Настоящее изобретение относится к обработке и декодированию аудиосигнала, и, в частности, к устройству и способу для улучшения перехода от маскированного участка аудиосигнала к последующему участку аудиосигнала.
В случае подверженной ошибкам сети, любой кодек пытается уменьшить искажения из-за этих потерь. Уровень техники сфокусирован на маскировании потерянной информации посредством разных способов, от простого приглушения или вычитания шума, до усовершенствованных способов, таких как предсказание, основанное на прошлых хороших кадрах. Один явный пропущенный большой источник искажений из-за потерь пакета находится в восстановлении (несколько хороших кадров после потери).
Из-за долгосрочного предсказания, часто используемого в случае речевых кодеков, искажения восстановления могут быть действительно серьезными и распространение ошибки может повлиять на несколько следующих хороших кадров. Некоторые из предшествующих уровней техники пытаются смягчить эту проблему, см., например, [1] и [2].
В случае общих или аудио кодеков (любой кодек, работающий в области преобразований), можно найти много документации касательно маскирования потерь кадров подобно в [3]. Тем не менее, доступный предшествующий уровень техники не фокусируется на восстановлении кадров. Предполагается, что из-за природы кодека области преобразований, который осуществляет перекрытие и сложение, будут сглаживаться искажения перехода. Одним хорошим примером является AAC-ELD (AAC-ELD=Усовершенствованное Кодирование Аудиоматериалов - Улучшенная низкая задержка; см. [4]), используемый во время живого общения для связи по IP-сети.
Первые несколько кадров после потери кадров именуются «кадрами восстановления». Кодеки области преобразования предшествующего уровня техники, как представляется, не обеспечивают особой обработки касательно одного или более кадров восстановления. Иногда, возникают раздражающие искажения. Примером применительно к проблеме, которая может возникнуть при проведении восстановления, является наложение маскированного и хорошего волнового сигнала в части перекрытия и сложения, которое иногда приводит к раздражающим подъемам энергии.
Другой проблемой являются резкие изменения основного тона на границах кадра. Пример для случая речевых сигналов состоит в том, что когда основной тон исходного сигнала меняется и происходит потеря кадра, способ маскирования может предсказывать основной тон в конце кадра слегка неправильно. Данное слегка неправильное предсказание может вызывать скачок основного тона в следующий хороший кадр. Большая часть известных способов маскирования даже не используют предсказание, а используют лишь фиксированный основной тон, основанный на последнем действительном основном тоне, что может привести даже к большему несоответствию с первым хорошим кадром. Некоторые другие способы используют усовершенствованное предсказание, чтобы предсказывать дрейф, см., например, TD-TCX PLC (TD=Временная область; TCX=Кодированное с Преобразованием Возбуждение; PLC=Маскирование Потери Пакета) в EVS (EVS=Улучшенные Голосовые Услуги), см. [5].
Способы уровня техники для модифицирования основного тона в речевом сигнале, такие как TD-PSOLA (TD-PSOLA=Временной Области-Перекрытие со Сложением синхронизированное с Основным Тоном), см. [6] и [7], проводят интонационные модификации над речевым сигналом такие, как расширение/сокращение продолжительности (известное как растяжение времени), или проводят изменение собственной частоты (основного тона). Это выполняется, посредством разложения речевого сигнала на краткосрочные и синхронизированные по основному тону сигналы анализа, которые затем переставляются по оси времени и сочленяются постепенно. Тем не менее, сигнал в кадре восстановления разрушается после механизма перекрытия, когда основной тон в маскированном кадре и основной тон в исходном сигнале различаются. Механизм TD-PSOLA будет лишь переставлять искажение по осям времени, что неприемлемо для восстановления.
Цель настоящего изобретения состоит в предоставлении улучшенных концепций для обработки и декодирования аудиосигнала.
Цель настоящего изобретения решается посредством устройства, в соответствии с пунктом 1, посредством способа в соответствии с пунктом 35, и посредством компьютерной программы, в соответствии с пунктом 36.
Предоставляется устройство для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала.
Устройство содержит процессор, выполненный с возможностью генерирования декодированного участка аудиосигнала у аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала, при этом первый участок аудиосигнала зависит от маскированного участка аудиосигнала, и при этом второй участок аудиосигнала зависит от последующего участка аудиосигнала.
Более того, устройство содержит интерфейс вывода для вывода декодированного участка аудиосигнала.
Каждый из первого участка аудиосигнала и из второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок, при этом каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки, при этом множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки из множества позиций выборки и второй позиции выборки из множества позиций выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки.
Процессор выполнен с возможностью определения первого суб-участка первого участка аудиосигнала так, что первый суб-участок содержит меньше выборок, чем первый участок аудиосигнала.
Процессор выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый суб-участок первого участка аудиосигнала и используя второй участок аудиосигнала или второй суб-участок второго участка аудиосигнала так, что для каждой выборки из двух или более выборок второго участка аудиосигнала, позиция выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала равна позиции выборки одной из выборок декодированного участка аудиосигнала, и так, что значение выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала отличается от значения выборки у упомянутой одной из выборок декодированного участка аудиосигнала.
Более того, способ для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала. Способ содержит этапы, на которых:
- Генерируют декодированный участок аудиосигнала у аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала, при этом первый участок аудиосигнала зависит от маскированного участка аудиосигнала, и при этом второй участок аудиосигнала зависит от последующего участка аудиосигнала. И:
- Выводят декодированный участок аудиосигнала.
Каждый из первого участка аудиосигнала и из второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок, при этом каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки, при этом множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки из множества позиций выборки и второй позиции выборки из множества позиций выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки.
Этап, на котором генерируют декодированный аудиосигнал, содержит этап, на котором определяют первый суб-участок первого участка аудиосигнала так, что первый суб-участок содержит меньше выборок, чем первый участок аудиосигнала.
Более того, этап, на котором генерируют декодированный участок аудиосигнала проводится, используя первый суб-участок первого участка аудиосигнала и используя второй участок аудиосигнала или второй суб-участок второго участка аудиосигнала так, что для каждой выборки из двух или более выборок второго участка аудиосигнала, позиция выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала равна позиции выборки одной из выборок декодированного участка аудиосигнала, и так, что значение выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала отличается от значения выборки у упомянутой одной из выборок декодированного участка аудиосигнала.
Кроме того, предоставляется компьютерная программа, которая выполнена с возможностью реализации описанного выше способа при исполнении на компьютере или сигнальном процессоре.
Некоторые варианты осуществления предоставляют фильтр восстановления, инструмент для сглаживания и исправления перехода от потерянного кадра к первому хорошему кадру в (например, основанному на блоках) аудио кодеке. В соответствии с вариантами осуществления, фильтр восстановления может быть использован, чтобы фиксировать изменение основного тона в течение маскированного кадра в первом хорошем кадре речевого сигнала, а также чтобы сглаживать переход сигнала с шумами.
В частности, некоторые варианты осуществления основаны на обнаружении того, что длина модификации сигнала является ограниченной, начинающейся с последней выборки воспроизводимой в маскированном кадре до последней выборки первого хорошего кадра. Длина может быть увеличена сверх последней выборки в первом хорошем кадре, но тогда это может привести к распространению ошибки, которую будет трудно обработать в будущих кадрах. Таким образом, требуется быстрое восстановление. Для того чтобы восстанавливать речевую характеристику в случае несоответствия между потерянным и восстановленным кадром, основной тон сигнала в восстановленном кадре должен меняться медленно от основного тона в маскированном кадре до основного тона в восстановленном кадре в то время, как должно сохраняться ограничение длины модификации сигнала. При алгоритме TD-PSOLA, это может быть возможно только, если основной тон меняется на несколько целочисленных значений. Поскольку это очень редкий случай, TD-PSOLA не может быть применен в таких ситуациях.
В нижеследующем, варианты осуществления настоящего изобретения описываются более подробно со ссылкой на фигуры, на которых:
Фиг. 1a иллюстрирует устройство для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с вариантом осуществления.
Фиг. 1b иллюстрирует устройство для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с другим вариантом осуществления, реализующим концепцию перекрытия с адаптацией основного тона.
Фиг. 1c иллюстрирует устройство для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с другим вариантом осуществления, реализующим концепцию перекрытия возбуждения.
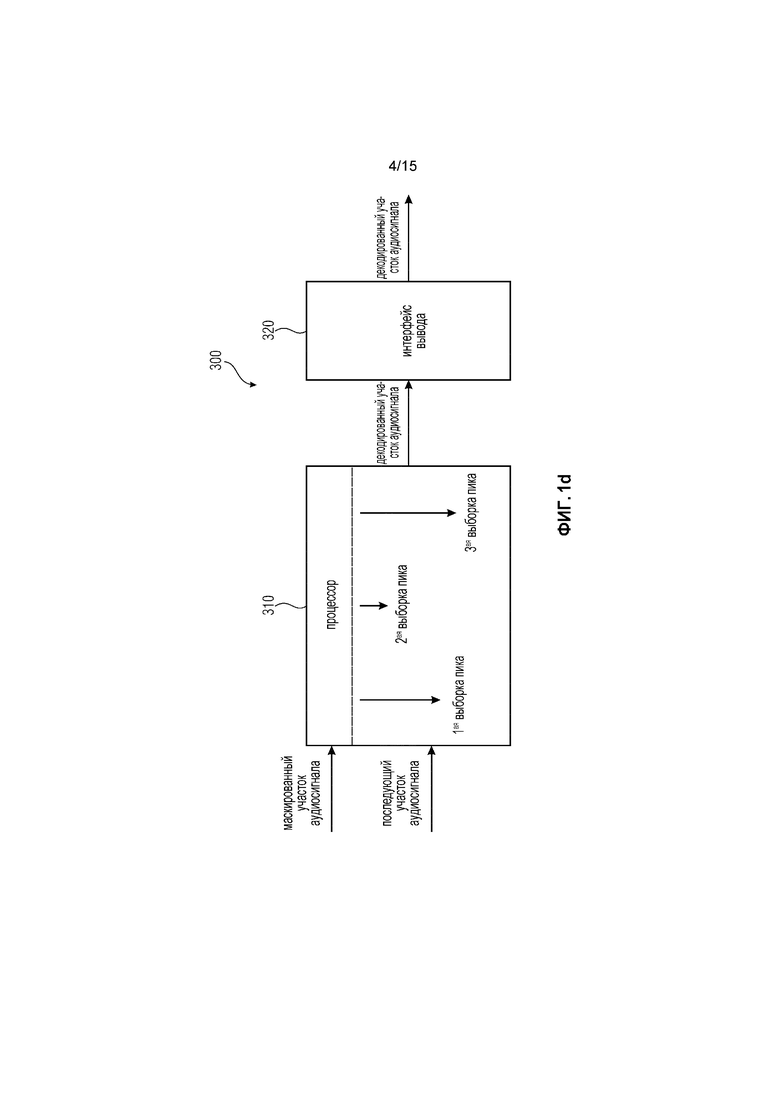
Фиг. 1d иллюстрирует устройство для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с дополнительным вариантом осуществления, реализующим гашение энергии.
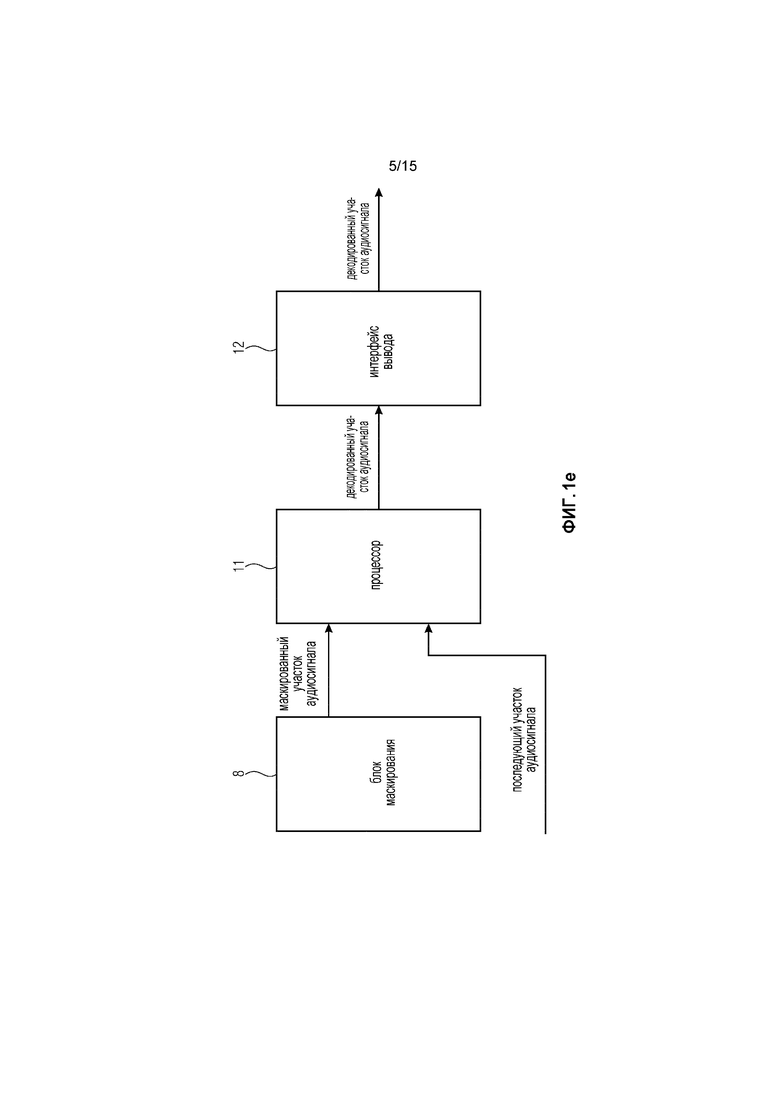
Фиг. 1e иллюстрирует устройство в соответствии с дополнительным вариантом осуществления, при этом устройство дополнительно содержит блок маскирования.
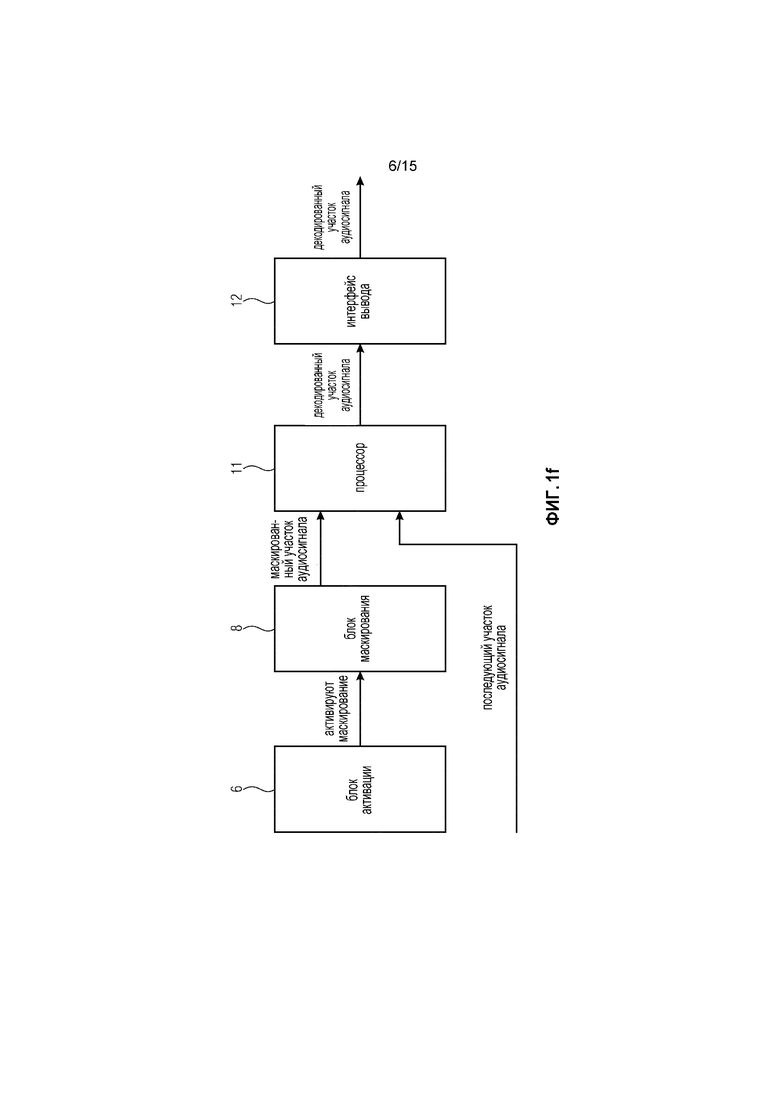
Фиг. 1f иллюстрирует устройство в соответствии с другим вариантом осуществления, при этом устройство дополнительно содержит блок активации для активации блока маскирования.
