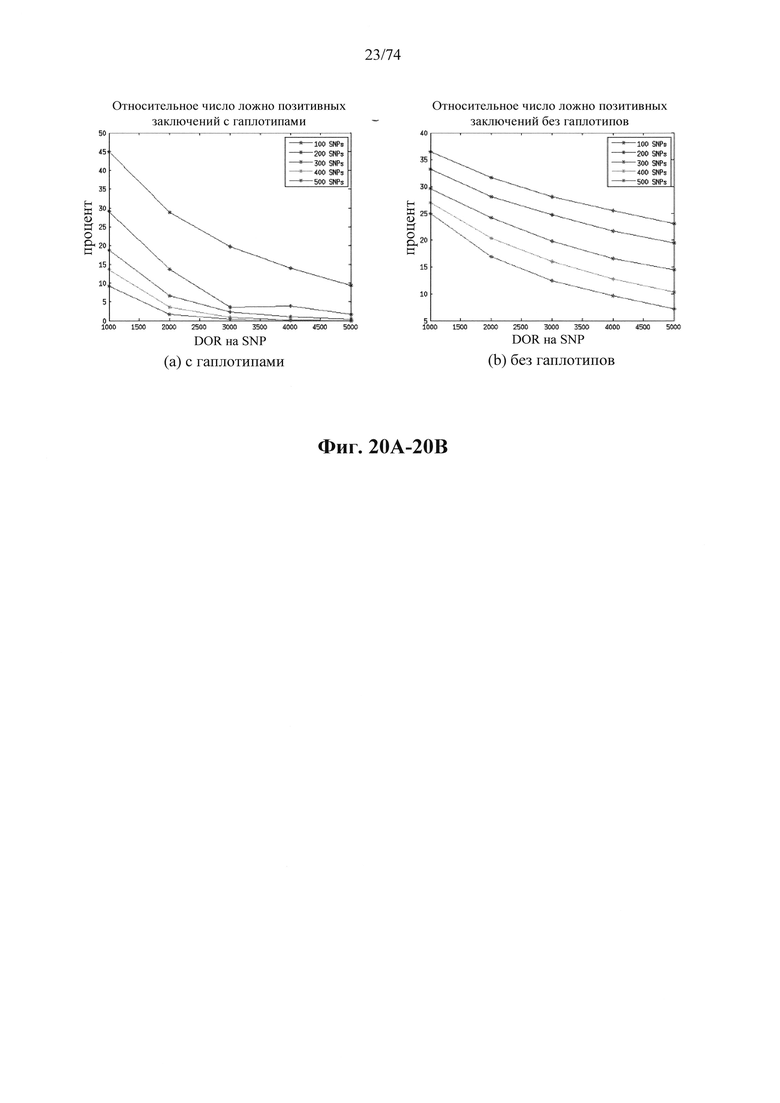
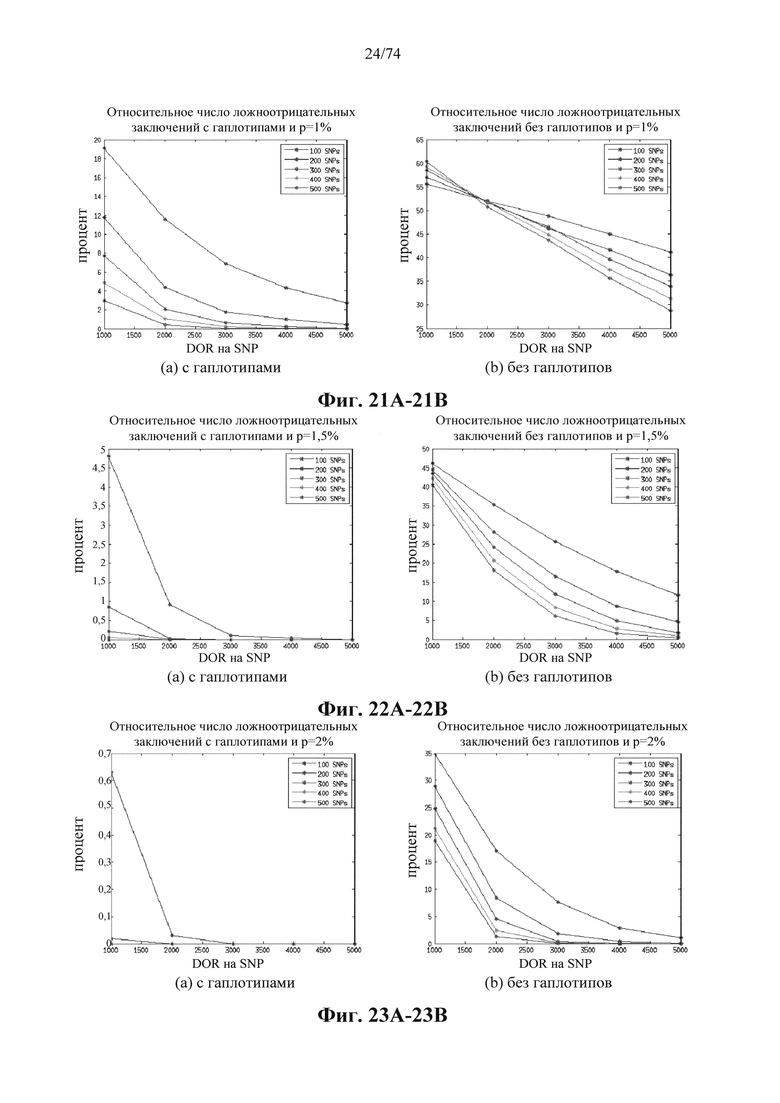
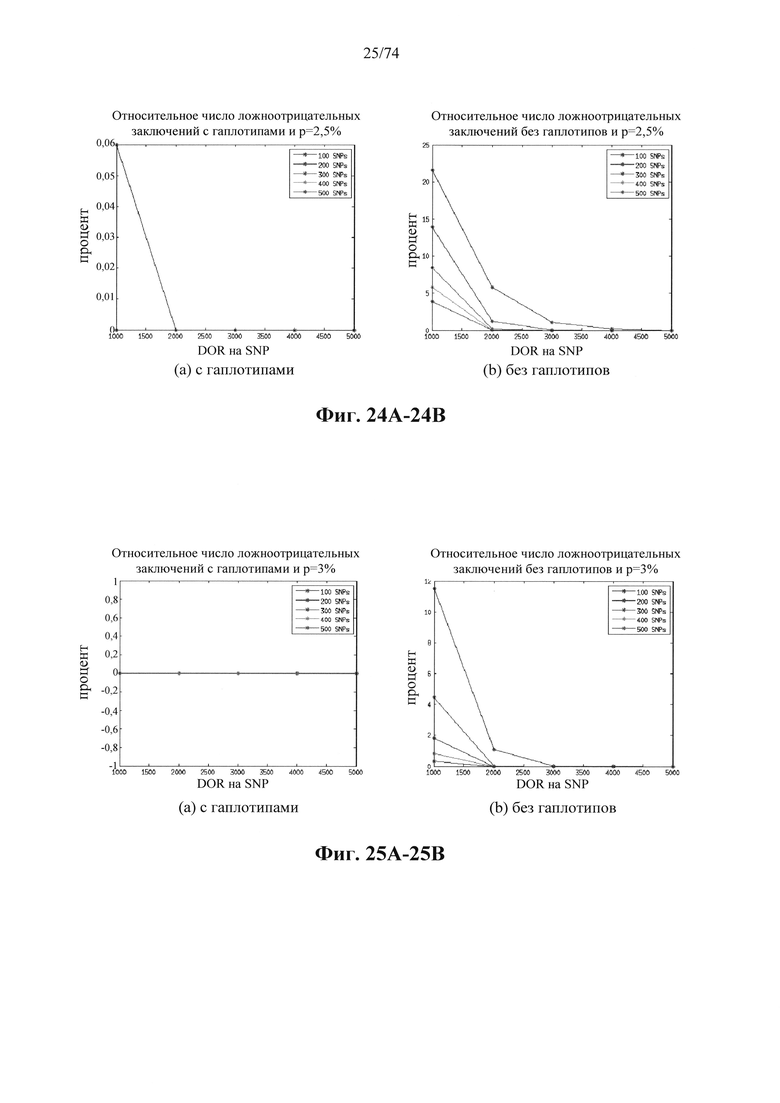
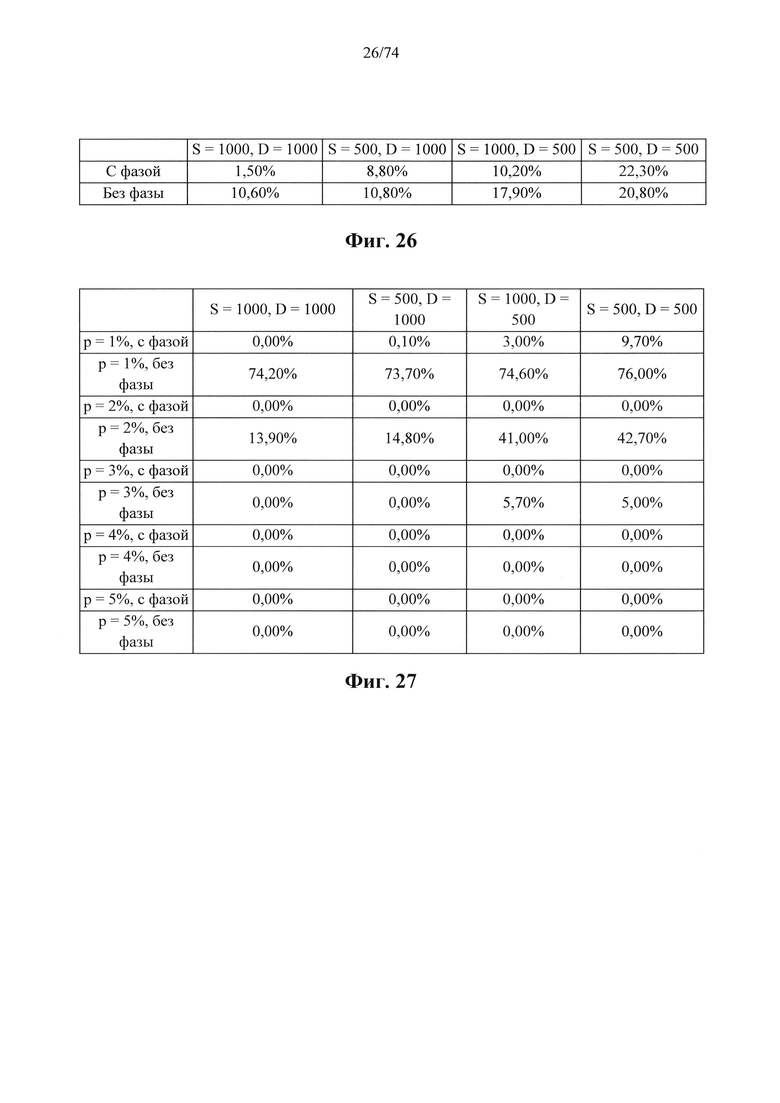
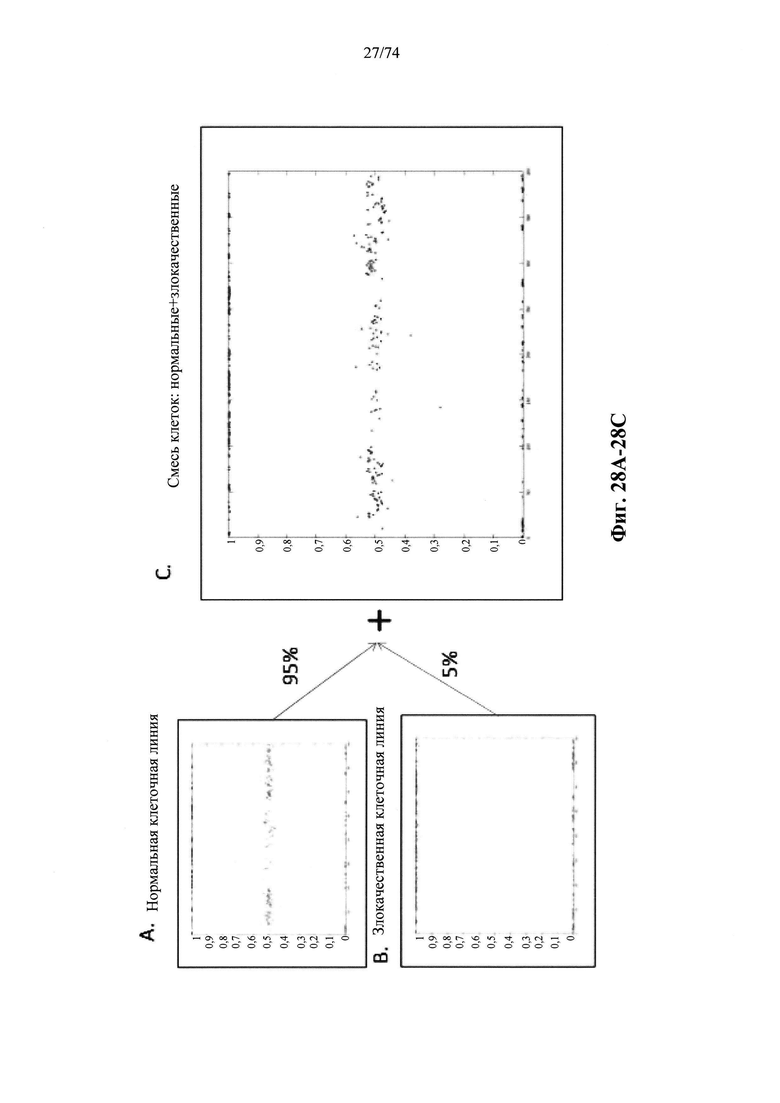
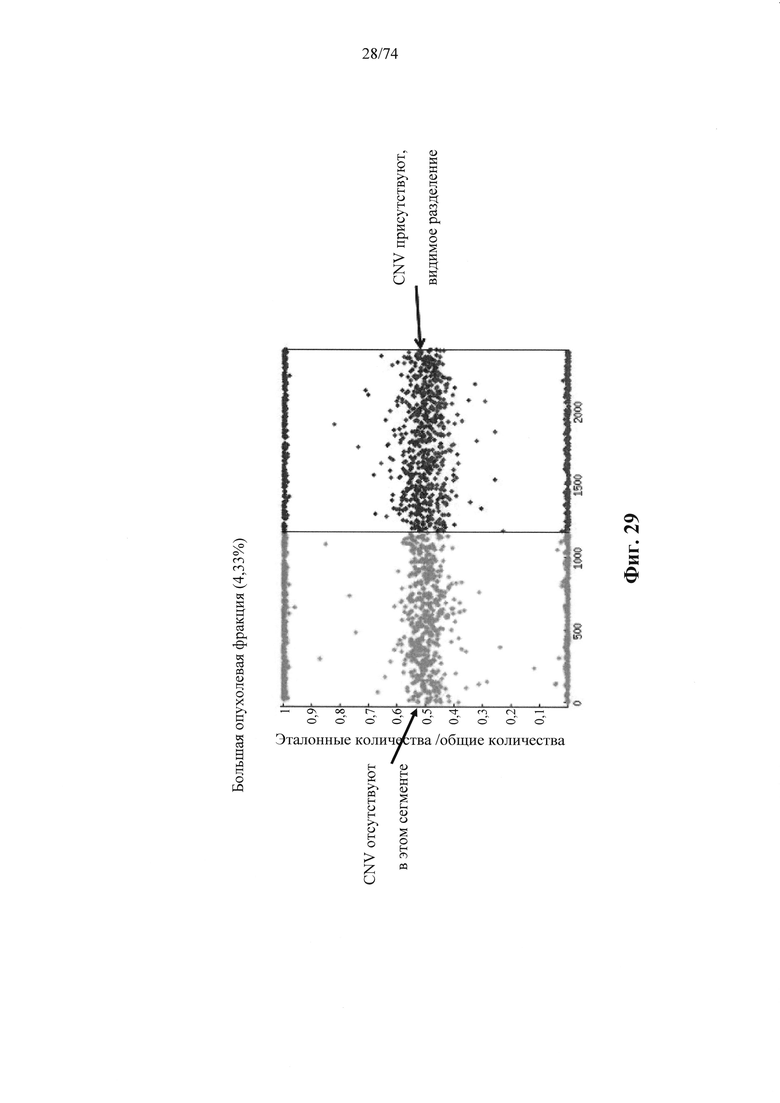
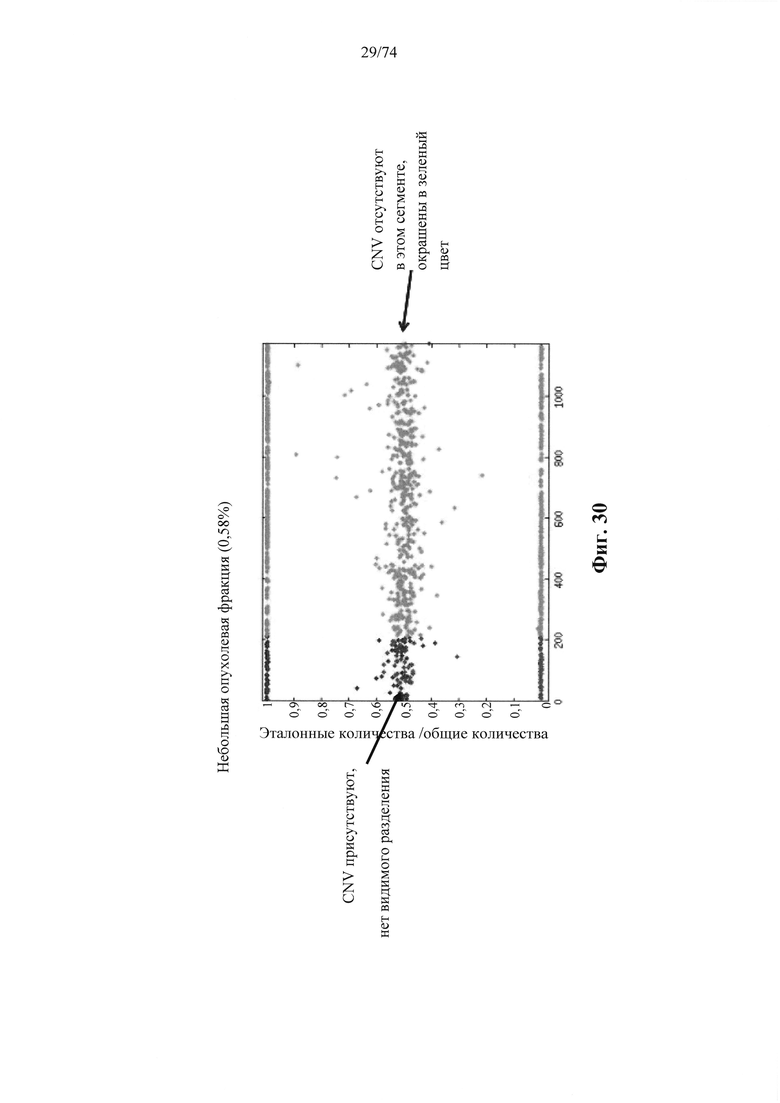
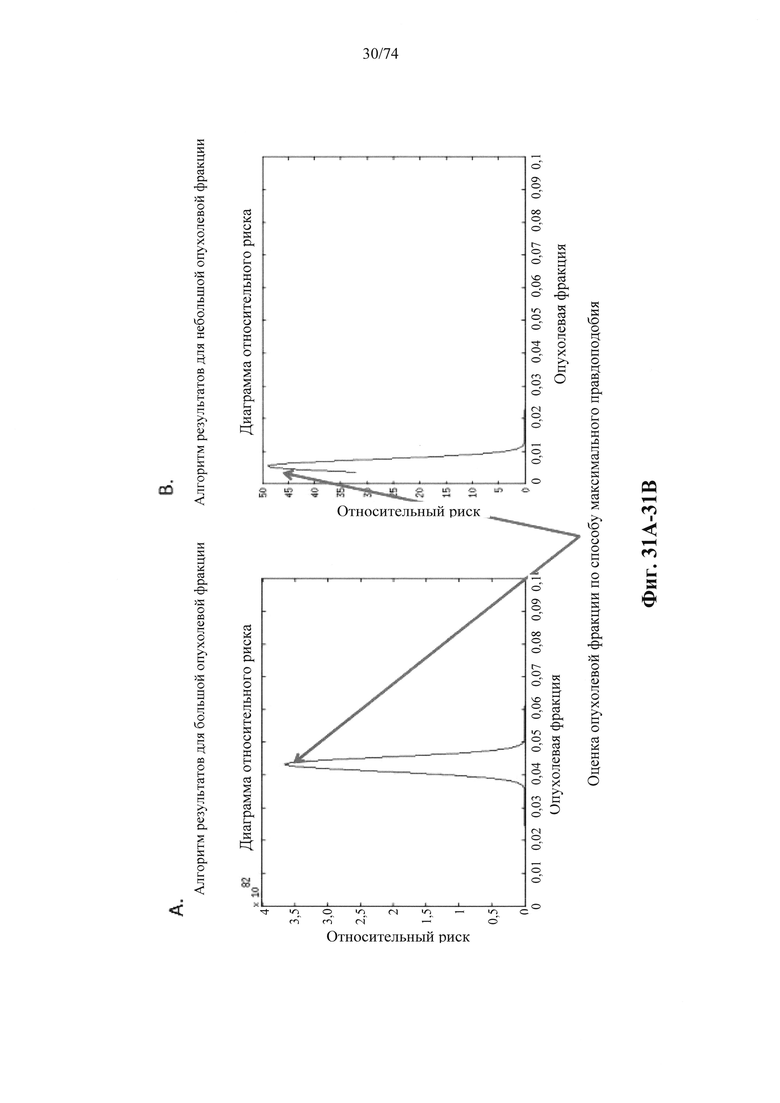
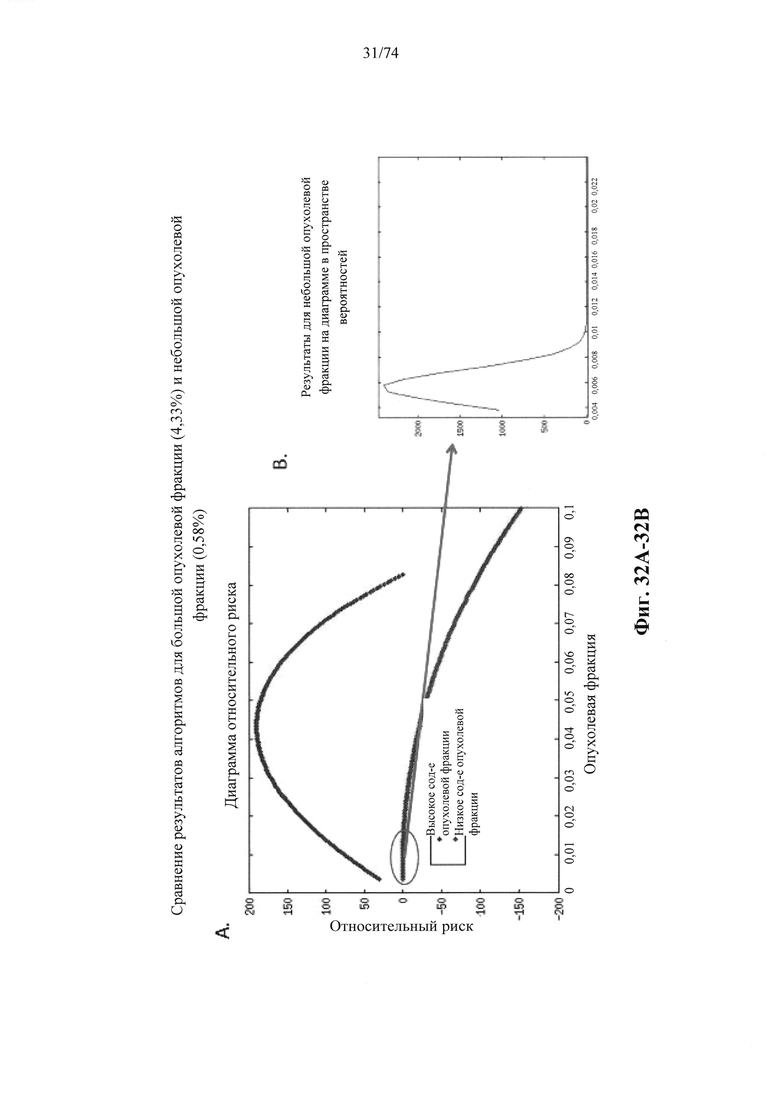
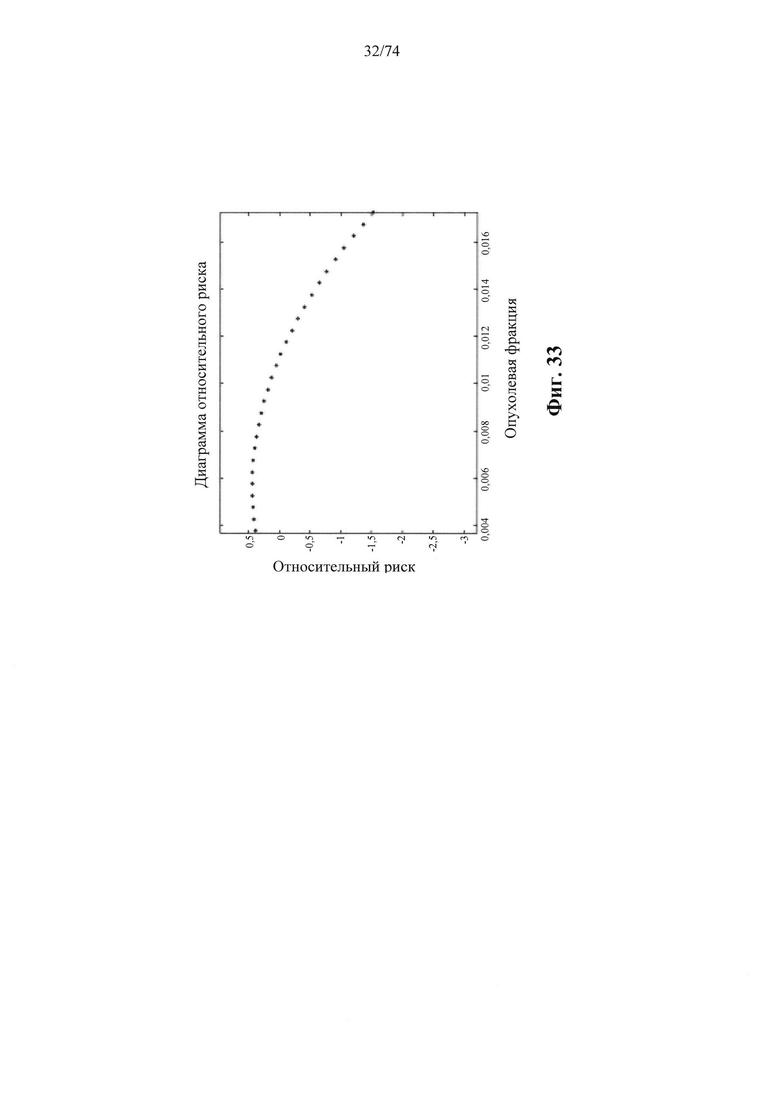
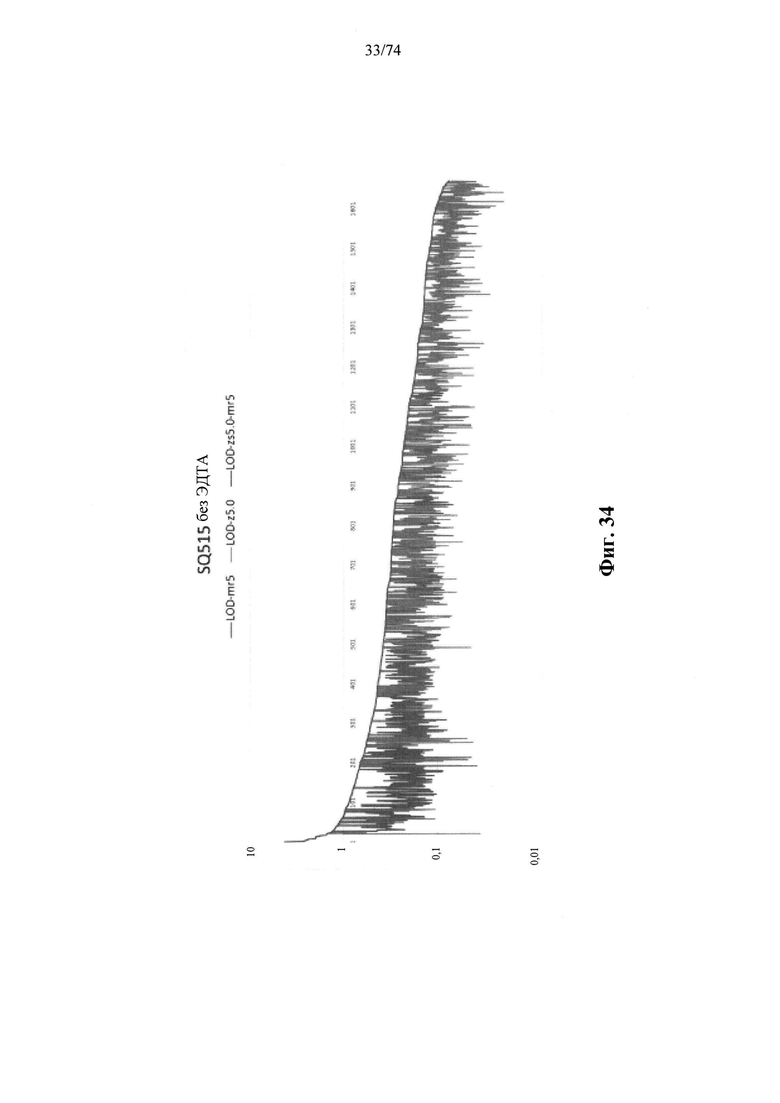
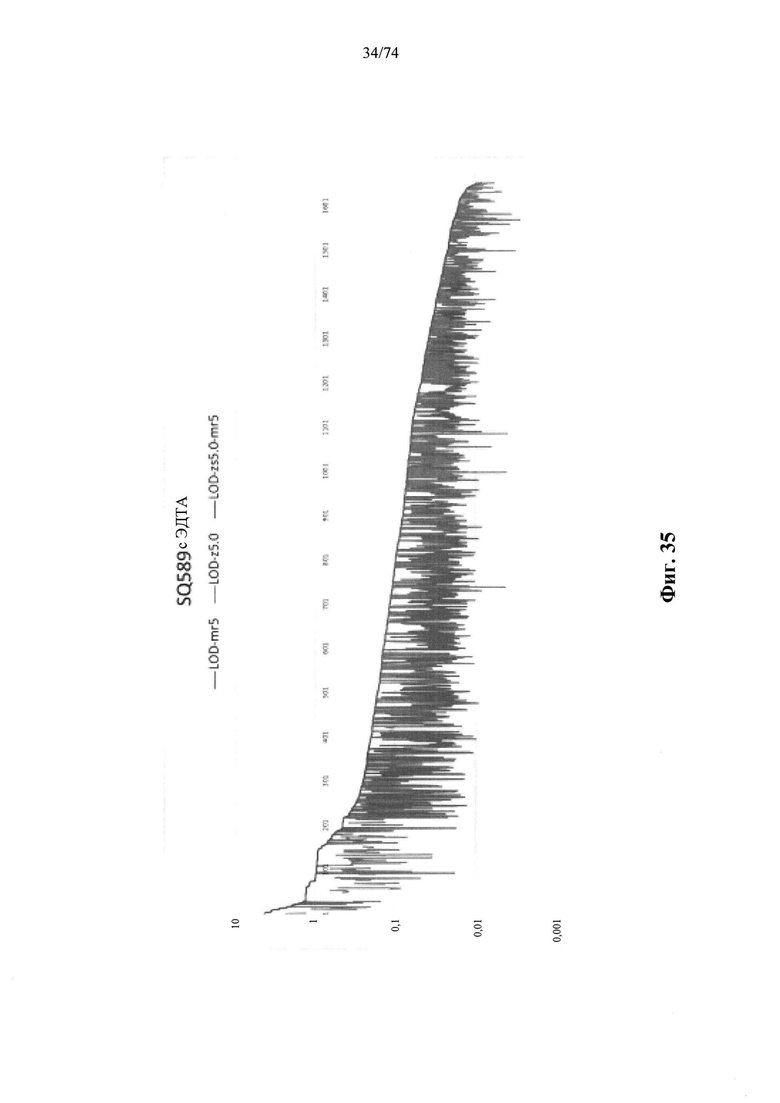
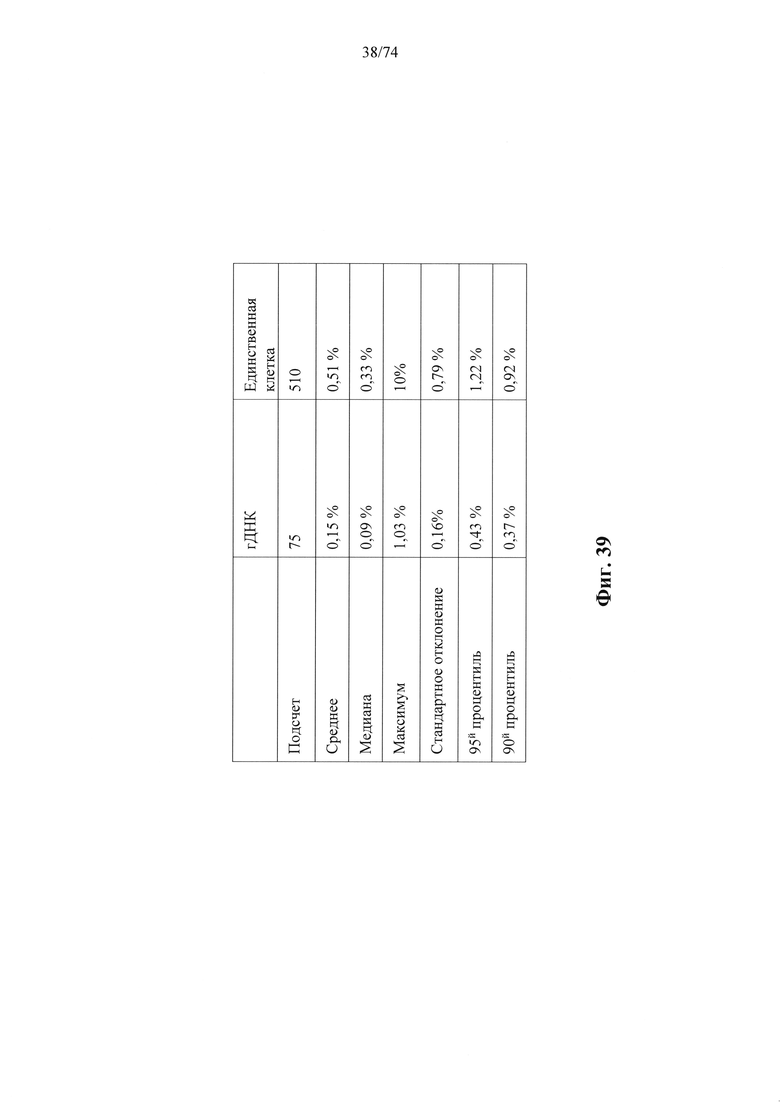
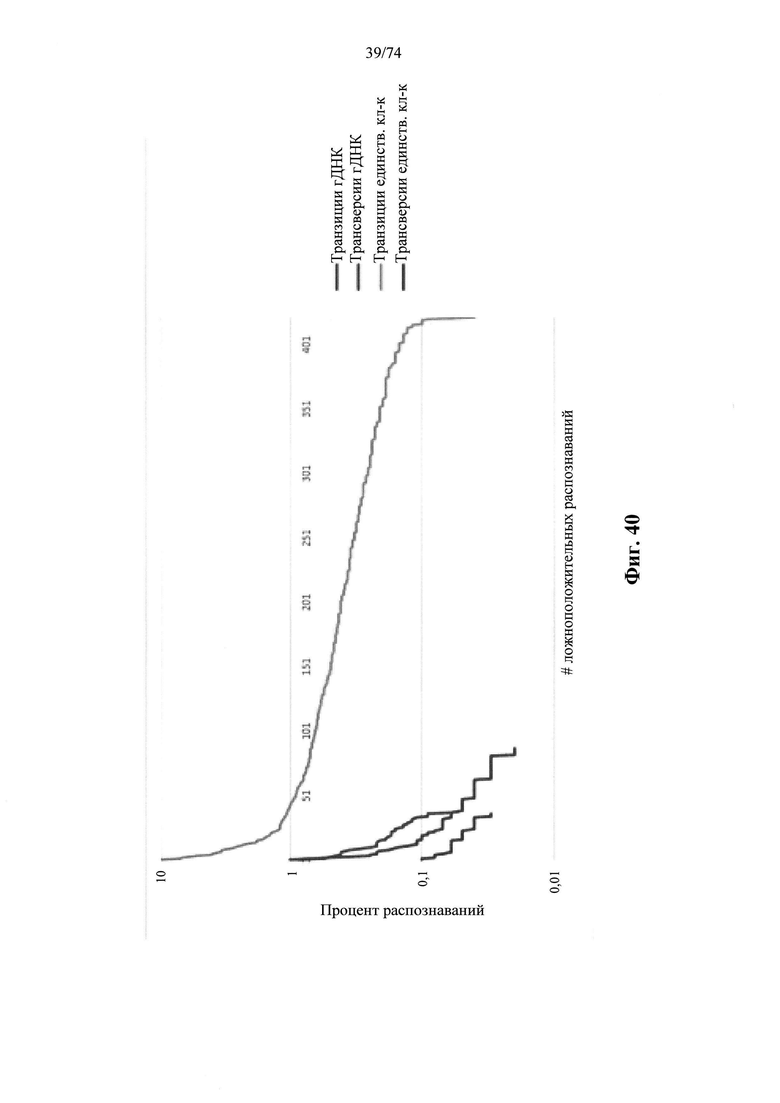
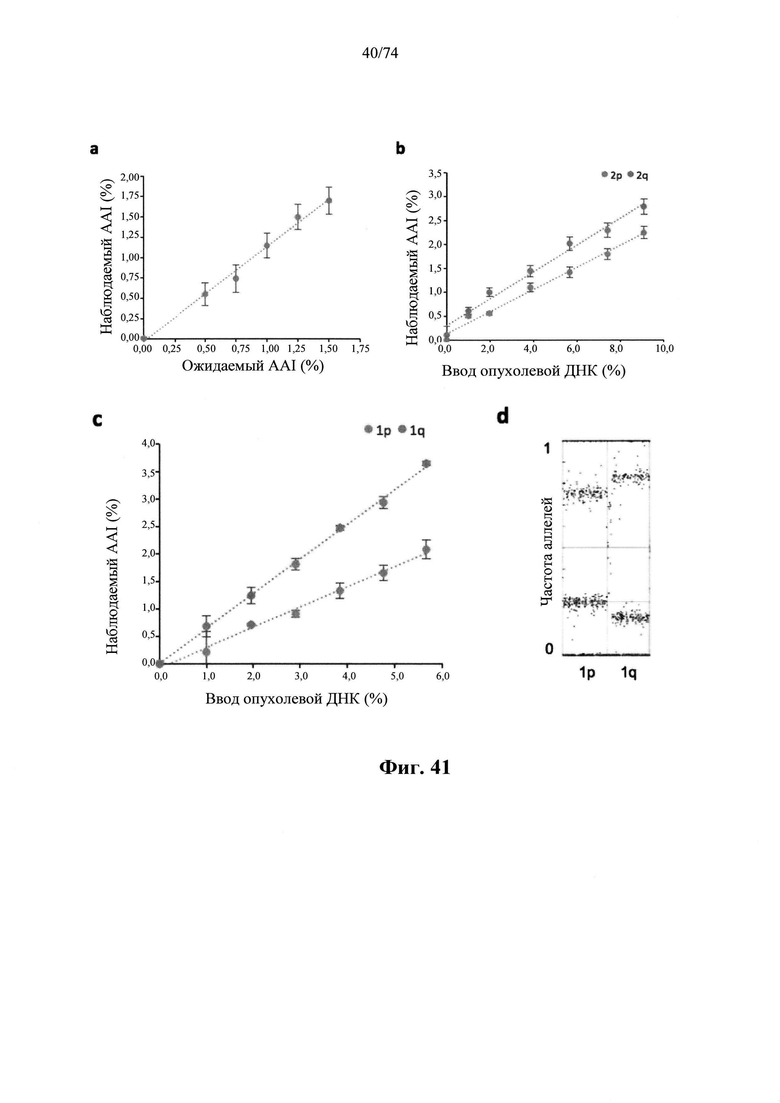
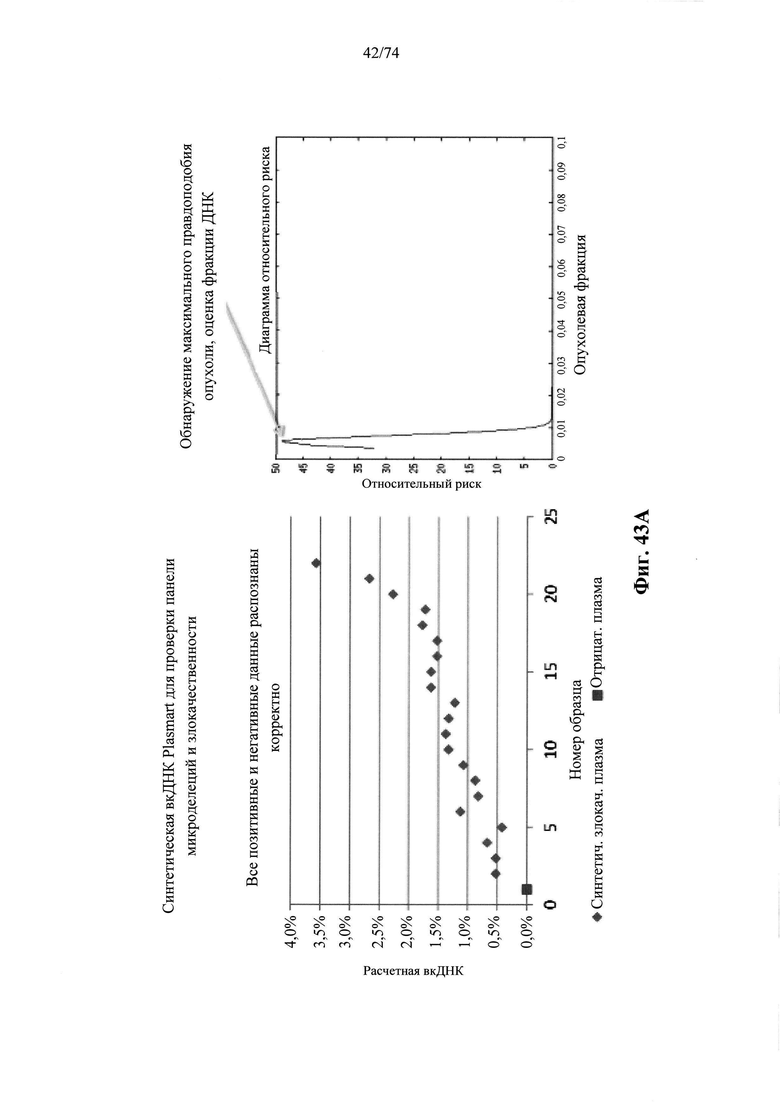
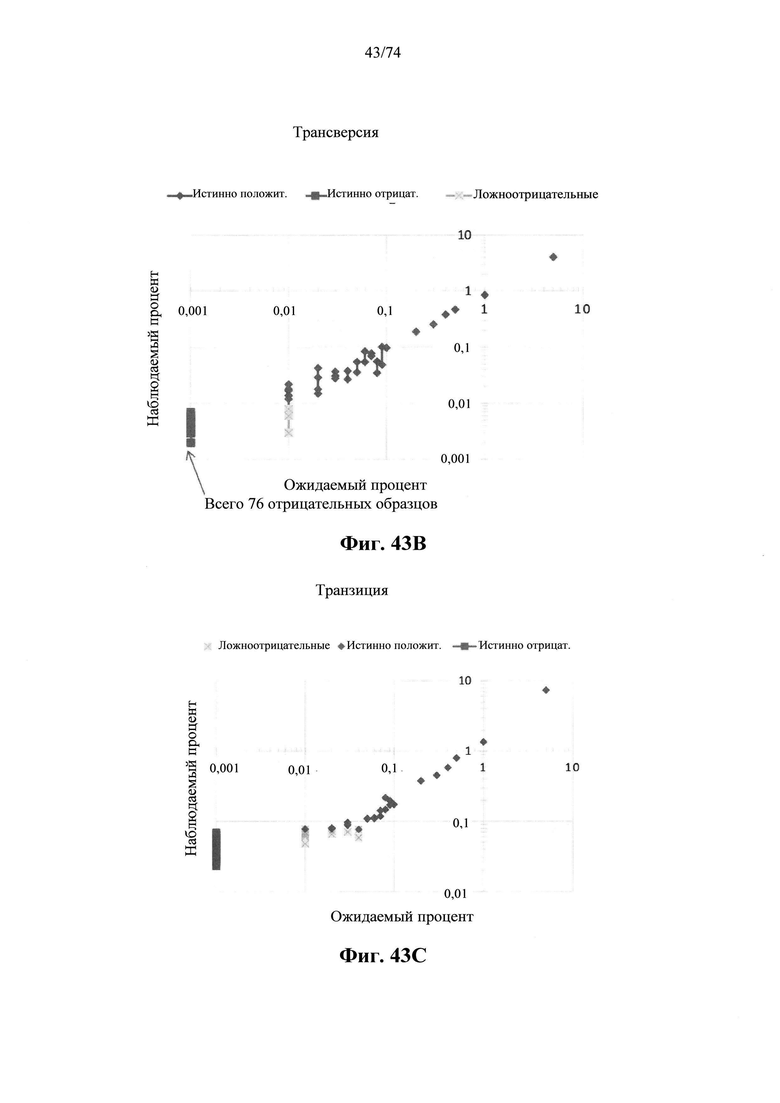

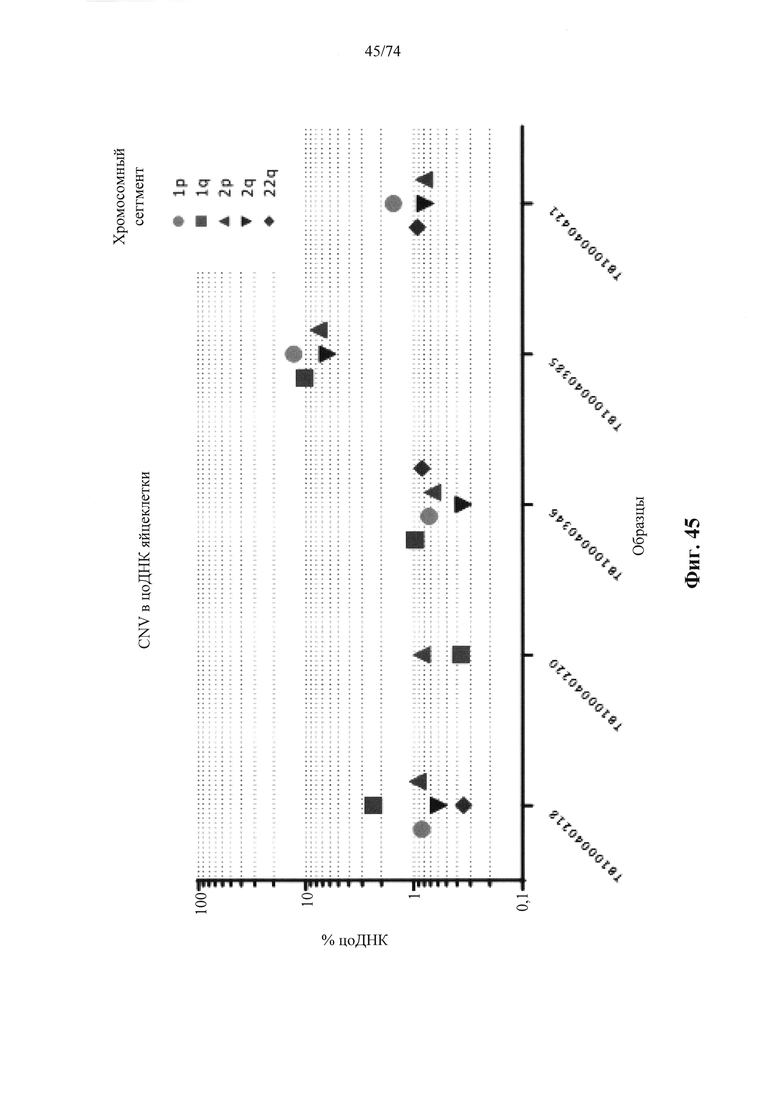
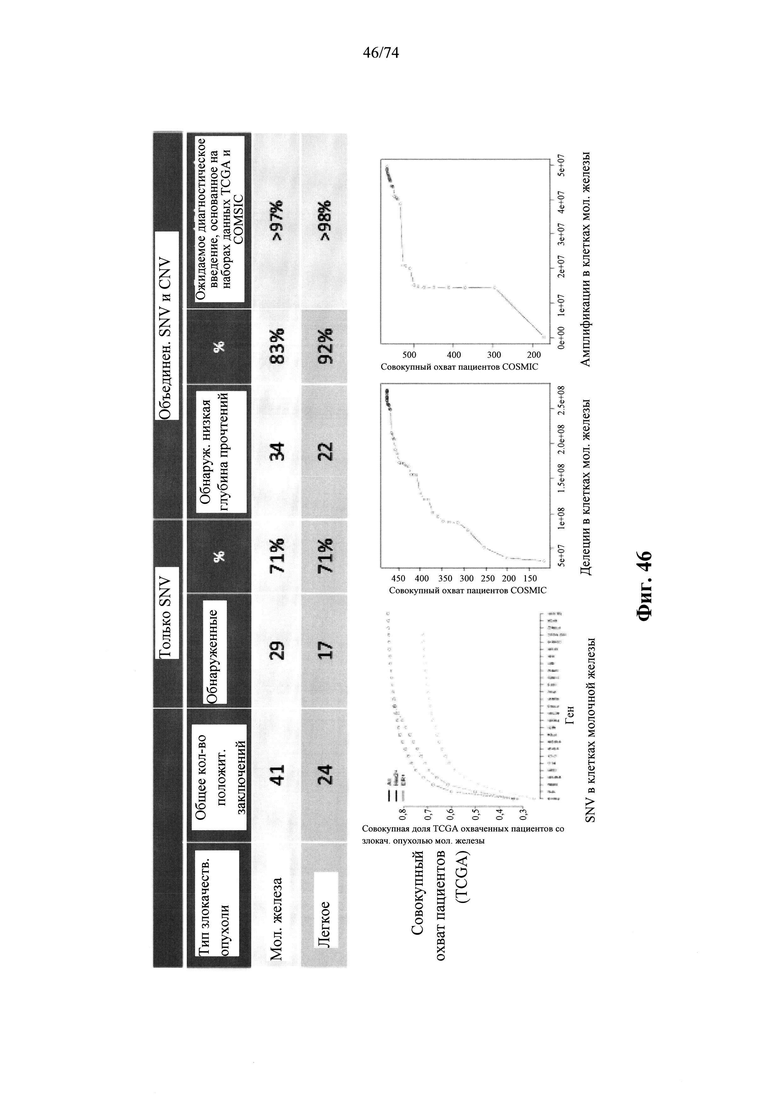
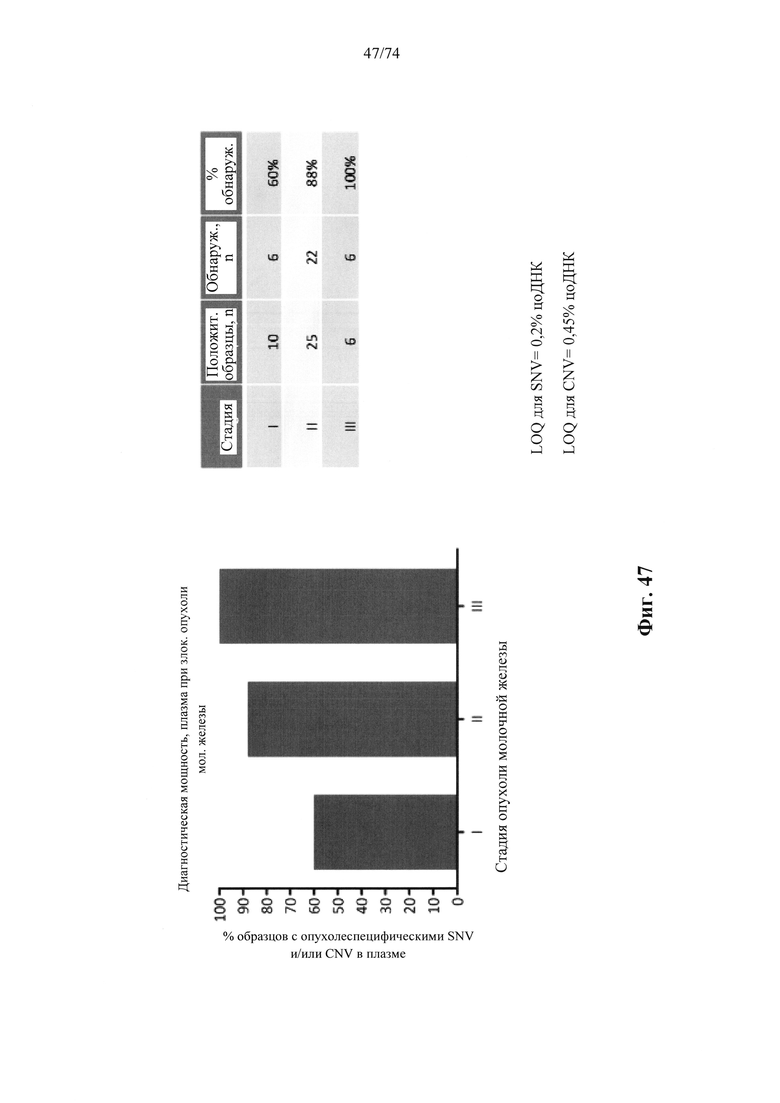



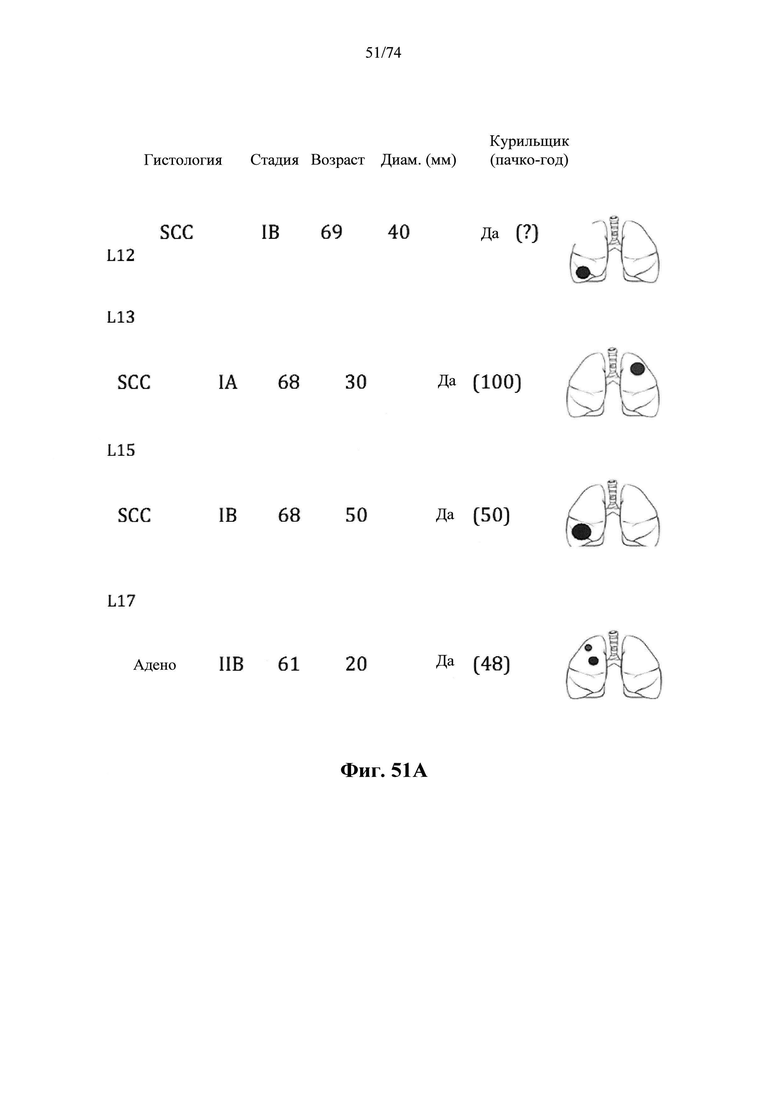
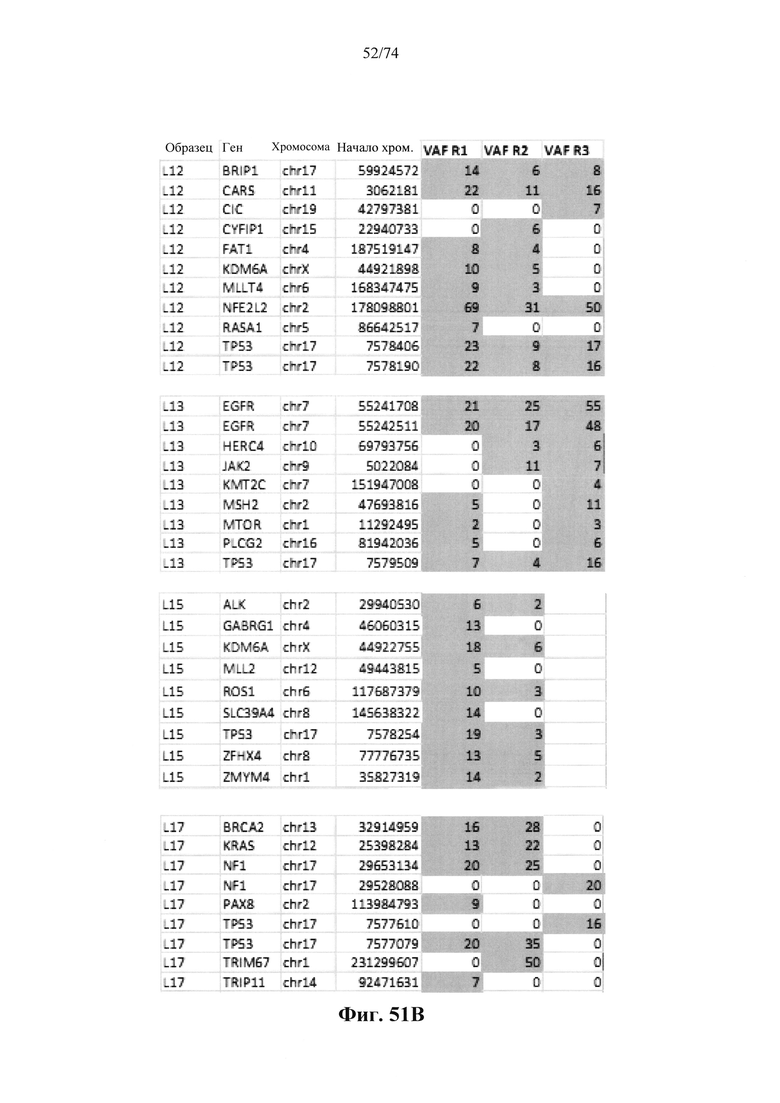

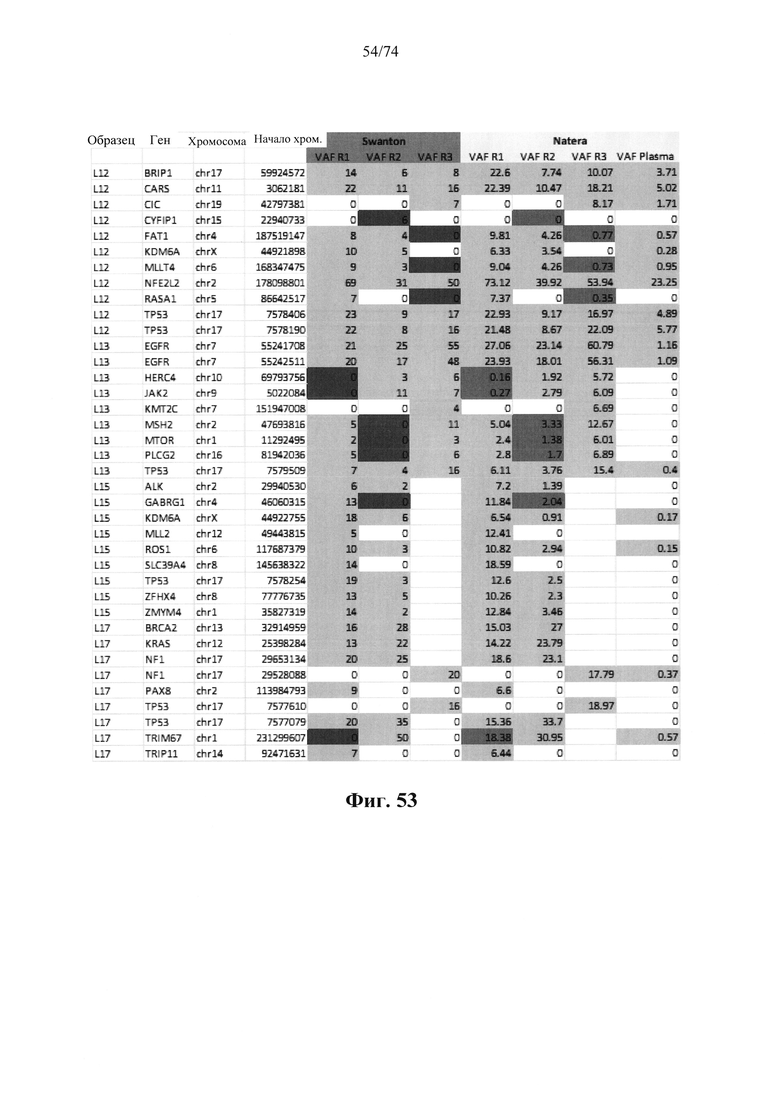
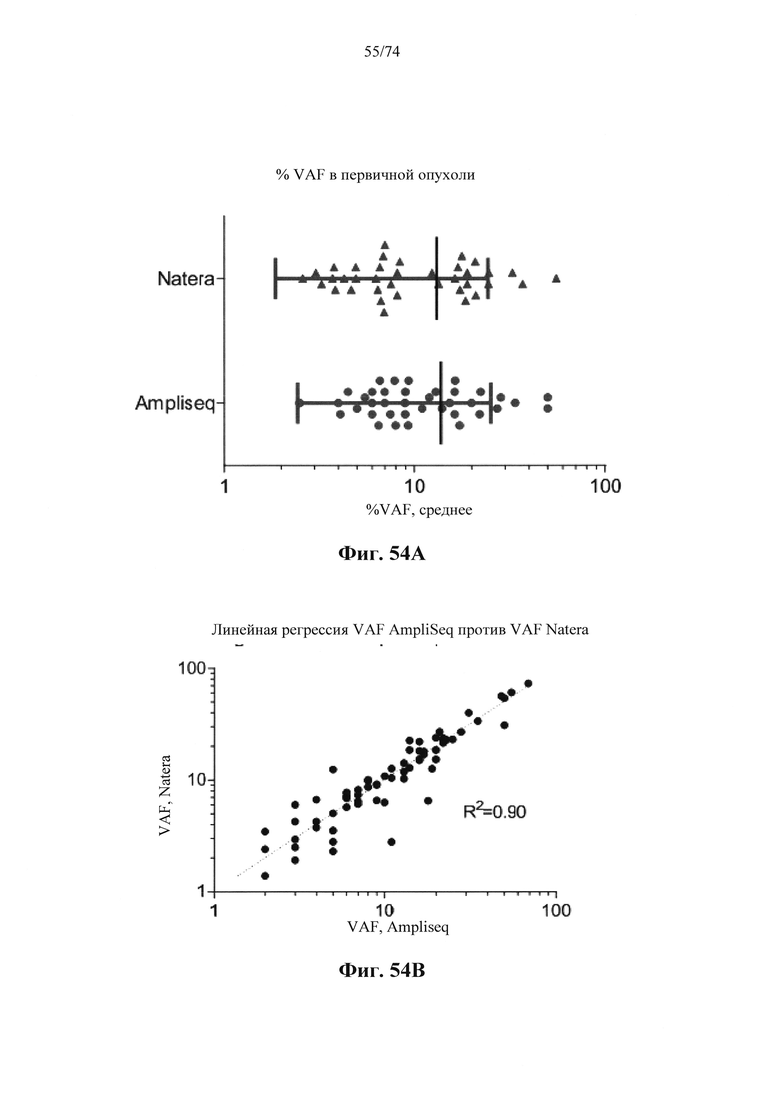
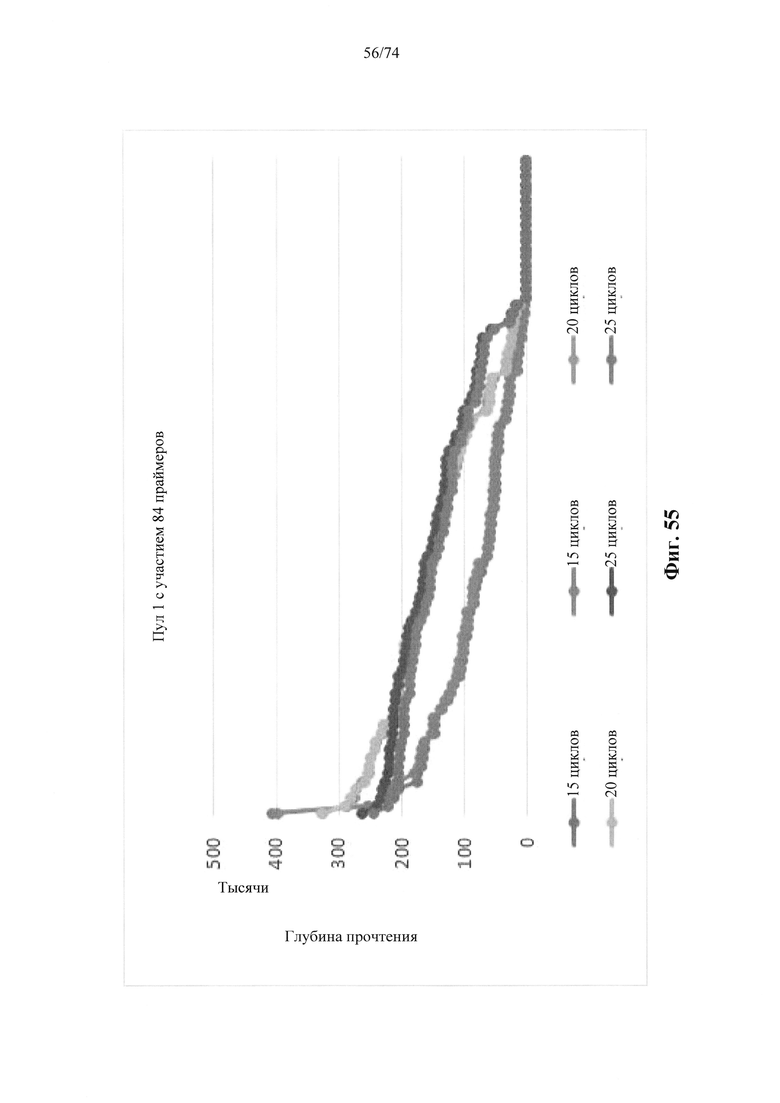
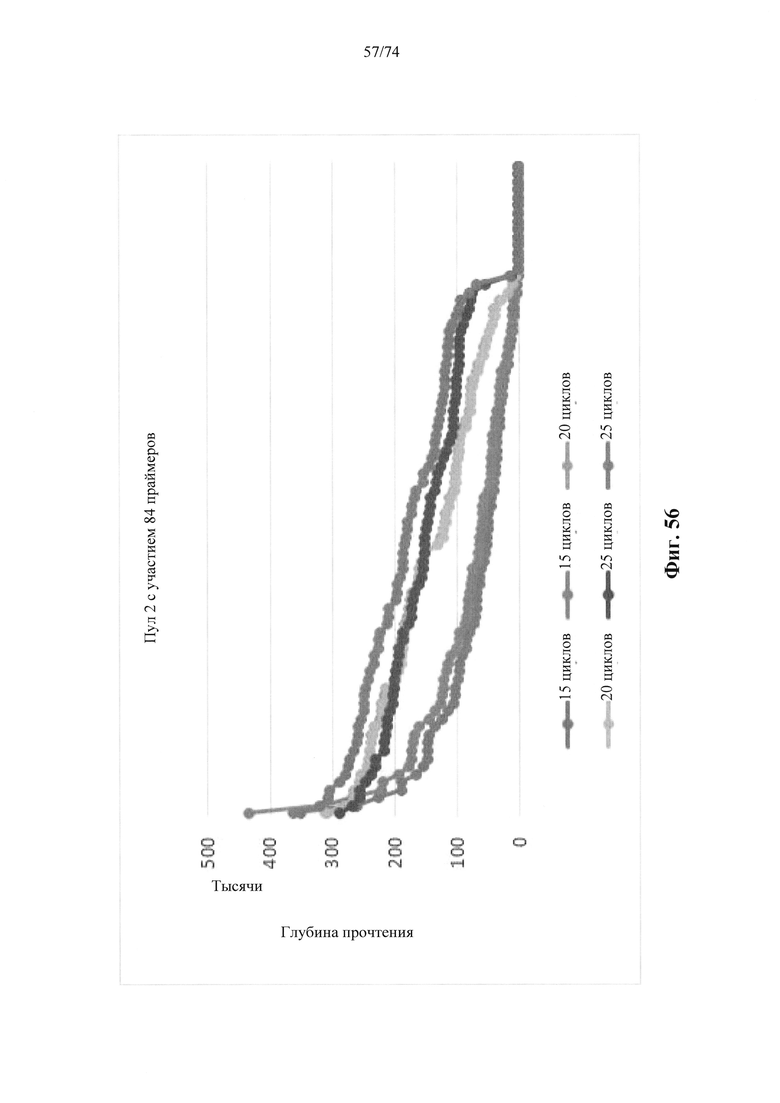
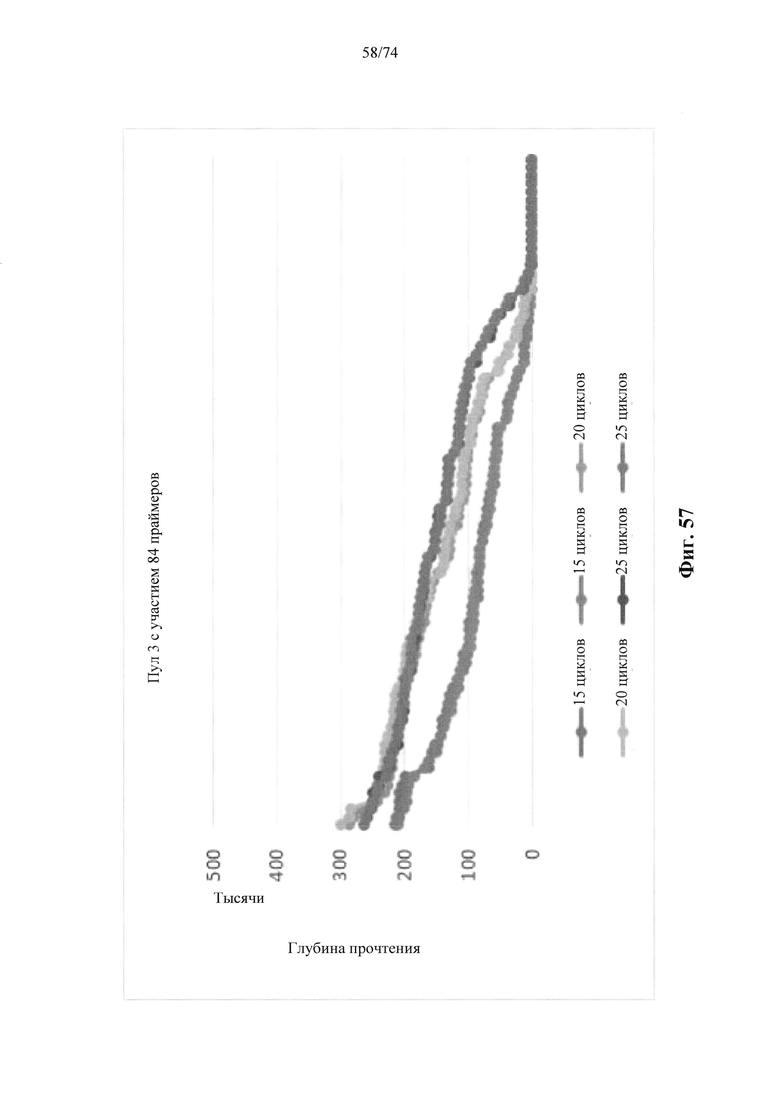
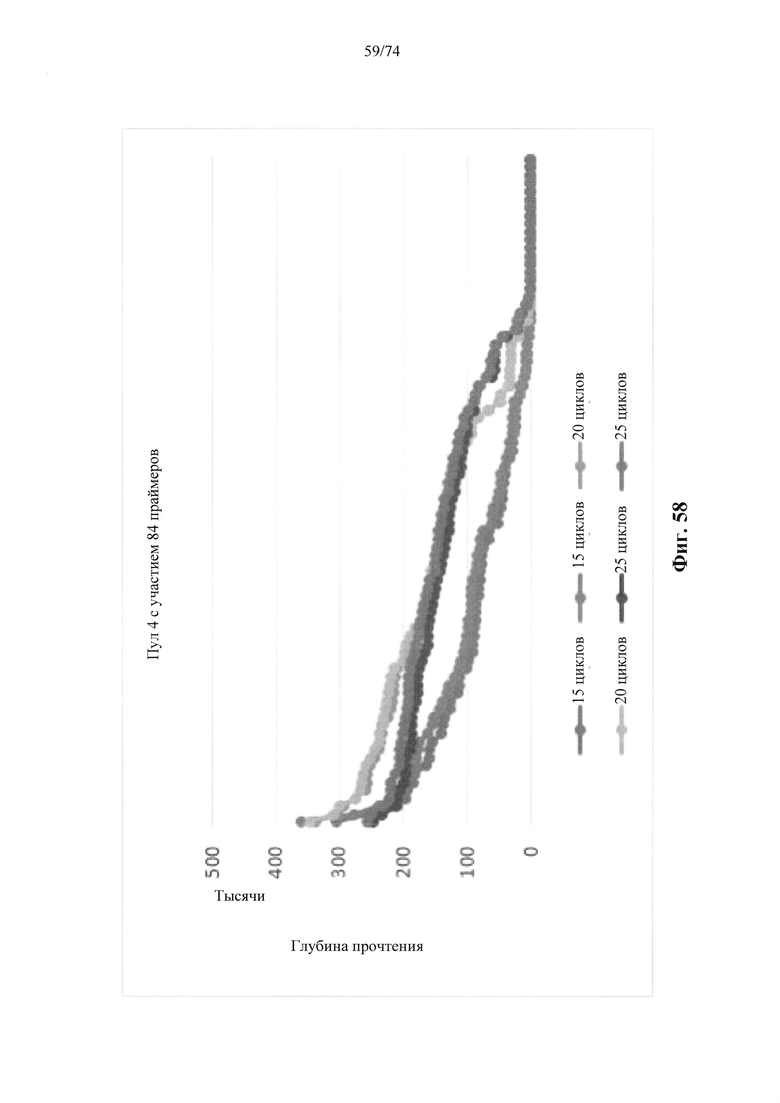
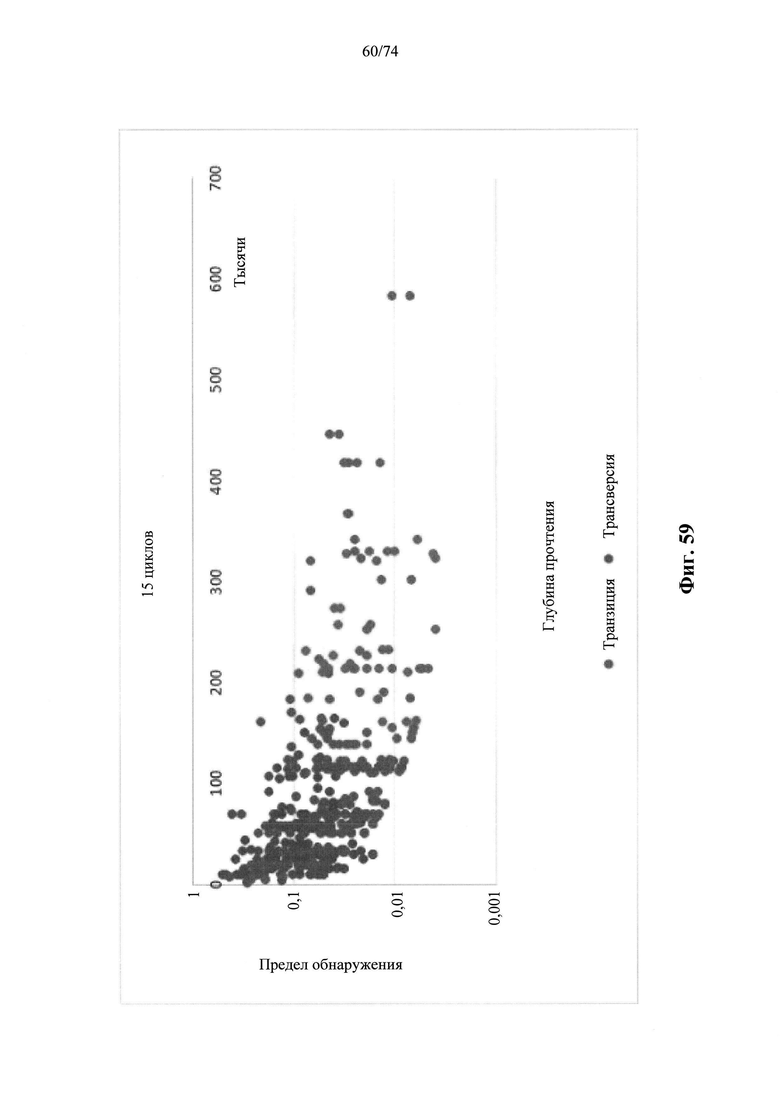
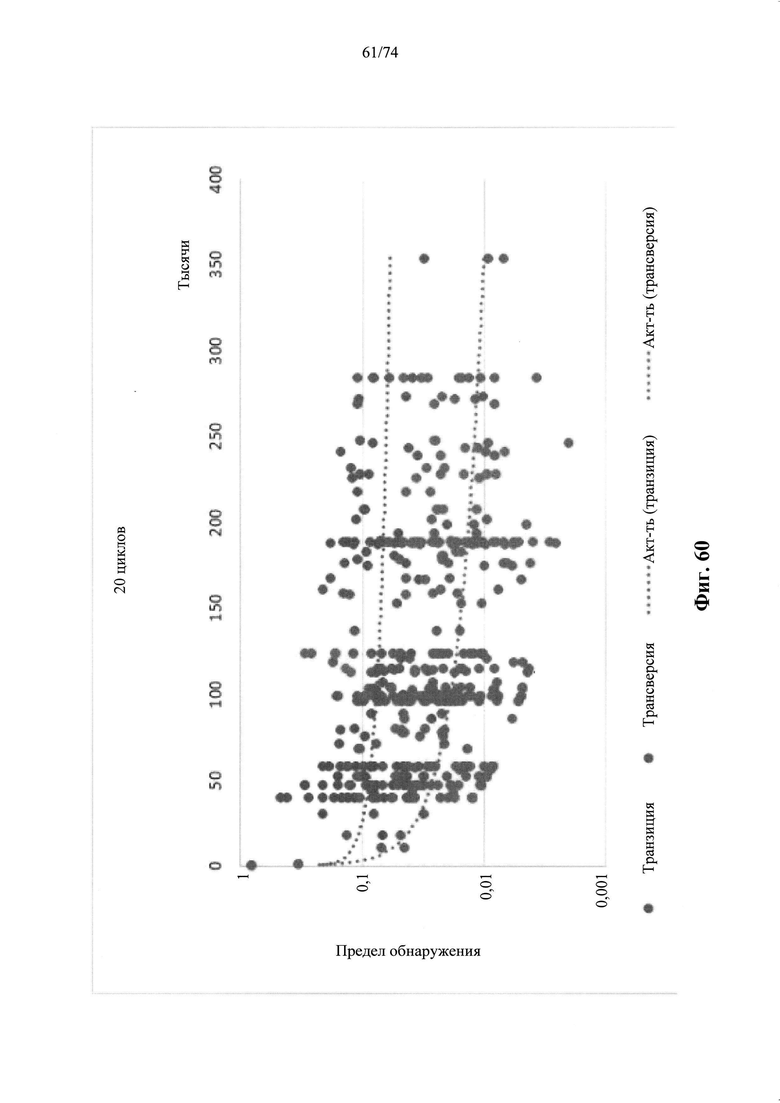
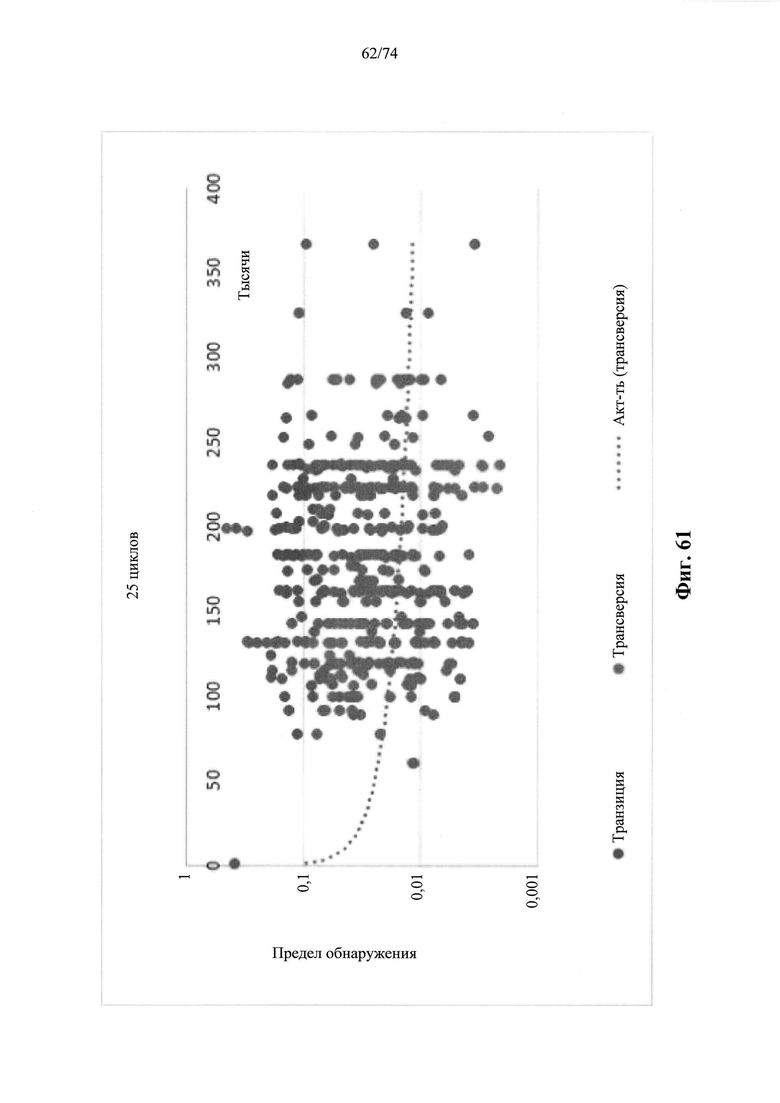

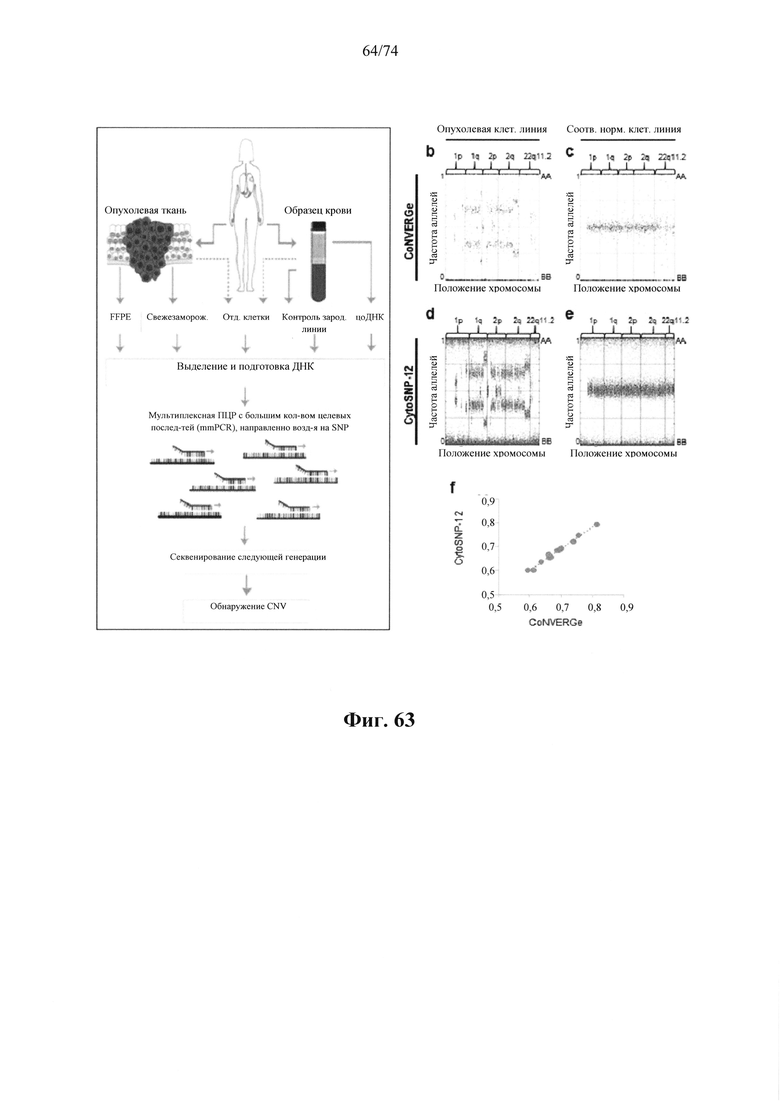
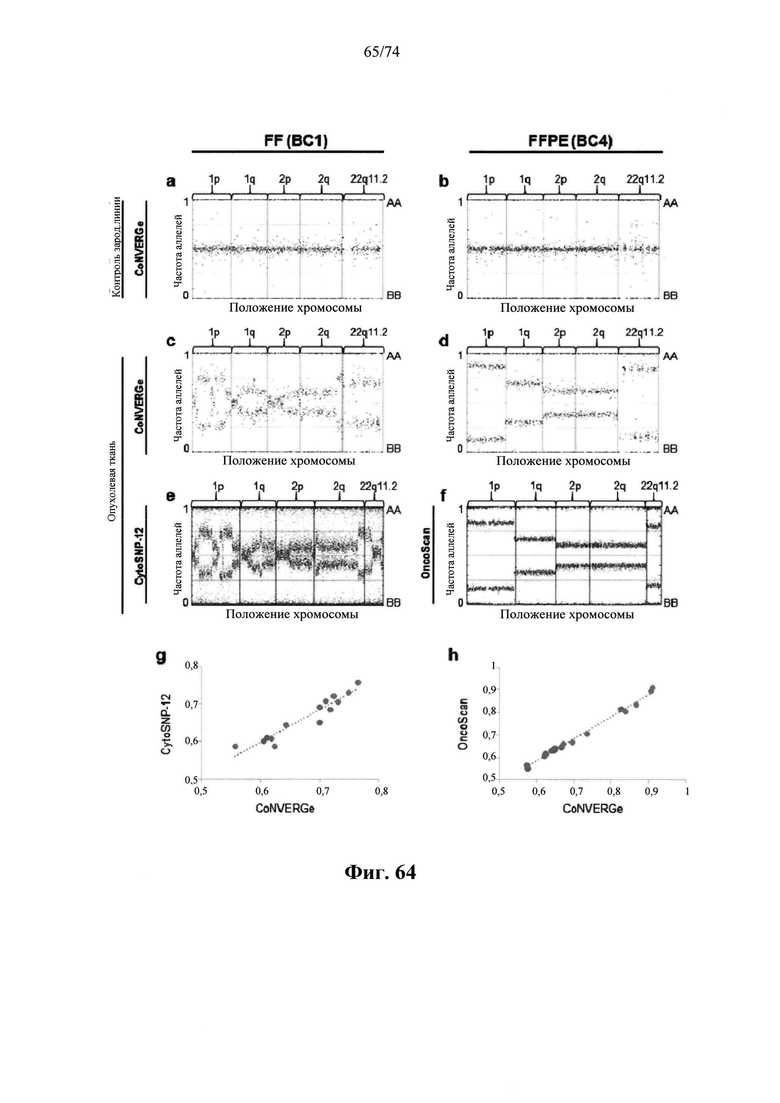
