ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Раскрытие относится к области разрешения доменного имени DNS сети Интернет и технологии поискового веб-робота и, в частности, к способу ассоциирования доменного имени с характеристикой посещения веб-сайта.
УРОВЕНЬ ТЕХНИКИ
DNS (система доменных имен) представляет собой распределенную базу данных, которая обеспечивает сопоставление между доменным именем и IP-адресом в сети Интернет.DNS может предоставить пользователю возможность осуществить доступ к сети Интернет более удобным образом без запоминания IP-строк чисел, которые могут быть непосредственно считаны машиной. «Технология разрешения имени DNS» означает, что при посещении веб-сайта пользователь сначала вводит в браузере его доменное имя и нажимает клавишу ввода. Затем браузер инициирует запрос DNS. С помощью технологии DNS браузер может получить IP-адрес сервера, соответствующий доменному имени, и инициировать HTTP-запрос для этого IP-адреса.
Технология поискового веб-робота представляет собой программу или сценарий, который автоматически сканирует веб-информацию согласно определенным правилам. Технология поискового веб-робота имитирует пользователя, инициирующего HTTP-запрос для веб-сайта, и записывает DNS-запрос, сформированный во время этого процесса.
Значение данных DNS всегда оставлялось без внимания и рассматривалось только как соответствующее отношение между IP и доменным именем, таким образом в настоящее время никто на рынке не стал бы осуществлять ассоциирование с помощью данных DNS.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Раскрытие обеспечивает способ ассоциирования доменного имени с характеристикой посещения веб-сайта. Посредством комбинации сбора журналов DNS и технологии поискового веб-робота анализ характеристики просмотра сети Интернет пользователем также может быть осуществлен и с помощью журнала DNS.
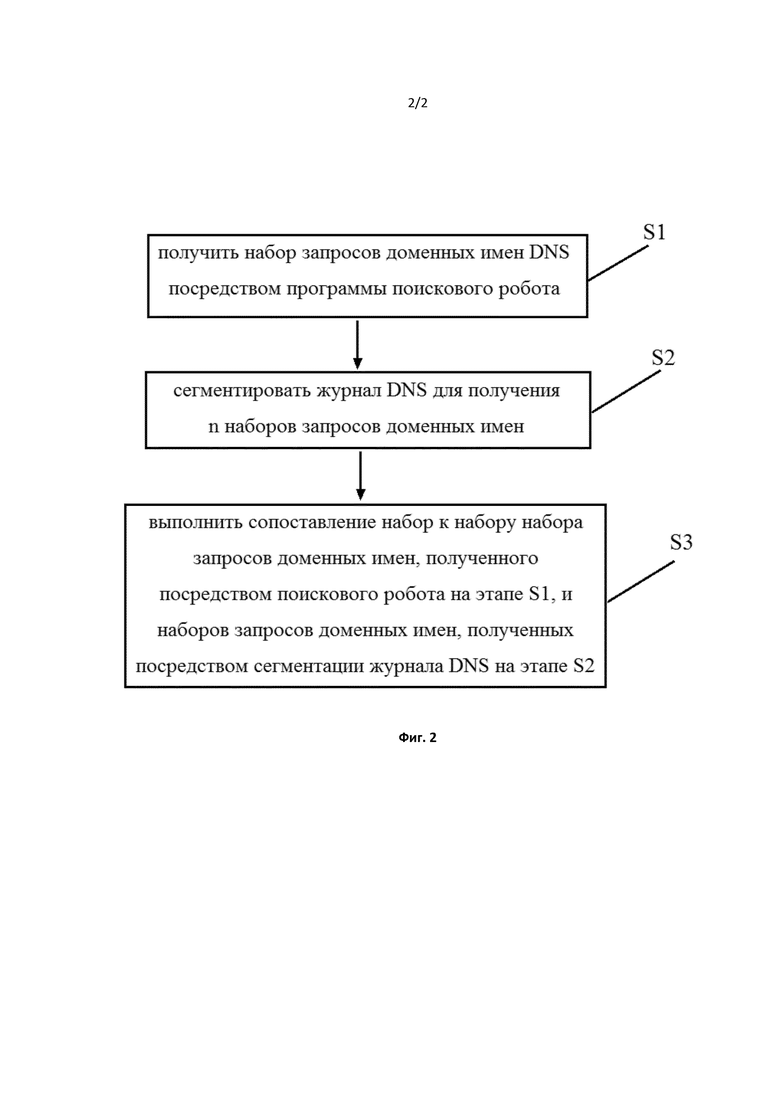
В этом раскрытии способ ассоциирования доменного имени с характеристикой посещения веб-сайта включает в себя следующие этапы: этап S1, на котором имитируют характеристику посещения веб-сайта пользователем посредством программы поискового робота так, чтобы получить все запросы доменных имен DNS в текущем HTTP-запросе, т.е. просканированный набор запросов доменных имен DNS; этап S2, на котором сегментируют журнал DNS для получения n наборов запросов доменных имен, где n - целое число, большее или равное 1; и этап S3, на котором выполняют сопоставление набор к набору просканированного набора запросов доменных имен DNS на этапе S1 и наборов запросов доменных имен, полученных посредством сегментации журнала DNS на этапе S2, и, если один из наборов запросов доменных имен, полученных посредством сегментации журнала DNS, равен или содержится в просканированном наборе запросов доменных имен DNS, учитывают, что журнал DNS указывает то, что пользователь перешел (click) по доменному имени URL, запрошенного программой поискового робота во время сканирования.
