Уровень техники
[0001] Пользователи все больше полагаются на облачные ресурсы для онлайновой деятельности, такой как осуществление деловых и личных связей, онлайновых совещаний, демонстрации экрана, видео-чатов, передачи сообщений и другого использования различных ресурсов, доступных от поставщиков служб. Различные приложения и пользовательские данные, связанные со взаимодействием с пользователем, могут сохраняться в базах данных, связанных с ресурсами. Обычно база данных может включать в себя много разных индивидуальных разделов или узлов базы данных, по которым распределены данные. Разделы могут быть распределены по нескольким разным физическим устройствам и серверам. Элементы данных могут быть связаны с идентификаторами, такими как значения ключей, которые указывают, какой из разделов соответствует данным. Идентификаторы могут использоваться для распределения данных и ссылки на данные для выполнения операций, таких как добавление, осуществление доступа и изменение соответствующих элементов данных.
[0002] Со временем объем данных, сохраненных в базе данных, растет, и в какой-то момент емкость запоминающего устройства может быть расширена, чтобы разместить объем данных и запросов. Один традиционный подход расширения базы данных включает в себя остановку служб для базы данных и/или доступа к базе данных, добавление нового запоминающего устройства/разделов к базе данных и затем повторное распределение всех существующих ранее данных по новому размещению разделов. В этом подходе существующие ранее данные перемещаются в новые местоположения, и этот процесс перемещения может занимать довольно много времени для крупных баз данных. Таким образом, традиционные методики расширения базы данных могут довольно сильно нарушать работу служб, предоставляемых пользователям, и занять значительное количество времени для обработки и повторной вставки данных в новые местоположения в обновленном размещении разделов.
Сущность изобретения
[0003] В настоящем документе описаны методики составной функции разбиения, которые могут быть использованы для повторного разбиения базы данных без перемещения существующих данных. В одной или более реализациях база данных разбивается в первом размещении, связанном с первой функцией разбиения. База данных повторно разбивается для формирования второго размещения, связанного со второй функцией разбиения. Создается запись принадлежности ключей для элементов данных в разделах, существующих во время повторного разбиения, которая может использоваться для распознавания данных, соответствующих первому размещению. В одном подходе запись принадлежности ключей конфигурируется как фильтр Блума, который компактным образом представляет ключи или другие идентификаторы, связанные с первым размещением разделов. Составная функция разбиения, которая включает в себя первую функцию разбиения и вторую функцию разбиения, задается и используется для последующих операций базы данных во втором размещении. Составная функция разбиения выполнена с возможностью применять первую функцию разбиения для данных, имеющих ключи, найденные в записи принадлежности ключей, и применять вторую функцию разбиения для других данных, имеющих ключи, которые не найдены в записи принадлежности ключей. Повторное разбиение выполняется таким образом, что элементы данных, существующие во время повторного разбиения, сохраняют свои соответствующие местоположения в разделах первого размещения.
[0004] Это описание сущности изобретения обеспечено для того, чтобы в упрощенной форме представить выбор концепций, которые далее описаны в подробном описании. Это описание сущности изобретения не предназначено для выявления ключевых признаков или существенных признаков заявленного предмета изобретения, а также не предназначено для использования в качестве средства определения объема заявленного предмета изобретения.
Краткое описание чертежей
[0005] Подробное описание дано со ссылками на сопроводительные чертежи. На фигурах самая левая цифра (цифры) номера для ссылки идентифицирует фигуру, на которой впервые появляется номер для ссылки. Использование одинаковых номеров для ссылок в разных случаях в описании и на фигурах может указывать на аналогичные или идентичные элементы. Объекты, представленные на фигурах, могут являться показателем одного или более объектов, и, таким образом, в последующем обсуждении ссылка может делаться взаимозаменяемым образом на единственные или множественные формы объектов.
[0006] Фиг. 1 - иллюстративная операционная среда, которая выполнена с возможностью использовать методики для составных функций разбиения.
[0007] Фиг. 2 изображает иллюстративное размещение разделов для системы базы данных в соответствии с одной или более реализациями.
[0008] Фиг. 3 изображает другое иллюстративное размещение разделов для системы базы данных, представляющее расширение системы, показанной на фиг. 2, в соответствии с одной или более реализациями.
[0009] Фиг. 4 изображает другое иллюстративное размещение разделов для системы базы данных в соответствии с одной или более реализациями.
[0010] Фиг. 5 изображает представление назначения разделов слотам в соответствии с одной или более реализациями.
[0011] Фиг. 6 - блок-схема последовательности операций, изображающая иллюстративную процедуру, в которой задается составная функция разбиения, в соответствии с одной или более реализациями.
[0012] Фиг. 7 блок-схема последовательности операций, изображающая иллюстративную процедуру, в которой составная функция разбиения используется для маршрутизации запросов к размещениям, разделов в соответствии с одной или более реализациями.
[0013] Фиг. 8 - иллюстративная система, имеющая устройства и компоненты, которые могут использоваться для реализации аспектов методик, описанных в настоящем документе.
Подробное описание
Обзор
[0014] Со временем объем данных, хранящихся в базе данных, может вырасти, и в какой-то момент емкость запоминающего устройства может быть расширена, чтобы разместить объем данных и запросов. Один традиционный подход к расширению базы данных включает в себя закрытие базы данных для создания новых разделов и распределения всех существующих ранее данных в новом размещении разделов, что является затратным по времени и нарушает работу для пользователей.
[0015] В настоящем документе описаны методики составной функции разбиения, которые могут быть использованы для повторного разбиения базы данных на разделы без перемещения существующих данных. В одной или более реализациях база данных разбивается в первом размещении, связанном с первой функцией разбиения. База данных повторно разбивается для формирования второго размещения, связанного со второй функцией разбиения. Создается запись принадлежности ключей для элементов данных в разделах, существующих во время повторного разбиения, которая может использоваться для распознавания данных, соответствующих первому размещению. В одном подходе запись принадлежности ключей выполняется как фильтр Блума, который компактным образом представляет ключи или другие идентификаторы, связанные с первым размещением разделов. Составная функция разбиения, которая включает в себя первую функцию разбиения и вторую функцию разбиения, задается и используется для последующих операций базы данных во втором размещении. Составная функция разбиения выполнена с возможностью применять первую функцию разбиения для данных, имеющих ключи, находящиеся в записи принадлежности ключей, и применять вторую функцию разбиения для других данных, имеющих ключи, которые не находятся в записи принадлежности ключей. Повторное разбиение выполняется таким образом, что элементы данных, существующие во время повторного разбиения, сохраняют свои соответствующие местоположения в разделах первого размещения.
[0016] С использованием методик составной функции разбиения согласно настоящему описанию возможно поддерживать существующие данные в их соответствующем местоположении в размещении разделов во время повторного разбиения базы данных. Таким образом, не требуется перемещать большие количества данных, что сокращает количество времени, связанное с повторным разбиением. Кроме того, использование фильтра Блума или другого сжатого представления принадлежности ключей дает возможность быстрых оценок для различения данных, связанных с разными размещениями разделов (например, эпох разделов), и выбора правильных функций разбиения для управления запросами данных. Кроме того, запись принадлежности ключей выполнена как имеющая относительно небольшой размер, что делает запись управляемой, а распределение записи для использования разными серверами, разделами и компонентами системы базы данных выполнимым.
[0017] В последующем обсуждении сначала описывается иллюстративная среда, которая может использовать методики, описанные в настоящем документе. Затем описываются иллюстративные подробные сведения и процедуры, которые могут быть реализованы в иллюстративной среде, а также в другой среде. Следовательно, иллюстративные подробные сведения и процедуры не ограничены иллюстративной средой, и иллюстративная среда не ограничена иллюстративными подробными сведениями и процедурами. Наконец, обсуждаются иллюстративная система и компоненты системы, которые могут использоваться для реализации аспектов методик, описанных в настоящем документе.
Иллюстративная среда
[0018] Фиг. 1 является иллюстрацией среды 100 в иллюстративной реализации, которая выполнена с возможностью использовать методики, описанные в настоящем документе. Иллюстрированная среда 100 включает в себя клиентское устройство 102, другое клиентское устройство 104 и поставщика 106 служб, которые соединены с возможностью связи через сеть 108. Клиентское устройство 102, другое клиентское устройство 104 и поставщик 106 служб могут быть реализованы одним или более вычислительными устройствами, а также могут являться представителями одного или более объектов.
[0019] Вычислительное устройство может быть сконфигурировано разными методами. Например, вычислительное устройство может быть сконфигурировано как компьютер, который способен осуществлять связь по сети 108, например, настольный компьютер, мобильная станция, бытовой прибор для развлечений, телеприставка, соединенная с возможностью связи с устройством отображения, беспроводной телефон, игровая приставка и т.д. Таким образом, вычислительное устройство может находиться в ряду от устройств со значительными ресурсами памяти и процессора (например, персональные компьютеры, игровые приставки) до устройств с ограниченными ресурсами памяти и/или обработки (например, традиционные телеприставки, переносные игровые приставки). Кроме того, хотя в некоторых случаях показано единственное вычислительное устройство, вычислительное устройство может быть представлено как множество разных устройств, например, несколько серверов поставщика 106 служб, используемых коммерческим предприятием для выполнения операций, и так далее. Дополнительные примеры вычислительных систем и устройств, подходящих для реализации методик, описанных в настоящем документе, описаны ниже относительно фиг. 8.
[0020] Хотя сеть 108 проиллюстрирована как Интернет, сеть может предполагать большое разнообразие конфигураций. Например, сеть 108 может включать в себя широкомасштабную сеть (WAN), локальную сеть (LAN), беспроводную сеть, телефонную сеть общего пользования, интранет, одноранговую сеть и так далее. Кроме того, хотя показана единственная сеть 108, сеть 108 может быть сконфигурирована с возможностью включать в себя несколько сетей.
[0021] Клиентское устройство 102 далее проиллюстрировано как включающее в себя операционную систему 110. Операционная система 110 выполнена с возможностью абстрагировать базовую функциональность базового устройства для приложений 112, которые могут быть исполнены на клиентском устройстве 102. Например, операционная система 110 может выполнять абстрагирование функциональности процессора, памяти, сеть и/или дисплея, в результате чего приложения 112 могут быть написаны без знания о том, "как" эта базовая функциональность реализована. Приложения 112, например, могут обеспечивать данные операционной системе 110 для их визуализации и отображения посредством устройства отображения, как проиллюстрировано, без понимания того, каким образом будет выполнена эта визуализация. Как правило, подразумевается, что множество приложений 112, связанных с клиентскими устройствами, включают в себя, но без ограничения, комплект приложений для продуктивной работы, который объединяет несколько модулей офисного пакета приложений, веб-браузер, игры, мультимедийный проигрыватель, текстовой процессор, программу обработки электронных таблиц, менеджер фотоизображений и т.д.
[0022] Клиентское устройство 102 и другое клиентское устройство каждое проиллюстрировано как включающее в себя модуль 114 связи. Модули связи представляют функциональность для предоставления возможности различных видов связи через сеть 108. Примеры модулей связи включают в себя приложение голосовой связи (например, клиент VoIP), приложение видеосвязи, приложение обмена сообщениями, приложение для совместного использования информационного содержания, браузер для осуществления доступа к веб-контенту и их комбинации. Модуль 114 связи, например, дает возможность объединять различные методики связи для обеспечения разнообразных сценариев связи. Это включает в себя, но без ограничения, реализацию интегрированной функциональности для индикаторов присутствия пользователя, видеосвязи, сотрудничества и совещаний в режиме онлайн, мгновенного обмена сообщениями (IM) и голосовых вызовов. Кроме того, модуль связи может быть выполнен с возможностью осуществлять доступ к онлайновым ресурсам (например, к информационному содержанию и службам), просматривать веб-страницы и сайты, устанавливать соединения связи с поставщиками служб и другими клиентами и предоставлять возможность для различных других взаимодействий через пользовательские интерфейсы 116, которые могут быть выданы через модули связи. По меньшей мере, в некоторых реализациях модуль 114 связи представляет приложение, которое развернуто и установлено локально на клиентском устройстве. Дополнительно или в качестве альтернативы, модуль 114 связи может быть реализован полностью или частично как удаленное приложение, к которому осуществляется доступ и которое исполняется через веб-браузер (например, веб-приложение), как удаленная служба от поставщика, с использованием методик одноранговых сетей и т.д.
