ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится в общем к области компьютерных технологий, в частности, к способам обработки и анализа аудиозаписей. Его можно использовать в различных устройствах для передачи, приема и записи речи для улучшения пользовательского восприятия при прослушивании речевых записей.
УРОВЕНЬ ТЕХНИКИ
Улучшение речевого сигнала (SE) направлено на восстановление чистого речевого сигнала из зашумленных входных сигналов. SE повышает разборчивость и понятность речи, способствуя улучшению пользовательского восприятия. Улучшение речевого сигнала представляет наибольший интерес среди специалистов по обработке аудиосигнала ввиду его фундаментального значения в электросвязи.
Эта проблема имеет много решений в традиционной обработке сигналов, но каждое такое решение опирается на некоторые предположения, лежащие в основе модели шума. Благодаря последним достижениям в глубоком обучении, подходы на основе больших данных в наши дни возобладали в области улучшения речевого сигнала.
Одно популярное направление в методах глубокого обучения, использующихся для улучшения речевого сигнала, базируется на извлечении сигнала во временной области. Эти методы непосредственно отображают зашумленную форму волны в чистую, обычно оставляя в стороне любую информацию о спектре сигнала, что может приводить к потере эффективности. Эти подходы обычно используют структуру сверточного кодера-декодера (CED).
Например, [1] и [2] используют сеть CED в качестве генератора, использующего для обучения полностью сверточный дискриминатор. Некоторые из этих подходов дополнительно используют нейронные модули, способные захватывать информацию длительной временной последовательности, например, ячейки долгой краткосрочной памяти [3] и трансформеры [4].
Другое направление исследования опирается на оценивание представления оконного преобразования Фурье (STFT) (комплексного спектра). Подходы, соответствующие этим направлениям, ориентированы на прогнозирование коэффициентов STFT для чистого сигнала непосредственно [5] или коррекцию спектра зашумленного сигнала путем оценивания различных масок для изменения амплитуд и фаз [5]. В общем случае, следует отметить, что, в отношении заявленного здесь метода, STFT является функцией, которая помогает получить комплексный спектр из входного аудиосигнала. На основании амплитуд STFT, можно получить амплитудную спектрограмму (также просто именуемую здесь спектрограммой). Спектрограмма получается из начального аудиосигнала следующим образом: из входного сигнала получают амплитуды посредством STFT и строят из них спектрограмму. В контексте настоящего изобретения, термины STFT, представление STFT, комплексный спектр можно использовать взаимозаменяемо.
Например, в документах MetricGAN [6] и MetricGAN+ [7] используется двунаправленный LSTM для прогнозирования двоичных масок для амплитудной спектрограммы, непосредственно оптимизирующих объективные метрики общего качества речевого сигнала, и сообщения результатов уровня техники для этих метрик. Прямое оценивание фаз спектрограммы обычно представляется затруднительным, и для упрощения этой задачи предлагаются различные ухищрения. Эти методы включают в себя использование комплекснозначных сетей, отвязывание амплитуды и использование отдельных вокодерных сетей для синтеза формы волны.
Источник Kong, Q., Cao, Y., Liu, H., Choi, K., & Wang, Y. (2021). Decoupling magnitude and phase estimation with deep resunet for music source separation. (arXiv preprint arXiv:2109,05418) раскрывает использование архитектуры UNet для оценивания коэффициентов оконного преобразования Фурье. Метод из уровня техники использует базовые свертки в архитектуре UNet. Однако данный источник из уровня техники не описывает использование быстрой свертки Фурье в архитектуре UNet, что критически влияет на качество формируемой речи, поскольку позволяет лучше использовать параметры нейронной сети.
Источник Chi, L., Jiang, B., & Mu, Y. (2020). Fast Fourier convolution. Advances in Neural Information Processing Systems, 33, 4479-4488 вводит понятие нейронного оператора быстрой свертки Фурье и применяет его для распознавания изображения, распознавания действия видео и обнаружение человеческой ключевой точки. Этот источник можно рассматривать как ближайший аналог из уровня техники по отношению к заявленному изобретению. Однако этот ближайший аналог из уровня техники не предусматривает улучшение речевого сигнала с использованием быстрой свертки Фурье для восстановления спектрограммы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Данный раздел, в котором раскрыты различные аспекты заявленного изобретения, предназначен для обеспечения краткого обзора заявленных объектов изобретения и их вариантов осуществления. Ниже приведены подробные характеристики технических средств и способов, которые реализуют сочетания признаков заявленного изобретения. Ни данное раскрытие изобретения, ни подробное описание, приведенное ниже совместно с сопровождающими чертежами, не следует рассматривать как определяющие объем заявленного изобретения. Объем правовой охраны заявленного изобретения определяется только нижеследующей формулой изобретения.
Техническая проблема, решаемая настоящим изобретением, состоит в улучшение речевого сигнала с использованием быстрой свертки Фурье для восстановления представления STFT. В настоящем изобретении представление STFT прогнозируется напрямую (т.е. прогнозируется не только амплитудная спектрограмма). Однако, в объеме принципа настоящего изобретения, можно прогнозировать также спектрограмму. Следует отметить, что восстановление (прогнозирование) спектрограммы является более простой задачей, поскольку амплитудная спектрограмма не содержит информации о фазах (фазной информации), тогда как STFT содержит как амплитудную, так и фазовую информацию.
Задача настоящего изобретения состоит в создании усовершенствованного способа и устройства для подавления шума в речевом сигнале и/или улучшения звукового сигнала, содержащего речь.
Технический результат, достигаемый с использованием заявленного изобретения, состоит в повышении качества речи, подавлении шума и/или улучшении речевой компоненты в речевом аудиосигнале.
В первом аспекте настоящая задача решается способом подавления шума в речевом сигнале с использованием по меньшей мере одного оператора быстрой свертки Фурье, причем способ содержит: разделение каналов входного тензора на локальную и глобальную ветви; использование обычных сверточных слоев для локальных преобразований тензора на локальной ветви; осуществление преобразования Фурье в частотном измерении тензора глобальной ветви; обновление карты характеристик глобальной ветви в спектральной области посредством поточечных сверточных слоев; применение обратного преобразования Фурье к обновленной карте характеристик глобальной ветви; и суммирование активаций локальной и глобальной ветвей. Каналы входного тензора можно вывести из входной спектрограммы, представляющей аудиосигнал, содержащий речь.
Следует отметить, что, согласно принципу настоящего изобретения, входной тензор для FFC можно получить как из амплитудной спектрограммы, так и из представления STFT. В примерах практической реализации настоящего изобретения, входной тензор получается из представления STFT, однако изобретение не ограничивается этим источником входного тензора, что также подтверждается экспериментами с прогнозированием фазы, которые осуществлялись на амплитудных спектрограммах, но не представлении STFT, чтобы показать, что быстрая свертка Фурье хороша при прогнозировании фазной информации, и мотивировать ее использование в этом случае для улучшения речевого сигнала или подавления шума в нем. Следует отметить, что это также делает быстрые свертки Фурье потенциально жизнеспособными для других применений, например, кодирования речевых сигналов, расширения полосы и т.д.
Суммированные активации локальной и глобальной ветвей могут отражаться в выходной спектрограмме, представляющей улучшенный аудиосигнал, содержащий речь. По меньшей мере один оператор быстрой свертки Фурье может быть частью архитектуры нейронной сети с автоэнкодером быстрой свертки Фурье (FFC-AE). По меньшей мере один оператор быстрой свертки Фурье может быть частью архитектуры нейронной сети с U-Net быстрой свертки Фурье (FFC-UNet).
Обновление карты характеристик глобальной ветви может содержать: применение действительного одномерного быстрого преобразования Фурье в частотном измерении входного тензора и конкатенацию действительной и мнимой частей спектра в канальном измерении; применение сверточного блока (с ядром 1×1) в частотной области; применение обратного преобразования Фурье. По меньшей мере один оператор быстрой свертки Фурье может применяться в частотном измерении. Способ может содержать использование сверточной нейронной сети, использующей одну или более моделей машинного обучения (ML), обученных посредством инструментария мультидискриминаторного состязательного обучения.
Во втором аспекте настоящая задача решается устройством для подавления шума в речевом сигнале с использованием оператора быстрой свертки Фурье, причем устройство содержит: память; и процессор, соединенный с памятью, причем процессор, при выполнении инструкций, сохраненных в памяти, выполнен с возможностью: разделения каналов входного тензора на локальную и глобальную ветви; использования обычных сверточных слоев для локальных преобразований тензора на локальной ветви; осуществления преобразования Фурье в частотном измерении тензора глобальной ветви; обновления карты характеристик глобальной ветви в спектральной области посредством поточечных сверточных слоев; применения обратного преобразования Фурье к обновленной карте характеристик глобальной ветви; и суммирования активаций локальной и глобальной ветвей.
В третьем аспекте настоящая задача решается машиночитаемым носителем, на котором хранятся исполняемые процессором инструкции, которые, при выполнении по меньшей мере одним процессором, предписывают по меньшей мере одному процессору осуществлять способ вышеупомянутого первого аспекта.
