Изобретение относится к речевым кодерам с линейным предсказанием и использованием метода анализа через синтез. Такие речевые кодеры используются, например, в сотовых системах радиосвязи.
Синтезирующая часть речевого кодера с линейным предсказанием и использованием метода анализа через синтез [1] состоит из трех основных блоков, а именно из синтезирующего фильтра для кодирования с линейным предсказанием (LPC), адаптивного кодового словаря и какого-либо вида фиксированного возбуждения. Синтез речи осуществляется фильтрацией вектора возбуждения фильтром кодирования с линейным предсказанием для получения сигнала синтезированной речи. Вектор возбуждения формируется сложением вместе масштабированных вариантов векторов, поступающих из адаптивного кодового словаря, и фиксированного возбуждения. Анализирующая часть кодера на основе метода анализа через синтез включает в основном анализ кодирования с линейным предсказанием и анализ возбуждения. Анализ возбуждения представляет собой поиск индексов или других параметров для возбуждения, например, индексов для кодового словаря, параметров усиления для сигнала возбуждения или амплитуд и позиций для импульсов возбуждения.
Структура возбуждения, используемая в речевом кодере на основе метода анализа через синтез, является существенной с точки зрения качества восстанавливаемой речи, сложности поиска и устойчивости к ошибкам в битах (робастности). Для обеспечения высокого качества возбуждение должно быть насыщенным, то есть содержать как импульсные, так и шумоподобные составляющие. Для уменьшения сложности возбуждение должно быть до некоторой степени структурированным, поскольку в структурированном кодовом словаре поиск кода возбуждения упрощается. Для обеспечения высокой робастности в условиях радиосвязи с подвижными объектами чувствительность к ошибкам в битах для незащищенных битов кода возбуждения должна быть низкой.
Для достижения насыщенности возбуждения были предложены процедуры так называемого смешанного возбуждения [2-8]. Смесь обычно состоит из последовательностей импульсов и шума. Импульсное возбуждение необходимо в начальных, взрывных и звонких фрагментах речи. Шумоподобные последовательности необходимы для глухих звуков.
Для понижения сложности структурированного возбуждения было предложено несколько методов. Многоимпульсное возбуждение (MPE) описано в [9], оно включает импульсы, описываемые позицией и амплитудой. Возбуждение регулярными импульсами (RPE) описано в [10] и состоит из последовательности регулярно (эквидистантно) расположенных импульсов, описываемой "сеткой" (позицией первого импульса) и амплитудами импульсов. Возбуждение преобразованными бинарными импульсами (TBPE) описано в [11-12] и включает в себя бинарную последовательность импульсов, которая преобразуется формирующей матрицей для получения последовательности регулярно расположенных импульсов, имеющей Гауссовский характер. Возбуждение векторной суммой (VSE) описано в [13] и включает несколько базисных векторов, которые объединяются в выходной вектор. Для формирования вектора возбуждения базовые векторы умножаются на +1 или на -1 и суммируются. Методы поиска с низкой сложностью существуют для всех этих структурированных возбуждений.
Для обеспечения робастности предложены защита старшего бита [14], присвоение индекса [15] и фазовое позиционное кодирование [16].
Задачей настоящего изобретения является создание речевого кодера с линейным предсказанием и использованием анализа через синтез, который обеспечивает как высокое качество (полноту возбуждения), так и малую сложность поиска, а также высокую устойчивость в условиях радиосвязи с подвижными объектами.
Данная задача решается с помощью речевого кодера в соответствии с п. 1 формулы изобретения.
Изобретение вместе с другими его целями и преимуществами будет понятно из следующего описания, приводимого вместе с прилагаемыми чертежами.
На фиг. 1 показана блок-схема типичного кодера с линейным предсказанием и использованием метода анализа через синтез.
Фиг. 2 поясняет принцип многоимпульсного возбуждения.
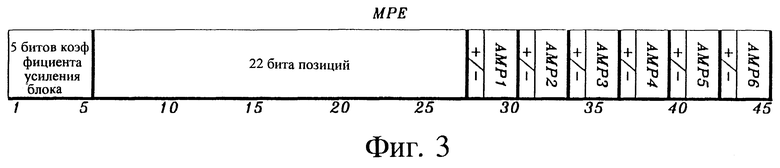
На фиг. 3 показана схема распределения битов для многоимпульсного возбуждения.
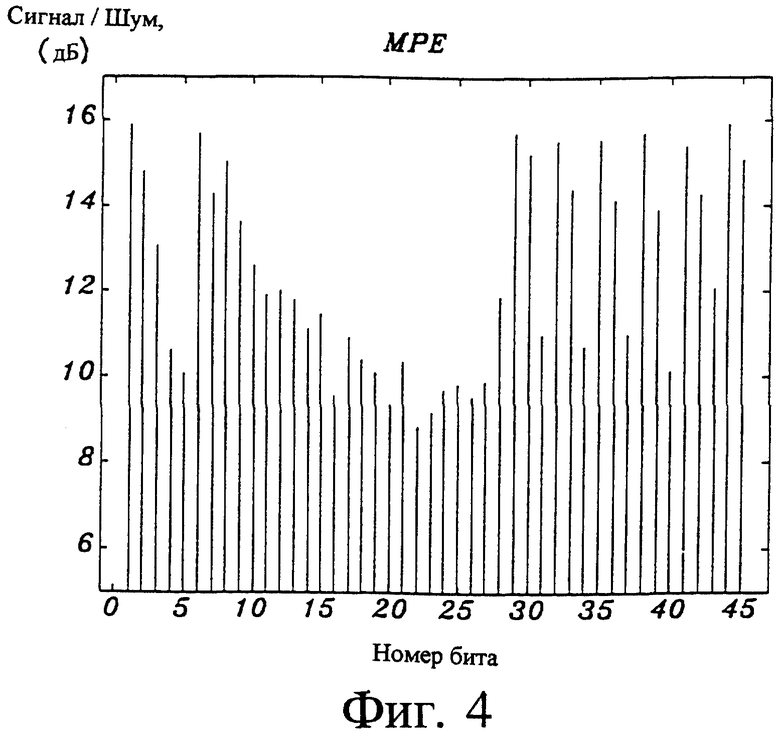
На фиг. 4 показан график, иллюстрирующий чувствительность к ошибкам в битах для многоимпульсного возбуждения, показанного на фиг. 3.
