ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится в целом к обработке изображений, а более конкретно - к системам и способам создания случайных искажений и аугментации данных изображений, в том числе для использования в обучении моделей машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[0002] Машинное обучение позволяет вычислительным системам обучаться выполнять задачи, исходя из наблюдаемых данных. Алгоритмы машинного обучения могут позволить вычислительным системам обучаться без явного программирования. Методы машинного обучения могут включать, в том числе, нейронные сети, обучение деревьев решений, глубокое обучение и т.д. Модель машинного обучения, например, нейронная сеть, может использоваться в решениях, относящихся к распознаванию изображений, включая оптическое распознавание символов. Наблюдаемые данные в случае распознавания изображений могут быть множеством изображений. Нейронная сеть, таким образом, может быть снабжена обучающими выборками изображений, по которым нейронная сеть может научиться распознаванию изображений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения, описанный в примере способ создания аугментации изображения может содержать: получение обрабатывающим устройством одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения на практике; предоставление обрабатывающим устройством одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, при этом первое множество слоев использует фильтры изображений; предоставление первого результата первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, при этом второй слой использует для вычислений случайные наборы параметров; получение параметров искажений от второго слоя вычислительных блоков; создание одного или более вторых изображений на основе одного или более первых изображений и параметров искажений; получение в качестве третьего выхода одного или более вторых изображений; и добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения описанная в примере система для создания аугментации изображений может содержать: память и процессор, соединенный с памятью, настроенный на выполнение следующих операций: получение обрабатывающим устройством одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения на практике; предоставление обрабатывающим устройством одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, при этом первое множество слоев использует фильтры изображений; предоставление первого результата первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, при этом второй слой использует для вычислений случайные наборы параметров; получение параметров искажений от второго слоя вычислительных блоков; создание одного или более вторых изображений на основе одного или более первых изображений и параметров искажений; получение в качестве третьего выхода одного или более вторых изображений; и добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих в себя: получение обрабатывающим устройством одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения на практике; предоставление обрабатывающим устройством одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, при этом первое множество слоев использует фильтры изображений; предоставление первого результата первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, при этом второй слой использует для вычислений случайные наборы параметров; получение параметров искажений от второго слоя вычислительных блоков; создание одного или более вторых изображений на основе одного или более первых изображений и параметров искажений; получение в качестве третьего выхода одного или более вторых изображений; и добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[0007] На Фиг. 1 приведена схема компонентов верхнего уровня примера архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
[0008] На Фиг. 2 приведен пример системы аугментации в соответствии с одним или более вариантами реализации настоящего изобретения.
[0009] На Фиг. 3 изображены слои вычислительных блоков в соответствии с одним или более вариантами реализации настоящего изобретения.
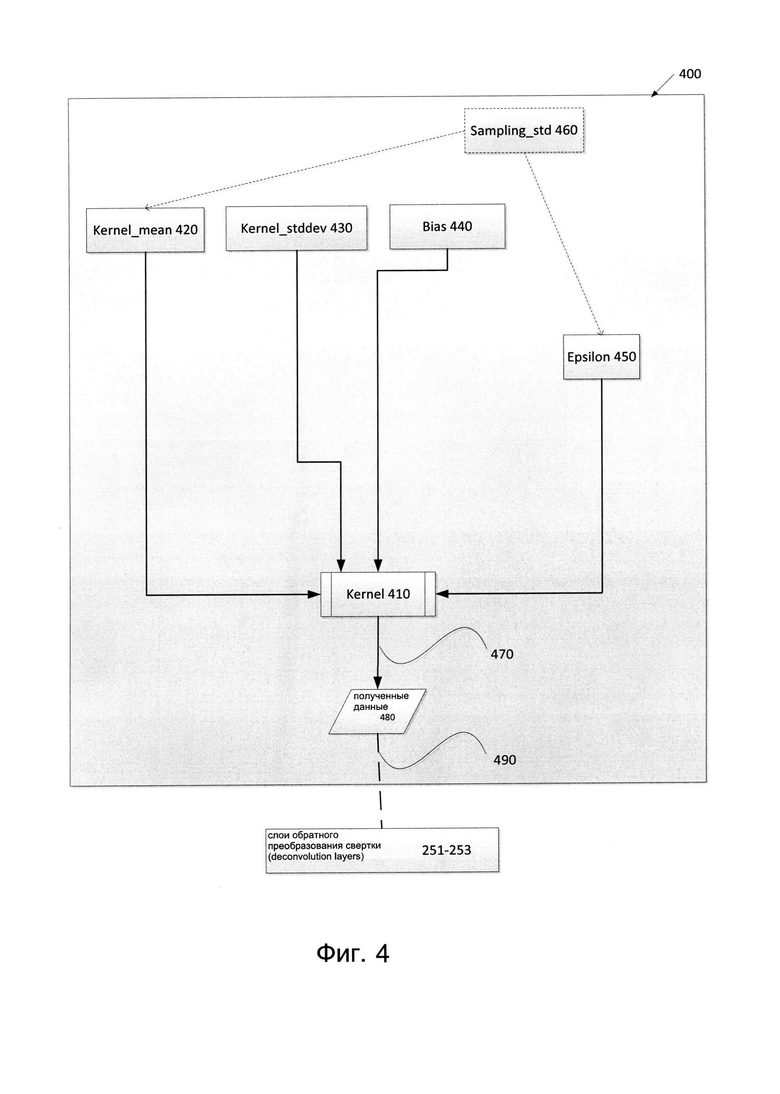
[0010] Фиг. 4 иллюстрирует пример случайного сверточного слоя в соответствии с одним или более вариантами реализации настоящего изобретения.
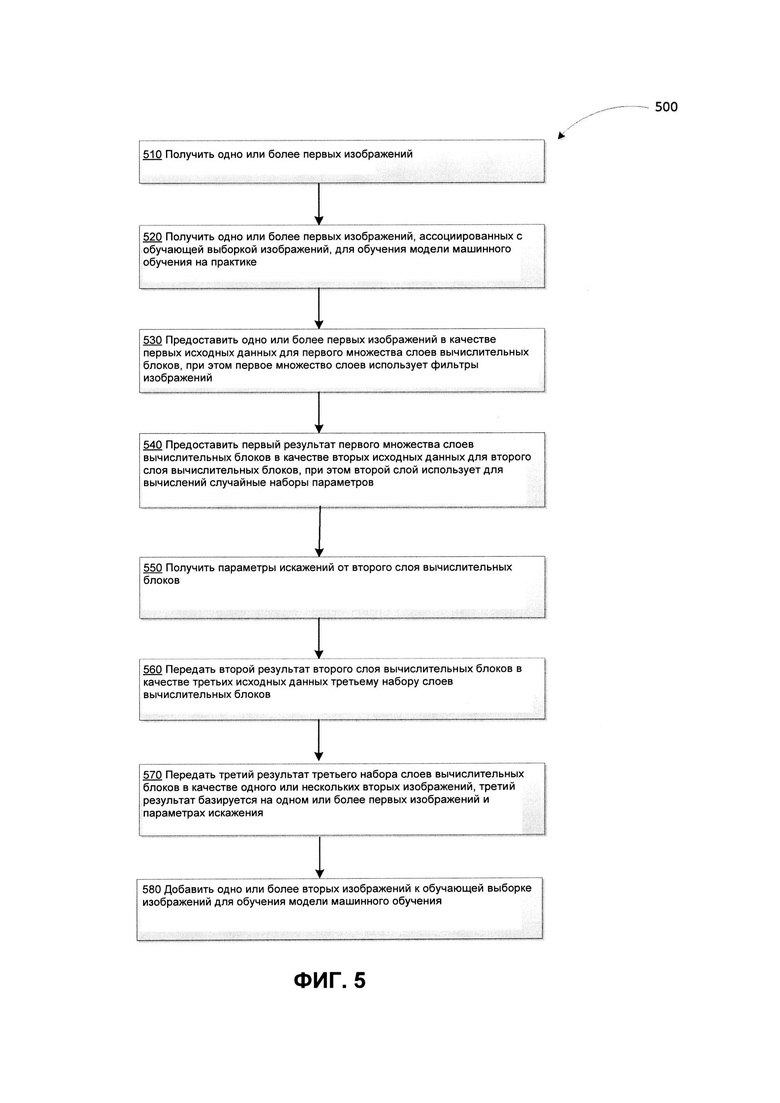
[0011] На Фиг. 5 приведена блок-схема одного иллюстративного примера способа репродуцирующей аугментации данных изображений в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
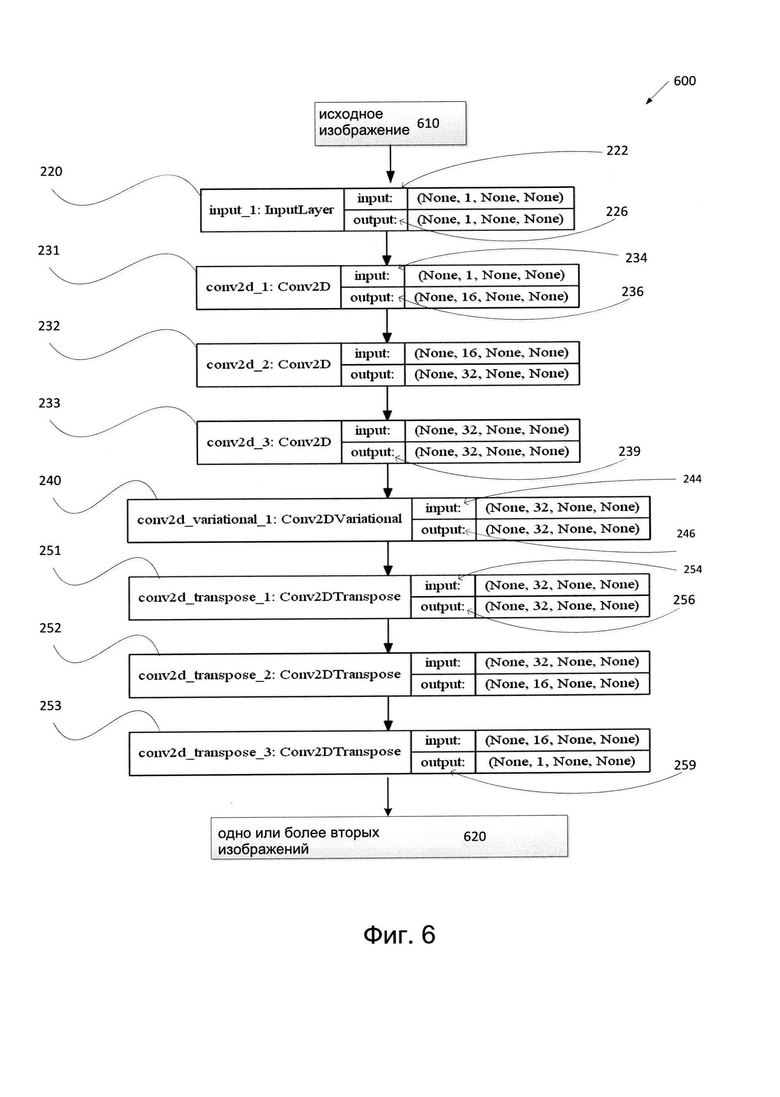
[0012] Фиг. 6 иллюстрирует пример аугментации изображений в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
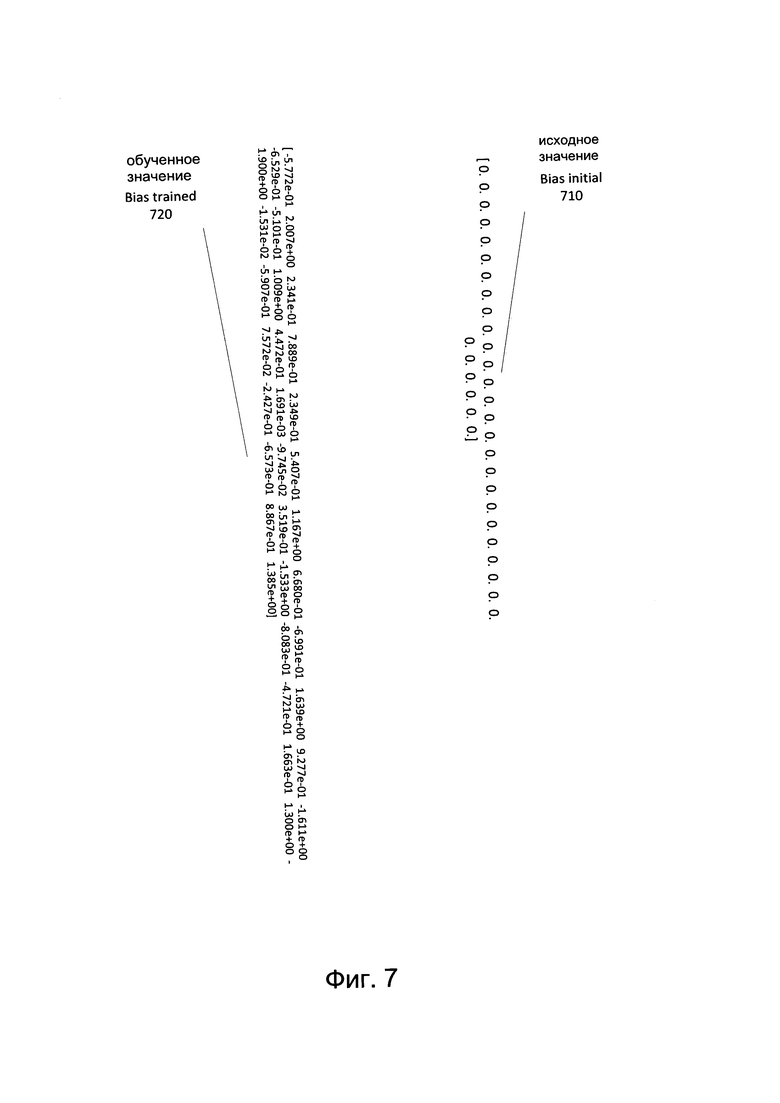
[0013] Фиг. 7 иллюстрирует пример матриц в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
[0014] Фиг. 8 иллюстрирует пример случайного искажения изображения в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
[0015] Фиг. 9 иллюстрирует пример случайно искаженных изображений символа CJK в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
[0016] Фиг. 10 иллюстрирует другой пример случайно искаженных изображений символа арабского алфавита в соответствии с одним или несколькими вариантами реализации настоящего изобретения.
