ОБЛАСТЬ ТЕХНИКИ
[001] Настоящая технология относится к алгоритмам машинного обучения и, конкретнее, к способу и системе ранжирования поисковых результатов с помощью алгоритма машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[001] Алгоритмы машинного обучения (MLA) используются для различных задач в компьютерных технологиях. Обычно, MLA используются для создания прогнозов, связанных с пользовательским взаимодействием с компьютерным устройством. Примером сферы использования MLA является пользовательское взаимодействие с содержимым, доступным, например, в сети Интернет.
[002] Объем доступной информации на различных интернет-ресурсах экспоненциально вырос за последние несколько лет. Были разработаны различные решения, которые позволяют обычному пользователю находить информацию, которую он(а) ищет. Примером такого решения является поисковая система. Примеры поисковых систем включают в себя такие поисковые системы как GOOGLE™, YANDEX™, YAHOO!™ и другие. Пользователь может получить доступ к интерфейсу поисковой системы и подтвердить поисковый запрос, связанный с информацией, которую пользователь хочет найти в Интернете. В ответ на поисковый запрос поисковые системы предоставляют ранжированный список результатов поиска. Ранжированный список результатов поиска создается на основе различных алгоритмов ранжирования, которые реализованы в конкретной поисковой системе, и которые используются пользователем, производящим поиск. Общей целью таких алгоритмов ранжирования является представление наиболее релевантных результатов вверху ранжированного списка, а менее релевантных результатов - на менее высоких позициях ранжированного списка результатов поиска (а наименее релевантные результаты поиска будут расположены внизу ранжированного списка результатов поиска).
[003] Поисковые системы обычно являются хорошим поисковым инструментом в том случае, когда пользователю заранее известно, что именно он(а) хочет найти. Другими словами, если пользователь заинтересован в получении информации о наиболее популярных местах в Италии (т.е. поисковая тема известна), пользователь может ввести поисковый запрос: «Наиболее популярные места в Италии». Поисковая система предоставит ранжированный список интернет-ресурсов, которые потенциально являются релевантными по отношению к поисковому запросу. Пользователь далее может просматривать ранжированный список результатов поиска для того, чтобы получить информацию, в которой он заинтересован, в данном случае - о посещаемых местах в Италии. Если пользователь по какой-либо причине не удовлетворен представленными результатами, пользователь может произвести вторичный поиск, уточнив запрос, например «наиболее популярные места в Италии летом», «наиболее популярные места на юге Италии», «Наиболее популярные места в Италии для романтичного отдыха».
[004] В примере поисковой системы, алгоритм машинного обучения (MLA) используется для создания ранжированных поисковых результатов. Когда пользователь вводит поисковый запрос, поисковая система создает список релевантных веб-ресурсов (на основе анализа просмотренных веб-ресурсов, указание на которые хранится в базе данных поискового робота в форме списков словопозиций или тому подобного). Далее поисковая система выполняет MLA для ранжирования таким образом созданного списка поисковых результатов. ML А ранжирует список поисковых результатов на основе их релевантности для поискового запроса. Подобный MLA "обучается" для прогнозирования релевантности данного поискового результата для поискового запроса на основе множества "факторов", связанных с данным поисковым результатом, а также указаний на взаимодействия прошлых пользователей с поисковыми результатами, когда они вводили аналогичные поисковые запросы в прошлом.
[002] Американская патентная заявка №8,898,156 В2, озаглавленная "Query expansion for web search" (англ. "Расширение запроса для веб-поиска") и выданная 25 ноября 2014 года компании Microsoft, описывает системы, способы и устройства для извлечения результатов запроса на основе, по меньшей мере частично, запроса и одного или нескольких аналогичных запросов. При получении запроса, могут быть идентифицированы и/или вычислены один или несколько аналогичных запросов. В одном варианте осуществления технологии, запросы могут определяться на основе, по меньшей мере, частично, данных о кликах, которые соответствуют ранее введенным запросам. Информация, связанная с запросом и каждым из аналогичных запросов, может быть получена, ранжирована и скомбинирована. Скомбинированные результаты запроса могут далее заново ранжироваться на основе, по меньшей мере, частично на степени актуальности и/или релевантности для предыдущего введенного запроса. Заново ранжированные результаты запроса могут далее выводиться пользователю, который ввел оригинальный запрос.
[003] Американская патентная заявка №8,606,786, озаглавленная "Determining а similarity measure between queries" (англ. "Определение величины сходства между запросами") и выданная 10 декабря 2013 года компании Microsoft, описывает систему, включающую в себя компонент приема, который получает набор данных и включает в себя множество запросов, введенных пользователями в поисковую систему, и множество поисковых результатов, выбранных пользователями при вводе множества запросов. Компонент определения распределения определяет распределение кликов по поисковых результатам, выбранным пользователями в отношении множества запросов. Компонент пометки помечает два запроса во множестве запросов как по сути аналогичные друг другу на основе, по меньшей меньшей отчасти, распределения кликов по поисковым результатам, выбранным пользователями в отношении множества запросов.
[004] Американская патентная заявка №9,009,146 В1, озаглавленная "Ranking search results based on similar queries" (англ. "Ранжирование поисковых результатов на основе аналогичных запросов") и выданная 14 апреля 2015 компании Google, описывает исполняемый на компьютере способ предоставления ввода в процесс ранжирования документов для ранжирования множества документов, причем процесс ранжирования документов использует в качестве ввода качество статистики по результатам для индивидуального документа во множестве документов, причем множество документов было идентифицировано в ответ на запрос, и качество статистики по результатам относится к запросу и индивидуальному документу. Способ для предоставления ввода может включать в себя, для первого документа, идентифицированного как поисковый результат введенного пользователем запроса, оценку одного или нескольких других запросов на основе сходства с введенным пользователем запросов, причем каждый из одного или нескольких запросов отличается от введенного пользователем запроса.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[005] Разработчики настоящего технического решения рассматривали по меньшей мере одну проблему, соответствующую известному уровню техники.
[006] Разработчики настоящей технологии разработали варианты осуществления настоящей технологии на основе класса моделей глубокого обучения, также известных как Deep Structured Semantic Model (DSSM). Коротко говоря, DSSM является глубокой нейронной сетью, которая получает вводимые запросы и документы, и проецирует их в общее пространство с низкой размерностью, где релевантность документа для запроса вычисляется как расстояние между ними. Подобный подход обычно сочетается с методиками хэширования слов, которые позволяют обращаться с большими словарями и масштабировать семантические модели, используемые DSSM. DSSM позволяет прогнозировать отношения между двумя текстами на основе пользовательского поведения.
[007] Настоящая технология выполнена с возможность создавать факторы и обучающие данные для нейронной сети на основе модифицированной версии DSSM. DSSM обучена предсказывать похожесть двух поисковых запросов - нового поискового запроса и ранее-отображаемого поискового запроса. Знания о прогнозируемой похожести поисковых запросов позволяют создавать дополнительный фактор ранжирования - на основе знания (например, о предыдущих пользовательских взаимодействиях с документами, показанными предыдущим пользователям, связанных с ранее-отображаемым поисковым запросом), связанного с ранее-отображаемым поисковым запросом, причем дополнительный фактор ранжирования может далее использоваться алгоритмами ранжирования, например, системой ранжирования MatrixNet, которая используется поисковой системой Яндекс™ для ранжирования документов на основе их релевантности для данного поискового запроса в поисковой системе.
[008] Конкретнее, разработчики настоящей технологии обратили внимание, что операторы поисковых систем, такие как Google™, Yandex™, Bing™ и Yahoo™, среди прочего, обладают доступом к большому числу данных о пользовательском взаимодействии в отношении поисковых результатов, отображающихся в ответ на пользовательские запросы, которые могут быть использованы для сравнения запросов и связанных поисковых результатов.
[009] Разработчики настоящей технологии также предполагают, что различные запросы могут приводить к одним и тем же документам, и, следовательно, сходство между двумя запросами может оцениваться с помощью близости "путей" между поисковыми запросами, которые инициировали появление документа на предыдущей странице результатов поиска (SERP). Подобный подход может, например, быть использован для обучения MLA сопоставлению нового запроса с аналогичным старым запросом, что может быть связано с поисковыми результатами, которые могут относиться к пользователю, который вводит новый запрос в поисковую систему.
[0010] Таким образом, варианты осуществления настоящей технологии направлены на способ и систему для ранжирования поисковых результатов с помощью алгоритма машинного обучения.
[0011] Первым объектом настоящей технологии является исполняемый на компьютере способ ранжирования поисковых результатов с помощью первого алгоритма машинного обучения (MLA), причем способ выполняется сервером, на котором расположен второй MLA, который был обучен определять сходство запросов на основе их текстового содержимого, причем способ включает в себя: получение вторым MLA нового запроса, извлечение вторым MLA из базы данных поискового журнала, документа, который был введен на сервер поисковой системы, вычисление вторым MLA соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов, выбор вторым MLA из множества поисковых запросов, данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства, извлечение вторым MLA набора поисковых результатов, связанных с данным прошлым запросом, причем каждый поисковый результат из набора поисковых результатов связан с соответствующей аннотацией, включающей в себя: по меньшей мере один соответствующий поисковый запрос, который был использован для получения доступа к соответствующему поисковому результату на сервере поисковой системы; вычисление вторым MLA для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства; и использование соответствующего второго параметра сходства в качестве фактора ранжирования первым MLA для ранжирования соответствующих поисковых результатов в качестве поисковых результатов для нового запроса.
[0012] В некоторых вариантах осуществления, способ дополнительно включает в себя: во время фазы обучения: извлечение из базы данных поискового журнала множества поисковых запросов, которое было введено на сервер поисковой системы, причем множество поисковых запросов связано с соответствующим набором поисковых результатов, и каждый соответствующий поисковый результат соответствующего набора поисковых результатов связан по меньшей мере с одним соответствующим параметром пользовательского взаимодействия; вычисление, для каждого запроса из множества поисковых запросов, соответствующего вектора запроса на основе по меньшей мере одного параметра пользовательского взаимодействия, связанного с каждым поисковым результатом из соответствующего набора поисковых результатов; вычисление, для каждой возможной пары запросов из множества поисковых запросов, на основе соответствующих векторов запроса каждого запроса из пары запросов, соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами в паре запросов; создание набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства; обучение второго MLA на наборе обучающих объектов для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
[0013] В некоторых вариантах осуществления технологии, соответствующая аннотация далее включает в себя: по меньшей мере один соответствующий параметр пользовательского взаимодействия, причем по меньшей мере один соответствующий параметр пользовательского взаимодействия указывает на пользовательское поведение с соответствующим поисковым результатом по меньшей одного пользователя после ввода по меньшей мере одного соответствующего запроса в сервер поисковой системы.
[0014] В некоторых вариантах осуществления технологии, во время фазы обучения, соответствующий параметр сходства вычисляется путем использования одного из: скалярного произведения или коэффициента Отиаи (косинусного коэффициента).
[0015] В некоторых вариантах осуществления технологии, соответствующий второй параметр сходства вычисляется вторым MLA на основе: соответствующего параметра сходства между новым запросом и по меньшей мере одним соответствующим поисковым запросом, включенным в соответствующую аннотацию; и по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующую аннотацию.
[0016] В некоторых вариантах осуществления технологии, вычисление вторым MLA для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства включает в себя: перемножение соответствующего параметра сходства и по меньшей мере одного соответствующего параметра пользовательского взаимодействия.
[0017] В некоторых вариантах осуществления технологии, обучение второго MLA на наборе обучающих объектов для определения параметра сходства новой пары запросов основано по меньшей мере на соответствующем текстовом свойстве каждого запроса из новой пары запросов.
[0018] В некоторых вариантах осуществления технологии, второй MLA является нейронной сетью.
[0019] В некоторых вариантах осуществления технологии, первый MLA является алгоритмом на основе дерева решений.
[0020] В некоторых вариантах осуществления технологии, первый MLA использует множество дополнительных факторов для ранжирования, и причем соответствующий второй параметр сходства добавляется ко множеству дополнительных факторов для ранжирования.
[0021] В некоторых вариантах осуществления технологии, параметр пользовательского взаимодействия является по меньшей мере одним из: кликабельность или время простоя.
[0022] В некоторых вариантах осуществления технологии, способ дополнительно включает в себя, до этапа получения нового запроса: создание множества аннотаций, включающих в себя соответствующие аннотации; и сохранение множества аннотаций в хранилище сервера.
[0023] В некоторых вариантах осуществления технологии, создание множества векторов аннотации выполняется с помощью третьего обученного MLA.
[0024] Вторым объектом настоящей технологии является система ранжирования поисковых результатов с помощью первого алгоритма машинного обучения (MLA), причем система выполняется вторым MLA на системе, и второй MLA был обучен определять сходство запросов на основе их текстового содержимого, причем система включает в себя:
процессор; постоянный машиночитаемый носитель компьютерной информации, содержащий инструкции, процессор; при выполнении инструкций, выполнен с возможностью осуществлять: получение вторым MLA нового запроса; извлечение вторым MLA из базы данных поискового журнала, документа, который был введен на сервер поисковой системы; вычисление вторым MLA соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов; выбор вторым MLA из множества поисковых запросов, данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства; извлечение вторым MLA набора поисковых результатов, связанных с данным предыдущим запросом, причем каждый поисковый результат из набора поисковых результатов связан с соответствующей аннотацией, включая: по меньшей мере один соответствующий поисковый запрос, который был использован для получения доступа к соответствующему поисковому результату на сервере поисковой системы; вычисление вторым MLA для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства; и использование соответствующего второго параметра сходства в качестве фактора ранжирования первым MLA для ранжирования соответствующих поисковых результатов в качестве поисковых результатов для нового запроса.
[0025] В некоторых вариантах осуществления технологии, процессор далее выполнен с возможностью осуществлять: во время фазы обучения: извлечение из базы данных поискового журнала множества поисковых запросов, которое было введено на сервер поисковой системы, причем множество поисковых запросов связано с соответствующим набором поисковых результатов, и каждый соответствующий поисковый результат соответствующего набора поисковых результатов связан по меньшей мере с одним соответствующим параметром пользовательского взаимодействия; вычисление, для каждого запроса из множества поисковых запросов, соответствующего вектора запроса на основе по меньшей мере одного параметра пользовательского взаимодействия, связанного с каждым поисковым результатом из соответствующего набора поисковых результатов; вычисление, для каждой возможной пары запросов из множества поисковых запросов, на основе соответствующих векторов запроса каждого запроса из пары запросов, соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами в паре запросов; создание набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства; обучение второго MLA на наборе обучающих объектов для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
[0026] В некоторых вариантах осуществления технологии, соответствующая аннотация далее включает в себя: по меньшей мере один соответствующий параметр пользовательского взаимодействия, причем по меньшей мере один соответствующий параметр пользовательского взаимодействия указывает на пользовательское поведение с соответствующим поисковым результатом по меньшей одного пользователя после ввода по меньшей мере одного соответствующего запроса в сервер поисковой системы.
[0027] В некоторых вариантах осуществления технологии, во время фазы обучения, соответствующий параметр сходства вычисляется путем использования одного из: скалярного произведения или коэффициента Отиаи (косинусного коэффициента).
[0028] В некоторых вариантах осуществления, соответствующий второй параметр сходства вычисляется вторым MLA на основе: соответствующего параметра сходства между новым запросом и по меньшей мере одним соответствующим поисковым запросом, включенным в соответствующую аннотацию, и по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующую аннотацию.
[0029] В некоторых вариантах осуществления технологии, для вычисления вторым MLA для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства, процессор выполнен с возможностью осуществлять: перемножение соответствующего параметра сходства и по меньшей мере одного соответствующего параметра пользовательского взаимодействия.
[0030] В некоторых вариантах осуществления технологии, обучение второго MLA на наборе обучающих объектов для определения параметра сходства новой пары запросов основано по меньшей мере на соответствующем текстовом факторе каждого запроса из новой пары запросов.
[0031] В некоторых вариантах осуществления технологии, второй MLA является нейронной сетью.
[0032] В некоторых вариантах осуществления технологии, первый MLA является алгоритмом на основе дерева решений.
[0033] В некоторых вариантах осуществления технологии, первый MLA использует множество дополнительных факторов для ранжирования, и причем соответствующий второй параметр сходства добавляется ко множеству дополнительных факторов для ранжирования.
[0034] В некоторых вариантах осуществления технологии, параметр пользовательского взаимодействия является по меньшей мере одним из: кликабельность или время простоя.
[0035] В некоторых вариантах осуществления технологии, процессор дополнительно выполнен с возможностью осуществлять, до этапа получения нового запроса: создание множества аннотаций, включающих в себя соответствующие аннотации; и сохранение множества аннотаций в хранилище системы.
[0036] В некоторых вариантах осуществления технологии, создание множества векторов аннотации выполняется с помощью третьего обученного MLA.
[0037] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения "сервер" не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение "по меньшей мере один сервер".
[0038] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения "электронное устройство" не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[0039] В контексте настоящего описания "база данных" подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. В контексте настоящего описания слова "первый", "второй", "третий" и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными.
[0040] В контексте настоящего описания "информация" включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[0041] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[0042] В контексте настоящего описания, если четко не указано иное, "указание" информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое), или же оно может являться уникальным дескриптором документа, идентифицирующим файл по отношению к конкретной файловой системе, или каким-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[0043] В контексте настоящего описания слова "первый", "второй", "третий" и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0044] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[0045] Дополнительные и/или альтернативные факторы, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0046] Для лучшего понимания настоящей технологии, а также других ее аспектов и факторов сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0047] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с неограничивающими вариантами осуществления настоящего технического решения.
[0048] На Фиг. 2 представлена схематическая диаграмма системы машинного обучения, выполненной в соответствии с вариантами осуществления настоящей технологии.
[0049] На Фиг. 3 представлена схематическая диаграмма процедуры создания обучающего набор, выполненной в соответствии с вариантами осуществления настоящей технологии.
[0050] На Фиг. 4 представлена схематической диаграммы четвертого MLA, выполненного в соответствии с вариантами осуществления настоящей технологии.
[0051] На Фиг. 5 представлена схематическая диаграмма процедуры использования четвертого MLA, показанного на Фиг. 4, реализованного в соответствии с вариантами осуществления настоящей технологии.
[0052] На Фиг. 6 представлена блок-схема способа создания набора обучающих объектов и обучения четвертого MLA, причем способ выполняется в системе, показанной на Фиг. 1, в соответствии с вариантами осуществления настоящей технологии.
[0053] На Фиг. 7 представлена блок-схема способа ранжирования поисковых результатов с помощью первого MLA, причем способ выполняется в системе, показанной на Фиг. 1, в соответствии с вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[0054] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема.
[0055] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0056] Некоторые полезные примеры модификаций настоящей технологии также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающего списка, и специалисты в данной области техники могут создавать другие модификации, остающиеся в границах объема настоящей технологии. Кроме того, те случаи, где не были представлены примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящей технологии.
[0057] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор, или нет.
[0058] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также в это может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[0059] Программные модули или простые модули, представляющие собой программное обеспечение, могут быть использованы здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[0060] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии.
[0061] На Фиг. 1 представлена система 100, реализованная в соответствии с неограничивающими вариантами осуществления настоящей технологии. Система 100 включает в себя первое клиентское устройство 110, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140, соединенные с сетью 200 передачи данных через соответствующую линию 205 передачи данных (пронумеровано только на Фиг. 1). Система 100 включает в себя сервер 210 поисковой системы, аналитический сервер 220 и обучающий сервер 230, соединенные с сетью 200 передачи данных с помощью их соответствующей линии 205 передачи данных.
[0062] Только в качестве примера, первое клиентское устройство ПО может быть выполнено как смартфон, второе клиентское устройство 120 может быть выполнено как ноутбук, третье клиентское устройство 130 может быть выполнено как смартфон и четвертое клиентское устройство 140 может быть выполнено как планшет. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 200 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии сеть 200 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[0063] То, как именно реализована данная линия 205 передачи данных, никак конкретно не ограничено, и будет зависеть только от того, как именно реализовано соответствующее одно из: первое клиентское устройство 110, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда по меньшей мере одно из первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140, реализовано как беспроводное устройство связи (например, смартфон), соответствующая одна из: линия 205 передачи данных может представлять собой беспроводную сеть передачи данных (например, среди прочего, линию передачи данных 3G, линию передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где по меньшей мере одно из первого клиентского устройства ПО, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140 реализованы соответственно как портативный компьютер, смартфон, планшет, соответствующая линия 205 передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
[0064] Важно иметь в виду, что варианты осуществления воплощения первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130, четвертого клиентского устройства 140, линии 205 передачи данных и сети 200 передачи данных представлены исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления первого клиентского устройства ПО, второго клиентского устройства 120, третьего клиентского устройства 130, четвертого клиентского устройства 140 и линии 205 передачи данных и сети 200 передачи данных. То есть, представленные здесь примеры не ограничивают объем настоящей технологии.
[0065] Несмотря на то, что представлено только четыре клиентских устройства 110,120, 130 и 140 (все показаны на Фиг. 1), подразумевается, что любое число клиентских устройств 110, 120, 130 и 140 может быть соединено с системой 100. Далее подразумевается, что в некоторых вариантах осуществления технологии, число клиентских устройств 110, 120, 130 и 140, которые включены в систему 100, может достигать десятков или сотен тысяч.
[0066] С сетью 200 передачи данных также соединен вышеупомянутый сервер 210 поисковой системы. Сервер 210 поисковой системы может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения, сервер 210 поисковой системы может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 210 поисковой системы может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 210 поисковой системы является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 210 хостинга содержимого может быть разделена, и может выполняться с помощью нескольких серверов. В некоторых вариантах осуществления настоящей технологии, сервер 210 поисковой системы находится под контролем и/или управлением поставщика поисковой систем, такого, например, как оператор поисковой системы Yandex. Как вариант, сервер 210 поисковой системы может находиться под контролем и/или управлением поставщика сервиса.
[0067] В общем случае задачей сервера 210 поисковой системы осуществляет (i) проведение поиска; (ii) проведение анализа результатов поиска и ранжирование результатов поиска; (iii) группировку результатов и компиляцию страницы результатов поиска (SERP) для вывода на электронное устройство (например, первое клиентское устройство 110, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140), причем электронное устройство использовалось для ввода поискового запроса, который привел к SERP.
[0068] Конфигурация сервера 210 поисковой системы для выполнения поиска конкретно ничем не ограничена. Специалистам в данной области техники будут понятны некоторые способы и средства для выполнения поиска с помощью сервера 210 поисковой системы и, соответственно, некоторые структурные компоненты сервера 210 поисковой системы будут описаны только на поверхностном уровне. Сервер 210 поисковой системы может содержать базу 212 данных поискового журнала.
[0069] В некоторых вариантах осуществления настоящей технологии, сервер 210 поисковой системы может выполнять несколько типов поисков, включая, среди прочего, общий поиск и вертикальный поиск.
[0070] Сервер 210 поисковой системы настроен на выполнение общих сетевых поисков, как известно в данной области техники. Сервер 210 поисковой системы также выполнен с возможностью осуществлять один или несколько вертикальных поисков, например, вертикальный поиск изображений, вертикальный поиск музыки, вертикальный поиск видеозаписей, вертикальный поиск новостей, вертикальный поиск карт и так далее. Сервер 210 поисковой системы также выполнен с возможностью осуществлять, как известно специалистам в данной области техники, алгоритм поискового робота - причем алгоритм инициирует сервер 210 поисковой системы "просматривать" Интернет и индексировать посещенные веб-сайты в одну или несколько индексных базы данных, например, базу 212 данных поискового журнала.
[0071] Сервер 210 поисковой системы выполнен с возможностью создавать ранжированный список результатов поиска, включая, результаты из общего веб-поиска и вертикального веб-поиска. Множество алгоритмов для ранжирования поисковых результатов известно и может быть использовано сервером 210 поисковой системы.
[0072] В качестве примера, не ограничивающего объем технологии, некоторые способы ранжирования результатов в соответствии с их релевантностью для введенного пользователем поискового запроса основаны на всех или некоторых из следующих критериев: (i) популярность данного поискового запроса или ответа на него в поисках; (ii) число выведенных результатов; (iii) включает ли в себя поисковый запрос какие-либо ключевые термины (например, "изображения", "видео", "погода" или т.п.), (iv) насколько часто конкретный поисковый запрос включает в себя ключевые термины при вводе его другими пользователями; (v) насколько часто другие пользователи при выполнении аналогичного поиска выбирали конкретный ресурс или конкретные результаты вертикального поиска, когда результаты были представлены на SERP. Север 210 поисковой системы может вычислять и назначать оценку релевантности (на основе другого перечисленного выше критерия) для каждого поискового результата, полученного в ответ на введенный пользователем поисковый запрос, и создавать SERP, причем поисковые результаты ранжированы в соответствии с их соответствующими оценками релевантности. В настоящем варианте осуществления технологии, сервер 210 поисковой системы может выполнять множество алгоритмов машинного обучения для ранжирования документов и/или создавать факторы для ранжирования документов.
[0073] Сервер 210 поисковой системы обычно содержит вышеупомянутую базу 212 данных поискового журнала.
[0074] В общем случае, база 212 данных поискового журнала может содержать индекс 214, журнал 216 запросов и журнал 218 пользовательских взаимодействий.
