Данная заявка испрашивает приоритет по предварительной заявке на патент (США) номер 62/943,903, поданной 5 декабря 2019 года, и заявке на патент EP номер 19213742.0, поданной 5 декабря 2019 года, обе из которых полностью содержатся в данном документе по ссылке.
Область техники
Настоящее раскрытие относится к области техники аудиообработки, в частности, оно относится к способу для обработки аудиосигналов с использованием маскирующей модели, которая основана на пороговом значении слышимости в тишине частотных интервалов аудиосигнала и измеренном значении энергии аудиосигнала для соответствующих частотных интервалов. Данное раскрытие дополнительно относится к устройству, которое допускает осуществление способа аудиообработки.
Уровень техники
Человеческий мозг не может регистрировать все аудиосигналы на всех различных частотах. Следовательно, при кодировании аудио, преимущественно удалять сигналы, которые находятся на частотах и на уровнях, которые не являются воспринимаемыми для слуховой системы человека. Это типично осуществляется через удаление нерелевантных компонентов из аудиосигнала. В контексте перцепционных аудиокодеров, предусмотрено два главных способа, за счет которых кодеры повышают эффективность сжатия. Они представляют собой удаление избыточности и нерелевантности сигналов. Избыточные (прогнозируемые) сигнальные компоненты типично удаляются в кодере и восстанавливаются в декодере. Нерелевантные сигнальные компоненты типично удаляются в аудиокодере посредством квантования и не восстанавливаются посредством аудиодекодера.
Типично, кодеры используют психоакустические модели, иногда также называемые «перцепционными моделями», для того, чтобы оценивать пороговое значение маскирования для аудиоспектра. Пороговое значение маскирования предоставляет оценку едва заметного искажения (JND), разрешенного в каждой из нескольких полос частот аудиоспектра. В соответствии с критическими полосами частот слуховой системы человека, полосы частот типично являются неравномерными по ширине. В типичном кодере, пороговое значение маскирования вводится в контур управления скоростью, который выбирает коэффициент масштабирования (и уровень шума квантования) для каждой из нескольких полос частот коэффициентов масштабирования. Производительность типичного кодера зависит от того, насколько близко оценка порогового значения маскирования находится к истинному уровню JND-шума, причем оценки порогового значения маскирования, превышающие уровень JND-шума, приводят к выделению меньшего числа битов, чем требуется для того, чтобы не допускать звукового искажения, и оценки порогового значения маскирования, ниже уровня JND-шума, приводят к выделению большего числа битов, чем требуется, потенциально за счет соседних полос частот.
Типично, кодер определяет пороговое значение маскирования посредством:
1) вычисления энергии сигналов аудиосигнала на шкале критических полос частот.
2) оценки частотного отклика сигнала после обработки посредством базилярной мембраны (также известной как функция возбуждения) посредством свертки энергий критических полос частот с набором функций разброса.
3) в каждой критической полосе частот, регулирования функции возбуждения вниз в этой полосе на величину, оцененную как достигающую уровня JND-шума.
Кроме того, модели для определения порогового значения маскирования зачастую содержат эвристические правила, которые разработаны посредством экспериментирования, но не базируются непосредственно на известных свойствах человеческого слуха.
Следовательно, имеется запас для улучшения в области техники вычисления пороговых значений маскирования на основе известных свойств человеческого слуха, чтобы улучшать выделение битов для полос частот аудиосигнала.
Сущность изобретения
С учетом вышеизложенного, в силу этого цель настоящего раскрытия заключается в том, чтобы преодолевать или смягчать, по меньшей мере, некоторые проблемы, поясненные выше. В частности, цель настоящего раскрытия заключается в том, чтобы предоставлять маскирующую модель на основе значения энергии аудиосигнала в полосе частот и порогового значения слышимости в тишине для этой полосы частот. Кроме того, цель настоящего раскрытия заключается в том, чтобы предоставлять маскирующую модель, которая уменьшает сложность кодирования аудио и повышает качество кодированного аудио согласно вышеуказанному. Дополнительные и/или альтернативные цели настоящего раскрытия должны быть очевидными для читателя этого раскрытия.
Согласно первому аспекту, предусмотрен способ обработки аудиосигнала, причем аудиосигнал содержит аудиоданные во множестве полос частот, при этом способ содержит:
- для каждой полосы частот из множества полос частот:
- определение значения энергии для аудиоданных полосы частот;
- определение порогового значения слышимости в тишине для полосы частот;
- вычисление значения чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине;
- вычисление порогового значения маскирования для полосы частот с использованием значения чувствительности и значения энергии;
- определение значения выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
Под термином «значение энергии» необходимо, в контексте настоящего описания изобретения, понимать то, что различные подходы могут использоваться для вычисления энергий, например, на основе полосного модифицированного дискретного косинусного преобразования (MDCT), дискретного преобразования Фурье (DFT) или комплексного MDCT (CMDCT). Следует отметить, что несколько значений энергии могут вычисляться для полосы частот и затем комбинироваться подходящим способом для того, чтобы формировать одно значение энергии для полосы частот. В настоящем описании изобретения, «значение энергии» может означать энергию, выражаемую на линейной шкале или на шкале в дБ.
Под термином «полоса частот» необходимо, в контексте настоящего описания изобретения, понимать то, что полоса частот представляет собой интервал в частотной области, разграниченный посредством нижней и верхней частоты, имеющий частотный диапазон. Следует отметить, что множество полос частот аудиосигнала, который должен кодироваться, не должны обязательно иметь идентичную ширину/диапазон. Например, полоса относительно более низких частот может иметь ширину в 100-200 Гц, в то время как полоса относительно более высоких частот может иметь ширину в 3000-3500 Гц. Типично, ширины полос частот увеличиваются по мере того, как увеличивается частота, так что полосы частот между полосой относительно более низких частот и полосой относительно более высоких частот типично могут иметь ширины, располагающиеся в пределах 100-3000 Гц.
Под термином «значение чувствительности (SV)» необходимо, в контексте настоящего описания изобретения, понимать аппроксимацию регулирования, требуемого в данной критической полосе частот для того, чтобы достигать JND-искажения для слушателя-человека с нормальным слухом. Чтобы учитывать преимущества маскирования по критическим полосам частот, SV для каждой полосы может зависеть не только от характеристик сигналов в этой полосе, но также и от сигналов в соседних полосах частот. SV для каждой полосы типично применяется в качестве смещения или регулирования для функции возбуждения в результате применения порогового значения в тишине, чтобы извлекать конечное пороговое значение маскирования. Любой шум, который находится ниже порогового значения маскирования, является неслышимым.
SV для конкретной полосы частот, например, может вычисляться с использованием соотношения между значением энергии этой полосы частот и пороговым значением слышимости в тишине для этой полосы частот или разности либо любого другого показателя, сравнивающего значение энергии и пороговое значение слышимости в тишине.
В типичных кодерах предшествующего уровня техники, регулирование, проводимое для функции возбуждения вниз в критических полосах частот, типично является инвариантным с уровнем сигнала, за исключением применения порогового значения в тишине в конце. Как результат, типично, оцененное пороговое значение маскирования может не полностью коррелироваться с поведением при маскировании слуховой системы человека.
Таким образом, выражения регулирования для JND типично являются независимыми от уровня. Такие модели типично основаны на данных маскирования для относительно громких или относительно тихих сигналов. Этот подход может ограничивать производительность кодека, например, посредством недооценки истинного порогового JND-значения для сигнальных компонентов с низким уровнем, что приводит в результате к избыточному выделению битов кадрам, содержащим относительно тихие прохождения сигналов. Эта проблема возникает для кодеров, работающих в режиме с постоянной скоростью следования битов с битовым резервуаром, а также для кодеров с переменной скоростью следования битов. На аудиоконтент, характеризуемый посредством сверхдинамических изменений уровня, например, речь, оказывается негативное влияние.
В настоящем раскрытии, посредством вычисления порогового значения маскирования на основе как SV, так и значения энергии, пороговое значение маскирования может более точно захватывать наблюдаемое поведение при маскировании слуховой системы человека, за счет этого обеспечивая более высокое качество аудиосигналов.
Кроме того, при кодировании аудиосигнала с использованием модели, которая более верно захватывает наблюдаемое поведение при маскировании слуховой системы человека, способ может более точно оценивать число битов, требуемое для того, чтобы удовлетворять предварительно заданному целевому показателю качества, предоставляющему аудиосигнал с постоянным качеством, и в силу этого избыточно или недостаточно выделяет биты менее часто. В вариантах осуществления, в которых постоянная скорость следования битов требуется, способ может предоставлять аудиосигналы повышенного качества вследствие улучшенной стратегии выделения битов.
Способ дополнительно может предоставлять лучшее совпадение с субъективно измеренными данными маскирования. С использованием описанной модели кодирования аудио, может достигаться одиночная модель, подходящая для всех уровней записи звука или аудиоконтента. Преимущественно, модель может упрощать кодирование аудиосигналов с постоянным качеством независимо от свойств аудиосигнала, который должен кодироваться. Некоторые примеры свойств аудиосигналов представляют собой основной тон, уровень громкости или длительность, хотя следует отметить, что имеется множество других свойств аудиосигналов.
Общее описание вариантов осуществления
Согласно некоторым вариантам осуществления, вычисление порогового значения маскирования содержит применение функции разброса к одному из следующего: значения энергии для полос частот; или преобразованные значения энергии полос частот; для определения значения возбуждения для полосы частот, и комбинирование значения чувствительности со значением возбуждения.
Функция возбуждения может рассматриваться в качестве распределения энергии вдоль базилярной мембраны внутреннего уха. Значение возбуждения в силу этого представляет собой значение, вычисленное из этой функции для конкретной полосы частот.
Чтобы эмулировать звуковую обработку в базилярной мембране уха и сглаживать показатели прогнозируемости по частоте, функция разброса применяется к значениям энергии или преобразованным версиям значений энергии. Например, функция разброса может применяться к значениям энергии, преобразованным в область уровней громкости (т.е. возведение значений энергии в степень ~0,25-0,3). В других вариантах осуществления, функция разброса может применяться к значениям энергии, возведенным в степень 0,5-0,6. Функция разброса из ISO/IEC, 11172-3:1993(E), может использоваться.
В случае если значение чувствительности и значение возбуждения задаются в децибелах (дБ), этап комбинирования может содержать вычисление порогового значения маскирования посредством вычитания значения чувствительности из значения возбуждения. На шкале интенсивности, пороговое значение маскирования вычисляется как частное значения возбуждения и значения чувствительности.
Необязательно, пороговое значение маскирования извлекается посредством пороговой обработки с пороговым значением в тишине, например, пороговое значение маскирования=max(пороговое значение маскирования, пороговое значение слышимости в тишине).
Согласно некоторым вариантам осуществления, вычисление порогового значения маскирования содержит комбинирование значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и применение функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования.
Например, пороговое значение маскирования может определяться в качестве max(промежуточное пороговое значение, пороговое значение слышимости в тишине).
Согласно некоторым вариантам осуществления, способ дополнительно содержит квантование аудиовыборок аудиоданных полосы частот в ответ на значение выделения битов. Преимущественно, кодер может кодировать аудио с постоянным качеством или на постоянной скорости следования битов с повышенным качеством звука. Кодер дополнительно может кодировать квантованные аудиоданные полосы частот в поток битов.
Способ, описанный в данном документе, может использоваться также на стороне декодера. Согласно некоторым вариантам осуществления, аудиосигнал представляет собой кодированный поток битов, содержащий кодированное значение энергии для полосы частот, при этом определение значения энергии для аудиоданных полосы частот содержит декодирование кодированного значения энергии из кодированного потока битов. На стороне декодера, определенное значение выделения битов может использоваться для извлечения квантованных аудиовыборок аудиоданных полосы частот из кодированного потока битов. Преимущественно, значение выделения битов для каждой полосы частот каждого аудиокадра не должно включаться в поток битов, а вместо этого может определяться на стороне декодера. Скорость следования битов кодированного потока битов в силу этого может уменьшаться.
Согласно некоторым вариантам осуществления, способ дополнительно содержит деквантование квантованных аудиовыборок аудиоданных полосы частот и комбинирование деквантованных аудиовыборок аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал.
Согласно некоторым вариантам осуществления, определение значения выделения битов содержит регулирование порогового значения маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала. В этом варианте осуществления, если число битов, требуемых посредством номинального порогового значения маскирования, может быть больше (или меньше) числа битов, доступных для того, чтобы удовлетворять требованию по скорости следования битов, пороговое значение маскирования может регулироваться таким образом, чтобы выделять больше или меньшее число битов с тем, чтобы использовать максимально возможное количество битов, без превышения целевой скорости следования битов. Например, регулирование порогового значения маскирования может содержать: регулирование порогового значения маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала.
При определении и задании энергии и порогового значения слышимости, могут использоваться различные измерения. Согласно некоторым вариантам осуществления, значение энергии, пороговое значение слышимости в тишине и пороговое значение маскирования задаются в децибелах (дБ), что обеспечивает простоту для модели, поскольку децибел представляет собой общее измерение для громкости звука/энергии.
Согласно некоторым вариантам осуществления, способ содержит этап определения множества полос частот аудиосигнала в соответствии со шкалой эквивалентной прямоугольной полосы пропускания (ERB). ERB-шкала предоставляет аппроксимацию полосами пропускания слуховой системы человека с использованием удобного упрощения моделирования слуховых фильтров в качестве прямоугольных полосовых фильтров. Преимущественно, использование ERB может быть преимущественным при кодировании аудиосигнала в соответствии со слуховой системой человека.
Согласно некоторым вариантам осуществления, в которых SV задается в дБ в качестве разностного регулирования для функции возбуждения, этап определения значения выделения битов содержит назначение большего числа битов для полосы частот, имеющей более высокое SV, по сравнению с упомянутой полосой частот, имеющей более низкое SV. Преимущественно, может достигаться постоянное качество звучания кодированного аудиосигнала. SV управляет смещением функции возбуждения, которая, после применения порогового значения в тишине, дает в результате пороговое значение маскирования. Положительные значения чувствительности снижают пороговое значение маскирования. Отрицательные значения чувствительности повышают пороговое значение маскирования. Следовательно, увеличение значения чувствительности соответствует более низким пороговым значениям маскирования и в силу этого большему числу выделенных битов. Значение чувствительности для полосы частот в силу этого может рассматриваться как соответствующее чувствительности слуховой системы человека к шуму (артефактами при кодировании) в полосе частот аудиосигнала.
Согласно некоторым вариантам осуществления, этап вычисления SV для полосы частот содержит вычисление первого SV с использованием уровня ощущения, при этом уровень ощущения представляет собой разность, на шкале в дБ, между значением энергии и пороговым значением слышимости в тишине.
Под термином «разность» необходимо, в контексте настоящего описания изобретения, понимать вычитание порогового значения слышимости в тишине (выражаемого в дБ) из значения энергии (выражаемого в дБ).
Термин «уровень ощущения», используемый в данном документе, задается как уровень звука относительно порогового значения в тишине для этого звука для среднестатистического слушателя. Термин введен автором C.J. Moore в работе «An Introduction to the Psychology of Hearing», пятый выпуск, стр. 403, Academic Press (2003).
Следует отметить, что определение точного SV может достигаться различными способами.
Согласно некоторым вариантам осуществления, этап вычисления первого SV содержит умножение уровня ощущения на первый скаляр. Преимущественно, большая точность SV может достигаться со ссылкой на слуховую систему человека при низкой сложности. Посредством умножения первого скаляра на функцию, разность и SV могут легко преобразовываться друг в друга, чтобы лучше соответствовать слуховой системе человека.
Первый скаляр может быть частотно-зависимым или постоянным по всем полосам частот.
Согласно некоторым вариантам осуществления, этап вычисления первого SV содержит суммирование второго скаляра с уровнем ощущения, умноженным на первый скаляр. Второй скаляр может быть частотно-зависимым или постоянным по всем полосам частот.
Преимущественно, большая точность SV может достигаться со ссылкой на слуховую систему человека при низкой сложности. Посредством суммирования второго скаляра с функцией, преобразование между разностью и SV может легко изменяться, чтобы лучше соответствовать слуховой системе человека.
Согласно некоторым вариантам осуществления, этап вычисления SV содержит использование первого SV в качестве SV для полосы частот.
Согласно некоторым вариантам осуществления, этап вычисления SV для полосы частот содержит вычисление второго SV с использованием уровня ощущения и взвешивание первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала.
В качестве примера, такие характеристики аудиосигнала могут представлять собой полосу пропускания, тон по сравнению с шумом, номинальный уровень или уровень мощности в децибелах (дБ). Тем не менее, следует отметить, что аудиосигнал имеет множество характеристик, которые могут использоваться в способе. Посредством взвешивания первого и второго SV, может получаться пороговое значение маскирования, близкое к JND. Преимущественно, постоянное качество звучания может достигаться независимо от аудиоконтента аудиосигнала.
В этом варианте осуществления, зашумленный и громкий аудиосигнал, при использовании вышеуказанной модели, в которой два SVS вычисляются и взвешиваются, может давать в результате кодированный высококачественный аудиосигнал. Не настолько зашумленный и мягкий аудиосигнал также может, при использовании идентичной модели, давать в результате идентичный уровень качества для кодированного аудиосигнала. С другой стороны, в двухрежимном кодере предшествующего уровня техники, для аудиосигналов, которые не могут надежно классифицироваться, таких как диалог, смешиваемый с аплодисментами, кодер должен выбирать, например, между режимом аплодисментов или режимом по умолчанию, и режим, выбранный посредством кодера, может не быть оптимальным. Альтернативно, кодер может выбирать кодировать различные сегменты сигнала с различными режимами, что может приводить к звуковым артефактам при переключении, которые снижают качество кодированного сигнала. Для однорежимной модели, в которой первое и второе SV вычисляются и взвешиваются, нет необходимости определять то, какие части аудиосигнала следует кодировать с различными режимами. Кроме того, однорежимная модель подходит для множества аудиосигналов, независимо от аудиоконтента (речь, музыка и т.д.) упомянутых аудиосигналов. Посредством предоставления одиночной модели, нет необходимости для классификации аудиовыборок, чтобы определять то, какой режим должен применяться для кодирования. Кроме того, проблема выбора режима для сигнала, который граничит между режимами, смягчается, и не допускаются снижения качества звучания вследствие выполнения, посредством кодера, менее оптимального выбора режима.
Следует отметить, что в некоторых вариантах осуществления, дополнительный SVS может задаваться и включаться при вычислении конечного SV (посредством взвешивания>2 SVS). Эти различные SVS могут взвешиваться на основе переходных характеристик аудиосигнала.
Согласно некоторым вариантам осуществления, этап вычисления второго SV для полосы частот содержит умножение уровня ощущения на третий скаляр, отличающийся от первого скаляра. Третий скаляр может быть частотно-зависимым или постоянным по всем полосам частот.
Посредством умножения функции на третий скаляр, точность SV со ссылкой на слуховую систему может повышаться для аудиосигналов с различными характеристиками, например, аудиосигналов с высокой степенью шумоподобных по сравнению с тоноподобными характеристиками. Третий скаляр может обеспечивать возможность преобразования SV, с тем чтобы предоставлять обобщенную модель для кодирования аудио. SV является таким, как следует из вышеуказанного, и дополнительно описывается ниже, с заданием в качестве функции от уровня ощущения. Посредством преобразования SV согласно различным характеристикам аудиосигнала, взаимосвязь между пороговым значением слышимости и значением энергии может оставаться, в то время как наклон SV по сравнению с уровнем ощущения может изменяться согласно различным характеристикам аудиосигнала. Преимущественно, биты могут выделяться, чтобы предоставлять кодированный аудиосигнал с высоким качеством.
Согласно некоторым вариантам осуществления, этап вычисления второго SV содержит суммирование четвертого скаляра с уровнем ощущения, умноженным на третий скаляр, причем четвертый скаляр отличается от второго скаляра. Следует отметить, что четвертому скаляру могут назначаться различные значения, с целью повышения точности SV со ссылкой на слуховую систему человека. Четвертый скаляр может быть частотно-зависимым или постоянным по всем полосам частот.
Согласно некоторым вариантам осуществления, этап взвешивания первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала содержит вычисление значения, представляющего весовой коэффициент, причем значение находится в диапазоне между 0-1, при этом этап вычисления SV для полосы частот содержит умножение одного из первого и второго SV на значение и умножение другого из первого или второго SV на единицу минус значение и сложение двух результирующих сумм между собой, чтобы формировать SV для полосы частот.
Другими словами, первое и второе SV смешиваются в качестве линейного комбинирования с весовыми коэффициентами, которые суммируются в единицу, при этом весовые коэффициенты зависят от упомянутой по меньшей мере одной характеристики аудиосигнала.
Посредством вычисления полного SV посредством взвешивания первого и второго SV, преобразование между уровнем ощущения и SV может быть выполнено с возможностью отражать характеристики маскирования различных типов аудиосигнала. Преимущественно, может достигаться гибкая модель с низкой сложностью для определения значения выделения битов полосы частот, которая предоставляет высококачественные кодированные аудиосигналы.
Согласно некоторым вариантам осуществления по меньшей мере одна характеристика задает оцененную тональность полосы частот аудиосигнала.
Следует отметить, что предусмотрено множество различных способов оценивать тональность аудиосигнала. Тональность представляет взаимосвязи между тональными характеристиками в аудиосигнале (например, нотами, аккордами, ключами, основными тонами и т.д.). Преимущественно, использование оцененной тональности полосы частот аудиосигнала в качестве характеристики для взвешивания первого и второго SV может повышать точность SV со ссылкой на слуховую систему человека. Кроме того, посредством использования тональности, субъективное качество звучания может повышаться.
Согласно некоторым вариантам осуществления по меньшей мере одна характеристика задает оцененный уровень шума в полосе частот аудиосигнала. Преимущественно, шум аудиосигнала может маскироваться со ссылкой на слуховую систему человека, чтобы достигать высококачественного кодированного аудиосигнала.
Согласно некоторым вариантам осуществления, оцененная тональность вычисляется с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала. В некоторых вариантах осуществления, идентичный набор частотных коэффициентов используется как для вычисления порогового значения маскирования, так и для оценки тональности. В других вариантах осуществления, оценка тональности выполняется с использованием отдельной, комплекснозначной гребенки фильтров. Следует отметить, что любой набор частотных коэффициентов является возможным, в зависимости от точности оцененной тональности, которая требуется, и доступных вычислительных ресурсов. Например, использование только действительных MDCT-коэффициентов должно быть вычислительно менее затратным, чем использование CMDCT-коэффициентов, но менее точным. Посредством получения точной оцененной тональности, субъективное качество звучания дополнительно может повышаться.
Согласно некоторым вариантам осуществления, линейное прогнозирующее кодирование (LPC) адаптивно применяется к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты. LPC может использоваться вместо фиксированного прогнозирования для того, чтобы достигать более точных оценок тональности аудиосигналов.
Следует отметить, что окна анализа LPC могут иметь различные длины. Посредством варьирования длины окна анализа, может гибко реализовываться требуемая переменная частотно-временная инфраструктура. Согласно некоторым вариантам осуществления, длина окна анализа LPC варьируется как функция от полосы частот. В некоторых вариантах осуществления, относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
Согласно некоторым вариантам осуществления, порядок прогнозирования LPC варьируется как функция от полосы частот. В качестве примера, порядок прогнозирования LPC может выбираться таким образом, что различение между вводом чистого шума и сигналами с тональными компонентами (клавесин, речь и т.д.) максимизируется.
Следует отметить, что частотный диапазон аудиосигнала может кодироваться как различные диапазоны.
Согласно некоторым вариантам осуществления, частотный диапазон аудиосигнала составляет между 200-7000 Гц.
Согласно некоторым вариантам осуществления, этап определения порогового значения слышимости в тишине для полосы частот содержит использование предварительно заданной таблицы, задающей пороговое значение слышимости для по меньшей мере некоторых частот. Предварительно заданная таблица может предварительно сохраняться в кодере, осуществляющем способ, за счет этого обеспечивая возможность обновления предварительно заданной таблицы без влияния на совместимость декодера. Преимущественно, сложность предоставления высококачественного кодированного аудиосигнала может уменьшаться.
Согласно некоторым вариантам осуществления, динамический диапазон аудиосигнала уменьшается с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот. Посредством компандирования аудиосигнала в кодере и применения комплементарного расширения в декодере, способ кодирования может предоставлять более высококачественный декодированный аудиосигнал. Компандирование аудиосигнала может предоставлять возможность кодирования меньшего числа битов при поддержании высокого качества звука.
Согласно некоторым вариантам осуществления, способ содержит этап задания функции разброса для полосы частот в зависимости от уровня ощущения таким образом, что эффектом функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения.
Согласно второму аспекту по меньшей мере одна из вышеуказанных целей достигается посредством устройства, содержащего:
- приемный компонент, выполненный с возможностью принимать аудиосигнал, причем аудиосигнал содержит аудиоданные во множестве полос частот;
- компонент анализа, выполненный с возможностью определять множество полос частот аудиосигнала;
- причем компонент анализа дополнительно выполнен с возможностью, для каждой полосы частот из множества полос частот:
-- определять значение энергии для аудиоданных полосы частот;
-- определять пороговое значение слышимости в тишине для полосы частот;
-- вычислять значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине;
-- вычислять пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии;
-- определять значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью:
вычислять пороговое значение маскирования посредством применения функции разброса к одному из следующего:
- значения энергии для полос частот; или
- преобразованные значения энергии полос частот;
для определения значения возбуждения для полосы частот, и
комбинировать значение чувствительности со значением возбуждения
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять пороговое значение маскирования посредством комбинирования значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и применения функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования.
Согласно некоторым вариантам осуществления, в которых устройство представляет собой кодер, устройство дополнительно содержит компонент кодирования, выполненный с возможностью квантовать аудиовыборки аудиоданных полосы частот в ответ на значение выделения битов.
Согласно некоторым вариантам осуществления, компонент кодирования дополнительно выполнен с возможностью кодировать квантованные аудиоданные полосы частот в поток битов.
Согласно некоторым вариантам осуществления, в которых устройство представляет собой декодер, аудиосигнал представляет собой кодированный поток битов, содержащий кодированное значение энергии для полосы частот, и устройство дополнительно содержит компонент декодирования, выполненный с возможностью декодировать кодированное значение энергии из кодированного потока битов, и компонент анализа использует декодированное значение энергии при определении значения энергии.
Согласно некоторым вариантам осуществления, компонент декодирования выполнен с возможностью извлекать квантованные аудиовыборки аудиоданных полосы частот из кодированного потока битов в ответ на значение выделения битов.
Согласно некоторым вариантам осуществления, компонент декодирования дополнительно выполнен с возможностью деквантовать квантованные аудиовыборки аудиоданных полосы частот и комбинировать деквантованные аудиовыборки аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью: при определении значения выделения битов, регулировать пороговое значение маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью: при регулировании порогового значения маскирования, регулировать пороговое значение маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью задавать значение энергии, пороговое значение слышимости в тишине и пороговое значение маскирования в децибелах (дБ).
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью определять множество полос частот аудиосигнала в соответствии со шкалой эквивалентной прямоугольной полосы пропускания (ERB).
Согласно некоторым вариантам осуществления, в которых SV задается в дБ в качестве разностного регулирования для функции возбуждения, компонент анализа выполнен с возможностью определять значение выделения битов посредством назначения большего числа битов для полосы частот, имеющей более высокое SV, по сравнению с упомянутой полосой частот, имеющей более низкое SV.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять SV для полосы частот посредством вычисления первого SV с использованием уровня ощущения, при этом уровень ощущения представляет собой разность между значением энергии и пороговым значением слышимости в тишине.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять первое SV посредством умножения уровня ощущения на первый скаляр.
Согласно некоторым вариантам осуществления, первый скаляр является частотно-зависимым.
Согласно некоторым вариантам осуществления, первый скаляр является постоянным по всем полосам частот.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять первое SV посредством суммирования второго скаляра с уровнем ощущения, умноженным на первый скаляр.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять SV посредством использования первого SV в качестве SV для полосы частот.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять SV для полосы частот посредством дополнительного вычисления второго SV с использованием уровня ощущения и взвешивания первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять второе SV для полосы частот посредством умножения уровня ощущения на третий скаляр, отличающийся от первого скаляра.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять второе SV посредством суммирования четвертого скаляра с уровнем ощущения, умноженным на третий скаляр, причем четвертый скаляр отличается от второго скаляра.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью выполнять взвешивание первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала посредством вычисления значения, представляющего весовой коэффициент, причем значение находится в диапазоне между 0-1, и вычисления SV для полосы частот посредством умножения одного из первого и второго SV на значение и умножения другого из первого или второго SV на единицу минус значение и сложения двух результирующих сумм между собой, чтобы формировать SV для полосы частот.
Согласно некоторым вариантам осуществления по меньшей мере одна характеристика задает оцененную тональность полосы частот аудиосигнала.
Согласно некоторым вариантам осуществления по меньшей мере одна характеристика задает оцененный уровень шума в полосе частот аудиосигнала.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью вычислять оцененную тональность с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью адаптивно применять LPC к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты.
Согласно некоторым вариантам осуществления, длина окна анализа LPC варьируется как функция от полосы частот.
Согласно некоторым вариантам осуществления, относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
Согласно некоторым вариантам осуществления, порядок прогнозирования LPC варьируется как функция от полосы частот.
Согласно некоторым вариантам осуществления, частотный диапазон аудиосигнала составляет между 200-7000 Гц.
Согласно некоторым вариантам осуществления, устройство дополнительно содержит запоминающее устройство, причем запоминающее устройство сохраняет таблицу, задающую пороговое значение слышимости в тишине для по меньшей мере некоторых частот, и компонент анализа выполнен с возможностью определять пороговое значение слышимости в тишине для полосы частот посредством использования предварительно заданной таблицы.
Согласно некоторым вариантам осуществления, устройство дополнительно содержит компонент компандирования, выполненный с возможностью уменьшать динамический диапазон аудиосигнала с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот.
Согласно некоторым вариантам осуществления, компонент анализа выполнен с возможностью задавать функцию разброса для полосы частот в зависимости от уровня ощущения таким образом, что эффект функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения.
Согласно некоторым вариантам осуществления, устройство реализуется в устройстве двусторонней связи в реальном времени.
Второй аспект, в общем, может иметь преимущества, идентичные преимуществам первого аспекта.
Согласно третьему аспекту, предусмотрен способ для оценки тональности входного сигнала, содержащий этапы:
- применения гребенки фильтров, чтобы достигать набора частотных коэффициентов;
- вычисления оцененной тональности с использованием адаптивного прогнозирования частотных коэффициентов.
Согласно некоторым вариантам осуществления, этап вычисления оцененной тональности содержит применение адаптивного линейного прогнозирования (LPC) к частотным коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются частотные коэффициенты.
Согласно некоторым вариантам осуществления, длина окна анализа LPC варьируется как функция от полосы частот.
Согласно некоторым вариантам осуществления, относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
Согласно некоторым вариантам осуществления, порядок прогнозирования LPC варьируется как функция от полосы частот.
Согласно некоторым вариантам осуществления, гребенка фильтров содержит одно из следующего: 128-полосная комплексная MDCT- или DFT-гребенка фильтров и 64-полосная гребенка комплексных квадратурных зеркальных фильтров (CQMF).
Согласно некоторым вариантам осуществления, окно анализа LPC представляет собой асимметричное окно Хэмминга.
Согласно некоторым вариантам осуществления, способ содержит этап:
- взвешивания показателей прогнозируемости из адаптивного прогнозирования согласно относительной перцепционной важности каждого показателя прогнозируемости.
Согласно некоторым вариантам осуществления, этап взвешивания показателей прогнозируемости, содержащихся в каждой частотно-временной плитке, содержит одно из следующего: взвешивание на основе энергии или уровня громкости входного сигнала.
Согласно некоторым вариантам осуществления, способ дополнительно содержит этап:
- комбинирования показателей прогнозируемости из адаптивного прогнозирования частотных коэффициентов таким образом, что они совпадают с временным и частотным разрешением гребенки фильтров.
Дополнительно следует отметить, что раскрытие относится ко всем возможным комбинациям признаков, если в явной форме не указано иное.
Краткое описание чертежей
Вышеуказанные, а также дополнительные цели, признаки и преимущества настоящего раскрытия должны лучше пониматься посредством нижеприведенного иллюстративного и неограничивающего подробного описания вариантов осуществления настоящего раскрытия, со ссылкой на прилагаемые чертежи, на которых идентичные ссылки с номерами используются для аналогичных элементов, при этом:
Фиг. 1 показывает данные маскирования для аудиосигналов.
Фиг. 2 показывает данные маскирования для аудиосигналов.
Фиг. 3 показывает экспериментальные данные отношения «сигнал-маска» (SMR) относительно уровня ощущения для множества тонов на различных частотах и прямолинейной модели данных.
Фиг. 4 показывает общее представление способа для вычисления порогового значения маскирования согласно некоторым вариантам осуществления.
Фиг. 5 показывает SV относительно уровня ощущения для чистых тонов и чистого шума согласно некоторым вариантам осуществления.
Фиг. 6 показывает блок-схему для оценки тональности для полосы частот входного кадра согласно некоторым вариантам осуществления.
Фиг. 7 показывает компонент анализа для определения значений выделения битов полос частот входного аудиосигнала согласно некоторым вариантам осуществления,
Фиг. 8 показывает кодер, реализующий компонент анализа по фиг. 7,
Фиг. 9 показывает декодер, реализующий компонент анализа по фиг. 7,
Фиг. 10 показывает результаты из примера измеренного SV для JND в качестве функции от уровня смешения тона/шума (SNR),
Фиг. 11 показывает график оцененной тональности по сравнению с оценками непрогнозируемости, как задано на фиг. 6 относительно предшествующего уровня техники.
Подробное описание вариантов осуществления
Ниже подробнее описывается настоящее раскрытие со ссылкой на прилагаемые чертежи, на которых показаны варианты осуществления раскрытия. В дальнейшем описываются системы и устройства, раскрытые в данном документе, в ходе работы.
Ниже, известный аудиоформат используется в качестве контекста для примерной иллюстрации настоящего раскрытия. Тем не менее, следует отметить, что объем раскрытия не ограничен этим известным форматом, и различные варианты осуществления, описанные в данном документе, могут использоваться для любого подходящего аудиоформата.
Для примерного формата, в данный момент предусмотрено два повсеместно используемых режима для кодирования аудио. Необходимость выбирать то, какой режим является самым подходящим для аудиосигнала, может представлять собой сложное решение, и качество кодированного аудиосигнала может страдать, если выбирается режим, который не является подходящим для аудиосигнала. Два типичных режима представляют собой режим по умолчанию и аплодисменты. Текущие режимы являются отличающимися, и в обоих режимах, кодер оценивает пороговое значение маскирования из оценки энергии сигнала и SV, которое является инвариантным с уровнем сигнала, за исключением применения порогового значения в тишине в конце. Режим по умолчанию дополнительно применяет унаследованную функцию, наследуемую из кодера с поддержкой MPEG-слоя III, но перцепционное обоснование для этой функции не является строгим. Дополнительно, пороговое значение маскирования вводится в контур управления скоростью, который выбирает коэффициент масштабирования (и уровень квантования) для каждой из нескольких полос частот коэффициентов масштабирования. В силу этого, производительность зависит от того, насколько близко оценка порогового значения маскирования находится к истинному уровню JND-шума.
В большинстве моделей предшествующего уровня техники, выражения требуемого SMR для JND, до применения порогового значения в тишине, являются независимыми от уровня. Такие модели типично основаны на данных маскирования для относительно громких или относительно тихих сигналов, но не обоих адаптивно. Этот подход может ограничивать производительность кодека, в одном примере, посредством недооценки истинного порогового JND-значения для сигнальных компонентов с низким уровнем, что приводит в результате к избыточному выделению битов кадрам, содержащим относительно тихие прохождения сигналов. Эта проблема возникает для кодеров, работающих в режиме с постоянной скоростью следования битов с битовым резервуаром, а также для кодеров с переменной скоростью следования битов. На аудиоконтент, характеризуемый посредством сверхдинамических изменений уровня (к примеру, речь), оказывается негативное влияние.
Распространенная проблема с моделями предшествующего уровня техники заключается в том, что они формируют ниже необходимого пороговое значение маскирования, что также приводит к избыточному выделению битов в полосе частот. Соответственно, это уменьшает число доступных битов для других полос, в силу этого уменьшая качество кодированных аудиосигналов.
Настоящее раскрытие нацелено на преодоление некоторых вышеуказанных проблем за счет предоставления одиночной модели, которая работает идентично или лучше для большей части аудиоконтента, чем двухрежимная модель предшествующего уровня техники или одиночная модель, в силу оценки более точного SMR.
Субъективные тесты на основе прослушивания с использованием монофонического контента указывают то, что новый кодер превосходит текущий кодер для речевого контента. Кроме того, новый кодер является значительно более эффективным в вариантах применения с переменной скоростью следования битов, в которых кодер выделяет только число битов, необходимое для того, чтобы удовлетворять предварительно заданному целевому показателю качества, предоставляя постоянное качество звучания.
В одном эксперименте, первый субъективный тест на основе прослушивания выполнен с тремя кодерами, причем один из них работает в режиме по умолчанию, один работает в режиме аплодисментов, и один работает с использованием зависимого от уровня маскирования, и с разноплановым набором тестовых аудиоэлементов, чтобы количественно определять преимущества зависимого от уровня маскирования. Кодер с использованием зависимого от уровня маскирования дает в результате увеличение среднего субъективного качества в среднем на 3 и 14 точек относительно кодеров в режиме по умолчанию и в режиме аплодисментов, соответственно. Более существенно, зависимое от уровня маскирование улучшает два речевых элемента в среднем на 8 точек относительно кодера по умолчанию.
Фиг. 7 показывает в качестве примера компонент 700 анализа. Как подробнее описано ниже в сочетании с фиг. 8 и 9, компонент анализа может реализовываться в кодере 800 или декодере 900. В других вариантах осуществления, компонент анализа реализуется в отдельном устройстве и, например, соединяется с кодером или декодером.
Компонент 700 анализа содержит схему, выполненную с возможностью осуществлять способ для обработки аудиосигнала, с тем чтобы определять значение выделения битов для полос частот аудиосигнала. Схема может содержать один или более процессоров.
Компонент 700 анализа выполнен с возможностью выполнять множество действий, которые примерно иллюстрируются ниже.
Компонент 700 анализа выполнен с возможностью определять S02 множество полос частот входного аудиосигнала. Множество полос частот содержат частотный диапазон. Следует отметить, что каждая из множества из полос частот аудиосигнала, который должен кодироваться, не должна обязательно иметь идентичную ширину/диапазон. В одном примере, первая полоса относительно более низких частот может иметь диапазон в 100-200 Гц, в то время как другая полоса относительно более высоких частот может иметь диапазон в 3000-3500 Гц. В одном варианте осуществления, частотный диапазон аудиосигнала может составлять 200-7000 Гц. Дополнительно, следует отметить, что предусмотрено множество различных частотных диапазонов для аудиосигналов, которые могут расширяться до частот выше 7000 Гц и/или ниже 200 Гц. Как следует понимать, предусмотрены различные способы определения полос частот для аудиосигнала. В одном варианте осуществления, компонент 700 анализа выполнен с возможностью определять S02 полосы частот в соответствии со шкалой эквивалентной прямоугольной полосы пропускания (ERB). ERB-шкала обеспечивает аппроксимацию полосами пропускания фильтров слуховой системы человека. Кроме того, использование ERB-шкалы предоставляет упрощение моделирования фильтров в качестве прямоугольных полосовых фильтров.
Компонент анализа дополнительно выполнен с возможностью определять S18 значение выделения битов каждой полосы частот с использованием следующего анализа аудиоданных каждой полосы частот.
Компонент 700 анализа определяет S04 значение энергии для аудиоданных полосы частот. Значение энергии, например, может представлять собой полосную MDCT-энергию.
Дополнительно, компонент 700 анализа определяет S06 пороговое значение слышимости в тишине для полосы частот. В одном варианте осуществления, компонент 700 анализа содержит запоминающий компонент или соединяется с таким компонентом. Запоминающий компонент сохраняет таблицу, задающую пороговое значение слышимости в тишине для по меньшей мере некоторых частот. Следует отметить, что такой запоминающий компонент может сохранять различную информацию. Другими словами, определение S06 порогового значения слышимости в тишине для полосы частот может содержать использование предварительно заданной таблицы, задающей пороговое значение слышимости для по меньшей мере некоторых частот. В некоторых вариантах осуществления, предварительно заданная таблица, задающая пороговое значение слышимости, может быть заменимой, обеспечивая возможность внесения улучшений в кодер без влияния на совместимость декодера.
С использованием значения энергии и порогового значения слышимости в тишине, значение чувствительности (SV) может вычисляться S08. Следует понимать то, что SV может вычисляться S08 различными способами с использованием значения энергии и порогового значения слышимости в тишине. SV, например, может вычисляться S08 с использованием соотношения между значением энергии и пороговым значением слышимости в тишине или разности либо любого другого показателя, сравнивающего значение энергии и пороговое значение слышимости в тишине. Значение чувствительности должно пониматься как величина, например, заданная в дБ.
В одном варианте осуществления, первое SV вычисляется S10 с использованием разности между значением энергии и пороговым значением слышимости в тишине, также называемой в этом раскрытии «уровнем ощущения». Необязательно, первое SV может вычисляться S10 посредством умножения уровня ощущения на первый скаляр. В некоторых вариантах осуществления, первое SV может вычисляться S10 посредством суммирования второго скаляра с разностью, умноженной на первый скаляр. В этом варианте осуществления, первое SV для полосы частот в силу этого вычисляется как альфа*(энергия полосы частот-hthresh)+бета, где альфа является первым скаляром, бета является вторым скаляром, энергия полосы частот является аудиосигналом значения энергии в полосе частот, и hthresh является пороговым значением в тишине для полосы частот. В некоторых вариантах осуществления, второй скаляр не включается в вычисление SV для уменьшения сложности.
Степень, в которой первое SV варьируется в зависимости от разности между значением энергии и пороговым значением в тишине для различных полос частот, определяется посредством анализа множества измеренных данных маскирования. Следует отметить, что нижеприведенные измерения и схемы, описанные в сочетании с фиг. 1-3, предоставляются в качестве примера, с использованием разности между значением энергии и пороговым значением слышимости в тишине в каждой полосе частот, т.е. уровня ощущения. Тем не менее, специалисты в данной области техники понимают, что если использованы другие способы вычисления SV, например, с использованием соотношения между энергией и пороговым значением слышимости для каждой полосы частот, другие данные должны получаться в результате экспериментов.
Фиг. 1 показывает в качестве примера измеренные данные маскирования для тонов в 200 Гц при различных уровнях звукового давления (SPL). Пороговые значения 104, 106, 108, 110, 112 маскирования представляются относительно порогового значения 102 слышимости в тишине (полужирная линия). Пороговое значение 1 104 маскирования связано с тоном в 200 Гц при SPL в 60 дБ. Пороговое значение 2 106 маскирования связано с тоном в 200 Гц при SPL в 80 дБ. Пороговое значение 3 108 маскирования связано с тоном в 200 Гц при SPL в 90 дБ. Пороговое значение 4 110 маскирования связано с тоном в 200 Гц при SPL в 100 дБ. Пороговое значение 5 112 маскирования связано с тоном в 200 Гц при SPL в 105 дБ. Как видно из фиг. 1, разность между уровнем маскера тоном (т.е. при 60, 80, 90, 100 и 105 дБ, не конкретно указывается на фиг. 1, но легко наблюдается за счет слежения за маркировками на вертикальной оси от соответствующего уровня звука до маркировки в 200 Гц на горизонтальной оси) и пороговым значением маскирования при 200 Гц увеличивается для увеличивающейся интенсивности звука маскера тоном. Для маскера тоном в 60 дБ, разность составляет приблизительно 18 дБ (60 дБ для маскера тоном и 42 дБ для порогового значения 104 маскирования), а для маскера тоном в 105 дБ, разность составляет приблизительно 32 дБ (105 дБ для маскера тоном и 73 для порогового значения 112 маскирования).
Фиг. 2 показывает аналогичный шаблон для маскера тоном в 500 Гц. На фиг. 2, пороговые значения 204, 206, 208, 210 маскирования, для данных маскирования при различных уровнях звукового давления (SPL) (на идентичных уровнях, как показано на фиг. 2, за исключением того, что маскер тоном в 500 Гц не показан на фиг. 2) представляются относительно порогового значения 102 слышимости в тишине (полужирная линия).
В одном примере, измеренные данные маскирования (т.е. как проиллюстрировано на фиг. 1 и 2) могут использоваться для того, чтобы извлекать значение чувствительности (SV) по сравнению с уровнем ощущения, когда рассматриваются тональные или синусоидальные волновые сигналы. Следует понимать, что предусмотрены возможные параметры, отличающиеся от параметров, примерно проиллюстрированных на фиг. 1-2, которые могут использоваться для того, чтобы извлекать требуемый SV. В этом примере, рассматривается маскирование для артефактов кодирования в акустической критической полосе частот на частоте маскера синусоидальных волн.
Фиг. 3 показывает в качестве примера модель SMR в качестве объединителя узкополосного шума для маскирования тоном для различных уровней ощущения тона и частот. SMR представляется в качестве функции от уровня ощущения с прямолинейной моделью 302. Прямолинейная модель 302 представляет собой объединитель измеренных SMR-кривых 1-6, называемых 304, 306, 310, 312, 314, 316 на фиг. 3. Кривая 1 304 показывает измеренные SMR-значения для сигнала на частоте 200 Гц. Кривая 2 306 показывает измеренные SMR-значения для сигнала на частоте 500 Гц. Кривая 3 310 показывает измеренные SMR-значения для другого сигнала на частоте 500 Гц. Кривая 4 312 показывает измеренные SMR-значения для сигнала на частоте 1000 Гц. Кривая 5 314 показывает измеренные SMR-значения для сигнала на частоте 2000 Гц. Кривая 6 316 показывает измеренные SMR-значения для сигнала на частоте 5000 Гц.
Фиг. 3 показывает то, что согласно этому примеру, наклон SMR по сравнению с уровня ощущения в 0,35 дБ*(уровень маскера относительно порогового значения в тишине на этой частоте)+3 дБ может представлять собой обоснованную аппроксимацию для частотного диапазона 200-4000 Гц. Тем не менее, следует отметить, что прямолинейная модель 302 на фиг. 3 может представлять собой обоснованную аппроксимацию для других частотных диапазонов. В этом примере, смещение в децибелах для требуемого SMR варьируется вплоть до 10 дБ при средних уровнях, но, вероятно, сходится на высоких и низких уровнях.
В некоторых вариантах осуществления, пороговое значение в тишине может модифицироваться посредством задания порогового значения для всех полос ниже 4 кГц равным глобальному минимальному пороговому значению. Пороговое значение в тишине должно задаваться равным минимальному значению в каждой полосе при кодировании. Например, в кодеке с преобразованием с адаптивным блочным переключением, наименьшая полоса частот кратчайшего блока преобразования может иметь ширину в 750 Гц. Как можно видеть на фиг. 1-2, уровень (в дБ) порогового значения слышимости в тишине быстро падает с 20-750 Гц. Пороговое значение этой всей полосы затем может задаваться равным фактическому пороговому значению в тишине при 750 Гц. Идентичный этап применяется для всех других полос в кратчайшем блоке. Затем эти значения интерполируются, чтобы получать пороговые значения в тишине для всех других длин блоков преобразования. Этот подход обеспечивает то, что пороговое значение в тишине находится на согласованном уровне для всех длин блоков, и не допускает нежелательных артефактов при модуляции шума квантования, когда кодек переключает длины преобразования. Альтернативный, более простой подход заключается в том, чтобы задавать пороговые значения для всех полос ниже 4 кГц равным глобальному минимальному пороговому значению. Использование этого отрегулированного порогового значения в тишине должно приводить к другим значениям для первого и/или второго скаляра, как должны понимать специалисты в данной области техники.
Следует отметить, что пороговое значение в тишине на фиг. 1-2 умеренно размещается на 20 дБ ниже значения, которое оно составляет при традиционном предположении относительно пикового уровня воспроизведения SPL в 105 дБ. В одном варианте осуществления, пороговое значение задается на основе пикового уровня воспроизведения в 115 дБ. Это предоставляет степень устойчивости, в частности, для вариантов применения с переменной скоростью следования битов, при воспроизведении декодированного аудио на уровне, который отличается от предполагаемого уровня.
Модель на фиг. 3 извлекается посредством усреднения результатов экспериментов на основе узкополосного шума для маскирования тоном для различных частот. Сигнальные компоненты с более высоким уровнем ощущения принимают более высокое SVS. В одном примере, для каждого увеличения на 3 дБ энергии полосы частот выше порогового значения слышимости в тишине, SV увеличивается на 1 дБ. Зависимая от уровня SV-модель на фиг. 3 для полосы j частот, SV(j), выражается следующим образом:
SV(j)=max(0, 0,35*(Eb(j)-Q(j))+),
где Eb(j) и Q(j) (в этом примере выражаются в дБ) являются полосной MDCT-энергией и пороговым значением в тишине, соответственно.
Следует понимать, что очевидно изменять скаляры, представленные в вышеуказанном уравнении, посредством изменения конфигурации компонента анализа. Скаляры могут модифицироваться, чтобы регулировать вычисление SV, чтобы лучше соответствовать некоторым аудиосигналам. Первый скаляр, например, может располагаться в диапазоне между 0,2 и 0,5. Второй скаляр, например, может располагаться в диапазоне между 2,5 и 3,5.
В модели по фиг. 3, первый скаляр и второй скаляр являются постоянными по всем полосам частот. Тем не менее, в других вариантах осуществления, первый и/или второй скаляр являются частотно-зависимыми.
В одном варианте осуществления первое SV вычисляется S10 и используется в качестве SV для полосы частот, как показано на фиг. 3.
В одном варианте осуществления, прямолинейная модель 302 на фиг. 3 расширяется, чтобы более точно оценивать SV для входных сигналов с высокими уровнями шума. Некоторые примеры входных сигналов с высоким уровнем шума могут представлять собой аплодисменты или дождь либо шипящие звуки речи. Тем не менее, следует понимать, что предусмотрено множество различных сигналов с высокими уровнями шума. В качестве примера, при использовании технологии, идентичной технологии для случая для шума для маскирования тоном, SV может вычисляться как более точное для некоторых сигналов.
Во втором варианте осуществления, следует предполагать, что имеется идентичная прямолинейная взаимосвязь между SV и уровнем ощущения с высокими уровнями шума, но с другим наклоном. Наклон линии наилучшего приближения составляет примерно половину наклона для случая для шума для маскирования тоном. Это соответствие верифицируется с использованием аналогичных экспериментов, как показано на фиг. 1-3, но для маскера шумом вместо маскера тоном. Следовательно, обобщенная модель может реализовываться посредством адаптации SV-правила в зависимости от характеристик входных сигналов.
Следовательно, в одном варианте осуществления, необязательное второе SV вычисляется S12 и комбинируется, необязательно с использованием фиксированного или адаптивного комбинирования со взвешиванием, с первым SV, чтобы задавать конечное SV. В этих вариантах осуществления, компонент 700 анализа дополнительно выполнен с возможностью, при вычислении S08 SV для полосы частот, вычислять S12 второе SV с использованием разности между определенной энергией S04 и определенным пороговым значением слышимости S06 в тишине (уровня ощущения) и взвешивания первого и второго SV на основе по меньшей мере одной определенной характеристики S14 входного аудиосигнала. Следует понимать, что любая подходящая характеристика аудиосигнала может использоваться для вычисления S08 SV. В одном варианте осуществления по меньшей мере одна характеристика представляет собой оцененную тональность сигнала. Альтернативно, в одном варианте осуществления по меньшей мере одна характеристика представляет собой оцененный уровень шума для сигнала.
В одном варианте осуществления, оцененная тональность вычисляется с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала. Ниже описываются варианты осуществления для оценки тональности аудиосигнала.
Следует понимать, что можно использовать любой набор частотных коэффициентов. В качестве примера, один способ предшествующего уровня техники основан на фиксированном прогнозировании второго порядка абсолютной DFT-величины и фазы во времени (ISO/IEC, 11172-3:1993(E), «Information technology - Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s -Part 3: Audio.»). Согласно этому способу, чтобы обеспечивать различные компромиссы по частотно-временному разрешению для различных частот, перекрывающиеся DFT с длиной 512 и 128 (т.е. с числом комплексных DFT-коэффициентов) вычисляются параллельно. Компонент 700 анализа может обобщать способ предшествующего уровня техники таким образом, чтобы использовать адаптивное линейное прогнозирование комплексных MDCT-(CMDCT)-коэффициентов. В некоторых вариантах осуществления, линейное прогнозное кодирование (LPC) может адаптивно применяться к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты. Адаптивное линейное прогнозирование обеспечивает быстро развивающиеся гармоники в среднем диапазоне в вокализованной речи и музыке, с тем чтобы формировать более высокие оценки тональности, чем фиксированное прогнозирование. Помимо этого, требуемая переменная время-частотная инфраструктура может гибко реализовываться, без необходимости параллельной CMDCT-гребенки фильтров, посредством варьирования длины окна анализа LPC и/или порядка прогнозирования в качестве функции от частоты. Другими словами, длина функции аналитического LPC-кодирования может варьироваться в качестве функции от полосы частот. Дополнительно, порядок прогнозирования LPC также может варьироваться в качестве функции от полосы частот. Оптимальные параметры LPC-анализа могут выбираться офлайн для каждой полосы частот посредством максимизации разности в среднем усилении для прогнозирования для сложных в обработке сигналов и независимом и идентично распределенным (IID) гауссовом шуме. Примеры сложных в обработке сигналов могут представлять собой речь или клавесин. Тем не менее, следует понимать то, что предусмотрено множество различных сигналов, которые могут классифицироваться как сложные в обработке. Самые длинные окна анализа LPC типично используются на низких частотах, в то время как постепенно меньшие окна анализа LPC используются на верхних частотах. Другими словами, относительно более длинное окно анализа LPC может использоваться для полос относительно более низких частот для того, чтобы захватывать большую периодичность таких сигналов. Параметры LPC-анализа предоставляют гибкое средство для управления характеристиками формирования шума квантования кодера.
Ниже подробно описываются варианты осуществления того, как оценивать тональность аудиосигнала, в сочетании с фиг. 6.
В некоторых вариантах осуществления, взвешивание первого и второго SV основано на оценке тональности T. T является непрерывной переменной в пределах от 0 для чистых шумовых сигналов до 1 для чистых синусоид и разреженных компонентов гармонического сигнала. Первое и второе SV в силу этого могут смешиваться в качестве линейного комбинирования с весовыми коэффициентами, которые суммируются в единицу, при этом весовые коэффициенты зависят от T. Другими словами, взвешивание первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала может содержать вычисление значения, представляющего весовой коэффициент, причем значение находится в диапазоне между 0-1, при этом этап вычисления S08 SV для полосы частот содержит умножение одного из первого и второго SV на значение и умножение другого из первого или второго SV на единицу минус значение и сложение двух результирующих сумм между собой, чтобы формировать S08 SV для полосы частот.
Следует понимать то, что функция для вычисления S08 SV может модифицироваться различными способами посредством модификации скаляров.
В одном варианте осуществления, компонент 704 анализа выполнен с возможностью использовать третий скаляр при вычислении S12 второго SV.
В качестве примера, второе SV может вычисляться S12 посредством умножения разности на третий скаляр, отличающийся от первого скаляра. Следует понимать то, что третьему скаляру могут назначаться различные значения. Третий скаляр, например, может быть значением, располагающимся в диапазоне между 0,05 и 0,2. Третий скаляр может располагаться в диапазоне между 0,1 и 0,15.
В одном варианте осуществления, компонент 704 анализа выполнен с возможностью использовать четвертый скаляр при вычислении S12 второго SV.
В качестве примера, второе SV может вычисляться S12 посредством суммирования четвертого скаляра с разностью, умноженной на третий скаляр, причем четвертый скаляр отличается от второго скаляра. Следует понимать то, что четвертому скаляру могут назначаться различные значения. Четвертый скаляр, например, может располагаться в диапазоне между 3,5 и 4,5. Четвертый скаляр типично задается в соответствии с пороговым значением в тишине.
Следует отметить, что второй и четвертый скаляры могут значительно варьироваться в зависимости от задания для порогового значения в тишине. Важный аспект этих терминов заключатся в том, что они обеспечивают возможность компромисса по числу битов, выделяемых тональным и шумоподобным сигналам. Они также являются полезными для калибровки модели таким образом, что шум, выделяемый точно для уровня и формы порогового значения маскирования, является едва заметным для среднестатистического слушателя.
В одном варианте осуществления, компонент анализа выполнен с возможностью вычислять S12 второе SV посредством умножения разности на 0,15 и суммирования 4 с результатом.
Затем в качестве примера, полное SV может вычисляться S08 в качестве комбинирования со взвешиванием SV-правил для чистых синусоид и чистых шумовых сигналов, например:
SV(j)=max(0, T*(0,32*(Eb(j)-Q(j))+3)+(1-T)*(0,13*(Eb(j)-Q(j))+4)).
Фиг. 5 показывает модель SV по сравнению с уровня ощущения для трех различных типов сигналов. Тональная SV-модель 502 иллюстрирует поведение модели для сигналов, имеющих T=1. Шумовая SV-модель 504 иллюстрирует поведение модели для сигналов, имеющих T=0. Смешанная тональная и шумовая SV-модель 506 иллюстрирует поведение модели, когда T=0,65.
Соответственно, компонент 700 анализа может быть выполнен с возможностью смешиваться между моделями маскирования тоном и маскирования шумом. Другими словами, для очень тоноподобных сигналов, кодер главным образом использует конфигурации, подходящие для тоноподобных сигналов. Для очень шумоподобных сигналов, кодер главным образом использует конфигурации, подходящие для шумоподобных сигналов. Для промежуточных сигналов, кодер использует смешение конфигураций, причем пропорции тоноподобных и шумоподобных конфигураций зависят от внутриполосной тональности.
Возвращаясь к фиг. 7, с использованием значения чувствительности и значения энергии, пороговое значение маскирования затем может вычисляться S16, которое затем может использоваться, в комбинации со значением энергии, для определения S18 значения выделения битов полосы частот.
Преимущественно, компонент 700 анализа вычисляет S16 пороговое значение маскирования посредством вычитания переменного смещения (значения чувствительности) из энергии сигналов или значений, вычисленных на основе энергии сигналов. Переменное смещение, как пояснено выше, например, основано на разности (уровне ощущения) между значением энергии и тихим пороговым значением слышимости. В частности, по мере того, как уровень ощущения увеличивается, переменное смещение увеличивается, и наоборот. Такой способ вычисления порогового значения маскирования предоставляет лучшее совпадение с субъективно измеренными данными маскирования и в силу этого приводит к улучшенному выделению битов. Повышение субъективного качества декодированного аудиосигнала может быть самым заметным для высокоуровневых сигналов. Модели предшествующего уровня техники с использованием независимого от уровня смещения формируют ниже необходимого пороговое значение маскирования для более тихих сигналов, что приводит к избыточному выделению битов и, как следствие, уменьшает доступное число битов для других полос и других кадров, содержащих более громкие сигнальные компоненты.
В качестве сравнения, модели предшествующего уровня техники типично определяют пороговое значение маскирования просто посредством вычитания фиксированного смещения из энергии внутриполосных сигналов. Например, в некоторых случаях идентичное смещение используется независимо от того, насколько близко энергия полосы частот находится к пороговому значению слышимости. Компонент 700 анализа вместо этого определяет пороговое значение маскирования посредством вычитания переменного смещения из энергии сигналов.
Пороговое значение маскирования может вычисляться S16 различными способами. В одном варианте осуществления, вычисление порогового значения маскирования содержит применение функции разброса к одному из следующего: линейные значения энергии для полос частот; или преобразованные значения энергии полос частот. Другими словами, в одном варианте осуществления, функция разброса применяется к значениям энергии для полос частот. В другом варианте осуществления, значения энергии сначала преобразуются до того, как функция разброса применяется. Преобразование может содержать преобразование линейных значений энергии в область уровней громкости посредством возведения значений энергии в степень ~0,25-0,3. Преобразование альтернативно может содержать возведение значений энергии в степень 0,5-0,6, что, как обнаружено, обеспечивает еще лучшее качество звука для некоторых аудиоформатов.
В силу этого, значение возбуждения определяется для полосы частот. Значение возбуждения затем комбинируется со значением чувствительности, чтобы вычислять пороговое значение маскирования. На шкале в дБ, комбинирование значения чувствительности и значения возбуждения содержит вычитание значения чувствительности из значения возбуждения. В области интенсивности, вместо этого используется разделение.
В другом варианте осуществления, функция разброса применяется после комбинирования значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение. В этом варианте осуществления, вычисление порогового значения маскирования содержит комбинирование значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и применение функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования.
Необязательно, для всех вышеуказанных вариантов осуществления, пороговое значение маскирования извлекается посредством пороговой обработки с пороговым значением в тишине, например, пороговое значение маскирования=max(пороговое значение маскирования, пороговое значение слышимости в тишине).
В одном варианте осуществления, функция разброса для полосы частот зависит от уровня ощущения таким образом, что эффект функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения. Типично, функции разброса задаются на абсолютной SPL-шкале. Использование альтернативного способа для задания функции разброса может предоставлять более обобщенную психоакустическую модель при внесении только минимальной дополнительной вычислительной сложности. На сегодняшний день, множество кодеров, по-видимому, применяют функции разброса, которые являются наиболее подходящими для тихих сигналов. Это представляет собой консервативный проектный подход, но степень маскирования в частотной области должна недооцениваться для более громких сигналов, что может приводить к выделению большего числа битов, чем требуется в определенных полосах, что, соответственно, оставляет меньшее число битов, доступных для других полос и, возможно, приводит к пониженному качеству. Соответственно, компонент 700 анализа может быть выполнен с возможностью задавать функцию разброса для полосы частот в зависимости от разности между определенным значением энергии S04 и определенным пороговым значением слышимости S06 в тишине, что приводит к улучшенному выделению битов.
В некоторых вариантах осуществления, определение S18 значения выделения битов для полосы частот содержит вычисление SMR для полосы частот, составляющего значение энергии для полосы частот, вычитаемое посредством вычисленного порогового (S16) значения маскирования для полосы частот. В некоторых вариантах осуществления, дополнительное фиксированное смещение вычитается. Определение S18 значения выделения битов затем основано на величине SMR. В некоторых вариантах осуществления, значение выделения битов подвергается пороговой обработке при заданном максимальном значении выделения битов, например, 12 битов.
В некоторых вариантах осуществления, определение S18 значения выделения битов содержит регулирование S20 порогового значения маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала. Регулирование S20 порогового значения маскирования может содержать регулирование порогового значения маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала. Как упомянуто выше, преобразование из линейной энергетической области в область уровней громкости содержит возведение каждой энергии в степень ~0,25-0,3.
В общем, компонент 700 анализа назначает S18 большее число битов для полосы частот, имеющей более высокое SV (когда SV задается в дБ в качестве разностного регулирования для функции возбуждения) по сравнению с тем, если упомянутая полоса частот имеет более низкое SV.
Компонент 700 анализа в некоторых вариантах осуществления может реализовываться в кодере 800. Такие варианты осуществления показаны на фиг. 8. В этом варианте осуществления, кодер 800 содержит приемный компонент 802, выполненный с возможностью принимать аудиосигнал 806. Кодер дополнительно содержит компонент 804 кодирования, выполненный с возможностью использовать значения выделения битов, определенные S18 посредством компонента 700 анализа для целей кодирования. Например, компонент 804 кодирования выполнен с возможностью квантовать аудиовыборки аудиоданных полосы частот в ответ на значение выделения битов и кодировать квантованные аудиоданные полосы частот в поток 808 битов. В некоторых вариантах осуществления, кодер 800 дополнительно содержит компонент компандирования (не показан), выполненный с возможностью уменьшать динамический диапазон аудиосигнала с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот. Признак компандирования уменьшает динамический диапазон входных сигналов до кодирования с преобразованием. Признак компандирования может получать преимущества из кодированного качества сигналов, содержащих плотные неустановившиеся смешения, такие как дождь и аплодисменты. В одном примере, компандирование входных сигналов и вариант осуществления вычисления S10 только первого SV и его использования S08 в качестве SV могут работать синергетически, чтобы формировать более высокую производительность, чем любой признак отдельно. В этом варианте осуществления, динамический диапазон аудиосигнала уменьшается с использованием алгоритма компандирования до этапа кодирования аудиосигнала с использованием ассоциированного SV. Признак компандирования дополнительно может уменьшать число битов, которые следует кодировать, при поддержании высокого качества звука.
В некоторых вариантах осуществления, компонент 700 анализа реализуется в декодере 900. Этот вариант осуществления показан на фиг. 9. В этом варианте осуществления, декодер 900 содержит приемный компонент 902, выполненный с возможностью принимать аудиосигнал 906, имеющий форму кодированного потока битов, содержащего кодированное значение энергии для полос частот аудиосигнала. Декодер дополнительно содержит компонент 904 декодирования, выполненный с возможностью использовать значения выделения битов, определенные S18 посредством компонента 700 анализа, для целей декодирования. Компонент 904 декодирования выполнен с возможностью декодировать кодированное значение энергии из кодированного потока 906 битов, при этом компонент 700 анализа использует декодированное значение энергии при определении значения энергии. Компонент 904 декодирования дополнительно выполнен с возможностью извлекать квантованные аудиовыборки аудиоданных полосы частот из кодированного потока 906 битов в ответ на значение выделения битов. Компонент 904 декодирования дополнительно выполнен с возможностью деквантовать квантованные аудиовыборки аудиоданных полосы частот и комбинировать деквантованные аудиовыборки аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал 908.
Следует отметить, что компонент 700 анализа и соответствующий способ могут использоваться с любым аудиоформатом.
Маскирование с использованием изобретаемых способов, описанных в данном документе, предоставляет лучшее совпадение с субъективно измеренными данными маскирования и в силу этого приводит к улучшенному выделению битов. Вариант осуществления для использования вычисленного S10 первого SV в качестве SV для полосы частот предоставляет существенное улучшение по сравнению с кодером по умолчанию для речевых сигналов. Это является важным, поскольку речевые сигналы представляют собой очень критический элемент типичного широковещательного и кинематографического контента.
В некоторых вариантах осуществления, кодер 800 и/или декодер 900, реализующие этот вариант осуществления (или альтернативно, вариант осуществления для вычисления S12 также второго SV), реализуются в устройстве двусторонней связи в реальном времени. Преимущественно, более простой вариант осуществления может использоваться в таком устройстве, с учетом более низкой сложности такого способа кодирования. Тем не менее, следует отметить, что предусмотрено множество вариантов применения и возможных вариантов использования кодера 800 и/или декодера 900.
Кодер 800 за счет этого точно захватывает наблюдаемое поведение при маскировании слуховой системы человека. Это приводит к более высокой производительности кодека, чем кодеры по умолчанию для вариантов применения с постоянной скоростью следования битов и с переменной скоростью следования битов.
Субъективное улучшение, в некоторых вариантах осуществления, может быть наиболее заметным для сигналов с относительно высоким уровнем, поскольку кодеры по умолчанию, которые извлекают пороговые значения маскирования на основе независимого от уровня смещения (вместо использования SV), имеют тенденцию избыточно выделять биты сигнальным компонентам с низким уровнем.
Фиг. 4 показывает общее представление примерного способа вычисления порогового значения маскирования, как описано выше, в котором оценка тональности используется для взвешивания первого и второго SV. Как показано на фиг. 4, входной аудиокадр вводится в MDCT-гребенку фильтров. Длина преобразования, вводимая в MDCT-гребенку фильтров, также принимается посредством модуля оценки тональности (подробно описан ниже в сочетании с фиг. 6). Модуль оценки тональности выводит оценку Tj(m) тональности в пределах 0-1, по одному набору для каждого MDCT-преобразования, как подробнее описано ниже. В этой системе обозначений, j является индексом полосы частот, и m является индексом MDCT-блока.
Коэффициенты MDCT-преобразования используются для того, чтобы определять значение энергии для каждой полосы частот. Функция разброса применяется к значениям энергии полос частот для того, чтобы извлекать функцию возбуждения. На конечных этапах примерного способа по фиг. 4, как описано в данном документе, значения энергии и пороговое значение в тишине используются для того, чтобы вычислять первое и второе SV, затем они взвешиваются посредством оценок Tj(m) тональности и применяются к значениям возбуждения, чтобы в завершение формировать пороговое значение маскирования для каждой полосы частот.
Ниже описывается вариант осуществления способа оценки тональности на основе адаптивного прогнозирования в сочетании с фиг. 6.
Входной кадр 602 предоставляет входные выборки. Гребенка 604 фильтров выполнена с возможностью принимать входные выборки из входного кадра 602. Следует отметить, что имеются различные гребенки 604 фильтров, которые могут использоваться. В одном примере, используется CMDCT, в котором N=128. В другом примере, может использоваться CQMF, в котором N=64. Гребенка 604 фильтров выполнена с возможностью отправлять комплексные частотные коэффициенты 606 (Xk(n), полоса k частот во время n) в компонент 608 LPC-анализа и в компонент 605 оценки непрогнозируемости. Структура по фиг. 6 повторяется для каждой CMDCT/CQMF-полосы частот. Компонент 608 LPC-анализа в сочетании с компонентом 605 оценки непрогнозируемости выполнен с возможностью предоставлять набор значений 609 непрогнозируемости (μk(n)), который соответствует частотным коэффициентам 606.
С учетом того факта, что временные выборки в одном CMDCT-блоке затрагивают три смежных CMDCT-блока, 3-отводный FIR-фильтр используется для того, чтобы сглаживать оценки непрогнозируемости на двухстадийной стадии 620 сглаживания. Это улучшает гладкость оценок тональности (а в силу этого также и декодированного аудио). Аналогичный подход используется для других гребенок фильтров, например, CQMF с N=64.
Компонент 610 отображения выполнен с возможностью принимать сглаженные значения непрогнозируемости, длину 612 преобразования и энергию полосы частот (вычисленную посредством поля 611 на фиг. 6). После того, как оценки непрогнозируемости сглаживаются, они комбинируются между собой во времени, чтобы отражать ненулевую часть функции MDCT-кодирования со взвешиванием, к которой они должны впоследствии применяться. Это может быть важным, в частности, для динамически изменяющихся сигналов, таких как речь, чтобы максимизировать четкость декодированного выходного сигнала. Компонент 610 отображения дополнительно выполнен с возможностью отправлять отображенные входные данные 613 (Zk(n)) в качестве выходных данных в компонент 614 разброса и нормализации. Компонент 614 разброса и нормализации выполнен с возможностью применять функцию разброса к входным данным 613 и отправлять набор модифицированных данных 615 (Uk(n)) в компонент 616 отображения тональности. Компонент 616 отображения тональности выполнен с возможностью отображать входные данные 615 (непрогнозируемость) в один или более наборов оценок 618 тональности.
Более подробно относительно фиг. 6, согласно некоторым вариантам осуществления, синусоидальное окно (оконная функция) применяется к блокам с 50%-ым перекрытием входных выборок, извлеченных из одного кадра 602 длины 4096, с последующим 128-точечными CMDCT. Выбор гребенки 604 фильтров не является критическим; например, также может использоваться комплексная QMF-гребенка 604 фильтров, которая уже существует в известном кодере. Для набора комплексных частотных коэффициентов 606 из блока 604, Xk(n), k=1, ..., N, формируется соответствующий набор значений 609 непрогнозируемости. Непрогнозируемость μk(n) для полосы k частот во время n задается следующим образом:
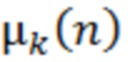 =
= 
- где:
αki является набором pk коэффициентов комплексного прогнозирования для k-ой полосы частот, и pk является порядком прогнозирования LPC для идентичной полосы. Значения μk(n) 609 непрогнозируемости располагаются в диапазоне 0-1 для чистых тонов и чистого шума, соответственно.
В каждом частотном CMDCT-элементе k разрешения, группа из Lk последовательных коэффициентов Xk(n-m), m=1, ..., Lk, обрабатывается окном и анализируется для того, чтобы формировать комплексные коэффициенты прогнозирования порядка pk (pk<Lk). Коэффициенты прогнозирования aki, i=1, ..., pk, затем используются для того, чтобы вычислять значения 609 непрогнозируемости, соответствующие Xk(n). Обнаружено, что из множества оцененных окон анализа LPC, было найдено почти симметричное окно Хэмминга, которое максимизирует усиления для прогнозирования. Степень асимметрии варьируется как функция от CMDCT-элемента разрешения. Значения непрогнозируемости для всех полос затем фильтруются посредством набора двухстадийных сглаживающих фильтров 620, чтобы не допускать резких изменений во времени. Примерный двухстадийный фильтр состоит из 3-отводного FIR в каскаде с традиционным экспоненциальным сглаживающим фильтром. FIR-фильтр принимает значения 609 μk(n) непрогнозируемости и формирует частично сглаженные выходные сигналы μk'(n). Выходной FIR-сигнал затем дополнительно обрабатывается посредством экспоненциального сглаживающего фильтра, чтобы формировать μk''(n).
В одном варианте осуществления, IIR-фильтры с быстрой атакой и медленным затуханием могут использоваться для экспоненциальных сглаживающих фильтров. Эти фильтры предоставляют средства для независимого управления временами атаки и затухания. Ввод находится в области тональности (1- μk'(n)), и дифференциальные уравнения задаются следующим образом:
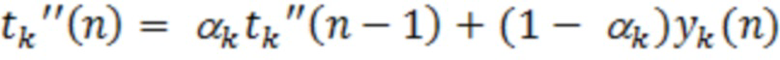
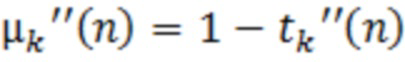 ,
,
где αk и βk являются коэффициентами атаки и затухания для полосы k частот, соответственно, tk''(n) являются сглаженными оценкам тональности, и yk(n) являются переменными промежуточного состояния. Постоянные времени атаки и затухания типично варьируются в качестве функции от номера полосы частот. В вышеприведенном третьем уравнении, выводы фильтров с быстрой атакой и медленным затуханием преобразуются обратно в непрогнозируемости для последующей обработки на 610.
Без сглаживания, оценки тональности имеют тенденцию флуктуировать по последовательным блокам преобразования, приводя к флуктуации оценок порогового значения маскирования. Это в свою очередь может приводить к звуковой модуляции шума квантования в выводе декодера, в частности, на низких и средних частотах. Способ, который эффективно разрешает эту проблему, заключается в том, чтобы проектировать коэффициенты фильтрации для атаки/затухания из известных временных характеристик человеческих акустических фильтров. Этот подход приводит к постоянным времени атаки/затухания, которые являются, в общем, самыми длинными на низких частотах и самыми короткими на высоких частотах.
На следующей стадии по фиг. 6, энергии CMDCT-элементов разрешения и сглаженные значения непрогнозируемости из всех CMDCT-блоков повторно дискретизируются и комбинируются в группы (отображаются) 610 таким образом, что они совпадают с временным и частотным разрешением каждого MDCT-преобразования(й) в текущем кадре. Повторно дискретизированные значения 613 непрогнозируемости взвешиваются согласно своей относительной перцепционной важности и комбинируются во времени по мере необходимости. Примерные перцепционные взвешивания включают в себя возведенную в квадрат L2-норму (энергию) и уровень громкости. Затем, для того, чтобы обеспечивать совпадение с разбросом, применяемым к полосным MDCT-энергиям, значения непрогнозируемости разбрасываются по частоте посредством применения функции разброса (614), например, из ISO/IEC, 11172-3:1993(E). На конечном этапе, повторно дискретизированные, разбросанные и нормализованные значения 615 непрогнозируемости отображаются 616 в один или более наборов оценок 618 тональности в диапазоне от 0 до 1, включительно: один набор для каждого MDCT-преобразования.
Фиг. 10 показывает результаты из примера экспериментально измеренного SV для JND в качестве функции от различных коэффициентов смешения тона+узкополосного шума (SNR). Центральные частоты в 500 Гц 804, в 1 кГц 802 и в 4 кГц 806 использованы с SNR маскера в пределах от -10 дБ до 40 дБ. Маскер представляется в субъекты на уровне SPL в 80 дБ. Средняя кривая 808 (полужирная линия) представляет SV-среднее по всем трем центральным частотам.
В варианте осуществления, другая функция отображения тональности (отличающаяся от правила отображения тональности в 11172-3:1993 ISO/IEC) калибруется для, по меньшей мере частично, результатов перцепционных экспериментов на основе маскирования смешанных тональных+узкополосных шумовых сигналов. Цель этого варианта осуществления состоит в том, чтобы определять JND-уровень для маскера, состоящего из смешения тона+узкополосного шума, и маскируемого, состоящего из декоррелированного узкополосного шума на идентичной частоте. Эксперимент повторяется на множестве уровней смешения тона/шума маскера и на множестве частот. Результат экспериментов может использоваться для калибровки отображения тональности, как описано ниже.
В одном варианте осуществления, сначала, каждое из управляющих воздействий для тона+узкополосного шума вводится в модуль оценки тональности, чтобы захватывать ассоциированные значения непрогнозируемости. Из этих результатов, формируется таблица, которая ассоциирует каждое значение непрогнозируемости с требуемым SMR. Посредством комбинирования этой таблицы с правилом отображения тональности в SMR для маскирования тоном+узкополосным шумом, которое совпадает с SMR-диапазоном, точки извлекаются на кривой, задающей отображение непрогнозируемости в тональность, требуемое для калибровки модели. На конечном этапе, извлекается параметрическая функция, которая аппроксимирует извлеченную кривую калибровки. Этапы эксперимента на основе маскирования и калибровки могут повторяться на множестве частот и уровней входного сигнала.
Фиг. 11 показывает в качестве примера результаты эксперимента одного варианта осуществления. Он представляет целевую кривую 904 калибровки и параметрическую модель/функцию 902 (штрихпунктирная линия), которая аппроксимирует извлеченную кривую калибровки для 128-точечного CMDCT с синусоидальным окном и 50%-м перекрытием. Пример предшествующего уровня техники включается на чертеже для сравнения (пунктирная линия 906). В примере, LPC-анализ представляет собой третий порядок с длиной окна, равной 6. В этом варианте осуществления, параметрическая функция T(μ) отображает непрогнозируемость в тональность согласно следующему:
T(μ)=min(max(a*μ3+b*μ2+c*μ+d, 0), 1)
Значения для четырех параметров (a, b, c, d) извлекаются, чтобы аппроксимировать целевую кривую калибровки. В примере, показанном на фиг. 11, значения параметров модели для a, b, c и d составляют -13,0233, 15,9513, -8,1012, 2,1319.
Хотя использование оценки тональности в перцепционных моделях известно в предшествующем уровне техники (ISO/IEC, 11172-3:1993(E), пунктирная линия 906 на фиг. 11), модели предшествующего уровня техники работают независимо от уровня. В ISO/IEC, 11172-3:1993(E), SMR-модель адаптируется на основе оцененной тональности между 6 и приблизительно 30 дБ для чистых шумовых и тональных сигналов, соответственно. Зависимая от уровня модель, описанная в данном документе с калиброванной функцией отображения тональности, реализована при моделировании и превосходит модель предшествующего уровня техники, как определено посредством объективного показателя качества и посредством тестов на основе прослушивания.
Дополнительные варианты осуществления настоящего раскрытия должны становиться очевидными для специалистов в данной области техники после изучения вышеприведенного описания. Даже если настоящее описание и чертежи раскрывают варианты осуществления и примеры, раскрытие не ограничивается этими конкретными примерами. Множество модификаций и варьирований могут вноситься без отступления от объема настоящего раскрытия, который задается посредством прилагаемой формулы изобретения. Любые ссылки с номерами, содержащиеся в формуле изобретения, не должны пониматься как ограничивающие ее объем.
Дополнительно, варьирования в раскрытых вариантах осуществления могут пониматься и осуществляться специалистами в данной области техники при применении на практике раскрытия, после изучения чертежей, раскрытия и прилагаемой формулы изобретения. В формуле изобретения, слово «содержащий» не исключает другие элементы или этапы, а использование единственного числа не исключает множества. Простой факт того, что определенные средства упомянуты в различных зависимых пунктах формулы изобретения, не означает того, что комбинация этих средств не может преимущественно использоваться.
Системы и способы, раскрытые выше, могут реализовываться как программное обеспечение, микропрограммное обеспечение, аппаратные средства либо комбинация вышеозначенного. В аппаратной реализации, разделение задач между функциональными модулями, упоминаемыми в вышеприведенном описании, не обязательно соответствует разделению на физические модули; наоборот, один физический компонент может иметь несколько функциональностей, и одна задача может выполняться посредством нескольких физических компонентов совместно. Определенные компоненты или все компоненты могут реализовываться как программное обеспечение, выполняемое посредством процессора цифровых сигналов или микропроцессора, либо реализовываться как аппаратные средства или как специализированная интегральная схема. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители данных (или энергонезависимые носители) и среды связи (или энергозависимые среды). Специалистам в данной области техники известно, что термин «компьютерные носители данных» включает в себя энергозависимые и энергонезависимые, съемные и стационарные носители, реализованные в любом способе или технологии для хранения информации (к примеру, как машиночитаемые инструкции, структуры данных, программные модули или другие данные). Компьютерные носители данных включают в себя, но не только, RAM, ROM, EEPROM, флэш-память или другую технологию запоминающих устройств, CD-ROM, универсальные цифровые диски (DVD) или другие устройства хранения данных на оптических дисках, магнитные кассеты, магнитную ленту, устройства хранения данных на магнитных дисках или другие магнитные устройства хранения данных либо любой другой носитель, который может использоваться для хранения требуемой информации, и к которому может осуществляться доступ посредством компьютера. Дополнительно, специалистам в данной области техники известно то, что среды связи типично осуществляют машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна или другой транспортный механизм, и включают в себя любые среды доставки информации.
Различные аспекты настоящего раскрытия сущности могут приниматься во внимание из следующих перечислимых примерных вариантов осуществления (EEE):
EEE1. Способ для обработки аудиосигнала, причем аудиосигнал содержит аудиоданные во множестве полос частот, при этом способ содержит:
- для каждой полосы частот из множества полос частот:
- определение значения энергии для аудиоданных полосы частот;
- определение порогового значения слышимости в тишине для полосы частот;
- вычисление значения чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине;
- вычисление порогового значения маскирования для полосы частот с использованием значения чувствительности и значения энергии;
- определение значения выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
EEE2. Способ по EEE1, в котором вычисление порогового значения маскирования содержит применение функции разброса к одному из следующего:
- значения энергии для полос частот; или
- преобразованные значения энергии полос частот;
для определения значения возбуждения для полосы частот, и
комбинирование значения чувствительности со значением возбуждения.
EEE3. Способ по EEE1, в котором вычисление порогового значения маскирования содержит комбинирование значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и применение функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования.
EEE4. Способ по любому предыдущему EEE, дополнительно содержащий квантование аудиовыборок аудиоданных полосы частот в ответ на значение выделения битов.
EEE5. Способ по EEE4, дополнительно содержащий кодирование квантованных аудиоданных полосы частот в поток битов.
EEE6. Способ по любому из EEE1-EEE3, в котором аудиосигнал представляет собой кодированный поток битов, содержащий кодированное значение энергии для полосы частот, и при этом определение значение энергии для аудиоданных полосы частот содержит декодирование кодированного значения энергии из кодированного потока битов.
EEE7. Способ по EEE6, дополнительно содержащий извлечение квантованных аудиовыборок аудиоданных полосы частот из кодированного потока битов в ответ на значение выделения битов.
EEE8. Способ по EEE7, дополнительно содержащий деквантование квантованных аудиовыборок аудиоданных полосы частот и комбинирование деквантованных аудиовыборок аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал.
EEE9: Способ по любому предыдущему EEE, в котором определение значения выделения битов содержит регулирование порогового значения маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала.
EEE10. Способ по EEE9, в котором регулирование порогового значения маскирования содержит:
- регулирование порогового значения маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала.
EEE11. Способ по любому предыдущему EEE, в котором значение энергии, пороговое значение слышимости в тишине и пороговое значение маскирования задаются в децибелах (дБ).
EEE12. Способ по любому предыдущему EEE, дополнительно содержащий этап определения множества полос частот аудиосигнала в соответствии со шкалой эквивалентной прямоугольной полосы пропускания (ERB).
EEE13. Способ по EEE2 или по любому предыдущему EEE, зависимому от EEE2, в котором SV задается в дБ в качестве разностного регулирования для значения возбуждения, при этом этап определения значения выделения битов содержит назначение большего числа битов для полосы частот, имеющей более высокое SV, по сравнению с упомянутой полосой частот, имеющей более низкое SV.
EEE14. Способ по любому предыдущему EEE, в котором этап вычисления SV для полосы частот содержит вычисление первого SV с использованием уровня ощущения, при этом уровень ощущения представляет собой разность, на шкале в дБ, между значением энергии и пороговым значением слышимости в тишине.
EEE15. Способ по EEE14, в котором этап вычисления первого SV содержит умножение уровня ощущения на первый скаляр.
EEE16. Способ по EEE15, в котором первый скаляр является частотно-зависимым.
EEE17. Способ по EEE15, в котором первый скаляр является постоянным по всем полосам частот.
EEE18. Способ по любому из EEE15-EEE17, в котором этап вычисления первого SV содержит суммирование второго скаляра с уровнем ощущения, умноженным на первый скаляр.
EEE16. Способ по любому из EEE14-EEE18, в котором этап вычисления SV содержит использование первого SV в качестве SV для полосы частот.
EEE20. Способ по любому из EEE14-EEE18, в котором этап вычисления SV для полосы частот содержит вычисление второго SV с использованием уровня ощущения и взвешивание первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала.
EEE21. Способ по EEE20, в котором этап вычисления второго SV для полосы частот содержит умножение уровня ощущения на третий скаляр, отличающийся от первого скаляра.
EEE22. Способ по EEE21, в котором этап вычисления второго SV содержит суммирование четвертого скаляра с уровнем ощущения, умноженным на третий скаляр, причем четвертый скаляр отличается от второго скаляра.
EEE23. Способ по любому из EEE20-EEE22, в котором этап взвешивания первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала содержит вычисление значения, представляющего весовой коэффициент, причем значение находится в диапазоне между 0-1, при этом этап вычисления SV для полосы частот содержит умножение одного из первого и второго SV на значение и умножение другого из первого или второго SV на единицу минус значение и сложение двух результирующих сумм между собой, чтобы формировать SV для полосы частот.
EEE24. Способ по любому из EEE20-EEE23, в котором по меньшей мере одна характеристика задает оцененную тональность полосы частот аудиосигнала.
EEE25. Способ по любому из EEE20-EEE23, в котором по меньшей мере одна характеристика задает оцененный уровень шума в полосе частот аудиосигнала.
EEE26. Способ по EEE24, в котором оцененная тональность вычисляется с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала.
EEE27. Способ по EEE26, в котором линейное прогнозирующее кодирование (LPC) адаптивно применяется к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты.
EEE28. Способ по EEE27, в котором длина окна анализа LPC варьируется как функция от полосы частот.
EEE29. Способ по EEE28, в котором относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
EEE30. Способ по любому из EEE27-EEE29, в котором порядок прогнозирования LPC варьируется как функция от полосы частот.
EEE31. Способ по любому предыдущему EEE, в котором частотный диапазон аудиосигнала составляет между 200-7000 Гц.
EEE32. Способ по любому предыдущему EEE, в котором этап определения порогового значения слышимости в тишине для полосы частот содержит использование предварительно заданной таблицы, задающей пороговое значение слышимости для по меньшей мере некоторых частот.
EEE33. Способ по EEE4 или по любому другому EEE, зависимому от EEE4, в котором динамический диапазон аудиосигнала уменьшается с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот.
EEE34. Способ по EEE14 или по любому из EEE15-EEE33, зависимых от EEE14, дополнительно содержащий этап задания функции разброса для полосы частот в зависимости от уровня ощущения таким образом, что эффект функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения.
EEE35. Устройство, содержащее:
- приемный компонент, выполненный с возможностью принимать аудиосигнал, причем аудиосигнал содержит аудиоданные во множестве полос частот;
- компонент анализа, выполненный с возможностью определять множество полос частот аудиосигнала;
- причем компонент анализа дополнительно выполнен с возможностью, для каждой полосы частот из множества полос частот:
- определять значение энергии для аудиоданных полосы частот;
- определять пороговое значение слышимости в тишине для полосы частот;
- вычислять значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине;
- вычислять пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии;
- определять значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
EEE36. Устройство по EEE35, в котором компонент анализа выполнен с возможностью:
вычислять пороговое значение маскирования посредством применения функции разброса к одному из следующего:
- значения энергии для полос частот; или
- преобразованные значения энергии полос частот;
для определения значения возбуждения для полосы частот, и
комбинировать значение чувствительности со значением возбуждения.
EEE37. Устройство по EEE35, в котором компонент анализа выполнен с возможностью вычислять пороговое значение маскирования посредством комбинирования значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и применения функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования.
EEE38. Устройство по любому из EEE35-EEE37, представляющее собой кодер, дополнительно содержащее компонент кодирования, выполненный с возможностью квантовать аудиовыборки аудиоданных полосы частот в ответ на значение выделения битов.
EEE33. Устройство по EEE38, в котором компонент кодирования дополнительно выполнен с возможностью кодировать квантованные аудиоданные полосы частот в поток битов.
EEE40. Устройство по любому из EEE35-EEE37 представляющее собой декодер, в котором аудиосигнал представляет собой кодированный поток битов, содержащий кодированное значение энергии для полосы частот, причем устройство дополнительно содержит компонент декодирования, выполненный с возможностью декодировать кодированное значение энергии из кодированного потока битов, при этом компонент анализа использует декодированное значение энергии при определении значения энергии.
EEE41. Устройство по EEE40, в котором компонент декодирования выполнен с возможностью извлекать квантованные аудиовыборки аудиоданных полосы частот из кодированного потока битов в ответ на значение выделения битов.
EEE42. Устройство по EEE41, в котором компонент декодирования дополнительно выполнен с возможностью деквантовать квантованные аудиовыборки аудиоданных полосы частот и комбинировать деквантованные аудиовыборки аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал.
EEE43. Устройство по любому из EEE35-EEE42, в котором компонент анализа выполнен с возможностью: при определении значения выделения битов, регулировать пороговое значение маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала.
EEE44. Устройство по EEE43, в котором компонент анализа выполнен с возможностью: при регулировании порогового значения маскирования, регулировать пороговое значение маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала.
EEE45. Устройство по любому из EEE35-EEE44, в котором компонент анализа выполнен с возможностью задавать значение энергии, пороговое значение слышимости в тишине и пороговое значение маскирования в децибелах (дБ).
EEE46. Устройство по любому из EEE35-EEE45, в котором компонент анализа выполнен с возможностью определять множество полос частот аудиосигнала в соответствии со шкалой эквивалентной прямоугольной полосы пропускания (ERB).
EEE47. Устройство по EEE36 или по любому из EEE37-EEE46, зависимых от EEE36, в котором SV задается в дБ в качестве разностного регулирования для значения возбуждения, при этом компонент анализа выполнен с возможностью определять значение выделения битов посредством назначения большего числа битов для полосы частот, имеющей более высокое SV, по сравнению с упомянутой полосой частот, имеющей более низкое SV.
EEE48. Устройство по любому из EEE35-EEE47, в котором компонент анализа выполнен с возможностью вычислять SV для полосы частот посредством вычисления первого SV с использованием уровня ощущения, при этом уровень ощущения представляет собой разность, на шкале в дБ, между значением энергии и пороговым значением слышимости в тишине.
EEE43. Устройство по EEE48, в котором компонент анализа выполнен с возможностью вычислять первое SV посредством умножения уровня ощущения на первый скаляр.
EEE50. Устройство по EEE49, в котором первый скаляр является частотно-зависимым.
EEE51. Устройство по EEE49, в котором первый скаляр является постоянным по всем полосам частот.
EEE52. Устройство по EEE49-EE51, в котором компонент анализа выполнен с возможностью вычислять первое SV посредством суммирования второго скаляра с уровнем ощущения, умноженным на первый скаляр.
EEE53. Устройство по любому из EEE48-EEE52, в котором компонент анализа выполнен с возможностью вычислять SV посредством использования первого SV в качестве SV для полосы частот.
EEE54. Устройство по любому из EEE48-EEE52, в котором компонент анализа выполнен с возможностью вычислять SV для полосы частот посредством дополнительного вычисления второго SV с использованием уровня ощущения и взвешивания первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала.
EEE55. Устройство по EEE54, в котором компонент анализа выполнен с возможностью вычислять второе SV для полосы частот посредством умножения уровня ощущения на третий скаляр, отличающийся от первого скаляра.
EEE56. Устройство по EEE55, в котором компонент анализа выполнен с возможностью вычислять второе SV посредством суммирования четвертого скаляра с уровнем ощущения, умноженным на третий скаляр, причем четвертый скаляр отличается от второго скаляра.
EEE57. Устройство по любому из EEE54-EEE55, в котором компонент анализа выполнен с возможностью выполнять взвешивание первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала посредством вычисления значения, представляющего весовой коэффициент, причем значение находится в диапазоне между 0-1, и вычисления SV для полосы частот посредством умножения одного из первого и второго SV на значение и умножения другого из первого или второго SV на единицу минус значение и сложения двух результирующих сумм между собой, чтобы формировать SV для полосы частот.
EEE58. Устройство по любому из EEE54-EEE57, в котором по меньшей мере одна характеристика задает оцененную тональность полосы частот аудиосигнала.
EEE53. Устройство по любому из EEE54-EEE57, в котором по меньшей мере одна характеристика задает оцененный уровень шума в полосе частот аудиосигнала.
EEE60. Устройство по EEE58, в котором компонент анализа выполнен с возможностью вычислять оцененную тональность с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала.
EEE61. Устройство по EEE60, в котором компонент анализа выполнен с возможностью адаптивно применять LPC к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты.
EEE62. Устройство по EEE61, в котором длина окна анализа LPC варьируется как функция от полосы частот.
EEE63. Устройство по EEE62, в котором относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
EEE64. Устройство по любому из EEE62-EEE63, в котором порядок прогнозирования LPC варьируется как функция от полосы частот.
EEE65. Устройство по любому из EEE35-EEE64, в котором частотный диапазон аудиосигнала составляет между 200-7000 Гц.
EEE66. Устройство по любому из EEE35-EEE65, дополнительно содержащее запоминающее устройство, причем запоминающее устройство сохраняет таблицу, задающую пороговое значение слышимости в тишине для по меньшей мере некоторых частот, при этом компонент анализа выполнен с возможностью определять пороговое значение слышимости в тишине для полосы частот посредством использования предварительно заданной таблицы.
EEE67. Устройство по EEE38 или по любому другому EEE, зависимому от EEE38, дополнительно содержащее компонент компандирования, выполненный с возможностью уменьшать динамический диапазон аудиосигнала с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот.
EEE68. Устройство по EEE48 или по любому из EEE49-EEE67, зависимых от EEE48, в котором компонент анализа выполнен с возможностью задавать функцию разброса для полосы частот в зависимости от уровня ощущения таким образом, что эффект функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения.
EEE63. Устройство по любому из EEE35-EEE67, реализованное в устройстве двусторонней связи в реальном времени.
EEE70. Способ для оценки тональности входного сигнала, содержащий этапы:
- применения гребенки фильтров, чтобы достигать набора частотных коэффициентов;
- вычисления оцененной тональности с использованием адаптивного прогнозирования частотных коэффициентов.
EEE71. Способ по EEE70, в котором этап вычисления оцененной тональности содержит применение адаптивного линейного прогнозирования к частотным коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются частотные коэффициенты.
EEE72. Способ по EEE70, в котором длина окна анализа LPC варьируется как функция от полосы частот.
EEE73. Способ по EEE72, в котором относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
EEE74. Способ по любому из EEE72-EEE73, в котором порядок прогнозирования LPC варьируется как функция от полосы частот.
EEE75. Способ по любому из EEE70-EEE74, в котором гребенка фильтров содержит одно из следующего: 128-полосная комплексная MDCT- или DFT-гребенка фильтров и 64-полосная комплексная QMF-гребенка фильтров.
EEE76. Способ по любому из EEE71-EEE73, в котором окно анализа LPC представляет собой асимметричное окно Хэмминга.
EEE77. Способ по любому из EEE70-EEE76, содержащий этап:
- взвешивания показателей прогнозируемости из адаптивного прогнозирования согласно относительной перцепционной важности каждого показателя прогнозируемости.
EEE78. Способ по EEE77, в котором этап взвешивания показателей прогнозируемости, содержащихся в каждой частотно-временной плитке, содержит одно из следующего: взвешивание на основе энергии или уровня громкости входного сигнала.
EEE73. Способ по любому из EEE70-EEE78, дополнительно содержащий этап:
- комбинирования показателей прогнозируемости из адаптивного прогнозирования частотных коэффициентов таким образом, что они совпадают с временным и частотным разрешением гребенки фильтров.
EEE80. Способ по EEE2 или по любому из EEE4-EEE34, зависимых от EEE2, в котором значение чувствительности и значение возбуждения задаются в децибелах (дБ), и этап комбинирования содержит вычитание значения чувствительности из значения возбуждения, или при этом значение чувствительности и значение возбуждения задаются на шкале интенсивности, и этап комбинирования содержит вычисление частного значения возбуждения и значения чувствительности.
EEE81. Способ по EEE3 или по любому из EEE4-EEE34, зависимых от EEE3, в котором значение энергии и значение чувствительности задаются в децибелах (дБ), и этап комбинирования содержит вычитание значения чувствительности из значения энергии, или при этом значение энергии и значение чувствительности задаются на шкале интенсивности, и этап комбинирования содержит вычисление частного значения энергии и значения чувствительности.
EEE82. Способ по любому из EEE1-EEE34 или EEE80-EEE81, в котором вычисление значения чувствительности содержит вычисление соотношения или разности между значением энергии полосы частот и пороговым значением слышимости в тишине для полосы частот.
EEE83. Компьютерный программный продукт, содержащий машиночитаемый носитель данных с инструкциями, адаптированными с возможностью осуществлять способ по любому из EEE1-34 или EEE80-82 при выполнении посредством устройства, имеющего возможности обработки.
EEE84. Компьютерный программный продукт, содержащий машиночитаемый носитель данных с инструкциями, адаптированными с возможностью осуществлять способ по любому из EEE70-79 при выполнении посредством устройства, имеющего возможности обработки.
EEE85. Устройство по EEE36 или по любому из EEE38-EEE69, зависимых от EEE36, в котором значение чувствительности и значение возбуждения задаются в децибелах (дБ), и этап комбинирования содержит вычитание значения чувствительности из значения возбуждения, или при этом значение чувствительности и значение возбуждения задаются на шкале интенсивности, и этап комбинирования содержит вычисление частного значения возбуждения и значения чувствительности.
EEE86. Устройство по EEE37 или по любому из EEE38-EEE69, зависимых от EEE37, в котором значение энергии и значение чувствительности задаются в децибелах (дБ), и этап комбинирования содержит вычитание значения чувствительности из значения энергии, или при этом значение энергии и значение чувствительности задаются на шкале интенсивности, и этап комбинирования содержит вычисление частного значения энергии и значения чувствительности.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ СВОБОДНО ВЫБИРАЕМЫХ СДВИГОВ ЧАСТОТЫ В ОБЛАСТИ ПОДДИАПАЗОНОВ | 2013 |
|
RU2595889C1 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ЗНАЧЕНИЯ КОМПЕНСАЦИИ | 2017 |
|
RU2727728C1 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| СИСТЕМЫ И СПОСОБЫ ВЫПОЛНЕНИЯ ФИЛЬТРАЦИИ ДЛЯ ОПРЕДЕЛЕНИЯ УСИЛЕНИЯ | 2013 |
|
RU2643628C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА, ИМЕЮЩЕГО ИМПУЛЬСОПОДОБНУЮ И СТАЦИОНАРНУЮ СОСТАВЛЯЮЩИЕ, СПОСОБЫ КОДИРОВАНИЯ, ДЕКОДЕР, СПОСОБ ДЕКОДИРОВАНИЯ И КОДИРОВАННЫЙ АУДИОСИГНАЛ | 2008 |
|
RU2439721C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
| УСТРОЙСТВО КВАНТОВАНИЯ АУДИОДАННЫХ, УСТРОЙСТВО ДЕКВАНТОВАНИЯ АУДИОДАННЫХ И СООТВЕТСТВУЮЩИЕ СПОСОБЫ | 2021 |
|
RU2807462C1 |
| АУДИОДЕКОДЕР, АУДИОКОДЕР И СВЯЗАННЫЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ ОБЪЕДИНЕННОГО КОДИРОВАНИЯ ПАРАМЕТРОВ МАСШТАБИРОВАНИЯ ДЛЯ КАНАЛОВ МНОГОКАНАЛЬНОГО АУДИОСИГНАЛА | 2021 |
|
RU2809981C1 |
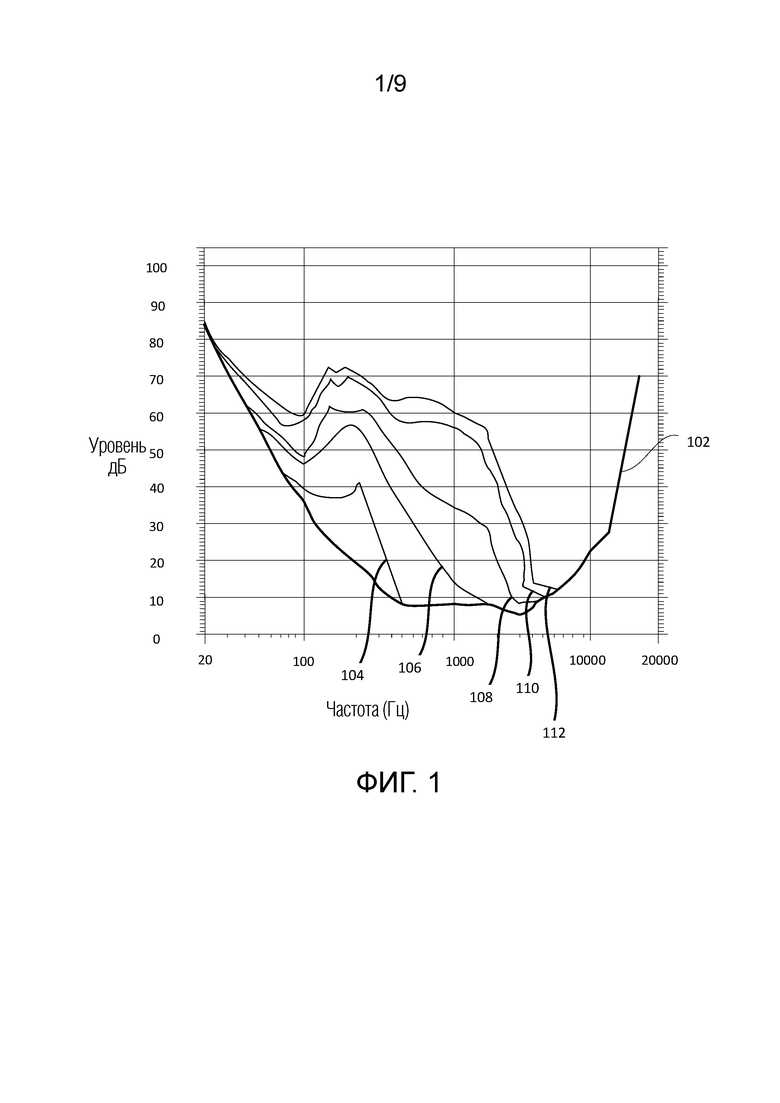
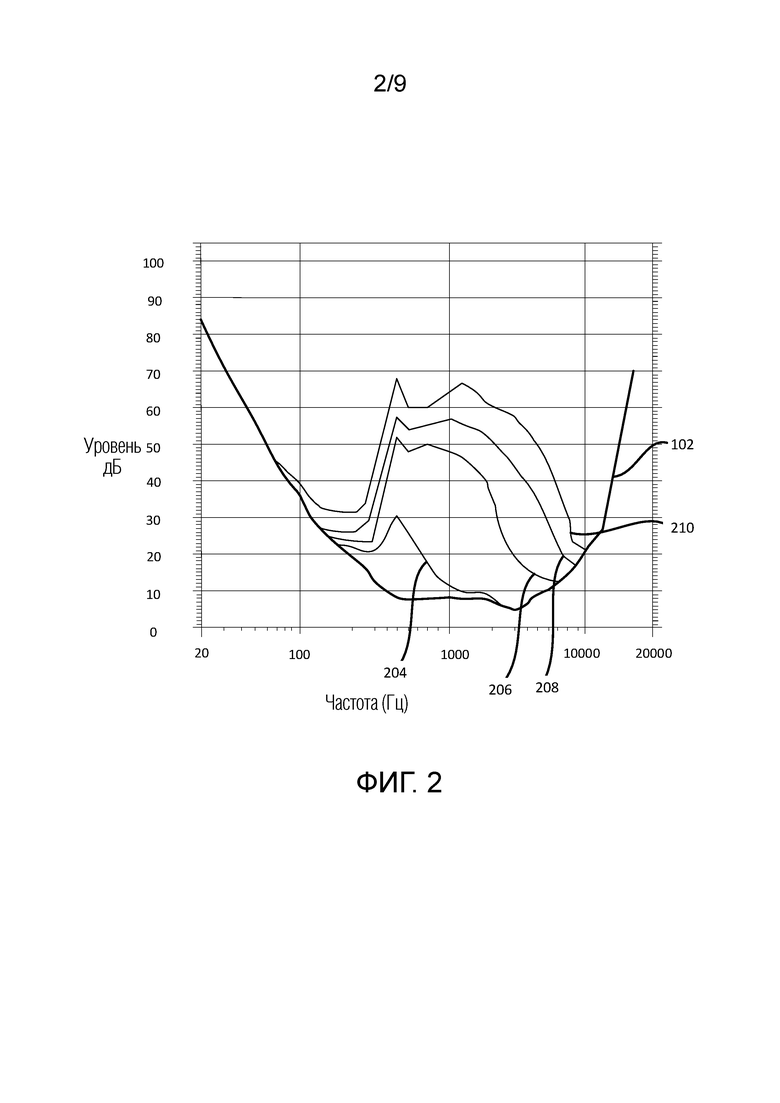
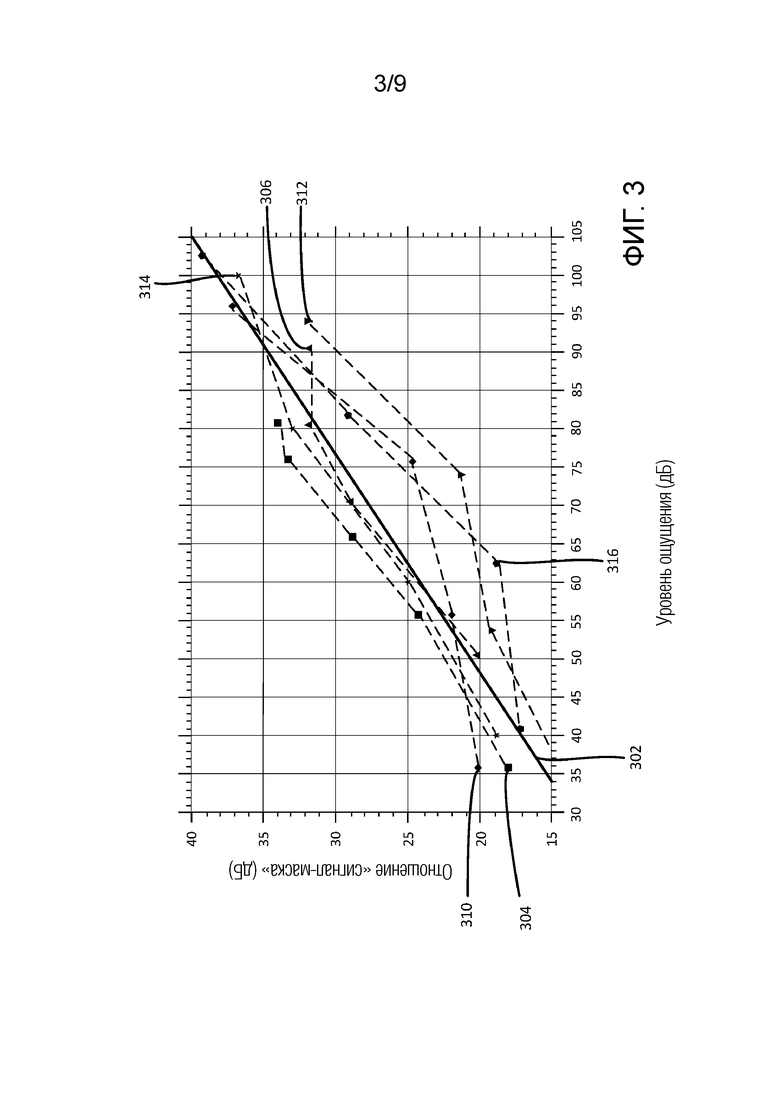
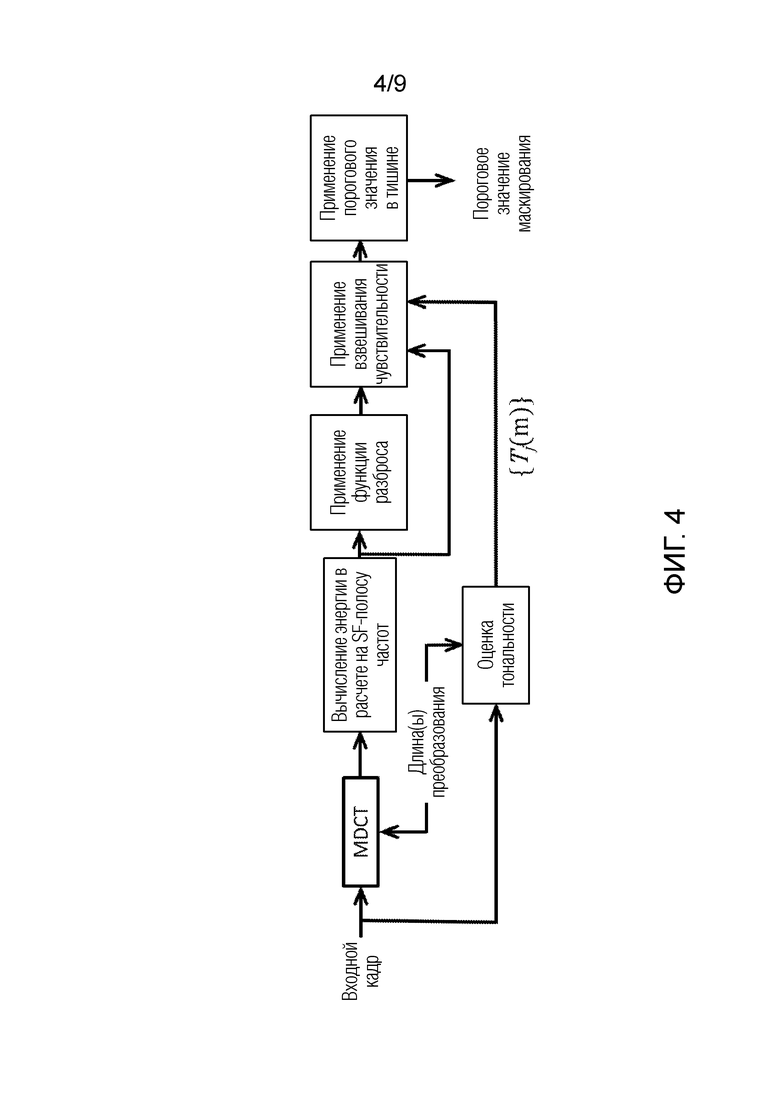
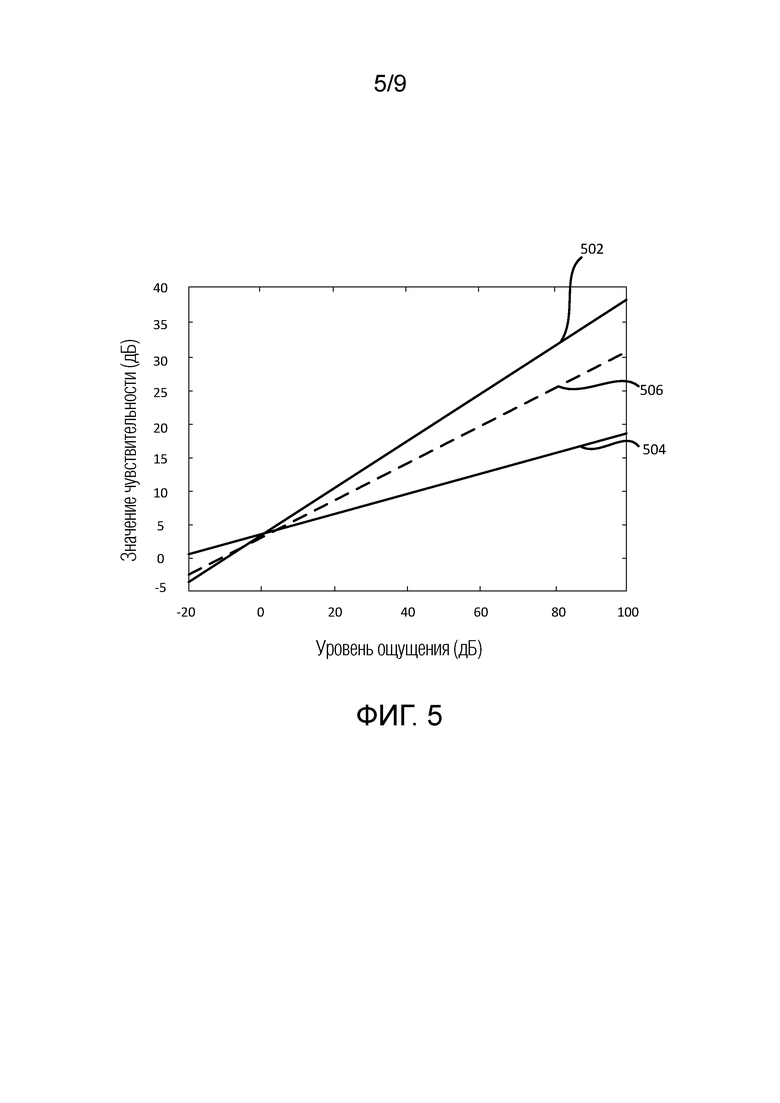
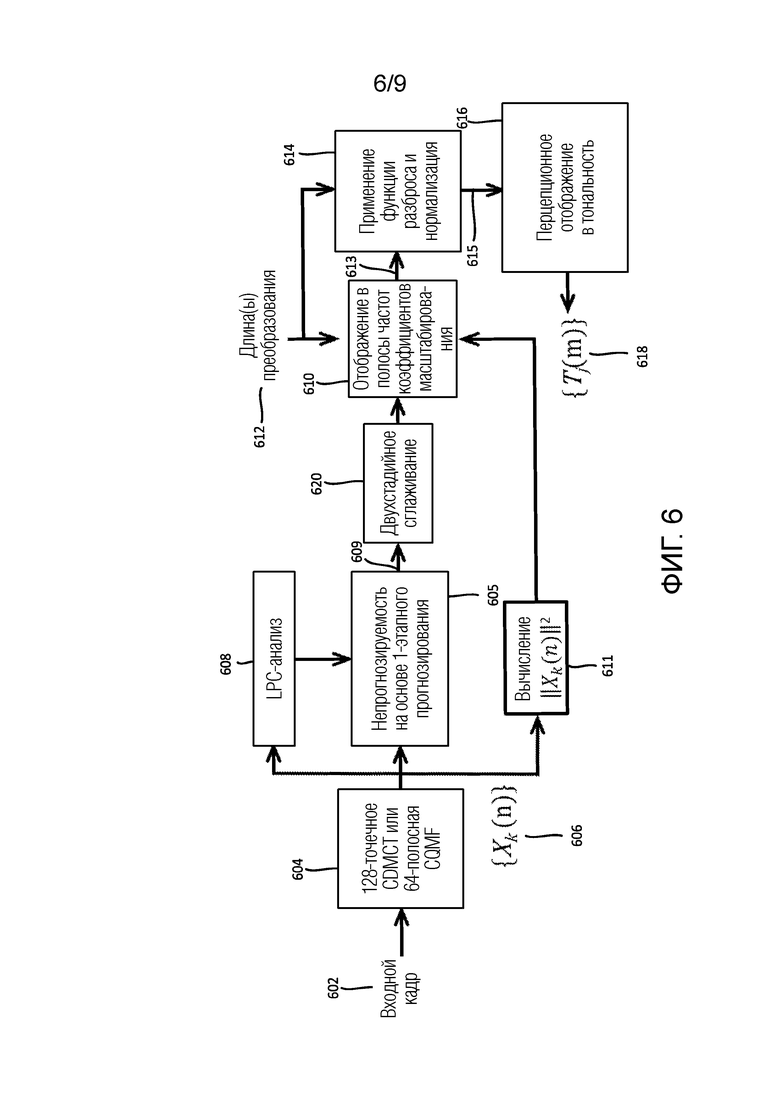
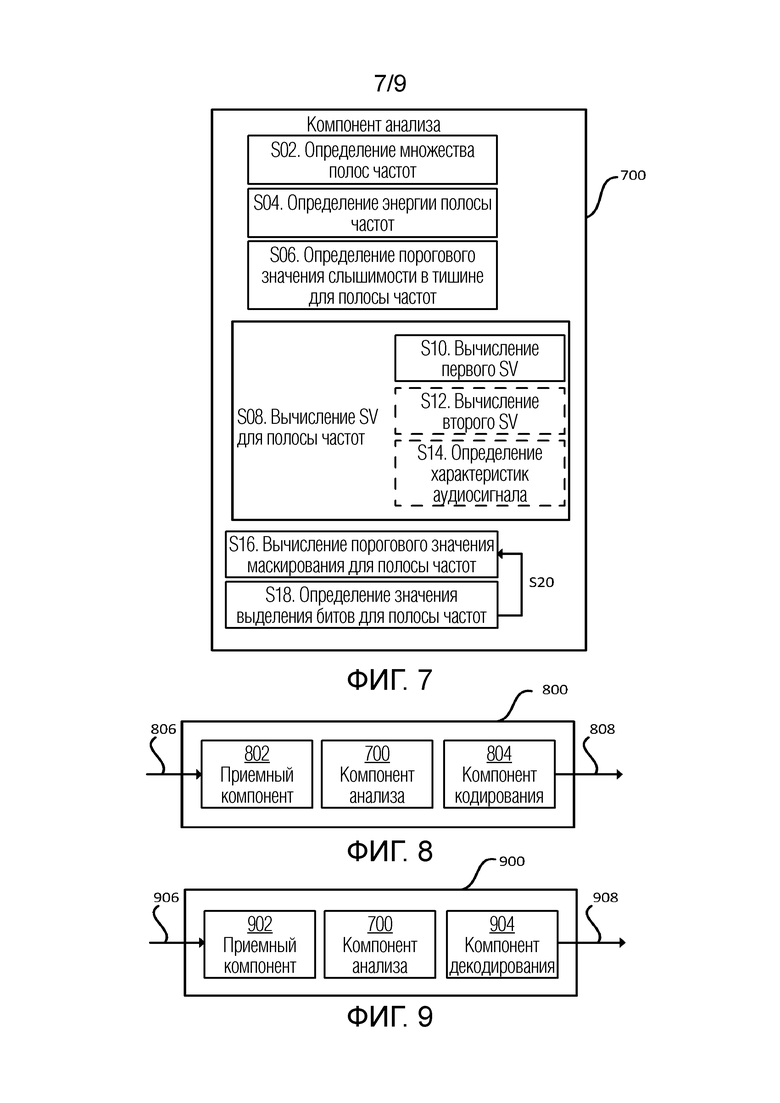
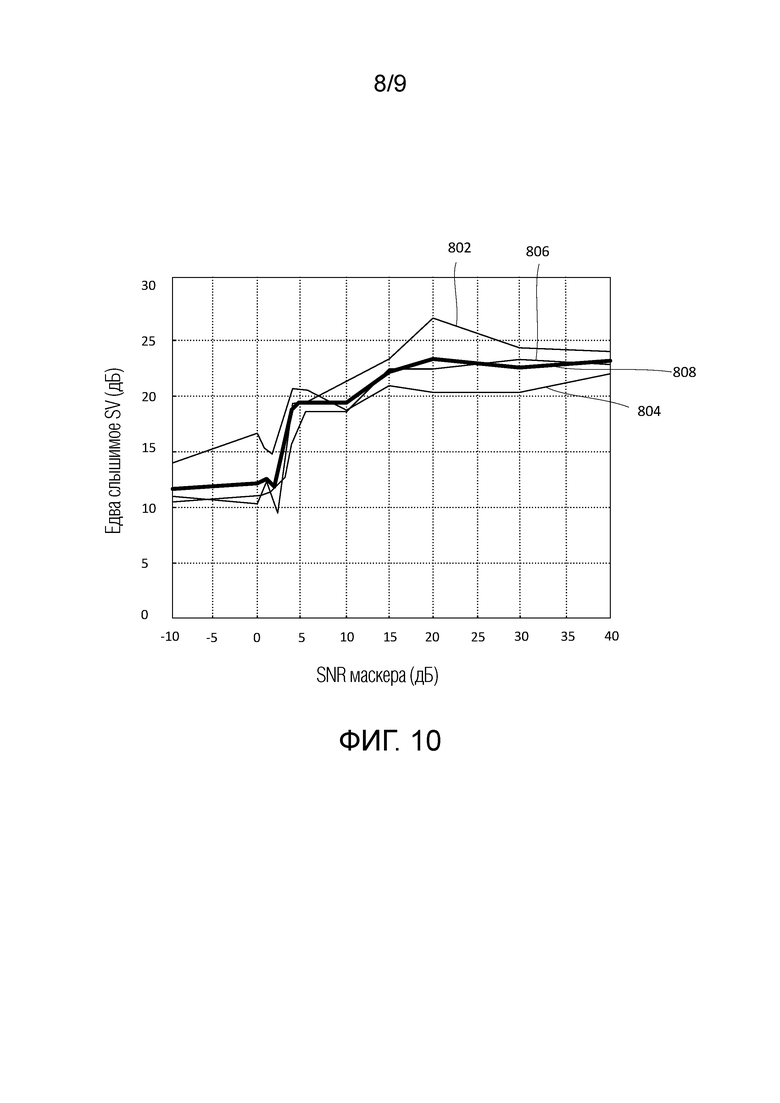
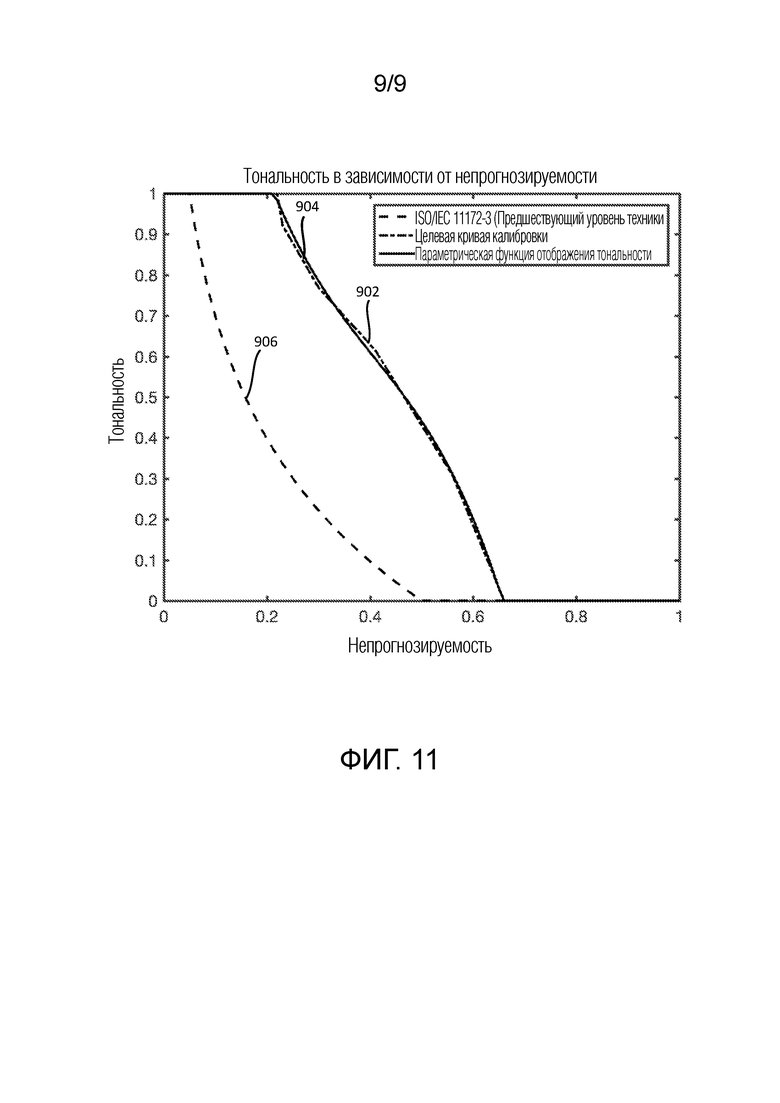
Настоящее раскрытие сущности относится к области техники кодирования аудио, в частности оно относится к способу для кодирования аудиосигналов через маскирующую модель на основе порогового значения слышимости частотных интервалов аудиосигнала и измеренной энергии аудиосигнала для соответствующих частотных интервалов. Раскрытие сущности дополнительно относится к кодеру, который допускает осуществление способа кодирования аудио. Заявленная группа изобретений обеспечивает уменьшение сложности кодирования аудио и повышение качества кодированного аудио. 5 н. и 25 з.п. ф-лы, 11 ил.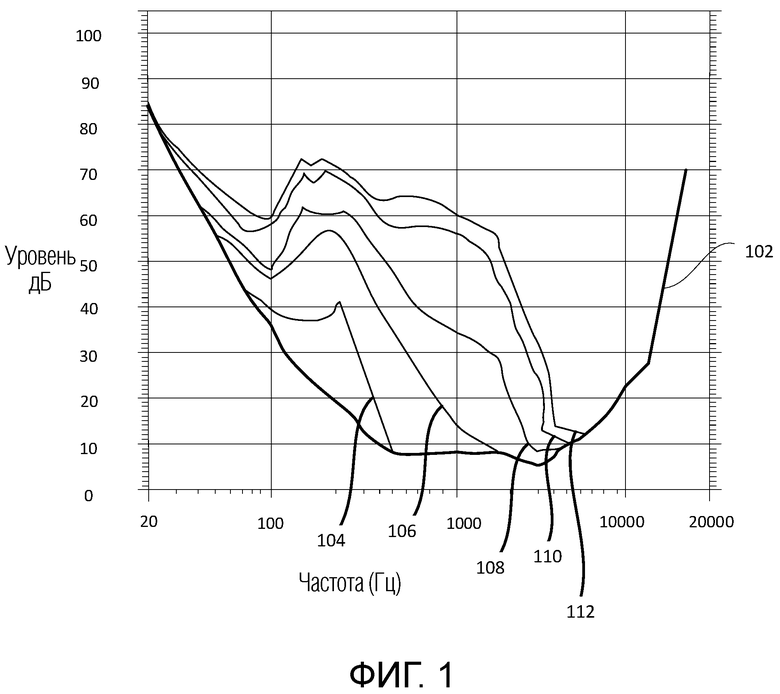
1. Способ для обработки аудиосигнала, причем аудиосигнал содержит аудиоданные во множестве полос частот, при этом способ содержит этапы, на которых:
- для каждой полосы частот из множества полос частот:
- определяют значение энергии для аудиоданных полосы частот;
- определяют пороговое значение слышимости в тишине для полосы частот;
- вычисляют значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине, при этом вычисление значения чувствительности содержит этап, на котором вычисляют соотношение или разность между значением энергии полосы частот и пороговым значением слышимости в тишине для полосы частот;
- вычисляют пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии, при этом вычисление порогового значения маскирования содержит этапы, на которых:
определяют значение возбуждения для полосы частот путем применения функции разброса к одному из следующего: значений энергии для полос частот; или преобразованных значений энергии полос частот; и
комбинируют значение чувствительности со значением возбуждения, при этом комбинирование включает в себя либо, по шкале дБ, вычитание значения чувствительности из значения возбуждения; либо, по шкале интенсивности, вычитание частного значения возбуждения и значения чувствительности; и
- определяют значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
2. Способ для обработки аудиосигнала, причем аудиосигнал содержит аудиоданные во множестве полос частот, при этом способ содержит этапы, на которых:
- для каждой полосы частот из множества полос частот:
- определяют значение энергии для аудиоданных полосы частот;
- определяют пороговое значение слышимости в тишине для полосы частот;
- вычисляют значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине, при этом вычисление значения чувствительности содержит этап, на котором вычисляют соотношение или разность между значением энергии полосы частот и пороговым значением слышимости в тишине для полосы частот;
- вычисляют пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии, при этом вычисление порогового значения маскирования содержит этапы, на которых:
комбинируют значение энергии и значение чувствительности, чтобы определять промежуточное пороговое значение, и
применяют функцию разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования; и
- определяют значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
3. Способ по любому из предшествующих пунктов, в котором если пороговое значение слышимости в тишине больше вычисленного порогового значения маскирования, вычисленное пороговое значение маскирования заменяется пороговым значением слышимости в тишине.
4. Способ по любому из предшествующих пунктов, в котором определение значения выделения битов содержит этап, на котором регулируют пороговое значение маскирования, чтобы достигать выделения битов, которое удовлетворяет целевой скорости следования битов для аудиосигнала, при этом регулирование порогового значения маскирования содержит этап, на котором:
- регулируют пороговое значение маскирования посредством суммирования постоянного смещения с пороговым значением маскирования в области уровней громкости до тех пор, пока не удовлетворяется целевая скорость следования битов для аудиосигнала.
5. Способ по п. 1, в котором этап определения значения выделения битов содержит этап, на котором назначают большее число битов для полосы частот, имеющей более высокое SV, по сравнению с упомянутой полосой частот, имеющей более низкое SV.
6. Способ по любому из предшествующих пунктов, в котором этап вычисления SV для полосы частот содержит этап, на котором вычисляют первое SV с использованием уровня ощущения, при этом уровень ощущения представляет собой разность, по шкале дБ, между значением энергии и пороговым значением слышимости в тишине.
7. Способ по п. 6, в котором этап вычисления первого SV содержит этап, на котором умножают уровень ощущения на первый скаляр.
8. Способ по п. 7, в котором первый скаляр является частотно-зависимым.
9. Способ по п. 7, в котором первый скаляр является постоянным по всем полосам частот.
10. Способ по любому из пп. 6-9, в котором этап вычисления SV содержит этап, на котором используют первое SV в качестве SV для полосы частот.
11. Способ по любому из пп. 6-9, в котором этап вычисления SV для полосы частот содержит этап, на котором вычисляют второе SV с использованием уровня ощущения и взвешивают первое и второе SV на основе по меньшей мере одной характеристики аудиосигнала.
12. Способ по п. 11, в котором этап вычисления второго SV для полосы частот содержит этап, на котором умножают уровень ощущения на третий скаляр, отличающийся от первого скаляра.
13. Способ по любому из пп. 11, 12, в котором этап взвешивания первого и второго SV на основе по меньшей мере одной характеристики аудиосигнала содержит этап, на котором вычисляют значение, представляющее весовой коэффициент, причем значение находится в диапазоне между 0-1, при этом этап вычисления SV для полосы частот содержит этап, на котором умножают одно из первого и второго SV на упомянутое значение и умножают другое из первого или второго SV на единицу минус упомянутое значение и складывают два результирующих итога между собой, чтобы формировать SV для полосы частот.
14. Способ по пп. 11-13, в котором по меньшей мере одна характеристика задает оцененный уровень тональности в полосе частот аудиосигнала.
15. Способ по п. 14, в котором оцененная тональность вычисляется с использованием адаптивного прогнозирования частотных коэффициентов, вычисленных из полосы частот аудиосигнала.
16. Способ по п. 15, в котором линейное прогнозирующее кодирование (LPC) адаптивно применяется к MDCT-коэффициентам на основе полосы частот аудиосигнала, из которого вычисляются MDCT-коэффициенты.
17. Способ по п. 16, в котором длина окна анализа LPC варьируется как функция от полосы частот.
18. Способ по п. 17, в котором относительно более длинное окно анализа LPC используется для полос относительно более низких частот.
19. Способ по любому из пп. 16-18, в котором порядок прогнозирования LPC варьируется как функция от полосы частот.
20. Способ по любому из пп. 6-19, дополнительно содержащий этап, на котором задают функцию разброса для полосы частот в зависимости от уровня ощущения таким образом, что эффект функции разброса в полосе частот с относительно более высоким уровнем ощущения является большим по сравнению с эффектом функции разброса в полосе частот с относительно более низким уровнем ощущения.
21. Способ по любому из предшествующих пунктов, в котором этап определения порогового значения слышимости в тишине для полосы частот содержит этап, на котором используют предварительно заданную таблицу, задающую пороговое значение слышимости для по меньшей мере некоторых частот.
22. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором квантуют аудиовыборки аудиоданных полосы частот в ответ на значение выделения битов.
23. Способ по п. 22, дополнительно содержащий этап, на котором кодируют квантованные аудиоданные полосы частот в поток битов.
24. Способ по любому из пп. 22, 23, в котором динамический диапазон аудиосигнала уменьшается с использованием алгоритма компандирования до квантования аудиовыборок аудиоданных полос частот.
25. Способ по любому из пп. 1-21, в котором аудиосигнал представляет собой кодированный поток битов, содержащий кодированное значение энергии для полосы частот, и при этом определение значения энергии для аудиоданных полосы частот содержит этап, на котором декодируют кодированное значение энергии из кодированного потока битов.
26. Способ по п. 25, дополнительно содержащий этап, на котором извлекают квантованные аудиовыборки аудиоданных полосы частот из кодированного потока битов в ответ на значение выделения битов.
27. Способ по п. 26, дополнительно содержащий этап, на котором деквантуют квантованные аудиовыборки аудиоданных полосы частот и комбинируют деквантованные аудиовыборки аудиоданных каждой полосы частот для того, чтобы формировать декодированный аудиосигнал.
28. Устройство для обработки аудиосигнала, содержащее:
- приемный компонент, выполненный с возможностью принимать аудиосигнал, причем аудиосигнал содержит аудиоданные во множестве полос частот;
- компонент анализа, выполненный с возможностью определять множество полос частот аудиосигнала;
причем компонент анализа дополнительно выполнен с возможностью, для каждой полосы частот из множества полос частот:
- определять значение энергии для аудиоданных полосы частот;
- определять пороговое значение слышимости в тишине для полосы частот;
- вычислять значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине, при этом вычисление значения чувствительности содержит вычисление соотношения или разности между значением энергии полосы частот и пороговым значением слышимости в тишине для полосы частот;
- вычислять пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии, при этом вычисление порогового значения маскирования содержит:
определение значения возбуждения для полосы частот путем применения функции разброса к одному из следующего: значений энергии для полос частот; или преобразованных значений энергии полос частот, и
комбинирование значения чувствительности со значением возбуждения, при этом комбинирование включает в себя либо, по шкале дБ, вычитание значения чувствительности из значения возбуждения; либо, по шкале интенсивности, вычитание частного значения возбуждения и значения чувствительности; и
- определять значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
29. Устройство для обработки аудиосигнала, содержащее:
- приемный компонент, выполненный с возможностью принимать аудиосигнал, причем аудиосигнал содержит аудиоданные во множестве полос частот;
- компонент анализа, выполненный с возможностью определять множество полос частот аудиосигнала;
причем компонент анализа дополнительно выполнен с возможностью, для каждой полосы частот из множества полос частот:
- определять значение энергии для аудиоданных полосы частот;
- определять пороговое значение слышимости в тишине для полосы частот;
- вычислять значение чувствительности (SV) для полосы частот с использованием значения энергии и порогового значения слышимости в тишине, при этом вычисление значения чувствительности содержит вычисление соотношения или разности между значением энергии полосы частот и пороговым значением слышимости в тишине для полосы частот;
- вычислять пороговое значение маскирования для полосы частот с использованием значения чувствительности и значения энергии, при этом вычисление порогового значения маскирования содержит:
комбинирование значения энергии и значения чувствительности, чтобы определять промежуточное пороговое значение, и
применение функции разброса к промежуточному пороговому значению, чтобы определять пороговое значение маскирования; и
- определять значение выделения битов полосы частот с использованием значения энергии и порогового значения маскирования.
30. Машиночитаемый носитель данных с инструкциями, адаптированными с возможностью осуществлять способ по любому из пп. 1-27 при выполнении посредством устройства, имеющего возможности обработки.
| JAN H PLASBERG et al | |||
| "The Sensitivity Matrix: Using Advanced Auditory Models in Speech and Audio Processing", vol.15, 01.01.2007 | |||
| US 2017110134 A1, 20.04.2017 | |||
| KR 20170125058 A, 13.11.2017 | |||
| Устройство для определения местоположения источника сигналов | 2016 |
|
RU2631906C1 |