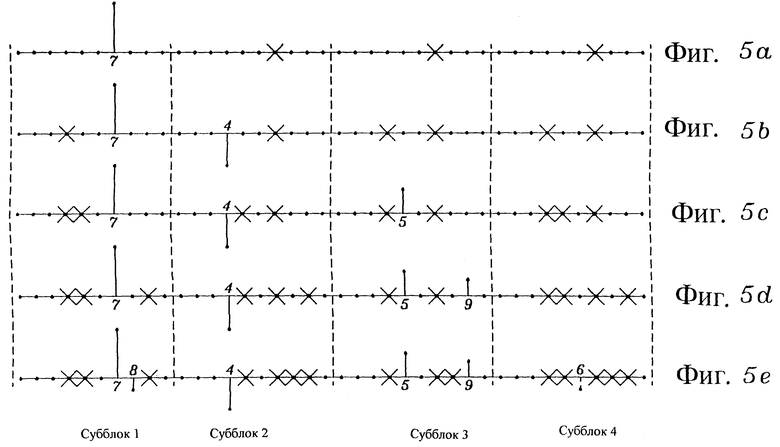
Фиг. 5 (a-e) поясняет принцип многоимпульсного возбуждения с кодированием фазы позиции.
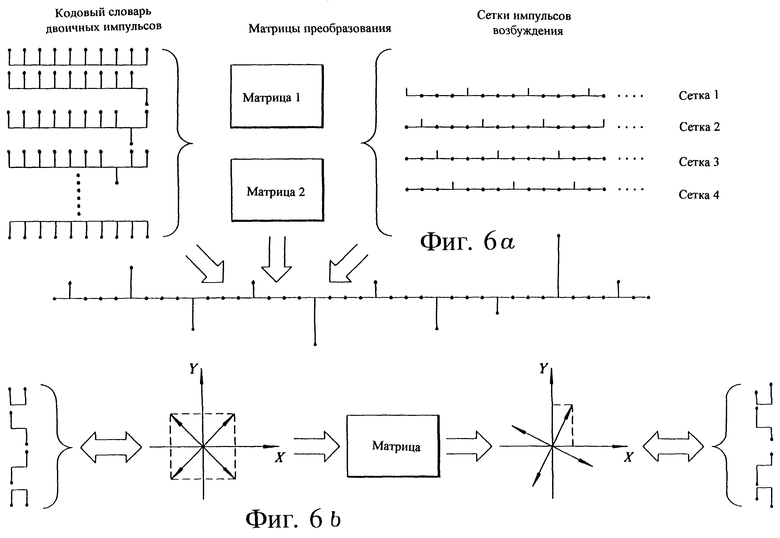
Фиг. 6a поясняет принцип возбуждения с использованием преобразованных бинарных импульсов.
Фиг. 6b поясняет возбуждение с использованием преобразованных бинарных импульсов для частного случая использования только двух импульсов.
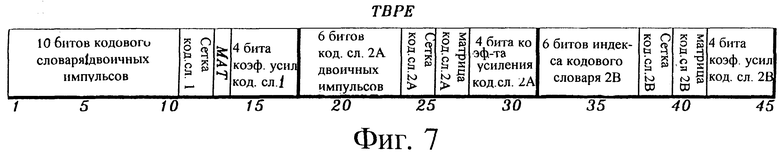
На фиг. 7 показана схема распределения битов для возбуждения с использованием преобразованных бинарных импульсов.
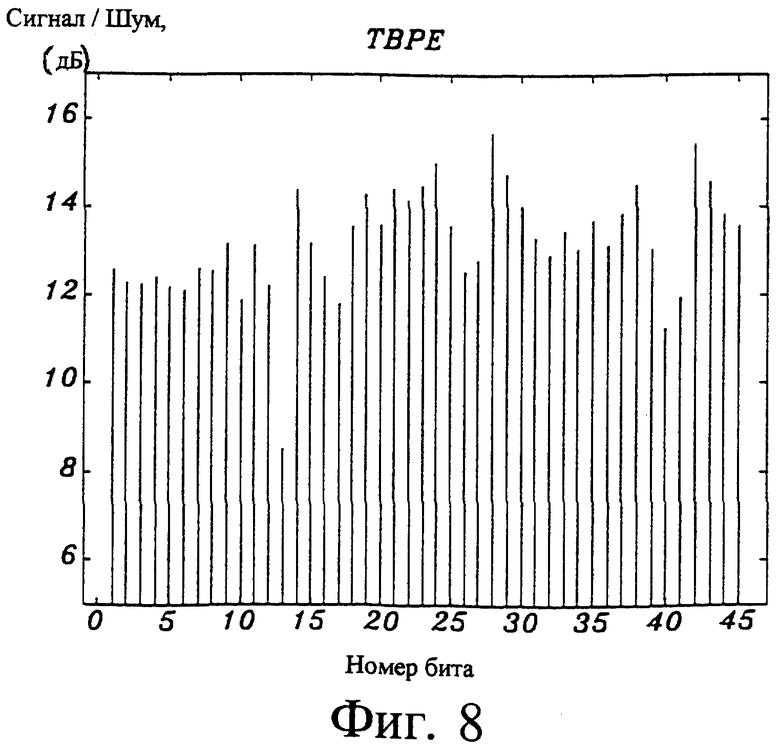
На фиг. 8 показан график, иллюстрирующий чувствительность к ошибкам в битах для случая возбуждения с использованием преобразованных бинарных импульсов.
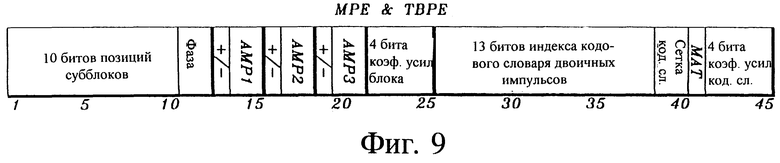
На фиг. 9 показана схема распределения бит для комбинированного возбуждения с использованием многих импульсов и преобразованных бинарных импульсов в соответствии с предпочтительной формой осуществления изобретения.