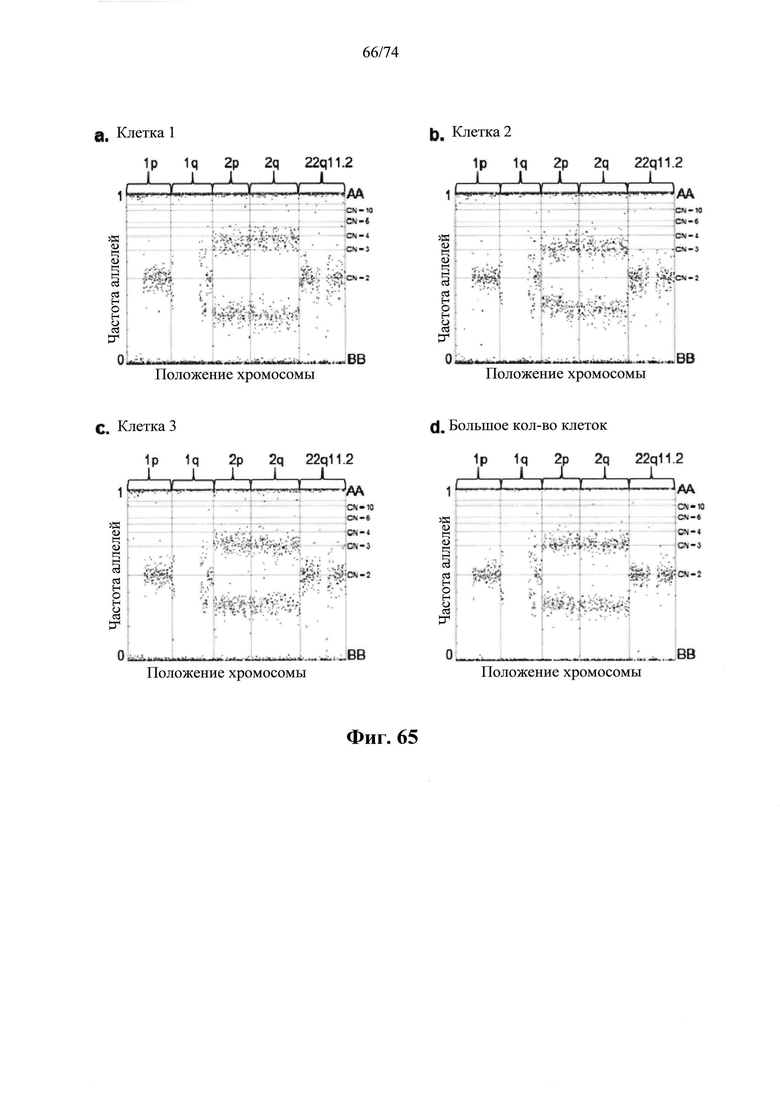
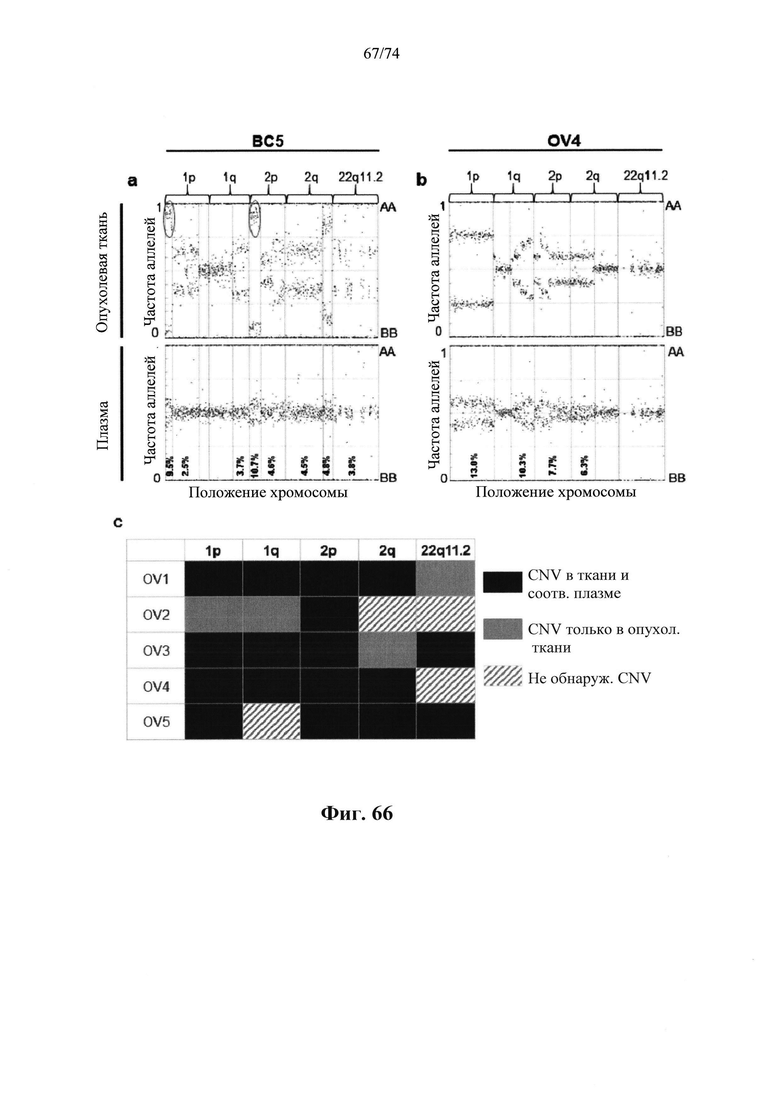
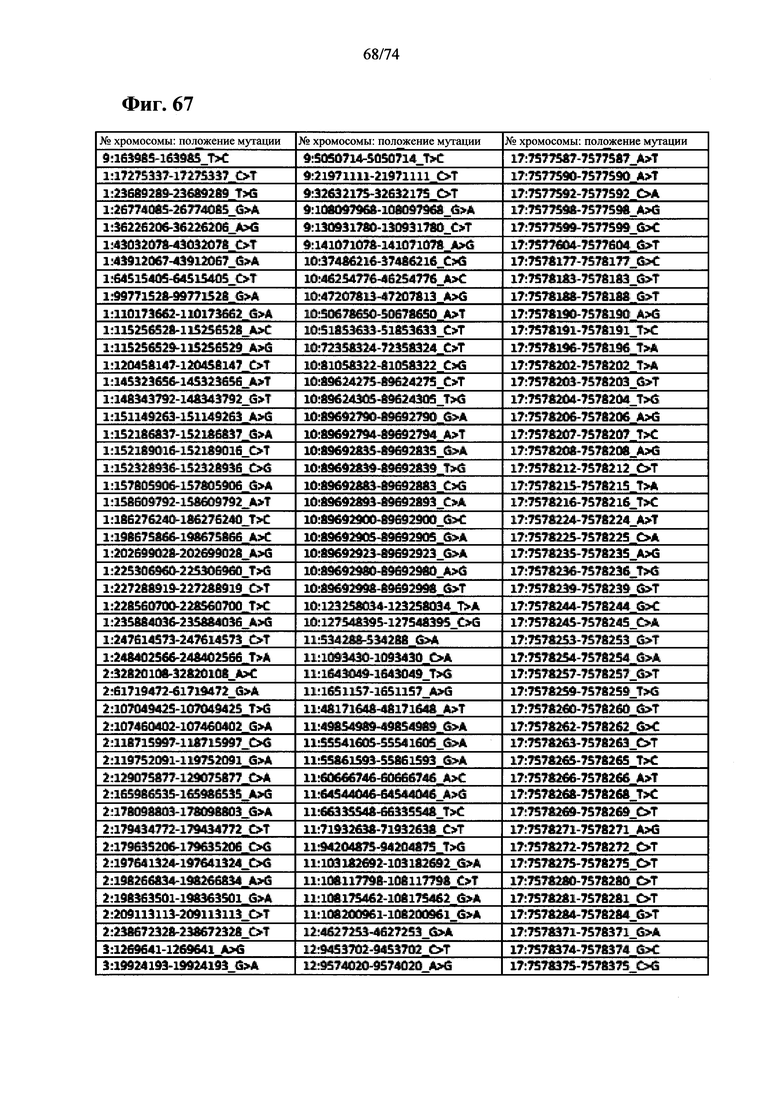

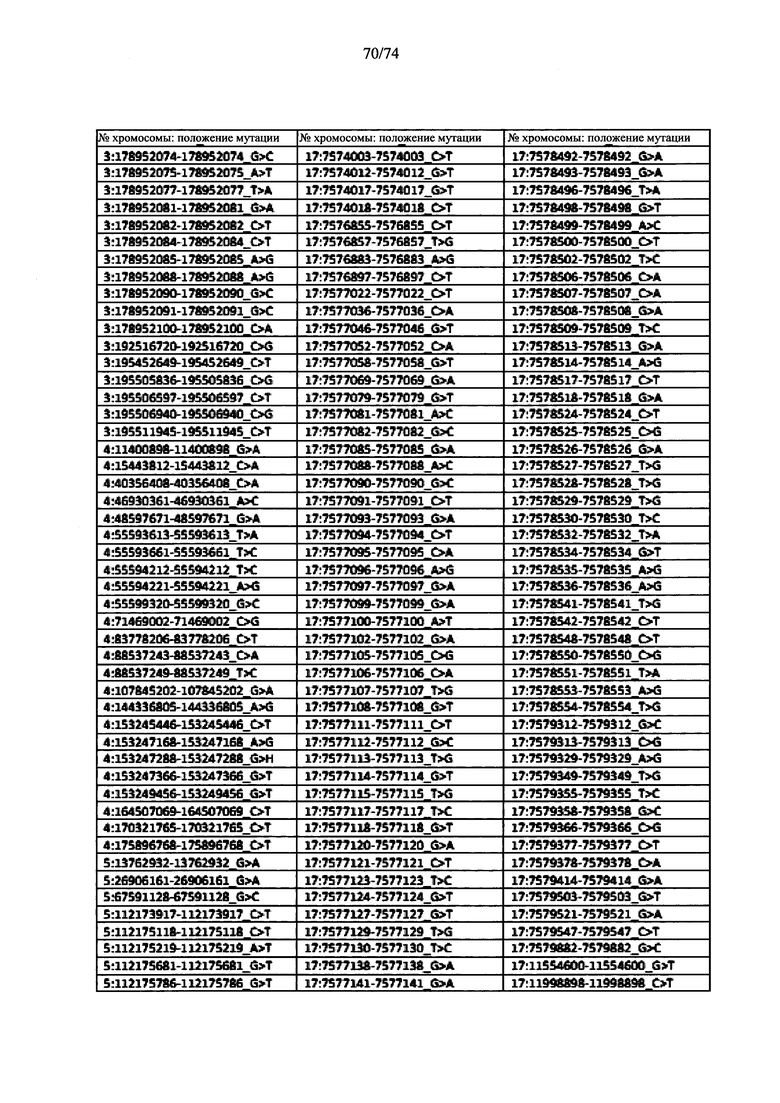
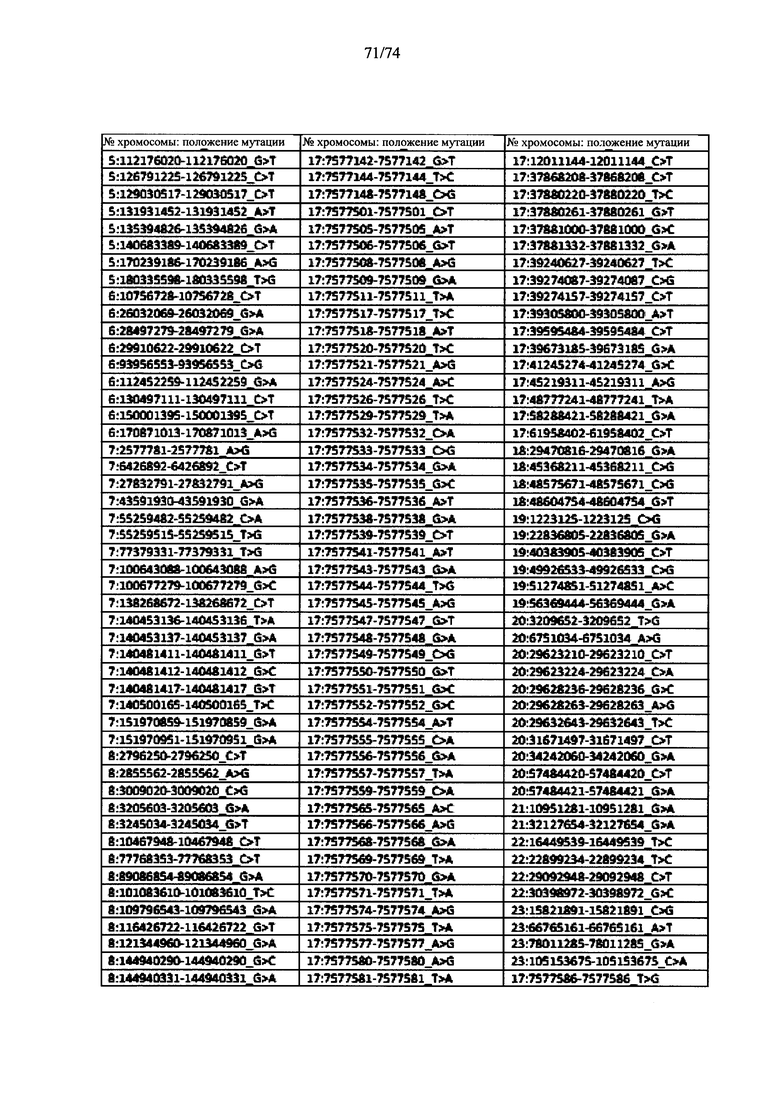
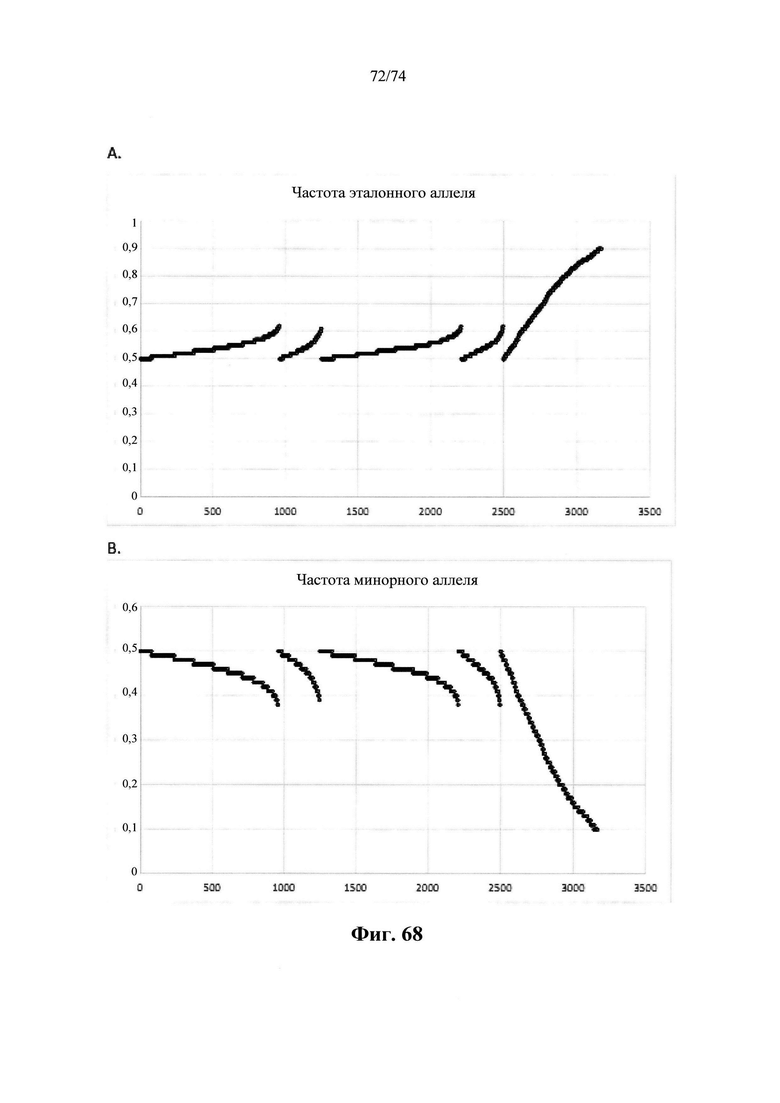
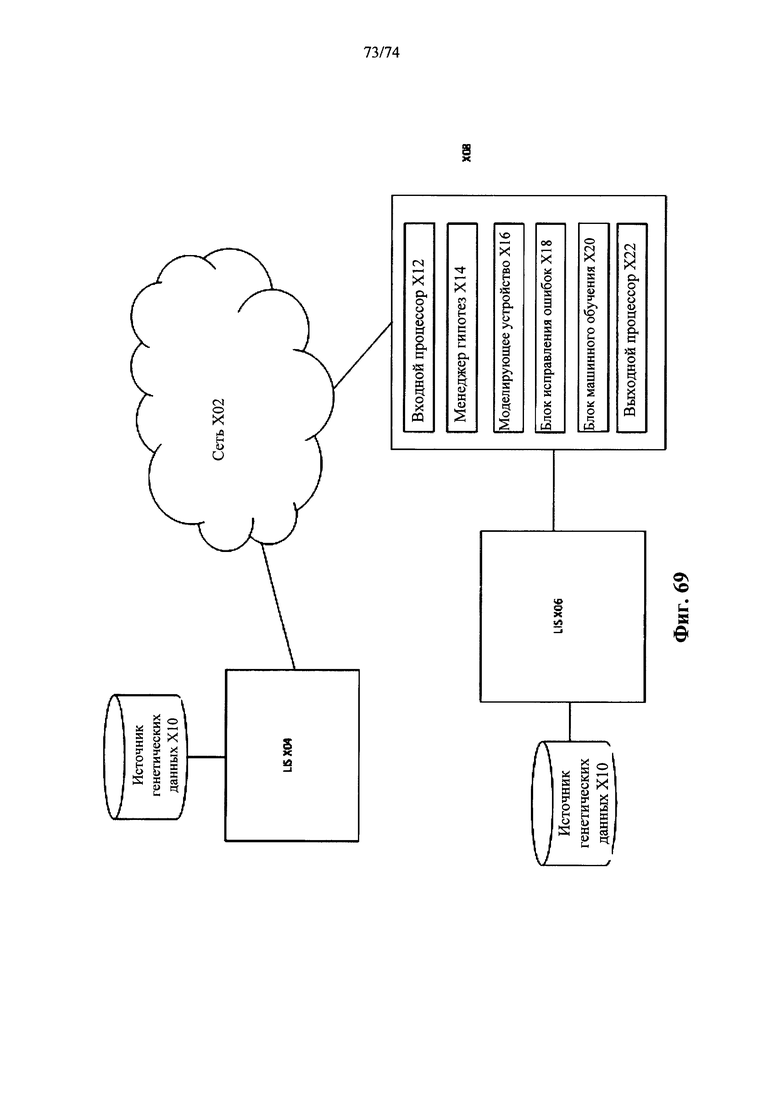
Изобретение относится к биотехнологии, в частности к способу обнаружения плоидности хромосомных сегментов или целых хромосом, для обнаружения однонуклеотидных вариантов и для обнаружения, как плоидности хромосомных сегментов, так и однонуклеотидных вариантов. Согласно некоторым аспектам в настоящем изобретении предусмотрены способы для обнаружения злокачественной опухоли или хромосомных аномалий у вынашиваемого плода. 2 н. и 15 з.п. ф-лы, 70 ил., 1 табл., 15 пр.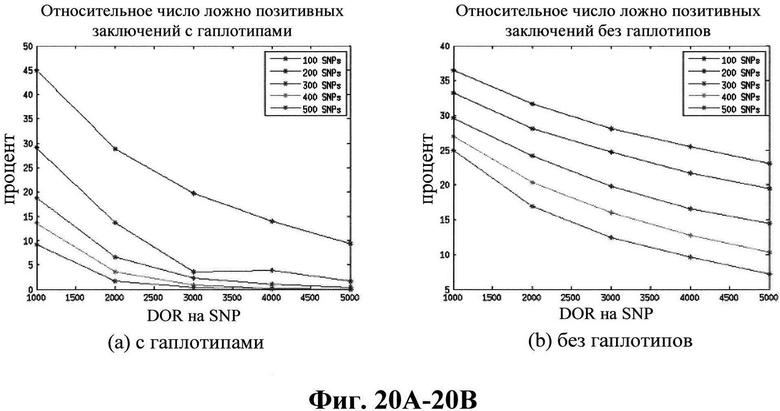
1. Способ определения плоидности хромосомного сегмента в образце индивидуума, предусматривающий:
a. выделение циркулирующей опухолевой ДНК из образца крови, образца сыворотки или образца плазмы от индивидуума, у которого подозревают наличие злокачественной опухоли;
b. амплификацию по меньшей мере 1000 полиморфных локусов, связанных с вариацией числа копий, связанной со злокачественной опухолью, из циркулирующей опухолевой ДНК для получения ампликонов;
