1. Область техники, к которой относится изобретение
Варианты осуществления согласно изобретению создают блоки маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра или большего числа аудиокадров в кодированной аудиоинформации.
Варианты осуществления согласно изобретению создают аудиодекодеры для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем декодеры содержат блоки маскирования ошибок.
Некоторые варианты осуществления согласно изобретению создают способы для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации.
Некоторые варианты осуществления согласно изобретению создают компьютерные программы для осуществления одного из упомянутых способов.
Некоторые варианты осуществления связаны с использованием адаптивного коэффициента затухания для аудиокодеков частотной области.
2. Уровень техники
В последние годы возрастает потребность в цифровой передаче и хранении аудиоконтента. Однако аудиоконтент часто передается по ненадежным каналам, что повышает риск потери блоков данных (например, пакеты) содержащий один или более аудиокадров (например, в форме кодированного представления, в частности, кодированного представления в частотной области или кодированного представления во временной области). В некоторых ситуациях, можно запрашивать повторение (повторную передачу) потерянных аудиокадров (или блоков данных, в частности, пакетов, содержащих один или более потерянных аудиокадров). Однако это обычно вносит существенную задержку и, таким образом, требует обширной буферизации аудиокадров. В других случаях, вряд-ли возможно запрашивать потерянных аудиокадров.
Для получения хорошего или, по меньшей мере, приемлемого, качества аудиосигнала в случае потери аудиокадров без обеспечения обширной буферизации (что будет потреблять большой объем памяти и также будет существенно снижать возможности в реальном времени кодирования аудиосигнала) желательно иметь принципы, чтобы обрабатывать потерю одного или более аудиокадров. В частности, желательно иметь принципы, которые способствуют повышению качества аудиосигнала или, по меньшей мере, приемлемого качества аудиосигнала, даже в случае потери аудиокадров.
В прошлом были разработаны некоторое принципы маскирования ошибок, которые можно использовать в разных принципах кодирования аудиосигнала. Традиционным методом маскирования в усовершенствованном аудиокодеке (AAC) является замена шума. Он действует в частотной области и пригоден для зашумленных и музыкальных элементов.
Также были разработаны методы затухания для снижения интенсивности замещающих кадров (или спектральных значений). Эти методы часто основываются на масштабировании замещающего кадра с предварительно определенным коэффициентом (коэффициентом затухания). Обычно коэффициент затухания представляется значением между 0 и 1: чем ниже коэффициент затухания, тем сильнее затухание.
В случае потерь пакетов, речевые и аудиокодеки обычно осуществляют затухание до нулевого или фонового шума во избежание раздражающих артефактов повторения. В G.719 [1], например, синтезированный сигнал масштабируется в сторону уменьшения с коэффициентом 0,5 и затем используется как реконструированные коэффициенты преобразования для текущего кадра. Для всех декодеров семейства AAC наподобие [2], замаскированный спектр подвергается затуханию с постоянным коэффициентом затухания, равным 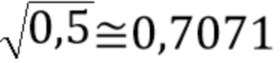 , когда не разрешено никакой дополнительной задержки. Этот коэффициент затухания применяется на полном спектре независимо от характеристик сигнала.
, когда не разрешено никакой дополнительной задержки. Этот коэффициент затухания применяется на полном спектре независимо от характеристик сигнала.
Однако, в особенности, для речевых или переходных сигналов, такой метод затухания не является полностью удовлетворительным. Когда первый потерянный кадр располагается сразу после конца слова, замена шума предусматривает повторение предыдущего надлежащим образом декодированного аудиокадра, т.е. кадра, в котором заканчивается слово: бесполезная часть речи (не несущая информации) будет повторяться, создавая раздражающие пост-эхо. См., например, фиг. 10 (с эхо) по сравнению с фиг. 11 (где эхо не присутствует). На фиг. 10 и 11 частота отложена по оси ординат, и время отложена по оси абсцисс (в сотнях мс или мс × 100).
Это эхо является прямым, неизбежным следствием повторения надлежащим образом декодированного аудиокадра.
Предпочтительно преодолеть такой технический недостаток. В G.729,1 [3] и EVS [4] предложены адаптивные методы затухания, которые зависят от устойчивости характеристик сигнала. Коэффициент затухания зависит от параметров класса последних хороших принятых суперкадров и количества последовательных стертых суперкадров. Коэффициент дополнительно зависит от устойчивости LP фильтра для невокализованных суперкадров (осуществляется классификация между вокализованными и невокализованными кадрами). Поскольку в декодерах AAC наподобие AAC-ELD [5] не существует характеристик сигнала, кодек подвергает затуханию замаскированный сигнал вслепую с фиксированным коэффициентом, что может приводить к рассмотренным выше раздражающим артефактам повторения.
В некоторых условиях было установлено, что раздражающие артефакты могут генерироваться дырами в спектральном представлении.
Необходимо решение для преодоления или, по меньшей мере, снижения влияния, по меньшей мере, некоторых из недостатков уровня техники.
3. Сущность изобретения
В соответствии с вариантами осуществления изобретения, предусмотрен блок маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации. Блок маскирования ошибок выполнен с возможностью обеспечения аудиоинформации маскирования ошибок с использованием маскирования в частотной области на основании надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок выполнен с возможностью подвергания затуханию замаскированного аудиокадра согласно разным коэффициентам затухания для разных полос частот.
В соответствии с вариантами осуществления изобретения, также предусмотрен блок маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации. Блок маскирования ошибок выполнен с возможностью обеспечения аудиоинформации маскирования ошибок для потерянного аудиокадра на основании надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок может быть выполнен с возможностью вывода одного или более коэффициентов затухания на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок выполнен с возможностью осуществления затухания с использованием коэффициента(ов) затухания.
Было установлено, что, соответственно, проблемы, обусловленные артефактами пост-эхо, можно решить с использованием метода на основе анализа характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Характеристики сигнала обеспечивают точную информацию об энергии сигнала, которую можно использовать для классификации аудиоинформации и для подавления замаскированного аудиокадра согласно такой классификации.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью вывода коэффициента затухания на основании характеристик декодированного представления во временной области надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Например, можно распознавать, что предыдущий надлежащим образом декодированный аудиокадр содержит конец слова или речи (или, в целом, снижение энергии по времени) просто на основании аспектов такого представления во временной области. Также, разные признаки декодированного аудиокадра (наподобие временной модуляции, переходный символ и пр., можно вывести с хорошей точностью из декодированного представления).
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью осуществления анализа декодированного представления во временной области, и вывода коэффициента затухания на основании анализа.
Соответственно, можно напрямую выводить коэффициент затухания путем анализа декодированного представления во временной области. Анализ декодированного представления обычно значительно точнее, чем оценивание характеристик сигнала с использованием входных параметров декодирования. В этом случае, анализ не осуществляется на кодере.
Альтернативно, некоторые характеристики сигнала вычисляются на кодере и отправляются в битовом потоке, на котором декодер затем определяет коэффициент затухания.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью вывода коэффициента затухания на основании временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Фактически, было отмечено, что можно определять природу надлежащим образом декодированного аудиокадра (который должен ʺзамещатьʺ неправильно принятый кадр) путем анализа его энергетического тренда. Поскольку речь (и другая назначенная аудиоинформация, например, музыка), в целом, предусматривает большую энергию, чем шум, спад энергии в кадре можно использовать как указание наступления конца слова. Поэтому, можно подвергать затуханию аудиоинформацию по-разному на основании определенной природы ранее надлежащим образом декодированного аудиокадра. Применяя разные затухания к кадрам разной природы, можно подавлять возникновение артефактов пост-эхо.
Было установлено, что декодированное представление (который может принимать форму представления во временной области) представляет временное изменение аудиосигнала точнее, чем кодированное представление, и что, таким образом, преимущественно выводить коэффициент затухания (или даже несколько коэффициентов затухания) на основании характеристик декодированного представления (причем характеристики декодированного представления можно, например, выводить путем анализа декодированного представления).
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью вычисления энергии первого участка декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или его взвешенной версии, и
вычисления энергии второго участка декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или его взвешенной версии. Начало первого участка декодированного представления предшествует по времени началу второго участка декодированного представления, или среднее временных значений первого участка предшествует по времени среднему временных значений второго участка. Блок маскирования ошибок может быть выполнен с возможностью вычисления коэффициента затухания в зависимости от энергии первого участка и в зависимости от энергии второго участка.
Соответственно, можно вычислять энергетический тренд (например, реализованный значением энергетического тренда): если предыдущий во времени участок кадра имеет большую энергию, чем последующий участок кадра, конец речи (или, в целом, снижение энергии по времени) можно определять с достаточной степенью точности. Заметим, что, первый участок кадра может содержать второй участок (или наоборот). Среднее по времени первого участка предшествует среднему по времени второго участка (например, центр первого участка предшествует по времени центру второго участка).
В частности, второй участок декодированного представления может содержать последний интервал выборок декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Первый участок декодированного представления может содержать все выборки надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или интервал выборок надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, который перекрывает второй участок, при том что по меньшей мере некоторые из выборок первого участка предшествуют всем выборкам второго участка.
Соответственно, один из выводов, лежащих в основе вариантов осуществления настоящего изобретения основан на наблюдении, что раздражающие артефакты повторения возникают, в основном, когда потерянный кадр следует за концом речи: вместо воспроизведения тишины или шума, фрагмент слова бесполезно повторяется. Это одна из причин, по которой варианты осуществления изобретения основаны на понимании того, что потерянный кадр (или первый из последовательности последовательных потерянных кадров) является кадром, следующим за концом слова (или речи), например, путем распознавания, что последний надлежащим образом декодированный аудиокадр является кадром, следующим за концом слова (или речи), или, в более общем случае, кадром, в котором уровень энергии резко снижен. (В ряде случаев, когда кадр является достаточно длинным, например 80 мс, даже если потеря кадра происходит на полпути в ходе спада энергии может существовать некоторая разновидность пост-эхо.)
Можно вычислять отношения между:
- энергией на концевом участке декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или на концевом участке масштабированной версии декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
- полной энергией в декодированном представлении надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или в масштабированной версии декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для получения коэффициента затухания.
Хотя первый участок может содержать все выборки кадра, второй участок может содержать только выборки второй половины того же кадра (или некоторых из второй половины формулы изобретения); делением значения, связанного с энергией, связанной со вторым участком, на значение, связанное с энергией, связанной с первым участком (например, целым кадром), можно получать значение (когда первый участок содержит целый кадр, значение может быть заключено между 0 и 1 и может выражаться в процентах): чем ниже значение (или процент), тем более вероятно, что кадр содержит конец слова (или существенное снижение энергии по времени).
В некоторых вариантах осуществления, частное, равное нулю, может означать, что энергия отсутствует в выборках второго участка, указывая, что выборки второго участка несут ʺтишинуʺ в качестве уникальной информации.
Согласно одному варианту осуществления, временной энергетический тренд  можно вычислять с использованием формулы:
можно вычислять с использованием формулы:
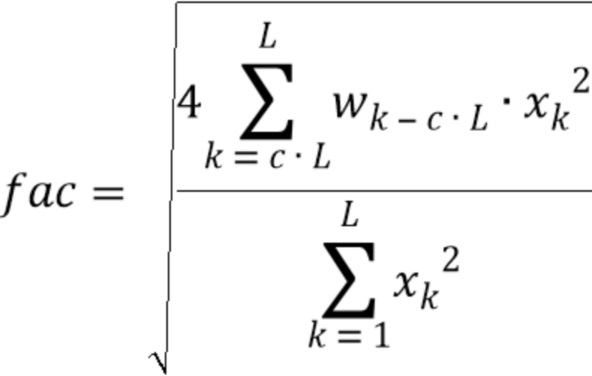
где значение L - длина кадра в выборках, xk - (значение на основании) значения выборки сигнала, wk - весовой коэффициент, и c - значение между 0,5 и 0,9, предпочтительно между 0,6 и 0,8, более предпочтительно между 0,65 и 0,75, и еще более предпочтительно 0,7. Значение L может быть длиной кадра в выборках (например, в количестве 1024), xk может быть значением выборки сигнала, wk может быть весовым коэффициентом, и c может быть значением между 0,5 и 0,9, предпочтительно между 0,6 и 0,8, более предпочтительно между 0,65 и 0,75, и еще более предпочтительно 0,7.
Заметим, что, 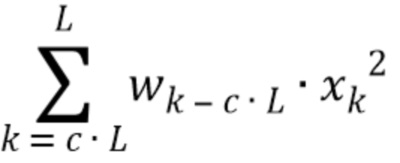 учитывает интегральную энергию последних выборок кадра (в частности, взвешенных окном), тогда как
учитывает интегральную энергию последних выборок кадра (в частности, взвешенных окном), тогда как 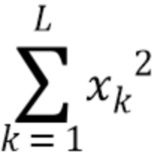 выражает интегральную энергию, связанную с целым кадром.
выражает интегральную энергию, связанную с целым кадром.
Также можно вычислять весовой коэффициент, который проверяет следующее условие:
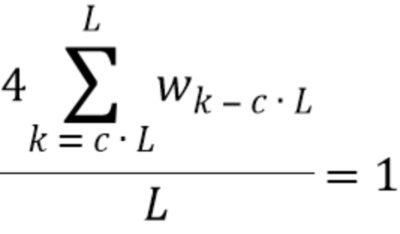
Было отмечено, что надлежащий весовой коэффициент равен:
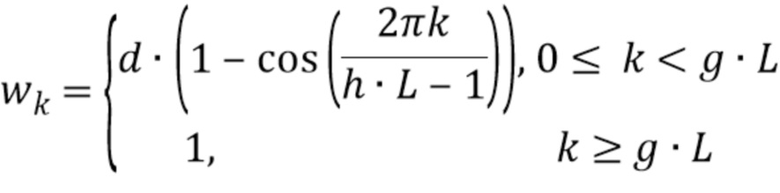
где d - значение между 0,4 и 0,6, предпочтительно между 0,49 и 0,51, более предпочтительно между 0,499 и 0,501, и еще более предпочтительно 0,5; где h - значение между 0,15 и 0,25, предпочтительно между 0,19 и 0,21, более предпочтительно между 0,199 и 0,201, и еще более предпочтительно 0,2; и где g - значение между 0,05 и 0,15, предпочтительно между 0,09 и 0,11, и более предпочтительно 0,1.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью снижения коэффициента затухания в отношении предыдущего замаскированного аудиокадра и для подвергания затуханию, по меньшей мере, одного последующего замаскированного аудиокадра, после ранее замаскированного аудиокадра с использованием сниженного коэффициента затухания.
Это решение является особенно преимущественным, когда несколько последовательных кадров неправильно декодируется. Таким образом, аудиосигнал будет подавляться надлежащим образом.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью осуществления затухания согласно более чем экспоненциальному спаду по времени в течение, по меньшей мере, трех последовательных замаскированных аудиокадров.
Было отмечено, что более чем экспоненциальный спад по времени для коэффициентов затухания, связанных с затуханием, предпочтителен и позволяет получать хороший компромисс между плавностью затухания и необходимостью снижать интенсивность аудиоинформации. В частности, было отмечено, что особенно подходящий спад получается путем итерационного умножения предыдущего коэффициента затухания на 0,9 во втором последовательном потерянном кадре, на 0,75 в третьем последовательном потерянном кадре, на 0,5 для третьего последовательного потерянного кадра, на 0,2 в четвертом и далее последовательных потерянных кадров.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью определения значения энергетического тренда, количественно описывающего временной энергетический тренд декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок также может быть выполнен с возможностью использования значения энергетического тренда, или его масштабированной версии, для задания коэффициента затухания.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления коэффициента затухания на предварительно определенное значение, более низкое, чем текущее значение энергетического тренда, если текущее значение энергетического тренда лежит в предварительно определенном диапазоне, указывающем сравнительно малое снижение энергии со временем.
Соответственно, если временной энергетический тренд близок к 1 (или, по меньшей мере, больше порога, который может быть (1/2)1/2), можно с достаточной степенью точности определить, что надлежащим образом декодированный аудиокадр не содержит конца речи (или так или иначе не является аудиокадром, в котором энергия резко уменьшается). Поэтому можно использовать фиксированное значение затухания.
В соответствии с аспектом изобретения, маскирование ошибок может быть сконфигурировано для определения коэффициента затухания, так чтобы коэффициент затухания был равен текущему значению энергетического тренда или изменялся линейно с изменением значения энергетического тренда, если текущее значение энергетического тренда лежит вне предварительно определенного диапазона и указывает сравнительно большее снижение энергии со временем.
Соответственно, если временной энергетический тренд меньше порога (например, который может быть равен 1/21/2), можно с достаточной степенью точности определить, что надлежащим образом декодированный аудиокадр содержит конец слова (или речи). Поэтому можно использовать сниженное значение затухания для увеличения скорости затухания, таким образом, избегая пост-эхо согласно изобретению.
В соответствии с аспектом изобретения, маскирование ошибок может быть сконфигурировано для:
- установления коэффициента затухания на первое предварительно определенное значение (которое может быть, например, значением между 0,95 или 0,97 и 1), которое указывает меньшее затухание, чем второе предварительно определенное значение (которое может быть равно, например, 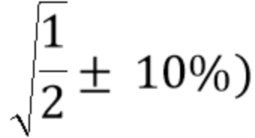 ), если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и/или
), если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и/или
- установления коэффициента затухания на второе предварительно определенное значение, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь не заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, и/или
- установления коэффициента затухания на значение, основанное на значении энергетического тренда или его масштабированной версии, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь спадает или заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру.
Путем классификации надлежащим образом декодированного аудиокадра (например, как окончание шума/речи в кадре/продолжение речи), может осуществляться три разных затухания:
- слабое затухание или полное отсутствие затухания шума (что предпочтительно для шума);
- среднее затухание, когда речь не заканчивается в надлежащим образом декодированном аудиокадре (в отсутствие риска раздражающего эха);
- сильное затухание, когда речь заканчивается в надлежащим образом декодированном аудиокадре (поэтому нивелирующее эффекты раздражающего эха).
Маскирование ошибок сконфигурировано для определения разных коэффициентов затухания для разных полос частот.
В соответствии с аспектом изобретения, блок маскирования ошибок выполнен с возможностью вывода коэффициента затухания, так чтобы коэффициент затухания отражал экстраполяцию временного изменения уровня энергии на концевом участке последнего надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, на потерянный аудиокадр.
В соответствии с аспектом изобретения, блок маскирования ошибок выполнен с возможностью масштабирования спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициента затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
В соответствии с аспектом изобретения, блок маскирования ошибок выполнен с возможностью масштабирования спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициента затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
В соответствии с аспектом изобретения, блок маскирования ошибок выполнен с возможностью осуществления преобразования из спектральной области во временную область для получения декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
В соответствии с вариантами осуществления изобретения, предусмотрен способ маскирования ошибок аудиоинформации для маскирования потери аудиокадра в кодированной аудиоинформации, содержащий следующие этапы:
- вывод коэффициента затухания на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
- осуществление затухания с использованием коэффициента затухания.
Способ можно использовать совместно с любым из рассмотренных выше аспектов изобретения.
В соответствии с вариантами осуществления изобретения, предусмотрена компьютерная программа для осуществления способа, отвечающий изобретению и/или для управления вариантами осуществления продукта изобретения, рассмотренными выше, когда компьютерная программа выполняется на компьютере.
В соответствии с вариантами осуществления изобретения, предусмотрен аудиодекодер для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем аудиодекодер содержит блок маскирования ошибок, как рассмотрено выше, или реализации способа, как рассмотрено выше.
В соответствии с вариантами осуществления изобретения, предусмотрен блок маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации, причем блок маскирования ошибок выполнен с возможностью обеспечения аудиоинформации маскирования ошибок на основании надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок выполнен с возможностью осуществления затухания с использованием разных коэффициентов затухания для разных полос частот.
Было отмечено, что можно использовать разные коэффициенты затухания для разных полос одного и того же спектрального представления аудиокадра. Соответственно, можно избегать возникновения раздражающих артефактов вследствие спектральных дыр, поскольку можно, например, применять к полосе частот (или спектральному бину), который является шумоподобным, другой коэффициент затухания чем к полосе частот (или спектральному бину), который является речеподобным (или который содержит, по большей части, речь).
Таким образом, коэффициенты затухания могут быть адаптированы к характеристикам сигнала разных полос частот или разных спектральных бинов, или к временному изменению энергии в разных полосах частот или спектральных бинах.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью вывода коэффициентов затухания на основании характеристик представления в спектральной области надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью адаптации одного или более коэффициентов затухания, например, для подвергания затуханию вокализованных полос частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, быстрее, чем невокализованные или шумоподобные полосы частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Адаптируя затухание к каждой полосе частот (или спектральному бину), можно получить оптимальный характер затухания: в частности, спектральные полосы, связанные с речью, могут подавляться быстрее, чем спектральные полосы, связанные с шумом, таким образом, снижая раздражение человека, слушающего декодированную аудиоинформацию.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью адаптации одного или более коэффициентов затухания, для подвергания затуханию одной или более полос частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру и имеющего сравнительно более высокую энергию в расчете на спектральный бин, быстрее, чем одна или более полос частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и имеющего сравнительно более низкую энергию в расчете на спектральный бин.
Согласно принципу изобретения, предполагается, что полосы с сравнительно более высокой энергией в расчете на спектральный бин содержат больше речевой информации, чем шума. Таким образом, предлагается увеличить затухание этих полос, связанных с речью, при этом лишь медленно подвергая затуханию низкоэнергетичные (шумоподобные) полосы частот.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления коэффициента затухания, для, по меньшей мере, одной полосы частот, на основании сравнения между значением энергии связанным с, по меньшей мере, одной полосой частот в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, и порогом.
Сравнение с порогом позволяет осуществлять простое (но важное) испытание, результатом которого является, помимо прочего, определение полосы, предположительно, несущей информацию, относящуюся либо к речи, либо к шуму.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью использования предварительно определенного коэффициента затухания для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Блок маскирования ошибок может быть выполнен с возможностью использования коэффициента затухания, который меньше предварительно определенного коэффициента затухания для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога.
Соответственно, полосы более высокой энергии будут подавляться быстрее, чем полосы более низкой энергии, тем самым снижая раздражение слушателя.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью использования коэффициента затухания, представляющего сравнительно более медленное затухание для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Блок маскирования ошибок может быть выполнен с возможностью использования коэффициента затухания, представляющего сравнительно более быстрое затухание для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью задания коэффициента затухания как предварительно определенное значение, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Блок маскирования ошибок может быть выполнен с возможностью, если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога, вывода коэффициента затухания для, по меньшей мере, одной полосы частот на основании значения временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для подвергания затуханию, по меньшей мере, одной полосы частот, быстрее, чем когда значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога.
Можно не только подавлять более высокие энергетические полосы (предположительно относящиеся к речи) быстрее, чем более низкие энергетические полосы, но также можно подвергать затуханию полосы согласно изменению надлежащим образом декодированного аудиокадра. Если, например, изменение энергии надлежащим образом декодированного аудиокадра указывает, что последний является кадром, в котором слово (или речь) закончилось(ась), предпочтительно увеличивать подавление более высоких энергетических полос, предположительно относящихся к речи. Соответственно, раздражающих артефактов эха можно избежать, когда надлежащим образом декодированный аудиокадр содержит конец слова.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью задания разных порогов для разных полос частот.
Например, полоса с большим количеством бинов, но низкой интенсивностью, предположительно может быть связана с шумом. Напротив, полоса с высокой энергией предположительно может быть связана с речью. Таким образом, различие между этими полосами можно получить путем сравнения с разными порогами для разных полос.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления порога на основании значения энергии, или среднего значения энергии, или ожидаемого значения энергии, по меньшей мере, одной полосы частот.
Полоса с низкой энергией, например, предположительно может быть связана с шумом. Напротив, полоса с высокой энергией предположительно может быть связана с речью. Таким образом, различие между этими полосами можно получить путем выбора, для каждой полосы, порога который зависит от значения энергии, или среднего значения энергии, или ожидаемого значения энергии полосы.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления порога на основании отношения между значением энергии надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и количества спектральных линий во всем спектре надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления порога на основании временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Временной энергетический тренд может содержать информацию о том, содержит ли надлежащим образом декодированный аудиокадр информацию, имеется ли в кадре конец слова, или нет. Предпочтительно быстрее подавлять кадры, следующие за аудиокадрами, содержащими конец слова, во избежание раздражающих артефактов эха. Поэтому, может быть предпочтительно выбирать порог на основании временного энергетического тренда. Чем выше вероятность встретить окончание слова в надлежащим образом декодированном кадре (энергетический тренд, близкий к 0), тем ниже порог, и быстрее происходит затухание полосы.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью установления порога для i-ой полосы частот с использованием формулы:
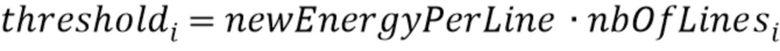
Значение 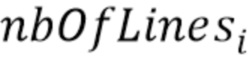 может быть равно количеству линий в i-ой полосе частот, и
может быть равно количеству линий в i-ой полосе частот, и
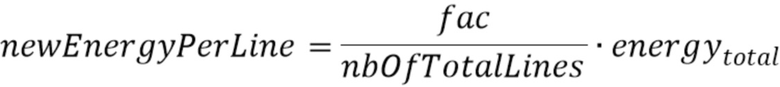
Значение 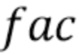 может быть величиной, представляющей временной энергетический тренд в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, или значением затухания, выведенным из величины, представляющей временной энергетический тренд в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру. Значение
может быть величиной, представляющей временной энергетический тренд в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, или значением затухания, выведенным из величины, представляющей временной энергетический тренд в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру. Значение 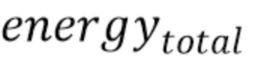 может быть полной энергией по всем полосам частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Значение
может быть полной энергией по всем полосам частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Значение 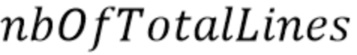 может быть суммарным количеством спектральных линий надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
может быть суммарным количеством спектральных линий надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью осуществления затухания с использованием разных коэффициентов затухания для разных диапазонов масштабного коэффициента. Разные масштабные коэффициенты для масштабирования обратно квантованных спектральных значений могут быть связаны с разными диапазонами масштабного коэффициента.
В соответствии с аспектом изобретения, Блок маскирования ошибок может быть выполнен с возможностью масштабировать спектральное представление аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициентов затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью масштабировать разные полосы частот спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием разных коэффициентов затухания, чтобы, таким образом, подвергать затуханию спектральные значения разных полос частот с разными скоростями затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
Соответственно, можно получить надлежащее маскирование, в котором полосы, содержащие информацию, например, речь, подавляются в большей степени, чем содержащие шум.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью:
- установления коэффициента затухания, связанного с данной полосой частот, на первое предварительно определенное значение (например, между 0,95 и 1), которое указывает меньшее затухание, чем второе предварительно определенное значение (например, около 1/21/2), если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и/или
- установления коэффициента затухания, связанного с данной полосой частот, на второе предварительно определенное значение, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь не заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, и/или
- установления коэффициента затухания, связанного с данной полосой частот, на значение, основанное на значении энергетического тренда или его масштабированной версии, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь спадает или заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру.
Например, можно различать полосы, содержащие информацию, например, речь (или назначенную аудиоинформацию, например, музыку), и содержащие шум. Полосы, содержащие назначенную аудиоинформацию, могут подавляться быстрее, чем содержащий шум. В случае, когда ранее декодированный аудиокадр содержит конец слова (или речи или так или иначе назначенной аудиоинформации), затухание сравнительно усиливается (например, путем уменьшения коэффициента затухания).
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью сравнения энергии в данной полосе частот с порогом. Блок маскирования ошибок может быть выполнен с возможностью обеспечения масштабного коэффициента для данной полосы частот, который выведен на основании временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, если энергия в данной полосе частот больше порога. Блок маскирования ошибок может быть выполнен с возможностью установления коэффициента затухания на первое предварительно определенное значение, которое указывает меньшее затухание, чем второе предварительно определенное значение, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и если энергия в данной полосе частот меньше порога. Блок маскирования ошибок может быть выполнен с возможностью установления коэффициента затухания на второе предварительно определенное значение, если надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, как не шумоподобный.
В соответствии с аспектом изобретения, блок маскирования ошибок может быть выполнен с возможностью осуществления преобразования из спектральной области во временную область для получения декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Варианты осуществления изобретения также относятся к способу обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации, причем способ содержит:
- обеспечение аудиоинформации маскирования ошибок на основании надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру; и
- осуществление затухания с использованием разных коэффициентов затухания для разных полос частот
Способ, отвечающий изобретению, может реализовать один или более из рассмотренных выше аспектов.
Варианты осуществления изобретения также относятся к компьютерной программе для осуществления способов, отвечающих изобретению, когда компьютерная программа выполняется на компьютере и/или для реализации рассмотренных выше аспектов продукта.
Варианты осуществления изобретения также относятся к аудиодекодеру, содержащему блок маскирования ошибок, как рассмотрено выше.
Аудиодекодер может быть выполнен с возможностью масштабировать спектральные значения разных диапазонов масштабного коэффициента спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием разных масштабных коэффициентов
Рассмотренные выше аспекты можно комбинировать друг с другом.
4. Краткое описание чертежей
Далее варианты осуществления настоящего изобретения будут описаны со ссылкой на прилагаемые чертежи, в которых:
фиг. 1 - блок-схема блока маскирования согласно изобретению;
фиг. 2 - блок-схема аудиодекодера согласно варианту осуществления настоящего изобретения;
фиг. 3 - блок-схема аудиодекодера согласно другому варианту осуществления настоящего изобретения;
фиг. 4 - блок-схема маскирования в частотной области согласно варианту осуществления изобретения;
фиг. 5 - частности вычисления значения энергетического тренда согласно варианту осуществления изобретения;
фиг. 6 - частности подразделения кадра, используемого для вычисления энергетического тренда согласно варианту осуществления варианта осуществления изобретения;
фиг. 7 - диаграммы взвешивания (ʺмодифицированное окно Ханнаʺ), используемые для вычисления значения энергетического тренда согласно варианту осуществления изобретения;
фиг. 8 - варианты осуществления средства, используемого для вычисления коэффициента затухания согласно варианту осуществления изобретения;
фиг. 9 - варианты осуществления способов маскирования, отвечающих изобретению;
фиг. 10-11 - сравнительные примеры диаграмм сигнала;
фиг. 12 - пример определения порогов согласно варианту осуществления изобретения;
фиг. 13 - сравнительные примеры диаграмм сигнала;
фиг. 14-15 - варианты осуществления средства, используемого для вычисления коэффициента затухания согласно варианту осуществления изобретения;
фиг. 16 - варианты осуществления способов маскирования, отвечающих изобретению.
5. Описание вариантов осуществления
В настоящем разделе рассмотрены варианты осуществления изобретения со ссылкой на чертежи.
5.1. Блок маскирования ошибок согласно фиг. 1
На фиг. 1 показана блок-схема блока 100 маскирования ошибок согласно изобретению.
Блок 100 маскирования ошибок обеспечивает аудиоинформацию 107 маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации. На блок 100 маскирования ошибок поступает аудиоинформация, например, спектральная версия (или представление) 101 надлежащим образом декодированного аудиокадра. Дополнительно, на блок 100 маскирования ошибок поступает аудиоинформация, например, версия 102 (или представление) во временной области надлежащим образом декодированного аудиокадра (в частности, того же надлежащим образом декодированного аудиокадра, спектральное значение которого поступает в качестве 101). Постобработанную версию 102' можно использовать вместо сигнала 102 во временной области (далее, для краткости будут рассматриваться только сигнал 102 во временной области, хотя изобретение можно реализовать с использованием постобработанной версии 102').
Блок 100 маскирования ошибок выполнен с возможностью вывода коэффициента 103 затухания на основании характеристик декодированного представления 102 надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Блок 100 маскирования ошибок выполнен с возможностью осуществления затухания с использованием коэффициента 103 затухания.
Пример затухания можно реализовать посредством блока 104 масштабирования, чтобы масштабировать спектральную версию 101 надлежащим образом декодированного аудиокадра с использованием коэффициента 103 затухания.
Блок 110 определения коэффициента затухания можно реализовать для вывода коэффициента 103 затухания на основании версии 102 во временной области надлежащим образом декодированного аудиокадра.
Блок 110 определения коэффициента затухания может выводить коэффициент 103 затухания на основании характеристик декодированного представления 102 во временной области надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Анализатор 111 энергетического тренда можно использовать для осуществления анализа надлежащим образом декодированного аудиокадра 102. Согласно некоторым реализациям, тренд энергии в кадре можно анализировать.
Блок отображения (или вычислитель) 112 коэффициента затухания можно использовать для масштабирования коэффициента затухания (например, при получении нескольких последовательных неверных кадров данных).
Кроме того, посредством блока 117 добавления шума, шум можно, в необязательном порядке, добавлять к масштабированной версии 105 представления в частотной области 101, для вывода представления в частотной области 107 замаскированного кадра.
Заметим, что, согласно варианту осуществления блока 100 маскирования ошибок, спектральное представление 101 надлежащим образом декодированного кадра можно, в необязательном порядке, делить на разные полосы; блок 104 масштабирования может, в этом случае, пользоваться множеством масштабных коэффициентов, по одному для каждой из полос.
5.2. Блок маскирования ошибок согласно фиг. 2
На фиг. 2 показана блок-схема аудиодекодера 200, согласно варианту осуществления настоящего изобретения. Аудиодекодер 200 принимает кодированную аудиоинформацию 210, которая может, например, содержать аудиокадр, кодированный в представлении в частотной области. Кодированная аудиоинформация 210, в принципе, принимается по ненадежному каналу, из-за чего время от времени происходит потеря кадра. Аудиодекодер 200 дополнительно обеспечивает, на основании кодированной аудиоинформации 210, декодированную аудиоинформацию 212.
Аудиодекодер 200 может содержать блок 220 декодирования/обработки, который обеспечивает декодированную аудиоинформацию на основании кодированной аудиоинформации в отсутствие потери кадра.
Аудиодекодер 200 дополнительно содержит блок 230 маскирования ошибок (который можно реализовать посредством блока 100 маскирования ошибок), обеспечивающий аудиоинформацию 232 маскирования ошибок. Блок 230 маскирования ошибок сконфигурирован для обеспечения аудиоинформации 232 маскирования ошибок (105, 107) для маскирования потери аудиокадра.
