ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение относится к автоматизированному способу и системе автоматической полиграфической проверки с помощью алгоритмов машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[0002] Классические полиграфические скрининги регулярно используются значимыми предприятиями, такими как банки, правоохранительные структуры и федеральные органы власти. Основное беспокойство научных сообществ заключается в том, что эти скрининги склонны к содержанию ошибок. Однако эти ошибки могут быть следствием не только метода, но и человека (полиграфолога).
[0003] Безопасность клиентских денег и данных (например, транзакций) заложена в основе банковской культуры и репутации. В качестве одного из инструментов защиты клиентов, только с согласия кандидатов и сотрудников, и в соответствии с законодательством, банк использует полиграфические скрининги (ПС). Они применяются при найме кандидатов на рисковых направлениях, чтобы предотвратить наем ненадежного человека. Чтобы обнаружить нарушение, сотрудники на особо рисковых позициях регулярно проходят проверку. ПС включает следующие темы: наркотические вещества, зависимость от азартных игр, инсайдерская торговля, разглашение конфиденциальной информации, взяточничество, коррупция, незаконные присвоение средств и мошенничество. Финансовая отрасль - не единственная, использующая ПС; другие примеры - такие важные отрасли, как авиация, промышленность и правоохранительные структуры во всем мире [1, 2].
[0004] Классический полиграф - это устройство, записывающее сердечно-сосудистую активность (такую как сердечный пульс), грудное и брюшное дыхание, гальваническая реакция кожи (электрическая активность кожи или ЭАК) и дрожь. Полиграфолог задает вопросы испытуемому, на которые получает ответы «да» или «нет». Обзоры классического полиграфа и методологии построения вопросов представлены в [3, 4, 5].
[0005] Нетрадиционные исследования обнаружения лжи используют - анализ видео и аудио [6] (включая мимику лица [7, 8], реакцию зрачка [9] и задержку между вопросом и ответом [10]), электромиографию (ЭМГ) [11], электроэнцефалографию (ЭЭГ) [12], магнитно-резонансную томографию [13, 14] или письменные последовательности (динамика нажатия клавиш) [15] - в дополнение к классическим полиграфическим данным.
[0006] Некоторые из этих исследований даже получили возможность на освоение новой области, так детектор лжи iBorderCtrl тестируется в европейских аэропортах [16, 17] или VeriPol применяется испанской полицией на делах о страховых требованиях [18, 19]. Классический полиграф остается инструментом выбора в традиционных задачах, как скрининг при найме и уголовные или внутренние расследования.
[0007] Полиграф имеет длинную историю критики от ученых из области психологии и права, а также и со стороны общества и правительства [1, 23]. Основная обеспокоенность заключается в том, что эта методика надежно не определяет ложь и правду. И все же «парадоксально, хотя Конгресс выражает глубокое беспокойство по поводу эффективности данной технологии, ЕРРА разрешает использование детекторов лжи в случае, если точность результата имеет первостепенное значение: национальная оборона, безопасность и законные текущие расследования» [22].
[0008] Критика данной методики предоставляет много аргументов, почему полиграфический скрининг может потерпеть неудачу при обнаружении лжи или отметить правду как ложь. Например, «Полиграфические тестирования оценивают не обман, а ситуации, которые построены так, чтобы вызвать и оценить страх» [24].
[0009] Правдивый младший менеджер может бояться, что его назовут коррупционером больше, чем хладнокровный старший менеджер боится быть пойманным на лжи полиграфологом. Еще один пример конструктивной критики - призыв к стандартизации процедуры полиграфического скрининга и обучения полиграфолога [25]. Ошибки полиграфолога могут происходить, например, когда полиграфолог неопытен, уставший, отвлечен или предвзят [26].
[0010] Существует простое решение проверки качества: всегда проводить проверку еще одним полиграфологом, который подтвердит или опровергнет заключение предыдущего полиграфолога [27]. Чтобы провести проверку полиграфического отчета, другому полиграфологу требуется пересмотреть запись скрининга, включающую полиграмму (графическое представление данных с датчиков, связанных с вопросами полиграфолога и ответами испытуемого), иногда аудио- и видеозапись и сравнить его заключение с оригинальным. Данная проверка занимает минимум половину времени от скрининга. Стандартный скрининг длится минимум два часа. Таким образом, повторная проверка стоит и времени, и денег. По этой причине, отделения внутренней безопасности проводят повторные проверки редко или не проводят их вообще. Другая причина, по которой проверки вторым полиграфологом могут быть не эффективны: второй полиграфолог может допустить ту же самую ошибку, которую допустил оригинальный полиграфолог.
[0011] Общим недостатком существующих решений в данной области является присутствие человеческого фактора при полиграфической проверке, что негативно сказывается на точности и скорости проверки, а также отсутствие автоматизированного процесса повторной проверки.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0012] В заявленном техническом решении предлагается новый подход, к автоматической полиграфической проверке с использованием моделей машинного обучения (МО).
[0013] Эффективность данного решения подтверждается существенным приростом точности и скорости проведения автоматической полиграфической проверки.
[0014] Таким образом, решается техническая проблема точной и скоростной автоматической полиграфической проверки.
[0015] Техническим результатом, достигающимся при решении данной проблемы, является повышение точности полиграфической проверки.
[0016] Дополнительным техническим результатом, достигающимся при решении данной проблемы, является повышение скорости полиграфической проверки.
[0017] Также дополнительным техническим результатом, достигающимся при решении данной проблемы, является автоматизация процесса полиграфической проверки.
[0018] Указанные технические результаты достигаются благодаря осуществлению компьютерно-реализуемого способа автоматической полиграфической проверки, выполняемого с помощью вычислительной системы, содержащей по меньшей мере две модели машинного обучения, при этом способ выполняет этапы, на которых:
- получают записи полиграфических проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса;
- получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию;
- осуществляют обработку полученных сигналов с помощью первой модели машинного обучения (МО), причем в ходе указанной обработки осуществляются:
 определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса;
определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса;
 извлечение переменных из каждого сигнала на определенных временных интервалах;
извлечение переменных из каждого сигнала на определенных временных интервалах;
 обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора;
обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора;
 подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО;
подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО;
 передача выходного значения 1-й модели МО на вход 2-й модели МО;
передача выходного значения 1-й модели МО на вход 2-й модели МО;
- с помощью второй модели машинного обучения (МО) осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
 разделение дополнительных данных на категориальные и численные переменные;
разделение дополнительных данных на категориальные и численные переменные;
 обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных;
обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных;
 конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора;
конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора;
 подача вектора во 2-ю модель МО для получения выходного значения 2-й модели МО;
подача вектора во 2-ю модель МО для получения выходного значения 2-й модели МО;
 сравнение выходного значения 2-й модели с заданным пороговым значением; и
сравнение выходного значения 2-й модели с заданным пороговым значением; и
- определяют, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения.
[0019] В одном из частных вариантов реализации способа модели МО определяют ответ как правдивый или ложный не по одному полученному ответу, а по совокупности вопросов и ответов, связанных с темой полиграфической проверки, при этом получаемые переменные сигналы объединяются в единый вектор, либо усредняются перед передачей в модели МО.
[0020] В другом частном варианте реализации способа 1-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
[0021] В другом частном варианте реализации способа 2-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
[0022] В другом частном варианте реализации способа модели МО обучены на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
[0023] В другом частном варианте реализации способа записи полиграфных проверок, содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакции (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмму, фотоплетизмограмму, термических, движения зрачка или их комбинации.
[0024] В другом частном варианте реализации способа дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
[0025] Кроме того, заявленный технический результат достигается за счет системы автоматической полиграфической проверки, содержащей:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа автоматической полиграфической проверки.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0026] Признаки и преимущества настоящего изобретения станут очевидными из приводимого ниже подробного описания изобретения и прилагаемых чертежей.
[0027] Фиг. 1 иллюстрирует пример реализации способа автоматической полиграфической проверки с помощью одной модели МО.
[0028] Фиг. 2 иллюстрирует пример реализации способа автоматической полиграфической проверки с помощью двух моделей МО.
[0029] Фиг. 3 иллюстрирует пример реализации способа автоматической полиграфической проверки с помощью двух ансамблей моделей МО.
[0030] Фиг. 4 иллюстрирует пример реализации способа автоматической полиграфической проверки с помощью трех ансамблей моделей МО.
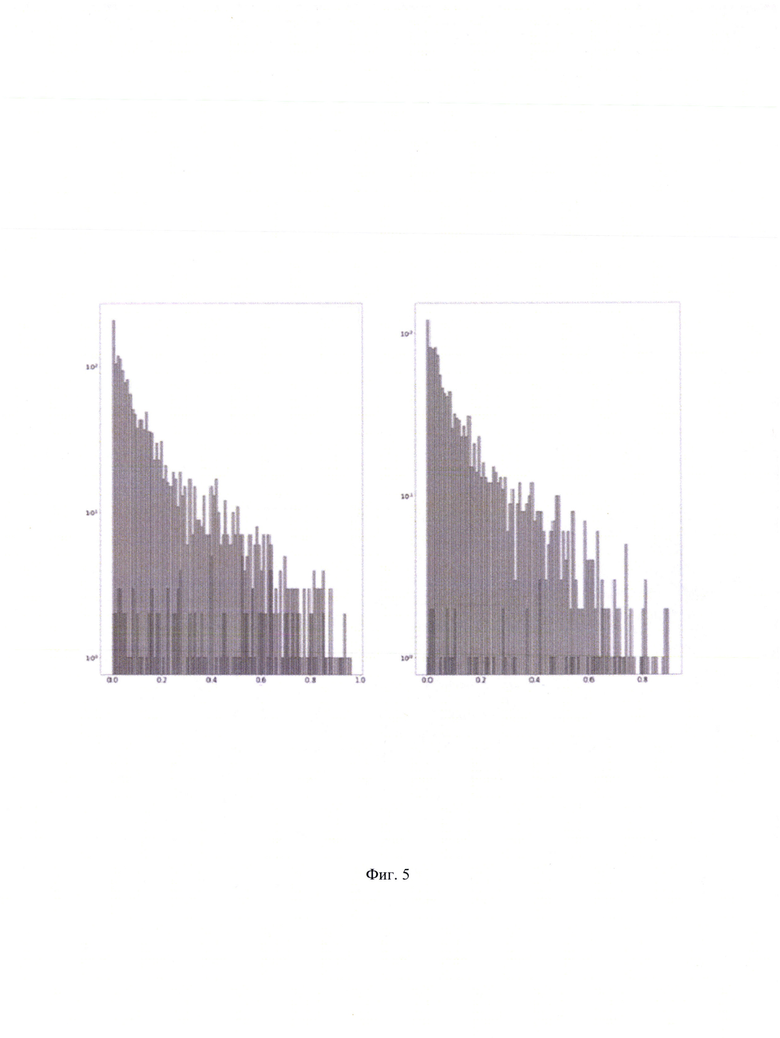
[0031] Фиг. 5 иллюстрирует график, где модель и полиграфолог сошлись и не сошлись во мнениях в зависимости от оценки модели.
