Настоящее изобретение относится к обработке аудиосигналов и, в частности, к устройству и способу для гармонического/перкуссионного/остаточного разделения звука с использованием структурного тензора на спектрограммах.
Возможность разделять звук на его гармонический и перкуссионный компонент представляет собой эффективный этап предварительной обработки для многих вариантов применения.
Хотя "гармоническое/перкуссионное/(остаточное) разделение" является общим термином, оно вводит в заблуждение, поскольку оно подразумевает гармоническую структуру с синусоидами, имеющими частоту, равную целому кратному от основной частоты. Даже несмотря на то, что правильный термин должен быть "тональное/перкуссионное/(остаточное) разделение", термин "гармоническое" вместо "тонального" используется далее для более простого понимания.
Использование разделенного перкуссионного компонента звукозаписи, например, может приводить к повышению качества для отслеживания биения (см. [1]), анализа ритма и переложения ритм-инструментов. Разделенный гармонический компонент является подходящим для переложения инструментов с несколькими основными тонами и обнаружения хорды (см. [3]). Кроме того, гармоническое/перкуссионное разделение может использоваться для целей повторного микширования, таких как изменение отношения уровня между обоими компонентами сигнала (см. [4]), что приводит к "более плавному" или "более штампованному" общему восприятию звука.
Некоторые способы для гармонического/перкуссионного разделения звука базируются на таком допущении, что гармонические звуки имеют горизонтальную структуру на спектрограмме уровня входного сигнала (в направлении времени), в то время как перкуссионные звуки появляются в качестве вертикальных структур (в направлении частоты). В работе авторов Ono и др. представлен способ, который сначала создает гармонически/перкуссионно улучшенные спектрограммы посредством диффузии в частотно-временном направлении (см. [5]). Посредством сравнения этих улучшенных представлений впоследствии, может извлекаться решение, если звук является гармоническим или перкуссионным.
Аналогичный способ опубликован в работе автора Fitzgerald, в которой улучшенные спектрограммы вычислены посредством использования медианной фильтрации в перпендикулярных направлениях вместо диффузии (см. [6]), что приводит к аналогичным результатам при одновременном снижении вычислительной сложности.
Под влиянием модели прохождения сигналов "синусоды+переходные части+шум" (S+T+N) (см. [7], [8], [9]), эта инфраструктура стремится описывать соответствующие компоненты сигнала посредством небольшого набора параметров. Способ Fitzgerald затем расширен на гармоническое/перкуссионное/остаточное (HPR) разделение в [10]. Поскольку аудиосигналы зачастую состоят из звуков, которые не являются ни четко гармоническими, ни перкуссионными, эта процедура захватывает эти звуки в третьем остаточном компоненте. Хотя некоторые из этих остаточных сигналов четко имеют изотропную, ни горизонтальную, ни вертикальную, структуру (такую, как, например, шум), существуют звуки, которые не имеют четкой горизонтальной структуры, но, тем не менее, переносят тональную информацию и могут восприниматься как гармоническая часть звука. Пример представляет собой частотно-модулированные тона, которые могут возникать в записях вследствие игры на скрипке или вокалов, в которых они, как говорят, имеют "вибрато". Вследствие стратегии распознавания горизонтальных либо вертикальных структур вышеуказанные способы не всегда имеют возможность захватывать такие звуки в своем гармоническом компоненте.
Процедура гармонического/перкуссионного разделения на основе неотрицательной матричной факторизации, которая допускает захват гармонических звуков с негоризонтальными спектральными структурами в гармоническом компоненте, предложена в [11]. Тем не менее, она не включает в себя третий остаточный компонент.
Если обобщить вышесказанное, недавние способы основываются на таком наблюдении, что, в представлении в виде спектрограммы, гармонические звуки приводят к горизонтальным структурам, а перкуссионные звуки приводят к вертикальным структурам. Кроме того, эти способы ассоциируют структуры, которые не являются ни горизонтальными, ни вертикальными (т.е. негармонические, неперкуссионные звуки), с остаточной категорией. Тем не менее, это допущение не применимо для таких сигналов, как частотно-модулированные тона, которые демонстрируют колеблющиеся спектральные структуры, тем не менее, при одновременном переносе тональной информации.
Структурный тензор, инструментальное средство, используемое в обработке изображений (см. [12], [13]), применяется к полутоновым изображениям для обнаружения краев и углов (см. [14]), либо для того, чтобы оценивать ориентацию объекта. Структурный тензор уже использован для предварительной обработки и извлечения признаков в аудиообработке (см. [15], [16]).
Цель настоящего изобретения заключается в том, чтобы предоставлять усовершенствованные принципы для обработки аудиосигналов. Цель настоящего изобретения достигается посредством устройства по п. 1, посредством способа по п. 16 и посредством компьютерной программы по п. 17.
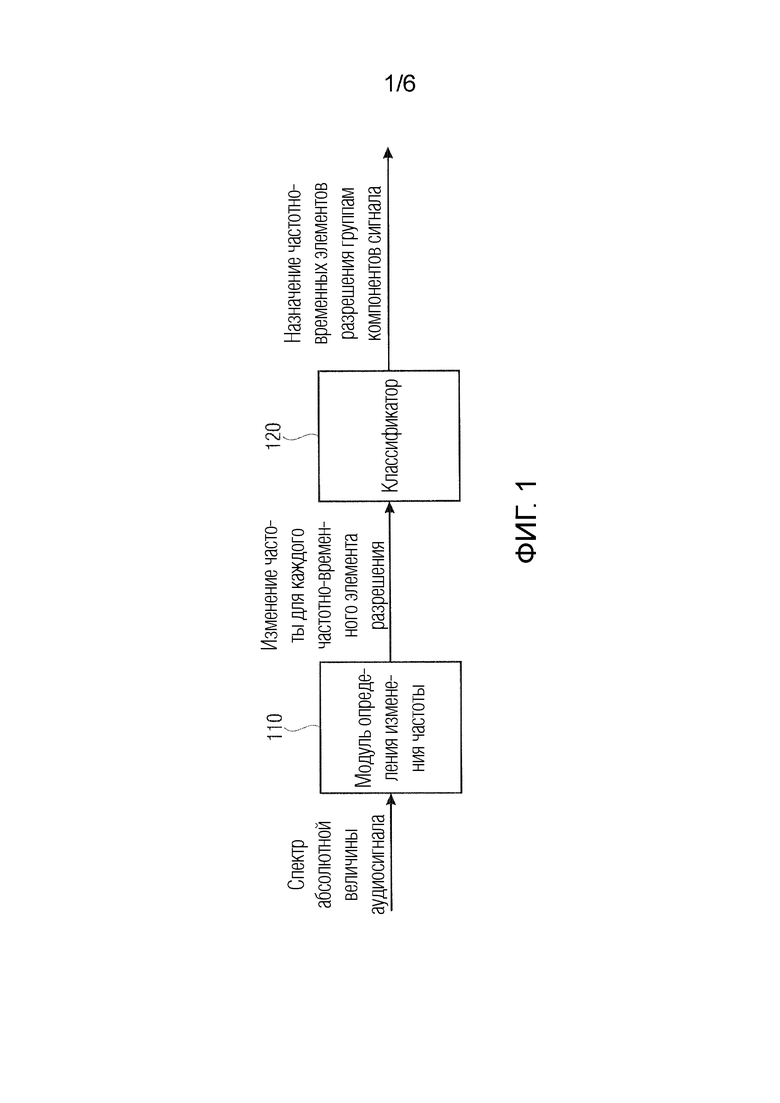
Предусмотрено устройство для анализа спектрограммы уровня аудиосигнала. Устройство содержит модуль определения изменения частоты, выполненный с возможностью определять изменение частоты для каждого частотно-временного бина (элемента разрешения) из множества частотно-временных бинов спектрограммы уровня аудиосигнала в зависимости от спектрограммы уровня аудиосигнала. Кроме того, устройство содержит классификатор, выполненный с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина.
Кроме того, предусмотрен способ для анализа спектрограммы уровня аудиосигнала. Способ содержит:
- определение изменения частоты для каждого частотно-временного бина из множества частотно-временных бинов спектрограммы уровня аудиосигнала в зависимости от спектрограммы уровня аудиосигнала; и
- назначение каждого частотно-временного бина из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина.
Кроме того, предусмотрена компьютерная программа, при этом компьютерная программа выполнена с возможностью реализовывать вышеописанный способ при выполнении на компьютере или в процессоре сигналов.
