Техническое решение относится к области поиска аналогов коллекторов со схожими свойствами и заполнения пропуска пропущенных значений описательных атрибутов коллектора.
Выявление аналогичных коллекторов важно при планировании разработки нового месторождения либо при оценке неопределенностей разрабатываемого коллектора, в случае малого количества исходных данных. Обычно информация о новом районе ограничена или вообще отсутствует. Традиционно поиск аналогичных коллекторов ведется опытными геологами. Этот поиск зависит от наличия специалистов, а результаты во многом зависят от геологии местности и количества исходных данных.
Известно техническое решение для автоматического восстановления отсутствующих параметров месторождения для сопоставления с аналогами, опубликованное в патенте US9159022B2, опубл. 13.10.2015, Repsol SA, International Business Machines Corp. Описываемое решение включает систему извлечения параметров, интерактивно идентифицирующую управляющие ключевые параметры (CKP) в сохраненном списке месторождений/скважин и автоматически извлекает оценочное значение для отсутствующих значений параметров и выборочно заменяет иерархические параметры, хронологические параметры и параметры ранжирования. После чего производится отбор скважин-аналогов с учетом предыдущих шагов. Общим признаком с заявляемым изобретением является использование записей с параметрами месторождений.
Известно техническое решение опубликованное в журнале «SPE Economics & Management» - «New Approach to Identify Analogous Reservoirs» (https://www.onepetro.org/journal-paper/SPE-166449-PA), опубликовано в октябре 2014 года. Описываемое решение включает четыре шага: предварительную обработку данных, выбор ключевых параметров, многомерный анализ и ранжирование сходства. Первый шаг включает анализ и предварительную обработку данных. При выборе ключевых параметров определяются переменные, оказывающие наибольшее влияние на оцениваемый случай. При многомерном анализе применяется несколько методов, таких как анализ главных компонентов (PCA) и кластерный анализ. На этапе ранжирования по сходству применяется функцию подобия к группе ранее выбранных «аналогичных резервуаров», создавая рейтинг сходства аналогичных резервуаров. Общим признаком с заявляемым изобретением является использование записей с параметрами месторождений.
Недостатком описанных подходов является меньшая точность определения месторождений аналогов, отсутствие имплементации наработанного экспертного опыта.
Техническая задача – создание способа (средства) для поиска аналогов месторождения и способа обучения классификатора для поиска аналогов месторождения с высокой точностью, эффективностью, учитывающее экспертный опыт.
Технический результат – повышение точности и эффективности поиска аналогов месторождения, повышение точности классифицирования схожести (является аналогом или нет) месторождений. Заявленный технический результат достигается всеми заявленными вариантами (вариациями) технического решения.
Компьютерно-реализуемый способ поиска аналогов месторождений, включает по крайней мере следующие шаги: получают первую и вторую выборку записей из по крайней мере одной базы данных месторождений и их атрибутов, причем первая выборка записей содержит месторождения первого типа, описываемые первой группой атрибутов, а вторая выборка записей содержит месторождения второго типа, описываемые второй группой атрибутов; формируют первую размечаемую выборку путём: группировки записей по общности осадконакопления в первой выборке; разбиения групп записей Gi первой выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt; формируют вторую размечаемую выборку путём: группировки записей по общности осадконакопления во второй выборке; разбиения групп записей Gi второй выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе j Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt; производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи в подгруппе эксперты помечают характеризует ли данная запись месторождение, которое является аналогом целевого месторождения в данной подгруппе; формируют первую и вторую обучающие выборки из соответственно первой и второй размеченной выборки путём: отбора только тех записей, которые помечены в качестве аналогов целевого месторождения в подгруппе двумя и более экспертами; восстановления пропущенных значений атрибутов в записях выборки; преобразования атрибутов записей выборки для использования классификатором градиентного бустинга; производят обучение первого классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей первой обучающей выборки; производят обучение второго классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей второй обучающей выборки; получают от пользователя тип месторождения и значения его атрибутов, для определения его аналогов; производят преобразование полученных атрибутов месторождения для использования классификатором и осуществляют поиск аналогов с использованием обученного классификатора, соответствующего типу месторождения; предъявляют пользователю информацию о результатах поиска. В некоторых вариантах реализации технического решения первым типом месторождения является терригенное месторождение, а вторым типом - карбонатное месторождение.
В некоторых вариантах реализации технического решения первая группа атрибутов включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов (structural_setting, main_lithology, main_depositional_system, main_depositional_environment, porosity_type_main, gross_thickness_average, net_pay_thickness_average, porosity_matrix_average, permeability_air_average, water_saturation_average, tectonic_regime).
В некоторых вариантах реализации технического решения вторая группа атрибутов включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов, основная структура карбонатных пород по r.j. dunham modified 1971, литогенетический тип коллектора, тип трещинного коллектора (structural_setting, main_lithology, main_depositional_system, main_depositional_environment, porosity_type_main, gross_thickness_average, net_pay_thickness_average, porosity_matrix_average, permeability_air_average, water_saturation_average, tectonic_regime, tectonic_regime, main depositional texture for carbonate, diagenetic_reservoir_type, fractured_reservoir_type).
В некоторых вариантах реализации технического решения восстановление пропущенных значений атрибутов осуществляют с использованием метода градиентного бустинга
В некоторых вариантах реализации технического решения восстановление пропущенных значений атрибутов осуществляют с использованием алгоритма машинного обучения Random Forest.
В некоторых вариантах реализации технического решения для градиентного бустинга используется Catboost или xgboost или Adaboost.
