Изобретение относится к медицине, а именно к кардиологии, может быть использовано для диагностики острого коронарного синдрома в медицинских учреждениях при первичном контакте с пациентами, поступившими по неотложным показаниям с предварительным диагнозом «острый коронарный синдром (ОКС)».
Известно, что сроки оказания специализированной медицинской помощи и адекватная маршрутизация пациентов с ОКС напрямую оказывают влияние на прогноз заболевания и вероятность развития неблагоприятных исходов ( В., James S., Agewall S., Antunes M., Bucciarelli-Ducci С,
В., James S., Agewall S., Antunes M., Bucciarelli-Ducci С,
Bueno H. et al. ESC Guidelines for the management of acute myocardial infarction in patients presenting with ST-segment elevation. European Heart Journal. 2017; 39 (2): 119-177). При этом клинический анализ крови один из наиболее доступных методов диагностики в практической медицине, отражающий системные патологические процессы в организме человека на основе количественной оценки клеточного состава и морфологии крови. Современные автоматические гематологические анализаторы имеют возможность характеризовать более 20 параметров клеток крови. Часть информации в клиническом анализе крови предоставляется анализаторами в графическом виде. Гематологические анализаторы, дифференцирующие общее количество лейкоцитов (WBC) на 5 субпопуляций (5 diff-анализаторы): нейтрофилы (NEU), лимфоциты (LYM), моноциты (MON), эозинофилы (EOS), базофилы (BAS) - графическую информацию о клеточном составе представляют в виде графиков рассеивания -скаттерограмм (англ. scatter), на которых каждая точка соответствует одной клетке. При этом по оси X и Y могут быть выбраны различные морфологические характеристики клетки - размер, сложность, лобулярность и другие (Takubo Т., Tatsumi N. Further evolution and leukocyte differential using an automated blood cell counter. Rinsho Byori. 1995;43(9):925-930). Ввиду большого объема получаемой информации о картине крови пациента врачи зачастую не в состоянии ее исчерпывающе интерпретировать относительно клинической ситуации (Chaudhury A., Noiret L., Higgins J. White blood cell population dynamics for risk stratification of acute coronary syndrome. Proceedings of the National Academy of Sciences, 2017; 114(46), pp.12344-12349). С ростом количества цифровых данных, предоставляемых аналитическими системами, растет потенциальная перспектива применения методов машинного обучения для увеличения эффективности доступной диагностической информации в интересах пациента (Pieszko K., Hiczkiewicz J., Budzianowski P.,  J., Budzianowski J., Blaszczynski J.,
J., Budzianowski J., Blaszczynski J.,  R., Burchardt, P. Machine-learned models using hematological inflammation markers in the prediction of short-term acute coronary syndrome outcomes. Journal of Translational Medicine, 2018; 16(1):334).
R., Burchardt, P. Machine-learned models using hematological inflammation markers in the prediction of short-term acute coronary syndrome outcomes. Journal of Translational Medicine, 2018; 16(1):334).
Известен способ прогнозирования течения и исхода острого коронарного синдрома. В способе электрокардиографически определяют в двенадцати отведениях (I-V6): сумма отклонений сегмента ST, сумма элевации сегмента ST, сумма депрессии сегмента ST, корригированная дисперсия интервала QT с учетом частоты сердечных сокращений, рассчитанной по формуле Базета, объем поражения миокарда, рассчитанный по стандартной электрокардиограмме и дополнительным отведениям по Слопаку (S1-S4) и по Нэбу (D, А, I). Данные параметры используют для построения модели, позволяющей прогнозировать течение и исход ОКС, для чего используют дискриминантный анализ с последовательным включением переменных в итоге в модель включают степень левожелудочковой недостаточности, объем поражения миокарда, корригированную дисперсию интервала DQTc, частоту сердечных сокращений, возраст пациента, сумму депрессии сегмента ST, сумму отклонений сегмента ST. Затем определяют классификационную функцию для пациентов с ОКС с неблагоприятным, сомнительным и благоприятным исходом, полученные коэффициенты подставляют в формулу дискриминантного анализа и рассчитывают дискриминаторы групп R1-R3 (патент RU2401053, МПК А61 В 5/00, опубл. 10.10.2010 г.).
Известен способ прогнозирования острого коронарного синдрома. В способе проводят холтеровское мониторирование ЭКГ и спирометрии на 15-20-е сутки от начала заболевания. При показателях спирометрии: резервный объем вдоха меньше 1,78 л; жизненная емкость легких меньше 3,71 л; функциональная жизненная емкость легких меньше 3,80 л; средняя объемная скорость меньше 2,80 л/с и показателях холтеровского мониторирования: средняя величина 5-минутных стандартных отклонений R-R-интервалов, вычисленных за 24 часа - SDNN index больше 25 мс; квадратный корень из среднего значения квадратов разностей величин последовательных интервалов R-R - RMSSD меньше 24 мс; количество случаев, в которых разница между длительностью последовательных R-R-интервалов превышает 50 мс - NN50 меньше 1333; процент последовательных интервалов R-R, различие между которыми превышает 50 мс - pNN50 меньше 4,3%, циркадный индекс больше 1,2; триангулярный индекс больше 46 регистрируют отрицательный прогноз развития острого коронарного синдрома (патент RU2410021, МПК А61В 5/04, опубл. 27.01.2011 г.).
Недостатком описанных аналогов является многокомпонентность инструментальной диагностики, которая занимает сравнительно длительное время. Кроме того, перечисленные инструментальные методы диагностики (эхокардиография, холтеровское мониторирование) чаще всего недоступны при первичном контакте с пациентом в приемном отделении даже специализированных стационаров.
Способы диагностики ОКС по анализу крови пациента исследовались в следующих работах: Chaudhury A., Noiret L., Higgins J. White blood cell population dynamics for risk stratification of acute coronary syndrome. Proceedings of the National Academy of Sciences, 2017; 114(46), pp. 12344-12349; Pieszko K., Hiczkiewicz J., Budzianowski P.,  J., Budzianowski J.,
J., Budzianowski J., J.,
J.,  R., Burchardt, P. Machine-learned models using hematological inflammation markers in the prediction of short-term acute coronary syndrome outcomes. Journal of Translational Medicine, 2018; 16(1):334.
R., Burchardt, P. Machine-learned models using hematological inflammation markers in the prediction of short-term acute coronary syndrome outcomes. Journal of Translational Medicine, 2018; 16(1):334.
Однако в вышеописанных работах не были учтены возможности ансамблевого метода машинного обучения, ввиду чего не были достигнуты высокие показатели правильной диагностики нозологии.
Технической проблемой изобретения является разработка способа диагностики ОКС, который повысит качество оказания медицинской помощи пациентам с острым коронарным синдромом при первичном контакте на госпитальном этапе.
Технический результат - повышение правильности постановки диагноза пациенту с точностью до 95-96,77%.
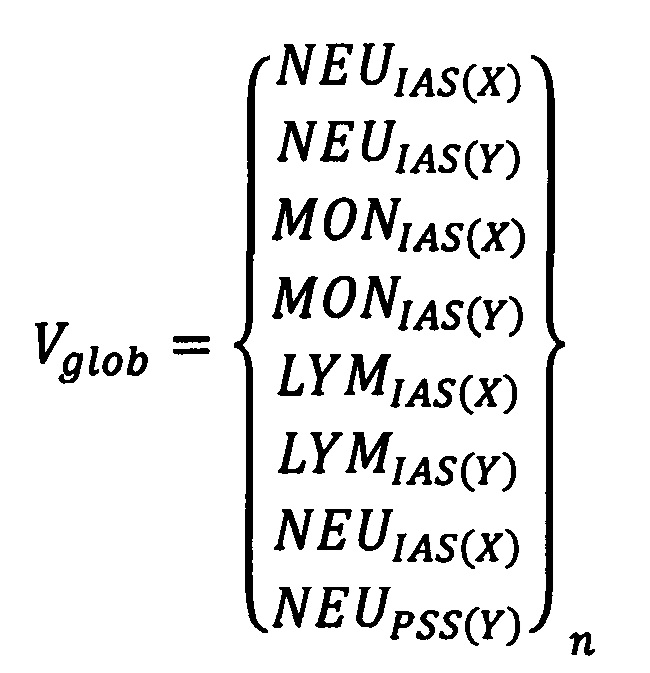
Проблема решается, а технический результат достигается способом диагностики острого коронарного синдрома, при котором предварительно формируют базу данных, содержащую информацию о результатах клинического анализа крови пациентов с острым коронарным синдромом и здоровых людей группы контроля, которую в дальнейшем используют для обучения нейронных сетей, после чего осуществляют взятие цельной венозной крови обследуемого пациента, перемешивают пробу крови, затем производят исследование клинического анализа крови на автоматическом гематологическом анализаторе, после этого результаты исследования копируют с анализатора в виде FCS-файлов и переносят на персональный компьютер для предварительной обработки и машинного анализа, причем предварительная обработка включает перевод оператором при помощи программного обеспечения, позволяющего работать с FCS-файлами, графических изображений в виде скатерограмм анализа крови пациента в цифровой эквивалент - вектор, который содержит информацию обо всех исследованных клетках в виде данных их расположения по осям скатерограммы X и Y, при этом оператор с учетом морфологических показателей представленных на анализ клеток крови дифференцирует их на три субпопуляции: нейтрофилы, лимфоциты и моноциты, после чего полученный результат в цифровом эквиваленте сохраняют в отдельный файл программы для работы с электронными таблицами, затем в вышеуказанном цифровом эквиваленте скатерограммы анализа крови пациента - векторе отсекают последние элементы, а именно, координаты клеток, так, чтобы количество элементов обследуемого пациента соответствовало количеству элементов пациентов, результаты которых находятся в предварительно сформированной базе данных, после чего все элементы векторов обследуемого пациента объединяются последовательно в один общий глобальный вектор Vglob:
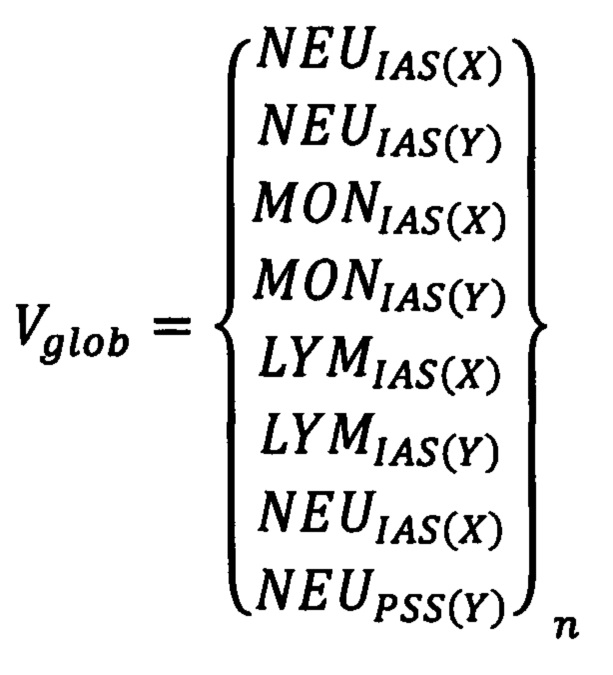
где NEU - нейтрофилы, MON - моноциты, LYM - лимфоциты, IAS и PSS - режимы лазерной детекции клеток в гематологическом анализаторе, X и Y - значение координат по осям абсцисс и ординат на скатерограмме клинического анализа крови, n - общее количество выявленных клеток,
затем стандартизируют полученный вектор путем вычитания из глобального вектора обследуемого пациента среднего значения соответствующих векторов из предварительно сформированной базы данных и последующего деления на стандартное отклонение соответствующих векторов базы данных следующим образом:
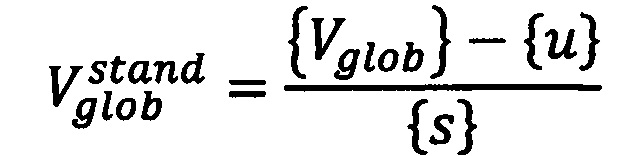
где {u} - указанное среднее значение, a {s} - вектор стандартных отклонений каждого элемента в предварительно собранной базе данных, затем применяют метод главных компонент для уменьшения размерности признаков с n элементов до 2-4 главных компонент {Xn}, сохранив при этом как можно больше изменчивости признаков, посредством программного обеспечения для математических вычислений, в результате получают сокращенный вектор вида:
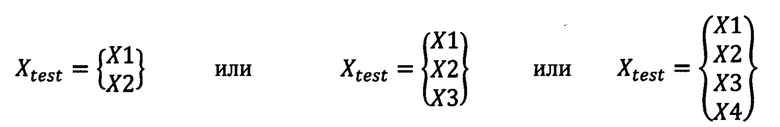
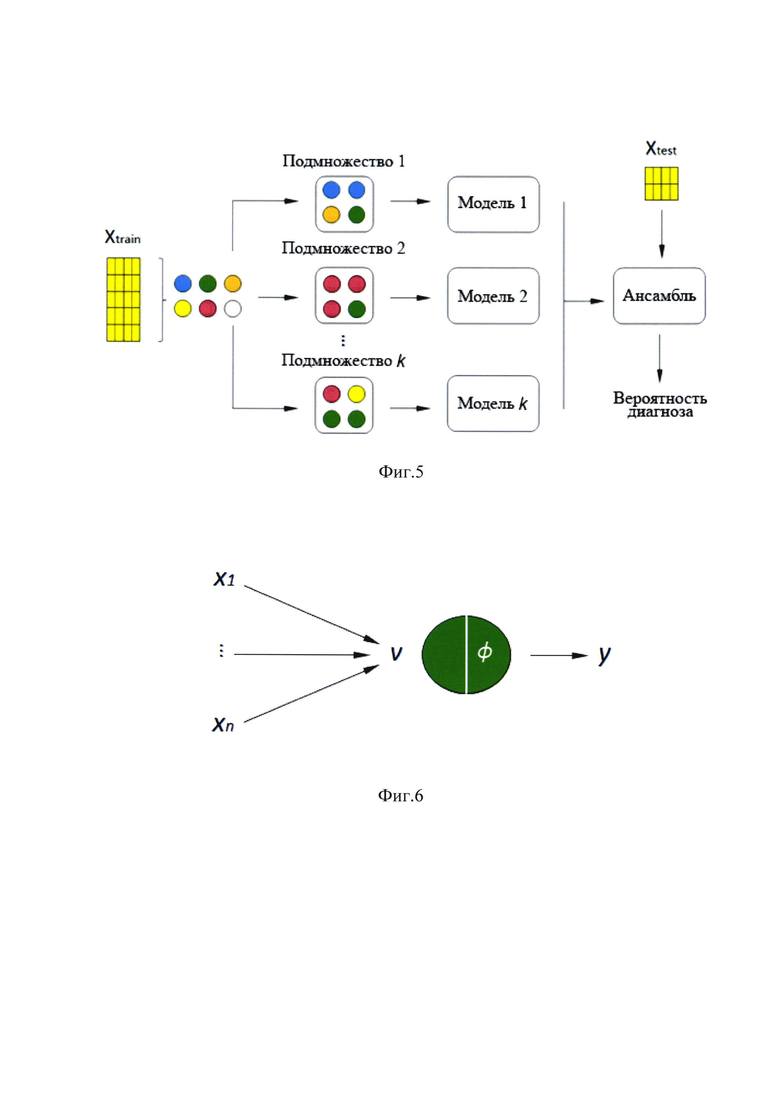
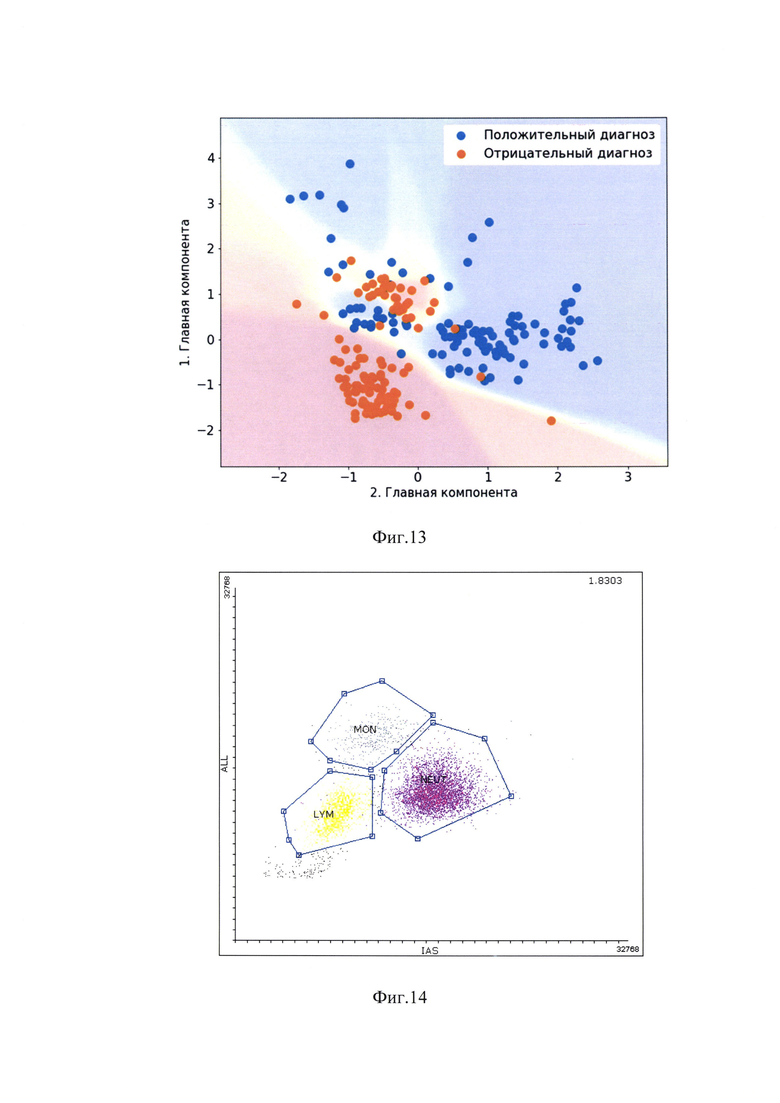
где X1, Х2, Х3, Х4 - главные компоненты сокращенного вектора, при этом количество главных компонент зависит от наиболее успешной комбинации, позволяющей достичь наилучшего результата анализа, затем производят стандартизацию с помощью описанных выше действий уже сокращенного вектора до вида  , после чего применяют ансамбль из нейронных сетей, которые обучают на предварительно сформированной базе данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем внесения информации в программное обеспечение для машинного анализа об их результатах клинического анализа крови и окончательного диагноза - «острый коронарный синдром» или «здоров», при этом количество нейронных сетей в ансамбле зависит от результатов оценки точности предсказания окончательного диагноза и составляет от 1 до 10, при этом используют композиции алгоритмов, причем из множества обучающей выборки отбирают от 1 до n подмножеств истинных данных из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества, чтобы затем передать их математическим моделям для анализа с последующей агрегацией данных в ансамбль и расчета вероятности положительного диагноза, рассматривая нейронные сети как модели, при этом подмножества рассматривают как репрезентативные и независимые значения истинного распределения данных, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод, причем после обучения нейронных сетей и их агрегации в ансамбль проверяется их точность на тестовой выборке, при этом по итогу обучения нейронных сетей и приемлемому результату тестирования, при условии ошибки результатов оценки менее 5%, аналогичным образом производят исследование клинического анализа крови обследуемого пациента, а для оценки положительного диагноза в процентах строят график (фиг. 13), где используют поля вероятности для классификации диагнозов в двухмерном подпространстве, которые представляют собой оси абсцисс и ординат, соответствующих главным компонентам, причем указанные поля рассматривают как зрение нейронных сетей для неизвестных случаев, при этом диагноз обследуемому пациенту ставят следующим образом: если результаты пациента окажутся в области графика, выделенной для отрицательного диагноза, то ансамбль нейронных сетей выдаст наиболее высокую вероятность для отрицательного диагноза, если в области графика, выделенной для положительного диагноза - наиболее высокую вероятность для положительного диагноза - острый коронарный синдром.