Далее подробнее описываются варианты осуществления настоящего изобретения в отношении чертежей, на которых:
Фиг. 1 иллюстрирует устройство для анализа спектрограммы уровня аудиосигнала согласно варианту осуществления,
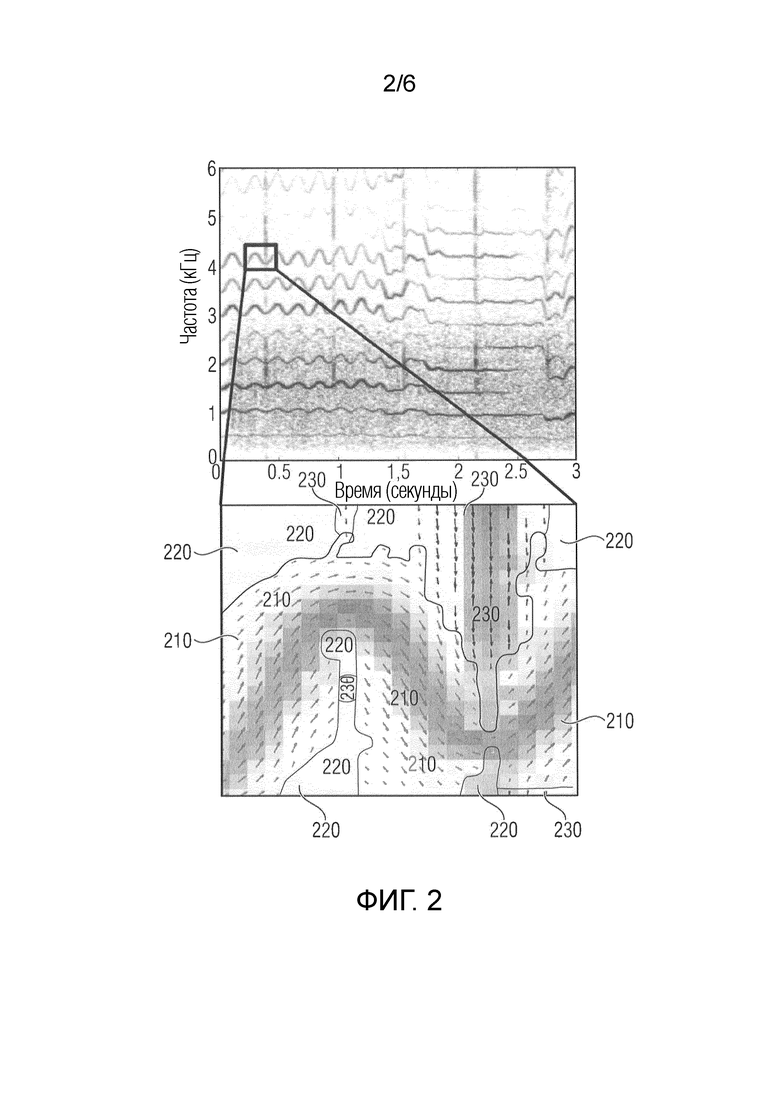
Фиг. 2 иллюстрирует спектрограмму смешения певческого голоса, кастаньет и аплодисментов с увеличенной по масштабу областью, согласно варианту осуществления, при этом ориентация стрелок указывает направление, и при этом длина стрелок указывает показатель анизотропии,
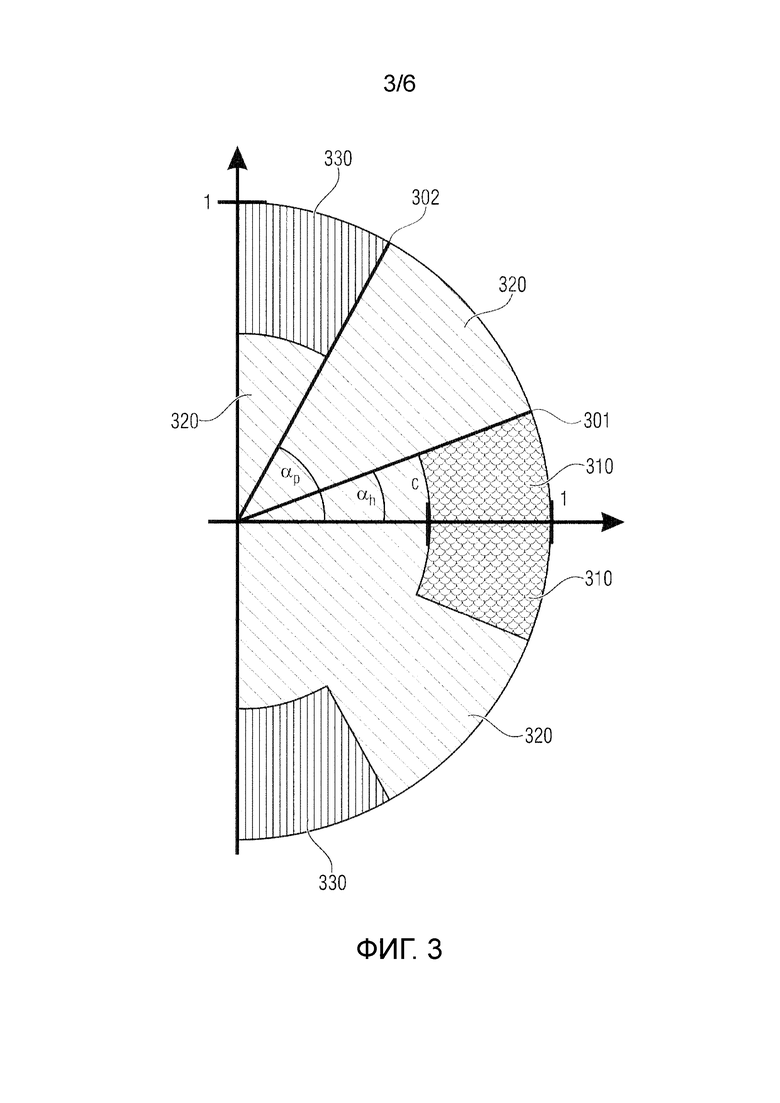
Фиг. 3 иллюстрирует диапазон значений ориентации/анизотропии, вычисленных посредством использования структурного тензора согласно варианту осуществления,
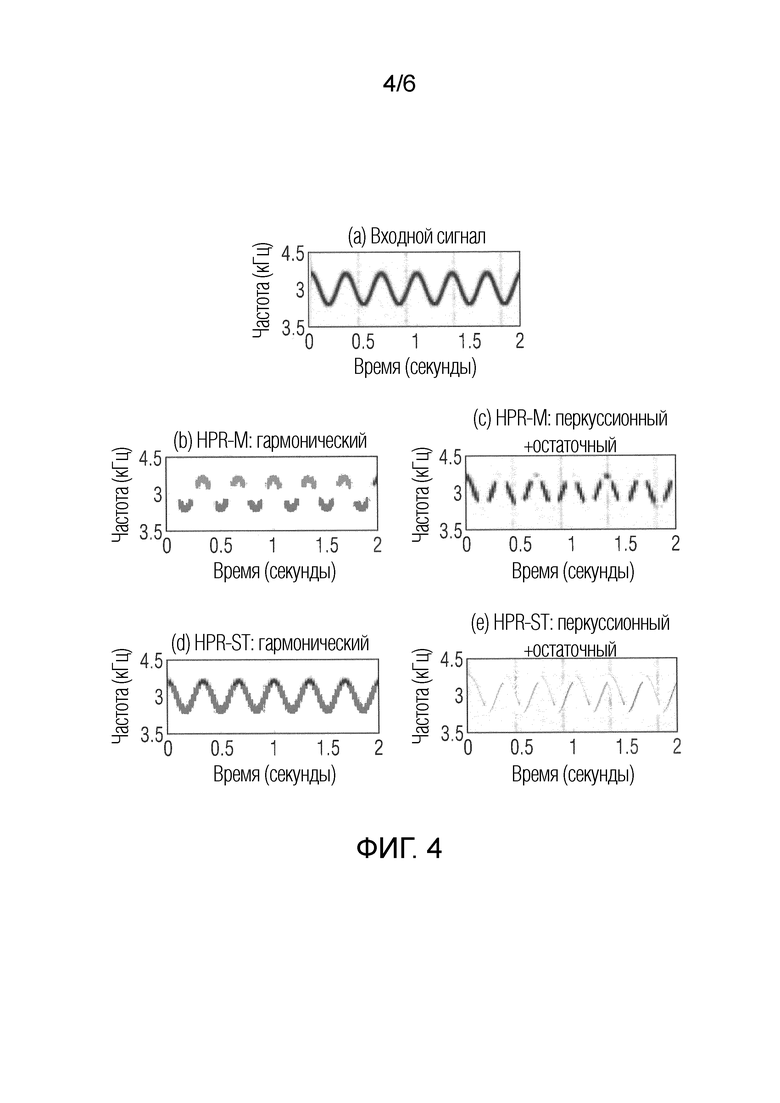
Фиг. 4 иллюстрирует сравнение между HPR-M- и HPR-ST-способом для отрывка синтетического входного сигнала,
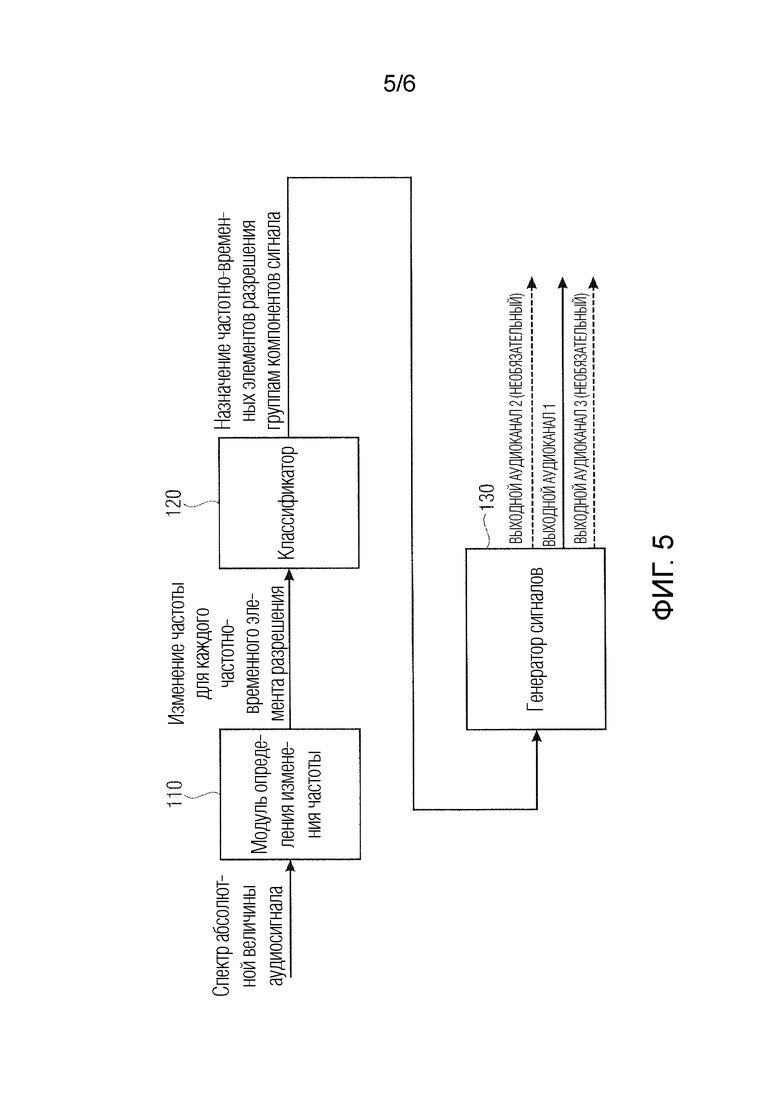
Фиг. 5 иллюстрирует устройство, согласно варианту осуществления, при этом устройство содержит генератор сигналов, и
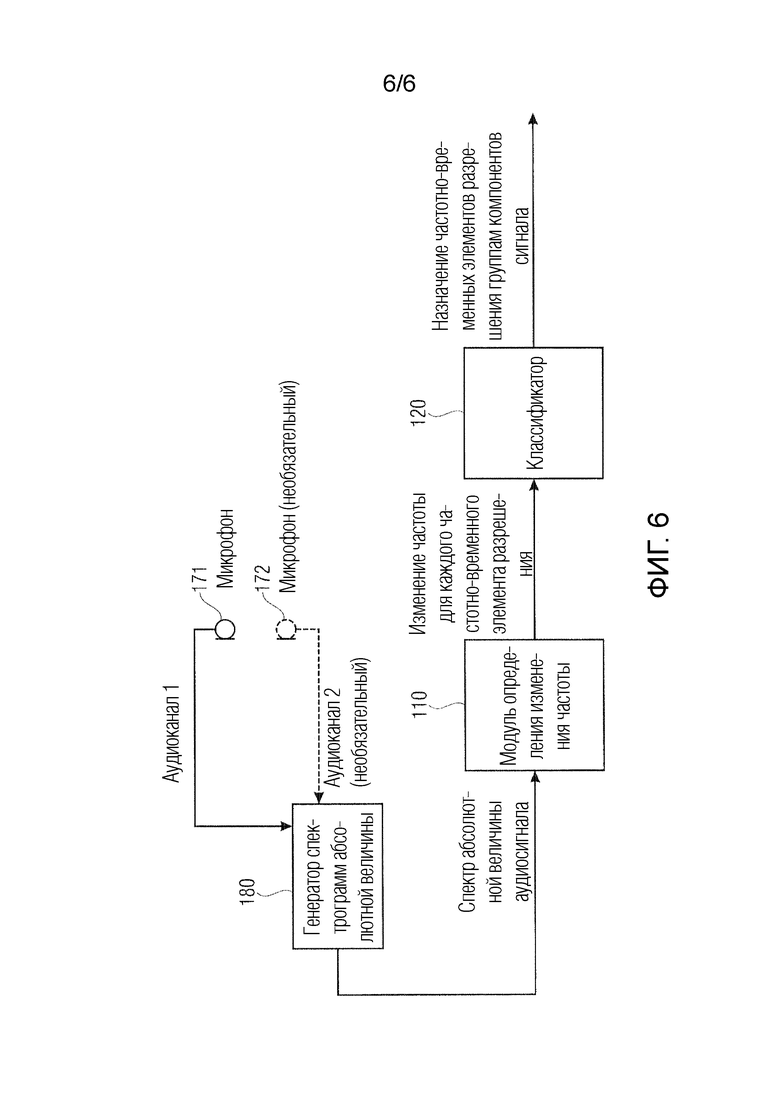
Фиг. 6 иллюстрирует устройство, согласно варианту осуществления, при этом устройство содержит один или более микрофонов для записи аудиосигнала.