[0023] Поставщик 106 служб включает в себя функциональность, выполненную с возможностью управлять различными ресурсами 118, которые можно сделать доступными по сети 108, например, менеджер 120 ресурсов, как изображено на фиг. 1. Менеджер 120 ресурсов представляет различную функциональность для управления ресурсами 118 и данными, относящимися к ресурсам, как обсуждается в настоящем документе. Поставщик 106 служб может обеспечивать различные ресурсы 118 через веб-страницы или другие пользовательские интерфейсы 116, связь с которыми осуществляется по сети, для выдачи посредством одного или более клиентов через веб-браузер или другое клиентское приложение. Поставщик 106 служб выполнен с возможностью управлять доступом к ресурсам 118, функционированием ресурсов и конфигурацией пользовательских интерфейсов 116 для обеспечения ресурсов 122 и так далее. Поставщик 106 служб может представлять одно или более серверных устройств, используемых для обеспечения различных ресурсов 118.
[0024] Кроме того, менеджер 120 ресурсов может быть выполнен с возможностью реализовывать функции 122 разбиения для управления базами 124 данных, связанными с ресурсами 118, которые могут быть разбиты и повторно разбиты на множество разделов 126 (также называемых сегментами). В целом функция разбиения выполнена с возможностью задавать, каким образом данные распределены по размещению разделов, а также может быть использована для маршрутизации запросов данных к соответствующим разделам. По меньшей мере, некоторые функции 122 разбиения могут являться составными функциями разбиения, которые сконфигурированы и работают таким образом, как описано выше и ниже. Дополнительные подробные сведения относительно формирования и использования составных функций разбиения могут быть найдены в отношении следующих чертежей.
[0025] По меньшей мере, в некоторых вариантах осуществления клиенты могут осуществлять доступ к ресурсам 118, обеспечиваемым поставщиком 106 служб, через клиентские/пользовательские учетные записи, для которых клиенты аутентифицированы. Например, для осуществления доступа к ресурсам 118 клиентское устройство может обеспечить имя пользователя и пароль, которые аутентифицируются службой аутентификации. Когда аутентификация успешна (например, клиент ʺявляется тем, кем он представилсяʺ), служба аутентификации может передать токен (или другой подходящий идентификатор/секретный ключ аутентификации) для разрешения доступа к соответствующим ресурсам. Одна аутентификация может соответствовать одному или более ресурсам, в результате чего аутентификация для единственной учетной записи посредством "однократного входа в систему" может обеспечить доступ к индивидуальным ресурсам, к ресурсам от нескольких поставщиков 106 служб и/или ко всему набору ресурсов, доступных от поставщика 106 служб.
[0026] Обычно ресурсы 118, сделанные доступными поставщиком 106 служб, могут включать в себя любую подходящую комбинацию служб и/или информационного содержания, как правило, сделанными доступными по сети одним или более поставщиками. Некоторые примеры служб включают в себя, но без ограничения, службу поиска, почтовую службу, службу мгновенных сообщений, онлайновый комплект приложений для продуктивной работы, службу совместной работы (например, службу, которая объединяет функциональность для одной или более служб из вызовов VoIP, онлайновых совещаний и конференций, демонстрации экрана, службы унифицированных коммуникаций (UC&C), мгновенного обмена сообщениями, видео-чатов, голосовой связи и т.д.), и службу аутентификации для управления доступом клиентов к ресурсам 118. Информационное содержание может включать в себя различные комбинации текста, мультимедийных потоков, документов, файлов приложений, фотоизображений, мультипликации из аудио/видеофайлов, изображений, веб-страниц, веб-приложений, приложений для устройств, информационного содержания для отображения посредством браузера или другого клиентского приложения и т.п.
[0027] Рассмотрев описанную выше иллюстративную среду, рассмотрим теперь описание некоторых иллюстративных подробных сведений и процедур методик составной функции разбиения в соответствии с одной или более реализациями.
Подробные сведения о составной функции разбиения
[0028] Этот раздел документа описывает подробные сведения методик составной функции разбиения и иллюстративные процедуры, которые могут быть использованы для повторного разбиения базы данных без перемещения существующих данных, в соответствии с одной или более реализациями. Вообще говоря, разбиение представляет собой методику, которая может использоваться для масштабирования баз данных. Разбиение может включать в себя разделение записей/элементов данных на несвязные подмножества, называемые разделами 126 (также называемые сегментами). Разбиение может быть основано на подходящих идентификаторах для записей, одним примером которых являются первичные ключи записей. Разделы могут быть физически распределены по нескольким разным серверам и/или запоминающим устройствам (например, по узлам базы данных). В одном подходе каждому разделу может быть назначен отдельный сервер базы данных, в результате чего существует взаимно однозначное отображение между узлами базы данных и разделами. Кроме того, или в качестве альтернативы, один или несколько разделов могут быть логически разделены по серверам/запоминающим устройствам, в результате чего пространство, распределенное для данного раздела, может быть расположено на двух или более индивидуальных узлах базы данных.
[0029] В этом контексте данное размещение разделов имеет конечную величину потребляемой емкости запоминающего устройства по мере заполнения базы данных. В какой-то момент времени может быть достигнут порог емкости, при котором емкость запоминающего устройства, вероятно, придется расширить, чтобы сделать возможным продолжение работы с базой данных. Расширение базы данных может включать в себя добавление одного или более разделов к существующему размещению разделов, чтобы создать другое размещение разделов с большей емкостью запоминающего устройства. Расширение базы данных также упоминается в настоящем документе как повторное разбиение. Повторное разбиение может произойти для сбалансированной системы, в которой каждый узел базы данных становится одинаково насыщенным либо в отношении объема хранящихся данных, либо в отношении частоты запросов доступа к данным. В этом случае дополнительное запоминающее устройство (например, другой сервер/запоминающее устройство) может быть добавлено с помощью новой функции разбиения, выполненной с возможностью использовать в своих интересах дополнительное запоминающее устройство. Повторное разбиение также может произойти для неравномерно сбалансированной системы, в которой некоторые узлы базы данных близки к пределам запоминающего устройства, в то время как другие узлы мало загружены и имеют запасное свободное пространство. В этой ситуации узлы базы данных могут остаться теми же, но может быть задана новая функция разбиения, которая выполнена с возможностью оказывать предпочтение менее используемым узлам по сравнению с более нагруженными узлами.
[0030] В соответствии с методиками, описанными в настоящем документе, повторное разбиение может быть выполнено таким образом, что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения. Другими словами, данные, уже имеющиеся в базе данных во время повторного разбиения, не перемещаются в результате повторного разбиения, что дает в результате сокращенное время обработки и использования ресурсов. Это может быть достигнуто посредством использования составной функции разбиения, как пояснено в настоящем документе, которая выполнена с возможностью выборочно применять несколько разных базовых функций разбиения, соответствующих последовательным размещениям разделов или ʺэпохам разделовʺ, для обработки запросов данных. Чтобы сделать это, составная функция разбиения может включать в себя или иным образом использовать записи принадлежности ключей для распознавания эпох разделов, которым соответствует каждый запрос данных, и применять подходящую функцию разбиения для эпохи разделов, которая распознана для обработки запроса.
[0031] Рассмотрим теперь примеры на фиг. 2-5, которые иллюстрируют более подробные сведения и концепции относительно составных функций разбиения и записей принадлежности ключей, а также повторного разбиения с использованием составных функций разбиения. В частности, фиг. 2 в целом изображает под номером 200 иллюстративное размещение разделов для системы базы данных в соответствии с одной или более реализациями. В иллюстрированном примере представлен сервер 202, который может быть связан с поставщиком 106 служб, как пояснено относительно фиг. 1. Сервер 202 может быть выполнен с возможностью обеспечивать функциональность, связанную с веб-приложением 204 и/или другими ресурсами 118. Сервер 202 также включает в себя менеджер 120 ресурсов, который может работать, как пояснено в настоящем документе, чтобы управлять взаимодействиями с веб-приложением 204 и запоминающим устройством данных, связанным с веб-приложением в соответствующей базе данных. Данные могут храниться на запоминающих устройствах, на которых заданы разделы 126 для базы данных, и которые могут быть реализованы через один или более серверов, которые могут включать в себя или не включить в себя сервер 202. В реализации один или более разделов 126 для базы данных могут быть обеспечены через сервер 202.
[0032] Менеджер 120 ресурсов в изображенном примере выполнен с возможностью реализовывать функцию p1 206(1) разбиения для размещения разделов, изображенного на фиг. 2, которое включает в себя два иллюстративных раздела, а именно, раздел 208(0) и раздел 208(1). Данные представлены в формате ключ-значение, где ключ - это первичный ключ записи данных, и значение представляет информационное содержание записи данных. Запросы данных могут быть сделаны для осуществления доступа к данным и выполнения операций над данными, в том числе, но без ограничения, добавления записей, удаления записей, модификации данных, операций считывания, операций записи и т.д. Для осуществления доступа к данным, чтобы выполнить операции, запрашивающее приложение использует ключ (или другой сопоставимый идентификатор), чтобы определить местоположение узла базы данных для раздела, соответствующего обозначенному ключу. Как только это сделано, к данным может быть осуществлен доступ из выбранного узла и/или раздела в соответствии с конкретными протоколами, форматами и/или технологией базы данных для системы базы данных, которая может отличаться для разных систем.
[0033] Функция p1 206(1) разбиения и функции 122 разбиения в целом дают возможность детерминированного выбора разделов на основе соответствующих ключей. Другими словами, функция всякий раз выбирает один и тот же раздел для данного ключа, с тем чтобы местоположение данных могло быть достоверно определено. Предусматриваются различные конфигурации функций 122 разбиения. В одном подходе функции разбиения могут быть выполнены как хеш-функции, которые при их применении к значениям ключей для запросов данных возвращают данные, идентифицирующие разделы базы данных, соответствующие значениям ключей.
[0034] В качестве примера и без ограничения, функция p разбиения может иметь форму p(k)=hash(k) mod N, где k - ключ, hash - хеш-функция, и N - количество разделов для данного размещения. В этом примере функция разбиения возвращает номер раздела от 0 до N-1. Хеш-функция присваивает большое целочисленное значение строке (или массиву байтов), представляющей ключ k или другие идентифицирующие данные. Хеш-функции, используемые в этой форме, могут быть выполненным с возможностью обеспечивать равномерное распределение значений. В качестве альтернативы, хеш-функция может быть выбрана/выполнена с возможностью, чтобы достигать распределения значений, которое может использоваться для отклонения размещения данных к конкретному разделу (например, к недостаточно используемым разделам). Функция деления по модулю mod N преобразует большое целочисленное значение обратно в диапазон от 0 до N-1, и это может использоваться в качестве идентификаторов для индивидуальных разделов в размещении разделов. В соответствии с этим функция разбиения может быть разработана таким образом, чтобы распределять данные по узлам/разделам базы данных в соответствии со схемой распределения, отраженной функцией разбиения.
[0035] В примере на фиг. 2 функция p1 206(1) разбиения выполнена с возможностью отображать записи для ключей k1 и k2 на первый раздел, который является разделом 208(0) в этом примере. Другими словами, функция p1 206(1) разбиения, оцененная для ключей k1 и k2, возвращает идентификатор для раздела 208(0), который является значением "0" в этом случае (например, (p1(k1)=p1(k2)=0). В соответствии с этим записи/значения данных, соответствующие ключам k1 и k2, могут быть сохранены на серверах/запоминающем устройстве и доступны с серверов/запоминающих устройств, связанных с разделом 208(0), как представлено на фиг. 2. Функция p1 206(1) разбиения также выполнена с возможностью отображать записи для ключей k3 и k4 на второй раздел, раздел 208(1). При этом функция, оцененная для ключей k3 и k4, возвращает идентификатор для раздела 208(1), который является значением "1" в этом случае (например, (p1(k3)=p1(k4)=1). В соответствии с этим записи/значения данных, соответствующие ключам k3 и k4, могут быть сохранены на серверах/запоминающем устройстве и доступны с серверов/запоминающих устройств, связанных с разделом 208(1), как представлено на фиг. 2.
[0036] Теперь, если достигнут порог емкости для иллюстративной системы, показанной на фиг. 2, дополнительная емкость может быть добавлена посредством включения дополнительных серверов/запоминающего устройства и повторного разбиения базы данных через новое размещение разделов. Рассмотрим, например, расширение от N до Nʹ > N, где, например, Nʹ=N+1 или Nʹ=2*N. Новым размещением разделов управляет новая функция разбиения, созданная, чтобы разместить дополнительную емкость/разделы. Новые данные могут затем быть распределены расширенной системе с использованием новой функции разбиения, которая может иметь форму pʹ(k)=hash(k) mod Nʹ, как описано выше. Местоположением существующих данных, тем не менее, управляет прежняя функция разбиения (например, функция p1 206(1) разбиения), и, таким образом, новая функция разбиения может недостоверно определять местоположение существующих данных, поскольку обычно две функции не выровнены (например, p(k) ≠ pʹ(k)). Традиционное решение включает в себя остановку службы базы данных на некоторый период времени, итерацию по существующим записям и выполнение операции удаления и повторной вставки в соответствии с новой функцией разбиения, чтобы обеспечить возможность последующего использования новой функции разбиения. Как упомянуто ранее, это может довольно сильно нарушать работу и занимать много времени для баз данных, имеющих большой объем данных и запросов.