Предпочтительно, на этапе S2, журнал DNS представляет собой журнал DNS, регистрирующий в день характеристики посещения.
Предпочтительно, на этапе S2, сегментация журнала DNS включает в себя двукратную сегментацию, т.е. сначала сегментацию, основанную на IP-адресе источника, а затем другую сегментацию, основанную на разнице между метками времени.
Предпочтительно, сегментация журнала DNS, основанная на IP-адресе источника, заключается в том, чтобы получать последовательные журналы DNS с одинаковым IP-адресом источника в течение периода времени.
Предпочтительно, сегментация, основанная разнице между метками времени, заключается в том, чтобы на основе разницы между метками времени в журналах DNS сегментировать журнал после того, как он был сегментирован на основе IP-адреса источника, и, если разница между метками времени в двух журналах DNS больше, чем определенный временной промежуток, два журнала DNS разделяются.
Предпочтительно, определенный временной промежуток
представляет собой три секунды.
Посредством способа ассоциирования доменного имени с характеристикой посещения веб-сайта согласно раскрытию анализ характеристики просмотра в сети Интернет пользователем также может быть осуществлен посредством журнала DNS.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 представляет собой схематическое представление набора запросов доменных имен DNS, просканированного программой поискового робота.
Фиг. 2 представляет собой блок-схему последовательности операций способа ассоциирования доменного имени с характеристикой посещения веб-сайта согласно раскрытию.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Далее раскрытие будет описано подробно со ссылкой на прилагаемые чертежи и варианты осуществления. Нижеследующие варианты осуществления не предназначены для ограничения изобретения. Изменения и преимущества, которые могут быть поняты специалистами в данной области техники, включены в настоящее раскрытие без отступления от сущности и объема раскрытия.
Как указано выше, DNS (система доменных имен) представляет собой распределенную базу данных, которая обеспечивает сопоставление между доменным именем и IP-адресом в сети Интернет.DNS может предоставить пользователю возможность осуществить доступ к сети Интернет более удобным образом без запоминания IP-строк чисел, которые могут быть непосредственно считаны машиной. При посещении веб-сайта пользователь сначала вводит в браузере его доменное имя и нажимает клавишу ввода. Затем браузер инициирует запрос DNS. С помощью технологии DNS браузер может получить IP-адрес сервера, соответствующий доменному имени, и инициировать HTTP-запрос для этого IP-адреса. Это является технологией разрешения имени DNS.
Журнал DNS может быть сформирован во время вышеупомянутого процесса разрешения доменного имени. В журнал DNS может записываться содержание ответов каждого запроса DNS и может почти записываться информация о доменных именах всех запросов пользователей. Формат журнала DNS описывается следующим образом:

Таким образом, журналы DNS состоят из «IP-адреса источника», «Доменного имени», «Метки времени», «IP разрешения» и «Кода состояния». Способ ассоциирования доменного имени с характеристикой посещения веб-сайта согласно раскрытию будет далее описан подробно со ссылкой на Фиг. 1.
Во-первых, характеристика посещения веб-сайта пользователем имитируется посредством программы поискового робота таким образом, чтобы получить все запросы доменных имен DNS в текущем HTTP-запросе, т.е. просканированный набор запросов доменных имен DNS (этап S1). Например, когда страница открывается или происходит переход по URL (ссылке), программа поискового робота может просканировать все запросы доменных имен DNS в текущем HTTP-запросе. Так как пользователь также может запросить другие доменные имена в дополнение к доменному имени текущего URL при переходе по URL, все запросы доменных имен DNS, сформированные после перехода по URL, могут быть получены с помощью технологии поискового робота. При этом единый указатель ресурса (URL) представляет собой компактное представление о расположении и способе доступа к ресурсам, которые доступны из Интернета, и является адресом стандартных ресурсов в сети Интернет. Каждый файл в сети Интернет имеет уникальный URL, который содержит информацию, указывающую расположение файла и то, как браузер должен его обрабатывать.
Например, пользователь перешел по определенному URL (ссылке), как показано ниже:

Программа поискового робота может просканировать все запросы доменных имен DNS, сформированные после перехода по URL, т.е. набор запросов доменных имен DNS, как подробно показано на Фиг. 1.
Затем журнал DNS сегментируется для получения n наборов запросов доменных имен, где n - целое число, большее или равное 1 (этап S2). При этом журнал DNS является журналом DNS, регистрирующим в день характеристики посещения. Сегментация включает в себя двукратную сегментацию, т.е. сначала сегментацию, основанную на IP-адресе источника, а затем другую сегментацию, основанную на разнице между метками времени.
1) Сегментация журнала DNS основана на IP-адресе источника, т.е. последовательные журналы DNS могут быть разделены, если IP-адрес источника журнала отличается. Сегментация, основанная на IP-адресе источника, заключается в получении последовательных журналов DNS с одинаковым IP-адресом источника в течение периода времени. Как показано ниже:

2) Сегментация, основанная на разнице между метками времени, означает, что после того, как журналы сегментируются на основе IP-адреса источника, они сегментируются на основе разницы между метками времени в журналах DNS. Если разница между метками времени в двух последовательных журналах больше, чем определенный временной промежуток, два журнала DNS разделяются (причиной для этого является то, что интервал между журналами настолько большой, что они рассматриваются как две различные характеристики). Определенный временной промежуток может быть настроен по желанию. В этом варианте осуществления определенный временной промежуток равен трем секундам, т.е. журнал может быть разделен, если интервал между метками времени больше, чем три секунды.
Например, журнал DNS IP-адреса источника 2.2.2.2 может быть дополнительно сегментирован на основе его разницы между метками времени, как показано ниже. (Метка времени 20141211035932 представляет собой 3 (часа):59(минут):32(секунды), 11 декабрь, 2014).
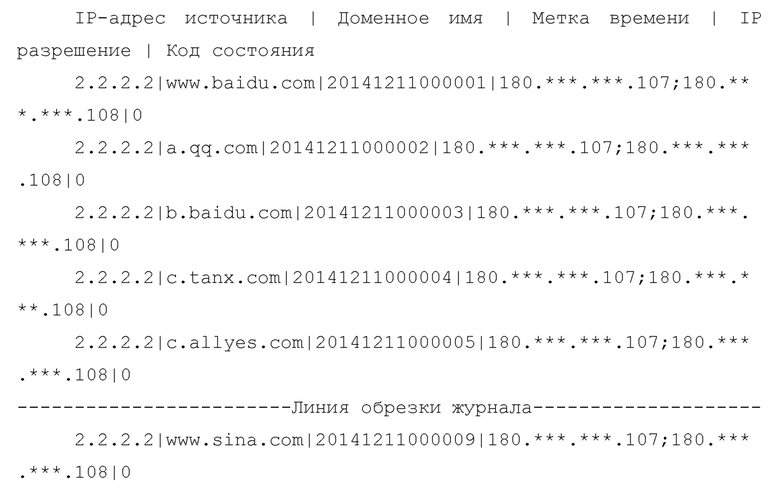
Как описано выше, так как разница между 05 секундами в метке времени 20141211000005 и 09 секундами в метке времени 20141211000009 равна четырем секундам (больше, чем три секунды), то журнал разделяется.
www.baidu.com, а. qq.com, b. baidu. com, ctanx.com, ctanx.com часть области набора запросов доменных имен в журнале DNS.
Затем выполняется сопоставление набор к набору набора запросов доменных имен, просканированного поисковым роботом на этапе S1, и наборов запросов доменных имен, полученных посредством сегментации журнала DNS на этапе S2, (этап S3). Правило сопоставления представляет собой [(a,b,c)=(b,c,a)=(а,с,b)].
