Настоящая заявка относится к контекстному энтропийному кодированию выборочных значений спектральной огибающей и его использованию при кодировании/сжатии аудио.
Множество современных аудиокодеров с потерями предшествующего уровня техники, к примеру, описанных в [1] и [2], основаны на MDCT-преобразовании и используют как уменьшение нерелевантности, так и уменьшение избыточности, для того чтобы минимизировать требуемую скорость передачи битов для заданного перцепционного качества. Уменьшение нерелевантности типично использует перцепционные ограничения слуховой системы человека, чтобы уменьшать точность представления или удалять информацию частоты, которая не является перцепционно релевантной. Уменьшение избыточности применяется, чтобы использовать статистическую структуру или корреляцию, чтобы достигать наиболее компактного представления оставшихся данных, типично посредством использования статистического моделирования в сочетании с энтропийным кодированием.
В числе прочего, принципы параметрического кодирования используются для того, чтобы эффективно кодировать аудиоконтент. С использованием параметрического кодирования, части аудиосигнала, такие как, например, части его спектрограммы, описываются с использованием параметров вместо использования фактических аудиовыборок временной области и т.п. Например, части спектрограммы аудиосигнала могут быть синтезированы на стороне декодера с потоком данных, просто содержащим параметры, такие как спектральная огибающая, и необязательные дополнительные параметры, управляющие синтезированием, чтобы адаптировать синтезированную часть спектрограммы к передаваемой спектральной огибающей. Новая технология такого вида представляет собой репликацию полос спектра (SBR), согласно которой базовый кодек используется для того, чтобы кодировать и передавать низкочастотный компонент аудиосигнала, тогда как передаваемая спектральная огибающая используется на стороне декодирования с тем, чтобы придавать спектральную форму/формировать спектральные репликации восстановления компонента полосы низких частот аудиосигнала, так чтобы синтезировать компонент полосы высоких частот аудиосигнала на стороне декодирования.
Спектральная огибающая в рамках структуры вышеуказанных технологий кодирования передается в потоке данных с некоторым подходящим спектрально-временным разрешением. Аналогично передаче выборочных значений спектральной огибающей, коэффициенты масштабирования для масштабирования коэффициентов спектральных линий либо коэффициенты частотной области, такие как MDCT-коэффициенты, аналогично передаются с некоторым подходящим спектрально-временным разрешением, которое является менее точным, чем исходное разрешение спектральных линий, менее точным, например, в спектральном смысле.
Фиксированная таблица кодирования методом Хаффмана может использоваться для того, чтобы передавать информацию относительно выборок, описывающих спектральную огибающую, либо коэффициентов масштабирования или коэффициентов частотной области. Усовершенствованный подход заключается в том, чтобы использовать контекстное кодирование, как, например, описано в [2] и [3], в которых контекст, используемый для того, чтобы выбирать распределение вероятностей для кодирования значения, перекрывает как время, так и частоту. Отдельная спектральная линия, к примеру, значение MDCT-коэффициента, представляет собой реальную проекцию комплексной спектральной линии, и она может казаться в определенной степени случайной по своему характеру, даже когда абсолютная величина комплексной спектральной линии является постоянной во времени, но фаза варьируется между кадрами. Это требует достаточной сложной схемы выбора, квантования и преобразования контекста для хороших результатов, как описано в [3].
При кодировании изображений, используемые контексты типично являются двумерными по осям X и Y изображения, к примеру, как указано в [4]. При кодировании изображений, значения находятся в линейной области или в степенной области, к примеру, посредством использования регулирования гаммы. Дополнительно, одно фиксированное линейное предсказание может использоваться в каждом контексте в качестве подбора плоскости, и устаревшего механизма обнаружения краев, и ошибка предсказания может кодироваться. Параметрическое кодирование Голомба или Голомба-Райса может использоваться для кодирования ошибок предсказания. Кодирование по длинам серий дополнительно используется для того, чтобы компенсировать сложности непосредственного кодирования сигналов с очень низкой энтропией, ниже 1 бита в расчете на выборку, например, с использованием побитового кодера.
Тем не менее, несмотря на улучшения в связи с кодированием коэффициентов масштабирования и/или спектральных огибающих, по-прежнему имеется необходимость в усовершенствованном принципе для кодирования выборочных значений спектральной огибающей. Соответственно, цель настоящего изобретения заключается в том, чтобы предоставлять принцип для кодирования спектральных значений спектральной огибающей.
Эта цель достигается посредством предмета независимых пунктов формулы изобретения.
Варианты осуществления, описанные в данном документе, основаны на таких выявленных сведениях, что усовершенствованный принцип для кодирования выборочных значений спектральной огибающей может получаться посредством комбинирования спектрально-временного предсказания, с одной стороны, и контекстного энтропийного кодирования остатков, с другой стороны, при одновременном конкретном определении контекста для текущего выборочного значения в зависимости от показателя для отклонения между парой уже кодированных/декодированных выборочных значений спектральной огибающей в спектрально-временном окружении текущего выборочного значения. Комбинация спектрально-временного предсказания, с одной стороны, и контекстного энтропийного кодирования остатков предсказания с выбором контекста в зависимости от показателя отклонения, с другой стороны, гармонирует с характером спектральных огибающих: гладкость спектральной огибающей приводит к компактным распределениям остатков предсказания, так что спектрально-временная взаимная корреляция почти полностью удаляется после предсказания и может игнорироваться в выборе контекста относительно энтропийного кодирования результата предсказания. Это, в свою очередь, сокращает объем служебной информации для управления контекстами. Тем не менее, использование показателя отклонения между уже кодированными/декодированными выборочными значениями в спектрально-временном окружении текущего выборочного значения по-прежнему обеспечивает адаптивность контекста, которая повышает эффективность энтропийного кодирования таким способом, который оправдывает дополнительный объем служебной информации, вызываемый в силу этого.
В соответствии с вариантами осуществления, описанными в дальнейшем в этом документе, линейное предсказание комбинировано с использованием разностного значения в качестве показателя отклонения, за счет этого поддерживая низким объем служебной информации для кодирования.
В соответствии с вариантом осуществления, позиция уже кодированных/декодированных выборочных значений, используемых для того, чтобы определять разностное значение, в конечном счете используемое для того, чтобы выбирать/определять контекст, выбирается таким образом, что они являются соседними между собой, по спектру или по времени, способом совмещения с текущим выборочным значением, т.е. они находятся вдоль одной линии параллельно временной или спектральной оси, и знак разностного значения дополнительно учитывается при определении/выборе контекста. Посредством этого показателя, тип "тренда" в остатке предсказания может учитываться при определении/выборе контекста для текущего выборочного значения только при одновременном целесообразном увеличении объема служебной информации для управления контекстом.
Предпочтительные варианты осуществления настоящей заявки описываются ниже со ссылкой на чертежи, на которых:
Фиг. 1 показывает схематический вид спектральной огибающей и иллюстрирует ее структуру из выборочных значений и возможного порядка декодирования, заданного для нее, а также возможное спектрально-временное окружение для текущего кодированного/декодированного выборочного значения спектральной огибающей;
Фиг. 2 показывает блок-схему контекстного энтропийного кодера для кодирования выборочных значений спектральной огибающей в соответствии с вариантом осуществления;
Фиг. 3 показывает схему, иллюстрирующую функцию квантования, которая может использоваться при квантовании показателя извлечения;
Фиг. 4 показывает блок-схему контекстного энтропийного декодера, соответствующего кодеру по фиг. 2;
Фиг. 5 показывает блок-схему контекстного энтропийного кодера для кодирования выборочных значений спектральной огибающей в соответствии с дополнительным вариантом осуществления;
Фиг. 6 показывает схему, иллюстрирующую размещение интервала энтропийно кодированных возможных значений остатка предсказания относительно полного интервала возможных значений остатков предсказания в соответствии с вариантом осуществления с использованием кодирования перехода;
Фиг. 7 показывает блок-схему контекстного энтропийного декодера, соответствующего кодеру по фиг. 5;
Фиг. 8 показывает возможное определение спектрально-временного окружения с использованием определенной системы обозначений;
Фиг. 9 показывает блок-схему параметрического аудиодекодера в соответствии с вариантом осуществления;
Фиг. 10 показывает схематический вид, иллюстрирующий возможный вариант реализации параметрического декодера по фиг. 9 посредством показа взаимосвязи между частотным интервалом, покрываемым спектральной огибающей, с одной стороны, и точной структурой, покрывающей другой интервал полного частотного диапазона аудиосигнала, с другой стороны;
Фиг. 11 показывает блок-схему аудиокодера, соответствующего параметрическому аудиодекодеру по фиг. 9 согласно варианту по фиг. 10;
Фиг. 12 показывает схему, иллюстрирующую вариант параметрического аудиодекодера по фиг. 9 при поддержке IGF (интеллектуального заполнения интервалов отсутствия сигнала);
Фиг. 13 показывает схему, иллюстрирующую спектр из спектрограммы точной структуры, т.е. спектральный срез, IGF-заполнение спектра и его формирование в соответствии со спектральной огибающей в соответствии с вариантом осуществления; и
Фиг. 14 показывает блок-схему аудиокодера, поддерживающего IGF, соответствующего варианту параметрического декодера по фиг. 9 в соответствии с фиг. 12.
В качестве обоснования вариантов осуществления, приведенных в данном документе ниже, которые являются, в общем, применимыми к кодированию спектральной огибающей, некоторые идеи, которые приводят к преимущественным вариантам осуществления, указанным ниже, представлены ниже с использованием интеллектуального заполнения интервалов отсутствия сигнала (IGF) в качестве примера. IGF является новым способом для того, чтобы значительно повышать качество кодированного сигнала даже на очень низких скоростях передачи битов. На предмет подробностей следует обратиться к нижеприведенному описанию. В любом случае, IGF учитывает тот факт, что значительная часть спектра в высокочастотной области квантуется до нуля вследствие типично недостаточного битового бюджета. Чтобы сохранять максимально возможно хорошей точную структуру области верхних частот, в IGF, информация в низкочастотной области используется в качестве источника для того, чтобы адаптивно заменять целевые области в высокочастотной области, которые в основном квантуются до нуля. Важное требование для того, чтобы достигать хорошего перцепционного качества, представляет собой совпадение декодированной энергетической огибающей спектральных коэффициентов с декодированной энергетической огибающей исходного сигнала. Чтобы достигать этого, средние спектральные энергии вычисляются для спектральных коэффициентов из одной или более последовательных полос частот AAC-коэффициентов масштабирования. Вычисление средних энергий с использованием границ, заданных посредством полос частот коэффициентов масштабирования, обусловлено посредством уже существующей тщательной подстройки этих границ к частям критических полос частот, которые являются характерными для человеческого слуха. Средние энергии преобразуются в представление на шкале в дБ с использованием формулы, аналогичной формуле для AAC-коэффициентов масштабирования, а затем равномерно квантуются. В IGF, различная точность квантования может быть необязательно использована в зависимости от запрашиваемой полной скорости передачи битов. Средние энергии составляют значительную часть информации, сформированной посредством IGF, так что их эффективное представление имеет высокую важность для общей производительности IGF.
Соответственно, в IGF, энергии коэффициентов масштабирования описывают спектральную огибающую. Энергии коэффициентов масштабирования (SFE) представляют спектральные значения, описывающие спектральную огибающую. Можно использовать специальные свойства SFE при их декодировании. В частности, выяснено, что в отличие от [2] и [3], SFE представляют средние значения спектральных MDCT-линий, и, соответственно, их значения являются гораздо более "сглаженными" и линейно коррелированными со средней абсолютной величиной соответствующих комплексных спектральных линий. С использованием этого факта, нижеприведенные варианты осуществления используют комбинацию предсказания выборочных значений спектральной огибающей, с одной стороны, и контекстного энтропийного кодирования остатка предсказания с использованием контекстов в зависимости от показателя отклонения пары соседних уже кодированных/декодированных выборочных значений спектральной огибающей, с другой стороны. Использование этой комбинации специально адаптировано к этому виду данных, которые должны кодироваться, т.е. к спектральной огибающей.
Чтобы упрощать понимание вариантов осуществления, подробнее указанных ниже, фиг. 1 показывает спектральную огибающую 10 и ее структуру из выборочных значений 12, которые дискретизируют спектральную огибающую 10 аудиосигнала с определенным спектрально-временным разрешением. На фиг. 1, выборочные значения 12 примерно размещаются вдоль временной оси 14 и спектральной оси 16. Каждое выборочное значение 12 описывает или задает высоту спектральной огибающей 10 в соответствующем пространственно-временном мозаичном фрагменте, покрывающем, например, определенный прямоугольник пространственно-временной области спектрограммы аудиосигнала. Таким образом, выборочные значения являются интегральными значениями, получаемыми посредством интегрирования спектрограммы по ассоциированному спектрально-временному мозаичному фрагменту. Выборочные значения 12 могут измерять высоту или интенсивность спектральной огибающей 10 с точки зрения энергии или некоторого другого физического показателя и могут задаваться в нелогарифмической или линейной области либо в логарифмической области, при этом логарифмическая область может предоставлять дополнительные преимущества вследствие своей характеристики дополнительного сглаживания выборочных значений вдоль осей 14 и 16, соответственно.
Следует отметить, что в отношении нижеприведенного описания, только в качестве иллюстрации предполагается то, что выборочные значения 12 регулярно упорядочены спектрально и временно, т.е. то, что соответствующие пространственно-временные мозаичные фрагменты, соответствующие выборочным значениям 12, регулярно покрывают полосу 18 частот из спектрограммы аудиосигнала, но такая регулярность не является обязательной. Вместо этого, также может использоваться нерегулярная дискретизация спектральной огибающей 10 посредством выборочных значений 12, причем каждое выборочное значение 12 представляет усредненное среднее высоты спектральной огибающей 10 в соответствующем пространственно-временном мозаичном фрагменте. Тем не менее, определения окружения, подробнее приведенные ниже, могут быть перенесены на такие альтернативные варианты осуществления нерегулярной дискретизации спектральной огибающей 10. Ниже представлено краткое изложение такого варианта.
Тем не менее, прежде всего следует отметить, что вышеуказанная спектральная огибающая может подвергаться кодированию и декодированию для передачи из кодера в декодер по различным причинам. Например, спектральная огибающая может использоваться для целей масштабируемости, с тем чтобы расширять базовое кодирование полосы низких частот аудиосигнала, а именно, расширять полосу низких частот до верхних частот, а именно, в полосу высоких частот, с которой связана спектральная огибающая. В этом случае, контекстные энтропийные декодеры/кодеры, описанные ниже, например, могут быть частью SBR-декодера/кодера. Альтернативно, они могут быть частью аудиокодеров/декодеров с использованием IGF, как уже упомянуто выше. В IGF, высокочастотная часть спектрограммы аудиосигнала дополнительно описывается с использованием спектральных значений, описывающих спектральную огибающую высокочастотных частей спектрограммы, с тем чтобы иметь возможность заполнять нулевые квантованные области спектрограммы в высокочастотной части с использованием спектральной огибающей. Ниже подробнее описываются сведения в этом отношении.