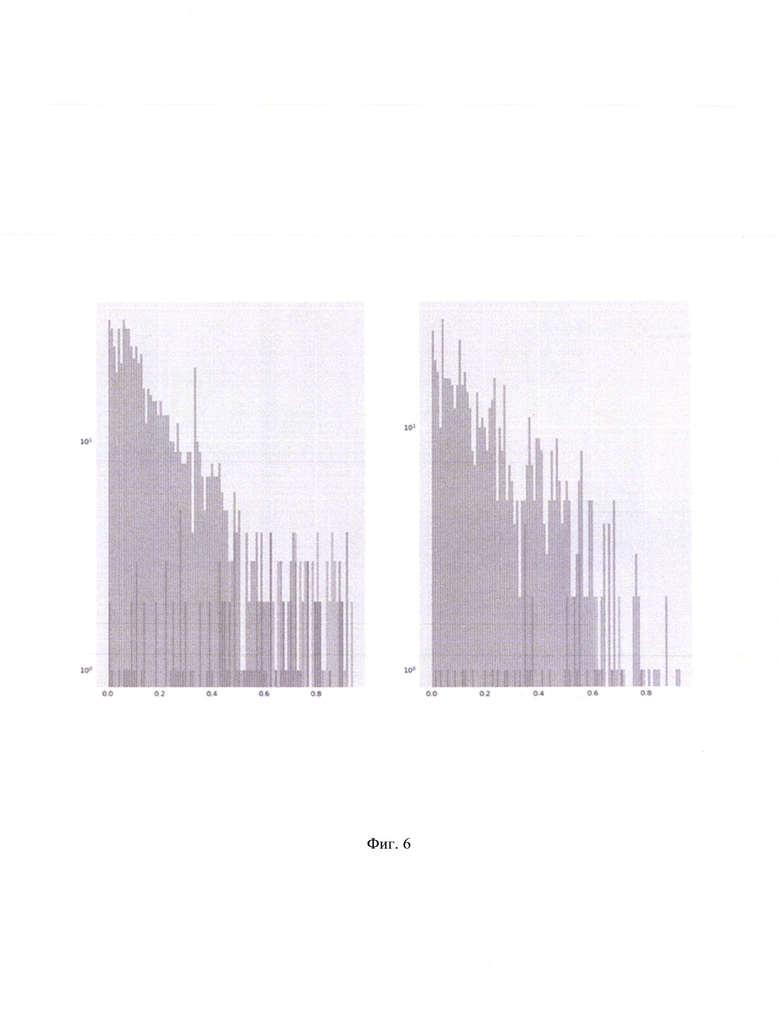
[0032] Фиг. 6 иллюстрирует распределение оценок для двух релевантных тем.
[0033] Фиг. 7 иллюстрирует пример реализации базовой модели.
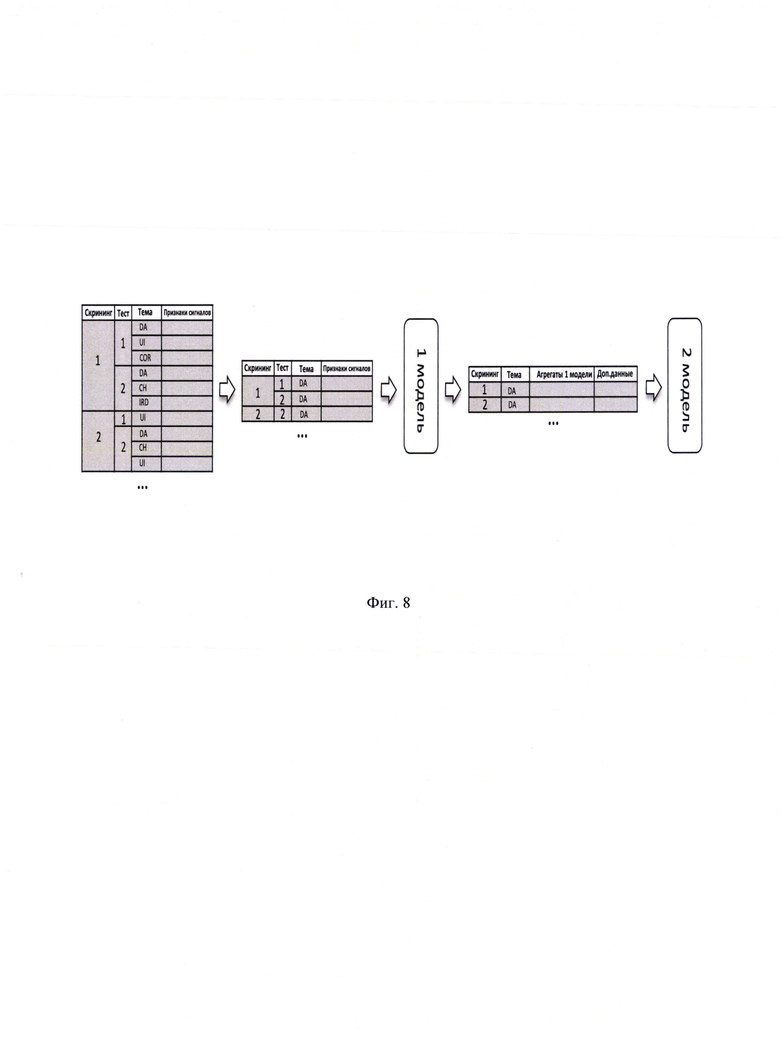
[0034] Фиг. 8 иллюстрирует пример реализации модели, обученной на одной теме.
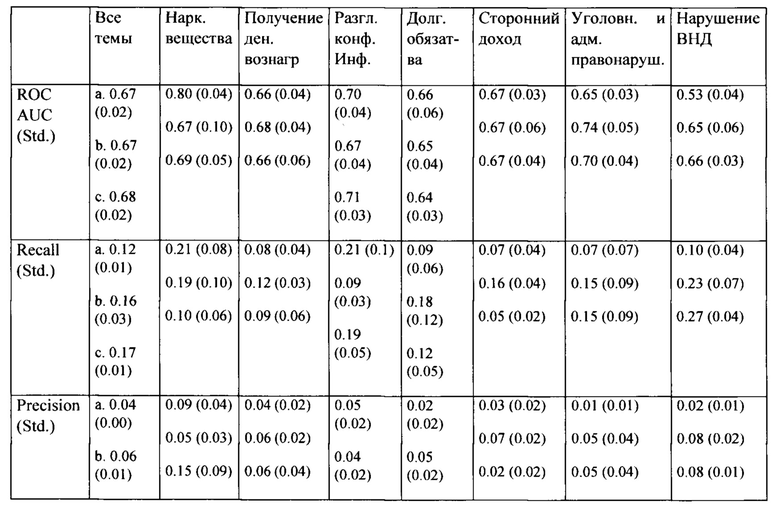
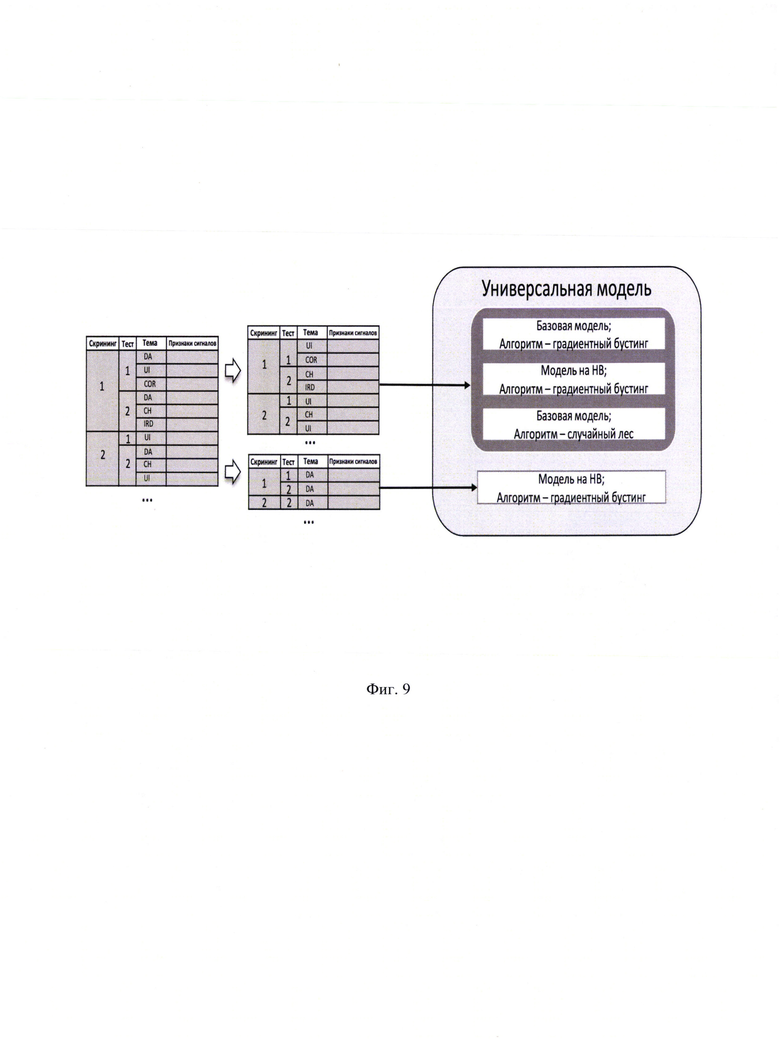
[0035] Фиг. 9 иллюстрирует пример реализации универсальной модели.
[0036] Фиг. 10 иллюстрирует пример свертки сигналов.
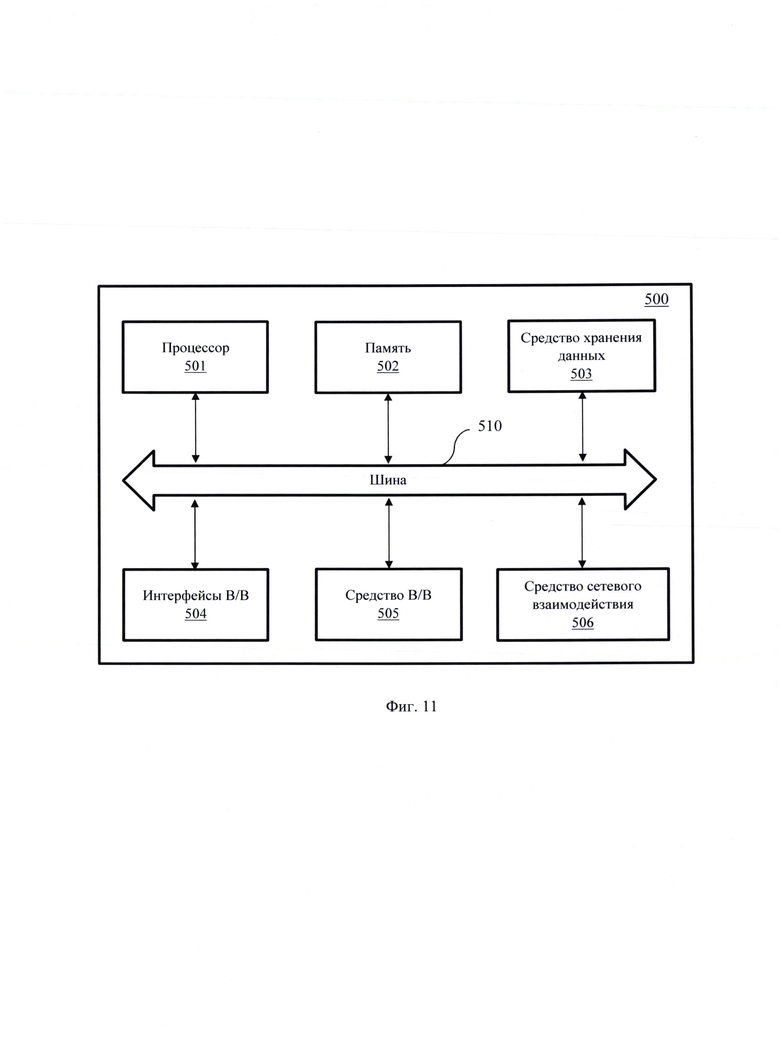
[0037] Фиг. 11 иллюстрирует общий вид системы автоматической полиграфической проверки.