c. секвенирование ампликонов для получения данных о частоте аллелей, сгенерированных из образца, содержащих количество каждого аллеля, присутствующего в образце, в каждом локусе в совокупности полиморфных локусов на хромосомном сегменте;
d. создание фазированной аллельной информации для совокупности полиморфных локусов путем оценки фазы данных о частоте аллелей;
e. создание индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности с использованием данных о частоте аллелей, где индивидуальные вероятности получают с использованием совокупности моделей, как различных состояний плоидности, так и фракций аллельного дисбаланса для совокупности полиморфных локусов;
f. создание совместных вероятностей для совокупности полиморфных локусов с использованием индивидуальных вероятностей и фазированной аллельной информации и учет взаимосвязи между полиморфными локусами на хромосомном сегменте; а также
g. выбор, основанный на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную плоидность, тем самым определяя плоидность хромосомного сегмента, и способ дополнительно предусматривает определение на основании выбора того, присутствует ли в клетках опухоли индивидуума вариация числа копий.
2. Способ по п. 1, при котором данные о частоте аллелей получают из данных о последовательности нуклеиновых кислот.
3. Способ по п. 1, дополнительно предусматривающий исправление ошибок в данных о частоте аллелей и использование исправленных данных о частоте аллелей для создания стадии индивидуальных вероятностей, где исправляемые ошибки представляют собой систематические ошибки эффективности амплификации аллелей.
4. Способ обнаружения хромосомной плоидности в образце индивидуума, предусматривающий:
a. выделение циркулирующей опухолевой ДНК из образца крови, образца сыворотки или образца плазмы от индивидуума, у которого подозревают наличие злокачественной опухоли;
b. амплификацию по меньшей мере 1000 полиморфных локусов, связанных с вариацией числа копий, связанной со злокачественной опухолью, из циркулирующей опухолевой ДНК для получения ампликонов;
c. секвенирование ампликонов для получения данных о последовательности нуклеиновой кислоты, сгенерированных из образца, для аллелей в совокупности полиморфных локусов на хромосомном сегменте у индивидуума;
d. обнаружение частот аллелей в совокупности локусов с использованием данных о последовательностях нуклеиновых кислот;
e. коррекция систематических ошибок эффективности амплификации аллелей в обнаруженных частотах аллелей для получения скорректированных частот аллелей для совокупности полиморфных локусов;
f. создание фазированной аллельной информации для совокупности полиморфных локусов путем оценки фазы данных о последовательностях нуклеиновых кислот;