Фиг. 2 показывает контекстный энтропийный кодер для кодирования выборочных значений 12 спектральной огибающей 10 аудиосигнала в соответствии с вариантом осуществления настоящей заявки.
Контекстный энтропийный кодер по фиг. 2, в общем, указывается с использованием ссылки с номером 20 и содержит модуль 22 предсказания, модуль 24 определения контекста, энтропийный кодер 26 и модуль 28 определения остатков. Модуль 24 определения контекста и модуль 22 предсказания имеют входы, на которых они имеют доступ к выборочным значениям 12 спектральной огибающей (фиг. 1). Энтропийный кодер 26 имеет управляющий вход, соединенный с выходом модуля 24 определения контекста, и вход данных, соединенный с выходом модуля 28 определения остатков. Модуль 28 определения остатков имеет два входа, один из которых соединен с выходом модуля 22 предсказания, а другой из которых предоставляет модулю 28 определения остатков доступ к выборочным значениям 12 спектральной огибающей 10. В частности, модуль 28 определения остатков принимает выборочное значение x, которое должно в данный момент кодироваться на входе, в то время как модуль 24 определения контекста и модуль 22 предсказания принимают на входах выборочные значения 12, уже кодированных и находящиеся в спектрально-временном окружении текущего выборочного значения x.
Модуль 22 предсказания выполнен с возможностью спектрально-временным методом предсказывать текущее выборочное значение x спектральной огибающей 10, чтобы получать оцененное значение 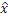 . Как проиллюстрировано в связи с более подробным вариантом осуществления, указанным ниже, модуль 22 предсказания может использовать линейное предсказание. В частности, при выполнении спектрально-временного предсказания, модуль 22 предсказания анализирует уже кодированные выборочные значения в спектрально-временном окружении текущего выборочного значения x. Обратимся, например, к фиг. 1. Текущее выборочное значение x проиллюстрировано с использованием полужирного непрерывно нарисованного контура. С использованием штриховки, показаны выборочные значения в спектрально-временном окружении текущей выборки x, которые, в соответствии с вариантом осуществления, формируют основу для спектрально-временного предсказания модуля 22 предсказания; "a", например, обозначает выборочное значение 12, непосредственно соседнее с текущей выборкой x, которое совместно размещается с текущей выборкой x спектрально, но предшествует текущей выборке x временно. Аналогично, соседнее выборочное значение b обозначает выборочное значение, непосредственно соседнее с текущей выборкой x, которое совместно размещается с текущим выборочным значением x временно, но связано с нижними частотами при по сравнении с текущим выборочным значением x, и выборочное значение c в спектрально-временном окружении текущего выборочного значения x является ближайшим соседним выборочным значением для текущего выборочного значения x, которое предшествует последнему временно и связано с нижними частотами. Спектрально-временное окружение может даже охватывать выборочные значения, представляющие следующие предпоследние соседние узлы текущей выборки x. Например, выборочное значение d отделяется от текущего выборочного значения x посредством выборочного значения a, т.е. оно совместно размещается с текущим выборочным значением x временно и предшествует текущему значению x, при этом только выборочное значение a позиционируется между ними. Аналогично, выборочное значение e граничит с выборочным значением x при совместном размещении с текущим выборочным значением x временно и граничном размещении с выборочным значением x вдоль спектральной оси 16, при этом только соседняя выборка b позиционируется между ними.
. Как проиллюстрировано в связи с более подробным вариантом осуществления, указанным ниже, модуль 22 предсказания может использовать линейное предсказание. В частности, при выполнении спектрально-временного предсказания, модуль 22 предсказания анализирует уже кодированные выборочные значения в спектрально-временном окружении текущего выборочного значения x. Обратимся, например, к фиг. 1. Текущее выборочное значение x проиллюстрировано с использованием полужирного непрерывно нарисованного контура. С использованием штриховки, показаны выборочные значения в спектрально-временном окружении текущей выборки x, которые, в соответствии с вариантом осуществления, формируют основу для спектрально-временного предсказания модуля 22 предсказания; "a", например, обозначает выборочное значение 12, непосредственно соседнее с текущей выборкой x, которое совместно размещается с текущей выборкой x спектрально, но предшествует текущей выборке x временно. Аналогично, соседнее выборочное значение b обозначает выборочное значение, непосредственно соседнее с текущей выборкой x, которое совместно размещается с текущим выборочным значением x временно, но связано с нижними частотами при по сравнении с текущим выборочным значением x, и выборочное значение c в спектрально-временном окружении текущего выборочного значения x является ближайшим соседним выборочным значением для текущего выборочного значения x, которое предшествует последнему временно и связано с нижними частотами. Спектрально-временное окружение может даже охватывать выборочные значения, представляющие следующие предпоследние соседние узлы текущей выборки x. Например, выборочное значение d отделяется от текущего выборочного значения x посредством выборочного значения a, т.е. оно совместно размещается с текущим выборочным значением x временно и предшествует текущему значению x, при этом только выборочное значение a позиционируется между ними. Аналогично, выборочное значение e граничит с выборочным значением x при совместном размещении с текущим выборочным значением x временно и граничном размещении с выборочным значением x вдоль спектральной оси 16, при этом только соседняя выборка b позиционируется между ними.
Как уже указано выше, хотя выборочные значения 12 предположительно регулярно упорядочены вдоль временных и спектральных осей 14 и 16, эта регулярность не является обязательной, и определение окружения и идентификация соседних выборочных значений может быть расширена на такой нерегулярный случай. Например, соседнее выборочное значение a может задаваться как значение, граничащее с верхним левым углом спектрально-временного мозаичного фрагмента текущей выборки вдоль временной оси с предшествованием верхнему левому углу временно. Аналогичные определения также могут использоваться для того, чтобы задавать другие соседние узлы, к примеру, соседние узлы b-e.
Как подробнее указано ниже, модуль 22 предсказания, в зависимости от спектрально-временной позиции текущего выборочного значения x, может использовать различный поднабор всех выборочных значений в спектрально-временном окружении, т.е. поднабор {a, b, c, d, e}. То, какой поднабор фактически используется, например, может зависеть от доступности соседних выборочных значений в спектрально-временном окружении, заданном посредством набора {a, b, c, d, e}. Соседние выборочные значения a, d и c, например, могут быть недоступными вследствие того, что текущее выборочное значение x следует сразу после точки произвольного доступа, т.е. точки во времени, позволяющей декодерам начинать декодирование таким образом, что зависимости от предыдущих частей спектральной огибающей 10 запрещаются/предотвращаются. Альтернативно, соседние выборочные значения b, c и e могут быть недоступными вследствие того, что текущее выборочное значение x представляет низкочастотный край интервала 18, так что позиция соответствующего соседнего выборочного значения выходит за пределы интервала 18. В любом случае, модуль 22 предсказания может спектрально-временным методом предсказывать текущее выборочное значение x посредством линейного комбинирования уже кодированных выборочных значений в спектрально-временном окружении.
Задача модуля 24 определения контекста состоит в том, чтобы выбирать один из нескольких поддерживаемых контекстов для энтропийного кодирования остатка предсказания, т.е. r=x-. С этой целью, модуль 24 определения контекста определяет контекст для текущего выборочного значения x в зависимости от показателя для отклонения между парой уже кодированных выборочных значений из числа a-e в спектрально-временном окружении. В конкретных вариантах осуществления, подробнее приведенных ниже, разность пары выборочных значений в спектрально-временном окружении используется в качестве показателя для отклонения между ними, к примеру, a-c, b-c, b-e, a-d и т.п., но альтернативно, могут использоваться другие показатели отклонения, такие как, например, частное (т.е. a/c, b/c, a/d), разность со степенью значения, не равная единице, к примеру, нечетное число n, не равное единице (т.е. (a-c)n, (b-c)n, (a-d)n), или некоторый другой тип показателя отклонения, к примеру, an-cn, bn-cn, an-dn или (a/c)n, (b/c)n, (a/d)n, где n≠1. Здесь, n также может быть любым значением, например, большим 1.
Как показано подробнее ниже, модуль 24 определения контекста может быть выполнен с возможностью определять контекст для текущего выборочного значения x в зависимости от первого показателя для отклонения между первой парой уже кодированных выборочных значений в спектрально-временном окружении и второго показателя для отклонения между второй парой уже кодированных выборочных значений в спектрально-временном окружении, причем первая пара является соседней между собой по спектру, а вторая пара является соседней между собой по времени. Например, могут использоваться разностные значения b-c и a-c, где a и c являются соседними между собой по спектру, а b и c являются соседними между собой по времени. Идентичный набор соседних выборочных значений, а именно, {a, c, b}, может использоваться посредством модуля 22 предсказания для того, чтобы получать оцененное значение , а именно, например, посредством их линейной комбинации. Различный набор соседних выборочных значений может использоваться для определения контекстов и/или предсказания в случаях определенной недоступности любого из выборочных значений a, c и/или b. Коэффициенты линейной комбинации, как подробнее изложено ниже, могут задаваться таким образом, что коэффициенты являются идентичными для различных контекстов, в случае если скорость передачи битов, на которой кодируется аудиосигнал, превышает предварительно определенное пороговое значение, и коэффициенты задаются отдельно для различных контекстов, в случае если скорость передачи битов ниже предварительно определенного порогового значения.
В качестве промежуточного примечания, следует отметить, что определение спектрально-временного окружения может быть адаптировано к порядку кодирования/декодирования, в котором контекстный энтропийный кодер 20 последовательно кодирует выборочные значения 12. Как показано на фиг. 1, например, контекстный энтропийный кодер может быть выполнен с возможностью последовательно кодировать выборочные значения 12 с использованием порядка 30 декодирования, который проходит выборочные значение 12 для каждого момента времени, при этом в каждый момент времени он идет от наименьшей к наибольшей частоте. Далее, "моменты времени" обозначаются как "кадры", но моменты времени альтернативно могут называться временными квантами, единицами времени и т.п. В любом случае, при использовании такого спектрального обхода перед временным упреждением, определение спектрально-временного окружения, которое расширяется до предшествующего времени и к нижним частотам, обеспечивает наибольшую осуществимую вероятность того, что соответствующие выборочные значения уже кодированы/декодированы и доступны. В данном случае, значения в окружении всегда уже кодированы/декодированы, если они присутствуют, но это может отличаться для другого окружения и пар в порядке декодирования. Естественно, декодер использует идентичный порядок 30 декодирования.
Выборочные значения 12, как уже обозначено выше, могут представлять спектральную огибающую 10 в логарифмической области. В частности, спектральные значения 12, возможно, уже квантованы в целочисленные значения с использованием логарифмической функции квантования. Соответственно, вследствие квантования, показатели отклонения, определенные посредством модуля 24 определения контекста, по сути уже могут быть целыми числами. Это, например, имеет место при использовании разности в качестве показателя отклонения. Независимо от внутренне присущего целочисленного характера показателя отклонения, определенного посредством модуля 24 определения контекста, модуль 24 определения контекста может подвергать показатель отклонения квантованию и определять контекст с использованием квантованного показателя. В частности, как указано ниже, функция квантования, используемая посредством модуля 24 определения контекста, может быть постоянной для значений показателя отклонения за пределами предварительно определенного интервала, причем предварительно определенный интервал, например, включает в себя нуль.
Фиг. 3 примерно показывает такую функцию 32 квантования, преобразующую неквантованные показатели отклонения в квантованные показатели отклонения, причем, в этом примере, вышеуказанный предварительно определенный интервал 34 идет от -2,5 до 2,5, при этом неквантованные значения показателя отклонения выше этого интервала постоянно преобразуются в квантованное значение показателя отклонения в 3, а неквантованные значения показателя отклонения ниже того интервала 34 постоянно преобразуются в квантованное значение показателя отклонения в -3. Соответственно, только семь контекстов различаются и должны поддерживаться посредством контекстного энтропийного кодера. В нижеуказанных примерах реализации, длина интервала 34 равна 5, как проиллюстрировано выше, при этом число элементов набора возможных значений для выборочных значений спектральной огибающей равно 2n (например=128), т.е. более чем в 16 раз превышает длину интервала. В случае использования кодирования перехода, как проиллюстрировано ниже, диапазон возможных значений для выборочных значений спектральной огибающей может быть задан как {0; 2n}, где n является целым числом, выбранным таким образом, что 2n+1 ниже числа элементов кодируемых возможных значений для значений остатка предсказания, которое составляет, в соответствии с конкретным примером реализации, описанным ниже, 311.
Энтропийный кодер 26 использует контекст, определенный посредством модуля 24 определения контекста, для того чтобы эффективно энтропийно кодировать остаток r предсказания, который, в свою очередь, определяется посредством модуля 28 определения остатков на основе фактического текущего выборочного значения x и оцененного значения , к примеру, посредством вычитания. Предпочтительно, используется арифметическое кодирование. Контексты, возможно, имеют ассоциированные постоянные распределения вероятностей. Для каждого контекста, распределение вероятностей, ассоциированное с ним, назначает определенное значение вероятности каждому возможному символу из символьного алфавита энтропийного кодера 26. Например, символьный алфавит энтропийного кодера 26 совпадает или покрывает диапазон возможных значений остатка r предсказания. В альтернативных вариантах осуществления, которые приводятся подробнее ниже, определенный механизм кодирования перехода может использоваться с тем, чтобы гарантировать то, что значение r, которое должно энтропийно кодироваться посредством энтропийного кодера 26, находится в символьном алфавите энтропийного кодера 26. При использовании арифметического кодирования, энтропийный кодер 26 использует распределение вероятностей определенного контекста, определенного посредством модуля 24 определения контекста, с тем чтобы подразделять текущий интервал вероятности, который представляет внутреннее состояние энтропийного кодера 26, на один подыинтервал в расчете на значение алфавита, при выборе одного из подыинтервалов в зависимости от фактического значения r и выводе арифметически кодированного потока битов, информирующего сторону декодирования в отношении обновлений смещения и ширины интервала вероятности, посредством использования, например, процесса ренормализации. Тем не менее, альтернативно, энтропийный кодер 26 может использовать, для каждого контекста, отдельную таблицу кодирования переменной длины, транслирующую распределение вероятностей соответствующего контекста в соответствующее преобразование возможных значений r в коды длины, соответствующей надлежащей частоте соответствующего возможного значения r. Также могут использоваться другие энтропийные кодеки.