, после чего применяют ансамбль из нейронных сетей, которые обучают на предварительно сформированной базе данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем внесения информации в программное обеспечение для машинного анализа об их результатах клинического анализа крови и окончательного диагноза - «острый коронарный синдром» или «здоров», при этом количество нейронных сетей в ансамбле зависит от результатов оценки точности предсказания окончательного диагноза и составляет от 1 до 10, при этом используют композиции алгоритмов, причем из множества обучающей выборки отбирают от 1 до n подмножеств истинных данных из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества, чтобы затем передать их математическим моделям для анализа с последующей агрегацией данных в ансамбль и расчета вероятности положительного диагноза, рассматривая нейронные сети как модели, при этом подмножества рассматривают как репрезентативные и независимые значения истинного распределения данных, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод, причем после обучения нейронных сетей и их агрегации в ансамбль проверяется их точность на тестовой выборке, при этом по итогу обучения нейронных сетей и приемлемому результату тестирования, при условии ошибки результатов оценки менее 5%, аналогичным образом производят исследование клинического анализа крови обследуемого пациента, а для оценки положительного диагноза в процентах строят график (фиг. 13), где используют поля вероятности для классификации диагнозов в двухмерном подпространстве, которые представляют собой оси абсцисс и ординат, соответствующих главным компонентам, причем указанные поля рассматривают как зрение нейронных сетей для неизвестных случаев, при этом диагноз обследуемому пациенту ставят следующим образом: если результаты пациента окажутся в области графика, выделенной для отрицательного диагноза, то ансамбль нейронных сетей выдаст наиболее высокую вероятность для отрицательного диагноза, если в области графика, выделенной для положительного диагноза - наиболее высокую вероятность для положительного диагноза - острый коронарный синдром.
Новизна и изобретательский уровень представленного решения достигается за счет того, что по сравнению с существующими аналогами впервые использован метод главных компонент с последующим ансамблевым методом обучения искусственных нейронных сетей для диагностики острого коронарного синдрома у пациентов на основе параметров крови, в результате чего удалось значимо повысить качество дифференциального обследования пациентов, уровень которого не достигался ранее.
Сущность изобретения поясняется рисунками, где показано:
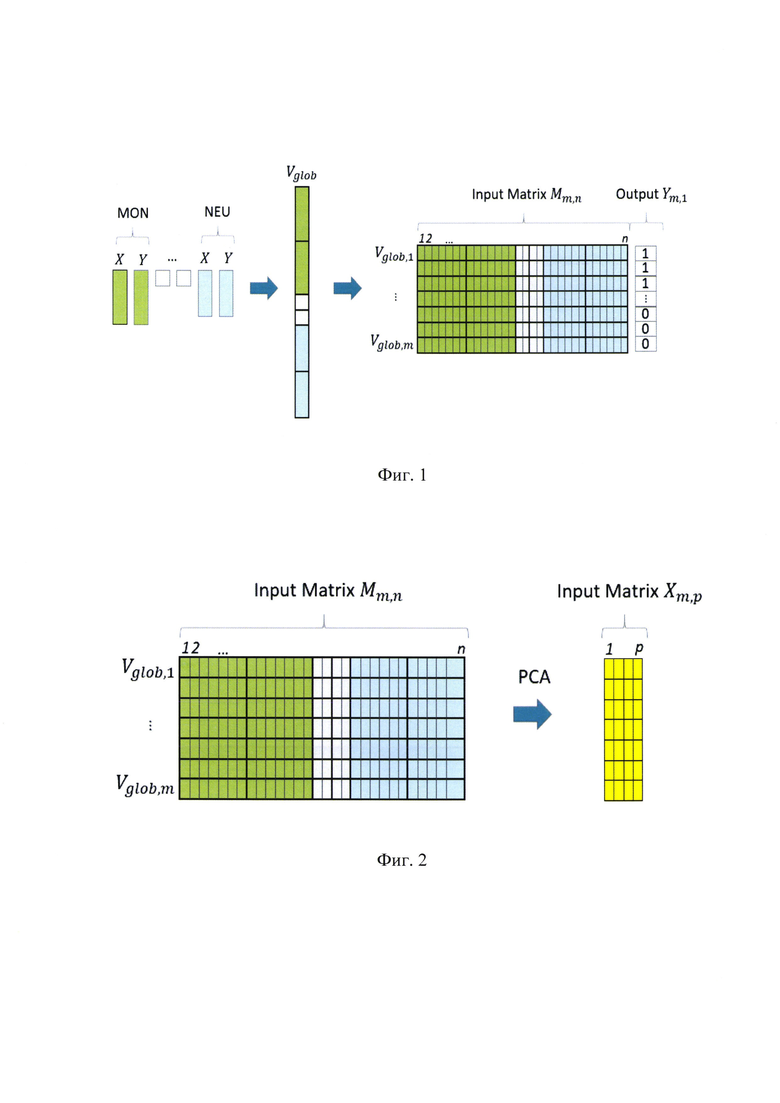
На фиг. 1 - создание исходной матрицы признаков крови пердварительной базы данных пациентов с ОКС и здоровых лиц, при этом на рисунке показано, как все векторы объединяются в один глобальный вектор Vglob, который соответствует положительному (1) или отрицательному (0) диагнозу, и далее глобальные векторы объединяются в матрицу Mm,n (Input Matrix), размер которой зависит от количества m диагнозов и n признаков (элементов) векторов. Каждая строка матрицы соответствует строке ответного вектора Ym,1 (Output);
На фиг .2 - иллюстрация применения метода главных компонент (Principal Component Analysis РСА) для уменьшения исходной матрицы, при этом показано, что метод главных компонент уменьшает матрицу Mm,n до Xm,p где размерность подпространства р≤n.;
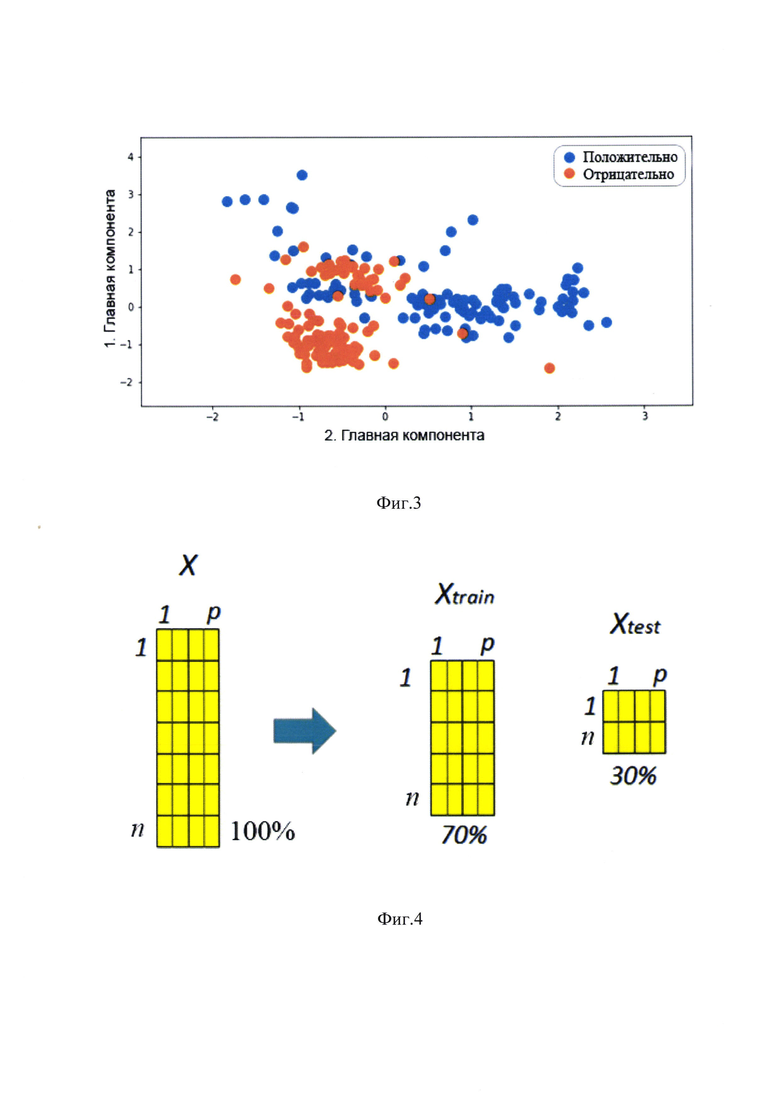
На фиг. 3 - визуализация кластеров в двухмерном подпространстве, которая показывает, что размерность, равная двум (р=2) позволяет визуализировать классы (положительный и отрицательный диагнозы) в двухмерном подпространстве, что показывает проекцию признаков на 2 главные компоненты, где голубой цвет точки соответствует положительному, а оранжевый цвет - отрицательному диагнозу;
На фиг. 4 - разделение исходной матрицы на обучающую и тестовую выборки, где для оценки методов машинного обучения - 70% матрицы были использованы для обучающей выборки Xtrain и 30% - для тестовой Xtest выборки;
На фиг. 5 - схема применения ансамблевого метода обучения нейронных сетей, где Xtrain - обучающая выборка, Xtest - тестовая выборка, а Модель 1 - Модель k - являются нейронными сетями, Подмножество 1 - Подмножество k - подмножества истинных данных из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля;
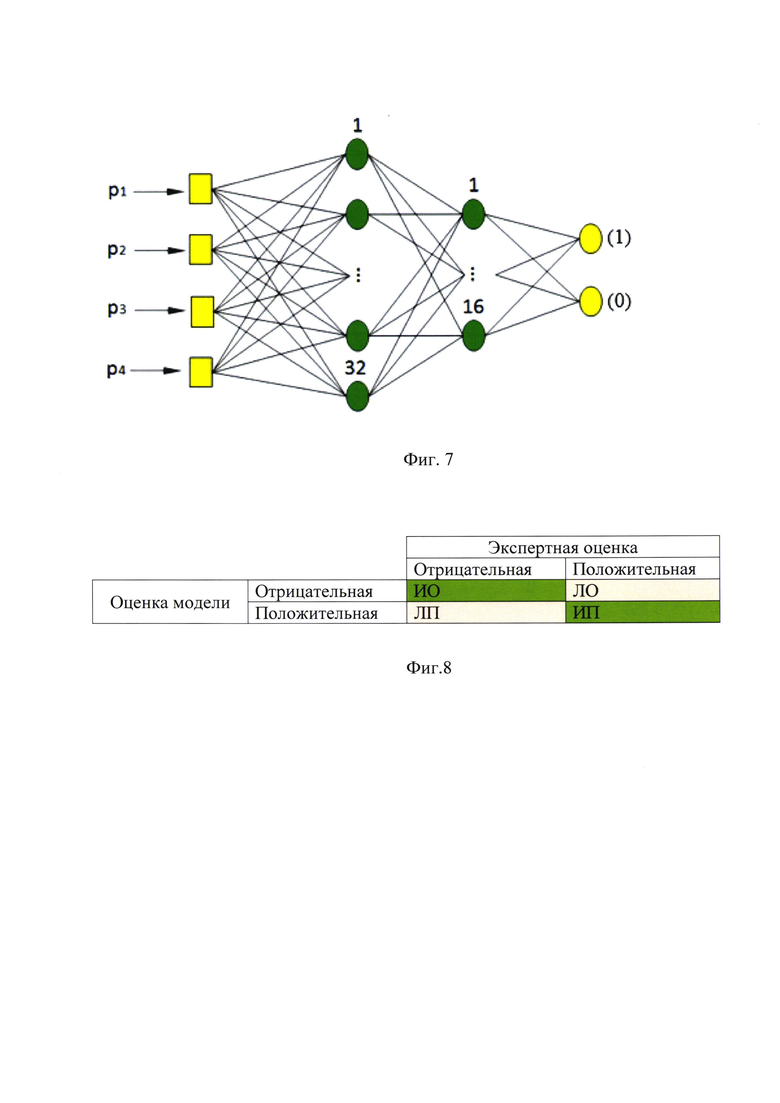
На фиг. 6 - показан принцип функционирования искусственного нейрона, при этом нейрон - это вычислительная единица, которая получает информацию и передает ее дальше. Нейрон получает суммарную информацию v=w1x1+…+wnxn всех нейронов с предыдущего скрытого слоя, где w это вес, умноженный на сигнал х. На выходе нейрона -суммарная информация v нормализуется с помощью функции активации у=φ(u). Функция активации нейрона φ определяет выходной сигнал, который определяется набором входных сигналов по аналогу биологического нейрона, где функция активации представляет скорость возбуждения потенциала действия в клетке;
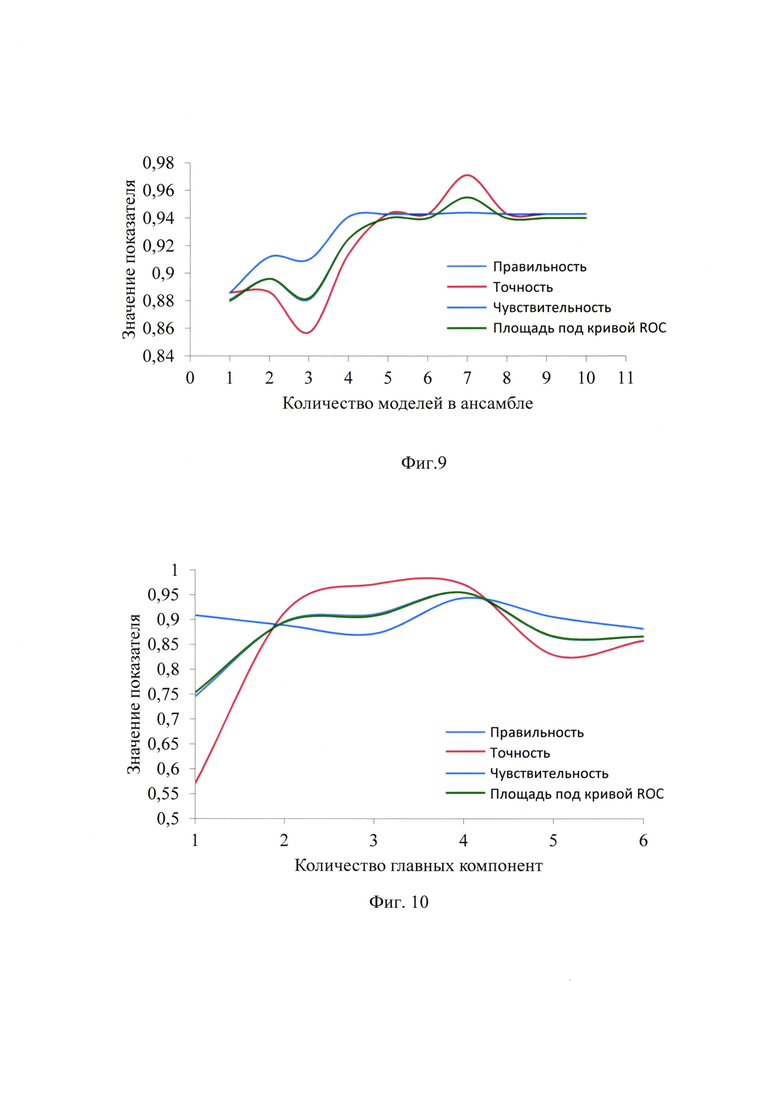
На фиг. 7 - архитектура многослойной нейронной сети, где 4 входа во входном слое - соответствуют 4 главным компонентам в подпространстве (p1-p4), а в первом скрытом слое находятся - 32 нейрона, во втором скрытом слое - 16 нейронов, при этом имеется 2 выхода в выходном слое соответствуют положительному (1) и отрицательному (0) диагнозам;
На фиг. 8 - матрица ошибок (confusion / error matrix) где ИП: Истинно-положительные классификации; ЛП: Ложно-положительные классификации; ЛО: Ложно-отрицательные классификации; ИО: Истинно-отрицательные классификации.
На фиг. 9 - влияние количества моделей в ансамбле нейронных сетей на точность предсказания;
На фиг. 10 - влияние главных компонент на точность диагностики ОКС;
На фиг. 11 - матрица ошибок (confusion / error matrix) на тестовой выборке предварительной базы данных пациентов и здоровых лиц;
На фиг. 12 - кривая чувствительности и специфичности (ROC) на тестовой выборке предварительной базы данных пациентов и здоровых лиц;
На фиг. 13 - график с полями вероятности для классификации неизвестных случаев;
На фиг. 14 - пример представления результатов анализа субпопуляций лейкоцитов посредством скатерограмм.
Способ осуществляют следующим образом.
Пациент поступает в приемный покой медицинской организации. Наряду с другими диагностическими процедурами у пациента производится взятие цельной венозной крови из кубитальной вены посредством, например, вакуумной системы взятия крови в пробирку типа Vacutest (KIMA, Италия) объемом 4 мл и нанесенным на внутреннюю поверхность стенок пробирки 7,2 мг К3ЭДТА. Далее пробирка перемешивается путем переворачивания и вращения в горизонтальной и вертикальной плоскостях в течение 30 секунд, после чего производится исследование клинического анализа крови в открытом режиме, например, на автоматическом гематологическом анализаторе CELL-DYN Sapphire (Abbott Laboratories, США). Результаты исследования копируют с анализатора в виде FCS-файлов и переносят на доступный персональный компьютер с целью предварительной обработки и машинного анализа. Предварительная обработка заключается в переводе графических изображений - скатерограмм (графики рассеивания) в цифровой эквивалент - вектор с указанием расположения каждой клетки по осям X и Y. Для осуществления данной задачи можно использовать бесплатное программное обеспечение «Flowing Software)) версия 2.5 для работы с FCS-файлами.
По окончанию обработки FCS-файлов информацию о результатах гематологического исследования сохраняют посредством, например, программы Microsoft Excel 2013. Полученные результаты далее подвергаются процедуре машинного анализа. Машинный анализ может осуществляться с применением свободной кроссплатформенной интерактивной интегрированной среды разработки ИСР (англ. Integrated development environment - IDE) Spyder (Scientific Python Development Environment) для научных расчетов на языке Python, обеспечивающей простоту использования функциональных возможностей и легковесность программной части.
При этом используют метод главных компонент (Principal Component Analysis РСА) на предварительной базе данных и последующее машинное обучение нейронных сетей. Метод главных компонент заключается в уменьшении размерности признаков, сохраняя при этом как можно больше изменчивости (информации) признаков (Dunteman G.H. Principal Component Analysis, 1989), входящих в векторы (X, Y) для графического описания характеристик параметров крови. Большие размеры векторов могут создавать проблемы для машинного обучения, так как модели прогнозирования, основанные на этих данных, подвержены риску переобучения (Kabari L.G., Nwame В.В., Principal Component Analysis (РСА) - An Effective Tool in Machine Learning, International Journals of Advanced Research in Computer Science and Software Engineering, ISSN: 2277-128X (Volume-9, Issue-5)). Кроме того, многие из признаков могут быть избыточными или сильно коррелированными, что также может привести к снижению точности диагностики. Этот метод также значительно увеличивает скорость вычисления.
Для применения метода главных компонент все векторы объединяются в один глобальный вектор Vglob, который соответствует положительному (1) или отрицательному (0) диагнозу. Глобальные векторы (фиг. 1) объединяются в матрицу признаков крови Mm,n (input matrix) размер которой зависит от количества т диагнозов и n признаков (элементов) векторов. Каждая строка матрицы соответствует строке ответного вектора Ym,1 (output).
Вычисление главных компонент сводится к сингулярному разложению матрицы, где главные компоненты - это собственные векторы ковариационной матрицы Ω=ММТ с максимальными собственными значениями, которые образуют подпространство, где р - желаемая размерность подпространства (Jolliffe I.T., Principal Component Analysis, 1986). Традиционным мотивом для выбора собственных векторов с максимальными собственными значениями является то, что собственные значения представляют собой величину дисперсии по конкретному собственному вектору.
Метод главных компонент уменьшает матрицу (фиг. 2) Мт,п→Xm,p, где размерность подпространства р≤n.Размерность, равная двум р=2 позволяет визуализировать классы (положительный и отрицательный диагнозы) в двухмерном подпространстве. Фиг. 3 показывает проекцию признаков на первые 2 главные компоненты, где голубой цвет точки соответствует положительному, а оранжевый цвет - отрицательному диагнозу. Можно обнаружить присутствие двух сконцентрированных оранжевых кластеров, которые принадлежат здоровым пациентам. Рассеянное голубое облако вне кластеров принадлежит больным пациентам. По сути задача машинного обучения состоит в том, чтобы найти обобщенные границы между кластерами в р-мерном подпространстве. Размерность, равная четырем р=4, позволила добиться наилучших результатов.
Сжатая матрица Xm,p и ответный вектор Ym,1 используются для машинного обучения с учителем (supervised learning), где необходимо решить задачу бинарной классификации. Машинное обучение - это область искусственного интеллекта, включающее в себя методы для обнаружения взаимосвязей и паттернов в базе данных (Langley P., Elements of Machine Learning, 19969). Существует неизвестная целевая зависимость -отображение y*:Xtrain,p→Ytrain, значения которой известны только на объектах конечной обучающей выборки (train set). Требуется построить алгоритм, который приближал бы неизвестную целевую зависимость, как на элементах выборки Xtrain,, так и на всем множестве X. Для оценки методов машинного обучения - 70% матрицы были использованы для обучающей выборки Xtrain (154 случаев) и 30% - для тестовой Xtest выборки (67 случаев).
Учитывая небольшую обучающую выборку (154 случаев) существует риск переобучения (overfitting). Переобучение это - феномен, когда обученная модель хорошо классифицирует случаи из обучающей выборки, но относительно плохо классифицирует случаи из тестовой выборки (Brownlee.J., Better Deep Learning: Train Faster, Reduce Overfitting, and Make Better Predictions, 2019). Алгоритм машинного обучения обладает способностью к обобщению только в том случае, если точность предсказания диагноза на тестовой выборке Xtest достаточно высока и предсказуема, то есть не сильно отличается от точности на обучающей выборке Xtrain.
Для усиления обобщения и улучшения результата был применен ансамблевый метод - бэггинг (bootstrap aggregating). Ансамбли - это парадигма машинного обучения, где несколько моделей обучаются для решения одной и той же проблемы и объединяются для получения лучших результатов (Langley P., Elements of Machine Learning, 1996). Бэггинг - это метод классификации, использующий композиции алгоритмов, каждый из которых параллельно обучается на подпространстве обучающей выборки Xtrain. Из множества обучающей выборки Xtrain отбираются к подмножеств путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества (фиг. 5).
Данные подмножеств передаются математическим моделям для анализа с последующей агрегацией результатов в ансамбль и расчета вероятности положительного диагноза, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод. Подмножества можно рассматривать как репрезентативные и независимые выборки истинного распределения данных. Результат классификации определяется путем голосования независимых моделей, где класс, предсказываемый каждой моделью, можно рассматривать как голос, а класс, который получает большинство голосов, является ответом ансамбля.
После обучения моделей и их агрегации в ансамбль проверяется точность на тестовой выборке Xtest.. X_train - обучающая выборка, X_test -тестовая выборка, а Модель 1 - Модель n - являются нейронными сетями, Подмножество 1 - Подмножество п - подмножества истинных данных из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля.
В качестве независимых моделей ансамбля - искусственные нейронные сети (Artificial Neural Networks ANNs) продемонстрировали самые лучшие результаты на тестовой выборке. ANNs представляют собой систему соединенных и взаимодействующих нейронов по Румельхарту (Rumelhart, David Е., Geoffrey Е. Hinton, and R. J. Williams. "Learning Internal Representations by Error Propagation". David E. Rumelhart, James L. McClelland, and the PDP research group, 1986).
Нейрон - это вычислительная единица, которая получает информацию и передает ее дальше. Нейрон получает суммарную информацию v=w1x1+…+wnxn всех нейронов с предыдущего скрытого слоя, где w это вес, умноженный на сигнал х. На выходе нейрона - суммарная информация v нормализуется с помощью функции активации у=φ(у). Функция активации нейрона φ определяет выходной сигнал, который определяется набором входных сигналов по аналогу биологического нейрона, где функция активации представляет скорость возбуждения потенциала действия в клетке (Krizhevsky A., Sutskever I., Hinton G.E., ImageNet Classification with Deep Convolutional Neural Networks, Advances in neural information processing systems 25(2), January 2012).
В качестве функции активации для всех нейронов был подобран линейный выпрямитель (Rectified linear unit ReLU). ReLU имеет простой пороговый переход в нуле, не подвержен насыщению и существенно повышает скорость сходимости стохастического градиентного спуска. Фиг. 7 показывает архитектуру нейронной сети, подобранную для данной задачи, где:
• 4 входа во входном слое - соответствуют 4 главным компонентам в подпространстве;
• в первом скрытом слое находятся - 32 нейронов, а во втором скрытом слое - 16 нейронов;
• 2 выхода в выходном слое соответствуют положительному и отрицательному диагнозам.
С математической точки зрения обучение нейронных сетей - это многопараметрическая задача нелинейной оптимизации, где необходимо найти глобальный минимум определенной целевой функции (Rojas, R., Neural Networks: A systematic Introduction, 1996). В бинарной классификации целевой функцией является перекрестная энтропия. В процессе оптимизации параметрами выступают весы w, которые оптимизируются до тех пор, пока ошибка предсказания не становится минимальной. Учитывая небольшой размер обучающей выборки - в качестве алгоритма для оптимизации был выбран Limited-memory BFGS (Broyden-Fletcher-Goldfarb-Shanno algorithm). LFBGS это - квазиньютоновский метод, основанный на накоплении информации о кривизне целевой функции по наблюдениям за изменение градиента (Pillo G., Giannessi F., Nonlinear Optimization and Applications, 1996).
Оценки модели можно сгруппировать в матрице ошибок (confusion или error matrix), как это показано на фиг. 8, где
• ИП: Истинно-положительные (true positives) классификации
• ЛП: Ложно-положительные (false positives) классификации
• ЛО: Ложно-отрицательные (false negatives) классификации
• ИО: Истинно-отрицательные (true negatives) классификации Для оценки качества моделей использовались следующие метрики:
• правильность (accuracy)
• точность (precision)
• чувствительность (recall)
• площадь под кривой ROC (AUC-ROC)
Правильность (accuracy) - самая простая метрика, дающая вероятность того, что диагноз будет предсказан правильно:
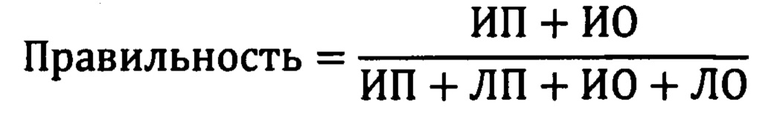
Точность (presicion) можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными:
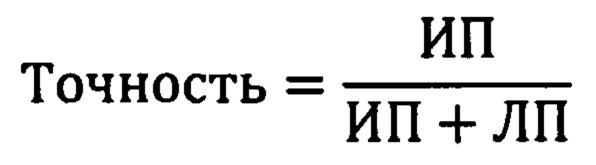
Чувствительность (recall) показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм:
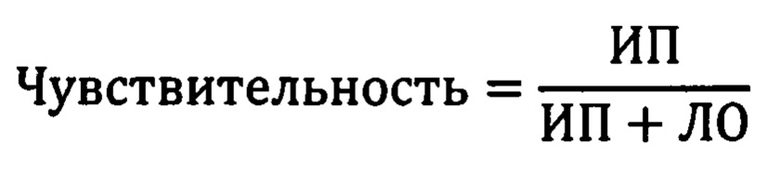
Одним из способов оценить модель в целом является площадь (Area Under Curve) под кривой ошибок ROC (Receiver Operating Charcteristic curve). Данная кривая представляет собой линию в координатах чувствительности и специфичности - Специфичность=ЛП/(ЛП+ИО). Специфичность показывает, какую долю из объектов отрицательного класса алгоритм предсказал неверно. В идеальном случае, когда классификатор предсказывает все правильно (Чувствительность =1, Специфичность =0), площадь под кривой будет равна единице, в противном случае, площадь под кривой ошибок будет стремиться к 0,5, так как классификатор будет выдавать одинаковое количество ИП и ЛП. Крутизна кривой имеет также важное значение, поскольку при максимальной чувствительности и минимальной специфичности кривая в идеале должна стремиться к точке (0,1). Наиболее часто AUC-ROC более 0,9 свидетельствует о высокой точности модели (McDowell I., Measuring Health: A Guide to Rating Scales and Questionnaires, 2006).
В Таблице 1 и на фиг.9 показано влияние количества моделей в ансамбле на точность предсказания. Ансамбль, состоящий из 7 нейронных сетей, продемонстрировал лучшие результаты на тестовой выборке.
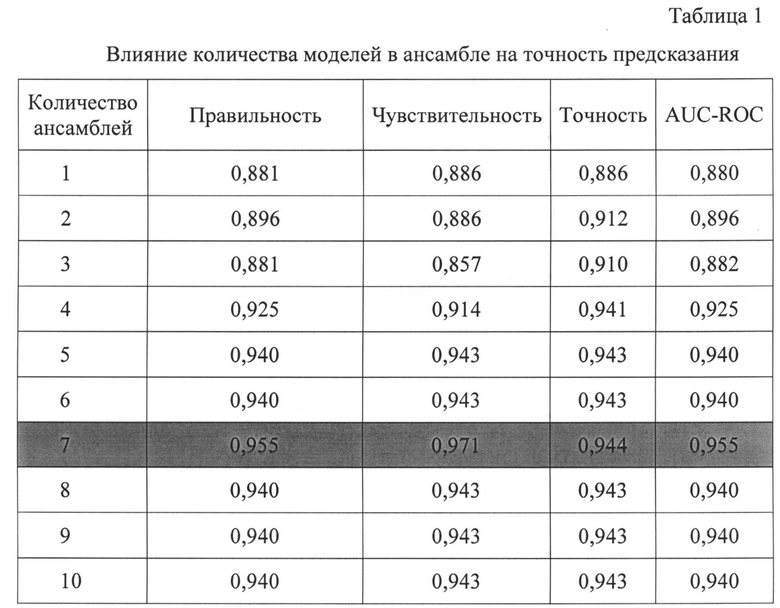
В Таб. 2 и на фиг. 10 показано влияние главных компонент на точность предсказания. Очевидно, что в 4-мерном подпространстве ансамбль демонстрирует наилучшую точность предсказания на тестовой выборке.
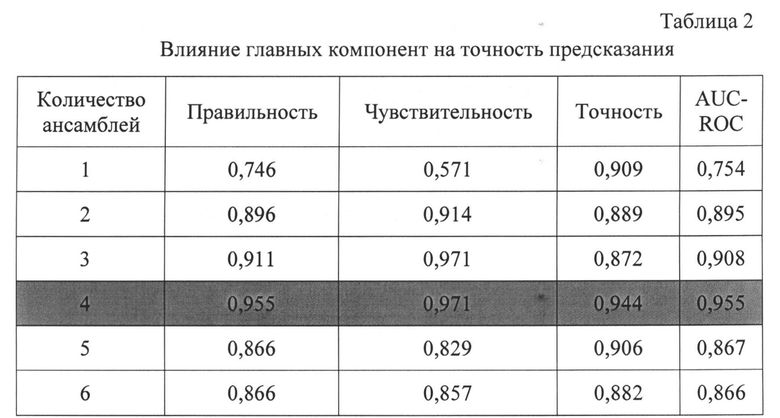
Ансамбль нейронных сетей (ANNs) продемонстрировал доминирование над другими моделями на тестовой выборке. При применении нейронных сетей достигается правильность (accuracy) 0,955 на тестовой выборке. Предложенные алгоритмы правильно классифицировали 34 из 36 положительных пациентов и 30 из 31 отрицательных пациентов. Фиг. 11 демонстрирует матрицу ошибок ансамбля нейронных сетей на тестовой выборке, где 34 из 36 истинно-положительных и 30 из 31 истинно-отрицательных диагнозов были классифицированы правильно.
На фиг. 12 продемонстрирована ROC кривая тестовой выборки, из которой следует высокое качество ансамбля нейронных сетей.
Фиг. 13 визуализирует поля вероятности для классификации диагнозов в двухмерном подпространстве, где оси соответствует двум главным компонентам. Эти поля можно рассматривать, как зрение нейронных сетей для неизвестных случаев. Упрощенно говоря, если результаты пациента окажутся в красном поле, то ансамбль нейронных сетей предположит наиболее высокую вероятность для отрицательного диагноза, если в синем поле, то - наиболее высокую вероятность для положительного диагноза.
В качестве библиотеки стандартных нейронных сетей для составления ансамбля применяют Scikit-learn - наиболее распространенный выбор для решения задач классического машинного обучения. В результате специалист получает заключение о вероятности отрицательного или положительного диагнозов, выраженные в процентах.
В дальнейшем заключительный этап может осуществляться в автоматическом режиме посредством лабораторной информационной системы и после валидации результата специалистом клинической лаборатории передаваться в госпитальную информационную систему для принятия окончательного решения лечащим врачом.
Проведение описанной диагностики возможно осуществлять на основании результатов клинического анализа крови, получаемых в течение первых минут пребывания пациента в приемном отделении еще до получения других лабораторных и инструментальных методов обследования, что значительно повышает качество оказания медицинской помощи.
Пример осуществления способа на пациенте с подтвержденным в результате его осуществления «положительным» диагнозом.
Пациент Ж. 36 лет поступил в приемное отделение СПб ГБУЗ «Городская многопрофильная больница №2» 07.06.2018 с предварительным диагнозом «ИБС. Острый коронарный синдром без подъема сегмента ST. Острая сердечная недостаточность. Класс I по Killip» через два часа после появления типичного болевого синдрома. В приемном отделении выполнено электрокардиографическое исследование, по результатам которого так же не выявлено элевации сегмента ST на электрокардиограмме. Далее были взяты образцы венозной крови для лабораторного исследования, в том числе для исследования высокочувствительным методом сердечного тропонина I и клинического анализа крови. Результаты лабораторных исследований: мочевина 4.2 ммоль/л (3.0-9.2); АЛТ 16 ед./л (0-55); ACT 12 ед./л (5-34); белок общий 70 г/л (64 - 83); креатинин 74 мкмоль/л (64 - 111); билирубин общий 6.2 мкмоль/л (3.4-20.5); глюкоза 7.5 ммоль/л (3.9-5.5); калий 3.7 ммоль/л (3.5 - 5.1); натрий 137 ммоль/л (135-145); кальций ионизированный 1.23 ммоль/л (1.13-1.32); АПТВ 78.7 с (25.1-36.5); MHO 0.97 (0.90-1.20); протромбин 118.0% (70.0-140.0); протромбиновое время 11.0 с (9.4-12.5); (WBC) Лейкоциты 12.4 10Е9/л (4.0-9.0); (NEUT) нейтрофилы 10.0*109/л (2.0-5.5); (NEUT%) Нейтрофилы 80.0% (48.0-78.0); (LYM) лимфоциты 1.79*109/л (1.20-3.00); (LYM%) лимфоциты 14.3% (19.0-37.0); (MON) моноциты 0.57 109/л (0.09-0.60); (MON%) моноциты 4.6% (3.0-11.0); (EOS) эозинофилы 0.07*109/л (0.00-0.30); (EOS%) эозинофилы 0.52% (1.00-5.00); (BAS) базофилы 0.07*109/л (0.00-0.06); (BAS%) базофилы 0.52% (0.00-1.00); (HGB) гемоглобин 134 г/л (130-160); (НСТ) гематокрит 40.7% (40.0-48.0); (RBC) эритроциты 4.45 10*12/л (4.00 - 5.60); (МСН) среднее содержание гемоглобина в эритроцитах 30.1 пг (24.0-34.0); (МСНС) средняя концентрация гемоглобина в эритроцитах 32.9 г/дл (30.0-38.0); (MCV) средний объем эритроцитов 91.4 фл (75.0-95.0); (RDW-CV) распределение эритроцитов по величине 11.0% (11.5-16.5); (PLT) тромбоциты 262*109/л (180-400); (MPV) средний объем тромбоцитов 11.5 фл (7.4-10.4); сердечный тропонин I (высокочувствительный метод) 37.9 нг/мл (верхний референсный предел 26,2 нг/мл).
Результат предварительной обработки скатерограммы клинического анализа крови пациента включал следующие показатели: нейтрофилы (NEU) состоят из 5346 элементов по IAS(X) и 5346 элементов по IAS(Y). Моноциты (MON) состоят из 347 элементов по IAS(X) и 347 элементов по IAS(Y). Лимфоциты (LYM) состоят из 968 элементов по IAS(X) и 968 элементов по IAS(Y) и еще одни нейтрофилы (NEU) из 4336 по PSS(X) и 4336 элементов по IAS(Y). Первым шагом необходимо провести отсечение последних элементов, чтобы количество элементов нового пациента соответствовало количеству элементов пациентов, находящихся в существующей базе данных. При этом элементы отсекаются с конца. Таким образом, нейтрофилы (NEU) сокращаются с 5346 до 891 по IAS(X) и IAS(Y), моноциты (MON) с 347 до 127 по IAS(X) и IAS(Y), лимфоциты (LYM) с 968 до 261 по IAS(X) и IAS(Y) и нейтрофилы (NEU) с 4336 до 829 по IAS(X) и IAS(Y).
После отсечения все элементы векторов объединяются в один общий глобальный вектор Vglob, который состоит в общей сложности из 4216 элементов:
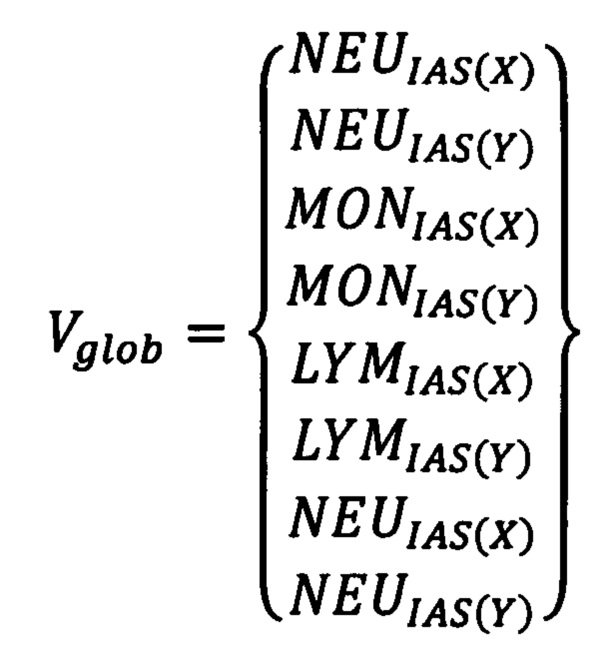
Глобальный вектор подвергается стандартизации путем удаления среднего значения и масштабирования до единичной дисперсии на основе предварительно сформированной базы данных.
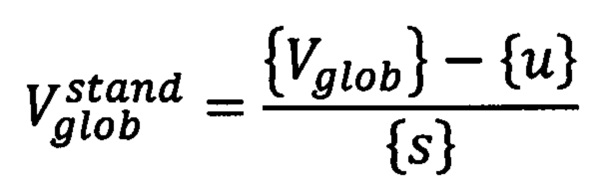
где {u} вектор средних значений, a {s} вектор стандартных отклонений каждого из 4216 элементов в базе данных. Для стандартизации используется функционал StandardScaler библиотеки Scikit Learn (Библиотека алгоритмов машинного обучения Scikit-learn [Интернет-ресурс] https://scikit-learn.org/stable/ (дата обращения 06.02.2020)).
После стандартизации применяется метод главных компонент (РСА), чтобы уменьшить размерность признаков с 4216 элементов до 4 элементов, которые называются главными компонентами, сохранив при этом как можно больше изменчивости (информации) признаков [6]. Для этого используется функционал РСА библиотеки Scikit Learn.
При применении метода главных компонент, все 4216 элементов вектора 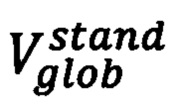 сводятся в 4-мерном подпространстве к следующему вектору:
сводятся в 4-мерном подпространстве к следующему вектору:
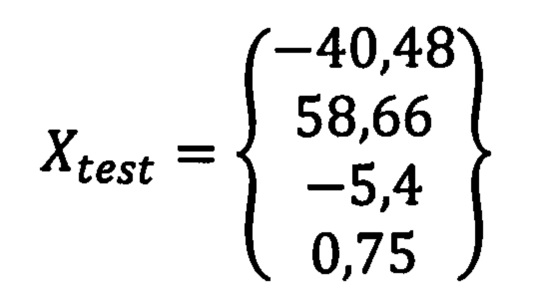
После применения метода главных компонент вектор Xtest вновь подвергается стандартизации путем удаления среднего значения и масштабирования до единичной дисперсии на основе статистических данных главных компонент базы данных в 4-мерном подпространстве:
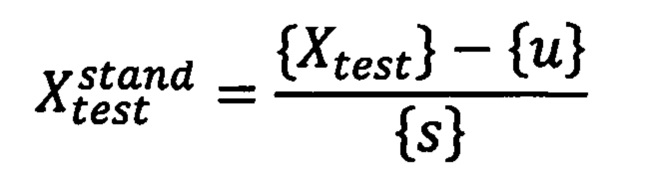
Где {u} вектор средних значений в базе данных:
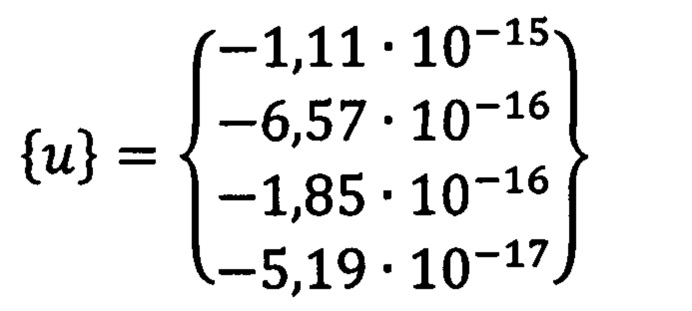
a {s} вектор стандартных отклонений каждого из 4 элементов в базе данных:
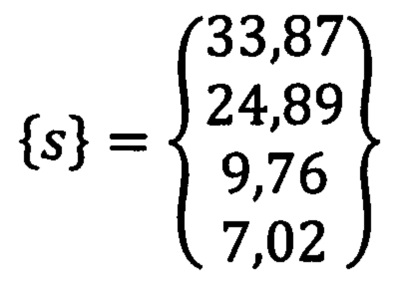
В результате, получаем сокращенный и стандартизированный вектор:
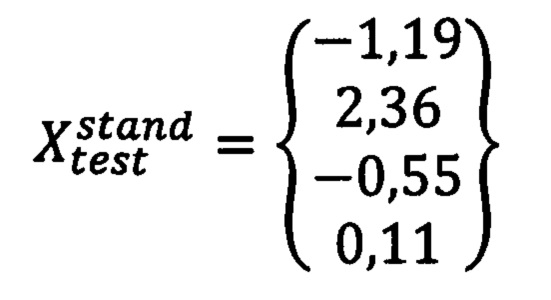
На первый взгляд из значений этого вектора  сложно извлечь информацию для диагностики пациента. Для этого используется ансабмль из 7 нейронных сетей, которые были обучены на 154 подобных векторах, продемонстрировав высокую точность на тестовой выборке. Все четыре элемента служат при этом входными сигналами для 7 нейронных сетей. Для обучения нейронных сетей был использован функционал MLPClassifier библиотеки Scikit Learn. Для создания ансамбля был использован функционал BaggingClassifier библиотеки Scikit Learn. Сам ансамбль хранится в формате.sav (model.sav) и должен быть использован для предсказания каждого нового случая. По сути этот файл содержит матрицу весов каждого слоя всех семи нейросетей с прямой связью. Предсказание осуществляется посредством продвижения сигналов через два каждый слой, где сигналы умножаются на матрицу весов и активируются на выходе каждого слоя. Последний слой состоит из двух выходов, где первый выход выдает вероятность для отрицательного диагноза, а второй выход -вероятность для положительного диагноза. В случае с вышеописанным пациентом ансамбль выдал следующие результаты:
сложно извлечь информацию для диагностики пациента. Для этого используется ансабмль из 7 нейронных сетей, которые были обучены на 154 подобных векторах, продемонстрировав высокую точность на тестовой выборке. Все четыре элемента служат при этом входными сигналами для 7 нейронных сетей. Для обучения нейронных сетей был использован функционал MLPClassifier библиотеки Scikit Learn. Для создания ансамбля был использован функционал BaggingClassifier библиотеки Scikit Learn. Сам ансамбль хранится в формате.sav (model.sav) и должен быть использован для предсказания каждого нового случая. По сути этот файл содержит матрицу весов каждого слоя всех семи нейросетей с прямой связью. Предсказание осуществляется посредством продвижения сигналов через два каждый слой, где сигналы умножаются на матрицу весов и активируются на выходе каждого слоя. Последний слой состоит из двух выходов, где первый выход выдает вероятность для отрицательного диагноза, а второй выход -вероятность для положительного диагноза. В случае с вышеописанным пациентом ансамбль выдал следующие результаты:
4.14850972е-03,9.95851490е-01
Из чего следует, что вероятность отрицательного диагноза составляет 0,4148%, а вероятность положительного диагноза составляет 99,585%, что определяет пациента как имеющего высокий риск развития неблагоприятных сердечно-сосудистых исходов.
Принято решение о проведении чрескожного коронарного вмешательства. Пациенту выполнено коронароангиографическое исследование с последующей транслюминальной баллонной дилатации и стентированием инфаркт-зависимой коронарной артерии.
КОРОНАРОГРАФИЯ №7175 от 07.06.2018: Левый тип кровообращения. Левая коронарная артерия: Ствол - без стенозов. Передняя межжелудочковая ветвь (ПМЖВ) - стеноз устья 5-50%, субокклюзия в средней трети. A.intermedia - стеноз в проксимальной трети 90%. Диагональные ветви (ДВ) - без стенозов. Огибающая ветвь (ОВ) - без стенозов. Ветви тупого края (ВТК): без стенозов. Правая коронарная артерия: гипоплазирована. Ветвь острого края (ВОК) - без стенозов. Задне-боковая ветвь (ЗБВ) - без стенозов. Задняя межжелудочковая ветвь (ЗМЖВ) - без стенозов.
КОРОНАРОПЛАСТИКА И СТЕНТИРОВАНИЕ ПМЖВ №7176 от 07.06.18: Предилятация зоны стеноза ПМЖВ (средняя треть) БК 2,0*20,0 мм, р=18 атм. Стент с лекарственным покрытием 2,75*33,0 мм имплантирован в среднюю треть ПМЖВ, р=16 атм. Контроль: кровоток TIMI III grade flow.
На рентгенограммах грудной клетки в 2-х проекциях от 08.06.2018 инфильтративных теней не выявлено. Корни структурны, не расширены, левый - частично перекрыт.Легочный рисунок не изменен. Диафрагма контурируется. Тень сердца без особенностей. Синусы свободны.
Проведено лечение: бета-блокаторы, ИАПФ, антикоагулянты, двойная дезагрегантная терапия, статины (доза крестора снижена 20->10 мг/сут в связи с повышением уровня трансаминаз), гастропротекторы. От реабилитационного лечения в санатории пациент отказался.
В постоперационном периоде максимальные концентрации сердечного тропонина I при динамическом наблюдении достигли 7522,5 нг/мл. Госпитализация продлилась в течение 12 суток. Окончательный диагноз: «ИБС. Острый инфаркт миокарда передне-перегородочной области, высоких боковых отделов левого желудочка без подъема сегмента ST от 07.06.18. Коронаропластика и стентирование ПМЖВ от 07.06.18». Пациент выписан 19.06.2018 для дальнейшего диспансерного наблюдения по месту жительства.
Проведение описанного способа возможно осуществлять на основании результатов клинического анализа крови, получаемых в течение первых минут пребывания пациента в приемном отделении еще до получения других лабораторных и инструментальных методов обследования, что значительно повысит качество оказания медицинской помощи.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИАГНОСТИКИ ПАТОЛОГИИ ЗРИТЕЛЬНОГО НЕРВА | 2012 |
|
RU2496404C1 |
| СПОСОБ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ МИКРОБОВ И СЛОЖНЫХ АМИНОКИСЛОТ | 2007 |
|
RU2362145C2 |
| Способ диагностики онкологического заболевания крови | 2022 |
|
RU2803281C1 |
| СПОСОБ И СИСТЕМА НЕИНВАЗИВНОЙ СКРИНИНГОВОЙ ОЦЕНКИ ФИЗИОЛОГИЧЕСКИХ ПАРАМЕТРОВ И ПАТОЛОГИЙ | 2016 |
|
RU2657384C2 |
| Способ биогибридного скрининга рака легкого, рака желудка, сахарного диабета и туберкулеза легких по выдыхаемому обследуемым воздуху | 2022 |
|
RU2797334C1 |
| СПОСОБ РАСЧЕТА КРЕДИТНОГО РЕЙТИНГА КЛИЕНТА | 2019 |
|
RU2723448C1 |
| Способ и система поддержки принятия врачебных решений с использованием математических моделей представления пациентов | 2017 |
|
RU2703679C2 |
| Способ формирования математических моделей пациента с использованием технологий искусственного интеллекта | 2017 |
|
RU2720363C2 |
| Способ прогнозирования возобновления клиники ишемической болезни сердца с помощью нейронных сетей у пациентов после эндоваскулярного вмешательства | 2017 |
|
RU2675067C1 |
| СПОСОБ ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ ПОСЛЕ ОПЕРАЦИЙ ШУНТИРОВАНИЯ КОРОНАРНЫХ АРТЕРИЙ В УСЛОВИЯХ ИСКУССТВЕННОГО КРОВООБРАЩЕНИЯ | 2013 |
|
RU2536279C1 |
Изобретение относится к медицинской технике, а именно к способу диагностики острого коронарного синдрома. Способ включает формирование базы данных, содержащей информацию о результатах клинического анализа крови пациентов с острым коронарным синдромом и здоровых людей группы контроля, которую в дальнейшем используют для обучения нейронных сетей, после чего осуществляют взятие цельной венозной крови обследуемого пациента, перемешивают пробу крови, затем производят исследование клинического анализа крови на автоматическом гематологическом анализаторе, после этого результаты исследования копируют с анализатора в виде FCS-файлов и переносят на персональный компьютер для предварительной обработки и машинного анализа, причем предварительная обработка включает перевод оператором при помощи программного обеспечения, позволяющего работать с FCS-файлами, графических изображений в виде скатерограмм анализа крови пациента в цифровой эквивалент - вектор, который содержит информацию обо всех исследованных клетках в виде данных их расположения по осям скатерограммы X и Y, при этом оператор с учетом морфологических показателей представленных на анализ клеток крови дифференцирует их на три субпопуляции: нейтрофилы, лимфоциты и моноциты, после чего полученный результат в цифровом эквиваленте сохраняют в отдельный файл программы для работы с электронными таблицами, затем в вышеуказанном цифровом эквиваленте скатерограммы анализа крови пациента - векторе отсекают последние элементы, а именно координаты клеток, так, чтобы количество элементов обследуемого пациента соответствовало количеству элементов пациентов, результаты которых находятся в предварительно сформированной базе данных, после чего все элементы векторов обследуемого пациента объединяются последовательно в один общий глобальный вектор Vglob, затем стандартизируют полученный вектор путем вычитания из глобального вектора обследуемого пациента среднего значения соответствующих векторов из предварительно сформированной базы данных и последующего деления на стандартное отклонение соответствующих векторов базы данных, затем применяют метод главных компонент для уменьшения размерности признаков с n элементов до 2-4 главных компонент {Xn}, сохранив при этом как можно больше изменчивости признаков, посредством программного обеспечения для математических вычислений, в результате получают сокращенный вектор, затем производят стандартизацию с помощью описанных выше действий уже сокращенного вектора до вида  , после чего применяют ансамбль из нейронных сетей, которые обучают на предварительно сформированной базе данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем внесения информации в программное обеспечение для машинного анализа об их результатах клинического анализа крови и окончательного диагноза - «острый коронарный синдром» или «здоров», при этом количество нейронных сетей в ансамбле зависит от результатов оценки точности предсказания окончательного диагноза и составляет от 1 до 10, при этом используют композиции алгоритмов, каждый из которых параллельно обучают на подпространстве обучающей выборки из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля, причем из множества обучающей выборки отбирают от 1 до n подмножеств путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества, чтобы затем передать их математическим моделям для анализа с последующей агрегацией данных в ансамбль и расчета вероятности положительного диагноза, при этом подмножества рассматривают как репрезентативные и независимые значения истинного распределения данных, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод, причем после обучения нейронных сетей и их агрегации в ансамбль проверяется их точность на тестовой выборке, при этом по итогу обучения нейронных сетей и приемлемому результату тестирования, при условии ошибки результатов оценки менее 5%, аналогичным образом производят исследование клинического анализа крови обследуемого пациента, а для оценки положительного диагноза в процентах строят график, где используют поля вероятности для классификации диагнозов в двухмерном подпространстве, которые представляют собой оси абсцисс и ординат, соответствующих главным компонентам, причем указанные поля рассматривают как зрение нейронных сетей для неизвестных случаев, при этом диагноз обследуемому пациенту ставят следующим образом: если результаты пациента окажутся в области графика, выделенной для отрицательного диагноза, то ансамбль нейронных сетей выдаст наиболее высокую вероятность для отрицательного диагноза, если в области графика, выделенной для положительного диагноза - наиболее высокую вероятность для положительного диагноза - острый коронарный синдром. Техническим результатом является повышение правильности постановки диагноза пациенту с точностью до 95-96,77%. 14 ил., 2 табл.
, после чего применяют ансамбль из нейронных сетей, которые обучают на предварительно сформированной базе данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем внесения информации в программное обеспечение для машинного анализа об их результатах клинического анализа крови и окончательного диагноза - «острый коронарный синдром» или «здоров», при этом количество нейронных сетей в ансамбле зависит от результатов оценки точности предсказания окончательного диагноза и составляет от 1 до 10, при этом используют композиции алгоритмов, каждый из которых параллельно обучают на подпространстве обучающей выборки из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля, причем из множества обучающей выборки отбирают от 1 до n подмножеств путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества, чтобы затем передать их математическим моделям для анализа с последующей агрегацией данных в ансамбль и расчета вероятности положительного диагноза, при этом подмножества рассматривают как репрезентативные и независимые значения истинного распределения данных, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод, причем после обучения нейронных сетей и их агрегации в ансамбль проверяется их точность на тестовой выборке, при этом по итогу обучения нейронных сетей и приемлемому результату тестирования, при условии ошибки результатов оценки менее 5%, аналогичным образом производят исследование клинического анализа крови обследуемого пациента, а для оценки положительного диагноза в процентах строят график, где используют поля вероятности для классификации диагнозов в двухмерном подпространстве, которые представляют собой оси абсцисс и ординат, соответствующих главным компонентам, причем указанные поля рассматривают как зрение нейронных сетей для неизвестных случаев, при этом диагноз обследуемому пациенту ставят следующим образом: если результаты пациента окажутся в области графика, выделенной для отрицательного диагноза, то ансамбль нейронных сетей выдаст наиболее высокую вероятность для отрицательного диагноза, если в области графика, выделенной для положительного диагноза - наиболее высокую вероятность для положительного диагноза - острый коронарный синдром. Техническим результатом является повышение правильности постановки диагноза пациенту с точностью до 95-96,77%. 14 ил., 2 табл.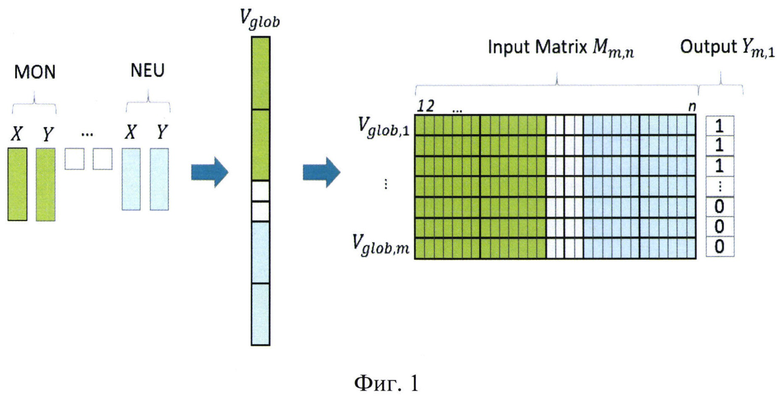
Способ диагностики острого коронарного синдрома, при котором предварительно формируют базу данных, содержащую информацию о результатах клинического анализа крови пациентов с острым коронарным синдромом и здоровых людей группы контроля, которую в дальнейшем используют для обучения нейронных сетей, после чего осуществляют взятие цельной венозной крови обследуемого пациента, перемешивают пробу крови, затем производят исследование клинического анализа крови на автоматическом гематологическом анализаторе, после этого результаты исследования копируют с анализатора в виде FCS-файлов и переносят на персональный компьютер для предварительной обработки и машинного анализа, причем предварительная обработка включает перевод оператором при помощи программного обеспечения, позволяющего работать с FCS-файлами, графических изображений в виде скатерограмм анализа крови пациента в цифровой эквивалент - вектор, который содержит информацию обо всех исследованных клетках в виде данных их расположения по осям скатерограммы X и Y, при этом оператор с учетом морфологических показателей представленных на анализ клеток крови дифференцирует их на три субпопуляции: нейтрофилы, лимфоциты и моноциты, после чего полученный результат в цифровом эквиваленте сохраняют в отдельный файл программы для работы с электронными таблицами, затем в вышеуказанном цифровом эквиваленте скатерограммы анализа крови пациента - векторе отсекают последние элементы, а именно координаты клеток, так, чтобы количество элементов обследуемого пациента соответствовало количеству элементов пациентов, результаты которых находятся в предварительно сформированной базе данных, после чего все элементы векторов обследуемого пациента объединяются последовательно в один общий глобальный вектор Vglob:
где NEU - нейтрофилы, MON - моноциты, LYM - лимфоциты, IAS и PSS - режимы лазерной детекции клеток в гематологическом анализаторе, X и Y - значение координат по осям абсцисс и ординат на скатерограмме клинического анализа крови, n - общее количество выявленных клеток,
затем стандартизируют полученный вектор путем вычитания из глобального вектора обследуемого пациента среднего значения соответствующих векторов из предварительно сформированной базы данных и последующего деления на стандартное отклонение соответствующих векторов базы данных следующим образом:
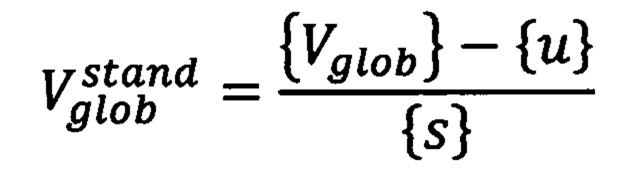
где {u} - указанное среднее значение, a {s} - вектор стандартных отклонений каждого элемента в предварительно собранной базе данных, затем применяют метод главных компонент для уменьшения размерности признаков с n элементов до 2-4 главных компонент {Xn}, сохранив при этом как можно больше изменчивости признаков, посредством программного обеспечения для математических вычислений, в результате получают сокращенный вектор вида:
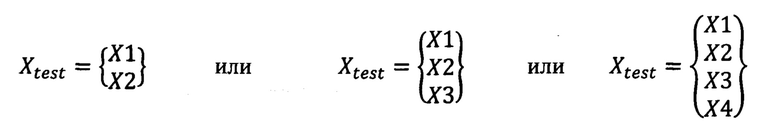
где X1, Х2, Х3, Х4 - главные компоненты сокращенного вектора, при этом количество главных компонент зависит от наиболее успешной комбинации, позволяющей достичь наилучшего результата анализа, затем производят стандартизацию с помощью описанных выше действий уже сокращенного вектора до вида  , после чего применяют ансамбль из нейронных сетей,
, после чего применяют ансамбль из нейронных сетей,
которые обучают на предварительно сформированной базе данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем внесения информации в программное обеспечение для машинного анализа об их результатах клинического анализа крови и окончательного диагноза - «острый коронарный синдром» или «здоров», при этом количество нейронных сетей в ансамбле зависит от результатов оценки точности предсказания окончательного диагноза и составляет от 1 до 10, при этом используют композиции алгоритмов, каждый из которых параллельно обучают на подпространстве обучающей выборки из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля, причем из множества обучающей выборки отбирают от 1 до n подмножеств истинных данных из предварительно сформированной базы данных пациентов с острым коронарным синдромом и здоровых людей группы контроля путем случайного выбора элементов с повторениями в каждом из наблюдений подмножества, чтобы затем передать их математическим моделям для анализа с последующей агрегацией данных в ансамбль и расчета вероятности положительного диагноза, рассматривая нейронные сети как модели, при этом подмножества рассматривают как репрезентативные и независимые значения истинного распределения данных, и на каждом из подмножеств обучают нейронную сеть как модель, при этом применяют ансамблевый метод, причем после обучения нейронных сетей и их агрегации в ансамбль проверяется их точность на тестовой выборке, при этом по итогу обучения нейронных сетей и приемлемому результату тестирования, при условии ошибки результатов оценки менее 5%, аналогичным образом производят исследование клинического анализа крови обследуемого пациента, а для оценки положительного диагноза в процентах строят график, где используют поля вероятности для классификации диагнозов в двухмерном подпространстве, которые представляют собой оси абсцисс и ординат, соответствующих главным компонентам, причем указанные поля рассматривают как зрение нейронных сетей для неизвестных случаев, при этом диагноз обследуемому пациенту ставят следующим образом: если результаты пациента окажутся в области графика, выделенной для отрицательного диагноза, то ансамбль нейронных сетей выдаст наиболее высокую вероятность для отрицательного диагноза, если в области графика, выделенной для положительного диагноза - наиболее высокую вероятность для положительного диагноза - острый коронарный синдром.
| СПОСОБ НЕЙРОСЕТЕВОГО АНАЛИЗА СОСТОЯНИЯ СЕРДЦА | 2018 |
|
RU2704913C1 |
| СПОСОБ ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ ПОСЛЕ ОПЕРАЦИЙ ШУНТИРОВАНИЯ КОРОНАРНЫХ АРТЕРИЙ В УСЛОВИЯХ ИСКУССТВЕННОГО КРОВООБРАЩЕНИЯ | 2013 |
|
RU2536279C1 |
| US 20050004485 A1, 06.01.2005 | |||
| US 20160135706 A1, 19.05.2016. | |||