В некоторых вариантах реализации технического решения для выбора гиперпараметров градиентного бустинга используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
В некоторых вариантах реализации технического решения для выбора гиперпараметров алгоритма машинного обучения Random Forest используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
В некоторых вариантах реализации технического решения компьютерно-реализуемый способ обучения классификатора для поиска аналогов месторождений, включает по крайней мере следующие шаги:
- получают выборку записей из по крайней мере одной базы данных месторождений и их атрибутов, причем выборка записей содержит месторождения одного типа, описываемые группой атрибутов; формируют размечаемую выборку путём: группировки записей по общности осадконакопления в выборке; разбиения групп записей Gi выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt; производят разметку размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи в подгруппе эксперты помечают характеризует ли данная запись месторождение, которое является аналогом целевого месторождения в данной подгруппе; формируют обучающую выборку из размеченной выборки путём: отбора только тех записей, которые помечены в качестве аналогов целевого месторождения в подгруппе двумя и более экспертами; восстановления пропущенных значений атрибутов в записях выборки; преобразования атрибутов записей выборки для использования классификатором градиентного бустинга; производят обучение классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей обучающей выборки.
В некоторых вариантах реализации технического решения типом месторождения является терригенное месторождение или карбонатное месторождение.
В некоторых вариантах реализации технического решения группы атрибутов для терригенных месторождений включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов.
В некоторых вариантах реализации технического решения группа атрибутов для карбонатных месторождений включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов, основная структура карбонатных пород по r.j. dunham modified 1971, литогенетический тип коллектора, тип трещинного коллектора.
В некоторых вариантах реализации технического решения компьютерно-реализуемый способ поиска аналогов месторождений, выполненный с использованием способа обучения классификатора для поиска аналогов месторождений описанного ранее, включает по крайней мере следующие шаги: Получают выборку записей терригенных месторождений и обучают первый классификатор для поиска аналогов месторождений; Получают выборку записей карбонатных месторождений и обучают второй классификатор для поиска аналогов месторождений; Получают от пользователя тип месторождения и значения его атрибутов, для определения его аналогов; Производят преобразование полученных атрибутов месторождения и осуществляют поиск аналогов с использованием обученного первого или второго классификатора, соответствующего типу месторождения; Предъявляют пользователю информацию о результатах поиска.
В некоторых вариантах реализации технического решения система для поиска аналогов месторождений, включает по крайней мере один процессор, оперативную память, и машиночитаемые инструкции для выполнения способа поиска аналогов согласно способу описанному ранее.
В некоторых вариантах реализации технического решения система для обучения классификатора для поиска аналогов месторождений, включающая по крайней мере один процессор, оперативную память, и машиночитаемые инструкции для выполнения способа обучения классификатора для поиска аналогов месторождений согласно способу, описанному ранее.
В некоторых вариантах реализации технического решения машиночитаемый носитель, содержит машинные инструкции способа поиска аналогов согласно вариантам реализации описанным ранее, выполненный с возможностью чтения данных инструкций и исполнения их процессором.
Машиночитаемый носитель, содержит машинные инструкции способа обучения классификатора для поиска аналогов месторождений согласно способу, описанному ранее, выполненный с возможностью чтения данных инструкций и исполнения их процессором.
Все описанные в данном техническом решении шаги способа (а так же все шаги/действия что указаны на фиг.1 – 3) могут выполняться процессором (одним или более), который загружает инструкции и данные из памяти (ОЗУ, ПЗУ) и производит их выполнение/обработку.
На фиг. 1 показан примерный вариант осуществления способа обучения классификатора в одном из вариантов реализации.
На фиг. 2 показан примерный вариант осуществления поиска аналога месторождения.
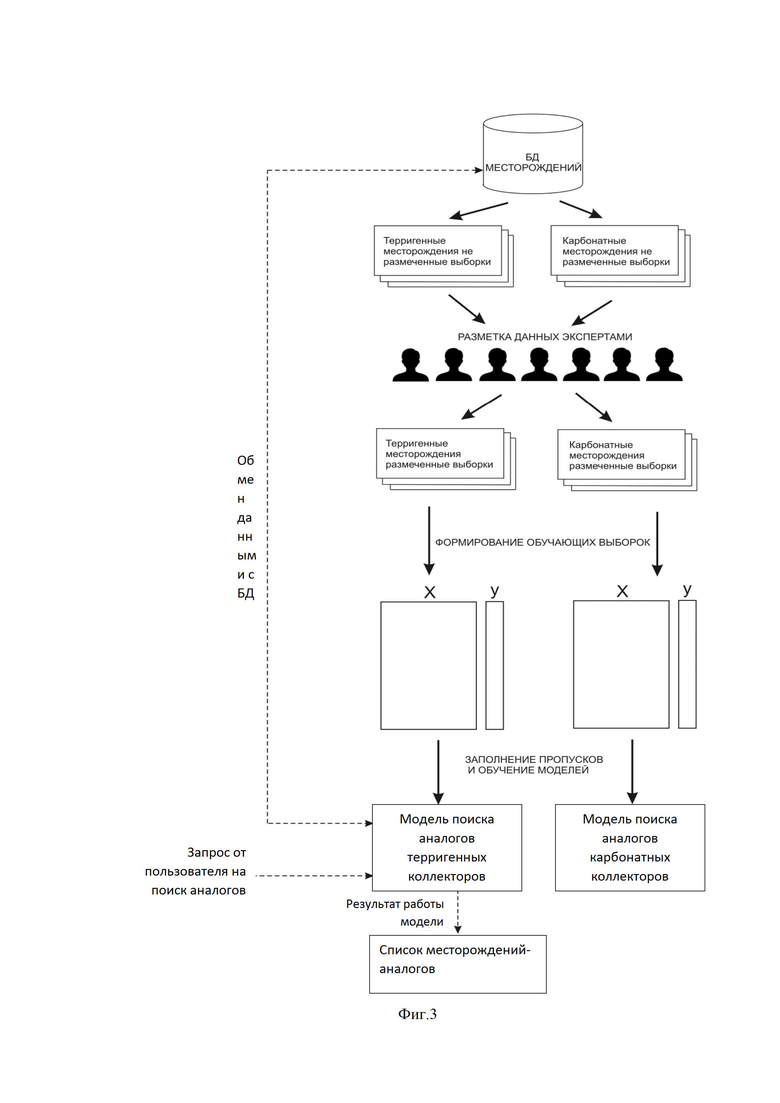
На фиг. 3 показана иллюстративная общая схема технического решения, показывающая все этапы работы (выполнения, исполнения), согласно одному из вариантов реализации.
