ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящая группа изобретений относится к области обработки изображений и, в частности, к способу и системе для преобразования изображения в изображение с прорисованными деталями.
УРОВЕНЬ ТЕХНИКИ
В настоящее время большинство электронных мобильных устройств, таких как смартфоны, мобильные телефоны, портативные компьютеры, планшетные компьютеры, компактные фотоаппараты и т.д., оснащено камерами для регистрации изображений, и ввиду их портативности пользователи очень часто используют их для съемки различных фотографий и видео. Однако качество изображений, полученных с помощью таких мобильных устройств, зависит от множества факторов, в частности: качества системы линз в камере мобильного устройства (как правило, такие мобильные устройства оснащены объективом низкой разрешающей способности ввиду использования линз малого диаметра и стекла низкого качества, как следствие, качество фотографий сложных детализированных объектов или поверхностей значительно ухудшается), уровня освещенности (чем ниже уровень освещенности, тем больше шумов появляется на изображении) и т.п.
Из уровня техники известно множество решений, направленных на улучшение качества зарегистрированных камерой изображений, которые основываются на следующих типах алгоритмов: алгоритм подавления шума (denoising), обобщенный алгоритм улучшения изображения (enhancing) и алгоритм добавления резкости (sharpening). При применении алгоритма подавления шума или встроенного в камеру подавителя шумов неизбежно наряду с тем, что убираются шумы, на изображении разрушаются и мелкие детали, т.е. происходит сглаживание изображения. Обобщенный алгоритм улучшения изображения направлен на обработку всего изображения путем улучшения некоторой или нескольких его основных характеристик, например, яркости и/или контрастности. Однако такой алгоритм при обработке изображений не учитывает и, следовательно, также не восстанавливает в случае необходимости мелкие детали на изображениях. Алгоритм добавления резкости также направлен на обработку всего изображения, таким образом, наряду с добавлением резкости для размытой границы на изображении, данный алгоритм также добавляет лишние артефакты в те части изображения, где границы изначально обладали достаточной резкостью. Кроме того, данный алгоритм также не способен улучшить однородные части изображений, в частности, восстановить детали структуры однородной поверхности, объекта и т.п. Таким образом, алгоритмы таких типов не адаптированы к контенту изображения, а основываются на некотором общем исходном условии для улучшения изображения.
Из уровня техники известно решение, раскрытое в US 20130170767 A1 («Image content enhancement using a dictionary technique»), в котором по заранее определенным наборам фрагментов изображений низкого и высокого разрешений, соответственно, строятся словари, в которых упомянутые фрагменты сохраняются в виде разреженного кода (разложение фрагментов по базису, в котором коэффициенты разложения в своем большинстве нулевые). Эти словари используются для преобразования фрагментов изображения с низким разрешением в высокое разрешение путем выбора фрагмента из набора фрагментов с высоким разрешением, соответствующего входному фрагменту из набора фрагментов с низким разрешением. Однако в данном известном решении словари строятся с использованием конкретного оператора ухудшения, что ограничивает его область применения: если фрагмент входного изображения не является полученным с помощью такого конкретного оператора ухудшения, тогда корректное улучшение изображения не сможет быть выполнено. Другими словами, данное решение применимо только к улучшению изображений с низким разрешением, полученных путем применения заданного конкретного оператора ухудшения к изображению с высоким разрешением.
Из уровня техники также известно решение, раскрытое в US 20180338082 A1 («Target Image Quality Enhancement Using A Guide Image»), в котором раскрывается способ улучшения выбранного пользователем изображения с низкой детализацией с использованием отдельно захваченного изображения с высокой детализацией, которое содержит аналогичный контент. Улучшение изображения производится посредством соотнесения пикселей на выбранном пользователем изображении и отдельно захваченном изображении. Например, данное решение может быть применено при съемке некоторого видеоряда, в котором часть кадров получена с высокой детализацией, а часть - с низкой. В таком случае пиксели на кадрах с низкой детализацией будут заменены соответствующими пикселями с кадров с высокой детализацией. Однако необходимо наличие такого отдельно захваченного изображения, и качество улучшенных изображений изначально ограничено качеством этого отдельно захваченного изображения с высокой детализацией. Кроме того, так как необходимо, чтобы такое отдельно захваченное изображение имело аналогичный контент, его съемка производится подряд с выбранным пользователем изображением (например, съемка видеоряда) и, следовательно, используется одно и то же устройство съемки, которое обладает одними и теми же недостатками, которые не будут устранены. Также важно отметить, что исходное изображение для улучшения выбирается пользователем вручную, равно как и то изображение, которое следует считать отдельно захваченным изображением для улучшения исходного, т.е. данное решение не может быть применено для автоматического улучшения изображений.
Решение, раскрытое в US 20170256033 A1 («Image upsampling using global and local constraints»), описывает способ, в котором применяется сверточная нейронная сеть, обученная на парах изображений, причем одно изображение из пары является изображением с низком разрешением, а другое - этим же изображением с более высоким разрешением. В частности, пара изображений формируется путем получения изображения с упомянутым более высоким разрешением, а затем уменьшения его разрешения, например, в два раза билинейным или бикубическим алгоритмом. На вход сверточной нейронной сети подают изображение с низким разрешением, а на выход - изображение с более высоким разрешением из той же пары изображений, тем самым сверточная нейронная сеть обучается строить регрессию между этими изображениями (восстанавливать изображение с более высоким разрешением на основе изображения с низким). Однако данное решение не способно осуществить обработку изображений с разрешением порядка 4K (т.е. 3840×2160) и выше, т.к. полносвязные слои этой сети настроены под определенное разрешение. При этом, даже в случае использования на входе изображения с разрешением, например 2K (1920×1080), количество весов одного только первого полносвязного слоя будет (как минимум) более (1920*1080)*(1920*1080) (>4 триллионов), что требует соответствующей вычислительной мощности и соответствующего объема памяти, доступных только узкому кругу специализированных вычислительных машин, например, на суперкомпьютерах. Кроме того, обучающая выборка такой сверточной нейронной сети ограничивает применение данного решения для восстановления изображений примененными при обучении алгоритмами для уменьшения разрешения, однако в реальной жизни существует многообразие возможных методов ухудшения разрешения, многие из которых не сводятся к таким простым алгоритмам как билинейный или бикубический (например, ухудшение изображения вызвано низким разрешением оптики и т.д.).
Также известно и решение, раскрытое в US 20160239942 A1 («Adaptive sharpening in image processing and display»), в котором описанный способ делает изображение более четким, применяя функцию усиления к входным градиентам каждого пикселя, чтобы улучшить границы низкой интенсивности, подавить шумовые градиенты и сохранить четкие градиенты краев. В частности, при применении данного способа пиксели «сдвигаются» друг к другу, преобразуя размытую границу в четкую. Однако данный способ порождает и множество визуальных артефактов на изображении при попытках улучшить множество градиентов, не относящихся к размытым границам, а также является чувствительным к изменению масштаба восстанавливаемых изображений. Кроме того, данный способ также не способен восстановить детали в областях, в которых они были чрезмерно сглажены, например, за счет алгоритма устранения шума/встроенного в камеру подавителя шумов или за счет низкого разрешения оптики и т.п.
Известны также такие решения как «Fast and efficient image quality enhancement via desubpixel CNN», T. Van Vu et al., KAIST, 2018 (FEQE), «Enhanced deep residual networks for single image super-resolution», B. Lim et al., Seoul National University, 2017 (EDSR) и «Wide Activation for Efficient and Accurate Image Super-Resolution», J. Yu et al., Adobe Research (WDSR), в которых описываются модели сверточных нейронных сетей, которые обучаются на парах из фрагмента изображений и этого же фрагмента с уменьшенным разрешением. Первое из перечисленных решений обучается на фрагментах, разрешение которых уменьшено в 4 раза, и использует остаточные и десубпиксельные (преобразующие блоки пространственных данных в глубину) блоки для увеличения разрешения исходного изображения в 4 раза. Два других решения обучаются на фрагментах, разрешение которых уменьшено в 2 раза, и используют улучшенные остаточные блоки для увеличения разрешения исходного изображения в 2 раза. Однако способы обучения/обучающие выборки таких сверточных нейронных сетей ограничивают применение данного решения для восстановления изображений примененными при обучении алгоритмами для уменьшения разрешения, т.е. исходные изображения не могут быть улучшены в областях, которые эти модели сетей не распознают в качестве областей, полученных в результате конкретного алгоритма уменьшения разрешения, использованного при обучении.
