1. УРОВЕНЬ ТЕХНИКИ
Декодер обычно используется для того, чтобы декодировать поток битов (например, принимаемый или сохраненный в устройстве хранения данных). Несмотря на это, сигнал может подвергаться шуму, такому как, например, шум квантования. Ослабление этого шума следовательно представляет собой важную цель.
2. КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1.1 показывает декодер согласно примеру.
Фиг. 1.2 показывает схематизацию на частотно/пространственно-временном графике версии сигнала, указывающую контекст.
Фиг. 1.3 показывает декодер согласно примеру.
Фиг. 1.4 показывает способ согласно примеру.
Фиг. 1.5 показывает схематизации на частотно/пространственно-временном графике и графиках абсолютной величины/частоты версии сигнала.
Фиг. 2.1 показывает схематизации частотно/пространственно-временных графиков версии сигнала, указывающие контексты.
Фиг. 2.2 показывает гистограммы, полученные с помощью примеров.
Фиг. 2.3 показывает спектрограммы речи согласно примерам.
Фиг. 2.4 показывает пример декодера и кодера.
Фиг. 2.5 показывает графики с результатами, полученными с помощью примеров.
Фиг. 2.6 показывает результаты тестирования, полученные с помощью примеров.
Фиг. 3.1 показывает схематизацию на частотно/пространственно-временном графике версии сигнала, указывающую контекст.
Фиг. 3.2 показывает гистограммы, полученные с помощью примеров.
Фиг. 3.3 показывает блок-схему обучения речевых моделей.
Фиг. 3.4 показывает гистограммы, полученные с помощью примеров.
Фиг. 3.5 показывает графики, представляющие улучшение SNR с помощью примеров.
Фиг. 3.6 показывает пример декодера и кодера.
Фиг. 3.7 показывает графики относительно примеров.
Фиг. 3.8 показывает корреляционный график.
Фиг. 4.1 показывает систему согласно примеру.
Фиг. 4.2 показывает схему согласно примеру.
Фиг. 4.3 показывает схему согласно примеру.
Фиг. 5.1 показывает этап способа согласно примерам.
Фиг. 5.2 показывает общий способ.
Фиг. 5.3 показывает процессорную систему согласно примеру.
Фиг. 5.4 показывает систему кодера/декодера согласно примеру.
3. СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В соответствии с аспектом, предусмотрен декодер для декодирования сигнала частотной области, заданного в потоке битов, причем входной сигнал частотной области подвергается шуму квантования, причем декодер содержит:
- модуль считывания потоков битов для предоставления, из потока битов, версии входного сигнала в качестве последовательности кадров, причем каждый кадр подразделяется на множество элементов разрешения (бинов), причем каждый элемент разрешения имеет дискретизированное значение;
- модуль задания контекстов, выполненный с возможностью задавать контекст для одного обрабатываемого элемента разрешения, причем контекст включает в себя по меньшей мере один дополнительный элемент разрешения в предварительно определенной позиционной взаимосвязи с обрабатываемым элементом разрешения;
- модуль оценки статистических взаимосвязей и/или информации, выполненный с возможностью предоставлять статистические взаимосвязи и/или информацию между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения, при этом модуль оценки статистических взаимосвязей включает в себя модуль оценки взаимосвязей и/или информации по шуму квантования, выполненный с возможностью предоставлять статистические взаимосвязи и/или информацию относительно шума квантования;
- модуль оценки значений, выполненный с возможностью обрабатывать и получать оценку значения обрабатываемого элемента разрешения на основе оцененных статистических взаимосвязей и/или информации и статистических взаимосвязей и/или информации относительно шума квантования; и
- модуль преобразования, который преобразует оцененный сигнал в сигнал временной области.
В соответствии с аспектом, раскрывается декодер для декодирования сигнала частотной области, заданного в потоке битов, причем входной сигнал частотной области подвергается шуму, причем декодер содержит:
- модуль считывания потоков битов, который предоставляет, из потока битов, версию входного сигнала в качестве последовательности кадров, причем каждый кадр подразделяется на множество элементов разрешения, причем каждый элемент разрешения имеет дискретизированное значение;
- модуль задания контекстов, выполненный с возможностью задавать контекст для одного обрабатываемого элемента разрешения, причем контекст включает в себя по меньшей мере один дополнительный элемент разрешения в предварительно определенной позиционной взаимосвязи с обрабатываемым элементом разрешения;
- модуль оценки статистических взаимосвязей и/или информации, выполненный с возможностью предоставлять статистические взаимосвязи и/или информацию между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения, при этом модуль оценки статистических взаимосвязей включает в себя модуль оценки взаимосвязей и/или информации по шуму, выполненный с возможностью предоставлять статистические взаимосвязи и/или информацию относительно шума;
- модуль оценки значений, выполненный с возможностью обрабатывать и получать оценку значения обрабатываемого элемента разрешения на основе оцененных статистических взаимосвязей и/или информации и статистических взаимосвязей и/или информации относительно шума; и
- модуль преобразования, который преобразует оцененный сигнал в сигнал временной области.
Согласно аспекту, шум представляет собой шум, который не представляет собой шум квантования. Согласно аспекту, шум представляет собой шум квантования.
Согласно аспекту, модуль задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент разрешения из ранее обработанных элементов разрешения.
Согласно аспекту, модуль задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент разрешения на основе полосы частот элемента разрешения.
Согласно аспекту, модуль задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент разрешения, в пределах предварительно определенного порогового значения, из числа элементов разрешения, которые уже обработаны.
Согласно аспекту, модуль задания контекстов выполнен с возможностью выбирать различные контексты для элементов разрешения в различных полосах частот.
Согласно аспекту, модуль оценки значений выполнен с возможностью работать в качестве фильтра Винера, чтобы предоставлять оптимальную оценку входного сигнала.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения, по меньшей мере, из одного дискретизированного значения по меньшей мере одного дополнительного элемента разрешения.
Согласно аспекту, декодер дополнительно содержит модуль измерений, выполненный с возможностью предоставлять измеренное значение, ассоциированное с ранее выполняемой оценкой(ами) по меньшей мере одного дополнительного элемента разрешения контекста,
- при этом модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе измеренного значения.
Согласно аспекту, измеренное значение представляет собой значение, ассоциированное с энергией по меньшей мере одного дополнительного элемента разрешения контекста.
Согласно аспекту, измеренное значение представляет собой усиление, ассоциированное, по меньшей мере, с одним дополнительным элементом разрешения контекста.
Согласно аспекту, модуль измерений выполнен с возможностью получать усиление в качестве скалярного произведения векторов, при этом первый вектор содержит значение(я) по меньшей мере одного дополнительного элемента разрешения контекста, и второй вектор представляет собой транспонированный сопряженный элемент первого вектора.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в качестве предварительно заданных оценок и/или ожидаемых статистических взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в качестве взаимосвязей на основе позиционных взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию независимо от значений обрабатываемого элемента разрешения и/или по меньшей мере одного дополнительного элемента разрешения контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в форме значений дисперсии, ковариации, корреляции и/или автокорреляции.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в форме матрицы, устанавливающей взаимосвязи значений дисперсии, ковариации, корреляции и/или автокорреляции между обрабатываемым элементом разрешения и/или по меньшей мере одним дополнительным элементом разрешения контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в форме нормализованной матрицы, устанавливающей взаимосвязи значений дисперсии, ковариации, корреляции и/или автокорреляции между обрабатываемым элементом разрешения и/или по меньшей мере одним дополнительным элементом разрешения контекста.
Согласно аспекту, матрица получается посредством оффлайнового обучения.
Согласно аспекту, модуль оценки значений выполнен с возможностью масштабировать элементы матрицы посредством энергозависимого значения или значения усиления таким образом, чтобы принимать во внимание варьирования энергии и/или усиления обрабатываемого элемента разрешения и/или по меньшей мере одного дополнительного элемента разрешения контекста.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе следующей взаимосвязи:
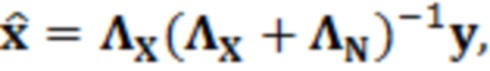
где 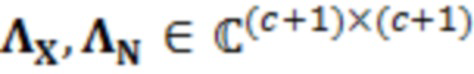 являются шумовыми и ковариационными матрицами, соответственно, и
являются шумовыми и ковариационными матрицами, соответственно, и 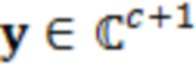 является вектором зашумленных наблюдений с c+1 размерностями, c является контекстной длиной.
является вектором зашумленных наблюдений с c+1 размерностями, c является контекстной длиной.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента (123) разрешения на основе следующей взаимосвязи:
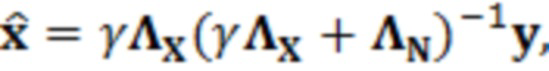
где 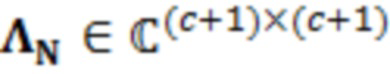 является нормализованной ковариационной матрицей, является шумовой ковариационной матрицей, является вектором зашумленных наблюдений с c+1 размерностями и ассоциирован с обрабатываемым элементом разрешения и дополнительными элементами разрешения контекста, c является контекстной длиной, γ является усилением масштабирования.
является нормализованной ковариационной матрицей, является шумовой ковариационной матрицей, является вектором зашумленных наблюдений с c+1 размерностями и ассоциирован с обрабатываемым элементом разрешения и дополнительными элементами разрешения контекста, c является контекстной длиной, γ является усилением масштабирования.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения при условии, что дискретизированные значения каждого из дополнительных элементов разрешения контекста соответствуют оцененному значению дополнительных элементов разрешения контекста.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения при условии, что дискретизированное значение обрабатываемого элемента разрешения предположительно должно быть между наибольшим значением и наименьшим значением.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе максимума функции вероятности.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе ожидаемого значения.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе ожидания многовариантной случайной гауссовой переменной.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе ожидания условной многовариантной случайной гауссовой переменной.
Согласно аспекту, дискретизированные значения находятся в области логарифмической амплитудно-частотной характеристики.
Согласно аспекту, дискретизированные значения находятся в перцепционной области.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять среднее значение сигнала в модуль оценки значений.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять среднее значение чистого сигнала на основе связанных с дисперсией и/или связанных с ковариацией взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять среднее значение чистого сигнала на основе ожидаемого значения обрабатываемого элемента (123) разрешения.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью обновлять среднее значение сигнала на основе оцененного контекста.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять связанное с дисперсией и/или связанное со значением среднеквадратического отклонения значение в модуль оценки значений.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять связанное с дисперсией и/или связанное со значением среднеквадратического отклонения значение на основе связанных с дисперсией и/или связанных с ковариацией взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения контекста в модуль оценки значений.
Согласно аспекту, модуль оценки взаимосвязей и/или информации по шуму выполнен с возможностью предоставлять, для каждого элемента разрешения, наибольшее значение и наименьшее значение для оценки сигнала на основе ожидания сигнала, которое должно быть между наибольшим и наименьшим значением.
Согласно аспекту, версия входного сигнала имеет квантованное значение, которое представляет собой уровень квантования, при этом уровень квантования представляет собой значение, выбранное из дискретного числа уровней квантования.
Согласно аспекту, число и/или значения, и/или масштабы уровней квантования передаются в служебных сигналах посредством кодера и/или передаются в служебных сигналах в потоке битов.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения с точки зрения следующего:
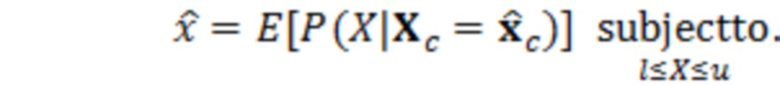
где 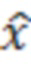 является оценкой обрабатываемого элемента разрешения, l и u являются нижним и верхним пределами текущих элементов разрешения квантования, соответственно, и
является оценкой обрабатываемого элемента разрешения, l и u являются нижним и верхним пределами текущих элементов разрешения квантования, соответственно, и 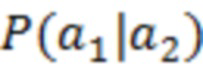 является условной вероятностью
является условной вероятностью 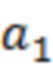 , с учетом
, с учетом 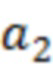 ,
, 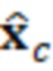 является оцененным контекстным вектором.
является оцененным контекстным вектором.
Согласно аспекту, модуль оценки значений выполнен с возможностью получать оценку значения обрабатываемого элемента разрешения на основе ожидания:
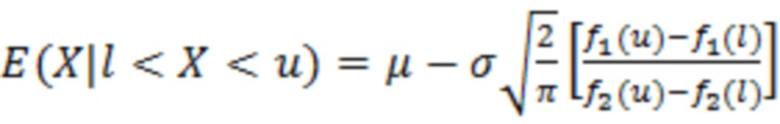 ,
,
где X является конкретным значением [X] обрабатываемого элемента разрешения, выражаемого как усеченная случайная гауссова переменная, при l<X<u, где l является нижним предельным пороговым значением, и u является наибольшим значением, 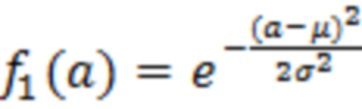 и
и 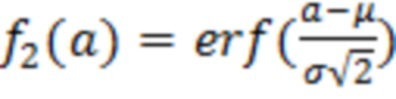 ,
, 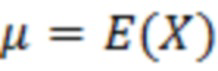 , μ и σ являются средним и дисперсией распределения.
, μ и σ являются средним и дисперсией распределения.
Согласно аспекту, предварительно определенная позиционная взаимосвязь получается посредством оффлайнового обучения.
Согласно аспекту по меньшей мере одно из статистических взаимосвязей и/или информации между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения получается посредством оффлайнового обучения.
Согласно аспекту по меньшей мере одно из взаимосвязей и/или информации по шуму квантования получается посредством оффлайнового обучения.
Согласно аспекту, входной сигнал представляет собой аудиосигнал.
Согласно аспекту, входной сигнал представляет собой речевой сигнал.
Согласно аспекту по меньшей мере один из модуля задания контекстов, модуля оценки статистических взаимосвязей и/или информации, модуля оценки взаимосвязей и/или информации по шуму и модуля оценки значений выполнен с возможностью выполнять операцию постфильтрации, чтобы получать чистую оценку входного сигнала.
Согласно аспекту, модуль задания контекстов выполнен с возможностью задавать контекст с множеством дополнительных элементов разрешения.
Согласно аспекту, модуль задания контекстов выполнен с возможностью задавать контекст в качестве просто соединенного окружения элементов разрешения на частотно-временном графике.
Согласно аспекту, модуль считывания потоков битов выполнен с возможностью избегать декодирования межкадровой информации из потока битов.
Согласно аспекту, декодер дополнительно выполнен с возможностью определять скорость передачи битов сигнала, и в случае если скорость передачи битов выше предварительно определенного порогового значения скорости передачи битов, обходить по меньшей мере один из модуля задания контекстов, модуля оценки статистических взаимосвязей и/или информации, модуля оценки взаимосвязей и/или информации по шуму, модуля оценки значений.
Согласно аспекту, декодер дополнительно содержит модуль хранения обработанных элементов разрешения, сохраняющий информацию относительно ранее обработанных элементов разрешения,
- причем модуль задания контекстов выполнен с возможностью задавать контекст с использованием по меньшей мере одного ранее обработанного элемента разрешения в качестве по меньшей мере одного из дополнительных элементов разрешения.
Согласно аспекту, модуль задания контекстов выполнен с возможностью задавать контекст с использованием по меньшей мере одного необработанного элемента разрешения в качестве по меньшей мере одного из дополнительных элементов разрешения.
Согласно аспекту, модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию в форме матрицы, устанавливающей взаимосвязи значений дисперсии, ковариации, корреляции и/или автокорреляции между обрабатываемым элементом разрешения и/или по меньшей мере одним дополнительным элементом разрешения контекста,
- при этом модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью выбирать одну матрицу из множества предварительно заданных матриц на основе показателей, ассоциированных с гармоничностью входного сигнала.
Согласно аспекту, модуль оценки взаимосвязей и/или информации по шуму выполнен с возможностью предоставлять статистические взаимосвязи и/или информацию относительно шума в форме матрицы, устанавливающей взаимосвязи значений дисперсии, ковариации, корреляции и/или автокорреляции, ассоциированных с шумом,
- при этом модуль оценки статистических взаимосвязей и/или информации выполнен с возможностью выбирать одну матрицу из множества предварительно заданных матриц на основе показателей, ассоциированных с гармоничностью входного сигнала.
Также предусмотрена система, содержащая кодер и декодер согласно любому из вышеприведенных и/или нижеприведенных аспектов, причем кодер выполнен с возможностью предоставлять поток битов с кодированным входным сигналом.
В примерах, предусмотрен способ, содержащий:
- задание контекста для одного обрабатываемого элемента разрешения входного сигнала, причем контекст включает в себя по меньшей мере один дополнительный элемент разрешения в предварительно определенной позиционной взаимосвязи, в частотно/пространственно-временном представлении, с обрабатываемым элементом разрешения;
- на основе статистических взаимосвязей и/или информации между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения и статистических взаимосвязей и/или информации относительно шума квантования, оценку значения обрабатываемого элемента разрешения.
В примерах, предусмотрен способ, содержащий:
- задание контекста для одного обрабатываемого элемента разрешения входного сигнала, причем контекст включает в себя по меньшей мере один дополнительный элемент разрешения в предварительно определенной позиционной взаимосвязи, в частотно/пространственно-временном представлении, с обрабатываемым элементом разрешения;
- на основе статистических взаимосвязей и/или информации между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения и статистических взаимосвязей и/или информации относительно шума, который не представляет собой шум квантования, оценку значения обрабатываемого элемента разрешения.
Один из вышеприведенных способов может использовать оборудование по любому из вышеприведенных и/или нижеприведенных аспектов.
В примерах, предусмотрен энергонезависимый модуль хранения, сохраняющий инструкции, которые, при выполнении посредством процессора, инструктируют процессору осуществлять любой из способов по любому из вышеприведенных и/или нижеприведенных аспектов.
4.1. ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
4.1.1. Примеры
Фиг. 1.1 показывает пример декодера 110. Фиг. 1.2 показывает представление версии 120 сигнала, обработанной посредством декодера 110.
Декодер 110 может декодировать входной сигнал частотной области, кодированный в потоке 111 битов (потоке цифровых данных), который сформирован посредством кодера. Поток 111 битов может сохраняться, например, в запоминающем устройстве или передаваться в приемное устройство, ассоциированное с декодером 110.
При формировании потока битов, входной сигнал частотной области может подвергаться шуму квантования. В других примерах, входной сигнал частотной области может подвергаться другим типам шума. Ниже описываются технологии, которые позволяют исключать, ограничивать или уменьшать уровень шума.
Декодер 110 может содержать модуль 113 считывания потоков битов (приемное устройство связи, модуль считывания массового запоминающего устройства и т.д.). Модуль 113 считывания потоков битов может предоставлять, из потока 111 битов, версию 113' исходного входного сигнала (представленного с помощью 120 на фиг. 1.2 в частотно-временном двумерном пространстве). Версия 113', 120 входного сигнала может рассматриваться в качестве последовательности кадров 121. В примере, каждый кадр 121 может представлять собой представление в частотной области (FD) исходного входного сигнала для временного кванта. Например, каждый кадр 121 может быть ассоциирован с временным квантом 20 мс (другие длины могут задаваться). Каждый из кадров 121 может идентифицироваться с помощью целого числа t дискретной последовательности дискретных временных квантов. Например, (t+1)-ый кадр является непосредственно последующим относительно t-ого кадра. Каждый кадр 121 может подразделяться на множество спектральных элементов разрешения (здесь указываемых в качестве 123-126). Для каждого кадра 121, каждый элемент разрешения ассоциирован с конкретной частотой и/или конкретной полосой частот. Полосы частот могут быть предварительно определены, в том смысле, что каждый элемент разрешения кадра может заранее назначаться конкретной полосе частот. Полосы частот могут нумероваться в дискретных последовательностях, причем каждая полоса частот идентифицируется посредством постепенно увеличивающегося номера k. Например, (k+1)-ая полоса частот может иметь более высокую частоту, чем k-ая полоса частот.
Поток 111 битов (и, как следствие, сигнал 113', 120) может предоставляться таким образом, что каждый частотно-временной элемент разрешения (бин) ассоциирован с конкретным значением (например, дискретизированным значением). Дискретизированное значение, в общем, выражается как Y(k, t) и, в некоторых случаях, может представлять собой комплексное значение. В некоторых примерах дискретизированное значение Y(k, t) может представлять собой уникальные сведения, которые декодер 110 имеет относительно исходного значения во временном кванте t в полосе k частот. Соответственно, дискретизированное значение Y(k, t), в общем, ухудшается посредством шума квантования, поскольку необходимость квантования исходного входного сигнала, в кодере, вводит ошибки аппроксимации при формировании потока битов и/или при оцифровке исходного аналогового сигнала. (Другие типы шума также могут схематизироваться в других примерах). Дискретизированное значение Y(k, t) (зашумленная речь) может пониматься как выражаемое со следующей точки зрения:
Y(k, t)=X(k, t)+V(k, t),
где X(k, t) является чистым сигналом (который должен предпочтительно получаться), и V(k, t) является сигналом шума квантования (или другим типом шумового сигнала). Следует отметить, что можно добиваться адаптированной, оптимальной оценки чистого сигнала за счет технологий, описанных здесь.
Операции могут предоставлять то, что каждый элемент разрешения обрабатывается в одно конкретное время, например, рекурсивно. На каждой итерации, идентифицируется элемент разрешения, который должен обрабатываться (например, элемент 123 или C0 разрешения, на фиг. 1.2, ассоциированный с моментом t=4 и полосой частот k=3, причем элемент разрешения упоминается как "обрабатываемый элемент разрешения"). Относительно обрабатываемого элемента 123 разрешения, другие элементы разрешения сигнала 120 (113') могут разделяться на два класса:
- первый класс необработанных элементов 126 разрешения (указываемых с помощью пунктирной окружностью на фиг. 1.2), например, элементов разрешения, которые должны обрабатываться на будущих итерациях; и
- второй класс уже обработанных элементов 124, 125 разрешения (указываемых с помощью квадратов на фиг. 1.2), например, элементов разрешения, которые обработаны на предыдущих итерациях.
Можно получать для одного обрабатываемого элемента 123 разрешения оптимальную оценку на основе по меньшей мере одного дополнительного элемента разрешения (который может представлять собой один из возведенных в квадрат элементов разрешения на фиг. 1.2). По меньшей мере, один дополнительный элемент разрешения может представлять собой множество элементов разрешения.
Декодер 110 может содержать модуль 114 задания контекстов, который задает контекст 114' (или контекстный блок) для одного обрабатываемого элемента 123 (C0) разрешения. Контекст 114' включает в себя по меньшей мере один дополнительный элемент разрешения (например, группу элементов разрешения (бинов)) в предварительно определенной позиционной взаимосвязи с обрабатываемым элементом 123 разрешения. В примере по фиг. 1.2, контекст 114' элемента 123 (C0) разрешения формируется посредством десяти дополнительных элементов 124 (118') разрешения, указываемых с помощью C1-C10 (общее число дополнительных элементов разрешения, формирующих один контекст, здесь указывается с помощью "c": на фиг. 1.2, c=10). Дополнительные элементы 124 (C1-C10) разрешения могут представлять собой элементы разрешения в окружении обрабатываемого элемента 123 (C0) разрешения и/или могут представлять собой уже обработанные элементы разрешения (например, их значение, возможно, уже получено во время предыдущих итераций). Дополнительные элементы 124 (C1-C10) разрешения могут представлять собой элементы разрешения (например, из числа уже обработанных элементов разрешения), которые являются ближайшими к обрабатываемому элементу 123 (C0) разрешения (например, те элементы разрешения, которые имеют расстояние от C0, меньшее предварительно определенного порогового значения, например, в три позиции). Дополнительные элементы 124 (C1-C10) разрешения могут представлять собой элементы разрешения (например, из числа уже обработанных элементов разрешения), которые предположительно должны иметь наибольшую корреляцию с обрабатываемым элементом 123 (C0) разрешения. Контекст 114' может задаваться в окружении таким образом, чтобы избегать "провалов" в том смысле, что в частотно-временном представлении все контекстные элементы 124 разрешения находятся непосредственно рядом друг с другом и с обрабатываемым элементом 123 разрешения (причем контекстные элементы 124 разрешения за счет этого формируют "просто соединенное" окружение). (Уже обработанные элементы разрешения, которые, несмотря на это, не выбираются для контекста 114' обрабатываемого элемента 123 разрешения, показаны с помощью пунктирных квадратов и указываются с помощью 125). Дополнительные элементы 124 (C1-C10) разрешения могут иметь пронумерованную взаимосвязь друг с другом (например, C1, C2, ..., Cc, при этом c является числом элементов разрешения в контексте 114', например, 10). Каждый из дополнительных элементов 124 (C1-C10) разрешения контекста 114' может находиться в фиксированной позиции относительно обрабатываемого элемента 123 (C0) разрешения. Позиционные взаимосвязи между дополнительными элементами 124 (C1-C10) разрешения и обрабатываемым элементом 123 (C0) разрешения могут быть основаны на конкретной полосе частот 122 (например, на основе номера k полосы частот). В примере по фиг. 1.2, обрабатываемый элемент 123 (C0) разрешения находится в 3-ей полосе частот (k=3) и в момент t (в этом случае, t=4). В этом случае, может быть предусмотрено, что:
- первый дополнительный элемент C1 разрешения контекста 114' представляет собой элемент разрешения в момент t-1=3 в полосе частот k=3;
- второй дополнительный элемент C2 разрешения контекста 114' представляет собой элемент разрешения в момент t=4 в полосе частот k-1=2;
- третий дополнительный элемент C3 разрешения контекста 114' представляет собой элемент разрешения в момент t-1=3 в полосе частот k-1=2;
- четвертый дополнительный элемент C4 разрешения контекста 114' представляет собой элемент разрешения в момент t-1=3 в полосе частот k+1=4;
- и т.д.
(В дальнейших частях настоящего документа, "контекстный элемент разрешения" может использоваться для того, чтобы указывать "дополнительный элемент 124 разрешения" контекста).
В примерах, после обработки всех элементов разрешения общего t-ого кадра, все элементы разрешения последующего (t+1)-ого кадра могут обрабатываться. Для каждого общего t-ого кадра, все элементы разрешения t-ого кадра могут итеративно обрабатываться. Несмотря на это, могут предоставляться другие последовательности и/или тракты.