Для полноты, фиг. 2 показывает то, что квантователь 36 может быть соединен перед входом модуля 28 определения остатков, для которого текущее выборочное значение x является входящим, с тем чтобы получать текущее выборочное значение x, к примеру, как уже указано выше, посредством использования логарифмической функции квантования, например, применяемой к неквантованному выборочному значению x.
Фиг. 4 показывает контекстный энтропийный декодер в соответствии с вариантом осуществления, который соответствует контекстному энтропийному кодеру по фиг. 2.
Контекстный энтропийный декодер по фиг. 4 указывается с использованием ссылки с номером 40 и истолковывается аналогично кодеру по фиг. 2. Соответственно, контекстный энтропийный декодер 40 содержит модуль 42 предсказания, модуль 44 определения контекста, энтропийный декодер 46 и модуль 48 комбинирования. Модуль 44 определения контекста и модуль 42 предсказания работают аналогично модулю 22 предсказания и модулю 24 определения контекста кодера 20 по фиг. 2. Иными словами, модуль 42 предсказания спектрально-временным методом предсказывает текущее выборочное значение x, т.е. выборочное значение, которое должно в данный момент декодироваться, чтобы получать оцененное значение , и выводит его в модуль 48 комбинирования, и модуль 44 определения контекста определяет контекст для энтропийного декодирования остатка r предсказания текущего выборочного значения x в зависимости от показателя отклонения между парой уже декодированных выборочных значений в спектрально-временном окружении выборочного значения x с информированием энтропийного декодера 46 в отношении контекста, определенного через его управляющий вход. Соответственно, как модуль 44 определения контекста, так и модуль 42 предсказания имеют доступ к выборочным значениям в спектрально-временном окружении. Модуль 48 комбинирования имеет два входа, соединенных с выходами модуля 42 предсказания и энтропийного декодера 46, соответственно, и выход для вывода текущего выборочного значения. В частности, энтропийный кодер 46 энтропийно декодирует остаточное значение r для текущих выборочных значений x с использованием контекста, определенного посредством модуля 44 определения контекста, и модуль 48 комбинирования комбинирует оцененное значение и соответствующее остаточное значение r, чтобы получать текущее выборочное значение x, к примеру, посредством суммирования. Только для полноты, фиг. 4 показывает то, что деквантователь 50 может следовать после выхода модуля 48 комбинирования, с тем чтобы деквантовать выборочное значение, выводимое посредством модуля 48 комбинирования, к примеру, посредством его подвергания преобразованию из логарифмической области в линейную область с использованием, например, показательной функции.
Энтропийный декодер 46 выполняет в обратном порядке энтропийное кодирование, выполняемое посредством энтропийного кодера 26. Иными словами, энтропийный декодер также управляет числом контекстов и использует, для текущего выборочного значения x, контекст, выбранный посредством модуля 44 определения контекста, причем каждый контекст имеет ассоциированное соответствующее распределение вероятностей, которое назначает каждому возможному значению r определенную вероятность, которая является идентичной вероятности, выбранной посредством модуля 24 определения контекста для энтропийного кодера 26.
При использовании арифметического кодирования, энтропийный декодер 46, например, выполняет в обратном порядке последовательность подразделения на интервалы энтропийного кодера 26. Внутреннее состояние энтропийного декодера 46, например, задается посредством ширины интервала вероятности текущего интервала и значения смещения, указывающего, в текущем интервале вероятности, на подыинтервал из текущего интервала вероятности, которому соответствует фактическое значение r текущего выборочного значения x. Энтропийный декодер 46 обновляет интервал вероятности и значение смещения с использованием входящего арифметически кодированного потока битов, выводимого посредством энтропийного кодера 26, к примеру, посредством процесса ренормализации, и получает фактическое значение r посредством анализа значения смещения и идентификации подыинтервала, в который оно попадает.
Как уже упомянуто выше, может быть преимущественным ограничивать энтропийное кодирование остаточных значений некоторым небольшим подыинтервалом возможных значений остатков r предсказания. Фиг. 5 показывает модификацию контекстного энтропийного кодера по фиг. 2, чтобы реализовывать это. В дополнение к элементам, показанным на фиг. 2, энтропийный кодер контекста по фиг. 5 содержит контроллер, соединенный между модулем 28 определения остатков и энтропийным кодером 26, а именно, контроллер 60, а также обработчик 62 кодирования перехода, управляемый через контроллер 60.
Функциональность контроллера 60 кратко проиллюстрирована на фиг. 5. Как проиллюстрировано на фиг. 5, контроллер 60 анализирует первоначально определенное остаточное значение r, определенное посредством модуля 28 определения остатков на основе сравнения фактического выборочного значения x и его оцененного значения . В частности, контроллер 60 анализирует то, находится r в пределах или за пределами предварительно определенного интервала значений, как проиллюстрировано на фиг. 5 в 64. Обратимся, например, к фиг. 6. Фиг. 6 показывает по оси X возможные значения начального остатка r предсказания, в то время как ось Y показывает фактически энтропийно кодированное r. Дополнительно, фиг. 6 показывает диапазон возможных значений начального остатка r предсказания, а именно, 66, и вышеуказанный предварительно определенный интервал 68, участвующий в проверке 64. Предположим, например, что выборочные значения 12 являются целочисленными значениями между 0 и 2n-1, включительно. Затем диапазон 66 возможных значений для остатка r предсказания может составлять от -(2n-1) до 2n-1 включительно, и абсолютные значения границ 70 и 72 интервала для интервала 68 могут быть меньше или равны 2n-2, т.е. абсолютные значения границ интервала могут быть меньше 1/8 числа элементов набора возможных значений в диапазоне 66. В одном из примеров реализации, изложенных ниже в связи с xHE-AAC, интервал 68 составляет от -12 до +12 включительно, границы 70 и 72 интервала составляют -13 и +13, и кодирование перехода расширяет интервал 68 посредством кодирования VLC-кодированного абсолютного значения, а именно, расширяет интервал 68 до -/+(13+15) с использованием 4 битов и до -/+(13+15+127) с использованием еще 7 битов, если предыдущие 4 бита равны 15. Таким образом, остаток предсказания может кодироваться в диапазоне от -/+155 включительно, чтобы в достаточной степени покрывать диапазон 66 возможных значений для остатка предсказания, который, в свою очередь, составляет от -127 до 127. Как можно видеть, число элементов [127; 127] составляет 255, и 13, т.е. абсолютные значения внутренних пределов 70 и 72, меньше 32≈255/8. При сравнении длины интервала 68 с числом элементов возможных значений, кодируемых с использованием кодирования перехода, т.е. [-155; 155], обнаруживается то, что абсолютные значения внутренних границ 70 и 72 преимущественно могут быть выбраны меньшими 1/8 или даже 1/16 от упомянутого числа элементов (здесь 311).
В случае начального остатка r предсказания, размещающегося в пределах интервала 68, контроллер 60 инструктирует энтропийному кодеру 26 энтропийно кодировать этот начальный остаток r предсказания непосредственно. Специальные меры не должны предприниматься. Тем не менее, если r, предоставляемое посредством модуля 28 определения остатков, находится за пределами интервала 68, процедура кодирования перехода инициируется посредством контроллера 60. В частности, ближайшие соседние значения, непосредственно соседние с границами 70 и 72 интервала для интервала 68, в соответствии с одним вариантом осуществления, могут принадлежать символьному алфавиту энтропийного кодера 26 и непосредственно служить в качестве кодов перехода. Иными словами, символьный алфавит энтропийного кодера 26 должен охватывать все значения интервала 68 плюс непосредственно соседние значения ниже и выше этого интервала 68, как указано с помощью фигурной скобки 74, и контроллер 60 должен просто уменьшать значение, которое должно энтропийно кодироваться, вплоть до наибольшего значения 76 алфавита, непосредственно соседнего с верхней границей 72 интервала 68, в случае если остаточное значение r превышает верхнюю границу 72 интервала 68, и должен перенаправлять в энтропийный кодер 26 наименьшее значение 78 алфавита, непосредственно соседнее с нижней границей 70 интервала 68, в случае если начальный остаток r предсказания меньше нижней границы 70 интервала 68.
Посредством использования вышеприведенного варианта осуществления, энтропийно кодированное значение r соответствует, т.е. равно, фактическому остатку предсказания в случае, если он находится в пределах интервала 68. Тем не менее, если энтропийно кодированное значение r равно значению 76, то очевидно, что фактический остаток r предсказания текущего выборочного значения x равен 76 или некоторому значению выше него, а если энтропийно кодированное остаточное значение r равно значению 78, то фактический остаток r предсказания равен этому значению 78 или некоторому значению ниже означенного. Иными словами, в этом случае фактически предусмотрено два кода 76 и 78 перехода. В случае нахождения начального значения r за пределами интервала 68, контроллер 60 инициирует обработчик 62 кодирования перехода, чтобы вставлять в поток данных, в котором энтропийный кодер 26 выводит энтропийно кодированный поток данных, кодирование, которое позволяет декодеру восстанавливать фактический остаток предсказания, либо автономным способом независимо от энтропийно кодированного значения r, равного коду 76 или 78 перехода, либо в зависимости от него. Например, обработчик 62 кодирования перехода может записывать в поток данных фактический остаток r предсказания непосредственно с использованием двоичного представления достаточной длины в битах, к примеру, длины 2n+1, включающий в себя знак фактического остатка r предсказания или просто абсолютное значение фактического остатка r предсказания с использованием двоичного представления длины в битах 2n с использованием кода 76 перехода для передачи в служебных сигналах знака "плюс" и кода 78 перехода для передачи в служебных сигналах знака "минус". Альтернативно, просто абсолютное значение разности между значением r начального остатка предсказания и значением кода 76 перехода кодируется в случае начального остатка предсказания, превышающего верхнюю границу 72, и абсолютное значение разности между начальным остатком r предсказания и значением кода 78 перехода в случае начального остатка предсказания, размещающегося ниже нижней границы 70. Это, в соответствии с одним примером реализации, выполняется с использованием условного кодирования. Во-первых, min(|x-|-13; 15) кодируется в случае кодирования перехода с использованием четырех битов, а если min(|x-|-13; 15) равно 15, то |x-|-13-15 кодируется с использованием еще семи битов.
Очевидно, кодирование перехода является менее сложным по сравнению с кодированием обычных остатков предсказания, находящихся в пределах интервала 68. Адаптивность контекста, например, не используется. Вместо этого, кодирование значения, кодированного в случае кодирования перехода, может выполняться посредством простой записи двоичного представления для значения, к примеру, |r| или даже x, непосредственно. Тем не менее, интервал 68 предпочтительно выбирается таким образом, что процедура кодирования перехода осуществляется статистически редко и просто представляет "выпадающие значения" в статистике выборочных значений x.
Фиг. 7 показывает модификацию контекстного энтропийного декодера по фиг. 4, аналогичного или соответствующего энтропийному кодеру по фиг. 5. Аналогично энтропийному кодеру по фиг. 5, контекстный энтропийный декодер по фиг. 7 отличается от контекстного энтропийного декодера, показанного на фиг. 4, тем, что контроллер 71 соединен между энтропийным декодером 46, с одной стороны, и модулем 48 комбинирования, с другой стороны, при этом энтропийный декодер по фиг. 7 дополнительно содержит обработчик 73 кода перехода. Аналогично фиг. 5, контроллер 71 выполняет проверку 74 того, энтропийно декодированное значение r, выводимое посредством энтропийного декодера 46, находится в пределах интервала 68 или соответствует некоторому коду перехода. Если применяется второй случай, обработчик 73 кода перехода инициирован посредством контроллера 71, с тем чтобы извлекать из потока данных, также переносящего поток энтропийно кодированных данных, энтропийно декодированный посредством энтропийного декодера 46, вышеуказанный код, вставленный посредством обработчика 62 кода перехода, к примеру, двоичное представление достаточной длины в битах, которое может указывать фактический остаток r предсказания автономным способом, независимо от кода перехода, указываемого посредством энтропийно декодированного значения r, либо способом, зависимым от фактического кода перехода, который допускает энтропийно декодированное значение r, как уже пояснено в связи с фиг. 6. Например, обработчик 73 кода перехода считывает двоичное представление значения из потока данных, суммирует его с абсолютным значением кода перехода, т.е. абсолютным значением верхней или нижней границы, соответственно, и использует в качестве знака значения, считывает знак соответствующей границы, т.е. знак "плюс" для верхней границы, знак "минус" для нижней границы. Может использоваться условное кодирование. Иными словами, если энтропийно декодированное значение r, выводимое посредством энтропийного декодера 46, находится за пределами интервала 68, обработчик 73 кода перехода может сначала считывать, например, p-битовое абсолютное значение из потока данных и проверять то, составляет оно или нет 2p-1. Если нет, энтропийно декодированное значение r обновляется посредством суммирования p-битового абсолютного значения с энтропийно декодированным значением r, если код перехода представляет собой верхнюю границу 72, и вычитания p-битового абсолютного значения из энтропийно декодированного значения r, если код перехода представляет собой нижнюю границу 70. Тем не менее, если p-битовое абсолютное значение равно 2p-1, то q-битовое другое абсолютное значение считывается из потока битов, и энтропийно декодированное значение r обновляется посредством суммирования q-битового абсолютного значения плюс 2p-1 с энтропийно декодированным значением r, если код перехода представляет собой верхнюю границу 72, и вычитания p-битового абсолютного значения плюс 2p-1 из энтропийно декодированного значения r, если код перехода представляет собой нижнюю границу 70.
Тем не менее, фиг. 7 показывает также другую альтернативу. Согласно этой альтернативе, процедура кодирования перехода, реализованная посредством обработчиков 62 и 72 кода перехода, кодирует полное выборочное значение x непосредственно, так что в случаях кода перехода, оцененное значение является избыточным. Например, 2n-битовое представление может быть достаточным в этом случае и указывать значение x.
В качестве только меры предосторожности, следует отметить, что другой способ реализации кодирования перехода также должен быть осуществимым с помощью этих альтернативных вариантов осуществления, за счет вообще отказа от энтропийного декодирования для спектральных значений, остаток предсказания которых превышает или находится за пределами интервала 68. Например, для каждого элемента синтаксиса может передаваться флаг, указывающий то, кодируется он или нет с использованием энтропийного кодирования, либо то, используется или нет кодирование перехода. В этом случае, для каждого выборочного значения флаг должен указывать выбранный способ кодирования.
Далее описывается конкретный пример для реализации вышеописанных вариантов осуществления. В частности, явный пример, изложенный ниже, иллюстрирует, как разрешать вышеуказанную недоступность определенных ранее кодированных/декодированных выборочных значений в спектрально-временном окружении. Дополнительно, конкретные примеры представлены для задания диапазона 66 возможных значений, интервала 68, функции 32 квантования, диапазона 34 и т.д. Ниже описывается то, что конкретный пример может использоваться в связи с IGF. Тем не менее, следует отметить, что описание, изложенное ниже, может быть легко перенесено на другие случаи, в которых временная сетка, в которой размещаются выборочные значения спектральной огибающей, например, задается посредством единиц времени, отличных от кадров, таких как группы временных QMF-квантов, и спектральное разрешение аналогично задается посредством подгруппировки подполос частот на спектрально-временные мозаичные фрагменты.
Обозначим с помощью t (время) номер кадра во времени, а f (частота) – позицию соответствующего выборочного значения спектральной огибающей по коэффициентам масштабирования (или группам коэффициентов масштабирования). Выборочные значения далее называются "SFE-значением". Требуется кодировать значение x, с использованием информации, уже доступной из ранее декодированных кадров в позициях (t-1), (t-2),..., и из текущего кадра в позиции (t) на частотах (f-1), (f-2),...,. Ситуация снова проиллюстрирована на фиг. 8.
Для независимого кадра задано t=0. Независимый кадр представляет собой кадр, который определяет себя в качестве точки произвольного доступа для объекта декодирования. Таким образом, он представляет момент времени, в который произвольный доступ в декодирование является осуществимым на стороне декодирования. В отношении спектральной оси 16, первая SFE 12, ассоциированная с наименьшей частотой, должна иметь f=0. На фиг. 8, соседние узлы во времени и по частоте (доступные как в кодере, так и в декодере), которые используются для вычисления контекста, как имеет место на фиг. 1, представляют собой a, b, c, d и e.
Предусмотрено несколько случаев, в зависимости от того, t=0 или f=0 либо нет. В каждом случае и в каждом контексте, можно вычислять адаптивную оценку значения x, на основе соседних узлов, следующим образом:

Значения b-e и a-c представляют, как уже обозначено выше, показатели отклонения. Они представляют ожидаемую величину шумности изменчивости по частоте около значения, которое должно быть декодировано/кодировано, а именно, x. Значения b-c и a-d представляют ожидаемую величину шумности изменчивости во времени около x. Чтобы значительно уменьшать общее число контекстов, они могут быть нелинейно квантованы до того, как они используются для того, чтобы выбирать контекст, так, как, например, изложено относительно фиг. 3. Контекст указывает доверие оцененного значения  или эквивалентно пиковость распределения кодирования. Например, функция квантования может быть такой, как проиллюстрировано на фиг. 3. Она может задаваться как
или эквивалентно пиковость распределения кодирования. Например, функция квантования может быть такой, как проиллюстрировано на фиг. 3. Она может задаваться как 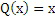 для
для 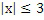 , и
, и 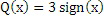 для
для 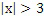 . Эта функция квантования преобразует все целочисленные значения в семь значений {-3,-2,-1, 0, 1, 2, 3}. Обратим внимание на следующее. В записи , уже использовано то, что разность двух целых чисел сама является целым числом. Формула может записываться как Q(x)=rInt(x), чтобы соответствовать более общему описанию, приведенному выше, и функции на фиг. 3, соответственно. Тем не менее, при использовании только для целочисленных вводов для показателя отклонения, Q(x)=x является функционально эквивалентным Q(x)=rInt(x), для целочисленного x, где .
. Эта функция квантования преобразует все целочисленные значения в семь значений {-3,-2,-1, 0, 1, 2, 3}. Обратим внимание на следующее. В записи , уже использовано то, что разность двух целых чисел сама является целым числом. Формула может записываться как Q(x)=rInt(x), чтобы соответствовать более общему описанию, приведенному выше, и функции на фиг. 3, соответственно. Тем не менее, при использовании только для целочисленных вводов для показателя отклонения, Q(x)=x является функционально эквивалентным Q(x)=rInt(x), для целочисленного x, где .
Члены se02[.], se20[.] и se11[.][.] в вышеприведенной таблице представляют собой векторы/матрицы контекстов. Иными словами, каждая из записей этих векторов/матриц является/представляет индекс контекста, индексирующий один из доступных контекстов. Каждый из этих трех векторов/матриц может индексировать контекст из непересекающихся наборов контекстов. Иными словами, различные наборы контекстов могут быть выбраны посредством вышеуказанного модуля определения контекста в зависимости от условия доступности. Вышеприведенная таблица примерно различает шесть различных условий доступности. Кроме того, контекст, соответствующий se01 и se10, может соответствовать контекстам, отличающимся от контекстов для групп контекста, индексированных посредством se02, se20 и se11. Оцененное значение  вычисляется в качестве
вычисляется в качестве 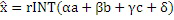 . Для более высоких скоростей передачи битов может использоваться
. Для более высоких скоростей передачи битов может использоваться  ,
,  ,
, 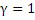 и
и 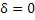 , а для более низких скоростей передачи битов отдельный набор коэффициентов может использоваться для каждого контекста, на основе информации из набора обучающих данных.
, а для более низких скоростей передачи битов отдельный набор коэффициентов может использоваться для каждого контекста, на основе информации из набора обучающих данных.
Ошибка предсказания или остаток предсказания 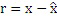 может кодироваться с использованием отдельного распределения для каждого контекста, извлекаемого с использованием информации, извлеченной из характерного набора обучающих данных. Два специальных символа могут использоваться на обеих сторонах распределения 74 кодирования, а именно, 76 и 78, чтобы указывать большие отрицательные или положительные значения за пределами диапазона, которые затем кодируются с использованием технологии кодирования перехода, как уже указано выше. Например, в соответствии с примером реализации, min(|x-|-13; 15) кодируется в случае кодирования перехода с использованием четырех битов, а если min(|x-|-13; 15) равно 15, то |x-|-13-15 кодируется с использованием еще семи битов.
может кодироваться с использованием отдельного распределения для каждого контекста, извлекаемого с использованием информации, извлеченной из характерного набора обучающих данных. Два специальных символа могут использоваться на обеих сторонах распределения 74 кодирования, а именно, 76 и 78, чтобы указывать большие отрицательные или положительные значения за пределами диапазона, которые затем кодируются с использованием технологии кодирования перехода, как уже указано выше. Например, в соответствии с примером реализации, min(|x-|-13; 15) кодируется в случае кодирования перехода с использованием четырех битов, а если min(|x-|-13; 15) равно 15, то |x-|-13-15 кодируется с использованием еще семи битов.
Относительно следующих чертежей, описываются различные варианты касательно того, как вышеуказанные контекстные энтропийные кодеры/декодеры могут быть встроены в соответствующие аудиодекодеры/кодеры. Фиг. 9 показывает, например, параметрический декодер 80, в который преимущественно может встраиваться контекстный энтропийный декодер 40 в соответствии с любым из вышеуказанных вариантов осуществления. Параметрический декодер 80 содержит, помимо контекстного энтропийного декодера 40, модуль 82 определения точной структуры и спектральный формирователь 84. Необязательно, параметрический декодер 80 содержит обратный преобразователь 86. Контекстный энтропийный декодер 40 принимает, как указано выше, энтропийно кодированный поток 88 данных, кодированный в соответствии с любым из вышеуказанных вариантов осуществления контекстного энтропийного кодера. Потоку88 данных, соответственно, имеет кодированную спектральную огибающую. Контекстный энтропийный декодер 40 декодирует, вышеуказанным способом, выборочные значения спектральной огибающей аудиосигнала, который параметрический декодер 80 стремится восстанавливать. Модуль 82 определения точной структуры выполнен с возможностью определять точную структуру спектрограммы этого аудиосигнала. С этой целью, модуль 82 определения точной структуры может принимать информацию извне, к примеру, другой поток части данных, также содержащий поток 88 данных. Дополнительные альтернативы описываются ниже. Тем не менее, в другой альтернативе, модуль 82 определения точной структуры может непосредственно определять точную структуру с использованием случайного или псевдослучайного процесса. Спектральный формирователь 84, в свою очередь, выполнен с возможностью формировать точную структуру согласно спектральной огибающей, как задано посредством спектральных значений, декодированных посредством контекстного энтропийного декодера 40. Другими словами, входы спектрального формирователя 84 соединены с выходами контекстного энтропийного декодера 40 и модуля 82 определения точной структуры, соответственно, чтобы принимать из них спектральную огибающую, с одной стороны, и точную структуру спектрограммы аудиосигнала, с другой стороны, и спектральный формирователь 84 выводит на выходе точную структуру спектрограммы с формой, определенной согласно спектральной огибающей. Обратный преобразователь 86 может выполнять обратное преобразование для точной структуры определенной формы, с тем чтобы выводить восстановление аудиосигнала на выходе.
В частности, точный модуль 82 определения может быть выполнен с возможностью определять точную структуру спектрограммы с использованием, по меньшей мере, одного из формирования искусственного случайного шума, повторного формирования спектра и декодирования на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии. Первые два варианта описываются относительно фиг. 10. Фиг. 10 иллюстрирует такой вариант, при котором спектральная огибающая 10, декодированная посредством контекстного энтропийного декодера 40, связана с частотным интервалом 18, который формирует расширение диапазона верхних частот для интервала 90 нижних частот, т.е. интервал 18 расширяет интервал 90 нижних частот к верхним частотам, т.е. интервал 19 граничит с интервалом 18 на его стороне более высокой частоты. Соответственно, фиг. 10 показывает такой вариант, при котором аудиосигнал, который должен воспроизводиться посредством параметрического декодера 80, фактически покрывает частотный интервал 92, из которого интервал 18 просто представляет высокочастотную часть полного частотного интервала 92. Как показано на фиг. 9, параметрический декодер 80, например, может дополнительно содержать низкочастотный декодер 94, выполненный с возможностью декодировать поток 96 низкочастотных данных, сопровождающий поток 88 данных, с тем чтобы получать версию полосы низких частот аудиосигнала на выходе. Спектрограмма этой низкочастотной версии проиллюстрирована на фиг. 10 с использованием ссылки с номером 98. Вместе, эта частотная версия 98 аудиосигнала и точная структура определенной формы в пределах интервала 18 приводят к восстановлению аудиосигналов полного частотного интервала 92, т.е. его спектрограммы через полный частотный интервал 92. Как указано посредством пунктирных линий на фиг. 9, обратный преобразователь 86 может выполнять обратное преобразование для полного интервала 92. В этой структуре, модуль 82 определения точной структуры может принимать низкочастотную версию 98 из декодера 94 во временной области или в частотной области. В первом случае, модуль 82 определения точной структуры может подвергать принимаемую низкочастотную версию преобразованию в спектральную область, с тем чтобы получать спектрограмму 98 и получать точную структуру, форма которой должна быть определена посредством спектрального формирователя 84 согласно спектральной огибающей, предоставленной посредством контекстного энтропийного декодера 40, с использованием повторного формирования спектра, как проиллюстрировано с использованием стрелки 100. Тем не менее, как уже указано выше, модуль 82 определения точной структуры может даже не принимать низкочастотную версию аудиосигнала из LF-декодера 94 и формировать точную структуру исключительно с использованием случайного или псевдослучайного процесса.
Соответствующий параметрический кодер, соответствующий параметрическому декодеру согласно фиг. 9 и 10, проиллюстрирован на фиг. 11. Параметрический кодер по фиг. 11 содержит частотный разделитель 110, принимающий аудиосигнал 112, который должен кодироваться, кодер 114 полосы высоких частот и кодер 116 полосы низких частот. Частотный разделитель 110 разлагает входящий аудиосигнал 112 на два компонента, а именно, на первый сигнал 118, соответствующий фильтрованной по верхним частотам версии входящего аудиосигнала 112, и низкочастотный сигнал 120, соответствующий фильтрованной по нижним частотам версии входящего аудиосигнала 112, при этом полосы частот, покрываемые высокочастотными и низкочастотными сигналами 118 и 120, граничат между собой при некоторой частоте разделения (сравните 122 на фиг. 10). Кодер 116 полосы низких частот принимает низкочастотный сигнал 120 и кодирует его в поток низкочастотных данных, а именно, 96, и кодер 114 полосы высоких частот вычисляет выборочные значения, описывающие спектральную огибающую высокочастотного сигнала 118 в высокочастотном интервале 18. Кодер 114 полосы высоких частот также содержит вышеописанный контекстный энтропийный кодер для кодирования этих выборочных значений спектральной огибающей. Кодер 116 полосы низких частот, например, может представлять собой кодер с преобразованием, и спектрально-временное разрешение, с которым кодер 116 полосы низких частот кодирует преобразование или спектрограмму низкочастотного сигнала 120 может превышать спектрально-временное разрешение, с которым выборочные значения 12 разрешают спектральную огибающую высокочастотного сигнала 118. Соответственно, кодер 114 полосы высоких частот выводит, в числе прочего, поток 88 данных. Как показано посредством пунктирной линии 124 на фиг. 11, кодер 116 полосы низких частот может выводить информацию в кодер 114 полосы высоких частот, к примеру, чтобы управлять кодером 114 полосы высоких частот относительно этого формирования выборочных значений, описывающих спектральную огибающую, или, по меньшей мере, относительно выбора спектрально-временного разрешения, с которым выборочные значения дискретизируют спектральную огибающую.
Фиг. 12 показывает другой вариант реализации параметрического декодера 80 по фиг. 9 и, в частности, модуля 82 определения точной структуры. В частности, в соответствии с примером по фиг. 12, непосредственно модуль 82 определения точной структуры принимает поток данных и определяет, на его основе, точную структуру спектрограммы аудиосигналов с использованием декодирования на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии. Иными словами, непосредственно модуль 82 определения точной структуры восстанавливает из потока данных точную структуру в форме спектрограммы, состоящей, например, из временной последовательности спектров перекрывающегося преобразования. Тем не менее, в случае фиг. 12, точная структура, определенная таким способом посредством точной структуры 82, связана с первым частотным интервалом 130 и совпадает с полным частотным интервалом аудиосигнала, т.е. 92.
В примере по фиг. 12, частотный интервал 18, с которым связана спектральная огибающая 10, полностью перекрывается с интервалом 130. В частности, интервал 18 формирует высокочастотную часть интервала 130. Например, многие спектральные линии в спектрограмме 132, восстановленной посредством модуля 82 определения точной структуры и покрывающей частотный интервал 130, квантуются до нуля, в частности, в высокочастотной части 18. Тем не менее, для того чтобы восстанавливать аудиосигнал в высоком качестве, даже в высокочастотной части 18 на обоснованной скорости передачи битов, параметрический декодер 80 использует спектральную огибающую 10. Спектральные значения 12 спектральной огибающей 10 описывают спектральную огибающую аудиосигнала в высокочастотной части 18 со спектральным временным разрешением, которое является менее точным, чем спектрально-временное разрешение спектрограммы 132, декодированной посредством модуля 82 определения точной структуры. Например, спектрально-временное разрешение спектральной огибающей 10 является менее точным в спектральном отношении, т.е. ее спектральное разрешение является менее точным, чем степень детализации по спектральным линиям точной структуры 132. Как описано выше, спектрально, выборочные значения 12 спектральной огибающей 10 могут описывать, например, спектральную огибающую 10 в полосах 134 частот, в которые спектральные линии спектрограммы 132 группируются для масштабирования на основе полос частот коэффициентов масштабирования касательно коэффициентов спектральных линий.