Специалистам в данной области техники очевидно, что принцип изобретения не ограничивается изложенными выше аспектами, и изобретение может принимать форму других предметов изобретения, например, устройства, компьютерной программы или компьютерного программного продукта. Дополнительные признаки, которые могут характеризовать конкретные варианты осуществления настоящего изобретения, будут очевидны специалистам в данной области техники из приведенного ниже подробного описания вариантов осуществления.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Чертежи приведены в данном документе для облегчения понимания сущности настоящего изобретения. Чертежи схематичны и не выполнены в масштабе. Чертежи служат только для иллюстрации и не предназначены для определения объема настоящего изобретения.
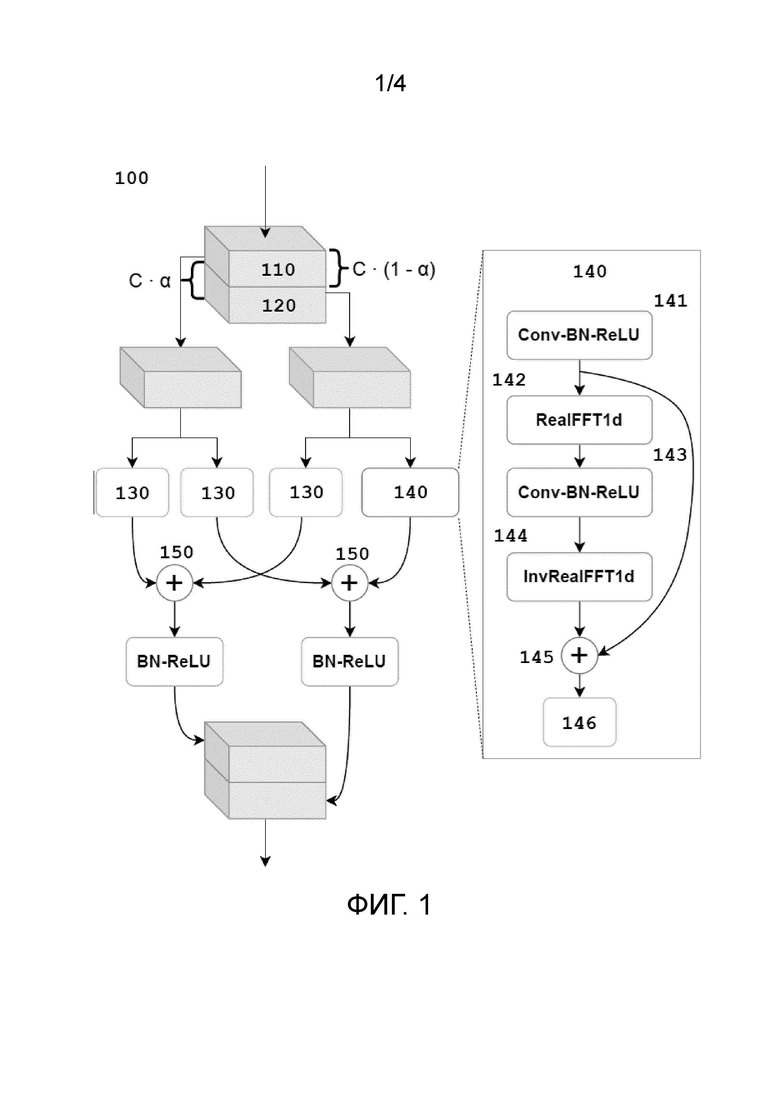
Фиг. 1 иллюстрирует схему устройства подавления шума в речевом сигнале согласно настоящему изобретению.
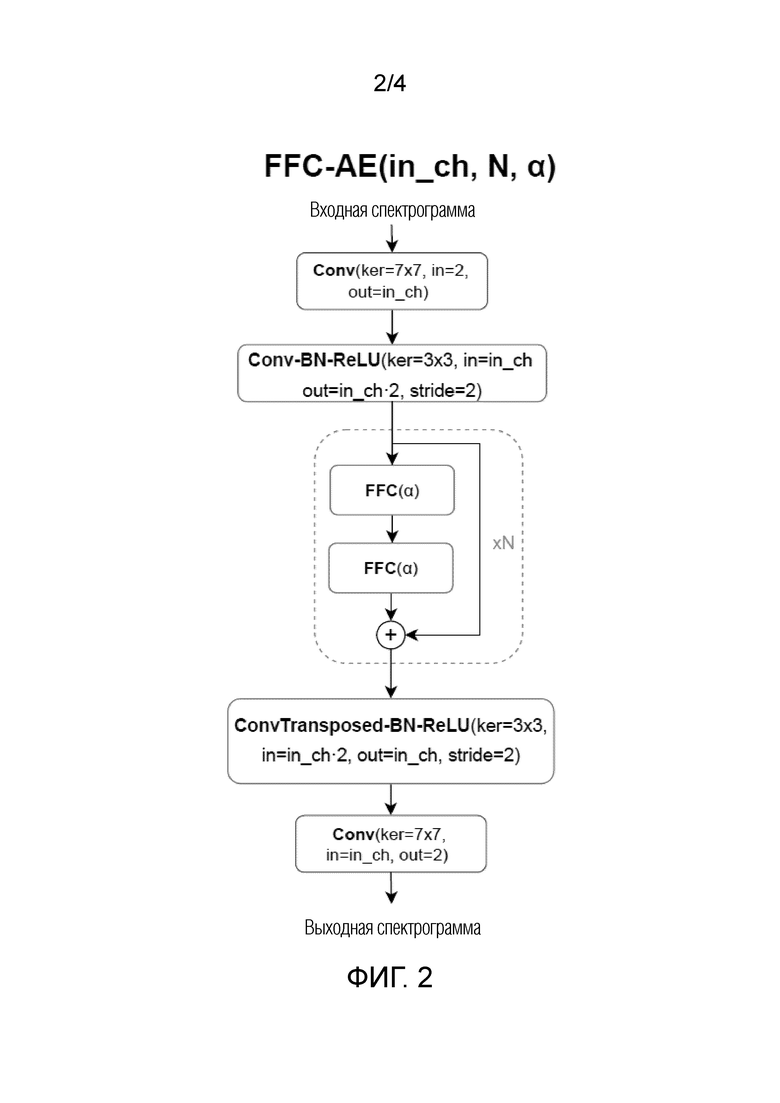
Фиг. 2 схематически иллюстрирует архитектуру нейронного модуля FFC-AE, используемого в настоящем изобретении.
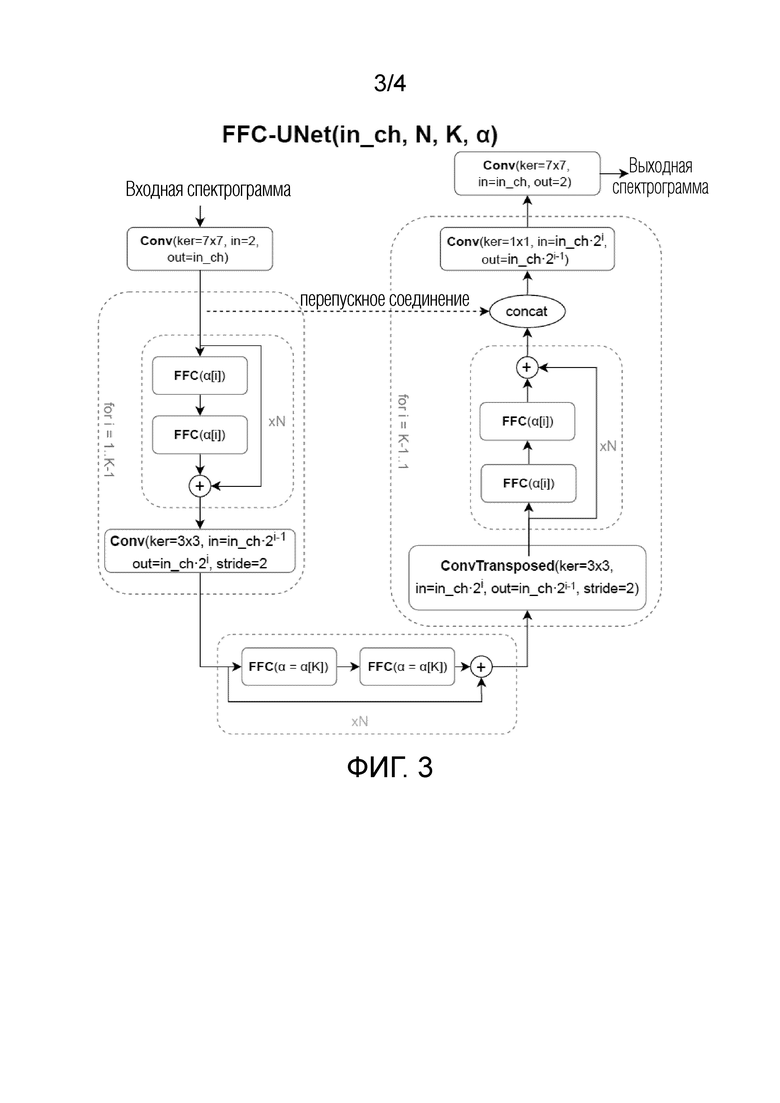
Фиг. 3 схематически иллюстрирует архитектуру нейронный модуль FFC-Unet, используемого в настоящем изобретении.