Для каждого t-ого кадра, позиционные взаимосвязи между обрабатываемым элементом 123 (C0) разрешения и дополнительными элементами 124 разрешения, формирующими контекст 114' (120), в силу этого могут задаваться на основе конкретной полосы k частот обрабатываемого элемента 123 (C0) разрешения. Когда, в ходе предыдущей итерации, обрабатываемый элемент разрешения представляет собой элемент разрешения, в данный момент указываемый как C6 (t=4, k=1), другая форма контекста выбрана, поскольку отсутствуют заданные полосы частот ниже k=1. Тем не менее, когда обрабатываемый элемент разрешения представляет собой элемент разрешения в t=3, k=3 (в данный момент указываемый как C1), контекст имеет идентичную форму с контекстом по фиг. 1.2 (но смещен на один момент времени влево). Например, на фиг. 2.1, контекст 114' для элемента 123 (C0) разрешения по фиг. 2.1(a) сравнивается с контекстом 114'' для элемента C2 разрешения, ранее используемого, когда C2 представляет собой обрабатываемый элемент разрешения: контексты 114' и 114'' отличаются друг от друга.
Следовательно, модуль 114 задания контекстов может представлять собой модуль, который итеративно, для каждого обрабатываемого элемента 123 (C0) разрешения, извлекает дополнительные элементы 124 (118', C1-C10), чтобы формировать контекст 114', содержащий уже обработанные элементы разрешения, имеющие ожидаемую высокую корреляцию с обрабатываемым элементом 123 (C0) разрешения (в частности, форма контекста может быть основана на конкретной частоте обрабатываемого элемента 123 разрешения).
Декодер 110 может содержать модуль 115 оценки статистических взаимосвязей и/или информации, чтобы предоставлять статистические взаимосвязи и/или информацию 115', 119' между обрабатываемым элементом 123 (C0) разрешения и контекстными элементами 118', 124 разрешения. Модуль 115 оценки статистических взаимосвязей и/или информации может включать в себя модуль 119 оценки взаимосвязей и/или информации по шуму квантования, чтобы оценивать взаимосвязи и/или информацию 119' относительно шума квантования и/или статистические связанные с шумом взаимосвязи между шумом, затрагивающим каждый элемент 124 (C1-C10) разрешения контекста 114' и/или обрабатываемый элемент 123 (C0) разрешения.
В примерах, ожидаемая взаимосвязь 115' может содержать матрицу (например, ковариационную матрицу), содержащую ожидаемые ковариационные взаимосвязи (или другие ожидаемые статистические взаимосвязи) между элементами разрешения (например, обрабатываемым элементом C0 разрешения и дополнительными элементами C1-C10 разрешения контекста). Матрица может представлять собой квадратную матрицу, для которой каждая строка и каждый столбец ассоциированы с элементом разрешения. Следовательно, размерности матрицы могут составлять (c+1)x(c+1) (например, 11 в примере по фиг. 1.2). В примерах, каждый элемент матрицы может указывать ожидаемую ковариацию (и/или корреляцию, и/или другую статистическую взаимосвязь) между элементом разрешения, ассоциированным со строкой матрицы, и элементом разрешения, ассоциированным со столбцом матрицы. Матрица может быть эрмитовой (симметричной в случае действительных коэффициентов). Матрица может содержать, по диагонали, значение дисперсии, ассоциированное с каждым элементом разрешения. В примере, вместо матрицы, могут использоваться другие формы преобразований.
В примерах, ожидаемая взаимосвязь и/или информация 119' по шуму может формироваться посредством статистической взаимосвязи. Тем не менее, в этом случае, статистическая взаимосвязь может означать шум квантования. Различные ковариации могут использоваться для различных полос частот.
В примерах, взаимосвязь и/или информация 119' по шуму квантования может содержать матрицу (например, ковариационную матрицу), содержащую ожидаемые ковариационные взаимосвязи (или другие ожидаемые статистические взаимосвязи) между шумом квантования, затрагивающим элементы разрешения. Матрица может представлять собой квадратную матрицу, для которой каждая строка и каждый столбец ассоциированы с элементом разрешения. Следовательно, размерности матрицы могут составлять (c+1)x(c+1) (например, 11). В примерах, каждый элемент матрицы может указывать ожидаемую ковариацию (и/или корреляцию, и/или другую статистическую взаимосвязь) между шумом квантования, ухудшающим элемент разрешения, ассоциированный со строкой, и элементом разрешения, ассоциированным со столбцом. Ковариационная матрица может быть эрмитовой (симметричной в случае действительных коэффициентов). Матрица может содержать, по диагонали, значение дисперсии, ассоциированное с каждым элементом разрешения. В примере, вместо матрицы, могут использоваться другие формы преобразований.
Следует отметить, что посредством обработки дискретизированного значения Y(k, t) с использованием ожидаемых статистических взаимосвязей между элементами разрешения, может получаться лучшая оценка чистого значения X(k, t).
Декодер 110 может содержать модуль 116 оценки значений, который обрабатывает и получает оценку 116' дискретизированного значения X(k, t) (в обрабатываемом элементе 123 разрешения, C0) сигнала 113' на основе ожидаемых статистических взаимосвязей и/или информации и/или статистических взаимосвязей и/или информации 119' относительно шума квантования 119'.
Оценка 116', которая представляет собой хорошую оценку чистого значения X(k, t), в силу этого может предоставляться в модуль 117 FD-TD-преобразования, чтобы получать усовершенствованный выходной TD-сигнал 112.
Оценка 116' может сохраняться в модуле 118 хранения обработанных элементов разрешения (например, в ассоциации с моментом t времени и/или с полосой k частот). Сохраненное значение оценки 116', на последующих итерациях, может предоставлять уже обработанную оценку 116' в модуль 114 задания контекстов в качестве дополнительного элемента 118' разрешения (см. выше) таким образом, чтобы задавать контекстные элементы 124 разрешения.
Фиг. 1.3 показывает подробности декодера 130, который, в некоторых аспектах, может представлять собой декодер 110. В этом случае, декодер 130 работает, в модуле 116 оценки значений, в качестве фильтра Винера.
В примерах, оцененная статистическая взаимосвязь и/или информация 115' может содержать нормализованную матрицу 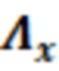 истого. Нормализованная матрица может представлять собой нормализованную корреляционную матрицу и может быть независимой от конкретного дискретизированного значения Y(k, t). Нормализованная матрица
истого. Нормализованная матрица может представлять собой нормализованную корреляционную матрицу и может быть независимой от конкретного дискретизированного значения Y(k, t). Нормализованная матрица 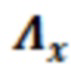 может представлять собой матрицу, которая содержит, например, взаимосвязи между элементами C0-C10 разрешения. Нормализованная матрица
может представлять собой матрицу, которая содержит, например, взаимосвязи между элементами C0-C10 разрешения. Нормализованная матрица 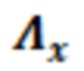 может быть статической и может сохраняться, например, в запоминающем устройстве.
может быть статической и может сохраняться, например, в запоминающем устройстве.
В примерах, оцененная статистическая взаимосвязь и/или информация 119' относительно шума квантования может содержать шумовую матрицу 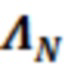 . Эта матрица может представлять собой корреляционную матрицу и может представлять взаимосвязи относительно шумового сигнала V(k, t), независимо от значения конкретного дискретизированного значения Y(k, t). Шумовая матрица может представлять собой матрицу, которая оценивает взаимосвязи между шумовыми сигналами из числа элементов C0-C10 разрешения, например, независимо от чистого речевого значения Y(k, t).
. Эта матрица может представлять собой корреляционную матрицу и может представлять взаимосвязи относительно шумового сигнала V(k, t), независимо от значения конкретного дискретизированного значения Y(k, t). Шумовая матрица может представлять собой матрицу, которая оценивает взаимосвязи между шумовыми сигналами из числа элементов C0-C10 разрешения, например, независимо от чистого речевого значения Y(k, t).
В примерах, модуль 131 измерений (например, модуль оценки усиления) может предоставлять измеренное значение 131' ранее выполняемой оценки(ок) 116'. Измеренное значение 131', например, может представлять собой значение энергии и/или усиление γ ранее выполняемой оценки(ок) 116' (значение энергии, и/или усиление γ в силу этого может зависеть от контекста 114'). В общих чертах, оценка 116' и значение 113' обрабатываемого элемента разрешения 123 могут рассматриваться в качестве вектора 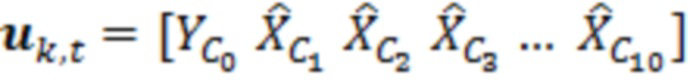 , где
, где 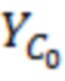 является дискретизированным значением текущего обрабатываемого элемента 123 (C0) разрешения, и
является дискретизированным значением текущего обрабатываемого элемента 123 (C0) разрешения, и 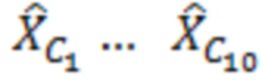 являются ранее полученными значениями для контекстных элементов 124 (C1-C10) разрешения. Можно нормализовать вектор
являются ранее полученными значениями для контекстных элементов 124 (C1-C10) разрешения. Можно нормализовать вектор 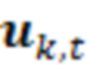 таким образом, чтобы получать нормализованный вектор
таким образом, чтобы получать нормализованный вектор 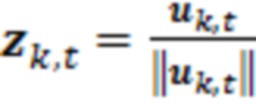 . Также можно получать усиление γ в качестве скалярного произведения нормализованного вектора посредством его транспонирования, например, чтобы получать
. Также можно получать усиление γ в качестве скалярного произведения нормализованного вектора посредством его транспонирования, например, чтобы получать 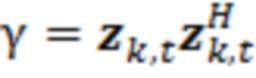 (где
(где 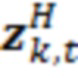 является транспонированием
является транспонированием 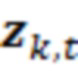 таким образом, что γ является скалярным действительным числом).
таким образом, что γ является скалярным действительным числом).
Модуль 132 масштабирования может использоваться для того, чтобы масштабировать нормализованную матрицу посредством усиления γ, чтобы получать масштабированную матрицу 132', которая принимает во внимание измерение энергии (и/или усиление γ), ассоциированное с конкурсом обрабатываемого элемента 123 разрешения. Следует принимать во внимание, что речевые сигналы имеют большие флуктуации в усилении. В силу этого может получаться новая матрица 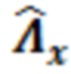 , которая принимает во внимание энергию. В частности, тогда как матрица и матрица могут быть предварительно заданными (и/или содержать элементы, предварительно сохраненные в запоминающем устройстве), матрица фактически вычисляется посредством обработки. В альтернативных примерах, вместо вычисления матрицы , матрица может выбираться из множества предварительно сохраненных матриц , причем каждая предварительно сохраненная матрица
, которая принимает во внимание энергию. В частности, тогда как матрица и матрица могут быть предварительно заданными (и/или содержать элементы, предварительно сохраненные в запоминающем устройстве), матрица фактически вычисляется посредством обработки. В альтернативных примерах, вместо вычисления матрицы , матрица может выбираться из множества предварительно сохраненных матриц , причем каждая предварительно сохраненная матрица 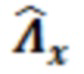 ассоциирована с конкретным диапазоном измеренных значений усиления и/или энергии.
ассоциирована с конкретным диапазоном измеренных значений усиления и/или энергии.
После вычисления или выбора матрицы , сумматор 133 может использоваться для того, чтобы суммировать, поэлементно, элементы матрицы с элементами шумовой матрицы 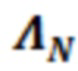 , с тем чтобы получать суммированное значение 133' (суммированную матрицу
, с тем чтобы получать суммированное значение 133' (суммированную матрицу 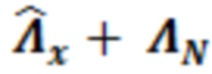 ). В альтернативных примерах, вместо вычисления, суммированная матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных суммированных матриц.
). В альтернативных примерах, вместо вычисления, суммированная матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных суммированных матриц.
В блоке 134 инверсии, суммированная матрица может инвертироваться, чтобы получать 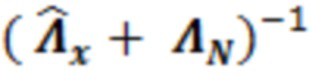 в качестве значения 134'. В альтернативных примерах, вместо вычисления, инвертированная матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных инвертированных матриц.
в качестве значения 134'. В альтернативных примерах, вместо вычисления, инвертированная матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных инвертированных матриц.
Инвертированная матрица (значение 134') может умножаться на , чтобы получать значение 135' в качестве 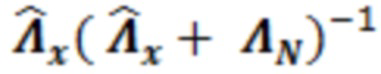 . В альтернативных примерах, вместо вычисления, матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных матриц.
. В альтернативных примерах, вместо вычисления, матрица может выбираться, на основе измеренных значений усиления и/или энергии, из множества предварительно сохраненных матриц.
В этот момент, в умножителе 136 значение 135' может умножаться на входной векторный сигнал y. Входной векторный сигнал может рассматриваться в качестве вектора 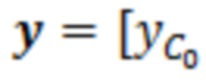
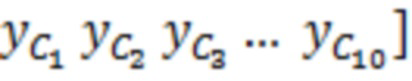 , который содержит зашумленные вводы, ассоциированные с элементом 123 (C0) разрешения, который должен обрабатываться, и контекстными элементами (C1-C10) разрешения.
, который содержит зашумленные вводы, ассоциированные с элементом 123 (C0) разрешения, который должен обрабатываться, и контекстными элементами (C1-C10) разрешения.
Вывод 136' умножителя 136 в силу этого может составлять 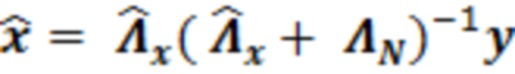 , что касается фильтра Винера.
, что касается фильтра Винера.
На фиг. 1.4, показывается способ 140 согласно примеру (например, одному из вышеприведенных примеров). На этапе 141, обрабатываемый элемент 123 (C0) разрешения (или обрабатываемый элемент разрешения) задается как элемент разрешения в момент t, в полосе k частот и с дискретизированным значением Y(k, t). На этапе 142 (например, обработанном посредством модуля 114 задания контекстов), форма контекста извлекается на основе полосы k частот (форма, зависящая от полосы k частот, может сохраняться в запоминающем устройстве). Форма контекста также задает контекст 114' после того, как учтены момент t и полоса k частот. На этапе 143 (например, обработанном посредством модуля 114 задания контекстов), контекстные элементы C1-C10 (118', 124) разрешения в силу этого задаются (например, ранее обработанные элементы разрешения, которые находятся в контексте) и нумеруются согласно предварительно заданному порядку (который может сохраняться в запоминающем устройстве вместе с формой и также может быть основан на полосе k частот). На этапе 144 (например, обработанном посредством модуля 115 оценки), могут получаться матрицы (например, нормализованная матрица , шумовая матрица или другая из матриц, поясненных выше и т.д.). На этапе 145 (например, обработанном посредством модуля 116 оценки значений), значение для обрабатываемого элемента C0 разрешения может получаться, например, с использованием фильтра Винера. В примерах, значение энергии, ассоциированное с энергией (например, вышеуказанным усилением γ), может использоваться, как пояснено выше. На этапе 146, верифицируется то, если имеются другие полосы частот, ассоциированные с моментом t с другим элементом 126 разрешения, еще не обработанным. Если имеются другие полосы частот (например, полоса k+1 частот), которые должны обрабатываться, то на этапе 147 значение полосы частот обновляется (например, k++), и новый обрабатываемый элемент C0 разрешения выбирается в момент t и в полосе k+1 частот, чтобы повторно итеративно проходить через операции от этапа 141. Если на этапе 146 верифицируется то, что другие полосы частот не должны обрабатываться (например, поскольку отсутствует другой элемент разрешения, который должен обрабатываться в полосе k+1 частот), то на этапе 148 момент t времени обновляется (например, или t++), и первая полоса частот (например, k=1) выбирается, чтобы повторно итеративно проходить через операции от этапа 141.
Обратимся к фиг. 1.5. Хотя фиг. 1.5(a) соответствует фиг. 1.2 и показывает последовательность дискретизированных значений Y(k, t) (ассоциированных с элементом разрешения) в частотно/пространственно-временном представлении. Фиг. 1.5(b) показывает последовательность дискретизированных значений на графике абсолютной величины/частоты для момента t-1 времени, и фиг. 1.5(c) показывает последовательность дискретизированных значений на графике абсолютной величины/частоты для момента t времени, который представляет собой момент времени, ассоциированный с текущим обрабатываемым элементом 123 (C0) разрешения. Дискретизированные значения Y(k, t) квантуются и указываются на фиг. 1.5(b) и 1.5(c). Для каждого элемента разрешения может задаваться множество уровней QL(t, k) квантования (например, уровень квантования может представлять собой одно из дискретного числа уровней квантования, и число и/или значения, и/или масштабы уровней квантования могут передаваться в служебных сигналах посредством кодера, например, и/или могут передаваться в служебных сигналах в потоке 111 битов). Дискретизированное значение Y(k, t) обязательно должно представлять собой один из уровней квантования. Дискретизированные значения могут находиться в логарифмической области. Дискретизированные значения могут находиться в перцепционной области. Каждое из значений каждого элемента разрешения может пониматься как один из квантованных уровней (которые составляют дискретное число), который может выбираться (например, записанный в потоке 111 битов). Верхнее пороговое значение u (наибольшее значение) и нижнее пороговое значение l (наименьшее значение) задается для каждого k и t (обозначения 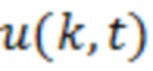 и здесь избегаются для краткости). Эти наибольшие и наименьшие значения могут задаваться посредством модуля 119 оценки взаимосвязей и/или информации по шуму. Наибольшие и наименьшие значения фактически представляют собой информацию, связанную с ячейкой квантования, используемой для квантования значения X(k, t), и выдают информацию относительно динамического из шума квантования.
и здесь избегаются для краткости). Эти наибольшие и наименьшие значения могут задаваться посредством модуля 119 оценки взаимосвязей и/или информации по шуму. Наибольшие и наименьшие значения фактически представляют собой информацию, связанную с ячейкой квантования, используемой для квантования значения X(k, t), и выдают информацию относительно динамического из шума квантования.
Можно устанавливать оптимальную оценку значения 116' каждого элемента разрешения в качестве ожидания условного вероятности значения X, составляющего между наибольшим значением u и нижним предельным пороговым значением l, при условии, что квантованное дискретизированное значение обрабатываемого элемента 123 (C0) разрешения и контекстных элементов 124 разрешения равно оцененным значениям обрабатываемого элемента разрешения и оцененных значений дополнительных элементов разрешения контекста, соответственно. Таким образом, можно оценивать абсолютную величину обрабатываемого элемента 123 (C0) разрешения. Можно получать значение математического ожидания на основе средних значений (μ) чистых значений X и значения (σ) среднеквадратического отклонения, которое может предоставляться, например, посредством модуля оценки статистических взаимосвязей и/или информации.
Можно получать средние значения (μ) чистых значений X и значений (σ) среднеквадратического отклонения на основе процедуры, подробно поясненной ниже, которая может быть итеративной.
Например (см. также 4.1.3 и его подразделы), среднее значение чистого сигнала X может получаться посредством обновления неусловного среднего значения (μ1), вычисленного для обрабатываемого элемента 123 разрешения без учета контекста, чтобы получать новое среднее значение (μup), которое учитывает контекстные элементы 124 (C1-C10) разрешения. На каждой итерации, неусловное вычисленное среднее значение (μ1) может модифицироваться с использованием разности между оцененными значениями (выражаемыми с помощью вектора ) для обрабатываемого элемента 123 (C0) разрешения и контекстных элементов разрешения и средними значениями (выражаемыми с помощью вектора 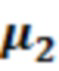 ) контекстных элементов 124 разрешения. Эти значения могут умножаться на значения, ассоциированные с ковариацией и/или дисперсией между обрабатываемым элементом 123 (C0) разрешения и контекстными элементами 124 (C1-C10) разрешения.
) контекстных элементов 124 разрешения. Эти значения могут умножаться на значения, ассоциированные с ковариацией и/или дисперсией между обрабатываемым элементом 123 (C0) разрешения и контекстными элементами 124 (C1-C10) разрешения.
Значение (σ) среднеквадратического отклонения может получаться из дисперсионных и ковариационных взаимосвязей (например, ковариационной матрицы 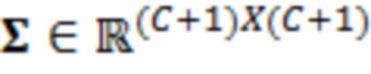 ) между обрабатываемым элементом 123 (C0) разрешения и контекстными элементами 124 (C1-C10) разрешения.
) между обрабатываемым элементом 123 (C0) разрешения и контекстными элементами 124 (C1-C10) разрешения.
Пример способа для получения ожидания (и в силу этого для оценки значения X 116') может предоставляться посредством следующего псевдокода:
function estimation (k, t)
//относительно Y(k, t) для получения X оценки (116')
for t=1 to maxInstants
//последовательный выбор момента t
for k=1 to Number_of_bins_at_instant_t
//в цикле все элементы разрешения
QL<- GetQuantizationLevels(Y(k, t))
//определение того, сколько уровней квантования предоставляется для Y(k, t)
l, u<- GetQuantizationLimits(QL, Y(k, t))
//получение квантованных пределов u и l (например, из модуля 119 оценки взаимосвязей и/или информации по шуму)
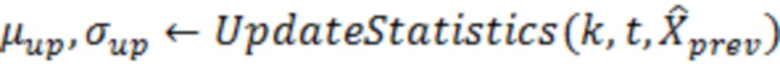
//μup и σup (обновленные значения) получаются
pdf  truncatedGaussian(mu_up, sigma_up, l,u)
truncatedGaussian(mu_up, sigma_up, l,u)
//функция распределения вероятностей вычисляется
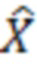 expectation(pdf)
expectation(pdf)
//ожидание вычисляется
end for
end for
endfunction
4.1.2. Постфильтрация с комплексными спектральными корреляциями для кодирования речи и аудио
Примеры в этом разделе и в его подразделах главным образом относятся к технологиям для постфильтрации с комплексными спектральными корреляциями для кодирования речи и аудио.
В настоящих примерах, упоминаются следующие чертежи:
Фиг. 2.1: (a) контекстный блок размера L=10(b), рекуррентный контекстный блок контекстного элемента разрешения C2.
Фиг. 2.2: гистограммы (a) традиционного квантованного вывода ,(b) ошибки квантования (c) квантованного вывода с использованием рандомизации, (d) ошибки квантования с использованием рандомизации. Ввод представляет собой декоррелированный распределенный гауссов сигнал.
Фиг. 2.3: спектрограммы (i) истинной речи, (ii) квантованной речи и (iii) речи, квантованной после рандомизации.
Фиг. 2.4: блок-схема предложенной системы, включающая в себя моделирование кодека для тестирования.
Фиг. 2.5: графики, показывающие (a) pSNR и (b) pSNR-улучшение после постфильтрации, и (c) pSNR-улучшение для различных контекстов.
Фиг. 2.6: MUSHRA-тест на основе прослушивания приводит к a) количественным показателям для всех элементов по всем условиям, b) разностным количественным показателям для каждого входного pSNR-условия, усредненным по мужскому и женскому полу. Оракул, более низкие привязочные и скрытые опорные количественные показатели опущены для ясности.
Примеры в этом разделе и в подразделе также могут ссылаться и/или подробно пояснять примеры фиг. 1.3 и 14 и, если обобщить, фиг. 1.1, 1.2 и 1.5.
Настоящие речевые кодеки достигают хорошего компромисса между качеством, скоростью передачи битов и сложностью. Тем не менее, сохранение производительности за пределами целевого диапазона скоростей передачи битов остается сложным. Чтобы повышать производительность, множество кодеков используют технологии предварительной и постфильтрации, чтобы уменьшать перцепционный эффект шума квантования. Здесь, предлагается способ постфильтрации, чтобы ослаблять шум квантования, который использует комплексные спектральные корреляции речевых сигналов. Поскольку традиционные речевые кодеки не могут передавать информацию с временными зависимостями, поскольку ошибки при передаче могут приводить к серьезному распространению ошибок, корреляция моделируется оффлайн и используется в декодере, за счет этого исключая необходимость передавать вспомогательную информацию. Объективная оценка указывает среднее улучшение в 4 дБ перцепционного SNR сигналов с использованием контекстного постфильтра относительно зашумленного сигнала и среднее улучшение в 2 дБ относительно традиционного фильтра Винера. Эти результаты подтверждаются посредством улучшения вплоть до 30 MUSHRA-баллов в субъективном тесте на основе прослушивания.
4.1.2.1. Введение
Кодирование речи, процесс сжатия речевых сигналов для эффективной передачи и хранения, представляет собой необходимый компонент в технологиях обработки речи. Он используется почти во всех устройствах, участвующих в передаче, хранении или рендеринге речевых сигналов. Хотя стандартные речевые кодеки достигают прозрачной производительности вокруг целевых скоростей передачи битов, производительность кодеков страдает с точки зрения эффективности и сложности за пределами целевого диапазона скоростей передачи битов [5].
Конкретно, на более низких скоростях передачи битов, ухудшение производительности обусловлено тем, что значительные части сигнала квантуются до нуля, что вызывает в результате разреженный сигнал, который часто переключается между нулевым и ненулевым. Это приводит к искаженному качеству сигнала, которое перцепционно характеризуется в качестве музыкального шума. Современные кодеки, такие как EVS, USAC [3, 15], уменьшают эффект шума квантования посредством реализации способов постобработки [5, 14]. Многие из этих способов должны реализовываться как в кодере, так и декодере, в силу этого требуя изменений базовой структуры кодека и иногда также передачи дополнительной вспомогательной информации. Кроме того, большинство этих способов акцентирует внимание на ослаблении эффекта искажений, а не причины для искажений.
Технологии уменьшения уровня шума, широко приспосабливаемые в обработке речи, зачастую используются в качестве предварительных фильтров, чтобы уменьшать фоновый шум в кодировании речи. Тем не менее, применение этих способов для ослабления шума квантования еще не полностью исследовано. Причины этого представляют собой то, что (i) информация из нульквантованных элементов разрешения не может быть восстановлена посредством использования только традиционных технологий фильтрации, и то, что (ii) шум квантования имеет высокую корреляцию с речью на низких скоростях передачи битов, в силу чего различение между распределениями речи и шума квантования для уменьшения уровня шума является затруднительным; они дополнительно поясняются в разделе 4.1.2.2.
Фундаментально, речь представляет медленно изменяющийся сигнал, за счет чего это имеет высокую временную корреляцию [9]. В последнее время, MVDR-фильтры и фильтры Винера с использованием внутренней временной и частотной корреляции в речи предлагаются и демонстрируют значительный потенциал в отношении уменьшения уровня шума [1, 9, 13]. Тем не менее, речевые кодеки отказываются от передачи информации с такой временной зависимостью, чтобы избегать распространения ошибок как следствие потерь информации. Следовательно, применение корреляции речи для кодирования речи или ослабления шума квантования не достаточно изучено, до недавнего времени; прилагаемая статья [10] представляет преимущества включения корреляций в спектр речевой абсолютной величины для уменьшения шума квантования.
Положения этой работы заключаются в следующем: (i) моделирование комплексного речевого спектра, чтобы включать контекстную информацию, внутреннюю в речь, (ii) формулирование проблемы таким образом, что модели являются независимыми от больших флуктуаций в речевых сигналах, и повторение корреляции между выборками обеспечивает возможность включать гораздо больший объем контекстной информации, (iii) получение аналитического решения таким образом, что фильтр является оптимальным в смысле минимальной среднеквадратической ошибки. Следует начинать посредством анализа возможности применения традиционных технологий уменьшения уровня шума для ослабления шума квантования, после чего моделировать комплексный речевой спектр и использовать его в декодере для того, чтобы оценивать речь из наблюдения поврежденного сигнала. Этот подход исключает необходимость передачи дополнительной вспомогательной информации.