Спектральный формирователь 84 затем может, с использованием выборочных значений 12, заполнять спектральные линии в группах спектральных линий или спектрально-временных мозаичных фрагментах, соответствующих надлежащим выборочным значениям 12 с использованием таких механизмов, как повторное формирование спектра или формирование искусственного шума, регулирование результирующего уровня точной структуры или энергии в соответствующем спектрально-временном мозаичном фрагменте/группе коэффициентов масштабирования согласно соответствующему выборочному значению, описывающему спектральную огибающую. Обратимся, например, к фиг. 13. Фиг. 13 примерно показывает спектр из спектрограммы 132, соответствующей одному кадру или моменту времени, к примеру, моменту 136 времени на фиг. 12. Спектр примерно указывается с использованием ссылки с номером 140. Как проиллюстрировано на фиг. 13, его некоторые части 142 квантуются до нуля. Фиг. 13 показывает высокочастотную часть 18 и подразделение спектральных линий спектра 140 на полосы частот коэффициентов масштабирования, указываемые посредством фигурных скобок. С использованием x и b, и e, фиг. 13 примерно иллюстрирует, что три выборочных значения 12 описывают спектральную огибающую в высокочастотной части 18 в момент 136 времени: по одному для каждой полосы частот коэффициентов масштабирования. В каждой полосе частот коэффициентов масштабирования, соответствующей этим выборочным значениям e, b и x, модуль 82 определения точной структуры формирует точную структуру, по меньшей мере, в нулевых квантованных частях 142 спектра 140, как проиллюстрировано посредством областей 144 со штриховкой, к примеру, посредством повторного формирования спектра из части 146 нижних частот полного частотного интервала 130 и затем регулирования энергии результирующего спектра посредством масштабирования искусственной точной структуры 144 согласно или с использованием выборочных значений e, b и x. Интересно отметить, что имеются ненулевые квантованные части 148 спектра 140 между или внутри полос частот коэффициентов масштабирования высокочастотной части 18, и соответственно, с использованием интеллектуального заполнения интервалов отсутствия сигнала согласно фиг. 12, целесообразно позиционировать пики внутри спектра 140 даже в высокочастотной части 18 полного частотного интервала 130 с разрешением спектральных линий и в любой позиции спектральной линии, тем не менее, с возможностью заполнять нулевые квантованные части 142 с использованием выборочных значений x, b и e для формирования точной структуры, вставленной в этих нулевых квантованных частях 142.
В завершение, фиг. 14 показывает возможный параметрический кодер для ввода данных в параметрический декодер по фиг. 9 в случае осуществления согласно описанию фиг. 12 и 13. В частности, в этом случае параметрический кодер может содержать преобразователь 150, выполненный с возможностью спектрально разлагать входящий аудиосигнал 152 на полную спектрограмму, покрывающую полный частотный интервал 130. Перекрывающееся преобразование с возможно изменяющейся длиной преобразования может использоваться. Кодер 154 на основе спектральных линий кодирует, с разрешением спектральных линий, эту спектрограмму. С этой целью, кодер 154 на основе спектральных линий принимает как высокочастотную часть 18, так и оставшуюся низкочастотную часть из преобразователя 150, причем обе части без интервала отсутствия сигнала и без перекрытия покрывают полный частотный интервал 130. Параметрический высокочастотный кодер 156 просто принимает высокочастотную часть 18 спектрограммы 132 из преобразователя 150 и формирует, по меньшей мере, поток 88 данных, т.е. выборочные значения, описывающие спектральную огибающую в высокочастотной части 18.
Иными словами, в соответствии с вариантами осуществления по фиг. 12-14, спектрограмма 132 аудиосигнала кодируется в поток 158 данных посредством кодера 154 на основе спектральных линий. Соответственно, кодер 154 на основе спектральных линий может кодировать одно значение спектральной линии в расчете на спектральную линию полного интервала 130 для каждого момента времени или кадра 136. Небольшие прямоугольники 160 на фиг. 12 показывают эти значения спектральных линий. Вдоль спектральной оси 16, спектральные линии могут группироваться в полосы частот коэффициентов масштабирования. Другими словами, частотный интервал 16 может подразделяться на полосы частот коэффициентов масштабирования, состоящие из групп спектральных линий. Кодер 154 на основе спектральных линий может выбирать коэффициент масштабирования для каждой полосы частот коэффициентов масштабирования в каждый момент времени, с тем, чтобы масштабировать квантованные значения 160 спектральных линий, кодированные через поток 158 данных. При спектрально-временном разрешении, которое, по меньшей мере, является менее точным, чем спектрально-временная сетка, заданная посредством моментов времени и спектральных линий, в которых значения 160 спектральных линий регулярно упорядочены и которые могут совпадать с растром, заданным посредством разрешения коэффициентов масштабирования, параметрический высокочастотный кодер 156 описывает спектральную огибающую в высокочастотной части 18. Интересно отметить, что ненулевые квантованные значения 160 спектральных линий, масштабированные согласно коэффициенту масштабирования полосы частот коэффициентов масштабирования, в которую они попадают, могут быть вкраплены, с разрешением спектральных линий, в любой позиции в высокочастотной части 18, и, соответственно, они переживают высокочастотный синтез на стороне декодирования в спектральном формирователе 84 с использованием выборочных значений, описывающих спектральную огибающую в высокочастотной части, поскольку модуль 82 определения точной структуры и спектральный формирователь 84 ограничивают, например, их синтез точной структуры, и формирования в нулевые квантованные части 142 в высокочастотной части 18 спектрограммы 132. В целом, в результате получается очень эффективный компромисс между расходуемой скоростью передачи битов, с одной стороны, и получаемым качеством, с другой стороны.
Как обозначено посредством пунктирной стрелки на фиг. 14, указываемой как 164, кодер 154 на основе спектральных линий может информировать параметрический высокочастотный кодер 156, например, в отношении восстанавливаемой версии спектрограммы 132, восстанавливаемой из потока 158 данных, причем параметрический высокочастотный кодер 156 использует этой информации, например, для того чтобы управлять формированием выборочных значений 12 и/или спектрально-временным разрешением представления спектральной огибающей 10 посредством выборочных значений 12.
Обобщая вышеуказанное, вышеописанные варианты осуществления используют преимущество специальных свойств выборочных значений спектральных огибающих, причем в отличие от [2] и [3], такие выборочные значения представляют средние значения линий спектров. Во всех вышеуказанных вариантах осуществления, преобразования могут использовать MDCT, и соответственно, обратное MDCT может использоваться для всех обратных преобразований. В любом случае, такие выборочные значения спектральных огибающих являются гораздо более "сглаженными" и линейно коррелированными со средней абсолютной величиной соответствующих комплексных спектральных линий. Помимо этого, в соответствии, по меньшей мере, с некоторыми вышеописанными вариантами осуществления, выборочные значения спектральной огибающей, далее называемые "SFE-значениями", фактически представляют собой область дБ либо, если обобщать, логарифмическую область, которая является логарифмическим представлением. Это дополнительно повышает "гладкость" по сравнению со значениями в линейной области или степенной области для спектральных линий. Например, в AAC степенная экспонента составляет 0,75. В отличие от [4], по меньшей мере, в некоторых вариантах осуществления, выборочные значения спектральной огибающей находятся в логарифмической области, и свойства и структура распределений кодирования существенно отличается (в зависимости от абсолютной величины, одно значение в логарифмической области типично преобразуется в экспоненциально растущее число значений в линейной области). Соответственно, по меньшей мере, некоторые вышеописанные варианты осуществления используют преимущество логарифмического представления при квантовании контекста (типично присутствует меньшее число контекстов) и при кодировании хвостовых частей распределения в каждом контексте (хвостовые части каждого распределения являются более широкими). В отличие от [2], некоторые вышеописанные варианты осуществления дополнительно используют фиксированное или адаптивное линейное предсказание в каждом контексте, на основе данных, идентичных данным, используемым при вычислении квантованного контекста. Этот подход является полезным для существенного уменьшения числа контекстов при одновременном получении оптимальной производительности. В отличие, например, от [4], по меньшей мере, в некоторых вариантах осуществления линейное предсказание в логарифмической области имеет существенно отличающееся использование и значимость. Например, оно позволяет идеально предсказывать области спектра с постоянной энергией и также области спектра с постепенным нарастанием и постепенным затуханием сигнала. В отличие от [4], некоторые вышеописанные варианты осуществления используют арифметическое кодирование, которое обеспечивает оптимальное кодирование произвольных распределений с использованием информации, извлеченной из характерного набора обучающих данных. В отличие от [2], который также использует арифметическое кодирование, в соответствии с вышеописанными вариантами осуществления, кодируются значения ошибки предсказания, а не исходные значения. Кроме того, в вышеописанных вариантах осуществления кодирование в битовой плоскости не должно использоваться. Тем не менее, кодирование в битовой плоскости должно требовать нескольких этапов арифметического кодирования для каждого целочисленного значения. По сравнению с этим, в соответствии с вышеописанными вариантами осуществления, каждое выборочное значение спектральной огибающей может быть кодировано/декодировано на одном этапе, включающем в себя, как указано выше, необязательное использование кодирования перехода для значений за пределами центра общего распределения выборочных значений, которое гораздо быстрее.
Снова кратко обобщая вариант осуществления декодера параметров, поддерживающего IGF, как описано выше относительно фиг. 9, 12 и 13, согласно этому варианту осуществления, модуль 82 определения точной структуры выполнен с возможностью использовать декодирование на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии, с тем чтобы извлекать точную структуру 132 спектрограммы аудиосигнала в первом частотном интервале 130, а именно, в полном частотном интервале. *Декодирование на основе частотных линий обозначает тот факт, что модуль 82 определения точной структуры принимает значения 160 спектральных линий из потока данных, размещаемого, спектрально, в шаге спектральной линии, за счет этого формируя спектр 136 для каждого момента времени, соответствующий соответствующему временному отрезку. Использование спектрального предсказания, например, может заключать в себе дифференциальное кодирование этих значений спектральных линий вдоль спектральной оси 16, т.е. просто разность с непосредственно спектрально предыдущим значением спектральной линии декодируется из потока данных и затем суммируется с этим предшествующим элементом. Извлечение (получение) контекста спектральной энтропии может обозначать тот факт, что контекст для энтропийного декодирования соответствующего значения 160 спектральной линии может зависеть, т.е. может быть аддитивным образом выбран на основе, от уже декодированных значений спектральных линий в спектрально-временном окружении или, по меньшей мере, в спектральном окружении текущего декодированного значения 160 спектральной линии. Чтобы заполнять нулевые квантованные части 142 точной структуры, модуль 82 определения точной структуры может использовать формирование искусственного случайного шума и/или повторное формирование спектра. Модуль 82 определения точной структуры выполняет это только во втором частотном интервале 18, который, например, может ограничиваться высокочастотной частью полного частотного интервала 130. Части, спектрально повторно сформированные, например, могут быть извлекаться из оставшейся частотной части 146. Спектральный формирователь затем выполняет формирование точной структуры, полученной таким способом согласно спектральной огибающей, описанной посредством выборочных значений 12 в нулевых квантованных частях. А именно, доля ненулевых квантованных частей точной структуры в пределах интервала 18 в результате точной структуры после формирования является независимой от фактической спектральной огибающей 10. Это означает следующее: формирование искусственного случайного шума и/или повторное формирование спектра, т.е. заполнение, ограничивается нулевыми квантованными частями 142 полностью, так что в конечном спектре точной структуры только части 142 заполнены посредством формирования искусственного случайного шума и/или повторного формирования спектра с использованием формирования спектральной огибающей, при этом ненулевые доли 148 остаются как есть, вкрапленными между частями 142, либо альтернативно, в результате выполняется все из формирования искусственного случайного шума и/или повторного формирования спектра, а именно, соответствующая синтезированная точная структура также, аддитивным способом, накладывается на части 148, с последующим формированием результирующей синтезированной точной структуры согласно спектральной огибающей 10. Тем не менее, даже в этом случае, сохраняется доля посредством ненулевых квантованных частей 148 первоначально декодированной точной структуры.
Относительно варианта осуществления по фиг. 12-14, в завершение следует отметить, что процедура или принцип IGF (интеллектуального заполнения интервалов отсутствия сигнала), описанная относительно этих чертежей, значительно повышает качество кодированного сигнала даже на очень низких скоростях передачи битов, причем значительная часть спектра в высокочастотной области 18 квантуется до нуля вследствие типично недостаточного битового бюджета. Чтобы сохранять в максимально возможной степени точную структуру области 18 верхних частот, IGF-информации, низкочастотная область используется в качестве источника, чтобы адаптивно заменять целевые области высокочастотной области, которые в основном квантуются до нуля, т.е. области 142. Важное требование для того, чтобы достигать хорошего перцепционного качества, представляет собой совпадение декодированной энергетической огибающей спектральных коэффициентов с декодированной энергетической огибающей исходного сигнала. Чтобы достигать этого, средние спектральные энергии вычисляются для спектральных коэффициентов из одной или более последовательных полос частот AAC-коэффициентов масштабирования. Результирующие значения являются выборочными значениями 12, описывающими спектральную огибающую. Вычисление средних с использованием границ, заданных посредством полос частот коэффициентов масштабирования, обусловлено посредством уже существующей тщательной подстройки этих границ к частям критических полос частот, которые являются характерными для человеческого слуха. Средние энергии могут преобразовываться, как описано выше, в логарифмическое, к примеру, на шкале в дБ, представление с использованием формулы, которая, например, может быть аналогичной формуле, уже известной для AAC-коэффициентов масштабирования, и затем равномерно квантоваться. В IGF, различная точность квантования может быть необязательно использована в зависимости от запрашиваемой полной скорости передачи битов. Средние энергии составляют значительную часть информации, сформированной посредством IGF, так что их эффективное представление в потоке 88 данных является очень важным для общей производительности принципа IGF.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, жесткого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, содержащую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
[1] International Standard ISO/IEC 14496-3:2005 "Information technology – Coding of audio-visual objects – Part 3: Audio, 2005 год.
[2] International Standard ISO/IEC 23003-3:2012, Information technology – MPEG audio technologies – Part 3: Unified Speech and Audio Coding, 2012 год.
[3] B. Edler и N. Meine: Improved Quantization and Lossless Coding for Subband Audio Coding, AES 118th Convention, май 2005 года.
[4] M.J. Weinberger и G. Seroussi: The LOCO-I Lossless Image Compression Algorithm: Principles and Standardization into JPEG-LS, 1999 год. Доступен по адресу: http://www.hpl.hp.com/research/info_theory/loco/HPL-98-193R1.pdf
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ СПЕКТРАЛЬНЫХ КОЭФФИЦИЕНТОВ СПЕКТРА АУДИОСИГНАЛА | 2014 |
|
RU2638734C2 |
| ЗАПОЛНЕНИЕ ШУМОМ ПРИ МНОГОКАНАЛЬНОМ КОДИРОВАНИИ АУДИО | 2014 |
|
RU2661776C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ИМПУЛЬСНЫХ И ОСТАТОЧНЫХ ЧАСТЕЙ ЗВУКОВОГО СИГНАЛА | 2022 |
|
RU2825308C2 |
| ОСНОВАННОЕ НА ЛИНЕЙНОМ ПРЕДСКАЗАНИИ КОДИРОВАНИЕ АУДИО С ИСПОЛЬЗОВАНИЕМ УЛУЧШЕННОЙ ОЦЕНКИ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТЕЙ | 2013 |
|
RU2651187C2 |
| АУДИО ДЕКОДЕР, АУДИО КОДЕР, СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ АУДИО СИГНАЛА, СПОСОБ КОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА, КОМПЬЮТЕРНАЯ ПРОГРАММА И АУДИО СИГНАЛ | 2009 |
|
RU2543302C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА, ИМЕЮЩЕГО ИМПУЛЬСОПОДОБНУЮ И СТАЦИОНАРНУЮ СОСТАВЛЯЮЩИЕ, СПОСОБЫ КОДИРОВАНИЯ, ДЕКОДЕР, СПОСОБ ДЕКОДИРОВАНИЯ И КОДИРОВАННЫЙ АУДИОСИГНАЛ | 2008 |
|
RU2439721C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УМЕНЬШЕНИЯ КОЛИЧЕСТВА КОНТЕКСТНЫХ МОДЕЛЕЙ ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ ФЛАГА ЗНАЧИМОСТИ КОЭФФИЦИЕНТА ПРЕОБРАЗОВАНИЯ | 2020 |
|
RU2783341C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2658883C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2021 |
|
RU2776910C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2615681C2 |
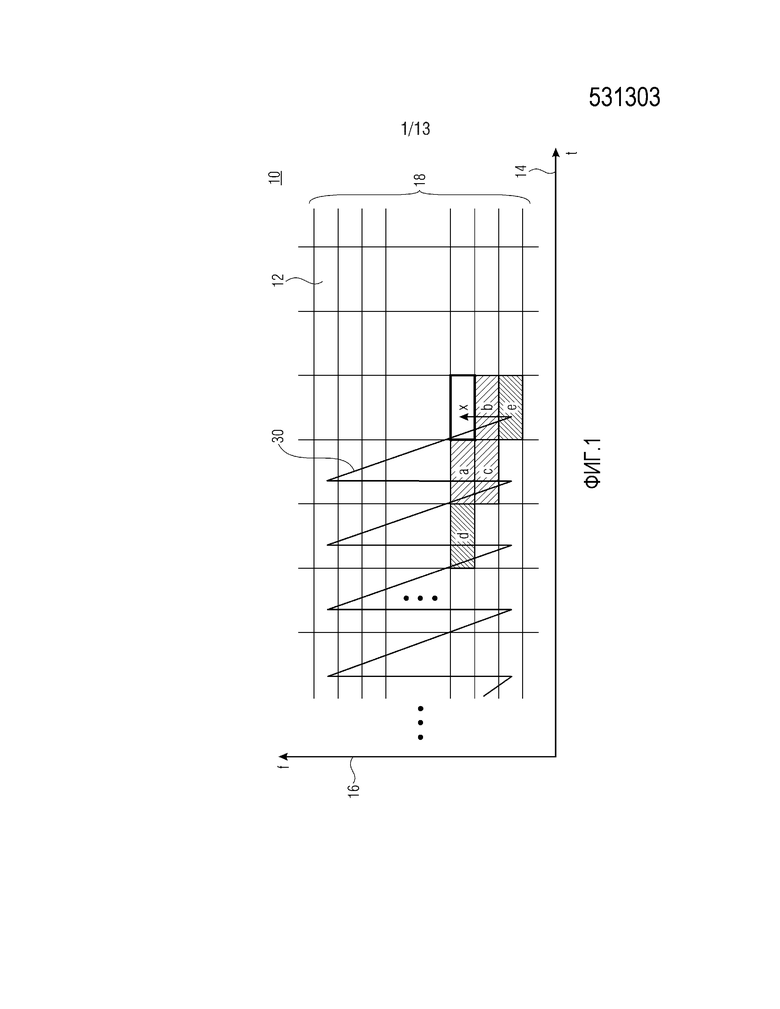
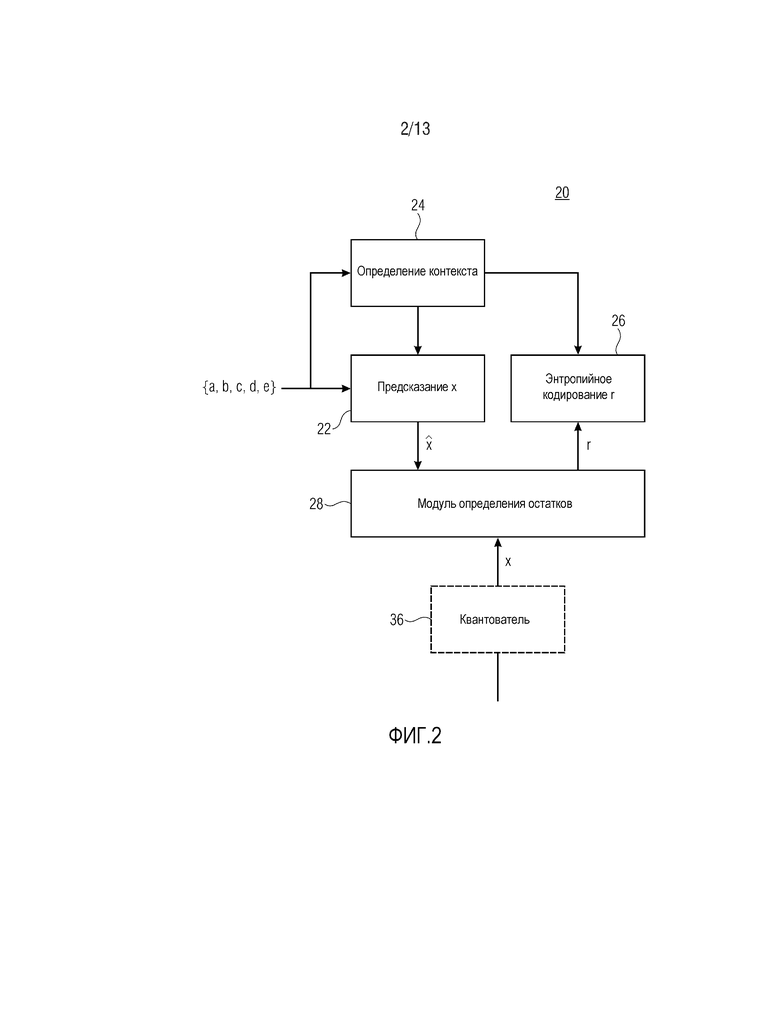

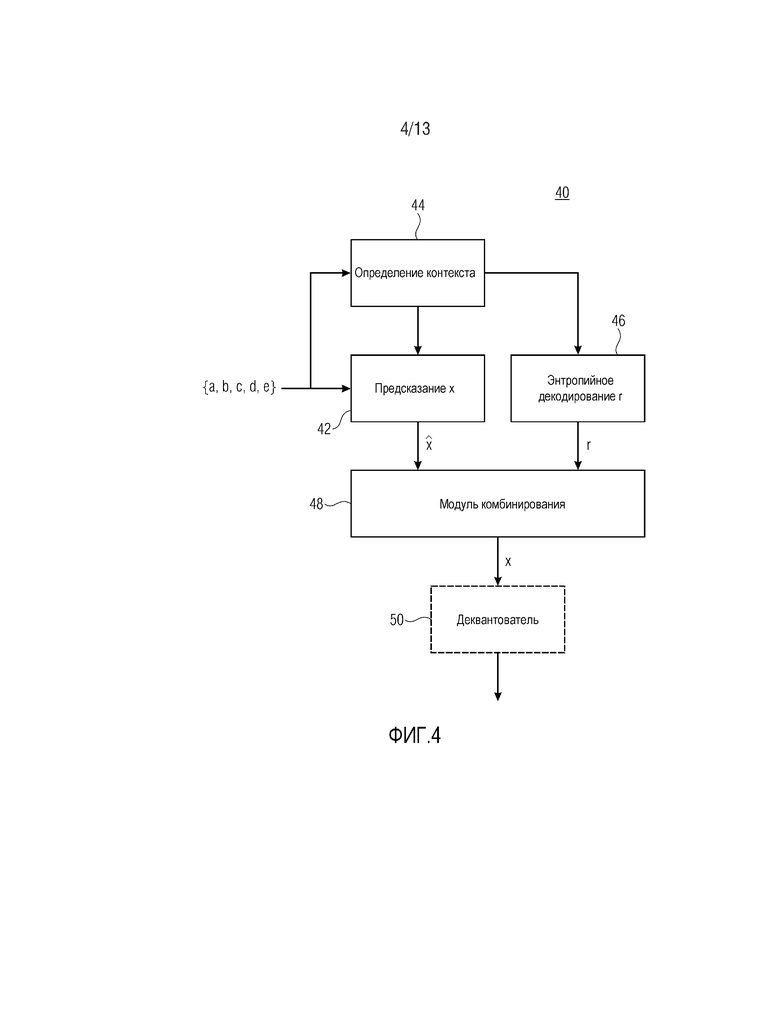
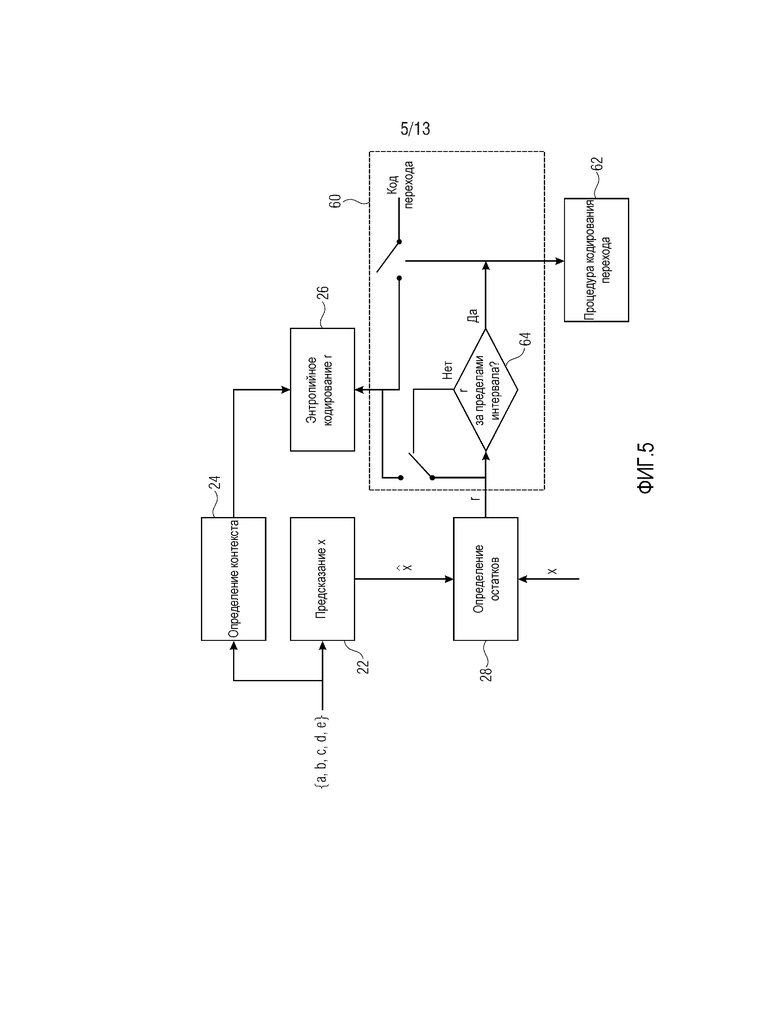
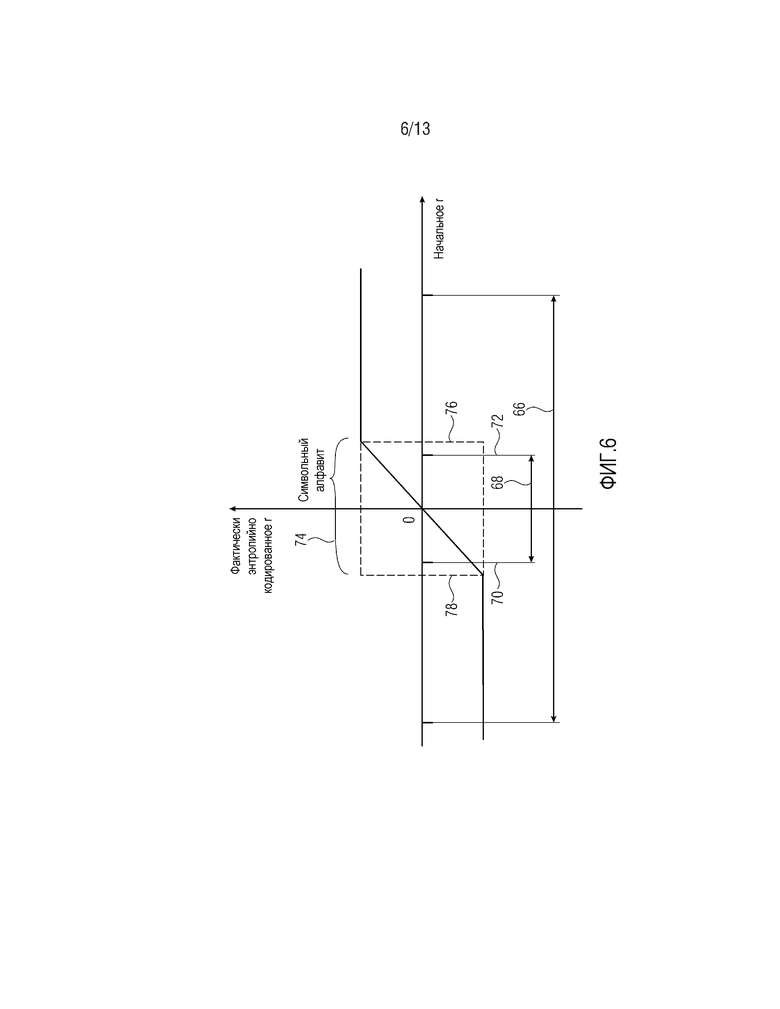
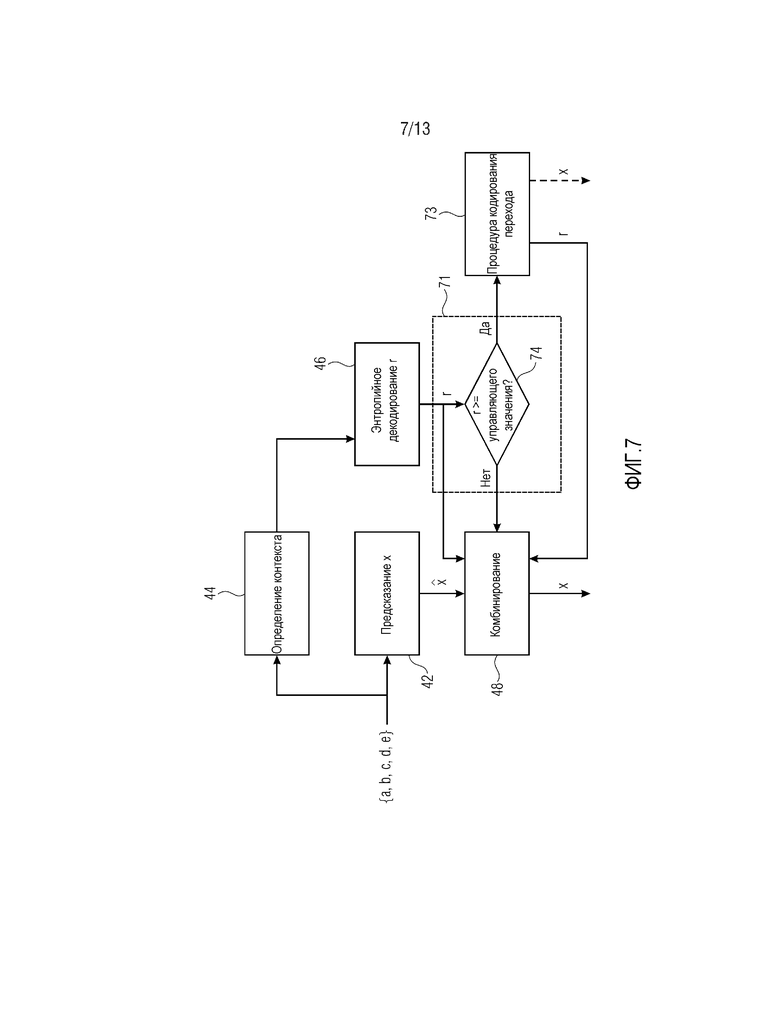
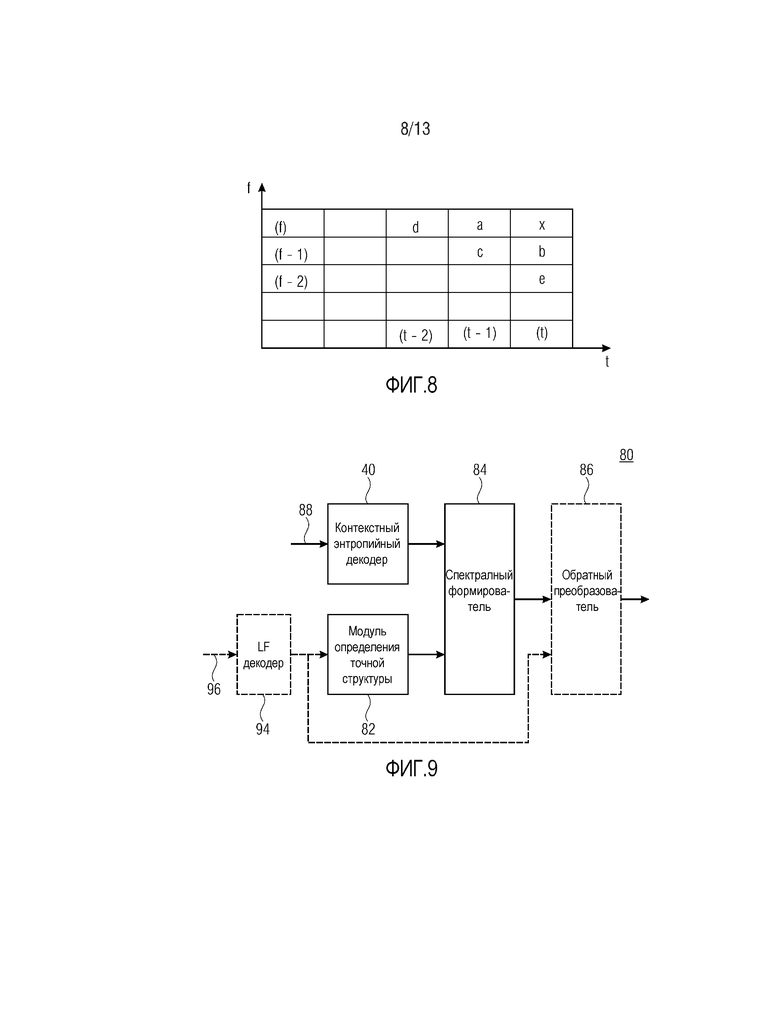
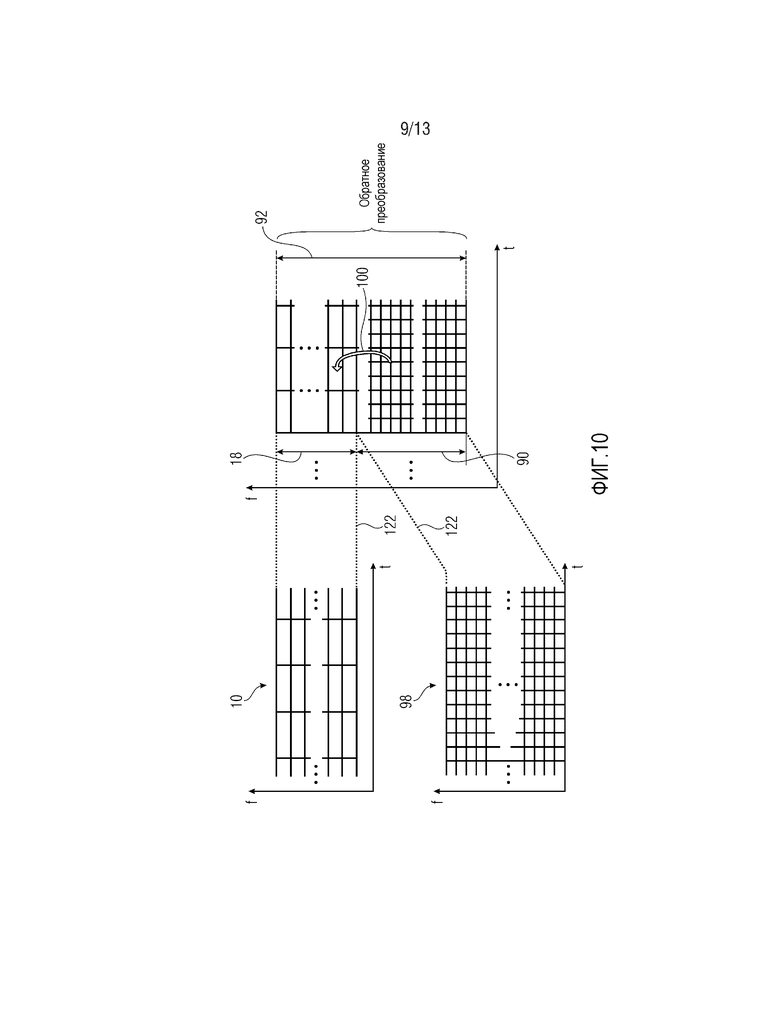
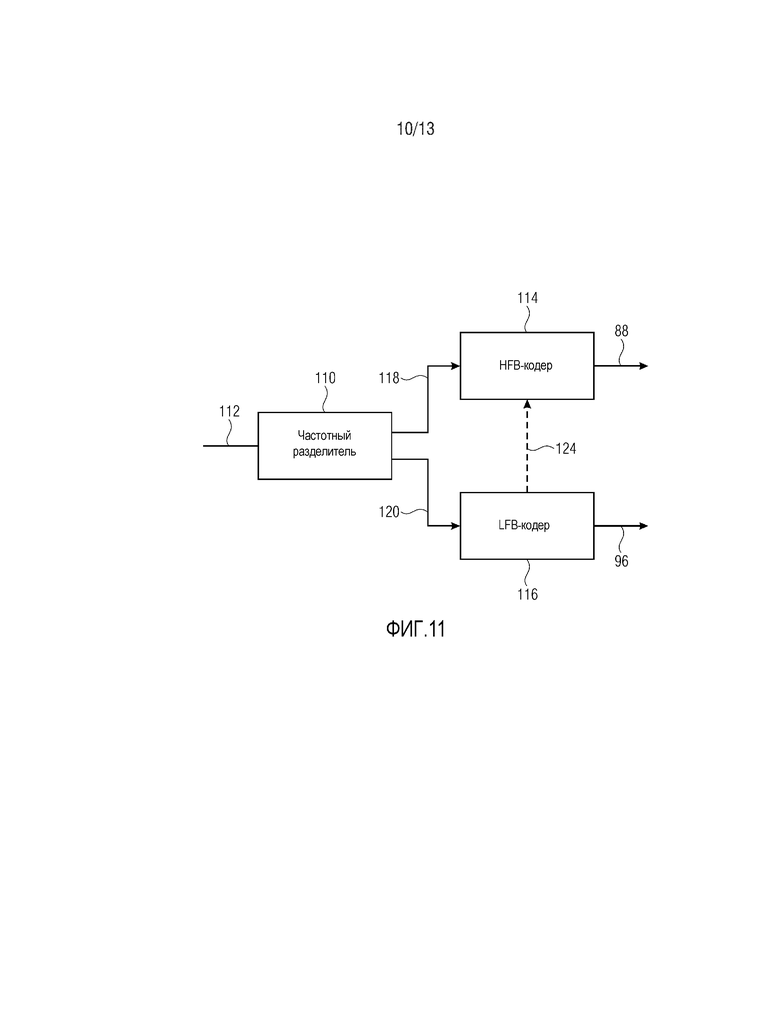
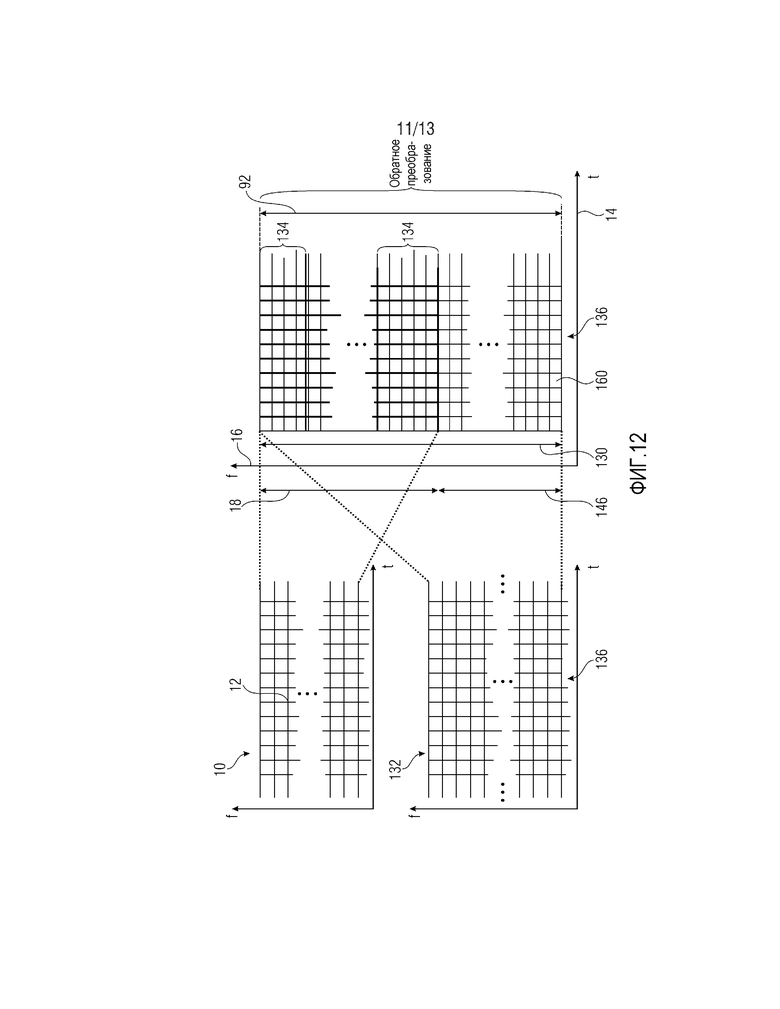
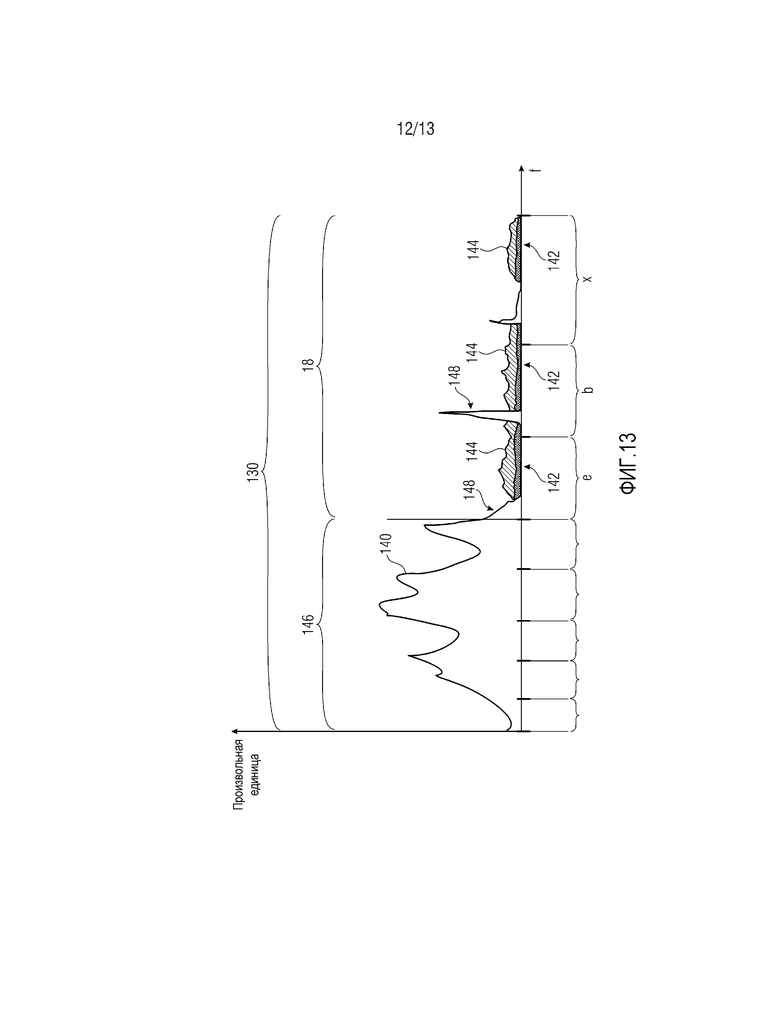
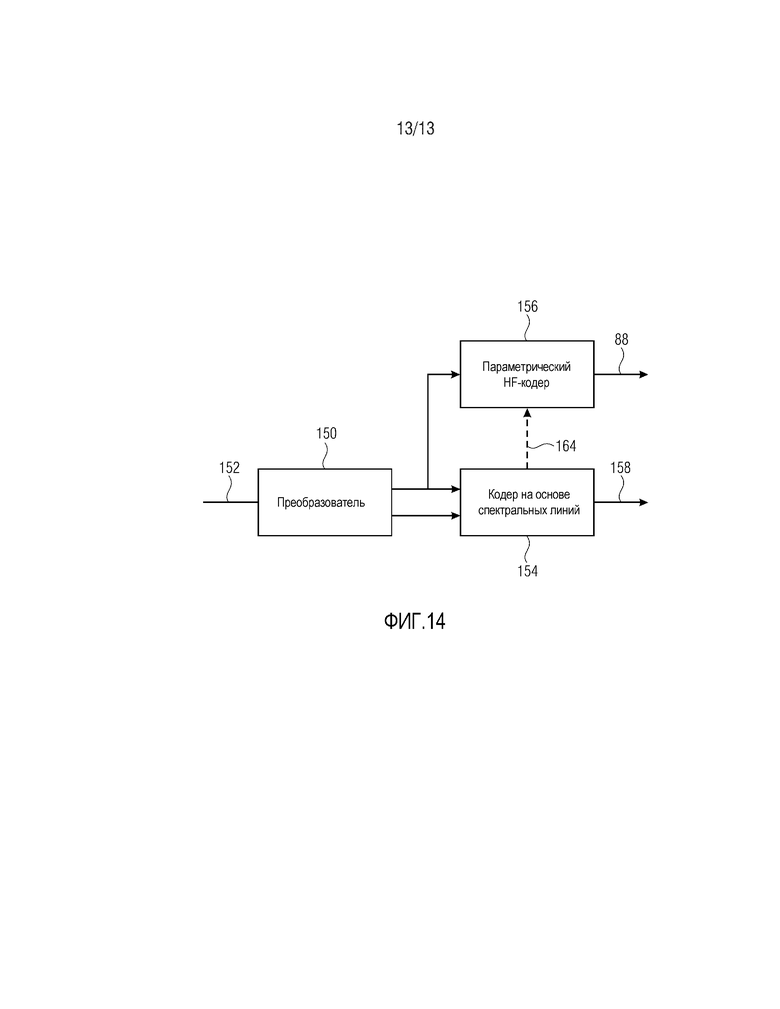
Изобретение относится к средствам для контекстного энтропийного кодирования выборочных значений спектральной огибающей. Технический результат заключается в повышении эффективности кодирования. Спектрально-временным методом предсказывают текущее выборочное значение спектральной огибающей, чтобы получать оцененное значение для текущего выборочного значения. Определяют контекст для текущего выборочного значения в зависимости от показателя для отклонения между парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения. Энтропийно декодируют значение остатка предсказания для текущего выборочного значения с использованием упомянутого определенного контекста. Комбинируют оцененное значение и значение остатка предсказания для того, чтобы получать текущее выборочное значение. 7 н. и 17 з.п. ф-лы, 14 ил.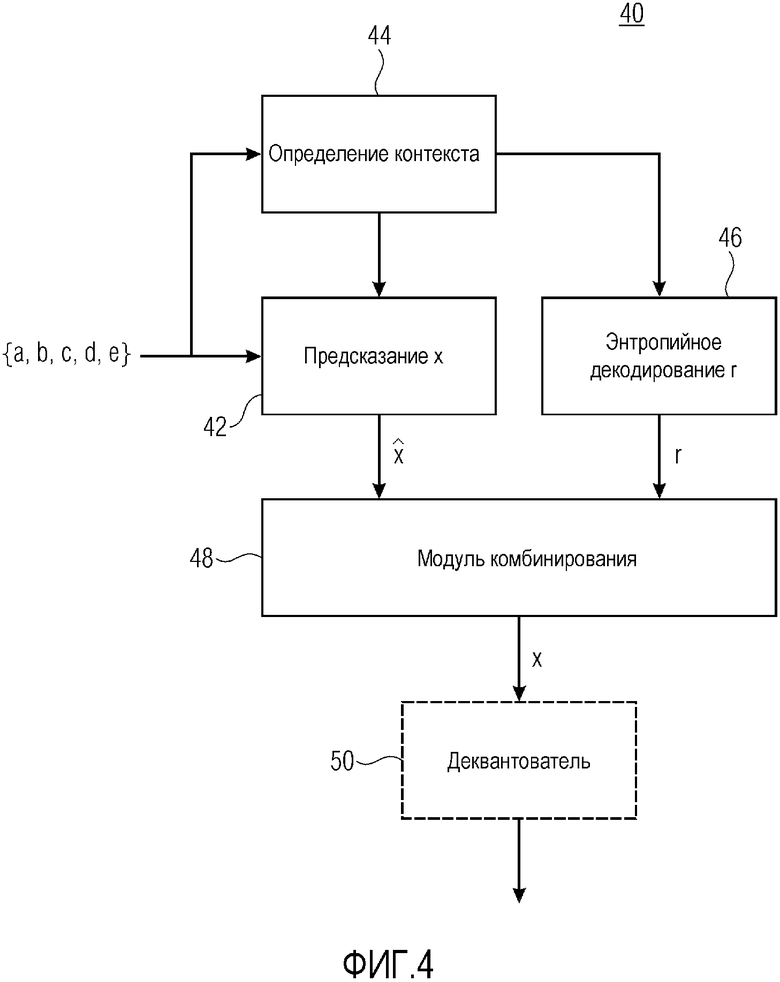
1. Контекстный энтропийный декодер для декодирования выборочных значений спектральной огибающей аудиосигнала, выполненный с возможностью:
спектрально-временным методом предсказывать текущее выборочное значение спектральной огибающей, чтобы получать оцененное значение для текущего выборочного значения;
определять контекст для текущего выборочного значения в зависимости от показателя для отклонения между парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения;
энтропийно декодировать значение остатка предсказания для текущего выборочного значения с использованием упомянутого определенного контекста; и
комбинировать оцененное значение и значение остатка предсказания для того, чтобы получать текущее выборочное значение.
2. Контекстный энтропийный декодер по п. 1, дополнительно выполненный с возможностью осуществлять спектрально-временное предсказание посредством линейного предсказания.
3. Контекстный энтропийный декодер по п. 1 или 2, дополнительно выполненный с возможностью использовать разность со знаком между парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения с тем, чтобы измерять отклонение.
4. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, дополнительно выполненный с возможностью определять контекст для текущего выборочного значения в зависимости от первого показателя для отклонения между первой парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения и второго показателя для отклонения между второй парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения, причем первая пара является соседней между собой по спектру, а вторая пара является соседней между собой по времени.
5. Контекстный энтропийный декодер по п. 4, дополнительно выполненный с возможностью спектрально-временным методом предсказывать текущее выборочное значение спектральной огибающей посредством линейного комбинирования уже декодированных выборочных значений первых и вторых пар.
6. Контекстный энтропийный декодер по п. 5, дополнительно выполненный с возможностью задавать коэффициенты линейной комбинации таким образом, что коэффициенты являются идентичными для разных контекстов, в случае если скорость передачи битов, на которой кодируется аудиосигнал, превышает предварительно определенное пороговое значение, и упомянутые коэффициенты задаются отдельно для разных контекстов, в случае если скорость передачи битов ниже предварительно определенного порогового значения.
7. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, дополнительно выполненный с возможностью, при декодировании выборочных значений спектральной огибающей, последовательно декодировать выборочные значения с использованием порядка декодирования, который проходит по выборочным значениям для каждого момента времени, при этом в каждый момент времени он идет от наименьшей к наибольшей частоте.
8. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, дополнительно выполненный с возможностью, при определении контекста, квантовать показатель для отклонения и определять контекст с использованием квантованного показателя.
9. Контекстный энтропийный декодер по п. 8, дополнительно выполненный с возможностью использовать функцию квантования при квантовании показателя для отклонения, которое является постоянным для значений показателя для отклонения за пределами предварительно определенного интервала, причем предварительно определенный интервал включает в себя нуль.
10. Контекстный энтропийный декодер по п. 9, в котором значения спектральной огибающей представляются как целые числа, и длина предварительно определенного интервала меньше или равна 1/16 числа представляемых состояний целочисленного представления значений спектральной огибающей.
11. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, дополнительно выполненный с возможностью переводить текущее выборочное значение, извлеченное посредством комбинации, из логарифмической области в линейную область.
12. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, при этом контекстный энтропийный декодер управляет числом контекстов, причем каждый контекст имеет ассоциированное распределение вероятностей, которое назначает каждому возможному значению значения остатка предсказания соответствующую вероятность, при этом контекстный энтропийный декодер дополнительно выполнен с возможностью, при энтропийном декодировании значений остатка предсказания, последовательно декодировать выборочные значения по порядку декодирования и использовать набор контекстно-индивидуальных распределений вероятностей, который является постоянным во время последовательного декодирования выборочных значений спектральной огибающей.
13. Контекстный энтропийный декодер по любому одному из предыдущих пунктов, дополнительно выполненный с возможностью, при энтропийном декодировании значения остатка предсказания, использовать механизм кодирования перехода в случае, если значение остатка предсказания находится за пределами предварительно определенного диапазона значений.
14. Контекстный энтропийный декодер по п. 13, в котором выборочные значения спектральной огибающей представляются как целые числа, и значение остатка предсказания представляется как целое число, и абсолютные значения границ интервала предварительно определенного диапазона значений ниже или равны 1/8 числа представляемых состояний значения остатка предсказания.
15. Параметрический декодер, содержащий:
контекстный энтропийный декодер для декодирования выборочных значений спектральной огибающей аудиосигнала по любому из предшествующих пунктов;
модуль определения точной структуры, выполненный с возможностью принимать значения спектральных линий из потока данных, причем значения спектральных линий выбираются спектрально с шагом спектральных линий спектрограммы аудиосигнала, с тем чтобы определять точную структуру упомянутой спектрограммы; и
спектральный формирователь, выполненный с возможностью формировать точную структуру согласно спектральной огибающей.
16. Параметрический декодер по п. 15, в котором модуль определения точной структуры выполнен с возможностью определять точную структуру спектрограммы с использованием по меньшей мере одного из:
формирования искусственного случайного шума,
повторного формирования спектра, и