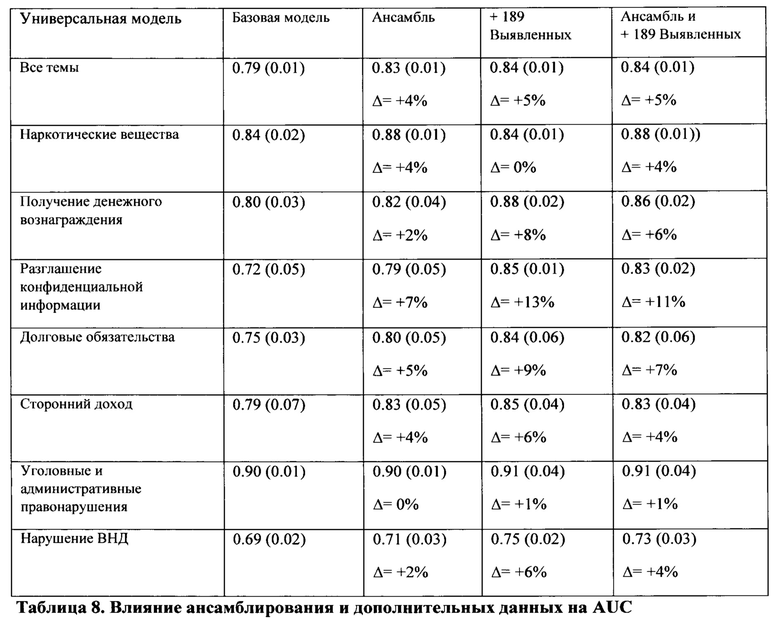
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0038] Данное техническое решение может быть реализовано на компьютере, в виде автоматизированной информационной системы (АИС) или машиночитаемого носителя, содержащего инструкции для выполнения вышеупомянутого способа.
[0039] Техническое решение может быть реализовано в виде распределенной компьютерной системы.
[0040] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0041] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0042] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0043] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0044] Для данного технического решения была построена базовая модель второго мнения, обученная на исторических данных из реальных ответов 2094 полиграфических скринингов, включающих поле «Выявлена ложь», заполненное полиграфологами, которые проводили скрининг.
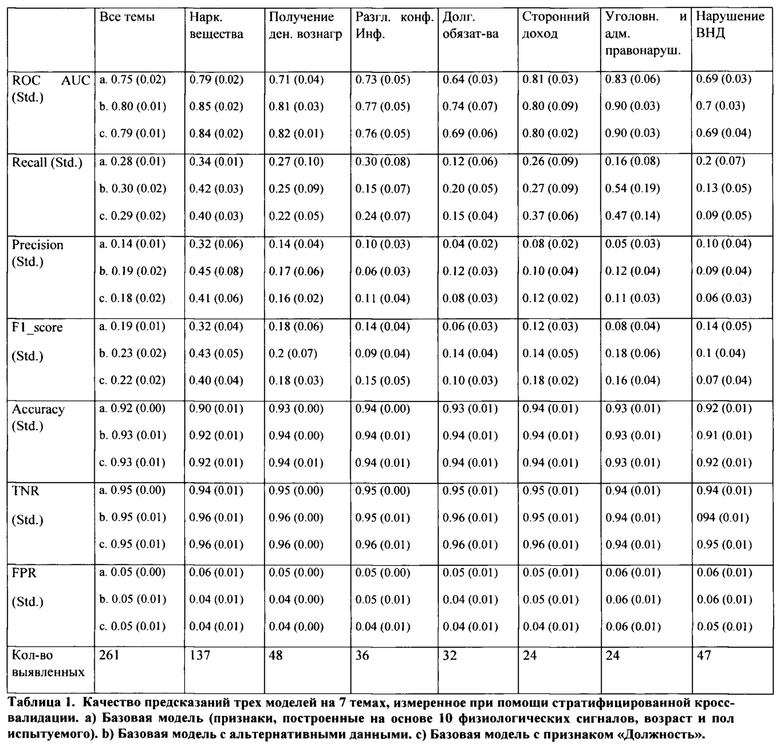
[0045] Данное техническое решение демонстрирует метрики качества базовой модели в Таблице 1.а, в колонке «все темы». Основные метрики это ROC AUC (receiver operating characteristic, рабочая характеристика приемника) и TPR (целевой рейтинг target rating point) при FPR=0.05.
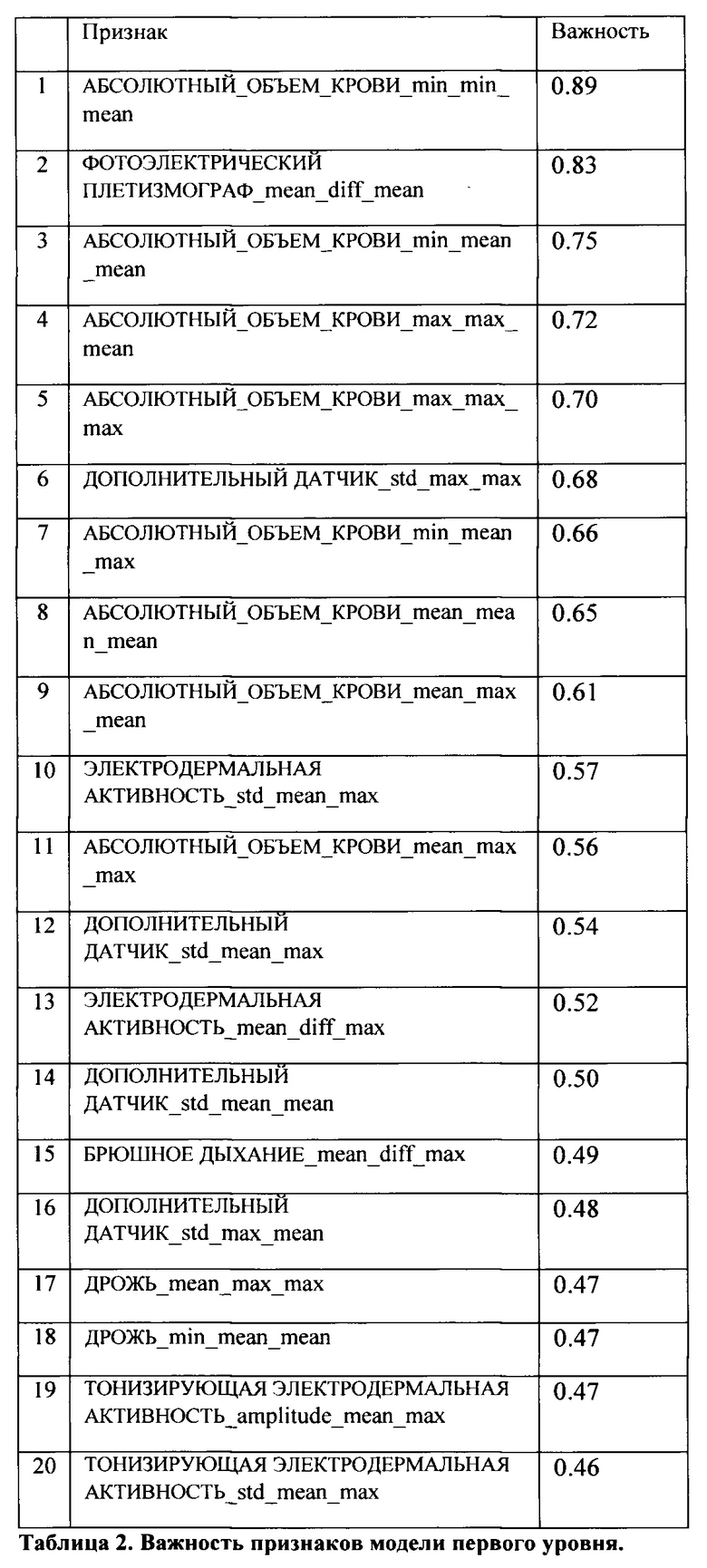
[0046] Таблицы 2 и 3 отражают важность признаков, основанных на 10 физиологических сигналах и признаков пол и возраст испытуемого; детали построения признаков второго уровня будут описаны ниже. Фиг. 5 отображает график, где модель и полиграфолог сошлись и не сошлись во мнениях в зависимости от оценки модели.
[0047] Также было измерено качество модели, применив ее к каждой из семи тем скрининга (Таблица 1.а).
[0048] Оценка эффективности модели влечет за собой использование примерно 100 человеко-часов, потому что это потребует задействовать настоящего полиграфолога, который будет проверять множество полиграфических скринингов, отобранных на основании оценки модели.

[0049] Также было предположено, что информация о геомагнитных бурях на Земле [28] и погодных условиях в городе в день скрининга может улучшить качество предсказания модели. Основой для этого предположения было то, что во время геомагнитных бурь и при разных погодных условиях люди могут вести себя по-другому, что может выражаться в небольшом изменении физиологических сигналов или данные датчика могут быть немного смещены, или оба этих случая.
[0050] Также был получен ID полиграфолога из расчета того, что эти данные могут помочь модели, так как разные полиграфологи могут вызывать немного разные физиологические реакции у испытуемых, или полиграфическое оборудование, назначенное каждому полиграфологу может иметь разную погрешность измерений. Также были собраны данные о должностях испытуемых, потому что люди с разным образованием и подготовкой могут говорить правду и ложь по-разному.
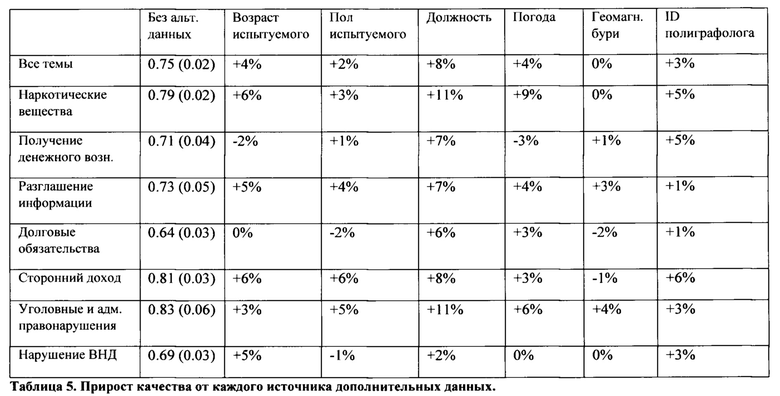
[0051] Таблица 1.b отражает качество базовой модели, обученной с альтернативными данными, а Таблица 4 показывать важность этих признаков. Улучшения от каждого источника относительно модели, построенной только на данных физиологических сигналов, показаны в Таблице 5.
[0052] Как показывает эксперимент, все альтернативные данные улучшают качество модели, однако были оставлены только возраст, пол, должность и геомагнитные бури для эксплуатации (Таблица 1.с).
[0053] Погода демонстрирует высокий прирост качества и высокую важность, и было опасение, что это может быть по техническим причинам: данные имеют сильный дисбаланс по доле выявленных по городам. Чтобы исключить смещение, вызванное дисбалансом городов, были взяты данные только по одному городу, но погода все равно имела высокое значение важности.
[0054] Таким образом, можно сделать вывод, что погода - это значимые альтернативные данные. Однако на всей выборки погода может нести в себе информацию о городе, и оценка модели может быть смещенной из-за дисбаланса выявленных по городам. В то время как признак ID полиграфолога демонстрирует умеренный прирост качества, природа данного признака требует более глубокого изучение до того, как использовать этот признак при эксплуатации модели.