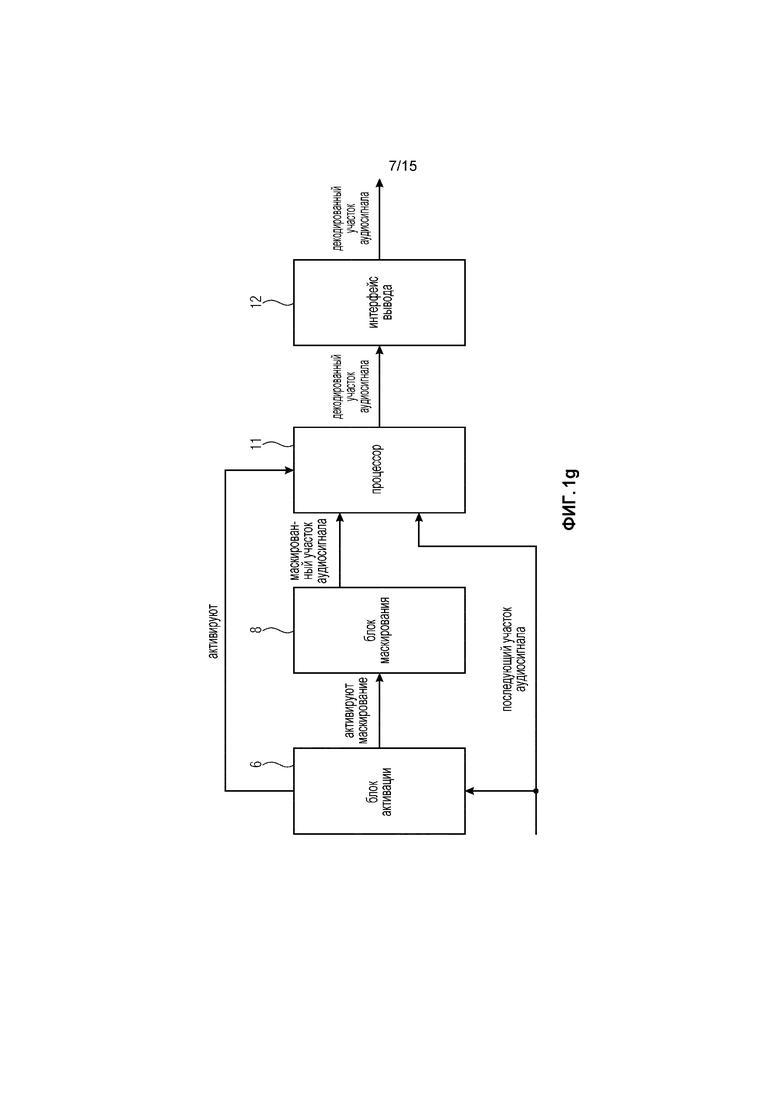
Фиг. 1g иллюстрирует устройство в соответствии с дополнительным вариантом осуществления, в котором блок активации дополнительно выполнен с возможностью активации процессора.
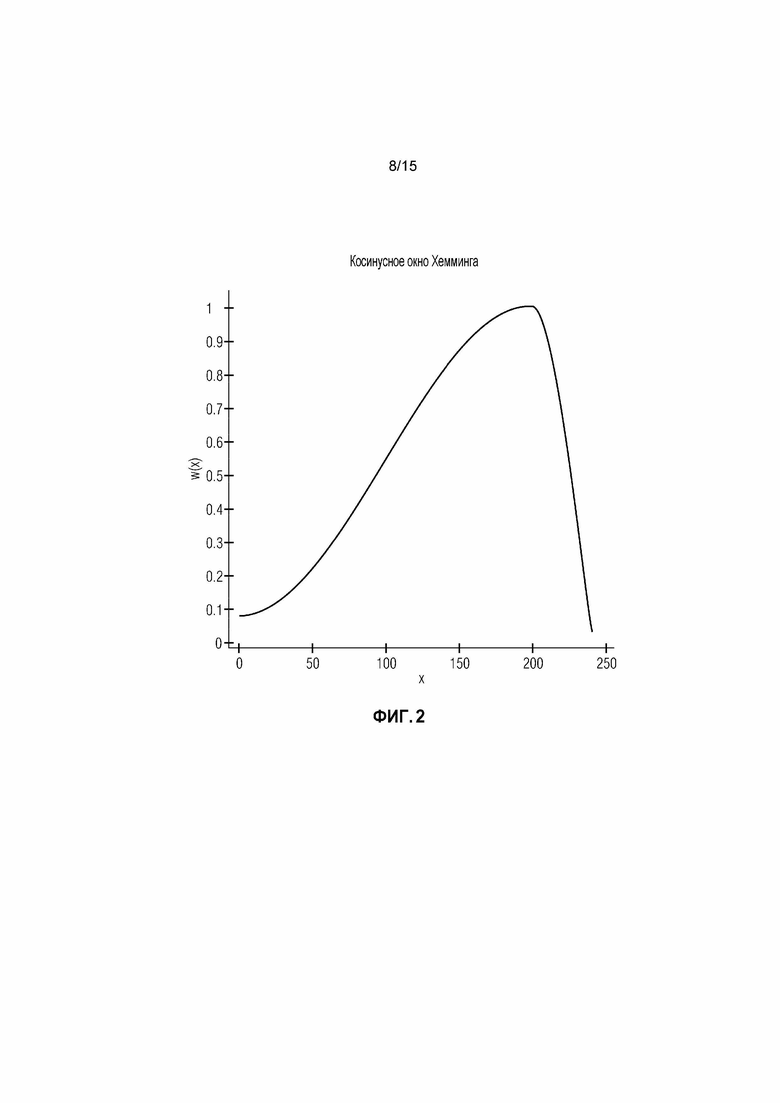
Фиг. 2 иллюстрирует косинусное окно Хемминга в соответствии с вариантом осуществления.
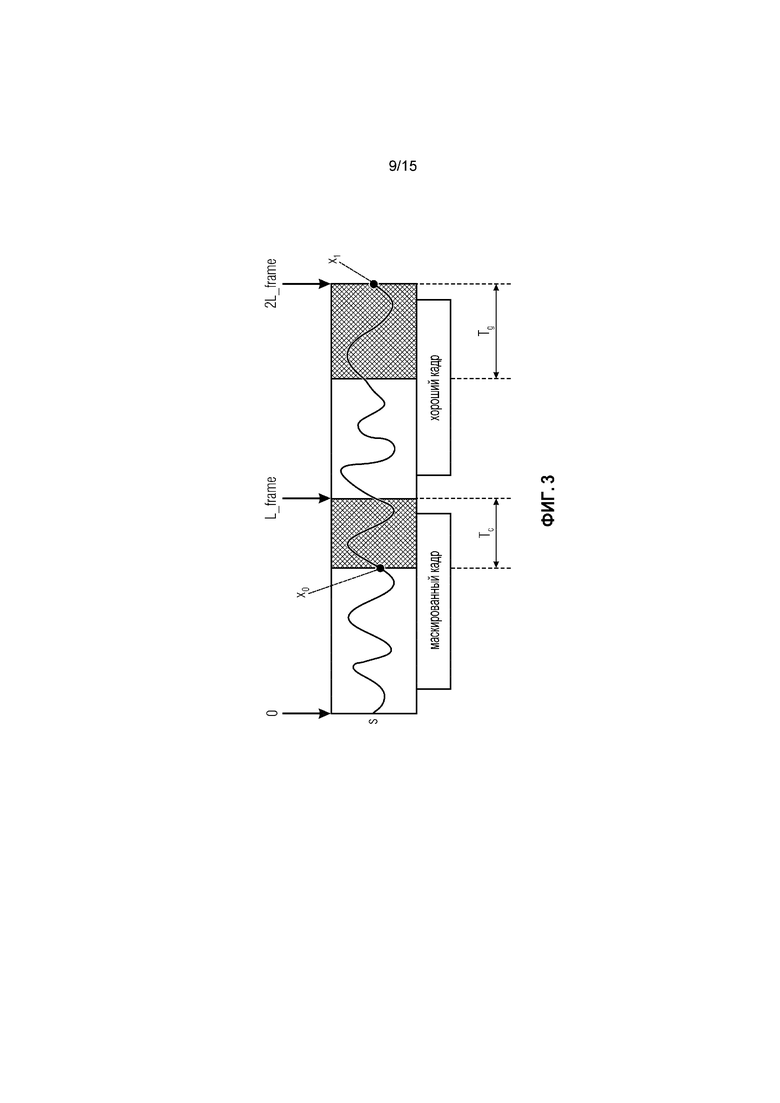
Фиг. 3 иллюстрирует маскированный кадр и хороший кадр в соответствии с таким вариантом осуществления.
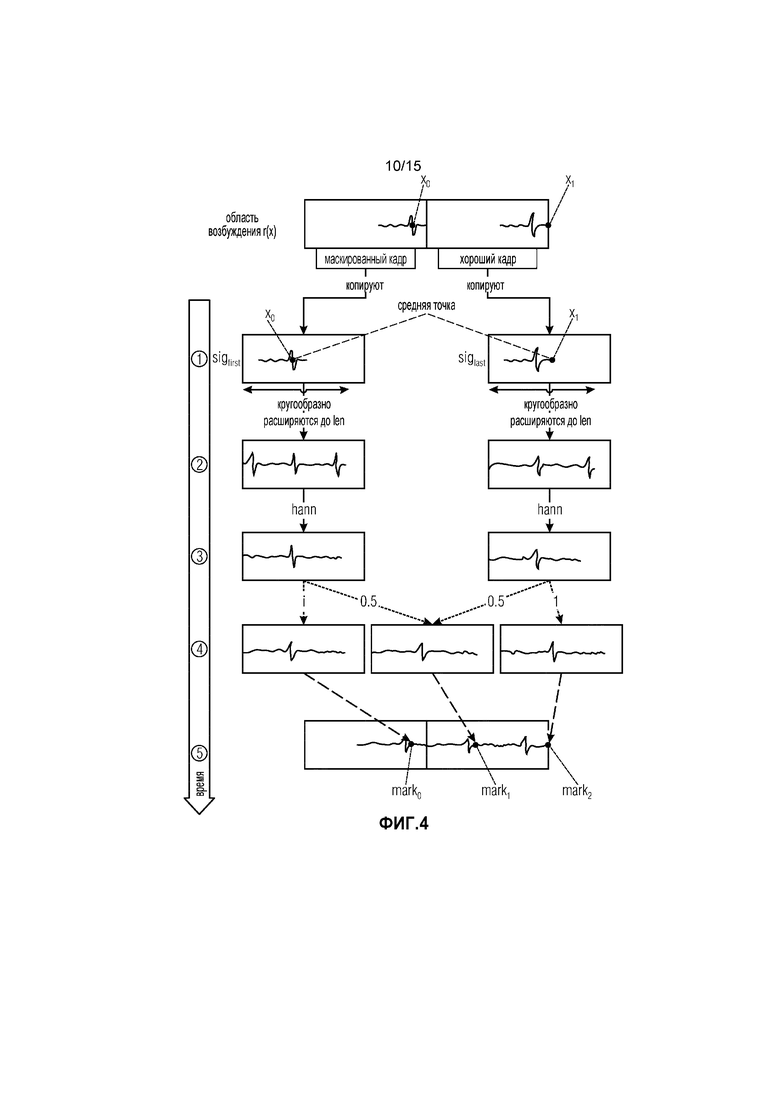
Фиг. 4 иллюстрирует генерирование двух прототипов, реализующих перекрытие с адаптацией основного тона в соответствии с вариантом осуществления. И:
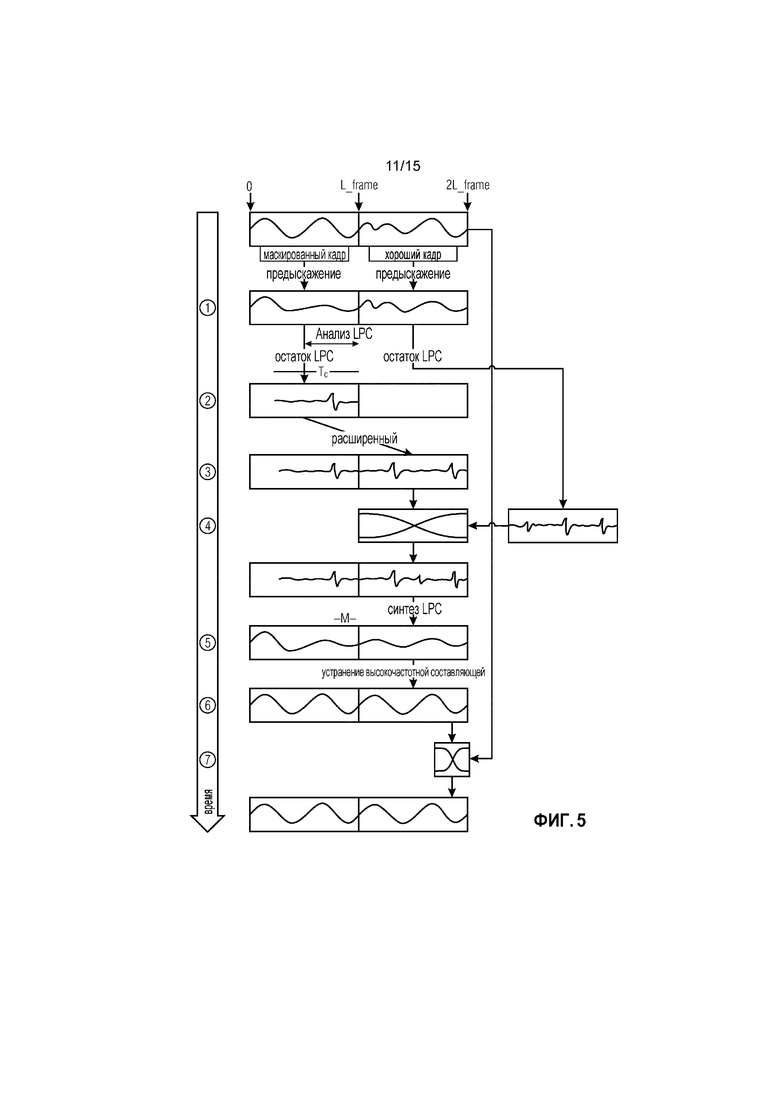
Фиг. 5 иллюстрирует перекрытие возбуждения в соответствии с вариантом осуществления.
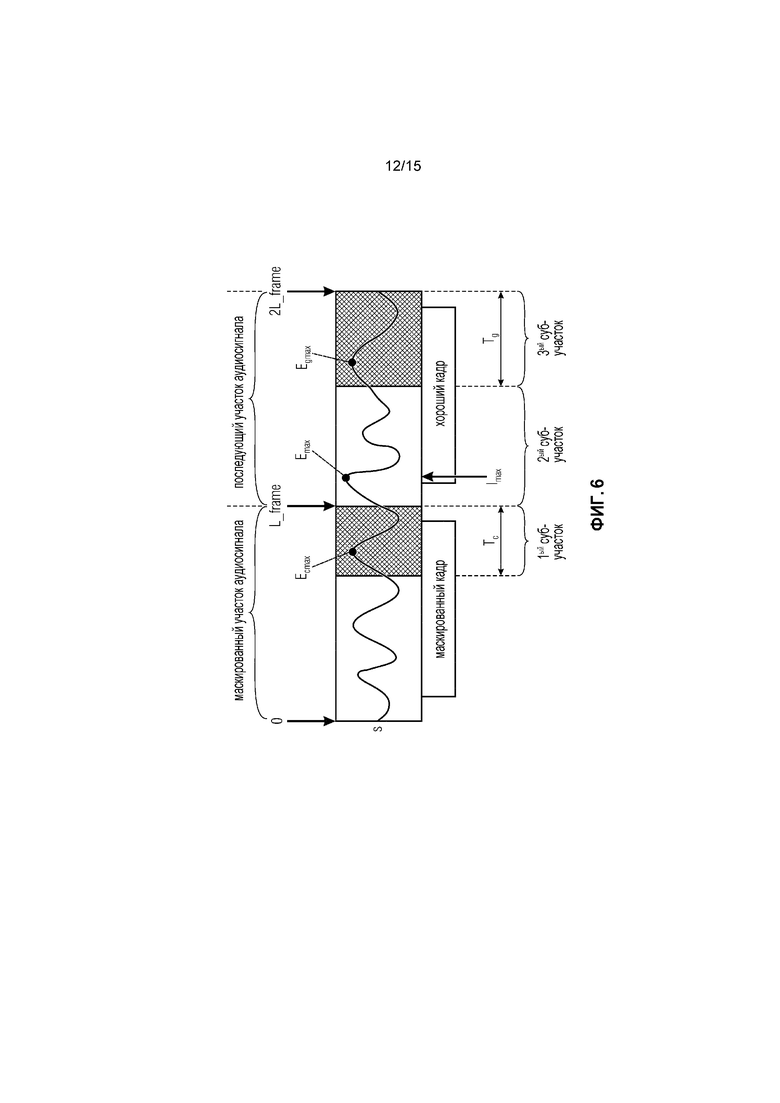
Фиг. 6 иллюстрирует маскированный кадр и хороший кадр в соответствии с вариантом осуществления.
