ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области компьютерной обработки больших данных, в частности, к системе автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени.
УРОВЕНЬ ТЕХНИКИ
В настоящее время существует потребность в оптимизации процессов, реализуемых в компаниях, заводах, предприятиях. Возможность контролировать изменения ключевых показателей деятельности - это залог успеха любой современной организации, что также позволяет прогнозировать и контролировать изменения ключевых показателей деятельности организации и вовремя реагировать на происходящие изменения. Своевременно выявляя изменения, происходящие в деятельности организации, можно повлиять на эти изменения и подготовится к их последствиям.
Из уровня техники известно решение US20160378830A1 (ADBA S A, опубл. 2016-12-29), описывающее систему сбора и анализа больших данных, состоящую из: сырых данных, получаемых из разных источников, адаптеров, которые обрабатывают сырые данные, основную meta-БД, куда скидываются все настройки и расположение региональных БД, аналитический модуль, интерфейс доступа, пользовательский интерфейс. Основная задача, данного решения - быстрый анализ локализованных данных с последующим информированием и с возможным более глубоким анализом нескольких территорий. Это даёт возможность быстрого реагирования на разные виды событий: террористические, рыночные, геологические, коммерческие, социальные и т.п. Что экономит денежные средства/время и позволяет почти мгновенно реагировать на события. При этом, данное решение относится инструментам для получения и всестороннего анализа бизнес-данных, но не решает задачу контроля качества данных.
Из уровня техники известно решение EP3220267A1 (BUSINESS OBJECTS SOFTWARE LTD, опубл. 2017-09-20), которое описывает подсистему надстройки к распределенным системам таким, например, как Apache Spark, и оптимизирует процесс прогнозирования данных. Делегирование операций обработки данных осуществляется на переменном множестве узлов. Оптимизация прогнозного моделирования осуществляется как на стороне клиента, так и сервера, например, Hadoop. При этом, в данном решении отсутствует возможность мониторинга качества данных получаемых из различных источников в режиме реального времени.
Из уровня техники известно решение US9516053B1 (SPLUNK INC, опубл. 2016-12-06), в котором описан подход поиска аномальных данных в сети на пакетном уровне для оценки уровня безопасности системы: анализ с задержкой или в режиме реального времени на усмотрение админа. В данном решении осуществляется анализ и мониторинг за компьютерными сетями. Аномальные всплески визуализируются, и система подсказывает, что имеется всплеск/провал, что может означать прорыв безопасности, например, взлом системы. При этом, в данном решении отсутствует возможность мониторинга качества данных получаемых из различных источников в режиме реального времени.
Из уровня техники известно решение KR20180042865A (UPTAKE TECH INC, опубл. 2018-04-26), которое описывает платформу для оптимизации бизнес процессов внутри предприятия, где компания производитель может с помощью этой платформы настроить контроль за поставщиками, оборудованием, другими компаниями. Каждый из датчиков оповещает систему о своем состоянии и дальше могут срабатывать определенные правила. Это довольно сложно конфигурируемая система, ориентированная на оптимизацию процесса производства. Основное в этом изобретении - контроль передачи данных. Если один узел задерживает, то все последующие узлы и транспорт должны быть оповещены об этом. Это экономит и бюджет и снимает бронирование излишних ресурсов. При этом, в данном решении отсутствует возможность мониторинга качества данных получаемых из различных источников в режиме реального времени.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание платформенной системы автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени, которая охарактеризована в независимом пункте формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в повышении качества и точности анализа данных получаемых из различных источников в режиме реального времени.
Дополнительным техническим результатом является обнаружение отклонение в полученных данных и оперативное информирование о них соответствующих пользователей до того, как эти отклонения окажут существенное негативное влияние на технологические процессы.
В предпочтительном варианте реализации заявлена компьютерно-реализуемая система автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени, содержащая:
- модуль веб-приложения, который выполнен с возможностью добавлять новые источники мониторинга в систему, осуществлять конфигурирование расширенных параметров мониторинга, просматривать историю случившихся событий и отчетность по мониторингам, а также визуализировать обнаруженные отклонения в данных;
- модуль интеграционных коннекторов, который выполнен с возможностью подключения системы к различным источникам для получения данных и выполнен с возможностью преобразования этих данных в единый внутренний формат для дальнейшей унифицированной обработки;
- модуль машинного обучения, который самостоятельно обучается определять качество полученных данных в режиме реального времени, во время которого:
• получает от коннекторов преобразованные данные из различных источников на протяжении заданного периода времени и сохраняет в общую выборку;
• запускает процесс инициализации мониторинга сохраненной выборки путем определения шкал изменения данных, при этом для каждого показателя из выборки в соответствии с определенной шкалой рассчитываются статистики, на основе рассчитанных статистик для каждого показателя запускается алгоритм инициализации проверок;
• после завершения обучения в базу данных сохраняются параметры обученной модели;
- модуль машинного обучения применяет параметры обученной модели для последующего мониторинга получаемых новых данных по установленному расписанию, при этом, на новых корректных данных модуль машинного обучения постоянно до обучается, если текущая модель плохо улавливает зависимости в новых данных, то модуль осуществляет полное переобучение;
- в случае если после мониторинга полученных новых данных были обнаружены отклонения, модуль агрегации нотификаций формирует текст с ошибками;
- модуль интеграции с каналами информирования отправляет текст с ошибками соответствующим пользователям.
В частном варианте различными источниками данных могут быть: Oracle Database, Hive, Kafka, PostgreSQL, Terradata, Prometheus, видео и аудио потоки данных.
В другом частном варианте алгоритм машинного обучения реализован в Python.
В другом частном варианте каналами информирования могут быть: SMS канал, e-mail, Jira, Trello, Telegram-канал.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг. 1 иллюстрирует компьютерно-реализуемую систему автоматического мониторинга качества данных;
Фиг. 2 иллюстрирует график результатов серий тестов на разных объемах и репрезентативность выборок;
Фиг. 3 иллюстрирует график функции размера выборки;
Фиг. 4 иллюстрирует алгоритм определения шкал измерения показателей;
Фиг. 5 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Заявленное решение реализовано на высокодоступной отказоустойчивой платформе и отличается простотой настройки, использования, администрирования и мониторинга работы.
Настоящее изобретение направлено на обеспечение компьютерно-реализуемой системы автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени.
Качество данных - это критерий, определяющий полноту, точность, актуальность и возможность интерпретации данных. Данные могут быть высокого и низкого качества. Данные высокого качества - это полные, точные, актуальные данные, которые поддаются интерпретации. Такие данные обеспечивают получение качественного результата: знаний, которые смогут поддерживать процесс принятия решений.
Данные низкого качества - это так называемые грязные данные. Грязные данные могут появиться по разным причинам, таким как ошибка при вводе данных, использование иных форматов представления или единиц измерения, несоответствие стандартам, отсутствие своевременного обновления, неудачное обновление всех копий данных, неудачное удаление записей-дубликатов и т.д.
Заявленное решение предоставляет предприятиям такие необходимые функции, как:
- работа с большими и потоковыми данными реального времени;
- коннекторы к множеству современных источников данных (включая Hadoop, работа с аудио и видео данными);
- нотификация пользователя о значимых отклонениях по различным каналам;
- возможность использования системы как облачного сервиса;
- функциональность инцидент-менеджмента.
Потоковые данные поступают на больших скоростях и быстро аккумулируются в большие объёмы. Максимальную пользу из таких данных можно извлечь, только если собирать и анализировать их в реальном времени.
Как представлено на Фиг. 1, заявленная компьютерно-реализуемая система автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени (100) включает в себя следующий набор основных модулей:
модуль веб-приложения (101);
модуль интеграционных коннекторов (102);
модуль машинного обучения (103);
модуль агрегации нотификаций (104);
модуль интеграции с каналами информирования (105).
При разработке модулей системы применяется современный подход использования микросервисной архитектуры.
Перед началом работы системы осуществляется первый этап: необходимо определить, в каких именно источниках хранятся данные, которые должны попасть в заявленную систему, т.е. осуществить выбор внешних источников данных. Такими источниками могут быть. Например, Oracle Database, Hive, Apache Kafka, Cassandra, Sqoop, PostgreSQL, Terradata, Prometheus и любые другие источники. Также установлен Apache nifi, как универсальный ETL инструмент с удобным графическим интерфейсом.
Также реализована работа с мультимедиа данными (аудио и видео). С помощью моделей машинного обучения (нейронные сети, модели на основе Марковских цепей, различные классификаторы) определяют основные метки данных. Например, количество людей в единицу времени в видеопотоке или новостная тематика в rss лентах. Высчитываемая статистка определяется моделью, которая выбирается при создании etl процесса. Таким образом, мультимедиа данные можно конвертировать в структурированный вид и использовать для мониторинга данных или других нужд.
Указанные выше примеры источников не ограничиваются приведенной реализацией, поскольку они постоянно расширяются.
Второй этап: это выбор объекта для мониторинга. Выбор таблиц/коллекций в базе данных. Один мониторинг - одна таблица, один объект базы данных (в случае потоковых данных могут быть несколько объектов). Все возможные варианты подтягиваются автоматически.
Осуществляется выбор полей для мониторинга - выбор полей в таблице/коллекции. Доступны три вида:
Дата - показатель, по которому будет происходить агрегация данных по времени. Может быть не больше одного.
Группировка показателей - показатель, по которому будет происходить группировка данных. Можно выбрать любое количество.
Показатели мониторинга - показатели, которые будут анализироваться системой. Есть возможность выбора всех показателей по кнопке «Выбрать все».
Кроме того, выбирается период поступления данных из источников, также задаётся название и описание.
Выгрузка может производиться по истечении заданного временного интервала (день, неделя, месяц или квартал). В некоторых случаях предусматривается возможность внерегламентного извлечения данных после завершения определенного бизнес-события (приобретение нового бизнеса, открытие филиала, поступление большой партии товаров).
В расписании мониторинга также настраивается периодичность запусков проверок мониторинга. Время необходимо выбрать с расчетом, что новые данные уже доступны в источнике.
Также осуществляется форма настроек уведомлений для предупреждений, такими каналами информирования могут быть: SMS канал, e-mail, Jira, Trello, Telegram-канал.
Указанные выше настройки осуществляются в модуле веб-приложения (101), который реализует возможность управления системой посредством простого и удобного пользовательского интерфейса.
Кроме того, модуль веб-приложения (101) выполнен с возможностью добавлять новые источники мониторинга в систему, осуществлять конфигурирование расширенных параметров мониторинга, просматривать историю случившихся событий и отчетность по мониторингам, а также визуализировать обнаруженные отклонения в данных.
При добавлении новых источников работа системы не нарушается.