[0075] Задачей индекса 214 является индексирование документов, таких как, без установления ограничений, веб-страницы, изображения, PDF, документы Word™, документы PowerPoint™, которые были просмотрены (или открыты) поисковым роботом сервера 210 поисковой системы. В некоторых вариантах осуществления настоящей технологии, индекс 214 ведется в форме списков словопозиций. Таким образом, когда пользователь одного из первого клиентского устройства ПО, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140 вводит запроса и выполняет поиск на сервере 210 поисковой системы, сервер 210 поисковой системы анализирует индекса 214 и извлекает документы, которые содержат термины запроса, и ранжирует их в соответствии с алгоритмом ранжирования.
[0076] Целью журнала 216 запросов является занесение в журнал поисков, которые осуществлялись с помощью сервера 210 поисковой системы. Конкретнее, журнал 216 запросов поддерживает термины поисковых запросов (т.е. связанные поисковые слова) и связанные поисковые результаты. Следует отметить, что журнал 216 запросов поддерживается анонимным образом - т.е. поисковые запросы не отслеживаются до пользователей, которые вводят поисковый запрос.
[0077] Конкретнее, журнал 216 запросов может включать в себя список запросов с их соответствующими терминами, с информацией о документах, которые перечислены сервером 210 поисковой системы, в ответ на соответствующий запрос, временную отметку, и может также включать в себя список пользователей, идентифицированных с помощью анонимных ID (или совсем без ID) и соответствующих документов, на которые был совершен клик после ввода запроса. В некоторых вариантах осуществления технологии, журнал 216 запросов может обновляться каждый раз, когда выполняется новый запрос на сервере 210 поисковой системы. В других вариантах осуществления технологии, журнал 216 запросов может обновляться в заранее определенные моменты. В некоторых вариантах осуществления технологии, может быть множество копий журнала 216 запроса, и каждая соответствует журналу 216 запросов в различные моменты времени.
[0078] Журнал 218 пользовательских взаимодействий может быть связан с журналом 216 запросов, и списком параметров пользовательских взаимодействий, которые отслеживались сервером 220 аналитики, после того как пользователь ввел запрос и кликнул на один или несколько документов на SERP на сервере 210 поисковой системы. В качестве неограничивающего примера, журнал 218 пользовательских взаимодействий может содержать ссылку на документ, которая может быть идентифицирована с помощью номера ID или URL, список запросов, в котором каждый запрос из списка запросов связан со списком документов, и каждый документ связан со множеством параметров пользовательских взаимодействий (если с документом взаимодействовали), что будет описано более подробно в следующих параграфах. Множество параметров пользовательских взаимодействий может в общем случае отслеживаться и компилироваться сервером 220 аналитики и, в некоторых вариантах осуществления технологии, может быть перечислен для каждого индивидуального пользователя.
[0079] В некоторых вариантах осуществления настоящей технологии, журнал 216 запросов и журнал 218 пользовательских взаимодействий могут быть реализованы как единый журнал.
[0080] С сетью 200 передачи данных также соединен вышеупомянутый сервер 220 аналитики. Сервер 220 аналитики может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 220 аналитики может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 220 аналитики может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 220 аналитики является одиночным сервером. В других неограничивающих вариантах осуществления настоящей технологии, функциональность сервера 220 аналитики может быть разделена, и может выполняться с помощью нескольких серверов. В других вариантах осуществления технологии, функции сервера 220 аналитики могут выполняться полностью или частично сервером 210 поисковой системы. В некоторых вариантах осуществления настоящей технологии, сервер 220 аналитики находится под контролем и/или управлением оператора поисковой системы. Как вариант, сервер 220 аналитики может находиться под контролем и/или управлением другого поставщика сервиса.
[0081] В общем случае, целью сервера 220 аналитики является отслеживание пользовательских взаимодействий с поисковыми результатами, которые предоставляются сервером 210 поисковой системы в ответ на пользовательские запросы (например, совершенные пользователями одного из первого клиентского устройства ПО, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140). Сервер 220 аналитики может отслеживать пользовательские взаимодействия (например, или данные о кликах), когда пользователи выполняют общие веб-поиски и вертикальные веб-поиски на сервере 210 поисковой системы. Пользовательские взаимодействия могут отслеживаться сервером 220 аналитики в форме параметров пользовательских взаимодействий.
[0082] Неограничивающие примеры параметров пользовательских взаимодействий, которые отслеживаются сервером 220 аналитики, включают в себя:
- Loss/Win: был ли совершен клик по документу в ответ на поисковый запрос или нет.
- Время пребывания: время, которое пользователь проводит на документе до возвращения на SERP,
- Длинное/короткое нажатие: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами на SERP.
- Показатель кликабельности (CTR): Число кликов на элемент, деленное на число раз, когда элемент был показан (показы).
[0083] Естественно, вышепредставленный список не является исчерпывающим и может включать в себя другие типы параметров пользовательского взаимодействия, не выходя за границы настоящей технологии.
[0084] Сервер 220 аналитика может передавать отслеживаемые параметры пользовательских взаимодействий серверу 210 поисковой системы таким образом, что они могут сохраняться в журнале 218 пользовательских взаимодействий. В некоторых вариантах осуществления технологии, сервер 220 аналитики может сохранять параметры пользовательских взаимодействий и соответствующие поисковые результаты локально в журнале пользовательских взаимодействий (не показан). В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 220 аналитики и сервера 210 поисковой системы может быть разделена, и может выполняться с помощью одного сервера.
[0085] К сети передачи данных также присоединен вышеупомянутый обучающий сервер 230. Обучающий сервер 230 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии, обучающий сервер 230 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что обучающий сервер 230 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, обучающий сервер 230 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих его объем, функциональность обучающего сервера 230 может быть разделена и может выполняться с помощью нескольких серверов. В контексте настоящей технологии, обучающий сервер 230 может осуществлять часть описанных способов и систем. В некоторых вариантах осуществления настоящей технологии, обучающий сервер 230 находится под контролем и/или управлением оператора поисковой системы. Как вариант, обучающий сервер 230 может находиться под контролем и/или управлением другого поставщика сервиса.
[0086] В общем случае, целью обучающего сервера 230 является обучение одного или нескольких алгоритмов машинного обучения (MLA), используемых сервером 210 поисковой системы, сервером 220 аналитики и/или другими серверами (не показано), связанными с оператором поисковой системы. Сервер 230 может, в качестве примера, обучать один или несколько алгоритмов машинного обучения, связанных с поставщиком поисковой системы для оптимизации общих веб-поисков, вертикальных веб-поисков, предоставления рекомендаций, результатов прогнозов и других приложений. Обучение и оптимизация ML А может осуществляться в заранее определенные периоды времени или когда это считается необходимым со стороны поставщика поисковой системы.
[0087] Обучающий сервер 230 может поддерживать обучающую базу 232 данных для сохранения обучающих объектов и/или свойств для различных MLA, используемых сервером 210 поисковой системы, сервером 220 аналитики и/или другими серверами (не показано), связанными с оператором поисковой системы.
[0088] В представленных вариантах осуществления технологии, сервер 230 может быть выполнен с возможностью обучать (1) первый MLA для ранжирования документов на сервере 210 поисковой системы, (2) второй MLA для создания факторов, которые могут использоваться первым MLA, (3) третий MLA для создания аннотаций для документов, что может использоваться по меньшей мере одним из первого MLA, второго MLA и четвертого MLA, и (4) четвертый MLA для сравнения запросов и создания параметров сходства, аннотации, которые могут использоваться по меньшей мере некоторыми из первого MLA и второго MLA. Первый MLA, второй MLA, третий MLA и четвертый MLA будут описаны более подробно в следующих параграфах. Несмотря на то, что описание относится к общему веб-поиску документов, например, веб-страниц, настоящая технология может также применяться, по меньшей мере частично, к вертикальным поискам и к другим типам документов, например, результатам изображений, видеозаписей, музыке, новостям и другим типам поисков. Следует отметить, что все или некоторые из первого MLA, второго MLA, третьего MLA и четвертого MLA могут осуществляться как единый MLA.
[0089] На Фиг. 2, система 300 машинного обучения представлена в соответствии с неограничивающими вариантами осуществления настоящей технологии. Система 300 машинного обучения включает в себя первый MLA 320, второй MLA 340, третий MLA 360, четвертый MLA 380.
[0090] Первый MLA 320 может в общем случае быть выполнена с возможностью ранжирования поисковых результатов на сервере 210 поисковой системы и может выполнять алгоритм деревьев решений с использованием градиентного бустинга (GBRT). Коротко говоря, GBRT основан на деревьях решений, в котором создается прогностическая модель в форме ансамбля деревьев. Ансамбль деревьев создается ступенчатым способом. Каждое последующее дерево решений в ансамбле деревьев решений сосредоточено на обучении на основе тех итераций в предыдущем дереве решений, которые были "слабыми моделями" в предыдущей(их) итерации(ях) в ансамбле деревьев решений (т.е. теми, которые связаны с маловероятным прогнозом / высокой вероятностью ошибки). Бустинг представляет собой способ, нацеленный на улучшение качества прогнозирования MLA. В этом сценарии, вместо того, чтобы полагаться на прогноз одного обученного алгоритма (например, одного дерева решений) система использует несколько обученных алгоритмов (т.е. ансамбль деревьев решений) и принимает окончательное решение на основе множества прогнозируемых результатов этих алгоритмов.
[0091] В бустинге деревьев решений, первый MLA 320 сначала создает первое дерево, затем второе, что улучшает прогноз результата, полученного от первого дерева, а затем третье дерево, которое улучшает прогноз результата, полученного от первых двух деревьев, и так далее. Таким образом, первый MLA 320 в некотором смысле создает ансамбль деревьев решений, где каждое последующее дерево становится лучше предыдущего, конкретно сосредотачиваясь на слабых моделях из предыдущих итераций деревьев решений. Другими словами, каждое дерево создается на одном и том же обучающем наборе обучающих объектов, и, тем не менее, обучающие объекты, в которых первое дерево совершает "ошибки" в прогнозировании, являются приоритетными для второго дерева и т.д. Эти "сильные" обучающие объекты (те, которые на предыдущих итерациях деревьев решений были спрогнозированы менее точно), получают более высокие весовые коэффициенты, чем те, для которых были получены удовлетворительные прогнозы.
[0092] Первый ML А 320 может, таким образом, использоваться для классификации и/или регрессии и/или ранжирования сервером 210 поисковой системы. Первый MLA 320 может быть главным алгоритмом ранжирования сервера 210 поисковой системы или быть часть алгоритма ранжирования сервера 210 поисковой системы.
[0093] Второй MLA 340 может выполнять модифицированную модель DSSM (Deep Structured Semantic Model) 350. В общем случае, целью второго MLA 340 является обогащение факторов документа, например, факторов, которые могут использовать первый MLA 320 для ранжирования документов на основе оценки релевантности. Второй MLA 340 выполнен с возможностью тренировать модифицированный DSSM 350 по меньшей мере на поисковом запросе и заголовке документа. Модифицированный DSSM 350 в общем случае получает в качестве ввода словесные униграммы (целые слова), словесные биграммы (пары слов) и словесные триграммы (последовательность трех слов). В некоторых вариантах осуществления настоящей технологии, модифицированная DSSM 350 может также получать в виде ввода словесные N-граммы, где n превышает 3. Модифицированный DSSM 350 также обучается на параметрах пользовательских взаимодействий, таких как, без установления ограничений: клик/отсутствие клика, остановка сессии, число уникальных кликов за сессию, кликабельность и т.д. Вывод второго MLA 340 может использоваться как ввод для первого MLA 320.
[0094] Третий MLA 360 выполнен с возможностью создавать аннотации для документов, которые могут использоваться как ввод по меньшей мере одним из первого MLA 320, второго MLA 340 и второго MLA 380. В настоящем варианте осуществления технологии, аннотации могут использоваться для обучения по меньшей мере одного из первого MLA 320, второго MLA 340 и четвертого MLA 380 или может напрямую использоваться как факторы по меньшей мере одним из первого MLA 320 и четвертого MLA 380. Третий MLA 360 может создавать аннотации в форме векторов аннотации, которые могут использоваться модифицированным DSSM 350 второго MLA 340 и четвертым MLA 380, например, для сопоставления запросов и документов, для сравнения запросов и документов, и для создания прогнозов пользовательского взаимодействия с данным документом.
[0095] Вектор аннотации, который связан с документом, может в общем случае включать в себя: соответствующий поисковый запрос, который был использован для получения доступа к соответствующему документу на сервере 210 поисковой системы и по меньшей мере одному соответствующему параметру пользовательского взаимодействия (указывающему на пользовательское взаимодействие с документом в ответ на поисковый запрос). В некоторых вариантах осуществления технологии, вектор аннотации может далее включать в себя множество факторов запроса соответствующего поискового запроса, причем множество факторов запроса по меньшей мере частично указывают на лингвистические факторы соответствующего поискового запроса. Лингвистические факторы могут включать в себя семантические факторы запроса, грамматические факторы запроса и лексические факторы запроса. Таким образом, документ может быть связан с одним или несколькими векторами аннотации.
