ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Раскрытие относится к области разрешения имени DNS сети Интернет и, в частности, к способу анализа источника и адресата Интернет-трафика.
УРОВЕНЬ ТЕХНИКИ
Так называемые источник и адресат Интернет-трафика относятся к последовательности путей доступа к веб-сайту, включающей в себя конкретный веб-сайт, к которому сначала осуществляет доступ пользователь, и другие веб-сайты, к которым пользователь осуществляет доступ позже. Существует только один основной подход для подтверждения источника трафика веб-сайта, а именно, добавить JavaScript-код для отслеживания на страницу веб-сайта. Наиболее распространены инструменты обнаружения от сторонних производителей, такие как Google Analytics и Baidu Analytics.
Вышеописанные статистические модели обладают огромными ограничениями, заключающимися в следующем: каждый веб-сайт может знать только веб-сайт, к которому посетитель осуществлял доступ в последний раз, и не может узнать о множестве веб-сайтов, к которым посетитель осуществлял доступ до того, а также узнать, куда посетитель перейдет после того, как покинет его. DNS (система доменных имен) представляет собой распределенную базу данных, которая обеспечивает сопоставление между доменным именем и IP-адресом в сети Интернет.DNS может предоставить пользователю возможность осуществить доступ к сети Интернет более удобным образом без запоминания IP-строк чисел, которые могут быть непосредственно считаны машиной. «Технология разрешения имени DNS» означает, что когда пользователю необходимо осуществить доступ к веб-сайту, пользователю необходимо ввести в браузере его доменное имя; после нажатия клавиши ввода пользователем браузер сначала инициирует запрос DNS; и с помощью технологии DNS браузер получает IP-адрес сервера, соответствующий доменному имени, и затем инициирует HTTP-запрос для этого IP-адреса.
В журналы DNS может записываться содержание ответов каждого запроса DNS и может почти записываться информация о доменных именах всех запросов пользователей. Однако журналы могут содержать слишком много неправильной и недействительной информации. Например, сервер также может инициировать запросы DNS таким образом, чтобы сформировать большой объем информации о доменных именах, и поисковые роботы сети Интернет и даже сетевые атаки будут формировать большое количество запросов DNS. Эти запросы не способны правильно и эффективно отразить реальные пути осуществления доступа пользователем.
В настоящее время не существует хороших способов для анализа всех путей осуществления доступа посетителями сети Интернет на рынке. Настоящее раскрытие заполняет этот пробел, оно обеспечивает способ анализа трафика веб-сайта для выяснения, с каких веб-сайтов он поступает, и на какие веб-сайты он перейдет после ухода, посредством повторной обработки журналов DNS.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Принимая во внимание вышеописанные недостатки, раскрытие обеспечивает способ анализа источника и адресата Интернет-трафика. С помощью способа согласно раскрытию характеристика не относящихся к человеку осуществлений доступа удаляется в журналах в максимально возможной степени, так что источник и адресат Интернет-трафика могут быть получены эффективно.