Другими словами, блок 220 декодирования/обработки может обеспечивать декодированную аудиоинформацию 222 для аудиокадров, кодированных в форме представления в частотной области, т.е. в форме кодированного представления, кодированные значения которых выражают интенсивности в разных частотных бинах. Другими словами, блок 220 декодирования/обработки может, например, содержать аудиодекодер частотной области, который выводит набор спектральных значений из кодированной аудиоинформации 210 и осуществляет преобразование из частотной области во временную область, чтобы, таким образом, выводить представление во временной области, которое образует декодированную аудиоинформацию 222 или образует основу для обеспечения декодированной аудиоинформации 122 в случае наличия дополнительной постобработки.
Кроме того, следует отметить, что аудиодекодер 200 может дополняться любым из признаков и функциональных возможностей, описанных в дальнейшем, по отдельности или совместно.
Блок 230 маскирования ошибок также может подвергать затуханию разные полосы с разными коэффициентами затухания в некоторых вариантах осуществления.
5.3. Аудиодекодер согласно фиг. 3
На фиг. 3 показана блок-схема аудиодекодера 300, согласно варианту осуществления изобретения.
Аудиодекодер 300 выполнен с возможностью приема кодированной аудиоинформации 310 и обеспечения, на ее основе, декодированной аудиоинформации 312. Аудиодекодер 300 содержит анализатор 320 битового потока (который также может именова блоком разложения битового потокаʺ). Анализатор 320 битового потока принимает кодированную аудиоинформации 310 и обеспечивает, на ее основе, представление 322 в частотной области и, возможно, дополнительную информацию 324 управления. Представление 322 в частотной области может, например, содержать кодированные спектральные значения 326, кодированные масштабные коэффициенты 328 и, в необязательном порядке, дополнительную вспомогательную информацию 330, которая может, например, управлять конкретными этапами обработки, например, заполнением шумом, промежуточной обработкой или постобработкой. Аудиодекодер 300 также содержит блок 340 декодирования спектральных значений, который сконфигурирован для приема кодированных спектральных значений 326 и для обеспечения, на основе этого, набора декодированных спектральных значений 342. Аудиодекодер 300 также может содержать блок 350 декодирования масштабных коэффициентов, который может быть сконфигурирован для приема кодированных масштабных коэффициентов 328 и обеспечения, на их основе, набора декодированных масштабных коэффициентов 352.
Альтернативно блоку декодирования масштабных коэффициентов, может использоваться блок 354 преобразования LPC в масштабный коэффициент, например, в случае, когда кодированная аудиоинформация содержит кодированную информацию LPC вместо информации о масштабных коэффициентах. Однако, в некоторых режимах кодирования (например, в режиме декодирования TCX аудиодекодера USAC или в аудиодекодере EVS) набор коэффициентов LPC может использоваться для вывода набора масштабных коэффициентов на стороне аудиодекодера. Эта функциональная возможность может достигаться блоком 354 преобразования LPC в масштабный коэффициент.
Аудиодекодер 300 также может содержать блок 360 масштабирования, который может быть выполнен с возможностью применения набора масштабированных коэффициентов 352 к набору спектральных значений 342, для получения, таким образом, набора масштабированных декодированных спектральных значений 362. Например, первая полоса частот, содержащая несколько декодированных спектральных значений 342, может масштабироваться с использованием первого масштабного коэффициента, и второй полоса частот, содержащая несколько декодированных спектральных значений 342, может масштабироваться с использованием второго масштабного коэффициента. Соответственно, получается набор масштабированных декодированных спектральных значений 362. Аудиодекодер 300 может дополнительно содержать необязательный блок 366 обработки, который может применять некоторую обработку к масштабированным декодированным спектральным значениям 362. Например, необязательный блок 366 обработки может содержать заполнение шумом или некоторые другие операции.
Аудиодекодер 300 также может содержать блок 370 преобразования из частотной области во временную область, которое сконфигурировано для приема масштабированных декодированных спектральных значений 362, или их обработанной версии 378, и для обеспечения представления 372 во временной области, связанного с набором масштабированных декодированных спектральных значений 362. Например, блок 370 преобразования из частотной области во временную область может обеспечивать представление 372 во временной области, которое связано с кадром или подкадром аудиоконтента. Например, преобразование из частотной области во временную область может принимать набор коэффициентов MDCT (которые можно рассматривать как масштабированные декодированные спектральные значения) и обеспечивать, на ее основе, блок выборок во временной области, который может образовывать представление 372 во временной области.
Аудиодекодер 300 может, в необязательном порядке, содержать блок 376 постобработки, который может принимать представление 372 во временной области и несколько модифицировать представление 372 во временной области, чтобы, таким образом, получать постобработанную версию 378 представления 372 во временной области.
Согласно изобретению, аудиодекодер 300 содержит блок 380 маскирования ошибок (который можно реализовать одним из блоков 100 или 230 маскирования). Блок 380 маскирования ошибок принимает декодированные спектральные значения 362 (которые могут воплощать значения 101) или их постобработанную версию 368.
Блок 380 маскирования ошибок также может принимать представление 372 во временной области (которое может воплощать значение 102) от преобразования из частотной области во временную область, или постобработанные значения 378 (которые могут воплощать значение 102') из необязательного блока 376 постобработки. Однако, согласно варианту осуществления в котором маскирование ошибок применяет разные коэффициенты затухания к разным полосам частот, но не выводит один или более коэффициентов затухания на основании декодированного представления надлежащим образом декодированного аудиокадра, может не требоваться, чтобы блок 380 маскирования ошибок принимал сигналы 372, 378.
Дополнительно, блок 380 маскирования ошибок обеспечивает аудиоинформацию 382 маскирования ошибок для одного или более потерянных аудиокадров. В случае потери аудиокадра, вследствие чего, например, кодированные спектральные значения 326 для упомянутого аудиокадра (или подкадра аудиосигнала) недоступны, блок 380 маскирования ошибок может обеспечивать аудиоинформацию маскирования ошибок. Аудиоинформация маскирования ошибок может быть представлением в частотной области аудиоконтента (которое может обеспечиваться в блок 370 преобразования из частотной области во временную область) или представлением во временной области аудиоконтента (которое может обеспечиваться в блок 390 объединения сигналов).
Следует отметить, что блок 380 маскирования ошибок может, например, осуществлять функциональную возможность блока 100 маскирования ошибок и/или вышеописанного блока 230 маскирования ошибок. Блок 380 маскирования ошибок может выводить сигнал 382 маскирования во временной области в блок 390 объединения сигналов, или сигнал 382' маскирования в частотной области в блок 370 преобразования из частотной области во временную область.
В отношении маскирования ошибок, следует отметить, что маскирование ошибок не происходит одновременно с декодированием кадра. Например, если кадр n является хорошим, то осуществляется нормальное декодирование, и в конце сохраняется некоторая переменная, которая будет помогать, если нужно замаскировать следующий кадр, то, в случае потери кадра n+1 вызывается функция маскирования, дающая переменную, поступающую из предыдущего хорошего кадра. Некоторые переменные также будут обновляться для помощи при потере следующего кадра или после восстановления до следующего хорошего кадра.
Аудиодекодер 300 также содержит блок 390 объединения сигналов, который выполнен с возможностью приема представления 372 во временной области (или постобработанного представления 378 во временной области в случае наличия блока 376 постобработки). Кроме того, блок 390 объединения сигналов может принимать аудиоинформацию 382 маскирования ошибок, которая обычно также является представлением во временной области аудиосигнала маскирования ошибок, обеспеченного для потерянного аудиокадра. Блок 390 объединения сигналов может, например, объединять представления во временной области, связанные с последующими аудиокадрами. В случае, когда существуют последующие надлежащим образом декодированные аудиокадры, блок 390 объединения сигналов может объединять (например, путем сложения с перекрытием) представления во временной области, связанные с этими последующими надлежащим образом декодированными аудиокадрами. Однако в случае потери аудиокадра, блок 390 объединения сигналов может объединять (например, путем сложения с перекрытием) представление во временной области, связанное с надлежащим образом декодированным аудиокадром, предшествующим потерянному аудиокадру, и аудиоинформацию маскирования ошибок, связанную с потерянным аудиокадром, чтобы, таким образом, иметь плавный переход между надлежащим образом принятым аудиокадром и потерянным аудиокадром. Аналогично, блок 390 объединения сигналов может быть выполнен с возможностью объединения (например, сложения с перекрытием) аудиоинформации маскирования ошибок, связанной с потерянным аудиокадром, и представления во временной области, связанного с другим надлежащим образом декодированным аудиокадром, следующим за потерянным аудиокадром (или другой аудиоинформации маскирования ошибок, связанной с другим потерянным аудиокадром в случае потери нескольких последовательных аудиокадров).
Соответственно, блок 390 объединения сигналов может обеспечивать декодированную аудиоинформацию 312, так что представление 372 во временной области или его постобработанная версия 378 обеспечивается для надлежащим образом декодированных аудиокадров, и так что аудиоинформация 382 маскирования ошибок обеспечивается для потерянных аудиокадров, причем операция сложения с перекрытием обычно осуществляется между аудиоинформацией (независимо от того, обеспечивается ли она блоком 370 преобразования из частотной области во временную область или блоком 380 маскирования ошибок) последующих аудиокадров. Поскольку некоторые кодеки имеют некоторое наложение спектров в части перекрытия и добавления, которую необходимо отменить, в необязательном порядке можно создавать некоторое искусственное наложение спектров на половине кадра, созданного для осуществления сложения с перекрытием.
Следует отметить, что функциональная возможность аудиодекодера 300 аналогична функциональной возможности аудиодекодера 200 согласно фиг. 2. Кроме того, следует отметить, что аудиодекодер 300 согласно фиг. 3 может дополняться любым из признаков и функциональных возможностей, описанных здесь. В частности, блок 380 маскирования ошибок может дополняться любым из признаков и функциональных возможностей, описанных здесь в отношении маскирования ошибок.
В одном варианте осуществления, блок 380 маскирования ошибок может осуществлять маскирование в диапазонах масштабного коэффициента, например, как описано ниже со ссылкой на фиг. 14. В этом случае, коэффициенты затухания могут обеспечиваться или не обеспечиваться на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра.
5.4. Маскирование ошибок в частотной области и затухание
Здесь обеспечена некоторая информация, относящаяся к маскированию в частотной области, которое можно реализовать или использовать блоком 100 маскирования ошибок. Например, функциональную возможность, описанную ниже, можно получать, частично или полностью, в блоке 104 масштабирования.
Функция маскирования в частотной области увеличивает задержку декодера на один кадр.
Маскирование в частотной области действует на спектральных данных, например, непосредственно до окончательного частотно-временного преобразования. В случае повреждения единственного кадра, маскирование может интерполировать между последним (или одним из последних) хорошим кадром (надлежащим образом декодированным аудиокадром) и первым хорошим кадром для создания спектральных данных для пропущенного кадра. Предыдущий кадр можно обрабатывать посредством частотно-временного преобразования (например, блоком 370 преобразования из частотной области во временную область). Если повреждено несколько кадров, маскирование осуществляет сначала затухание на основании немного модифицированных спектральных значений из последнего хорошего кадра. При наличии хороших кадров, маскирование подвергает затуханию новые спектральные данные.
Маскирование в частотной области изображено на фиг. 4. На этапе 401 производится определение (например, на основании CRC или аналогичной стратегии), если текущая аудиоинформация содержит надлежащим образом декодированный кадр. Если результат определения положителен, спектральное значение надлежащим образом декодированного кадра используется в качестве правильной аудиоинформации на этапе 402. Спектр также записывается в буфере 403 для дополнительного использования.
Если результат определения отрицателен (поврежденный кадр), на этапе 404 ранее записанное спектральное представление 405 предыдущего надлежащим образом декодированного аудиокадра (сохраненного в буфере на этапе 403 в предыдущем цикле) используется для замены поврежденного (и отброшенного) аудиокадра.
В частности, блок 407 копирования и масштабирования копирует и масштабирует спектральные значения частотных бинов (или спектральных бинов) 405a, 405b, …, в частотном диапазоне ранее записанного надлежащим образом декодированного спектрального представления 405 предыдущего надлежащим образом декодированного аудиокадра, для получения значения частотных бинов (или спектральных бинов) 406a, 406b, …, подлежащих использованию вместо поврежденного аудиокадра.
Каждое из спектральных значений можно умножать на общее значение масштабирования, или на соответствующий коэффициент (или коэффициент затухания) согласно конкретной информации, переносимой полосой. Также, шум можно, в необязательном порядке, добавлять в спектральных значениях 406.
Дополнительно, один или более коэффициентов 410 затухания можно использовать для подавления сигнала для итерационного снижения интенсивности сигнала в случае последовательных маскирований.
В частности, разные коэффициенты 410 затухания можно, в необязательном порядке, использовать в некоторых вариантах осуществления, чтобы по-разному подавлять разные полосы (например диапазоны масштабного коэффициента).
В итоге, блок 407 копирования и масштабирования может воплощать блок 104 масштабирования, и этап 404 может, в необязательном порядке, также содержать функциональную возможность блока вставки 107 шума.
5.5. Анализ временного энергетического тренда надлежащим образом декодированного аудиокадра
Согласно вариантам осуществления изобретения, можно выводить коэффициенты затухания (например, в блок 110, 230, 380, или 404) на основании характеристик декодированного представления во временной области (например, 102, 102', 372, 378) надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
На фиг. 5 показан пример анализатора 500 энергетического тренда, который может воплощать анализатор 111. Анализатор 500 энергетического тренда содержит участок памяти (например, буфер) 501, в котором выборки представления во временной области надлежащим образом декодированного аудиокадра сохраняются. Количество выборок может быть равно 1024 согласно некоторым вариантам осуществления. В каждом поле буфера хранится значение одной выборки.
Первый участок 502 может формироваться некоторым количеством выборок или также всеми выборками. Второй участок 503 может формироваться некоторым количеством выборок, например, последними 30% выборок (например, около 307 выборок из 1024), или поднабором выборок второй половины кадра. Среднее по времени первого участка 502 предшествует среднему по времени второго участка 503. Важное количество выборок первого участка 502 может предшествовать большинству выборок второго участка 503.
В блоке 504 можно вычислять значение 504', связанное с энергией второго участка 503 (или представляющее энергию второго участка 503). Весовые значения 507, полученные блоком 506 взвешивания, также можно применять ко второму участку 503. Например, вычислитель энергетического тренда может содержать (например, вычислением разности или частного) значения 504', 505', для вывода значения энергетического тренда.
В блоке 505 можно вычислять значение 505', связанное с энергией первого участка 505.
Вычислитель 508 энергетического тренда можно использовать для получения значения энергетического тренда 509 и можно использовать, например, для вычисления коэффициента затухания.
Согласно некоторым вариантам осуществления, даже если маскирование осуществляется для использования разных коэффициентов затухания для разных спектральных полос представления в частотной области надлежащим образом декодированного аудиокадра, значение энергетического тренда не изменяется для разных полос того же кадра. Напротив, единственное значение энергетического тренда можно вычислять для данного кадра.
5.6. Первый и второй участки кадра
Для получения (или выбора) первого и второго участков кадра (например, для вычисления значения энергетического тренда), можно использовать несколько стратегий.
На фиг. 6(a) показано, что первый участок 502 образован начальным интервалом выборок, тогда как второй участок 503 содержит все выборки кадра. В альтернативных вариантах осуществления, первый участок образован группой выборок, которые берутся только в начальном интервале кадра, тогда как второй участок образован группой выборок, взятой на протяжении целого кадра (не только в начальном интервале).
На фиг. 6(b) показано, что первый участок 502 содержит все (или почти все) выборки кадра, тогда как второй участок 503 образован окончательным интервалом (или группой) выборок. Например, первый участок 502 может содержать 1024 выборки и второй участок 503 только последние 30% выборок.
На фиг. 6(c) показано, что первый участок 502 содержит начальные выборки кадра, тогда как второй участок 503 содержит окончательный интервал (или группу) выборок.
На фиг. 6(d) показан вариант осуществления, в котором первый и второй участки являются двумя разными интервалами (или группами выборок, только взятыми из двух разных интервалов), при том что большинство (или значительная группа) выборок первого участка предшествует большинству (или значительной группе) выборок второго участка.
Если каждая из выборок связана с временем t0, t1, t2 … tL (t0 и tL, соответственно, являются первым и последним моментами выборки кадра, например, первой и 1024-ой выборками кадра), и участок кадра, в целом, образован интервалом моментов времени, который начинается в момент 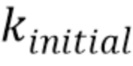 и заканчивается в момент
и заканчивается в момент 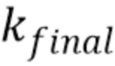 , среднее по времени первого интервала обеспечивается согласно
, среднее по времени первого интервала обеспечивается согласно
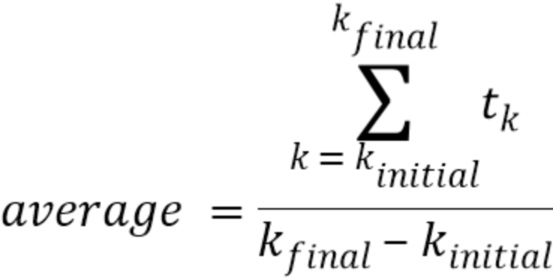
Например, среднее по времени второго участка 503 на фиг. 6(a) и среднее по времени первого участка 502 на фиг. 6(b) находится в точности в середине кадра.
Вариант осуществления, представленный на фиг. 6(b) считается предпочтительным вариантом осуществления, который будет упоминаться в следующих разделах.
5.7. Временной энергетический тренд
Значение временного энергетического тренда (например, 509) можно вычислять (например, в вычислителе 508 тренда) с использованием формулы:
где L - длина кадра (например, надлежащим образом декодированного аудиокадра) в выборках, xk - значение выборки сигнала (например, значение декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру), wk - весовой коэффициент, и c - значение между 0,5 и 0,9, предпочтительно между 0,6 и 0,8, более предпочтительно между 0,65 и 0,75, и еще более предпочтительно 0,7.
учитывает интегральную энергию второго участка (например, окончательный интервал) надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру; учитывает интегральную энергию связанный с первым участком надлежащим образом декодированного аудиокадра (в этом случае, целого кадра, как указано на фиг. 6(b)).
Путем задания первого участка и второго участка аудиокадра согласно фиг. 6(b), значение временного энергетического тренда fac - значение между 0 и 1. В этом случае, временной энергетический тренд fac может быть назначен как процент: если вся энергия распределяется в последнем интервале кадра, процент энергетического тренда будет 100%. Если вся энергия распределяется в начале кадра, энергетический тренд будет 0%.
Также можно вычислять весовой коэффициент, который проверяет следующее условие для проверки следующего уравнения:
Было отмечено, что надлежащий весовой коэффициент равен:
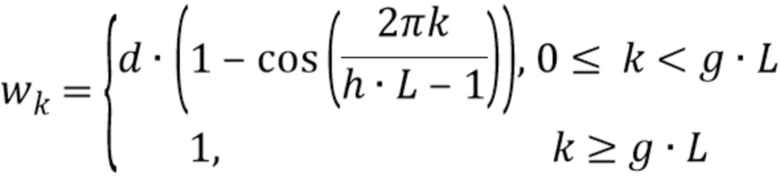
где d - значение между 0,4 и 0,6, предпочтительно между 0,49 и 0,51, более предпочтительно между 0,499 и 0,501, и еще более предпочтительно 0,5; где h - значение между 0,15 и 0,25, предпочтительно между 0,19 и 0,21, более предпочтительно между 0,199 и 0,201, и еще более предпочтительно 0,2; и где g - значение между 0,05 и 0,15, предпочтительно между 0,09 и 0,11, и более предпочтительно 0,1.
Другими словами, значения  окна могут быть нормализованными.
окна могут быть нормализованными.
На фиг. 7 показан графическое представление 700 весового коэффициента.
Значение энергетического тренда количественно описывает временной энергетический тренд декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Его значение, или его масштабированная (или ограниченная) версия, можно использовать для задания коэффициента затухания (например, 103 или 410).
5.8.1. Вычисление коэффициента затухания
На фиг. 8(a) показан пример вычислителя 800 коэффициента затухания, который может воплощать вычислитель 112. В блоке 804, значение 801 энергетического тренда (например, 509) сравнивается с порогом 802. Получается коэффициент 803 затухания (который может воплощать значения 103 или 410).
Коэффициент 803 затухания может быть установлен (например, блоком 804) на предварительно определенное значение, более низкое, чем текущее значение энергетического тренда (например, указывающее более сильное затухание или снижение энергии со временем по сравнению со значением энергетического тренда), если текущее значение энергетического тренда лежит в предварительно определенном диапазоне, указывающем сравнительно малое снижение энергии со временем.
Коэффициент 803 затухания также может быть установлен равным текущему значению 801 энергетического тренда, или может изменяться линейно с изменением значения 801 энергетического тренда, если текущее значение 801 энергетического тренда лежит вне предварительно определенного диапазона и указывает сравнительно большее снижение энергии со временем.
Заметим, что, когда разные коэффициенты затухания заданы для разных полос, другой коэффициент 803 затухания можно получать для каждой полосы надлежащим образом декодированного аудиокадра. Например, для каждой полосы частот может задаваться отдельный порог 802.
На фиг. 8(b) показано, в качестве дополнительного примера, определение 810 коэффициента затухания, осуществляемого с использованием значения энергетического тренда (например, 509 или 801). В блоке 811 осуществляется анализ значения энергетического тренда. Анализ может предусматривать вычисление значения временного энергетического тренда согласно одному из рассмотренных выше примеров.
Если распознается, что надлежащим образом декодированный аудиокадр, по большей части, содержит шум, слабое затухание (или вовсе без затухания) осуществляется в блоке 812, например, путем задания коэффициента затухания на 0,98 или 1.
Если распознается, что надлежащим образом декодированный аудиокадр, по большей части, содержит речь, но слово не заканчивается в надлежащим образом декодированном аудиокадре (или что значение энергетического тренда указывает сравнительно меньшее снижение энергии со временем), сниженное (среднее) затухание осуществляется в блоке 813, например, путем задания коэффициента затухания 0,7071.
Если распознается, что надлежащим образом декодированный аудиокадр содержит окончание речи в одном и том же кадре (или что значение энергетического тренда указывает значительное снижение энергии в надлежащим образом декодированном аудиокадре), быстрое затухание осуществляется в блоке 814. Когда значение временного энергетического тренда вычисляется, как описано выше (и первый и второй участки кадра задаются аналогично варианту осуществления, представленному на фиг. 6(b)), можно также задавать коэффициент 803 затухания как то же значение (или масштабированное значение) значения 801 энергетического тренда (или 509).
В основном, можно осуществлять варианты осуществления, в которых коэффициент затухания отражает экстраполяцию временного изменения уровня энергии на концевом участке последнего надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, на потерянный аудиокадр.
Заметим, что, когда разные коэффициенты затухания заданы для разных полос, этапы 811-814 могут осуществляться для каждой полосы надлежащим образом декодированного аудиокадра.
5.8.2. Снижение коэффициента затухания
Можно сконфигурировать блок маскирования ошибок таким образом, что, в случае потери нескольких последовательных кадров, коэффициент затухания снижается, например, согласно более чем экспоненциальному спаду.
На фиг. 8(c) показан вариант фиг. 8(a) в котором блок 807 масштабирования обеспечивает масштабированную версию 803' коэффициента 803 затухания. Тогда как блок 804 сравнения действует путем сравнения значения 801 энергетического тренда с порогом 802, коэффициент 803 затухания сохраняется в буфере 804. При потере двух последовательных кадров, коэффициент затухания, сохраненный в буфере 804 (который используется для первого потерянного кадра или для предыдущего кадра) умножается на коэффициент, содержащийся в поисковой таблице 805, для получения коэффициента затухания для второго потерянного кадра или, в целом, для последующих кадров или текущего.
Для последовательных потерь кадра, коэффициент затухания текущего кадра  может зависеть от предыдущего
может зависеть от предыдущего 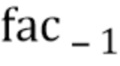 :
:
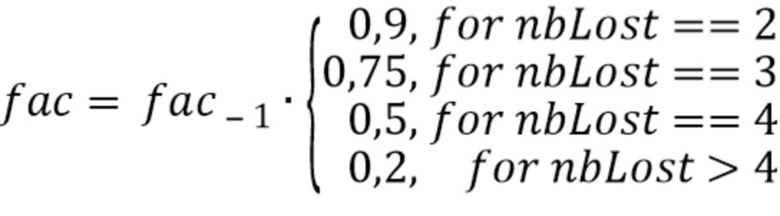
где 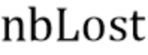 - количество последовательных потерянных кадров. Это приводит к снижению пост-эха вследствие более быстрого затухания.
- количество последовательных потерянных кадров. Это приводит к снижению пост-эха вследствие более быстрого затухания.
Заметим, что, когда разные коэффициенты затухания заданы для разных полос, разные снижения можно применять к разным полосам частот.
5.9. Способы, отвечающие изобретению
На фиг. 9(a) показан способ 900 маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации, содержащий следующие этапы:
- на этапе 910, вывод коэффициента затухания (например, коэффициента 103, 803 или 803' затухания) на основании характеристик декодированного представления (например, 102) надлежащим образом декодированного аудиокадра (например, содержащегося в 501), предшествующего потерянному аудиокадру, и
- на этапе 920, осуществление затухания (например, в блоке 811-814) с использованием коэффициента затухания.
На фиг. 9(b) показан вариант 900b, в котором, до этапа 910, осуществляется этап 905, на котором анализируется значение энергетического тренда надлежащим образом декодированного аудиокадра.
Заметим, что, когда разные коэффициенты затухания заданы для разных полос, способы повторяются (например, посредством итерации) для разных полос надлежащим образом декодированного аудиокадра.
6. Ход действий варианта осуществления изобретения и экспериментальные результаты
Предлагается подвергать затуханию замаскированный кадр согласно изобретению.
На фиг. 10 показана диаграмма 1000 со спектральным видом сигнала, в котором некоторые кадры, обозначенные 1002 и 1003, замаскированы традиционным методом. Несмотря на то, что в предыдущем надлежащим образом декодированном кадре речь заканчивалась, раздражающее эхо искусственно формируется.
в особенности, для речевых или переходных сигналов, статического коэффициента затухания недостаточно. Например если первый потерянный кадр располагается сразу после конца слова, это приведет к раздражающим пост-эхо (см. левую фигуру внизу). Для предотвращения этого, коэффициент затухания нужно адаптировать к текущему сигналу. Согласно G.729,1 [3] и EVS [4], предлагается адаптивное затухание, которое зависит от устойчивости характеристик сигнала. Таким образом, коэффициент зависит от параметров класса последних хороших принятых суперкадров и количества последовательных стертых суперкадров. Коэффициент дополнительно зависит от устойчивости LP фильтра для невокализованных суперкадров. Поскольку в декодерах AAC наподобие AAC-ELD [5] не существует характеристик сигнала, кодек подвергает затуханию замаскированный сигнал вслепую с фиксированным коэффициентом, что может приводить к вышеописанным раздражающим артефактам повторения.
Для решения проблемы согласно варианту осуществления, рассматривается значение временного энергетического тренда последнего синтезированного хорошего кадра 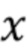 (например, надлежащим образом декодированного аудиокадра), для вычисления нового коэффициента затухания для первого потерянного кадра. Изменение уровня энергии по времени в последнем кадре экстраполируется на следующий кадр, который будет определять коэффициент затухания. Таким образом, коэффициент затухания вычисляется путем установления энергии последних выборок относительно энергии полного предыдущего хорошего кадра :
(например, надлежащим образом декодированного аудиокадра), для вычисления нового коэффициента затухания для первого потерянного кадра. Изменение уровня энергии по времени в последнем кадре экстраполируется на следующий кадр, который будет определять коэффициент затухания. Таким образом, коэффициент затухания вычисляется путем установления энергии последних выборок относительно энергии полного предыдущего хорошего кадра :
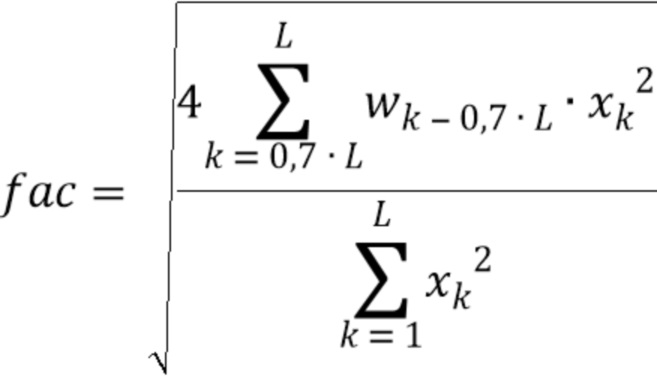
где 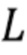 - длина кадра, и - модифицированное окно Ханна:
- длина кадра, и - модифицированное окно Ханна:
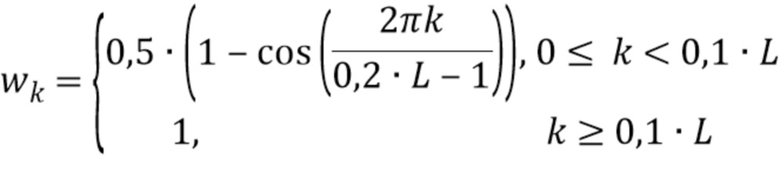
Форма окна задается таким образом, что
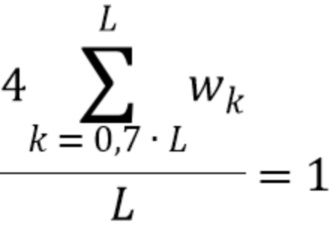
По сравнению с [1], где статический коэффициент затухания 0,7071 всегда применяется ко всему спектру, вычисленный коэффициент затухания будет использоваться, если он меньше значения, принятого по умолчанию 0,7071; в противном случае, будет использоваться 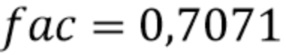 . В ряде случаев заранее известны характеристики сигнала, которыми могут быть энергетическая устойчивость сигнала или класс сигнала, указывающие, имеет ли сигнал вокализованную, зашумленную или атаковую характеристику. Затем (например, если надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру классифицируется как зашумленный), иногда полезно подвергать затуханию медленнее, с использованием вычисленного коэффициента затухания. Например если сигнал действительно зашумлен, желательно поддерживать энергию постоянной, что особенно помогает для единственной потери кадра. Наконец, коэффициент затухания можно максимизировать до 1, для предотвращения артефактов увеличения высокой энергии.
. В ряде случаев заранее известны характеристики сигнала, которыми могут быть энергетическая устойчивость сигнала или класс сигнала, указывающие, имеет ли сигнал вокализованную, зашумленную или атаковую характеристику. Затем (например, если надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру классифицируется как зашумленный), иногда полезно подвергать затуханию медленнее, с использованием вычисленного коэффициента затухания. Например если сигнал действительно зашумлен, желательно поддерживать энергию постоянной, что особенно помогает для единственной потери кадра. Наконец, коэффициент затухания можно максимизировать до 1, для предотвращения артефактов увеличения высокой энергии.
В уровне техники [1] спектр масштабируется с постоянным коэффициентом 0,7071 в ходе нескольких потерь кадра. В подходе, отвечающем изобретению, адаптивный коэффициент затухания используется только в первом замаскированном кадре. Для последовательной потери кадра, коэффициент затухания текущего кадра () будет зависеть от предыдущего (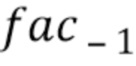 ):
):
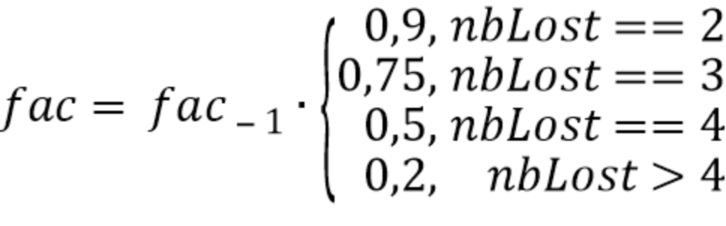
где 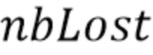 - количество последовательных потерянных кадров. Это приводит к снижению пост-эха вследствие более быстрого затухания (или индекс, указывающий, является ли текущий кадр вторым, третьим, четвертым, …, потерянным кадром из последовательности потерянных кадров).
- количество последовательных потерянных кадров. Это приводит к снижению пост-эха вследствие более быстрого затухания (или индекс, указывающий, является ли текущий кадр вторым, третьим, четвертым, …, потерянным кадром из последовательности потерянных кадров).
Как можно видеть на фиг. 11, области 1002 и 1003 (которые в уровне техники будут испытывать влияние раздражающих эхо) теперь предпочтительно ʺполироватьʺ.
7. Дополнительные варианты осуществления настоящего изобретения
На фиг. 14 показано маскирование 1400 ошибок, в котором разные полосы частот (или бины) одного и того же надлежащим образом декодированного аудиокадра подавляются по-разному. Хотя возможно, не обязательно воплощать фиг. 1 или 3 для воплощения фиг. 14.
Согласно фиг. 2 и 4, блок маскирования ошибок получается с целью обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации. Блок маскирования ошибок выполнен с возможностью обеспечения аудиоинформации маскирования ошибок на основании надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Блок маскирования ошибок выполнен с возможностью осуществления затухания с использованием разных коэффициентов затухания для разных полос частот.
Разные бины, хранящиеся в разных участках 405a, 405b, …, 405g памяти (например, буферах), масштабируются с разными коэффициентами 1408a, 1408b, …, 1408g затухания (коэффициенты затухания умножаются на значения бинов на блоках 407a, 407b, …, 407g масштабирования), для получения разных бинов, хранящихся в разных участках 406a, 406b, …, 406g памяти аудиоинформации маскирования.
Согласно одному варианту осуществления, можно выводить разные коэффициенты затухания на основании характеристик представления в спектральной области надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
На фиг. 14 показано, что представление FD надлежащим образом декодированного аудиокадра подразделяется в блоке 1402 между разными полосами 1403a, 1403b, …, 1403g частот. Одно или более значений спектральных бинов каждой полосы масштабируются на этапе 1404a, 1404b, …, 1404g. Затем значения полос составляются друг с другом и преобразуются в блоке 1406 (который может быть идентичен рассмотренному выше блоку 370) и могут использоваться как аудиоинформация 1407 маскирования.
В действительности блока 1402 не существует, и, в простом варианте осуществления, он представляет только логическое группирование значений спектральных бинов. Аналогично, блока 1405 в действительности не существует, но он представляет логическую комбинацию модифицированных (масштабированных) спектральных значений.
Можно адаптировать один или более коэффициентов затухания, для подвергания затуханию вокализованных полос частот (или полос частот, имеющих сравнительно высокую энергию) надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, быстрее, чем невокализованные или шумоподобные полосы частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Согласно одному варианту осуществления, можно адаптировать коэффициенты 1408a, 1408b, …, 1408g затухания, для подвергания затуханию одной или более полос частот (т.е. i-ой полосы всего спектра) надлежащим образом декодированного аудиокадра, имеющего сравнительно более высокую энергию в расчете на спектральный бин быстрее, чем одна или более полос частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и имеющего сравнительно более низкую энергию в расчете на спектральный бин.
Как можно видеть на фиг. 15(a), в блоке 1504 сравнения можно устанавливать коэффициент 1503 затухания, для, по меньшей мере, одной полосы 1403a, 1403b, …, 1403g частот, на основании сравнения между значением 1501 энергии, связанным с, по меньшей мере, одной полосой частот в надлежащим образом декодированном аудиокадре, и порогом 1502.
Согласно одному варианту осуществления, можно использовать предварительно определенного коэффициента затухания для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Можно использовать коэффициент затухания, который меньше предварительно определенного коэффициента затухания (что может, вообще говоря, указывать более сильное затухание или более быстрое затухание) для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога.
Согласно одному варианту осуществления, можно использовать коэффициент затухания, представляющего сравнительно более медленное затухание для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Блок маскирования ошибок может быть выполнен с возможностью использования коэффициента затухания, представляющего сравнительно более быстрое затухание для, по меньшей мере, одной полосы частот, если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога.
Согласно одному варианту осуществления, можно задавать коэффициент затухания как предварительно определенное значение, если значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога. Если значение энергии, связанное с, по меньшей мере, одной полосой частот, выше порога, можно выводить коэффициент затухания для, по меньшей мере, одной полосы частот на основании значения временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для подвергания затуханию, по меньшей мере, одной полосы частот, быстрее, чем когда значение энергии, связанное с, по меньшей мере, одной полосой частот, ниже порога.
На фиг. 15(b) показано определение 1510, осуществляемое путем сравнения значения, связанного с энергией одной полосы (например, i-ой полосы спектра надлежащим образом декодированного аудиокадра) с порогом (например, порогом 1502). В блоке 1511 осуществляется определение. Определение может предусматривать вычисление значения временного энергетического тренда в i-ой полосе частот согласно одному из рассмотренных выше примеров (см. также вышеприведенные фиг. 5 и 8(b) и соответствующие отрывки описания).
Если распознается, что i-я полоса надлежащим образом декодированного аудиокадра содержит шум (например, значение, связанное с энергией полосы ниже порога), слабое затухание (или полное отсутствие затухания) осуществляется в блоке 1512, например, путем задания коэффициента затухания равным значением, заключенным между 0,95 и 1.
Если распознается, что i-я полоса содержит речь, но слово не заканчивается в надлежащим образом декодированном аудиокадре (или снижение энергии со временем меньше предварительно определенного порога), сниженное затухание осуществляется в блоке 1513, например, путем задания коэффициента затухания 0,7071.
В частности, если распознается, что i-я полоса надлежащим образом декодированного аудиокадра содержит элемент окончания речи в одном и том же кадре, сильное затухание осуществляется в блоке 1514. Когда значение временного энергетического тренда вычисляется, как описано выше (и первый и второй участки кадра задаются аналогично варианту осуществления, представленному на фиг. 6(b)), можно также для задания коэффициента затухания как то же значение (или масштабированное значение) значения 801 энергетического тренда для полосы i.
Однако не требуется ограничивать изобретение только двумя коэффициентами затухания (используемыми в блоке 1512 или 1513). Можно также задавать более двух коэффициентов по умолчанию: например, значение, близкое к 0,7071, как среднее затухание (1513); 0,9 для более низких полос; 0,95 для средних полос; 0,98 для более высоких полос как малый коэффициент (1512) затухания, или 0,9, если класс сигнала является вокализованным, и 0,95, если класс сигнала является невокализованным, как малый коэффициент (1512) затухания, и т.д.
Как можно видеть на фиг. 15(c), можно задавать разные пороги 1501i, 1501(i+1), и т.д., для разных полос частот i, i+1, и т.д., для получения разных коэффициентов 1503i, 1503(i+1) затухания и т.д. На фиг. 12 приведен пример, в котором порог изменяется согласно частоте, исходя из того, что значения, связанные с энергией разных полос (или диапазонам масштабного коэффициента) сравниваются с разными порогами.
В частности, можно устанавливать порог на основании значения энергии, или среднего значения энергии, или ожидаемого значения энергии, по меньшей мере, одной полосы частот.
Согласно одному варианту осуществления, можно устанавливать порог на основании отношения между значением энергии надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и количества спектральных линий во всем спектре надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Порог может основываться на значении временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Порог для i-ой полосы частот можно получать с использованием формулы:
где - количество линий в i-ой полосе частот,
причем
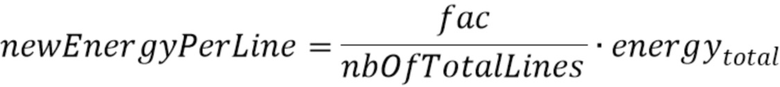
Значение представляет значение временного энергетического тренда в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, или значение затухания, выведенное из величины, представляющей значение временного энергетического тренда в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру. Значение - полная энергия по всем полосам частот надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Значение - суммарное количество спектральных линий надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
Полосы могут быть диапазонами масштабного коэффициента, спектральные значения которого масштабируются с использованием разных масштабных коэффициентов. Разные масштабные коэффициенты для масштабирования обратно квантованных спектральных значений связаны с разными диапазонами масштабного коэффициента. Можно масштабировать спектральное представление аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициентов затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
Можно масштабировать разные полосы частот спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием разных коэффициентов затухания, чтобы, таким образом, подвергать затуханию спектральные значения разных полос частот с разными скоростями затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
Согласно фиг. 15(b), для каждой i-ой полосы надлежащим образом декодированного кадра можно:
- в блоке 1512, устанавливать коэффициент затухания, связанный с i-ой полосой частот, на первое предварительно определенное значение, которое указывает меньшее затухание, чем второе предварительно определенное значение, если в блоке 1511 распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и/или
- в блоке 1513, устанавливать коэффициент затухания, связанный с i-ой полосой частот, на второе предварительно определенное значение, если в блоке 1511 распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь не заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, и/или
- в блоке 1514, устанавливать коэффициент затухания, связанный с i-ой полосой частот на значение, основанное на значении энергетического тренда или его масштабированной версии, если в блоке 1511 распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь спадает или заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру;
- в блоке 1515 выбирается новая полоса i+1, и вышеописанная процедура повторяется для новой полосы.
Согласно одному варианту осуществления, блок маскирования ошибок выполнен с возможностью сравнения энергии в данной i-ой полосе частот с порогом (например, 1502), и
- блок маскирования ошибок обеспечивает масштабный коэффициент для данной i-ой полосы частот, которая выводится на основании значения временного энергетического тренда декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, если энергия в данной i-ой полосе частот больше порога; и
- блок маскирования ошибок устанавливает коэффициент затухания на первое предварительно определенное значение (например, в блоке 1512), которое указывает меньшее затухание, чем второе предварительно определенное значение, если распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и если энергия в данной i-ой полосе частот меньше порога; и/или
- блок маскирования ошибок выполнен с возможностью установления коэффициента затухания на второе предварительно определенное значение, если надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, распознается, предпочтительно на основании информации битового потока или на основании анализа сигнала, как не шумоподобный.
Согласно одному варианту осуществления, блок маскирования ошибок осуществляет преобразование из спектральной области во временную область (например, на этапе 1406), для получения декодированного представления (например, 1407) надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
На фиг. 16(a) показан способ 1600 маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации, в котором спектральное представление надлежащим образом декодированного аудиокадра подразделяется на 1, 2, …, i, и т.д. полос, причем способ содержит следующие этапы:
- на этапе 1605, выбор первой полосы 1 (например, i:=1);
- на этапе 910, вывод коэффициента затухания на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру для полосы i;
- на этапе 920, осуществление затухания с использованием коэффициента затухания для полосы i;
- на этапе 1630, выбор новой полосы i+1;
- повторение этой процедуры для всех полос спектрального вида надлежащим образом декодированного аудиокадра.
На фиг. 16(b) показан вариант 1600b в котором, до этапа 910 (см. фиг. 16(a)), осуществляется этап 905, на котором анализируется значение энергетического тренда надлежащим образом декодированного аудиокадра.
В способах 1600 и 1600b сохранены ссылочные позиции способов 900 и 900b, чтобы подчеркнуть сходство различных вариантов осуществления способа.
8. Ход действия варианта осуществления изобретения и экспериментальные результаты
Согласно аспекту изобретения, установлено, что удобно подвергать затуханию замаскированный кадр путем подвергания затуханию разных полос сигнала с использованием разных коэффициентов затухания.
Было установлено, что не всегда желательно подавлять каждую часть сигнала с одинаковой скоростью. Например в случае речи с фоновым шумом желательно подвергать затуханию вокализованную часть сигнала, не слишком подвергая затуханию фоновый шум, во избежание появления раздражающих артефактов из дыр в спектре. Таким образом, коэффициент затухания по-разному применяется на разных частотных областях сигнала в некоторых вариантах осуществления. Это может осуществляться на основании LPC или масштабных коэффициентов.
Одним применением является затухание, зависящее от диапазона масштабного коэффициента, объясненное ниже (см. также фиг. 12).
Для предотвращения энергетических щелей/ спектральных дыр в диапазонах масштабного коэффициента низкой энергии (SFB), которые могут возникать в традиционном способе, коэффициент затухания будет применяться во всем диапазоне масштабного коэффициента. Если энергия SFB выше определенного порога, будет использоваться адаптированный коэффициент затухания (который можно получать, например, как описано в разделе "временной энергетический тренд"). В противном случае, будет применяться коэффициент затухания по умолчанию 0,7071 (1/21/2) (см., например, фиг. 12). В ряде случаев полезно подвергать затуханию SFB, которые ниже порога, еще медленнее; благодаря чему эти части не обращаются в нуль, и это означает, что сигнал затухает вплоть до затухания белого шума.
Порог может, например, зависеть от количества линий в каждой полосе. Это означает, что для SFB 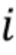 порог равен:
порог равен:
где - количество линий в i-ом SFB и
где - полное количество линии во всем спектре, и 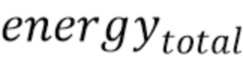 - полная энергия по всем SFB.
- полная энергия по всем SFB.
Пример может обеспечиваться результатами фиг. 13(a) и (b) (ось ординат: время в сотнях мс или мс × 100; ось абсцисс: частота), в котором график 1300a не подвергнутого затуханию сигнала сравнивается с графиком 1300b подвергнутого затуханию сигнала. Области 1301 более сильного затухания (по большей части, речь, в частности, кадры, в которых речь закончилась) показаны в контрпозиции к областям 1302 без изменения (по большей части, не подвергнутого затуханию шума). В частности, область 1301 более сильного затухания, возникающая на фиг. 13(a), надлежащим образом подавляется на фиг. 13(b), таким образом, снижая раздражающие эхо. Напротив, шум областей 1302 не подавляется, что предпочтительно.
9. Выводы
Описано адаптивное затухание для маскирования потери пакетов в аудиокодеках частотной области.
В случае потерь пакетов, речевые и аудиокодеки обычно осуществляют затухание до нуля или фонового шума для предотвращения раздражающих артефактов повторения. Для всех декодеров семейства AAC замаскированный спектр подвергается затуханию с постоянным коэффициентом затухания независимо от характеристик сигнала. В частности, для речевых или переходных сигналов, статического коэффициента затухания может быть недостаточно. Таким образом, варианты осуществления согласно изобретению вычисляют адаптивный коэффициент затухания в зависимости от значения временного энергетического тренда последнего хорошего кадра. Кроме того, частотно-адаптивное затухание применяется на замаскированном спектре во избежание раздражающих дыр в спектре.
Варианты осуществления можно использовать, в технических областях ELD, XLD, DRM или MPEG-H, например, совместно с аудиодекодерами такого рода.
10. Дополнительные замечания
В случае потерь пакетов, речевые и аудиокодеки обычно осуществляют затухание до нулевого или фонового шума во избежание раздражающих артефактов повторения.
Для всех декодеров семейства AAC замаскированный спектр подвергается затуханию с постоянным коэффициентом затухания независимо от характеристик сигнала.
В особенности, для речевых или переходных сигналов, статического коэффициента затухания недостаточно.
Таким образом, обеспечивается инструмент для вычисления адаптивного коэффициент затухания в зависимости от временного энергетического тренда последнего хорошего кадра.
Кроме того, частотно-адаптивное затухание применяется на замаскированном спектре во избежание раздражающих дыр в спектре.
11. Альтернативные реализации
Хотя некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа может выполняться посредством (или с использованием) аппаратного устройства, например, микропроцессора, программируемого компьютера или электронной схемы. В некоторых вариантах осуществления, один или более из наиболее важных этапов способа могут выполняться таким устройством.
В зависимости от определенных требований к реализации, варианты осуществления изобретения можно реализовать аппаратными средствами или программными средствами. Реализация может осуществляться с использованием цифрового запоминающего носителя, например, флоппи-диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флеш-памяти, где хранятся электронно считываемые сигналы управления, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, благодаря чему осуществляется соответствующий способ. Таким образом, цифровой запоминающий носитель может быть компьютерно-считываемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, благодаря чему осуществляется один из описанных здесь способов.
В целом, варианты осуществления настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, причем программный код способен осуществлять один из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа, отвечающего изобретению является, таким образом, компьютерной программой, имеющей программный код для осуществления одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов, отвечающих изобретению, является, таким образом, носителем данных (или цифровым запоминающим носителем, или компьютерно-считываемым носителем), содержащим записанную на нем компьютерную программу для осуществления одного из описанных здесь способов. Носитель данных, цифровой запоминающий носитель или записанный носитель обычно являются материальными и/или некратковременными.
Дополнительный вариант осуществления способа, отвечающего изобретению является, таким образом, потоком данных или последовательностью сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов может, например, переноситься через соединение для передачи данных, например, интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптированное для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью переноса (например, электронного или оптического) компьютерной программы для осуществления одного из описанных здесь способов на приемник. Приемником может быть, например, компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система может, например, содержать файловый сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, вентильная матрица, программируемая пользователем) может использоваться для осуществления некоторых или всех функциональных возможностей описанных здесь способов. В некоторых вариантах осуществления, вентильная матрица, программируемая пользователем, может взаимодействовать с микропроцессором для осуществления одного из описанных здесь способов. В целом, способы предпочтительно осуществляются любым аппаратным устройством.
Описанное здесь устройство можно реализовать с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Описанные здесь способы могут осуществляться с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Вышеописанные варианты осуществления призваны лишь иллюстрировать принципы настоящего изобретения. Следует понимать, что специалисты в данной области техники могут предложить модификации и вариации описанных здесь конфигураций и деталей. Таким образом, оно ограничивается только объемом нижеследующей формулы изобретения, но не конкретными деталями, представленными посредством описания и объяснения рассмотренных здесь вариантов осуществления.
12. Библиография
[1] 3GPP TS 26.402 "Enhanced aacPlus general audio codec; Additional decoder tools (Release 11)",
[2] J. Lecomte, et al, "Enhanced time domain packet loss concealment in switched speech/audio codec", submitted to IEEE ICASSP, Brisbane, Australia, Apr. 2015.
[3] WO 2015063045 A1
[4] "Apparatus and method for improved concealment of the adaptive codebook in ACELP-like concealment employing improved pitch lag estimation", 2014, PCT/EP2014/062589
[5] "Apparatus and method for improved concealment of the adaptive codebook in ACELP-like concealment employing improved pulse "synchronization", 2014, PCT/EP2014/062578
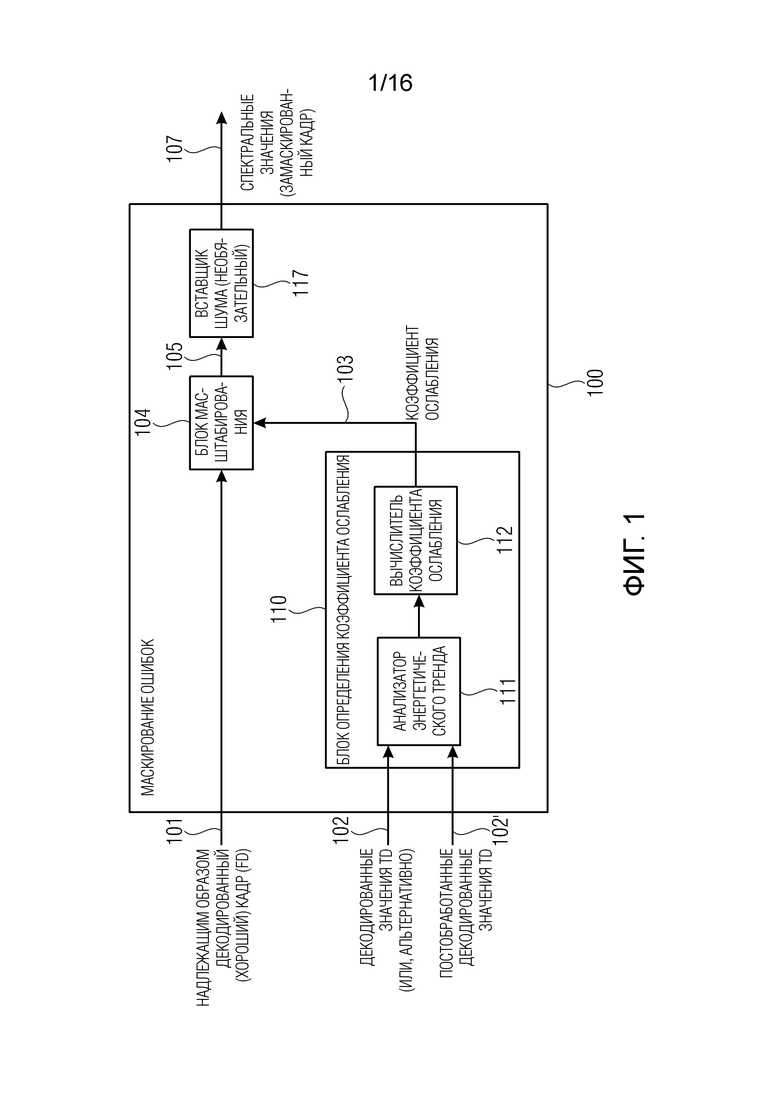
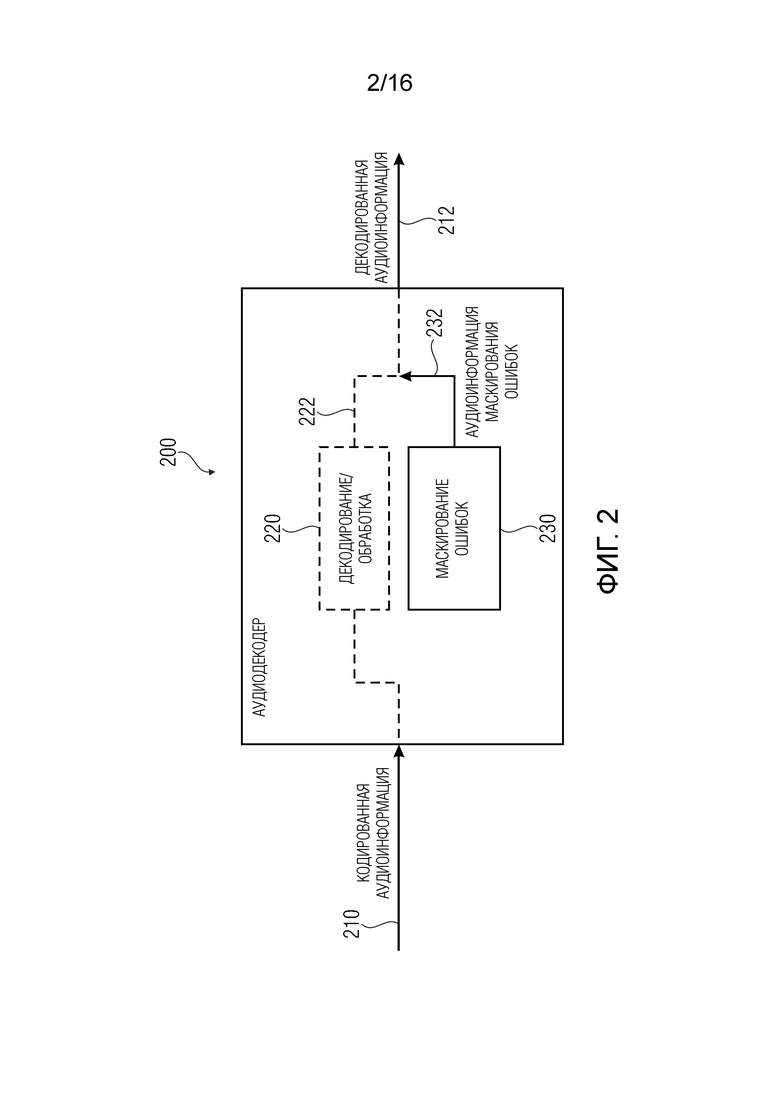
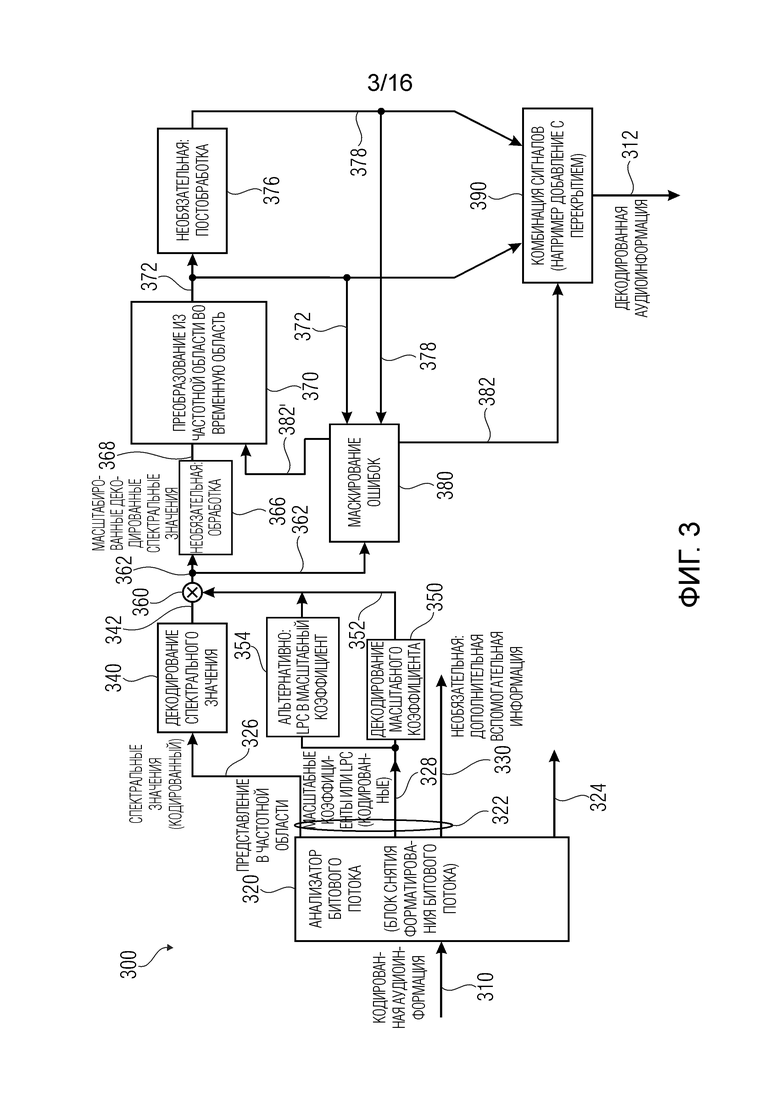
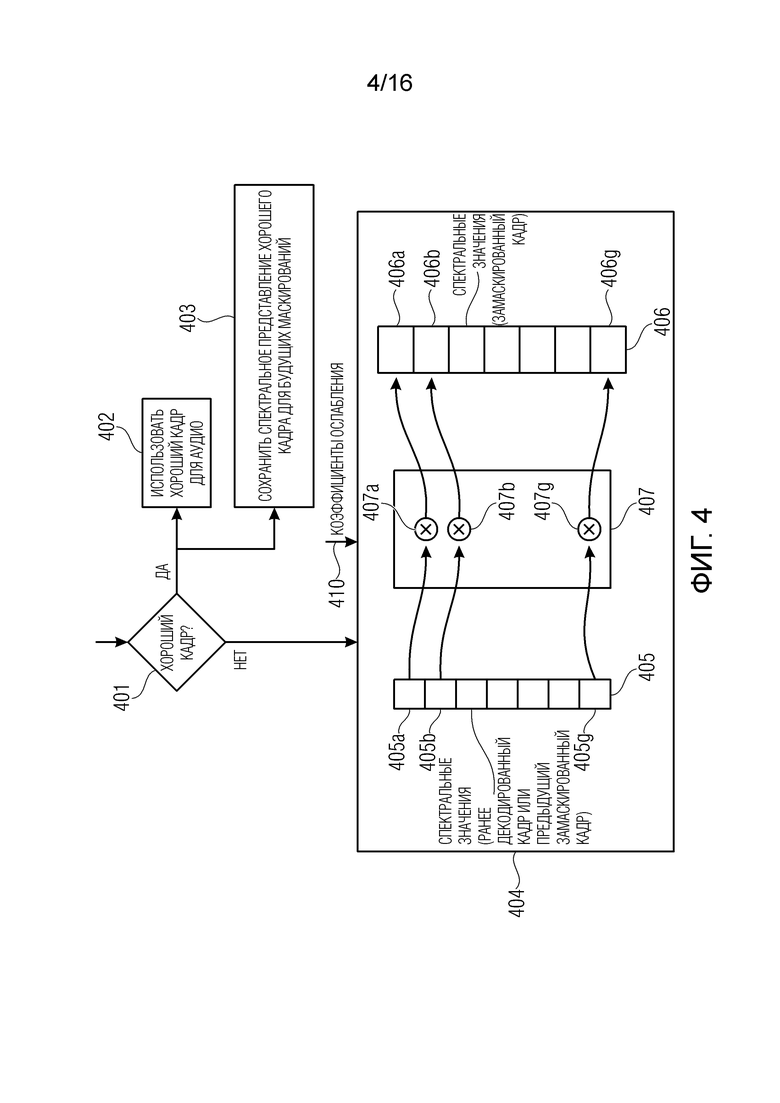
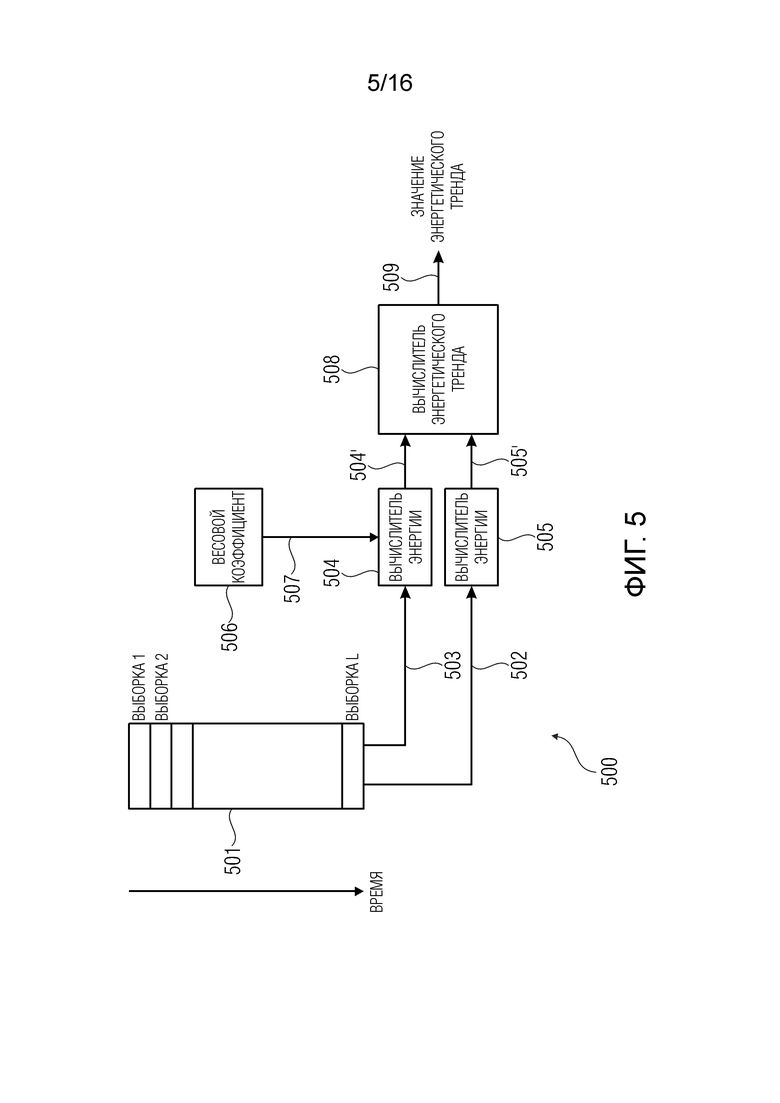
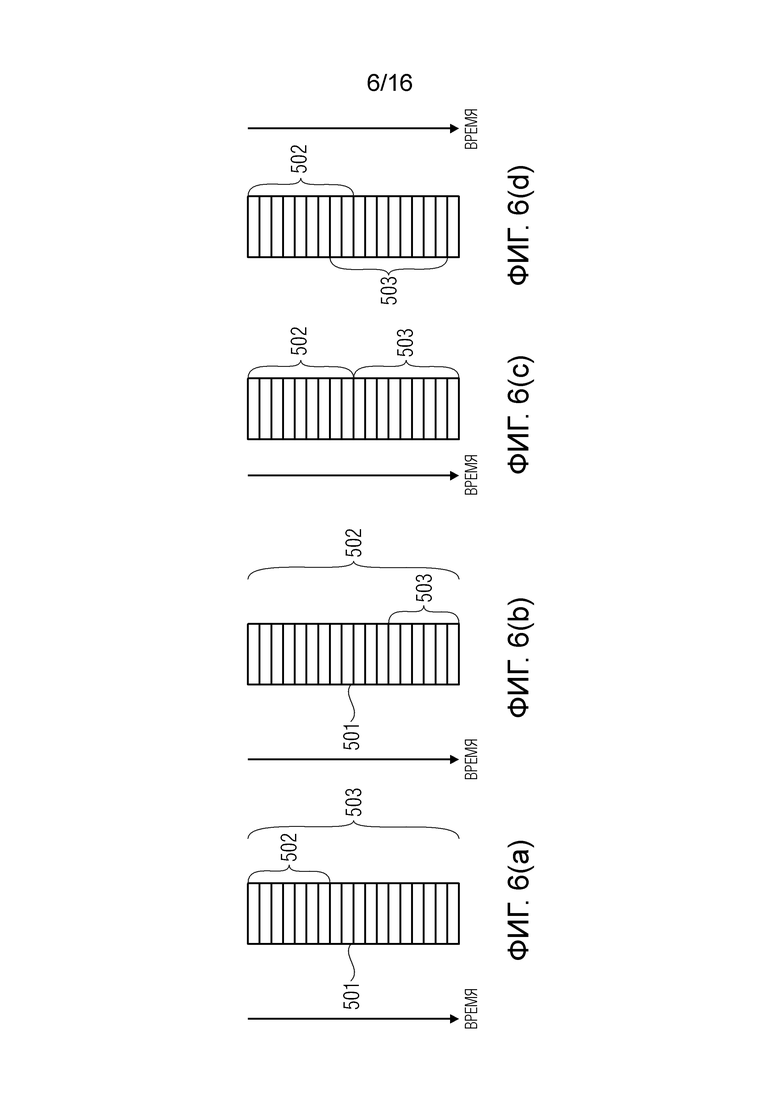
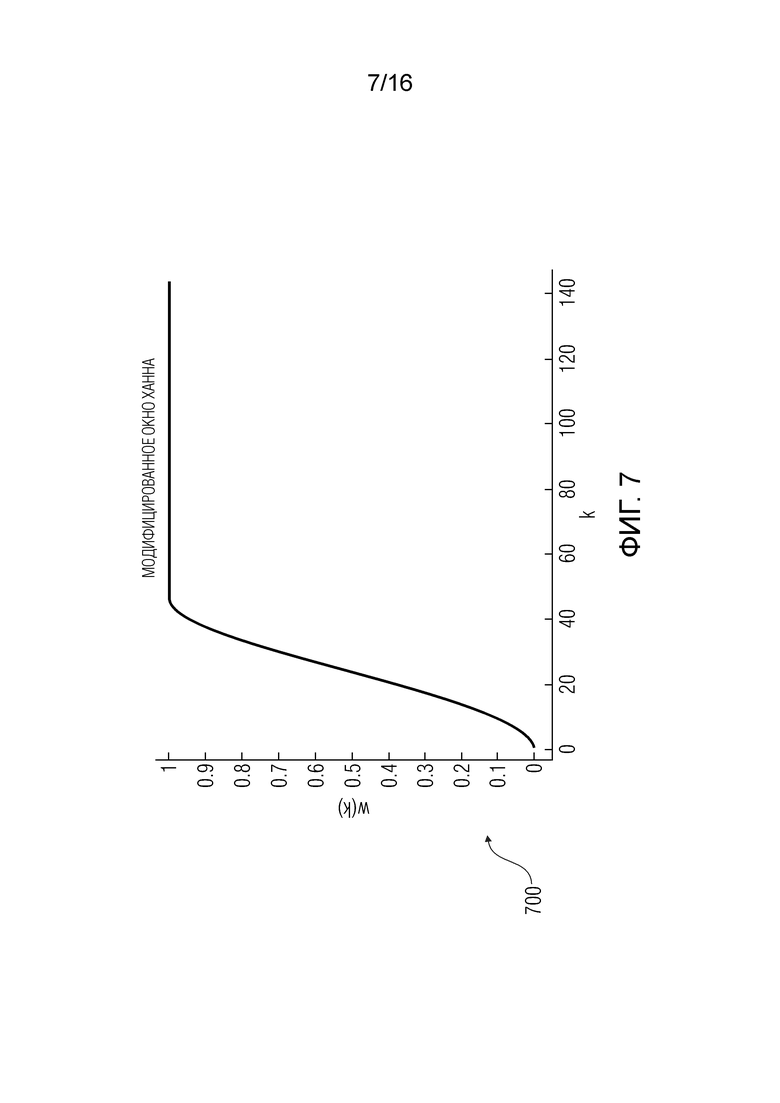
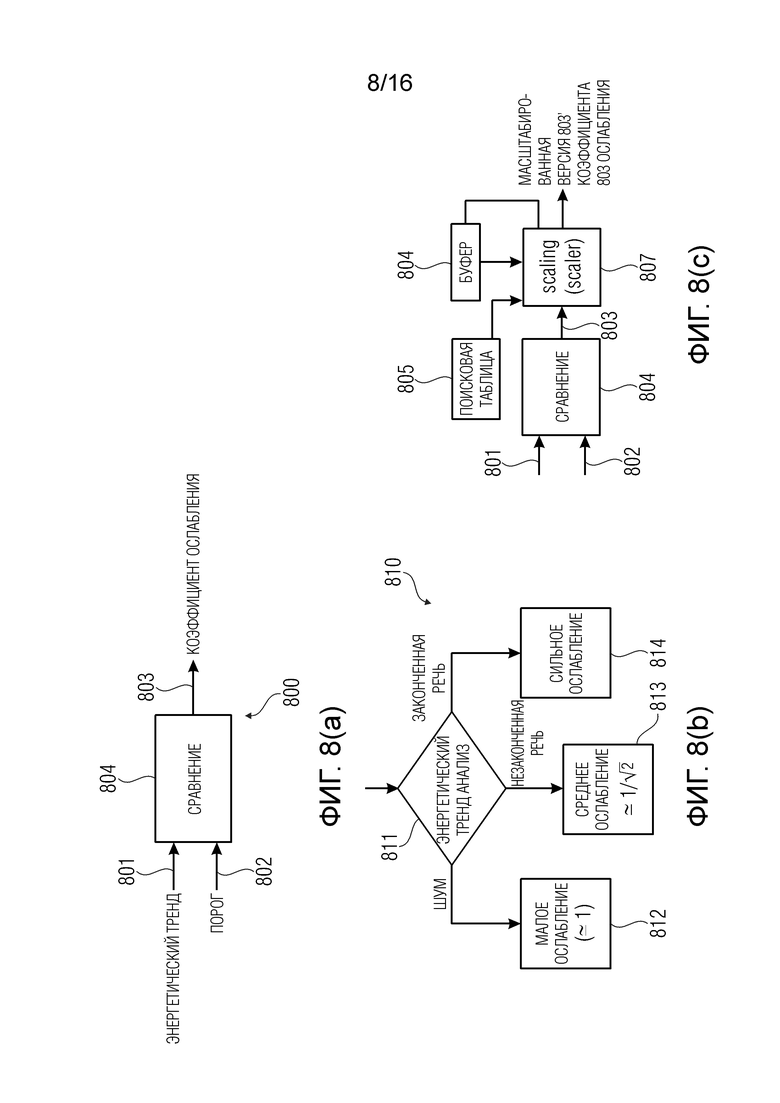
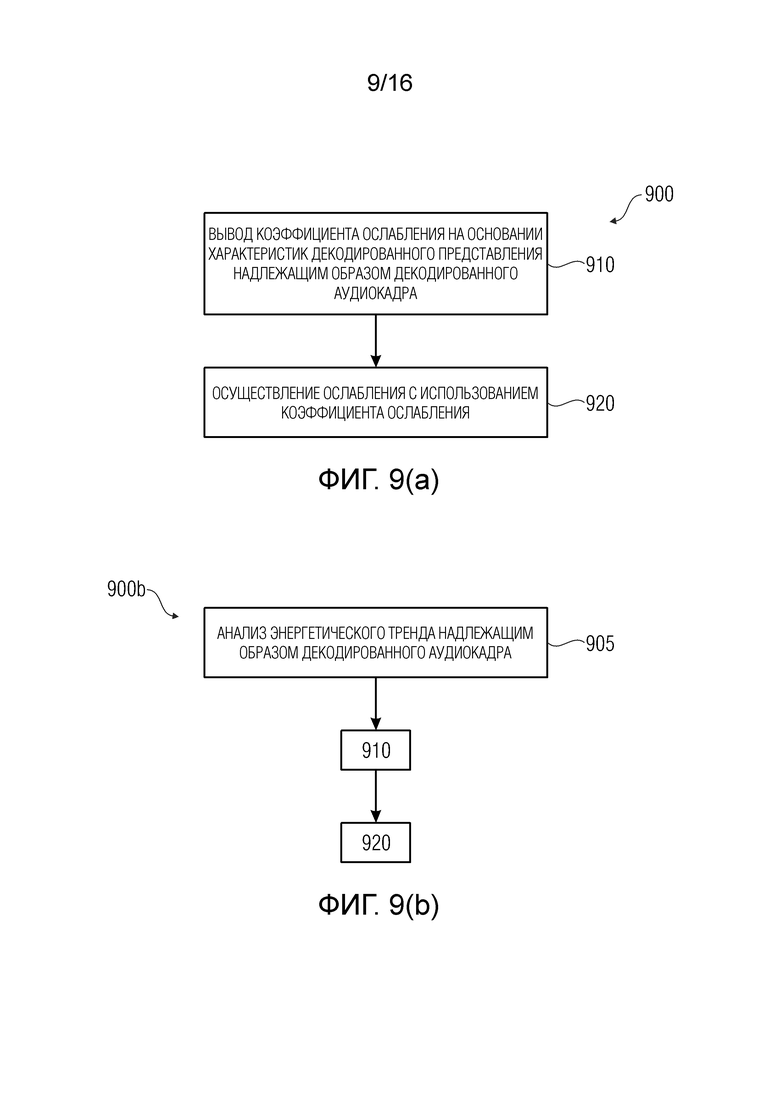
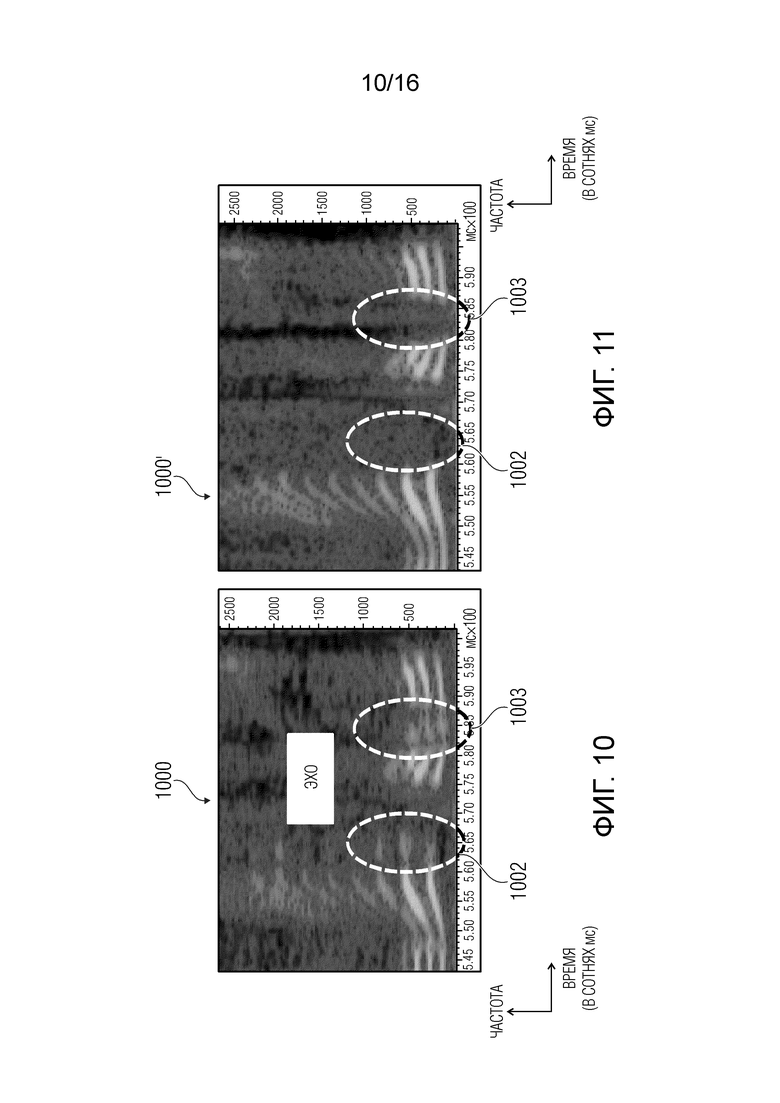
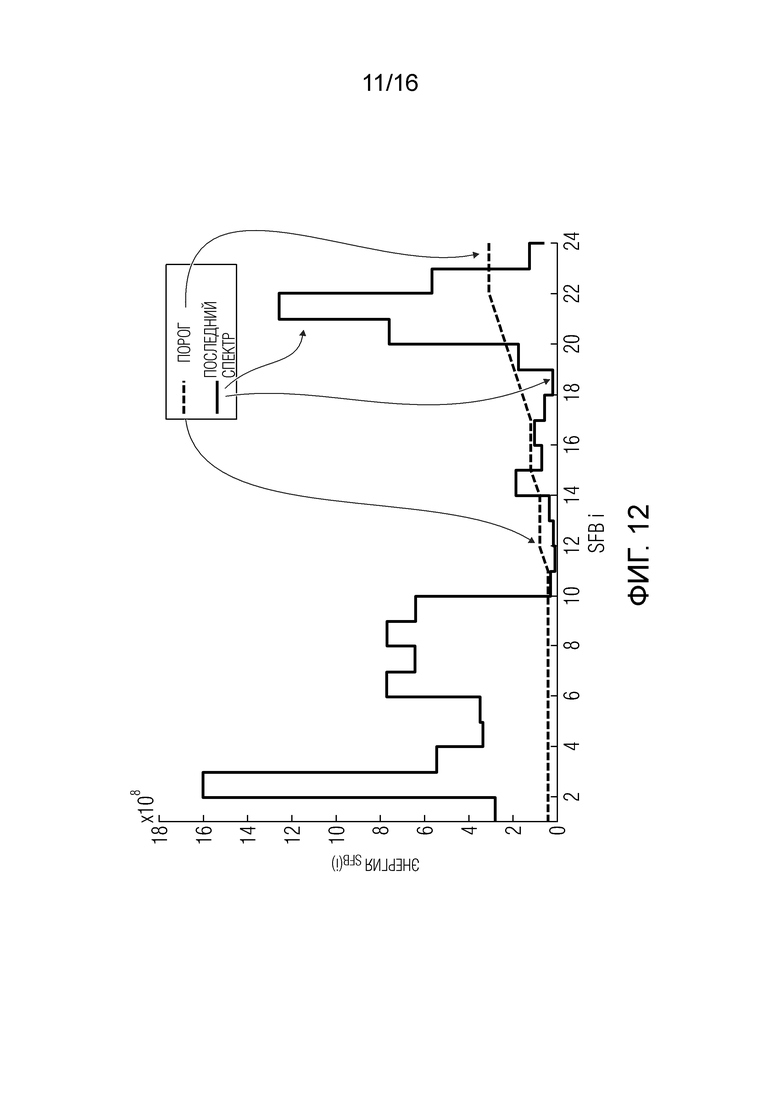
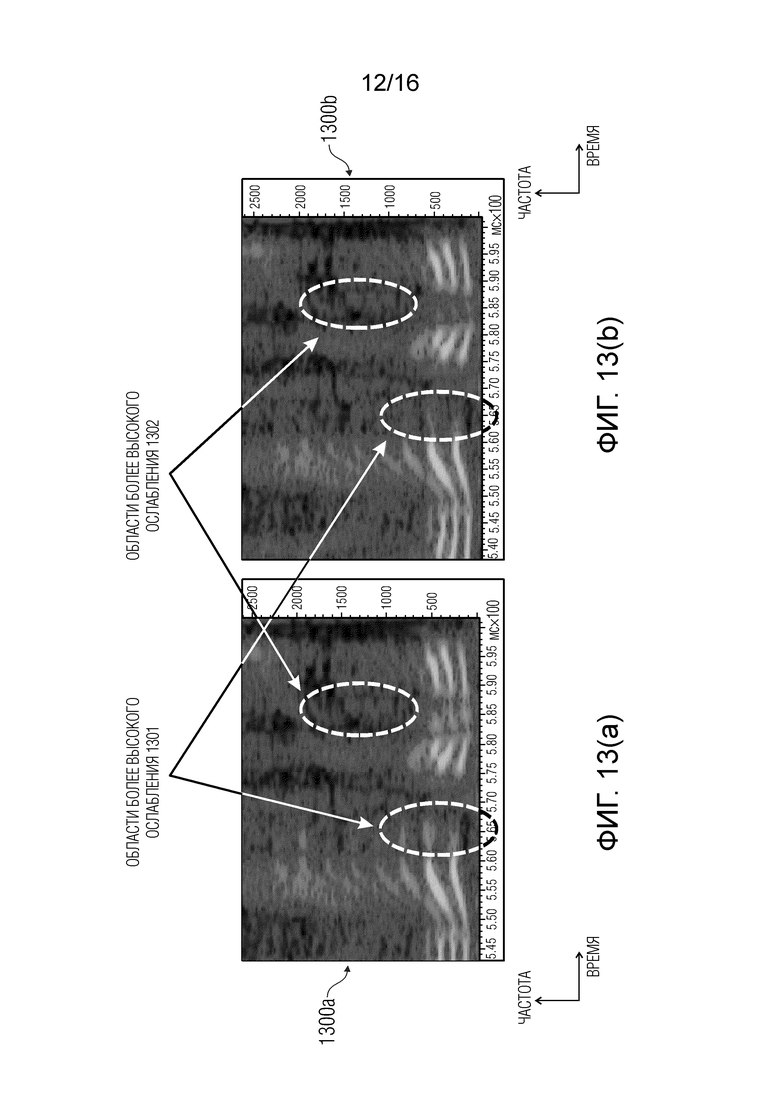
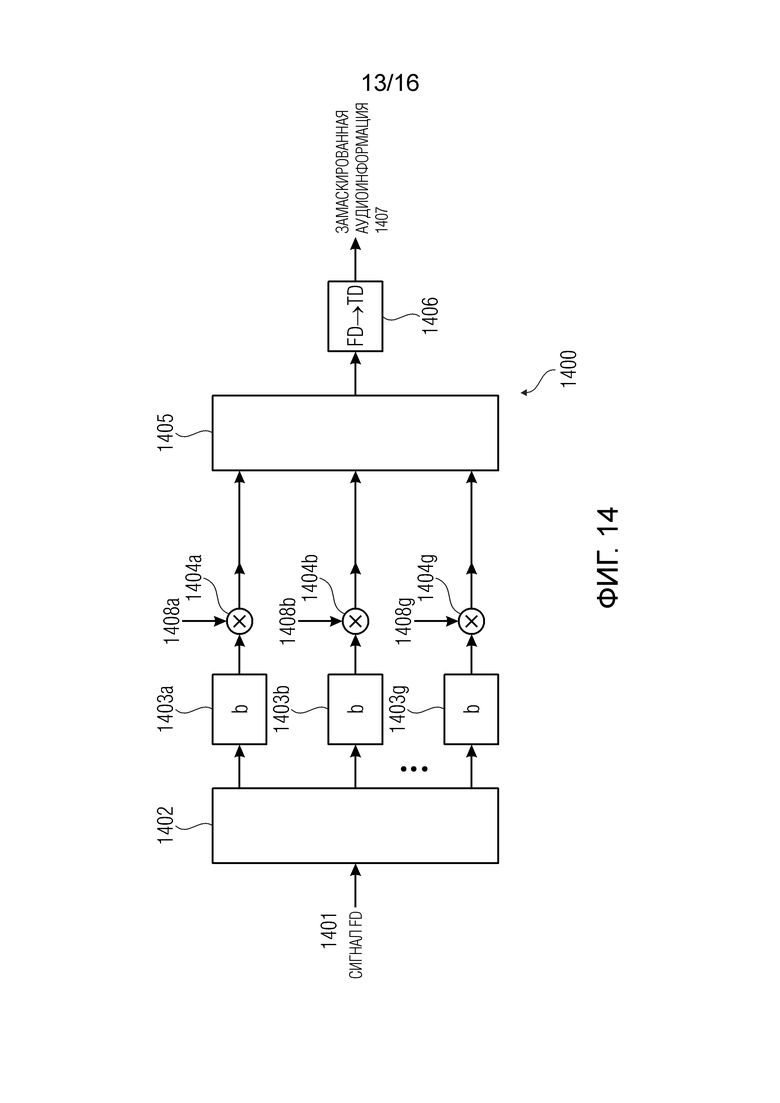
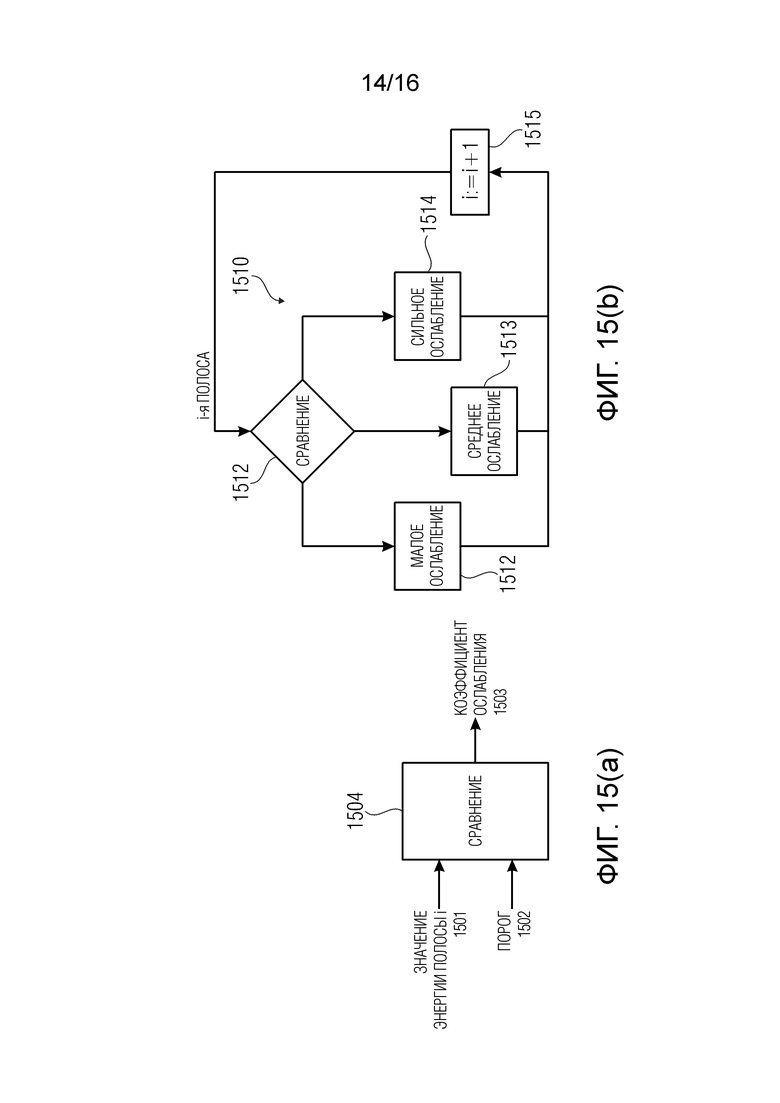
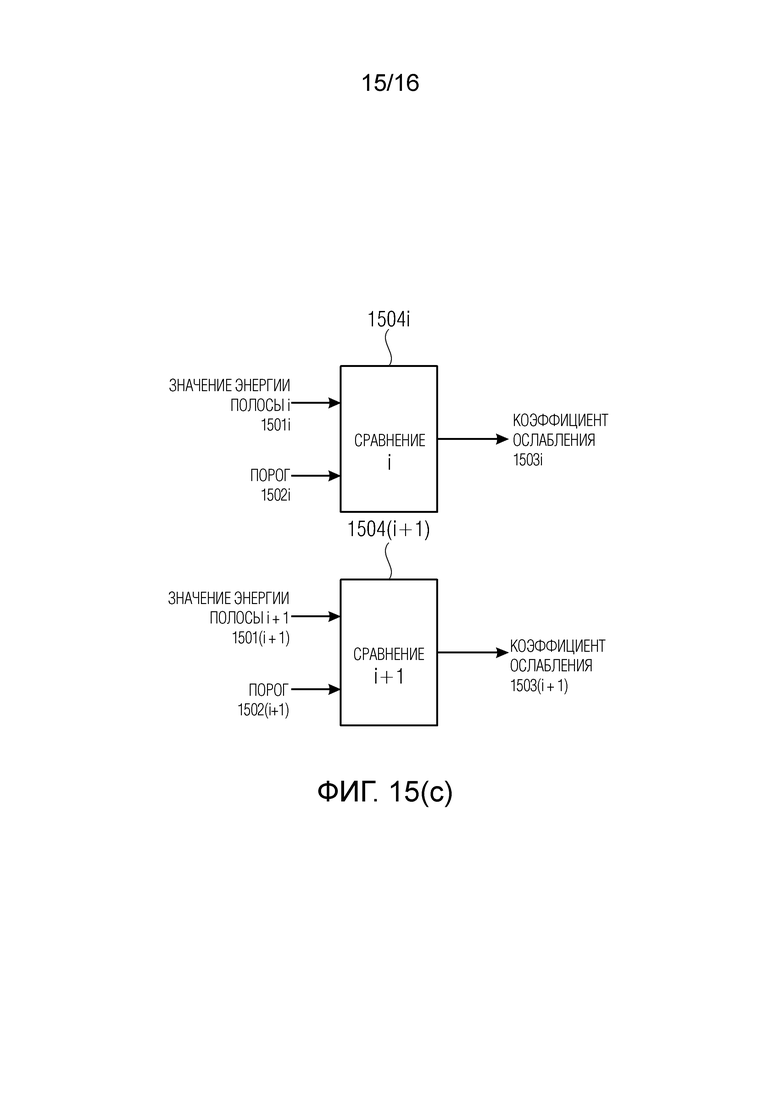
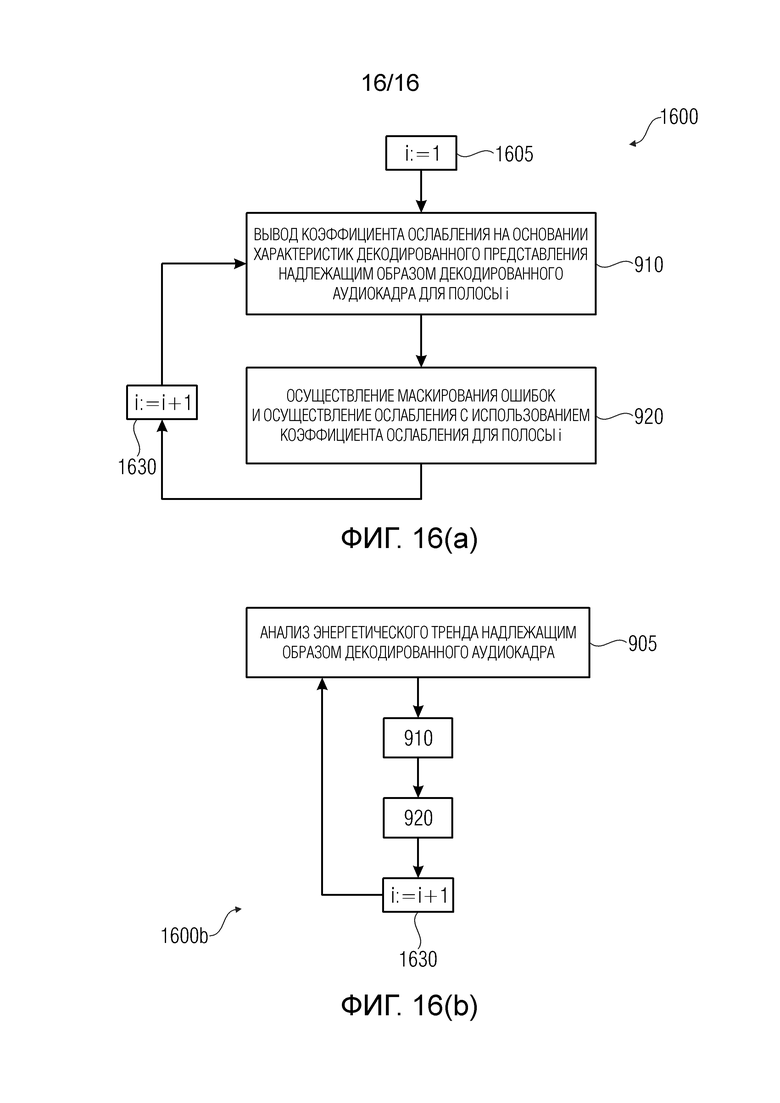
Изобретение относится к средствам для кодирования и декодирования аудио. Технический результат заключается в повышении эффективности кодирования аудиосигнала. Выводят коэффициент затухания на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру. Осуществляют затухание с использованием коэффициента затухания. Вычисляют отношение между энергией на концевом участке декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или на концевом участке масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и полной энергией в декодированном представлении упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или в масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для получения коэффициента затухания. 4 н. и 22 з.п. ф-лы, 26 ил.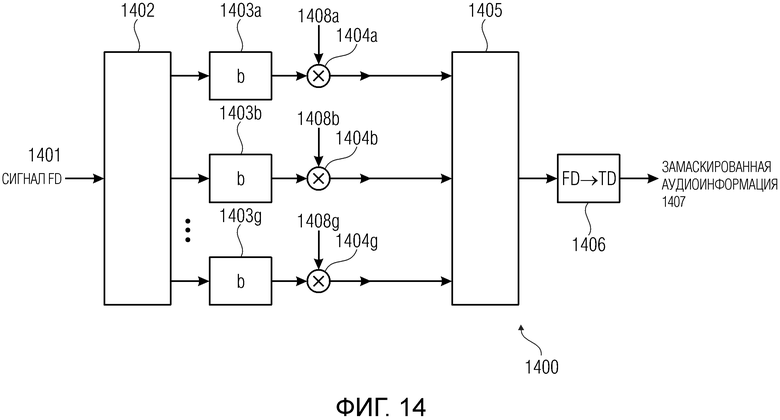
1. Блок (100, 230, 380) маскирования ошибок для обеспечения аудиоинформации (107, 232, 382) маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации (210),
причем блок маскирования ошибок выполнен с возможностью обеспечения аудиоинформации маскирования ошибок для потерянного аудиокадра на основании надлежащим образом декодированного аудиокадра (102, 403, 501), предшествующего потерянному аудиокадру,
причем блок маскирования ошибок выполнен с возможностью вывода (804, 811, 910, 1504) коэффициента (103, 410, 803, 1408a-1408c) затухания на основании характеристик декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
причем блок маскирования ошибок выполнен с возможностью осуществления затухания (104, 404, 812-814, 920) с использованием коэффициента (103, 410, 803, 1408a-1408c) затухания,
причем блок маскирования ошибок выполнен с возможностью вычисления отношения между:
энергией на концевом участке декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или на концевом участке масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
полной энергией в декодированном представлении упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или в масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для получения коэффициента (103, 410, 803, 1408a-1408c) затухания.
2. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вывода коэффициента (103, 410, 803, 1408a-1408c) затухания на основании характеристик декодированного представления (102, 372) во временной области надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
3. Блок маскирования ошибок по п. 2, причем блок маскирования ошибок выполнен с возможностью осуществления анализа (111, 500) декодированного представления (102) во временной области, и вывода коэффициента (103, 410, 803, 1408a-1408c) затухания на основании анализа декодированного представления во временной области.
4. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вывода коэффициента (103, 410, 803, 1408a-1408c) затухания на основании временного энергетического тренда (509, 801) декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
5. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вычисления энергии первого участка (502) декодированного представления надлежащим образом декодированного аудиокадра (501), предшествующего потерянному аудиокадру, или его взвешенной версии.
6. Блок маскирования ошибок по п. 1, выполненный с возможностью вычисления энергии второго участка (503) декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или его взвешенной версии.
7. Блок маскирования ошибок по п. 5, выполненный с возможностью вычисления энергии второго участка (503) декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или его взвешенной версии, при том что начало первого участка декодированного представления предшествует по времени началу второго участка декодированного представления.
8. Блок маскирования ошибок по п. 5, выполненный с возможностью вычисления энергии второго участка (503) декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или его взвешенной версии, при том что среднее временных значений первого участка предшествует по времени среднему временных значений второго участка.
9. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вычисления коэффициента (103, 410, 803, 1408a-1408c) затухания в зависимости от энергии первого участка и в зависимости от энергии второго участка.
10. Блок маскирования ошибок по п. 5, в котором второй участок декодированного представления содержит последний интервал выборок декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
при этом первый участок декодированного представления содержит все выборки надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или интервал выборок надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, который перекрывает второй участок, при том что по меньшей мере некоторые из выборок первого участка предшествуют всем выборкам второго участка.
11. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вычисления временного энергетического тренда с использованием формулы:
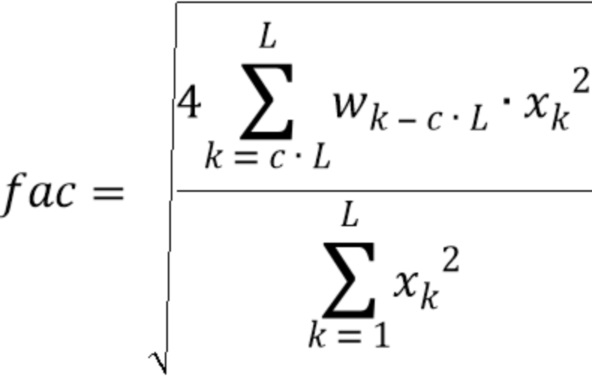
где L - длина кадра в выборках, 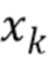 - значение выборки сигнала,
- значение выборки сигнала, 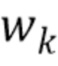 - весовой коэффициент, и
- весовой коэффициент, и 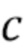 - значение между 0,5 и 0,9.
- значение между 0,5 и 0,9.
12. Блок маскирования ошибок по п. 8, причем блок маскирования ошибок выполнен с возможностью определения весового коэффициента для проверки условия:
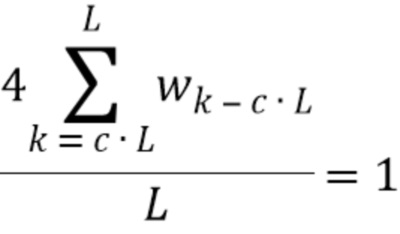 .
.
13. Блок маскирования ошибок по п. 11, причем блок маскирования ошибок выполнен с возможностью определения весового коэффициента как
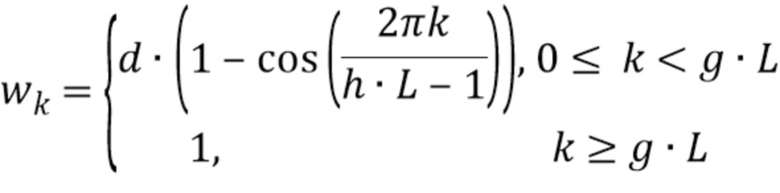 ,
,
где 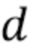 - значение между 0,4 и 0,6,
- значение между 0,4 и 0,6,
где 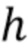 - значение между 0,15 и 0,25, и
- значение между 0,15 и 0,25, и
где 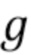 - значение между 0,05 и 0,15.
- значение между 0,05 и 0,15.
14. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью снижения коэффициента (103, 410, 803, 1408a-1408c) затухания в отношении предыдущего замаскированного аудиокадра и для подвергания затуханию, по меньшей мере, одного последующего замаскированного аудиокадра, после ранее замаскированного аудиокадра с использованием сниженного коэффициента (103, 410, 803, 1408a-1408c) затухания.
15. Блок маскирования ошибок по п. 13, причем блок маскирования ошибок выполнен с возможностью осуществления затухания согласно более чем экспоненциальному спаду по времени в течение, по меньшей мере, трех последовательных замаскированных аудиокадров.
16. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью определения значения энергетического тренда, количественно описывающего временной энергетический тренд декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
причем блок маскирования ошибок выполнен с возможностью использования значения энергетического тренда, или его масштабированной версии, для задания коэффициента (103, 410, 803, 1408a-1408c) затухания.
17. Блок маскирования ошибок по п. 15, причем блок маскирования ошибок выполнен с возможностью установления коэффициента (103, 410, 803, 1408a-1408c) затухания на предварительно определенное значение, более низкое, чем текущее значение энергетического тренда, если текущее значение энергетического тренда лежит в предварительно определенном диапазоне, указывающем сравнительно малое снижение энергии со временем.
18. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью:
установления коэффициента (103, 410, 803, 1408a-1408c) затухания на первое предварительно определенное значение, которое указывает меньшее затухание, чем второе предварительно определенное значение, если распознается, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является шумоподобным, и/или
установления коэффициента (103, 410, 803, 1408a-1408c) затухания на второе предварительно определенное значение, если распознается, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь не заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру, и/или
установления коэффициента (103, 410, 803, 1408a-1408c) затухания на значение, основанное на значении энергетического тренда или его масштабированной версии, если распознается, что надлежащим образом декодированный аудиокадр, предшествующий потерянному аудиокадру, является речеподобным, причем речь спадает или заканчивается в надлежащим образом декодированном аудиокадре, предшествующем потерянному аудиокадру.
19. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью определения разных коэффициентов (103, 410, 803, 1408a-1408c) затухания для разных полос частот.
20. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью вывода коэффициента (103, 410, 803, 1408a-1408c) затухания, так чтобы коэффициент (103, 410, 803, 1408a-1408c) затухания отражал экстраполяцию временного изменения уровня энергии на концевом участке последнего надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, на потерянный аудиокадр.
21. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью подвергания затуханию аудиоконтента аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициента (103, 410, 803, 1408a-1408c) затухания.
22. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью масштабирования спектрального представления аудиокадра, предшествующего потерянному аудиокадру, с использованием коэффициента (103, 410, 803, 1408a-1408c) затухания, для вывода замаскированного спектрального представления потерянного аудиокадра.
23. Блок маскирования ошибок по п. 1, причем блок маскирования ошибок выполнен с возможностью осуществления преобразования из спектральной области во временную область для получения декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру.
24. Способ маскирования ошибок для обеспечения аудиоинформации маскирования ошибок для маскирования потери аудиокадра в кодированной аудиоинформации, содержащий этапы, на которых:
выводят коэффициент (103, 410, 803, 1408a-1408c) затухания на основании характеристик декодированного представления надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и осуществляют затухание с использованием коэффициента затухания,
причем способ включает в себя этап, на котором вычисляют отношение между:
энергией на концевом участке декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или на концевом участке масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, и
полной энергией в декодированном представлении упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, или в масштабированной версии декодированного представления упомянутого надлежащим образом декодированного аудиокадра, предшествующего потерянному аудиокадру, для получения коэффициента (103, 410, 803, 1408a-1408c) затухания.
25. Компьютерно-считываемый носитель, содержащий сохраненную на нем компьютерную программу, которая предписывает компьютеру осуществлять способ по п. 24, когда компьютерная программа выполняется на компьютере.
26. Аудиодекодер для обеспечения декодированной аудиоинформации на основании кодированной аудиоинформации, причем аудиодекодер содержит блок маскирования ошибок по п. 1.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| WO 2015063044 A1, 07.05.2015 | |||
| КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И СПОСОБ | 2012 |
|
RU2488897C1 |