[0096] Четвертый MLA 380 может в общем случае быть выполнен с возможностью сравнивать поисковые запросы части пары поисковых запросов, и создавать параметры сходства, которые указывают на уровень сходства между запросами в паре. Четвертый MLA 380, после обучения, может также быть выполнен с возможностью определять прошлый запрос, который аналогичен текущему введенному запросу, на основе, по меньшей мере, анализа сходства прошлого запроса и текущего введенного запроса.
[0097] Четвертый MLA 380 может обучаться на наборе обучающих объектов для изучения отношений между запросами из пары и параметра сходства, который был создан на основе аналогичных поисковых результатов, полученных в ответ на запросы и соответствующие параметры пользовательских взаимодействий. В качестве неограничивающего примера, четвертый MLA 380 может использовать текстовое содержимое и факторы запросов, которые являются частью пары для установления отношений между запроса и параметром сходства. После обучения, четвертый MLA 380 может далее быть способен выбирать аналогичный запрос, когда ему предоставляются новый, ранее не виденный запрос, и прогнозировать параметр сходства, который может быть использован как фактор первым MLA 320 и/или вторым MLA 340. В представленных вариантах осуществления настоящей технологии, четвертый MLA 380 может быть реализован как нейронная сеть. В некоторых вариантах осуществления настоящей технологии, третий MLA 360 и четвертый MLA 380 могут быть реализованы как единый MLA.
[0098] Как четвертый MLA 380 обучается и используется будет описано далее более подробно со ссылкой на Фиг. 3-7.
[0099] На Фиг. 3, представлена схематическая диаграмма процедуры 400 создания обучающего набора, выполненной в соответствии с неограничивающими вариантами осуществления настоящей технологии. Процедура создания обучающего набора 400 может выполняться обучающим сервером 230. Целью процедуры 400 создания обучающего набора является создание набора обучающих объектов, которые могут быть использованы для обучения четвертого MLA 380.
[00100] Процедура 400 создания обучающего набора включает в себя агрегатор 420, устройство 440 создания вектора запроса и устройство 460 создания параметра сходства.
[00101] Агрегатор 420 может в общем случае быть выполнен с возможностью извлекать, агрегировать, отфильтровывать и связывать друг с другом запросы, документы и параметры пользовательского взаимодействия.
[00102] Агрегатор 420 может извлекать, из журнала 216 запросов базы 212 данных поискового журнала сервера 210 поисковой системы, указания на множество поисковых запросов 402. Указание на множество поисковых запросов 402 может включать в себя заранее определенное число поисковых запросов. В некоторых вариантах осуществления настоящей технологии, каждый поисковый запрос 404 в указании на множество поисковых запросов 402 может быть ссылкой на поисковый запрос, числовое представление поискового запроса или действительный поисковый запрос. В других вариантах осуществления настоящей технологии, каждый поисковый запрос 404 в указании на множество поисковых запросов 402 может быть вектором, включающим в себя поисковый запрос и факторы поискового запроса. Число поисковых запросов 404 в указании из множества поисковых запросов 402 никак не ограничено и зависит от того, как реализован четвертый MLA 380/ В качестве неограничивающего примера, указание на множество поисковых запросов 402 может включать в себя 10000 наиболее популярных поисковых запросов, введенных в сервер 210 поисковой системы.
[00103] В некоторых альтернативных вариантах осуществления настоящей технологии, поисковые запросы 404 в указании на множество поисковых запросов 402 могут выбираться на основе конкретного критерия, например, без установки ограничений: популярности запросов на сервере 210 поискового системы, лингвистических факторов поисковых запросов 404, соответствующих поисковых результатов, связанных с поисковыми запросам 404 и т.д. В альтернативных вариантах осуществления технологии, поисковые запросы 404 в указании на множество поисковых запросов 402 могут выбираться случайным образом.
[00104] Агрегатор 420 может извлекать из журнала 216 запросов базы 212 данных поискового журнала сервера 210 поисковой системы, указание на множество поисковых результатов 406, причем указание на множество поисковых результатов 406 включает в себя соответствующий набор поисковых результатов 408, связанный соответственно с каждым поисковым запросом 404 из указания на множество поисковых запросов 402. Число поисковых результатов в соответствующем наборе поисковых результатов 408 может быть заранее определено, например, соответствующий набор поисковых результатов 408 может включать в себя только 100 верхних поисковых результатов, полученных в ответ на соответствующий поисковый запрос 404.
[00105] Агрегатор 420 может извлекать, из журнала 218 пользовательских взаимодействий базы 212 данных поискового журнала сервера 210 поисковой системы, указания на множество параметров 410 пользовательского взаимодействия. Указание на множество параметров 410 пользовательского взаимодействия включает в себя множество соответствующих наборов параметров 412 пользовательских взаимодействий, причем каждый соответствующий набор параметров 412 пользовательских взаимодействий соответствует набору поисковых результатов 408, где данный поисковый результат из соответствующего набора поисковых результатов 408 связан с одним или несколькими параметрами пользовательского взаимодействия из соответствующего набора параметров 412 пользовательского взаимодействия. В общем случае, каждый из параметров пользовательского взаимодействия из каждого соответствующего набора параметров 412 пользовательского взаимодействия может указывать на пользовательское поведение одного или нескольких пользователей после ввода соответствующего поискового запроса 404 в сервер 210 поисковой системы, и после нажатия на один или несколько поисковых результатов в соответствующем наборе поисковых результатов 408 во время поисковой сессии на сервере 210 поисковой системы, в качестве примера, с помощью одного из первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140.
[00106] В некоторых вариантах осуществления настоящей технологии, в зависимости от того, как выполнен четвертый MLA 380, агрегатор 420 может извлекать один или несколько конкретных параметров пользовательского взаимодействия, которые релевантны данной задаче, и не обязательно извлекает все параметры пользовательского взаимодействия, отслеживаемые сервером 220 аналитики и сохраненные в журнале 218 пользовательского взаимодействия базы 212 данных поискового журнала. В качестве неограничивающего примера в представленном варианте осуществления технологии, агрегатор 420 может извлекать соответствующее время простоя для каждого поискового результата в соответствующем наборе поисковых результатов 408.
[00107] В общем случае, параметры пользовательского взаимодействия могут быть агрегированными параметрами пользовательских взаимодействий от множества пользователей, и могут не представлять собой индивидуальные параметры пользовательского взаимодействия. В некоторых вариантах осуществления настоящей технологии, где по меньшей мере один из первого MLA 320, второго MLA 340, третьего MLA 360 и четвертого MLA 380 может быть выполнен с возможностью персонализированного поиска, и агрегатор 420 может агрегировать параметры пользовательского взаимодействия для одного пользователя.
[00108] Агрегатор 420 может далее связывать каждый из соответствующих поисковых запросов 404 с соответствующим набором поисковых результатов 408 и соответствующим набором параметров 412 пользовательского взаимодействия, и выводить набор соответствующих результатов и параметров 430 пользовательского взаимодействия. Набор соответствующих результатов и параметров 430 пользовательского взаимодействия включает в себя множество векторов соответствующих результатов и параметров 432 пользовательского взаимодействия. В некоторых вариантах осуществления настоящей технологии, каждый из соответствующих поисковых запросов 404 с соответствующим набором поисковых результатов 408 и соответствующим набором параметров 412 пользовательского взаимодействия может быть уже взаимосвязан в форме набора связанных результатов и параметров 430 пользовательского взаимодействия в журнале базы 212 данных поискового журнала сервера поисковой системы.
[00109] Устройство 440 создания вектора запроса может получать в качестве ввода набор связанных результатов и параметров 430 пользовательского взаимодействия для вывода множества векторов 450 запроса, соответствующих каждому из набора связанных результатов и параметров 430 пользовательского взаимодействия.
[00110] В общем случае, целью устройства 440 создания вектора запроса является создание соответствующего вектора 452 для каждого соответствующего набора поисковых результатов 408 и параметров 430 пользовательского взаимодействия, полученных в ответ на соответствующий поисковый запрос 404.
[00111] Способ, в соответствии с которым представлен каждый соответствующий вектор 452 запроса, никак не ограничен, и в общем случае целью соответствующего вектора 452 запроса является включении информации о поисковых результатах и параметрах пользовательского взаимодействия, полученной в ответ на запрос в векторном виде, таким образом, чтобы его можно было сравнивать с другим соответствующим векторов, и чтобы можно было оценить сходство между двумя векторами запроса.
[00112] В настоящем варианте осуществления технологии, каждый ряд и колонка соответствующего вектора 452 запроса, связанного с соответствующим поисковым запросом 404, могут соответствовать соответствующему поисковому результату из соответствующего набора поисковых запросов 408, и каждый элемент может соответствовать наличию параметру пользовательского взаимодействия из соответствующего набора параметров 412 пользовательских взаимодействий, например, элемент может быть равен 1, если параметр пользовательского взаимодействия есть, или параметр пользовательского взаимодействия находится выше заранее определенного порога, и равен 0, если параметр пользовательского взаимодействия отсутствует или если параметр пользовательского взаимодействия находится ниже заранее определенного порога. В качестве примера, если время простоя для соответствующего поискового результата есть, элемент может быть равен 1, а если время простоя отсутствует, элемент может быть равен 0. В альтернативных вариантах осуществления технологии, каждый соответствующий вектор 452 запроса может включать в себя значение каждого параметра пользовательского взаимодействия.
[00113] В некоторых вариантах осуществления технологии, когда более одного параметра пользовательского взаимодействия учитывается для поискового результата, каждый соответствующий вектор 452 запрос может быть матрицей или может быть более одного соответствующего вектора 452 запроса для соответствующего поискового запроса 404 (каждый из которых соответствует различным параметрам пользовательского взаимодействия), который может быть связан с каждым из соответствующего набора связанных результатов и параметров 432 пользовательского взаимодействия.
[00114] Устройство 440 создания вектора запроса может далее выводить множество векторов 450 запроса.
[00115] Устройство 460 создания параметра сходства может получать в качестве ввода множество векторов 450 запроса для вывода набора кортежей (машем.) 470 сходства, причем каждый кортеж 472 в наборе кортежей 370 сходства включает пару запросов, и соответствующий параметр сходства указывает на уровень сходства между двумя запросами в паре запросов.
[00116] В общем случае, целью устройства 460 создания параметров сходства является вычисление, для каждой возможной пары запросов в указании на множество поисковых запросов 402, соответствующего параметра сходства. Соответствующий параметр сходства указывает на уровень сходства между запросами, включенными в пару запросов, на основе (i) сходного поискового результата, полученного в ответ на запросы из пары и, (ii) пользовательских взаимодействий с соответствующими сходными поисковыми результатами.
[00117] В качестве неограничивающего примера, в настоящем варианте осуществления технологии, каждый соответствующий параметр сходства для соответствующей пары запросов может быть получен путем выполнения скалярного умножения соответствующих векторов запроса, связанных с соответствующими запросами в паре. Таким образом, соответствующий параметр сходства может напрямую указывать на сходство между запросами, например, параметр сходства 10 может указывать на то, что два поисковых запроса обладают по меньшей мере 10 сходными результатами, и что 10 сходных результатов обладают параметром пользовательского взаимодействия, например, временем простоя. В некоторых вариантах осуществления настоящей технологии, соответствующий параметр сходства может быть относительным, например, если есть 10 сходных результатов, которые обладают временем простоя из общего количества 20 результатов, параметр сходства может составлять 10/20 = 0,5 или 50%. В некоторых вариантах осуществления настоящей технологии, параметр сходства может быть взвешен на основе другого критерия.
[00118] В тех вариантах осуществления технологии, где более одного параметра пользовательского взаимодействия может быть связано с каждым поисковым результатом, может быть более одного соответствующего параметра сходства в кортеже 472 для каждой пары (каждый соответствует различным параметрам пользовательского взаимодействия) или соответствующий параметр сходства в кортеже 472 может быть единственным числом, которое содержит информацию об одном или нескольких параметрах пользовательского взаимодействия.
[00119] В альтернативных вариантах осуществления технологии, другие известные в данной области техники способы могут использоваться для оценки сходства между запросами, например, без установления ограничений, коэффициент Отиаи, двудольные графы и коэффициент корреляции Пирсона.
[00120] Устройство 460 создания параметра сходства может далее выводить набор кортежей 470 сходства. Набор кортежей 470 сходства включает в себя кортеж 472 для каждой возможной пары поисковых запросов, причем каждый кортеж 472 представлен в форме <qi, qj, Sij>, и кортеж 472 включает в себя указание на первый запрос qi из пары, указание на второй запрос qj из пары и параметр Sij сходства между первым запросом qi и вторым запросом qj. Таким образом, соответствующий параметр сходства может представлять собой метку соответствующей пары поисковых запросов.
[00121] Набор кортежей 470 сходства может сохранять в обучающей базе 323 данных обучающего сервера 230. В качестве неограничивающего примера, каждый соответствующий кортеж 472 может сохраняться как обучающий объект из набора обучающих объектов (не показано) в обучающей базе 232 данных обучающего сервера 230.