Первоначальная обработка данных
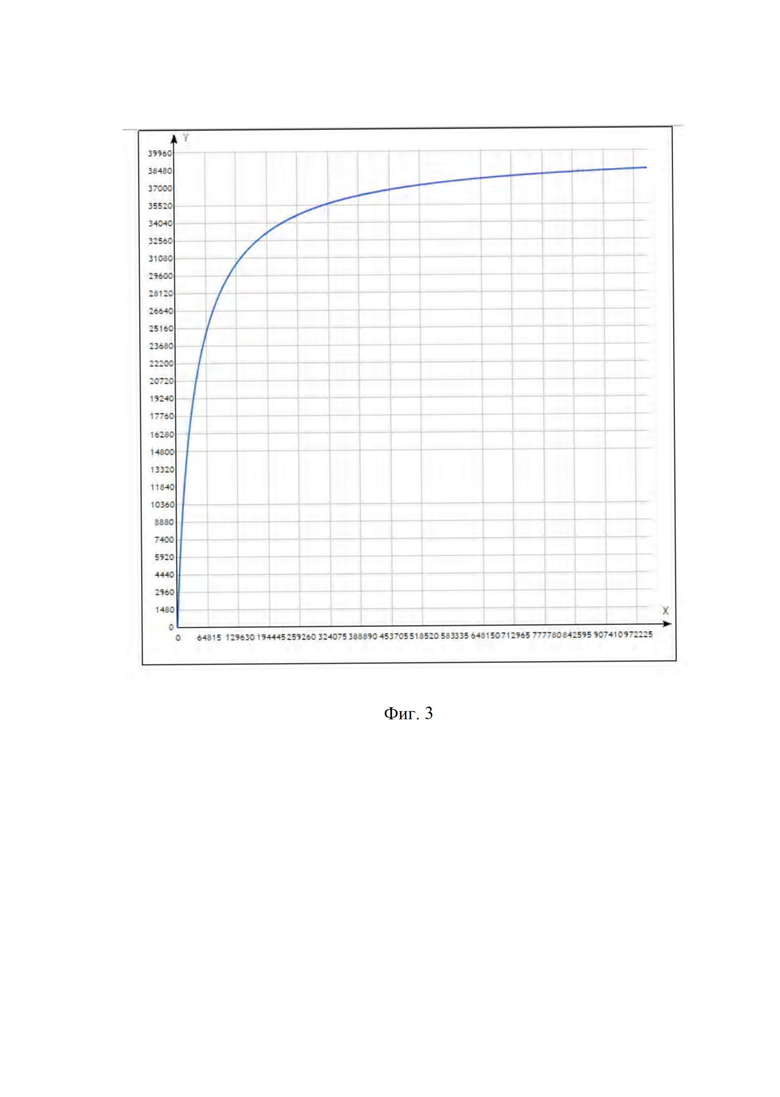
После подключения модуля интеграционных коннекторов (102) к различным источникам в режиме реального времени запускается процесс выгрузки данных. Размер выборки данных определяется автоматически по формуле случайной выборки, выработанной в процессе большого количества испытаний на статистическую репрезентативность по многим параметрам вне зависимости от типа распределения данных.
Ниже приведена формула простой случайной выборки:
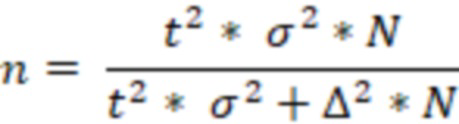
где,
t - значение t статистики для выбранного уровня значимости
σ - стандартное отклонение исследуемой переменной
∆ - предельная ошибка выборки
N - размер генеральной совокупности.
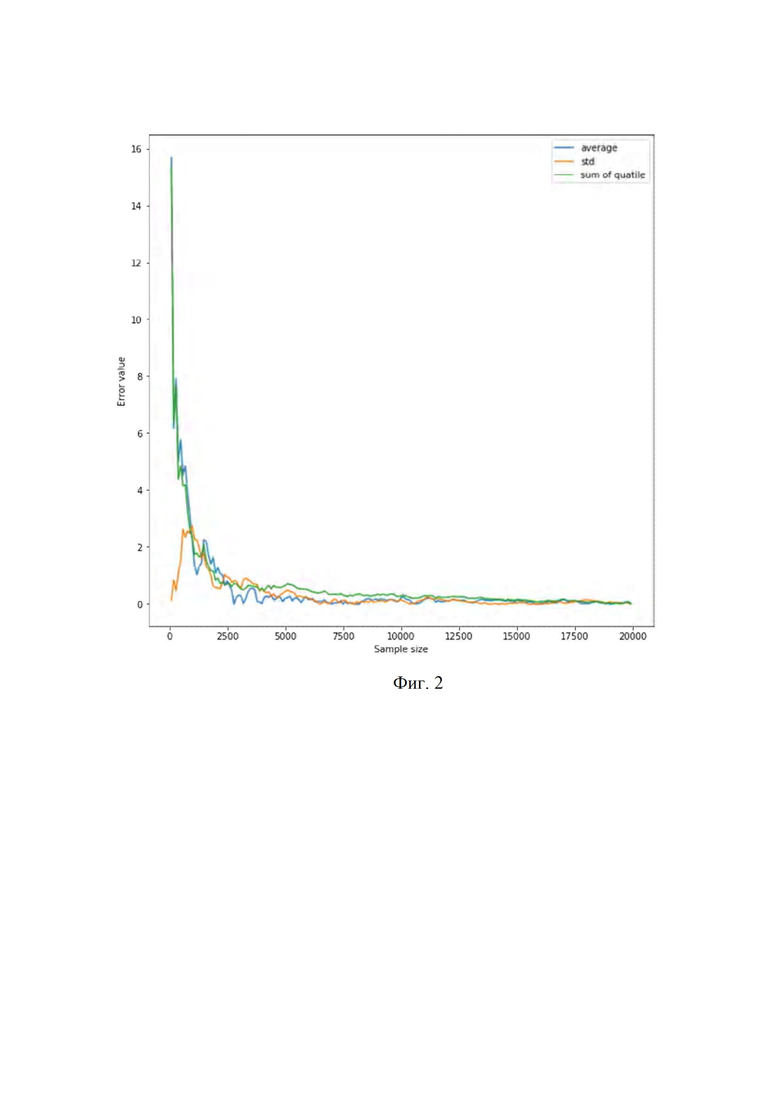
Однако формулы этого семейства оперируют статистикой одной переменной и высчитывают размер репрезентативной выборки для исследуемого параметра. Для определения размера выборки вне зависимости от количества параметров и типов распределения этих параметров проводилось большое количество тестов для определения функции определения выборки и параметров этой функции. За основные KPI качества выборки использовались показатели изменения среднего значения показателя, стандартного отклонения и модальная сумма разницы квантилей (от 10% квантиля до 90%).