[0037] Методики составной функции разбиения, описанные в настоящем документе, тем не менее, могут использоваться для повторного разбиения базы данных без перемещения существующих данных. В целом составная функция разбиения использует записи принадлежности ключей для разных размещений разделов, чтобы выбрать соответствующую функцию разбиения для использования для данной операции базы данных. В этом случае функция разбиения, посредством которой конкретные данные были распределены первоначально базе данных, продолжает использоваться для конкретных данных даже после повторного разбиения. Записи принадлежности ключей позволяют выбирать правильную функцию для применения, и составная функция разбиения выполнена с возможностью использовать комбинацию двух или более индивидуальных функций разбиения, каждая из которых соответствует отдельной эпохе разделов.
[0038] Для иллюстрации рассмотрим фиг. 3, которая в целом под номером 300 изображает другое иллюстративное размещение разделов для системы базы данных, представляющее расширение системы, показанной на фиг. 2, в соответствии с одной или более реализациями. В этом примере дополнительный раздел 208(2) изображен как включенный в размещение разделов на фиг. 3. Кроме того, менеджер 120 ресурсов проиллюстрирован как реализация составной функции 302 разбиения, которая управляет распределением данных для размещения разделов на фиг. 3. Составная функция 302 разбиения выполнена с возможностью объединять прежнюю функцию для размещения, показанного на фиг. 2, функцию p1 206(1) разбиения, с новой функцией, функцией function p2 206(2) разбиения, установленной для повторного размещения разделов, показанного на фиг. 3. Составная функция 302 разбиения также выполнена с возможностью включать в себя или использовать запись b1 304(1) ключа, которая может использоваться для распознавания соответствия значений ключей с индивидуальной функцией разбиения, включенной в составную функцию 302 разбиения. В одном подходе запись b1 304(1) ключа обеспечивает механизм для идентификации того, какие значения ключей связаны с прежней функцией (функцией p1 206(1) разбиения), и, таким образом, для выбора этой функции для обработки соответствующих запросов данных. Функция function p2 206(2) разбиения может использоваться для других запросов данных, которые не соответствуют значениям ключей, содержащимся в записи b1 304(1) ключа.
[0039] В этом примере записи данных/значения, связанные с ключами k1, k3, k3 и k4, заранее существуют в системе и распределены по двум разделам, как показано на фиг. 2. Может произойти повторное разбиение для добавления дополнительного раздела, как показано на фиг. 3. В реализациях система базы данных может быть остановлена для создания дополнительного раздела (разделов) и установки составной функции разбиения. Как часть повторного разбиения существующие ключи в системе (например, k1, k2, k3 и k4) обрабатываются для создания записей принадлежности ключей во время повторного разбиения, которое представлено записью b1 304(1) ключа. Следует отметить, что эта обработка может занять значительно меньше времени относительно количества времени, которое было бы потрачено для перемещения существующих записей в соответствии с новой функцией разбиения.
[0040] Составная функция 302 разбиения может быть задана следующим образом. Функция p1 206(1) разбиения представляет собой первоначальную функцию разбиения для размещения двух разделов и может иметь форму p1(k)=hash(k) mod 2. Функция function p2 206(2) разбиения представляет собой новую функцию разбиения, установленную для расширенного размещения трех разделов, и может иметь форму p2(k)=hash(k) mod 3. Теперь составная функция 302 разбиения, представленная как pʹ(k), может быть выражена как:
pʹ(k)=p1(k) для любого k, для которого b1(k)=истина, или pʹ(k)=p2(k) в ином случае.
[0041] Другими словами, выполняется проверка, чтобы увидеть, включено ли значение ключа в запись b1 304 (1) ключа. Если значение ключа найдено, для обработки соответствующего запроса используется функция p1. Иначе, если значение ключа не найдено, для обработки соответствующего запроса используется функция p2. С использованием составной функции 302 разбиения существующие записи могут оставаться в своих исходных местоположениях, поскольку их местоположение по-прежнему определяется с использованием p1. Новые записи могут выполнять заполнение данными по размещению раздела, включающего в себя новый раздел, с использованием p2. Следовательно, в дальнейшем используется все множество узлов базы данных.
[0042] Записи принадлежности ключей, такие как запись b1 304(1) ключа на фиг. 3, могут быть выполнены любым подходящим методом для различения ключей, связанных с разными размещениями разделов и/или эпохами разделов. Неформатированные списки ключей, соответствующих каждому размещению/эпохе, могут использоваться в одной или более реализациях. Тем не менее, на практике размер неформатированного списка ключей может затруднять распределение списков разным серверам баз данных и узлам и занимать значительный объем памяти. В соответствии с этим в дополнение или в качестве альтернативы использованию неформатированных списков может использоваться компактное представление ключей в сжатом формате. Предусматривается множество разных сжатых структур данных, которые могут быть выполнены с возможностью идентифицировать ключи, соответствующие элементам данных, существующим в базе данных во время повторного разбиения. Примеры сжатых структур данных среди прочего включают в себя, но без ограничения, битовую карту, массивы, матрицы и фильтры.
[0043] Другим примером сжатой структуры данных, которая может быть пригодной для записей принадлежности ключей в одной или более реализациях, является фильтр Блума. Фильтр Блума представляет собой структуру данных, которая выполнена с возможностью запоминать принадлежность к множеству значений экономичным по занимаемому объему методом. В частности, для заданного множества ключей S={k1, …, kN} может быть создан фильтр Блума для "запоминания" существования каждого ключа во множестве S. Поскольку фильтр Блума является экономичным по занимаемому объему, он не запоминает просто список всех ключей. Вместо этого фильтр Блума поддерживает битовый вектор, в котором для каждого ключа k из множества S бит устанавливается в индексе hash(k) mod M, где hash - хеш-функция (которая может отличаться или не отличаться от хеш-функций, связанных с функциями разбиения), и M - длина битового вектора. Чтобы определить принадлежность к множеству для любого данного ключа k, выполняется поиск бита в позиции hash(k) mod М. Если бит установлен, ключ является элементом множества, иначе не является. Битовый вектор является очень экономичным по занимаемому объему, и тем самым он позволяет сохранить фильтр Блума в памяти узлов базы данных даже для больших количеств ключей, которые, как правило, находятся в базах данных, поддерживающих крупные приложения.
[0044] Следует отметить, что фильтр Блума представляет собой вероятностную структуру данных, которая производит некоторые ложноположительные ошибки. Например, ключ k2, который не является элементом множества S, в результате хеширования может быть преобразован в такое же значение, как и ключ k1, который является элементом S. Эта ошибка известна как коллизия хеш-функции. Частота появления ошибок мала, но они все же возможны. В соответствии с этим для небольшого количества ключей, которые не являются элементами S, фильтр Блума может неправильно классифицировать их как элементы множества. Вероятность ошибок может быть минимизирована посредством расширения длины битового вектора и/или посредством использования нескольких хеш-функций и разрешение вопроса принадлежности на основе проверки установки нескольких битов, обозначенных этими хеш-функциями. Таким образом, фильтр Блума может быть выборочно выполнен с возможностью управлять ошибками посредством определения длины битового вектора и выбора одной или более хеш-функций для использования для фильтра Блума. На практике может быть сделан компромисс для установки приемлемой частоты появления ошибок с учетом ограничений на объем памяти, потребляемой фильтром Блума, и задержки/затрат на вычисления хеш-функций. Частота появления ошибок является приемлемой с учетом того, что если фильтр Блума ошибочно распознает ключ для новых данных как являющийся элементом множества, то он будет делать это всякий раз одинаково. Таким образом, местоположение данных может быть достоверно определено, даже если они размещены с использованием прежней функции разбиения. Кроме того, фильтр Блума не возвращает ложноотрицательные ошибки для ключей, которые являются элементами множества (например, ключей для существующих ранее записей), таким образом, старые данные могут остаться в первоначальных местоположениях, и их расположение может быть достоверно определено в первоначальных местоположениях. В одном подходе конфигурация фильтра Блума может включать в себя установку конфигурируемого допуска, который определяет, как часто производятся ложноположительные ошибки. В свою очередь степень компактности фильтра Блума зависит от конфигурируемого допуска. Например, более высокая степень компактности может быть достигнута посредством установки конфигурируемого допуска, чтобы производить или "допускать" больше ложноположительных ошибок. На практике может быть достигнута очень высокая степень компактности, поскольку местоположение ошибочно распознанных элементов данных может быть по-прежнему достоверно определено с использованием функции из предыдущей эпохи. Другими словами, эффект ошибок фильтра Блума может быть незначительным, то есть, может быть допустимой относительно большая частота ошибок, и, таким образом, могут использоваться очень компактные конфигурации фильтров Блума.
[0045] Рассмотрим теперь пример, представленный на фиг. 3, в котором четыре новые записи добавляются к системе после повторного разбиения. В целях этого примера предположим, что запись b1 304(1) ключа выполнена как фильтр Блума, как только что описано. Ключи k1, k3, k3 и k4 существовали в системе ранее и будут распознаны как являющиеся элементами фильтра Блума. В соответствии с этим запросами, связанными с этими ключами, управляет функция p1 206(1) разбиения. Ключи k5 и k6, как оказывается, не являются элементами фильтра Блума и могут быть назначены функцией p2 206(2) разбиения для раздела 208(1). Ключ k7 также не оказывается в фильтре Блума и назначается функцией p2 206(2) разбиения для нового раздела базы 3 данных. Ключ k8 представляет собой интересный случай, поскольку это новый ключ, который появился после повторного разбиения, и все же вследствие ошибки фильтра Блума, как описано выше, он неправильно классифицирован как элемент, и, следовательно, назначен функцией p1 206(1) разбиения для раздела 208(1). Хотя, как отмечено, это не вызывает проблем с целостностью данных или способностью определять местоположение данных, соответствующих ключу k8, поскольку фильтр Блума будет всякий раз одинаково ошибочно распознавать ключ k8 и, таким образом, достоверно маршрутизировать запросы данных.
[0046] Далее следует отметить, что процесс повторного разбиения, описанный в настоящем документе, может быть выполнен многократно для последовательных эпох разделов. Концепции, описанные выше относительно фиг. 1-3, могут быть применены к обобщенному случаю, который включает в себя несколько операций повторного разбиения. Например, прежняя функция p1 в предыдущем примере может являться другой составной функцией разбиения, которая соответствует предыдущему повторному разбиению. Другими словами, составная функция разбиения, установленная для текущего размещения разделов, может включать в себя одну или более других составных функций разбиения для предыдущих размещений.
[0047] Для дополнительной иллюстрации рассмотрим фиг. 4, которая в целом под номером 400 изображает другое иллюстративное размещение разделов для системы базы данных в соответствии с одной или более реализациями. В частности, фиг. 4 изображает обобщенный случай нескольких разделов базы данных (от 1 до N) и нескольких операций повторного разбиения, каждая из которых не приводит к перемещению существующих данных в новые местоположения в размещении разделов. В этом примере период эксплуатации системы базы данных может иметь серию последовательных эпох разделов (от 1 до M). Каждая эпоха разделов связана с соответствующей функцией 122 разбиения, которая задает, каким образом распределять и располагать данные для разделов, существующих для этой эпохи разделов. Кроме того, повторное разбиение представляет конец предыдущей эпохи разделов и начало новой эпохи разделов. Фильтры Блума или другие записи принадлежности ключей, существующие в конце каждой эпохи, могут быть установлены как часть повторного разбиения. Таким образом, разные эпохи разделов могут быть связаны с разными записями принадлежности ключей, которые могут использоваться для распознавания правильных функций 122 разбиения для применения для запроса данных.