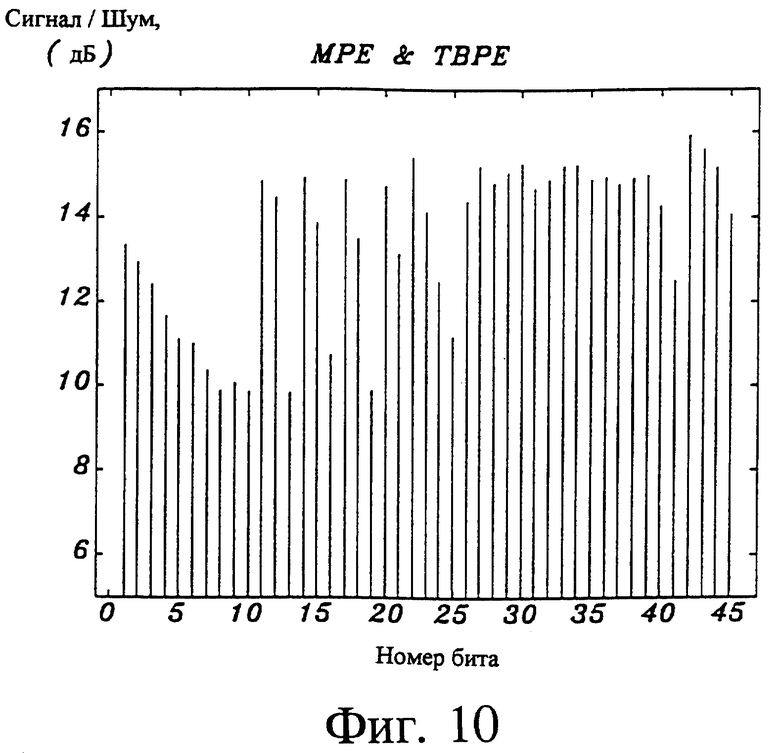
На фиг. 10 показан график, иллюстрирующий чувствительность к ошибкам в битах для комбинированного возбуждения с использованием многих импульсов и преобразованных бинарных импульсов в соответствии с предпочтительной формой осуществления изобретения.
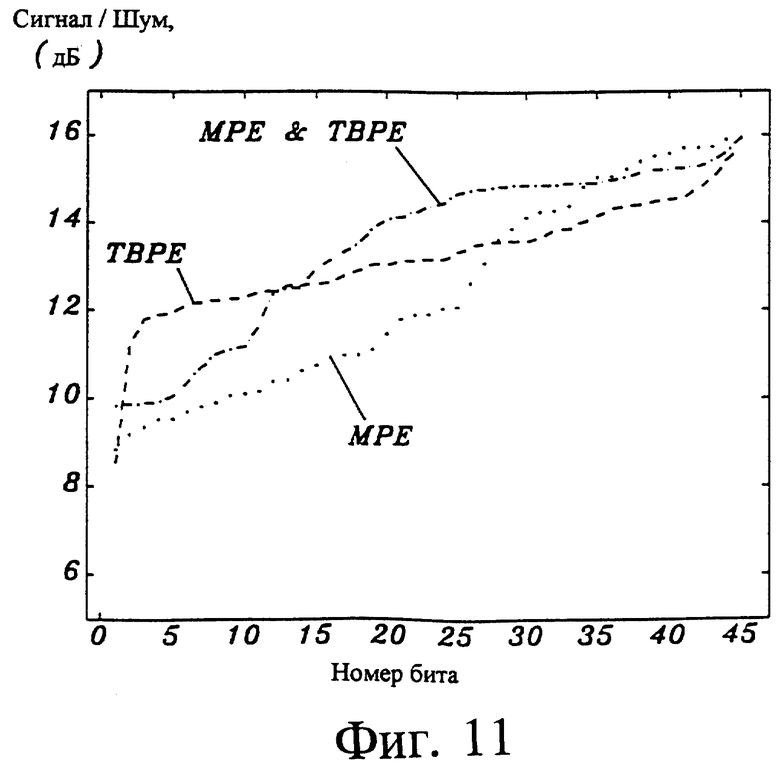
На фиг. 11 сравнивается чувствительность к ошибкам в битах для случаев, показанных на фиг. 4, 8 и 10 и рассортированных по чувствительности к ошибкам в битах.
На фиг. 12 показана блок-схема предпочтительного варианта выполнения речевого кодера в соответствии с настоящим изобретением.
Следующее описание приводится со ссылкой на сотовую систему подвижной связи общеевропейского стандарта GSM. Однако понятно, что принципы настоящего изобретения могут быть применены также и к другим сотовым системам радиосвязи.
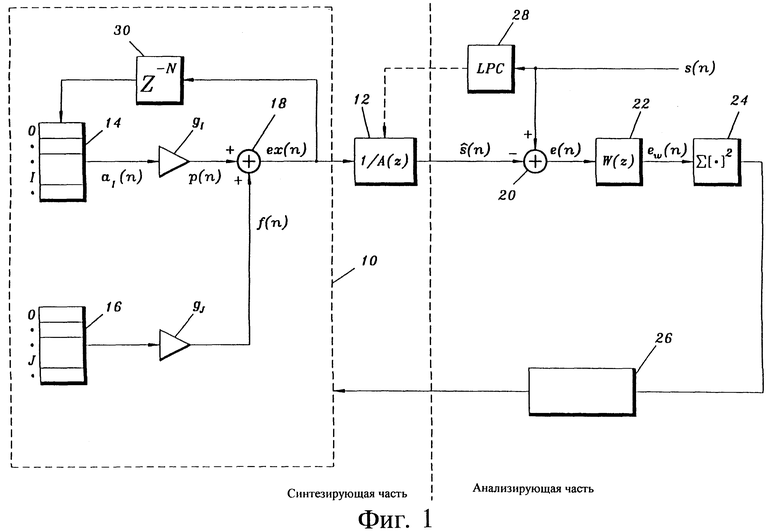
На фиг. 1 показана блок-схема типичного кодера с линейным предсказанием и использованием метода анализа через синтез. Кодер состоит из синтезирующей части, показанной слева от вертикальной штриховой оси, и анализирующей части, показанной справа от этой оси. Синтезирующая часть по существу содержит два блока, а именно блок 10 генерации кода возбуждения и синтезирующий фильтр 12 кодирования с линейным предсказанием. Блок 10 генерации кода возбуждения содержит адаптивный кодовый словарь 14, фиксированный кодовый словарь 16 и сумматор 18. Вектор a1(n), выбранный из адаптивного кодового словаря 14, умножается на коэффициент усиления (масштабный коэффициент) g1 для формирования сигнала p(n). Таким же образом вектор возбуждения из фиксированного кодового словаря 16 умножается на коэффициент усиления gj для формирования сигнала f(n). Сигналы p(n) и f(n) суммируются в сумматоре 18 для формирования вектора возбуждения ex(n), который возбуждает синтезирующий фильтр 12 кодирования с линейным предсказанием для формирования оценочного вектора речевого сигнала s(n).