4.1.2.2. Моделирование и технология
На низких скоростях передачи битов, традиционные способы энтропийного кодирования вызывают в результате разреженный сигнал, что зачастую приводит к перцепционному артефакту, известному как музыкальный шум. Информация из таких спектральных провалов не может восстанавливаться посредством традиционных подходов, таких как фильтрация Винера, поскольку они главным образом модифицируют усиление. Кроме того, общие технологии уменьшения уровня шума, используемые в обработке речи, моделируют речевые и шумовые характеристики и выполняют уменьшение посредством различения между собой. Тем не менее, на низких скоростях передачи битов, шум квантования имеет высокую корреляцию с базовым речевым сигналом, за счет этого затрудняя различение между ними. Фиг. 2.2-2.3 иллюстрируют эти проблемы; фиг. 2.2(a) показывает распределение декодированного сигнала, который является чрезвычайно разреженным, и фиг. 2.2(b) показывает распределение шума квантования для входной последовательности белого гауссова шума. Фиг. 2.3(i) и 2.3(ii) иллюстрируют спектрограмму истинной речи и декодированной речи, моделированной на низкой скорости передачи битов, соответственно.
Чтобы смягчать эти проблемы, можно применять рандомизацию перед кодированием сигнала [2, 7, 18]. Рандомизация представляет собой тип размывания [11], который ранее использован в речевых кодеках [19], чтобы повышать перцепционное качество сигнала, и последние работы [6, 18] обеспечивают возможность применять рандомизацию без увеличения скорости передачи битов. Эффект применения рандомизации в кодировании демонстрируется на фиг. 2.2(c) и (d) и фиг. 2.3(c); иллюстрации четко показывают, что рандомизация сохраняет декодированное распределение речи и предотвращает разреженность сигнала. Дополнительно, она также придает шуму квантования более декоррелированную характеристику, за счет этого обеспечивая применение общих технологий уменьшения уровня шума из публикаций по обработке речи [8].
Вследствие размывания, предполагается, что шум квантования представляет собой аддитивный и декоррелированный процесс с нормальным распределением:
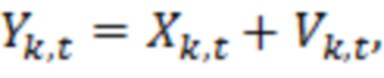 (2.1)
(2.1)
где Y, X и V являются комплекснозначными кратковременными значениями в частотной области зашумленных, чистых речевых и шумовых сигналов, соответственно; k обозначает частотный элемент разрешения во временном кадре t. Помимо этого, предполагается, что X и V являются нулевыми средними случайными гауссовыми переменными. Цель состоит в том, чтобы оценивать 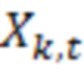 из наблюдения
из наблюдения 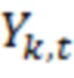 , а также с использованием ранее оцененных выборок . называется контекстом .
, а также с использованием ранее оцененных выборок . называется контекстом .
Оценка чистого речевого сигнала,  , известная как фильтр Винера [8], задается следующим образом:
, известная как фильтр Винера [8], задается следующим образом:
(2.2)
где являются речевыми и шумовыми ковариационными матрицами, соответственно, и является вектором зашумленных наблюдений с c+1 размерностями, c является контекстной длиной. Ковариации в уравнении 2.2 представляют корреляцию между частотно-временными элементами разрешения, которые называются "контекстным окружением". Ковариационные матрицы обучаются оффлайн из базы данных речевых сигналов. Информация относительно шумовых характеристик также включается в процесс, посредством моделирования целевого типа шума (шума квантования), аналогично речевым сигналам. Поскольку проектное решение кодера известно, точно известны характеристики квантования, в силу чего конструирование шумовой ковариации 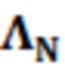 представляет собой простую задачу.
представляет собой простую задачу.
Контекстное окружение: Пример контекстного окружения размера 10 представляется на фиг. 2.1(a). На чертеже, блок 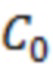 представляет рассматриваемый частотный элемент разрешения. Блоки
представляет рассматриваемый частотный элемент разрешения. Блоки 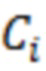 ,
, 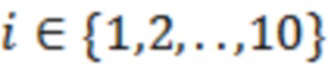 представляют собой частотные элементы разрешения, рассматриваемые в немедленном окружении. В этом конкретном примере, контекстные элементы разрешения охватывают текущий временной кадр и два предыдущих временных кадра и два нижних и верхних частотных элемента разрешения. Контекстное окружение включает в себя только те частотные элементы разрешения, в которых чистая речь уже оценена. Структурирование контекстного окружения здесь является аналогичным варианту применения кодирования, в котором контекстная информация используется для того, чтобы повышать эффективность энтропийного кодирования [12]. В дополнение к включению информации из окружения прямого контекста, контекстное окружение элементов разрешения в контекстном блоке также интегрируется в процесс фильтрации, приводя к использованию большей контекстной информации, аналогично IIR-фильтрации. Это проиллюстрировано на фиг 2.1(b), на котором синяя линия иллюстрирует контекстный блок контекстного элемента C2 разрешения. Математическая формулировка окружения конкретно представлена в следующем разделе.
представляют собой частотные элементы разрешения, рассматриваемые в немедленном окружении. В этом конкретном примере, контекстные элементы разрешения охватывают текущий временной кадр и два предыдущих временных кадра и два нижних и верхних частотных элемента разрешения. Контекстное окружение включает в себя только те частотные элементы разрешения, в которых чистая речь уже оценена. Структурирование контекстного окружения здесь является аналогичным варианту применения кодирования, в котором контекстная информация используется для того, чтобы повышать эффективность энтропийного кодирования [12]. В дополнение к включению информации из окружения прямого контекста, контекстное окружение элементов разрешения в контекстном блоке также интегрируется в процесс фильтрации, приводя к использованию большей контекстной информации, аналогично IIR-фильтрации. Это проиллюстрировано на фиг 2.1(b), на котором синяя линия иллюстрирует контекстный блок контекстного элемента C2 разрешения. Математическая формулировка окружения конкретно представлена в следующем разделе.
Моделирование нормализованной ковариации и усиления: Речевые сигналы имеют большие флуктуации в усилении и структуре спектральной огибающей. Чтобы эффективно моделировать точную спектральную структуру [4], используется нормализация для того, чтобы удалять эффект этой флуктуации. Усиление вычисляется во время ослабления шума из усиления Винера в текущем элементе разрешения и оценок в предыдущих частотных элементах разрешения. Нормализованная ковариация и оцененное усиление используются вместе, чтобы получать оценку текущей частотной выборки. Этот этап является важным, поскольку он обеспечивает возможность использовать фактическую речевую статистику для уменьшения уровня шума, несмотря на большие флуктуации.
Контекстный вектор задается как 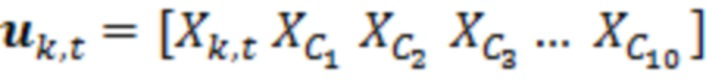 , в силу чего нормализованный контекстный вектор представляет собой
, в силу чего нормализованный контекстный вектор представляет собой 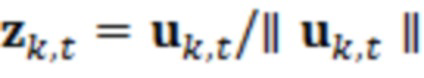 . Речевая ковариация задается как
. Речевая ковариация задается как 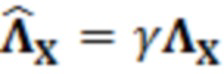 , где
, где 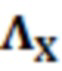 является нормализованной ковариацией, и γ представляет усиление. Усиление вычисляется во время постфильтрации на основе уже обработанных значений в качестве
является нормализованной ковариацией, и γ представляет усиление. Усиление вычисляется во время постфильтрации на основе уже обработанных значений в качестве 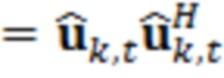 , где
, где 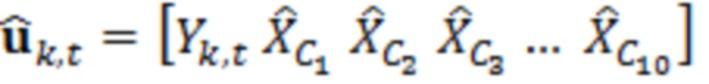 является контекстным вектором, сформированным посредством обрабатываемого элемента разрешения и уже обработанных значений контекста. Нормализованные ковариации вычисляются из набора речевых данных следующим образом:
является контекстным вектором, сформированным посредством обрабатываемого элемента разрешения и уже обработанных значений контекста. Нормализованные ковариации вычисляются из набора речевых данных следующим образом:
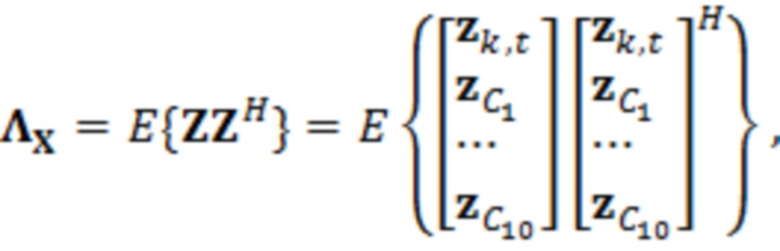 (2.3)
(2.3)
Из уравнения 2.3, следует отметить, что этот подход обеспечивает возможность включать корреляцию из окружения, гораздо большего контекстного размера, и дополнительной информации, за счет этого экономя вычислительные ресурсы. Статистика по шуму вычисляется следующим образом:
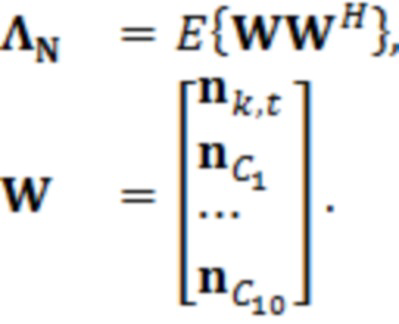 (2.4)
(2.4)
где 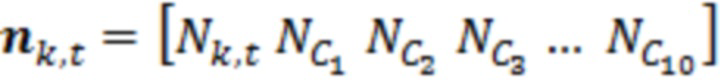 является контекстным шумовым вектором, заданным в момент t времени и в частотном элементе k разрешения. Следует отметить, что в уравнении 2.4, нормализация не требуется для шумовых моделей. В завершение, уравнение для оцененного чистого речевого сигнала является следующим:
является контекстным шумовым вектором, заданным в момент t времени и в частотном элементе k разрешения. Следует отметить, что в уравнении 2.4, нормализация не требуется для шумовых моделей. В завершение, уравнение для оцененного чистого речевого сигнала является следующим:
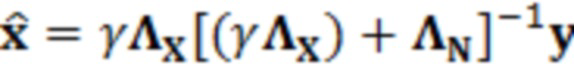 (2.5)
(2.5)
Вследствие формулирования, сложность способа является линейно пропорциональной контекстному размеру. Предложенный способ отличается от двумерной фильтрации Винера в [17] тем, что он работает с использованием комплексного спектра абсолютной величины, в силу чего нет необходимости использовать зашумленную фазу для того, чтобы восстанавливать сигнал, в отличие от традиционных способов. Дополнительно, в отличие от одномерных и двумерных фильтров Винера, которые применяют усиление модуля масштабирования к зашумленному спектру абсолютной величины, предложенный фильтр включает информацию из предыдущих оценок, чтобы вычислять векторное усиление. Следовательно, относительно предыдущей работы, новизна этого способа заключается в способе, которым контекстная информация включается в фильтр, в силу этого адаптируя систему к варьированиям речевого сигнала.
4.1.2.3. Эксперименты и результаты
Предложенный способ оценен с использованием объективных и субъективных тестов. Использовано перцепционное SNR (pSNR) [3, 5] в качестве объективного показателя, поскольку оно аппроксимирует человеческое восприятие, и оно уже доступно в типичном речевом кодеке. Для субъективной оценки, осуществлен MUSHRA-тест на основе прослушивания.
4.1.2.3.1. Общее представление системы
Структура системы проиллюстрирована на фиг. 2.4 (в примерах, она может быть аналогичной TCX-режиму в 3GPP EVS [3]). Во-первых, STFT применяется (этап 241) к входящему звуковому сигналу 240', чтобы преобразовывать его в сигнал (242') в частотной области. Здесь можно использовать STFT вместо стандартного MDCT, так что результаты являются легко переносимыми в варианты применения для улучшения речи. Неофициальные эксперименты верифицируют то, что выбор преобразования не приводит к неожиданным проблемам в результатах [8, 5].
Чтобы обеспечивать то, что шум кодирования имеет наименьший перцепционный эффект, сигнал 241' частотной области перцепционно взвешивается в блоке 242, чтобы получать взвешенный сигнал 242'. После блока 243 предварительной обработки, вычисляется перцепционная модель в блоке 244 (например, используемая в EVS-кодеке [3]), на основе коэффициентов линейного прогнозирования (LPC). После взвешивания сигнала с перцепционной огибающей, сигнал нормализуется и энтропийно кодируется (не показано). Для простой воспроизводимости, шум квантования смоделирован в блоке 244 (что не представляет собой обязательную часть продаваемого продукта) посредством перцепционно взвешенного гауссова шума, согласно пояснению в разделе 4.1.2.2. В силу этого может формироваться кодек 242'' (который может представлять собой поток 111 битов).
Таким образом, вывод 244' кодека/блока 244 моделирования шума квантования (QN), на фиг. 2.4, представляет собой поврежденный декодированный сигнал. Предложенный способ фильтрации применяется на этой стадии. Блок 246 улучшения может получать оффлайново обученные речевые и шумовые модели 245' из блока 245 (который может содержать запоминающее устройство, включающее в себя оффлайновые модели). Блок 246 улучшения может содержать, например, модули 115 и 119 оценки. Блок улучшения может включать в себя, например, модуль 116 оценки значений. После процесса уменьшения уровня шума, сигнал 246' (который может представлять собой пример сигнала 116') взвешивается посредством обратной перцепционной огибающей в блоке 247, и после этого, в блоке 248, преобразуется обратно во временную область, чтобы получать улучшенный декодированный речевой сигнал 249, который, например, может представлять собой звуковой вывод 249.
4.1.2.3.2. Объективная оценка
Экспериментальная компоновка: Процесс разделяется на фазы обучения и тестирования. В фазе обучения, оцениваются статические нормализованные речевые ковариации для контекстных размеров 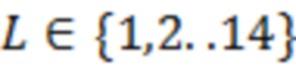 из речевых данных. Для обучения, выбрано 50 случайных выборок из обучающего набора базы данных TIMIT [20]. Все сигналы повторно дискретизируются при 12,8 кГц, и синусоидальная функция кодирования со взвешиванием применяется к кадрам размера в 20 мс с 50%-м перекрытием. Кодированные со взвешиванием сигналы затем преобразуются в частотную область. Поскольку улучшение применяется в перцепционной области, также моделируется речь в перцепционной области. Для каждой выборки элемента разрешения в перцепционной области, контекстные окружения составляются в матрицы, как описано в разделе 4.1.2.2, и ковариации вычисляются. Аналогично получаются шумовые модели с использованием перцепционно взвешенного гауссова шума.
из речевых данных. Для обучения, выбрано 50 случайных выборок из обучающего набора базы данных TIMIT [20]. Все сигналы повторно дискретизируются при 12,8 кГц, и синусоидальная функция кодирования со взвешиванием применяется к кадрам размера в 20 мс с 50%-м перекрытием. Кодированные со взвешиванием сигналы затем преобразуются в частотную область. Поскольку улучшение применяется в перцепционной области, также моделируется речь в перцепционной области. Для каждой выборки элемента разрешения в перцепционной области, контекстные окружения составляются в матрицы, как описано в разделе 4.1.2.2, и ковариации вычисляются. Аналогично получаются шумовые модели с использованием перцепционно взвешенного гауссова шума.
Для тестирования, 105 речевых выборок случайно выбираются из базы данных. Зашумленные выборки формируются в качестве аддитивной суммы речи и моделируемого шума. Уровни речи и шума управляются таким образом, что способ для pSNR тестируется в пределах 0-20 дБ с помощью 5 выборок для каждого pSNR-уровня, чтобы соответствовать типичному рабочему диапазону кодеков. Для каждой выборки, протестированы 14 контекстных размеров. Для сравнения, зашумленные выборки улучшены с использованием фильтра с оракулом, при этом традиционный фильтр Винера использует истинный шум в качестве оценки шума, т.е. оптимальное усиление Винера известно.
Результаты оценки: Результаты проиллюстрированы на фиг. 2.5. Выходное pSNR традиционного фильтра Винера, фильтра с оракулом и ослабление шума с использованием фильтров контекстной длины 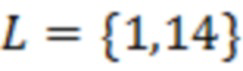 проиллюстрировано на фиг. 2.5(a). На фиг. 2.5(b), дифференциальное выходное pSNR, которое представляет собой улучшение выходного pSNR относительно pSNR сигнала, поврежденного посредством шума квантования, проиллюстрировано по диапазону входного pSNR для различных подходов к фильтрации. Эти графики демонстрируют то, что традиционный фильтр Винера значительно улучшает зашумленный сигнал, с улучшением в 3 дБ при более низких pSNR и улучшением в 1 дБ при более высоких pSNR. Дополнительно, контекстный фильтр L=14 показывает улучшение в 6 дБ при более высоких pSNR и улучшение приблизительно в 2 дБ при более низком pSNR.
проиллюстрировано на фиг. 2.5(a). На фиг. 2.5(b), дифференциальное выходное pSNR, которое представляет собой улучшение выходного pSNR относительно pSNR сигнала, поврежденного посредством шума квантования, проиллюстрировано по диапазону входного pSNR для различных подходов к фильтрации. Эти графики демонстрируют то, что традиционный фильтр Винера значительно улучшает зашумленный сигнал, с улучшением в 3 дБ при более низких pSNR и улучшением в 1 дБ при более высоких pSNR. Дополнительно, контекстный фильтр L=14 показывает улучшение в 6 дБ при более высоких pSNR и улучшение приблизительно в 2 дБ при более низком pSNR.
Фиг. 2.5(c) демонстрирует эффект контекстного размера при различных входных pSNR. Можно отметить, что при более низких pSNR контекстный размер оказывает значительное влияние на ослабление шума; улучшение pSNR увеличивается с увеличением контекстного размера. Тем не менее, скорость улучшения относительно контекстного размера снижается по мере того, как контекстный размер увеличивается, и имеет тенденцию к насыщенности для L>10. При более высоких входных pSNR, улучшение достигает насыщенности при относительно меньшем контекстном размере.
4.1.2.3.3. Субъективная оценка
Качество предложенного способа оценено с помощью субъективного MUSHRA-теста на основе прослушивания [16]. Тест состоит из шести элементов, и каждый элемент состоит из 8 тестовых условий. Участие принимают слушатели, как эксперты, так и не эксперты, в возрасте 20-43 лет. Тем не менее, выбраны только рейтинги тех участников, которые количественно оценивают скрытый опорный элемент более чем в 90 MUSHRA-баллов, что приводит к 15 слушателям, количественные показатели которых включены для этой оценки.
Шесть предложений случайно выбраны из базы данных TIMIT, чтобы формировать тестовые элементы. Элементы сформированы посредством добавления перцепционного шума, чтобы моделировать шум кодирования таким образом, что pSNR результирующих сигналов задается фиксированно равным 2, 5 и 8 дБ. Для каждого pSNR, сформирована одна позиция мужского и женского пола. Каждый элемент состоит из 8 условий: зашумленный (отсутствие улучшения), идеальное улучшение с известным шумом (оракул), традиционный фильтр Винера, выборки из предложенного способа с контекстными размерами в один (L=1), шесть (L=6), четырнадцать (L=14), в дополнение к сигналу нижних частот в 3,5 кГц в качестве более низкого привязочного и скрытого опорного элемента, согласно MUSHRA-стандарту.
Результаты представляются на фиг. 2.6. Из фиг. 2.6(a), следует отметить, что предложенный способ, даже с наименьшим контекстом L=1, согласованно показывает улучшение по сравнению с поврежденным сигналом, в большинстве случаев без перекрытия между доверительными интервалами. Между традиционным фильтром Винера и предложенным способом, среднему условия L=1 присваивается рейтинг приблизительно на 10 баллов выше в среднем. Аналогично, L=14 присваивается рейтинг приблизительно на 30 MUSHRA-баллов выше фильтра Винера. Для всех элементов, количественные показатели L=14 не перекрываются с количественными показателями фильтра Винера и находятся близко к идеальному условию, в частности, при более высоких pSNR. Эти наблюдения дополнительно поддерживаются на разностном графике, проиллюстрированном на фиг. 2.6(b). Количественные показатели для каждого pSNR усреднены по позициям мужского и женского пола. Разностные количественные показатели получены посредством поддержания количественных показателей условия Винера в качестве опорных и получения разности между тремя условиями по контекстному размеру и условием отсутствия улучшения. Из этих результатов, можно прийти к выводу что в дополнение к размыванию, которое может повышать перцепционное качество декодированного сигнала [11], применение уменьшения уровня шума в декодере с использованием традиционных технологий и дополнительно, с использованием моделей, включающих корреляцию, внутренне присущую в комплексном речевом спектре, позволяет значительно улучшать pSNR.
4.1.2.4. Заключение
Предлагается способ частотно-временной фильтрации для ослабления шума квантования в кодировании речи и аудио, в котором корреляция статистически моделируется и используется в декодере. Следовательно, способ не требует передачи дополнительной временной информации, за счет этого исключая вероятность распространения ошибок вследствие потерь при передаче. Посредством включения контекстной информации, наблюдается pSNR-улучшение в 6 дБ в наилучшем случае и в 2 дБ в типичном варианте применения; субъективно, наблюдается улучшение в 10-30 MUSHRA-баллов.
В этом разделе, зафиксирован выбор контекстного окружения для определенного контекстного размера. Хотя это предоставляет базовую линию для ожидаемого улучшения на основе контекстного размера, интересно анализировать влияние выбора оптимального контекстного окружения. Дополнительно, поскольку MVDR-фильтр демонстрирует существенное улучшение в отношении уменьшения фонового шума, сравнение между MVDR- и предложенным MMSE-способом должно рассматриваться для этого варианта применения.
В общих словах, показано, что предложенный способ повышает субъективное и объективное качество, и он может использоваться для того, чтобы повышать качество любых речевых и аудиокодеков.
4.1.2.5 Библиографический список
[1] Y. Huang and J. Benesty, “A multi-frame approach to the frequency-domain single-channel noise reduction problem,” IEEE Transactions on Audio, Speech, and Language Processing, издание 20, номер 4, стр. 1256-1269, 2012.
[2] T. Bäckström, F. Ghido, and J. Fischer, “Blind recovery of perceptual models in distributed speech and audio coding,” in Interspeech. 1em plus 0.5em minus 0.4em ISCA, 2016, стр. 2483-2487.
[3] “EVS codec detailed algorithmic description; 3GPP technical specification,” http://www.3gpp.org/DynaReport/26445.htm .
[4] T. Bäckström, “Estimation of the probability distribution of spectral fine structure in the speech source,” in Interspeech, 2017.
[5] Speech Coding with Code-Excited Linear Prediction. 1em plus 0.5em minus 0.4em Springer, 2017.
[6] T. Bäckström, J. Fischer, and S. Das, “Dithered quantization for frequency-domain speech and audio coding,” in Interspeech, 2018.
[7] T. Bäckström and J. Fischer, “Coding of parametric models with randomized quantization in a distributed speech and audio codec,” in Proceedings of the 12. ITG Symposium on Speech Communication. 1em plus 0.5em minus 0.4em VDE, 2016, стр. 1-5.
[8] J. Benesty, M. M. Sondhi, and Y. Huang, Springer handbook of speech processing. 1em plus 0.5em minus 0.4em Springer Science & Business Media, 2007.
[9] J. Benesty and Y. Huang, “A single-channel noise reduction MVDR filter,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2011, стр. 273-276.
[10] S. Das and T. Bäckström, “Postfiltering using log-magnitude spectrum for speech and audio coding,” in Interspeech, 2018.
[11] R. W. Floyd and L. Steinberg, “An adaptive algorithm for spatial gray-scale,” in Proc. Soc. Inf. Disp., издание 17, 1976, стр. 75-77.
[12] G. Fuchs, V. Subbaraman, and M. Multrus, “Efficient context adaptive entropy coding for real-time applications,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2011, стр. 493-496.
[13] H. Huang, L. Zhao, J. Chen, and J. Benesty, “A minimum variance distortionless response filter based on the bifrequency spectrum for single-channel noise reduction,” Digital Signal Processing, издание 33, стр. 169-179, 2014.
[14] M. Neuendorf, P. Gournay, M. Multrus, J. Lecomte, B. Bessette, R. Geiger, S. Bayer, G. Fuchs, J. Hilpert, N. Rettelbach et al., “A novel scheme for low bitrate unified speech and audio coding-MPEG RM0,” in Audio Engineering Society Convention 126. 1em plus 0.5em minus 0.4em Audio Engineering Society, 2009.
[15] --, “Unified speech and audio coding scheme for high quality at low bitrates,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2009, стр. 1-4.
[16] M. Schoeffler, F. R. Stöter, B. Edler, and J. Herre, “Towards the next generation of web-based experiments: a case study assessing basic audio quality following the ITU-R recommendation BS. 1534 (MUSHRA),” in 1st Web Audio Conference. 1em plus 0.5em minus 0.4em Citeseer, 2015.
[17] Y. Soon and S. N. Koh, “Speech enhancement using 2-D Fourier transform,” IEEE Transactions on speech and audio processing, издание 11, номер 6, стр. 717-724, 2003.
[18] T. Bäckström and J. Fischer, “Fast randomization for distributed low-bitrate coding of speech and audio,” IEEE/ACM Trans. Audio, Speech, Lang. Process., 2017.
[19] J.-M. Valin, G. Maxwell, T. B. Terriberry, and K. Vos, “High-quality, low-delay music coding in the OPUS codec,” in Audio Engineering Society Convention 135. 1em plus 0.5em minus 0.4em Audio Engineering Society, 2013.
[20] V. Zue, S. Seneff, and J. Glass, “Speech database development at MIT: TIMIT and beyond,” Speech Communication, издание 9, номер 4, стр. 351-356, 1990.
4.1.3. Постфильтрация, например, с использованием спектра логарифмической амплитудно-частотной характеристики для кодирования речи и аудио
Примеры в этом разделе и в подразделах главным образом ссылаются на технологии для постфильтрации с использованием спектра логарифмической амплитудно-частотной характеристики для кодирования речи и аудио.
Примеры в этом разделе и в подразделах могут лучше указывать конкретные случаи, например, фиг. 1.1 и 1.2.
В настоящем примере, упоминаются следующие чертежи:
Фиг. 3.1: Контекстное окружение размера C=10. Предыдущие оцененные элементы разрешения выбираются и упорядочиваются на основе расстояния от текущей выборки.
Фиг. 3.2: Гистограммы речевой абсолютной величины в (a) линейной области, (b) логарифмической области, в произвольном частотном элементе разрешения.
Фиг. 3.3: Обучение речевых моделей.
Фиг. 3.4: Гистограммы распределения речи: (a) истинное (b) оцененное: ML, (c) оцененной: EL.
Фиг. 3.5: Графики, представляющие улучшение SNR с использованием предложенного способа для различных контекстных размеров.
Фиг. 3.6: Общее представление систем.
Фиг. 3.7: Примерные графики, иллюстрирующие истинный, квантованный и оцененный речевой сигнал (i) в фиксированной полосе частот по всем временным кадрам, (ii) в фиксированном временном кадре по всем полосам частот.
Фиг. 3.8: Графики рассеяния истинной, квантованной и оцененной речи в нульквантованных элементах разрешения для (a) C=1, (b) C=40. Графики демонстрируют корреляцию между оцененной и истинной речью.
Усовершенствованные алгоритмы кодирования приводят в результате к высококачественным сигналам с хорошей эффективностью кодирования в пределах целевых диапазонов скоростей передачи битов, но их производительность страдает за пределами целевого диапазона. На более низких скоростях передачи битов, ухудшение производительности обусловлено тем, что декодированные сигналы являются разреженными, что вызывает перцепционно приглушенную и искаженную характеристику сигнала. Стандартные кодеки сокращают такие искажения посредством применения способов заполнения шумом и постфильтрации. Здесь, предлагается способ постобработки на основе моделирования внутренне присущей частотно-временной корреляции в спектре логарифмической амплитудно-частотной характеристики. Цель состоит в том, чтобы улучшать перцепционное SNR декодированных сигналов и уменьшать искажения, вызываемые посредством разреженности сигнала. Объективные показатели показывают среднее улучшение в 1,5 дБ для входного перцепционного SNR в диапазоне 4-18 дБ. Улучшение является особенно заметным в компонентах, которые квантованы до нуля.
4.1.3.1. Введение
Речевые и аудиокодеки составляют неотъемлемые части большинства вариантов применения аудиообработки, и в последнее время наблюдается быстрое развитие стандартов кодирования, таких как MPEG USAC [18, 16] и 3GPP EVS [13]. Эти стандарты переориентированы на унификацию кодирования аудио и речи, обеспечивают кодирование сверхширокополосных и полнополосных речевых сигналов, а также дополнительную поддержку речи по IP. Базовые алгоритмы кодирования в этих кодеках, ACELP и TCX, обеспечивают в результате перцепционно прозрачное качество на средних и высоких скоростях передачи битов в пределах целевых диапазонов скоростей передачи битов. Тем не менее, производительность ухудшается, когда кодеки работают за пределами этого диапазона. В частности, для кодирования с низкой скоростью передачи битов в частотной области, снижение производительности обусловлено тем, что меньшее число битов являются доступными для кодирования, за счет чего зоны с более низкой энергией квантуются до нуля. Такие спектральные провалы в декодированном сигнале обеспечивают перцепционно искаженную и приглушенную характеристику сигнала, что может быть раздражающим для слушателя.
Чтобы получать удовлетворительную производительность за пределами целевых диапазонов скоростей передачи битов, стандартные кодеки, такие как CELP, используют способы предварительной и постобработки, которые основаны главным образом на эвристике. В частности, чтобы уменьшать искажение, вызываемое посредством шума квантования на низких скоростях передачи битов, кодеки реализуют способы либо в процессе кодирования, либо строго в качестве постфильтра в декодере. Улучшение формант и постфильтры нижних звуковых частот представляют собой общепринятые способы [9], которые модифицируют декодированный сигнал на основе знаний того, как и где шум квантования перцепционно искажает сигнал. Улучшение формант формирует таблицу кодирования, чтобы внутренне иметь меньше энергии в зонах, подверженных шуму, и применяется как в кодере, так и в декодере. Напротив, постфильтр нижних звуковых частот удаляет шумоподобный компонент между гармоническими линиями и реализуется только в декодере.
Другой наиболее часто используемый способ представляет собой заполнение шумом, при котором псевдослучайный шум добавляется в сигнал [16], поскольку точное кодирование шумоподобных компонентов не является важным для восприятия. Помимо этого, подход помогает в уменьшении перцепционного эффекта искажений, вызываемых посредством разреженности, на сигнал. Качество заполнения шумом может повышаться посредством параметризации шумоподобного сигнала, например, посредством его усиления, в кодере и передачи усиления в декодер.
Преимущество способов постфильтрации по сравнению с другими способами состоит в том, что они реализуются только в декодере, в силу чего они не требуют модификаций структуры кодер-декодера, и при этом им не требуется передача вспомогательной информации. Тем не менее, большинство этих способов акцентируют внимание на решении эффекта проблемы, вместо того, чтобы исправлять причину.
Здесь, предлагается способ постобработки, чтобы повышать качество сигнала на низких скоростях передачи битов, посредством моделирования внутренне присущей частотно-временной корреляции в спектре речевой абсолютной величины и исследования потенциала использования этой информации, чтобы уменьшать шум квантования. Преимущества этого подхода состоят в том, что он не требует передачи вспомогательной информации и работает с использованием только квантованного сигнала в качестве наблюдения и речевых моделей, обученных офлайн. Поскольку он применяется в декодере после процесса декодирования, он не требует изменений базовой структуры кодека; подход наценен на искажения сигнала посредством оценки информации, потерянной во время процесса кодирования с использованием исходной модели. Новизна этой работы заключается (i) во включении информации формант в речевые сигналы с использованием моделирования логарифмической амплитудно-частотной характеристики, (ii) в представлении внутренне присущей контекстной информации в спектральной абсолютной величине речи в логарифмической области в качестве многовариантного гауссова распределения, (iii) в нахождении оптимума, для оценки истинной речи, в качестве ожидаемого вероятности усеченного гауссова распределения.
4.1.3.2. Модели спектра речевой абсолютной величины
Форманты являются фундаментальным индикатором лингвистического контента в речи и проявляются посредством спектральной огибающей абсолютной величины речи, в силу чего спектр абсолютной величины составляет важную часть исходного моделирования [10, 21]. Предшествующее исследование показывает то, что частотные коэффициенты речи лучше всего представляются посредством лапласова или гамма-распределения [1, 4, 2, 3]. Следовательно, спектр абсолютной величины речи представляет собой экспоненциальное распределение, как показано на фиг. 3.2a. Чертеж демонстрирует то, что распределение концентрируется при низких значениях абсолютной величины. Это затруднительно использовать в качестве модели вследствие проблем числовой точности. Кроме того, трудно обеспечивать то, что оценки являются положительными, только посредством использования общих математических операций. Эта проблема решается посредством преобразования спектра в область логарифмической амплитудно-частотной характеристики. Поскольку логарифм является нелинейным, он перераспределяет ось абсолютных величин таким образом, что распределение экспоненциально распределенной абсолютной величины напоминает нормальное распределение в логарифмическом представлении (фиг. 3.2b). Это обеспечивает возможность аппроксимировать распределение спектра логарифмической амплитудно-частотной характеристики с использованием гауссовой функции плотности распределения вероятностей (PDF).
В последние годы, контекстная информация в речи вызывает растущий интерес [11]. Информация межкадровой и межчастотной корреляции исследована ранее в обработке акустических сигналов, для уменьшения уровня шума [11, 5, 14]. Технологии MVDR-фильтрации и фильтрации Винера используют предыдущие временные или частотные кадры, чтобы получать оценку сигнала в текущем частотно-временном элементе разрешения. Результаты указывают существенное повышение качества выходного сигнала. В этой работе используется аналогичная контекстная информация для того, чтобы моделировать речь. В частности, исследуется достоверность использования логарифмической амплитудно-частотной характеристики для того, чтобы моделировать контекст, и его представления с использованием многовариантных гауссовых распределений. Контекстное окружение выбирается на основе расстояния от контекстного элемента разрешения до рассматриваемого элемента разрешения. Фиг. 3.1 иллюстрирует контекстное окружение размера 10 и указывает порядок, в котором предыдущие оценки ассимилируются в контекстные векторы.
Общее представление процесса 330 моделирования (обучения) представляется на фиг. 3.3. Входной речевой сигнал 331 преобразуется в сигнал 332' частотной области частотная область посредством кодирования со взвешиванием и последующего применения кратковременного преобразования Фурье (STFT) в блоке 332. Сигнал 332' частотной области затем предварительно обрабатывается в блоке 333, чтобы получать предварительно обработанный сигнал 333'. Предварительно обработанный сигнал 333' используется для того, чтобы извлекать перцепционную модель посредством вычисления, например, перцепционной огибающей, аналогично CELP [7, 9]. Перцепционная модель используется в блоке 334 для перцепционного взвешивания сигнала 332' частотной области, чтобы получать перцепционно взвешенный сигнал 334'. В завершение, контекстные векторы 335' (например, элементы разрешения, которые должны составлять контекст для каждого элемента разрешения, который должен обрабатываться) извлекаются для каждого выборочного частотного элемента разрешения в блоке 335, и затем ковариационная матрица 336' для каждой полосы частот оценивается в блоке 336, за счет этого предоставляя требуемые речевые модели.
Другими словами, обученные модели 336' содержат:
- правила для задания контекста (например, на основе полосы k частот); и/или
- модель речи (например, значения, которые используются для нормализованной ковариационной матрицы ), используемую посредством модуля 115 оценки для формирования статистических взаимосвязей и/или информации 115' между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения, формирующего контекст; и/или
- модель шума (например, шума квантования), которая используется посредством модуля 119 оценки для формирования статистических взаимосвязей и/или информации шума (например, значения, которые используются, например, для задания матрицы 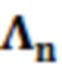 ).
).
Исследованы контекстные размеры вплоть до 40, что включает в себя приблизительно по четыре предыдущих временных кадра, нижние и верхние частотные элементы разрешения, каждый. Следует отметить, что работа ведется с STFT вместо MDCT, которое используется в стандартных кодеках, чтобы поддерживать расширяемость этой работы на варианты применения для улучшения. Расширение этой работы на MDCT проводится в данный момент, и неофициальные тесты предоставляют понимание, аналогичное этому документу.
4.1.3.3. Формулирование проблемы
Цель состоит в том, чтобы оценивать чистый речевой сигнал из наблюдения зашумленного декодированного сигнала с использованием статистических априорных вероятностей. С этой целью, проблема формулируется в качестве максимального вероятности (ML) текущей выборки, с учетом наблюдения и предыдущих оценок. Предположим, что выборка 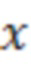 квантована до уровня
квантована до уровня 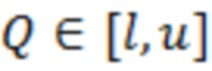 квантования. В таком случае можно выражать проблему оптимизации следующим образом:
квантования. В таком случае можно выражать проблему оптимизации следующим образом:
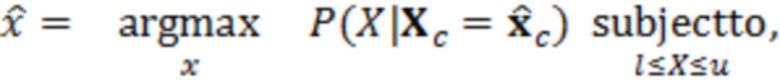 (3.1)
(3.1)
где является оценкой текущей выборки, l и u являются нижним и верхним пределами текущих элементов разрешения квантования, соответственно, и является условной вероятностью , с учетом , является оцененным контекстным вектором. Фиг. 3.1 иллюстрирует конструирование контекстного вектора размера C=10, при этом числа представляют порядок, в котором включаются частотные элементы разрешения. Уровни квантования получаются из декодированного сигнала, и из сведений по способу квантования, используемому в кодеке, можно задавать пределы квантования; нижний и верхний пределы конкретного уровня квантования задаются в середине между предыдущим и следующим уровнями, соответственно.
Чтобы иллюстрировать выполнение уравнения 3.1, оно решено с использованием общих численных методов. Фиг. 3.4 иллюстрирует результаты через распределения истинной речи (a) и оцененной речи (b), в элементах разрешения, квантованных до нуля. Элементы разрешения масштабируются таким образом, что варьирующиеся l и u задаются фиксированно равными 0,1, соответственно, чтобы анализировать и сравнивать относительное распределение оценок в элементе разрешения квантования. В (b), наблюдается высокая плотность данных около 1, что подразумевает то, то что оценки смещаются к верхним пределам. Это называется "проблемой краев". Чтобы смягчать эту проблему, задается речевая оценка в качестве ожидаемого вероятности (EL) [17, 8], следующим образом:
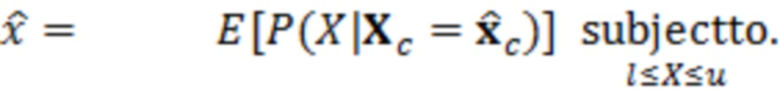 (3.2)
(3.2)
Результирующее распределение речи с использованием EL демонстрируется на фиг. 3.4c, что указывает относительно лучшее совпадение между распределениями оцененной речи и истинной речи. В завершение, чтобы получать аналитическое решение, ограничивающее условие включается в моделирование себя, за счет чего распределение моделируется в качестве усеченной гауссовой PDF [12]. В приложениях A и B (4.1.3.6.1 и 4.1.3.6.2), демонстрируется то, как решение может получаться в качестве усеченного гауссиана. Следующий алгоритм представляет общее представление способа оценки.

4.1.3.4. Эксперименты и результаты
Цель состоит в том, чтобы оценивать преимущество моделирования спектра логарифмической амплитудно-частотной характеристики. Поскольку модели огибающей представляют собой основной способ для моделирования спектра абсолютной величины в традиционных кодеках, оцениваются эффект статистических априорных вероятностей с точки зрения полного спектра, а также только для огибающей. Следовательно, помимо оценки предложенного способа для оценки речи из зашумленного спектра абсолютной величины речи, он также тестируется для оценки спектральной огибающей из наблюдения зашумленной огибающей. Чтобы получать спектральную огибающую, после преобразования сигнала в частотную область, кепстр вычисляется, и 20 более низких коэффициентов сохраняются, и он преобразуется обратно в частотную область. Следующие этапы моделирования огибающей являются идентичными спектральному моделированию абсолютной величины, представленному в разделе 4.1.3.2 и фиг. 3.3, т.е. получению контекстного вектора и ковариационной оценки.
4.1.3.4.1. Общее представление системы
Общая блок-схема системы 360 представляется на фиг. 3.6. В кодере 360a, сигналы 361 разделяются на кадры (например, в 20 мс с 50%-м перекрытием и, например, синусоидальным кодированием со взвешиванием). Речевой ввод 361 затем может преобразовываться в блоке 362 в сигнал 362' частотной области, например, с использованием STFT. После предварительной обработки в блоке 363 и перцепционного взвешивания в блоке 364 сигнала посредством спектральной огибающей, спектр абсолютной величины квантуется в блоке 365 и энтропийно кодируется в блоке 366 с использованием арифметического кодирования [19], чтобы получать кодированный сигнал 366 (который может представлять собой пример потока 111 битов).
В декодере 360b, обратный процесс реализуется в блоке 367 (который может представлять собой пример модуля 113 считывания потоков битов), чтобы декодировать кодированный сигнал 366'. Декодированный сигнал 366' может повреждаться посредством шума квантования, и цель состоит в том, чтобы использовать предложенный способ постобработки, чтобы повышать выходное качество. Следует отметить, что способ применяется в перцепционно взвешенной области. Предоставляется блок 368 логарифмического преобразования.
Блок 369 постфильтрации (который может реализовывать элементы 114, 115, 119, 116 и/или 130 поясненных выше) позволяет уменьшать эффекты шума квантования, как пояснено выше, на основе речевых моделей, которые, например, могут представлять собой обученные модели 336' и/или правила для задания контекста (например, на основе полосы k частот), и/или статистических взаимосвязей и/или информации 115' (например, нормализованной ковариационной матрицы ) между и/или информацией относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения, формирующего контекст, и/или статистических взаимосвязей и/или информации 119' (например, матрицы ) относительно шума (например, шума квантования).
После постобработки, оцененная речь преобразуется обратно во временную область посредством применения обратных перцепционных весовых коэффициентов в блоке 369a и обратного преобразования частоты в блоке 369b. Истинная фаза используется для того, чтобы восстанавливать сигнал обратно во временную область.
4.1.3.4.2. Экспериментальная компоновка
Для обучения, использованы 250 речевых выборок из обучающего набора базы данных TIMIT [22]. Блок-схема процесса обучения представляется на фиг. 3.3. Для тестирования, 10 речевых выборок случайно выбраны из тестового набора базы данных. Кодек основан на EVS-кодеке [6] в TCX-режиме, и параметры кодека выбраны таким образом, что перцепционное SNR (pSNR) [6, 9] находится в диапазоне, типичном для кодеков. Следовательно, кодирование моделируется на 12 различных скоростях передачи битов от 9,6 до 128 Кбит/с, что обеспечивает pSNR-значения в аппроксимированном диапазоне 4 и 18 дБ. Следует отметить, что TCX-режим EVS не включает постфильтрацию. Для каждого тестового случая, применяется постфильтр к декодированному сигналу с контекстными размерами ∈ {1,4,8,10,14,20,40}. Контекстные векторы получаются согласно описанию в разделе 4.1.3.2 и иллюстрации на фиг. 3.1. Для тестов с использованием спектра абсолютной величины, pSNR постобработанного сигнала сравнивается с pSNR зашумленного квантованного сигнала. Для тестов на основе спектральной огибающей, отношение "сигнал-шум" (SNR) между истинной и оцененной огибающей используется в качестве количественного показателя.
4.1.3.4.3. Результаты и анализ
Среднее качественных показателей по этим 10 речевым выборкам проиллюстрировано на фиг. 3.4. Графики (a) и (b) представляют результаты оценки с использованием спектра абсолютной величины, и графики (c) и (d) соответствуют тестам на основе спектральной огибающей. Для спектра и огибающей, включение контекстной информации показывает согласованное улучшение SNR. Степень улучшения проиллюстрирована на графиках (b) и (d). Для спектра абсолютной величины, улучшение варьируется от 1,5 до 2,2 дБ по всему контексту при низком входном pSNR и от 0,2 до на 1,2 дБ при более высоком входном pSNR. Для спектральных огибающих, тренд является аналогичным; улучшение по сравнению с контекстом от 1,25 до 2,75 дБ при более низком входном SNR и от 0,5 до 2,25 при более высоком входном SNR. При входном SNR приблизительно в 10 дБ, улучшение достигает максимума для всех контекстных размеров.
Для спектра абсолютной величины, повышение качества между контекстным размером 1 и 4 является очень большим, приблизительно на 0,5 дБ по всем входным pSNR. Посредством увеличения контекстного размера, можно дополнительно улучшать pSNR, но скорость улучшения является относительно более низкой для размеров от 4 до 40. Кроме того, улучшение является значительно более низким при более высоких входных pSNR. Делается вывод, что контекстный размер приблизительно в 10 выборок представляет собой хороший компромисс между точностью и сложностью. Тем не менее, выбор контекстного размера также может зависеть от целевого устройства для обработки. Например, если устройство обладает вычислительными ресурсами, высокий контекстный размер может использоваться для максимального улучшения.
Фиг. 3.7: Примерные графики, иллюстрирующие истинный, квантованный и оцененный речевой сигнал (i) в фиксированной полосе частот по всем временным кадрам, (ii) в фиксированном временном кадре по всем полосам частот.
Выполнение предложенного способа дополнительно иллюстрируется на фиг. 3.7-3.8, с входным pSNR в 8,2 дБ. Важное наблюдение из всех графиков на фиг. 3.7 состоит в том, что в частности, в элементах разрешения, квантованных до нуля, предложенный способ позволяет оценивать абсолютную величину, которая находится близко к истинной абсолютной величине. Дополнительно из фиг. 3.7(ii), по-видимому, оценки придерживаются спектральной огибающей, за счет чего можно прийти к выводу, что гауссовы распределения преимущественно включают информацию спектральной огибающей и не большую часть информации основного тона. Следовательно, также могут приспосабливаться дополнительные способы моделирования для основного тона.
Графики рассеяния на фиг. 3.8 представляют корреляцию между истинной, оцененной и квантованной речевой абсолютной величиной в нульквантованных элементах разрешения для C=1 и C=40. Эти графики дополнительно демонстрируют, что контекст является полезным в оценке речи в элементах разрешения, в которых информация не существует. Таким образом, этот способ может быть полезным в оценке спектральных абсолютных величин в алгоритмах заполнения шумом. На графиках рассеяния, квантованный, истинный и оцененный спектр речевой абсолютной величины представляется посредством красных, черных и синих точек, соответственно. Следует отметить, что хотя корреляция является положительной для обоих размеров, корреляция является значительно более высокой и в большей степени задается для C=40.
4.1.3.5. Пояснение и заключения
В этих разделах, исследовано использование контекстной информации, внутренне присущей в речи, для уменьшения шума квантования. Предлагается способ постобработки с акцентированием внимания на оценке речевых выборок в декодере из квантованного сигнала с использованием статистических априорных вероятностей. Результаты указывают то, что включение корреляции речи не только улучшает pSNR, но также и предоставляет спектральные оценки абсолютной величины для алгоритмов заполнения шумом. Хотя фокус данной статьи представляет собой моделирование спектральной абсолютной величины, объединенный способ моделирования абсолютной величины и фазы, на основе текущего понимания и результатов из прилагаемой статьи [20], представляет собой естественный следующий этап.
Этот раздел также начинается с базирования на восстановлении спектральной огибающей из высококвантованных зашумленных огибающих посредством включения информации для контекстного окружения.
4.1.3.6. Приложения
4.1.3.6.1. Приложение A. Усеченная гауссова PDF
Следует задавать и , где μ, σ являются статистическими параметрами распределения, и erf является функцией ошибок. Затем ожидание унивариативной случайной гауссовой переменной X вычисляется следующим образом:
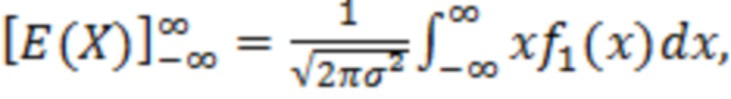 (3.3)
(3.3)
Традиционно, когда 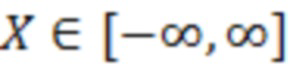 , решение уравнения 3.3 приводит к
, решение уравнения 3.3 приводит к 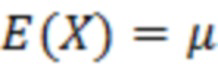 . Тем не менее, для усеченной случайной гауссовой переменной, при l<X<u, взаимосвязь является следующей:
. Тем не менее, для усеченной случайной гауссовой переменной, при l<X<u, взаимосвязь является следующей:
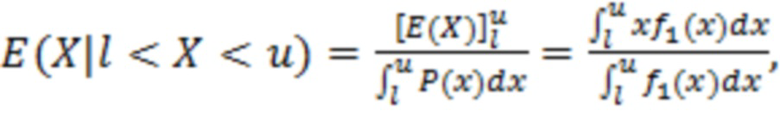 (3.4)
(3.4)
что дает в результате следующее уравнение, чтобы вычислять ожидание усеченной унивариативной случайной гауссовой переменной:
(3.5)
4.1.3.6.2. Приложение В. Условные гауссовы параметры
Пусть контекстный вектор задается как 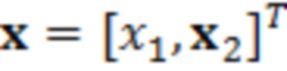 , при этом
, при этом  представляет текущий рассматриваемый элемент разрешения, и
представляет текущий рассматриваемый элемент разрешения, и 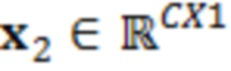 является контекстом. В таком случае
является контекстом. В таком случае 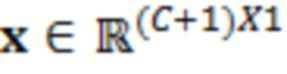 , где C является контекстным размером. Статистические модели представляются посредством вектора
, где C является контекстным размером. Статистические модели представляются посредством вектора 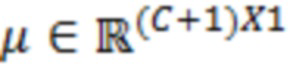 средних значений и ковариационной матрицы таким образом, что
средних значений и ковариационной матрицы таким образом, что 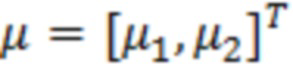 с размерностями, идентичными
с размерностями, идентичными 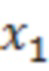 и
и 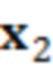 , и следующими ковариациями:
, и следующими ковариациями:
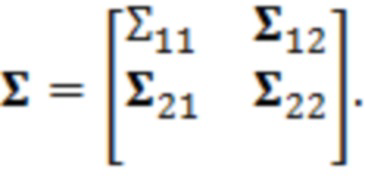 (3.6)
(3.6)
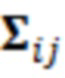 являются сегментами
являются сегментами 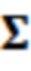 с размерностями
с размерностями 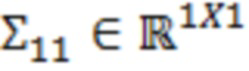 ,
, 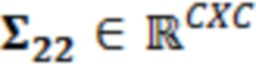 ,
, 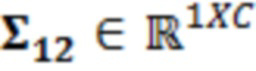 и
и 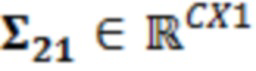 . Таким образом, обновленная статистика распределения текущего элемента разрешения на основе оцененного контекста [15]:
. Таким образом, обновленная статистика распределения текущего элемента разрешения на основе оцененного контекста [15]:
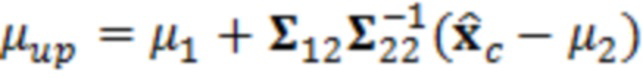 (3.7)
(3.7)
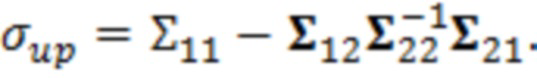 (3.8)
(3.8)
4.1.3.7 Библиографический список
[1] J. Porter and S. Boll, “Optimal estimators for spectral restoration of noisy speech,” in ICASSP, издание 9, март 1984, стр. 53-56.
[2] C. Breithaupt and R. Martin, “MMSE estimation of magnitude-squared DFT coefficients with superGaussian priors,” in ICASSP, издание 1, апрель 2003, стр. I-896-I-899 издание1.
[3] T. H. Dat, K. Takeda, and F. Itakura, “Generalized gamma modeling of speech and its online estimation for speech enhancement,” in ICASSP, издание 4, март 2005, стр. iv/181-iv/184 Издание 4.
[4] R. Martin, “Speech enhancement using MMSE short time spectral estimation with gamma distributed speech priors,” in ICASSP, издание 1, май 2002, стр. I-253-I-256.
[5] Y. Huang and J. Benesty, “A multi-frame approach to the frequency-domain single-channel noise reduction problem,” IEEE Transactions on Audio, Speech, and Language Processing, издание 20, номер 4, стр. 1256-1269, 2012.
[6] “EVS codec detailed algorithmic description; 3GPP technical specification,” http://www.3gpp.org/DynaReport/26445.htm .
[7] T. Bäckström and C. R. Helmrich, “Arithmetic coding of speech and audio spectra using TCX based on linear predictive spectral envelopes,” in ICASSP, апрель 2015, стр. 5127-5131.
[8] Y. I. Abramovich and O. Besson, “Regularized covariance matrix estimation in complex elliptically symmetric distributions using the expected likelihood approach part 1: The over-sampled case,” IEEE Transactions on Signal Processing, издание 61, номер 23, стр. 5807-5818, 2013.
[9] T. Bäckström, Speech Coding with Code-Excited Linear Prediction. 1em plus 0.5em minus 0.4em Springer, 2017.
[10] J. Benesty, M. M. Sondhi, and Y. Huang, Springer handbook of speech processing. 1em plus 0.5em minus 0.4em Springer Science & Business Media, 2007.
[11] J. Benesty and Y. Huang, “A single-channel noise reduction MVDR filter,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2011, стр. 273-276.
[12] N. Chopin, “Fast simulation of truncated Gaussian distributions,” Statistics and Computing, издание 21, номер 2, стр. 275-288, 2011.
[13] M. Dietz, M. Multrus, V. Eksler, V. Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilache et al., “Overview of the EVS codec architecture,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2015, стр. 5698-5702.
[14] H. Huang, L. Zhao, J. Chen, and J. Benesty, “A minimum variance distortionless response filter based on the bifrequency spectrum for single-channel noise reduction,” Digital Signal Processing, издание 33, стр. 169-179, 2014.
[15] S. Korse, G. Fuchs, and T. Bäckström, “GMM-based iterative entropy coding for spectral envelopes of speech and audio,” in ICASSP. 1em plus 0.5em minus 0.4em IEEE, 2018.
[16] M. Neuendorf, P. Gournay, M. Multrus, J. Lecomte, B. Bessette, R. Geiger, S. Bayer, G. Fuchs, J. Hilpert, N. Rettelbach et al., “A novel scheme for low bitrate unified speech and audio coding-MPEG RM0,” in Audio Engineering Society Convention 126. 1em plus 0.5em minus 0.4em Audio Engineering Society, 2009.
[17] E. T. Northardt, I. Bilik, and Y. I. Abramovich, “Spatial compressive sensing for direction-of-arrival estimation with bias mitigation via expected likelihood,” IEEE Transactions on Signal Processing, издание 61, номер 5, стр. 1183-1195, 2013.
[18] S. Quackenbush, “MPEG unified speech and audio coding,” IEEE MultiMedia, издание 20, номер 2, стр. 72-78, 2013.
[19] J. Rissanen and G. G. Langdon, “Arithmetic coding,” IBM Journal of research and development, издание 23, номер 2, стр. 149-162, 1979.
[20] S. Das and T. Bäckström, “Postfiltering with complex spectral correlations for speech and audio coding,” в Interspeech, 2018.
[21] T. Barker, “Non-negative factorisation techniques for sound source separation,” Ph.D. dissertation, Tampere University of Technology, 2017.
[22] V. Zue, S. Seneff, and J. Glass, “Speech database development at MIT: TIMIT and beyond,” Speech Communication, издание 9, номер 4, стр. 351-356, 1990.
4.1.4. Дополнительные примеры
4.1.4.1. Структура систем
Предложенный способ применяет фильтрацию в частотно-временной области, чтобы уменьшать уровень шума. Он проектируется специально для ослабления шума квантования речевого и аудиокодека, но он является применимым к любой задаче для уменьшения уровня шума. Фиг. 1 иллюстрирует структуру системы.
Алгоритм ослабления шума основан на оптимальной фильтрации в нормализованной частотно-временной области. Он содержит следующие важные подробности:
1. Чтобы уменьшать сложность при сохранении производительности, фильтрация применяется только к непосредственному окружению каждого частотно-временного элемента разрешения. Это окружение здесь называется "контекстом" элемента разрешения.
2. Фильтрация является рекурсивной в том смысле, что контекст содержит оценки чистого сигнала, когда они доступны. Другими словами, когда применяется ослабление шума в итерации по каждому частотно-временному элементу разрешения, те элементы разрешения, которые уже обработаны, возвращаются на следующие итерации (см. фиг. 2). Это создает контур обратной связи, аналогичный авторегрессивной фильтрации. Преимущества являются двойными:
3. Поскольку ранее оцененные выборки используют контекст, отличный от контекста текущей выборки, фактически используется более крупный контекст в оценке текущей выборки. Посредством использования большего объема данных, с большой вероятностью получается лучшее качество.
4. Ранее оцененные выборки, в общем, не являются идеальными оценками, что означает то, что оценки имеют некоторую ошибку. Посредством обработки ранее оцененных выборок, как если они представляют собой чистые выборки, текущая выборка смещается к ошибкам, аналогичным ошибкам ранее оцененных выборок. Хотя это может увеличивать фактическую ошибку, ошибка затем лучше соответствует исходной модели, т.е. сигнал в большей степени напоминает статистику полезного сигнала. Другими словами, для речевого сигнала, фильтрованная речь должна лучше напоминать речь, даже если абсолютная ошибка не обязательно минимизируется.
5. Энергия контекста имеет высокое варьирование по времени и по частоте, и при этом энергия шума квантования эффективно является постоянной, если предполагается, что точность квантования является постоянной. Поскольку оптимальные фильтры основаны на оценках ковариации, величина энергии, которую, как оказывается, имеет текущий контекст, в силу этого имеет большой эффект на ковариацию и в за счет этого на оптимальный фильтр. Чтобы принимать во внимание такие варьирования энергии, необходимо применять нормализацию в некоторой части процесса. В текущей реализации, ковариация требуемого источника нормализуется таким образом, что она совпадает с контекстом ввода до обработки посредством нормы контекста (см. фиг. 4.3). Другие реализации нормализации являются легко возможными, в зависимости от требований общей инфраструктуры.
6. В текущей работе, использована фильтрация Винера, поскольку она представляет собой известный и хорошо понимаемый способ для извлечения оптимальных фильтров. Очевидно, что специалисты в данной области техники могут выбирать любое другое проектное решение для фильтра по выбору, такое как критерии оптимизации на основе отклика без искажений с минимальной дисперсией (MVDR).
Фиг. 4.2 является иллюстрацией рекурсивного характера примеров предложенной оценки. Для каждой выборки, извлекается контекст, который имеет выборки из зашумленного входного кадра, оценки предыдущих чистых кадров и оценки предыдущих выборок в текущем кадре. Эти контексты затем используются для того, чтобы находить оценку текущей выборки, которые затем объединенно формируют оценку чистого текущего кадра.
Фиг. 4.3 показывает оптимальную фильтрацию одной выборки из ее контекста, включающую в себя оценку усиления (нормы) текущего контекста, нормализацию (масштабирование) исходной ковариации с использованием этого усиления, вычисление оптимального фильтра с использованием масштабированной ковариации требуемого сигнала источника и ковариации шума квантования и, в завершение, применение оптимального фильтра, чтобы получать оценку выходного сигнала.
4.1.4.2. Преимущество предложения по сравнению с предшествующим уровнем техники
4.4.4.2.1. Традиционные подходы кодирования
Основная новизна предложенного способа заключается в том, что он принимает во внимание статистические свойства речевого сигнала в частотно-временном представлении во времени. Традиционные кодеки связи, такие как 3GPP EVS, используют статистику сигнала в энтропийном кодере и исходное моделирование только по частотам в текущем кадре [1]. Широковещательные кодеки, такие как MPEG USAC, используют некоторую частотно-временную информацию в своих энтропийных кодерах также во времени, но только в ограниченной степени [2].
Причина неохотного использования межкадровой информации состоит в том, что если информация теряется в передаче, то отсутствует возможность корректно восстанавливать сигнал. В частности, не освобождается только тот кадр, который теряется, но поскольку следующие кадры зависят от потерянного кадра, также следующие кадры либо некорректно восстанавливаются, либо полностью теряются. Использование межкадровой информации в кодировании в силу этого приводит к значительному распространению ошибок в случае потерь кадров.
Напротив, текущее предложение не требует передачи межкадровой информации. Статистика сигнала определяется оффлайн в форме ковариационных матриц контекста как для полезного сигнала, так и для шума квантования. В силу этого можно использовать межкадровую информацию в декодере без риска распространения ошибок, поскольку межкадровая статистика оценивается оффлайн.
Предложенный способ является применимым в качестве способа постобработки для любого кодека. Основное ограничение заключается в том, что если традиционный кодек работает на очень низкой скорости передачи битов, то значительные части сигнала квантуются до нуля, что значительно снижает эффективность предложенного способа. Тем не менее, на низких скоростях можно использовать рандомизированные способы квантования, так что ошибка квантования лучше напоминает гауссов шум [3,4]. Это обеспечивает применимость предложенного способа, по меньшей мере:
1. на средних и высоких скоростях передачи битов, при традиционных проектных решений кодека, и
2. на низких скоростях передачи битов, при использовании рандомизированного квантования.
Предложенный подход в силу этого использует статистические модели сигнала двумя способами; внутрикадровая информация кодируется с использованием традиционных способов энтропийного кодирования, и межкадровая информация используется для ослабления шума в декодере на этапе постобработки. Такое применение исходного моделирования на стороне декодера является знакомым из способов распределенного кодирования, в которых продемонстрировано, что не важно то, применяется статистическое моделирование как в кодере, так и в декодере либо только в декодере [5]. Насколько известно, данный подход представляет собой первый вариант применения этого признака в кодировании речи и аудио, за рамками вариантов применения распределенного кодирования.
4.1.4.2.2. Ослабление шума
Относительно недавно продемонстрировано, что варианты применения для ослабления шума получают значительные преимущества от включения статистической информации во времени в частотно-временной области. В частности, в работе Benesty и др. применяются традиционные оптимальные фильтры, такие как MVDR в частотно-временной области, чтобы уменьшать фоновые шумы [6, 7]. Хотя первичное применение предложенного способа заключается в ослаблении шума квантования, он может естественно также применяться к общей проблеме ослабления шума, аналогично работе Benesty. Тем не менее, отличие заключается в том, что явно выбраны те частотно-временные элементы разрешения для контекста, которые имеют наибольшую корреляцию с текущим элементом разрешения. В отличие от этого, работа Benesty применяет фильтрацию только во времени, но не применяет в соседних частотах. Посредством более свободного выбора между частотно-временными элементами разрешения, можно выбирать те частотные элементы разрешения, которые обеспечивают наибольшее повышение качества с наименьшим контекстным размером, за счет чего уменьшается вычислительная сложность.
4.1.4.3. Расширения
Предусмотрено определенное число естественных расширений, которые вытекают естественно из предложенного способа и которые могут применяться к аспектам и примерам, раскрытым выше и ниже:
1. Выше, контекст содержит только зашумленную текущую выборку и предыдущие оценки чистого сигнала. Тем не менее, контекст может включать в себя также частотно-временные соседние элементы, которые еще не обработаны. Таким образом, можно использовать контекст, в который включаются самые полезные соседние элементы, и если доступны, используются оцененные чистые выборки, в противном случае зашумленные выборки. Зашумленные соседние элементы в таком случае естественно должны иметь ковариацию для шума, аналогичную ковариации текущей выборки.
2. Оценки чистого сигнала естественно являются не идеальными и также содержат некоторую ошибку, но выше предполагается, что оценки предшествующего сигнала не имеют ошибки. Чтобы повышать качество, можно включать также оценку остаточного шума для предшествующего сигнала.
3. Текущая работа акцентирует внимание на ослаблении шума квантования, но очевидно, что также можно включать фоновые шумы. В таком случае требуется включать только соответствующую шумовую ковариацию в процесс минимизации [8].
4. Здесь представлен способ, применяемый только к одноканальным сигналам, но ясно можно расширять его на многоканальные сигналы с использованием традиционных способов [8].
5. Текущая реализация использует ковариации, которые оцениваются оффлайн, и только масштабирование из требуемой исходной ковариации адаптировано к сигналу. Очевидно, что адаптивные модели ковариации должны быть полезными, если имеется дополнительная информация относительно сигнала. Например, если имеется индикатор величины вокализации речевого сигнала или оценки отношения "гармоники-шум" (HNR), можно адаптировать требуемую исходную ковариацию таким образом, что она совпадает с вокализацией или HNR, соответственно. Аналогично, если тип квантователя или режим изменяется каждый кадр, можно использовать это для того, чтобы адаптировать ковариацию шума квантования. Посредством удостоверения в том, что ковариации совпадают со статистикой наблюдаемого сигнала, очевидно, должны получаться лучшие оценки полезного сигнала.
6. Контекст в текущей реализации выбирается из ближайших соседних элементов в частотно-временной сетке. Тем не менее, отсутствуют ограничения на то, чтобы использовать только эти выборки; можно свободно выбирать любую полезную информацию, которая доступна. Например, можно использовать информацию относительно гармонической структуры сигнала, чтобы выбирать выборки в контексте, которые соответствуют гребенчатой структуре гармонического сигнала. Помимо этого, если имеется доступ к модели огибающей, можно использовать ее для того, чтобы оценивать статистику спектральных частотных элементов разрешения, аналогично [9]. Если обобщить, можно использовать любую доступную информацию, которая коррелируется с текущей выборкой, чтобы улучшать оценку чистого сигнала.
4.1.4.4. Библиографический список
[1] 3GPP, TS 26.445, EVS Codec Detailed Algorithmic Description; 3GPP Technical Specification (Release 12), 2014 год.
[2] ISO/IEC 23003-3:2012, "MPEG-D (MPEG audio technologies), Part 3: Unified speech and audio coding", 2012 год.
[3] T Bäckström, F Ghido и J Fischer, "Blind recovery of perceptual models in distributed speech and audio coding", in Proc. Interspeech, 2016 год, стр. 2483-2487.
[4] T Bäckström и J Fischer, "Fast randomization for distributed low-bitrate coding of speech and audio", accepted to IEEE/ACM Trans. Audio, Speech, Lang. Process., 2017 год.
[5] R. Mudumbai, G. Barriac и U. Madhow, "On the feasibility of distributed beamforming in wireless networks", Wireless Communications, IEEE Transactions on, издание 6, номер 5, стр. 1754-1763, 2007 год.
[6] Y.A. Huang и J. Benesty, "A multi-frame approach to the frequency-domain single-channel noise reduction problem", IEEE Transactions on Audio, Speech and Language Processing, издание 20, номер 4, стр. 1256-1269, 2012 год.
[7] J. Benesty и Y. Huang, "A single-channel noise reduction MVDR filter", in ICASSP. IEEE, 2011, стр. 273-276.
[8] J Benesty, M Sondhi и Y Huang, "Springer Handbook of Speech Processing", Springer, 2008 год.
[9] T Bäckström и C R Helmrich, "Arithmetic coding of speech and audio spectra using TCX based on linear predictive spectral envelopes", in Proc. ICASSP, апрель 2015 года, стр. 5127-5131.
4.1.5. Дополнительные аспекты
4.1.5.1. Дополнительные технические требования и дополнительные сведения
В вышеприведенных примерах, нет необходимости межкадровой информации, кодированной в потоке 111 битов. Следовательно, в примерах по меньшей мере один из модуля 114 задания контекстов, модуля 115 оценки статистических взаимосвязей и/или информации, модуля 119 оценки взаимосвязей и/или информации по шуму квантования и модуля 116 оценки значений, использует межкадровую информацию в декодере, за счет этого уменьшая рабочие данные и риск распространения ошибок в случае потерь пакетов или битов.
В вышеприведенных примерах, главным образом упоминается шум квантования. Тем не менее, другие виды шума могут быть разрешены в других примерах.
Следует отметить, что большинство технологий, описанных выше, являются, в частности, эффективными для низких скоростей передачи битов. Следовательно, может быть возможным реализовывать технологию выбора между:
- режимом с более низкой скоростью передачи битов, в котором технологии выше используются; и
- режимом с более высокой скоростью передачи битов, в котором предложенная постфильтрация обходится.
Фиг. 5.1 показывает пример 510, который может реализовываться посредством декодера 110 в некоторых примерах. Определение 511 выполняется относительно скорости передачи битов. Если скорость передачи битов ниже предварительно определенного порогового значения, контекстная фильтрация, как описано выше, выполняется на 512. Если скорость передачи битов выше предварительно определенного порогового значения, контекстная фильтрация пропускается на 513.
В примерах, модуль 114 задания контекстов может формировать контекст 114' с использованием по меньшей мере одного необработанного элемента 126 разрешения. Со ссылкой на фиг. 1.5, в некоторых примерах, контекст 114' в силу этого может содержать по меньшей мере один из элементов 126 разрешения в кружке. Следовательно, в некоторых примерах, использование модуля 118 хранения обработанных элементов разрешения может избегаться или дополняться посредством соединения 11'' (фиг. 1.1), которое предоставляет модуль 114 задания контекстов, по меньшей мере, с одним необработанным элементом 126 разрешения.
В вышеприведенных примерах, модуль 115 оценки статистических взаимосвязей и/или информации и/или модуль 119 оценки взаимосвязей и/или информации по шуму могут сохранять множество матриц (например, 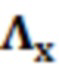 ,
, 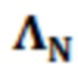 ). Выбор матрицы, которая должна использоваться, может выполняться на основе показателей для входного сигнала (например, в контексте 114' и/или в обрабатываемом элементе 123 разрешения). Различные гармоничности (например, определенные с помощью отношения "гармоничность-шум" или других показателей) в силу этого, например, может быть ассоциирована с различными матрицами , .
). Выбор матрицы, которая должна использоваться, может выполняться на основе показателей для входного сигнала (например, в контексте 114' и/или в обрабатываемом элементе 123 разрешения). Различные гармоничности (например, определенные с помощью отношения "гармоничность-шум" или других показателей) в силу этого, например, может быть ассоциирована с различными матрицами , .
Альтернативно, различные нормы контекста (например, определенные с помощью измерения нормы контекста необработанных значений элементов разрешения или других показателей) в силу этого, например, могут быть ассоциированы с различными матрицами , .
4.1.5.2. Способы
Операции оборудования, раскрытого выше, могут представлять собой способы согласно настоящему раскрытию сущности.
Общий пример способа показывается на фиг. 5.2, который означает:
- первый этап 521 (например, выполняемый посредством модуля 114 задания контекстов), на котором задается контекст (например, 114') для одного обрабатываемого элемента разрешения (например, 123) входного сигнала, причем контекст (например, 114') включает в себя по меньшей мере один дополнительный элемент разрешения (например, 118', 124) в предварительно определенной позиционной взаимосвязи, в частотно/пространственно-временном представлении, с обрабатываемым элементом разрешения (например, 123);
- второй этап 522 (например, выполняемый посредством по меньшей мере одного из компонентов 115, 119, 116), на котором, на основе статистических взаимосвязей и/или информации (например, 115') между и/или информацией относительно обрабатываемого элемента разрешения (например, 123) и по меньшей мере одного дополнительного элемента разрешения (например, 118', 124) и статистических взаимосвязей и/или информации (например, 119') относительно шума (например, шума квантования и/или других видов шума), оценивается значение (например, 116') обрабатываемого элемента разрешения (например, 123).
В примерах, способ можно повторно итеративно проходиться, например, после этапа 522, заново активируется этап 521, например, посредством обновления обрабатываемого элемента разрешения и посредством выбора нового контекста.
Способы, такие как способ 520, могут дополняться посредством операции, поясненной выше.
4.1.5.3. Модуль хранения
Как показано на фиг. 5.3, операции оборудования (например, 113, 114, 116, 118, 115, 117, 119 и т.д.) и способов, раскрытых выше, могут реализовываться посредством процессорной системы 530. Она может содержать энергонезависимый модуль 534 хранения, который, при выполнении посредством процессора 532, может работать с возможностью уменьшать уровень шума. Показывается порт 53 ввода-вывода, который может предоставлять данные (такие как входной сигнал 111) в процессор 532, например, из приемной антенны и/или модуля хранения (например, в котором входной сигнал 111 сохраняется).
4.1.5.4. Система
Фиг. 5.4 показывает систему 540, содержащую кодер 542 и декодер 130 (или другой кодер, как описано выше). Кодер 542 выполнен с возможностью предоставлять поток 111 битов с кодированным входной сигнал, например, в беспроводном режиме (например, с помощью радиочастотной и/или ультразвуковой, и/или оптической связи) или посредством сохранения потока битов 111 в стойке хранения.
4.1.5.5. Дополнительные примеры
Обычно, примеры могут реализовываться как компьютерный программный продукт с программными инструкциями, причем программные инструкции выполнены с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программные инструкции, например, могут сохраняться на машиночитаемом носителе.
Другие примеры содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, пример способа в силу этого представляет собой компьютерную программу, имеющую программные инструкции для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный пример способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель записи являются материальными и/или энергонезависимыми, в отличие от сигналов, которые являются нематериальными и энергозависимыми.
Следовательно, дополнительный пример способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может передаваться через соединение для передачи данных, например, через Интернет.
Дополнительный пример содержит средство обработки, например, компьютер или программируемое логическое устройство, осуществляющие один из способов, описанных в данном документе.
Дополнительный пример содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный пример содержит оборудование или систему, передающую (например, электронным или оптическим образом) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых примерах, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых примерах, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. Обычно, способы могут осуществляться посредством любого соответствующего аппаратного оборудования.
Вышеописанные примеры являются только иллюстративными для принципов, поясненных выше. Следует понимать, что модификации и варьирования компоновок и подробностей, описанных в данном документе, должны становиться очевидными. В силу этого, подразумевается, что они ограничены посредством объема нависшей формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения примеров в данном документе.
Идентичные или эквивалентные элементы или элементы с идентичной или эквивалентной функциональностью обозначаются в нижеприведенном описании посредством идентичных или эквивалентных ссылок с номерами даже при появлении на различных чертежах.