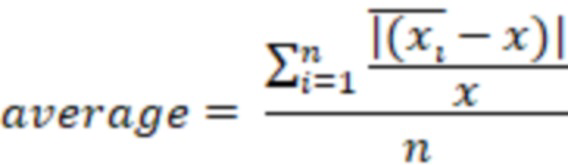
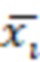 - среднее значение i-ого показателя выборки
- среднее значение i-ого показателя выборки
 - среднее значение i-ого показателя по генеральной совокупности
- среднее значение i-ого показателя по генеральной совокупности
 - количество показателей
- количество показателей

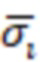 - стандартное отклонение i-ого показателя выборки
- стандартное отклонение i-ого показателя выборки
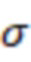 - стандартное отклонение i-ого показателя по генеральной совокупности
- стандартное отклонение i-ого показателя по генеральной совокупности
n - количество показателей
Q - относительное отклонение квантилей от 10% до 90% с шагом в 10%.
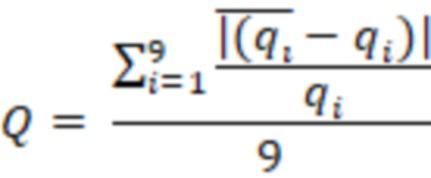
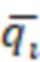 – i-ый квантиль показателя по выборочной совокупности (i изменяется в диапазоне 10%-90% с шагом в 10%)
– i-ый квантиль показателя по выборочной совокупности (i изменяется в диапазоне 10%-90% с шагом в 10%)
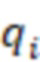 – i-ый квантиль показателя по генеральной совокупности
– i-ый квантиль показателя по генеральной совокупности
n – количество показателей
На основе графического анализа (фиг. 3) и результатов проведенных тестов была определена следующая функция размера выборки:
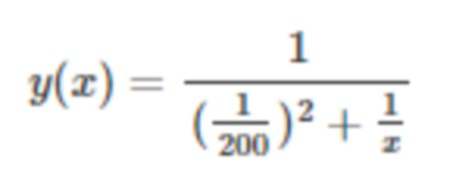 .
.
Исходные данные расположены в разнородных источниках самых разнообразных типов и форматов, поскольку созданы в различных приложениях, и, кроме того, могут использовать различную кодировку, в то время как для решения задач анализа и мониторинга данных должны быть преобразованы в единый универсальный формат, который поддерживается заявленной системой.
Поэтому модуль интеграционных коннекторов (102) осуществляет преобразование полученных данных в единый внутренний формат для дальнейшей унифицированной обработки.
Преобразованные данные из различных источников передаются в модуль машинного обучения (103), который сохраняет полученные данные в общую выборку и на основе этих данных самостоятельно обучается определять качество полученных данных в режиме реального времени.
В зависимости от типа мониторинга, обучение может продолжаться от нескольких минут до 14 дней (в случае потоковых данных). На время обучения также влияет корректность исторических данных. Во время обучения - модуль машинного обучения анализирует данные и выделяет зависимости, допустимые значения и т.п.
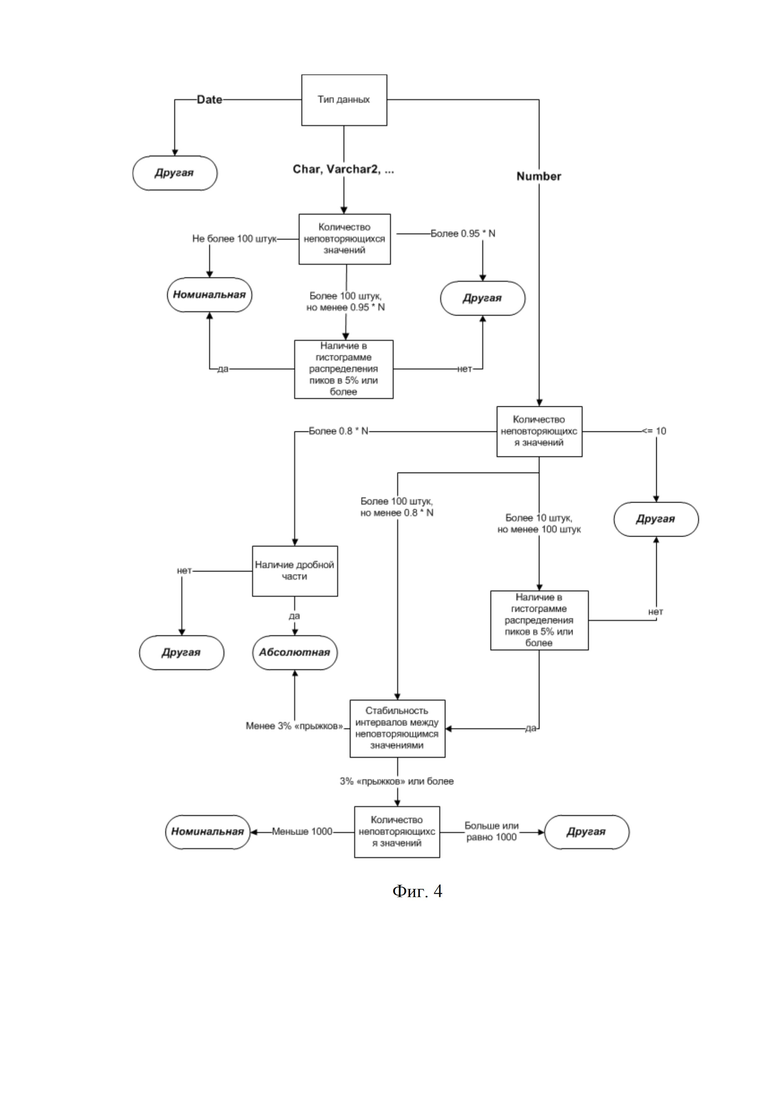
Во время обучения запускает процесс инициализации мониторинга сохраненной выборки путем определения шкал изменения данных. Определение шкал изменения данных является одним из связующих ядер системы. При этом для каждого показателя из выборки в соответствии с определенной шкалой рассчитываются статистики, на основе рассчитанных статистик для каждого показателя запускается алгоритм инициализации проверок.