[00122] На Фиг. 4 представлена схематическая диаграмма процедуры 500 обучения четвертого MLA 380, выполненная в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00123] В представленном неограничивающем варианте осуществления технологии, четвертый MLA 380 является нейронной сетью, которая обладает входным слоем 510, множеством скрытых слоев 520 и выходным слоем 530.
[00124] Четвертый MLA 380 может получать в качестве ввода набор кортежей 470 сходства.
[00125] В общем случае, как было объяснено ранее, целью четвертого MLA 380 является обучение, на предоставленном наборе кортежей 470 сходства, где каждый кортеж 472 включает в себя запросы из пары запросов и связанные параметры сходства, узнаванию запросов, которые могут быть сходны, без предыдущего просмотра (например, в обучающем примере) по меньшей мере одного запроса из пары, и вычислению параметров сходства.
[00126] Входной слой 510 может получать в качестве ввода кортеж 472 из набора кортежей 470 сходства. В некоторых вариантах осуществления настоящей технологии, каждый кортеж 472 из набора кортежей 470 сходства может быть разделен на множество входов: первый запрос, второй запрос, пару запросов, включающую в себя первый и второй запрос, и параметр сходства между первым и вторым запросами. В общем случае, параметр сходства может представлять собой метку, связанную с парой запросов.
[00127] Четвертый MLA 380 может быть выполнен с возможностью изучать множество факторов каждого запроса во время фазы обучения. Четвертый MLA 380 может учитывать, в качестве неограничивающего примера, семантические факторы запроса, грамматические факторы запроса и лексические факторы запроса. Четвертый MLA 380 может либо создавать факторы или извлекать факторы из базы данных факторов (не показано).
[00128] В качестве другого неограничивающего примера, четвертый MLA 380 может использовать word2vec и модель "набор слов" (bag-of-words) для анализа вхождений запросов из пары запросов в различные документы, и создавать свою модель на основе вхождений запросов и параметра сходства.
[00129] Четвертый MLA 380 может, таким образом, создавать модель путем создания взвешенного соединения нейронов во множестве скрытых слоев 520, что может быть использовано для вычисления параметра сходства между двумя запросами.
[00130] На Фиг. 5 показана блок-схема фазы 600 использования, которая выполняется четвертым MLA 380 обучающего сервера 230, представленная в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00131] Фаза 600 использования, которая выполняется четвертым MLA 380, включает в себя первый агрегатор 620 и второе устройство 640 создания параметра сходства.
[00132] Первый агрегатор 620 может в общем случае быть выполнен с возможностью получать новый запрос и извлекать множество запросов 610.
[00133] Новый запрос 605 в общем случае является запросом, который четвертый MLA 380 (или другие MLA) раньше не видели, т.е. четвертый MLA 380 ранее не обучался на новом запросе 605. В некоторых вариантах осуществления технологии, четвертый MLA 380 мог видеть термины нового запроса 605. Четвертый MLA 380 может также быть выполнен с возможностью вычислять и/или извлекать факторы нового запроса 605.
[00134] Первый агрегатор 620 четвертого MLA 380 может извлекать множество прошлых запросов 610 из журнала 216 запросов базы 212 данных поискового журнала сервера 210 поисковой системы. В общем случае, множество прошлых запросов 610 могло быть просмотрено раньше четвертым MLA 380 во время фазы обучения или предыдущей фазы использования.
[00135] Четвертый MLA 380 может вычислять соответствующий параметр 627 сходства между каждым из прошлых запросов 612 из множества прошлых запросов 610 и новым запросом 605. Первый агрегатор 620 может выводить набор кортежей 622 сходства, причем набор кортежей 622 сходства включает в себя соответствующий кортеж 625 для каждой пары запросов, и кортеж 625 включает в себя (1) новый запрос 605, (2) соответствующий прошлый запрос 612, и (3) соответствующий параметр сходства между новым запросом 605 и соответствующим прошлым запросом 612.
[00136] Второе устройство 640 создания параметра сходства четвертого MLA 380 может получать в качестве ввода набор кортежей 622 сходства и выбирать кортеж 625, связанный с прошлым запросом (не показано), обладающим наиболее высоким параметром сходства, который указывает на то, что прошлый запрос считается наиболее близким к новому запросу 605, что было сочтено четвертым MLA 380.
[00137] Второе устройство 640 создания параметра сходства четвертого ML А 380 может получать набор поисковых результатов 630, связанных с данным прошлым запросом, который обладает наиболее высоким параметром сходства. Число поисковых запросов в наборе поисковых запросов 630 может быть заранее определено, например, 100 верхних поисковых результатов, полученных в ответ на данный прошлый запрос, обладающий наиболее высоким параметром сходства. Каждый соответствующий поисковый результат 632 из набора поисковых результатов 630 может быть связан с одним или несколькими соответствующими векторами 634 аннотации, которые были ранее созданы третьим MLA 360. Каждый соответствующий вектор 634 аннотации может в общем случае включать в себя: соответствующий поисковый запрос, который был использован для получения доступа к соответствующему поисковому результату 632 на сервере 210 поисковой системы и по меньшей мере одному соответствующему параметру пользовательского взаимодействия. В некоторых вариантах осуществления технологии, соответствующий вектор 634 аннотации может далее включать в себя множество факторов запроса соответствующего поискового запроса, причем множество факторов запроса по меньшей мере частично указывают на лингвистические факторы соответствующего поискового запроса 404. Лингвистические факторы могут включать в себя семантические факторы запроса, грамматические факторы запроса и лексические факторы запроса.
[00138] Второе устройство 640 создания параметра сходства четвертого ML А 380 может далее сравнивать соответствующий второй параметр 652 сходства для каждого вектора 634 аннотации, связанного с соответствующим поисковым результатом 632 из набора поисковых результатов 630, и выводить набор.
[00139] Соответствующий второй параметр 652 сходства может быть вычислен на основе (1) по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующий вектор 634 аннотации, и (2) соответствующего параметра сходства, вычисленного по сходству между новым запросом 605 и соответствующим вектором 634 аннотации, который включает в себя соответствующий запрос, который был использован для получения доступа к соответствующему поисковому результату 632, связанному с соответствующим вектором 634 аннотации. В некоторых вариантах осуществления технологии, соответствующий второй параметр 652 сходства может быть выполнен путем умножения по меньшей мере одного параметра пользовательского взаимодействия с соответствующим параметром сходства между новым запросом 605 и соответствующим запросом, включенным в соответствующий вектор 634 аннотации. В тех вариантах осуществления технологии, где может быть более одного соответствующего вектора 634 аннотации для соответствующего поискового результата 632, второй соответствующий параметр 652 сходства может быть вычислен для каждого из множества вектором 634 аннотации, и вторые соответствующие параметры 652 сходства могут представлять собой, в качестве примера, усредненный или наиболее высокий из вторых соответствующих параметров 652 сходства может быть выбран для соответствующего поискового результата 632.
[00140] Соответствующий второй параметр 652 сходства может, следовательно, представлять собой параметр, соединяющий новый запрос 605 и соответствующий поисковый результат 632, связанный с прошлым запросом, который по большей части сходный с новым запросом 605, и может указывать на уровень близости между новым запросом 605 и каждым соответствующим поисковым результатом 632 из набора поисковых результатов 630, связанных с прошлым запросом. Соответствующий второй параметр 652 сходства для соответствующего поискового результата 632 может также интерпретироваться как спрогнозированный параметр пользовательского взаимодействия, который взвешен с помощью параметра сходства между новым запросом 605 и соответствующим запросом, включенным в соответствующий вектор 634 аннотации.
[00141] Второе устройство 640 создания параметра сходства четвертого MLA 380 может далее выводить набор факторов 650 ранжирования, который включает в себя некоторые или все из: множества кортежей, которые включают в себя указание на новый запрос 605, и соответствующий поисковый результат 632 и/или соответствующий вектор 634 аннотаций, и соответствующий второй параметр 652 сходства.
[00142] Таким образом, набор факторов 650 ранжирования может быть связан, например, в обучающей базе 232 данных с новым запросом 605. Набор факторов 650 ранжирования может быть использован первым MLA 320 в качестве факторов для ранжирования поисковых результатов (включая набор поисковых результатов 630) при получении нового запроса 605.
[00143] В некоторых вариантах осуществления настоящей технологии, новый запрос 605 может быть связан только с поисковыми результатами, которые обладают соответствующим вторым параметром 652 сходства, находящимся выше заранее определенного порога.
[00144] На Фиг. 6 представлена блок-схема способа 700 создания набора обучающих объектов и обучения четвертого MLA 380. Способ 700 выполняется обучающим сервером 230.
[00145] Способ 700 может начинаться на этапе 702.
[00146] ЭТАП 702: извлечение из базы данных поискового журнала множества поисковых запросов, которое было введено на сервер поисковой системы, причем множество поисковых запросов связано с соответствующим набором поисковых результатов, и каждый соответствующий поисковый результат соответствующего набора поисковых результатов связан с соответствующим параметром пользовательского взаимодействия.
[00147] На этапе 702 агрегатор 420 обучающего сервера 230 может извлекать, из журнала 216 запросов базы 212 данных поискового журнала, указание на множество поисковых запросов 402, которые были введены в сервер 210 поисковой системы. Агрегатор 420 может извлекать из журнала 216 запросов базы 212 данных поискового журнала указание на множество поисковых результатов 406, причем указание на множество поисковых результатов 406 включает в себя соответствующий набор поисковых результатов 408 для каждого поискового запроса 404 из указания на множество поисковых запросов 402. Агрегатор 420 может также извлекать из журнала 218 пользовательского взаимодействия 212 данных поискового журнала указание на множество параметров 410 пользовательского взаимодействия, причем указание на множество параметров 410 пользовательского взаимодействия включает в себя соответствующий набор параметров 412 пользовательского взаимодействия для каждого из соответствующего набора поисковых запросов 408. Соответствующий набор параметров 412 пользовательского взаимодействия может включать в себя один или несколько соответствующих параметров пользовательского взаимодействия для соответствующего поискового результата в соответствующем наборе поисковых результатов 408, связанном с соответствующим поисковым запросом 404. Агрегатор 420 может далее связывать каждый из соответствующих поисковых запросов 404 с соответствующим набором поисковых результатов 408 и соответствующим набором параметров 412 пользовательского взаимодействия, и выводить соответствующий набор связанных результатов и параметров 430 пользовательского взаимодействия. В некоторых вариантах осуществления настоящей технологии, каждый из соответствующих поисковых запросов 404, соответствующий набор поисковых результатов 408 и соответствующий набор параметров 412 пользовательского взаимодействия могут быть уже взаимосвязаны в базе 212 данных поискового журнала, и агрегатор 420 может напрямую извлекать соответствующий набор связанных результатов и параметров 432 пользовательского взаимодействия для каждого поискового запроса 404 из поискового журнала базы 212 данных.
[00148] Способ 700 далее может перейти к выполнению этапа 704.
[00149] ЭТАП 704: вычисление, для каждого запроса из множества поисковых запросов, соответствующего вектора запроса на основе соответствующего параметра пользовательского взаимодействия, связанного с каждым поисковым результатом из соответствующего набора поисковых результатов.
[00150] На этапе 704 устройство 440 создания вектора запроса может вычислять для каждого поискового запроса 404 в указании на множество поисковых запросов 402, соответствующий вектор 452 запроса на основе одного или нескольких параметров пользовательского взаимодействий из набора параметров 412 пользовательского взаимодействия, связанных с каждым поисковым результатом из соответствующего набора поисковых результатов 408. Каждый вектор 452 запроса может указывать на наличие одного или нескольких параметров пользовательского взаимодействия в отношении поисковых результатов из соответствующего набора поисковых результатов 408, полученных в ответ на соответствующий поисковый запрос 404. Устройство 440 создания вектора запроса может выводить множество векторов 450 запроса.
[00151] Способ 700 далее может перейти к выполнению этапа 706.
[00152] ЭТАП 706: вычисление, для каждой возможной пары запросов из множества поисковых запросов, на основе соответствующих векторов запроса каждого запроса из пары запросов, соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами в паре запросов.
[00153] На этапе 706, устройство 460 создания параметра сходства может осуществлять вычисление, для каждой возможной пары запросов из указания на множество поисковых запросов 402, на основе соответствующих векторов 452 запроса каждого поискового запроса 404 из пары запросов, соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами 404 в паре запросов. В одном варианте осуществления технологии, соответствующий параметр сходства может быть вычислен путем скалярного умножения соответствующих векторов 452 запроса связанном с каждым запросом из пары запросов.
[00154] Способ 700 далее может перейти к выполнению этапа 708.
[00155] ЭТАП 708: создание набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства
[00156] На этапе 708, устройство 460 создания параметра сходства может осуществлять создание набора кортежей 470 сходства, причем кортеж 472 из набора кортежей 470 сходства включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства. Набор кортежей 470 сходства может сохраняться как набор обучающих объектов в обучающей базе 323 данных обучающего сервера 230.
[00157] Способ 700 далее может перейти к выполнению этапа 710.
[00158] ЭТАП 710: обучение MLA на наборе обучающих объектов для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
[00159] На этапе 710, четвертый MLA 380 может быть обучен на наборе 470 сходства для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
[00160] Далее способ 700 завершается.
[00161] На Фиг. 7 показана блок-схема способа 800 для ранжирования поисковых результатов с помощью первого MLA 320, представленная в соответствии с неограничивающими вариантами осуществления настоящей технологии. Способ 800 может выполняться первым MLA 320 и четвертым MLA 380 обучающего сервера 230.
[00162] Способ 800 может начинаться на этапе 802.
[00163] ЭТАП 802: получение нового запроса
[00164] На этапе 802 четвертый MLA 380 может получать новый запрос 605, который является запросом, который не был ранее просмотрен четвертым MLA 380.
[00165] Способ 800 далее может перейти к выполнению этапа 804.
[00166] ЭТАП 804: извлечение из базы данных множества поисковых запросов, которые были введены на сервер поисковой системы
[00167] На этапе 804, четвертый MLA 380 может извлекать, из базы 212 данных поискового журнала сервера 210 поисковой системы, множество запросов 610, которые были введены в сервер 210 поисковой системы.
[00168] Способ 800 далее может перейти к выполнению этапа 806.
[00169] ЭТАП 806: вычисление соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов
[00170] На этапе 806, четвертый MLA 380 может вычислять соответствующий параметр 627 сходства между новым запросом 605 и каждым предыдущим запросом 612 из множества предыдущих запросов 610. Соответствующий параметр 627 сходства может быть основан на текстовых факторах каждого из нового запроса и каждого предыдущего запроса 612 из множества прошлых запросов 610. Четвертый MLA 380 может выводить набор кортежей 622 сходства, и каждый 625 включает в себя новый запрос 605, соответствующий прошлый запрос 612 и соответствующий параметр 627 сходства.
[00171] Способ 800 далее может перейти к выполнению этапа 808.
[00172] ЭТАП 808: выбор из множества поисковых запросов, данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства
[00173] На этапе 808, четвертый MLA 380 может осуществлять выбор из набора кортежей 622 сходства, кортеж 625, связанный с данным прошлым запросом 612, обладающим наиболее высоким соответствующим параметром 627 сходства.
[00174] Способ 800 далее может перейти к выполнению этапа 810.
[00175] ЭТАП 810: извлечение набора поисковых результатов, связанных с данным прошлым запросом, причем каждый поисковый результат из набора поисковых результатов связан с аннотацией, включая:
множество соответствующих поисковых запросов, которые были использованы для получения доступа к соответствующему поисковому результату на сервере поисковой системы
[00176] На этапе 810, четвертый MLA 380 может извлекать набор поисковых результатов 630, связанный с данным прошлым запросом, который обладает наиболее высоким параметром сходства, причем каждый поисковый результат 632 из набора поисковых результатов 630 связан с соответствующим вектором 534 аннотации, который включается в себя: множество соответствующих поисковых запросов, которые были использованы для получения доступа к соответствующему поисковому результату на сервере 210 поисковой системы, и по меньшей мере один соответствующий параметр пользовательского взаимодействия, который указывает на пользовательское поведение с соответствующим поисковым результатом 632 по меньшей мере одним пользователем после ввода по меньшей мере одного соответствующего запроса в сервер поисковой системы. В некоторых вариантах осуществления технологии, соответствующий вектор 634 аннотации может далее включать в себя множество факторов запроса соответствующего поискового запроса в соответствующем векторе 634 аннотации, причем множество факторов запроса по меньшей мере частично указывают на лингвистические факторы соответствующего запроса.
[00177] Способ 800 далее может перейти к выполнению этапа 812.
[00178] ЭТАП 812: вычисление для каждого соответствующего одного из множества соответствующих поисковых запросов, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства
[00179] На этапе 812, четвертый MLA 380 может осуществлять вычисление для каждого соответствующего одного из множества соответствующих поисковых запросов, который был использован для получения доступа к соответствующему поисковому результату 632, соответствующего второго параметра 652 сходства. Соответствующий второй параметр 652 сходства может быть вычислен на основе (1) по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующий вектор 634 аннотации, и (2) соответствующий параметр сходства, вычисленный между новым запросом 605, и соответствующий запрос, который был использован для получения доступа к соответствующему поисковому результату 632, связанному с соответствующим вектором 634 аннотации. В некоторых вариантах осуществления технологии, соответствующий второй параметр 652 сходства может быть выполнен путем умножения по меньшей мере одного параметра пользовательского взаимодействия с соответствующим параметром сходства между новым запросом 605 и соответствующим запросом, включенным в соответствующий вектор 634 аннотации.
[00180] Способ 800 далее может перейти к выполнению этапа 814.
[00181] ЭТАП 814: использование соответствующего второго параметра сходства в качестве фактора ранжирования для ранжирования соответствующих поисковых результатов в качестве поисковых результатов для нового запроса.
[00182] На этапе 814, четвертый MLA 380 может осуществлять использование соответствующего второго параметра сходства в качестве фактора ранжирования для ранжирования соответствующих поисковых результатов 630 в качестве поисковых результатов для нового запроса 605.
[00183] Далее способ 800 завершается.
[00184] Настоящая технология способствует более эффективной обработке приложений для поиска информации, что позволяет сохранить вычислительные ресурсы и время как на клиентских устройствах, так и сервере, путем представления более релевантных результатов пользователями в ответ на запросы.
[00185] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без проявления некоторых технических результатов, а другие варианты могут быть реализованы с проявлением других технических результатов или вовсе без них.
[00186] Некоторые из этих этапов, а также процессы передачи-получения сигнала являются хорошо известными в данной области техники и поэтому для упрощения были опущены в некоторых частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, опто-волоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00187] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
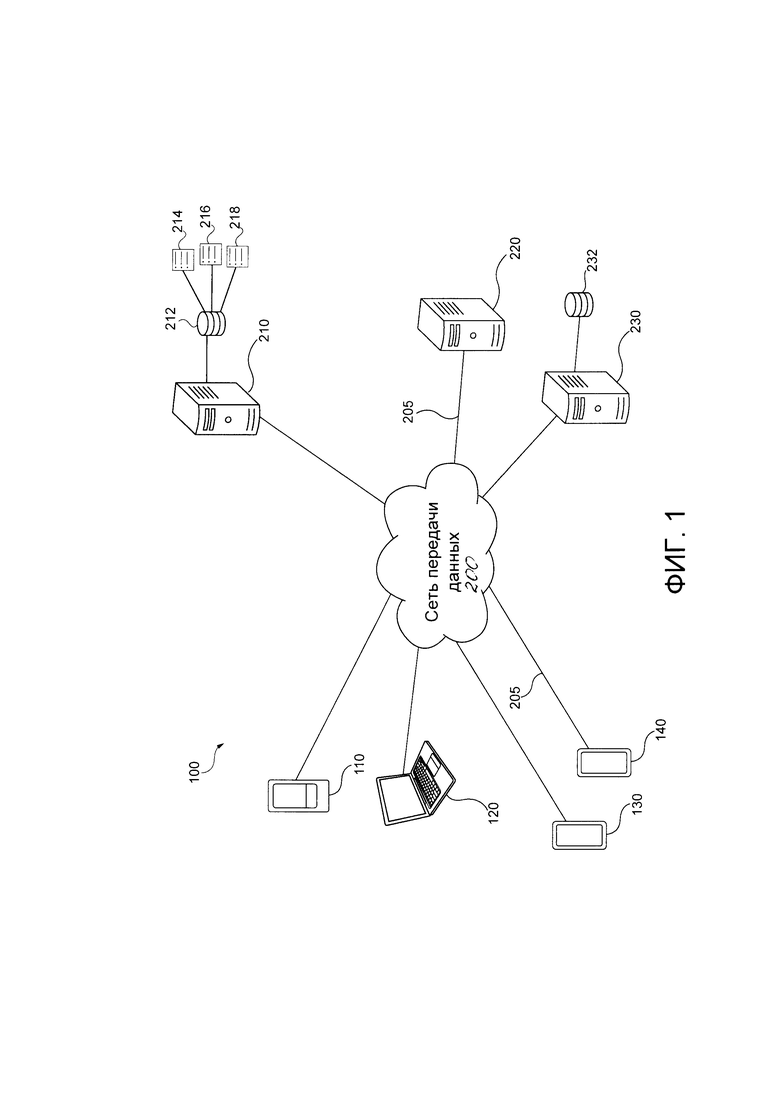