[0048] Текущей эпохой M разделов управляет составная функция 402 разбиения, которая является комбинацией нескольких хеш-функций p1,..., pM разбиения, имеющих ссылки 206(1),..., 206 (M), для каждой эпохи разделов. Кроме того, записи b1,..., bM-1 ключей, имеющие ссылки 304(1),..., 304(M-1), изображены как установленные для каждой из эпох разделов перед текущей эпохой. Составная функция 402 разбиения может быть выполнена с возможностью проверять, найдено ли значение ключа в какой-либо из записей ключей, и затем применять соответствующую функцию разбиения, когда определена принадлежность одной из записей ключей. В одном подходе проверка начинается с проверки записи ключа для самой старой эпохи и затем последовательно проходит через каждую эпоху от самой старой до самой новой, пока не будет найдено соответствие. Если соответствие не найдено ни в одной из записей ключей, выбирается и применяется функция pM(206(M)) для текущей эпохи. В этом контексте составная функция 402 разбиения может быть выражена следующим образом:
если k найден в фильтре b1, то установить p(k)=p1(k)
иначе если k найден в фильтре b2, то установить p(k)=p2(k)
... продолжать оценки для прошедших эпох
иначе если k найден фильтре bM-1, то установить p(k)=pM-1(k)
иначе установить p(k)=pM(k)
Представление иллюстративной составной функции 402 разбиения на псевдокоде:
repeat for i from 1 to M
if bi(k) == true
return pi(k)
return pM(k)
[0049] В соответствии с приведенным выше обсуждением, составная функция разбиения, выполненная с возможностью выборочно применять функции разбиения для двух или более эпох разделов, может быть задана для управления операциями базы данных и запросами для текущей эпохи. В одной или более реализациях составная функция разбиения выполнена с возможностью обеспечивать в значительной степени равное распределение новых записей данных по разделам в текущем размещении разделов. Тем не менее, в зависимости от распределения данных, которые существуют во время повторного разбиения, распределение новых данных может создать или не создать приемлемый баланс нагрузки, поскольку новый добавленный раздел может иметь намного больше доступного объема памяти, чем существующие разделы, на которых уже хранятся старые данные.
[0050] Например, рассмотрим систему с N разделами, расширенную до Nʹ с использованием функций разбиения hash(k) mod N и hash(k) mod Nʹ. В целях примера предположим, что N=2 и Nʹ=3, как в примерах на фиг. 2 и 3, соответственно. Соответствующие функции разбиения p1(k)=hash(k) mod 2 и p2(k)=hash(k) mod 3 разместят некоторые данные в новый раздел, но существующие разделы будут, вероятно, более загружены вследствие условий загрузки во время повторного разбиения. Следовательно, распределение может привести к несбалансированной системе.
[0051] Соответственно, вместе с методиками составной функции разбиения, описанными в настоящем документе, также может быть обеспечен признак перебалансировки. В одном подходе признак перебалансировки может быть обеспечен как опция, которая может быть выборочно включена или выключена, чтобы отклонить распределение новых данных к новым и/или недостаточно использованным разделам. Кроме того, или в качестве альтернативы, менеджер 120 ресурсов может быть выполнен с возможностью автоматически реализовать перебалансировку на основе факторов, таких как доступная емкость разделов, объем запросов, скорость увеличения данных и т.д. Обычно признак перебалансировки может включать в себя использование модифицированной хеш-функции, выполненной с возможностью содержать фактор отклонения, чтобы вызывать распределение новых данных в один или более назначенных разделов более часто, чем в другие разделы. Например, фактор отклонения может вызвать неравномерное распределение данных для распределения большего количества данных новым разделам, добавленным для повторно конфигурируемого размещения, чем старым разделам, существовавшим до операции повторного разбиения. Предусматриваются различные методики отклонения распределения к конкретному разделу. Например, фактор отклонения может действовать таким образом, чтобы определять конфигурируемый интервал, в котором запросы распределяются выбранному разделу, даже если хеш-функция указала бы другой раздел. Таким образом, система может быть настроена на автоматическое распределение запросов выбранному разделу в интервале (например, каждый третий или четвертый запрос). В другом подходе фактор отклонения может динамически изменяться на основе относительной нагрузки разделов, в результате чего первоначально больше запросов распределяется выбранному разделу, но со временем функция постепенно может возвращаться к равномерному распределению. Например, фактор отклонения может изменяться в соответствии с функцией затухания, которая создает эффект уменьшения фактора отклонения со временем по мере заполнения выбранного раздела данными.
[0052] В другом подходе фактор отклонения реализован через модифицированную функцию разбиения, которая использует концепцию слотов для отклонения распределения новым разделам в размещении. При этом модифицированная функция разбиения задает несколько слотов, количество которых больше, чем количество разделов. Затем слоты логически назначаются разделам, так что новый раздел или выбранный раздел может быть назначен более чем одному из слотов. Хеш-функция выполнена с возможностью возвращать данные, идентифицирующие слоты, и распределять данные соответствующим разделам. Поскольку значения, возвращенные хеш-функцией, охватывают количество слотов, данные будут распределяться более часто к тому разделу, который назначен более чем одному из слотов относительно разделов, назначенным всего одному слоту.
[0053] Для иллюстрации рассмотрим фиг. 5, которая в целом под номером 500 изображает представление назначения разделам слотов в соответствии с одной или более реализациями. Показаны три раздела 208(0), 208(1), 208(2) из примера на фиг. 3. Несколько слотов 502 заданы и назначены разделам. В этом примере четыре слота 502 назначены трем разделам 208(0), 208(1), 208(2), причем каждому из разделов 208(0) и 208(1) (например, старым разделам) назначен один слот, и разделу 208(2) (например, новому разделу) назначены два слота.
[0054] Для функции разбиения, имеющей общую форму p(k)=hash(k) mod N, как отмечено выше, модификация для реализации отклонения включает в себя замену значения N на значение S, где S - количество слотов. Кроме того, могут храниться данные, указывающие назначения слотов, чтобы отображать возвращенную идентификацию слота на фактические разделы. Затем разбиение вычисляется в два этапа:
(1) вычислить слот=hash(k) mod S, где S - количество слотов
(2) отобразить слот на раздел с использованием данных, указывающих назначение слотов
[0055] Когда приходят новые данные, больше ключей отображается на новый раздел, и в соответствии с этим новый раздел заполняется с большей скоростью, чем старые разделы, и принимает больше нагрузки. В конечном счете система может приблизиться к балансу между разделами, и с этого момента продолжение отклонения к более новому разделу может привести к возврату дисбаланса, и на этот раз слишком нагружается новый раздел. Чтобы решить эту проблему, может быть выполнена другая операция повторного разбиения согласно настоящему описанию, которая использует те же самые разделы, но возвращает переключение от хеш-функции с отклонением обратно к "стандартной" функции, которая не использует слоты или факторы отклонения. В данном случае дополнительное повторное разбиение выполняется для обновления функции разбиения без добавления большей емкости. После этого дополнительного повторного разбиения система будет одновременно уравновешена и расширена.
Иллюстративные процедуры
[0056] Далее описываются методики, которые могут быть реализованы с использованием ранее описанных систем и устройства. Аспекты каждой из процедур могут быть реализованы в аппаратных средствах, программно-аппаратном обеспечении или программном обеспечении, или их комбинации. Процедуры показаны как множество блоков, которые определяют операции, выполняемые одним или более устройствами, и не обязательно ограничены порядком, показанным для выполнения операций соответствующими блоками. В частях последующего описания может быть сделана ссылка на среду 100, показанную на фиг. 1, и примеры, показанные на фиг. 2-5. В качестве примера аспекты процедур могут быть выполнены посредством подходящим образом сконфигурированного вычислительного устройства, такого как одно или более серверных устройств, связанных с поставщиком 106 служб, выполненным с возможностью обеспечивать ресурсы 118, и/или с менеджером 120 ресурсов.
[0057] Функциональность, признаки и концепции, описанные относительно примеров, показанных на фиг. 1-5, могут использоваться в контексте процедур, описанных в настоящем документе. Кроме того, функциональность, признаки и концепции, описанные ниже относительно разных процедур, могут обмениваться среди разных процедур и не ограничены реализацией в контексте индивидуальной процедуры. Кроме того, блоки, связанные с разными репрезентативными процедурами и соответствующими чертежами в настоящем документе, могут быть применены вместе и/или по-разному объединены. В соответствии с этим индивидуальная функциональность, признаки и концепции, описанные относительно разных иллюстративных сред, устройств, компонентов и процедур во всем этом документе, могут использоваться в любых подходящих комбинациях и не ограничены конкретными комбинациями, представленными перечисленными примерами.
[0058] Фиг. 6 является блок-схемой последовательности операций, изображающей иллюстративную процедуру 600, в которой составная функция разбиения задана в соответствии с одной или более реализациями. База данных разбивается с помощью первой функции разбиения (блок 602). Например, менеджер 120 ресурсов может управлять базой 124 данных, связанной с ресурсами 118, как пояснено ранее. База 124 данных может быть разделена на несколько разделов 126, которые заданы и/или которыми управляют через функцию 122 разбиения, реализованную менеджером 120 ресурсов или иным образом.
[0059] Впоследствии база данных повторно разбивается (блок 604). Повторное разбиение может быть инициировано автоматически или по указанию пользователя. Повторное разбиение может быть выполнено, когда емкость запоминающего устройства существующего размещения раздела достигает порогового уровня использования. В этом случае повторное разбиение может включать в себя добавление большей емкости запоминающего устройства. Дополнительно, или в качестве альтернативы, повторное разбиение может быть выполнено по другим причинам, например, для перебалансировки разделов, как пояснено в настоящем документе, для изменения функции разбиения, чтобы достигнуть конкретной цели распределения, для отмены хеш-функции с отклонением, чтобы вернуться к сбалансированному распределению, и т.д.
[0060] Как часть повторного разбиения создается запись принадлежности ключей для элементов данных, расположенных в разделах, существующих во время повторного разбиения (блок 606), и добавляется один или более новых разделов, связанных со второй функцией разбиения (608). Для реализации записи принадлежности ключей могут использоваться различные методики, как пояснено ранее в настоящем документе. Например, фильтр Блума или другая сжатая структура данных могут использоваться для записи значений ключей или других подходящих идентификаторов, связанных с элементами данных, расположенными в разделах, существующих во время повторного разбиения. Кроме того, новые разделы могут быть добавлены для увеличения емкости запоминающего устройства и создания нового размещения разделов. Как пояснено в настоящем документе, новое размещение разделов связано со второй функцией разбиения, которая отвечает за новые разделы и выполнена с возможностью распределять новые данные и по новым, и по старым разделам.
[0061] Дополнительно, для последующих операций базы данных задана составная функция разбиения, которая выполнена с возможностью применять первую функцию разбиения для данных, имеющих значения ключей, находящиеся в записи принадлежности ключей, или в ином случае применять вторую функцию разбиения для данных, имеющих значения ключей, не находящиеся в записи принадлежности ключей (блок 610). Затем составная функция разбиения применяется для управления запросами данных, связанными с базой данных (блок 612). Обычно составная функция разбиения выполнена с возможностью использовать запись или записи принадлежности ключей для отображения значений ключей/идентификаторов для данных на соответствующие функции разбиения, связанные с разными эпохами разделов. Затем запросы данных могут быть обработаны в соответствии с соответствующими функциями разбиения, возвращенными посредством применения составной функции разбиения. Использование подхода составной функции разбиения, поясненного в настоящем документе, дает возможность выполнить повторное разбиение таким образом, что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения. Другими словами, старые данные не перемещаются. Различные подробные сведения и примеры относительно составных функций разбиения, которые могут использоваться в связи с процедурой 600, были пояснены ранее относительно фиг. 1-5.
[0062] Фиг. 7 является блок-схемой последовательности операций, изображающей иллюстративную процедуру 700, в которой составная функция разбиения используется для маршрутизации запросов о размещении разделов в соответствии с одной или более реализациями. Запись идентификаторов устанавливается для данных, соответствующих первой функции разбиения, связанной с первым размещением одного или более разделов для базы данных (блок 702). Запись идентификаторов может быть выполнена как фильтр Блума согласно настоящему описанию или как другая подходящая структура данных, которая может использоваться для указания принадлежности данных относительно размещения одного или более разделов (например, эпохи разделов). Идентификаторы могут быть выполнены как значения ключей, как пояснено в настоящем документе, хотя предусматриваются также другие идентификаторы, такие как идентифицирующие строки, значения хэш-функции для содержания данных и т.д. Первое размещение одного или более разделов может соответствовать начальной конфигурации базы данных (например, начальной эпохе разделов). Кроме того, или в качестве альтернативы, первое размещение одного или более разделов может являться результатом повторного разбиения размещения для предыдущей эпохи, в этом случае первая функция разбиения может быть выполнена как составная функция.
