Уровень техники
Хэш-таблицы представляют собой фундаментальный строительный блок в различных приложениях, таких как базы данных, поисковые системы, статистическая обработка и языки динамических сценариев. Хэш-таблицы представляют собой семейство контейнеров, которые ассоциируют ключи со значениями. Хэш-таблицы рассчитывают положение размещения для элемента, сохраненного на входе таблицы, то есть адресуемого сегмента, используя его хеш-значение и текущую емкость контейнера. Однако контейнеры обычно должны динамически увеличивать емкость, что означает либо изменение размещения или выделение дополнительного объема памяти. Поэтому увеличение емкости приводит к недействительности размещения элемента и требует перемещения элементов в новые места, что обычно называется повторным хешированием.
Для известных алгоритмов параллельной обработки хеш-таблиц, когда поток принимает решение изменить размеры контейнера, он блокирует (то есть временно останавливает) некоторые (или даже все) одновременно выполняемые операции по таблице до тех пор, пока он не закончит оба процесса изменения размеров и повторного хеширования. Это приводит к деградации параллельного выполнения операций, и, таким образом, рабочих характеристик. Другая проблема состоит в том, что время выполнения и сложность операций при изменении размеров существенно отличаются от тех же операций без изменения размеров.
Краткое описание чертежей
На фиг.1 показана блок-схема последовательности операций способа для обновления хеш-таблицы в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг.2А показана блок-схема сегмента в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг.2В показана блок-схема, иллюстрирующая выделение новых сегментов в соответствии с одним вариантом осуществления настоящего изобретения.
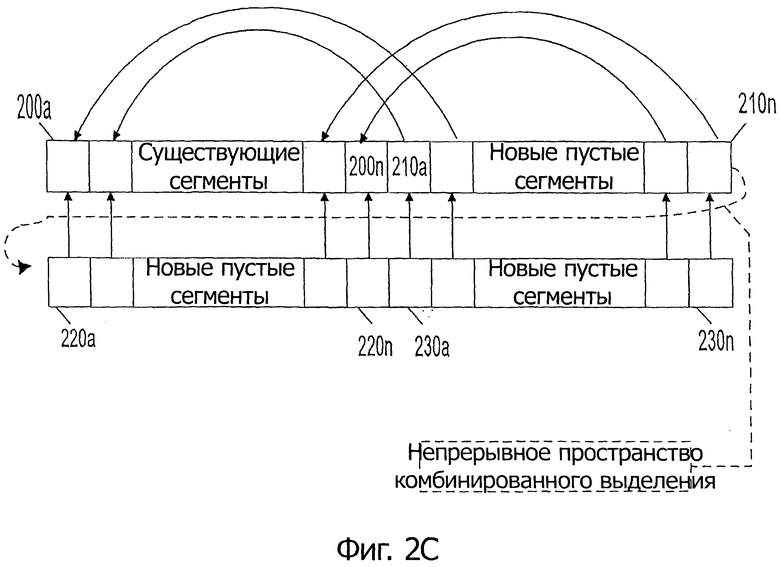
На фиг.2С показана блок-схема, иллюстрирующая выделение новых сегментов в соответствии с другим вариантом осуществления настоящего изобретения.
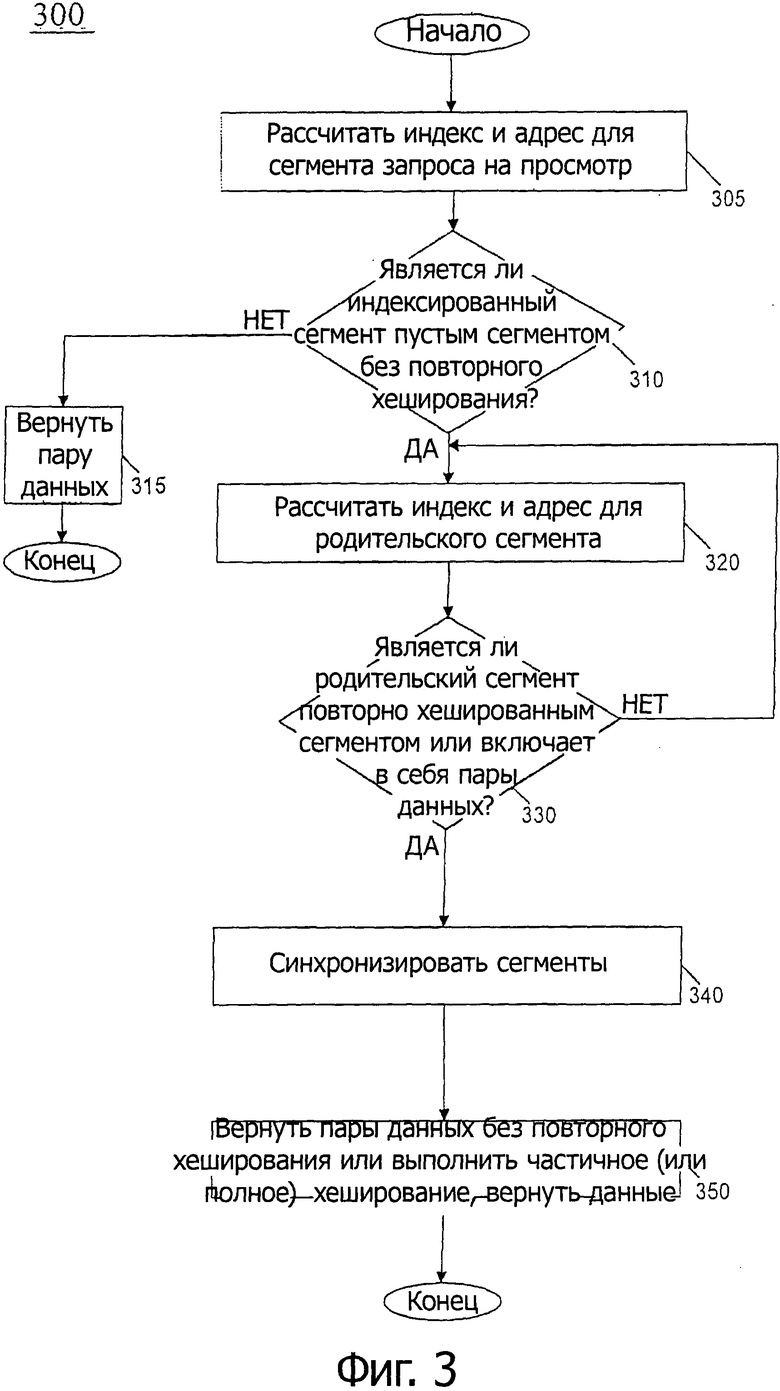
На фиг.3 показана блок-схема последовательности операций способа для выполнения поиска/повторного хеширования в соответствии с вариантом осуществления настоящего изобретения.