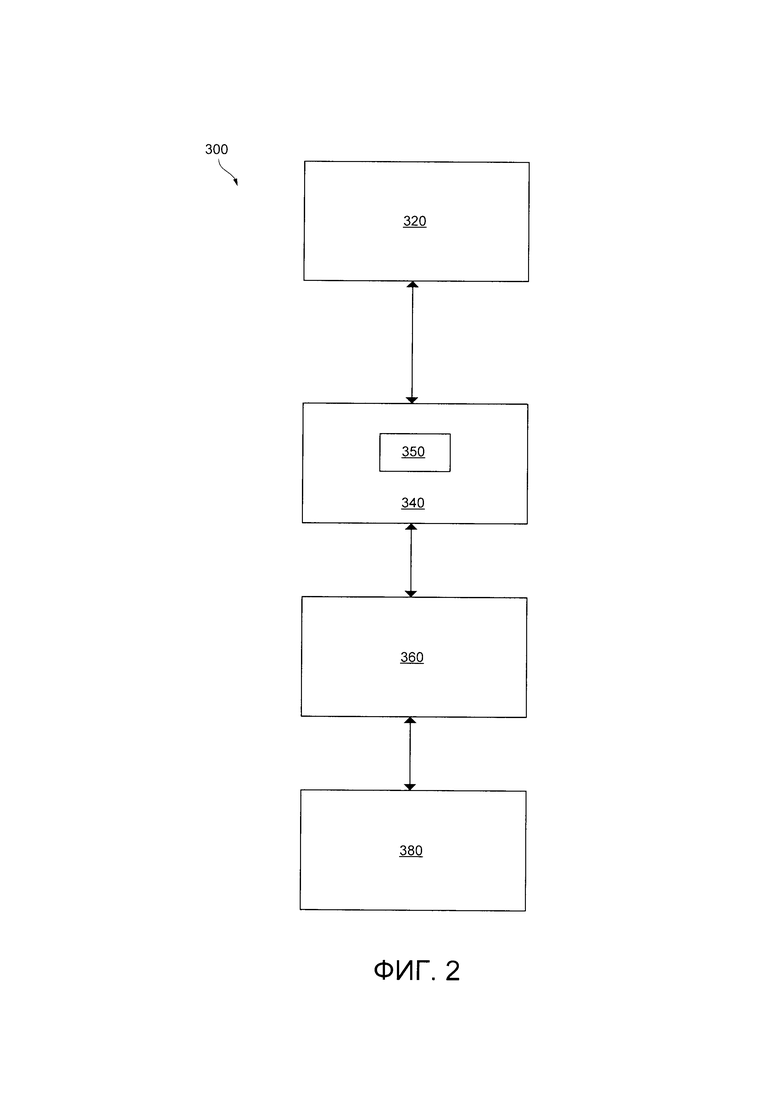
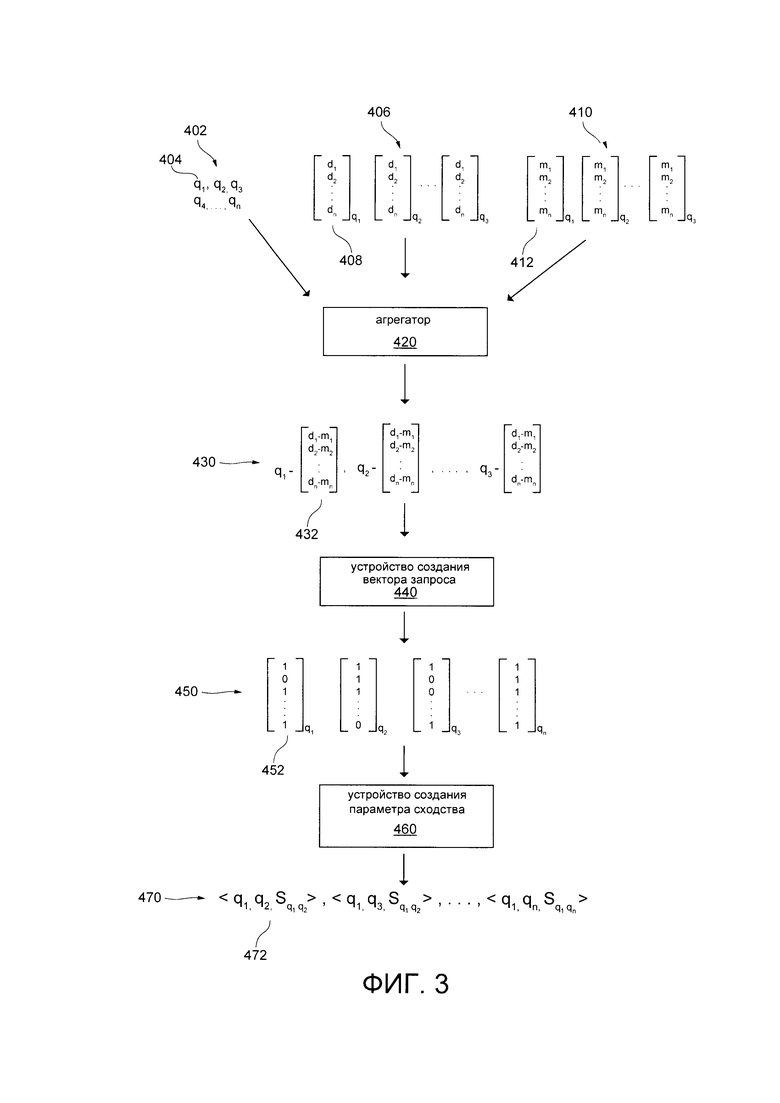
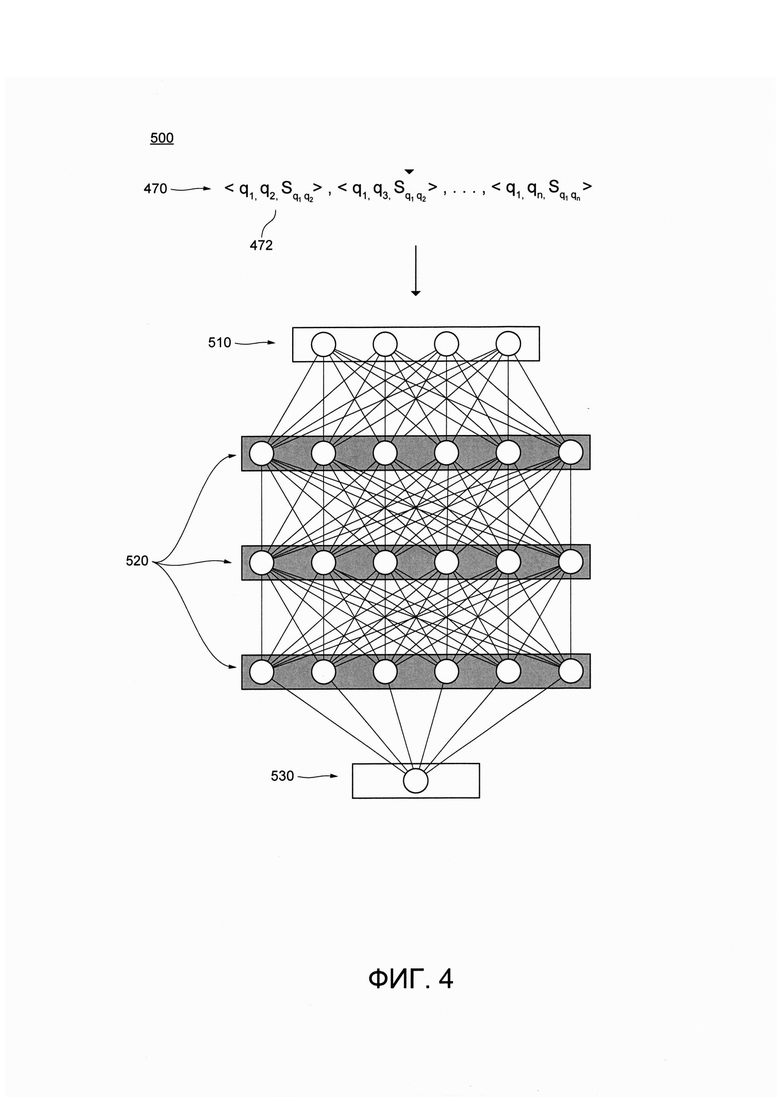
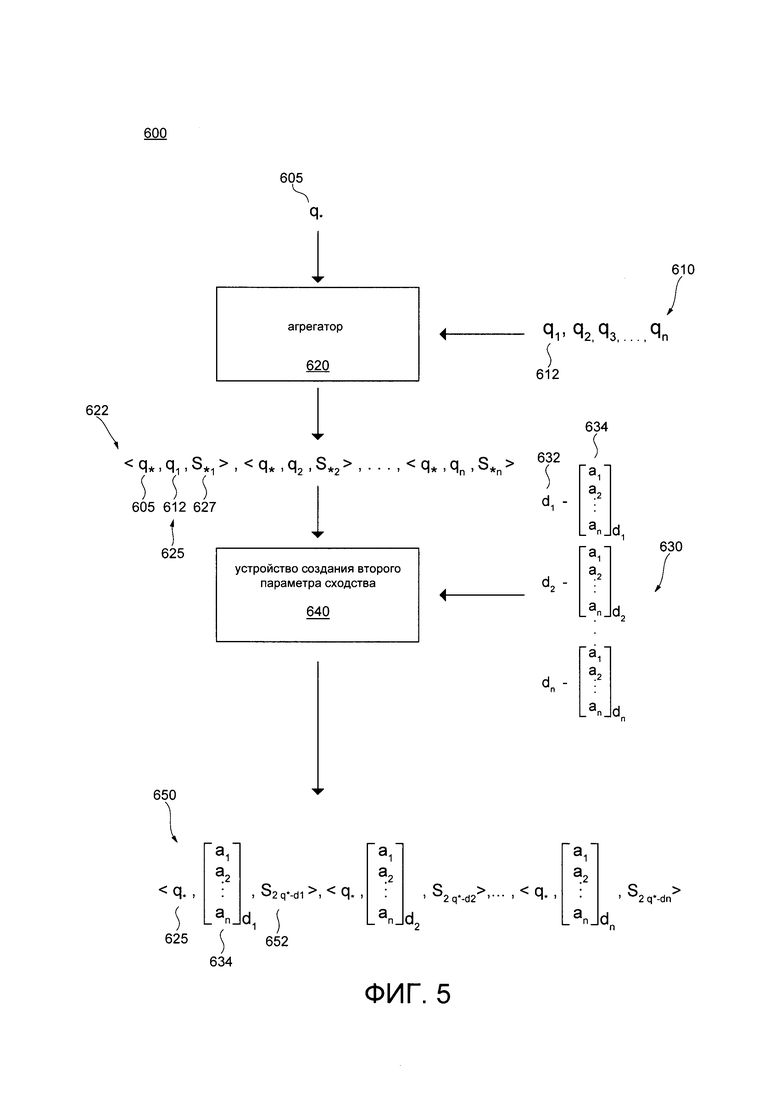
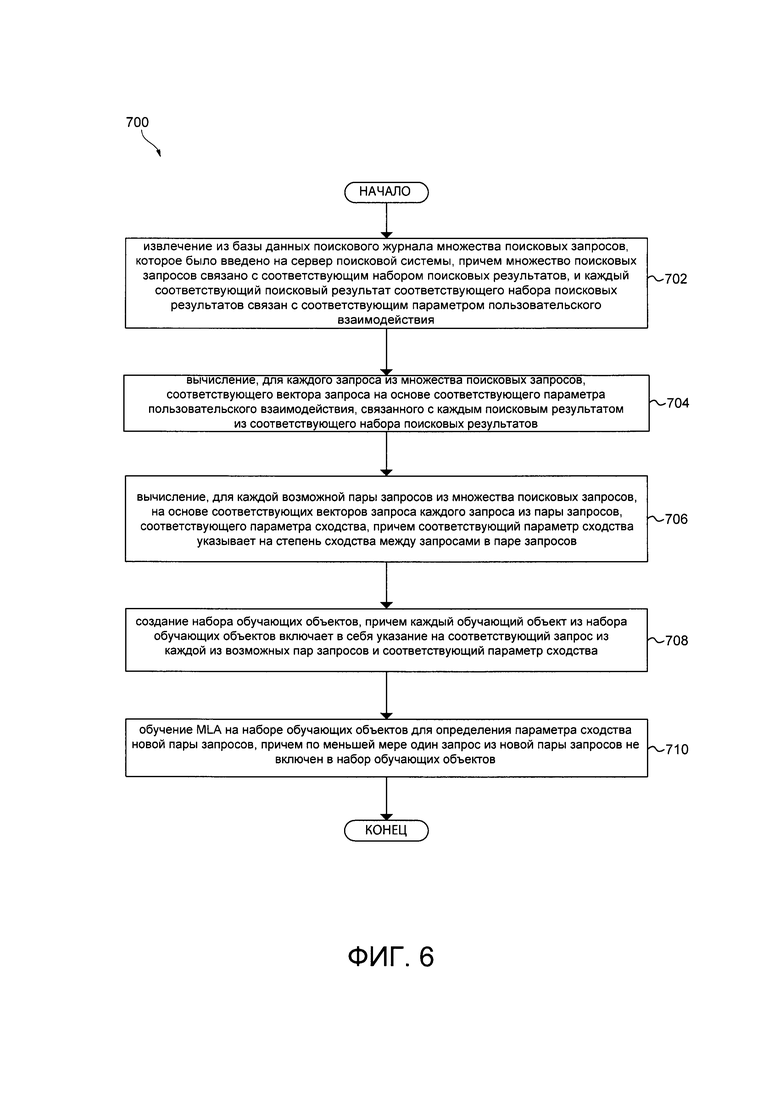
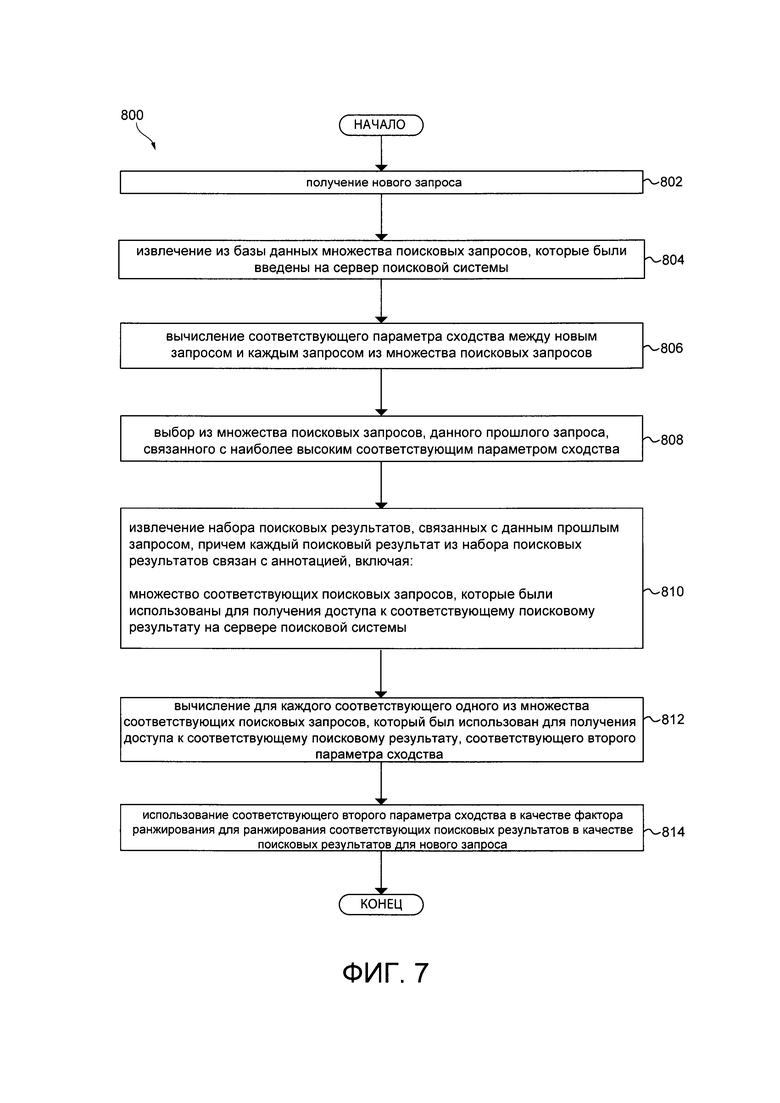
Изобретение относится к средствам ранжирования поисковых результатов. Техническим результатом является повышение эффективности ранжирования поисковых результатов. Способ ранжирования поисковых результатов с помощью алгоритма машинного обучения (MLA), который был обучен определять сходство запросов на основе их текстового содержимого, включает: получение нового запроса, извлечение множества поисковых запросов, вычисление соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов, выбор данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства, извлечение набора поисковых результатов, связанных с данным прошлым запросом, причем каждый из набора поисковых результатов связан с аннотацией, включающей в себя соответствующие поисковые запросы, и вычисление для каждого соответствующего запроса из множества соответствовавших запросов, которые были использованы для получения доступа к соответствующему поисковому результату, второго параметра сходства, и использование соответствующего второго параметра сходства как фактора ранжирования для ранжирования соответствующих поисковых результатов в качестве поисковых результатов для нового запроса. 2 н. и 24 з.п. ф-лы, 7 ил.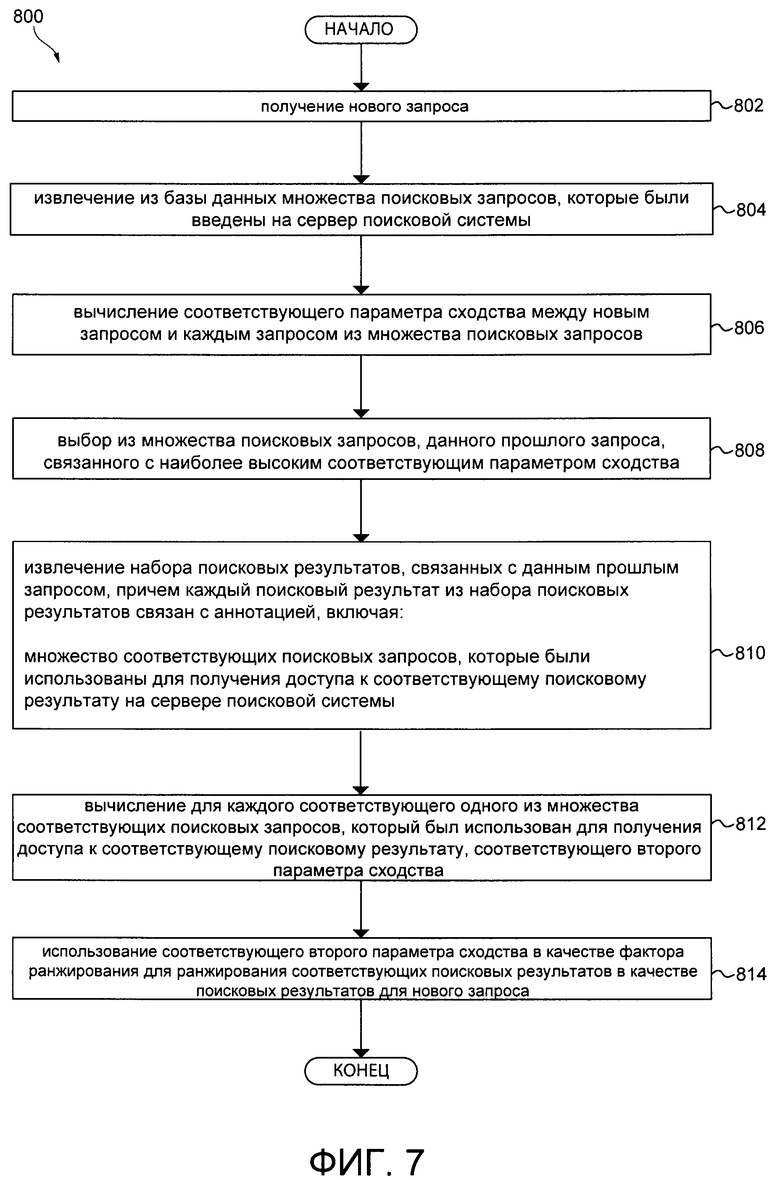
1. Исполняемый на компьютере способ ранжирования поисковых результатов с помощью первого алгоритма машинного обучения, причем способ выполняется сервером, на котором расположен второй алгоритм машинного обучения, который был обучен определять сходство запросов на основе их текстового содержимого, причем способ включает в себя:
получение вторым алгоритмом машинного обучения нового запроса;
извлечение вторым алгоритмом машинного обучения из базы данных поискового журнала документа, который был введен на сервер поисковой системы;
извлечение вторым алгоритмом машинного обучения из базы данных поискового журнала множество поисковых запросов, которые были введены на сервер поисковой системы;
вычисление вторым алгоритмом машинного обучения соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов;
выбор вторым алгоритмом машинного обучения из множества поисковых запросов данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства;
извлечение вторым алгоритмом машинного обучения набора поисковых результатов, связанных с данным прошлым запросом, причем каждый поисковый результат из набора поисковых результатов связан с соответствующей аннотацией, включая:
по меньшей мере один соответствующий поисковый запрос, который был использован для получения доступа к соответствующему поисковому результату на сервере поисковой системы;
вычисление вторым алгоритмом машинного обучения для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства; и
использование соответствующего второго параметра сходства в качестве фактора ранжирования первым алгоритмом машинного обучения для ранжирования связанных поисковых результатов в качестве поисковых результатов для нового запроса.
2. Способ по п. 1, дополнительно включающий в себя:
во время фазы обучения:
извлечение из базы данных поискового журнала множества поисковых запросов, которое было введено на сервер поисковой системы, причем множество поисковых запросов связано с соответствующим набором поисковых результатов, и каждый соответствующий поисковый результат соответствующего набора поисковых результатов связан по меньшей мере с одним соответствующим параметром пользовательского взаимодействия;
вычисление для каждого запроса из множества поисковых запросов соответствующего вектора запроса на основе по меньшей мере одного параметра пользовательского взаимодействия, связанного с каждым поисковым результатом из соответствующего набора поисковых результатов;
вычисление для каждой возможной пары запросов из множества поисковых запросов на основе соответствующих векторов запроса каждого запроса из пары запросов соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами в паре запросов;
создание набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства;
обучение второго алгоритма машинного обучения на наборе обучающих объектов для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
3. Способ по п. 2, в котором соответствующая аннотация дополнительно включает в себя:
по меньшей мере один соответствующий параметр пользовательского взаимодействия, причем по меньшей мере один соответствующий параметр пользовательского взаимодействия указывает на пользовательское поведение с соответствующим поисковым результатом по меньшей мере одного пользователя после ввода по меньшей мере одного соответствующего запроса в сервер поисковой системы.
4. Способ по п. 2, в котором во время фазы обучения соответствующий параметр сходства вычисляется путем использования одного из: скалярного произведения или коэффициента Отиаи.
5. Способ по п. 3, в котором соответствующий второй параметр сходства вычисляется вторым алгоритмом машинного обучения на основе:
соответствующего параметра сходства между новым запросом и по меньшей мере одним соответствующим поисковым запросом, включенным в соответствующую аннотацию; и
по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующую аннотацию.
6. Способ по п. 5, в котором вычисление вторым алгоритмом машинного обучения для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства включает в себя:
перемножение соответствующего параметра сходства и по меньшей мере одного соответствующего параметра пользовательского взаимодействия.
7. Способ по п. 4, в котором обучение второго алгоритма машинного обучения на наборе обучающих объектов для определения параметра сходства новой пары запросов основано по меньшей мере на соответствующем текстовом свойстве каждого запроса из новой пары запросов.
8. Способ по п. 7, в котором второй алгоритм машинного обучения представляет собой нейронную сеть.
9. Способ по п. 8, в котором первым алгоритмом машинного обучения является алгоритм на основе дерева решений.
10. Способ по п. 9, в котором первый алгоритм машинного обучения использует множество дополнительных факторов для ранжирования, и причем соответствующий второй параметр сходства добавляется ко множеству дополнительных факторов для ранжирования.
11. Способ по п. 1, в котором параметр пользовательского взаимодействия является по меньшей мере одним из: кликабельность или время простоя.
12. Способ по п. 3, в котором способ дополнительно включает в себя до этапа получения нового запроса:
создание множества аннотаций, включающих в себя соответствующие аннотации; и