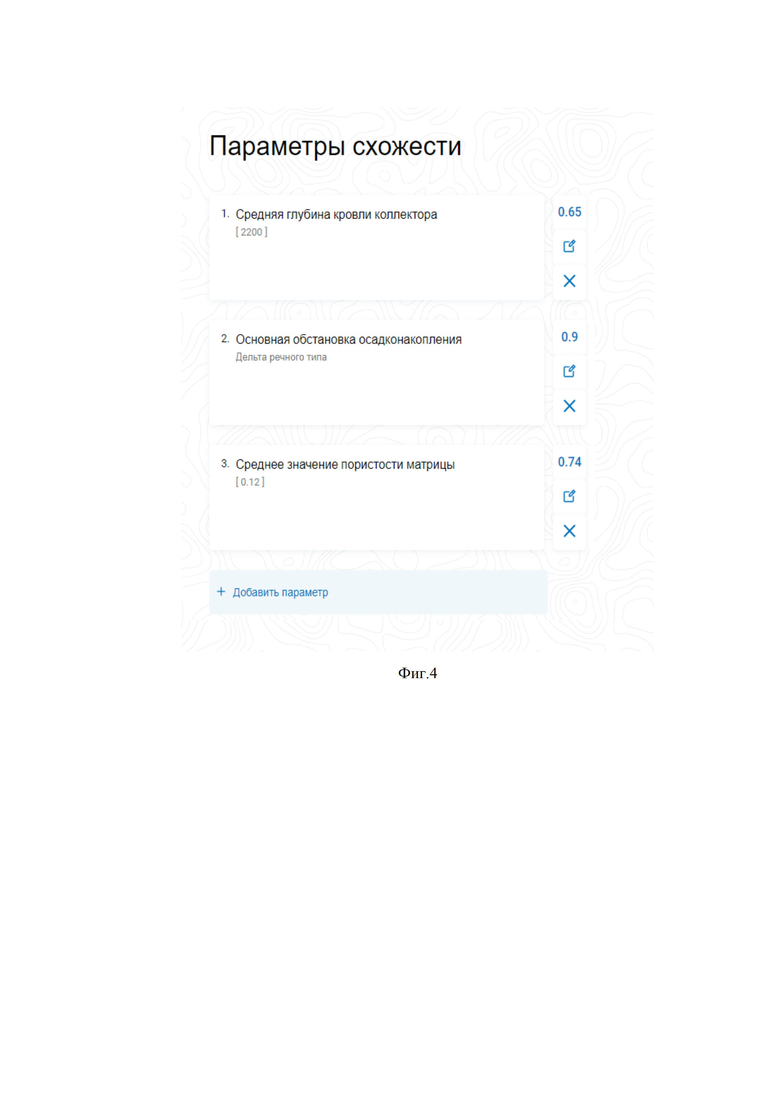
На фиг. 4 показан иллюстративный пример пользовательского интерфейса с введенными атрибутами месторождения, для которого будет производиться поиск аналогов.
На фиг. 5 показан иллюстративный пример пользовательского интерфейса отображения результатов поиска аналогов, введенного пользователем месторождения.
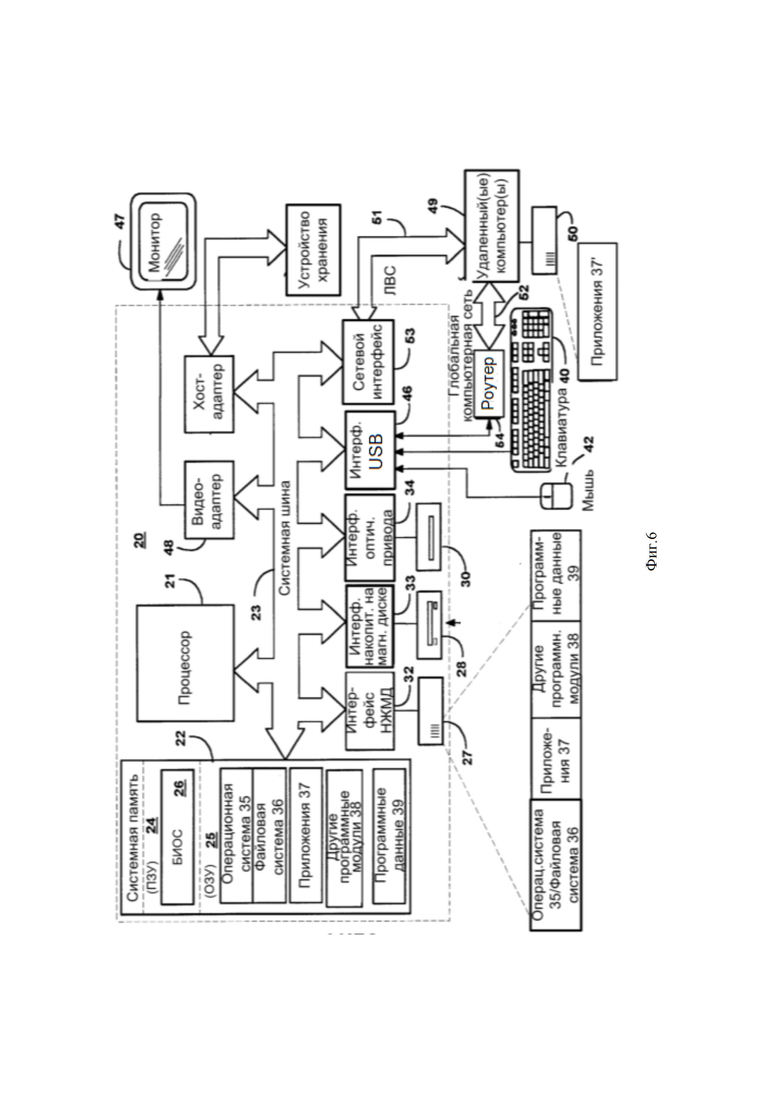
На фиг. 6 показан иллюстративный пример системы, используемой для выполнения (исполнения) технического решения, согласно описанным вариантам реализации.