Фиг. 1 иллюстрирует устройство для анализа спектрограммы уровня аудиосигнала согласно вариантам осуществления.
Устройство содержит модуль 110 определения изменения частоты. Модуль 110 определения изменения частоты выполнен с возможностью определять изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов спектрограммы уровня аудиосигнала в зависимости от спектрограммы уровня аудиосигнала.
Кроме того, устройство содержит классификатор 120. Классификатор 120 выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина.
Согласно варианту осуществления, модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от угла 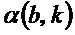 для упомянутого частотно-временного бина. Угол для упомянутого частотно-временного бина зависит от спектрограммы уровня аудиосигнала.
для упомянутого частотно-временного бина. Угол для упомянутого частотно-временного бина зависит от спектрограммы уровня аудиосигнала.
В варианте осуществления, модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов дополнительно в зависимости от частоты fs дискретизации аудиосигнала и в зависимости от длины N аналитической оконной функции, и в зависимости от размера H скачка аналитической оконной функции.
Согласно варианту осуществления, модуль 110 определения изменения частоты устройства выполнен с возможностью определять изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от формулы:
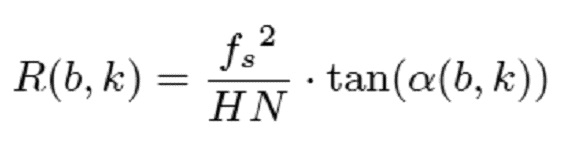
 указывает частотно-временной бин из множества частотно-временных бинов, при этом
указывает частотно-временной бин из множества частотно-временных бинов, при этом  указывает изменение частоты для упомянутого частотно-временного бина
указывает изменение частоты для упомянутого частотно-временного бина 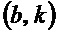 , при этом b указывает время, при этом k указывает частоту, при этом fs указывает частоту дискретизации аудиосигнала, при этом N указывает длину аналитической оконной функции, при этом H указывает размер скачка аналитической оконной функции, и при этом
, при этом b указывает время, при этом k указывает частоту, при этом fs указывает частоту дискретизации аудиосигнала, при этом N указывает длину аналитической оконной функции, при этом H указывает размер скачка аналитической оконной функции, и при этом 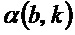 указывает угол для упомянутого частотно-временного бина , при этом угол зависит от спектрограммы уровня.
указывает угол для упомянутого частотно-временного бина , при этом угол зависит от спектрограммы уровня.
В варианте осуществления, модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять частную производную Sb спектрограммы S уровня аудиосигнала относительно временного индекса. В таком варианте осуществления, модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять частную производную Sk спектрограммы S уровня аудиосигнала относительно временного индекса.
Кроме того, в таком варианте осуществления модуль 110 определения изменения частоты выполнен с возможностью определять структурный тензор 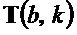 для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от частной производной Sb спектрограммы S уровня аудиосигнала относительно временного индекса и в зависимости от частной производной Sk спектрограммы S уровня аудиосигнала относительно частотного индекса.
для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от частной производной Sb спектрограммы S уровня аудиосигнала относительно временного индекса и в зависимости от частной производной Sk спектрограммы S уровня аудиосигнала относительно частотного индекса.
Кроме того, в таком варианте осуществления модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять угол для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от структурного тензора 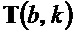 для упомянутого частотно-временного бина .
для упомянутого частотно-временного бина .
Согласно варианту осуществления, модуль 110 определения изменения частоты, например, может быть выполнен с возможностью определять угол для каждого частотно-временного бина из множества частотно-временных бинов посредством определения двух компонентов 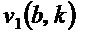 и
и 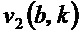 собственного вектора
собственного вектора 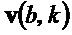 структурного тензора () упомянутого частотно-временного бина и посредством определения угла () для упомянутого частотно-временного бина
структурного тензора () упомянутого частотно-временного бина и посредством определения угла () для упомянутого частотно-временного бина 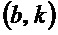 согласно следующему:
согласно следующему:
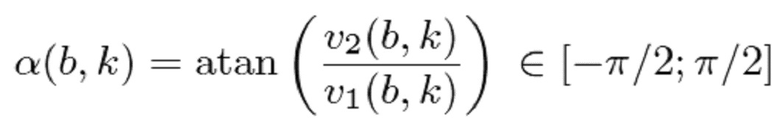 .
.
указывает угол для упомянутого частотно-временного бина , при этом b указывает время, при этом k указывает частоту, и при этом atan() указывает обратную функцию тангенса.
В варианте осуществления классификатор 120, например, может быть выполнен с возможностью определять показатель анизотропии для каждого частотно-временного бина из множества частотно-временных бинов в зависимости, по меньшей мере, от одной из формул:
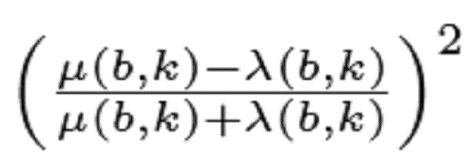
и
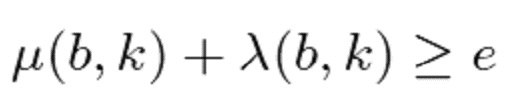 ,
,
 является первым собственным значением, λ
является первым собственным значением, λ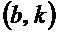 является вторым собственным значением структурного тензора (
является вторым собственным значением структурного тензора (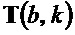 ) упомянутого частотно-временного бина , и
) упомянутого частотно-временного бина , и  .
.
В таком варианте осуществления классификатор 120, например, может быть выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала дополнительно в зависимости от изменения показателя анизотропии.
Согласно варианту осуществления классификатор 120, например, может быть выполнен с возможностью определять показатель анизотропии для упомянутого частотно-временного бина в зависимости от формулы:
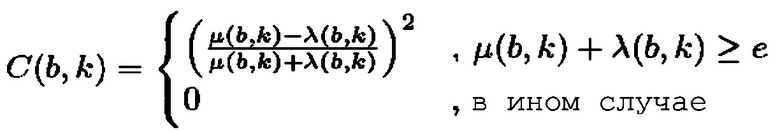
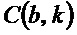 является показателем анизотропии в зависимости от упомянутого частотно-временного бина , и при этом классификатор 120 выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель анизотропии меньше первого порогового значения c, либо при этом классификатор 120 выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель анизотропии меньше или равен первому пороговому значению c, при этом
является показателем анизотропии в зависимости от упомянутого частотно-временного бина , и при этом классификатор 120 выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель анизотропии меньше первого порогового значения c, либо при этом классификатор 120 выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель анизотропии меньше или равен первому пороговому значению c, при этом  .
.
В варианте осуществления классификатор 120, например, может быть выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина , так что классификатор 120 назначает частотно-временной бин из множества частотно-временных бинов группе гармонических компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, меньше или нет абсолютное значение 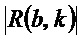 изменения частоты, определенного для упомянутого частотно-временного бина , второго порогового значения
изменения частоты, определенного для упомянутого частотно-временного бина , второго порогового значения 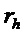 , либо в зависимости от того, меньше или равно либо нет абсолютное значение
, либо в зависимости от того, меньше или равно либо нет абсолютное значение 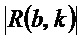 изменения частоты, определенного для упомянутого частотно-временного бина , второму пороговому значению
изменения частоты, определенного для упомянутого частотно-временного бина , второму пороговому значению 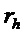 , при этом
, при этом  .
.
Согласно варианту осуществления классификатор 120, например, может быть выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина , так что классификатор 120 назначает частотно-временной бин из множества частотно-временных бинов группе перкуссионных компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, превышает или нет абсолютное значение изменения частоты, определенного для упомянутого частотно-временного бина , третье пороговое значение 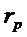 , либо в зависимости от того, превышает или равно либо нет абсолютное значение изменения () частоты, определенного для упомянутого частотно-временного бина
, либо в зависимости от того, превышает или равно либо нет абсолютное значение изменения () частоты, определенного для упомянутого частотно-временного бина 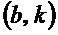 , третьему пороговому значению
, третьему пороговому значению 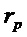 , при этом
, при этом 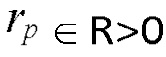 .
.
Далее предоставляется подробное описание вариантов осуществления.
Варианты осуществления предоставляют усовершенствованные принципы для гармонического/перкуссионного/остаточного разделения звука на основе структурного тензора. Некоторые варианты осуществления захватывают частотно-модулированные звуки, которые содержат тональную информацию в гармоническом компоненте, посредством использования информации относительно ориентации спектральных структур, предоставленной посредством структурного тензора.
Некоторые варианты осуществления основаны на таких выявленных сведениях, что строгая классификация на горизонтальные и вертикальные является неподходящей для этих сигналов и может приводить к утечке тональной информации в остаточный компонент. Варианты осуществления относятся к новому способу, который вместо этого использует структурный тензор, математическое инструментальное средство, для того чтобы вычислять преобладающие углы ориентации на спектрограмме уровня. Варианты осуществления используют эту информацию ориентации для того, чтобы отличать между гармоническими, перкуссионными и остаточными компонентами сигнала, даже в случае частотно-модулированных сигналов. В завершение, эффективность принципа вариантов осуществления верифицируется посредством как объективных показателей оценки, так и аудиопримеров.
Кроме того, некоторые варианты осуществления основаны на таких выявленных сведениях, что структурный тензор может считаться "черным ящиком", в котором ввод представляет собой полутоновое изображение, а выводы представляют собой углы n для каждого пиксела, соответствующего направлению наименьшего изменения и показателю достоверности или анизотропии для этого направления для каждого пиксела. Структурный тензор дополнительно предлагает возможность сглаживания, что уменьшает влияние шума для повышенной устойчивости. Кроме того показатель достоверности может использоваться для того, чтобы определять качество оцененных углов. Низкое значение этого показателя достоверности указывает то, что пиксел находится в области с постоянной яркостью без четкого направления.
Изменение локальной частоты, например, может извлекаться из углов, полученных посредством структурного тензора. Из этих углов можно определять то, принадлежит частотно-временной бин на спектрограмме гармоническому (=с низким изменением локальной частоты) или перкуссионному (=с высоким или бесконечным изменением локальной частоты) компоненту.
Предусмотрены улучшенные варианты осуществления для гармонической/перкуссионной/остаточной классификации и разделения.
Гармоническое/перкуссионное/остаточное разделение звука представляет собой полезное инструментальное средство предварительной обработки для таких вариантов применения, как переложение инструментов с несколькими основными тонами или извлечение ритма. Вместо выполнения поиска только строго горизонтальных и вертикальных структур, некоторые варианты осуществления определяют преобладающие углы ориентации, а также локальную анизотропию на спектрограмме посредством использования структурного тензора, известного из обработки изображений.
В вариантах осуществления предоставляемая информация относительно ориентации спектральных структур затем может использоваться для того, чтобы различать между гармоническими, перкуссионными и остаточными компонентами сигнала посредством задания соответствующих пороговых значений, см. фиг. 2.
Фиг. 2 иллюстрирует спектрограмму смешения певческого голоса, кастаньет и аплодисментов с увеличенной по масштабу областью, дополнительно показывающую направление (ориентация стрелок) и показатель анизотропии (длина стрелок), полученные посредством структурного тензора. Цвет стрелок указывает то, назначается соответствующий частотно-временной бин гармоническому компоненту (зоны 210) перкуссионному компоненту (зоны 230) или остаточному компоненту (зоны 220), на основе информации ориентации и анизотропии.
Все бины, имеющие ни высокую, ни низкую скорость изменения локальной частоты либо показатель достоверности, который указывает постоянную область, назначены таким образом, что они принадлежат остаточному компоненту. Пример для этого разделения спектрограммы можно видеть на фиг. 2. Варианты осуществления лучше работают для аудиосигналов, содержащих частотно-модулированные звуки, чем аналогичные способы, работающие на спектрограмме уровня.
Сначала описывается принцип структурного тензора, и этот общий принцип расширяется с возможностью применения в контексте аудиообработки.
В дальнейшем матрицы и векторы записываются в качестве полужирных букв для удобства обозначения. Кроме того, оператор (⋅) используется для того, чтобы индексировать конкретный элемент. В этом случае, матрица или вектор записывается в качестве неполужирной буквы, чтобы показывать ее скалярное использование.
Сначала описывается вычисление спектрограммы согласно вариантам осуществления. Аудиосигнал, например, может представлять собой (дискретный) входной аудиосигнал.
Структурный тензор может применяться к представлению в виде спектрограммы дискретного входного аудиосигнала 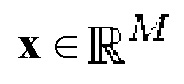 с частотой дискретизации в fs. Для спектрального анализа x, используется кратковременное преобразование Фурье (STFT):
с частотой дискретизации в fs. Для спектрального анализа x, используется кратковременное преобразование Фурье (STFT):
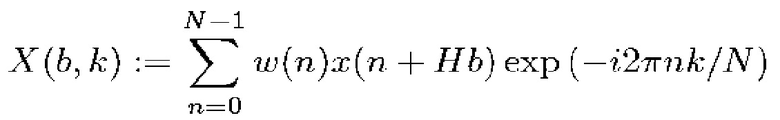 , (1)
, (1)
где X(b,k) ∈ C, b обозначает индекс кадра, k является частотным индексом, и w ∈ RN является оконной функцией длины N (другими словами: N является длиной аналитической оконной функции). H ∈ N, H ≤ N представляет размер скачка аналитической оконной функции. Следует отметить, что поскольку STFT-спектр имеет определенную симметрию вокруг точки Найквиста в 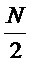 , обработка, например, может ограничиваться как 0 ≤ k ≤
, обработка, например, может ограничиваться как 0 ≤ k ≤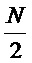 , поскольку симметрия может восстанавливаться в ходе обратного STFT.
, поскольку симметрия может восстанавливаться в ходе обратного STFT.
Посредством использования вышеприведенной формулы (1), может получаться спектрограмма. Спектрограмма содержит множество спектров, при этом множество спектров следуют друг за другом во времени. Второй спектр из множества спектров следует за первым спектром во времени, если существуют, по меньшей мере, несколько вторых выборок временной области, которые используются для того, чтобы формировать второй спектр, и которые не используются для того, чтобы формировать первый спектр, и которые представляют собой выборки временной области, которые ссылаются на последующий момент времени относительно вторых выборок временной области, которые используются для того, чтобы формировать первый спектр. Оконные функции выборок временной области, используемых для формирования граничащих по времени спектров, например, могут перекрываться.
В вариантах осуществления длина N аналитической оконной функции, например, может задаваться следующим образом:
256 выборок ≤ N ≤ 2048 выборок.
В некоторых вариантах осуществления длина аналитической оконной функции, например, может составлять 2048. В других вариантах осуществления длина аналитической оконной функции, например, может составлять 1024 выборок. В дополнительных вариантах осуществления длина аналитической оконной функции, например, может составлять 768 выборок. В еще дополнительных вариантах осуществления длина аналитической оконной функции, например, может составлять 256 выборок.
В вариантах осуществления размер H скачка при анализе, например, может составлять в диапазоне между 25% и 75% от аналитической оконной функции. В таких вариантах осуществления:
0,25 N ≤ H ≤ 0,75 Н.
Таким образом, в таких вариантах осуществления, если аналитическая оконная функция имеет, например, 2048 выборок (N=2048), размер скачка при анализе, например, может составлять в диапазоне:
512 выборок ≤ H ≤ 1536 выборок.
Если аналитическая оконная функция имеет, например, 256 выборок (N=256), размер скачка при анализе, например, может составлять в диапазоне:
64 выборки ≤ H ≤ 192 выборки.
В предпочтительных вариантах осуществления размер скачка при анализе, например, может составлять 50% от аналитической оконной функции. Это соответствует перекрытию оконных функций для двух последующих аналитических оконных функций в 50%.
В некоторых вариантах осуществления размер скачка при анализе, например, может составлять 25% от аналитической оконной функции. Это соответствует перекрытию оконных функций для двух последующих аналитических оконных функций в 75%.
В других вариантах осуществления размер скачка при анализе, например, может составлять 75% от аналитической оконной функции. Это соответствует перекрытию оконных функций для двух последующих аналитических оконных функций в 25%.
Следует отметить, что принципы настоящего изобретения являются применимыми для любого вида преобразования из временной области в спектральную область, к примеру, для MDCT (модифицированного дискретного косинусного преобразования), MDST (модифицированного дискретного синусного преобразования), DSTFT (дискретного кратковременного преобразования Фурье) и т.д.
Действительнозначная логарифмическая спектрограмма, например, может вычисляться следующим образом:
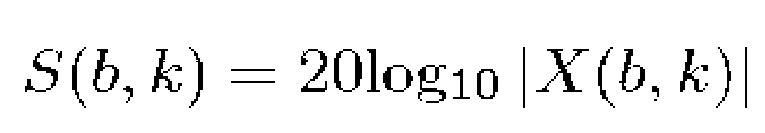 (2)
(2)
Спектрограмма уровня аудиосигнала может упоминаться как S, и значение спектрограммы уровня для частотно-временного бина 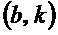 может упоминаться как
может упоминаться как 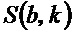 .
.
Далее описывается вычисление структурного тензора согласно вариантам осуществления.
Для вычисления структурного тензора необходимы частные производные S. Частная производная относительно временного индекса b задается следующим образом:
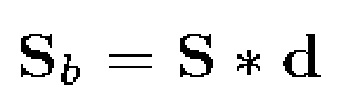 (3)
(3)
тогда как частная производная относительно частотного индекса k задается следующим образом:
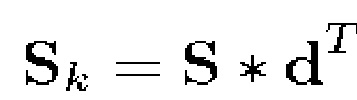 , (4)
, (4)
где d является дискретным оператором дифференцирования (например, для центральных разностей можно выбирать d=[-1,0,1]/2), и 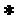 обозначает двумерную свертку.
обозначает двумерную свертку.
Кроме того, он может задаваться:
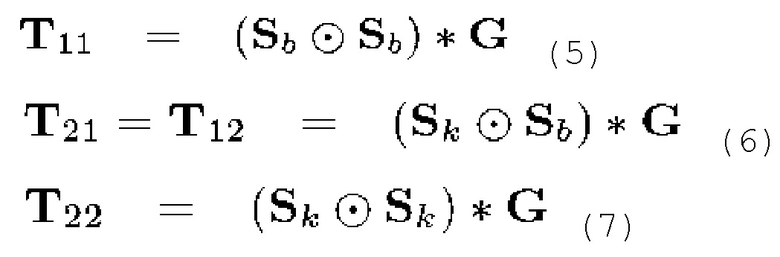
где  является поточечным матричным умножением, также известным как произведение Адамара, и G является двумерным сглаживающим гауссовым фильтром, имеющим среднеквадратическое отклонение
является поточечным матричным умножением, также известным как произведение Адамара, и G является двумерным сглаживающим гауссовым фильтром, имеющим среднеквадратическое отклонение 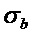 в направлении временного индекса и
в направлении временного индекса и 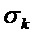 в направлении частотного индекса. Структурный тензор затем предоставляется посредством симметричной и положительной полуопределенной матрицы 2×2:
в направлении частотного индекса. Структурный тензор затем предоставляется посредством симметричной и положительной полуопределенной матрицы 2×2:
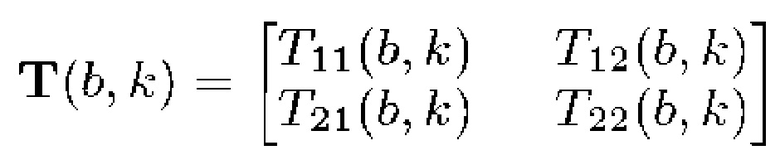 (8)
(8)
Структурный тензор содержит информацию относительно доминирующей ориентации спектрограммы в позиции 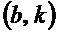 . Следует отметить, что в частном случае, в котором G является скаляром, не содержит больше информации, чем градиент в этой позиции на спектрограмме. Тем не менее, в отличие от градиента, структурный тензор может сглаживаться посредством G без эффектов подавления, что обеспечивает его большую устойчивость к шуму.
. Следует отметить, что в частном случае, в котором G является скаляром, не содержит больше информации, чем градиент в этой позиции на спектрограмме. Тем не менее, в отличие от градиента, структурный тензор может сглаживаться посредством G без эффектов подавления, что обеспечивает его большую устойчивость к шуму.
Следует отметить, что структурный тензор задается для каждого частотно-временного бина 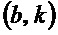 из множества частотно-временных бинов. Таким образом, когда рассматриваются множество частотно-временных бинов, например, частотно-временные бины
из множества частотно-временных бинов. Таким образом, когда рассматриваются множество частотно-временных бинов, например, частотно-временные бины 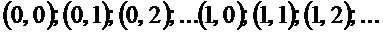 , то существуют множество структурных тензоров
, то существуют множество структурных тензоров 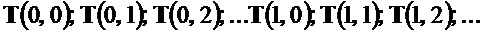 . Например, для каждого частотно-временного бина из множества частотно-временных бинов, определяется один структурный тензор .
. Например, для каждого частотно-временного бина из множества частотно-временных бинов, определяется один структурный тензор .
Далее описывается вычисление углов и показателя анизотропии согласно вариантам осуществления.
Информация относительно ориентации для каждого бина на спектрограмме получается посредством вычисления собственных значений 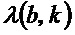 ,
, 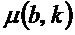 с
с  и соответствующих собственных векторов
и соответствующих собственных векторов 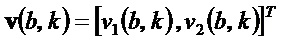 и
и 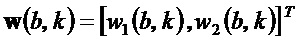 структурного тензора . Следует отметить, что
структурного тензора . Следует отметить, что 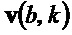 , собственный вектор, соответствующий меньшему собственному значению , указывает в направление наименьшего изменения спектрограммы при индексе
, собственный вектор, соответствующий меньшему собственному значению , указывает в направление наименьшего изменения спектрограммы при индексе 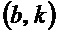 , тогда как
, тогда как 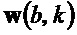 указывает в направлении наибольшего изменения. Таким образом, угол ориентации в конкретном бине может получаться следующим образом:
указывает в направлении наибольшего изменения. Таким образом, угол ориентации в конкретном бине может получаться следующим образом:
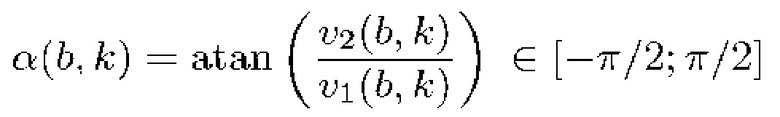 (9)
(9)
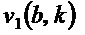 и являются компонентами собственного вектора
и являются компонентами собственного вектора 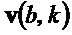 .
.
atan() указывает обратную функцию тангенса.
Помимо этого, показатель анизотропии:
(10)
при может определяться для каждого бина. Следует отметить, что 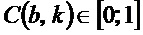 . Значения
. Значения 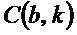 , близкие к 1, указывают высокую анизотропию спектрограммы при индексе , в то время как постоянное окружение приводит к значениям, близким к 0. Пороговое значение
, близкие к 1, указывают высокую анизотропию спектрограммы при индексе , в то время как постоянное окружение приводит к значениям, близким к 0. Пороговое значение 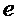 , которое задает предел для того, что должно считаться анизотропным, может выбираться, чтобы дополнительно увеличивать устойчивость к шуму.
, которое задает предел для того, что должно считаться анизотропным, может выбираться, чтобы дополнительно увеличивать устойчивость к шуму.
Физический смысл угла 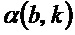 может пониматься посредством рассмотрения непрерывного сигнала с изменением мгновенной частоты
может пониматься посредством рассмотрения непрерывного сигнала с изменением мгновенной частоты 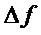 в течение временного интервала
в течение временного интервала 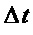 . Таким образом, скорость
. Таким образом, скорость 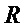 изменения мгновенной частоты обозначается посредством следующего:
изменения мгновенной частоты обозначается посредством следующего:
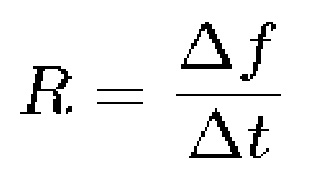 (11)
(11)
Например, согласно вариантам осуществления, углы (указываются посредством направления стрелок на фиг. 2), полученные посредством структурного тензора, например, могут транслироваться в скорость изменения локальной частоты:
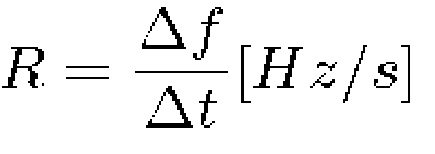 (11a)
(11a)
для каждого частотно-временного бина спектрограммы.
Изменение частоты для каждого частотно-временного бина, например, может упоминаться как скорость изменения мгновенной частоты.
При рассмотрении частоты дискретизации, длины и размера скачка применяемого STFT-анализа, отношение между углами на спектрограмме и скоростью изменения мгновенной частоты для каждого бина может извлекаться посредством следующего:
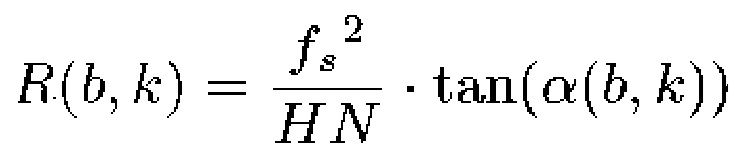 (12)
(12)
Также среднеквадратические отклонения сглаживающего фильтра G в дискретной области и  могут преобразовываться в непрерывные физические параметры
могут преобразовываться в непрерывные физические параметры  и
и 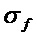 посредством следующего:
посредством следующего:
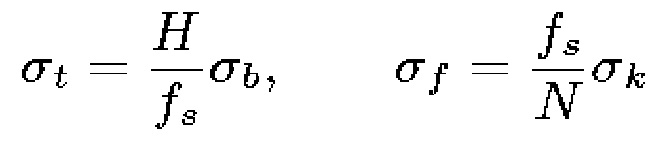 (13)
(13)
Далее описывается гармоническое/перкуссионное/остаточное разделение с использованием структурного тензора.
Информация, полученная через структурный тензор, может применяться к задаче HPR-разделения, например, чтобы классифицировать каждый бин на спектрограмме в качестве части гармонического, перкуссионного или остаточного компонента входного сигнала.
Варианты осуществления основаны на таких выявленных сведениях, что бины, назначаемые гармоническим компонентам, должны принадлежать достаточно горизонтальным структурам, тогда как бины, принадлежащие достаточно вертикальным структурам, должны назначаться перкуссионному компоненту. Кроме того, бины, которые не принадлежат ни одному виду ориентированной структуры, должны назначаться остаточному компоненту.
Согласно вариантам осуществления бин например, может назначаться гармоническому компоненту, если он удовлетворяет первому из следующих двух ограничений.
Согласно предпочтительным вариантам осуществления бин , например, может назначаться гармоническому компоненту, если он удовлетворяет обоим из следующих двух ограничений:
- Первое ограничение, например, может заключаться в том, что абсолютное значение угла меньше (или равно) порогового значения 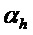 . Пороговое значение
. Пороговое значение 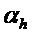 , например, может составлять в диапазоне
, например, может составлять в диапазоне 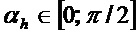 . Это означает то, что бин должен быть частью некоторой спектральной структуры, которая не имеет наклона, большего или меньшего
. Это означает то, что бин должен быть частью некоторой спектральной структуры, которая не имеет наклона, большего или меньшего 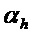 . Таким образом, частотно-модулированные звуки также могут рассматриваться в качестве части гармонического компонента, в зависимости от параметра
. Таким образом, частотно-модулированные звуки также могут рассматриваться в качестве части гармонического компонента, в зависимости от параметра 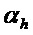 .
.
- Второе ограничение, например, может заключаться в том, что показатель 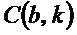 анизотропии поддерживает то, что бин является частью некоторой направленной анизотропной структуры и в силу этого превышает второе пороговое значение c. Следует отметить, что для данного бина , угол и показатель анизотропии вместе задают точку в R2, заданную в полярных координатах.
анизотропии поддерживает то, что бин является частью некоторой направленной анизотропной структуры и в силу этого превышает второе пороговое значение c. Следует отметить, что для данного бина , угол и показатель анизотропии вместе задают точку в R2, заданную в полярных координатах.
Аналогично, в вариантах осуществления другое пороговое значение 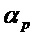 угла назначается, чтобы задавать то, когда бин должен назначаться перкуссионному компоненту (зоны 330 с вертикальными линиями на фиг. 3).
угла назначается, чтобы задавать то, когда бин должен назначаться перкуссионному компоненту (зоны 330 с вертикальными линиями на фиг. 3).
Таким образом, согласно вариантам осуществления бин , например, может назначаться перкуссионному компоненту, если он удовлетворяет первому из следующих двух ограничений.
Согласно предпочтительным вариантам осуществления бин , например, может назначаться перкуссионному компоненту, если он удовлетворяет обоим из следующих двух ограничений:
- Первое ограничение, например, может заключаться в том, что абсолютное значение угла превышает (или равно) пороговое значение 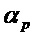 . Пороговое значение
. Пороговое значение 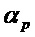 , например, может составлять в диапазоне
, например, может составлять в диапазоне 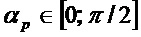 . Это означает то, что бин должен быть частью некоторой спектральной структуры, которая не имеет наклона, большего или меньшего
. Это означает то, что бин должен быть частью некоторой спектральной структуры, которая не имеет наклона, большего или меньшего 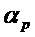 . Таким образом, частотно-модулированные звуки также могут рассматриваться в качестве части гармонического компонента, в зависимости от параметра
. Таким образом, частотно-модулированные звуки также могут рассматриваться в качестве части гармонического компонента, в зависимости от параметра 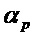 .
.
- Второе ограничение, например, может заключаться в том, что показатель анизотропии поддерживает то, что бин является частью некоторой направленной анизотропной структуры и в силу этого превышает второе пороговое значение c. Следует отметить, что для данного бина , угол и показатель анизотропии вместе задают точку в R2, заданную в полярных координатах.
В завершение, в вариантах осуществления все бины, которые не назначаются ни гармоническому, ни перкуссионному компоненту, например, могут назначаться остаточному компоненту.
Вышеописанный процесс назначения может выражаться посредством задания маски для гармонического компонента Mh, маски для перкуссионного компонента Mp и маски для остаточного компонента Mr.
Следует отметить, что вместо использования порогового значения 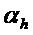 и порогового значения
и порогового значения 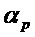 , пороговые значения в вариантах осуществления, например, могут задаваться для максимальной абсолютной скорости
, пороговые значения в вариантах осуществления, например, могут задаваться для максимальной абсолютной скорости 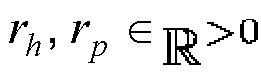 изменения частоты при
изменения частоты при 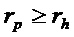 , чтобы обеспечивать для выбора параметров лучшую физическую интерпретацию. В таком случае маски задаются следующим образом:
, чтобы обеспечивать для выбора параметров лучшую физическую интерпретацию. В таком случае маски задаются следующим образом:
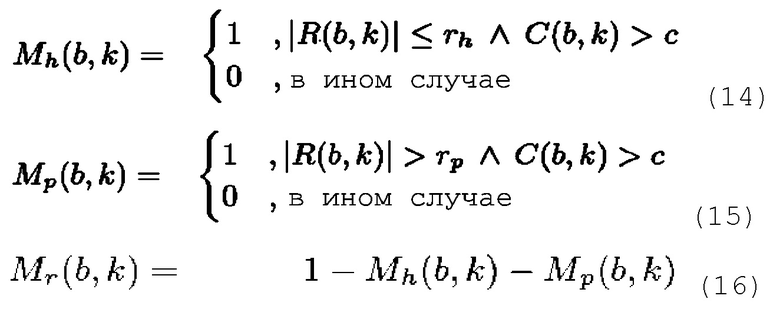
В завершение, STFT гармонического компонента Xh, перкуссионного компонента Xp и остаточного компонента Xr получается следующим образом:
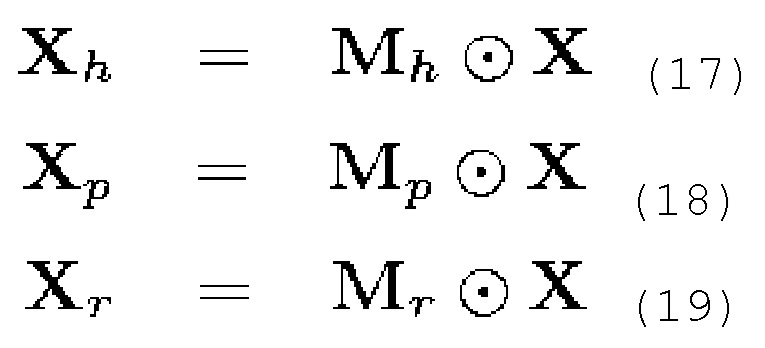
Соответствующие временные сигналы затем могут вычисляться через обратное STFT.
Фиг. 3 иллюстрирует диапазон значений ориентации/анизотропии, вычисленных посредством структурного тензора.
В частности, фиг. 3 иллюстрирует поднабор всех точек, которые приводят к назначению для гармонического компонента. В частности, значения в зонах 310 с волнистыми линиями приводят к назначению для гармонического компонента.
Значения в зонах 330 с вертикальными линиями приводят к назначению для перкуссионного компонента.
Значения в зонах 320, которые являются пунктирными, приводят к назначению для остаточного компонента.
Пороговое значение 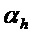 задает линию 301 на фиг. 3, а пороговое значение задает линию 302 на фиг. 3.
задает линию 301 на фиг. 3, а пороговое значение задает линию 302 на фиг. 3.
Фиг. 5 иллюстрирует устройство, согласно варианту осуществления при этом устройство содержит генератор 130 сигналов, выполненный с возможностью формировать выходной аудиосигнал в зависимости от назначения множества частотно-временных бинов двум или более групп компонентов сигнала.
Например, генератор сигналов может фильтровать различные компоненты аудиосигнала посредством применения различных весовых коэффициентов к значениям уровня частотно-временных бинов различных групп компонентов сигнала. Например, группа гармонических компонентов сигнала может иметь первый весовой коэффициент wh, группа перкуссионных компонентов сигнала может иметь второй весовой коэффициент wp, и группа остаточных компонентов сигнала может иметь первый весовой коэффициент wr, и значение уровня каждого частотно-временного бина из множества частотно-временных бинов, например, может взвешиваться с весовым коэффициентом группы компонентов сигнала, которой назначается частотно-временной бин.
Например, чтобы подчеркнуть гармонические компоненты сигнала, в варианте осуществления, в котором весовые коэффициенты умножаются на линейные значения уровня, например:
wh=1,3, wp=0,7, и wr=0,2
Например, чтобы подчеркнуть гармонические компоненты сигнала, в варианте осуществления, в котором весовые коэффициенты добавляются в логарифмические значения уровня, например:
wh=-0,35, wp=+0,26, и wr=-1,61
Например, чтобы подчеркнуть перкуссионные компоненты сигнала, в варианте осуществления, в котором весовые коэффициенты умножаются на линейные значения уровня, например:
wh=0,7, wp=1,3, и wr=0,2
Например, чтобы подчеркнуть перкуссионные компоненты сигнала, в варианте осуществления, в котором весовые коэффициенты добавляются в логарифмические значения уровня, например:
wh=-0,35, wp=+0,26, и wr=-1,61
Таким образом, генератор 130 сигналов выполнен с возможностью применять весовой коэффициент к значению уровня каждого частотно-временного бина из множества частотно-временных бинов, чтобы получать выходной аудиосигнал, при этом весовой коэффициент, который применяется к упомянутому частотно-временному бину, зависит от группы компонентов сигнала, которой назначается упомянутый частотно-временной бин.
В конкретном варианте осуществления по фиг. 5 процессор 130 сигналов, например, может представлять собой повышающий микшер, выполненный с возможностью микшировать с увеличением количества каналов аудиосигнал, чтобы получать выходной аудиосигнал, содержащий два или более выходных аудиоканалов. Повышающий микшер, например, может быть выполнен с возможностью формировать два или более выходных аудиоканалов в зависимости от назначения множества частотно-временных бинов двум или более групп компонентов сигнала.
Например, два или более выходных аудиоканалов могут формироваться из аудиосигнала, фильтрующего различные компоненты аудиосигнала посредством применения различных весовых коэффициентов к частотно-временным бинам значений уровня различных групп компонентов сигнала, как описано выше.
Тем не менее, для того чтобы формировать различные аудиоканалы, могут использоваться различные веса для групп компонентов сигнала, которые, например, могут быть конкретными для каждого из различных выходных аудиоканалов.
Например, для первого выходного аудиоканала, веса, которые должны добавляться в логарифмические значения уровня, например, могут составлять:
w1h=+0,26, w1p=-0,35, и w1r=-1,61.
Кроме того, для второго выходного аудиоканала, веса, которые должны добавляться в логарифмические значения уровня, например, могут составлять:
w2h=+0,35, w2p=-0,26, и w2r=-1,61.
Например, при повышающем микшировании аудиосигнала, чтобы получать пять выходных аудиоканалов, передний левый, центральный, правый, левый объемного звучания и правый объемного звучания:
- Гармонический весовой коэффициент w1h может быть больше для формирования левого, центрального и правого выходных аудиоканалов по сравнению с гармоническим весовым коэффициентом w2h для формирования левого и правого выходных аудиоканалов объемного звучания.
- Перкуссионный весовой коэффициент w1p может быть меньшим для формирования левого, центрального и правого выходных аудиоканалов по сравнению с перкуссионным весовым коэффициентом w2p для формирования левого и правого выходных аудиоканалов объемного звучания.
Отдельные весовые коэффициенты могут использоваться для каждого выходного аудиоканала, который должен формироваться.
Фиг. 6 иллюстрирует устройство согласно варианту осуществления, при этом устройство содержит один или более микрофонов 171, 172 для записи аудиосигнала.
На фиг. 6, первый микрофон 171 записывает первый аудиоканал аудиосигнала. Необязательный второй микрофон 172 записывает необязательный второй аудиоканал аудиосигнала.
Кроме того, устройство по фиг. 6 дополнительно содержит генератор 180 спектрограмм уровня для формирования спектрограммы уровня аудиосигнала из аудиосигнала, который содержит первый аудиоканал и необязательно содержит необязательный второй аудиоканал. Формирование спектрограммы уровня из аудиосигнала является известным принципом для специалистов в данной области техники.
Далее рассматривается оценка вариантов осуществления.
Чтобы показывать эффективность вариантов осуществления в захвате частотно-модулированных звуков в гармоническом компоненте, HPR-способ на основе структурного тензора (HPR-ST) согласно вариантам осуществления сравнивается с неитеративным способом на основе медианной фильтрации, представленным в [10] (HPR-M). Дополнительно, показатели также вычисляются для результатов разделения с идеальными двоичными масками (IBM), которые служат в качестве опорного уровня для максимального достижимого качества разделения.
При рассмотрении параметров тестируемой системы для HPR-ST, а также для HPR-M, STFT-параметры выбраны как составляющие fs=22050 Гц, N=1024 и H=256, с использованием синусоидальной оконной функции для w. Параметры разделения для HPR-M выбраны аналогично экспериментам, выполняемым в [10]. Согласно вариантам осуществления структурный тензор вычисляется с использованием дифференциального оператора, например, оператора Шарра [17] в качестве дискретного оператора d дифференцирования. Сглаживание выполнено с использованием изотропного гауссова фильтра 9×9 со среднеквадратическими отклонениями 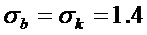 , который приводит к
, который приводит к 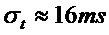 и
и 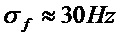 . В завершение, пороговые значения для разделения заданы равными
. В завершение, пороговые значения для разделения заданы равными 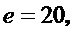
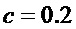 и
и 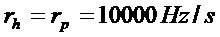 .
.
Следует отметить, что посредством выбора 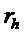 и
и 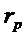 согласно вариантам осуществления, даже очень крутые структуры на спектрограмме назначаются гармоническому компоненту. Варианты осуществления используют наблюдения относительно звуков вибрато реального мира, как, например, показано на фиг. 2. Здесь, можно видеть, что в некоторых случаях вибрато певческим голосом имеет очень высокую скорость изменения мгновенной частоты. Кроме того, следует отметить, что посредством выбора
согласно вариантам осуществления, даже очень крутые структуры на спектрограмме назначаются гармоническому компоненту. Варианты осуществления используют наблюдения относительно звуков вибрато реального мира, как, например, показано на фиг. 2. Здесь, можно видеть, что в некоторых случаях вибрато певческим голосом имеет очень высокую скорость изменения мгновенной частоты. Кроме того, следует отметить, что посредством выбора 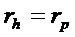 , назначение бина на спектрограмме остаточному компоненту зависит чисто от его показателя анизотропии.
, назначение бина на спектрограмме остаточному компоненту зависит чисто от его показателя анизотропии.
Эффективность HPR-ST согласно вариантам осуществления оценена посредством сравнения его со способом на основе медианной фильтрации предшествующего уровня техники (HPR-M), представленным в [10], посредством как объективных показателей оценки, так и аудиопримеров.
Чтобы сравнивать поведение HPR-ST согласно вариантам осуществления и HPR-M предшествующего уровня техники при применении к сигналам, содержащим частотно-модулированные звуки, чтобы получать объективные результаты, сформированы два тестовых элемента.
Тестовый элемент 1 состоит из наложения чисто синтетических звуков. Гармонический источник выбран в качестве тона вибрато с основной частотой в 1000 Гц, частотой вибрато в 3 Гц, охватом вибрато в 50 Гц и 4 обертонами. Для перкуссионного источника, используются несколько импульсов, в то время как белый шум представляет ни гармонический, ни перкуссионный остаточный источник.
Тестовый элемент 2 сформирован посредством наложения сигналов реального мира певческого голоса с вибрато (гармоническим компонентом), кастаньетами (перкуссионным компонентом) и аплодисментами (ни гармоническим, ни перкуссионным компонентом).
При интерпретации HPR-разделения этих элементов в качестве задачи разделения источников, вычислены стандартные показатели оценки разделения источников (отношение "сигнал источника-искажения" (SDR), отношение "сигнал источника-помехи" (SIR) и отношение "сигнал источника-артефакты" (SAR), как представлено в [18]) для результатов разделения обеих процедур. Результаты показаны в табл. 1.
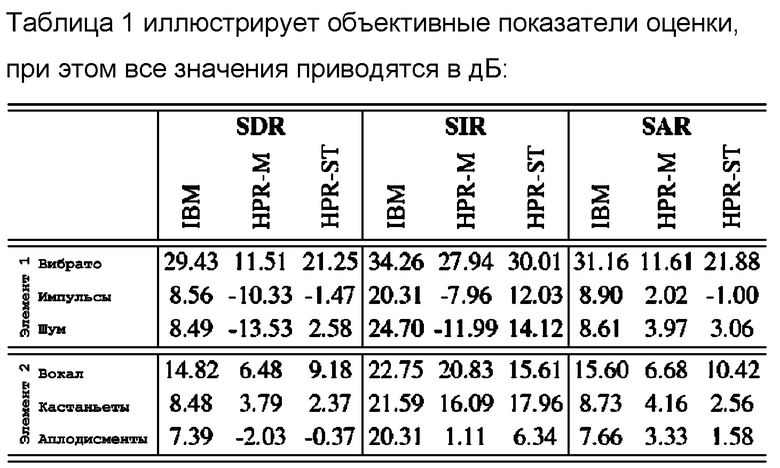
Для элемента 1, HPR-ST дает в результате SDR в 21,25 дБ для тона вибрато и в силу этого находится ближе к оптимальному результату разделения IBM (29,43 дБ), чем к результату разделения HPR-M (11,51 дБ). Это указывает то, что HPR-ST улучшается при захвате этого частотно-модулированного звука в гармоническом компоненте по сравнению с HPRM. Это также показано на фиг. 4.
Фиг. 4 иллюстрирует сравнение между HPR-M- и HPR-ST-способом для выдержки синтетического входного сигнала (элемент 1). Для улучшенной видимости, спектрограммы вычислены с отличающимися STFT-параметрами по сравнению с параметрами, используемыми для алгоритмов разделения.
Фиг. 4(a) иллюстрирует частоту входного сигнала относительно времени. На фиг. 4, проиллюстрированы спектрограммы гармонических компонентов и суммы перкуссионного и остаточного компонента, вычисленных для обеих процедур. Можно видеть, что для HPR-M, крутые наклоны тона вибрато просачиваются в остаточный компонент (фиг. 4(b) и (c)), в то время как HPR-ST (фиг. 4(d) и (e)) дает в результате хорошее разделение. Он также поясняет очень низкие SIR-значения HPRM для остаточного компонента по сравнению с HPR-ST (-11,99 дБ по сравнению с 14,12 дБ).
Следует отметить, что высокое SIR-значение HPR-M для гармонического компонента отражает только то, что имеется небольшое количество мешающих звуков от других компонентов, а не то, что звук вибрато хорошо захвачен в целом. В общем, большинство наблюдений для элемента 1 являются менее выраженными, но также и допустимыми для смешения звуков реального мира в элементе 2. Для этого элемента, SIR-значение HPR-M для вокалов даже превышает SIR-значение HPR-ST (20,83 дБ по сравнению с 15,61 дБ). С другой стороны, низкое SIR-значение для аплодисментов поддерживает то, что части вибрато в вокалах просачиваются в остаточный компонент для HPR-M (1,11 дБ), в то время как остаточный компонент HPR-ST содержит меньшее количество мешающих звуков (6,34 дБ). Это указывает то, что варианты осуществления допускают захват частотно-модулированных структур вокалов гораздо лучше, чем HPR-M.
Если обобщить результаты, для сигналов, которые содержат частотно-модулированные тона, HPR-ST-принцип вариантов осуществления предоставляет гораздо лучшие результаты разделения по сравнению с HPR-M.
Некоторые варианты осуществления используют структурный тензор для обнаружения певческого голоса (обнаружение певческого голоса согласно предшествующему уровню техники описывается в [2]).
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления один или более наиболее важных этапов способа могут выполняться посредством этого устройства.
В зависимости от определенных требований к реализации варианты осуществления изобретения могут реализовываться в аппаратных средствах либо в программном обеспечении, либо, по меньшей мере, частично в аппаратных средствах, либо, по меньшей мере, частично в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой запоминающий носитель может быть компьютерно-читаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой запоминающий носитель (цифровой запоминающий носитель или компьютерно-читаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными типично является материальным и/или некратковременным.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Устройство, описанное в данном документе, может реализовываться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] Aggelos Gkiokas, Vassilios Katsouros, George Carayannis и Themos Stafylakis, "Music tempo estimation and beat tracking by applying source separation and metrical relations", in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2012 год, стр. 421-424.
[2] Bernhard Lehner, Gerhard Widmer и Reinhard Sonnleitner, "On the reduction of false positives in singing voice detection", in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014 год, стр. 7480-7484.
[3] Yushi Ueda, Yuuki Uchiyama, Takuya Nishimoto, Nobutaka Ono и Shigeki Sagayama, "HMM-based approach for automatic chord detection using refined acoustic features", in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, Texas, USA, 2010 год, стр. 5518-5521.
[4] Nobutaka Ono, Kenichi Miyamoto, Hirokazu Kameoka и Shigeki Sagayama, "A real-time equalizer of harmonic and percussive components in music signals", in Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Philadelphia, Pennsylvania, USA, 2008 год, стр. 139-144.
[5] Nobutaka Ono, Kenichi Miyamoto, Jonathan LeRoux, Hirokazu Kameoka и Shigeki Sagayama, "Separation of the monaural audio signal into harmonic/percussive components by complementary diffusion on spectrogram", in European Signal Processing Conference, Lausanne, Switzerland, 2008 год, стр. 240-244.
[6] Derry Fitzgerald, "Harmonic/percussive separation using median filtering", in Proceedings of the International Conference on Digital Audio Effects (DAFX), Graz, Austria, 2010 год, стр. 246-253.
[7] Scott N. Levine и Julius O. Smith III, "A sines+transients+noise audio representation for data compression and time/pitch scale modications", in Proceedings of the AES Convention, 1998 год.
[8] Tony S. Verma и Teresa H.Y. Meng, "An analysis/synthesis tool for transient signals that allows the flexible sines+transients+noise model for audio", in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seattle, Washington, USA, май 1998 года, стр. 3573-3576.
[9] Laurent Daudet, "Sparse and structured decompositions of signals with the molecular matching pursuit", IEEE Transactions on Audio, Speech and Language Processing, издание 14, номер 5, стр. 1808-1816, сентябрь 2006 года.
[10] Jonathan Driedger, Meinard Müller и Sascha Disch, "Extending harmonic-percussive separation of audio signals", in Proceedings of the International Conference on Music Information Retrieval (ISMIR), Taipei, Taiwan, 2014 год, стр. 611-616.
[11] Jeongsoo Park и Kyogu Lee, "Harmonic-percussive source separation using harmonicity and sparsity constraints", in Proceedings of the International Conference on Music Information Retrieval (ISMIR), Málaga, Spain, 2015 год, стр. 148-154.
[12] Josef Bigun и Gösta H. Granlund, "Optimal orientation detection of linear symmetry", in Proceedings of the IEEE First International Conference on Computer Vision, London, UK, 1987 год, стр. 433-438.
[13] Hans Knutsson, "Representing local structure using tensors", in 6th Scandinavian Conference on Image Analysis, Oulu, Finland, 1989 год, стр. 244-251.
[14] Chris Harris и Mike Stephens, "A combined corner and edge detector", in Proceedings of the 4th Alvey Vision Conference, Manchester, UK, 1988 год, стр. 147-151.
[15] Rolf Bardeli, "Similarity search in animal sound databases", IEEE Transactions on Multimedia, издание 11, номер 1, стр. 68-76, январь 2009 года.
[16] Matthias Zeppelzauer, Angela S. Stöger и Christian Breiteneder, "Acoustic detection of elephant presence in noisy environments", in Proceedings of the 2nd ACM International Workshop on Multimedia Analysis for Ecological Data, Barcelona, Spain, 2013 год, стр. 3-8.
[17] Hanno Scharr, "Optimale Operatoren in der digitalen Bildverarbeitung", Dissertation, IWR, Fakultät für Physik und Astronomie, Universität Heidelberg, Heidelberg, Germany, 2000 год.
[18] Emmanuel Vincent, Rémi Gribonval и Cédric Févotte, "Performance measurement in blind audio source separation", IEEE Transactions on Audio, Speech and Language Processing, издание 14, номер 4, стр. 1462-1469, 2006 год.
Заявленное устройство относится к устройству для анализа спектрограммы уровня аудиосигнала. Устройство содержит модуль определения изменения частоты, выполненный с возможностью определять изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов спектрограммы уровня аудиосигнала в зависимости от спектрограммы уровня аудиосигнала. Кроме того, устройство содержит классификатор, выполненный с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина. Устройство обеспечивает усовершенствованные принципы обработки аудиосигнала. 3 н. и 14 з.п. ф-лы, 6 ил.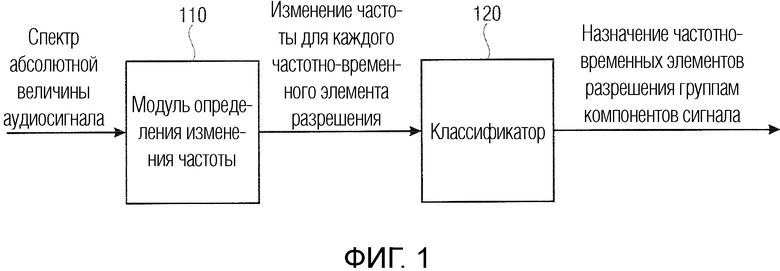
1. Устройство для анализа амплитудной спектрограммы аудиосигнала, содержащее:
- модуль (110) определения изменения частоты, выполненный с возможностью определения изменения частоты для каждого частотно-временного бина из множества частотно-временных бинов амплитудной спектрограммы аудиосигнала в зависимости от амплитудной спектрограммы аудиосигнала, и
- классификатор (120), выполненный с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина.
2. Устройство по п. 1,
- в котором модуль (110) определения изменения частоты выполнен с возможностью определения изменения частоты для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от угла (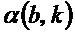 ) для упомянутого частотно-временного бина, при этом угол () для упомянутого частотно-временного бина зависит от амплитудной спектрограммы аудиосигнала.
) для упомянутого частотно-временного бина, при этом угол () для упомянутого частотно-временного бина зависит от амплитудной спектрограммы аудиосигнала.