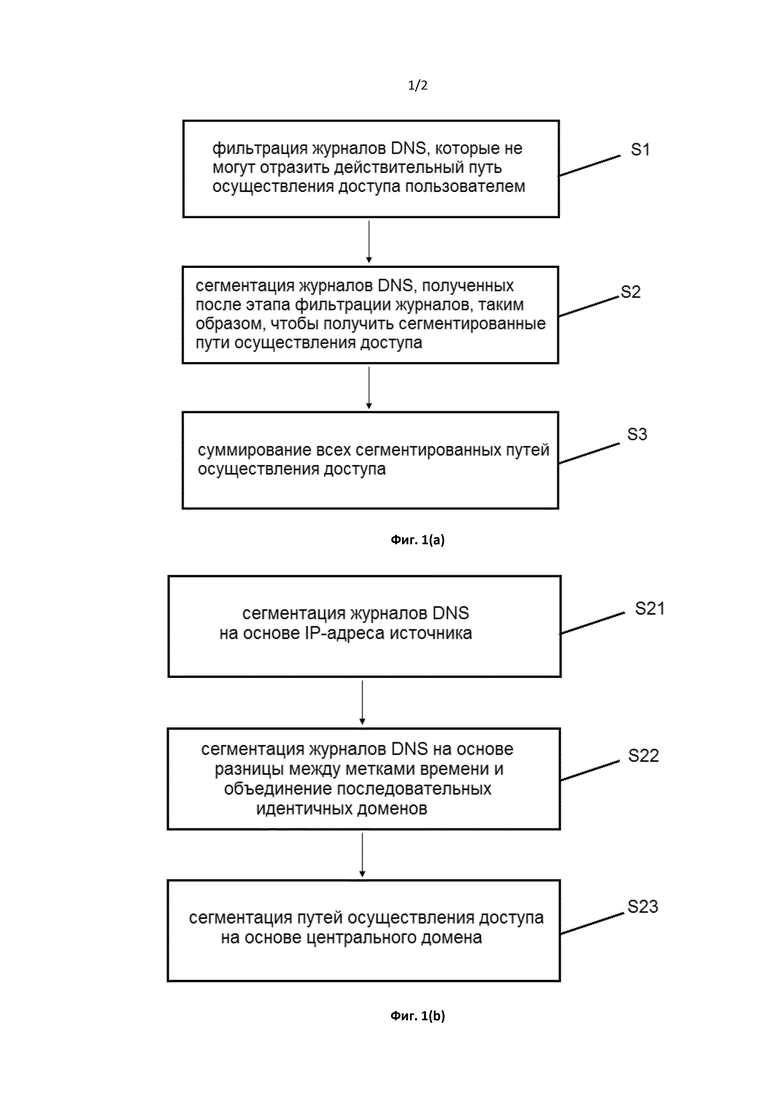
Способ анализа источника и адресата Интернет-трафика согласно раскрытию, который получает источник и адресата Интернет-трафика посредством обработки журнала DNS, включает в себя следующие этапы:
этап фильтрации журналов, на котором осуществляют фильтрацию журналов DNS, которые не могут отразить действительный путь осуществления доступа пользователем; этап сегментации журнала, на котором на основе IP-адреса источника, разницы между метками времени и центрального домена последовательно сегментируют журналы DNS, полученные после этапа фильтрации журналов, для получения сегментированных путей осуществления доступа; и этап суммирования данных, на котором суммируют все сегментированные пути осуществления доступа.
Предпочтительно, посредством установки черного списка и белого списка на этапе фильтрации журналов сохраняются журналы DNS, содержащие запросы доменных имен, представляющие значительный интерес, а журналы DNS, содержащие не относящиеся к человеку запросы доменных имен, сформированные сервером, удаляются.
Предпочтительно, удаление журналов DNS дополнительно включает в себя удаление журналов, к котором осуществляет доступ корпоративный IP-адрес, и журналов, в которых IP-адрес не преобразован.
Предпочтительно, сегментация журнала DNS, основанная на IP-адресе источника, заключается в том, чтобы получать последовательные журналы DNS с одинаковым IP-адресом источника в течение периода времени.
Предпочтительно, сегментация журналов, основанная на разнице между метками времени, заключается в том, чтобы на основе разницы между метками времени в журналах DNS сегментировать журналы после того, как они были сегментированы на основе IP-адреса источника, и, если разница между метками времени в двух журналах DNS больше, чем определенный временной промежуток, два журнала DNS разделяются.
Предпочтительно, определенный временной промежуток представляет собой три секунды.
Предпочтительно, способ анализа после этапа, на котором сегментируют журналы DNS на основе разницы между метками времени, дополнительно включает в себя этап объединения, на котором преобразуют доменное имя в путях осуществления доступа, полученных посредством сегментации, в домен, и объединяют последовательные идентичные домены таким образом, чтобы получить путь IP-адреса источника.
Предпочтительно, сегментация, основанная на центральном домене, заключается в том, чтобы сегментировать путь IP-адреса источника на основе центрального домена, и путь осуществления доступа, полученный после сегментации, представляет собой: доменное имя источника n + … + доменное имя источника 1 + центральное доменное имя + доменное имя адресата 1 + … + доменное имя адресата n, и центральный домен представляет собой домен, который главным образом анализируется на основе пользовательских/системных требований.