g. создание индивидуальных вероятностей частот аллелей для полиморфных локусов для различных состояний плоидности путем сравнения скорректированных частот аллелей с совокупностью моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов;
h. создание совместных вероятностей для совокупности полиморфных локусов путем объединения индивидуальных вероятностей с учетом связи между полиморфными локусами на хромосомном сегменте; а также
i. выбор, основанный на совместных вероятностях, наиболее подходящей модели, указывающей на хромосомную плоидность, и способ дополнительно предусматривает
определение на основании выбора того, присутствует ли в клетках опухоли индивидуума вариация числа копий.
5. Способ по любому из пп. 1-4, при котором индивидуальные вероятности создаются путем моделирования состояний плоидности первого гомолога хромосомного сегмента и второго гомолога хромосомного сегмента, причем состояния плоидности заключаются в том, что:
(1) все клетки характеризуются отсутствием делеции или амплификации первого гомолога или второго гомолога хромосомного сегмента;
(2) по меньшей мере некоторые клетки характеризуются наличием делеции первого гомолога или амплификации второго гомолога хромосомного сегмента; а также
(3) по меньшей мере некоторые клетки характеризуются наличием делеции второго гомолога или амплификации первого гомолога хромосомного сегмента.
6. Способ по п. 4, при котором ошибки, которые исправляются, содержат загрязнение от окружающей среды и загрязнение генотипа и определяются для гомозиготных аллелей в образце.
7. Способ по п. 4, при котором отбор осуществляется путем анализа величины разницы между фазированной аллельной информацией и расчетными частотами аллелей, полученными для моделей, и выбирается модель с меньшей величиной разницы.
8. Способ по любому из пп. 1-3, 4, 6 и 7, при котором индивидуальные вероятности частот аллелей
(i) получают на основании бета-биномиальной модели ожидаемых и наблюдаемых частот аллелей в совокупности полиморфных локусов; или
(ii) получают с использованием Байесовского классификатора.
9. Способ по любому из пп. 2 или 4, при котором данные о последовательности нуклеиновой кислоты получают посредством выполнения секвенирования ДНК с высокой пропускной способностью множества копий серий ампликонов, полученных с использованием мультиплексной реакции амплификации, причем каждый ампликон из серии ампликонов
охватывает по меньшей мере один полиморфный локус совокупности полиморфных локусов и причем каждый из полиморфных локусов совокупности амплифицируется.
10. Способ по п. 9, при котором мультиплексную реакцию амплификации
(i) осуществляют в условиях ограниченного количества праймера; или
(ii) содержит от 1000 до 100000 мультиплексных реакций.
11. Способ по п. 9, при котором хромосомную плоидность определяют для совокупности хромосомных сегментов в образце.