3. Устройство по п. 2,
- в котором модуль (110) определения изменения частоты выполнен с возможностью определения изменения частоты для каждого частотно-временного бина из множества частотно-временных бинов дополнительно в зависимости от частоты (fs) дискретизации аудиосигнала, и в зависимости от длины (N) аналитической оконной функции, и в зависимости от размера (H) скачка аналитической оконной функции.
4. Устройство по п. 3,
- в котором модуль (110) определения изменения частоты устройства выполнен с возможностью определения изменения частоты для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от формулы:
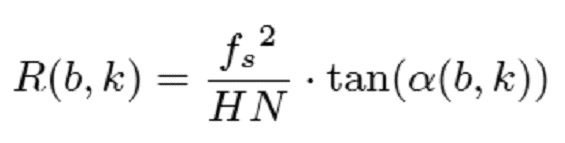
- при этом 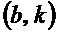 указывает частотно-временной бин из множества частотно-временных бинов,
указывает частотно-временной бин из множества частотно-временных бинов,
- при этом 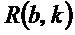 указывает изменение частоты для упомянутого частотно-временного бина ,
указывает изменение частоты для упомянутого частотно-временного бина ,
- при этом b указывает время,
- при этом k указывает частоту,
- при этом fs указывает частоту дискретизации аудиосигнала,
- при этом N указывает длину аналитической оконной функции,
- при этом H указывает размер скачка аналитической оконной функции, и
- при этом 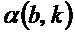 указывает угол для упомянутого частотно-временного бина
указывает угол для упомянутого частотно-временного бина 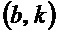 , при этом угол зависит от амплитудной спектрограммы.
, при этом угол зависит от амплитудной спектрограммы.
5. Устройство по п. 2,
- в котором модуль (110) определения изменения частоты выполнен с возможностью определения частной производной (Sb) амплитудной спектрограммы (S) аудиосигнала относительно временного индекса,
- при этом модуль (110) определения изменения частоты выполнен с возможностью определения частной производной (Sk) амплитудной спектрограммы (S) аудиосигнала относительно временного индекса, и
- при этом модуль (110) определения изменения частоты выполнен с возможностью определения структурного тензора (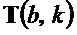 ) для каждого частотно-временного бина
) для каждого частотно-временного бина 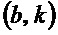 из множества частотно-временных бинов в зависимости от частной производной (Sb) амплитудной спектрограммы (S) аудиосигнала относительно временного индекса и в зависимости от частной производной (Sk) амплитудной спектрограммы (S) аудиосигнала относительно частотного индекса, и
из множества частотно-временных бинов в зависимости от частной производной (Sb) амплитудной спектрограммы (S) аудиосигнала относительно временного индекса и в зависимости от частной производной (Sk) амплитудной спектрограммы (S) аудиосигнала относительно частотного индекса, и
- при этом модуль (110) определения изменения частоты выполнен с возможностью определения угла () для каждого частотно-временного бина из множества частотно-временных бинов в зависимости от структурного тензора (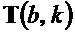 ) для упомянутого частотно-временного бина .
) для упомянутого частотно-временного бина .
6. Устройство по п. 5,
- в котором модуль (110) определения изменения частоты выполнен с возможностью определения угла () для каждого частотно-временного бина из множества частотно-временных бинов посредством определения двух компонентов 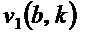 и
и 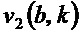 собственного вектора
собственного вектора 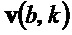 структурного тензора () упомянутого частотно-временного бина и посредством определения угла () для упомянутого частотно-временного бина согласно следующему:
структурного тензора () упомянутого частотно-временного бина и посредством определения угла () для упомянутого частотно-временного бина согласно следующему:
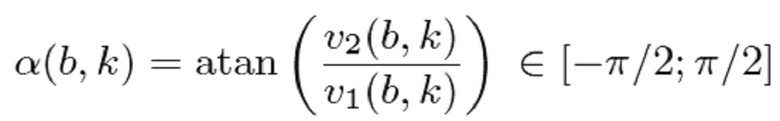
- при этом указывает угол для упомянутого частотно-временного бина ,
- при этом b указывает время,
- при этом k указывает частоту, и
- при этом atan() указывает обратную функцию тангенса.
7. Устройство по п. 5,
- в котором классификатор (120) выполнен с возможностью определения показателя анизотропии для каждого частотно-временного бина 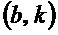 из множества частотно-временных бинов в зависимости, по меньшей мере, от одной из формул:
из множества частотно-временных бинов в зависимости, по меньшей мере, от одной из формул:
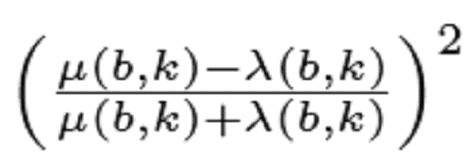
и
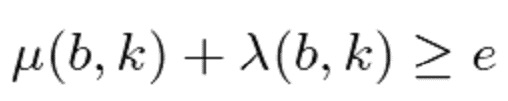 ,
,
- при этом 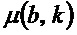 является первым собственным значением, λ
является первым собственным значением, λ является вторым собственным значением структурного тензора (
является вторым собственным значением структурного тензора (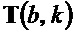 ) упомянутого частотно-временного бина , и
) упомянутого частотно-временного бина , и  ,
,
- при этом классификатор (120) выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала дополнительно в зависимости от изменения показателя анизотропии.
8. Устройство по п. 7,
- в котором классификатор (120) выполнен с возможностью определять показатель анизотропии для упомянутого частотно-временного бина в зависимости от формулы:
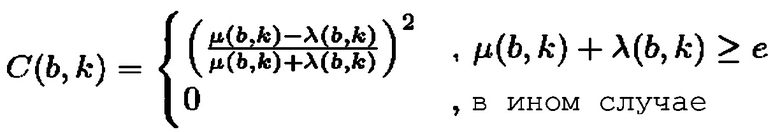
- при этом 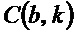 является показателем анизотропии в зависимости от упомянутого частотно-временного бина
является показателем анизотропии в зависимости от упомянутого частотно-временного бина 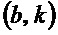 , и
, и
- при этом классификатор (120) выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель () анизотропии меньше первого порогового значения c, либо при этом классификатор (120) выполнен с возможностью назначать упомянутый частотно-временной бин группе остаточных компонентов из двух или более групп компонентов сигнала, если показатель () анизотропии меньше или равен первому пороговому значению c,
- при этом  .
.
9. Устройство по п. 1, в котором классификатор (120) выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения () частоты, определенного для упомянутого частотно-временного бина 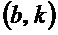 , так что классификатор (120) назначает частотно-временной бин из множества частотно-временных бинов группе гармонических компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, меньше или нет абсолютное значение (
, так что классификатор (120) назначает частотно-временной бин из множества частотно-временных бинов группе гармонических компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, меньше или нет абсолютное значение (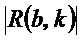 ) изменения () частоты, определенного для упомянутого частотно-временного бина
) изменения () частоты, определенного для упомянутого частотно-временного бина 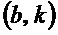 , второго порогового значения
, второго порогового значения 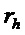 , либо в зависимости от того, меньше или равно либо нет абсолютное значение (
, либо в зависимости от того, меньше или равно либо нет абсолютное значение (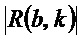 ) изменения () частоты, определенного для упомянутого частотно-временного бина , второму пороговому значению
) изменения () частоты, определенного для упомянутого частотно-временного бина , второму пороговому значению 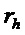 ,
,
- при этом  .
.
10. Устройство по п. 1, в котором классификатор (120) выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения () частоты, определенного для упомянутого частотно-временного бина , так что классификатор (120) назначает частотно-временной бин из множества частотно-временных бинов группе перкуссионных компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, превышает или нет абсолютное значение () изменения () частоты, определенного для упомянутого частотно-временного бина , третье пороговое значение 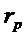 , либо в зависимости от того, превышает или равно либо нет абсолютное значение () изменения () частоты, определенного для упомянутого частотно-временного бина , третьему пороговому значению
, либо в зависимости от того, превышает или равно либо нет абсолютное значение () изменения () частоты, определенного для упомянутого частотно-временного бина , третьему пороговому значению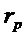 ,
,
- при этом 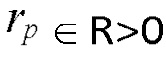 .
.
11. Устройство по п. 9, в котором классификатор (120) выполнен с возможностью назначать каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения () частоты, определенного для упомянутого частотно-временного бина , так что классификатор (120) назначает частотно-временной бин из множества частотно-временных бинов группе перкуссионных компонентов сигнала из двух или более групп компонентов сигнала в зависимости от того, превышает или нет абсолютное значение () изменения () частоты, определенного для упомянутого частотно-временного бина , третье пороговое значение , либо в зависимости от того, превышает или равно либо нет абсолютное значение () изменения () частоты, определенного для упомянутого частотно-временного бина , третьему пороговому значению,
- при этом .
12. Устройство по п. 1, при этом устройство содержит генератор (130) сигналов, выполненный с возможностью формировать выходной аудиосигнал в зависимости от назначения множества частотно-временных бинов двум или более группам компонентов сигнала.
13. Устройство по п. 12, в котором генератор (130) сигналов выполнен с возможностью применять весовой коэффициент к значению (wh, wp, wr) амплитуды каждого частотно-временного бина из множества частотно-временных бинов, чтобы получать выходной аудиосигнал, при этом весовой коэффициент (wh, wp, wr), который применяется к упомянутому частотно-временному бину, зависит от группы компонентов сигнала, которой назначается упомянутый частотно-временной бин.
14. Устройство по п. 12,
- в котором процессор сигналов (130) представляет собой повышающий микшер, выполненный с возможностью повышающего микширования аудиосигнала, чтобы получать выходной аудиосигнал, содержащий два или более выходных аудиоканала,
- при этом повышающий микшер выполнен с возможностью формировать два или более выходных аудиоканала в зависимости от назначения множества частотно-временных бинов двум или более группам компонентов сигнала.
15. Устройство по п. 1,
- при этом устройство содержит один или более микрофонов (171, 172) для записи аудиосигнала, и
- при этом устройство дополнительно содержит генератор (180) амплитудных спектрограмм для формирования амплитудной спектрограммы аудиосигнала из аудиосигнала.
16. Способ для анализа амплитудной спектрограммы аудиосигнала, содержащий этапы, на которых:
- определяют изменение частоты для каждого частотно-временного бина из множества частотно-временных бинов амплитудной спектрограммы аудиосигнала в зависимости от амплитудной спектрограммы аудиосигнала, и
- назначают каждый частотно-временной бин из множества частотно-временных бинов группе компонентов сигнала из двух или более групп компонентов сигнала в зависимости от изменения частоты, определенного для упомянутого частотно-временного бина.
17. Цифровой носитель хранения данных, содержащий компьютерную программу для реализации способа по п. 16 при выполнении на компьютере или в процессоре сигналов.
| JP 2010054802 A, 11.03.2010 | |||
| WO 2013038459 A1, 21.03.2013 | |||
| JP 2011221156 A, 04.11.2011 | |||
| Железобетонная балка | 1977 |
|
SU638698A1 |