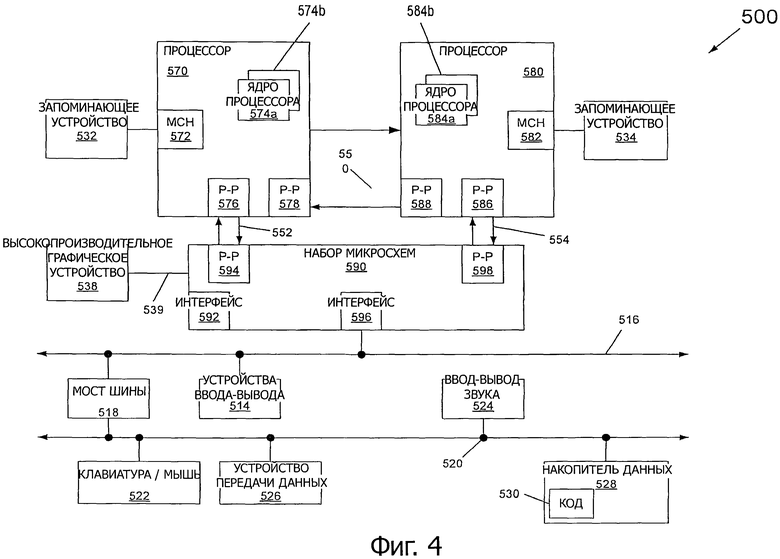
На фиг.4 представлена блок-схема системы в соответствии с одним вариантом осуществления настоящего изобретения.
Подробное описание изобретения
Варианты осуществления можно использовать для параллельного выполнения изменения размеров и выполняемого по требованию для каждого адресуемого сегмента повторного хеширования для одновременно обрабатываемой хеш-таблицы, которая представляет собой совместно используемое запоминающее устройство, доступ к которому осуществляется одним или больше потоками, которые могут выполнять одно или больше ядер многопроцессорной системы, такой, как система, имеющая один или больше многоядерных процессоров. Они применимы для хеш-таблиц, где адресуемый сегмент может содержать набор элементов. Для простоты предположим, что исходная емкость таблицы представляет собой степень двух. Остаток деления хеш-значения для элемента на емкость приводит к получению индекса адресуемого сегмента, в котором содержится элемент. В некоторых вариантах осуществления, в результате упрощения, индекс адресуемого сегмента также может быть рассчитан по следующей формуле:
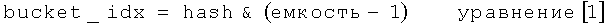
где hash представляет собой значение хеш-функции, которое получают путем расчета хеш-функции, в которой ключ применяют для хеш-функции, которая генерирует значение хеш-функции, и знак "&" обозначает побитную операцию "И" для двоичных представлений. В одном варианте осуществления емкость может быть выражена в единицах количества адресуемых сегментов хеш-таблицы, хотя объем настоящего изобретения не ограничен в этом отношении.
Для увеличения емкости алгоритм в соответствии с вариантом осуществления настоящего изобретения может выделять такое количество адресуемых сегментов, какое уже существует, и поддерживают старые сегменты, удваивая, таким образом, количество сегментов. Каждый новый сегмент логически отображают на существующий сегмент (родительский), который имеет индекс, включающий в себя то же значение (то есть набор битов), что и индекс нового сегмента, за исключением наибольшего бита, содержащего значение 1. Например, если индекс сегмента составляет 00101101 в бинарном выражении, тогда соответствующий индекс родительского сегмента представляет собой 00001101. А именно индекс родительского сегмента может быть получен следующим образом:
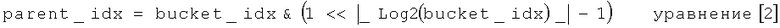
где << обозначает сдвиг двоичного левого операнда на количество битов, указанное правым операндом.
Во многих вариантах осуществлении некоторые новые сегменты могут иметь другие новые сегменты, в качестве родительских. Выделение, которое приводит к этому, может быть скомбинировано в одиночный запрос памяти в некоторых вариантах осуществлении, как описано ниже.
Рассмотрим теперь фиг.1, на которой показана блок-схема последовательности операций способа, для обновления хеш-таблицы в соответствии с одним вариантом осуществления настоящего изобретения. Как показано на фиг.1, способ 10 может начаться путем определения того, что в хеш-таблице требуется увеличенное пространство (блок 20). Хотя объем настоящего изобретения не ограничен в этом отношении, такое определение может быть выполнено на основе коэффициента загрузки таблицы, например, системным программным обеспечением после операции вставки новой пары данных, когда количество данных, сохраненных в хеш-таблице, достигает заданного порогового значения, например определенного процента всей величины таблицы. Конечно, другие способы определения того, что требуется увеличенное пространство, можно использовать в других вариантах осуществления. Например, пользователь может указывать количество сегментов в вызове обратной операции.
После такого определения управление переходит в блок 30, где может быть выделено определенное количество новых сегментов. Более конкретно, может быть выделено количество сегментов, соответствующее настоящему количеству сегментов в хеш-таблице. Таким образом, количество сегментов, выделенных в таблице, удваивается. В одном варианте осуществления вызывают распределитель для получения требуемого объема запоминающего устройства, и сегменты инициализируют, как новые пустые сегменты. Затем такое новое пространство может быть опубликовано (блок 40). В то время как объем настоящего изобретения не ограничен в этом отношении, публикация может быть выполнена через обновление до переменной, содержащей величину емкости. В одном варианте осуществления обновление может выполняться через сохранение с операцией высвобождения (или с помощью элементарной записи) до значения "емкости". В качестве альтернативы, такое обновление может представлять маску, которая соответствует значению емкости минус 1. Таким образом, путем выделения новых сегментов и публикации этого нового пространства выделение заканчивают без необходимости выполнения полного повторного хеширования данных, присутствующих в исходных сегментах, в новые сегменты. Таким образом, выделение выполняют независимо от повторного хеширования, и его заканчивают путем публикации нового пространства. Каждый сегмент во вновь опубликованном пространстве первоначально повторно маркируют, как нехешированный.