[0055] Например, если на самом деле улучшению качества способствует не ID полиграфолога, a ID полиграфа, то при смене устройства одним полиграфологом будет получена неверная оценка модели.


[0057] Если обучить отдельную модель для каждой темы, то результаты будут лучше, чем результаты базовой модели с геомагнитными бурями. Таблица 6 демонстрирует, что было получено +2% ROC AUC (6% относительного прироста), если модель обучалась только на теме наркотические вещества. Таким образом, разделение на темы поможет модели лучше обучаться и делать заключение.
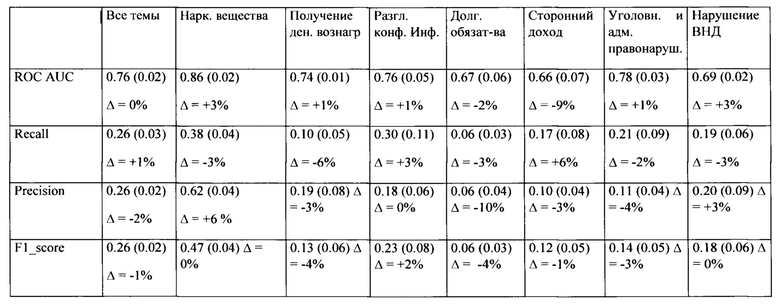
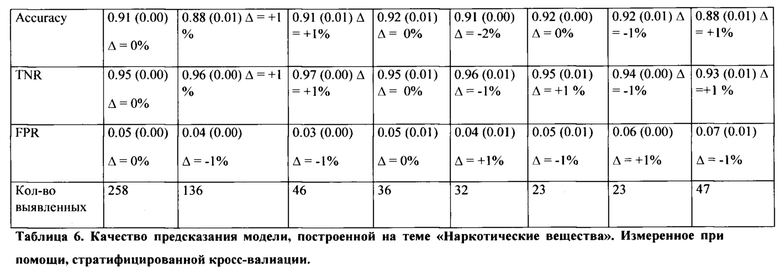
[0059] Модель, обученная на наркотических вещества, о которой велась речь в предыдущем параграфе, была применена ко всем остальным шести темам (Таблица 6). В сравнении с универсальной моделью качество модели на наркотических веществах колеблется от темы к теме. Это доказывает, что модель, обученная на одной теме, может быть использована на остальных темах пусть и с незначительными падениями качества для некоторых тем.
[0060] В Таблице 1 показано, что модель на некоторых темах (таких как наркотические вещества и уголовные правонарушения) работает лучше, чем на других темах (таких как сторонний доход и нарушение ВНД). Это наблюдение соответствует давней проблеме скринингов: люди не могут с уверенностью ответить на вопрос, когда полностью не уверены в ответе.
[0061] Например, в банке присутствует сотни ВНД, в каждом из которых множество страниц, и это, не упоминая о различных версиях, поэтому люди могут быть не уверены, нарушали ли они хотя бы один нормативный документ. Похожая ситуация наблюдается со сторонним доходом: некоторые люди начинают задаваться вопросом по типу «если я получал деньги от родственников, является ли это сторонним доходом?» и т.п.
[0062] Также данное наблюдение может быть использовано для улучшения качества базовой модели. Если будут найдены темы, на которых люди не уверены, то модель должна быть не уверена, обучившись на этих темах.
[0063] Неопределенные темы были удалены из всей выборки, однако в Таблице 7 видно, что это действие значимо не улучшило качество модели, и качество скоринга «размытых» тем упало либо осталось неизменным. Это связано с тем, что доля выявленных в скринингах по «размытым» темам в обучающей выборке незначительна.
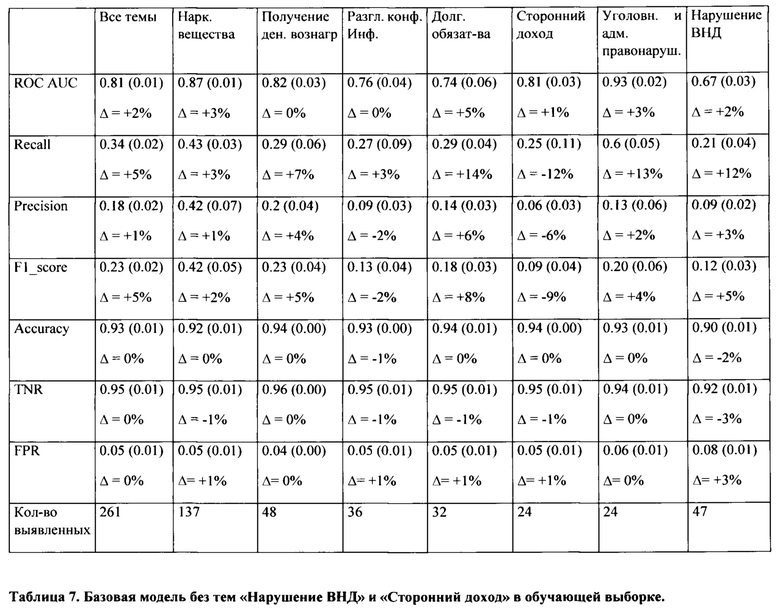
[0064] Построенная универсальная модель, которую описывали выше, не использует название темы в качестве признака для обучения и оценки. Причина этого заключается в том, что была необходима модель, которая может оценивать любую тему в скрининге, а не только 7 тем, которые присутствуют в обучающей выборке.
[0065] Ниже в таблице 11 показано как использование названия темы в роли дополнительного признака влияет на качество модели. Показано, что знание темы помогает модели оценивать «размытую» тему нарушение ВНД, в то время как качество по другим темам осталось неизменным.
[0066] Перед добавлением признака «название темы» была сбалансирована выборка по количеству выявленных риск-факторов в скринингах по темам. Эта балансировка заключается в уменьшении числа выявленных по теме наркотические вещества в 4 раза. В Таблице 11 показано, что это сокращение уменьшает качество темы наркотические вещества, которая раньше всегда была необъяснимым лидером.
[0067] Качество по теме наркотические вещества сравнялось с ближайшими по качеству темами, такими как получение денежного вознаграждения и уголовные, и административные правонарушения. Это наблюдение объясняет предыдущее лидерство темы НВ - это было по причине того, что по данной теме имелось наибольшее число объектов минорного класса (выявлено сокрытие информации) по сравнению с другими темами.
[0068] Было измерено улучшение качества от добавления новых, дополнительных скринингов с выявленными риск-факторами, и проведены эксперименты с различными вариациями ансамблей. Результаты представлены в Таблице 8.
[0069] Суммарно ансамблирование и дополнительные данные увеличили AUC на 5% по всем темам и на 11% на выбранных темах.
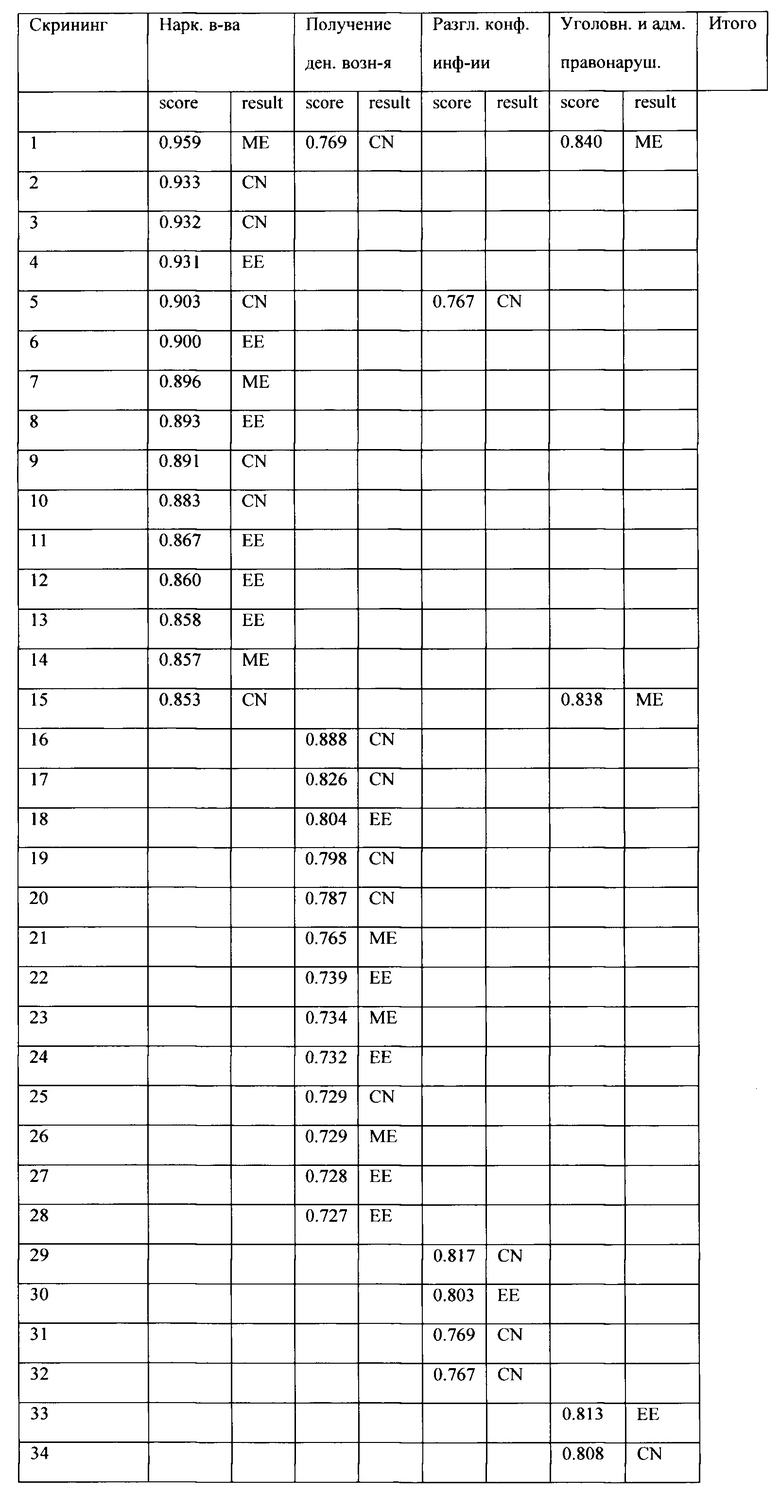
[0070] Теперь можно сравнить работу двух продвинутых моделей: Универсальной модели (ансамбль с альтернативными данными) и модели, обученной на теме НВ (модель на одной теме с альтернативными данными). Тестирования поиска ошибок полиграфологов проводится среди 2094 архивных скринингов. Поиск ошибок полиграфологов проводится в двух темах, которые наиболее распространены в скринингах. Были отобраны скрининги, в которых полиграфолог сделал заключение, что тема не выявлена, но модель уверенно утверждает, что выявлена ложь.
[0071] Основываясь на 15 наивысших оценках модели, обученной на теме Наркотические вещества, было отобрано 15 выводов полиграфологов с заключением «Не выявлено» в качества кандидатов на ошибку полиграфолога по теме «Наркотические вещества». Таким же путем, основываясь на оценках универсальной модели, было отобрано 15/5/5 заключений «Не выявлено» для тем «Получение денежного вознаграждения»/ «Разглашение конфиденциальной информации»/ «Уголовные и административные правонарушения». Таким образом, получилось 40 заключений по 36 скринингам.