Предпочтительно, все пути осуществления доступа IP-адреса источника, которые получены после этапа сегментации на основе центрального домена, суммируются на этапе суммирования данных.
Посредством способа анализа согласно этому раскрытию источник и адресат Интернет-трафика могут быть освоены таким образом, чтобы можно было обеспечить улучшенный анализ и оптимизацию трафика вебсайта. Кроме того, будучи полностью осведомленным о направлении потока всего Интернет-трафика, состояние трафика других веб-сайтов может быть проанализировано и понято комплексно так, чтобы узнать все.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1(a) и 1(b) представляют собой блок-схемы последовательности операций способа анализа источника и адресата Интернет-трафика согласно раскрытию; и
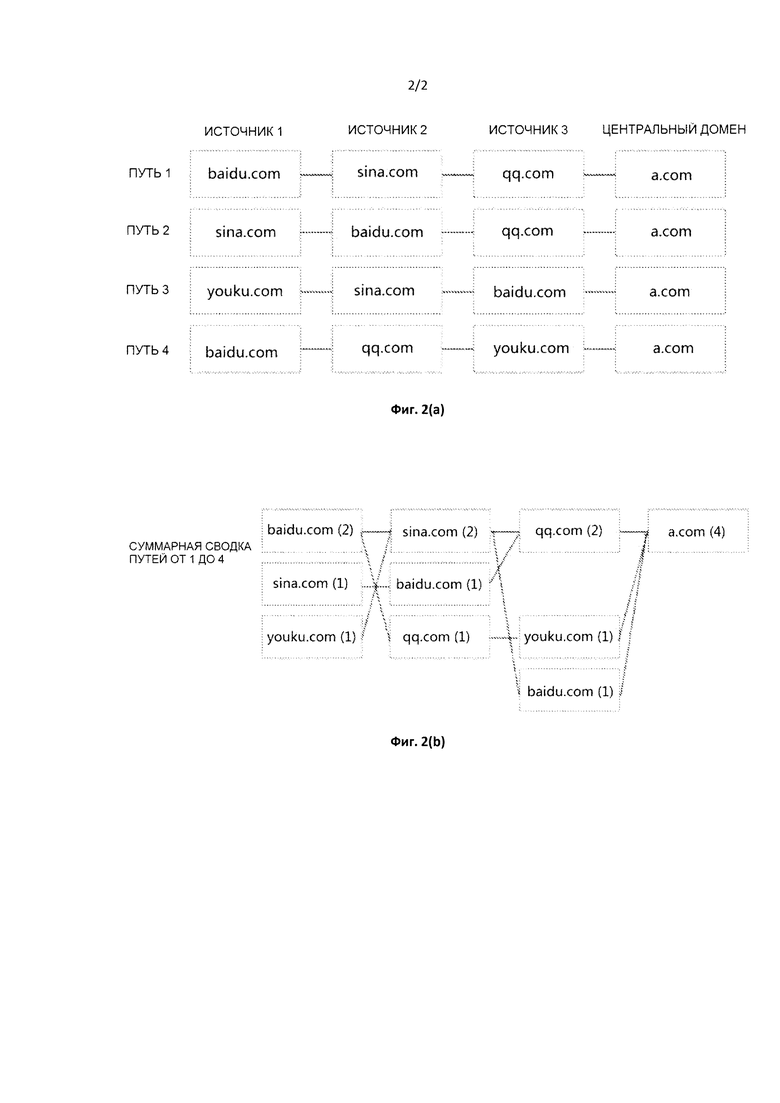
Фиг. 2(a) и 2(b) представляют собой схематические диаграммы источника трафика, полученного посредством способа анализа источника и адресата Интернет-трафика согласно раскрытию.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Далее раскрытие будет описано подробно со ссылкой на прилагаемые чертежи и варианты осуществления. Нижеследующие варианты осуществления не предназначены для ограничения изобретения. Изменения и преимущества, которые могут быть поняты специалистами в данной области техники, включены в настоящее раскрытие без отступления от сущности и объема раскрытия.