Шкала (измерительная шкала) - это знаковая система, для которой задано отображение (операция измерения), ставящее в соответствие реальным объектам (событиям) тот или иной элемент (значение) шкалы. Формально, шкалой называют кортеж, <X, φ, Y>, где X - множество реальных объектов (событий), φ - отображение, Y - множество элементов (значений) знаковой системы (Анфилатов В. С., Емельянов А. А., Кукушкин А. А. Системный анализ в управлении. - М. Финансы и статистика, 2002. - 368 с).
Шкала измерения имеет несколько классификаций. В заявленном решении все данные будут разделяться на 3 типа:
- номинальная шкала;
- абсолютная шкала;
- и другая (все остальные типы).
Так как в теории не существует четкого алгоритма определения шкал показателя, то был разработан собственный алгоритм, который представлен на фиг. 5.
Ниже представлены пояснения к блок схеме, изображенной на фиг. 5:
Тип данных - тип данных, которые заложены в источнике данных (мета данные источника).
N - количество записей в выборке.
Наличие в гистограмме распределение пиков в 5% или более – высчитывается доля каждого значения во всем массиве. Если доля хотя бы одного значения больше 0,05, то признак принимает значение «Да», в противном случае «Нет».
Стабильность интервалов между неповторяющимися значениями – показатель непрерывности данных, показывающий долю резких скачков из всей совокупности. Алгоритм расчета:
1. Формируется гистограмма распределения данных в виде таблицы value: [count]. Value - значение массива, count - количество value в массиве.
2. Высчитывается дополнительный показатель:
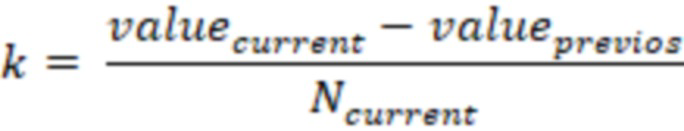
 – текущее значение гистограммы
– текущее значение гистограммы
 – предыдущее значение гистограммы
– предыдущее значение гистограммы
 – количество из гистограммы
– количество из гистограммы
На выходе получаем value: [count, k]
3. Высчитываем еще 2 показателя.
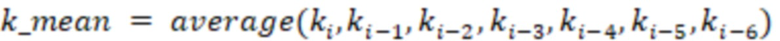
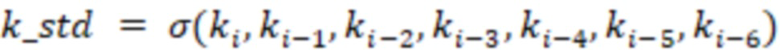
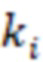 - текущее значение k.
- текущее значение k.
На выходе получаем value: [count, k, k_mean, k_std]
4. Высчитываем показатель непрерывности.
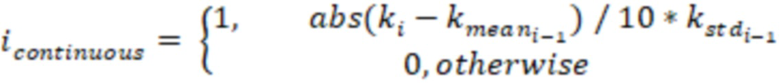
На выходе получаем value: [count, k, k_mean, k_std, i_continious]
5. Высчитываем среднее значение i_continious по всей таблице.
В большинстве хранилищах данных заполняемость полей находится на низком уровне. Для того, чтобы отличить реальные данные от тех, которые заполняются программно (например, нулями или NULL или еще каким-то значением). Например, скорринговый балл (вероятность какого-либо события для объекта) изменятся от 0 до 1. В случае, если этот бал не может быть посчитан, он может быть проставлен как -99. Значения -99 будет сильно смещать среднее значение, тип распределения данных и т.п.
Алгоритм применим ко всем показателям с типом данных NUMBER. Для определения значений «по умолчанию» необходимо построить гистограмму распределения данных в последнем доступном периоде без разделения на аналитические единицы. Значение показателя NULL в гистограмме не учитывается.
Значения «по умолчанию» определяются как такие значения, что:
• не равны нулю;
• находятся на краях гистограммы, т.е. соответствуют максимальному или минимальному значению;
• высота столбца гистограммы в них, входит в список трех самых высоких столбцов;
• высота столбца гистограммы в них превышает среднюю высоту столбцов гистограммы минимум на 3 стандартных отклонения.
Определение больших долей.
Среди всех значений из гистограммы необходимо определить наибольшие по доле. В дальнейшем эти значения будут использоваться для проверки на сохранение долевого распределения. Мониторинг долевого распределения позволит отслеживать заполняемость большей части данных.
Выбор показателей для слежения происходит на случайных выборках в последних периодах. Количество периодов для анализа определяется следующим образом:
N = {7 - дневная периодичность; 5 - недельная периодичность; 3 - месячная периодичность; 3 - годовая периодичность}.
1. В каждом из последних периодов: выбираются показатели с долей более 1% (более 10% для абсолютных шкал);
2. Упорядочивают по убыванию доли;
3. Продвигаясь сверху вниз по упорядоченному списку формируется набор показателей для мониторинга следующим образом:
3.0. инициализация алгоритма:
• гистограмма пустая;
• список отдельных мониторингов долей пуст;
3.1. проверка: текущее значение отличаются от следующего более чем в 3 раза?
ДА: 3.1.1. проверка: гистограмма пустая?
ДА: 3.1.1.1. текущее значение добавить в список отдельных мониторингов, перейти на следующее по величине доли значение и провести проверку 3.1.
НЕТ: 3.1.1.2. текущее значение добавить в гистограмму и завершить алгоритм.
НЕТ: 3.1.2. добавить текущее значение в гистограмму.
3.1.3. проверка: в гистограмме 5 значений?
ДА: 3.1.3.1. завершить алгоритм.
НЕТ: 3.1.3.2. перейти на следующее по величине доли значение и провести проверку 3.1.
В итоговый список отдельных мониторингов попадают значения, которые во всех периодах попали в анализ и как минимум 1 раз были в списке отдельных мониторингов.
В итоговую гистограмму попадают значения, которые во всех периодах были в гистограмме. Если в гистограмме осталось только 1 значение, необходимо сформировать для него отдельный мониторинг и очистить гистограмму.
Значения, попавшие в гистограмму, будут отслеживаться в рамках одного наблюдения. Для каждого значения в списке отдельных мониторингов формируются независимые наблюдения.
Ниже описан расчёт статистик для каждого показателя.