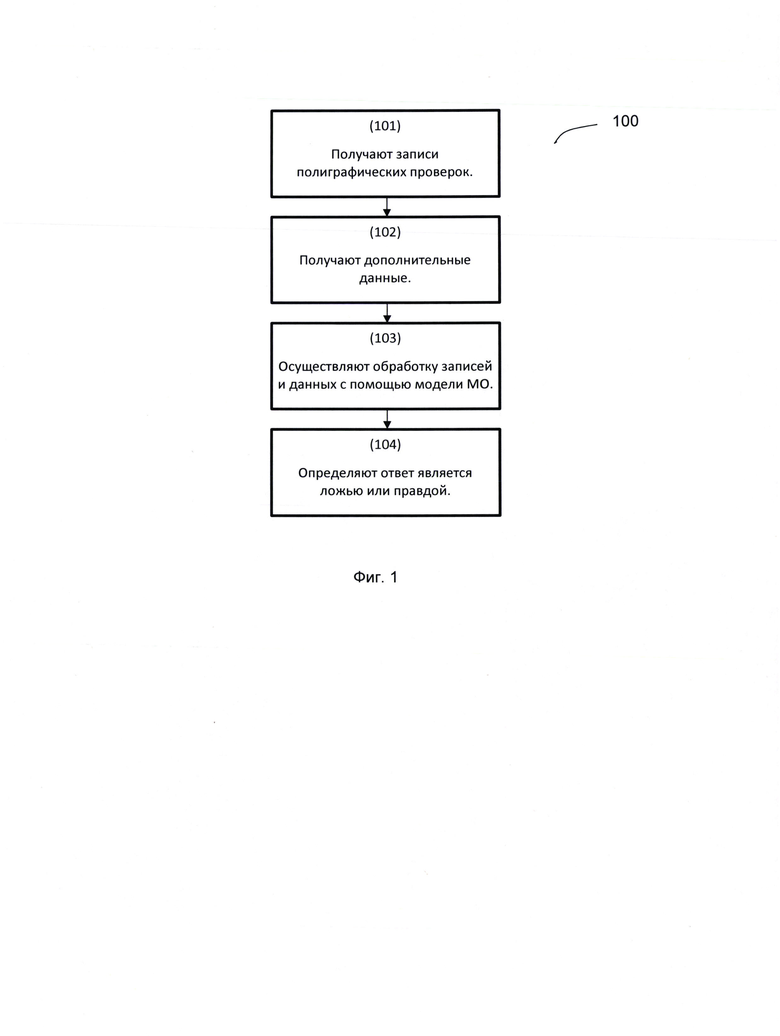
[0072] Данные 36 скринингов были проверены через слепую повторную проверку у двух полиграфологов. Полиграфологи не знали результаты скринингов и не передавали результаты друг другу. Причина проведения двух проверок заключается в том, что в случае расхождения выводов оригинального заключения и одной из повторных проверок, будет слово одного полиграфолога против другого.
[0073] В эксперименте участвовали чрезвычайно опытные полиграфологи, и существует предположение, что доля ошибок полиграфологов среди всех скринигов колеблется от 0,0 до 1,0%.
[0074] Обзор двух повторных проверок представлен в Таблице 9. Распределения оценок для двух релевантных тем представлены на Фиг. 6.
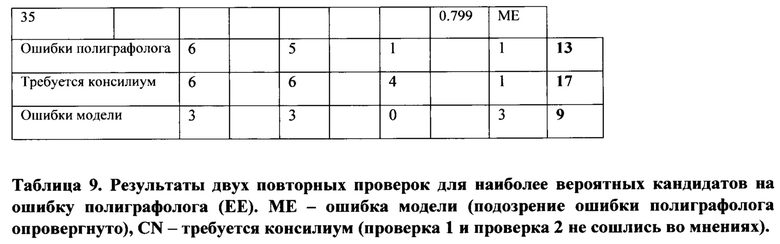
[0075] Путем проверки 39 выводов в 35 скрининга (из 2094 скринингов) было обнаружено 30 проблемных заключений, в которых ошибка полиграфолога подтверждена двумя проверками (13 заключений) или одна из проверок не согласилась с оригинальным заключением (17 заключений). Оставшиеся 9 заключений - ошибки модели, т.е. оригинальное заключение было верное, что и подтвердили обе повторные проверки.
[0076] Было ожидаемо, что будут случаи расхождения результатов двух повторных проверок, т.к. бывают трудные случаи, в которых решение не очевидно. Для подобных трудных случаев собирается консилиум, на которых полиграфологи обсуждают их конфликтующие заключения и приходят к единому мнению.
[0077] Было замечено, что в некоторых проблемных скринингах (заключение «Выявлено» в одной или в обеих перепроверках), полиграфологи, которые проводили перепроверку, пометили, что экзаменуемый оказывал противодействие. Пропуск противодействия является ошибкой полиграфолога по определению.
Описание данных
[0078] Датасет состоит из 2094 исторических полиграфических проверок типа скрининг, включающие в себя метки «Выявлено сокрытие информации» и «Не выявлено сокрытие информации», проставленные полиграфологами, которые проводили скрининги. Эти скрининги проводились на кандидатах и персонале банка на рисковых направлениях, с их согласия и в соответствии с законодательством, перед наймом, повышением или каждый год, в зависимости от позиции. Полиграфический скрининг включает в себя подмножество из 14 тем, включая наркотические вещества и получение денежного вознаграждения.
[0079] Запись скрининга включает в себя физиологические сигналы испытуемого, аудио и вопросы в текстовом формате. Каждый вопрос имеет три временных метки для каждого предъявления: начало вопроса, заданного полиграфологом, конец вопроса и момент ответа. Каждый вопрос классифицируется на четыре типа.
[0080] Типы вопросов:

[0081] Примеры вопросов:


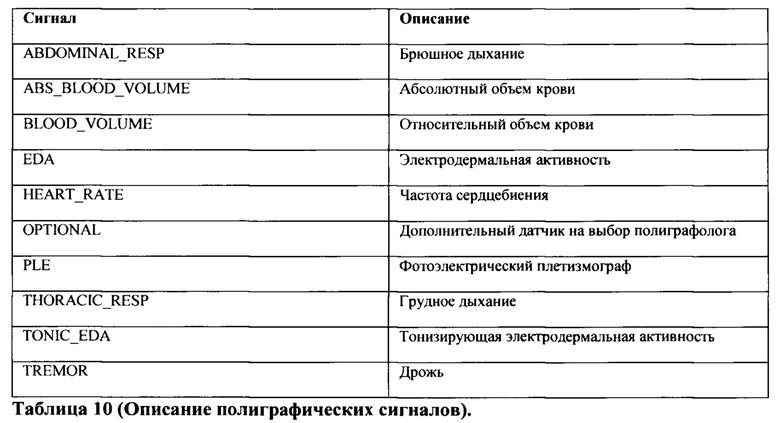
[0082] В дополнение к физиологическим сигналам, Таблица 10 фиксирует пол и возраст испытуемого.
[0083] Скрининг проводился на полиграфе Polyconius, модель 7.
Обработка данных
[0084] Основная задача - оценить вывод полиграфолога (Выявлено или Не выявлено) для определенной темы в скрининге.
[0085] Для построения модели были представлены данные в следующем формате: каждая строка в наборе данных представляет из себя запись скрининга по конкретной теме в конкретном тесте для одного экзаменуемого. Целевая переменная размечена как «Выявлено» или «Не Выявлено». Может наблюдаться смещение из-за такой разметки, так как испытуемый может солгать не на всех текстах по теме в течение скрининга.
[0086] Физиологические сигналы были извлечены из временных окон согласно временным меткам вопросов. Таким образом, изначально строка - это временной ряд физиологического сигнала для конкретного предъявления по конкретной теме.
[0087] Для каждого предъявления проверочного и контрольного вопросов сгенерировали базовые статистики: минимальное, максимальное, среднее, амплитуду и стандартное отклонение. Далее использовались минимальное, максимальное, среднее и стандартное отклонение в качестве агрегатных функций на каждом шаге. Данные каждого предъявления были сгруппированы по вопросам. Был создан дополнительный признак, характеризующий разницу между первым и последующими предъявлениями. Похожим образом вопросы были сгруппированы по темам внутри каждого теста. В конце концов каждая строка включает в себя 600 признаков, извлеченных из записи полиграфического скрининга по конкретной теме в конкретном тесте (Фиг. 10).
Модели
[0088] В данном техническом решении был использован ансамбль типа стэкинг, который состоял из двух уровней моделей, основанных на алгоритме градиентного бустинга. Двухуровневая структура требовалась для того, чтобы избежать «проклятия размерности». Модель первого уровня была обучена на 600 признаках, построенных на физиологических сигналах для каждой темы, делая заключение Выявлено/Не выявлено для каждого теста внутри скрининга. На вход второй модели подавались агрегированные ка каждой теме выходные значения первой модели.
[0089] Модель второго уровня имела следующие признаки:
pred_proba_max - максимальная вероятность выявления лжи среди тестов;
pred_proba_mean - средняя вероятность выявления лжи;
pred_proba_min - минимальная вероятность обнаружения лжи среды тестов;
pred_proba_diff - разница между максимальным и средним значением вероятностей.
[0090] Эти вероятности объединяется с альтернативными данными (биографические данные, данные о магнитных бурях и т.п.). Полученный набор данных подается на вход второй модели, которая выдает вероятность лжи на скрининге по определенной теме.
Базовая модель
[0091] Данная модель (Фиг. 7) не получает информацию о темах в момент обучения и предсказания. Информация о темах используется для дальнейшей агрегации внутри скрининга. Например, в первом скрининге происходит агрегация по теме «Наркотические вещества» по всем тестам, то же самое происходит, например, с темой «Инсайдерская торговля» во втором скрининге.
Модель, обученная на одной теме
[0092] Логика построения модели и создания признаков такая же, как и в базовой модели. Различие заключается в том, что для обучения берутся признаки только для одной темы. Отобраны данные только по одной теме перед тем, как применяется модель первого уровня. На Фиг. 8 показан порядок обучения модели для темы наркотические вещества, в то время как остальные темы убраны из тренировочного набора данных.
Универсальная модель
[0093] Было принято решение использовать лучшие стороны моделей, описанных выше. Таким образом, был построен ансамбль из существующих архитектур (Фиг. 9). После серии экспериментов лучший результат показала архитектура, в которой усредняется степень уверенности следующих моделей:
базовая модель - алгоритм: градиентный бустинг; с альтернативными данными;
модель на одной теме - алгоритм: градиентный бустинг; с альтернативными данными;
базовая модель - алгоритм: случайный лес.
[0094] Данный ансамбль был применен ко всем темам, кроме темы Наркотические вещества. Помимо привычных преимуществ ансамблей было рационально использовать разные архитектуры (градиентный бустинг и случайный лес) для того, чтобы исключить чистую ошибку модели, и выделены будут те скрининги, в которых присутствует ошибка полиграфолога.
[0095] Как показано на Фиг. 1 способ автоматической полиграфической проверки (100), выполняется с помощью вычислительной системы, содержащей модель машинного обучения, и состоит из нескольких взаимосвязанных этапов.
[0096] На этапе 101 получают записи полиграфных проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса.
[0097] Далее на этапе 102 получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию.
[0098] Далее на этапе 103 осуществляют обработку полученных сигналов и дополнительных данных с помощью модели машинного обучения (МО), причем в ходе указанной обработки осуществляются:
 определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
 извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
 обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
 разделение дополнительных данных на категориальные и численные переменные;
разделение дополнительных данных на категориальные и численные переменные;
 обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
 конкатенация обработанных переменных, извлеченных из каждого сигнала, и обработанных дополнительных переменных, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
конкатенация обработанных переменных, извлеченных из каждого сигнала, и обработанных дополнительных переменных, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
 подача упомянутого вектора в модель МО для получения выходного значения модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
подача упомянутого вектора в модель МО для получения выходного значения модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
 сравнение выходного значения модели с заданным пороговым значением.
сравнение выходного значения модели с заданным пороговым значением.
[0099] И на этапе 104 определяют, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения.
[0100] В одном из частных вариантов реализации способа модель МО определяет ответ как правдивый или ложный не по одному полученному ответу, а по совокупности вопросов и ответов, связанных с темой полиграфической проверки, при этом получаемые переменные сигналы объединяются в единый вектор, либо усредняются перед передачей в модели МО.
[0101] В другом частном варианте реализации способа модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
[0102] В другом частном варианте реализации способа модель МО обучена на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
[0103] В другом частном варианте реализации способа записи полиграфических проверок содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакции (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмму, фотоплетизмограмму, термических, движения зрачка или их комбинации.
[0104] В другом частном варианте реализации способа дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
[0105] Реализация данного технического решения на базе одной модели МО, позволяет автоматизировать процесс полиграфических проверок и с высокой точностью выявлять сокрытие информации.
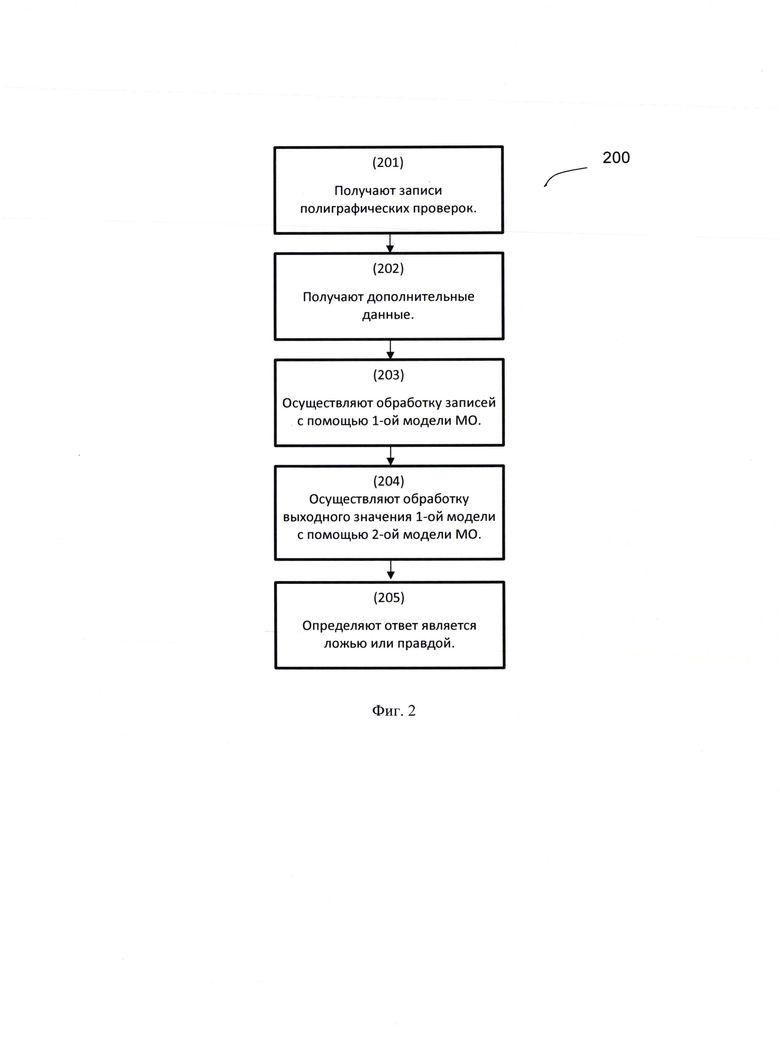
[0106] Как показано на Фиг. 2 в другом частном варианте реализации, способ автоматической полиграфической проверки (200), выполняется с помощью вычислительной системы, содержащей по меньшей мере две модели машинного обучения, и состоит из нескольких взаимосвязанных этапов.
[0107] На этапе 201 получают записи полиграфных проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса.
[0108] Дале на этапе 202 получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию.
[0109] Далее на этапе 203 осуществляют обработку полученных сигналов с помощью первой модели машинного обучения (МО), причем в ходе указанной обработки осуществляются:
 определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
 извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
 обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
 подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
 передача выходного значения 1-й модели МО на вход 2-й модели МО.
передача выходного значения 1-й модели МО на вход 2-й модели МО.
[0110] Далее на этапе 204 с помощью второй модели машинного обучения (МО) осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
 разделение дополнительных данных на категориальные и численные переменные;
разделение дополнительных данных на категориальные и численные переменные;
 обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
 конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
 подача вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
подача вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
 сравнение выходного значения 2-й модели с заданным пороговым значением.
сравнение выходного значения 2-й модели с заданным пороговым значением.
[0111] И на этапе 205 определяют, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения.
[0112] В одном из частных вариантов реализации способа модели МО определяют ответ как правдивый или ложный не по одному полученному ответу, а по совокупности вопросов и ответов, связанных с темой полиграфической проверки, при этом получаемые переменные сигналы объединяются в единый вектор, либо усредняются перед передачей в модели МО.
[0113] В другом частном варианте реализации способа 1-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
[0114] В другом частном варианте реализации способа 2-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
[0115] В другом частном варианте реализации способа модели МО обучены на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
[0116] В другом частном варианте реализации способа записи полиграфических проверок содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакции (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмму, фотоплетизмограмму, термических, движения зрачка или их комбинации.
[0117] В другом частном варианте реализации способа дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
[0118] Реализация данного технического решения на базе двух моделей МО, позволяет автоматизировать процесс полиграфических проверок и с высокой точностью выявлять сокрытие информации. Данная реализация позволяет повысить точность выявления сокрытия информации за счет предварительного обсчета физиологических данных в модели первого уровня и использования уже агрегатов из первой модели (с добавлением доп. нефизиологических данных) в модели 2-го уровня.
[0119] Как показано на Фиг. 3 в другом частном варианте реализации, способ автоматической полиграфической проверки (300), выполняется с помощью вычислительной системы, содержащей по меньшей мере два ансамбля моделей машинного обучения, и состоит из нескольких взаимосвязанных этапов.
[0120] На этапе 301 получают записи полиграфических проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса.
[0121] Далее на этапе 302 получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию.
[0122] Далее на этапе 303 осуществляют обработку полученных сигналов с помощью первого ансамбля моделей МО, обученного на одной теме, причем в ходе указанной обработки осуществляется:
 обработка сигналов первой моделью МО, в ходе которой выполняются:
обработка сигналов первой моделью МО, в ходе которой выполняются:
• определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
• извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
• обработка полученных переменных из сигналов, при которой выполняются нормализация и конкатенация обработанных переменных, и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• передачу выходного значения 1-й модели МО на вход 2-й модели МО.
 с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
• разделение дополнительных данных на категориальные и численные переменные;
• обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
• подача упомянутого вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• подача выходного значения 2-ой модели МО в третью модель МО, для формирования выходного значения первого ансамбля.
[0123] Далее на этапе 304 осуществляют обработку полученных сигналов с помощью второго ансамбля моделей МО, обученного на комбинации тем, причем в ходе указанной обработки осуществляется:
 обработка сигналов первой моделью МО, в ходе которой выполняются:
обработка сигналов первой моделью МО, в ходе которой выполняются:
• определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
• извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
• обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• передача выходного значения 1-й модели МО на вход 2-й модели МО;
 с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
• разделение дополнительных данных на категориальные и численные переменные;
• обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
• подача упомянутого вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• подача выходного значения 2-ой модели МО в третью модель МО, для формирования выходного значения второго ансамбля.
[0124] Далее на этапе 305 с помощью третьей модели МО осуществляют обработку выходных значений первого и второго ансамблей МО, причем в ходе указанной обработки осуществляются:
 конкатенация обработанных выходных значений первого и второго ансамблей, и построение на их основе вектора;
конкатенация обработанных выходных значений первого и второго ансамблей, и построение на их основе вектора;
 подача упомянутого вектора в 3-ю модель МО для получения выходного значения 3-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
подача упомянутого вектора в 3-ю модель МО для получения выходного значения 3-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
 сравнение выходного значения 3-й модели с заданным пороговым значением.
сравнение выходного значения 3-й модели с заданным пороговым значением.
[0125] И на этапе 306 определяют, что ответ является ложью если выходное значение выше или равно пороговому значению или ответ является правдой если выходное значение ниже порогового значения.
[0126] В одно из частных вариантов реализации способа модели МО обучены на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
[0127] В другом частном варианте реализации способа модели МО первого и второго ансамблей имеют тип, выбираемый из группы: градиентный бустинг, случайный лес, или нейронная сеть.
[0128] В другом частном варианте реализации способа третья модель МО имеет тип, выбираемый из группы: логистическая регрессия, случайный лес, градиентный бустинг или усреднение.
[0129] В другом частном варианте реализации способа записи полиграфических проверок содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакции (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмму, фотоплетизмограмму, термических, движения зрачка или их комбинации.
[0130] В другом частном варианте реализации способа дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
[0131] Реализация данного технического решения на базе двух ансамблей моделей МО, позволяет автоматизировать процесс полиграфических проверок и с высокой точностью выявлять сокрытие информации. Данная реализация позволяет повысить точность выявления сокрытия информации за счет различий архитектур между двумя ансамблями и за счет добавления верхнеуровневой модели.
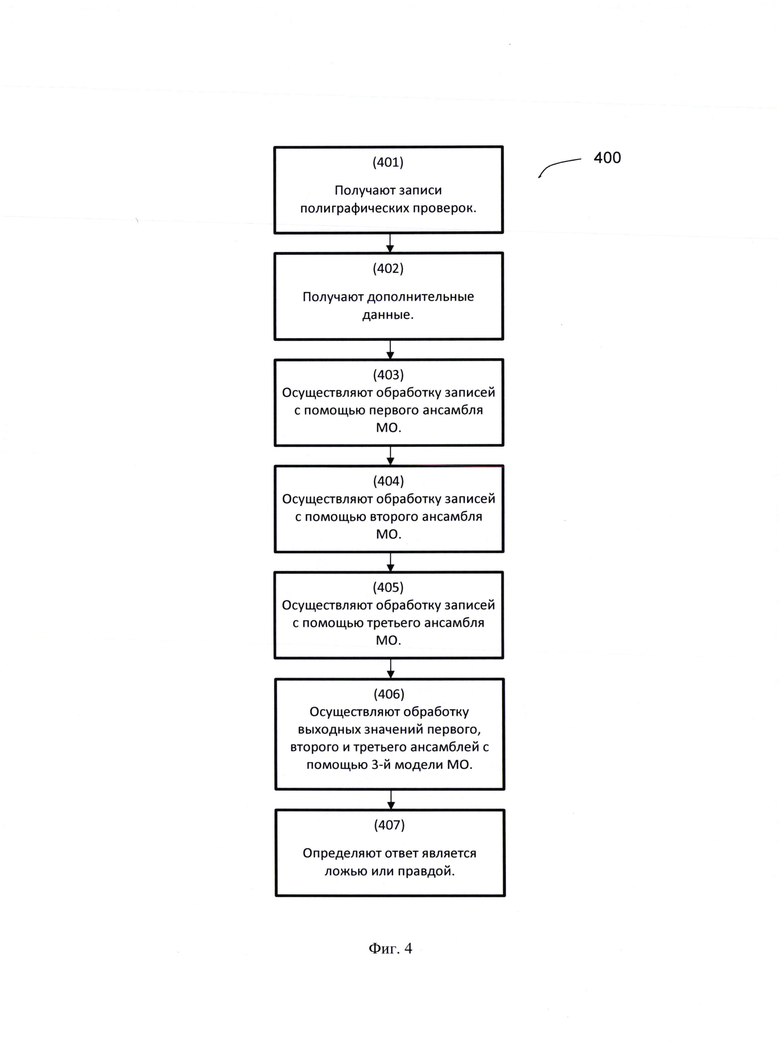
[0132] Как показано на Фиг. 3 в другом частном варианте реализации, способ автоматической полиграфической проверки (400), выполняется с помощью вычислительной системы, содержащей по меньшей мере три ансамбля моделей машинного обучения, и состоит из нескольких взаимосвязанных этапов.
[0133] На этапе 401 получают записи полиграфических проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса.
[0134] Далее на этапе 402 получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию.
[0135] Далее на этапе 403 осуществляют обработку полученных сигналов с помощью первого ансамбля моделей МО, обученного на одной теме, причем в ходе указанной обработки осуществляется:
 обработка сигналов первой моделью МО, в ходе которой выполняются:
обработка сигналов первой моделью МО, в ходе которой выполняются:
• определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
• извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
• обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1- й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• передача выходного значения 1-й модели МО на вход 2-й модели МО;
 с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
• разделение дополнительных данных на категориальные и численные переменные;
• обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
• подача упомянутого вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• подача выходного значения 2-ой модели МО в третью модель МО, для формирования выходного значения первого ансамбля.
[0136] Далее на этапе 404 осуществляют обработку полученных сигналов с помощью второго ансамбля моделей МО, обученного на комбинации тем, причем в ходе указанной обработки осуществляется:
 обработка сигналов первой моделью МО, в ходе которой выполняются:
обработка сигналов первой моделью МО, в ходе которой выполняются:
• определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
• извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
• обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1. подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• передача выходного значения 1-й модели МО на вход 2-й модели МО;
 с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
• разделение дополнительных данных на категориальные и численные переменные;
• обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
• подача упомянутого вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• подача выходного значения 2-ой модели МО в третью модель МО, для формирования выходного значения второго ансамбля.
[0137] Далее на этапе 405 осуществляют обработку полученных сигналов с помощью третьего ансамбля моделей машинного обучения, обученного на комбинации тем, причем в ходе указанной обработки осуществляется:
 обработка сигналов первой моделью МО, в ходе которой выполняются:
обработка сигналов первой моделью МО, в ходе которой выполняются:
• определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса. На данном этапе, в зависимости от логики построения модели, выделяются временные метки только тех вопросов (и ответов), физиологические данные которых будут участвовать в обучении и тестировании модели. Например, в универсальной модели используются вопросы по всем темам, поэтому будут выбраны все метки;
• извлечение переменных из каждого сигнала на определенных временных интервалах. На данном этапе из базы данных извлекаются физиологические сигналы на выбранных ранее интервалах;
• обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• передача выходного значения 1-й модели МО на вход 2-й модели МО;
 с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
с помощью второй модели МО осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляются:
• разделение дополнительных данных на категориальные и численные переменные;
• обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
• конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора. На данном этапе, из всех выбранных релевантных для конкретного вывода полиграфолога данных, получают один вектор, одинаково применимый как для тренировки модели (при наличии вывода полиграфолога), так и для принятия моделью решения (выявлено / не выявлено);
• подача упомянутого вектора во 2-ю модель МО для получения выходного значения 2-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
• подача выходного значения 2-ой модели МО в третью модель МО, для формирования выходного значения третьего ансамбля.
[0138] Далее на этапе 406 с помощью третьей модели МО осуществляют обработку выходных значений первого, второго и третьего ансамблей МО, причем в ходе указанной обработки осуществляются:
 конкатенация обработанных выходных значений первого, второго и третьего ансамблей, и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
конкатенация обработанных выходных значений первого, второго и третьего ансамблей, и построение на их основе вектора. На данном этапе каждое значение численной переменной становится равным значению от 0 до 1;
 подача упомянутого вектора в 3-ю модель МО для получения выходного значения 3-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
подача упомянутого вектора в 3-ю модель МО для получения выходного значения 3-й модели МО. На данном этапе получают скор модели в интервале от 0 до 1;
 сравнение выходного значения 3-й модели с заданным пороговым значением.
сравнение выходного значения 3-й модели с заданным пороговым значением.
[0139] И на этапе 407 осуществляют определение того, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения.
[0140] В одном из частных вариантов реализации способа модели МО обучены на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
[0141] В другом частном варианте реализации способа модели МО первого, второго и третьего ансамблей имеют тип, выбираемый из группы: градиентный бустинг, случайный лес, или нейронная сеть.
[0142] В другом частном варианте реализации способа третья модель МО имеет тип, выбираемый из группы: логистическая регрессия, случайный лес, градиентный бустинг или усреднение.
[0143] В другом частном варианте реализации способа записи полиграфических проверок содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакция (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмма, фотоплетизмограмма, термические, движения зрачка или их комбинации.
[0144] В другом частном варианте реализации способа дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
[0145] Реализация данного технического решения на базе трех ансамблей моделей МО, позволяет автоматизировать процесс полиграфических проверок и с высокой точностью выявлять сокрытие информации. Данная реализация позволяет повысить точность выявления сокрытия информации за счет различий архитектур между тремя ансамблями и за счет добавления верхнеуровневой модели.
[0146] На Фиг. 11 представлен пример общего вида вычислительной системы (500), которая обеспечивает реализацию заявленных способа или является частью компьютерной системы, например, сервером, персональным компьютером, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
[0147] В общем случае, система (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (302) и ПЗУ (503), интерфейсы ввода/вывода (504), устройства ввода/вывода (1105), и устройство для сетевого взаимодействия (506).
[0148] Процессор (501) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в системе (500) также необходимо учитывать графический процессор, например, GPU NVIDIA или Graphcore, тип которых также является пригодным для полного или частичного выполнения способа, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[0149] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом в качестве ОЗУ (502) может выступать доступный объем памяти графической карты или графического процессора.
[0150] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флеш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0151] Для организации работы компонентов системы (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0152] Для обеспечения взаимодействия пользователя с вычислительной системой (300) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорную панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0153] Средство сетевого взаимодействия (506) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (306) может использоваться, но не ограничиваться: Ethernet-карта, GSM-модем, GPRS-модем, LTE-модем, 5G-модем, модуль спутниковой связи, NFC-модуль, Bluetooth- и/или BLE-модуль, Wi-Fi-модуль и др.
[0154] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
Источники информации:
[1] М. Harris, "The Lie Generator: Inside the Black Mirror World of Polygraph Job Screenings," in Wired.com, 2018.
[2] B. Banerjee and G. Chatterjee, "The world of lie detection: a study into state of lie detection usage by state and society in Asia, Africa and Europe," 2021.
[3] S. E. Fienberg, J. J. Blascovich, J. T. Cacioppo, R. J. Davidson, P. Ekman, D. L. Faigman et al. "The polygraph and lie detection," in National Research Council, the National Academies Press, Washington, DC, 2003.
[4] A. Slavkovic, "Evaluating polygraph data," in Carnegie Mellon University, 2002.
[5] J. Synnott, D. Dietzel and M. Ioannou, "The Polygraph: History, Methodology and Current Status," in Reviewing Crime Psychology, 2020.
[6] G. Krishnamurthy, N. Majumder, S. Poria and E. Cambria, "A Deep Learning Approach for Multimodal Deception Detection," in 19th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing), Hanoi, Vietnam, 2018.
[7] D. Avola, L. Cinque, G. L. Foresti and D. Pannone, "Automatic Deception Detection in RGB videos using Facial Action Units," in ICDSC 2019: Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, 2019.
[8] N. Samadiani, G. Huang, B. Cai, W. Luo, C.-H. Chi, Y. Xiang and J. He, "A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data," in Sensors, Vol.19, Issue 8, Sp. issue Sensor Applications on Face Analysis, 2019.
[9] A. K. Webb, C. R. Honts, J. C. Kircher, P. Bernhardt and A. E. Cook, "Effectiveness of pupil diameter in a probable-lie comparison question test for deception," in Legal and Criminological Psychology, vol.14, issue 2, 2010.
[10] J. J. Walczyk, K. T. Mahoney, D. Doverspike and D. A. Griffith-Ross, "Cognitive Lie Detection: Response Time and Consistency of Answers as Cues to Deception," in Journal of Business and Psychology, vol.24, 2009.
[11] A. Shuster, L. Inzelberg, O. Ossmy, L. Izakson, Y. Hanein and D. Levy, "Lie to my face: An electromyography approach to the study of deceptive behavior," in Brain and Behavior, vol.11, issue 12, 2021.
[12] V. Abootalebi, M. H. Moradi and M. A. Khalilzadeh, "A new approach for EEG feature extraction in P300-based lie detection," in Computer Methods and Programs in Biomedicine, vol.94, issue 1, 2009.
[13] A. Kozel, K. Johnson, Q. Mu, E. Grenesko, S. Laken and M. George, "Detecting Deception Using Functional Magnetic Resonance Imaging," in Biological Psychiatry, vol.58, issue 8, 2005.
[14] M. J. Farah, J. B. Hutchinson, E. A. Phelps and A. D. Wagner, "Functional MRI-based lie detection: scientific and societal challenges," in Nature Reviews Neuroscience, vol.14, 2014.
[15] M. Monaro, C. Galante, R. Spolaor, Q. Q. Li, L. Gamberini, M. Conti and G. Sartori, "Covert lie detection using keyboard dynamics," in Nature, Scientific Reports, vol.8, 2018.
[16] L. Sousedikova, M. Hromada and M. Adamek, "Analysis of Artificial Intelligence Lie Detector Developed for Airport Security," in Tomas Bata University in Zlin, 2021.
[17] J.  and L. Dencik, "The politics of deceptive borders: "biomarkers of deceit and the case of iBorderCtrl", in Information, Communication & Society, vol. 25, issue 3, 2022.
and L. Dencik, "The politics of deceptive borders: "biomarkers of deceit and the case of iBorderCtrl", in Information, Communication & Society, vol. 25, issue 3, 2022.
[18] L.  F. Liberatore, J. Camacho-Collados and M. Camacho-Collados, "Applying automatic text-based detection of deceptive language to police reports: Extracting behavioral patterns from a multi-step classification model to understand how we lie to the police," in Knowledge-Based Systems, vol. 149, 2018.
F. Liberatore, J. Camacho-Collados and M. Camacho-Collados, "Applying automatic text-based detection of deceptive language to police reports: Extracting behavioral patterns from a multi-step classification model to understand how we lie to the police," in Knowledge-Based Systems, vol. 149, 2018.
[19] "Police use a computer to expose false testimony. A lie-detection system being used by Spanish police highlights concerns about algorithms", in Nature, Editorial, 2018.
[20] G. Ben-Shakhar and W. Iacono, "Fallacies in the estimation of the validity of the Comparison Question Polygraph Test: A reply to Ginton (2020)", in Investigative Psychology and Offender Profiling, vol. 18, issue 3, 2021.
[21] D. Grubin and L. Madsen, "Lie detection and the polygraph: A historical review", in the Journal of Forensic Psychiatry & Psychology, 2005.
[22] C. Hinkle, "The Modern Lie Detector: AI-Powered Affect Screening and the Employee Polygraph Protection Act (EPPA)," in the Georgetown Law Journal, vol.109, Georgetown, 2021.