Как указано выше, DNS (система доменных имен) представляет собой распределенную базу данных, которая обеспечивает сопоставление между доменным именем и IP-адресом в сети Интернет.DNS может предоставить пользователю возможность осуществить доступ к сети Интернет более удобным образом без запоминания IP-строк чисел, которые могут быть непосредственно считаны машиной. При осуществлении доступа к веб-сайту пользователь сначала вводит в браузере его доменное имя и нажимает клавишу ввода. Затем браузер инициирует запрос DNS. С помощью технологии DNS браузер получает IP-адрес сервера, соответствующий доменному имени, и затем инициирует HTTP-запрос для этого IP-адреса. Вышеописанные этапы являются технологией разрешения имени DNS.
Журналы DNS могут быть сформированы во время вышеупомянутого процесса разрешения доменного имени. В журналы DNS может записываться содержание ответов каждого запроса DNS и может почти записываться информация о доменных именах всех запросов пользователей. Формат журналов DNS описывается следующим образом:

Таким образом, журнал DNS состоит из «IP-адреса источника», «Доменного имени», «Метки времени», «1Р разрешения» и «Кода состояния».
Так как журнал DNS включает в себя информацию о доменном имени всех запросов пользователей, авторы настоящего изобретения полагают, что источник и адресат трафика веб-сайта анализируются посредством повторной обработки журнала DNS. Однако журнал также включает в себя большой объем неправильной и недействительной информации. Например, сервер также может инициировать запросы DNS таким образом, чтобы сформировать большой объем информации о доменных именах, и поисковые роботы сети Интернет и даже сетевые атаки будут формировать большое количество запросов DNS. Эти запросы не способны правильно и эффективно отразить реальные пути осуществления доступа пользователем. На основе вышеописанной ситуации авторы настоящего изобретения полагают, что посредством очистки характеристик не относящихся к человеку осуществлений доступа в журнале в максимально возможной степени эффективно получаю источник и адресата Интернет-трафика.
Фиг. 1 представляет собой блок-схему последовательности операций способа анализа источника и адресата Интернет-трафика согласно раскрытию. Как показано на Фиг. 1, способ анализа источника и адресата Интернет-трафика в этом раскрытии включает в себя следующие этапы.
Во-первых, отфильтровываются (этап S1) журналы DNS, которые не могут отразить действительный путь осуществления доступа. Как описано выше, так как запрос DNS включает в себя множество доменных имен, которые не могу правильно и эффективно отражать действительный путь осуществления доступа, требуется очистка. Например, посредством установки черного списка и белого списка сохраняются журналы DNS, содержащие запросы доменных имен, представляющие значительный интерес, а журналы DNS, содержащие не относящиеся к человеку запросы доменных имен, сформированные сервером, удаляются. Не относящиеся к человеку запросы доменных имен, сформированные сервером, могут быть удалены посредством установки черного списка. Некоторые доменные имена, представляющие значительный интерес, могут быть сохранены посредством установки белого списка. Белый список имеет более высокий приоритет по сравнению с черным списком. Кроме того, удаление журналов DNS дополнительно включает в себя удаление журналов, к котором осуществляет доступ корпоративный IP-адрес, и журналов, в которых IP-адрес не преобразован, причем корпоративный IP-адрес удаляется, так как он может формировать журналы, к которым осуществляется доступ множеством человек одновременно, и влиять на оценку индивидуального отслеживания доступа; и журнал с непреобразованным IP-адресом удаляется, т.е. удаляется журнал с ошибкой доступа. Фильтрация журналов выполняется с использованием различных показателей таким образом, чтобы можно было получить журналы DNS, отражающие действительный путь осуществления доступа пользователем.
Затем журналы DNS, полученные после этапа фильтрации журналов, сегментируются на основе IP-адреса источника, разницы между метками времени и центрального домена таким образом, чтобы получить (этап S2) сегментированный домен.
Подробные этапы заключаются в следующем.
1) Обеспечиваются сегментации на основе IP-адреса (этап S21) источника. Журнал DNS сегментируют на основе IP-адреса источника, чтобы получать последовательные журналы DNS с одинаковым IP-адресом источника в течение периода времени.