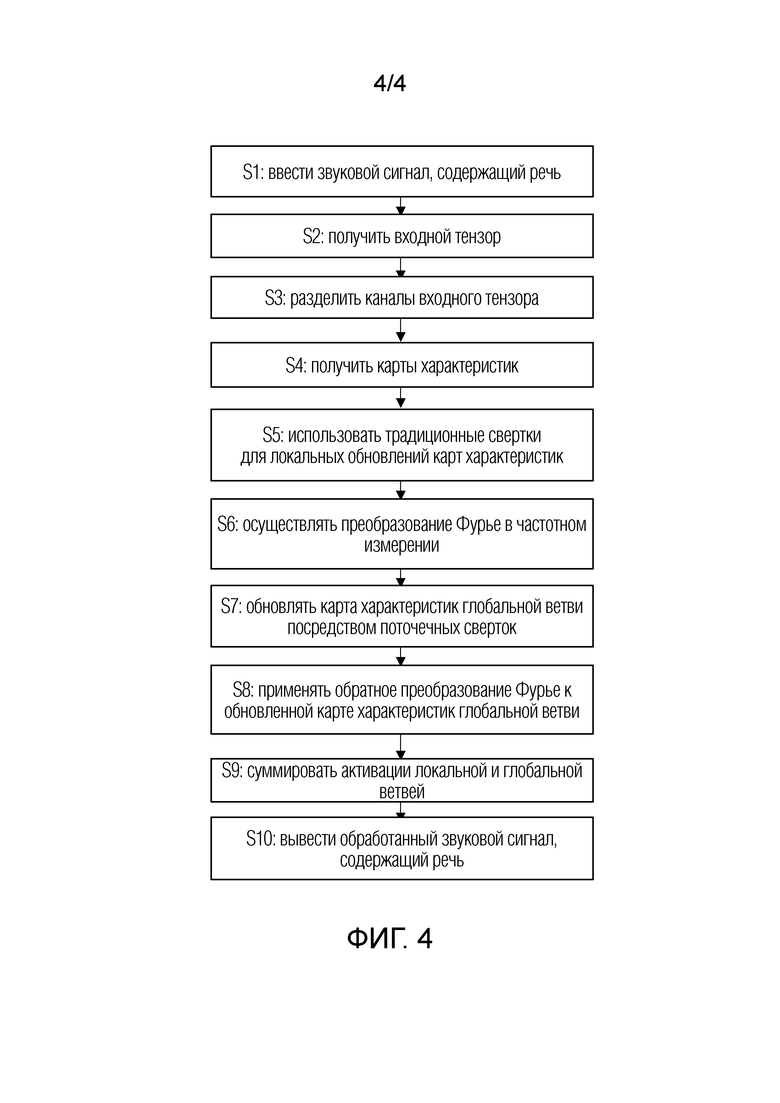
Фиг. 4 - блок-схема способа подавления шума в речевом сигнале согласно изобретению.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Иллюстративные варианты осуществления настоящего изобретения подробно описаны ниже. Иллюстративные варианты осуществления проиллюстрированы на сопровождающих чертежах, на которых одинаковые или аналогичные ссылочные позиции обозначают одинаковые или аналогичные элементы или элементы, которые имеют одинаковые или аналогичные функции. Иллюстративные варианты осуществления, описанные с обращением к сопровождающим чертежам, являются примерными и используются лишь для объяснения настоящего изобретения и не подлежат рассмотрению в плане каких-либо его ограничений.
В настоящем изобретении предложен способ подавления шума в речевом сигнале с использованием оператора быстрой свертки Фурье, который решает проблему стандартного одноканального подавления шума в речевом сигнале. Другими словами, изобретение ставит задачей обучение отображению зашумленной формы волны y=x+n с аддитивным шумом n в чистую x. Изобретение использует нейронный оператор быстрой свертки Фурье для улучшения речевого сигнала и подавления шума. Способ, отвечающий изобретению, может применяться в различных устройствах, поддерживающих вычисления с плавающей точкой или фиксированной точкой.
Быстрая свертка Фурье (FFC) представляет собой недавно предложенный нейронный оператор, демонстрирующий многообещающую производительность, в порядке неограничительного примера, в ряде задач компьютерного зрения. Оператор FFC позволяет использовать операции в большом рецептивном поле в ранних слоях нейронной сети. В частности, оператор FFC показал себя особенно полезным для восстановления периодических структур, которые часто встречаются в обработке аудиосигнала.
Авторы настоящего изобретения установили, что быстрая свертка Фурье хороша при прогнозировании фазной информации для дальнейшего использования с целью улучшения речевого сигнала или подавления шума в нем.
Авторы настоящего изобретения установили, что нейронные сети на основе быстрой свертки Фурье превосходят аналогичные сверточные модели и демонстрируют результаты, лучшие или сравнимые с другими моделями улучшение речевого сигнала.
В настоящем изобретении быстрая свертка Фурье используется в архитектурах U-Net и автоэнкодера. В порядке неограничительного примера, в соответствии с настоящим изобретением, быстрая свертка Фурье применяется посредством следующих основных этапов:
a) разделение каналов входного тензора на локальную и глобальную ветви;
b) использование обычных сверточных слоев для локальных преобразований тензоров на локальной ветви;
c) осуществление преобразования Фурье в частотном измерении тензора глобальной ветви, его обновление в спектральной области посредством поточечных сверточных слоев и применение обратного преобразования Фурье; и
d) суммирование активаций локальной и глобальной ветвей.
Способ, отвечающий изобретению, действует на аудиоконтенте, например, одном или более аудиосигналов, включающих в себя один или более каналов, в частности, но без ограничения, единственный канал.
В общем случае, звуковой (аудио) сигнал, записанный в акустических условиях реального мира, может содержать нежелательный шум, созданный окружающей средой и/или записывающим оборудованием. Это приводит к тому, что результирующая цифровая характеризация аудиосигнала содержит нежелательный шум. Цифровую характеризацию следует фильтровать для устранения нежелательного шума.
Однако каждый тип шума требует своего собственного типа фильтра, который следует выбирать вручную или искать среди наборов фильтров. Отфильтровывание шума на частотах, отличных от человеческой речи может преимущественно достигаться посредством моделей глубокого обучения. В отличие от фильтров, выбранных и подготовленных заранее, нейронные сети преимущественно охватывают более разнообразные типы шума и могут дополнительно обучаться путем добавления новых типов шума.
В общем случае, записанный звук (аудиосигнал) состоит из множества звуковых волн, которые одновременно достигают микрофонного датчика в течение периода времени. Аудиосигнал также может именоваться формой волны. Сигналы имеют непрерывную природу и, при записи на цифровое устройство через датчик, они в целом проходят процедуры дискретизации и квантования. Дискретизация связана с частотой дискретизации, и квантование связано с сигналом, хранящимся с некоторой заданной точностью. В результате, действительные числа сохраняются как конечные числа с плавающей точкой с конечной точностью (числом битов, необходимых для хранения числа). Чем выше точность, тем лучше фактическая амплитуда может отображаться в дискретизированную.
Таким образом, форма волны представляет собой длинный вектор из чисел с плавающей точкой. Зашумленная форма волны содержит некоторый шум, который в целом носит аддитивный характер поверх предположительно чистой формы волны (которая предположительно представляет речь в контексте настоящего изобретения). Поэтому необходимо определять, какие частоты содержат более сложный входной сигнал.
В настоящем изобретении, модели глубокого обучения действуют на (представлении) STFT, и отвечающий изобретению подход к нейронной сети предусматривает отыскание такого отображения (обучения нейронной сети), которое будет обучать отличать шум от чистой речи и удалять первый. STFT позволяет использовать информацию о частотах и фазах для обучения нейронных сетей с этой целью.
В этом смысле, оконное преобразование Фурье (STFT) является последовательностью преобразований Фурье оконного сигнала, фокусируется на более коротких последовательностях аудиосигнала. STFT обеспечивает локализованную по времени частотную информацию для ситуаций, в которых частотные компоненты сигнала изменяются со временем. Оконное преобразование Фурье широко используется для обработки речи, поскольку эти сигналы обычно обладают гармоническими структурами. Отвечающий изобретению подход к подавлению шума базируется на идентификации изменений частоты по временной оси сигнала.
Технически это осуществляется подразделением аудиосигнала, содержащего речь, на более короткие интервалы и применением быстрого преобразования Фурье (FFT) по отдельности для каждого такого интервала, что достигается изменением коэффициентов преобразование Фурье путем введения данной ненулевой оконной функции на каждом интервале.
Важно отметить, что, как упомянуто выше, в случае зашумленного речевого сигнала, шум имеет аддитивную структуру, поэтому, в зашумленной спектрограмме, вместо “тишины” на некоторых частотах присутствует некоторый шум, заглушающий чистую речь. Эта характерная аддитивная структура шума используется в настоящем изобретении для отличения речи от шума и, соответственно, обучения нейронных сетей.
Как упомянуто выше, на первом этапе применения FFC к речевому аудиосигналу, каналы входного тензора делятся на локальную и глобальную ветви.
Используемый здесь термин «тензор» в общем следует понимать как своего рода линейный многокомпонентный (например, алгебраический) объект, определяемый в конечномерном векторном пространстве конечной. Входной тензор выводится из входного сигнала с использованием любого подходящего способа, хорошо известного в технике. В частности, представление STFT в процессе обучения является 4-мерным тензором размера (Batch_Size, Frequency bins, Time bins, 2). Это означает, что необходимо дискретизировать с повышением количество каналов от 2 (действительного и комплексного в последнем измерении) до произвольного числа (настоящее изобретение не ограничивается никаким конкретным числом, при условии, что наблюдается компромисс между сложностью модели в отношении количества вычисляемых параметров и количества производимых операций и ее качеством, благодаря чему эти две характеристики уравновешиваются, таким образом, с одной стороны, получается наилучшее доступное качество, и, с другой стороны, модель остается по возможности малой).
С этой целью используются нейронные операторы наподобие сверток, перемежающиеся с некоторыми нелинейностями, которые помогают дискретизировать с повышением каналы, поддерживая поток информации через сеть. Количество каналов, которые определяют эти операции, являются гиперпараметрами, подлежащими тонкой настройке для получения наилучших результатов из модели, которая используется в методах, отвечающих изобретению. Гиперпараметры характеризуются в нижеследующих описаниях соответствующих операторов. В общем случае, следует понимать, что свертка, будь то 1-мерная, 2-мерная или 3-мерная операция, определяется как функция, имеющая следующее параметры: input_channels, output_channels, kernel_size, а также некоторые факультативные, например, конкретные параметры известное как “stride”, “padding” и т.д. Более формальное определение в отношении данного инструментария (например, PyTorch) можно найти, например, по адресу: https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html.
Будучи определенной этими параметрами, свертка может преобразовывать данный входной тензор по-разному:
- если input_channels < output_channels, то входной тензор дискретизируется с повышением в канальном измерении;
- если input_channels > output_channels, то входной тензор дискретизируется с понижением в канальном измерении;
- иначе измерение каналов остается неизменным.
Другие параметры, например, “stride”, “padding” и kernel_size определяют преобразование входным тензором в других измерениях (не каналах), в частности, останутся ли они неизменными или будут дискретизированы с понижением.
Несмотря на то, что они являются несколько более сложными, чем Linear Layers, свертки являются по существу линейными операциями. Поэтому, чтобы свертки могли обучаться нелинейным отображениям, нужно вносить нелинейности.
FFC делит аудиоканалы входного тензора на локальную и глобальную ветви. Следует отметить, что операция разделения в настоящем контексте является частным случаем более общей операции, которая в этой области техники обычно носит название «слайсинг», и которая может осуществляться в произвольном количестве измерений и реализована в обычных инструментариях глубокого обучения, например, PyTorch, TensorFlow, JAX и т.д. и является неотъемлемой особенностью, например, языка программирования python.
Функция разделения, определяемая на тензоре, является операцией, которая делит тензор в данном измерении в некоторой заданной пропорции, что приводит к нескольким меньшим подмножествам входного тензора одинакового размера во всех измерениях кроме одного, в котором осуществлялась операция. В FFC, разделение осуществляется в канальном измерении для получения двух тензоров, один из которых отправляется в локальную ветвь, а другой в глобальную ветвь, как показано, в частности, на фиг. 1.
Локальная ветвь использует обычные сверточные слои для локальных преобразований тензора на локальной ветви. В этом контексте, термин «карты характеристик» (тензоры) можно использовать взаимозаменяемо с термином «активации», как объяснено здесь, в смысле некоторых промежуточных представлений, тензоров, полученных путем применения некоторых нейронных операторов.
Глобальная ветвь осуществляет преобразование Фурье карты характеристик и обновляет ее в спектральной области, влияя на глобальный контекст. Настоящее изобретение осуществляет преобразование Фурье только в частотных измерениях карт характеристик (соответствующих спектрограммами STFT).
В частности, настоящее изобретение реализует глобальную ветвь слоя FFC в три этапа:
1. Применение действительного одномерного быстрого преобразование Фурье в частотном измерении входной карты характеристик и конкатенация действительной и мнимой частей спектра в канальном измерении:
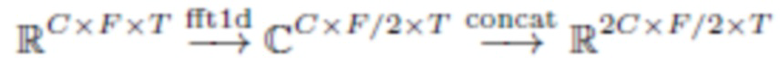
2. Применение сверточного блока (с ядром 1×1) в частотной области:
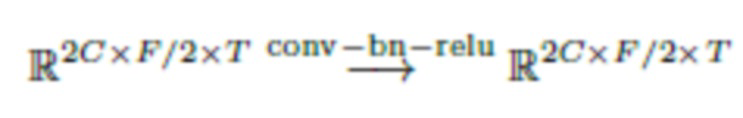
3. Применение обратного преобразования Фурье:
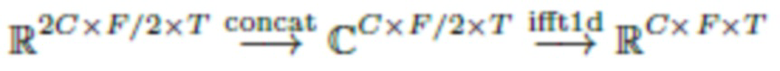
Глобальная и локальная ветви взаимодействуют друг с другом путем суммирования активаций, как показано на фиг. 1.
Активация представляет собой выходной сигнал произвольного нейронного слоя (по сравнению с активацией нейронов в действительном биологическом мозгу). В случае блоков FFC, локальная ветвь содержит два отдельных слоя свертки (модуль 130 на фиг. 1), выходные сигналы которых суммируются, и глобальная ветвь является линейной комбинацией (или, более тривиально, суммой) сверточного слоя (модуль 130 на фиг. 1) и слоя спектрального преобразования (модуль 131 на фиг. 1). Другими словами, в контексте настоящего изобретения, активации являются выходными сигналами каждого отдельного нейронного слоя (в частности, сверточного слоя (модуль 130) или слоя спектрального преобразования (модуль 131)). Активации также можно рассматривать как промежуточные представления нейронной сети, достигаемые последовательной (поблочной) обработки данного входного сигнала.
В одном или более неограничивающих иллюстративных вариантах осуществления настоящее изобретение использует ту же разновидность FFC, которая была исследована в источнике [10] для ретуширования изображения, за исключением того, что настоящее изобретение использует одномерное преобразование Фурье в частотном измерении.
На фиг. 1 показана схема устройства подавления шума в речевом сигнале согласно изобретению, использующего нейронный модуль быстрой свертки Фурье для улучшения речевого сигнала. Параметр 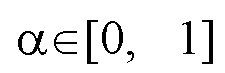 управляет отношением каналов, используемых в глобальной ветви модуля.
управляет отношением каналов, используемых в глобальной ветви модуля.
Затем обычные сверточные слои используются для локальных преобразований тензора на локальной ветви. Операцию свертки можно описать как применение обучаемого скользящего фильтра и взаимодействие с различными частями входного тензора, в ходе которого получается выходной тензор. Буквально, для каждой пары входного и выходного каналов операции свертки (как объяснено здесь), применяется фильтр с некоторым kernel_size, и этот фильтр «скользит» по входному тензору, объединяя информацию из различных частей входного тензора.
Поэтому, в контексте настоящего изобретения, свертки означают операции, которые осуществляют локальные обновления, где «локальность» определяется размером фильтра, т.е. чем крупнее свертки, тем он лучше захватывает нелокальные особенности, содержащиеся во входном тензоре. Однако увеличение размер свертки является затратным в отношении вычисления. «Локальные обновления» в этом контексте указывает этот локальный характер операции свертки в отличие от слоя спектрального преобразования (части глобальной ветви), который глобально взаимодействует с тензором.
Преобразование Фурье осуществляется нейронной сетью в частотном измерении карты характеристик глобальной ветви, что приводит к обновлению карты характеристик в спектральной области посредством поточечных сверточных слоев, после чего применяется обратное преобразование Фурье.
В итоге активации локальной и глобальной ветвей суммируются, что дает аудиосигнал с улучшенной речью и/или шумом, сниженным до такой степени, что речь в обработанном аудиосигнале становится отчетливо понятной и постижимой слушателем независимо от уровня громкости обработанного аудиосигнала при воспроизведении.
Настоящее изобретение реализует две архитектуры нейронной сети для улучшения речевого сигнала. Первая (FFC-AE) инспирирована [10]. Эта архитектура изображена на фиг. 2 (слева). Вторая архитектура инспирирована классической работой [11] и показана на фиг. 2 (справа). Эти две архитектуры нейронной сети будут более подробно описаны ниже в отношении соответствующих аспектов настоящего изобретения.
FFC-AE
В контексте настоящего изобретения, первый модель архитектура также именуется автоэнкодером быстрой свертки Фурье (FFC-AE). FFC-AE по существу является автоэнкодером быстрой свертки Фурье, который применяет архитектуру, впервые описанную в источнике [15], для конкретной задачи улучшения речевого сигнала. Эта архитектура состоит из сверточного кодера (также именуемого шаговой сверткой), который дискретизирует с понижением входному спектрограмму во временном и частотном измерениях с коэффициентом два. За кодером следует ряд остаточных блоков, каждый из которых состоит из двух последовательных модулей быстрой свертки Фурье. Затем выходной сигнал остаточных блоков дискретизируется с повышением посредством транспонированной свертки и используется для прогнозирования действительной и мнимой частей обесшумленной спектрограммы.
Архитектура FFC-AE в соответствии с настоящим изобретением функционирует с использованием следующих операторов.
Сначала входная речь, содержащая представление STFT аудиосигнала (или, при необходимости, спектрограмма) обрабатывается с использованием операторов Conv-BN-ReLU, характеризуемого параметрами (ker=7×7, in=2, out=in_ch), и Conv-BN-ReLU, характеризуемого параметрами (ker=3×3, in=in_ch out=in_ch·2, stride=2). Затем, FFC(α) осуществляется N раз, где α - действительное число ∈ [0, 1], N определяемое количество остаточных блоков FFC. Результаты FFC суммируются и обрабатываются оператором транспонированной свертки ConvTransposed-BN-ReLU (ker=3×3, in=in_ch·2, out=in_ch, stride=2). Затем оператор свертки Conv(ker=7×7, in=in_ch, out=2) обрабатывает представление STFT. Затем представление выводится. В данном случае, параметр in_ch определяет общую ширину сетей, N определяет количество остаточных блоков FFC, α - действительное число ∈ [0, 1], как упомянуто выше.
Транспонированная свертка представляет собой операцию, противоположную свертке. Свертка характеризуется гиперпараметром “stride”, который определяет, насколько плотно или разреженно обучаемые фильтры применяются к данному тензору (чем больше stride, тем больше тензор дискретизируется с понижением в частотном и временном измерениях). Транспонированная свертка, вместо понижающей дискретизации, дискретизирует с повышением данный тензор в частотном и временном измерениях. Ядра обозначают размеры фильтра сверток.
обучение модели в настоящем изобретении осуществляется партиями выборок. Методы, которые улучшают обучение модели и делают процедуру более устойчивой, включают в себя Batch Normalization (BN), посредством вычисления статистик среднего и стандартного отклонения из данной партии выборок и нормализации входного сигнала посредством этих статистик.
ReLU является нелинейной функций активации, которая отображает отрицательные выходные значения в нуль, оставляя при этом неотрицательные выходные значения без изменения. Нелинейности критичны для обучения нейронных сетей.
Хотя увеличение коэффициентов понижающей дискретизации приводит к дополнительному сокращению количества операций в ходе выведения, авторы настоящего изобретения установили, что оно также приводит к значительному снижению производительности (качеству удаления шума), тогда как коэффициент 2 обеспечивает хороший компромисс между производительностью и сложностью.
FFC-UNet
Вторая архитектура нейронной сети, используемая в настоящем изобретении, именуется здесь FFC-UNet. В данном случае слои FFC включены в архитектуру U-Net. На каждом уровне структуры U-Net, используются несколько остаточных блоков FFC со сверточной повышающей дискретизацией или понижающей дискретизацией. В частности, авторы настоящего изобретения нашли полезным сделать параметр α (отношение каналов, идущих в глобальную ветвь быстрой свертки Фурье) зависящим от уровня U-Net, где используется FFC.
Более высокие уровни структуры U-Net работают с более высокими разрешениями данных, где присутствуют периодические структуры, тогда как более низкие уровни работают в грубом масштабе, лишенном периодической структуры. В более общем случае, как указано в [8], более глубокие слои нейронных сетей в основном предположительно используют локальные паттерны, тогда как самые верхние слои настоятельно требуют глобального контекста при обработке информации. Таким образом, глобальная ветвь слоев FFC менее полезна в грубых масштабах, и настоящее изобретение уменьшает параметр α, начиная с 0,75 на самом верхнем уровне до 0 на нижнем слое с шагом 0,25.
Архитектура FFC-UNet в соответствии с настоящим изобретением функционирует с использованием следующих операторов.
Сначала входная спектрограмма обрабатывается с использованием оператора свертки Conv(ker=7×7, in=2, out=in_ch). Затем обработка переходит к оператору Conv(ker=1×1, in=in_ch·2i-1 out=in_ch·2i, stride=2), после чего операция FFC(α[i]) осуществляется N раз, где N определяет количество остаточных блоков FFC, для i=1..K-1. FFC(α=α[K]) осуществляется N раз, и результаты суммируются, и затем обрабатываются оператором свертки ConvTransposed(ker=1×1, in=in_ch·2i, out=in_ch·2i-1, stride=2), после чего операция FFC(α[i]) осуществляется N раз, для i=K-1..1, и результаты суммируются. Оператор Conv(ker=1×1, in=in_ch·2i, out=in_ch·2i-1) обрабатывает результат упомянутого суммирования, который затем обеспечивается для обработки оператором Conv(ker=7×7, in=in_ch, out=2), и обработанная спектрограмма в итоге выводится.
Следует отметить, что, в добавление к использованию K, которое обозначает глубину архитектуры FFC-UNet, а также K вещественных чисел ∈ [0, 1], архитектура FFC-UNet также отличается наличием перепускного соединения, которое переносит результаты Conv(ker=7×7, in=2, out=in_ch) непосредственно на оператор конкатенации, который также выполнен с возможностью конкатенации вышеупомянутых суммированных результатов NxFFC(α[i]).
Через перепускное соединение, некоторые промежуточные представления отправляются из вышерасположенного слоя нейронной сети в нижерасположенный для облегчения реконструкции. Таким образом, получается тензор из вышерасположенного слоя, а также некоторый выходной сигнал из более недавнего слоя, и они конкатенируются в канальном измерении. Поскольку это приводит к удвоению количества каналов, информация объединяется со сверточным слоем, который уменьшает количество каналов в два раза.
Описав архитектуры FFC-AE и FFC-UNet нейронной сети, используемые в настоящем изобретении для осуществления быстрого преобразования Фурье на входной спектрограмме речевого сигнала, обратимся к описанию устройства для подавления шума в речевом сигнале, которое реализует принципы настоящего изобретения.
Возвращаясь к фиг. 1, опишем более подробно отвечающее изобретению устройство для подавления шума в речевом сигнале с использованием оператора быстрой свертки Фурье. Устройство 100 для подавления шума в речевом сигнале с использованием оператора быстрой свертки Фурье, также дополнительно именуемое здесь устройство 100 подавления шума в речевом сигнале, содержит модуль 110 локальной ветви и модуль 120 глобальной ветви, каждый из которых содержит по меньшей мере один модуль 130 свертки 3×3. Кроме того, модуль глобальной ветви также содержит модуль 140 спектрального преобразования. Дополнительно, устройство 100 подавления шума в речевом сигнале также содержит один или более модулей 150 суммирование.
Модуль 140 спектрального преобразования содержит массив модулей 141, 142, 143, 144 оператора свертки, модуль 145 суммирования и 1×1 модуль 146 свертки.
Следует отметить, что модули устройства 100 подавления шума в речевом сигнале можно реализовать самыми разными путями в зависимости от сценария реализации настоящего изобретения. В частности, эти модули, которые отвечают за различные операторы свертки или различные другие операторы нейронной сети, элементы и т.д., можно реализовать с использованием одного или более процессоров, например, компьютерных процессоров общего назначения (CPU), цифровых сигнальных процессоров (DSP) микропроцессоров и т.д., работающих под управлением соответствующих программных элементов, интегральных схем, вентильных матриц, программируемых пользователем (FPGA) или любого другого аналогичного средства, хорошо известного специалистам в данной области техники. Для обеспечения входного аудиосигнала, например, звукового сигнала содержащего, речь, для устройства 100 подавления шума в речевом сигнале, в конкретных вариантах осуществления изобретения также можно использовать соответствующее средство ввода, например, один или более микрофонов, аналого-цифровых преобразователей (ADC) и т.д. Средство вывода для вывода улучшенного аудиосигнала, например, улучшенного и/или обесшумленного звукового сигнала, содержащего речь, в конкретных вариантах осуществления изобретения также можно использовать соответствующее средство вывода, например, цифро-аналоговые преобразователи (DAC), громкоговоритель(и) для воспроизведения улучшенного аудиосигнала, например, улучшенного и/или обесшумленного звукового сигнала, содержащего речь. Однако следует понимать, что изобретение не ограничивается никакими деталями, касающимися наличия и/или конкретным характером этих средств ввода/вывода или конкретным аппаратным средством обработки, используемым для реализации модулей устройства 100 подавления шума в речевом сигнале, как упомянуто выше.
Также необходимо отчетливо понимать, что по меньшей мере модули устройства 100 подавления шума в речевом сигнале можно реализовать в форме программного обеспечения, обеспеченного на одном или более языках программирования, или в форме исполнимого кода, что хорошо известно специалистам в данной области техники. Такое программное обеспечение может быть реализовано в виде компьютерной программы или программ, компьютерного программного продукта, в частности, реализованного на материальном машиночитаемом носителе любого подходящего вида, элемента(ов) компьютерной программы, блоков или модулей. Оно может храниться локально или распределяться по одной или более проводным или беспроводным сетям, с использованием одного или более удаленных серверов и т.д. Эти детали не ограничивают объем настоящего изобретения.
Таким образом, устройство 100 подавления шума в речевом сигнале также может содержать по меньшей мере одно запоминающее устройство, например, RAM, ROM, флеш-память, EPROM, EEPROM и т.д. и/или сменный носитель данных, для постоянного или временного хранения соответствующих программных инструкций, а также сигналов и/или данных участвующих в подавление шума в речевом сигнале и/или его улучшении в соответствии с настоящим изобретением. Детали, касающиеся такого запоминающего устройства, предусмотрены в различных вариантах осуществления настоящего изобретения и не ограничивают объем настоящего изобретения.
Одна или более нейронных сетей, где реализованы модули отвечающего изобретению устройства 100 подавления шума в речевом сигнале и/или соответствующие этапы способа и, в частности, архитектуры FFC-AE и FFC-Unet, как описано выше, используют одну или более моделей машинного обучения (ML), которые могут быть преимущественно обучены усовершенствовать методы улучшения речевого сигнала или подавления шума в нем, лежащих в основе настоящее изобретение. Перейдем к более подробному описанию обучения модели ML.
Обучение
Спрогнозированная спектрограмма оконного преобразования Фурье преобразуется в форму волны посредством обратного оконного преобразования Фурье.
Изобретение может использовать инструментарий мультидискриминаторного состязательного обучения, предложенный в [12], для обучения моделей ML. Этот инструментарий состоит из трех потерь, а именно потерь GAN, потерь на согласовании характеристик и потери на мел-спектрограмме.
Обучение нейронных сетей в соответствии с настоящим изобретением будет описано ниже более подробно. Заметим, однако, что изобретение не ограничивается этими конкретными деталями. Инструментарий мультидискриминаторного состязательного обучения, как упомянуто выше, может использовать порождающие состязательные сети (GAN), которые относятся к широко используемому типу нейронной порождающей модели. В общем случае, GAN состоят из генераторных и дискриминаторных нейронных сетей, которые состязаются друг с другом. Генераторная сеть обучается отображению из исходной области в целевую область, тогда как дискриминатор обучается отличать действительные объекты от генерируемых в целевой области. Таким образом, дискриминатор предписывает генератору создавать выборки, неотличимые от реальных.
В контексте настоящего изобретения, генератор обучается удалять шум из сигнала для получения чистого, тогда как несколько дискриминаторов обучаются отличать между выходные сигналы генераторов от эталонных чистых форм волны. Обратная связь дискриминаторов проходит также через генератор, что позволяет обоим обучаться в состязательном стиле.
Потери GAN
Потери GAN представляют собой потери, используемые для состязательного обучения. Настоящее изобретение использует потери LS-GAN [13] для генератора Gθ с параметрами θ и дискриминаторами  (для дополнительных подробностей см., например источник [12]) с параметрами ϕi, …, ϕk, которые составляют комбинацию всех весовых коэффициентов в нейронной сети:
(для дополнительных подробностей см., например источник [12]) с параметрами ϕi, …, ϕk, которые составляют комбинацию всех весовых коэффициентов в нейронной сети:
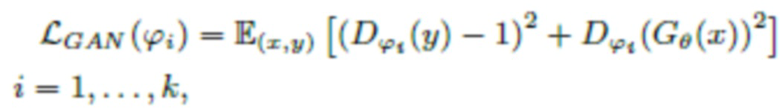
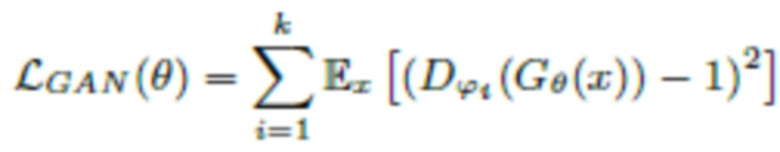 ,
,
где y обозначает эталонный аудиосигнал, и x - его зашумленную версию; D - дискриминатор с множеством параметров {ϕi} где i=1…k (k=3 - количество дискриминаторов); G - генератор с параметрами θ.
В соответствии с изобретением, генераторы действуют на зашумленных формах волны (x -> G(x)), тогда как дискриминаторы действуют на эталонных формах волны (y -> D(y)), а также выходных сигналах генераторов (G(x) -> D(G(x))).
E обозначает математическое ожидание взятое в пространстве обеих зашумленной и эталонной форм волны для обучения дискриминатора (E(x, y)), и зашумленном пространстве для обучения генератора (Ex), ∑ - сумма по всем дискриминаторам. На практике математическое ожидание оценивается методом Монте-Карло, и потери вычисляются на небольших подвыборках (батчах), а не на всем массиве данных.
|| . ||1 обозначают потери L1 (абсолютная разность значений).
Потери на согласовании характеристик
Потери на согласовании особенностей вычисляются как расстояние L1 между промежуточными активациями дискриминаторов, вычисленными для эталонной выборки, и условно сгенерированными (см., например [14]):
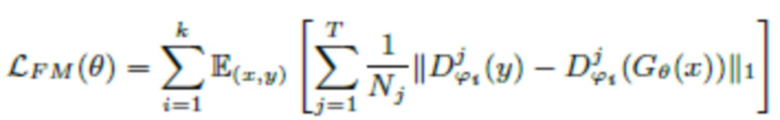
где T обозначает количество слоев в дискриминаторе; 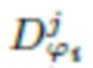 и
и 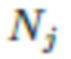 обозначают активации и размер активаций в j-ом слое i-го дискриминатора, соответственно.
обозначают активации и размер активаций в j-ом слое i-го дискриминатора, соответственно.
Потери на мел-спектрограмме
Потери на мел-спектрограмме это расстояние L1 между мел-спектрограммой формы волны, синтезированной генератором, и мел-спектрограммой эталонной формы волны.
Они определяется как
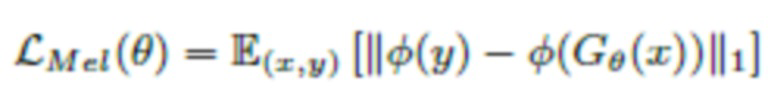
где φ - функция, которая преобразует форму волны в соответствующую мел-спектрограмму.
Окончательные потери
Окончательные потери для генератора и дискриминаторов выражаются в виде:
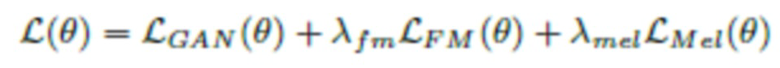
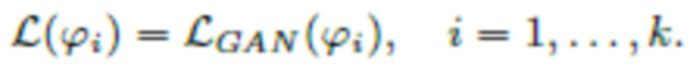
Во всех экспериментах были заданы λfm=2 и λmel=45.
Обращаясь к фиг. 4, рассмотрим этапы способа подавления шума в речевом сигнале с использованием по меньшей мере одного оператора быстрой свертки Фурье в соответствии с изобретением.
На этапе S1 звуковой сигнал, содержащий речь, поступает на устройство подавления шума в речевом сигнале согласно изобретению. Звуковой сигнал, содержащий речь, может вводиться с использованием одного или более средств, например, микрофона(ов), при необходимости через по меньшей мере один аналого-цифровой преобразователь (ADC). Однако такой способ ввода звукового сигнала, содержащего речь, не ограничивает разнообразие возможностей, и, в порядке альтернативы, звуковой (аудио) сигнал, содержащий речь, может приниматься в форме цифрового сигнала через одну или более сетей связи (проводных или беспроводных) и т.д.
На этапе S2 входной тензор выводится из (при необходимости, оцифрованного) звукового сигнала, содержащего речь, как описано выше, однако это может осуществляться любым подходящим способом, хорошо известным в технике.
На этапе S3 каналы входного тензора делятся на локальную и глобальную ветви, как описано выше.
На этапе S4 карты характеристик получаются для глобальной и локальной ветвей, как описано выше.
На этапе S5 обычные сверточные слои используются для локальных преобразований тензора на локальной ветви. В данном случае, нейронные операторы FFC-AE и FFC-UNet могут применяться, как описано выше.
На этапе S6 преобразование Фурье осуществляется в частотном измерении карты характеристик глобальной ветви.
На этапе S7 карта характеристик глобальной ветви обновляется в спектральной области посредством поточечных сверточных слоев, причем поточечный сверточный слой означает свертку с размером фильтра в единицу.
На этапе S8 обратное преобразование Фурье применяется к обновленной карте характеристик глобальной ветви.
На этапе S9 активации локальной и глобальной ветвей суммируются.
На этапе S10 выводится обработанный звуковой сигнал, содержащий речь, в котором речь улучшена и/или обесшумлена посредством вышеупомянутых операций. Это может включать в себя преобразование обработанного сигнала в аналоговый сигнал для дальнейшего воспроизведения, например, с помощью одного или более громкоговорителей посредством одного или более цифро-аналоговых преобразователей (DAC), но такое преобразование является факультативным и не ограничивает объем настоящего изобретения. Эффект подавления шума в речевом сигнале можно продемонстрировать на спектрограмме соответствующего аудиосигнала: как упомянуто выше, известно, что шум имеет аддитивную структуру, поэтому, на зашумленной спектрограмме, на некоторых частотах присутствует некоторая величина шума вместо «тишины», тогда как чистая речь приглушается. Напротив, в результате реализации способа, отвечающего изобретению, речь является громкой и ясной на всех частотах или большинстве частот в спектрограмме результирующего (обработанного) аудиосигнала, тогда как шум существенно снижается как в не содержащей речь, так и «речевой» частях соответствующего обработанного сигнала.
Примеры реализации настоящего изобретения будут описаны ниже, с экспериментальными данными из оценивания производительности методов, отвечающих изобретению, на иллюстративных массивах данных, как описано ниже.
Массивы данных
В практических реализациях настоящего изобретения использовались два набора данных для оценивания эффективности предложенных методов подавления шума в речевом сигнале. Первым из них был массив данных VCTK-DEMAND (см., например [15]), который является стандартным набором данных для систем подавления шума в речевом сигнале. Обучающий набор состоял из 28 говорящих с 4 отношениями сигнал-шум (SNR) (15, 10, 5 и 0 дБ) и содержал 11572 высказывания. Испытательный набор (824 высказывания) состоял из 2 говорящих, невидимых для модели в ходе обучения с 4 SNR (17,5, 12,5, 7,5 и 2,5 дБ).
В качестве второго набора данных был выбран набор данных Deep Noise Supression Challenge (DNS) (см., например [16]). 100 часов обучающих данных было синтезировано с использованием предоставленных кодов и конфигурации по умолчанию. Единственное изменение состоит в том, что искусственная реверберация в ходе синтеза не использовалась. Модели были протестированы на двух видах испытательных наборов. В качестве первого набора (DNS-CUSTOM) были выбраны контрольные данные, случайно выбранные и исключенные из синтезированных 100 часов обучающих данных. Вторым (DNS-BLIND) был стандартный слепой испытательный набор из хранилища DNS. Эти данные записывались в присутствие естественного шума в сценариях реального мира.
Метрики
Для объективного оценивания выборок в рассматриваемых задачах использовались традиционные метрики WB-PESQ (см. [17]), STOI (см. [18]), масштабно-инвариантное отношение сигнал-искажение (SI-SDR) (см. [19]). Помимо традиционных метрик качества речевого сигнала, авторы настоящего изобретения рассматривают абсолютную меру объективного качества речевого сигнала на основе прямого прогнозирования показателя MOS согласно тонко настроенной модели wave2vec2.0 (WV-MOS).
Примеры
Далее настоящее изобретение будет проиллюстрировано практическими примерами реализации. Во всех примерах сигналы преобразуются в спектральную область с использованием STFT с окном Ханна размером 1024 и размером скачка 256. Для модели FFC-AE авторы настоящего изобретения установили α=0,75, in_ch=32, N=9. Для FFC-UNet, K=4, N=4, in_ch=32 и α=0,75 постепенно уменьшались при переходе от верхних слоев к нижним согласно расписанию, описанному в разделе 2.3. Модели обучались на протяжении 500 эпох с размером партии 16. Использовали оптимизатор Адама с темпом обучения 0,0002.
Оценивание фазы
Результаты оценивания фазы на массиве данных LJ-Speech приведены ниже в таблице 1.
Способность модели FFC-AE оценивать фазы тестировали на основе амплитудных спектрограмм на массиве данных LJ-Speech (см. [23]) и сравнивали с аналогичными архитектурами с базовыми свертками. Также производили сравнение с моделью U-Net (базовой U-Net) и моделью, которая идентична FFC-AE за исключением того, что все Фурье-блоки в глобальной ветви заменены базовыми свертками (FFC-AE (абл.)).
Модели обучались для прогнозирования синуса и косинуса фаз из амплитудной спектрограммы и снабжались полными амплитудными спектрограммами. Следует отметить, что, в общем случае, обучение синусу и косинусу фаз означает обучение комплексному спектру из амплитудной спектрограммы (которая не содержит комплексной информации и, таким образом, информации о фазы). Комплексные числа могут быть представлены синусами и косинусами по формуле Эйлера (это соответствие позволяет преобразовывать их между собой). Для подавления шума в речевом сигнале, фазная информация использовалось в экспериментах за счет обучения на STFT. Результаты приведены выше в таблице 1. FFC-AE значительно превосходит другие модели прогнозирования фазы, хотя имеет меньше параметров.
Улучшение речевого сигнала
Качество предложенных моделей сравнивали с моделями из литературы на обоих описанных выше наборах данных. На Voicebank, как можно видеть из таблицы 2, FFC-AE значительно превосходила большинство остальных моделей по WV-MOS и давала конкурентоспособные результаты на других метриках с учетом ее компактного размера модели. FFC-UNet была сопоставима с DEMUCS [3] по качеству в отношении WV-MOS, будучи в 8 раз меньше по размеру. Согласно критерию DNS (таблица 3), оба модели, используемые в методах, отвечающих изобретению, превосходили FullSubNet (см. [22]) (одну из лучших моделей в DNS Challenge 2021) в отношении WV-MOS на обоих испытательных наборах DNS-CUSTOM и DNS-BLIND.
Результаты подавления шума в речевом сигнале представлены ниже в таблице 2.
В нижеследующей таблице 3 представлены экспериментальные данные, иллюстрирующие практический пример реализации настоящего изобретения, который демонстрируют результаты подавления шума в речевом сигнале на массиве данных DNS. * (звездочка) в таблице 3 указывает результаты на DNS-BLIND.
Варианты осуществления настоящего изобретения, как описано выше, предусматривают новую архитектуру для подавления шума в речевом сигнале. Архитектура строится на недавно предложенном нейронном операторе быстрой свертки Фурье [8]. Результаты демонстрируют, что предложенные модели работают лучше или так же, как традиционные системы.
В частности, предложенная архитектура значительно превосходит ближайший аналог [21], который использует базовые свертки внутри архитектуры U-Net. Напротив, предложенная архитектура использует быструю свертку Фурье и достигает более высокой производительности при гораздо меньшем количестве параметров. Настоящий метод является новым и отвечающим изобретению по меньшей мере в том, что нейронный оператор быстрой свертки Фурье для улучшения речевого сигнала и подавления шума показал нетривиальный результат высокой эффективности быстрой свертки Фурье для восстановления спектрограммы.
Выше были описаны способ и устройство для улучшения речевого сигнала и подавления шума в звуковом сигнале, содержащем речь. Специалисты в данной области техники должны понять, что изобретение можно реализовать различными комбинациями аппаратных и программных средств, и никакие подобные конкретные комбинации не ограничивают объем настоящего изобретения. Вышеописанные модули, которые составляют отвечающее изобретению устройство, можно реализовать в форме отдельного аппаратного средства, или два или более модулей можно реализовать в виде одного аппаратного средства, или отвечающую изобретению систему можно реализовать в виде одного или более компьютеров, процессоров (CPU) например, процессоров общего назначения или специализированных процессоров, например, цифровых сигнальных процессоров (DSP), или одной или более ASIC, FPGA, логических элементов и т.д. В качестве альтернативы, один или более модулей можно реализовать как программное средство, например, программу или программы, элемент(ы) или модуль(и) компьютерной программы которые управляют одним или более компьютерами, CPU и т.д. для осуществления этапов способа и/или операций, подробно описанных выше. Это программное средство может быть реализовано на одном или более машиночитаемых носителей, которые хорошо известны специалистам в данной области техники, может храниться в одном или более блоках памяти, например, ROM, RAM, флеш-памяти, EEPROM и т.д., или поступать, например, от удаленных серверов через одно или более соединения проводной и/или беспроводной сети, интернет, соединение Ethernet, LAN или, при необходимости, другие локальные или глобальные компьютерные сети.
Специалисты в данной области техники должны понять, что только некоторые из возможных примеров методов и материалов и технических средств, позволяющих реализовать варианты осуществления настоящего изобретения, описаны выше и показаны в чертежах. Подробное описание вышеприведенных вариантов осуществления изобретения не предназначено для ограничения настоящего изобретения или определения объема его правовой охраны.
Другие варианты осуществления, которые могут входить в объем настоящего изобретения, могут быть предложены специалистами в данной области техники по изучении вышеприведенного описания изобретения с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены подлежат включению в объем настоящего изобретения. Все упомянутые и рассмотренные здесь источники из уровня техники настоящим включены в данное описание путем ссылки, когда это применимо.
При том, что настоящее изобретение описано и проиллюстрировано с обращением к различным вариантам осуществления, специалистам в данной области техники следует понимать, что могут быть выполнены различные изменения, касающиеся его формы и конкретных подробностей, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.
Библиография
[1] M. Tagliasacchi, Y. Li, K. Misiunas, and D. Roblek, “Seanet: A multi-modal speech enhancement network,” arXiv preprint arXiv:2009,02095, 2020.
[2] S. Pascual, A. Bonafonte, and J. Serra, “Segan: Speech enhancement generative adversarial network,” arXiv preprint arXiv:1703,09452, 2017.
[3] A. Defossez, G. Synnaeve, and Y. Adi, “Real time speech enhancement in the waveform domain,” in Interspeech, 2020.
[4] E. Kim and H. Seo, “SE-Conformer: Time-Domain Speech Enhancement Using Conformer,” in Proc. Interspeech 2021, 2021, pp. 2736-2740.
[5] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee, “Phase-aware speech enhancement with deep complex u-net,” in International Conference on Learning Representations, 2018.
[6] S.-W. Fu, C.-F. Liao, Y. Tsao, and S.-D. Lin, “Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement,” in International Conference on Machine Learning. PMLR, 2019, pp. 2031-2041.
[7] S.-W. Fu, C. Yu, T.-A. Hsieh, P. Plantinga, M. Ravanelli, X. Lu, and Y. Tsao, “Metricgan+: An improved version of metricgan for speech enhancement,” arXiv preprint arXiv:2104,03538, 2021.
[8] L. Chi, B. Jiang, and Y. Mu, “Fast fourier convolution,” Advances in Neural Information Processing Systems, vol. 33, pp. 4479-4488, 2020.
[9] H. J. Nussbaumer, “The fast fourier transform,” in Fast Fourier Transform and Convolution Algorithms. Springer, 1981, pp. 80-111.
[10] R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V. Lempitsky, “Resolution-robust large mask inpainting with fourier convolutions,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2149-2159.
[11] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234-241.
[12] J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” arXiv preprint arXiv:2010,05646, 2020.
[13] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley, “Least squares generative adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2794-2802.
[14] K. Kumar, R. Kumar, T. de Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. de Br'ebisson, Y. Bengio, and A. Courville, “Melgan: Generative adversarial networks for conditional waveform synthesis,” arXiv preprint arXiv:1910,06711, 2019.
[15] C. Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[16] H. Dubey, V. Gopal, R. Cutler, A. Aazami, S. Matusevych, S. Braun, S. E. Eskimez, M. Thakker, T. Yoshioka, H. Gamper et al., “Icassp 2022 deep noise suppression challenge,” arXiv preprint arXiv:2202,13288, 2022.
[17] A.W. Rix, J.G. Beerends, M.P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749-752.
[18] C.H. Taal, R.C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time-frequency weighted noisy speech,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125-2136, 2011.
[19] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “Sdr-half-baked or well done?” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626-630.
[20] H. Liu, Q. Kong, Q. Tian, Y. Zhao, D. Wang, C. Huang, and Y. Wang, “Voicefixer: Toward general speech restoration with neural vocoder,” arXiv preprint arXiv:2109,13731, 2021.
[21] Q. Kong, Y. Cao, H. Liu, K. Choi, and Y. Wang, “Decoupling magnitude and phase estimation with deep resunet for music source separation,” arXiv preprint arXiv:2109,05418, 2021.
[22] X. Hao, X. Su, R. Horaud, and X. Li, “Fullsubnet: a full-band and sub-band fusion model for real-time single-channel speech enhancement,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6633-6637.
[23] K. Ito and L. Johnson, “The lj speech dataset,” https://keithito.com/LJ-Speech-Dataset/, 2017.
| название | год | авторы | номер документа |
|---|---|---|---|
| Неконтролируемое восстановление голоса с использованием модели безусловной диффузии без учителя | 2023 |
|
RU2823017C1 |
| Способ улучшения речевого сигнала с низкой задержкой, вычислительное устройство и считываемый компьютером носитель, реализующий упомянутый способ | 2023 |
|
RU2802279C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ ПАЦИЕНТА НА НАЛИЧИЕ ПРИЗНАКОВ РЕСПИРАТОРНОЙ ИНФЕКЦИИ ПОСРЕДСТВОМ CNN С МЕХАНИЗМОМ ВНИМАНИЯ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2021 |
|
RU2758648C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ ГЛУБОКОГО ФИЛЬТРА | 2020 |
|
RU2788939C1 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ГЕНЕРАЦИИ АУДИОСИГНАЛА С РАСШИРЕННОЙ ПОЛОСОЙ С ИСПОЛЬЗОВАНИЕМ ПРОЦЕССОРА НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2745298C1 |
| ТЕХНОЛОГИЯ АНАЛИЗА АКУСТИЧЕСКИХ ДАННЫХ НА НАЛИЧИЕ ПРИЗНАКОВ ЗАБОЛЕВАНИЯ COVID-19 | 2021 |
|
RU2758649C1 |
| Способ диагностики признаков бронхолегочных заболеваний, сопутствующих заболеванию вирусом COVID-19 | 2021 |
|
RU2758550C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ ВОЛНОВОЙ ФОРМЫ | 2021 |
|
RU2803488C2 |
Изобретение относится к области аудиообработки. Технический результат заключается в повышении точности подавления шума в речевом сигнале. Технический результат достигается за счет того, что разделяют каналы входного тензора на локальную и глобальную ветви; используют обычные сверточные слои для локальных обновлений карт преобразований тензора на локальной ветви; осуществляют преобразование Фурье в частотном измерении тензора глобальной ветви; обновляют карту характеристик глобальной ветви в спектральной области посредством поточечных сверточных слоев; применяют обратное преобразование Фурье к обновленной карте характеристик глобальной ветви; и суммируют активации локальной и глобальной ветвей. 3 н. и 7 з.п. ф-лы, 4 ил., 3 табл.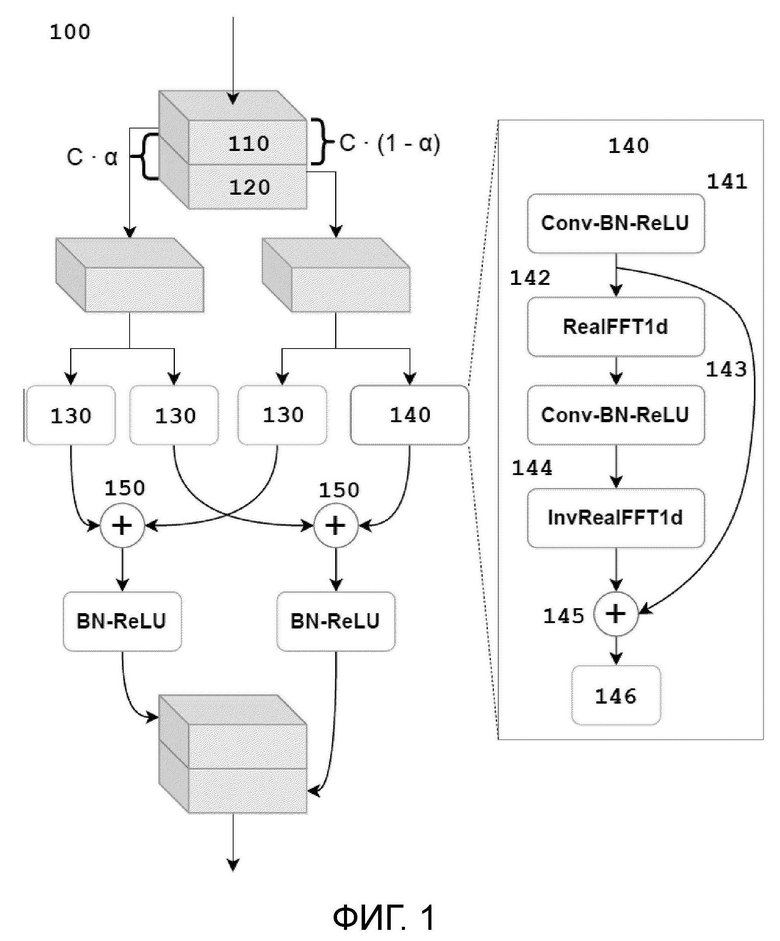
1. Способ подавления шума в речевом сигнале с использованием по меньшей мере одного оператора быстрой свертки Фурье, причем способ содержит этапы, на которых:
разделяют каналы входного тензора на локальную и глобальную ветви;
используют обычные сверточные слои для локальных обновлений карт преобразований тензора на локальной ветви;
осуществляют преобразование Фурье в частотном измерении тензора глобальной ветви;
обновляют карту характеристик глобальной ветви в спектральной области посредством поточечных сверточных слоев;
применяют обратное преобразование Фурье к обновленной карте характеристик глобальной ветви; и
суммируют активации локальной и глобальной ветвей.
2. Способ по п. 1, в котором каналы входного тензора выводятся из входной спектрограммы, представляющей аудиосигнал, содержащий речь.
3. Способ по п. 1, в котором суммированные активации локальной и глобальной ветвей отражаются в выходной спектрограмме, представляющей улучшенный аудиосигнал, содержащий речь.
4. Способ по п. 1, в котором по меньшей мере один оператор быстрой свертки Фурье является частью архитектуры нейронной сети с автоэнкодером быстрой свертки Фурье (FFC-AE).
5. Способ по п. 1, в котором по меньшей мере один оператор быстрой свертки Фурье является частью архитектуры нейронной сети с быстрой сверткой Фурье U-Net (FFC-UNet).
6. Способ по п. 1, в котором обновление карты характеристик глобальной ветви содержит этапы, на которых:
применяют действительное одномерное быстрое преобразование Фурье в частотном измерении входной карты характеристик и конкатенируют действительную и мнимую части спектра в канальном измерении:
применяют сверточный блок (с ядром 1×1) в частотной области;
применяют обратное преобразование Фурье.
7. Способ по п. 1, в котором по меньшей мере один оператор быстрой свертки Фурье применяется в частотном измерении.
8. Способ по п. 1, причем способ содержит этапы, на которых используют сверточную нейронную сеть, использующую одну или более моделей машинного обучения (ML), обученных посредством инструментария мультидискриминаторного состязательного обучения.
9. Устройство для подавления шума в речевом сигнале с использованием оператора быстрой свертки Фурье, причем устройство содержит:
память; и
процессор, соединенный с памятью, причем процессор, при выполнении инструкций, сохраненных в памяти, выполнен с возможностью:
разделения каналов входного тензора на локальную и глобальную ветви;
использования обычных сверточных слоев для локальных обновлений карт преобразований тензора на локальной ветви;
осуществления преобразования Фурье в частотном измерении тензора глобальной ветви;
обновления карты характеристик глобальной ветви в спектральной области посредством поточечных сверточных слоев;
применения обратного преобразования Фурье к обновленной карте характеристик глобальной ветви; и
суммирования активаций локальной и глобальной ветвей.
10. Машиночитаемый носитель, на котором хранятся исполняемые процессором инструкции, которые, при выполнении по меньшей мере одним процессором, предписывают по меньшей мере одному процессору осуществлять способ по любому из пп. 1-8.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 6625629 B1, 23.09.2003 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2010 |
|
RU2517315C2 |