Из уровня техники также известны и решения «Deep Photo Enhancer: Unpaired Learning for Image Enhancement From Photographs With GANs», Y. S. Chen et al., National Taiwan University, 2018 (DPE) и «DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks», A. Ignatov et al., ETH Zurich, 2017 (DPED), в которых для улучшения изображений используются порождающие состязательные сети (GAN). Первое из указанных решений описывает модель циклической GAN, которая обучалась на основе пар не сопоставленных изображений, причем одно из изображений в паре обязательно является изображением с высоким качеством, полученным за счет его обработки профессиональными фотографами. Однако данное решение улучшает только глобальные характеристики изображения, такие как передача цвета, яркость, отображение теней и т.п., при этом оно не способно восстановить мелкие детали на изображении. Второе из перечисленных решений описывает модель GAN, которая обучалась на основе пар приближенно сопоставленных изображений, одно из которых является изображением DSLR-качества (снято на цифровой зеркальный фотоаппарат), а другое - изображением, снятым на современный мобильный телефон, причем обоими устройствами снята одна и та же сцена. Однако изображение, улучшенное в соответствии с этим решением, получается чрезмерно засвеченным; кроме того, на изображении появляются излишние детали, подобные шуму, т.е. оно также не способно корректно восстановить/прорисовать мелкие детали на изображении. Кроме того, все вышеуказанные решения не обладают согласованностью в пределах большой области, т.е. даже при улучшении части/частей протяженного объекта на изображении данные решения не сопоставят, что эти части принадлежат одному и тому же протяженному объекту для его единообразного улучшения естественным образом.
Таким образом, существует необходимость в способе преобразования изображения в изображение с прорисованными деталями, которые были размыты, засвечены или иным образом не визуализированы на изображении, который естественным образом бы отображал прорисованные детали на изображении, в том числе, протяженные детали, обладающие свойством самоподобия, такие как волосы человека.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задача настоящего изобретения состоит в устранении упомянутых выше недостатков, присущих известным из уровня техники решениям, в частности, в обеспечении способа и системы для преобразования изображения, на котором детали были размыты или иным образом не визуализированы, в изображение с прорисованными естественным образом деталями.
Указанная задача решается посредством способа и системы, которые охарактеризованы в независимых пунктах формулы изобретения. Дополнительные варианты осуществления настоящего изобретения представлены в зависимых пунктах формулы изобретения.
Согласно первому аспекту настоящего изобретения предложен способ формирования общей функции потерь для обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, содержащий этапы, на которых:
- получают пару изображений, включающую в себя входной фрагмент PL низкого качества и входной фрагмент PH более высокого качества, причем входной фрагмент PL низкого качества представляет собой изображение, снятое с высоким значением ISO и низким значением выдержки, а входной фрагмент PH более высокого качества представляет собой изображение, снятое с более низким значением ISO и более высоким значением выдержки;
- подают каждый из входных фрагментов (PL, PH) на вход соответствующей сиамской сверточной нейронной подсети и обрабатывают поданные входные фрагменты (PL, PH) для получения выходных фрагментов (P'L, P'H) изображения, соответственно, причем в кодирующей части каждой сиамской сверточной нейронной подсети используются вложенные ядра свертки;
- вычисляют регрессионную разницу D(P'L, PH);
- вычисляют модулированную ретенционную разницу D(P'L, PL)⊙D(P'H, PH);
- формируют общую функцию потерь путем суммирования регрессионной разницы и модулированной ретенционной разницы для обучения сверточной нейронной сети как D(P'L, PH)+D(P'L, PL)⊙D(P'H, PH) и
- обучают сверточную нейронную сеть на основе сформированной общей функции потерь.
Согласно одному варианту осуществления градиент функции потерь по отношению к весовым коэффициентам θ сиамской нейронной сверточной подсети, вычисляется следующим образом:
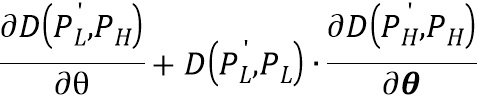 .
.
Согласно одному варианту осуществления значение ISO и значение выдержки входных фрагментов настраиваются таким образом, чтобы суммарная яркость входных фрагментов была одинаковая.
Согласно второму аспекту настоящего изобретения предложена система для преобразования изображения в изображение с прорисованными деталями, содержащая:
- устройство захвата изображений, выполненное с возможностью захвата изображения;
- память, выполненную с возможностью хранения модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, обученной с учетом общей функции потерь, сформированной согласно вышеупомянутому способу формирования общей функции потерь для обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, и захваченного изображения; и
- устройство обработки, выполненное с возможностью обработки захваченного изображения с помощью сохраненной модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями.
Технический результат, достигаемый посредством использования настоящей группы изобретений, заключается в обеспечении изображения, на котором мелкие детали изображения восстановлены и прорисованы естественным образом, и сохраняется целостность протяженных объектов на изображении, обладающих свойством самоподобия. Кроме того, для хранения модели сверточной нейронной сети согласно настоящему изобретению требуется небольшая емкость запоминающего устройства за счет наличия достаточно небольшого количества весовых коэффициентов сверточной нейронной сети.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Эти и другие признаки и преимущества настоящего изобретения станут очевидны после прочтения нижеследующего описания и просмотра сопроводительных чертежей, на которых:
на Фиг. 1 представлена примерная пара изображений с различными настройками качества, захваченная для обучения сверточной нейронной сети;
на Фиг. 2 показана схема способа обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями согласно предпочтительному варианту осуществления настоящего изобретения;
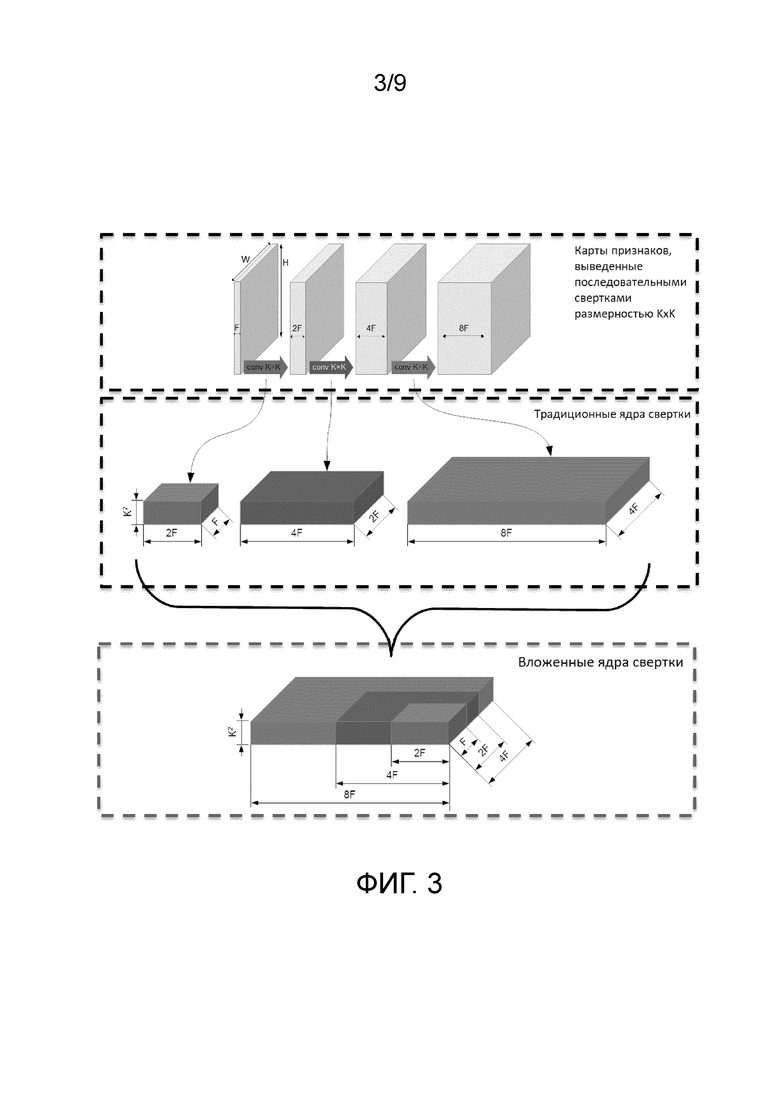
на Фиг. 3 изображена структура вложенных ядер свертки, применяемых при обучении заявленной сверточной нейронной сети согласно предпочтительному варианту осуществления настоящего изобретения;
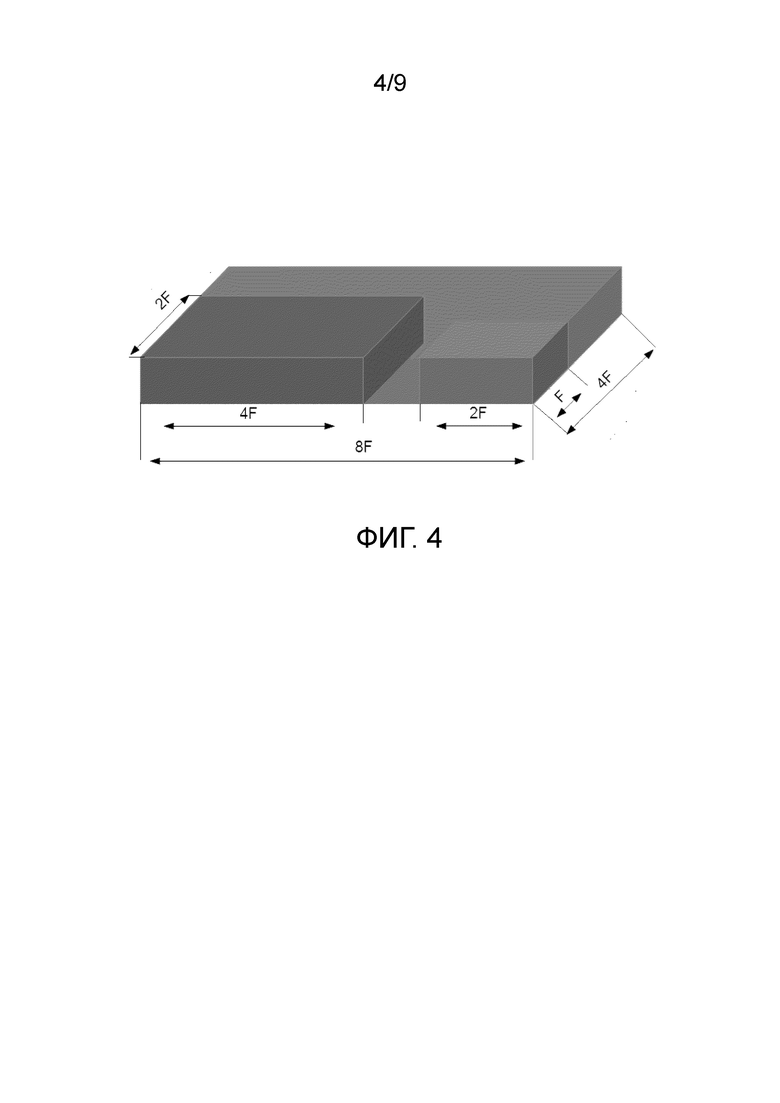
на Фиг. 4 изображена структура ядер свертки, применяемых при обучении заявленной сверточной нейронной сети согласно альтернативному варианту осуществления настоящего изобретения;
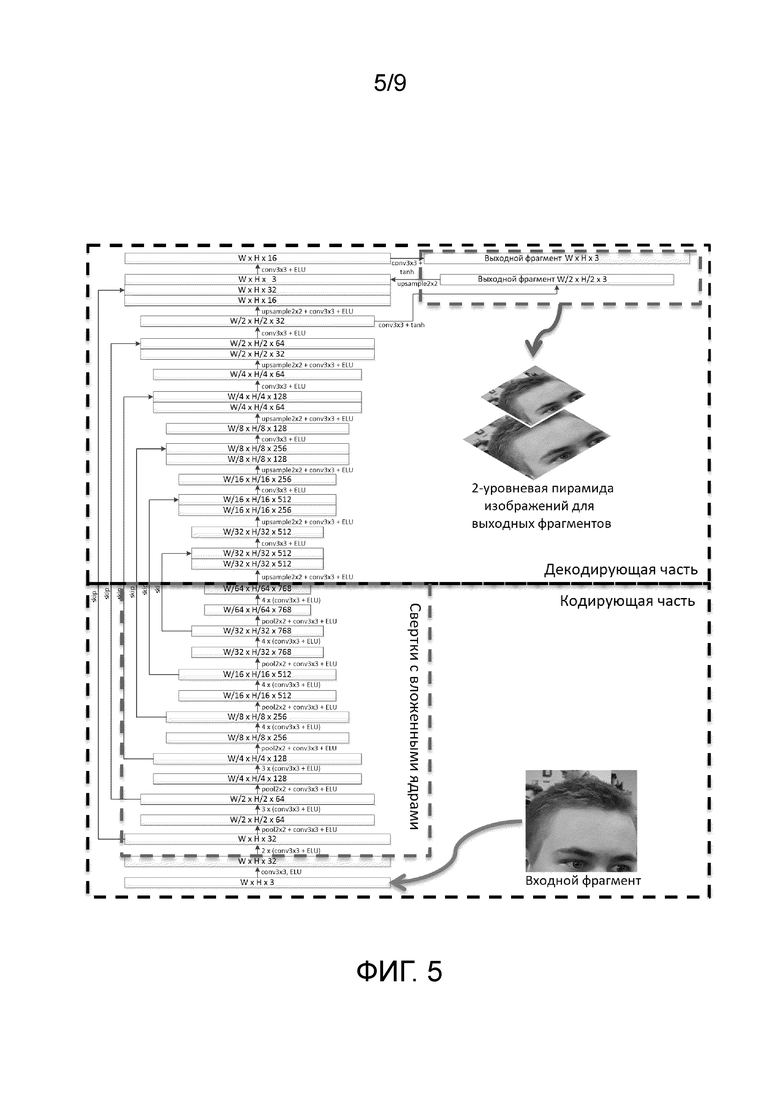
на Фиг. 5 показана подробная схема обработки входного изображения с помощью сиамской сверточной нейронной подсети в соответствии с примерным вариантом осуществления настоящего изобретения;
на Фиг. 6a показана пара входного изображения и изображения, полученного в результате обработки входного изображения согласно варианту осуществления настоящего изобретения;
на Фиг. 6b показана пара входного изображения и изображения, полученного в результате обработки входного изображения согласно варианту осуществления настоящего изобретения;
на Фиг. 6с показана пара входного изображения и изображения, полученного в результате обработки входного изображения согласно варианту осуществления настоящего изобретения;
на Фиг. 6d показана пара входного изображения и изображения, полученного в результате обработки входного изображения согласно варианту осуществления настоящего изобретения;
на Фиг. 7 показана таблица сравнения результатов оценки качества изображений, обработанных согласно варианту осуществления настоящего изобретения и согласно известным решениям уровня техники.
Представленные на чертежах фигуры служат только для иллюстрации вариантов осуществления настоящего изобретения и никак его не ограничивают.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Различные варианты осуществления настоящего изобретения описываются в дальнейшем более подробно со ссылкой на чертежи. Однако настоящее изобретение может быть воплощено во многих других формах и не должно истолковываться как ограниченное любой конкретной структурой или функцией, представленной в нижеследующем описании. На основании настоящего описания специалист в данной области техники поймет, что объем правовой охраны настоящего изобретения охватывает любой вариант осуществления настоящего изобретения, раскрытый в данном документе, вне зависимости от того, реализован ли он независимо или в сочетании с любым другим вариантом осуществления настоящего изобретения. Например, система может быть реализована или способ может быть осуществлен на практике с использованием любого числа вариантов осуществления, изложенных в данном документе. Кроме того, следует понимать, что любой вариант осуществления настоящего изобретения, раскрытый в данном документе, может быть воплощен с помощью одного или более элементов формулы изобретения.
Слово «примерный» используется в данном документе в значении «служащий в качестве примера или иллюстрации». Любой вариант реализации, описанный в данном документе как «примерный», необязательно должен истолковываться как предпочтительный или обладающий преимуществом над другими вариантами реализации.
Согласно настоящему изобретению предложено использование сверточной нейронной сети для преобразования исходного изображения в изображение с прорисованными деталями, т.е. для построения изображения с более высоким уровнем детализации по сравнению с уровнем детализации исходного изображения, на котором эти детали были размыты или иным образом сглажены. Другими словами, сверточная нейронная сеть обучается преобразовывать фрагмент изображения низкого качества во фрагмент изображения более высокого качества, при этом не теряя информативность фрагмента. При обучении сверточной нейронной сети на ее вход подаются пары изображений, каждая из которых включает в себя фрагмент изображения низкого качества и фрагмент изображения более высокого качества, причем каждый из фрагментов обрабатывается соответствующей сиамской нейронной сверточной подсетью, а общая функция потерь основана на разнице между входными и выходными фрагментами. Кроме того, в этих сиамских нейронных сверточных подсетях используются вложенные ядра свертки для учета свойства самоподобия на изображениях и уменьшения переобучения сети, которые и обеспечивают использование достаточно небольшого количества весовых коэффициентов сверточной нейронной сети, что в результате сокращает необходимый объем емкости запоминающего устройства для хранения заявленной модели.
