Ссылка на родственную заявку
[0001] Настоящее изобретение испрашивает приоритет по заявке на патент КНР №201610262499.2, поданной 25 апреля 2016 года, содержание которой полностью включено в настоящее описание посредством ссылки.
Область техники, к которой относится изобретение
[0002] Область техники настоящего изобретения относится к технической области компьютеров, в частности, к технической области Интернета, и, в частности, к способу и устройству распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы.
Предпосылки создания изобретения
[0003] С развитием человеко-машинной интеллектуальной технологии все больше вопросно-ответных систем используют технологию человеко-машинного интеллекта. Существующая человеко-машинная интеллектуальная вопросно-ответная система обычно имеет форму "один вопрос и один ответ", то есть вводимые пользователем данные по умолчанию считаются полным предложением, а затем ответ на вопрос возвращается как ответ на полное предложение. Фактически же, в процессе человеко-машинного диалога пользователь может разделить полное предложение на множество сегментированных предложений для выразительности. Например, пользователь может разделить "Я хочу спросить, сколько времени потребуется, чтобы вещи были доставлены в Пекин" для ввода на два сегментированных предложения "Я хочу спросить" и "сколько времени займет доставка вещей в Пекин". Для этой ситуации необходимо, чтобы человеко-машинная интеллектуальная вопросно-ответная система точно оценивала целостность предложения, вводимого пользователем.
[0004] Существующая человеко-машинная интеллектуальная вопросно-ответная система обычно использует модель китайского языка (N-граммную модель), чтобы судить о вероятности того, что введенное предложение является полным предложением, предсказывая вероятность появления следующего слова. Однако из-за ограничений самой N-граммной модели значение N обычно составляет всего 2 или 3, то есть появление текущего слова связано только с предыдущими одним или двумя словами, в результате этого из-за недостатка информации модель не способна точно определить, является ли введенное предложение полным предложением.
Сущность изобретения
[0005] Целью настоящего изобретения является предложить усовершенствованный способ и устройства распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, чтобы решить технические проблемы, упомянутые в вышеприведенном разделе предпосылок создания изобретения.
[0006] В первом аспекте настоящее изобретение предлагает способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, и этот способ включает в себя: прием текущего предложения, вводимого пользователем; ввод текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, при этом модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и определение текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
[0007] В некоторых формах осуществления способ дополнительно включает в себя: определение на основе модели языка на базе рекуррентной нейронной сети второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению; определение текущего предложения и предыдущего предложения, примыкающего к текущему предложению, как сегментированных предложений, если вторая вероятность больше заданного второго порога; и объединение текущего предложения с предыдущим предложением как полного предложения.
[0008] В некоторых формах осуществления способ дополнительно включает в себя создание модели распознавания сегментированных предложений, которое включает в себя: получение корпуса вопросов, причем корпус вопросов содержит множество языковых материалов вопросов, а языковые материалы вопросов - это полные предложения; сегментацию языковых материалов вопросов для порождения множества сегментированных предложений; определение оценки сегментированного предложения в соответствии с числом слов, содержащихся в сегментированном предложении, и числом слов, содержащихся в полном предложении, соответствующем сегментированному предложению, причем эта оценка используется для представления вероятности того, что сегментированное предложение, соответствующее оценке, - это полное предложение; определение вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети; и обучение для получения модели распознавания сегментированных предложений, используя вероятности каждого из сегментированных предложений и оценок сегментированных предложений в качестве обучающих образцов.
[0009] В некоторых формах осуществления сегментация языковых материалов вопросов для порождения множества сегментированных предложений включает в себя порождение сегментированных предложений, включающее: сегментацию первого языкового материала вопросов для получения первого языкового материала вопросов, состоящего из n слов, причем первый языковой материал вопросов является языковым материалом вопросов в корпусе вопросов, а n - натуральное число; взятие от 1-го до i-го слов из первого языкового материала вопросов для порождения i-го предложения, где 1≤i≤n; порождение n сегментированных предложений, соответствующих первому языковому материалу вопросов; и на основе этапа порождения сегментированных предложений, порождение сегментированных предложений, соответствующих первым языковым материалам вопросов в корпусе вопросов.
[0010] В некоторых формах осуществления изобретения способ дополнительно включает в себя: определение текущего предложения как сегментированного предложения, если первая вероятность меньше или равна заданному первому порогу; и порождение информации подсказки для подсказки пользователю продолжить ввод.
[0011] Во втором аспекте настоящее изобретение предлагает устройство распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, и это устройство содержит: модуль приема текущего предложения, сконфигурированный для приема текущего предложения, вводимого пользователем; модуль получения первой вероятности, сконфигурированный для ввода текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и модуль определения полного предложения, сконфигурированный для определения текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
[0012] В некоторых формах осуществления устройство дополнительно содержит: модуль определения второй вероятности, сконфигурированный для определения на основе модели языка на базе рекуррентной нейронной сети второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению; определения текущего предложения и предыдущего предложения, примыкающего к текущему предложению, сегментированными предложениями, если вторая вероятность больше заданного второго порога, и объединения текущего предложения с предыдущим предложением в виде полного предложения.
[0013] В некоторых формах осуществления устройство дополнительно содержит: модуль установления модели распознавания сегментированных предложений, сконфигурированный для установления модели распознавания сегментированных предложений и содержащий: блок получения корпуса вопросов, сконфигурированный для получения корпуса вопросов, причем корпус вопросов включает в себя множество языковых материалов вопросов, а языковые материалы вопросов - это полные предложения; блок порождения сегментированных предложений, сконфигурированный для сегментации языковых материалов вопросов с целью порождения множества сегментированных предложений; блок определения оценки, сконфигурированный для определения оценки сегментированного предложения в соответствии с числом слов, содержащихся в сегментированном предложении, и числом слов, содержащихся в полном предложении, соответствующем сегментированному предложению, причем эта оценка используется для представления вероятности того, что сегментированное предложение, соответствующее оценке, - это полное предложение; блок определения вероятности, сконфигурированный для определения вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети; и блок обучения модели распознавания сегментированных предложений, сконфигурированный для обучения для получения модели распознавания сегментированных предложений, используя вероятности каждого из сегментированных предложений и оценок сегментированных предложений в качестве обучающих образцов.
[0014] В некоторых формах осуществления блок порождения сегментированных предложений специально сконфигурирован для порождения сегментированных предложений, включающего: сегментацию первого языкового материала вопросов для получения первого языкового материала вопросов, состоящего из n слов, причем первый языковой материал вопросов является языковым материалом вопросов в корпусе вопросов, а n - натуральное число; взятие от 1-го до i-го слов из первого языкового материала вопросов для порождения i-го предложения, где 1≤i≤n; порождение n сегментированных предложений, соответствующих первому языковому материалу вопросов; и на основе этапа порождения сегментированных предложений, порождение сегментированных предложений, соответствующих первым языковым материалам вопросов в корпусе вопросов.
[0015] В некоторых формах осуществления устройство дополнительно содержит: модуль определения сегментированного предложения, сконфигурированный для определения текущего предложения как сегментированного предложения, если первая вероятность меньше или равна заданному первому порогу; и порождения информации подсказки для подсказки пользователю продолжить ввод.
[0016] В соответствии со способом и устройством распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, предлагаемых настоящим изобретением, сначала принимается текущее предложение, вводимое пользователем, затем принятое текущее предложение вводится в предварительно подготовленную сегментированную модель распознавания предложения, чтобы получить первую вероятность того, что текущее предложение является полным предложением, затем определяется, является ли первая вероятность больше заданного первого порога, и если первая вероятность больше заданного первого порога, текущее предложение определяется как полное предложение. Способ объединяет модель китайского языка и модель языка на базе рекуррентной нейронной сети для получения модели распознавания сегментированных предложений с целью определения вероятности того, что текущее предложение является полным предложением, и модель распознавания сегментированных предложений может повысить точность человеко-машинной интеллектуальной вопросно-ответной системы при определении того, что текущее предложение является полным предложением.