Для каждого показателя в соответствии с определенной шкалой рассчитываются статистики. Рассчитываются разные статистики:
• среднее значение показателя
• доли значений показателя
• количество null значений
• количество не null значений
• количество неповторяющихся значений
• коэффициент корреляции
• количество нулевых значений
• количество положительных и отрицательных значений
• хвосты распределений
Алгоритм расчета статистик однопроходный и распределенный.
На основе рассчитанных статистик для каждого показателя запускается алгоритм инициализации проверок и моделей. На выходе получаем список оптимальных проверок для каждого показателя. Список проверок формируется исходя из извлеченной информации о данных. Основной акцент делается на непересекаемость проверок, чтобы одна и та же природа ошибки (например, доля пустых значений увеличилась в 2 раза) не была определена 2 и более раз.
Инициализация проверок.
Для комплексного покрытия всех возможных разладок систем был разработан список возможных проверок и условия их включения. Проверки делятся на логические и статистические.
Логические проверки.
Проверки данного типа проверяются булево условие для каждого значения поля, статистические проверяют статистику (среднее, количество неповторяющихся значений, доля какого-либо значения поля и т.п.).
Ниже представлена таблица 1 с логическими проверками и их условиями включения, а также условиями срабатывания.
Таблица 1
1Разладка системы – момент изменения поведения системы.
MINR – Разрешающая способность выборочной статистики. 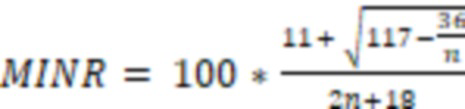 , где n – размер выборочной совокупности. MINR процент объектов интерпретируется системой как статистически значимой группой.
, где n – размер выборочной совокупности. MINR процент объектов интерпретируется системой как статистически значимой группой.
Пример:
Для включения проверки на «Отсутствие данных» необходимо чтобы в выборке обучения не было пустых значений, и проверка на «Наличие заполненных» не была включена. Для срабатывания проверки (детектирования ошибки) нужно чтобы в новом периоде (выборка за новый период) процент пустых значений был больше MINR и 0,5%. Например, в новом периоде из 10000 значений, то система посчитает данные ошибочные если среди 10000 значений будет больше 50 пустых (MINR = 0.1% -> max(MINR, 0.5) = 0.5 -> 10000*0.5% = 50).
Статистические проверки.
- Объем
Проверка количества строк в источнике данных. Необходимо для мониторинга заполняемости источника данных. Проверяемая статистика: количество записей в источнике за период.
- Тренд:
Проверка среднего значения показателя. Необходимо для мониторинга среднего значения.
Условия включения проверки:
▪ Тип данных - number
▪ В периоде инициализации после исключения значений по умолчанию, null и 0 в массиве данных больше 20% исходных данных.
Проверяемая статистика: среднее значение показателя без учета значений по умолчанию, null, 0 и статистических выбросов.
- Доли:
Проверка долевого распределения. Необходимо для мониторинга долей значений показателя.
Условия включения проверки:
▪ Шкала измерения показателя абсолютная или номинальная
▪ Найдены значения для слежения (согласно алгоритму определения долей).
Проверяемая статистика: количество неповторяющихся значений.
- Вариативность:
Проверка количества неповторяющихся значений. Необходимо для мониторинга неповторяющихся значений.
Условия включения проверки:
▪ Шкала измерения показателя - абсолютная
▪ Результат оценки доли неповторяющихся значений по выборке от 30% до 95%.
Проверяемая статистика: количество неповторяющихся значений.
- Зависимость:
Проверка корреляционной зависимости между показателями. Проверка используется для наблюдения за зависимостью между полями. Например, если одно поле зависит напрямую от других, модель выявляет зависимость и предупреждает об ошибке, если зависимость нарушается.
Условия включения проверки:
▪ Шкала измерения показателя – абсолютная
▪ Коэффициент корреляции Пирсона больше 0,5.
Обучение статистических моделей
Для каждой выбранной модели и проверки запускается процесс обучения по истории. Период обучения зависит от выбранной модели, вариативности показателя и доступной истории. Приведем пример обучения для какой-нибудь проверки. Допустим, нам надо построить модель для проверки на средний возраст клиентов в банковском клиентском профиле. Алгоритм обучения выглядит следующим образом:
I. Накопление нужной истории данных. Допустим, клиентский профиль пересчитывается ежедневно, следовательно, нам надо минимум 14 дней истории (то есть, 14 последний значений среднего возраста клиентов). Количество нужных периодов заложено в системных параметрах.
II. После накопления нужно истории (допустим, мы получили 14 средних значений) запускается процесс определения оптимальной модели. Временной ряд делиться на тестовую и контрольную выборку. На тестовой выборке строятся разные модели (модель скользящего среднего, авторегрессионная модель, линейная модель, регрессионное дерево и т.п.). На контрольной выборке высчитывается ошибка каждой модели (среднеквадратичная ошибка). По минимальному значению ошибки выбирается оптимальная модель.
III. Если ошибка (MAPE) на контрольной выборке превышает 0.2, то модель считается недообученной и возвращаемся к пункту I (берем среднее значение возраста 15 дней назад и т.д.).
IV. После того как модель определена, на основе ошибки высчитывается стандартное отклонение прогнозного и реального значения по контрольной выборке. Затем высчитывается параметр чувствительности модели:
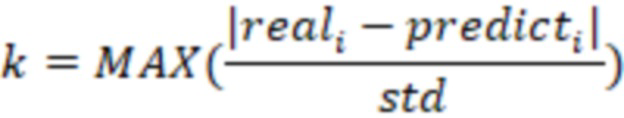
где
 - реальное значение в контрольной выборке
- реальное значение в контрольной выборке
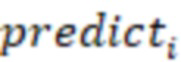 - модельное значение в контрольной выборке
- модельное значение в контрольной выборке
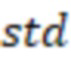 - стандартное отклонение прогнозного и реального значения
- стандартное отклонение прогнозного и реального значения
V. В системе фиксируются параметры модели и прогнозное значение на новый период. Например, на выходе мы полили модель авторегрессии с параметрами (p=2, d=0, q=1), чувствительность модели равно 1.34, стандартное отклонение равно 0.4, а прогноз на следующий день = 41.8 лет.