12. Способ по любому из пп. 1-3, 4, 6 и 7, в котором средний аллельный дисбаланс, превышающий 0,45%, свидетельствует о присутствии в клетках опухоли индивидуума вариации числа копий.
13. Способ по любому из пп. 1-3, 4, 6 или 7, при котором образец представляет собой образец плазмы от индивидуума, у которого ранее имелась солидная опухоль.
14. Способ по любому из пп. 1-3, 4, 6 или 7, дополнительно предусматривающий определение, представлен ли однонуклеотидный вариант в образце в целевой совокупности однонуклеотидных вариантов, причем обнаружение либо вариации числа копий, либо однонуклеотидного варианта, либо и того и другого указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце.
15. Способ по п. 13, дополнительно предусматривающий получение информации о гаплотипе хромосомного сегмента для опухоли индивидуума и использование информации о гаплотипе для создания совокупности моделей различных состояний плоидности и фракций аллельного дисбаланса совокупности полиморфных локусов.
16. Способ по любому из пп. 1-3, 4, 6 или 7, дополнительно предусматривающий
(i) удаление выбросов из скорректированных данных о частоте аллеля перед сравнением скорректированных частот аллелей с совокупностью моделей; или
(ii) реализацию способа на контрольном образце с известным средним соотношением аллельного дисбаланса.
17. Способ по любому из пп. 2-3, 4, 6 или 7, дополнительно предусматривающий определение, представлен ли однонуклеотидный вариант в образце в целевой совокупности однонуклеотидных вариантов, причем обнаружение либо вариации числа копий, либо однонуклеотидного варианта, либо и того и другого указывает на наличие циркулирующих опухолевых нуклеиновых кислот в образце, при этом данные о последовательности нуклеиновой кислоты получают посредством выполнения секвенирования ДНК с высокой пропускной способностью множества копий серий ампликонов, полученных с использованием мультиплексной реакции амплификации, причем каждый ампликон из серии ампликонов охватывает по меньшей мере один полиморфный локус совокупности полиморфных локусов и причем каждый из полиморфных локусов совокупности амплифицируется, и где образец крови, образец плазмы или образец сыворотки используется для определения, присутствует ли в клетках опухоли индивидуума вариация числа копий, или однонуклеотидная вариация, или и то и другое.
| SHU-YI SU et al., Inferring combined CNV/SNP haplotypes from genotype data, BIOINFORMATICS, 2010, v.26, no.11, p.p.:1437-1445 | |||
| WO 2013130848 A1, 06.09.2013 | |||
| WO 2014018080 A1, 30.01.2014 | |||
| СПОСОБ ПРОГНОЗИРОВАНИЯ РЕЦИДИВА СЕРОЗНОГО РАКА ЯИЧНИКОВ | 2005 |
|
RU2290078C1 |
| US 6214558 B1, 14.08.1996. | |||