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР, АУДИОДЕКОДЕР И АУДИОПРОЦЕССОР, ИМЕЮЩИЙ ДИНАМИЧЕСКИ ИЗМЕНЯЮЩУЮСЯ ХАРАКТЕРИСТИКУ ПЕРЕКОСА | 2007 |
|
RU2418322C2 |
| КОНТЕКСТНОЕ ЭНТРОПИЙНОЕ КОДИРОВАНИЕ ВЫБОРОЧНЫХ ЗНАЧЕНИЙ СПЕКТРАЛЬНОЙ ОГИБАЮЩЕЙ | 2014 |
|
RU2663363C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ КОДИРОВАНИЯ И/ИЛИ ДЕКОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ФОНОВОГО ШУМА В МНОГОКАНАЛЬНОМ ВХОДНОМ СИГНАЛЕ | 2021 |
|
RU2836622C1 |
| КОДЕР, ДЕКОДЕР И СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 2015 |
|
RU2662407C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ СИГНАЛА | 2007 |
|
RU2414009C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КВАНТОВАНИЯ УСИЛЕНИЯ В ШИРОКОПОЛОСНОМ РЕЧЕВОМ КОДИРОВАНИИ С ПЕРЕМЕННОЙ БИТОВОЙ СКОРОСТЬЮ ПЕРЕДАЧИ | 2004 |
|
RU2316059C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА С ИНТЕЛЛЕКТУАЛЬНЫМ ЗАПОЛНЕНИЕМ ИНТЕРВАЛОВ В СПЕКТРАЛЬНОЙ ОБЛАСТИ | 2014 |
|
RU2635890C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2014 |
|
RU2651229C2 |
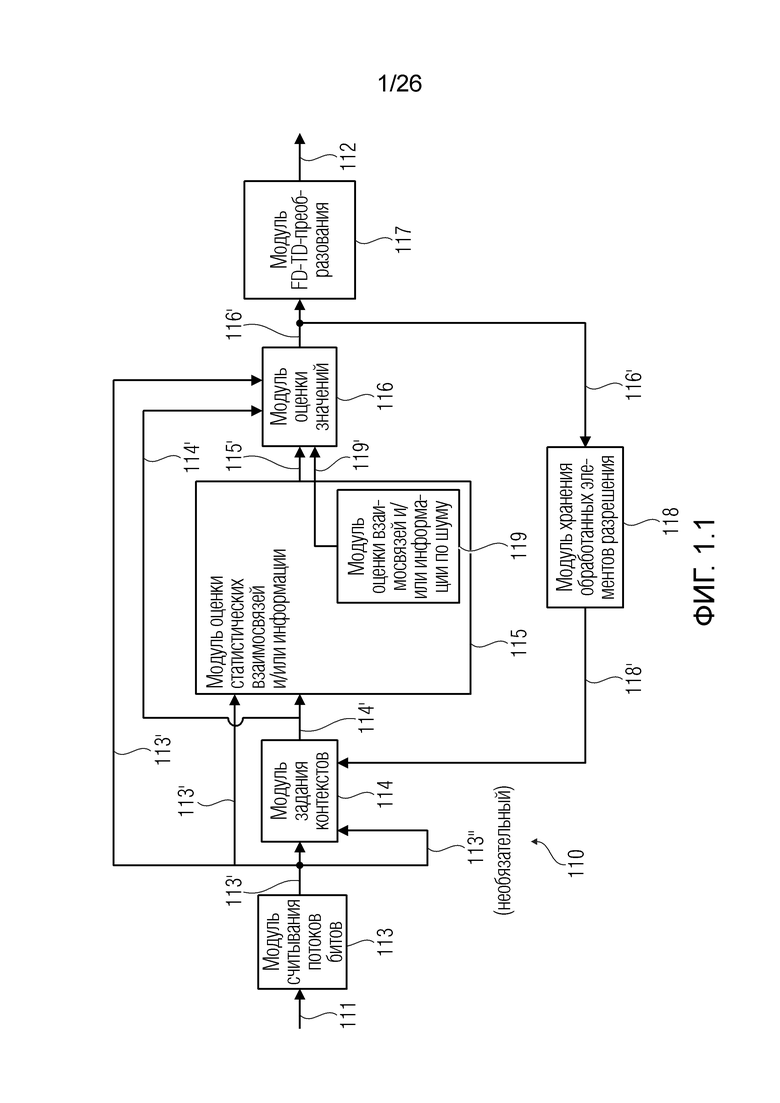
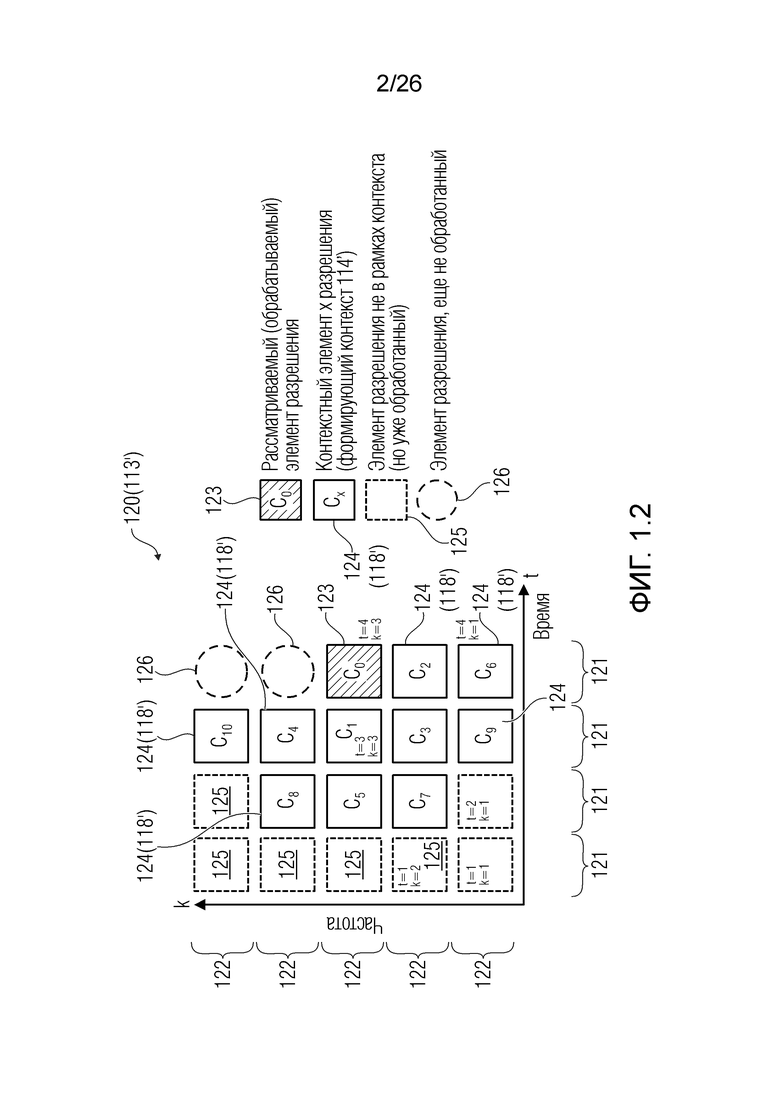
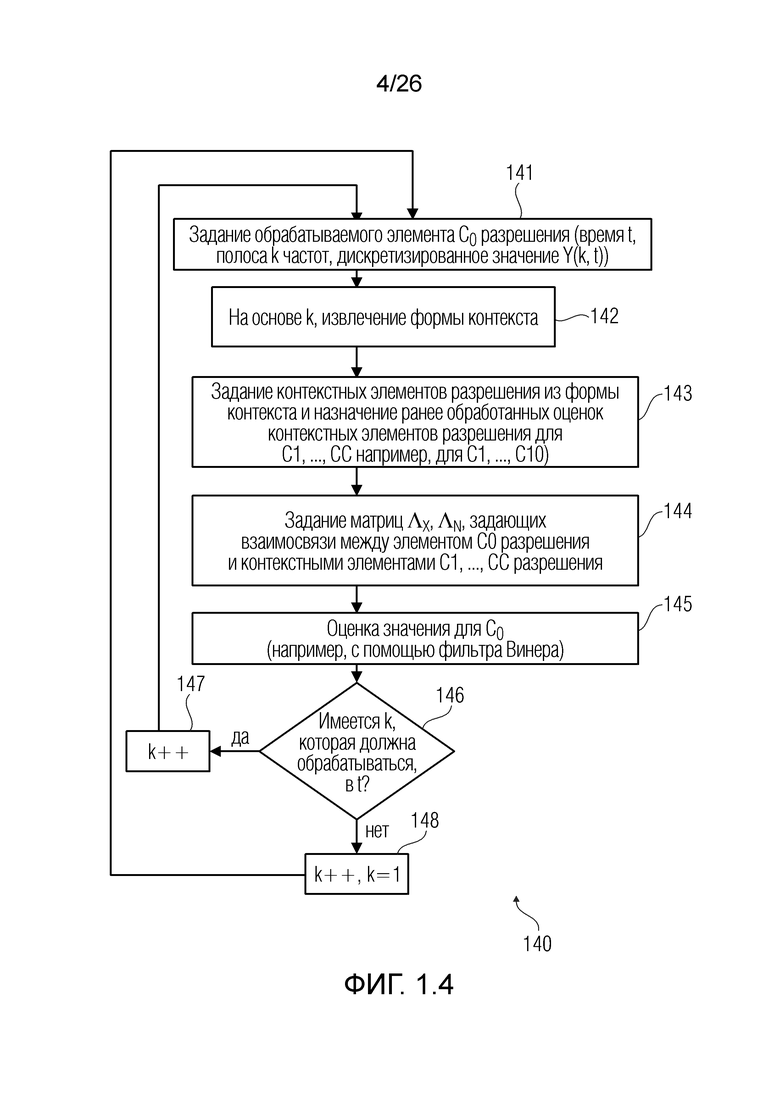
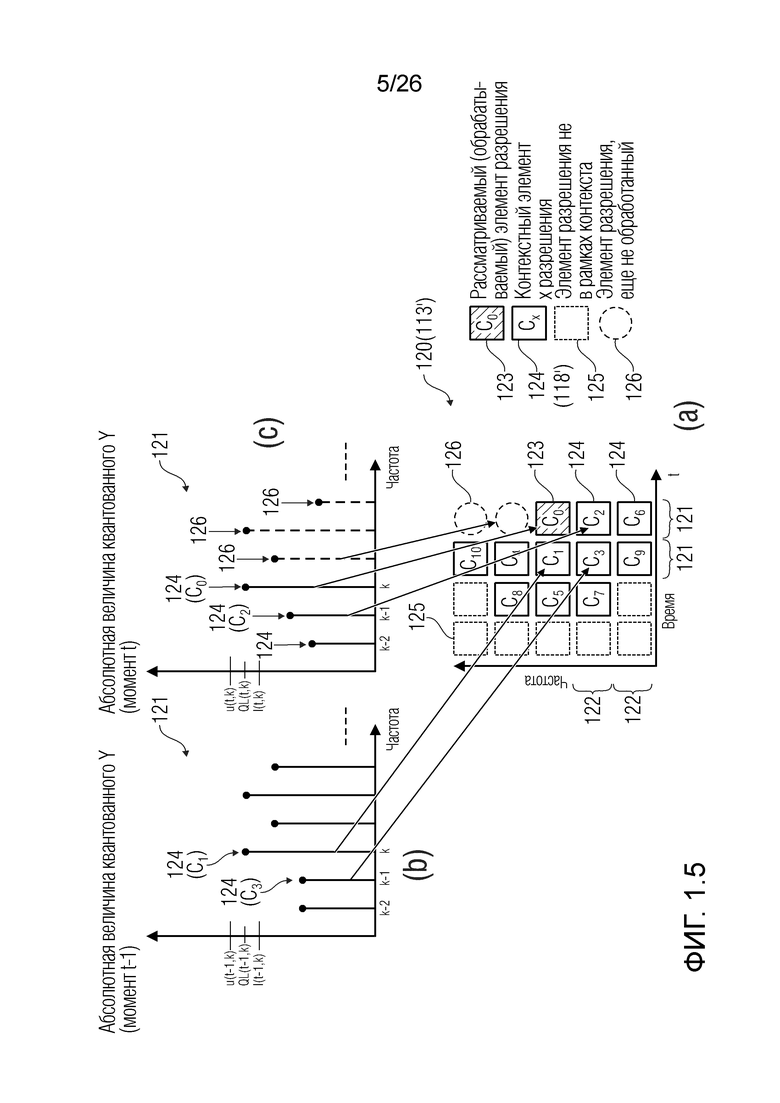
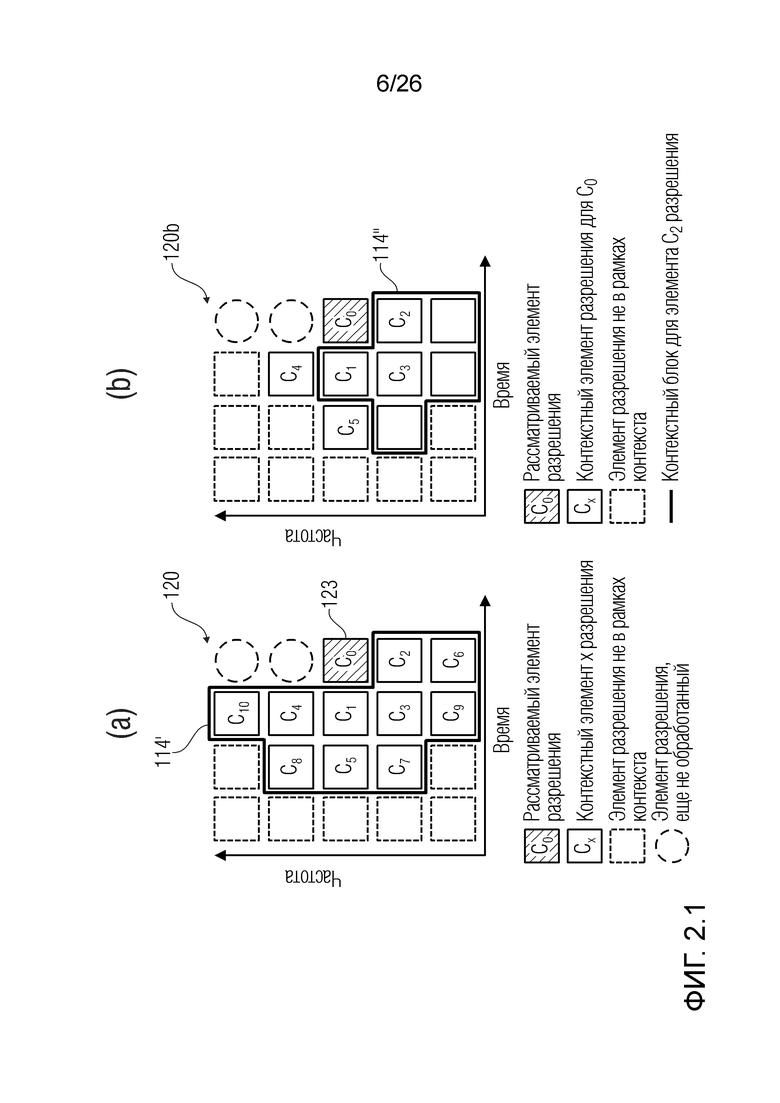
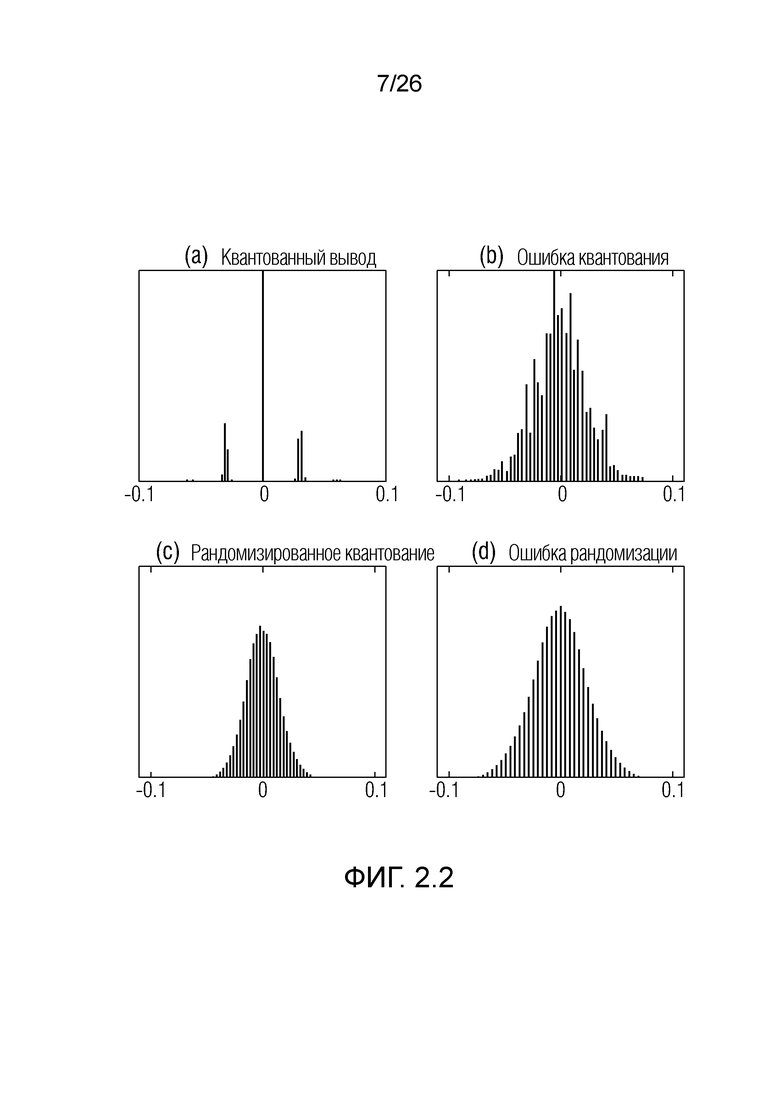

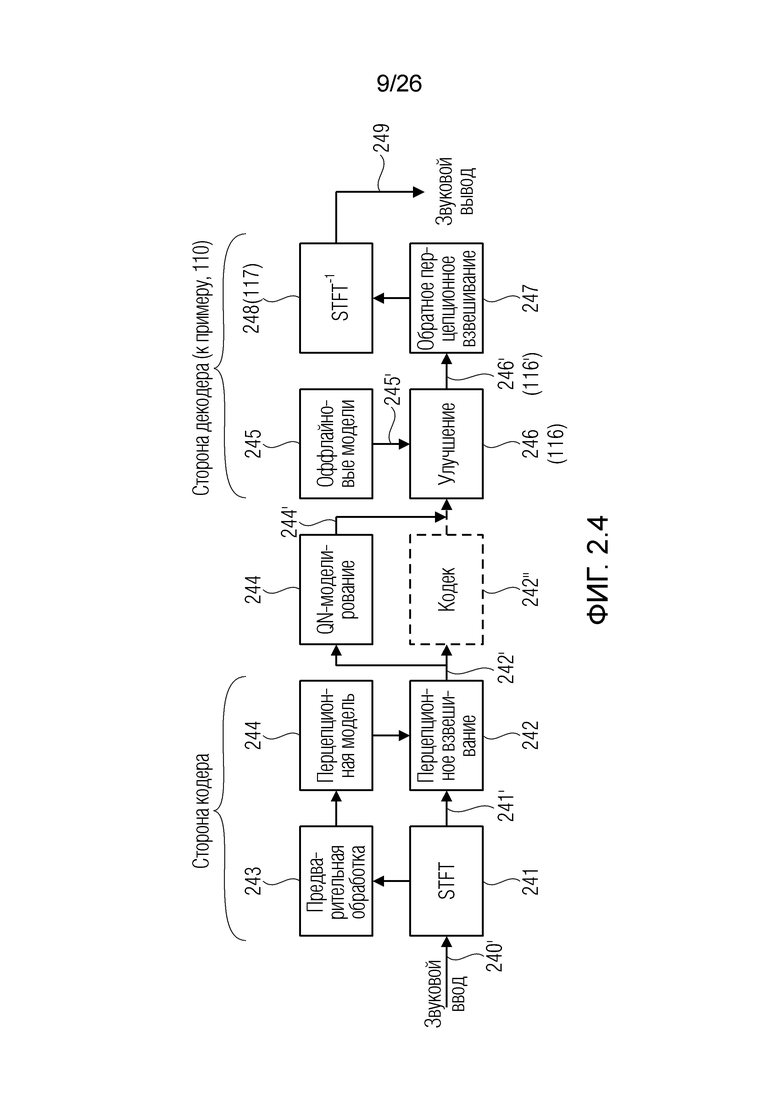
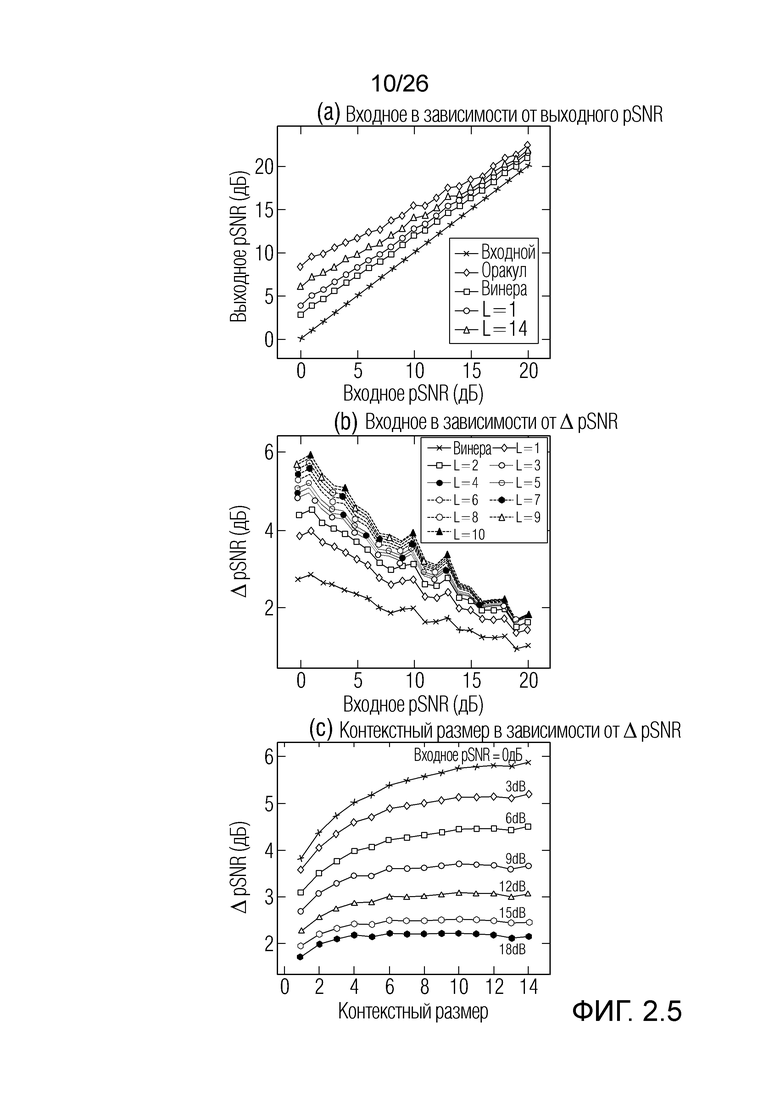
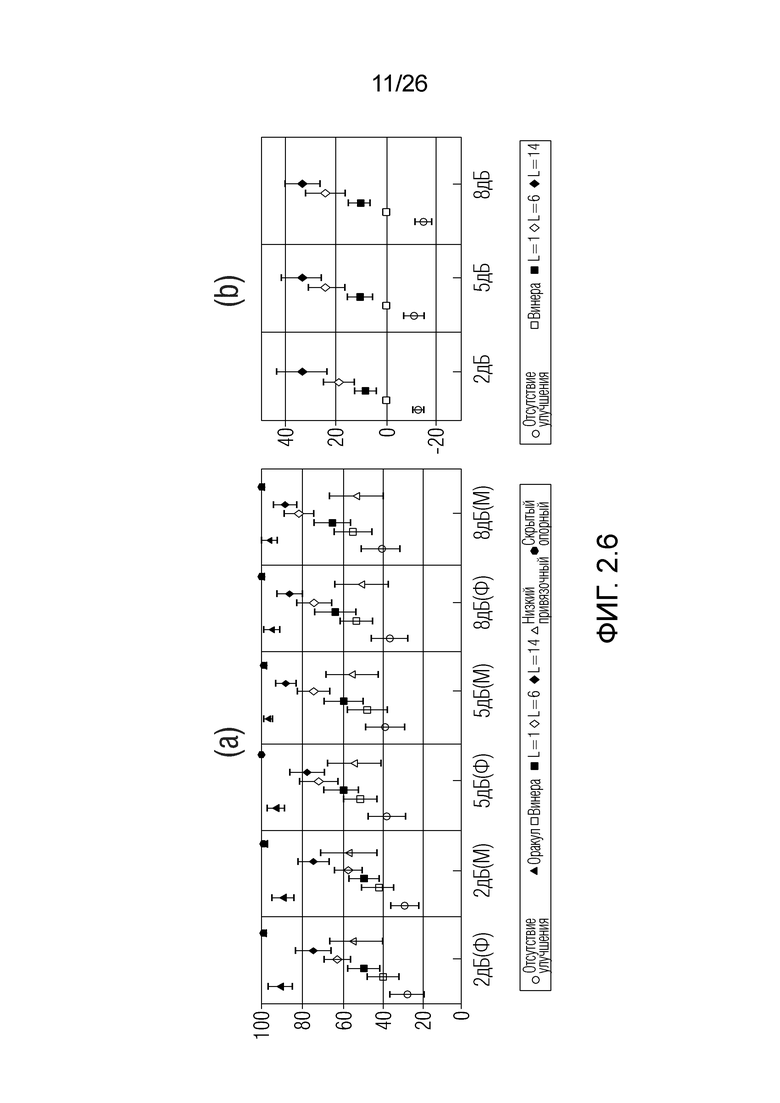
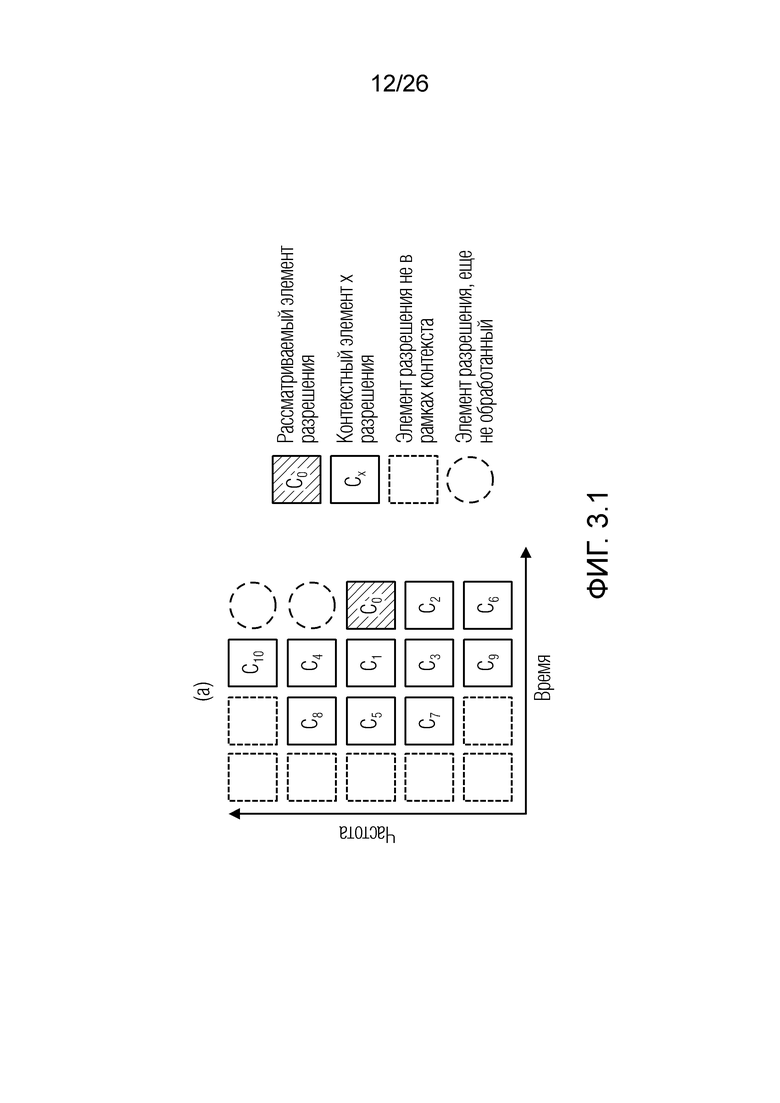
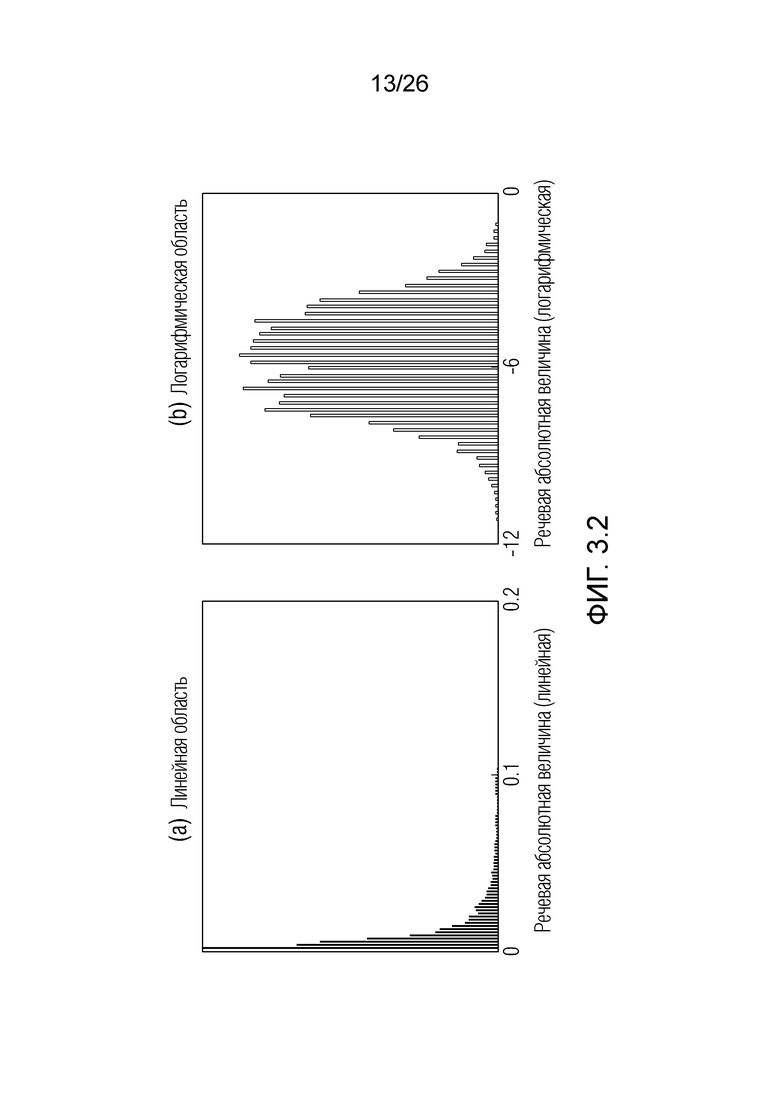
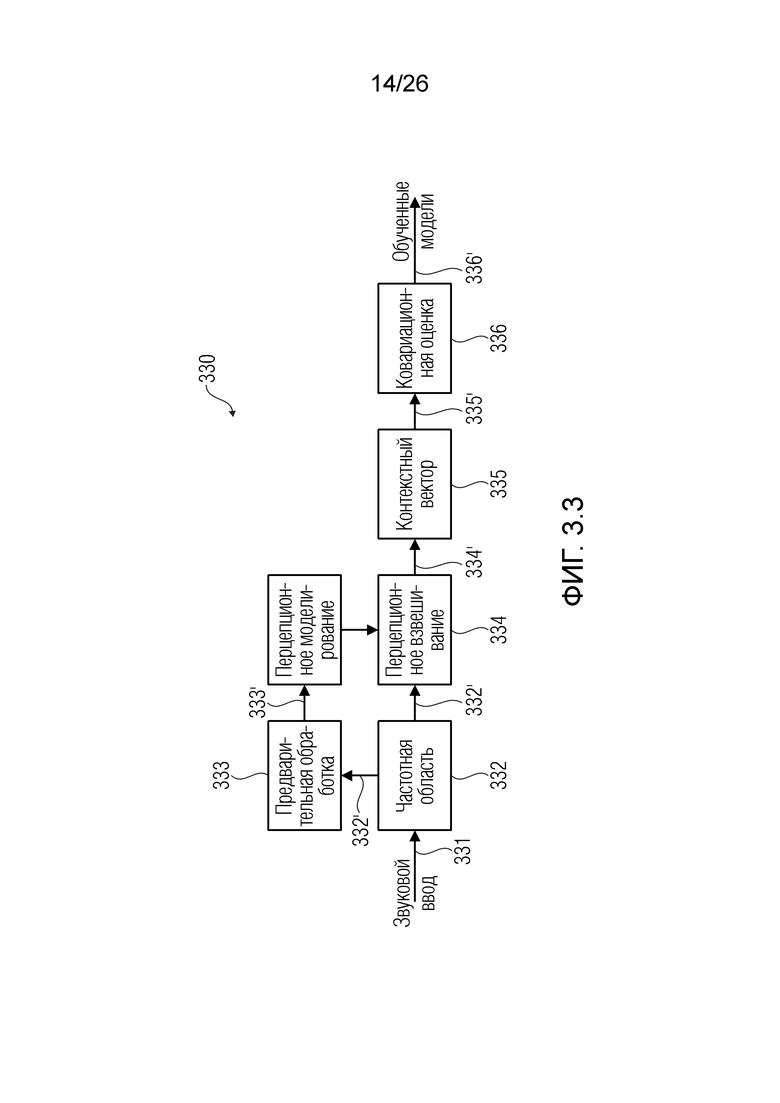
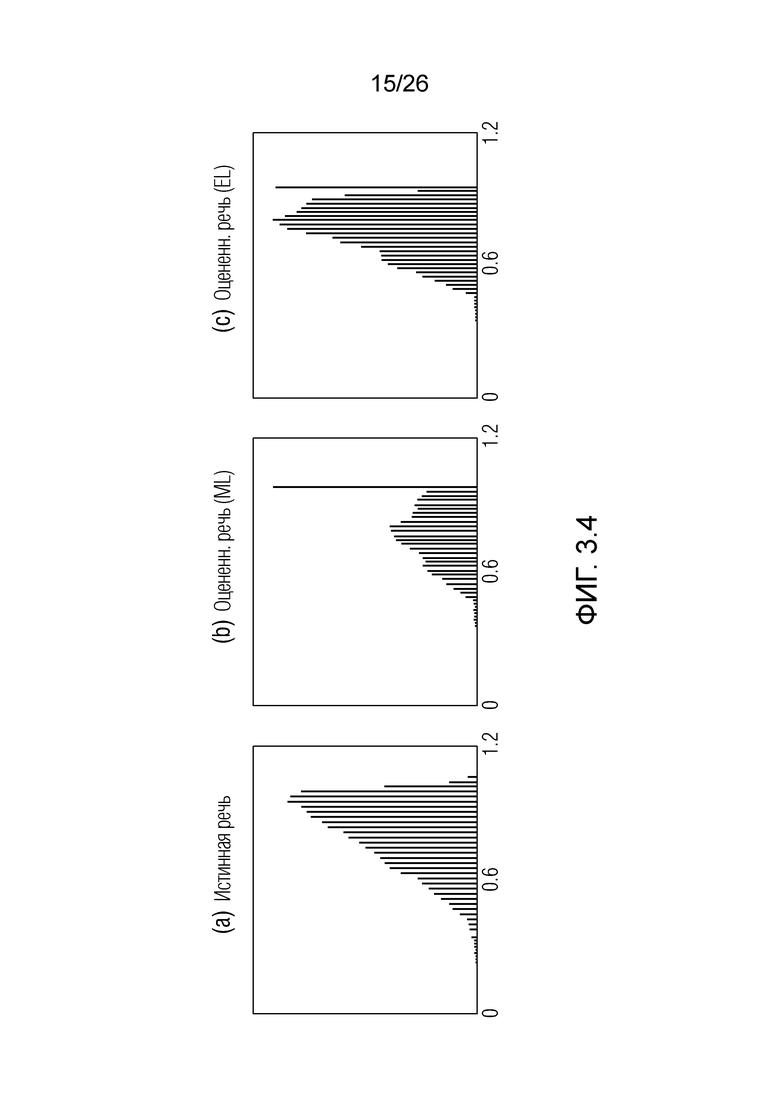
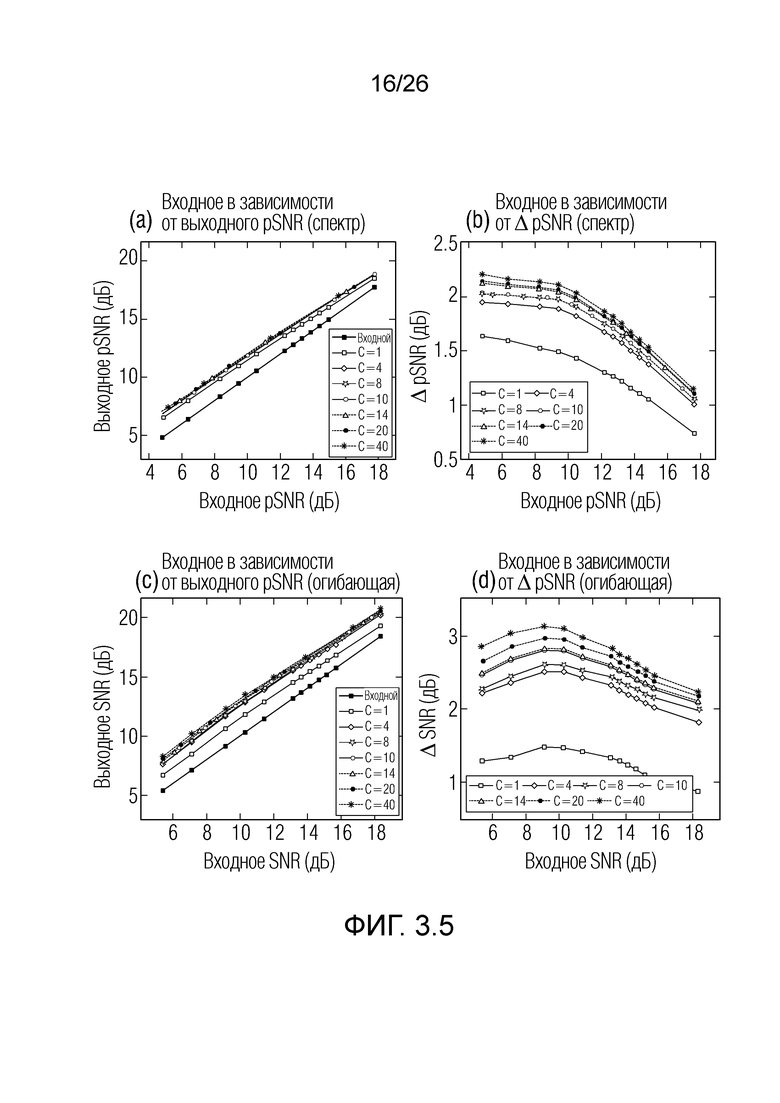
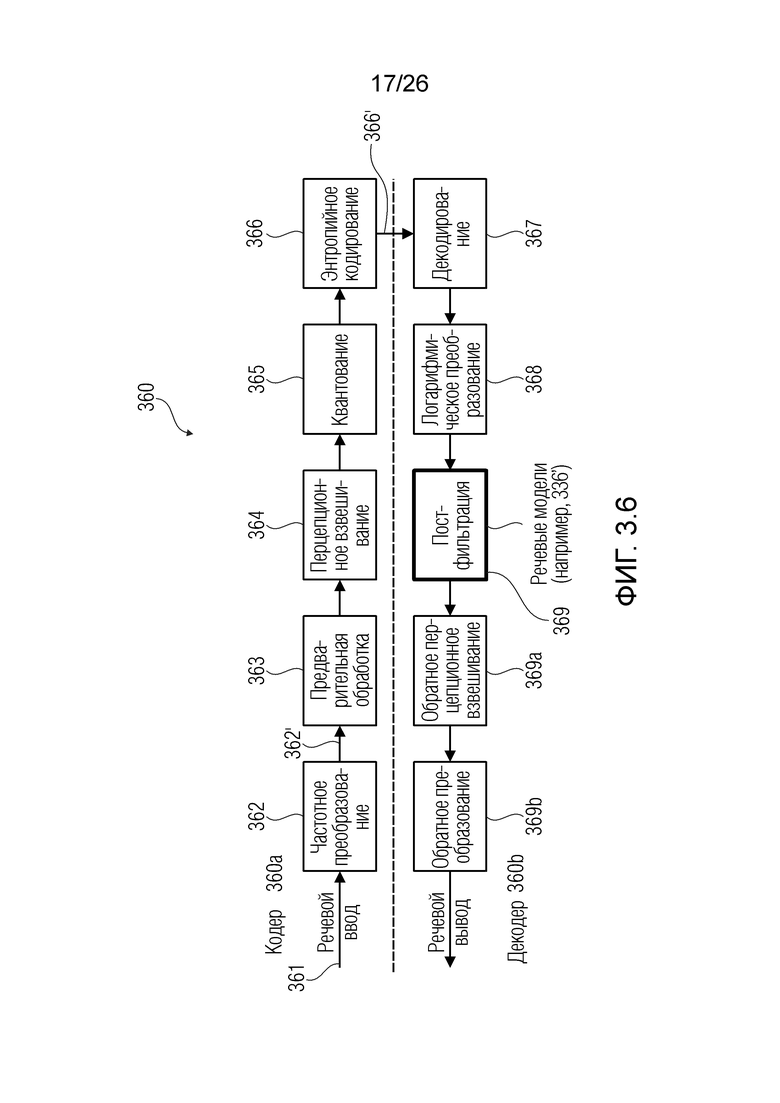
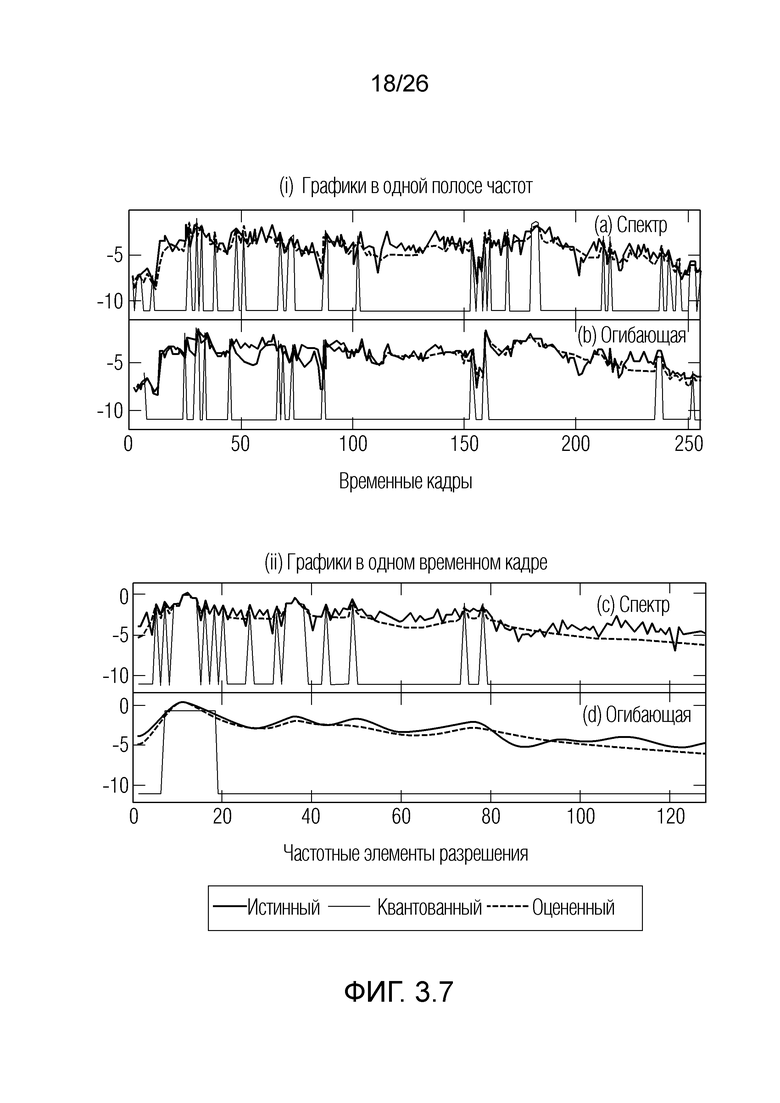
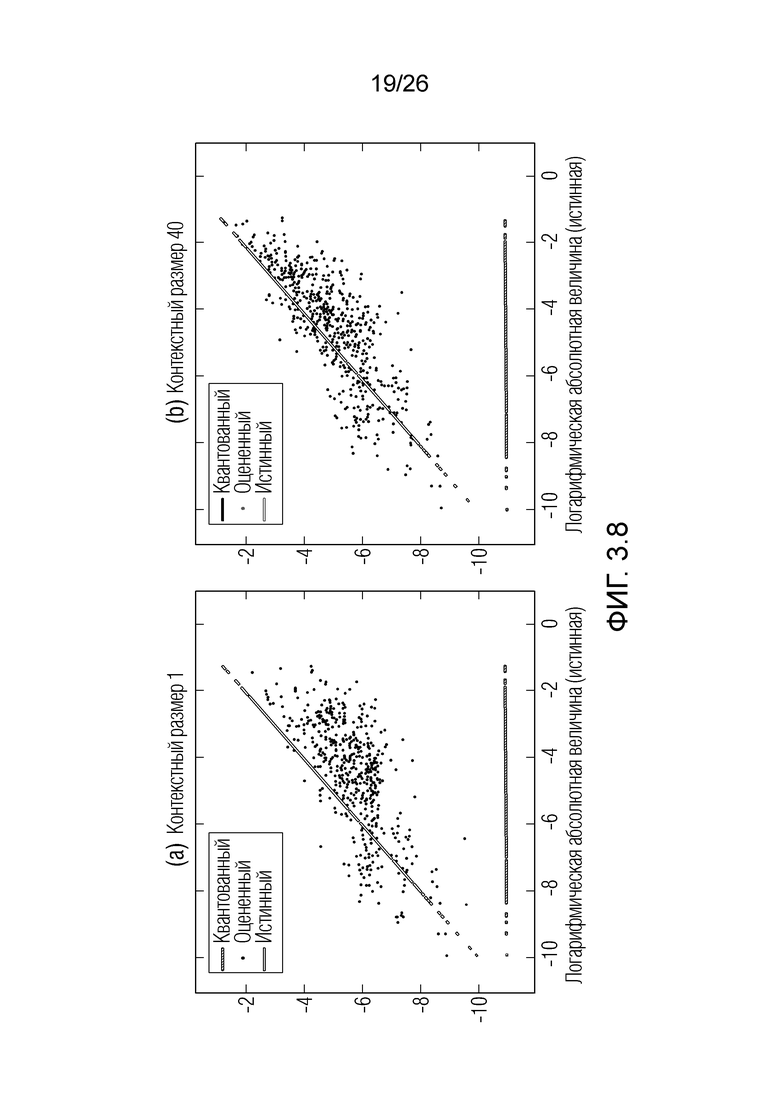
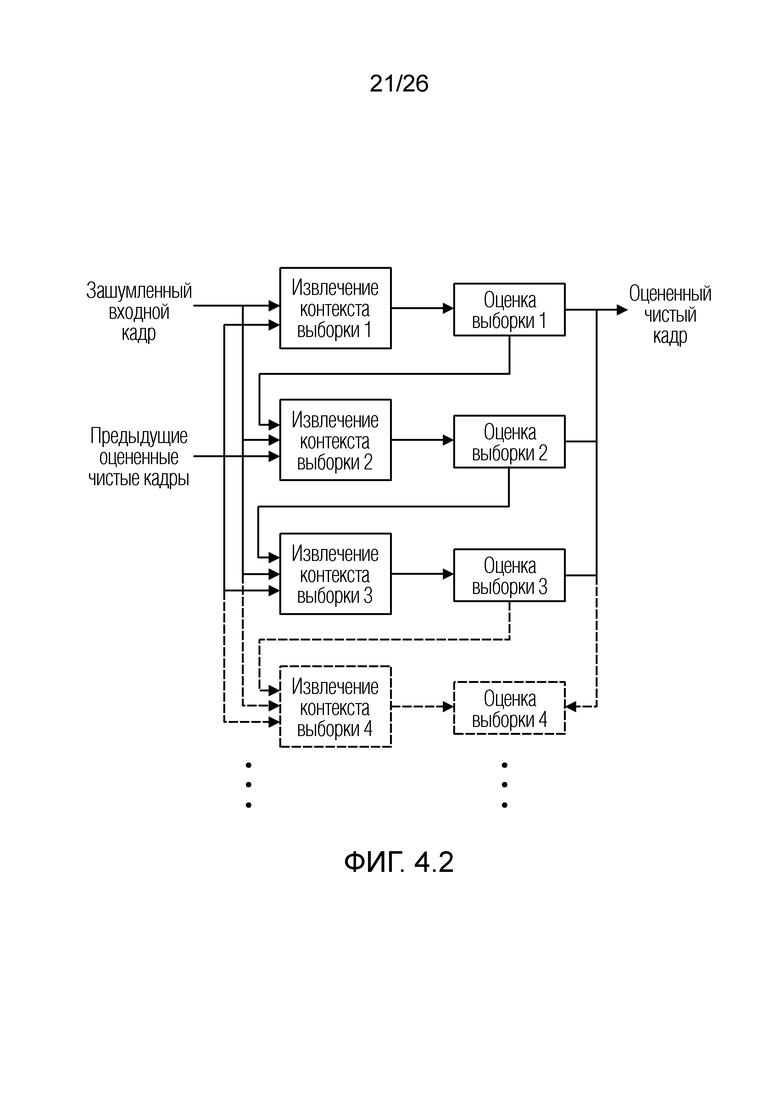
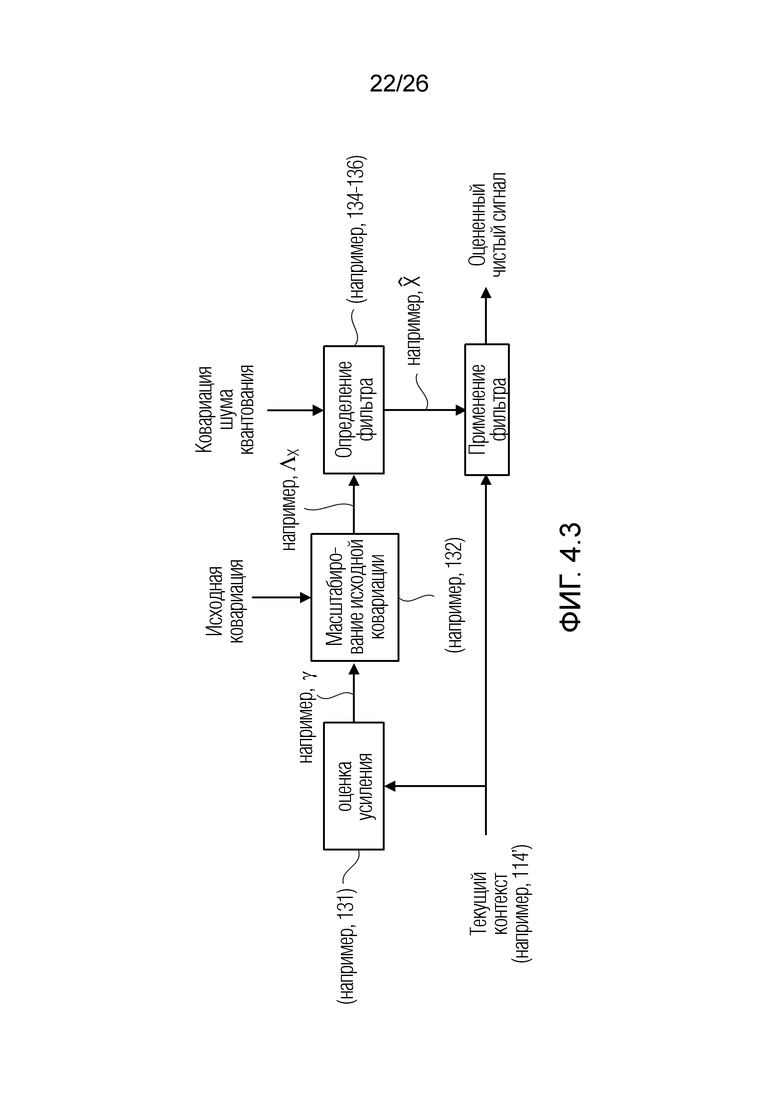
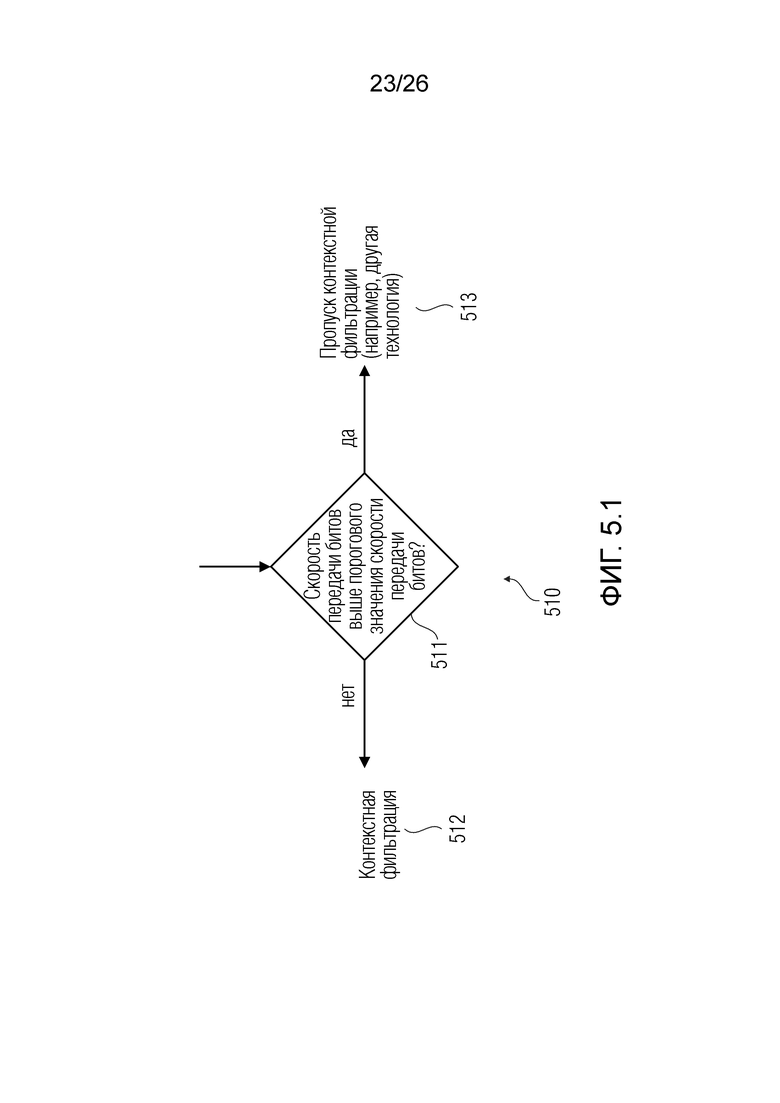
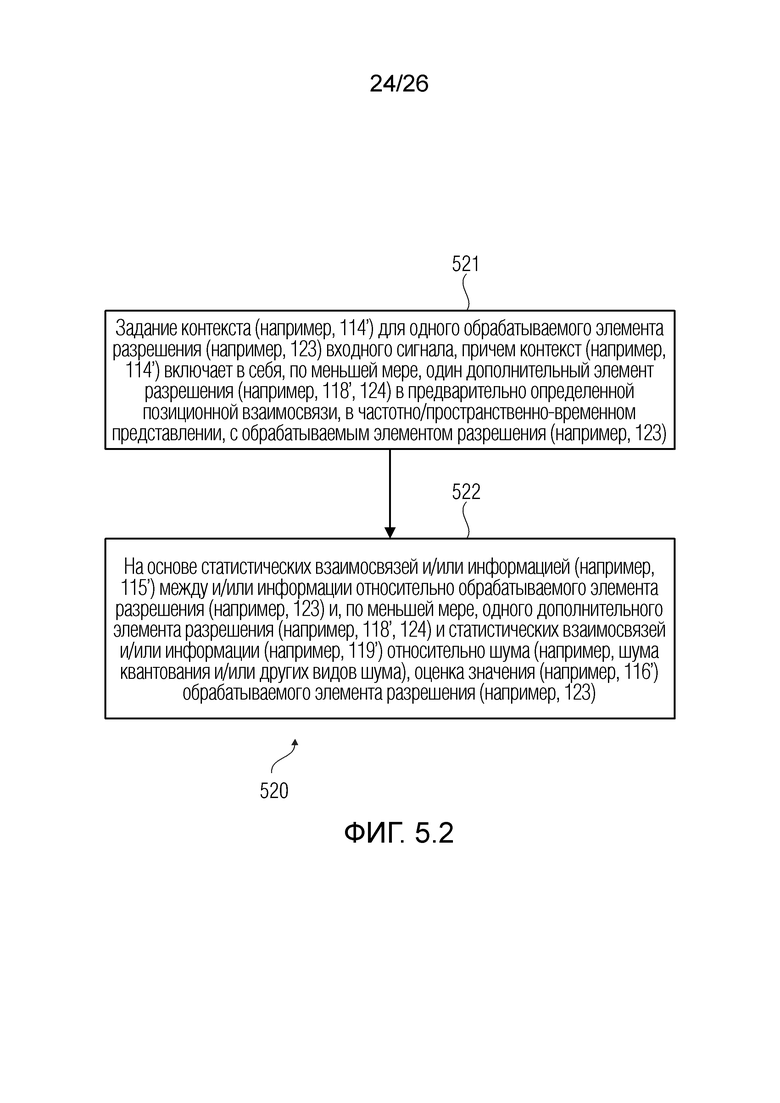
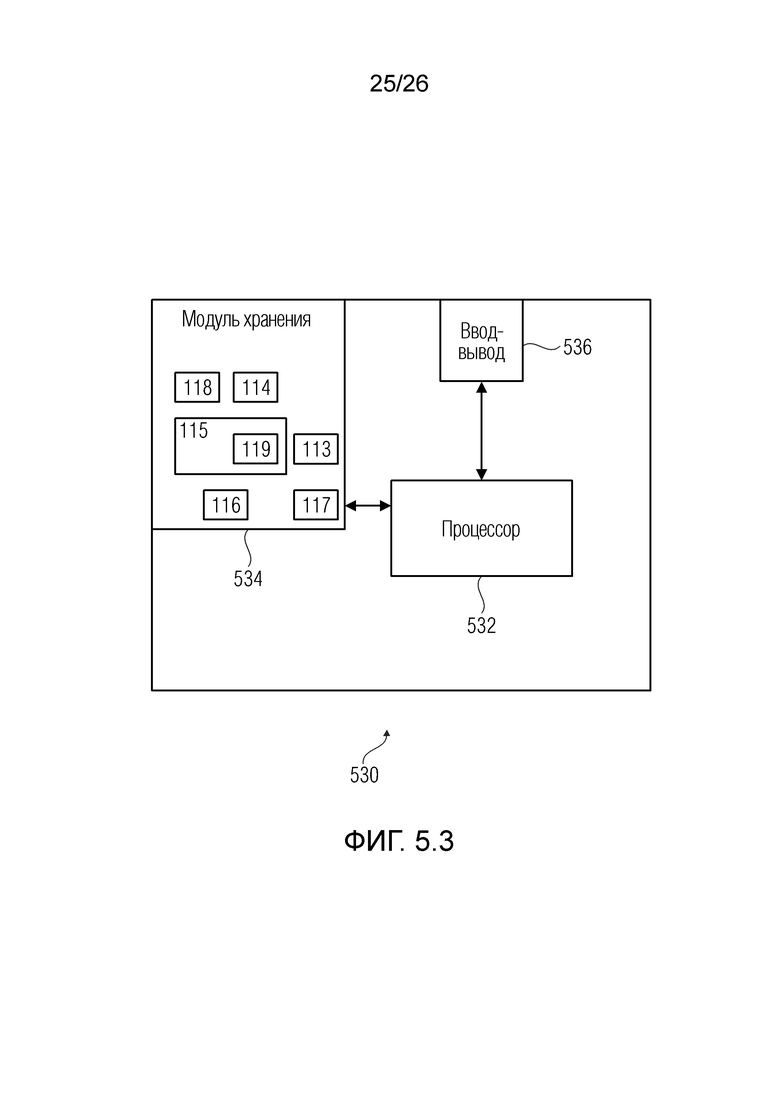
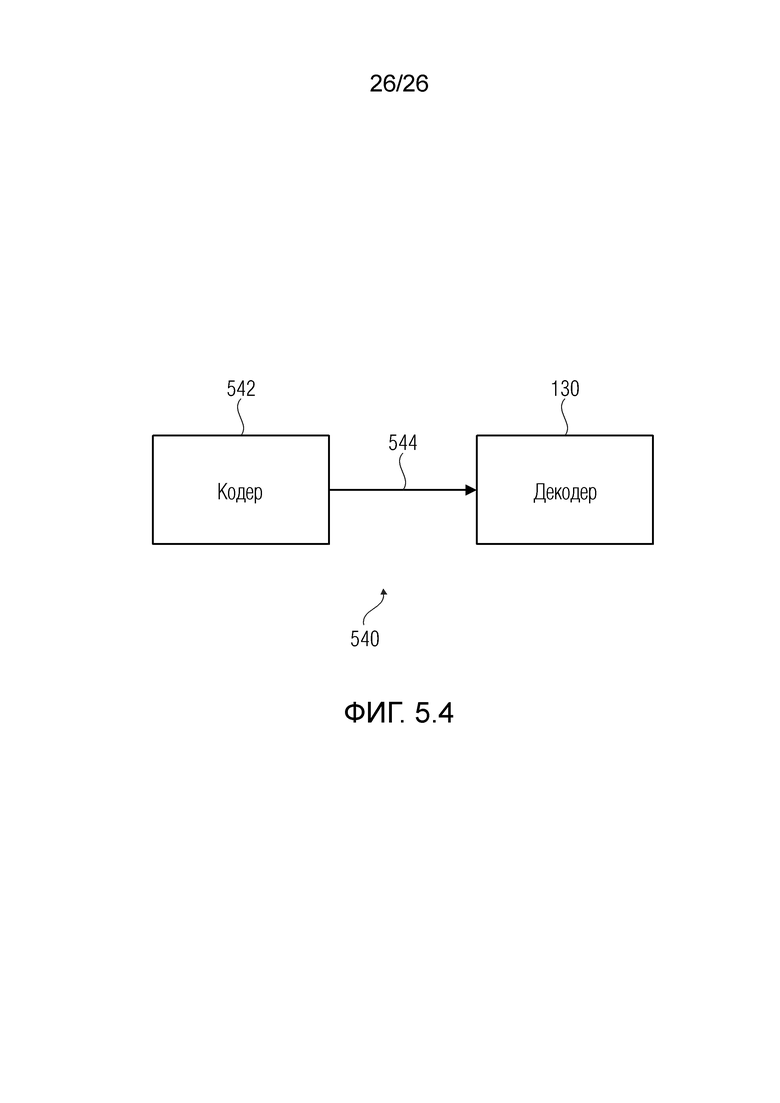
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в обеспечении ослабления шума при преобразовании оценки значения обрабатываемого элемента разрешения в сигнал временной области. Технический результат достигается на основе статистических взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения, информации относительно обрабатываемого элемента разрешения и по меньшей мере одного дополнительного элемента разрешения, статистических взаимосвязей и информации относительно шума, при этом статистические взаимосвязи и информация включают в себя связанное с дисперсией и/или связанное со значением среднеквадратического отклонения значение, предоставленное на основе связанных с дисперсией и связанных с ковариацией взаимосвязей между обрабатываемым элементом разрешения и по меньшей мере одним дополнительным элементом разрешения контекста, при этом статистические взаимосвязи и информация относительно шума включают в себя, для каждого элемента разрешения, наибольшее значение и наименьшее значение для оценки сигнала на основе ожидания сигнала, которое должно быть между наибольшим значением и наименьшим значением. 6 н. и 48 з.п. ф-лы, 26 ил.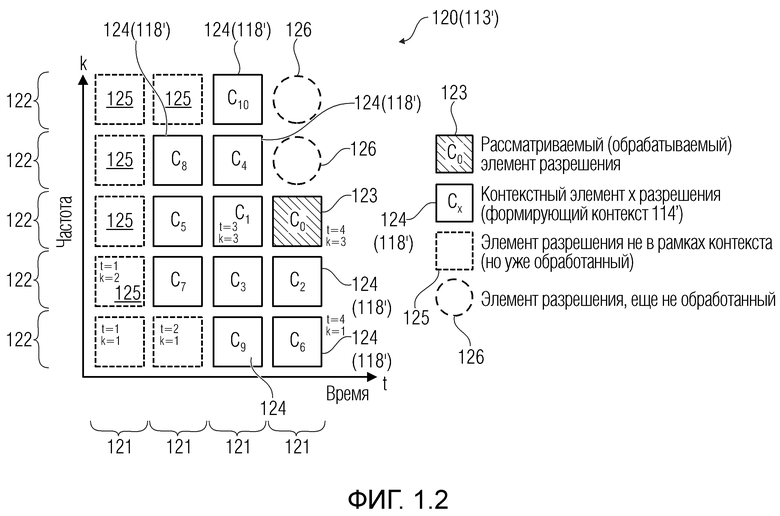
1. Декодер (110) для декодирования входного сигнала частотной области, заданного в потоке (111) битов, причем входной сигнал частотной области подвергается шуму, причем декодер (110) содержит:
- модуль (113) считывания потоков битов для предоставления, из потока (111) битов, версии (113', 120) входного сигнала частотной области в качестве последовательности кадров (121), причем каждый кадр (121) подразделяется на множество элементов (123-126) разрешения, причем каждый элемент разрешения имеет дискретизированное значение;
- модуль (114) задания контекстов, выполненный с возможностью задавать контекст (114') для одного обрабатываемого элемента (123) разрешения, причем контекст (114') включает в себя по меньшей мере один дополнительный элемент (118', 124) разрешения в предварительно определенной позиционной взаимосвязи с обрабатываемым элементом (123) разрешения;
- модуль (115) оценки статистических взаимосвязей и информации, выполненный с возможностью предоставлять:
- статистические взаимосвязи (115') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения, причем статистические взаимосвязи (115') предоставляются в форме ковариаций или корреляций; и
- информацию относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения, причем информация предоставляется в форме дисперсии или автокорреляций,
- при этом модуль (115) оценки статистических взаимосвязей и информации включает в себя модуль (119) оценки взаимосвязей и информации по шуму, выполненный с возможностью предоставлять статистические взаимосвязи и информацию (119') относительно шума, при этом статистические взаимосвязи и информация (119') относительно шума содержат шумовую матрицу (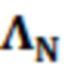 ), оценивающую взаимосвязи между шумовыми сигналами между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения;
), оценивающую взаимосвязи между шумовыми сигналами между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения;
- модуль (116) оценки значений, выполненный с возможностью обрабатывать и получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе оцененных статистических взаимосвязей (119') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения и информации (115', 119') относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения и статистических взаимосвязей и информации (119') относительно шума, и
- модуль (117) преобразования, который преобразует оценку (116') в сигнал (112) временной области.
2. Декодер по п. 1, в котором шум представляет собой шум квантования.
3. Декодер по п. 1, в котором шум представляет собой шум, который не представляет собой шум квантования.
4. Декодер по п. 1, в котором модуль (114) задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент (118', 124) разрешения из ранее обработанных элементов (124, 125) разрешения.
5. Декодер по п. 1, в котором модуль (114) задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент (118', 124) разрешения на основе полосы (122) частот элемента разрешения.
6. Декодер по п. 1, в котором модуль (114) задания контекстов выполнен с возможностью выбирать по меньшей мере один дополнительный элемент (118', 124) разрешения, в пределах предварительно определенного порогового значения позиции, из элементов разрешения, которые уже обработаны.
7. Декодер по п. 1, в котором модуль (114) задания контекстов выполнен с возможностью выбирать различные контексты для элементов разрешения в различных полосах частот.
8. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью работать в качестве фильтра Винера, чтобы предоставлять оптимальную оценку входного сигнала частотной области.
9. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения по меньшей мере из одного дискретизированного значения по меньшей мере одного дополнительного элемента (118', 124) разрешения.
10. Декодер по п. 1, дополнительно содержащий модуль (131) измерений, выполненный с возможностью предоставлять измеренное значение (131'), ассоциированное с ранее выполняемой оценкой(ами) (116') по меньшей мере одного дополнительного элемента (118', 124) разрешения контекста (114'),
- при этом модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе измеренного значения (131').
11. Декодер по п. 10, в котором измеренное значение (131') представляет собой значение, ассоциированное с энергией по меньшей мере одного дополнительного элемента (118', 124) разрешения контекста (114').
12. Декодер по п. 10, в котором измеренное значение (131') представляет собой усиление (γ), ассоциированное по меньшей мере с одним дополнительным элементом (118', 124) разрешения контекста (114').
13. Декодер по п. 12, в котором модуль (131) измерений выполнен с возможностью получать усиление (γ) в качестве скалярного произведения векторов, при этом первый вектор содержит значение(я) по меньшей мере одного дополнительного элемента (118', 124) разрешения контекста (114'), и второй вектор представляет собой транспонированный сопряженный элемент первого вектора.
14. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') в качестве предварительно заданных оценок или ожидаемых статистических взаимосвязей между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114').
15. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') в качестве взаимосвязей на основе позиционных взаимосвязей между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114').
16. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') независимо от значений обрабатываемого элемента (123) разрешения или по меньшей мере одного дополнительного элемента (118', 124) разрешения контекста (114').
17. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') в форме матрицы, устанавливающей взаимосвязи значений дисперсии и ковариации или значений корреляции и автокорреляции между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114').
18. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') в форме нормализованной матрицы, устанавливающей взаимосвязи значений дисперсии и ковариации или значений корреляции и автокорреляции между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114').
19. Декодер по п. 17, в котором модуль (116) оценки значений выполнен с возможностью масштабировать (132) элементы матрицы посредством энергозависимого значения или значения (131') усиления таким образом, чтобы принимать во внимание варьирования энергии и усиления обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения контекста (114').
20. Декодер по п. 1, в котором модуль оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе следующей взаимосвязи:
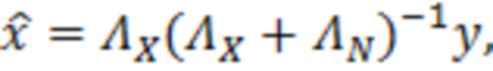
где 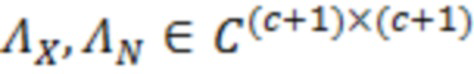 являются шумовой и ковариационной матрицей, соответственно, и
являются шумовой и ковариационной матрицей, соответственно, и 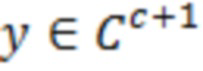 является вектором зашумленных наблюдений с c+1 размерностями, c является контекстной длиной.
является вектором зашумленных наблюдений с c+1 размерностями, c является контекстной длиной.
21. Декодер по п. 1,
- в котором статистические взаимосвязи (115') между информацией относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения включают в себя нормализованную ковариационную матрицу 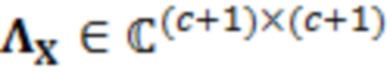 ,
,
- при этом статистические взаимосвязи и информация (119') относительно шума включает в себя шумовую матрицу 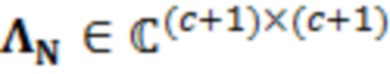 ,
,
- при этом вектор зашумленных наблюдений 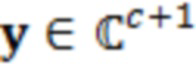 задается с c+1 размерностями, c является контекстной длиной, при этом вектор зашумленных наблюдений является
задается с c+1 размерностями, c является контекстной длиной, при этом вектор зашумленных наблюдений является 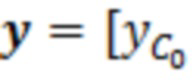
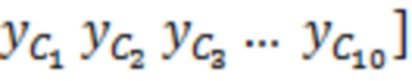 и содержит зашумленный ввод
и содержит зашумленный ввод 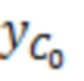 , ассоциированный с обрабатываемым элементом (123) (C0) разрешения, и
, ассоциированный с обрабатываемым элементом (123) (C0) разрешения, и 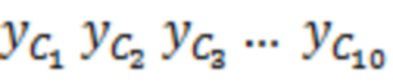 является по меньшей мере одним дополнительным элементом (C1-C10) разрешения,
является по меньшей мере одним дополнительным элементом (C1-C10) разрешения,
- при этом модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе следующей взаимосвязи:
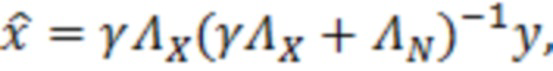
причем γ представляет собой усиление.
22. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения при условии, что дискретизированные значения каждого из дополнительных элементов (124) разрешения контекста (114') соответствуют оцененному значению дополнительных элементов (124) разрешения контекста (114').
23. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения при условии, что дискретизированное значение обрабатываемого элемента (123) разрешения ожидается быть между наибольшим значением и наименьшим значением.
24. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе максимума функции вероятности.
25. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе ожидаемого значения.
26. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе ожидания многовариантной случайной гауссовой переменной.
27. Декодер по п. 1, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе ожидания условной многовариантной случайной гауссовой переменной.
28. Декодер по п. 1, в котором дискретизированные значения находятся в области логарифмической амплитудно-частотной характеристики.
29. Декодер по п. 1, в котором дискретизированные значения находятся в перцепционной области.
30. Декодер (110) для декодирования входного сигнала частотной области, заданного в потоке (111) битов, причем входной сигнал частотной области подвергается шуму, причем декодер (110) содержит:
- модуль (113) считывания потоков битов для предоставления, из потока (111) битов, версии (113', 120) входного сигнала частотной области в качестве последовательности кадров (121), причем каждый кадр (121) подразделяется на множество элементов (123-126) разрешения, причем каждый элемент разрешения имеет дискретизированное значение;
- модуль (114) задания контекстов, выполненный с возможностью задавать контекст (114') для одного обрабатываемого элемента (123) разрешения, причем контекст (114') включает в себя по меньшей мере один дополнительный элемент (118', 124) разрешения в предварительно определенной позиционной взаимосвязи с обрабатываемым элементом (123) разрешения;
- модуль (115) оценки статистических взаимосвязей и информации, выполненный с возможностью предоставлять статистические взаимосвязи (115') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения и информацию относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения, при этом взаимосвязи и информация включают в себя связанное с дисперсией и/или связанное со значением среднеквадратического отклонения значение на основе связанных с дисперсией и связанных с ковариацией взаимосвязей между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114'), в модуль (116) оценки значений,
- при этом модуль (115) оценки статистических взаимосвязей и информации включает в себя модуль (119) оценки взаимосвязей и информации по шуму, выполненный с возможностью предоставлять статистические взаимосвязи и информацию (119') относительно шума, при этом статистические взаимосвязи и информация (119') относительно шума включают в себя, для каждого элемента разрешения, наибольшее значение и наименьшее значение для оценки сигнала на основе ожидания сигнала, которое должно быть между наибольшим значением и наименьшим значением;
- модуль (116) оценки значений, выполненный с возможностью обрабатывать и получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе оцененных статистических взаимосвязей (115') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения и информации (115', 119') относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения и статистических взаимосвязей и информации (119') относительно шума; и
- причем декодер дополнительно содержит модуль (117) преобразования, который преобразует оценку (116') в сигнал (112) временной области.
31. Декодер по п. 30, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять среднее значение сигнала в модуль (116) оценки значений.
32. Декодер по п. 30, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять среднее значение чистого сигнала на основе связанных с дисперсией и связанных с ковариацией взаимосвязей между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114').
33. Декодер по п. 30, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять среднее значение чистого сигнала на основе ожидаемого значения обрабатываемого элемента (123) разрешения.
34. Декодер по п. 33, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью обновлять среднее значение сигнала на основе оцененного контекста.
35. Декодер по п. 30, в котором версия (113', 120) входного сигнала частотной области имеет квантованное значение, которое представляет собой уровень квантования, при этом уровень квантования представляет собой значение, выбранное из дискретного числа уровней квантования.
36. Декодер по п. 35, в котором число или значения, или масштабы уровней квантования передаются в служебных сигналах в потоке (111) битов.
37. Декодер по п. 1 или 30, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения с точки зрения следующего:
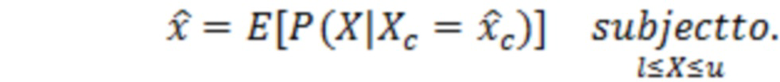
где 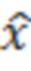 является оценкой обрабатываемого элемента (123) разрешения, l и u являются нижним и верхним пределами текущих элементов разрешения квантования, соответственно, и
является оценкой обрабатываемого элемента (123) разрешения, l и u являются нижним и верхним пределами текущих элементов разрешения квантования, соответственно, и 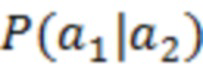 является условной вероятностью
является условной вероятностью 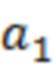 , с учетом
, с учетом 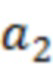 ,
, 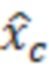 является оцененным контекстным вектором.
является оцененным контекстным вектором.
38. Декодер по п. 1 или 30, в котором модуль (116) оценки значений выполнен с возможностью получать оценку (116') значения обрабатываемого элемента (123) разрешения на основе ожидания:
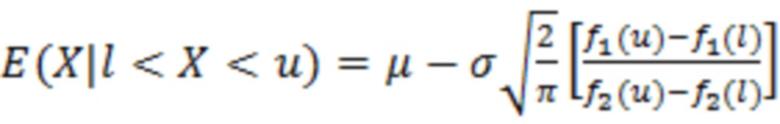 ,
,
где X является конкретным значением обрабатываемого элемента (123) разрешения, выражаемого как усеченная случайная гауссова переменная, при l<X<u, где l является наименьшим значением, и u является наибольшим значением, 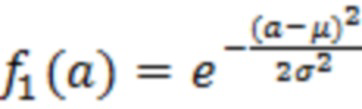 и
и 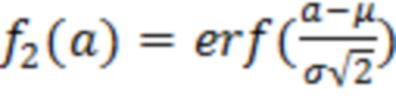 ,
, 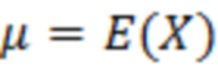 , μ и σ являются средним и дисперсией распределения.
, μ и σ являются средним и дисперсией распределения.
39. Декодер по п. 1 или 30, в котором входной сигнал частотной области представляет собой аудиосигнал.
40. Декодер по п. 1 или 30, в котором входной сигнал частотной области представляет собой речевой сигнал.
41. Декодер по п. 1 или 30, в котором по меньшей мере один из модуля (114) задания контекстов, модуля (115) оценки статистических взаимосвязей и информации, модуля (119) оценки взаимосвязей и информации по шуму и модуля (116) оценки значений выполнен с возможностью выполнять операцию постфильтрации, чтобы получать чистую оценку (116') входного сигнала частотной области.
42. Декодер по п. 1 или 30, в котором модуль (114) задания контекстов выполнен с возможностью задавать контекст (114') с множеством дополнительных элементов (124) разрешения.
43. Декодер по п. 1 или 30, в котором модуль (114) задания контекстов выполнен с возможностью задавать контекст (114') в качестве просто соединенного окружения элементов разрешения на частотно-временном графике.
44. Декодер по п. 1 или 30, в котором модуль (113) считывания потоков битов выполнен с возможностью избегать декодирования межкадровой информации из потока (111) битов.
45. Декодер по п. 1 или 30, дополнительно содержащий модуль (118) хранения обработанных элементов разрешения, сохраняющий информацию относительно ранее обработанных элементов (124, 125) разрешения,
- причем модуль (114) задания контекстов выполнен с возможностью задавать контекст (114') с использованием по меньшей мере одного ранее обработанного элемента разрешения в качестве по меньшей мере одного из дополнительных элементов (124) разрешения.
46. Декодер по п. 1 или 30, в котором модуль (114) задания контекстов выполнен с возможностью задавать контекст (114') с использованием по меньшей мере одного необработанного элемента разрешения (126) в качестве по меньшей мере одного из дополнительных элементов разрешения.
47. Декодер по п. 1, в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью предоставлять статистические взаимосвязи и информацию (115') в форме матрицы (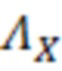 ), устанавливающей взаимосвязи значений дисперсии и ковариации или значений корреляции и автокорреляции между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114'),
), устанавливающей взаимосвязи значений дисперсии и ковариации или значений корреляции и автокорреляции между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114'),
- в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью выбирать одну матрицу из множества предварительно заданных матриц на основе показателей, ассоциированных с гармоничностью входного сигнала частотной области.
48. Декодер по п. 1,
- в котором модуль (115) оценки статистических взаимосвязей и информации выполнен с возможностью выбирать одну матрицу из множества предварительно заданных матриц на основе показателей, ассоциированных с гармоничностью входного сигнала частотной области.
49. Система кодирования и декодирования входного сигнала частотной области, заданного в потоке битов, содержащая кодер и декодер по п. 1 или 30, при этом кодер выполнен с возможностью предоставлять поток (111) битов с кодированным входным сигналом частотной области.
50. Способ для декодирования входного сигнала частотной области, заданного в потоке (111) битов, причем входной сигнал частотной области подвергается шуму, при этом способ содержит этапы, на которых:
- предоставляют, из потока (111) битов, версию (113', 120) входного сигнала частотной области в качестве последовательности кадров (121), причем каждый кадр (121) подразделяется на множество элементов (123-126) разрешения, причем каждый элемент разрешения имеет дискретизированное значение;
- задают контекст (114') для одного обрабатываемого элемента (123) разрешения входного сигнала частотной области, причем контекст (114') включает в себя по меньшей мере один дополнительный элемент (118', 124) разрешения в предварительно определенной позиционной взаимосвязи, в частотно/пространственно-временном представлении, с обрабатываемым элементом (123) разрешения;
- на основе статистических взаимосвязей (115') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения, информации относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения, статистических взаимосвязей и информации (119') относительно шума, при этом статистические взаимосвязи (115') предоставляются в форме ковариаций или корреляций, и информация предоставляется в форме дисперсии или автокорреляций, при этом статистические взаимосвязи и информация (119') относительно шума содержат шумовую матрицу (), оценивающую взаимосвязи между шумовыми сигналами для обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения:
- оценивают значение (116') обрабатываемого элемента (123) разрешения и
- преобразуют оценку (116') в сигнал (112) временной области.
51. Способ для декодирования входного сигнала частотной области, заданного в потоке (111) битов, причем входной сигнал частотной области подвергается шуму, при этом способ содержит этапы, на которых:
- предоставляют, из потока (111) битов, версию (113', 120) входного сигнала частотной области в качестве последовательности кадров (121), причем каждый кадр (121) подразделяется на множество элементов (123-126) разрешения, причем каждый элемент разрешения имеет дискретизированное значение;
- задают контекст (114') для одного обрабатываемого элемента (123) разрешения входного сигнала частотной области, причем контекст (114') включает в себя по меньшей мере один дополнительный элемент (118', 124) разрешения в предварительно определенной позиционной взаимосвязи, в частотно/пространственно-временном представлении, с обрабатываемым элементом (123) разрешения;
- на основе статистических взаимосвязей (115') между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения, информации относительно обрабатываемого элемента (123) разрешения и по меньшей мере одного дополнительного элемента (118', 124) разрешения, статистических взаимосвязей и информации (119') относительно шума, при этом статистические взаимосвязи и информация включают в себя связанное с дисперсией и/или связанное со значением среднеквадратического отклонения значение, предоставленное на основе связанных с дисперсией и связанных с ковариацией взаимосвязей между обрабатываемым элементом (123) разрешения и по меньшей мере одним дополнительным элементом (118', 124) разрешения контекста (114'), при этом статистические взаимосвязи и информация (119') относительно шума включают в себя, для каждого элемента разрешения, наибольшее значение и наименьшее значение для оценки сигнала на основе ожидания сигнала, которое должно быть между наибольшим значением и наименьшим значением;
- оценивают значение (116') обрабатываемого элемента (123) разрешения и
- преобразуют оценку (116') в сигнал (112) временной области.
52. Способ по п. 50, в котором шум представляет собой шум квантования.
53. Способ по п. 50, в котором шум представляет собой шум, который не представляет собой шум квантования.
54. Энергонезависимый модуль хранения, сохраняющий инструкции, которые, при выполнении посредством процессора, инструктируют процессору осуществлять любой из способов по п. 50 или 51.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБЫ И УСТРОЙСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ СИГНАЛОВ | 2012 |
|
RU2592412C2 |