Ниже даны некоторые термины и их определения, используемые в рамках описываемого технического решения.
По литологическому составу коллекторами нефти и газа являются терригенные (пески, алевриты, песчаники, алевролиты и некоторые глинистые породы), карбонатные (известняки, мел, доломиты), вулканогенно- осадочные и кремнистые породы.
Карбонатные коллекторы отличаются от терригенных по характеру происходящих в них преобразований в постседиментационный период.
Классификация Dunham – это классификация, позволяющая разделить карбонатный коллектор на породы в зависимости от долевого соотношения карбонатных зерен и матрикса. Классификации Dunham была первоначально разработана R.J. Dunham в 1962 году, и впоследствии модифицирована Embry и Klovan в 1971 году, чтобы дополнительно включать в себя крупнозернистые известняки и отложения, которые были органически связаны во время осаждения.
Бустинг (англ. boosting — усиление) — композиционный метаалгоритм машинного обучения, применяется, главным образом, для уменьшения смещения, а также дисперсии в обучении с учителем. Также определяется как семейство алгоритмов машинного обучения, преобразующих слабые обучающие алгоритмы к сильным.
Random forest (с англ. — «случайный лес») — алгоритм/способ машинного обучения, заключающийся в использовании комитета (ансамбля) решающих деревьев. Алгоритм/способ сочетает в себе две основные идеи: метод бэггинга Бреймана, и метод случайных подпространств. Алгоритм/способ применяется для задач классификации, регрессии и кластеризации. Основная идея заключается в использовании большого ансамбля решающих деревьев, каждое из которых само по себе даёт очень невысокое качество классификации, но за счёт их большого количества результат получается хорошим.
Функция потерь (лосс функция) — функция, которая в теории статистических решений характеризует потери при неправильном принятии решений на основе наблюдаемых данных.
В машинном обучении гиперпараметр — это параметр, значение которого используется для управления процессом обучения.
Кросс - валидация, перекрёстная проверка (кросс-проверка, скользящий контроль, англ. cross-validation) - метод оценки аналитической модели и её поведения на независимых данных. При оценке модели имеющиеся в наличии данные разбиваются на k частей. Затем на k−1 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется k раз; в итоге каждая из k частей данных используется для тестирования. В результате получается оценка эффективности выбранной модели с наиболее равномерным использованием имеющихся данных.
Компьютерно-реализуемый способ поиска аналогов месторождений, включает по крайней мере следующие шаги:
Получают первую и вторую выборку (записей) из по крайней мере одной базы данных месторождений и их атрибутов.
Причем первая выборка (записей) содержит месторождения первого типа, например терригенного, описываемые первой группой атрибутов, а вторая выборка (записей) содержит карбонатные месторождения, описываемые второй группой атрибутов.
В качестве атрибутов первой группы месторождений (терригенных) могут использоваться, в частности:
структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов.
В качестве атрибутов второй группы месторождений, например карбонатных, могут использоваться атрибуты терригенных и по крайней мере следующие дополнительный атрибуты: основная структура карбонатных пород по r.j. dunham modified, 1971, литогенетический тип коллектора, тип трещинного коллектора.
В общем виде на данном шаге (фиг.1, 101) получают выборку записей («строки записей таблицы») из базы данных месторождений и ее атрибуты/группы атрибутов («столбцы записей таблицы»).
Значение каждого атрибута характеризует все месторождение (или пласт месторождения) в целом.
В качестве базы данных (хранилища данных) может выступать любой источник данных, но не ограничиваясь, файл, плоский файл, реляционная, иерархическая, объектно-ориентированная база данных, key-value хранилище. Используемое хранилище/база данных не влияют на суть технического решения. Используемые хранилища могут быть локальными или внешними/удаленными (remote).
Группируют записи первой и второй выборки по общности осадконакопления
Группировка записей выборки (формируются группы записей выборки по общности осадконакопления) производится (осуществляется) по полю (атрибуту) основная обстановка осадконакопления (фиг.1, 102).
В некоторых вариантах реализации технического решения группировка может производиться средствами СУБД, например, при помощи команды GROUP BY языка SQL или любыми аналогичными средствами.
Формируют первую размечаемую выборку из сгруппированных записей первой выборки, причем каждую группу Gi разбивают на подгруппы Gij размером Gij_cnt и для каждой подгруппы Gij задают случайным образом целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt.
Формируют вторую размечаемую выборку из сгруппированных записей второй выборки, причем каждую группу Gi разбивают на подгруппы Gij размером Gij_cnt и для каждой подгруппы Gij задают случайным образом целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt.
В некоторых вариантах реализации технического решения индексы (итераторы) i,j являются целыми числами (натуральными), большими нуля и ограничены только объемом выборки (количеством записей) базы данных (могут быть например, 200, 300, 400, 500, но не ограничиваясь).
В некоторых вариантах реализации технического решения Gi_cnt, Gij_cnt являются целыми числами (натуральными), большими или равными нулю (могут быть например, 5, 10, 100, но не ограничиваясь).
Например, в выборке может находится 200 записей, причем 20 записей первой группы осадконакопления, 64 записи второй группы осадконакопления и 116 записей третьей группы осадконакопления. Таким образом индекс(итератор) i (Gi) будет находится в диапазоне от 1 до 3, Gi_cnt = 3. Пусть задана функциональная зависимость в виде целочисленного деления на константу Kst = 5. Тогда каждая группа Gi будет разбита на подгруппы: G1 – 4 подгруппы, G2 – 12 подгрупп, G3 – 23 подгруппы. Таким образом индекс(итератор) j для G1 находится в диапазоне 1..4, для G2 – 1..12, для G3 – 1..23. Следовательно максимальное значение для итераторов в данном примере будет i =3, j = 23
В общем виде на данном шаге формируют размечаемую выборку из сгруппированных записей выборки, причем каждую группу Gi разбивают на подгруппы Gij размером Gij_cnt и для каждой подгруппы Gij задают случайным образом целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt (фиг.1, 103).
В некоторых вариантах реализации функциональная зависимость Gij_cnt описывается как количество записей в группе Gi_cnt деленное на некоторую заданную пользователем или разработчиком системы константу Kst (например, Kst может находится в диапазоне от [2..Gi_cnt-1]).
В некоторых вариантах реализации функциональная зависимость Ki имеет логарифмический вид Ki = Ln(Gi_cnt). Для функциональной зависимости могут использоваться любые функции и их комбинации, дающие итоговый целочисленный результат. В некоторых вариантах реализации в качестве функциональной зависимости может использоваться генератор случайных чисел с ограничением диапазона выдаваемых значений [2..Gi_cnt-1].
В некоторых вариантах реализации формируют первую/вторую размечаемую выборку путём: группировки записей по общности осадконакопления (в соответствующей) первой/второй выборке; разбиения групп записей Gi первой/второй выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе Gij целевое месторождение Target_Gij, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt.
Производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи эксперты выбирают месторождения-аналоги целевого месторождения.
В общем виде в данном шаге производят разметку размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи эксперты (эксперты-геологи) выбирают месторождения-аналоги целевого месторождения (фиг.1, 104).
В некоторых вариантах реализации технического решения для эксперта (эксперта-геолога) (их может быть два и более) отображается интерфейс, где выводится (отображается) размечаемые (первая и вторая) выборки. Так как выборки состоят из подгрупп Gij для каждой из которых назначено свое целевое месторождение, то в интерфейсе эксперта-геолога отдельно выделяется (отображается, помечается) целевое месторождение, для которого эксперты-геологи отмечают/устанавливают (в интерфейсе) месторождения-аналоги в рамках подгруппы Gij. Формат отображения данных, целевого месторождения не влияют на суть технического решения. Эксперты-геологи могут работать как в одном, едином интерфейсе, так и отдельно друг от друга. Работы по разметке могут вестись как последовательно (каждый следующий эксперт начинает после завершения предыдущего) так и параллельно, но независимо друг от друга (эксперты-геологи не видят/не умеют доступа к ответам других экспертов-геологов).
В некоторых вариантах реализации технического решения производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи k в подгруппе Gij эксперты помечают характеризует ли данная запись k месторождение, которое является аналогом целевого месторождения Target_Gij в данной подгруппе Gij.
В некоторых вариантах реализации технического решения производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждого месторождения (характеризующей его записи) в подгруппе Gij эксперты помечают является оно аналогом целевого месторождения Target_Gij в данной подгруппе Gij.
Данные о месторождениях-аналогах целевого месторождения (подгруппы Gij) могут храниться в различных форматах данных (числовые, логические, текстовые) и должны однозначно показывать (быть связаны) с подгруппой Gij и целевым месторождением данной подгруппы. В итоге по факту разметки получаются первая и вторая размеченные выборки, где для каждой подгруппы Gij указаны аналоги целевого месторождения.
Формируют первую обучающую выборку из первой размеченной выборки и вторую обучающую выборку из второй размеченной выборки путем отбора только тех записей, в которых аналоги в одной и той же записи совпали у двух и более экспертов
В общем виде на данном шаге формируют обучающую выборку из размеченной выборки путем отбора только тех записей, в которых аналоги в одной и той же записи совпали у двух и более экспертов (фиг.1, 105).
После этапа разметки первой и второй выборки двумя или более экспертами-геологами происходит отбор записей, где мнения двух и более экспертов-геологов совпали. Если одно и то же месторождение в группе Gij было отмечено как аналог целевого месторождения двумя и более экспертами, то запись, включающая данное месторождение, попадет в обучающую выборку.
Восстанавливают пропущенные значения атрибутов в первой и второй обучающей выборки.
В общем виде на данном шаге восстанавливают пропущенные значения атрибутов в обучающей выборке (фиг.1, 106).
В некоторых случаях данные в выборке могут содержать пропущенные значения атрибутов. Для более эффективной работы необходимо заполнить/восстановить эти пропущенные значения.
Одни и те же виды моделей машинного обучения могут требовать различные предположения, веса или скорости обучения для различных видов данных. Эти параметры называются гиперпараметрами и их следует настраивать так, чтобы модель могла оптимально решить задачу обучения. Для этого находится кортеж гиперпараметров, который даёт оптимальную модель, оптимизирующую заданную функцию потерь на заданных независимых данных.
Для каждого из атрибутов выборки (столбцов таблицы) производилось обучение модели с использованием градиентного бустинга (например, CatBoost, xgBoost, Adaboost и д.р.) и алгоритма машинного обучения Random Forest, на вход каждой модели которых подавались все остальные атрибуты выборки, кроме тех, значения которых необходимо восстановить (предсказать).
Так, например, если у нас имеется выборка, включающая следующие атрибуты: a, b, c, d, e, и имеются записи в которых пропущены значения атрибута b, то для обучения указанных моделей будут использоваться атрибуты a, c, d, e для предсказания/восстановления значения b. После обучения для каждой из моделей определяют величину ошибки при восстановлении/предсказании пропущенного значения атрибута. Для дальнейшей обработки оставляют (используют) ту модель, где величина ошибки наименьшая.