[0017] На Фиг. 11 представлена подробная схема компонентов примера вычислительной системы, внутри которой исполняются инструкции, которые вызывают выполнение вычислительной системой любого из одного или более способов, раскрываемых в этом документе.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0018] В настоящем документе описываются способы и системы репродуцирующей аугментации данных изображений для обучающей выборки изображений, используемой для модели машинного обучения.
[0019] В настоящем документе термин «вычислительная система» означает устройство обработки данных, оснащенное универсальным процессором, памятью и по меньшей мере одним интерфейсом связи. Примерами вычислительных систем, которые могут использовать описанные в этом документе методы, являются, в частности, настольные компьютеры, ноутбуки, планшетные компьютеры и смартфоны.
[0020] Модели машинного обучения могут использоваться для распознавания изображений, включая оптическое распознавание символов (OCR, Optical Character Recognition), распознавание образов, распознавание фотографий, распознавание лиц и т.д. Например, нейронную сеть можно использовать в качестве модели машинного обучения для распознавания изображений. Модель машинного обучения может поставляться с примерами изображений в качестве обучающих выборок изображений, на которых может проходить обучение модель машинного обучения. Чем больше и разнообразнее обучающая выборка, тем лучше она может обучить модель машинного обучения. Однако обеспечение модели машинного обучения разнообразными примерами обучающих изображений в достаточном количестве часто является трудной задачей из-за ограниченной доступности этих изображений. Кроме того, создание исходных выборок обучающих изображений является непомерной задачей, поскольку в ходе первого этапа может присутствовать лишь небольшое количество примеров изображений, которых недостаточно для обучения модели.
[0021] Можно сделать попытку получить большое количество обучающих примеров с помощью методов аугментации, которые позволяют создать искусственные образцы изображений из исходных существующих изображений. Эти методы могут включать создание изменений или искажений исходного изображения для получения немного отличающегося варианта исходного изображения. Таким образом можно получать из каждого исходного изображения множество обучающих образцов с искажениями. Традиционные системы включают применение множества задач и (или) последовательных действий к каждому исходному изображению для их аугментации, с целью получения одного обучающего образца с одним типом искажения. Этот процесс требует много ресурсов и подвержен ошибкам. При использовании традиционных методов можно получить лишь ограниченное количество аугментированных изображений (например, одно аугментированное изображение на одно исходное изображение). Кроме того, в традиционных системах используемые техники могут включать применение определенного типа искажения для каждого имеющегося исходного изображения. Определенный тип искажения может быть основан на определенных правилах или ограничениях. Так, например, при аугментации отдельных исходных изображений со сходными характеристиками, например, изображений с различными символами китайского-японского-корейского языков (CJK, Chinese-Japanese-Korean), искажения, применяемые к каждому из исходных изображений, могут приводить к сходным искажениям, и в результате вызывать неточности и трудности при обучении модели. Традиционные методы не предусматривают наложение случайных искажений, близких к естественно искаженным изображениям и без ограничения количества синтетических (т.е. искусственно) искаженных изображений, получаемых из одного исходного изображения. Если изображения не похожи на изображения, искаженные естественным (натуральным) образом, использование этих изображений в машинном обучении может привести к неэффективному обучению распознаванию других, естественно искаженных изображений (изображений, содержащих естественные (натуральные) искажения). Таким образом, традиционные методики могут привести к неэффективности, неточности, предрасположенности к ошибкам, медленной работе и трудоемкости.
[0022] Описанные в настоящем документе системы и способы представляют улучшения в системе аугментации изображений. Аугментация изображений добавляет ценность к базовым данным изображения путем добавления дополнительной информации, таким образом увеличивая размер набора данных изображений. Для аугментации (т.е. увеличения, расширения и т.д.) данных изображений может использоваться автоэнкодер (АЕ, autoencoder). Автоэнкодер представляет собой модель машинного обучения (например, нейронную сеть) прямого распространения (т.е. для симуляции схемы распределения данных в исходных данных), которая восстанавливает входной сигнал на выходе. Эта нейронная сеть может содержать входной слой, выходной слой и один или более скрытых слоев, где выходной слой восстанавливает входные данные. Автоэнкодеры построены так, что они не могут точно копировать входные данные в выходной слой. Входной сигнал в автоэнкодерах восстанавливается с некоторыми ошибками, и нейронная сеть сводит к минимуму ошибки при обучении, выбирая наиболее важные характеристики. Один из типов автоэнкодеров включает вариационные автоэнкодеры (VAE, variational autoencoder), которые могут использоваться для обучения скрытых представлений (например, скрытых переменных, которые выводятся с помощью математической модели из видимых переменных). В некоторых примерах автоэнкодеры могут использоваться для обучения репродуцирующих моделей данных. Репродуцирующая модель - это модель для генерации всех значений явления, как тех, которые можно наблюдать, так и целевых значений, которые можно только вычислить из наблюдаемых. Некоторые системы аугментации могут использовать сверточные нейронные сети (CNN, Convolutional Neural Networks). Свертку можно описать как процесс добавления каждого элемента изображения к соседним с ним элементам, с обработкой (например, умножением) на определенное число. Сверточные нейронные сети (CNN, Convolutional Neural Networks) могут содержать слои вычислительных блоков для иерархической обработки визуальных данных, и могут напрямую передавать результат одного слоя на другой слой, извлекая определенные признаки из исходных изображений. Каждый из слоев может рассматриваться как сверточный слой или имеющим отношение к слою свертки.
[0023] Описанные в настоящем документе системы и способы представляют значительные улучшения систем аугментации изображений за счет включения в изображения случайных искажений. Описанные в настоящем документе системы используют наборы случайных параметров для аугментации изображений. Эта технология обеспечивает эффективное создание полезных синтетических обучающих выборок данных для модели машинного обучения. Системы, представленные в этом документе, используются для единичного исходного изображения и добавляют близкие к естественным случайные искажения в исходное изображение каждый раз, когда исходное изображение проходит через усовершенствованную систему аугментации, и делает это без ограничения на количество аугментаций исходного изображения. Она также обеспечивает регулировку резкости и грубости вносимых в исходное изображение искажений.
[0024] В одном из вариантов реализации системы и способы по этому документу предназначены для улучшенного слоя сверточной нейронной сети. Улучшенный слой может быть новым слоем, который использует наборы случайных параметров. В описании изобретения улучшенный слой может называться «случайным сверточным слоем», «случайным слоем», «вариационным сверточным слоем» и (или) «вариационным слоем». В одном из примеров реализации одно или более изображений могут быть получены входным слоем сверточной нейронной сети (CNN, Convolutional Neural Network). Входной слой может напрямую передавать одно или более изображений другому множеству слоев сверточной нейронной сети, которые могут быть двумерными слоями с разным количеством фильтров и каналов изображений. Множество слоев может содержать итеративную фильтрацию одного или более изображений, передающую изображения с одного слоя на другой в множестве слоев. Отфильтрованные изображения могут поступать на случайный сверточный слой сверточной нейронной сети. Случайный слой может использовать для вычислений случайные наборы параметров. Случайный слой может содержать матрицы с обучаемыми параметрами, такие как матрица значений математического ожидания, матрица значений стандартных отклонений, матрица значений смещения, а также матрицу «epsilon» с необучаемыми параметрами. Матрица средних значений может инициализироваться случайными значениями. Матрица epsilon может базироваться на значении нормального распределения и произвольном значении стандартного отклонения при каждом выполнении вычисления для этого уровня. Эти матрицы могут использоваться для генерации случайной матрицы kernel (ядро свертки) для случайного слоя. Из случайного слоя можно получить случайные параметры искажения. Результат случайного слоя может быть подан на вход слоя обратного преобразования свертки (deconvolution layer) сверточной нейронной сети (CNN, Convolutional Neural Network), где исходные изображения могут быть восстановлены и на них могут быть наложены случайные искажения. Результатом работы слоя обратного преобразования свертки (deconvolution layer) могут быть одно или более изображений с наложенными случайными искажениями. Одно или более изображений с наложенными случайными искажениями могут быть добавлены в обучающую выборку изображений для обучения модели машинного обучения. Модель машинного обучения может быть машиной опорных векторов, нейронной сетью и т.д. После обучения модель машинного обучения может использоваться для автоматического распознавания новых изображений.
[0025] Как описано в этом документе, случайная аугментация обеспечивает случайные искажения на выходе нейронной сети при каждом проходе одного и того же изображения через систему аугментации. Используя способы, описанные в этом документе, можно получить из одного изображения неограниченное количество случайно искаженных изображений. Случайные искажения можно получить, используя случайные правила и (или) случайные значения. Каждое случайное искажение может в максимальной степени соответствовать реальному (т.е. естественному, натуральному) искажению. Случайный сверточный слой может быть встроен в другую нейронную сеть, например, автоэнкодер (АЕ), вариативный автоэнкодер (VAE, variational autoencoder) и т.д. В одном из примеров реализации случайный сверточный слой может быть встроен в автоэнкодер (хотя не обязательно ограничивать его автоэнкодером). Синтетический (т.е. моделируемый) аугментированный набор данных изображений, получаемый с помощью описанных в этом документе системам и способов, позволяет включать в обучающую выборку изображений неограниченное количество различных типов изображений, повышая качество, точность и эффективность обучения нейронной сети. Такая обработка изображений эффективно повышает качество распознавания изображений. Качество распознавания изображений, обеспечиваемое системами и способами по настоящему изобретению, позволяет значительно увеличить точность оптического распознавания символов (OCR, Optical Character Recognition) по сравнению с различными стандартными способами. Кроме того, случайный сверточный слой может обеспечить лучшую аугментацию больших изображений, изображений высокого разрешения, редких изображений, изображений, содержащих иероглифы, символы CJK, строки арабского языка или другие сложные символы. Однако содержание настоящего раскрытия изобретения не ограничивается этими типами изображений, а включает любые типы изображений.
[0026] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
[0027] На Фиг. 1 изображена схема компонентов верхнего уровня для примера системной архитектуры 100 в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 100 включает вычислительное устройство ПО, хранилище 120 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN, local area network) или распределенной сетью (WAN, wide area network)), a также их комбинацией.
[0028] Изображение 140 может использоваться в качестве исходного изображения, для которого будет выполнена аугментация. В одном из примеров изображение 140 может быть цифровым изображением документа 141. В другом примере изображение 140 может быть включено в документ 141. Документ 141 может быть печатным документом, электронным документом и т.д. Изображение 140 может включать элемент 142, представляющий, например, символ, лицо, шаблон, большое изображение, изображение высокого разрешения, редкое изображение или любой другой тип изображения. Изображение 140 может содержать или быть частью документа с одним или более предложениями, каждое из которых содержит одно или более слов, состоящих из одного или более символов. Один или более символов могут включать, не ограничиваясь этим, иероглифы, символы CJK, строки арабского алфавита или другие сложные символы.
[0029] Изображение 140 может быть получено любым подходящим способом. Например, цифровая копия изображения 140 может быть получена сканированием документа 141 или фотографированием документа 141. Кроме того, в некоторых вариантах реализации изобретения клиентское устройство, которое подключается к серверу по сети 130, может загружать цифровую копию документа 140 на сервер. В некоторых вариантах реализации изобретения, где клиентское устройство соединено с сервером по сети 130, клиентское устройство может загружать изображение 140 с сервера. Изображение 140 может содержать документ в одной или более своих частей. В одном из примеров изображение 140 может содержать документ 141 полностью. В другом примере изображение 140 может содержать часть документа 141. В еще одном примере изображение 140 может содержать несколько частей документа 141. Изображение 140 может содержать несколько изображений. Изображение 140 может содержать несколько элементов 142, несколько документов 141, и т.д. Изображение 140 может использоваться для создания дополнительных изображений для обучения набора моделей машинного обучения.
[0030] Сервер 150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием. Сервер 150 может содержать систему случайной аугментации 151. Набор моделей машинного обучения 114 может быть обучен с помощью обучающих изображений 116, которые были созданы с использованием системы случайной аугментации 151. Система случайной аугментации 151 может создавать множество обучающих изображений 116 из одного изображения (например, изображения 140) и предоставлять изображения 116 для обучения набора моделей машинного обучения 114. Набор моделей машинного обучения 114 может быть составлен, например, из одного уровня линейных или нелинейных операций (например, машины опорных векторов [SVM, support vector machine]) или может представлять собой глубокую сеть, т.е. модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязные нейронные сети. Например, нейронную сеть для OCR можно обучать с использованием аугментированного набора данных (т.е. изображений 116), полученного с помощью системы случайной аугментации 151.
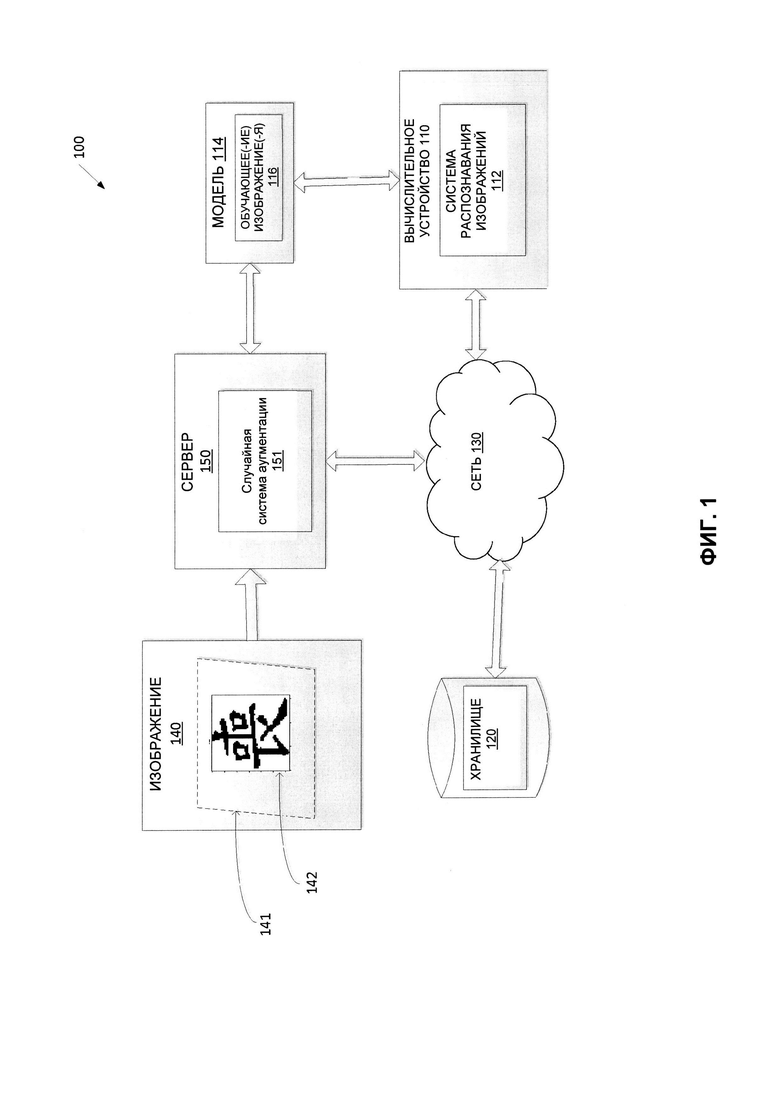
[0031] Набор моделей машинного обучения 114 с помощью обучающих данных можно обучать распознавать содержимое различных изображений. После обучения набора моделей машинного обучения 114 набор моделей машинного обучения 114 может быть использован в системе распознавания изображений 112 для анализа новых изображений.
[0032] Хранилище 120 может представлять собой постоянную память, которая в состоянии хранить изображение 140, элемент 142 и (или) документ 141, обучающие изображения 116, а также различные структуры данных, используемые различными компонентами системы 100. Хранилище 120 может располагаться на одном или более запоминающих устройствах, таких как основная память, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то, что хранилище изображено отдельно от вычислительного устройства 110 и сервера 150, в одной из реализаций изобретения хранилище 120 может быть частью вычислительного устройства 110 или сервера 150. В некоторых вариантах реализации хранилище 120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например, объектно-ориентированной базы данных, реляционной базы данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 130.
[0033] Вычислительное устройство 110 может использоваться для выполнения распознавания изображений. Вычислительное устройство 110 может содержать систему распознавания изображений 112. Распознавание изображений может включать, не ограничиваясь этим, распознавание символов, оптическое распознавание символов, распознавание образов, распознавание фотографий, распознавание лиц и т.д. Вычислительное устройство 110 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в этом изобретении.
[0034] Система распознавания изображений 112 может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 110 и выполняемые на одном или более устройствах обработки вычислительного устройства 110. В одном из вариантов реализации система распознавания изображений 112 может использовать набор обученных моделей машинного обучения 114, которые были обучены распознаванию различных изображений. Этот набор моделей машинного обучения 114 может быть обучен на выборке изображений 116. В некоторых вариантах реализации набор обученных моделей машинного обучения 114 может быть частью системы распознавания изображений 112 или может быть доступен для доступа с другой машины (например, сервера 150) через систему распознавания изображений 112. На основе результата работы набора обученных моделей машинного обучения 114 система распознавания изображений 112 может распознавать объекты на различных изображениях, например, содержимое документа, включая одно или более предполагаемых слов, предложений, логотипов, шаблонов, лиц и т.д.
[0035] Фиг. 2 иллюстрирует пример системы аугментации 200 для аугментации данных изображений в соответствии с одним или более вариантами реализации настоящего изобретения. Система аугментации 200 может содержать систему случайной аугментации 151, показанную на Фиг. 1. Система аугментации 200 может использоваться для аугментации (т.е. увеличения, расширения и т.д.) количества точек данных для использования в модели машинного обучения. В одном из примеров реализации система аугментации 200 может быть нейронной сетью (NN, neural network), сверточной нейронной сетью (CNN, Convolutional Neural Network), или частью NN или CNN. В другом примере реализации система аугментации 200 может быть автоэнкодером (АЕ, autoencoder) или частью АЕ. В еще одном примере реализации система аугментации 200 может быть особым типом АЕ, например, вариационным автоэнкодером (VAE, variational autoencoder) или частью VAE. АЕ и VAE могут реконструировать и восстанавливать вариант входного сигнала на выходе. Система аугментации 200 может содержать сверточную нейронную сеть (CNN, Convolutional Neural Network) 210. Сверточные нейронные сети могут содержать слои вычислительных блоков для иерархической обработки визуальных данных и могут напрямую передавать результат одного слоя на другой слой, извлекая определенные сущности из исходных изображений. Как показано на Фиг. 2, пример CNN 210 может содержать вычислительные блоки 220, 231, 232, 233, 240, 251, 252, 253 («вычислительные блоки 220-253»). Вычислительные блоки в CNN 210 могут быть организованы в слои. Каждый слой или набор слоев может быть предназначен для выполнения функций определенного типа. Например, вычислительный блок 220 может представлять входной слой 220, вычислительные блоки 231-233 могут представлять первый набор сверточных слоев (т.е. слой 231, слой 232, слой 233), вычислительный блок 240 может представлять второй сверточный слой 240 (например, случайный сверточный слой), вычислительные блоки 251-253 могут представлять третий набор сверточных слоев (т.е. слой 251, слой 252, слой 253) и т.д. Каждый из слоев может быть расположен последовательно. Изображение, получаемое CNN 210 в качестве входного сигнала, может обрабатываться иерархически, начиная с первого (т.е. входного) слоя, каждым из слоев. CNN 210 может передавать результаты работы одного слоя напрямую в качестве входа следующего слоя и получать восстановленное изображение в виде результата работы последнего слоя (т.е. слоя 253).