декодирования на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии.
17. Параметрический декодер по п. 15 или 16, дополнительно содержащий декодер интервала нижних частот, выполненный с возможностью декодировать интервал нижних частот спектрограммы аудиосигнала, при этом контекстный энтропийный декодер, модуль определения точной структуры и спектральный формирователь имеют такую конфигурацию, в которой формирование точной структуры согласно спектральной огибающей выполняется в пределах спектрального расширения диапазона верхних частот для интервала нижних частот.
18. Параметрический декодер по п. 17, в котором декодер интервала нижних частот выполнен с возможностью определять точную структуру спектрограммы с использованием декодирования на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии или спектрального разложения декодированного аудиосигнала полосы низких частот временной области.
19. Параметрический декодер по п. 15 или 16, в котором модуль определения точной структуры выполнен с возможностью использовать декодирование на основе спектральных линий с использованием спектрального предсказания и/или извлечения контекста спектральной энтропии, с тем чтобы извлекать точную структуру спектрограммы аудиосигнала в первом частотном интервале, находить нулевые квантованные части точной структуры во втором частотном интервале, перекрывающем первый частотный интервал, и применять формирование искусственного случайного шума и/или повторное формирование спектра к нулевым квантованным частям, при этом спектральный формирователь выполнен с возможностью осуществлять формирование точной структуры согласно спектральной огибающей в нулевых квантованных частях.
20. Контекстный энтропийный кодер для кодирования выборочных значений спектральной огибающей аудиосигнала, выполненный с возможностью:
спектрально-временным методом предсказывать текущее выборочное значение спектральной огибающей, чтобы получать оцененное значение для текущего выборочного значения;
определять контекст для текущего выборочного значения в зависимости от показателя для отклонения между парой уже кодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения;
определять значение остатка предсказания на основе отклонения между оцененным значением и текущим выборочным значением; и
энтропийно кодировать значение остатка предсказания для текущего выборочного значения с использованием упомянутого определенного контекста.
21. Способ декодирования выборочных значений спектральной огибающей аудиосигнала с использованием контекстного энтропийного декодирования, содержащий этапы, на которых:
спектрально-временным методом предсказывают текущее выборочное значение спектральной огибающей, чтобы получать оцененное значение для текущего выборочного значения;
определяют контекст для текущего выборочного значения в зависимости от показателя для отклонения между парой уже декодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения;
энтропийно декодируют значение остатка предсказания для текущего выборочного значения с использованием упомянутого определенного контекста; и
комбинируют оцененное значение и значение остатка предсказания для того, чтобы получать текущее выборочное значение.
22. Способ кодирования выборочных значений спектральной огибающей аудиосигнала с использованием контекстного энтропийного кодирования, содержащий этапы, на которых:
спектрально-временным методом предсказывают текущее выборочное значение спектральной огибающей, чтобы получать оцененное значение для текущего выборочного значения;
определяют контекст для текущего выборочного значения в зависимости от показателя для отклонения между парой уже кодированных выборочных значений спектральной огибающей в спектрально-временной окрестности текущего выборочного значения;
определяют значение остатка предсказания на основе отклонения между оцененным значением и текущим выборочным значением; и
энтропийно кодируют значение остатка предсказания для текущего выборочного значения с использованием упомянутого определенного контекста.
23. Считываемый компьютером носитель данных, хранящий компьютерную программу, содержащую программный код для осуществления, при выполнении на компьютере, способа по п. 21.
24. Считываемый компьютером носитель данных, хранящий компьютерную программу, содержащую программный код для осуществления, при выполнении на компьютере, способа по п. 22.
| US 6978236 B1, 20.12.2005 | |||
| WO 00/45379 A2, 03.08.2000 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| RU 2011104002 A, 20.08.2012. | |||