В анализирующей части оценочный вектор s(n) вычитается из вектора s(n) реального речевого сигнала в сумматоре 20 для формирования сигнала ошибки e(n). Этот сигнал ошибки подается на взвешивающий фильтр 22 для формирования вектора взвешенной ошибки ew(n). Компоненты этого взвешенного вектора ошибки возводятся в квадрат и суммируются в блоке 24 для формирования меры энергии вектора взвешенной ошибки.
Блок 26 минимизации минимизирует этот вектор взвешенной ошибки путем выбора такой комбинации коэффициента усиления gj и вектора из фиксированного кодового словаря 16, которая дает наименьшую величину энергии, то есть после фильтрации в фильтре 12 лучше всего аппроксимирует вектор s(n) речевого сигнала. Эта оптимизация делится на два этапа. На первом этапе предполагается, что f(n)=0, и определяются наилучший вектор из адаптивного кодового словаря 14 и соответствующий g1. Алгоритм для определения этих параметров приведен в Приложении. Когда эти параметры определены, в соответствии с аналогичным алгоритмом из фиксированного кодового словаря 16 выбирается вектор и соответствующий коэффициент усиления gj. В этом случае определенные параметры из адаптивного кодового словаря 14 фиксируются на своих определенных значениях.
Параметры фильтра 12 обновляются для каждого кадра речевого сигнала (160 отсчетов) с помощью анализа кадра речевого сигнала в анализаторе 28 линейного кодирования с предсказанием. Это обновление обозначено соединением, показанным штриховой линией, между анализатором 28 и фильтром 12. Кроме того, между выходом сумматора 18 и адаптивным кодовым словарем 14 имеется элемент 30 задержки. Таким образом, адаптивный кодовый словарь 14 обновляется окончательно выбранным вектором возбуждения ex(n). Это выполняется на субкадровой основе, каждый кадр делится на четыре субкадра (по 40 отсчетов).
Как было отмечено выше, используемая структура возбуждения от фиксированного кодового словаря является существенной с точки зрения качества восстановленной речи, сложности поиска и устойчивости к ошибкам в битах. Чтобы получить высокое качество, возбуждение должно быть насыщенным, то есть содержать как импульсные, так и шумоподобные составляющие. Для уменьшения сложности возбуждение должно быть до некоторой степени структурированным. Поиск кода возбуждения в структурированном кодовом словаре относительно несложен. Для достижения высокой робастности в условиях радиосвязи с подвижными объектами чувствительность к ошибкам в битах для незащищенных битов кода возбуждения должна быть низкой. Это не является настолько важным для защищенных (кодированных канальным кодом) битов кода возбуждения. Таким образом, чувствительность к ошибкам в битах в коде возбуждения для защищенных и незащищенных битов должна быть различной. Обычно незащищенный класс битов будет ограничивать работоспособность в каналах с высокой вероятностью появления ошибок в битах.
Как было упомянуто выше, высокая робастность может быть достигнута защитой с помощью канального кодирования, но ограничения по ширине полосы обычно ограничивают долю дополнительно передаваемой информации, используемой для избыточного канального кодирования битов, до 60-80%. Поскольку для получения высоких рабочих характеристик при кодировании обычно необходима скорость кода около 1/2 или более, не все биты могут быть защищены. Некоторые из битов должны быть очень устойчивыми к ошибкам, чтобы их можно было передавать без защиты канальным кодированием. Таким образом, биты при кодировании речи должны иметь существенно неравную чувствительность к ошибкам. Для получения очень высоких рабочих характеристик следует обратить особое внимание на то, что рабочую характеристику обычно ограничивают незащищенные биты.
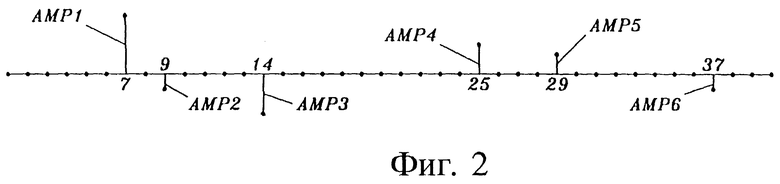
Известно, что для обеспечения высокого качества при более высоких скоростях передачи бит применяют многоимпульсное возбуждение, которое поясняется на фиг. 2. Например, известно, что 6-8 импульсов на 40 отсчетов (или 5 мс) дают хорошее качество. На фиг. 2 показано 6 импульсов, распределенных по субкадру. Вектор возбуждения может быть описан позициями этих импульсов (в примере - позиции 7, 9, 14, 25, 29, 37) и амплитудами импульсов (в примере АМР1-АМР6). Методы для нахождения этих параметров описаны в [9]. Обычно амплитуды представляют только форму вектора возбуждения. Поэтому коэффициент усиления блока используется для представления усиления этой формы базисного вектора. На фиг. 3 показан пример формата для распределения битов в типичном сигнале многоимпульсного возбуждения, содержащем шесть импульсов. В этом примере пять битов используются для скалярного квантованного коэффициента усиления блока (масштабирования импульсов), один бит используется для знака каждого импульса, два бита - для скалярного квантования амплитуды каждого импульса и (40 по 6) = 22 бита для кодирования позиций импульсов с использованием комбинаторной схемы кодирования позиции (см. [1], с. 360, и Приложение). Это составляет в сумме 5+6+12+22=45 бит/5 мс=9 кбит/с.
Известно, что чувствительность к ошибкам в битах сигнала многоимпульсного возбуждения для некоторых битов относительно высока. Это иллюстрирует график на фиг. 4. На этом чертеже показано отношение сигнал/шум восстановленной речи для 100%-ной вероятности ошибок в битах для каждой битовой позиции сигнала возбуждения. Таким образом, позиция каждого бита на фиг. 1 по отдельности устанавливается на неправильное значение, в то время как позиции остальных битов являются правильными. Восстановленный сигнал сравнивается с исходным сигналом и вычисляется отношение сигнал/шум. Таким образом, длина каждой линии на фиг. 4 представляет чувствительность восстановленной речи к ошибке в этой битовой позиции. Высокое отношение сигнал/шум на фиг. 4 означает низкую чувствительность к ошибкам в битах.
Из фиг. 4 можно видеть, что старшие биты коэффициента усиления блока (биты 3-5) очень чувствительны к ошибкам в битах, в то время как младшие биты коэффициента усиления блока (биты 1-2) менее чувствительны. Кроме того, знаки импульсов (биты 28, 31, 34, 37, 40 и 43) также очень чувствительны к ошибкам в битах. Биты амплитуд (биты 29, 30, 32, 33, 35, 36, 38, 39, 41, 42, 44 и 45) менее чувствительны к ошибкам в битах. В зависимости от используемой схемы кодирования позиций биты позиций импульсов (биты 6-27) являются более или менее чувствительными к ошибкам в битах. Для комбинаторной схемы, такой как на фиг. 3 и 4, позиции всех импульсов кодируются совместно в одно кодовое слово. Ошибки в битах в таком кодовом слове будут перемещать все позиции импульсов вокруг, делая многие биты (биты 11-27) чувствительными к ошибкам в битах.
Одним из способов уменьшения чувствительности к ошибкам в битах при кодировании позиций импульсов является наложение ограничений на позиции импульсов. Одной из схем кодирования этого типа является фазовое позиционное кодирование [16] . Эта схема кодирования позиций импульсов имеет более высокую эффективность кодирования, чем комбинаторная схема, однако за счет несколько более низкого качества речи. Принципы фазового позиционного кодирования поясняются на фиг. 5a-5e. При таком кодировании общее количество позиций делится на число субблоков, на фиг. 5 - 4 субблока. Каждый субблок содержит некоторое число фаз, на фиг. 5 - десять фаз. На дозволенную позицию импульса накладываются ограничения. Допускается только один импульс в каждой фазе. Это означает, что позиции могут быть кодированы с помощью описания позиций фаз и субблочных позиций импульсов. Позиции фаз кодируются с использованием комбинаторных схем. Старшие биты субблочных позиций будут иметь высокую чувствительность к ошибкам в битах. С другой стороны, младшие биты кодовых слов позиций фаз будут иметь более низкую чувствительность к ошибкам в битах.
На фиг. 5 (a-e) предполагается, что импульсы формируются с помощью того же самого сигнала, что и импульсы на фиг. 2. На первом шаге определяется позиция самого сильного импульса. Он соответствует импульсу в позиции 7 на фиг. 2. Этот импульс показан на фиг. 5a. Так как позиция 7 импульса соответствует фазе 7, фаза 7 всех других субблоков должна быть вычеркнута как запрещенная позиция импульса для оставшихся импульсов. На фиг. 5b второй наиболее сильный импульс находится в позиции 14, которая соответствует субблоку 2 и фазе 4, и это означает, что фаза 4 запрещена для оставшихся импульсов. На фиг. 5c и 5d импульсы в позициях 25 и 29 определяются аналогичным образом. Следующий им пульс, который нужно определить, - это импульс, соответствующий импульсу в позиции 9 на фиг. 2. Однако фаза 9 уже запрещена. По этому импульс необходимо поместить на одну из тех позиций, фазы которых остаются разрешенными. Выбранной позицией является та, которая дает наилучшую аппроксимацию выходного сигнала возбуждения. В примере импульс размещен в фазе 8 субблока 1. Заметим, что поскольку импульс должен быть сдвинут относительно соответствующего импульса (АМР2) на фиг. 2, то его амплитуда также может быть изменена. Наконец, определяется оставшийся импульс, соответствующий импульсу на позиции 37 на фиг. 2. Эта фаза (7) также запрещена. Вместо нее импульс формируется в фазе 6 субблока 4. Этот импульс обозначен на фиг. 5e штриховой линией.
Одна из главных проблем при многоимпульсном возбуждении заключается в том, что декодер на приемном конце не знает, какие из этих многих импульсов являются наиболее важными. Наиболее важные импульсы являются также импульсами, которые наиболее чувствительны к ошибкам в битах. Наиболее важные импульсы обычно находят первыми при последовательном поиске в кодере, и они обычно имеют наибольшие амплитуды. Однако вследствие кодирования позиций наиболее чувствительная информация рассеивается по битам. Это увеличивает уровень чувствительности для всех битов вместо обеспечения неравной чувствительности битов к ошибкам, как было бы желательно. Одним из решений этой проблемы могло бы быть разделение импульсов на две группы. Первая группа будет состоять из первых найденных импульсов. Это будет делать первую группу более чувствительной к ошибкам в битах. Кроме того, разделение кодирования возбуждения на две части и использование кодирования позиций фаз будет увеличивать различие битов по чувствительности к ошибкам в битах. Недостатком метода разделения является то, что эффективность кодирования второй группы ниже. Поэтому требуется более эффективное кодирование второй группы возбуждения. Необходима также низкая чувствительность к ошибкам, так как эти биты могут передаваться незащищенными.
Известно применение возбуждения с использованием стохастического кодового словаря для обеспечения высокого качества при более низких скоростях передачи битов, чем при многоимпульсном возбуждении. Однако сложность поиска в стохастическом кодовом словаре является высокой, делая реализацию трудной, если не невозможной. Существуют методы для снижения сложности, например, применение смещенных прореженных кодовых словарей. Однако даже при этих методах сложность остается слишком высокой для более высоких скоростей передачи битов. Другим недостатком является чувствительность к ошибкам в битах. Одиночная ошибка в бите может заставить декодер использовать совершенно другую стохастическую последовательность из кодового словаря.
Известно, что для обеспечения при равных скоростях передачи битов эффективности, близкой к эффективности при стохастическом возбуждении, применяют возбуждение преобразованными двоичными импульсами (TBPE). Структура такого кодового словаря делает поиск в высшей степени эффективным. Требования к постоянной памяти также низкие. Матрицы преобразования используются, чтобы делать возбуждение более близким к Гауссовому. Свойственная этому методу структура с регулярными интервалами между импульсами делает возбуждение разреженным. Основным недостатком этого метода является то, что качество понижается, если сохраняются методы поиска с низкой сложностью, в то время как размер кодового словаря возрастает. Расположение с регулярными интервалами ограничивает улучшение рабочих характеристик, если скорость передачи битов увеличивается. Возбуждение преобразованными двоичными импульсами подробно описано в [11-12] и описывается ниже со ссылками на фиг. 6a-b.
Фиг. 6a поясняет принципы, на которых основано возбуждение преобразованными двоичными импульсами. Кодовый словарь двоичных импульсов может содержать векторы, включающие, например, 10 составляющих. Каждая составляющая вектора направлена вверх (+1) или вниз (-1), как показано на фиг. 6a. Кодовый словарь двоичных импульсов содержит все возможные комбинации таких векторов. Векторы этого кодового словаря можно рассматривать как набор всех векторов, которые направлены на "углы" 10-мерного "куба". Таким образом, концы векторов равномерно распределяются по поверхности 10-мерной сферы.
Кроме того, возбуждение преобразованными двоичными импульсами содержит одну или несколько матриц преобразования (матрица 1 и матрица 2 на фиг. 6a). Они являются заранее вычисленными матрицами, записанными в постоянное запоминающее устройство. Эти матрицы выполняют действия с векторами, хранящимися в кодовом словаре двоичных импульсов, формируя набор преобразованных векторов. Наконец, преобразованные векторы распределяются по наборам сеток возбуждающих импульсов. Результатом являются четыре различных варианта "стохастических" кодовых словарей с регулярными интервалами для каждой матрицы. Вектор из одного из этих кодовых словарей (основанный на сетке 2) показан как конечный результат на фиг. 6a. Целью процедуры поиска является нахождение таких индекса кодового словаря двоичных импульсов, матрицы преобразования и структуры возбуждающих импульсов, которые вместе дают наименьшую взвешенную ошибку.
Операция матричного преобразования более подробно поясняется на фиг. 6b. В этом случае считается, что кодовый словарь двоичных импульсов состоит только из двух позиций (это является нереалистичным предположением, однако помогает пояснить принципы, на которых основана операция преобразования). Все возможные двоичные векторы кодового словаря двоичных импульсов показаны в левой части фиг. 6b. Эти векторы могут рассматриваться как эквивалентные векторам, направленным в углы 2-мерного "куба", т.е. квадрата, изображенного штриховыми линиями в левой части фиг. 6b. Теперь эти векторы преобразуются матрицей. Этой матрицей может быть, например, ортогональная матрица, которая поворачивает весь "куб". Преобразованные двоичные векторы включают в себя проекции отдельных преобразованных векторов на оси X и Y соответственно. Полученный в итоге преобразованный двоичный код показан в правой части фиг. 6b. После преобразования преобразованные векторы распределяются по набору сеток, как было объяснено со ссылкой на фиг. 6a.
На фиг. 7 показан формат распределения битов для типичного возбуждения преобразованными двоичными импульсами. В этом примере используется двухступенчатый кодовый словарь возбуждения преобразованными двоичными импульсами, в котором кодовый словарь 1 кода возбуждения преобразованными двоичными импульсами является кодовым словарем с 40 отсчетами, а вторая ступень разделена на два кодовых словаря 2A, 2B возбуждения преобразованными двоичными импульсами по 20 отсчетов. Кодовый словарь 1 использует десять битов для индекса кодового словаря двоичных импульсов, два бита для сеток кодового словаря 1, один бит для матриц кодового словаря 1 и четыре бита для коэффициента усиления кодового словаря 1. Кодовые словари 2A, 2B используют 2х6 битов для индекса кодового словаря двоичных импульсов, 2х2 бита для сеток кодового словаря, 2х2 бита для матриц кодового словаря и 2х4 бита для коэффициента усиления кодового словаря. В сумме это дает 45 бит/5 мс = 9 кбит/с.
Чувствительность к ошибкам в битах для возбуждения преобразованными двоичными импульсами, показанными на фиг. 7, приведена на фиг. 8. Структура, свойственная возбуждению преобразованными двоичными импульсами, дает индекс в коде Грея в кодовых словарях бинарных импульсов. Это означает, что кодовые слова, близкие по расстоянию Хэмминга, близки также и по расстоянию вектора возбуждения. Одиночная ошибка в бите будет лишь изменять знак одного из регулярных импульсов. Поэтому позиции битов в индексе на фиг. 8 в грубом приближении одинаковы по чувствительности (биты 1-10 для кодового словаря 1 двоичных импульсов, биты 18-23 для кодового словаря 2A двоичных импульсов и биты 32-37 для кодового словаря 2B двоичных импульсов). Первый кодовый словарь, содержащий в себе индекс, сетку и матрицу (биты 1-10, биты 11-12, 13), имеет более высокую чувствительность. Бит матрицы (бит 13) в этом примере показывает очень высокую чувствительность. Кроме того, коэффициент усиления первого кодового словаря (биты 14-17) имеет более высокую чувствительность, чем коэффициенты усиления второго кодового словаря (биты 14-17, 28-31, 42-45). Одной из проблем является то, что чувствительность распределяется по битам. Чувствительность в общем является более низкой, чем для битов многоимпульсного возбуждения, но имеется только незначительно неравная чувствительность к ошибкам. Однако эта структура имеет присущее ей назначение индексов и низкую сложность. Это делает возбуждение преобразованными двоичными импульсами весьма подходящим для замены второй части многоимпульсного возбуждения, рассмотренного выше.
Структурой, предлагаемой в настоящем изобретении, является смешанное возбуждение, использующее несколько многоимпульсных сигналов и кодовый словарь возбуждения преобразованными двоичными импульсами. Позиции импульсов в предпочтительном случае кодируются схемой кодирования с ограничением позиций, такой как описанное выше фазовое позиционное кодирование. Смешанное возбуждение, использующее импульсы и последовательности преобразованных двоичных импульсов (шума) улучшает качество. Поиск сигналов многоимпульсного возбуждения и возбуждения преобразованными двоичными импульсами выполняется по схемам с низкой сложностью. Смесь битов многоимпульсного возбуждения и возбуждения преобразованными двоичными импульсами имеет существенно неравную чувствительность к ошибкам, которая хорошо подходит к схеме неравной защиты от ошибок с некоторыми незащищенными битами.
Фиг. 9 поясняет пример формата для распределения битов в предпочтительной форме осуществления настоящего изобретения. В этом примере имеются три источника многоимпульсного возбуждения и один кодовый словарь с 13-битовым индексом (13 двоичными импульсами) возбуждения преобразованными двоичными импульсами с четырьмя сетками и двумя матрицами. Кодирование позиций фаз осуществляется с использованием десяти субблоков и четырех фаз. Это дает 3х2log(10) = 10 бит для позиций субблоков и (4 по 3) = 2 бита для кодовых слов фазы, 3х1 битов для знаков импульсов, 3х2 битов для амплитуд импульсов, четыре бита для коэффициента усиления блока, 13 битов для индекса кодового словаря двоичных импульсов, 2 бита для сетки, 1 бит для матрицы и четыре бита для коэффициента усиления кодового словаря. Все это складывается: 10+2+3+6+4+13+2+1+4 = 45 бит/5 мс = 9 кбит/с.
Фиг. 10 поясняет чувствительность к ошибкам в битах для смешанного возбуждения в соответствии с предпочтительной формой осуществления настоящего изобретения. Из фиг. 10 явствует, что некоторые из битов многоимпульсного возбуждения (биты 1-21) более чувствительны к ошибкам в битах, чем индекс кодового словаря возбуждения преобразованными двоичными импульсами (биты 26-41). Кодирование позиций фаз делает некоторые из битов позиционирования импульсов менее чувствительными к ошибкам в битах (биты 1-3 позиций субблоков и биты 11-12 слов кода фазы). Амплитуды импульсов (биты 14-15, 17-18, 20-21) менее чувствительны, чем знаки (биты 13, 16, 19). Биты в индексе возбуждения преобразованными двоичными импульсами (биты 26-38) равны по чувствительности, а их чувствительность очень низка по сравнению со знаками и позициями импульсов. Некоторые из битов коэффициента усиления блока многоимпульсного возбуждения (биты 24-25) являются более чувствительными. Бит для матрицы преобразования (бит 41) также чувствителен.
Три схемы, описанные выше и проиллюстрированные на фиг. 4, 8 и 10, сравниваются с точки зрения чувствительности к ошибкам в битах на фиг. 11. На фиг. 11 биты каждой схемы отсортированы в порядке их чувствительности к ошибкам от наивысшей до наинизшей чувствительности. Из фиг. 11 можно видеть, что многоимпульсное возбуждение (MPE) и смешанное возбуждение (MPE & TBPE - многоимпульсное возбуждение и возбуждение преобразованными двоичными импульсами) имеют наиболее неравномерную чувствительность к ошибкам. Возбуждение преобразованными двоичными импульсами имеет наиболее сглаженную характеристику чувствительности, и эта чувствительность в общем ниже, чем у многоимпульсного возбуждения. Смешанное возбуждение имеет более низкую чувствительность, чем многоимпульсное возбуждение, что делает смешанное возбуждение более робастным. Смешанное возбуждение имеет также несколько очень чувствительных битов (биты 1-12) и несколько нечувствительных битов (биты 24-45), что делает это возбуждение удобным для неравной защиты от ошибок. Поскольку число нечувствительных битов для смешанного возбуждения больше, чем для многоимпульсного возбуждения, рабочие характеристики незащищенного класса битов в каналах низкого качества будут лучше.
Фиг. 12 поясняет предпочтительный вариант выполнения речевого кодера в соответствии с настоящим изобретением. Существенным отличием речевого кодера на фиг. 1 от речевого кодера на фиг. 12 является то, что фиксированный кодовый словарь 16 (фиг. 1) заменен генератором 32 смешанного возбуждения, содержащим средства генерации многоимпульсного возбуждения, выполненные в виде генератора 34 многоимпульсного возбуждения, и средства генерации возбуждения преобразованными двоичными импульсами, выполненные в виде генератора 36 возбуждения преобразованными двоичными импульсами.
Упомянутые средства генерации многоимпульсного возбуждения могут содержать средства генерации импульсов с ограничением позиций импульсов и средства фазового позиционного кодирования.
Соответствующие коэффициенты усиления блоков обозначены на фиг. 12 как gM и gT соответственно. Сигналы возбуждения от генераторов 34, 36 складываются в средствах объединения многоимпульсного возбуждения и возбуждения преобразованными двоичными импульсами, выполненных в виде сумматора 38. Далее в средствах объединения многоимпульсного возбуждения, возбуждения преобразованными двоичными импульсами и адаптивного возбуждения, выполненных в виде сумматора 18, смешанное возбуждение добавляется к возбуждению от адаптивного кодового словаря.
Пример алгоритма, используемого в структуре кодера со смешанным возбуждением в соответствии с настоящим изобретением, приведен ниже. Алгоритм содержит все части, которые характерны для речевого кодера. Алгоритм состоит из шести основных секций. Секции многоимпульсного возбуждения и возбуждения преобразованными двоичными импульсами, которые составляют смешанное возбуждение, расширены, чтобы показать содержание анализа структуры смешанного возбуждения. Одной частью, осуществляющей обработку на кадровой основе, например, для каждого кадра из 160 отсчетов, является секция анализа линейного кодирования с предсказанием, которая вычисляет и квантует параметры фильтра кратковременного синтеза. Остальные пять секций осуществляют обработку на субкадровой основе, например, выполняя ее для каждого субкадра из 40 отсчетов. Первой из них является предварительная обработка субкадров, то есть выделение параметров, второй является долговременный анализ или анализ с адаптивным кодовым словарем, третьей - анализ для многоимпульсного возбуждения, четвертой - анализ для возбуждения преобразованными двоичными импульсами и пятой - обновление состояния.
Пример алгоритма
Анализ кодирования с линейным предсказанием
Для каждого субкадра (1-4) выполнить
Предварительную обработку субкадра
Анализ кодирования с линейным предсказанием (поиск в адаптивном кодовом словаре)
Многоимпульсное возбуждение (MPE)
Вычислить импульсную характеристику взвешивающего фильтра
Вычислить автокорреляционную функцию импульсной характеристики
Вычислить функцию взаимной корреляции между импульсной характеристикой и взвешенным остатком после анализа кодирования с линейным предсказанием
Поиск позиций и амплитуд импульсов для многоимпульсного возбуждения
Квантование амплитуд и коэффициента усиления блока
Образование вектора обновления многоимпульсного возбуждения
Формирование кодовых слов позиций
Формирование нового взвешенного остатка после анализа многоимпульсного возбуждения
Возбуждение преобразованными двоичными импульсами (TBPE)
Вычислить импульсную характеристику взвешивающего фильтра
Вычислить функцию взаимной корреляции между импульсной характеристикой и взвешенным остатком после анализа многоимпульсного возбуждения
Для каждой матрицы выполнить
Для каждой структуры выполнить
Вычислить функцию взаимной корреляции матрицы
Аппроксимировать импульсы со знаком функции взаимной корреляции
Сформировать взвешенное обновление возбуждения преобразованными двоичными импульсами и сравнить
Формирование слов кода позиций возбуждения преобразованными двоичными импульсами
Квантование коэффициента усиления для сигнала возбуждения преобразованными двоичными импульсами
Образование вектора обновления возбуждения преобразованными двоичными импульсами
Обновление состояния
Приложение
Данное приложение кратко излагает алгоритм определения наилучшего индекса i адаптивного кодового словаря и соответствующего коэффициента усиления gi кодового словаря при поиске методом перебора. Сигналы показаны также на фиг. 1.
ex(n) = p(n) - Вектор возбуждения (f(n) = 0)
p(n) = gi·ai(n) - Масштабированный вектор из адаптивного кодового словаря
s(n) = h(n)*p(n) - Синтезированный речевой сигнал (* = символ свертки)
e(n) = s(n) - s(n) - Вектор ошибки
ew(n) = w(n)*(s(n) - s(n)) - Взвешенная ошибка
E = Σ [ew(n)]2 n=0...N-1 - Взвешенная среднеквадратическая ошибка
N = 40 (например) - Длина вектора
sw(n) = w(n)*s(n) - Взвешенный речевой сигнал
bw(n) = w(n)*h(n) - Взвешенная импульсная характеристика для синтезирующего фильтра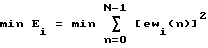 - Поиск оптимального индекса в адаптивном кодовом словаре
- Поиск оптимального индекса в адаптивном кодовом словаре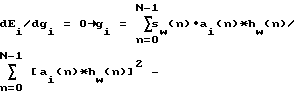
- Коэффициент усиления для индекса i
Список литературы
1. P. Kroon, E. Deprettere
A class of analysis-by-synthesis predictive coders for high quality speech coding at rates between 4.6 and 16 kbit/s.
IEEE Jour. Sel. Areas Corn., vol. SAC-6, N 2, Feb., 1988.
2. H. Chen, W.C. Wong, C.C. Ко
Low-delay hybrid vector excitation linear predictive speech coding
Electronics letters, vol. 29, N 25, 1993.
3. D. Lin
Code-excited linear prediction using a mixed source model Proc. ASSP DSP workshop, 1986.
4. D. Lin
Ultra-fast CELP coding using deterministic multi-codebook innovations.
IEEE ICASSP-92, San Francisco, 1992.
5. N. Moreau, P.Dymarski
Mixed excitation celp coder.
Eurospeech-89, Paris, Sep., 1989.
6. К. Ozawa
A hybrid speech coding based on multi-pulse and CELP at 3.2 kb/s.
IEEE ICASSP-90, Albuguergue, 1990.
7. R. Zinser, S. Koch
4800 and 7200 bit/sec hybrid codebook multipulse coding.
IEEE ICASSP-89, Glasgow, 1989.
8. R. Zinser
Hybrid switched multi-pulse/stochastic speech coding technique.
Патент США N 5060269
9. В. Atal, J. Remde
A new model of LPC excitation for producing natural-sounding speech at low bit rates.
IEEE ICASSP-82, Paris, 1982.
10. P. Vary, K. Hellwig, R. Hofmann
A regular-pulse excited linear predictive codec.
Speech Communication 7, North-Holland, 1988.
11. R.A. Salami
Binary code excited linear prediction (BCELP): New approach to celp coding of speech without codebooks.
Electronics letters, vol. 25, N 6, march, 1989.
12. R. Salami
Binary pulse excitation: A novel approach to low complexity CELP coding.
Kluwer Academic Pub., Advances in speech coding, 1991.
13. I. Gerson, M. Jasiuk
Vector sum excited linear prediction (VSELP).
Kluwer Academic Pub., Advances in speech coding, 1991.
14. R. Cox, W.B. Kleijn, P. Kroon
Robust celp coders for noisy backgrounds and noisy channels.
IEEE ICASSP-89, Glasgow, 1989.
15. N. Сох
Error control and index assignment for speech codecs.
Kluwer Academic Press, 1993.
16. T.B.Minde
Excitation pulse positioning method in a linear predictive speech coder.
Патент США N 5193140
Изобретение относится к речевым кодерам и может использоваться в сотовых системах радиосвязи. Техническим результатом является повышение качества и упрощение поиска, а также повышение устойчивости в условиях радиосвязи с подвижными объектами. Для этого синтезирующая часть изобретения содержит адаптивный кодовый словарь, средства генерации возбуждения преобразованными двоичными импульсами и средства объединения многоимпульсного возбуждения, возбуждения преобразованными двоичными импульсами и адаптивного возбуждения. 2 з.п. ф-лы, 12 ил.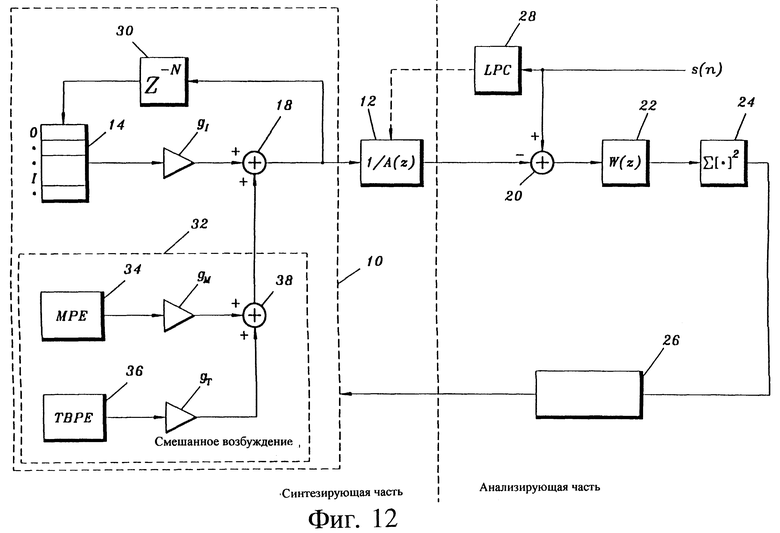
| PETER KROON et al | |||
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| "IEEE Joournal on Selected areas in communications", Febryary, 1988, vol | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Замкнутая радиосеть с несколькими контурами и с одной неподвижной точкой опоры | 1918 |
|
SU353A1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 0 |
|
SU329557A1 |
| Цифровой вокодер | 1979 |
|
SU838706A1 |
| Прогнозирующий вокодер | 1978 |
|
SU788151A1 |
| Линейный прогнозирующий вокодер | 1975 |
|
SU517041A1 |
| US 4932061 A, 05.06.1990 | |||
| US 4980916 A, 25.12.1990 | |||
| US 5195168 A, 16.03.1993 | |||
| Шланговое соединение | 0 |
|
SU88A1 |