Краткое описание чертежей
[0017] Другие особенности, цели и преимущества настоящего изобретения станут более очевидными после прочтения подробного описания не ограничивающих форм осуществления изобретения, сделанного со ссылкой на следующие чертежи:
[0018] Фиг. 1 - иллюстративная схема архитектуры системы, к которой может быть применено настоящее изобретение.
[0019] Фиг. 2 - блок-схема формы осуществления способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в соответствии с настоящим изобретением.
[0020] Фиг. 3 - блок-схема реализации получения предварительно обучаемой модели распознавания сегментированных предложений в способе распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в соответствии с настоящим изобретением.
[0021] Фиг. 4 - блок-схема другой формы осуществления способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в соответствии с настоящим изобретением.
[0022] Фиг. 5 - структурная схема формы осуществления устройства распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в соответствии с настоящим изобретением.
[0023] Фиг. 6 - структурная схема компьютерной системы терминального устройства или сервера, подходящей для реализации форм осуществления настоящего изобретения.
Подробное описание форм осуществления изобретения
[0024] Настоящее изобретение будет подробно описано ниже в сочетании с сопроводительными чертежами и формами осуществления. Следует понимать, что конкретные формы осуществления, описанные здесь, используются просто для объяснения соответствующего изобретения, а не для ограничения изобретения. Кроме того, следует отметить, что для удобства описания на прилагаемых чертежах показаны только блоки, относящиеся к соответствующему изобретению.
[0025] Следует также отметить, что формы осуществления в настоящем описании и отличительные особенности в формах осуществления могут быть объединены друг с другом на бесконфликтной основе. Настоящее изобретение будет подробно описано ниже со ссылкой на прилагаемые чертежи и в комбинации с формами осуществления.
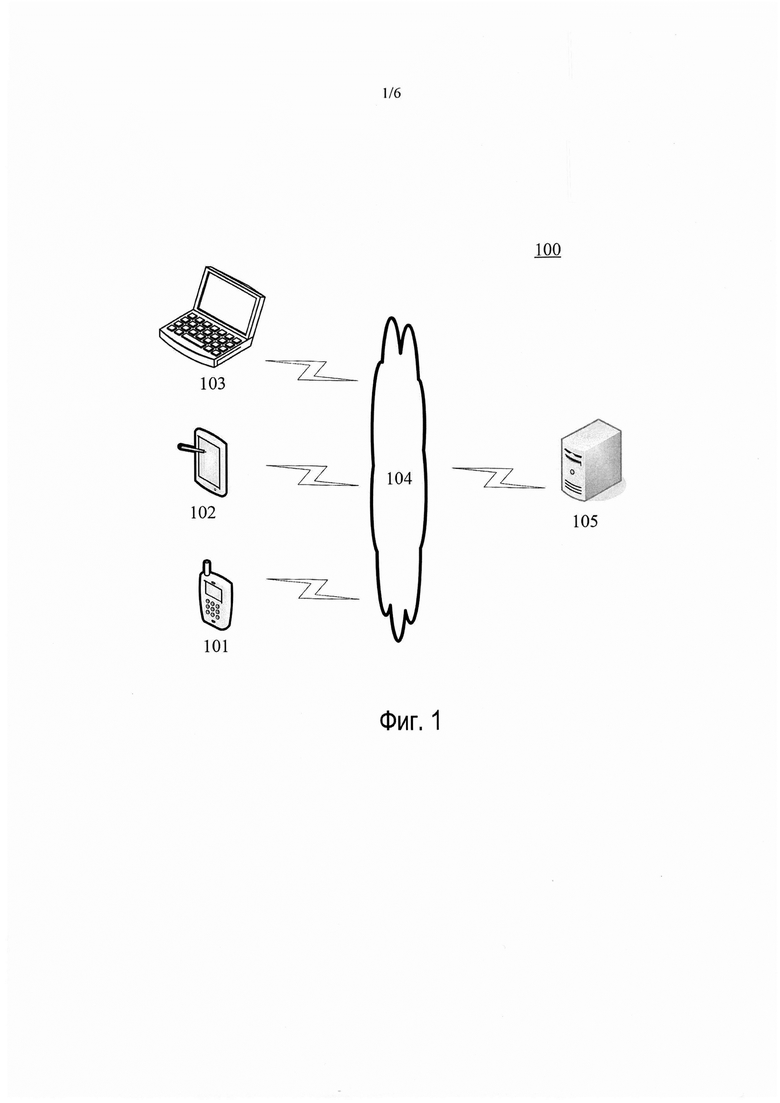
[0026] На фиг. 1 показан пример архитектуры системы 100, в которой применяется способ или устройство распознавания сегментированных предложений для человеко-машинной интеллектуальной системы в соответствии с формами осуществления настоящего изобретения.
[0027] Как показано на фиг. 1, архитектура системы 100 может содержать терминальные устройства 101, 102 и 103, сеть 104 и сервер 105. Сеть 104 служит в качестве среды, обеспечивающей линию связи между терминальными устройствами 101, 102 и 103 и сервером 105. Сеть 104 может содержать различные типы соединений, такие как проводные или беспроводные линии передачи или оптические волокна.
[0028] Пользователь может использовать терминальные устройства 101, 102 и 103 для взаимодействия с сервером 105 через сеть 104 для передачи или приема сообщений и т.п. Различные коммуникационные клиентские приложения, такие как программное обеспечение для обмена мгновенными сообщениями, торговые приложения, поисковые приложения, приложения браузера веб-страниц и программное обеспечение социальной платформы, могут быть установлены на терминальных устройствах 101, 102 и 103.
[0029] Терминальные устройства 101, 102 и 103 могут быть различными электронными устройствами, включающими экран дисплея и поддерживающими человеко-машинное интеллектуальную постановку вопросов и получение ответов, включая, среди прочего, смартфоны, планшетные компьютеры, электронные книги, проигрыватели формата МР3 (Moving Picture Experts Group Audio Layer III, технологии сжатия звука группы экспертов по движущимся изображениям уровня 3), проигрыватели формата МР4 (Moving Picture Experts Group Audio Layer IV, технологии сжатия изображения группы экспертов по движущимся изображениям уровня 4), ноутбуки и настольные компьютеры.
[0030] Сервер 105 может быть сервером, предоставляющим различные услуги, например, внутренним сервером для обеспечения поддержки текущему предложению, передаваемому терминальными устройствами 101, 102 и 103. Внутренний сервер может выполнять обработку, такую как статистические вычисления или анализ над данными, такими как принятое текущее предложение, и возвращать результат обработки терминальному устройству.
[0031] Следует отметить, что способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы обычно выполняется сервером 105. Соответственно, устройство обновления данных объекта обычно устанавливается на сервере 105.
[0032] Следует принимать во внимание, что числа терминальных устройств, сетей и серверов на фиг. 1 являются лишь иллюстративными. Любое число терминальных устройств, сетей и серверов может предоставляться на основе реальных требований.