После завершения процесса обучения происходит финишная настройка параметров модели и фиксация всех параметров в системе, в базу данных сохраняются параметры обученной модели. После чего система готова к работе и запускает проверку новых данных по расписанию.
При наступлении даты плановой проверки: система автоматически запускает проверку новых данных. После завершения проверки - строятся новые графики по поступившим данным. Если данных поступивших за все время после создания мониторинга менее Nmax: данные дополняются из данных, на которых проходила инициализация (обучение).
Проверка новых данных
Модуль машинного обучения (103) применяет параметры обученной модели для последующего мониторинга получаемых новых данных по установленному расписанию, при этом, на новых корректных данных модуль машинного обучения постоянно до обучается, если текущая модель плохо улавливает зависимости в новых данных, то модуль осуществляет полное переобучение.
После завершения обучения на истории и фиксации всех параметров запускается процесс проверки периодов. Согласно выбранному расписанию запускается процесс проверки новых данных на корректность. Новые данные проверяются на соответствие прогнозу. Новое значение считается корректным если оно находится в интервале:
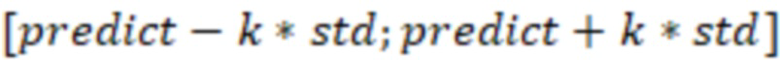 .
.
Согласно примеру выше, если средний возраст клиента в новый день будет в интервале [41.8 - 1.34*0.4; 41.8 + 1.34*0.4] == [41.264; 42.336], то система посчитает новые данные корректными.
Нотификация пользователя об ошибках
В случае если после мониторинга полученных новых данных были обнаружены отклонения, модуль агрегации нотификаций (104) формирует текст с ошибками.
Модуль интеграции с каналами информирования (105) отправляет текст с ошибками соответствующим пользователям. Существуют несколько способов оповещения пользователя об ошибках: sms, e-mail, trello, telegram, jira.
Оповещение об обнаруженных событиях позволяет пользователям немедленного на них отреагировать. Параллельно решение сохраняет данные в средах обработки, таких как Hadoop, для дальнейшего использования и сопоставления их с историческими данных, для предиктивной аналитики.
Hadoop - открытая программный каркас (framework) для работы с гигантскими объемами данных включая имплементацию MapReduce. MapReduce – модель параллельной обработки для гигантских наборов данных в распределенных системах, имплементированная в Hadoop.
В истории отображаются результаты всех проверок мониторинга, в том числе выявленные ошибки и предупреждения.
На Фиг. 5 далее будет представлена общая схема вычислительного устройства (500), обеспечивающего обработку данных, необходимую для реализации заявленной системы автоматического мониторинга качества данных получаемых из различных источников в режиме реального времени.
В общем случае вычислительное устройство (500) содержит такие компоненты, как: один или более процессоров (501), по меньшей мере одну память (502), средство хранения данных (503), интерфейсы ввода/вывода (504), средство В/В (505), средства сетевого взаимодействия (506).
Процессор (501) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (500) или функциональности одного или более его компонентов. Процессор (501) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (502).
Память (502), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (503) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (503) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (504) представляют собой стандартные средства для подключения и работы несколько устройств, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (504) зависит от конкретного исполнения устройства (500), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент и т.п.
Средства сетевого взаимодействия (506) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (505) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (500) сопряжены посредством общей шины передачи данных (510).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЗАЦИИ СКВОЗНОГО (END-TO-END) ТЕСТИРОВАНИЯ С ПОМОЩЬЮ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2839253C1 |
| ОПТИМИЗАЦИЯ УСТАНОВОЧНЫХ ЗНАЧЕНИЙ СИГНАЛИЗАЦИИ ДЛЯ КОНСУЛЬТАЦИЙ НА ОСНОВЕ СИГНАЛИЗАЦИИ С ИСПОЛЬЗОВАНИЕМ ЕЕ ОБНОВЛЕНИЯ | 2015 |
|
RU2675048C9 |
| КОМПЬЮТЕРИЗИРОВАННЫЙ СПОСОБ РАЗРАБОТКИ И УПРАВЛЕНИЯ МОДЕЛЯМИ СКОРИНГА | 2018 |
|
RU2680760C1 |
| Система сбора и анализа данных о нарушениях | 2023 |
|
RU2833783C1 |
| СПОСОБ И СИСТЕМА ОЦЕНКИ ВЕРОЯТНОСТИ ВОЗНИКНОВЕНИЯ КРИТИЧЕСКИХ ДЕФЕКТОВ ПО КИБЕРБЕЗОПАСНОСТИ НА ПРИЕМО-СДАТОЧНЫХ ИСПЫТАНИЯХ РЕЛИЗОВ ПРОДУКТОВ | 2020 |
|
RU2745369C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ | 2023 |
|
RU2809489C1 |
| СПОСОБ И СИСТЕМА СИМУЛЯЦИИ В ВИРТУАЛЬНЫХ ЛАБОРАТОРИЯХ ПО ЭЛЕКТРОДИНАМИКЕ | 2020 |
|
RU2751439C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ С ПРИМЕНЕНИЕМ ДВУХ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2810149C1 |
| СПОСОБ И СИСТЕМА ПРОГНОЗИРОВАНИЯ РИСКОВ КИБЕРБЕЗОПАСНОСТИ ПРИ РАЗРАБОТКЕ ПРОГРАММНЫХ ПРОДУКТОВ | 2020 |
|
RU2745371C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ С ПРИМЕНЕНИЕМ ДВУХ АНСАМБЛЕЙ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2809490C1 |

Изобретение относится к области вычислительной техники. Технический результат заключается в повышении качества и точности анализа данных. Система содержит: модуль веб-приложения, выполненный с возможностью добавлять новые источники мониторинга в систему, осуществлять конфигурирование расширенных параметров мониторинга, просматривать историю случившихся событий и отчетность по мониторингам; модуль интеграционных коннекторов, выполненный с возможностью подключения системы к различным источникам для получения данных; модуль машинного обучения, который самостоятельно обучается определять качество полученных данных в режиме реального времени, во время которого: получает от коннекторов преобразованные данные из различных источников на протяжении заданного периода времени и сохраняет в общую выборку; запускает процесс инициализации мониторинга сохраненной выборки путем определения шкал изменения данных, при этом для каждого показателя из выборки в соответствии с определенной шкалой рассчитываются статистики, на основе рассчитанных статистик для каждого показателя запускается алгоритм инициализации проверок; после завершения обучения в базу данных сохраняются параметры обученной модели. 3 з.п. ф-лы, 5 ил. 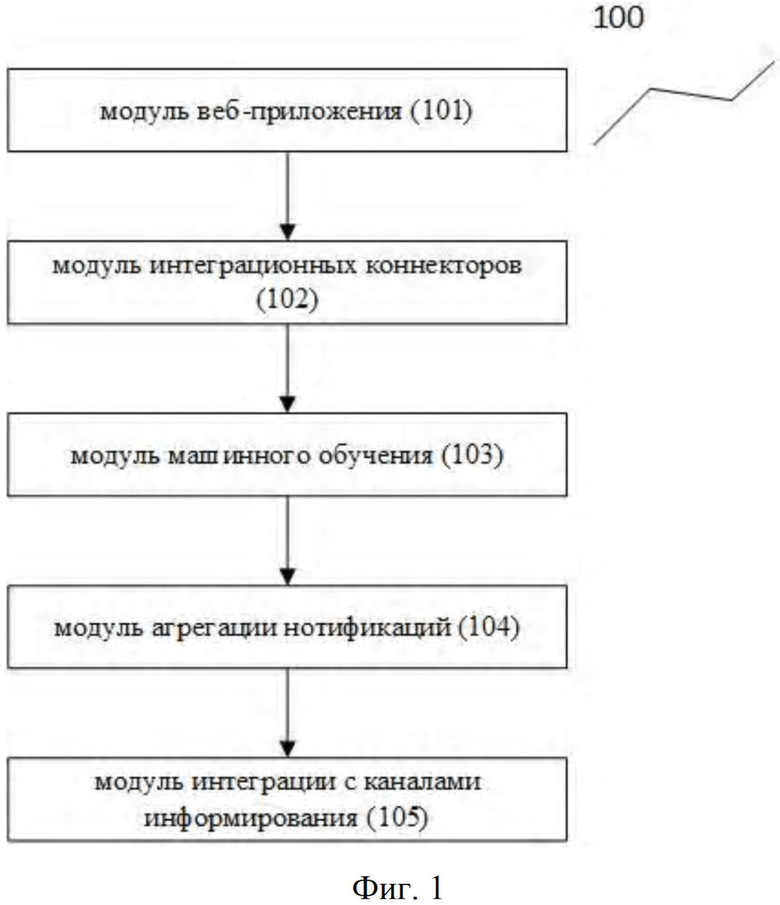
1. Компьютерно-реализуемая система автоматического мониторинга качества данных, получаемых из различных источников в режиме реального времени, содержащая:
модуль веб-приложения, который выполнен с возможностью добавлять новые источники мониторинга в систему, осуществлять конфигурирование расширенных параметров мониторинга, просматривать историю случившихся событий и отчетность по мониторингам, а также визуализировать обнаруженные отклонения в данных;
модуль интеграционных коннекторов, который выполнен с возможностью подключения системы к различным источникам для получения данных и выполнен с возможностью преобразования этих данных в единый внутренний формат для дальнейшей унифицированной обработки;
модуль машинного обучения, который самостоятельно обучается определять качество полученных данных в режиме реального времени, во время которого:
получает от коннекторов преобразованные данные из различных источников на протяжении заданного периода времени и сохраняет в общую выборку;
запускает процесс инициализации мониторинга сохраненной выборки путем определения шкал изменения данных, при этом для каждого показателя из выборки в соответствии с определенной шкалой рассчитываются статистики, на основе рассчитанных статистик для каждого показателя запускается алгоритм инициализации проверок;
после завершения обучения в базу данных сохраняются параметры обученной модели;
модуль машинного обучения применяет параметры обученной модели для последующего мониторинга получаемых новых данных по установленному расписанию, при этом на новых корректных данных модуль машинного обучения постоянно дообучается, если текущая модель плохо улавливает зависимости в новых данных, то модуль осуществляет полное переобучение;
в случае если после мониторинга полученных новых данных были обнаружены отклонения, модуль агрегации нотификаций формирует текст с ошибками;
модуль интеграции с каналами информирования отправляет текст с ошибками соответствующим пользователям.
2. Система по п. 1, характеризующаяся тем, что различными источниками данных могут быть: Oracle Database, Hive, Kafka, PostgreSQL, Terradata, Prometheus.
3. Система по п. 1, характеризующаяся тем, что алгоритм машинного обучения реализован в Python.
4. Система по п. 1, характеризующаяся тем, что каналами информирования могут быть: SMS канал, e-mail, Jira, Trello, Telegram-канал.
| Токарный резец | 1924 |
|
SU2016A1 |
| EP 3220267 A1, 20.09.2017 | |||
| US 9516053 B1, 06.12.2016 | |||
| KR 20180042865 A, 26.04.2018 | |||
| СПОСОБ ЗАЩИТЫ ВЕБ-ПРИЛОЖЕНИЙ ПРИ ПОМОЩИ ИНТЕЛЛЕКТУАЛЬНОГО СЕТЕВОГО ЭКРАНА С ИСПОЛЬЗОВАНИЕМ АВТОМАТИЧЕСКОГО ПОСТРОЕНИЯ МОДЕЛЕЙ ПРИЛОЖЕНИЙ | 2017 |
|
RU2659482C1 |