Пары изображений для обучения упомянутой нейронной сети захватывают с помощью любого подходящего устройства, содержащего камеру и выполненного с возможностью захвата изображений с различными настройками качества, например, с помощью мобильного устройства, на котором установлено приложение для захвата таких изображений. Каждая входная пара фрагментов является согласованной, т.е. оба фрагмента одной пары изображают одну и ту же сцену примерно в один и тот же момент времени, однако эти фрагменты сняты с разными настройками (например, выдержка, ISO). Каждый фрагмент PL и PH (PL - фрагмент с низким качеством и PH - фрагмент с более высоким качеством) изображения одной пары обрабатывается по отдельности соответствующей сиамской сверточной нейронной подсетью для построения выходных фрагментов P'L и P'H изображения. Выходной фрагмент P'L и входной фрагмент PH затем используются для формирования регрессионной разницы D(P'L, PH) -компонент, который отвечает за улучшение фрагмента с низким качеством, выходные фрагменты P'L и P'H и входные фрагменты PL и PH при этом используются для формирования модулированной ретенционной разницы D(P'L, PL)⊙D(P'H, PH) -компонент, который отвечает за сохранение качества фрагмента с более высоким качеством. Эти разницы суммируются для получения общей функции потерь, которая и используется для обучения всей сверточной нейронной сети. Причем применяемый метод обратного распространения ошибки не учитывает D(P'L, PL) (данная разница не минимизируется), следовательно, градиент функции потерь по отношению к весовым коэффициентам θ сиамской нейронной сверточной подсети, вычисляется следующим образом:
,
что будет подробнее описано далее.
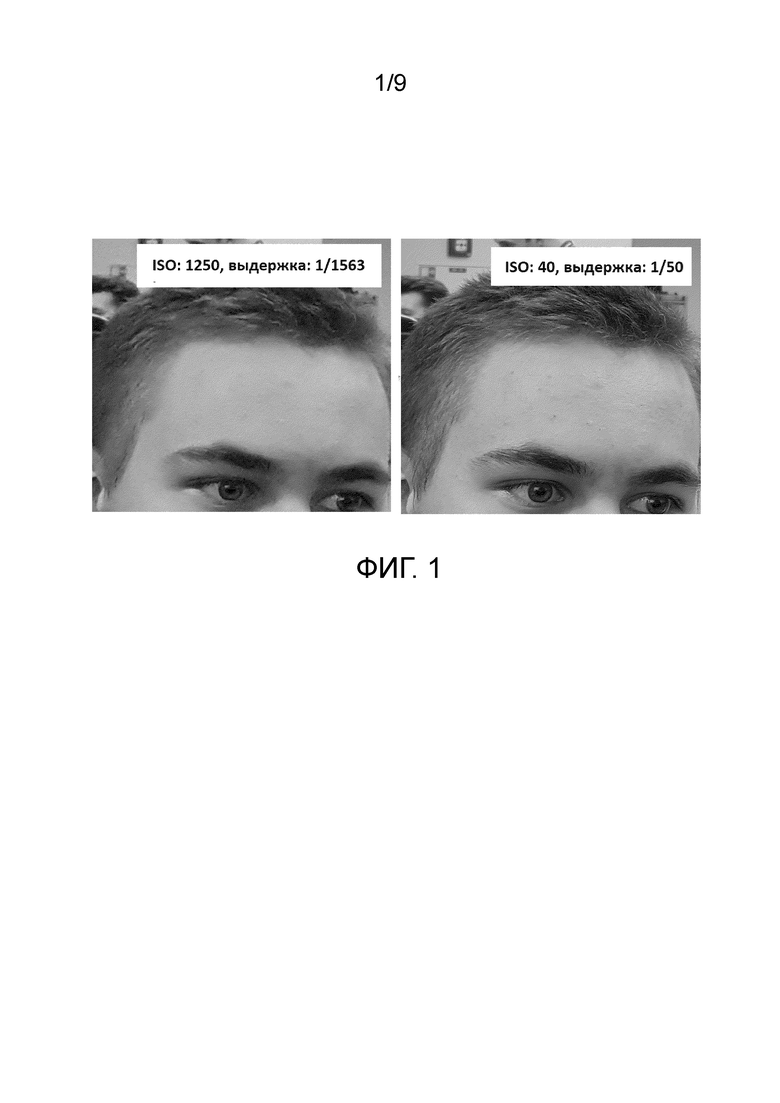
На Фиг. 1 представлена примерная пара изображений, захваченных с помощью мобильного устройства с установленным на нем приложением для захвата изображений с различными настройками качества. На изображениях отображена верхняя часть головы человека, включая волосы этого человека. Упомянутое приложение позволяет выставить необходимый параметр ISO при захвате каждого изображения, причем параметры выдержки и апертуры затем автоматически будут подстроены приложением, чтобы суммарная яркость захваченной пары изображений была одинаковая. Опционально, эти параметры могут быть выставлены вручную на любом удобном устройстве, выполненном с возможностью захвата изображений. Согласно одному варианту осуществления под изображением с низким качеством подразумевается изображение, снятое с высоким значением ISO и низким значением выдержки, а под изображением с более высоким качеством подразумевается изображение, снятое с более низким значением ISO и более высоким значением выдержки по сравнению с этими же параметрами, примененными при снятии изображения с низким качеством. В частности, на Фиг. 1 представлена пара изображений: изображение с низким качеством имеет следующие параметры - ISO: 1250, а выдержка 1/1563, а изображение с более высоким качеством - ISO: 40, а выдержка - 1/50. На Фиг. 1 наглядно отображено, что структура волос человека на втором изображении отображена значительно лучше, чем на первом.
Согласно предпочтительному варианту осуществления конечные пользователи получают заранее обученную модель сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями (в частности, для построения изображения с более высоким качеством на основе изображения с низким качеством); однако согласно альтернативному варианту осуществления возможно предоставление решения, согласно которому конечный пользователь сначала самостоятельно собирает базу данных для обучения сверточной нейронной сети (т.е. захватывает ряд пар изображений для обучения в соответствии с интересами пользователя), причем собранная конечным пользователем база данных затем загружается в облачное хранилище, в котором сверточная нейронная сеть обучается на основе собранной конечным пользователем базы данных, после чего обученная на такой базе данных модель сверточной нейронной сети предоставляется конечному пользователю. Таким образом, согласно альтернативному варианту осуществления модель сверточной нейронной сети является адаптированной к пользовательским данным.
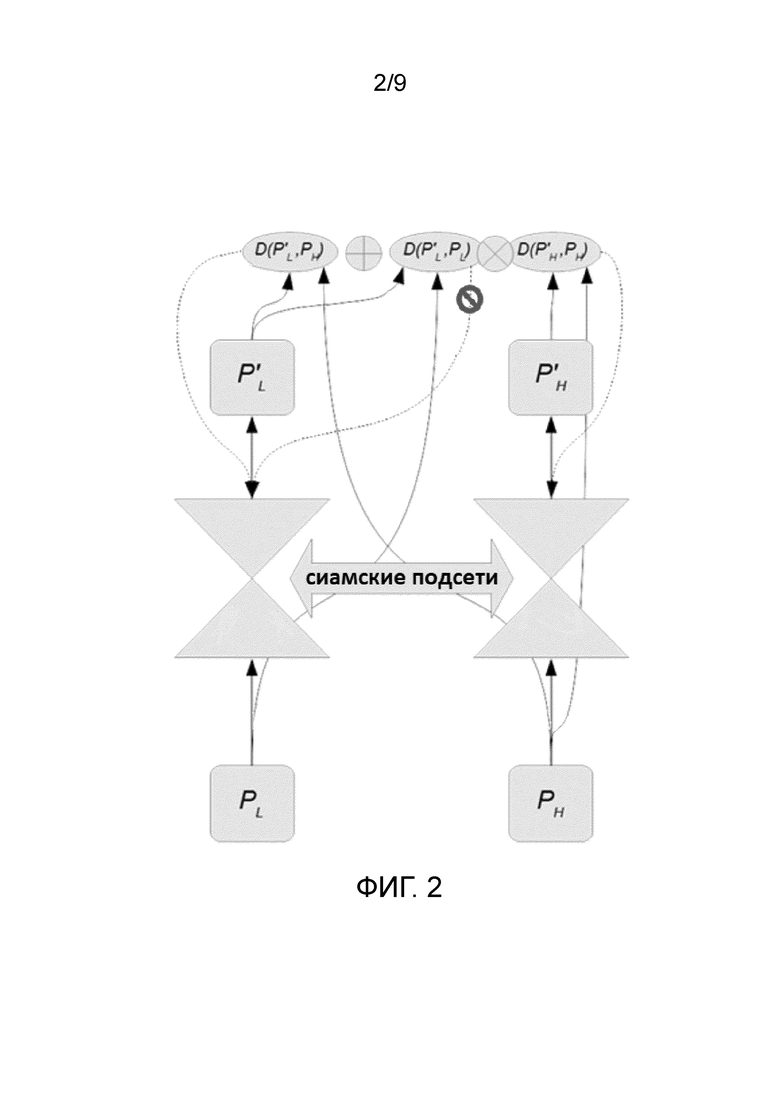
Далее способ обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями описывается подробно со ссылкой на Фиг. 2. Изначально для обучения нейронной сети получают пару изображений, т.е. фрагмент PL с низким качеством и фрагмент PH с более высоким качеством, как описано выше. Данные изображения обрабатываются по-отдельности сиамскими сверточными нейронными подсетями для построения выходных фрагментов P'L и P'H изображения, причем упомянутые сиамские сверточные нейронные подсети имеют одинаковые весовые коэффициенты для единообразной обработки обоих изображений пары. В результате обработки сиамскими сверточными нейронными подсетями производится прорисовка деталей входных фрагментов, причем в процессе обработки сиамская сверточная нейронная подсеть стремится увеличить уровень детализации входного фрагмента PL для получения выходного фрагмента P'L, существенно не меняя при этом входной фрагмент PH при получении выходного фрагмента P'H.