Например, IP-адрес источника 1.1.1.1 отличается от IP-адреса источника 2.2.2.2, следовательно, журнал сегментируется. Это показывается следующим образом:
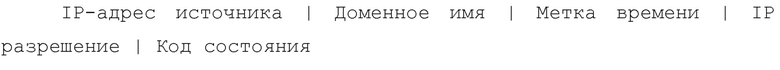

2) Затем журналы, сегментированные на основе IP-адреса источника, сегментируются на основе разницы между метками времени (этап S22). Сегментация на основе разницы между метками времени означает то, что после того, как журналы сегментируются на основе IP-адреса источника, они сегментируются на основе разницы между метками времени в журналах DNS. Если разница между метками времени в двух журналах DNS больше, чем определенный временной промежуток, два журнала DNS разделяются (причиной для сегментации является то, что интервал между журналами настолько большой, что два журнала рассматриваются как две различные характеристики). Определенный временной промежуток может быть настроен как требуется. В этом варианте осуществления определенный временной промежуток равен трем секундам, т.е. журнал может быть сегментирован, если интервалы между метками времени больше, чем три секунды.
Например, как показано ниже, журнал DNS IP-адреса источника 2.2.2.2 дополнительно сегментирован на основе его разницы между метками времени (Метка времени 20141211035932 указывает 3 (часа):59(минут):32(секунды) 11 декабря 2014).


Как описано выше, так как разница между 05 секундами в метке времени 20141211000005 и 09 секундами в метке времени 20141211000009 равна четырем секундам (больше, чем три секунды), то журнал разделяется. Разница между 20141211000009 и 201412110000015 равна шести секундам, таким образом, журнал также разделяется.
Как описано выше, журнал сегментируется на шесть частей. IP-адрес источника 2.2.2.2 в первой части журнала осуществил доступ к пяти доменным именам, состоящим из www.baidu.com, а. qq.com, b. baidu.com, с. tanx.com и с. allyes.com. Согласно способу оценки характеристики осуществления доступа пользователем можно заключить, что пользователь на самом деле осуществил доступ только к www.baidu.com, а остальные четыре доменных имени являются лишь запросами доменных имен, дополнительно сформированными после того, как пользователь переходит (click) на www.baidu.com, и они не являются действительными характеристиками осуществления доступа пользователем. Следовательно, из первой части журнала может быть заключено, что пользователь осуществляет доступ к пути доменного имени, т.е. www.baidu.com. Способ определения характеристики осуществления доступа пользователем, упомянутый в данном документе, заключается в следующем: когда пользователь переходит по URL, помимо доменного имени текущего URL запрашиваются некоторые другие доменные имена. Все запросы других доменных имен, произведенные после запроса доменного имени URL, могут быть получены с помощью технологии поискового робота, и просканированные запросы доменных имен сопоставляются с частью доменных имен, сегментированных из журнала DNS, таким образом, что может быть получено соответствие между журналом DNS и доменным именем, к которому на самом деле был осуществлен доступ пользователем. На основе соответствия, полученного этим способом, может быть выяснено, что эта часть журнала отражает то, что пользователь на самом деле осуществляет доступ к www.baidu.com. Вторая часть журнала содержит только www.sina.com, следовательно, www.sina.com является путем доменного имени, к которому осуществлялся доступ пользователем.
После соединения путей упомянутых выше журналов полученные пути представляются следующим образом:

Затем пути, полученные посредством сегментации на основе разницы между метками времени, объединяются в соответствии с одним и тем же доменом, т.е. доменом второго уровня в настоящем примере, и объединенный результат представляется следующим образом:
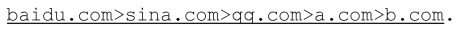
Вышеописанный путь представляет собой путь по характеристикам осуществления доступа IP-адресом источника, и все пути осуществления доступа всех IP-адресов источников могут быть вычислены по такому правилу.
3) Далее вышеописанные результаты сегментируются на основе центрального домена (этап S23). Центральный домен, который главным образом анализируется на основе пользовательских/системных требований, анализируется для того, чтобы узнать, откуда пользователь перешел на центральный домен, и к каким доменам пользователь затем перейдет от центрального домена. Например, а.com в журнале рассматривается в качестве центрального домена, и это показывается следующим образом:
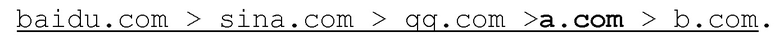
Например, ниже перечислены четыре пути вышеупомянутого IP-адреса источника, и в качестве примера в каждом пути приведены только домены источников первых трех слоев центрального домена, и логика обработки пути после центрального домена соответствует логике обработки пути до обработки центрального домена. Фактическое количество слоев может быть отрегулировано в соответствии с конкретными потребностями. Они также показаны на Фиг. 2(a):

В заключение все четыре пути осуществления доступа вышеупомянутого IP-адреса источника суммируются на этапе суммирования данных. Диаграмма суммирования показана на Фиг. 2(b).
Суммарная сводка центрального домена представляет собой четыре a.com.
Суммарная сводка Домена 1 Источника представляет собой два qq.com, один baidu.com и один youku.com.
Суммарная сводка Домена 2 Источника представляет собой два sina.com, один baidu.com и один qq.com.
Суммарная сводка Домена 3 Источника представляет собой два baidu.com, один sina.com и один youku.com.
На основе визуализирующего чертежа, как показано на Фиг. 2(b), можно ясно увидеть, к каким доменам на последнем этапе был осуществлен доступ пользователем, осуществляющим доступ к центральному домену a.com, и к каким доменам был осуществлен доступ пользователем до этого, и т.д.
Когда все IP-адреса источников обрабатываются согласно упомянутой логике, можно увидеть источник и адресата всего Интернет-трафика.
Посредством способа анализа согласно этому раскрытию источник и адресат Интернет-трафика могут быть могут быть освоены на основе центрального доменного имени, подлежащего анализу, таким образом, чтобы можно было обеспечить улучшенный анализ и оптимизацию трафика веб-сайта для веб-сайта центрального доменного имени. Кроме того, при полной осведомленности о направлении потока всего Интернет-трафика состояние трафика других веб-сайтов может быть проанализировано и понято комплексно так, чтобы узнать все.
Аспекты, описанные выше, представляют собой только предпочтительные варианты осуществления раскрытия, и они не предназначены для ограничения объема этого раскрытия. Любые эквивалентные изменения и модификации, сделанные в соответствии с формулой изобретения этого раскрытия, должны подпадать в пределы технического объема этого раскрытия.
Изобретение относится к области разрешения имени DNS сети Интернет. Технический результат заключается в расширении арсенала средств. Способ получает источник и адресата Интернет-трафика посредством обработки журналов DNS и включает этап фильтрации журналов, на котором осуществляют фильтрацию журналов DNS, которые не могут отразить действительный путь осуществления доступа пользователем, этап сегментации журнала, на котором на основе IP-адреса источника, разницы между метками времени и центрального домена последовательно сегментируют журналы DNS, полученные после этапа фильтрации журналов, для получения сегментированных путей осуществления доступа и этап суммирования данных, на котором суммируют все сегментированные пути осуществления доступа. 8 з.п. ф-лы, 4 ил.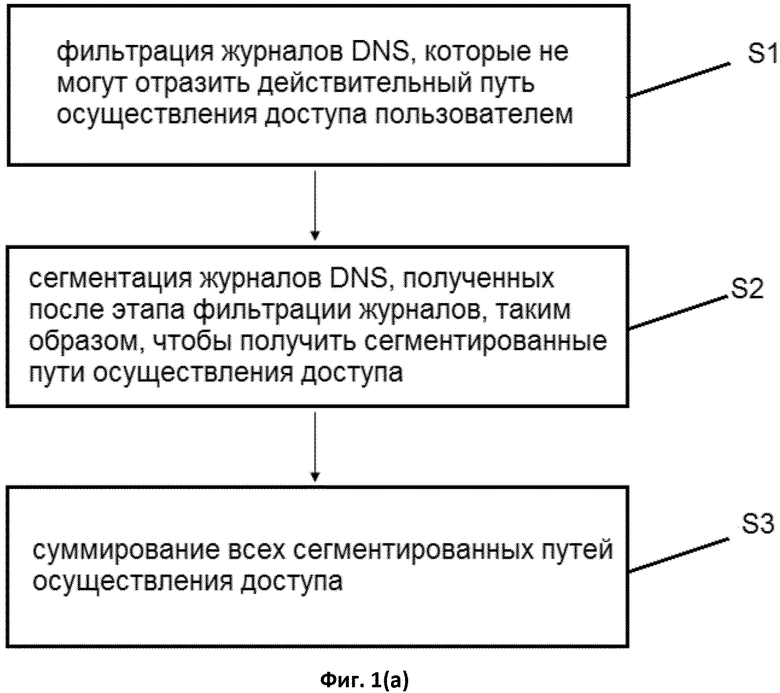