В качестве метрик качества может использоваться среднеквадратичная ошибка (RMSE) и относительная ошибка (MAPE):
Для числовых атрибутов в качестве функции потерь (лосс функции) используется среднеквадратичная ошибка MSE, а метрика – среднеквадратичное отклонение RMSE.
Для категориальных атрибутов (например, структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, тектонический режим формирования комплексов. основная структура карбонатных пород по r.j. dunham modified, 1971, литогенетический тип коллектора, тип трещинного коллектора) используется мультилейбл softmax, а метрика – accuracy.
Softmax - это обобщение логистической функции для многомерного случая. Функция Softmax применяется в машинном обучении для задач классификации, когда количество возможных классов больше двух.
Для выбора гиперпараметров градиентного бустинга и Random Forest в некоторых вариантах реализации технического решения используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции (Randomized Search). Затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется (используется) поиск по сетке (или вариация параметров) Grid Search.
В некоторых вариантах реализации технического решения при обучении модели используется кросс-валидация.
Производят преобразование атрибутов записей первой обучающей выборки и второй обучающей выборки
В общем виде на данном шаге производят преобразование атрибутов записей обучающей выборки (фиг.1, 107).
Преобразование атрибутов записей первой и второй обучающей выборки производится (осуществляется следующим образом):
- для категориальных признаков проверяют (осуществляют, смотрят) соответствие категории у пары месторождений (формируются новые записи в количестве равном 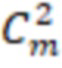 сочетаний без повторений, где m-количество месторождений в обучающей выборке). Если категории одинаковые, новый признак устанавливается = 1 (или true для логических типов данных), если разные = 0 (false);
сочетаний без повторений, где m-количество месторождений в обучающей выборке). Если категории одинаковые, новый признак устанавливается = 1 (или true для логических типов данных), если разные = 0 (false);
- для числовых атрибутов формируют и вычисляют новый признак равный модулю разности значений соответствующего признака у пары месторождений, таким образом для каждой пары числовых атрибутов x и y посчитан новый атрибут по следующей формуле:
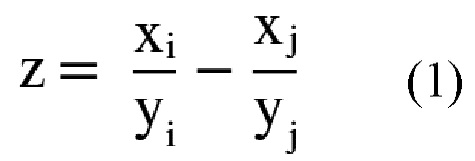
где xi, xj – значения признака “x” пары месторождений i, j;
yi, yj – значения признака “y” пары месторождений i, j.
Таким образом, будет вычислено 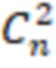 (сочетания без повторений из n по 2, где n – количество числовых признаков) пар признаков.
(сочетания без повторений из n по 2, где n – количество числовых признаков) пар признаков.
Предположим, что у нас четыре числовых атрибута a, b, c, d, то будут рассмотрены (вычислены) модули разности у следующих пар атрибутов: (a, b); (a, c); (b, c); (a, d); (b;d); (c;d). Для каждой пары атрибутов будет вычислен новый атрибут, например, для пары (b,c):
Z = 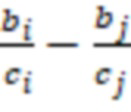
В некоторых вариантах реализации преобразованные записи выборки сохраняют в хранилище данных для последующего использования производят обучение первого классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей первой обучающей выборки,
производят обучение второго классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей второй обучающей выборки.
В общем виде на данном шаге производят обучение классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей обучающей выборки (фиг.1, 108).
Преобразованные атрибуты записей первой обучающей выборки (соответствующей терригенным месторождениям) и второй обучающей выборки (соответствующей карбонатным месторождениям) подаются на вход соответствующего классификатора с (каждый классификатор обучается раздельно на своей обучающей выборке) и производят обучение классификатора методом градиентного бустинга. На вход классификатора подаются пары месторождений с указанием являются ли данные месторождения аналогами по отношению друг к другу или нет.
В качестве используемых библиотек/алгоритмов/способов градиентного бустинга могут использоваться Catboost, xgboost, Adaboost и другие.
Для выбора гиперпараметров градиентного бустинга в некоторых вариантах реализации технического решения используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции (Randomized Search). Затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется (используется) поиск по сетке (или вариация параметров) Grid Search.
В некоторых вариантах реализации технического решения при обучении классификатора используется кросс-валидация.
Получают от пользователя тип месторождения и значения его атрибутов для определения его аналогов.
На данном этапе (фиг.2, 203) пользователь вводит имеющиеся у него данные о месторождении, аналоги которого он хочет найти (фиг.4). Пользователь может ввести как часть значений атрибутов, так и все значения атрибутов в соответствии с описанными ранее списками атрибутов для каждого типа месторождения. Ввод может осуществляться как при помощи средств ввода/вывода, так и из источников данных (файлы, таблицы, базы данных, хранилища данных и т.д.).
Производят преобразование полученных атрибутов месторождения и осуществляют поиск аналогов с использованием обученного классификатора, соответствующего типу месторождения.
Преобразования (фиг.2, 204) полученных от пользователя атрибутов месторождения (числовых и категориальных) осуществляют согласно описанным ранее последовательностям действий (фиг.1, 107).
Далее итеративно проходят по всем записям базы данных месторождений (которая использовалась на шаге 101 с преобразованием атрибутов каждой записи согласно шагу 107 или сохранена на шаге 107) и передают на вход соответствующего обученного классификатора (терригенного, карбонатного или иного) преобразованные атрибуты пользовательского месторождения и запись текущей итерации (текущую запись, запись на которой стоит курсор базы данных, запись на которую указывает итератор и т.д.). Получив данные записи на входе классификатор производит необходимую обработку и выдает результат является ли запись текущей итерации аналогом пользовательского месторождения. Пройдя итеративно по всем записям, получается (формируется) список аналогов пользовательского месторождения. В случае отсутствия аналогов список может быть пуст (содержать пустое значение, nil, Null, []) или может содержать информацию обо всех месторождениях с указанием, что они не являются аналогами.