Далее высчитываются соответствующие разницы, необходимые для вычисления общей функции потерь для обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями. Регрессионная разница вычисляется на основе выходного фрагмента 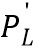 и входного фрагмента PH как D(, PH) любым известным способом, например, как абсолютная величина потери (известная также как L1-норма -
и входного фрагмента PH как D(, PH) любым известным способом, например, как абсолютная величина потери (известная также как L1-норма - 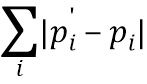 ) или как квадратичная функция потерь (известная также как L2-норма -
) или как квадратичная функция потерь (известная также как L2-норма - 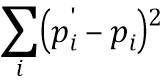 ), где
), где 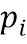 - элементы фрагмента PH, а
- элементы фрагмента PH, а 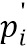 - элементы фрагмента P'L, соответственно. Кроме того, разница D может вычисляться как перцептивная разница
- элементы фрагмента P'L, соответственно. Кроме того, разница D может вычисляться как перцептивная разница 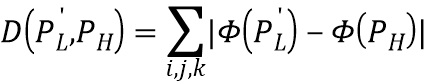 , где
, где 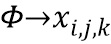 (функция, полученная в результате обучения модели распознавания классов изображений, построенной Visual Geometry Group (VGG)). В дополнение к регрессионной разнице формируется модулированная ретенционная разница, причем модулированная ретенционная разница формируется на основе как выходных фрагментов и
(функция, полученная в результате обучения модели распознавания классов изображений, построенной Visual Geometry Group (VGG)). В дополнение к регрессионной разнице формируется модулированная ретенционная разница, причем модулированная ретенционная разница формируется на основе как выходных фрагментов и 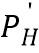 , так и входных фрагментов PL и PH как D(P'L, PL)⊙D(P'H, PH), при этом разница D вычисляется аналогично любым вышеупомянутым известным способом.
, так и входных фрагментов PL и PH как D(P'L, PL)⊙D(P'H, PH), при этом разница D вычисляется аналогично любым вышеупомянутым известным способом.
Эти разницы (регрессионная и модулированная ретенционная) суммируются для получения общей функции потерь, которая и используется для обучения всей сверточной нейронной сети - D(P'L, PH)+D(P'L, PL)⊙D(P'H, PH). В частности, общая функция потерь вычисляется следующим образом:
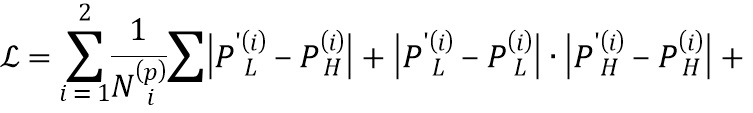
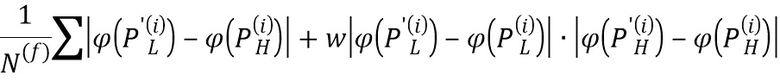
где 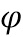 представляет собой преобразование 4-го уровня нейронной сети VGG-19 (см. Simonyan K., Zisserman A., статья «Very deep convolutional networks for large-scale image recognition», 2014), i - индекс уровня пирамиды изображений,
представляет собой преобразование 4-го уровня нейронной сети VGG-19 (см. Simonyan K., Zisserman A., статья «Very deep convolutional networks for large-scale image recognition», 2014), i - индекс уровня пирамиды изображений, 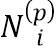 - количество пикселей на iом уровне пирамиды изображений,
- количество пикселей на iом уровне пирамиды изображений, 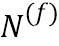 - количество признаков VGG 4ого уровня, а w представляет собой эмпирически подобранный положительный параметр. В частности, согласно предпочтительному варианту осуществления на основе множества проведенных экспериментов параметр w=0,001. Упомянутое преобразование
- количество признаков VGG 4ого уровня, а w представляет собой эмпирически подобранный положительный параметр. В частности, согласно предпочтительному варианту осуществления на основе множества проведенных экспериментов параметр w=0,001. Упомянутое преобразование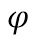 устроено следующим образом: на вход обученной нейронной сети VGG-19 подается фрагмент изображения размера W x H x 3 (W - ширина, H - высота, 3 соответствует трем цветовым каналам RGB), выходом же преобразования считается выход 4-го уровня сети VGG-19 (см. таблицу 1 вышеуказанной статьи, самый правый столбец - конфигурация Е, выход верхнего слоя, помеченного жирным шрифтом как conv3-512), представляющий собой тензор размера W/8 x H/8×512.
устроено следующим образом: на вход обученной нейронной сети VGG-19 подается фрагмент изображения размера W x H x 3 (W - ширина, H - высота, 3 соответствует трем цветовым каналам RGB), выходом же преобразования считается выход 4-го уровня сети VGG-19 (см. таблицу 1 вышеуказанной статьи, самый правый столбец - конфигурация Е, выход верхнего слоя, помеченного жирным шрифтом как conv3-512), представляющий собой тензор размера W/8 x H/8×512.
При этом, как указано выше, применяемый метод обратного распространения ошибки не учитывает D(P'L, PL), следовательно, градиент функции потерь по отношению к весовым коэффициентам θ сиамской нейронной сверточной подсети, которая обрабатывала фрагмент PL, вычисляется следующим образом:
,
где 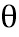 - весовые коэффициенты сиамской сверточной нейронной подсети.
- весовые коэффициенты сиамской сверточной нейронной подсети.
В частности, по правилам дифференцирования градиент функции потерь по весовым коэффициентам подсети должен выглядеть следующим образом: 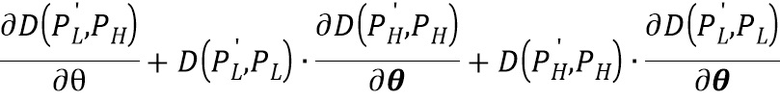 , однако согласно настоящему изобретению последнее слагаемое, содержащее производную D(P'L, PL), не учитывается, как указано выше. Таким образом, производится «блокировка» распространения ошибки от разницы D(P'L, PL). Таким образом, обеспечивается избирательное улучшение областей изображения с низким качеством даже без соответствующих парных областей хорошего качества посредством восстановления или дорисовки деталей изображения. Другими словами, за счет учета модулированной ретенционной разницы сверточная нейронная сеть обучается учитывать наиболее «ценные» области на изображениях с более высоким качеством на основе того, насколько аналогичные области на изображениях с низким качеством подвергались изменениям на выходе обработки сиамской сверточной нейронной подсетью (если некоторая область на изображении с низким качеством не подверглась изменениям, то аналогичная область на изображении с более высоким качеством считается менее ценной при обучении, и наоборот). Таким образом, сверточная нейронная сеть не принимает изображение с более высоким качеством за эталонное изображение, а учится распознавать и улучшать области с низким качеством и в этом изображении.
, однако согласно настоящему изобретению последнее слагаемое, содержащее производную D(P'L, PL), не учитывается, как указано выше. Таким образом, производится «блокировка» распространения ошибки от разницы D(P'L, PL). Таким образом, обеспечивается избирательное улучшение областей изображения с низким качеством даже без соответствующих парных областей хорошего качества посредством восстановления или дорисовки деталей изображения. Другими словами, за счет учета модулированной ретенционной разницы сверточная нейронная сеть обучается учитывать наиболее «ценные» области на изображениях с более высоким качеством на основе того, насколько аналогичные области на изображениях с низким качеством подвергались изменениям на выходе обработки сиамской сверточной нейронной подсетью (если некоторая область на изображении с низким качеством не подверглась изменениям, то аналогичная область на изображении с более высоким качеством считается менее ценной при обучении, и наоборот). Таким образом, сверточная нейронная сеть не принимает изображение с более высоким качеством за эталонное изображение, а учится распознавать и улучшать области с низким качеством и в этом изображении.
На Фиг. 3 изображена структура вложенных ядер свертки, применяемых в кодирующей части сиамских сверточных нейронных подсетей при обучении заявленной сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями. В известных моделях сверточных нейронных сетей применяемые при обучении ядра свертки обновляются независимо друг от друга, что зачастую приводит к большой емкости модели (множество весовых коэффициентов сети), что является основной причиной проблемы переобучения сверточных нейронных сетей, что в свою очередь снижает эффективность применения такой модели сверточной нейронной сети при обработке незнакомых ей баз данных. Согласно же настоящему варианту осуществления для всех ядер свертки предполагается использовать единый набор, т.е. предполагается использование вложенных ядер свертки, что позволяет увеличить рецептивное поле без увеличения количества используемых весовых коэффициентов.
Вышеупомянутый единый набор весовых коэффициентов ядра свертки имеет размерность наибольшей свертки, применяемой при обучении сверточной нейронной сети. Каждой свертке (кроме первой, которая является отдельной, т.к. она работает непосредственно с исходными RGB-данными входного фрагмента) затем назначается соответствующий поднабор весовых коэффициентов ядра. В частности, на Фиг. 3 изображен пример, согласно которому три последовательные свертки размерностью KxK последовательно преобразуют карту признаков размерностью HxWxF в карты признаков размерностями HxWx2F, HxWx4F и HxWx8F. Наибольшая свертка в данном примере имеет ядро с размерностью KxKx8Fx4F (на фигуре KxK изображено в виде K2 для наглядного отображения). Согласно настоящему варианту осуществления в данном примере наибольшая свертка распространяется на все три операции свертки: первая операция свертки «получает» субтензор размерностью K×K×2F×F от общего единого набора, вторая - размерностью K×K×4F×2F, а третья - получает весь тензор размерностью KxKx8Fx4F. Во время обучения весовые коэффициенты ядер свертки обновляются согласно этому распределению, т.е. при обновлении набора весовых коэффициентов всегда учитывается, что часть весовых коэффициентов большей свертки всегда совпадает с весовыми коэффициентами меньшей свертки.
Такое применение вложенных сверток позволяет значительно увеличить рецептивное поле сверточной нейронной сети без увеличения количества весовых коэффициентов сверточной нейронной сети, тем самым обеспечивая больший визуальный контекст для обработки изображения без риска возникновения переобучения. Кроме того, такой подход обеспечивает согласованность мелких деталей на изображении, в том числе, протяженных деталей, обладающих свойством самоподобия, таких как волосы человека, так как свертки всех уровней обладают одинаковыми весовыми коэффициентами меньшей свертки, которые ищут и учитывают на изображении самоподобные части. Таким образом, заявленная модель сверточной нейронной сети позволяет применять одинаковые весовые коэффициенты к картам признаков различных размерностей, тем самым распознавая признаки самоподобия объектов, которые присутствуют на обрабатываемых изображениях.
Согласно альтернативному варианту осуществления возможно применение единого набора весовых коэффициентов, в котором ядра свертки не вложены друг в друга, а распределены по наибольшей применяемой свертке (см. Фиг. 4). Несмотря на то, что согласно данному альтернативному варианту осуществления количество весовых коэффициентов сверточной нейронной сети также сокращается, такой подход не обеспечивает согласованность мелких деталей на изображении, т.е. целостность деталей на построенном изображении с более высоким качеством ухудшается по сравнению с построенным изображением согласно предыдущему варианту осуществления.
На Фиг. 5 показана подробная схема обработки с помощью сиамской сверточной нейронной подсети в соответствии с примерным вариантом осуществления настоящего изобретения. Данная подсеть имеет U-Net архитектуру (часть сжимающего кодирования, за которой следует часть декодирования). Как было указано выше, каждый из фрагментов (фрагмент с низким качеством и фрагмент с более высоким качеством) независимо поступают на вход каждый своей сиамской сверточной нейронной подсети. На выходе такой сиамской сверточной нейронной подсети получают 2-уровневую пирамиду изображений для выходных фрагментов. Опционально, пирамида изображений с большим количеством уровней может быть получена, однако экспериментально было выяснено, что пирамида изображений большего размера качество существенно не улучшает. Часть сжимающего кодирования подсети использует свертки с вложенными ядрами, как указано выше (кроме первой применяемой свертки). Как наглядно изображено на фигуре, входной фрагмент (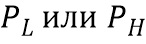 ), подаваемый на вход подсети, имеет размерность WxHx3, затем этот фрагмент обрабатывается внутри упомянутой подсети (свертка (conv) 3×3, функция активации ELU)), в результате чего получается массив с глубиной 32 (размерность WxHx32). Все свертки, применяемые далее при обработке внутри подсети, являются вложенными свертками, как указано выше. В частности, далее при обработке внутри подсети получается массив аналогичной размерности (дважды применяется операция свертки 3×3 с функцией активации ELU). Затем применяется операция подвыборки (pool) 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается вдвое, а глубина (количество карт признаков) становится 64 (W/2 x H/2×64). Далее трижды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина и высота которого, а также и глубина, остаются неизменными. Затем применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 128 (W/4 x H/4×128). Далее снова трижды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 256 (W/8 x H/8×256). Далее четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 512 (W/16 x H/16×512). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 768 (W/32 x H/32×768). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. После очередного применения операции подвыборки 2×2, операции свертки 3×3 с функцией активации ELU получается массив, ширина и высота которого уменьшается еще вдвое, а глубина остается неизменной (W/64 x H/64×768). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными, при этом завершается обработка кодирующей частью подсети. Таким образом, при обработке в части сжимающего кодирования подсети высота и ширина изображения уменьшаются (в итоге в 64 раза), а количество карт признаков растет вплоть до 768 карт признаков. Затем в части декодирования размер изображения снова увеличивается. Кроме того, как наглядно изображено на Фиг. 5, в заявленной сиамской сверточной нейронной подсети используются так называемые skip-связи (связи переноса), которые связывают слои упомянутой подсети, которые не соседствуют друг с другом, для сохранения деталей первоначального входного фрагмента путем переноса соответствующего массива из части сжимающего кодирования в часть декодирования и его конкатенации с массивом, имеющем соответствующие высоту и ширину. Например, первая операция skip-связи (отмеченная на фигуре как «skip») переносит выход второго слоя, т.е. массив с размерностью W x H x 32, в часть декодирования и конкатенирует его с выходом очередного слоя, имеющего размеры W x H x 16, и т.п. Операция увеличения разрешения, применяемая в части декодирования, отмечена на чертеже как «upsample». В частности, при обработке в декодирующей части подсети применяется операция увеличения разрешения 2×2, свертка 3×3 и функция активации ELU, в результате чего получается массив с размерностью W/32 x H/32×512, кроме того, в данную часть с помощью операции переноса переносится также и массив с соответствующей размерностью, как изображено на фигуре, после конкатенации с которым получается массив размера W/32 x H/32×1024. Затем также применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив размера W/32 x H/32×512. После чего аналогично кодирующей части чередуются применение операции увеличения разрешения 2×2, операции свертки 3×3 и функции активации ELU, за которой следует применение операции переноса массива соответствующей размерности, и применение операции свертки 3×3 с функцией активации ELU. После получения массива с размерностью W/2 x H/2×32 в результате применения операции свертки 3×3 с функцией активации ELU, альтернативно применению операции увеличения разрешения 2×2, свертки 3×3 и функции активации ELU, также применяется и операция свертки 3×3 с функцией активации tanh, в результате чего получается выходной фрагмент размерностью W/2 x H/2×3 (второй уровень пирамиды выходных фрагментов). К данному фрагменту применяется операция увеличения разрешения 2×2, в результате чего получается массив с размерностью W x H x 3, который конкатенируется с перенесенным из кодирующей части массивом размера W x H x 32 и выходом очередной свертки декодирующей части, имеющим размер W x H x 16, далее к результату конкатенации применяется операция свертки 3×3 с функцией активации ELU - в результате получается массив с размерностью W x H x 16, к которому также применяется операция свертки 3×3 с функцией активации tanh для получения выходного фрагмента размерностью W x H x 3 (первый уровень пирамиды выходных фрагментов). Благодаря использованию вложенных ядер свертки представленная сиамская сверточная нейронная подсеть содержит относительно небольшое количество обучаемых весовых коэффициентов - 17,5M. Та же архитектура без применения вложенных ядер свертки содержит 77,4M обучаемых весовых коэффициентов (больше в 4,4 раза), но с тем же рецептивным полем.
), подаваемый на вход подсети, имеет размерность WxHx3, затем этот фрагмент обрабатывается внутри упомянутой подсети (свертка (conv) 3×3, функция активации ELU)), в результате чего получается массив с глубиной 32 (размерность WxHx32). Все свертки, применяемые далее при обработке внутри подсети, являются вложенными свертками, как указано выше. В частности, далее при обработке внутри подсети получается массив аналогичной размерности (дважды применяется операция свертки 3×3 с функцией активации ELU). Затем применяется операция подвыборки (pool) 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается вдвое, а глубина (количество карт признаков) становится 64 (W/2 x H/2×64). Далее трижды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина и высота которого, а также и глубина, остаются неизменными. Затем применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 128 (W/4 x H/4×128). Далее снова трижды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 256 (W/8 x H/8×256). Далее четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 512 (W/16 x H/16×512). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. Затем снова применяется операция подвыборки 2×2, операция свертки 3×3 с функцией активации ELU, в результате получается массив, ширина и высота которого уменьшается еще вдвое, а глубина становится 768 (W/32 x H/32×768). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными. После очередного применения операции подвыборки 2×2, операции свертки 3×3 с функцией активации ELU получается массив, ширина и высота которого уменьшается еще вдвое, а глубина остается неизменной (W/64 x H/64×768). Затем снова четырежды применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив, ширина, высота и глубина которого остаются неизменными, при этом завершается обработка кодирующей частью подсети. Таким образом, при обработке в части сжимающего кодирования подсети высота и ширина изображения уменьшаются (в итоге в 64 раза), а количество карт признаков растет вплоть до 768 карт признаков. Затем в части декодирования размер изображения снова увеличивается. Кроме того, как наглядно изображено на Фиг. 5, в заявленной сиамской сверточной нейронной подсети используются так называемые skip-связи (связи переноса), которые связывают слои упомянутой подсети, которые не соседствуют друг с другом, для сохранения деталей первоначального входного фрагмента путем переноса соответствующего массива из части сжимающего кодирования в часть декодирования и его конкатенации с массивом, имеющем соответствующие высоту и ширину. Например, первая операция skip-связи (отмеченная на фигуре как «skip») переносит выход второго слоя, т.е. массив с размерностью W x H x 32, в часть декодирования и конкатенирует его с выходом очередного слоя, имеющего размеры W x H x 16, и т.п. Операция увеличения разрешения, применяемая в части декодирования, отмечена на чертеже как «upsample». В частности, при обработке в декодирующей части подсети применяется операция увеличения разрешения 2×2, свертка 3×3 и функция активации ELU, в результате чего получается массив с размерностью W/32 x H/32×512, кроме того, в данную часть с помощью операции переноса переносится также и массив с соответствующей размерностью, как изображено на фигуре, после конкатенации с которым получается массив размера W/32 x H/32×1024. Затем также применяется операция свертки 3×3 с функцией активации ELU, в результате чего получается массив размера W/32 x H/32×512. После чего аналогично кодирующей части чередуются применение операции увеличения разрешения 2×2, операции свертки 3×3 и функции активации ELU, за которой следует применение операции переноса массива соответствующей размерности, и применение операции свертки 3×3 с функцией активации ELU. После получения массива с размерностью W/2 x H/2×32 в результате применения операции свертки 3×3 с функцией активации ELU, альтернативно применению операции увеличения разрешения 2×2, свертки 3×3 и функции активации ELU, также применяется и операция свертки 3×3 с функцией активации tanh, в результате чего получается выходной фрагмент размерностью W/2 x H/2×3 (второй уровень пирамиды выходных фрагментов). К данному фрагменту применяется операция увеличения разрешения 2×2, в результате чего получается массив с размерностью W x H x 3, который конкатенируется с перенесенным из кодирующей части массивом размера W x H x 32 и выходом очередной свертки декодирующей части, имеющим размер W x H x 16, далее к результату конкатенации применяется операция свертки 3×3 с функцией активации ELU - в результате получается массив с размерностью W x H x 16, к которому также применяется операция свертки 3×3 с функцией активации tanh для получения выходного фрагмента размерностью W x H x 3 (первый уровень пирамиды выходных фрагментов). Благодаря использованию вложенных ядер свертки представленная сиамская сверточная нейронная подсеть содержит относительно небольшое количество обучаемых весовых коэффициентов - 17,5M. Та же архитектура без применения вложенных ядер свертки содержит 77,4M обучаемых весовых коэффициентов (больше в 4,4 раза), но с тем же рецептивным полем.
На Фиг. 6a, 6b, 6c и 6d представлены пары входного изображения и изображения, полученного в результате обработки входного изображения согласно варианту осуществления настоящего изобретения, т.е. данные фигуры демонстрируют результат применения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, обученной согласно представленному в настоящем документе способу. На каждой из указанных фигур слева изображено входное изображение (в частности, изображение с низким качеством), а справа - результат, построенный в результате применения сверточной нейронной сети, обученной согласно представленному в настоящем документе способу (в частности, изображение с более высоким качеством). На фигурах прямоугольными областями выделены области, в которых наглядно отображено улучшение, произведенное с помощью заявленной сверточной нейронной сети, в частности, более четко прорисованная структура волос, более четко прорисованная структура одежды/ткани, более четкая структура кожного покрова на затемненном изображении и т.п., причем все эти более четко прорисованные детали прорисованы естественным образом.
Предложенная система для преобразования изображения в изображение с прорисованными деталями содержит устройство захвата изображений, выполненное с возможностью захвата изображения, подлежащего обработке. Упомянутое устройство захвата изображений дополнительно может быть выполнено с возможностью захвата изображений с разными настройками качества для сбора персональной обучающей выборки, как описано выше. Предложенная система также содержит память, выполненную с возможностью хранения модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, обученной согласно настоящему изобретению, а также захваченного изображения и персональной обучающей выборки, собранной с помощью устройства захвата изображений. Кроме того, система содержит устройство обработки, выполненное с возможностью обработки захваченного изображения с помощью сохраненной модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями. Кроме того, память также выполнена с возможностью хранения результатов обработки захваченных изображений.
Для оценки качества изображений, полученных согласно настоящему изобретению, использовались следующие метрики оценки качества: кумулятивная вероятность обнаружения размытия (CPBD) и средневзвешенная глубокая оценка качества изображений (WaDIQaM-NR). На Фиг. 7 приведена таблица сравнения результатов согласно обученному способу в соответствии с заявленным изобретением и в соответствии с известными решениями, приведенными в разделе уровень техники, а также широко применимыми приложениями «Let's enhance» (алгоритм по добавлению текстуры и алгоритм по увеличению разрешения) и «Photoshop» (фильтр "нерезкое маскирование"). Метрика CPBD оценки качества оценивает только четкость/размытие изображения, и, соответственно, чем больше полученное значение, тем лучше оценивается качество изображения. Метрика WaDIQaM-NR оценки качества является обученной не-эталонной метрикой качества изображения, которая оценивает изображение в целом, причем для этой метрики, чем значение оценки меньше, тем лучше. Как наглядно следует из таблицы, средняя оценка качества изображений, построенных согласно настоящему изобретению, полученная по метрике CPBD, равна 0,65, что соразмерно с аналогичной оценкой, полученной для способов, раскрытых в EDSR и WDSR. Средняя оценка же, полученная по метрике WaDIQaM-NR, равна 32.1, что является лучшим результатом среди всех рассмотренных решений.
Дополнительно важно отметить, что в зависимости от набора данных, использованных для обучения заявленной сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, полученная модель сверточной нейронной сети будет обладать рядом внутренних свойств, присущих изображениям, обработанным данной моделью, которые наиболее наглядно могут быть отображены на изображениях, не сходных с изображениями из использованного для обучения набора данных и не обладающих информационным контекстом (например, часть однотонного рисунка и пр.). Таким образом, обработка таких изображений посторонними решениями позволит обнаружить использование заявленного изобретения в этих посторонних решениях.
Настоящее изобретение может быть применено во многих отраслях, требующих обработку изображений, в частности:
- для обработки фотографий, причем с помощью специального приложения конечный пользователь может самостоятельно собрать персональную базу обучающих данных для адаптированной обработки изображений (таким образом, при желании улучшения портретных фотографий, пользователь может собрать массив обучающих данных, содержащих множество портретов, а при желании улучшения фотографий животных или растительности, пользователь может самостоятельно собрать массив обучающих данных, содержащих множество животных или пейзажей, соответственно, при этом также могут быть использованы и любые известные собранные массивы обучающих данных);
- для формирования эффекта «красоты», например, за счет сбора массива обучающих данных, содержащих красивые лица (например, с макияжем, без «изъянов» и пр.), можно обучить сверточную нейронную сеть применять эффект «красоты» к обрабатываемым изображениям лиц;
- для улучшения качества изображений, захваченных уличными камерами безопасности, например, улучшение изображения номера автомобиля или лица преступника и т.п.;
- для улучшения изображений виртуальной реальности;
- для улучшения распознавания текстов на изображениях;
- для лучшего детектирования сходных объектов на изображениях.