1. Способ анализа источника и адресата Интернет-трафика, заключающийся в получении источника и адресата Интернет-трафика пользователя посредством обработки журнала DNS, причем способ содержит следующие этапы:
этап фильтрации журналов, на котором осуществляют фильтрацию журналов DNS, чтобы получить журналы DNS, отражающие действительный путь осуществления доступа пользователем;
этап сегментации журнала, в котором последовательная сегментация журналов DNS основана на IP-адресе источника, на разнице между метками времени в журналах DNS и основана на данных, откуда пользователь перешел на центральный домен;
получают данные после этапа фильтрации журналов для определения сегментированных путей осуществления доступа пользователя; и
этап суммирования данных, на котором суммируют все сегментированные пути осуществления доступа IP адреса пользователя.
2. Способ анализа по п.1, причем посредством установки черного списка и белого списка на этапе фильтрации журналов журналы DNS, содержащие запросы доменных имен, представляющие значительный интерес, сохраняют, а журналы DNS, содержащие не относящиеся к человеку запросы доменных имен, сформированные сервером, удаляют.
3. Способ анализа по п.2, причем удаление журналов DNS дополнительно включает в себя удаление журналов, к которым осуществляет доступ корпоративный IP-адрес, и журналов, в которых IP-адрес не преобразован.
4. Способ анализа по п.3, причем сегментация журнала DNS, основанная на IP-адресе источника, заключается в том, чтобы получать последовательные журналы DNS с одинаковым IP-адресом источника в течение периода времени.
5. Способ анализа по п.4, причем сегментация журналов, основанная на разнице между метками времени, заключается в том, чтобы на основе разницы между метками времени в журналах DNS сегментировать журналы после того, как они были сегментированы на основе IP-адреса источника, и, если разница между метками времени в двух журналах DNS больше, чем определенный временной промежуток, два журнала DNS разделяются.
6. Способ анализа по п.5, причем определенный временной промежуток представляет собой три секунды.
7. Способ анализа по п.6, дополнительно содержащий после этапа, на котором сегментируют журналы DNS на основе разницы между метками времени, этап объединения, на котором преобразуют доменное имя в путях осуществления доступа, полученных посредством сегментации, в домен, и объединяют последовательные идентичные домены таким образом, чтобы получить путь IP-адреса источника.
8. Способ анализа по п.7, причем сегментация, основанная на центральном домене, заключается в том, чтобы сегментировать путь IP-адреса источника на основе центрального домена, и путь осуществления доступа, полученный после сегментации, представляет собой:
доменное имя n источника + ... + доменное имя 1 источника + центральное доменное имя + доменное имя 1 адресата + ... + доменное имя n адресата, и
центральный домен представляет собой домен, который главным образом анализируется на основе пользовательских/системных требований.
9. Способ анализа по п.8, причем все пути осуществления доступа IP-адреса источника, которые получены после этапа сегментации на основе центрального домена, суммируются на этапе суммирования данных.
| CN 105357054 A, 24.02.2016 | |||
| Сборная железобетонная крепь, преимущественно для трапецеидальной выработки | 1955 |
|
SU105758A1 |
| СИСТЕМА ДИНАМИЧЕСКОЙ DNS ДЛЯ ЧАСТНЫХ СЕТЕЙ | 2009 |
|
RU2490814C2 |
| RU 2011150510 A, 20.06.2013 | |||
| CN 102004883 A, 06.04.2011 | |||
| US 20030188119 A1, 02.10.2003. | |||