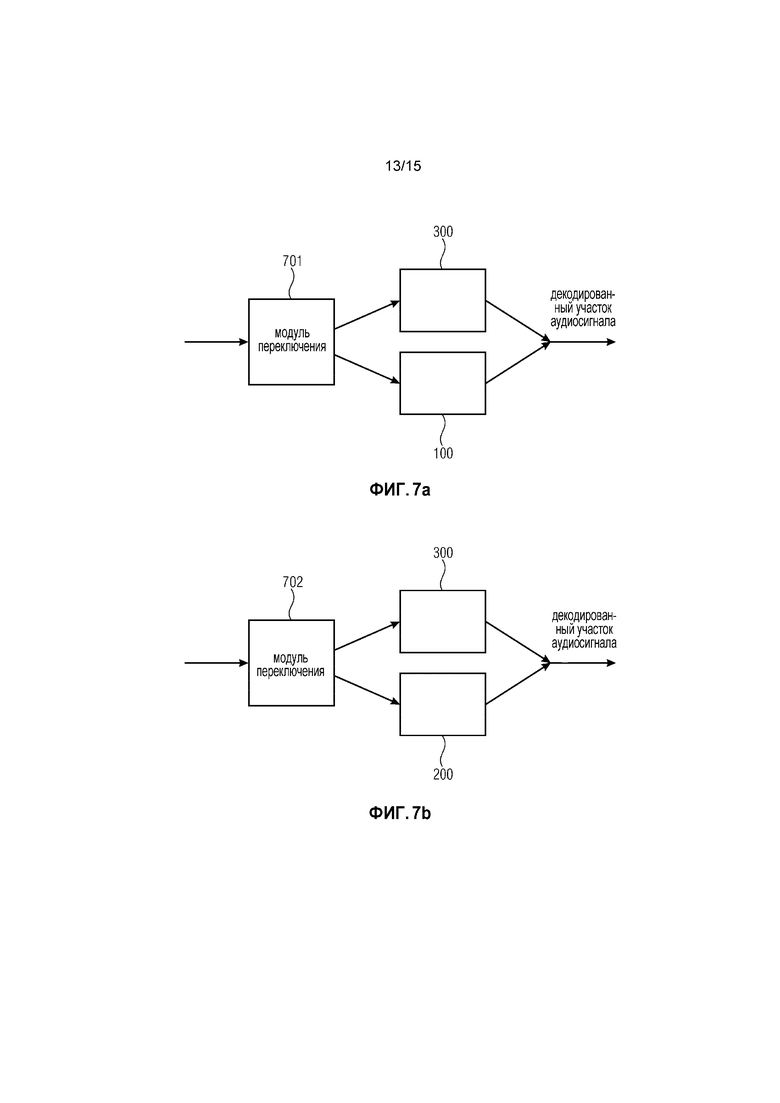
Фиг. 7a иллюстрирует систему в соответствии с вариантом осуществления.
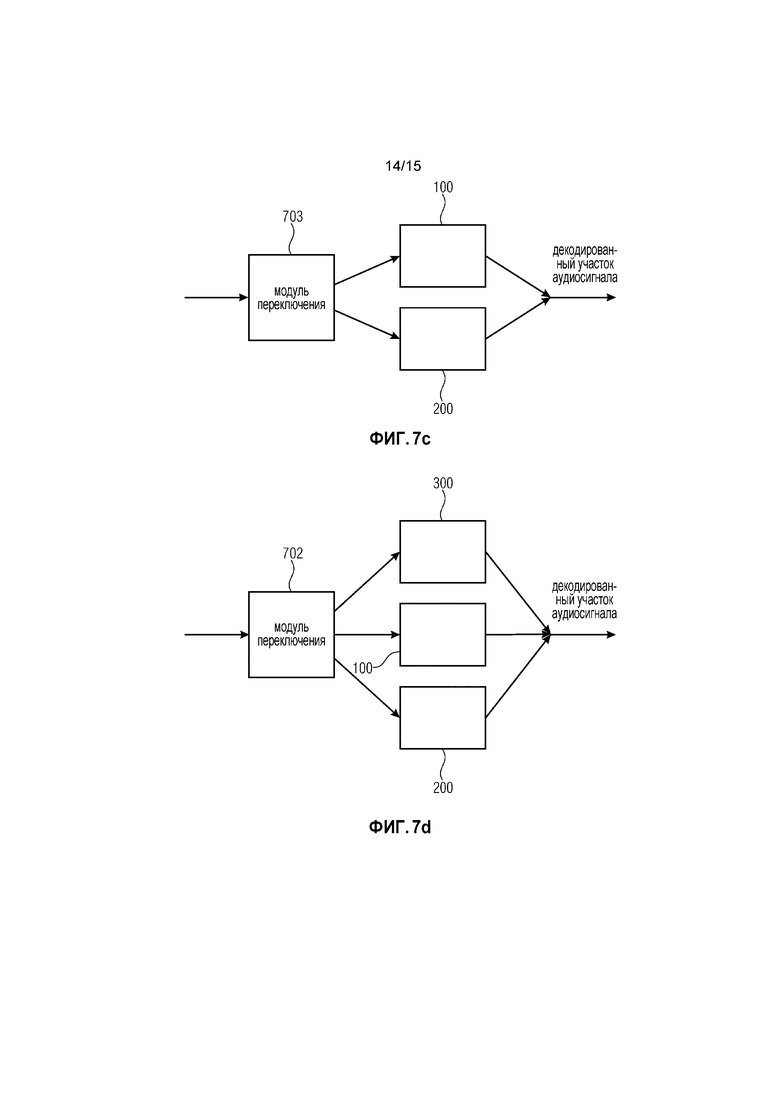
Фиг. 7b иллюстрирует систему в соответствии с другим вариантом осуществления.
Фиг. 7c иллюстрирует систему в соответствии с дополнительным вариантом осуществления.
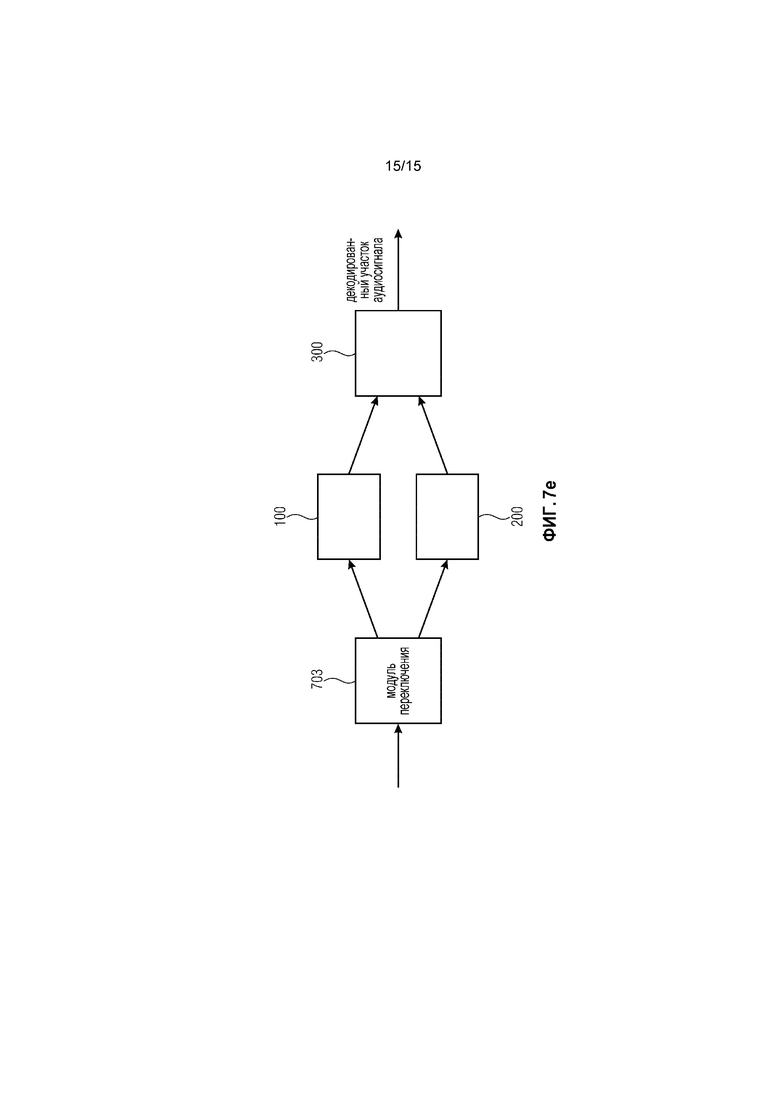
Фиг. 7d иллюстрирует систему в соответствии с еще одним дополнительным вариантом осуществления. И:
Фиг. 7e иллюстрирует систему в соответствии с другим вариантом осуществления.
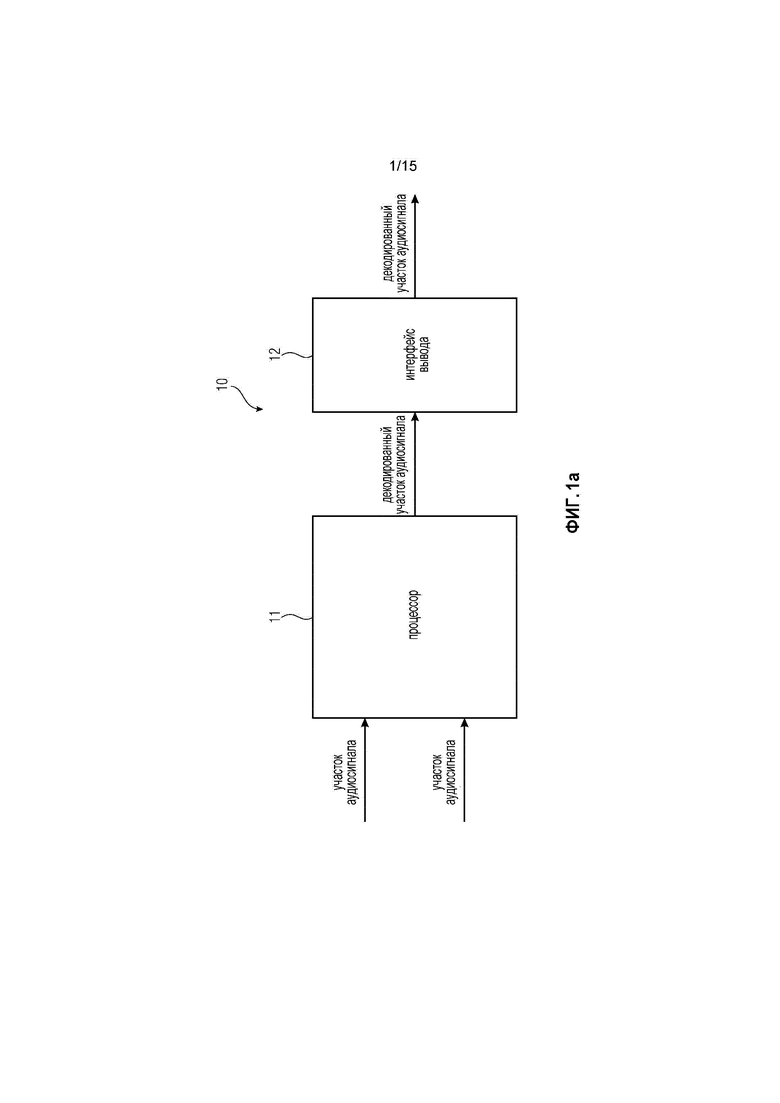
Фиг. 1a иллюстрирует устройство 10 для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с вариантом осуществления.
Устройство 10 содержит процессор 11, выполненный с возможностью генерирования декодированного участка аудиосигнала у аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала, при этом первый участок аудиосигнала зависит от маскированного участка аудиосигнала, и при этом второй участок аудиосигнала зависит от последующего участка аудиосигнала.
В некоторых вариантах осуществления, первый участок аудиосигнала может, например, быть извлечен из маскированного участка аудиосигнала, но может, например, быть отличным от маскированного участка аудиосигнала, и/или второй участок аудиосигнала может, например, быть извлечен из последующего участка аудиосигнала, но может, например, быть отличным от последующего участка аудиосигнала.
В других вариантах осуществления, первый участок аудиосигнала может, например, быть (равным) маскированным участком аудиосигнала, а второй участок аудиосигнала может, например, быть последующим участком аудиосигнала.
Более того, устройство 10 содержит интерфейс 12 вывода для вывода декодированного участка аудиосигнала.
Каждый из первого участка аудиосигнала и из второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок, при этом каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки, при этом множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки из множества позиций выборки и второй позиции выборки из множества позиций выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки.
Например, выборка определяется посредством позиции выборки и значения выборки. Например, позиция выборки может определять значение оси x (значение оси абсцисс) у выборки, а значение выборки может определять значение оси y (значение оси ординат) той же самой в двумерной системе координат. Таким образом, рассматривая конкретную выборку, все выборки расположенные слева от конкретной выборки внутри двумерной системы координат являются предшествующими элементами конкретной выборки (так как их позиция выборки меньше позиции выборки у конкретной выборки) Все выборки расположенные справа от конкретной выборки внутри двумерной системы координат являются последующими элементами конкретной выборки (так как их позиция выборки больше позиции выборки у конкретной выборки).
Процессор 11 выполнен с возможностью определения первого суб-участка первого участка аудиосигнала так, что первый суб-участок содержит меньше выборок чем первый участок аудиосигнала.
Процессор 11 выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый суб-участок первого участка аудиосигнала и используя второй участок аудиосигнала или второй суб-участок второго участка аудиосигнала так, что для каждой выборки из двух или более выборок второго участка аудиосигнала, позиция выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала равна позиции выборки одной из выборок декодированного участка аудиосигнала, и так, что значение выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала отличается от значения выборки у упомянутой одной из выборок декодированного участка аудиосигнала.
Таким образом, в некоторых вариантах осуществления процессор 11 выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый суб-участок и используя второй участок аудиосигнала.
В других вариантах осуществления, процессор 11 служит для генерирования декодированного участка аудиосигнала, используя первый суб-участок и используя второй суб-участок второго участка аудиосигнала. Второй суб-участок может содержать меньше выборок чем второй участок аудиосигнала.
Варианты осуществления основаны на обнаружении того, что преимущественным является улучшение перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала посредством модифицирования выборок последующего участка аудиосигнала, а не только посредством регулировки выборок маскированного аудиосигнала. Также посредством модифицирования выборок корректно принятого кадра, переход от маскированного участка аудиосигнала (например, у маскированного кадра аудиосигнала) к последующему участку аудиосигнала (например, у последующего кадра аудиосигнала) может быть улучшен.
Таким образом, декодированный участок аудиосигнала генерируется, используя первый и второй участок аудиосигнала, но декодированный участок аудиосигнала (по меньшей мере, две или более) содержит выборки, которые назначаются позициям выборки в качестве выборок второго участка аудиосигнала (в зависимости от последующего участка аудиосигнала), чьи значения выборки отличаются. Это означает, что для этих выборок, значения выборок у соответствующих выборок не берутся как они есть, а вместо этого модифицируются, чтобы получить соответствующие выборки декодированного участка аудиосигнала.
Касательно первого участка аудиосигнала и второго участка аудиосигнала, процессор 11 может, например, принимать первый участок аудиосигнала и второй участок аудиосигнала.
Или, в другом варианте осуществления, например, процессор 11 может, например, принимать маскированный участок аудиосигнала и может определять первый участок аудиосигнала из маскированного участка аудиосигнала, и процессор 11 может, например, принимать последующий участок аудиосигнала и может определять второй участок аудиосигнала из последующего участка аудиосигнала.
Или, в дополнительном варианте осуществления, например, процессор 11 может, например, принимать кадры аудиосигнала; процессор 11 может, например, определять, что первый кадр потерян или что первый кадр искажен. Процессор 11 затем может проводить маскирование и может, например, генерировать маскированный участок аудиосигнала в соответствии с концепциями уровня техники. Более того, процессор 11 может, например, принимать, второй кадр аудиосигнала и может, получать последующий участок аудиосигнала из второго кадра аудиосигнала. Фиг. 1e иллюстрирует такой вариант осуществления.
В некоторых вариантах осуществления, первый участок аудиосигнала может, например, быть участком остаточного сигнала первого остаточного сигнала, являющегося остаточным сигналом по отношению к маскированной части аудиосигнала. Второй участок аудиосигнала может, например, в некоторых вариантах осуществления, быть участком остаточного сигнала второго остаточного сигнала, являющегося остаточным сигналом по отношению к последующему участку аудиосигнала.
На Фиг. 1e, устройство 10 дополнительно содержит блок 8 маскирования, выполненный с возможностью проведения маскирования для текущего кадра, который является ошибочным или который потерян, чтобы получать маскированный участок аудиосигнала.
В соответствии с вариантами осуществления Фиг. 1e, устройство дополнительно содержит блок 8 маскирования. Блок 8 маскирования может, например, быть выполнен с возможностью проведения маскирования в соответствии с уровнем техники, если кадр потерян или искажен. Блок 8 маскирования затем доставляет маскированный участок аудиосигнала процессору 11. В таком варианте осуществления, маскированный участок аудиосигнала может, например, быть маскированным участком аудиосигнала для ошибочного или потерянного кадра, для которого было проведено маскирование. Последующий участок аудиосигнала может, например, быть последующим участком аудиосигнала (последующего) кадра аудиосигнала, для которого не проводилось маскирование. Последующий кадр аудиосигнала, может, например, следовать за ошибочным или потерянным кадром по времени.
Фиг. 1f иллюстрирует варианты осуществления, при этом устройство 10 дополнительно содержит блок 6 активации, который может, например, быть выполнен с возможностью обнаружения, потерян ли или ошибочен ли текущий кадр. Например, блок 6 активации может, например, делать вывод о том, что текущий кадр потерян, если он не прибыл в рамках предварительно определенного лимита времени после последнего принятого кадра. Или, например, блок активации может, например, делать вывод о том, что текущий кадр потерян, если прибывает дальнейший кадр, например, последующий кадр, который имеет номер кадра больше чем у текущего кадра. Блок 6 активации может, например, делать вывод о том, что кадр является ошибочным, если, например, принятая контрольная сумма или принятые контрольные биты не равны вычисленной контрольной сумме или вычисленным контрольным битам, которые вычислены блоком активации.
Блок 6 активации Фиг. 1f может, например, быть выполнен с возможностью активации блока 8 маскирования, чтобы проводить маскирование для текущего кадра, если текущий кадр потерян или является ошибочным.
Фиг. 1g иллюстрирует варианты осуществления, в которых блок 6 активации может, например, быть выполнен с возможностью обнаружения, прибывает ли последующий кадр, который не является ошибочным, если текущий кадр потерян или был ошибочным. В варианте осуществления Фиг. 1g, блок 6 активации может, например, быть выполнен с возможностью активации процессора (8), чтобы генерировать декодированный участок аудиосигнала, если текущий кадр потерян или является ошибочным и если прибывает последующий кадр, который не является ошибочным.
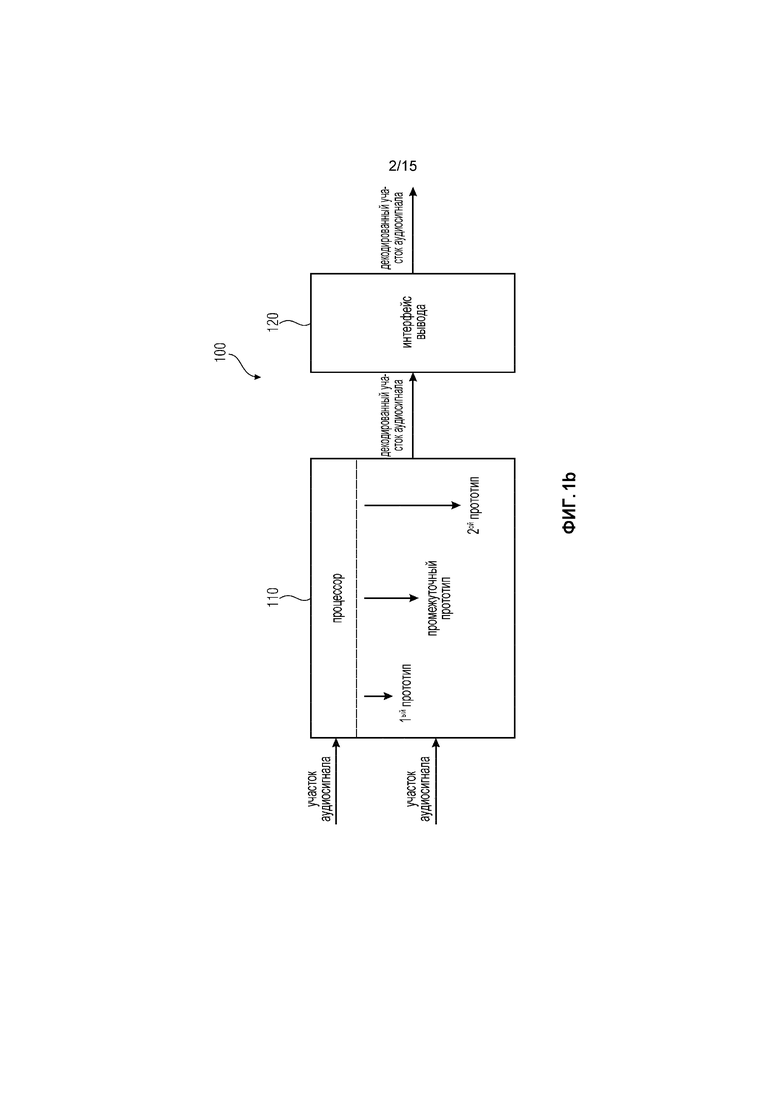
Фиг. 1b иллюстрирует устройство 100 для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с другим вариантом осуществления. Устройство Фиг. 1b реализует концепцию перекрытия с адаптацией основного тона.
Устройство 100 Фиг. 1b является конкретным вариантом осуществления устройство 10 Фиг. 1a. Процессор 110 Фиг. 1b является конкретным вариантом осуществления процессора 11 Фиг. 1a. Интерфейс 120 вывода Фиг. 1b является конкретным вариантом осуществления интерфейса 12 вывода Фиг. 1a.
В варианте осуществления Фиг. 1b, процессор 110 может, например, быть выполнен с возможностью определения второго участка-прототипа сигнала, являющегося суб-участком второго участка аудиосигнала так, что второй суб-участок содержит меньше выборок, чем второй участок аудиосигнала.
Процессор 110 может, например, быть выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения каждого из одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала, являющегося первым суб-участком, и второго участка-прототипа сигнала.
На Фиг. 1b, процессор 110 может, например, быть выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый участок-прототип сигнала и используя один или более промежуточные участки-прототипы сигнала и используя второй участок-прототип сигнала.
В соответствии с вариантом осуществления, процессор 110 может, например, быть выполнен с возможностью генерирования декодированного участка аудиосигнала посредством объединения первого участка-прототипа сигнала и одного или более промежуточных участков-прототипов сигнала и второго участка-прототипа сигнала.
В варианте осуществления, процессор 110 выполнен с возможностью определения множества из трех или более позиций выборки маркера определения множества из трех или более позиций выборки маркера, при этом каждая из трех или более позиций выборки маркера является позицией выборки, по меньшей мере, одного из первого участка аудиосигнала и второго участка аудиосигнала. Более того, процессор 110 выполнен с возможностью выбора позиции выборки у выборки второго участка аудиосигнала, которая является последующим элементом для любой другой позиции выборки у любой другой выборки второго участка аудиосигнала, в качестве конечной позиции выборки из трех или более позиций выборки маркера. Кроме того, процессор 110 выполнен с возможностью определения начальной позиции выборки из трех или более позиций выборки маркера посредством выбора позиции выборки из первого участка аудиосигнала в зависимости от корреляции между первым суб-участком первого участка аудиосигнала и втором суб-участком второго участка аудиосигнала. Более того, процессор 110 выполнен с возможность определения одной или более промежуточных позиций выборки из трех или более позиций выборки маркера в зависимости от начальной позиции выборки из трех или более позиций выборки маркера и в зависимости от конечной позиции выборки из трех или более позиций выборки маркера. Кроме того, процессор 110 выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения каждой из упомянутых одной или более промежуточных позиций выборки промежуточного участка-прототипа сигнала у одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала и второго участка-прототипа сигнала в зависимости от упомянутой промежуточной позиции выборки.
В соответствии с вариантом осуществления, процессор 110 выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения для каждой из упомянутых одной или более промежуточных позиций выборки промежуточного участка-прототипа сигнала у одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала и второго участка-прототипа сигнала в соответствии с
sigi=(1-α) ⋅ sigfirst+α ⋅ siglast
где
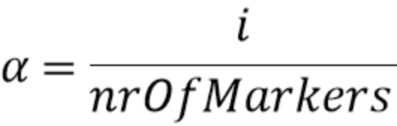
при этом i является целым числом, при i≥1, при этом nrOfMarkers является числом трех или более позиций выборки маркера минус 1, при этом sigi является i-ым промежуточным участком-прототипом сигнала из одного или более промежуточного участка-прототипа сигнала, при этом sigfirst является первым участком-прототипом сигнала, при этом siglast является вторым участком-прототипом сигнала.
В варианте осуществления, процессор 110 выполнен с возможностью определения одной или более промежуточных позиций выборки из трех или более позиций выборки маркера в зависимости от
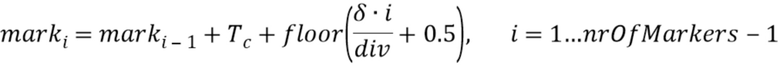
или в зависимости от
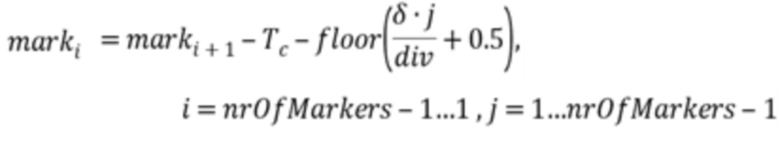
при этом 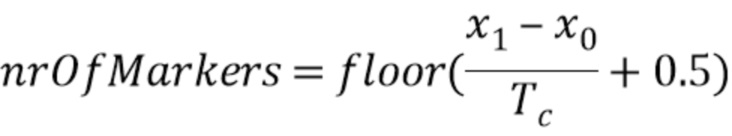 ,
,
при этом 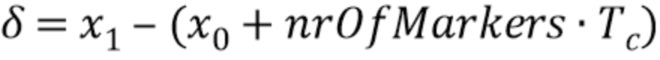 ,
,
при этом 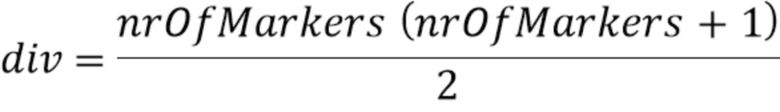 ,
,
при этом i является целым числом, при i≥1, при этом nrOfMarkers является числом трех или более позиций выборки маркера минус 1, при этом marki является i-ой промежуточной позицией выборки из трех или более позиций выборки маркера, при этом marki-1 является i-1-ой промежуточной позицией выборки из трех или более позиций выборки маркера, при этом marki+1 является i+1-ой промежуточной позицией выборки из трех или более позиций выборки маркера, при этом x0 является начальной позицией выборки из трех или более позиций выборки маркера, при этом x1 является конечной позицией выборки трех или более позиций выборки маркера, и при этом Tc указывает отставание основного тона.
В соответствии с вариантом осуществления, процессор 110 выполнен с возможностью определения первого участка аудиосигнала в зависимости от маскированного участка аудиосигнала и в зависимости от множества третьих коэффициентов фильтра, при этом множество третьих коэффициентов фильтра зависит от маскированного участка аудиосигнала и от последующего участка аудиосигнала, и при этом процессор 110 выполнен с возможностью определения второго участка аудиосигнала в зависимости от последующего участка аудиосигнала и от множества третьих коэффициентов фильтра.
В варианте осуществления, процессор 110 может, например, содержать фильтр, при этом процессор 110 выполнен с возможностью применения фильтра с третьими коэффициентами фильтра к маскированному участку аудиосигнала, чтобы получать первый участок аудиосигнала, и при этом процессор 110 выполнен с возможностью применения фильтра с третьими коэффициентами фильтра к последующему участку аудиосигнала, чтобы получать второй участок аудиосигнала.
В соответствии с вариантом осуществления, процессор 110 выполнен с возможностью определения множества первых коэффициентов фильтра в зависимости от маскированного участка аудиосигнала, при этом процессор 110 выполнен с возможностью определения множества вторых коэффициентов фильтра в зависимости от последующего участка аудиосигнала, при этом процессор 110 выполнен с возможностью определения каждого из третьих коэффициентов фильтра в зависимости от сочетания одного или более из первых коэффициентов фильтра и одного или более из вторых коэффициентов фильтра.
В варианте осуществления, коэффициенты фильтра из множества первых коэффициентов фильтра и из множества вторых коэффициентов фильтра и из множества третьих коэффициентов фильтра являются параметрами Кодирования с Линейным Предсказанием у Фильтра с Линейным Предсказанием.
В соответствии с вариантом осуществления, процессор 110 выполнен с возможностью определения каждого коэффициента фильтра из третьих коэффициентов фильтра в соответствии с формулой:
A=0.5 ⋅ Aconc+0.5 ⋅ Agood
при этом A указывает значение коэффициента фильтра у упомянутого коэффициента фильтра, при этом Aconc указывает значение коэффициента у коэффициента фильтра из множества первых коэффициентов фильтра, и при этом Agood указывает значение коэффициента у коэффициента фильтра из множества вторых коэффициентов фильтра.
В варианте осуществления, процессор 110 выполнен с возможностью применения косинусного окна, определяемого посредством
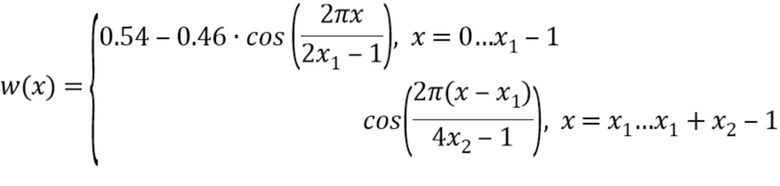
к маскированному участку аудиосигнала, чтобы получать маскированный участок сигнала, полученный методом окна, при этом процессор 110 выполнен с возможностью применения упомянутого косинусного окна к последующему участку аудиосигнала, чтобы получать последующий участок сигнала, полученный методом окна, при этом процессор 110 выполнен с возможностью определения множества первых коэффициентов фильтра в зависимости от маскированного участка сигнала, полученного методом окна, при этом процессор 110 выполнен с возможностью определения множества вторых коэффициентов фильтра в зависимости от последующего участка сигнала, полученного методом окна, и при этом каждая из x и x1 и x2 является позицией выборки из множества позиций выборки.
В соответствии с вариантом осуществления, процессор 110 может, например, быть выполнен с возможностью выбора в качестве упомянутого первого участка-прототипа сигнала, суб-участка из множества суб-участков-кандидатов первого участка аудиосигнала в зависимости от множества корреляций каждого суб-участка из множества суб-участков-кандидатов первого участка аудиосигнала и из упомянутого второго суб-участка второго участка аудиосигнала. Процессор 110 может, например, быть выполнен с возможностью выбора, в качестве начальной позиции выборки из трех или более позиций выборки маркера, позиции выборки из множества выборок упомянутого первого участка-прототипа сигнала, которая является предшествующим элементом для любой другой позиции выборки любой другой выборки упомянутого первого участка-прототипа сигнала.
В варианте осуществления, процессор 110 может, например, быть выполнен с возможностью выбора в качестве упомянутого первого участка-прототипа сигнала, суб-участка из упомянутых суб-участков-кандидатов, корреляция которого с упомянутым вторым суб-участком имеет наивысшее значение корреляции среди упомянутого множества корреляций.
В соответствии с вариантом осуществления, процессор 110 выполнен с возможностью определения для каждой корреляции из множества корреляций значения корреляции в соответствии с формулой,
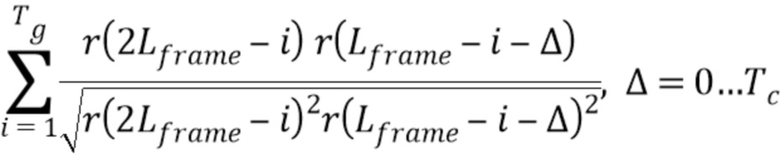
при этом Lframe указывает число выборок второго участка аудиосигнала равное числу выборок первого участка аудиосигнала, при этом r(2 Lframe - i) указывает значение выборки у выборки второго участка аудиосигнала в позиции выборки 2 Lframe - i, при этом r( Lframe - i - Δ) указывает значение выборки у выборки первого участка аудиосигнала в позиции выборки Lframe - i - Δ, при этом для каждой из множества корреляций суб-участка-кандидата из множества суб-участков-кандидатов и упомянутого второго суб-участка, Δ указывает число и зависит от упомянутого суб-участка-кандидата.
Перекрытие с адаптацией основного тона используется, чтобы компенсировать различия основного тона, которые могут возникать между основным тоном начала первого хорошего декодированного кадра после потери кадра и основным тоном в конце кадра, маскированного с помощью TD PLC. Сигнал работает в области LPC, чтобы сгладить сконструированный сигнал в конце алгоритма с помощью фильтра синтеза LPC. В области LPC, момент с наивысшим сходством обнаруживается посредством взаимной корреляции, как объясняется ниже и основной тон сигнала медленно развивается из последнего отставания Tc основного тона до нового Tg, чтобы избежать резких изменений основного тона.
В нижеследующем, описывается перекрытие с адаптацией основного тона в соответствии с конкретными вариантами осуществления.
Устройство или способ в соответствии с такими вариантами осуществления, могут, например, быть реализованы следующим образом:
Вычисляют параметры LPC 16 порядка Aconc и Agood по маскированному сигналу с предыскажениями s(0: Lframe - 1) и первому хорошему кадру s(Lframe:2Lframe - 1) соответственно с помощью косинусного окна Хемминга, например, косинусного окна Хемминга следующей формы:
где x1=200 и x2=40 для длины кадра в 480 выборок.
Фиг. 2 иллюстрирует такое косинусное окно Хемминга в соответствии с вариантом осуществления. Форма окна может, например, быть разработана так, что последние выборки сигнала у части сигнала имеют наивысшее влияние при анализе.
Выполняют интерполяцию в LSP-области, чтобы получить A=0.5 ⋅ Aconc+0.5 ⋅ Agood
Вычисляют остаточные сигналы LPC с A в маскированном кадре:
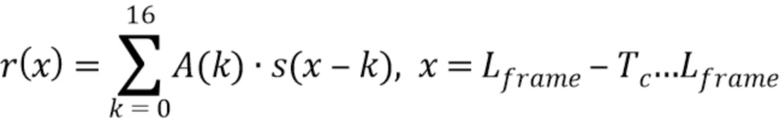
и первом хорошем кадре:
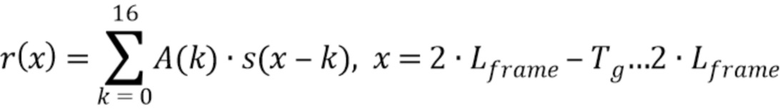
Находят момент x0, который представляет собой максимальное сходство между концом маскированного кадра и концом хорошего кадра x1 являющегося 2Lframe - 1.
Фиг. 3 иллюстрирует маскированный кадр и хороший кадр в соответствии с таким вариантом осуществления.
Получение x0 выполняется посредством нахождения максимума нормализованной взаимной корреляции:
Обычно нормализация выполняется в конце корреляции: например при поиске основного тона, нормализация выполняется после корреляции, когда значение основного тона уже найдено.
Здесь нормализация выполняется во время корреляции, чтобы быть надежной против колебаний энергии между сигналами. По соображениям сложности, термы нормализации вычисляются по схеме обновления. Только для начального значения
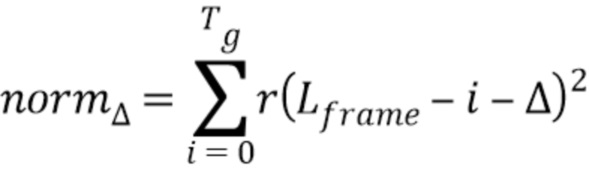
при Δ=0, например, могут быть вычислены полные скалярные произведения. Для следующего приращения Δ, терм может, например, быть обновлен следующим образом:
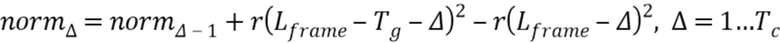
Чтобы медленно развивать отставание основного тона от последнего Tc(x0) до нового Tg(x1), должны быть между установлены моменты mark (маркер), где
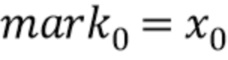
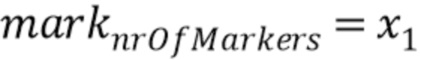
Если nrOfMarkers ниже одно или выше 12, алгоритм переключается на гашение энергии. В противном случае, δ > 0 и Tc < Tg или δ < 0 и Tc > Tg, где
и
,
маркеры вычисляются слева направо следующим образом:
в противном случае, маркеры строятся справа налево:
Следует отметить, что nrOfMarkers является числом всех маркеров минус 1. Или выражаясь другим образом, nrOfMarkers является числом всех позиций выборки маркера минус 1, так как x0=mark0 и x1=marknrOfMarkers являются также маркерами/ позициями выборки маркера. Например, если nrOfMarkers=4, тогда присутствует 5 маркеров/ 5 позиций выборки маркера, а именно mark0, mark1, mark2, mark3 и mark4.
Применительно к синтезированному сигналу, входные сегменты вырезания являются полученными методом окна и установлены вокруг момента mark. (сегменты являются сдвинутыми по времени, чтобы центрироваться по мгновенному маркеру). Чтобы осуществлять медленное сглаживание от маскированной формы сигнала до свободного от перекрытия хорошего сигнала, сегменты будут линейным сочетанием двух неперекрывающихся частей: являющихся концом маскированного кадра и концом хорошего кадра. Далее именуемых как прототипы sigfirst и siglast.
Длина len прототипов является удвоенным наименьшим расстоянием маркера минус 1, чтобы предотвращать возможные увеличения энергии при операции синтеза перекрытия со сложением. Если расстояние между двумя маркерами не находится между Tc и Tg, это будет приводить в проблемам на границах. (Таким образом, в конкретном варианте осуществления, алгоритм может, например, прекращаться в этих случаях и может, например, переключаться на гашение энергии. Гашение энергии будет описано ниже).
Прототипы вырезаются из сигнала r(x) возбуждения с помощью длин Tc и Tg так, что x0 и x1 устанавливаются в средние точки sigfirst и siglast (см. этап 1 на Фиг. 4). Затем, они кругообразно расширяются, чтобы достигать длины len (см. этап 2 на Фиг. 4). Впоследствии, они получаются методом окна с помощью окна Хенинга (см. этап 3 на Фиг. 4), чтобы избежать искажений в регионах перекрытия.
Прототип для маркера i вычисляется следующим образом (см. этап 4 на Фиг. 4):
sigi= (1-α) ⋅ sigfirst+ α ⋅ siglast
где
Затем, прототипы устанавливаются со средней точкой в соответствующих позициях маркера и суммируются (см. этап 5 на Фиг. 4).
В заключение, сконструированный сигнал сначала фильтруется с помощью фильтра синтеза LPC с параметрами A фильтра, и затем фильтруются с помощью фильтра устранения высокочастотных составляющих, чтобы получить его обратно в исходной области сигнала.
Осуществляется плавное микширование сигнала с исходным декодированным сигналом, чтобы предотвратить искажения на границах кадра.
Фиг. 4 иллюстрирует генерирование двух прототипов в соответствии с таким вариантом осуществления.
По соображением безопасности, гашение энергии, например, как описывается ниже, должно быть применено к полученному плавным перекрытием сигналу, чтобы устранить опасность того, что энергия сильно увеличивается в восстановленном кадре.
Касательно вырезания прототипов для x0 и x1 упомянутых выше, x0 и x1 являются точками во времени, когда оба остаточных сигнала имеют наивысшее сходство. sigfirst и siglast, прототипы для x0 и x1, имеют len=«удвоенному наименьшему расстоянию маркера минус 1». Таким образом, длина является всегда нечетной, что приводит к тому, что sigfirst и siglast имеют одну среднюю точку. Остаточные сигналы с длиной Tc (у маскированного кадра) и с длиной Tg (у хорошего кадра), теперь помещены так, что x0 располагается в средней точке sigfirst, и так, что x1 располагается в средней точке siglast. Впоследствии они могут быть кругообразно расширены, чтобы заполнять все выборки от 1 до len у sigfirst и siglast.
В нижеследующем, описывается перекрытие возбуждения в соответствии с вариантом осуществления.
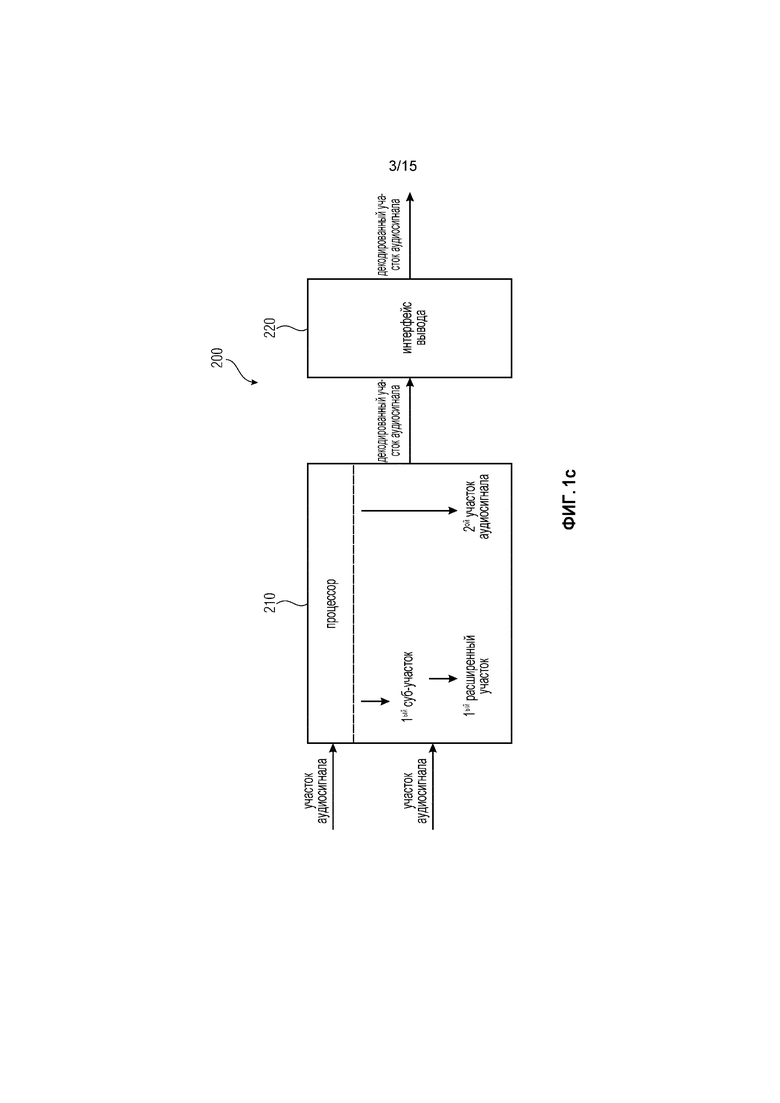
Фиг. 1c иллюстрирует устройство 200 для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с другим вариантом осуществления. Устройство Фиг. 1c реализует концепцию перекрытия возбуждения.
Устройство 200 Фиг. 1c является конкретным вариантом осуществления устройства 10 Фиг. 1a. Процессор 210 Фиг. 1c является конкретным вариантом осуществления процессора 11 Фиг. 1a. Интерфейс 220 вывода Фиг. 1c является конкретным вариантом осуществления интерфейса 12 вывода Фиг. 1a.
На Фиг. 1c, процессор 210 может, например, быть выполнен с возможностью генерирования первого расширенного участка сигнала в зависимости от первого суб-участка так, что первый расширенный участок сигнала отличается от первого участка аудиосигнала, и так что первый расширенный участок сигнала имеет больше выборок, чем первый суб-участок.
Кроме того, процессор 210 Фиг. 1c может, например, быть выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый расширенный участок сигнала и используя второй участок аудиосигнала.
В соответствии с вариантом осуществления, процессор 210 выполнен с возможностью генерирования декодированного участка аудиосигнала посредством проведения плавного микширования первого расширенного участка сигнала со вторым участком аудиосигнала, чтобы получить плавно смикшированный участок сигнала.
В варианте осуществления, процессор 210 может, например, быть выполнен с возможностью генерирования первого суб-участка из первого участка аудиосигнала так, что длина первого суб-участка равна отставанию основного тона первого участка аудиосигнала (Tc).
В соответствии с вариантом осуществления, процессор 210 может, например, быть выполнен с возможностью генерирования первого расширенного участка сигнала так, что число выборок первого расширенного участка сигнала равно числу выборок упомянутого отставания основного тона у первого участка аудиосигнала плюс число выборок второго участка аудиосигнала (Tc+число выборок второго участка аудиосигнала).
В варианте осуществления, процессор 210 может, например, быть выполнен с возможностью определения первого участка аудиосигнала в зависимости от маскированного участка аудиосигнала и в зависимости от множества коэффициентов фильтра, при этом множество коэффициентов фильтра зависят от маскированного участка аудиосигнала. Более того, процессор 210 может, например, быть выполнен с возможностью определения второго участка аудиосигнала в зависимости от последующего участка аудиосигнала и от множества коэффициентов фильтра.
В соответствии с вариантом осуществления, процессор 210 может, например, содержать фильтр. Более того, процессор 210 может, например, быть выполнен с возможностью применения фильтра с коэффициентами фильтра к маскированному участку аудиосигнала, чтобы получать первый участок аудиосигнала. Кроме того, процессор 210 может, например, быть выполнен с возможностью применения фильтра с коэффициентами фильтра к последующему участку аудиосигнала, чтобы получать второй участок аудиосигнала.
В варианте осуществления, коэффициенты фильтра из множества коэффициентов фильтра могут, например, быть параметрами Кодирования с Линейным Предсказанием у Фильтра с Линейным Предсказанием.
В соответствии с вариантом осуществления, процессор 210 может, например, быть выполнен с возможностью применения косинусного окна, определяемого посредством
к маскированному участку аудиосигнала, чтобы получать маскированный участок сигнала, полученный методом окна. Процессор 210 может, например, быть выполнен с возможностью определения множества коэффициентов фильтра в зависимости от маскированного участка сигнала, полученного методом окна, при этом каждое из x и x1 и x2 является позицией выборки из множества позиций выборки.
Фиг. 5 иллюстрирует перекрытие возбуждения в соответствии с таким вариантом осуществления.
Устройство, реализующее перекрытие возбуждения, является выполняющим плавное микширование в области возбуждения между прямым повторением маскированного кадра с декодированным сигналом чтобы обеспечивать медленное сглаживание между двумя сигналами.
Устройство или способ в соответствии с такими вариантами осуществления, могут, например, быть реализованы следующим образом:
Сначала, Анализ LPC 16 порядка выполняется по концу с предыскажениями предыдущего кадра (см. этап 1 на Фиг. 5) с косинусным окном Хемминга точно также как выполняется при способе перекрытия с адаптацией основного тона.
Фильтр LPC применяется, чтобы получить сигналы возбуждения в маскированном кадре и первом хорошем кадре (см. этап 2 на Фиг. 5).
Чтобы построить кадр восстановления, последние Tc выборки возбуждения маскированного кадра прямо повторяются, чтобы создать полную длину кадра (см. этап 3 на Фиг. 5). Это будет использовано для перекрытия с первым хорошим кадром.
Расширенное возбуждение затем плавно микшируется с возбуждением первого хорошего кадра (см. этап 4 на Фиг. 5).
Впоследствии, синтез LPC применяется к полученному плавным микшированием сигналу (см. этап 5 на Фиг. 5) с воспоминаниями, являющимися последними выборками с предыскажениями маскированного кадра, чтобы сгладить переход между маскированным и первым хорошим кадром.
В заключение, фильтр устранения высокочастотных составляющих применяется к синтезированному сигналу (см. этап 6 на Фиг. 5), чтобы получить сигнал обратно в исходной области.
Новый сконструированный сигнал плавно микшируется с исходным декодированным сигналом (см. этап 7 на Фиг. 5), чтобы предотвратить искажения на границах кадра.
В нижеследующем, описывается гашение энергии в соответствии с вариантами осуществления.
Фиг. 1d иллюстрирует варианты осуществления, при этом первый участок аудиосигнала является маскированным участком аудиосигнала, при этом второй участок аудиосигнала является последующим участком аудиосигнала.
Устройство 300 Фиг. 1d является конкретным вариантом осуществления устройства 10 Фиг. 1a. Процессор 310 Фиг. 1d является конкретным вариантом осуществления процессора 11 Фиг. 1a. Интерфейс 320 вывода Фиг. 1d является конкретным вариантом осуществления интерфейса 12 вывода Фиг. 1a.
Процессор 310 Фиг. 1d может, например, быть выполнен с возможностью определения первого суб-участка у маскированного участка аудиосигнала, являющегося первым суб-участком первого участка аудиосигнала так, что первый суб-участок содержит одну или более из выборок маскированного участка аудиосигнала, но содержит меньше выборок, чем маскированный участок аудиосигнала, и так, что каждая позиция выборки у выборок первого суб-участка является последующим элементом любой позиции выборки у любой выборки маскированного участка аудиосигнала, которая не содержится первым суб-участком.
Более того, процессор 310 Фиг. 1d может, например, быть выполнен с возможностью определения третьего суб-участка у последующего участка аудиосигнала так, что третий суб-участок содержит одну или более выборки последующего участка аудиосигнала, но содержит меньше выборок чем последующий участок аудиосигнала, и так, что каждая позиция выборки у каждой из выборок третьего суб-участка является последующим элементом любой позиции выборки у любой выборки последующего участка аудиосигнала, которая не содержится третьим суб-участком.
Кроме того, процессор 310 Фиг. 1d может, например, быть выполнен с возможностью определения второго суб-участка у последующего участка аудиосигнала, являющегося вторым суб-участком второго участка аудиосигнала так, что любая выборка последующего участка аудиосигнала, которая не содержится третьим суб-участком, содержится вторым суб-участком последующего участка аудиосигнала.
В вариантах осуществления в соответствии с Фиг. 1d, процессор 310 может, например, быть выполнен с возможностью определения первой выборки пика из выборок первого суб-участка маскированного участка аудиосигнала так, что значение выборки у первой выборки пика больше или равно любому другому значению выборки любой другой выборки первого суб-участка у маскированного участка аудиосигнала. Процессор 310 Фиг. 1d может, например, быть выполнен с возможностью определения второй выборки пика из выборок второго суб-участка у последующего участка аудиосигнала так, что значение выборки у второй выборки пика больше или равно любому другому значению выборки любой другой выборки второго суб-участка у последующего участка аудиосигнала. Более того, процессор 310 Фиг. 1d может, например, быть выполнен с возможностью определения третьей выборки пика из выборок третьего суб-участка у последующего участка аудиосигнала так, что значение выборки третьей выборки пика больше или равно любому другому значению выборки любой другой выборки третьего суб-участка у последующего участка аудиосигнала.
Если и только если условие удовлетворяется, процессор 310 Фиг. 1d может, например, быть выполнен с возможностью модифицирования каждого значения выборки у каждой выборки последующего участка аудиосигнала, которая является предшествующим элементом у второй выборки пика, чтобы генерировать декодированный участок аудиосигнала.
Условием может, например, быть то, что как значение выборки у второй выборки пика больше значения выборки у первой выборки пика, так и что значение выборки у второй выборки пика больше значения выборки у третьей выборки пика.
Или, условием может, например, быть то, что как первое отношение между значением выборки у второй выборки пика и значением выборки у первой выборки пика больше первого порогового значения, так и второе отношение между значением выборки у второй выборки пика и значением выборки у третьей выборки пика больше второго порогового значения.
В соответствии с вариантом осуществления, условием может, например, быть то, что как значение выборки у второй выборки пика больше значения выборки у первой выборки пика, так и что значение выборки у второй выборки пика больше значения выборки у третьей выборки пика.
В варианте осуществления, условием может, например, быть что как первое отношение больше первого порогового значения, так и второе отношение больше второго порогового значения.
В соответствии с вариантом осуществления, первое пороговое значение может, например, быть больше 1.1, и второе пороговое значение может, например, быть больше 1.1.
В варианте осуществления, первое пороговое значение может, например, быть равным второму пороговому значению.
В соответствии с вариантом осуществления, если и только если условие удовлетворяется, процессор 310 может, например, быть выполнен с возможностью модифицирования каждого значения выборки у каждой выборки последующего участка аудиосигнала, которая является предшествующим элементом у второй выборки пика в соответствии с
smodified(Lframe+i)=s(Lframe+i) ⋅ αi
при этом Lframe указывает позицию выборки у выборки последующего участка аудиосигнала, которая является предшествующим элементом для любой другой позиции выборки любой другой выборки последующего участка аудиосигнала,
при этом Lframe+i является целым числом, указывающим позицию выборки у i+1-ой выборки последующего участка аудиосигнала,
при этом 0≤i≤Imax - 1, при этом Imax - 1 указывает позицию выборки у второй выборки пика,
при этом s(Lframe+i) является значением выборки у i+1-ой выборки последующего участка аудиосигнала, до модифицирования процессором 310,
при этом smodified(Lframe+i) является значением выборки у i+1-ой выборки последующего участка аудиосигнала, после модифицирования процессором 310,
при этом 0 < αi < 1.
В варианте осуществления,
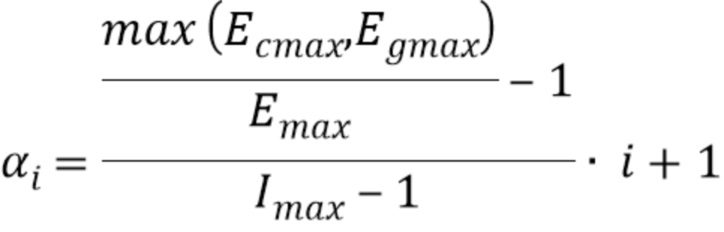
при этом Ecmax является значением выборки у первой выборки пика, при этом Emax является значением выборки у второй выборки пика, и при этом Egmax является значением выборки у третьей выборки пика.
В соответствии с вариантом осуществления, если и только если условие удовлетворяется, процессор 310 может, например, быть выполнен с возможностью модифицирования значения выборки каждой выборки у двух или более выборок из множества выборок последующего участка аудиосигнала, которые являются последующими элементами второй выборки пика, чтобы генерировать декодированный участок аудиосигнала в соответствии с
smodified(Imax+k)=s(Imax+k) ⋅ αi,
при этом Imax+k является целым числом, указывающим позицию выборки у Imax+k+1 -ой выборки последующего участка аудиосигнала.
Фиг. 6 является дополнительной иллюстрацией маскированного кадра и хорошего кадра в соответствии с вариантом осуществления. В частности, Фиг. 6 иллюстрирует маскированный участок аудиосигнала, последующий участок аудиосигнала, первый суб-участок, второй суб-участок и третий суб-участок.
Гашение энергии используется, чтобы удалить высокие увеличения энергии в перекрывающей части сигнала между последним маскированным кадром и первым хорошим кадром. Это выполняется посредством медленного гашения региона сигнала до значения амплитуды пика.
Подход в соответствии с вариантом осуществления может, например, быть реализован следующим образом:
- Находят максимальные значения амплитуды в:
- последних Tc выборках предыдущего маскированного кадра: Ecmax
- последних Tg выборках в первом хорошем кадре: Egmax
- и в этом регионе: Emax
Ecmax является первой выборкой пика, Emax является второй выборкой пика и Egmax является третьей выборкой пика.
- Затем будет гаситься декодированный сигнал в первом хорошем кадре, если
Ecmax < Emax > Egmax
В других вариантах осуществления, первый хороший кадр будет гаситься, если
( и
и  )
)
Например, 1.1 < thresholdValue1<4 и 1.1 < thresholdValue2<4
- Первая часть декодированного сигнала будет гаситься следующим образом:
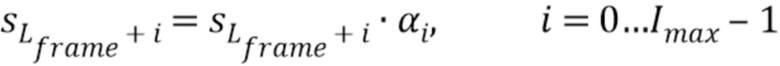
где Imax является индексом Emax и
- вторая часть будет гаситься следующим образом:

где
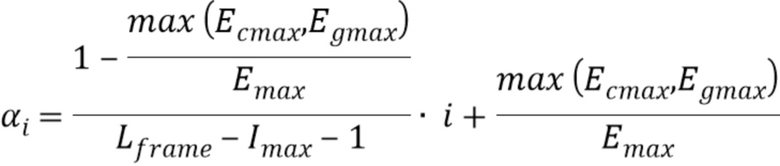
В предпочтительных вариантах осуществления, по причинам безопасности, гашение энергии может, например, быть применено к плавно микшированному сигналу, чтобы исключить опасность того, что энергия сильно увеличивается в кадре восстановления.
Теперь, предоставляются сочетания разных улучшенных концепций перехода в соответствии с вариантами осуществления.
Фиг. 7a иллюстрирует систему для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с вариантом осуществления.
Система содержит модуль 701 переключения, устройство 300 для реализации гашения энергии, как описано выше со ссылкой на Фиг. 1d, и устройство 100 для реализации перекрытия с адаптацией основного тона, как описано выше со ссылкой на Фиг. 1b.
Модуль 701 переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства 300 для реализации гашения энергии и из устройства 100 для реализации перекрытия с адаптацией основного тона для генерирования декодированного участка аудиосигнала.
Фиг. 7b иллюстрирует систему для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с другим вариантом осуществления.
Система содержит модуль 702 переключения, устройство 300 для реализации гашения энергии, как описано выше со ссылкой на Фиг. 1d, и устройство 200 для реализации перекрытия возбуждения, как описано выше со ссылкой на Фиг. 1c.
Модуль 702 переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства 300 для реализации гашения энергии и из устройства 200 для реализации перекрытия возбуждения для генерирования декодированного участка аудиосигнала.
Фиг. 7c иллюстрирует систему для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с дополнительным вариантом осуществления.
Система содержит модуль 703 переключения, устройство 100 для реализации перекрытия с адаптацией основного тона, как описано выше со ссылкой на Фиг. 1b, и устройство 200 для реализации перекрытия возбуждения, как описано выше со ссылкой на Фиг. 1c.
Модуль 703 переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства 100 для реализации перекрытия с адаптацией основного тона и из устройства 200 для реализации перекрытия возбуждения для генерирования декодированного участка аудиосигнала.
Фиг. 7d иллюстрирует систему для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с еще одним дополнительным вариантом осуществления.
Система содержит модуль 701 переключения, устройство 300 для реализации гашения энергии, как описано выше со ссылкой на Фиг. 1d, устройство 100 для реализации перекрытия с адаптацией основного тона, как описано выше со ссылкой на Фиг. 1b, и устройство 200 для реализации перекрытия возбуждения, как описано выше со ссылкой на Фиг. 1c.
Модуль 701 переключения выполнен с возможностью выбора в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства 300 для реализации гашения энергии и из устройства 100 для реализации перекрытия с адаптацией основного тона и из устройства 200 для реализации перекрытия возбуждения для генерирования декодированного участка аудиосигнала.
В соответствии с вариантами осуществления, модуль 704 переключения может, например, быть выполнен с возможностью определения, содержит или нет, по меньшей мере, один из маскированного кадра аудиосигнала и последующего кадра аудиосигнала речь. Более того, модуль 704 переключения может, например, быть выполнен с возможностью выбора устройства 300 для реализации гашения энергии для генерирования декодированного участка аудиосигнала, если маскированный кадр аудиосигнала и последующий кадр аудиосигнала не содержат речь.
В вариантах осуществления, модуль 704 переключения может, например, быть выполнен с возможностью выбора упомянутого одного из устройства 100 для реализации перекрытия с адаптацией основного тона и из устройства 200 для реализации перекрытия возбуждения и из устройства 300 для реализации гашения энергии для генерирования декодированного участка аудиосигнала в зависимости от длины кадра у последующего кадра аудиосигнала и в зависимости от, по меньшей мере, одного из основного тона у маскированного участка аудиосигнала или основного тона у последующего участка аудиосигнала, при этом последующий участок аудиосигнала является участком аудиосигнала у последующего кадра аудиосигнала.
Фиг. 7e иллюстрирует систему для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала в соответствии с дополнительным вариантом осуществления.
Как на Фиг. 7c, система Фиг. 7e содержит модуль 703 переключения, устройство 100 для реализации перекрытия с адаптацией основного тона, как описано выше со ссылкой на Фиг. 1b, и устройство 200 для реализации перекрытия возбуждения, как описано выше со ссылкой на Фиг. 1c.
Модуль 703 переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства 100 для реализации перекрытия с адаптацией основного тона и из устройства 200 для реализации перекрытия возбуждения для генерирования декодированного участка аудиосигнала.
Более того, система Фиг. 7e дополнительно содержит устройство 300 для реализации гашения энергии, как описано выше со ссылкой на Фиг. 1d.
Модуль 703 переключения Фиг. 7e может, например, быть выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, упомянутого одного из устройства 100 для реализации перекрытия с адаптацией основного тона и из устройства 200 для реализации перекрытия возбуждения, чтобы генерировать промежуточный участок аудиосигнала,
В варианте осуществления Фиг. 7e, устройство 300 для реализации гашения энергии может, например, быть выполнено с возможностью обработки промежуточного участка аудиосигнала, чтобы генерировать декодированный участок аудиосигнала.
Теперь, описываются конкретные варианты осуществления. В частности, предоставляются концепции для конкретных реализаций модулей 701, 702, 703 и 704 переключения.
Например, первый вариант осуществления, предоставляющий сочетание разных улучшенных концепций перехода, может, например, быть использован для любого кодека области преобразований:
Первый этап состоит в обнаружении, является ли сигнал подобным речи с выдающимся основным тоном (примером являются элементы чистой речи, речь с фоновым шумом или речь поверх музыки) или нет.
Если сигнал является подобным речи, тогда
- находят Основной Тон Tc в последнем маскированном кадре
- находят Основной Тон Tg в первом хорошем кадре
- если энергия увеличивается в части перекрытия от последнего маскированного кадра
- если основной тон хорошего кадра отличается от маскированного основного тона более 3 выборок
→ выполняют фильтр восстановления
- иначе
→ выполняют гашение энергии
- в противном случае
→ выполняют гашение энергии
Если выше выбирается фильтр восстановления, тогда
- если маскированный основной тон Tc или хороший основной тон Tg выше длины кадра Lframe
→ выполняют гашение энергии
- иначе если маскированный основной тон или хороший основной тон выше половины длины кадра и нормализованное значение взаимной корреляции xCorr меньше пороговой величины
→ выполняют перекрытие возбуждения
- иначе если маскированный основной тон или хороший основной тон ниже половины длины кадра
→ применяют перекрытие с адаптацией основного тона
Например, сначала, маскированный кадр тестируется в отношении наличия речи (присутствует ли речь может, например, быть видно из методики маскирования). Позже, хороший кадр может, например, также быть протестирован в отношении присутствия речи, например, используя нормализованное значение взаимной корреляции xCorr.
Часть перекрытия, упомянутая выше, может, например, быть 2ым суб-участком, иллюстрируемым, например, на Фиг. 6, что означает, что часть перекрытия является хорошим кадром от первой выборки до выборки «Длина кадра минус Tg».
Теперь, предоставляется второй вариант осуществления, предоставляющий сочетание разных улучшенных концепций перехода. Такой второй вариант осуществления может, например, быть использован для кодека AAC-ELD, где два способа маскирования ошибки кадра являются способом временной области и частотной области.
Способ временной области является синтезирующим потерянный кадр с подходом экстраполяции основного тона и именуется TD PLC (см. [8]).
Способ частотной области является способом маскирования уровня техники для кодека AAC-ELD, именуемым Замещением Шума (NS), который использует знаковую зашифрованную копию предыдущего хорошего кадра.
Во втором варианте осуществления, первое деление выполняется в зависимости от последнего способа маскирования:
- Если последний кадр был маскирован с помощью TD PLC:
- находят Основной Тон в первом хорошем кадре
- если энергия увеличивается в части перекрытия от последнего маскированного кадра
-- если основной тон хорошего кадра отличается от маскированного основного тона более чем на 3 выборки
→ выполняют фильтр восстановления
-- иначе
→ выполняют гашение энергии
- если последний кадр был маскирован с помощью NS:
→ выполняют гашение энергии
Более того, во втором варианте осуществления, второе деление выполняется в фильтре восстановления следующим образом:
- если маскированный основной тон Tc (основной тон в последнем кадре, который был маскирован) или хороший основной тон Tg (основной тон в первом хорошем кадре) выше длины кадра Lframe
→ выполняют гашение энергии
- если маскированный основной тон или хороший основной тон выше половины длины кадра и нормализованное значение взаимной корреляции xCorr меньше пороговой величины
→ выполняют перекрытие возбуждения
- если маскированный основной тон или хороший основной тон ниже половины длины кадра
→ применяют перекрытие с адаптацией основного тона
Предоставляется множество вариантов осуществления.
В соответствии с вариантами осуществления, предоставляется фильтр для улучшения перехода между маскированным потерянным кадром у кодированного в области преобразований сигнала и одним или более кадрами кодированного в области преобразований сигнала последующими за маскированным потерянным кадром.
В вариантах осуществления, фильтр может, например, быть сконфигурирован в соответствии с упомянутым ранее описанием.
В соответствии с вариантами осуществления, предоставляется декодер области преобразований, содержащий фильтр в соответствии с одним из описанных выше вариантов осуществления.
Более того, предоставляется способ для выполнения декодером области преобразований, как описано выше.
Кроме того, предоставляется компьютерная программа для выполнения способа, как описано выше.
Несмотря на то, что некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или элемента или признака у соответствующего устройства. Некоторые или все из этапов способа могут быть исполнены посредством (или используя) устройство аппаратного обеспечения, подобное, например, микропроцессору, программируемому компьютеру или электронной цепи. В некоторых вариантах осуществления, один или более из наиболее важных этапов способа могут быть исполнены таким устройством.
В зависимости от некоторых требований реализации, варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении или, по меньшей мере, частично в аппаратном обеспечении или, по меньшей мере, частично в программном обеспечении. Реализация может быть выполнена используя цифровой запоминающий носитель информации, например, гибкий диск, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-память, с электронно-читаемыми сигналами управления, хранящимися в них, которые взаимодействует (или выполнены с возможностью взаимодействия) с программируемой компьютерной системой так, что выполняется соответствующий способ. Вследствие этого, цифровой запоминающий носитель информации может быть машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных с электронно-читаемыми сигналами управления, которые выполнены с возможностью взаимодействия с программируемой компьютерной системой так, что выполняется один из описанных в данном документе способов.
В целом, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с кодом программы, причем код программы работает для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Код программы может, например, быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данном документе, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения является, вследствие этого, компьютерной программой с кодом программы для выполнения одного из способов, описываемых в данном документе, когда компьютерная программа работает на компьютере.
Дополнительным вариантом осуществления способов изобретения является, вследствие этого, носитель данных (или цифровой запоминающий носитель информации, или машиночитаемый носитель информации), содержащий, записанную на нем, компьютерную программу для выполнения одного из способов, описанных в данном документе. Носитель данных, цифровой запоминающий носитель информации или записанный носитель информации являются, как правило, вещественными и/или не временными.
Дополнительным вариантом осуществления способа изобретения является, вследствие этого, поток данных или последовательность сигналов, представляющие собой компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, могут, например, быть выполнены с возможностью переноса через соединение связи для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описываемых в данном документе.
Дополнительный вариант осуществления содержит компьютер с инсталлированной на нем компьютерной программой для выполнения одного из способов, описываемых в данном документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненные с возможностью переноса (например, электронным или оптическим образом) компьютерной программы для выполнения одного из способов, описываемых в данном документе, приемнику. Приемник может, например, быть компьютером, мобильным устройством, устройством памяти или подобным. Устройство или система могут, например, быть выполнены в виде файлового сервера для переноса компьютерной программы приемнику.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая вентильная матрица) может быть использовано, чтобы выполнять некоторую или всю функциональность способов, описываемых в данном документе. В некоторых вариантах осуществления, программируемая вентильная матрица может взаимодействовать с микропроцессором для того, чтобы выполнять один из способов, описываемых в данном документе. В целом, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Устройство, описываемое в данном документе, может быть реализовано, используя устройство аппаратного обеспечения, или используя компьютер, или используя сочетание устройства аппаратного обеспечения и компьютера.
Способы, описываемые в данном документе, могут быть выполнены, используя устройство аппаратного обеспечения, или используя компьютер, или используя сочетание устройства аппаратного обеспечения и компьютера.
Описанные выше варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и вариации компоновок и подробностей, описанных в данном документе, будут очевидны специалистам в соответствующей области техники. Вследствие этого, подразумевается, что ограничение накладывается только объемом предстоящей патентной формулы изобретения, а не конкретными подробностями, представленными в качестве описания и объяснения вариантов осуществления в данном документе.
Список цитированной литературы:
[1] Philippe Gournay: «Improved Frame Loss Recovery Using Closed-Loop Estimation of Very Low Bit Rate Side Information», Interspeech 2008, Брисбен, Австралия, 22-26 сентября 2008 г.
[2] Mohamed Chibani, Roch Lefebvre, Philippe Gournay: «Resynchronization of the Adaptive Codebook in a Constrained CELP Codec after a frame erasure», 2006 International Conference on Acoustics, Speech and Signal Processing (ICASSP'2006), Тулуза, Франция 14-19 марта 2006 г.
[3] S.-U.Ryu, E. Choy, и K. Rose, «Encoder assisted frame loss concealment for MPEG-A AC decoder», ICASSP IEEE Int. Conf. Acoust. Speech Signal Process Proc., том 5, стр.169-172, май 2006 г.
[4] ISO/IEC 14496-3:2005/Amd 9:2008: Enhanced low delay AAC, доступен по адресу: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=46457
[5] J. Lecomte, и др., «Enhanced time domain packet loss concealment in switched speech/audio codec», представленный IEEE ICASSP, Брисбен, Австралия, апрель 2015 г.
[6] E. Moulines и J. Laroche, «Non-parametric techniques for pitch-scale and timescale modification of speech», Speech Communication, том 16, стр. 175-205, 1995 г.
[7] Европейский Патент EP 363233 B1: «Method and apparatus for speech synthesis by wave form overlapping and adding».
[8] Международная Патентная Заявка WO 2015063045 A1: «Audio Decoder and Method for Providing a Decoded Audio Information using an Error Concealment Modifying a Time Domain Excitation Signal».
[9] Schnell, M.; Schmidt, M.; Jander, M.; Albert, T.; Geiger, R.; Ruoppila, V.; Ekstrand, P.; Grill, B., «MPEG-4 enhanced low delay AAC - a new standard for high quality communication», Audio Engineering Society: 125th Audio Engineering Society Convention 2008; 2-5 октября 2008 г., Сан-Франциско, США.
Изобретение относится к средствам для улучшения перехода от маскированного участка аудиосигнала к последующему участку аудиосигнала. Технический результат заключается в повышении эффективности маскирования участков аудиосигнала. Генерируют декодированный участок аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала. Первый участок аудиосигнала зависит от маскированного участка аудиосигнала и второй участок аудиосигнала зависит от последующего участка аудиосигнала. Выводят декодированный участок аудиосигнала. Каждый из первого участка аудиосигнала и второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок. Каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки. Множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки и второй позиции выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки. 8 н. и 35 з.п. ф-лы, 17 ил.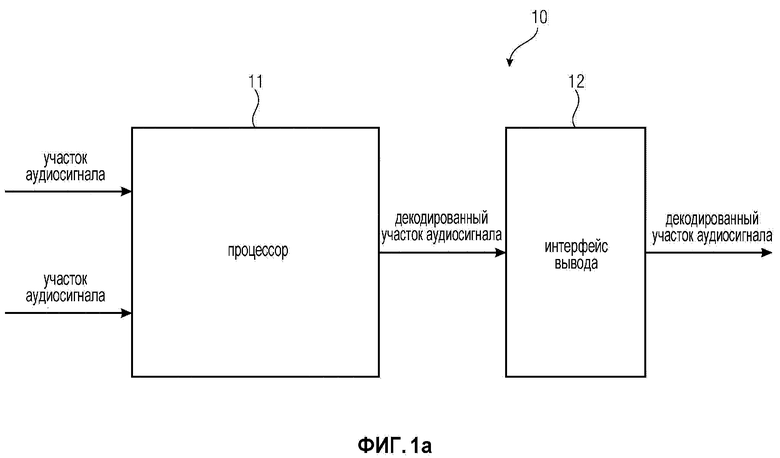
1. Устройство (10; 100; 200; 300) для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом устройство (10; 100; 200; 300) содержит:
процессор (11; 110; 210; 310), выполненный с возможностью генерирования декодированного участка аудиосигнала у аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала, при этом первый участок аудиосигнала зависит от маскированного участка аудиосигнала, и при этом второй участок аудиосигнала зависит от последующего участка аудиосигнала, и
интерфейс (12; 120; 220; 320) вывода для вывода декодированного участка аудиосигнала,
при этом каждый из первого участка аудиосигнала и из второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок, при этом каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки, при этом множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки из множества позиций выборки и второй позиции выборки из множества позиций выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки,
при этом процессор (11; 110; 210; 310) выполнен с возможностью определения первого суб-участка первого участка аудиосигнала так, что первый суб-участок содержит меньше выборок, чем первый участок аудиосигнала, и
при этом процессор (11; 110; 210; 310) выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый суб-участок первого участка аудиосигнала и используя второй участок аудиосигнала или второй суб-участок второго участка аудиосигнала так, что для каждой выборки из двух или более выборок второго участка аудиосигнала, позиция выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала равна позиции выборки одной из выборок декодированного участка аудиосигнала, и так, что значение выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала отличается от значения выборки у упомянутой одной из выборок декодированного участка аудиосигнала.
2. Устройство (100) по п. 1,
в котором процессор (110) выполнен с возможностью определения второго участка-прототипа сигнала, являющегося суб-участком второго участка аудиосигнала так, что второй суб-участок содержит меньше выборок, чем второй участок аудиосигнала, и
при этом процессор (110) выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения каждого из одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала, являющегося первым суб-участком, и второго участка-прототипа сигнала,
при этом процессор (110) выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый участок-прототип сигнала и используя один или более промежуточных участков-прототипов сигнала и используя второй участок-прототип сигнала.
3. Устройство (100) по п. 2, в котором процессор (110) выполнен с возможностью генерирования декодированного участка аудиосигнала посредством объединения первого участка-прототипа сигнала и одного или более промежуточных участков-прототипов сигнала и второго участка-прототипа сигнала.
4. Устройство (100) по п. 2 или 3,
в котором процессор (110) выполнен с возможностью определения множества из трех или более позиций выборки маркера, при этом каждая из трех или более позиций выборки маркера является позицией выборки, по меньшей мере, одного из первого участка аудиосигнала и второго участка аудиосигнала,
при этом процессор (110) выполнен с возможностью выбора позиции выборки у выборки второго участка аудиосигнала, которая является последующим элементом для любой другой позиции выборки у любой другой выборки второго участка аудиосигнала, в качестве конечной позиции выборки из трех или более позиций выборки маркера,
при этом процессор (110) выполнен с возможностью определения начальной позиции выборки из трех или более позиций выборки маркера посредством выбора позиции выборки из первого участка аудиосигнала в зависимости от корреляции между первым суб-участком первого участка аудиосигнала и втором суб-участком второго участка аудиосигнала,
при этом процессор (110) выполнен с возможностью определения одной или более промежуточных позиций выборки из трех или более позиций выборки маркера в зависимости от начальной позиции выборки из трех или более позиций выборки маркера и в зависимости от конечной позиции выборки из трех или более позиций выборки маркера, и
при этом процессор (110) выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения каждой из упомянутых одной или более промежуточных позиций выборки промежуточного участка-прототипа сигнала у одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала и второго участка-прототипа сигнала в зависимости от упомянутой промежуточной позиции выборки.
5. Устройство (100) по п. 4,
при этом процессор (110) выполнен с возможностью определения одного или более промежуточных участков-прототипов сигнала посредством определения для каждой из упомянутых одной или более промежуточных позиций выборки промежуточного участка-прототипа сигнала у одного или более промежуточных участков-прототипов сигнала посредством объединения первого участка-прототипа сигнала и второго участка-прототипа сигнала в соответствии с
sigi=(1-α) ⋅ sigfirst+α ⋅ siglast
где
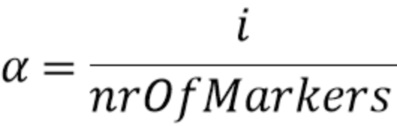
при этом i является целым числом, при i≥1,
при этом nrOfMarkers является числом трех или более позиций выборки маркера минус 1,
при этом sigi является i-м промежуточным участком-прототипом сигнала из одного или более промежуточных участков-прототипов сигнала,
при этом sigfirst является первым участком-прототипом сигнала,
при этом siglast является вторым участком-прототипом сигнала.
6. Устройство (100) по п. 4 или 5,
при этом процессор (110) выполнен с возможностью определения одной или более промежуточных позиций выборки из трех или более позиций выборки маркера в зависимости от
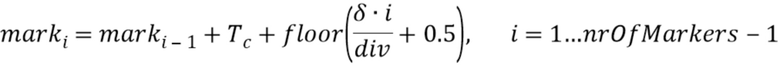
или в зависимости от
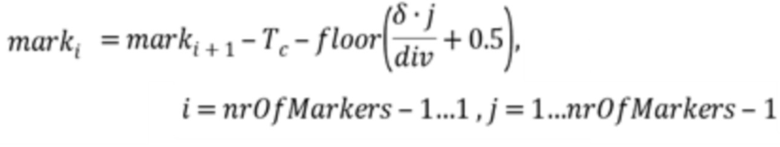
при этом 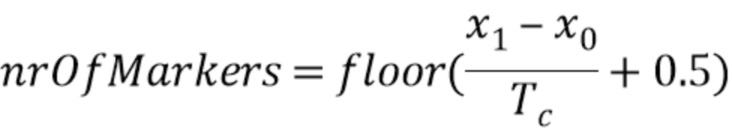 ,
,
при этом 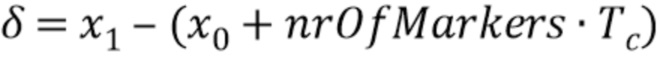 ,
,
при этом 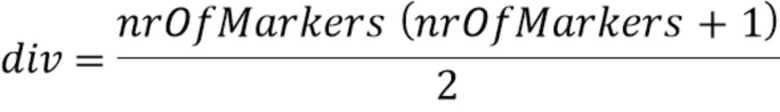 ,
,
при этом i является целым числом, при i≥1,
при этом nrOfMarkers является числом трех или более позиций выборки маркера минус 1,
при этом marki является i-й промежуточной позицией выборки из трех или более позиций выборки маркера,
при этом marki-1 является i-1-й промежуточной позицией выборки из трех или более позиций выборки маркера,
при этом marki+1 является i+1-й промежуточной позицией выборки из трех или более позиций выборки маркера,
при этом x0 является начальной позицией выборки из трех или более позиций выборки маркера,
при этом x1 является конечной позицией выборки трех или более позиций выборки маркера, и
при этом Tc указывает отставание основного тона.
7. Устройство (100) по одному из пп. 4-6,
в котором процессор (110) выполнен с возможностью выбора в качестве упомянутого первого участка-прототипа сигнала, суб-участка из множества суб-участков-кандидатов первого участка аудиосигнала в зависимости от множества корреляций каждого суб-участка из множества суб-участков-кандидатов первого участка аудиосигнала и из упомянутого второго суб-участка второго участка аудиосигнала,
при этом процессор (110) выполнен с возможностью выбора, в качестве начальной позиции выборки из трех или более позиций выборки маркера, позиции выборки из множества выборок упомянутого первого участка-прототипа сигнала, которая является предшествующим элементом для любой другой позиции выборки любой другой выборки упомянутого первого участка-прототипа сигнала.
8. Устройство (100) по п. 7, в котором процессор (110) выполнен с возможностью выбора в качестве упомянутого первого участка-прототипа сигнала, суб-участка из упомянутых суб-участков-кандидатов, корреляция которого с упомянутым вторым суб-участком имеет наивысшее значение корреляции среди упомянутого множества корреляций.
9. Устройство (100) по п. 7 или 8,
в котором процессор (110) выполнен с возможностью определения для каждой корреляции из множества корреляций значения корреляции в соответствии с формулой,
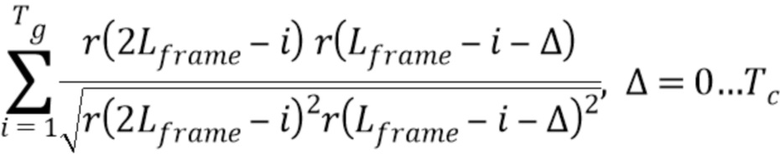
при этом Lframe указывает число выборок второго участка аудиосигнала, равное числу выборок первого участка аудиосигнала,
при этом r(2 Lframe - i) указывает значение выборки у выборки второго участка аудиосигнала в позиции выборки 2 Lframe - i,
при этом r( Lframe - i - Δ) указывает значение выборки у выборки первого участка аудиосигнала в позиции выборки Lframe - i - Δ,
при этом для каждой из множества корреляций суб-участка-кандидата из множества суб-участков-кандидатов и упомянутого второго суб-участка, Δ указывает число и зависит от упомянутого суб-участка-кандидата.
10. Устройство (100) по одному из пп. 4-9,
в котором процессор (110) выполнен с возможностью определения первого участка аудиосигнала в зависимости от маскированного участка аудиосигнала и в зависимости от множества третьих коэффициентов фильтра, при этом множество третьих коэффициентов фильтра зависит от маскированного участка аудиосигнала и от последующего участка аудиосигнала, и
при этом процессор (110) выполнен с возможностью определения второго участка аудиосигнала в зависимости от последующего участка аудиосигнала и от множества третьих коэффициентов фильтра.
11. Устройство (100) по п. 10,
в котором процессор (110) содержит фильтр,
при этом процессор (110) выполнен с возможностью применения фильтра с третьими коэффициентами фильтра к маскированному участку аудиосигнала, чтобы получать первый участок аудиосигнала, и
при этом процессор (110) выполнен с возможностью применения фильтра с третьими коэффициентами фильтра к последующему участку аудиосигнала, чтобы получать второй участок аудиосигнала.
12. Устройство (100) по п. 10 или 11,
в котором процессор (110) выполнен с возможностью определения множества первых коэффициентов фильтра в зависимости от маскированного участка аудиосигнала,
при этом процессор (110) выполнен с возможностью определения множества вторых коэффициентов фильтра в зависимости от последующего участка аудиосигнала,
при этом процессор (110) выполнен с возможностью определения каждого из третьих коэффициентов фильтра в зависимости от сочетания одного или более из первых коэффициентов фильтра и одного или более из вторых коэффициентов фильтра.