После сопоставления считается, что журнал DNS указывает, что пользователь перешел по доменному имени (т.е. доменному имени URL, запрошенному поисковым роботом во время сканирования), если часть множества запросов доменных имен в журнале DNS включена в набор запросов доменных имен, просканированный поисковым роботом, или два набора равны друг другу. Например,
URL (как характеристика перехода пользователем), просканированный поисковым роботом, представляет собой www.а.com/doc/1234. Набор А всех просканированных запросов доменных имен представляет собой «www.a.com, www.b.com, www.с.com, www.d.com, и www.е.com».
Часть набора В запросов доменных имен после сегментации журнала DNS представляет собой «www.a.com, www.b.com, www.e.com, и www.d.com».
Как указано выше, когда набор В включен в набор А, считается, что набор В запросов доменных имен отражает www.а.com/doc/1234. который является характеристикой посещения пользователем, отображаемой набором А доменных имен. Таким образом, характеристики просмотра сети Интернет пользователями также могут быть проанализированы с помощью журнала DNS.
Аспекты, описанные выше, представляют собой только предпочтительные варианты осуществления раскрытия, и они не предназначены для ограничения объема раскрытия. Любые эквивалентные изменения или модификации, сделанные в соответствии с содержанием формулы изобретения раскрытия, должны подпадать в пределы технического объема раскрытия.

Изобретение относится к области вычислительной техники. Технический результат заключается в повышении удобства анализа характеристик просмотра в сети Интернет. Способ содержит этапы: имитируют характеристику посещения веб-сайта пользователем посредством поискового робота так; сегментируют журнал DNS для получения n наборов запросов доменных имен; и выполняют сопоставление набор к набору просканированного набора запросов доменных имен DNS и n наборов запросов доменных имен, полученных посредством сегментации журнала DNS, и, если один из n наборов запросов доменных имен, полученных посредством сегментации журнала DNS, равен или содержится в просканированном наборе запросов доменных имен DNS, учитывают, что журнал DNS указывает, что пользователь перешел по доменному имени единого указателя ресурса (URL), запрошенного поисковым роботом во время сканирования. 5 з.п. ф-лы, 2 ил.
1. Реализуемый компьютером способ анализа характеристики посещения веб-сайта пользователем, содержащий следующие этапы:
этап S1, на котором имитируют характеристику посещения веб-сайта пользователем посредством поискового робота так, чтобы получить все запросы доменных имен системы доменных имен (DNS) в текущем HTTP-запросе, т.е. просканированный набор запросов доменных имен DNS;
этап S2, на котором сегментируют журнал DNS для получения n наборов запросов доменных имен, где n – целое число, большее или равное 1; и
этап S3, на котором выполняют сопоставление набор к набору просканированного набора запросов доменных имен DNS на этапе S1 и n наборов запросов доменных имен, полученных посредством сегментации журнала DNS на этапе S2, и, если один из n наборов запросов доменных имен, полученных посредством сегментации журнала DNS, равен или содержится в просканированном наборе запросов доменных имен DNS, учитывают, что журнал DNS указывает, что пользователь перешел по доменному имени единого указателя ресурса (URL), запрошенного поисковым роботом во время сканирования.
2. Способ по п.1, причем журнал DNS на этапе S2 представляет собой журнал DNS на день характеристики посещения.
3. Способ по п.1, причем сегментация журнала DNS на этапе S2 включает в себя двукратную сегментацию, т.е. сначала сегментацию на основе IP-адреса источника, а затем другую сегментацию на основе разницы между метками времени.
4. Способ по п.3, причем сегментация журнала DNS на основе IP-адреса источника заключается в получении последовательных журналов DNS с одинаковыми IP-адресами источника в течение периода времени.
5. Способ по п.4, причем сегментация на основе разницы между метками времени заключается в сегментации на основе разницы между метками времени в журналах DNS журнала, после того, как он был сегментирован на основе IP-адреса источника, и, если разница между метками времени в двух журналах DNS больше, чем определенный временной промежуток, два журнала DNS разделяются.
6. Способ по п.5, причем определенный временной промежуток представляет собой три секунды.
| CN 105005600 A, 28.10.2015 | |||
| CN 104065532 A, 24.09.2014 | |||
| CN 103389983 A, 13.11.2013 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |