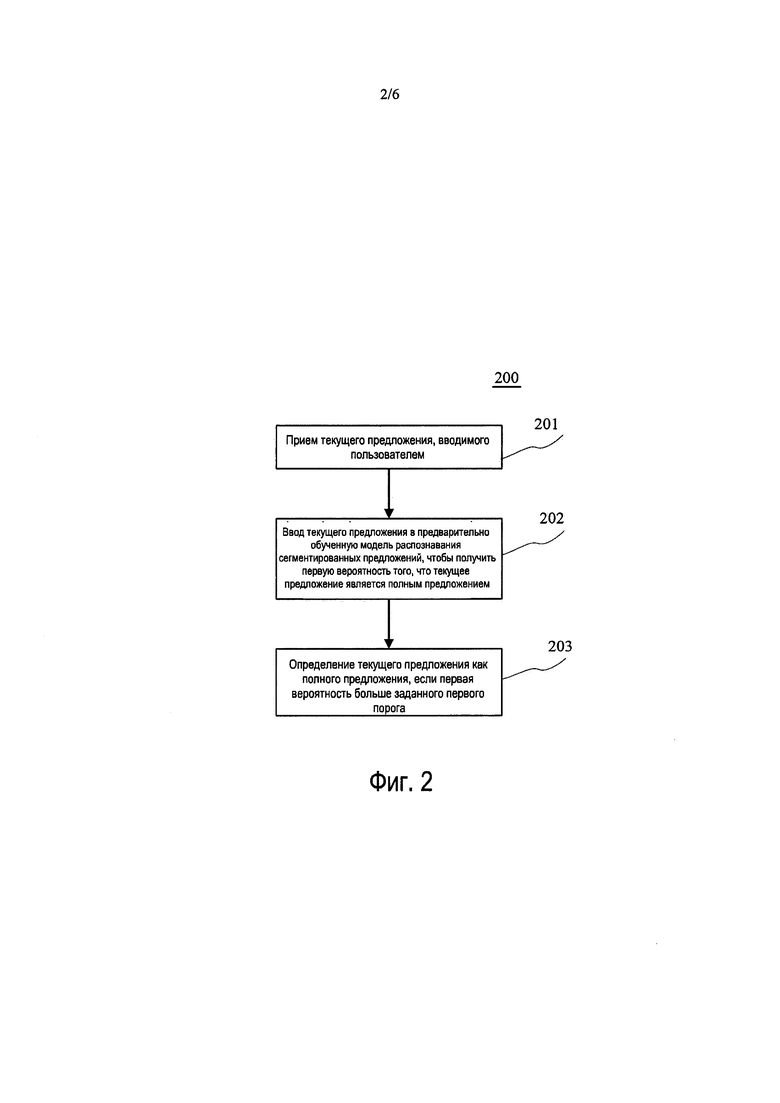
[0033] Обратимся снова к фиг. 2, на которой показана блок-схема 200 формы осуществления способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в соответствии с настоящим изобретением. Способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы включает в себя:
[0034] Этап 201: прием текущего предложения, вводимого пользователем.
[0035] В настоящей форме осуществления изобретения электронное устройство (например, сервер, показанный на фиг. 1), на котором выполняется человеко-машинный интеллектуальный способ вопросов-ответов, может принимать текущее предложение, вводимое пользователем, в режиме проводного соединения или в режиме беспроводного соединения с терминала, который используется пользователем для выполнения человеко-машинной интеллектуальной постановки вопросов и получение ответов. Следует отметить, что указанный выше режим беспроводного соединения может включать в себя, но не быть ограниченным, соединение 3G/4G, соединение Wi-Fi, соединение технологии Bluetooth, соединение технологии широкополосного доступа в микроволновом диапазоне (Worldwide Interoperability for Microwave Access, WiMAX), соединение по сетевому протоколу Zigbee, соединение UWB (Ultra-Wide Band, сверхширокополосное) и другие известные в настоящее время или разработанные в будущем режимы беспроводного соединения.
[0036] Как правило, в человеко-машинной интеллектуальной вопросно-ответной системе после того, как пользователь выполняет ввод один раз, считается, что пользователь ввел текущее предложение независимо от того, является ли предложение полным предложением. Например, когда пользователь хочет спросить, сколько времени потребуется для доставки вещей в Пекин, независимо от того, является ли ввод пользователя сегментированным предложением, аналогичным "Я хочу спросить" или полным предложением типа "Я хочу спросить, сколько времени потребуется для доставки вещей в Пекин", ввод пользователя может быть рассмотрен как текущее предложение.
[0037] Этап 202: ввод текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением.
[0038] В настоящей форме осуществления изобретения электронное устройство, на котором выполняется способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, может заранее подготовить модель распознавания сегментированных предложений, и модель распознавания сегментированных предложений может быть использована для определения первой вероятности того, что текущее предложение является полным предложением, в соответствии с вероятностью, соответствующей модели китайского языка для текущего предложения, введенного пользователем, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети. На основании ввода текущего предложения пользователем, принятого на этапе 201, электронное устройство может ввести текущее предложение в модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением.
[0039] Этап 203: определение текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
[0040] В настоящей форме осуществления изобретения электронное устройство, на котором выполняется способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, может задать первый порог, а затем исходя из первой вероятности того, что текущее предложение является полным предложением, полученной на этапе 202, электронное устройство может судить о соотношении между первой вероятностью и первым порогом, и если первая вероятность больше заданного первого порога, текущее предложение может считаться полным предложением.
[0041] В некоторых опциональных формах осуществления настоящего изобретения, если первая вероятность меньше или равна заданному первому порогу, текущее предложение может рассматриваться как сегментированное предложение. Электронное устройство может порождать информацию подсказки для подсказки пользователю продолжить ввод, которая может быть похожа на "ну, говорите, пожалуйста" или что-либо подобное.
[0042] В соответствии со способом распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, представленным вышеприведенной формой осуществления настоящего изобретения, сначала принимается текущее предложение, введенное пользователем, затем принятое текущее предложение вводится в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, далее определяется, является ли первая вероятность большей заданного первого порога, и если первая вероятность больше заданного первого порога, текущее предложение определяется как полное предложение. Этот способ объединяет модель китайского языка и модель языка на базе рекуррентной нейронной сети для получения модели распознавания сегментированных предложений с целью определения вероятности того, что текущее предложение является полным предложением. Модель распознавания сегментированных предложений может улучшить точность суждения человеко-машинной интеллектуальной вопросно-ответной системы о том, что текущее предложение является полным предложением.
[0043] В некоторых опциональных схемах предварительно обучаемая модель распознавания сегментированных предложений, используемая на этапе 202, может быть установлена посредством блок-схемы 300, показанной на фиг. 3.
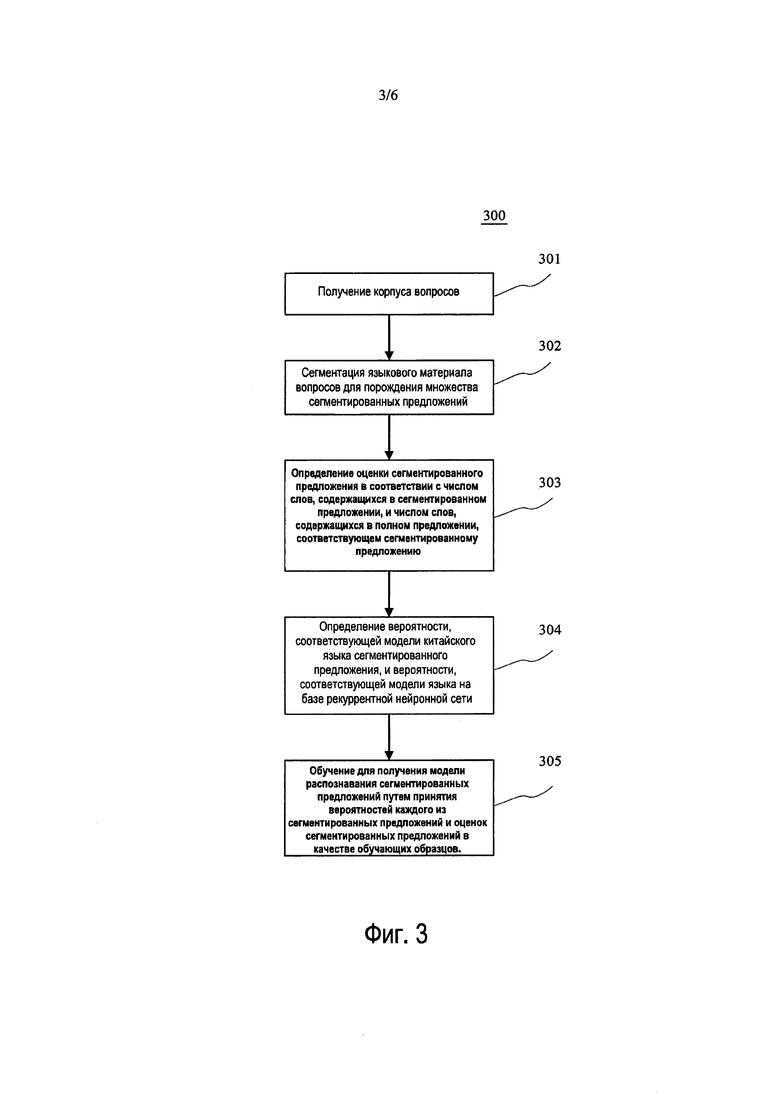
[0044] Этап 301: получение корпуса вопросов.
[0045] В этой реализации электронное устройство, на котором выполняется способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, может выбирать языковые материалы полных вопросов из данных человеко-машинных вопросов-ответов за прошлое время, чтобы сформировать корпус вопросов. Корпус вопросов здесь может содержать множество языковых материалов вопросов, где каждый из языковых материалов вопросов является полным предложением. В качестве примера приводятся данные о консультативной человеко-машинной интеллектуальной вопросно-ответной системе в области электронной коммерции, эти данные включают в себя данные онлайн-консультаций и данные офлайн-консультаций, и данные офлайн-консультаций обычно являются относительно полными предложениями, поскольку они не являются реальными интерактивными данными в реальном времени. Вследствие этого данные офлайн-консультаций в человеко-машинной интеллектуальной вопросно-ответной системе могут быть выбраны для формирования вышеупомянутого корпуса вопросов.
[0046] Следует отметить, что электронному устройству необходимо также дополнительно обработать полученный корпус вопросов. Во-первых, языковые материалы вопросов, содержащие множество полных предложений, могут быть сегментированы по предложениям. Здесь запятые, паузы и т.п. в языковых материалах вопросов могут быть удалены, а вопросительные знаки, точки, восклицательные знаки и т.п. могут использоваться в качестве разделителей для сегментации языковых материалов вопросов. Во-вторых, конечная метка (тег), такая как <end>, может быть добавлена в конце каждого полного предложения.
[0047] Этап 302: сегментация языкового материала вопросов для порождения множества сегментированных предложений.
[0048] В настоящей форме осуществления изобретения электронное устройство может сегментировать каждый из языковых материалов вопросов в корпусе вопросов различными способами. После этого, согласно пословной сегментации, порождаются сегментированные предложения, соответствующие каждому из языковых материалов вопросов. Взяв в качестве примера языкового материала вопросов "имеет ли этот мобильный телефон металлический корпус"  сначала можно выполнить пословную сегментацию, чтобы получить результат пословной сегментации как "имеет ли этот мобильный телефон металлический корпус"
сначала можно выполнить пословную сегментацию, чтобы получить результат пословной сегментации как "имеет ли этот мобильный телефон металлический корпус"  а затем получить сегментированные предложения, соответствующие языковому материалу вопроса.
а затем получить сегментированные предложения, соответствующие языковому материалу вопроса.
[0049] Следует отметить, что электронное устройство может получать сегментированные предложения, соответствующие каждому из языковых материалов вопросов, посредством следующих шагов: во-первых, электронное устройство может выполнить пословную сегментацию на первом языковом материале вопросов, чтобы получить первый корпус вопросов, состоящий из n слов; первым языковым материалом вопросов здесь может быть любой языковой материал вопросов в корпусе вопросов, а n - натуральное число; после этого электронное устройство может брать слова с 1-го по i-e из первого языкового материала вопросов для порождения i-го сегментированного предложения; и, наконец, согласно указанному выше способу порождаются n сегментированных предложений, соответствующих первому языковому материалу вопросов, где 1≤i≤n. Электронное устройство может использовать способ для порождения сегментированных предложений, соответствующих каждому из языковых материалов вопросов в корпусе вопросов. Например, если первым языковым материалом вопросов является "имеет ли этот мобильный телефон металлический корпус"  сначала этот первый языковой материал вопросов может быть подвергнут пословной сегментации, чтобы получить результат пословной сегментации как "имеет ли этот мобильный телефон металлический корпус"
сначала этот первый языковой материал вопросов может быть подвергнут пословной сегментации, чтобы получить результат пословной сегментации как "имеет ли этот мобильный телефон металлический корпус" 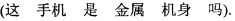 Можно видеть, что первый языковой материал вопросов содержит шесть слов, а затем можно получить шесть сегментированных предложений, соответствующих первому языковому материалу вопросов. Шестью сегментированными предложениями первого языкового материала вопросов соответственно являются: "этот"
Можно видеть, что первый языковой материал вопросов содержит шесть слов, а затем можно получить шесть сегментированных предложений, соответствующих первому языковому материалу вопросов. Шестью сегментированными предложениями первого языкового материала вопросов соответственно являются: "этот" 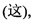 "этот мобильный телефон"
"этот мобильный телефон" 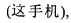 "этот мобильный телефон имеет"
"этот мобильный телефон имеет"  "этот мобильный телефон имеет металлический"
"этот мобильный телефон имеет металлический"  "этот мобильный телефон имеет металлический корпус"
"этот мобильный телефон имеет металлический корпус"  "имеет ли этот мобильный телефон металлический корпус"
"имеет ли этот мобильный телефон металлический корпус" 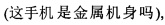 при этом "имеет ли этот мобильный телефон металлический корпус" можно рассматривать как один из видов сегментированного предложения.
при этом "имеет ли этот мобильный телефон металлический корпус" можно рассматривать как один из видов сегментированного предложения.
[0050] Этап 303: определение оценки сегментированного предложения в зависимости от числа слов, содержащихся в сегментированном предложении, и числа слов, содержащихся в полном предложении, соответствующем этому сегментированному предложению.
[0051] В этой реализации на основе первого языкового материала вопросов и полученных на этапе 302 сегментированных предложений, соответствующих первому языковому материалу вопросов, электронное устройство может определить число слов, содержащихся в сегментированном предложении и полном предложении, соответствующем сегментированному предложению, и разделить число слов, содержащихся в каждом из сегментированных предложений, на число слов, содержащихся в полном предложении, соответствующем сегментированному предложению, для получения оценки, а именно вероятности того, что сегментированное предложение является полным предложением. Принимая в качестве примера первый языковой материал вопросов "имеет ли этот мобильный телефон металлический корпус"  и его соответствующие сегментированные предложения, включающие "этот мобильный телефон имеет"
и его соответствующие сегментированные предложения, включающие "этот мобильный телефон имеет"  и "имеет ли этот мобильный телефон металлический корпус"
и "имеет ли этот мобильный телефон металлический корпус"  число слов, содержащихся в первом языковом материале вопросов равно 6, а количества слов, содержащихся в соответствующих вышеприведенных сегментированных предложениях, равны 3 и 6. Таким образом, оценки, используемые для характеризации вероятностей того, что два сегментированных предложения являются полными предложениями, равны 0,5 и 1.
число слов, содержащихся в первом языковом материале вопросов равно 6, а количества слов, содержащихся в соответствующих вышеприведенных сегментированных предложениях, равны 3 и 6. Таким образом, оценки, используемые для характеризации вероятностей того, что два сегментированных предложения являются полными предложениями, равны 0,5 и 1.
[0052] Этап 304: определение вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети.
[0053] В этой реализации электронное устройство определяет вероятность того, что сегментированные предложения являются полным предложением, соответственно с использованием модели китайского языка и модели языка на базе рекуррентной нейронной сети. По сравнению со способом определения вероятности полного предложения только моделью китайского языка в известном уровне техники, этот способ может эффективно избежать проблемы низкой точности модели, вызванной недостатком данных.
[0054] Этап 305: обучение для получения модели распознавания сегментированных предложений путем принятия вероятностей каждого из сегментированных предложений и оценок сегментированных предложений в качестве обучающих образцов.
[0055] В этой реализации на основе оценок сегментированного предложения, определенных на этапе 303, и вероятности, соответствующей модели китайского языка каждого из сегментированных предложений, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети, определенной на этапе 304, электронное устройство может осуществлять обучение с использованием алгоритма линейной регрессии и т.п., чтобы порождать вышеупомянутую модель распознавания сегментированных предложений. Модель распознавания сегментированных предложений здесь может быть формулой вида y=ƒ(x1,x2), где x1 и х2 относятся к вероятности, соответствующей модели китайского языка некоторого предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети, соответственно, и у относится к вероятности того, что предложение является полным предложением.
[0056] В соответствии со способом обучения модели распознавания сегментированных предложений, обеспечиваемой реализацией вышеупомянутой формы осуществления настоящего изобретения, каждый из языковых материалов вопросов в корпусе вопросов сегментируется для получения сегментированных предложений, соответствующих каждому из языковых материалов вопросов, затем оценки каждого из сегментированных предложений, вероятность, соответствующая модели китайского языка, и вероятность, соответствующая модели языка на базе рекуррентной нейронной сети, получают в качестве обучающих данных, и, наконец, модель распознавания сегментированных предложений получается путем обучения обучающими данными при принятии алгоритма линейной регрессии и т.п., при этом модель распознавания сегментированных предложений объединяет преимущества модели китайского языка и модели языка на базе рекуррентной нейронной сети, так что точность человеко-машинной интеллектуальной вопросно-ответной системы при оценке того, является ли текущее предложение полным предложением, может быть эффективно улучшена.
[0057] Далее обратимся к фиг. 4, на ней показана блок-схема 400 другой формы осуществления способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы. Блок-схема 400 способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы включает в себя:
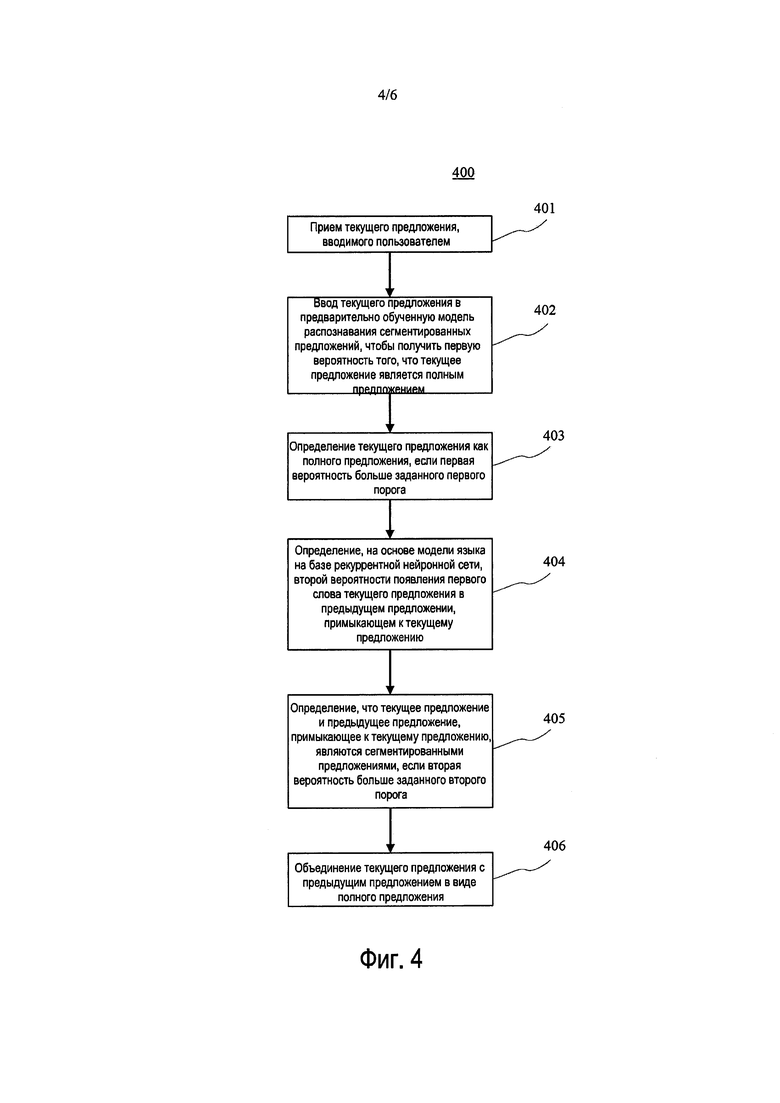
[0058] Этап 401: прием текущего предложения, вводимого пользователем.
[0059] В настоящей форме осуществления изобретения электронное устройство (например, сервер, показанный на фиг. 1), на котором выполняется способ человеко-машинных интеллектуальных вопросов и ответов, может принимать текущее предложение, введенное пользователем, в режиме проводного соединения или в режиме беспроводного соединения с терминала, который используется пользователем для выполнения человеко-машинных интеллектуальных вопросов и ответов.
[0060] Этап 402: ввод текущего предложение в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением.
[0061] В настоящей форме осуществления изобретения электронное устройство, на котором выполняется способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, может вводить текущее предложение, введенное пользователем, в обучаемую модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением. Модель распознавания сегментированных предложений здесь может быть использована для определения первой вероятности того, что текущее предложение является полным предложением, в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, вводимого пользователем, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети.
[0062] Этап 403: определение текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
[0063] В настоящей форме осуществления изобретения электронное устройство, на котором выполняется способ распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, может задать первый порог, а затем на основе первой вероятности того, что текущее предложение является полным предложение, полученной на этапе 402, электронное устройство может судить о соотношении между первой вероятностью и первым порогом, и если первая вероятность больше заданного первого порога, текущее предложение может рассматриваться как полное предложение.
[0064] Этап 404: определение на основе модели языка на базе рекуррентной нейронной сети второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению.
[0065] В настоящей форме осуществления изобретения, исходя из того, что текущее предложение определено как полное предложение на этапе 403, электронное устройство может сначала получить предыдущее предложение, примыкающее к текущему предложению, и первое слово в текущем предложении, а затем предсказать, с использованием модели языка на базе рекуррентной нейронной сети, вторую вероятность появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению.
[0066] Этап 405: определение, что текущее предложение и предыдущее предложение, примыкающее к текущему предложению, являются сегментированными предложениями, если вторая вероятность больше заданного второго порога.
[0067] В настоящей форме осуществления изобретения электронное устройство может предварительно установить второй порог, а затем сравнить вторую вероятность со вторым порогом. Текущее предложение и предыдущее предложение, примыкающее к текущему предложению, можно рассматривать как сегментированные предложения, если результатом сравнения является то, что вторая вероятность больше второго порога. Предыдущее предложение, примыкающее к текущему предложению, можно рассматривать как полное предложение, если результатом сравнения является то, что вторая вероятность меньше или равна второму порогу.
[0068] Этап 406: объединение текущего предложения с предыдущим предложением в виде полного предложения.
[0069] В настоящей форме осуществления изобретения на основе того, что текущее предложение и предыдущее предложение, примыкающее к текущему предложению, определяются на этапе 405 как сегментированные предложения, электронное устройство может объединять текущее предложение с предыдущим предложением, примыкающим к текущему предложению, в виде полного предложения. Следовательно, этапы 404, 405 и 406 можно рассматривать как дополнительное суждение о том, является ли текущее предложение полным предложением, и точность оценки того, является ли текущее предложение полным предложением, может быть дополнительно улучшена. Кроме того, эта форма осуществления реализует форму "нескольких вопросов и одного ответа" человеко-машинной интеллектуальной вопросно-ответной системы, то есть когда пользователь вводит более одного сегментированного предложения, человеко-машинная интеллектуальная вопросно-ответная система может дать ответ для обратной связи один раз.
[0070] Как можно видеть из фиг. 4, по сравнению с формой осуществления, соответствующей фиг. 2, блок-схема 400 способа распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы в настоящей форме осуществления изобретения включает этап дальнейшего суждения о том, является ли текущее предложение полным предложением. Следовательно, согласно схеме, описанной в настоящей форме осуществления изобретения, можно судить о том, является ли текущее предложение полным предложением, с помощью модели языка на базе рекуррентной нейронной сети, что дополнительно повышает точность оценки того, является ли текущее предложение полным предложением.
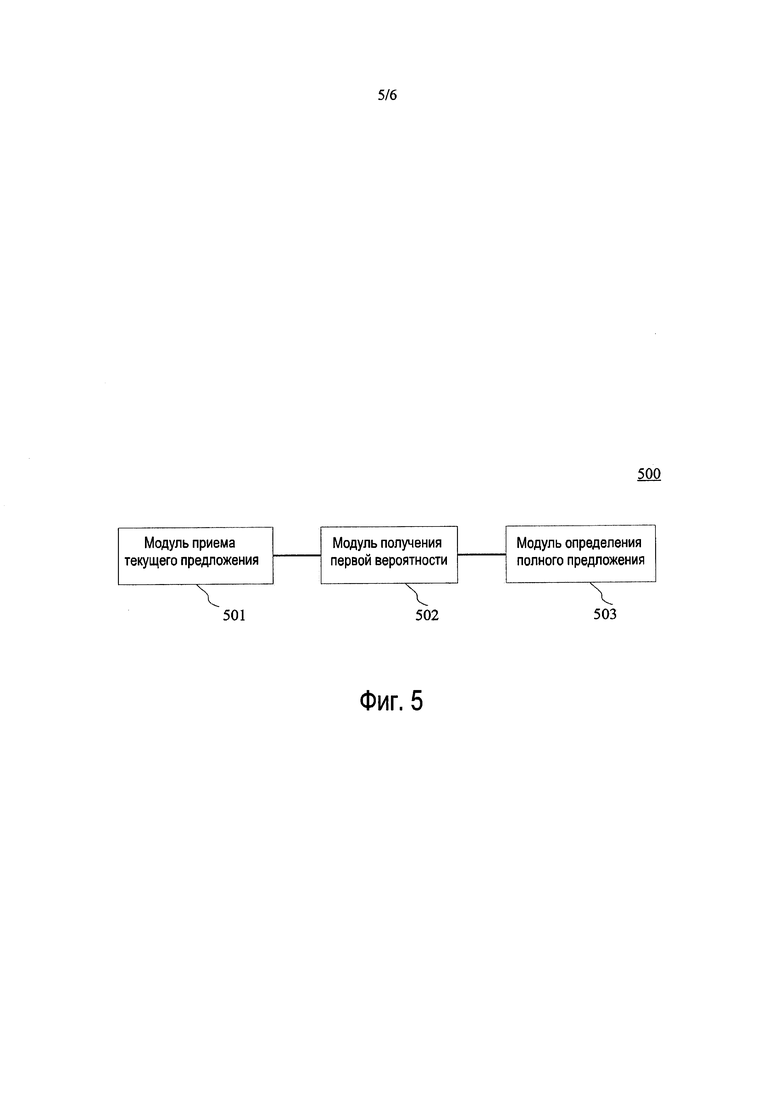
[0071] Далее, как показано на фиг. 5, в качестве реализации способа, показанного на приведенных выше чертежах, настоящее изобретение предлагает форму осуществления устройства распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, эта форма осуществления устройства соответствует форме осуществления способа, показанного на фиг. 2, и устройство может быть применено к различным типам электронных устройств.
[0072] Как показано на фиг. 5, человеко-машинное интеллектуальное вопросно-ответное устройство 500, как описано в настоящей форме осуществления изобретения, содержит модуль 501 приема текущего предложения, модуль 502 получения первой вероятности и модуль 503 определения полного предложения. Модуль 501 приема текущего предложения сконфигурирован для приема текущего предложения, вводимого пользователем; первый модуль 502 получения вероятности сконфигурирован для ввода текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и модуль 503 определения полного предложения сконфигурирован для определения текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
[0073] В некоторых опциональных формах осуществления настоящего изобретения устройство 500 дополнительно содержит модуль определения второй вероятности (не показан), который сконфигурирован для определения, на основе модели языка на базе рекуррентной нейронной сети, второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению; определения текущего предложения и предыдущего предложения, примыкающего к текущему предложению, как сегментированных предложений, если вторая вероятность больше заданного второго порога, и объединения текущего предложения с предыдущим предложением в виде полного предложения.
[0074] В некоторых опциональных формах осуществления настоящего изобретения устройство 500 дополнительно содержит модуль установления модели распознавания сегментированных предложений (не показан), который сконфигурирован для установления модели распознавания сегментированных предложений и содержит: блок получения корпуса вопросов (не показан), сконфигурированный для получения корпуса вопросов, причем корпус вопросов включает в себя множество языковых материалов вопросов, и языковые материалы вопросов - это полные предложения; блок порождения сегментированных предложений (не показан), сконфигурированный для сегментации языковых материалов вопросов для порождения множества сегментированных предложений; блок определения оценки (не показанный), сконфигурированный для определения оценки сегментированного предложения в соответствии с числом слов, содержащихся в сегментированном предложении, и числом слов, содержащихся в полном предложении, соответствующем сегментированному предложению, причем оценка используется для представления вероятности того, что сегментированное предложение, соответствующее оценке, является полным предложением; блок определения вероятности (не показан), сконфигурированный для определения вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети; и блок обучения модели распознавания сегментированных предложений (не показан), сконфигурированный для обучения с целью получения модели распознавания сегментированных предложений, принимая вероятности каждого из сегментированных предложений и оценки сегментированных предложений в качестве обучающих образцов.
[0075] В некоторых опциональных формах осуществления настоящего изобретения блок порождения сегментированных предложений (не показанный) специально сконфигурирован для порождения сегментированных предложений каждого из языковых материалов вопросов, и порождение сегментированных предложений включает в себя: сегментацию первого языкового материала вопросов для получения первого языкового материала вопросов, состоящего из n слов, причем первым языковым материалом вопросов является некоторый языковой материал вопросов в корпусе вопросов, а n - натуральное число; взятие от 1-го до i-го слов из первого языкового материала вопросов для порождения i-го предложения, где 1≤i≤n; порождение n сегментированных предложений, соответствующих первому языковому материалу вопросов; и на основе порождения сегментированных предложений, порождение сегментированных предложений, соответствующих первым языковым материалам вопросов в корпусе вопросов.
[0076] В некоторых опциональных формах осуществления настоящего изобретения устройство 500 дополнительно содержит модуль распознавания сегментированных предложений (не показан), который сконфигурирован для определения текущего предложения как сегментированного предложения, если первая вероятность меньше или равна заданному первому порогу, и порождения информации подсказки для подсказки пользователю продолжить ввод.
[0077] Специалистам в данной области техники должно быть понятно, что устройство 500 распознавания сегментированных предложений для человеко-машинной интеллектуальной вопросно-ответной системы дополнительно содержит некоторые другие хорошо известные структуры, такие как процессор, память и т.п., и эти хорошо известные структуры не показаны на фиг. 5, чтобы не затенять излишне формы осуществления настоящего изобретения.
[0078] Обратимся к фиг. 6, на которой показана структурная схема компьютерной системы 600, приспособленной для реализации терминального устройства или сервера согласно формам осуществления настоящего изобретения.
[0079] Как показано на фиг. 6, компьютерная система 600 содержит центральный процессор (Central Processing Unit, CPU) 601, который может выполнять различные соответствующие действия и процессы в соответствии с программой, хранящейся в памяти 602 только для чтения (Read-Only Memory, ROM), или программой, загруженной в оперативную память (Random Access Memory, RAM) 603 из блока 608 хранения. Память RAM 603 хранит также различные программы и данные, необходимые операциям системы 600. Процессор CPU 601, память ROM 602 и память RAM 603 соединены друг с другом посредством шины 604. Интерфейс 605 ввода/вывода (Input/Output, I/O) также подключен к шине 604.
[0080] К интерфейсу I/O 605 подключаются следующие компоненты: блок 606 ввода, включающий клавиатуру, мышь и т.п.; блок 607 вывода, содержащий электроннолучевую трубку (Cathode Ray Tube, CRT), жидкокристаллическое дисплейное устройство (Liquid Crystal Display Device, LCD), громкоговоритель и т.д.; блок 608 хранения, содержащий жесткий диск и т.п., и блок 609 связи, содержащий карту сетевого интерфейса, такую как карта локальной вычислительной сети (Local Area Network, LAN), и модем. Блок 609 связи осуществляет процессы связи через сеть, такую как Интернет. Привод 610 также подключается к интерфейсу I/O 605 по мере необходимости. Съемный носитель 611, такой как магнитный диск, оптический диск, магнитооптический диск и полупроводниковое запоминающее устройство, может быть установлен на привод 610, чтобы обеспечить выборку компьютерной программы из съемного носителя 611, и ее установку в блок 608 хранения по мере необходимости.
[0081] В частности, согласно формам осуществления настоящего изобретения процесс, описанный выше со ссылкой на блок-схему, может быть реализован в программе программного обеспечения для компьютера. Например, форма осуществления настоящего изобретения включает в себя компьютерный программный продукт, содержащий компьютерную программу, которая материально встроена в машиночитаемый носитель. Компьютерная программа содержит программные коды для выполнения способа, как показано на блок-схеме. В такой форме осуществления изобретения компьютерная программа может быть загружена и установлена из сети посредством блока 609 связи и/или может быть установлена со съемного носителя 611.
[0082] Блок-схемы на прилагаемых чертежах иллюстрируют архитектуры, функции и операции, которые могут быть реализованы в соответствии с системами, способами и программными продуктами для компьютера различных форм осуществления настоящего изобретения. В этом отношении каждый из блоков на блок-схемах может представлять собой модуль, сегмент программы или часть кода; упомянутый модуль, сегмент программы или часть кода содержит одну или несколько исполняемых команд для реализации указанных логических функций. Следует также отметить, что в некоторых альтернативных реализациях функции, обозначенные блоками, могут встречаться в последовательности, отличной от последовательностей, показанных на чертежах. Например, любые два блока, представленные последовательно, могут выполняться, по существу, параллельно или они могут иногда быть в обратной последовательности, в зависимости от используемой функции. Следует также отметить, что каждый блок на блок-схемах, а также комбинация блоков могут быть реализованы с использованием специальной аппаратной системы, выполняющей определенные функции или операции, или комбинацией выделенного аппаратного обеспечения и команд для компьютера.
[0083] Блоки или модули, участвующие в формах осуществления настоящего изобретения, могут быть реализованы с помощью программного обеспечения или аппаратного обеспечения. Описанные блоки или модули также могут быть предусмотрены в процессоре, например, описываться как: процессор, содержащий модуль приема текущего предложения, модуль получения первой вероятности и модуль определения полного предложения, причем наименования этих блоков или модулей в некоторых случаях не представляют собой ограничение для таких блоков или модулей. Например, модуль приема текущего предложения может быть описан также как "модуль для приема текущего предложения, вводимого пользователем".
[0084] В другом аспекте настоящее изобретение дополнительно предлагает энергонезависимый носитель данных для компьютера. Энергонезависимый носитель данных для компьютера может быть энергонезависимым носителем данных для компьютера, включенным в устройство в вышеописанных формах осуществления, или автономным энергонезависимым носителем данных для компьютера, не смонтированным в устройство. Энергонезависимый носитель данных для компьютера хранит одну или несколько программ. Одна или несколько программ, выполняемых устройством, заставляют устройство: принимать текущее предложение, вводимое пользователем; вводить текущее предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и определять текущее предложение как полное предложение, если первая вероятность больше заданного первого порога.
[0085] В приведенном выше описании приводится только пояснение предпочтительных форм осуществления настоящего изобретения и используемых технических принципов. Специалистам в данной области техники должно быть понятно, что объем настоящего изобретения не ограничивается техническими решениями, образованными конкретными комбинациями вышеописанных технических характеристик. Объем изобретения должен охватывать также другие технические решения, образованные любыми комбинациями вышеописанных технических характеристик или их эквивалентных характеристик, не отступая от концепции изобретения. Например, в технических схемах, образованных описанными выше признаками, эти признаки могут быть заменены, не ограничиваясь этим, техническими признаками, имеющими функции, аналогичные раскрытым в настоящем описании.
Изобретение относится к области распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы. Техническим результатом является повышение точности распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы. Способ распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы включает: прием текущего предложения, вводимого пользователем; ввод текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и определение текущего предложения как полного предложения, если первая вероятность больше заданного первого порога. 4 н. и 8 з.п. ф-лы, 6 ил.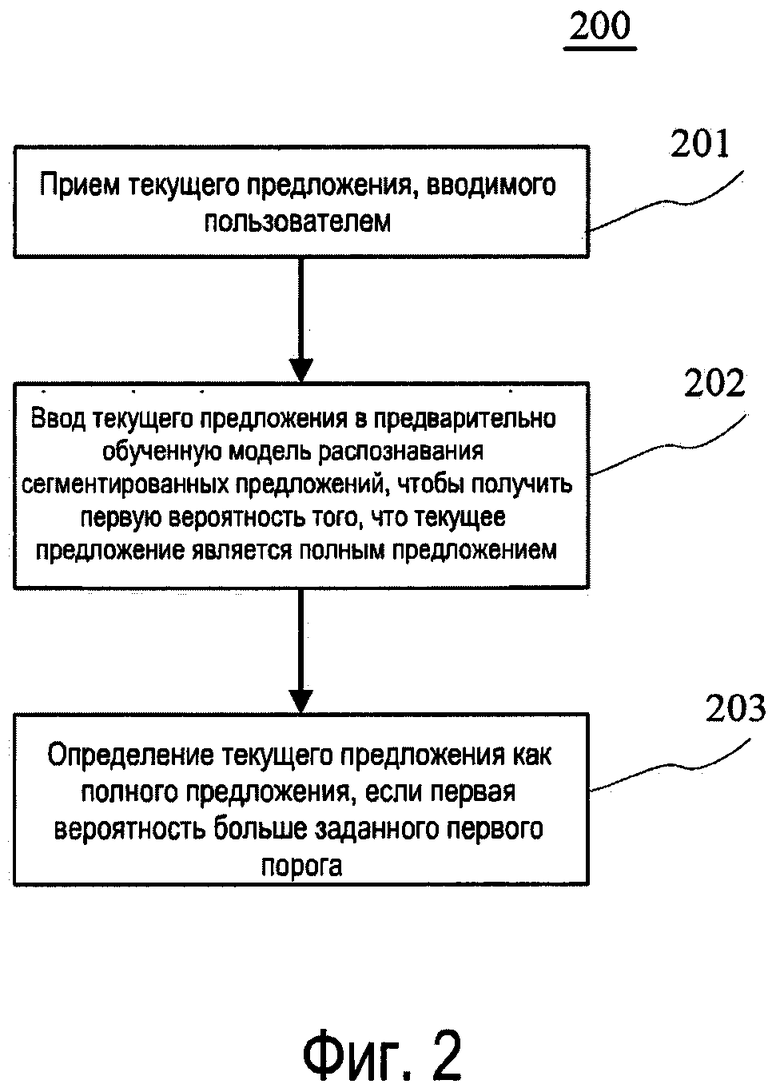
1. Способ распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, включающий:
прием текущего предложения, вводимого пользователем;
ввод текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и
определение текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
2. Способ по п. 1, дополнительно включающий:
определение, на основе модели языка на базе рекуррентной нейронной сети, второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению;
определение текущего предложения и предыдущего предложения, примыкающего к текущему предложению, как сегментированных предложений, если вторая вероятность больше заданного второго порога; и
объединение текущего предложения с предыдущим предложением в виде полного предложения.
3. Способ по п. 2, дополнительно включающий:
создание модели распознавания сегментированных предложений, включающее:
получение корпуса вопросов, причем корпус вопросов содержит множество языковых материалов вопросов, а языковые материалы вопросов являются полными предложениями;
сегментацию языковых материалов вопросов для порождения множества сегментированных предложений;
определение оценки сегментированного предложения в соответствии с числом слов, содержащихся в сегментированном предложении, и числом слов, содержащихся в полном предложении, соответствующем сегментированному предложению, причем эта оценка используется для представления вероятности того, что сегментированное предложение, соответствующее оценке, - это полное предложение;
определение вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети; и
обучение для получения модели распознавания сегментированных предложений путем использования вероятности каждого из сегментированных предложений и оценок сегментированных предложений в качестве обучающих образцов.
4. Способ по п. 3, в котором сегментация языковых материалов вопросов для порождения множества сегментированных предложений включает в себя:
порождение сегментированных предложений, включающее: сегментацию первого языкового материала вопросов для получения первого языкового материала вопросов, состоящего из n слов, причем первый языковой материал вопросов является языковым материалом в корпусе вопросов, a n - натуральное число; взятие от 1-го до i-го слов из первого языкового материала вопросов для порождения i-го предложения, где 1≤i≤n; порождение n сегментированных предложений, соответствующих первому языковому материалу вопросов; и
порождение, на основе этапа порождения сегментированных предложений, сегментированных предложений, соответствующих первым языковым материалам вопросов в корпусе вопросов.
5. Способ по п. 1, дополнительно включающий:
определение текущего предложения как сегментированного предложения, если первая вероятность меньше или равна заданному первому порогу; и
порождение информации подсказки для подсказки пользователю продолжить ввод.
6. Устройство для распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, содержащее:
модуль приема текущего предложения, сконфигурированный для приема текущего предложения, вводимого пользователем;
модуль получения первой вероятности, сконфигурированный для ввода текущего предложения в предварительно обученную модель распознавания сегментированных предложений, чтобы получить первую вероятность того, что текущее предложение является полным предложением, причем модель распознавания сегментированных предложений используется для определения первой вероятности в соответствии с вероятностью, соответствующей модели китайского языка текущего предложения, и вероятностью, соответствующей модели языка на базе рекуррентной нейронной сети; и
модуль определения полного предложения, сконфигурированный для определения текущего предложения как полного предложения, если первая вероятность больше заданного первого порога.
7. Устройство по п. 6, дополнительно содержащее:
модуль определения второй вероятности, сконфигурированный для определения, на основе модели языка на базе рекуррентной нейронной сети, второй вероятности появления первого слова текущего предложения в предыдущем предложении, примыкающем к текущему предложению;
определения текущего предложения и предыдущего предложения, примыкающего к текущему предложению, как сегментированных предложений, если вторая вероятность больше заданного второго порога; и
объединения текущего предложения с предыдущим предложением в виде полного предложения.
8. Устройство по п. 7, дополнительно содержащее:
модуль установления модели распознавания сегментированных предложений, сконфигурированный для установления модели распознавания сегментированных предложений и содержащий:
блок получения корпуса вопросов, сконфигурированный для получения корпуса вопросов, причем корпус вопросов включает в себя множество языковых материалов вопросов, а языковые материалы вопросов - это полные предложения;
блок порождения сегментированных предложений, сконфигурированный для сегментации языковых материалов вопросов с целью порождения множества сегментированных предложений;
блок определения оценки, сконфигурированный для определения оценки сегментированного предложения в соответствии с числом слов, содержащихся в сегментированном предложении, и числом слов, содержащихся в полном предложении, соответствующем сегментированному предложению, причем эта оценка используется для представления вероятности того, что сегментированное предложение, соответствующее оценке, - это полное предложение;
блок определения вероятности, сконфигурированный для определения вероятности, соответствующей модели китайского языка сегментированного предложения, и вероятности, соответствующей модели языка на базе рекуррентной нейронной сети; и
блок обучения модели распознавания сегментированных предложений, сконфигурированный для обучения для получения модели распознавания сегментированных предложений путем использования вероятности каждого из сегментированных предложений и оценок сегментированных предложений в качестве обучающих образцов.
9. Устройство по п. 8, в котором блок порождения сегментированных предложений сконфигурирован для:
порождения сегментированных предложений, включающего: сегментацию первого языкового материала вопросов для получения первого языкового материала вопросов, состоящего из n слов, причем первый языковый материал вопросов является языковым материалом вопросов в корпусе вопросов, a n - натуральное число; взятие от 1-го до i-го слов из первого языкового материала вопросов для порождения i-го предложения, где 1≤i≤n; порождение n сегментированных предложений, соответствующих первому языковому материалу вопросов; и
порождение, на основе этапа порождения сегментированных предложений, сегментированных предложений, соответствующих первым языковым материалам вопросов в корпусе вопросов.
10. Устройство по п. 6, дополнительно содержащее:
модуль определения сегментированного предложения, сконфигурированный для определения текущего предложения как сегментированного предложения, если первая вероятность меньше или равна заданному первому порогу; и
порождения информации подсказки для подсказки пользователю продолжить ввод.
11. Устройство для распознавания полных предложений для человеко-машинной интеллектуальной вопросно-ответной системы, содержащее:
процессор; и
память,
причем память хранит машиночитаемые команды, которые могут выполняться процессором, и когда эти машиночитаемые команды выполняются, процессор выполняет способ по одному из пп. 1-5.
12. Энергонезависимый компьютерный носитель данных, хранящий считываемые компьютером команды, которые могут выполняться процессором, и когда эти машиночитаемые команды выполняются, процессор выполняет способ по одному из пп. 1-5.
| CN 102880611 A, 16.01.2013 | |||
| CN 103050115 A, 17.04.2013 | |||
| Способ фосфатирования металлов | 1941 |
|
SU67700A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРЕДОСТАВЛЕНИЯ РЕЧЕВОГО ИНТЕРФЕЙСА | 2009 |
|
RU2494476C2 |