[0063] Размещение разделов для базы данных реконфигурируется для добавления, по меньшей мере одного дополнительного раздела для увеличения емкости запоминающего устройства в реконфигурируемом размещении (блок 704). При этом может произойти повторное разбиение, как пояснено ранее, для добавления дополнительной емкости к системе. Повторное разбиение дает в результате реконфигурированное размещение, которое может иметь больше разделов, чем первое размещение. В соответствии с этим генерируется составная функция разбиения, которая объединяет первую функцию разбиения, связанную с первым размещением, и вторую функцию разбиения, связанную с реконфигурированным размещением, составная функция разбиения выполнена с возможностью использовать запись идентификаторов, чтобы выявить, следует ли применить первую функцию разбиения или вторую функцию разбиения для маршрутизации запросов данных между разделами для базы данных (блок 706). Затем запросы данных маршрутизируются с использованием составной функции разбиения (блок 708). Как описано ранее, может быть сгенерирована составная функция разбиения, которая отвечает за две или более последовательных эпох разделов, связанных с разными размещениями разделов. Разные размещения могут быть связаны с разными индивидуальным функциям разбиения и/или разным количеством разделов (хотя одинаковое количество разделов может использоваться в течение двух или более эпох в некоторых сценариях (например, перебалансировки). Разные эпохи/размещения также могут быть связаны с соответствующими записями идентификаторов, которые могут использоваться для распознавания принадлежности данных/запросов в конкретных эпохах. Затем подходящие функции разбиения отображаются на данные/запросы и используются для маршрутизации данных/запроса к соответствующим разделам. Составная функция разбиения выполнена с возможностью объединять две или более функций разбиения, связанных с последовательными эпохами разделов с каждой эпохой разделов, соответствующей конкретному размещению разделов для базы данных. Различные дополнительные подробные сведения и примеры относительно составных функций разбиения, которые могут использоваться в связи с процедурой 700, были пояснены ранее относительно фиг. 1-6.
[0064] Рассмотрев некоторые иллюстративные процедуры, рассмотрим теперь описание иллюстративной системы и устройств, которые могут использоваться для реализации аспекты методик, описанных в настоящем документе в одной или более реализациях.
Иллюстративная система и устройство
[0065] Фиг. 8 в целом под номером 800 демонстрирует иллюстративную систему, которая включает в себя иллюстративное вычислительное устройство 802, которое представляет одно или более вычислительных систем и/или устройств, которые могут реализовать различные методики, описанные в настоящем документе. Вычислительное устройство 802 может являться, например, сервером поставщика служб, устройством, связанным с клиентом (например, клиентским устройством), системой на микросхеме и/или любым другим подходящим вычислительным устройством или вычислительной системой.
[0066] Иллюстративное вычислительное устройство 802, как продемонстрировано, включает в себя систему 804 обработки, один или несколько машиночитаемых носителей 806 и один или несколько интерфейсов 808 ввода/вывода, которые соединены с возможностью осуществления связи друг с другом. Хотя не показано, вычислительное устройство 802 может дополнительно включать в себя системную шину или другую систему переноса данных и команд, которая соединяет различные компоненты один с другим. Системная шина может включать в себя любую одну или комбинацию разных структур шин, таких как шина памяти или контроллер памяти, периферийная шина, универсальная последовательная шина и/или шина процессора или локальная шина, которая использует любое множество шинных архитектур. Предусматривается также множество других примеров, таких как линии управления и данных.
[0067] Система 804 обработки представляет функциональность для выполнения одной или более операций с использованием аппаратных средств. В соответствии с этим система 804 обработки проиллюстрирована как включающая в себя аппаратные компоненты 810, которые могут быть выполнены как процессоры, функциональные блоки и т.д. Это может включать в себя реализацию в аппаратных средствах, таких как специализированная интегральная схема или другое логическое устройство, сформированное с использованием одного или нескольких полупроводников. Аппаратные компоненты 810 не ограничены материалами, из которых они сформированы, или механизмами обработки, используемыми в них. Например, процессоры могут состоять из полупроводника (полупроводников) и/или транзисторов (например, электронные интегральные схемы (IC)). В таком контексте исполняемые процессором команды могут представлять собой исполняемые в электронном виде команды.
[0068] Машиночитаемые носители 806 проиллюстрированы как включающие в себя память/запоминающее устройство 812. Память/запоминающее устройство 812 представляет емкость памяти/запоминающего устройства, связанную с одним или более машиночитаемыми носителями. Память/запоминающее устройство 812 может включать в себя энергозависимые носители (такие как оперативное запоминающее устройство (ОЗУ; RAM)) и/или энергонезависимые носители (такие как постоянное запоминающее устройство (ПЗУ; ROM), флэш-память, оптические диски, магнитные диски и т.д.). Память/запоминающее устройство 812 может включать в себя фиксированные носители (например, ОЗУ, ПЗУ, фиксированный накопитель на жестком диске и так далее), а также съемные носители (например, флэш-память, съемный накопитель на жестком диске, оптический диск и т.д.). Машиночитаемые носители 806 могут быть выполнены множеством других методов, как описано ниже.
[0069] Интерфейс (интерфейсы) 808 ввода-вывода представляет функциональность, которая позволяет пользователю вводить команды и информацию в вычислительное устройство 802, а также позволяет представлять информацию пользователю и/или другим компонентам или устройствам с использованием различных устройств ввода/вывода. Примеры устройств ввода включают в себя клавиатуру, устройство управления курсором (например, мышь), микрофон, сканер, сенсорную функциональность (например, емкостные или другие датчики, которые выполнены с возможностью обнаруживать физическое прикосновение), камера (например, камера, которая может использовать длины волн в видимом или невидимом диапазоне, такие как инфракрасные частоты для обнаружения движения, которые не включает в себя прикосновения как жесты) и т.д. Примеры устройств вывода включают в себя устройство отображения (например, монитор или проектор), динамики, принтер, сетевая карту, тактильное устройство и т.д. Таким образом, вычислительное устройство 802 может быть выполнено множеством методов, как описано ниже, для поддержки взаимодействия с пользователем.
[0070] Различные методики могут быть описаны в настоящем документе в общем контексте программного обеспечения, аппаратных компонентов или программных модулей. Обычно такие модули включают в себя подпрограммы, программы, объекты, элементы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Используемые здесь термины "модуль", "функциональность" и "компонент" в целом представляют программное обеспечение, программно-аппаратное обеспечение, аппаратные средства или их комбинацию. Признаки методик, описанных в настоящем документе, не зависят от платформы, и это означает, что методики могут быть реализованы на множестве коммерческих вычислительных платформ, имеющих множество процессоров.
[0071] Реализация описанных модулей и методик может быть сохранена или передана через некоторую форму машиночитаемых носителей. Машиночитаемые носители могут включать в себя множество носителей, к которым может осуществить доступ вычислительное устройство 802. В качестве примера, но не ограничения, машиночитаемые носители могут включать в себя ʺмашиночитаемые запоминающие носителиʺ и "коммуникационные носители".
[0072] ʺМашиночитаемые запоминающие носителиʺ относятся к носителям и/или устройствам, которые дают возможность хранения информации в отличие от простой передачи сигнала, несущих волн или сигналов как таковых. Таким образом, машиночитаемые запоминающие носители не включает в себя носители, несущие сигнал, или сигналы как таковые. Машиночитаемые запоминающие носители включают в себя аппаратные средства, такие как энергозависимые и энергонезависимые, сменные и несъемные носители и/или запоминающие устройства, реализованные способом или по технологии, подходящей для запоминающего устройства информации, такими как машиночитаемые команды, структуры данных, программные модули, логические элементы/схемы или другие данные. Примеры машиночитаемых запоминающих носителей могут включать в себя, но без ограничения, оперативное запоминающее устройство (ОЗУ; RAM), постоянное запоминающее устройство (ПЗУ; ROM), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ; EEPROM), флэш-память или другую технологию памяти, компакт-диск, предназначенный только для чтения (CD-ROM), цифровые универсальные диски (DVD) или другое оптическое запоминающее устройство, жесткие диски, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитном диске или другие магнитные запоминающие устройства, или другое запоминающее устройство, материальные носители или изделия производства, подходящие для хранения желаемой информации, и к которым может осуществить доступ компьютер.
[0073] "Коммуникационные носители" могут относиться к несущему сигнал носителю, который выполнен с возможностью передавать команды аппаратным средствам вычислительного устройства 802, например, через сеть. Коммуникационные носители, как правило, могут воплощать машиночитаемые команды, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущие, сигналы данных или другой транспортный механизм. Носители сигналов также включают в себя любые информационные носители доставки. Термин ʺмодулированный сигнал данныхʺ означает сигнал, который имеет одну или более его характеристик установленными или измененными таким методом, чтобы закодировать информацию в сигнале. В качестве примера, но без ограничения, коммуникационные носители включают в себя проводные носители, такие как проводное сетевое соединение или прямое проводное соединение, и беспроводные носители, такие как акустические, радиочастотные, инфракрасные и другие беспроводные носители.
[0074] Как описано ранее, аппаратные компоненты 810 и машиночитаемые носители 806 представляют инструкции, модули, программируемые логические схемы устройств и/или фиксированные логические схемы устройств, реализованные в форме аппаратных средств, которые могут использоваться в некоторых вариантах осуществления для реализации, по меньшей мере, некоторых аспектов методик, описанных в настоящем документе. Аппаратные компоненты могут включать в себя компоненты интегральной схемы или системы на микросхеме, специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA), сложного программируемого логического устройства (CPLD) и других реализаций из кремния или других устройств. В этом контексте аппаратный компонент может действовать в качестве устройства обработки, которое выполняет задачи программы, заданные командами, модулями и/или логической схемой, воплощенными посредством аппаратного элемента, а также устройства, используемого для хранения команд для исполнения, например, машиночитаемых запоминающих носителей, описанных ранее.
[0075] Комбинации описанного выше также могут использоваться для реализации различных методик и модулей, описанных в настоящем документе. В соответствии с этим, программное обеспечение, аппаратные средства или программные модули, в том числе приложения 112, модуль 114 связи, менеджер 120 ресурсов и другие программные модули, могут быть реализованы как одна или более команд и/или логических схем, воплощенных на некоторой форме машиночитаемых запоминающих носителей и/или одном или более аппаратных компонентах 810. Вычислительное устройство 802 может быть выполнено с возможностью реализовывать конкретные команды и/или функции, соответствующие программным и/или аппаратным модулям. В соответствии с этим реализация модулей как модуль, который является исполняемым посредством вычислительного устройства 802 как программное обеспечение, может быть достигнута, по меньшей мере, частично в аппаратных средствах, например, посредством использования машиночитаемых запоминающих носителей и/или аппаратных компонентов 810 системы обработки. Команды и/или функции могут быть исполняемыми/действующими посредством одного или более изделий производства (например, одного или более вычислительных устройств 802 и/или системы обработки 804) для реализации методики, модулей и примеров, описанных в настоящем документе.
[0076] Как далее проиллюстрировано на фиг. 8, иллюстративная система 800 дает возможность среде электронной глобализации для цельного пользовательского восприятия при работе приложений на персональном компьютере (PC), телевизионном устройстве и/или устройстве мобильной связи. Службы и приложения работают в значительной степени аналогично во всех трех средах для общего пользовательского восприятия при переходе от одного устройства на другое при использовании приложения, игре в видеоигру, просмотре видеофильма и так далее.
[0077] В иллюстративной системе 800 несколько устройств связаны через центральное вычислительное устройство. Центральное вычислительное устройство может быть локальным для нескольких устройств или может быть расположено удаленно от нескольких устройств. В одном варианте осуществления центральное вычислительное устройство может являться облаком из одного или более серверных компьютеров, которые соединены с несколькими устройствами через сеть, Интернет или другую линию передачи данных.
[0078] В одном варианте осуществления эта архитектура взаимодействия делает возможной доставку функциональности на несколько устройств для обеспечения общего и цельного восприятия для пользователя нескольких устройств. Каждое из нескольких устройств может иметь разные физические требования и возможности, и центральное вычислительное устройство использует платформу для возможности поставки на устройство восприятия, которое одновременно является приспособленным для устройства и тем не менее общим для всех устройств. В одном варианте осуществления создан класс целевых устройств, и события приспособлены для универсального класса устройств. Класс устройств может быть задан физическими характеристиками, типами использования или другими общими характеристиками устройств.
[0079] В различных реализациях вычислительное устройство 802 может принимать множество различных конфигураций, например, для использования на компьютере 814, мобильном телефоне 816 и телевизоре 818. Каждая из этих конфигураций включает в себя устройства, которые могут иметь в целом разные конструкции и возможности, и, таким образом, вычислительное устройство 802 может быть выполнено в соответствии с одним или более разных классов устройств. Например, вычислительное устройство 802 может быть реализовано как класс устройств компьютера 814, который включает в себя персональный компьютер, настольный компьютер, многоэкранный компьютер, ноутбук, нетбук и так далее.