Специалистам в данной области техники должно быть понятно, что функции, описанные в данном документе, могут быть реализованы в аппаратном обеспечении, программном обеспечении, аппаратно-программном обеспечении или любой их комбинации. Будучи реализованными в программном обеспечении, упомянутые функции могут храниться на или передаваться в виде одной или более инструкций или кода на машиночитаемом носителе. Машиночитаемые носители включают в себя любой носитель информации, который обеспечивает перенос компьютерной программы из одного места в другое. Носитель информации может быть любым доступным носителем, доступ к которому осуществляется посредством компьютера. В качестве примера, но не ограничения, такие машиночитаемые носители могут представлять собой RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптических дисках, накопитель на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель информации, который может использоваться для переноса или хранения требуемого программного кода в виде инструкций или структур данных и доступ к которому можно осуществлять с помощью компьютера. Кроме того, если программное обеспечение передается из веб-сайта, сервера или другого удаленного источника с использованием коаксиальных кабелей, оптоволоконных кабелей, витой пары, цифровой абонентской линии связи (DSL) или с использованием беспроводных технологий, таких как инфракрасные, радио и микроволны, то такие проводные и беспроводные средства подпадают под определение носителя. Комбинации вышеозвученных носителей информации должны также попадать в объем охраны настоящего изобретения.
Хотя в настоящем описании показаны примерные варианты реализации изобретения, следует понимать, что различные изменения и модификации могут быть выполнены, не выходя за рамки объема охраны настоящего изобретения, определяемого прилагаемой формулой изобретения. Функции, этапы и/или действия, упоминаемые в пунктах формулы изобретения, характеризующих способ, в соответствии с вариантами реализации настоящего изобретения, описанными в данном документе, необязательно должны выполняться в каком-то конкретном порядке, если не отмечено или не оговорено иное. Более того, упоминание элементов системы в единственном числе не исключает множества таких элементов, если в явном виде не указано иное.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ ВОССТАНОВЛЕНИЯ ИЗОБРАЖЕНИЯ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ КАРТЫ ГЛУБИНЫ ИЗОБРАЖЕНИЯ (ВАРИАНТЫ) | 2018 |
|
RU2698402C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОВМЕСТНОГО ВЫПОЛНЕНИЯ ДЕБАЙЕРИЗАЦИИ И УСТРАНЕНИЯ ШУМОВ ИЗОБРАЖЕНИЯ С ПОМОЩЬЮ НЕЙРОННОЙ СЕТИ | 2020 |
|
RU2764395C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ, СПОСОБ И УСТРОЙСТВО ОБУЧЕНИЯ | 2021 |
|
RU2773420C1 |
| НЕЙРОННАЯ СЕТЬ ДЛЯ ГЕНЕРАЦИИ СИНТЕТИЧЕСКИХ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2698997C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ПОМОЩЬЮ СИНТЕТИЧЕСКИХ ФОТОРЕАЛИСТИЧНЫХ СОДЕРЖАЩИХ ЗНАКИ ИЗОБРАЖЕНИЙ | 2018 |
|
RU2709661C1 |
| РЕПРОДУЦИРУЮЩАЯ АУГМЕНТАЦИЯ ДАННЫХ ИЗОБРАЖЕНИЯ | 2018 |
|
RU2716322C2 |
| Способ выявления объектов на изображении плана-схемы объекта строительства | 2022 |
|
RU2785821C1 |
| СПОСОБЫ ОБУЧЕНИЯ ГЛУБОКИХ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2767337C2 |
| СПОСОБЫ РЕКОНСТРУКЦИИ КАРТЫ ГЛУБИНЫ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ИХ РЕАЛИЗАЦИИ | 2020 |
|
RU2745010C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ, ИНВАРИАНТНОЙ К СДВИГУ | 2017 |
|
RU2656990C1 |




Настоящая группа изобретений относится к области обработки изображений, в частности к способу и системе для преобразования изображения в изображение с прорисованными деталями. Технический результат заключается в обеспечении изображения, на котором мелкие детали изображения восстановлены и прорисованы естественным образом и сохраняется целостность протяженных объектов на изображении, обладающих свойством самоподобия. Способ содержит этапы: получают пару изображений, включающую в себя входной фрагмент PL низкого качества и входной фрагмент PH более высокого качества; подают каждый из входных фрагментов (PL, PH) на вход соответствующей сиамской сверточной нейронной подсети и обрабатывают поданные входные фрагменты (PL, PH) для получения выходных фрагментов (P'L, P'H) изображения; вычисляют регрессионную разницу D(P'L, PH); вычисляют модулированную ретенционную разницу D(P'L, PL)⊙D(P'H, PH); формируют общую функцию потерь и обучают сверточную нейронную сеть на основе сформированной общей функции потерь. 2 н. и 2 з.п. ф-лы, 7 ил.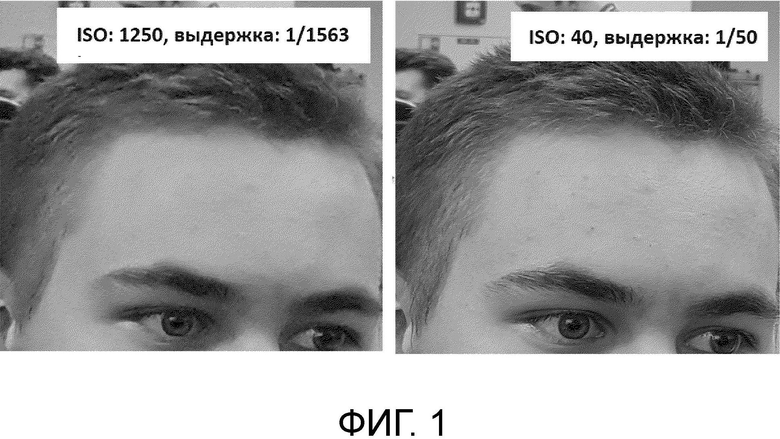
1. Способ формирования общей функции потерь для обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, содержащий этапы, на которых:
- получают пару изображений, включающую в себя входной фрагмент PL низкого качества и входной фрагмент PH более высокого качества, причем входной фрагмент PL низкого качества представляет собой изображение, снятое с высоким значением ISO и низким значением выдержки, а входной фрагмент PH более высокого качества представляет собой изображение, снятое с более низким значением ISO и более высоким значением выдержки;
- подают каждый из входных фрагментов (PL, PH) на вход соответствующей сиамской сверточной нейронной подсети и обрабатывают поданные входные фрагменты (PL, PH) для получения выходных фрагментов (P'L, P'H) изображения соответственно, причем в кодирующей части каждой сиамской сверточной нейронной подсети используются вложенные ядра свертки;
- вычисляют регрессионную разницу D(P'L, PH);
- вычисляют модулированную ретенционную разницу D(P'L, PL)⊙D(P'H, PH);
- формируют общую функцию потерь путем суммирования регрессионной разницы и модулированной ретенционной разницы для обучения сверточной нейронной сети как D(P'L, PH)+D(P'L, PL)⊙D(P'H, PH) и
- обучают сверточную нейронную сеть на основе сформированной общей функции потерь.
2. Способ по п. 1, в котором градиент функции потерь по отношению к весовым коэффициентам θ сиамской нейронной сверточной подсети вычисляется следующим образом:
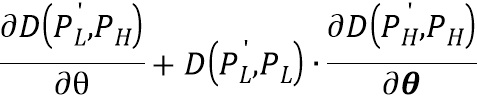 .
.
3. Способ по п. 1, в котором значение ISO и значение выдержки входных фрагментов настраиваются таким образом, чтобы суммарная яркость входных фрагментов была одинаковая.
4. Система для преобразования изображения в изображение с прорисованными деталями, содержащая:
- устройство захвата изображений, выполненное с возможностью захвата изображения;
- память, выполненную с возможностью хранения модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями, обученной с учетом общей функции потерь, сформированной согласно способу формирования общей функции потерь для обучения сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями по п.1, и захваченного изображения; и
- устройство обработки, выполненное с возможностью обработки захваченного изображения с помощью сохраненной модели сверточной нейронной сети для преобразования изображения в изображение с прорисованными деталями.
| US2013170767 A1, 04.07.2013 | |||
| US2018338082 A1, 22.11.2018 | |||
| US2017256033 A1, 07.09.2017 | |||
| CN109426858 A, 05.03.2019 | |||
| УСТРОЙСТВО АССОЦИАТИВНОЙ ПАМЯТИ (ВАРИАНТЫ) И СПОСОБ РАСПОЗНАВАНИЯ ОБРАЗОВ (ВАРИАНТЫ) | 1991 |
|
RU2193797C2 |