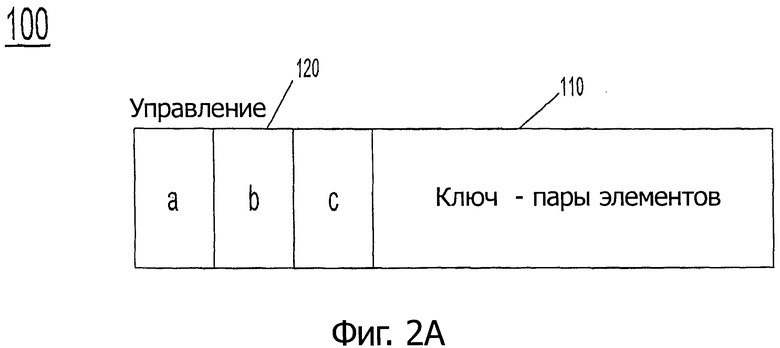
Рассмотрим теперь фиг.2А, на которой показана блок-схема адресуемого сегмента в соответствии с одним вариантом осуществления настоящего изобретения. Как показано на фиг.2А, сегмент 100 может включать в себя данные, а именно участок 110 данных, который включает в себя ключ и пары элементов, называемых здесь, в общем, парами данных. Участок 110 данных может, в случае необходимости, содержать ограниченный набор (массив) пар, непосредственно (внедренных) и опосредованно, например, через указатель. Кроме того, присутствует информация 120 управления. Различная информация может быть включена в информацию 120 управления, включающую в себя, например, объект (а) синхронизации, такой как взаимное исключение, поле (b) управления, которое может включать в себя различную информацию, такую как флаги, счетчики и т.д., и поле (с) состояния повторного хеширования, которое может включать в себя различную информацию, обозначающую, был ли повторно хеширован заданный сегмент, и количество уровней повторного хеширования (которые могут использоваться для подхода "один-множество", описанного ниже).
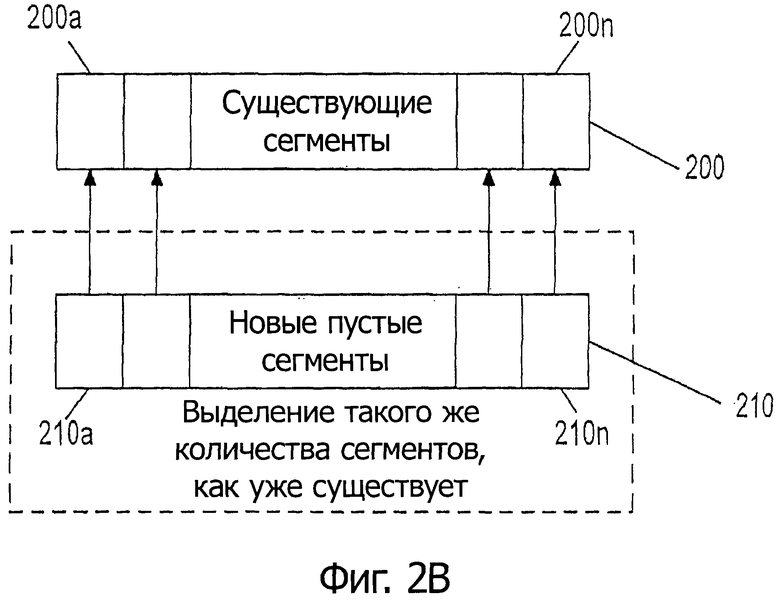
Рассмотрим теперь фиг.2В, на которой показана блок-схемы, иллюстрирующая выделение новых сегментов в соответствии с вариантом осуществления настоящего изобретения. Как показано на фиг.2В, присутствует множество существующих сегментов 200а-200n. Каждый такой сегмент может соответствовать сегменту 100 по фиг.2А, в качестве примера. В соответствии с операцией изменения размещения новые сегменты логически отображают на родительские сегменты, формируя новый набор пустых сегментов 210а-210n. Как можно видеть, выделение выполняется для того же количества сегментов, какое уже существует. Каждый из этих новых сегментов логически отображается на один из родительских сегментов и помечается, как не подвергавшийся повторному хешированию, например, в его информации 120 управления, такой как поле (с) повторного хеширования, показанное на фиг.2А.
В других случаях, по меньшей мере, некоторые из новых сегментов могут быть отображены на другие новые сегменты, как показано на фиг.2С. Таким образом, фиг.2С представляет собой поднабор фиг.2В, и в ней описаны две отдельных возможности: (1) родительские сегменты также могут не быть повторно хешированными; и (2) выделения могут быть скомбинированы. Как можно видеть, новые пустые сегменты 210а-210n отображаются на существующие сегменты 200а-200n. В свою очередь, дополнительные новые пустые сегменты 220а-220n также отображаются на существующие сегменты 200а-200n. Кроме того, другие новые пустые сегменты 230а-230n отображаются на новые пустые сегменты 210а-210n. Следует отметить, что новые пустые сегменты, начинающиеся в сегменте 210а и заканчивающиеся в 230n, могут представлять собой непрерывное пространство комбинированных выделений, и количество сегментов может быть удвоено несколько раз одновременно, например количество сегментов может быть умножено на коэффициент 4.
После выделения и публикации нового значения емкости, с помощью операции просмотра рассчитывают индекс сегмента, используя новое значение емкости. После публикации новой емкости любая операция просмотра нового сегмента должна вначале просматривать родительский сегмент (сегменты), и в случае необходимости (но в конечном итоге) выполняют повторное хеширование ее (их) содержания в новый сегмент (сегменты). Таким образом, работа по повторному хешированию может быть задержана и разделена по последующим операциям в пределах контейнера. Рассчитанный индекс, с использованием нового значения емкости может указывать на сегмент, помеченный, как не подвергавшийся повторному хешированию. Если это так, операция просмотра может переходить вначале на просмотр родительского сегмента, родительского сегмента для родительского сегмента и т.д., до тех пор, пока не будет найден сегмент, подвергавшийся повторному хешированию или необходимый ключ. Когда будет найдена требуемая информация, результаты просмотра могут быть возвращены по запросу. Также, кроме того, повторное хеширование может происходить для каждого сегмента (обрабатываемых сегментов). Такое повторное хеширование может называться ленивым повторным хешированием, поскольку для него не используются время и затраты для выполнения полного повторного хеширования всей таблицы по изменению положения, а только отдельное повторное хеширование сегмента (по требованию) может происходить в ответ на запрос просмотра. В качестве альтернативы, такое повторное хеширование может происходить по внешнему запросу (пользователя).
Таким образом, в случае необходимости (но в конечном итоге), все элементы, которых это касается, могут быть повторно хешированы, путем перемещения пар данных в новый сегмент (сегменты), если они принадлежат ему. С этой целью возможны различные стратегии. В качестве примера, два состояния можно использовать для идентификации сегментов, повторно хешированных и не повторно хешированных. В этом варианте осуществления предусмотрен специально выделенный владелец для операции повторного хеширования. С этой целью поток блокирует сегмент, используя взаимно исключающую синхронизацию, таким образом, что никакой другой поток не может получить доступ к нему в течение времени операции и, таким образом, должен подождать.
Третье состояние может быть добавлено, а именно состояние "частично повторно хешировано" так, что другие потоки могут одновременно получать доступ к новому сегменту, который повторно хешируют, или участвовать в повторном хешировании одного и того же родительского повторного сегмента. Основное назначение воплощения в третьем состоянии состоит в том, чтобы разблокировать потоки, которые, в противном случае, должны были ожидать до тех пор, пока произойдет повторное хеширование сегмента другим потоком.
Для логики двух состояний может быть выполнено рекурсивное повторное хеширование между двумя сегментами (например, родительским и следующим потомком), или может применяться подход "один-множество", где родительский сегмент повторно хешируют во все не хешированные повторно потомки. Для алгоритма рекурсивного повторного хеширования с двумя состояниями переменная одного состояния (например, присутствующая в информации 120 управления на фиг.2А) может быть представлена с состояниями НОВЫЙ (пустой без повторного хеширования), ПУСТОЙ (но повторно хешированный) и ЗАПОЛНЕННЫЙ (повторно хешированный). Например, указатель на пары данных может представлять все три состояния и все еще относиться к данным. Следует отметить, что вариант воплощения "один - множество" использует дополнительный элемент структуры данных адресуемого сегмента, который выражает количество уровней повторного хеширования (емкость) для сегмента.
На фиг.3 показана блок-схема последовательности операций способа для выполнения просмотра/повторного хеширования в соответствии с вариантом осуществления настоящего изобретения. Эта блок-схема последовательности операций предназначена для представления обзора высокого уровня, который соответствует как взаимно-однозначному (рекурсивному) подходу, так и подходу "один-множество", любой из которых может быть воплощен, и оба из которых дополнительно описаны ниже. Запрос на просмотр может представлять запрос, предназначенный только для операции поиска или операции вставки. Для простоты описания будет описана операция поиска. Как показано на фиг.3, способ 300 может начинаться с расчета индекса адресуемого сегмента и адреса для запроса просмотра (блок 305). Например, ключ, ассоциированный с запрашиваемой парой данных, может быть предусмотрен в хеш-функции, которая генерирует хеш-значение, которое вместе с емкостью хеш-таблицы можно использовать для получения индекса и, таким образом, адреса в запоминающем устройстве. Далее может быть определено, представляет ли запрос на просмотр повторно не хешированный пустой сегмент (ромб 310). В противном случае, просмотр может быть выполнен путем получения доступа к индексированному сегменту, и представления пары (пар) данных по запросу (блок 315). Следует отметить, что дополнительные операции, такие как синхронизация, поиск через сегмент, проверка состояния "гонки" и в случае необходимости повторный запуск всей операции поиска (если будет детектирована гонка) могут быть выполнены во время этого этапа, как будет дополнительно описано ниже.
Если вместо этого определяют, что запрос на поиск представляет собой сегмент, не подвергавшийся повторному хешированию, управление переходит в блок 320. В блоке 320 могут быть рассчитаны индекс и адрес для родительского сегмента. Как описано выше, такой индекс может быть рассчитан в соответствии с Уравнением 2, в некоторых вариантах осуществления. Когда индекс рассчитывают, его можно использовать для получения доступа к родительскому сегменту. Такой сегмент во время доступа может проверяться для определения, был ли он повторно хеширован или включает ли он в себя запрашиваемую пару данных (ромб 330). Такое определение может быть основано частично на состоянии повторного хеширования сегмента. Если будет найден повторно хешированный сегмент, сегменты могут быть синхронизированы (блок 340), и пара данных может быть возвращена по запросу (блок 350). В противном случае управление переходит обратно в блок 320 для дальнейшей итерации в этой петле цикла. Синхронизация в блоке 340 может включать в себя блокирование сегментов, представляющих интерес, до выполнения какого-либо поиска или операции повторного хеширования. Следует отметить, что в блоке 350 решение в отношении повторного хеширования может зависеть от заданного алгоритма, который может обеспечить повторное хеширование по запросу, частичное повторное хеширование или повторное хеширование по специально выделенным потокам. Если выполняется повторное хеширование, состояние повторного хеширования одного или больше сегментов может быть обновлено, когда выполняют повторное хеширование. Для подхода "один-множество" изменяются состояния родительских и всех новых сегментов. Следует отметить, что в этот момент, после повторного хеширования, из родительского сегмента могут быть сняты некоторые пары для перемещения их в сегменты - потомки (состояние, измененное для подхода "один-множество").
Поскольку сегменты никогда не освобождают или не перемещают одновременно, некоторые алгоритмы, не использующие блокирование или не содержащие фиксацию, могут использоваться для доступа к сегментам и внедренным в них данным. Таким образом, могут быть повышены рабочие характеристики и масштабируемость приложений, используя хеш-таблицы.
Когда множество потоков получают доступ к хеш-таблице, как к совместно используемому ресурсу, становится возможным возникновение состояния гонки при просмотре повторного хеширования. Если ключ не будет найден, также возможно, что он был одновременно перемещен при повторном хешировании сегмента. Для того, чтобы удостовериться, что ключ не существует, текущую емкость требуется сравнить с исходной емкостью, которая использовалась для расчета индекса сегмента. Если они не равны, тогда можно затем определить, являются ли индексы сегмента, рассчитанные по этим значениями, отличными друг от друга (оба сравнения могут быть сведены к последнему одному). Если это так, и если ближайший сегмент-наследник был повторно хеширован, или его повторно хешируют, просмотр должен быть повторно запущен (для того, чтобы удостовериться, что ключ не существует). Следует отметить, что может существовать не только один наследник, если емкость была умножена более чем на 2. В качестве одного примера состояния гонки рассмотрим следующую последовательность, которая возможна в одновременно исполняемой среде:
Таблица 1
1. Поток 1: получают текущую емкость и рассчитывают индекс (X) сегмента для операции просмотра.
2. Поток 2: заканчивают выделение новых сегментов и публикуют новую емкость.
3. Поток 3: получают новое значение емкости и начинают повторное хеширование сегмента (X) в новое пространство (Y).
4. Поток 1: продолжается в результате поиска в сегменте (X) элемента и не может его найти. Но это не означает, что такой элемент не существует во всей таблице, поскольку он мог быть перемещен (в Y) из-за одновременного роста (2) и повторного хеширования (3).
Рассмотрим теперь Таблицу 2, здесь показан пример псевдокода, для определения существования состояния гонки в соответствии с вариантом осуществления настоящего изобретения, а именно, примерный алгоритм для проверки, может ли возникнуть коллизия во время повторного хеширования.
Таблица 2
bool check_rehashmg_collision (hash, capacity_old, capacity_new) {
if((hash & (capacity_old-l)) !=(hash & (capacity_new-l))) {
//найти следующую применимую маску после старого уровня while((hash & capacity_old)=0)
capacity_old=(capacity_old<<1);
capacity_pld=(capacity_old<<1);
//проверить, происходит ли повторное хеширование или было выполнено
if(! is_marked_for_rehashing (hash & (capacity_old-1)))
return true; / / просмотр должен быть запущен повторно
}
return false; / / коллизия отсутствует
}
В одном варианте осуществления может использоваться рекурсивный алгоритм повторного хеширования с двумя состояниями, с тремя функциями, а именно функцией просмотра, функцией получения сегмента, которая выполняет синхронизацию и вызов третьей функции, а именно функции повторного хеширования. Рассмотрим теперь Таблицу 3, которая представлена в виде псевдокода для такого рекурсивного алгоритма повторного хеширования с двумя состояниями.
Таблица 3
Просмотр:
1. рассчитать хеш-значение для заданного ключа
2. получить текущее значение емкости и рассчитать индекс сегмента (используя хеш-значение и емкость)
3. вызвать: Get bucket для считывания
4. выполнить поиск ключа в сегменте
а. если будет найден: высвободить сегмент и вернуть данные, для которых должна быть выполнена обработка
5. не найден: проверить наличие гонки при повторном хешировании (например, в соответствии с Таблицей 2)
а. если гонка не возникла: [может быть выполнена операция вставки или] высвободить сегмент и вернуться
b. гонка детектирована: высвободить сегмент и перейти к (2)
Get bucket (воплощение для блокирования считывания-записи):
1. рассчитать/получить адрес сегмента
2. получить состояние сегмента
а. если НОВЫЙ (не повторно хешированный): попытаться получить исключительный доступ к сегменту (некоторые потоки могут успешно выполняться), если не так: перейти к (3)
b. получен: если состояние сегмента все еще НОВЫЙ (двойная проверка), вызвать: повторное хеширование сегмента и затем возврат
3. получить установленный доступ к сегменту
Get bucket (воплощение только для взаимно исключающих блокирований):
1. рассчитать адрес сегмента, используя значения хеш-функции и емкости
2. получить (исключительный) доступ к сегменту
3. получить состояние сегмента
а. если НОВЫЙ (не повторное сегментированный): вызвать: сегмент Rehash bucket
Rehash bucket: (который выполняют при исключительном блокировании, в соответствии с алгоритмом "Get bucket"),
1. пометить новый сегмент, как повторно хешированный
2. рассчитать индекс родительского сегмента
3. вызвать: Получить родительский сегмент для считывания
4. для каждого элемента данных в родительском сегменте:
а. рассчитать значение хеш-функции
b. проверить, следует ли переместить элемент в новый сегмент, и если да:
i. в случае необходимости обновить родительский сегмент до получения исключительного доступа (если блокирование было прервано для обновления, повторно возобновить, начиная с (4)),
ii. переместить элемент из родительского сегмента в новый сегмент
Следует отметить, что взаимная связь между функциями Rehash bucket и Get bucket означает, что этот алгоритм является рекурсивным. Следует также отметить, что алгоритм одновременного повторного хеширования в соответствии с вариантом осуществления настоящего изобретения не требует определенных алгоритмов фиксации, поскольку вместо этого он только устанавливает уровень синхронизации. Например, "получить сегмент для считывания" может означать любое фактическое использование: получение исключительного блокирования, совместно используемого (блоком считывания) блокирования, или даже использование только счетчика версии (для операции считывания без блокирования).
В еще одном другом варианте осуществления можно использовать подход "один-множество". В Таблице 4 показана презентация в виде псевдокода для алгоритма "один-множество".
Таблица 4
Просмотр:
1. рассчитать значение хеш-функции для заданного ключа
2. получить текущее значение емкости и рассчитать индекс сегмента (используя значение хеш-функции и емкость) и адрес
3. получить состояние сегмента, если он не был повторно хеширован (новый):
а. найти ближайший повторно хешированный корень (родительский/прародительский и т.д.) сегмента
b. пытаться получить исключительный доступ к корневому сегменту, пока не будет получен, или состояние нового сегмента не будет изменено на "повторно сегментированный"
если состояние изменяется: освободить блокирование в случае необходимости и перейти к (4)
с. вызвать: Rehash bucket
4. получить определенный доступ к сегменту
5. выполнить поиск ключа в сегменте
d. если будет найден: высвободить сегмент и вернуть данные, который должны быть обработаны
6. если не будет найден: проверить наличие гонки повторного хеширования (например, в соответствии с Таблицей 2)
е. если гонка отсутствует: [может быть выполнена операция вставки или] высвободить сегмент и вернуться
f. гонка детектирована: высвободить сегмент и перейти в (2)
Rehash bucket: (который выполняют при исключительном блокировании),
1. для корневого сегмента и каждого из всех его сегментов наследников:
а. сохранить значение емкости для поля уровня повторного хеширования (и таким образом, пометить сегмент, как повторно хешированный)
2. для каждого элемента данных в корневом сегменте:
b. рассчитать значение хеш-функции
с. проверить, следует ли переместить элемент в новый сегмент, и если да:
i. переместить элемент для родительского сегмента в соответствующий новый сегмент
Вариант осуществления может быть воплощен в коде для соответствующего контейнера в библиотеке. Таким образом, в различных вариантах осуществления, вместо блокирования всего контейнера (или участка контейнера) для обновлений, выделение может выделять такое количество сегментов, которое уже существует, и поддерживать старые сегменты, удваивая, таким образом, количество сегментов. Каждый новый сегмент помечается как повторно не хешированный, и его логически отображают на существующий сегмент (родительский) с тем же индексом. В некоторых вариантах осуществления выделение также может быть скомбинировано в одну публикацию, и может использоваться один запрос памяти. Таким образом, изменение размеров в соответствии с вариантом осуществления настоящего изобретения не нарушает одновременность, поскольку оно не делает недействительными, не блокирует существующие сегменты.
Варианты осуществления могут быть воплощены во множестве различных типов системы. Рассмотрим теперь фиг.4, на которой показана блок-схема системы в соответствии с вариантом осуществления настоящего изобретения. Как показано на фиг.4, многопроцессорная система 500 представляет собой систему взаимного двухточечного соединения, и включает в себя первый процессор 570 и второй процессор 580, соединенные через взаимное двухточечное соединение 550. Как показано на фиг.4, каждый из процессоров 570 и 580 может представлять собой многоядерные процессоры, включающие в себя первое и второе ядра процессора (то есть ядра 574а и 574b процессора и ядра 584а и 584b процессора), хотя потенциально намного большее количество ядер могут присутствовать в процессорах. Ядра процессора могут выполнять различные потоки, которые могут обращаться к хеш-таблицам, сохраненным в системном запоминающем устройстве, в соответствии с вариантом осуществления настоящего изобретения, описанным выше.
Все еще обращаясь к фиг.4, первый процессор 570 дополнительно включает в себя концентратор 572 контроллера памяти (МСН) и двухточечные интерфейсы 576 и 578 (Р-Р). Аналогично, второй процессор 580 включает в себя МСН 582 и интерфейсы 586 и 588 Р-Р. Как показано на фиг.4, МСН 572 и 582 соединяют процессоры с соответствующим запоминающими устройствами, а именно запоминающим устройством 532 и запоминающим устройством 534, которые могут представлять собой части оперативного запоминающего устройства (например, динамического оперативного запоминающего устройства (DRAM)), локально установленные для соответствующих процессоров, и которые могут сохранять одну или больше хеш-таблиц, которые могут быть одновременно повторно хешированы в соответствии с вариантом осуществления настоящего изобретения. Первый процессор 570 и второй процессор 580 могут быть соединены с набором микросхем 590 через взаимные соединения 552 и 554 Р-Р соответственно. Как показано на фиг.4, набор 590 микросхем включает в себя интерфейсы 594 и 598 Р-Р.
Кроме того, набор 590 микросхем включает в себя интерфейс 592 для соединения набора 590 микросхем с высокопроизводительным графическим механизмом 538 через Р-Р взаимные соединения 539. В свою очередь, набор 590 микросхем может быть соединен с первой шиной 516 через интерфейс 596. Как показано на фиг.3, различные устройства 514 входа-выхода (I/O) могут быть соединены с первой шиной 516, вместе с мостом 518 шины, который соединяет первую шину 516 со второй шиной 520. Различные устройства могут быть соединены со второй шиной 520, включающей в себя, например, клавиатуру/мышь 522, устройство 526 передачи данных и накопитель данных; модуль 528, такой как привод диска, или другое устройство - накопитель информации, которое может включать в себя код 530, в одном варианте осуществления. Кроме того, аудиовход 524 I/O может быть соединен со второй шиной 520.
Варианты осуществления могут быть воплощены в коде и могут быть сохранены на носителе записи, на котором записаны инструкции, которые могут использоваться для программирования системы, для выполнения инструкций. Носитель записи может включать в себя, но не ограничен этим, любой тип диска, включая в себя гибкие диски, оптические диски, постоянное запоминающее устройство на компактных дисках (CD-ROM), компакт-диски, предназначенные для перезаписи (CD-RW), и магнитооптические диски, полупроводниковые устройства, такие как постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), такие как динамические оперативные запоминающие устройства (DRAM), статические оперативные запоминающие устройства (SRAM), стираемые программируемые постоянные запоминающие устройства (EPROM), запоминающее устройство типа флэш, электрически стираемые программируемые постоянные запоминающие устройства памяти (EEPROM), магнитные или оптические карты, или любые другие типы носителей, пригодные для сохранения электронных инструкций.
В то время как настоящее изобретение было описано со ссылкой на ограниченное количество вариантов осуществления, для специалиста в данной области техники будут понятны множество модификаций и изменений для него. Предполагается, что приложенные формулы изобретения охватывают все такие модификации и изменения и попадают в пределы истинной сущности и объема данного настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ДВУХПРОХОДНОЕ ХЕШ ИЗВЛЕЧЕНИЕ ТЕКСТОВЫХ СТРОК | 2008 |
|
RU2464630C2 |
| СОХРАНЯЮЩАЯ КОНФИДЕНЦИАЛЬНОСТЬ СЛУЖБА ДОМЕННЫХ ИМЕН (DNS) | 2021 |
|
RU2837326C2 |
| ИЗВЕЩЕНИЯ ПОИСКА ЗНАЧИТЕЛЬНЫХ ИЗМЕНЕНИЙ | 2007 |
|
RU2436152C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| АУТЕНТИФИКАЦИЯ В ЗАЩИЩЕННОЙ КОМПЬЮТЕРИЗОВАННОЙ ИГРОВОЙ СИСТЕМЕ | 2003 |
|
RU2302276C2 |
| УЛУЧШЕНИЕ БЕЗОПАСНОСТИ ПАССИВНОЙ ОПТИЧЕСКОЙ СЕТИ, ОСНОВАННОЙ НА ИНТЕРФЕЙСЕ АДМИНИСТРАТИВНОГО УПРАВЛЕНИЯ ТЕРМИНАЛОМ ОПТИЧЕСКОЙ СЕТИ | 2010 |
|
RU2507691C2 |
| СИСТЕМА И СПОСОБ ДЛЯ КЛИЕНТ-ОБОСНОВАННОГО ПОИСКА ВЕБ-АГЕНТОМ | 2004 |
|
RU2383920C2 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНЫЕ БИБЛИОТЕКИ ОДИНОЧНЫХ ЯДЕР И ОДИНОЧНЫХ КЛЕТОК И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ИСПОЛЬЗОВАНИЯ | 2020 |
|
RU2838545C2 |
| СИНХРОНИЗАЦИЯ ХЭШЕЙ МАНДАТОВ МЕЖДУ СЛУЖБАМИ КАТАЛОГОВ | 2014 |
|
RU2671045C2 |
Изобретение относится к области обработки хеш-таблиц. Техническим результатом является параллельное выполнение изменения размеров и выполняемого по требованию для каждого адресуемого сегмента повторного хеширования для одновременно обрабатываемой хеш-таблицы, которая представляет собой совместно используемое запоминающее устройство, доступ к которому осуществляется одним или больше потоками, которые могут выполнять одно или больше ядер многопроцессорной системы, такой как система, имеющая один или больше многоядерных процессоров. Раскрывается способ для выделения второго количества сегментов для хеш-таблицы, совместно одновременно используемой множеством потоков, где второе количество сегментов логически отображают на соответствующий родительский сегмент первого количества сегментов, и публикуют обновленную емкость хеш-таблицы для завершения выделения без выполнения какого-либо повторного хеширования, таким образом, что повторное хеширование может быть выполнено позже по требованию для каждого сегмента. 3 н. и 17 з.п. ф-лы, 6 ил., 4 табл.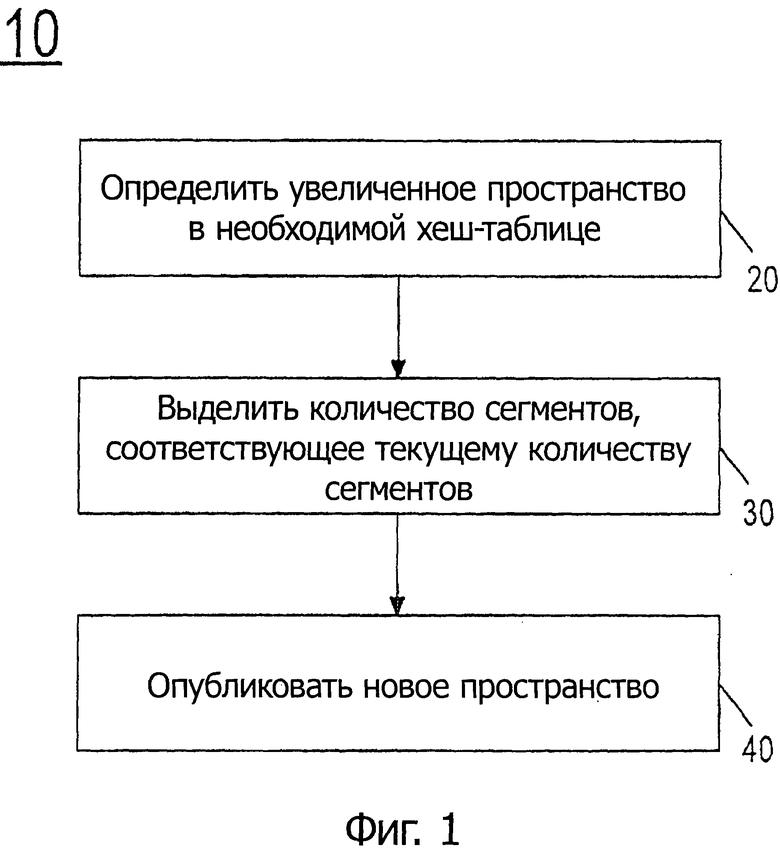
1. Способ для выделения второго количества сегментов для хэш-таблицы, совместно одновременно используемой множеством потоков, содержащий этапы, на которых:
выделяют второе количество сегментов для хеш-таблицы, совместно одновременно используемой множеством потоков, при этом хеш-таблица имеет первое количество сегментов, второе количество сегментов, по меньшей мере, равно первому количеству сегментов, и каждый из второго количества сегментов логически отображают на соответствующий родительский один из первого или второго количества сегментов; и
публикуют обновленную емкость хеш-таблицы, включающей в себя первое и второе количество сегментов, при этом выделение заканчивается посредством публикации обновленной емкости и без выполнения повторного хеширования элементов содержания первого количества сегментов.
2. Способ по п.1, дополнительно содержащий этап, на котором выполняют проверку, не блокируя сегмент, чтобы определить, необходимо ли повторное хеширование.
3. Способ по п.1, дополнительно содержащий этап, на котором затем выполняют повторное хеширование элементов содержания первого сегмента из первого количества сегментов до второго сегмента второго количества сегментов, выполняя операцию поиска для пары данных, присутствующей в первом сегменте.
4. Способ по п.1, дополнительно содержащий этапы, на которых вычисляют индекс сегмента, используя обновленную емкость, получают доступ к сегменту, используя индекс сегмента, определяют, что сегмент не был повторно хеширован, и рекурсивно вычисляют родительский индекс сегмента для родительского сегмента, пока повторно хешированный корневой сегмент не будет найден, на который сегмент логически отображает, используя обновленную емкость.
5. Способ по п.4, дополнительно содержащий этап, на котором выполняют повторное хеширование, по меньшей мере, части элементов содержания повторно хешированного корневого сегмента до сегмента во время выполнения или до выполнения поиска пары данных запроса поиска.
6. Способ по п.5, дополнительно содержащий этап, на котором устанавливают частичный индикатор повторного хеширования, когда только часть элементов содержания корневого сегмента повторно хеширована.
7. Способ по п.4, дополнительно содержащий поиск сегментов для пары данных запроса поиска и возврат пары данных, и без выполнения повторного хеширования элементов содержания сегментов.
8. Способ по п.1, дополнительно содержащий этапы, на которых в ответ на операцию поиска первым потоком, который не находит запрашиваемую пару данных в первом сегменте первого количества сегментов, сравнивают текущую величину емкости хеш-таблицы со значением емкости хеш-таблицы, использовавшимся при определении индекса сегмента для операции поиска, и если величина тока и значение являются разными, вычисляют индекс самого близкого сегмента наследника, получают доступ к самому близкому сегменту наследника и определяют состояние повторного хеширования для самого близкого сегмента наследника.
9. Способ по п.8, дополнительно содержащий этап, на котором повторно запускают операцию поиска, если состояние повторного хеширования не обозначает новое (повторно не хешированное) состояние.
10. Способ по п.1, дополнительно содержащий этап, на котором объединяют множество выделений в одиночное выделение для второго количества сегментов.
11. Способ по п.1, дополнительно содержащий этапы, на которых публикуют множество выделений и публикуют обновленную емкость один раз для множества выделений.
12. Изделие, содержащее машиносчитываемый носитель информации, включающий в себя инструкции, которые при их выполнении устройством обеспечивают возможность для устройства выполнить способ для выделения второго количества сегментов для хэш-таблицы, совместно одновременно используемой множеством потоков, содержащий этапы, на которых:
выделяют второе количество сегментов для хеш-таблицы, совместно одновременно используемой множеством потоков, при этом хеш-таблица имеет первое количество сегментов, второе количество сегментов, по меньшей мере, равно первому количеству сегментов, и каждый из второго количества сегментов логически отображают на соответствующий родительский один из первого или второго количества сегментов; и
публикуют обновленную емкость хеш-таблицы, включающей в себя первое и второе количество сегментов, при этом выделение заканчивается посредством публикации обновленной емкости и без выполнения повторного хеширования элементов содержания первого количества сегментов.
13. Изделие по п.12, в котором способ дополнительно содержит выполнение проверки, не блокируя сегмент, чтобы определить, необходимо ли повторное хеширование.
14. Изделие по п.12, в котором способ дополнительно содержит выполнение повторного хеширования элементов содержания первого сегмента из первого количества сегментов до второго сегмента второго количества сегментов, выполняя операцию поиска для пары данных, присутствующей в первом сегменте.
15. Изделие по п.12, в котором способ дополнительно содержит вычисление индекса сегмента, используя обновленную емкость, получение доступа к сегменту, используя индекс сегмента, определение, что сегмент не был повторно хеширован, и рекурсивное вычисление родительского индекса сегмента для родительского сегмента, пока повторно хешированный корневой сегмент не будет найден, на который сегмент логически отображает, используя обновленную емкость.
16. Система для выделения второго количества сегментов для хэш-таблицы, совместно одновременно используемой множеством потоков, содержащая:
микропроцессор, включающий в себя первое ядро и второе ядро, каждое предназначенное для выполнения одного или больше потоков, при этом первый поток должен выделять второе количество сегментов для хеш-таблицы, совместно используемой одновременно множеством потоков, причем хеш-таблица ранее имела первое количество сегментов, второе количество сегментов, по меньшей мере, равно первому количеству сегментов, где каждое второе количество сегментов логически отображают либо на соответствующего родителя одного из первого количества сегментов, или на один из второго количества сегментов, и публиковать обновленную емкость хеш-таблицы, включающей в себя первое и второе количество сегментов, при этом первый поток должен закончить выделение посредством публикации обновленной емкости и без выполнения повторного хеширования элементов содержания первого количества сегментов, и второй поток должен выполнить операцию поиска в первом сегменте первого количества сегментов, не проверяя переменную блокировки, чтобы определить, необходимо ли повторное хеширование; и
совместно используемое запоминающее устройство, соединенное с микропроцессором, для содержания хеш-таблицы, при этом доступ к хеш-таблице одновременно получают, по меньшей мере, некоторые из множества потоков.
17. Система по п.16, в которой третий поток должен выполнить повторное хеширование элементов содержания от первого сегмента, содержащего первое количество сегментов, до второго сегмента, содержащего второе количество сегментов, при выполнении операции поиска для пары данных, присутствующих в первом сегменте.
18. Система по п.16, в которой второй поток должен вычислять индекс сегмента для сегмента, содержащего второе количество сегментов, используя обновленную емкость, получить доступ к сегменту, используя индекс сегмента, определить, что сегмент не был повторно хеширован, и рекурсивно вычислять индекс родительского сегмента для родительского сегмента, на который сегмент был логически отображен, пока не будет найден повторно хешированный корневой сегмент.
19. Система по п.18, в которой второй поток должен повторно хешировать, по меньшей мере, часть элементов содержания повторно хешированного корневого сегмента до сегмента во время выполнения или до выполнения поиска пары данных запроса на поиск.
20. Система по п.19, в которой второй поток должен установить частичный индикатор повторного хеширования корневого сегмента, когда только часть элементов содержания корневого сегмента повторно хеширована.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 7809916 B1, 05.10.2010 | |||
| Способ и регулятор для автоматического регулирования воздушного винта изменяемого шага | 1941 |
|
SU71016A1 |