Предъявляют пользователю информацию о результатах поиска.
Полученные результаты поиска (фиг.2, 205) отображаются/предъявляются (фиг.5) пользователю в текстовом или графическом виде, при помощи текстового (CUI) или графического интерфейса (GUI) или в виде результата (списка найденных скважин и их характеристик/атрибутов), доступного для внешних сервисов, внешних вызовов функций. В некоторых вариантах реализации отображаемые результаты могут ранжироваться/сортироваться по «степени близости» скважин-аналогов к искомой скважине. Степень близости может вычисляться по метрикам на основании характеристик найденных скважин.
Фиг. 6 представляет пример компьютерной системы общего назначения используемой для реализации описанного способа, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жёсткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жёсткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жёсткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жёсткий диск 27, , но следует понимать, что возможно применение иных типов компьютерных носителей информации, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через интерфейс USB 46, который в свою очередь подсоединён к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта. Монитор 47 или иной тип устройства отображения также подсоединён к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащён другими периферийными устройствами вывода (не отображены).
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удалёнными компьютерами 49. Удалённый компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 6. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключён к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать роутер 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Роутер 54, который является внутренним или внешним устройством, подключён к системной шине 23 посредством USB порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведённые в описании сведения являются примерами, которые не ограничивают объём настоящего технического решения, определённого формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2681356C1 |
| Способ разметки и верификации текстовых данных | 2023 |
|
RU2832840C1 |
| Система и способ двухэтапной классификации файлов | 2018 |
|
RU2708356C1 |
| Способ выбора оптимального дизайна гидроразрыва пласта на основе интеллектуального анализа полевых данных для увеличения добычи углеводородного сырья | 2021 |
|
RU2775034C1 |
| СПОСОБ РАСЧЕТА КРЕДИТНОГО РЕЙТИНГА КЛИЕНТА | 2019 |
|
RU2723448C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ВЕРОЯТНОСТИ АКТГ-ЭКТОПИРОВАННОГО СИНДРОМА У ПАЦИЕНТОВ C АКТГ-ЗАВИСИМЫМ ЭНДОГЕННЫМ ГИПЕРКОРТИЦИЗМОМ | 2023 |
|
RU2814146C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СИСТЕМА МОНИТОРИНГА РЕЖИМОВ ГОРЕНИЯ ТОПЛИВА ПУТЕМ АНАЛИЗА ИЗОБРАЖЕНИЙ ФАКЕЛА ПРИ ПОМОЩИ КЛАССИФИКАТОРА НА ОСНОВЕ СВЁРТОЧНОЙ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2713850C1 |



Группа изобретений относится к области поиска аналогов коллекторов со схожими свойствами и заполнения пропуска пропущенных значений описательных атрибутов коллектора. Компьютерно-реализуемый способ поиска аналогов месторождений включает по крайней мере следующие шаги: получают первую и вторую выборку записей из по крайней мере одной базы данных месторождений и их атрибутов. Причем первая выборка записей содержит месторождения первого типа, описываемые первой группой атрибутов, а вторая выборка записей содержит месторождения второго типа, описываемые второй группой атрибутов. Формируют первую размечаемую выборку; формируют вторую размечаемую выборку; производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов. Причем для каждой записи в подгруппе эксперты помечают, характеризует ли данная запись месторождение, которое является аналогом целевого месторождения в данной подгруппе. Формируют первую и вторую обучающие выборки из соответственно первой и второй размеченной выборки. Производят обучение первого классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей первой обучающей выборки; производят обучение второго классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей второй обучающей выборки. Получают от пользователя тип месторождения и значения его атрибутов, для определения его аналогов; производят преобразование полученных атрибутов для использования классификатором месторождения и осуществляют поиск аналогов с использованием обученного классификатора, соответствующего типу месторождения; предъявляют пользователю информацию о результатах поиска. 9 н. и 17 з.п. ф-лы, 6 ил.
1. Компьютерно-реализуемый способ поиска аналогов месторождений включает по крайней мере следующие шаги:
- получают первую и вторую выборку записей из по крайней мере одной базы данных месторождений и их атрибутов, причем первая выборка записей содержит месторождения первого типа, описываемые первой группой атрибутов, а вторая выборка записей содержит месторождения второго типа, описываемые второй группой атрибутов;
- формируют первую размечаемую выборку с помощью:
- группировки записей по общности осадконакопления в первой выборке;
- разбиения групп записей Gi первой выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt;
- формируют вторую размечаемую выборку с помощью:
- группировки записей по общности осадконакопления во второй выборке;
- разбиения групп записей Gi второй выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе j Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt;
- производят разметку первой и второй размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи в подгруппе эксперты помечают, характеризует ли данная запись месторождение, которое является аналогом целевого месторождения в данной подгруппе;
- формируют первую и вторую обучающие выборки из соответственно первой и второй размеченной выборки с помощью:
- отбора только тех записей, которые помечены в качестве аналогов целевого месторождения в подгруппе двумя и более экспертами;
- восстановления пропущенных значений атрибутов в записях выборки;
- преобразования атрибутов записей выборки для использования классификатором градиентного бустинга;
- производят обучение первого классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей первой обучающей выборки;
- производят обучение второго классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей второй обучающей выборки;
- получают от пользователя тип месторождения и значения его атрибутов, для определения его аналогов;
- производят преобразование полученных атрибутов месторождения для использования классификатором и осуществляют поиск аналогов с использованием обученного классификатора, соответствующего типу месторождения;
- предъявляют пользователю информацию о результатах поиска.
2. Способ по п.1, в котором первым типом месторождения является терригенное месторождение, а вторым типом - карбонатное месторождение.
3. Способ по п.1, в котором первая группа атрибутов включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов.