[0080] Вычислительное устройство также 802 может быть реализовано как класс устройств мобильного телефона 816, который включает в себя устройства мобильной связи, такие как мобильный телефон, переносной музыкальный проигрыватель, переносное игровое устройство, планшетный компьютер, многоэкранный компьютер и так далее. Вычислительное устройство 802 также может быть реализовано как класс устройств телевизора 818, который включает в себя устройства, имеющие обычно большие экраны или соединенные с большими экранами в обстановке непринужденного просмотра. Эти устройства включают в себя телевизоры, телеприставки, игровые консоли и так далее.
[0081] Методики, описанные в настоящем документе, могут поддерживаться этими различными конфигурациями вычислительного устройства 802 и не ограничены конкретными примерами методик, описанными в настоящем документе. Это проиллюстрировано посредством включения менеджера 120 ресурсов в вычислительное устройство 802. Функциональность менеджера 120 ресурсов и других модулей также может быть реализована полностью или частично посредством использования распределенной системы, например, по "облаку" 820 через платформу 822, как описано ниже.
[0082] Облако 820 включает в себя и/или представляет платформу 822 для ресурсов 824. Платформа 822 абстрагирует базовую функциональность аппаратных средств (например, серверов) и программных ресурсов облака 820. Ресурсы 824 могут включать в себя приложения и/или данные, которые могут быть использованы, в то время как компьютерная обработка исполняется на серверах, которые являются удаленными от вычислительного устройства 802. Ресурсы 824 также могут включать в себя службы, предоставляемые по Интернету и/или через абонентскую сеть, например, сеть сотовой связи или сеть Wi-Fi.
[0083] Платформа 822 может абстрагировать ресурсы и функции для соединения вычислительного устройства 802 с другими вычислительными устройствами. Платформа 822 также может служить для абстрагирования масштабирования ресурсов, чтобы обеспечить соответствующий уровень масштаба для встречающегося спроса для ресурсов 824, которые реализованы через платформу 822. В соответствии с этим в варианте осуществления подсоединенного устройства реализация функциональности, описанной в настоящем документе, может быть распределена по всей системе 800. Например, функциональность может быть реализована частично на вычислительном устройстве 802, а также через платформу 822, которая абстрагирует функциональность облака 820.
Иллюстративные реализации
[0084] Иллюстративные реализации составных функций разбиения, описанных в настоящем документе, включают в себя, но без ограничения, один пример или любые комбинации одного или более из следующих примеров:
[0085] Способ, реализованный посредством вычислительного устройства, содержащий: разбиение базы данных с помощью первой функции разбиения; и повторное разбиение базы данных посредством: создания записи принадлежности ключей для элементов данных, расположенных в разделах, существующих во время повторного разбиения; добавления одного или более новых разделов, связанных со второй функцией разбиения; задания составной функции разбиения для последующих операций базы данных, выполненной с возможностью: применять первую функцию разбиения для данных, имеющих значения ключей, находящиеся в записи принадлежности ключей; или применять вторую функцию разбиения для данных, имеющих значения ключей, не находящиеся в записи принадлежности ключей.
[0086] Описанный выше способ, в котором повторное разбиение выполняется таким образом, что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения.
[0087] Описанный выше способ, в котором запись принадлежности ключей выполнена с возможностью делать запись значений ключей, связанных с элементами данных, расположенными в разделах, существующих во время повторного разбиения.
[0088] Описанный выше способ, в котором запись принадлежности ключей содержит сжатую структуру данных, выполненную с возможностью идентифицировать ключи, соответствующие элементам данных, существующим в базе данных во время повторного разбиения.
[0089] Описанный выше способ, в котором запись принадлежности ключей содержит фильтр Блума.
[0090] Описанный выше способ, в котором составная функция разбиения выполнена с возможностью объединять две или более функций разбиения, связанных с последовательными эпохами разделов, каждая эпоха разделов соответствует конкретному размещению разделов для базы данных.
[0091] Описанный выше способ, в котором первая функция разбиения и вторая функция разбиения выполнены как хеш-функции, которые при их применении к значениям ключей для запросов данных возвращают данные, идентифицирующие разделы базы данных, соответствующие значениям ключей.
[0092] Описанный выше способ, в котором первая функция разбиения содержит предшествующую составную функцию, установленную для предыдущего повторного разбиения базы данных для добавления дополнительной емкости запоминающего устройства, причем составная функция разбиения, которая задана, выполнена с возможностью применять предшествующую составную функцию для данных, имеющих значения ключей, находящиеся в записи принадлежности ключей, и вторую функцию разбиения для других данных.
[0093] Описанный выше способ, в котором комбинированная функция разбиения выполнена с возможностью смещать распределение данных к размещению новых элементов данных на новых разделах, чтобы сбалансировать распределение данных по разделам базы данных.
[0094] Описанный выше способ, в котором комбинированная функция разбиения ошибочно распознает, по меньшей мере, некоторые значения ключей для новых элементов данных как находящиеся в записи принадлежности ключей таким образом, что элементы данных, связанные с ошибочно распознанными значениями ключей, распределяются и постоянно располагаются в разделах, существующих во время повторного разбиения.
[0095] Вычислительное устройство, содержащее: систему обработки; и один или более модулей, которые при их исполнении системой обработки выполняют операции для повторного разбиения базы данных для увеличения емкости запоминающего устройства, включающие в себя: создание записи принадлежности ключей для элементов данных, расположенных в разделах базы данных, существующих во время повторного разбиения, разделы базы данных, существующие во время повторного разбиения, связаны с первой функцией разбиения; добавление нового раздела, связанного со второй функцией разбиения; и задание составной функции разбиения для обработки последующих запросов к базе данных, выполненной с возможностью: применять первую функцию разбиения для запросов данных, включающих в себя значения ключа, находящиеся в записи принадлежности ключей; или применять вторую функцию разбиения для запросов данных, включающих в себя значения ключа, не находящиеся в записи принадлежности ключей, в результате чего элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения в разделах, существующих во время повторного разбиения.
[0096] Описанное выше вычислительное устройство, в котором запись принадлежности ключей выполнена как фильтр Блума, имеющий битовые значения, установленные для ключей, связанных с элементами данных, существующих во время повторного разбиения, для указания на принадлежность для ключей через фильтр Блума.
[0097] Описанное выше вычислительное устройство, в котором: фильтр Блума производит ложноположительные ошибки в соответствии с конфигурируемым допуском, который предписывает ошибочно распознавать и обрабатывать с использованием первой функции разбиения, по меньшей мере, часть элементов данных, созданных после повторного разбиения, причем ложноположительные ошибки являются постоянными, так что шибочно распознанные элементы данных достоверно располагаются с использованием первой функции разбиения; и степень компактности фильтра Блума зависит от конфигурируемого допуска.
[0098] Описанное выше вычислительное устройство, в котором составная функция разбиения выполнена с возможностью объединять вторую функцию разбиения со множеством индивидуальных функций разбиения, связанных с несколькими предыдущими операциями для повторного разбиения базы данных.
[0099] Описанное выше вычислительное устройство, в котором вторая функция разбиения выполнена с возможностью распределять данные по разделам базы данных, существующим во время повторного разбиения, и новым разделам.
[00100] Способ, реализованный вычислительным устройством, содержащий: установление записи идентификаторов для данных, соответствующих первой функции разбиения, связанной с первым размещением одного или более разделов для базы данных; реформирование размещения разделов для базы данных для добавления по меньшей мере одного дополнительного раздела для увеличения емкости запоминающего устройства в реконфигурированном размещении; генерацию составной функции разбиения, которая объединяет первую функцию разбиения, связанную с первым размещением, и вторую функцию разбиения, связанную с реконфигурированным размещением, составная функция разбиения выполнена с возможностью использовать запись идентификаторов для выявления, следует ли применить первую функцию разбиения или вторую функцию разбиения для маршрутизации запросов данных между разделами для базы данных; и маршрутизируют запросы данных с использованием составной функции разбиения.
[00101] Описанный выше способ, в котором маршрутизация запросов данных с использованием составной функции разбиения содержит для каждого запроса данных: использование записи идентификаторов для выявления, включен ли идентификатор, связанный с запросом данных, в запись идентификаторов; и когда идентификатор включен, маршрутизацию запроса данных с использованием первой функции разбиения; или, когда идентификатор не включен, маршрутизацию запроса данных с использованием второй функции разбиения.
[00102] Описанный выше способ, в котором запросы данных содержат запросы на осуществление доступа, добавление или модификацию элементов данных в разделах базы данных.
[00103] Описанный выше способ, в котором элементы данных, существующие до реконфигурации, не перемещаются в другие местоположения в результате реконфигурации.
[00104] Описанный выше способ, в котором вторая функция разбиения содержит модифицированную хеш-функцию, выполненную с возможностью включать в себя фактор отклонения, чтобы вызывать распределение новых данных в по меньшей мере один дополнительный раздел, добавленный для реконфигурированного размещения, более часто, чем в один или более разделов, существовавших для первого размещения.
Заключение
[00105] Хотя сущность изобретения была описана на языке, специфичном для структурных признаков и/или действий способов, следует понимать, что сущность изобретения, заданная в приложенной формуле изобретения, не обязательно ограничивается описанными выше конкретными признаками или действиями. Вместо этого конкретные признаки и действия раскрыты в качестве примерных форм реализации заявленной сущности изобретения.