13. Устройство (100) по п. 12, в котором коэффициенты фильтра из множества первых коэффициентов фильтра и из множества вторых коэффициентов фильтра и из множества третьих коэффициентов фильтра являются параметрами Кодирования с Линейным Предсказанием у Фильтра с Линейным Предсказанием.
14. Устройство (100) по п. 12 или 13,
в котором процессор (110) выполнен с возможностью определения каждого коэффициента фильтра из третьих коэффициентов фильтра в соответствии с формулой:
A=0.5 ⋅ Aconc+0.5 ⋅ Agood
при этом A указывает значение коэффициента фильтра у упомянутого коэффициента фильтра,
при этом Aconc указывает значение коэффициента у коэффициента фильтра из множества первых коэффициентов фильтра, и
при этом Agood указывает значение коэффициента у коэффициента фильтра из множества вторых коэффициентов фильтра.
15. Устройство (100) по одному из пп. 12-14,
в котором процессор (110) выполнен с возможностью применения косинусного окна, определяемого посредством
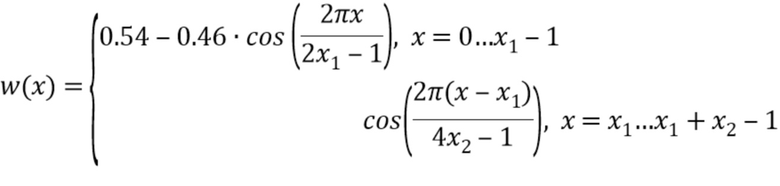
к маскированному участку аудиосигнала, чтобы получать маскированный участок сигнала, полученный методом окна,
при этом процессор (110) выполнен с возможностью применения упомянутого косинусного окна к последующему участку аудиосигнала, чтобы получать последующий участок сигнала, полученный методом окна,
при этом процессор (110) выполнен с возможностью определения множества первых коэффициентов фильтра в зависимости от маскированного участка сигнала, полученного методом окна,
при этом процессор (110) выполнен с возможностью определения множества вторых коэффициентов фильтра в зависимости от последующего участка сигнала, полученного методом окна, и
при этом каждая из x и x1 и x2 является позицией выборки из множества позиций выборки.
16. Устройство (200) по п. 1,
в котором процессор (210) выполнен с возможностью генерирования первого расширенного участка сигнала в зависимости от первого суб-участка так, что первый расширенный участок сигнала отличается от первого участка аудиосигнала, и так что первый расширенный участок сигнала имеет больше выборок, чем первый суб-участок,
при этом процессор (210) выполнен с возможностью генерирования декодированного участка аудиосигнала, используя первый расширенный участок сигнала и используя второй участок аудиосигнала.
17. Устройство (200) по п. 16, в котором процессор (210) выполнен с возможностью генерирования декодированного участка аудиосигнала посредством проведения плавного микширования первого расширенного участка сигнала со вторым участком аудиосигнала, чтобы получить плавно смикшированный участок сигнала.
18. Устройство (200) по п. 16 или 17, в котором процессор (210) выполнен с возможностью генерирования первого суб-участка из первого участка аудиосигнала так, что длина первого суб-участка равна отставанию основного тона первого участка аудиосигнала.
19. Устройство (200) по п. 18, в котором процессор (210) выполнен с возможностью генерирования первого расширенного участка сигнала так, что число выборок первого расширенного участка сигнала равно числу выборок упомянутого отставания основного тона у первого участка аудиосигнала плюс число выборок второго участка аудиосигнала.
20. Устройство (200) по одному из пп. 16-19,
в котором процессор (210) выполнен с возможностью определения первого участка аудиосигнала в зависимости от маскированного участка аудиосигнала и в зависимости от множества коэффициентов фильтра, при этом множество коэффициентов фильтра зависят от маскированного участка аудиосигнала, и
при этом процессор (210) выполнен с возможностью определения второго участка аудиосигнала в зависимости от последующего участка аудиосигнала и от множества коэффициентов фильтра.
21. Устройство (200) по п. 20,
в котором процессор (210) содержит фильтр,
при этом процессор (210) выполнен с возможностью применения фильтра с коэффициентами фильтра к маскированному участку аудиосигнала, чтобы получать первый участок аудиосигнала, и
при этом процессор (210) выполнен с возможностью применения фильтра с коэффициентами фильтра к последующему участку аудиосигнала, чтобы получать второй участок аудиосигнала.
22. Устройство (200) по п. 21, в котором коэффициенты фильтра из множества коэффициентов фильтра являются параметрами Кодирования с Линейным Предсказанием у Фильтра с Линейным Предсказанием.
23. Устройство (200) по одному из пп. 20-22,
в котором процессор (210) выполнен с возможностью применения косинусного окна, определяемого посредством
к маскированному участку аудиосигнала, чтобы получать маскированный участок сигнала, полученный методом окна,
при этом процессор (210) выполнен с возможностью определения множества коэффициентов фильтра в зависимости от маскированного участка сигнала, полученного методом окна,
при этом каждое из x и x1 и x2 является позицией выборки из множества позиций выборки.
24. Устройство (300) по п. 1,
при этом первый участок аудиосигнала является маскированным участком аудиосигнала, при этом второй участок аудиосигнала является последующим участком аудиосигнала,
при этом процессор (310) выполнен с возможностью определения первого суб-участка у маскированного участка аудиосигнала, являющегося первым суб-участком первого участка аудиосигнала так, что первый суб-участок содержит одну или более из выборок маскированного участка аудиосигнала, но содержит меньше выборок, чем маскированный участок аудиосигнала, и так, что каждая позиция выборки у выборок первого суб-участка является последующим элементом любой позиции выборки у любой выборки маскированного участка аудиосигнала, которая не содержится первым суб-участком,
при этом процессор (310) выполнен с возможностью определения третьего суб-участка у последующего участка аудиосигнала так, что третий суб-участок содержит одну или более выборки последующего участка аудиосигнала, но содержит меньше выборок чем последующий участок аудиосигнала, и так, что каждая позиция выборки у каждой из выборок третьего суб-участка является последующим элементом любой позиции выборки у любой выборки последующего участка аудиосигнала, которая не содержится третьим суб-участком,
при этом процессор (310) выполнен с возможностью определения второго суб-участка у последующего участка аудиосигнала, являющегося вторым суб-участком второго участка аудиосигнала так, что любая выборка последующего участка аудиосигнала, которая не содержится третьим суб-участком, содержится вторым суб-участком последующего участка аудиосигнала,
при этом процессор (310) выполнен с возможностью определения первой выборки пика из выборок первого суб-участка маскированного участка аудиосигнала так, что значение выборки у первой выборки пика больше или равно любому другому значению выборки любой другой выборки первого суб-участка у маскированного участка аудиосигнала, при этом процессор (310) выполнен с возможностью определения второй выборки пика из выборок второго суб-участка у последующего участка аудиосигнала так, что значение выборки у второй выборки пика больше или равно любому другому значению выборки любой другой выборки второго суб-участка у последующего участка аудиосигнала, при этом процессор (310) выполнен с возможностью определения третьей выборки пика из выборок третьего суб-участка у последующего участка аудиосигнала так, что значение выборки третьей выборки пика больше или равно любому другому значению выборки любой другой выборки третьего суб-участка у последующего участка аудиосигнала,
при этом, если и только если условие удовлетворяется, процессор (310) выполнен с возможностью модифицирования каждого значения выборки у каждой выборки последующего участка аудиосигнала, которая является предшествующим элементом у второй выборки пика, чтобы генерировать декодированный участок аудиосигнала,
при этом условие состоит в том, что как значение выборки у второй выборки пика больше значения выборки у первой выборки пика, так и что значение выборки у второй выборки пика больше значения выборки у третьей выборки пика, или
условие состоит в том, что как первое отношение между значением выборки у второй выборки пика и значением выборки у первой выборки пика больше первого порогового значения, так и второе отношение между значением выборки у второй выборки пика и значением выборки у третьей выборки пика больше второго порогового значения.
25. Устройство (300) по п. 24, в котором условие состоит в том, что как значение выборки у второй выборки пика больше значения выборки у первой выборки пика, так и что значение выборки у второй выборки пика больше значения выборки у третьей выборки пика.
26. Устройство (300) по п. 24, в котором условие состоит в том, что как первое отношение больше первого порогового значения, так и второе отношение больше второго порогового значения.
27. Устройство (300) по п. 26, в котором первое пороговое значение является больше 1.1, и при этом второе пороговое значение является больше 1.1.
28. Устройство (300) по п. 26 или 27, в котором первое пороговое значение равно второму пороговому значению.
29. Устройство (300) по одному из пп. 24-28,
в котором, если и только если условие удовлетворяется, процессор (310) выполнен с возможностью модифицирования каждого значения выборки у каждой выборки последующего участка аудиосигнала, которая является предшествующим элементом у второй выборки пика в соответствии с
smodified(Lframe+i)=s(Lframe+i) ⋅ αi
при этом Lframe указывает позицию выборки у выборки последующего участка аудиосигнала, которая является предшествующим элементом для любой другой позиции выборки любой другой выборки последующего участка аудиосигнала,
при этом Lframe+i является целым числом, указывающим позицию выборки у i+1-й выборки последующего участка аудиосигнала,
при этом 0≤i≤Imax - 1, при этом Imax - 1 указывает позицию выборки у второй выборки пика,
при этом s(Lframe+i) является значением выборки у i+1-й выборки последующего участка аудиосигнала, до модифицирования процессором (310),
при этом smodified(Lframe+i) является значением выборки у i+1-й выборки последующего участка аудиосигнала, после модифицирования процессором (310),
при этом 0 < αi < 1.
30. Устройство (300) по п. 29,
в котором
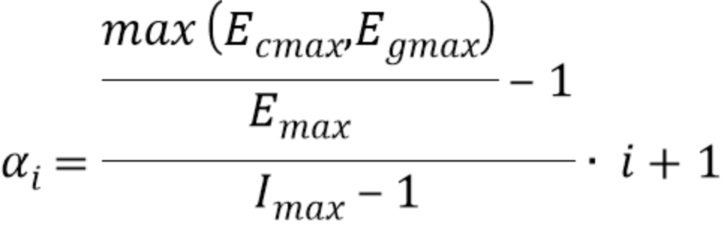
при этом Ecmax является значением выборки у первой выборки пика,
при этом Emax является значением выборки у второй выборки пика,
при этом Egmax является значением выборки у третьей выборки пика.
31. Устройство (300) по п. 29 или 30,
в котором, если и только если условие удовлетворяется, процессор (310) выполнен с возможностью модифицирования значения выборки каждой выборки у двух или более выборок из множества выборок последующего участка аудиосигнала, которые являются последующими элементами второй выборки пика, чтобы генерировать декодированный участок аудиосигнала в соответствии с
smodified(Imax+k)=s(Imax+k) ⋅ αi,
при этом Imax+k является целым числом, указывающим позицию выборки у Imax+k+1-й выборки последующего участка аудиосигнала.
32. Устройство (10; 100; 200; 300) по одному из предшествующих пунктов, при этом устройство (10; 100; 200; 300) дополнительно содержит блок (8) маскирования, выполненный с возможностью проведения маскирования для текущего кадра, который является ошибочным или который потерян, чтобы получать маскированный участок аудиосигнала.
33. Устройство (10; 100; 200; 300) по п. 32,
при этом устройство (10; 100; 200; 300) дополнительно содержит блок (6) активации, который выполнен с возможностью обнаружения, потерян ли или ошибочен ли текущий кадр,
при этом блок (6) активации выполнен с возможностью активации блока (8) маскирования, чтобы проводить маскирование для текущего кадра, если текущий кадр потерян или является ошибочным.
34. Устройство (10; 100; 200; 300) по п. 33,
в котором блок (6) активации выполнен с возможностью обнаружения, прибывает ли последующий кадр, который не является ошибочным, если текущий кадр потерян или был ошибочным, и
при этом блок (6) активации выполнен с возможностью активации процессора (8), чтобы генерировать декодированный участок аудиосигнала, если текущий кадр потерян или является ошибочным и если прибывает последующий кадр, который не является ошибочным.
35. Способ для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом способ содержит этапы, на которых:
генерируют декодированный участок аудиосигнала у аудиосигнала в зависимости от первого участка аудиосигнала и в зависимости от второго участка аудиосигнала, при этом первый участок аудиосигнала зависит от маскированного участка аудиосигнала, и при этом второй участок аудиосигнала зависит от последующего участка аудиосигнала, и
выводят декодированный участок аудиосигнала,
при этом каждый из первого участка аудиосигнала и из второго участка аудиосигнала и из декодированного участка аудиосигнала содержит множество выборок, при этом каждая из множества выборок первого участка аудиосигнала и второго участка аудиосигнала и декодированного участка аудиосигнала определяется посредством позиции выборки из множества позиций выборки и посредством значения выборки, при этом множество позиций выборки упорядочены так, что для каждой пары из первой позиции выборки из множества позиций выборки и второй позиции выборки из множества позиций выборки, отличной от первой позиции выборки, первая позиция выборки является либо последующим элементом, либо предшествующим элементом второй позиции выборки,
при этом этап, на котором генерируют декодированный аудиосигнал, содержит этап, на котором определяют первый суб-участок первого участка аудиосигнала так, что первый суб-участок содержит меньше выборок, чем первый участок аудиосигнала,
при этом этап, на котором генерируют декодированный участок аудиосигнала проводится, используя первый суб-участок первого участка аудиосигнала и используя второй участок аудиосигнала или второй суб-участок второго участка аудиосигнала так, что для каждой выборки из двух или более выборок второго участка аудиосигнала, позиция выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала равна позиции выборки одной из выборок декодированного участка аудиосигнала, и так, что значение выборки у упомянутой выборки из двух или более выборок второго участка аудиосигнала отличается от значения выборки у упомянутой одной из выборок декодированного участка аудиосигнала.
36. Цифровой запоминающий носитель информации, содержащий компьютерную программу, которая при исполнении на компьютере или сигнальном процессоре побуждает компьютер или сигнальный процессор реализовать способ по п. 35.
37. Система для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом система содержит:
модуль (701) переключения,
устройство (300) по п. 24, и
устройство (100) по п. 2,
при этом модуль (701) переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства (300) по п. 24 и устройства (100) по п. 2.
38. Система для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом система содержит:
модуль (702) переключения,
устройство (300) по п. 24, и
устройство (200) по п. 16,
при этом модуль (702) переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства (300) по п. 24 и устройства (200) по п. 16.
39. Система для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом система содержит:
модуль (703) переключения,
устройство (100) по п. 2, и
устройство (200) по п. 16,
при этом модуль (703) переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства (100) по п. 2 и устройства (200) по п. 16.
40. Система для улучшения перехода от маскированного участка аудиосигнала у аудиосигнала к последующему участку аудиосигнала у аудиосигнала, при этом система содержит:
модуль (704) переключения,
устройство (100) по п. 2,
устройство (200) по п. 16, и
устройство (300) по п. 24,
при этом модуль (704) переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, одного из устройства (100) по п. 2 и устройства (200) по п. 16 и устройства (300) по п. 24.
41. Система по п. 40,
в которой модуль (704) переключения выполнен с возможностью определения, содержит или нет, по меньшей мере, один из маскированного кадра аудиосигнала и последующего кадра аудиосигнала речь, и
при этом модуль (704) переключения выполнен с возможностью выбора устройства (300) по п. 24, если маскированный кадр аудиосигнала и последующий кадр аудиосигнала не содержат речь.
42. Система по п. 40 или 41, в которой модуль (704) переключения выполнен с возможностью выбора упомянутого одного из устройства (100) по п. 2 и устройства (200) по п. 16 и устройства (300) по п. 24 для генерирования декодированного участка аудиосигнала в зависимости от длины кадра у последующего кадра аудиосигнала и в зависимости от, по меньшей мере, одного из основного тона у маскированного участка аудиосигнала или основного тона у последующего участка аудиосигнала, при этом последующий участок аудиосигнала является участком аудиосигнала у последующего кадра аудиосигнала.
43. Система по п. 39,
при этом система дополнительно содержит устройство (300) по п. 24,
при этом модуль (703) переключения выполнен с возможностью выбора, в зависимости от маскированного участка аудиосигнала и в зависимости от последующего участка аудиосигнала, упомянутого одного из устройства (100) по п. 2 и устройства (200) по п. 16, чтобы генерировать промежуточный участок аудиосигнала,
при этом устройство (300) по п. 24 выполнено с возможностью обработки промежуточного участка аудиосигнала, чтобы генерировать декодированный участок аудиосигнала.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И СПОСОБ | 2012 |
|
RU2488897C1 |

