ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное изобретение относится к области машинного обучения, а именно к искусственным нейронным сетям, инвариантным к сдвигу. В частности, настоящее изобретение относится к обработке и распознаванию сигналов, таких как изображения, видео или звук, с помощью таких искусственных нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
В настоящее время нейронные сети являются одним из эффективно применяемых подходов для распознавания, регрессии, предсказания и/или классификации сигналов. В частности, для обработки и распознавания данных изображений, видео, звука (например, речи) и 3D-данных (например, медицинских данных), как правило, применяется сверточная нейронная сеть (CNN). CNN обучается и вырабатывает необходимую иерархию признаков (иначе говоря, ядра свертки) во время процесса обучения на основании примерного размеченного набора данных, для которого заданы правильные ответы распознавания. Другими словами, во время процесса обучения нейронная сеть подбирает весовые коэффициенты для ядер свертки, причем на первых слоях весовые коэффициенты соответствуют некоторым общим признакам, присущим всем сигналам заданного типа, например, изображениям. Для изображений такими признаками могут быть, например, линии под разными углами. Количество слоев в нейронной сети задает глубину нейронной сети. Переходя глубже, т.е. к последующим слоям, сеть начинает выделять более сложные признаки, и весовые коэффициенты ядер свертки становятся более специфичными к конкретным заданным классам или конкретной задаче регрессии. Последний слой сверточной нейронной сети выполняет классификацию или регрессию, в зависимости от постановки задачи, на основе информации, полученной от предыдущих слоев. Подбор весовых коэффициентов для ядер свертки, например, осуществляется в соответствии с методом обратного распространения ошибки.
Таким образом, CNN может распознавать данные (например, классифицировать объект на изображении) на основе упомянутых ядер и выдавать в качестве выходного сигнала одно наиболее вероятное наименование класса объекта (Топ-1 класс) или несколько наиболее вероятных наименований классов, например, 5 наиболее вероятных наименований классов (Топ-5 классов). Для сравнения качества классификации, как правило, используются метрики «Топ-1 ошибка» и «Топ-5 ошибка». При использовании метрики «Топ-1 ошибка» классификация входного сигнала нейронной сетью считается правильной, если правильный ответ совпал с Топ-1 классом. При использовании метрики «Топ-5 ошибка» классификация сигнала нейронной сетью считается правильной, если правильный ответ попал в Топ-5 классов, выданных сетью.
За последние годы глубина применяемых нейронных сетей увеличилась, приведя к большей точности в отношении правильных ответов для различных задач машинного распознавания образов, при этом размеры ядер свертки уменьшились. В частности, С 2010 года ведется конкурс ILSVRC (ImageNet Large Scale Visual Recognition Challenge - соревнование по распознаванию образов в наборе данных ImageNet), в рамках которого было установлено, что в 2010 году ошибка классификации по метрике Топ-1 при использовании известных неглубоких сетей составляла 28,2%, а в 2011 году - 25,8%. В 2012 году глубина применяемой сети (AlexNet) увеличилась до 8 слоев, а ошибка составила 16,4%; этот результат был улучшен в 2013 году при достижении ошибки, составляющей 11,7%. В 2014 году глубина применяемой нейронной сети уже составляла 19 слоев, что позволяло осуществлять распознавание объектов с ошибкой, составляющей лишь 7,3% (сеть VGG). В этом же году была разработана другая известная сеть - GoogleNet, глубина которой составляла 22 слоя, а ошибка составляла 6,7%. Наилучший результат был достигнут в 2015 году при применении сети ResNet с глубиной 152 слоя и размером ядра свертки 3×3, а ошибка составляла лишь 3,57%. Однако использование таких глубоких сверточных нейронных сетей требует высокого потребления вычислительных ресурсов, а именно большого объема памяти, так как многократное применение операций свертки является времязатратным и трудоемким.
Одним из известных решений, описывающих параллельную сверточную нейронную сеть, является решение, раскрытое, например, в патентном документе WO 2014/105865 A1 (Google Inc., «System and method for parallelizing convolutional neural networks» - Система и способ для параллельных сверточных нейронных сетей). Известная CNN реализуется множеством сверточных нейронных сетей, каждая из которых находится на соответствующем узле обработки. Каждая CNN имеет множество слоев. Подмножество слоев взаимосвязано между узлами обработки таким образом, чтобы сигналы активации продвигались далее по узлам. Недостатком известного решения является высокое потребление вычислительных ресурсов.
В документе US 20140180986 A1 (Google Inc., «System and method for addressing overfitting in a neural network» - Система и способ для регулировки переобучения в нейронной сети) предложена система обучения нейронной сети. Переключатель связан с детекторами признаков по крайней мере в некоторых слоях нейронной сети. Для каждого примера для обучения переключатель избирательно отключает каждый из детекторов признаков в соответствии с заранее заданной вероятностью. Затем весовые коэффициенты каждого примера для обучения нормируются для применения нейронной сети к данным для испытания. Однако при реализации данного известного решения объем потребляемой памяти также велик вследствие наличия огромного количества параметров в сети.
Таким образом, проблема существующего уровня техники заключается в том, что процесс обучения представляет собой трудную математическую и вычислительную задачу, которая требует значительных ресурсов аппаратного обеспечения, ресурсов времени и трудозатрат.
Задачей настоящего изобретения является создание более быстрой и простой архитектуры нейронной сети для обработки изображения, видео или звука, в частности, важно спроектировать простую и эффективную нейронную сеть, минимизировав при этом количество гиперпараметров (например, количество слоев, размеры ядер), которые необходимо задавать человеку при настройке архитектуры нейронной сети.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Указанная задача решается посредством способа и системы, которые охарактеризованы в независимых пунктах формулы изобретения. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах формулы изобретения.
Согласно настоящему изобретению предложен эффективный путь, в соответствии с которым вместо операции свертки применяются операции сдвига и линейной взвешенной суммы, за счет чего избегаются слои с трудоемкими операциями свертки, что приводит к меньшим вычислительным затратам при сохранении высокой точности распознавания, при этом элементы сигнала по-прежнему рассматриваются в контексте, т.е. с учетом некоторой окрестности рассматриваемого элемента. Указанное преимущество достигается за счет сведения операции линейной взвешенной суммы к хорошо известному алгоритму обобщенного перемножения матриц (GEMM), при этом использование дополнительной памяти не требуется. Операции GEMM оптимизированы для GPU/CPU, что в результате приводит к меньшему потреблению вычислительных ресурсов.
Согласно первому аспекту заявленной группы изобретений предложен способ обработки сигналов с помощью нейронной сети, имеющей N слоев, содержащий этапы, на которых:
- подают входные данные на текущий слой обученной нейронной сети, причем входные данные представляют собой набор числовых значений сигнала для обработки;
- обрабатывают поданные входные данные для получения выходных данных; и
- если номер текущего слоя нейронной сети меньше N, переходят на следующий слой нейронной сети и повторяют этапы способа с использованием полученных выходных данных в качестве входных данных, и
- если номер текущего слоя нейронной сети равен N, выводят полученные выходные данные;
причем этап обработки содержит применение операции сдвига входных данных в одном из заданных направлений для получения сдвинутых входных данных, вычисление линейной взвешенной суммы входных данных и суммирование сдвинутых входных данных и результата вычисления взвешенной суммы для получения выходных данных, причем данная обработка применяется в отношении каждого заданного направления, или применение операции сдвига входных данных в одном или более заданных направлениях для получения сдвинутых входных данных в каждом из одного или более заданных направлений, вычисление линейной взвешенной суммы сдвинутых входных данных в каждом из одного или более заданных направлений и суммирование результатов вычисления взвешенной суммы для каждого из одного или более заданных направлений и входных данных для получения выходных данных.
При этом вычисление линейной взвешенной суммы сводится к операции обобщенного перемножения двух матриц (GEMM).
Способ дополнительно содержит предварительные этапы, на которых:
- получают примерный размеченный набор данных для обучения;
- обучают нейронную сеть на основе полученного примерного размеченного набора данных путем определения соответствующих весовых коэффициентов.
Сигналом, подлежащим обработке, может являться изображение, а заданное направление может представлять собой направление в сторону одного из прилегающих соседних пикселей, при этом соседние пиксели определяются исключительно топологией данных (например, 1Д (звук), 2Д (изображение) и 3Д (видео), и т.д., и т.п.).
Выходные данные представляют собой наименование сигнала, классификацию сигнала или список наиболее вероятных наименований сигнала или другой искомый сигнал, в случае задачи регрессии.
Согласно другому аспекту заявленной группы изобретений предложена система для обработки сигналов с помощью нейронной сети, имеющей N слоев, содержащая:
- устройство приема, выполненное с возможностью принимать входные данные, представляющие собой набор числовых значений сигнала для обработки;
- память, выполненную с возможностью хранить принятые входные данные;
- устройство обработки, выполненное с возможностью считывать входные данные из памяти и выполнять этапы способа обработки сигналов согласно первому аспекту, причем устройство обработки дополнительно выполнено с возможностью записи выходных данных, выведенных устройством обработки, в память.
Упомянутое устройство обработки представляет собой центральный процессор (CPU) и/или графический процессор (GPU).
Технические эффекты настоящего изобретения заключаются в следующем:
- простота: уменьшение количества гиперпараметров, которые необходимо настраивать при разработке новой нейронной сети для конкретной задачи;
- быстрота: меньшие затраты по времени и потребление меньшего объема памяти для CPU и GPU за счет непосредственного осуществления GEMM вместо операции свертки без дополнительных подготовительных ресурсозатратных операций, как будет указано далее;
- точность: обладает такой же степенью точности, как и применяемые в настоящее время сверточные нейронные сети;
- мобильная обработка (в мобильном устройстве): без необходимости в дополнительном аппаратном обеспечении или облачной поддержке.
Таким образом, технический результат, достигаемый посредством использования настоящей группы изобретений, заключается в уменьшении потребления вычислительных ресурсов при распознавании сигналов с помощью нейронной сети с сохранением высокой степени точности распознавания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Эти и другие признаки и преимущества настоящего изобретения станут очевидны после прочтения нижеследующего описания и просмотра сопроводительных чертежей, на которых:
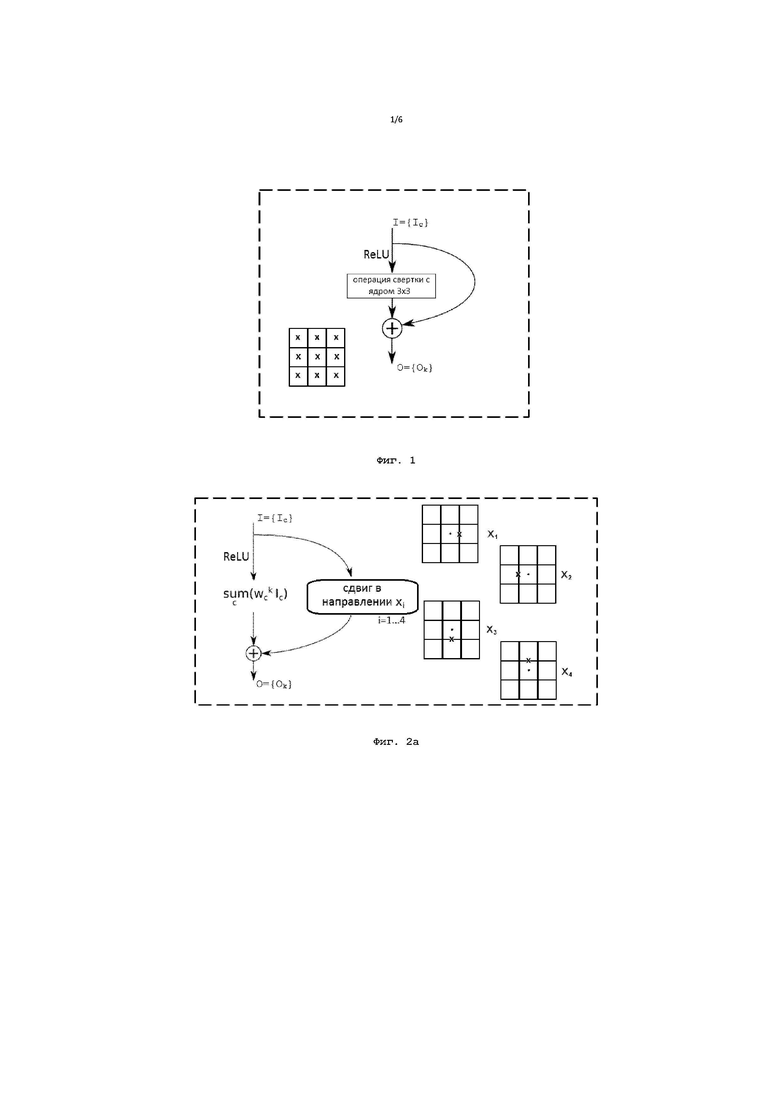
Фиг. 1 иллюстрирует схематическое изображение единичного блока сети в соответствии с известной сверточной нейронной сетью;
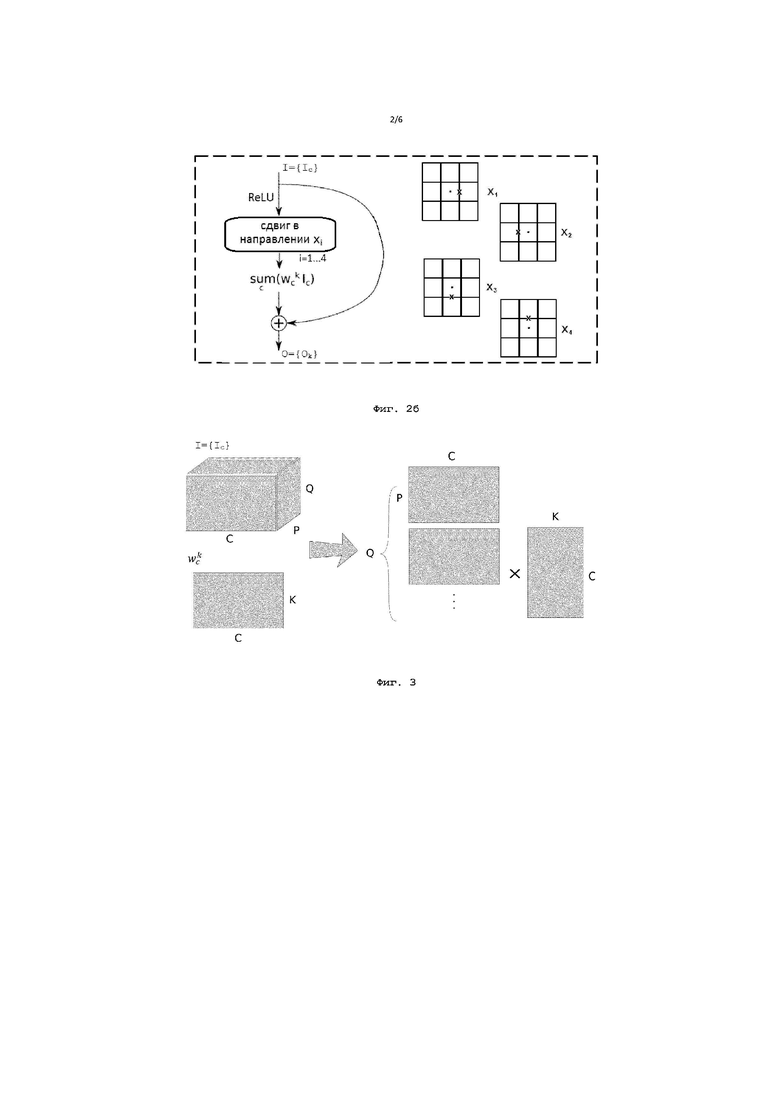
Фиг. 2а иллюстрирует схематическое изображение одного варианта единичного блока сети в соответствии с вариантом осуществления изобретения;
Фиг. 2б иллюстрирует схематическое изображение другого варианта единичного блока сети в соответствии с вариантом осуществления изобретения;
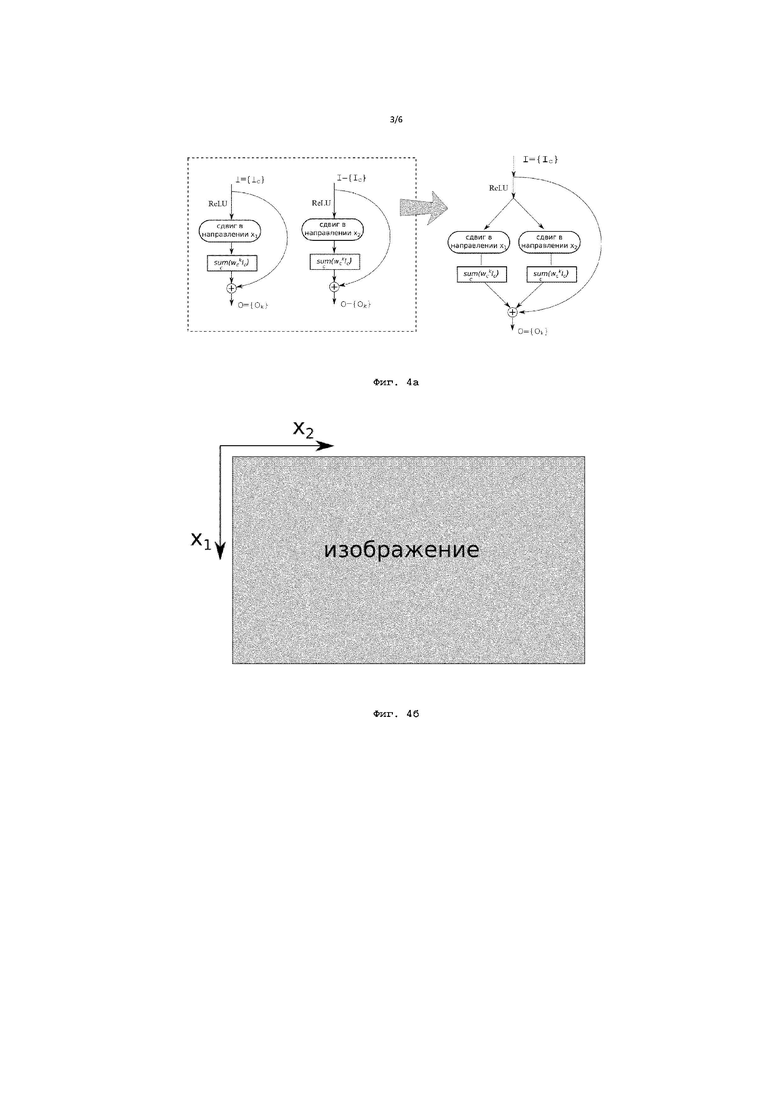
Фиг. 3 иллюстрирует сведение вычислений к умножению двумерных матриц;
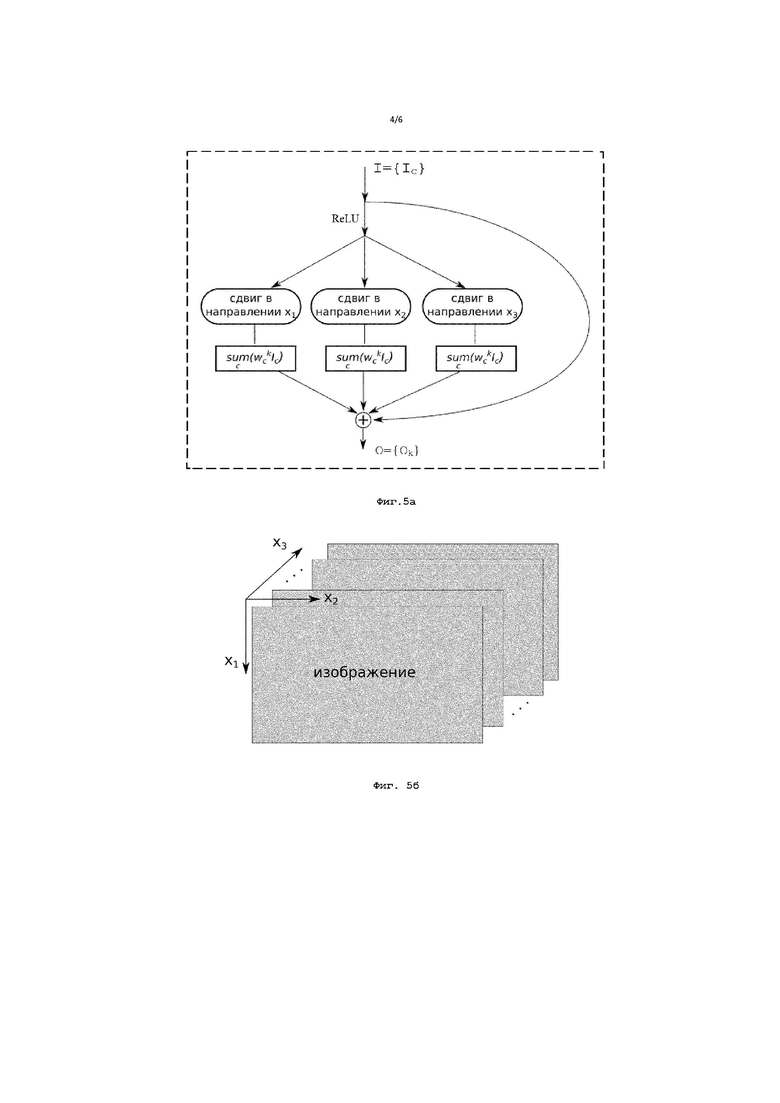
Фиг. 4а иллюстрирует схематическое изображение сведения применения двух параллельных операций сдвига в разных направлениях к одновременному применению операций сдвига в этих направлениях в соответствии с вариантом осуществления изобретения;
Фиг. 4б иллюстрирует примерное представление двух направлений в отношении рассматриваемого изображения;
Фиг. 5а иллюстрирует схематическое изображение единичного блока сети при рассмотрении набора последовательных изображений с одновременным применением операций сдвига в трех направлениях в соответствии с вариантом осуществления изобретения;
Фиг. 5б иллюстрирует примерное представление трех направлений в отношении рассматриваемого набора последовательных изображений;
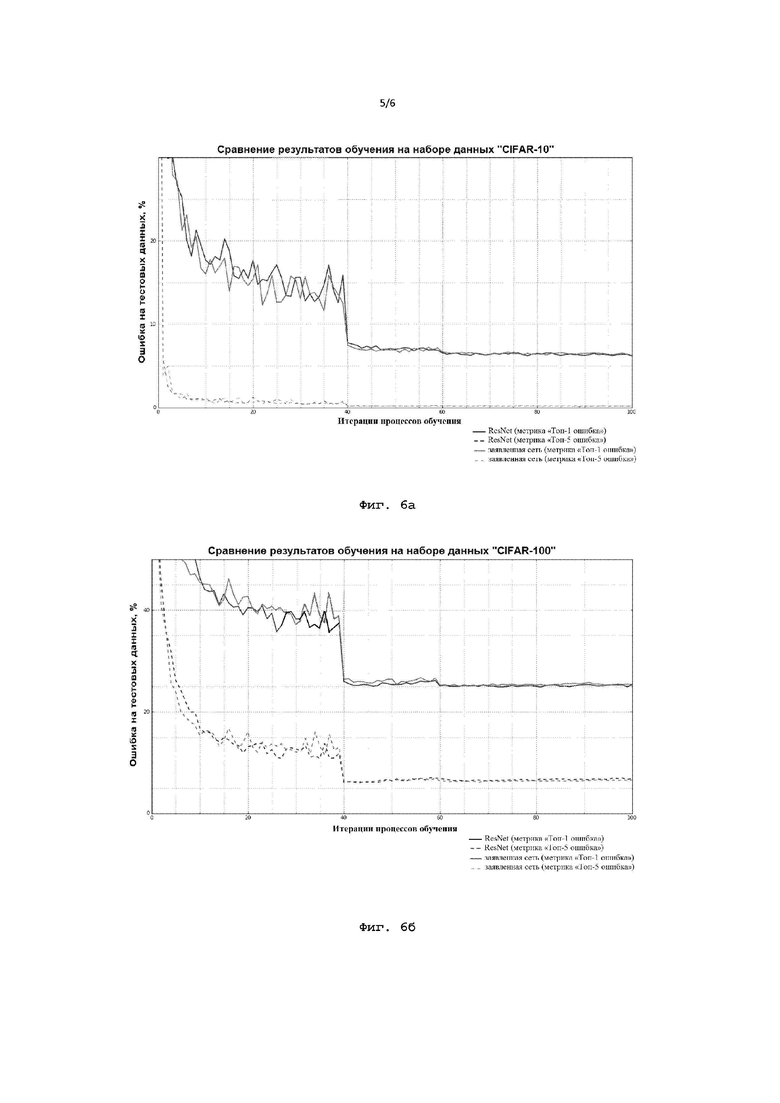
Фиг. 6а иллюстрирует график сравнения точности результатов обучения предложенной нейронной сети с нейронной сетью ResNet на основе набора данных CIFAR-10;
Фиг. 6б иллюстрирует график сравнения точности результатов обучения предложенной нейронной сети с нейронной сетью ResNet на основе набора данных CIFAR-100;
Фиг. 6в иллюстрирует график сравнения точности результатов обучения предложенной нейронной сети с нейронной сетью ResNet на основе набора данных ImageNet;
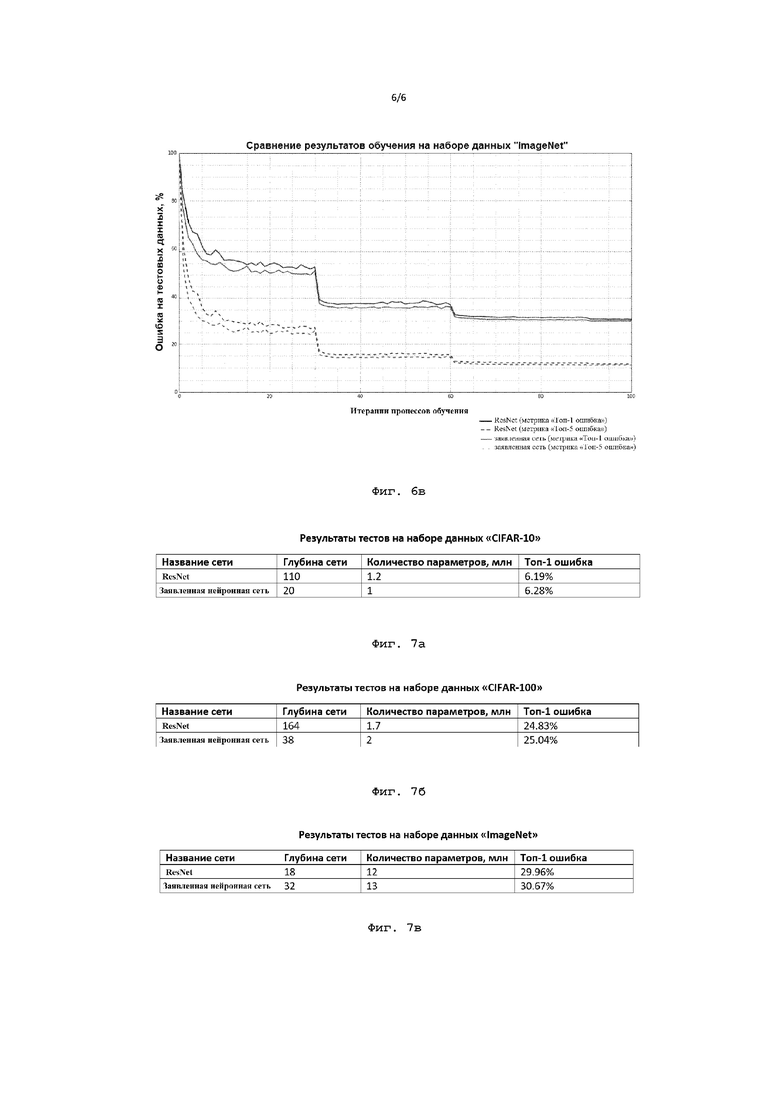
Фиг. 7а иллюстрирует результаты тестов на основе набора данных CIFAR-10 для известной нейронной сети ResNet и предложенной нейронной сети;
Фиг. 7б иллюстрирует результаты тестов на основе набора данных CIFAR-100 для известной нейронной сети ResNet и предложенной нейронной сети;
Фиг. 7в иллюстрирует результаты тестов на основе набора данных ImageNet для известной нейронной сети ResNet и предложенной нейронной сети.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Различные варианты осуществления настоящего изобретения описываются в дальнейшем более подробно со ссылкой на чертежи. Однако настоящее изобретение может быть воплощено во многих других формах и не должно истолковываться как ограниченное любой конкретной структурой или функцией, представленной в нижеследующем описании. На основании настоящего описания специалист в данной области техники поймет, что объем правовой охраны настоящего изобретения охватывает любой вариант осуществления настоящего изобретения, раскрытый в данном документе, вне зависимости от того, реализован ли он независимо или в сочетании с любым другим вариантом осуществления настоящего изобретения. Например, система может быть реализована или способ может быть осуществлен на практике с использованием любого числа вариантов осуществления, изложенных в данном документе. Кроме того, следует понимать, что любой вариант осуществления настоящего изобретения, раскрытый в данном документе, может быть воплощен с помощью одного или более элементов формулы изобретения.
Слово «примерный» используется в данном документе в значении «служащий в качестве примера или иллюстрации». Любой вариант осуществления, описанный в данном документе как «примерный», необязательно должен истолковываться как предпочтительный или обладающий преимуществом над другими вариантами осуществления.
Далее описан вариант осуществления настоящего изобретения на примере обработки изображений, однако заявленное изобретение также применимо и для обработки сигналов другого типа, например, видео, звука (речи), медицинских 3D-данных. Под входными данными в настоящем документе могут подразумеваться любые данные, выраженные в виде матрицы чисел, составляющих изображение, ряда чисел, составляющих звуковой поток; многомерных массивов чисел, составляющих видео поток или медицинские данные и т.п. Например, в полутоновом черно-белом изображении числовое значение пикселя выражается от 0 (черный пиксель) до 255 (белый пиксель). В цветном изображении, например, каждый пиксель имеет 3 канала: B (синий), G (зеленый) и R (красный), каждый из которых выражается в диапазоне от 0 до 255 и т.п.
По определению, свертка - это математическая операция, применяемая к двум функциям, порождающая третью функцию, которая иногда может рассматриваться как модифицированная версия первой из них. В этом случае вторая функция называется ядром свертки. Суть операции свертки (или фильтрации с ядром) заключается в том, что каждый фрагмент обрабатываемого изображения умножается на матрицу (ядро свертки) поэлементно, а результат суммируется и записывается в аналогичную позицию каждого элемента выходного изображения. Основное свойство такой фильтрации заключается в том, что при правильной нормировке сигнала выходное значение в каждом пикселе тем больше, чем больше фрагмент изображения в окрестности пикселя похож на само ядро. Таким образом, изображение, свернутое с неким ядром, даст нам другое изображение того же размера, каждый пиксель которого будет означать степень похожести фрагмента изображения на ядро свертки, т.е. обладать значением от 0 (пиксель и его окрестность, т.е. фрагмент изображения, не похожи на ядро свертки) до 1 (пиксель и его окрестность совпадают с ядром свертки). Такое другое изображение называется картой признаков. Для повышения эффективности архитектуры сети в отношении затрачиваемого времени и памяти в известных сверточных нейронных сетях прибегают к использованию ядер небольшого размера. При этом при уменьшении размера ядра в таких сетях архитектура сети становится проще, но значительно глубже для достижения большей точности, как это было показано при раскрытии уровня техники. В настоящее время, как правило, используются ядра свертки размером 3×3, или последовательно применяются ядра свертки размером 1×3 и 3×1 - сепарабельная свертка. Сепарабельная свертка позволяет уменьшить количество требуемых операций для выполнения поставленной задачи. Согласно настоящему изобретению трудоемкая операция свертки не применяется, а применяемую операцию можно назвать вырожденной сверткой с применением ядра размера 1×1. При этом сохраняется локальный характер обработки данных, т.к. по-прежнему учитывается связность обрабатываемого сигнала. Иными словами, учитывается попарная связь соседних пикселей.
Как правило, операция свертки выполняется достаточно медленно, а размер ядра - это дополнительный параметр, который необходимо задавать при разработке сети для конкретной задачи, что обусловлено необходимостью рассматривать как пиксель, так и некоторую окрестность вокруг него. В частности, при рассмотрении традиционной сети с размером ядра свертки 3×3 необходимо рассматривать текущий пиксель, а также 8 соседних пикселей, включая расположенные по диагонали, и 9 соответствующих весовых коэффициентов.
Для известной нейронной сети AlexNet при обработке изображения операции свертки в сумме занимают большую часть времени работы GPU и CPU, в частности 95% времени для GPU и 90% времени для CPU тратится на выполнение операций свертки в слоях сети. При этом операция активации (ReLU), которая представляет собой функцию, применяемую для нелинейного отображения входных данных с целью улучшения обобщающей способности, и операция подвыборки (pooling) пикселей, выполняющая уменьшение размерности сформированных карт признаков, по существу сохраняя только значимую информацию, не требуют большого количества времени или памяти на реализацию.
На Фиг. 1 приведено схематическое изображение единичного блока в соответствии с традиционной нейронной сетью, применение которого будет повторяться N раз, т.е. столько раз, какова глубина сети. Согласно Фиг. 1 в традиционной нейронной сети входные данные I={Ic} изображения размера PxQ, где P - ширина изображения, Q - его высота, а c=1…C - это номер канала, проходят два пути обработки, при этом входные данные представляют собой матрицу числовых значений изображения. В частности, рассматривая каналы цветного изображения B (синий), G (зеленый) и R (красный), при рассмотрении 1 пикселя рассматривается 3 числовых значения-канала и т.п. При этом входные данные по существу представляют собой набор из C карт признаков размера PxQ. На первом пути к входным данным применяется функция активации (ReLU), после чего входные данные претерпевают операцию свертки, а по второму пути входные данные проходят без изменения. При этом размер ядра зависит от количества C каналов на входе, поскольку каждое ядро также является многоканальным (количество каналов в ядре совпадает с количеством каналов на входе). Затем результаты обоих путей складываются для получения выходных данных O={Ok}, которые по существу представляют собой набор из K карт признаков размера PxQ. Далее прохождение двух вышеупомянутых путей инициируется заново с картами признаков, подаваемыми в упомянутый блок уже в качестве входных данных, и т.д. Однако следует отметить, что операция активации также может быть применена и после операции свертки, и после операции суммирования, или не применена вовсе, что остается на усмотрение инженера при выполнении конкретной поставленной задачи. В примере, представленном на Фиг. 1, применяется ядро свертки размера 3×3; при этом на данной фигуре также изображена область, включающая в себя текущий пиксель и его окрестность. Крестиками в данной области отмечены те позиции-пиксели, рассмотрение которых необходимо для получения информации о текущем пикселе с его окрестностью на одном слое нейронной сети - всего 9 параметров. При применении каждого ядра свертки на выходе получается 1 изображение размером PxQ - размер исходного изображения; таким образом, при применении K ядер будет получена матрица PxQxK, где K - количество каналов в выходном изображении (количество каналов на выходе равно количеству ядер). Например, при применении 10 ядер получаем данные с размером, равным уже P x Q x 10, т.к. будет получено 10 результатов разных сверток.
На Фиг. 2а и 2б схематически изображены два варианта единичного блока в соответствии с раскрытой в настоящем изобретении нейронной сетью, применение которого также будет повторяться N раз, что соответствует глубине сети. Согласно предлагаемой нейронной сети принятые с помощью соответствующего устройства приема входные данные I={Ic} также проходят два пути обработки, где c - это номер канала. Согласно первому варианту, изображенному на Фиг. 2а, на первом пути к входным данным применяется функция активации (ReLU), после чего входные данные претерпевают операцию вычисления линейной взвешенной суммы (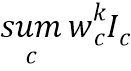 , где wck - весовые коэффициенты, а k=1…K - номер ядра, который по существу соответствует номеру соответствующего канала на выходе) для применения обобщенного перемножения матриц (GEMM) вместо операций свертки. По второму пути входные данные проходят без изменения, но со сдвигом в одном из направлений xi, где i=1…4-4 параметра (весовые коэффициенты, представляющие связь с каждым из 4 соседних пикселей только по горизонтали и вертикали). Операция сдвига в настоящем документе понимается в значении логического сдвига элементов набора числовых значений в заданном направлении. В частности, при применении операции сдвига к входным данным в направлении xi числовые значения в матрице сдвигаются в этом направлении на одну позицию, а освободившиеся от числовых значений позиции заполняются нулями, что в данном случае аналогично умножению упомянутой матрицы числовых значений изображения на соответствующую матрицу сдвига. Получившийся в результате применения операции сдвига набор числовых значений в дальнейшем называется сдвинутыми входными данными.
, где wck - весовые коэффициенты, а k=1…K - номер ядра, который по существу соответствует номеру соответствующего канала на выходе) для применения обобщенного перемножения матриц (GEMM) вместо операций свертки. По второму пути входные данные проходят без изменения, но со сдвигом в одном из направлений xi, где i=1…4-4 параметра (весовые коэффициенты, представляющие связь с каждым из 4 соседних пикселей только по горизонтали и вертикали). Операция сдвига в настоящем документе понимается в значении логического сдвига элементов набора числовых значений в заданном направлении. В частности, при применении операции сдвига к входным данным в направлении xi числовые значения в матрице сдвигаются в этом направлении на одну позицию, а освободившиеся от числовых значений позиции заполняются нулями, что в данном случае аналогично умножению упомянутой матрицы числовых значений изображения на соответствующую матрицу сдвига. Получившийся в результате применения операции сдвига набор числовых значений в дальнейшем называется сдвинутыми входными данными.
Затем результаты обоих путей складываются для получения выходных данных O={Ok}, которые представляют собой карты признаков. Далее прохождение двух вышеупомянутых путей инициируется заново с картами признаков уже в качестве входных данных и т.д.
Согласно второму варианту, изображенному на Фиг. 2б, на первом пути к входным данным применяется функция активации (ReLU), после чего входные данные претерпевают операцию сдвига в одном из направлений xi, где i=1…4. Далее на первом пути применяется операция вычисления линейной взвешенной суммы (). По второму пути входные данные проходят без изменения. Затем результаты обоих путей складываются для получения выходных данных O={Ok}, и прохождение двух вышеупомянутых путей инициируется заново с выходными данными уже в качестве входных данных и т.д. Согласно настоящему раскрытию операция активации также может быть применена и после операции свертки, и после операции суммирования или не применена вовсе, что остается на усмотрение инженера при выполнении конкретной поставленной задачи.
На данных фигурах также изображена область, включающая в себя текущий пиксель и его окрестность, на которой крестиками отмечены те позиции-связи, рассмотрение которых необходимо для получения информации о текущем пикселе с его окрестностью - вышеупомянутые 4 параметра, соответствующие весовым коэффициентам, присваиваемым отмеченным позициям-связям. Текущий пиксель в области на фигурах отмечен точкой. При этом на одном слое нейронной сети рассматривается одна изображенная область, т.е. пиксель в связи (совокупности) с соседним пикселем. Таким образом, для получения информации о текущем пикселе с его окрестностью рассматривается простая обработка 4 параметров в 4 слоях нейронной сети вместо известной до сих пор сложной обработки 9 параметров в одном слое. Применяемые операции сдвига и вычисления линейной взвешенной суммы проще и требуют меньших вычислительных затрат по сравнению с операцией свертки, а меньшее количество параметров для анализа той же окрестности рассматриваемого пикселя обеспечивает необходимость в меньшем объеме памяти, что дополнительно делает применение заявленного способа на мобильных устройствах более доступным.
Как было упомянуто выше, в нейронной сети также может применяться операция подвыборки (pooling). Традиционно операция подвыборки применяется для уменьшения размерности данных, чтобы получить максимум возможной информации из доступных данных в разном масштабе, т.е. необходимость в применении подвыборки зависит от конкретных прикладных задач. Таким образом, операция подвыборки может применяться на каждом слое нейронной сети, на любом этапе этого слоя, или не применяться вовсе.
В настоящем изобретении, как это уже было указано выше, рассматривается не пиксель, а связь пикселя с соседним пикселем в одном из четырех направлений, что выражается в том, что один весовой коэффициент присваивается не одному пикселю, как это традиционно осуществляется, а сразу двум соседним пикселям. Однако необходимо отметить, что диагональные пиксели также учитываются согласно заявленному изобретению, так как одновременно с тем, как оценивается связь пикселя, например, с его соседним сверху пикселем, в отношении соседнего сверху пикселя также оценивается его связь с его соседним сбоку пикселем и т.д. Таким образом, как это было указано выше, в известной сверточной нейронной сети пиксель и область вокруг этого пикселя можно проанализировать по рассмотрению одного слоя и 9 параметров, соответствующих настраиваемым весовым коэффициентам (см. Фиг. 1), в то время как в настоящем изобретении данная область также будет проанализирована, но по рассмотрению 4 слоев сети и 4 параметров, по 1 параметру на каждый слой (см. Фиг. 2а и Фиг. 2б).
Операция свертки, в общем, эквивалентна обобщенному перемножению матриц (GEMM), в частности, умножению трехмерных матриц, которое в известных сверточных нейронных сетях производится множество раз. Однако в традиционных подходах для обеспечения возможности применения GEMM необходимо соответствующим образом преобразовывать данные, перегруппировывать и копировать их в памяти, что приводит к увеличению потребляемых ресурсов. Программная реализация такой операции включает в себя цикл с 6 уровнями вложения, так как на выходе получают трехмерный результат (пиксель с 3 координатами k, p, q и вычисление суммы по трем размерностям c, r, s). Классическая формула свертки, которая может быть записана для трехмерного случая, будет выглядеть следующим образом:
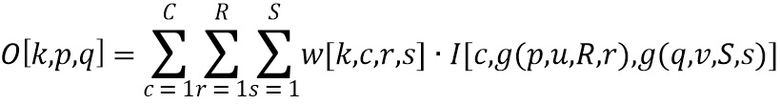
где w - набор из K ядер свертки размера CxRxS, C - количество каналов в ядрах (соответствует вышеупомянутому количеству каналов на входе, т.е. карт признаков в I), R - ширина ядер свертки, S - высота ядер свертки, I - набор из C карт признаков размера PxQ (входные данные), O - набор из К карт признаков размера PxQ (выходные данные), k - номер карты признаков выходных данных (равен номеру ядра свертки), p=1,…,P и q=1,…,Q - координаты текущего пикселя выходного изображения, c=1,…,C - номер карты признаков входных данных (соответствует номеру канала), r=1,…,R и s=1,…,S - локальные координаты в окрестности текущего пикселя, g - функция, контролирующая шаг по пикселям входных данных (например, через один, через два и т.п.), u и v - размеры шага по пикселям по вертикали и горизонтали. Такое программное вычисление не эффективно, так как необходимо осуществлять либо последовательное суммирование, либо распараллеливать процесс посредством создания копии, что нежелательно заполнит память. В связи с этим традиционный подход является очень сложным и ресурсозатратным.
Заявленное техническое решение аналогично применению линейной взвешенной суммы, т.к. размеры ядер R=1, S=1, т.е. фактически исключению операции свертки как таковой. Настоящее изобретение сводится к перемножению двух двумерных матриц (непосредственно GEMM):
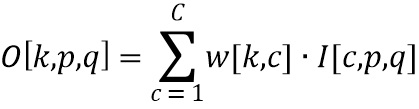
Несмотря на то, что I представляет собой трехмерную матрицу, она хранится в памяти линейно, и к ней можно осуществлять доступ в памяти как к двумерной, что наглядно изображено на Фиг. 3. При этом w - это матрица весовых коэффициентов одного слоя нейронной сети, каждая строка в которой является вектором коэффициентов линейной взвешенной суммы (аналогом ядра свертки размером 1×1хC). Таким образом, выполнение k операций 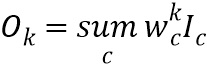 сводится к одному перемножению двух матриц (см. Фиг. 3). Осуществление доступа к памяти и считывание необходимой информации, хранящейся в ней, выполняется с помощью соответствующего устройства обработки, которое сконфигурировано с возможностью выполнять все вышеупомянутые операции, необходимые для обработки принятых сигналов. Такое устройство обработки может представлять собой, например, центральный процессор (CPU) и/или графический процессор (GPU). При этом отпадает необходимость предварительной обработки входных данных перед применением GEMM.
сводится к одному перемножению двух матриц (см. Фиг. 3). Осуществление доступа к памяти и считывание необходимой информации, хранящейся в ней, выполняется с помощью соответствующего устройства обработки, которое сконфигурировано с возможностью выполнять все вышеупомянутые операции, необходимые для обработки принятых сигналов. Такое устройство обработки может представлять собой, например, центральный процессор (CPU) и/или графический процессор (GPU). При этом отпадает необходимость предварительной обработки входных данных перед применением GEMM.
Согласно другому варианту осуществления предлагается одновременное применение операций сдвига в двух или более разных направлениях. Применение операций сдвига сразу в двух направлениях изображено на Фиг. 4а в виде двух параллельных вышеописанных путей со сдвигом в двух разных направлениях - x1 и x2, результаты которых складываются друг с другом и с входными данными без изменения. Полученные таким образом выходные данные затем снова подаются на вход представленного единичного блока в качестве входных данных и т.д. При применении данного другого варианта осуществления не происходит усложнений, т.к. при таком подходе количество ядер делится на количество разных направлений; таким образом, количество параметров в слое сети остается неизменным.
Для наглядности на Фиг. 4б проиллюстрировано примерное представление направлений x1 и x2 в отношении рассматриваемого изображения. Разумеется, операция сдвига может быть применена одновременно в любых двух возможных направлениях из четырех направлений x1, x2, x3(соответствует направлению - x1) и x4(соответствует направлению - x2).
На Фиг. 5а изображено схематическое изображение единичного блока в соответствии с заявленной нейронной сетью при рассмотрении набора последовательных изображений, согласно которому одновременно применяются операции сдвига, по существу, сразу в трех направлениях x1, x2 и x3, причем в настоящем варианте осуществления направление x3 по существу соответствует «оси времени», т.е. заданной последовательности изображений в наборе, в частности, последовательности кадров в видео. Примерное представление обозначенных трех направлений в отношении рассматриваемого набора последовательных изображений показано на Фиг. 5б. Применение такого единичного блока также будет повторяться N раз, что соответствует глубине сети. Как наглядно изображено на Фиг. 5а, данный вариант осуществления аналогичен вышеописанному одновременному применению операций сдвига на примере применения операций сдвига одновременно в двух направлениях, т.е. параллельно применяются три вышеописанных пути со сдвигом в трех разных направлениях - x1, x2 и x3, результаты которых складываются друг с другом и с входными данными без изменения. Полученные таким образом выходные данные затем снова подаются на вход представленного единичного блока в качестве входных данных и т.д. Таким образом, один слой заявленной нейронной сети согласно данному варианту осуществления прорабатывает весь массив изображений в последовательности (в частности, кадров в видео) одновременно и передает все выходные денные на следующий слой в качестве входных.
На Фиг. 6а, 6б и 6в показаны графики сравнения точности результатов обучения заявленной нейронной сети с нейронной сетью ResNet на основе наборов данных CIFAR-10, CIFAR-100 и ImageNet, соответственно. Набор данных CIFAR-10 представляет собой набор данных, содержащий множество изображений из 10 различных классов. Набор данных CIFAR-100 - набор данных, содержащий множество изображений из 100 различных классов. ImageNet же является самым большим набором данных из 1000 категорий, содержащих более 1,2 миллиона изображений. Отношение итераций процесса обучения к значению процента ошибки для нейронной сети ResNet известно, например, из источника «Identity Mappings in Deep Residual Networks» (Kaiming He и др.). Исходя из результатов сравнения можно сделать вывод о том, что значение точности предложенного способа не уступает или приблизительно равно значению точности результатов в соответствии с традиционной сверточной нейронной сетью ResNet (приводится сравнение значений для метрик «Топ-1 ошибка» и «Топ-5 ошибка»). Результаты для метрики «Топ-1 ошибка» на графиках показаны с помощью сплошных линий, а результаты для метрики «Топ-5 ошибка» - с помощью пунктирных линий, при этом результаты для известной сверточной нейронной сети (с размером ядра свертки 3×3) выполнены черным цветом, а результаты для заявленной сети (с применением операций сдвига и вычисления линейной взвешенной суммы) -серым. Следует также отметить, что при рассмотрении результатов обучения на наборе CIFAR-10 для известной сети ResNet было рассмотрено 110 слоев и 1,15 млн параметров, а при рассмотрении результатов обучения на этом наборе для заявленной нейронной сети было рассмотрено 20 слоев и 1 млн параметров. На наборе CIFAR-100 для известной сети ResNet было рассмотрено 164 слоя и 1,7 млн параметров, а для заявленной нейронной сети было рассмотрено 38 слоев и 2 млн параметров. На наборе ImageNet для известной сети ResNet было рассмотрено 18 слоев и 12 млн параметров, а для заявленной нейронной сети было рассмотрено 32 слоя и 13 млн параметров. Как наглядно изображено на графиках, заявленная нейронная сеть не уступает известной нейронной сети по точности, обладая схожими значениями процента ошибки на протяжении всех итераций процесса обучения.
На Фиг. 7а, 7б и 7в приведены краткие таблицы результатов тестов в метрике «Топ-1 ошибка» для известной сети ResNet и заявленной нейронной сети на основе наборов данных CIFAR-10, CIFAR-100 и ImageNet, соответственно. В частности, ошибка сети ResNet на основе набора данных CIFAR-10 составляет 6,19%, в то время как ошибка настоящей сети на основе этого же набора данных составляет 6,28%; ошибка сети ResNet на основе набора данных CIFAR-100 составляет 24,83%, в то время как ошибка настоящей сети на основе этого же набора данных составляет 25,04%; а ошибка сети ResNet на основе набора данных ImageNet составляет 29,96%, в то время как ошибка настоящей сети на основе этого же набора данных составляет 30,67%. Данные тестовые результаты также подтверждают то, что заявленная нейронная сеть не уступает в точности известной сети ResNet.
Следует отметить, что в отношении других известных нейронных сетей, например, таких как NIN, DSN, FitNet, Highway, ELU, original-ResNet, stoc-depth, pre-act-ResNet и др., получены аналогичные результаты сравнения, подтверждающие что заявленная нейронная сеть не уступает или приблизительно равна по точности в сравнении с данными известными нейронными сетями, результаты применения которых раскрыты, например, в статье «Wide residual networks» (Sergey Zagoruyko, Nikos Komodakis, в редакции от 14 июня 2017), в частности, в таблице 5 на стр. 8 данной статьи. При этом следует отметить, что сети, обладающие незначительно большим значением процента точности (т.е. меньшим значением процента ошибки), используют гораздо большее количество параметров.
Дополнительно следует отметить, что для обнаружения типа сети или проверки применения конкретной сети, зная ее параметры, можно наложить на изображение специально сконструированный шумовой сигнал. На глаз для человека изображение не изменится, однако результат распознавания станет неверным, т.к. нейронная сеть будет введена в заблуждение. Конкретный неверный результат распознавания заведомо известен разработчику сконструированного шумового сигнала, что позволяет ему детектировать применение конкретной нейронной сети, для которой данный шумовой сигнал был сконструирован. Способы конструирования таких сигналов известны из уровня техники и раскрыты, например, в источнике информации: ʺIntriguing properties of neural networksʺ, Christian Szegedy et al., ArXiv, 2013.
Заявленное изобретение может найти применение в области самоуправляемых транспортных средств (для распознавания изображений и видео, в частности, для обнаружения пешеходов, дорожных знаков и транспортных средств), видео конференциях (для обработки видео, в частности, для сжатия и расшифровки видео, «улучшения» видео посредством достройки деталей), медицине (ультразвуковая область, в частности, обнаружение повреждений, улучшение качества изображения посредством удаления шумов), безопасности мобильных устройств (для идентификации пользователя, в частности, распознавания радужной оболочки глаз, лица или отпечатков пальцев).
Специалисты в данной области техники должны понимать, что показанные варианты осуществления являются примерными и, по мере необходимости, могут быть скорректированы для достижения большей эффективности в конкретном применении, если в описании конкретно не указано иное. Упоминание элементов системы в единственном числе не исключает множества таких элементов, если в явном виде не указано иное.
Хотя в настоящем описании показаны примерные варианты осуществления изобретения, следует понимать, что различные изменения и модификации могут быть выполнены, не выходя за рамки объема охраны настоящего изобретения, определяемого прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОД ДЛЯ ВЫДЕЛЕНИЯ И КЛАССИФИКАЦИИ ТИПОВ КЛЕТОК КРОВИ С ПОМОЩЬЮ ГЛУБОКИХ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ | 2019 |
|
RU2732895C1 |
| СИСТЕМА СЖАТИЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ИТЕРАТИВНОГО ПРИМЕНЕНИЯ ТЕНЗОРНЫХ АППРОКСИМАЦИЙ | 2019 |
|
RU2734579C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ, УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЙ И НОСИТЕЛЬ ДАННЫХ | 2018 |
|
RU2709437C1 |
| СПОСОБ ФОРМИРОВАНИЯ ОБЩЕЙ ФУНКЦИИ ПОТЕРЬ ДЛЯ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЯ В ИЗОБРАЖЕНИЕ С ПРОРИСОВАННЫМИ ДЕТАЛЯМИ И СИСТЕМА ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЯ В ИЗОБРАЖЕНИЕ С ПРОРИСОВАННЫМИ ДЕТАЛЯМИ | 2019 |
|
RU2706891C1 |
| ОБУЧЕНИЕ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ НА ГРАФИЧЕСКИХ ПРОЦЕССОРАХ | 2006 |
|
RU2424561C2 |
| СПОСОБ И УСТРОЙСТВО ИДЕНТИФИКАЦИИ ЧАСТЕЙ ФРАГМЕНТИРОВАННОГО МАТЕРИАЛА В ПРЕДЕЛАХ ИЗОБРАЖЕНИЯ | 2016 |
|
RU2694021C1 |
| СПОСОБ И УСТРОЙСТВО ОПРЕДЕЛЕНИЯ МЕСТОНАХОЖДЕНИЯ ИЗНАШИВАЕМОЙ ДЕТАЛИ НА ИЗОБРАЖЕНИИ РАБОЧЕГО ИНСТРУМЕНТА | 2016 |
|
RU2713684C2 |
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| Способ выявления объектов на изображении плана-схемы объекта строительства | 2022 |
|
RU2785821C1 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ГЛУБИННЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2743931C1 |
Группа изобретений относится к искусственным нейронным сетям и может быть использована для обработки и распознавания сигналов, таких как изображения, видео или звук. Техническим результатом является уменьшение потребления вычислительных ресурсов с сохранением высокой степени точности распознавания. Способ содержит этапы, на которых подают входные данные на текущий слой обученной нейронной сети, обрабатывают поданные входные данные для получения выходных данных, и если номер текущего слоя нейронной сети меньше N, переходят на следующий слой нейронной сети, если равен N, выводят полученные выходные данные. Этап обработки содержит применение операции сдвига входных данных в одном из заданных направлений, вычисление линейной взвешенной суммы входных данных и суммирование сдвинутых входных данных и результата вычисления взвешенной суммы для получения выходных данных, причем данная обработка применяется в отношении каждого заданного направления, или применение операции сдвига входных данных в одном или более заданных направлениях для получения сдвинутых входных данных в каждом из заданных направлений, вычисление линейной взвешенной суммы сдвинутых входных данных в каждом из заданных направлений и суммирование входных данных и результатов вычисления взвешенной суммы для каждого из заданных направлений для получения выходных данных. 2 н. и 8 з.п. ф-лы, 14 ил.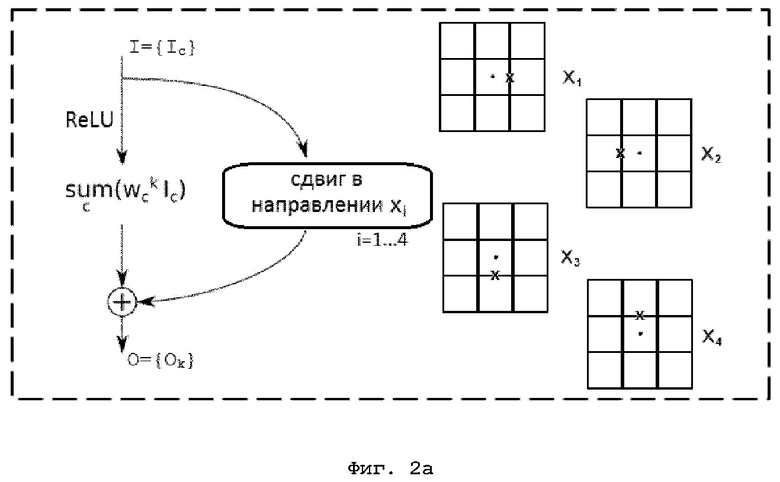
1. Способ обработки сигналов с помощью нейронной сети, имеющей N слоев, содержащий этапы, на которых:
- подают входные данные на текущий слой обученной нейронной сети, причем входные данные представляют собой набор числовых значений сигнала для обработки;
- обрабатывают поданные входные данные для получения выходных данных; и
- если номер текущего слоя нейронной сети меньше N, переходят на следующий слой нейронной сети и повторяют этапы способа с использованием полученных выходных данных в качестве входных данных, и
- если номер текущего слоя нейронной сети равен N, выводят полученные выходные данные;
причем этап обработки содержит:
применение операции сдвига входных данных в одном из заданных направлений для получения сдвинутых входных данных, вычисление линейной взвешенной суммы входных данных и суммирование сдвинутых входных данных и результата вычисления взвешенной суммы для получения выходных данных, причем данная обработка применяется в отношении каждого заданного направления, или
применение операции сдвига входных данных в одном или более заданных направлениях для получения сдвинутых входных данных в каждом из одного или более заданных направлений, вычисление линейной взвешенной суммы сдвинутых входных данных в каждом из одного или более заданных направлений и суммирование входных данных и результатов вычисления взвешенной суммы для каждого из одного или более заданных направлений для получения выходных данных.
2. Способ по п.1, причем вычисление линейной взвешенной суммы сводится к операции обобщенного перемножения двух матриц (GEMM).
3. Способ по п.1, причем способ дополнительно содержит предварительные этапы, на которых:
- получают примерный размеченный набор данных для обучения;
- обучают нейронную сеть на основе полученного примерного размеченного набора данных путем определения соответствующих весовых коэффициентов.
4. Способ по п.1, дополнительно содержащий этапы, на которых применяют операции активации и/или подвыборки пикселей в любом заранее установленном порядке.
5. Способ по п.1, причем сигналом является изображение, а заданные направления представляют собой направления в сторону каждого из прилегающих соседних пикселей.
6. Способ по п.1, причем выходные данные представляют собой наименование сигнала.
7. Способ по п.1, причем выходные данные представляют собой классификацию сигнала.
8. Способ по п.1, причем выходные данные представляют собой список наиболее вероятных наименований сигнала.
9. Система для обработки сигналов с помощью нейронной сети, имеющей N слоев, содержащая:
- устройство приема, выполненное с возможностью принимать входные данные, представляющие собой набор числовых значений сигнала для обработки;
- память, выполненную с возможностью хранить принятые входные данные;
- устройство обработки, выполненное с возможностью считывать входные данные из памяти и выполнять этапы способа обработки сигналов по п.1,
причем устройство обработки дополнительно выполнено с возможностью записи выходных данных, выведенных устройством обработки, в память.
10. Система для обработки сигналов с помощью нейронной сети по п.9, в которой устройство обработки представляет собой центральный процессор (CPU) и/или графический процессор (GPU).
| US 5263107 A, 16.11.1993 | |||
| US 5799134 A, 25.08.1998 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ОБУЧЕНИЕ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ НА ГРАФИЧЕСКИХ ПРОЦЕССОРАХ | 2006 |
|
RU2424561C2 |