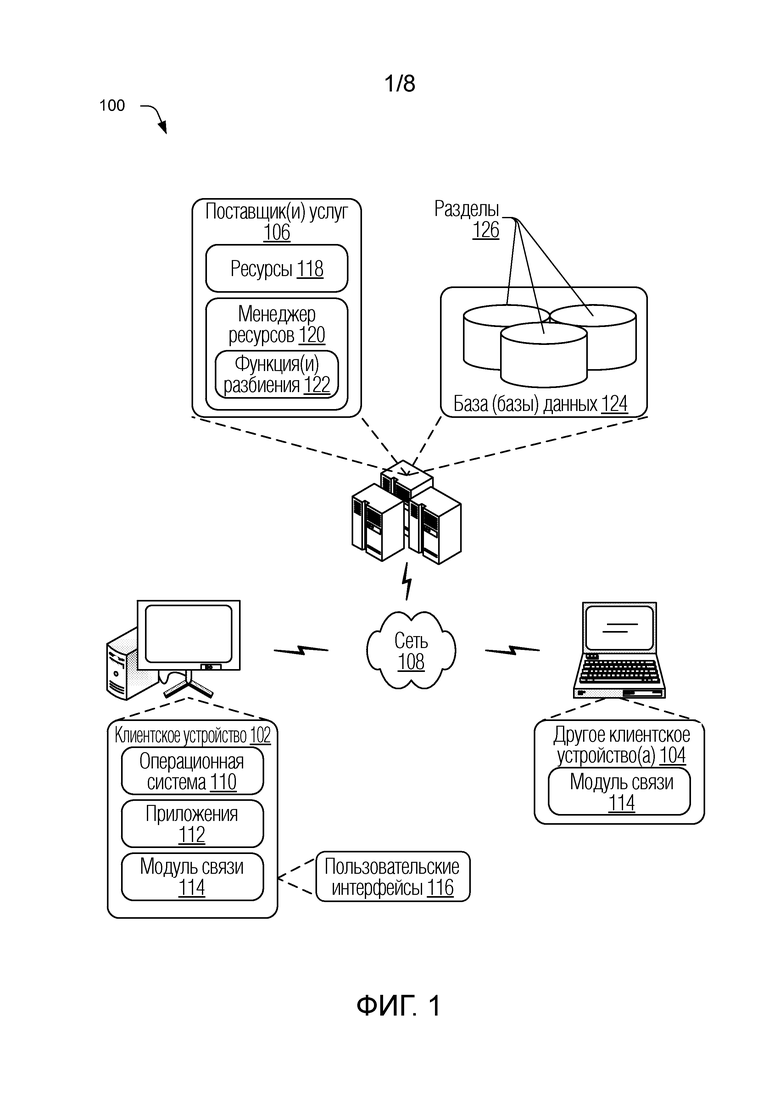
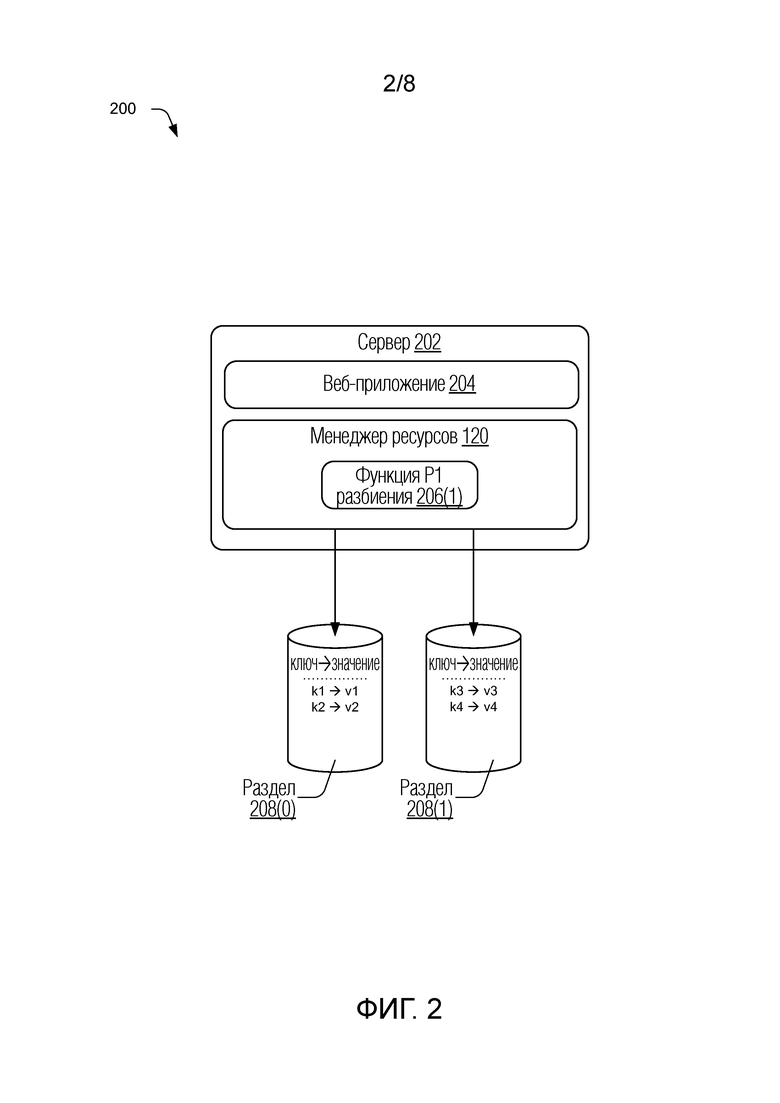
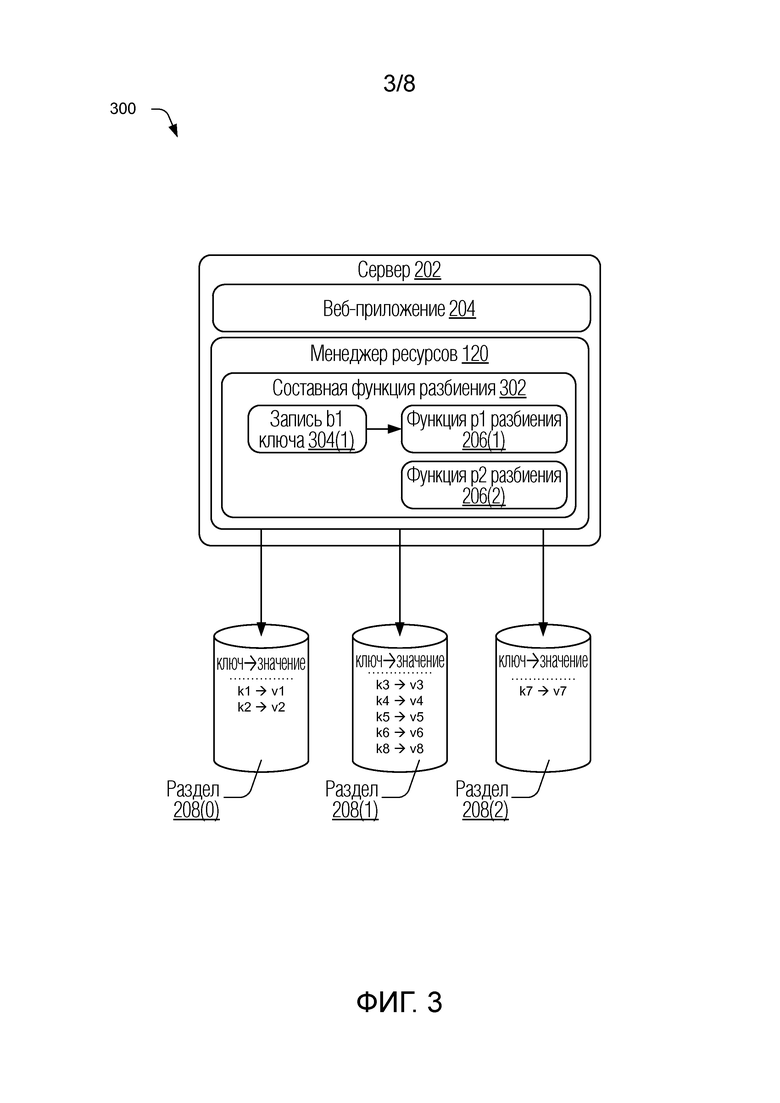
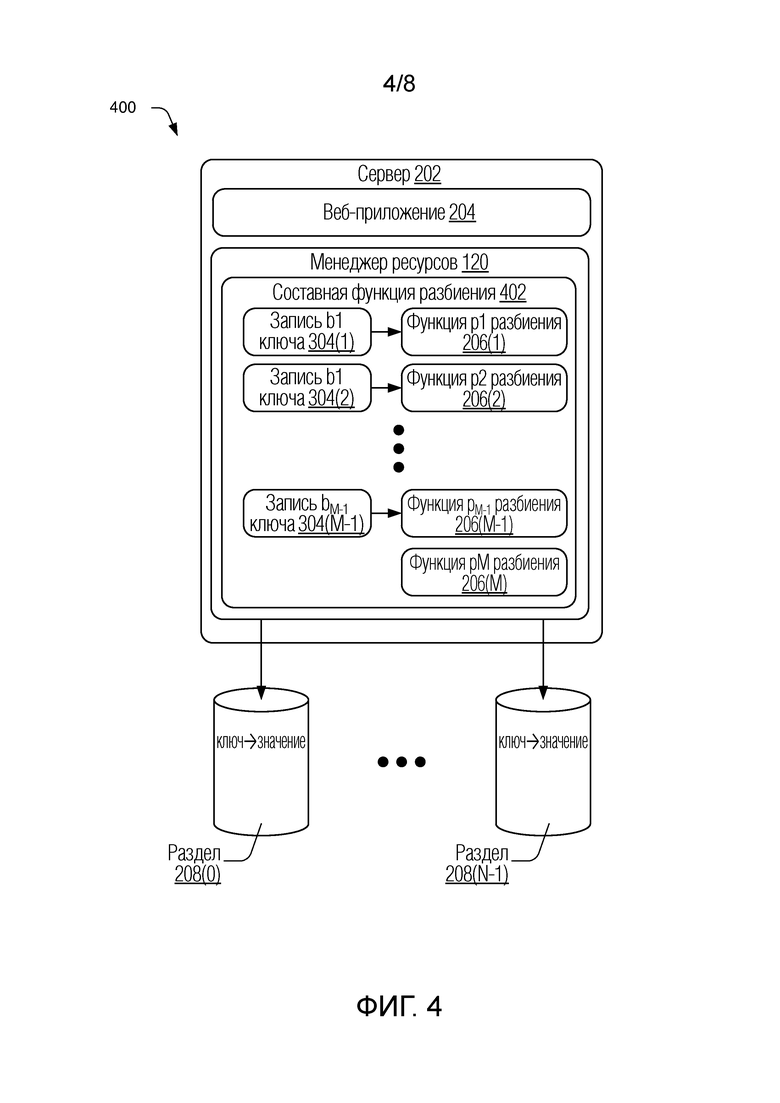
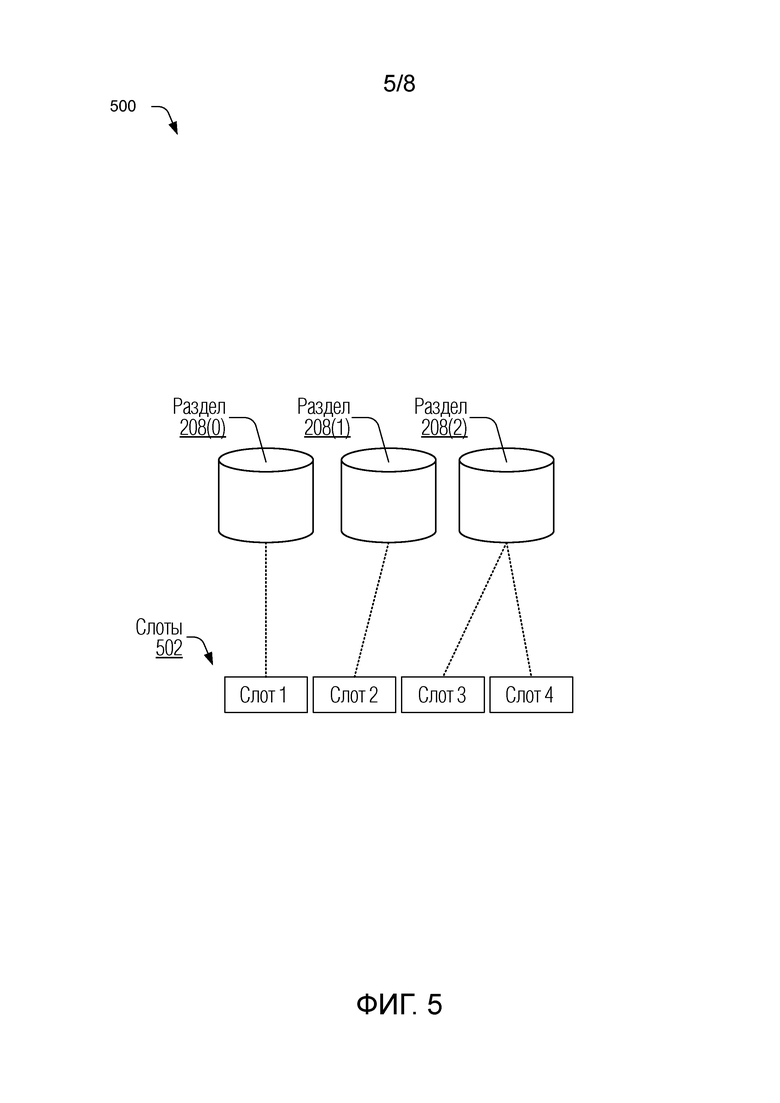
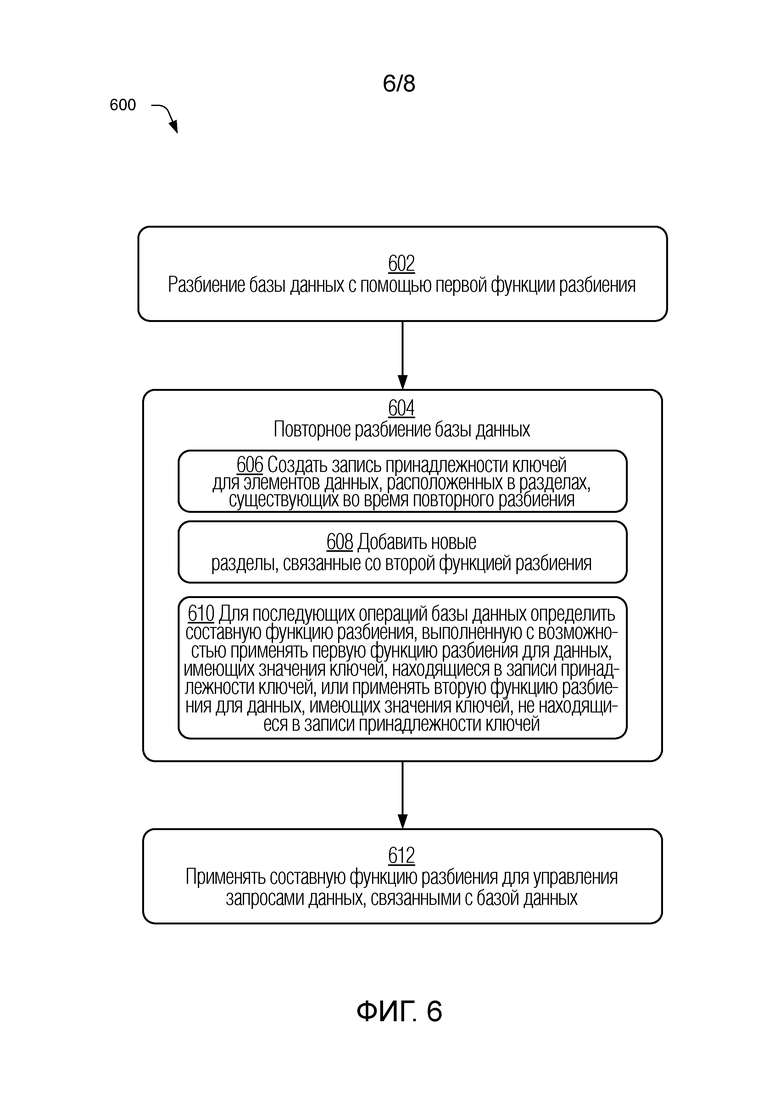
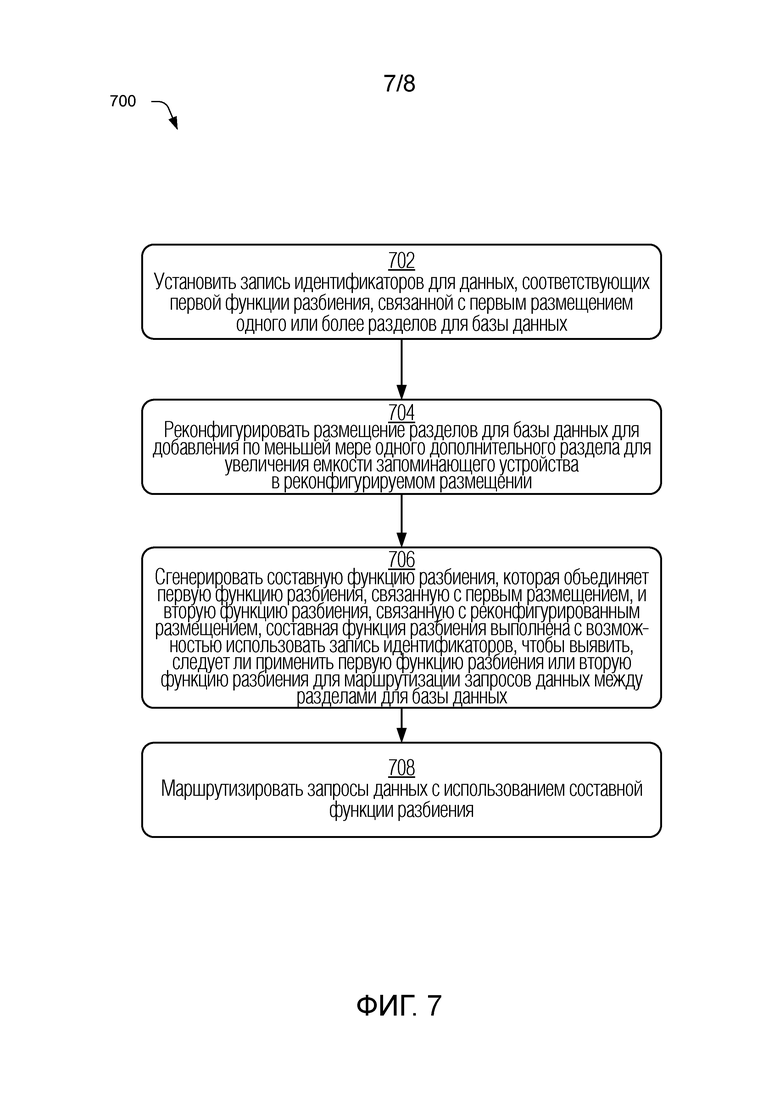
Изобретение относится к области вычислительной техники. Технический результат заключается в снижении времени для обработки и повторной вставки данных в новые местоположения базы данных в обновленном размещении разделов базы данных. Технический результат достигается за счет этапов, на которых: создают запись принадлежности ключей для элементов данных, расположенных в разделах, существующих во время повторного разбиения, причем запись принадлежности ключей выполнена с возможностью записывать значения ключей, связанных с элементами данных, расположенными в разделах, существующих во время повторного разбиения, и при этом повторное разбиение выполняется таким образом, что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения; добавляют один или более новых разделов, связанных со второй функцией разбиения; задают составную функцию разбиения для последующих операций базы данных, выполненную с возможностью: применения первой функции разбиения для данных, имеющих значения ключей, найденные в записи принадлежности ключей; или применения второй функции разбиения для данных, имеющих значения ключей, не найденные в записи принадлежности ключей. 2 н. и 11 з.п. ф-лы, 8 ил.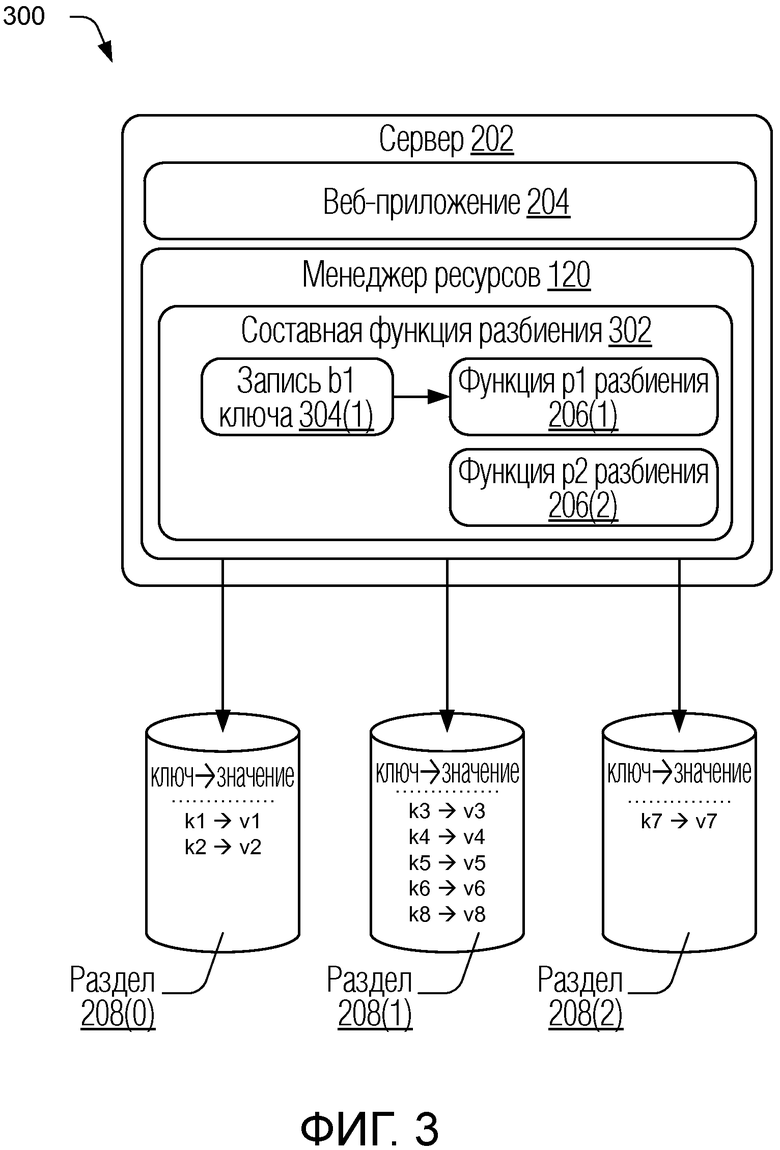
1. Способ повторного разбиения базы данных, реализованный посредством вычислительного устройства, причем способ содержит этапы, на которых:
выполняют разбиение базы данных с помощью первой функции разбиения и
выполняют повторное разбиение базы данных посредством этапов, на которых:
создают запись принадлежности ключей для элементов данных, расположенных в разделах, существующих во время повторного разбиения, причем запись принадлежности ключей выполнена с возможностью записывать значения ключей, связанных с элементами данных, расположенными в разделах, существующих во время повторного разбиения, и при этом повторное разбиение выполняется таким образом, что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения;
добавляют один или более новых разделов, связанных со второй функцией разбиения;
задают составную функцию разбиения для последующих операций базы данных, выполненную с возможностью:
применения первой функции разбиения для данных, имеющих значения ключей, найденные в записи принадлежности ключей; или
применения второй функции разбиения для данных, имеющих значения ключей, не найденные в записи принадлежности ключей.
2. Способ по п. 1, в котором запись принадлежности ключей содержит сжатую структуру данных, выполненную с возможностью идентифицировать ключи, соответствующие элементам данных, существующим в базе данных во время повторного разбиения.
3. Способ по п. 1, в котором запись принадлежности ключей содержит фильтр Блума.
4. Способ по п. 1, в котором составная функция разбиения выполнена с возможностью объединять две или более функций разбиения, причем каждая из двух или более функций разбиения соответствует последовательному размещению разделов для базы данных.
5. Способ по п. 1, в котором первая функция разбиения и вторая функция разбиения сконфигурированы как хеш-функции, которые при их применении к значениям ключей для запросов данных возвращают данные, идентифицирующие разделы базы данных, соответствующие значениям ключей.
6. Способ по п. 1, в котором первая функция разбиения содержит предшествующую составную функцию, установленную для предыдущего повторного разбиения базы данных для добавления дополнительной емкости запоминающего устройства, и при этом составная функция разбиения, которая задана, выполнена с возможностью применять предшествующую составную функцию для данных, имеющих значения ключей, найденных в записи принадлежности ключей, и вторую функцию разбиения для других данных.
7. Способ по п. 1, в котором составная функция разбиения выполнена с возможностью смещать распределение данных к размещению новых элементов данных на новых разделах, чтобы сбалансировать распределение данных по разделам базы данных.
8. Способ по п. 1, в котором составная функция разбиения ошибочно распознает, по меньшей мере, некоторые значения ключей для новых элементов данных как найденные в записи принадлежности ключей таким образом, что элементы данных, связанные с ошибочно распознанными значениями ключей, распределяются и постоянно располагаются в разделах, существующих во время повторного разбиения.
9. Вычислительное устройство, содержащее:
систему обработки и
один или более модулей, которые при их исполнении системой обработки выполняют операции для повторного разбиения базы данных для увеличения емкости запоминающего устройства, включающие в себя:
создание записи принадлежности ключей для элементов данных, расположенных в разделах базы данных, существующих во время повторного разбиения, причем разделы базы данных, существующие во время повторного разбиения, связаны с первой функцией разбиения;
добавление нового раздела, связанного со второй функцией разбиения; и
задание составной функции разбиения для обработки последующих запросов к базе данных, выполненной с возможностью:
применять первую функцию разбиения для запросов данных, включающих в себя значения ключа, найденные в записи принадлежности ключей; или
применять вторую функцию разбиения для запросов данных, включающих в себя значения ключа, не найденные в записи принадлежности ключей,
так что элементы данных, расположенные в разделах, существующих во время повторного разбиения, сохраняют свои соответствующие местоположения в разделах, существующих во время повторного разбиения.
10. Вычислительное устройство по п. 9, в котором запись принадлежности ключей сконфигурирована как фильтр Блума, имеющий битовые значения, установленные для ключей, связанных с элементами данных, существующих во время повторного разбиения, для указания принадлежности для ключей через фильтр Блума.
11. Вычислительное устройство по п. 10, в котором:
фильтр Блума производит ложноположительные ошибки в соответствии с конфигурируемым допуском, который предписывает ошибочно распознавать и обрабатывать с использованием первой функции разбиения, по меньшей мере, часть элементов данных, созданных после повторного разбиения, причем ложноположительные ошибки являются постоянными, так что ошибочно распознанные элементы данных достоверно располагаются с использованием первой функции разбиения; и
степень компактности фильтра Блума зависит от конфигурируемого допуска.
12. Вычислительное устройство по п. 9, в котором составная функция разбиения выполнена с возможностью объединять вторую функцию разбиения с множеством индивидуальных функций разбиения, связанных с множественными предыдущими операциями для повторного разбиения базы данных.
13. Вычислительное устройство по п. 9, в котором вторая функция разбиения выполнена с возможностью распределять данные по разделам базы данных, существующим во время повторного разбиения, и новому разделу.
| СПОСОБ И СИСТЕМА СОГЛАСОВАНИЯ СХЕМ БАЗ ДАННЫХ WEB | 2005 |
|
RU2386997C2 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 8554762 B1, 08.10.2013 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