[23] J. Bittle, "Lie detectors have always been suspect. AI has made the problem worse", in MIT Technology review, 2020.
[24] L. Saxe, "Science and the CQT polygraph - A theoretical critique", in Integrative Physiological and Behavioral Science, 1991.
[25] A. M. Perkey, "Recommendations for uniform polygraph examinations for preemployment screening of law enforcement applicants," in University of Wisconsin-Platteville, 2021.
[26] W. Egerton, "Use of the Polygraph to Screen Police Candidates," in Law Enforcement Management Institute of Texas (LEMIT), North Richland Hills, Texas, 2020.
[27] D. Baur, "Federal Psychophysiological Detection of Deception Examiner Handbook", in Counterintelligence Field Activity Technical Manual, 2006.
[28] J. Matzka, O. Bronkalla, K. Tornow, K. Elger and C. Stolle, "Geomagnetic Kp index V. 1.0.," in GFZ Data Services. https://doi.org/10.5880/Kp.0001, Potsdam, Germany, 2021.
[29] C. R. Honts and S. Amato, "Automation of a screening polygraph test increases accuracy," in Psychology, Crime & Law, vol.13, issue 2, 2007.
[30] A. Mambreyan, E. Punskaya and H. Gunes, "Dataset Bias in Deception Detection", in 26TH International Conference on Pattern Recognition, Montreal, Quebec, 2022.
[31] M. Abouelenien,  R. Mihalcea and M. Burzo, "Detecting Deceptive Behavior via Integration of Discriminative Features from Multiple Modalities," in IEEE Transactions on Information Forensics and Security, vol.12, issue 5, 2016.
R. Mihalcea and M. Burzo, "Detecting Deceptive Behavior via Integration of Discriminative Features from Multiple Modalities," in IEEE Transactions on Information Forensics and Security, vol.12, issue 5, 2016.
[32] Interfax, "Bill on possible ban on transfer abroad of Russians' personal data being submitted to State Duma", in https://interfax.com/newsroom/top-stories/77833/, 2022.
[33] M. Handler and N. Hernandez, "Introduction to the NCCA ASCII Standard," in Polygraph & Forensic Credibility Assessment: A Journal of Science and Field Practice, 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ С ПРИМЕНЕНИЕМ ТРЕХ АНСАМБЛЕЙ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2809595C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ С ПРИМЕНЕНИЕМ ДВУХ АНСАМБЛЕЙ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2809490C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПОЛИГРАФИЧЕСКОЙ ПРОВЕРКИ | 2023 |
|
RU2809489C1 |
| СПОСОБ РАСЧЕТА КРЕДИТНОГО РЕЙТИНГА КЛИЕНТА | 2019 |
|
RU2723448C1 |
| СПОСОБ И СИСТЕМА ОЦЕНКИ ВЕРОЯТНОСТИ ВОЗНИКНОВЕНИЯ КРИТИЧЕСКИХ ДЕФЕКТОВ ПО КИБЕРБЕЗОПАСНОСТИ НА ПРИЕМО-СДАТОЧНЫХ ИСПЫТАНИЯХ РЕЛИЗОВ ПРОДУКТОВ | 2020 |
|
RU2745369C1 |
| СПОСОБ И СИСТЕМА ПРОГНОЗИРОВАНИЯ РИСКОВ КИБЕРБЕЗОПАСНОСТИ ПРИ РАЗРАБОТКЕ ПРОГРАММНЫХ ПРОДУКТОВ | 2020 |
|
RU2745371C1 |
| Способ психофизиологического тестирования на полиграфе | 2017 |
|
RU2669733C1 |
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
| СПОСОБ И СИСТЕМА СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВЕ ПРЕДИКТИВНЫХ МОДЕЛЕЙ | 2020 |
|
RU2759087C1 |
| СПОСОБ И СЕРВЕР ПРЕОБРАЗОВАНИЯ ЗНАЧЕНИЯ КАТЕГОРИАЛЬНОГО ФАКТОРА В ЕГО ЧИСЛОВОЕ ПРЕДСТАВЛЕНИЕ | 2017 |
|
RU2693324C2 |



Изобретение относится к автоматизированному способу и системе автоматической полиграфической проверки с помощью алгоритмов машинного обучения. Техническим результатом от реализации заявленного способа является повышение точности полиграфической проверки. Указанный технический результат достигается благодаря осуществлению компьютерно-реализуемого способа автоматической полиграфической проверки, выполняемого с помощью вычислительной системы, содержащей по меньшей мере две модели машинного обучения, при этом способ выполняет этапы, на которых: получают записи полиграфических проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса; получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию; осуществляют обработку полученных сигналов с помощью первой модели машинного обучения (МО), с помощью второй модели машинного обучения (МО) осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, и определяют, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения. 2 н. и 6 з.п. ф-лы, 11 ил., 11 табл.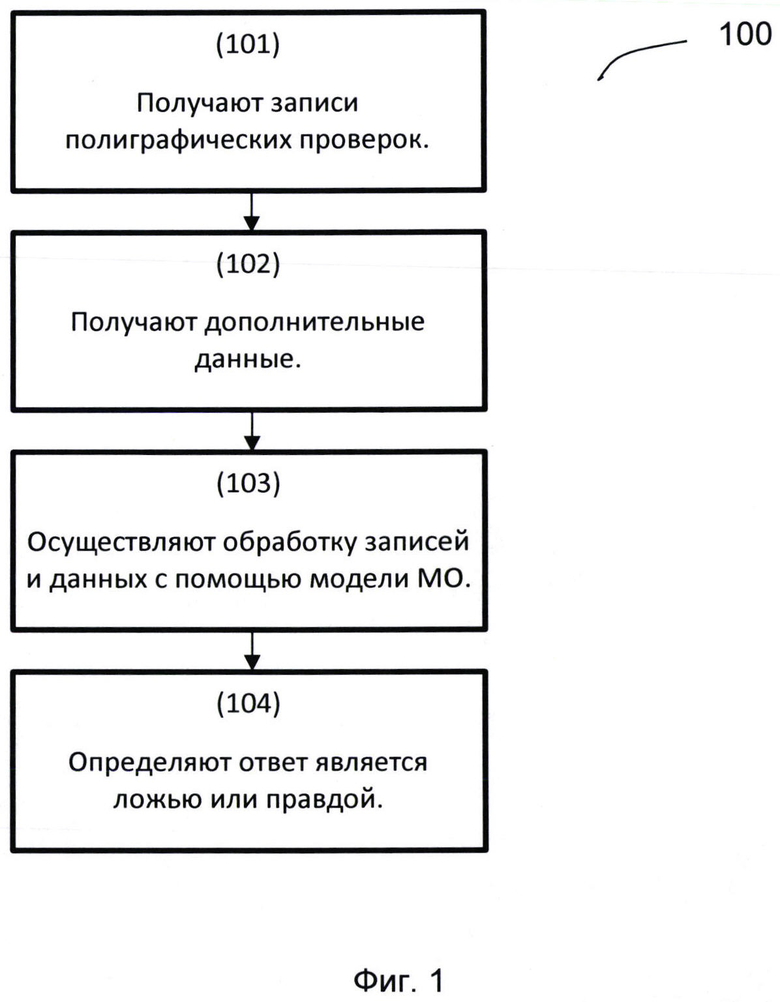
1. Компьютерно-реализуемый способ автоматической проверки испытуемого с помощью полиграфа с использованием вычислительной системы, содержащей по меньшей мере две модели машинного обучения, при этом способ выполняет этапы, на которых:
- получают записи полиграфических проверок, содержащие по меньшей мере сигналы датчиков с временными шкалами, на которых промаркированы начало и конец вопроса;
- получают дополнительные данные, содержащие по меньшей мере возраст проверяемого, пол, должностную информацию;
- осуществляют обработку полученных сигналов с помощью первой модели машинного обучения (МО), причем в ходе указанной обработки осуществляется:
 определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса;
определение временных интервалов для извлечения переменных на основе временных меток начала и конца вопроса и временной метки ответа, и на основе типа и темы вопроса;
извлечение переменных из каждого сигнала на определенных временных интервалах;
обработка полученных переменных из сигналов, при которой выполняется нормализация и конкатенация обработанных переменных, и построение на их основе вектора;
подача упомянутого вектора в 1-ю модель МО для получения выходного значения 1-й модели МО;
передача выходного значения 1-й модели МО на вход 2-й модели МО;
- с помощью второй модели машинного обучения (МО) осуществляют обработку выходного значения 1-й модели МО, и дополнительных данных, причем в ходе указанной обработки осуществляется:
разделение дополнительных данных на категориальные и численные переменные;
обработка полученных переменных из дополнительных данных, при которой выполняется векторизация категориальных переменных и нормализация численных переменных;
конкатенация обработанных дополнительных переменных, а также выходного значения 1-й модели МО, и построение на их основе вектора;
подача вектора во 2-ю модель МО для получения выходного значения 2-й модели МО;
сравнение выходного значения 2-й модели с заданным пороговым значением; и
- определяют, что ответ является ложью, если выходное значение выше или равно пороговому значению или ответ является правдой, если выходное значение ниже порогового значения.
2. Способ по п. 1, характеризующийся тем, что модели МО определяют ответ как правдивый или ложный не по одному полученному ответу, а по совокупности вопросов и ответов, связанных с темой полиграфической проверки, при этом получаемые переменные сигналы объединяются в единый вектор, либо усредняются перед передачей в модели МО.
3. Способ по п. 1, характеризующийся тем, что 1-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
4. Способ по п. 1, характеризующийся тем, что 2-я модель МО имеет тип градиентный бустинг, случайный лес, или нейронная сеть.
5. Способ по п. 1, характеризующийся тем, что модели МО обучены на одной из тем для проверок или их комбинации, где темами для проверок являются: наркотические вещества, получение дополнительного вознаграждения, разглашение конфиденциальной информации, долговые обязательства, сторонний доход, уголовные правонарушения, административные правонарушения, нарушения внутренних нормативных документов (ВНД).
6. Способ по п. 1, характеризующийся тем, что записи полиграфных проверок содержат сигналы с датчиков, включающие по меньшей мере одно из: частота сердечного сокращения (ЧСС), кожно-гальваническая реакция (КГР), артериальное давление, верхнее и нижнее дыхание, пьезоплетизмограмму, фотоплетизмограмму, термических, движения зрачка или их комбинации.
7. Способ по п. 1, характеризующийся тем, что дополнительные данные содержат по меньшей мере одно из: идентификационный номер полиграфологов, идентификационный номер полиграфов, информацию о погодных условиях, результаты электроэнцефалограммы, магнитно-резонансной томографии, функциональной ближней инфракрасной спектроскопии, информацию о геомагнитных бурях или их комбинации.
8. Система автоматической проверки испытуемого с помощью полиграфа с использованием по меньшей мере двух моделей машинного обучения, содержащая:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп. 1-7.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ АНАЛИЗА ПОВЕДЕНИЯ ЧЕЛОВЕКА | 2002 |
|
RU2292839C2 |
| US 11048921 B2, 29.06.2021 | |||
| US 10524713 B2, 07.01.2020 | |||
| Труфанов A.И | |||
| и др | |||
| "Технология цифровых двойников в психофизиологическом тестировании" ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В НАУКЕ, УПРАВЛЕНИИ, СОЦИАЛЬНОЙ СФЕРЕ И МЕДИЦИНЕ | |||
| Паровоз для отопления неспекающейся каменноугольной мелочью | 1916 |
|
SU14A1 |

