Изобретение относится к области способов обработки данных в части получения информационных выборок по запросу пользователя и может быть использовано в оборудовании обработки данных.
Постоянное увеличение объема данных и многообразие форматов их представления, потребность их применения в различных сферах деятельности общества обуславливают необходимость в совершенствовании способов их обработки. Одним из направлений повышения скорости обработки больших структурированных высокоактивных данных является совершенствование способов выполнения запросов (https://www.oracle.com/ru/emerging-technologies/), в том числе и при выполнении операции JOIN посредством параллельного ее выполнения над фрагментами таблиц из запроса пользователя с последующим объединением результатов (https://www.teradata.com, https://www.ibm.com/it-infrastructure/power/accelerated-computing). Согласно (Carlson, R., Steen, В., Tillman, A.M., & 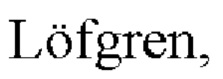 G. LCI data modelling and a database design. The International Journal of Life Cycle Assessment, 3(2), PP. 106-113), к высокоактивным данным относятся данные, коэффициент активности использования которых равен или стремится к единице, и характеризуется отношением их общего количества к количеству данных, задействованных при выполнении операций над ними. К числу отраслей, в которых используются такие данные, относятся государственный сектор, здравоохранение, производство, финансовые услуги, энергетика и добыча природных ресурсов, связь и мультимедиа, туризм и транспорт, направленные на финансовую трансформацию, оптимизацию активов, взаимодействие с потребителями (клиентами) (https://azure.microsoft.com/ru-ru/solutions/#solutions-by-industry, https://www.sas.com/ru_ru/software/how-to-buy/request-price-quote.html, https://www.oracle.com/ru/emerging-technologies/).
G. LCI data modelling and a database design. The International Journal of Life Cycle Assessment, 3(2), PP. 106-113), к высокоактивным данным относятся данные, коэффициент активности использования которых равен или стремится к единице, и характеризуется отношением их общего количества к количеству данных, задействованных при выполнении операций над ними. К числу отраслей, в которых используются такие данные, относятся государственный сектор, здравоохранение, производство, финансовые услуги, энергетика и добыча природных ресурсов, связь и мультимедиа, туризм и транспорт, направленные на финансовую трансформацию, оптимизацию активов, взаимодействие с потребителями (клиентами) (https://azure.microsoft.com/ru-ru/solutions/#solutions-by-industry, https://www.sas.com/ru_ru/software/how-to-buy/request-price-quote.html, https://www.oracle.com/ru/emerging-technologies/).
Известен способ, описанный в изобретении «Cardinality and Selectivity Estimation Using Asingle Table JOIN Index» (МПК: G06F 17/30, патент на изобретение US 8914354 B2, дата публикации 16.12.2014), включающий в себя запрос к базе данных, который содержит один или несколько предикатов запроса и ссылается на одну или несколько таблиц базы данных. В запросе идентифицирован один или несколько индексов соединения для соответствующих таблиц базы данных по запросу базы данных. Индексы соединения содержат предикаты индекса соединения и включают один или несколько столбцов соединения в списке выбора. Количество строк, выбранное предикатами запроса, рассчитывается, по крайней мере, частично с использованием количества строк или статистики одного или нескольких индексов соединения. Селективность предиката базовой таблицы рассчитывается, по меньшей мере, частично из рассчитанного количества строк. Количество элементов объединения оценивается, по меньшей мере, частично из числа строк и статистики идентифицированного индексов объединения. Недостатком данного способа является низкая скорость выполнения операции JOIN при обработке больших структурированных высокоактивных данных, что обусловлено наличием практически всех возможных значений ключей, определяемых условием отбора, в обоих таблицах-операндах операции JOIN.
Известен способ, описанный в изобретении «JOIN Operation Partitioining» (МПК: G06F 7/00, G06F 17/30, патент на изобретение US 9665624 B2, дата публикации 18.12.2014), заключающийся в распределении таблиц на основе вычисления хеш-индексов ключей таблиц. Недостатком данного способа является низкая скорость выполнения операции JOIN при обработке больших структурированных высокоактивных данных, что обусловлено увеличением времени распределения таблиц при использовании хеш-индексов.
Наиболее близким по технической сущности к заявляемому изобретению является способ, описанный в изобретении «System, Method, and Computer-readable Medium for Duplication Optimization for Parallel JOIN Operations on Similarly Large Skewed Tables» (МПК: G06F 17/30, патент на изобретение US 8099409 B2, дата публикации 17.01.2012), заключающийся в получении обеих таблиц-операндов и условия отбора строк в операции, распределении строк таблиц-операндов в форме таблиц-фрагментов между множеством модулей обработки с последующим параллельным выполнением операции JOIN в модулях обработки и одновременным объединением результатов. Недостатком данного способа является низкая скорость выполнения операции JOIN при обработке больших структурированных высокоактивных данных, что обусловлено использованием таблицы-фрагмента, которая представляет собой полную таблицу-операнд, содержащую, в том числе не используемые при выполнении операции JOIN строки.
Технической задачей изобретения является повышение скорости обработки больших структурированных высокоактивных данных.
Технический результат изобретения состоит в снижении времени выполнения операции JOIN при обработке больших структурированных высокоактивных данных.
Это достигается тем, что в известном способе, включающем получение обеих таблиц-операндов и условия отбора строк в операции, распределение строк таблиц-операндов в форме таблиц-фрагментов между множеством модулей обработки с последующим параллельным выполнением операции JOIN в модулях обработки и одновременным объединением результатов, распределению строк таблиц-фрагментов между множеством модулей обработки предшествует формирование сводной таблицы метаданных на основе вычисления частоты вхождения строк с каждым значением ключа операции JOIN в таблицах-операндах и последующее распределение строк из обеих таблиц-операндов в таблицы-фрагменты осуществляется на основе сводной таблицы метаданных, причем каждая пара таблиц-фрагментов в одном модуле обработки содержит только те строки, значения ключей которых находятся во взаимно-однозначном соответствии друг другу.
Сущность изобретения поясняется чертежами, где на фиг. 1 представлена обобщенная структурная схема системы, реализующей способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных, на фиг. 2 представлен способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных, на фиг. 3 представлен алгоритм формирования сводной таблицы метаданных на основе вычисления частоты использования ключей операции JOIN в таблицах-операндах, на фиг. 4 представлен алгоритм распределения строк из обеих таблиц-операндов в таблицы-фрагменты в каждый модуль обработки на основе сводной таблицы метаданных.
На графических изображениях приняты следующие обозначения:
Р, Q - таблицы-операнды операции JOIN
indP, indQ - таблицы метаданных для таблиц-операндов Ρ и Q соответственно;
indPQ - сводная таблица метаданных 123;
nHi - вспомогательная переменная, используемая для обращения к строке из таблицы метаданных 123;
nLow - вспомогательная переменная, используемая для обращения к строке из таблицы метаданных 123;
nPM - вспомогательная переменная, соответствующая порядковому номеру модуля обработки 1101…110Z из диапазона 1…z;
Key(j) - операция получения значения ключа строки с номером j;
kHi, kLow - вспомогательные переменные, используемые для хранения текущего значения ключа;
indPQ.Rowcount - операция определения количества строк в таблице метаданных indPQ;
← - операция присваивания переменной значения произвольного типа, в том числе табличного;
(nPM+1) MOD z - операция увеличения на единицу целого числа по модулю z;
indP ∩ indQ(indP.K, indP.M×indQ.M) - результат выполнения операции пересечения таблиц indP и indQ с вычислением произведения частот indP.M×indQ.M использования ключей K операции JOIN в таблицах-операндах.
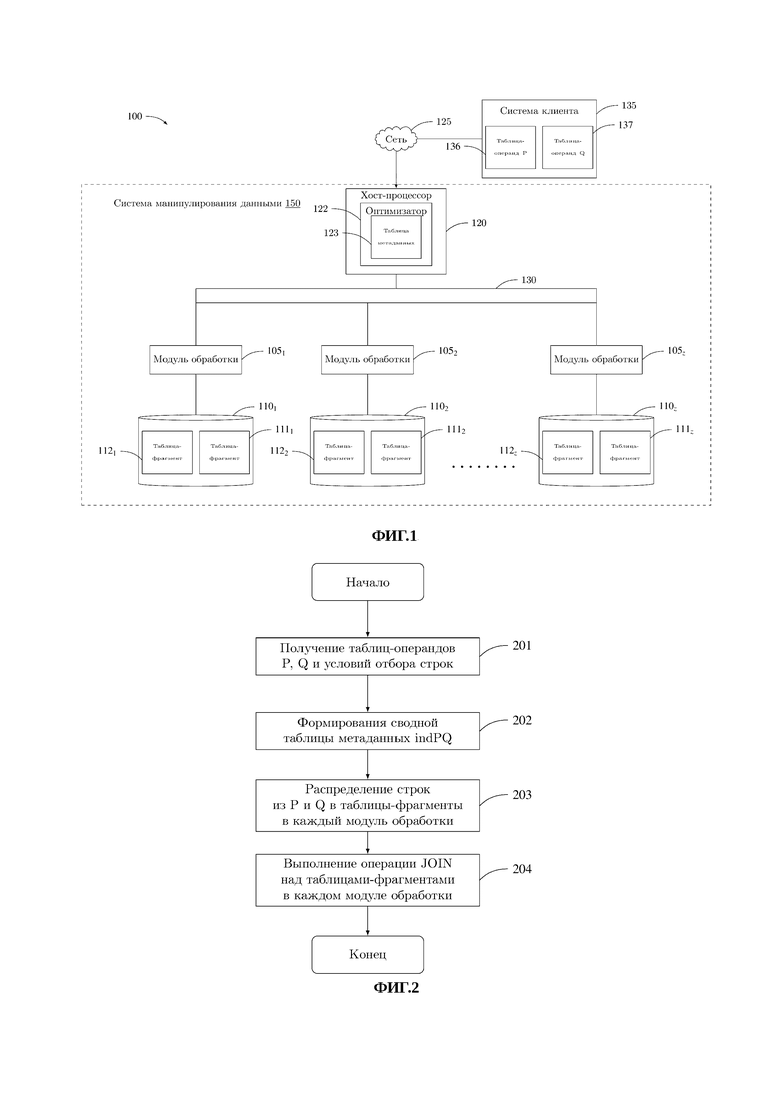
Способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных осуществляется с помощью системы, изображенной на фиг.1.
Система 100 включает в себя: систему клиента 135, сеть передачи данных 125 и систему манипулирования данными 150.
Система клиента 135 представляет собой электронное устройство, располагающее аппаратными и программными возможностями манипулирования данными с использованием СУБД на основе SQL, например, сервер баз данных, настольный компьютер, мобильный компьютер, планшет, мобильный телефон и так далее. Реализация манипулирования данными на основе SQL в электронных устройствах известно из области техники и в настоящем описании подробно не рассматривается. Несмотря на то, что в описании упоминается одна система клиента, система 100 может включать более одной системы клиента 135.
Сеть 125 для передачи данных может быть представлена в виде глобальной, локальной, частной сети передачи данных. В сети 125 обмен данными возникает по линиям передачи данных разного типа, например, по беспроводным или проводным линиям.
Система манипулирования данными 150 состоит из хост-процессора 120, представляющего собой программно-аппаратный комплекс, в состав аппаратных средств которого входит, как минимум, один многоядерные процессор, например, CPU Intel Core i7, Intel Xeon, устройства взаимодействия с глобальной, локальной частной сетями передачи данных и высокоскоростной локальной вычислительной сетью, а в состав программных средств которого входят операционная система, обеспечивающая многопоточное выполнение приложений, СУБД с процедурным языком манипулирования данными, например, Transact-SQL, PL/SQL, PL/pgSQL. Устройство и принцип работы хост-процессора 120 известен из области техники и в настоящем описании подробно не рассматривается. Хост-процессор 120 связан с модулями обработки 1051…105z посредством высокоскоростной локальной сети 130, например, Infiniband. Модули обработки 1051…105z представляют собой программно-аппаратные комплексы, которые имеют архитектуру аналогичную хост-процессору 120, но могут отличиться от него вычислительной производительностью и отсутствием средств взаимодействия с глобальной, локальной частной сетями передачи данных. Каждый из модулей обработки 1051…l05z связан с накопителем данных 1101…110z, представляющим собой не менее одного устройства для хранения данных, например твердотельного накопителя. Способы передачи данных между элементами системы манипулирования данными 150 известны из области техники и в настоящем описании подробно не рассматриваются. В состав программного обеспечения хост-процессора 120 включена программа-оптимизатор 122, реализующая заявленный способ.
На фиг. 2 представлен способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных.
На этапе 201 осуществляется получение таблиц-операндов 136 и 137 и условий отбора строк по глобальной, локальной, частной сетям передачи данных 125 от системы клиента 135 в хост-процессор 120, который выполняет код программы-оптимизатора 122. Способ передачи таблиц-операндов и условия отбора строк по глобальной, локальной частной сетям передачи данных известен из области техники и в настоящем описании подробно не рассматривается.
На этапе 202 при выполнении кода программы-оптимизатора 122 осуществляется формирование сводной таблицы метаданных indPQ на основе вычисления частоты вхождения строк с каждым значением ключа операции JOIN в таблицах-операндах.
На этапе 203 производится распределение строк из таблиц-операндов Ρ и Q в таблицы-фрагменты 1111…112z в каждый модуль обработки 1051…105z на основе сводной таблицы метаданных indPQ.
На этапе 204 выполняется операция JOIN над таблицами-фрагментами 1111…112z в каждом модуле обработки 1051…105z с одновременным объединением результатов. Способ выполнения операции JOIN в модулях обработки известен из области техники и в настоящем описании подробно не рассматривается.
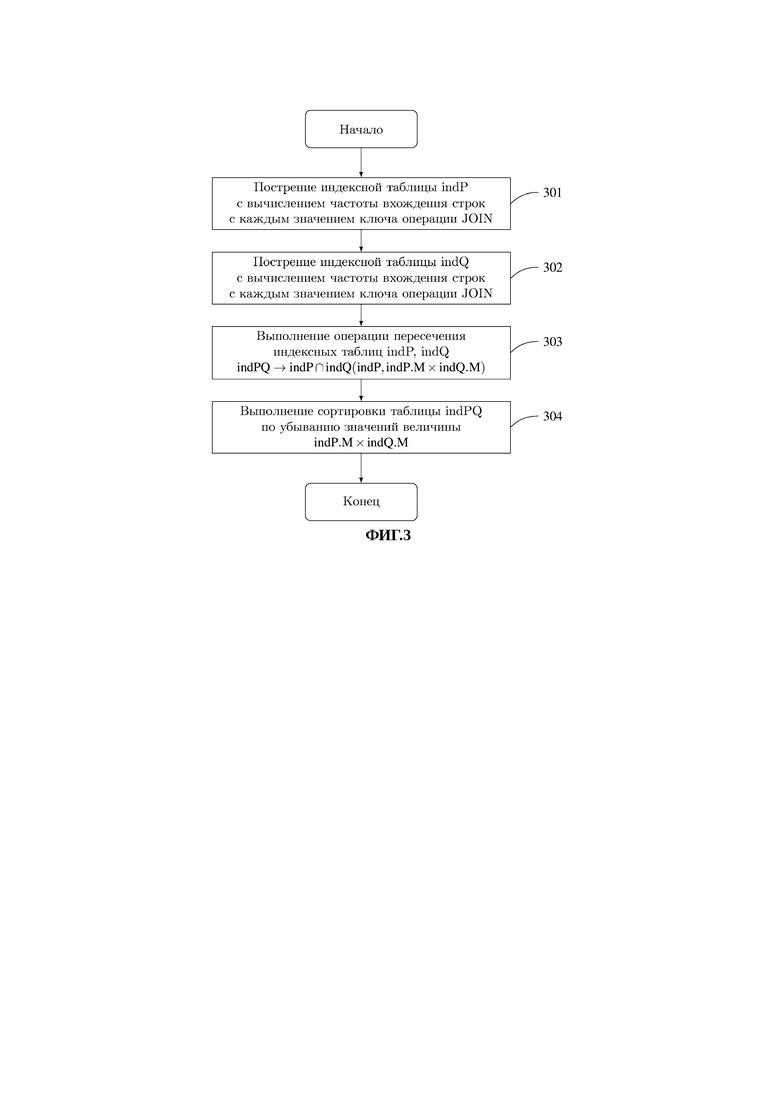
Этап 202 реализуется с помощью последовательности действий, представленных на фиг. 3. Этап 203 реализуется с помощью последовательности действий, представленных на фиг. 4.
На этапе 301 оптимизатором 122 для каждого значения ключа операции JOIN, входящего в условие отбора, производится подсчет количества строк в таблице-операнде Ρ (136), соответствующих данному значению ключа, с занесением значения ключа и частоты вхождения строк в индексную таблицу indP. Данный этап может быть выполнен, например, с помощью SQL-запроса:
INSERT INTO indP (K, M) SELECT PK, SUM(1) AS Μ FROM Ρ ORDER BY P.K GROUP BY P.K;
На этапе 302 оптимизатором 122 для каждого значения ключа операции JOIN, входящего в условие отбора, производится подсчет количества строк в таблице-операнде Q (137), соответствующих данному значению ключа, с занесением значения ключа и частоты вхождения строк в индексную таблицу indQ. Данный этап может быть выполнен, например, с помощью SQL-запроса:
INSERT INTO indQ (K, Μ) SELECT Q.K, SUM(1) AS Μ FROM Q ORDER BY Q.K GROUP BY Q.K;
На этапе 303 оптимизатором 122 выполняется операция пересечения индексных таблиц indP и indQ, в результате выполнения которой получается сводная таблица метаданных indPQ 123. Сводная таблица метаданных содержит N строк по количеству значений ключа, участвующих в операции JOIN. При этом для больших структурированных высокоактивных данных число N больше числа модулей обработки 1051…105z.
На этапе 304 оптимизатором 122 сводная таблица метаданных indPQ 123 упорядочивается по убыванию значений величины произведений количеств строк таблиц-операндов.
Этапы 303 и 304 могут быть выполнены, например, с использованием SQL-запроса:
INSERT INTO indPQ (K, Μ) SELECT indPK, indP.M×indQ.M AS Μ FROM indP, indQ WHERE indP.K=indQ.M ORDER BY Μ DESC
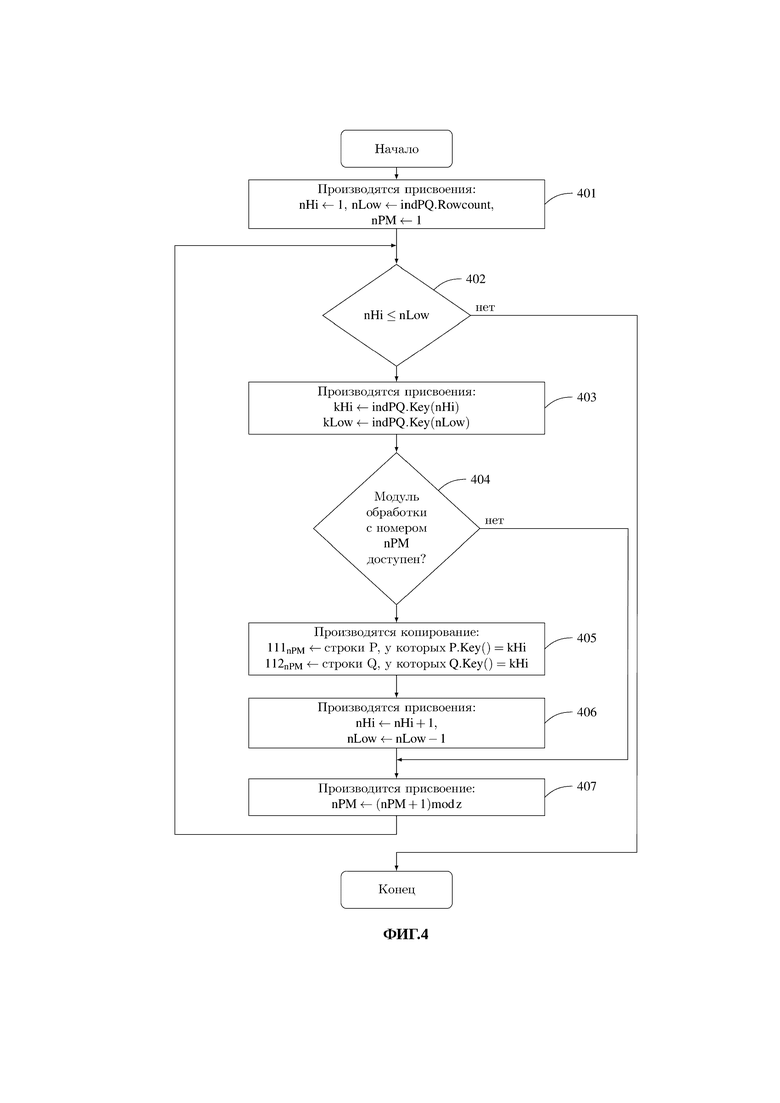
Выполняется распределение строк таблиц-операндов 136 и 137 между парами таблиц-фрагментов 1111 и 1121, …, 111z и 112z, которое в рамках этапа 203 реализуется алгоритмом распределения строк из обеих таблиц-операндов в таблицы-фрагменты в каждый модуль обработки на основе сводной таблицы метаданных, представленным на фиг. 4.
На этапе 401 двум вспомогательным переменным nHi и nLow производится присвоение значений, соответствующих номерам первой и последней строк в таблице метаданных indPQ 123, вспомогательной переменной nPM присваивается значение единица.
На этапе 402 производится проверка завершенности операции распределения пар таблиц-фрагментов 1111…112z, состоящая в проверке условия nHi≤nLow. Если данное условие выполняется, то осуществляется переход к этапу 403, в противном случае выполнение распределения завершается.
На этапе 403 из сводной таблицы метаданных indPQ выбираются строки с номерами nHi и nLow, и вспомогательным переменным kHi и kLow присваиваются значения ключей, соответствующих данным строкам.
На этапе 404 производится проверка готовности модуля обработки с номером nPM к получению данных от хост-процессора 122. Если модуль обработки с порядковым номером nPM готов к приему данных, то производится переход к этапу 405, в противном случае - к этапу 407.
На этапе 405 из таблиц-операндов Ρ (136) и Q (137) производится копирование строк, значения ключей которых соответствуют значениям kHi и kLow в таблицы-фрагменты 111nPM и 112nPM на накопителе данных 110nPM модуля обработки 105nPM посредством высокоскоростной локальной сети 130.
На этапе 406 производится увеличение значения nHi на единицу и уменьшение значения nLow на единицу.
На этапе 407 производится присвоение вспомогательной переменной nPM значения, увеличенного на единицу по модулю z, после чего производится возвращение к этапу 402.
Технический результат изобретения обеспечивается использованием в заявляемом способе следующих теоретических предпосылок. Для параллельного выполнения операции обработки больших структурированных высокоактивных данных выбрана следующая разновидность операции JOIN:
Ρ INNER JOIN Q ON π(P.K, Q.K);
Таблицы-операнды Ρ и Q (136 и 137) представляют собой совокупности классов эквивалентности, которые содержат не менее одной строки, и рассматриваются как фактор-множества эквивалентности PK и QK, порожденные ключом K. Предикат π определен на множествах экземпляров ключа K в таблицах-операндах P и Q (136 и 137) и реализует условие отбора. Κ1, …, Kn представляют собой множество значений ключа K. При этом операция JOIN определена как объединение классов эквивалентности новой таблиц-операндов  полученных в результате выполнения групповой операции F(PKi×Qki) на декартовом произведении соответствующих классов эквивалентности таблиц-операндов.
полученных в результате выполнения групповой операции F(PKi×Qki) на декартовом произведении соответствующих классов эквивалентности таблиц-операндов.
Для параллельной реализации операции JOIN используются метаданные, определяющие распределение строк таблицы по классам эквивалентности. При этом таблицам P и Q (136 и 137) ставятся в соответствие индексные таблицы со схемами indP(K, Μ) и indQ(K, Μ), которые представляют собой множества строк indP={<K1, Μ1>, …,<Kn, Mn>} и indQ={<K1, M1>, …, <Kn, Mm>}, где Kj, - значение ключа K, Mj - количество записей в j-м классе эквивалентности, строки которого содержат Kj, Μ - целочисленное поле.
Таблица-результат параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных содержит только те классы эквивалентности, которые принадлежат пересечению индексных таблиц indP ∩ indQ. Результатом выполнения этой операции является сводная таблица метаданных indPQ 123, содержащая составной ключ K и поле М, значение которого равно indP.M×indQ.M и относительно которого сводная таблица метаданных indPQ 123 упорядочена по убыванию.
Использование сводной таблицы метаданных indPQ 123 позволяет распределить таблицы-операнды Ρ и Q (136 и 137) между независимыми модулями обработки 1051…105z в форме пар таблиц-фрагментов 1111 и 1121, 111z и 112z, сохраняемых на накопителях 1101…110Z. При этом классы эквивалентности, записи которых содержат одинаковые значения ключа K, расположены в одной и только одной паре таблиц-фрагментов 1111 и 1121, 111z и 112z.
В результате выполнения операции PnPM INNER JOIN QnPM получается таблица, содержащая 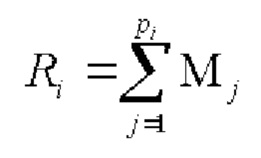 строк, где PnPM и QnPM - таблицы-фрагменты 111nPM и 112nPM соответственно в модуле обработки с порядковым номером nPM. При этом очевидно, что чем меньше значение разности между наибольшим Rmax и наименьшим количеством обрабатываемых строк, тем ниже общее время выполнения операции JOIN при обработке больших структурированных высокоактивных данных, содержащихся в таблицах-операндах P и Q (136 и 137).
строк, где PnPM и QnPM - таблицы-фрагменты 111nPM и 112nPM соответственно в модуле обработки с порядковым номером nPM. При этом очевидно, что чем меньше значение разности между наибольшим Rmax и наименьшим количеством обрабатываемых строк, тем ниже общее время выполнения операции JOIN при обработке больших структурированных высокоактивных данных, содержащихся в таблицах-операндах P и Q (136 и 137).
Снижение времени выполнения операции JOIN при обработке больших структурированных высокоактивных данных в заявленном изобретении следует из того, что сводная таблица метаданных indPQ 123, есть результат операции indP ∩ indQ и пары таблиц-фрагментов 1111 и 1121, …, 111z и 112z не содержат строк, которые не используются при выполнении операции JOIN. В способе, описанном в прототипе, используется таблица-фрагмент, которая представляет собой полную таблицу-операнд, содержащую, в том числе и не используемые при выполнении операции JOIN строки, что увеличивает время выполнения операции JOIN при обработке больших структурированных высокоактивных данных, по сравнению с заявляемым способом.
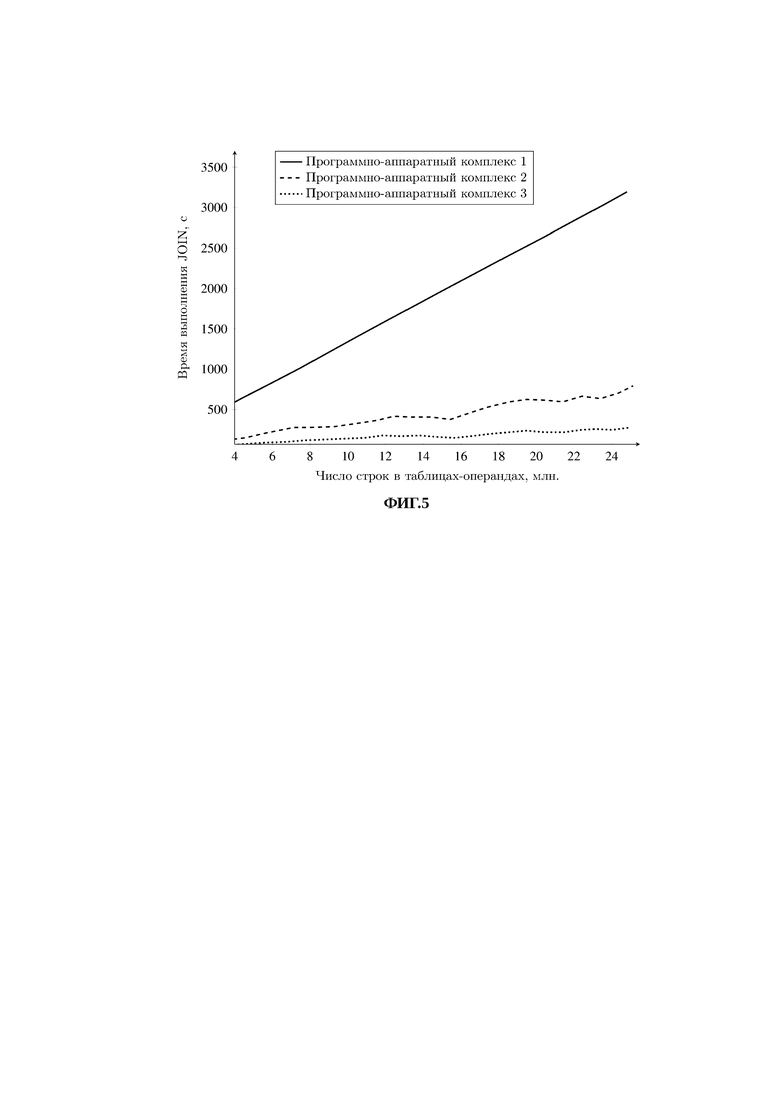
Заявленный технический результат подтверждается результатом вычислительного эксперимента, в ходе которого для параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных использованы программно-аппаратные комплексы:
1. В первом случае программно-аппаратный комплекс состоял только из системы клиента 135, на котором располагалась база данных клиента и таблицы 136 и 137, над которыми выполнялась операция JOIN.
2. Во втором случае программно-аппаратных комплекс состоял из системы клиента 135, на котором располагалась база данных клиента и таблицы 136 и 137, системы обработки, в состав которой входили хост-процессор 120 и два модуля обработки 1051 и 1052. Хост-процессор 120 связан с системой клиента 135 через сеть Интернет, а с модулями обработки 1051 и 1052 - высокоскоростной локальной вычислительной сетью.
3. В третьем случае программно-аппаратный комплекс состоял из системы клиента 135, на котором располагалась база данных клиента и таблицы 136 и 137, системы обработки, в состав которой входили хост-процессор 120 и четыре модуля обработки 1051, …, 1054. Хост-процессор 120 связан с системой клиента 135 через сеть Интернет, а с модулями обработки 1051, …, 1054 - высокоскоростной локальной вычислительной сетью.
Эксперимент проводился для таблиц Ρ и Q (136, 137), число строк в которых изменялось от 4000000 до 25000.000.
Результаты эксперимента приведены на фиг. 5.
Представленные на фиг. 5 графики подтверждают тот факт, что реализация заявленного способа параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных обеспечивает существенное снижение времени выполнения операции JOIN при обработке больших структурированных высокоактивных данных.
ИСТОЧНИКИ ИНФОРМАЦИИ
1. Современные технологии для трансформации бизнеса / URL: https:// www.oracle.com/ru/emerging-technologies/, дата обращения 02.07.2020.
2. Премиум-возможности современной облачной аналитической платформы / URL: https://www.teradata.com, дата обращения 02.07.2020.
3. IMB Power Systems: accelerated computing servers / URL: https://www.ibm.com/ it-infrastructure/power/accelerated-computing, дата обращения 02.07.2020.
4. Carlson, R., Steen, В., Tillman, A. M., & 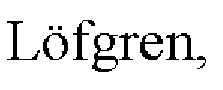 G. LCI data modelling and a database design./The International Journal of Life Cycle Assessment, 3(2), PP. 106-113.
G. LCI data modelling and a database design./The International Journal of Life Cycle Assessment, 3(2), PP. 106-113.
5. Решения Azure/ URL: https://azure.microsoft.com/ru-ru/solutions/#solutions-by-industry/, дата обращения 02.07.2020.
6. Компании, которые работают с SAS / URL: https://www.sas.com/ru_ru/software/ how-to-buy/request-price-quote.html, дата обращения 02.07.2020.
7. Новые технологии предоставляют конкурентные преимущества/ URL: https://www.oracle.com/ru/emerging-technologies/, дата обращения 02.07.2020.
8. Патент US №8914354 В2 от 16.12.2014 Cardinality and Selectivity Estimation Using Asingle Table JOIN Index/Au Grace, Korlapati Rama Krishna, Chen Haiyan
9. Патент US №9665624 B2 от 18.12.2014 JOIN Operation Partitioining/ Gopi K. Attaluri, Vijayshankar Raman.
10. Патент US №8099409 B2 от 17.01.2012 System, Method, and Computer-readable Medium for Duplication Optimization for Parallel JOIN Operations on Similarly Large Skewed Tables/ Zhou Xin, Kostamaa Olli Pekka.
| название | год | авторы | номер документа |
|---|---|---|---|
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| РАСШИРЯЕМЫЙ ЯЗЫК ЗАПРОСОВ С ПОДДЕРЖКОЙ ДЛЯ РАСШИРЕНИЯ ТИПОВ ДАННЫХ | 2007 |
|
RU2434276C2 |
| СПОСОБ ВЫПОЛНЕНИЯ МАШИННОЙ КОМАНДЫ, КОМПЬЮТЕРНАЯ СИСТЕМА И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ, ОБЕСПЕЧИВАЮЩИЕ РАСЧЕТ РАССТОЯНИЯ ОТ ПОЛОЖЕНИЯ В ОСНОВНОЙ ПАМЯТИ ДО ГРАНИЦЫ БЛОКА ОСНОВНОЙ ПАМЯТИ | 2012 |
|
RU2568920C2 |
| ОПРЕДЕЛЕНИЕ ФОРМАТОВ ТРАНСЛЯЦИИ ДЛЯ ФУНКЦИЙ АДАПТЕРА ВО ВРЕМЯ ВЫПОЛНЕНИЯ | 2010 |
|
RU2556418C2 |
| ИЗМЕРИТЕЛЬНОЕ СРЕДСТВО ДЛЯ ФУНКЦИЙ АДАПТЕРА | 2010 |
|
RU2523194C2 |
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
| КОМАНДА ДЛЯ ЗАГРУЗКИ ДАННЫХ ДО ЗАДАННОЙ ГРАНИЦЫ ПАМЯТИ, УКАЗАННОЙ КОМАНДОЙ | 2012 |
|
RU2565496C2 |
| СРЕДСТВО ДЛЯ УСТАНОВКИ КЛЮЧА БЕЗ ПЕРЕВОДА В ПАССИВНОЕ СОСТОЯНИЕ | 2010 |
|
RU2542953C2 |
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ ОТКРЫТИЯ ОБЛАСТЕЙ РАБОЧЕЙ КНИГИ В КАЧЕСТВЕ ИСТОЧНИКА ДАННЫХ | 2005 |
|
RU2406147C2 |
| АКТИВАЦИЯ/ДЕАКТИВАЦИЯ АДАПТЕРОВ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2010 |
|
RU2562372C2 |
Изобретение относится к способу параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных. Технический результат заключается в повышении производительности обработки данных. В способе в компьютерно-реализуемой системе манипулирования данными, использующей язык SQL, после получения хост-процессором обеих таблиц-операндов и условий отбора строк в операции производится распределение строк таблиц-операндов между множеством модулей обработки в форме таблиц-фрагментов с последующим параллельным выполнением операции SQL JOIN в модулях обработки над этими фрагментами таблиц-операндов с одновременным объединением результатов, при этом распределению строк таблиц-фрагментов между множеством модулей обработки предшествует осуществляемое хост-процессором формирование для каждой таблицы-операнда индексной таблицы, в которой каждая строка содержит значение ключа операции SQL JOIN и значение количества строк в данной таблице-операнде, соответствующее этому ключу, выполнение операции пересечения сформированных индексных таблиц с вычислением произведения частот использования ключей операции SQL JOIN в таблицах-операндах, упорядочивание полученной сводной таблицы метаданных по убыванию значений величины произведения частот использования ключей, отбор строк таблиц-операндов в таблицы-фрагменты осуществляется по значениям ключей, соответствующих строкам сводной таблицы метаданных, таким образом, что каждая пара таблиц-фрагментов в одном модуле обработки содержит только те строки таблиц-операндов, которые имеют одинаковое значение ключа. 5 ил.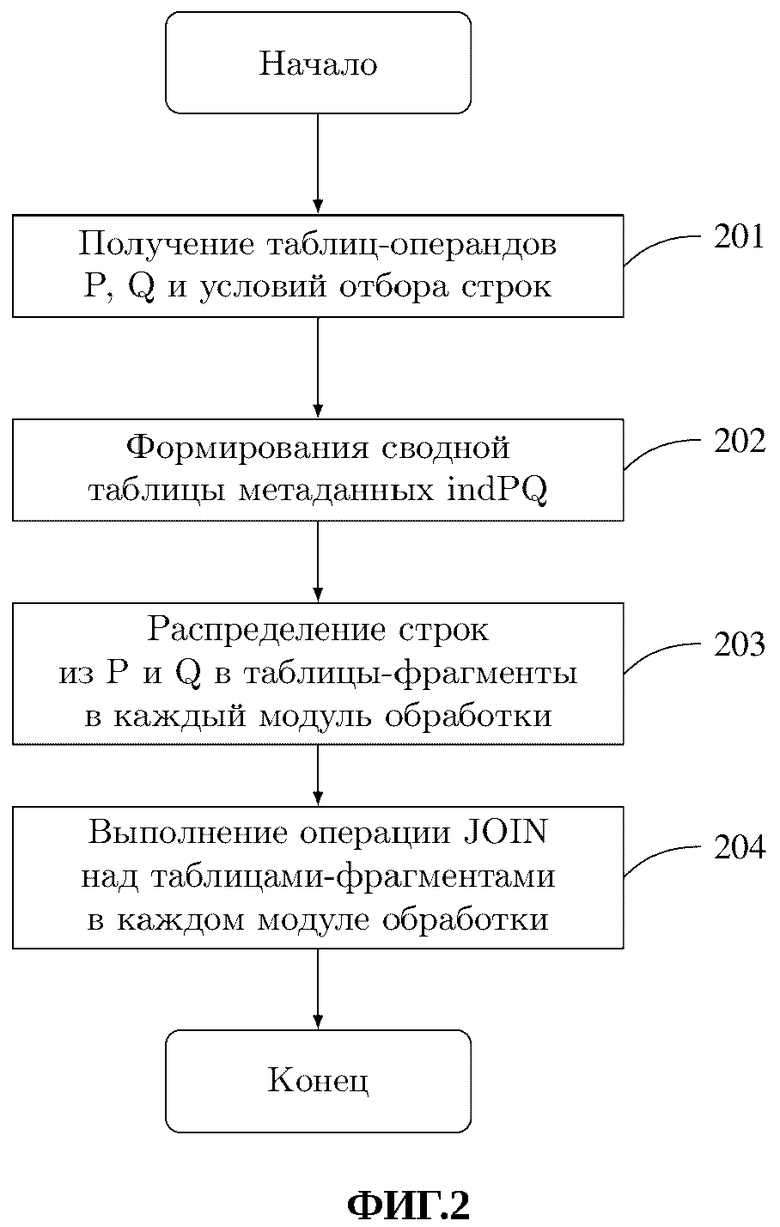
Способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных, заключающийся в том, что в компьютерно-реализуемой системе манипулирования данными, использующей язык SQL, после получения хост-процессором обеих таблиц-операндов и условий отбора строк в операции производится распределение строк таблиц-операндов между множеством модулей обработки в форме таблиц-фрагментов с последующим параллельным выполнением операции SQL JOIN в модулях обработки над этими фрагментами таблиц-операндов с одновременным объединением результатов, отличающийся тем, что распределению строк таблиц-фрагментов между множеством модулей обработки предшествует осуществляемое хост-процессором формирование для каждой таблицы-операнда индексной таблицы, в которой каждая строка содержит значение ключа операции SQL JOIN и значение количества строк в данной таблице-операнде, соответствующее этому ключу, выполнение операции пересечения сформированных индексных таблиц с вычислением произведения частот использования ключей операции SQL JOIN в таблицах-операндах, упорядочивание полученной сводной таблицы метаданных по убыванию значений величины произведения частот использования ключей, отбор строк таблиц-операндов в таблицы-фрагменты осуществляется по значениям ключей, соответствующих строкам сводной таблицы метаданных, таким образом, что каждая пара таблиц-фрагментов в одном модуле обработки содержит только те строки таблиц-операндов, которые имеют одинаковое значение ключа.
| US 8099409 B2, 17.01.2012 | |||
| US 9665624 B2, 30.05.2017 | |||
| US 8914354 B2, 16.12.2014 | |||
| US 10380112 B2, 13.08.2019 | |||
| US 6957210 B1, 18.10.2005 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 10268639 B2, 23.04.2019 | |||
| Электрическое сопротивление для нагревательных приборов и нагревательный элемент для этих приборов | 1922 |
|
SU1997A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |