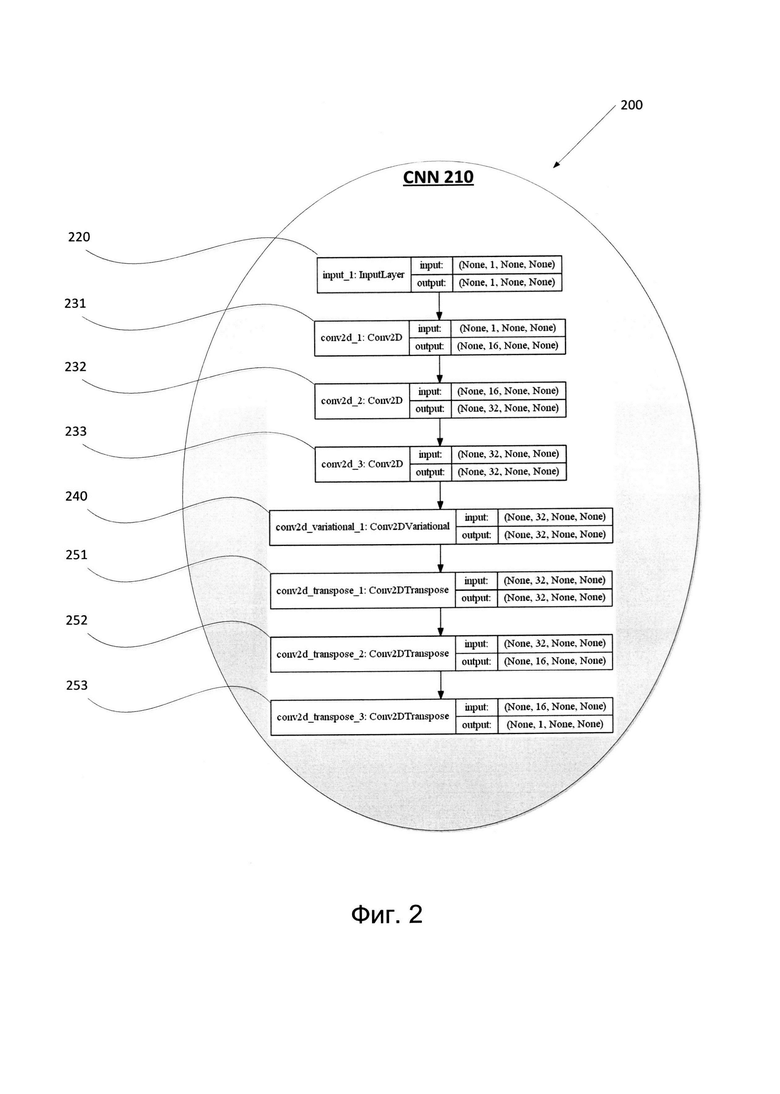
[0036] На Фиг. 3 изображены различные слои вычислительных блоков системы случайной аугментации 300 в соответствии с одним или более вариантами реализации настоящего изобретения. Система случайной аугментации 300 может быть аналогичной или сходной с системой аугментации 200 и (или) включать или быть частью системы случайной аугментации 151. Система случайной аугментации 300 может содержать сверточную нейронную сеть, например, CNN 210. Вычислительные блоки CNN 210 могут получать один или несколько параметров в качестве исходных данных для различных слоев. Параметры могут включать, не ограничиваясь этим, высоту изображения, ширину изображения, размер фильтра, число каналов, количество фильтров, количество изображений и т.д. Эти параметры могут быть числовыми значениями, символами, строками и т.д. Некоторые параметры могут быть необязательными. В одном из примеров вместо конкретного числового значения или символа может использоваться значение «попе». Значения некоторых параметров могут соответствовать значениям пикселей, например, для высоты изображения или ширины изображения.
[0037] В одном из вариантов реализации система случайной аугментации 300 может содержать входной слой 220. Входной слой 220 может использоваться для получения одного или нескольких изображений. Полученные одно или несколько изображений могут иметь произвольные размеры, например, произвольные значения высоты, произвольные значения ширины и т.д. Изображение может иметь любой размер. Эти одно или более изображений могут включать изображения любого типа. Одно или более изображений могут включать, не ограничиваясь этим, изображения различного размера (т.е. малого, среднего, большого), разного разрешения (т.е. высокого и низкого разрешения), редкие изображения, изображения, содержащие символы (например, иероглифы, символы CJK, символы арабского алфавита) и т.д. Входной слой может использоваться для передачи входных значений на следующий слой CNN. В связи с этим входной слой может получать сигнал изображения в определенном формате и передавать те же самые значения в качестве результата работы входного слоя на последующие слои. Например, вычислительный блок входного слоя 220 может получать в качестве исходных данных 222 один или более параметров, например, количество изображений в пакете (batch) изображений, количество каналов, высоту изображения, ширину изображения и т.д. Различные изображения могут иметь разные размеры, без ограничений. Если в качестве входных данных передается несколько изображений, каждое из этих изображений может обрабатываться отдельно. В одном из вариантов реализации входной слой 220 может быть предназначен для получения исходных данных 222 в формате «(число изображений в пакете, число каналов, высота изображения, ширина изображения)». Пример значений исходных данных 222, подаваемых на входной слой 220: «(None, 1, None, None)», как показано на Фиг. 3. В одном из вариантов реализации входной слой 220 может быть предназначен для генерации результата 226 в формате «(число изображений в пакете, число каналов, высота изображения, ширина изображения)». Примером значений результата 226, генерируемого входным слоем 220, может быть «(None, 1, None, None)», как показано на Фиг. 3, совпадающие со значениями исходных данных 222. В одном из примеров реализации канал может соответствовать цветовому каналу, например, серое изображение может иметь один канал, а изображение RGB (Red-Green-Blue) может иметь три канала, один для красного цвета, один для зеленого и один для синего.
[0038] В одном из вариантов реализации система случайной аугментации 300 может содержать различные сверточные слои. Сверточные слои могут быть логически сгруппированы. Сверточные слои могут использоваться для выполнения фильтрации исходного изображения или представления исходного изображения в виде приращений фрагментов исходного изображения. Фрагмент можно получить, разделив исходное изображение на множество частей. Фильтры изображений, используемые в сверточном слое, могут быть представлены в виде матриц или массивов чисел. Числа в массивах (или матрицах) могут рассматриваться как веса или наборы параметров. Применение фильтра к фрагменту исходного изображения может включать вычисление скалярного произведения весов матрицы на значения пикселей обрабатываемого фрагмента. Каждый фрагмент может содержать несколько значений пикселей. Таким образом, вычисление скалярного произведения может быть поэлементным умножением, то есть каждое значение пикселя во фрагменте может умножаться на веса матрицы. Для суммирования результатов скалярных произведений каждого фрагмента может использоваться матрица «kernel» (небольшого размера). Матрица kernel может быть ядром свертки, выполняемой на каждом из сверточных слоев.
[0039] В одном из вариантов реализации система случайной аугментации 300 может включать первый набор слоев вычислительных блоков в качестве первого набора сверточных слоев 231, 232, 233. Каждый из первого набора сверточных слоев может быть двумерными вычислительными блоками. Например, два измерения могут включать высоту и ширину. Первый набор сверточных слоев может использовать определенные фильтры и каналы изображений. Фильтр изображений может удалять компоненты или функции сигнала изображения. Первый набор сверточных слоев может использоваться для обработки представления изображения. Представление изображения может быть обработанной версией исходного изображения. На Фиг. 3 представлен пример формата слоя 231 из первого набора сверточных слоев 231-233. Например, вычислительный блок сверточного слоя 231 может получать в качестве исходных данных 234 один или более параметров, например, количество изображений в пакете (batch) изображений, количество каналов, высоту изображения, ширину изображения и т.д. В одном из вариантов реализации сверточный слой 231 (а также слои 232 и 233) может быть предназначен для получения исходных данных 234 в формате «(число изображений в пакете, число каналов, высота изображения, ширина изображения)». В одном из примеров сверточный слой 231 может быть предназначен для вычисления результата 236 как «(число изображений в пакете, число фильтров, высота изображения, деленная на 2, ширина изображения, деленная на 2)». Первый набор сверточных слоев 231-233 может использоваться для выполнения фильтрации изображения по фрагментам (т.е. определенным частям) этого изображения. Каждый из первого набора сверточных слоев 231-233 может содержать отдельный фильтр для каждого из каналов (например, красного, зеленого и синего цвета для изображения RGB). В первом наборе сверточных слоев могут использоваться две матрицы обучающихся весов (или наборов параметров). Обучающиеся веса могут включать матрицу kernel и матрицу bias. Веса в матрице kernel могут быть изначально неизвестны и определяться в ходе процесса обучения. Смещения определяются по попиксельному смещению, применяемому к результату свертки. Таким образом, матрица bias может содержать уникальные скалярные значения, которые добавляются к результату каждого фильтра слоя для добавления определенного смещения или отклонения к выходным значениям. Функции матрицы bias могут включать определенное смещение, ее входы и выходы всегда равны 1.
[0040] В одном из вариантов реализации система случайной аугментации 300 может содержать второй слой вычислительных блоков в качестве второго сверточного слоя 240. Второй сверточный слой может также быть известен под названием случайного сверточного слоя или вариационного сверточного слоя. Случайный сверточный слой может быть двумерным вычислительным блоком. Случайный сверточный слой может выполнять дополнительную фильтрацию изображений с использованием случайных параметров и создавать случайные параметры искажения для модификации изображения. Параметры искажения, полученные со случайного слоя, могут накладываться на представление изображения. На Фиг. 3 представлен пример формата случайного сверточного слоя 240 (например, вариативного слоя). Например, вычислительный блок случайного слоя 240 может получать в качестве исходных данных 244 один или более параметров, например, количество изображений в пакете (batch) изображений, количество каналов, высоту изображения, ширину изображения и т.д. В одном из вариантов реализации сверточный слой 231 (а также слои 232 и 233) может быть предназначен для получения исходных данных 234 в формате «(число изображений в пакете, число каналов, высота изображения, ширина изображения)». Параметр Filtersin может представлять число каналов у входного тензора. Например, значением параметра Filters in может быть 32 или другое значение. Это значение может изменяться в соответствии с решаемой проблемой. Например, решаемая проблема может зависеть от содержания исходного изображения. Значения могут быть модифицируемыми системой элементами, которые выбираются, исходя из типа входящего изображения. В одном из примеров случайный слой 231 может быть предназначен для вычисления результата 236 как «(число изображений в пакете, filters_out, высота изображения, ширина изображения)». Параметр Filters_out может представлять число фильтров, применяемых к входному тензору. В одном из примеров тензор может быть математическим объектом, используемым для описания линейных отношений между векторами, скалярами и др. Например, значением параметра Filters_out может быть 32 или другое значение. Это значение может изменяться в соответствии с решаемой проблемой. Функции случайного сверточного слоя 240 могут быть дополнительно разъяснены со ссылкой на Фиг. 4.
[0041] В одном из вариантов реализации система случайной аугментации 300 может включать третий набор слоев вычислительных блоков в качестве третьего набора сверточных слоев 251, 252, 253. Третий набор сверточных слоев может также называться транспонируемым сверточным слоем. Каждый из обратных сверточных слоев может быть двумерными вычислительными блоками. Обратные сверточные слои могут использовать отдельные каналы и наборы фильтров изображений для восстановления представления изображения с примеренными к нему параметрами искажения. На Фиг. 3 представлен пример формата слоя 251 из первого набора сверточных слоев 251-253. Например, вычислительный блок обратного сверточного слоя 251 может получать в качестве исходных данных 254 один или более параметров, например, количество изображений в пакете (batch) изображений, количество каналов, высоту изображения, ширину изображения и т.д. В одном из вариантов реализации обратный сверточный слой 251 (а также слои 252 и 253) может быть предназначен для получения исходных данных 254 в формате «(число изображений в пакете, число каналов, высота изображения, ширина изображения)». В одном из примеров обратный сверточный слой 251 может быть предназначен для вычисления результата 256 в виде «(число изображений в пакете, число фильтров, высота изображения, умноженная на 2, ширина изображения, умноженная на 2)».
[0042] Фиг. 4 иллюстрирует пример случайного сверточного слоя 400 в соответствии с одним или более вариантами реализации настоящего изобретения. Случайный сверточный слой 400 может совпадать или быть похожим на случайный сверточный слой 240 на Фиг. 2 и Фиг. 3. Представление исходного изображения может быть изменено с помощью случайных параметров искажения, выбранных случайным сверточным слоем 400. Для выполнения свертки в случайном сверточном слое может использоваться случайная матрица «kernel». Выполнение свертки в случайном слое может включать применение фильтров к представлению исходного изображения. Эти фильтры могут применяться аналогично тому, как они применялись в первом наборе сверточных слоев 231-233, с использованием одной или более матриц и с выполнением аналогичных вычислений. Размерность случайной матрицы kernel может быть аналогична размерности матрицы kernel первого набора сверточных слоев. Однако веса наборов параметров, используемых в одной или более матрицах случайного слоя могут различаться или порождаться способом, отличающимся от способа для первого набора слоев.
[0043] Вычисления случайной матрицы kernel случайного сверточного слоя может включать выбор значения стандартного отклонения выборки. Например, параметр слоя 400, sampling_std 460, может использоваться в качестве стандартного отклонения (standard deviation) выборки для случайного сверточного слоя 400. Значение sampling_std 460 может выбираться произвольно, в зависимости от решаемой задачи. Например, значения sampling_std 460 могут включать, не ограничиваясь этим, 0,1, 0,2, 0,3, 0,4 или другие числовые значения. В одном из вариантов реализации аугментация изображения автоэнкодера (АЕ) или другого типа нейронной сети (NN, neural network) параметр sampling_std 460 может задавать «грубость» искажения, применяемого к представлению исходного изображения. Чем больше значение sampling_std 460, тем грубее (т.е. более зернистым) может быть наложенное искажение изображения.
[0044] В одном из вариантов реализации случайный сверточный слой 400 может содержать матрицу kernel (матрица ядра свертки) 410, которая может представлять случайную матрицу kernel (случайная матрица ядра свертки). Матрица kernel может создаваться на основе одной или нескольких матриц. Например, случайный сверточный слой 400 может оперировать на базе четырех матриц: 1) матрицы kernel_mean 420 (матрица со случайной инициализацией), 2) матрицы kernel_stddev 430 (обучаемая матрица), 3) матрицы bias 440 (матрица смещения) и 4) матрицы epsilon 450 (случайная матрица). Первые три матрицы 420, 430 и 440 могут содержать обучающиеся веса наборов параметров. Матрица kernel_mean 420, матрица kernel_stddev 430 и матрица epsilon 450 могут быть четырехмерными матрицами с параметрами высоты фильтра (filters_height), ширины фильтра (filters_width), параметрами filters_in и filters_out. Параметры высоты фильтра и ширины фильтра могут представлять размер фильтра. В одном из примеров реализации высота фильтра может иметь значение «3» (т.е. 3 пикселя), и ширина фильтра может иметь значение «3». Параметр filters_in может быть количеством каналов на входе матрицы. Параметр filters_out может быть количеством фильтров, которые следует применить к входному тензору. В одном из примеров реализации параметры filters_in и filters_out могут иметь значение «32» или другое значение. Значения filters_height и (или) filters_out могут меняться, в соответствии с решаемой задачей.
[0045] В одном из примеров матрица kernel_mean 420 может быть матрицей средних значений (mean values). Матрица kernel_mean 420 может быть инициализирована случайными значениями. Матрица kernel_mean 420 может иметь форму, одинаковую или сходную с матрицей kernel первого набора сверточных слоев. Различия между матрицей kernel 410 и матрицей kernel_mean 420 могут определяться значением выбранного sampling_std 460, поскольку sampling_std 460 используется для вычисления стандартного отклонения, применяемого к матрице kernel_mean 420 для порождения матрицы kernel 410. Матрица kernel_mean 420, матрица kernel_stddev 430 и матрица epsilon 450 могут иметь форму, сходную с матрицей kernel первого набора сверточных слоев.
[0046] В одном из примеров матрица kernel_stddev 430 может быть матрицей значений стандартных отклонений. Матрица kernel_stddev 430 может быть инициализирована нулевыми значениями. Матрица kernel_stddev 430 может иметь форму, одинаковую или сходную с матрицей kernel первого набора сверточных слоев.
[0047] В одном из примеров матрица bias 440 может быть матрицей значений смещения. Матрица bias 440 может создаваться, исходя из количества фильтров, применяемых на входе случайного слоя. Матрица bias 440 может иметь роль, аналогичную или сходную с ролью матрицы смещений первого набора сверточных слоев (т.е. наложение пиксельного смещения на результаты свертки). Размеры матрицы bias 440 могут определяться параметром filters_out. Как указано выше, параметр filters_out может быть числом фильтров, применяемых на входе матрицы.
[0048] В одном из примеров реализации матрица epsilon 450 может быть матрицей, основанной на произвольном значении случайного отклонения и значении нормального распределения. Матрица epsilon может быть нелинейной матрицей. Матрица epsilon 450 может быть инициализирована случайными значениями. Матрица epsilon может генерироваться заново при каждом проходе входных данных через случайный слой. Например, для порождения матрицы epsilon может использоваться генератор случайных чисел. Матрица epsilon 450 может создаваться из нормального распределения со средним значением, равным нулю, и значением стандартного отклонения sampling_std 460. Форма матрицы epsilon 450 может совпадать с формой матрицы kernel_mean 420.
[0049] Случайная матрица kernel случайного сверточного слоя может генерироваться на основе одной или более матриц с использованием указанной формулы. Например, матрица kernel 410 может вычисляться с использованием следующей формулы:
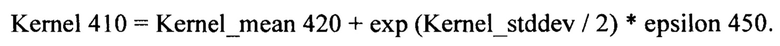
[0050] Таким образом, веса наборов параметров, созданных для матрицы kernel 410, могут каждый раз выбираться случайным образом и генерироваться из нормального распределения, полученного в ходе процесса обучения CNN. В соответствии с формулой случайная матрица kernel 410 может быть нормальным вектором со средним значением «kernel_mean 420» и значением стандартного отклонения «ехр (Kernel_stddev / 2)». Вычисление случайной матрицы kernel может включать арифметические операции, выполняемые попиксельно. Вместо определения общего параметра искажения для всего исходного изображения определение параметров искажения может выполняться для каждой части (т.е. фрагмента) исходного изображения по отдельности. Каждая часть изображения может отдельно обрабатываться CNN, позволяя в результате получить локальное преобразование исходного изображения для каждой его части. Свертка, выполняемая со сгенерированной случайной матрицей kernel (случайной матрицей ядра свертки), применяемая к данным изображения на входе случайного слоя, может вносить случайные параметры искажения изображения в представление исходного изображения.
[0051] Операция свертки 470 для случайного сверточного слоя может выполняться с использованием случайной матрицы kernel 410, и полученные данные 480 могут быть переданы обратным сверточным слоям 251-253 в качестве результата 490 операции свертки 470. Таким образом, возможна генерация одного или более случайно искаженных изображений из одного исходного изображения каждый раз, когда представление исходного изображения пропускается через случайный сверточный слой после, например, обучения АЕ, которое включает этот слой и аугментацию набора данных изображений для обучающей выборки изображений для модели машинного обучения.
[0052] На Фиг. 5 приведена блок-схема одного иллюстративного примера способа 500 для создания аугментации данных изображений в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 500 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 1100 на Фиг. 11), реализующей этот способ. В некоторых вариантах реализации способ 500 может выполняться в одном потоке обработки. Кроме того, способ вычисления 500 может выполняться в двух или более потоках обработки, при этом в каждом потоке будут выполняться одна или несколько отдельных функций, процедур, подпрограмм или операций способа. В качестве иллюстративного примера потоки обработки способа 500 можно синхронизировать (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 500, могут выполняться асинхронно друг относительно друга. Таким образом, несмотря на то, что Фиг. 5 и соответствующее описание содержат список операций для способа 500 в определенном порядке, в различных вариантах осуществления способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке. В одном из вариантов реализации способ 500 может выполняться на случайной системе аугментации 151 с Фиг. 1.
[0053] На шаге 510 вычислительная система, реализующая способ 500, может получать один или более первых изображений, используемых для обучения набора моделей машинного обучения. Одно или более первых изображений могут использоваться в качестве исходных изображений, для которых можно выполнить аугментацию с помощью способа 500. Можно, хотя и необязательно, использовать способ 500 для предварительной обработки исходного изображения, включая изменение масштаба, операций Собеля (например, операции Собеля-Фельдмана), Кэнни (т.е. детектора границ Кэнни), морфологических и других операций обработки. Например, Фиг. 6 иллюстрирует получение исходного изображения 610 как части системы аугментации 600. Система аугментации 600 может быть аналогичной или сходной с системами аугментации 200 и (или) 300. На Фиг. 6 показан пример взаимодействий между различными компонентами и слоями системы случайной аугментации и приведены примеры значений, используемых в этих компонентах в соответствии с настоящим изобретением. Одно или более первых изображений могут иметь произвольные размерности, то есть произвольные значения высоты, произвольные значения ширины и т.д., и могут иметь одинаковый размер. Эти одно или более изображений могут включать изображения любого типа. Эти одно или более изображений могут включать, не ограничиваясь этим, изображения различного размера (т.е. малого, среднего, большого), разного разрешения (т.е. высокого и низкого разрешения), редкие изображения, изображения, содержащие символы (например, иероглифы, символы CJK, символы арабского алфавита или символы других известных типов) и т.д.
[0054] На шаге 520 вычислительная система, реализующая способ 500, может получать одно или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения в ходе обучения. Модель машинного обучения может включать нейронную сеть, например, сверточную нейронную сеть (CNN, Convolutional Neural Network). Как показано на Фиг. 6, исходное изображение 610 может быть получено входным слоем 220 вычислительных блоков 220-253. Соответствующий формату «(число изображений в пакете, число каналов, высота изображения, ширина изображения)» пример значений на входе 222, поступающий на входной слой 220 - «(None, 1, None, None)». В этом примере значение «1» может быть числом каналов. Соответствующий формату «(число изображений в пакете, число каналов, высота изображения, ширина изображения)» пример значений на выходе 226, создаваемый входным слоем 220 - «(None, 1, None, None)», то есть совпадающий со значениями на входе 222, по существу передает сигнал входного изображения на следующий слой CNN.
[0055] На шаге 530 вычислительная система может предоставлять одно или более входных изображений в качестве первых исходных данных для первого набора слоев вычислительных блоков. Первый набор слоев может использовать фильтры изображений, как описано со ссылкой на Фиг. 3. В одном из примеров реализации первые исходные данные для первого набора слоев могут включать деление первого изображения на множество частей и предоставление каждой части из множества частей на первый набор слоев вычислительных блоков. Как показано на Фиг. 6, система случайной аугментации 600 может включать первый набор слоев вычислительных блоков в качестве первого набора сверточных слоев 231, 232, 233. Одно или более первых изображений (например, исходное изображение 610) может использоваться как первые исходные данные 234 для первого набора слоев 231-233. В частности, результат 226 входного слоя 220 может предоставляться в качестве исходных данных 234 первому набору сверточных слоев 231. Каждый слой из первого набора сверточных слоев 231-233 может использоваться для итеративной фильтрации и масштабирования одного или более изображений (например, изображения 610). Итеративный процесс может включать передачу результата одного слоя в качестве исходных данных для следующего слоя для дальнейшей обработки. Пример значений исходных данных 234, передаваемых первому набору сверточных слоев 231 - «(None, 1, None, None)», что совпадает со значениями результата 226 входного слоя 220. Как и в случае формата «(число изображений в пакете, число фильтров, высота изображения / 2, ширина изображения / 2)», примером значений результата 236, генерируемого входным слоем 231, будет «(None, 16, None, None)». В этом примере значение «16» может быть числом используемых фильтров, выбранным системой для этого слоя. В ходе итеративного процесса результат 239 может быть создан последним слоем 233 первого набора слоев 231-233. Примером значений результата 239 будет «(None, 32, None, None)». В этом примере значение «32» может быть числом используемых фильтров, выбранным системой для этого слоя.
[0056] На шаге 540 вычислительная система может представить первый результат первого набора слоев вычислительных блоков в качестве вторых исходных данных второго слоя вычислительных блоков. Второй слой может использовать для вычислений в слое случайные наборы параметров. Кроме того, вычислительная система может генерировать случайную матрицу kernel для второго слоя вычислительных блоков, исходя из одной или нескольких матриц. Одна или более матриц могут содержать одну или более: 1) первых матриц средних значений, первая матрица инициализируется случайными значениями; 2) вторых матриц значений стандартного отклонения, вторая матрица инициализируется нулевыми значениями; 3) третьих матриц значений смещения, третья матрица инициализируется числом фильтров, применяемых ко вторым исходным данным, или 4) четвертых матриц (например, матриц epsilon) на базе произвольного значения стандартного отклонения и значения нормального распределения. В одном из примеров произвольное стандартное отклонение определяет грубость искажений изображения. Параметры одной или более матриц могут включать как минимум один из параметров: высота фильтра, ширина фильтра, высота изображения, ширина изображения, размер фильтра, число каналов, число фильтров или число изображений. Высота изображения и ширина изображения могут содержать произвольные значения. В одном из примеров первая матрица, вторая матрица и третья матрица могут содержать обучаемые параметры.
[0057] Как показано на Фиг. 6, система случайной аугментации 600 может содержать второй слой вычислительных блоков в качестве второго сверточного слоя (например, случайного слоя) 240. Первый результат 239 первого набора слоев 231-233 может быть использован в качестве вторых исходных данных 244 второго слоя 240. В частности, результат 239 первого набора сверточного слоя 233 может быть использован как в качестве исходных данных 244 второго слоя (например, случайного слоя) 240. В соответствии с форматом «(число изображений в пакете, filters_in, высота изображения, ширина изображения)» значений на входе этого слоя, пример значений на входе 244, поступающий на случайный слой - «(None, 32, None, None)». В этом примере значение «32» может быть значением параметра filters_in или количеством каналов входного тензора. Входное значение 244 может обрабатываться с использованием функций случайного сверточного слоя 240 (например, как указано на Фиг. 4) и давать результат 246. Соответствует формату «(число изображений в пакете, filters_out, высота изображения, ширина изображения)». Пример значений для результата 246, полученного от случайного слоя 240 - «(None, 32, None, None)». В этом примере значение «32» может быть значением параметра filters_out или количеством фильтров, применяемых к входному тензору.
[0058] На шаге 550 вычислительная система может получать параметры искажения со второго слоя вычислительных блоков. Параметры искажения, полученные со случайного слоя, могут накладываться на представление входного изображения 610 на Фиг. 6. Вычислительная система может получать параметр искажения для каждой из множества частей первого изображения. Свертка, выполняемая со сгенерированной случайной матрицей kernel, применяемая к данным изображения на входе случайного слоя, может вносить случайные параметры искажения изображения в представление исходного изображения.
[0059] На шаге 560 вычислительная система может передавать второй результат второго слоя вычислительных блоков в качестве третьих исходных данных третьему набору слоев вычислительных блоков. В одном из примеров второй слой может представлять собой слой обратной свертки. Как показано на Фиг. 6, система случайной аугментации 600 может включать третий набор слоев вычислительных блоков в качестве третьего набора сверточных слоев 251, 252, 253. Второй результат 246 второго слоя 240 может быть передан в качестве третьих исходных данных 254 третьему набору слоев 251-253. В частности, результат 246 случайного слоя 240 может предоставляться в качестве исходных данных 254 третьему набору сверточных слоев 251. В соответствии с форматом «(число изображений в пакете, число каналов, высота изображения, ширина изображения)» пример значений исходных данных 254, предоставляемых третьему набору сверточных слоев 251, может быть «(None, 32, None, None)», что совпадает со значением результата 246 случайного слоя 240. В этом примере значение «32» может быть числом фильтров. Как и в случае формата «(число изображений в пакете, число каналов, высота изображения * 2, ширина изображения * 2)», примером значений результата 256, генерируемого обратным сверточным слоем 251, будет «(None, 32, None, None)». В этом примере значение «32» может быть числом каналов. Каждый слой из третьего набора сверточных слоев 251-253 может использоваться для итеративной фильтрации и масштабирования исходных данных 254 для восстановления исходного изображения, передачи результата каждого слоя из третьего набора слоев (например, слоев обратного преобразования свертки) в качестве исходных данных для последующего слоя обратного преобразования свертки. В ходе итеративного процесса результат 259 может быть создан последним слоем 253 третьего набора слоев 251-253. Примером значений результата 259 будет «(None, 1, None, None)». В этом примере значение «1» может быть числом каналов.
[0060] На шаге 570 вычислительная система может передавать третий результат третьего набора слоев вычислительных блоков в качестве одного или нескольких вторых изображений, третий результат базируется на одном или более первых изображений и параметрах искажения. Как показано на Фиг. 6, третий результат 259 третьего набора слоев 251-253 может быть представлен одним или более вторых изображений 620. Одно или более вторых изображений 620 могут содержать случайные искажения, добавленные к представлению (т.е. обработанной версии) первого изображения (т.е. исходного изображения 610).
[0061] На шаге 580 вычислительная система может добавлять одно или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения. Например, одно или более вторых изображений 620 (как показано на Фиг. 6) могут быть добавлены к обучающим изображениям 116 (как показано на Фиг. 1).
[0062] Фиг. 7 иллюстрирует пример матрицы bias в соответствии с одним или более вариантами реализации настоящего изобретения. Исходное значение смещения 710 показывает, что все исходные значения смещения могут быть нулевыми. После прохода значений смещения через процесс машинного обучения матрица bias может содержать различные значения. Например, обученное значение смещения 720 показывает, что исходные нули значений матрицы bias могут быть замещены различными числовыми значениями.
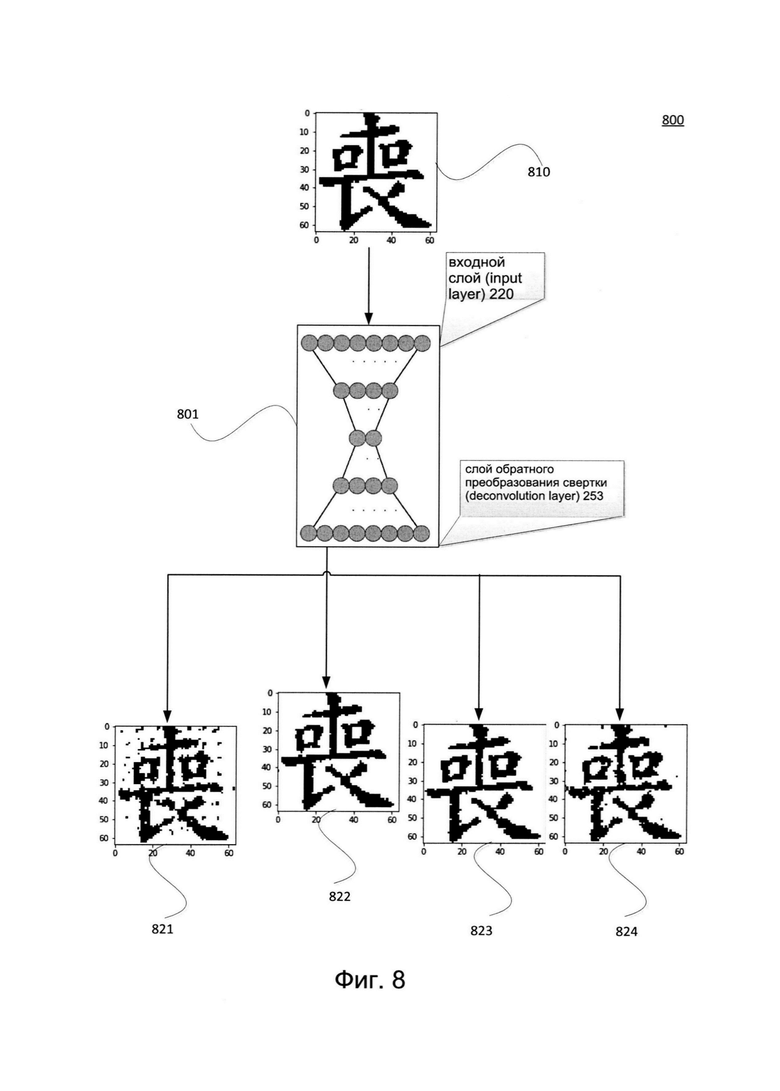
[0063] Фиг. 8 иллюстрирует пример системы аугментации 800 для случайного искажения изображения в соответствии с одним или более вариантами реализации настоящего изобретения. Система аугментации 800 может быть аналогичной или сходной с системами аугментации 200, 300 и (или) 600. Система аугментации 800 может содержать автоэнкодер 801 со слоями вычислительных блоков. Один из вычислительных блоков автоэнкодера 801 может содержать случайный сверточный слой, использующий случайную матрицу kernel. Исходное изображение 810 может приниматься входным слоем 220 автоэнкодера 801. В этом примере изображение 810 содержит символ CJK. Над исходным изображением 810 может выполняться операция свертки, включающая использование случайной матрицы kernel случайного сверточного слоя. В результате последней операции свертки, выполняемой над представлением исходного изображения 810 (например, обработанной версией исходных данных 810), обратный сверточный слой 253 может выдавать одно из случайно искаженных изображений 821, 822, 823 и 824. Изображений 821, 822, 823 и 824 может быть модифицированной версией исходного изображения 810, которое изменялось при помощи обратной свертки каждый раз, когда исходное изображение 810 проходило через автоэнкодер 801. Изображения 821, 822, 823 и 824 соответствуют естественным образом искаженным изображениям исходных данных 810 и отличаются друг от друга. Изображения 821, 822, 823 и 824 соответствуют аугментированному набору данных, полученному из единственного исходного изображения 810. Изображения 821, 822, 823 и 824 могут быть добавлены в обучающую выборку изображений (например, обучающих изображений 116 на Фиг. 1) для обучения модели машинного обучения, которая может распознавать версию исходного изображения 810.
[0064] В других вариантах реализации 801 может быть нейронной сетью, сверточной нейронной сетью, вариационным автоэнкодером и т.д.
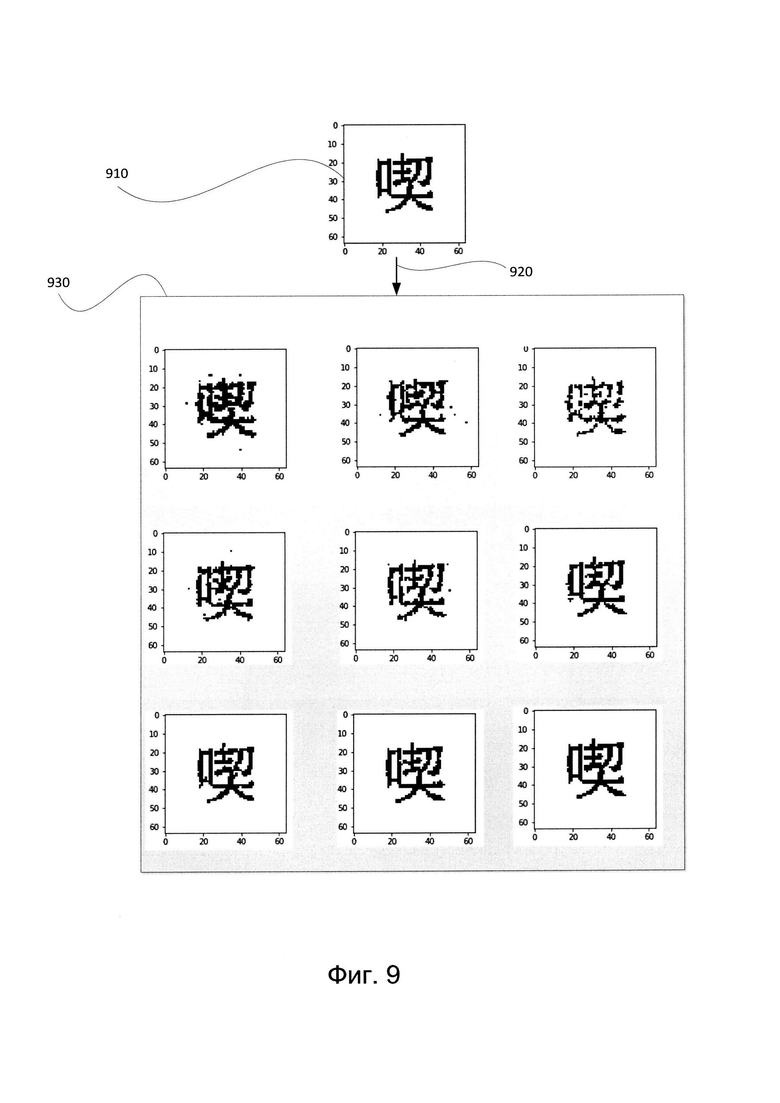
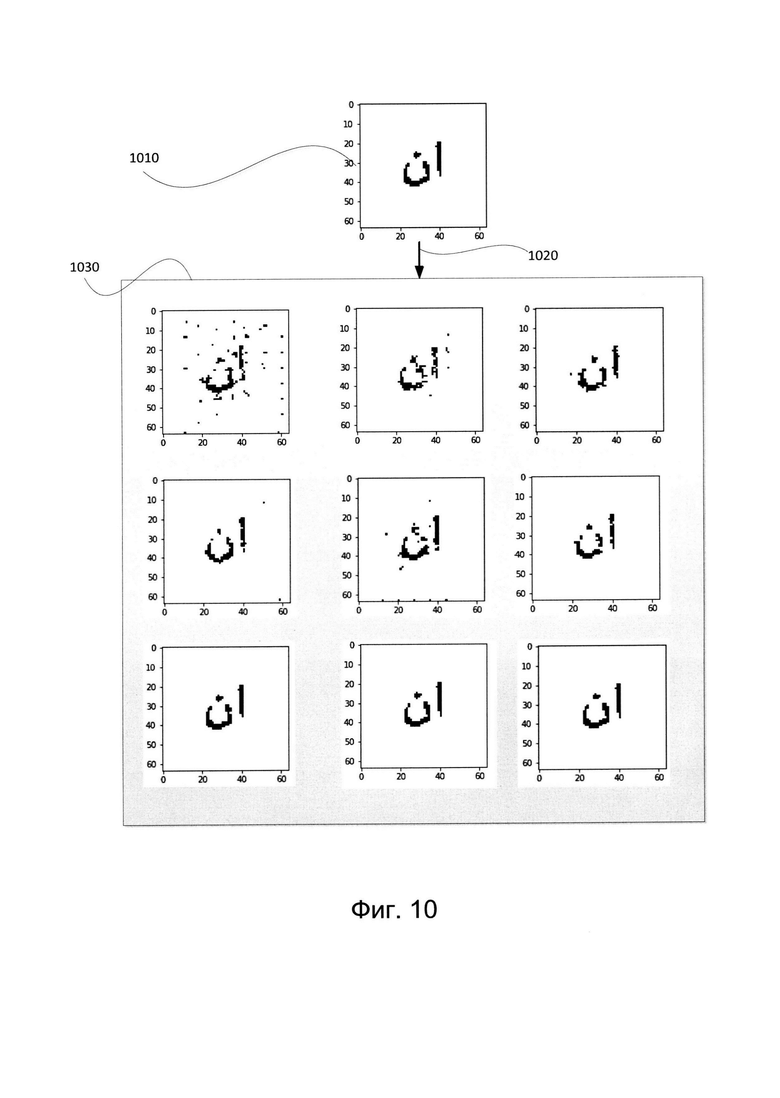
[0065] Фиг. 9 и 10 иллюстрируют примеры случайно искаженных изображений в соответствии с одним или более вариантами реализации настоящего изобретения. Фиг. 9 иллюстрирует случайную аугментацию исходного изображения 910. В этом примере изображение 910 содержит символ CJK. Исходное изображение 910 может быть дополнено с помощью процесса случайной аугментации 920 (т.е. использования системы случайной аугментации 151, показанной на Фиг. 1) для получения набора изображений-результатов 930. Изображения-результаты 930 включают девять различных изображений, которые являются случайно искаженными вариантами исходного изображения 910. Таким образом, набор изображений-результатов 930 представляет собой набор аугментированных данных, созданный из одного исходного изображения 910. Фиг. 10 иллюстрирует случайную аугментацию исходного изображения 1010. В этом примере изображение 1010 содержит символ арабского алфавита. Исходное изображение 1010 может быть дополнено с помощью процесса случайной аугментации 1020 (т.е. использования системы случайной аугментации 151, показанной на Фиг. 1) для получения набора изображений-результатов 1030. Изображения-результаты 1030 включают девять различных изображений, которые являются случайно искаженными вариантами исходного изображения 1010. Таким образом, набор изображений-результатов 1030 представляет собой набор аугментированных данных, созданный из одного исходного изображения 910.
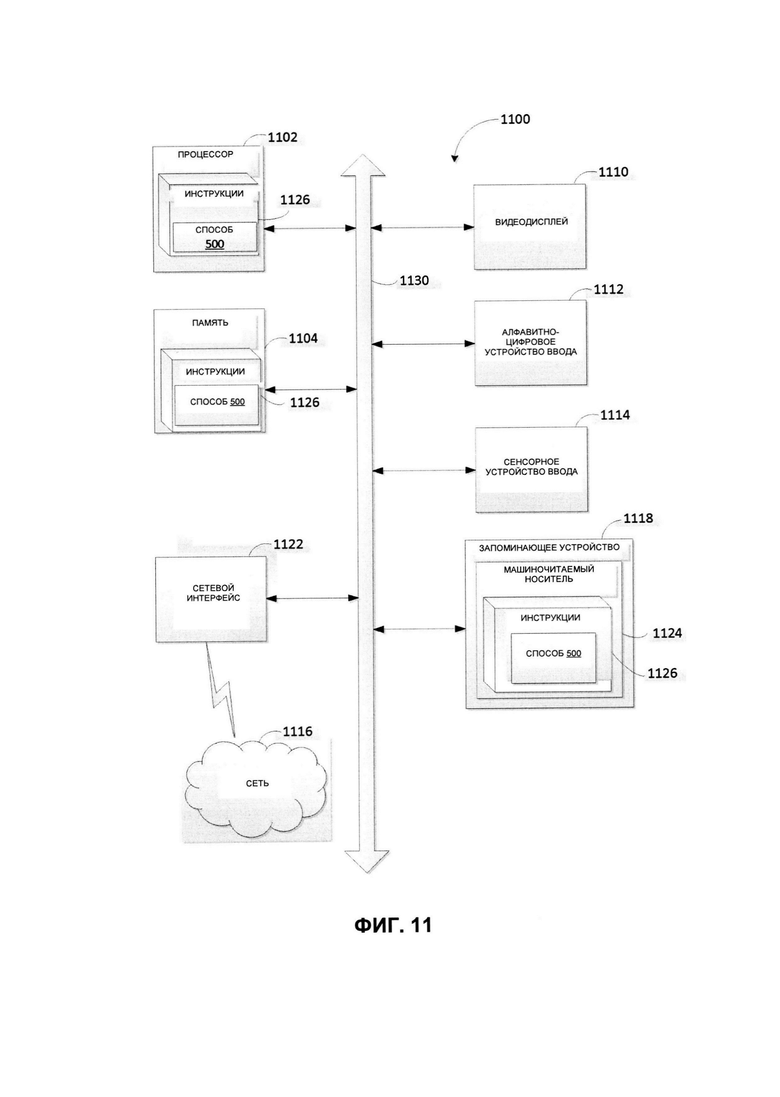
[0066] На Фиг. 11 представлена подробная схема компонентов примера вычислительной системы, внутри которой исполняются инструкции, которые вызывают выполнение вычислительной системой какого-либо одного или более способов, рассматриваемых в этом документе. Вычислительная система 1100 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 1100 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер», или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 1100 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB, set-top box), карманным ПК (PDA, Personal Digital Assistant), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то, что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[0067] Пример вычислительной системы 1100 включает процессор 1102, основное запоминающее устройство 1104 (например, постоянное запоминающее устройство (ROM, read-only memory) или динамическое оперативное запоминающее устройство (DRAM, dynamic random access memory)) и устройство хранения данных 1118, которые взаимодействуют друг с другом по шине 1130.
[0068] Процессор 1102 может быть представлен одним или более универсальными устройствами обработки данных, такими как микропроцессор, центральный процессор и т.п. В частности, процессор 1102 может представлять собой микропроцессор с полным набором команд (CISC, complex instruction set computing), микропроцессор с сокращенным набором команд (RISC, reduced instruction set computing), микропроцессор с командными словами сверхбольшой длины (VLIW, very long instruction word), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 1102 также может представлять собой одно или более устройств обработки специального назначения, такие как специализированная интегральная схема (ASIC, application specific integrated circuit), программируемая пользователем вентильная матрица (FPGA, field programmable gate array), процессор цифровых сигналов (DSP, digital signal processor), сетевой процессор или тому подобное. Процессор 1102 выполнен с возможностью исполнения инструкций 1126 для выполнения операций и функций способа 500 создания аугментации изображения, как описано выше в этом документе.
[0069] Вычислительная система 1100 может дополнительно включать устройство сетевого интерфейса 1122, устройство визуального отображения 1110, устройство ввода символов 1112 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 1114.
[0070] Устройство хранения данных 1118 может включать машиночитаемый носитель данных 1124, в котором хранится один или более наборов команд 1126, в которых реализован один или более способов или функций, описанных в данном варианте реализации изобретения. Инструкции 1126 во время выполнения их в вычислительной системе 1100 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 1104 и (или) в процессоре 1102, при этом основное запоминающее устройство 1104 и процессор 1102 также представляют собой машиночитаемый носитель данных. Команды 1126 также могут передаваться или приниматься по сети 1116 через устройство сетевого интерфейса 1122.
[0071] В отдельных вариантах осуществления инструкции 1126 могут включать инструкции способа 500 создания аугментации изображений, как описано выше в этом документе. Хотя машиночитаемый носитель данных 1124 показан в примере на Фиг. 11 в виде одного носителя, термин «машиночитаемый носитель» следует понимать в широком смысле, подразумевающем один или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять один или более способов, описанных в настоящем описании изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[0072] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, таких как специализированная интегральная схема (ASIC, application specific integrated circuit), программируемая пользователем вентильная матрица (FPGA, field programmable gate array), процессор цифровых сигналов (DSP, digital signal processor) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[0073] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[0074] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать, и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0075] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемые к этим величинам. Если явно не указано обратное, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «определение», «изменение», «создание» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах и устройствах памяти вычислительной системы, в другие данные, также представленные в виде физических величин в устройствах памяти или регистрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[0076] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[0077] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА МОНИТОРИНГА РЕЖИМОВ ГОРЕНИЯ ТОПЛИВА ПУТЕМ АНАЛИЗА ИЗОБРАЖЕНИЙ ФАКЕЛА ПРИ ПОМОЩИ КЛАССИФИКАТОРА НА ОСНОВЕ СВЁРТОЧНОЙ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2713850C1 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| СПОСОБ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРАВДОПОДОБНОГО ОТОБРАЖЕНИЯ ТЕЧЕНИЯ ВРЕМЕНИ СУТОЧНОГО МАСШТАБА | 2020 |
|
RU2745209C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ОБФУСЦИРОВАННЫХ ВРЕДОНОСНЫХ КОМАНД В СИСТЕМНОЙ КОНСОЛИ ОПЕРАЦИОННОЙ СИСТЕМЫ | 2024 |
|
RU2838483C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ МОШЕННИЧЕСКИХ ТРАНЗАКЦИЙ ПОЛЬЗОВАТЕЛЯ | 2024 |
|
RU2839053C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ПОМОЩЬЮ СИНТЕТИЧЕСКИХ ФОТОРЕАЛИСТИЧНЫХ СОДЕРЖАЩИХ ЗНАКИ ИЗОБРАЖЕНИЙ | 2018 |
|
RU2709661C1 |
| ДЕТЕКТИРОВАНИЕ И ИДЕНТИФИКАЦИЯ ОБЪЕКТОВ НА ИЗОБРАЖЕНИЯХ | 2020 |
|
RU2726185C1 |
| СПОСОБ ВОССТАНОВЛЕНИЯ БАЛАНСА БЕЛОГО НА ИЗОБРАЖЕНИИ | 2023 |
|
RU2837078C2 |
| Способ детектирования и дисперсионного анализа частиц в текучей среде с применением метода искусственного интеллекта | 2024 |
|
RU2833482C1 |
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ОСУЩЕСТВЛЯТЬ РАЗМЕТКИ ТЕЛЕРЕНТГЕНОГРАММ В ПРЯМОЙ И БОКОВОЙ ПРОЕКЦИЯХ | 2019 |
|
RU2717911C1 |
Изобретение относится к способу и системе случайной аугментации данных для использования в обучении моделей машинного обучения. Техническим результатом является повышение эффективности создания обучающих выборок данных для модели машинного обучения без ограничения на количество аугментаций исходного изображения. Способ содержит этапы: получения одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения; предоставления одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, причем первое множество слоев использует фильтры изображений; предоставления первого результата первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, при этом второй слой использует для вычислений случайные наборы параметров; получение параметров искажений от второго слоя вычислительных блоков; создание одного или более вторых изображений на основе одного или более первых изображений и параметров искажений; получение в качестве третьего выхода одного или более вторых изображений и добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения. 3 н. и 17 з.п. ф-лы, 11 ил.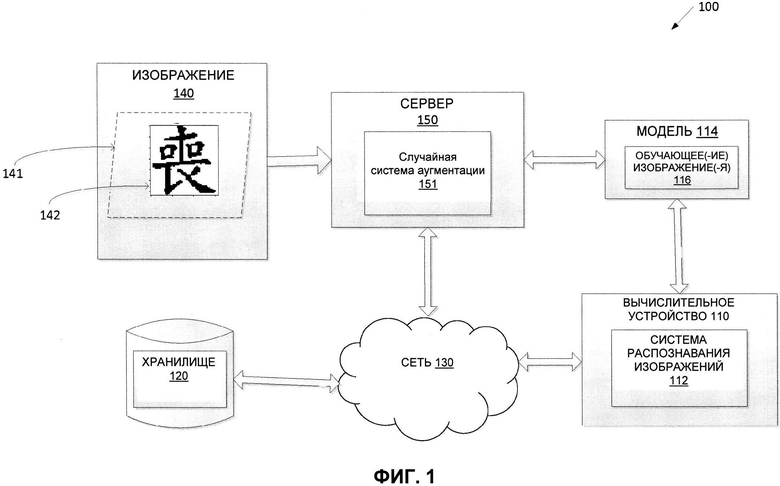
1. Способ случайной аугментации данных, содержащий этапы:
получение обрабатывающим устройством одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения в обучении;
предоставление обрабатывающим устройством одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, где первое множество слоев применяет фильтры изображений;
предоставление первого выхода первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, где второй слой применяет для вычислений случайные наборы параметров;
получение параметров искажений от второго слоя вычислительных блоков;
генерация одного или более вторых изображений на основе одного или более первых изображений и параметров искажений;
получение в качестве третьего выхода одного или более вторых изображений; и
добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
2. Способ по п. 1, дополнительно содержащий:
предоставление второго выхода второго слоя вычислительных блоков в качестве третьего входа в третий набор слоев вычислительных блоков.
3. Способ по п. 1, отличающийся тем, что модель машинного обучения содержит сверточную нейронную сеть.
4. Способ по п. 1, в котором предоставление первого входа включает:
разделение одного или более первых изображений на множество частей; и
предоставление каждой части из множества частей первому набору слоев вычислительных блоков.
5. Способ по п. 4, в котором получение параметров искажения включает:
получение параметров искажения для каждой части из множества частей одного или более первых изображений.
6. Способ по п. 1, дополнительно содержащий:
генерацию случайной матрицы ядра свертки для второго слоя вычислительных блоков на основе одной или более матриц.
7. Способ по п. 6, в котором одна или более матриц включают одну или более:
первых матриц средних значений, первая матрица инициализируется случайными значениями;
вторых матриц значений стандартного отклонения, вторая матрица инициализируется нулевыми значениями;
третьих матриц значений смещения, третья матрица базируется на количестве фильтров, применяемых ко второму входу; или
четвертых матриц, которые базируются на произвольном значении стандартного отклонения и значении нормального распределения.
8. Способ по п. 7, в котором произвольное значение стандартного отклонения задает грубость искажения изображения.
9. Способ по п. 6, в котором параметры одной или более матриц могут включать по меньшей мере один из параметров: высота фильтра, ширина фильтра, высота изображения, ширина изображения, размер фильтра, число каналов, число фильтров или число изображений.
10. Способ по п. 9, в котором высота изображения и ширина изображения могут содержать произвольные значения.
11. Способ по п. 1, в котором одно или более первых изображений включают одно или более из:
одного или более иероглифов;
одного или более символов китайского-японского-корейского языков;
одну или более арабских строк; или
комбинацию из одного или более других символов.
12. Способ по п. 1, в котором генерация одного или более вторых изображений включает:
генерацию одного или более вторых изображений, соответствующих естественно искаженным изображениям.
13. Способ по п. 1, в котором построение одного или более вторых изображений дополнительно включает выполнение свертки перед передачей одного или более вторых изображений в качестве третьего выхода.
14. Способ по п. 7, в котором первая матрица, вторая матрица и третья матрица содержат обучаемые параметры.
15. Система случайной аугментации данных, содержащая компоненты:
память; и
процессор, взаимосвязанный с указанной памятью, обеспечивающий:
получение одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения в обучении;
предоставление одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, где первое множество слоев применяет фильтры изображений;
предоставление первого выхода первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, где второй слой применяет для вычислений случайные наборы параметров;
получение параметров искажений от второго слоя вычислительных блоков;
генерация одного или более вторых изображений на основе одного или более первых изображений и параметров искажений;
получение в качестве третьего выхода одного или более вторых изображений; и
добавление одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
16. Система по п. 15, отличающаяся тем, что процессор дополнительно обеспечивает:
генерацию случайной матрицы ядра свертки для второго слоя вычислительных блоков на основе одной или более матриц.
17. Система по п. 16, в которой одна или более матриц включают одну или более из:
первых матриц средних значений, где первая матрица инициализируется случайными значениями;
вторых матриц значений стандартного отклонения, где вторая матрица инициализируется нулевыми значениями;
третьих матриц значений смещения, где третья матрица базируется на количестве фильтров, применяемых ко второму входу; или
четвертых матриц, которые базируются на произвольном значении стандартного отклонения и значении нормального распределения.
18. Система по п. 17, в которой произвольное значение стандартного отклонения задает грубость искажений изображения.
19. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при их исполнении вычислительным устройством побуждают его к:
получению одного или более первых изображений, ассоциированных с обучающей выборкой изображений для обучения модели машинного обучения в обучении;
предоставлению одного или более первых изображений в качестве первого входа для первого множества слоев вычислительных блоков, где первое множество слоев применяет фильтры изображений;
предоставлению первого выхода первого множества слоев вычислительных блоков в качестве второго входа для второго слоя вычислительных блоков, где второй слой применяет для вычислений случайные наборы параметров;
получению параметров искажений от второго слоя вычислительных блоков;
генерации одного или более вторых изображений на основе одного или более первых изображений и параметров искажений;
получению в качестве третьего выхода одного или более вторых изображений; и
добавлению одного или более вторых изображений к обучающей выборке изображений для обучения модели машинного обучения.
20. Носитель по п. 19, в котором для получения первого входа обрабатывающее устройство выполняет:
разделение одного или более первых изображений на множество частей; и
предоставление каждой части из множества частей первому набору слоев вычислительных блоков.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| СПОСОБ ОБУЧЕНИЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ | 2014 |
|
RU2566979C1 |
| СПОСОБ ОБУЧЕНИЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ | 2012 |
|
RU2504006C1 |