4. Способ по п.1, в котором вторая группа атрибутов включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов, основная структура карбонатных пород по r.j. dunham modified 1971, литогенетический тип коллектора, тип трещинного коллектора.
5. Способ по п.1, в котором восстановление пропущенных значений атрибутов осуществляют с использованием метода градиентного бустинга.
6. Способ по п.1, в котором восстановление пропущенных значений атрибутов осуществляют с использованием алгоритма машинного обучения Random Forest.
7. Способ по п.1, в котором для градиентного бустинга используется Catboost или xgboost или Adaboost.
8. Способ по п.1 или 5, в котором для выбора гиперпараметров градиентного бустинга используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
9. Способ по п.6, в котором для выбора гиперпараметров алгоритма машинного обучения Random Forest используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
10. Компьютерно-реализуемый способ обучения классификатора для поиска аналогов месторождений включает по крайней мере следующие шаги:
- получают выборку записей из по крайней мере одной базы данных месторождений и их атрибутов, причем выборка записей содержит месторождения одного типа, описываемые группой атрибутов;
- формируют размечаемую выборку с помощью:
- группировки записей по общности осадконакопления в выборке;
- разбиения групп записей Gi выборки на подгруппы Gij размером Gij_cnt и случайным образом выбирают в каждой подгруппе Gij целевое месторождение, где Gij_cnt функционально зависит от количества записей в группе Gi_cnt;
- производят разметку размечаемой выборки при помощи по крайней мере двух экспертов, причем для каждой записи в подгруппе эксперты помечают, характеризует ли данная запись месторождение, которое является аналогом целевого месторождения в данной подгруппе;
- формируют обучающую выборку из размеченной выборки с помощью:
- отбора только тех записей, которые помечены в качестве аналогов целевого месторождения в подгруппе двумя и более экспертами;
- восстановления пропущенных значений атрибутов в записях выборки;
- преобразования атрибутов записей выборки для использования классификатором градиентного бустинга;
- производят обучение классификатора при помощи градиентного бустинга с использованием преобразованных атрибутов записей обучающей выборки.
11. Способ по п.10, в котором типом месторождения является терригенное месторождение.
12. Способ по п.10, в котором типом месторождения является карбонатное месторождение.
13. Способ по п.11, в котором группа атрибутов для терригенных месторождений включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов.
14. Способ по п.12, в котором группа атрибутов для карбонатных месторождений включает по крайней мере следующие атрибуты: структурная принадлежность, основной литологический состав коллектора, основная система осадконакопления, основная обстановка осадконакопления, основной тип пористости, среднее значение общей толщины коллектора, среднее значение эффективной углеводородонасыщенной толщины коллектора, среднее значение пористости матрицы, среднее значение проницаемости по воздуху, среднее значение водонасыщенности, тектонический режим формирования комплексов, основная структура карбонатных пород по r.j. dunham modified 1971, литогенетический тип коллектора, тип трещинного коллектора.
15. Способ по п.10, в котором восстановление пропущенных значений атрибутов осуществляют с использованием метода градиентного бустинга.
16. Способ по п.10, в котором восстановление пропущенных значений атрибутов осуществляют с использованием алгоритма машинного обучения Random Forest.
17. Способ по п.10, в котором для градиентного бустинга используется Catboost или xgboost или Adaboost.
18. Способ по п.10 или 15, в котором для выбора гиперпараметров градиентного бустинга используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
19. Способ по п.16, в котором для выбора гиперпараметров алгоритма машинного обучения Random Forest используется случайное сэмплирование значений гиперпараметров для определения минимумов значений лосс функции и затем в определенных случайным сэмплированием диапазонах гиперпараметров для уточнения минимальных значений лосс функции выполняется поиск по сетке Grid Search.
20. Компьютерно-реализуемый способ поиска аналогов месторождений включает по крайней мере следующие шаги:
- получают выборку записей терригенных месторождений и обучают первый классификатор для поиска аналогов месторождений согласно способу по п.10;
- получают выборку записей карбонатных месторождений и обучают второй классификатор для поиска аналогов месторождений согласно способу по п.10;
- получают от пользователя тип месторождения и значения его атрибутов, для определения его аналогов;
- производят преобразование полученных атрибутов месторождения и осуществляют поиск аналогов с использованием обученного первого или второго классификатора, соответствующего типу месторождения;
- предъявляют пользователю информацию о результатах поиска.
21. Система для поиска аналогов месторождений, включающая по крайней мере один процессор, оперативную память и машиночитаемые инструкции для выполнения способа поиска аналогов согласно способу по пп.1-9.
22. Система для обучения классификатора для поиска аналогов месторождений, включающая по крайней мере один процессор, оперативную память и машиночитаемые инструкции для выполнения способа обучения классификатора для поиска аналогов месторождений согласно способу по пп.10-19.
23. Система для поиска аналогов месторождений, включающая по крайней мере один процессор, оперативную память и машиночитаемые инструкции для выполнения способа поиска аналогов согласно способу по п.20.
24. Машиночитаемый носитель, содержащий машинные инструкции способа поиска аналогов согласно пп.1-9, выполненный с возможностью чтения данных инструкций и исполнения их процессором.
25. Машиночитаемый носитель, содержащий машинные инструкции способа обучения классификатора для поиска аналогов месторождений согласно пп.10-19, выполненный с возможностью чтения данных инструкций и исполнения их процессором.
26. Машиночитаемый носитель, содержащий машинные инструкции способа поиска аналогов согласно п.20, выполненный с возможностью чтения данных инструкций и исполнения их процессором.
| H | |||
| MARTIN RODRIGUEZ, New Approach To Identify Analogous Reservoirs, журнал "SPE Economics & Management", Volume 6, Issue 04, October 2014 | |||
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2649792C2 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2681356C1 |
| US 7899253 B2, 01.03.2011 | |||
| US9031331 B2, 30.01.2014. | |||