сохранение множества аннотаций в хранилище сервера.
13. Способ по п. 8, в котором создание множества аннотаций выполняется третьим алгоритмом машинного обучения.
14. Система ранжирования поисковых результатов с помощью первого алгоритма машинного обучения, причем система выполняется вторым алгоритмом машинного обучения на системе, и второй алгоритм машинного обучения был обучен определять сходство запросов на основе их текстового содержимого, причем система включает в себя:
процессор;
постоянный машиночитаемый носитель компьютерной информации, содержащий инструкции, процессор при выполнении инструкций, выполнен с возможностью осуществлять:
получение вторым алгоритмом машинного обучения нового запроса;
извлечение вторым алгоритмом машинного обучения из базы данных поискового журнала документа, который был введен на сервер поисковой системы;
извлечение вторым алгоритмом машинного обучения из базы данных поискового журнала множества поисковых запросов, которые были введены на сервер поисковой системы;
вычисление вторым алгоритмом машинного обучения соответствующего параметра сходства между новым запросом и каждым запросом из множества поисковых запросов;
выбор вторым алгоритмом машинного обучения из множества поисковых запросов данного прошлого запроса, связанного с наиболее высоким соответствующим параметром сходства;
извлечение вторым алгоритмом машинного обучения набора поисковых результатов, связанных с данным прошлым запросом, причем каждый поисковый результат из набора поисковых результатов связан с соответствующей аннотацией, включая:
по меньшей мере один соответствующий поисковый запрос, который был использован для получения доступа к соответствующему поисковому результату на сервере поисковой системы;
вычисление вторым алгоритмом машинного обучения для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства; и
использование соответствующего второго параметра сходства в качестве фактора ранжирования первым алгоритмом машинного обучения для ранжирования соответствующих поисковых результатов в качестве поисковых результатов для нового запроса.
15. Система по п. 14, в которой процессор выполнен с дополнительной возможностью осуществлять:
во время фазы обучения:
извлечение из базы данных поискового журнала множества поисковых запросов, которое было введено на сервер поисковой системы, причем множество поисковых запросов связано с соответствующим набором поисковых результатов, и каждый соответствующий поисковый результат соответствующего набора поисковых результатов связан по меньшей мере с одним соответствующим параметром пользовательского взаимодействия;
вычисление для каждого запроса из множества поисковых запросов соответствующего вектора запроса на основе по меньшей мере одного параметра пользовательского взаимодействия, связанного с каждым поисковым результатом из соответствующего набора поисковых результатов;
вычисление для каждой возможной пары запросов из множества поисковых запросов на основе соответствующих векторов запроса каждого запроса из пары запросов соответствующего параметра сходства, причем соответствующий параметр сходства указывает на степень сходства между запросами в паре запросов;
создание набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя указание на соответствующий запрос из каждой из возможных пар запросов и соответствующий параметр сходства;
обучение второго алгоритма машинного обучения на наборе обучающих объектов для определения параметра сходства новой пары запросов, причем по меньшей мере один запрос из новой пары запросов не включен в набор обучающих объектов.
16. Система по п. 14, в которой соответствующая аннотация дополнительно включает в себя:
по меньшей мере один соответствующий параметр пользовательского взаимодействия, причем по меньшей мере один соответствующий параметр пользовательского взаимодействия указывает на пользовательское поведение с соответствующим поисковым результатом по меньшей мере одного пользователя после ввода по меньшей мере одного соответствующего запроса в сервер поисковой системы.
17. Система по п. 15, в которой во время фазы обучения соответствующий параметр сходства вычисляется путем использования одного из: скалярного произведения или коэффициента Отиаи.
18. Система по п. 16, в которой соответствующий второй параметр сходства вычисляется вторым алгоритмом машинного обучения на основе:
соответствующего параметра сходства между новым запросом и по меньшей мере одним соответствующим поисковым запросом, включенным в соответствующую аннотацию; и
по меньшей мере одного соответствующего параметра пользовательского взаимодействия, включенного в соответствующую аннотацию.
19. Система по п. 18, в которой для вычисления вторым алгоритмом машинного обучения для каждого из по меньшей мере одного соответствующего поискового запроса, который был использован для получения доступа к соответствующему поисковому результату, соответствующего второго параметра сходства, процессор выполнен с возможностью осуществлять:
перемножение соответствующего параметра сходства и по меньшей мере одного соответствующего параметра пользовательского взаимодействия.
20. Система по п. 17, в которой обучение второго алгоритма машинного обучения на наборе обучающих объектов для определения параметра сходства новой пары запросов основано по меньшей мере на соответствующем текстовом свойстве каждого запроса из новой пары запросов.
21. Система по п. 20, в которой второй алгоритм машинного обучения является нейронной сетью.
22. Система по п. 21, в которой первый алгоритм машинного обучения реализуется как алгоритм машинного обучения на основе дерева решений.
23. Система по п. 22, в которой первый алгоритм машинного обучения использует множество дополнительных факторов для ранжирования, и причем соответствующий второй параметр сходства добавляется ко множеству дополнительных факторов для ранжирования.
24. Система по п. 14, в которой параметр пользовательского взаимодействия является по меньшей мере одним из: кликабельность или время простоя.
25. Система по п. 16, в которой процессор далее выполнен с возможностью до этапа получения нового запроса осуществлять:
создание множества аннотаций, включающих в себя соответствующие аннотации; и
сохранение множества аннотаций в хранилище системы.
26. Система по п. 21, в которой создание множества векторов аннотации производится с помощью третьего алгоритма машинного обучения.
| US 9009146 B1, 14.04.2015 | |||
| US 8606786 B2, 10.12.2013 | |||
| US 8898156 B2, 25.11.2014 | |||
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКОВОЙ ВЫДАЧИ | 2017 |
|
RU2643466C1 |
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |

