Область техники, к которой относится изобретение
[001] Настоящая технология относится в целом к извлечению информации и, в частности, к способу и системе для расширения запросов с целью ранжирования результатов поиска с использованием алгоритма машинного обучения.
Уровень техники
[001] Алгоритмы машинного обучения (MLA, Machine Learning Algorithm) используются для удовлетворения разнообразных потребностей в компьютерных технологиях. Обычно алгоритмы MLA используются для формирования прогноза, связанного с взаимодействием пользователя и компьютерного устройства. В качестве примера одной из сфер, где требуется такой прогноз, можно привести действия пользователя в отношении контента, доступного в сети Интернет.
[002] Объем информации, доступной посредством различных Интернет-ресурсов, в течение последних нескольких лет увеличивается экспоненциально. Для помощи типичному пользователю в поиске необходимой информации было разработано несколько решений. Одним из примеров таких решений является поисковая система. В качестве примера можно привести поисковые системы GOOGLE™, YANDEX™, YAHOO!™ и т.д. Пользователь может получать доступ к интерфейсу поисковой системы и передавать поисковый запрос, связанный с информацией, которую требуется найти в сети Интернет. В ответ на поисковый запрос поисковая система выдает ранжированный список результатов поиска. Ранжированный список результатов поиска формируется на основе различных алгоритмов ранжирования, применяемых конкретной поисковой системой, используемой пользователем для поиска. Общая цель таких алгоритмов ранжирования заключается в представлении наиболее релевантных результатов поиска в верхней части ранжированного списка, тогда как менее релевантные результаты поиска могут располагаться в ранжированном списке на менее заметных местах (наименее релевантные результаты поиска находятся в нижней части ранжированного списка).
[003] Поисковые системы обычно обеспечивают хороший инструментарий для обработки поискового запроса, когда пользователь заранее знает, что требуется найти. Иными словами, если пользователь заинтересован в получении информации о наиболее популярных местах в Италии (т.е. известна тема поиска) он может отправить поисковый запрос: «Наиболее популярные места в Италии?». В ответ поисковая система выдает ранжированный список Интернет-ресурсов, потенциально релевантных поисковому запросу. Пользователь может просмотреть ранжированный список результатов поиска, чтобы получить требуемую информацию, касающуюся мест для посещения в Италии. Если пользователь по какой-либо причине не удовлетворен полученными результатами поиска, он может выполнить повторный поиск, например, с более точным поисковым запросом, таким как «Наиболее популярные места в Италии летом?», «Наиболее популярные места на юге Италии?», «Наиболее популярные места для романтического отпуска в Италии?».
[004] В примере поисковой системы для формирования ранжированных результатов поиска используется алгоритм MLA. Когда пользователь отправляет поисковый запрос, поисковая система формирует список релевантных веб-ресурсов (на основе анализа просмотренных обходчиком веб-ресурсов, указания на которые хранятся в базе данных обходчика в виде списков вхождений (posting lists) и т.п.). Затем поисковая система использует алгоритм MLA для ранжирования сформированного таким образом списка результатов поиска. Алгоритм MLA ранжирует список результатов поиска на основе их релевантности поисковому запросу. Такой алгоритм MLA «обучен» прогнозировать степень соответствия результата поиска поисковому запросу на основе большого количества «признаков», связанных с данным результатом поиска, и на основе указаний на предыдущие действия пользователей в отношении результатов при отправке подобных поисковых запросов в прошлом.
[005] В патенте US 7877385 B2 «Information retrieval using query-document pair information)) (Microsoft, выдан 25 января 2011 г.) описано извлечение информации с использованием данных о паре запрос-документ. В одном варианте осуществления выполняется доступ к записи «кликов», содержащей информацию о запросах и документах, где был зарегистрирован выбор пользователей для пар запрос-документ. Затем осуществляется формирование или доступ к графу «кликов». Он содержит соединенные ребрами узлы, каждый из которых представляет документ или запрос, а каждое ребро представляет по меньшей мере один зарегистрированный «клик». С учетом по меньшей мере одного первого узла в графе «кликов» определяется степень сходства между первым узлом и каждым из одного или нескольких вторых узлов. Затем вторые узлы ранжируются на основе результатов определения степени сходства и это ранжирование используется для извлечения информации из записи «кликов».
[006] В патенте US 8606786 B2 «Determining a similarity measure between queries)) (Microsoft, выдан 10 декабря 2013 г.) описана система, содержащая компонент приемника, который принимает набор данных, хранящийся на машиночитаемом физическом носителе информации вычислительного устройства и содержащий множество запросов к поисковой системе, сделанных пользователями, и множество результатов поиска, выбранных пользователями после направления множества запросов. Компонент определителя распределения определяет распределения «кликов» для результатов поиска, выбранных пользователями для множества запросов. Компонент присвоения меток маркирует по меньшей мере два запроса во множестве запросов как по существу подобные друг другу, по меньшей мере частично основываясь на распределениях «кликов» для результатов поиска, выбранных пользователями для множества запросов.
[007] В патенте US 9659248 B1 «Machine learning and training a computer-implemented neural network to retrieve semantically equivalent questions using hybrid in-memory representations» (IBM, выдан 25 мая 2017 г.) описано определение семантически эквивалентного текста или вопросов с использованием гибридных представлений на основе обучения нейронной сети. Для расчета семантического сходства между вопросами или текстами могут быть сформированы распределенные векторные представления вопросов или текстов на основе взвешенного набора слов и сверточных нейронных сетей (CNN, Convolutional Neural Network). Для расчета семантического сходства могут совместно использоваться распределенные векторные представления на основе взвешенного набора слов и сетей CNN. Функция потерь попарного ранжирования обучает нейронную сеть. В одном варианте осуществления параметры системы обучаются путем минимизации функции потерь попарного ранжирования на обучающем наборе с использованием стохастического градиентного спуска (SGD, Stochastic Gradient Descent).
[008] В патенте US 8606786 B2 «Determining a similarity measure between queries» (Microsoft, выдан 10 декабря 2013 г.) описана система, содержащая компонент приемника, который принимает набор данных, хранящийся на машиночитаемом физическом носителе информации вычислительного устройства и содержащий множество запросов, выданных пользователями в поисковую систему, и множество результатов поиска, выбранных пользователями после направления множества запросов. Компонент определителя распределения определяет распределения «кликов» для результатов поиска, выбранных пользователями для множества запросов. Компонент присвоения меток маркирует по меньшей мере два запроса во множестве запросов как по существу подобные друг другу, по меньшей мере частично основываясь на распределениях «кликов» для результатов поиска, выбранных пользователями для множества запросов.
[009] В патентной заявке US 2018/0032897 A1 «Event clustering and classification with document embedding» (IBM, опубликована 1 февраля 2018 г.) описано векторное представление для документа, сформированное на основе кластеризации слов в документе. Выбираются репрезентативные кластеры и в качестве векторного представления документа определяется взвешенная сумма векторных представлений слов в выбранных кластерах. На основе векторных представлений документов документам присваиваются метки. С использованием этих документов обучается алгоритм машинного обучения. Алгоритм машинного обучения прогнозирует метку документа на основе векторного представления этого документа.
Раскрытие изобретения
[002] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Варианты осуществления данной технологии способны обеспечить и/или расширить объем подходов и/или способов достижения целей и решения задач данной технологии.
[003] Разработчики настоящей технологии обнаружили по меньшей мере одну техническую проблему, связанную с известными решениями.
[004] Разработчики настоящей технологии обнаружили, что в некоторых ситуациях результаты поиска высшего ранга, отображаемые на странице результатов поисковой системы (SERP, Search Engine Results Page) в ответ на запрос, могут не удовлетворять пользователя, который может просматривать другие страницы SERP и выбирать результаты поиска более низкого ранга в поисках нужной информации, при этом такие результаты поиска иногда могут обеспечивать пользователю удовлетворительный ответ (или более адекватный ответ по сравнению с результатами более высокого ранга).
[005] Разработчикам настоящей технологии известно, что операторам поисковых систем, таких как Google™, Yandex™, Bing™, Yahoo™ и т.д., доступны, среди прочего, журналы, содержащие большое количество данных о действиях пользователей после получения прошлых результатов поиска в ответ на прошлые пользовательские запросы (информация, которая обычно хранится в журналах поиска и доступна алгоритмам MLA поисковой системы).
[006] Варианты осуществления настоящей технологии разработаны на основе понимания разработчиками того, что результаты поиска, предоставленные в ответ на некоторый запрос ранжирующим алгоритмом MLA, могут быть ранжированы с учетом дополнительных факторов ранжирования, таких как прошлые запросы, подобные этому запросу, а также соответствующие параметры сходства, указывающие на соответствующую степень сходства между этим запросом и подобными прошлыми запросами. В различных вариантах осуществления изобретения такой параметр сходства может быть определен на основе данных о действиях пользователей с подобными результатами поиска, предоставленными в ответ на данный запрос и подобные запросы, и на основе текстового сходства между данным запросом и подобными запросами.
[007] В частности, настоящая технология позволяет (а) определить прошлые запросы, подобные отправленному запросу, которые могли ранее отправляться в поисковую систему, и улучшать ранжирующий алгоритм MLA поисковой системы путем использования подобных прошлых запросов для ранжирования результатов поиска в ответ на отправленный запрос; (б) определять с использованием алгоритма MLA запросы, подобные вновь отправленному запросу, которые могли ранее не отправляться в поисковую систему, и улучшать ранжирующий алгоритм MLA поисковой системы с использованием подобных запросов для ранжирования результатов поиска в ответ на вновь отправленный запрос.
[008] Таким образом, настоящая технология относится к способам и системам для расширения поисковых запросов с целью ранжирования результатов поиска.
[009] Этот подход способен обеспечить пользователю более адекватные ответы, в результате чего сокращается до минимума необходимость просмотра пользователем нескольких страниц SERP или повторной отправки запросов для поиска необходимой информации, что, в свою очередь, позволяет экономить вычислительные ресурсы как клиентского устройства, связанного с пользователем, так и сервера поисковой системы.
[0010] Согласно первому аспекту настоящей технологии реализован способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи. Способ включает в себя: прием сервером от электронного устройства указания на текущий запрос; формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему запросу; извлечение сервером из базы данных множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в виде результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов; расчет сервером соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и на прошлых документах из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов; выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и передачу сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0011] В некоторых вариантах осуществления изобретения текущий документ из набора текущих документов связан с прошлыми действиями некоторых из множества прошлых пользователей в отношении этого документа, представленного в ответ на прошлый запрос, подобный текущему запросу, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос, а расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении текущих документов из набора текущих документов и на прошлых действиях пользователей в отношении прошлых документов из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов.
[0012] В некоторых вариантах осуществления изобретения способ перед извлечением множества прошлых запросов дополнительно включает в себя формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей, связанных с текущими документами. Способ перед расчетом соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов дополнительно включает в себя формирование сервером вектора соответствующего запроса, связанного с соответствующим запросом из множества прошлых запросов, на основе прошлых документов из соответствующего набора прошлых документов и прошлых действий пользователей в отношении прошлых документов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
[0013] В некоторых вариантах осуществления изобретения ранжирование набора текущих документов для получения ранжированного набора документов дополнительно включает в себя учет первым алгоритмом MLA соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
[0014] В некоторых вариантах осуществления изобретения соответствующий параметр сходства рассчитывается с использованием скалярного умножения или на основе близости косинусов углов вектора текущего запроса и вектора соответствующего запроса.
[0015] Согласно другому аспекту настоящей технологии реализован компьютерный способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, выполняемый сервером, содержащим второй алгоритм MLA, обученный определять сходство запросов на основе текстового контента. Сервер связан с базой данных и связан с электронным устройством через сеть связи. Способ включает в себя: прием сервером от электронного устройства указания на текущий запрос, ранее не отправлявшийся серверу; формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; извлечение вторым алгоритмом MLA из базы данных множества прошлых запросов, каждый из которых ранее отправлялся серверу; расчет вторым алгоритмом MLA соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на по меньшей мере одном текстовом признаке нового запроса и по меньшей мере одном текстовом признаке этого запроса из множества прошлых запросов; выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и передачу сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0016] В некоторых вариантах осуществления изобретения способ перед извлечением множества прошлых запросов дополнительно включает в себя формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса. При этом способ перед расчетом соответствующего параметра сходства дополнительно включает в себя получение вторым алгоритмом MLA из базы данных вектора соответствующего запроса, связанного с одним из множества прошлых запросов и сформированного на основе по меньшей мере одного соответствующего текстового признака этого запроса из множества прошлых запросов, а расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
[0017] В некоторых вариантах осуществления изобретения извлечение множества прошлых запросов основано на векторе текущего запроса.
[0018] В некоторых вариантах осуществления изобретения способ на этапе обучения дополнительно включает в себя получение сервером из связанной с сервером второй базы данных набора обучающих объектов, ранее сформированного сервером, при этом обучающий объект из набора обучающих объектов содержит первый прошлый запрос и второй прошлый запрос, которые были выбраны на основе соответствующего параметра сходства между первым прошлым запросом и вторым прошлым запросом, рассчитанного на основе прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых документов, представленных в ответ на второй прошлый запрос; формирование вектора первого прошлого запроса на основе по меньшей мере одного текстового признака первого прошлого запроса; формирование вектора второго прошлого запроса на основе по меньшей мере одного текстового признака второго прошлого запроса; обучение второго алгоритма MLA на наборе обучающих объектов для определения параметра сходства между вектором нового запроса, ранее не отправлявшегося серверу, и соответствующим вектором прошлого запроса из множества прошлых запросов.
[0019] В некоторых вариантах осуществления изобретения расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на второй прошлый запрос.
[0020] В некоторых вариантах осуществления изобретения параметр сходства, превышающий заранее заданный порог, используется в качестве положительной метки для обучения.
[0021] В некоторых вариантах осуществления изобретения ранжирование набора текущих документов для получения ранжированного набора документов дополнительно включает в себя учет первым алгоритмом MLA соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
[0022] В некоторых вариантах осуществления изобретения обучение второго алгоритма MLA включает в себя использование алгоритма вида поиска K ближайших соседей (FINNS, K-Nearest Neighbor Search), а способ после обучения второго алгоритма MLA дополнительно включает в себя формирование сервером в базе данных для каждого прошлого запроса из множества прошлых запросов вектора соответствующего запроса, связанного с этим прошлым запросом, и указания на этот прошлый запрос, а также сохранение в базе данных вектора соответствующего запроса.
[0023] В некоторых вариантах осуществления изобретения алгоритм вида K-NSS представляет собой алгоритм иерархического малого мира (HNSW, Hierarchical Navigable Small World).
[0024] Согласно другому аспекту настоящей технологии реализован компьютерный способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи, и включающий в себя: прием сервером от электронного устройства указания на текущий запрос; формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; определение сервером наличия прошлых действий пользователей в отношении текущих документов из набора текущих документов, выполненных в связи с прошлым запросом, подобным текущему запросу; извлечение сервером из базы данных набора из множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос, а извлечение выполняется следующим образом: в ответ на положительный результат определения - формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей в отношении текущих документов из набора текущих документов; формирование сервером вектора соответствующего запроса, связанного с каждым запросом из множества прошлых запросов, на основе прошлых документов и прошлых действий пользователей в отношении прошлых документов из соответствующего набора прошлых документов; выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса; в ответ на отрицательный результат определения - формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса; формирование сервером вектора соответствующего запроса, связанного с каждым прошлым запросом из множества прошлых запросов, на основе по меньшей мере одного текстового признака этого прошлого запроса; выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим по меньшей мере один прошлый запрос в наборе из множества прошлых запросов; и передачу сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0025] Согласно другому аспекту настоящей технологии реализован компьютерный способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи. Способ включает в себя: прием сервером от электронного устройства указания на текущий запрос; формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; извлечение сервером из базы данных множества прошлых запросов на основе указания на текущий запрос; расчет сервером соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим вхождение поисковых терминов по меньшей мере одного прошлого запроса из множества прошлых запросов в документ из набора текущих документов таким образом, что это вхождение поисковых терминов повышает ранг этого текущего документа; и передачу сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0026] Согласно другому аспекту настоящей технологии реализована система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, связанная с базой данных и связанная с электронным устройством через сеть связи. Система содержит процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью инициирования выполнения следующих действий при выполнении этих команд: прием от электронного устройства указания на текущий запрос; формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; извлечение из базы данных множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов; расчет соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и на прошлых документах из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов; выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и передача страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0027] В некоторых вариантах осуществления изобретения текущий документ из набора текущих документов связан с прошлыми действиями некоторых из множества прошлых пользователей в отношении этого документа, представленного в ответ на прошлый запрос, подобный текущему запросу, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на этот прошлый запрос, а расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователя в отношении текущих документов из набора текущих документов и на прошлых действиях пользователя в отношении прошлых документов из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов.
[0028] В некоторых вариантах осуществления изобретения процессор дополнительно выполнен с возможностью выполнения следующего действия перед извлечением множества прошлых запросов: формирование вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей, связанных с текущими документами. Процессор также дополнительно выполнен с возможностью выполнения следующего действия перед расчетом соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов: формирование вектора соответствующего запроса, связанного с соответствующим запросом из множества прошлых запросов, на основе прошлых документов из соответствующего набора прошлых документов и прошлых действий пользователей в отношении прошлых документов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
[0029] В некоторых вариантах осуществления изобретения с целью ранжирования набора текущих документов для получения ранжированного набора документов процессор дополнительно выполнен с возможностью учета первым алгоритмом MLA соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
[0030] В некоторых вариантах осуществления изобретения соответствующий параметр сходства рассчитывается с использованием скалярного умножения или на основе близости косинусов углов вектора текущего запроса и вектора соответствующего запроса.
[0031] Согласно другому аспекту настоящей технологии реализована система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, в которой выполняется второй алгоритм MLA, обученный определять сходство запросов на основе текстового контента. Система связана с базой данных и связана с электронным устройством через сеть связи и содержит процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью инициирования выполнения следующих действий при выполнении команд: формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; извлечение вторым алгоритмом MLA из базы данных множества прошлых запросов, каждый из которых ранее отправлялся в систему; расчет вторым алгоритмом MLA соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на по меньшей мере одном текстовом признаке нового запроса и по меньшей мере одном текстовом признаке этого запроса из множества прошлых запросов; выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и передача страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0032] В некоторых вариантах осуществления изобретения процессор дополнительно выполнен с возможностью выполнения следующего действия перед извлечением множества прошлых запросов: формирование вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса. Процессор также дополнительно выполнен с возможностью инициирования выполнения следующего действия перед расчетом соответствующего параметра сходства: получение вторым алгоритмом MLA из базы данных вектора соответствующего запроса, связанного с запросом из множества прошлых запросов и сформированного на основе по меньшей мере одного соответствующего текстового признака этого запроса из множества прошлых запросов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
[0033] В некоторых вариантах осуществления изобретения извлечение множества прошлых запросов основано на векторе текущего запроса.
[0034] В некоторых вариантах осуществления изобретения процессор дополнительно выполнен с возможностью выполнения на этапе обучения следующих действий: получение из связанной с системой второй базы данных набора обучающих объектов, ранее сформированного системой, при этом обучающий объект из набора обучающих объектов содержит первый прошлый запрос и второй прошлый запрос, которые были выбраны на основе соответствующего параметра сходства между первым прошлым запросом и вторым прошлым запросом, рассчитанного на основе прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых документов, представленных в ответ на второй прошлый запрос; формирование вектора первого прошлого запроса на основе по меньшей мере одного текстового признака первого прошлого запроса; формирование вектора второго прошлого запроса на основе по меньшей мере одного текстового признака второго прошлого запроса; обучение второго алгоритма MLA на наборе обучающих объектов для определения параметра сходства между вектором нового запроса, ранее не отправлявшегося в систему, и соответствующим вектором прошлого запроса из множества прошлых запросов.
[0035] В некоторых вариантах осуществления изобретения расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователя с прошлыми документами, представленными в ответ на первый прошлый запрос, и прошлых действиях пользователя с прошлыми документами, представленными в ответ на второй прошлый запрос.
[0036] В некоторых вариантах осуществления изобретения параметр сходства, превышающий заранее заданный порог, используется в качестве положительной метки для обучения.
[0037] В некоторых вариантах осуществления изобретения с целью ранжирования набора текущих документов для получения ранжированного набора документов процессор выполнен с возможностью учета первым алгоритмом MLA соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
[0038] В некоторых вариантах осуществления изобретения обучение второго алгоритма MLA включает в себя использование алгоритма вида поиска K ближайших соседей (К-NNS), а процессор дополнительно выполнен с возможностью выполнения следующих действий после обучения второго алгоритма MLA: формирование в базе данных для каждого прошлого запроса из множества прошлых запросов вектора соответствующего запроса, связанного с этим прошлым запросом, и указания на этот прошлый запрос; сохранение вектора соответствующего запроса в базе данных.
[0039] В некоторых вариантах осуществления изобретения алгоритм вида K-NSS представляет собой алгоритм иерархического малого мира (HNSW, Hierarchical Navigable Small World).
[0040] Согласно другому аспекту настоящей технологии реализована система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, связанная с базой данных и связанная с электронным устройством через сеть связи. Система содержит: процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью инициирования выполнения следующих действий при выполнении команд: прием от электронного устройства указания на текущий запрос; формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему запросу; определение наличия прошлых действий пользователей в отношении текущих документов из набора текущих документов, выполненных в связи с прошлым запросом, подобным текущему запросу; извлечение из базы данных набора из множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос, а извлечение выполняется следующим образом: в ответ на положительный результат определения - формирование вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей в отношении текущих документов из набора текущих документов; формирование вектора соответствующего запроса, связанного с каждым запросом из множества прошлых запросов, на основе прошлых документов и прошлых действий пользователей в отношении прошлых документов из соответствующего набора прошлых документов; выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса; в ответ на отрицательный результат определения - формирование вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса; формирование вектора соответствующего запроса, связанного с каждым прошлым запросом из множества прошлых запросов, на основе по меньшей мере одного текстового признака этого прошлого запроса; выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим по меньшей мере один прошлый запрос в наборе из множества прошлых запросов; и передача страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0041] Согласно другому аспекту настоящей технологии реализована система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма MLA, связанная с базой данных и связанная с электронным устройством через сеть связи. Система содержит: процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью инициирования выполнения следующих действий при выполнении команд: прием от электронного устройства указания на текущий запрос; формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу; извлечение из базы данных множества прошлых запросов на основе указания на текущий запрос; расчет соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов; ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим вхождение поисковых терминов по меньшей мере одного прошлого запроса из множества прошлых запросов в документ из набора текущих документов таким образом, что это вхождение поисковых терминов повышает ранг этого текущего документа; и передача страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[0042] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для данной технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[0043] В контексте настоящего описания термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения данной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер в отношении других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[0044] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[0045] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д., но не ограничивается ими.
[0046] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[0047] В контексте настоящего описания, если явно не указано другое, в качестве указания на информационный элемент может выступать сам информационный элемент, а также указатель, ссылка, гиперссылка или другое косвенное средство, с помощью которого получатель данных может найти место в сети, памяти, базе данных или другой пригодной для чтения компьютером среде, откуда можно извлечь этот информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое) или указание может представлять собой уникальный дескриптор документа, указывающий на файл в определенной файловой системе, или на какие-либо другие средства для указания получателю данных места в сети, адреса в памяти, таблицы в базе данных или другого места, где можно получить доступ к файлу. Специалисту в данной области должно быть очевидно, что степень точности, требуемая для такого указания, зависит от объема предварительных пояснений относительно интерпретации информации, которой обмениваются отправитель и получатель указания. Например, если перед началом обмена данными между отправителем и получателем известно, что указание на информационный элемент будет представлять собой ключ базы данных для элемента в определенной таблице заранее заданной базы данных, содержащей этот информационный элемент, то для эффективной передачи такого информационного элемента получателю достаточно оправить ключ базы данных, даже если сам информационный элемент не передается между отправителем и получателем данных.
[0048] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, вида, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[0049] Каждый вариант реализации настоящей технологии относится к по меньшей мере одному из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты данной технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[0050] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления данной технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[0051] Дальнейшее описание приведено для лучшего понимания данной технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[0052] На фиг. 1 представлена схема системы, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[0053] На фиг. 2 приведена схема системы на основе алгоритма машинного обучения, соответствующей вариантам осуществления настоящей технологии, в составе представленной на фиг. 1 системы.
[0054] На фиг. 3 приведена схема процедуры формирования сходных запросов, соответствующей вариантам осуществления настоящей технологии и выполняемой в представленной на фиг. 1 системе.
[0055] На фиг. 4 приведена схема процедуры расширения запросов, соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии и выполняемой в представленной на фиг. 1 системе.
[0056] На фиг. 5 приведена схема этапа обучения второго алгоритма MLA, соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии и выполняемого в представленной на фиг. 1 системе.
[0057] На фиг. 6 приведена схема этапа использования второго алгоритма MLA, соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии и выполняемого в представленной на фиг. 1 системе.
[0058] На фиг. 7 и 8 приведена блок-схема способа ранжирования результатов поиска с использованием первого алгоритма MLA, соответствующего вариантам осуществления настоящей технологии и выполняемого в представленной на фиг. 1 системе.
[0059] На фиг. 9 приведена блок-схема способа ранжирования результатов поиска с использованием первого алгоритма MLA и второго алгоритма MLA, соответствующего вариантам осуществления настоящей технологии и выполняемого в представленной на фиг. 1 системе
Осуществление изобретения
[0060] Представленные в данном описании примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники могут разработать различные способы и устройства, которые здесь явно не описаны и не показаны, но осуществляют принципы настоящей технологии в пределах ее существа и объема.
[0061] Кроме того, чтобы способствовать лучшему пониманию, следующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[0062] В некоторых случаях также приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ данной технологии. Представленные модификации не составляют исчерпывающего перечня и специалист в данной области может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[0063] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также ее конкретные примеры предназначены для охвата ее структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, осуществляющих принципы настоящей технологии. Аналогично, должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п.соответствуют различным процессам, которые могут быть представлены в машиночитаемой среде и могут выполняться с использованием компьютера или процессора, независимо от того, показан или не показан такой компьютер или процессор явным образом.
[0064] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут выполняться с использованием специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение, в совокупности с этим программным обеспечением. При использовании процессора эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU, Central Processing Unit), или специализированный процессор, такой как графический процессор (GPU, Graphics Processing Unit). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP, Digital Signal Processor), сетевой процессор, специализированную интегральную схему (ASIC, Application Specific Integrated Circuit), программируемую логическую схему (FPGA, Field Programmable Gate Array), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, обычные и/или заказные.
[0065] Программные модули или просто модули, реализуемые в виде программного обеспечения, могут быть представлены в данном документе как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумевающимися.
[0066] С учетом вышеизложенных принципов далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[0067] На фиг. 1 представлена соответствующая не имеющим ограничительного характера вариантам осуществления настоящей технологии система 100. Система 100 содержит первое клиентское устройство 110, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140, соединенные с сетью 200 связи через соответствующую линию 205 связи (только одна из них обозначена на фиг. 1). Система 100 содержит сервер 210 поисковой системы, сервер 220 отслеживания и обучающий сервер 230, соединенные с сетью 200 связи соответствующей линией 205 связи.
[0068] Например, первое клиентское устройство 110 может быть реализовано как смартфон, второе клиентское устройство 120 может быть реализовано как ноутбук, третье клиентское устройство 130 может быть реализовано как смартфон, четвертое клиентское устройство 140 может быть реализовано как планшет. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 200 связи может использоваться сеть Интернет. В других вариантах осуществления настоящей технологии сеть 200 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, частной сети связи и т.д.
[0069] На реализацию линии 205 связи не накладывается каких-либо особых ограничений, она зависит от реализации соответствующих первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140. Только в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где по меньшей мере одно из первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140 реализовано как беспроводное устройство связи (такое как смартфон), соответствующая линия 205 связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где по меньшей мере одно из первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140 реализовано как ноутбук, смартфон или планшетный компьютер, соответствующая линия 205 связи может быть беспроводной (такой как Wireless Fidelity или кратко WiFi®, Bluetooth® и т.п.) или проводной (такой как соединение на основе Ethernet).
[0070] Очевидно, что варианты реализации первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130, четвертого клиентского устройства 140, линии 205 связи и сети 200 связи приведены только для иллюстрации. Специалисту в данной области должны быть очевидны и другие конкретные детали реализации первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130, четвертого клиентского устройства 140, линии 205 связи и сети 200 связи. Представленные выше примеры никоим образом не ограничивают объем настоящей технологии.
[0071] Несмотря на то, что только четыре клиентских устройства 110, 120, 130 и 140 показаны на фиг. 1, предполагается, что с системой 100 может быть соединено любое количество клиентских устройств 110, 120, 130 и 140. Также предполагается, что в некоторых вариантах осуществления с системой 100 могут быть соединены десятки или сотни тысяч клиентских устройств 110, 120, 130 и 140.
[0072] Сервер поисковой системы
[0073] С сетью 200 связи также соединен вышеупомянутый сервер 210 поисковой системы. Сервер 210 поисковой системы может быть реализован как традиционный компьютерный сервер. В примере осуществления настоящей технологии сервер 210 поисковой системы может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Сервер 210 поисковой системы может быть реализован на основе любых других подходящих аппаратных средств и/или программного обеспечения и/или встроенного программного обеспечении либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 210 поисковой системы представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 210 поисковой системы могут быть распределены между несколькими серверами. В некоторых вариантах осуществления настоящей технологии сервер 210 поисковой системы контролируется и/или управляется оператором поисковой системы. В качестве альтернативы, сервер 210 поисковой системы может контролироваться и/или управляться поставщиком услуг.
[0074] В общем случае, сервер 210 поисковой системы предназначен для (а) выполнения поиска; (б) выполнения анализа результатов поиска и ранжирования результатов поиска в ответ на поисковый запрос (который может учитывать подобные запросы, определенные с использованием настоящей технологии); (в) объединения результатов в группы и формирования страницы SERP для его направления электронному устройству (такому как первое клиентское устройство 110, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140), использовавшемуся для отправки поискового запроса, в результате выполнения которого сформирована страница SERP.
[0075] На конфигурацию сервера 210 поисковой системы для выполнения поиска не накладывается каких-либо особых ограничений. Специалисту в данной области известен ряд способов и средств выполнения поиска с использованием сервера 210 поисковой системы, поэтому различные структурные компоненты сервера 210 поисковой системы описаны обобщенно. Сервер 210 поисковой системы способен поддерживать базу 212 данных журнала поиска.
[0076] В некоторых вариантах осуществления настоящей технологии сервер 210 поисковой системы может выполнять поиск нескольких видов, включая общий поиск и вертикальный поиск, но не ограничиваясь ими.
[0077] Сервер 210 поисковой системы способен выполнять общие веб-поиски, как известно специалисту в данной области. Сервер 210 поисковой системы также способен выполнять один или несколько вертикальных поисков, таких как вертикальный поиск изображений, вертикальный поиск музыкальных произведений, вертикальный поиск видеоматериалов, вертикальный поиск новостей, вертикальный поиск карт и т.д. Сервер 210 поисковой системы также способен, как известно специалисту в данной области, выполнять алгоритм обходчика, согласно которому сервер 210 поисковой системы выполняет обход сети Интернет и индексирует посещенные веб-сайты в одной или нескольких индексных базах данных, таких как база 212 данных журнала поиска.
[0078] Сервер 210 поисковой системы способен формировать ранжированный список результатов поиска, включающий в себя результаты общего веб-поиска и вертикального веб-поиска. Известно множество алгоритмов ранжирования результатов поиска, которые могут быть реализованы с использованием сервера 210 поисковой системы.
[0079] Только в качестве примера, не имеющего ограничительного характера, некоторые известные способы ранжирования результатов поиска по степени соответствия предоставленному пользователем поисковому запросу основаны на некоторых или всех следующих критериях: (а) популярность поискового запроса или соответствующего ответа при выполнении поисков; (б) количество результатов поиска; (в) наличие в запросе определяющих терминов (таких как «изображения», «фильмы», «погода» и т.п.); (г) частота использования поискового запроса с определяющими терминами другими пользователями; (д) частота выбора другими пользователями, выполнявшими аналогичный поиск, определенного ресурса или определенных результатов вертикального поиска, когда результаты представлялись с использованием страницы SERP. Сервер 210 поисковой системы может рассчитывать и назначать коэффициент релевантности (основанный на различных представленных выше критериях) для каждого результата поиска, полученного по направленному пользователем поисковому запросу, а также формировать страницу SERP, где результаты поиска ранжируются согласно их коэффициентам релевантности. В настоящем варианте осуществления изобретения сервер 210 поисковой системы может выполнять множество алгоритмов машинного обучения для ранжирования документов и/или формировать признаки для ранжирования документов.
[0080] Сервер 210 поисковой системы обычно поддерживает вышеупомянутую базу 212 данных журнала поиска, содержащую индекс 214.
[0081] Индекс 214 предназначен для индексирования документов, таких как вебстраницы, изображения, файлы в формате PDF, документы Word™, документы PowerPoint™, которые были просмотрены (или обнаружены) обходчиком сервера 210 поисковой системы. В некоторых вариантах осуществления настоящей технологии индекс 214 поддерживается в виде списков вхождений. Когда пользователь первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140 вводит запрос и выполняет поиск на сервере 210 поисковой системы, сервер 210 поисковой системы анализирует индекс 214 и извлекает документы, содержащие термины из запроса, а затем ранжирует их согласно алгоритму ранжирования. [0082] Сервер отслеживания
[0083] С сетью 200 связи также соединен вышеупомянутый сервер 220 отслеживания. Сервер 220 отслеживания может быть реализован как традиционный компьютерный сервер. В примере осуществления настоящей технологии сервер 220 отслеживания может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 220 отслеживания может быть реализован на основе любых других подходящих аппаратных средств и/или программного обеспечения и/или встроенного программного обеспечении либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 220 отслеживания представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 220 отслеживания могут быть распределены между несколькими серверами. В других вариантах осуществления изобретения функции сервера 220 отслеживания могут полностью или частично выполняться сервером 210 поисковой системы. В некоторых вариантах осуществления настоящей технологии сервер 220 отслеживания контролируется и/или управляется оператором поисковой системы. В качестве альтернативы, сервер 220 отслеживания может контролироваться и/или управляться другим поставщиком услуг.
[0084] В общем случае, сервер 220 отслеживания предназначен для отслеживания действия пользователей в отношении результатов, предоставленных сервером 210 поисковой системы по запросам пользователей (например, выполненных пользователями первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140). Сервер 220 отслеживания может отслеживать действия пользователей (по данным о выборе пользователями), когда пользователи выполняют общие веб-поиски и вертикальные веб-поиски на сервере 210 поисковой системы, и сохранять эти действия пользователей в базе 222 данных отслеживания.
[0085] Не имеющие ограничительного характера примеры действий пользователей, отслеживаемых сервером 220 отслеживания, включают в себя:
- успех/неудача: был документ выбран в ответ на поисковый запрос или нет;
- время пребывания: время, затраченное пользователем на ознакомление с документом перед возвратом на страницу SERP;
- длинный/короткий «клик»: было ли действие пользователя в отношении документа длинным или коротким по сравнению с действием пользователя в отношении других документов на странице SERP;
- коэффициент «кликов» (CTR, click-through rate): количество случаев выбора элемента, деленное на количество отображений (показов) этого элемента.
[0086] Разумеется, что представленный выше список не является исчерпывающим и он может включать в себя другие виды действий пользователей без выхода за границы настоящей технологии. В некоторых вариантах осуществления изобретения сервер 220 отслеживания может объединять данные о действиях пользователей (которые в не имеющем ограничительного характера примере могут включать в себя действия пользователей в течение каждого часа) и формировать данные о действиях пользователей для сохранения в базе 222 данных отслеживания в подходящем для реализации настоящей технологии формате (которые в не имеющем ограничительного характера примере могут представлять собой действия пользователей в течение заранее заданного периода времени длительностью 3 месяца). В других вариантах осуществления изобретения сервер 220 отслеживания может сохранять данные о действиях пользователей в необработанном виде в базе 222 данных отслеживания таким образом, чтобы они могли извлекаться и объединяться по меньшей мере одним из сервера 210 поисковой системы, сервера 230 обучения или другого сервера (не показан) в формате, подходящем для реализации настоящей технологии.
[0087] Сервер 220 отслеживания обычно поддерживает вышеупомянутую базу 222 данных отслеживания, содержащую журнал 226 запросов и журнал 228 действий пользователей.
[0088] Журнал 226 запросов предназначен для регистрации поисков, выполненных с использованием сервера 210 поисковой системы. В частности, в журнале 226 запросов хранятся термины поисковых запросов (т.е. соответствующие поисковые слова) и соответствующие результаты поиска. Следует отметить, что журнал 226 запросов поддерживается в обезличенной форме, т.е. для поисковых запросов невозможно определить отправивших их пользователей.
[0089] В частности, журнал 226 запросов может содержать список запросов с соответствующими терминами, с информацией о документах, предоставленных сервером 210 поисковой системы в ответ на соответствующий запрос, и с отметкой времени. Он также может содержать список пользователей, идентифицируемых с использованием анонимных идентификаторов (или вообще без идентификаторов), и соответствующие документы, выбранные ими после отправки запроса. В некоторых вариантах осуществления изобретения журнал 226 запросов может обновляться при каждом выполнении нового поиска на сервере 210 поисковой системы. В других вариантах осуществления изобретения журнал 226 запросов может обновляться в заранее заданные моменты времени. В некоторых вариантах осуществления изобретения может существовать множество копий журнала 226 запросов, каждая из которых соответствует журналу 226 запросов в различные моменты времени.
[0090] Журнал 228 действий пользователей может быть связан с журналом 226 запросов и может содержать действия пользователей, отслеживаемые сервером 220 отслеживания после того, как пользователь отправил запрос и выбрал на сервере 210 поисковой системы один или несколько документов на странице SERP. В не имеющем ограничительного характера примере журнал 228 действий пользователей может содержать ссылку на документ, который может быть идентифицирован с использованием идентификационного номера или универсального указателя ресурсов (URL, Uniform Resource Locator), и список запросов, каждый из которых связан со списком документов, каждый из которых связан с множеством действий пользователей (если осуществлялись действия с документом), что более подробно описано ниже. Множество действий пользователей, в общем случае, может отслеживаться и объединяться сервером 220 отслеживания и в некоторых вариантах осуществления изобретения оно может учитываться для каждого отдельного пользователя.
[0091] В некоторых вариантах осуществления изобретения сервер 220 отслеживания может отправлять отслеженные запросы, результат поиска и действия пользователей серверу 210 поисковой системы, который может сохранять отслеженные запросы, действия пользователей и связанные с ними результаты поиска в базе 212 данных журнала поиска. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 220 отслеживания и сервера 210 поисковой системы могут быть реализованы одним сервером.
[0092] Сервер обучения
[0093] С сетью 200 связи также соединен вышеупомянутый сервер 230 обучения. Сервер 230 обучения может быть реализован как традиционный компьютерный сервер. В примере осуществления настоящей технологии сервер 230 обучения может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 230 обучения может быть реализован на основе любых других подходящих аппаратных средств и/или программного обеспечения и/или встроенного программного обеспечении либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 230 обучения представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 230 обучения могут быть распределены между несколькими серверами. В контексте настоящей технологии в сервере 230 обучения могут быть частично реализованы описанные здесь способы и система. В некоторых вариантах осуществления настоящей технологии сервер 230 обучения контролируется и/или управляется оператором поисковой системы. В качестве альтернативы, сервер 230 обучения может контролироваться и/или управляться другим поставщиком услуг.
[0094] Сервер 230 обучения предназначен для обучения одного или нескольких алгоритмов машинного обучения (MLA), используемых сервером 210 поисковой системы, сервером 220 отслеживания и/или другими серверами (не показаны), связанными с оператором поисковой системы. Сервер 230 обучения может, например, обучать один или несколько алгоритмов MLA, связанных с поставщиком услуг поисковой системы, для оптимизации общих и вертикальных веб-поисков, предоставления рекомендаций, прогнозирования итогов и других сфер применения. Обучение и оптимизация алгоритмов MLA могут выполняться в течение заранее заданного периода времени или когда поставщик услуг поисковой системы сочтет это необходимым.
[0095] Сервер 230 обучения может поддерживать базу 232 данных обучения для хранения обучающих объектов и/или признаков для различных алгоритмов MLA, используемых сервером 210 поисковой системы, сервером 220 отслеживания и/или другими серверами (не показаны), связанными с оператором поисковой системы.
[0096] В представленных здесь вариантах осуществления изобретения (см. фиг. 2) сервер 230 обучения может быть способным обучать (1) первый алгоритм 320 MLA с целью ранжирования документов на сервере 210 поисковой системы и (2) второй алгоритм 340 MLA с целью формирования набора запросов для расширения текущих отправленных запросов и с целью формирования связанных с ними параметров сходства, которые могут использоваться первым алгоритмом 320 MLA. Первый алгоритм 320 MLA и второй алгоритм 340 MLA более подробно описаны ниже. Несмотря на то, что это описание относится к общим веб-поискам документов, таких как веб-страницы, настоящая технология также может по меньшей мере частично применяться для вертикальных поисков и для документов других видов, таких как изображения, видеоматериалы, музыка, новости, и для других видов поисков. Следует отметить, что в некоторых вариантах осуществления изобретения первый алгоритм 320 MLA и второй алгоритм 340 MLA могут быть реализованы в нескольких алгоритмах MLA или в одном алгоритме MLA.
[0097] Представленная на фиг. 3 система 300 машинного обучения соответствует не имеющим ограничительного характера вариантам осуществления настоящей технологии. Система 300 машинного обучения содержит первый алгоритм 320 ML А и второй алгоритм 340 ML А.
[0098] Первый алгоритм MLA
[0099] В общем случае, первый алгоритм 320 MLA может быть способным ранжировать результаты поиска на сервере 210 поисковой системы и в не имеющем ограничительного характера примере может реализовывать алгоритм градиентного бустинга дерева решений (GBRT, Gradient Boosted Decision Tree). Вкратце, алгоритм GBRT основан на деревьях решений, с использованием которых формируется прогнозирующая модель в виде ансамбля деревьев. Ансамбль деревьев строится поэтапно. Каждое последующее дерево решений в ансамбле деревьев решений фокусирует обучение на тех итерациях предыдущего дерева решений, которые были «слабыми учениками» на предыдущей итерации (или на нескольких итерациях) ансамбля деревьев решений (т.е. были связанны с неудовлетворительным прогнозом или с большой ошибкой). Бустинг представляет собой способ, нацеленный на повышение качества прогнозирования алгоритма MLA. В этом сценарии система использует прогноз не одного обученного алгоритма (одного дерева решений), а большого количества обученных алгоритмов (ансамбля деревьев решений) и принимает окончательное решение на основе нескольких результатов прогнозирования этими алгоритмами.
[00100] При бустинге деревьев решений первый алгоритм 320 MLA сначала строит первое дерево, затем второе дерево, улучшающее результат прогнозирования первым деревом, затем третье дерево, улучшающее результат прогнозирования первыми двумя деревьями, и т.д. Таким образом, первый алгоритм 320 MLA в известном смысле создает ансамбль деревьев решений, где каждое последующее дерево лучше предыдущего, в частности, ориентируясь на «слабых учеников» предыдущих итераций деревьев решений. Иными словами, каждое дерево строится на том же обучающем наборе обучающих объектов, тем не менее, обучающие объекты, для которых первое дерево допустило «ошибки» при прогнозировании, имеют приоритет при построении второго дерева и т.д. Эти «сложные» обучающие объекты (для которых на предыдущих итерациях деревьев решений получались менее точные прогнозы) взвешиваются с большими весовыми коэффициентами по сравнению с объектами, где предыдущее дерево обеспечило удовлетворительный прогноз.
[00101] Таким образом, первый алгоритм 320 MLA может использовать сортировку и/или регрессию для ранжирования документов. Первый алгоритм 320 MLA может представлять собой основной алгоритм сервера 210 поисковой системы или один из алгоритмов ранжирования сервера 210 поисковой системы или часть другого алгоритма ранжирования сервера 210 поисковой системы.
[00102] Второй алгоритм MLA
[00103] В общем случае, второй алгоритм 340 MLA может быть способным сравнивать поисковые запросы и формировать параметры сходства, указывающие на уровень сходства между запросами. После обучения второй алгоритм 340 MLA также может быть способным определять по меньшей мере один прошлый запрос, подобный текущему отправленному запросу, который может представлять собой новый «свежий» запрос, ранее не отправлявшийся серверу 210 поисковой системы, по меньшей мере на основе анализа сходства по меньшей мере одного прошлого запроса и текущего отправленного запроса.
[00104] Второй алгоритм 340 MLA может быть обучен на наборе обучающих объектов, чтобы получать информацию о взаимосвязях между соответствующими запросами и параметрами сходства соответствующих пар запросов, сформированных ранее, например, сервером 210 поисковой системы или сервером 230 обучения, на основе сходных результатов поиска, полученных в ответ на эти запросы, и связанных с этими результатами поиска действий пользователей. В не имеющем ограничительного характера примере второй алгоритм 340 MLA может использовать текстовый контент и признаки запросов в паре, а также ранее рассчитанный параметр сходства, основанный на сходных результатах поиска для запросов в этой паре, для «изучения» корреляции между текстовыми признаками запросов и параметром сходства, который может использоваться в качестве «расстояния», указывающего на степень сходства запросов в паре.
[00105] Несмотря на то, что в настоящем описании сходство запросов по меньшей мере частично определяется на основе сходных «результатов поиска» и «действий пользователей», настоящая технология может применяться для цифровых файлов других видов, таких как программные приложения, видеоигры, изображения, видеоматериалы и т.п.Кроме того, для настоящей технологии не требуется наличие действий пользователей в каждом варианте осуществления и вместо действий пользователей могут учитываться или не учитываться другие факторы или признаки, в зависимости от вида цифровых файлов, например, представления, время, расстояние и т.д.
[00106] После обучения второй алгоритм 340 MLA может быть способным выбирать один или несколько запросов, подобных новому и ранее не известному запросу, прогнозировать параметры сходства и предоставлять один или несколько схожих запросов и параметров сходства первому алгоритму 320 MLA таким образом, чтобы они могли быть использованы в качестве признаков для ранжирования результатов поиска в ответ на новый и ранее не известный запрос. В представленном здесь варианте осуществления изобретения второй алгоритм 340 MLA может быть реализован в виде нейронной сети.
[00107] На фиг. 3 представлена соответствующая не имеющим ограничительного характера вариантам осуществления настоящей технологии схема процедуры 400 формирования сходных запросов.
[00108] Процедура 400 формирования сходных запросов может выполняться автономно и синхронно (т.е. через заранее заданные интервалы времени) сервером 230 обучения. В других вариантах осуществления изобретения процедура 400 формирования сходных запросов может выполняться сервером 210 поисковой системы или другим сервером (не показан).
[00109] В общем случае, процедура 400 формирования сходных запросов предназначена (а) для расчета соответствующих векторов запросов для запросов, ранее отправленных серверу 210 поисковой системы, при этом векторы запросов содержат информацию о результатах поиска, представленных в ответ на запрос, и в некоторых вариантах осуществления изобретения - действия пользователей в отношении результатов; и (б) для расчета с использованием этих векторов запросов параметров сходства между ранее отправленным запросами, указывающих на степень сходства между запросами на основе сходных результатов писка и в некоторых вариантах осуществления изобретения - действий пользователей со сходными результатами поиска.
[00110] В некоторых вариантах осуществления изобретения процедура 400 формирования сходных запросов может рассчитывать векторы запросов для ранее отправленных запросов, которые затем могут сохраняться в базе 232 данных обучения (или в другой (не показанной) базе данных). Затем векторы запросов могут быть использованы сервером 210 поисковой системы после приема текущего запроса, ранее отправленного серверу 210 поисковой системы, и сервер 210 поисковой системы может рассчитывать параметры сходства между текущим запросом и прошлыми запросами на основе связанных векторов запросов, сохраненных в базе 232 данных обучения. Затем первый алгоритм 320 MLA может расширять текущий запрос с использованием запросов, имеющих соответствующий параметр сходства с текущим запросом, превышающий порог.
[00111] В других вариантах осуществления изобретения процедура 400 формирования сходных запросов может рассчитывать векторы запросов для ранее отправленных запросов, а также параметры сходства между векторами запросов, и может сохранять векторы запросов и параметры сходства в базе 232 данных обучения (или в другой базе данных). Сервер 210 поисковой системы после приема текущего запроса, ранее отправлявшегося серверу 210 поисковой системы, может извлекать из базы 232 данных обучения запросы, имеющие соответствующий параметр сходства, превышающий порог, чтобы расширить текущий запрос.
[00112] Выходные данные процедуры 400 формирования сходных запросов могут быть использованы сервером 230 обучения для обучения второго алгоритма 340 MLA с целью расширения неизвестного запроса (т.е. запроса, ранее не отправлявшегося серверу 210 поисковой системы).
[00113] Процедура 400 формирования сходных запросов включает в себя действия формирователя 420 векторов запросов и формирователя 450 параметров сходства.
[00114] Формирователь векторов
[00115] В общем случае, формирователь 420 векторов запросов может быть способным извлекать поисковые запросы, результаты поиска, представленные в ответ на поисковые запросы, и действия пользователей, связанные с каждым результатом поиска, чтобы формировать для каждого запроса соответствующий вектор, содержащий информацию о соответствующих результатах поиска и соответствующих действиях пользователей, связанных с результатами поиска. В некоторых вариантах осуществления изобретения формирователь 420 векторов запросов может формировать соответствующий вектор для каждого запроса на основе результатов поиска.
[00116] Формирователь 420 векторов запросов может извлекать из журнала 226 запросов базы 222 данных отслеживания сервера 220 отслеживания указание на множество 402 поисковых запросов. В общем случае, каждый поисковый запрос 404 в указании на множество 402 поисковых запросов представляет собой поисковый запрос, ранее отправлявшийся серверу 210 поисковой системы. В некоторых вариантах осуществления изобретения каждый поисковый запрос 404 в указании на множество 402 поисковых запросов может представлять собой ссылку на поисковый запрос, числовое представление поискового запроса или текст поискового запроса. Указание на множество 402 поисковых запросов может содержать заранее заданное количество поисковых запросов. Количество поисковых запросов 404 в указании на множество 402 поисковых запросов не ограничено. В не имеющем ограничительного характера примере указание на множество 402 поисковых запросов может содержать 10000000 наиболее популярных поисковых запросов, ранее отправленных пользователями (такими как пользователи первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 и четвертого клиентского устройства 140) серверу 210 поисковой системы.
[00117] В некоторых вариантах осуществления изобретения каждый поисковый запрос 404 в указании на множество 402 поисковых запросов может быть выбран на основе конкретных критериев, таких как популярность запроса на сервере 210 поисковой системы, лингвистические признаки поискового запроса 404, соответствующие результаты поиска, связанные с поисковым запросом 404, и т.д. В других вариантах осуществления изобретения каждый поисковый запрос 404 в указании на множество 402 поисковых запросов может быть выбран случайным образом.
[00118] Формирователь 420 векторов запросов может извлекать из журнала 226 запросов и/или из журнала 228 действий пользователей базы 222 данных отслеживания сервера 220 отслеживания указание на множество 406 результатов поиска. Это указание на множество 406 результатов поиска для каждого поискового запроса 404 в указании на множество 402 поисковых запросов содержит соответствующий набор 408 результатов поиска, предоставленный в ответ на поисковый запрос 404. Каждый соответствующий результат 410 поиска из соответствующего набора 408 результатов поиска может быть связан с одним или несколькими соответствующими действиями 412 пользователей. В общем случае, каждое из одного или нескольких действий 412 пользователей может указывать на поведение одного или нескольких пользователей после отправки поискового запроса 404 серверу 210 поисковой системы, при этом один или несколько пользователей могли выбирать или выполнять иные действия в отношении одного или нескольких результатов поиска в соответствующем наборе 408 результатов поиска в течение сеанса поиска на сервере 210 поисковой системы, например, с использованием первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140. В некоторых вариантах осуществления изобретения формирователь 420 векторов запросов может извлекать одно или несколько конкретных действий пользователей, подходящих для решения конкретной задачи, но не обязательно все действия пользователей, отслеженные сервером 220 отслеживания и сохраненные в журнале 228 действий пользователей базы 212 данных журнала поиска.
[00119] В общем случае, одно или несколько соответствующих действий 412 пользователей могут представлять собой обобщения действий множества пользователей (например, сколько раз в общей сложности был выбран данный результат 410 поиска) и могут не являться действиями отдельного пользователя (т.е. действиями конкретного пользователя).
[00120] Затем формирователь 420 векторов запросов для каждого соответствующего поискового запроса 404, связанного с соответствующим набором 408 результатов поиска, может рассчитывать соответствующий вектор 442 запроса, который для соответствующего поискового запроса 404 содержит информацию из каждого соответствующего набора 408 результатов поиска, включая соответствующий результат 410 поиска и соответствующее действие 412 пользователя.
[00121] На способ представления каждого соответствующего вектора 442 запроса не накладывается каких-либо ограничений. В общем случае, соответствующий вектор 442 запроса предназначен для включения информации о результатах поиска и действиях пользователей, отслеженных в ответ на запрос, в этот вектор таким образом, чтобы его можно было сравнить с другим соответствующим вектором и чтобы сходство двух запросов можно было оценить с использованием векторов запросов в качестве «посредников» путем сравнения сходных результатов поиска и соответствующих пользовательских действий.
[00122] В представленном варианте осуществления каждая строка или столбец соответствующего вектора 442 запроса, связанного с соответствующим поисковым запросом 404, может соответствовать соответствующему результату 410 поиска из соответствующего набора 408 результатов поиска, а каждый элемент может соответствовать наличию соответствующего действия 412 пользователя. Например, элемент может быть равен 1, если имеется действие пользователя или если действие пользователя превышает заранее заданный порог, и равен 0, если отсутствует действие пользователя или если действие пользователя ниже заранее заданного порога. В других вариантах осуществления изобретения элемент вектора может иметь значение соответствующего действия 412 пользователя, связанного с соответствующим результатом 410 поиска. Соответствующий вектор 432 запроса также может быть представлен в двоичном виде.
[00123] В некоторых вариантах осуществления изобретения, когда несколько видов действий пользователей учитываются для соответствующего результата 410 поиска, каждый соответствующий вектор 442 запроса может быть представлен в виде матрицы или может быть сформировано несколько соответствующих векторов 442 запроса для каждого соответствующего поискового запроса 404 (т.е. соответствующих разным видам действий пользователей).
[00124] Затем формирователь 420 векторов запросов может выдать множество 440 векторов запросов, в котором каждый вектор 442 запроса связан с соответствующим поисковым запросом 404 в указании на множество 402 поисковых запросов.
[00125] В некоторых вариантах осуществления изобретения множество 440 векторов запросов может быть сохранено в базе 232 данных обучения сервера 230 обучения для последующего использования. В других вариантах осуществления изобретения множество 440 векторов запросов может быть сохранено в базе данных векторов запросов сервера 210 поисковой системы таким образом, чтобы сравнение векторов запросов, описанное ниже, могло выполняться, только когда сервер 210 поисковой системы принимает текущий запрос от пользователя, связанного с клиентским устройством (таким как первое клиентское устройство ПО, второе клиентское устройство 120, третье клиентское устройство 130 и четвертое клиентское устройство 140).
[00126] Формирователь параметров сходства
[00127] Формирователь 450 параметров сходства может в качестве входных данных принимать множество 440 векторов запросов и выдавать набор 460 кортежей сходства, в котором каждый кортеж 462 содержит пару 464 запросов и соответствующий параметр 466 сходства, указывающий на уровень сходства двух запросов в паре 464 запросов.
[00128] В общем случае, формирователь 450 параметров сходства предназначен для расчета соответствующего параметра 466 сходства для каждой возможной соответствующей пары 464 запросов в указании на множество 402 поисковых запросов. Соответствующий параметр 466 сходства указывает на уровень сходства запросов в паре 464 запросов на основании по меньшей мере одного из: (а) сходных результатов поиска, полученных в ответ на запросы из пары 464 запросов; и (б) действий пользователей с соответствующими сходными результатами поиска. Уровень сходства может быть оценен путем сравнения векторов запросов, связанных с каждым запросом в паре запросов.
[00129] В не имеющем ограничительного характера примере настоящего варианта осуществления изобретения соответствующий параметр 466 сходства для пары 464 запросов может быть получен путем выполнения скалярного умножения соответствующих связанных векторов 442 запросов из набора 440 векторов запросов. Соответствующий параметр 466 сходства может непосредственно указывать на сходство запросов на основе их результатов поиска и действий пользователей. В не имеющем ограничительного характера примере соответствующий параметр 466 сходства, имеющий значение 10, может указывать на то, что два поисковых запроса в паре 464 запросов имеют по меньшей мере 10 сходных результатов поиска и что для 10 сходных результатов имеются действия пользователей, например, в виде коэффициента CTR (в качестве не имеющего ограничительного характера примера для результата поиска в векторе запроса наличие коэффициента CTR свыше заранее заданного порога 0,6 соответствует значению 1, а наличие коэффициента CTR ниже заранее заданного порога 0,6 соответствует значению 0). В некоторых вариантах осуществления изобретения соответствующий параметр сходства может быть относительным, например, если имеется 10 сходных результатов поиска, имеющих коэффициент CTR, из общего количества результатов поиска, равного 20, то соответствующий параметр 466 сходства может быть равен 10/20=0,5 или 50%. В некоторых вариантах осуществления изобретения соответствующий параметр 466 сходства может быть взвешен на основе различных критериев. В других вариантах осуществления изобретения, где вектор 422 запроса содержит значения для каждого действия пользователя, соответствующий параметр 466 сходства может представлять собой результат скалярного умножения этих значений. В не имеющем ограничительного характера примере для пары 464 значений, имеющих 3 сходных результата поиска, с первым вектором запроса из пары 464 запросов, имеющим значения CTR (0,2 0,5 0,7) для 3 результатов поиска, и вторым вектором запроса из пары 464 запросов, имеющим значения CTR (0,65 0,2 0,4) для 3 результатов поиска, соответствующий параметр 466 сходства может быть рассчитан следующим образом: 0,2×(0,65)+0,5×(0,2)+0,7×(0,4)=0,51 (при этом несходные результаты могут игнорироваться).
[00130] В тех вариантах осуществления изобретения, где с каждыми результатом поиска связаны действия пользователей нескольких видов, кортежи 462 для каждой пары могут содержать несколько соответствующих параметров 466 сходства (соответствующих разным видам действий пользователей) или соответствующий параметр 466 сходства в кортеже 462 может представлять собой сумму соответствующих параметров сходства.
[00131] В других вариантах осуществления изобретения для количественной оценки сходства запросов на основе сходных результатов поиска и действий пользователей могут использоваться другие известные способы, такие как близость косинусов углов, двудольные графы, коэффициент корреляции Пирсона и т.д.
[00132] Затем формирователь 450 параметров сходства может выдавать набор 460 кортежей сходства. Набор 460 кортежей сходства содержит для каждой возможной пары поисковых запросов соответствующий кортеж 462, представленный в виде <qi, qi, Sij> и содержащий указание на первый запрос qi из пары 464 запросов, указание на второй запрос qi из пары 464 запросов и параметр 466 Sij сходства первого запроса qi и второго запроса qi.
[00133] Набор 460 кортежей сходства может быть сохранен в базе 232 данных обучения сервера 230 обучения или в другой базе данных, такой как база данных (не показана), связанная с сервером 210 поисковой системы.
[00134] В не имеющем ограничительного характера примере каждый соответствующий кортеж 462 может быть сохранен в виде обучающего объекта из набора обучающих объектов (не показан) в базе 232 данных обучения сервера 230 обучения. Кроме того, в некоторых вариантах осуществления изобретения каждый соответствующий кортеж 462, сохраненный в качестве обучающего объекта, также может содержать соответствующие векторы 442 запросов, связанные с каждым указанием на запрос в паре 464 запросов.
[00135] На фиг. 4 представлена соответствующая не имеющим ограничительного характера вариантам осуществления настоящей технологии схема процедуры 500 расширения запросов.
[00136] Процедура 500 расширения запросов может выполняться сервером 210 поисковой системы. В некоторых вариантах осуществления изобретения процедура 500 расширения запросов может выполняться сервером 230 обучения или другим сервером (не показан). Выходные данные процедуры 500 расширения запросов могут быть использованы сервером 230 обучения для обучения второго алгоритма 340 MLA с целью расширения неизвестного запроса, ранее не отправлявшегося серверу 210 поисковой системы.
[00137] В процедуре 500 расширения запросов задействованы извлекатель 520 результатов поиска, формирователь 550 векторов запросов, формирователь 570 параметров сходства, селектор 590 и первый алгоритм 320 MLA.
[00138] Процедура 500 расширения запросов может выполняться, когда указание на текущий запрос 515 принято сервером 210 поисковой системы.
[00139] В некоторых вариантах осуществления изобретения, где множество векторов запросов было ранее сохранено в базе 232 данных обучения, например, во время выполнения процедуры 400 формирования сходных запросов, процедура 500 расширения запросов может начинаться формирователем 570 параметров сходства. В других вариантах осуществления изобретения, где множество векторов запросов ранее не сохранялось в базе 232 данных обучения, процедура 500 расширения запросов может начинаться извлекателем 520 результатов поиска.
[00140] Извлекатель результатов поиска
[00141] Извлекатель 520 результатов поиска может принимать указание на текущий запрос 515 от сервера 210 поисковой системы или непосредственно от клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140. После приема указания на текущий запрос 515 извлекатель 520 результатов поиска может формировать набор 532 текущих результатов поиска в ответ на текущий запрос 515. Извлекатель 520 результатов поиска может формировать набор 532 текущих результатов поиска подобно тому, как после отправки пользователем электронного устройства запроса серверу 210 поисковой системы этот сервер извлекает из индекса 214 набор документов, релевантных запросу (или указание на него), для представления в качестве результатов поиска. В общем случае, указание на текущий запрос 515 представляет собой указание на запрос, ранее отправлявшийся серверу 210 поисковой системы, которому соответствуют действия 536 пользователей, связанные с каждым результатом 534 поиска из набора 532 текущих результатов поиска. В других вариантах осуществления изобретения, где действия пользователей не учитываются, указание на текущий запрос 515 могло ранее отправляться или не отправляться серверу 210 поисковой системы.
[00142] В некоторых вариантах осуществления изобретения, где множество векторов запросов ранее не сохранялось в базе 232 данных обучения, извлекатель 520 результатов поиска может извлекать множество 540 запросов и результатов поиска на основе набора 532 текущих результатов поиска, связанного с текущим запросом 515, при этом каждый набор 542 результатов поиска был представлен в ответ на соответствующий запрос 541. В общем случае, каждый набор 542 результатов поиска содержит один или несколько соответствующих результатов поиска, подобных результатам поиска из набора 532 текущих результатов поиска, предоставленного в ответ на текущий запрос 515. Каждый соответствующий результат 544 поиска из набора 542 результатов поиска связан с соответствующими действиями пользователей, выполненными соответствующим множеством пользователей после отправки соответствующего запроса 541.
[00143] Затем извлекатель 520 результатов поиска может выдавать множество 540 запросов и результатов поиска и набор 532 текущих результатов поиска, связанный с текущим запросом 515. [00144] Формирователь векторов запросов
[00145] Затем множество 540 запросов и результатов поиска и набор 532 текущих результатов поиска, связанных с текущим запросом 515, могут приниматься формирователем 550 векторов запросов.
[00146] Формирователь 550 векторов запросов подобен формирователю 420 векторов запросов, представленному на фиг. 3. Формирователь 550 векторов запросов может формировать вектор 560 текущего запроса для набора 532 текущих результатов поиска, связанных с текущим запросом 515, например, если база 232 данных обучения не содержит вектор 560 текущего запроса (который мог быть ранее сформирован, например, формирователем 420 векторов запросов, представленным на фиг. 3).
[00147] Формирователь 550 векторов запросов может формировать для множества 540 запросов и результатов поиска набор 564 векторов запросов, содержащий соответствующий вектор 566 запроса для каждого набора 542 результатов поиска, связанного с соответствующим запросом 541.
[00148] В некоторых вариантах осуществления изобретения, где база 232 данных обучения содержит множество ранее сформированных векторов запросов (которые могли быть сформированы автономно формирователем 420 векторов запросов, представленным на фиг. 3), формирователь 550 векторов запросов может извлекать по меньшей мере часть набора 564 векторов запросов из базы 232 данных обучения и может формировать другую часть набора 564 векторов запросов, если она не была ранее сформирована и сохранена в базе 232 данных обучения.
[00149] Формирователь 550 векторов запросов может выдавать вектор 560 текущего запроса, связанный с указанием на текущий запрос 515. Формирователь 550 векторов запросов может выдавать набор 564 векторов запросов, в котором каждый соответствующий вектор 566 запроса представляет соответствующий набор 542 результатов поиска, связанный с соответствующим запросом 541 во множестве 540 запросов и результатов поиска.
[00150] Формирователь параметров сходства
[00151] Вектор 560 текущего запроса и набор 564 векторов запросов могут приниматься формирователем 570 параметров сходства.
[00152] Формирователь 570 параметров сходства подобен формирователю 450 параметров сходства, представленному на фиг. 3. Формирователь 570 параметров сходства может формировать соответствующий параметр 586 сходства между текущим запросом 515 и каждым соответствующим запросом 541 из множества 540 запросов и результатов поиска с использованием вектора 560 текущего запроса и каждого соответствующего вектора 566 запроса из набора 564 векторов запросов.
[00153] В не имеющем ограничительного характера примере настоящего варианта осуществления изобретения соответствующий параметр 586 сходства для пары 584 запросов, содержащей текущий запрос 515 и соответствующий запрос 541, может быть получен путем выполнения скалярного умножения соответствующих векторов 566 запросов из набора 564 векторов запросов и вектора 560 текущего запроса. В других вариантах осуществления изобретения для количественной оценки сходства запросов на основе сходных результатов поиска и действий пользователей могут использоваться другие известные способы, такие как близость косинусов углов, двудольные графы, коэффициент корреляции Пирсона и т.д.
[00154] Формирователь 570 параметров сходства может выдавать набор 580 кортежей сходства, в котором каждый соответствующий кортеж 582 сходства содержит пару 584 запросов и соответствующий параметр 586 сходства, указывающий на уровень сходства текущего запроса 515 и соответствующего запроса 541 в паре 584 запросов.
[00155] В некоторых вариантах осуществления изобретения набор 580 кортежей сходства может сохраняться в базе 232 данных обучения.
[00156] Селектор
[00157] Затем набор 580 кортежей сходства может приниматься селектором 590.
[00158] В общем случае, селектор 590 предназначен для выбора подмножества 592 запросов из множества 540 запросов и результатов поиска с использованием набора 580 кортежей сходства. На способ выбора подмножества 592 запросов не накладывается каких-либо ограничений.
[00159] Селектор 590 может выбирать каждый соответствующий запрос 594 подмножества 592 запросов на основе соответствующего превышающего заранее заданный порог параметра 586 сходства между текущим запросом 515 и соответствующим запросом 541 из набора 580 кортежей сходства. Дополнительно или в качестве альтернативы, селектор 590 может выбирать заранее заданное количество запросов, связанных с наибольшими значениями параметров сходства (например, могут быть выбраны запросы, связанные с первыми пятью параметрами сходства в наборе 580 кортежей сходства).
[00160] Затем селектор 590 может выдавать подмножество 592 запросов, в котором каждый соответствующий запрос 594 связан с соответствующим параметром 596 сходства и выбран на основе соответствующего параметра 596 сходства между текущим запросом 515 и соответствующим запросом 594, превышающего заранее заданный порог, и/или соответствующего параметра 596 сходства между текущим запросом 515 и соответствующим запросом 594 в пределах заранее заданного количества наибольших значений параметра сходства. Подмножество 592 запросов может использоваться для расширения текущего запроса 515 с целью ранжирования набора 532 текущих результатов поиска, связанного с текущим запросом 515. На способ использования подмножества 592 запросов для расширения текущего запроса 515 не накладывается каких-либо ограничений.
[00161] Расширение текущего запроса
[00162] Затем подмножество 592 запросов может приниматься первым алгоритмом 320 MLA сервера 210 поисковой системы. В некоторых вариантах осуществления изобретения первый алгоритм 320 MLA может быть предварительно обучен на сервере 320 обучения, чтобы ранжировать результаты поиска на основе сходных поисковых запросов.
[00163] Подмножество 592 запросов может быть использовано в функции ранжирования первого алгоритма 320 MLA таким образом, чтобы первый алгоритм 320 MLA включал в себя термины каждого соответствующего запроса 594 из подмножества 592 запросов, которые могут учитываться при ранжировании каждого соответствующего результата 534 поиска из набора 532 текущих результатов поиска. Подмножество 592 запросов может быть использовано первым алгоритмом 320 MLA в качестве ранжирующих признаков для ранжирования набора 532 текущих результатов поиска в ответ на текущий запрос 515.
[00164] В не имеющем ограничительного характера примере один или несколько результатов поиска из набора 532 текущих результатов поиска могут иметь «повышенный» ранг, поскольку они содержат термины одного или нескольких запросов из подмножества 592 запросов. Дополнительно или в качестве альтернативы, соответствующий параметр 596 сходства, связанный с каждым соответствующим запросом 594 в подмножестве 592 запросов, может быть использован для взвешивания влияния поисковых терминов при ранжировании, т.е. запросу из подмножества 592 запросов с большим параметром сходства может придаваться большее значение при ранжировании каждого соответствующего результата 534 поиска из набора 532 текущих результатов поиска.
[00165] Затем первый алгоритм 320 MLA может выдавать страницу 598 SERP, где набор 532 текущих результатов поиска, сформированный в ответ на текущий запрос 515, ранжирован первым алгоритмом 320 MLA с учетом подмножества 592 запросов. В не имеющем ограничительного характера примере результат поиска из набора 532 текущих результатов поиска, который при ранжировании получил бы низкий ранг, попал бы на третью или четвертую страницу SERP и имел бы меньше шансов на выполнение действия в его отношении, если бы не было учтено подмножество 592 запросов, может быть ранжирован среди первых пяти результатов поиска на странице SERP, поскольку данный результат поиска включает в себя часть терминов запросов из подмножества 592 запросов и может содержать полезную информацию, которую ищет пользователь и которую он мог бы пропустить, если бы этому результату поиска не был присвоен более высокий ранг.
[00166] На фиг. 5 представлена схема соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии этапа 600 обучения второго алгоритма 340 MLA.
[00167] Этап 600 обучения второго алгоритма 340 MLA может выполняться сервером 230 обучения.
[00168] В общем случае, этап 600 обучения второго алгоритма 340 MLA может выполняться, когда база 232 данных обучения содержит обучающие объекты или кортежи, количество которых превышает заранее заданный порог. В не имеющем ограничительного характера примере этап 600 обучения может выполняться, когда в базе 232 данных обучения хранится 100000000 кортежей, таких как кортежи, сформированные во время выполнения процедуры 400 формирования сходных запросов, представленной на фиг. 3, и/или процедуры 500 расширения запросов, представленной на фиг. 4.
[00169] На этапе 600 обучения задействован формирователь 610 обучающих наборов, второй формирователь 630 векторов запросов, второй алгоритм 340 MLA и компилятор 660 базы данных.
[00170] Формирователь обучающих наборов
[00171] В общем случае, формирователь 610 обучающих наборов предназначен для получения из базы 232 данных обучения множества 620 кортежей, при этом каждый соответствующий кортеж 622 содержит соответствующий первый запрос 624, соответствующий второй запрос 626 и соответствующий параметр 628 сходства между соответствующим первым запросом 624 и соответствующим вторым запросом 626, указывающий на степень сходства между соответствующим первым запросом 624 и соответствующим вторым запросом 626. Соответствующий параметр 628 сходства ранее был сформирован во время выполнения процедуры 400 формирования сходных запросов, представленной на фиг. 3, и/или процедуры 500 расширения запросов, представленной на фиг. 4, путем сравнения соответствующих векторов запросов (не показаны), связанных с соответствующим первым запросом 624 и соответствующим вторым запросом 626, при этом соответствующие векторы запросов содержали соответствующие результаты поиска и соответствующие действия пользователей, выполненные соответствующими пользователями в ответ на соответствующий первый запрос 624 и соответствующий второй запрос 626.
[00172] В некоторых вариантах осуществления изобретения соответствующие кортежи во множестве 620 кортежей, содержащие сходный запрос, могут быть связаны друг с другом.
[00173] Второй формирователь векторов запросов
[00174] Множество 620 кортежей может быть принято в качестве входных данных вторым формирователем 630 векторов запросов. Второй формирователь 630 векторов запросов предназначен для формирования второго набора 640 обучающих объектов, при этом каждый соответствующий обучающий объект 642 содержит соответствующий первый вектор 644 запроса для соответствующего первого запроса 624, соответствующий второй вектор 646 запроса для соответствующего второго запроса 626 и соответствующий параметр 628 сходства между соответствующим первым запросом 624 и соответствующим вторым запросом 626.
[00175] В общем случае, для каждого соответствующего обучающего объекта 642 из второго набора 640 обучающих объектов второй формирователь 630 векторов запросов с использованием алгоритма векторизации слов может формировать соответствующий первый вектор 644 запроса для соответствующего первого запроса 624 на основе терминов соответствующего первого запроса 624 и соответствующий второй вектор 646 запроса для соответствующего второго запроса 626 на основе терминов соответствующего второго запроса 626.
[00176] В общем случае, алгоритм векторизации слов предназначен для представления слова в виде вектора действительных чисел с помощью набора способов языкового моделирования и формирования признаков, используемых для обработки естественного языка (NLP, Natural Language Processing). На вид алгоритма векторизации слов не накладывается каких-либо ограничений, например, могут использоваться алгоритмы word2vec, латентное размещение Дирихле (Latent Dirichlet Allocation) и т.д. Выбранные один или несколько алгоритмов векторизации слов способны создавать вектор запроса таким образом, чтобы векторы запросов со сходными текстами были в основном сходны. Иными словами, выбранные один или несколько способов векторизации слов обеспечивают отображение сходных запросов в сходные векторы запросов (т.е. векторы элементов, близкие в многомерном пространстве). В некоторых вариантах осуществления изобретения второй формирователь 530 векторов запросов может представлять собой алгоритм MLA, обученный для формирования векторных представлений слов, в виде нейронной сети и т.д.
[00177] Второй формирователь 630 векторов запросов может выдавать второй набор 640 обучающих объектов.
[00178] Второй алгоритм MLA
[00179] Набор 640 обучающих объектов может приниматься в качестве входных данных вторым алгоритмом 340 MLA, который может быть обучен на каждом обучающем объекте 642 из набора 640 обучающих объектов, при этом каждый обучающий объект 642 содержит соответствующий первый вектор 644 запроса, соответствующий второй вектор 646 запроса и соответствующий второй параметр 648 сходства, который может быть использован в качестве метки для обучения второго алгоритма 340 MLA.
[00180] В общем случае, второй алгоритм 340 MLA предназначен (после завершения этапа 600 обучения) для выполнения расчета соответствующего параметра сходства между новым ранее не известным запросом (т.е. запросом, ранее не отправлявшимся серверу 210 поисковой системы и/или запросом, на котором не был обучен второй алгоритм 340 MLA), представленным соответствующим вектором запроса, полученным путем векторизации слов, и ранее отправленным запросом, представленным соответствующим вектором запроса, полученным путем векторизации слов.
[00181] В некоторых вариантах осуществления изобретения второй алгоритм 340 MLA может реализовывать алгоритм вида K-NNS, предполагающий определение некоторой функции расстояния (такой как соответствующие вторые параметры 648 сходства в наборе 640 обучающих объектов) между элементами данных (такими как первый вектор 644 запроса и второй вектор 646 запроса в каждом обучающем объекте 642 из набора 640 обучающих объектов), направленной на поиск K векторов запросов из набора 640 обучающих объектов с минимальным расстоянием до заданного вектора запроса.
[00182] В настоящем варианте осуществления изобретения второй алгоритм 640 MLA реализует алгоритм HNSW, представляющий собой основанную на графе структуру инкрементного приближенного поиска K ближайших соседей (K-ANNS, K Approximate Nearest Neighbors Search). Вкратце, алгоритм HNSW представляет собой поисковую структуру на основе графа малого мира с вершинами, соответствующими сохраненным элементам (т.е. векторам запросов), с ребрами, соответствующими связям между ними, и является вариантом алгоритма «жадного» поиска. Алгоритм HNSW начинается с точки входа в вершину, рассчитывает расстояние (т.е. второй параметр сходства на основе векторов запросов, сформированных вторым формирователем 630 векторов запросов) от запроса q до каждой вершины из списка друзей (friend list) текущей вершины (который может содержать векторы запросов, сходные с вектором запроса q), а затем выбирает вершину с минимальным расстоянием. Если расстояние между запросом и выбранной вершиной меньше расстояния между запросом и текущим элементом, алгоритм переходит к выбранной вершине, которая становится новой текущей вершиной. Выполнение алгоритма прекращается, когда он достигает локального минимума - вершины, список друзей которой не содержит вершину, более близкую к запросу, чем текущая вершина. Элемент, представляющий собой локальный минимум для запроса q, может быть истинным ближайшим элементом запроса q из всех элементов набора X или ложным ближайшим элементом (ошибкой).
[00183] Таким образом, второй алгоритм 340 MLA, реализующий алгоритм HNSW, после обучения может принимать новый ранее не известный запрос (не показан), рассчитывать вектор этого нового запроса (не показан) и извлекать подмножество из набора запросов (не показан), сохраненных в базе 232 данных обучения, где каждый соответствующий запрос (представлен соответствующим вектором запроса) подмножества запросов имеет минимальное расстояние до вектора нового запроса. Таким образом, значение, обратно пропорциональное минимальному расстоянию, может представлять собой второй параметр сходства, указывающий на степень сходства между новым запросом и соответствующим запросом из подмножества запросов с использованием вектора нового запроса и вектора соответствующего запроса, сформированного вторым формирователем 630 векторов запросов.
[00184] В общем случае, второй алгоритм 340 MLA может рассчитывать параметры сходства между запросами в паре на основе текстовых признаков запросов, которые могут быть подобными параметру сходства, рассчитанному на основе сходных результатов поиска и действий пользователей. Таким образом, второй алгоритм 340 MLA после обучения может рассчитывать параметры сходства между запросами любого вида (т.е. ранее известными или ранее не известными запросами) и в случаях, когда параметр сходства между известными запросами рассчитан на основе их текстовых признаков, параметр сходства может быть аналогичным параметру сходства, рассчитанному на основе сходных результатов поиска и/или действий пользователей.
[00185] На фиг. 6 представлена схема соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии этапа 700 использования второго алгоритма 340 MLA. Этап 700 использования второго алгоритма 340 MLA может выполняться сервером 210 поисковой системы. В других вариантах осуществления изобретения этап 700 использования может выполняться совместно сервером 230 обучения и сервером 210 поисковой системы.
[00186] На этапе 700 использования задействованы второй формирователь 630 векторов запросов, второй алгоритм 340 MLA, селектор 740 и первый алгоритм 320 MLA.
[00187] Второй формирователь 630 векторов запросов может принимать в качестве входных данных новый запрос 702, ранее не отправлявшийся серверу 210 поисковой системы.
[00188] Второй формирователь 630 поисковых запросов может формировать вектор 710 нового запроса на основе терминов нового запроса 702 с использованием алгоритма векторизации слов. Затем второй формирователь 630 векторов запросов может выдавать вектор 710 нового запроса, связанный с новым запросом 702.
[00189] Затем вектор 710 нового запроса может приниматься в качестве входных данных вторым алгоритмом 340 MLA. Второй алгоритм 340 MLA может реализовывать алгоритм HNSW, рассчитывать второй параметр 724 сходства между вектором 710 нового запроса и множеством 715 векторов запросов, хранящимся в базе 232 данных обучения, при этом каждый вектор 717 соответствующего запроса связан с соответствующим запросом 719. Затем второй алгоритм 340 MLA может на основе множества 715 векторов запросов выдавать набор 720 запросов, в котором каждый соответствующий запрос 722 связан с соответствующим вторым параметром 724 сходства, указывающим на степень сходства между соответствующим запросом 722 и новым запросом 702 на основе по меньшей мере одного текстового признака соответствующего запроса 722 (т.е. вектора соответствующего запроса) и по меньшей мере одного текстового признака нового запроса 702 (т.е. вектора 710 нового запроса).
[00190] Затем набор 720 запросов может приниматься селектором 740. Селектор 740 может выбирать подмножество 745 запросов из набора 720 запросов на основе соответствующего второго параметра 724 сходства, превышающего заранее заданный порог.
[00191] Дополнительно или в качестве альтернативы, селектор 740 может выбирать заранее заданное количество запросов, имеющих наибольшее значение второго параметра сходства, из набора 720 запросов для включения в подмножество 745 запросов. Затем подмножество 745 запросов может использоваться для расширения нового запроса 702.
[00192] В некоторых вариантах осуществления изобретения функции селектора 740 могут быть реализованы во втором алгоритме 340 MLA, т.е. второй алгоритм 340 MLA может извлекать только запросы, связанные с соответствующим вторым параметром 724 сходства, превышающим порог, и непосредственно выдавать подмножество 745 запросов.
[00193] Затем подмножество 745 запросов может приниматься первым алгоритмом 320 MLA. Первый алгоритм 320 MLA может извлекать из индекса 214 набор 750 результатов поиска на основе терминов нового запроса 702. Затем первый алгоритм 320 MLA может ранжировать набор результатов 750 поиска для получения страницы 760 SERP. В некоторых вариантах осуществления изобретения первый алгоритм 320 MLA может извлекать набор результатов 750 поиска, когда указание на новый запрос 702 принимается вторым формирователем 630 векторов запросов.
[00194] Подмножество 745 запросов может быть использовано в функции ранжирования первого алгоритма 320 MLA таким образом, чтобы первый алгоритм 320 MLA включал в себя термины каждого соответствующего запроса 742 из подмножества 745 запросов, которые могут учитываться при ранжировании набора 750 результатов поиска. Подмножество 745 запросов может быть использовано первым алгоритмом 320 MLA в качестве ранжирующих признаков для ранжирования набора 750 результатов поиска в ответ на новый запрос 702.
[00195] В не имеющем ограничительного характера примере один или несколько результатов поиска из набора 750 результатов поиска могут иметь «повышенный» ранг, поскольку они содержат термины запросов из подмножества 745 запросов. Дополнительно или в качестве альтернативы, соответствующие параметры 744 сходства, связанные с каждым соответствующим запросом 742 в подмножестве 745 запросов, могут быть использованы для взвешивания влияния поисковых терминов при ранжировании, т.е. запросу из подмножества 745 запросов с большим вторым параметром сходства может придаваться большее значение при ранжировании набора 750 результатов поиска.
[00196] Затем первый алгоритм 320 MLA может выдавать страницу 760 SERP, где набор 750 результатов поиска, сформированный в ответ на новый запрос 702, ранжирован с учетом подмножества 745 запросов или расширен с использованием подмножества 745 запросов.
[00197] На фиг. 7 и 8 представлена блок-схема соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии способа 800 ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма 320 MLA.
[00198] Способ 800 может выполняться сервером 210 поисковой системы, когда сервер 210 поисковой системы принимает запрос, ранее отправлявшийся серверу 210 поисковой системы и имеющий действия пользователей в отношении результатов, представленных в ответ на этот запрос.
[00199] Способ 800 может начинаться с шага 802.
[00200] Шаг 802: прием сервером от электронного устройства указания на текущий запрос.
[00201] На шаге 802 сервер 210 поисковой системы может принимать от первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140 указание на текущий запрос 515, которое представляет собой указание на запрос, ранее отправлявшийся серверу 210 поисковой системы.
[00202] Затем способ 800 может продолжаться на шаге 804.
[00203] Шаг 804: формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему запросу, при этом текущий документ из набора текущих документов связан с прошлыми действиями некоторых пользователей из множества прошлых пользователей в отношении этого документа, представленного в ответ на прошлый запрос, подобный текущему запросу.
[00204] На шаге 804 после приема указания на текущий запрос 515 извлекатель 520 результатов поиска может формировать набор 532 текущих результатов поиска, релевантный текущему запросу 515, в ответ на текущий запрос 515. Извлекатель 520 результатов поиска может формировать набор 532 текущих результатов поиска подобно тому, как сервер 210 поисковой системы принимает поисковый запрос и в ответ формирует результаты поиска: путем извлечения из индекса 214 набора документов (или указания на них), связанных с терминами запроса, для представления в качестве результатов поиска. Каждый соответствующий результат 534 поиска из набора 532 текущих результатов поиска связан с соответствующими действиями 536 пользователей, выполненными соответствующим множеством пользователей после отправки текущего запроса 515.
[00205] Затем способ 800 может продолжаться на шаге 806.
[00206] Шаг 806: формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей, связанных с текущими документами.
[00207] На шаге 806 формирователь 550 векторов запросов может формировать вектор 560 текущего запроса, связанный с указанием на текущий запрос 515 на основе набора 532 текущих результатов поиска, при этом каждый соответствующий результат 534 поиска связан с соответствующими действиями 536 пользователей.
[00208] Затем способ 800 может продолжаться на шаге 808.
[00209] Шаг 808: извлечение сервером из базы данных множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос.
[00210] На шаге 808 извлекатель результатов поиска может извлечь из журнала 226 запросов и/или журнала 228 действий пользователей множество 540 запросов и результатов поиска на основе набора 532 текущих результатов поиска, связанного с текущим запросом 515, при этом каждый соответствующий набор 542 результатов поиска был представлен в ответ на соответствующий запрос 541. Каждый соответствующий результат 544 поиска из набора 542 результатов поиска связан с соответствующими действиями 546 пользователей, выполненными соответствующим множеством пользователей после отправки соответствующего запроса 541.
[00211] Затем способ 800 может продолжаться на шаге 810.
[00212] Шаг 810: формирование сервером вектора соответствующего запроса, связанного с соответствующим запросом из множества прошлых запросов, на основе прошлых документов из соответствующего набора прошлых документов и прошлых действий пользователей в отношении прошлых документов.
[00213] На шаге 810 формирователь 550 векторов запросов может формировать для множества 540 запросов и результатов поиска набор 564 векторов запросов, содержащий соответствующий вектор 566 запроса для каждого набора 542 результатов поиска, связанного с соответствующим запросом 541, при этом каждый соответствующий вектор 566 запроса формируется на основе каждого соответствующего результата 544 поиска из набора 542 результатов поиска, связанного с соответствующими действиями 546 пользователей.
[00214] Затем способ 800 может продолжаться на шаге 812.
[00215] Шаг 812: расчет сервером соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и прошлых документах из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов.
[00216] На шаге 812 формирователь 570 параметров сходства может формировать набор 580 кортежей сходства, при этом каждый соответствующий кортеж 582 сходства содержит пару 584 запросов, включая текущий запрос 515 и соответствующий запрос 541, и соответствующий параметр 586 сходства между текущим запросом 515 и соответствующим запросом с использованием вектора 560 текущего запроса и соответствующего вектора 566 запроса из набора 564 векторов запросов. В некоторых вариантах осуществления изобретения соответствующий параметр 586 сходства может быть рассчитан путем выполнения скалярного умножения соответствующих векторов 566 запросов и вектора 560 текущего запроса.
[00217] Затем способ 800 может продолжаться на шаге 814.
[00218] Шаг 814: выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства.
[00219] На шаге 814 селектор 590 может выбирать каждый соответствующий запрос 594 для добавления в подмножество 592 запросов на основе превышения заранее заданного порога соответствующим параметром 586 сходства между текущим запросом 515 и соответствующим запросом 541 из набора 580 кортежей сходства. Дополнительно или в качестве альтернативы, селектор 590 может выбирать заранее заданное количество запросов, связанных с наибольшими значениями параметров сходства (например, могут быть выбраны запросы, связанные с первыми пятью параметрами сходства в наборе 580 кортежей сходства).
[00220] Затем способ 800 может продолжаться на шаге 816.
[00221] Шаг 816: ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывая подмножество из множества прошлых запросов в качестве ранжирующего признака.
[00222] На шаге 818 подмножество 592 запросов может использоваться первым алгоритмом 320 MLA с целью расширения текущего запроса 515 для ранжирования набора 532 текущих результатов поиска. Подмножество 592 запросов может быть включено в состав функции ранжирования первого алгоритма 320 MLA таким образом, чтобы первый алгоритм 320 MLA включал в себя термины каждого соответствующего запроса 594 из подмножества 592 запросов, которые могут учитываться при ранжировании набора 532 текущих результатов поиска. Подмножество 592 запросов может быть использовано первым алгоритмом 320 MLA в качестве ранжирующих признаков для ранжирования набора 532 текущих результатов поиска в ответ на текущий запрос 515. Соответствующие параметры 596 сходства, связанные с каждым соответствующим запросом 594 в подмножестве 592 запросов, могут быть использованы для взвешивания влияния поисковых терминов при ранжировании, т.е. запросу из подмножества 592 запросов с большим параметром сходства может придаваться большее значение при ранжировании набора 532 текущих результатов поиска.
[00223] Затем способ 800 может продолжаться на шаге 818.
[00224] Шаг 818: передача сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[00225] На шаге 818 сервер 210 поисковой системы может формировать страницу 598 SERP, где набор 532 текущих результатов поиска, сформированный в ответ на текущий запрос 515, ранжирован первым алгоритмом 320 MLA с учетом подмножества 592 запросов. Затем страница 598 SERP может передаваться первому клиентскому устройству 110, второму клиентскому устройству 120, третьему клиентскому устройству 130 или четвертому клиентскому устройству 140.
[00226] На этом способ 800 может быть завершен.
[00227] На фиг. 9 представлена блок-схема соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии способа 900 ранжирования результатов поиска в ответ на новый запрос с использованием второго алгоритма 340 MLA и первого алгоритма 320 MLA.
[00228] В общем случае, второй алгоритм 340 MLA обучен определять сходство запроса на основе его текстового контента, например, путем предоставления обучающих примеров пар запросов и параметров сходства, которые ранее были сформированы способом 800, и путем обучения определению второго параметра сходства на основе векторных представлений слов запросов в парах с использованием алгоритма HNSW. Способ 900 может выполняться вторым алгоритмом 340 MLA после приема нового запроса, ранее не отправлявшегося серверу 210 поисковой системы (т.е. действия пользователей в отношении результатов отсутствуют).
[00229] В некоторых вариантах осуществления изобретения способ 900 может выполняться вторым алгоритмом 340 MLA при каждом приеме запроса сервером 210 поисковой системы, при этом запрос ранее мог отправляться или не отправляться серверу 210 поисковой системы.
[00230] Способ 900 может начинаться с шага 902.
[00231] Шаг 902: прием сервером от электронного устройства указания на текущий запрос, ранее не отправлявшийся серверу.
[00232] На шаге 902 второй формирователь 630 векторов запросов может принимать от первого клиентского устройства 110, второго клиентского устройства 120, третьего клиентского устройства 130 или четвертого клиентского устройства 140 новый запрос 702, ранее не отправлявшийся серверу 210 поисковой системы. В некоторых вариантах осуществления изобретения новый запрос 702 ранее отправлялся серверу 210 поисковой системы.
[00233] Затем способ 900 может продолжаться на шаге 904.
[00234] Шаг 904: формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу.
[00235] На шаге 904 первый алгоритм 320 MLA может формировать набор 750 результатов поиска путем извлечения из индекса 214 набора 750 результатов поиска на основе терминов нового запроса 702, при этом набор 750 результатов поиска содержит результаты поиска, имеющие отношение к новому запросу 702.
[00236] Затем способ 900 может продолжаться на шаге 906.
[00237] Шаг 906: формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса.
[00238] На шаге 906 второй формирователь 630 поисковых запросов может формировать вектор 710 нового запроса на основе терминов нового запроса 702 с использованием алгоритма векторизации слов.
[00239] Затем способ 900 может продолжаться на шаге 908.
[00240] Шаг 908: извлечение вторым алгоритмом MLA из базы данных множества прошлых запросов, каждый из которых ранее отправлялся серверу, при этом запрос из множества прошлых запросов связан с соответствующим вектором запроса, сформированным на основе по меньшей мере одного соответствующего текстового признака этого запроса из множества прошлых запросов, а извлечение основано на втором параметре сходства, который был рассчитан вторым алгоритмом MLA и основан на векторе текущего запроса и векторе соответствующего запроса.
[00241] На шаге 908 второй алгоритм 340 MLA может реализовывать алгоритм HNSW и рассчитывать второй параметр 724 сходства между вектором 710 нового запроса и множеством 715 векторов запросов, хранящихся в базе 232 данных обучения, при этом каждый вектор 717 соответствующего запроса связан с соответствующим запросом 719. Затем второй алгоритм 340 MLA может выдавать набор 720 запросов, в котором каждый соответствующий запрос 722 связан с соответствующим вторым параметром 724 сходства, указывающим на степень сходства между соответствующим запросом 722 и новым запросом 702 на основе вектора 717 соответствующего запроса и вектора 710 нового запроса.
[00242] Затем способ 900 может продолжаться на шаге 910.
[00243] Шаг 910: выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства.
[00244] На шаге 910 селектор 740 может выбирать подмножество 745 запросов из набора 720 запросов на основе превышения соответствующим вторым параметром 724 сходства заранее заданного порога.
[00245] Затем способ 900 может продолжаться на шаге 912.
[00246] Шаг 912: ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом MLA, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака.
[00247] На шаге 912 подмножество 745 запросов может быть использовано в функции ранжирования первого алгоритма 320 MLA таким образом, чтобы первый алгоритм 320 MLA включал в себя термины каждого соответствующего запроса 742 из подмножества 745 запросов, которые могут учитываться при ранжировании набора 750 результатов поиска. Подмножество 745 запросов может быть использовано первым алгоритмом 320 MLA в качестве ранжирующих признаков для ранжирования набора 750 результатов поиска в ответ на новый запрос 702. В не имеющем ограничительного характера примере один или несколько результатов поиска из набора 750 результатов поиска могут иметь «повышенный» ранг, поскольку они содержат термины запросов из подмножества 745 запросов. Дополнительно или в качестве альтернативы, соответствующие параметры сходства, связанные с каждым соответствующим запросом 742 в подмножестве 745 запросов, могут быть использованы для взвешивания влияния поисковых терминов при ранжировании, т.е. запросу из подмножества 745 запросов с большим вторым параметром сходства может придаваться большее значение при ранжировании набора 750 результатов поиска.
[00248] Затем способ 900 может продолжаться на шаге 914.
[00249] Шаг 914: передача сервером страницы SERP, содержащей ранжированный набор документов, для отображения на электронном устройстве.
[00250] На шаге 914 первый алгоритм 320 MLA может формировать страницу 760 SERP, содержащую набор 750 результатов поиска, сформированный в ответ на новый запрос 702 и ранжированный с учетом подмножества 745 запросов. Затем страница 760 SERP может передаваться первому клиентскому устройству 110, второму клиентскому устройству 120, третьему клиентскому устройству 130 или четвертому клиентскому устройству 140.
[00251] На этом способ 900 может быть завершен.
[00252] Способ 800 и способ 900 могут выполняться параллельно или могут быть объединены, например, путем проверки наличия текущего запроса в журнале 226 запросов, принятого сервером 210 поисковой системы, и выполнения способа 800 в случае положительного результата проверки или выполнения способа 900 в случае отрицательного результата проверки.
[00253] В других не имеющих ограничительного характера вариантах осуществления изобретения после достаточного обучения второго алгоритма 340 MLA (например, когда ошибка алгоритма оказывается ниже порога или на основании решения операторов второго алгоритма 340 MLA) способ 900 может выполняться после каждого приема сервером 210 поисковой системы запроса, который ранее мог отправляться или не отправляться серверу 210 поисковой системы.
[00254] Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления данной технологии преследуют цель расширения арсенала технических решений определенной технической проблемы: усовершенствование ранжирования набора результатов поиска в ответ на запрос путем улучшения ранжирующего алгоритма MLA с использованием запросов, которые считаются подобными текущему запросу, что позволяет усовершенствовать ранжирование некоторых результатов поиска из набора результатов поиска. Такие технические решения способны обеспечить экономию ресурсов, таких как объем памяти, производительность и время, как в клиентских устройствах, так и на сервере поисковой системы.
[00255] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
[00256] Некоторые из этих шагов и передаваемых или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях описания для упрощения. Сигналы могут передаваться или приниматься с использованием оптических средств (таких как волоконно-оптическое соединение), электронных средств (таких как проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
[00257] Изменения и усовершенствования описанных ранее вариантов осуществления настоящей технологии очевидны для специалиста в данной области. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Объем охраны данной технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| Способ и сервер для представления пользователю интересующих точек на карте | 2020 |
|
RU2793286C2 |
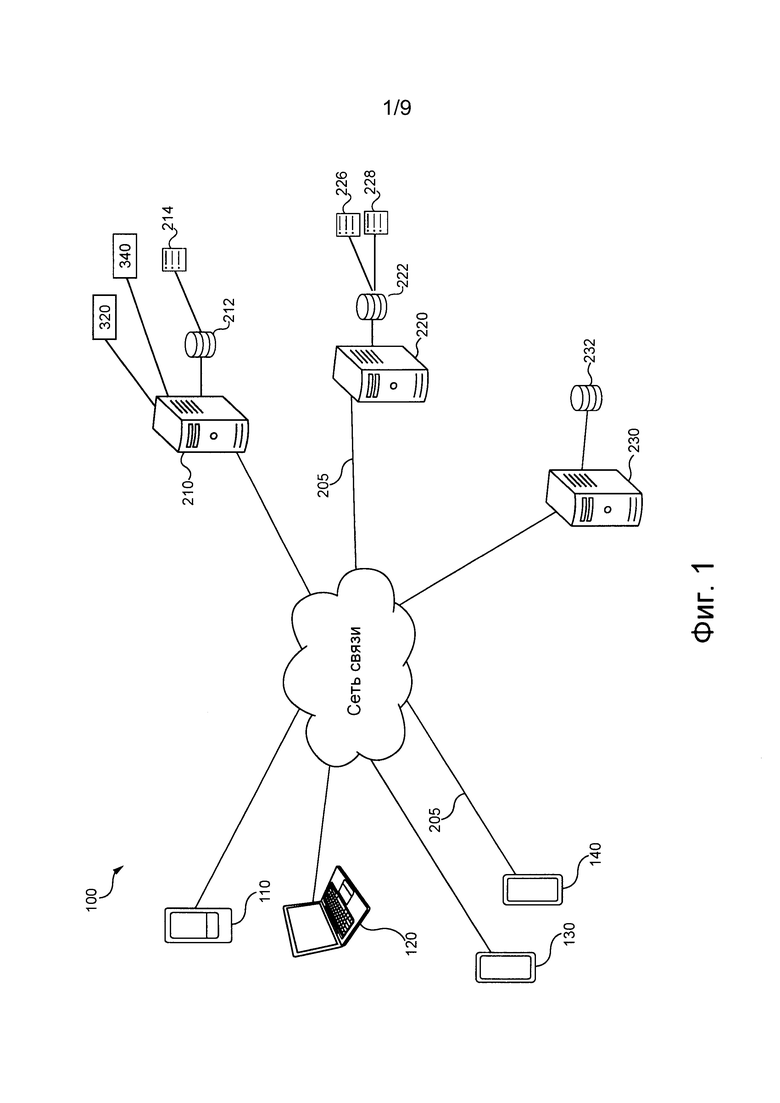

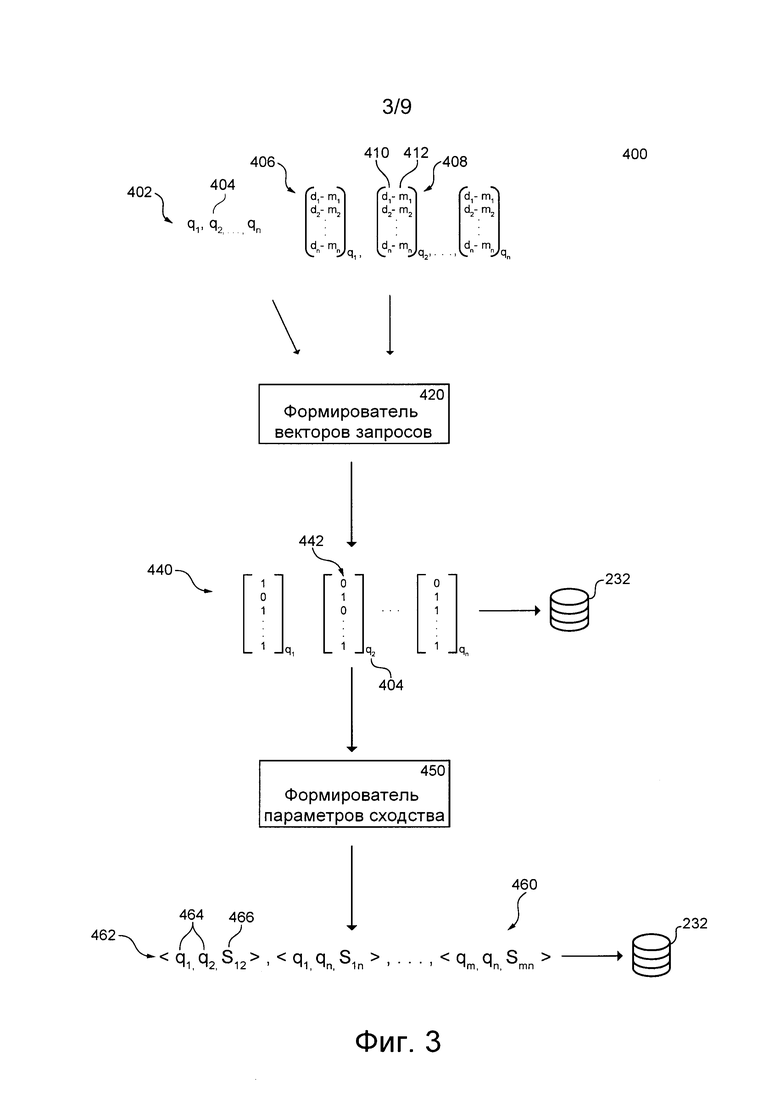
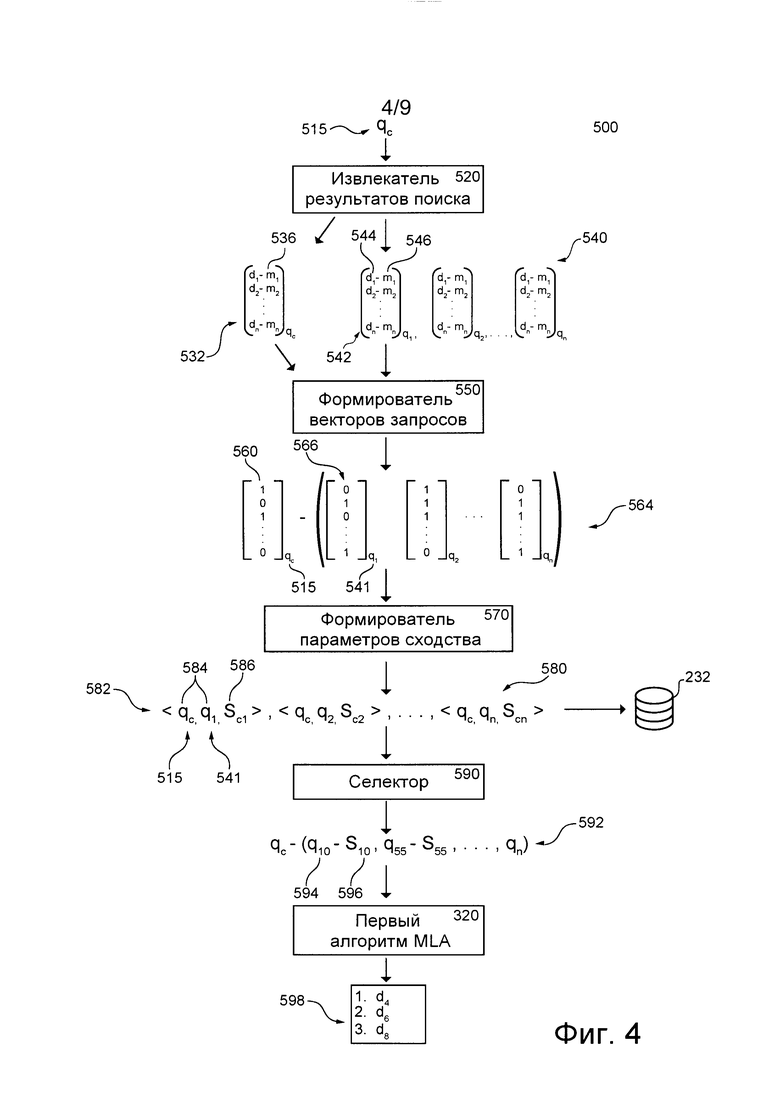
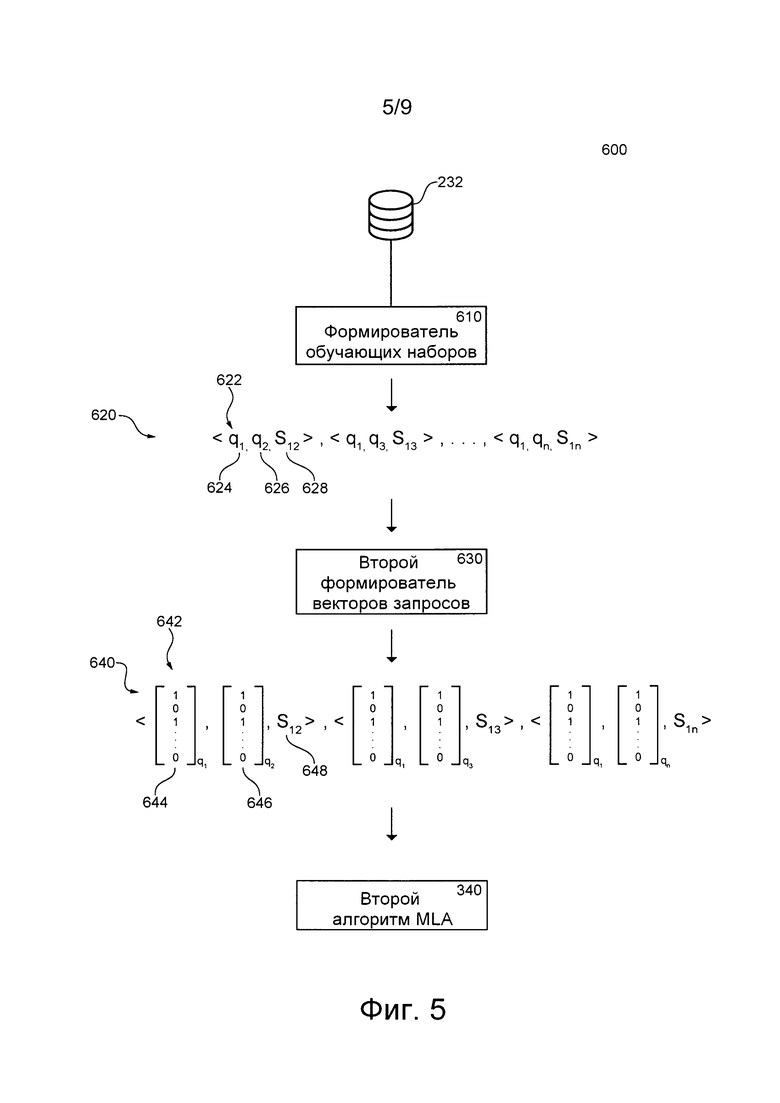
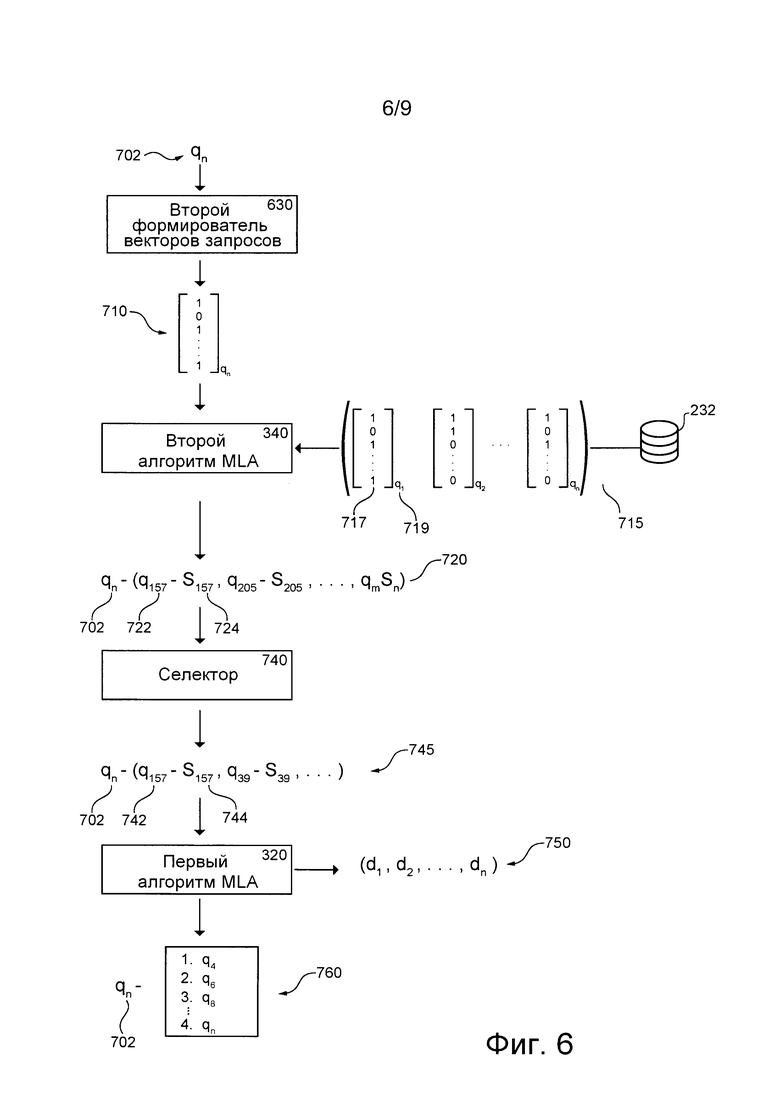
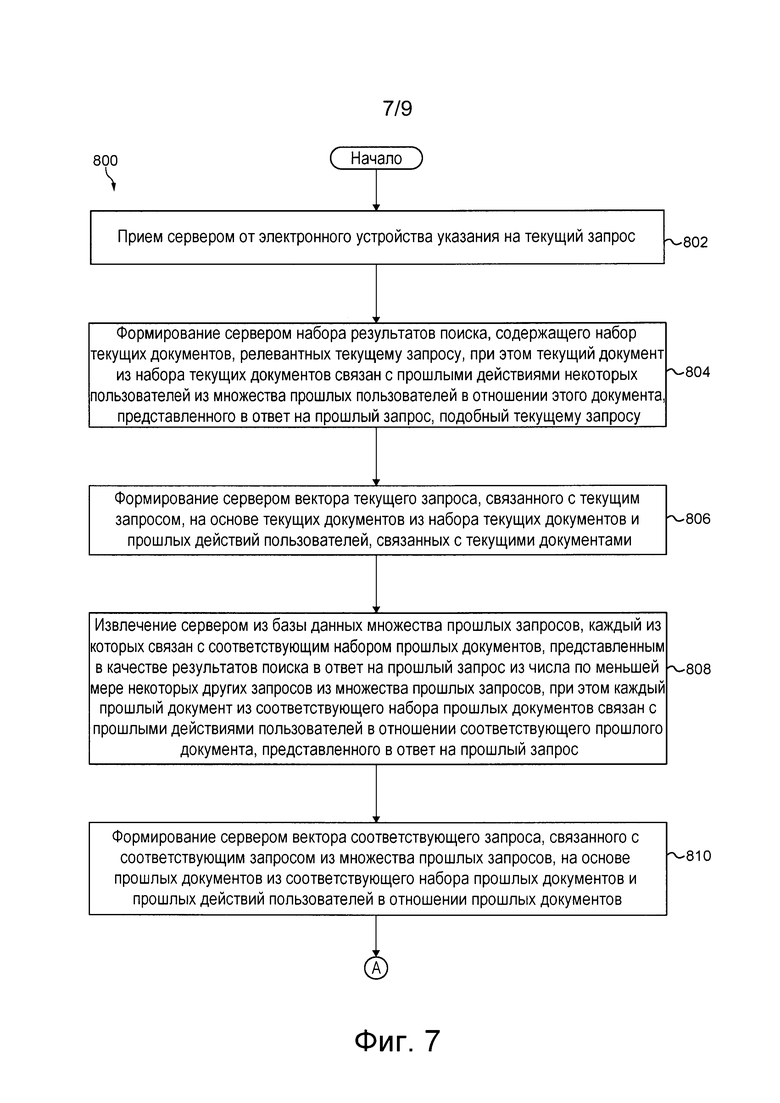
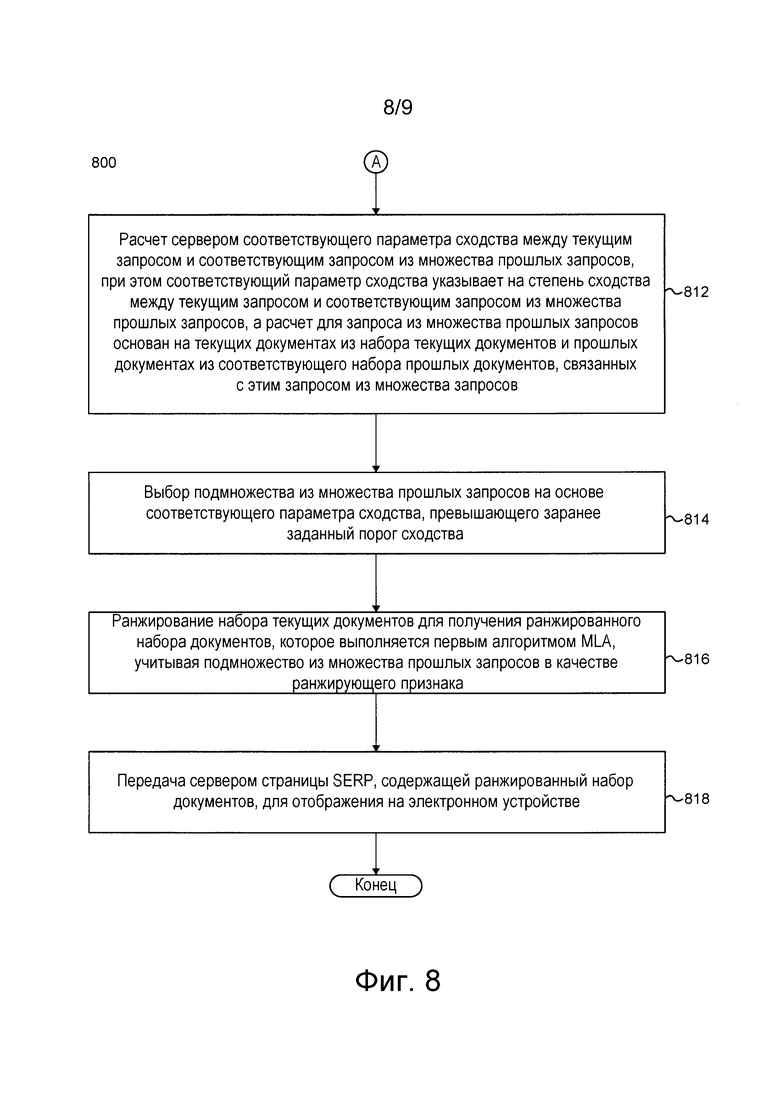
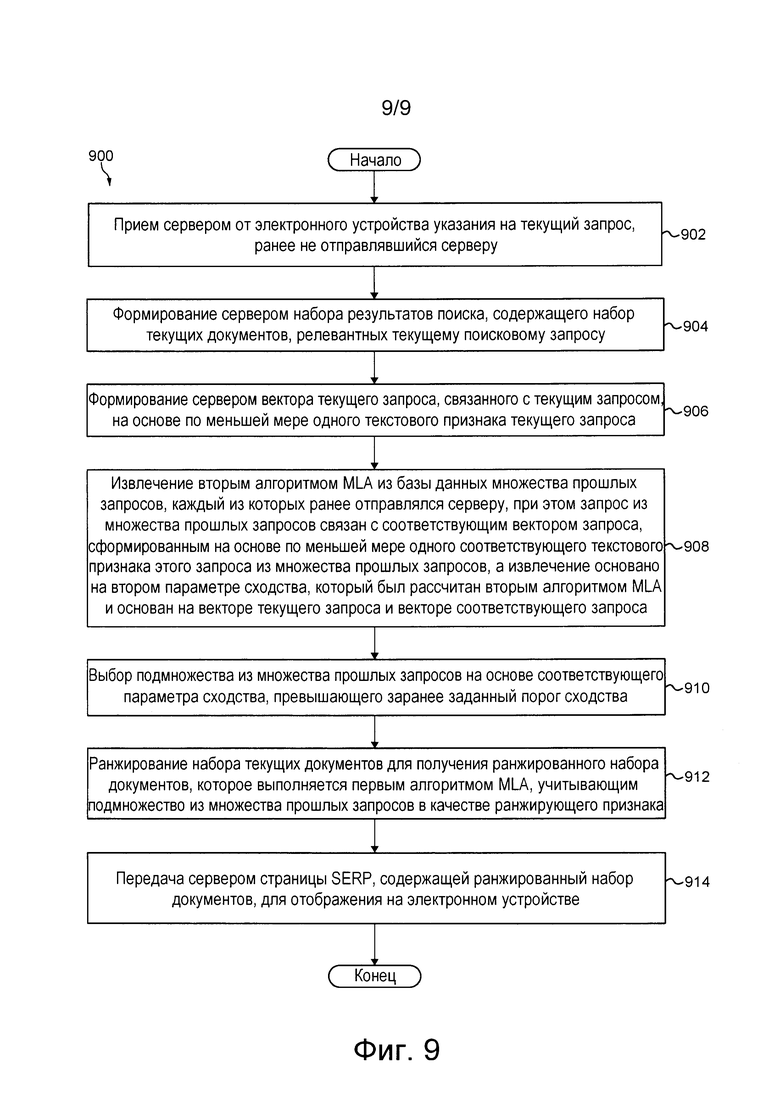
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности ранжирования результатов поиска. Технический результат достигается за счет расчета соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и прошлых документов из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов. 8 н. и 24 з.п. ф-лы, 9 ил.
1. Реализуемый компьютером способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи, и включающий в себя:
- прием сервером от электронного устройства указания на текущий запрос;
- формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему запросу;
- извлечение сервером из базы данных множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов;
- расчет сервером соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и прошлых документах из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов;
- выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и
- передачу сервером страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
2. Способ по п. 1, отличающийся тем, что текущий документ из набора текущих документов связан с прошлыми действиями некоторых из множества прошлых пользователей в отношении этого документа, представленного в ответ на прошлый запрос, подобный текущему запросу, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на этот прошлый запрос, а расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении текущих документов из набора текущих документов и на прошлых действиях пользователей в отношении прошлых документов из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов.
3. Способ по п. 2, отличающийся тем, что перед извлечением множества прошлых запросов он дополнительно включает в себя формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей, связанных с текущими документами, при этом способ перед расчетом соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов дополнительно включает в себя формирование сервером вектора соответствующего запроса, связанного с соответствующим запросом из множества прошлых запросов, на основе прошлых документов из соответствующего набора прошлых документов и прошлых действий пользователей в отношении прошлых документов, а расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
4. Способ по п. 3, отличающийся тем, что ранжирование набора текущих документов для получения ранжированного набора документов дополнительно включает в себя учет первым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
5. Способ по п. 4, отличающийся тем, что соответствующий параметр сходства рассчитывается с использованием скалярного умножения или на основе близости косинусов углов вектора текущего запроса и вектора соответствующего запроса.
6. Реализуемый компьютером способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи, содержащим второй алгоритм машинного обучения, обученный определять сходство запросов на основе текстового контента, и включающий в себя:
- прием сервером от электронного устройства указания на текущий запрос, ранее не отправлявшийся серверу;
- формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- извлечение вторым алгоритмом машинного обучения из базы данных множества прошлых запросов, каждый из которых ранее отправлялся серверу;
- расчет вторым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на по меньшей мере одном текстовом признаке нового запроса и по меньшей мере одном текстовом признаке этого запроса из множества прошлых запросов;
- выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и
- передачу сервером страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
7. Способ по п. 6, отличающийся тем, что перед извлечением множества прошлых запросов он дополнительно включает в себя формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса, при этом способ перед расчетом соответствующего параметра сходства дополнительно включает в себя получение вторым алгоритмом машинного обучения из базы данных вектора соответствующего запроса, связанного с запросом из множества прошлых запросов и сформированного на основе по меньшей мере одного соответствующего текстового признака этого запроса из множества прошлых запросов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
8. Способ по п. 7, отличающийся тем, что извлечение множества прошлых запросов основано на векторе текущего запроса.
9. Способ по п. 7, отличающийся тем, что на этапе обучения дополнительно включает в себя:
- получение сервером из связанной с сервером второй базы данных набора обучающих объектов, ранее сформированного сервером, при этом обучающий объект из набора обучающих объектов содержит первый прошлый запрос и второй прошлый запрос, которые были выбраны на основе соответствующего параметра сходства между первым прошлым запросом и вторым прошлым запросом, рассчитанного на основе прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых документов, представленных в ответ на второй прошлый запрос;
- формирование вектора первого прошлого запроса на основе по меньшей мере одного текстового признака первого прошлого запроса;
- формирование вектора второго прошлого запроса на основе по меньшей мере одного текстового признака второго прошлого запроса;
- обучение второго алгоритма MLA на наборе обучающих объектов для определения параметра сходства между вектором нового запроса, ранее не отправлявшегося серверу, и соответствующим вектором прошлого запроса из множества прошлых запросов.
10. Способ по п. 9, отличающийся тем, что расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на второй прошлый запрос.
11. Способ по п. 10, отличающийся тем, что параметр сходства, превышающий заранее заданный порог, используется в качестве положительной метки для обучения.
12. Способ по п. 9, отличающийся тем, что ранжирование набора текущих документов для получения ранжированного набора документов дополнительно включает в себя учет первым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
13. Способ по п. 9, отличающийся тем, что обучение второго алгоритма машинного обучения включает в себя использование алгоритма вида поиска K ближайших соседей (K-NNS), а способ после обучения второго алгоритма машинного обучения дополнительно включает в себя формирование сервером в базе данных для каждого прошлого запроса из множества прошлых запросов вектора соответствующего запроса, связанного с этим прошлым запросом, и указания на этот прошлый запрос, а также сохранение вектора соответствующего запроса в базе данных.
14. Способ по п. 9, отличающийся тем, что алгоритм вида K-NSS представляет собой алгоритм иерархического малого мира (HNSW).
15. Реализуемый компьютером способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи, и включающий в себя:
- прием сервером от электронного устройства указания на текущий запрос;
- формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- определение сервером наличия прошлых действий пользователей в отношении текущих документов из набора текущих документов, выполненных в связи с прошлым запросом, подобным текущему запросу;
- извлечение сервером из базы данных набора из множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос, при этом извлечение выполняется следующим образом:
- в ответ на положительный результат определения:
- формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей в отношении текущих документов из набора текущих документов;
- формирование сервером вектора соответствующего запроса, связанного с каждым запросом из множества прошлых запросов, на основе прошлых документов и прошлых действий пользователей в отношении прошлых документов из соответствующего набора прошлых документов;
- выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса;
- в ответ на отрицательный результат определения:
- формирование сервером вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса;
- формирование сервером вектора соответствующего запроса, связанного с каждым прошлым запросом из множества прошлых запросов, на основе по меньшей мере одного текстового признака этого прошлого запроса;
- выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим по меньшей мере один прошлый запрос в наборе из множества прошлых запросов;
- передачу сервером страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
16. Реализуемый компьютером способ ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, выполняемый сервером, связанным с базой данных и связанным с электронным устройством через сеть связи, и включающий в себя:
- прием сервером от электронного устройства указания на текущий запрос;
- формирование сервером набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- извлечение сервером из базы данных множества прошлых запросов на основе указания на текущий запрос;
- расчет сервером соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим вхождение поисковых терминов по меньшей мере одного прошлого запроса из множества прошлых запросов в документ из набора текущих документов таким образом, что это вхождение поисковых терминов повышает ранг этого текущего документа; и
- передачу сервером страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
17. Система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, связанная с базой данных и связанная с электронным устройством через сеть связи, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при выполнении которых процессор инициирует выполнение следующих действий:
- прием от электронного устройства указания на текущий запрос;
- формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему запросу;
- извлечение из базы данных множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов;
- расчет соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на текущих документах из набора текущих документов и прошлых документах из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов;
- выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и
- передача страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
18. Система по п. 17, отличающаяся тем, что текущий документ из набора текущих документов связан с прошлыми действиями некоторых из множества прошлых пользователей в отношении этого документа, представленного в ответ на прошлый запрос, подобный текущему запросу, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на этот прошлый запрос, а расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении текущих документов из набора текущих документов и на прошлых действиях пользователей в отношении прошлых документов из соответствующего набора прошлых документов, связанных с этим запросом из множества запросов.
19. Система по п. 18, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующего действия перед извлечением множества прошлых запросов: формирование вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей, связанных с текущими документами; и дополнительно выполнен с возможностью выполнения следующего действия перед расчетом соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов: формирование вектора соответствующего запроса, связанного с соответствующим запросом из множества прошлых запросов, на основе прошлых документов из соответствующего набора прошлых документов и прошлых действий пользователей в отношении прошлых документов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
20. Система по п. 19, отличающаяся тем, что с целью ранжирования набора текущих документов для получения ранжированного набора документов процессор дополнительно выполнен с возможностью учета первым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
21. Система по п. 20, отличающаяся тем, что соответствующий параметр сходства рассчитывается с использованием скалярного умножения или на основе близости косинусов углов вектора текущего запроса и вектора соответствующего запроса.
22. Система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, способная выполнять второй алгоритм машинного обучения, обученный определять сходство запросов на основе текстового контента, связанная с базой данных и связанная с электронным устройством через сеть связи, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при выполнении которых процессор инициирует выполнение следующих действий:
- прием от электронного устройства указания на текущий запрос, ранее не отправлявшийся в систему;
- формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- извлечение вторым алгоритмом машинного обучения из базы данных множества прошлых запросов, каждый из которых ранее отправлялся в систему;
- расчет вторым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, а расчет для запроса из множества прошлых запросов основан на по меньшей мере одном текстовом признаке нового запроса и по меньшей мере одном текстовом признаке этого запроса из множества прошлых запросов;
- выбор подмножества из множества прошлых запросов на основе соответствующего параметра сходства, превышающего заранее заданный порог сходства;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим подмножество из множества прошлых запросов в качестве ранжирующего признака; и
- передача страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
23. Система по п. 22, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующего действия перед извлечением множества прошлых запросов: формирование вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса; и дополнительно выполнен с возможностью инициирования выполнения следующего действия перед расчетом соответствующего параметра сходства: получение вторым алгоритмом машинного обучения из базы данных вектора соответствующего запроса, связанного с запросом из множества прошлых запросов и сформированного на основе по меньшей мере одного соответствующего текстового признака этого запроса из множества прошлых запросов, при этом расчет соответствующего параметра сходства основан на векторе текущего запроса и векторе соответствующего запроса.
24. Система по п. 23, отличающаяся тем, что извлечение множества прошлых запросов основано на векторе текущего запроса.
25. Система по п. 23, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения на этапе обучения следующих действий:
- получение из связанной с системой второй базы данных набора обучающих объектов, ранее сформированного системой, при этом обучающий объект из набора обучающих объектов содержит первый прошлый запрос и второй прошлый запрос, которые были выбраны на основе соответствующего параметра сходства между первым прошлым запросом и вторым прошлым запросом, рассчитанного на основе прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых документов, представленных в ответ на второй прошлый запрос;
- формирование вектора первого прошлого запроса на основе по меньшей мере одного текстового признака первого прошлого запроса;
- формирование вектора второго прошлого запроса на основе по меньшей мере одного текстового признака второго прошлого запроса;
- обучение второго алгоритма MLA на наборе обучающих объектов для определения параметра сходства между вектором нового запроса, ранее не отправлявшегося в систему, и соответствующим вектором прошлого запроса из множества прошлых запросов.
26. Система по п. 25, отличающаяся тем, что расчет соответствующего параметра сходства дополнительно основан на прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на первый прошлый запрос, и прошлых действиях пользователей в отношении прошлых документов, представленных в ответ на второй прошлый запрос.
27. Система по п. 26, отличающаяся тем, что параметр сходства, превышающий заранее заданный порог, используется в качестве положительной метки для обучения.
28. Система по п. 25, отличающаяся тем, что с целью ранжирования набора текущих документов для получения ранжированного набора документов процессор выполнен с возможностью учета первым алгоритмом машинного обучения соответствующего параметра сходства между текущим запросом и по меньшей мере одним прошлым запросом в качестве веса ранжирующего признака.
29. Система по п. 25, отличающаяся тем, что обучение второго алгоритма машинного обучения включает в себя использование алгоритма вида поиска K ближайших соседей (K-NNS), а процессор дополнительно выполнен с возможностью выполнения следующих действий после обучения второго алгоритма машинного обучения:
- формирование в базе данных для каждого прошлого запроса из множества прошлых запросов вектора соответствующего запроса, связанного с этим прошлым запросом, и указания на этот прошлый запрос; и
- сохранение вектора соответствующего запроса в базе данных.
30. Система по п. 29, отличающаяся тем, что алгоритм вида K-NSS представляет собой алгоритм иерархического малого мира (HNSW).
31. Система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, связанная с базой данных и связанная с электронным устройством через сеть связи, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при выполнении которых процессор инициирует выполнение следующих действий:
- прием от электронного устройства указания на текущий запрос;
- формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- определение наличия прошлых действий пользователей в отношении текущих документов из набора текущих документов, выполненных в связи с прошлым запросом, подобным текущему запросу;
- извлечение из базы данных набора из множества прошлых запросов, каждый из которых связан с соответствующим набором прошлых документов, представленным в качестве результатов поиска в ответ на прошлый запрос из числа по меньшей мере некоторых других запросов из множества прошлых запросов, при этом каждый прошлый документ из соответствующего набора прошлых документов связан с прошлыми действиями пользователей в отношении соответствующего прошлого документа, представленного в ответ на прошлый запрос, при этом извлечение выполняется следующим образом:
- в ответ на положительный результат определения:
- формирование вектора текущего запроса, связанного с текущим запросом, на основе текущих документов из набора текущих документов и прошлых действий пользователей в отношении текущих документов из набора текущих документов;
- формирование вектора соответствующего запроса, связанного с каждым запросом из множества прошлых запросов, на основе прошлых документов и прошлых действий пользователей в отношении прошлых документов из соответствующего набора прошлых документов;
- выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса;
- в ответ на отрицательный результат определения:
- формирование вектора текущего запроса, связанного с текущим запросом, на основе по меньшей мере одного текстового признака текущего запроса;
- формирование вектора соответствующего запроса, связанного с каждым прошлым запросом из множества прошлых запросов, на основе по меньшей мере одного текстового признака этого прошлого запроса;
- выбор множества прошлых запросов на основе сходства вектора текущего запроса и вектора соответствующего запроса;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим по меньшей мере один прошлый запрос в наборе из множества прошлых запросов;
- передача страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
32. Система для ранжирования результатов поиска в ответ на текущий запрос с использованием первого алгоритма машинного обучения, связанная с базой данных и связанная с электронным устройством через сеть связи, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при выполнении которых процессор инициирует выполнение следующих действий:
- прием от электронного устройства указания на текущий запрос;
- формирование набора результатов поиска, содержащего набор текущих документов, релевантных текущему поисковому запросу;
- извлечение из базы данных множества прошлых запросов на основе указания на текущий запрос;
- расчет соответствующего параметра сходства между текущим запросом и соответствующим запросом из множества прошлых запросов, при этом соответствующий параметр сходства указывает на степень сходства между текущим запросом и соответствующим запросом из множества прошлых запросов;
- ранжирование набора текущих документов для получения ранжированного набора документов, которое выполняется первым алгоритмом машинного обучения, учитывающим вхождение поисковых терминов по меньшей мере одного прошлого запроса из множества прошлых запросов в документ из набора текущих документов таким образом, что это вхождение поисковых терминов повышает ранг этого текущего документа; и
- передача страницы результатов поисковой системы (SERP), содержащей ранжированный набор документов, для отображения на электронном устройстве.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| РАНЖИРАТОР РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2608886C2 |

